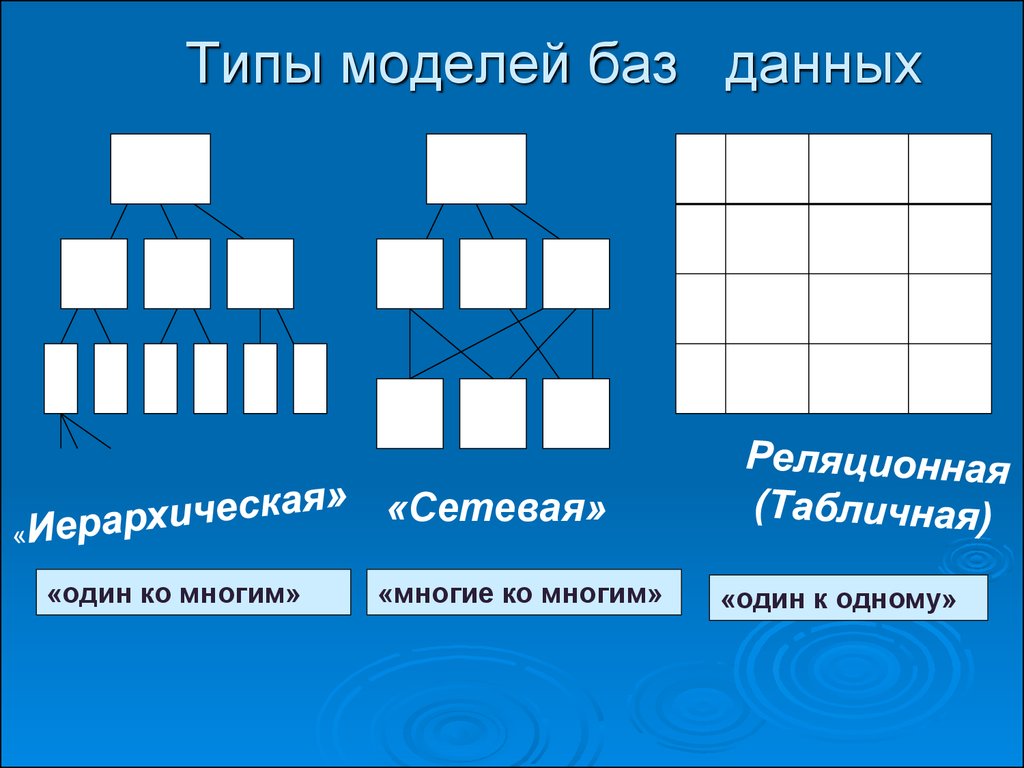
Модели баз данных
- Основные виды баз данных и их модели
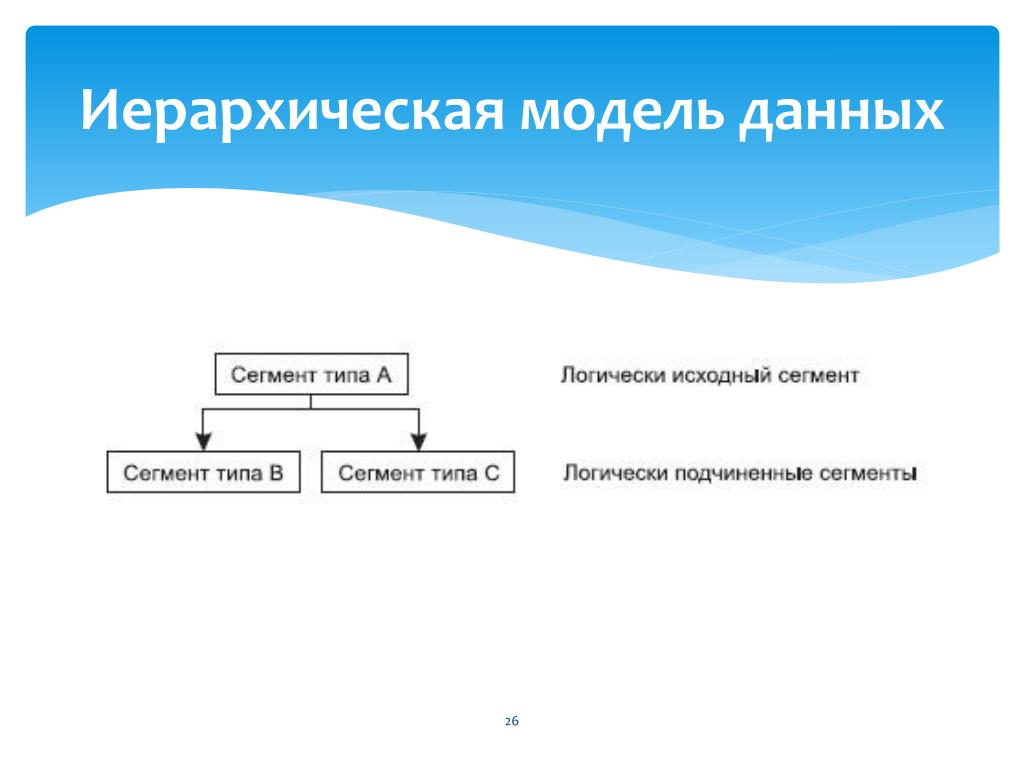
- Модели баз данных — иерархическая база данных
- Иерархическая база данных — пример
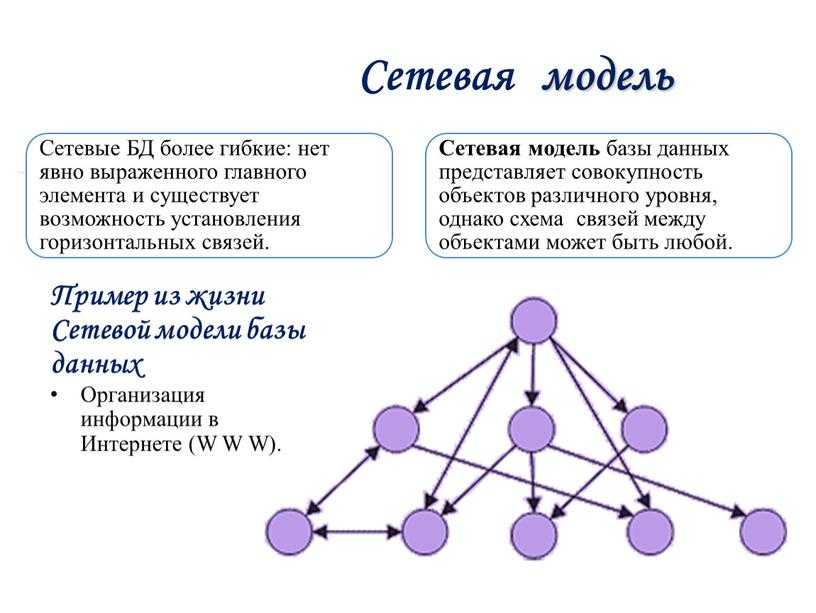
- Сетевая модель базы данных
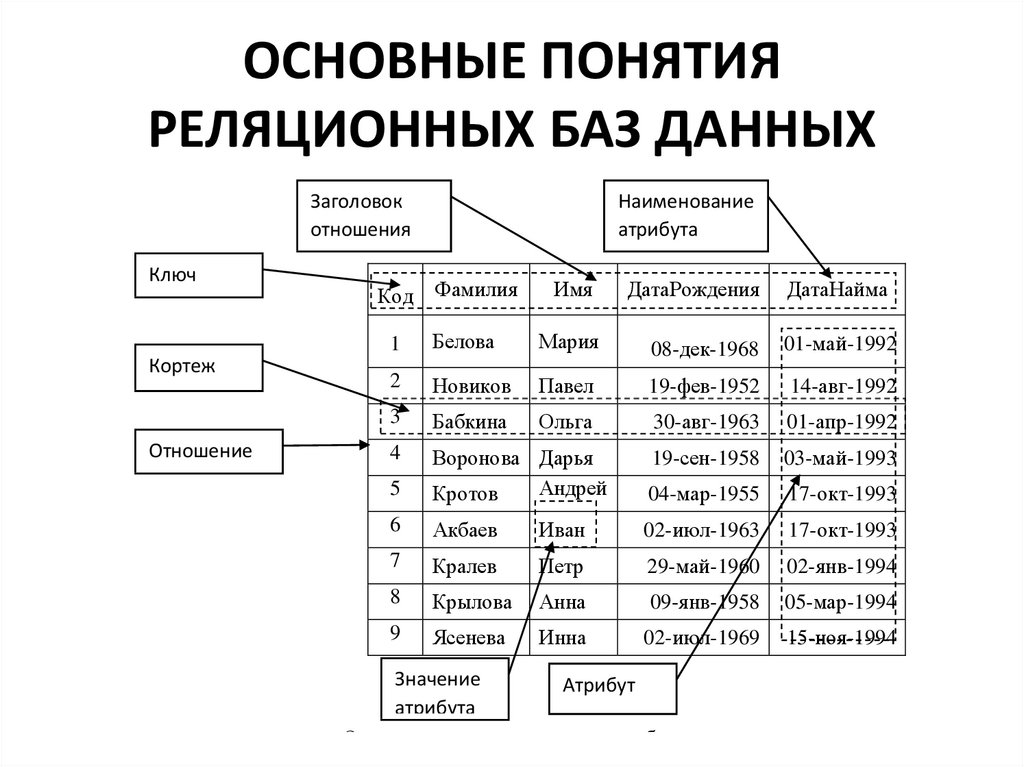
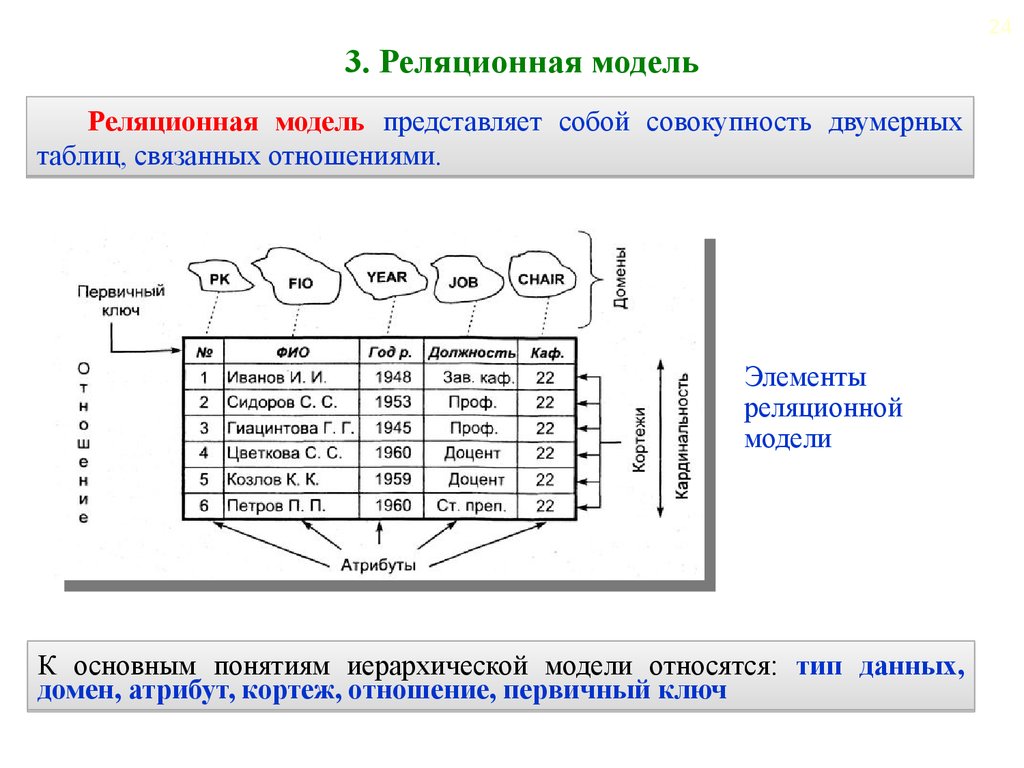
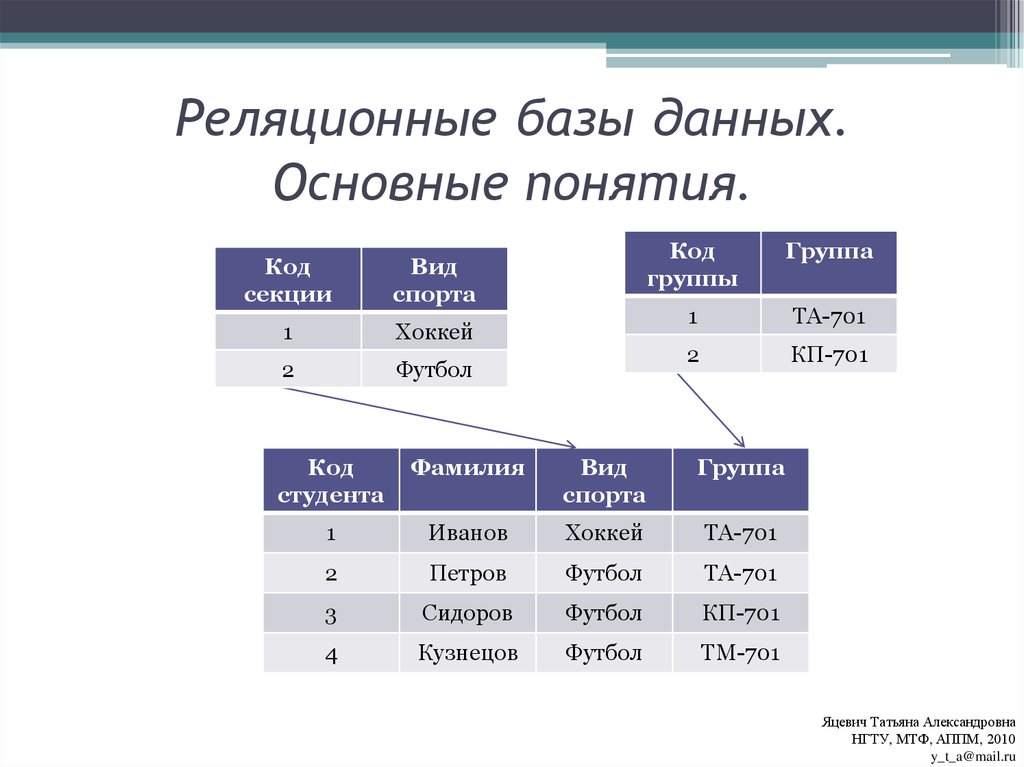
- Реляционная модель базы данных
- Сравниваем три модели баз данных
- «Один к одному»
- «Один ко многим»
- «Многие ко многим»
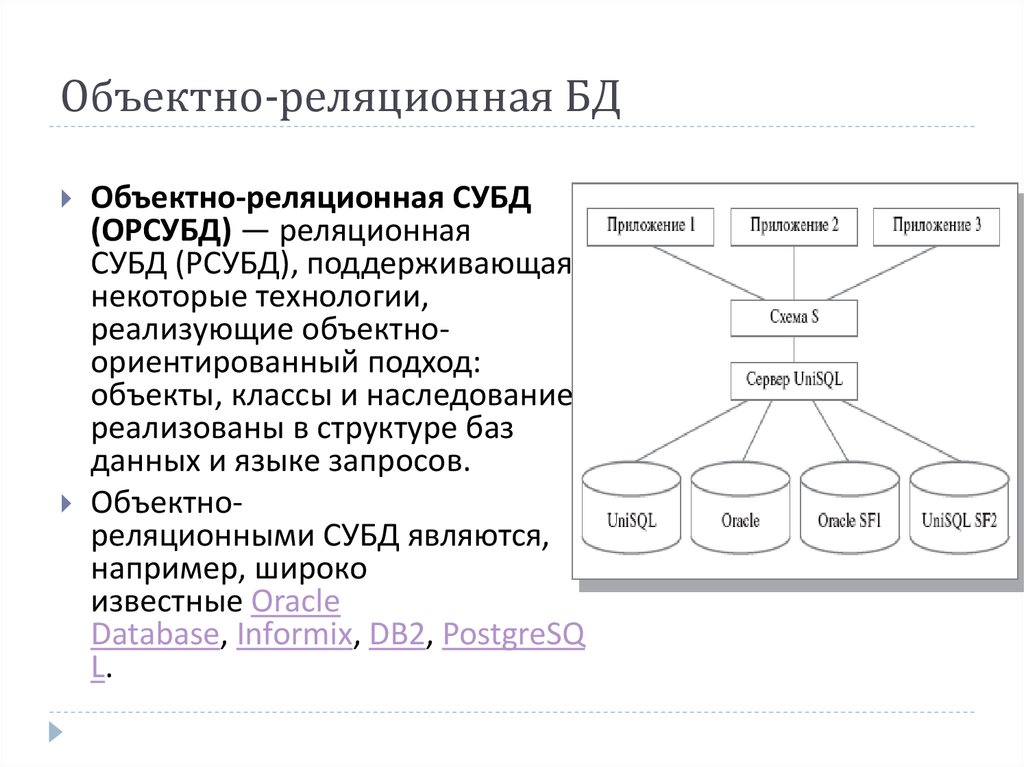
- Другие модели баз данных (ООСУБД)
СУБД используют различные модели баз данных. Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Иерархическая модель базы данных подразумевает, что элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
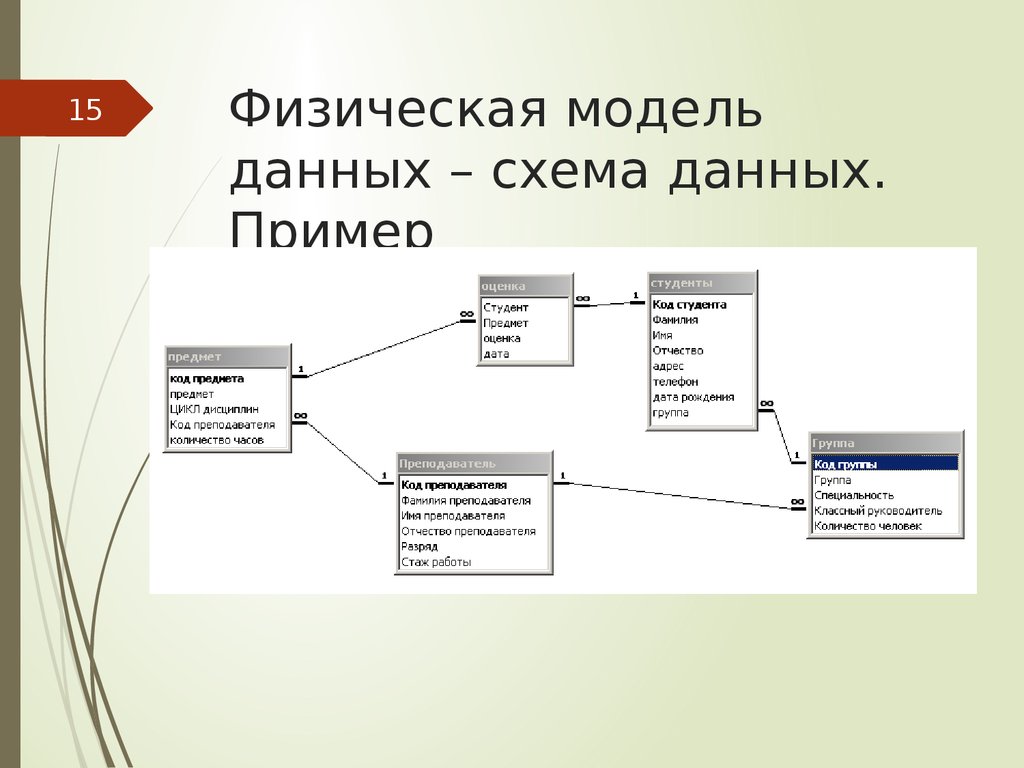
Иерархическая модель данных организует их в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату.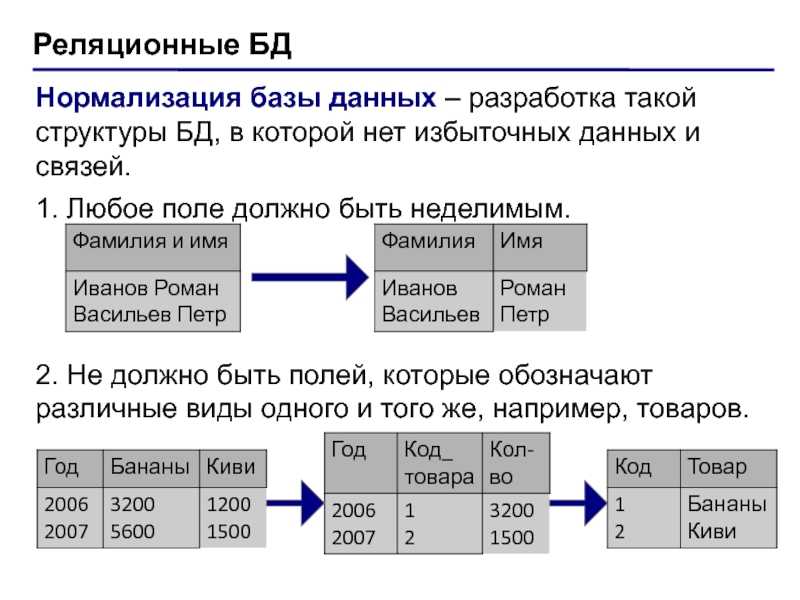 Организация также может хранить информацию о его детях, их имена и даты рождения.
Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.


Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.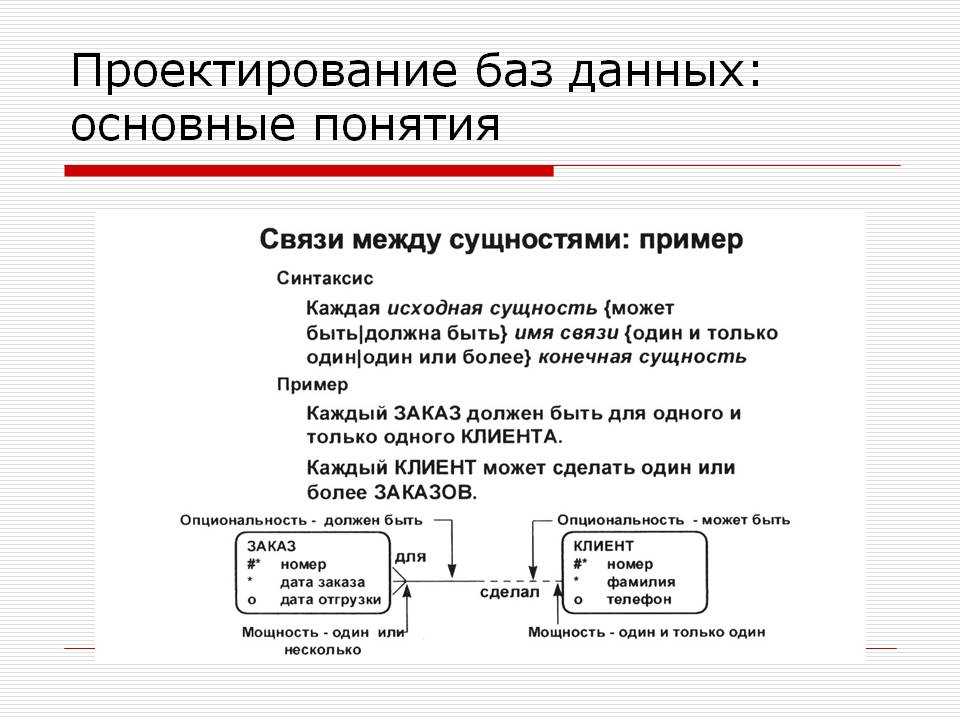
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
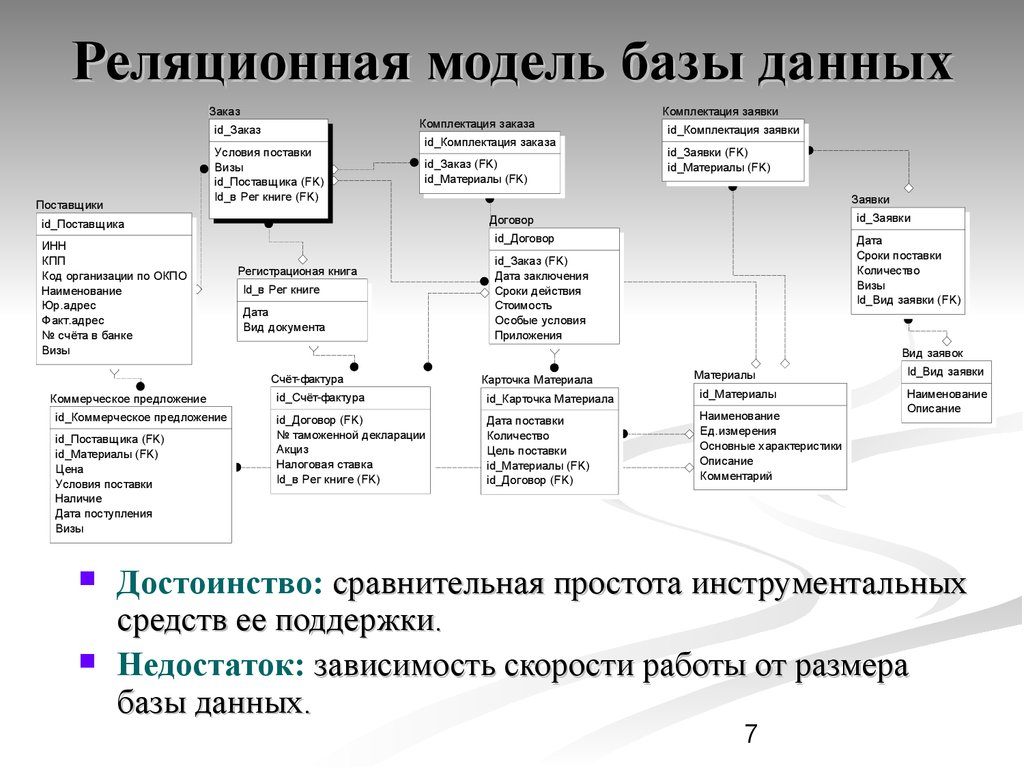
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД.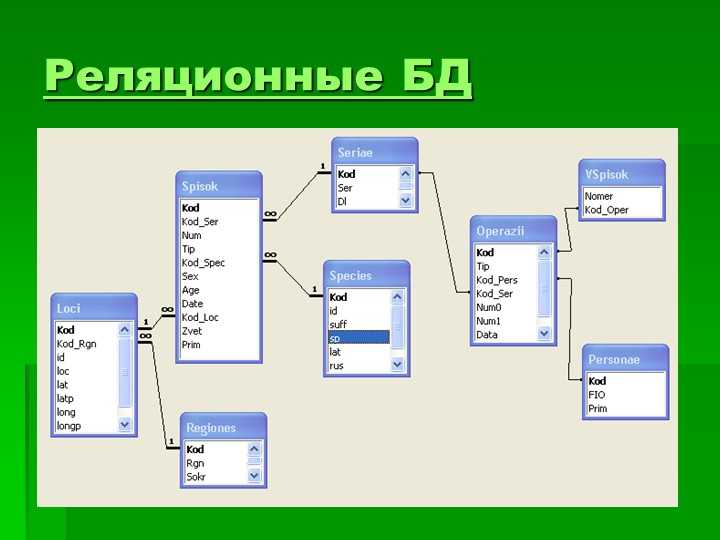 Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
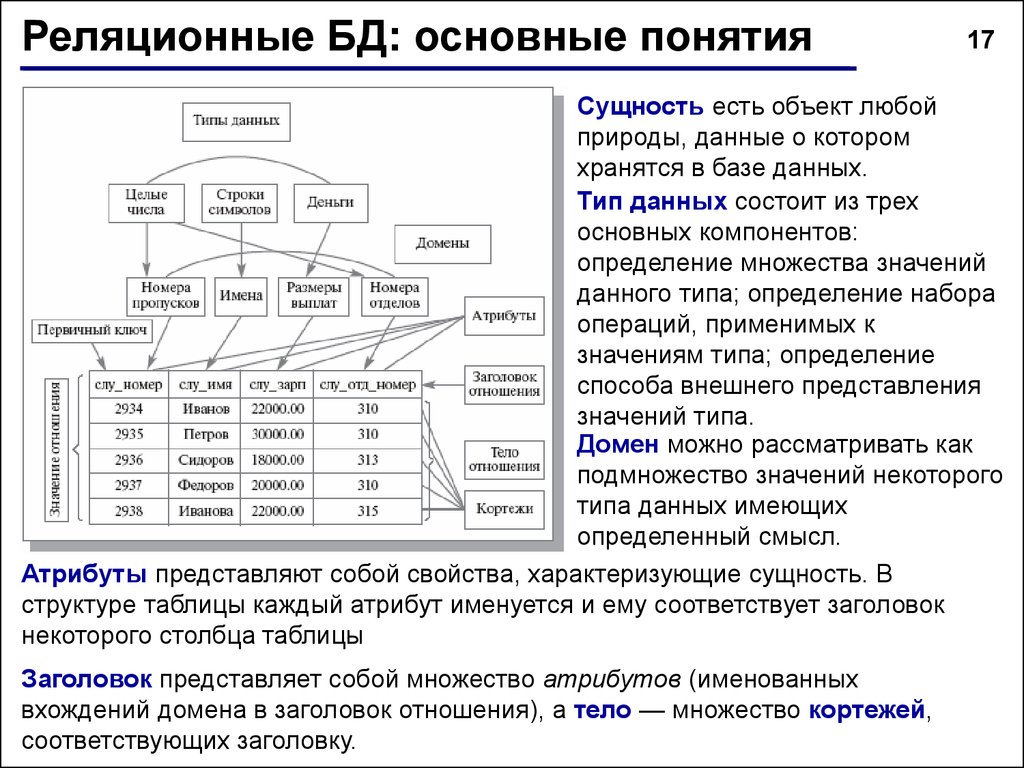
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими.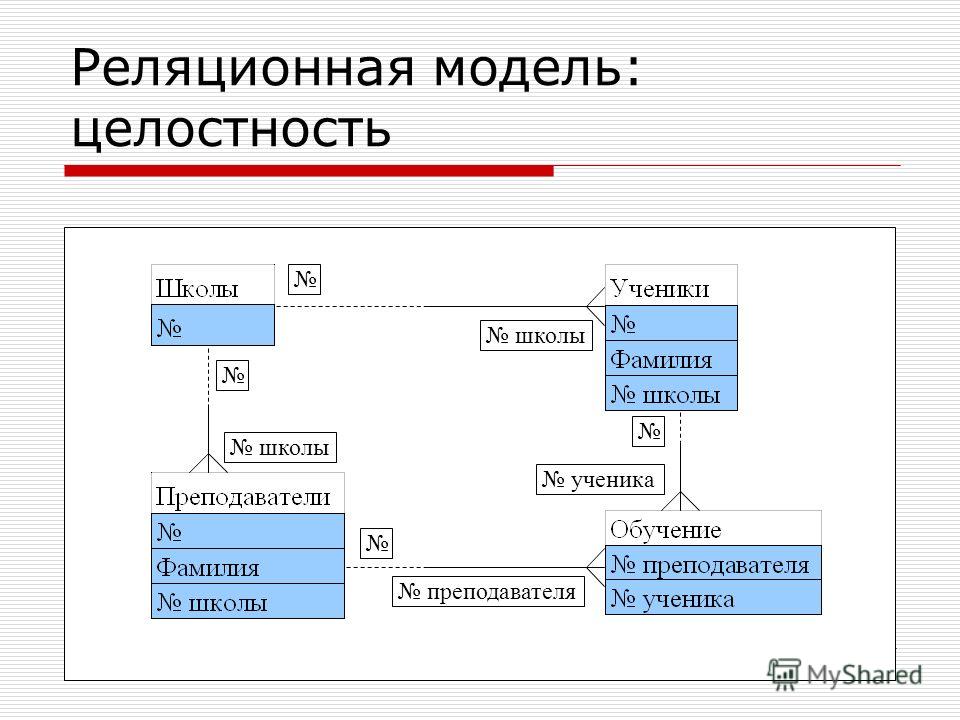 Например, Сотрудник -> Отдел.
Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.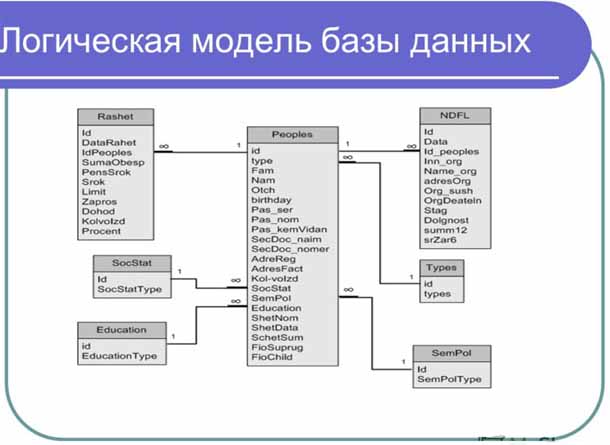
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
 То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Пожалуйста, опубликуйте свои отзывы по текущей теме материала. За комментарии, лайки, дизлайки, подписки, отклики огромное вам спасибо!
