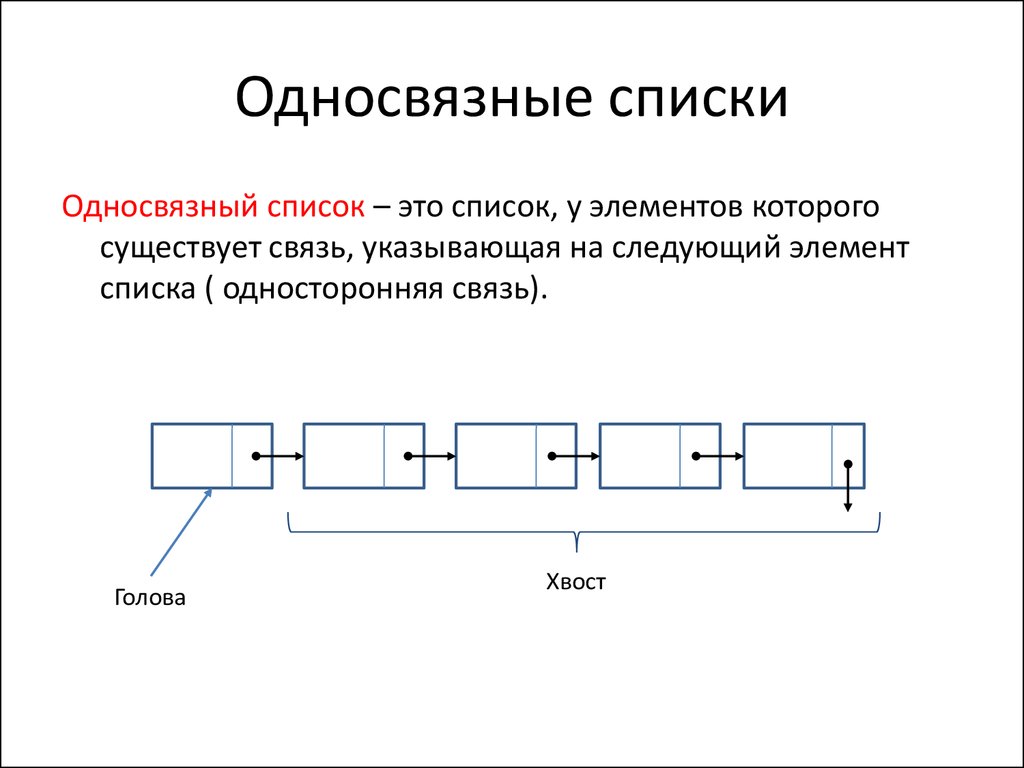
Односвязный список | это… Что такое Односвязный список?
ТолкованиеПеревод
- Односвязный список
В информатике, cвя́зный спи́сок — структура данных, состоящая из узлов, каждый из которых содержит как собственные данные, так и одну или две ссылки («связки») на следующее и/или предыдущее поле. Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Содержание
- 1 Виды связных списков
- 1.1 Линейный связный список
- 1.1.1 Односвязный список
- 1.1.2 Двусвязный список
- 1.1.3 XOR-связный список
- 1.2 Кольцевой связный список
- 1.
 3 Список с пропусками
3 Список с пропусками - 1.4 Развёрнутый связный список
- 1.1 Линейный связный список
- 2 Достоинства
- 3 Недостатки
- 4 См. также
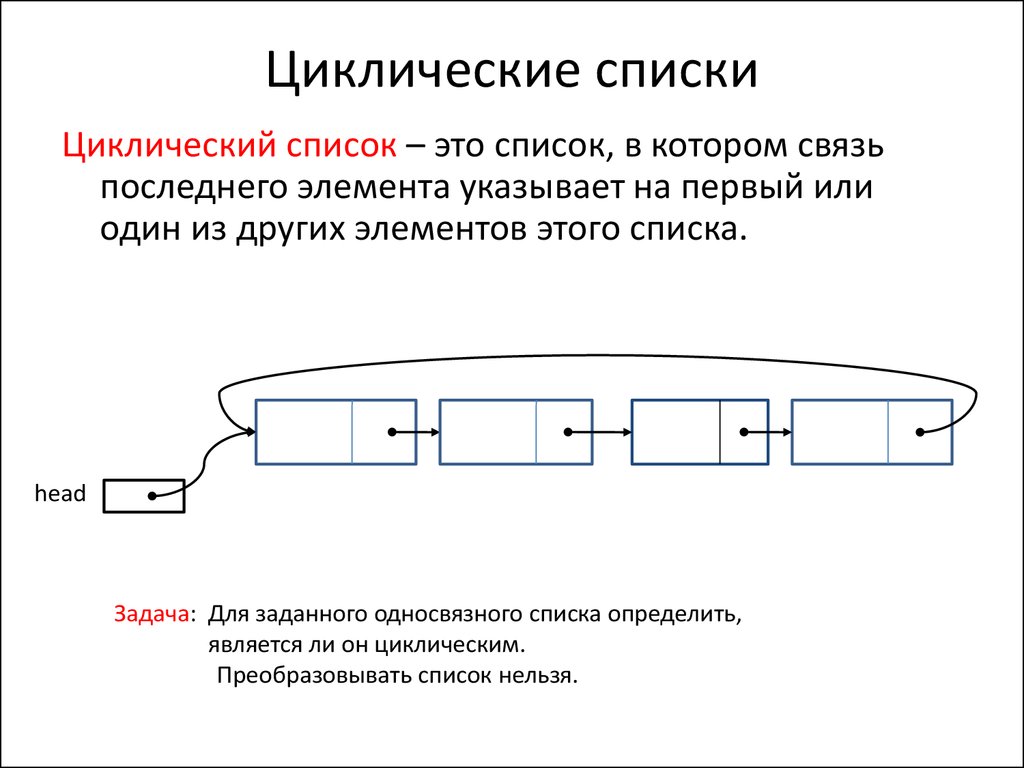
Виды связных списков
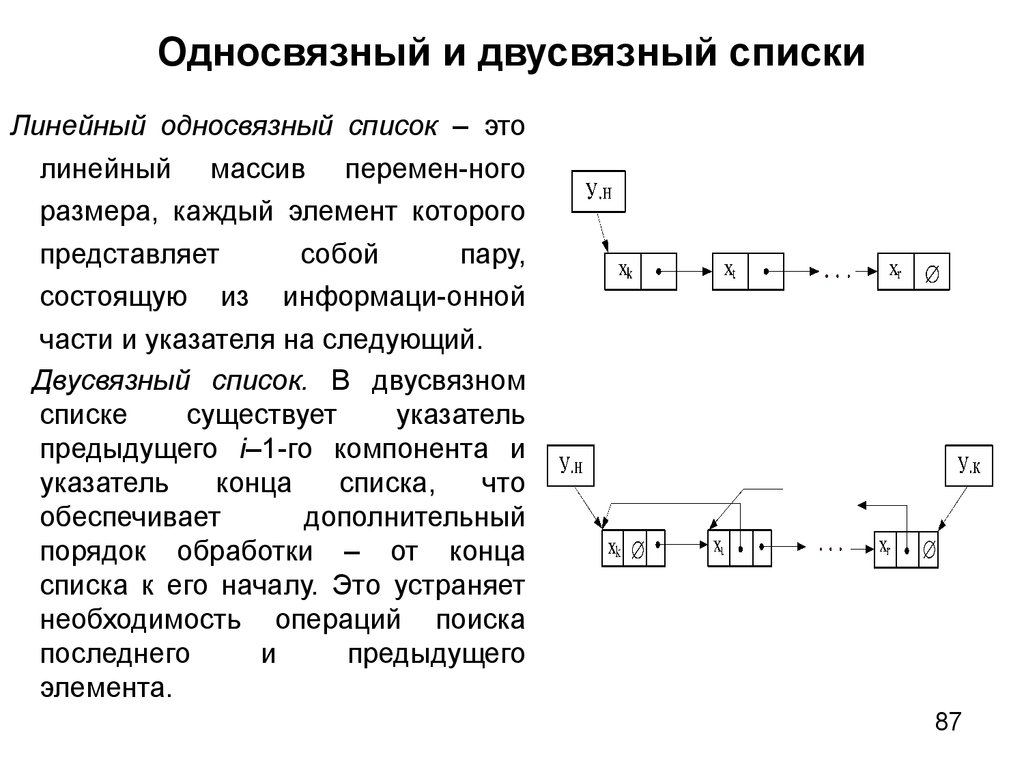
Линейный связный список
Односвязный список
В односвязном списке можно передвигаться только в сторону конца списка. Узнать адрес предыдущего элемента из данного невозможно.
Двусвязный список
По двусвязному списку можно передвигаться в любом направлении — как к началу, так и к концу. В этом списке проще производить удаление и перестановку элементов, т.к. всегда известны адреса тех элементов списка, указатели которых направлены на изменяемый элемент.
XOR-связный список
Основная статья: XOR-связный список
Кольцевой связный список
Разновидностью связных списков является кольцевой (циклический, замкнутый) список. Он тоже может быть односвязным или двусвязным. Последний элемент кольцевого списка содержит указатель на первый, а первый (в случае двусвязного списка) — на последний.
