Парсинг XML с использованием lxml
Ранее мы рассматривали некоторые встроенные в Python XML парсеры. В этой статье, мы рассмотрим один интересный сторонний пакет lxml от codespeak. Он, в частности, использует API ElementTree. Пакет lxml имеет поддержку XPath и XSLT, включая API для SAX и API уровня С для совместимости с модулями C/Pyrex. В статье мы рассмотрим следующее:
- Парсинг XML используя lxml
- Пример рефакторинга
- Как выполнять парсинг XML с lxml.objectify
- Как создавать XML с lxml.objectify
В этой статье, мы используем примеры, основанные на примерах парсинга minidom, и посмотрим, как выполнять парсинг при помощи lxml Python. Вот пример XML из программы, которая была написана для отслеживания назначений:
<?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> <appointment> <begin>1234360800</begin> <duration>1800</duration> <subject>Check MS Office website for updates</subject> <location></location> <uid>604f4792-eb89-478b-a14f-dd34d3cc6c21-1234360800</uid> <state>dismissed</state> </appointment> </zAppointments>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | <?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> <appointment> <duration>1800</duration> <subject>Check MS Office website for updates</subject> <location></location> <uid>604f4792-eb89-478b-a14f-dd34d3cc6c21-1234360800</uid> <state>dismissed</state> </appointment> </zAppointments> |
Давайте посмотрим, как происходит парсинг с использованием lxml.
Парсинг XML с lxml
Данный пример XML показывает два назначения. Время начинается спустя секунды после эпохи. Наш uid сгенерирован на основе хеша начала времени и ключа. Время сигнала – несколько секунд после эпохи, но не раньше начала времени. Состояние – если назначение было отменено или перенесено, или нет, так или иначе. Остальная часть XML, как мы видим, в пояснении не нуждается. Давайте взглянем на то, как делается парсинг:
# -*- coding: utf-8 -*- from lxml import etree def parseXML(xmlFile): «»» Парсинг XML «»» with open(xmlFile) as fobj: xml = fobj.read() root = etree.fromstring(xml) for appt in root.getchildren(): for elem in appt.getchildren(): if not elem.text: text = «None» else: text = elem.text print(elem.tag + » => » + text) if __name__ == «__main__»: parseXML(«example.xml»)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | # -*- coding: utf-8 -*- from lxml import etree
def parseXML(xmlFile): «»» Парсинг XML «»» with open(xmlFile) as fobj: xml = fobj.read()
root = etree.fromstring(xml)
for appt in root.getchildren(): for elem in appt.getchildren(): if not elem.text: text = «None» else: text = elem.text
print(elem.tag + » => » + text)
if __name__ == «__main__»: parseXML(«example.xml») |
Во первых, мы импортировали необходимые модули, а именно модуль etree из пакета lxml Python и функцию StringIO из встроенного модуля StringIO. Наша функция parseXML принимает один аргумент: путь к рассматриваемому файлу XML. Мы открываем файл, читаем и закрываем его. Теперь начинается самое веселое. Мы используем функцию парсинга etree, чтобы парсировать код XML, который вернулся из модуля StringIO. По причинам, которые я не могу полностью понять, функция парсинга требует файловый объект. В любом случае, мы итерируем контекст (другими словами, объект
Парсинг на примере книги
Что-ж, результат нашего примера немного скучный. Большую часть времени, вам нужно будет сохранить извлеченные данные, и сделать с ними что-нибудь, а не просто вывести его в stdout. Так что в следующем нашем примере мы создадим структуру данных для сбора результатов. В данном примере структура наших данных будет представлять собой список словарей. Мы используем пример книги MSDN. Сохраните следующий код XML под названием
<?xml version=»1.0″?> <catalog> <book> <author>Gambardella, Matthew</author> <title>XML Developer’s Guide</title> <genre>Computer</genre> <price>44.95</price> <publish_date>2000-10-01</publish_date> <description>An in-depth look at creating applications with XML.</description> </book> <book> <author>Ralls, Kim</author> <title>Midnight Rain</title> <genre>Fantasy</genre> <price>5.95</price> <publish_date>2000-12-16</publish_date> <description>A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world.</description> </book> <book> <author>Corets, Eva</author> <title>Maeve Ascendant</title> <genre>Fantasy</genre> <price>5.95</price> <publish_date>2000-11-17</publish_date> <description>After the collapse of a nanotechnology society in England, the young survivors lay the foundation for a new society.</description> </book> </catalog>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | <?xml version=»1.0″?> <catalog> <book> <author>Gambardella, Matthew</author> <title>XML Developer’s Guide</title> <genre>Computer</genre> <price>44.95</price> <publish_date>2000-10-01</publish_date> <description>An in-depth look at creating applications with XML.</description> </book> <book> <author>Ralls, Kim</author> <title>Midnight Rain</title> <genre>Fantasy</genre> <price>5.95</price> <publish_date>2000-12-16</publish_date> <description>A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world.</description> </book> <book> <author>Corets, Eva</author> <title>Maeve Ascendant</title> <genre>Fantasy</genre> <price>5.95</price> <publish_date>2000-11-17</publish_date> <description>After the collapse of a nanotechnology society in England, the young survivors lay the foundation for a new society.</description> </book> </catalog> |
Теперь мы выполним парсинг данного XML и вставим его в нашу структуру данных!
