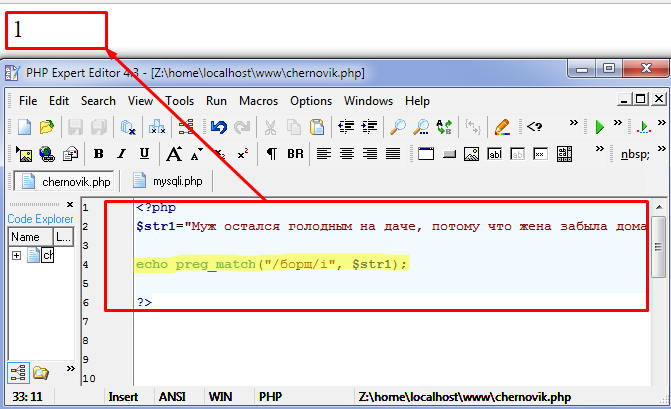
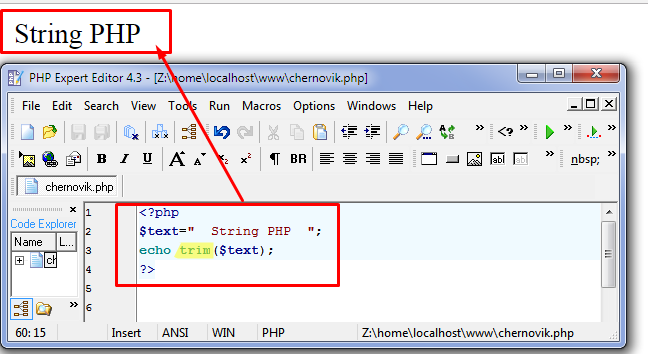
Методы строк в Ruby | 8HOST.COM
17 ноября, 2017 11:58 дп 11 496 views | 1 комментарийRuby | Amber | 1 Comment
Строки Ruby предлагают множество встроенных методов для управления и изменения текста.
Данный мануал научит вас использовать методы строк, а именно определять длину строк, индексировать и разделять строки, извлекать подстроки, добавлять и удалять пробелы и другие символы, изменять регистр символов в строках, находить и заменять текст.
Читайте также: Работа со строками в Ruby
Определение длины строки
Метод length возвращает количество символов в строке. Этот метод можно применить, чтобы установить ограничения длины пароля или обрезать длинные строки.
Рассмотрим такой пример:
open_source = "8host contributes to open source."
print open_source.length
33
Метод учитывает все символы в строке, включая буквы, числа, пробелы и символы.
Чтобы найти пустую строку, можно использовать логический метод empty?.
name = ""
name.empty? # true
name = "8host"
name.empty? # false
name = " "
name.empty? # false
Доступ к символу в строке
Чтобы отобразить или использовать в других операциях символы из строк, используйте метод slice.
Как и в массивах, в строках каждый элемент (символ) соответствует индексу. Индексация начинается с 0.
Строка 8host индексируется так:
0 1 2 3 4
8 h o s t
Метод slice позволяет извлекать символ или диапазон символов из строки. Передавая в качестве аргумента индекс, вы получите символ, который соответствует этому индексу. Передав два числа через запятую, вы получите все символы в заданном диапазоне включительно. Метод slice принимает диапазоны в виде 1..4.
"8host".slice(0) # "8"
"8host". slice(1,2) # "ho"
slice(1,2) # "ho"
"8host".slice(1..4) # "host"
Синтаксис [] является псевдонимом slice:
"8host"[0] # "8"
"8host"[1,2] # "ho"
"8host"[1..4] # "host"
Получить доступ к символам в конце строки можно с помощью отрицательного индекса. -1 выведет последний символ строки, -2 – предпоследний и т.д.
Также вы можете преобразовать строку в массив значений.
"8host".chars # ["8", "h", "o", "s", "t"]
Это позволяет управлять или изменять символы в строке.
Преобразование в верхний и нижний регистр
Методы upcase и downcase возвращают строку, преобразовывая символы в верхний и нижний регистр соответственно. Небуквенные символы не будут меняться.
Попробуйте преобразовать строку 8host Blog в верхний регистр:
name = "8host Blog"
print name.upcase
8HOST BLOG
Теперь переведите ее в нижний регистр:
print name.downcase
8host blog
Функции upcase и downcase позволяют оценить и сравнить строки, сводя их к одному регистру. К примеру, если пользователь вводит имя с большой буквы, программа сможет перевести его в нижний регистр и сравнить с известным ей значением.
К примеру, если пользователь вводит имя с большой буквы, программа сможет перевести его в нижний регистр и сравнить с известным ей значением.
Строки Ruby используют метод capitalize, чтобы переписать все слова в строке с большой буквы.
" blog".capitalize # " Blog"
Также в Ruby есть метод swapcase, который обращает регистр строки. Например:
text = "Blog"
print text.swapcase
bLOG
Методы downcase, upcase, captalize и swapcase возвращают новую строку, не изменяя исходную строку. Об этом важно помнить.
Рассмотрим такой пример:
text = "world"
text.capitalize
print "Hello, #{text}!"
Hello, world!
Хотя метод capitalize применен к переменной text, программа не использует значение, преобразованное методом capitalize. Чтобы изменить это, программу нужно переписать.
text = " world"
text = text.capitalize
print "Hello, #{text}!"
Hello, World!
Методы downcase!, upcase!, capitalize! и swapcase! изменяют исходную строку.
text = "world"
text = text.capitalize!
print "Hello, #{text}!"
Работа с отступами
Если вы пишете программу, которая должна форматировать текст, вам нужно добавить отступы перед, после или вокруг строки, чтобы она совпадала с другими данными. И наоборот – иногда необходимо удалить ненужные символы с начала или конца строк (например, лишние пробелы или специальные символы).
