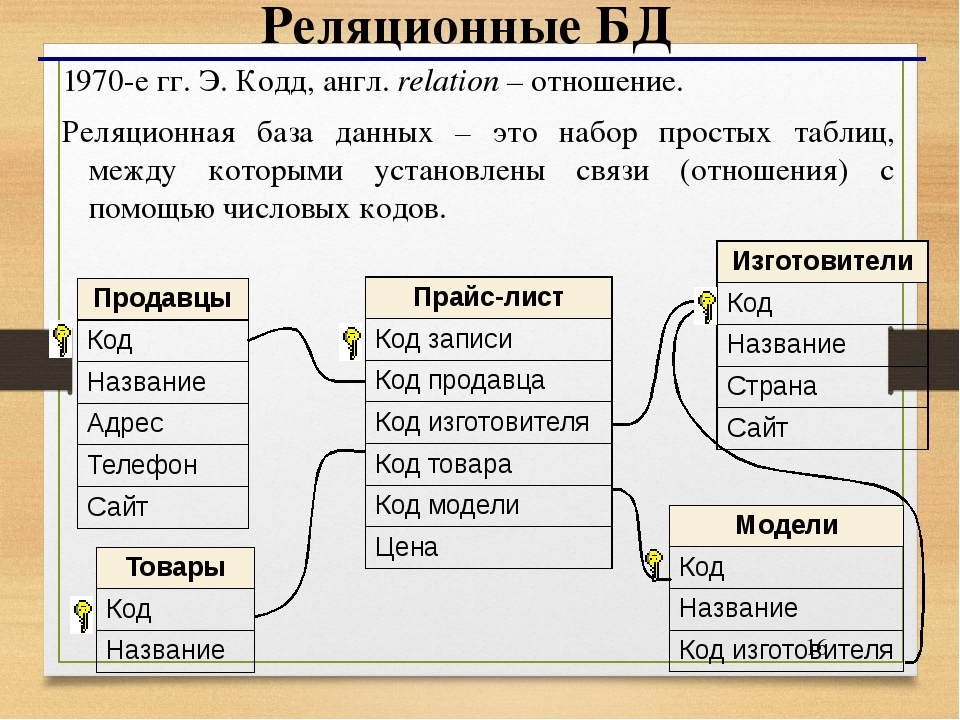
Основы реляционных баз данных (РБД) с нуля – курс основ баз данных для начинающих, 24 урока
Включено в курс
24 урока (видео и/или текст)
23 упражнения в тренажере
65 проверочных тестов
Самостоятельная работа
Дополнительные материалы
Помощь в «Обсуждениях»
Доступ к остальным курсам платформы
Чему вы научитесь
- Создавать полноценные базы данных для приложений на любых языках
- Правильно организовывать (нормализовать) архитектуру хранения данных с помощью нормальных форм
- Отображать предметную область на таблицы с учетом связей между сущностями (o2o, o2m, m2m)
- Выполнять запросы на выборку данных по сложным условиям
Описание
На этом курсе вы изучите основы реляционных баз данных. Вы узнаете больше об архитектуре СУБД и языке SQL. В итоге вы научитесь создавать таблицы, добавлять, модифицировать и удалять данные. Курс пригодится, если вы решите использовать базу данных в вашем приложении или вам нужно использовать данные из базы в любых других местах. Знания из этого курса помогают выполнять запросы для выборки данных, объединять таблицы и использовать транзакции. Этот курс подойдет программистам и другим специалистам, которые работают с базами данных и выборками из них. Чтобы учиться было проще, стоит заранее изучить курс Основы командной строки.
Знания из этого курса помогают выполнять запросы для выборки данных, объединять таблицы и использовать транзакции. Этот курс подойдет программистам и другим специалистам, которые работают с базами данных и выборками из них. Чтобы учиться было проще, стоит заранее изучить курс Основы командной строки.
postgresql транзакции нормальные формы СУБД SQL
Программа курса
Продолжительность 27 часов
Введение
Познакомиться с курсом
теория
Архитектура СУБД
Узнать, как устроены СУБД
теория
тесты
Подготовка к работе
Создать пользователя и базу данных
теория
тесты
Структура реляционной базы данных
Познакомиться с табличной организацией данных
теория
тесты
Создание таблиц
Научиться создавать таблицы и познакомиться с базовыми типами данных в PostgreSQL
теория
тесты
упражнение
Вставка и модификация данных
Научиться наполнять базу данных и изменять ее содержимое
теория
тесты
упражнение
Выборка данных
Познакомиться с SELECT и научиться делать простые SQL запросы
теория
тесты
упражнение
Реляционная модель данных
Узнать про фундамент, на котором стоит любая реляционная база данных
теория
тесты
упражнение
Первая нормальная форма
Разобраться с первой нормальной формой
теория
тесты
Вторая нормальная форма
Разобраться со второй нормальной формой
теория
упражнение
Третья нормальная форма
Разобраться с третьей нормальной формой
теория
тесты
упражнение
Автоинкремент
Научиться генерировать ключи автоматически
теория
тесты
упражнение
Онтология
Познакомиться с сущностями, связями и ERD
теория
тесты
упражнение
Ограничения
Научиться использовать UNIQUE и NOT NULL
теория
тесты
упражнение
Изменение структуры таблицы (ALTER)
Научиться изменять структуру существующей таблицы
теория
тесты
упражнение
Сортировка (ORDER)
Научиться сортировать данные в прямом и обратном порядке
теория
тесты
упражнение
Условия (WHERE)
Научиться строить условия при выполнении запросов в базу данных
теория
тесты
Лимит (LIMIT)
Научиться ограничивать выборку
теория
тесты
упражнение
DISTINCT
Познакомиться с простым способом находить уникальные записи
теория
тесты
Функции
Научиться пользоваться агрегатными функциями для расчетов
теория
тесты
упражнение
Группировка (GROUP)
Научиться применять агрегатные функции к группам записей по определенному признаку
теория
упражнение
Соединения (JOINS)
Познакомиться с запросами позволяющими объединять разные таблицы в одну
теория
тесты
упражнение
Транзакционность
Научиться выполнять запросы внутри транзакции, разобраться с ACID
теория
упражнение
Производительность
Познакомиться со способами обеспечения скорости выполнения запросов (индексы, Explain)
теория
Самостоятельная работа
Дополнительные задания, которые позволяют закрепить полученную теорию
Формат обучения
Испытания
Это практические задания, которые мы советуем выполнить после завершения курса.
