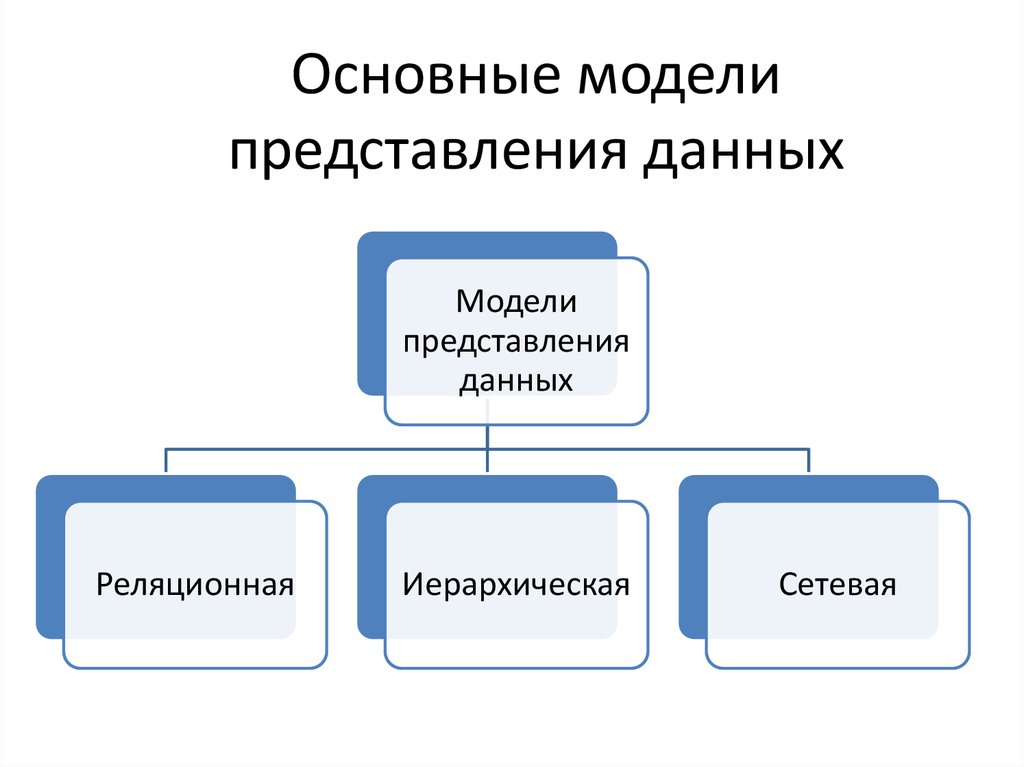
Модель данных. Большая российская энциклопедия
Моде́ль да́нных, множество допустимых типов данных, а также отношений и операций, определённых на данных этих типов. С математической точки зрения модель данных может трактоваться как алгебраическая система. В информационных технологиях модель данных служит инструментом проектирования, создания и использования баз данных и некоторых других информационных ресурсов.
Понятие модели данных возникло на ранней стадии развития технологий баз данных, а впоследствии стало использоваться и в других областях информационных технологий, например, в веб-технологиях, в технологиях информационных систем, основанных на знаниях, в системах интеграции данных из множества источников. Одной из ранних публикаций, в которой используется понятие модели данных, хотя без какого-либо явного определения, является широко известная статья Э. Кодда (Codd. 1970), описывающая предложенную им реляционную модель данных. Ранее эта работа была опубликована как отчет автора, выполненный в исследовательском центре компании IBM в Сан-Хосе (Калифорния).
Первоначально термин употреблялся как синоним структуры данных конкретной базы данных. Структурная трактовка полностью согласовывалась с математическим определением понятия модели как множества с заданными на нём отношениями, что оправдывало использование этого термина. Она и до сих пор встречается в литературе. Объектом моделирования при этом являются не данные вообще, а конкретная база данных. При такой трактовке модель данных – это результат моделирования базы данных, описание которого называется схемой базы данных (или схемой данных в информационных технологиях, оперирующих иными источниками данных).
В процессе развития теории и технологий баз данных возникла потребность в термине, который обозначал бы не результат, а инструмент моделирования данных, и для этой цели также стали использовать термин «модель данных». Поэтому для корректной трактовки смысла этого термина нужно учитывать контекст использования. Далее будут рассматриваться свойства только моделей данных – инструментов моделирования.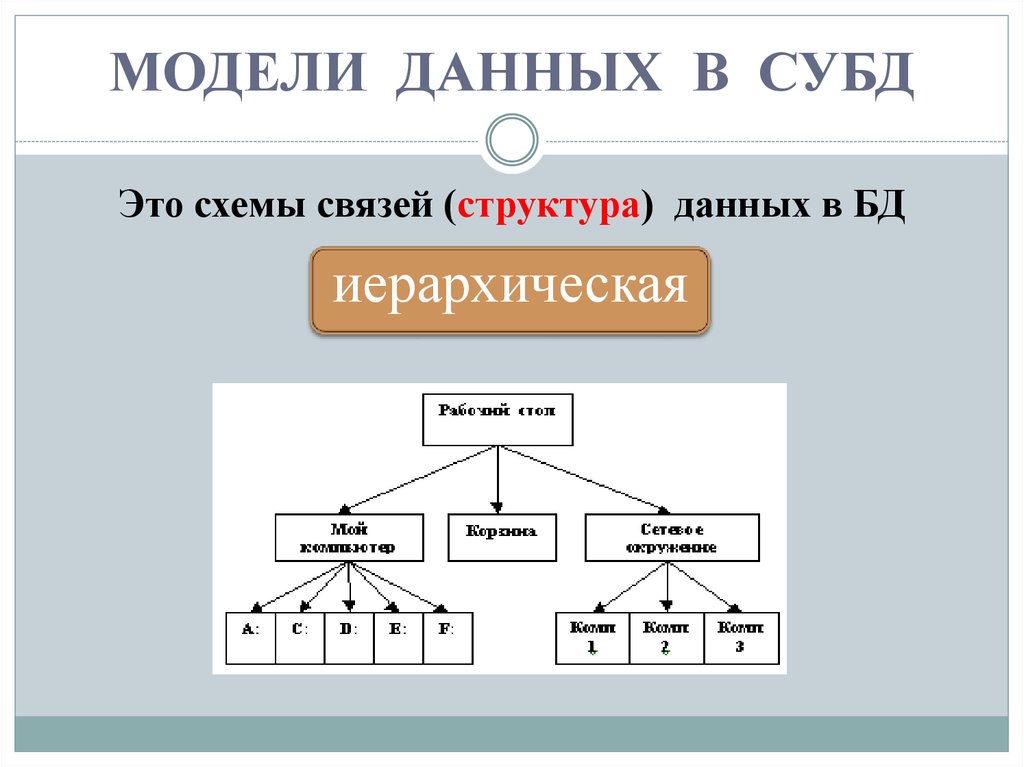 Определение, соответствующее пониманию как инструмента моделирования, было предложено в Тьюринговской лекции Э. Кодда (Codd. 1982).
Определение, соответствующее пониманию как инструмента моделирования, было предложено в Тьюринговской лекции Э. Кодда (Codd. 1982).
Полнофункциональная модель данных как инструментальное средство должна включать структурный и операционный компоненты. Структурный компонент предоставляет средства описания допустимых структур данных и ограничений целостности, которым должны удовлетворять их корректные состояния. Указанными средствами представляется для конкретной базы данных её схема базы данных, которая является по отношению к ней метаданными. Операционный компонент модели данных включает средства манипулирования данными, позволяющие осуществлять поиск требуемых данных, запоминать, модифицировать их и выполнять другие операции, состав которых специфичен для конкретной модели данных.
Наряду с полнофункциональными моделями данных существуют и широко используются на практике модели данных с неполными функциями, обладающие только дескриптивными средствами – структурным компонентом, например, широко используемая модель «сущность – связь» (ER-модель).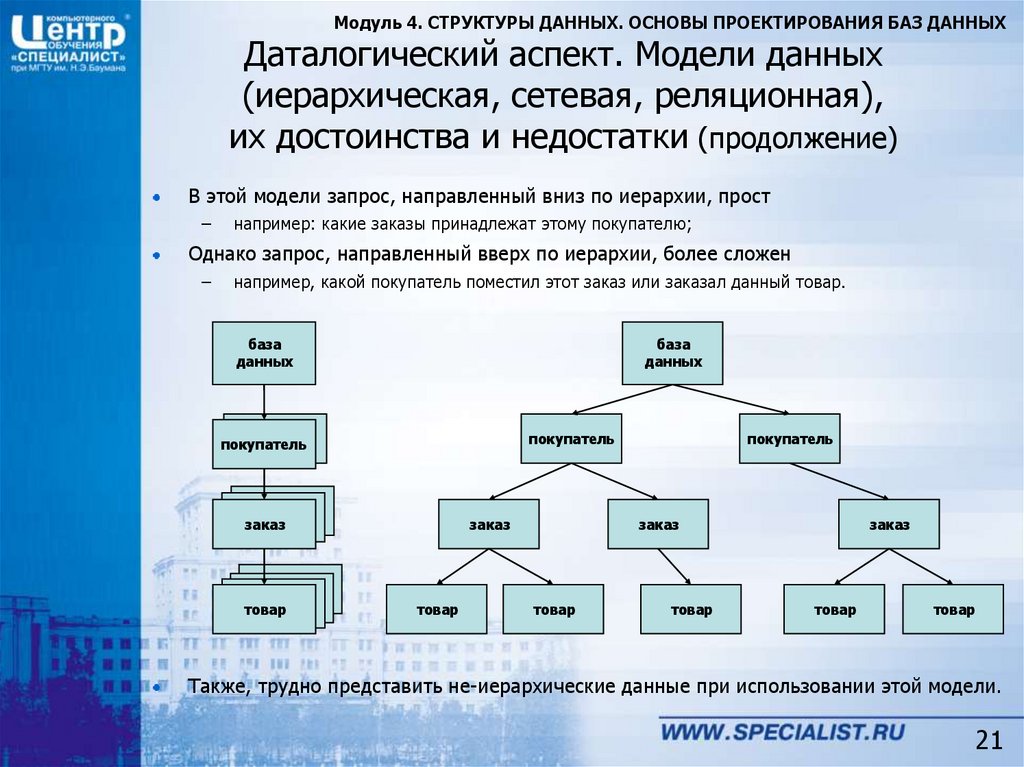
Механизмы, реализующие модели данных, являются ключевыми функциональными компонентами программных продуктов, обеспечивающих управление данными в информационных системах, которые основаны на технологиях баз данных. Такие системы называют системами баз данных, а указанные программные продукты – системами управления базами данных (СУБД).
Модели данных являются также основой автоматизированных систем проектирования баз данных (см. CASE-технологии). В таких системах проектировщик описывает структуру предметной области системы базы данных средствами, удобными для восприятия человеком и независимыми от СУБД, выбранной для разработки системы базы данных. Это может быть некоторая модель данных, например ER-модель, диаграмма классов языка UML, подходящая онтология и др. На основе созданного описания, называемого концептуальной схемой предметной области, автоматически генерируется схема базы данных, представленная средствами той модели данных, которая поддерживается выбранной целевой СУБД.
Модель данных, реализованная в конкретной СУБД, определяет множество всевозможных баз данных, которыми эта СУБД может управлять. СУБД использует средства реализованной её механизмами модели данных как на стадии разработки управляемых ею баз данных, так и на стадии их использования. Разработчик системы базы данных прежде всего настраивает выбранную СУБД для работы с создаваемой базой данных, задавая схему базы данных, созданную им «вручную» или, как указывалось выше, автоматизированным образом. На стадии использования модели механизмы СУБД на основе заданной схемы базы данных позволяют корректно интерпретировать её данные и применять операционные возможности СУБД для выполнения требуемых действий над ними.
Решая указанные задачи, модели данных выполняют вместе с тем другую важную функцию в системах баз данных – функцию поддержки иерархии абстракции данных, хранимых в системе. Выполнение этой функции обеспечивается благодаря многоуровневой архитектуре СУБД. При этом реальные данные представлены только на нижнем уровне архитектуры – в среде хранения базы данных.
Для поддержки иерархии абстракции данных механизмы каждого уровня многоуровневой архитектуры СУБД реализуют некоторую модель данных, обеспечивающую соответствующее представление данных и операции над ними её средствами. Кроме того, СУБД обладает механизмами отображения моделей данных между смежными уровнями многоуровневой архитектуры. Операции над данными более высокого уровня архитектуры отображаются с помощью таких механизмов в соответствующие операции над соответствующими данными более низкого уровня до тех пор, пока процесс отображения не достигнет операций над реально хранимыми данными, представленными на нижнем уровне архитектуры. На каждом из более верхних уровней данные формируются, когда они необходимы, из данных смежных нижних уровней в соответствии с их описанием. Каждая группа специалистов, имеющих дело с системой базы данных, взаимодействует с соответствующим ей уровнем архитектуры СУБД, на котором поддерживается представление данных, адекватное её потребностям. Благодаря такому подходу пользователь системы базы данных избавлен от необходимости знать, как реально хранится база данных во внешней памяти. Кроме того, он «видит» только ту часть базы данных, которая ему нужна, и она может быть представлена совсем не так, как «выглядит» полная база данных.
Кроме того, он «видит» только ту часть базы данных, которая ему нужна, и она может быть представлена совсем не так, как «выглядит» полная база данных.
Проблемы отображения моделей данных возникают также в распределённых системах баз данных, в системах интеграции данных из нескольких источников. Для обеспечения интегрированного представления данных и возможности оперирования ими в таких системах также используются отображения моделей данных, средствами которых представлены фрагменты распределённой базы данных или интегрируемые источники, в единую глобальную модель данных, поддерживаемую такой системой.
Можно различными способами охарактеризовать конкретную модель данных и описать её функциональность. Например, это можно сделать вербально на естественном языке. Некоторые модели могут быть описаны формализованным образом. Так, для реляционной модели Э. Кодд предложил строгое математическое описание. Однако для практического использования в технологиях управления данными модель данных должна быть представлена в виде специальных языковых средств – набора строго определенных искусственных языков или единого языка, определяющих функциональные возможности её структурного и операционного компонентов.
Структурный компонент модели данных представляется языком описания (определения) данных. Средствами такого языка определяются схемы баз данных, которыми способна управлять используемая СУБД. Операционный компонент модели данных может быть ориентирован на т. н. конечного пользователя – пользователя, взаимодействующего с системой базы данных в интерактивном режиме, или на пользователя-программиста, разрабатывающего приложения системы базы данных. Языки, предназначенные для конечного пользователя, называются языками запросов. Они позволяют осуществлять поиск, выборку, обновление или удаление данных из базы данных. Некоторые языки запросов дают возможность также генерировать различные агрегированные или статистические данные. Языки, предназначенные для пользователей-программистов, называются языками манипулирования данными. Для них создаются связывания с традиционными языками программирования, в среде которых используются их функции – вставка, обновление, удаление, выборка данных, навигация по структуре базы данных (для графовых моделей) и др.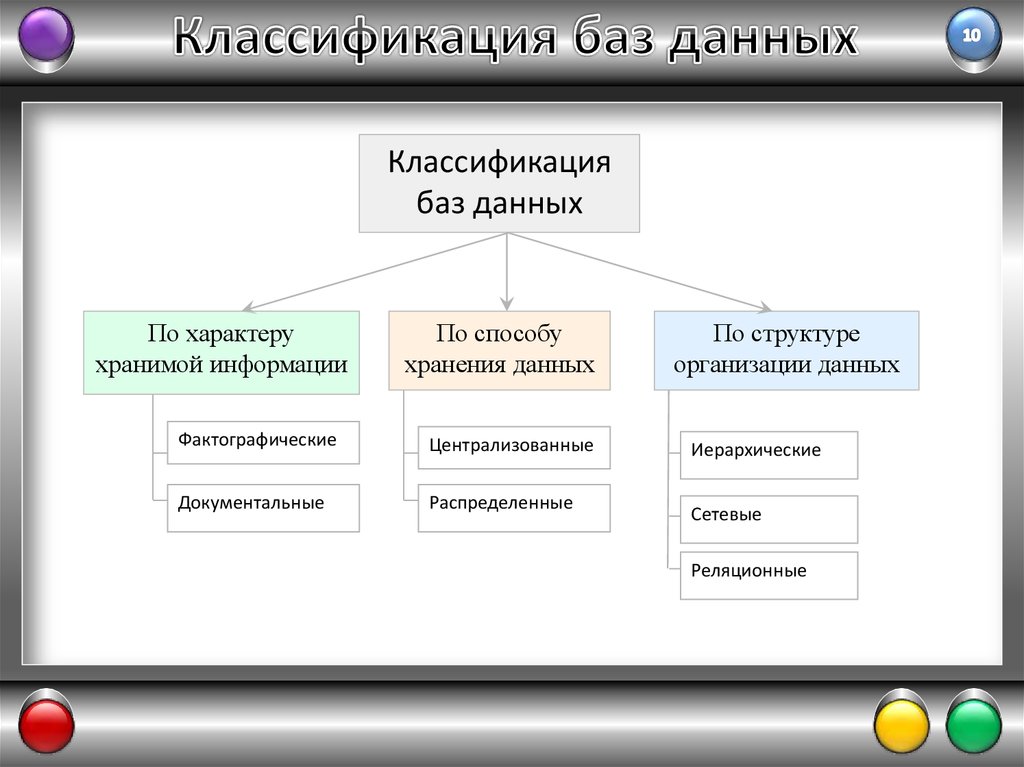
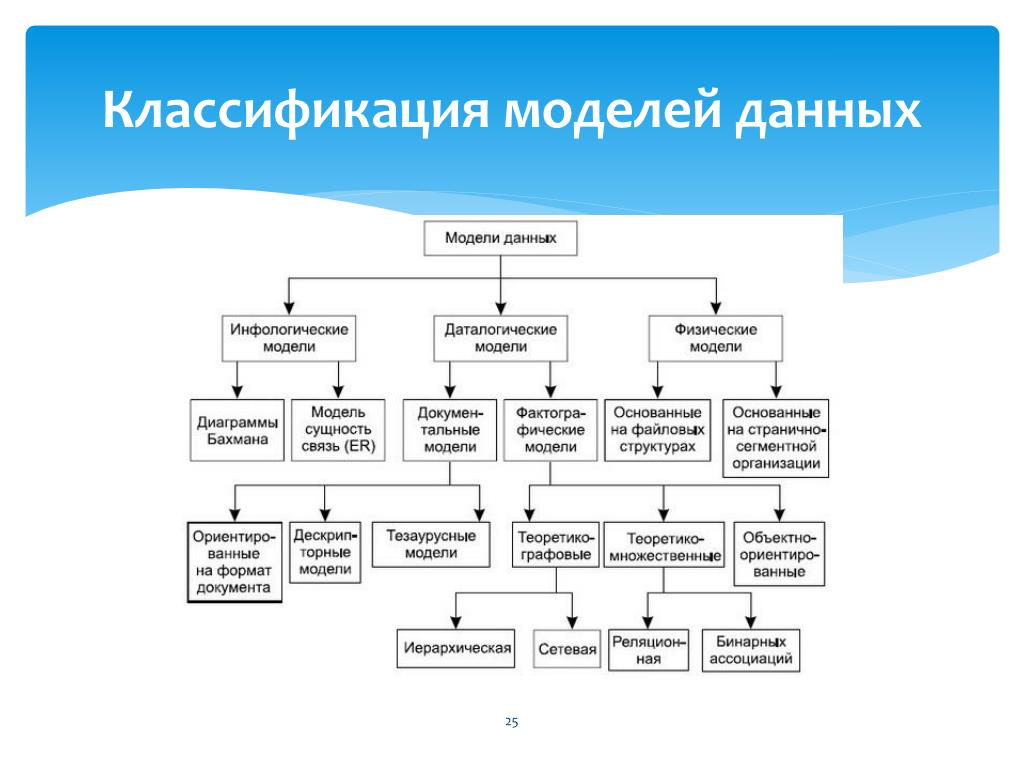
Со времени рождения технологий баз данных (начало 1960-х гг.) было создано множество разнообразных моделей данных для прикладных применений, многие из которых продолжают использоваться в настоящее время, а также для исследовательских целей. Главные их различия заключаются в том, для какого уровня архитектуры СУБД они предназначены, в парадигме моделирования, на которой они основаны, в степени формализованности и уровне семантики данных, которые они позволяют представлять, в особенностях их структурного и операционного компонентов, универсальности или специализированности области применения.
