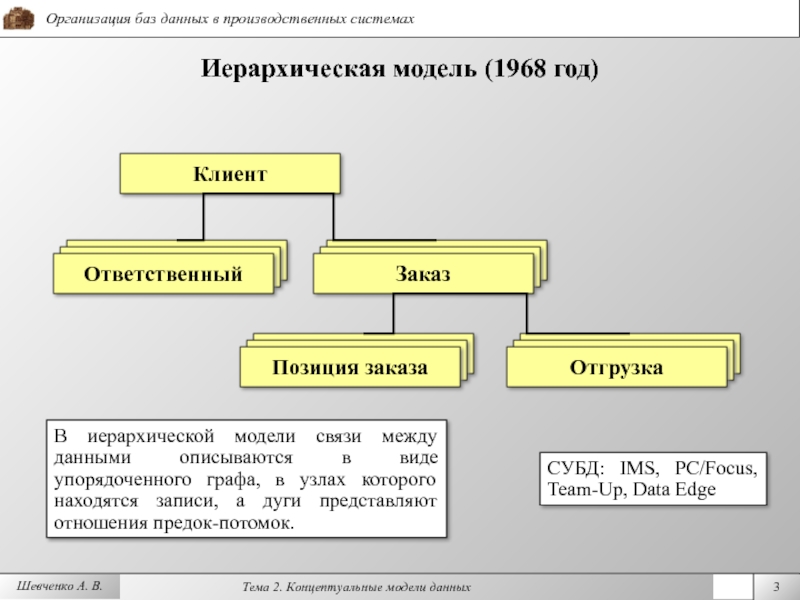
08. Иерархический и сетевой подходы при построении баз данных, основные понятия, достоинства и недостатки.
Иерархические базы данных: могут быть представлены как дерево, состоящее из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и т. д.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Схема 1 пример иерархичской БД
Достоинства | Недостатки |
·
Простота организации. · Наиболее быстрый доступ к информации (заранее известны все вершины и все ключи к доступу информациии).
| · Избыточность — нельзя ссылаться на одно и то же, необходимо дублировать информацию. · Не любая предметная область может быть представлена такой структурой. · При изменении структуры модели данных требуется изменение программного обеспечения и программных средств или создание нового. |
Примеры иерархических БД:
· System2000
· TDMS
Основное отличие от иерархической модели в том что у потомка может быть любое число предков а в иерархической только один.
Тип связи определяется для двух
типов записи: предка и потомка. Экземпляр типа связи состоит из одного
экземпляра типа записи предка и упорядоченного набора экземпляров типа записи
потомка.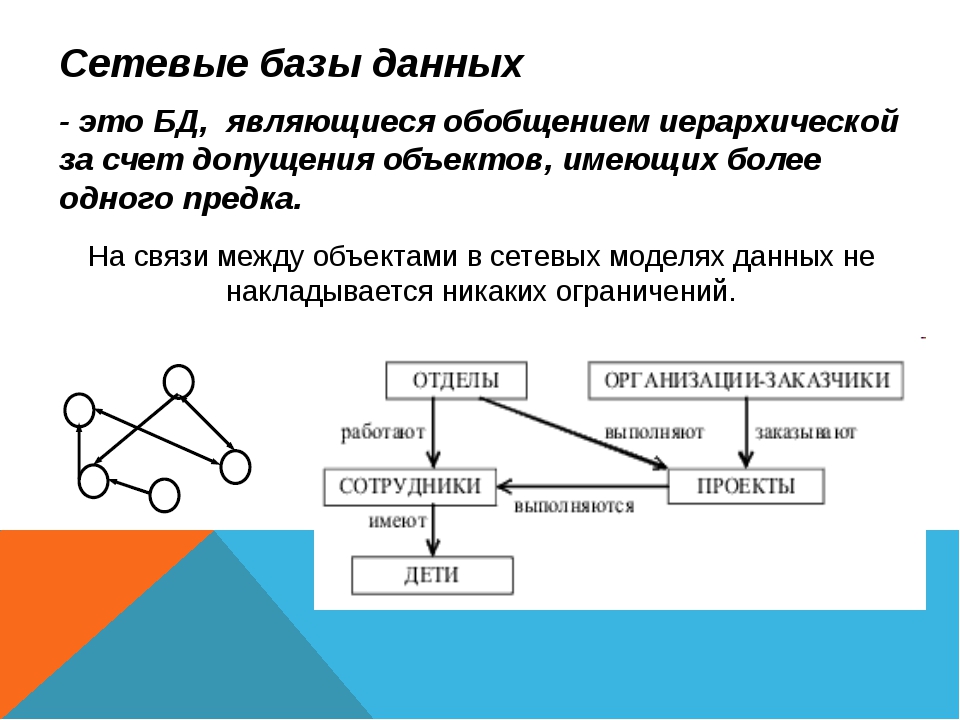
Схема 2 Сетевая БД
Достоинства | Недостатки |
· Более адекватно отражает состав и структуру предметной области за счет дополнительных связей между отдельными компонентами (Более гибкая модель). · Быстрый доступ к информации БД. Всё определяется на этапе проектирования. · Простота реализации | · При изменении информации требуется изменение программного обеспечения (доработка).
|
Примеры сетевых БД:
· dbVista
· СООБЗ Cerebrum
УРОК 1
УРОК 1.
Тема. Первое ознакомление с базами
данных. Фактографические и документальные базы данных. Иерархическая, сетевая,
реляционная модель базы данных. Основные
объекты баз данных. Системы управления базами данных. СУБД Ассеss. Особенности
реляционных БД. Знакомство и робота с конкретной базой данных. Поиск информации
в базе данных.
Иерархическая, сетевая,
реляционная модель базы данных. Основные
объекты баз данных. Системы управления базами данных. СУБД Ассеss. Особенности
реляционных БД. Знакомство и робота с конкретной базой данных. Поиск информации
в базе данных.
Цель урока:
Учебная:
Ø Показать значимость материала, его применение в практической деятельности;
Ø Предоставить начальные представления из темы;
Ø Показать разные формы организации данных в БД.
Развивающая:
Ø Развитие памяти, развитие свойств внимательности и моторной координации.
Воспитательная:
Ø Формирование интереса к изучению новых информационных технологий;
Ø Формирование привычек собранности, аккуратности при работе по ПК.
Тип урока: урок усвоения новых знаний
ХОД УРОКА
1.
Вопрос к ученикам:
В чем состоит основное назначение Microsoft Excel?
Прогнозируемый ответ учеников:
Табличный процессор Microsoft Excel помогает в формировании и обработке информации, представленной в виде таблиц практически любой сложности.
Большинство данных, которые подлежат обработке в разнообразных сферах человеческой деятельности, могут быть представлены в виде таблиц. Большее того, в виде таблиц можно представить текстовые данные. Назовите примеры текстовых данных
Припомним, что информация для обработки называется данными.
Сегодня мы начнем рассматривать не просто данные, а базы данных; не каждый блок информации можно назвать базой данных
II.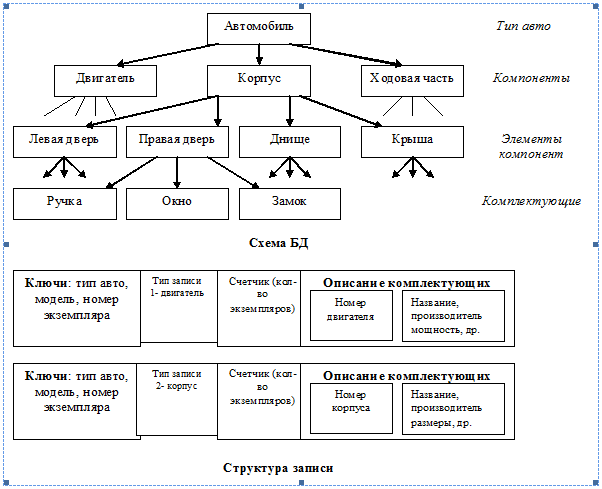 Изложение
нового материала.
Изложение
нового материала.
На уроке мы познакомимся с новыми понятиями.(обращаю внимание на доску, где записанные эти понятия)
Новые термины и понятия: базы данных, Фактографические и документальные базы данных системы управления базами данных, структуры организации данных в БД, иерархическая, сетевая и реляционная модели БД, объекты СУБД Ассеss — их определение.
Конспект ученика:
Задание:
Открыть презентацию
«,
в которой найти ответы на вопросы. Вопросы и ответы записать в тетрадь.
• Определение Базы данных (БД)
• Виды баз данных (фактографические и документальные)?
• Что такое СУБД?.
• Типы СУБД(иерархические, сетевые, реляционные
• Что такое реляционные СУБД?
•
Как называются строки
и столбцы таблицы.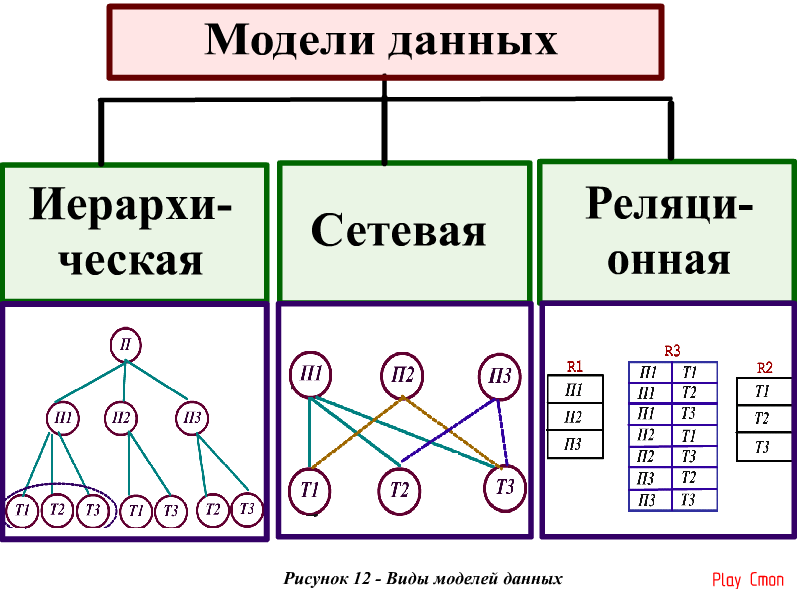
• Что такое ключевое поле?
• Основные объекты СУБД Ms ACCESS
• Типы данных Microsoft Access(переписать в тетрадь)
• Примеры СУБД
База данных (БД) — это совокупность взаимосвязанных данных, которые хранятся во внешней памяти компьютера, и организованы по определенным правилам, которые предполагают общие принципы описания, хранения и обработки данных.
Приведите примеры.
Прогнозируемый ответ (Примеры: БД относительно наличия медикаментов; БД в системе расписания самолетов, поездов или БД продажи билетов транспорта; БД документов учеников школы, картотека отдела кадров или у библиотеки и т.п..)
Базы данных делятся на фактографические и документальные.
Фактографические БД содержат короткие сведения об объектах, поданные в точно определенном формате (1-3), например, Автор, название, год издания …
В документальных БД содержится информация
разного типа: текстовая, звуковая, графическая, мультимедийная
(4, 5).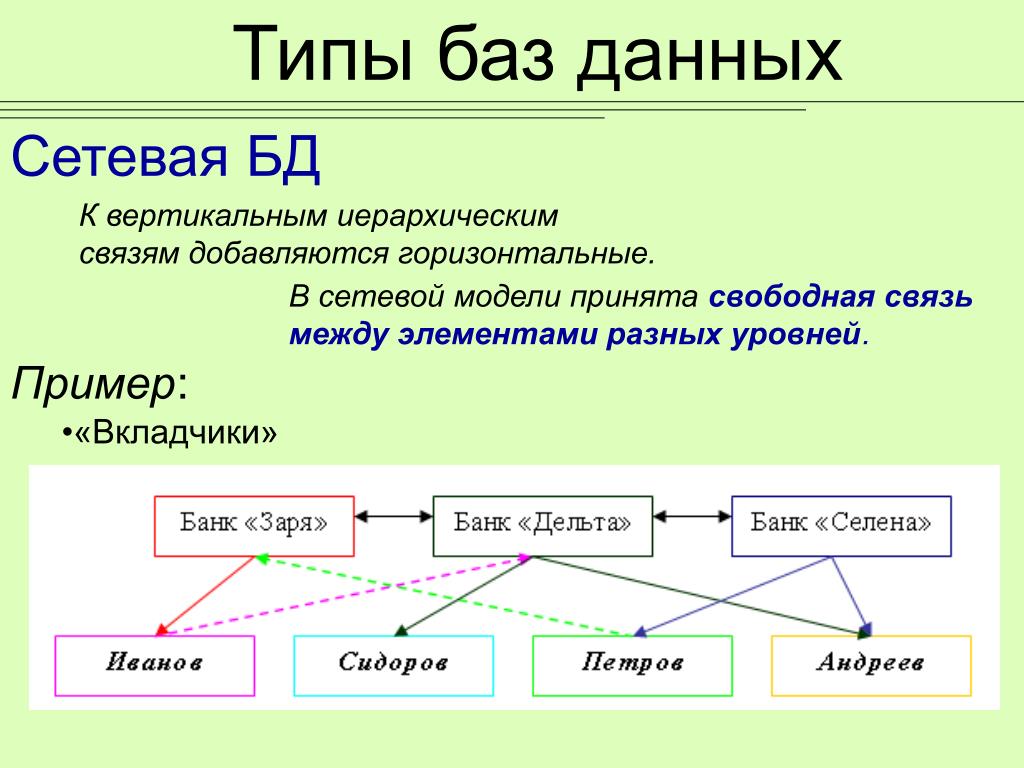 Например, БД современной музыки может содержать тексты и ноты песен,
фотографии авторов, звуковые записи, видеоклипы.
Например, БД современной музыки может содержать тексты и ноты песен,
фотографии авторов, звуковые записи, видеоклипы.
Появление компьютерной техники повысила эффективность работы с базами данных. Доступ к данным иd управления ними происходит в среде специального программного пакету — системы управления базами данных (СУБД).
СУБД – Это программное обеспечение (ПО), которое позволяет создавать БД, обновлять и дополнять информацию, обеспечивать гибкий доступ к информации. СУБД создает на экране компьютера определенную среду для работы пользователя (интерфейс), и имеет определенные режимы работы и систему команд.
За структурой организации информации в БД различают такие модели баз данных: иерархическая, сетевая и реляційна.
Иерархическая модель базы данных. Эта модель представляет
собой структуру данных, которые благоустроенные за подчинением от общего к
конкретного; напоминает «дерево» (граф), поэтому имеет такие самые параметры:
уровень, узел, связь.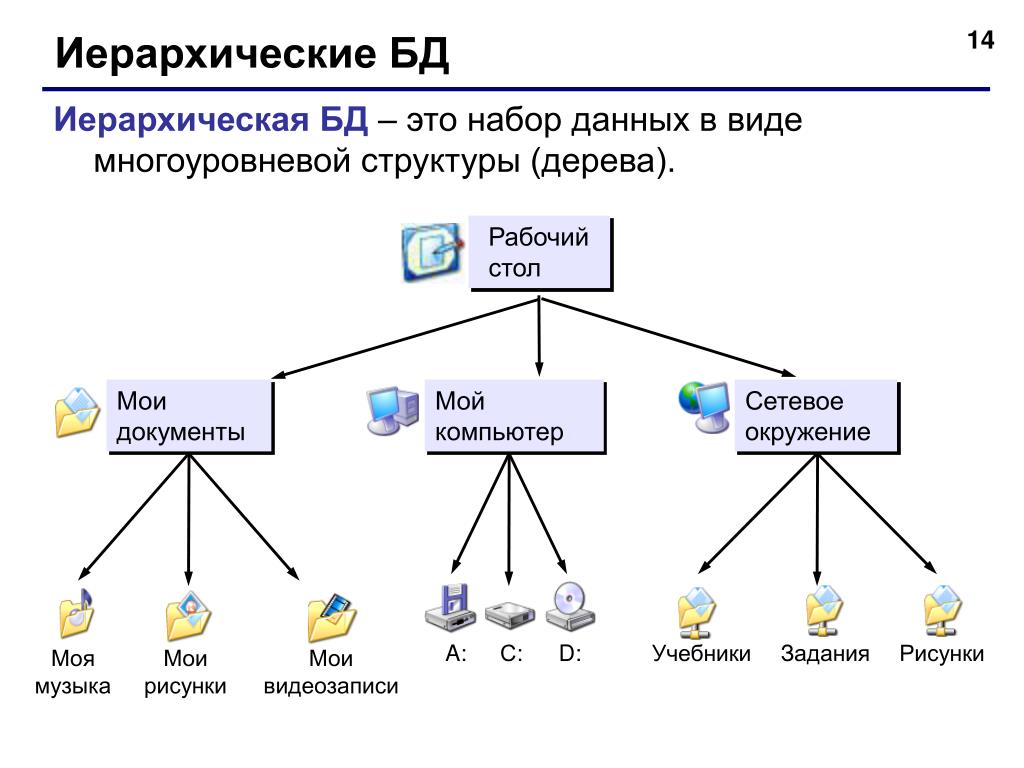
Иерархическая модель школьной базы данных
1 уровень (высочайший)
——————————————————————————————————
|
|
——————————————————————————————————-
3 уровень
———————————————————————————————————
4 уровень
Схема №1
Иерархическая модель базы данных имеет такие свойства: несколько узлов низшего
уровня связанные только с одним узлом высшего уровня; дерево иерархии имеет
только одну вершину, которая не подлежит другой; каждый узел носит собственное
имя, есть только один маршрут от вершины дерева (корневого узла) к любому
узлу структуры.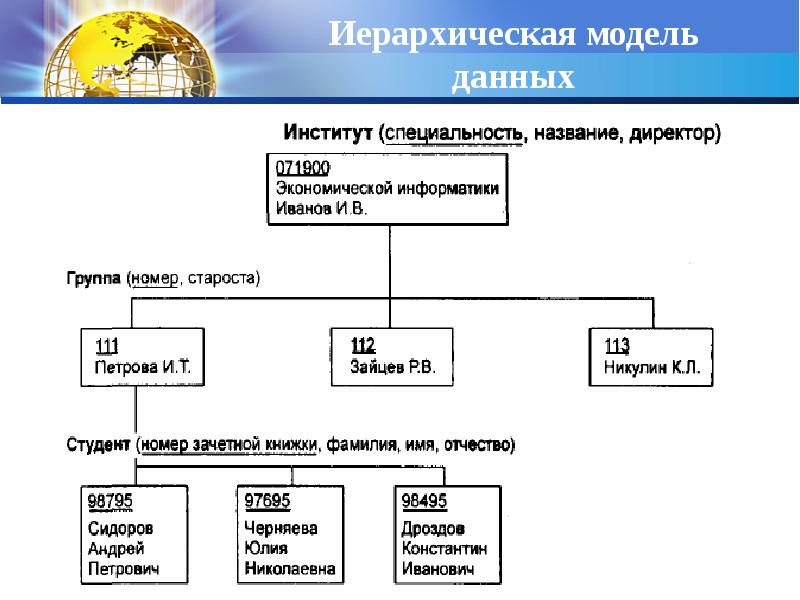
Сетевая модель базы данных. Общим видом она похожая на иерархическую. Имеет такие самые составные структуры, вирізняється характером отношения между ними. Между элементами структуры произвольный, не ограниченный количеством элемент-связь. Сетевую модель работы преподавателей в школе приведен на схеме 2.(кодопроекція – сжема№2)
Сетевая модель работы преподавателей в школе
Схема №2
Реляционная модель базы
даних. (Происхождение названия от латинского слова relatio
— отношение). Модель построена на взаимоотношениях между составными структуры.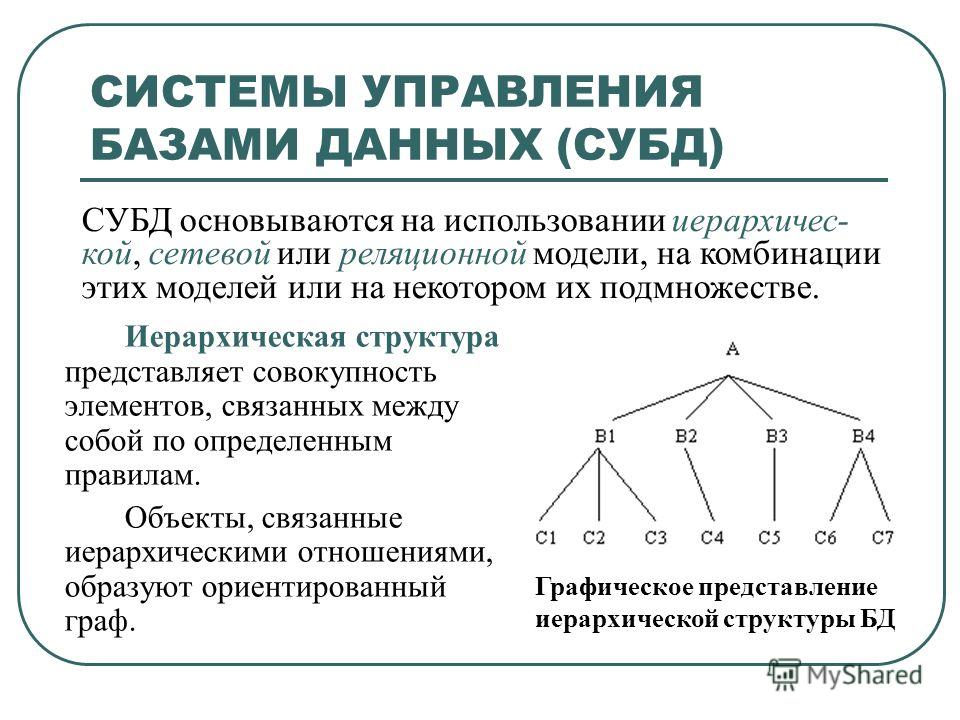 Представляет собой одну таблицу или совокупность взаимосвязанных двумерных
таблиц (табл. 1 кодопозитив).