Список с пропусками
Основная статья: Список с пропусками
Развёрнутый связный список
Основная статья: Развёрнутый связный список
Достоинства
- лёгкость добавления и удаления элементов
- размер ограничен только объёмом памяти компьютера и разрядностью указателей
Недостатки
- сложность определения адреса элемента по его индексу (номеру) в списке
- на поля-указатели (указатели на следующий и предыдущий элемент) расходуется дополнительная память (в массивах, например, указатели не нужны)
- работа со списком медленнее, чем с массивами, так как к любому элементу списка можно обратиться, только пройдя все предшествующие ему элементы
- элементы списка могут быть расположены в памяти разреженно, что окажет негативный эффект на кэширование процессора
- над связными списками гораздо труднее (хотя и в принципе возможно) производить параллельные векторные операции, такие как вычисление суммы
См.
также- Список структур данных
- Стек
- Очередь
- Дерево
- Сортировка связного списка
- 1 Виды связных списков
 3 Список с пропусками
3 Список с пропусками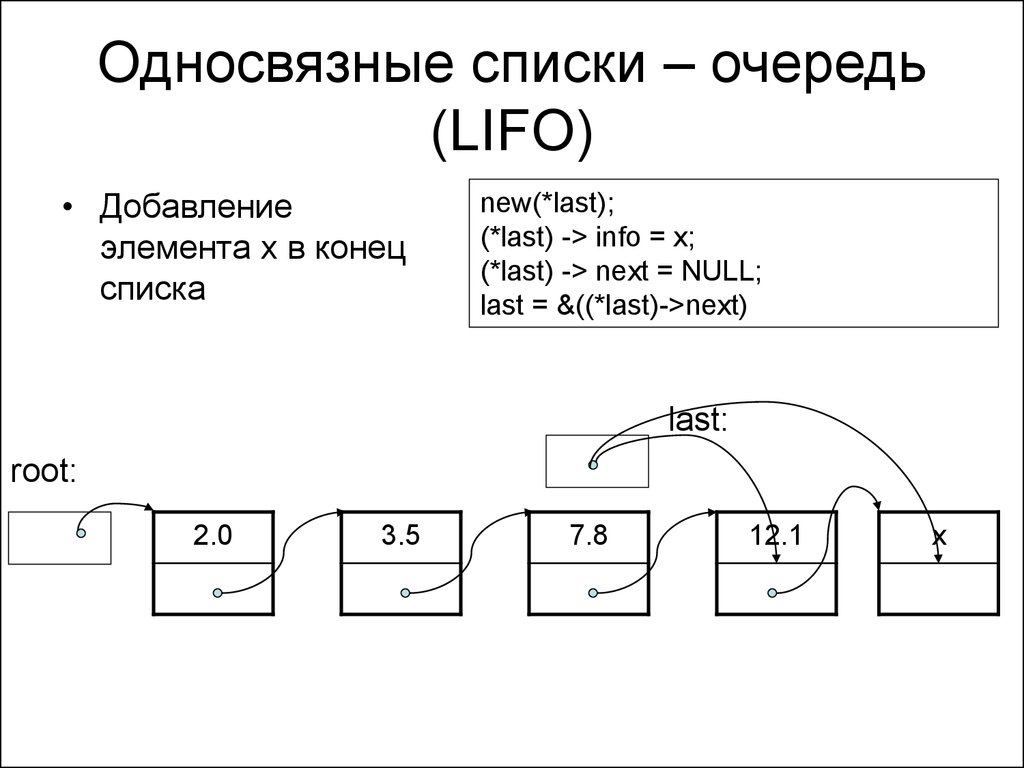
 также
такжеWikimedia Foundation. 2010.
Игры ⚽ Нужно решить контрольную?
- Односвязное пространство
- Односвязность
Полезное
#8. Односвязный список. Структура и основные операции
Смотреть материал на видео
Мы продолжаем курс по структурам данных. На прошлых занятиях мы подробно ознакомились со статическими и динамическими массивами. Пришло время сделать следующий шаг и рассмотреть новую структуру – односвязный список.
Я начну с основных
недостатков динамических массивов. Как мы уже говорили, если физического
размера недостаточно, то создается новый массив длиной, скажем, в два раза
больше прежнего и в первую половину копируются данные из первого массива. Это достаточно
ресурсоемкая операция, составляющая O(n), особенно,
когда число элементов n стремительно
растет.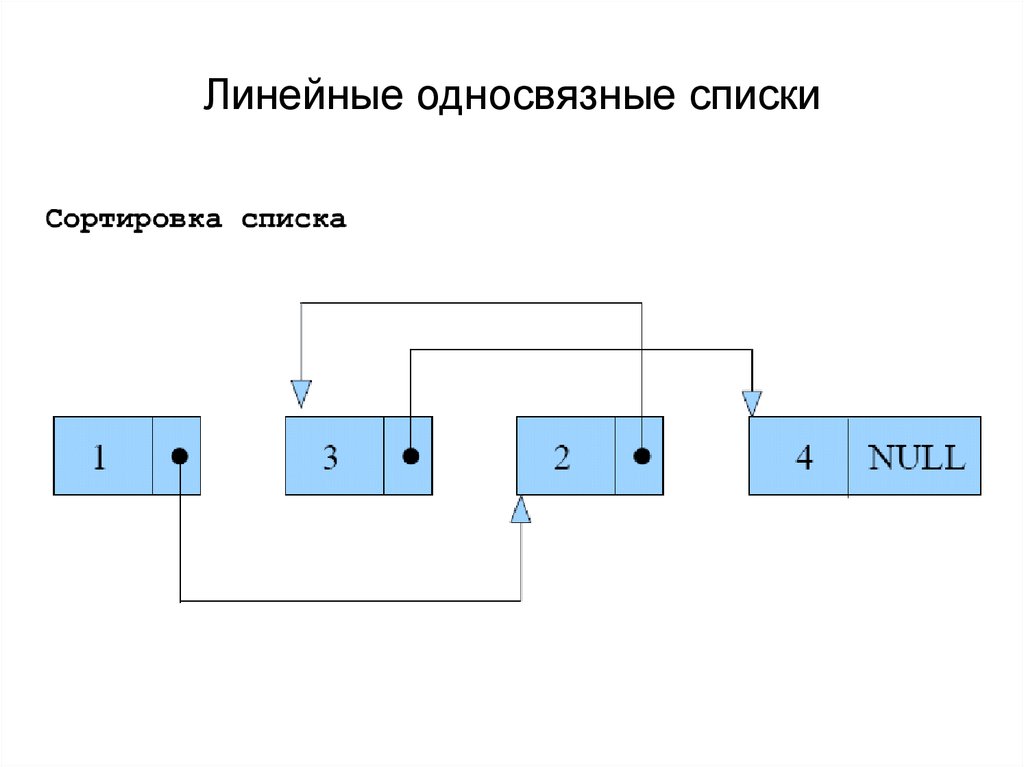
Давайте
попробуем решить эти проблемы. Что если при увеличении физического размера
динамического массива мы просто выделим еще один такой же кусок где то в
памяти, то есть, данные уже не будут идти строго друг за другом, а находиться в
разных областях. Очевидно, при таком подходе нам не пришлось бы копировать уже
имеющиеся данные в новый массив, и не требовалось бы искать все большую и
большую непрерывную область памяти. Мало того, скорость добавления нового
элемента происходила бы за константное время O(1) –
значительно быстрее, чем в классическом динамическом массиве. Видите, сколько
сразу плюсов мы получаем от такой идеи организации данных! Осталось только выяснить,
как нам осуществить переход от последнего элемента первого массива к первому
элементу второго массива? Самое простое и очевидное что можно сделать – это
хранить в последнем элементе ссылку на следующий блок данных.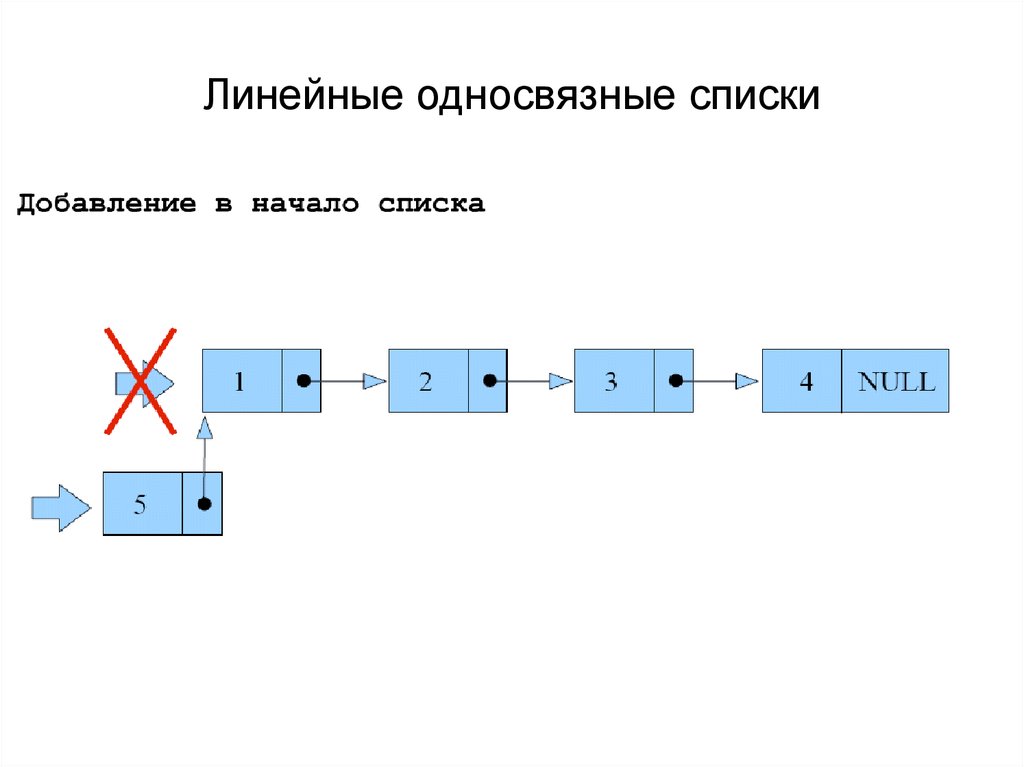
А теперь возведем такую структуру в некий абсолют: вообще откажемся от массивов, а вместо них определим отдельные элементы, которые будут ссылаться друг на друга, пока последний элемент не будет иметь ссылку на NULL, или None, или какое-либо другое предопределенное значение, которое означает конец последовательности.