Рекомендуемые программы
профессия
• от 6 300 ₽ в месяц
Python-разработчик
Разработка веб-приложений на Django
10 месяцев •
с нуля
Старт 18 мая
профессия
• от 6 300 ₽ в месяц
Java-разработчик
Разработка приложений на языке Java
10 месяцев •
с нуля
Старт 18 мая
профессия
• от 6 300 ₽ в месяц
PHP-разработчик
Разработка веб-приложений на Laravel
10 месяцев •
с нуля
Старт 18 мая
профессия
• от 6 183 ₽ в месяц
Инженер по тестированию
Ручное тестирование веб-приложений
4 месяца •
с нуля
Старт 18 мая
профессия
• от 6 300 ₽ в месяц
Node. js-разработчик
js-разработчик
Разработка бэкенд-компонентов для веб-приложений
10 месяцев •
с нуля
Старт 18 мая
профессия
• от 10 080 ₽ в месяц
Fullstack-разработчик
Разработка фронтенд- и бэкенд-компонентов для веб-приложений
16 месяцев •
с нуля
Старт 18 мая
Выборка данных | Основы реляционных баз данных
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
В этом уроке разберем одну из самых часто используемых операций SQL — SELECT. С помощью этой команды выполняют выборку данных из таблиц.
Запросы выполняемые в этом уроке, можно повторить локально, используя подготовленную базу данных или через сервис sqlfiddle
Выборка данных
В типичных веб-приложениях данные выбираются в 10 раз чаще, чем модифицируются. Для этого используют запрос SELECT. Его простая форма выглядит так:
SELECT * FROM users;
Этот запрос достает все содержимое таблицы users.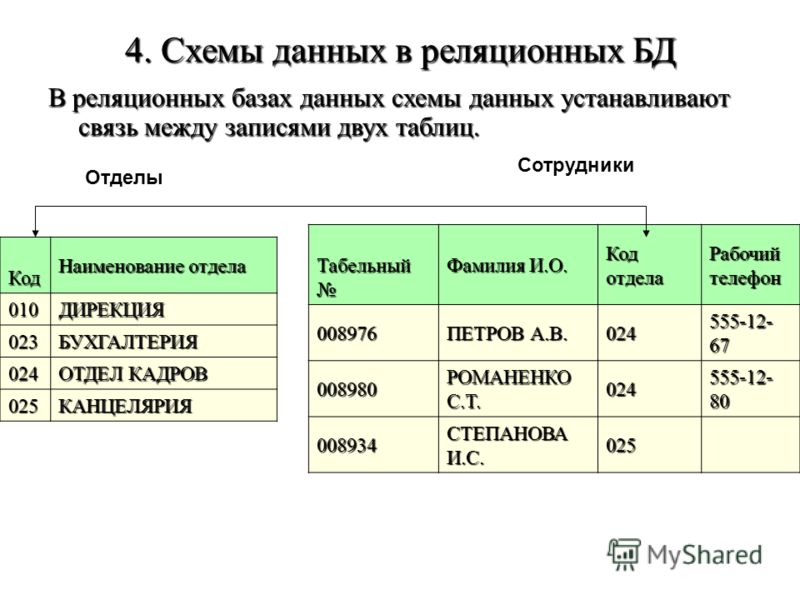 Звездочка в примере означает все поля. Если поля нужны не все, то достаточно перечислить их через запятую вместо звездочки:
Звездочка в примере означает все поля. Если поля нужны не все, то достаточно перечислить их через запятую вместо звездочки:
SELECT username, email FROM users;
Поля необязательно перечислять в том же порядке, в котором они идут в таблице. В результате такого запроса порядок полей в выводе будет соответствовать не тому, что в таблице, а указанному в части SELECT.
На практике выборка, которая извлекает все записи, встречается редко. Дело в том, что у таблиц бывают большие объемы и нужно ограничивать вывод для конкретного пользователя. В этом случае используется WHERE, который мы рассматривали в прошлом уроке. Он работает одинаково вне зависимости от типа выполняемого запроса, будь-то UPDATE, DELETE или SELECT:
-- После WHERE указывается имя поля, которое сравнивается с некоторым значением (это один из вариантов) -- Выбираем всех пользователей, которые родились ранее 21 октября 2018 года SELECT * FROM users WHERE birthday < '2018-10-21';
Даже в таком варианте количество возможных записей может быть слишком большим. Поэтому нужно сделать так, чтобы из всей информации выбиралось ограниченное количество записей.
Поэтому нужно сделать так, чтобы из всей информации выбиралось ограниченное количество записей.
Пагинация
Когда записей очень много, можно реализовать пагинацию — она позволяет перемещаться по страницам, если их много. Этот механизм можно реализовать целиком в коде. Но так не делают, потому что количество данных, перегоняемых из базы данных в код, может быть огромным. На такую задачу не хватит ресурсов сервера. Поэтому пагинацию реализуют на уровне базы данных.
Чтобы реализовать его, используют LIMIT — ограничение на количество записей, которые выбирают из базы данных:
SELECT * FROM users LIMIT 3;
Число после LIMIT — это количество записей, которые мы хотим выбрать. В нашем примере запрос выберет не больше трех записей. Если в таблице их меньше, то выберутся все. Количество записей в лимите можно увеличивать или уменьшать.
SQL не гарантирует порядка в выборках выше. Если не указать сортировку, то мы не можем знать, в каком порядке вернутся данные.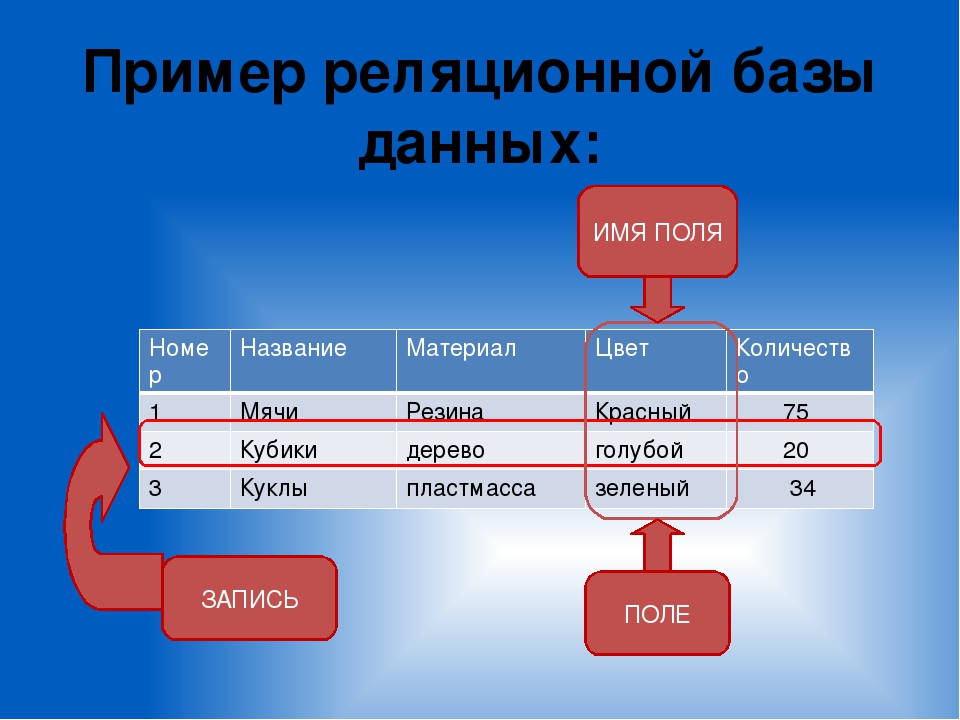 Поэтому в подобных выборках всегда присутствует секция
Поэтому в подобных выборках всегда присутствует секция ORDER BY:
SELECT * FROM users ORDER BY birthday;
Такой запрос отсортирует данные по ключу birthday в прямом порядке — кто родился раньше, будет выше. Если нужно отсортировать в обратном порядке, то надо добавить ключевое слово DESC:
SELECT * FROM users ORDER BY birthday DESC;
Такой запрос вернет пользователей, отсортированных по дню рождения в обратном порядке — выше будут те, кто младше.
