Многопоточный парсинг на PHP | Трепачёв Дмитрий
В случае, если вы парсите большие сайты, парсинг может затянутся на достаточно длительное время — на часы или даже дни. Проблема в том, что ваш парсер не использует все ресурсы вашего компьютера и интернет канала, к примеру, когда PHP скрипт делает запрос к странице сайта, который он парсит, то он достаточно долго ожидает ответ этого сайта — скрипт дальше не выполняется, а ждет ответа этой страницы.
Для ускорения процесса можно запустить несколько PHP скриптов, каждый из которых будет парсить свои страницы сайта. В этом случае процесс парсинга существенно ускорится — порой в десятки раз.
Для начала будем считать, что парсинг осуществляется на вашем локальном компьютере, а не в интернете на сервере. Часто парсер на сервер и не надо выкладывать, если он разовый, а не периодический.
На самом деле PHP — не самый подходящий язык для многопоточного парсинга,
но что делать — чаще всего сайт интегрируется с парсером, а сайт работает
на PHP, или же вы кроме PHP ничего и не знаете — и нет смысла учить другой язык
ради написания парсера.
Разделение потоков
Пусть скрипт, который осуществляет парсинг, называется parser.php. Мы можем запускать его с разными GET параметрами, разделяя разные потоки. Например: parser.php?num=1, parser.php?num=2 и так далее.
Самое простое, что мы можем сделать — открыть этот скрипт в нескольких вкладках браузера с разными GET параметрами, тем самым запустив несколько копий этого PHP скрипта.
Хорошо, у нас сейчас запущено несколько копий одного скрипта, и каждая копия будет парсить разные страницы одного сайта — это мы указываем разными GET параметрами.
Теперь нам надо разделить обязанности копий скрипта — указать каждой копии, что именно она должна парсить. Это разделение обычно зависит от структуры того сайта, который мы парсим.
Самое простое, что можно сделать, это разделить потоки по главному меню сайта: каждый пункт — отдельный поток.
Получится столько потоков для парсинга — сколько пунктов в меню. Каждый поток запускаем своим GET запросом и каждый поток
заходит на свою страницу меню, собирает оттуда ссылки (например, подменю или пагинацию)
проходит по этим ссылкам, и так далее.
Каждый поток запускаем своим GET запросом и каждый поток
заходит на свою страницу меню, собирает оттуда ссылки (например, подменю или пагинацию)
проходит по этим ссылкам, и так далее.
Можно сделать и посложнее. Сделаем скрипт-инициатор, который строит план парсинга. Его удобно использовать, например, в таком случае — когда на одной странице сайта находятся ссылки на все страницы, которые вам нужно спарсить. В этом случае скрипт-инициатор парсит эти ссылки, сохраняет в базу данных.
Затем в дело вступают потоки. Запускаем столько потоков, сколько нам нужно. Каждый поток перед запуском берет из таблицы одну запись из БД, помечает в специальном поле, что эта ссылка в обработке, и начинает парсить страницу по ссылке. Следующий поток берет следующую незанятую запись из БД, помечает ее занятой, парсит ее и так далее.
Записей в базе может быть больше, чем запущенных потоков.
Поэтому, как только поток отработал свою ссылку, он помечает ее как завершенную
и берет следующую незанятую ссылку.
В общем и целом, как запускать потоки, зависит от того сайта, который вы парсите и от вашей фантазии. Дело опыта, поэтому в задачах вы обязательно потренируетесь в этом.
Особенность браузеров
Когда вы запускаете потоки, открывая вкладки в браузере — вас ждет подвох. На самом деле сработают первые 6-10 вкладок (зависит от браузера). Остальные просто повисят до конца парсинга и сработают только после того, как первые 6-10 вкладок закончат свою загрузку.
Это связано с устройством браузеров — они разрешают одновременно для одного сайта обрабатывать 6-10 запросов и ничего с этим не сделать. Пока эти запросы не будут выполнены — остальные ожидают.
Где это может вылезти —
к примеру у вас на сайте 20 CSS файлов. В этом случае время загрузки существенно
увеличится, так как они будут грузится по 6-10 файлов,
а остальные будут ожидать. Поэтому на реальных сайтах
CSS файлы сливают в один, а картинки иконок сливают в спрайты —
ноги растут отсюда.
Что с этим делать — мы сейчас и разберем. Повторюсь — пока речь идет о парсинге на локальном компьютере. Вообще открытие несколько вкладок — не самая удачная и удобная идея (хотя самая быстрая в реализации). Существую и более настоящие потоки, реализованные средствами PHP — о них чуть ниже.
Автоматически запускаем потоки
Представим, что вы бы хотели запустить парсинг в 50 потоков. Не очень удобно открывать 50 вкладок в браузере.
Если попытаться, например, обратиться к 50 страницам через PHP, например, через file_get_contents или через CURL, то 50 потоков запустить не получится, так как PHP скрипт будет ждать окончания загрузки file_get_contents.
Нужно нечто асинхронное, например сокеты или AJAX.
Давайте откроем 50 потоков с помощью AJAX. Будем каждый поток запускать с таймаутом так, чтобы каждый поток запускался на секунду позже предыдущего — в этом случае мы обойдем ограничение на открытие 6-10 страниц в браузере:
var count = 50; var url = 'http://paser.php'; for (var i = 1; i
 php';
for (var i = 1; i
php';
for (var i = 1; i Как это работает: первый поток имеет задержку timeout: 1000 милисекунд — одну секунду. Если страница не ответит за это время (а она не ответит, так как парсинг длится дольше), то загрузка оборвется. Второй поток имеет задержку timeout: 1000*2 = 2000 — 2 секунды. Ну и так далее.
Самое главное — нужно настроить в PHP ignore_user_abord — в этом случае AJAX будет запускать поток, обрывать загрузку — но PHP скрипт все равно будет работать, несмотря на то, что браузер уже оборвал загрузку.
Настройки сервера
Тут будет информация о добавлении дополнительных ресурсов PHP серверу при парсинге на локальном компьютере. Добавлю попозже.
Многопоточные запросы CURL
Изучите это, это и это.
Запуск нескольких процессов на PHP
Добавлю попозже.
Настоящие потоки на PHP
Изучите это: настоящие потоки, модуль php, еще.
Что вам делать дальше:
Приступайте к решению задач по следующей ссылке: задачи к уроку.
Когда все решите — переходите к изучению новой темы.
← Предыдущая страница Следующая страница →
Как написать парсер на php
Чтобы написать хороший и работоспособный скрипт для парсинга контента нужно потратить немало времени. А подходить к сайту-донору, в большинстве случаев, стоит индивидуально, так как есть масса нюансов, которые могут усложнить решение нашей задачи. Сегодня мы рассмотрим и реализуем скрипт парсера при помощи CURL, а для примера получим категории и товары одного из популярных магазинов.
Если вы попали на эту статью из поиска, то перед вами, наверняка, стоит конкретная задача и вы еще не задумывались над тем, для чего ещё вам может пригодится парсер. Поэтому, перед тем как вдаваться в теорию и непосредственно в код, предлагаю прочесть предыдущею статью – парсер новостей, где был рассмотрен один из простых вариантов, да и я буду периодически ссылаться на неё.
Работать мы будем с CURL, но для начала давайте разберёмся, что эта аббревиатура обозначает. CURL – это программа командной строки, позволяющая нам общаться с серверами используя для этого различные протоколы, в нашем случаи HTTP и HTTPS. Для работы с CURL в PHP есть библиотека libcurl, функции которой мы и будем использовать для отправки запросов и получения ответов от сервера.
CURL – это программа командной строки, позволяющая нам общаться с серверами используя для этого различные протоколы, в нашем случаи HTTP и HTTPS. Для работы с CURL в PHP есть библиотека libcurl, функции которой мы и будем использовать для отправки запросов и получения ответов от сервера.
Двигаемся дальше и определяемся с нашей целью. Для примера я выбрал наверняка всем известный магазин svyaznoy . Для того, чтобы спарсить категории этого магазина, предлагаю перейти на страницу каталога:
Как можно увидеть из скриншота все категории находятся в ненумерованном списке, а подкатегории:
Внутри отельного элемента списка в таком же ненумерованном. Структура несложная, осталось только её получить. Товары мы возьмем из раздела «Все телефоны»:
На странице получается 24 товара, у каждого мы вытянем: картинку, название, ссылку на товар, характеристики и цену.
Пишем скрипт парсера
Если вы уже прочли предыдущею статью, то из неё можно было подчеркнуть, что процесс и скрипт парсинга сайта состоит из двух частей:
- Нужно получить HTML код страницы, которой нам необходим;
- Разбор полученного кода с сохранением данных и дальнейшей обработки их (как и в первой статье по парсингу мы будем использовать phpQuery, в ней же вы найдете, как установить её через composer).

Для решения первого пункта мы напишем простой класс с одним статическим методом, который будет оберткой над CURL. Так код можно будет использовать в дальнейшем и, если необходимо, модифицировать его. Первое, с чем нам нужно определиться — как будет называться класс и метод и какие будут у него обязательные параметры:
Основной метод, который у нас будет – это getPage() и у него всего один обязательный параметр URL страницы, которой мы будем парсить. Что ещё будет уметь наш замечательный метод, и какие значения мы будем обрабатывать в нем:
- $useragent – нам важно иметь возможность устанавливать заголовок User-Agent, так мы сможем сделать наши обращения к серверу похожими на обращения из браузера;
- $timeout – будет отвечать за время выполнения запроса на сервер;
- $connecttimeout – так же важно указывать время ожидания соединения;
- $head – если нам потребуется проверить только заголовки, которые отдаёт сервер на наш запрос этот параметр нам просто будет необходим;
- $cookie_file – тут всё просто: файл, в который будут записывать куки нашего донора контента и при обращении передаваться;
- $cookie_session – иногда может быть необходимо, запрещать передачу сессионных кук;
- $proxy_ip – параметр говорящий, IP прокси-сервера, мы сегодня спарсим пару страниц, но если необходимо несколько тысяч, то без проксей никак;
- $proxy_port – соответственно порт прокси-сервера;
- $proxy_type – тип прокси CURLPROXY_HTTP, CURLPROXY_SOCKS4, CURLPROXY_SOCKS5, CURLPROXY_SOCKS4A или CURLPROXY_SOCKS5_HOSTNAME;
- $headers – выше мы указали параметр, отвечающий за заголовок User-Agent, но иногда нужно передать помимо его и другие, для это нам потребуется массив заголовков;
- $post – для отправки POST запроса.
Конечно, обрабатываемых значений много и не всё мы будем использовать для нашей сегодняшней задачи, но разобрать их стоит, так как при парсинге больше одной страницы многое выше описанное пригодится. И так добавим их в наш скрипт:
Как видите, у всех параметров есть значения по умолчанию. Двигаемся дальше и следующей строчкой напишем кусок кода, который будет очищать файл с куками при запросе:
Так мы обезопасим себя от ситуации, когда по какой-либо причине не создался файл.
Для работы с CURL нам необходимо вначале инициализировать сеанс, а по завершению работы его закрыть, также при работе важно учесть возможные ошибки, которые наверняка появятся, а при успешном получении ответа вернуть результат, сделаем мы это таким образам:
Первое, что вы могли заметить – это статическое свойство $error_codes, к которому мы обращаемся, но при этом его ещё не описали. Это массив с расшифровкой кодов функции curl_errno(), давайте его добавим, а потом разберем, что происходит выше.
После того, как мы инициализировали соединения через функцию curl_setopt(), установим несколько параметров для текущего сеанса:
- CURLOPT_URL – первый и обязательный — это адрес, на который мы обращаемся;
- CURLINFO_HEADER_OUT –массив с информацией о текущем соединении.