Чтобы добавить пробелы с обоих концов строки, используйте метод center:
"8host",center(21) # " 8host "
Чтобы использовать другой символ, укажите строку как аргумент:
" [8host] ".center(21, "<>") # "<><><> [8host] <><><>"
Методы ljust и rjust добавляют пробелы и символы слева и справа от строки соответственно и работают как метод center:
"8host".ljust(20) # "8host "
"8host".rjust(20) # " 8host"
"8host". rjust(20, "!") # "!!!!!!!!!!!!!!!8host"
rjust(20, "!") # "!!!!!!!!!!!!!!!8host"
Чтобы удалить пробелы справа и слева соответственно, используйте методы rstrip и lstrip. Метод strip удаляет пробелы с обеих сторон.
" 8host".rstrip # "8host"
"8host ".lstrip # "8host"
" 8host ".strip # "8host"
Для изменения исходной строки используйте методы center!, ljust!, rjust!, lstrip!, rstrip! и strip!
Чтобы удалить последний символ строки, используйте метод chop.
"8host".chop # "8hos"
Это особенно полезно, если вам нужно удалить символ новой строки (\n).
"This string has a newline\n".chop
Метод chop не изменяет исходную строку, а возвращает новую строку. Метод chop! Переписывает исходную строку.
Метод chomp может удалить несколько символов с конца строки.
"8host".chomp("st") # "8ho"
Если вы не укажете строку, которую нужно удалить, chomp удалит символ новой строки.
"This string has a newline\n".chomp # "This string has a newline
Однако если в строке нет символа новой строки, метод chomp просто вернет исходную строку.
"8host".chomp # "8host"
Потому chomp безопаснее использовать для удаления символов новой строки, чем chop, который всегда удаляет последний символ.
В Ruby есть метод chomp!, который изменяет исходную строку. В отличие от метода chomp, его версия chomp! возвращает nil, если строка не была изменена.
string = "Hello\n"
string.chomp! # "Hello"
string = "Hello"
string.chomp! # nil
Поиск символов и текста
Метод include? позволяет проверить, есть ли в строке искомая строка. Если она есть, он возвращает true, а если нет – false.
"8host".include?("о") # true
"8host".include?("b") # false
Метод index возвращает индекс искомого символа. Также он может определить индекс первого символа подстроки. При запросе несуществующего символа он возвращает nil.
При запросе несуществующего символа он возвращает nil.
"8host".index("h") # 1
"8host".index("os") # 2
"8host".index("blog") # nil
Метод index находит только первое совпадение.
text = "8host has a blog"
text.index("o") # 2
Строка содержит и другие символы «о», но метод выводит только первое совпадение.
Чтобы найти другие совпадения, можно преобразовать строку в массив и использовать методы массивов для итерации по полученному массиву и поиска других совпадений.
Помимо поиска символов в строке, вы можете проверить, начинается ли строка с символа или подстроки, используя start_with? метод:
text = "8host has a blog"
text.start_with?("8") # true
text.start_with?("8host " # true
Метод start_with? принимает несколько строк и возвращает true, если совпадает хотя бы одна из них
text = "8host has a blog"
text.start_with?("8host the Blog", "8host") # true
Вы можете использовать метод end_with? чтобы узнать, заканчивается ли строка указанной подстрокой.
text = "8host has a blog"
text.end_with?("blog") # true
text.end_with?("site") # false
text.end_with?("site", "blog") # true
Замена текста в строках
Функция поиска и замены текстовых процессоров позволяет искать строку и заменять ее другой строкой. В Ruby это делается с помощью методов sub и gsub.
Метод sub заменяет часть строки на другую.
Попробуйте изменить строку:
blog = "8host has a blog"
print blog.sub("has","had")
Метод sub заменяет только первое совпадение. Рассмотрим такой пример с двумя вхождениями искомого слова:
blog = "8host has a blog. The blog has articles"
print blog.sub("has","had")
8host had a blog. The blog has articles
Чтобы изменить все совпадения, используйте метод gsub, который выполняет глобальную замену:
blog = "8host has a blog. The blog has articles"
print blog. gsub("has","had")
gsub("has","had")
8host had a blog. The blog had articles
Методы sub и gsub всегда возвращают новые строки, оставляя исходные строки неизменными. Рассмотрим следующий пример:
text = "8host has a blog"
text.gsub("blog", "site")
print text
8host has a blog
Результат получается не тот, потому что программа не выполняет подстановку и не использует результат gsub в новой переменной. Чтобы получить ожидаемый результат, нужно переписать программу следующим образом:
text = "8host has a blog"
text = text.sub("blog", "site")
print text
Кроме того, вы можете использовать метод sub!, который изменяет исходную строку.
text = "8host has a good blog"
text.sub!("good", "nice")
text.sub!("blog", "site")
print text
8host has a nice site
Метод gsub! выполняет глобальную замену.
Методы sub и gsub принимают регулярные выражения в качестве шаблона поиска. Давайте заменим все гласные в строке символом @:
"8host has a good blog". gsub /[aeiou]/, "@"
gsub /[aeiou]/, "@"
"8h@st h@s @ g@@d bl@g"
Также вы можете использовать хэш, чтобы указать, как заменить отдельные символы или фрагменты. Давайте заменим все буквы а на @ и все буквы о нулями:
"8host has a good blog".gsub /[aeiou]/, {"a" => "@", "o" => "0"}
# "8h0st h@s @ g00d bl0g"
Вы можете использовать эти методы для выполнения более сложных замещений.
Заключение
В этом мануале вы научились управлять строками с помощью встроенных методов.
Многие из методов работы со строками представлены в двух вариантах: один оставляет строку неизменной, а второй изменяет исходную строку. Какой из них вы используете, зависит от ваших потребностей.
Однако код, который не изменяет исходные данные, в дальнейшем может быть проще отлаживать.
Читайте также:
- Работа со строками в Ruby
- Работа с массивами в Ruby
- Типы данных в Ruby
- Методы массивов в Ruby
Help — коллекция статей, исходников, книг, ответов на вопросы программирования на языке программирования Delphi и Pascal.
