Управление группами поисковых запросов — Вебмастер. Справка
Для повышения качества данных 24 марта 2021 года мы улучшили фильтрацию роботных запросов в отчетах по поисковым фразам в Вебмастере. Это могло привести к существенным коррективам значений кликов и показов, что не говорит о наличии проблем у сайта. Внесенные изменения не влияют на результаты поиска.
Управление группами запросов в Вебмастере помогает:узнавать, по каким запросам страницы сайта отображаются в поиске, и какие страницы сайта отображаются по этим запросам;
видеть краткую статистику состояния сайта в поисковой выдаче;
добавлять собственные поисковые запросы в Вебмастер;
отслеживать краткую статистику по поисковым запросам;
формировать группы запросов, чтобы получать детальную информацию на странице Статистика поисковых запросов.
Появление ссылки на сайт в результатах поиска Яндекса по некоторому запросу. Показом не является потенциальное появление ссылки на второй и последующих страницах результатов поиска, если пользователь эти страницы не открывал.
Показом не является потенциальное появление ссылки на второй и последующих страницах результатов поиска, если пользователь эти страницы не открывал.
Переход посетителя на сайт со страницы результатов поиска Яндекса.
\n «}}»>, Позицией сайта считается номер на страницах результатов поиска Яндекса, которому соответствует ссылка, ведущая на ваш сайт. В течение дня сайт может занимать разные позиции по одной поисковой фразе, поэтому сервис показывает среднее значение за весь день.»}}»>, \nОтношение числа кликов на сниппет к числу его показов, измеряется в процентах. Можно сказать, что этот показатель говорит о привлекательности сниппета страницы сайта.
\n «}}»>. Это усредненные значения за последние 7 дней, доступные на странице Статистика поисковых запросов. Вы можете отслеживать данные по поисковым запросам и по URL страниц, которые отображаются по этим запросам.- Группы запросов
- Загрузка собственных запросов
- Фильтрация запросов
- Вопросы и ответы
По умолчанию в Вебмастере доступно несколько групп запросов:
Все запросы — общий список запросов, по которым ваш сайт показывался в ТОП-50 результатов поиска Яндекса.

Загруженные — запросы, которые были добавлены вручную.
Избранные — специальная группа. Позволяет отслеживать данные по отдельным запросам (например, отслеживать изменения позиций по ключевым фразам). Информация по каждому запросу из этой группы доступна на странице Статистика поисковых запросов.

Вы можете добавить собственные группы, чтобы объединить запросы, с которыми работаете чаще всего.
Примечание. Можно добавить до 500 запросов в одну группу (до 1000 запросов в группу Избранные). Для одного сайта может быть создано не более 100 групп.
Чтобы создать группу, нужно скопировать поисковые запросы из общего списка. Вы можете использовать несколько способов:
- Создать группу во время копирования
Выберите группу Все запросы и отметьте необходимые запросы.
Внизу страницы нажмите кнопку Копировать выбранные запросы в группу.
В появившемся окне введите название группы и нажмите кнопку Сохранить.
Новая группа отобразится в списке Группы запросов.Под списком Группы запросов нажмите кнопку Создать группу.
В появившемся окне введите название группы и нажмите кнопку Сохранить. Новая группа отобразится в списке Группы запросов.
Выберите группу Все запросы и отметьте необходимые запросы.
Внизу страницы нажмите кнопку Копировать выбранные запросы в группу.
В появившемся окне выберите из выпадающего списка название созданной группы и нажмите кнопку Сохранить. Запросы отобразятся в выбранной группе.
Выберите группу Все запросы и отметьте необходимые запросы.
Внизу страницы нажмите кнопку Добавить запросы в избранное. Запросы отобразятся в группе Избранные.
 Новая группа отобразится в списке Группы запросов.
Новая группа отобразится в списке Группы запросов.- Пример объединения группы по ключевой фразе
- [мобильные телефоны]
- [сенсорные телефоны]
- [интернет магазин телефонов]
- [купить мобильный телефон]
- [купить телефон самсунг]
- [магазин мобильных телефонов]
Допустим, вы продвигаете интернет-магазин телефонов. Вас интересуют запросы, связанные с названиями сотовых телефонов, производителями, покупкой, характеристиками:
Вас интересуют запросы, связанные с названиями сотовых телефонов, производителями, покупкой, характеристиками:
Для этих запросов можно создать группу по слову «телефон» и просмотреть статистику.
Если вы только что создали новую группу, статистика по этой группе не будет отображена. Подождите несколько дней, пока данные накопятся.
При необходимости вы можете управлять созданной группой, нажав значок :
переименовать;
удалить;
если для группы сохранен фильтр, его можно сохранить для другой группы.
Вы можете добавить в сервис поисковые фразы, которые не попали в список запросов. Загрузить фразы можно в группу Избранные и в группы, созданные вручную.
Примечание. Для одного сайта можно загрузить до 10 000 запросов.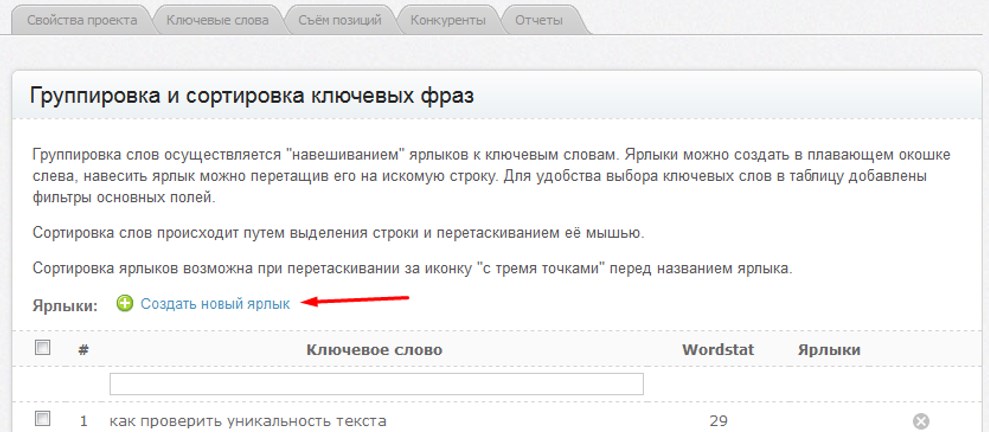
Доступно несколько способов загрузки:
Примечание. Количество запросов (строк) в тексте или файле не должно превышать 500.
Сразу после окончания загрузки фразы отобразятся в группе, в которую их добавили. При этом список фраз будет автоматически отфильтрован по значению добавленные вручную. В этом режиме вы можете удалить добавленный запрос. Чтобы увидеть все запросы группы, выберите значение по фильтру.
Также добавленные запросы всегда отображаются в группе Загруженные.
Запросы можно фильтровать по параметрам (например, числу показов в результатах поиска, числу кликов, тексту запроса и пр.).
Например, отфильтруем запросы по адресу страницы — сформируем список запросов, по которым Блок информации о найденном документе, который отображается в результатах поиска. Сниппет состоит из заголовка и описания или аннотации документа, а также может включать дополнительную информацию о сайте. Подробно»}}»> этой страницы отображается в результатах поиска:
Нажмите ссылку Добавить фильтр.
Выберите фильтр URL в выпадающем списке и значение содержит. Затем введите в поле часть URL (например, /category/).
Нажмите кнопку Фильтровать.