# -*- coding: utf-8 -*- from lxml import etree def parseBookXML(xmlFile): with open(xmlFile) as fobj: xml = fobj.read() root = etree.fromstring(xml) book_dict = {} books = [] for book in root.getchildren(): for elem in book.getchildren(): if not elem.text: text = «None» else: text = elem.text print(elem.tag + » => » + text) book_dict[elem.tag] = text if book.tag == «book»: books.append(book_dict) book_dict = {} return books if __name__ == «__main__»: parseBookXML(«books.xml»)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | # -*- coding: utf-8 -*- from lxml import etree
def parseBookXML(xmlFile): with open(xmlFile) as fobj: xml = fobj.read()
root = etree.fromstring(xml)
book_dict = {} books = [] for book in root.getchildren(): for elem in book.getchildren(): if not elem.text: text = «None» else: text = elem.text print(elem.tag + » => » + text) book_dict[elem.tag] = text
if book.tag == «book»: books.append(book_dict) book_dict = {}
return books
if __name__ == «__main__»: parseBookXML(«books.xml») |
Данный пример весьма похож на предыдущий, так что мы сосредоточимся только на различиях между ними. Перед началом итерации над контекстом, мы создадим объект пустого словаря и пустой список Python. Далее, в цикле, мы создадим наш словарь вот так:
book_dict[elem.tag] = text
book_dict[elem.tag] = text |
Текст может быть как elem.text так и None. Наконец, если тег окажется книгой, тогда мы в конце книжной секции, и нам нужно добавить словарь в наш список, а также сбросить словарь для следующей книги. Как мы видим, это именно то, что мы сделали. Более реалистичным примером будет размещение извлеченных данных в Python класс Book. Ранее я делал последнее с json feeds. Теперь мы готовы к тому, чтобы приступить к парсингу XML с lxml.objectify!
Парсинг XML с lxml.objectify
Модуль lxml содержит модуль, под названием objectify, который превращает документы XML в объекты Python. Для меня данная возможность оказалась весьма кстати во время работы, надеюсь, вам она тоже пригодиться. Вам может понадобиться немного помучаться при его установке, так как pip не работает с lxml в Windows. Обязательно перейдите в Индекс пакетов Python (https://pypi.python.org/pypi) и поищите версию, которая была разработана под вашу версию Python.
Установка lxml: http://lxml.de/installation.html
В любом случае, после установки, мы можем начать исследовать это чудесный кусок XML снова:
<?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> <appointment> <begin>1234360800</begin> <duration>1800</duration> <subject>Check MS Office website for updates</subject> <location></location> <uid>604f4792-eb89-478b-a14f-dd34d3cc6c21-1234360800</uid> <state>dismissed</state> </appointment> </zAppointments>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | <?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> <appointment> <begin>1234360800</begin> <duration>1800</duration> <subject>Check MS Office website for updates</subject> <location></location> <uid>604f4792-eb89-478b-a14f-dd34d3cc6c21-1234360800</uid> <state>dismissed</state> </appointment> </zAppointments> |
Теперь нам нужно написать код, который может выполнять парсинг и модифицировать XML. Давайте взглянем на это небольшое демо, которое показывает кучу чудесных возможностей, которые нам дает objectify.