Используя функцию curl_exec(), мы осуществляем непосредственно запрос при помощи CURL, а результат сохраняем в переменную $content, по умолчанию после успешной отработки результат отобразиться на экране, а в $content упадет true. Отследить попутную информацию при запросе нам поможет функция curl_getinfo(). Также важно, если произойдет ошибка — результат общения будет false, поэтому, ниже по коду мы используем строгое равенство с учетом типов. Осталось рассмотреть ещё две функции это curl_error() – вернёт сообщение об ошибке, и curl_errno() – код ошибки. Результатом работы метода getPage() будет массив, а чтобы его увидеть давайте им воспользуемся, а для теста сделаем запрос на сервис httpbin для получения своего IP.
Если вывести на экран, то у вас должна быть похожая картина:
Если произойдет ошибка, то результат будет выглядеть так:
При успешном запросе мы получаем заполненную ячейку массива data с контентом и информацией о запросе, при ошибке заполняется ячейка error. Из первого скриншота вы могли заметить первую неприятность, о которой я выше писал контент сохранился не в переменную, а отрисовался на странице. Чтобы решить это, нам нужно добавить ещё один параметр сеанса CURLOPT_RETURNTRANSFER.
Обращаясь к страницам, мы можем обнаружить, что они осуществляют редирект на другие, чтобы получить конечный результат добавляем:
Теперь можно увидеть более приятную картину:
Двигаемся далее, мы описали переменные $useragent, $timeout и $connecttimeout. Добавляем их в наш скрипт:
Для того, чтобы получить заголовки ответа, нам потребуется добавить следующий код:
Мы отключили вывод тела документа и включили вывод шапки в результате:
Для работы со ссылками с SSL сертификатом, добавляем:
Уже получается весьма неплохой скрипт парсера контента, мы добрались до кук и тут стоит отметить — частая проблема, когда они не сохраняются. Одной из основных причин может быть указание относительного пути, поэтому нам стоит это учесть и написать следующие строки:
Одной из основных причин может быть указание относительного пути, поэтому нам стоит это учесть и написать следующие строки:
Предлагаю проверить, а для этого я попробую вытянуть куки со своего сайта:
Всё получилось, двигаемся дальше и нам осталось добавить в параметры сеанса: прокси, заголовки и возможность отправки запросов POST:
Это малая доля параметров, с которыми можно работать, все остальные находятся в официальной документации PHP . Вот мы завершили с нашей оберткой, и пришло время, что-нибудь спарсить!
Парсим категории и товары с сайта
Теперь, при помощи нашего класса Parser, мы можем сделать запрос и получить страницу с контентом. Давайте и поступим:
Следующим шагом разбираем пришедший ответ и сохраняем название и ссылку категории в результирующий массив:
Чуть более подробно работу с phpQuery я разобрал в первой статье по парсингу контента. Если вкратце, то мы пробегаемся по DOM дереву и вытягиваем нужные нам данные, их я решил протримить, чтобы убрать лишние пробелы. А теперь выведем категории на экран:
А теперь выведем категории на экран:
В результате мы получили все ссылки на категории. Для получения товаров используем тот же принцип:
Получаем страницу, тут я увеличил время соединения, так как 5 секунд не хватило, и разбираем её, парся необходимый контент:
Теперь проверим, что у нас получилось, и выведем на экран:
Вот мы и написали парсер контента PHP, как видите, нет нечего сложного, при помощи этого скрипта можно легко спарсить страницы любого сайта, но перед тем, как заканчивать статью, хотелось пояснить некоторые моменты. Во-первых, если вы хотите парсить более одной страницы, то не стоит забывать, что сам процесс парсинга ресурса затратная операция, поэтому в идеале лучше, чтобы скрипт был вынесен на отдельный сервер, где и будет запускаться по крону. Ещё один момент — к каждому донору стоит подходить индивидуально, так как, во-первых: у них разный HTML код и он, с течением времени, может меняться, во-вторых: могут быть различные защиты от парсинга и проверки, поэтому для подбора необходимого набора заголовков и параметров может потребоваться отладочный прокси (я пользуюсь Fiddler). И последние, что я добавлю — используйте для парсинга прокси и чем больше, тем лучше, так как, когда на сервер донора полетят тысячи запросов, то неизбежно IP, с которого осуществляется обращение будет забанен, поэтому стоит прогонять свои запросы через прокси-сервера.
И последние, что я добавлю — используйте для парсинга прокси и чем больше, тем лучше, так как, когда на сервер донора полетят тысячи запросов, то неизбежно IP, с которого осуществляется обращение будет забанен, поэтому стоит прогонять свои запросы через прокси-сервера.
Сегодня я хочу рассказать, как написать html парсер, а также с какими проблемами я столкнулся, разрабатывая подобный парсер на php. А проблем было много. И в первой части я расскажу о проектировании парсера, и о возникших проблемах, ведь html парсер отличается от парсера привычных всем языков программирования.
Введение
Я старался написать текст этой статьи максимально понятно, чтобы любой, кто даже не знаком с общим устройством парсеров мог понять то, как работает html парсер.
Здесь и далее в статье я буду называть документ, содержащий html просто «Документ».
Dom дерево, находящееся в элементе, будет называться «Подмассив».
Что должен делать парсер?
Давайте сначала определимся, что должен делать парсер, чтобы в будущем отталкиваться от этого при разработке. А именно, парсер должен:
А именно, парсер должен:
- Проектировать dom-дерево на основе документа
- Если есть ошибки в документе, то он должен их решать
- Находить элементы в dom-дереве
- Находить children элементы
- Находить текст
Впрочем, это мелочи. Основного функционала вполне хватит, чтобы поломать голову пару ночей напролет.
Но тут есть проблема, с которой я столкнулся сразу же: Html — это не просто язык, это язык гипертекста. У такого языка свой синтаксис, и обычный парсер не подойдет.
Разделяй и властвуй
Для начала, нужно разделить работу парсера на два этапа:
- Отделение обычного текста от тегов
- Сортировка всех полученных тегов в dom дерево
Для описания первого этапа я нарисовал схему, которая наглядно показывает, как обрабатываются данные на первом этапе:
Я решил опустить все мелкие детали. Например, как отличить, что после открывающего «<» идет тег, а не текст? Об этом я расскажу в следующих частях.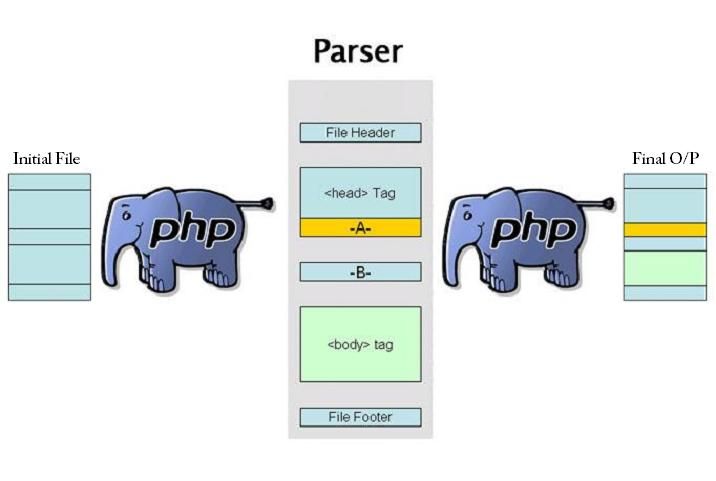 Пока что этого вполне хватит.
Пока что этого вполне хватит.
Также тут стоит уточнить. Логично, что в документе помимо тегов есть еще и текст. Говоря простым языком, если парсер найдет открывающий тег и если в нем будет текст, он запишет его после открывающего тега в виде отдельного тега. Такой тег будет считаться как одиночный и не будет участвовать в дальнейшей работе парсера.
Ну и второй этап. Самый сложный с точки зрения проектирования, и самый простой на первый взгляд с точки зрения понимания:
В данном случаи уровень означает уровень рекурсии. То есть если парсер нашел открывающий тег, он вызывает самого себя, «входит на уровень ниже», и так будет продолжаться до тех пор, пока не будет найден закрывающий тег. В этом случаи рекурсия выдает результат, «Выходит на уровень выше». Но, как обстоят дела с одиночными тегами? Такие теги считаются рекурсией ни как открывающие, ни как закрывающие. Они просто переходят в dom «Как есть».
В итоге у нас получится что-то вроде этого:
Что там насчет поиска элементов?
А теперь давайте поговорим про поиск элементов. Но тут не все так однозначно, как можно подумать. Сначала стоит разобраться, по каким критериям мы ищем элементы. Тут все просто, мы ищем их по тем же критериям, как это делает Javascript: теги, классы и идентификаторы. Но тут проблема. Дело в том, что тег может быть только один, а вот классов и идентификаторов у одного элемента — множество, либо вообще не быть. Поэтому, поиск элемента по тегу будет отличаться от поиска по классу или идентификатору. Я нарисовал схему поиска по тегу, но не волнуйтесь: поиск по классу или идентификатору не особо отличаются.
Но тут не все так однозначно, как можно подумать. Сначала стоит разобраться, по каким критериям мы ищем элементы. Тут все просто, мы ищем их по тем же критериям, как это делает Javascript: теги, классы и идентификаторы. Но тут проблема. Дело в том, что тег может быть только один, а вот классов и идентификаторов у одного элемента — множество, либо вообще не быть. Поэтому, поиск элемента по тегу будет отличаться от поиска по классу или идентификатору. Я нарисовал схему поиска по тегу, но не волнуйтесь: поиск по классу или идентификатору не особо отличаются.
Немного уточнений. Под исходным значением я имел в виду название тега, «div» например. Также, если элемент не равен исходному значению, но у него есть подмассив с подходящим элементом, в результат запишется именно подходящий элемент с его подмассивом, если таковой существует.
Стоит также сказать, что у парсера будет функция, позволяющая искать определенный элемент в документе. Это заметно ускорит производительность парсера, что позволит ему выполняться быстрее. Можно будет, например, взять только первый найденный элемент, или пятый, как вы захотите. Согласитесь, в таком случаи парсеру будет гораздо проще искать элементы.
Можно будет, например, взять только первый найденный элемент, или пятый, как вы захотите. Согласитесь, в таком случаи парсеру будет гораздо проще искать элементы.
Поиск children элементов
Хорошо, с поиском элементов разобрались, а как насчет children элементов? Тут тоже все просто: наш парсер будет брать все вложенные подмассивы найденных до этого элементов, если таковые существуют. Если таковых нет, парсер выведет пустой результат и пойдет дальше:
Поиск текста
Тут говорить особо не о чем. Парсер просто будет брать весь полученный текст из подмассива и выводить его.
Ошибки
Документ может содержать ошибки, с которыми наш скрипт должен успешно справляться, либо, если ошибка критическая, выводить ее на экран. Тут будет приведен список всех возможных ошибок, о которых, в будущем, мы будем говорить:
- Символ «>» не был найден
Такая ошибка будет возникать в том случаи, если парсер дошел до конца документа и не нашел закрывающего символа «>». - Неизвестное значение атрибута
Данная ошибка сигнализирует о том, что была проведена попытка передачи значения атрибуту когда закрывающий тег был найден.
Script, style и комментарии
В парсере теги script и style будут сразу же пропускаться, поскольку я не вижу смысл их записывать. С комментариями ситуация другая. Если вы захотите из записывать, то вы сможете включить отдельную функцию скрипта, и тогда он будет их записывать. Комментарии будут записываться точно так же как и текст, то есть как отдельный тег.