Представляет собой одну таблицу или совокупность взаимосвязанных двумерных
таблиц (табл. 1 кодопозитив).
Реляционная модель со сведениями об учениках одного класса
Таблица 1
|
№ личного дела |
Фамилия |
Имя |
Отчество |
Дата рождения |
|
I-123 |
Иванов |
Иван |
Иванович |
29.02.1988 |
|
Б-67 |
Буренко |
Анна |
Сергеевна |
07. |
|
|
|
|
|
|
 08.1988
08.1988
Реляционная модель создана на основе двумерной таблицы.
Строка таблицы — это запись, которая содержит информацию об отдельном объекте таблицы (один ученик). Структура записей одинаковая; совокупность элементов данных, из которых складывается запись, называется полем. Информация записи находится в полях. Пол таблицы — это колонка таблицы.
Одинаковые записи в таблицы не допускаются. Поскольку во всех записях
есть одни и одни и те же поля, им предоставляют уникальные имена (фамилия
ученика, имя ученика,…). Пол может быть однородным за типом за всеми записями
в колонке (или текстов данные, или числовые и т.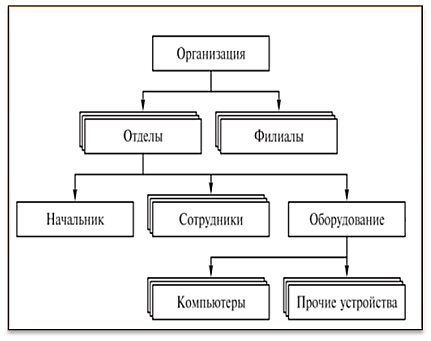 п.).
п.).
Реляционная модель одной базы данных, как правило, содержит несколько таблиц, связь между которыми осуществляется с помощью специального поля — ключа.
Примеры реляционных СУБД: Access, FохВаsе, FохРго, Сlіррег и Ассеss.
Прибавление МS Ассеss есть системой управления базами данных, которое входит в состав пакету Місrоsоft Office и предназначенная для работы за персональным компьютером или в сети под руководством операционной системы Windows База данных СУБД Ассеss есть реляційною базой данных, которая состоит из взаимосвязанных двумерных таблиц.
СУБД Ассеss дает возможность:
Ø проектировать табличные объекты базы данных;
Ø устанавливать связи между таблицами;
Ø вводить, сохранять, пересматривать, сортировать, модифицировать данные таблицы с использованием аппарата алгебры логики и индексирование;
Ø
создавать и использовать объекты БД.
Объекты СУБД Ассеss
База данных — файл, который содержит разные объекты сохранения данных.
Таблица (tables) — организация сохранения данных в виде двумерного массива есть основным объектом БД. Остаток — производные от таблицы.
Формы (forms) — объекты для изображения данных из таблиц на экране в удобном для просмотре и обработки виде.
Запить (queries) — объекты для выбора и фильтраци данных таблицы за определенными критериями (условиями).
Отчеты (reports) — формирование документа данных из таблицы для печати.
Макросы (macros) — описание дои в виде последовательности команд и их автоматического выполнения.
Модули (modules) — программы на Visuаl Ваsіс, которые разрабатывает пользователь для реализации нестандартных процедур.
По окончании работы с презентацией учащиеся отвечают на вопросы:
• Определение Базы данных (БД)
• Виды баз данных (фактографические и документальные)?
•
Что такое СУБД?.
• Типы СУБД(иерархические, сетевые, реляционные
• Что такое реляционные СУБД?
• Как называются строки и столбцы таблицы.
• Что такое ключевое поле?
• Основные объекты СУБД Ms ACCESS
• Типы данных Microsoft Access(переписать в тетрадь)
• Примеры СУБД
III. Практическая работа с базой данных «Борей».
• Выполнение практической работы(по карточкам)
• Ученики получают алгоритм работы с готовой базой данных.
Алгоритм
a.
Откройте пакет Місгоsоft Ассеss (Пуск/Программы/Місгоsоft Office/ Місrоsoft Ассеss.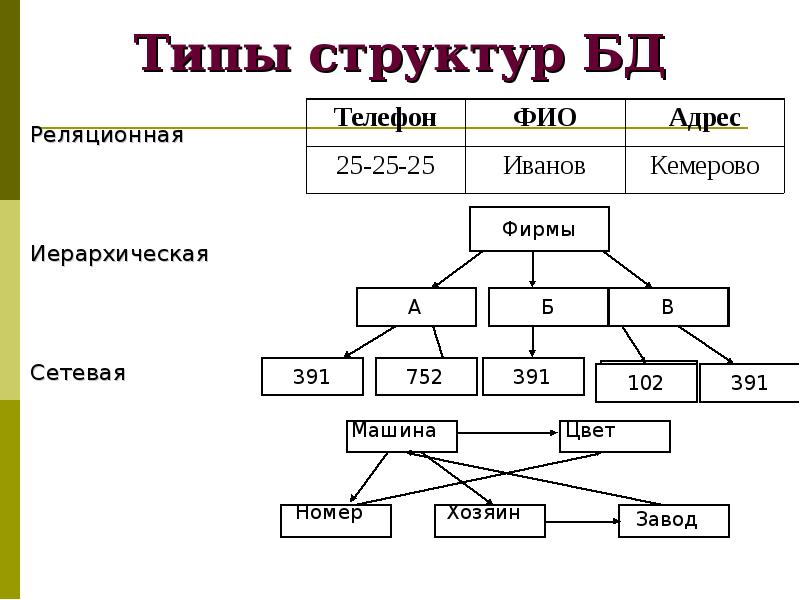
b. В окне СУБД Ассеss выберите команду «открыть» и укажите на БД «Борей».
c. Выберите в данной базе объект таблицы (для открытия объекта дважды кликните мышкой на объекте).
d. Выберите и зафиксируйте в тетради из таблицы Заказы и за кодом заказа 10253 и 10260 имя клиента и сотрудника.
e. Раскройте таблицу Сотрудники, просмотрите в ней сведения о записанных сотрудниках и их фотографиях (для этого активизируйте значения в поле Фотографии).
f. В таблицы Клиенты и в поле Название найдите уже знакомые имена клиентов и зафиксируйте номер записи клиента в этой таблице и ее код.
g. Закройте таблицы.
h.
Активизируйте объект Формы.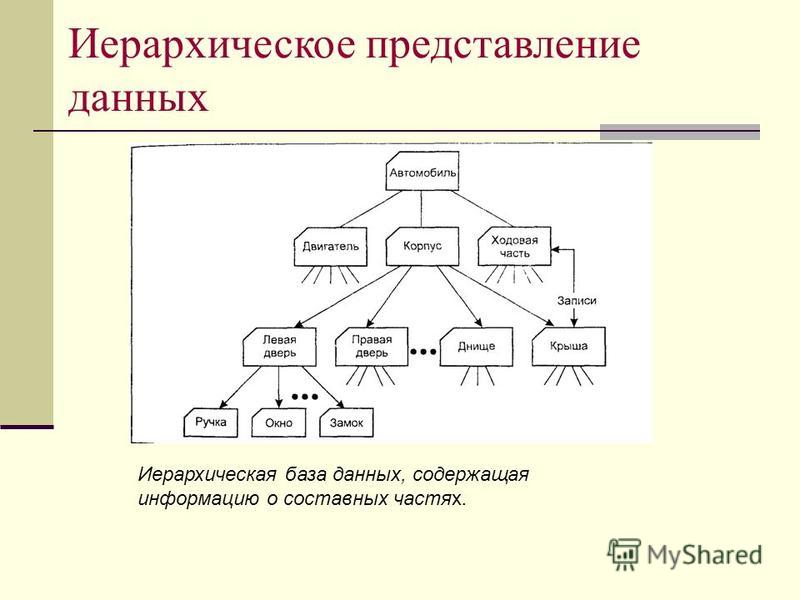
i. Выберите форму Сотрудники и просмотрите оформление данных указанных сотрудников.
j. В форме Телефоны клиентов ознакомьтесь с номерами телефонов Ваших клиентов.
k. Активизируйте объект Запросы.
l. Выберите запрос Сведения в заказах, просмотрите товары, которые заказало ваши клиенты.
m. В форме Типы просмотрите данные протовари клиентов.
n. Ознакомьтесь с оформлением отчета запомощью Отчета (Товары по типу).
o. Ознакомьтесь с остатком объектов по своему желанию.
p. Закройте объекты БД и СУБД.
III. Домашнее задание: выучить конспект.
IV.
Подведение итогов урока.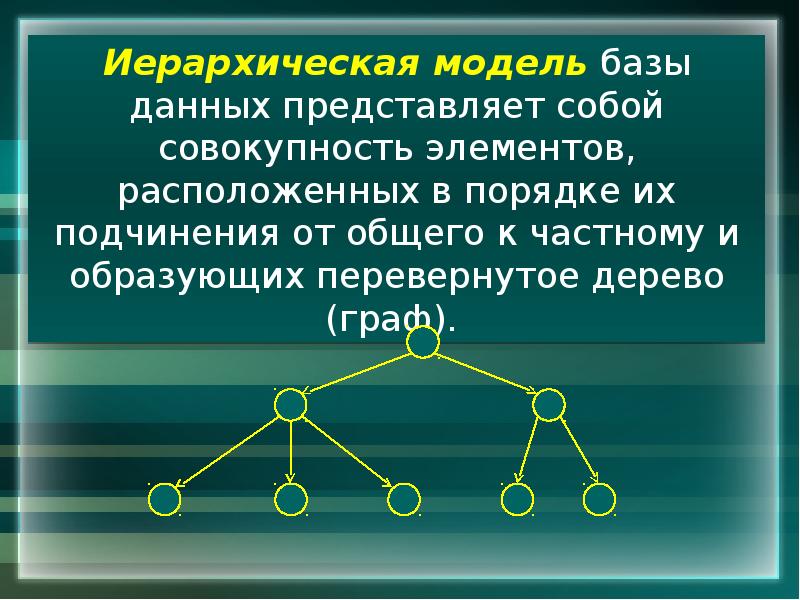 Выставление оценок за работу на уроке.
Выставление оценок за работу на уроке.
Что ноаого вы сегодня узнали?
Урок 7. База данных – основа информационной системы. Базы данных (табличные, иерархические, сетевые)
Урок 7. База данных – основа информационной системы. Базы данных (табличные, иерархические, сетевые). Системы управления базами данных (СУБД). Реляционные базы данных. Многотабличные базы данных
База данных — основа информационной системы (§ 5)
Что такое база данныхОсновой для многих информационных систем (прежде всего, информационно-справочных систем) являются базы данных.
База данных (БД) — это совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы и отражающих состояние и взаимодействие объектов в определенной предметной области.
Под вычислительной системой здесь понимается отдельный компьютер или компьютерная сеть. В первом случае база данных называется централизованной, во втором случае — распределенной.
База данных является компьютерной информационной моделью некоторой реальной системы. Например, книжного фонда библиотеки, кадрового состава предприятия, учебного процесса в школе и т. д. Такую систему называют предметной областью базы данных и информационной системы, в которую БД входит.
Описание структуры данных, хранимых в БД, называется моделью представления данных, или моделью данных. В теории БД известны три классические модели данных: иерархическая, сетевая и реляционная (табличная). По виду используемой модели данных базы данных делятся на иерархические, сетевые и реляционные (табличные).
В последние годы при разработке информационных систем стали использоваться и другие виды моделей данных. К ним относятся объектно-ориентированные, объектно-реляционные, многомерные и другие модели. Классическим вариантом, и пока наиболее распространенным, остается реляционная модель. В курсе информатики основной школы вы уже знакомились с основами реляционных БД. Вспомним главные понятия, связанные с ними.
Классическим вариантом, и пока наиболее распространенным, остается реляционная модель. В курсе информатики основной школы вы уже знакомились с основами реляционных БД. Вспомним главные понятия, связанные с ними.
Основной информационной единицей реляционной БД является таблица. База данных может состоять из одной таблицы (одно-табличная БД) или из множества взаимосвязанных таблиц (многотабличная БД).
Структурными составляющими таблицы являются записи и поля.
Каждая запись содержит информацию об отдельном объекте системы: одной книге в библиотеке, одном сотруднике предприятия и т. п. А каждое поле — это определенная характеристика (свойство, атрибут) объекта: название книги, автор книги, фамилия сотрудника, год рождения и т. п. Поля таблицы должны иметь несовпадающие имена.
В одной таблице не должно быть повторяющихся записей.
Для каждой таблицы реляционной БД определяется главный ключ — поле или совокупность полей, однозначно определяющих запись.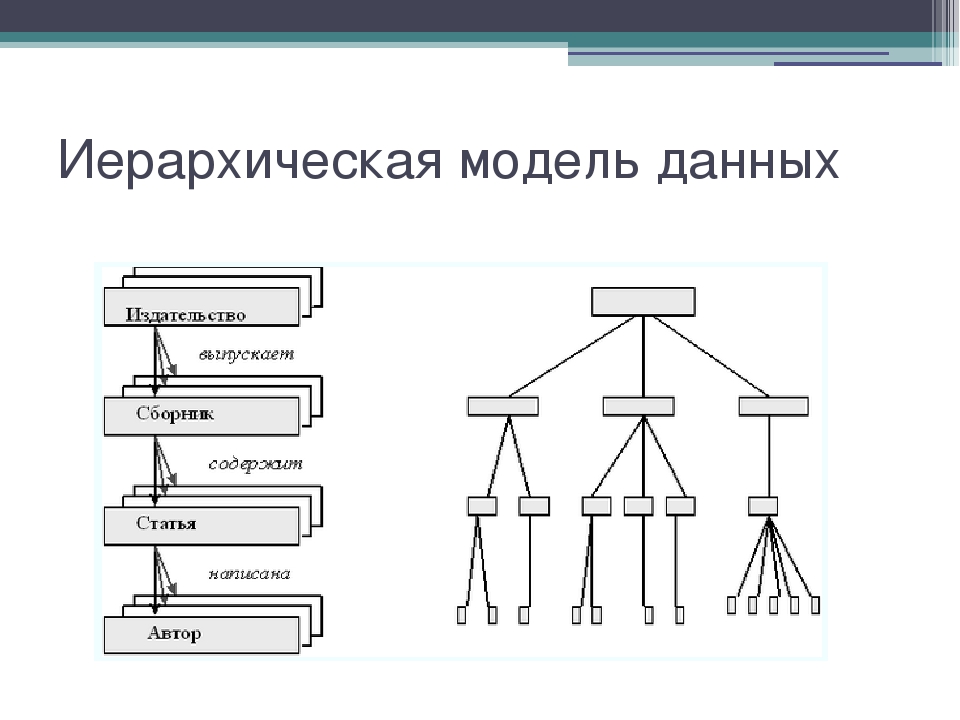 Иначе говоря, значение главного ключа не должно повторяться в разных записях. Например, в библиотечной базе данных в качестве такого ключа может быть выбран инвентарный номер книги, который не может совпадать у разных книг.
Иначе говоря, значение главного ключа не должно повторяться в разных записях. Например, в библиотечной базе данных в качестве такого ключа может быть выбран инвентарный номер книги, который не может совпадать у разных книг.
Для строчного представления структуры таблицы применяется следующая форма:
Подчеркиваются поля, составляющие главный ключ.
В теории реляционных баз данных таблица называется отношением. Отношение по-английски — relation. Отсюда происходит название «реляционные базы данных». ИМЯ ТАБЛИЦЫ в нашем примере — это имя отношения.
Примеры отношений:
Каждое поле таблицы имеет определенный тип. С типом связаны два свойства поля:
1) множество значений, которые оно может принимать;
2) множество операций, которые над ним можно выполнять.
Поле имеет также формат (длину).
