азы для новичков / Хабр
В преддверии старта нового потока по курсу «Backend-разработчик на PHP», а также смежного с ним курса «Framework Laravel», хотим поделиться статьей, которую подготовил наш внештатный автор.
Внимание! данная статья не имеет отношения к программе курса и будет полезна только для новичков. Для получения более углубленных знаний приглашаем вас посетить бесплатный двухдневный онлайн интенсив по теме: «Создание Telegram-бота для заказа кофе в заведении и оплаты онлайн». Второй день интенсива будет проходить тут.
Всем привет! Всех с наступившим [20]{2,}0 годом. Сегодня я хочу затронуть тему, которая иногда является темой для шуток от «Да зачем тебе все это учить, если есть уже есть готовые решения» до «может тебе еще и весь Perl выучить?». Однако время идет, множество программистов начинают осваивать регулярные выражения, а на Хабре нет ни одной свежей (
 Пришло время написать ещё одну!
Пришло время написать ещё одну!Регулярные выражения в отрыве от их конкретной реализации
Регулярные выражения (обозначаемые в английском как RegEx или как regex) являются инструментальным средством, которое применяется для различных вариантов изучения и обработки текста: поиска, проверки, поиска и замены того или иного элемента, состоящего из букв или цифр (или любых других символов, в том числе специальных символов и символов пунктуации). Изначально регулярные выражения пришли в мир программирования из среды научных исследований, которые проводились в 50-е годы в области математики.
Спустя десятилетия принципы и идеи были перенесены в среду операционной системы UNIX (в частности вошли в утилиту grep) и были реализованы в языке программирования Perl, который на заре интернета широко использовался на бэкенде (и по сей день используется, но уже меньше) для такой задачи, как, например, валидация форм.
Если они вроде простые, тогда почему такие страшные на первый взгляд?
На самом деле любое выражение может быть «регулярным» и применяться для проверки или поиска каких-либо символов.
Положим у нас есть следующий текст:
Pavel knows too much. Pavel using nginx and he’s not rambler.
Сейчас регулярные выражения нашли оба вхождения слова Pavel. Здорово, но звучит не очень полезно (разве что только вы зачем-то пытаетесь проанализировать что-то вроде количества упоминания слова
Вариативность выражения
Если ваше регулярное выражение вариативно (например, вам известна только некоторая его часть и нужно найти количество вхождений годов, начиная от 2000 и заканчивая 2099), то мы можем использовать следующее регулярное выражение: 20. .
.
Текст: Молодые писатели пишут много чего. Например писатель 2002 года рождения очень отличается от 2008 и
Здесь у нас с помощью регулярного выражения найдутся все годы, но пока в этом нет никакого смысла. Скорее всего нам не нужны годы дальше 2012 (хотя молодые писатели младше 8 лет могут обидеться, но не об этом сейчас). Стоит изучить наборы символов, но об этом попозже, потому как сейчас поговорим про другую важную часть регулярных выражений: экранирование метасимволов.
Представим, что нам нужно найти количество вхождений файлов с расширением .doc (допустим, мы экспортируем только определенные файлы загруженные в нашу базу данных). Но ведь точка обозначает просто любой символ? Так как же быть?
Тут к нам на помощь приходит экранирование метасимволов обратным слешем \. Теперь выражение .doc:
Регулярное выражение: \. doc
doc
Текст: kursach.doc , nepodozritelneyfail.exe, work.doc, shaprgalka.rtf doc
Как видите, мы успешно можем найти количество файлов с расширением .doc в списке. Однако мы не сможем вытащить полные имена файлов с помощью данного регулярного выражения, например, в массив. Пришло время взглянуть на наборы символов.
Совпадение с целым набором символов
В регулярных выражениях совпадения с набором обеспечивается с помощью метасимволов — квадратных скобочек.jpg.
Регулярное выражение: [0-9]\.jpg
Текст: 1.jpg, 2.jpg, 3.jpg, photo.jpg, anime.jpg, 8.jpg, jkl.jpg
Стоит отметить, что имя файлов из более 1 цифры наше регулярное выражение не охватит.
Таблица пробельных метасимволов
| [\b] | возврат на один символ |
| \f | перевод страницы |
| \n | перевод строки |
| \r | возрат каретки |
| \t | табуляция |
| \v | вертикальная табуляция |
Множественный выбор: делаем простую валидацию
Вооружившись полученными знаниями, попробуем сделать регулярное выражение, которое находит, например, слова короче 3 букв (стандартная задача для антиспама). Если мы попробуем использовать следующее регулярное выражение —
Если мы попробуем использовать следующее регулярное выражение — \w{1,3} (в котором метасимвол \w указывает на любой символ, а фигурные скобки обозначают количество символов от сколько до скольки, то у нас выделятся все символы подряд — нужно как-то обозначить начало и конец слов в тексте. Для этого нам потребуется метасимвол
Регулярное выражение: \b\w{1,3}\b:
Текст: good word
not
egg
Неплохо! Теперь слова короче трех букв не смогут попадать в нашу базу данных. Посмотрим на валидацию почтового адреса:
Регулярное выражение: \w+@\w+\.\w+
Требования: в электронной почте в начале должен быть любой символ (цифры или буквы, ведь электронная почта, которая состоит только из цифр в начале, встречается довольно часто). Потом идет символ @, затем — сколько угодно символов, после чего экранированная точка (т.е. просто точка) и домен первого уровня.
Подробнее рассмотрим повторение символов
Теперь давайте поподробнее разберем, как можно в регулярных выражениях задать повторение символов. К примеру вы хотите найти любые комбинации цифр от 2-6 в тексте:
К примеру вы хотите найти любые комбинации цифр от 2-6 в тексте:
Регулярное выражение: [2-6]+
Текст: Here are come’s 89 different 234 digits 24 .
Давайте я приведу таблицу всех квантификаторов метасимволов:
| * | символы повторяются 0 и до бесконечности |
| + | повторяются от 1 и до бесконечности |
| {n} | повторяются точно n раз |
| {n,} | от n и до бесконечности |
| {n1, n2} | от n1 и до n2 раз точно |
| ? | 0 или 1 символ, не больше |
В применении квантификаторов нет ничего сложного. Кроме одного нюанса: жадные и ленивые квантификаторы. Приведем таблицу:
| * | *? |
| + | +? |
| {n,} | {n,}? |
Ленивые квантификаторы отличаются от жадных тем, что они выхватывают минимальное, а не максимальное количество символов.
Регулярное выражение: <h[1-7]>.*?<\/h[1-7]>
Текст: <h7> hello </h7> lorem ipsum avada kedavra <h7> buy</h7>
Все сработало успешно, однако только благодаря ленивому квантификатору. В случае применения жадного квантификатора у нас выделился бы весь текст между тегами (полагаю, в иллюстрации это не нуждается).
Границы символьных строк
Границы символьных строк мы уже использовали выше. Приведем здесь более подробную таблицу:
| \b | граница слова |
| \B | не граница слова |
| \A | начало строки |
| \Z | конец строки |
| \G | конец действия |
Работа с подвыражениями
Подвыражения в регулярных выражениях делаются с помощью метасимвола группировки ().
Приведем пример регулярного выражения, которое универсально может находить различные вариации IP — адресов.
Регулярное выражение: (((25[0-5])|(2[0-4]\d)|(1\d{2})|(\d{1,2}))\.){3}(((25[0-5]|(2[0-4]\d)|(1\d{2})|(\d{1,2}))))
Текст: 255.255.255.255 просто адрес
191.198.174.192 wikipedia
87.240.190.67 vk
31.13.72.36 facebook
Здесь используется логический оператор | (или), который позволяет нам составить регулярное выражение, которое соответствует правилу, по которому составляются IP- адреса. В IP адресе должно быть от 1 и до 3 цифр, в котором число из трех чисел может начинаться с 1, с 2 (или тогда вторая цифра должна быть в пределах от 0 и до 4), или начинаться с 25, и тогда 3 цифра оказывается в пределах от 0 и до 5. Также между каждой комбинацией цифр должна стоять точка. Используя приведенные выше таблицы, постарайтесь сами расшифровать регулярное выражение сверху. Регулярные выражения в начале пугают своей длинной, но длинные не значит сложные.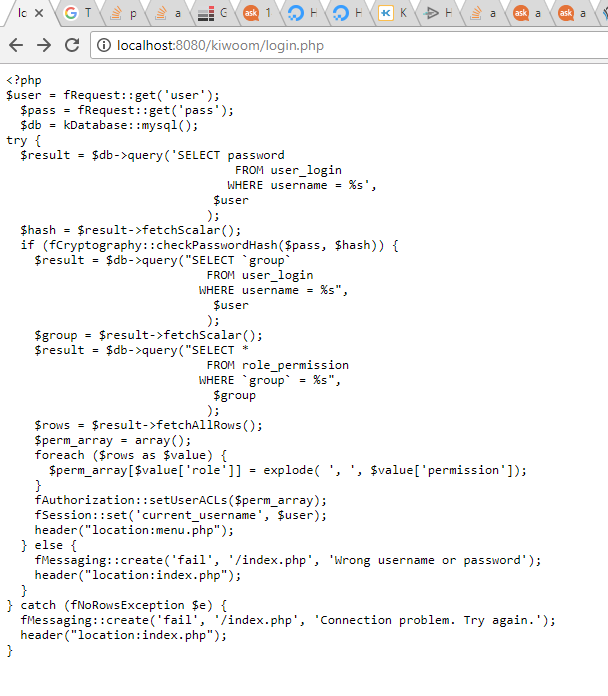
Просмотр вперед
Для просмотра выражения на любую комбинацию определенных символов указывается шаблон по которому обнаруживается, но не возвращается, совпадение. По существу, просмотр вперед определяет подвыражение и поэтому он формируется соответствующим образом. Синтаксический шаблон для просмотра вперед состоит из подвыражения, перед которым стоит ?=, а после равно следует сопоставляемый текст.
Приведем конкретную задачу: есть пароль, который должен состоят не менее чем из 7 символов и должен обязательно включать как минимум одну заглавную букву и цифру. Здесь все будет несколько сложнее, потому как пользователь должен иметь возможность поставить заглавную букву как в начале, так и в середине предложения (и тоже самое должно повторяться с буквой).
Следовательно, нам потребуется просмотр выражения вперед. Кроме того, нам нужно разбить на группы знаки. И я хочу ограничить его размеры от 8 и до 22 знаков:
Регулярное выражение: /^(?=. *[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/
*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/
Текст: Qwerty123
Im789098
weakpassword
Особенности работы регулярных выражений именно в PHP
Для изучения работы регулярных выражений в PHP, изучите функции в официальной документации PCRE (Perl Compatible Regular Expressions) которая доступна на официальном сайте. Выражение должно быть заключено в разделители, например, в прямые слеши.
Разделителем могут выступать произвольные символы, кроме буквенно-цифровых, обратного слеша ‘\’ и нулевого байта. Если символ разделителя встречается в шаблоне, его необходимо экранировать \. В качестве разделителей доступны комбинации, пришедшие из Perl: (), {}, [].
Какие функции используются в php? В пакете PCRE предоставляются следующие функции для поддержки регулярных выражений:
- preg_grep() — выполняет поиск и возвращает массив совпадений.
- preg_match() — выполняет поиск первого совпадения с помощью регулярных выражений
- preg_match_all() — выполняет глобальный поиск с помощью регулярных выражений
- preg_quote() — принимает шаблон и возвращает его экранированную версию
- preg_replace() — выполняет операцию поиска и замены
- preg_replace_callback() — тоже выполняет операцию поиска и замены, но используют callback – функцию для любой конкретной замены
- preg_split() — разбивает символьную строку на подстроки
Для организации совпадения без учета регистра букв служит модификатор i.
С помощью модификатора m можно активировать режим обработки многострочного текста.
Замещающие строки допускается вычислять в виде кода PHP. Для активизации данного режима служит модификатор e.
Во всех функциях preg_replace(), preg_replace_callback() и preg_split() поддерживается дополнительный аргумент, который вводит ограничения на максимальное количество замен или разбиений.
Обратные ссылки могут обозначаться с помощью знака $ (например $1), а в более ранних версиях вместо знака $ применяются знаки \\.
Метасимволы \E, \l, \L, \u и \U не используются (поэтому они и не были упомянуты в этой статье).
Наша статья была бы неполной без классов символов POSIX, которые также работают в PHP (и в общем вполне могут повысить читабельность ваших регулярок, но не все их спешат учить, потому как часто ломают логику выражения).
| [[:alnum:]] | Любая буква английского алфавита или цифра |
| [[:alpha:]] | Любая буква ([a-zA-Z]) |
| [[:blank:]] | Пробельный символ или символ с кодом 0 и 255 |
| [[:digit:]] | Любая цифра ([0-9]) |
| [[:lower:]] | Любая строчная буква английского алфавита ([a-z]) |
| [[:upper:]] | Любая заглавная буква английского алфавита ([A-Z]) |
| [[:punct:]] | Любой знак пунктуации |
| [[:space:]] | Любой пробельный символ |
| [[:xdigit:]] | Любая шестнадцатеричная цифра ([0-9a-fA-F]) |
Под конец приведу пример конкретной реализации регулярных выражений в PHP, используя упомянутые выше реализации. (?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/’;
if (preg_match($pattern_name, $name) &&
preg_match($pattern_mail, $mail) &&
preg_match($pattern_password, $_POST[‘password’])) {
# тут происходит, к примеру, регистрация нового пользователя, отправка ему письма, и внесение в базу данных
}
(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/’;
if (preg_match($pattern_name, $name) &&
preg_match($pattern_mail, $mail) &&
preg_match($pattern_password, $_POST[‘password’])) {
# тут происходит, к примеру, регистрация нового пользователя, отправка ему письма, и внесение в базу данных
}
Всем спасибо за внимание! Конечно, сегодня мы затронули только часть регулярных выражений и о них можно написать ещё несколько статей. К примеру, мы не поговорили о реализации поиска повторений одинаковых слов в тексте. Но я надеюсь, что полученных знаний хватит, чтобы осмысленно написать свою первую валидацию формы и уже потом перейти к более зубодробительным вещам.
По традиции, несколько полезных ссылок:
Шпаргалка от MIT по регулярным выражениям
Официальная часть документации php по регулярным выражениям.
На этом все. До встречи на интенсиве!
Второй день интенсива пройдет тут
Уроки PHP – регулярные выражения с примерами
В сегодняшней статье мы рассмотрим регулярные выражения в PHP, а также увидим практические примеры использования регулярных выражений в PHP скриптах.
Основы регулярных выражений в PHP
В самом начале появления регулярных выражений на них была возложена задача помощи при работе со строками в Unix системах. Позже они стали активно использоваться не только в других системах, но и в разных языках программирования.
В PHP регулярные выражения используются для синтаксического анализа текста в соответствии с определенным шаблоном. Используя регулярные выражения, вы можете легко найти по шаблону нужный текст в строке, и заменить его, если нужно, или просто сделать проверку на наличие такого текста.
