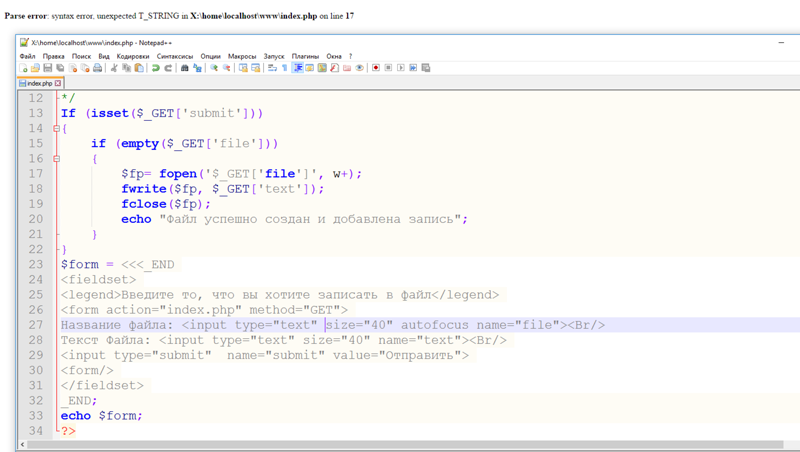
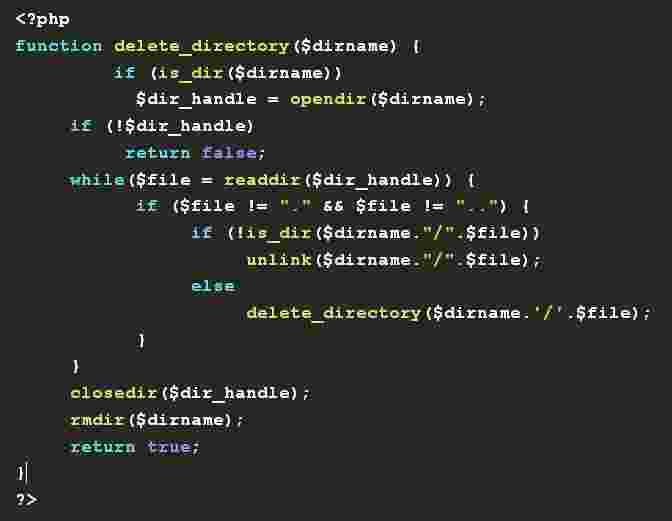
В этом руководстве мы узнаем, как удалять строки, соответствующие определенному шаблону в файле, используя SED.
SED – это потоковый редактор, который выполняет базовую фильтрацию текста и преобразования входного потока (файла или ввода из конвейера).
Удалить строки, соответствующие определенному шаблону в файле, используя SED
В нашем предыдущем руководстве мы рассмотрели, как удалять сктроки, соответствующие определенным шаблонам в VIM.
Вы можете проверить этот метод, перейдя по ссылке ниже;
? Удалить строки, соответствующие определенному шаблону в файле, используя VIM
Теперь давайте рассмотрим различные примеры удаления строк, соответствующих определенному шаблону, в файле с помощью SED.
Для демонстрации мы будем использовать семь цветов радуги в файле.
cat colors This is color red This is color orange This is color yellow This is color green This is color blue This is color indigo This is color violet
Как и в VIM, мы будем использовать команду d для удаления определенного пространства шаблонов с помощью SED.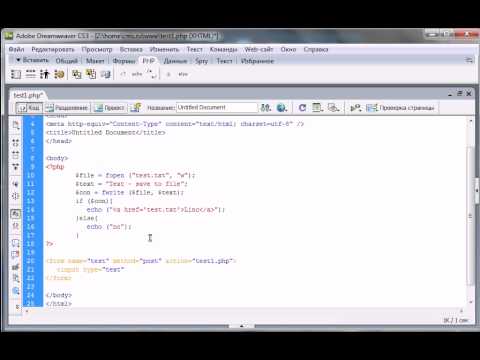
Для начала, если вы хотите удалить строку, содержащую ключевое слово, вы должны запустить sed, как показано ниже.
sed -i '/pattern/d' file
Где опция -i указывает место в файл.
Если вам нужно выполнить пробный прогон (без фактического удаления строки с ключевым словом) и вывести результат в стандартный вывод, опустите опцию -i.
Например, удалите строку, содержащую ключевое слово green, которую вы запустите;
sed '/green/d' colors This is color red This is color orange This is color yellow This is color blue This is color indigo This is color violet
Точно так же вы можете запустить команду sed с опцией -n и командой p, (!p).
sed -n '/green/!p' colors This is color red This is color orange This is color yellow This is color blue This is color indigo This is color violet
Удалить строки, содержащие несколько ключевых слов, например, удалить строки с ключевым словом green или строки с ключевым словом violet. \t*$/d’ colors
\t*$/d’ colors
Что ж, это лишь малая часть того, что мы могли бы рассказать о том, как удалять строки, соответствующие определенному шаблону в файле, используя
Не стесняйтесь добавлять больше примеров и предложений в комментариях ниже.
Поделитесь статьей:
Удаляем комментарии и пустые строки из файла на Linux
Удаляем комментарии и пустые строки из файла на Linux. При редактировании каких-либо конфигурационных файлов, в них присутствуют закомментированные и пустые строки — это не очень удобно (по крайней мере для чтения). Файлы можно отредактировать вручную, если в нем несколько закомментированных и пустых строк, но если файл имеет тысячи таких строк, это трудно сделать вручную. Сегодня в статье научимся избавляться от лишних пустых и закомментированных строк в файле.
Что такое комментарии в программировании?
Если вы загляните в исходный код или файл конфигурации, вы заметите, что многие строки начинаются со звездочки «*», косой черты «/», или хеша «#», или точки с запятой «;».
Эти строки известны как Комментарии.
В программировании комментарий — это удобочитаемое описание или аннотация, используемая для пояснения целей фрагментов кода.
Они помогают пользователям и другим программистам легко понять, что делает код.
Как правило, комментарии и пустые строки будут игнорироваться компиляторами и интерпретаторами. Они предназначены только для программистов.
Синтаксис комментариев варьируется в зависимости от языка программирования.
Теперь давайте посмотрим, как исключить или пропустить эти комментарии и пустые строки и отображать только те строки, которые не закомментированы.