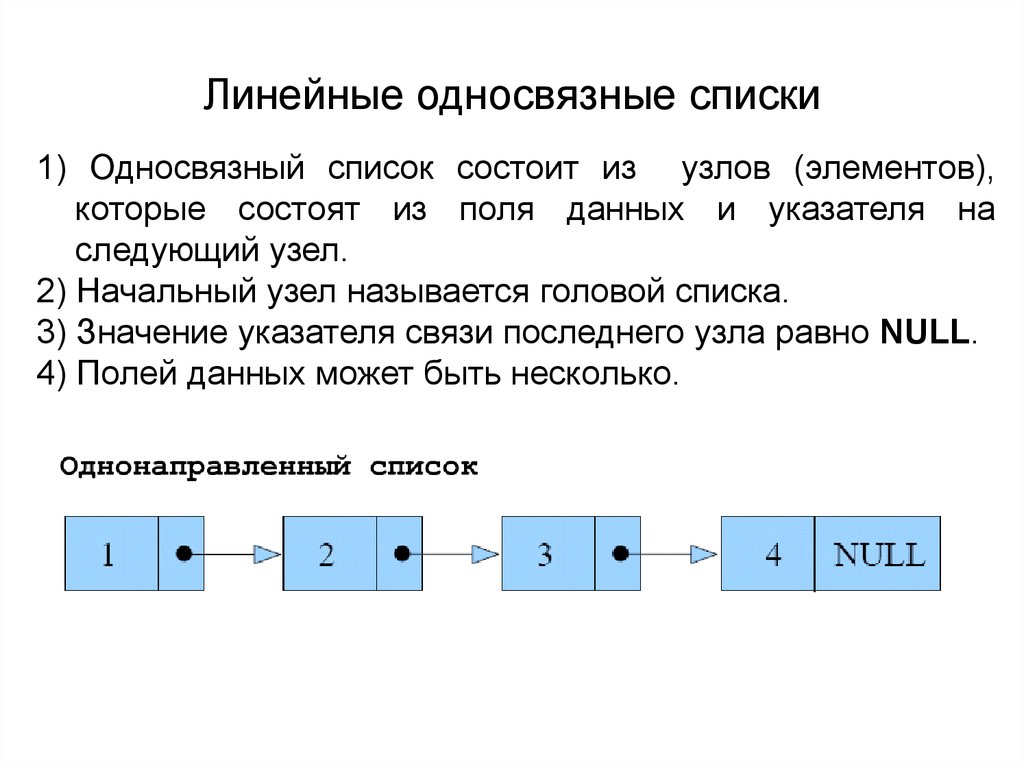
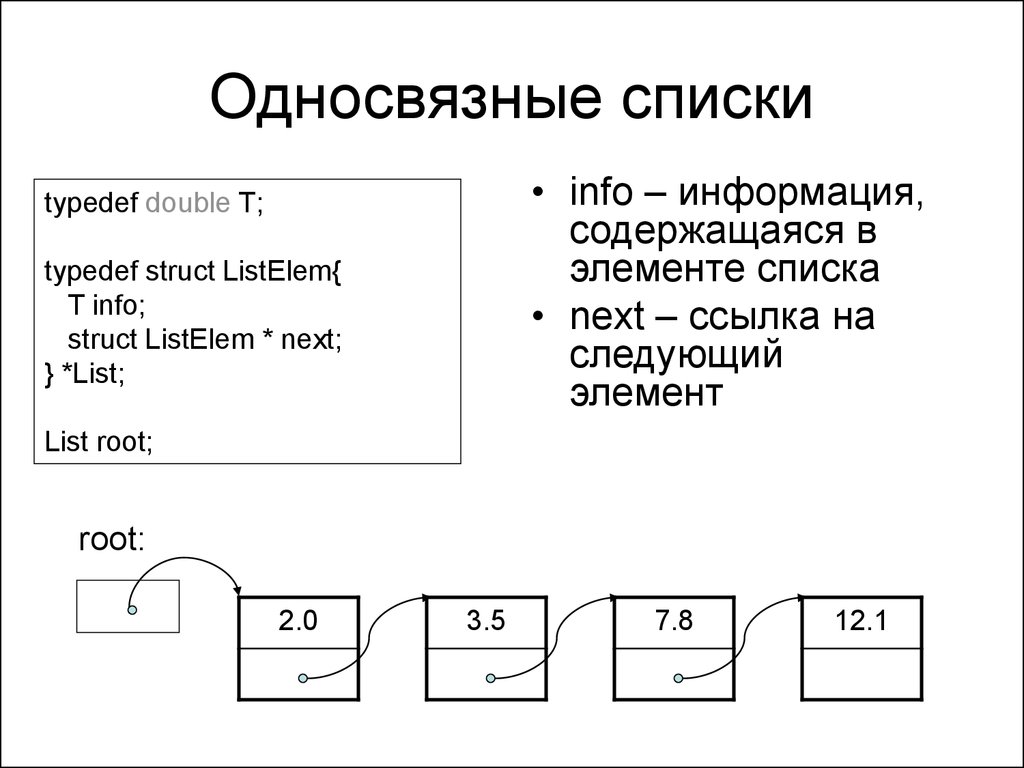
Такая структура данных, в которой элементы ссылаются друг на друга по порядку в одном направлении, начиная от первого и до последнего, получила название односвязный список.
Добавление элементов в конец и начало односвязного списка
Давайте теперь
посмотрим, какие основные операции можно выполнять с этой структурой данных.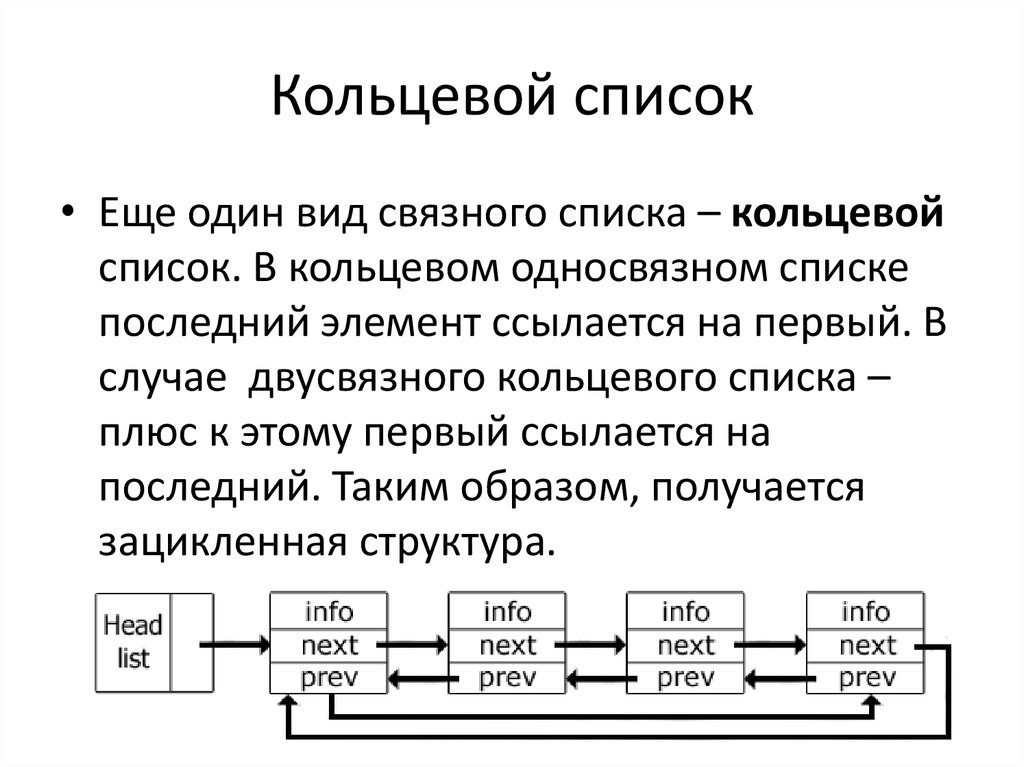
Предположим, что в списке всего два объекта. На первый элемент (объект) всегда ссылается переменная head, а на последний – переменная tail:
Мы хотим добавить в конец еще один элемент. Для этого, сначала нужно создать сам объект нового элемента списка (пусть на него ссылается временная переменная node). Затем, по ссылке tail выбираем последний элемент списка (который скоро станет предпоследним) и ссылку next меняем со значения NULL на значение адреса добавляемого объекта node. В свою очередь, у объекта node ссылку next устанавливаем равную NULL. И последнее, переменной tail присваиваем значение node так, чтобы tail указывала на последний элемент списка.