Типы регулярных выражений
Существует 2 типа регулярных выражений:
- Perl совместимый
- POSIX расширенный
Perl совместимые функции – это такие как preg_match, preg_replace, а версии POSIX – такие как ereg, eregi. Учтите, что последние функции считаются устаревшими в PHP 5.3.0 и были удалены в PHP 7. world$
world$
world*world+world?world{1}world{1,}world{2,3}wo(rld)*earth|worldw. wW]
wW]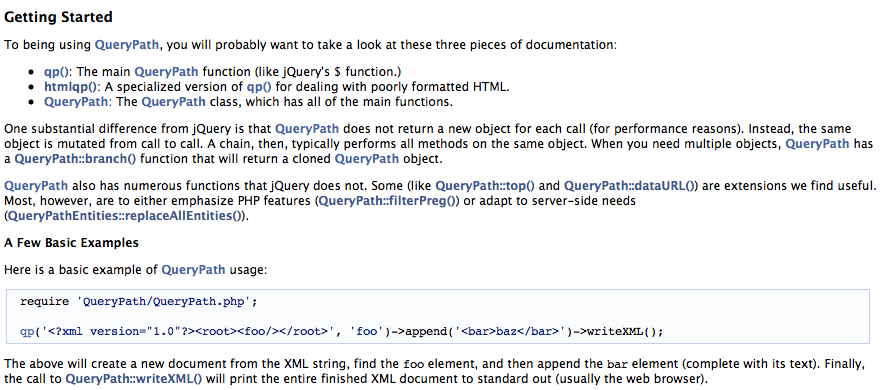 wW]
wW]
Теперь перейдем к более сложному регулярному выражению с подробным объяснением.
Практические примеры сложных регулярных выражений
Теперь, когда вы знаете теорию и основной синтаксис регулярных выражений в PHP, пришло время создать и проанализировать некоторые более сложные примеры.
1) Проверка имени пользователя с помощью регулярного выражения
Начнем с проверки имени пользователя. Если у вас есть форма регистрации, вам понадобится проверять на правильность имена пользователей. Предположим, вы не хотите, чтобы в имени были какие-либо специальные символы, кроме «_.-» и, конечно, имя должно содержать буквы и возможно цифры. Кроме того, вам может понадобиться контролировать длину имени пользователя, например от 4 до 20 символов.
Сначала нам нужно определить доступные символы. Это можно реализовать с помощью следующего кода:
[a-zA-Z0-9_.
 #(([a-fA-F0-9]{3}$)|([a-fA-F0-9]{6}$))/';
$color = "#1AA";
if (preg_match($pattern, $color)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
#(([a-fA-F0-9]{3}$)|([a-fA-F0-9]{6}$))/';
$color = "#1AA";
if (preg_match($pattern, $color)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
3) Проверка электронной почты клиента с использованием регулярного выражения
Теперь давайте посмотрим, как мы можем проверить адрес электронной почты с помощью регулярных выражений. Сначала внимательно рассмотрите следующие примеры адресов почты:
[email protected] [email protected] [email protected]
Как мы можем видеть, символ @ является обязательным элементом в адресе электронной почты. Помимо этого должен быть какой-то набор символов до и после этого элемента. Точнее, после него должно идти допустимое доменное имя.
Таким образом, первая часть должна быть строкой с буквами, цифрами или некоторыми специальными символами, такими как _-.. В шаблоне мы можем написать это следующим образом:
^[a-zA-Z0-9_.
 [a-zA-Z0-9._-]+@[a-zA-Z0-9-]+\.[a-zA-Z.]{2,5}$/';
$email = "
[a-zA-Z0-9._-]+@[a-zA-Z0-9-]+\.[a-zA-Z.]{2,5}$/';
$email = "
Надеемся, что сегодняшняя статья помогла вам при знакомстве с регулярными выражениями в PHP, а практические примеры пригодятся вам при использовании регулярных выражений в собственных PHP скриптах.
Теги: php
- 4379
- Опубликовано
- PHP, Уроки программирования
- прокомментируйте статью
- расскажите друзьям
Php preg match регулярные выражения • Вэб-шпаргалка для интернет предпринимателей!
Содержание
- 1 Что такое регулярные выражения?
- 1. [a-zA-Z0-9._-]+@[a-zA-Z0-9-]+.[a-zA-Z.]<2,5>$/] «
- 1.7 Заключение
- 1.
- 2 Набор символов
- 3 Квантификатор
- 4 Якоря
- 5 Жадность
- 6 Функции для работы с регулярными выражениями
- 6.0.1 preg_grep
- 6.0.2 preg_match
- 6.0.3 Пример кода
- 6.0.4 Пример кода
- 6.0.5 Пример кода
- 6.0.6 preg_match_all
- 6.0.7 Пример кода
- 6.0.8 Пример кода
- 6.0.9 Пример кода
- 6.0.10 Пример кода
- 6.0.11 preg_quote
- 6.0.12 Пример кода
- 6.0.13 Пример кода
- 6.0.14 preg_replace
- 6.0.15 Пример кода: Замена по нескольким шаблонам
- 6.0.16 Пример кода: Использование модификатора /e
- 6.0.17 Пример кода: Преобразует все HTML-теги к верхнему регистру
- 6.0.18 preg_replace_callback
- 6.0.19 Пример кода
- 6.0.20 preg_split
- 6.0.21 Примеры кода
- 7 Вступление
- 8 Пример использования функций
- 9 Модификаторы шаблонов
- 10 Метасимволы в регулярных выражениях
- 11 Операторы [] и ()
- 12 Примеры из реальной жизни
- 12. ) для создания сложных выражений.
Для чего используются регулярные выражения:
- Регулярные выражения упрощают идентификацию строковых данных путем вызова одной функции. Это экономит время при составлении кода;
- При проверке введенных пользователем данных, таких как адрес электронной почты, домен сайта, номер телефона, IP-адрес ;
- Выделение ключевых слов в результатах поиска;
- Регулярные выражения могут использоваться для идентификации тегов и их замены.
Регулярные выражения в PHP
PHP содержит встроенные функции, которые позволяют работать с регулярными выражениями. Теперь рассмотрим часто используемые функции регулярных выражений PHP .
- preg_match — используется для выполнения сопоставления с шаблоном строки. Она возвращает true , если совпадение найдено, и false , если совпадение не найдено;
- preg_split — используется для разбивки строки по шаблону, результат возвращается в виде числового массива;
- preg_replace – используется для поиска по шаблону и замены на указанную строку.
Ниже приведен синтаксис функций регулярных выражений, таких как preg_match , preg_split или PHP regexp replace :
«имя_функции» — это либо preg_match , либо preg_split , либо preg_replace .
«/…/» — косые черты обозначают начало и конец регулярного выражения.
«‘/шаблон/’» — шаблон, который нам нужно сопоставить.
«объект» — строка, с которой нужно сопоставлять шаблон.Теперь рассмотрим практические примеры использования упомянутых выше функций.
Preg_match
В первом примере функция preg_match используется для выполнения простого сопоставления шаблоном для слова guru в заданном URL-адресе .
В приведенном ниже коде показан вариант реализации данного примера:
Рассмотрим ту часть кода, которая отвечает за вывод «preg_match (‘/ guru /’, $ my_url)» .«preg_match(…)» — функция PHP match regexp .
«‘/Guru/’» — шаблон регулярного выражения.
«$My_url» — переменная, содержащая текст, с которым нужно сопоставить шаблон. PH/ — любая строка, которая начинается с PH.$ Обозначает шаблон в конце строки. /com$/ — guru99.com,yahoo.com и т.д. * Обозначает любое количество символов, ноль или больше. /com*/ — computer, communication и т.д. + Требуется вхождение перед метасимволом символа (ов) хотя бы один раз. /yah+oo/ — yahoo. Символ экранирования. /yahoo+.com/ — воспринимает точку, как дословное значение. […] Класс символов. /[abc]/ — abc. a-z Обозначает строчные буквы. /a-z/ — cool, happy и т.д. A-Z Обозначает заглавные буквы. /A-Z/ — WHAT, HOW, WHY и т.д. 0-9 Обозначает любые цифры от 0 до 9. /0-4/ — 0,1,2,3,4. Теперь рассмотрим сложный PHP regexp пример, в котором проверяется валидность адреса электронной почты:
Результат: адрес электронной почты name@company.
[a-zA-Z0-9._-]» соответствует любым буквам в нижнем или верхнем регистре, цифрам от 0 до 9 и точкам, подчеркиваниям или тире.
«+@[a-zA-Z0-9-]» соответствует символу @ , за которым следуют буквы в нижнем или верхнем регистре, цифры от 0 до 9 или дефисы.
«+.[a-zA-Z.]<2,5>$/» указывает точку, используя обратную косую черту, затем должны следовать любые буквы в нижнем или верхнем регистре, количество символов в конце строки должно быть от 2 до 5.
Метасимволы являются полезными, когда речь идет о сопоставлении на соответствие шаблонам.Заключение
- PHP regexp — это алгоритм поиска по шаблону;
- Регулярные выражения полезны при выполнении проверок валидности, создании HTML-шаблонов , которые распознают теги и т. д.;
- PHP имеет встроенные функции для работы с регулярными выражениями: preg_match , preg_split и preg_replace ;
- Метасимволы позволяют создавать сложные шаблоны.
Данная публикация представляет собой перевод статьи « PHP Regular Expressions » , подготовленной дружной командой проекта Интернет-технологии.
руРегулярные выражения позволяют найти в строке последовательности, соответствующие шаблону. Например шаблон «Вася(.*)Пупкин» позволит найти последовательность когда между словами Вася и Пупкин будет любое количество любых символов. Если надо найти шесть цифр, то пишем «[0-9]<6>» (если, например, от шести до восьми цифр, тогда «[0-9]<6,8>»). Здесь разделены такие вещи как указатель набора символов и указатель необходимого количества:
Вместо набора символов может быть использовано обозначение любого символа — точка, может быть указан конкретный набор символов (поддерживаются последовательности — упоминавшиеся «0-9»). Может быть указано «кроме данного набора символов».
Указатель количества символов в официальной документации по php называется «квантификатор». Термин удобный и не несет в себе кривотолков. Итак, квантификатор может иметь как конкретное значение — либо одно фиксированное («<6>»), либо как числовой промежуток («<6,8>»), так и абстрактное «любое число, в т.
ч. 0″ («*»), «любое натуральное число» — от 1 до бесконечности («+»: «document[0-9]+.txt»), «либо 0, либо 1» («?»). По умолчанию квантификатор для данного набора символов равен единице («document[0-9].txt»).Для более гибкого поиска сочетаний эти связки «набор символов — квантификатор» можно объединять в метаструктуры.
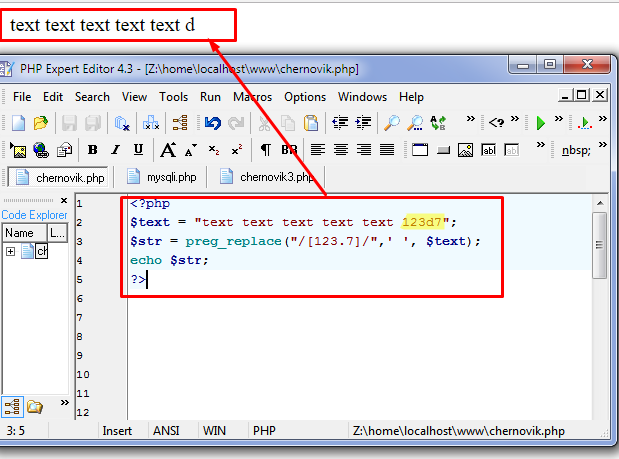
Как всякий гибкий инструмент, регулярные выражения гибки, но не абсолютно: зона их применения ограничена. Например, если вам надо заменить в тексте одну фиксированную строку на другую, фиксированную опять же, пользуйтесь str_replace. Разработчики php слезно умоляют не пользоваться ради этого сложными функциями ereg_replace или preg_replace, ведь при их вызове происходит процесс интерпретации строки, а это серьезно потребляет ресурсы системы. К сожалению, это любимые грабли начинающих php-программистов.
Пользуйтесь функциями регулярных выражений только если вы не знаете точно, какая «там» строка. Из примеров: поисковый код , в котором из строки поиска вырезаются служебные символы и короткие слова а так же вырезаются лишние пробелы (вернее, все пробелы сжимаются: » +» заменяется на один пробел).
При помощи этих функций я проверяю email пользователя, оставляющего свой отзыв. Много полезного можно сделать, но важно иметь в виду: регулярные выражения не всесильны. Например, сложную замену в большом тексте ими лучше не делать. Ведь, к примеру, комбинация «(.*)» в программном плане означает перебор всех символов текста. А если шаблон не привязан к началу или концу строки, то и сам шаблон «двигается» программой через весь текст, и получается двойной перебор, вернее перебор в квадрате. Нетрудно догадаться, что еще одна комбинация «(.*)» означает перебор в кубе, и так далее. Возведите в третью степень, скажем, 5 килобайт текста. Получается 125 000 000 000 (прописью: сто двадцать пять миллиардов операций). Конечно же, если подходить строго, там стольких операций не будет, а будет раза в четыре-восемь меньше, но важен сам порядок цифр.Набор символов
. точка любой символ [ ] квадратные скобки класс символов («любое из»). ]Кроме пробельных символов | (одно|другое) На этом месте может быть один из перечисленных вариантов, например: (Вася|Петя|Маша). Если Вы не хотите, чтобы это попало в выборку используйте (?: . ) Не пользуйтесь классом символов для обозначения всего лишь одного (вместо «[ ]+» вполне сойдет » +»). Не пишите в классе символов точку это ведь любой символ, тогда другие символы в классе будут просто лишними (а в негативном классе получится отрицание всех символов).
Квантификатор
Квантификатором можно указать как конкретное значение, так и пределы. Если число заданных подпадает под пределы квантификатора, фрагмент выражения считается совпавшим с разбираемой строкой. Синтаксис:
Если нужно указать только необходимый минимум, а максимума нет, просто ставим запятую и не пишем второе число: «<5,>» («минимум 5»). Для наиболее часто употребляемых квантификаторов есть специальные обозначения:
* «звёздочка» или знак умножения + плюс ? вопросительный знак На практике такие символы используются чаще, чем фигурные скобки.
» и «$» совпадают с началом и концом отдельных строк.s символ «.» (точка) совпадает и с переносом строки (по умолчанию нет) A привязка к началу текста E заставляет символ «$» совпадать только с концом текста. Игнорируется, если установлен парамерт m. U Инвертирует «жадность» для каждого квантификатора (если же после квантификатора стоит «?», этот квантификатор перестает быть «жадным»). e Строка замены интерпретитуется как PHP код. Функции для работы с регулярными выражениями
- preg_grep — Возвращает массив вхождений, которые соответствуют шаблону
- preg_match — Выполняет проверку на соответствие регулярному выражению. Данная функция ищет только первое совпадение!
- preg_match_all — Выполняет глобальный поиск шаблона в строке
- preg_quote — Экранирует символы в регулярных выражениях. Т.е. вставляет слэши перед всеми служебными символами (например, скобками, квадратными скобками и т. п.), чтобы те воспринимались буквально. Если у вас есть какой-либо ввод информации пользователем, и вы проверяете его с помощью регулярных выражений, то лучше перед этим заэкранировать служебные символы в пришедшей переменной
- preg_replace — Выполняет поиск и замену по регулярному выражению
- preg_replace_callback — Выполняет поиск по регулярному выражению и замену
- preg_split — Разбивает строку по регулярному выражению
preg_grep
Функция preg_grep — Возвращает массив вхождений, которые соответствуют шаблону
array preg_grep (string pattern, array input [, int flags])
preg_grep() возвращает массив, состоящий из элементов входящего массива input, которые соответствуют заданному шаблону pattern.