На этом базовые возможности SELECT заканчиваются. Все части запроса, которые мы рассмотрели, комбинируются друг с другом и даже могут использоваться одновременно:
-- Порядок следования частей `WHERE`, `ORDER BY` и `LIMIT` в SQL запросе фиксирован. SELECT username, created_at FROM users WHERE birthday < '2018-10-21' ORDER BY birthday DESC LIMIT 2;
Запрос читается практически как фраза на английском языке: «Выбрать поля username и created_at из таблицы users для пользователей, которые родились раньше 2018-10-21. Результат должен быть отсортирован по дню рождения в обратном порядке. Ограничить выборку двумя записями.»
Результат должен быть отсортирован по дню рождения в обратном порядке. Ограничить выборку двумя записями.»
Чтобы было удобно считывать код, длинные запросы разбивают на строчки:
SELECT
username,
created_at
FROM users
WHERE birthday < '2018-10-21'
ORDER BY birthday DESC
LIMIT 2;
В будущих уроках мы рассмотрим каждую из этих частей подробнее.
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Электронная почта *
Отправляя форму, вы принимаете «Соглашение об обработке персональных данных» и условия «Оферты», а также соглашаетесь с «Условиями использования»
Наши выпускники работают в компаниях:
Основы работы с базами данных: концепции и примеры для начинающих
Приступим… Важность хорошо представленных данных нельзя недооценивать в современном цифровом ландшафте. Компании по всему миру сосредотачивают все свои стратегии на данных, чтобы лучше понимать своих клиентов. Facebook, Amazon, Netflix и Google — лишь некоторые из крупных корпораций, чья бизнес-модель вращается вокруг предоставления персонализированных рекомендаций своим пользователям. Это стало возможным только благодаря систематизированным данным.
Компании по всему миру сосредотачивают все свои стратегии на данных, чтобы лучше понимать своих клиентов. Facebook, Amazon, Netflix и Google — лишь некоторые из крупных корпораций, чья бизнес-модель вращается вокруг предоставления персонализированных рекомендаций своим пользователям. Это стало возможным только благодаря систематизированным данным.
Организованные данные могут быть любым представлением данных, которое позволяет вам собирать ценные сведения. Что еще необходимо, так это то, что это должно иметь отношение к вашему отделу. Если вы работаете в страховой фирме, вам понадобится информация, включающая кредитную историю клиентов, их возраст, банковские записи и т. д. Вас не будут волновать их любимые телепередачи или книги, которые они любят читать.
Все данные имеют большое значение, вам просто нужно убедиться, что вы имеете дело с тем, что касается вашей конечной цели.
Иногда вам нужно будет обрабатывать несколько наборов данных вместе, чтобы получить полезную информацию. Когда речь идет о нескольких наборах данных, все может очень легко усложниться, и постоянное перемещение туда и обратно между кучами данных может занять много времени.
Основы базы данных: что такое база данных?
Наиболее эффективным способом хранения данных является использование базы данных. База данных состоит из таблиц, содержащих столбцы и строки. Каждой категории дается своя таблица. Например, у компании может быть таблица для информации о клиентах, а другая — для данных о продажах. Вы можете думать о таблице как о таблице расширений. Внутри электронной таблицы есть столбцы и строки данных. Однако для базы данных каждая строка называется записью, а каждая ячейка называется полем.
Когда люди говорят о базе данных, они обычно имеют в виду реляционную базу данных. Это самый старый тип базы данных, который используется уже более 40 лет.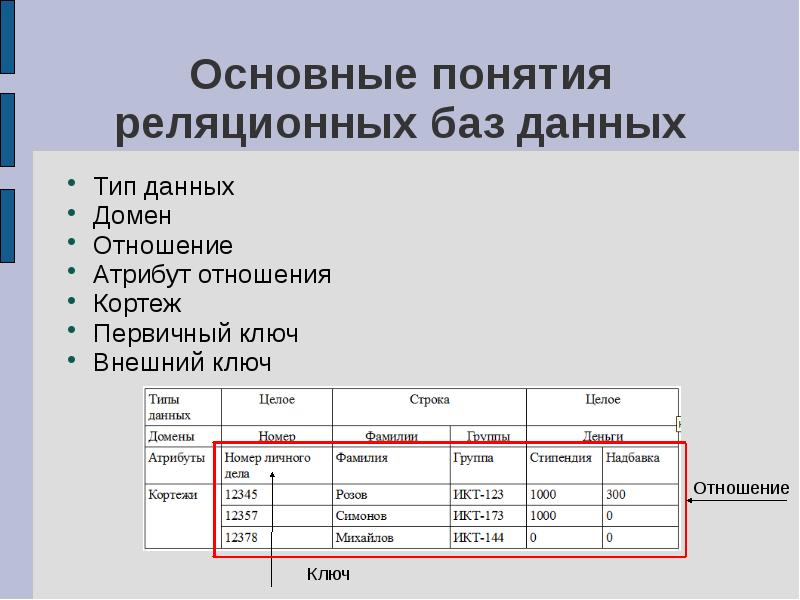
Реляционная база данных состоит из 3 компонентов высокого уровня:
- Таблицы
- Отношения
- Ключи
С помощью этих активов вы можете легко связать зеттабайты (1 000 000 000 000 000 000 000 байт) данных во что-то значимое, что можно легко просмотреть по желанию, чтобы увидеть все, что вы хотите.