Вывод содержимого файлов без комментариев и пустых строк на Linux
Позвольте мне показать вам содержимое файла sources.list в одной из моих систем Ubuntu:
cat /etc/apt/sources.list
Вывод:
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu ## team, and may not be under a free licence.Please satisfy yourself as to ## your rights to use the software. Also, please note that software in ## multiverse WILL NOT receive any review or updates from the Ubuntu ## security team. deb http://archive.ubuntu.com/ubuntu focal multiverse # deb-src http://archive.ubuntu.com/ubuntu focal multiverse deb http://archive.ubuntu.com/ubuntu focal-updates multiverse # deb-src http://archive.ubuntu.com/ubuntu focal-updates multiverse ## N.B. software from this repository may not have been tested as ## extensively as that contained in the main release, although it includes ## newer versions of some applications which may provide useful features. ## Also, please note that software in backports WILL NOT receive any review ## or updates from the Ubuntu security team. deb http://archive.ubuntu.com/ubuntu focal-backports main restricted universe multiverse # deb-src http://archive.ubuntu.com/ubuntu focal-backports main restricted universe multiverse ## Uncomment the following two lines to add software from Canonical's ## 'partner' repository. ## This software is not part of Ubuntu, but is offered by Canonical and the ## respective vendors as a service to Ubuntu users. # deb http://archive.canonical.com/ubuntu focal partner # deb-src http://archive.canonical.com/ubuntu focal partner deb http://security.ubuntu.com/ubuntu focal-security main restricted # deb-src http://security.ubuntu.com/ubuntu focal-security main restricted deb http://security.ubuntu.com/ubuntu focal-security universe # deb-src http://security.ubuntu.com/ubuntu focal-security universe deb http://security.ubuntu.com/ubuntu focal-security multiverse # deb-src http://security.ubuntu.com/ubuntu focal-security multiverse

Вы видите, что многие строки закомментированы символом «#». Это делает файл неудобным для чтения. Это небольшой файл, так что это не страшно.Но когда вы читаете очень длинные файлы конфигурации, например, «httpd.conf» или «php.ini», вам придется пройти через множество комментариев и пустых строк, и будет немного сложно найти, какие строки активны, а какие нет.
Пример вывода вышеуказанной команды:
deb http://archive.ubuntu.com/ubuntu focal main restricted deb http://archive.ubuntu.com/ubuntu focal-updates main restricted deb http://archive.ubuntu.com/ubuntu focal universe deb http://archive.ubuntu.com/ubuntu focal-updates universe deb http://archive.ubuntu.com/ubuntu focal multiverse deb http://archive.ubuntu.com/ubuntu focal-updates multiverse deb http://archive.ubuntu.com/ubuntu focal-backports main restricted universe multiverse deb http://security.ubuntu.com/ubuntu focal-security main restricted deb http://security.ubuntu.com/ubuntu focal-security universe deb http://security.ubuntu.com/ubuntu focal-security multiverse
Все комментарии и пустые строки исчезли.
Теперь вывод вполне читабелен.Я предпочитаю способом через grep фильтровать ненужные строки, отображаемые в выводе. *\/$/d’
*\/$/d’
Если есть вопросы, то пишем в комментариях.
Также можете помочь проекту, заранее всем СПАСИБО!!!
.RSS
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
0 0 vote
Рейтинг статьи
Удаление ненужных строк в листе Excel
Как удалить ненужные строки и столбцы на листе Excel
( Это не займет столько времени, сколько может предложить первый взгляд, и это безопасно!)
Есть два листа, упомянутых в процедуре ниже.
Давайте назовем ваш оригинальный лист YourOriginalSheet(он представляет
Назовем другой лист ShortSheet, который будет содержать копию только соответствующих ячеек.
(1) В YourOriginalSheet, Selectа Copyдиапазон соответствующих ячеек (не вставить еще нигде).
(2) Добавьте новый лист с именем ShortSheet, поместите курсор в ячейку, представляющую верхний левый угол копируемого диапазона (вероятно A1), и вставьте так:
(2a) Paste Special...> Formulas
(2b) Paste Special...>Values
(2c) Paste Special...>Formats
(2d) Paste Special...>Column Widths
(2e) Включите другие Paste Specialварианты, которые, по вашему мнению, могут помочь сделать лист лучше.
(3) Нажмите, Ctrl-Shift-Endчтобы найти нижний правый угол, ShortSheetчтобы убедиться, что он содержит все соответствующие данные.
(4) Saveрабочая тетрадь. (
( Save As ...новый файл, если вы хотите сделать резервную копию.)
(5) Удалить YourOriginalSheet(соответствующие данные в настоящее время сохраняются в ShortSheet.)
(6) Переименуйте ShortSheetв фактическое имя вашего оригинального листа.
Ничего не изменилось, за исключением того, что книга стала намного меньше, поэтому все макросы, внешние ссылки на этот лист и т. Д. Должны работать.
Вот macroдля выполнения шагов в (2).
Sub pasteSpecialAll()
Selection.PasteSpecial Paste:=xlPasteFormulas, Operation:=xlNone, SkipBlanks:=False, Transpose:=False
Selection.PasteSpecial Paste:=xlPasteColumnWidths, Operation:=xlNone, SkipBlanks:=False, Transpose:=False
Selection.PasteSpecial Paste:=xlPasteValues, Operation:=xlNone, SkipBlanks:=False, Transpose:=False
Selection.PasteSpecial Paste:=xlPasteFormats, Operation:=xlNone, SkipBlanks:=False, Transpose:=False
End Sub
Перед использованием макроса Утилита sed это мощный потоковый редактор текста с поддержкой регулярных выражений. В sed нет поддержки опережающих и ретроспективных проверок в регулярках! Для замены с использованием расширенного синтаксиса regex используйте: В Шаблон: В качестве разделителей можно использовать любые символы (напрмиер: Опции утилиты: Флаги строки-команды (указывать в конце маски): Вывести строки 1-5: Вывести файлы соответствующие маске: Строки длиннее 80 символов: Удалить последние N=2 символа: Вырезать / запомнить последние N=4 символа: #sed, #regexp, #bash Надо удалить повторяющиеся строки в текстовом файле. Для этого воспользуемся Notepad++. Прямой функции в Notepad++ нет, но можно воспользоваться некоторыми функциями, чтобы всё реализовать. Допустим, что у нас есть файл такого содержания: [email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected] Запустите окно замены в файле и введите команду При этом настройки замены должны быть как на рисунке: И нажмите Заменить всё. Если надо удалить повторы так, чтобы оставалось первые варианты строк, а не последние, то тут надо по другому поступить. Идея простая. Мы меняем порядок строк, а потом просто применяем первый способ, а потом меняем обратно. Для этого нам потребуется плагин TextFX. По ссылке рассказывается и про его установку. Итак, нужно сделать следующие действия для изменения порядка строк. Выделите весь текст Ctrl + A. Вставьте номера строкам: TextFX → TextFX Tools → Insert Line Numbers. Если стоит флажок TextFX → TextFX Tools → +Sort ascending, то его убрать. Отсортируем строки TextFX → TextFX Tools → Sort lines case sensitive (at column). Удаляем номера строк TextFX → TextFX Tools → Delete Line Numbers or First Word.Select и Copy соответствующего диапазона, как было сделано в шаге (1). $/d’ example.txt