 — это среда быстрой разработки, в которой в качестве языка программирования используется язык Delphi. Язык Delphi — строго типизированный объектно-ориентированный язык, в основе которого лежит хорошо знакомый программистам Object Pascal.
— это среда быстрой разработки, в которой в качестве языка программирования используется язык Delphi. Язык Delphi — строго типизированный объектно-ориентированный язык, в основе которого лежит хорошо знакомый программистам Object Pascal.На сайте Delphi-Help вы можете скачать книги по Delphi, для дальнейшего изучения этого удивительного языка программирования. Также в файловом архиве доступны компоненты, исходники, программы для облегчения разработки своих собственных приложений. Все материалы и файлы на сайте бесплатны.
Это необходимо знать каждому программисту:
- Работа с ADO в Delphi
- Цикл с постусловием (REPEAT-UNTIL)
- Цикл с параметром (FOR)
- Цикл с предусловием (WHILE-DO)
- Циклические алгоритмы.
 Цикл с предусловием.
Цикл с предусловием. - Хранимые процедуры
- Создание и изменение базы данных в InterBase/Firebird
- Использование TWebBrowser (статья)
- Одномерные массивы. Формирование массива и вывод его элементов
- Руководство по TDbf
- Копирование и восстановление базы данных в InterBase / Firebird
- Алгоритм 3. Сортировка шейкером
- Работа с BLOB-полями в клиентских приложениях InterBase и Firebird на основе компонентов FIBPlus
- SQL-запросы в Delphi
- Учетные записи пользователя в InterBase/Firebird
- Ограничения базы данных
- TADOConnection
- Индексы
- Компонент Chart
- Типизированные файлы
- Список ошибок BDE
- QuickReport руководство
- Алгоритм 2. Пузырьковая сортировка
- Задача 579 на Pascal — Шифр Цезаря
- FIBPlus: Обработка ошибок базы данных
- Нетипизированные файлы
- Решение уравнения методом хорд, методом касательных (метод Ньютона), методом половинного деления, методом простых итераций
- Дипломная работа: Разработка базы данных для информатизации деятельности предприятия малого бизнеса Delphi
- Количество вхождений подстроки в строку
- Использование текстовых файлов для импорта и экспорта
- Сумма прописью (хорошая функция)
- Создание собственной кнопки в Delphi
- Firebird взаимодействие с NULL
- Как посчитать факториал?
- Как узнать номер недели данного дня в году?
- Devrace FIBPlus: Оптимизация сетевого трафика в приложениях на Delphi и C++ Builder
- Счетчик посещений на Delphi
- Cпроектировать и написать программу «Интерпретатор» на Pascal
- Перевод чисел из одной системы исчисления в другую
- Rave Reports-руководство разработчика
 Цикл с предусловием.
Цикл с предусловием. Сортировка шейкером
Сортировка шейкером Пузырьковая сортировка
Пузырьковая сортировкаОбщение
Авторизация
Логин
Пароль
Запомнить меня
- Забыли пароль?
- Забыли логин?
- Типизированные файлы
Типизированные файлы Тип файлов, для которого нет поддержки в OS…
- Задача 579 на Pascal — Шифр Цезаря
Задача 579 на Pascal — Шифр Цезаря Шифр Цезаря.
Этот… - Нетипизированные файлы
Нетипизированные файлы Третий тип файлов Паскаля, это нетипизированные файлы, этот…
- Использование текстовых файлов для импорта и экспорта
Использование текстовых файлов для импорта и экспорта Текстовые файлы являются…
- Как изменить дату создания файла?
Как изменить дату создания файла? function SetFileDateTime( const FileName: string;…
- Как изменить атрибуты файла?
Как изменить атрибуты файла? r — ReadOnly h — Hidden…
 Этот…
Этот…Счетчики
Файловый архив — популярное
FastReport full source v5. 2.12 2.12 | 25996 |
| Базы данных в Delphi | 22078 |
| Практикум по Delphi для решения прикладных задач | 19095 |
| Delphi. Учимся на примерах | 16267 |
| Delphi 7 для профессионалов | 14424 |
| Программирование в Delphi 7 | 7107 |
| Delphi. Профессиональное программирование | 6690 |
Основы Delphi. Профессиональный подход Профессиональный подход | 5219 |
| Assembler. Учебный курс | 4084 |
| Графика в проектах Delphi | 4082 |
| Розница ИП v1.3 | 2769 |
| Delphi 7 | 2509 |
| DevExpress VCL Component | 2454 |
| TXLSFile 4.0 | 2078 |
| AlphaControls package | 2034 |
Последние статьи
- Рисуем на рабочем столе
Вы можете использовать поверхность рабочего стола для вывода любой графики.
Этот способ может понадобится для написания различных напоминалок, показ праздников. Вы можете поселить на рабочем столе забавного персонажа из комикса… - Работа с потоками в Delphi
Нередко встречал на форумах мнения, что потоки не нужны вообще, любую программу можно написать так, что она будет замечательно работать и без них. Конечно, если не делать ничего серьёзней…
- Перестановка чисел без третей переменой
Перестановка чисел без третей переменной. В данной статье рассмотрим способ, как поменять местами значения двух переменных без использования третей.
Для этого нам понадобится, скажем, два edit и одна кнопка. Разместите…
 Этот способ может понадобится для написания различных напоминалок, показ праздников. Вы можете поселить на рабочем столе забавного персонажа из комикса…
Этот способ может понадобится для написания различных напоминалок, показ праздников. Вы можете поселить на рабочем столе забавного персонажа из комикса… Для этого нам понадобится, скажем, два edit и одна кнопка. Разместите…
Для этого нам понадобится, скажем, два edit и одна кнопка. Разместите…Последние комментарии
Можно ли разделить строку после определенного c…
Информационный бюллетень сообщества и предстоящие события за май 2023 г.