МКМихаил Кузнецовавтор-переводчик статьи «Types of Database Models | Database Management System»
Модели баз данных
- Основные виды баз данных и их модели
- Модели баз данных — иерархическая база данных
- Иерархическая база данных — пример
- Сетевая модель базы данных
- Реляционная модель базы данных
- Сравниваем три модели баз данных
- «Один к одному»
- «Один ко многим»
- «Многие ко многим»
- Другие модели баз данных (ООСУБД)
СУБД используют различные модели баз данных.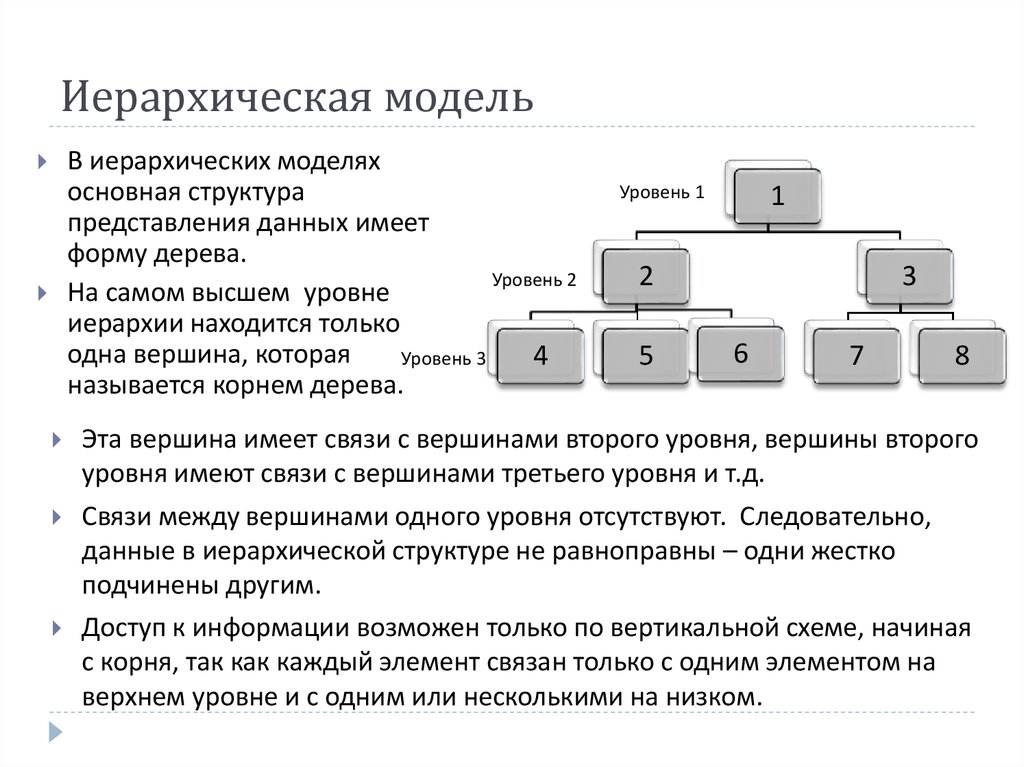 Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Иерархическая модель базы данных подразумевает, что элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель данных организует их в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.
Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I.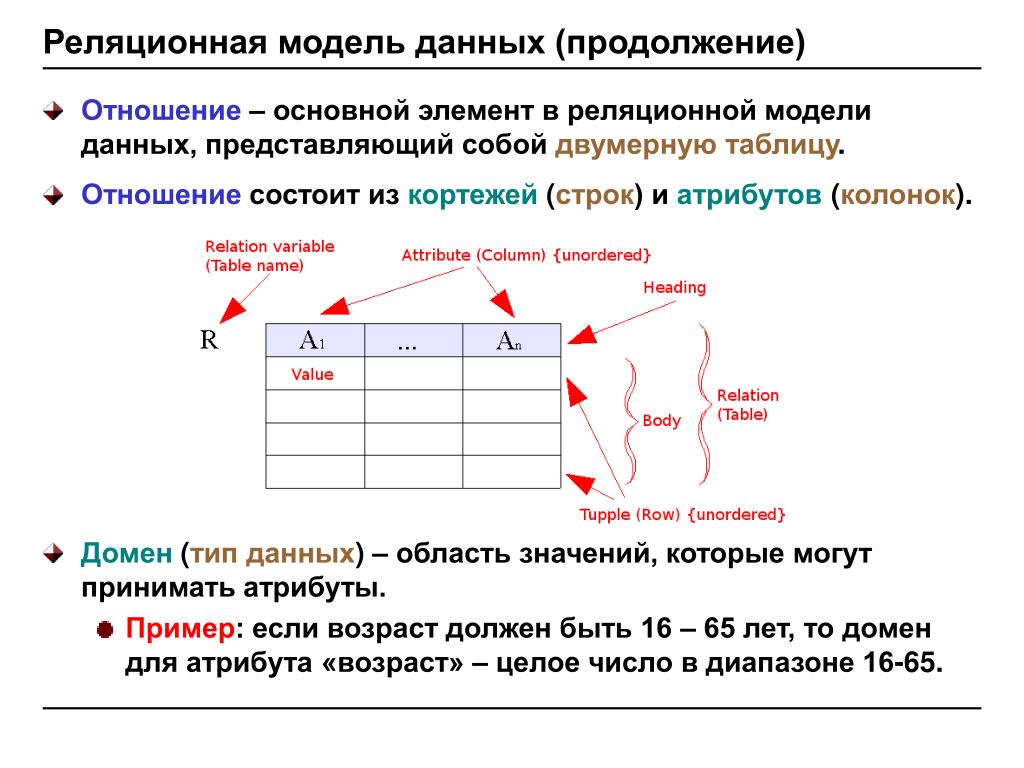 Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД.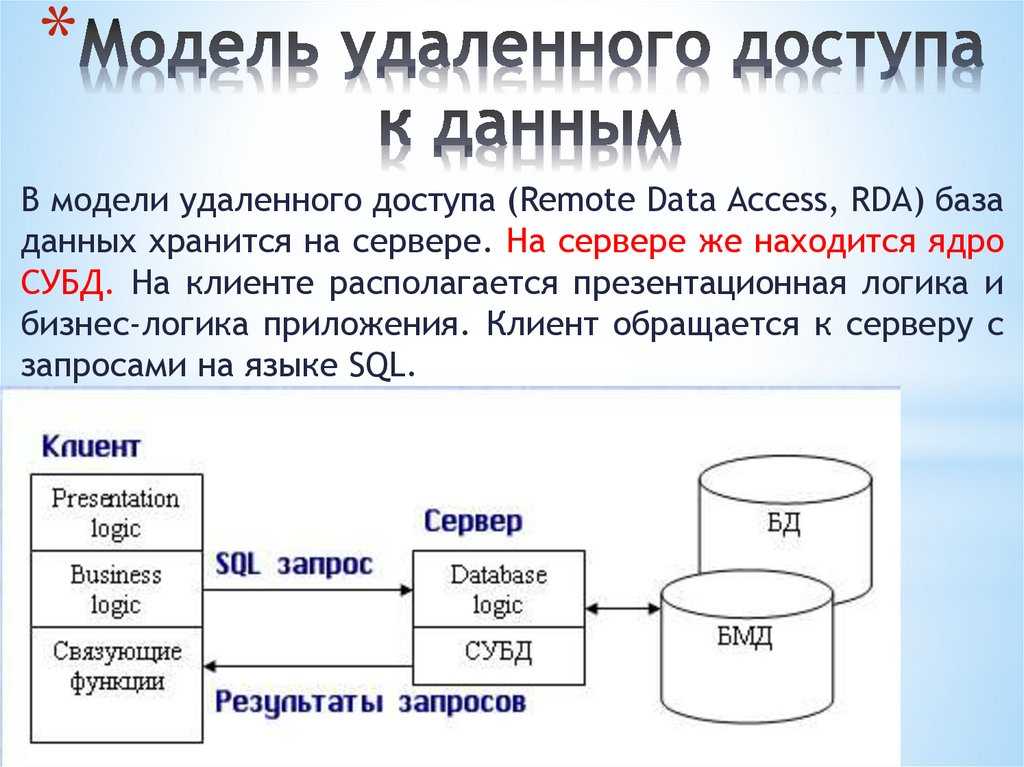 Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими.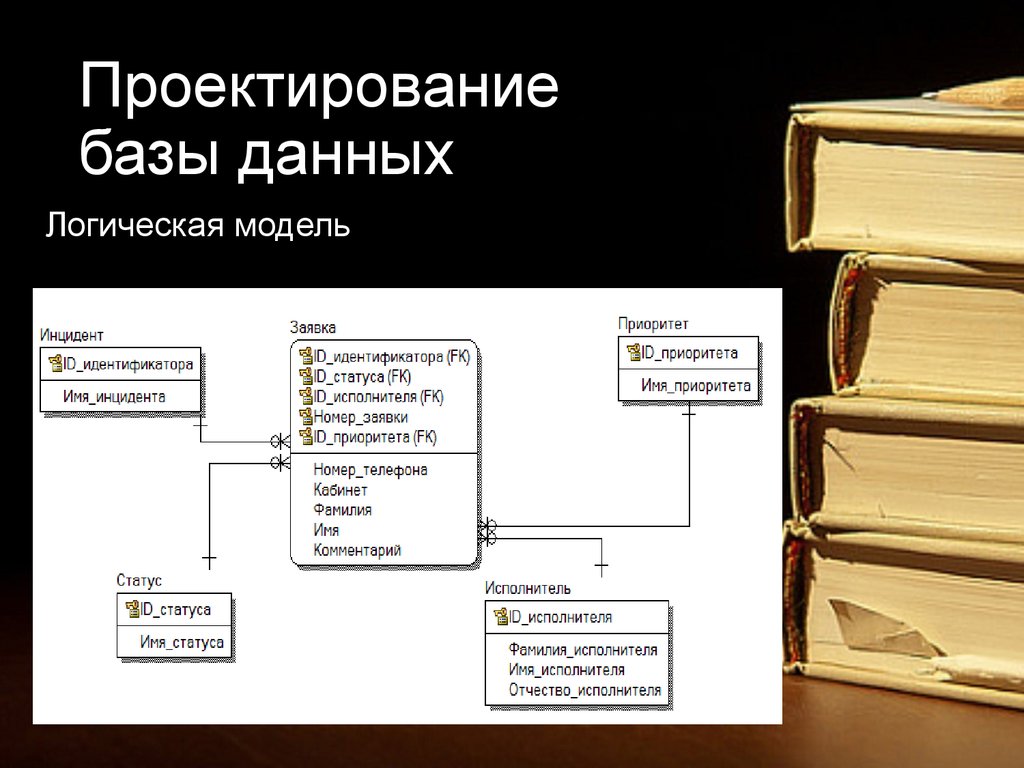 Например, Сотрудник -> Отдел.
Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.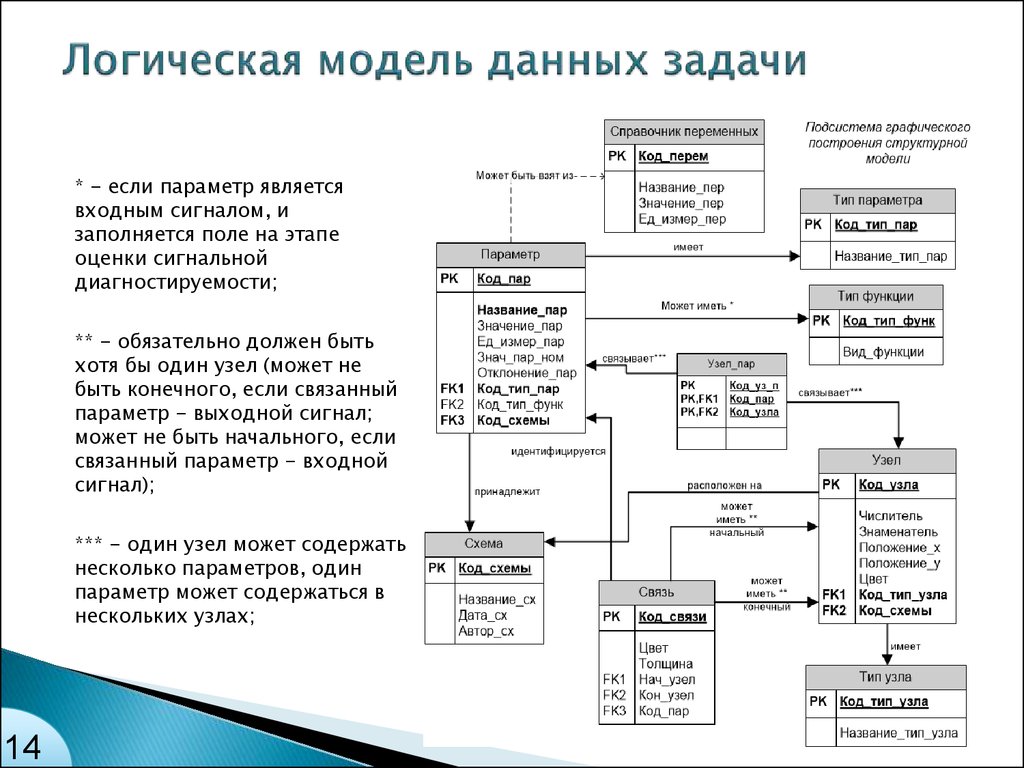
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
 То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
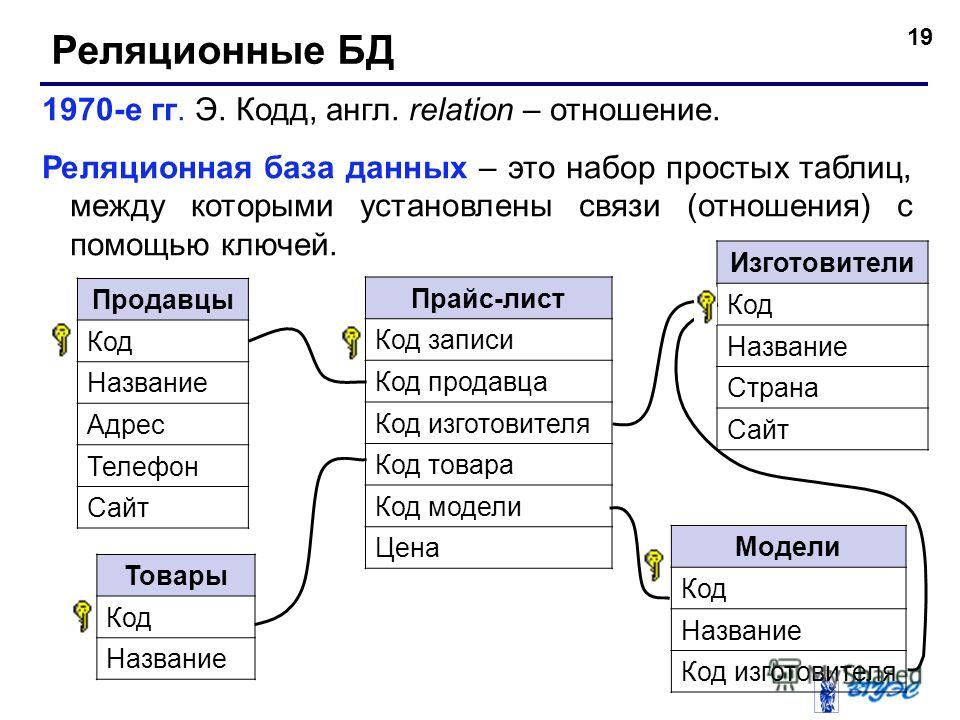
Пожалуйста, опубликуйте свои отзывы по текущей теме материала. За комментарии, лайки, дизлайки, подписки, отклики огромное вам спасибо!
МКМихаил Кузнецовавтор-переводчик статьи «Types of Database Models | Database Management System»
Моделирование данных: обзор / Хабр
В работе мы с коллегами часто видим как компании сталкиваются с проблемой управления данными – когда таблиц и запросов становится сильно много и управлять всем этим очень сложно. В таких ситуациях мы рекомендуем моделировать данные. Чтобы разобраться, что это такое – я перевела статью-обзор про моделирование данных от Towards Data Science, в которой кроме основных терминов и понятий можно найти наглядный пример использования моделирования данных в ритейле. Вперед под кат!
Вперед под кат!
Если вы посмотрите на любое программное приложение, то увидите, что на фундаментальном уровне оно занимается организацией, обработкой и представлением данных для выполнения бизнес-требований.
Модель данных — это концептуальное представление для выражения и передачи бизнес-требований. Она наглядно показывает характер данных, бизнес-правила, управляющие данными, и то, как данные будут организованы в базе данных.
Моделирование данных можно сравнить со строительством дома. Допустим, компании ABC необходимо построить дом для гостей (база данных). Компания вызывает архитектора (разработчик моделей данных) и объясняет требования к зданию (бизнес-требования). Архитектор (модельер данных) разрабатывает план (модель данных) и передает его компании ABC. Наконец, компания ABC вызывает инженеров-строителей (администраторов баз данных и разработчиков баз данных) для строительства дома.