Далее рассматриваются некоторые наиболее известные модели данных:
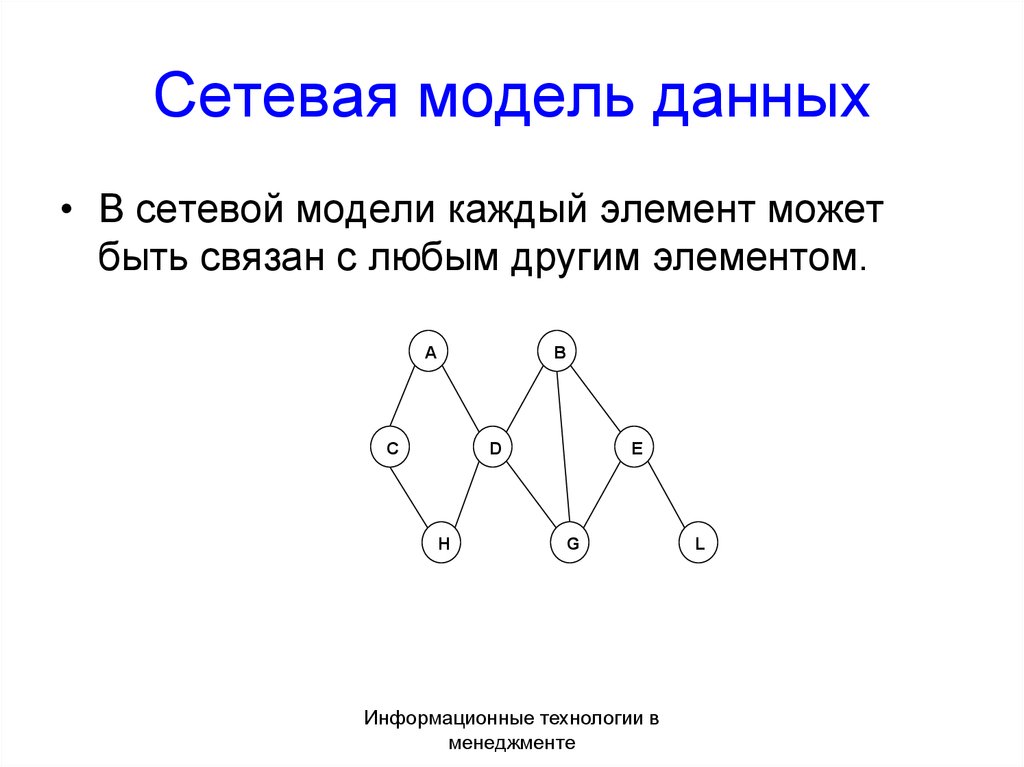
Графовая модель. Модель данных, в которой допустимые структуры данных могут быть представлены в виде графа общего или какого-либо специального вида, например в виде дерева. Необходимую группу операций в языке манипулирования данными, основанном на такой модели, представляют навигационные операции. Операции над данными здесь имеют позаписный (англ.
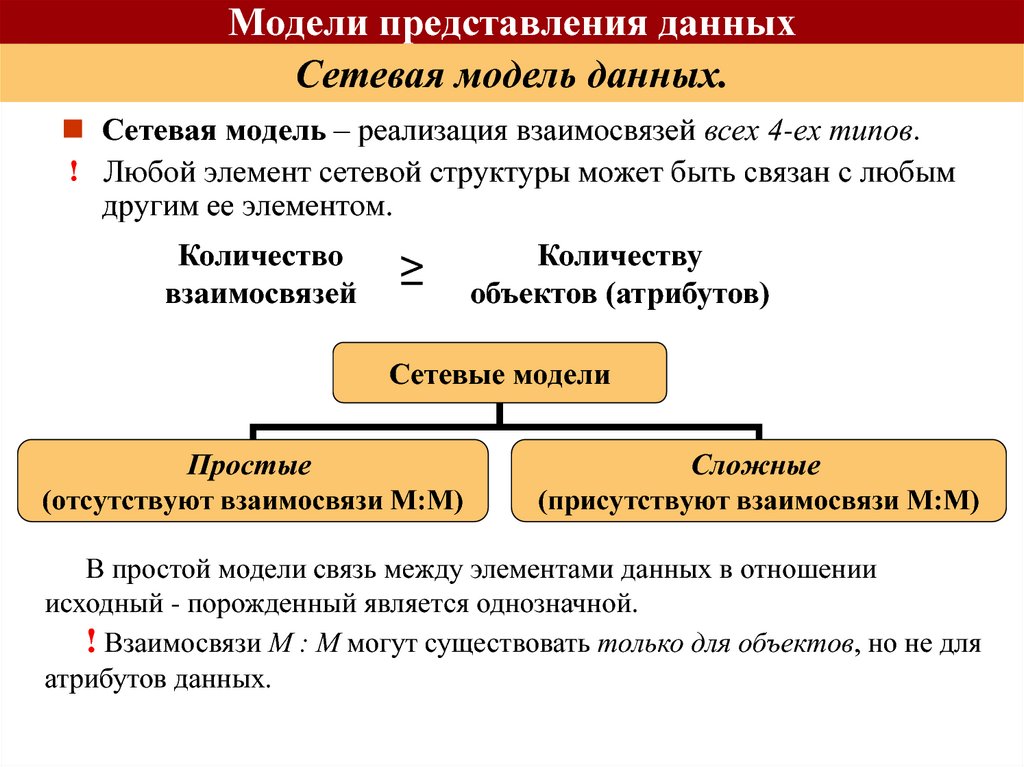
 Record-by-Record), не множественный характер. К графовым моделям относятся, в частности, иерархическая модель, сетевая модель данных CODASYL, RDF-модели, т. е. модели, основанные на RDF-графах.
Record-by-Record), не множественный характер. К графовым моделям относятся, в частности, иерархическая модель, сетевая модель данных CODASYL, RDF-модели, т. е. модели, основанные на RDF-графах.Модель «сущность – связь». Модель данных, кратко называемая ER-моделью (от англ. Entity-Relationship Model) и предназначенная, по замыслу автора, для описания модели предметной области в процессе проектирования базы данных. Однако эта модель была использована позднее также в ряде экспериментальных СУБД. Основными элементами ER-модели являются именованные множества сущностей, множества связей между ними, которые могут быть двуместными или многоместными, ориентированными или неориентированными. Сущности и связи обладают атрибутами. В модели вводится ограничение целостности данных – зависимость по существованию, ассоциируемое с двумя множествами сущностей. Это ограничение является близким по смыслу к ограничению целостности по ссылкам в реляционной модели.
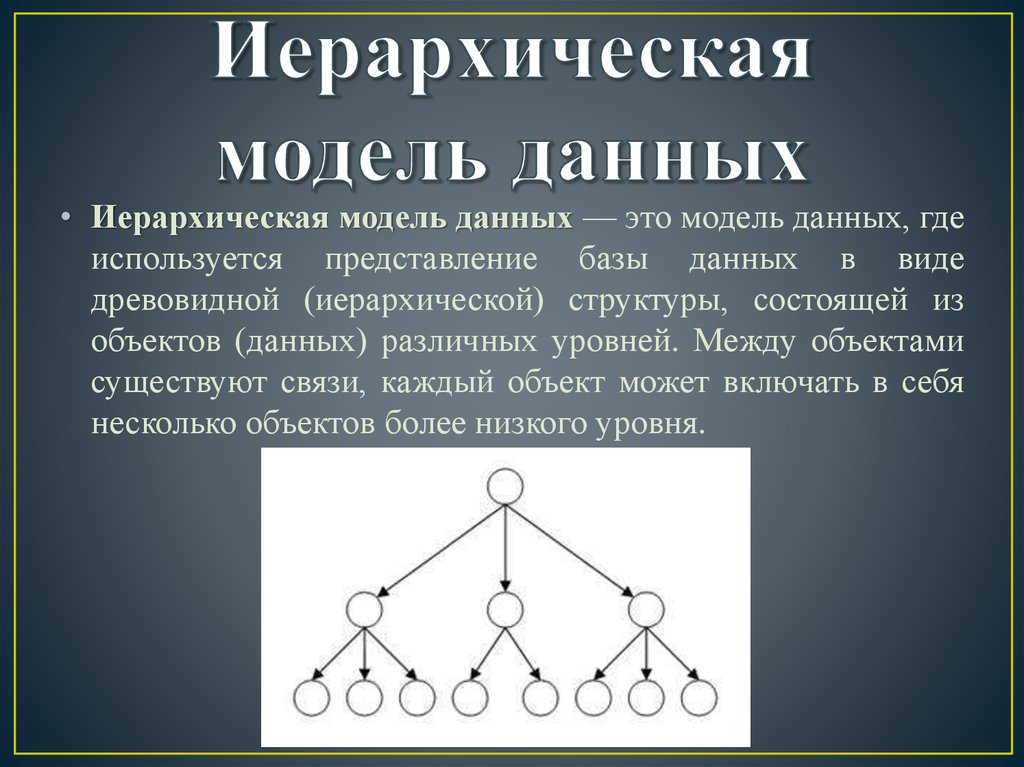
Иерархическая модель.
Модель данных, в основе которой используется иерархическая древовидная структура данных. Вершинами этой структуры являются записи различных типов, называемые сегментами и состоящие из простых элементов данных различных типов. При этом родительской записи соответствует произвольное число экземпляров подчиненных записей каждого типа. Экземпляр записи каждого типа идентифицируется уникальным ключом, определенным для этого типа. База данных представляет собой совокупность таких деревьев. В модели данных предусматриваются навигационные операции по структуре базы данных и операция поиска сегмента. Поддерживается концепция текущего состояния – вершины дерева структуры данных (в терминах экземпляров, а не типов), достигнутая в результате последней выполненной навигационной операции. Навигационные операции могут использовать идентификацию целевой записи относительно этого текущего состояния. Наряду с навигационными операциями поддерживаются операции манипулирования данными – вставка, обновление и удаление записей с естественным каскадным распространением операции удаления. Иерархическая модель данных активно использовалась во многих СУБД на платформе мейнфреймов до появления реляционных систем. Наиболее известным её представителем является модель данных СУБД IMS компании IBM, первая версия которой была разработана в конце 1960-х гг.
 Record-by-Record), не множественный характер. К графовым моделям относятся, в частности, иерархическая модель, сетевая модель данных CODASYL, RDF-модели, т. е. модели, основанные на RDF-графах.
Record-by-Record), не множественный характер. К графовым моделям относятся, в частности, иерархическая модель, сетевая модель данных CODASYL, RDF-модели, т. е. модели, основанные на RDF-графах.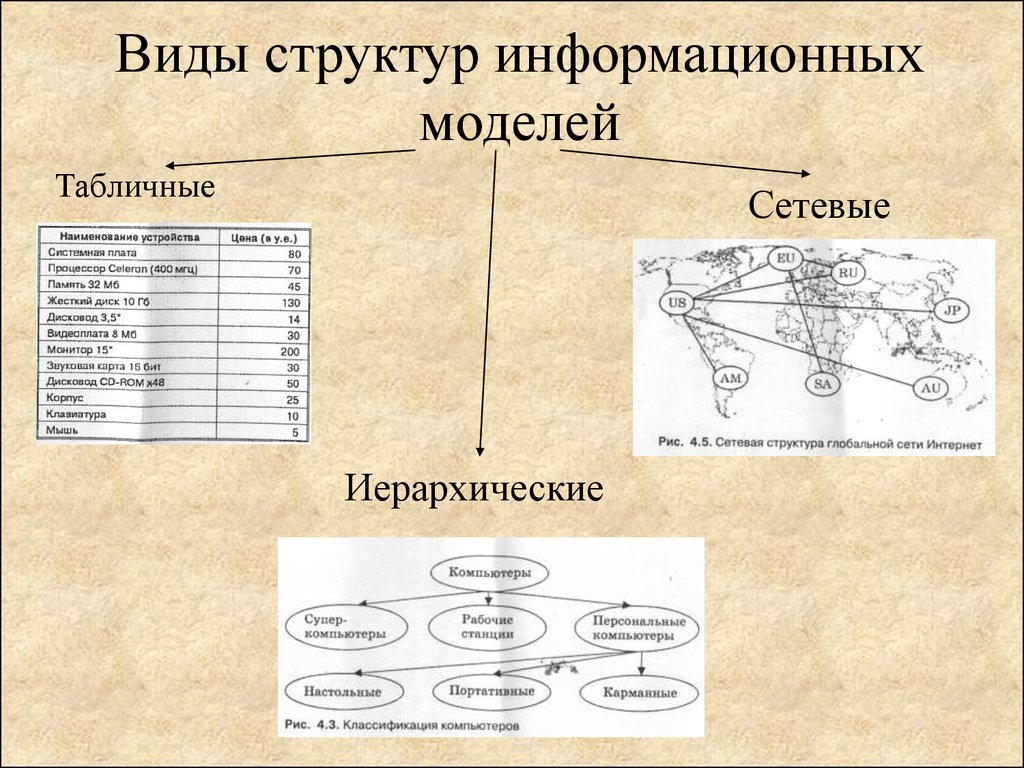 Модель данных, в основе которой используется иерархическая древовидная структура данных. Вершинами этой структуры являются записи различных типов, называемые сегментами и состоящие из простых элементов данных различных типов. При этом родительской записи соответствует произвольное число экземпляров подчиненных записей каждого типа. Экземпляр записи каждого типа идентифицируется уникальным ключом, определенным для этого типа. База данных представляет собой совокупность таких деревьев. В модели данных предусматриваются навигационные операции по структуре базы данных и операция поиска сегмента. Поддерживается концепция текущего состояния – вершины дерева структуры данных (в терминах экземпляров, а не типов), достигнутая в результате последней выполненной навигационной операции. Навигационные операции могут использовать идентификацию целевой записи относительно этого текущего состояния. Наряду с навигационными операциями поддерживаются операции манипулирования данными – вставка, обновление и удаление записей с естественным каскадным распространением операции удаления.
Модель данных, в основе которой используется иерархическая древовидная структура данных. Вершинами этой структуры являются записи различных типов, называемые сегментами и состоящие из простых элементов данных различных типов. При этом родительской записи соответствует произвольное число экземпляров подчиненных записей каждого типа. Экземпляр записи каждого типа идентифицируется уникальным ключом, определенным для этого типа. База данных представляет собой совокупность таких деревьев. В модели данных предусматриваются навигационные операции по структуре базы данных и операция поиска сегмента. Поддерживается концепция текущего состояния – вершины дерева структуры данных (в терминах экземпляров, а не типов), достигнутая в результате последней выполненной навигационной операции. Навигационные операции могут использовать идентификацию целевой записи относительно этого текущего состояния. Наряду с навигационными операциями поддерживаются операции манипулирования данными – вставка, обновление и удаление записей с естественным каскадным распространением операции удаления.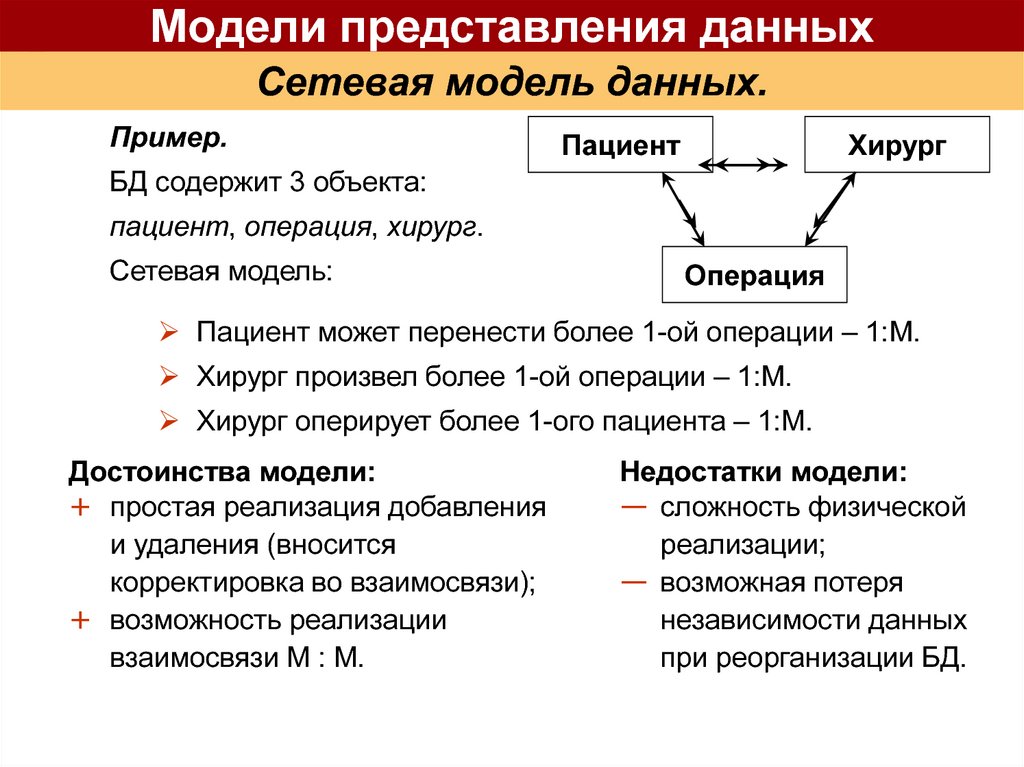 Иерархическая модель данных активно использовалась во многих СУБД на платформе мейнфреймов до появления реляционных систем. Наиболее известным её представителем является модель данных СУБД IMS компании IBM, первая версия которой была разработана в конце 1960-х гг.
Иерархическая модель данных активно использовалась во многих СУБД на платформе мейнфреймов до появления реляционных систем. Наиболее известным её представителем является модель данных СУБД IMS компании IBM, первая версия которой была разработана в конце 1960-х гг.Сетевая модель данных CODASYL. Модель данных, начальная версия которой была конструктивно описана Рабочей группой по базам данных CODASYL в её отчете, выпущенном в 1969 г. В отчете были впервые высказаны концепции многоуровневой архитектуры СУБД, представлен полный комплекс языковых средств описания данных и манипулирования данными, связанных со всеми архитектурными уровнями СУБД. В дальнейшем предложенные языковые спецификации получили серьёзное развитие в работах образованного для этой цели Комитета по языку описания данных CODASYL, а также ряда других комитетов, действующих в рамках этой организации. Эта модель относится к категории графовых моделей, представляет собой разновидность сетевой модели данных.
Имеет дело со структурами данных, конструируемыми из записей, которые подобны по своей структуре записям языка COBOL, и связей вида «N:1», причем все экземпляры записей – участников связи соединяются в список. Такие структуры данных называются наборами CODASYL, или просто наборами. Записи и наборы типизируются. База данных состоит из экземпляров типов наборов и экземпляров типов записей, описанных в схеме. Экземпляр типа записи может принадлежать многим наборам, но только не нескольким экземплярам наборов одного типа, или не принадлежит никакому набору. В модели предусмотрены средства навигации и манипулирования данными такой структуры.
 Имеет дело со структурами данных, конструируемыми из записей, которые подобны по своей структуре записям языка COBOL, и связей вида «N:1», причем все экземпляры записей – участников связи соединяются в список. Такие структуры данных называются наборами CODASYL, или просто наборами. Записи и наборы типизируются. База данных состоит из экземпляров типов наборов и экземпляров типов записей, описанных в схеме. Экземпляр типа записи может принадлежать многим наборам, но только не нескольким экземплярам наборов одного типа, или не принадлежит никакому набору. В модели предусмотрены средства навигации и манипулирования данными такой структуры.
Имеет дело со структурами данных, конструируемыми из записей, которые подобны по своей структуре записям языка COBOL, и связей вида «N:1», причем все экземпляры записей – участников связи соединяются в список. Такие структуры данных называются наборами CODASYL, или просто наборами. Записи и наборы типизируются. База данных состоит из экземпляров типов наборов и экземпляров типов записей, описанных в схеме. Экземпляр типа записи может принадлежать многим наборам, но только не нескольким экземплярам наборов одного типа, или не принадлежит никакому набору. В модели предусмотрены средства навигации и манипулирования данными такой структуры.Реляционная модель Э. Кодда. Модель данных, основанная на математическом понятии отношения и представлении отношений в форме таблиц. Операционные возможности модели имеют две эквивалентные формы – в терминах реляционной алгебры и реляционного исчисления. В отличие от других её версий, модель, опубликованная в (Codd. 1970), получила название базовой реляционной модели.