$/d’ example.txt удалить пустые строки и комментарии из файла example.txt echo ‘test’ | tr ‘[:lower:]’ ‘[:upper:]’ преобразовать символы из нижнего регистра в верхний sed -e ‘1d’ result.txt удалить первую строку из файла example.txt sed -n ‘/string1/p’ отобразить только строки содержашие «string1» sed -e ‘s / *$//‘ example.txt удалить пустые символы в в конце каждой строки sed -e ‘s /string1//g’ example.txt удалить строку «string1» из текста не изменяя всего остального sed -n ‘1,8p;5q’ example.txt взять из файла с первой по восьмую строки и из них вывести первые пять sed -n ‘5p;5q’ example.txt вывести пятую строку sed -e ‘s/0*/0/g’ example.txt заменить последовательность из любого количества нулей одним нулём cat -n file1 пронумеровать строки при выводе содержимого файла cat example.  txt
txt | awk ‘NR%2==1’ при выводе содержимого файла, не выводить чётные строки файла echo a b c | awk ‘{print $1}’ вывести первую колонку. Разделение, по-умолчанию, по проблелу/пробелам или символу/символам табуляции echo a b c | awk ‘{print $1,$3}’ вывести первую и треью колонки. Разделение, по-умолчанию, по проблелу/пробелам или символу/символам табуляции paste file1 file2 объединить содержимое file1 и file2 в виде таблицы: строка 1 из file1 = строка 1 колонка 1-n, строка 1 из file2 = строка 1 колонка n+1-m paste -d ‘+’ file1 file2 объединить содержимое file1 и file2 в виде таблицы с разделителем «+» sort file1 file2 отсортировать содержимое двух файлов sort file1 file2 | uniq отсортировать содержимое двух файлов, не отображая повторов sort file1 file2 | uniq -u отсортировать содержимое двух файлов, отображая только уникальные строки (строки, встречающиеся в обоих файлах, не выводятся на стандартное устройство вывода) sort file1 file2 | uniq -d отсортировать содержимое двух файлов, отображая только повторяющиеся строки comm -1 file1 file2 сравнить содержимое двух файлов, не отображая строки принадлежащие файлу ‘file1’ comm -2 file1 file2 сравнить содержимое двух файлов, не отображая строки принадлежащие файлу ‘file2’ comm -3 file1 file2 сравнить содержимое двух файлов, удаляя строки встречающиеся в обоих файлах sed в linux — примеры использования
 С помощью sed вы можете заменять шаблоны текста (причем непосредственно в файле!), удалять строки (элементы массива), выводить подходящие по маске строки (подобно grep). Редактор sed поддерживает применение нескольких команд и расширенный синтаксис регулярных выражений (при котором не нужно экранировать спец. символы).
С помощью sed вы можете заменять шаблоны текста (причем непосредственно в файле!), удалять строки (элементы массива), выводить подходящие по маске строки (подобно grep). Редактор sed поддерживает применение нескольких команд и расширенный синтаксис регулярных выражений (при котором не нужно экранировать спец. символы).Важно!
find . -type f -name '*.blade.php' -exec perl -p -i -e 's/(?<!\{)\{\{(?!\{)/\{!!/g' {} \;Внимание!
sed довольно проблемно работать с символом перевода строки! Самое удобное решение — это:echo "text" | perl -pe 's/\n/_/'sed [-opt] 's/regex/replace/flag' input-file
sed 's/regex/replace/flag' # замена найденных подстрок
sed '1,5s/regex/replace/gi' # замена только в указанном диапазоне строк
sed -r 's/regex/replace/g' # расширенный синтаксис regex (со спец символами)
sed 's/regex//g' # удалить найденные подстроки
sed '/regex/d' # удалить строки подходящие по маске
sed -n 2p # вывести 2ю строку
sed -n '/composer/p' # вывести только строки подходящие по маске
sed 's/1-9/&/p' # & при замене означает сам ОБРАЗЕЦ
#, @). Match части (которые внутри круглых скобок) доступны как
Match части (которые внутри круглых скобок) доступны как \1, \2, \n.-p вывести на экран
-d удалить
-i выполнять изменения непосредственно в файле
-n не выводить результат замены/поиска на экран (--quiet, --silent)
-e указывает на передачу инструкции (команда замены/удаления или выражение для поиска/фильтрации). Нужен, если Вы передаете более 1 инструкции
-E расширенный regex, ближе к JavaScript, Go. Активны спец символы: [0-9]+
-r расширенный regex синтаксис. Спец символы активны по умолчанию (--regexp-extended)
-P perl-совместимый regex синтаксис
-s consider files as separate rather than as a single continuous long stream (--separate)
g глобальный поиск/замена, а не только первое совпадение
i,-l регистро-независимый поиск
p, печать найденных подстрок
d удалить строкиПримеры
Фильтрация строк
sed '1,5p'
head -5
ls | sed -n '/composer/p'sed -n '/^. $/d'
$/d'echo "latest" | sed "s/..$//" # lateИзвлечение подстрок
echo "latest" | sed "s/.*\(....$\)/\1/" # testУдаление дублирующих строк в Notepad++
Первый способ
 Повторяющиеся строки удаляться. Но при этом останутся не первые варианты строк, а последние повторы.
Повторяющиеся строки удаляться. Но при этом останутся не первые варианты строк, а последние повторы.Второй способ
 !//!
!//!
—
What if you’ve forgot to give sudo when you’ve opened the /etc/group file as shown below? In this case, instead of coming out of the file (and loosing all your changes) and executing the vim command with sudo, you can do the following.
$ vim /etc/group
:w !sudo tee %
Note: “:w !sudo tee %” will save the file as root privilege, even if you didn’t use sudo command to open it.
—
Использование стиля “подсветил — посмотрел — выполнил” совместно с визуальным режимом оказалось очень удобной практикой. Такое комбинирование стилей выделения используется при решении задач типа “в данной функции переименовать переменную foo в bar” и подобных. Такая (и подобные) задачи решаются последовательностью действий:
Символы ’, означающие начало и конец текущего выделенного блока, и определяющие диапазон применения команды :s, Vim подставляет автоматически при отдаче любой команды из режима визуального выделения. $/d
$/d
Раздвинуть подряд идущие строки (обратное предыдущему действие, каждая строка станет параграфом)
Нужно при форматировании текста под 76 символов, из формата, как его сохраняет Word, когда каждый абзац становится строкой в текстовом файле.