Ключевые термины в моделировании данных
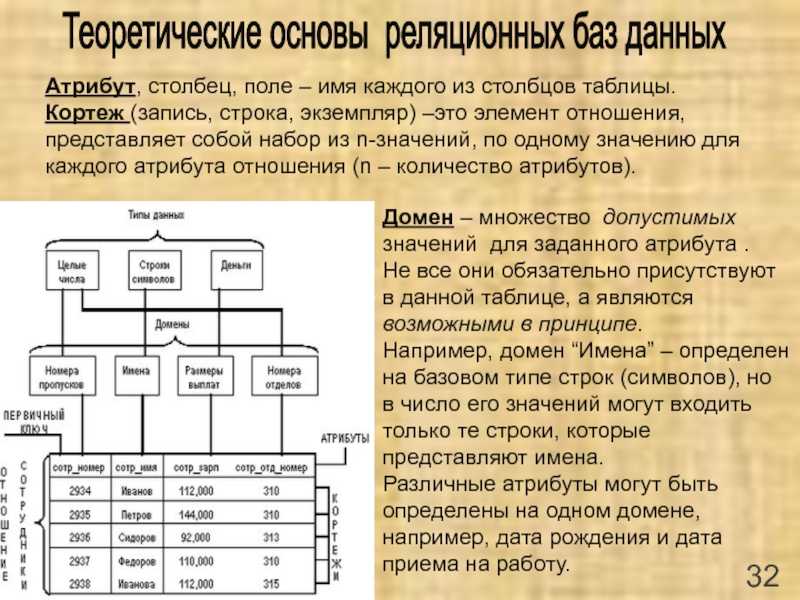
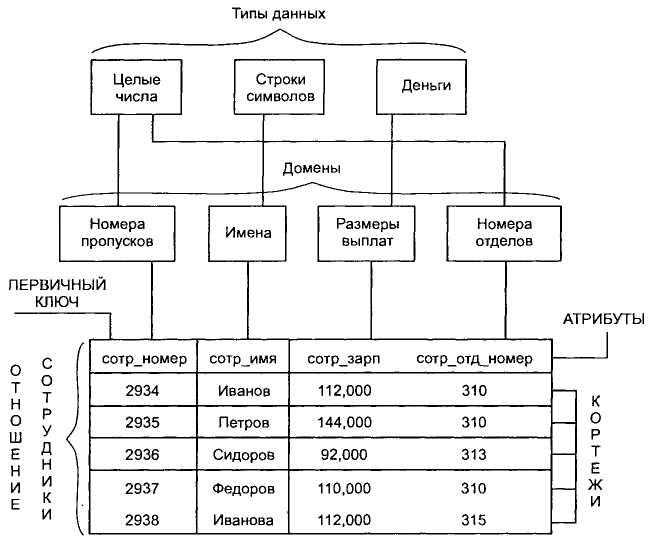
Сущности и атрибуты. Сущности — это «вещи» в бизнес-среде, о которых мы хотим хранить данные, например, продукты, клиенты, заказы и т.д. Атрибуты используются для организации и структурирования данных. Например, нам необходимо хранить определенную информацию о продаваемых нами продуктах, такую как отпускная цена или доступное количество. Эти фрагменты данных являются атрибутами сущности Product. Сущности обычно представляют собой таблицы базы данных, а атрибуты — столбцы этих таблиц.
Сущности — это «вещи» в бизнес-среде, о которых мы хотим хранить данные, например, продукты, клиенты, заказы и т.д. Атрибуты используются для организации и структурирования данных. Например, нам необходимо хранить определенную информацию о продаваемых нами продуктах, такую как отпускная цена или доступное количество. Эти фрагменты данных являются атрибутами сущности Product. Сущности обычно представляют собой таблицы базы данных, а атрибуты — столбцы этих таблиц.
Взаимосвязь. Взаимосвязь между сущностями описывает, как одна сущность связана с другой. В модели данных сущности могут быть связаны как: «один к одному», «многие к одному» или «многие ко многим».
Сущность пересечения. Если между сущностями есть связь типа «многие ко многим», то можно использовать сущность пересечения, чтобы декомпозировать эту связь и привести ее к типу «многие к одному» и «один ко многим».
Простой пример: есть 2 сущности — телешоу и человек. Каждое телешоу может смотреть один или несколько человек, в то время как человек может смотреть одно или несколько телешоу.
Эту проблему можно решить, введя новую пересекающуюся сущность «Просмотр записи»:
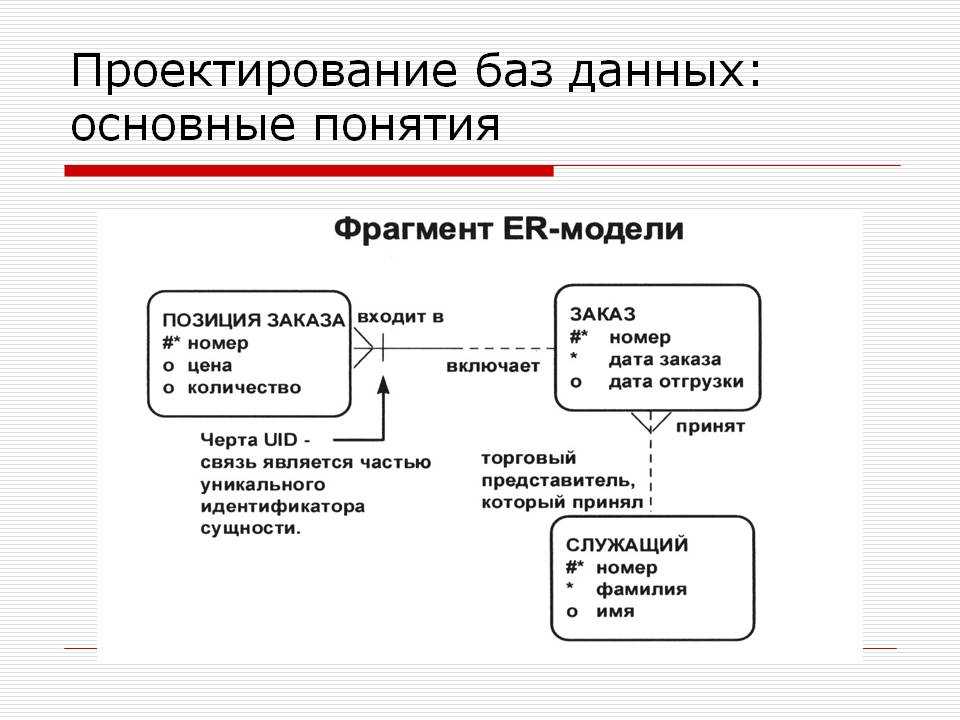
ER диаграмма показывает сущности и отношения между ними. ER-диаграмма может принимать форму концептуальной модели данных, логической модели данных или физической модели данных.
Концептуальная модель данных включает в себя все основные сущности и связи, не содержит подробных сведений об атрибутах и часто используется на начальном этапе планирования. Пример:
Логическая модель данных — это расширение концептуальной модели данных. Она включает в себя все сущности, атрибуты, ключи и взаимосвязи, которые представляют бизнес-информацию и определяют бизнес-правила. Пример:
Физическая модель данных включает в себя все необходимые таблицы, столбцы, связи, свойства базы данных для физической реализации баз данных. Производительность базы данных, стратегия индексации, физическое хранилище и денормализация — важные параметры физической модели.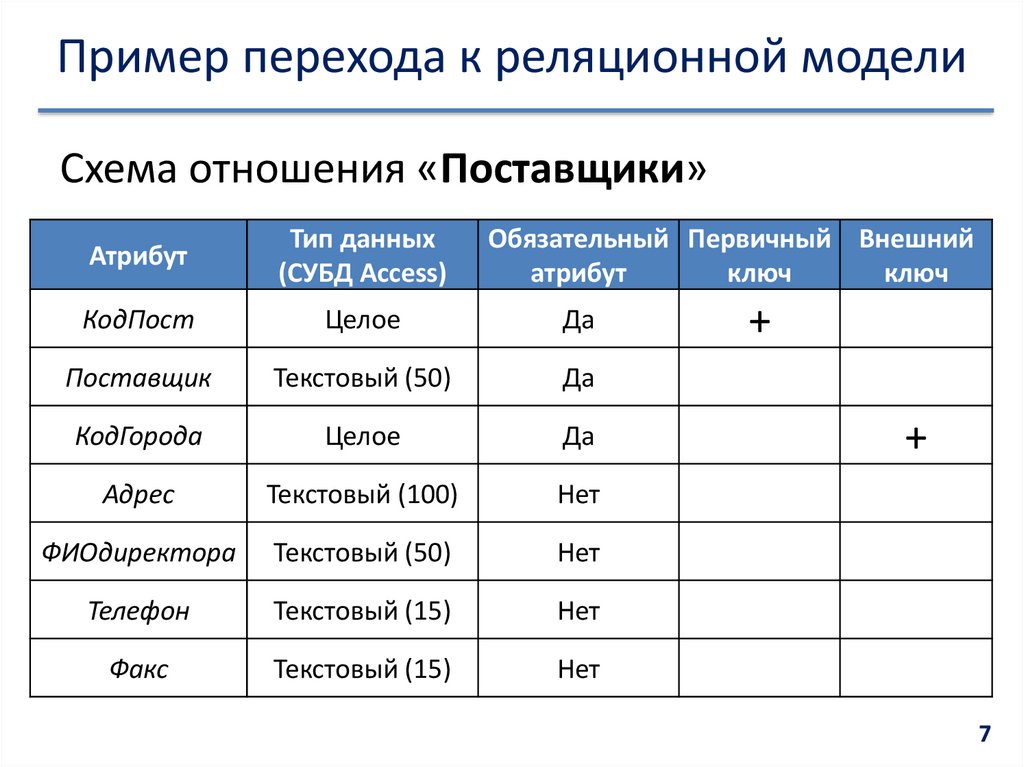 Пример:
Пример:
Основные этапы моделирования данных:
Реляционное vs размерное моделирование
В зависимости от бизнес-требований ваша модель данных может быть реляционной или размерной. Реляционная модель — это метод проектирования, направленный на устранение избыточности данных. Данные делятся на множество дискретных сущностей, каждая из которых становится таблицей в реляционной базе данных. Таблицы обычно нормализованы до 3-й нормальной формы. В OLTP приложениях используется эта методология.
В размерной модели данные денормализованы для повышения производительности. Здесь данные разделены на измерения и факты и упорядочены таким образом, чтобы пользователю было легче извлекать информацию и создавать отчеты.
Кейс
Компания ABC имеет 200 продуктовых магазинов в восьми городах. В каждом магазине есть разные отделы, такие как «Товары повседневного спроса», «Косметика», «Замороженные продукты», «Молочные продукты» и т.д. В каждом магазине на полках находится около 20 000 отдельных товаров.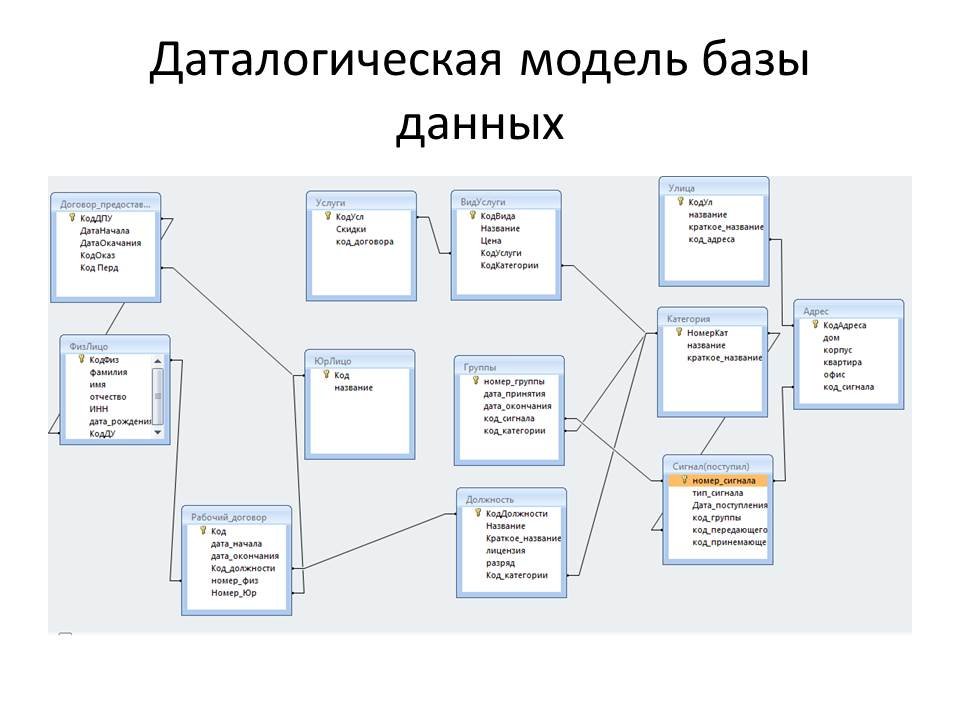 Отдельные продукты называются складскими единицами (SKU). Около 6 000 артикулов поступают от сторонних производителей и имеют штрих-коды, нанесенные на упаковку продукта. Эти штрих-коды называются универсальными кодами продукта (UPC). Данные собираются POS-системой в 2 местах: у входной двери для покупателей, и у задней двери, где поставщики осуществляют доставку.
Отдельные продукты называются складскими единицами (SKU). Около 6 000 артикулов поступают от сторонних производителей и имеют штрих-коды, нанесенные на упаковку продукта. Эти штрих-коды называются универсальными кодами продукта (UPC). Данные собираются POS-системой в 2 местах: у входной двери для покупателей, и у задней двери, где поставщики осуществляют доставку.
В продуктовом магазине менеджмент занимается логистикой заказа, хранением и продажами продуктов. Также продолжают расти рекламные активности, такие как временные скидки, реклама в газетах и т.д.
Разработайте модель данных для анализа операций этой продуктовой сети.
Решение
Шаг 1. Сбор бизнес-требований
Руководство хочет лучше понимать покупки клиентов, фиксируемые POS-системой. Модель должна позволять анализировать, какие товары продаются, в каких магазинах, в какие дни и по каким акционным условиям. Кроме того, это складская среда, поэтому необходима размерная модель.
Шаг 2: Идентификация сущностей
В случае размерной модели нам необходимо идентифицировать наши факты и измерения.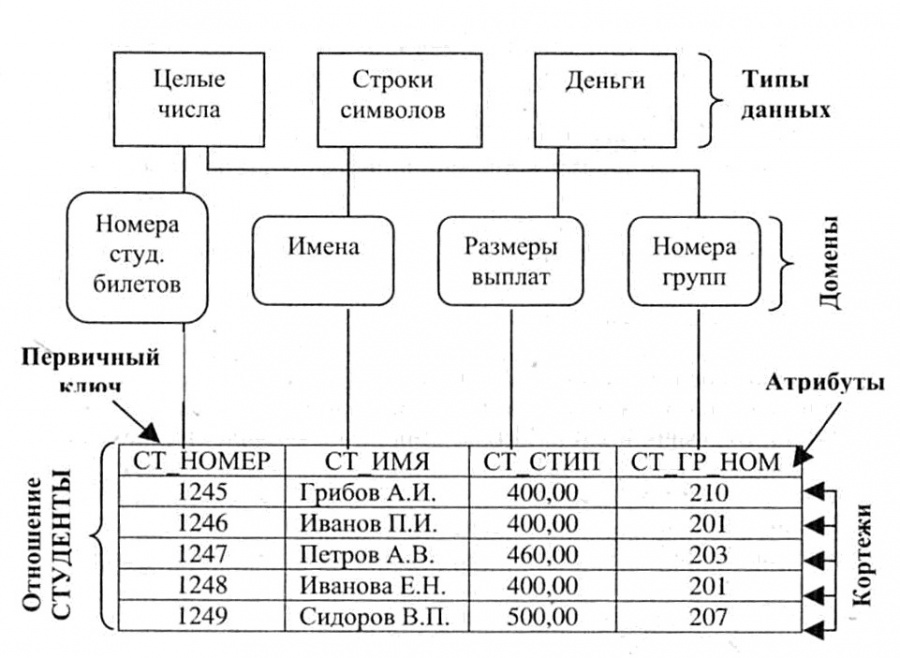 Перед разработкой модели необходимо уточнить объем требуемых данных. Согласно требованию, нам нужно видеть данные о конкретном продукте в определенном магазине в определенный день по определенной схеме продвижения. Это дает нам представление о необходимых сущностях:
Перед разработкой модели необходимо уточнить объем требуемых данных. Согласно требованию, нам нужно видеть данные о конкретном продукте в определенном магазине в определенный день по определенной схеме продвижения. Это дает нам представление о необходимых сущностях:
Date Dimension
Product Dimension
Store Dimension
Promotion Dimension
Количество, которое необходимо рассчитать (например, объем продаж, прибыль и т.д), будет отражено в таблице с фактическими продажами.
Шаг 3: Концептуальная модель данных
Предварительная модель данных будет создана на основе информации, собранной о сущностях. В нашем случае она будет выглядеть так:
Шаг 4: Доработка атрибутов и создание логической модели данных
Теперь необходимо завершить работу над атрибутами для сущностей. В нашем случае дорабатываются следующие атрибуты:
Date Dimension:
Product:
Store:
Promotion:
Sales Fact:
Номер транзакции.
Объем продаж (например, количество банок овощного супа с лапшой).
Сумма продаж в долларах: количество продаж * цена за единицу.
Стоимость в долларах: стоимость продукта, взимаемая поставщиком.
Сумма валовой прибыли в долларах: доход от продаж — затраты.
Логическая модель данных будет выглядеть так:
Шаг 5: Создание физических таблиц в базе данных
С помощью инструмента моделирования данных или с помощью кастомных скриптов теперь можно создавать физические таблицы в базе данных.
Думаю, теперь стало достаточно очевидно, что моделирование данных — одна из важнейших задач при разработке программного приложения. И оно закладывает основу для организации, хранения, извлечения и представления данных.
