Парсинг при помощи JAVA / Хабр
. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.5.2) 2022-01-24 04:46:48.318 INFO 42654 --- [ main] com.ParsingProjectApplication : No active profile set, falling back to default profiles: default 2022-01-24 04:46:49.028 INFO 42654 --- [ main] .s.d.r.c.RepositoryConfigurationDelegate : Bootstrapping Spring Data JPA repositories in DEFAULT mode. 2022-01-24 04:46:49.174 INFO 42654 --- [ main] .s.d.r.c.RepositoryConfigurationDelegate : Finished Spring Data repository scanning in 142 ms. Found 1 JPA repository interfaces. 2022-01-24 04:46:49.455 INFO 42654 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http) 2022-01-24 04:46:49.460 INFO 42654 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2022-01-24 04:46:49.460 INFO 42654 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.48] 2022-01-24 04:46:49.514 INFO 42654 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2022-01-24 04:46:49.514 INFO 42654 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 1158 ms 2022-01-24 04:46:49.677 INFO 42654 --- [ main] o.hibernate.jpa.internal.util.LogHelper : HHH000204: Processing PersistenceUnitInfo [name: default] 2022-01-24 04:46:49.696 INFO 42654 --- [ main] org.hibernate.Version : HHH000412: Hibernate ORM core version 5.4.32.Final 2022-01-24 04:46:49.746 INFO 42654 --- [ main] o.hibernate.annotations.common.Version : HCANN000001: Hibernate Commons Annotations {5. 1.2.Final} 2022-01-24 04:46:49.790 WARN 42654 --- [ main] com.zaxxer.hikari.HikariConfig : HikariPool-1 - idleTimeout has been set but has no effect because the pool is operating as a fixed size pool. 2022-01-24 04:46:49.790 INFO 42654 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting... 2022-01-24 04:46:49.951 INFO 42654 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed. 2022-01-24 04:46:49.960 INFO 42654 --- [ main] org.hibernate.dialect.Dialect : HHH000400: Using dialect: org.hibernate.dialect.PostgreSQL94Dialect Hibernate: drop table if exists course_dto_once cascade 2022-01-24 04:46:50.236 WARN 42654 --- [ main] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Warning Code: 0, SQLState: 00000 2022-01-24 04:46:50.236 WARN 42654 --- [ main] o.h.engine.jdbc.spi.SqlExceptionHelper : table "course_dto_once" does not exist, skipping Hibernate: drop sequence if exists hibernate_sequence 2022-01-24 04:46:50. 237 WARN 42654 --- [ main] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Warning Code: 0, SQLState: 00000 2022-01-24 04:46:50.237 WARN 42654 --- [ main] o.h.engine.jdbc.spi.SqlExceptionHelper : sequence "hibernate_sequence" does not exist, skipping Hibernate: create sequence hibernate_sequence start 1 increment 1 Hibernate: create table course_dto_once ( id int8 not null, char_code varchar(255), name varchar(255), nominal int4 not null, num_code varchar(255), value float8 not null, primary key (id) ) 2022-01-24 04:46:50.318 INFO 42654 --- [ main] o.h.e.t.j.p.i.JtaPlatformInitiator : HHH000490: Using JtaPlatform implementation: [org.hibernate.engine.transaction.jta.platform.internal.NoJtaPlatform] 2022-01-24 04:46:50.322 INFO 42654 --- [ main] j.LocalContainerEntityManagerFactoryBean : Initialized JPA EntityManagerFactory for persistence unit 'default' 2022-01-24 04:46:50. 480 WARN 42654 --- [ main] JpaBaseConfiguration$JpaWebConfiguration : spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning 2022-01-24 04:46:50.661 INFO 42654 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2022-01-24 04:46:50.668 INFO 42654 --- [ main] com.ParsingProjectApplication : Started ParsingProjectApplication in 2.682 seconds (JVM running for 3.006) 2022-01-24 04:52:00.787 INFO 42654 --- [nio-8080-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet' 2022-01-24 04:52:00.788 INFO 42654 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet' 2022-01-24 04:52:00.788 INFO 42654 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 0 ms Австралийский доллар (numCode = 036, charCode = AUD, nominal = 1, value = 55. 1633) Азербайджанский манат (numCode = 944, charCode = AZN, nominal = 1, value = 45.1385) Фунт стерлингов Соединенного королевства (numCode = 826, charCode = GBP, nominal = 1, value = 103.9997) Армянских драмов (numCode = 051, charCode = AMD, nominal = 100, value = 15.9539) Белорусский рубль (numCode = 933, charCode = BYN, nominal = 1, value = 29.8058) Болгарский лев (numCode = 975, charCode = BGN, nominal = 1, value = 44.4607) Бразильский реал (numCode = 986, charCode = BRL, nominal = 1, value = 14.1505) Венгерских форинтов (numCode = 348, charCode = HUF, nominal = 100, value = 24.35) Гонконгских долларов (numCode = 344, charCode = HKD, nominal = 10, value = 98.4699) Датская крона (numCode = 208, charCode = DKK, nominal = 1, value = 11.6842) Доллар США (numCode = 840, charCode = USD, nominal = 1, value = 76.6903) Евро (numCode = 978, charCode = EUR, nominal = 1, value = 86.9054) Индийских рупий (numCode = 356, charCode = INR, nominal = 10, value = 10.2985) Казахстанских тенге (numCode = 398, charCode = KZT, nominal = 100, value = 17. 5815) Канадский доллар (numCode = 124, charCode = CAD, nominal = 1, value = 61.2102) Киргизских сомов (numCode = 417, charCode = KGS, nominal = 100, value = 90.427) Китайский юань (numCode = 156, charCode = CNY, nominal = 1, value = 12.0972) Молдавских леев (numCode = 498, charCode = MDL, nominal = 10, value = 42.4055) Норвежских крон (numCode = 578, charCode = NOK, nominal = 10, value = 86.796) Польский злотый (numCode = 985, charCode = PLN, nominal = 1, value = 19.2264) Румынский лей (numCode = 946, charCode = RON, nominal = 1, value = 17.5847) СДР (специальные права заимствования) (numCode = 960, charCode = XDR, nominal = 1, value = 107.5497) Сингапурский доллар (numCode = 702, charCode = SGD, nominal = 1, value = 56.9722) Таджикских сомони (numCode = 972, charCode = TJS, nominal = 10, value = 67.8976) Турецких лир (numCode = 949, charCode = TRY, nominal = 10, value = 57.1544) Новый туркменский манат (numCode = 934, charCode = TMT, nominal = 1, value = 21.9429) Узбекских сумов (numCode = 860, charCode = UZS, nominal = 10000, value = 70. 7797) Украинских гривен (numCode = 980, charCode = UAH, nominal = 10, value = 27.0692) Чешских крон (numCode = 203, charCode = CZK, nominal = 10, value = 35.819) Шведских крон (numCode = 752, charCode = SEK, nominal = 10, value = 83.537) Швейцарский франк (numCode = 756, charCode = CHF, nominal = 1, value = 83.8787) Южноафриканских рэндов (numCode = 710, charCode = ZAR, nominal = 10, value = 50.6156) Вон Республики Корея (numCode = 410, charCode = KRW, nominal = 1000, value = 64.3418) Японских иен (numCode = 392, charCode = JPY, nominal = 100, value = 67.3165) Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: select nextval ('hibernate_sequence') Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?) Hibernate: insert into course_dto_once (char_code, name, nominal, num_code, value, id) values (?, ?, ?, ?, ?, ?)
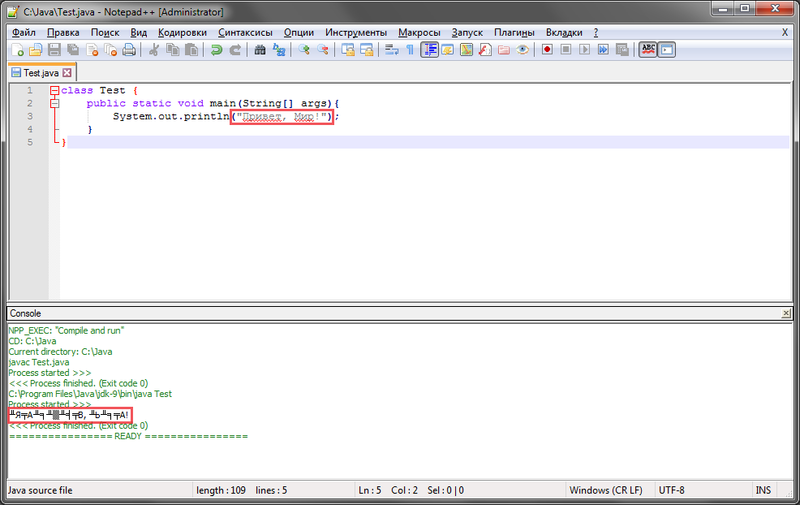
Как написать парсер на java
Многие компании используют парсинг сайтов , чтобы агрегировать информацию из конкурентных ресурсов. Ее можно получить из HTML-кода веб-страниц. Но только не ту, которая находится в картинках или другом медийном контенте. В этом руководстве мы научимся парсить данные с помощью Java .