Позднее (1979) Э. Кодд опубликовал расширенную реляционную модель RM/T, значительно обогатившую базовую версию. Были предложены важные дополнения, включенные позднее в стандарт SQL, касающиеся, в частности, ограничений целостности по ссылке. Благодаря простоте и естественности структуры данных и манипулятивных операций, полной независимости от среды хранения данных, поддержке виртуальных, а не физических связей между данными (на основе значений данных, а не указателей), существованию её строгого формального определения реляционная модель позволила сформировать развитую математическую теорию основанных на ней баз данных, а СУБД, поддерживающие реляционную модель, заняли доминирующее положение среди инструментальных средств разработки систем баз данных. Компания IBM, сотрудником которой являлся Э. Кодд, разработала язык SEQUEL, воплощающий функциональность предложенной реляционной модели и послуживший в дальнейшем прототипом стандарта SQL. Хотя SQL квалифицируется как язык запросов, он является единым полнофункциональным языком модели данных, обладающим как дескриптивными (структурный компонент модели), так и операционными возможностями. В действующей версии стандарта ISO этого языка он воплощает объектно-реляционную модель данных. Эта гибридная модель сочетает возможности реляционных моделей с объектными свойствами данных. Стандарт включает также ряд расширений: для создания темпоральных систем баз данных, для интерактивной аналитической обработки данных (OLAP), а также средства связывания для ряда традиционных, в частности объектных, языков программирования.Темпоральная модель данных. Модель данных, предусматривающая поддержку концепции времени. Развитые модели такого рода поддерживают концепцию двумерного времени. При этом различаются действительное время – время, когда факт имел место в реальности, и время транзакции – время, когда факт помещается в систему. Вместе с тем возможно использование и третьего аспекта времени – времени, определяемого пользователем. Это измерение времени не поддерживается моделью, и интерпретация таких временных свойств является заботой пользователя или приложения. Концепция двумерного времени была впервые предложена еще в 1981 г.
в дипломной работе студента Калифорнийского университета UCLA Я. Бен-Цви (J. Ben-Zvi).Объектная модель. Модель данных, многочисленные разновидности которой получили широкое распространение в области программирования, баз данных и информационных систем. Основное понятие таких моделей – понятие объекта, т. е. сущности, обладающей состоянием и поведением. Состояние объекта определяется совокупностью его атрибутов, которые могут принимать значения предписанных типов. Поведение, в свою очередь, определяется совокупностью операций (методов), специфицированных для этого объекта. Для объектов поддерживается их индивидуальность, которая не изменяется при изменении состояния объекта. Принципиально важно, что различаются интерфейсы объектов и их реализации. Интерфейс определяет свойства объекта, видимые пользователю, – его свойства и сигнатуры операций. Реализация определяет внутренние свойства объекта, которые инкапсулируются интерфейсом и остаются скрытыми от пользователя. Объекты в объектных моделях типизируются.
Различаются встроенные типы объектов – объектов с предопределенными свойствами, и типы объектов, определяемые пользователем. Предусматривается наследование свойств типа объектами подтипа. Разработаны также объектные модели, которые наряду с атомарными типами объектов поддерживают сложные типы – контейнеры и типы-коллекции. Стандартом де-факто объектной модели для систем баз данных стал стандарт ODMG.Многомерная модель. Модель данных, оперирующая многомерными представлениями данных (в виде гиперкуба). Разновидности многомерной модели стали широко использоваться в середине 1990-х гг. в связи с развитием технологий OLAP. Основные понятия такой модели – измерение и ячейка. Каждое измерение представляет собой множество однородных значений данных, образующее грань гиперкуба. Примерами измерений являются годы, месяцы, кварталы, регионы, города, районы, названия предприятий, виды продукции и т. п. Измерения играют роль индексов, совокупности значений которых идентифицируют в гиперкубе конкретные его ячейки, или осей координат в многомерной системе координат гиперкуба.
Ячейки (называемые также показателями) представляют собой, как правило, числовые величины. Операционные возможности многомерных моделей данных, используемых в OLAP, ориентированы на поддержку анализа данных. Предусматривается конструирование разнообразных агрегаций данных в рамках заданного гиперкуба, построение различных его проекций – подмножеств гиперкуба, полученных путем фиксации значений каких-либо измерений, детализация (дезагрегация) и вращение (изменение порядка измерений) данных, а также ряд других операций.Модели данных СУБД NoSQL. Как альтернатива системам баз данных SQL, с начала 2000-х гг. развивается направление NoSQL. Основное внимание при этом уделяется системам баз данных, которые предназначены для хранения и анализа больших объемов неструктурированной информации, а также для распределённого хранения. Для СУБД NoSQL нет какой-либо стандартизованной модели данных, и для каждой пользователю необходимо осваивать её программное обеспечение. В отличие от реляционных баз данных, структура данных не регламентирована (или слабо типизирована, если проводить аналогии с языками программирования) – можно включать новые элементы структуры и задавать их значения без предварительного соответствующего изменения схемы базы данных.
Модель данных XML. В процессе развития веб-технологий в 1990-х гг. начал создаваться Консорциумом Всемирной паутины (англ. World Wide Web Consortium – W3C) и использоваться на практике комплекс новых стандартов веб-технологий – стандартов XML. Эти стандарты нашли применение и в технологиях баз данных. Стали разрабатываться системы баз данных XML. При этом использовалось несколько различных моделей данных с языком описания данных DTD или XML Schema. Наиболее распространенным является вариант модели, представленной совокупностью языка DTD в этой функции и языка запросов XQuery.
 Позднее (1979) Э. Кодд опубликовал расширенную реляционную модель RM/T, значительно обогатившую базовую версию. Были предложены важные дополнения, включенные позднее в стандарт SQL, касающиеся, в частности, ограничений целостности по ссылке. Благодаря простоте и естественности структуры данных и манипулятивных операций, полной независимости от среды хранения данных, поддержке виртуальных, а не физических связей между данными (на основе значений данных, а не указателей), существованию её строгого формального определения реляционная модель позволила сформировать развитую математическую теорию основанных на ней баз данных, а СУБД, поддерживающие реляционную модель, заняли доминирующее положение среди инструментальных средств разработки систем баз данных. Компания IBM, сотрудником которой являлся Э. Кодд, разработала язык SEQUEL, воплощающий функциональность предложенной реляционной модели и послуживший в дальнейшем прототипом стандарта SQL. Хотя SQL квалифицируется как язык запросов, он является единым полнофункциональным языком модели данных, обладающим как дескриптивными (структурный компонент модели), так и операционными возможностями.
Позднее (1979) Э. Кодд опубликовал расширенную реляционную модель RM/T, значительно обогатившую базовую версию. Были предложены важные дополнения, включенные позднее в стандарт SQL, касающиеся, в частности, ограничений целостности по ссылке. Благодаря простоте и естественности структуры данных и манипулятивных операций, полной независимости от среды хранения данных, поддержке виртуальных, а не физических связей между данными (на основе значений данных, а не указателей), существованию её строгого формального определения реляционная модель позволила сформировать развитую математическую теорию основанных на ней баз данных, а СУБД, поддерживающие реляционную модель, заняли доминирующее положение среди инструментальных средств разработки систем баз данных. Компания IBM, сотрудником которой являлся Э. Кодд, разработала язык SEQUEL, воплощающий функциональность предложенной реляционной модели и послуживший в дальнейшем прототипом стандарта SQL. Хотя SQL квалифицируется как язык запросов, он является единым полнофункциональным языком модели данных, обладающим как дескриптивными (структурный компонент модели), так и операционными возможностями. В действующей версии стандарта ISO этого языка он воплощает объектно-реляционную модель данных. Эта гибридная модель сочетает возможности реляционных моделей с объектными свойствами данных. Стандарт включает также ряд расширений: для создания темпоральных систем баз данных, для интерактивной аналитической обработки данных (OLAP), а также средства связывания для ряда традиционных, в частности объектных, языков программирования.
В действующей версии стандарта ISO этого языка он воплощает объектно-реляционную модель данных. Эта гибридная модель сочетает возможности реляционных моделей с объектными свойствами данных. Стандарт включает также ряд расширений: для создания темпоральных систем баз данных, для интерактивной аналитической обработки данных (OLAP), а также средства связывания для ряда традиционных, в частности объектных, языков программирования.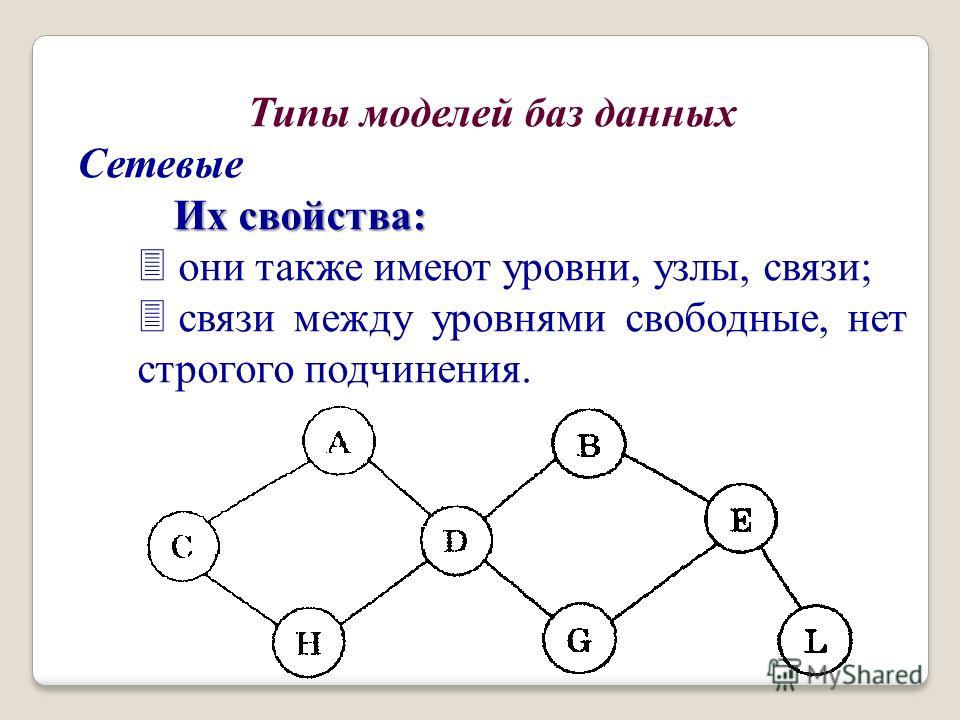 в дипломной работе студента Калифорнийского университета UCLA Я. Бен-Цви (J. Ben-Zvi).
в дипломной работе студента Калифорнийского университета UCLA Я. Бен-Цви (J. Ben-Zvi). Различаются встроенные типы объектов – объектов с предопределенными свойствами, и типы объектов, определяемые пользователем. Предусматривается наследование свойств типа объектами подтипа. Разработаны также объектные модели, которые наряду с атомарными типами объектов поддерживают сложные типы – контейнеры и типы-коллекции. Стандартом де-факто объектной модели для систем баз данных стал стандарт ODMG.
Различаются встроенные типы объектов – объектов с предопределенными свойствами, и типы объектов, определяемые пользователем. Предусматривается наследование свойств типа объектами подтипа. Разработаны также объектные модели, которые наряду с атомарными типами объектов поддерживают сложные типы – контейнеры и типы-коллекции. Стандартом де-факто объектной модели для систем баз данных стал стандарт ODMG. Ячейки (называемые также показателями) представляют собой, как правило, числовые величины. Операционные возможности многомерных моделей данных, используемых в OLAP, ориентированы на поддержку анализа данных. Предусматривается конструирование разнообразных агрегаций данных в рамках заданного гиперкуба, построение различных его проекций – подмножеств гиперкуба, полученных путем фиксации значений каких-либо измерений, детализация (дезагрегация) и вращение (изменение порядка измерений) данных, а также ряд других операций.
Ячейки (называемые также показателями) представляют собой, как правило, числовые величины. Операционные возможности многомерных моделей данных, используемых в OLAP, ориентированы на поддержку анализа данных. Предусматривается конструирование разнообразных агрегаций данных в рамках заданного гиперкуба, построение различных его проекций – подмножеств гиперкуба, полученных путем фиксации значений каких-либо измерений, детализация (дезагрегация) и вращение (изменение порядка измерений) данных, а также ряд других операций.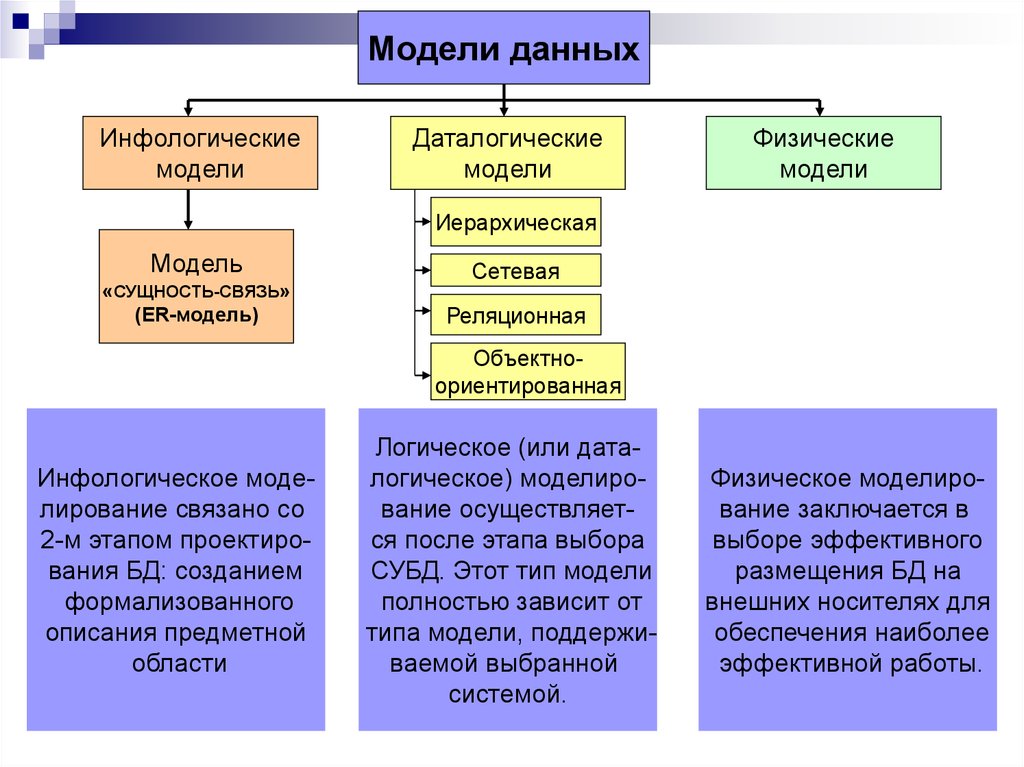
Важность роли моделей данных в технологиях баз данных подтверждается тем фактом, что за работы в области разработки моделей данных одной из самых престижных наград в области информатики – премии Тьюринга, присуждаемой международной организацией Ассоциация вычислительной техники (англ. Association for Computing Machinery – ACM) – в разное время были удостоены идеолог сетевой модели данных CODASYL Ч.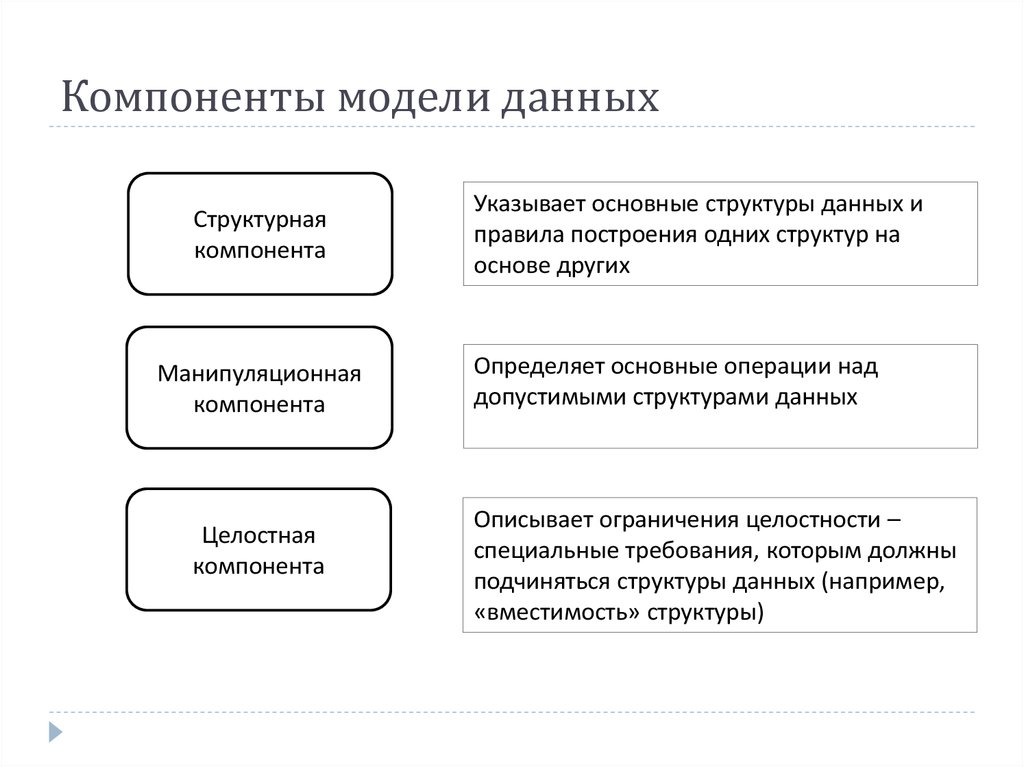 Бахман (1973) и создатель реляционной модели Э. Кодд (1981).
Бахман (1973) и создатель реляционной модели Э. Кодд (1981).
Что такое моделирование данных? – Описание моделирования данных – AWS
\n\n
Вы также можете использовать AWS Amplify DataStore для более быстрого и простого моделирования данных при создании мобильных и веб-приложений. У него есть визуальный и основанный на коде интерфейс для определения модели данных с отношениями, что ускорит разработку приложения.
\n\n
Начните работу с моделированием данных в AWS, создав бесплатный аккаунт уже сегодня.
\n»,»id»:»seo-faq-pairs#how-can-aws-help-with-data-modeling»,»customSort»:»6″},»metadata»:{«tags»:[{«id»:»seo-faq-pairs#faq-collections#data-modeling»,»name»:»data-modeling»,»namespaceId»:»seo-faq-pairs#faq-collections»,»description»:»
моделирование данных
\n»,»metadata»:{}}]}}]},»metadata»:{«auth»:{},»pagination»:{«present»:true}},»context»:{«environment»:{«stage»:»prod»,»region»:»us-east-1″},»sdkVersion»:»1.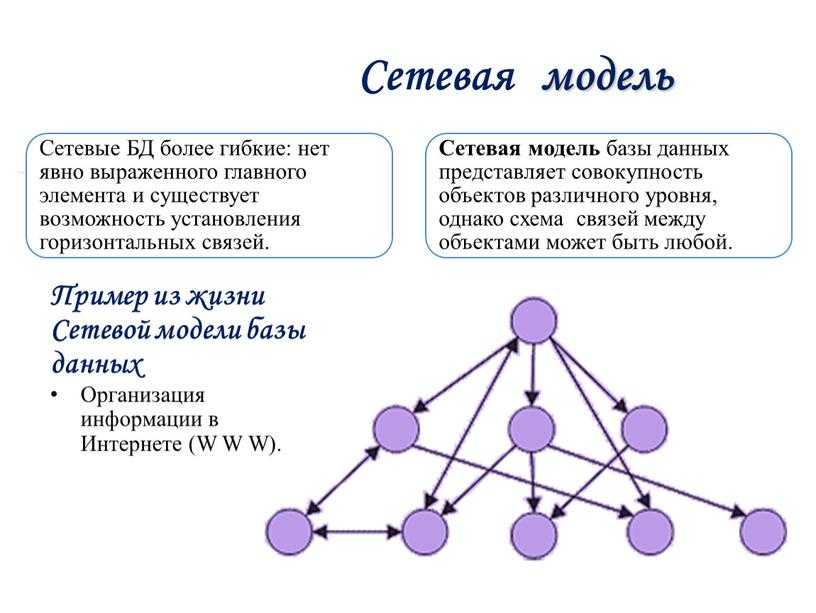
\n\n
Вы также можете использовать AWS Amplify DataStore для более быстрого и простого моделирования данных при создании мобильных и веб-приложений. У него есть визуальный и основанный на коде интерфейс для определения модели данных с отношениями, что ускорит разработку приложения.