Что такое модель данных в СУБД и каковы ее типы?
Модель данных
Модель данных дает нам представление о том, как будет выглядеть окончательная система после ее полной реализации. Он определяет элементы данных и отношения между элементами данных. Модели данных используются для демонстрации того, как данные хранятся, подключаются, доступны и обновляются в системе управления базами данных. Здесь мы используем набор символов и текста для представления информации, чтобы члены организации могли общаться и понимать ее. Хотя в настоящее время используется много моделей данных, реляционная модель является наиболее широко используемой моделью. Помимо реляционной модели, существует множество других типов моделей данных, которые мы подробно рассмотрим в этом блоге. Вот некоторые из моделей данных в СУБД:
Он определяет элементы данных и отношения между элементами данных. Модели данных используются для демонстрации того, как данные хранятся, подключаются, доступны и обновляются в системе управления базами данных. Здесь мы используем набор символов и текста для представления информации, чтобы члены организации могли общаться и понимать ее. Хотя в настоящее время используется много моделей данных, реляционная модель является наиболее широко используемой моделью. Помимо реляционной модели, существует множество других типов моделей данных, которые мы подробно рассмотрим в этом блоге. Вот некоторые из моделей данных в СУБД:
- Иерархическая модель
- Сетевая модель
- Модель объекта
- Реляционная модель
- Модель объектно-ориентированной модели данных
- Модель доклада
- Модель с плоскими данными
- Контекстная модель данных
Иерархическая модель
Иерархическая модель была первой моделью СУБД.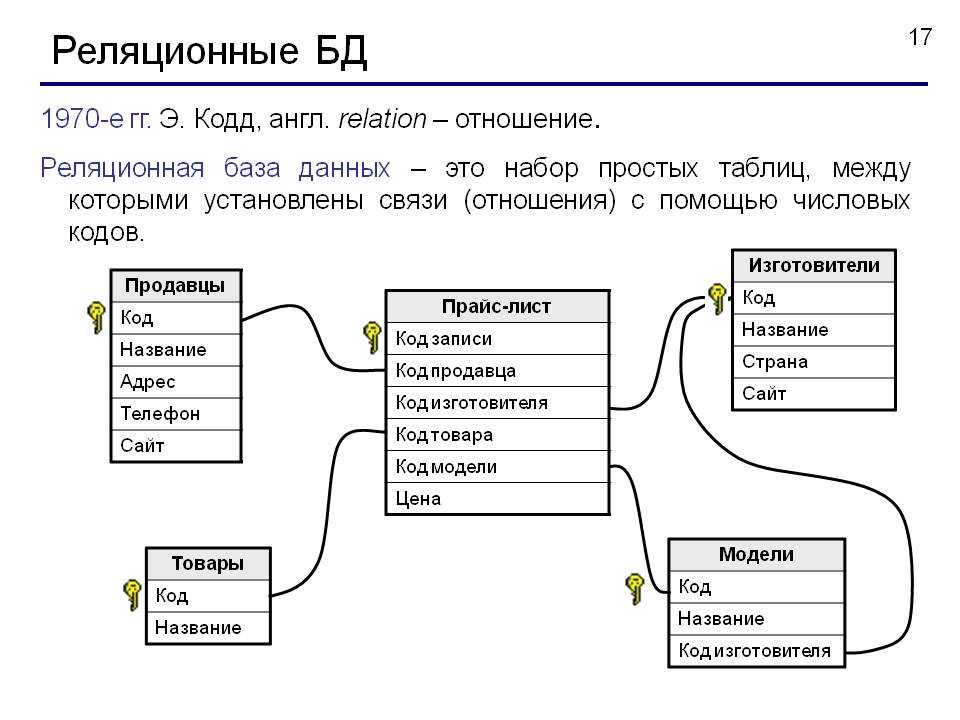 Эта модель организует данные в виде иерархической древовидной структуры. Иерархия начинается с корня, имеющего корневые данные, а затем расширяется в виде дерева, добавляя дочерний узел к родительскому узлу. Эта модель легко представляет некоторые отношения реального мира, такие как рецепты блюд, карта сайта веб-сайта и т. д. Пример: Мы можем представить связь между обувью, представленной на веб-сайте магазина, следующим образом:
Эта модель организует данные в виде иерархической древовидной структуры. Иерархия начинается с корня, имеющего корневые данные, а затем расширяется в виде дерева, добавляя дочерний узел к родительскому узлу. Эта модель легко представляет некоторые отношения реального мира, такие как рецепты блюд, карта сайта веб-сайта и т. д. Пример: Мы можем представить связь между обувью, представленной на веб-сайте магазина, следующим образом:
Особенности иерархической модели
- Связь «один ко многим»: Данные здесь организованы в древовидной структуре, где между типами данных существует отношение «один ко многим». Кроме того, может быть только один путь от родителя к любому узлу. Пример: В приведенном выше примере, если мы хотим перейти к узлу кроссовки у нас есть только один путь, чтобы добраться туда, то есть через узел мужской обуви.
- Связь родитель-потомок: Каждый дочерний узел имеет родительский узел, но родительский узел может иметь более одного дочернего узла. Несколько родителей не допускаются.
- Проблема удаления: При удалении родительского узла дочерний узел автоматически удаляется.
- Указатели: Указатели используются для связи родительского узла с дочерним узлом и используются для навигации между сохраненными данными. Пример: В приведенном выше примере узел ‘ обувь ‘ указывает на два других узла ‘ женская обувь ‘ и узел ‘ мужская обувь ‘.
 Несколько родителей не допускаются.
Несколько родителей не допускаются.Преимущества иерархической модели
- Очень просто и быстро перемещаться по древовидной структуре.
- Любое изменение в родительском узле автоматически отражается в дочернем узле, поэтому целостность данных сохраняется.
Недостатки иерархической модели
- Сложные отношения не поддерживаются.
- Поскольку он не поддерживает более одного родителя дочернего узла, поэтому, если у нас есть какие-то сложные отношения, в которых дочерний узел должен иметь два родительских узла, то это не может быть представлено с использованием этой модели.
- При удалении родительского узла дочерний узел автоматически удаляется.
Сетевая модель
Эта модель является расширением иерархической модели. Это была самая популярная модель до появления реляционной модели. Эта модель такая же, как и иерархическая модель, с той лишь разницей, что запись может иметь более одного родителя. Он заменяет иерархическое дерево графом. Пример: В приведенном ниже примере мы видим, что у node student есть два родителя, т. е. отдел CSE и библиотека. Ранее это было невозможно в иерархической модели.
Особенности сетевой модели
- Возможность объединения большего количества отношений: В этой модели чем больше отношений, тем больше связаны данные. Эта модель позволяет управлять отношениями «один к одному», а также отношениями «многие ко многим».
- Много путей: Поскольку связей больше, к одной и той же записи может быть несколько путей. Это делает доступ к данным быстрым и простым.
- Циклический связанный список: Операции над сетевой моделью выполняются с помощью циклического связанного списка. Текущая позиция поддерживается с помощью программы, и эта позиция перемещается по записям в соответствии с отношениями.
 Это делает доступ к данным быстрым и простым.
Это делает доступ к данным быстрым и простым.Преимущества сетевой модели
- Доступ к данным осуществляется быстрее по сравнению с иерархической моделью. Это связано с тем, что данные более связаны в сетевой модели, и может быть более одного пути к определенному узлу. Таким образом, данные могут быть доступны разными способами.
- Поскольку существует связь родитель-потомок, целостность данных присутствует. Любое изменение в родительской записи отражается в дочерней записи.
Недостатки сетевой модели
- Поскольку необходимо обрабатывать все больше и больше взаимосвязей, система может усложняться. Таким образом, пользователь должен иметь подробные знания о модели, чтобы работать с моделью.
- Любые изменения, такие как обновление, удаление, вставка, очень сложны.
Модель Entity-Relationship
Модель Entity-Relationship или просто ER Model — это высокоуровневая диаграмма модели данных. В этой модели мы представляем реальную проблему в графической форме, чтобы ее было легко понять заинтересованным сторонам. Разработчикам также очень легко понять систему, просто взглянув на ER-диаграмму. Мы используем диаграмму ER как визуальный инструмент для представления модели ER. Диаграмма ER состоит из следующих трех компонентов:
- Сущности: Сущности существуют в реальном мире. Это может быть человек, место или даже понятие. Пример: Учителя, Студенты, Курсы, Здание, Департамент и т. д. являются некоторыми элементами системы управления школой.
- Атрибуты: Сущность содержит реальное свойство, называемое атрибутом. Это характеристики этого атрибута. Пример: Учитель сущности имеет такие свойства, как идентификатор учителя, зарплата, возраст и т. д.
- Связь: Связь показывает, как связаны два атрибута. Пример: Учитель работает в отделе.
 д.
д.Пример:
На приведенной выше диаграмме сущностями являются Учитель и Отдел. Атрибутами сущности Учитель являются имя_учителя, идентификатор_учителя, возраст, зарплата, номер мобильного телефона. Атрибутами сущности Отдел являются Dept_id, Dept_name. Два объекта связаны с помощью отношения. Здесь каждый учитель работает на кафедру.
Особенности модели ER
- Графическое представление для лучшего понимания: Это очень легко и просто понять, поэтому разработчики могут использовать его для общения с заинтересованными сторонами.
- ER-диаграмма: ER-диаграмма используется как визуальный инструмент для представления модели.
- Проектирование базы данных: Эта модель помогает разработчикам баз данных создавать базы данных и широко используется при проектировании баз данных.
Преимущества модели ER
- Простота: Концептуально модель ER очень легко построить. Если мы знаем взаимосвязь между атрибутами и сущностями, мы можем легко построить диаграмму ER для модели.
- Средство эффективного общения : Эта модель широко используется разработчиками баз данных для обмена идеями.
- Простое преобразование в любую модель : Эта модель хорошо согласуется с реляционной моделью и может быть легко преобразована в реляционную модель путем преобразования модели ER в таблицу. Эту модель также можно преобразовать в любую другую модель, такую как сетевая модель, иерархическая модель и т. д.
Недостатки модели ER
- Отсутствует отраслевой стандарт для обозначений: Отраслевой стандарт для разработки модели ER отсутствует. Таким образом, один разработчик может использовать обозначения, которые не понимают другие разработчики.
- Скрытая информация: Некоторая информация может быть потеряна или скрыта в модели ER. Поскольку это представление высокого уровня, есть вероятность, что некоторые детали информации могут быть скрыты.
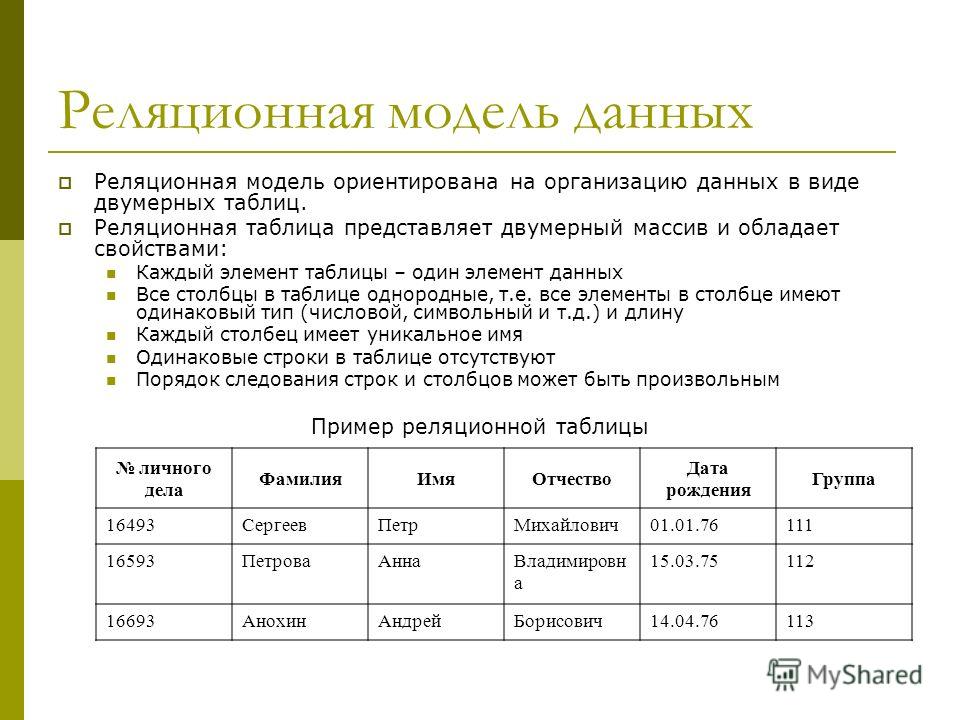
Реляционная модель
Реляционная модель — наиболее широко используемая модель. В этой модели данные хранятся в виде двумерной таблицы. Вся информация хранится в виде строк и столбцов. Базовая структура реляционной модели — таблицы. Итак, таблицы также называются отношениями в реляционной модели. Пример: В этом примере у нас есть таблица Employee.
Особенности реляционной модели
- Кортежи : Каждая строка в таблице называется кортежем. Строка содержит всю информацию о любом экземпляре объекта. В приведенном выше примере каждая строка содержит всю информацию о каком-либо конкретном человеке, как первая строка содержит информацию о Джоне.
- Атрибут или поле: Атрибуты — это свойство, определяющее таблицу или отношение. Значения атрибута должны быть из одного домена. В приведенном выше примере у нас есть разные атрибуты сотрудника 9.0033 как Salary, Mobile_no и т.д.
 Значения атрибута должны быть из одного домена. В приведенном выше примере у нас есть разные атрибуты сотрудника 9.0033 как Salary, Mobile_no и т.д.
Значения атрибута должны быть из одного домена. В приведенном выше примере у нас есть разные атрибуты сотрудника 9.0033 как Salary, Mobile_no и т.д.Преимущества реляционной модели
- Простая: Эта модель более проста по сравнению с сетевой и иерархической моделью.
- Масштабируемость: Эту модель можно легко масштабировать, поскольку мы можем добавлять столько строк и столбцов, сколько захотим.
- Структурная независимость: Мы можем вносить изменения в структуру базы данных без изменения способа доступа к данным. Когда мы можем вносить изменения в структуру базы данных, не затрагивая возможности СУБД по доступу к данным, мы можем сказать, что достигнута структурная независимость.
Недостатки релятинальной модели
- Накладные расходы на оборудование: Чтобы скрыть сложности и упростить работу пользователя, эта модель требует более мощных аппаратных компьютеров и устройств хранения данных.
- Плохой дизайн: Поскольку реляционная модель очень проста в разработке и использовании. Таким образом, пользователям не нужно знать, как хранятся данные, чтобы получить к ним доступ. Эта простота дизайна может привести к разработке плохой базы данных, которая замедлится, если база данных будет расти.
Но все эти недостатки незначительны по сравнению с преимуществами реляционной модели. Этих проблем можно избежать с помощью правильной реализации и организации.
Объектно-ориентированная модель данных
Реальные проблемы более точно представлены в объектно-ориентированной модели данных. В этой модели и данные, и отношения представлены в одной структуре, известной как объект. Мы можем хранить аудио, видео, изображения и т. д. в базе данных, что было невозможно в реляционной модели (хотя вы можете хранить аудио и видео в реляционной базе данных, рекомендуется не хранить в реляционной базе данных). В этой модели еще два объекта связаны ссылками.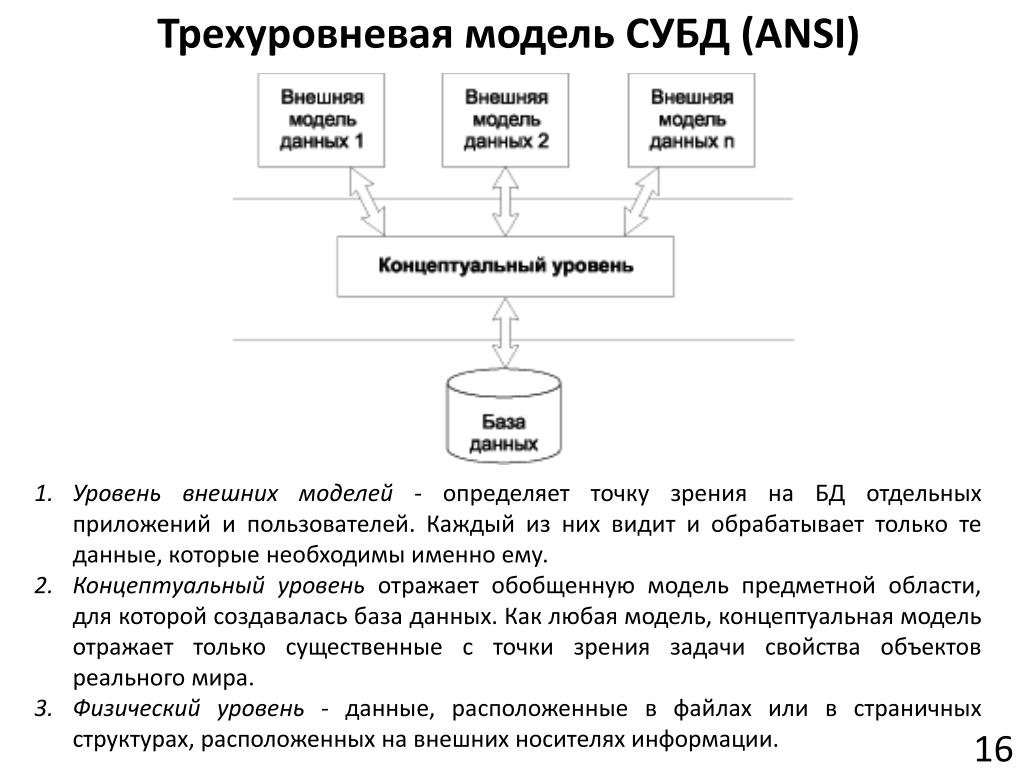 Мы используем эту связь, чтобы связать один объект с другими объектами. Это можно понять на примере, приведенном ниже.