Ее можно получить из HTML-кода веб-страниц. Но только не ту, которая находится в картинках или другом медийном контенте. В этом руководстве мы научимся парсить данные с помощью Java .
Обязательные условия
- Базовые знания Java ;
- Основы XPath .
Инструменты
Вам потребуется Java 8 и браузер HtmlUnit
Если вы используете Eclipse , советую изменить максимальную длину в окне подробностей ( при нажатии на вкладку «Переменные» ), чтобы можно было видеть весь HTML-код веб-страницы.
Парсер на java: пример-получим данные из интернет-магазина
В примере парсинга сайта Java мы извлечем информацию с интернет-магазина. Соберем имена, цены, а также картинки и экспортируем их в формат JSON .
Сначала посмотрим, что происходит при поиске товара в магазине. Для этого откройте « Инструменты разработчика » в Chrome и перейдите на вкладку « Network »:
Также можно использовать
Теперь откройте среду разработки. Пришло время писать код. Для выполнения запроса в HtmlUnit нужен WebClient . Сначала нужно отключить JavaScript , так как в нашем примере он не нужен, и без него страница будет загружаться быстрее:
Для выполнения запроса в HtmlUnit нужен WebClient . Сначала нужно отключить JavaScript , так как в нашем примере он не нужен, и без него страница будет загружаться быстрее:
В объекте HtmlPage будет HTML-код , доступ к которому можно получить с помощью метода asXml() . Вытянем с сайта названия, изображения и цены. Для этого нужно внимательно просмотреть структуру DOM :
Для парсинга страниц сайта есть несколько способов выбрать тег HTML , используя HtmlUnit :
- getHtmlElementById(String id) ;
- getFirstByXPath(String Xpath)-getByXPath(String XPath) , который возвращает список.
Поскольку мы не можем использовать ID , чтобы выбрать теги, нужно составить выражение Xpath .
XPath — это язык запросов для выбора элементов XML ( в нашем случае HTML ).
Сначала нужно выбрать все теги <p> с классом ` result-info . Затем выполнить итерацию в списке, и для каждого предмета выбрать название, цену и URL , а также вывести на экран.
Затем сохраним данные в формате JSON , используя библиотеку Jackson . Для представления элементов, полученных при парсинге email адресов с сайта , нам понадобится POJO ( объект языка Java ).
Для представления элементов, полученных при парсинге email адресов с сайта , нам понадобится POJO ( объект языка Java ).
Затем добавим это в файл pom.xml :
Теперь нужно создать элемент, задать атрибуты, конвертировать в строку или файл JSON и немного адаптировать предыдущий код парсинга данных с сайта :
Не останавливайтесь
Этот пример парсинга другого сайта не идеален, многое можно улучшить:
- Поиск по городам;
- Обработка пагинации;
- Поиск по нескольким критериям.
Код примера находится здесь .
Пожалуйста, оставляйте свои комментарии по текущей теме материала. Мы очень благодарим вас за ваши комментарии, отклики, лайки, подписки, дизлайки!
Пожалуйста, оставьте ваши комментарии по текущей теме статьи. Мы очень благодарим вас за ваши комментарии, отклики, лайки, дизлайки, подписки!
Написать парсер для сайта
Здравствуйте. Начну с того, что изучаю пайтон около полтора месяца, успел прочитать Лутца.
Как написать парсер фотографий с сайта
Всем привет.нужн парсер фотографий с 1 сайта.Поможет кто ?
как написать свой движок для сайта?
Всем привет. Дорогие форумчане, меня интересует один несрочный вопросец — как написать свой движок.
Свой парсер кривого fb2 (xml)
есть очень много примерно таких файлов <?xml version="1.0" encoding="utf-8"?> <FictionBook.
берете любой парсер html.
получаете данные с сайта, загоняете в парсер
вытаскиваете нужную информацию
Парсер сайта и ссылок с сайта
Добрый день. Подскажите, как реализовать парсер сайта, с которого парсятся все URL и в свою.
Парсер сайта
Хотел написать парсер для страницы http://www.lighting.philips.ru/prof. Использую Jsoup для.
Парсер сайта
Здравствуйте, нужна помощь с парсером. Нужно спарсить https://bittrex.com/home/markets, допустим.
Парсер сайта
Решил попрактиковаться и написать собственный парсер. Собственно сделал половину работы, вот хочу.
Собственно сделал половину работы, вот хочу.
Недавно пробегал на Хабре пост про базу доменных имен с электронной почтой. Решил написать парсер, чтоб благополучно слить всю эту базу. Но так как очень быстро сервис загнулся в силу хабраэффекта (а может админы пофиксили, черт его знает), я пошел дальше и нашел просто базу доменов в plaintext’е в зоне .RU. Решил ее пропарсить с помощью whois на nic.ru. Но на последнем действует скрипт, благополучно притормаживая слив базы с одного ip адреса. Выход — использование proxy листа. И, будучи благополучно задушенным жабой покупать прокси листы, я решил написать на Java два скрипта:
1. Парсит samair.ru/proxy и сливает в mysql прокси лист.
2. Проходит по базе и проверяет timeout полученных проксей.
База данных
Скрин структуры базы из PhpMyAdmin
Итак, сначала парсер.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java. net.HttpURLConnection;
net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.ProtocolException;
import java.net.URL;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class ProxyHunter
/**
* @param args
* @throws ClassNotFoundException
* @throws SQLException
* @throws IOException
*/
public static void main ( String [] args ) throws ClassNotFoundException, SQLException, IOException // TODO Auto-generated method stub
Class.forName ( «com.mysql.jdbc.Driver» ) ;
//подключаем драйвер MySQL
Connection conn = DriverManager.getConnection ( «jdbc:mysql://192.168.1.7:3306/database» , «username» , «password» ) ;
//192.168.1.7 — имя хоста, можно подставить хоть localhost
//database — имя базы данных для экспорта
//username, password — имя пользователя и пароль для MySQL
Statement st = conn. createStatement () ;
createStatement () ;
URL connection = null ;
String [] replacements = new String [ 10 ] ;
String host = null ;
String port = null ;
String anon_level = null ;
String country = null ;
int cursor = 0 ;
HttpURLConnection urlconn = null ;
int n = 1 ;
while ( n <= 50 )
if ( n < 10 )
connection = new URL ( «www.samair.ru/proxy/ip-address-0»; +n+ «.htm» ) ;
>
else
connection = new URL ( «www.samair.ru/proxy/ip-address-«; +n+ «.htm» ) ;
>
System.out.println ( «Starting page: » +Integer.toString ( n )) ;
urlconn = ( HttpURLConnection ) connection.openConnection () ;
urlconn.setRequestMethod ( «GET» ) ;
urlconn.connect () ;
//посылаем GET запрос на список проксей samair’а
java.io.InputStream in = urlconn.getInputStream () ;
BufferedReader reader = new BufferedReader ( new InputStreamReader ( in )) ;
String text = null ;
String line = null ;
while (( line = reader. readLine ()) != null )
readLine ()) != null )
text += line;
>
//парсим текст страницы
replacements = text.substring ( text.indexOf ( «<script src=\»http://samair.ru:81/js/m.js» type=»text/javascript»> ) + «<script src=\»http://samair.ru:81/js/m.js» type=»text/javascript»> .length () , text.indexOf ( «</script></head>» )) .split ( «;» ) ;
//на самаире, возможно, в целях защиты от парсеров порты в списке выводятся javascript’ом
//в начале страницы рандомом задаются 10 переменных для каждой цыфры, затем они скриптом же и выводятся в таблицу
//replacements — как раз массив этих переменных
cursor = text.indexOf ( «<tr><td>» ) ;
while ( cursor != — 1 )
cursor += «<tr><td>» .length () ;
host = text.substring ( cursor, text.indexOf ( «<script type=\»text/javascript\»>» , cursor )) ;
//host — адрес прокси сервера
port = text.substring ( text.indexOf ( «>document.write(\»:\»+» , cursor ) + «>document. write(\»:\»+» .length () , text.indexOf ( «)</script>» , cursor )) ;
write(\»:\»+» .length () , text.indexOf ( «)</script>» , cursor )) ;
port = removeChar ( port, ‘+’ ) ;
for ( int i = 0 ; i< 10 ; i++ )
port = port.replaceAll ( replacements [ i ] .split ( » #000000″>)[ 0 ] , replacements [ i ] .split ( » #000000″>)[ 1 ]) ;
//подставляем вместо букв циферки
>
//port — порт сервера
cursor = text.indexOf ( «</td><td>» , cursor ) + «</td><td>» .length () ;
anon_level = text.substring ( cursor, text.indexOf ( «</td><td>» , cursor )) ;
cursor = text.indexOf ( «</td><td>» , cursor ) + «</td><td>» .length () ;
cursor = text.indexOf ( «</td><td>» , cursor ) + «</td><td>» .length () ;
country = text.substring ( cursor, text.indexOf ( «</td></tr>» , cursor )) ;