Заключение
Эту статью скорее нужно считать небольшим экскурсом в тему парсеров html. Я ее написал для тех, кто задумывается над написанием своего парсера, либо для тех, кому просто интересно. Поверьте, это действительно весело!
Данная статья является первой вводной частью. В следующих частях этого цикла уже будет участвовать непосредственно код, и будет меньше картинок с алгоритмами(что прекрасно, потому что рисовать я их не умею). Stay tuned!
Stay tuned!
Очень многие из нас хотели бы быстро наполнить сайт контентом. Я покажу вам, как несколько тысяч материалов собрать всего лишь за несколько часов.
Парсер на php — раз плюнуть!
Приветствую вас, наши дорогие читатели. Сегодня решил написать сложную статью про парсеры (сбор информации со сторонних ресурсов).
Скажу сразу, что вам потребуется знание основ программирования на php. В противном случае почитайте теории. Я не буду рассказывать азы, а сразу полезу показывать всё на практике.
Шаг 1 — PHP Simple HTML DOM Parser
Для парсинга сайтов мы будем использовать простецкую библиотечку под названием PHP Simple HTML DOM Parser, которую вы сможете скачать на сайте разработчика. Данный класс поможет вам работать с DOM-моделью страницы (дерево документа). Т.е. главная идея нашей будущей программы будет состоять из следующих пунктов:
- Скачиваем нужную страницу сайта
- Разбираем её по элементы (div, table, img и прочее)
- В соответствии с логикой получим определённые данные.

Давайте же начнём написание нашего php парсера сайтов.
Для начала подключим нашу библиотеку с помощью следующей строки кода:
Шаг 2 — Скачиваем страничку
На этом этапе мы смогли подключить файл к проекту и теперь пришла пора скачать страничку для парсинга.
В нашей библе есть две функции для получения удалённой страницы сайта. Вот эти функции
- str_get_htm() — получает в качестве параметров обычную строку. Это полезно, если вы стянули страничку с помощью CURL или метода file_get_contents. Пример использования:
После скачивания каждой страницы вам требуется подчищать память, дабы парсеру было легче работать и не так сильно грузился ваш сервер. Эта функция вызовется с помощью данного кода:
Шаг 3 — Ищем нужные элементы на странице
После получения DOM-модели мы можем приступить непосредственно к поиску нужного элемента-блока в полученном коде.
Большая часть функций поиска использует метод find(selector, [index]). Если не указывать индекс, то функция возвратит массив всех полученных элементов. В противном случае метод вернёт элемент с номером [index].
Если не указывать индекс, то функция возвратит массив всех полученных элементов. В противном случае метод вернёт элемент с номером [index].
Давайте же приведу вам первый пример. Спарсим мою страничку и найдём все картинки.
Шаг 4 — Параметры поиска
Надеюсь все уже поняли, что в метод find() можно писать как теги (‘a’), так и id’шники (‘#id’), классы (‘.myclass’), комбинации из предыдущих элементов (‘div #id1 span .class’). Таким образом вы сможете найти любой элемент на странице.
Если метод поиска ничего не найдёт, то он возвратит пустой массив, который приведёт к конфликту. Для этого надо указывать проверку с помощью фукнции count(), которую я использовал выше в примере.
Также вы можете производить поиск по наличию атрибутов у искомого элемента. Пример:
Замечу, что у каждого вложенного тега так же есть возможность поиска!
Есть много вариантов поиска по атрибутам. Перечислять не стану, для более полного руководства прошу пройти на сайт разработчиков 🙂
Обычный текст, без тегов и прочего, можно искать так find(‘text’). Комментарии аналогично find(‘comment’).
Комментарии аналогично find(‘comment’).
Шаг 5 — Поля элементов
Каждый найденный элемент имеет несколько структур:
- $seo->tag Прочитает или запишет имя тега искомого элемента.
- $seo->outertext Прочитает или запишет всю HTML-структуру элемента с ним включительно.
- $seo->innertext Прочитает или запишет внутреннюю HTML-структуру элемента.
- $seo->plaintext Прочитает или запишет обычный текст в элементе. Запись в данное поле ничего не поменяет, хоть возможность изменения как бы присутствует.
Эта возможность очень просто позволяет бегать по DOM-дереву и перебирать его в зависимости от ваших нужд.
Если вы захотите затереть какой-либо элемент из дерева, то просто обнулить значение outertext, т.е. $div->outertext = «» ; Можно поэксперементировать с удалением элементов.
P.S. Я обнаружил проблему с кодировками при очистке и всяческими манипуляциями с полем innertext . Пришлось использовать outertext и затем с помощью функции strip_tags удалял ненужные теги.
Пришлось использовать outertext и затем с помощью функции strip_tags удалял ненужные теги.
Шаг 6 — Дочерние элементы
Разработчики данной библиотеки позаботились так же и о том, чтобы вам было легко перемещаться по дочерним и родительским элементам дерева. Для этого ими были любезно созданы следующие методы:
- $seo->children ( [int $index] ) Возвращает N-ый дочерний элемент, иначе возвращает массив, состоящий из всех дочерних элементов.
- $seo->parent() Возвращает родительский элемент искомого элемента.
- $seo->first_child() Возвращает первый дочерний элемент искомого элемента, или NULL, если результат пустой
- $seo->last_child() Возвращает последний дочерний элемент искомого элемента, или null, если результат пустой
- $seo->next_sibling() Возвращает следующий родственный элемент искомого элемента, или null, если результат пустой
- $seo->prev_sibling() Возвращает предыдущий родственный элемент искомого элемента, или null, если результат пустой
Я особо не пользовался этими возможностями, потому что они ещё ни разу не пригодились мне. Хотя один раз при разборе таблицы использовал, потому что они структурированы, что делает разбор очень простым и лёгким.
Шаг 7 — Практика
Перейдём к практике. Я решил отдать вам на растерзание одну функцию, что использовал при написании парсера текстов песен на один из своих сайтов. Пытался досконально подробно описать код. Смотрите комментарии и задавайте вопросы.
Так сильно увлекаясь парсингом сайтов, я удивляюсь самому себе, насколько мало информации я публикую на эту тему. Сегодня я решил немного поправить эту несправедливость. В этой статье я хочу показать, как сделать быстрый парсер на PHP, в частности парсер фильмов с кинопоиска средствами PHP.
Примите к сведению, что при парсинге мы полагаемся на определённую DOM-структуру сайта, определённые css-селекторы в HTML-разметке страницы. Потому, держите в уме вероятность того, что структура сайта в будущем будет обновлена, и парсер, возможно перестанет работать. И, вероятно, с кодом из этой статьи случится то же самое, когда сайт-донор обновит разметку.
Большинство PHP-разработчиков, хоть раз в жизни делали парсер. Будь то с использованием file_get_contents, или curl, но, уверен, каждый хоть раз в жизни парсил информацию из Web-а. И это не удивительно, ведь очень часто появляется необходимость в копировании большого количества информации со сторонних сайтов, особенно для новых, пустых сайтов, нуждающихся в автоматическом наполнении.
Алгоритм парсинга аналогичен тому, что вы бы открыли нужный URL в браузере, просмотрели бы сайт, и скопировали бы нужную вам информацию себе. Но если таких действий нужно будет проделать несколько тысяч раз, то это становится довольно затруднительно. И, к счастью, это можно легко автоматизировать с помощью скриптов. В этой статье я покажу, как написать быстрый парсер, используя асинхронные запросы.
Зачем люди пишут парсеры
Немного отклонившися от курса этой статьи, на живом примере расскажу, где из популярных сайтов используется регулярный парсинг и наполнение с другого более популярного сайта.
Существует один сайт, уверен, на который вы натыкались в гугле при поиске решений проблем при программировании — qaru.site. И идея этого сайта как раз и строится на основу двух парсеров. Первый из которых копирует вопросы со всей информацией с популярного англоязычного сайта-аналога stackoverflow.com. А задача второго — переводить текст вопроса и ответов с английского на русский (с первого взгляда кажется, что это производится через Google Translate).
То, есть, если рассматривать роль парсера в проекте qaru.site, то, без раздумий можно утверждать то, что парсер в этом проекте — это 80% его успеха. Ведь, вместо того, чтобы развивать свой форум с нуля, просто было скопировано большое количество реальной информации с другого сайта. И из-за того, что эта информация в оригинале была на английском, то, со стороны поисковых систем её перевод расценивается как условно-полностью уникальный текст (невзирая на то, что перевод постов там сродни «я твой дом труба шатать»).
Но, это только один пример, придуманный сходу. .
Задача
В этой статье я напишу простой WEB-парсер информации о фильме с Кинопоиска, который будет получать детали этого фильма:
Почему я использую ReactPHP для выполнения асинхронных запросов? Если кратко — это быстрее. Если представить, что мы хотим спарсить все фильмы с первой страницы популярных фильмов, то для получения данных о всех фильмах понадобится выполнить 1 запрос на получение списка, и 200 запросов на получение подробной информации о каждом фильме отдельно. В итоге, 201 запрос, выполняя его в синхронном режиме, последовательно друг за другом может занять достаточно много времени.
И в противовес этому, представьте, что есть возможность запустить обработку всех этих запросов одновременно. И в этом случае, данные будут скопированы на порядок быстрее. Давайте попробуем.
Настройка проекта
Перед тем, как начать, с помощью композера нужно установить несколько зависимостей.
Сначала, установим асинхронный HTTP-клиент buzz-react. Это простой PSR-7 HTTP клиент, который поможет выполнять асинхронные HTTP-запросы.
Для того, чтобы из целой html-страницы получить определённые «куски» с нужной для нас информацией, используем библиотеку для парсинга по DOM-структуре. Я использую DiDOM
Теперь, можем начинать. Для начала, напишем такой код:
Мы сделали задел проекта для начала, определили инстанс HTTP-клиента. Следующий шаг — выполнение запросов.
Делаем запросы
Интерфейс класса Clue\React\Buzz\Browser достаточно простой и прямолинейный. Имена методов соответствуют HTTP-методам, которые он выполняет: GET-метод соответствует методу get(), GET-post(), PUT-put() и т.д. И каждый из этих методов возвращает Promise (если вы знакомы с JavaScript, или ранее работали с ReactPHP, то это не должно вызвать у вас вопросов). Если вы не знаете, что это, то на даном этапе объяснения не имеют большого смысла, дальше будет пример, после которого всё станет понятно.
Для текущей задачи нам будет достаточно одного метода get($url, $headers = []) :
В коде выше будет описана анонимная функция, которая после успешного запроса выведет HTML-разметку на экран. Эта функция принимает ответ экземпляра \Psr\Http\Message\ResponseInterface . В этой функции мы можем описать обработчик ответа, который вернёт из этого промиса (Promise) распарсенную информацию, без лишнего HTML-кода.
Как вы можете заметить, алгоритм парсинга достаточно прост:
- Делаем запрос и получаем промис.
- Пишем обработчик этого промиса.
- Парсим нужную информацию внутри этого обработчика.
- Если нужно, повторяем первый шаг.
Работа с DOM документа
Страница фильма, которую мы парсим не требует никакой авторизации. Если посмотреть на исходный код этой страницы, то можно увидеть, что все данные, за которыми мы охотимся, доступны внутри HTML. Иногда бывают случаи, когда анализ сайта, его противопарсинговые защиты, обход алгоритмов защиты и т.д. занимают на порядок больше времени, чем написание самого кода парсера.