\n\n
Начните работу с моделированием данных в AWS, создав бесплатный аккаунт уже сегодня.
\n»}}]]}
Что такое моделирование данных?
Моделирование данных – это процесс создания визуального представления или чертежа, определяющего системы сбора и управления информацией в любой организации. Этот план или модель данных помогает различным заинтересованным сторонам, таким как аналитики данных, ученые и инженеры, создать единое представление о данных организации. Модель описывает, какие данные собирает компания, взаимосвязь между различными наборами данных и методы, которые будут использоваться для хранения и анализа данных.
Почему моделирование данных важно?
Сегодня организации собирают большое количество данных из множества различных источников. Однако необработанных данных недостаточно. Вам необходимо анализировать данные для получения действенных выводов, которые помогут вам принимать выгодные бизнес-решения. Точный анализ данных требует их эффективного сбора, хранения и обработки. Существует несколько технологий баз данных и инструментов обработки данных, а разные наборы данных требуют разных инструментов для эффективного анализа.
Моделирование данных дает вам возможность понять ваши данные и сделать правильный выбор технологии для их хранения и управления ими. Подобно тому, как архитектор разрабатывает чертеж перед строительством дома, заинтересованные стороны бизнеса разрабатывают модель данных, прежде чем создавать решения баз данных для своей организации.
Моделирование данных дает следующие преимущества:
- Сокращает количество ошибок при разработке программного обеспечения для баз данных
- Способствует скорости и эффективности проектирования и создания баз данных
- Обеспечивает согласованность документации данных и системного дизайна в рамках всей организации
- Способствует коммуникации между инженерами по данным и командами бизнес-аналитики
Какие существуют типы моделей данных?
Моделирование данных обычно начинается с концептуального представления данных, а затем их повторного представления в контексте выбранных технологий.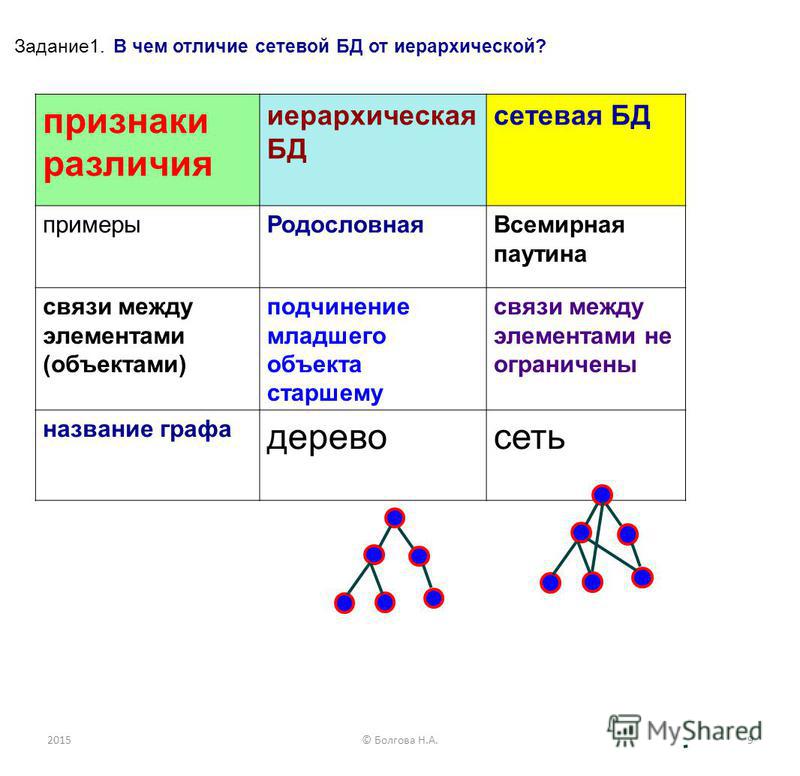 Аналитики и заинтересованные стороны создают несколько различных типов моделей данных на этапе проектирования данных. Ниже перечислены три основных типа моделей данных:
Аналитики и заинтересованные стороны создают несколько различных типов моделей данных на этапе проектирования данных. Ниже перечислены три основных типа моделей данных:
Концептуальная модель данных
Концептуальные модели данных дают общее представление о данных и объясняют следующее:
- данные, которые содержит система;
- атрибуты данных и условия или ограничения на данные;
- бизнес-правила, к которым относятся данные;
- оптимальная организация данных;
- требования к безопасности и целостности данных.
Заинтересованные стороны и аналитики обычно создают концептуальную модель. Это простое диаграммное представление, которое не следует формальным правилам моделирования данных. Важно то, что оно помогает как техническим, так и нетехническим заинтересованным сторонам разделить общее видение и согласовать цель, объем и дизайн проекта по работе с данными.
Пример концептуальной модели данных
Например, концептуальная модель данных для автосалона может представлять собой следующие сущности данных:
- Сущность «Шоурум», которая представляет информацию о различных торговых точках дилерского центра.
- Сущность «Автомобили», которая представляет несколько автомобилей, имеющихся у дилерского центра в настоящее время.
- Сущность «Клиенты», которая представляет всех клиентов, совершивших покупку в дилерском центре.
- Сущность «Продажи», которая представляет информацию о фактической продаже.
- Сущность «Продавец», которая представляет информацию обо всех продавцах, работающих в дилерском центре.
Эта концептуальная модель также будет включать бизнес-требования, например:
- Каждый автомобиль должен принадлежать определенному шоуруму.
- Каждая продажа должна иметь как минимум одного продавца и одного клиента, связанных с ней.
- Каждый автомобиль должен иметь название марки и номер продукта.
- Каждый клиент должен указать свой номер телефона и адрес электронной почты.
Таким образом, концептуальные модели выступают в качестве моста между бизнес-правилами и лежащей в их основе физической системой управления базами данных (СУБД).
Логическая модель данных
Логические модели данных отображают концептуальные классы данных на технических структурах данных. Они дают более подробную информацию о концепциях данных и их сложных отношениях, которые были определены в концептуальной модели данных, например:
- Типы данных различных атрибутов (например, строка или число)
- Взаимосвязи между объектами данных
- Первичные атрибуты или ключевые поля в данных
Архитекторы данных и аналитики совместно работают над созданием логической модели. Они следуют одной из нескольких формальных систем моделирования данных для создания представления. Иногда гибкие команды могут пропустить этот шаг и перейти от концептуальных к физическим моделям напрямую. Однако эти модели полезны для проектирования больших баз данных, называемых хранилищами данных, и для проектирования систем автоматической отчетности.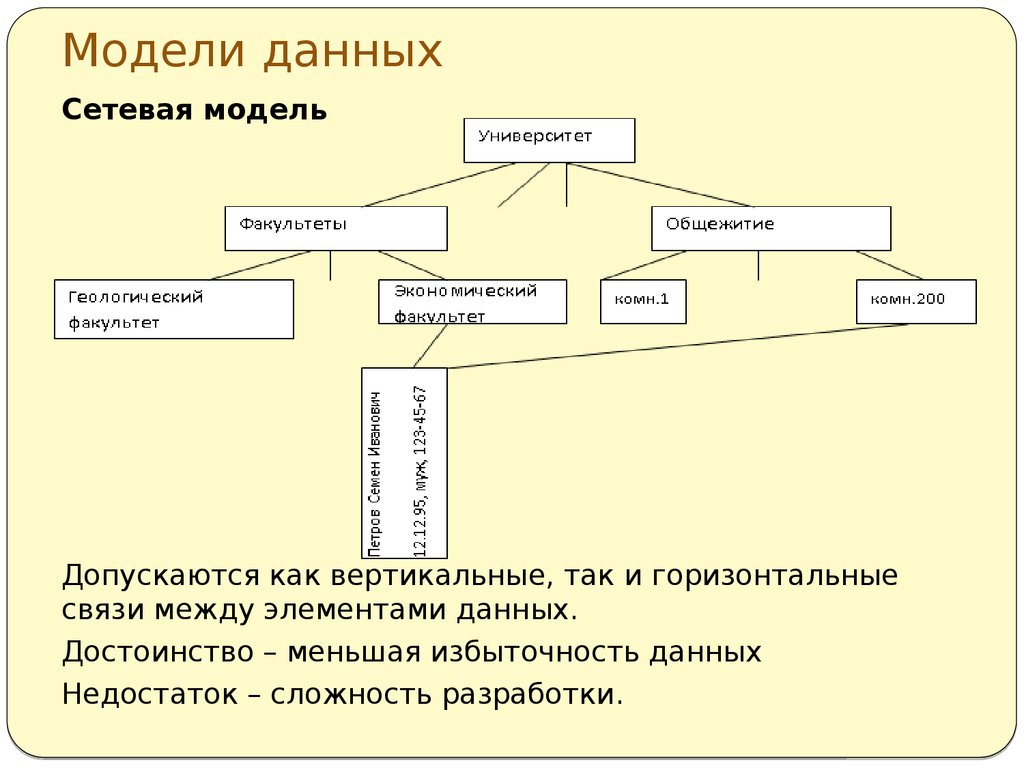
Пример логической модели данных
В нашем примере с автосалоном логическая модель данных расширяет концептуальную модель и позволяет глубже рассмотреть классы данных следующим образом:
- Сущность «Шоурум» имеет такие поля, как название и местоположение в виде текстовых данных и номер телефона в виде числовых данных.
- Сущность «Клиенты» имеет поле адреса электронной почты с форматом [email protected] или [email protected]. Длина имени поля может составлять не более 100 символов.
- Сущность «Продажи» имеет в качестве полей имя клиента и имя продавца, а также дату продажи как тип данных даты и сумму как десятичный тип данных.
Таким образом, логические модели служат связующим звеном между концептуальной моделью данных и базовой технологией и языком баз данных, которые разработчики используют для создания базы данных. Однако они не зависят от технологии, и вы можете реализовать их на любом языке баз данных.
Физическая модель данных
Физические модели данных отображают логические модели данных на конкретную технологию СУБД и используют терминологию программного обеспечения. Например, они предоставляют подробную информацию о следующем:
- Типы полей данных, представленные в СУБД
- Отношения между данными, представленные в СУБД
- Дополнительные детали, такие как настройка производительности
Инженеры по обработке данных создают физическую модель перед окончательной реализацией дизайна. Они также следуют формальным методам моделирования данных, чтобы убедиться, что охватили все аспекты проектирования.
Пример физической модели данных
Предположим, что автосалон решил создать архив данных в сервисе Гибкое извлечение данных Amazon S3 Glacier. Их физическая модель данных описывает следующие характеристики:
- В «Продажах» сумма продажи – это тип данных float, а дата продажи – тип данных timestamp.
- В «Клиентах» имя клиента является строковым типом данных.
- В терминологии S3 Glacier Flexible Retrieval хранилище – это географическое местоположение ваших данных.
Ваша физическая модель данных также включает дополнительные детали, например в каком регионе AWS вы создадите свое хранилище. Таким образом, физическая модель данных выступает в качестве моста между логической моделью данных и конечной технологической реализацией.
Какие существуют методы моделирования данных?
Методы моделирования данных – это различные методы, которые вы можете использовать для создания различных моделей данных. Эти подходы развивались с течением времени в результате инноваций в концепциях баз данных и управления данными. Ниже представлены основные типы моделирования данных.
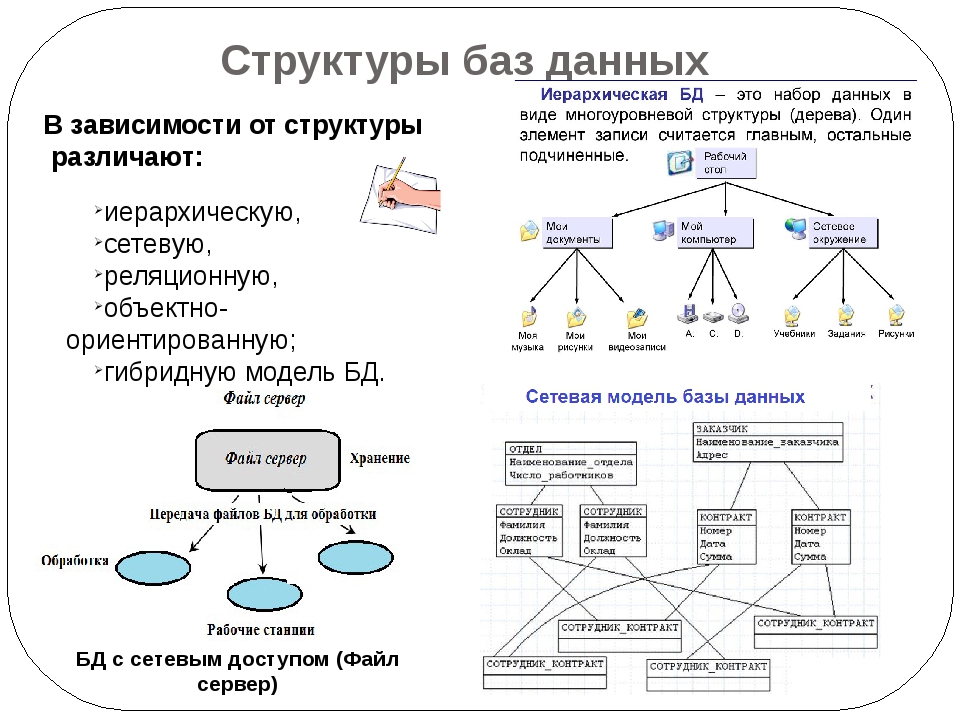
Иерархическое моделирование данных
При иерархическом моделировании данных вы можете представить отношения между различными элементами данных в древовидном формате.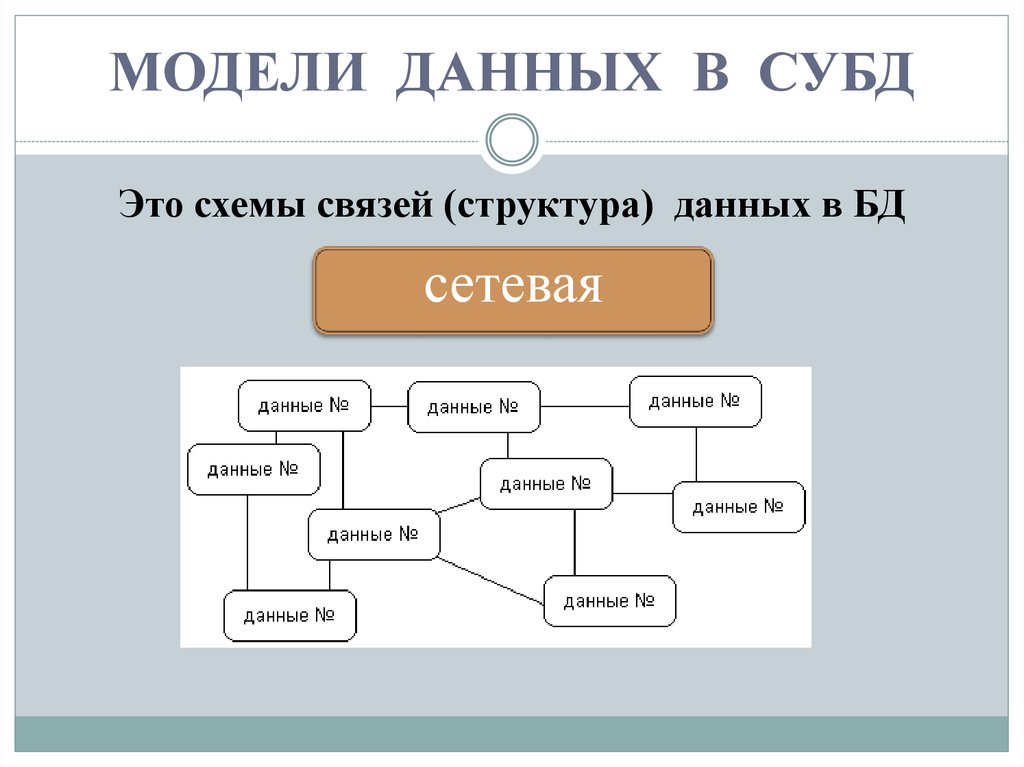 Иерархические модели данных представляют собой отношения «один ко многим», когда родительские или корневые классы данных отображаются на несколько дочерних.
Иерархические модели данных представляют собой отношения «один ко многим», когда родительские или корневые классы данных отображаются на несколько дочерних.
В примере с автосалоном родительский класс Шоурумы будет иметь дочерние сущности Автомобили и Продавцы, поскольку в одном шоуруме есть несколько автомобилей и работает несколько продавцов.
Графовое моделирование данных
Иерархическое моделирование данных со временем превратилось в графовое. Графовые модели данных представляют отношения данных, в которых сущности рассматриваются одинаково. Сущности могут связываться друг с другом отношениями «один ко многим» или «многие ко многим» без понятия «родительский» или «дочерний».
Например, в одном шоуруме может работать несколько продавцов, а один продавец может также работать в нескольких шоурумах, если их смены отличаются в зависимости от местоположения.
Реляционное моделирование данных
Реляционное моделирование данных – это популярный подход к моделированию, который визуализирует классы данных в виде таблиц. Различные таблицы данных соединяются или связываются друг с другом с помощью ключей, которые представляют реальные отношения между сущностями. Вы можете использовать технологию реляционных баз данных для хранения структурированных данных, а реляционная модель данных – это полезный метод представления структуры реляционной базы данных.
Различные таблицы данных соединяются или связываются друг с другом с помощью ключей, которые представляют реальные отношения между сущностями. Вы можете использовать технологию реляционных баз данных для хранения структурированных данных, а реляционная модель данных – это полезный метод представления структуры реляционной базы данных.
Например, автосалон будет иметь реляционные модели данных, представляющие таблицу «Продавцы» и таблицу «Автомобили», как показано здесь:
| Идентификатор продавца | Имя |
| 1 | Ольга |
| 2 | Иван |
| Идентификатор автомобиля | Бренд автомобиля |
| C1 | XYZ |
| C2 | ABC |
Идентификатор продавца и идентификатор автомобиля – это первичные ключи, которые однозначно идентифицируют отдельные объекты реального мира.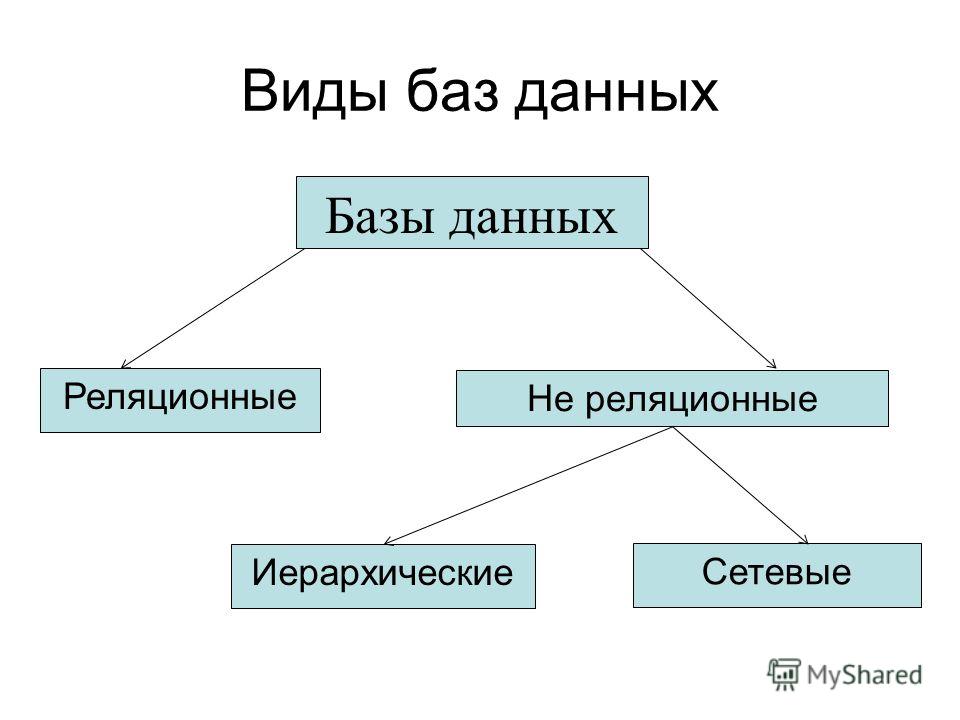 В таблице шоурума эти первичные ключи действуют как внешние ключи, связывающие сегменты данных.