Существуют четыре основных типа для полей БД: символьный, числовой, логический и дата.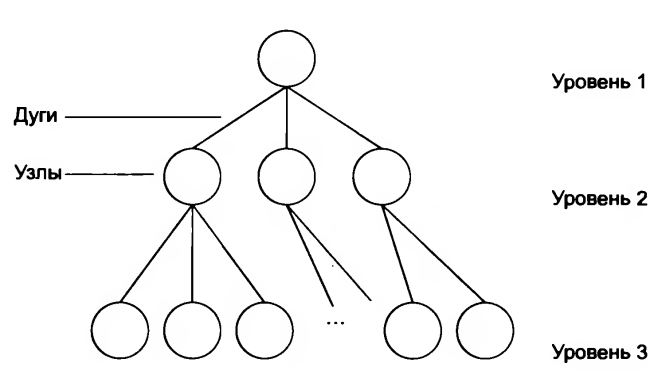 Для полей таблиц БИБЛИОТЕКА и БОЛЬНИЦА могут быть установлены следующие типы:
Для полей таблиц БИБЛИОТЕКА и БОЛЬНИЦА могут быть установлены следующие типы:
символьный тип: АВТОР, НАЗВАНИЕ, ИЗДАТЕЛЬСТВО, ПАЦИЕНТ, ДИАГНОЗ;
числовой тип: ИНВ_НОМЕР, ГОД_ИЗД, ПАЛАТА, НОМЕР МЕСТА;
дата: ДАТА_ПОСТУП;
логический: ПЕРВИЧНЫЙ.
В нашем случае поле ПЕРВИЧНЫЙ показывает, поступил больной в больницу с данным диагнозом впервые или повторно. Те записи, где значение этого поля равно TRUE (ИСТИНА), относятся к первичным больным, значение FALSE (ЛОЖЬ) отмечает повторных больных. Таким образом, поле логического типа может принимать только два значения.
В таблице БОЛЬНИЦА используется составной ключ — состоящий из двух полей: ПАЛАТА и НОМЕР МЕСТА. Только их сочетание не повторяется в разных записях (ведь фамилии пациентов могут совпадать).
Система управления базами данных (СУБД)Система управления базами данных (СУБД) — комплекс языковых и программных средств, предназначенных для создания, ведения и использования базы данных многими пользователями.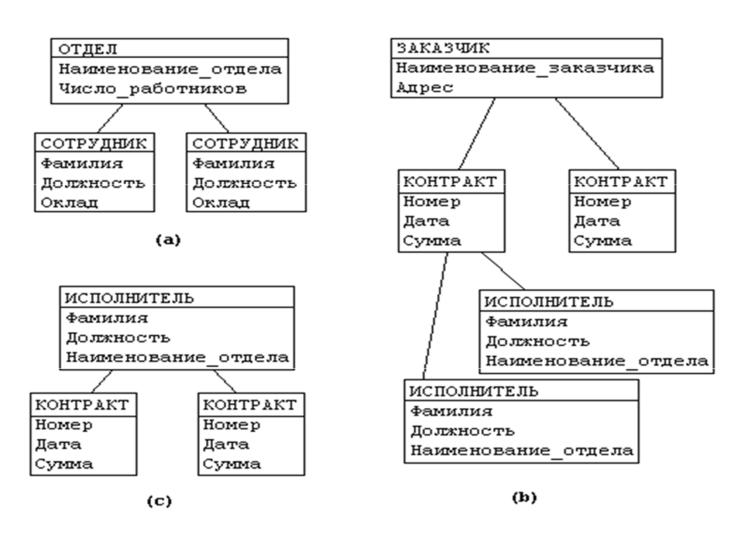
В зависимости от вида используемой модели данных различаются иерархические, сетевые и реляционные СУБД.
Наибольшее распространение на персональных компьютерах получили так называемые полнофунациональные реляционные СУБД. Они выполняют одновременно как функцию системных средств, так и функцию пользовательского инструмента для создания приложений. Примером СУБД такого типа является Microsoft Access.
Полноценная информационная система на компьютере состоит из трех частей:
СУБД + база данных + приложения.
Основные действия, которые пользователь может выполнять с помощью СУБД:
• создание структуры базы данных;
• заполнение базы данных информацией;
• изменение (редактирование) структуры и содержания базы данных;
• поиск информации в БД;
• сортировка данных.
Вопросы и задания
1. а) Для чего предназначены базы данных? Выберите верный ответ:
1) для выполнения вычислений на компьютере;
2) для осуществления хранения, поиска и сортировки данных;
3) для принятия управляющих решений.
б) Какие существуют варианты классификации БД?
в) Почему реляционный вид БД является наиболее распространенным?
г) Что такое запись в реляционной БД?
д) Что такое поле, тип поля; какие бывают типы полей?
е) Что такое главный ключ записи?
2. Определите главный ключ и типы полей в следующих отношениях: АВТОБУСЫ (НОМЕР МАРШРУТА, НАЧАЛЬНАЯ ОСТАНОВКА, КОНЕЧНАЯ ОСТАНОВКА) КИНО (КИНОТЕАТР, СЕАНС, ФИЛЬМ, РОССИЙСКИЙ, ДЛИТЕЛЬНОСТЬ) УРОКИ (ДЕНЬ НЕДЕЛИ, НОМЕР УРОКА, КЛАСС, ПРЕДМЕТ, ПРЕПОДАВАТЕЛЬ)
3. Опишите структуру записей (имена полей, типы полей, главные ключи) для баз данных: РЕЙСЫ САМОЛЕТОВ, ШКОЛЫ ГОРОДА, СТРАНЫ МИРА.
Модель данных иерархическая — Энциклопедия по экономике
Минимальный расход памяти. Для задач, допускающих реализацию с помощью любой из трех моделей данных, иерархическая модель позволяет получить представление с минимально требуемой памятью. [c.125]
[c.125] Автоматизацию работы базы данных обеспечивает СУБД, которая манипулирует с конкретной моделью организации данных на носителе. При построении логической модели данных выбирается один из трех подходов моделирования иерархический, сетевой, реляционный. [c.147]
Модель накопления данных формализует описание информационной базы, которая в компьютерном виде представляется базой данных. Процесс перехода от информационного (смыслового) уровня к физическому отличается трехуровневой системой моделей представления информационной базы концептуальной, логической и физической схем. Концептуальная схема информационной базы (КСБ) описывает информационное содержание предлагаемой области, т.е. какая и в каком объеме информация должна накапливаться при реализации информационной технологии. Логическая схема информационной базы (ЛСБ) должна формализованно описать ее структуру и взаимосвязь элементов информации. При этом могут быть использованы различные подходы реляционный, иерархический, сетевой. Выбор подхода определяет и систему управления базой данных, которая, в свою очередь, определяет физическую модель данных — физическую схему информационной базы (ФСБ), описывающую методы размещения данных и доступа к ним на машинных (физических) носителях информации.
[c.56]
Выбор подхода определяет и систему управления базой данных, которая, в свою очередь, определяет физическую модель данных — физическую схему информационной базы (ФСБ), описывающую методы размещения данных и доступа к ним на машинных (физических) носителях информации.
[c.56]
Применение того или иного вида взаимосвязей определило три основные модели баз данных иерархическую, сетевую, реляционную. [c.142]
В иерархической модели используется вид связи между элементами данных «один ко многим». Если применяется взаимосвязь вида «многие ко многим», то приходят к сетевой модели данных. [c.143]
Для построения системы управления базами данных (СУБД) ориентированной логической модели рекомендуется отобразить полученную концептуальную модель сначала в общую иерархическую модель, а затем,накладывая на нее ограничения конкретной СУБД, получить отображение в модель данных конкретной СУБД -. Но в связи с тем, что возможности модели данных СУБД ИНЕС шире общей иерархической модели, целесообразно проводить отображение сразу в модель ИНЕС. [c.26]
[c.26]
В большинстве СУБД, таких, как ОКА и БАНК-ОС, используются модели данных, в которых на первый план выдвигается эффективное представление данных во внешней памяти ЭВМ, а не отражение семантики моделируемых объектов [22, с. 1]. Наилучшим образом требованиям эффективного представления данных на физическом уровне отвечают иерархические, сетевые и в меньшей степени реляционные модели данных. [c.115]
Модели данных анализируются с учетом применяемых информационных конструкций, операций и ограничений. Для применения синтаксических моделей данных характерно использование единого аппарата функциональных зависимостей. Он позволяет производить нормализацию реляционных баз данных, создавать корректные сетевые и иерархические базы данных. Исследуются также ациклические базы данных. [c.4]Принципиальными различиями обладают три модели данных — реляционная, сетевая и иерархическая, у которых разные множества допустимых информационных конструкций. Существующие СУБД обеспечивают реализацию возможностей этих моделей данных с теми или иными ограничениями и уточнениями, что дает повод говорить о наличии самостоятельной модели данных у каждой СУБД. Однако при создании СУБД происходит модификация модели данных исходя из удобства программной реализации системы.
[c.32]
Существующие СУБД обеспечивают реализацию возможностей этих моделей данных с теми или иными ограничениями и уточнениями, что дает повод говорить о наличии самостоятельной модели данных у каждой СУБД. Однако при создании СУБД происходит модификация модели данных исходя из удобства программной реализации системы.
[c.32]
Количество существенно различных моделей данных определяется наличием различных множеств информационных конструкций. С этой точки зрения принципиальными различиями обладают три модели данных — реляционная, сетевая и иерархическая. [c.60]
Иерархическая модель данных [c.117]
Иерархическая модель данных имеет много общих черт с сетевой моделью данных, хронологически она появилась даже раньше, чем сетевая. Допустимыми информационными конструкциями в иерархической модели данных являются отношение, веерное отношение и иерархическая база данных. В отличие от ранее рассмотренных моделей данных, где предполагалось, что информационным отображением одной предметной области является одна база данных, в иерархической модели данных допускается отображение одной предметной области в несколько иерархических баз данных. [c.117]
[c.117]
Понятия отношения и веерного отношения в иерархической модели данных не изменяются. [c.117]
Ограничение, которое поддерживается в иерархической модели данных, состоит в невозможности нарушения требований, фигурирующих в определении иерархической базы данных. Это ограничение обеспечивается специальной укладкой значений отношений в памяти ЭВМ. Ниже мы рассмотрим одну из простейших реализаций укладки иерархической БД. [c.119]
Итоговая иерархическая структура содержит две иерархические базы данных. В некоторых иерархических СУБД не допускается логическая связь баз данных, определенная в п.6 алгоритма, так как формально это является нарушением ограничения 2 иерархической модели данных. [c.122]
Достоинствами иерархической модели данных являются следующие. х [c.125]
Общеупотребительной в таких случаях является иерархическая модель данных с наличием ссылок на тематически смежные записи данных в тех случаях, когда это необходимо.
[c. 136]
136]
Семантические модели данных представляют собой средство представления структуры предметной области. Такие модели имеют много общего с иерархическими и сетевыми моделями данных, они могут использоваться как средство построения структуры соответствующих баз данных. [c.187]
В ранних методах моделирования основное внимание уделялось формам представления моделируемых данных. Модели определяли такие структуры представления данных, которые были бы удобны для хранения и манипулирования ими внутри ЭВМ. К данному классу относятся, в частности, сетевые и иерархические модели данных. Функции этих моделей ограничиваются возможностями средств вычислительной техники, в связи с чем их можно оценить как не соответствующие задачам сквозного проектирования. [c.40]
Полученные формулировки функций вместе с их индексами, показывающими принадлежность к определенному системному уровню, были сведены в иерархическую функциональную модель (ФМ) (блок 7). В данном случае декомпозиция была проведена до четвертого уровня включительно (рис. 2.11).
[c.82]
2.11).
[c.82]
Достоинством систем, использующих модель иерархической детализации, является простота построения и практически неограниченные возможности наращивания детализации и глубины аналитического учета. Данная модель организации аналитического учета поддерживает сходимость аналитического и синтетического учета, т.к. сумма всех конечных остатков по аналитике и является остатком по синтетике . [c.109]
Дайте характеристику иерархической модели аналитического учета. Приведите варианты реализации данной модели. Отметьте положительные стороны и недостатки данной модели. [c.128]
Такая организация проектирования названа проектированием сверху вниз (не путать с одноименным стилем программирования). Упоминаемая функциональная иерархия — очень важный признак рассматриваемых подходов. Из-за определяющего влияния на процессы и результаты проектирования ИС иерархических структур для представления функций и данных в ИС применявшиеся подходы получили общее условное название — структурное проектирование . Привычность и доступность иерархических моделей были привлекательным фактором. В [34], основываясь на результатах сравнительных исследований, опубликованных к тому времени, и на собственных наблюдениях, авторы формулировали
[c.133]
Привычность и доступность иерархических моделей были привлекательным фактором. В [34], основываясь на результатах сравнительных исследований, опубликованных к тому времени, и на собственных наблюдениях, авторы формулировали
[c.133]
Рассмотрим теперь пример использования СУБД «ИНЭС-2М» для построения АБД в АСН. Система ИНХ-2М сочетает в себе черты трех основных моделей данных иерархической, сетевой, реляционной и включает в себя средства обработки информации (или банк задач), который служит для накопления прикладных программ, предназначенных для решения различных задач [ ]. В частности, в банк задач ИГЭС-2М включаются непосредственно счетные программы межотраслевого дина -мического баланса, определения отраслевых планов, проведения плановых расчетов. Банк задач должен содержать также каталоги алго -ритмов, заданий на счет, средства преобразований структур данных. [c.53]
Данная модель была предложена Э. Ф. Коддом (Е. F. odd) в начале 70-х гг. и вместе с иерархической и сетевой моделями составляет множество так называемых великих моделей.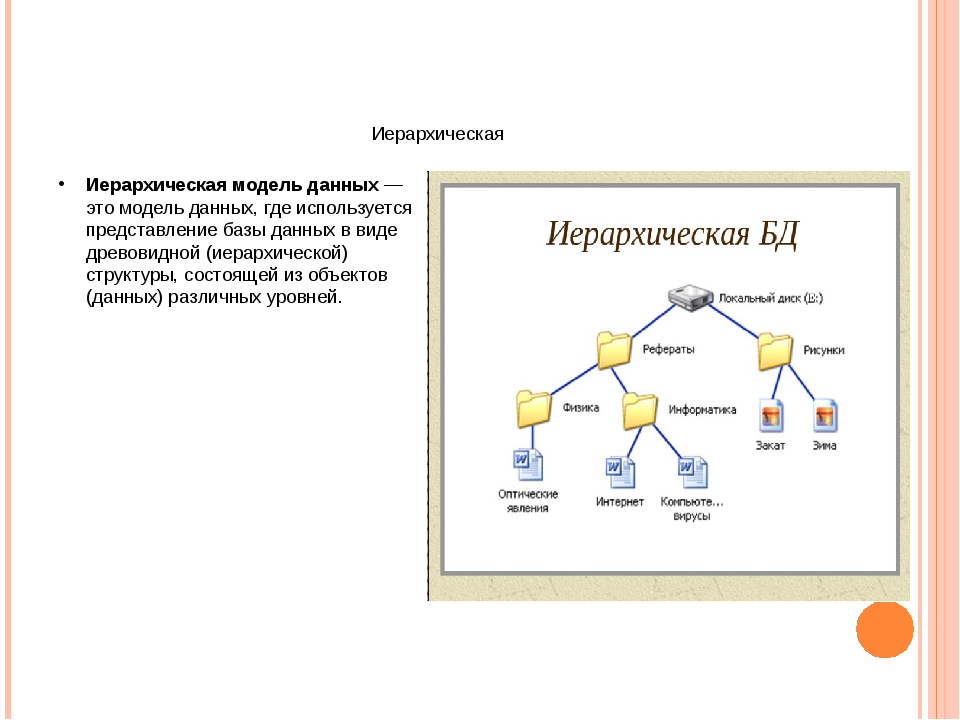 В основе реляционной модели данных лежат не графические, а табличные методы и средства представления данных и манипулирования ими. В реляционной модели для отображе-
[c.376]
В основе реляционной модели данных лежат не графические, а табличные методы и средства представления данных и манипулирования ими. В реляционной модели для отображе-
[c.376]
Современные инструменты моделирования сохраняют модели во внутренней базе данных, позволяя при этом размещать созданные модели в иерархической структуре папок.64 Некоторые инструменты моделирования, например, ARIS Toolset IDS S heer AG дополнительно располагает [c.78]
Отношение нормализовано, если каждая клетка кортежа является простым значением, не соегоящнк из групп. (Альтернатива в таблице СЛУЖАЩИЙ может существовать столбец ДЕТИ, представляющий собой группу реквизитов (имя, год рождения, месяц, дай рождения). Это вызывает необходимость замены поля ДЕТИ другой таблицей, что нарушает требования реляционной модели данных и приводит к сетевому или иерархическому отношению. [c.78]
Дается характеристика компонентов экономических информационных систем (ЭИС)—вычислительной системы, базы данных, программного обеспечения рассматриваются этапы нежизненного цикла — проектирование, внедрение, эксплуатация, развитие. Моделирование представлений информации в ЭИС предполагает использование синтаксических моделей данных (реляционной, сетевой и иерархической) и семантических моделей (семантические сети, фреймы и др.). Моделирование процессов опирается на сети Петри. Теоретические методы проектирования иллюстрируются практическими задачами. Для иллюстрации методов обработки данных используются языки Паскаль, SQL, dBASE и Пролог (3-е изд.—1993 г.).
[c.2]
Моделирование представлений информации в ЭИС предполагает использование синтаксических моделей данных (реляционной, сетевой и иерархической) и семантических моделей (семантические сети, фреймы и др.). Моделирование процессов опирается на сети Петри. Теоретические методы проектирования иллюстрируются практическими задачами. Для иллюстрации методов обработки данных используются языки Паскаль, SQL, dBASE и Пролог (3-е изд.—1993 г.).
[c.2]
При описании предметной области экономической системы и соответствующей СОЭИ средствами моделей семейства «сущность — атрибут — связь» реквизиту можно сопоставить атрибут. Интерпретация остальных компонентов информационных совокупностей бывает неоднозначна. Наиболее естественное использование средств модели данных состоит в сопоставлении типов сущностей показателям. Тогда составные единицы информации представляются типами связей, взаимосвязь отдельных показателей остается вне концептуальной модели. Необходимо отметить, что представление иерархических информационных компонентов требует дополнительных средств, поскольку двухуровневые структуры «сущность — связь» не обеспечивают прямого моделирования глубоких иерархических структур единиц информации и документов.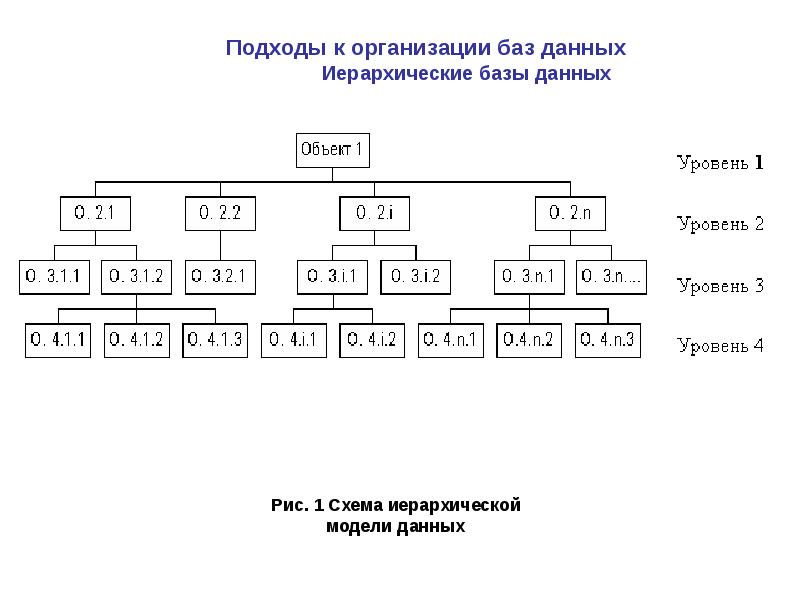 Базовые средства рассматриваемого подхода не приспособлены также для моделирования классификаторов и номенклатур, используемых для определения множества допустимых значений информационных компонентов.