Добро пожаловать в наш Информационный бюллетень сообщества за май 2023 г., где мы будем освещать последние новости, выпуски, предстоящие события и отличная работа наших участников в сообществах Biz Apps. Если вы новичок в этой группе LinkedIn, обязательно подпишитесь здесь, в новостях и объявлениях, чтобы быть в курсе последних новостей от нашей постоянно растущей сети участников, которые «изменили свое представление о коде». ПОСЛЕДНИЕ НОВОСТИ
«Понедельники в Microsoft» в прямом эфире на LinkedIn — 8:00 по тихоокеанскому стандартному времени — понедельник, 15 мая — выпейте утренний кофе в понедельник и присоединяйтесь к главным менеджерам программы Хизер Кук и Каруане Гатиму на премьере эпизода «Понедельники в Microsoft»! Это шоу положит начало запуску нового канала сообщества Microsoft в LinkedIn и охватит целый ряд горячих тем из #PowerPlatform, #ModernWork, #Dynamics365, #AI и всего, что между ними. Просто нажмите на изображение ниже, чтобы зарегистрироваться и присоединиться к команде в прямом эфире в понедельник, 15 мая 2023 года, в 8:00 по тихоокеанскому стандартному времени. Надеюсь увидеть тебя там! Исполнительный основной доклад | День успеха клиентов Microsoft
CVP for Business Applications & Platform, Charles Lamanna, делится последними усовершенствованиями и обновлениями продукта #BusinessApplications, чтобы помочь клиентам достичь результатов в бизнесе. S01E13 Power Platform Connections — 12:00 по тихоокеанскому стандартному времени — четверг, 11 мая
В тринадцатом эпизоде Power Platform Connections Хьюго Бернье глубоко погружается в мысли соведущего Дэвида Уорнера II, а также рецензирует замечательные работы Денниса Гедегебюра, Кейта Атертона, Майкла Мегеля, Кэт Шнайдер и других.
Нажмите ниже, чтобы подписаться и получить уведомление, с Дэвидом и Хьюго LIVE в чате YouTube с 12:00 по тихоокеанскому стандартному времени. И используйте хэштег #PowerPlatformConnects в социальных сетях, чтобы получить шанс представить свою работу в шоу.
Просто нажмите на изображение ниже, чтобы зарегистрироваться и присоединиться к команде в прямом эфире в понедельник, 15 мая 2023 года, в 8:00 по тихоокеанскому стандартному времени. Надеюсь увидеть тебя там! Исполнительный основной доклад | День успеха клиентов Microsoft
CVP for Business Applications & Platform, Charles Lamanna, делится последними усовершенствованиями и обновлениями продукта #BusinessApplications, чтобы помочь клиентам достичь результатов в бизнесе. S01E13 Power Platform Connections — 12:00 по тихоокеанскому стандартному времени — четверг, 11 мая
В тринадцатом эпизоде Power Platform Connections Хьюго Бернье глубоко погружается в мысли соведущего Дэвида Уорнера II, а также рецензирует замечательные работы Денниса Гедегебюра, Кейта Атертона, Майкла Мегеля, Кэт Шнайдер и других.
Нажмите ниже, чтобы подписаться и получить уведомление, с Дэвидом и Хьюго LIVE в чате YouTube с 12:00 по тихоокеанскому стандартному времени. И используйте хэштег #PowerPlatformConnects в социальных сетях, чтобы получить шанс представить свою работу в шоу. ПРЕДСТОЯЩИЕ СОБЫТИЯ Конференция European Power Platform: продажа ранних билетов заканчивается!
Ранняя продажа билетов на конференцию European Power Platform заканчивается в пятницу, 12 мая 2023 года!
#EPPC23 собирает сообщества Microsoft Power Platform Communities на три дня непревзойденного личного обучения, общения и вдохновения, включая три вдохновляющих основных доклада, шесть полнодневных учебных пособий для экспертов и более восьмидесяти пяти специализированных сессий с приглашенными докладчиками, включая Эйприл Даннэм. , Дона Саркар, Илья Файнберг, Джанет Робб, Даниэль Ласкевиц, Руи Сантос, Йенс Кристиан Шредер, Марко Рокка и многие другие. Подробно ознакомьтесь с последними достижениями продуктов, услышав мнение самых ярких умов в пространстве #PowerApps .
Нажмите здесь, чтобы забронировать билет сегодня и сэкономить! Конференция DynamicMinds — Словения — 22-24 мая 2023 г.
Уже совсем скоро состоится конференция DynamicsMinds Conference, которая пройдет в Словении с 22 по 24 мая 2023 года, где блестящие умы встречаются, общаются и делятся друг с другом!
На этой замечательной конференции Power Platform и Dynamics 365 выступило множество замечательных спикеров, в том числе Георг Гланчниг, Дона Саркар, Томми Скауэ, Моник Хейворд, Александр Тотович, Рэйчел Профитт, Орельен Клер, Ана Инес Уррутиа де Соуза, Лука Пеллегрини, Бостьян Голоб, Шеннон Маллинз, Елена Баева, Иван Фикко, Гуро Фаллер, Вивиан Восс, Эндрю Бибби, Триша Синклер, Роджер Гилкрист, Сара Лагерквист, Стив Мордью и многие другие.
ПРЕДСТОЯЩИЕ СОБЫТИЯ Конференция European Power Platform: продажа ранних билетов заканчивается!
Ранняя продажа билетов на конференцию European Power Platform заканчивается в пятницу, 12 мая 2023 года!
#EPPC23 собирает сообщества Microsoft Power Platform Communities на три дня непревзойденного личного обучения, общения и вдохновения, включая три вдохновляющих основных доклада, шесть полнодневных учебных пособий для экспертов и более восьмидесяти пяти специализированных сессий с приглашенными докладчиками, включая Эйприл Даннэм. , Дона Саркар, Илья Файнберг, Джанет Робб, Даниэль Ласкевиц, Руи Сантос, Йенс Кристиан Шредер, Марко Рокка и многие другие. Подробно ознакомьтесь с последними достижениями продуктов, услышав мнение самых ярких умов в пространстве #PowerApps .