Мы используем эту связь, чтобы связать один объект с другими объектами. Это можно понять на примере, приведенном ниже.
В приведенном выше примере у нас есть два объекта Сотрудник и Отдел. Все данные и отношения каждого объекта содержатся как единое целое. Такие атрибуты, как имя, должность_названия сотрудника и методы, которые будут выполняться этим объектом, хранятся как один объект. Два объекта связаны через общий атрибут, т. е. Department_id, и связь между ними будет осуществляться с помощью этого общего идентификатора.
Объектно-реляционная модель
Как следует из названия, это комбинация реляционной модели и объектно-ориентированной модели. Эта модель была построена, чтобы заполнить пробел между объектно-ориентированной моделью и реляционной моделью. У нас может быть много расширенных функций, например, мы можем создавать сложные типы данных в соответствии с нашими требованиями, используя существующие типы данных. Проблема с этой моделью в том, что она может стать сложной и трудной в обращении.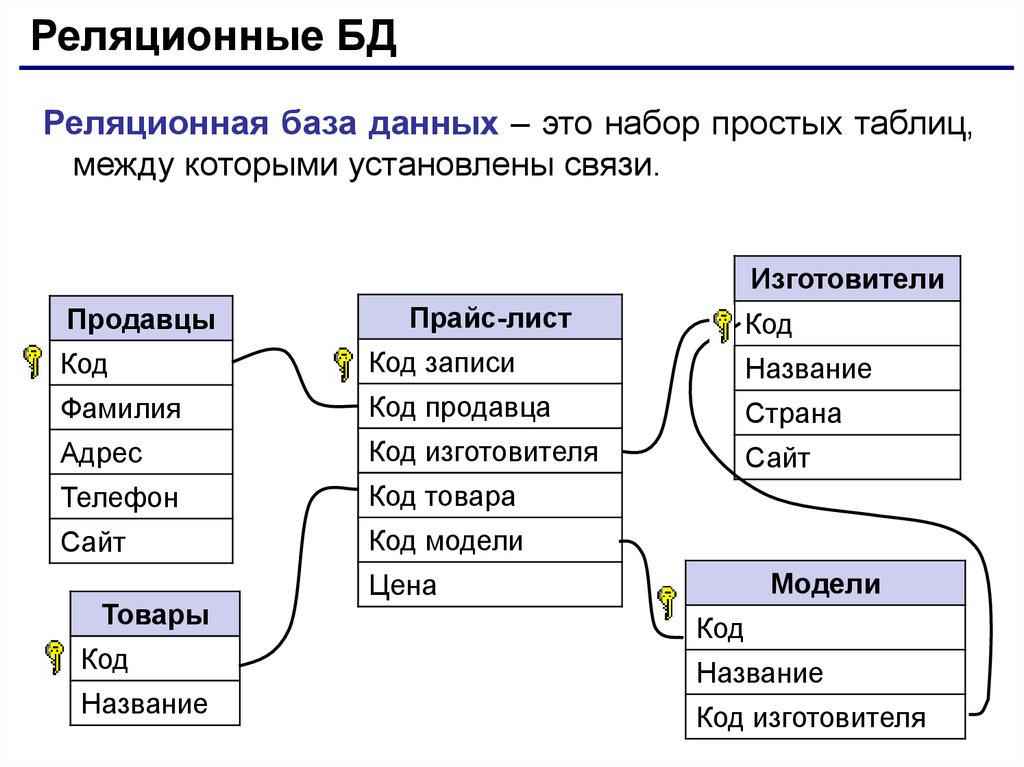 Таким образом, требуется правильное понимание этой модели.
Таким образом, требуется правильное понимание этой модели.
Плоская модель данных
Это простая модель, в которой база данных представлена в виде таблицы, состоящей из строк и столбцов. Чтобы получить доступ к любым данным, компьютер должен прочитать всю таблицу. Это делает режимы медленными и неэффективными.
Полуструктурированная модель
Полуструктурированная модель представляет собой развитую форму реляционной модели. В этой модели мы не можем провести различие между данными и схемой. Пример: Веб-источники данных, в которых мы не можем различить схему и данные веб-сайта. В этой модели некоторые объекты могут иметь отсутствующие атрибуты, а другие могут иметь дополнительный атрибут. Эта модель обеспечивает гибкость в хранении данных. Это также дает гибкость атрибутам. Пример: Если мы храним какое-либо значение в любом атрибуте, то это значение может быть либо атомарным значением, либо набором значений.
Ассоциативная модель данных
Ассоциативная модель данных — это модель, в которой данные разделены на две части.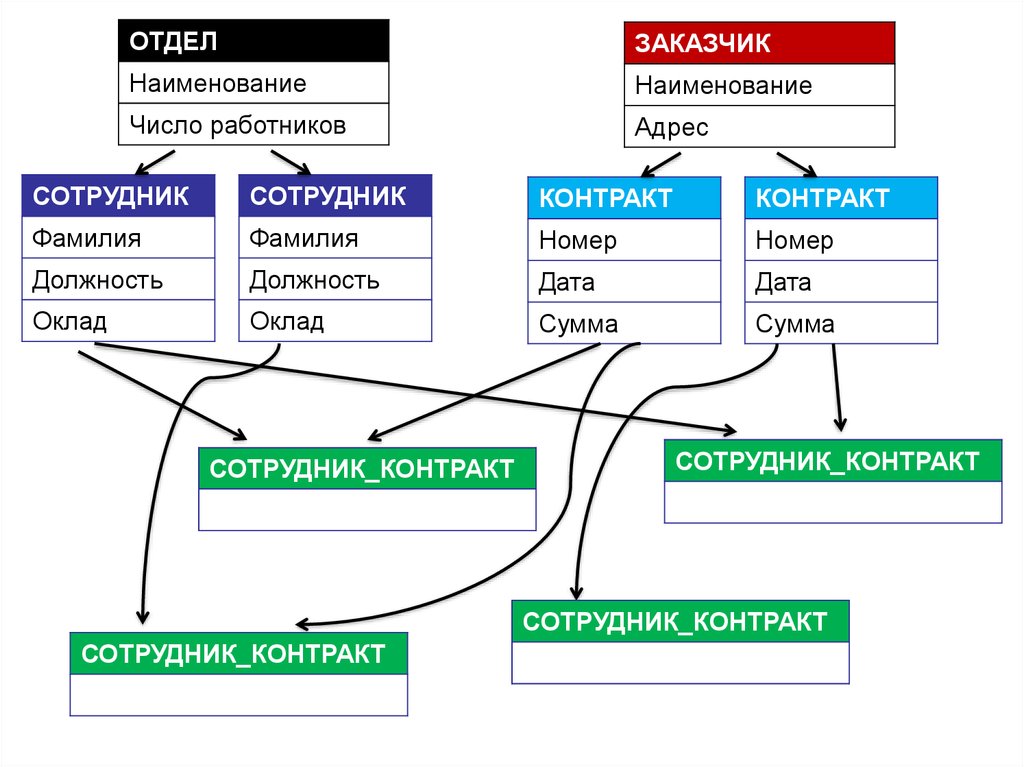 Все, что имеет независимое существование, называется сущностью , а отношения между этими сущностями называются ассоциацией . Данные, разделенные на две части, называются элементами и ссылками.
Все, что имеет независимое существование, называется сущностью , а отношения между этими сущностями называются ассоциацией . Данные, разделенные на две части, называются элементами и ссылками.
- Элемент : Элементы содержат имя и идентификатор (некоторое числовое значение).
- Ссылки: Ссылки содержат идентификатор, источник, глагол и тему.
Пример : Допустим, у нас есть утверждение «Чемпионат мира по футболу проводится в Лондоне с 30 мая 2020 года». В этих данных необходимо сохранить две ссылки:
- Чемпионат мира проводится в Лондоне. Источник здесь — «чемпионат мира», глагол «существует», а цель — «Лондон».
- …от 30 мая 2020 года. Источник здесь — предыдущая ссылка, глагол — «от», цель — «30 мая 2020 года».
Это представлено в таблице следующим образом:
Контекстная модель данных
Контекстная модель данных представляет собой набор нескольких моделей.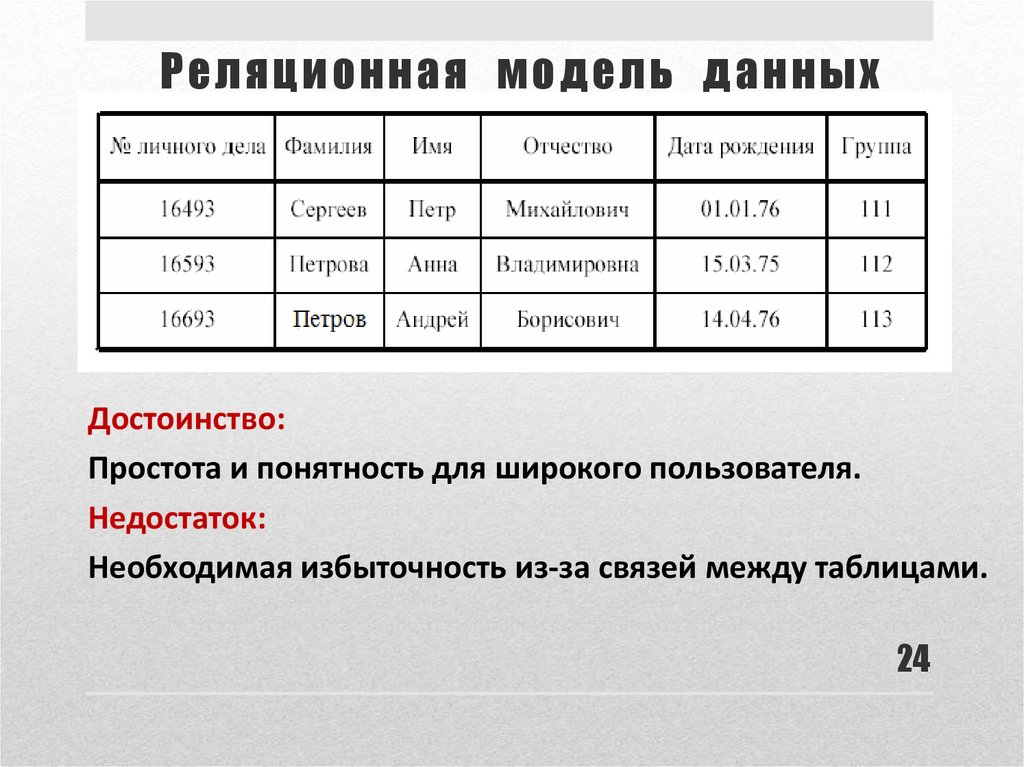 Он состоит из таких моделей, как сетевая модель, реляционные модели и т. д. Используя эту модель, мы можем выполнять различные типы задач, которые невозможно выполнить с помощью какой-либо одной модели.
Он состоит из таких моделей, как сетевая модель, реляционные модели и т. д. Используя эту модель, мы можем выполнять различные типы задач, которые невозможно выполнить с помощью какой-либо одной модели.
Это все о различных моделях данных СУБД. Надеюсь, вы сегодня узнали что-то новое.
Поделитесь этим блогом с друзьями, чтобы распространять информацию. Посетите наш канал YouTube для получения дополнительной информации. Вы можете прочитать больше блогов здесь.
Продолжайте учиться 🙂
Team AfterAcademy!
Что такое моделирование данных? Типы (концептуальные, логические, физические)
Автор Дэвид Тейлор
ЧасыОбновлено
Что такое моделирование данных?
Моделирование данных (моделирование данных) — это процесс создания модели данных для хранения данных в базе данных.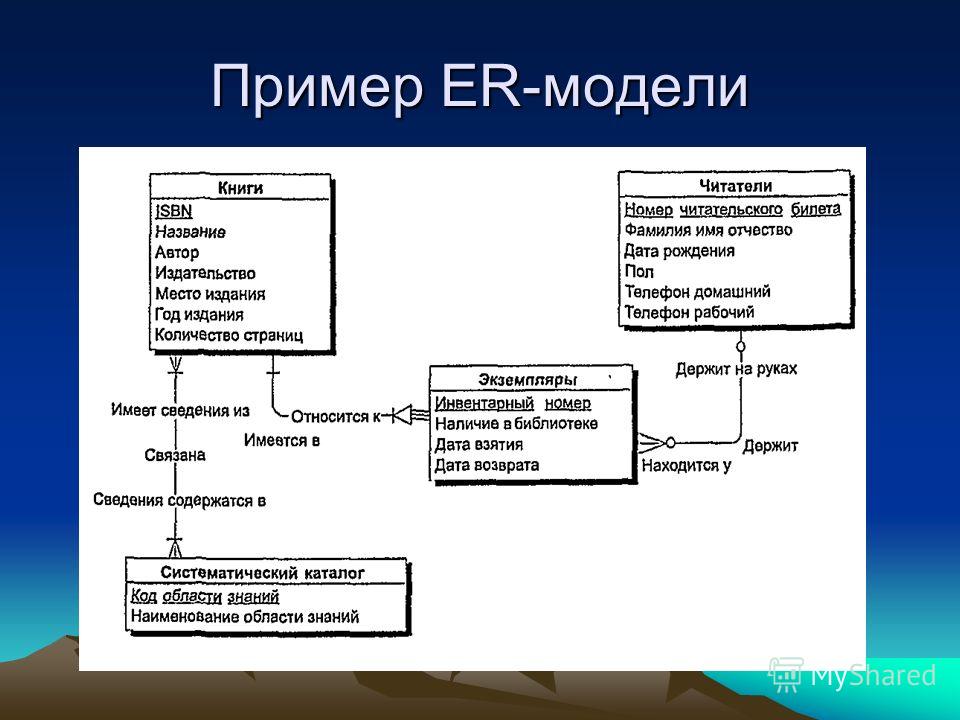 Эта модель данных представляет собой концептуальное представление объектов данных, связей между различными объектами данных и правил.
Эта модель данных представляет собой концептуальное представление объектов данных, связей между различными объектами данных и правил.
Моделирование данных помогает в визуальном представлении данных и обеспечивает соблюдение бизнес-правил, нормативных требований и государственной политики в отношении данных. Модели данных обеспечивают согласованность соглашений об именах, значений по умолчанию, семантики, безопасности и качества данных.
Модели данных в СУБД
Модель данных определяется как абстрактная модель, которая организует описание данных, семантику данных и ограничения согласованности данных. Модель данных делает акцент на том, какие данные необходимы и как они должны быть организованы, а не на том, какие операции будут выполняться с данными. Модель данных похожа на план здания архитектора, который помогает создавать концептуальные модели и устанавливать отношения между элементами данных.
Два типа методов моделирования данных:
- Модель отношений сущностей (E-R)
- UML (унифицированный язык моделирования)
Мы подробно обсудим их позже.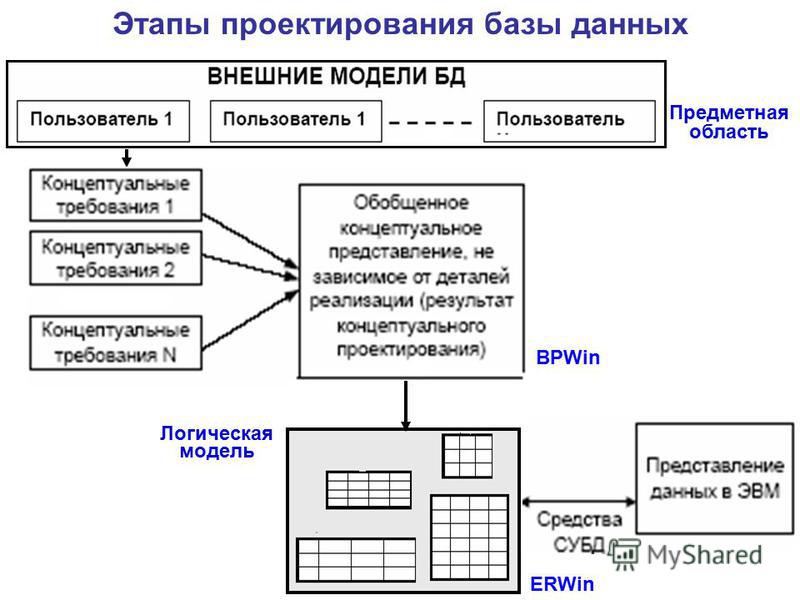
- Зачем использовать модель данных?