Вы хотите просмотреть определенный сегмент ваших данных? Легко выполнимо. Вы хотите посмотреть на ОДИН конкретный результат из множества миллионов? Без проблем. Как насчет того, чтобы посмотреть на эти 27 аномалий в ваших данных, за которыми было бы интересно наблюдать? Реляционные базы данных всегда будут прикрывать вашу спину. Гибкость, обеспечиваемая реляционной базой данных, не имеет себе равных. Ничто не было настолько популярным и полезным, как реляционные базы данных, и на то есть веские причины.
Теперь давайте подробно обсудим каждый из этих трех компонентов, чтобы понять, что они из себя представляют.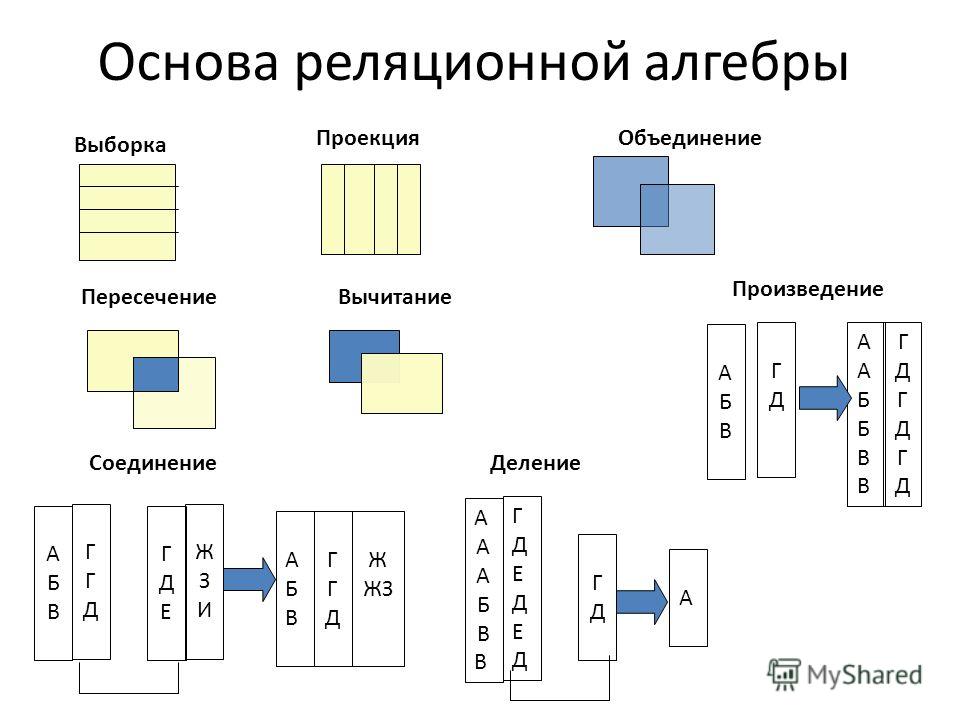
Таблицы — это Microsoft Excel, эквивалентный одной электронной таблице. Их также можно классифицировать как автономные наборы данных. Таблицы используются для объединения наиболее тесно связанных данных. Очень простым примером таблицы может быть набор данных о людях, который содержит кучу имен людей, должностей, номеров менеджеров, дат найма, зарплат и комиссионных.
Эта информация будет храниться в формате столбцов и строк. Строки и столбцы также являются основой таблицы.
Там, где столбцы используются для хранения различной информации об одном человеке, в строках хранится информация о разных людях. Когда они оба соединены вместе, в итоге получается таблица, полная информации. Давайте обсудим их обоих более подробно.
Столбцы используются для дифференциации имеющейся у нас информации об одном наблюдаемом объекте. В таблице, содержащей информацию о людях, столбцы будут использоваться для хранения другой информации. Если таблица, как упоминалось выше, содержит имена людей, должности, номера менеджеров, даты приема на работу, зарплаты и комиссионные, то в этой таблице будет 6 столбцов плюс столбец первичного ключа, который мы обсудим в следующих разделах.
В таблице, содержащей информацию о людях, столбцы будут использоваться для хранения другой информации. Если таблица, как упоминалось выше, содержит имена людей, должности, номера менеджеров, даты приема на работу, зарплаты и комиссионные, то в этой таблице будет 6 столбцов плюс столбец первичного ключа, который мы обсудим в следующих разделах.
Каждый столбец можно настроить так, чтобы в него можно было вводить информацию только определенного типа. Этот аспект обеспечивает столь необходимую целостность данных. Например, столбец о зарплате должен содержать только цифры, верно? Хотя это правда, люди, работающие с базами данных, — люди, и поэтому они могут случайно ввести в них что-то еще. Чтобы этого не произошло, столбцы могут быть спроектированы таким образом, чтобы в них можно было вводить информацию только определенного типа.
То же самое касается столбца электронной почты. Все, что не заканчивается на типичный «@abc.com», не должно быть разрешено в этом столбце.
Настройка столбца практически безгранична. Доступно множество пресетов и пользовательских опций.
Доступно множество пресетов и пользовательских опций.
Строки таблицы представляют количество наблюдаемых объектов, на которые мы смотрим. Проще говоря, если в таблице людей есть 3 строки, это означает, что в ней есть данные о 3 разных людях. Каждая строка представляет отдельного человека, а в столбцах будет отображаться соответствующая информация.
Строки позволяют нам видеть отдельные записи в таблице. Каждая строка также содержит первичный ключ, который позволяет нам легко искать отдельные записи.
КлючиКлючи обеспечивают уникальную идентификацию для всех строк в таблице. Без ключей было бы невозможно различать записи, содержащие одинаковую информацию в своих столбцах. Два человека в таблице могут иметь одинаковые имена и дни рождения, и без уникального ключа их будет трудно различить, что может привести к ненужной путанице.
Предположим, вы сотрудник отдела кадров, который должен отправить письмо с увольнением парню по имени Джон Доу и письмо о повышении другому человеку с таким же именем. Представьте, если это перепутается, оба получат письмо об увольнении или повышении. Разговор о корпоративном кошмаре, не так ли?
Представьте, если это перепутается, оба получат письмо об увольнении или повышении. Разговор о корпоративном кошмаре, не так ли?
Существует два типа ключей, которые вам следует знать: первичный ключ и внешний ключ.
Как вы уже догадались – базовый первичный ключ. Первичный ключПервичные ключи позволяют искать каждую строку в таблице. Это может быть один столбец или комбинация столбцов, составляющих уникальный идентификационный номер.
Внешний ключВнешние ключи используются для связывания таблиц в базе данных. Эти связи называются отношениями.