[c.47]
Базовые средства рассматриваемого подхода не приспособлены также для моделирования классификаторов и номенклатур, используемых для определения множества допустимых значений информационных компонентов.
[c.47]
На практике и в науке используются различные организационные модели [13]. Иерархические модели имеют централизованную структуру. Другие модели допускают спонтанные действия и поддерживают проектные группы. На основе разделения компетентности между компьютерным центром и специализированными отделами при применении персональных компьютеров можно определить показатель централизации [9]. Высокая степень регуляции защиты данных и безопасности ведет к ограничению самопроизвола пользователя при работе с оборудованием ОД. Использование модели стоимость — прибыль совместно с централизацией дало следующий результат Полностью централизованная разработка инфраструктуры нужна в крайне редких случаях. Введение частично автономных, децентрализованных системных компонентов неизбежно. Задача компьютерного центра от чистой обработки переходит к планированию, разработке и координированию [11]. [c.151]
[c.151]
Как отмечает Б. Мигачев, данный метод является предпочтительным для определения обобщенного показателя качества в сложных иерархических моделях, то есть в случаях, когда переменные обобщенной функции представляют собой функции других наборов переменных. В нашем примере [c.36]
Недостатками данной модели являются жесткая фик-сированность взаимосвязей между элементами данных, вследствие чего любые изменения связей требуют изменения структуры, а также жесткая зависимость физической и логической организации данных. Быстрота доступа в иерархической модели достигнута за счет потери информационной гибкости (за один проход по дереву невозможно, например, получить информацию о том, какие поставщики поставляют, скажем, товар Т,). Указанные недостатки ограничивают применение иерархической структуры. [c.143]
На рис. 3.10 приведена схема построения модели фасетной организации аналитического учета. На рис. 3.10 а) показана общая схема, а на рис. 3.10 б) дано представление примера 1 (с. 107), приведенного при рассмотрении иерархической классификации.
[c.111]
107), приведенного при рассмотрении иерархической классификации.
[c.111]
Данный способ применяется в системах с моделью иерархической организации аналитического учета второй модификации, которая опирается на нетипизированные аналитические счета. Он использован в программах Финансы без проблем , Инфо-Бухгал-тер , семействе программ Лука . [c.124]
На этапе вертикального факторного анализа исследуются преимущественно формсигьныв (иерархические) связи между факторами хозяйственной деятельности, которые складываются в многоуровневую математическую цепочку (см. схему 38). Предприятие же, как и любая сложная система, характеризуется единством формальных (вертикальных) и функциональных (горизонтальных) связей между факторами (см. схему 8). Например если в модели вертикального факторного анализа нет взаимозависимости между блоками Физический объем реализации и Прямые коммерческие расходы , то это не означает, что связь между этими двумя факторами в хозяйственной деятельности предприятия совсем, просто данная зависимость носит функционачьный (горизонтальный) характер и исследуется на второй стадии комплексного анализа операционного бюджета— стадии горизонтального межфакторного анализа.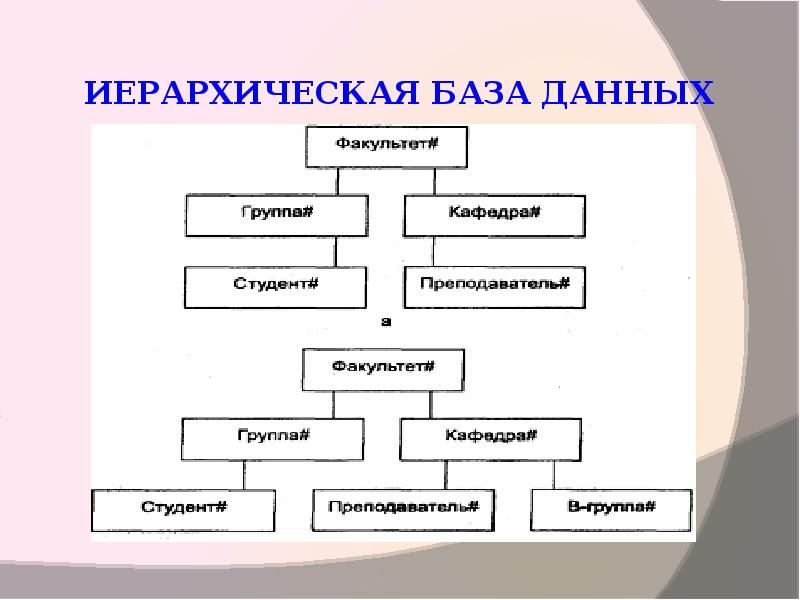 Строго говоря, уже на первой стадии анализируются некоторые горизонтальные связи (например, при расчете факторов отклонений цен, количества, объемов и пр.), ибо исследовать форму, полностью абстрагируясь от содержательной стороны, просто невозможно. Тем не менее диалектика перехода от формы к содержанию обусловливает необходимость содержательного (горизонтального) анализа на основе количественных данных формальной (вертикальной) модели. Отчет о финансовых результатах по видам продукции, на базе которого производится изучение взаимозависимостей издержки—объем— прибыль , как раз является основой горизонтального анализа. На первой же стадии исследованию, в основном, подвергаются сводные данные управленческого отчета о финансовых результатах, построенного на основе сводного отчета о финансовых результатах (табл. 53).
[c.325]
Строго говоря, уже на первой стадии анализируются некоторые горизонтальные связи (например, при расчете факторов отклонений цен, количества, объемов и пр.), ибо исследовать форму, полностью абстрагируясь от содержательной стороны, просто невозможно. Тем не менее диалектика перехода от формы к содержанию обусловливает необходимость содержательного (горизонтального) анализа на основе количественных данных формальной (вертикальной) модели. Отчет о финансовых результатах по видам продукции, на базе которого производится изучение взаимозависимостей издержки—объем— прибыль , как раз является основой горизонтального анализа. На первой же стадии исследованию, в основном, подвергаются сводные данные управленческого отчета о финансовых результатах, построенного на основе сводного отчета о финансовых результатах (табл. 53).
[c.325]
В данной главе мы, прежде всего, покажем, как модели кооперативного поведения, возникающего в результате подражания среди агентов, организованных в иерархическую структуру, демонстрируют вышеназванное критическое явление, украшенное «логопериодичностью».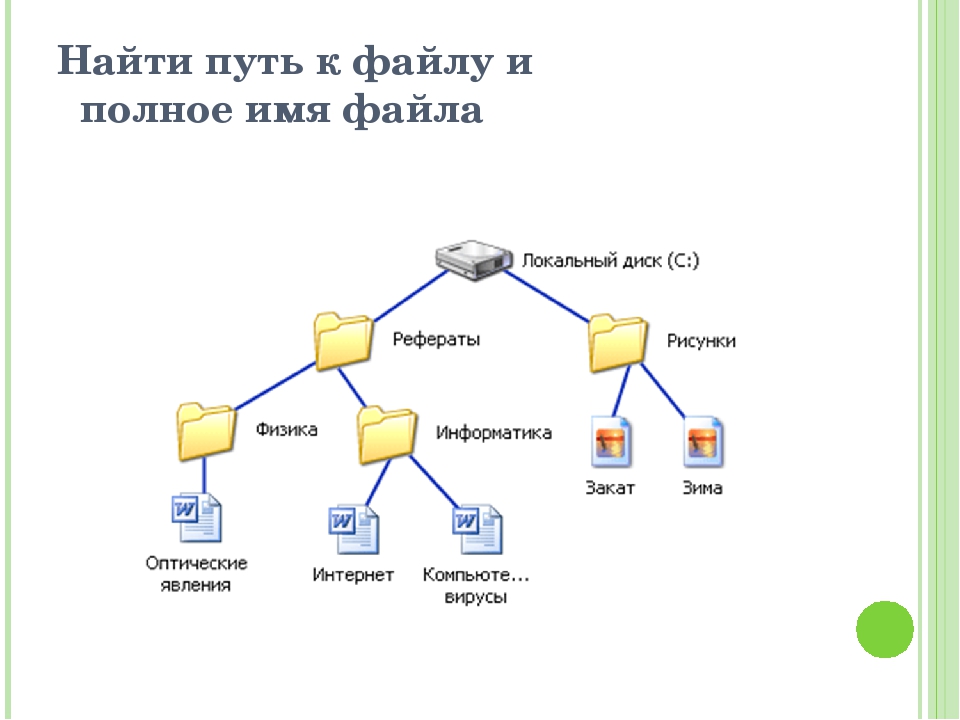 Логопериодичность оказывается прямым и общим признаком существования предпочтительного масштабирующего фактора подобия, (что потом мы назовем инвариантностью дискретной шкалы), соответствующего увеличительному множителю, связывающему один уровень иерархии со следующим. Затем мы немного формализуем эту идею и покажем, как замечательная техника, называемая «группа перенормировок или ренормгруппа», извлекает выгоду из существования мультимаштабного самоподобия свойств критического явления, чтобы вывести фундаментальное и точное описание этих моделей. Мы обеспечим несколько наглядных примеров, включая обобщенную функцию Вейерштрасса (Weierstrass) — фрактальную модель ценовых траекторий фондового рынка, которая является непрерывной, но демонстрирует неровные структуры на всех масштабах увеличения.
[c.176]
Логопериодичность оказывается прямым и общим признаком существования предпочтительного масштабирующего фактора подобия, (что потом мы назовем инвариантностью дискретной шкалы), соответствующего увеличительному множителю, связывающему один уровень иерархии со следующим. Затем мы немного формализуем эту идею и покажем, как замечательная техника, называемая «группа перенормировок или ренормгруппа», извлекает выгоду из существования мультимаштабного самоподобия свойств критического явления, чтобы вывести фундаментальное и точное описание этих моделей. Мы обеспечим несколько наглядных примеров, включая обобщенную функцию Вейерштрасса (Weierstrass) — фрактальную модель ценовых траекторий фондового рынка, которая является непрерывной, но демонстрирует неровные структуры на всех масштабах увеличения.
[c.176]
Для некоторых конфигураций количество весов явно превосходило число входных данных (наблюдений). Хотя недостаток степеней свободы делает оценку сомнительной, мы приводим здесь результаты работы 13-27-1 модели, чтобы проиллюстрировать доказанную Колмогоровым в 1957 г.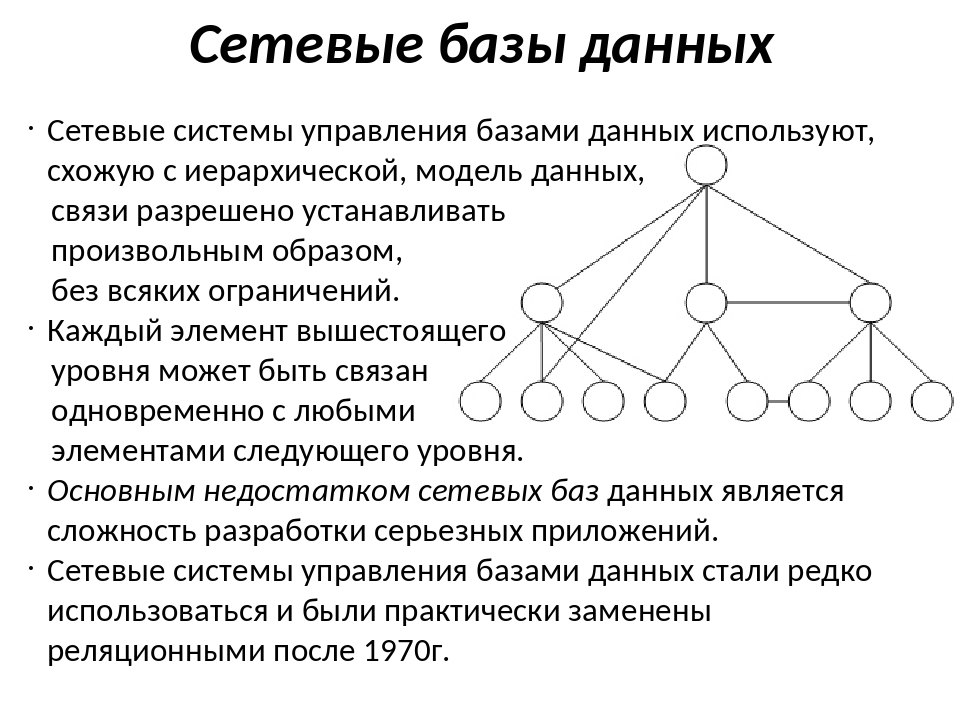 и популяризованную Хехт-Нильсеном [137] теорему о существовании отображения. Эта теорема утверждает, что любая непрерывная функция может быть реализована трехслойной нейронной сетью, имеющей во входном слое т (в нашем случае 13) элементов, промасштабированных на [0,1], (2т-1-1) элементов-процессоров в единственном скрытом слое и п элементов в выходном слое. Таким образом, гарантируется, что иерархическая многослойная нейронная сеть может решить любую нелинейно отделимую задачу и может точно реализовать любое отображение га-мерных входных векторов в и-мерные выходные. При этом теорема ничего не говорит нам ни о возможности реализовать отображение посредством сети меньших размеров, ни о том, что для этого подойдут обычно используемые сигмоидные преобразования.
[c.100]
и популяризованную Хехт-Нильсеном [137] теорему о существовании отображения. Эта теорема утверждает, что любая непрерывная функция может быть реализована трехслойной нейронной сетью, имеющей во входном слое т (в нашем случае 13) элементов, промасштабированных на [0,1], (2т-1-1) элементов-процессоров в единственном скрытом слое и п элементов в выходном слое. Таким образом, гарантируется, что иерархическая многослойная нейронная сеть может решить любую нелинейно отделимую задачу и может точно реализовать любое отображение га-мерных входных векторов в и-мерные выходные. При этом теорема ничего не говорит нам ни о возможности реализовать отображение посредством сети меньших размеров, ни о том, что для этого подойдут обычно используемые сигмоидные преобразования.
[c.100]
В качестве методологической базы построения и применения профилей сложных распределенных ИС предлагается использовать ГОСТ Р ИСО/МЭК ТО 10000-1, 2-99 Информационная технология. Основы и таксономия профилей международных стандартов Часть 1 Общие положения и основы документирования Часть 2 Принципы и таксономия профилей взаимосвязи открытых систем Часть 3 Принципы и таксономия профилей среды открытой системы , определяющую основы и таксономию профилей среды открытых систем, предлагается использовать при построении и применении профилей ИС как документ прямого применения. Эталонная модель среды открытых систем (OSE/RM) определяет разделение любой информационной системы на приложения (прикладные программы и программные комплексы) и среду, в которой эти приложения функционируют. Между приложениями и средой определяются стандартизованные интерфейсы (Appli ation Program Interfa e — APT), являющиеся необходимой частью профилей любой открытой системы. Кроме того, в профилях ИС могут быть определены унифицированные интерфейсы взаимодействия прикладных программ (функциональных частей) между собой и як ерфейсы взаимодействия между компонентами среды ИС. В соответствии с определениями профиля и базовых стандартов, входящих в профиль, по ГОСТ Р ИСО/МЭК ТО 10000 спецификации выполняемых функций и интерфейсов взаимодействия могут быть оформлены как профиль каждого компонента системы. Таким образом, профили ИС как сложной системы с иерархической структурой могут включать в себя стандартизованные описания функций, выполняемых данной системой, и взаимодействия с внешней для нее средой, стандартизованные интерфейсы между приложениями и средой ИС и профили отдельных функциональных компонентов, входящих в систему.
[c.67]
Эталонная модель среды открытых систем (OSE/RM) определяет разделение любой информационной системы на приложения (прикладные программы и программные комплексы) и среду, в которой эти приложения функционируют. Между приложениями и средой определяются стандартизованные интерфейсы (Appli ation Program Interfa e — APT), являющиеся необходимой частью профилей любой открытой системы. Кроме того, в профилях ИС могут быть определены унифицированные интерфейсы взаимодействия прикладных программ (функциональных частей) между собой и як ерфейсы взаимодействия между компонентами среды ИС. В соответствии с определениями профиля и базовых стандартов, входящих в профиль, по ГОСТ Р ИСО/МЭК ТО 10000 спецификации выполняемых функций и интерфейсов взаимодействия могут быть оформлены как профиль каждого компонента системы. Таким образом, профили ИС как сложной системы с иерархической структурой могут включать в себя стандартизованные описания функций, выполняемых данной системой, и взаимодействия с внешней для нее средой, стандартизованные интерфейсы между приложениями и средой ИС и профили отдельных функциональных компонентов, входящих в систему.
[c.67]
Информационные объекты и модели. Информационные ресурсы ФСЗН могут быть представлены в виде иерархической совокупности объектов определенного типа. Число типов данных достаточно велико, но конечно. Это дает возможность перечислить все информационные объекты, классифицировать и описать их. [c.279]
Семантический инструмент построения баз данных | Открытые системы. СУБД
Примером инструмента для построения баз данных и приложений, который призван повысить удобство проектирования и эксплуатации баз данных, может служить qWORD-XML.
В 70-е годы реляционная модель данных возникла как ответ на потребность в простой СУБД, соответствующей уровню развития компьютерной технологии своего времени. Сегодня гораздо важнее удобство проектирования и эксплуатации баз данных, а то, что когда-то казалось простым, математически строгим и логичным, стало восприниматься как неудобное. Инструментарий qWORD-XML разработки компании СП. АРМ служит для построения как оперативных, так и аналитических систем, совмещая в себе средства для построения и применения баз данных.
Семантическое расширение реляционной модели
Большая часть данных, возникающих в ходе деятельности предприятия, представлена в виде электронных и бумажных документов. С точки зрения манипулирования этими данными все аспекты хозяйственной деятельности либо являются документооборотом, либо могут быть формально к нему сведены. Сегодня доминирующее положение занимают реляционные СУБД, которые обеспечивают удобный способ хранения информации в виде таблиц.