//получаем остальную лабуду — тип сервера и страна, не пропадать же траффику зря) хотя они и вряд ли понадобятся
ResultSet rs = st. executeQuery ( «select host, port from proxies where host = ‘» +host+ «‘ and port = ‘» +port+ «‘» ) ;
executeQuery ( «select host, port from proxies where host = ‘» +host+ «‘ and port = ‘» +port+ «‘» ) ;
if ( !rs.next ())
st.executeUpdate ( «INSERT INTO proxies (host, port, anon_level, country) VALUES (‘» +host+ «‘, ‘» +port+ «‘, ‘» +anon_level+ «‘, ‘» +country+ «‘)» ) ;
System.out.println ( «Added: » +host+ «:» +port ) ;
//Если такого хоста и порта в базе еще нету, то вносим его туда
>
cursor = text.indexOf ( «<tr><td>» , cursor ) ;
>
n++;
>
st.close () ;
conn.close () ;
>
public static String removeChar ( String s, char c ) String r = «» ;
for ( int i = 0 ; i < s.length () ; i ++ ) if ( s.charAt ( i ) != c ) r += s.charAt ( i ) ;
>
return r;
>
И непосредственно сам чекер
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java. net.HttpURLConnection;
net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.ProtocolException;
import java.net.URL;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class ProxyHunter
/**
* @param args
* @throws ClassNotFoundException
* @throws SQLException
* @throws IOException
*/
public static void main ( String [] args ) throws ClassNotFoundException, SQLException, IOException // TODO Auto-generated method stub
Class.forName ( «com.mysql.jdbc.Driver» ) ;
//подключаем драйвер MySQL
Connection conn = DriverManager.getConnection ( «jdbc:mysql://192.168.1.7:3306/database» , «username» , «password» ) ;
//192.168.1.7 — имя хоста, можно подставить хоть localhost
//database — имя базы данных для экспорта
//username, password — имя пользователя и пароль для MySQL
Statement st = conn. createStatement () ;
createStatement () ;
URL connection = null ;
String [] replacements = new String [ 10 ] ;
String host = null ;
String port = null ;
String anon_level = null ;
String country = null ;
int cursor = 0 ;
HttpURLConnection urlconn = null ;
int n = 1 ;
while ( n <= 100 )
if ( n < 10 )
connection = new URL ( «www.samair.ru/proxy/ip-address-0»; +n+ «.htm» ) ;
>
else
connection = new URL ( «www.samair.ru/proxy/ip-address-«; +n+ «.htm» ) ;
>
System.out.println ( «Starting page: » +Integer.toString ( n )) ;
urlconn = ( HttpURLConnection ) connection.openConnection () ;
urlconn.setRequestMethod ( «GET» ) ;
urlconn.connect () ;
//посылаем GET запрос на список проксей samair’а
java.io.InputStream in = urlconn.getInputStream () ;
BufferedReader reader = new BufferedReader ( new InputStreamReader ( in )) ;
String text = null ;
String line = null ;
while (( line = reader. readLine ()) != null )
readLine ()) != null )
text += line;
>
//парсим текст страницы
replacements = text.substring ( text.indexOf ( «<script src=\»http://samair.ru:81/js/m.js» type=»text/javascript»> ) + «<script src=\»http://samair.ru:81/js/m.js» type=»text/javascript»> .length () , text.indexOf ( «</script></head>» )) .split ( «;» ) ;
//на самаире, возможно, в целях защиты от парсеров порты в списке выводятся javascript’ом
//в начале страницы рандомом задаются 10 переменных для каждой цыфры, затем они скриптом же и выводятся в таблицу
//replacements — как раз массив этих переменных
cursor = text.indexOf ( «<tr><td>» ) ;
while ( cursor != — 1 )
cursor += «<tr><td>» .length () ;
//host — адрес прокси сервера
//каким-то непонятным китайским рандомом у самаира порт проксей выводится либо javascript’ом
//либо plaintext’ом
//обрабатываем
if ( text.indexOf ( «>document. write(\»:\»+» , cursor ) != — 1 )
write(\»:\»+» , cursor ) != — 1 )
//это для javascript
host = text.substring ( cursor, text.indexOf ( «<script type=\»text/javascript\»>» , cursor )) ;
port = text.substring ( text.indexOf ( «>document.write(\»:\»+» , cursor ) + «>document.write(\»:\»+» .length () , text.indexOf ( «)</script>» , cursor )) ;
port = removeChar ( port, ‘+’ ) ;
for ( int i = 0 ; i< 10 ; i++ )
port = port.replaceAll ( replacements [ i ] .split ( » #000000″>)[ 0 ] , replacements [ i ] .split ( » #000000″>)[ 1 ]) ;
//подставляем вместо букв циферки
>
>
else
//это plaintext
host = text.substring ( cursor, text.indexOf ( «:» , cursor )) ;
port = text.substring ( text.indexOf ( «:» , cursor ) + 1 , text.indexOf ( «</td><td>» , cursor )) ;
>
//port — порт сервера
cursor = text.indexOf ( «</td><td>» , cursor ) + «</td><td>» .length () ;
anon_level = text. substring ( cursor, text.indexOf ( «</td><td>» , cursor )) ;
substring ( cursor, text.indexOf ( «</td><td>» , cursor )) ;
cursor = text.indexOf ( «</td><td>» , cursor ) + «</td><td>» .length () ;
cursor = text.indexOf ( «</td><td>» , cursor ) + «</td><td>» .length () ;
country = text.substring ( cursor, text.indexOf ( «</td></tr>» , cursor )) ;
//получаем остальную лабуду — тип сервера и страна, не пропадать же траффику зря) хотя они и вряд ли понадобятся
ResultSet rs = st.executeQuery ( «select host, port from proxies where host = ‘» +host+ «‘ and port = ‘» +port+ «‘» ) ;
if ( !rs.next ())
st.executeUpdate ( «INSERT INTO proxies (host, port, anon_level, country) VALUES (‘» +host+ «‘, ‘» +port+ «‘, ‘» +anon_level+ «‘, ‘» +country+ «‘)» ) ;
System.out.println ( «Added: » +host+ «:» +port ) ;
//Если такого хоста и порта в базе еще нету, то вносим его туда
>
cursor = text.indexOf ( «<tr><td>» , cursor ) ;
>
n++;
>
st. close () ;
close () ;
conn.close () ;
>
public static String removeChar ( String s, char c ) String r = «» ;
for ( int i = 0 ; i < s.length () ; i ++ ) if ( s.charAt ( i ) != c ) r += s.charAt ( i ) ;
>
return r;
>
Вообще, меня терзают сомнения по поводу правильности реализации массива с потоками. Думается, что в Java есть что-то специальное для таких целей, но я реализовал первое что пришло в голову — массив потоков.
И не ругайте за изобретение велосипеда. Тут цель была just for fun плюс с MySQL’ем поработать. Для красоты вывода этого добра в консоль можно закоментировать все PrintStackTrace()’ы.
Результат
Кусок проверенной базы. -1 в latency означает дохлую проксю.
P.S.
Драйвер MySQL можно скачать здесь: www.mysql.com/products/connector
Выбрать там JDBC Driver for MySQL (Connector/J). Архив распаковать, выдрать оттуда файлик mysql-connector-java-5.1.10-bin. jar и закинуть его в папку с проектом. Потом в Eclipse правой кнопкой по проекту -> Properties -> Java Build Path -> Libraries -> Add JARs и подцепить его там.
jar и закинуть его в папку с проектом. Потом в Eclipse правой кнопкой по проекту -> Properties -> Java Build Path -> Libraries -> Add JARs и подцепить его там.
Вот то, что должно получится.
В вопросе какая-то каша. Разве в Visual Studio есть поддержка Java?
> простые проги которые я писал на html
Какая связь между Java и HTML?
Сначала надо изучить язык программирования хотя бы на хорошем базовом уровне, только потом можно приступать к созданию полезной программы, даже если она несложная. Судя по тому, что ты не заешь как написать и запустить простейшую программу, тебе рано думать про парсер сайтов.
Скачай книгу по Java и читай. Там найдёшь ответы на все свои вопросы. Дед Мазай 2
Другие интересные вопросы и ответы
Возможно ли изучить программирование за лето?
Источник: habrastorage.org
Смотря что ты хочешь изучить и что имеешь ввиду под программированием.
Если html+css — да, вполне возможно. Но это верстка а не программирование. SQL — так же возможно, но и работу с БД я так же не могу назвать настоящим программированием.
SQL — так же возможно, но и работу с БД я так же не могу назвать настоящим программированием.
Если же брать серьезное программирование — однозначное нет. Минимум год самообучения по 8-12 часов в день. Минимум — если у тебя уже есть некая база и неплохо поставленная логика. Значительно больше если нет.
У меня была очень сильная база (я несколько лет работал в IT конторе мирового масштаба(входит в первую десятку по размеру) международной тех.поддержкой высшего уровня[там было 5 таких] а так же QA[тестировщиком], а так же некую базу программирования уже имел), но у меня пошло пол года по 8-12 часов в день что бы достичь некоего более-менее неплохого уровня на C#. По факту недостаточного что бы работать полноценным программистом. Но все же достаточного для автоматизации.