Параметр flags может принимать следующие значения:
PREG_GREP_INVERT
В случае, если этот флаг установлен, функция preg_grep(), возвращает те элементы массива, которые не соответствуют заданному шаблону pattern.
Результат, возвращаемый функцией preg_grep() использует те же индексы, что и массив исходных данных. Если такое поведение вам не подходит, примените array_values() к массиву, возвращаемому preg_grep() для реиндексации.
Пример кода:preg_match
Функция preg_match — Выполняет проверку на соответствие регулярному выражению
int preg_match ( string pattern, string subject [, array matches [, int flags [, int offset]]]) Ищет в заданном тексте subject совпадения с шаблоном pattern
В случае, если дополнительный параметр matches указан, он будет заполнен результатами поиска. Элемент $matches[0] будет содержать часть строки, соответствующую вхождению всего шаблона, $matches[1] — часть строки, соответствующую первой подмаске, и так далее.
flags может принимать следующие значения:
PREG_OFFSET_CAPTURE
В случае, если этот флаг указан, для каждой найденной подстроки будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.Поиск осуществляется слева направо, с начала строки. Дополнительный параметр offset может быть использован для указания альтернативной начальной позиции для поиска. Аналогичного результата можно достичь, заменив subject на substr()($subject, $offset).
Функция preg_match() возвращает количество найденных соответствий. Это может быть 0 (совпадения не найдены) и 1, поскольку preg_match() прекращает свою работу после первого найденного совпадения. Если необходимо найти либо сосчитать все совпадения, следует воспользоваться функцией preg_match_all(). Функция preg_match() возвращает FALSE в случае, если во время выполнения возникли какие-либо ошибки.
Рекомендация: Не используйте функцию preg_match(), если необходимо проверить наличие подстроки в заданной строке. Используйте для этого strpos() либо strstr(), поскольку они выполнят эту задачу гораздо быстрее.
Пример кода
Пример кода
Пример кода
preg_match_all
Функция preg_match_all — Выполняет глобальный поиск шаблона в строке
int preg_match_all (string pattern, string subject, array matches [, int flags [, int offset]])
Ищет в строке subject все совпадения с шаблоном pattern и помещает результат в массив matches в порядке, определяемом комбинацией флагов flags.
После нахождения первого соответствия последующие поиски будут осуществляться не с начала строки, а от конца последнего найденного вхождения.
Дополнительный параметр flags может комбинировать следующие значения (необходимо понимать, что использование PREG_PATTERN_ORDER одновременно с PREG_SET_ORDER бессмысленно):
PREG_PATTERN_ORDER
Если этот флаг установлен, результат будет упорядочен следующим образом: элемент $matches[0] содержит массив полных вхождений шаблона, элемент $matches[1] содержит массив вхождений первой подмаски, и так далее.Пример кода
Как мы видим, $out[0] содержит массив полных вхождений шаблона, а элемент $out[1] содержит массив подстрок, содержащихся в тегах.
PREG_SET_ORDER
Если этот флаг установлен, результат будет упорядочен следующим образом: элемент $matches[0] содержит первый набор вхождений, элемент $matches[1] содержит второй набор вхождений, и так далее.Пример кода
В таком случае массив $matches[0] содержит первый набор вхождений, а именно: элемент $matches[0][0] содержит первое вхождение всего шаблона, элемент $matches[0][1] содержит первое вхождение первой подмаски, и так далее.
Аналогично массив $matches[1] содержит второй набор вхождений, и так для каждого найденного набора.PREG_OFFSET_CAPTURE
В случае, если этот флаг указан, для каждой найденной подстроки будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.В случае, если никакой флаг не используется, по умолчанию используется PREG_PATTERN_ORDER.
Поиск осуществляется слева направо, с начала строки. Дополнительный параметр offset может быть использован для указания альтернативной начальной позиции для поиска. Аналогичного результата можно достичь, заменив subject на substr()($subject, $offset).
Возвращает количество найденных вхождений шаблона (может быть нулем) либо FALSE, если во время выполнения возникли какие-либо ошибки.
Пример кода
Пример кода
preg_quote
Функция preg_quote — Экранирует символы в регулярных выражениях
string preg_quote (string str [, string delimiter])
Функция preg_quote() принимает строку str и добавляет обратный слеш перед каждым служебным символом.
] $ ( ) < >= ! | :Пример кода
Пример кода
preg_replace
Функция preg_replace — Выполняет поиск и замену по регулярному выражению
mixed preg_replace ( mixed pattern, mixed replacement, mixed subject [, int limit])
Выполняет поиск в строке subject совпадений с шаблоном pattern и заменяет их на replacement. В случае, если параметр limit указан, будет произведена замена limit вхождений шаблона; в случае, если limit опущен либо равняется -1, будут заменены все вхождения шаблона.
Replacement может содержать ссылки вида \n либо (начиная с PHP 4.0.4) $n, причем последний вариант предпочтительней. Каждая такая ссылка, будет заменена на подстроку, соответствующую n’нной заключенной в круглые скобки подмаске. n может принимать значения от 0 до 99, причем ссылка \0 (либо $0) соответствует вхождению всего шаблона. Подмаски нумеруются слева направо, начиная с единицы.
При использовании замены по шаблону с использованием ссылок на подмаски может возникнуть ситуация, когда непосредственно за маской следует цифра.
В таком случае нотация вида \n приводит к ошибке: ссылка на первую подмаску, за которой следует цифра 1, запишется как \11, что будет интерпретировано как ссылка на одиннадцатую подмаску. Это недоразумение можно устранить, если воспользоваться конструкцией $<1>1, указывающей на изолированную ссылку на первую подмаску, и следующую за ней цифру 1.Результатом работы этого примера будет:
Если во время выполнения функции были обнаружены совпадения с шаблоном, будет возвращено измененное значение subject, в противном случае будет возвращен исходный текст subject.
Первые три параметра функции preg_replace() могут быть одномерными массивами. В случае, если массив использует ключи, при обработке массива они будут взяты в том порядке, в котором они расположены в массиве. Указание ключей в массиве для pattern и replacement не является обязательным. Если вы все же решили использовать индексы, для сопоставления шаблонов и строк, участвующих в замене, используйте функцию ksort() для каждого из массивов.
В случае, если параметр subject является массивом, поиск и замена по шаблону производятся для каждого из его элементов. Возвращаемый результат также будет массивом.
В случае, если параметры pattern и replacement являются массивами, preg_replace() поочередно извлекает из обоих массивов по паре элементов и использует их для операции поиска и замены. Если массив replacement содержит больше элементов, чем pattern, вместо недостающих элементов для замены будут взяты пустые строки. В случае, если pattern является массивом, а replacement — строкой, по каждому элементу массива pattern будет осущесвтлен поиск и замена на pattern (шаблоном будут поочередно все элементы массива, в то время как строка замены остается фиксированной). Вариант, когда pattern является строкой, а replacement — массивом, не имеет смысла.
Модификатор /e меняет поведение функции preg_replace() таким образом, что параметр replacement после выполнения необходимых подстановок интерпретируется как PHP-код и только после этого используется для замены.
Используя данный модификатор, будьте внимательны: параметр replacement должен содержать корректный PHP-код, в противном случае в строке, содержащей вызов функции preg_replace(), возникнет ошибка синтаксиса.Пример кода: Замена по нескольким шаблонам
Этот пример выведет:
Пример кода: Использование модификатора /e
Пример кода: Преобразует все HTML-теги к верхнему регистру
preg_replace_callback
Функция preg_replace_callback — Выполняет поиск по регулярному выражению и замену с использованием функции обратного вызова
mixed preg_replace_callback (mixed pattern, callback callback, mixed subject [, int limit])
Поведение этой функции во многом напоминает preg_replace(), за исключением того, что вместо параметра replacement необходимо указывать callback функцию, которой в качестве входящего параметра передается массив найденных вхождений. Ожидаемый результат — строка, которой будет произведена замена.
Пример кода
preg_split
Функция preg_split — Разбивает строку по регулярному выражению
array preg_split (string pattern, string subject [, int limit [, int flags]])
Возвращает массив, состоящий из подстрок заданной строки subject, которая разбита по границам, соответствующим шаблону pattern.
В случае, если параметр limit указан, функция возвращает не более, чем limit подстрок. Специальное значение limit, равное -1, подразумевает отсутствие ограничения, это весьма полезно для указания еще одного опционального параметра flags.
flags может быть произвольной комбинацией следующих флагов (соединение происходит при помощи оператора ‘|’):
PREG_SPLIT_NO_EMPTY
В случае, если этот флаг указан, функция preg_split() вернет только непустые подстроки.PREG_SPLIT_DELIM_CAPTURE
В случае, если этот флаг указан, выражение, заключенное в круглые скобки в разделяющем шаблоне, также извлекается из заданной строки и возвращается функцией. Этот флаг был добавлен в PHP 4.0.5.PREG_SPLIT_OFFSET_CAPTURE
В случае, если этот флаг указан, для каждой найденной подстроки, будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.Примеры кода
В случае, если после открывающей круглой скобки следует «?:«, захват строки не происходит, и текущая подмаска не нумеруется. Например, если строка «the white queen» сопоставляется с шаблоном the ((?:red|white) (king|queen)), будут захвачены подстроки «white queen» и «queen», и они будут пронумерованы 1 и 2 соответственно:
Меня зовут Виталий Котов и я немного знаю о регулярных выражениях. Под катом я расскажу основы работы с ними. На эту тему написано много теоретических статей. В этой статье я решил сделать упор на количество примеров. Мне кажется, что это лучший способ показать возможности этого инструмента.
Некоторые из них для наглядности будут показаны на примере языков программирования PHP или JavaScript, но в целом они работают независимо от ЯП.
Из названия понятно, что статья ориентирована на самый начальный уровень — тех, кто еще ни разу не использовал регулярные выражения в своих программах или делал это без должного понимания.
В конце статьи я в двух словах расскажу, какие задачи нельзя решить регулярными выражениями и какие инструменты для этого стоит использовать.
Вступление
Регулярные выражения — язык поиска подстроки или подстрок в тексте. Для поиска используется паттерн (шаблон, маска), состоящий из символов и метасимволов (символы, которые обозначают не сами себя, а набор символов).
Это довольно мощный инструмент, который может пригодиться во многих случая — поиск, проверка на корректность строки и т.д. Спектр его возможностей трудно уместить в одну статью.
В PHP работа с регулярными выражениями заключается в наборе функций, из которых я чаще всего использую следующие:
- preg_match (http://php.net/manual/en/function.preg-match.php)
- preg_match_all (http://php.net/manual/en/function.preg-match-all.php)
- preg_replace (http://php.net/manual/en/function.preg-replace.php)
Для работы с ними нужен текст, в котором мы будем искать или заменять подстроки, а также само регулярное выражение, описывающее правило поиска.
0-9]$# - %[a-zA-Z0-9_-]%
Если необходимо использовать разделитель внутри шаблона, его нужно проэкранировать с помощью обратной косой черты. Если разделитель часто используется в шаблоне, в целях удобочитаемости, лучше выбрать другой разделитель для этого шаблона.
- /http:///
- #http://#
В JavaScript регулярные выражения реализованы отдельным объектом RegExp и интегрированы в методы строк.
Создать регулярное выражение можно так:
Или более короткий вариант:
Пример самого простого регулярного выражения для поиска:
В этом примере мы просто ищем все символы “o”.
В PHP разница между preg_match и preg_match_all в том, что первая функция найдет только первый match и закончит поиск, в то время как вторая функция вернет все вхождения.
Пример кода на PHP:
Пробуем то же самое для второй функции:
В последнем случае функция вернула все вхождения, которые есть в нашем тексте.
Тот же пример на JavaScript:
Модификаторы шаблонов
Для регулярных выражений существует набор модификаторов, которые меняют работу поиска.
’ соответствует только началу обрабатываемого текста, в то время как метасимвол конца строки ‘$’ соответствует концу текста. Если этот модификатор используется, метасимволы «начало строки» и «конец строки» также соответствуют позициям перед произвольным символом перевода и строки и, соответственно, после, как и в самом начале, и в самом конце строки. - 12.
 [a-zA-Z0-9._-]+@[a-zA-Z0-9-]+.[a-zA-Z.]<2,5>$/] «
[a-zA-Z0-9._-]+@[a-zA-Z0-9-]+.[a-zA-Z.]<2,5>$/] «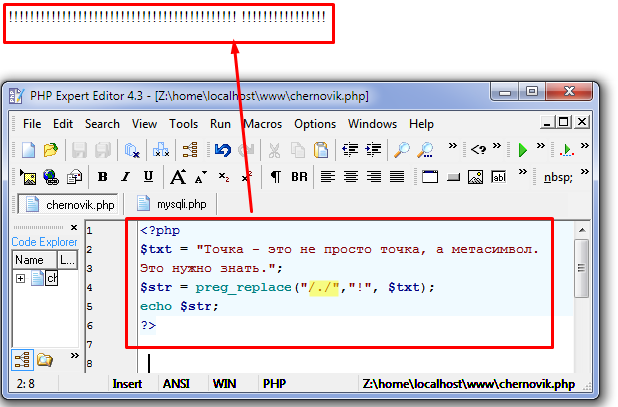 ) для создания сложных выражений.
) для создания сложных выражений.
 PH/ — любая строка, которая начинается с PH.
PH/ — любая строка, которая начинается с PH.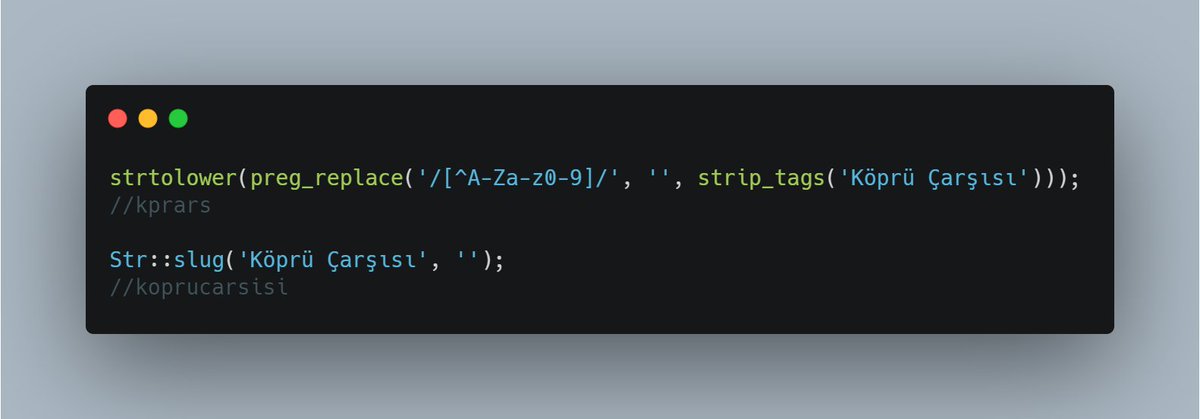 [a-zA-Z0-9._-]» соответствует любым буквам в нижнем или верхнем регистре, цифрам от 0 до 9 и точкам, подчеркиваниям или тире.
[a-zA-Z0-9._-]» соответствует любым буквам в нижнем или верхнем регистре, цифрам от 0 до 9 и точкам, подчеркиваниям или тире.  ру
ру ч. 0″ («*»), «любое натуральное число» — от 1 до бесконечности («+»: «document[0-9]+.txt»), «либо 0, либо 1» («?»). По умолчанию квантификатор для данного набора символов равен единице («document[0-9].txt»).