Теперь, когда мы научились получать ответ (содержимое WEB-страницы), можем начать работу с DOM-ом этого документа. Для этого, как я и ранее писал, я буду использовать Didom, подробнее о котором вы можете почитать здесь.
Для начала работы, нужно создать экземпляр класса \DiDom\Document , конструктор которого принимает HTML-разметку.
Внутри обработчика мы создали экземпляр класса \DiDom\Document , передав ему HTML-ответ, приведённый к строке. Теперь, нужно выбрать нужные данные, используя соответствующие CSS-селекторы.
Заголовки (Title, Alternative Title)
Заголовок может быть получен с тега h2 (который единственнный на всей странице).
Метод first($selector) ищет первый элемент, соответствующий указанному селектору. После чего, к найденного элемента вызывается метод text() , который возвращает текст, содержащийся в этом элементе. Навигация и парсинг DOM-дерева выглядит очень похожим с jQuery:
Таблица параметров
Такие параметры фильма, как год , страна , слоган и т.д. находятся в таблице с классом info .
А ещё из разметки можно увидеть, что нужные нам параметры находятся во втором столбце (td) каждой из строк таблицы (tr). Но, нам не нужно сильно запариваться по поводу парсинга информации, так как можно увидеть, что в каждой строке таблицы есть только по одной ссылке, которые, как раз таки, и содержат внутри себя текст параметров.
Для этого, напишем код, получая сначала все строки таблицы, а потом обращаясь к ним по индексу:
Время и рейтинг (time, rating)
Информация о времени находится в той же таблице, которую парсили в прошлом шаге. Для получение данных, можно, как и в прошлом коде, обратиться по индексу:
Однако, изучив детальнее, можно увидеть, что у блока «время» есть уникальный идентификатор runtime, которым мы и воспользуемся.
И в этом случае, код будет выглядеть:
И, аналогично поступим с рейтингом. Он, правда, не имеет тега id, однако, класс блога рейтинга уникальный, и не повторяется на странице, потому будем обращаться по нему:
Итого, код парсера будет выглядеть так:
Написание класса парсера
Теперь пришло время собрать все части спаршеных данных вместе. Логина по выполнению запроса может быть помещена в отдельную функцию/класс, а так же, нужно добавить более гибкую функциональность, добавив возможность указания разных URL-адресов. Для этого, создадим класс KinopoiskParser
Класс KinopoiskParser принимает объект Browser как зависимость в свой конструктор. Функциональность этого класса достаточно проста: в нём существует 2 метода: parse() — который принимает массив URL-адресов на фильмы, и getData() , который возвращает массив всех спаршенных данных о фильмах.
Теперь, наконец-то, можем попробовать этот парсер в действии:
В этом коде мы создали объект парсера, передали его методу URL-адреса для парсинга, после чего, запустили обработчик цикла событий. События будут обрабатываться до тех пор, пока все запросы не будут выполнены, и результаты, в которых нуждаемся, не спаршены с HTML-разметки. Как результат, эти запросы выполняются параллельно, потому, итоговое время выполнения скрипта будет равно самому медленному из наших запросов.
Результат будет выглядеть примерно так:
Дальше вы можете продолжать писать парсер как угодно: разделив его на несколько файлов, добавить запись результатов в базу данных. Главная цель этой статьи была показать, как выполнять асинхронные запросы в PHP и обрабатывать ответ с помощью DOM-парсинга.
Добавление таймайта
Этот парсер может быть немного улучшим путём добавление таймаута на выполнение запроса. Просто, что будет, если самый медленный из запросов будет слишком медленным? И вместо того, чтобы ждать его завершения, мы можем указать таймаут — максимальное время, за которое он может отработать. Иначе же, если он не впишется в рамки этого таймаута, каждый из таких медленных запросов будет отменён. Для реализации такого функционала мы будем использовать встроенные возможности ReactPHP.
В чём идея:
- Получить промис запроса.
- Задать таймер.
- Когда время таймера наступит — отменить выполнение промиса.
Для этого, немного модифицируем код класса парсера KinopoiskParser , добавив в конструктор зависимость от \React\EventLoop\LoopInterface :
После чего, модифицируем метод parse() так, чтобы он мог принимать таймаут.
Если аргумент $timeout не будет передан, то будет применён таймаут по-умолчанию — 5 секунд . И, в случае, когда запрос не успевает отработать за указанное время, то этот промис отменяется. В текущем случае, все запросы, которые будут занимать больше времени, чем 5 секунд будут отменены. В случае же, если промис находится в режиме settled , то есть, когда запрос успешно выполнен, метод cancel() не создаст никакого эффекта.
Для примера, если мы не желаем ждать дольше, чем 3 секунды, напишем код:
Некоторые сайты не любят людей, парсящие их ресурс, и пытаются бороться с ними. Когда вы делаете парсинг для личных целей, при небольшом количестве запросов — ничего страшного. Но, если попробовать выполнить сотни параллельных запросов с одного IP — вы можете натолкнуться на проблемы. Сайту может не понравиться то, что вы делаете запросы слишком часто и много, и, скорее всего, заблокирует вас. В этом случае вам очень пригодятся прокси. В следующей статье я как раз и опишу процесс работы с прокси с этим клиентом в асинхронном режиме.
Резюме
В этой статье я показал, как работать с ReactPHP, показал примеры работы с ним, реализовав пример простого php парсера кинопоиска. Так же, в этой статье было рассмотрено, как парсить html на php, с помощью php dom парсера DiDOM, который является лучшим DOM-парсером на PHP. К слову, DiDOM — это отличная замена всем известного php simple dom parser-а. Надеюсь, что теперь вы без проблем сможете написать парсер контента собственными руками на php. И, полностью освоив материал этой статьи, выполняя запросы асинхронно, вы значительно прибавите в скорости и качестве парсеров.
Хорошего парсинга.
Честно говоря, кинопоиск — не самый удачный ресурс для демонстрации парсинга данных, ввиду того, что он огрантчивает IP при частых запросах. Но, хочу подчеркнуть, что концепция этой статьи как раз не приследует цель написать парсер кинопоиска. А главная цель — демонстрация алгоритма, по которому разрабатываются парсеры, а так же, как разработка парсеров ложится на асинхронный код.
Как сделать парсер на php
Пишем быстрый PHP парсер (scraper)
Так сильно увлекаясь парсингом сайтов, я удивляюсь самому себе, насколько мало информации я публикую на эту тему. Сегодня я решил немного поправить эту несправедливость. В этой статье я хочу показать, как сделать быстрый парсер на PHP, в частности парсер фильмов с кинопоиска средствами PHP.
Примите к сведению, что при парсинге мы полагаемся на определённую DOM-структуру сайта, определённые css-селекторы в HTML-разметке страницы. Потому, держите в уме вероятность того, что структура сайта в будущем будет обновлена, и парсер, возможно перестанет работать. И, вероятно, с кодом из этой статьи случится то же самое, когда сайт-донор обновит разметку.
Большинство PHP-разработчиков, хоть раз в жизни делали парсер. Будь то с использованием file_get_contents, или curl, но, уверен, каждый хоть раз в жизни парсил информацию из Web-а. И это не удивительно, ведь очень часто появляется необходимость в копировании большого количества информации со сторонних сайтов, особенно для новых, пустых сайтов, нуждающихся в автоматическом наполнении.
Алгоритм парсинга аналогичен тому, что вы бы открыли нужный URL в браузере, просмотрели бы сайт, и скопировали бы нужную вам информацию себе. Но если таких действий нужно будет проделать несколько тысяч раз, то это становится довольно затруднительно. И, к счастью, это можно легко автоматизировать с помощью скриптов. В этой статье я покажу, как написать быстрый парсер, используя асинхронные запросы.
Зачем люди пишут парсеры
Немного отклонившися от курса этой статьи, на живом примере расскажу, где из популярных сайтов используется регулярный парсинг и наполнение с другого более популярного сайта.
Существует один сайт, уверен, на который вы натыкались в гугле при поиске решений проблем при программировании — qaru.site. И идея этого сайта как раз и строится на основу двух парсеров. Первый из которых копирует вопросы со всей информацией с популярного англоязычного сайта-аналога stackoverflow.com. А задача второго — переводить текст вопроса и ответов с английского на русский (с первого взгляда кажется, что это производится через Google Translate). .
Задача
В этой статье я напишу простой WEB-парсер информации о фильме с Кинопоиска, который будет получать детали этого фильма:
Почему я использую ReactPHP для выполнения асинхронных запросов? Если кратко — это быстрее. Если представить, что мы хотим спарсить все фильмы с первой страницы популярных фильмов, то для получения данных о всех фильмах понадобится выполнить 1 запрос на получение списка, и 200 запросов на получение подробной информации о каждом фильме отдельно. В итоге, 201 запрос, выполняя его в синхронном режиме, последовательно друг за другом может занять достаточно много времени.
И в противовес этому, представьте, что есть возможность запустить обработку всех этих запросов одновременно. И в этом случае, данные будут скопированы на порядок быстрее. Давайте попробуем.
Настройка проекта
Перед тем, как начать, с помощью композера нужно установить несколько зависимостей.
Сначала, установим асинхронный HTTP-клиент buzz-react. Это простой PSR-7 HTTP клиент, который поможет выполнять асинхронные HTTP-запросы.
Для того, чтобы из целой html-страницы получить определённые «куски» с нужной для нас информацией, используем библиотеку для парсинга по DOM-структуре. Я использую DiDOM
Теперь, можем начинать. Для начала, напишем такой код:
Мы сделали задел проекта для начала, определили инстанс HTTP-клиента. Следующий шаг — выполнение запросов.
Делаем запросы
Интерфейс класса Clue\React\Buzz\Browser достаточно простой и прямолинейный. Имена методов соответствуют HTTP-методам, которые он выполняет: GET-метод соответствует методу get(), GET-post(), PUT-put() и т.д. И каждый из этих методов возвращает Promise (если вы знакомы с JavaScript, или ранее работали с ReactPHP, то это не должно вызвать у вас вопросов). Если вы не знаете, что это, то на даном этапе объяснения не имеют большого смысла, дальше будет пример, после которого всё станет понятно.
Для текущей задачи нам будет достаточно одного метода get($url, $headers = []) :
В коде выше будет описана анонимная функция, которая после успешного запроса выведет HTML-разметку на экран. Эта функция принимает ответ экземпляра \Psr\Http\Message\ResponseInterface . В этой функции мы можем описать обработчик ответа, который вернёт из этого промиса (Promise) распарсенную информацию, без лишнего HTML-кода.
Как вы можете заметить, алгоритм парсинга достаточно прост:
- Делаем запрос и получаем промис.
- Пишем обработчик этого промиса.
- Парсим нужную информацию внутри этого обработчика.
- Если нужно, повторяем первый шаг.
Работа с DOM документа
Страница фильма, которую мы парсим не требует никакой авторизации. Если посмотреть на исходный код этой страницы, то можно увидеть, что все данные, за которыми мы охотимся, доступны внутри HTML. Иногда бывают случаи, когда анализ сайта, его противопарсинговые защиты, обход алгоритмов защиты и т.д. занимают на порядок больше времени, чем написание самого кода парсера.
Теперь, когда мы научились получать ответ (содержимое WEB-страницы), можем начать работу с DOM-ом этого документа. Для этого, как я и ранее писал, я буду использовать Didom, подробнее о котором вы можете почитать здесь.
Для начала работы, нужно создать экземпляр класса \DiDom\Document , конструктор которого принимает HTML-разметку.
Внутри обработчика мы создали экземпляр класса \DiDom\Document , передав ему HTML-ответ, приведённый к строке. Теперь, нужно выбрать нужные данные, используя соответствующие CSS-селекторы.