Структуру данных большинства реальных документов можно представить как произвольное иерархическое дерево с горизонтальными связями. Документы полностью хранятся в одной ячейке таблицы реляционной базы либо разбиваются на множество таблиц, а некоторые таблицы из разных документов объединяются. Однако в реляционной базе данных мы уже имеем дело с другими документами, поэтому алгоритм обработки реального документа нельзя сделать основой алгоритма программного кода хранимой процедуры. Реальные документы снова появляются лишь на уровне приложения. Здесь, по сути, мы имеем дело не с отображением, а с перепроектированием документов и, соответственно, документооборота.
Как известно, целью реляционного подхода было преодоление ограничений ранних систем — иерархических и сетевых. Реляционная модель достаточна для моделирования предметных областей, но само проектирование базы в терминах отношений часто оказывается очень сложным. Потребность проектировщиков в более удобных и мощных средствах представления предметной области вызвала появление семантического моделирования. Основная цель исследований в этой области состоит в том, чтобы сделать СУБД более «разумными», максимально отражающими особенности прикладной области. Если в основу СУБД будет положена модель данных, более соответствующая семантике предметной области, то и построенные на ее основе базы данных будут больше соответствовать реальным системам, а проектирование баз данных значительно упростится.
qWORD-XML основывается на расширенной реляционной модели данных RM/T [1], семантически более полной, чем базовая реляционная модель. RM/T была предложена Тедом Коддом в 1979 году для расширения семантических аспектов реляционной модели и поддерживает определенную атомарную и молекулярную семантику. Первая представляется n-мерными отношениями (в крайнем случае бинарными), которые являются минимальными смысловыми единицами, а вторая — смысловыми единицами, большими n-мерных отношений. RM/T поддерживает четыре измерения молекулярной семантики: декартову агрегацию, обобщение, агрегацию покрытия и предшествование событий. Характеристическая агрегация и обобщение могут быть описаны древовидной структурой, а ассоциативная агрегация и агрегация покрытия — горизонтальными связями между объектами. Таким образом, в RM/T, по сути, предлагается введение молекулярной структуры (дерева с горизонтальными связями) поверх атомарной структуры (n-мерного отношения).
Логико-математический аппарат иерархической базы данных с горизонтальными связями в общем случае намного сложнее, чем в реляционной базе данных. В RM/T для реализации связей между объектами используются специальные графовые отношения, соответственно предусматривается специальный набор операций манипулирования такими отношениями. Поэтому в операционном плане RM/T ориентирована на программистов, а не на пользователей, но в структурном плане более естественна и интуитивно понятна.
Из-за своей сложности RM/T не получила в свое время широкого распространения, но появление и развитие платформы XML сделало возможным формальное описание иерархической модели с горизонтальными связями. Причиной возврата к иерархической модели данных (в варианте XML) стало более естественное для человека отображение семантики предметной области. В модели данных XML допустимыми структурами являются деревья, узлы которых — элементы, обладающие атрибутами и содержанием. Для адресации в дереве элементов используется язык XPath, в котором предполагается упорядоченность элементов дерева. Горизонтальные связи между элементами могут быть определены с помощью языков XLink и XPointer. Для запросов по дереву элементов служит язык XQuery, а для преобразования структуры дерева элементов — язык XSLT. Объектная модель документа DOM включает в себя набор низкоуровневых операций манипулирования узлами документа.
Технология XML возникла из языка описания документов, а потому структура данных реального документа и операции манипулирования документами естественным образом описываются языками платформы XML. При использовании модели данных XML появляется возможность отображения документов и алгоритмов их обработки в базу данных на уровне СУБД, а не на уровне приложения. В этом случае построение информационных систем становится в большей степени описательным, декларативным, а сами системы больше соответствуют семантике предметной области.
Обеспечение динамики систем
Современные подходы к моделированию данных (реляционный и объектный) ориентированы в первую очередь на статическое моделирование прикладной области. В лучшем случае используется практика долгой и тщательной разработки схемы данных, а уже потом ее фиксации и реализации в информационной системе, но не учитывается то, что введенные данные могут изменяться (а не только пополняться). Благодаря реализации модели данных XML появляется возможность учитывать и поддерживать изменчивость и расширяемость схемы базы и изменчивость самих данных, причем без декларирования явным образом общей схемы базы данных. Это позволяет вести непрерывную разработку приложений с учетом развития предметной области.
Для XML-документов могут быть использованы различные языки описания схем, например XDR, XML Schema, Relax NG, Schematron. Некоторые языки поддерживают открытую модель информационного наполнения, что позволяет добавлять в XML-документ элементы и их атрибуты, которые не были предварительно описаны в продекларированной схеме документа. Следовательно, применение модели данных XML позволяет модифицировать схему данных не только в процессе создания базы данных, но и во время ее эксплуатации.
Важно отметить, что в модели данных XML не возникает проблем с отсутствием значений. Если значение некоторого элемента или атрибута элемента не определено, то этот элемент или атрибут просто отсутствует в XML-документе. Следовательно, модель данных XML естественным образом подходит для описания разреженных данных.
Фактически, в qWORD-XML иерархическая модель данных в варианте XML накладывается поверх реляционной, что позволяет, с одной стороны, сохранить строгость реляционной модели, а с другой — привнести в нее дополнительную молекулярную семантику [2]. Таким образом, обеспечивается совмещение достоинств реляционной и дореляционных моделей.
Иерархия моделируется как дерево информационных объектов со специфичным для данного объекта набором понятий («реквизитов»). Объекты соответствуют элементам XML-документа, а понятия — атрибутам элементов. С другой точки зрения объекты соответствуют реляционным отношениям, а понятия — атрибутам отношений (рис. 1).
Взаимосвязь объектов (дерево объектной структуры) строится за счет суррогатных первичных ключей, структурированных специальным образом: между данными реализуются информационные связи. Структурирование ключа делает его значимым и позволяет помимо однозначной идентификации экземпляра объекта получить ряд дополнительных возможностей.
Ключ разбивается на отдельные значимые фрагменты. Для каждого объекта при его описании задается длина кода экземпляра. Фрагмент ключа из N символов кодирует 52N экземпляров. Таким образом, длина ключа однозначно определяет уровень иерархии, на котором находится объект, и максимальное количество экземпляров объекта на этом уровне. Используя метод редукции ключа, можно получить доступ к любому предку данного экземпляра объекта.
Горизонтальные связи объектов можно получать за счет применения одинаковых значений понятий в разных объектах. Возможность описывать виртуальные и ссылочные объекты позволяет создавать отображения иерархии, не соответствующей спроектированному дереву.
Понятия объектов могут быть структурированными (упорядоченное множество слов) и неструктурированными (текст, рисунок, звук, видео). Слова значений структурированных понятий кодируются суррогатными кодами. Для таких слов создаются домены, представляющие собой два словаря: прямой словарь связывает слово значения с суррогатным кодом, а обратный связывает суррогатный код со словом значения. Экземпляр объекта (кортеж отношения) связывает слова значений понятий из разных доменов через их суррогатные коды (рис. 2). Кроме того, прямой словарь используется для индексации значений понятий, что позволяет осуществлять быстрый поиск. Кодирование слов значений также решает проблему избыточности данных, свойственную иерархической организации.
Изменчивость данных во времени учитывается за счет поддержки системой динамических связей между элементами данных (рис. 3). Такие связи могут быть описаны с помощью языков XLink и XPointer. Рассмотрим пример базы данных (рис. 3а). Гражданам выдаются документы, в которых есть ссылки на адреса их регистрации. Если адрес изменяется, то для ранее созданного документа должна сохраняться ссылка на правильный адрес.
При взгляде на базу с точки зрения прикладного значения данных документов объекты должны располагаться так, как показано на рис 3б. Для создания такого отображения объект «Адрес» описывается как ссылочный, и для него устанавливается флаг «Производить динамическую коррекцию». В этом случае при модификации экземпляра «Адрес» система будет автоматически создавать и модифицировать для экземпляра «Документ» значение понятия прямой связи с экземпляром «Адрес».
Например, пусть код экземпляра объекта «Гражданин» равен AAAА. При создании экземпляра «Документ» ему присваивается код AAAА|АА. При создании экземпляра «Адрес» ему присваивается код AAAА|А, а в понятие прямой связи экземпляра «Документ» автоматически записывается значение А (дополнение к коду экземпляра «Гражданин», позволяющее получить код экземпляра «Адрес», на который ссылается данный экземпляр «Документ»). Теперь, предположим, создается новый экземпляр «Документ» AAAА|АB. Если «Адрес» не изменяется, то в понятие прямой связи этого экземпляра «Документ» автоматически записывается значение А (рис. 3в). При модификации «Адреса» автоматически создается его новый экземпляр AAAА|B, в который копируются неизмененные значения понятий из экземпляра AAAА|А. В понятие прямой связи экземпляра «Документ» AAAА|АB записывается значение В, а значение понятия прямой связи экземпляра «Документ» AAAА|АА не изменяется (рис. 3г).
Оперативные и аналитические системы
На практике предприятия используют две отдельные базы данных: с оперативными данными (транзакционные системы, OLTP), предназначенную для поддержки текущей деятельности организации, и с аналитическими данными (системы поддержки принятия решения, DSS), предназначенную для поддержки принятия решений. Эти системы различаются по условиям функционирования и требованиям к ресурсам. OLTP-системы обычно характеризуются жесткими требованиями к производительности, предсказуемым уровнем общей нагрузки и высоким коэффициентом использования. DSS, напротив, обычно варьируются по требованиям к производительности, уровень их нагрузки непрогнозируем и им с непредсказуемой регулярностью приходится обрабатывать большие объемы данных. С помощью qWORD-XML возможна реализация как оперативных, так и аналитических информационных систем.
Для большей гибкости и свободы принятия проектных решений система не может строиться как надстройка над какой-либо SQL- или объектной СУБД. Такие системы не предоставляют непосредственного доступа к физическим структурам хранения, а обеспечивают высокоуровневые объектные или SQL-интерфейсы. Соответственно, возникнут сложности при реализации физического уровня надстраиваемой СУБД. Так как ее физические структуры не являются ни отношениями, ни объектами, неизбежны потери производительности при их представлении отношениями или объектами. Поэтому qWORD-XML реализуется как надстройка над M-системой.
М — процедурный язык программирования без жесткой парадигмы, который стандартизирован ISO, ANSI и FIPS. Главным достоинством М-систем является эффективный механизм управления внешней памятью в виде B*-деревьев, которые на логическом уровне представляются через глобалы — хранимые на диске и рассортированные по строковым индексам массивы произвольной размерности. Память в массиве занимают лишь те элементы, для которых определено значение. Координация доступа к глобальным переменным в многопользовательской среде осуществляется с помощью блокировок; М поддерживает обработку транзакций и сетевое взаимодействие. На этом языке могут быть реализованы все известные модели данных. Вместе с тем M — это прежде всего язык разработки СУБД, а не работы с ними.
В качестве надстройки над М-системой могут использоваться СУБД Cache? компании InterSystems или GT.M компании Sanchez Computer Associates. Эти СУБД имеют все характеристики промышленных систем, такие как высокая производительность, надежность, масштабируемость, открытость и переносимость. Еще один важный фактор — стоимость решения. М-системы могут служить основой для реализации оперативных и аналитических систем, поскольку удовлетворяют основным требованиям к этим системам: высокая производительность и эффективная обработка транзакций для OLTP-систем, эффективное хранение и обработка больших объемов данных, высокий уровень безопасности данных для DSS-решений.
Cache? — коммерческий продукт, а GT.M имеет открытую архитектуру, реализация которой в версии для платформы x86/Linux свободно распространяется вместе с исходными кодами. По своим встроенным инструментальным возможностям GT.M уступает Cache?, но благодаря открытости системы возможна реализация собственных интерфейсов.
Процедурная часть qWORD-XML реализуется на M, как и набор низкоуровневых операций, соответствующих интерфейсам DOM и предназначенных для работы с древовидной структурой. Пользовательские хранимые процедуры и триггеры также создаются в виде программ на M, в которых можно задействовать эти низкоуровневые операции.
Универсальная инструментальная среда
Современные промышленные СУБД имеют набор интерфейсов к внешним инструментам проектирования и разработки приложений или снабжаются собственными инструментальными средствами. qWORD-XML совмещает инструменты для построения и применения баз данных в рамках единого универсального визуального инструмента. Это облегчает работу пользователей, ускоряет разработку информационных систем и упрощает их сопровождение.
Инструментальная среда qWORD-XML представляет собой универсальный браузер, реализованный на Delphi как клиентское приложение к M-серверу. В универсальном браузере взаимодействие с базой данных осуществляется через экранные формы, описывающие либо все дерево объектов, либо его часть в виде, удобном для конкретного рабочего места. Отображение состоит в общем случае из дерева объектов, дерева экземпляров объектов и панелей инструментов (рис. 4). База данных проектируется визуально как набор взаимоувязанных объектов.
| Рис. 4. Пример отображения |
Экземпляры объектов в отображении показываются в виде дерева-таблицы. Каждый экземпляр объекта может занимать несколько строк и колонок дерева-таблицы для вывода значений его понятий. Объекты нижнего уровня могут «встраиваться» в произвольные строки объектов верхнего уровня. Понятия одного объекта выводятся в ячейках дерева-таблицы. Помимо значений понятий, в ячейках могут выводиться константы (заголовки), служащие для наглядности представления информации. В описании отображений допускается указать множество параметров, меняющих внешний вид окна, что позволяет получать традиционные виды экранных форм.
Экранное представление может быть создано с доступом ко всей информации или, за счет параметризации экранных форм, в виде последовательных вызовов экранов, содержащих часть информации в форме бланков или таблиц. Первый вариант удобен для аналитических задач, а второй позволяет построить традиционное оперативное приложение. Отображение также может интерпретироваться как выходная печатная форма, благодаря чему удается использовать отображения в качестве конструкторов печатных форм. Различных экранных представлений (отображений) базы данных допускается создавать сколько угодно.
Универсальный браузер обеспечивает всю работу пользователя с базой данных. Это проектирование структуры и построение приложений, просмотр, ввод и коррекция информации, поиск данных по произвольным запросам, аналитическая обработка информации и ее графическая интерпретация, формирование выходных печатных форм.
Рассмотрим, например, аналитическую обработку, смысл которой заключается в группировке и обобщении данных. Группировка обычно выполняется в соответствии со многими критериями. Аналитическая обработка возможна внутри одного отображения (рис. 5). Перед выполнением аналитической обработки можно организовать предварительный поиск данных по объектам и значениям их понятий. Для задания поисковых условий используется колонка «Условие». Результаты выводятся в виде различных графических изображений, перекрестной таблицы или экранной формы.
| Рис. 5. Отображение в режиме «Аналитик» |
Рассмотрим запрос, нацеленный на распределение документов по организациям (составам бюро), в которых выданы документы, и по полу граждан, которым выданы документы. Задание аналитического запроса устанавливается специальными маркерами A, D, Y в строках, соответствующих анализируемым признакам. Колонка A предназначена для пометки понятий, значения которых будут использованы в качестве индексов аналитического среза. Возможно задание сразу нескольких аналитических срезов (A1, A2 и т.д.). В данном случае мы задали срез A1 по кодам организаций, а A2 — по полам.
Колонка D предназначена для пометки понятий, значения которых будут применяться как вычисляемые агрегированные значения аналитического среза. В данном случае маркером D также помечено понятие «код организации», поскольку нам нужно просто получить количество документов. В колонках Num, Sum, Min, Max, Mid с помощью маркера Y выбираются необходимые агрегирующие функции: количество значений, их сумма, минимальное/максимальное значения, их среднее арифметическое. Колонка «Аналитика» предназначена для описания выражений преобразования значений из Аi и D до их агрегирования.
Что имеем
Поддерживаемая qWORD-XML иерархическая модель более естественно для человека отражает семантику предметной области. Схема базы данных не декларируется явным образом и может изменяться в процессе развития и эксплуатации информационной системы. qWORD-XML может служить для реализации как оперативных, так и аналитических систем, совмещая в рамках универсального браузера инструменты для построения и использования баз данных.
Литература
- Кодд Э.Ф. Расширение реляционной модели для лучшего отражения семантики. // СУБД, 1996, № 5.
- Веселов В., Долженков А. Опыт построения XML-СУБД // Открытые системы, 2002, № 6.
Анатолий Долженков ([email protected]) — директор по науке компании «СП. АРМ», Дмитрий Тимофеев ([email protected]) — аспирант Института информатики и автоматизации РАН (Санкт-Петербург).
Достоинства и недостатки систем баз данных
Дореляционные системы (иерархические и сетевые)
Достоинства
- Структуры данных в дореляционных системах являются наилучшими абстракциями для описания объектов и отношений в реальном мире, наиболее полно отражая семантику предметной области.
- Доступны развитые низкоуровневые средства управления данными во внешней памяти.
- Возможно построение вручную эффективных прикладных систем.
Недостатки
- Доступ к базе данных производится на уровне записей, между которыми поддерживаются явные связи. Следствиями этого являются низкоуровневый навигационный стиль программирования и сложность использования таких систем непрограммистами.
- Отсутствует физическая и логическая независимость данных, необходимы знания об их физической организации. Пользователю приходится выполнять оптимизацию доступа к базе данных без поддержки системы.
- Отсутствует теоретическая основа. Понятие модели данных фактически вошло в обиход специалистов только вместе с реляционным подходом, а абстрактные представления ранних СУБД появились позже.
Реляционные системы
Достоинства
- Создан простой и мощный математический аппарат, опирающийся на теорию множеств и математическую логику и обеспечивающий теоретический базис к организации баз данных.
- Обеспечена физическая и логическая независимость данных, а потому нет необходимости знать конкретную физическую организацию базы данных во внешней памяти.
- Единственной конструкцией данных в реляционной модели является отношение. Между данными реализуются виртуальные связи (на основании значений данных), а не физические (на основании указателей), как в ранних системах. Следствием этого является ненавигационный доступ к данным (отношения трактуются как операнды и результаты операции, а не обрабатываются поэлементно). Простота структуры данных и манипулятивных операций облегчает работу пользователей (как программистов, так и непрограммистов).
Недостатки
- Примитивность типов данных становится причиной ограничений применимости реляционной модели в нетрадиционных областях (например, САПР), в которых требуются сложные структуры.
- Возможности описания семантики предметной области минимальны. Реляционная база данных представляет собой совокупность взаимосвязанных отношений, для которых должны поддерживаться ограничения целостности данных.
Примеры использования qWORD-XML
Автоматизированная информационно-справочная и аналитическая система по проблемам инвалидности. Решение задач информационной поддержки специалистов, связанных с проблемами инвалидности (служба реабилитации, региональные органы управления).
Информационно-аналитическая система органов социальной защиты населения субъекта федерации. Задачи системы связаны с реализацией перевода всех специалистов органов социальной защиты на новый уровень информационной поддержки с формированием ведомственной «информационной вертикали» и поэтапным созданием единого информационного пространства социальной сферы субъекта федерации.