ч. 0″ («*»), «любое натуральное число» — от 1 до бесконечности («+»: «document[0-9]+.txt»), «либо 0, либо 1» («?»). По умолчанию квантификатор для данного набора символов равен единице («document[0-9].txt»). При помощи этих функций я проверяю email пользователя, оставляющего свой отзыв. Много полезного можно сделать, но важно иметь в виду: регулярные выражения не всесильны. Например, сложную замену в большом тексте ими лучше не делать. Ведь, к примеру, комбинация «(.*)» в программном плане означает перебор всех символов текста. А если шаблон не привязан к началу или концу строки, то и сам шаблон «двигается» программой через весь текст, и получается двойной перебор, вернее перебор в квадрате. Нетрудно догадаться, что еще одна комбинация «(.*)» означает перебор в кубе, и так далее. Возведите в третью степень, скажем, 5 килобайт текста. Получается 125 000 000 000 (прописью: сто двадцать пять миллиардов операций). Конечно же, если подходить строго, там стольких операций не будет, а будет раза в четыре-восемь меньше, но важен сам порядок цифр.
При помощи этих функций я проверяю email пользователя, оставляющего свой отзыв. Много полезного можно сделать, но важно иметь в виду: регулярные выражения не всесильны. Например, сложную замену в большом тексте ими лучше не делать. Ведь, к примеру, комбинация «(.*)» в программном плане означает перебор всех символов текста. А если шаблон не привязан к началу или концу строки, то и сам шаблон «двигается» программой через весь текст, и получается двойной перебор, вернее перебор в квадрате. Нетрудно догадаться, что еще одна комбинация «(.*)» означает перебор в кубе, и так далее. Возведите в третью степень, скажем, 5 килобайт текста. Получается 125 000 000 000 (прописью: сто двадцать пять миллиардов операций). Конечно же, если подходить строго, там стольких операций не будет, а будет раза в четыре-восемь меньше, но важен сам порядок цифр. ]
] » и «$» совпадают с началом и концом отдельных строк.
» и «$» совпадают с началом и концом отдельных строк. п.), чтобы те воспринимались буквально. Если у вас есть какой-либо ввод информации пользователем, и вы проверяете его с помощью регулярных выражений, то лучше перед этим заэкранировать служебные символы в пришедшей переменной
п.), чтобы те воспринимались буквально. Если у вас есть какой-либо ввод информации пользователем, и вы проверяете его с помощью регулярных выражений, то лучше перед этим заэкранировать служебные символы в пришедшей переменной


 Аналогично массив $matches[1] содержит второй набор вхождений, и так для каждого найденного набора.
Аналогично массив $matches[1] содержит второй набор вхождений, и так для каждого найденного набора. ] $ ( ) < >= ! | :
] $ ( ) < >= ! | : В таком случае нотация вида \n приводит к ошибке: ссылка на первую подмаску, за которой следует цифра 1, запишется как \11, что будет интерпретировано как ссылка на одиннадцатую подмаску. Это недоразумение можно устранить, если воспользоваться конструкцией $<1>1, указывающей на изолированную ссылку на первую подмаску, и следующую за ней цифру 1.
В таком случае нотация вида \n приводит к ошибке: ссылка на первую подмаску, за которой следует цифра 1, запишется как \11, что будет интерпретировано как ссылка на одиннадцатую подмаску. Это недоразумение можно устранить, если воспользоваться конструкцией $<1>1, указывающей на изолированную ссылку на первую подмаску, и следующую за ней цифру 1.
 Используя данный модификатор, будьте внимательны: параметр replacement должен содержать корректный PHP-код, в противном случае в строке, содержащей вызов функции preg_replace(), возникнет ошибка синтаксиса.
Используя данный модификатор, будьте внимательны: параметр replacement должен содержать корректный PHP-код, в противном случае в строке, содержащей вызов функции preg_replace(), возникнет ошибка синтаксиса.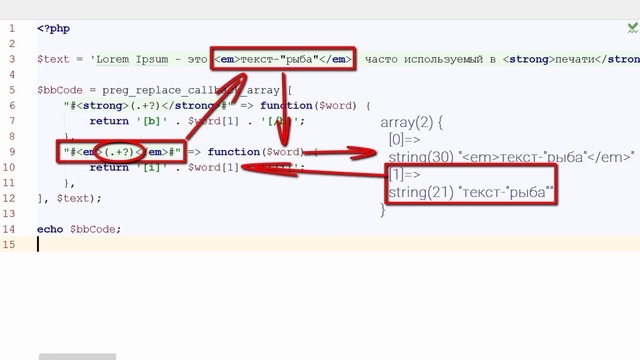

 0-9]$#
0-9]$# ’ соответствует только началу обрабатываемого текста, в то время как метасимвол конца строки ‘$’ соответствует концу текста. Если этот модификатор используется, метасимволы «начало строки» и «конец строки» также соответствуют позициям перед произвольным символом перевода и строки и, соответственно, после, как и в самом начале, и в самом конце строки.
’ соответствует только началу обрабатываемого текста, в то время как метасимвол конца строки ‘$’ соответствует концу текста. Если этот модификатор используется, метасимволы «начало строки» и «конец строки» также соответствуют позициям перед произвольным символом перевода и строки и, соответственно, после, как и в самом начале, и в самом конце строки.Об остальных модификаторах, используемых в PHP, можно почитать тут.
О том, какие вообще бывают модификаторы, можно почитать тут.
Пример предыдущего регулярного выражения с модификатором на JavaScript:
Метасимволы в регулярных выражениях
Примеры по началу будут довольно примитивные, потому что мы знакомимся с самыми основами. Чем больше мы узнаем, тем ближе к реалиям будут примеры.
Чаще всего мы заранее не знаем, какой текст нам придется парсить. Заранее известен только примерный набор правил. Будь то пинкод в смс, email в письме и т.п.
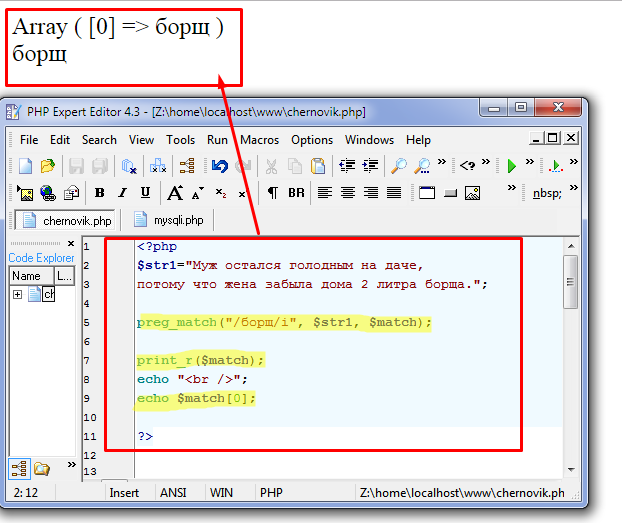
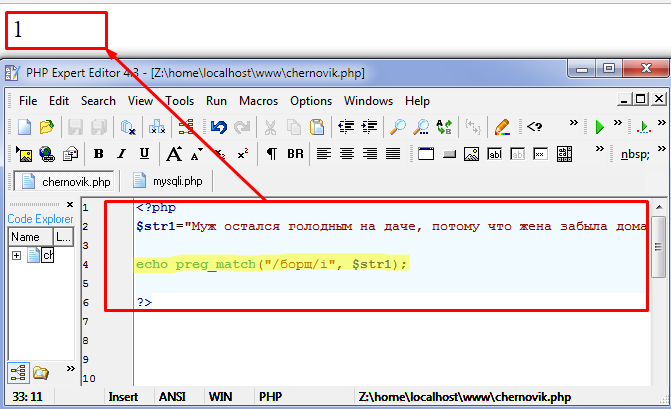
Первый пример, нам надо получить все числа из текста:
Чтобы выбрать любое число, надо собрать все числа, указав “[0123456789]”. Более коротко можно задать вот так: “[0-9]”. Для всех цифр существует метасимвол “d”. Он работает идентично.
Более коротко можно задать вот так: “[0-9]”. Для всех цифр существует метасимвол “d”. Он работает идентично.
Но если мы укажем регулярное выражение “/d/”, то нам вернётся только первая цифра. Мы, конечно, можем использовать модификатор “g”, но в таком случае каждая цифра вернется отдельным элементом массива, поскольку будет считаться новым вхождением.
Для того, чтобы вывести подстроку единым вхождением, существуют символы плюс “+” и звездочка “*”. Первый указывает, что нам подойдет подстрока, где есть как минимум один подходящий под набор символ. Второй — что данный набор символов может быть, а может и не быть, и это нормально. Помимо этого мы можем указать точное значение подходящих символов вот так: “”, где N — нужное количество. Или задать “от” и “до”, указав вот так: “”.
Сейчас будет пара примеров, чтобы это уложилось в голове:
Примерно так же мы работает с буквами, не забывая, что у них бывает регистр. Вот так можно задавать буквы:
- [a-z]
- [a-zA-Z]
- [а-яА-Я]
C кириллицей указанный диапазон работает по-разному для разных кодировок. s.]+”
s.]+”
Оказалось не так сложно. Теперь у нас есть email, собранный по частям. Рассмотрим на примере результата работы preg_match в PHP:
Получилось! Но что, если теперь нам надо по отдельности получить домен и имя по email? И как-то использовать дальше в коде? Вот тут нам поможет “захват”. Мы просто выбираем, что нам нужно, и оборачиваем знаками (), как в примере:
В массиве match нулевым элементом всегда идет полное вхождение регулярного выражения. А дальше по очереди идут “захваты”.
В PHP можно именовать “захваты”, используя следующий синтаксис:
Тогда массив матча станет ассоциативным:
Это сразу +100 к читаемости и кода, и регулярки.
Примеры из реальной жизни
Парсим письмо в поисках нового пароля:
Есть письмо с HTML-кодом, надо выдернуть из него новый пароль. (https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/’;
$var = ‘https://prowebmastering.ru’;
if (preg_match($pattern, $var)) {
echo ‘Проверка пройдена успешно!’;
} else {
echo ‘Проверка не пройдена!’;
}
(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/’;
$var = ‘https://prowebmastering.ru’;
if (preg_match($pattern, $var)) {
echo ‘Проверка пройдена успешно!’;
} else {
echo ‘Проверка не пройдена!’;
}
Что такое preg match php
preg_match
Ищет в заданном тексте subject совпадения с шаблоном pattern .
Список параметров
Искомый шаблон, строка.
В случае, если указан дополнительный параметр matches , он будет заполнен результатами поиска. Элемент $matches[0] будет содержать часть строки, соответствующую вхождению всего шаблона, $matches[1] — часть строки, соответствующую первой подмаске, и так далее.
flags может принимать значение следующего флага: PREG_OFFSET_CAPTURE В случае, если этот флаг указан, для каждой найденной подстроки будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемого массива matches в массив, каждый элемент которого содержит массив, содержащий в индексе с номером 0 найденную подстроку, а смещение этой подстроки в параметре subject — в индексе 1. , $ или (?<=x). Сравните:
, $ или (?<=x). Сравните:
Регулярные выражения в PHP.
Регулярные выражения позволяют найти в строке последовательности, соответствующие шаблону. Например шаблон «Вася(.*)Пупкин» позволит найти последовательность когда между словами Вася и Пупкин будет любое количество любых символов. Если надо найти шесть цифр, то пишем «[0-9]<6>» (если, например, от шести до восьми цифр, тогда «[0-9]<6,8>»). Здесь разделены такие вещи как указатель набора символов и указатель необходимого количества:
Вместо набора символов может быть использовано обозначение любого символа — точка, может быть указан конкретный набор символов (поддерживаются последовательности — упоминавшиеся «0-9»). Может быть указано «кроме данного набора символов».
Указатель количества символов в официальной документации по php называется «квантификатор». Термин удобный и не несет в себе кривотолков. Итак, квантификатор может иметь как конкретное значение — либо одно фиксированное («<6>»), либо как числовой промежуток («<6,8>»), так и абстрактное «любое число, в т. ч. 0″ («*»), «любое натуральное число» — от 1 до бесконечности («+»: «document[0-9]+.txt»), «либо 0, либо 1» («?»). По умолчанию квантификатор для данного набора символов равен единице («document[0-9].txt»).
ч. 0″ («*»), «любое натуральное число» — от 1 до бесконечности («+»: «document[0-9]+.txt»), «либо 0, либо 1» («?»). По умолчанию квантификатор для данного набора символов равен единице («document[0-9].txt»).
Для более гибкого поиска сочетаний эти связки «набор символов — квантификатор» можно объединять в метаструктуры.
Как всякий гибкий инструмент, регулярные выражения гибки, но не абсолютно: зона их применения ограничена. Например, если вам надо заменить в тексте одну фиксированную строку на другую, фиксированную опять же, пользуйтесь str_replace. Разработчики php слезно умоляют не пользоваться ради этого сложными функциями ereg_replace или preg_replace, ведь при их вызове происходит процесс интерпретации строки, а это серьезно потребляет ресурсы системы. К сожалению, это любимые грабли начинающих php-программистов.
Пользуйтесь функциями регулярных выражений только если вы не знаете точно, какая «там» строка. Из примеров: поисковый код , в котором из строки поиска вырезаются служебные символы и короткие слова а так же вырезаются лишние пробелы (вернее, все пробелы сжимаются: » +» заменяется на один пробел). При помощи этих функций я проверяю email пользователя, оставляющего свой отзыв. Много полезного можно сделать, но важно иметь в виду: регулярные выражения не всесильны. Например, сложную замену в большом тексте ими лучше не делать. Ведь, к примеру, комбинация «(.*)» в программном плане означает перебор всех символов текста. А если шаблон не привязан к началу или концу строки, то и сам шаблон «двигается» программой через весь текст, и получается двойной перебор, вернее перебор в квадрате. Нетрудно догадаться, что еще одна комбинация «(.*)» означает перебор в кубе, и так далее. Возведите в третью степень, скажем, 5 килобайт текста. Получается 125 000 000 000 (прописью: сто двадцать пять миллиардов операций). Конечно же, если подходить строго, там стольких операций не будет, а будет раза в четыре-восемь меньше, но важен сам порядок цифр.
Набор символов
| . | точка | любой символ | |
| [<символы>] | квадратные скобки | класс символов («любое из»). ] | Кроме пробельных символов |
| | | (одно|другое) | На этом месте может быть один из перечисленных вариантов, например: (Вася|Петя|Маша). Если Вы не хотите, чтобы это попало в выборку используйте (?: . ) |
Не пользуйтесь классом символов для обозначения всего лишь одного (вместо «[ ]+» вполне сойдет » +»). Не пишите в классе символов точку — это ведь любой символ, тогда другие символы в классе будут просто лишними (а в негативном классе получится отрицание всех символов).
Квантификатор
Квантификатором можно указать как конкретное значение, так и пределы. Если число заданных подпадает под пределы квантификатора, фрагмент выражения считается совпавшим с разбираемой строкой. Синтаксис:
Если нужно указать только необходимый минимум, а максимума нет, просто ставим запятую и не пишем второе число: «<5,>» («минимум 5»). Для наиболее часто употребляемых квантификаторов есть специальные обозначения:
На практике такие символы используются чаще, чем фигурные скобки. » и «$» совпадают с началом и концом отдельных строк.