Заголовки (Title, Alternative Title)
Заголовок может быть получен с тега h2 (который единственнный на всей странице).
Метод first($selector) ищет первый элемент, соответствующий указанному селектору. После чего, к найденного элемента вызывается метод text() , который возвращает текст, содержащийся в этом элементе. Навигация и парсинг DOM-дерева выглядит очень похожим с jQuery:
Таблица параметров
Такие параметры фильма, как год , страна , слоган и т.д. находятся в таблице с классом info .
А ещё из разметки можно увидеть, что нужные нам параметры находятся во втором столбце (td) каждой из строк таблицы (tr). Но, нам не нужно сильно запариваться по поводу парсинга информации, так как можно увидеть, что в каждой строке таблицы есть только по одной ссылке, которые, как раз таки, и содержат внутри себя текст параметров.
Для этого, напишем код, получая сначала все строки таблицы, а потом обращаясь к ним по индексу:
Время и рейтинг (time, rating)
Информация о времени находится в той же таблице, которую парсили в прошлом шаге. Для получение данных, можно, как и в прошлом коде, обратиться по индексу:
Однако, изучив детальнее, можно увидеть, что у блока «время» есть уникальный идентификатор runtime, которым мы и воспользуемся.
И в этом случае, код будет выглядеть:
И, аналогично поступим с рейтингом. Он, правда, не имеет тега id, однако, класс блога рейтинга уникальный, и не повторяется на странице, потому будем обращаться по нему:
Итого, код парсера будет выглядеть так:
Написание класса парсера
Теперь пришло время собрать все части спаршеных данных вместе. Логина по выполнению запроса может быть помещена в отдельную функцию/класс, а так же, нужно добавить более гибкую функциональность, добавив возможность указания разных URL-адресов. Для этого, создадим класс KinopoiskParser
Класс KinopoiskParser принимает объект Browser как зависимость в свой конструктор. Функциональность этого класса достаточно проста: в нём существует 2 метода: parse() — который принимает массив URL-адресов на фильмы, и getData() , который возвращает массив всех спаршенных данных о фильмах.
Теперь, наконец-то, можем попробовать этот парсер в действии:
В этом коде мы создали объект парсера, передали его методу URL-адреса для парсинга, после чего, запустили обработчик цикла событий. События будут обрабатываться до тех пор, пока все запросы не будут выполнены, и результаты, в которых нуждаемся, не спаршены с HTML-разметки. Как результат, эти запросы выполняются параллельно, потому, итоговое время выполнения скрипта будет равно самому медленному из наших запросов.
Результат будет выглядеть примерно так:
Дальше вы можете продолжать писать парсер как угодно: разделив его на несколько файлов, добавить запись результатов в базу данных. Главная цель этой статьи была показать, как выполнять асинхронные запросы в PHP и обрабатывать ответ с помощью DOM-парсинга.
Добавление таймайта
Этот парсер может быть немного улучшим путём добавление таймаута на выполнение запроса. Просто, что будет, если самый медленный из запросов будет слишком медленным? И вместо того, чтобы ждать его завершения, мы можем указать таймаут — максимальное время, за которое он может отработать. Иначе же, если он не впишется в рамки этого таймаута, каждый из таких медленных запросов будет отменён. Для реализации такого функционала мы будем использовать встроенные возможности ReactPHP.
В чём идея:
- Получить промис запроса.
- Задать таймер.
- Когда время таймера наступит — отменить выполнение промиса.
Для этого, немного модифицируем код класса парсера KinopoiskParser , добавив в конструктор зависимость от \React\EventLoop\LoopInterface :
После чего, модифицируем метод parse() так, чтобы он мог принимать таймаут.
Если аргумент $timeout не будет передан, то будет применён таймаут по-умолчанию — 5 секунд . И, в случае, когда запрос не успевает отработать за указанное время, то этот промис отменяется. В текущем случае, все запросы, которые будут занимать больше времени, чем 5 секунд будут отменены. В случае же, если промис находится в режиме settled , то есть, когда запрос успешно выполнен, метод cancel() не создаст никакого эффекта.
Для примера, если мы не желаем ждать дольше, чем 3 секунды, напишем код:
Некоторые сайты не любят людей, парсящие их ресурс, и пытаются бороться с ними. Когда вы делаете парсинг для личных целей, при небольшом количестве запросов — ничего страшного. Но, если попробовать выполнить сотни параллельных запросов с одного IP — вы можете натолкнуться на проблемы. Сайту может не понравиться то, что вы делаете запросы слишком часто и много, и, скорее всего, заблокирует вас. В этом случае вам очень пригодятся прокси. В следующей статье я как раз и опишу процесс работы с прокси с этим клиентом в асинхронном режиме.
Резюме
В этой статье я показал, как работать с ReactPHP, показал примеры работы с ним, реализовав пример простого php парсера кинопоиска. Так же, в этой статье было рассмотрено, как парсить html на php, с помощью php dom парсера DiDOM, который является лучшим DOM-парсером на PHP. К слову, DiDOM — это отличная замена всем известного php simple dom parser-а. Надеюсь, что теперь вы без проблем сможете написать парсер контента собственными руками на php. И, полностью освоив материал этой статьи, выполняя запросы асинхронно, вы значительно прибавите в скорости и качестве парсеров.
Хорошего парсинга.
Честно говоря, кинопоиск — не самый удачный ресурс для демонстрации парсинга данных, ввиду того, что он огрантчивает IP при частых запросах. Но, хочу подчеркнуть, что концепция этой статьи как раз не приследует цель написать парсер кинопоиска. А главная цель — демонстрация алгоритма, по которому разрабатываются парсеры, а так же, как разработка парсеров ложится на асинхронный код.
Парсинг HTML на PHP с использованием DiDOM
Время от времени разработчикам необходимо изучать веб-страницы, чтобы получить некоторую информацию с веб-сайта. Например, предположим, вы работаете над личным проектом, где вам нужно получить географическую информацию о столицах разных стран из Википедии. Для ввода этого вручную потребуется много времени. Однако, вы можете сделать это очень быстро, получив страницу Википедии с помощью PHP. Вы также сможете автоматически парсить HTML-код, чтобы получить конкретную информацию, вместо того чтобы проходить через всю разметку вручную.
В этом руководстве мы узнаем о быстром, удобном в использовании парсере HTML под названием DiDOM. Мы начнем с процесса установки, а затем узнаем, как извлекать информацию из разных элементов на веб-странице, используя различные типы селекторов, такие как теги, классы и т. д.
Установка и использование
Вы можете легко установить DiDOM в каталог проекта, выполнив следующую команду:
После выполнения указанной выше команды вы сможете загрузить HTML из строки, локального файла или веб-страницы. Вот пример:
Когда вы решите парсить HTML из документа, он уже может быть загружен и сохранен в переменной. В таких случаях вы можете просто передать эту переменную в Document() , а DiDOM подготовит строку для синтаксического анализа.
Если HTML должен быть загружен из файла или URL-адреса, вы можете передать это как первый параметр в Document() и установить для второго параметра значение true .
Вы также можете создать новый объект Document , используя new Document() без каких-либо параметров. В этом случае вы можете вызвать метод loadHtml() для загрузки HTML из строки и loadHtmlFile() для загрузки HTML из файла или веб-страницы.
Поиск элементов HTML
Первое, что вам нужно сделать, прежде чем получать HTML или текст из элемента, — это найти сам элемент. Самый простой способ сделать это — просто использовать метод find() и передать селектор CSS для вашего предполагаемого элемента в качестве первого параметра.
Вы также можете передать XPath для элемента в качестве первого параметра метода find() . Однако, для этого требуется передать Query::TYPE_XPATH в качестве второго параметра.
Если вы хотите использовать значения XPath для поиска элемента HTML, вы можете просто использовать метод xpath() вместо передачи Query::TYPE_XPATH в качестве второго параметра для find() каждый раз.
Если DiDOM может найти элементы, которые соответствуют переданному CSS-селектору или выражению XPATH, он вернет массив экземпляров DiDom\Element . Если такие элементы не найдены, он вернет пустой массив.
Поскольку эти методы возвращают массив, вы можете напрямую обращаться к n-му подходящему элементу, используя find()[n-1] .
Пример
В следующем примере мы будем получать внутренний HTML из всех заголовков первого и второго уровня в статье Википедии о Washington, D.C.
Начнем с создания нового объекта Document, передав URL-адрес статьи в Википедии о Washington, D.C. После этого мы получаем основной элемент заголовка с помощью метода find() и сохраняем его внутри переменной $main_heading . Теперь мы можем вызвать различные методы для этого элемента, такие как text() , innerHtml() , html() и т. д.
Для основного заголовка мы просто вызываем метод html() , который возвращает HTML всего элемента заголовка. Аналогично, мы можем получить HTML внутри определенного элемента, используя метод innerHtml() . Иногда вас будет больше интересовать текстовое содержимое элемента, а не его HTML. В таких случаях вы можете просто использовать метод text() , и с ним работа закончена.
Заголовки второго уровня делят нашу страницу в Википедии на определенные разделы. Однако, вам может понадобиться избавиться от некоторых из этих подзаголовков, таких как «См. также», «Примечания» и т. д.
Один из способов сделать это — перебрать все заголовки второго уровня и проверить значение, возвращаемое методом text() . Мы выходим из цикла, если текст возвращаемого заголовка «См. также».
Вы можете напрямую перейти на четвертый или шестой заголовок второго уровня, используя $document->find(‘h3’)[3] и $document->find(‘h3’)[5] соответственно.
Перемещение вверх и вниз по DOM
После того как вы получите доступ к определенному элементу, библиотека позволяет вам перемещаться вверх и вниз по дереву DOM для простого доступа к другим элементам.
Вы можете перейти к родительскому элементу HTML с помощью метода parent() . Аналогичным образом, вы можете перейти к следующему или предыдущему родственнику элемента, используя методы nextSibling() и previousSibling() .
Существует множество методов, позволяющих получить доступ к дочерним элементам DOM. Например, вы можете перейти к определенному дочернему элементу, используя метод child(n) . Аналогично, вы можете получить доступ к первому или последнему ребенку определенного элемента, используя методы firstChild() и lastChild() . Вы можете перебрать все дочерние элементы определенного элемента DOM с помощью метода children() .
Как только вы перейдете к определенному элементу, вы сможете получить доступ к его HTML и т. д., используя методы html() , innerHtml() и text() .
В следующем примере мы начинаем с элементов заголовка второго уровня и продолжаем проверять, содержит ли следующий сестринский элемент (sibling) некоторый текст. Как только мы обнаружим элемент (sibling) с некоторым текстом, мы выводим его в браузер.
Вы можете использовать подобный подход для циклического перехода по всем сестринским элементам (siblings), и выводить текст только, если он содержит определенную строку, или если элемент sibling является тегом абзаца и т. д. После того, как вы знаете основы, найти правильную информацию легко.
Манипулирование атрибутами элемента
Возможность получить или установить значение атрибута для разных элементов может оказаться очень полезной в определенных ситуациях. Например, мы можем получить значение атрибута src для всех тегов img в нашей статье в Википедии, используя $image_elem->attr(‘src’) . Аналогичным образом вы можете получить значение атрибутов href для всех тегов a в документе.
Существует три способа получить значение данного атрибута для элемента HTML. Вы можете использовать метод getAttribute(‘attrName’) и передать имя интересующего вас атрибута в качестве параметра. Вы также можете использовать метод attr(‘attrName’) , который работает так же, как getAttribute() . Наконец, библиотека также позволяет вам напрямую получить значение атрибута с помощью $elem->attrName . Это означает, что вы можете получить значение атрибута src для элемента изображения напрямую, используя $imageElem->src .