Как видите, все
достаточно просто. Скорость выполнения этой операции с точки зрения О большого
составляет O(1). Часто в
языках программирования эту операцию реализуют методом с названием push_back().
Часто в
языках программирования эту операцию реализуют методом с названием push_back().
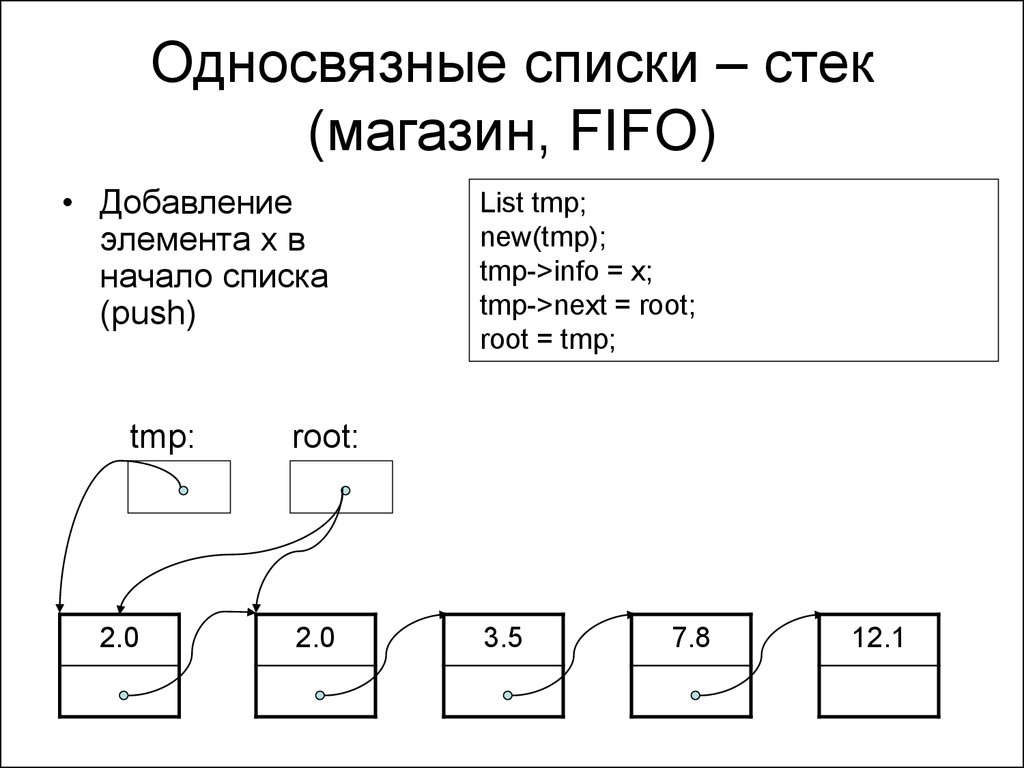
Давайте теперь посмотрим, как выполняется добавление элемента в начало односвязного списка. Пусть у нас имеются три элемента. На первый, по-прежнему, ссылается переменная head, а на последний – переменная tail:
Вначале также создаем новый объект, на который ссылается временная переменная node. Затем, значение ссылки next добавляемого элемента приравниваем значению head – адресу первого элемента списка, после чего head становится вторым. Поэтому присваиваем его значению переменной node так, чтобы head ссылалась на первый элемент списка:
Скорость выполнения этой операции также O(1), то есть, происходит за константное время и не зависит от размера списка (числа его элементов). Часто в языках программирования эту операцию реализуют методом под названием push
Доступ к произвольному элементу односвязного списка
Давайте теперь посмотрим, как можно обратиться к произвольному элементу односвязного списка. Предположим, у нас имеется список из четырех объектов:
Очевидно, для получения доступа к данным первого или последнего элемента достаточно воспользоваться ссылками head и tail. Например:
head.data – доступ к
данным первого элемента
tail.data – доступ к
данным последнего элемента
Но как нам
обратиться ко 2-му или 3-му элементу этого списка? Для этого придется по
цепочке двигаться от первого элемента до заданного k-го элемента,
используя ссылки next. Обычно для этого создают временную переменную
(ссылку на объект), допустим, с именем node. Изначально node равен head, то есть,
ссылается на первый элемент. Чтобы перейти к следующему элементу нужно node присвоить адрес
следующего объекта.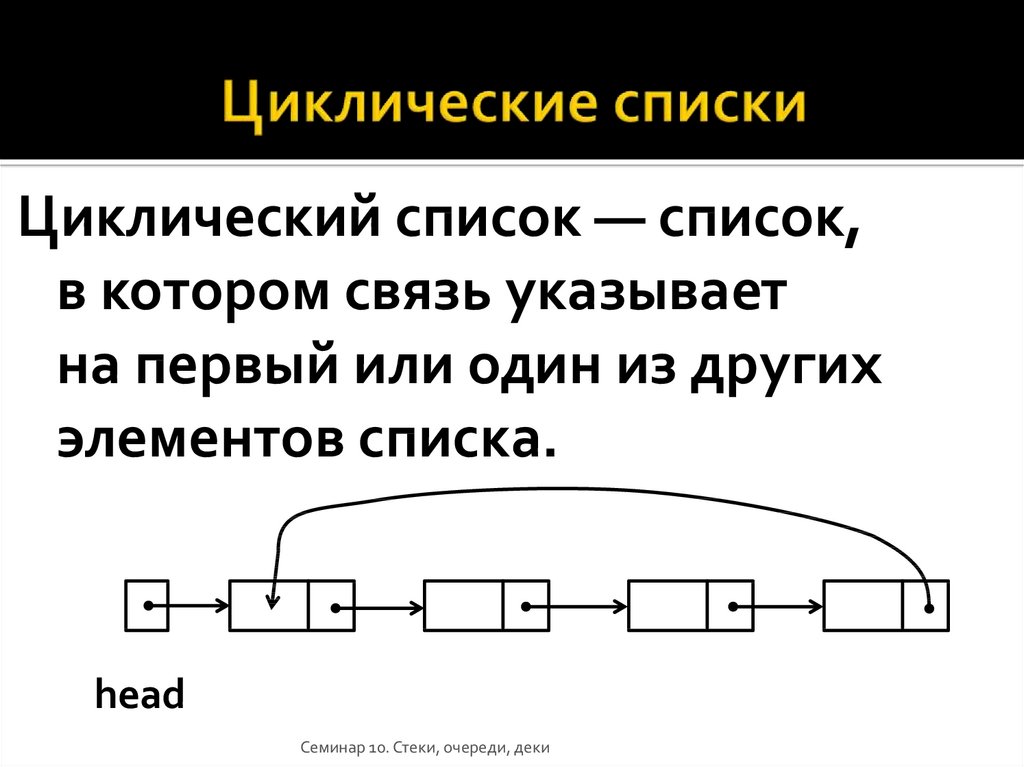
node = node.next
И указатель node будет ссылаться на второй элемент односвязного списка. Далее, можем действовать по циклу, перебирая все элементы от начала и до конца, пока значение next не будет равно NULL (или любому другому терминальному значению). Это значит, для доступа к произвольному k-му элементу, мы должны последовательно перебрать все предыдущие элементы. В итоге, сложность этой операции с точки зрения О большого, составляет O(n), где n – общее число элементов в односвязном списке. Как видите, в отличие от массивов, где доступ к произвольным элементам составляет O(1), здесь все несколько сложнее. Это та цена, которую мы платим за возможность быстрого добавления элементов в односвязный список, а также возможность хранить данные в разных областях памяти компьютера.
Вставка элемента в односвязный список
Постепенно мы с
вами дошли до вставок новых элементов в связный список. Как это делается и
насколько вычислительно сложно? Чтобы все было предельно просто и понятно, я
возьму небольшой односвязный список из четырех элементов. Наша задача вставить
пятый новый элемент после второго.
Как это делается и
насколько вычислительно сложно? Чтобы все было предельно просто и понятно, я
возьму небольшой односвязный список из четырех элементов. Наша задача вставить
пятый новый элемент после второго.