Нажмите здесь, чтобы забронировать билет сегодня и сэкономить! Конференция DynamicMinds — Словения — 22-24 мая 2023 г.
Уже совсем скоро состоится конференция DynamicsMinds Conference, которая пройдет в Словении с 22 по 24 мая 2023 года, где блестящие умы встречаются, общаются и делятся друг с другом!
На этой замечательной конференции Power Platform и Dynamics 365 выступило множество замечательных спикеров, в том числе Георг Гланчниг, Дона Саркар, Томми Скауэ, Моник Хейворд, Александр Тотович, Рэйчел Профитт, Орельен Клер, Ана Инес Уррутиа де Соуза, Лука Пеллегрини, Бостьян Голоб, Шеннон Маллинз, Елена Баева, Иван Фикко, Гуро Фаллер, Вивиан Восс, Эндрю Бибби, Триша Синклер, Роджер Гилкрист, Сара Лагерквист, Стив Мордью и многие другие. Нажмите здесь: Конференция DynamicsMinds для получения дополнительной информации об этой потрясающей конференции сообщества, охватывающей все аспекты Power Platform и не только. Конференция «Дни знаний» в Дании — 1-2 июня 2023 г.
Посетите «Дни знаний» — конференцию партнеров Directions 4, которая пройдет 1–2 июня в Оденсе, Дания и посвящена обучению сотрудников, обмену знаниями и повышению квалификации специалистов Business Central.
Эта фантастическая двухдневная конференция предлагает сочетание учебных занятий и семинаров, главной темой которых является Business Central и сопутствующие продукты. Есть большой список отраслевых экспертов, которые делятся своими знаниями, в том числе Иона В., Берт Вербек, Лиза Юхлин, Дуглас Роман, Каролина Эдвинссон, Ким Далсгаард Кристенсен, Инга Сартаускайте, Пейк Бех-Андерсен, Шеннон Маллинз, Джеймс Кроутер, Мона Боркстед Нильсен, Ренато Файдига, Вивиан Восс, Свен Ноомен, Паулиен Бускенс, Андри Мар Хельгасон, Кейлин Ханниган, Фредди Кристиансен, Сигне Агербо, Люк ван Вугт и многие другие.
Нажмите здесь: Конференция DynamicsMinds для получения дополнительной информации об этой потрясающей конференции сообщества, охватывающей все аспекты Power Platform и не только. Конференция «Дни знаний» в Дании — 1-2 июня 2023 г.
Посетите «Дни знаний» — конференцию партнеров Directions 4, которая пройдет 1–2 июня в Оденсе, Дания и посвящена обучению сотрудников, обмену знаниями и повышению квалификации специалистов Business Central.
Эта фантастическая двухдневная конференция предлагает сочетание учебных занятий и семинаров, главной темой которых является Business Central и сопутствующие продукты. Есть большой список отраслевых экспертов, которые делятся своими знаниями, в том числе Иона В., Берт Вербек, Лиза Юхлин, Дуглас Роман, Каролина Эдвинссон, Ким Далсгаард Кристенсен, Инга Сартаускайте, Пейк Бех-Андерсен, Шеннон Маллинз, Джеймс Кроутер, Мона Боркстед Нильсен, Ренато Файдига, Вивиан Восс, Свен Ноомен, Паулиен Бускенс, Андри Мар Хельгасон, Кейлин Ханниган, Фредди Кристиансен, Сигне Агербо, Люк ван Вугт и многие другие. Если вы хотите встретиться с отраслевыми экспертами, получить преимущество на рынке малого и среднего бизнеса и получить новые знания о Microsoft Dynamics Business Central, нажмите здесь Конференция Days of Knowledge в Дании, чтобы купить билет сегодня! ОСОБЕННОСТИ СООБЩЕСТВА
Посмотрите, как наши лучшие пользователи Super и Community достигают новых уровней! Эти трудолюбивые участники публикуют сообщения, отвечают на вопросы, хвалят и предлагают лучшие решения в своих сообществах. Мощные приложения:
Суперпользователи: @WarrenBelz, @LaurensM @BCBuizer
Пользователи сообщества: @Amik@ @mmollet, @Cr1t Силовой автомат:
Суперпользователи: @Expiscornovus , @grantjenkins, @abm
Пользователи сообщества: @Nived_Nambiar, @ManishSolanki Мощные виртуальные агенты:
Суперпользователи: @Pstork1, @Expiscornovus
Пользователи сообщества: @JoseA, @fernandosilva, @angerfire1213 Страницы силы:
Суперпользователи: @ragavanrajan
Пользователи сообщества: @Fubar, @Madhankumar_L,@gospa
ПОСЛЕДНИЕ СТАТЬИ В БЛОГЕ СООБЩЕСТВА
Блог сообщества Power Apps
Блог сообщества Power Automate
Блог сообщества Power Virtual Agents
Блог сообщества Power Pages
Ознакомьтесь с разделом «Использование сообщества», чтобы получить дополнительные полезные советы и информацию:
Power Apps , Power Automate, Power Virtual Agents, Power Pages
Если вы хотите встретиться с отраслевыми экспертами, получить преимущество на рынке малого и среднего бизнеса и получить новые знания о Microsoft Dynamics Business Central, нажмите здесь Конференция Days of Knowledge в Дании, чтобы купить билет сегодня! ОСОБЕННОСТИ СООБЩЕСТВА