:'<,’>s/$/\r/g
быстро вставить текст при включенном autoindent (set ai) — борьба с «лесенкой»
:r !cat
http://habrahabr.ru/blogs/vim/131951/
—
http://www.brezeale.com/technical_notes/vim_notes.shtml
Как удалить строки из файла с помощью команды sed
Команда sed означает Stream Editor . Он используется для выполнения основных преобразований текста в Linux.
sed — одна из важных команд, которая играет важную роль в манипуляциях с файлами. Его можно использовать для многих целей, некоторые из которых перечислены ниже:
- Чтобы удалить или удалить определенные строки, которые соответствуют заданному шаблону.

- Для удаления определенной строки в зависимости от позиции в файле.
- Удаление строк с помощью регулярных выражений.
В этой статье перечислены 27 примеров, которые помогут вам стать мастером в команде sed .
Если вы запомните эти команды, это сэкономит вам много времени, когда вам потребуется выполнять различные административные задачи в ваших проектах.
Также ознакомьтесь с этой статьей о том, как можно использовать команду sed для замены совпадающей строки в файле .
Примечание: Поскольку это демонстрационная статья, мы используем команду sed без опции -i , которая аналогична опции «пробный запуск» , и будет отображать фактический результат без внесение каких-либо изменений в файл.
Но если вы хотите удалить строки из исходного файла в реальной среде, используйте параметр -i с командой sed .
Чтобы продемонстрировать команду sed , мы создали файл ‘sed-demo.txt’ и добавили следующее содержимое с номерами строк для лучшего понимания.
# cat sed-demo.txt 1 Операционная система Linux 2 Операционная система Unix 3 RHEL 4 Красная шляпа 5 Fedora 6 Arch Linux 7 CentOS 8 Debian 9 Ubuntu 10 openSUSE
Часть-I) Удаление строк в зависимости от позиции в файле
В первой части показано, как использовать команду sed для удаления строк в зависимости от позиции в файле.
1) Как удалить первую строку из файла?
Чтобы удалить первую строку из файла, используйте следующий синтаксис:
Синтаксис:
sed ' Nd ' файл
Детали;
-
N— Обозначает «N-ю» строку в файле - d — Указывает на удаление строки.
Приведенная ниже команда sed удаляет первую строку из файла ‘sed-demo. txt’ :
txt’ :
# sed '1d' sed-demo.текст После удаления: 2 Операционная система Unix 3 RHEL 4 Красная шляпа 5 Fedora 6 Arch Linux 7 CentOS 8 Debian 9 Ubuntu 10 openSUSE
2) Как удалить последнюю строчку из файла?
Если вы хотите удалить последнюю строку файла, используйте следующий синтаксис ( $ обозначает последнюю строку файла).
Приведенная ниже команда sed удаляет последнюю строку из файла ‘sed-demo.txt’ :
# sed '$ d' sed-demo.текст После удаления: 1 Операционная система Linux 2 Операционная система Unix 3 RHEL 4 Красная шляпа 5 Fedora 6 Arch Linux 7 CentOS 8 Debian 9 Ubuntu
Следующая команда sed удаляет первую и последнюю строку из файла:
# sed '1d; $ d' sed-demo.txt После удаления: 2 Операционная система Unix 3 RHEL 4 Красная шляпа 5 Fedora 6 Arch Linux 7 CentOS 8 Debian 9 Ubuntu
3) Удаление определенной строки из файла
В этом примере мы удалим третью строку из ‘sed-demo. txt ’ с помощью команды sed , как показано ниже. Аналогично, любую строку можно удалить, введя номер строки вместо числа 3.
# sed '3d' sed-demo.txt После удаления: 1 Операционная система Linux 2 Операционная система Unix 4 Красная шляпа 5 Fedora 6 Arch Linux 7 CentOS 8 Debian 9 Ubuntu 10 openSUSE
4) Удаление диапазона строк
Команда sed удаляет любой диапазон заданных строк из файла. Нам нужно ввести «минимум» и «максимум» номеров строк.В приведенном ниже примере удаляются строки от 5 до 7.
# sed '5,7d' sed-demo.txt После удаления: 1 Операционная система Linux 2 Операционная система Unix 3 RHEL 4 Красная шляпа 8 Debian 9 Ubuntu 10 openSUSE
5) Как удалить несколько строк
Команда sed может удалить набор заданных строк.
В этом примере следующая команда sed удалит 1-ю, 5-ю, 9-ю и последнюю строку.
# sed '1d; 5d; 9d; $ d' sed-demo.текст После удаления: 2 Операционная система Unix 3 RHEL 4 Красная шляпа 6 Arch Linux 7 CentOS 8 Debian
5.a) Удаление строк, отличных от указанного диапазона
Используйте следующую команду sed, чтобы удалить все строки из файла, кроме указанного диапазона строк:
# sed '3,6! D' sed-demo.txt После удаления: 3 RHEL 4 Красная шляпа 5 Fedora 6 Arch Linux
Детали;
-
!— Оператор отрицания используется для сохранения указанных строк
Используйте команду ниже для удаления всех строк, кроме первой:
# sed '1! D' sed-demo.$ / d 'sed-demo.txt После удаления: 1 Операционная система Linux 2 Операционная система Unix 3 RHEL 4 Красная шляпа 5 Fedora 6 Arch Linux 7 CentOS 8 Debian 9 Ubuntu 10 openSUSE
Часть-II) Удаление линий на основе сопоставления с образцом
Во второй части показано, как использовать команду sed для удаления строк в файле, соответствующих заданному шаблону.
7) Удаление строк, содержащих узор
Следующая команда sed удалит строки, соответствующие шаблону System в ‘sed-demo.txt ’.
# sed '/ System / d' sed-demo.txt После удаления: 3 RHEL 4 Красная шляпа 5 Fedora 6 Arch Linux 7 CentOS 8 Debian 9 Ubuntu 10 openSUSE
8) Удаление строк, содержащих одну из нескольких строк
Следующая команда sed удаляет строки, которые соответствуют шаблону System или Linux из файла ‘sed-demo.txt’ :
# sed '/ System \ | Linux / d' sed-demo.txt После удаления: 3 RHEL 4 Красная шляпа 5 Fedora 7 CentOS 8 Debian 9 Ubuntu 10 openSUSE
9) Удаление строк, начинающихся с определенного символа
Следующая команда sed удалит все строки, начинающиеся с данного символа.(L). * (Система) / d ‘sed-demo-1. txt После удаления: Операционная система Unix
RHEL
Красная шляпа
Fedora
дебиан
убунту
Arch Linux — 1
2 — Манджаро
3 4 5 6
txt После удаления: Операционная система Unix
RHEL
Красная шляпа
Fedora
дебиан
убунту
Arch Linux — 1
2 — Манджаро
3 4 5 6
10) Удаление строк, заканчивающихся указанным символом
Следующая команда sed удаляет все строки, заканчивающиеся символом m :
# sed '/ m $ / d' sed-demo.txt После удаления: 3 RHEL 4 Красная шляпа 5 Fedora 6 Arch Linux 7 CentOS 8 Debian 9 Ubuntu 10 openSUSE
Следующая команда sed удаляет все строки, которые заканчиваются символом x или m :
# sed '/ [xm] $ / d' sed-demo.[A-Z] / d 'sed-demo-1.txt После удаления: дебиан убунту 2 - Манджаро 3 4 5 6
12) Удаление совпадающих строк шаблона с указанным диапазоном
Приведенная ниже команда sed удаляет шаблон Linux , только если он присутствует в строках с 1 по 6:
# sed '1,6 {/ Linux / d;}' sed-demo. txt.
После удаления:
2 Операционная система Unix
3 RHEL
4 Красная шляпа
5 Fedora
7 CentOS
8 Debian
9 Ubuntu
10 openSUSE 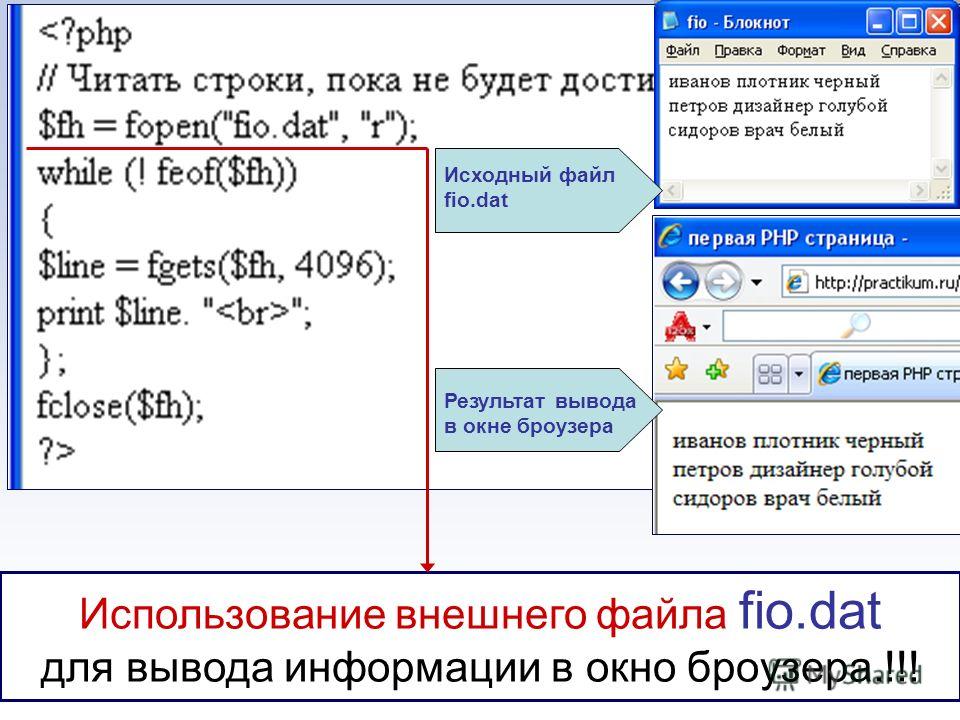 txt.
После удаления:
2 Операционная система Unix
3 RHEL
4 Красная шляпа
5 Fedora
7 CentOS
8 Debian
9 Ubuntu
10 openSUSE
txt.
После удаления:
2 Операционная система Unix
3 RHEL
4 Красная шляпа
5 Fedora
7 CentOS
8 Debian
9 Ubuntu
10 openSUSE 12.a) Удаление только последней строки, если она содержит заданный шаблон
Приведенная ниже команда sed удаляет только последнюю строку, если она содержит шаблон « openSUSE »
# sed '$ {/ openSUSE / d;}' sed-demo.текст
После удаления:
1 Операционная система Linux
2 Операционная система Unix
3 RHEL
4 Красная шляпа
5 Fedora
6 Arch Linux
7 CentOS
8 Debian
9 Ubuntu 13) Как удалить строки соответствия шаблону, а также следующую строку?
Используйте следующую команду sed , чтобы удалить строку, которая соответствует шаблону System , а также следующую строку в файле.
# sed '/ System / {N; d;}' sed-demo.txt
После удаления:
3 RHEL
4 Красная шляпа
5 Fedora
6 Arch Linux
7 CentOS
8 Debian
9 Ubuntu
10 openSUSE 13.
 а) Удаление строк от паттерна до последней строки
а) Удаление строк от паттерна до последней строкиПриведенная ниже команда sed удаляет строку, которая соответствует шаблону «CentOS» , а также удаляет все последующие строки до конца файла:
# sed '/ Centos /, $ d' sed-demo.txt После удаления: 1 Операционная система Linux 2 Операционная система Unix 3 RHEL 4 Красная шляпа 5 Fedora 6 Arch Linux
14) Удаление строк, содержащих цифры / числа
Приведенная ниже команда sed удаляет все строки, содержащие «цифр» :
# sed '/ [0-9] / d' sed-demo-1.[0-9] / d 'sed-demo-1.txt После удаления: Операционная система Linux Операционная система Unix RHEL Красная шляпа Fedora дебиан убунту Arch Linux - 1
Приведенная ниже команда sed удаляет все строки, заканчивающиеся цифрами:
# sed '/ [0-9] $ / d' sed-demo-1.txt После удаления: Операционная система Linux Операционная система Unix RHEL Красная шляпа Fedora дебиан убунту 2 - Манджаро
15) Удаление строк, содержащих буквенные символы из файла
Приведенная ниже команда sed удаляет все строки, содержащие любые буквенные символы.
# sed '/ [A-Za-z] / d' sed-demo-1.txt После удаления: 3 4 5 6
Удаление последней строки из файла в PHP
Удаление последней строки из файла — простой процесс и может быть выполнен всего за несколько строк кода.
// Считываем файл в массив
- $ lines = file ('file.txt');
// Извлечь последний элемент из массива
// Соединить массив обратно в строку
- $ file = join ('', $ lines);
// Записываем строку обратно в файл
- $ file_handle = fopen ('file.txt ',' w ');
- fputs ($ file_handle, $ file);
Одним из ограничений подхода в этом сценарии является то, что если файл достаточно большой, то при передаче всего файла в массив будет использоваться довольно много памяти, что может привести к тому, что сервер просто упадет. Вместо этого лучше всего идти от конца файла назад, пока мы не обнаружим первый разрыв строки. Следующий скрипт откусывает 50 символов за раз, пока не будет обнаружен разрыв строки (не тот, который находится в конце файла).В этот момент цикл завершается, и файл до тех пор, пока найденный разрыв строки не будет записан обратно в файл.
Следующий скрипт откусывает 50 символов за раз, пока не будет обнаружен разрыв строки (не тот, который находится в конце файла).В этот момент цикл завершается, и файл до тех пор, пока найденный разрыв строки не будет записан обратно в файл.