В таблице шоурума эти первичные ключи действуют как внешние ключи, связывающие сегменты данных.
| Идентификатор шоурума | Название шоурума | Идентификатор продавца | Идентификатор автомобиля |
| S1 | NY Showroom | 1 | C1 |
В реляционных базах данных первичный и внешний ключи работают вместе, чтобы показать взаимосвязь данных. В предыдущей таблице показано, что в шоурумах могут быть продавцы и автомобили.
Моделирование данных «сущность-связь»
Моделирование данных «сущность-связь» (ER) использует формальные диаграммы для представления отношений между сущностями в базе данных. Архитекторы данных используют несколько инструментов ER-моделирования для представления данных.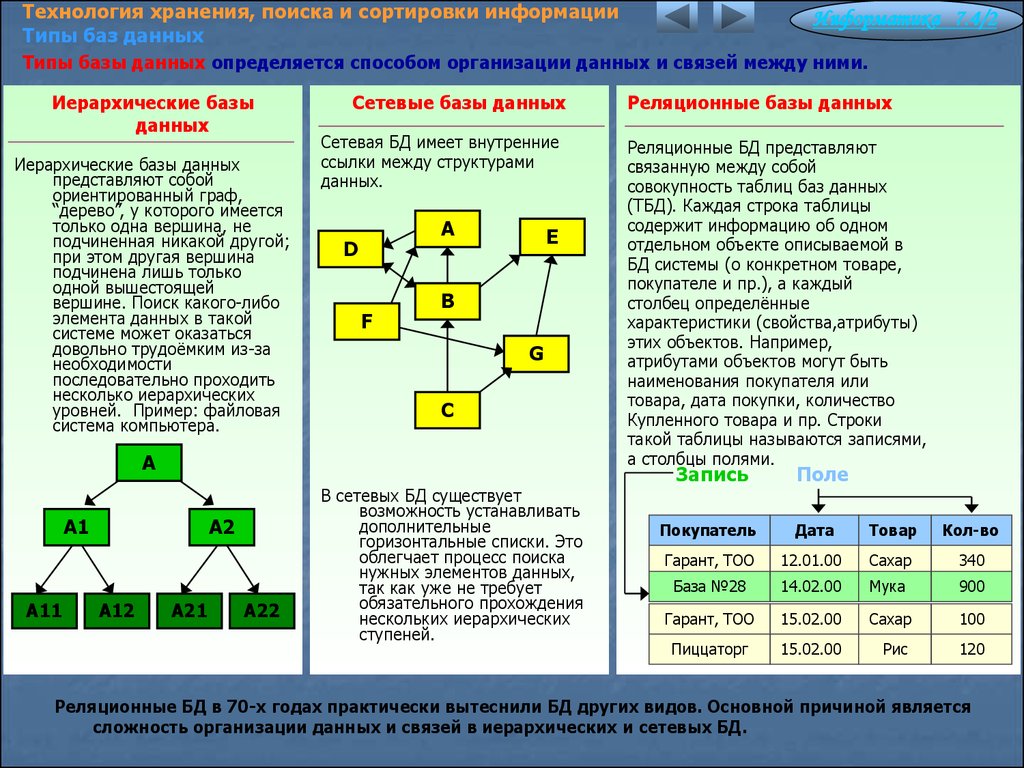
Объектно-ориентированное моделирование данных
В объектно-ориентированном программировании для хранения данных используются структуры данных, называемые объектами. Эти объекты данных являются программными абстракциями объектов реального мира. Например, в объектно-ориентированной модели данных автосалон будет иметь такие объекты данных, как «Клиенты», с такими атрибутами, как имя, адрес и номер телефона. Вы будете хранить данные о клиентах таким образом, чтобы каждый реальный клиент был представлен в виде объекта данных о клиенте.
Объектно-ориентированные модели данных преодолевают многие ограничения реляционных моделей данных и популярны в мультимедийных базах данных.
Многомерное моделирование данных
Современные корпоративные вычисления используют технологию хранилищ данных для хранения больших объемов данных для аналитики. Вы можете использовать проекты многомерного моделирования данных для их высокоскоростного хранения и извлечения из хранилища. Многомерные модели используют дублирование или избыточные данные и отдают приоритет производительности, а не использованию меньшего пространства для хранения данных.
Например, в многомерных моделях данных автосалон имеет такие измерения, как «Автомобиль», «Шоурум» и «Время». Показатель «Автомобиль» имеет такие атрибуты, как название и марка, а «Шоурум» – штат, город, название улицы и название шоурума.
В чем заключается процесс моделирования данных?
Процесс моделирования данных состоит из последовательности шагов, которые необходимо повторять до тех пор, пока не будет создана полная модель данных. В любой организации различные заинтересованные стороны объединяются для создания полного представления данных. Хотя этапы зависят от типа моделирования данных, ниже приведен общий обзор.
Шаг 1. Определите объекты и их свойства
Определите все сущности в вашей модели данных. Каждая сущность должна быть логически отличной от всех других сущностей и может представлять людей, места, вещи, понятия или события. Каждая сущность отличается от других, поскольку обладает одним или несколькими уникальными свойствами. В своей модели данных вы можете рассматривать сущности как существительные, а атрибуты – как прилагательные.
Шаг 2. Определите отношения между сущностями
В основе моделирования данных лежат отношения между различными сущностями. Бизнес-правила изначально определяют эти отношения на концептуальном уровне. Вы можете рассматривать отношения как глаголы в вашей модели данных. Например, продавец продает много автомобилей или в шоуруме работает много продавцов.
Шаг 3. Выберите метод моделирования данных
После концептуального осознания сущностей и их взаимосвязей вы можете определить метод моделирования данных, который лучше всего подходит для вашего случая. Например, вы можете использовать реляционное моделирование данных для структурированных данных, а многомерное – для неструктурированных.
Шаг 4. Оптимизируйте и примените на практике
Вы можете дополнительно оптимизировать модель данных в соответствии с вашими требованиями к технологии и производительности. Например, если вы планируете использовать Amazon Aurora и структурированный язык запросов (SQL), поместите свои сущности непосредственно в таблицы и определите связи с помощью внешних ключей.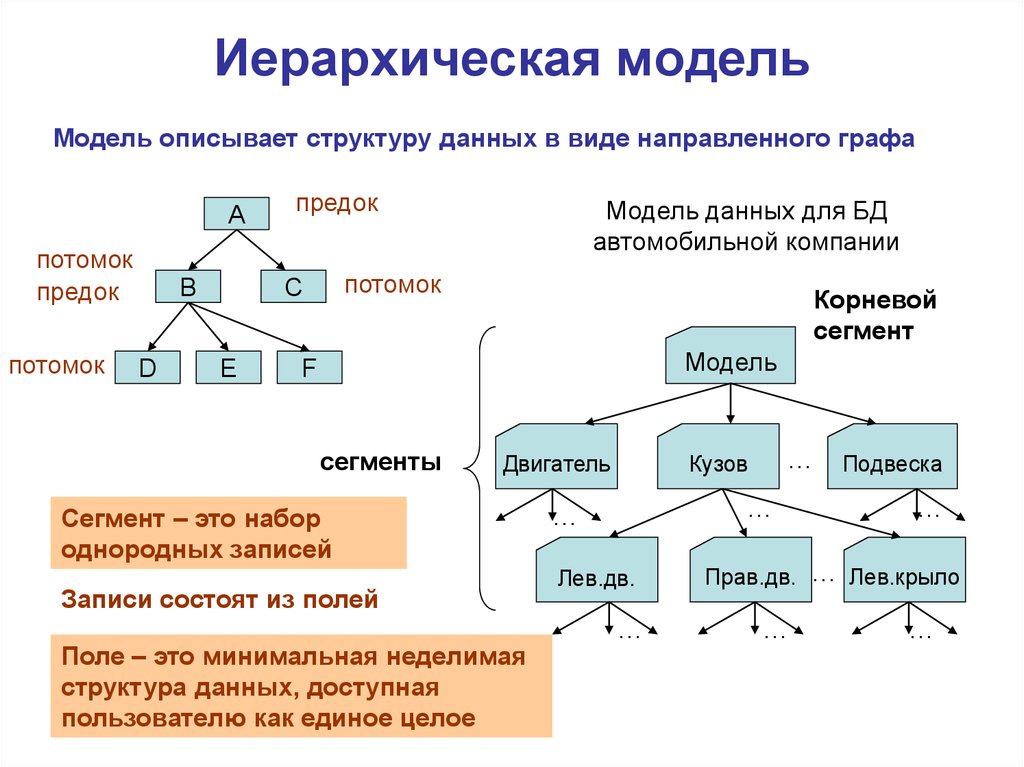 А если вы решите использовать Amazon DynamoDB, вам нужно будет продумать модели доступа до того, как вы смоделируете свою таблицу. Поскольку для DynamoDB приоритетом является скорость, вы сначала определяете, как будете обращаться к своим данным, а затем моделируете их в той форме, в которой они будут доступны.
А если вы решите использовать Amazon DynamoDB, вам нужно будет продумать модели доступа до того, как вы смоделируете свою таблицу. Поскольку для DynamoDB приоритетом является скорость, вы сначала определяете, как будете обращаться к своим данным, а затем моделируете их в той форме, в которой они будут доступны.
Как правило, вы будете неоднократно пересматривать эти шаги по мере изменения технологии и требований с течением времени.
Как AWS может помочь с моделированием данных?
Базы данных AWS включают более 15 движков баз данных для поддержки различных моделей данных. Например, вы можете использовать Службу реляционных данных Amazon (Amazon RDS) для реализации реляционных моделей данных и Amazon Neptune – для реализации графовых.
Вы также можете использовать AWS Amplify DataStore для более быстрого и простого моделирования данных при создании мобильных и веб-приложений. У него есть визуальный и основанный на коде интерфейс для определения модели данных с отношениями, что ускорит разработку приложения.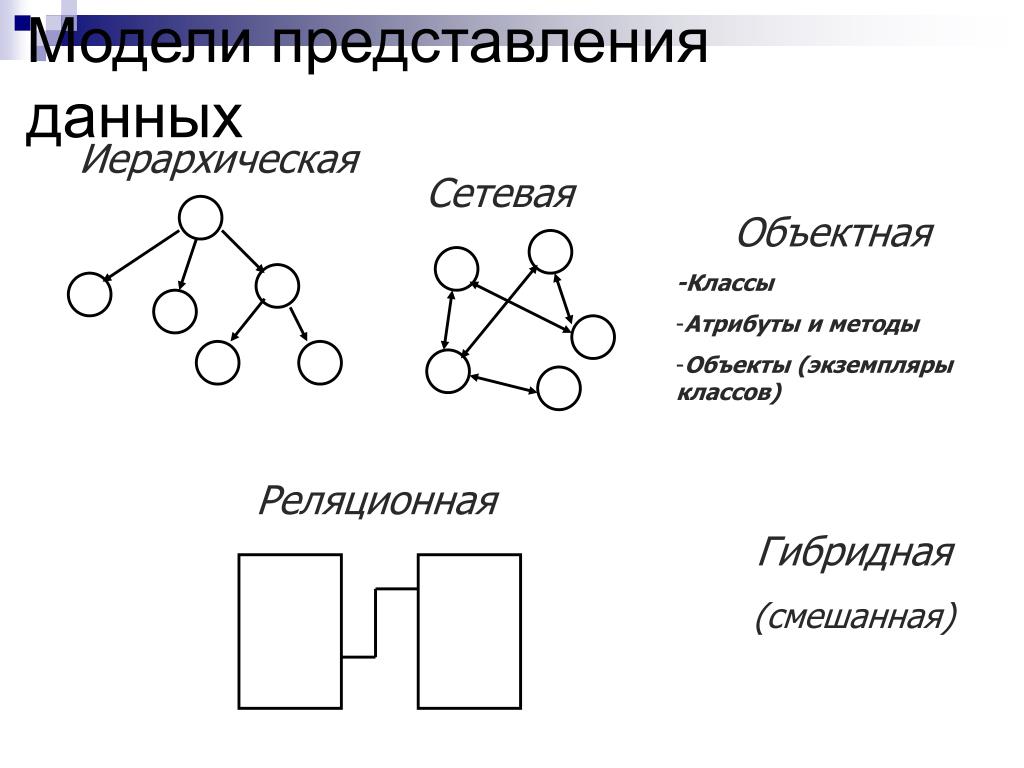
Начните работу с моделированием данных в AWS, создав бесплатный аккаунт уже сегодня.
Что такое моделирование данных? | Определение, важность и типы
Моделирование данных — это процесс построения диаграмм потоков данных. При создании новой или альтернативной структуры базы данных разработчик начинает с диаграммы того, как данные будут поступать в базу данных и выходить из нее. Эта блок-схема используется для определения характеристик форматов данных, структур и функций обработки базы данных для эффективной поддержки требований к потоку данных. После того, как база данных построена и развернута, модель данных живет, чтобы стать документацией и обоснованием того, почему существует база данных и как были спроектированы потоки данных.
Модель данных, полученная в результате этого процесса, обеспечивает структуру отношений между элементами данных в базе данных, а также руководство по использованию данных. Модели данных являются основополагающим элементом разработки программного обеспечения и аналитики.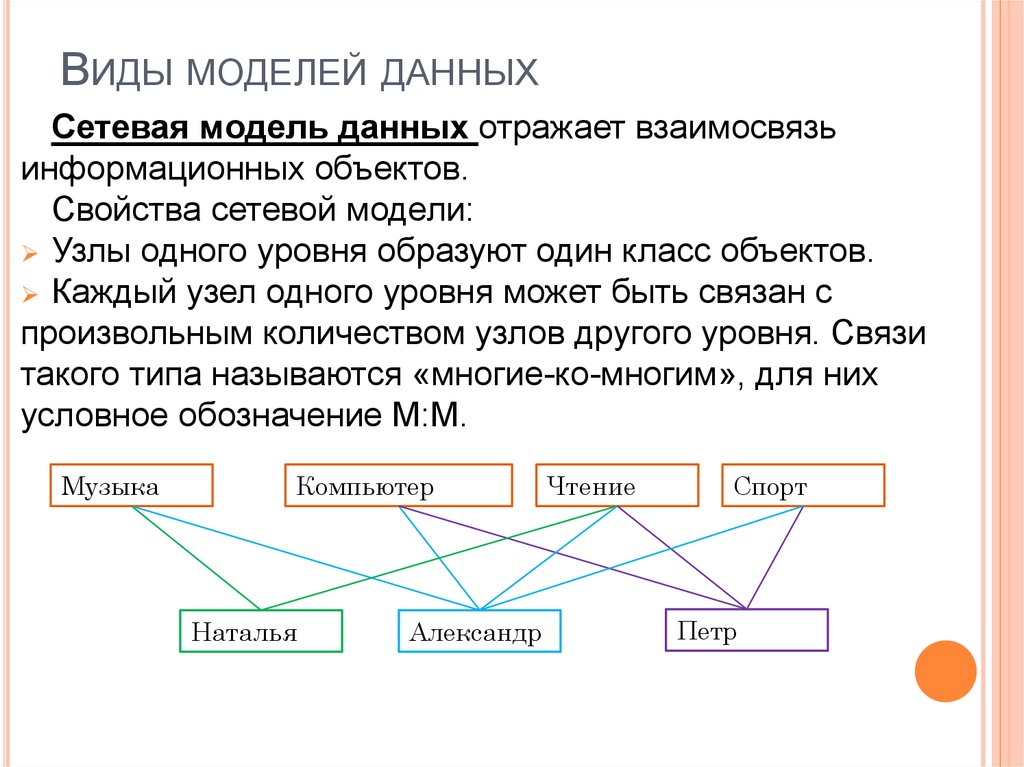 Они обеспечивают стандартизированный метод для определения и форматирования содержимого базы данных в разных системах, позволяя различным приложениям совместно использовать одни и те же данные.
Они обеспечивают стандартизированный метод для определения и форматирования содержимого базы данных в разных системах, позволяя различным приложениям совместно использовать одни и те же данные.
Почему важно моделирование данных?
Комплексная и оптимизированная модель данных помогает создать упрощенную логическую базу данных, которая устраняет избыточность, снижает требования к хранилищу и обеспечивает эффективное извлечение. Он также оснащает все системы «единым источником достоверной информации», что необходимо для эффективной работы и доказуемого соблюдения правил и нормативных требований. Моделирование данных — ключевой шаг в двух жизненно важных функциях цифрового предприятия.
Проекты по разработке программного обеспечения (новые или модификации), выполняемые ИТ-специалистами
Перед проектированием и созданием любого программного проекта необходимо иметь документированное представление о том, как будет выглядеть конечный продукт и как он будет себя вести.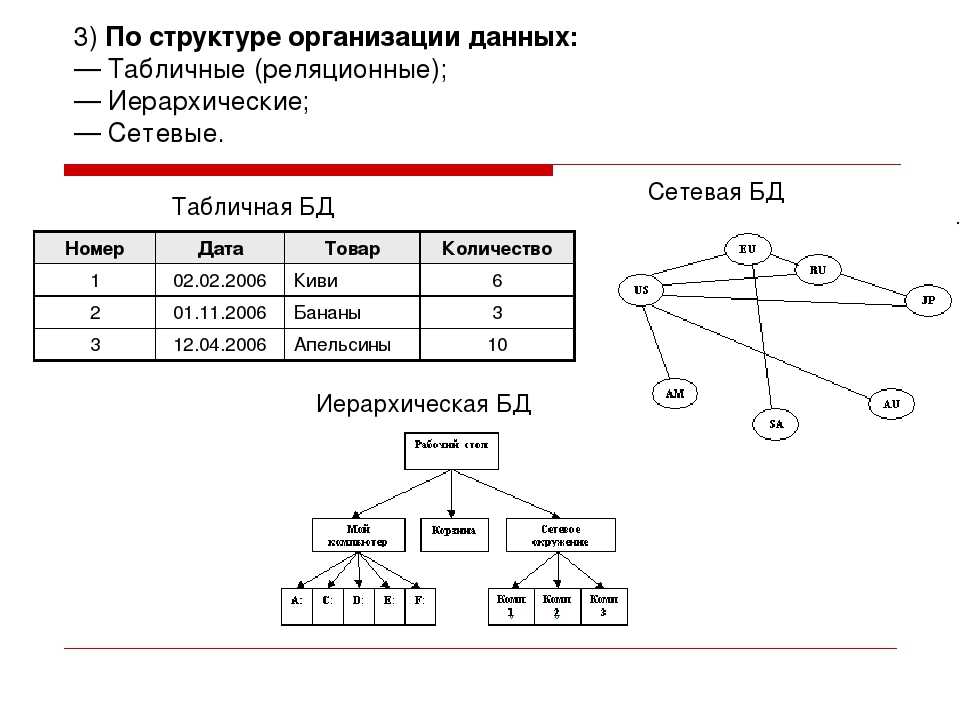 Большая часть этого видения — набор бизнес-правил, регулирующих желаемую функциональность. Другая часть — это описание данных — потоки данных (или модель данных) и структура базы данных для ее поддержки.
Большая часть этого видения — набор бизнес-правил, регулирующих желаемую функциональность. Другая часть — это описание данных — потоки данных (или модель данных) и структура базы данных для ее поддержки.