# -*- coding: utf-8 -*- from lxml import etree, objectify def parseXML(xmlFile): «»»Parse the XML file»»» with open(xmlFile) as f: xml = f.read() root = objectify.fromstring(xml) # возвращаем атрибуты как словарь. attrib = root.attrib # извлекаем данные данные. begin = root.appointment.begin uid = root.appointment.uid # в цикле выводим всю информацию про элементы (тэги и текст). for appt in root.getchildren(): for e in appt.getchildren(): print(«%s => %s» % (e.tag, e.text)) print() # пример как менять текст внутри элемента. root.appointment.begin = «something else» print(root.appointment.begin) # добавление нового элемента. root.appointment.new_element = «new data» # удаляем аннотации. objectify.deannotate(root) etree.cleanup_namespaces(root) obj_xml = etree.tostring(root, pretty_print=True) print(obj_xml) # сохраняем данные в файл. with open(«new.xml», «w») as f: f.write(obj_xml) if __name__ == «__main__»: f = r’path\to\sample.xml’ parseXML(f)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | # -*- coding: utf-8 -*- from lxml import etree, objectify
def parseXML(xmlFile): «»»Parse the XML file»»» with open(xmlFile) as f: xml = f.read()
root = objectify.fromstring(xml)
# возвращаем атрибуты как словарь. attrib = root.attrib
# извлекаем данные данные. begin = root.appointment.begin uid = root.appointment.uid
# в цикле выводим всю информацию про элементы (тэги и текст). for appt in root.getchildren(): for e in appt.getchildren(): print(«%s => %s» % (e.tag, e.text)) print()
# пример как менять текст внутри элемента. root.appointment.begin = «something else» print(root.appointment.begin)
# добавление нового элемента. root.appointment.new_element = «new data»
# удаляем аннотации. objectify.deannotate(root) etree.cleanup_namespaces(root) obj_xml = etree.tostring(root, pretty_print=True) print(obj_xml)
# сохраняем данные в файл. with open(«new.xml», «w») as f: f.write(obj_xml)
if __name__ == «__main__»: f = r’path\to\sample.xml’ parseXML(f) |
Данный код детально прокомментирован, но мы потратим немного времени на том, чтобы исключить все недопонимания. В начале, мы передали наш пример файла XML и использовали objectify. Если вам нужно получить доступ к атрибутам тега, используйте свойство attrib. Оно вернет словарь атрибутов тега. Для доступа к под-теговым элементам, вам нужно использовать точечную нотацию. Как вы видите, для того, чтобы попасть к началу значения тега, мы можем просто сделать что-то на подобии этого:
begin = root.appointment.begin
begin = root.appointment.begin |
Есть один момент, которого стоит опасаться, это когда значение имеет ведущие нули, так что они могут быть усечены после возврата значения. Если это имеет значение для вас, тогда вам нужно использовать следующий синтаксис:
begin = root.appointment.begin.text
begin = root.appointment.begin.text |
Если вам нужно выполнить итерацию над дочерними элементами, вы можете использовать метод iterchildren. Возможно, вам придется использовать вложенную структуру цикла for, чтобы получить все необходимое. Изменение значения элемента это также просто, как присвоение ему нового значения.
root.appointment.new_element = «new data»
root.appointment.new_element = «new data» |
Теперь мы готовы к тому, чтобы перейти к созданию XML при помощи lxml.objectify.
Создание XML при помощи lxml.objectify
Субпакет lxml.objectify очень удобный инструмент для парсинга и создания XML. В данном разделе мы рассмотрим, как создавать XML при помощи модуля lxml.objectify. Мы начнем с примера простого XML кода и попробуем копировать его. Приступим!
Мы будем использовать следующий XML в качестве нашего примера:
<?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> <appointment> <begin>1234360800</begin> <duration>1800</duration> <subject>Check MS Office website for updates</subject> <location></location> <uid>604f4792-eb89-478b-a14f-dd34d3cc6c21-1234360800</uid> <state>dismissed</state> </appointment> </zAppointments>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | <?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> <appointment> <begin>1234360800</begin> <duration>1800</duration> <subject>Check MS Office website for updates</subject> <location></location> <uid>604f4792-eb89-478b-a14f-dd34d3cc6c21-1234360800</uid> <state>dismissed</state> </appointment> </zAppointments> |
Давайте посмотрим, как мы будем использовать lxml.objectify для воссоздания XML:
# -*- coding: utf-8 -*- from lxml import etree, objectify def create_appt(data): «»» Создаем изначальную структуру XML. «»» appt = objectify.Element(«appointment») appt.begin = data[«begin»] appt.uid = data[«uid»] appt.alarmTime = data[«alarmTime»] appt.state = data[«state»] appt.location = data[«location»] appt.duration = data[«duration»] appt.subject = data[«subject»] return appt def create_xml(): «»» Создаем XML файл. «»» xml = »'<?xml version=»1.0″ encoding=»UTF-8″?> <zAppointments> </zAppointments> »’ root = objectify.fromstring(xml) root.set(«reminder», «15») appt = create_appt({«begin»:1181251680, «uid»:»040000008200E000″, «alarmTime»:1181572063, «state»:»», «location»:»», «duration»:1800, «subject»:»Bring pizza home»} ) root.append(appt) uid = «604f4792-eb89-478b-a14f-dd34d3cc6c21-1234360800» appt = create_appt({«begin»:1234360800, «uid»:uid, «alarmTime»:1181572063, «state»:»dismissed», «location»:»», «duration»:1800, «subject»:»Check MS Office website for updates»} ) root.append(appt) # удаляем все lxml аннотации. objectify.deannotate(root) etree.cleanup_namespaces(root) # конвертируем все в привычную нам xml структуру. obj_xml = etree.tostring(root, pretty_print=True, xml_declaration=True ) try: with open(«example.xml», «wb») as xml_writer: xml_writer.write(obj_xml) except IOError: pass if __name__ == «__main__»: create_xml()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | # -*- coding: utf-8 -*- from lxml import etree, objectify
def create_appt(data): «»» Создаем изначальную структуру XML. «»» appt = objectify.Element(«appointment») appt.begin = data[«begin»] appt.uid = data[«uid»] appt.alarmTime = data[«alarmTime»] appt.state = data[«state»] appt.location = data[«location»] appt.duration = data[«duration»] appt.subject = data[«subject»] return appt
def create_xml(): «»» Создаем XML файл. «»»
xml = »'<?xml version=»1.0″ encoding=»UTF-8″?> <zAppointments> </zAppointments> »’
root = objectify.fromstring(xml) root.set(«reminder», «15»)
appt = create_appt({«begin»:1181251680, «uid»:»040000008200E000″, «alarmTime»:1181572063, «state»:»», «location»:»», «duration»:1800, «subject»:»Bring pizza home»} )
root.append(appt)
uid = «604f4792-eb89-478b-a14f-dd34d3cc6c21-1234360800» appt = create_appt({«begin»:1234360800, «uid»:uid, «alarmTime»:1181572063, «state»:»dismissed», «location»:»», «duration»:1800, «subject»:»Check MS Office website for updates»}
|
python-scripts.com
Создание, Редактирование и Парсинг XML файла
Python содержит встроенные XML инструменты для парсинга, к которым вы можете получить доступ при помощи модуля xml. В данной статье мы рассмотрим два подмодуля xml:
Мы начнем с minidom по той причине, что де-факто он используется в качестве метода парсинга XML. После этого, мы взглянем на то, как использовать ElementTree для этих целей.