Посмотрите, как наши лучшие пользователи Super и Community достигают новых уровней! Эти трудолюбивые участники публикуют сообщения, отвечают на вопросы, хвалят и предлагают лучшие решения в своих сообществах. Мощные приложения:
Суперпользователи: @WarrenBelz, @LaurensM @BCBuizer
Пользователи сообщества: @Amik@ @mmollet, @Cr1t Силовой автомат:
Суперпользователи: @Expiscornovus , @grantjenkins, @abm
Пользователи сообщества: @Nived_Nambiar, @ManishSolanki Мощные виртуальные агенты:
Суперпользователи: @Pstork1, @Expiscornovus
Пользователи сообщества: @JoseA, @fernandosilva, @angerfire1213 Страницы силы:
Суперпользователи: @ragavanrajan
Пользователи сообщества: @Fubar, @Madhankumar_L,@gospa
ПОСЛЕДНИЕ СТАТЬИ В БЛОГЕ СООБЩЕСТВА
Блог сообщества Power Apps
Блог сообщества Power Automate
Блог сообщества Power Virtual Agents
Блог сообщества Power Pages
Ознакомьтесь с разделом «Использование сообщества», чтобы получить дополнительные полезные советы и информацию:
Power Apps , Power Automate, Power Virtual Agents, Power Pages
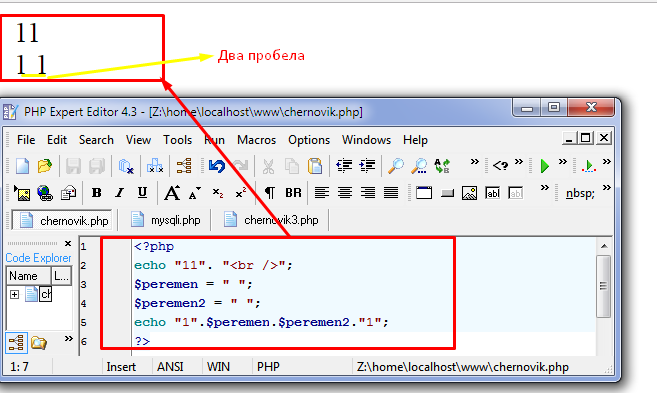
Удаляйте пробелы и другие символы или текстовые строки в Google Sheets из нескольких ячеек одновременно
Изучите формулы и способы удаления пробелов без формул, удалите специальные символы (даже первые/последние N символов) и одинаковые текстовые строки перед /после определенных символов из нескольких ячеек одновременно.
Удаление одной и той же части текста сразу из нескольких ячеек может быть таким же важным и сложным, как и добавление. Даже если вы знаете некоторые из способов, вы обязательно найдете новые в сегодняшней статье. Я делюсь множеством функций и их готовыми формулами и, как всегда, оставляю самые простые — бесформенные — напоследок 😉
Формулы для Google Таблиц для удаления текста из ячеек
Я начну со стандартных функций для Google Таблиц, которые удалят ваши текстовые строки и символы из ячеек. Универсальной функции для этого не существует, поэтому я приведу разные формулы и их комбинации для разных случаев.
Google Таблицы: удалить пробелы
Пробелы могут легко попасть в ячейки после импорта или при одновременном редактировании листа несколькими пользователями. На самом деле лишние пробелы настолько распространены, что в Google Sheets есть специальный инструмент Trim для удаления всех пробелов.
Просто выберите все ячейки Google Таблиц, из которых вы хотите удалить пробелы, и выберите Данные > Обрезать пробелы в меню электронной таблицы:
При выборе параметра все начальные и конечные пробелы в выделенном фрагменте будут полностью удалены, а все дополнительные пробелы между данными будут уменьшены до одного:
Удаление других специальных символов из текстовых строк в Google Sheets
Увы, Google Таблицы не предлагают инструмент для «обрезки» других символов, кроме пробелов. Здесь нужно иметь дело с формулами.
Здесь нужно иметь дело с формулами.
Совет. Или используйте вместо этого наш инструмент — Power Tools освободит ваш диапазон от любых символов, которые вы укажете, одним щелчком мыши, включая пробелы.
Здесь я обращался с хэштегами перед номерами квартир и номерами телефонов с тире и скобками между ними:
Я буду использовать формулы для удаления этих специальных символов.
В этом мне поможет функция ПОДСТАВИТЬ. Обычно он используется для замены одного символа на другой, но вы можете обратить это в свою пользу и заменить ненужные символы на… ну, ничего 🙂 Другими словами, удалите его.
Посмотрим, какой аргумент требуется функции:
ПОДСТАВИТЬ (текст_для_поиска, поиск_для, замена_с, [номер_вхождения])
- text_to_search — это либо текст для обработки, либо ячейка, содержащая этот текст. Необходимый.
- search_for это тот символ, который вы хотите найти и удалить. Необходимый.
- replace_with — символ, который вы вставите вместо ненужного символа. Необходимый.
- вхождение_номер — если есть несколько экземпляров искомого символа, здесь можно указать, какой из них заменить. Это совершенно необязательно, и если вы опустите этот аргумент, все экземпляры будут заменены чем-то новым ( replace_for ).
 Необходимый.
Необходимый.Итак, поиграем. Мне нужно найти хэштег ( # ) в A1 и заменить его на «ничего», которое в электронных таблицах отмечено двойными кавычками ( «» ). Имея все это в виду, я могу построить следующую формулу:
=ЗАМЕНИТЬ(A1,"#","")
Совет. Хэштег также заключен в двойные кавычки, так как именно так следует упоминать текстовые строки в формулах Google Sheets.