Очевидно, нам здесь понадобятся ссылки left и right на предыдущий и следующий элементы относительно добавляемого. Как их получить вы уже знаете: мы перебираем все элементы с самого начала и фиксируем два соседних, между которыми вставляется новый объект. Далее, создаем новый элемент в памяти компьютера, на который ссылается временная переменная node. Осталось только настроить связи ссылок next у объектов left и node. Из рисунка хорошо видно, что ссылка next объекта left должна вести на node, поэтому делаем присваивание:
left.next = node
А ссылка next объекта node должна вести на объект right, имеем:
node.next = right
Все, новый
объект вставлен в односвязный список.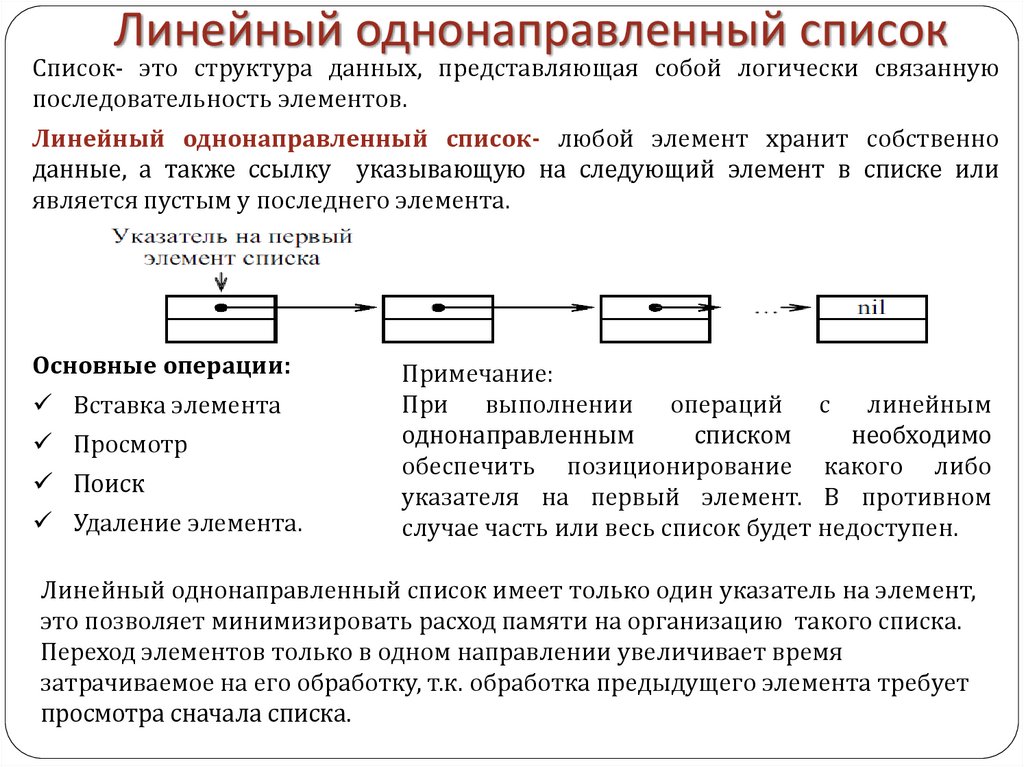 Часто в языках программирования эта
операция реализуется командой insert(). Самое сложное
в вычислительном плане здесь – это получить ссылку left объекта, после
которого планируется вставлять новый элемент. В общем случае для этого
требуется O(n) операций, что
не мало (n – число
элементов в списке). Однако если эта ссылка у нас уже есть, то сама операция
вставки занимает время O(1). А это уже значительно быстрее, чем
у массивов. Поэтому сложность зависит от конкретного использования односвязного
списка. Если у нас в распоряжении будут уже готовые ссылки на объекты, после
которых предполагаются вставки, то скорость выполнения операций будет высока. В
общем же случае, когда нужно сначала найти объект, а потом вставить новый, то
сложность становится линейной O(n).
Часто в языках программирования эта
операция реализуется командой insert(). Самое сложное
в вычислительном плане здесь – это получить ссылку left объекта, после
которого планируется вставлять новый элемент. В общем случае для этого
требуется O(n) операций, что
не мало (n – число
элементов в списке). Однако если эта ссылка у нас уже есть, то сама операция
вставки занимает время O(1). А это уже значительно быстрее, чем
у массивов. Поэтому сложность зависит от конкретного использования односвязного
списка. Если у нас в распоряжении будут уже готовые ссылки на объекты, после
которых предполагаются вставки, то скорость выполнения операций будет высока. В
общем же случае, когда нужно сначала найти объект, а потом вставить новый, то
сложность становится линейной O(n).
Удаление элементов из односвязного списка
В заключение
этого занятия рассмотрим обратные операции по удалению элементов из односвязного
списка. Начнем с удаления промежуточных объектов.
Начнем с удаления промежуточных объектов.
Давайте предположим, что в списке пять элементов и нам нужно удалить объект node:
Для этого достаточно у предыдущего объекта left переопределить ссылку next на объект right:
left.next = right
и освободить память, занимаемую объектом node:
Скорость самой операции удаления элемента node из односвязного списка выполняется за константное время O(1). Но для получения ссылок left и right требуется O(n) операций. Поэтому, в общем случае, имеем объем вычислений, равный O(n), где n – число элементов в списке.
В языках программирования эта операция часто реализуется командой erase().
Последнее, что мы рассмотрим на этом занятии – это удаление первого и последнего элементов односвязного списка.
Первый элемент
удаляется относительно просто.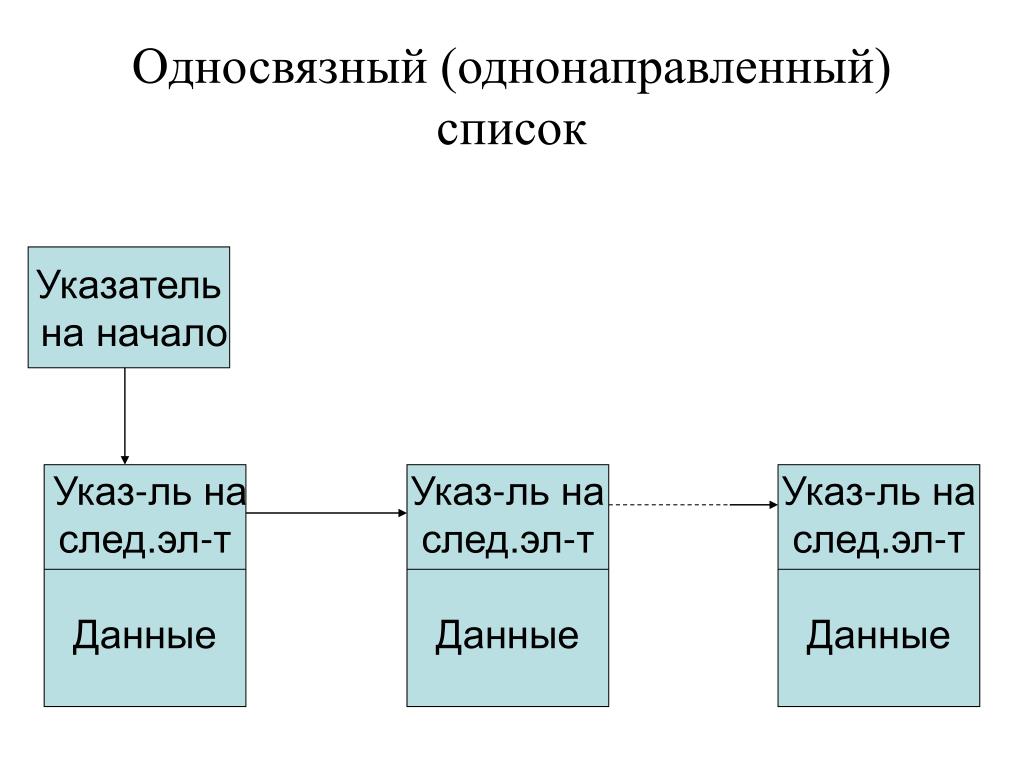 Нам достаточно переместить указатель head на следующий
элемент и освободить память, занимаемую элементом node:
Нам достаточно переместить указатель head на следующий
элемент и освободить память, занимаемую элементом node:
Как видите, все предельно просто. Скорость этой операции с точки зрения О большого O(1) и часто реализуется командой pop_front().
При удалении последнего элемента в односвязном списке нам необходимо сначала получить ссылку на предпоследний элемент, затем, освободить память последнего элемента tail. Изменить значение tail на node:
tail = node
и поменять значение ссылки next объекта node на NULL:
node.next = NULL
Скорость удаления самого элемента составляет O(1), но переход к предпоследнему элементу O(n). Поэтому общая вычислительная сложность этого алгоритма составляет O(n).
В языках
программирования эта операция часто реализуется командой pop_back().
Заключение
Подведем общие итоги этого занятия. Самые быстрые операции – это добавление элементов в начало и конец списка и удаление с начала списка. Остальные операции имеют сложность O(n).
|
Команда |
Big O |
|
|
Добавление в начало |
push_front() |
O(1) |
|
Добавление в конец |
push_back() |
O(1) |
|
Удаление с конца |
pop_back() |
O(n) |
|
Удаление с начала |
pop_front() |
O(1) |
|
Вставка элемента |
insert() |
O(n) |
|
Удаление промежуточных элементов |
erase() |
O(n) |
|
Доступ к элементу |
iterator |
O(n) |
На следующем
занятии мы продолжим эту тему и посмотрим на пример реализации односвязного
списка на языке программирования.