Функции для работы с регулярными выражениями
- — Возвращает массив вхождений, которые соответствуют шаблону — Выполняет проверку на соответствие регулярному выражению. Данная функция ищет только первое совпадение! — Выполняет глобальный поиск шаблона в строке — Экранирует символы в регулярных выражениях. Т.е. вставляет слэши перед всеми служебными символами (например, скобками, квадратными скобками и т.п.), чтобы те воспринимались буквально. Если у вас есть какой-либо ввод информации пользователем, и вы проверяете его с помощью регулярных выражений, то лучше перед этим заэкранировать служебные символы в пришедшей переменной — Выполняет поиск и замену по регулярному выражению — Выполняет поиск по регулярному выражению и замену — Разбивает строку по регулярному выражению
preg_grep
Функция preg_grep — Возвращает массив вхождений, которые соответствуют шаблону
array preg_grep (string pattern, array input [, int flags])
preg_grep() возвращает массив, состоящий из элементов входящего массива input, которые соответствуют заданному шаблону pattern.
Параметр flags может принимать следующие значения:
PREG_GREP_INVERT
В случае, если этот флаг установлен, функция preg_grep(), возвращает те элементы массива, которые не соответствуют заданному шаблону pattern.
Результат, возвращаемый функцией preg_grep() использует те же индексы, что и массив исходных данных. Если такое поведение вам не подходит, примените array_values() к массиву, возвращаемому preg_grep() для реиндексации.
Пример кода:
preg_match
Функция preg_match — Выполняет проверку на соответствие регулярному выражению
int preg_match ( string pattern, string subject [, array matches [, int flags [, int offset]]]) Ищет в заданном тексте subject совпадения с шаблоном pattern
В случае, если дополнительный параметр matches указан, он будет заполнен результатами поиска. Элемент $matches[0] будет содержать часть строки, соответствующую вхождению всего шаблона, $matches[1] — часть строки, соответствующую первой подмаске, и так далее.
flags может принимать следующие значения:
PREG_OFFSET_CAPTURE
В случае, если этот флаг указан, для каждой найденной подстроки будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.
Поиск осуществляется слева направо, с начала строки. Дополнительный параметр offset может быть использован для указания альтернативной начальной позиции для поиска. Аналогичного результата можно достичь, заменив subject на substr()($subject, $offset).
Функция preg_match() возвращает количество найденных соответствий. Это может быть 0 (совпадения не найдены) и 1, поскольку preg_match() прекращает свою работу после первого найденного совпадения. Если необходимо найти либо сосчитать все совпадения, следует воспользоваться функцией preg_match_all(). Функция preg_match() возвращает FALSE в случае, если во время выполнения возникли какие-либо ошибки.
Рекомендация: Не используйте функцию preg_match(), если необходимо проверить наличие подстроки в заданной строке. Используйте для этого strpos() либо strstr(), поскольку они выполнят эту задачу гораздо быстрее.
Пример кода
Пример кода
Пример кода
preg_match_all
Функция preg_match_all — Выполняет глобальный поиск шаблона в строке
int preg_match_all (string pattern, string subject, array matches [, int flags [, int offset]])
Ищет в строке subject все совпадения с шаблоном pattern и помещает результат в массив matches в порядке, определяемом комбинацией флагов flags.
После нахождения первого соответствия последующие поиски будут осуществляться не с начала строки, а от конца последнего найденного вхождения.
Дополнительный параметр flags может комбинировать следующие значения (необходимо понимать, что использование PREG_PATTERN_ORDER одновременно с PREG_SET_ORDER бессмысленно):
PREG_PATTERN_ORDER
Если этот флаг установлен, результат будет упорядочен следующим образом: элемент $matches[0] содержит массив полных вхождений шаблона, элемент $matches[1] содержит массив вхождений первой подмаски, и так далее.
Пример кода
Как мы видим, $out[0] содержит массив полных вхождений шаблона, а элемент $out[1] содержит массив подстрок, содержащихся в тегах.
PREG_SET_ORDER
Если этот флаг установлен, результат будет упорядочен следующим образом: элемент $matches[0] содержит первый набор вхождений, элемент $matches[1] содержит второй набор вхождений, и так далее.
Пример кода
В таком случае массив $matches[0] содержит первый набор вхождений, а именно: элемент $matches[0][0] содержит первое вхождение всего шаблона, элемент $matches[0][1] содержит первое вхождение первой подмаски, и так далее. Аналогично массив $matches[1] содержит второй набор вхождений, и так для каждого найденного набора.
PREG_OFFSET_CAPTURE
В случае, если этот флаг указан, для каждой найденной подстроки будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.
В случае, если никакой флаг не используется, по умолчанию используется PREG_PATTERN_ORDER.
Поиск осуществляется слева направо, с начала строки. Дополнительный параметр offset может быть использован для указания альтернативной начальной позиции для поиска. Аналогичного результата можно достичь, заменив subject на substr()($subject, $offset).
Возвращает количество найденных вхождений шаблона (может быть нулем) либо FALSE, если во время выполнения возникли какие-либо ошибки.
Пример кода
Пример кода
preg_quote
Функция preg_quote — Экранирует символы в регулярных выражениях
string preg_quote (string str [, string delimiter])
Функция preg_quote() принимает строку str и добавляет обратный слеш перед каждым служебным символом. Это бывает полезно, если в составлении шаблона участвуют строковые переменные, значение которых в процессе работы скрипта может меняться.
В случае, если дополнительный параметр delimiter указан, он будет также экранироваться. ] $ ( ) < >= ! < > | :
Пример кода
Пример кода
preg_replace
Функция preg_replace — Выполняет поиск и замену по регулярному выражению
mixed preg_replace ( mixed pattern, mixed replacement, mixed subject [, int limit])
Выполняет поиск в строке subject совпадений с шаблоном pattern и заменяет их на replacement. В случае, если параметр limit указан, будет произведена замена limit вхождений шаблона; в случае, если limit опущен либо равняется -1, будут заменены все вхождения шаблона.
Replacement может содержать ссылки вида \\n либо (начиная с PHP 4.0.4) $n, причем последний вариант предпочтительней. Каждая такая ссылка, будет заменена на подстроку, соответствующую n’нной заключенной в круглые скобки подмаске. n может принимать значения от 0 до 99, причем ссылка \\0 (либо $0) соответствует вхождению всего шаблона. Подмаски нумеруются слева направо, начиная с единицы.
При использовании замены по шаблону с использованием ссылок на подмаски может возникнуть ситуация, когда непосредственно за маской следует цифра. В таком случае нотация вида \\n приводит к ошибке: ссылка на первую подмаску, за которой следует цифра 1, запишется как \\11, что будет интерпретировано как ссылка на одиннадцатую подмаску. Это недоразумение можно устранить, если воспользоваться конструкцией \$<1>1, указывающей на изолированную ссылку на первую подмаску, и следующую за ней цифру 1.
Результатом работы этого примера будет:
Если во время выполнения функции были обнаружены совпадения с шаблоном, будет возвращено измененное значение subject, в противном случае будет возвращен исходный текст subject.
Первые три параметра функции preg_replace() могут быть одномерными массивами. В случае, если массив использует ключи, при обработке массива они будут взяты в том порядке, в котором они расположены в массиве. Указание ключей в массиве для pattern и replacement не является обязательным. Если вы все же решили использовать индексы, для сопоставления шаблонов и строк, участвующих в замене, используйте функцию ksort() для каждого из массивов.
В случае, если параметр subject является массивом, поиск и замена по шаблону производятся для каждого из его элементов. Возвращаемый результат также будет массивом.
В случае, если параметры pattern и replacement являются массивами, preg_replace() поочередно извлекает из обоих массивов по паре элементов и использует их для операции поиска и замены. Если массив replacement содержит больше элементов, чем pattern, вместо недостающих элементов для замены будут взяты пустые строки. В случае, если pattern является массивом, а replacement — строкой, по каждому элементу массива pattern будет осущесвтлен поиск и замена на pattern (шаблоном будут поочередно все элементы массива, в то время как строка замены остается фиксированной). Вариант, когда pattern является строкой, а replacement — массивом, не имеет смысла.
Модификатор /e меняет поведение функции preg_replace() таким образом, что параметр replacement после выполнения необходимых подстановок интерпретируется как PHP-код и только после этого используется для замены. Используя данный модификатор, будьте внимательны: параметр replacement должен содержать корректный PHP-код, в противном случае в строке, содержащей вызов функции preg_replace(), возникнет ошибка синтаксиса.
Пример кода: Замена по нескольким шаблонам
Этот пример выведет:
Пример кода: Использование модификатора /e
Пример кода: Преобразует все HTML-теги к верхнему регистру
preg_replace_callback
Функция preg_replace_callback — Выполняет поиск по регулярному выражению и замену с использованием функции обратного вызова
mixed preg_replace_callback (mixed pattern, callback callback, mixed subject [, int limit])
Поведение этой функции во многом напоминает preg_replace(), за исключением того, что вместо параметра replacement необходимо указывать callback функцию, которой в качестве входящего параметра передается массив найденных вхождений. Ожидаемый результат — строка, которой будет произведена замена.
Пример кода
preg_split
Функция preg_split — Разбивает строку по регулярному выражению
array preg_split (string pattern, string subject [, int limit [, int flags]])
Возвращает массив, состоящий из подстрок заданной строки subject, которая разбита по границам, соответствующим шаблону pattern.
В случае, если параметр limit указан, функция возвращает не более, чем limit подстрок. Специальное значение limit, равное -1, подразумевает отсутствие ограничения, это весьма полезно для указания еще одного опционального параметра flags.
flags может быть произвольной комбинацией следующих флагов (соединение происходит при помощи оператора ‘|’):
PREG_SPLIT_NO_EMPTY
В случае, если этот флаг указан, функция preg_split() вернет только непустые подстроки.
PREG_SPLIT_DELIM_CAPTURE
В случае, если этот флаг указан, выражение, заключенное в круглые скобки в разделяющем шаблоне, также извлекается из заданной строки и возвращается функцией. Этот флаг был добавлен в PHP 4.0.5.
PREG_SPLIT_OFFSET_CAPTURE
В случае, если этот флаг указан, для каждой найденной подстроки, будет указана ее позиция в исходной строке. Необходимо помнить, что этот флаг меняет формат возвращаемых данных: каждое вхождение возвращается в виде массива, в нулевом элементе которого содержится найденная подстрока, а в первом — смещение.
Примеры кода
В случае, если после открывающей круглой скобки следует «?:«, захват строки не происходит, и текущая подмаска не нумеруется. Например, если строка «the white queen» сопоставляется с шаблоном the ((?:red|white) (king|queen)), будут захвачены подстроки «white queen» и «queen», и они будут пронумерованы 1 и 2 соответственно:
Регулярные выражения в PHP часть 3 (preg_match)
У функции preg_match_all есть возможность выгружать не только найденные совпадения, но и найденные вариации, которые называются карманами. Эти карманы появляются, если использовать скобки ( ) Приведём пример: В этом примере переменная $b примет значение 3, а в переменной $a будет массив: В первом массиве будут содержаться найденные совпадения, а во втором содержимое первого кармана. Карманов может быть несколько, в зависимости от количества скобок ( ), которые использовались в регулярном выражении.
Скобки автоматически создают карманы. Если же нужно отказаться от создания кармана, то нужно добавить в начало скобок символы «?:«. Тогда в примере выше регулярное выражение примет такой вид «’#\bс(?:ы+)р\b#iu‘».
Карманы и preg_replace
Напомним, что регулярными выражениями необходимо использовать только в том случае, если нет никакого другого способа решения.
Ошибки в регулярных выражениях — это очень частое явление. Поэтому прибегайте к этому инструменту только в самых-самых безвыходных ситуациях, когда всё остальное уже опробовано.
Позитивный и негативный просмотр
Функцией preg_replace найденное выражение заменяется полностью на второй параметр. Но что делать, если нам не надо заменять всё найденное, а только часть? Для этого есть позитивный и негативный просмотр.
Представьте, что нужно заменить слово, не заменяя первую букву. Приведём пример реализации: Результат будет такой: Хоть буква «к» и стоит в регулярном выражении, но она стоит в специальных скобках (?<=к), которые проверяют наличие буквы, но не подставляют её на замену. Такие скобки называются позитивным просмотром. Можно сделать позитивный просмотр и в конце строки: Позитивный просмотр (?=е) проверяет, есть ли в конце строки буква «е». Происходит замена и получается такая строка: Теперь рассмотрим оба примера (просмотр в начале и в конце строки), но в негативном смысле. Негативный просмотр — это противоположность к позитивному и создаётся с помощью скобок (?<! ) для поиска символа вначале и (?! ) в конце. То есть он проверяет нет ли такого символа: Результат будет такой:
PHP (регулярное выражение) — определение. Примеры и проверка регулярных выражений
При работе с текстами в любом современном языке программирования разработчики постоянно встречаются с задачами проверки введенных данных на соответствие нужному шаблону, поиска и замены тестовых фрагментов и прочими типовыми операциями по обработке символьной информации. Разработка собственных алгоритмов проверки приводит к потере времени, несовместимости программного кода и сложности в его развитии и модернизации.
Бурное развитие Интернета и языков WEB-разработки потребовало создания универсальных и компактных средств обработки текстовой информации при минимальном количестве требуемого для этого кода. Не является исключением и популярный среди начинающих и профессиональных разработчиков язык PHP. Регулярное выражение как язык текстовых шаблонов позволяет упростить задачи обработки текста и уменьшить программный код на десятки и сотни строк. Многие задачи вообще невозможно решить без него.
Регулярные выражения в PHP
Язык PHP содержит три механизма работы с регулярными выражениями — «ereg», «mb_ereg» и «preg». Наиболее распространенным является интерфейс «preg», функции которого обеспечивают доступ к библиотеке поддержки регулярных выражений PCRE, изначально разработанной для языка Perl, которая входит в комплект PHP. Preg-функции ищут в заданной текстовой строке совпадения, согласно определенному шаблону на языке регулярных выражений.
Основы синтаксиса
В рамках короткой статьи невозможно подробно описать весь синтаксис регулярных выражений, для этого существует специальная литература. Приведем только основные элементы для показа широких возможностей для разработчика и понимания примеров кода.
В PHP регулярное выражение формально определяется очень сложно, и поэтому упростим описание. Регулярное выражение представляет собой текстовую строку. Она состоит из выделенного разделителем шаблона и модификатора, указывающего на то, каким образом его обрабатывать. Возможно включение в шаблоны различных альтернатив и повторений.
Например, в выражении /\d{3}-\d{2}-\d{2}/m разделителем будет «/», далее идет шаблон, а символ «m» будет модификатором.
Вся мощь регулярных выражений кодируется с помощью метасимволов. Основным метасимволом языка является обратный слэш — «\». Он меняет тип следующего за ним символа на противоположный (т. е. обычный символ превращается в метасимвол и наоборот). Другим важным метасимволом является прямая черта «|», задающая альтернативные варианты шаблона. Еще примеры метасимволов:
| ^ | Начало объекта или строки |
| ( | Начало подшаблона |
| ) | Окончание подшаблона |
| { | Начало квантификатора |
| } | Конец квантификатора |
| \d | десятичная цифра от 0 до 9 |
| \D | любой символ, не являющийся цифрой |
| \s | пустой символ, пробел, табуляция |
| \w | словарный символ |
PHP, обрабатывая регулярные выражения, пробел рассматривает как отдельный значимый символ, поэтому выражения АБВГДЕ и АБВ ГДЕ являются разными.