Как только вы получите доступ к атрибутам src, вы можете написать код для автоматической загрузки всех файлов изображений. Таким образом, вы сможете сэкономить много времени.
Вы также можете установить значение заданного атрибута, используя три разных способа. Во-первых, вы можете использовать метод setAttribute(‘attrName’, ‘attrValue’) для установки значения атрибута. Еще вы можете использовать метод attr(‘attrName’, ‘attrValue’) для установки значения атрибута. Наконец, вы можете установить значение атрибута для данного элемента, используя $Elem->attrName = ‘attrValue’ .
Добавление, удаление и замена элементов
Вы также можете внести изменения в загруженный HTML-документ, используя различные методы, предоставляемые библиотекой. Например, вы можете добавлять, заменять или удалять элементы из дерева DOM с помощью методов appendChild() , replace() и remove() .
Библиотека также позволяет создавать собственные HTML-элементы, чтобы добавлять их в исходный HTML-документ. Вы можете создать новый объект Element, используя new Element(‘tagName’, ‘tagContent’) .
Имейте в виду, что вы получите сообщение об ошибке Uncaught Error: Class ‘Element’ not found, если ваша программа не содержит строку use DiDom\Element перед созданием объекта элемента.
После того, как у вас есть элемент, вы можете либо добавить его к другим элементам DOM с помощью метода appendChild() , либо использовать метод replace() для использования вновь созданного элемента в качестве замены некоторого старого элемента HTML в документе. Следующий пример должен помочь в дальнейшем разъяснении этой концепции.
Первоначально в нашем документе нет элемента h3 с классом test-heading. Поэтому мы будем получать ошибку, если попытаемся получить доступ к такому элементу.
После проверки того, что такого элемента нет, мы создаем новый элемент h3 и меняем значение его атрибута class на test-heading.
После этого мы заменим первый элемент h2 в документе на наш недавно созданный элемент h3. Повторное использование метода find() в нашем документе, чтобы найти заголовок h3 с классом test-heading, теперь вернет элемент.
Последние мысли
В этом учебном руководстве описаны основы HTML-парсера PHP DiDOM. Мы начали с установки, а затем научились загружать HTML из строки, файла или URL. После этого мы обсудили, как найти определенный элемент на основе его CSS-селектора или XPath. Мы также узнали, как получить братьев и сестер, родителей или детей элемента. В остальных разделах рассказывается, как мы можем манипулировать атрибутами определенного элемента или добавлять, удалять и заменять элементы в документе HTML.
Если есть что-то, что вы хотели бы, чтобы я уточнил в руководстве, не стесняйтесь, дайте мне знать в комментариях.
Парсер на PHP с записью контента в БД
Нескольким читателям моего блога было интересно узнать «как объединить крон, базу данных и php парсер». Я постарался написать максимально простой и лаконичный скрипт, чтобы любой новичок смог в нём разобраться. Он состоит всего из одного файла index.php и 50 строк кода.
Я использовал 2 библиотеки:
- RedBean PHP, которая упрощает работу с БД и защищает от SQL инъекций ->читать подробнее
- phpQuery — порт jQuery на PHP, который позволяет добираться до нужных блоков в дебрях документа
Парсить в учебных целях мы будем один сайт о моде и красоте. Остановимся мы только на парсинге 10 статей, чтобы понять суть.
А вот и сам скрипт — файл index.php
Соединение с БД — файл db.php
Если мы запустим парсер, то в базе данных автоматически появятся 2 таблички. В таблице postprev запишется информация о превью статей (картинка, заголовок, небольшой текст и ссылка на сам пост). В таблицу post запишется уже полная информация о статьях.
Вот такая красота в итоге получается.
Таблица postprev
Таблица post
Как работает парсер?
- Подключаемся к нашей базе данных (файл db.php)
- Подключаем библиотеки
- Создаем константу, в которой хранится адрес сайта-донора
- Очищаем таблицы post и postprev в БД. Это нужно для того, чтобы при повторном запуске парсера, данные в таблицах не дублировались. Момент очень спорный. Возможно, можно было сделать проверку на совпадение с данными в БД и уже потом производить запись или назначать статусы (0 – не парсили, 1 — парсили). Если есть мысли, то пишите в комментариях
- Функцией file_get_contents получаем содержимое страницы
- Смотрим, как у сайта-донора устроена разметка постов
- Перебираем в цикле foreach все посты
- Проверяем разметку превью постов и смотрим, в каких тэгах находятся необходимые данные (заголовок, картинка и т.д.)
- Информацию о превью, которую мы спарсили записываем в БД. Делается это методом dispense библиотеки RedbeenPHP, который принимает всего 1 аргумент – название таблицы. Причем, если такой таблицы в БД нет, то он сам её корректно создаст
- В пункте 8 мы спарсили ссылки на посты. Теперь можно перебрать их в цикле, чтобы спарсить текст внутри статей и заголовоки
- По аналогии с пунктом 9 записываем информацию о статьях в БД
- Теперь вам остается лишь самостоятельно вывести информацию из БД на свой сайт
- Также можно настроить CRON на своем сервере, чтобы файл index.php автоматически запускался, например, раз в неделю. Делается это в разделе планировщик задач. Также можно попросить помощи у техподдержки хостинга.
Парсер с авторизацией | PHPClub
JavaScript отключён. Чтобы полноценно использовать наш сайт, включите JavaScript в своём браузере.
- Автор темы Corecess
- Дата начала
- Теги
- авторизация парсер
Corecess
Новичок
- #1
Здравствуйте! Есть модуль парсера, парсер — это импорт товаров. Как можно добавить авторизацию на сайте, откуда производится импорт? Буду крайне благодарна, сама, видимо, не в силах разобраться.
Фанат
oncle terrible
- #2
Не надо ничего парсить.
Парсинг убивет интернет, как растения-паразиты убивают лес.
Хозяева сайта который парсят, начинают защищаться от парсинга, что в итоге осложняет жизнь пользователям.
Уже сейчас интернет как Москва весь перегорожен заборами, на каждый чих надо вводить три капчи.
Надо или договориться с сайтом чтобы он предоставил ниформацию в нормальном формате, или вообще не парсить, а попробовать сделать что-то своё.
Corecess
Новичок
- #3
Фанат написал(а):
Не надо ничего парсить.
Парсинг убивет интернет, как растения-паразиты убивают лес.
Хозяева сайта который парсят, начинают защищаться от парсинга, что в итоге осложняет жизнь пользователям.
Уже сейчас интернет как Москва весь перегорожен заборами, на каждый чих надо вводить три капчи.
Надо или договориться с сайтом чтобы он предоставил ниформацию в нормальном формате, или вообще не парсить, а попробовать сделать что-то своё.Нажмите для раскрытия.
Это поставщик для дропшиппинга, который предоставляет файл xml для импорта товаров. Но почему-то он решил скрыть изображения для авторизации. Саппорт говорит, да, сначала надо авторизироваться, что б импорт товаров пришел нормально.
WMix
герр M:)ller
- #4
попробуй https://docs.guzzlephp.org/en/stable/ ну или по простому https://www.php.net/manual/ru/book.curl.php
Фанат
oncle terrible
- #5
импорт XML — это не парсер.
Это импорт XML
Войдите или зарегистрируйтесь для ответа.
Поделиться:
Facebook Twitter WhatsApp Ссылка
релизов · nikic/PHP-Parser · GitHub
nikic / PHP-парсер Общественный
- Уведомления
- Вилка 890
- Звезда 15,6к
Никик
v5.0.0альфа1
96037b3 СравнитьПредварительный выпуск
Предварительная версия
Подробные инструкции по миграции см. в UPGRADE-5.0.
Изменено
- Теперь для запуска PHP-Parser требуется PHP 7.1.
- Форматирование стандартного красивого принтера было скорректировано для более точного соответствия PSR-12.
- Внутреннее представление токена теперь использует класс
PhpParser\Token, который совместим с представлением токена PHP 8 (PhpToken). - Деструктуризация теперь всегда представлена с помощью
Expr\List_узлов, даже если он использует синтаксис[]. - Переименован ряд классов узлов и перемещены вещи, которые не были реальными выражениями/инструкциями, за пределы иерархии
Expr/Stmt. Прокладки совместимости для старых имен сохранены.
Добавлено
- Добавлено
Класс PhpVersion, который принимается во многих местах (например, ParserFactory, Parser, Lexer, PrettyPrinter) и дает более точный контроль над целевой версией PHP. - Добавлен синтаксический анализатор PHP 8, хотя он отличается от синтаксического анализатора PHP 7 только приоритетом конкатенации.
- Добавлен метод
Parser::getLexer(). - Добавлен класс
Modifiersв качестве заменыStmt\Class_::MODIFIER_*. - Добавлена поддержка возврата массива или
REMOVE_NODEизNodeVisitor::enterNode().
Удалено
- Парсер PHP 5 удален. Парсер PHP 7 был настроен для более изящной обработки кода PHP 5.
Никич
v4.15.1
0ef6c55 СравнитьПоследние
Последние
Исправлено
- Исправлено сохранение форматирования при добавлении нескольких атрибутов к классу/методу/и т. д., которые ранее не имели ни одного. Это исправляет регрессию в выпуске 4.15.0.
Никич
v4.15.0
617d022 СравнитьДобавлено
- PHP 8.2: добавлена поддержка типа
true. - PHP 8.2: добавлена поддержка типов DNF.
Фиксированный
- Поддержка
только для чтенияв качестве имени функции. - Добавлены
__serializeи__unserializeв список магических методов. - Проверка фиксированных границ в
Name::slice(). - Исправлено сохранение форматирования при добавлении атрибутов к классу/методу/и т. д., которых раньше не было.
Никич
v4.14.0
34bea19 СравнитьДобавлено
- Добавлена поддержка классов только для чтения.
- Добавлен атрибут
rawValueк узламLNumber,DNumberиString_, в котором хранится неанализированное значение литерала (например,"1_000", а не10100 9).
Никич
v4.13.2
210577f СравнитьДобавлено
- Добавлены построители для перечислений и случаев перечислений.
Исправлено
- NullsafeMethodCall теперь расширяется от CallLike.
- Свойство
namespacedName, заполненноеNameResolver, теперь объявляется на соответствующих узлах,
, чтобы избежать предупреждения об устаревании динамического свойства в PHP 8.2.
Никич
v4.13.1
63a79e8 СравнитьФиксированный
- Поддержка зарезервированных ключевых слов в качестве регистров перечисления.
- Поддержка распаковки массива в оценщике константных выражений.
Никич
v4.13.0
50953a2 СравнитьВ этом выпуске реализована полная поддержка PHP 8.1.
Добавлено
- [PHP 8.1] Добавлена поддержка типов пересечений с использованием нового
IntersectionTypeузел. Кроме того, был добавлен родительский классComplexTypeдляNullableType,UnionTypeиIntersectionType. - [PHP 8.1] Добавлена поддержка явных восьмеричных литералов.
- [PHP 8.1] Добавлена поддержка вызываемых объектов первого класса. Они представлены с помощью вызова, первым аргументом которого является
VariadicPlaceholder. Представление предназначено для прямой совместимости с приложением частичной функции, как и сама функция PHP. Узлы вызова теперь расширяются с Expr\CallLike, который предоставляет методisFirstClassCallable()для определения наличия идентификатора заполнителя.getArgs()можно использовать для подтверждения того, что вызов не является вызываемым объектом первого класса и возвращаетArg[]вместоarray.