Отношения Отношения помогают повысить эффективность команд. А, как мы все знаем, работа в команде делает работу мечты. Это та часть, где начинает развиваться связь между различными таблицами. Отношения позволяют множеству таблиц содержать разную, но связанную информацию, сохраняя при этом удобочитаемость и оптимизируя пространство.
Представьте себе небольшую компанию, в которой есть разные отделы и отделы для своих сотрудников, такие как страховой фонд, детский сад, электронный журнал посещаемости.
Хотя вся эта информация может быть полезной, прочитать ее всю вместе не получится. Если отдел кадров захочет увидеть информацию о страховке конкретного сотрудника, он не будет заниматься использованием детского сада. На самом деле, с таким количеством колонок читать будет труднее.
Хранение баз данных также не является поверхностным вопросом, так как они могут потребовать много места, как только они начнут расти в размерах. Для каждого компьютера в компании не оптимально иметь всю базу данных с точки зрения хранения и безопасности.
Чтобы решить эту проблему, между различными таблицами реализованы связи. Отношения, по сути, позволяют разделить информацию на полезные компоненты, которые подчеркивают удобочитаемость и эффективность. Это также означает, что разные отделы будут иметь доступ только к тому, что им нужно, а остальное не будет доступно на их компьютерах.
В приведенном выше примере с небольшой компанией наилучшим способом формирования отношений было бы наличие 4 таблиц. Каждый представляет сотрудников, страховой фонд, детский сад и журнал посещаемости.
Теперь информация довольно хорошо разделена. Следующим шагом является определение того, какая информация будет присутствовать в большинстве областей. В этом случае все, что мы разделим, будет использоваться сотрудниками, поэтому имеет смысл рассматривать его как нашу основную таблицу.
Подумайте, какую информацию должна содержать таблица сотрудников, исходя из собственного опыта работы в офисе. У каждого сотрудника есть основные столбцы имени, адреса, телефона, электронной почты и возраста, а также что-то, известное как идентификационный номер. Этот идентификационный номер уникален для каждого работника, а также служит первичным ключом таблицы сотрудников.
Используя идентификационный номер, мы можем искать информацию о любом сотруднике, который нам нужен, даже если у нас есть сотрудники с таким же именем. Если каким-то странным чудом все ваши сотрудники имеют одинаковое имя и возраст, вы все равно можете отличить их по идентификационному номеру. Означает ли это, что мы можем использовать идентификатор сотрудника для связи с другими таблицами? Абсолютно.
Формирование отношений с другими таблицами с помощью внешних ключейСтолбец идентификатора сотрудника из этой таблицы будет использоваться в качестве первичного ключа для других таблиц. Когда другие таблицы связаны таким образом, говорят, что они имеют внешний ключ. Это просто означает ключ извне. Этот внешний ключ позволяет нам связать всю остальную информацию с каждым работником. Вся информация, которую мы имеем в других таблицах, привязана к конкретным людям, поэтому наличие идентификатора сотрудника в каждой другой таблице имеет смысл.
В то время как многие технические аспекты определяют, как создаются отношения в сложных системах, это один из самых простых примеров, который вы можете найти в любой книге по реляционным базам данных.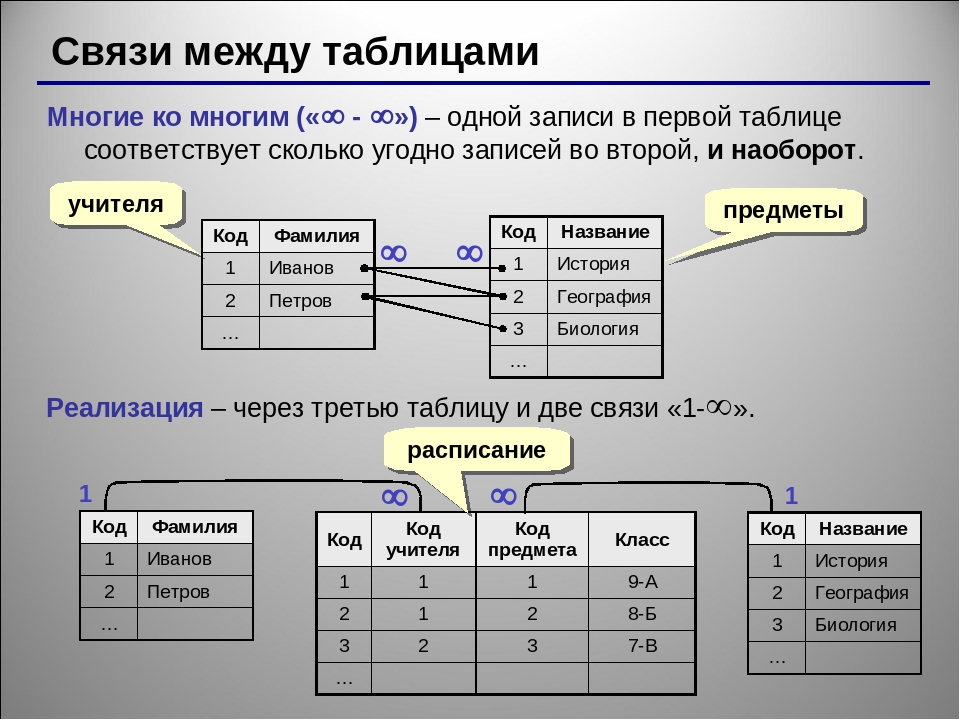
При обсуждении реляционных баз данных чаще всего можно услышать термины SQL и синонимы других свойств. Столбцы также могут называться атрибутами, полями или функциями. Строки также могут называться записями, записями или кортежами.
SQL — это язык программирования, разработанный для упрощения работы с базами данных. Силу этого инструмента нельзя недооценивать. Обладая сильным пониманием его основных концепций, вы можете делать с данными практически все, что захотите, когда дело доходит до понимания. Чаще всего SQL используется для извлечения (или запроса) данных из базы данных. С помощью этого языка вы можете указать, какие данные вам нужны и как должен выглядеть вывод. Вот как вы можете перенести данные из базы данных в Microsoft Excel или Google Sheets.
Чем реляционные базы данных отличаются от таблиц Excel/Google? В очень небольшом масштабе программы для работы с электронными таблицами могут работать хорошо. Но как только вы начинаете думать о масштабируемости, безопасности и удобстве использования, электронных таблиц становится недостаточно.
Но как только вы начинаете думать о масштабируемости, безопасности и удобстве использования, электронных таблиц становится недостаточно.