Автоматизированная информационно-справочная и аналитическая система «Реабилитационный восстановительный центр». Типовой комплекс для поддержки информационных потоков и баз данных, используемых в реабилитационных учреждениях.
Автоматизированная информационная система «Станция переливания крови». Система разработана для комплексной информатизации процесса заготовки, обследования, хранения и распределения крови и ее компонентов на станциях переливания, в отделениях переливания крови и банках крови. Система предлагает полный пакет администрирования доноров, возможности ведения их единой картотеки, взаимодействия с источниками и потребителями данных в смежных областях.
Семантический инструмент построения баз данных
Поделитесь материалом с коллегами и друзьями
Иерархическая база данных — это… Модели, примеры | 4 info
Иерархическая база данных — это БД, основанная на древовидной структуре. По принципу построения она чем-то схожа с файловой системой компьютера. У использования такой модели есть свои достоинства и недостатки, которые будут рассмотрены в этой статье, вместе с подробными примерами.
Виды баз данных
Как известно, различают четыре вида посторения БД:
- Реляционные — табличные СУБД, где информация представлена в виде строк-столбцов. По этому принципу строятся базы данных в «Аксесе», к примеру.
- Объектно-ориентированные — тесно связаны с ООП (программированием, в котором идет работа с объектами), и это их главный плюс, но, учитывая их небольшую производительность, они пока значительно уступают в распространенности реляционным.
- Гибридные — СУБД, вмещающие в себе сразу два указанных выше вида.
- Иерархические — объект внимания данной статьи. Это БД, характеризирующиеся древообразной структурой.
Наиболее известным примером иерархической базы данных является продукт, созданный компанией IBM («АйБиЭм»), под названием Information Management System (переводится как «Информационная система управления»), сокращенно IMS. Первая версия IMS вышла еще в прошлом, двадцатом веке, в шестьдесят восьмом году. Она используется для хранения и контроля данных и поныне.
Принцип построения иерархической модели
Иерархическая модель данных строится по следующему принципу:
- для каждого узла древовидной структуры ставится в соответствие некий сегмент;
- под сегментом понимаются поля данных с присвоенным каждому полю именем и выстроенные в один линейный кортеж;
- еще одно соответствие: один входной и несколько выходных сегментов для каждого исходного поля;
- для каждого структурного элемента существует одно и только одно место в системе иерархии;
- древовидная структура начинается с корневого элемента;
- у каждого подчиненного узла только один предок, но у каждого исходного может быть несколько потомков.
Применение иерархической структуры данных
Иерархическая база данных — это хранилище, применимое для тех систем, которым изначально свойственна древовидная структура. Для них выбирать подобное моделирование — логично.
Пример иерархической базы данных с изначально систематизированными степенями — воинское подразделение, в котором, как известно, четко определены ранги. Также это могут быть сложные механизмы, состоящие из все более упрощающихся к низу иерархии частичек. Для моделирования таких систем и приведения их к виду рассматриваемой БД нет необходимости в декомпозиции. Тем не менее такая ситуация складывается не всегда.
Кроме того, существует тенденция, при которой направленный вниз по структуре запрос проще, чем аналогичный вверх.
Основные операции над БД, построенными на иерархической модели
Структура иерархической базы данных позволяет успешно и практически беспроблемно (в зависимости от навыков и умений) совершать следующие операции (представлены самые основные, список всегда можно расширить мелкими дополнениями):
- поиск по базе данных того или иного элемента;
- переход по базе данных — от дерева к дереву;
- переход по дереву — от ветви к ветви;
- соответственно, переход по ветвям — поэлементно;
- работа с записями: вставка новой и/или удаление текущей, копирование, вырезание и т. д.
Обобщенное описание структуры
Термин «древовидная» для описания структуры упоминается в этой статье уже далеко не единожды. Пора рассказать, откуда он произошел. Все потому что иерархическая база данных — это такая БД, которая использует тип данных «дерево». Рассмотрим подробнее, что он из себя представляет.
Это составной тип: в каждый из элементов (узлов) вкладывается несколько последующих (один или более). А начинается все с одного корневого элемента. Суть в том, что каждый из кусочков типа «дерево», является подтипом, тоже «деревом». Много-много разветвленных, и все также упорядоченных структур.
Элементарные типы могут быть простыми и составными, но по существу это всегда записи. Но в простом записи присутствует один тип данных, а в составном — целая их совокупность.
Иерархической модели свойственен принцип потомков, когда каждый предыдущий сегмент является предком для последующего. Кроме того, потомок по отношению к вышестоящему типу является типом подчиненным, в то время как равнозначные один другому записи считаются близнецами.
Наполнение БД
Основными данными иерархической БД являются значения (числа или символы), которые хранятся в записях. Обходят такую базу данных обычно снизу вверх и слева направо.
Достоинства
Иерархическая база данных — это имеющая корневую папку БД, постепенно разветвляющаяся книзу. Учитывая, что подобная структура весьма схожа с файловой системой, такие базы успешно применяются для выполнения различных операций над данными ЭВМ. Итог: рациональное распределение ее памяти, а также весьма достойные показатели времени, затраченного на работу.
Иерархическая модель идеальна для применения ее для упорядоченной информации.
Недостатки
Однако те же особенности рассматриваемых СУБД, которые стали их основными достоинствами, определяют также и их недостатки. К примеру, громоздкость и сложность логических связей — опытному специалисту при работе с ранее неизвестной базой будет трудно разобраться, а простой пользователь и вовсе в ней «заблудится». Эта сложность понимания приводит к тому, что на самом деле не так много СУБД построены на иерархической модели. Примером иерархической базы данных является, кроме уже описанного продукта компании «АйБиЭм», «Ока» и МИРИС (производство России), а также Data Edge и Team-UP (от зарубежных корпораций).
Примеры
Иерархическая база данных — это многообразие различных уровней, на которых строятся взаимосвязи. Схематично она выглядит как перевернутый граф. Пример иерархической базы данных — любое государственное административное учреждение. Взять, допустим, школу.
На самом верхней уровне будет располагаться «лидер» администрации — директор. В его подчинении завучи, у завучей — преподаватели, который руководят параллелями классов. В каждой параллели энное их количество, а в каждом классе есть некоторое число учеников.
По такому же принципу можно расписать и управление какой-нибудь корпорацией. Глава компании или даже совет директоров на самом верху. Далее — все большее количество подразделений, в каждом из которых действует своя структура. Есть и общие черты: начальник в каждом отделе, его помощник, его секретарь, собственно, офисные сотрудники и так далее.
Применение в ЭВМ
Могут быть и более серьезные области применения. Яркий пример иерархической базы данных- это файловая система. Всем привычный «Проводник» строится в самом ядре операционной системы «Виндоус» именно по такой схеме, так же, как и многие другие файловые менеджеры.
Сетевые базы данных
Существуют:
- реляционные;
- иерархические;
- сетевые базы данных.
Почему мы вновь вспомнили о классификации? Поскольку, в отличие от реляционной, сетевая БД имеет с иерархической схожие черты.
Время вспомнить виды связей в базах данных. Есть связи «один-к-одному», «один-ко-многим» и «многие-ко-многим». Нас интересует последняя. В сетевой БД она проявляется следующим образом: у одного узла-наследника может быть сразу несколько предков. Свойство иметь несколько потомков также сохраняется. Можно сказать, что иерархические базы данных, сетевые базы данных сами по себе уже пример такого наследования. Предком в данном случае является именно иерархическая БД, так как принцип построения структуры в сетевых БД остается прежним.
Иерархия и реляционность
Название «реляционная» произошло от английского слова «отношение». Как уже упоминалось в начале статьи, они часто выражаются таблично. Но в предыдущем пункте мы указали, что иерархическая БД также может организовывать связи, значит ли это, что и между этими двумя типами есть некая объединяющая их тонкая ниточка?
Да. Помимо того, что и первый, и второй вид все еще относятся к базам данных, кроме этого признака есть еще одно общее свойство. Например, иерархическую БД (и сетевую заодно с ней) можно выразить в таблице. Суть здесь не в том, в каком виде представить информацию конечному пользователю (это уже вопрос юзабилити интерфейса), но по какому принципу была структурирована информация. Так, четкое деление на отделы со своими начальниками, подразделениями и прочим по-прежнему будет выражено в иерархии, но для удобства занесено в таблицу.
базы данных. — Павел Шерер
5-6 минут на прочтение
Те, кто читает мой цикл про дизайн данных регулярно, уже наверняка приметил, что каждую статью я начинаю с того, что советую сперва ознакомиться с первыми частями. Делаю я это по понятным причинам: если сразу залезть в дебри, можно очень быстро растерять мотивацию, ибо нифига не понятно. А чтобы не пришлось ковыряться в блоге, вот ссылки:
В прошлый раз мы говорили про самый базис матчасти: хранение, передачу информации, типы данных. Так вот эта статья будет посвящена именно хранению информации в БД, а следующая — передаче данных по API.
Мы не будем упарываться и съедать мозг сложными техническими историями — чаще всего продуктовому дизайнеру достаточно лишь верхнеуровневого понимания работы и различий между базами данных.
§ Зачем это дизайнеру
Затем же, зачем и остальной data design. Понимая, каким образом данные могут храниться и соотноситься между собой, грамотный продуктовый дизайнер может выстроить определенную модель отношений между сущностями в проекте. Стабилизация дальнейшей разработки стоит того, чтобы в самом начале потратить немного времени на выбор, например, подходящего типа БД.
При этом я вовсе не призываю всех дизайнеров бросать фигму и мчаться проектировать базы данных. Чаще всего, этим должен заниматься более технически подкованный человек (архитектор или даже специальный «дизайнер баз данных» — такой тоже есть). Однако понимание основ такого проектирования позволит существенно упростить работу этого самого архитектора. А заодно сделать более качественно проработанный продукт.
§ Немного вводных
Для начала — давайте вкратце пройдёмся по терминологии.
§ СУБД
Как я уже рассказывал в предыдущей статье, для управления базами данных требуется определённый софт. Без него БД — это просто файлы. Которые, к тому же, нельзя открыть обычными программами, вроде блокнота (чаще всего). Этот софт, необходимый для манипуляций с базами данных, называется СУБД — Системы Управления Базами Данных. Они позволяют создавать базы, структурировать, изменять/удалять/добавлять данные, защищать их и так далее.
§ Связи
Данные в БД должны быть связаны друг с другом. В основном, используются три вида таких связей:
- связь «один к одному»;
- связь «один ко многим»;
- связь «многие ко многим».
В чем их различие, понятно из названия. Но я всё равно немного расскажу об этом.
§ Один к одному
Этот тип связи встречается редко. И является, чаще всего, ошибкой проектирования.
При связи «один к одному» объект из одной части БД может быть связаны только с одним объектом из другой части. Сложно, поэтому покажу на примере.
Классический пример связи «один к одному» — это серия и номер паспорта. Здесь каждый номер привязан к серии и наоборот. Серия паспорта без номера бессмысленна, равно как и номер без серии.
Связь «один к одному»Как я уже говорил, чаще всего это ошибка проектирования. Куда правильнее сделать элемент «паспорт» со свойствами «серия» и «номер».
§ Один ко многим
В этом случае один объект может быть связан с одним или несколькими объектами в другой части БД. Но эти «вторые» объекты могут связаны только с одним «первым» объектом. Давайте снова на примере.
Есть база данных торгового предприятия. В базе есть клиенты и их заказы. Так вот у одного клиента может быть несколько заказов, тогда как заказ всегда относится только к одному клиенту.
Связь «один ко многи컧 Многие ко многим
Этот тип связи походит, когда связи могут «перекрещиваться» — когда один объект может иметь отношение к нескольким объектам из другой части БД, но и эти «вторые» объекты могут относиться к нескольким «первым» объектам.
Хороший пример — кино и актёры. В одном фильме могут сниматься несколько актёров (множественная связь «фильм-актёр»), но и у одного актёра может быть несколько фильмов, в которых он снимался (множественная связь «актёр-фильм»).
Связь «многие ко многим»Такой тип связи очень популярен в реляционных БД, о которых мы поговорим ниже.
§ Виды баз данных
Все БД можно очень чётко разделить на виды — в зависимости от модели данных, которую они используют.
§ Иерархическая БД
В иерархической БД данные хранятся, как папки на компьютере: всегда есть родительские элементы, а есть дочерние. Этот вид является самым «древним» — первые БД были преимущественно именно иерархическими. В современном мире они применяются редко, разве что для очень специфических задач.
Структура иерархической базы данныхЗдесь нельзя выстроить связи между данными типа «многие ко многим» — а это очень часто требуется в проектировании. Отчасти поэтому иерархический вид БД не особенно популярен.
Классический пример иерархической БД — реестр Windows.Иерархические БД следует использовать только в том случае, когда данные в вашем проекте всегда подчиняются строгой иерархии, а неожиданных связей между ними не возникнет даже при развитии системы.
Пример СУБД для иерархической базы данных — IMS от IBM.
§ Сетевая БД
Сетевая база данных — это те же иерархическая, но на стероидах. В ней можно устанавливать какие угодно связи: дочерний объект может обращаться к «предку предка» напрямую, минуя лишние шаги.
Здесь (обычно) тоже нельзя использовать связи типа «многие ко многим», но это компенсируется скоростью работы с большим количеством связанных данных.
Структура сетевой базы данныхСетевые БД стоит использовать, если в вашем проекте большое количество связей между объектами, и эти связи реально сложны и запутаны.
Отдельного упоминания заслуживают так называемые «графовые» БД — разновидность сетевых. Не буду на них останавливаться, если интересно, загуглите сами.
Пример сетевой графовой СУБД, распространяемой по свободной лицензии — OrientDB.
§ Реляционная БД
Самый распространённый вид баз данных. Особенность реляционных БД в чёткой и понятной структуре информации, представленной в виде двумерных таблиц. В каждой такой таблице есть строки (собственно, объекты данных) и столбцы (свойства этих объектов). При этом столбцы, как правило, подчиняются очень чёткой типизации: конкретный столбец может содержать только один тип данных — например, строку или число. При этом одинаковых строк (элементов) в таблице не может быть.
На рисунке ниже «столбцы» представлены «строками» не только для удобства восприятия, но и потому что именно так обычно визуализируются реляционные БД (об этом я расскажу чуть ниже).
Структура реляционной базы данныхВот так выглядит реляционная база данных в редакторе. По сути, каждая такая БД — это просто список тех самых двумерных таблиц:
Таблицы реляционной БДА вот пример структуры отдельной таблицы. Слова «meta_id», «post_id», «meta_key» и «meta_value» — это те самые «столбцы», которые несут в себе свойства элементов:
Структура таблицы реляционной БДИ вот, наконец, уже сами данные этой самой таблицы. Здесь строки — это элементы (объекты данных), а у столбцов «meta_id», «post_id», «meta_key» и «meta_value» есть конкретные значения — свойства этих элементов:
Данные отдельной таблицы реляционной БДЕсли данные в вашем проекте структурированы, по ним нужен быстрый поиск, то ваш выбор однозначно должен пасть на реляционную БД. Да и вообще, если сомневаетесь — используйте именно этот вид.
Сейчас самая популярная реляционная СУБД — MySQL от Oracle.
§ Остальные виды
На самом деле, существует еще довольно много других видов БД: объектно- или документо-ориентированные, функциональные и разные смеси, вроде объекто-реляционных баз. Но это, чаще всего, диковинки, заточенные под выполнение конкретных, довольно специфических задач. Но если тема вас зацепила, можете погуглить.
§ Визуализация
Результатом проектирования БД должен стать какой-то графический или текстовый объект — здесь всё понятно. Обычно это схема или несколько таблиц, связанных между собой. Человечество придумало огромное количество способов передать структуру данных, но наибольшее распространение получила так называемая ER-модель (её ещё называют ER-диаграммой).
По сути, это и есть диаграмма, в которой указаны все элементы, свойства и связи между ними. Стилизованную ER-диаграмму вы можете увидеть на всех миниатюрах к этому циклу статей. Вот она без лишней графики:
Пример ER-диаграммыА вот — настоящая ER-диаграмма (к слову, отнюдь не самая большая):
ER-диаграммаНаверное, стоило бы рассказать про ER-модель поподробнее, но мне, признаться, лень создавать еще один материал на эту тему. Нотация описана уже миллион раз и без проблем гуглится.
§ В заключение
Конечно, это только начало. Я многое не рассказал, и не собираюсь — просторы интернета ломятся от серьезных, вдумчивых статей про базы данных. Но подступаться к ним с нулевого уровня знаний всегда очень сложно. Теперь же вы хотя бы немного погружены в контекст. Хотя бы понимаете, куда копать — если захотите, конечно.
Следующие статьи цикла:
Понимание модели иерархической базы данных
Самой ранней моделью была иерархическая модель базы данных, напоминающая перевернутое дерево. Файлы связаны по принципу «родитель-потомок», при этом каждый родитель может иметь отношение к более чем одному дочернему элементу, но каждый дочерний элемент связан только с одним родителем. Большинство из вас знакомы с такой структурой — так работает большинство файловых систем. Обычно существует корневой каталог или каталог верхнего уровня, содержащий различные другие каталоги и файлы.Тогда каждый подкаталог может содержать больше файлов, каталогов и так далее. Каждый файл или каталог может существовать только в одном каталоге — у него только один родительский элемент. Как вы можете видеть на изображении ниже, A1 — это корневой каталог, а его дочерние элементы — B1 и B2 . B1 является родительским для C1 , C2 и C3 , которые, в свою очередь, имеют собственных дочерних элементов.
Эта модель, хотя и является значительным улучшением работы с несвязанными файлами, имеет ряд серьезных недостатков.Он хорошо представляет отношения «один ко многим» (у одного родителя много детей; например, в одном филиале компании много сотрудников), но у него есть проблемы с отношениями «многие ко многим». Такие отношения, как отношения между файлом продукта и файлом заказов, сложно реализовать в иерархической модели. В частности, заказ может содержать много продуктов, а продукт может присутствовать во многих заказах. Кроме того, иерархическая модель не является гибкой, поскольку добавление новых отношений может привести к массовым изменениям в существующей структуре, что, в свою очередь, означает, что все существующие приложения также должны измениться.Это не весело, когда кто-то забыл таблицу и хочет добавить ее в систему незадолго до запуска проекта! А разработка приложений сложна, потому что программисту необходимо хорошо знать структуру данных, чтобы пройти по модели и получить доступ к необходимым данным. Как вы видели в предыдущих главах, при доступе к данным из двух связанных таблиц вам нужно знать только те поля, которые вам требуются из этих двух таблиц. В иерархической модели вам нужно знать всю цепочку между ними.Например, чтобы связать данные из A1 и D4 , вам нужно выбрать маршрут: A1 , B1 , C3 и D4 .