// Имя файла
$ filename = 'file.txt';
// Открыть файл
- $ file_handle = fopen ($ filename, 'r');
// Настройка переменных цикла
$ linebreak = false;
$ file_start = false;
// Количество байтов для просмотра
$ bite = 50;
// Размер файла
// Поместите указатель в конец файла.
- fseek ($ file_handle, 0, SEEK_END);
while ($ linebreak === false && $ file_start === false) {
// Получить текущую позицию файла.
- $ pos = ftell ($ file_handle);
if ($ pos <$ bite) {
// Если позиция меньше байта, то перейти к началу файла
} else {
// Возвращаем символы $ bite в файл
- fseek ($ file_handle, - $ bite, SEEK_CUR);
}
// Чтение байтовых символов $ файла в строку.
- $ string = fread ($ file_handle, $ bite) или die («Невозможно прочитать из файла». $ Filename. «.»);
/ * Если мы прочитали до конца файла, нам нужно игнорировать
* последнюю строку, так как это будет символ новой строки.
* /
if ($ pos + $ bite> = $ sizes) {
}
// Поскольку мы fred () перешли в нужный нам файл для резервного копирования символов $ bite.
if ($ pos <$ bite) {
// Если позиция меньше байта, перейдите к началу файла
} else {
// Переместить вернуть символы $ bite в файл
- fseek ($ file_handle, - $ bite, SEEK_CUR);
}
// Есть ли разрыв строки в прочитанной нами строке?
// Установите для $ linebreak значение true, чтобы мы вышли из цикла
$ linebreak = true;
// Последняя строка в файле сразу после переноса строки
- $ line_end = ftell ($ file_handle) + $ lb + 1;
}
- if (ftell ($ file_handle) == 0) {
// Выход из цикла, если мы находимся в начале файла.
$ file_start = true;
}
}
if ($ linebreak === true) {
// Если мы нашли разрыв строки, то считываем файл в строку для записи без последней строчки.
- $ file_minus_lastline = fread ($ file_handle, $ line_end);
// Закройте файл
// Откройте файл в режиме записи и обрежьте его.
- $ file_handle = fopen ($ имя_файла, 'w +');
- fputs ($ file_handle, $ file_minus_lastline);
} else {
// Закройте файл, больше нечего делать.
}


Скрипт использует функции fseek () и ftell () для перемещения назад по файлу небольшими приращениями. Я протестировал это с несколькими размерами файлов от нескольких килобайт до более 100 мегабайт, и он работает очень быстро.Намного быстрее, чем преобразование файла в массив.
Фил является основателем и администратором #! code и является ИТ-специалистом, работающим на северо-западе Великобритании. Фил в настоящее время является разработчиком в Code Enigma.
Комментарии
Добавить новый комментарий
linux — Как удалить 1 строку кода из файлов PHP, содержащих определенную строку?
Это решение будет работать в UNIX-подобных системах. Он также будет работать в системах Windows, если вы установите Cygwin или что-то подобное.
Если оскорбительная строка всегда первая строка, то «хвост +2» будет лучшим способом избавиться от нее.
Я бы посоветовал вам перенаправить вывод «tail» в новый файл, чтобы вы могли провести небольшую проверку. Использование третьего файла, содержащего только строку вредоносного ПО (например, malware_line.txt), позволит вам убедиться, что вы не изменили свои файлы каким-либо неожиданным образом.
Если сценарий выводит следующее сообщение, вы захотите вручную проверить файл:
Файлы FILENAME. orig и FILENAME.check отличаются
 orig и FILENAME.check отличаются
orig и FILENAME.check отличаются
Вот сценарий, который удаляет только файлы формы первой строки с именами * .php или * .PHP. (Альтернативное решение дается, если строка с вредоносной программой существует где-то еще в файле, но тогда проверка не будет работать.)
найти. -name "* .php" -o -name "* .PHP" 2> / dev / null | пока читал FILENAME
делать
BADFILE = 0
# Если файл продолжает строку с вредоносным ПО, мы хотим удалить его
grep -q 'eval (gzinflate (base64_decode' $ FILENAME && BADFILE = 1
если [[$ BADFILE! = 0]]
тогда
echo "Обработка: $ FILENAME"
cp $ FILENAME $ {FILENAME}.orig # Сохраняем резервную копию файла
# Удалите оскорбительную "первую" строку.
tail +2 $ {FILENAME} .orig> $ {FILENAME} .fixed
##
## В качестве альтернативы вы можете использовать здесь "grep -v" вместо указанного выше "tail +2"
##, чтобы указать форму строки вредоносного ПО в любом месте файла.
## grep -v 'eval (gzinflate (base64_decode' $ FILENAME> $ {FILENAME} .fixed
# Убедитесь, что мы не обновили наш файл
cat malware_line.txt $ {FILENAME} .fixed> $ {FILENAME} .check # Восстановить поврежденный файл
# Сравните оригинал с воссозданным файлом, чтобы доказать, что вы только удалили
# строка вредоносного ПО
diff -q $ {ИМЯ ФАЙЛА}.orig $ {FILENAME} .check && cp $ {FILENAME}. Исправлено $ FILENAME
# Уборка за собой
rm -f $ {ИМЯ ФАЙЛА} .check
фи
сделано
 ## grep -v 'eval (gzinflate (base64_decode' $ FILENAME> $ {FILENAME} .fixed
# Убедитесь, что мы не обновили наш файл
cat malware_line.txt $ {FILENAME} .fixed> $ {FILENAME} .check # Восстановить поврежденный файл
# Сравните оригинал с воссозданным файлом, чтобы доказать, что вы только удалили
# строка вредоносного ПО
diff -q $ {ИМЯ ФАЙЛА}.orig $ {FILENAME} .check && cp $ {FILENAME}. Исправлено $ FILENAME
# Уборка за собой
rm -f $ {ИМЯ ФАЙЛА} .check
фи
сделано
## grep -v 'eval (gzinflate (base64_decode' $ FILENAME> $ {FILENAME} .fixed
# Убедитесь, что мы не обновили наш файл
cat malware_line.txt $ {FILENAME} .fixed> $ {FILENAME} .check # Восстановить поврежденный файл
# Сравните оригинал с воссозданным файлом, чтобы доказать, что вы только удалили
# строка вредоносного ПО
diff -q $ {ИМЯ ФАЙЛА}.orig $ {FILENAME} .check && cp $ {FILENAME}. Исправлено $ FILENAME
# Уборка за собой
rm -f $ {ИМЯ ФАЙЛА} .check
фи
сделано
Как избавиться от пустых строк кода в любом текстовом редакторе • WPShout
Иногда вы посмотрите на CSS, PHP, JavaScript или другой код или файл разметки и увидите одну или несколько пустых строк между каждой строкой актуальное содержание.