Затем скопируйте эту формулу вниз по столбцу, если Google Sheets не предлагает сделать это автоматически, и вы получите свои адреса без хэштегов:
А как же эти тире и скобки? Нужно ли создавать дополнительные формулы? Нисколько! Если вы вложите несколько функций ПОДСТАВКИ в одну формулу Google Таблиц, вы удалите все эти символы из каждой ячейки:
=ЗАМЕНИТЬ(ЗАМЕНИТЬ(ЗАМЕНИТЬ(ЗАМЕНИТЬ(A1,"#",""),"(",""),")",""),"-","")
Эта формула удаляет символы один за другим, и каждая ЗАМЕНА, начиная с середины, становится диапазоном для поиска следующей ЗАМЕНЫ:
Совет.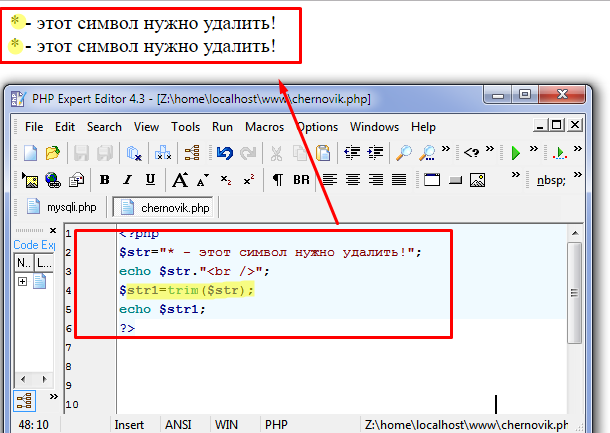 Более того, вы можете обернуть это в ArrayFormula и покрыть весь столбец сразу. В этом случае также измените ссылку на ячейку ( A1 ) на свои данные в столбце ( A1:A7 ):
Более того, вы можете обернуть это в ArrayFormula и покрыть весь столбец сразу. В этом случае также измените ссылку на ячейку ( A1 ) на свои данные в столбце ( A1:A7 ):
=Формуламассива(ЗАМЕНИТЬ(ЗАМЕНИТЬ(ЗАМЕНИТЬ(ЗАМЕНИТЬ(A1:A7,"#",""),"(",""),")",""),"-",""))
Удалить определенный текст из ячеек в Google Sheets
Хотя вы можете использовать вышеупомянутую функцию ПОДСТАВКИ для Google Таблиц для удаления текста из ячеек, я хотел бы также показать другую функцию — REGEXREPLACE.
Его имя является аббревиатурой от «regular expression replace». И я собираюсь использовать регулярные выражения для поиска строк, которые нужно удалить, и заменить их на 9.0023 ‘ ничего’ ( «» ).
Совет. Если вы не заинтересованы в использовании регулярных выражений, я опишу гораздо более простой способ в конце этого сообщения в блоге.
Совет. Если вы ищете способы поиска и удаления дубликатов в Google Таблицах, посетите этот пост в блоге.
REGEXREPLACE(текст, регулярное_выражение, замена)
Как видите, у функции есть три аргумента:
- текст — здесь вы ищете текстовую строку для удаления. Это может быть сам текст в двойных кавычках или ссылка на ячейку/диапазон с текстом.
- регулярное_выражение — ваш шаблон поиска, состоящий из различных комбинаций символов. Вы будете искать все строки, соответствующие этому шаблону. В этом споре и происходит все самое интересное, если можно так выразиться.
- замена — новая желаемая текстовая строка.
Предположим, что мои ячейки с данными также содержат название страны ( US ), если разные места в ячейках:
Как REGEXREPLACE поможет мне удалить его?
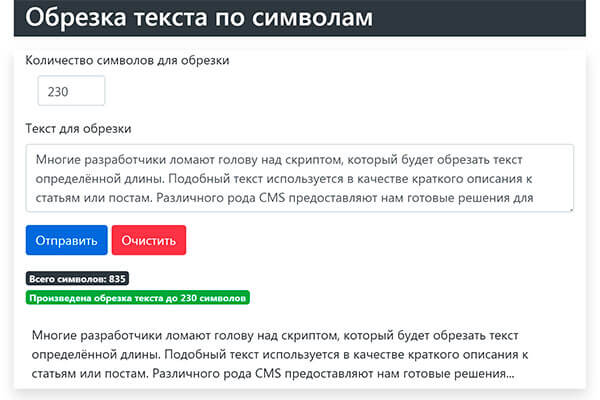
=REGEXREPLACE(A1,"(.*)US(.*)","$1 $2")
Вот как точно работает формула:
- сканирует содержимое ячейки A1
- для соответствия этой маске: «(.*)US(.*)»
Эта маска указывает функции искать US независимо от того, какое количество других символов может предшествовать (.
*) или следовать за (.*) названием страны.И вся маска заключена в двойные кавычки по требованию функции 🙂
- последний аргумент — «$1 $2» — это то, что я хочу получить взамен. $1 и $2 представляют одну из этих двух групп символов — (.*) — из предыдущего аргумента. Вы должны указать эти группы в третьем аргументе таким образом, чтобы формула могла вернуть все, что возможно стоит до и после US .
Что же касается самого US , то я просто не упоминаю его в 3-м аргументе — то есть хочу вернуть все из A1 без США .
 *) или следовать за (.*) названием страны.
*) или следовать за (.*) названием страны.Наконечник. Есть специальная страница, на которую вы можете ссылаться, чтобы создавать различные регулярные выражения и искать текст в разных позициях ячеек.
Совет. Что же касается тех оставшихся запятых, то от них поможет избавиться описанная выше функция ПОДСТАВИТЬ 😉 Можно даже ЗАМЕНИТЬ РЕГИСТР с ПОДСТАВКОЙ и решить все одной формулой:
=ПОДСТАВИТЬ(РЕГВЗАМЕН(A1,"(. *) США(.*)","$1 $2"),",","")
*) США(.*)","$1 $2"),",","")
Удалить текст до/после определенных символов во всех выделенных ячейках
Пример 1. Функция REGEXREPLACE для Google Sheets
Когда нужно избавиться от всего до и после определенных символов, также помогает REGEXREPLACE. Помните, функция требует 3 аргумента:
REGEXREPLACE(текст, регулярное_выражение, замена)
И, как я упоминал выше, когда представлял эту функцию, это вторая функция, которую вы должны использовать правильно, чтобы функция знала, что искать и удалять.
Итак, как удалить адреса и оставить в ячейках только номера телефонов?
Вот формула, которую я буду использовать:
=REGEXREPLACE(A1,".*\n.*(\+.*)","$1")
- Вот регулярное выражение, которое я использую в этом случае: «.*\n.*(\+.*)»
В первой части — .*\n.* — Я использую обратную косую черту +n , чтобы сказать, что в моей ячейке больше одной строки. Поэтому я хочу, чтобы функция удаляла все до и после разрыва строки (включая его).