Подшаблоны
В PHP регулярные подшаблоны выделяются круглыми скобками и иногда называются «подвыражениями». Выполняют следующие функции:
Выделение альтернатив. Например, шаблон жар(кое|птица|) совпадет со словами «жар», «жар-птица» и «жаркое». А без скобок это будет только пустая строка, «птица» и «жаркое».
«Захватывающий» подшаблон. Это означает, что если в шаблоне совпала подстрока, то в качестве результата возвращаются все совпадения. Для наглядности приведем пример. Дано следующее регулярное выражение: победитель получает((золотую|позолоченный)(медаль|кубок)) — и строка для поиска совпадений: «победитель получает золотую медаль». Кроме исходной фразы, в результате поиска будут выданы: «золотую медаль», «медаль», «золотую».
Операторы повторений (квадрификаторы)
При составлении регулярных выражений очень часто необходимо анализировать повторения чисел и символов. Это не является проблемой, если повторений не очень много. Но что делать, когда мы не знаем их точного числа? В таком случае необходимо использовать специальные метасимволы.
Для описания повторений применяются квадрификаторы – метасимволы для задания количества. Квадрификаторы бывают двух типов:
- общие, заключенные в скобки;
- сокращенные.
Общий квантификатор задет минимальное и максимальное количество разрешенных повторений элемента в виде двух чисел в фигурных скобках, например так: х{2,5}. Если максимальное количество повторений неизвестно, второй аргумент не указывается: х{2,}.
Сокращенные квантификаторы представляют собой символы для наиболее распространенных повторений во избежание лишней перегрузки синтаксиса. Обычно используются три сокращения:
1. * — ноль и больше повторений, что эквивалентно {0,}.
2. + — одно и более повторений, т. е. {1,}.
3. ? – ноль или только одно повторение — {0,1}.
Примеры регулярных выражений
Для тех, кто изучает регулярные выражения, примеры — лучший учебник. Мы приведем несколько, которые показывают их широкие возможности при минимуме усилий. Все программные коды полностью совместимы с версиями PHP 4.x и выше. Для полного понимания синтаксиса и использования всех возможностей языка рекомендуем книгу Дж. Фридла «Регулярные выражения», где полностью рассматривается синтаксис и имеются примеры регулярных выражений не только на PHP, но и для языков Python, Perl, MySQL, Java, Ruby и C#.
Проверка корректности адреса E-mail
Задача. Существует Интернет-страница, на которой у посетителя запрашивается адрес email. Регулярное выражение должно проверять правильность полученного адреса перед отправкой сообщений. Проверка не дает гарантии, что указанный почтовый ящик реально существует и принимает письма. Но отсеять заведомо неправильные адреса она может.
Решение. Как и в любом языке программирования, на PHP регулярные выражения email-проверки адреса могут быть реализованы разными способами, и примеры в этой статье не являются окончательным и единственным вариантом. Поэтому в каждом случае мы будем приводить перечень требований, которые нужно учесть при программировании, а конкретная реализация полностью зависит от разработчика.
Итак, выражение, проверяющее правильность email, должно проверять следующие условия:
- Наличие в исходной строке символа @ и отсутствие пробелов.
- Доменная часть адреса, за символом @, содержит только допустимые символы для доменных имен. То же относится и к имени пользователя.
- При проверке имени пользователя необходимо определить наличие специальных символов, таких как апостроф или вертикальная черта. Такие символы относятся к потенциально опасным и могут содержаться в таких видах нападений, как SQL-инъекции. Избегайте таких адресов.
- Имена пользователя допускают наличие только одной точки, которая не может быть первым или последним символом в строке.
- Доменное имя должно содержать не меньше двух и не более шести символов.
Пример, учитывающий все указанные условия, можно увидеть далее на рисунке. (https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
Теперь разберем его составляющие более подробно, используя рисунок.
| п.1 | Перед адресом URL не должно быть никаких символов |
| п.2 | Проверяем наличие обязательного префикса «http» |
| п.3 | Не должно быть символов |
| п.4 | Если присутствует «s», то URL указывает на защищенное соединение «https» |
| п.5 | Обязательный фрагмент «//» |
| п.6 | Нет символов |
| п. 7-9 | Проверка правильности домена первого уровня и наличия точки |
| п.10-13 | Контроль правильности написания домена второго уровня и точки |
| п.14-17 | Файловая структура URL — набор цифр, букв, подчёркиваний, дефисов, точек и слэш в конце |
Проверяем номера кредитных карт
Задача. Необходимо реализовать проверку правильности введенного номера пластиковой карты наиболее распространенных платежных систем. Рассмотрен вариант только для карт Visa и MasterCard.
Решение. При создании выражения необходимо учитывать возможное наличие во введенном номере пробелов. Цифры номера на карте разделены на группы для упрощения чтения и диктовки. Поэтому вполне естественно, что человек может попытаться ввести номер таким образом (т. е. используя пробелы).
Написать универсальное выражение, учитывающее возможные пробелы и дефисы, сложнее, чем просто отбросить все символы, кроме цифр. Поэтому в выражении рекомендуется использовать метасимвол /D, который удаляет все символы, кроме цифр.
Теперь можно переходить непосредственно к проверке номера. Все компании, выпускающие кредитные карты, используют уникальный формат номера. В примере это используется, и клиенту нет необходимости вводить наименование компании – она определяется по номеру. Карты Visa всегда начинаются с 4 и имеют длину номера в 13 или 16 цифр. MasterCard начинается в диапазоне 51-55 с длиной номера 16. В итоге получаем такое выражение:
Перед обработкой заказа можно провести дополнительную проверку последней цифры номера, которая вычисляется по алгоритму Луна. (36[0-6]|3[0-5][0-9]|[12][0-9]{2}|[1-9][0-9]?)$
Поиск IP-адреса
Задача. Необходимо определить, является ли заданная строка допустимым IP-адресом в формате IPv4 в диапазоне от 000.000.000.000-255.255.255.255.
Решение. Как и в любой задаче на языке PHP, регулярное выражение имеет множество варинтов. Например, такое:
Онлайн-проверка выражений
Проверка регулярных выражений на правильность для начинающих программистов может быть затруднительной из-за сложности синтаксиса, отличающегося от «обычных» языков программирования. Для решения данной проблемы существует множество онлайн-тестеров выражений, позволяющих легко проверить правильность созданного шаблона на реальном тексте. Программист вводит выражение и данные для проверки и мгновенно видит результат обработки. Обычно здесь же присутствует справочный раздел, где подробно описываются регулярные выражения, примеры и отличия реализации для наиболее распостраненных языков программирования.
Но полностью доверять результатам онлайн-сервисов не рекомендуется всем разработчикам, пользующимся PHP. Регулярное выражение, написанное и проверенное лично, повышает квалификацию и гарантирует отсутствие ошибок.
Автор:
Флоренца Евгений
Похожие статьи
Использование регулярных выражений с PHP
PHP — это язык с открытым исходным кодом для создания динамических веб-страниц. PHP имеет три набора функций, позволяющих работать с регулярными выражениями.
Самый важный набор функций регулярных выражений начинается с preg. Эти функции представляют собой оболочку PHP для библиотеки PCRE (Perl-совместимые регулярные выражения). Все, что сказано о разновидности регулярных выражений PCRE в учебнике по регулярным выражениям на этом веб-сайте, относится и к preg-функциям PHP. Когда в учебнике конкретно говорится о PHP, предполагается, что вы используете функции preg. Вы должны использовать функции preg для всего нового кода PHP, использующего регулярные выражения. PHP включает PCRE по умолчанию, начиная с PHP 4.2.0 (апрель 2002 г.).
Самый старый набор функций регулярных выражений — это те, которые начинаются с ereg. Они реализуют расширенные регулярные выражения POSIX, как и традиционная команда UNIX egrep. Эти функции в основном предназначены для обратной совместимости с PHP 3. Они официально объявлены устаревшими, начиная с PHP 5.3.0. Многие из более современных функций регулярных выражений, такие как ленивые квантификаторы, поиск и Unicode, не поддерживаются функциями ereg. Не позволяйте «расширенному» прозвищу обмануть вас. Стандарт POSIX был определен в 1986 году, и с тех пор регулярные выражения прошли долгий путь.
Последний набор представляет собой вариант набора ereg с префиксом mb_ для «многобайтового» имени функции. В то время как ereg обрабатывает регулярное выражение и строку темы как серию 8-битных символов, mb_ereg может работать с многобайтовыми символами из различных кодовых страниц. Если вы хотите, чтобы ваше регулярное выражение рассматривало символы Дальнего Востока как отдельные символы, вам нужно либо использовать функции mb_ereg, либо функции preg с модификатором /u. mb_ereg доступен в PHP 4.2.0 и более поздних версиях. Он использует тот же вариант POSIX ERE.
Набор функций preg
Все функции preg требуют указания регулярного выражения в виде строки с использованием синтаксиса Perl. В Perl /regex/ определяет регулярное выражение. В PHP это становится preg_match(‘/regex/’, $subject). Когда косая черта используется в качестве разделителя регулярного выражения, любая косая черта в регулярном выражении должна быть экранирована обратной косой чертой. Таким образом, https://www\.jgsoft\.com/ становится ‘/https:\/\/www\.jgsoft\.com\//’. Как и в Perl, функции preg позволяют использовать в качестве разделителей регулярных выражений любые небуквенно-цифровые символы. Регулярное выражение URL было бы более читабельным как «%https://www\.jgsoft\.com/%», используя знаки процента в качестве разделителей регулярных выражений, поскольку тогда вам не нужно экранировать косую черту. Вам пришлось бы избегать процентных знаков, если бы регулярное выражение их содержало.
В отличие от таких языков программирования, как C# или Java, PHP не требует экранирования всех символов обратной косой черты в строках. Если вы хотите включить обратную косую черту в качестве буквального символа в строку PHP, вам нужно экранировать ее только в том случае, если за ней следует другой символ, который необходимо экранировать. В одинарных кавычках необходимо экранировать только одинарную кавычку и обратную косую черту. Вот почему в приведенном выше регулярном выражении мне не нужно было удваивать обратную косую черту перед буквальными точками. Регулярное выражение \\ для соответствия одной обратной косой черте станет ‘/\\\\/’ в качестве строки preg PHP. Если вы не хотите использовать интерполяцию переменных в своем регулярном выражении, вы всегда должны использовать строки в одинарных кавычках для регулярных выражений в PHP, чтобы избежать беспорядочного дублирования обратной косой черты.
Чтобы указать параметры соответствия регулярных выражений, такие как нечувствительность к регистру, задаются так же, как в Perl. ‘/regex/i’ не учитывает регистр регулярных выражений. ‘/regex/s’ заставляет точку соответствовать всем символам. ‘/regex/m’ приводит к совпадению якорей начала и конца строки во встроенных новых строках в строке темы. ‘/regex/x’ включает режим свободного интервала. Вы можете указать несколько букв, чтобы включить несколько параметров. ‘/regex/mix’ включает все четыре параметра.
Специальным параметром является параметр /u, который включает режим сопоставления Unicode вместо стандартного 8-битного режима сопоставления. Вы должны указать /u для регулярных выражений, которые используют \x{FFFF}, \X или \p{L} для соответствия символам Unicode, графемам, свойствам или сценариям. PHP будет интерпретировать ‘/regex/u’ как строку UTF-8, а не как строку ASCII.
Подобно функции ereg, bool preg_match (шаблон строки, тема строки [ группы массивов]) возвращает TRUE, если шаблон регулярного выражения соответствует строке темы или части строки темы. Если вы укажете третий параметр, preg сохранит подстроку, соответствующую первой группе захвата, в $groups[1]. $groups[2] будет содержать вторую пару и так далее. Если шаблон регулярного выражения использует именованный захват, вы можете получить доступ к группам по имени с помощью $groups[‘name’]. $groups[0] будет содержать общее совпадение.
int preg_match_all (шаблон строки, тема строки, совпадения массива, флаги int) заполняет массив «совпадений» всеми совпадениями шаблона регулярного выражения в строке темы. Если вы укажете PREG_SET_ORDER в качестве флага, то $matches[0] будет массивом, содержащим совпадение и обратные ссылки первого совпадения, точно так же, как массив $groups, заполненный preg_match. $matches[1] содержит результаты второго совпадения и так далее. Если вы укажете PREG_PATTERN_ORDER, то $matches[0] — это массив с полными последовательными совпадениями регулярных выражений, $matches[1] — массив с первой обратной ссылкой всех совпадений, $matches[2] — массив со второй обратной ссылкой каждого совпадения, и т. д.
массив preg_grep (шаблон строки, предметы массива) возвращает массив, содержащий все строки в массиве «субъекты», которым может соответствовать шаблон регулярного выражения.
смешанный preg_replace (смешанный шаблон, смешанная замена, смешанная тема [ int limit]) возвращает строку, в которой все совпадения шаблона регулярного выражения в строке темы заменены строкой замены. Производятся максимально предельные замены. Одно ключевое отличие состоит в том, что все параметры, кроме limit, могут быть массивами, а не строками. В этом случае preg_replace выполняет свою работу несколько раз, одновременно перебирая элементы в массивах. Вы также можете использовать строки для одних параметров и массивы для других. Затем функция будет перебирать массивы и использовать одни и те же строки для каждой итерации. Использование массива шаблона и замены позволяет выполнять последовательность операций поиска и замены над одной строкой темы. Использование массива для строки темы позволяет выполнять одну и ту же операцию поиска и замены для многих строк темы.
preg_replace_callback (смешанный шаблон, замена обратного вызова, смешанная тема [ int limit]) работает точно так же, как preg_replace, за исключением того, что второй параметр принимает обратный вызов вместо строки или массива строк. Функция обратного вызова будет вызываться для каждого совпадения. Обратный вызов должен принимать один параметр. Этот параметр будет массивом строк, где элемент 0 содержит общее совпадение с регулярным выражением, а остальные элементы — текст, сопоставленный захваченными группами. Это тот же массив, который вы получили бы от preg_match. Функция обратного вызова должна возвращать текст, которым должно быть заменено совпадение. Верните пустую строку, чтобы удалить совпадение. Верните $groups[0], чтобы пропустить это совпадение.
Обратные вызовы позволяют выполнять мощные операции поиска и замены, которые невозможно выполнить с помощью одних только регулярных выражений. Например. если вы ищете регулярное выражение (\d+)\+(\d+), вы можете заменить 2+3 на 5, используя обратный вызов:
function regexadd($groups) {
вернуть $группы[1] + $группы[2];
} array preg_split (шаблон строки, тема строки [ int limit]) работает точно так же, как split, за исключением того, что он использует синтаксис Perl для шаблона регулярного выражения.