Это может выглядеть примерно так (обратите внимание на строки, а не на сам код):
class EM_DEBUG {
публичная функция __call ($ name, $ arguments) {
глобальный $ dbem_debug_options;
вернуть $ dbem_debug_options [$ name];
}
} Файлы WordPress иногда вызывают эту проблему, особенно если вы используете встроенные функции «Редактор тем» и «Редактор подключаемых модулей». В более общем смысле, пустые строки кода могут возникать, когда разные части программного обеспечения по-разному интерпретируют разрывы строк.
В более общем смысле, пустые строки кода могут возникать, когда разные части программного обеспечения по-разному интерпретируют разрывы строк.
Независимо от того, как вы получаете пустые строки в коде, в этой статье дается краткое описание того, как удалить их сразу, без необходимости прокручивать страницу и нажимать «удалить» сотни раз. Этот метод будет одинаково работать для удаления пустых строк независимо от языка программирования — он будет работать для PHP, JavaScript, Java, C # или чего-то еще, чем вы занимаетесь.
Почему пустые строки кода являются проблемой
Короткий ответ: «Они больше раздражают, чем проблему». На самом деле они ничего не сломают, — вот почему ваш код продолжает работать, — но они затрудняют чтение и изменение кода, особенно если вы имеете дело с несколькими разрывами строк на строку реального кода. Они также немного увеличивают размер ваших файлов, что приятно уменьшить.
Как массово удалить пустые строки кода
Вот очень простой трюк с текстовым редактором, позволяющий решить эту проблему, когда она возникает. В видео ниже рассматривается удаление пустых строк кода в Sublime Text, но любой текстовый редактор будет иметь очень похожий процесс для выполнения того же трюка. Сама демонстрация начинается в 1:50 видео.
В видео ниже рассматривается удаление пустых строк кода в Sublime Text, но любой текстовый редактор будет иметь очень похожий процесс для выполнения того же трюка. Сама демонстрация начинается в 1:50 видео.
И вот текстовое руководство к тому же процессу:
Пошаговое руководство: Как удалить пустые строки кода с помощью текстового редактора
- В файле, который вы хотите очистить, выберите две соседние строки, которые в них ничего нет. (Для этого, удерживая нажатой клавишу Shift, дважды нажмите стрелку «вправо».)
- Скопируйте ваш выбор с помощью Ctrl + C (ПК) или Cmd + C (Mac).
- Откройте в текстовом редакторе инструмент поиска и замены. Обычно это делается с помощью Ctrl + H (ПК) или Cmd + H (Mac).
- Вставьте выделенный фрагмент в поле «Найти…». Должно получиться две пустые строчки.
- В поле «Заменить…» снова вставьте выделенный фрагмент и один раз нажмите «Удалить». Это должно выглядеть как одна пустая строка.
- Запустите «Заменить все». На этом шаге все «двойные символы новой строки» заменяются на «одиночные новые строки», в результате чего пустые строки удаляются, а сам код остается на месте.
 На этом шаге все «двойные символы новой строки» заменяются на «одиночные новые строки», в результате чего пустые строки удаляются, а сам код остается на месте.
На этом шаге все «двойные символы новой строки» заменяются на «одиночные новые строки», в результате чего пустые строки удаляются, а сам код остается на месте.И все! Обратите внимание: этот метод работает даже для быстрого сжатия файлов с несколькими бесполезными пустыми строками на строку реального кода, например:
function ask_why () {
echo "Серьезно";
echo 'почему?';
} Однако вам, возможно, придется нажать «Заменить все» несколько раз, а не один раз.
Учимся кодировать?
Если вам нужны дополнительные рекомендации по широкому миру веб-разработки, ознакомьтесь с нашими бесплатными курсами, особенно с нашим подробным руководством по PHP для разработки WordPress:
PHP для разработки WordPress: бесплатный курс
Мы также всегда рады поздороваться и задать ваши вопросы в нашей группе в Facebook.Спасибо за чтение!
Удаление всех строк, содержащих строку в vi
Удаление всех строк, содержащих строку в vi Чтобы удалить все строки, содержащие конкретный
строка в vi или
Vim
текстовых редакторов, вы можете использовать команду g для глобального поиска
указанную строку, а затем, поставив «d» в конце командной строки,
укажите, что вы хотите удалить все строки, содержащие указанную строку. Например.,
Если бы я хотел удалить все строки, содержащие строку «собака», я мог бы использовать
следующая команда.
Эта команда также удалит все строки, содержащие слова «dog», «dogged» и т. Д.
Если бы я просто хотел удалить строки, содержащие слово «собака», я мог бы использовать : г / собака / день .
Вы, конечно, можете указать шаблон, по которому вы хотите искать, используя обычные выражения. Например, если бы я хотел удалить все строки, содержащие либо «собака», либо «свинья», я могу использовать команду ниже.
Поместив буквы «d» и «h» внутри скобках, я указываю vi, что он должен удалить все строка с буквой «d» или «h», за которой следует «og».
Если бы я хотел удалить все строки комментариев из сценария, я мог бы выполнить поиск любые строки, начинающиеся с символа решетки / решетки / числа. Например:
Каретка
указывает, что следующее должно быть в начале строки (доллар
Знак указывает, что то, что предшествует знаку доллара, должно быть в конце
линии).
Если вы хотите удалить любые строки, содержащие одно из нескольких указанных слов, вы можете разделить слова вертикальный бар, он же символ трубы (это персонаж, который вы получаете, когда нажимаете одновременно нажмите клавишу Shift и обратную косую черту, по крайней мере, на Клавиатуры на английском языке.Вертикальная черта означает «логическое или» функция должна выполняться. Например, если бы я хотел удалить любые строки, содержащие слова «кошка» или «собака», я мог бы использовать команду, показанную ниже.
Мне нужно поставить перед вертикальной чертой escape-символ, то есть обратная косая черта, чтобы «избежать» особого значения вертикальная черта, которая часто используется для «трубка» вывод одной команды в другую.
Если я хотел выполнить функцию «логическое и», например, чтобы удалить любые строки содержащий оба слова «кошка» и «собака», я мог бы использовать команду ниже.
Точка указывает на то, что любой символ может встречаться в указанном
позиция. Звездочка обозначает
квантификатор, указывающий ноль или более вхождений
предыдущий элемент. Таким образом, «. *» Означает, что между
«собака и кошка». Но я также должен поставить вертикальную черту, за которой следует
Звездочка обозначает
квантификатор, указывающий ноль или более вхождений
предыдущий элемент. Таким образом, «. *» Означает, что между
«собака и кошка». Но я также должен поставить вертикальную черту, за которой следует cat. * Dog для устранения случаев, когда оба слова встречаются в строке, но
«кошка» предшествует «собаке», а не следует за «собакой».