Исправлено
- Теперь можно использовать несколько модификаторов для продвигаемых свойств. В частности, это позволяет что-то вроде
public readonlyдля продвигаемых свойств. - Исправлена красивая печать комментариев в литералах массива с сохранением форматирования.
Никич
v4.12.0
6608f01 СравнитьДобавлено
- [PHP 8.1] Добавлена поддержка свойств только для чтения (через новый
MODIFIER_READONLY). - [PHP 8.1] Добавлена поддержка констант класса final.
Исправлено
- Исправлена совместимость с PHP 8.1. 9Токены 0018 и теперь канонизированы до токенов
T_AMPERSAND_FOLLOWED_BY_VAR_OR_VARARGиT_AMPERSAND_NOT_FOLLOWED_BY_VAR_OR_VARARG, используемых в PHP 8.1. Это происходит безоговорочно, независимо от того, используется ли эмулирующий лексер.
Никич
v4.11.0
fe14cf3 СравнитьДобавлено
-
BuilderFactory::args()теперь принимает именованные аргументы. -
BuilderFactory::attribute()добавлен. - Метод
addAttribute(), принимающийAttributeилиAttributeGroup, был добавлен ко всем компоновщикам, которые принимают атрибуты, такие какBuilder\Class_.
Исправлено
-
NameResolverтеперь обрабатывает перечисления. -
PrettyPrinterтеперь печатает поддержку типа enum. - Методы построителя для типов теперь обрабатывают свойство
никогда нетипа.
Никич
v4.10.5
4432ba3 СравнитьДобавлено
- [PHP 8.1] Добавлена поддержка перечислений. Они представлены узлами
Stmt\Enum_иStmt\EnumCase. - [PHP 8.1] Добавлена поддержка типа never. Этот тип теперь будет возвращаться как идентификатор
как имя. - Добавлено
Конструктор ClassConst.
Изменено
- Единицы кода, отличного от UTF-8, в строках теперь будут кодироваться в шестнадцатеричном формате.
Фиксированный
- Фиксированный приоритет стрелочных функций.
классов Ларса Мёллекена — классы PHP
| Все группы классов | > | Все авторы | > | Классы Ларса Мёллекена (25) | > | Состояние выполнения миссии | > | Репутация |
| |||||||||||||||||||||||||||||||
| А | Б | С | Д | Э | Ф | Г | Х | я | Дж | К | л | М | Н | О | Р | В | Р | С | Т | У | В | Вт | х | Д | З |
| |||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||
|
|
|
|
| ||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||
|
|
| А | Б | С | Д | Э | Ф | Г | Х | я | Дж | К | л | М | Н | О | Р | В | Р | С | Т | У | В | Вт | х | Д | З |
Команда php-parser — github.
com/z7zmey/php-parser — Пакеты Goкоманда модуль
Версия: v0.7.2 Последний Последний
Модуль этого пакета отсутствует в последней версии.
Перейти к последним Опубликовано: 26 июля 2020 г. Лицензия: Массачусетский технологический институт Импорт: 14 Импортировано: 0
ПРОЧТИ МЕНЯ ¶
Парсер PHP, написанный на Go
Этот проект использует инструменты goyacc и ragel для создания синтаксического анализатора PHP. Он анализирует исходный код в AST. Его можно использовать для написания инструментов статического анализа, рефакторинга, метрик, форматирования стиля кода.
Попробуйте онлайн: демонстрация
Особенности:
- Полная поддержка синтаксиса PHP 5 и PHP 7
- Представление абстрактного синтаксического дерева (AST)
- Пересечение АСТ
- Разрешение имен пространств имен
- Разбор файлов PHP с неверным синтаксисом
- Сохранение и печать свободно плавающих комментариев и пробелов
Кто использует
VKCOM/noverify — NoVerify — довольно быстрый линтер для PHP
quaslyte/phpgrep — phpgrep — инструмент для поиска кода PHP с учетом синтаксиса
Пример использования
основной пакет импорт ( "ФМТ" "Операционные системы" "github.Дорожная карта
- Схема потока управления (CFG)
- Парсер PhpDocComment
- Стабилизация API
Установите
перейдите на github.com/z7zmey/php-parser
CLI
php-parser [флаги] <путь> ...
| флаг | тип | описание |
|---|---|---|
| -р | логический | путь к файлу печати |
| -д | строка | Формат дампа: [custom, go, json, pretty-json] |
| -р | логический | разрешить имена |
| -ff | логический | анализировать и показывать свободно плавающие строки |
| -проф | строка | запуск профилировщика: [процессор, память, трассировка] |
| -php5 | логический | анализировать как PHP5 |
Выгрузить AST в стандартный вывод.
Преобразователь пространства имен
Преобразователь пространства имен — это посетитель, который разрешает полное имя узла и сохраняет в map[node.Node]string структура
- Для
Class,Interface,Trait,Function,Constantузлы сохраняет имя с текущим пространством имен. - Для узлов
Name,Relative,FullyQualifiedразрешаетиспользование псевдонимови сохраняет полное имя.
Документация ¶
Парсер для PHP, написанный на Go
Особенности:
- Полная поддержка синтаксиса PHP5 и PHP7
- Представление абстрактного синтаксического дерева
- Пересечение АСТ
- Преобразователь пространства имен
Установка:
перейдите на github.com/z7zmey/php-parser
CLI-дампер:
$GOPATH/bin/php-parser -php5 /path/to/file/or/dir
Пример использования пакета:
основной пакет импорт ( "ФМТ" "байты" "Операционные системы" "github.Исходные файлы ¶
Посмотреть все
- док.го
- main.go
Каталоги ¶
ошибки | |
свободно плавающий | |
выражение/назначение | |
выражение/бинарное | |
вып/каст | |
скаляр | |
парсер | |
php5 строка php5/php5. | строка php5/php5.y:2 |
php7 строка php7/php7.y:2 | строка php7/php7.y:2 |
позиция | |
позиционер | |
принтер | |
сканер линейный сканер/сканер.rl:1 | линейный сканер/сканер.rl:1 |
версия | |
посетитель Пакет посетитель содержит реализации walker.visitor Пакет посетитель содержит реализации walker.visitor Пакет посетитель содержит реализации walker. | Посетитель пакета содержит реализации walker.visitor Пакет посетителя содержит реализации walker.visitor Пакет посетителя содержит реализации walker.visitor Пакет посетителя содержит реализации walker.visitor Пакет посетителя содержит реализации walker.visitor |
Walker Обходчик пакетов объявляет ходьбу | Обходчик пакетов объявляет ходьбу |
dev-php/nikic-php-parser — Пакеты Gentoo
Пакеты
Получить Gentoo!
сайты gentoo.org
Доступные версии
| Версия | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 4. 13.2 : 0 | ~ amd64 | ~x86 | ~ альфа | ~ рука | рука64 | ~ia64 | ~ppc | ~ppc64 | риск | ~спарк |
Метаданные пакета
Восходящий
Remote-Id https://github. com/nikic/PHP-парсерЛицензия
MIT
Сопровождающий(ие)
PHP
Внешние ресурсы
- Связанные ошибки
- Отчет КИ (подробный)
- Репология
- Открытые пул-реквесты
- Документация
- Сообщения на форумах
- Браузер репозитория Git
- Git-журнал (короткая)
- Лента изменений
Понимание того, как анализируется PHP
Ранее вам напомнили, как веб-сервер отвечает на запрос статического HTML-файла. Следующие шаги описывают последовательность запроса-ответа для файла PHP:
Веб-браузер запрашивает документ с расширением .php (или любым расширением, установленным для обработки в качестве файла PHP).
Веб-сервер отправляет запрос анализатору PHP, который либо встроен в двоичный файл веб-сервера, либо существует отдельно в виде фильтра или исполняемого файла CGI.
Анализатор PHP сканирует запрошенный файл на наличие кода PHP.
Когда синтаксический анализатор PHP находит код PHP, он выполняет этот код и помещает полученный результат (если есть) в то место в файле, которое ранее занимал код.
Этот новый выходной файл отправляется обратно на веб-сервер.
Веб-сервер отправляет выходной файл в веб-браузер.
Веб-браузер отображает вывод.
Поскольку код PHP анализируется сервером, этот метод выполнения кода называется на стороне сервера. Когда код выполняется браузером, например, с помощью JavaScript, он называется на стороне клиента.
Code Cohabitation и теги PHP
Для объединения кода PHP с HTML код PHP должен быть экранировано, или отделено от HTML. Следующий метод является конфигурацией механизма PHP по умолчанию:
Движок PHP будет рассматривать все, что находится внутри открывающего тега , как код PHP. Вы также можете экранировать свой PHP-код, используя или с помощью открывающего тега .
Теперь пришло время написать первый скрипт. Ваш первый PHP-скрипт будет отображать «Hello World! Я использую PHP!» в окне браузера.
Сначала откройте свой любимый текстовый редактор и создайте простой текстовый файл с именем first.php. В этом текстовом файле введите следующий код:
Мой первый скрипт PHP Привет, мир! Я использую PHP!\n"; ?>
Сохраните этот файл и поместите его в корневой каталог документов вашего веб-сервера. Теперь откройте его в своем браузере по URL-адресу http://127.0.0.1/first.php. В окне браузера вы должны увидеть это:
Привет, мир! Я использую PHP!
| Примечание | Если у вашего сервера есть реальный компьютер и доменное имя, например www.yourcompany.com, вы можете использовать его вместо 127.0.0.1 (локальный хост по умолчанию). |
Если вы используете свой браузер для просмотра источника документа, вы должны просто увидеть это:
Мой первый PHP-скрипт Привет, мир! Я использую PHP!
Поскольку код PHP был обработан синтаксическим анализатором PHP, все, что остается видимым, — это вывод HTML.
Теперь взгляните на PHP-код, используемый в скрипте. Он содержит три элемента: команду (echo), строку (
Hello World. ..) и признак конца инструкции (;).
Теперь ознакомьтесь с командой echo, поскольку она, вероятно, будет наиболее часто используемой вами командой. Функция echo() используется для вывода информации — в данном случае для печати
Hello World! Я использую PHP!
в файле HTML. Терминатор инструкции является настолько важной концепцией, что заслуживает отдельного раздела.Важность терминатора инструкции
Обязательно требуется терминатор инструкции, также известный как точка с запятой. Если вы не закончите свою команду точкой с запятой, механизм PHP не будет правильно анализировать ваш PHP-код, и возникнут уродливые ошибки. Например, этот код:
Привет, мир! Я использую PHP!\n" echo "Это другое сообщение.
"; ?>
выдает эту неприятную ошибку:
Ошибка синтаксического анализа: ошибка синтаксического анализа, ожидается "," или ";" в /path/to/your/file/filename.php в строке 9
Избегайте этой ошибки любой ценой — не забывайте завершать команды точкой с запятой!
Экранирование кода
Не забывая заканчивать свои команды точкой с запятой, вы не забываете экранировать такие элементы, как кавычки. Когда вы используете кавычки внутри других кавычек, внутренние пары должны быть отделены от внешних пар с помощью escape-символа (\) (также известного как обратная косая черта). Например, следующий код вызовет еще одну ошибку синтаксического анализа, поскольку термин «круто» заключен в двойные кавычки внутри строки в двойных кавычках:
Я думаю, что это действительно "круто"!"; ?>
Вместо этого этот код должен выглядеть так:
Я думаю, что это действительно \"круто\"!"; ?>
Теперь, когда внутренние кавычки экранированы, синтаксический анализатор PHP пропустит их, потому что он знает, что эти символы должны быть просто напечатаны и что они не имеют никакого другого значения. Та же концепция верна для элементов в одинарных кавычках внутри других строк в одинарных кавычках — экранирование внутреннего элемента. Строки в одинарных кавычках внутри строк в двойных кавычках и наоборот не требуют экранирования символов.