Моделирование данных ведет запись видения и предоставляет дорожную карту для разработчиков программного обеспечения. Когда база данных и потоки данных полностью определены и задокументированы, а системы разработаны в соответствии с этими спецификациями, системы должны обеспечивать ожидаемую функциональность, необходимую для обеспечения точности данных (при условии, что процедуры были соблюдены должным образом) 9.0004
Аналитика и визуализация – или бизнес-аналитика – основной инструмент принятия решений для пользователей изготовление. Неудивительно, что спрос на аналитику данных резко вырос. Визуализация данных делает данные еще более доступными для пользователей за счет графического представления данных.
Современные модели данных преобразуют необработанные данные в полезную информацию, которую можно превратить в динамическую визуализацию.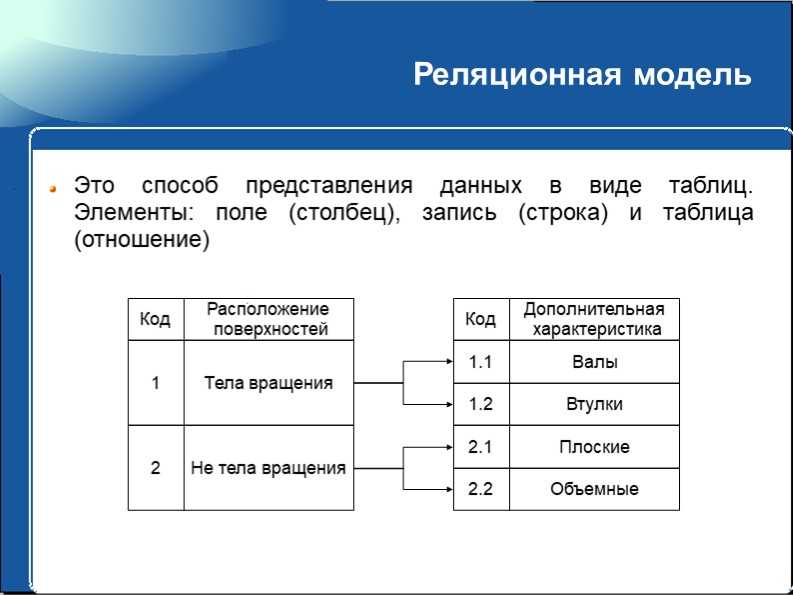 Моделирование данных подготавливает данные к анализу: очищает данные, определяет меры и измерения, а также улучшает данные путем создания иерархий, установки единиц и валют и добавления формул.
Моделирование данных подготавливает данные к анализу: очищает данные, определяет меры и измерения, а также улучшает данные путем создания иерархий, установки единиц и валют и добавления формул.
Какие существуют типы моделирования данных?
Три основных типа моделей данных: реляционная, многомерная и объектно-связная (E-R). Есть также несколько других, которые не используются повсеместно, в том числе иерархические, сетевые, объектно-ориентированные и многозначные. Тип модели определяет логическую структуру — то, как данные хранятся логически — и, следовательно, как они хранятся, организуются и извлекаются.
- Реляционная: Несмотря на «старый» подход, наиболее распространенной моделью базы данных, которая до сих пор используется, является реляционная, которая хранит данные в записях фиксированного формата и упорядочивает данные в таблицах со строками и столбцами. Самый простой тип модели данных состоит из двух элементов: показателей и измерений. Показатели — это числовые значения, такие как количество и доход, используемые в математических вычислениях, таких как сумма или среднее значение. Размеры могут быть текстовыми или числовыми. Они не используются в расчетах и включают описания или местоположения. Необработанные данные определяются как мера или измерение. Другая терминология, используемая при проектировании реляционных баз данных, включает «отношения» (таблица со строками и столбцами), «атрибуты» (столбцы), «кортежи» (строки) и «домен» (набор значений, допустимых в столбце). Хотя существуют дополнительные термины и структурные требования, определяющие реляционную базу данных, важным фактором являются отношения, определенные в этой структуре. Общие элементы данных (или ключи) связывают вместе таблицы и наборы данных. Таблицы также могут быть связаны явно, как родительские и дочерние отношения, включая отношения «один к одному», «один ко многим» или «многие ко многим».
- Многомерный: Менее жесткий и структурированный, размерный подход отдает предпочтение контекстуальной структуре данных, которая больше связана с бизнес-использованием или контекстом. Эта структура базы данных оптимизирована для онлайн-запросов и инструментов хранения данных. Критические элементы данных, такие как, например, количество транзакций, называются «фактами» и сопровождаются справочной информацией, называемой «параметрами», будь то идентификатор продукта, цена за единицу или дата транзакции. Таблица фактов — это основная таблица в многомерной модели. Поиск может быть быстрым и эффективным — данные для определенного вида деятельности хранятся вместе, — но отсутствие взаимосвязей может усложнить аналитический поиск и использование данных. Поскольку структура данных привязана к бизнес-функции, которая производит и использует данные, объединение данных, созданных разными системами (например, в хранилище данных), может быть проблематичным.
- Entity-Rich (ER): Модель ER представляет структуру бизнес-данных в графической форме, содержащую блоки различной формы для представления действий, функций или «сущностей» и линии для представления ассоциаций, зависимостей или «отношений». Затем модель ER используется для создания реляционной базы данных, в которой каждая строка представляет сущность, а поля в этой строке содержат атрибуты. Как и во всех реляционных базах данных, «ключевые» элементы данных используются для связывания таблиц.
 Показатели — это числовые значения, такие как количество и доход, используемые в математических вычислениях, таких как сумма или среднее значение. Размеры могут быть текстовыми или числовыми. Они не используются в расчетах и включают описания или местоположения. Необработанные данные определяются как мера или измерение. Другая терминология, используемая при проектировании реляционных баз данных, включает «отношения» (таблица со строками и столбцами), «атрибуты» (столбцы), «кортежи» (строки) и «домен» (набор значений, допустимых в столбце). Хотя существуют дополнительные термины и структурные требования, определяющие реляционную базу данных, важным фактором являются отношения, определенные в этой структуре. Общие элементы данных (или ключи) связывают вместе таблицы и наборы данных. Таблицы также могут быть связаны явно, как родительские и дочерние отношения, включая отношения «один к одному», «один ко многим» или «многие ко многим».
Показатели — это числовые значения, такие как количество и доход, используемые в математических вычислениях, таких как сумма или среднее значение. Размеры могут быть текстовыми или числовыми. Они не используются в расчетах и включают описания или местоположения. Необработанные данные определяются как мера или измерение. Другая терминология, используемая при проектировании реляционных баз данных, включает «отношения» (таблица со строками и столбцами), «атрибуты» (столбцы), «кортежи» (строки) и «домен» (набор значений, допустимых в столбце). Хотя существуют дополнительные термины и структурные требования, определяющие реляционную базу данных, важным фактором являются отношения, определенные в этой структуре. Общие элементы данных (или ключи) связывают вместе таблицы и наборы данных. Таблицы также могут быть связаны явно, как родительские и дочерние отношения, включая отношения «один к одному», «один ко многим» или «многие ко многим». Эта структура базы данных оптимизирована для онлайн-запросов и инструментов хранения данных. Критические элементы данных, такие как, например, количество транзакций, называются «фактами» и сопровождаются справочной информацией, называемой «параметрами», будь то идентификатор продукта, цена за единицу или дата транзакции. Таблица фактов — это основная таблица в многомерной модели. Поиск может быть быстрым и эффективным — данные для определенного вида деятельности хранятся вместе, — но отсутствие взаимосвязей может усложнить аналитический поиск и использование данных. Поскольку структура данных привязана к бизнес-функции, которая производит и использует данные, объединение данных, созданных разными системами (например, в хранилище данных), может быть проблематичным.
Эта структура базы данных оптимизирована для онлайн-запросов и инструментов хранения данных. Критические элементы данных, такие как, например, количество транзакций, называются «фактами» и сопровождаются справочной информацией, называемой «параметрами», будь то идентификатор продукта, цена за единицу или дата транзакции. Таблица фактов — это основная таблица в многомерной модели. Поиск может быть быстрым и эффективным — данные для определенного вида деятельности хранятся вместе, — но отсутствие взаимосвязей может усложнить аналитический поиск и использование данных. Поскольку структура данных привязана к бизнес-функции, которая производит и использует данные, объединение данных, созданных разными системами (например, в хранилище данных), может быть проблематичным. Затем модель ER используется для создания реляционной базы данных, в которой каждая строка представляет сущность, а поля в этой строке содержат атрибуты. Как и во всех реляционных базах данных, «ключевые» элементы данных используются для связывания таблиц.
Затем модель ER используется для создания реляционной базы данных, в которой каждая строка представляет сущность, а поля в этой строке содержат атрибуты. Как и во всех реляционных базах данных, «ключевые» элементы данных используются для связывания таблиц.Какие существуют три уровня абстракции данных?
Существует множество типов моделей данных с различными типами возможных макетов. Сообщество по обработке данных выделяет три вида моделирования для представления уровней мышления по мере разработки моделей.
Концептуальная модель данных
Это модель «общей картины», которая представляет общую структуру и содержание, но не детали плана данных. Это типичная отправная точка для моделирования данных, определения различных наборов данных и потоков данных в организации. Концептуальная модель представляет собой высокоуровневый план разработки логических и физических моделей и является важной частью документации по архитектуре данных.
Логическая модель данных
Второй уровень детализации — это логическая модель данных. Он наиболее тесно связан с общим определением «модели данных», поскольку описывает поток данных и содержимое базы данных. Логическая модель добавляет детали к общей структуре концептуальной модели, но не включает спецификации самой базы данных, поскольку модель может применяться к различным технологиям и продуктам баз данных. (Обратите внимание, что концептуальной модели может не быть, если проект относится к одному приложению или другой ограниченной системе.)
Физическая модель данных
Физическая модель базы данных описывает особенности реализации логической модели. Он должен содержать достаточно подробностей, чтобы технологи могли создать реальную структуру базы данных в аппаратном и программном обеспечении для поддержки приложений, которые будут ее использовать. Излишне говорить, что физическая модель данных специфична для конкретной программной системы базы данных. Может быть несколько физических моделей, полученных из одной логической модели, если будут использоваться разные системы баз данных.
Может быть несколько физических моделей, полученных из одной логической модели, если будут использоваться разные системы баз данных.
Процесс и методы моделирования данных
Моделирование данных по своей сути является нисходящим процессом, начиная с концептуальной модели для определения общего видения, затем переходя к логической модели и, наконец, к детальному проекту, содержащемуся в физической модели.
Построение концептуальной модели в основном представляет собой процесс преобразования идей в графическую форму, напоминающую блок-схему программиста-разработчика.
Современные инструменты моделирования данных могут помочь вам определить и построить логические и физические модели данных и базы данных. Вот несколько типичных методов и шагов моделирования данных:
- Определите объекты и создайте диаграмму отношений объектов (ERD). Объекты можно лучше описать как «элементы данных, представляющие интерес для вашего бизнеса». Например, «клиент» может быть сущностью. «Распродажа» — другое дело. В ERD вы документируете, как эти различные объекты связаны друг с другом в вашем бизнесе и какие связи высокого уровня существуют между ними.
- Определите факты, показатели и измерения. Факт — это часть ваших данных, которая указывает на конкретное событие или транзакцию, например продажу продукта. Ваши меры являются количественными, такими как количество, доход, стоимость и т. д. Ваши параметры — это качественные показатели, такие как описания, местоположения и даты.
- Создайте ссылку на просмотр данных с помощью графического инструмента или запросов SQL. Если вы не знакомы с SQL, графический инструмент является наиболее интуитивно понятным вариантом, позволяющим перетаскивать элементы в модель и визуально создавать соединения. При создании представления у вас есть возможность объединить таблицы и даже другие представления в один вывод. Когда вы выбираете источник в графическом представлении и перетаскиваете его поверх источника, уже связанного с выводом, у вас будет возможность либо соединить, либо создать объединение этих таблиц.
 Например, «клиент» может быть сущностью. «Распродажа» — другое дело. В ERD вы документируете, как эти различные объекты связаны друг с другом в вашем бизнесе и какие связи высокого уровня существуют между ними.
Например, «клиент» может быть сущностью. «Распродажа» — другое дело. В ERD вы документируете, как эти различные объекты связаны друг с другом в вашем бизнесе и какие связи высокого уровня существуют между ними.
Современные аналитические решения также могут помочь вам выбрать, отфильтровать и подключить источники данных с помощью графического отображения с помощью перетаскивания. Расширенные инструменты доступны для экспертов по данным, обычно работающих в ИТ, но пользователи также могут создавать свои собственные истории, визуально создавая модель данных и организуя таблицы, диаграммы, карты и другие объекты, чтобы рассказать историю на основе анализа данных.
Explore SAP Analytics Cloud
Создайте модель данных, чтобы рассказать историю на основе анализа данных.
Примеры моделирования данных
Для любого приложения — делового, развлекательного, личного или другого — моделирование данных является необходимым начальным шагом в проектировании системы и определении инфраструктуры, необходимой для работы системы. Это включает в себя любой тип транзакционной системы, набор или пакет приложений для обработки данных или любую другую систему, которая собирает, создает или использует данные.
Моделирование данных необходимо для хранения данных, поскольку хранилище данных представляет собой репозиторий для данных, поступающих из нескольких источников, которые, вероятно, содержат похожие или связанные данные в разных форматах. Сначала необходимо наметить форматы и структуру хранилища, чтобы определить, как манипулировать каждым входящим набором данных в соответствии с потребностями структуры хранилища, чтобы данные были полезны для анализа и интеллектуального анализа данных. Таким образом, модель данных является важным инструментом для аналитических инструментов, исполнительных информационных систем (панелей), интеллектуального анализа данных и интеграции со всеми без исключения системами данных и приложениями.
На ранних стадиях проектирования любой системы моделирование данных является ключевой предпосылкой, от которой зависят все остальные шаги и этапы для создания основы, на которую опираются все программы, функции и инструменты. Модель данных похожа на общий язык, который позволяет системам общаться посредством их понимания и принятия данных, как описано в модели. Это как никогда важно в современном мире больших данных, машинного обучения, искусственного интеллекта, подключения к облаку, Интернета вещей и распределенных систем, включая граничные вычисления.
Это как никогда важно в современном мире больших данных, машинного обучения, искусственного интеллекта, подключения к облаку, Интернета вещей и распределенных систем, включая граничные вычисления.
Эволюция моделирования данных
В самом прямом смысле моделирование данных существует столько же, сколько и обработка данных, их хранение и компьютерное программирование, хотя сам термин, вероятно, стал общеупотребительным лишь в то время, когда база данных Системы управления начали развиваться в 1960-х годах. В концепции планирования и проектирования новой структуры нет ничего нового или инновационного. Моделирование данных само по себе стало более структурированным и формализованным по мере того, как появилось больше данных, больше баз данных и больше разновидностей данных.
Сегодня моделирование данных важнее, чем когда-либо, поскольку технологи борются с новыми источниками данных (датчики IoT, устройства с функцией определения местоположения, потоки кликов, социальные сети) наряду с потоком неструктурированных данных (текст, аудио, видео, необработанные данные). выход датчика) – при объемах и скорости, превышающих возможности традиционных систем. В настоящее время существует постоянный спрос на новые системы, инновационные структуры и методы баз данных, а также новые модели данных, чтобы связать воедино эти новые усилия по разработке.
выход датчика) – при объемах и скорости, превышающих возможности традиционных систем. В настоящее время существует постоянный спрос на новые системы, инновационные структуры и методы баз данных, а также новые модели данных, чтобы связать воедино эти новые усилия по разработке.
Что дальше для моделирования данных?
Информационная связь и большие объемы данных из самых разных источников, включая датчики, голос, видео, электронную почту и т. д., расширяют возможности проектов моделирования для ИТ-специалистов. Интернет, безусловно, является одним из факторов, способствующих этой эволюции. Облако является важной частью решения, поскольку это единственная вычислительная инфраструктура, достаточно большая, достаточно масштабируемая и достаточно гибкая, чтобы соответствовать текущим и будущим требованиям в расширяющемся мире подключений.
Варианты проектирования базы данных также меняются. Десять лет назад доминирующей структурой базы данных была реляционная база данных, ориентированная на строки, использующая традиционную технологию дискового хранилища. Данные для типичной главной книги ERP или управления запасами хранились в десятках различных таблиц, которые необходимо обновлять и моделировать. Сегодня современные ERP-решения хранят активные данные в памяти, используя структуру столбцов, что позволяет значительно сократить количество таблиц и повысить скорость и эффективность.
Данные для типичной главной книги ERP или управления запасами хранились в десятках различных таблиц, которые необходимо обновлять и моделировать. Сегодня современные ERP-решения хранят активные данные в памяти, используя структуру столбцов, что позволяет значительно сократить количество таблиц и повысить скорость и эффективность.
Новые инструменты самообслуживания для профессионалов, доступные сегодня, будут продолжать совершенствоваться. Будут представлены новые инструменты, которые еще больше упростят моделирование и визуализацию данных и сделают сотрудничество более удобным.
Резюме
Хорошо продуманная и полная модель данных является ключом к созданию действительно функциональной, полезной, безопасной и точной базы данных. Начните с концептуальной модели, чтобы изложить все компоненты и функции модели данных. Затем доработайте эти планы до логической модели данных, которая описывает потоки данных и разъясняет определение того, какие данные необходимы и как они будут собираться, обрабатываться, храниться и распределяться. Логическая модель данных управляет физической моделью данных, специфичной для продукта базы данных, и является детальным проектным документом, который направляет создание базы данных и прикладного программного обеспечения.
Логическая модель данных управляет физической моделью данных, специфичной для продукта базы данных, и является детальным проектным документом, который направляет создание базы данных и прикладного программного обеспечения.
Хорошее моделирование данных и проектирование баз данных необходимы для разработки функциональных, надежных и безопасных прикладных систем и баз данных, которые хорошо работают с хранилищами данных и аналитическими инструментами, а также облегчают обмен данными с деловыми партнерами и между несколькими наборами приложений. Хорошо продуманные модели данных помогают обеспечить целостность данных, делая данные вашей компании еще более ценными и надежными.
Ознакомьтесь с современными инструментами моделирования данных
Соедините данные с бизнес-контекстом, чтобы предоставить бизнес-пользователям доступ к информации.
Другие материалы из этой серии
Информационный бюллетень SAP Insights
Идеи, которые вы больше нигде не найдете
Подпишитесь на порцию бизнес-аналитики, доставленную прямо в ваш почтовый ящик.
Дополнительная литература
Типы моделирования данных и примеры
Моделирование данных — это процесс создания визуального представления баз данных и информационных систем. Они могут представлять часть или всю базу данных с целью упрощения доступа и понимания типов данных в системе, а также отношений между различными точками данных и группами.
Для компаний отдельные модели данных строятся с учетом конкретных потребностей и требований организации, и их можно визуализировать на различных уровнях абстракции в зависимости от информации, которую необходимо извлечь для набора данных. Этот тип работы часто выполняется командой инженеров данных, аналитиков данных и архитекторов данных, а также администраторов баз данных, которые знакомы как с исходной базой данных, так и с потребностями организации.