Работаем с minidom
Для начала, нам нужен XML для парсинга. Давайте взглянем на следующий небольшой пример XML:
<?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> </zAppointments>
<?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> </zAppointments> |
Это типичный XML и читается он вполне интуитивно. В будущем вы, скорее всего, столкнетесь с более сложным примером XML, так что в нашем случае мы работаем с очень удобным материалом. В любом случае, сохраните описанный выше код XML под следующим названием: appt.xml
Давайте уделим больше времени на то, чтобы поближе познакомиться с парсингом данного файла в Python при помощи модуля minidom. Это достаточно длинный кусок кода, так что подготовьтесь:
# -*- coding: utf-8 -*- import xml.dom.minidom import urllib.request class ApptParser(object): def __init__(self, url, flag=’url’): self.list = [] self.appt_list = [] self.flag = flag self.rem_value = 0 xml = self.getXml(url) self.handleXml(xml) def getXml(self, url): try: print(url) f = urllib.request.urlopen(url) except: f = url doc = xml.dom.minidom.parse(f) node = doc.documentElement if node.nodeType == xml.dom.Node.ELEMENT_NODE: print(‘Элемент: %s’ % node.nodeName) for (name, value) in node.attributes.items(): print(‘ Attr — имя: %s значение: %s’ % (name, value)) return node def handleXml(self, xml): rem = xml.getElementsByTagName(‘zAppointments’) appointments = xml.getElementsByTagName(«appointment») self.handleAppts(appointments) def getElement(self, element): return self.getText(element.childNodes) def handleAppts(self, appts): for appt in appts: self.handleAppt(appt) self.list = [] def handleAppt(self, appt): begin = self.getElement(appt.getElementsByTagName(«begin»)[0]) duration = self.getElement(appt.getElementsByTagName(«duration»)[0]) subject = self.getElement(appt.getElementsByTagName(«subject»)[0]) location = self.getElement(appt.getElementsByTagName(«location»)[0]) uid = self.getElement(appt.getElementsByTagName(«uid»)[0]) self.list.append(begin) self.list.append(duration) self.list.append(subject) self.list.append(location) self.list.append(uid) if self.flag == ‘file’: try: state = self.getElement(appt.getElementsByTagName(«state»)[0]) self.list.append(state) alarm = self.getElement(appt.getElementsByTagName(«alarmTime»)[0]) self.list.append(alarm) except Exception as e: print(e) self.appt_list.append(self.list) def getText(self, nodelist): rc = «» for node in nodelist: if node.nodeType == node.TEXT_NODE: rc = rc + node.data return rc if __name__ == «__main__»: appt = ApptParser(«appt.xml») print(appt.appt_list)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | # -*- coding: utf-8 -*- import xml.dom.minidom import urllib.request
class ApptParser(object):
def __init__(self, url, flag=’url’): self.list = [] self.appt_list = [] self.flag = flag self.rem_value = 0 xml = self.getXml(url) self.handleXml(xml)
def getXml(self, url): try: print(url) f = urllib.request.urlopen(url) except: f = url
doc = xml.dom.minidom.parse(f) node = doc.documentElement if node.nodeType == xml.dom.Node.ELEMENT_NODE: print(‘Элемент: %s’ % node.nodeName) for (name, value) in node.attributes.items(): print(‘ Attr — имя: %s значение: %s’ % (name, value))
return node
def handleXml(self, xml): rem = xml.getElementsByTagName(‘zAppointments’) appointments = xml.getElementsByTagName(«appointment») self.handleAppts(appointments)
def getElement(self, element): return self.getText(element.childNodes)
def handleAppts(self, appts): for appt in appts: self.handleAppt(appt) self.list = []
def handleAppt(self, appt): begin = self.getElement(appt.getElementsByTagName(«begin»)[0]) duration = self.getElement(appt.getElementsByTagName(«duration»)[0]) subject = self.getElement(appt.getElementsByTagName(«subject»)[0]) location = self.getElement(appt.getElementsByTagName(«location»)[0]) uid = self.getElement(appt.getElementsByTagName(«uid»)[0])
self.list.append(begin) self.list.append(duration) self.list.append(subject) self.list.append(location) self.list.append(uid)
if self.flag == ‘file’: try: state = self.getElement(appt.getElementsByTagName(«state»)[0]) self.list.append(state) alarm = self.getElement(appt.getElementsByTagName(«alarmTime»)[0]) self.list.append(alarm) except Exception as e: print(e)
self.appt_list.append(self.list)
def getText(self, nodelist): rc = «» for node in nodelist: if node.nodeType == node.TEXT_NODE: rc = rc + node.data return rc
if __name__ == «__main__»: appt = ApptParser(«appt.xml») print(appt.appt_list) |