Видео по теме
#1. О большое (Big O) — верхняя оценка сложности алгоритмов
#2. О большое (Big O). Случаи логарифмической и факториальной сложности
#3. Статический массив. Структура, его преимущества и недостатки
#4. Примеры реализации статических массивов на C++
#5. Динамический массив. Принцип работы
#6. Реализация динамического массива на Python
#7. Реализация динамического массива на С++ с помощью std::vector
#8. Односвязный список. Структура и основные операции
#9. Делаем односвязный список на С++
#10. Двусвязный список. Структура и основные операции
#11. Делаем двусвязный список на С++
#12. Двусвязный список (list) в STL на С++
#13.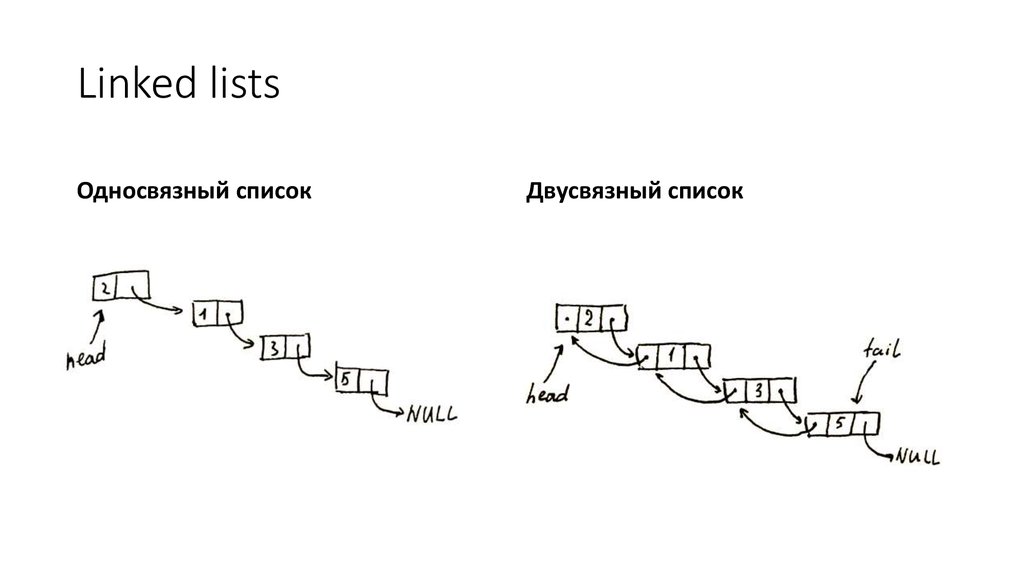 Очереди типов FIFO и LIFO
Очереди типов FIFO и LIFO
#14. Очередь collections.deque на Python
#15. Очередь deque библиотеки STL языка C++
#16. Стек. Структура и принцип работы
#17. Реализация стека на Python и C++
#18. Бинарные деревья. Начало
#19. Бинарное дерево. Способы обхода и удаления вершин
#20. Реализация бинарного дерева на Python
#21. Множества (set). Операции над множествами
#22. Множества set и multiset в C++
#23. Контейнер map библиотеки STL в C++
#24. Префиксное (нагруженное, Trie) дерево. Ассоциативные массивы
#25. Хэш-таблицы. Что это такое и как работают
#26. Хэш-функции. Универсальное хэширование
#27. Метод открытой адресации. Двойное хэширование
Двойное хэширование
#28. Использование хэш-таблиц в Python и С++
структур данных в JavaScript: односвязные списки | by Anıl Akgüneş
Односвязный список — это упорядоченная структура данных, которая может быть очень полезна для некоторых особых случаев, как и многие другие структуры данных.
Photo by JJ Ying on UnsplashОдносвязные списки (иногда называемые односвязными списками) позволяют хранить данные по порядку. Они похожи на массивы и поэтому их часто сравнивают друг с другом.
В некоторых случаях, когда массивы работают очень плохо, односвязный список блестит, и знание плюсов и минусов этих двух структур данных для упорядоченных списков может избавить вас от некоторых проблем с производительностью.
Первое отличие состоит в том, что массивы — это встроенная структура данных в JavaScript, которая поставляется со многими красивыми методами, такими как pop , unshift , filter , reduce , find и так далее, но односвязный список — это структуру данных, которую нам нужно настроить с помощью некоторых классов и методов JavaScript.
Обычно односвязный список состоит из узлов как элементов массивов. Эти узлы включают две вещи: значение и указатель 9.0012, и каждый указатель ссылается на другой узел.
Вот базовое представление односвязного списка. Это похоже на цепочку, каждый узел связан со следующим.
Представление узлов в односвязном списке.В JavaScript мы можем создать класс, который генерирует объекты-узлы. Давайте преобразуем изображение выше в код. Выглядит некрасиво, но скоро мы сделаем его красивее.
Базовое представление узлов в JavaScript.До сих пор мы видели узлы и их отношения друг с другом. Давайте углубимся в сам односвязный список.
Одиночные списки имеют три основных свойства: head , tail и length .
Изображение односвязного спискаМы можем преобразовать поток выше в код ниже.
Базовое представление односвязного списка в JavaScript. Однако это выглядит довольно бесполезно, потому что мы хотим иметь некоторые операции с нашими структурами данных, такие как вставка , удаление , поиск и доступ к данным.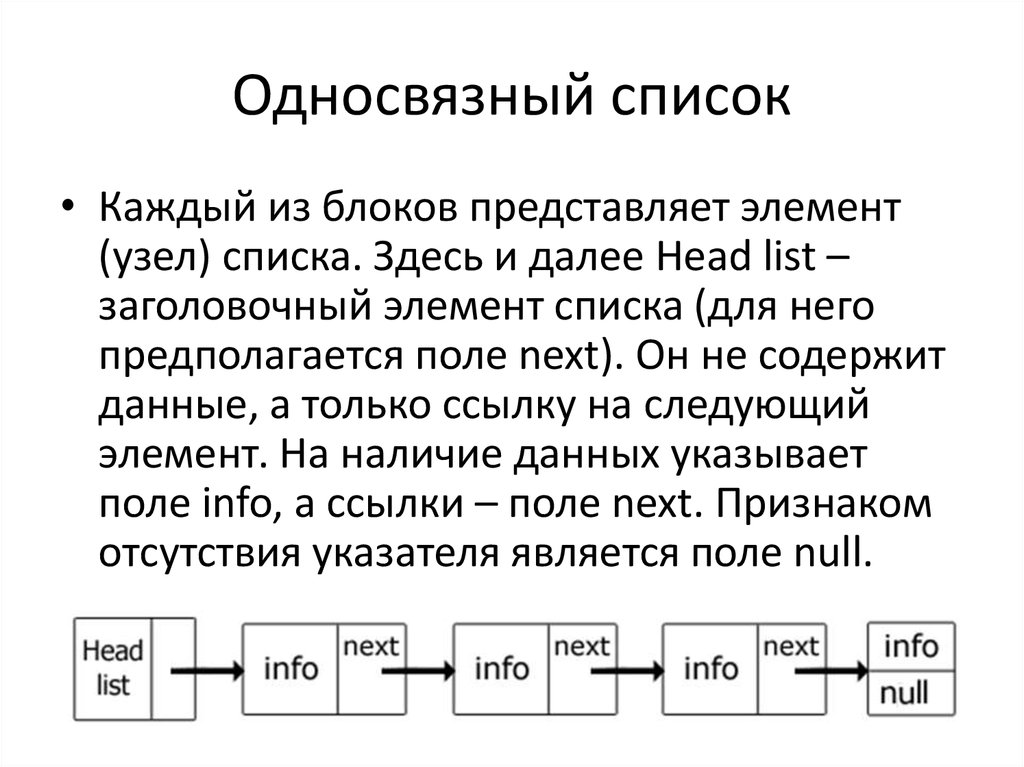
К сожалению, односвязный список не является встроенной структурой данных, поэтому нам нужно написать наши методы. Я уверен, что есть много симпатичных библиотек, предоставляющих структуру односвязного списка и множество методов с ней, но мы будем использовать наши методы с одним списком здесь. Начнем со вставки.
Это базовая структура односвязного списка с методом вставки, который добавляет узлы в конец списков.
Добавление метода push в односвязный список.Как и выше, нам нужно предоставить все методы, которые нам нужны в наших проектах. Ниже я приведу некоторые методы, которые часто используются в SLL.
После этого я сравню массивы и односвязные списки с точки зрения производительности с нотацией Big O.
Я предоставлю несколько общих методов с JavaScript. Если вас не интересует реализация, пропустите эту часть и посмотрите сравнение.
Кроме того, вы можете получить доступ к коду здесь: https://github.com/anlakgns/single-linked-list, чтобы поиграть с ним. Я уверен, что есть лучший и более компактный способ реализации этих методов, я просто хочу, чтобы здесь был понятный код, если у вас есть лучший способ сделать что-либо из этого, пожалуйста, поделитесь в комментариях.
Я уверен, что есть лучший и более компактный способ реализации этих методов, я просто хочу, чтобы здесь был понятный код, если у вас есть лучший способ сделать что-либо из этого, пожалуйста, поделитесь в комментариях.