Прежде чем внедрять структуру моделирования данных в информационные системы вашей компании, важно сначала понять, что делает базу данных полезной и удобной для извлечения информации и как она может помочь вам наметить соединения и рабочие процессы, необходимые на уровне базы данных.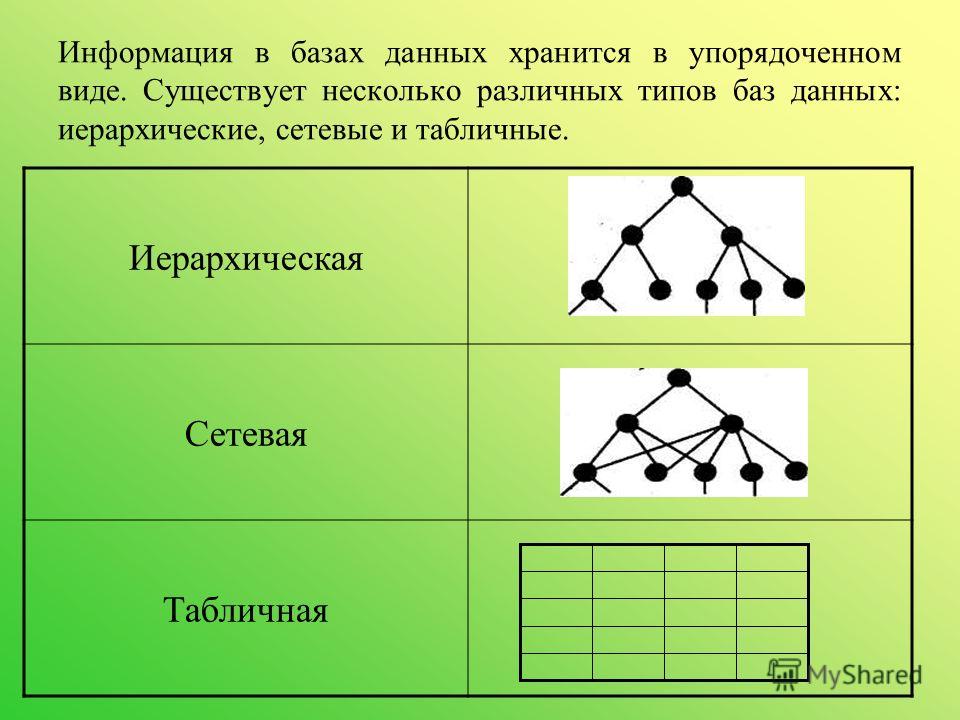
Эта статья поможет вам получить полное и широкое представление о том, как работает моделирование данных, какие существуют его типы и какую пользу оно может принести вашему бизнесу.
Содержание
- 3 типа категорий моделирования данных
- 4 типа инфраструктуры моделирования данных
- Как работает моделирование данных
- Особенности моделирования данных
- 5 Преимущества моделирования данных
- Четыре основных инструмента моделирования данных
Существуют различные типы методов моделирования данных, которые можно разделить на три основные категории: концептуальные, логические и физические. Каждый тип служит определенной цели в зависимости от используемого формата данных, способа их хранения и уровня абстракции, необходимого между различными точками данных.
Концептуальные модели данных, также называемые концептуальными схемами, представляют собой формы абстракции высокого уровня для представления данных, но они также являются наиболее простыми. Этот подход не углубляется в взаимосвязь между различными точками данных, а просто предлагает обобщенную схему всех наиболее известных структур данных.
Благодаря своей простоте концептуальные модели данных часто используются на первых этапах проекта. Они также не требуют высокого уровня знаний и опыта работы с базами данных, что делает их идеальным вариантом для использования на собраниях акционеров.
Ключевые отличия Концептуальные модели данных с высокой степенью абстракции используются для демонстрации того, какие данные находятся в системе. Как правило, они включают поверхностную информацию о данных, такую как классы, характеристики, отношения и ограничения. Они подходят для понимания масштаба проекта и определения его основных концепций.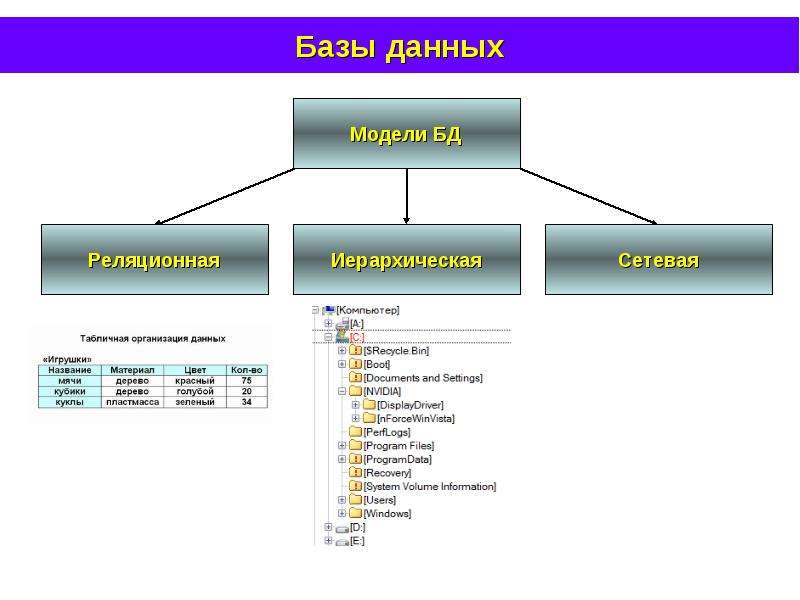
- Отправная точка для будущих моделей.
- Определяет объем проекта.
- Включает акционеров в процесс раннего проектирования.
- Предлагает широкий обзор информационной системы.
- Низкая окупаемость времени и усилий.
- Не хватает глубокого понимания и нюансов.
- Не подходит для больших систем и приложений.
- Недостаточно для более поздних стадий проекта.
Существует бесчисленное множество применений концептуального моделирования данных, помимо необходимости разработки или улучшения информационной системы. Его можно использовать для демонстрации отношений между различными системами или этапами процесса.
Для системы управления заказами абстрактная диаграмма может помочь представить взаимосвязь между различными операциями, которые выполняются, когда клиент размещает заказ. Он также может установить четкую взаимосвязь между витриной — цифровой или физической — и системой выставления счетов, отделом выполнения заказов и доставкой заказов.
Он также может установить четкую взаимосвязь между витриной — цифровой или физической — и системой выставления счетов, отделом выполнения заказов и доставкой заказов.
Логические модели данных, также называемые логическими схемами, представляют собой расширение базовой структуры, изложенной в концептуальных моделях, но учитывают больше реляционных факторов. Он включает в себя некоторые основные аннотации, касающиеся общих свойств или атрибутов данных, но ему по-прежнему не хватает глубокого внимания к фактическим единицам данных.
Ключевые отличияЭта модель особенно полезна в планах хранения данных, поскольку она полностью независима от физической инфраструктуры и может использоваться в качестве схемы для используемых данных в системе. Это позволяет визуально понять взаимосвязь между точками данных и системами, не слишком вникая в физическую природу системы.
Pros- Выполняет анализ влияния функций.
- Простой доступ к документации модели и ее ведение.
- Ускоряет процесс разработки информационной системы.
- Компоненты могут быть переработаны и переработаны в соответствии с отзывами.

- Структуру трудно модифицировать.
- Отсутствие подробных сведений об отношениях между точками данных.
- Ошибки трудно обнаружить.
- Отнимает много времени и энергии, особенно для больших баз данных.
Логическое моделирование данных больше подходит для баз данных с рядом сложных компонентов и взаимосвязей, которые необходимо отображать. Например, используя логическое моделирование для отображения всей цепочки поставок, вы можете легко получить доступ не только к именам атрибутов, но также к типу данных и их индикаторам для обязательных и необнуляемых столбцов.
Этот подход к представлению данных считается независимым от базы данных, поскольку в окончательном представлении типы данных по-прежнему абстрактны.
Физические модели данных, также называемые физическими схемами, представляют собой визуальное представление структуры данных, предназначенной для реализации в окончательной версии системы управления базами данных. Они также являются наиболее подробными из всех типов моделирования данных и обычно зарезервированы для последних шагов перед созданием базы данных.
Ключевые отличияФизические модели данных концептуализируют достаточно подробностей о точках данных и их взаимосвязях, чтобы создать схему или окончательный действенный план со всеми необходимыми инструкциями для построения базы данных. Они представляют все рациональные объекты данных и их взаимосвязи, предлагая детальное и специфичное для системы понимание свойств данных и правил.
Плюсы- Сокращает количество незавершенных и ошибочных внедрений системы.
- Представление структуры базы данных в высоком разрешении.
- Прямой перевод модели в структуру базы данных.
- Облегчает обнаружение ошибок.

- Для понимания требуются продвинутые технические навыки.
- Комплекс по проектированию и конструкции.
- Негибкость к изменениям в последнюю минуту.
Моделирование физических данных лучше всего использовать в качестве дорожной карты, которая направляет разработку системы или приложения. Являясь визуальным представлением всего содержимого базы данных и их взаимосвязей, он позволяет администраторам и разработчикам баз данных оценивать размер базы данных системы и соответствующим образом обеспечивать емкость.
4 типа инфраструктуры модели данных В дополнение к трем основным типам моделирования данных вы можете выбирать между несколькими различными типами дизайна и инфраструктуры для процесса визуализации. Выбор инфраструктуры будет определять, как данные визуализируются и отображаются в окончательном отображении. Для этого есть четыре типа, которые вы можете выбрать.
Для этого есть четыре типа, которые вы можете выбрать.
Иерархические модели данных имеют структуру, напоминающую генеалогическое древо, в котором данные организованы в виде отношений родитель-потомок. Этот тип позволяет различать записи с общим источником, в котором каждая запись может быть идентифицирована принадлежащим ей уникальным ключом, определяемым ее местом в древовидной структуре.
Ключевые отличияИерархическое моделирование данных наиболее известно благодаря своей древовидной структуре. Данные хранятся в виде записей и связаны через идентифицируемые ссылки, которые показывают, как они влияют друг на друга и связаны друг с другом.
Профи- Просто и понятно.
- Читается большинством языков программирования.
- Информацию можно удалять и добавлять.
- Быстрое и простое развертывание.
- Структурная зависимость.
- Может быть переполнен дублирующимися данными.
- Медленный поиск и извлечение определенных точек данных.
- Невозможно описать более сложные отношения, чем прямые связи родитель-потомок.
Иерархическое моделирование данных лучше всего использовать с легко классифицируемыми данными, которые можно разделить на отношения родитель-потомок.
Одним из примеров, когда это очень выгодно, является выполнение продаж, в которых существует множество товаров под одним и тем же именем, но их можно различать, связывая с одним заказом на продажу за раз. В этом сценарии заказ на продажу является родительским объектом, а товары — дочерними.
Реляционная модель данных В отличие от иерархических моделей данных, реляционные модели данных не ограничиваются моделью отношений родитель-потомок. Точки данных, системы и таблицы могут быть связаны друг с другом различными способами. Этот тип идеально подходит для хранения данных, которые необходимо быстро и легко извлекать с минимальной вычислительной мощностью.
Реляционные модели данных можно отличить, проверив, соответствуют ли они характеристикам ACID, то есть атомарности, непротиворечивости, изоляции и устойчивости.
Плюсы- Простота и удобство использования.
- Поддерживает целостность данных.
- Поддерживает одновременный многопользовательский доступ.
- Высокий уровень безопасности и защита паролем.
- Дорогие в установке и обслуживании.
- Проблема производительности с большими базами данных.
- Быстрый рост, которым трудно управлять.
- Требуется много физической памяти.
Реляционные модели данных лучше всего подходят для использования с последовательной информацией, которая связана, но может быть полезна по отдельности.
Одним из примеров является ведение базы данных членов, клиентов или пользователей заведения.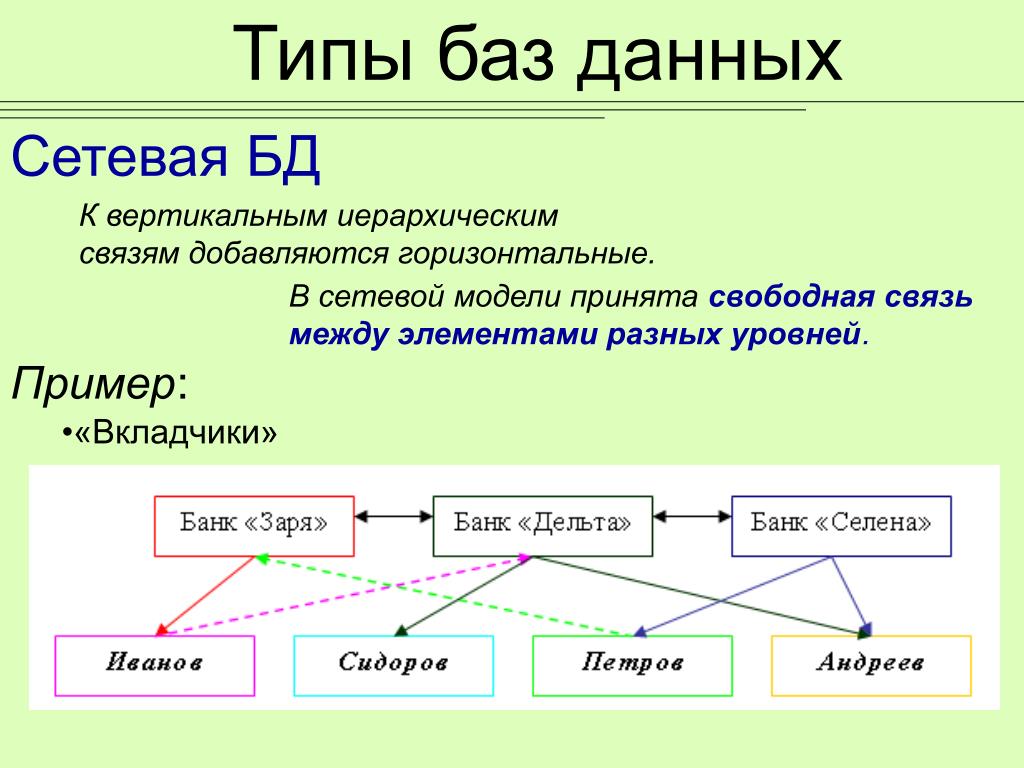 Структура строк и столбцов может использоваться для хранения имен и фамилий, дат рождения, номеров социального страхования и контактной информации, которые сгруппированы друг в друге как относящиеся к одному человеку.
Структура строк и столбцов может использоваться для хранения имен и фамилий, дат рождения, номеров социального страхования и контактной информации, которые сгруппированы друг в друге как относящиеся к одному человеку.
Модели данных «сущность-связь», также называемые диаграммами отношения сущностей (ERD), представляют собой визуальный способ представления данных, основанный на графике, изображающем взаимосвязь между точками данных, обычно людьми, реальными объектами, местами и событиями. , в информационной системе.
Этот тип чаще всего используется для лучшего понимания и анализа систем с целью выявления требований проблемной области или системы.
Основные отличия Модели данных ER лучше всего использовать для разработки базового проекта базы данных, поскольку в них рассматриваются основные концепции и детали, необходимые для реализации, с использованием визуального представления данных и взаимосвязей.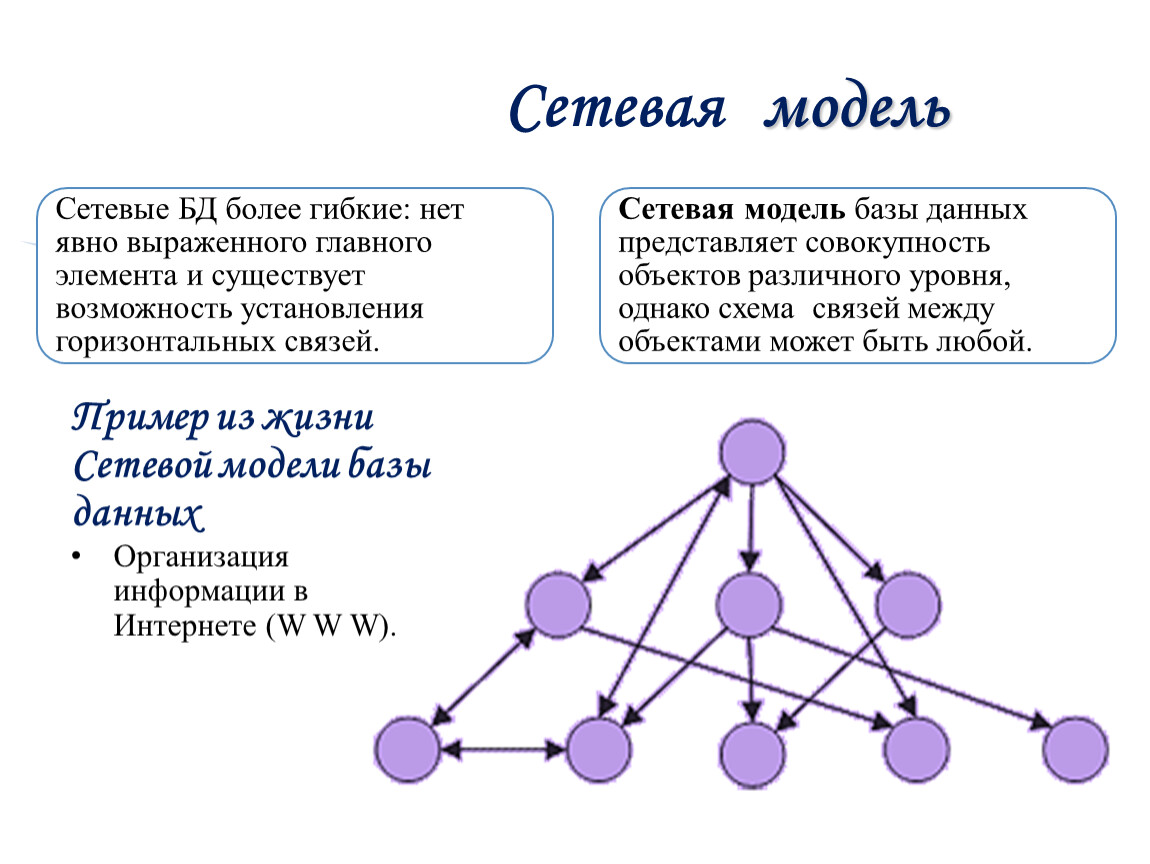
- Просто и понятно.
- Совместимость с системами управления базами данных (СУБД).
- Более глубокое, чем концептуальное моделирование.
- Сложно расширять и масштабировать.
- Сохраняет некоторую двусмысленность.
- Лучше всего подходит только для реляционных баз данных.
- Многословный и многословный.
Диаграммы ER показывают, как связаны базы данных, а также поток процессов от одной части системы к другой. Общее представление напоминает блок-схему, но с добавленными специальными символами, чтобы лучше объяснить различные отношения и операции, происходящие в системе.
Один из ярких примеров моделей ER используется в государственных учреждениях, таких как университеты, чтобы помочь им лучше классифицировать и анализировать демографические данные студентов. Диаграммы ER демонстрируют имена студентов и связывают их с пройденными ими курсами, видом транспорта и родом занятий.
Объектно-ориентированные модели данных — это вариант концептуального моделирования данных, в котором вместо этого используются объекты, чтобы сделать сложные точки данных реального мира более разборчивыми путем группировки объектов в иерархии классов. Подобно концептуальному моделированию, они чаще всего используются на ранних этапах разработки системы, особенно мультимедийных технологий с большим объемом данных.
Ключевые отличияВместо того, чтобы сосредотачиваться исключительно на отношениях между точками данных и объектами, объектно-ориентированное моделирование данных сосредотачивает данные реального объекта, группируя их вместе со всеми связанными данными, такими как вся личная информация и контактные данные физического лица.
Pros- Простота хранения и извлечения данных.
- Интегрируется с объектно-ориентированными языками программирования.
- Повышенная гибкость и надежность.
- Требует минимального обслуживания.

- Отсутствует универсальная модель данных.
- Очень сложный.
- Более высокая вероятность проблем с производительностью.
- Отсутствие адекватных механизмов безопасности.
Объектно-ориентированные модели данных позволяют предприятиям хранить данные о клиентах, разделяя отдельные атрибуты на различные таблицы, но не теряя связей между ними.
Объект в модели данных представляет тип клиента, за которым можно следовать в любом направлении для сбора оставшейся информации о клиенте без необходимости использования ненужных частей базы данных.