Реальное программирование — это не просто синтаксис языка. Программирование — это умение решать задачи. Как математические так и логические. Логические — в первую очередь! А так же знание ряда алгоритмов. А так же знание инструментов которыми пользуешься(например нужно понимать как внутри устроен List/LinkedList и Array для того,что бы их правильно оптимально использовать, просто знать что длинна аррея не меняется — НЕ ДОСТАТОЧНО). Синтаксиса языка НЕ ДОСТАТОЧНО кто бы тебе не говорил обратного.
Синтаксиса языка НЕ ДОСТАТОЧНО кто бы тебе не говорил обратного.
Что бы не быть баснословным, я наведу простой пример использования алгоритмов:
Алгоритм среднего между 2мя целыми числами нормального человека:
(a+b)/2
алгоритм среднего из 2х целых чисел программиста(умного, а не в кавычках):
a/2+b/2+(a%2+b%2)/2
где % — вычисление остачи от деления.
потому как первый алгоритм даст ровно в половине из возможных случаев неправильный ответет из-за переполнения памяти + еще в четверти случаях просто на одиницу меньше нужного. Заметьте! Не ошибку! А неправильный ответ в трех случаях из 4х! А «программист»(именно в кавычках) еще и не будет в курсе почему так
Для нецелочисленного типа данных(double, float) проще:
a/2+b/2
Как видишь, проблема не в синтаксисе как таковом Выучить синтаксис — как раз наименьшая из проблем. Хотя, замечу, что, даже, это для многих будет непосильной задачей.
С другой стороны — я за то что бы не грузить человека «паттернами» и излишними алгоритмами.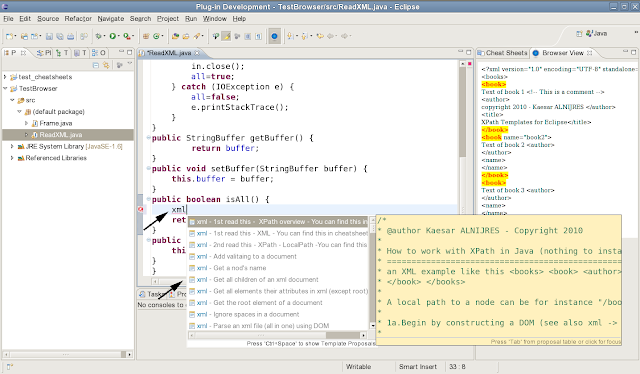 На новичков это подействует, скорее всего, негативно, чем позитивно. Типа…. «я слышал про паттерн ____________, вот задача на которую КАЖЕТСЯ подойдет он.» А потом решение задачи усложняется в разы. Ну или затягивается. Паттерны нужно не только знать, но и применять с умом. К алгоритмам так же нужны знания как и когда их лучше применять. Поэтому — БЕЗ ФАНАТИЗМА.
На новичков это подействует, скорее всего, негативно, чем позитивно. Типа…. «я слышал про паттерн ____________, вот задача на которую КАЖЕТСЯ подойдет он.» А потом решение задачи усложняется в разы. Ну или затягивается. Паттерны нужно не только знать, но и применять с умом. К алгоритмам так же нужны знания как и когда их лучше применять. Поэтому — БЕЗ ФАНАТИЗМА.
PS: человек снизу, который меня активно критикует(Jone Done), даже путает среду разработки и язык… Delphi — это не язык, а IDE, а язык там это Object Pascal.
Так же там в коментариях у нее я проверил ее «нормальные знания джавы»… Желающие посмотреть на «номально выучившую язык за 2,5 месяца» смотреть туда. И это при том что Я ДЖАВУ НЕ ЗНАЮ, а, так, посмотрел инфу не более чем 3 дня где-то пол года назад просто для общего развития и что бы лично сложить свое собственное мнение по языку.
Валерій Пістольний 49
Как написать программу на языке JAVA?
Можно ли написать сайт полностью на java скрипте?
Можно, но этим «сайтом» почти никто пользоваться не будет. Из соображений безопасности у большинства браузеров Java по-умолчанию отключена. А я сомневаюсь, что у вас будет настолько нужный пользователю сайт, чтобы искать настройки, которые включат использование Java.
Из соображений безопасности у большинства браузеров Java по-умолчанию отключена. А я сомневаюсь, что у вас будет настолько нужный пользователю сайт, чтобы искать настройки, которые включат использование Java.
Если вы имеете ввиду javascript, то тут конечно тоже можно написать но это выглядит как попытка забивать гвозди микроскопом. Да, и хоть один html будет нужен — для запуска javascript.
Напишите условие на языке Java, которое соответствует утверждению
Определи понятие «заключена между». Парабола и прямая делят плоскость на 5 областей. Любая точка, не лежащая на них, заключена между, логично?
Как начать изучать программирование с нуля на языке Java?
Если у Вас не очень технический бекграунд, то стоит начать с курса на платформе Javarush. Многие ее критикуют, но в их курсе реально очень доступно обьясняют базовые конструкции языка.
Если у Вас уже программировали на других языках, то есть бесплатный и хороший курс —
«Java. Базовый курс». Курс отхватывает все базовые возможности языка.
Курс отхватывает все базовые возможности языка.
Как написать парсер на java
Осваиваем SAX парсер: Quick start
Работая с JAXB и XPath API я столкнулся с необходимостью манипуляции namespace-ами XML-документов. Проблема решена и описана в посте Чтение XML-документа с помощью JAXB с заменой namespace. Решение этой проблемы было найдено в интернете. Ещё, небольшие поиски по интернету показали, что в большинстве случаев, когда речь идёт о SAX API, везде приводят один и тот же пример замены namespace-ов. Я решил разобраться с ситуацией и отправился на официальный сайт http://www.saxproject.org/. На официальном сайте я перечитал документацию и нашёл, почему везде выложен один и тот же пример. Этот же пример присутствует и в официальной документации…
Тем не менее, SAX API весьма важен и лежит в основе многих других технологий, поэтому я решил изучить SAX API немного подробнее. Ниже перевод материалов с официального сайта. Я нашёл их весьма интересными и заслуживающими более подробного изучения.
Оглавление
Требования
SAX — общий интерфейс реализованный для многими XML парсерами (и штуками, позиционирующими себя как XML парсеры), он практически является на столько же общим API для работы с XML, насколько JDBC является общим интерфейсом, реализованным для различных реляционных баз данных (и штруковинами, позиционирующими себя как реляционные базы данных). Если вы хотите использовать SAX, вам потребуются всё перечисленное ниже:
- Java 1.1 или современнее.
- SAX2-совместимый XML парсер, указанный в вашем Java classpath. Если вам нужен подобный парсер, смотрите ссылки.
- SAX2 дистрибутив, указанный в вашем Java classpath. (Наиболее вероятно, вы получите его вместе с вашим парсером).
- Большинство Java/XML дистрибутивов включают SAX2 парсер. Большинство Web application серверов используют его для работы с XML. Все дистрибутивы с поддержкой JAXP 1.1 включают поддержку SAX2.
Парсинг XML документа
Начните созданием класса, который наследует (extends) DefaultHandler:
Так как это Java — приложение, мы создадим статический метод main, который использует метод createXMLReader класса XMLReaderFactory для выбора SAX драйвера динамически (программно).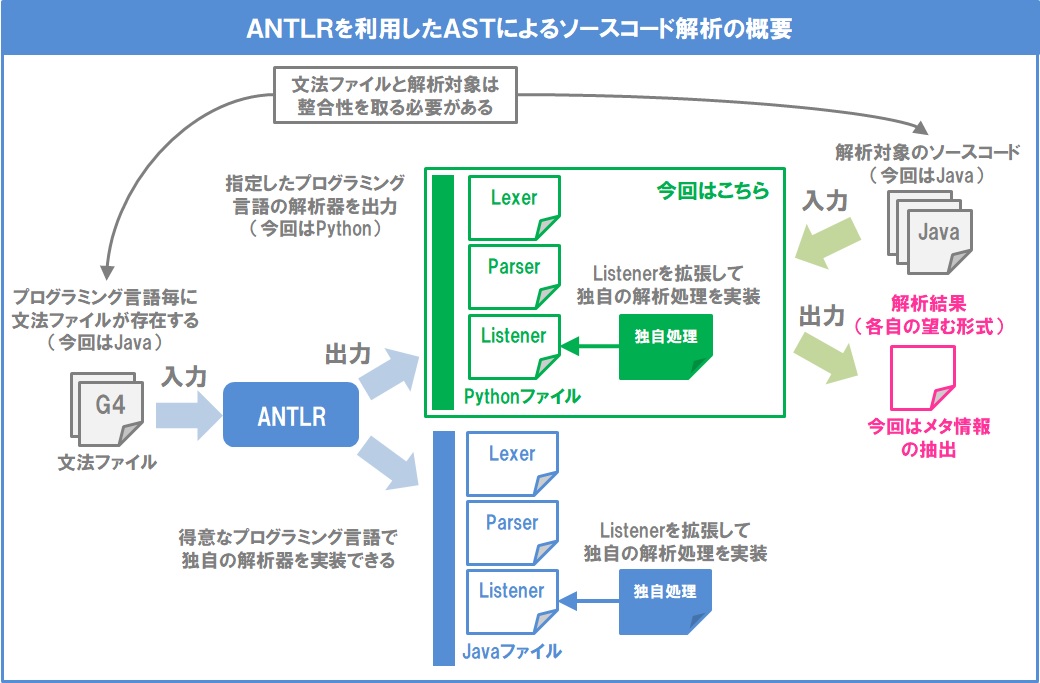 Обработка исключений удалена из примера для облегчения понимания. Реальное приложение должно обрабатывать исключения:
Обработка исключений удалена из примера для облегчения понимания. Реальное приложение должно обрабатывать исключения:
В случае, если ваша Java среда разработки автоматически не добавляет compiled-in default (или не настраивает META-INF/services/org.xl.sax.driver system resource), вам вероятно потребуется установить в Java system property оrg.xml.sax.driver значение, указывающее полный путь к SAX driver, как в примере:
Множество разных SAX2 драйверов распространены на сегодняшний день Поэтому в качестве имени класса вы можете использовать, например:
| Class Name | Notes |
|---|---|
| gnu.xml.aelfred2.SAXDriver | Lightweight non-validating parser; Free Software |
| gnu.xml.aelfred2.XmlReader | Optionally validates; Free Software |
| oracle.xml.parser.v2.SAXParser | Optionally validates; proprietary |
| org.apache.crimson.parser.XMLReaderImpl | Optionally validates; used in JDK 1. 4; Open Source 4; Open Source |
| org.apache.xerces.parsers.SAXParser | Optionally validates; Open Source |
Иначе, если вас не беспокоит привязка вашего приложения к определённому SAX драйверу, вы можете использовать его конструктор напрямую. Мы предполагаем, что SAX driver для вашего XML парсера называется com.example.xml.SAXDriver, однако, в реальности такого класса не существует. Вы должны знать имя настоящего драйвера для вашего парсера, чтобы использовать такой подход.