Это касается доступности данных более чем одному человеку. Хотя вы можете работать с предоставлением доступа к этой онлайн-таблице нескольким людям, это просто не сработает, когда вам нужно, чтобы множество разных отделов изучали ее каждый день. Вероятность того, что два человека будут работать над одним и тем же, весьма велика и может привести к серьезным проблемам. Если вы когда-либо одновременно работали с другим человеком в Google Docs, скорее всего, у вас были небольшие сбои.
Безопасность Данные очень ценны, и предоставление доступа к ним всем сотрудникам может привести к катастрофе. Не всем сотрудникам нужны все данные, и некоторые из них должны быть конфиденциальными. Например, у Amazon есть много конфиденциальных данных о клиентах: адреса, номера телефонов, информация о кредитных картах и т.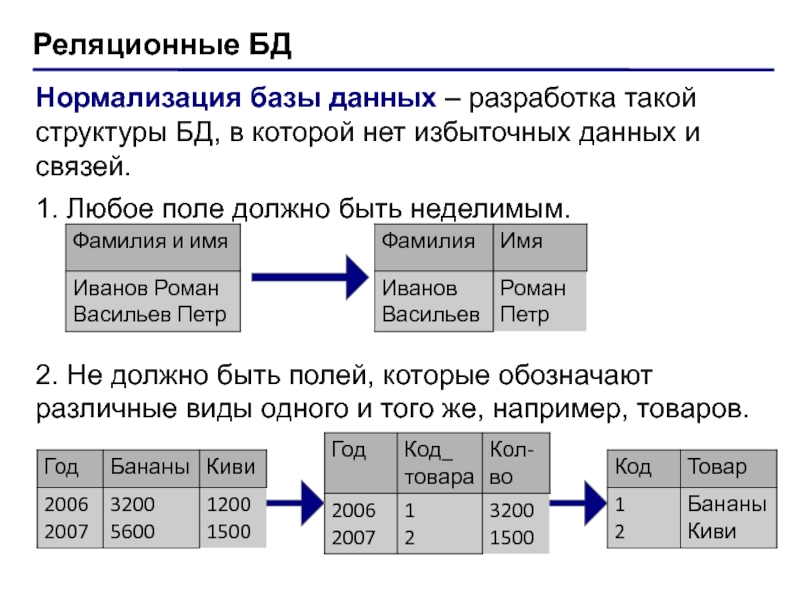 д. У них более 50 000 корпоративных сотрудников (более 700 000 корпоративных и некорпоративных), но у большинства нет доступа к этой информации. Amazon использует базы данных для ограничения доступа и защиты клиентов.
д. У них более 50 000 корпоративных сотрудников (более 700 000 корпоративных и некорпоративных), но у большинства нет доступа к этой информации. Amazon использует базы данных для ограничения доступа и защиты клиентов.
Если у вас есть тонны данных, но вы не можете найти эффективный способ извлечь из них информацию, это практически бесполезно. Инструменты, отличные от реляционных баз данных, просто не обладают такими возможностями для извлечения такой значимой информации, как SQL и другие языки баз данных.
По мере увеличения объемов данных вам, возможно, придется принудительно перейти на реляционную базу данных. Электронные таблицы могут обрабатывать только ограниченное количество данных. Таблицы Google имеют ограничение в 5 миллионов ячеек, и в настоящее время это действительно немного.
Его заполнение не займет много времени, а миграция 5 миллионов ячеек в базу данных будет проблематичной. Рекомендуется начинать миграцию в тот момент, когда вы наблюдаете рост. Базы данных могут обрабатывать столько, сколько вы можете им предложить, и именно поэтому кажется, что они реализованы везде, где существуют данные.
Базы данных могут обрабатывать столько, сколько вы можете им предложить, и именно поэтому кажется, что они реализованы везде, где существуют данные.
Гибкость, обеспечиваемая реляционной базой данных, не имеет себе равных. Ничто не было настолько популярным и полезным, как реляционные базы данных, и на то есть веские причины.Резюме
Подводя итог, мы рассмотрели, почему организованные данные важны и как вы можете организовать данные с помощью реляционной базы данных. Реляционная база данных состоит из нескольких таблиц данных, связанных между собой ключами и отношениями.
Таблицы, ключи и связи — это три основных компонента реляционной базы данных. Таблицы состоят из строк и столбцов. Строки представляют отдельные объекты в таблице, а столбцы представляют их атрибуты. Ключи (первичный и внешний) — это одно из ключевых понятий, благодаря которым реляционные базы данных работают. Отношения между таблицами — это связь, которая делает данные более значимыми. Они объясняют, как вещи на самом деле связаны и что их связывает.
Отношения между таблицами — это связь, которая делает данные более значимыми. Они объясняют, как вещи на самом деле связаны и что их связывает.
Без ключей и отношений, связывающих таблицы между собой, нет существенной разницы между несколькими электронными таблицами и реляционной базой данных.
Наконец, мы рассмотрели общий жаргон баз данных, с которым вам следует ознакомиться. В основном это синонимы других вещей, но они могут помочь узнать, о чем идет речь.
Статьи по теме
— Реляционные базы данных и нереляционные базы данных
— Облачные базы данных
— Неструктурированные данные
Основы реляционных баз данных | by Lukonde Mwila
Узнайте, что происходит под капотом MySQL, PostgreSQL и других реляционных баз данных
Опубликовано в
·
7 мин чтения
·
22 марта 2020 г.
На первый взгляд, это может кому-то покажется бессмысленным чтением. Зачем заморачиваться на такой элементарной теме? Кроме того, среди растущего числа крутых управляемых сервисов баз данных стоит ли все же знать основы работы баз данных?
Я бы сказал, что да. Действительно, этот пост может не относиться к вам напрямую, и это нормально. Однако данные являются неотъемлемой частью ряда современных приложений, и вы хотите знать, как лучше хранить их, управлять ими и запрашивать их.
Даже если вы выберете управляемую службу базы данных, вы должны быть уверены, что используете правильную службу в зависимости от потребностей вашего приложения и типа данных, с которыми вы работаете.
Как минимум, это может быть хорошим напоминанием или хорошим справочником для разработчиков начального уровня, стремящихся лучше понять реляционные базы данных. Я надеюсь, что это будет первая из многих статей на тему реляционных и нереляционных баз данных.
Начнем с некоторых основных ключевых фраз:
- Данные — набор значений или информации для определенной цели.

- База данных — организованный набор этих данных, обычно хранящихся в электронном формате.
- Система управления базами данных (СУБД) — Приложение, которое позволяет нам эффективно извлекать и управлять этими данными, например. MS SQL, MySQL, Oracle, Postgres и т. д.