Что такое иерархическая база данных
Иерархическая база данных
База данных хранит цифровые данные. Система управления базами данных (СУБД) — это программная система, которая использует стандартный метод для хранения и организации данных. СУБД предоставляет механизм доступа, вставки, обновления и удаления данных с помощью инструментов, запросов и программ.Существует несколько типов систем управления базами данных, таких как реляционные, сетевые, графические и иерархические. Узнайте больше о различных типах систем управления базами данных.Иерархическая база данных — это СУБД, которые представляют данные в древовидной форме. Отношения между записями — один ко многим. Это означает, что у одного родительского узла может быть много дочерних узлов. Иерархическая модель базы данных — это модель данных, в которой данные хранятся в виде записей, но связаны в древовидной структуре с помощью родителя и уровня.У каждой записи есть только один родитель. Первая запись модели данных — это корневая запись
На следующей диаграмме Автор — корневой узел. У корневого узла 4 потомка.
Корневая запись всегда находится на уровне 0 и является первым элементом, который необходимо пройти в модели данных. Дочерние элементы следующего уровня корневой записи — это уровень 1 и имеют корень в качестве своего родителя. Следующий уровень — Уровень 2 и так далее.
Давайте посмотрим на следующие 3 таблицы базы данных — Person, Authors и Books.
| <> Персональный стол | |||
| <> ID | Роль | Описание | ParentID |
| 1 | Автор | Записывает , говорит, поезда | 0 |
| Таблица авторов | |||
| ID | Имя | Описание | ParentID |
| 101 | Аллен О’Нил | Автор пишет на AI | 1 |
| 102 | Махеш Чанд | Автор пишет на C # | 1 |
| 103 | Дэвид Маккартер | Автор пишет на .NET | 1 |
| 104 | Радж Кумар | Автор пишет на AWS | 1 |
| Книжный стол | ||||
| ID 900 | Тема | Название | ParentID | |
| 1001 | ADO.NET | ADO.NET-программирование | 102 | |
| 1002 | GDI + | Программирование GDI + | 102 | |
| 1003 | C # | Обучение C # 8.0 | 102 | |
| 1004 |
В таблице Person хранится информация о типах людей. Каждая запись в таблице представляет человека. Один из примеров человека — Автор. В таблице авторов хранится информация об авторах.У автора есть идентификатор, имя, описание и родительский идентификатор.
Parent ID связывает автора с родителем, человеком. У автора может быть только один родитель.
В таблице «Книги» перечислены книги, написанные автором. В таблице книг есть ID, Тема, Заголовок и ParentID. ParentID — это связь между автором и книгами.
В некоторых случаях одна таблица может представлять данные из всех таблиц, просто связывая записи с их родительскими идентификаторами.
Следующая древовидная диаграмма представляет указанные выше табличные данные в иерархической форме с их родительским элементом и уровнем.
История иерархических баз данных
Иерархический формат был введен IBM в 1960-х годах для систем мэйнфреймов. На мэйнфреймах по-прежнему используются иерархические базы данных. IBM IMS — одна из самых популярных баз данных. IMS использует блоки данных, известные как сегменты. Каждый сегмент может содержать несколько частей данных, которые называются полями.Каждый сегмент может быть загружен и считан в память компьютера из базы данных.
Преимущества иерархических баз данных
Иерархические базы данных полезны, когда вам нужно представить данные в виде древовидной иерархии. Прекрасным примером иерархической модели данных является файл навигации или карта сайта веб-сайта. Организационная диаграмма компании — еще один пример иерархической базы данных.
Ключевые преимущества иерархических баз данных:
- Переход по древовидной структуре очень простой и быстрый благодаря формату отношений «один ко многим».Несколько основных языков программирования предоставляют функциональные возможности для чтения баз данных с древовидной структурой.
- Легко понять благодаря связи «один ко многим».
Основные недостатки иерархических баз данных:
- Это жесткий формат отношений «один ко многим». Это означает, что у ребенка не может быть более одного родителя.
- Несколько узлов с одним и тем же родительским элементом добавят избыточные данные.
- Перемещение одной записи с одного уровня на другой может быть сложной задачей.
Популярные иерархические базы данных
Самыми популярными иерархическими базами данных являются IBM Information Management System (IMS) и RDM Mobile. Реестр Windows — еще один пример реальных вариантов использования иерархической системы баз данных.
XML и XAML — два наиболее популярных и наиболее широко используемых хранилища данных, основанных на иерархической модели данных. В XML и XAML каждый файл начинается с корневого узла, который может быть одним или несколькими дочерними узлами.Каждый дочерний узел снова может иметь один или несколько дочерних узлов и так далее.
Ниже приведен пример файла XML, в котором каталог является корневым узлом.
Карта сайта веб-сайта — еще один пример иерархической модели данных, которая используется веб-мастерами и поисковой системой Google для идентификации содержимого веб-сайтов.
Вот еще несколько статей, которые могут вас заинтересовать:
Ссылки
https: // en.wikipedia.org/wiki/Hierarchical_database_model
МОДЕЛЬ ИЕРАРХИЧЕСКОЙ БАЗЫ ДАННЫХ
МОДЕЛЬ ИЕРАРХИЧЕСКОЙ БАЗЫ ДАННЫХИерархия основана на отношениях родитель-потомок
Основные понятия:
Типовые индикаторы, такие как D, E, W.и т. д.
Потомок узла
Поддерево узла
Уровень (0, 1, 2 и т. д.)
Иерархическая последовательность
(используется для линеаризации дерева)
Полный иерархический путь
(от корня к листу)
Дочерний указатель
Родительский указатель
Двойной указатель (родственный указатель)
Например, следующая иерархическая схема базы данных компании:
Древовидное представление вышеупомянутой иерархической схемы показано ниже:
Показаны два экземпляра типа PCR (DEPARTMENT и EMPLOYEE).
в (a), и два вхождения типа PCR (DEPARTMENT и PROJECT)
показаны в (б).
Иерархическая схема для части базы данных КОМПАНИИ выглядит следующим образом:
Иерархическое дерево вхождений иерархической схемы выглядит следующим образом:
Иерархическая последовательность для дерева вхождений следующая:
Тип PDBR
Используйте DBD, чтобы указать тип PDBR
Прохождение PDBR
Тип ЛДБР
DBD, PSB и PCB
Складская организация
Как приложение вызывает IMS
Тип PDBR выглядит следующим образом:
Тип LDBR показан на рисунке:
Чтобы указать тип PDBR, операторы DBD могут выглядеть так:
1 ИМЯ DBD = EDUCPDBD 2 НАЗВАНИЕ СЕГМА = КУРС, БАЙТЫ = 256 3 НАЗВАНИЕ ПОЛЯ = (№ КУРСА, ПОСЛ.), БАЙТЫ = 3, НАЧАЛО = 1 4 НАЗВАНИЕ ПОЛЯ = НАЗВАНИЕ, БАЙТЫ = 33, НАЧАЛО = 4 5 НАЗВАНИЕ ПОЛЯ = ОПИСАНИЕ, БАЙТЫ = 220, НАЧАЛО = 37 6 НАЗВАНИЕ СЕГМ = PREREQ, PARENT = COURSE, BYTES = 36 7 НАЗВАНИЕ ПОЛЯ = (№ КУРСА, ПОСЛ.), БАЙТЫ = 3, НАЧАЛО = 1 8 НАЗВАНИЕ ПОЛЯ = НАЗВАНИЕ, БАЙТЫ = 33, НАЧАЛО = 4 .....Чтобы указать тип LDBR, операторы DBD могут выглядеть так:
1 ТИП ПП = DB.DBNAME = EDUCPDBD, KEYLEN = 15 2 SENSEG NAME = COURSE.PROOPT = G 3 SENSEG ИМЯ = ПРЕДЛОЖЕНИЕ, РОДИТЕЛЬ = КУРС. ДОКАЗАТЕЛЬСТВО = G 4 ИМЯ = СТУДЕНТ, РОДИТЕЛЬ = ПРЕДЛОЖЕНИЕ, ДОКАЗАТЕЛЬСТВО = G
(1) Получить первое вхождение сегмента ПРЕДЛОЖЕНИЕ, чье местоположение — ‘MADRID’, мы можем использовать команду GET UNIQUE,
КУРС ГУ
ПРЕДЛОЖЕНИЕ (МЕСТОПОЛОЖЕНИЕ = ‘МАДРИД’)
Где (LOCATION = ‘MADRID’) называется АРГУМЕНТ ПОИСКА СЕГМЕНТА (SSA)
(2) Получить все сегменты СТУДЕНТ для ПРЕДЛОЖЕНИЯ КУРСА в Мадриде мы можем использовать GET UNIQUE, чтобы получить первый сегмент, и GET NEXT, чтобы получить последующие сегменты.
GU COURSE
ПРЕДЛОЖЕНИЕ (LOCATION = ‘MADRID’)
STUDENT
NS GN STUDENT
(Этот цикл завершается в сегменте, который не найден)
GO TO NS
(3) Аналогичным образом, чтобы получить только учащихся с оценкой «А» для курса предложение в Мадриде, мы можем добавить SSA в сегменте СТУДЕНТ,
GU COURSE
OFFERING (LOCATION = ‘MADRID’)
NS GN STUDENT (GRADE = ‘A’)
(Этот цикл завершается на не найденном сегменте)
GO TO NS
(4) Если имя сегмента не указано, GET NEXT можно использовать для получить все сегменты.
GU COURSE
NS GN
(Этот цикл завершается при извлечении всех сегментов)
GO TO NS
(5) Чтобы получить все дочерние сегменты в родительском сегменте, мы можем используйте GET NEXT WITHIN PARENT.
GU COURSE (COURSE # = ‘M23’)
OFFERING (DATE = ‘730813’)
NS GNP STUDENT
(Этот цикл завершается, когда все сегменты STUDENT
под тем же сегментом ПРЕДЛОЖЕНИЯ извлекаются)
ПЕРЕЙТИ К NS
(6) Точно так же мы можем получить все сегменты в корневом сегменте, следующее.
GU COURSE (COURSE # = ‘M23’)
NS GNP
(Этот цикл завершается, когда все сегменты ниже
извлекается корневой сегмент)
ПЕРЕЙТИ К NS
(7) Чтобы выполнить вставку нового сегмента, новый сегмент должен быть присутствует в рабочей области ввода / вывода. Затем может быть подана команда вставки.
ISRT COURSE (COURSE # = ‘M23’)
OFFERING (DATE = ‘730813’)
STUDENT
(8) Чтобы удалить сегмент, команда GET HOLD используется для «удержания» сегмент в рабочей области, после чего можно подать команду DLET.
КУРС GHU (КУРС № = ‘M23’)
ПРЕДЛОЖЕНИЕ (ДАТА = ‘730813’)
DLET
(9) Аналогичные команды используются для обновления сегмента.
GHU COURSE (COURSE # = ‘M23’)
OFFERING (DATE = ‘730813’)
(обновленный сегмент находится в рабочей области ввода-вывода)
REPL
Сегмент
Указатели
Динамическая структура данных
База данных MUMPS имеет следующую иерархическую схему.
Структура базы данных MUMPS следующая:
* 1 лекарственная запись
* 2 пациента
3 номер пациента
3 имя
3 срока давности рецепта
4 леченая проблема
* 5 прописанных препаратов
6 название препарата
6 количество
6 частота
В реализации структура базы данных MUMPS выглядит так: Чтобы создать структуру базы данных лекарств с использованием сегментов, мы можем использовать команды set для присвоения значений глобальным переменным, которые обозначаются | xyz.Первая команда присваивает имя «наркотик» запись в каталоге для базы данных drg.
набор | drg = ‘наркотик’
Аналогичным образом мы создаем сегмент следующего уровня,
набор | drg (pat) = ‘Лань’
, где «pat» — это уникальный цифровой ключ, номер пациента, для пациента, имя которого «Doe». В MUMPS все клавиши должны быть цифровыми.
Таким образом, нижние индексы глобальной переменной обозначают сегменты в разных уровни. уровни. Следовательно, предварительное объявление файла не требуется.
Чтобы создать сегмент следующего уровня, мы могли бы выполнить,
набор | drg (pat, date) = ‘1203’
Однако, поскольку никакие данные не будут храниться на этом уровне, это ненужный. Значение даты можно рассматривать как числовой ключ. Следовательно, мы можем перейти на следующий уровень для выполнения,
set | drg (pat, date, icd) = ‘Астма’
, который также присвоит числовое значение «дате».
Точно так же мы можем рассматривать dno (номер лекарства) как числовую клавишу и продолжать до последнего уровня,
set | drg (pat, date, icd, dno, 1) = ‘Decadron’
set | drg (pat, date, icd, dno, 2) = 15
set | drg (pat, date, icd, dno, 3 ) = 3
Для получения данных о лекарствах у нас есть ключи номер пациента (pat), дата рецепта (дата), номер проблемы (icd) и номер лекарства (dno).Все ключи являются числовыми индексами глобальной переменной drg. Следовательно, команда выборки:
установить имя препарата = | drg (pat, day, icd, dno, 1)
Извлечение сегмента достигается последовательным сканированием сегментов в на каждом уровне, пока не будет найдено совпадение.
Реализация MUMPS обычно использует цепочки блоков. Сегменты на каждом уровне упакованы в цепочку блоков и доступны последовательно.
Чтобы удалить запись и освободить хранилище, мы можем выполнить,
убить | drg (pat)
, который удалит связанные сегменты одного пациента путем удаления неиспользуемые блоки и возвращение освобожденных блоков в цепочки свободного пространства.
Иерархическая модель базы данных
Иерархические базы данных были первыми база данных, называемая IMS (Система управления информацией), которая была выпущена в 1960. Иерархические базы данных — это, как правило, большие базы данных с большими объемами. данных. Иерархическую базу данных легко понять, потому что мы имеем дело с иерархии каждый день. Подумайте о работе, у вас есть руководители, затем менеджеры, потом начальники, потом рабочие и так далее. По сути, иерархия — это метод организация данных в ранги, причем каждый ранг имеет более высокий приоритет, чем под этим.Иерархию можно представить как дерево или, как некоторые называют его, «перевернутое» дерево (см. рисунок 2.5). Инвертированные файлы или инверсия файлов ничего не имеют чтобы перевернуть что-нибудь вверх ногами. Скорее, это относится к процессу создание и индексирование. Например, многие старожилы до сих пор называют создание индекса для customer_number как «инвертирование файла по customer_number».
Иерархия — это просто набор «вещей» называются узлами, и узлы соединяются линиями или «ветвями». Ты можешь думать этих линий или ветвей как соединение со следующим уровнем более конкретных Информация.Самый высокий узел называется корневым узлом, и запросы должны проходить через этот узел на пути вниз по иерархии. В нашем примере (рис. 2-5) STORE — это корневой узел. Каждый узел, кроме корневого, подключен вверх к только один «родительский» узел. Узлы имеют отношения родитель-потомок, а родительский узел находится прямо над дочерним узлом. Мы также видим, что узел с именем CUSTOMERS является одним из родителей DRINKS. Поскольку дочерний узел всегда один уровень непосредственно под своим родительским узлом узел DRINKS является дочерним по отношению к CUSTOMER узел.Обратите внимание, что родительский узел может иметь более одного дочернего узла, но дочерний узел может иметь только одного родителя.
Рисунок 2-5 Пример иерархической диаграммы
Когда мы говорим об иерархической базе данных, узлы, о которых мы говорили, становятся «типами сегментов». Тип сегмента — это просто определяемая пользователем категория данных, и каждый сегмент содержит поля. Каждый сегмент имеет ключевое поле, а ключевое поле используется для извлечения данных из сегмент. В сегменте может быть одно или несколько полей, и большинство сегментов также содержат несколько полей поиска.
Продолжая рисунок 2-5, давайте добавим некоторые данные. поля в наш сегмент магазина. Начнем с вопроса, что нам нужно знать о в каждом магазине? Было бы неплохо знать название магазина, адрес и номер телефона. Итак, мы бы добавили эти три поля в сегмент Store. Затем мы спросим, как сделать мы хотим получить записи из нашего сегмента Store. Если бы мы сказали, что store_name и phone_number, мы бы сделали «Store_Name» — ключевое поле, а «Phone_Number» — поле поиска.
IMS хорошо подходит для моделирования систем, в которых объекты (сегменты) состоят из нисходящих отношений «один ко многим». Отношения устанавливаются с помощью «дочерних» и «двойных» указателей, и эти указатели встроены в префикс каждой записи в базе данных.
На рисунке 2-5 у нас есть шесть сегментов:
1. сегмент магазина
2. клиент
3. сотрудников
4. напитки
5. закуски
6. топливо
У нас также есть четыре иерархических пути:
1. магазин, покупатели, напитки;
2.магазин, покупатели, закуски;
3. магазин, покупатели, топливо;
4. магазин, сотрудник.
Иерархический путь — это то, как типы сегментов полученный путь похож на воображаемую линию, которая начинается в корневом сегменте и проходит через типы сегментов, пока не достигнет типа сегмента внизу перевернутого дерева. Одним из преимуществ иерархической базы данных является то, что если вы нужна была только информация о магазинах, программе нужно было только знать форматировать и получить доступ к сегменту магазина.Вам не нужно знать, что любой из другие пять сегментов даже существуют, каковы их поля или каковы отношения между сегментами есть.
Иерархические базы данных имеют жесткие правила в отношения и доступ к данным. Например, нужно получить доступ ко всем сегментам. через родительский сегмент. Исключением, конечно же, является корень сегмент, потому что у него нет родителя. Например, для получения данных о топливе в На рис. 2.5 вы начнете с сегмента магазина, затем сегмента клиента и затем получите топливный сегмент.
База данных IMS имеет одновременное управление, а полный механизм резервного копирования и восстановления. Резервное копирование и восстановление защищает систему из-за сбоя самой IMS, прикладной программы, сбоя базы данных и операционная система, программа управления сетью и т. д. сбой. Механизм восстановления для прикладных программ хранит изображения «до» и «после» каждой записи, которые был изменен, и эти изображения можно было использовать для «отката» базы данных, если транзакция не была завершена. Если произошел сбой диска, образы могли быть «с прокатом».IMS использовалась с CICS для разработки первой онлайновой базы данных системы для мэйнфреймов.
Три основных преимущества иерархических баз данных являются крупной базой с проверенной технологией, которая существует уже много лет, простота использования иерархии или древовидной структуры и скорость работы системы. Немного Недостатки иерархических баз данных связаны с жесткими правилами в отношения, вставка и удаление могут стать очень сложными, доступ к дочернему сегмент может быть выполнен только через родительский сегмент (начать с корневого сегмента).Хотя IMS очень хорошо моделирует иерархические отношения данных, сложные данные такие отношения, как многие-ко-многим и рекурсивные многие-ко-многим, такие как спецификация Отношения (ведомости материалов) должны были быть реализованы очень неуклюже, с использованием «фантомных» записей. База данных IMS также страдала от своей сложности. Чтобы стать профессионалом в IMS, вам потребуются месяцы обучения и опыта. Как В результате разработка IMS остается очень медленной и обременительной.