- Мы можем добавить pop-метод в наш односвязный класс, чтобы удалить последний узел в списке.
- Мы можем использовать метод сдвига для удаления узла в начале, что является очень дорогой операцией в массивах.
- Мы можем добавить узел в начале методом unshift.
- Мы можем использовать метод получения для доступа к определенному узлу, который очень дорог в односвязном списке.
- Мы можем обновить значение узла с помощью метода set.
- Мы можем использовать метод вставки , чтобы поместить узел в очень определенное место.
- Удалить метод для удаления узла в списке, который является довольно распространенным методом, нам нужна почти каждая структура данных.
- Это не требующий пояснений метод, который изменяет указатель на противоположную сторону, таким образом, мы можем перевернуть список.
Массивы — это встроенные структуры данных, а односвязный список — нет, нам нужно настроить или использовать библиотеку для его использования, это одно из основных отличий.
Выполнение основных операций с данными, таких как доступ, удаление и т. д., очень важно, когда дело доходит до выбора правильной структуры данных. Мы сравним эти две упорядоченные структуры данных в контексте того, как они выполняют эти операции.
Доступ к случайным данным
- SLL не имеет индексов, у них есть только указатели, поэтому доступ к случайным данным в SLL довольно дорог, потому что нам нужно начинать с головы и нужно переходить к следующему указателю, пока мы не найдем то, что нам нужно, но в массивах довольно легко с помощью индекса. Поэтому, если мы часто используем произвольный доступ в упорядоченном списке, SLL не является хорошим вариантом, используйте массивы.
- Big O (массив) — при индексах доступ к данным постоянный, не зависит от количества элементов в массиве. О(1)
- Big O (SLL) — ну, нам нужно пройтись по всем узлам благодаря указателю, пока не найдем правильный, поэтому нам нужно зациклиться, поэтому доступ к данным в SLL зависит от узлов в нем. O(n)
- Заключение. Массивы здесь явно выигрывают.
 Поэтому, если мы часто используем произвольный доступ в упорядоченном списке, SLL не является хорошим вариантом, используйте массивы.
Поэтому, если мы часто используем произвольный доступ в упорядоченном списке, SLL не является хорошим вариантом, используйте массивы.Вставка
- Массивы не подходят для вставки либо по той же причине, о которой мы упоминали выше, мы можем вставить элемент куда-нибудь, но после того, как все элементы в списке будут снова переиндексированы. SLL в некоторой степени лучше, но и не очень хороший вариант, потому что нам нужно найти конкретный узел с циклом.
- Big O (массив) — на самом деле это зависит от того, куда положить предмет. Если мы поместим в начале, это будет O (n), , если мы поместим в конце, это будет O (1), , если мы вставим в середине, это приведет к переиндексации после этого элемента, поэтому это будет O(n). Можно сказать среднее O(n)
- Большое O (SLL) — опять же тут зависит от того, куда опять ставить, для конца и начала это будет O(1). Для середины нам нужно сначала найти местоположение с помощью указателя, поэтому нам нужно перебрать узлы, поэтому это будет O(n) ,
- Вывод: нет явного победителя для случайной и конечной вставки, но для начальной вставки SLL лучше.
 Если мы поместим в начале, это будет O (n), , если мы поместим в конце, это будет O (1), , если мы вставим в середине, это приведет к переиндексации после этого элемента, поэтому это будет O(n). Можно сказать среднее O(n)
Если мы поместим в начале, это будет O (n), , если мы поместим в конце, это будет O (1), , если мы вставим в середине, это приведет к переиндексации после этого элемента, поэтому это будет O(n). Можно сказать среднее O(n) Удаление
- Удаление дорого для массивов. На самом деле это зависит от того, где находится элемент, но в любом случае, если рассматривать удаление в целом, массивы не годятся для этого. Поскольку каждый раз, когда мы удаляем что-то в массиве, все элементы должны быть переиндексированы, поэтому это снижает производительность, если мы часто используем удаление, массивы не являются хорошим вариантом, но то же самое и для SLL. Вставка и удаление большого O одинаковы, здесь вы также можете рассмотреть вставку для большого O.
- Вывод: нет явного победителя для случайного и конечного удаления, но для начального удаления SLL лучше.
 Вставка и удаление большого O одинаковы, здесь вы также можете рассмотреть вставку для большого O.
Вставка и удаление большого O одинаковы, здесь вы также можете рассмотреть вставку для большого O.Поиск
- Для поиска нам нужно просмотреть все элементы или узлы в обеих структурах, поэтому это зависит от количества элементов в списке. Вот почему оба O(n)
- Вывод, нет победителя, оба одинаковы
Общий вывод , SLL — отличная альтернатива массивам, если вы часто используете удаление и вставку в начало в упорядоченном списке.
Надеюсь, вам все понятно. Если вы думаете, что что-то не так или звучит странно, пожалуйста, дайте мне знать.
Не строить веб-монолиты. Используйте Bit для создания и компоновки несвязанных программных компонентов — в ваших любимых средах, таких как React или Node. Создавайте масштабируемые и модульные приложения с мощными и приятными возможностями разработки.
Пригласите свою команду в Bit Cloud , чтобы вместе размещать и совместно работать над компонентами, а также ускорять, масштабировать и стандартизировать разработку в команде. Попробуйте компонуемых внешних интерфейсов с Design System или Micro Frontends или изучите компонуемых внутренних интерфейсов с серверными компонентами .
Попробуйте →
Как мы создаем микроинтерфейсы
Создание микроинтерфейсов для ускорения и масштабирования процесса веб-разработки.
blog.bitsrc.io
Как мы создаем систему проектирования компонентов
Создание системы проектирования с компонентами для стандартизации и масштабирования процесса разработки пользовательского интерфейса.
blog.bitsrc.io
Компонуемое предприятие: руководство
Чтобы работать в 2022 году, современное предприятие должно стать компонуемым.

blog.bitsrc.io
Как создать компонуемый блог
Создание блога с нуля требует довольно много времени. Существует ряд движущихся частей, которые объединяются для создания…
bit.cloud
Знакомство с контентом, управляемым компонентами: применимый, компонуемый
С появлением таких технологий, как React и Angular, мы часто приходим к свяжите термин «компонент» в…
bit.cloud
Создание библиотеки компонентов составного пользовательского интерфейса
Как создать библиотеку компонентов. Библиотека компонентов React с составными компонентами.
bit.cloud
Односвязный список в JavaScript. Связанный список, как и массивы, является линейным… | Гульгина Аркин | Связанный список Startup
, как и массивы, представляет собой линейную структуру данных. Он содержит свойства головы, хвоста и длины. Как показано ниже, каждый элемент в связанном списке — это узел, который имеет значение и ссылку на следующий узел, или, если он хвостовой, указывает на ноль.
Зачем нам нужен связанный список, если у нас есть массивы?
Для вставки и удаления данных массивы могут быть дорогими. Связанный список, с другой стороны, имеет динамический размер и упрощает вставку и удаление. Однако есть один недостаток, в отличие от массивов, элементы в связном списке не имеют индексов по порядку, что не допускает произвольного доступа.
Существуют различные типы связанных списков, такие как односвязный список, двусвязный список и кольцевой связанный список. Поскольку односвязный список встречается чаще всего, давайте поговорим об односвязном списке в JavaScript.
Чтобы иметь четкое представление об односвязном списке, я реализую класс LinkedList в JavaScript.
Каждый узел связанного списка будет иметь два атрибута: значение и следующий, а связанный список будет иметь атрибуты начала, хвоста и длины.
https://gist.github.com/GAierken/eb9583bc1ffa78b8e1bb7438a7a49014Push
Как мы можем поместить новый узел в конец нашего списка? Создадим функцию push.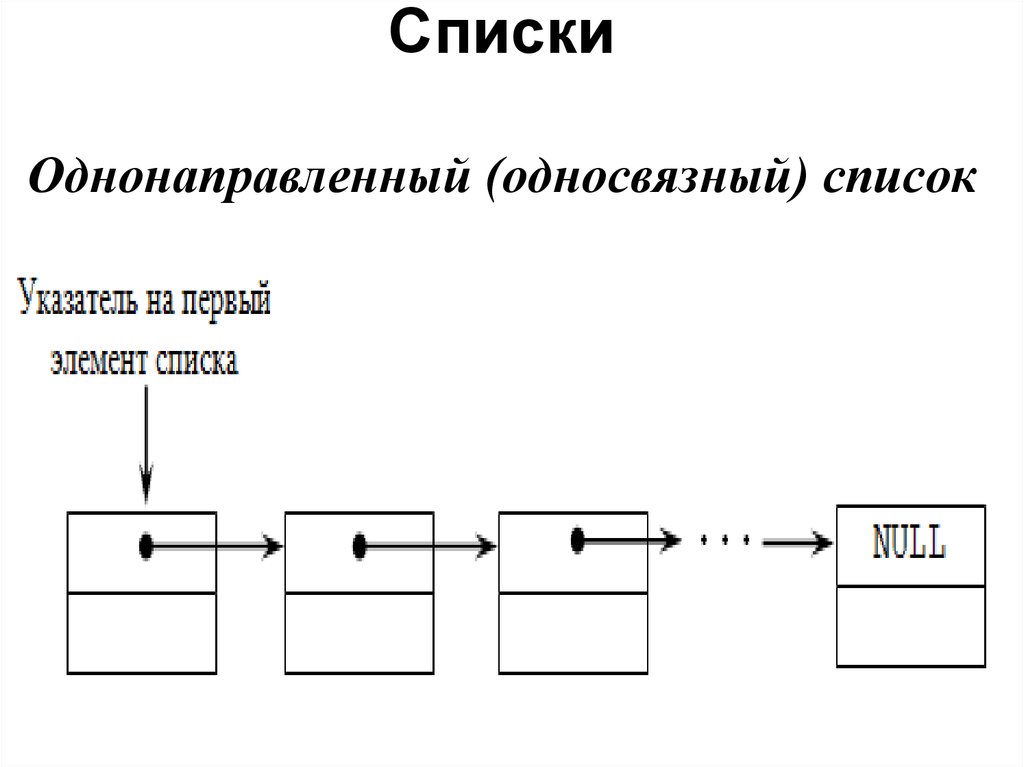 Во-первых, нам нужно создать новый узел, используя заданное значение, проверить, есть ли у списка заголовок (пустой ли он?) и не забыть увеличить размер списка.