Комментирование кода
Независимо от того, добавляете ли вы комментарии к статическим документам HTML или сценариям PHP, комментирование кода — хорошая привычка. Комментарии помогут вам и тем, кому позже придется редактировать ваши документы, получить представление о том, что происходит в ваших документах.
HTML-комментарии игнорируются браузером и заключаются в теги . Например, следующий комментарий напоминает вам, что код, следующий за ним, содержит ваш логотип:
Точно так же PHP-комментарии игнорируются механизмом синтаксического анализа. Комментариям PHP обычно предшествует двойная косая черта, например:
// это комментарий в коде PHP
В файлах PHP могут использоваться другие типы комментариев, например:
# Это стиль оболочки comment
и
/* Начинается комментарий в стиле C, занимающий две строки */
Комментарии HTML и PHP широко используются в этой книге для объяснения блоков кода. Привыкайте читать комментарии и постарайтесь выработать привычку их использовать. Написание чистого кода без ошибок, с большим количеством комментариев и пробелов сделает вас популярным среди ваших коллег-разработчиков, потому что им не придется слишком много работать, чтобы понять, что ваш код пытается сделать!
Теперь, когда вы знаете, как создаются и используются документы PHP, в следующем разделе вы познакомитесь с переменными и операторами PHP, которые станут неотъемлемой частью ваших скриптов.
Классификация содержания исторических газет: руководство, объединяющее R, bash и Vowpal Wabbit, часть 2
[Эта статья была впервые опубликована на Econometrics and Free Software и любезно предоставлена R-блогерами]. (Вы можете сообщить о проблеме с содержанием на этой странице здесь)
Хотите поделиться своим контентом с R-блогерами? нажмите здесь, если у вас есть блог, или здесь, если у вас его нет.
В части 1 этой серии я установил
up Vowpal Wabbit для классификации содержания газет. Теперь давайте воспользуемся моделью, чтобы сделать прогнозы и
посмотреть, как и если мы можем улучшить модель. Затем давайте обучим модель на всех данных.
Шаг 1: подготовка данных
Первый шаг заключается в импорте тестовых данных и их подготовке. Тестовые данные не должны быть большими и, таким образом, могут быть импортированы и обработаны в R.
Мне нужно удалить целевой столбец из тестового набора, иначе он будет использоваться для прогнозирования. Если не убрать этот столбец, точность модели будет очень высокой, но она будет неправильной. поскольку, конечно, у вас нет целевого столбца во время выполнения... потому что это столбец что вы хотите предсказать!
библиотека ("tidyverse")
библиотека ("мерка")
small_test <- read_delim("data_split/small_test.txt", "|",
escape_double = ЛОЖЬ, col_names = ЛОЖЬ,
trim_ws = ИСТИНА)
маленький_тест %>%
мутировать (X1 = " ") %>%
write_delim("data_split/small_test2. txt", col_names = FALSE, delim = "|") Я записал данные в файл с именем small_test2.txt и теперь могу использовать свою модель для прогнозирования:
system2("/home/cbrunos/miniconda3/bin/vw", args = "-t -i vw_models /small_oaa.model data_split/small_test2.txt -p data_split/small_oaa.predict") Прогнозы сохраняются в файле small_oaa.predict , который представляет собой обычный текстовый файл. Добавим эти
прогнозы исходному тестовому набору:
small_predictions <- read_delim("data_split/small_oaa.predict", "|",
escape_double = ЛОЖЬ, col_names = ЛОЖЬ,
trim_ws = ИСТИНА)
small_test <- small_test %>%
переименовать (правда = X1) %>%
мутировать(правда = фактор(правда, уровни = c("1", "2", "3", "4", "5")))
small_predictions <- small_predictions %>%
переименовать (прогнозы = X1) %>%
мутировать (прогнозы = фактор (прогнозы, уровни = с ("1", "2", "3", "4", "5")))
small_test <- small_test %>%
bind_cols(small_predictions) Шаг 2: использование модели и тестовых данных для оценки производительности
Мы можем использовать несколько показателей, включенных в {критерий} , для оценки производительности модели:
conf_mat(small_test, правда = правда, оценка = прогнозы)
точность (маленький_тест, правда = правда, оценка = прогнозы)
Правда
Прогноз 1 2 3 4 5
1 51 15 2 10 1
2 11 6 3 1 0
3 0 0 0 0 0
4 0 0 0 0 0
5 0 0 0 0 0
# Таблетка: 1 x 3
. метрика .оценщик .оценка
<хр> <хр> <дбл>
1 мультикласс точности 0,570 Мы видим, что модель никогда не предсказывала класс 3 , 4 или 5 . Можем ли мы улучшить, добавив некоторые
регуляризация? Давай выясним!
Шаг 3: добавление регуляризации
Прежде чем приступать к регуляризации, давайте попробуем изменить функцию затрат с логистической на функция шарнира:
# Обучение модели
шарнир_oaa_fit <- system2("/home/cbrunos/miniconda3/bin/vw", args = "--oaa 5 -d data_split/small_train.txt --loss_function шарнир -f vw_models/hinge_oaa.model", stderr = TRUE)
system2("/home/cbrunos/miniconda3/bin/vw", args = "-i vw_models/hinge_oaa.model -t -d data_split/small_test2.txt -p data_split/hinge_oaa.predict")
прогнозы <- read_delim("data_split/hinge_oaa.predict", "|",
escape_double = ЛОЖЬ, col_names = ЛОЖЬ,
trim_ws = ИСТИНА)
тест <- тест %>%
выбрать (-предсказания)
прогнозы <- прогнозы %>%
переименовать (прогнозы = X1) %>%
мутировать (прогнозы = фактор (прогнозы, уровни = с ("1", "2", "3", "4", "5")))
тест <- тест %>%
bind_cols (прогнозы)
conf_mat (тест, правда = правда, оценка = прогнозы)
точность (проверка, истина = истина, оценка = предсказания)
Правда
Прогноз 1 2 3 4 5
1 411 120 45 92 1
2 355 189 12 17 0
3 11 2 0 0 0
4 36 4 0 1 0
5 3 0 3 0 0
# Таблетка: 1 x 3
. метрика .оценщик .оценка
<хр> <хр> <дбл>
1 точность мультикласс 0.462 Ну не так получилось, но по крайней мере теперь мы знаем как изменить функцию потерь. Пойдем вернуться к логистическим потерям и добавить некоторую регуляризацию. Сначала обучим модель:
regul_oaa_fit <- system2("/home/cbrunos/miniconda3/bin/vw", args = "--oaa 5 --l1 0.005 --l2 0.005 -d data_split/small_train.txt - f vw_models/small_regul_oaa.model", stderr = TRUE) Теперь мы можем использовать его для прогнозирования:
system2("/home/cbrunos/miniconda3/bin/vw", args = "-i vw_models/small_regul_oaa.model -t -d data_split/test2.txt -p data_split/ small_regul_oaa.predict")
прогнозы <- read_delim("data_split/small_regul_oaa.predict", "|",
escape_double = ЛОЖЬ, col_names = ЛОЖЬ,
trim_ws = ИСТИНА)
тест <- тест %>%
выбрать (-предсказания)
прогнозы <- прогнозы %>%
переименовать (прогнозы = X1) %>%
мутировать (прогнозы = фактор (прогнозы, уровни = с ("1", "2", "3", "4", "5")))
тест <- тест %>%
bind_cols (прогнозы) Теперь мы можем использовать его для прогнозов:
conf_mat(тест, истина = истина, оценка = прогнозы)
точность (проверка, истина = истина, оценка = предсказания)
Правда
Прогноз 1 2 3 4 5
1 816 315 60 110 1
2 0 0 0 0 0
3 0 0 0 0 0
4 0 0 0 0 0
5 0 0 0 0 0
# Таблетка: 1 x 3
. метрика .оценщик .оценка
<хр> <хр> <дбл>
1 мультикласс точности 0,627 Итак, точность улучшилась, но модель теперь предсказывает только класс 1… давайте попробуем с другими значениями гиперпараметров:
regul_oaa_fit <- system2("/home/cbrunos/miniconda3/bin/vw", args = "--oaa 5 --l1 0,00015 --l2 0,00015 -d data_split/small_train.txt -f vw_models/small_regul_oaa.model", stderr = TRUE)
conf_mat (тест, правда = правда, оценка = прогнозы)
точность (проверка, истина = истина, оценка = предсказания)
Правда
Прогноз 1 2 3 4 5
1 784 300 57 108 1
2 32 14 3 2 0
3 0 1 0 0 0
4 0 0 0 0 0
5 0 0 0 0 0
# Таблетка: 1 x 3
.метрика .оценщик .оценка
<хр> <хр> <дбл>
1 мультикласс точности 0,613 Таким образом, точность ниже, чем раньше, но, по крайней мере, правильно прогнозируется больше категорий. В зависимости
в зависимости от ваших потребностей, вы должны учитывать различные показатели. Специально для задач классификации вы можете
не интересуйтесь точностью, особенно если данные сильно несбалансированы.
Во всяком случае, чтобы закончить этот пост в блоге, давайте обучим модель на всех данных и измерим время требуется для запуска полной модели.
Шаг 4: Обучение на всех данных
Давайте сначала разделим все данные на обучающую и тестовую выборку:
nb_lines <- system2("cat", args = "text_fr.txt | wc -l", stdout = TRUE)
system2("split", args = paste0("-l", floor(as.numeric(nb_lines)*0.995), " text_fr.txt data_split/"))
system2("mv", args = "data_split/aa data_split/train.txt")
system2("mv", args = "data_split/ab data_split/test.txt") Все данные содержат 260247 строк, а обучающая выборка весит 667 МБ, что довольно много. Давайте тренироваться простой множественный классификатор данных и посмотрите, сколько времени это займет:
тик <- Sys.time()
oaa_fit <- system2("/home/cbrunos/miniconda3/bin/vw", args = "--oaa 5 -d data_split/train.txt -f vw_models/oaa.model", stderr = TRUE)
Sys.time() - тик
Разница во времени 4,73266 с Да, вы правильно прочитали. Обучение классификатора на 667 МБ данных заняло менее 5 секунд!
Давайте посмотрим на последний объект:
oaa_fit [1] "final_regressor = vw_models/oaa.model" [2] "Количество битов веса = 18" [3] «скорость обучения = 0,5» [4] "initial_t = 0" [5] "мощность_t = 0,5" [6] «без кеша» [7] «Чтение файла данных = data_split/train.txt» [8] "количество источников = 1" [9] "среднее значение с момента примера пример текущий текущий текущий" [10] «функции прогнозирования метки последнего противовеса потери» [11] «1,000000 1,000000 1 1,0 2 1 253» [12] «0,500000 0,000000 2 2,0 2 2 499» [13] «0,250000 0,000000 4 4,0 2 2 6» [14] «0,250000 0,250000 8 8,0 1 1 2268» [15] «0,312500 0,375000 16 16,0 1 1 237» [16] "0,250000 0,187500 32 32,0 1 1 557" [17] "0,171875 0,093750 64 64,0 1 1 689" [18] "0,179688 0,187500 128 128,0 2 2 208" [19] «0,144531 0,109375 256 256,0 1 1 856» [20] "0,136719 0,128906 512 512,0 4 4 4" [21] "0,122070 0,107422 1024 1024,0 1 1 1353" [22] «0,106934 0,0