Этот код основан на примере из документации Python и стоит отметить, что, на мой взгляд, он немного уродливый. Давайте его разберем по кусочкам. Параметр url, который мы видим в классе ApptParser, может быть как url так и файлом. В методе getXml, мы используем обработчик исключений для того, чтобы попробовать открыть url. Если это привело к ошибке, значит url – это путь к файлу. Далее мы используем метод парсинга для парсинга XML. Далее мы изымаем node из XML. Мы опустим все условия, так как в данной статье это не принципиально. Наконец, мы возвращаем объект node. Технически, node является объектом XML, и мы передаем его методу handleXml. Чтобы получить все назначения в XML, мы делаем следующее:
xml.getElementsByTagName(«appointment»)
xml.getElementsByTagName(«appointment») |
После этого, мы передаем эту информацию методу handleAppts. Это большой объем информации. Хорошей идеей будет небольшой рефакторинг этого кода для этой цели, вместо передачи всей этой информации целиком, таким образом мы просто настраиваем переменные класса, после чего вызываем следующий метод без каких-либо аргументов. Я оставлю это в качестве упражнения для читателей. В любом случае, метод handleAppts только создает цикл в каждом назначении и вызывает метод handleAppt, чтобы вытянуть кое-какую дополнительную информации, добавляет данные в список и добавляет этот список в другой список. Идея в том, чтобы закончить со списком списков, которые содержат все соответствующие данные о встречах.
Мы собрали ТОП Книг для Python программиста которые помогут быстро изучить язык программирования Python. Список книг: Книги по PythonОбратите внимание на то, что метод handleAppt вызывает метод getElement, который, в свою очередь вызывает метод getText. Технически, вы можете пропустить вызов getElement и вызвать getText напрямую. С другой стороны, вам может понадобиться добавить дополнительную обработку в getElement для конвертации текста, или чего-то другого перед возвратом. Например, вам может понадобиться конвертировать целые числа, числа с запятыми или объекты decimal.Decimal. Давайте попробуем еще один пример с minidom, перед тем как двигаться дальше. Мы используем пример XML с сайта MSDN Майкрософт: http://msdn.microsoft.com/en-us/library/ms762271%28VS.85%29.aspx . Сохраните следующий код под названием example.xml
<?xml version=»1.0″?> <catalog> <book> <author>Gambardella, Matthew</author> <title>XML Developer’s Guide</title> <genre>Computer</genre> <price>44.95</price> <publish_date>2000-10-01</publish_date> <description>An in-depth look at creating applications with XML.</description> </book> <book> <author>Ralls, Kim</author> <title>Midnight Rain</title> <genre>Fantasy</genre> <price>5.95</price> <publish_date>2000-12-16</publish_date> <description>A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world.</description> </book> <book> <author>Corets, Eva</author> <title>Maeve Ascendant</title> <genre>Fantasy</genre> <price>5.95</price> <publish_date>2000-11-17</publish_date> <description>After the collapse of a nanotechnology society in England, the young survivors lay the foundation for a new society.</description> </book> </catalog>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | <?xml version=»1.0″?> <catalog> <book> <author>Gambardella, Matthew</author> <title>XML Developer’s Guide</title> <genre>Computer</genre> <price>44.95</price> <publish_date>2000-10-01</publish_date> <description>An in-depth look at creating applications with XML.</description> </book> <book> <author>Ralls, Kim</author> <title>Midnight Rain</title> <genre>Fantasy</genre> <price>5.95</price> <publish_date>2000-12-16</publish_date> <description>A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world.</description> </book> <book> <author>Corets, Eva</author> <title>Maeve Ascendant</title> <genre>Fantasy</genre> <price>5.95</price> <publish_date>2000-11-17</publish_date> <description>After the collapse of a nanotechnology society in England, the young survivors lay the foundation for a new society.</description> </book> </catalog> |
В этом примере мы выполнили парсинг XML, извлекли заголовки книги и вывели их в stdout. Давайте взглянем на код:
# -*- coding: utf-8 -*- import xml.dom.minidom as minidom def getTitles(xml): «»» Выводим все заголовки из xml. «»» doc = minidom.parse(xml) node = doc.documentElement books = doc.getElementsByTagName(«book») titles = [] for book in books: titleObj = book.getElementsByTagName(«title»)[0] titles.append(titleObj) for title in titles: nodes = title.childNodes for node in nodes: if node.nodeType == node.TEXT_NODE: print(node.data) if __name__ == «__main__»: document = ‘example.xml’ getTitles(document)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | # -*- coding: utf-8 -*- import xml.dom.minidom as minidom
def getTitles(xml): «»» Выводим все заголовки из xml. «»» doc = minidom.parse(xml) node = doc.documentElement books = doc.getElementsByTagName(«book»)