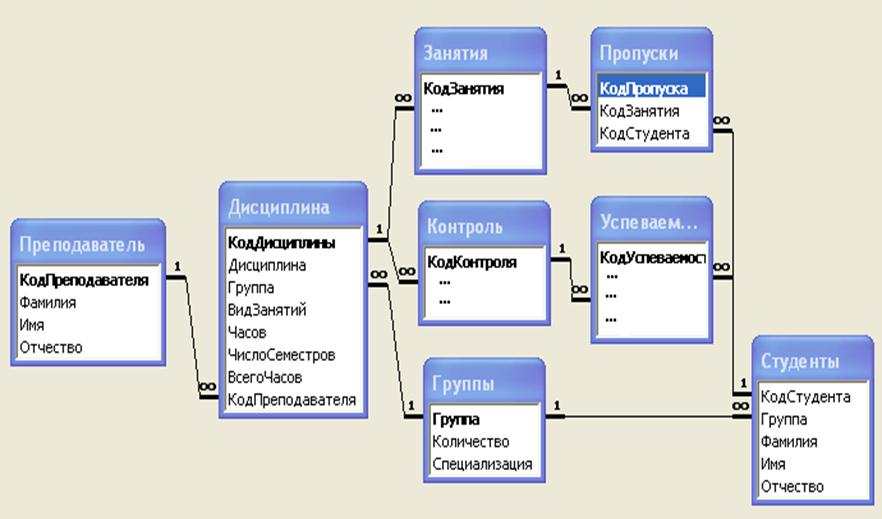
Обычно базы данных содержат несколько таблиц базы данных.
Таблица базы данных — это конструкция со строками и столбцами, которые используются для организации данных осмысленным образом, чтобы их можно было извлечь при необходимости.
Это базы данных с одной или несколькими таблицами, и эти таблицы каким-то образом связаны друг с другом. Таким образом, вместо того, чтобы помещать все данные в одну таблицу с бесчисленным количеством столбцов, мы используем несколько таблиц для удовлетворения необходимых требований.
Зачем это делать? Разделение таблиц позволяет нам более эффективно управлять данными, а определение отношений между этими таблицами позволяет нам извлекать данные в соответствии с нашими потребностями.
Чтобы определить эти отношения, нам нужно, чтобы эти таблицы могли обмениваться данными. Это вводит понятие первичные ключи.
Первичный ключ используется для уникальной идентификации каждой строки в таблице и может состоять из одного или нескольких столбцов.
Возьмем пример со старым студентом. У нас есть таблица, состоящая из различных атрибутов учащихся, таких как студенческий билет, имя, фамилия, дата рождения, адрес электронной почты и код оценки. Каждая строка представляет запись учащегося.
Чтобы однозначно идентифицировать каждого учащегося, мы могли бы использовать его идентификатор учащегося или столбец электронной почты в качестве первичного ключа. Эти потенциальные первичные ключи называются ключи-кандидаты .
Итак, мы можем назначить один из этих ключей-кандидатов в качестве нашего первичного ключа.
Вы также можете иметь несколько столбцов для создания первичного ключа, и в этом случае он будет называться составным ключом. Первичные ключи позволяют нам быстро запрашивать данные из этих таблиц без двусмысленности.
Первичные ключи позволяют нам быстро запрашивать данные из этих таблиц без двусмысленности.
Они также позволяют нам определять отношения с другими таблицами. Таким образом, первичный ключ таблицы может быть связан со столбцом в другой таблице, и эта связь называется внешний ключ .
Внешние ключи позволяют нам ссылаться на данные, хранящиеся в других таблицах, на основе определенной связи.
Например, используя тот же сценарий для таблицы учащихся, значение столбца кода оценки в строке (или записи) может быть первичным ключом другой таблицы, содержащей больше данных о разных оценках.
В этом случае код оценки является внешним ключом, который ссылается на соответствующие данные оценки из таблицы оценок. Внешние ключи не обязательно должны быть уникальными в таблице, где они являются внешними ключами. Один и тот же внешний ключ может повторяться несколько раз в таблице, расположенной в разных строках.
RDBM дают нам возможность получать данные, хранящиеся в них, и управлять ими. Это стало возможным благодаря SQL (язык структурированных запросов), который мы используем для взаимодействия с реляционными базами данных.
Это стало возможным благодаря SQL (язык структурированных запросов), который мы используем для взаимодействия с реляционными базами данных.
ВЫБЕРИТЕ * ОТ студентов, ГДЕ email='[email protected]';
Приведенный выше запрос извлечет любого существующего студента в таблице, который соответствует условию «ГДЕ». Здесь студент с адресом электронной почты «[email protected]».
Точно так же мы можем вставлять, обновлять и удалять записи, используя соответствующий синтаксис SQL.
Отношения «один ко многим»Первичный ключ одной таблицы может ссылаться на одну или несколько строк в других таблицах посредством отношения внешнего ключа. Таким образом, один класс может быть связан с несколькими учащимися этого класса в школе.
Отношения «многие ко многим»Отношения «многие ко многим» возникают, когда несколько записей в таблице связаны с несколькими записями в другой таблице.
Например, между клиентами и продуктами существует связь «многие ко многим»: клиенты могут приобретать различные продукты, а продукты могут приобретаться многими клиентами.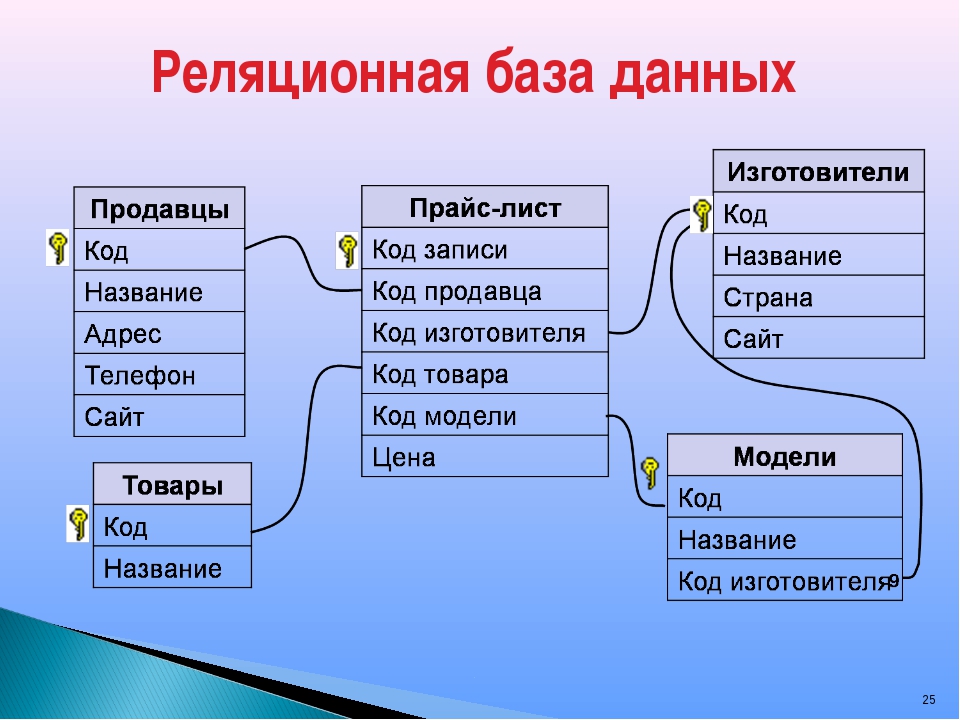
Что такое нормализация? Это процесс эффективной организации данных в таблицы, установления связей между ними и устранения избыточных данных.