Во-первых, нам нужно создать новый узел, используя заданное значение, проверить, есть ли у списка заголовок (пустой ли он?) и не забыть увеличить размер списка.
Pop
При нажатии нам нужно подумать о выталкивании, удалении последнего элемента. Если узла нет, верните неопределенное значение, иначе выполните цикл по списку, пока не дойдете до хвоста, установите свойство next предпоследнего узла равным нулю, сделайте вторым последним хвост, не забудьте уменьшить значение размер списка.
https://gist.github.com/GAierken/2c24fecb26f7453879ab471190fcba1eShift
Для удаления первого элемента, сдвига, как обычно, проверяем, не пуст ли список. Во-первых, сохраните текущую головку в переменной, установите головку как следующую за текущей головкой, уменьшите длину.
https://gist.github.com/GAierken/e6a11cdaf63d9620db33cef58d0a9507Unshift
Чтобы вставить узел в начало списка, проверяем, не пуст ли список, если нет, устанавливаем текущий заголовок следующий атрибут входящего узла, увеличивает размер.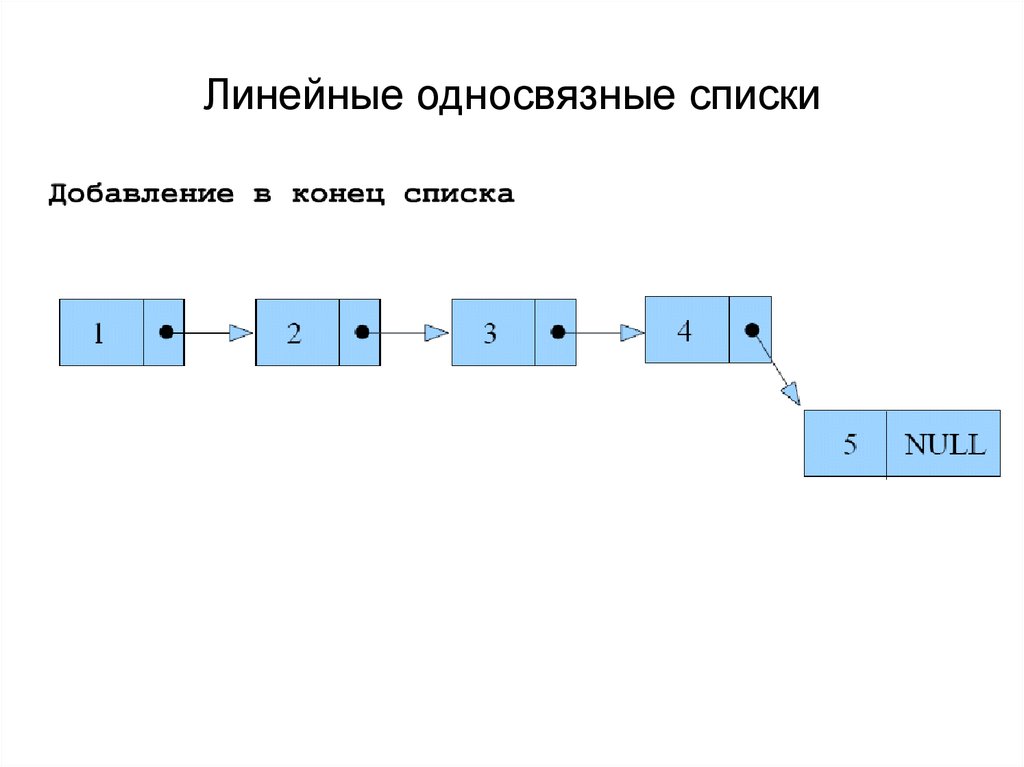
Получить
Несмотря на то, что связанный список не имеет индексов, мы все равно можем найти узел по заданному индексу. Сначала убедитесь, что заданный индекс больше нуля и меньше или равен длине списка. Затем мы перебираем список, пока не достигнем индекса.
https://gist.github.com/GAierken/6475bb388fe8b0f2b7f6507bb3cab446Set
Что делать, если мы хотим изменить узел в нашем списке? Мы находим узел с помощью get() и устанавливаем узел с заданными данными.
https://gist.github.com/GAierken/e9b0bb11849219914e2b3ee7b215d5d2Insert
Когда мы хотим вставить новый узел в список, сначала проверьте, больше ли индекс больше 0 и меньше длины. Если индекс равен длине, мы просто используем push(), если индекс равен 0, мы используем unshift(). Для других индексов нам нужно получить узел с индексом-1 и установить следующим свойством этого узла новый узел, а следующим свойством нового узла должно быть предыдущее следующее свойство, затем мы увеличиваем длину .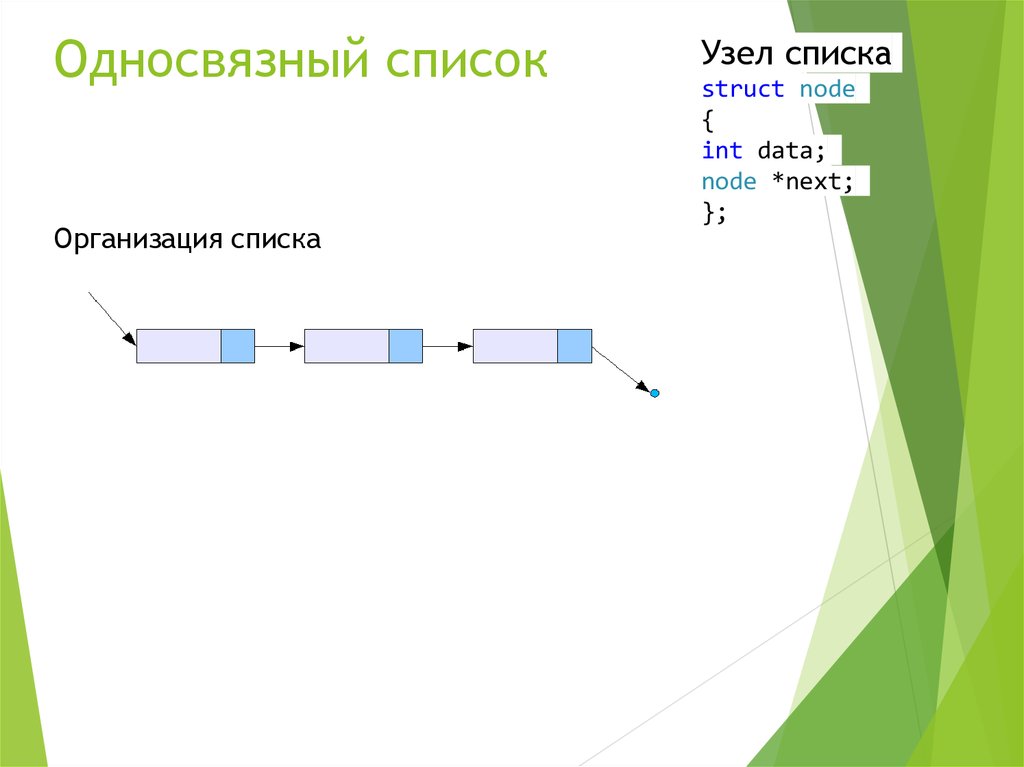
Remove
В отличие от pop и unshift, функция удаления удалит узел по заданному индексу. Как обычно, проверьте правильность индекса, если индекс равен length-1 или 0, используйте pop или shift. В противном случае мы получаем узел с индексом-1, устанавливаем следующее свойство в этом узле как следующее из следующего свойства, после чего уменьшаем размер.
https://gist.github.com/GAierken/e888104f65a836925b11e102584edd76Обратный
Окончательный обратный вопрос! Как перевернуть список? Во-первых, мы меняем голову и хвост, объявляем следующий и предыдущий, устанавливаем предыдущий как нуль. Проходим по списку.
https://gist.github.com/GAierken/556c13f4ccbc5bcd49584bd662b553deКакова большая сложность односвязного списка?
С таблицей будет понятнее.
Большой O односвязного списка С помощью этих основных функций мы сможем справиться с проблемами связанных списков.