См. руководство по PHP для получения дополнительной информации о наборе функций preg
Набор функций ereg
Функции ereg требуют указания регулярного выражения в виде строки, как и следовало ожидать. ereg(‘regex’, «subject») проверяет, соответствует ли регулярное выражение теме. Вы должны использовать одинарные кавычки при передаче регулярного выражения в виде буквальной строки. Некоторые специальные символы, такие как доллар и обратная косая черта, также являются специальными символами в строках PHP с двойными кавычками, но не в строках PHP с одинарными кавычками.
int ereg (шаблон строки, тема строки [ группы массивов]) возвращает длину совпадения, если шаблон регулярного выражения соответствует строке темы или части строки темы, или ноль в противном случае. Поскольку ноль оценивается как False, а ненулевое значение оценивается как True, вы можете использовать ereg в операторе if для проверки совпадения. Если вы укажете третий параметр, ereg сохранит подстроку, совпадающую с частью регулярного выражения, между первой парой скобок в $groups[1]. $groups[2] будет содержать вторую пару и так далее. Обратите внимание, что скобки только для группировки не поддерживаются ereg. ereg чувствителен к регистру. eregi является регистронезависимым эквивалентом.
строка ereg_replace (шаблон строки, замена строки, тема строки) заменяет все совпадения шаблона регулярного выражения в строке темы строкой замены. Вы можете использовать обратные ссылки в строке замены. \\0 — это полное соответствие регулярному выражению, \\1 — первая обратная ссылка, \\2 — вторая и т. д. Максимально возможная обратная ссылка — \\9. ereg_replace чувствителен к регистру. eregi_replace — нечувствительный к регистру эквивалент.
array split (шаблон строки, тема строки [ int limit]) разбивает строку темы на массив строк, используя шаблон регулярного выражения. Массив будет содержать подстроки между совпадениями регулярного выражения. Фактически совпадающий текст отбрасывается. Если вы укажете ограничение, результирующий массив будет содержать не более указанного количества подстрок. Строка темы будет разделена не более limit-1 раз, а последний элемент массива будет содержать неразделенный остаток строки темы. разделение чувствительно к регистру. spliti — эквивалент, нечувствительный к регистру.
Дополнительную информацию о наборе функций ereg см. в руководстве по PHP.
Набор функций mb_ereg
Функции mb_ereg работают точно так же, как и функции ereg, с одним ключевым отличием: в то время как ereg обрабатывает регулярное выражение и строку темы как серию 8-битных символов, mb_ereg может работать с многобайтовыми символами из различных кодовых страниц. Например. закодированное с помощью кодовой страницы Windows 936 (упрощенный китайский), слово 中国 («Китай») состоит из четырех байтов: D6D0B9FA. Использование функции ereg с регулярным выражением. в этой строке в результате будет получен первый байт D6. Точка соответствует ровно одному байту, так как функции ereg ориентированы на байты. Использование функции mb_ereg после вызова mb_regex_encoding(«CP936») даст в результате байты D6D0 или первый символ 中.
Чтобы убедиться, что ваше регулярное выражение использует правильную кодовую страницу, вызовите mb_regex_encoding() для установки кодовой страницы. Если вы этого не сделаете, кодовая страница Вместо этого используется функция mb_internal_encoding(), возвращаемая или устанавливаемая функцией
Если ваш скрипт PHP использует UTF-8, вы можете использовать функции preg с модификатором /u для сопоставления многобайтовых символов UTF-8 вместо отдельных байтов. функции не поддерживают никакие другие кодовые страницы.
Дополнительную информацию о наборе функций mb_ereg см. в руководстве по PHP.
Дополнительная литература
Книга Mastering Regular Expressions не только объясняет все, что вы хотите знать и не хотите знать о регулярных выражениях. В нем также есть отличная глава о наборе функций PHP preg, с подробностями о базовом механизме регулярных выражений PCRE и большим количеством примеров PHP-кода, демонстрирующих более продвинутые методы. В книге не рассматриваются наборы функций ereg и mb_ereg.
Мой обзор книги Mastering Regular Expressions
- Купить Mastering Regular Expressions на Amazon.com
- Купить Мастеринг регулярных выражений на Amazon.co.uk
- Купить Мастеринг регулярных выражений на Amazon.fr
- Купить Мастеринг регулярных выражений на Amazon.de
- Купить Reguläre Ausdrücke на Amazon.de
| Быстрый старт | Учебник | Инструменты и языки | Примеры | Ссылка | Обзоры книг |
| грэп | PowerGREP | Регулярное выражение друг | RegexMagic |
| EditPad Lite | EditPad Pro |
| Повышение | Дельфы | GNU (Linux) | Отличный | Ява | JavaScript | .NET | PCRE (C/C++) | PCRE2 (C/C++) | Перл | PHP | POSIX | PowerShell | Питон | Р | Руби | std::regex | Tcl | VBScript | Visual Basic 6 | wxвиджеты | XML-схема | Ходжо | XQuery и XPath | XRegExp |
| MySQL | Оракул | PostgreSQL |
URL-адрес страницы: https://www.regular-expressions.info/php.html
Последнее обновление страницы: 24 августа 2021 г.
Последнее обновление сайта: 14 сентября 2022 г.
Copyright © 2003-2022 Jan Goyvaerts. Все права защищены.
Регулярное выражение | PHP | Кодлабс
- Дом
- Учебник по php
- регулярное выражение
Регулярные выражения — это не что иное, как последовательность или шаблон символов. Они обеспечивают основу для функциональности сопоставления с образцом.
Используя регулярное выражение, вы можете искать определенную строку внутри другой строки, вы можете заменить одну строку другой строкой и вы можете разбить строку на несколько фрагментов.
PHP предлагает функции, специфичные для двух наборов функций регулярных выражений, каждый из которых соответствует определенному типу регулярных выражений. Вы можете использовать любой из них в зависимости от вашего удобства.
- Регулярные выражения POSIX
- Регулярные выражения в стиле PERL
Регулярные выражения POSIX
Структура регулярного выражения POSIX не отличается от структуры типичного арифметического выражения. Различные элементы (операторы) объединяются для формирования более сложных выражений.
Простейшее регулярное выражение — это выражение, которое соответствует одному символу, например g, внутри таких строк, как g, торг или сумка.
Давайте объясним несколько понятий, используемых в регулярных выражениях POSIX. После этого мы познакомим вас с функциями, связанными с регулярными выражениями.
Скобки
Скобки ([]) имеют особое значение при использовании в контексте регулярных выражений. Они используются для поиска диапазона символов.
| Старший № | Выражение и описание |
|---|---|
| 1 | [0-9] Соответствует любой десятичной цифре от 0 до 9. |
| 2 | [a-z] Соответствует любому символу от строчной буквы a до строчной буквы z. |
| 3 | [A-Z] Соответствует любому символу от прописной буквы A до прописной буквы Z. |
| 4 | [a-Z] Соответствует любому символу от строчной буквы a до прописной буквы Z. |
Диапазоны, показанные выше, являются общими, вы также можете использовать диапазон [0-3] для соответствия любой десятичной цифре от 0 до 3 или диапазон [b-v] для соответствия любому символу нижнего регистра в диапазоне от b до v.
Квантификаторы
Частота или положение последовательностей символов в квадратных скобках и отдельных символов может быть обозначено специальным символом. Каждый специальный символ имеет определенное значение. +, *, ?, {инт. range}, а все флаги $ следуют за последовательностью символов.
| Старший № | Выражение и описание |
|---|---|
| 1 | p+ Соответствует любой строке, содержащей хотя бы один p. |
| 2 | p* Соответствует любой строке, содержащей ноль или более символов p. |
| 3 | р? Он соответствует любой строке, содержащей ноль или более символов p. Это всего лишь альтернативный способ использования p*. |
| 4 | p{N} Соответствует любой строке, содержащей последовательность N p |
| 5 | p{2,3} Соответствует любой строке, содержащей последовательность из двух или трех символов p. 9.{2}$ Соответствует любой строке, содержащей ровно два символа. |
| 4 | p(hp)* Соответствует любой строке, содержащей p, за которой следует ноль или более экземпляров последовательности php. |
Предопределенные диапазоны символов
Для удобства программирования доступно несколько предопределенных диапазонов символов, также известных как классы символов. Классы символов определяют весь диапазон символов, например, алфавит или целочисленный набор:
| Старший № | Выражение и описание |
|---|---|
| 1 | [[:alpha:]] Соответствует любой строке, содержащей буквы от aA до zZ. |
| 2 | [[:digit:]] Соответствует любой строке, содержащей числовые цифры от 0 до 9. |
| 3 | [[:alnum:]] Соответствует любой строке, содержащей буквенно-цифровые символы от aA до zZ и от 0 до 9. |
| 4 | [[:space:]] Соответствует любой строке, содержащей пробел. |
Функции PHP Regexp POSIX
PHP в настоящее время предлагает семь функций для поиска строк с использованием регулярных выражений в стиле POSIX:
| Sr.No | Выражение и описание |
|---|---|
| 1 | ereg() Функция ereg() ищет в строке, заданной параметром string, строку, заданную шаблоном, возвращая значение true, если шаблон найден, и false в противном случае. |
| 2 | ereg_replace() Функция ereg_replace() ищет строку, заданную шаблоном, и заменяет шаблон заменой, если он найден. |
| 3 | eregi() Функция eregi() ищет в строке, указанной с помощью шаблона, строку, указанную с помощью строки. Поиск не чувствителен к регистру. |
| 4 | eregi_replace() Функция eregi_replace() работает точно так же, как ereg_replace(), за исключением того, что поиск шаблона в строке не чувствителен к регистру. |
| 5 | split() Функция split() разделит строку на различные элементы, границы каждого элемента основаны на наличии шаблона в строке. |
| 6 | spliti() Функция spliti() работает точно так же, как и родственная ей функция split(), за исключением того, что она не чувствительна к регистру. |
| 7 | sql_regcase() Функцию sql_regcase() можно рассматривать как служебную функцию, преобразующую каждый символ в строке входного параметра в выражение в квадратных скобках, содержащее два символа. |
Регулярные выражения в стиле PERL
Регулярные выражения в стиле Perl аналогичны своим аналогам в POSIX. Синтаксис POSIX можно использовать почти взаимозаменяемо с функциями регулярных выражений в стиле Perl. На самом деле вы можете использовать любой квантификатор, представленный в предыдущем разделе POSIX.
Давайте объясним несколько понятий, используемых в регулярных выражениях PERL. После этого мы познакомим вас с функциями, связанными с регулярными выражениями.
Метасимволы
Метасимвол — это просто буквенный символ, которому предшествует обратная косая черта, придающая комбинации особый смысл.
Например, вы можете искать большие денежные суммы, используя метасимвол ‘\d’: /([\d]+)000/, Здесь \d будет искать любую строку числового символа.
Ниже приведен список метасимволов, которые можно использовать в регулярных выражениях в стиле PERL.
| Символ | Описание |
|---|---|
| . | один символ |
| \с | символ пробела (пробел, табуляция, новая строка) |
| \С | непробельный символ |
| \д | цифра (0-9) |
| \Д | нецифра |
| \ш | 9айоу]соответствует одному символу вне заданного набора |
| фу | бар |
Модификаторы
Доступно несколько модификаторов, которые значительно упрощают работу с регулярными выражениями, например чувствительность к регистру, поиск в нескольких строках и т. д.
| Модификатор | Описание |
|---|---|
| я | 9и операторы $ теперь будут сопоставляться с границей новой строки, а не с границей строки|
| или | Вычисляет выражение только один раз |
| с | Позволяет использовать файлы . чтобы соответствовать символу новой строки |
| х | Позволяет использовать пробелы в выражении для ясности |
| г | Глобально находит все совпадения |
| кг | Позволяет продолжить поиск даже после сбоя глобального совпадения |
PHP Regexp Функции, совместимые с PERL
PHP предлагает следующие функции для поиска строк с использованием Perl-совместимых регулярных выражений
| Серийный номер | Функция и описание |
|---|---|
| 1 | preg_match() Функция preg_match() ищет в строке шаблон, возвращая значение true, если шаблон существует, и false в противном случае. |
| 2 | preg_match_all() Функция preg_match_all() сопоставляет все вхождения шаблона в строке. |
| 3 | preg_replace() Функция preg_replace() работает точно так же, как ereg_replace(), за исключением того, что в шаблоне и входных параметрах замены можно использовать регулярные выражения. |
| 4 | preg_split() Функция preg_split() работает точно так же, как split(), за исключением того, что в качестве входных параметров для шаблона принимаются регулярные выражения. |
| 5 | preg_grep() Функция preg_grep() ищет все элементы input_array, возвращая все элементы, соответствующие шаблону регулярного выражения. |
| 6 | preg_ quote() Цитата символов регулярного выражения |
Функция PHP Str_Replace() — Как заменить символы в строке в PHP
Давайте посмотрим, как мы можем использовать функцию str_replace() для замены всех вхождений данной строки внутри другой строки. Мы рассмотрим различные реализации и примеры, которые показывают расширение этой функции php.
Функция PHP str_replace() — это встроенная функция обработки текста, которая используется для замены всех вхождений данной строки поиска или массива строкой или массивом замены в данной строке или массиве. Функция возвращает строку или массив, в котором все вхождения нашего $searchValue заменены на $replaceValue в нашем целевом значении.
Параметры для функции Str_Replace():
Первые три параметра могут быть строкой или массивом и являются обязательными, а параметр $count является необязательным.
SearchValue
Это значение, либо строка, либо массив, который мы ищем, иногда называемый $needle. Используя массив сигналов, есть несколько строк, которые мы хотим найти в нашей цели.
ReplaceValue
Значение замены может быть либо строкой, либо массивом, и это значение, которое мы хотим заменить.
SubjectValue
Строка или массив, который мы хотим найти и заменить. Иногда этот параметр называют $haystack. Если этот параметр является массивом, функция выполняет поиск и замену для каждого элемента в subjectValue, а возвращаемое значение становится массивом.
Количество
Необязательный четвертый параметр, который можно использовать для установки количества замен, которые мы хотим удалить. Параметр count был добавлен в PHP 5.0.
Возвращаемые значения для функции Str_Replace():
Функция возвращает либо строку, либо массив со значениями замены. Если для subjectValue использовались массивы, то мы возвращаем массив каждого элемента, для которого функция выполняла поиск и замену.
К чему приведет функция echo str_replace()?Если мы передаем массивы для наших параметров $searchValue и $replaceValue, функция php str_replace() использует каждое значение в массиве $searchValue и заменяет его каждой строкой в массиве $replaceValue, как двойной цикл for.
В случае, когда массив $replaceValue содержит меньше элементов, чем массив, используемый для параметра $searchValue, функция str_replace() использует для замены пустую строку.
В случае, когда параметр $searchValue является массивом, а параметр $replaceValue является строкой, функция str_replace() заменяет каждый элемент в массиве строкой $replaceValue.
Функция str_replace() не влияет на исходную строку $subjectValue, но возвращает новую копию строки $subjectValue. Эта функция идеальна, когда вам не нужны сложные замены типов регулярных выражений.
Краткие примечания о функции PHP Str_Replace():
Эта функция заменяет значения слева направо в строке, что означает, что в случае множественных замен (с массивом) функция может заменить вновь вставленные значения более поздними значениями из Массив значений поиска.
Эта функция чувствительна к регистру, и вы должны использовать str_ireplace для замены с учетом регистра.
Давайте рассмотрим множество способов использования функции str_replace().
Простая замена строки PHP Примеры:
В этом примере кода выполняется замена строки с использованием функции str_replace со всеми строками в качестве входных данных. Мы заменяем строку «PHP» на «кодирование» в целевой строке $string1
. Вы заметите, что при запуске наша $string1 точно такая же, какой она была до выполнения замены строки в нашем $subjectValue. Str_replace не изменяет исходную строку, а воссоздает новую и возвращает ее в $string2.