Если бы я хотел удалить все строки, кроме тех, которые содержат конкретный
строку, я мог поставить восклицательный знак после команды g .Восклицательный знак означает операцию «логическое НЕ», то есть отрицание. Например.,
чтобы удалить все строки, не содержащие слова «собака», я мог бы использовать команду
ниже.
Если вместо этого я хотел бы удалить все строки, кроме тех, которые содержат слова «кошка» или «собака», я мог бы использовать команду ниже:
Вы можете указать диапазон строк, над которыми должна работать команда.
указав перед командой диапазон строк. Например, если бы я только хотел
удалить строки, содержащие слово «собака» из первых пяти строк, я мог бы использовать
команда ниже.
Или применить команду к строкам со 100 до последней строки, я мог бы используйте команду ниже, поскольку знак доллара указывает на последний линия.
PHP Удалить повторяющиеся строки
/ **
* RemoveDuplicatedLines
* Эта функция удаляет все повторяющиеся строки данного текстового файла.
*
* @param строка
* @param bool
* @return строка
* /
function RemoveDuplicatedLines ($ Filepath, $ IgnoreCase = false, $ NewLine = "\ n") {
if (! file_exists ($ Filepath)) {
$ ErrorMsg = 'Ошибка RemoveDuplicatedLines:';
$ ErrorMsg.= 'Данный файл'. $ Filepath. ' не существует!';
умереть ($ ErrorMsg);
}
$ Content = file_get_contents ($ Filepath);
$ Content = RemoveDuplicatedLinesByString ($ Content, $ IgnoreCase, $ NewLine);
// Доступен ли файл для записи?
if (! is_writeable ($ Filepath)) {
$ ErrorMsg = 'Ошибка RemoveDuplicatedLines:';
$ ErrorMsg. = 'Данный файл'. $ Filepath. 'не записывается!';
умереть ($ ErrorMsg);
}
// Записываем новый файл
$ FileResource = fopen ($ Filepath, 'w +');
fwrite ($ FileResource, $ Content);
fclose ($ FileResource);
}
/ **
* RemoveDuplicatedLinesByString
* Эта функция удаляет все повторяющиеся строки данной строки.*
* @param строка
* @param bool
* @return строка
* /
function RemoveDuplicatedLinesByString ($ Lines, $ IgnoreCase = false, $ NewLine = "\ n") {
если (is_array ($ Lines))
$ Lines = implode ($ NewLine, $ Lines);
$ Lines = взорвать ($ NewLine, $ Lines);
$ LineArray = массив ();
$ Дубликаты = 0;
// Проходим по всем строкам данного файла
for ($ Line = 0; $ Line Как удалить перенос строки в Notepad ++?
Как удалить разрывы строк в Notepad ++? - Суперпользователь Сеть обмена стеков
Сеть Stack Exchange состоит из 176 сообществ вопросов и ответов, включая Stack Overflow, крупнейшее и пользующееся наибольшим доверием онлайн-сообщество, где разработчики могут учиться, делиться своими знаниями и строить свою карьеру.
Посетить Stack Exchange- 0
- +0
- Авторизоваться
Подписаться
Super User - это сайт вопросов и ответов для компьютерных энтузиастов и опытных пользователей.Регистрация займет всего минуту.
Зарегистрируйтесь, чтобы присоединиться к этому сообществу Кто угодно может задать вопрос
Кто угодно может ответить
Лучшие ответы голосуются и поднимаются наверх
Спросил
Просмотрено
373к раз
Есть ли простой способ удалить перенос строки в Notepad ++?
Например:
Этот текст был разделен
в строках, и это длиннее, чем
3200 слов, так что было бы здорово
найти и заменить разрывы строк
как это.
Stevoisiak 10.4k2828 золотых знаков8181 серебряный знак129129 бронзовых знаков
Создан 12 дек.
Габриэль Габриэль 2,1601010 золотых знаков3232 серебряных знака4848 бронзовых знаков
2- Выделите строки, которые хотите соединить (или используйте Ctrl + A , чтобы выделить все)
- Выберите в меню Правка → Операции с линиями → Соединить линии или нажмите Ctrl + J .
При необходимости пробелы вставляются автоматически, чтобы слова не слипались
Создан 12 дек.
Джеймс Пи Джеймс П 10.2k55 золотых знаков3939 серебряных знаков4949 бронзовых знаков
6 УПРАВЛЕНИЕ + H
В режиме поиска Выбор Расширенный
Найти - \ r \ n Заменить - оставить пустым.
Создан 12 дек.
Офирис 1,68511 золотых знаков1414 серебряных знаков2121 бронзовый знак
4 У меня при использовании Win 7 пришлось использовать
\ r
в поле Найти и введите <пробел> в поле Заменить , чтобы между последним словом текущей строки и первым словом следующей строки оставался один пробел.
Создан 28 авг.
Алан МАлан М 16355 бронзовых знаков
2 Очень активный вопрос .Заработайте 10 репутации, чтобы ответить на этот вопрос. Требование репутации помогает защитить этот вопрос от спама и отсутствия ответов. Суперпользователь лучше всего работает с включенным JavaScript Ваша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
 'не записывается!';
умереть ($ ErrorMsg);
}
// Записываем новый файл
$ FileResource = fopen ($ Filepath, 'w +');
fwrite ($ FileResource, $ Content);
fclose ($ FileResource);
}
/ **
* RemoveDuplicatedLinesByString
* Эта функция удаляет все повторяющиеся строки данной строки.*
* @param строка
* @param bool
* @return строка
* /
function RemoveDuplicatedLinesByString ($ Lines, $ IgnoreCase = false, $ NewLine = "\ n") {
если (is_array ($ Lines))
$ Lines = implode ($ NewLine, $ Lines);
$ Lines = взорвать ($ NewLine, $ Lines);
$ LineArray = массив ();
$ Дубликаты = 0;
// Проходим по всем строкам данного файла
for ($ Line = 0; $ Line
'не записывается!';
умереть ($ ErrorMsg);
}
// Записываем новый файл
$ FileResource = fopen ($ Filepath, 'w +');
fwrite ($ FileResource, $ Content);
fclose ($ FileResource);
}
/ **
* RemoveDuplicatedLinesByString
* Эта функция удаляет все повторяющиеся строки данной строки.*
* @param строка
* @param bool
* @return строка
* /
function RemoveDuplicatedLinesByString ($ Lines, $ IgnoreCase = false, $ NewLine = "\ n") {
если (is_array ($ Lines))
$ Lines = implode ($ NewLine, $ Lines);
$ Lines = взорвать ($ NewLine, $ Lines);
$ LineArray = массив ();
$ Дубликаты = 0;
// Проходим по всем строкам данного файла
for ($ Line = 0; $ Line