Созданный объект может быть использован для парсинга XML-документов, но сначала, нужно зарегистрировать обработчики событий, которые парсер может использовать для передачи информации. Это делается с помощью методов setContentHandler и setErrorHandler интерфейса XMLReader. В настоящем приложении, эти обработчики будут обычно разными объектами, но для приведённого простого примера, мы помещаем эти обработчики в Top-level class. Таким образом нам нужно создать наш класс и зарегистрировать его в XMLReader:
Приведённый пример создаёт экземпляр MySAXApp для получения XML parsing events и регистрирует его в XML reader для получения regular content событий и error событий (есть другие виды событий, но они редко используются). Теперь давайте предположим, что все аргументы командной строки — имена файлов и мы будем пытаться парсить их по-одному используя метод parse из интерфейса XMLReader:
Теперь давайте предположим, что все аргументы командной строки — имена файлов и мы будем пытаться парсить их по-одному используя метод parse из интерфейса XMLReader:
Заметьте, что каждый reader должен быть представлен InputSource объектом, чтобы быть «распарсенным». Ниже полный пример описанного demo класса:
Вы можете откомпилировать этот код и запустить его (Не забудьте указать SAX driver класс в свойстве org.xml.sax.driver), однако ничего особенного не возникнет, если только ваш документ не содержит «плохой» XML, поскольку вы пока не установили обработчиков SAX событий для вашего приложения.
Обработка событий
Всё становится интересней когда вы начинаете реализовывать методы для реакции на XML parsing events ( помните мы зарегистрировали наш класс для получения XML parsing events в предыдущем разделе). Наиболее важные события — начало и завершение документа (start and end of the document), начало и завершение элемента (start and end of elements) и символьных данных.
Чтобы узнать про начало и завершение документа, клиентское приложение реализует методы startDocument и endDocument.
Обработчики событий start/endDocument не имеют аргументов. Когда SAX driver находит начало документа, он вызовет функцию startDocument один раз, когда найдёт завершение документа — вызовет endDocuemnt (даже если были обнаружены ошибки).
Приведённые примеры печатаю сообщения в стандартный output, но ваше приложение может содержать любой код для этих обработчиков, наиболее часто, этот код будет создавать какой то тип дерева в памяти, делать вывод, производить сохранение в базу данных или извлекать информацию из XML stream.
SAX driver будет сообщать о стартовых и конечных элементах практически также за исключением того, что он будет передавать несколько параметров в методы startElement и endElement.
Приведенные методы будут печатать в начале и конце каждого элемента. Перед именем элемента (local name) будет печататься namespace URI в фигурных скобках. Параметр qName содержит имя без namespace в формате XML 1.0, которое вы должны использовать для всех элементов не имеющих namespace URI. В этом Quick Introduction, мы не будем рассматривать как обрабатываются атрибуты. Атрибуты могут быть получены по имени или итерацией по ним как будто они хранятся в массиве.
Параметр qName содержит имя без namespace в формате XML 1.0, которое вы должны использовать для всех элементов не имеющих namespace URI. В этом Quick Introduction, мы не будем рассматривать как обрабатываются атрибуты. Атрибуты могут быть получены по имени или итерацией по ним как будто они хранятся в массиве.
Наконец, SAX2 передает (reports) обычные символьные данные через метод characters. Следующий пример напечатает все символьные данные на экран. Output будет возможно слегка длиннее потому что он производит escaping специальных символов (pretty-prints the output by escaping special characters):
Заметьте, что SAX driver может разбивать символьные данные как угодно, так что вы не можете рассчитывать на то, что все символьные данные придут в одном событии (single characters event).
Пример SAX2 приложения
Ниже пример готового приложения (конечно в настоящем приложении обработчики событий будут скорее всего реализованы в отдельном классе, а не в классе приложения).
Sample Output
Предположим обрабатывается следующий XML документ:
Если этот документ назван roses.xml и у вас есть SAX2 driver в classpath с именем com.example.xml.SAXDriver (приведённый в примере на деле не существует), в можете вызвать пример приложения примерно так:
При запуске, вы получить output подобный этому:
Заметьте, что даже этот короткий документ генерирует (по крайней мере) 25 событий: один на старт и завершение каждого из шести элементов (тегов), один на каждый из одиннадцати фрагментов символьных данных и один на старт и завершение документа.
Если у входного документа нет namespace нет атрибута xmlns=»http://www.megginson.com/ns/exp/poetry» указывающего, что элементы находятся в указанном namespace, outoput будет выглядеть подобно этому:
Наиболее вероятно, вам придется работать с обеими типами документов: c документами использующими XML namespace-ы и не использующими их. Документы могут быть также с разными элементами (часть элементов и атрибутов с namespace, часть нет). В любом случае убедитесь, что ваш код проверяет namespace URI элементов, а не просто рассчитывает на то, что он всегда есть или его всегда нет.
В любом случае убедитесь, что ваш код проверяет namespace URI элементов, а не просто рассчитывает на то, что он всегда есть или его всегда нет.
Разработка ПО и многое другое
Сегодняшней темой будет парсинг XML. Существуют две стратегии обработки XML документов: SAX и DOM.
SAX парсеры предлагают потоковую обработку данных основанную на событиях.
DOM парсеры преобразуют XML в дерево объектов, с которыми можно будет работать.
Рассмотрим пример простейшего SAX парсера.
Пусть у нас есть XML документ:
Код обработки документа может выглядеть следующим образом:
Поясняю код. Мы описываем класс MyParser , который будет обрабатывать события чтения данных. Выделено 5 событий:
- старт документ
- открытие тега
- данные внутри тега
- закрытие тега
- заканчиваем обработку документа
Такая методика позволяет обрабатывать достаточно большие XML(возможно размером несколько мегабайт/гигабайт). Это главное достоинство SAX парсеров.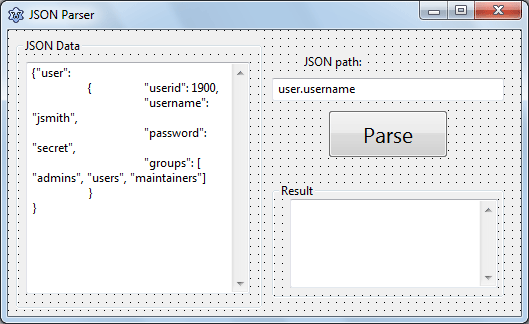 Скорость и возможность обрабатывать большие объемы данных.
Скорость и возможность обрабатывать большие объемы данных.
Главный недостаток — сложный код в случае сложной структуре XML файла. То есть если XML простой и линейный, то его легко анализировать SAX-парсером. Для XML со сложной структурой придется по возиться с алгоритмизацией.
Вернемся к примеру.
1-ое событие — начали обрабатывать документ. Наступает лишь раз в момент, когда мы начали анализировать файл. На этом этапе можно производить первичную инициализацию данных
2-ое событие — открылся тег. На этом этапе мы знаем имя тега и его атрибуты. Мы не знаем ни как глубоко вложен элемент, ни сколько там ещё внутри. Если это надо, то нужно обрабатывать алгоритмически
3-е событие — данные. Реальные данные между открытым и закрытым тегами. Нам дают массив символов, делайте с ним что хотите
4-ое событие — закрываем тег. Теперь мы знаем, тег закрыт, можем что-нибудь обработать алгоритмически
5-ое событие — документ обработан. Освобождаем лишние ресурсы, делаем пост обработку, если она нужна. Короче радуемся жизни, т.к. мы такие молодцы — обработали документ.