- Типы моделей данных
- Концептуальная модель данных
- Логическая модель данных
- Модель физических данных
- Преимущества и недостатки модели данных
Зачем использовать модель данных?
Основная цель использования модели данных:
- Обеспечивает точное представление всех объектов данных, требуемых базой данных. Пропуск данных приведет к созданию ошибочных отчетов и неправильным результатам.
- помогает определить реляционные таблицы, первичные и внешние ключи и хранимые процедуры.
- Он дает четкое представление о базовых данных и может использоваться разработчиками баз данных для создания физической базы данных.
- Также полезно определить отсутствующие и избыточные данные.
- Хотя первоначальное создание модели данных занимает много времени и сил, в долгосрочной перспективе это удешевляет и ускоряет обновление и обслуживание вашей ИТ-инфраструктуры.
Типы моделей данных в СУБД
Типы моделей данных : Существуют в основном три различных типа моделей данных: концептуальные модели данных, логические модели данных и физические модели данных, и каждая из них имеет определенное назначение. Модели данных используются для представления данных и способа их хранения в базе данных, а также для установления связи между элементами данных.
- Концептуальная модель данных: Эта модель данных определяет ЧТО содержит система. Эта модель обычно создается заинтересованными сторонами бизнеса и архитекторами данных.
- Логическая модель данных: Определяет КАК система должна быть реализована независимо от СУБД. Эта модель обычно создается архитекторами данных и бизнес-аналитиками. Цель состоит в том, чтобы разработать техническую карту правил и структур данных.
- Физическая модель данных : Эта модель данных описывает КАК система будет реализована с использованием конкретной системы СУБД. Эта модель обычно создается администратором баз данных и разработчиками. Целью является фактическая реализация базы данных.
Концептуальная модель данных
A Концептуальная модель данных представляет собой организованное представление понятий базы данных и их взаимосвязей. Целью создания концептуальной модели данных является установление сущностей, их атрибутов и отношений. На этом уровне моделирования данных вряд ли есть какая-либо подробная информация о фактической структуре базы данных. Заинтересованные стороны бизнеса и архитекторы данных обычно создают концептуальную модель данных.
На этом уровне моделирования данных вряд ли есть какая-либо подробная информация о фактической структуре базы данных. Заинтересованные стороны бизнеса и архитекторы данных обычно создают концептуальную модель данных.
3 основных арендатора концептуальной модели данных:
- Сущность : Реальная вещь
- Атрибут : Характеристики или свойства объекта
- Связь : Зависимость или ассоциация между двумя объектами
Пример модели данных:
- Клиент и Продукт — это две сущности. Номер и имя клиента являются атрибутами объекта «Клиент» .
- Название продукта и цена являются атрибутами сущности продукта
- Продажа – это отношения между покупателем и товаром
Характеристики концептуальной модели данных
- Обеспечивает охват бизнес-концепций в масштабах всей организации.
- Этот тип моделей данных разработан и разработан для бизнес-аудитории.
- Концептуальная модель разрабатывается независимо от технических характеристик оборудования, таких как емкость хранилища данных, местоположение или спецификации программного обеспечения, такие как поставщик СУБД и технология. Основное внимание уделяется представлению данных так, как пользователь увидит их в «реальном мире».
Концептуальные модели данных, известные как модели предметной области, создают общий словарь для всех заинтересованных сторон, устанавливая основные понятия и область применения.
Логическая модель данных
Логическая модель данных используется для определения структуры элементов данных и установления отношений между ними. Логическая модель данных добавляет дополнительную информацию к элементам концептуальной модели данных. Преимущество использования логической модели данных заключается в обеспечении основы для формирования базы физической модели. Однако структура моделирования остается общей.
На этом уровне моделирования данных первичный или вторичный ключ не определен.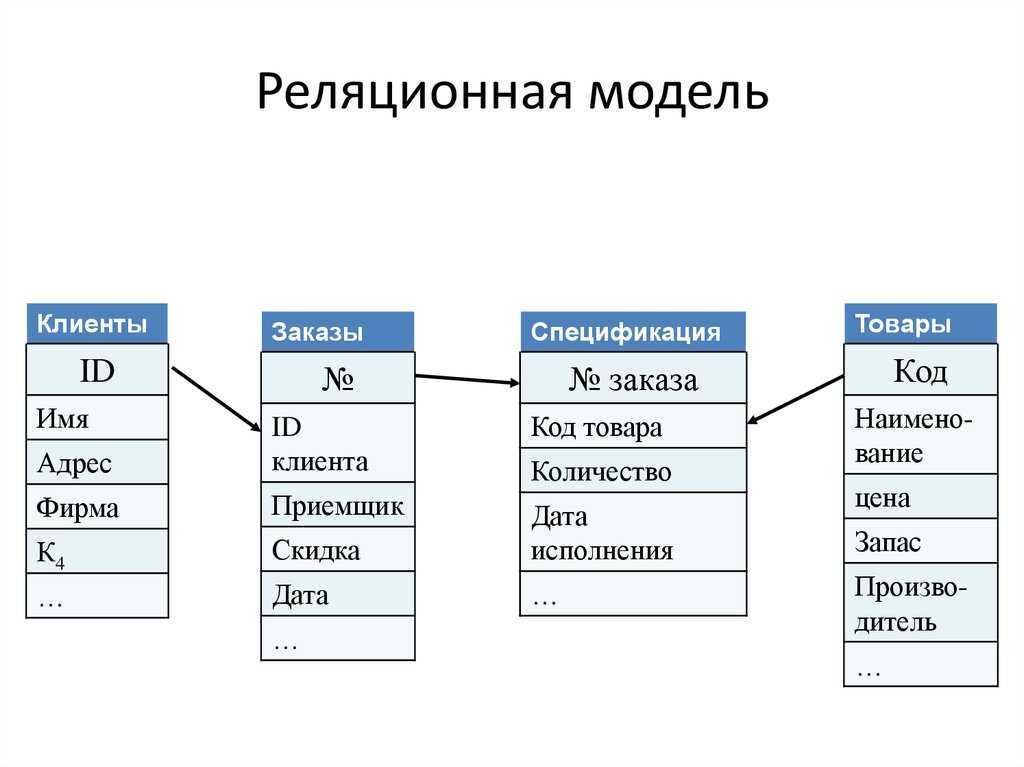 На этом уровне моделирования данных вам необходимо проверить и настроить детали соединителя, которые были установлены ранее для отношений.
На этом уровне моделирования данных вам необходимо проверить и настроить детали соединителя, которые были установлены ранее для отношений.
Характеристики логической модели данных
- Описывает потребности в данных для одного проекта, но может интегрироваться с другими логическими моделями данных в зависимости от объема проекта.
- Разработан и разработан независимо от СУБД.
- Атрибуты данных будут иметь типы данных с точной точностью и длиной.
- Процессы нормализации к модели обычно применяются до 3NF.
Физическая модель данных
Физическая модель данных описывает реализацию модели данных для конкретной базы данных. Он предлагает абстракцию базы данных и помогает генерировать схему. Это связано с богатством метаданных, предлагаемых физической моделью данных. Физическая модель данных также помогает визуализировать структуру базы данных за счет репликации ключей столбцов базы данных, ограничений, индексов, триггеров и других функций СУБД.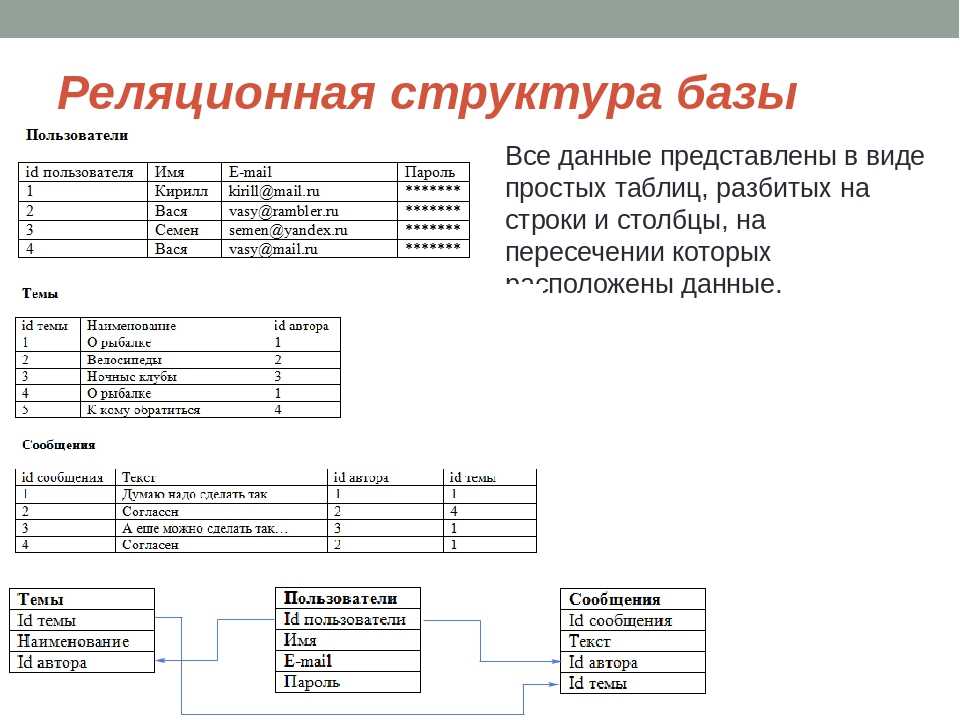
Характеристики физической модели данных:
- Физическая модель данных описывает потребность в данных для отдельного проекта или приложения, хотя она может быть интегрирована с другими моделями физических данных в зависимости от объема проекта. Модель данных
- содержит отношения между таблицами, которые учитывают кардинальность и допустимость значений NULL для отношений.
- Разработан для конкретной версии СУБД, местоположения, хранилища данных или технологии, которые будут использоваться в проекте.
- Столбцы должны иметь точные типы данных, назначенную длину и значения по умолчанию.
- Определены первичные и внешние ключи, представления, индексы, профили доступа, авторизации и т. д.
Преимущества и недостатки модели данных:
Преимущества модели данных:
- Основная цель разработки модели данных — обеспечить точное представление объектов данных, предлагаемых функциональной группой.
- Модель данных должна быть достаточно подробной, чтобы ее можно было использовать для построения физической базы данных.
- Информация в модели данных может использоваться для определения связи между таблицами, первичными и внешними ключами и хранимыми процедурами. Модель данных
- помогает бизнесу общаться внутри и между организациями.
- Модель данных помогает документировать сопоставления данных в процессе ETL
- Помогите распознать правильные источники данных для заполнения модели
Недостатки модели данных:
- Для разработки модели данных необходимо знать физические характеристики хранимых данных.
- Это навигационная система производит комплексную разработку приложений, управление. Таким образом, требуется знание биографической правды.
- Даже небольшие изменения в структуре требуют модификации всего приложения.
- В СУБД не установлен язык обработки данных.
Заключение
- Моделирование данных — это процесс разработки модели данных для хранения данных в базе данных. Модели данных
- обеспечивают согласованность соглашений об именах, значений по умолчанию, семантики, безопасности и качества данных. Структура модели данных
- помогает определить реляционные таблицы, первичные и внешние ключи и хранимые процедуры.
- Существует три типа концептуальных, логических и физических.
- Основная цель концептуальной модели — установить объекты, их атрибуты и отношения.
- Логическая модель данных определяет структуру элементов данных и устанавливает отношения между ними.
- Физическая модель данных описывает реализацию модели данных для конкретной базы данных.
- Основная цель разработки модели данных — убедиться, что объекты данных, предлагаемые функциональной группой, представлены точно.
- Самый большой недостаток заключается в том, что даже небольшие изменения в структуре требуют модификации всего приложения.
- Читая это руководство по моделированию данных, вы узнаете об основных понятиях, таких как что такое модель данных? Введение в различные типы моделей данных, преимущества, недостатки и пример модели данных.
Глава 5 Моделирование данных — Проектирование базы данных — 2-е издание
Основная часть
Эдриенн Уотт
Моделирование данных — это первый шаг в процессе проектирования базы данных. Этот этап иногда считается высокоуровневым и абстрактным этапом проектирования, также называемым концептуальным проектированием. Цель этого этапа – описать:
- Данные, содержащиеся в базе данных (например, сущности: студенты, преподаватели, курсы, предметы)
- Взаимосвязь между элементами данных (например, преподаватели наблюдают за студентами; преподаватели преподают курсы)
- Ограничения на данные (например, номер студента состоит ровно из восьми цифр; предмет имеет только четыре или шесть кредитных единиц)
На втором этапе элементы данных, взаимосвязи и ограничения выражаются с использованием концепций, предоставляемых высокоуровневой моделью данных. Поскольку эти концепции не включают детали реализации, результатом процесса моделирования данных является (полу)формальное представление структуры базы данных. Этот результат довольно легко понять, поэтому он используется в качестве эталона, чтобы убедиться, что все требования пользователя выполнены.
Этот результат довольно легко понять, поэтому он используется в качестве эталона, чтобы убедиться, что все требования пользователя выполнены.
Третий шаг — проектирование базы данных. На этом этапе у нас может быть два подэтапа: один называется логическая структура базы данных , который определяет базу данных в модели данных конкретной СУБД, а другой называется физическая конструкция базы данных , который определяет внутреннюю структуру хранения базы данных. Организация файлов или методы индексирования. Эти два подэтапа – этапы внедрения базы данных и создания операций/пользовательских интерфейсов.
На этапах проектирования базы данных данные представляются с использованием определенной модели данных. 9Модель данных 0648 представляет собой набор понятий или обозначений для описания данных, отношений данных, семантики данных и ограничений данных. Большинство моделей данных также включают в себя набор основных операций для манипулирования данными в базе данных.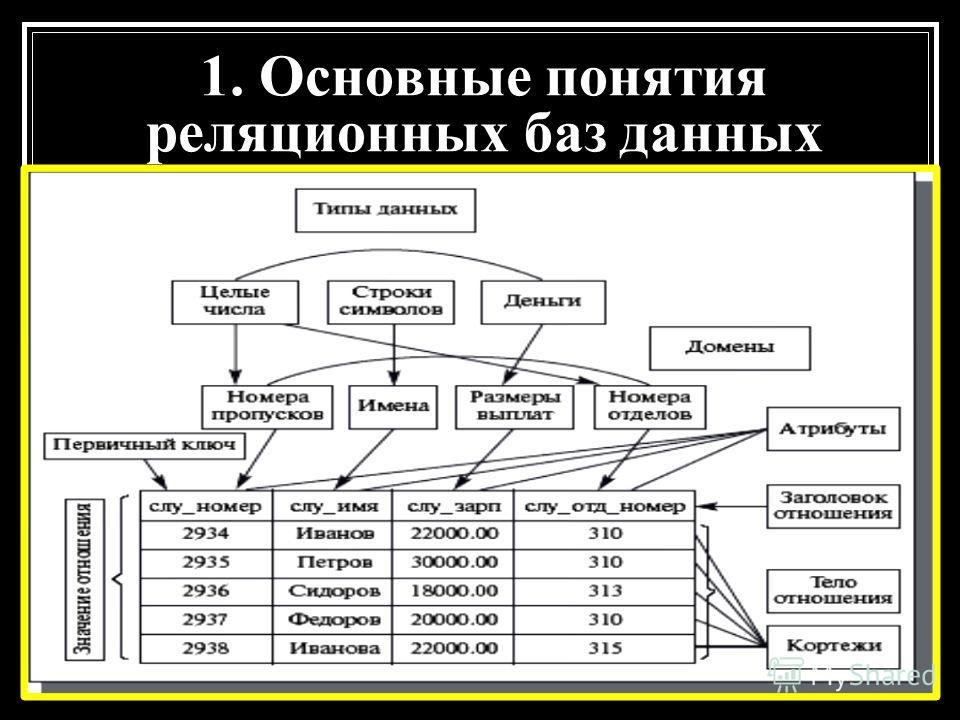
степеней абстракции данных
В этом разделе мы рассмотрим процесс проектирования базы данных с точки зрения специфики. Точно так же, как любое проектирование начинается с высокого уровня и переходит к постоянно возрастающему уровню детализации, так же происходит и с проектированием баз данных. Например, при строительстве дома вы начинаете с того, сколько спален и ванных комнат будет в доме, будет ли он одноуровневым или многоуровневым и т. д. перспектива. Этот уровень становится более подробным в отношении фактических размеров комнаты, того, как дом будет подключен, где будет размещена сантехника и т. д. Последний шаг — нанять подрядчика для строительства дома. Это взгляд на дизайн от высокого уровня абстракции до возрастающего уровня детализации.
Структура базы данных очень похожа на эту. Он начинается с того, что пользователи определяют бизнес-правила; затем проектировщики и аналитики базы данных создают проект базы данных; а затем администратор базы данных реализует проект с помощью СУБД.
В следующих подразделах представлены модели в порядке убывания уровня абстракции.