Следующий фрагмент кода показывает, что мы можем заменить несколько экземпляров одной и той же строки новой строкой $replaceValue.
Замена строки PHP несколькими экземплярами строки поискаФункция Str_Replace с несколькими заменами и поисками
В приведенном ниже примере функция str_replace() используется для замены любого экземпляра слов «понедельник», «вторник» или «среда» разными днями «Пятница», «Суббота» и «Воскресенье» в исходной строке «Сегодня понедельник, вторник или среда».
Как мы указывали выше, функция str_replace() заменяет экземпляры слева направо и может привести к замене уже замененных экземпляров. Слова, которые заменяются и добавляются к нашей строке $subjectValue, содержащей другое заменяющее слово, могут стать жертвой этого.
В этом примере «m» будет заменено на «matt», а затем каждая «t» станет строкой «tyler». В итоге мы получаем три разных экземпляра «tyler».
Советы от реального варианта использования Str_Replace()
При создании этого программного обеспечения для сопоставления продуктов мы использовали веб-скрапинг для сбора данных, которые мы могли использовать в качестве обучающих данных для различных моделей, которые мы использовали. Эти данные были необработанными и содержали много символов, которые необходимо было удалить. Функция str_replace() иногда используется для очистки и анализа важных данных из данных, извлеченных из Интернета, или данных текстовых файлов. Есть несколько вещей, которые вы должны иметь в виду в таком случае использования.
При замене шаблонов со схожими характеристиками всегда сначала перечисляйте наиболее надежные шаблоны. Многие шаблоны, которые вы обнаружите, будут похожи друг на друга или будут просто конкатенацией двух подшаблонов. Следите за этим при планировании массива поиска.
Постарайтесь сделать все возможное, чтобы ваши новые шаблоны замены не повлияли на данные, которые вы хотите извлечь. Удаление целых разделов входной строки всегда может привести к изменению способа чтения нужных вам данных.
Более подробные примеры замены строк PHP с помощью Str_Replace()
Давайте рассмотрим несколько мощных и эффективных способов использования функции str_replace() для выполнения различных задач.
Более быстрая замена строки несколькими строками $SubjectValue
При выполнении массива строк $subjectValue с помощью тех же поисков и замен почти в 3 раза быстрее использовать json_encode() для массива $subjectValue, использовать функцию str_replace(), затем json_decode () в конце. Функция возвращает нашу новую строку с замененными значениями.
При объединении различных операций код также становится намного чище. Примечание. Возможно, вы захотите установить для второго параметра значение «True» в функции json_decode, так как это по умолчанию вернет объект типа вместо ожидаемого массива. Будьте осторожны с вашими значениями $searchValue и $replaceValue. Если они содержат строки, соответствующие кодировке json, это может привести к проблемам.
Заменить только первое вхождение искомого значения
В этом примере функция заменяет только первое вхождение искомой строки в строке $subjectValue. Хотя это не использует str_replace(), этот метод имеет самое быстрое время выполнения из всех доступных вариантов. Пример взят из этого поста stackoverflow.
В приведенном выше коде $haystack — это строка темы, которую мы хотим найти и заменить. $Needle — это строка поиска, а $replace — строка замены.
Преобразование строки в URL-адрес с помощью PHP Str_Replace и др.
Допустим, мы хотим преобразовать строку, такую как «Это полностью, мой URL-адрес?» в URL-слаг, используемый для веб-сайта. Мы можем написать функцию, которая использует PHP-функции preg_replace(), strtolower() и str_replace.
Исходная строка сверху теперь становится «это полностью мой URL» после прохождения через эту функцию. Мы используем strtolower() для преобразования этой строки в нижний регистр, затем preg_replace позволяет нам использовать регулярные выражения для замены в нашей строке, затем, наконец, мы используем str_replace() для добавления «-». В конце перевернутая строка представляет собой замещающую строку с обрезанными ненужными символами «-».
Краткое примечание: preg_replace() заменяет найденные значения поиска строкой замены точно так же, как мы можем это сделать с помощью str_replace(). Мы также можем указать несколько замен с помощью массива.
Можно ли использовать функцию PHP Str_Replace() для ассоциативных массивов?
Ассоциативный массив с ключами в качестве значений поиска и значениями массива в качестве замещающих строк можно разбить и передать в функцию str_replace() путем захвата array_keys и array_values отдельно от ассоциативного массива. В следующем примере предполагается, что вы используете строку для $subjectValue для поиска.
Множественные замены теперь становятся немного чище, поскольку мы больше не можем иметь экземпляр, в котором количество значений замены и значений поиска будет одинаковым, при условии отсутствия нулей.
Str_Replace() — отличный способ, чувствительный к регистру, искать заданную строку или массив строк для строк и заменять их без причудливых правил замены. Функция позволяет указать несколько игл ($searchValue), несколько строк замены и несколько строк $subjectValue. Вдобавок к этому функция быстро заменяет найденные значения поиска с более быстрым временем выполнения, чем такие функции, как preg_replace.
Что такое функция preg_replace в php?
Функция preg_replace() — это встроенная функция PHP, которая используется для выполнения регулярного выражения для поиска и замены содержимого . Синтаксис: preg_replace($pattern, $replacement, $subject, $limit, $count)
Что делает Preg_replace в PHP?
Функция preg_replace() возвращает строку или массив строк, где все совпадения шаблона или списка шаблонов, найденных во входных данных, заменены подстроками . Есть три разных способа использования этой функции: 1. Один шаблон и строка замены.
В чем разница между Str_replace и Preg_replace?
str_replace заменяет конкретное вхождение строки, например, «foo» будет соответствовать и заменять только это: «foo». preg_replace выполнит сопоставление регулярных выражений, например «/f. {2}/» будет соответствовать и заменять «foo», а также «fey», «fir», «fox», «f12» и т. д.
.Реклама. ПРОДОЛЖИТЕ ЧИТАТЬ НИЖЕ
Что такое замена RegEx?
Процессор замены регулярных выражений позволяет выполнять расширенные замены текста путем сопоставления текстовых значений с регулярным выражением и замены совпадающего значения определенным значением или значением, полученным из совпавшего текста, например, путем замены всего Строка, совпадающая с регулярным выражением с …
Что такое Preg_match_all в PHP?
Функция preg_match_all() возвращает количество совпадений шаблона, найденных в строке, и заполняет переменную найденными совпадениями .
Какой из следующих модификаторов выполняет поиск без учета регистра?
Модификатор RegExp i в JavaScript используется для выполнения сравнения в строке без учета регистра.
Как заменить несколько символов в строке в PHP?
Подход 1: Использование функций str_replace() и str_split() в PHP . Функция str_replace() используется для замены нескольких символов в строке и принимает три параметра. Первый параметр — это массив заменяемых символов. 9A-Za-z0-9-]/’, «, $string), // Удаляет специальные символы. }
Что такое регулярное выражение в PHP?
Регулярное выражение — это последовательность символов, формирующая шаблон поиска . Когда вы ищете данные в тексте, вы можете использовать этот шаблон поиска, чтобы описать то, что вы ищете. Регулярное выражение может состоять из одного символа или более сложного шаблона.
Что такое регулярное выражение?
Регулярное выражение (регулярное выражение) состоит из последовательности подвыражений . В этом примере [0-9] и + . […] , известный как класс символов (или список скобок), заключает в себе список символов. Он соответствует любому ОДНОМУ символу в списке.
Что такое G в регулярном выражении?
Флаг « g » указывает, что регулярное выражение должно проверяться на все возможные совпадения в строке . Регулярное выражение, определенное как глобальное («g») и прилипающее («y»), будет игнорировать глобальный флаг и выполнять прилипающие совпадения.
Может ли регулярное выражение заменять символы?
Они используют шаблон регулярного выражения для определения всего или части текста, который должен заменить соответствующий текст во входной строке. Шаблон замены может состоять из одной или нескольких замен вместе с буквенными символами . Шаблоны замены предоставляются для перегрузок Regex.
Можно ли использовать регулярное выражение для замены строки?
Чтобы использовать регулярное выражение, первый аргумент замены будет заменен синтаксисом регулярного выражения , например /regex/ . Этот синтаксис служит шаблоном, в котором любые части строки, соответствующие ему, будут заменены новой подстрокой.
Что такое preg match?
Функция preg_match() — это встроенная функция PHP, которая выполняет сопоставление регулярного выражения . Эта функция ищет в строке шаблон и возвращает true, если шаблон существует, в противном случае возвращает false. Как правило, поиск начинается с начала строкового параметра $subject.
Какое значение возвращает функция Preg_match, если шаблон существует?
Возвращаемое значение: Возвращает true , если шаблон существует, иначе false.
Есть ли подстрока в строке PHP?
Вы можете использовать функцию PHP strpos(), чтобы проверить, содержит ли строка определенное слово или нет . Функция strpos() возвращает позицию первого вхождения подстроки в строку. Если подстрока не найдена, возвращается false. Также обратите внимание, что позиции строки начинаются с 0, а не с 1.
Что означает нечувствительность к регистру?
без учета регистра (несопоставимо) (информатика) Обработка или интерпретация прописных и строчных букв как одинаковых .
Что такое поиск без учета регистра?
Поиск без учета регистра является более полным, находя «Язык» (в начале предложения), «язык» и «ЯЗЫК» (в названии заглавными буквами ), поиск с учетом регистра находит компьютерный язык «БЕЙСИК», но исключить большую часть нежелательных экземпляров этого слова.
Как сопоставить регистронезависимое регулярное выражение?
Если вы хотите, чтобы только часть регулярного выражения была нечувствительна к регистру (как предполагал мой первоначальный ответ), у вас есть два варианта:
- Используйте модификаторы режима (?i) и [опционально] (?-i): (?i)G[a-b](?-i).*
- Поместите все варианты (т. е. строчные и прописные) в регулярное выражение — полезно, если модификаторы режима не поддерживаются: [gG][a-bA-B].*
Как заменить несколько строк в Python?
Нет способа заменить несколько разных строк разными, но вы можете многократно применять replace() . Он просто вызывает replace() по порядку, поэтому, если первый новый содержит следующий старый, первый новый также заменяется. Вы должны быть осторожны в порядке. 9a-zA-Z0-9]», «»),
Как удалить определенный символ из строки?
Удаление символа из строки в Java
- Используйте функцию замены для удаления символа из строки в Java.
- Используйте метод deleteCharAt для удаления символа из строки в Java.
- Используйте метод подстроки для удаления символа из строки в Java.
Как сделать строчные буквы в PHP?
Функция strtolower() преобразует строку в нижний регистр . Примечание. Эта функция безопасна для двоичных файлов. Связанные функции: strtoupper() — преобразует строку в верхний регистр.
Что такое интерполяция строк PHP?
Последнее изменение: 6 июня 2021 г. Интерполяция переменных — это добавление переменных между ними при указании строкового литерала . PHP будет анализировать интерполированные переменные и заменять переменную ее значением при обработке строкового литерала. В PHP строковый литерал может быть указан четырьмя способами, в одинарных кавычках. 9
Что означает * регулярное выражение?
Описание. Регулярные выражения (сокращенно «regex») — специальные строки, представляющие шаблон для сопоставления в операции поиска . Они являются важным инструментом в самых разных вычислительных приложениях, от языков программирования, таких как Java и Perl, до инструментов обработки текста, таких как grep, sed и текстовый редактор vim.
Что означает zA Z0 9?
Скобки указывают, что содержащийся в них шаблон будет сохранен в переменной 1. Символы в квадратных скобках [a-zA-Z0-9] означают, что любая буква (независимо от регистра) или цифра будут соответствовать . Знак * (звездочка) после квадратных скобок означает, что символы в квадратных скобках встречаются 0 или более раз.
Что такое регулярное выражение с обратной косой чертой?
Когда регулярные выражения видят обратную косую черту, они знают, что они должны интерпретировать следующий символ буквально . Регулярное выражение для соответствия IP-адресу 0.0.0.0 будет выглядеть так: 0.0.0.0. Используйте обратную косую черту, чтобы избежать любого специального символа и интерпретировать его буквально, например: \ (экранирует обратную косую черту)
Что такое многострочное в регулярном выражении? 9и языковые элементы $, чтобы они соответствовали началу и концу строки, а не началу и концу входной строки.
Что такое G и GI в регулярном выражении?
g Модификатор: глобальный. Все совпадения (не возвращаться при первом совпадении) Модификатор i: нечувствительный. Соответствие без учета регистра (игнорирует регистр [a-zA-Z])
Что такое глобальное регулярное выражение?
Глобальное регулярное выражение и печать (GREP) — это утилита поиска текста из командной строки, используемая в Unix 9.0022 . Команда «grep» ищет в файлах или стандартном вводе строки, соответствующие заданному регулярному выражению. Затем он печатает совпадающие строки в стандартный вывод программы.
Как найти число в регулярном выражении?
Для соответствия любому числу от 0 до 9 мы используем d в регулярном выражении . Он будет соответствовать любому однозначному числу от 0 до 9. d означает [0-9] или соответствует любому числу от 0 до 9. Вместо записи 0123456789 сокращенная версия будет [0-9], где [] используется для диапазона символов.
Что такое регулярное выражение группы захвата?
Группы захвата — это способ обработки нескольких символов как единого целого . Они создаются путем помещения символов, которые должны быть сгруппированы, внутри набора круглых скобок. Например, регулярное выражение (dog) создает единую группу, содержащую буквы «d», «o» и «g».
Как создать строку в регулярном выражении?
Если вы хотите сопоставить фактический «+», «. ‘ и т. д. символов, добавить обратную косую черту ( ) перед этим символом . Это укажет компьютеру рассматривать следующий символ как символ поиска и рассматривать его для сопоставления с образцом. Пример: d+[+-x*]d+ будет соответствовать таким шаблонам, как «2+2» и «3*9» в «(2+2) * 3*9».
Как заменить шаблон в строке?
Метод replace() возвращает новую строку с некоторыми или всеми совпадениями шаблона, замененными заменой . Шаблон может быть строкой или RegExp , а замена может быть строкой или функцией, вызываемой для каждого совпадения. Если шаблон является строкой, будет заменено только первое вхождение.
Как найти и заменить в регулярном выражении?
Поиск и замена текста с помощью регулярных выражений
- Нажмите Ctrl+R, чтобы открыть панель поиска и замены. …
- Введите строку поиска в верхнем поле и строку замены в нижнем поле. …
- Когда вы ищете текстовую строку, содержащую специальные символы регулярных выражений, GoLand автоматически экранирует их с люфтом в поле поиска.
Как вы используете функцию замены?
Синтаксис функций REPLACE и REPLACEB имеет следующие аргументы:
- Старый_текст Обязательный. Текст, в котором вы хотите заменить некоторые символы.
- Start_num Обязательно. Позиция символа в old_text, которую вы хотите заменить на new_text.
- Num_chars Требуется. …
- Требуемое число_байт. …
- Новый_текст Обязательно.
Является ли Preg_match чувствительным к регистру?
preg_match чувствителен к регистру . Матч. Добавьте букву «i» в конец строки шаблона, чтобы выполнить поиск без учета регистра.
Что из следующего используется preg match?
Какая из следующих функций используется для поиска строки? Объяснение: Функция preg_match() ищет в строке шаблон и возвращает true, если шаблон существует, и false в противном случае .