Короче радуемся жизни, т.к. мы такие молодцы — обработали документ.
В итоге программа выведет :
Надеюсь пример кому-нибудь помог.
Спасибо за внимание.
UPD: Сделал репозиторий на github, где буду выкладывать примеры для статей.
Советы по написанию парсера файлов на Java? [закрытый]
интерпретация блоков CSV является основным вопросом здесь.
Я знаю, как прочитать файл во что-то вроде String[] и некоторые из основных особенностей String , но я не думаю, что используя такие методы, как contains() и анализируя все символ за символом будет работать.
каким образом я могу сделать это в разумный способ?
-barfoob: boobs, foob, «foo bar»
12 ответов
есть причина, по которой все предполагают, что вы говорите о XML: изобретение проприетарного текстового формата файла требует очень сильная обоснование в лице зрелостью и доступностью XML-парсеров.
и ваш вопрос указывает на то, что у вас очень мало предварительных знаний о парсерах (в противном случае вы бы написали ANTLR или JavaCC грамматика вместо того, чтобы задавать этот вопрос) — что является еще одним веским аргументом против сворачивания собственного, кроме как в качестве учебного опыта.
Так как вход » отформатирован аналогично HTML«, то, вероятно, ваши данные лучше всего представлены с использованием древовидной структуры, а также, вероятно, что это XML или аналогично XML.
Если это так, я предлагаю самый умный способ проанализировать ваш файл-использовать синтаксический анализатор XML.
вот некоторые ресурсы, которые вы можете найти полезными:
- глава о синтаксическом анализе XML от Sun: http://java.sun.com/developer/Books/xmljava/ch03.pdf
- статья, которая может помочь вам начать работу qucikly:http://onjava.com/pub/a/onjava/2002/06/26/xml.html
Если документ является допустимым XML, то любой из других ответов будет работать. Если это не так, вы будете должны lex.
вы должны посмотреть ANTLR, даже если вы хотите написать парсер самостоятельно, ANTLR является отличной альтернативой. Или хотя бы посмотрите на YAML
этой и копаться в Википедии похожие статьи будет вполне достаточно.
в зависимости от того, насколько сложна ваша «схема», регулярное выражение может быть то, что вы хотите. Если вложенности много, то проще всего преобразовать в XML или JSON и использовать встроенный синтаксический анализатор.
Если вложенности много, то проще всего преобразовать в XML или JSON и использовать встроенный синтаксический анализатор.
люди правы в том, что стандартные форматы являются лучшей практикой, но давайте отложим это в сторону.
предполагая, что приведенный вами пример является репрезентативным, задача довольно тривиальна.
вы показываете строку с начальным маркером, отмеченную двоеточием, а затем список значений, разделенных запятыми. Разделите сначала двоеточие-пробел, а затем используйте split() на части справа. Обработка котировок также тривиальна.
после просмотра вашего образца ввода, я не вижу никакого сходства с HTML или XML:
-barfoob: boobs, foob, «foo bar»
если это то, что вы хотите разобрать, у меня есть альтернативное предложение, использовать синтаксический анализатор свойств Java (поставляется со стандартной Java), а затем разобрать оставшуюся часть каждой строки, используя свой собственный код. Вам нужно будет несколько изменить свой формат, чтобы это работало, так что это зависит от вас.
barfoob=boobs, foob, «foo bar»
свойства Java будут возможность вернуть вас barfoob как имя свойства и boobs, foob, «foo bar» как значение свойства. Вот где вы можете использовать свой пользовательский код, чтобы разделить значение свойства на boobs , foob и foo bar .
Я настоятельно рекомендую не изобретать колесо и использовать существующее решение, такое как подчеркивание, Fixedformat4j или jFFP это может все анализировать позиционные или разделенные запятыми файлы значений (лично я рекомендую Flatworm).
вы можете использовать Neko HTML parser в какой-то степени. Это зависит от того, как он обрабатывает нестандартный HTML.
Как создать клиентские парсеры на Java | Программа инженерного образования (EngEd)
Парсеры являются неотъемлемой частью любого языка программирования. Язык программирования Java предлагает множество парсеров с открытым исходным кодом, которые разработчики могут выбирать в зависимости от своих требований.
Однако найти тот, который полностью удовлетворит их потребности, непросто.
Большинство существующих синтаксических анализаторов, как правило, не удовлетворяют потребности разработчиков и имеют множество проблем с производительностью. Это заставляет разработчиков создавать собственные парсеры.
В этой статье обсуждаются многочисленные инструменты и библиотеки, используемые при создании пользовательских анализаторов на Java.
Содержание
- Введение
- Предпосылки
- Концепция синтаксического анализатора и синтаксического анализа
- Правила и грамматики
- Парсинг в Java
- Популярные инструменты и библиотеки для создания парсеров на Java
- Плюсы и минусы инструментов и библиотек для синтаксического анализа
- Заключение
- Дальнейшее чтение
Предварительные требования
Чтобы следовать этой статье, учащийся должен иметь:
- Базовое понимание того, как работают синтаксические анализаторы.
- Хорошее знание разработки приложений на языке программирования Java.

- Хорошее понимание обычных языков и контекстно-свободных грамматик.
- Обзор дизайна компилятора.
Концепция синтаксического анализатора и синтаксического анализа
Синтаксический анализ включает в себя разбиение и анализ блока кода на более мелкие компоненты кода с использованием некоторых правил.
Затем эти компоненты интерпретируются, модифицируются или управляются в соответствии с потребностями разработчиков для получения более глубокого значения или понимания.
Программа, выполняющая фактический синтаксический анализ, называется синтаксическим анализатором.
Парсер состоит из двух частей; сканер (токенизатор/лексер) и парсер.
Лексер и синтаксический анализатор выполняют задачи упорядоченно. Это означает, что лексер сначала прочитает входные данные и сгенерирует список токенов. Затем синтаксический анализатор считывает сгенерированные токены и выводит результаты.
Lexer распознает простые символы или слова в заданном алфавите. Механизмы регулярных выражений также могут легко реализовывать лексеры.
С другой стороны, синтаксический анализатор распознает структуру языка, что усложняет распознавание регулярных выражений.
Правила и грамматики
Правила относятся к инструкциям, которым следуют лексеры или синтаксические анализаторы при анализе. Набор этих правил образует грамматику.
Таким образом, грамматика состоит из набора правил, определяющих, как составлена каждая строка кода или конструкция.
Например, чтобы установить правило для инструкции IF , разработчик должен указать, должна ли инструкция начинаться с ключевого слова IF , а затем должна следовать левая скобка ( ( ).
Затем выражение должно быть вставлено и заключено в правую круглую скобку () ).
Что-то вроде Оператор IF (выражение) .
Если код или текст не соответствуют правилу, синтаксический анализатор зафиксирует и отобразит синтаксическую ошибку.
Анализ в Java
Существует три способа анализа в Java:
- Использование существующей библиотеки.
- Использование инструмента или библиотеки для создания синтаксического анализатора.
- Путем создания пользовательского синтаксического анализатора с нуля.
Использование существующих библиотек для синтаксического анализа
Этот метод наиболее известен для синтаксического анализа популярных и поддерживаемых языков, таких как XML или HTML.
Хорошая библиотека должна поддерживать API, которые могут создавать и изменять документы на заданном языке.
В большинстве случаев это дополнительная функция, которую нельзя найти во многих существующих парсерах.
Недостатком существующих библиотек является то, что они не очень распространены, и большинство из них поддерживают только определенные языки.
Создание пользовательского синтаксического анализатора Java
Если у разработчиков есть набор уникальных требований, лучшим вариантом является создание пользовательского синтаксического анализатора.
Это связано с тем, что язык, который они пытаются разобрать, не может быть проанализирован с помощью существующих синтаксических анализаторов. Кроме того, в инструментах генерации парсеров отсутствуют некоторые функции.
Разработчики также могут использовать этот метод, если хотят добиться наилучшей производительности или интегрировать различные компоненты. Недостатком этого метода является то, что он очень сложен и требует много времени.
Кроме того, разработчик должен знать, как написать парсер на Java. В качестве альтернативы можно сотрудничать с другими профессионалами, что может быть дорого.
Использование существующих инструментов и библиотек для создания синтаксического анализатора
Это один из лучших методов создания синтаксических анализаторов в Java. Это считается гибким и менее трудоемким способом создания парсера на Java.
В следующем разделе мы увидим, как мы можем использовать существующие инструменты и библиотеки для создания синтаксического анализатора.
Популярные инструменты и библиотеки для создания синтаксических анализаторов в Java
Генераторы синтаксических анализаторов — это инструменты, предназначенные для кодирования синтаксических анализаторов. С другой стороны, комбинаторы синтаксических анализаторов — это библиотеки, используемые для создания синтаксических анализаторов.
При построении парсера на Java для анализа обычных языков используется инструмент лексера.
Ниже приведены различные инструменты, используемые при написании парсера Java:
JFlex
Это генератор лексеров, использующий детерминированные конечные автоматы (DFA).
Он сопоставляет ввод в соответствии с определенной грамматикой, называемой «спецификации», и выполняет определенное действие.
JFlex можно использовать как отдельный инструмент или в сочетании с другими генераторами парсеров, такими как CUP или ANTLR .