Как работает моделирование данных Моделирование данных — это процесс визуализации взаимосвязей между различными точками данных и их расположения специалистом по моделированию данных, обычно администратором базы данных или архитектором данных, который работает в непосредственной близости от данных.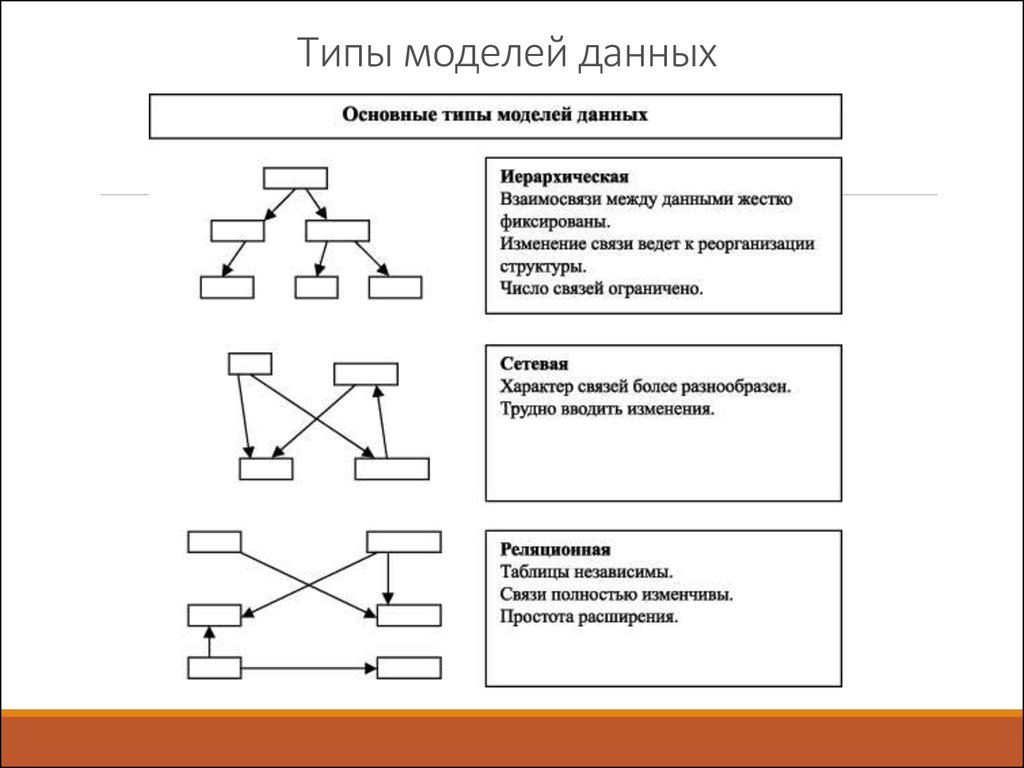 Первым и наиболее важным шагом моделирования данных является определение правильного типа приложений.
Первым и наиболее важным шагом моделирования данных является определение правильного типа приложений.
В зависимости от того, используете ли вы концептуальное, логическое или физическое моделирование данных, результирующая диаграмма может иметь разную степень простоты, детализации и абстракции. Выявление шаблонов доступа пользователей также может помочь определить наиболее важные части базы данных, которые необходимо представить, чтобы соответствовать потребностям вашего бизнеса.
Перед завершением процесса моделирования данных важно выполнить несколько тестовых запросов, чтобы определить достоверность модели данных.
Каковы особенности моделирования данныхКогда дело доходит до поиска подходящего инструмента моделирования данных или выбора подходящего подхода к моделированию данных, вам следует ожидать определенных функций и возможностей. Ниже приведены некоторые из ключевых особенностей любого подхода к моделированию данных.
Объекты данных и их атрибуты Объекты являются абстракциями реальных фрагментов данных.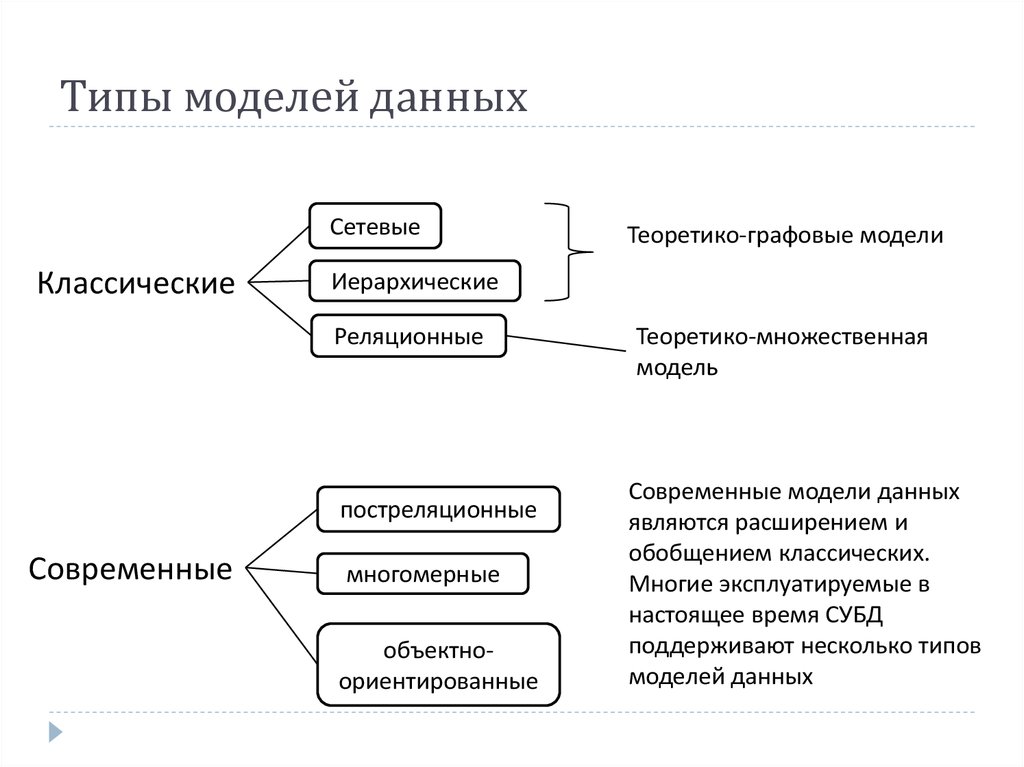 Атрибуты — это свойства, характеризующие эти объекты. Вы можете использовать их, чтобы найти сходства и установить связи между сущностями, которые известны как отношения.
Атрибуты — это свойства, характеризующие эти объекты. Вы можете использовать их, чтобы найти сходства и установить связи между сущностями, которые известны как отношения.
UML — это строительные блоки и передовой опыт моделирования данных. Это стандартный язык моделирования, который помогает специалистам по данным визуализировать и создавать соответствующие структуры моделей для своих потребностей в данных.
Нормализация с использованием уникальных ключейПри построении связей в большом наборе данных вы обнаружите, что для иллюстрации всех необходимых взаимосвязей необходимо повторить несколько единиц данных. Нормализация — это метод, который устраняет повторение путем назначения уникальных ключей или числовых значений различным группам объектов данных.
При таком подходе к маркировке вы сможете нормализовать или перечислить только ключи, вместо того чтобы повторять ввод данных в модель каждый раз, когда объекты формируют новую связь.
Моделирование данных дает предприятиям несколько явных преимуществ в рамках управления данными.
Улучшает качество данныхМоделирование данных позволяет заранее очистить, упорядочить и структурировать данные. Это позволяет выявлять дубликаты в данных и настраивать мониторинг для обеспечения их долгосрочного качества.
Экономит время и энергиюНесмотря на то, что это дополнительный шаг, который, возможно, придется повторять несколько раз в процессе разработки проекта, моделирование базы данных до начала работы устанавливает объем и ожидания для проекта.
Четкое моделирование данных гарантирует, что вы не потратите больше времени и ресурсов на шаг, чем это необходимо и оправдано самими данными.
Включение нетехнических отделов Ранние этапы разработки проекта часто слишком абстрактны, чтобы люди с небольшим или отсутствующим техническим опытом могли полностью его понять.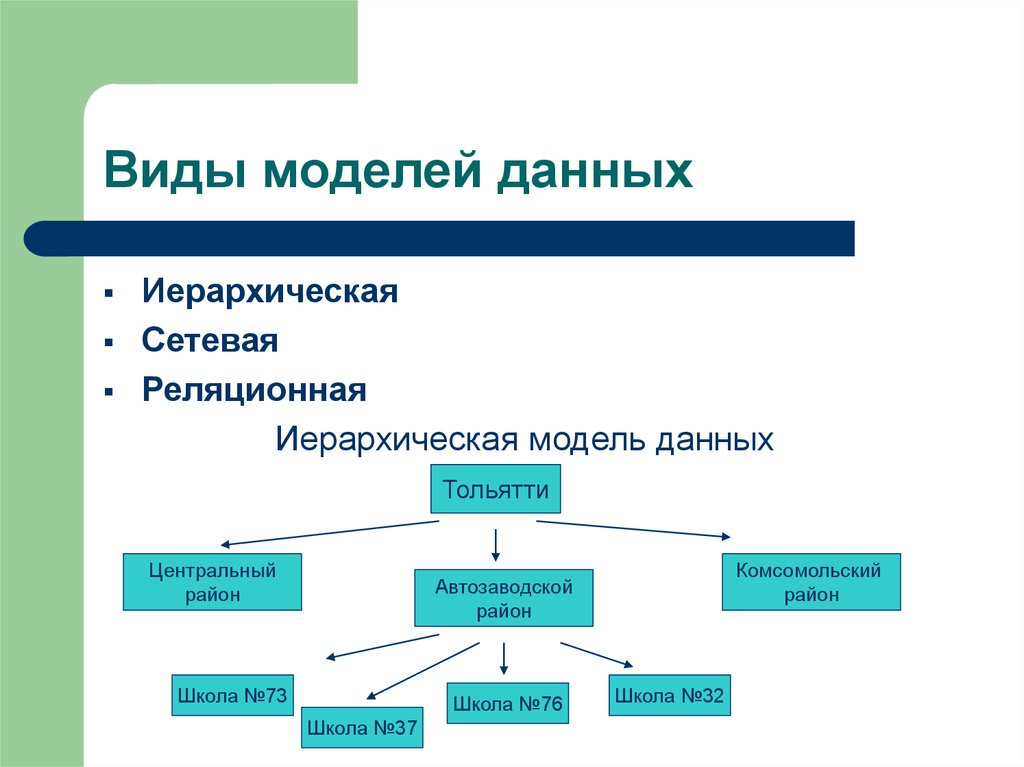
Визуальный характер моделирования данных, особенно концептуального моделирования данных, позволяет расширить сотрудничество и дискуссии между акционерами и нетехническими отделами, такими как отделы маркетинга и обслуживания клиентов.
Способствует соблюдению правилПравила конфиденциальности и безопасности должны быть включены на самых ранних этапах разработки системы. Моделирование данных позволяет разработчикам поместить все необходимые части для соответствия в инфраструктуру проекта.
Понимая, как точки данных связаны и взаимодействуют друг с другом, вы можете лучше установить планку безопасного и безопасного управления данными.
Улучшает проектную документацию Документация необходима для описания процесса разработки системы и помогает в решении любых будущих проблем или несоответствий, которые могут возникнуть, а также в обучении будущих сотрудников. Построив углубленную модель данных на ранней стадии процесса разработки, вы сможете включить ее в документацию системы, чтобы лучше понять, как она работает.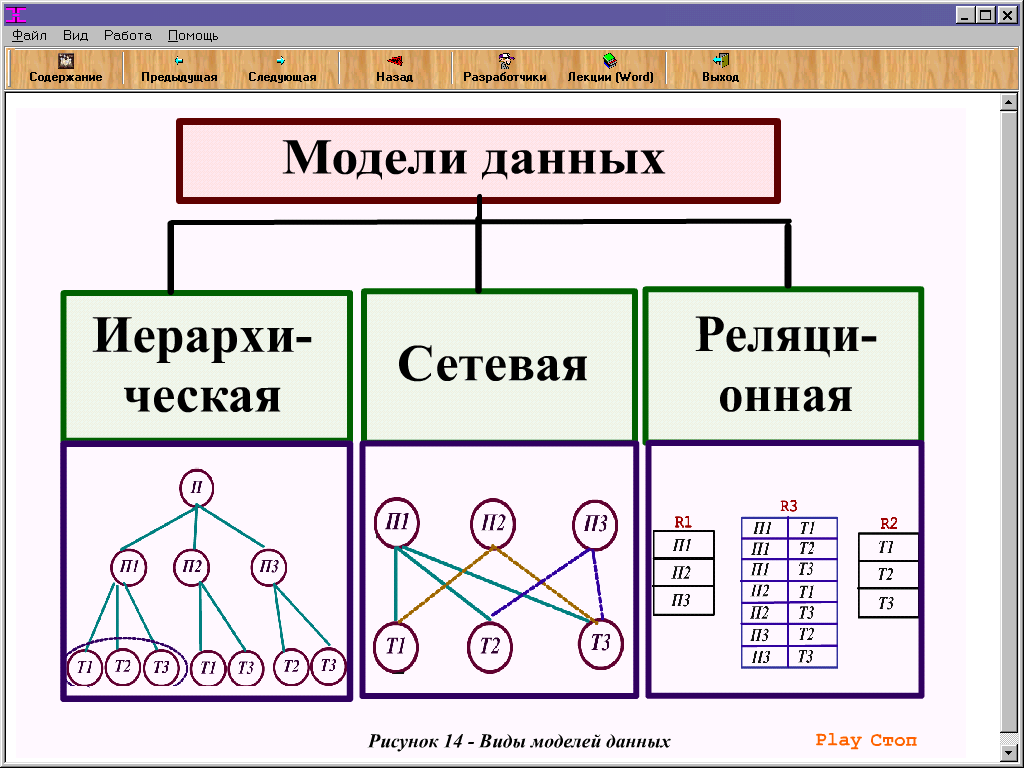
Моделирование данных стало опорой растущего рынка управления данными, в частности, благодаря оптимизированным моделям данных видимости данных, которые позволяют предприятиям предоставлять специалистам, не работающим с данными, в своих организациях.
Ожидается, что рынок управления данными будет расти со совокупным годовым темпом роста более 21% в период с 2021 по 2026 год, а его оценочная стоимость к 2026 году составит 5,28 миллиарда долларов, согласно исследованию ReportLinker. Большая часть этого роста будет связана с ужесточением глобальных правил в отношении данных, в первую очередь Общего регламента по защите данных (GDPR) в ЕС.
Этот очень прибыльный рынок стал движущей силой бесчисленных поставщиков технических услуг, создавших свои собственные инструменты моделирования данных — некоторые из них с открытым исходным кодом и бесплатные для использования.
Enterprise Architect Enterprise Architect — это графический инструмент, разработанный для многопользовательского доступа, подходящий как для начинающих, так и для опытных специалистов по моделированию данных.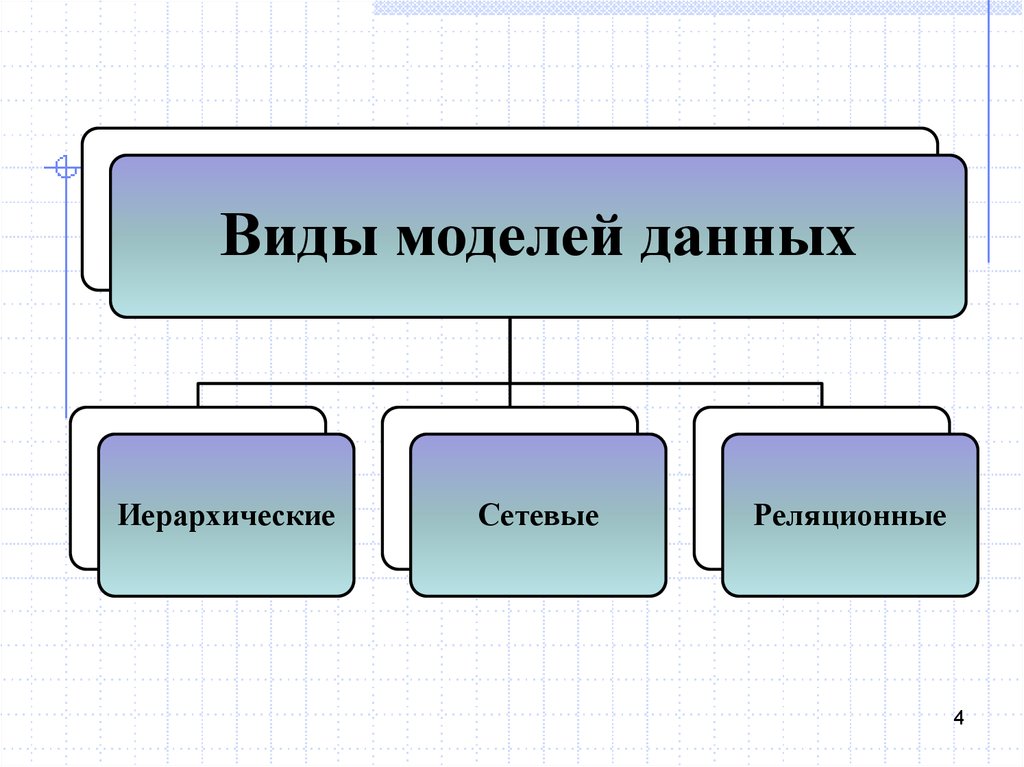 Благодаря ряду встроенных возможностей, начиная от визуализации данных, тестирования и обслуживания и заканчивая документированием и созданием отчетов, его можно использовать для визуального представления всех данных в ландшафте вашей системы.
Благодаря ряду встроенных возможностей, начиная от визуализации данных, тестирования и обслуживания и заканчивая документированием и созданием отчетов, его можно использовать для визуального представления всех данных в ландшафте вашей системы.
Apache Spark — это система обработки с открытым исходным кодом для управления большими данными и моделирования. Его можно использовать совершенно бесплатно без затрат на лицензирование, предоставляя пользователям интерфейс для программирования кластеров с неявной отказоустойчивостью и параллелизмом.
Средство моделирования данных Oracle SQL DeveloperСредство моделирования данных Oracle SQL Developer является частью среды Oracle. Хотя это и не открытый исходный код, его можно бесплатно использовать для разработки моделей данных, а также для создания, просмотра и редактирования концептуальных, логических и физических моделей данных.
RapidMiner RapidMiner — это платформа и инструмент для обработки данных корпоративного уровня, которые можно использовать для сбора, анализа и визуального представления данных.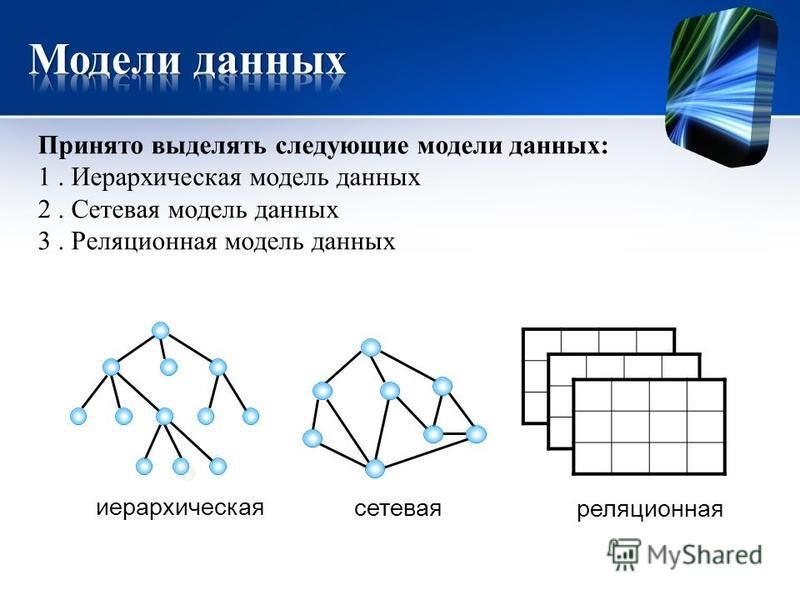 Он идеально подходит для начинающих и менее опытных пользователей благодаря удобному интерфейсу.
Он идеально подходит для начинающих и менее опытных пользователей благодаря удобному интерфейсу.
Он легко интегрируется с самыми разными типами источников данных, от Access, Teradata и Excel до Ingres, MySQL и IBM DB2 и многих других. Кроме того, он способен поддерживать подробный анализ данных на протяжении всего жизненного цикла искусственного интеллекта (ИИ).
Практический результат: Моделирование данныхМоделирование данных — это подход к визуальному представлению данных в виде графиков и диаграмм, различающихся по степени абстракции, уровню детализации и сложности. Существует множество типов и подходов к моделированию данных, но его основное преимущество заключается в том, что он помогает концептуализировать и руководить разработкой системы, зависящей от базы данных.
От бесплатных инструментов с открытым исходным кодом до корпоративных решений и платформ — вы можете автоматизировать и упростить большую часть процесса моделирования данных, сделав его более доступным для небольших групп и срочных проектов с ограниченным бюджетом.