titles = [] for book in books: titleObj = book.getElementsByTagName(«title»)[0] titles.append(titleObj)
for title in titles: nodes = title.childNodes for node in nodes: if node.nodeType == node.TEXT_NODE: print(node.data)
if __name__ == «__main__»: document = ‘example.xml’ getTitles(document) |
Данный код – это только одна короткая функция, которая принимает один аргумент, который является файлом XML. Мы импортируем модуль minidom и даем ему такое же название, чтобы упростить отсылки к нему. Далее мы выполняем парсинг XML. Первые две строки функции очень похожи на те, что были в предыдущем примере. Мы используем метод getElementsByTagName чтобы собрать нужные нам части XML, после чего выполнить итерацию над результатом и извлечь заголовки книги. Так, мы извлекаем объекты заголовков, так что нужно выполнить итерацию этих данных в том числе, а также вытащить обычный текст, по этой причине мы используем вложенные данные цикла. Давайте уделим немного времени на унаследованный модуль xml под названием ElementTree.
Парсинг с ElementTree
В данном разделе, мы научимся создавать XML файлы, редактировать и выполнять парсинг при помощи ElementTree. Для сравнения, мы используем тот же XML, который мы использовали в предыдущем разделе для того, чтобы продемонстрировать разницу в использовании minidom и ElementTree. Вот наш код:
<?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> </zAppointments>
<?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> </zAppointments> |
Давайте начнем с изучения того, как создавать такую XML структуру при помощи Python
Как создавать XML при помощи ElementTree
Создание XML при помощи ElementTree – это очень просто. В данном разделе, мы попытаемся создать написанный выше XML в Python. Давайте посмотрим на код:
# -*- coding: utf-8 -*- import xml.etree.ElementTree as xml def createXML(filename): «»» Создаем XML файл. «»» root = xml.Element(«zAppointments») appt = xml.Element(«appointment») root.append(appt) # создаем дочерний суб-элемент. begin = xml.SubElement(appt, «begin») begin.text = «1181251680» uid = xml.SubElement(appt, «uid») uid.text = «040000008200E000» alarmTime = xml.SubElement(appt, «alarmTime») alarmTime.text = «1181572063» state = xml.SubElement(appt, «state») location = xml.SubElement(appt, «location») duration = xml.SubElement(appt, «duration») duration.text = «1800» subject = xml.SubElement(appt, «subject») tree = xml.ElementTree(root) with open(filename, «w») as fh: tree.write(fh) if __name__ == «__main__»: createXML(«appt.xml»)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | # -*- coding: utf-8 -*- import xml.etree.ElementTree as xml
def createXML(filename): «»» Создаем XML файл. «»» root = xml.Element(«zAppointments») appt = xml.Element(«appointment») root.append(appt)
# создаем дочерний суб-элемент. begin = xml.SubElement(appt, «begin») begin.text = «1181251680»
uid = xml.SubElement(appt, «uid») uid.text = «040000008200E000»
alarmTime = xml.SubElement(appt, «alarmTime») alarmTime.text = «1181572063»
state = xml.SubElement(appt, «state»)
location = xml.SubElement(appt, «location»)
duration = xml.SubElement(appt, «duration») duration.text = «1800»
subject = xml.SubElement(appt, «subject»)
tree = xml.ElementTree(root) with open(filename, «w») as fh: tree.write(fh)
if __name__ == «__main__»: createXML(«appt.xml») |
Если вы запустите этот код, вы должны получить что-то вроде нижеизложенного (возможно в одной строке):
<?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state /> <location /> <duration>1800</duration> <subject /> </appointment> </zAppointments>
<?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state /> <location /> <duration>1800</duration> <subject /> </appointment> </zAppointments> |
Это очень похоже на исходный код и это, безусловно, действенный XML. Само собой, наши коды отличаются, но весьма похожи. Давайте уделим время для разбора кода и убедиться в том, что мы его хорошо понимаем. Для начала мы создаем корневой элемент при помощи функции Element модуля ElementTree. Далее, мы создаем элемент назначения и добавляем его к root. Далее, мы создаем SubElements, выполнив парсинг назначения объекта Element (appt) в SubElement наряду с именем, например, begin. Далее, для каждого SubElement, мы назначаем их текстовые свойства, для передачи значения. В конце скрипта мы создаем ElementTree и используем его для написания XML в файле. Теперь мы готовы к тому, чтобы научиться редактировать файл!