Вторая часть в скобках (\+.*) говорит о том, что я хочу сохранить знак плюс и все, что за ним следует. Я беру эту часть в скобки, чтобы сгруппировать ее и запомнить на потом.
Совет. Обратная косая черта используется перед плюсом, чтобы превратить его в нужный символ. Без него плюс был бы просто частью выражения, обозначающего какие-то другие символы (как, например, звездочка).
- Что касается последнего аргумента — $1 — он заставляет функцию возвращать ту единственную группу из второго аргумента: знак плюс и все, что следует за ним 9.*», «»)
Аналогичным образом можно удалить все телефонные номера, но сохранить адреса:
=REGEXREPLACE(A1,"(.*\n).*","$1")Только на этот раз вы говорите функции группировать (и возвращать) все до разрыва строки и очищать остальное:
Еще один случай, о котором я хотел бы упомянуть, касается дополнительной информации в скобках. Всякий раз, когда это не имеет значения, нет смысла держать его в ячейках.
И у вас есть все средства для удаления не только всего, что находится между ними, но и самих брекетов.REGEXREPLACE сделает это за один раз:
=REGEXREPLACE(A1,"\((.*)\)","")Формула принимает:
- символ открывающей скобки: \(
- символ закрывающего: \)
- и группа символов между ними: (.*)
и заменяет их на «ничего» (то есть удаляет их): «»
Все, что находится за их пределами, остается нетронутым.
Пример 2. ПРАВО+ДЛСТР+НАЙТИ
Есть еще несколько функций Google Sheets, которые позволяют удалять текст перед определенным символом. Они ПРАВЫ, ЛЕН и НАЙТИ.
Примечание. Эти функции помогут только в том случае, если сохраняемые записи имеют одинаковую длину, например номера телефонов в моем случае. Если это не так, просто используйте вместо этого REGEXREPLACE или, что еще лучше, более простой инструмент, описанный в конце.
Использование этого трио в определенном порядке поможет мне получить тот же результат и удалить весь текст перед символом — знак плюс:
=ПРАВО(A1,(ДЛСТР(A1)-(НАЙТИ("+",A1)-1)))Позвольте мне объяснить, как работает эта формула:
- НАЙТИ(«+»,A1)-1 находит номер позиции знака плюс в ячейке A1 ( 24 ) и вычитает 1, чтобы сумма не включала сам плюс: 23 .
- ДЛСТР(A1)-(НАЙТИ(«+»,A1)-1) проверяет общее количество символов в A1 ( 40 ) и вычитает из него 23 (подсчитано НАЙТИ): 17 .
- И затем RIGHT возвращает 17 символов с конца (справа) A1.
К сожалению, этот способ мало поможет убрать текст после разрыва строки в моем случае (очистить номера телефонов и сохранить адреса), так как адреса имеют разную длину.
Ну ничего. Инструмент в конце все равно делает эту работу лучше 😉
Удалить первые/последние N символов из строк в Google Sheets
Всякий раз, когда вам нужно удалить определенное количество разных символов из начала или конца ячейки, REGEXREPLACE и RIGHT/LEFT+LEN также помогут.
Примечание. Поскольку я уже представил эти функции выше, я буду краток и приведу несколько готовых формул. Или смело переходите к самому простому решению, описанному в самом конце.
Итак, как мне стереть коды с этих телефонных номеров? Или, другими словами, удалить первые 9 символов из ячеек:
- Используйте REGEXREPLACE. Создайте регулярное выражение, которое найдет и удалит все до 9-го символа (включая этот 9-й символ):
=REGEXREPLACE(A1,"(.{9})(.*)","$2")Совет. Чтобы удалить последние N символов, просто поменяйте местами группы в регулярном выражении:
=REGEXREPLACE(A1,"(.*)(.{9})","$1") - RIGHT/LEFT+LEN также подсчитывает количество символов для удаления и возврата оставшейся части с конца или начала ячейки соответственно:
=ВПРАВО(A1,ДЛИН(A1)-9)Совет. Чтобы удалить последние 9 символов из ячеек, замените ПРАВО на ЛЕВО:
=ЛЕВО(A1,ДЛСТР(A1)-9) - И последнее, но не менее важное — это функция REPLACE. Вы говорите ему взять 9 символов, начиная слева, и заменить их ничем ( «» ):
=ЗАМЕНИТЬ(A1,1,9,"")Примечание. Поскольку REPLACE требует начальной позиции для обработки текста, это не сработает, если вам нужно удалить N символов с конца ячейки.
Способ удаления определенного текста в Google Таблицах без формул — надстройка Power Tools
Функционирует и все хорошо, когда есть время убить. Но знаете ли вы, что есть специальный инструмент, который объединяет все вышеперечисленные способы, и все, что вам нужно сделать, это выбрать нужный переключатель? 🙂 Никаких формул, никаких лишних столбцов — лучшего помощника и пожелать нельзя ;D
Вам не нужно верить мне на слово, просто установите Power Tools и убедитесь сами:
- Первая группа позволяет удалять несколько подстрок или отдельных символов из любой позиции во всех выделенных ячейках одновременно:
- Следующий удаляет не только пробелы, но и разрывы строк, объекты и теги HTML, а также другие разделители и непечатаемые символы . Просто отметьте все необходимые галочки и нажмите Удалить :
- И, наконец, есть настройки для удаления текста в Google Таблицах по определенной позиции, первым/последним N символам или до/после символов :
Другой инструмент от Power Tools удалит единицы времени и даты из меток времени.

 И у вас есть все средства для удаления не только всего, что находится между ними, но и самих брекетов.
И у вас есть все средства для удаления не только всего, что находится между ними, но и самих брекетов.
 Создайте регулярное выражение, которое найдет и удалит все до 9-го символа (включая этот 9-й символ):
Создайте регулярное выражение, которое найдет и удалит все до 9-го символа (включая этот 9-й символ):