Как правило, нормализация выражается в формах нормализации, также известных как NF:
- 1NF — используется для устранения повторяющихся групп.
- 2NF — Используется для устранения избыточных данных.
- 3NF — Используется для исключения столбцов, не зависящих от ключа таблицы.
Обычно существует от трех до пяти NF, но мы собираемся ограничиться тремя.
1NF
Допустим, у нас есть таблица учеников со столбцами предмет 1, предмет 2 и так далее и тому подобное. Мы могли бы объединить эти тематические столбцы в один с именем предметов . Этот процесс известен как 1NF — первая нормальная форма.
2NF
Это создает еще одну проблему, мы получаем много избыточных данных в других столбцах, потому что мы собираем записи учащихся на основе каждого предмета, который они изучают.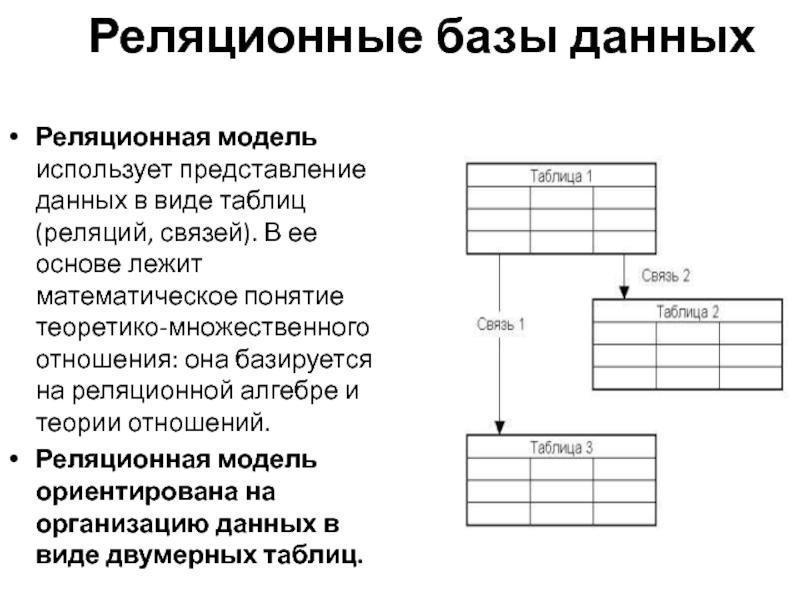
Чтобы решить эту проблему, мы разделили таблицу студентов на студентов и предметы. Это известно как 2NF — вторая нормальная форма.
3NF
Нам не нужно останавливаться на достигнутом, мы можем повысить эффективность и преобразовать таблицы в 3NF.
Для этого нужно искать столбцы, не зависящие напрямую от ключа таблицы. Что мы потом делаем с этими столбцами? Как вы уже догадались, мы перемещаем их в их собственные столы.
В приведенном выше примере идентификатор оценки столбца можно переместить в новую собственную таблицу, называемую оценками, которая будет иметь идентификатор оценки в качестве первичного ключа.
Важно помнить, что в 3NF все столбцы таблицы напрямую зависят от ключа таблицы.
Итак, это ненужная, кропотливая работа? Не совсем.
Если вы потратите время на моделирование взаимосвязей между таблицами, это поможет обеспечить эффективное хранение и организацию данных в вашей базе данных, а также устранит дублирование данных и обеспечит более высокий уровень целостности или согласованности данных.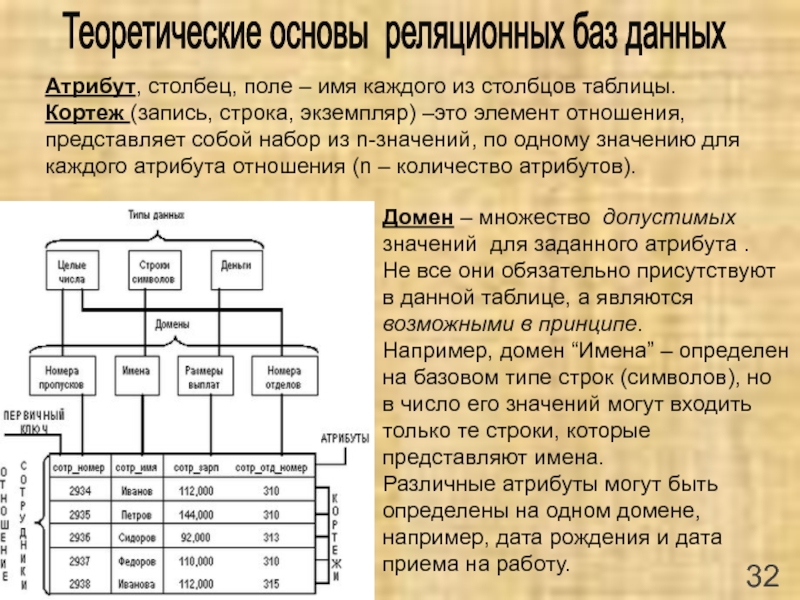
Чем ниже избыточность ваших данных, тем ниже будут затраты на хранение, что также может привести к повышению скорости.
Однако есть и обратная сторона. Результатом нормализации является несколько таблиц со множеством связей между ними.
Чем это плохо? Это означает, что для обработки требуется больше вычислительной мощности, что, в свою очередь, означает лучшую серверную инфраструктуру. Кроме того, SQL-запросы становятся более сложными, поскольку для извлечения данных необходимо обращаться к большему количеству таблиц.
Поведение ACIDРеляционные базы данных поддерживают следующий набор свойств:
- Атомарность — это означает, что транзакция может либо выполняться полностью, либо не выполняться вообще.
- Согласованность — после фиксации транзакции данные должны соответствовать заданной схеме.
- Изоляция — параллельные транзакции выполняются отдельно друг от друга.
- Долговечность — способность базы данных восстанавливаться после неожиданного сбоя или сбоя системы.