Так же, как иерархические базы данных используют указатели на логически связывать записи вместе, реализации объектов базы данных также используют указатели для связывания объектов.Как правило, объекты базы данных связываются с помощью своих идентификаторы объектов, как и иерархические записи, связаны с указателями. Это также часто можно увидеть естественные иерархии, которые будут представлены перестановки методов указателя дочернего близнеца.
Иерархическая модель с примерами и характеристиками
Автор: Проф. Фазал Рехман Шамиль
Последнее изменение: 5 августа 2020 г.
Иерархическая модель с примерами и характеристиками.
Что такое иерархическая модель?
Когда мы хотим спроектировать базу данных, существует множество моделей базы данных. Реляционные и сетевые модели — известные модели. Вы можете прочитать руководство по этим темам здесь, щелкнув название модели. В этом руководстве мы исследуем иерархическую модель базы данных.
Согласно иерархической модели, все записи имеют отношение родитель-потомок.
Иерархическая модель базы данных использует иерархическую последовательность, которая всегда начинается с левой стороны дерева.Наиболее широко используемой моделью базы данных является реляционная модель.
Приведите пример иерархической модели?
IMS — это иерархическая система управления базами данных. Система управления информацией IMS, представленная IBM в 1968 году.
Схема иерархической модели базы данных
Рисунок: иерархическая модельКаковы некоторые ограничения иерархической модели базы данных?
Недостатки иерархической модели
- Сложная иерархическая модель.
- В иерархической модели допускается использование одного родителя на каждого ребенка.
- Данные должны быть организованы иерархически, и это должно быть сделано без ущерба для информации.
- В иерархической модели отсутствует структурная независимость.
- Навигационная система представляет собой сложную иерархическую модель.
- В иерархической модели данные независимы.
- Иерархическая модель не поддерживает много-слишком много отношений.
Каковы характеристики иерархической модели?
Не поддерживает отношения «многие ко многим»:
Проблема удаления:
При удалении родителя автоматически удаляется и ребенок.
Иерархия данных:
Данные могут быть представлены в виде иерархического дерева, как показано на рисунке.
Каждая дочерняя запись может иметь только одну родительскую запись:
Иерархия через указатель:
Указатели используются для связывания записей. Указатель определяет, какая запись является родительской, а какая дочерней.
Минимизировать дисковый ввод и вывод:
Родительские и дочерние записи хранятся рядом друг с другом на запоминающем устройстве.Это помогает свести к минимуму ввод и вывод на жесткий диск.
Быстрая навигация:
Из-за небольшого расстояния между родителем и потомком время доступа к базе данных и производительность улучшаются. В иерархической модели навигация по базе данных выполняется очень быстро.
Предопределенные отношения между записями:
Все отношения предопределены. Корневые узлы, родители и потомок предопределены в схеме базы данных.
Сложно реорганизовать:
Из-за иерархии трудно реорганизовать базу данных.Реорганизовать сложно, потому что могут быть нарушены отношения между родителями и детьми.
| Разница | Иерархическая модель данных | Модель сетевых данных |
| Базовый | Существует родительский тип для дочернего типа Связь между записями. | Указатели или ссылки используются для отображения взаимосвязи между записями. |
| М: М Отношения | Иерархическая модель базы данных не поддерживает отношения M: M. | Модель сетевой базы данныхподдерживает отношения M: M. |
| Несогласованность данных | Возможно при обновлении и удалении данных. | Нет несоответствия данных. |
| Перемещение | Обход данных сложен. | Узел может быть доступен от родителя к потомку и аналогично от потомка к родителю. Это упрощает перемещение данных. |
| Структура | Иерархическая модель базы данных поддерживает древовидную структуру. | Модель сетевой базы данныхподдерживает графоподобную структуру. |
1. Иерархическая модель поддерживает отношения «многие ко многим» ? ДА / НЕТ
2. Иерархическая модель сложнее сетевой модели? ДА / НЕТ
2. Один дочерний элемент может иметь только родительский объект ? ДА / НЕТ
Иерархическая модель базы данных описывает набор _____ отношений?
Тема закрыта
Иерархическая модель с примерами и характеристиками.
CEO @ T4T utorials.com
Я приветствую всех вас, если вы хотите обсудить любую тему. Исследователям, учителям и студентам разрешается использовать контент в некоммерческих офлайн-целях. Кроме того, вы должны использовать ссылку на веб-сайт, если хотите использовать частичное содержание в исследовательских целях.
(PDF) Иерархическое управление базой данных: обзор
Иерархическое управление без данных ~ n ~
•
Наложенные ограничения вынуждают
раз организовать неестественную организацию данных
.Например, как наглядно показано до
, отношения N: M иногда могут быть представлены [7]
только неуклюжим образом
. [8]
• Из-за строгого иерархического упорядочивания операции, такие как вставка [9]
и удаление, становятся довольно сложными.
• Операция удаления может привести к потере [10]
информации, присутствующей в сценариях de-
, если пустые записи не разрешены.Следовательно, пользователи должны быть осторожны при выполнении операции удаления [111
].
• Иногда невозможно легко ответить на симметричный запрос
в архивной системе hier-
. Следовательно, структура базы данных может иметь тенденцию отражать потребности приложения.
Иногда критика концентрируется на
природе иерархических команд [13l
], которые считаются слишком процедурными.Каким образом на эту критику можно ответить, как мы [14]
видели в разделе «Общий выбор»,
см. Стр. 116, показывая, что могут быть реализованы интерфейсы более высокого уровня
. Именно таким образом
можно легко приспособить даже обычный пользовательский интерфейс.
ССЫЛКИ
[1] ABRIAL,
J. R., «Семантика данных»,
Data
[15]
base management,
Klimbie, J.W. and Koffe-
man, K. L., [Eds.], North-Holland Publ. Co.,
Амстердам, Нидерланды, 1974, стр. 1-59. [16]
[2] БАХМАН,
C. W., «Диаметр структуры данных
грамма»,
База данных
1, 2 (1969), 4-10.
[3]
BAYER, R .; AND McCREIGHT, E.,
«Организация —
и обслуживание крупных заказанных ин —
дескрипторов»,
Acta Informatica
1, 3 (1972), 173-189.[17]
[4]
BERNSTEIN,
P.
A .;
AND TSICHRITZI $, D. C.,
«Распределение хранилища в иерархических данных [18]
баз», Технический отчет CSRG-34, Com-
puter Systems Research Group, Univ. of
Toronto, May 1974 (появится в
Information
Systems Journal).
[19]
[5] BLEIER,
R.E., «Обработка иерархических данных
структур в системе управления данными SDC с временным разделением —
ement system (TDMS)», в
Proc.ACM
Национальная конф.
1967, ACM, New York, 1967,
pp 41-49. [.20]
[6] BLEIER, R.E .;
AND ~ ORHAUS, AH,
«Файл
Организация в SDC данных с разделением времени
•
123
°
система управления ~ frDMS),» ~,: b ~
In
Proc.
1FIP Congress
1908, Wol. 2. Северная Голландия
Publ. Co., Амстердам, The
Нидерланды,
1968, стр 1245-1252.
CORe. ДАННЫХ УПРАВЛЕНИЯ, «Справочное руководство по системе поиска доступа MARS VI multi
«,
44625500, 1970.
CII, «SOCRATE
manuel de
презентация,»
Справочный документ 4337 P / FR , Louvecien-
nes, Франция.
DATAPRO RESEARCH CORP., SYSTEM 2000—
MRI Systems Corporation,
Datapro
70,
(апрель 1972 г.).
HYERETT, G.D.;
DISSLY, C. W .;
И
HARD-
VE ~ ‘
GRA
,
W. T,
Руководство пользователя системы удаленного управления файлами
(RFMS), «TRM-16,
Computing Center, Univ. из Техаса,
, Остин, Техас, август 1971 г. «в
Proc.AFIPS, Spring Jr. Computer Conf.,
1966, Vol. 28, Spartan Books, New York,
1966, стр. 79-86.
HARDGRAW :, W.T., «Теоретические аспекты логических операций
над древовидными структурами и последствия
для управления обобщенными данными —
«, TSN-26, Computing Center, Univ.
из Техаса в Остине, Техас, август 1972 г. ~ ystems,
COINS-IV,
Plenum Press, Нью-Йорк, 1974.
IBM,
СИСТЕМА УПРАВЛЕНИЯ ИНФОРМАЦИЕЙ //
ВИРТУАЛЬНОЕ ХРАНИЛИЩЕ
(IMS / VS)
ПУБЛИКАЦИИ
1975:
Руководство по общей информации,
Gh30-1260-3.
Система ~ руководство по разработке приложений,
Sh30-9025-2.
Прикладная программа ~ справочное руководство,
Ш30-9026-2.
, Справочное руководство по системному программированию,
Ш30-
9027-2.
Справочник оператора,
Ш30-9028-1.
Справочник по утилитам,
Ш30-9029-2.
Справочник по сообщениям и кодам,
Ш30-
903О-2.
KNUTH, DE,
The art of computer program-
ming,
Vol. 1, Addison-Wesley Publ. Co.,
Reading, Mass., 1968, p. 316.
LOWENTHAL, Е.И. «Функциональный подход
к проектированию структур хранения данных MR gen-
централизованные системы управления данными», PhD
Дис., Univ.of Texas в Остине, Техас,
1971.
MRI SYSTEMS CORP.,
«SYSTEM ~ 000 general
information manual»,
Austin, Texas, 1972.
PARSONS, R.G .; Д. ~ Л ~, А.Г .; ANY YURKA-
NAN, C.V.,
«Требования к языку обработки данных
для системы управления базами данных-
tems»,
Computer J.
17, 2 (May 1974), 99-103.
SCHMID, H.A .; ЛЮБОЙ СВЕНСОН, Дж.R.,
«На
семантика
реляционной модели данных»,
в
Proe. ACM SIGMOD, Междунар. Конф. на
Управление данными,
1975, ACM, Нью-Йорк,
1975, стр. 211-223.
UNITED COMPUTING SYSTEMS,
Isc., UCS-
VI UNIDATA
справочник по системе управления данными
ence manual,
Kansas City, Missouri, 1970.
Computing Surveyz, VoL 8, No.1. Март 1976 г.
Что такое реляционная база данных?
Реляционная база данных — это набор информации, который упорядочивает точки данных с определенными отношениями для облегчения доступа. В модели реляционной базы данных структуры данных, включая таблицы данных, индексы и представления, остаются отдельными от физического хранилища, что позволяет администраторам редактировать физическое хранилище данных, не влияя на логическую структуру данных.
Таблицы данных, используемые в реляционной базе данных, хранят информацию о связанных объектах.Каждая строка содержит запись с уникальным идентификатором, известным как ключ, и каждый столбец содержит атрибуты данных. Каждая запись присваивает значение каждой функции, что упрощает выявление взаимосвязей между точками данных.
Стандартным пользовательским и прикладным программным интерфейсом (API) реляционной базы данных является язык структурированных запросов (SQL). Операторы SQL используются как для интерактивных запросов информации из реляционной базы данных, так и для сбора данных для отчетов. Необходимо соблюдать определенные правила целостности данных, чтобы реляционная база данных была точной и доступной.
Реляционные базы данных полезны для организаций всех типов и размеров, где необходимо согласованно управлять и защищать связанные точки данных. Например, предприятия электронной коммерции могут использовать реляционную модель для обработки покупок и отслеживания запасов. Реляционная база данных — это наиболее широко используемая модель базы данных.
Что входит в модель реляционной базы данных?Реляционная база данных была изобретена в 1970 году Э. Ф. Коддом, тогда еще молодым программистом в IBM.В своей статье «Реляционная модель данных для больших общих банков данных» Кодд предложил перейти от хранения данных в иерархических или навигационных структурах к организации данных в таблицах, содержащих строки и столбцы.
Каждая таблица — иногда называемая отношением — в реляционной базе данных содержит одну или несколько категорий данных в столбцах или атрибутов . Каждая строка — также называемая записью или кортежем — содержит уникальный экземпляр данных — или ключ — для категорий, определенных столбцами.Каждая таблица имеет уникальный первичный ключ, который идентифицирует информацию в таблице. Затем связь между таблицами может быть установлена с помощью внешних ключей — поля в таблице, которое ссылается на первичный ключ другой таблицы.
Например, типичная база данных для ввода бизнес-заказов будет включать таблицу, описывающую клиента, со столбцами для имени, адреса, номера телефона и т. Д. Другая таблица будет описывать заказ, включая такую информацию, как продукт, клиент, дата и цена продажи.
Затем пользователь реляционной базы данных может получить представление базы данных в соответствии со своими потребностями. Например, менеджеру филиала может быть интересен просмотр или отчет обо всех клиентах, купивших продукты после определенной даты. Менеджер по финансовым услугам в той же компании может из тех же таблиц получить отчет о счетах, которые необходимо оплатить.
Реляционная база данных включает таблицы, содержащие строки и столбцы.При создании реляционной базы данных вы можете определить область возможных значений в столбце данных и дополнительные ограничения, которые могут применяться к этому значению данных.Например, домен возможных клиентов может допускать до 10 возможных имен клиентов, но ограничен в одной таблице, позволяя указать только три из этих имен клиентов.
Два ограничения относятся к целостности данных, а также к первичному и внешнему ключам:
- Целостность объекта гарантирует, что первичный ключ в таблице уникален и что значение не установлено равным нулю.
- Ссылочная целостность требует, чтобы каждое значение в столбце внешнего ключа находилось в первичном ключе таблицы, из которой оно возникло.
Кроме того, реляционные базы данных обладают физической независимостью от данных. Это относится к способности системы вносить изменения во внутреннюю схему без изменения внешних схем или прикладных программ. Изменения внутренней схемы могут включать:
- использование новых запоминающих устройств;
- модифицирующие индексы;
- переход с одного метода доступа на другой;
- с использованием различных структур данных; и
- с использованием различных структур хранения или файловых организаций.
Логическая независимость данных — это способность системы управлять концептуальной схемой без изменения внешней схемы или прикладных программ. Изменения концептуальной схемы могут включать добавление или удаление новых отношений, сущностей или атрибутов без изменения существующих внешних схем или переписывания прикладных программ.
Примеры реляционных баз данных
Стандартные реляционные базы данных позволяют пользователям управлять заранее заданными отношениями данных в нескольких базах данных.Популярные примеры стандартных реляционных баз данных включают Microsoft SQL Server, Oracle Database, MySQL и IBM DB2.
Облачные реляционные базы данных или база данных как услуга (DBaaS) также широко используются, потому что они позволяют компаниям отдавать на аутсорсинг обслуживание баз данных, установку исправлений и поддержку инфраструктуры. Облачные реляционные базы данных включают Amazon Relational Database Service (RDS), Google Cloud SQL, IBM DB2 on Cloud, SQL Azure и Oracle Cloud.
Типы баз данныхСуществует ряд категорий баз данных, от базовых плоских файлов, не относящихся к NoSQL, и более новых графовых баз данных, которые считаются даже более реляционными, чем стандартные реляционные базы данных.
База данных плоских файлов состоит из одной таблицы данных, не имеющих взаимосвязи — обычно текстовых файлов. Этот тип файла позволяет пользователям указывать атрибуты данных, такие как столбцы и типы данных.
Плоский файл против реляционной базы данныхБаза данных NoSQL — это альтернатива реляционным базам данных, которая особенно полезна для работы с большими наборами распределенных данных. Эти базы данных могут поддерживать различные модели данных, включая форматы «ключ-значение», «документ», «столбец» и «график».
База данных графов выходит за рамки традиционных реляционных моделей данных на основе столбцов и строк; эта база данных NoSQL использует узлы и ребра, которые представляют связи между отношениями данных и могут обнаруживать новые отношения между данными. Базы данных Graph более сложны, чем реляционные базы данных, и поэтому их использование включает в себя механизмы обнаружения мошенничества или веб-рекомендаций.
Объектно-реляционная база данных (ORD) состоит из системы управления реляционными базами данных (RDBMS) и объектно-ориентированной системы управления базами данных (OODBMS).ORD содержит характеристики моделей RDBMS и OODBMS. В ORD для хранения данных используется традиционная база данных. Затем к нему обращаются и манипулируют с помощью запросов, написанных на языке запросов, таком как SQL. Следовательно, основной подход ORD основан на реляционной базе данных.
Однако ORD также можно рассматривать как объектное хранилище, особенно для программного обеспечения, написанного на объектно-ориентированном языке программирования (ООП), тем самым опираясь на объектно-ориентированные характеристики.В этой ситуации API-интерфейсы используются для хранения и извлечения данных.
Преимущества реляционных баз данныхОсновным преимуществом реляционных баз данных является то, что они позволяют пользователям легко классифицировать и хранить данные, которые впоследствии могут быть запрошены и отфильтрованы для извлечения конкретной информации для отчетов. Реляционные базы данных также легко расширяются и не зависят от физической организации. После создания исходной базы данных можно добавить новую категорию данных без изменения всех существующих приложений.
Другие преимущества реляционной базы данных:
- Точность: Данные сохраняются только один раз, что исключает дедупликацию данных.
- Гибкость: Пользователи могут легко выполнять сложные запросы.
- Сотрудничество: Несколько пользователей могут получить доступ к одной базе данных.
- Доверие: Модели реляционных баз данных зрелые и хорошо изученные.
- Безопасность: Данные в таблицах в СУБД могут быть ограничены, чтобы разрешить доступ только определенным пользователям.
Большинство программных продуктов на сегодняшнем рынке включают в себя как реляционные базы данных, так и стандартные базы данных. Следовательно, они могут управлять базами данных как в реляционной табличной форме, так и в файловой форме, или и то, и другое. По сути, на сегодняшнем рынке реляционная база данных — это база данных, и наоборот; тем не менее, между двумя системами по-прежнему существуют существенные различия в хранении данных.
Наиболее важное отличие состоит в том, что в реляционной базе данных данные хранятся в табличной форме или в виде таблицы со строками и столбцами, а в базе данных данные хранятся в виде файлов.Другие отличия включают:
- Нормализация базы данных присутствует в реляционной базе данных, но отсутствует в базе данных.
- Реляционная база данных поддерживает распределенную базу данных, а база данных не поддерживает распределенную базу данных.
- В реляционной базе данных значения данных хранятся в виде таблиц, и каждая таблица имеет первичный ключ. В базе данных данные обычно хранятся в иерархической или навигационной форме.
- Поскольку данные хранятся в виде таблиц в реляционной базе данных, то также сохраняется связь между этими значениями данных.Поскольку база данных хранит данные в виде файлов, между значениями или таблицами нет никакой связи.
- В реляционной базе данных ограничения целостности определены для ACID. С другой стороны, база данных не использует никаких средств защиты от манипуляций с данными.
- В то время как реляционная база данных предназначена для поддержки больших объемов данных и нескольких пользователей, база данных предназначена для работы с небольшими объемами данных и одним пользователем.
Последнее, важное отличие состоит в том, что хранилище данных в реляционной базе данных доступно, то есть значение может обновляться системой.Кроме того, данные в СУБД физически и логически независимы.
.