Внешние модели
- Представление пользовательского представления базы данных
- Содержит несколько различных внешних представлений
- Тесно связаны с реальным миром, как его воспринимает каждый пользователь
Концептуальные модели
- Обеспечение гибких возможностей структурирования данных
- Представить «общественное представление»: логическую структуру всей базы данных
- Содержат данные, хранящиеся в базе данных
- Показать отношения между данными, включая:
- Ограничения
- Семантическая информация (например, бизнес-правила)
- Информация о безопасности и целостности
- Рассматривайте базу данных как набор сущностей (объектов) различных видов
- Являются основой для идентификации и высокоуровневого описания основных объектов данных; они избегают подробностей
- Независимо от базы данных, которую вы будете использовать
Внутренние модели
Тремя наиболее известными моделями этого типа являются реляционная модель данных, сетевая модель данных и иерархическая модель данных.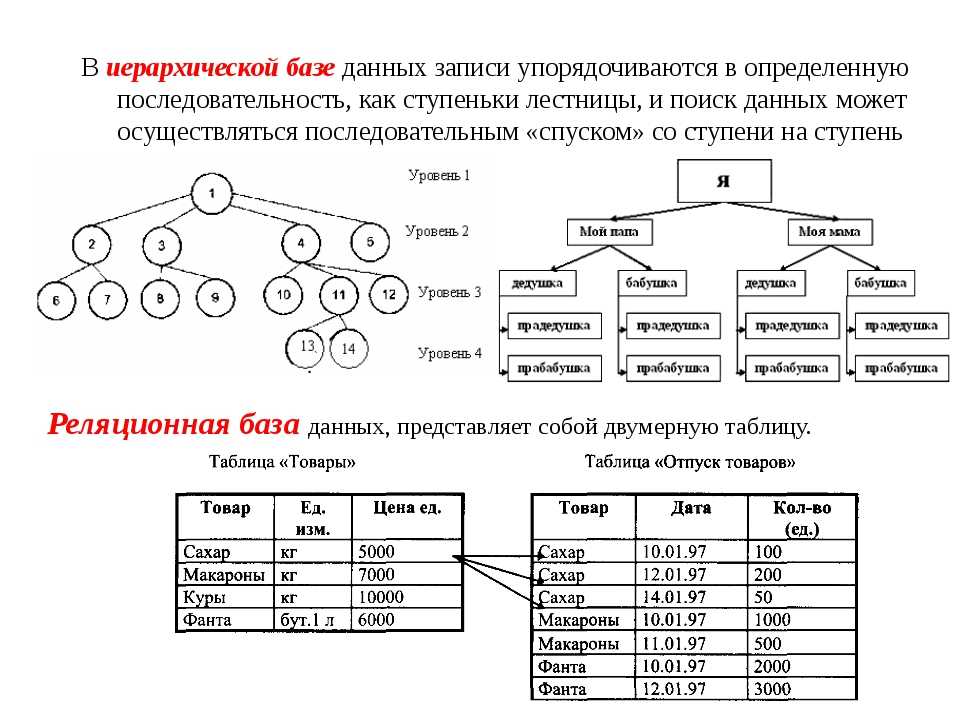 Эти внутренние модели:
Эти внутренние модели:
- Рассматривайте базу данных как набор записей фиксированного размера
- Ближе к физическому уровню или файловой структуре
- Представляют собой представление базы данных с точки зрения СУБД.
- Требовать от проектировщика согласования характеристик и ограничений концептуальной модели с характеристиками и ограничениями выбранной модели реализации
- Включить сопоставление сущностей концептуальной модели с таблицами реляционной модели
Физические модели
- Является физическим представлением базы данных
- Иметь самый низкий уровень абстракции
- Способ хранения данных; они имеют дело с
- Производительность во время выполнения
- Использование хранилища и сжатие
- Организация файлов и методы доступа
- Шифрование данных
- Физический уровень — управляется операционной системой (ОС)
- Обеспечьте понятия, описывающие детали того, как данные хранятся в памяти компьютера
Уровень абстракции данных
В графическом виде вы можете увидеть, как разные модели работают вместе. Давайте посмотрим на это с высшего уровня, внешней модели.
Давайте посмотрим на это с высшего уровня, внешней модели.
Внешняя модель — это представление данных конечным пользователем. Обычно база данных представляет собой корпоративную систему, которая обслуживает потребности нескольких отделов. Однако один отдел не заинтересован в просмотре данных других отделов (например, отдел кадров (HR) не хочет просматривать данные отдела продаж). Поэтому одно представление пользователя будет отличаться от другого.
Внешняя модель требует, чтобы разработчик подразделил набор требований и ограничений на функциональные модули, которые можно исследовать в рамках их внешних моделей (например, человеческие ресурсы в сравнении с продажами).
Как разработчик данных, вам необходимо понимать все данные, чтобы вы могли создать базу данных масштаба предприятия. Основываясь на потребностях различных отделов, концептуальная модель является первой созданной моделью.
На данном этапе концептуальная модель не зависит ни от программного, ни от аппаратного обеспечения. Это не зависит от программного обеспечения СУБД, используемого для реализации модели. Это не зависит от аппаратного обеспечения, используемого при реализации модели. Изменения в оборудовании или программном обеспечении СУБД не влияют на структуру базы данных на концептуальном уровне.
Это не зависит от программного обеспечения СУБД, используемого для реализации модели. Это не зависит от аппаратного обеспечения, используемого при реализации модели. Изменения в оборудовании или программном обеспечении СУБД не влияют на структуру базы данных на концептуальном уровне.
После того, как СУБД выбрана, ее можно внедрить. Это внутренняя модель. Здесь вы создаете все таблицы, ограничения, ключи, правила и т. д. Это часто называют логическим планом .
Физическая модель — это просто способ хранения данных на диске. У каждого поставщика базы данных есть свой способ хранения данных.
Рисунок 5.1. Уровни абстракции данных.Схемы
Схема — это общее описание базы данных, которое обычно представлено диаграмма отношений сущностей (ERD) . Существует множество подсхем, которые представляют внешние модели и, таким образом, отображают внешние представления данных. Ниже приведен список элементов, которые следует учитывать в процессе проектирования базы данных.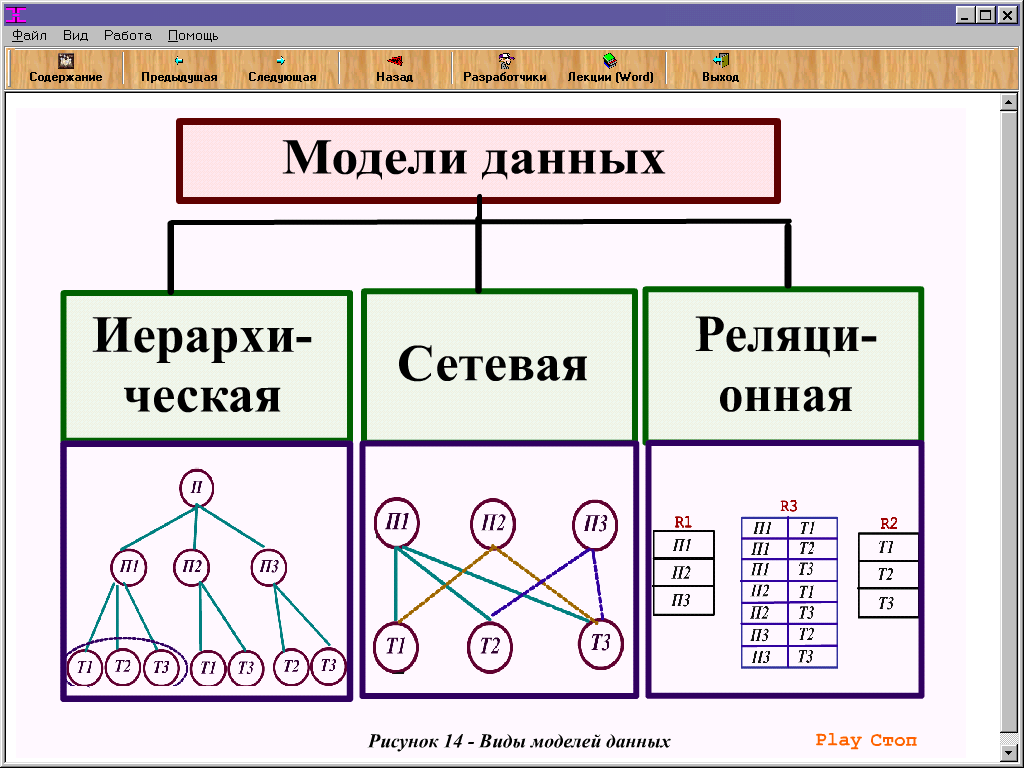
- Внешние схемы: несколько
- Несколько подсхем: они отображают несколько внешних представлений данных
- Концептуальная схема: есть только одна. Эта схема включает элементы данных, отношения и ограничения, представленные в ERD.
- Физическая схема: есть только одна
Независимость от логических и физических данных
Независимость от данных относится к невосприимчивости пользовательских приложений к изменениям, внесенным в определение и организацию данных. Абстракции данных раскрывают только те элементы, которые важны или имеют отношение к пользователю. Сложность скрыта от пользователя базы данных.
Независимость от данных и независимость от операций вместе составляют функцию абстракции данных. Существует два типа независимости данных: логическая и физическая.
Логическая независимость данных
Логическая схема – это концептуальный проект базы данных, выполненный на бумаге или на доске, очень похожий на архитектурные чертежи дома.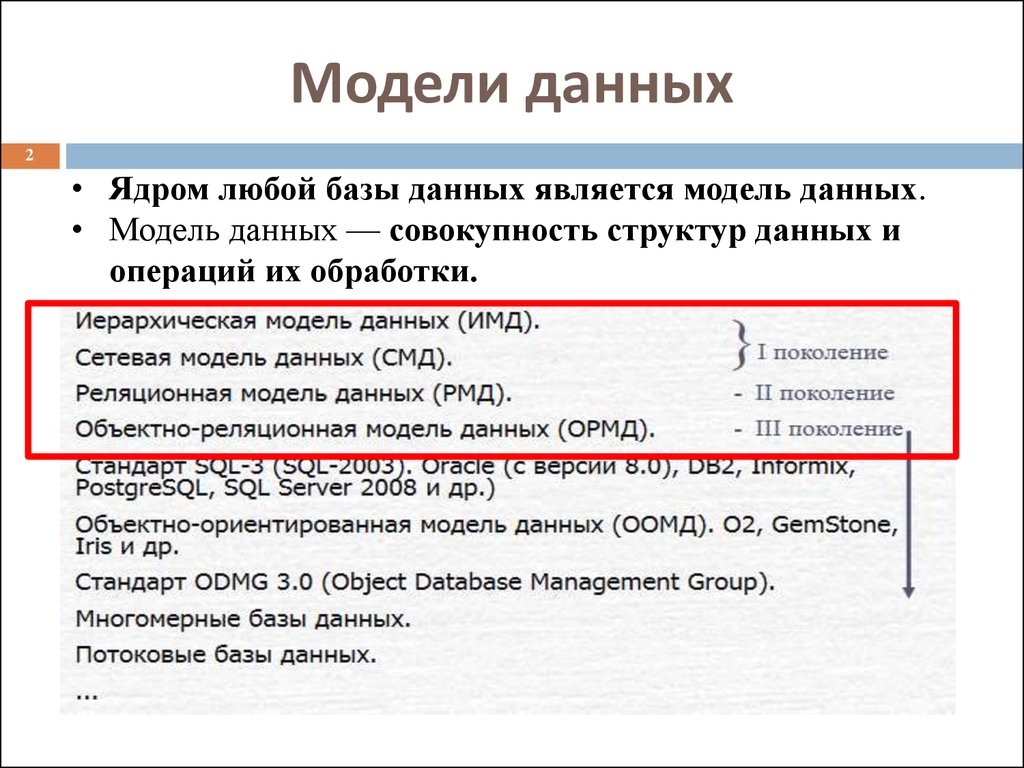 Возможность изменить логическую схему без изменения внешней схемы или пользовательского представления называется логической независимостью данных . Например, добавление или удаление новых сущностей, атрибутов или отношений к этой концептуальной схеме должно быть возможным без изменения существующих внешних схем или переписывания существующих прикладных программ.
Возможность изменить логическую схему без изменения внешней схемы или пользовательского представления называется логической независимостью данных . Например, добавление или удаление новых сущностей, атрибутов или отношений к этой концептуальной схеме должно быть возможным без изменения существующих внешних схем или переписывания существующих прикладных программ.
Другими словами, изменения логической схемы (например, изменения в структуре базы данных, такие как добавление столбца или других таблиц) не должны влиять на функцию приложения (внешние представления).
Физическая независимость данных
Независимость от физических данных относится к невосприимчивости внутренней модели к изменениям в физической модели. Логическая схема остается неизменной даже при внесении изменений в организацию файлов или структуры хранения, устройства хранения или стратегию индексирования.
Физическая независимость данных связана с сокрытием деталей структуры хранилища от пользовательских приложений. Приложения не должны заниматься этими вопросами, поскольку нет никакой разницы в операции, выполняемой с данными.
Приложения не должны заниматься этими вопросами, поскольку нет никакой разницы в операции, выполняемой с данными.
концептуальная модель : логическая структура всей базы данных
концептуальная схема : другой термин для обозначения логической схемы
независимость данных : иммунитет пользовательских приложений к изменениям, внесенным в определение и организацию данных
модель данных : набор понятий или обозначений для описания данных, отношений данных, семантики данных и ограничений данных
моделирование данных : первый шаг в процессе проектирования базы данных база данных в модели данных конкретной системы управления базами данных
физический дизайн базы данных : определяет внутреннюю структуру хранения базы данных, организацию файлов или методы индексирования
диаграмма отношений сущностей (ERD) : модель данных, описывающая базу данных, показывающая таблицы, атрибуты и отношения
внешняя модель : представляет представление пользователя о базе данных
внешняя схема : внутреннее представление пользователя
модель: представление базы данных с точки зрения СУБД
логическая независимость данных : возможность изменять логическую схему без изменения внешней схемы
логический проект : где вы создаете все таблицы, ограничения, ключи, правила и т.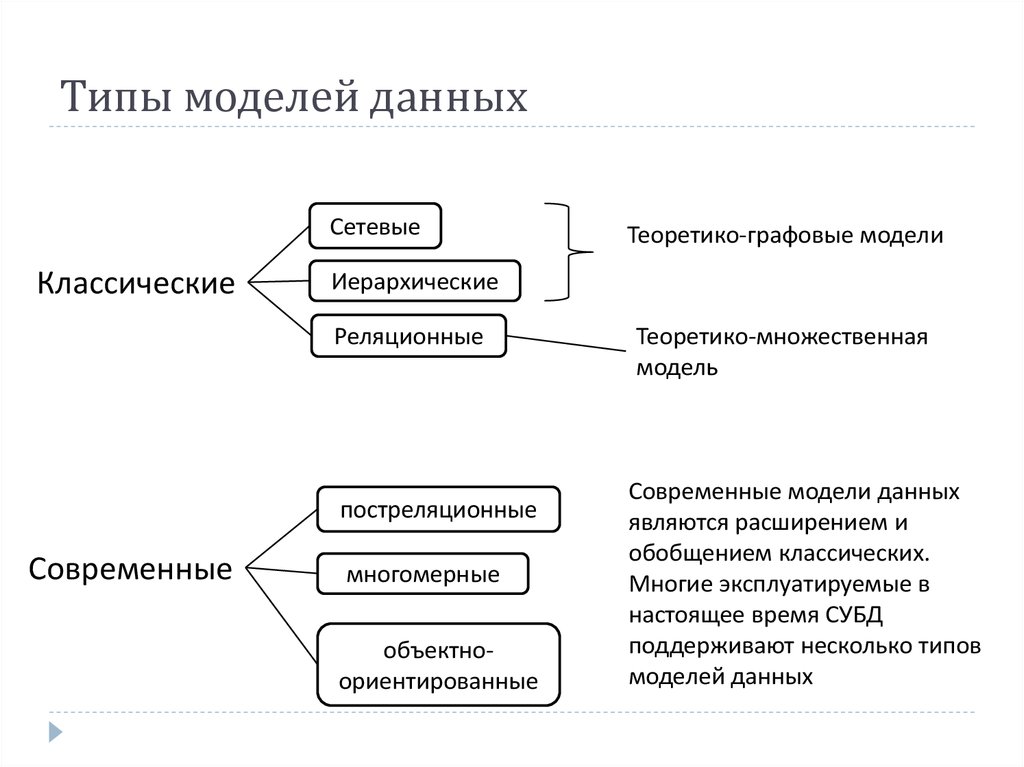 д.
д.
логическая схема : концептуальный проект базы данных, выполненный на бумаге или на доске, очень похожий на архитектурные чертежи дома
операционная система (ОС) : управляет физическим уровнем физической модели
независимость физических данных : иммунитет внутренней модели к изменениям в физической модели
физическая модель : физическое представление базы данных
схема : общее описание базы данных
- Опишите цель концептуального проекта.
- Чем концептуальный проект отличается от логического?
- Что такое внешняя модель?
- Что такое концептуальная модель?
- Что такое внутренняя модель?
- Что такое физическая модель?
- С какой моделью работает администратор базы данных?
- С какой моделью работает конечный пользователь?
- Что такое логическая независимость данных?
- Что такое независимость от физических данных?
См.