Как редактировать XML при помощи ElementTree
Редактирование XML при помощи ElementTree это также очень просто. Чтобы все было немного интереснее, мы добавим другой блок назначения в XML:
<?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> <appointment> <begin>1181253977</begin> <uid>sdlkjlkadhdakhdfd</uid> <alarmTime>1181588888</alarmTime> <state>TX</state> <location>Dallas</location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> </zAppointments>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | <?xml version=»1.0″ ?> <zAppointments reminder=»15″> <appointment> <begin>1181251680</begin> <uid>040000008200E000</uid> <alarmTime>1181572063</alarmTime> <state></state> <location></location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> <appointment> <begin>1181253977</begin> <uid>sdlkjlkadhdakhdfd</uid> <alarmTime>1181588888</alarmTime> <state>TX</state> <location>Dallas</location> <duration>1800</duration> <subject>Bring pizza home</subject> </appointment> </zAppointments> |
Теперь мы напишем код для того, чтобы изменить каждое значение тега begin от секунд, начиная с эпохи на что-нибудь более читабельное. Мы используем модуль time python, чтобы облегчить себе жизнь:
# -*- coding: utf-8 -*- import time import xml.etree.cElementTree as ET def editXML(filename): «»» Редактируем XML файл. «»» tree = ET.ElementTree(file=filename) root = tree.getroot() for begin_time in root.iter(«begin»): begin_time.text = time.ctime(int(begin_time.text)) tree = ET.ElementTree(root) with open(«updated.xml», «w») as f: tree.write(f) if __name__ == «__main__»: editXML(«original_appt.xml»)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # -*- coding: utf-8 -*- import time import xml.etree.cElementTree as ET
def editXML(filename): «»» Редактируем XML файл. «»» tree = ET.ElementTree(file=filename) root = tree.getroot()
for begin_time in root.iter(«begin»): begin_time.text = time.ctime(int(begin_time.text))
tree = ET.ElementTree(root) with open(«updated.xml», «w») as f: tree.write(f)
if __name__ == «__main__»: editXML(«original_appt.xml») |
Здесь мы создаем объект ElementTree под названием tree и извлечем из него root. Далее мы используем метод iter() чтобы найти все теги, помеченные “begin”. Обратите внимание на то, что метод iter() был добавлен в Python 2.7. В наем цикле for, мы указываем текстовое содержимое каждого объекта, чтобы по
python-scripts.com
Парсер xml — DOM и SAX
Парсер xml — это по сути програмный анализатор (синтаксический разборщик) xml документа. Задача парсера — прочитать документ с данными и как-то его представить пользователю (например, чтобы его можно было внести в базу данных или модифицировать).
В XML на сегодня есть 2 подхода к разбору документа: SAX и DOM. Дополнительно информацию о них ищите на сайте через форму поиска.
SAX — Simle API of XML, простой api для работы с xml файлами, довольно примитивный, но зато быстрый.
DOM — Document Object Model. На сегодня самый распространенный и продвинутый.
DOM парсер
На входе получает какой-то документ с данными, а на выходе выдает дерево объектов.
Когда мы работаем с xml, к нам в парсер могут приходить совершенно разные документы. И иногда бывает документ не для нас, и просто обработать его dom парсером будет неправильно (документ может быть неполным, не все указано, не та структура, некорректные данные). И нам надо отсеять все это на этапе обработки, т.е. т.н. валидация документа. Т.е. надо определить грамматику входящего xml документа.
И поэтому разработчики пошли по принципу декларативности: пусть парсер сам проверяет документ. Т.е. парсеру описывается набор правил, как должно быть, а он должен проверять, насколько данный документ похож, как должно быть. Среди таких описаний выделяют DTD. Рассмотрим ниже.
Описания DTD — Document Type Definition (определения типов документов)
DTD — это набор сокращений, некий язык описания (подобно xml), который позволяет указать, какие тэги мы ждем, т.е. какие элементы в нашем документе должны быть, сколько раз они имеют право повторяться, какие атрибуты должны быть у элементов, какие атрибуты обязательные и необязательные, какие сущности могут использоваться.