Грамматика или «спецификация» обычно отделяются символом %% и содержат следующие части:
- Пользовательский код обычно включается в сгенерированный класс.
- Макросы/опции.
- Правила лексера.
ANTLR
Это популярный генератор контекстно-свободных синтаксических анализаторов на Java. ANTLR также может генерировать парсеры для других языков.
Грамматика ANTLR состоит из двух частей — лексера и правил парсера.
Два правила определены неявно. Обратите внимание, что правила лексера начинаются с прописной буквы, а правила парсера — со строчной.
Правила лексера и парсера также могут быть определены явно.
APG
Это синтаксический анализатор рекурсивного спуска, который использует вариант расширенного BNF.
APG состоит из большего количества операторов, таких как синтаксические предикаты и специальные функции сопоставления.
Грамматика APG проста, ясна и легка для понимания. Он широко известен написанием парсеров Java, JavaScript, C и C++.
Coco/R
Он использует грамматику атрибутов для создания сканера и синтаксического анализатора, который является рекурсивно-приемлемым.
В грамматике атрибутов семантические правила определяются в варианте EBNF, а затем интерпретируются для изменения методов результирующего синтаксического анализатора.
Он хорошо документирован и содержит несколько примеров грамматики. Он хорошо известен тем, что пишет синтаксические анализаторы для языков Java, C++ и C#.
CUP
Это форма LALR, широко используемая для создания парсеров в Java.
CUP может хорошо работать с JFlex для создания правильных частей синтаксического анализатора. Он также предлагает плагин Eclipse для написания грамматики.
JavaCC
Этот инструмент имеет все действия и пользовательский код, необходимые для написания парсеров на Java.
Файл грамматики JavaCC не такой чистый, как ANTLR.
Тем не менее, он хорошо документирован и широко используется в различных проектах, таких как JavaParser. В нем не так много грамматики, хотя он поставляется с хранилищем грамматики.
JavaParser
JavaParser предлагает лексическое сохранение и красивую печать. Это означает, что код Java можно анализировать, изменять и печатать в исходном формате или красиво печатать.
Возможна интеграция с JavaSymbolSolver. Он также поддерживает все версии Java.
Плюсы и минусы инструментов и библиотек для синтаксического анализа
Большинство инструментов и библиотек для синтаксического анализа начинались как исследовательские работы и диссертации. Преимущество этих инструментов и библиотек в том, что они находятся в свободном доступе.
Однако для большинства этих инструментов отсутствует надлежащая документация и руководства пользователя. Это потому, что они не были разработаны для использования большим сообществом. Более того, большинство этих библиотек активно не поддерживаются их разработчиками.
Вывод
Разработка синтаксического анализатора на Java является более сложной деятельностью по сравнению с разработкой приложений на Java. Разработчики сталкиваются с многочисленными проблемами при создании парсеров для Java.
Из-за этой проблемы следует использовать такие инструменты, как JavaParser и JavaCC, чтобы упростить процесс разработки.
Люди должны исследовать инструменты, которые они намереваются использовать, и тщательно проверять свою документацию перед началом разработки.
Дополнительная литература
- Руководство по алгоритмам синтаксического анализа
- Общие сведения о JFlex
- Java с ANTLR
- Узнать ПНГ
- Генератор компиляторов COCO/R
- Обзор CUP
- Введение в JavaCC
- Разбор с помощью JavaParser
Экспертная оценка Вклад: Шришилеш П.С.
Инструменты, которые следует использовать для написания синтаксических анализаторов на Java.
Содержание
Обзор
Парсеры являются неотъемлемой частью любого языка программирования. Хотя в Java существует множество парсеров с открытым исходным кодом, которые легко доступны, и разработчики могут выбрать правильный в соответствии с требованиями, иногда тот, который вам нужен, недоступен. В этом случае разработчикам часто приходится создавать собственные парсеры на Java. Помимо недоступности, еще одной основной причиной разработки пользовательских синтаксических анализаторов являются проблемы с производительностью в доступных синтаксических анализаторах, их недостатки или их неспособность выполнить все требования.
Далее в этой статье мы раскроем различные способы самостоятельной генерации парсеров на Java с помощью доступных инструментов и библиотек Java.
Начало работы
Прежде чем углубляться в детали, давайте сначала разберемся, что означают термины «анализ» и «парсер».
Синтаксический анализ и синтаксический анализ
Обычно синтаксический анализ можно определить как процесс разбиения блока данных на более мелкие части на основе определенных заранее определенных правил. Затем эти части интерпретируются, модифицируются или управляются в соответствии с требованиями разработчиков.
Парсер — это программа, написанная для разбиения данных на более мелкие части. Парсер обычно состоит из двух частей: лексера, также называемого сканером или токенизатором, и самого парсера. Лексер и синтаксический анализатор работают последовательно, лексер сканирует входные данные и создает список токенов, затем синтаксический анализатор сканирует токены и выдает результат синтаксического анализа.
Правила и грамматики
Определения, используемые лексерами или синтаксическими анализаторами, называются правилами или продукциями. И все эти правила составляют грамматику. Проще говоря, грамматика — это список правил, определяющих, как должна быть составлена каждая конструкция или строка кода. Например, правило для оператора if должно указывать, что оно должно начинаться с ключевого слова «IF», за которым следует левая скобка, выражение, правая скобка и оператор.
Если код или текст не соответствуют правилу, синтаксический анализатор идентифицирует их как неправильные, что приводит к синтаксической ошибке.
Способы разбора в Java
Если вам нужно разобрать документ на Java, есть три основных способа сделать это.
- Как упоминалось ранее, используйте существующую библиотеку, которая поддерживает тот конкретный язык, который вы хотите анализировать: например, библиотеку для анализа XML.
- Если вы не можете найти существующий синтаксический анализатор, используйте инструмент или библиотеку для разработки синтаксического анализатора: например, ANTLR, который используется для создания синтаксических анализаторов для Java или любого другого языка.
- И, наконец, написание собственного синтаксического анализатора с нуля в соответствии с вашими требованиями.
Использование существующей библиотеки для анализа
Это хороший вариант для анализа известных и поддерживаемых языков, таких как XML или HTML. Хорошая библиотека обычно также включает в себя API для создания и изменения документов на этом языке. Это дополнительная функция, которой нет в базовом парсере. Ограничение в том, что такие библиотеки не очень распространены и поддерживают только самые распространенные языки.
Создание собственного анализатора Java
Вам может понадобиться этот вариант, если у вас есть особые потребности. В том смысле, что язык, который вам нужно разобрать, не может быть разобран с помощью доступных парсеров, и вы не можете получить необходимые функции в инструментах генерации парсеров. Для этого может быть несколько причин, например, вам нужна максимально возможная производительность или глубокая интеграция между различными компонентами, но это, безусловно, самый сложный и трудоемкий вариант из трех.
Вам также понадобятся исключительные навыки для написания синтаксического анализатора на Java или разработчик, который мог бы написать это для вас.
Использование существующих инструментов для написания синтаксического анализатора
Из всех трех случаев этот вариант используется чаще всего и считается лучшим способом создания синтаксических анализаторов на Java. Поскольку это наиболее гибкий и наименее затратный по времени вариант разработки парсера Java, мы в основном сосредоточимся на инструментах и библиотеках.
Библиотеки и инструменты для создания парсеров на Java
Во-первых, инструменты, которые используются для написания кода для синтаксического анализатора, известны как генераторы синтаксических анализаторов, а библиотеки, создающие синтаксические анализаторы, называются комбинаторами синтаксических анализаторов. Наряду с этим необходим еще один инструмент — лексический анализатор (лексеры), анализирующий обычные языки при написании парсеров на Java.
Ниже приведен список различных типов инструментов, необходимых для написания синтаксического анализатора Java:
· JFlex
JFlex — это генератор лексеров, основанный на детерминированных конечных автоматах (DFA). Он сопоставляет ввод в соответствии с определенной грамматикой, известной как спецификация, и выполняет соответствующее действие. Его также можно использовать как самостоятельный инструмент, но, будучи генератором лексеров, он предназначен для работы с генераторами парсеров: обычно он используется с CUP или ANTLR (мы обсудим их позже)
Спецификация (грамматика) разделена на три части, разделенные символом «%%»:
- код пользователя, который будет включен в сгенерированный класс,
- опции/макросы,
- , наконец, правила лексера.
· ANTLR
ANTLR — один из наиболее часто используемых генераторов контекстно-свободных синтаксических анализаторов в Java. Наряду с Java, ANTLR можно использовать для написания парсеров на многих других языках.
Его типичная грамматика делится на две части: правила лексера и правила парсера. Разделение является неявным, поскольку все правила, начинающиеся с прописной буквы, являются правилами лексера, тогда как правила, начинающиеся со строчной буквы, являются правилами синтаксического анализатора. Грамматики лексера и парсера также могут быть определены в отдельных файлах.
· APG
APG — еще один инструмент для создания синтаксических анализаторов на Java, но, в отличие от других примеров, это синтаксический анализатор с рекурсивным спуском, использующий вариант Augmented BNF. APG также поддерживает дополнительные операторы, такие как пользовательские функции сопоставления и синтаксические предикаты. Грамматика APG также очень проста и понятна. Он может генерировать парсеры на Java, C/C++ и JavaScript.