Сущность — это некая константа. Есть ‘встроенные’ константы – <, >, & — они заменяют запрещенные в xml символы. И есть расширяемые сущности, например, ©, . Свои собственные сущности можно определить так:
<!ENTITY today "Septemer 24, 2012">
<!ENTITY company "RUSAL">
//вызов этих сущностей
<?xml version="1.0"?>
<TEXT>
Сегодня &today;
Информация о &company;
</TEXT>Описание DTD на сегодня устарело, редко где применяется, но поскольку его еще можно встретить, знать его синтаксис лишним не будет:
<!DOCTYPE pricelist [
<!ELEMENT pricelist (book+)>
<!ELEMENT book (title,author+,price)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT price (#PCDATA)>
]>
<pricelist>
<book>
<title>Название</title>
<author>Автор</author>
<price>123</price>
</book>
</pricelist>В этом примере, мы объяснили анализатору, как должно быть, описали грамматику. Вместо #PCDATA подставляются наши данные по книгам.
Т.е. DTD — это набор правил для вашего анализатора, в котором сообщается, как выглядит ваш документ.
Но как сказать анализатору, что документ нужно проверять по нашему описанию (например, как в листинкг выше)? Есть 2 способа:
- Декларативный — см. пример листинга выше. При этом анализируемый документ называется ‘самодостаточный’ (standalone), т.е. у него есть и DTD, и сами данные. Такие документы используют очень редко, т.к. они много весят.
- Программный. Здесь нет самого DTD, есть только ссылка на него + наши данные. Но в реальности никакой файл по ссылке не загружается, это только команда браузеру переключиться в другой режим работы. Пример:
<!DOCTYPE books SYSTEM "http://phpmove.ru/books.dtd">
<book>
<title>Название</title>
<author>Автор</author>
<price>123</price>
</book>Самое главное назначение DTD — валидация, т.е. проверка документа на соответствие стандарту. Когда документ достаточно сложный, перед преобразованием его надо бы проверить.
1st-network.ru
Выгрузка товаров в XML с помощью парсера сайтов Q-Parser
1. В списке товаров нажмите «Выгрузить»
После загрузки товаров на парсер, находясь на странице со списком товаров, нажмите кнопку «Выгрузить».
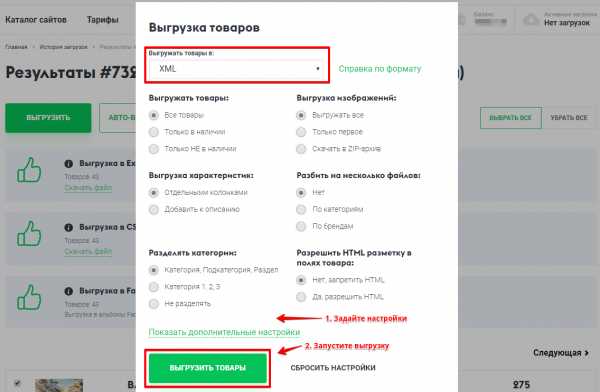
2. Задайте настройки файла
В появившемся окне выберите формат «XML» и задайте настройки формата.
Обратите внимание, что для выгрузки в Яндекс.Маркет используется отдельный формат.
Подробное описание каждой настройки вы можете найти ниже на этой странице.
3. Выгрузка запущена
Появится индикатор выгрузки товаров. Если не хотите ждать, вы можете выключить компьютер или закрыть браузер — выгрузка продолжится независимо от вас.
По окончанию выгрузки вы увидите ссылку на скачивание файла Excel. Если будет сформировано несколько файлов, появится список ссылок.
Общие настройки:
Выгружать товары — позволяет выбрать какие товары выгружать по признаку «Наличие» на сайте поставщика.
Порядок выгрузки товаров — позволяет выбрать порядок выгрузки товаров и установить выгрузку задом наперед при желании.
Разрешить HTML разметку в полях товара — разрешает или запрещает HTML-разметку в полях товара. Очень редко используется интернет-магазинами.
Выгрузка изображений — позволяет изменить число или способ выгрузки изображений.
Имеется возможность скачать все изображения товаров в виде архива. Для этого выберите опцию «Поместить в ZIP-архив» при выгрузке.
Выгрузка характеристик — позволяет выгрузить свойства товаров (цвета, размеры и пр.) отдельными полями в файле или просто добавить к общему описанию товара. При добавлении к описанию сами колонки остаются. Выбирается в зависимости от возможностей вашего интернет-магазина или сайта СП.
Выгрузка рядов — аналогично выгрузке характеристик, но в отношении рядов товара. Позволяет добавить инфомрацию о рядах к описанию.
Разделять категории — разделять вложенные категории на разные поля (по цифрам или по названиям).
Разбить на несколько файлов — позволяет разбить выгрузку на несколько файлов: по категориям или по брендам.
Кодировка файла — выбор кодировки файла. Если не знаете что это такое, уточните в техподдержке своего сайта или оставьте без изменений.
Нашли ошибку в выгрузке в этот формат?
Если вы обнаружили ошибку в формате выгрузки XML, пожалуйста, сообщите нам на [email protected] или в чат на сайте. Мы постараемся исправить выгрузку как можно скорее.
q-parser.ru