· Coco/R
Coco/R — это генератор компилятора, который создает сканер и анализатор рекурсивного спуска после получения атрибутивной грамматики. Атрибутная грамматика — это та, в которой правила написаны в варианте EBNF и могут быть аннотированы несколькими способами для изменения методов сгенерированного синтаксического анализатора.
Coco/R имеет прекрасную документацию с многочисленными примерами грамматики для лучшего понимания. Наряду с Java он также поддерживает C# и C++.
· CUP
CUP расшифровывается как Construction of Useful Parsers. Это генератор парсеров LALR (look-Ahead LR) для Java. Он просто генерирует правильные части парсера и хорошо подходит для использования с JFlex. Он также поставляется с плагином Eclipse, который помогает разработчикам в создании грамматики.
· JavaCC
JavaCC является наиболее широко используемым генератором парсеров для Java. Грамматика, которая поставляется с ним, содержит все действия и пользовательский код, необходимые для создания синтаксических анализаторов на Java. По сравнению с ANTLR файл грамматики не такой чистый и включает значительную часть исходного кода Java.
Благодаря частому использованию в очень важных проектах, таких как JavaParser, в его документации появилось хорошее содержание. Он предлагает репозиторий грамматик, но содержит не так много грамматик.
· Библиотеки Java для анализа Java: JavaParser
В одном особом случае, когда вы хотите проанализировать код Java на языке Java, лучше всего подойдет библиотека с именем JavaParser. Он поддерживает лексическое сохранение, а также красивую печать, что означает, что вы можете анализировать код Java, изменять его и печатать обратно либо с исходным форматированием, либо с красивой печатью. Его также можно использовать с JavaSymbolSolver. Он поддерживает все версии Java от 1 до 9.так что вам не нужно беспокоиться о том, какую версию вы должны использовать.
Плюсы и минусы использования инструментов синтаксического анализа
Многие из этих инструментов и библиотек были начаты как диссертация или исследовательский проект. Хорошей стороной этого является то, что эти инструменты, как правило, легко и бесплатно доступны их создателям. Однако, с другой стороны, часто не хватает хорошей документации о том, как их использовать. Это очевидно, поскольку они в первую очередь не предназначены для использования массовой аудиторией. Кроме того, некоторые инструменты заброшены без каких-либо новых обновлений, поскольку первоначальные авторы закончили работу со своей степенью магистра или доктора философии. градусов, поэтому они перестают их поддерживать.
Помня об этих моментах, вы должны выбрать правильный инструмент на основе доступной информации и просмотреть всю документацию, прежде чем использовать любой из этих инструментов для синтаксического анализа.
См. также: Понимание управления памятью в Java
Подведение итогов
Парсеры в Java — очень обширная тема, и она отличается от обычного мира разработки Java. Из-за этого было бы слишком много ожидать, что разработчик сможет писать синтаксические анализаторы на Java. Именно здесь эти инструменты проявляют себя наилучшим образом, поскольку теперь разработчикам стало намного проще создавать парсер на Java.
Java API для анализа текста, изображений и метаданных из PDF Word Excel HTML
Java API для анализа текста, изображений и метаданных из PDF Word Excel HTML GroupDocs.Parser для Java — это API для извлечения текста, изображений и метаданных, поддерживающий более 50 популярных типов документов для помощи в создании бизнес-приложений с функциями анализа необработанного, структурированного и форматированного текста. Он также поддерживает анализ документов с использованием предопределенных шаблонов и позволяет быстро и точно извлекать сложные данные из счетов-фактур и других типичных документов. GroupDocs.Parser для Java позволяет извлекать текст и метаданные из защищенных паролем файлов всех популярных форматов, включая документы обработки текста, электронные таблицы Excel, презентации PowerPoint, файлы OneNote, PDF и ZIP-архивы.
- At A
Glance
- Поддержанный
Форматы файлов
- Платформа
Независимость
Следующий обзор GroupDoc.parser для Java:
Pellacts 9001 2- Gets Input File
- Fetches Raw or Formatted Text
- Fetches Metadata
GroupDocs.Parser for Java supports following форматы файлов документов:
Извлечение текста- Текст : DOC, DOCX, DOT, DOTM, DOTX, DOCM, RTF, ODT, OTT, TXT, MD, WordprocessingML (XML)
- Электронные таблицы : XLS, XLSX, CSV, XLSM, XLSB, ODS, SpreadsheetML (XML), XLT, XLTX, XLTM, OTS, XLA, XLAM, TSV
- Презентации : PPT, PPTX, PPTM, PPS, PPSX, PPSM , POT, POTX, POTM, ODP, OTP
- OneNote : ONE
- Email : MSG, EML, EMLX, PST, OST, MS EXCHANGE SERVER, POP, IMAP Электронные публикации
- Переносимый документ : PDF, портфолио PDF, зашифрованный PDF
- На основе DOM : XML, HTML, XHTML, MHTML
- Сжатие и упаковка : ZIP, CHM
- Database : ADO. NET
- 20202021, UTF3, , . , UTF8 и UTF7
- Содержимое : UTF32 LE, UTF32 BE, UTF16 LE, UTF16 BE, UTF8 и ANSI
- Текст : DOC, ODT, DOCTX, DOTT, DOT,
- Электронные таблицы : XLS, XLSX, XLT, XLTX, XLTM, XLA, XLAM, OTS, ODS
- Презентации : PPT, PPTX, POT, POTX, POTM, PPSM, PPTM, OTP, ODP
- Электронный PDF
- Шаблон : DOTX, POTX
- Шаблон с макросоломной нормой : DOTM, PPM, PPSM, PPTM
- Опенд.0420 Текст : DOC, DOCX, DOCM, RTF, DOT, DOTM, DOTX, ODT
- Электронные таблицы : XLS, XLSX, XLSM, XLSB, ODS, XLT, XLTM, XLTX
- Презентации, PPT, PP: TX PPTM, ODP, POT, POTM, POTX, PPS, PPSX, PPSM
- Портативный документ : PDF, POT, POTM, POTX
- EBook : CHM, EPUB, FB2
- Markup : HTMML3
- 2020202010421: HTMML3
- Markup : HTMML3
- 2020: HTMML3
- . .Parser для Java
GroupDocs.Parser для Java поддерживает следующие операционные системы, платформы и менеджеры пакетов:
Operating Systems- Microsoft Windows Desktop
- Microsoft Windows Server
- Linux
- MacOS
- Java 7 (1.7) and above
- NetBeans
- IntelliJ IDEA
- Eclipse
- Maven
GroupDocs.Parser для Java Функции
Статистический подсчет встречаемости слов для одного или нескольких документов
Извлечение текста и метаданных из электронных таблиц Excel и шаблонов презентаций PowerPoint a Документ, использующий режим быстрого или стандартного извлечения текста
Определение типа носителя для XML-документов, защищенных паролем, и извлечение из них текста
Программное извлечение форматированного текста из презентации PowerPoint, сообщений электронной почты и вложений
Извлечение текста из одной или нескольких страниц документа OneNote
Извлечение необработанного текста из простого файла PDF или документа портфолио PDF Документы PDF, MS Word, Excel и презентации
Извлечение необработанного или форматированного текста из ячеек, строк и столбцов электронной таблицы Excel
Сбор необработанного или HTML-форматированного текста из документа Word и выдержка выделенного текста из документов
Получить данные из форм PDF и получить отформатированную таблицу из документа PDF или Word
Извлечь отдельное предложение или весь текст из файлов EPUB, CHM, Markdown и FB2 Документы EPUB, CHM и Word Processing
Извлечение текстовой области из документов для анализа и извлечения текста с неповрежденной структурой содержимого
Получение метаданных из поддерживаемых форматов документов
Извлечение всех или выбранных изображений из поддерживаемых форматов и поворот извлеченных изображений
Извлечение текста из файлов в Zip-архивах и OST-контейнерах — определение типов носителей для элементов Zip-контейнеров
Извлечение данных из почтового контейнера (Exchange веб-сервер, POP3, IMAP)
Быстрое, надежное и эффективное извлечение текста из контейнеров базы данных
Поиск простого текста, целых слов и регулярных выражений в документах
Подготовка шаблона документа, извлечение данных из документа и анализ полей данных и таблиц
Поиск и извлечение выделенных выражений в документах & Intersections
Извлечение и форматирование текста (шрифт, гиперссылки, заголовки, списки и таблицы) с помощью Markdown Formatter
Получение текста с помощью HTML Formatter и применение форматирования к абзацам, гиперссылкам, шрифтам, заголовкам, спискам и таблицам
Перемещение макета таблицы и обнаружение таблиц в прямоугольной области с помощью разделителей столбцов
Извлечение текста из фигур, объектов WordArt и текстовых блоков в форматах файлов Microsoft Office
Извлечение изображений в файлы — сохранение в JPG, PNG, GIF, Форматы BMP, PNG или WEBP
Извлечение текста из почтовых серверов и баз данных через JDBC
Получение текста с помощью форматирования обычного текста или HTML
С помощью GroupDocs.