По умолчанию в списке отображаются запросы. Чтобы в списке отобразились адреса страниц, нажмите URL.
Заданный фильтр можно сохранить в уже существующую группу или создать для него отдельную группу во время сохранения, нажав кнопку Сохранить.
Чтобы выбрать из общего списка нужные вам запросы, можно применить несколько фильтров. При добавлении фильтров используется оператор «И». Таким образом, каждая фраза в выборке будет отвечать одновременно всем заданным условиям фильтров.
Кроме этого, в фильтре по параметру Текст запроса можно указать условие с оператором «ИЛИ», используя символ |. Например, если указать в поле текст вебмастер|яндекс, то в результате отобразятся фразы, которые содержат хотя бы одно слово, указанное в условии фильтра.
- Почему позиции сайта резко снизились
На снижение позиций могут влиять изменения в алгоритмах ранжирования: периодически добавляются новые факторы ранжирования, удаляются устаревшие, изменяется вес факторов.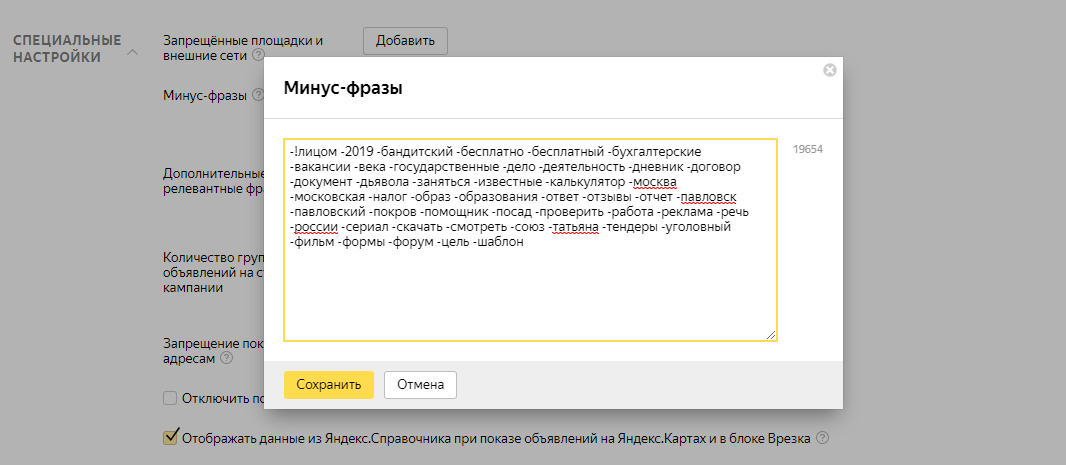
Кроме этого, на позиции в результатах поиска влияет качество сайта. Проверьте, не наложены ли на сайт ограничения в Вебмастере на странице Диагностика сайта.
За какое время показывается информацияПозиция на странице Управление группами запросов соответствует средней позиции сайта по данному запросу за последние 7 дней, доступной на странице Статистика поисковых запросов.
Чтобы посмотреть информацию о группе запросов за определенный период, на странице Статистика выберите интересующий период и группу запросов.
Отсутствуют данные о поисковых запросах. Почему?На странице отображается информация по тем запросам, по которым сайт чаще всего показывался в поиске на первых 50 позициях. Возможно, для вашего сайта пока нет запросов, удовлетворяющих этим требованиям. Кроме того, если вы только что добавили свой сайт в Вебмастер, необходимо некоторое время для сбора данных по вашему сайту. Обычно это происходит в течение недели.
Если данные о количестве кликов отсутствуют, скорее всего, за указанный период на ваш сайт не было переходов из результатов поиска.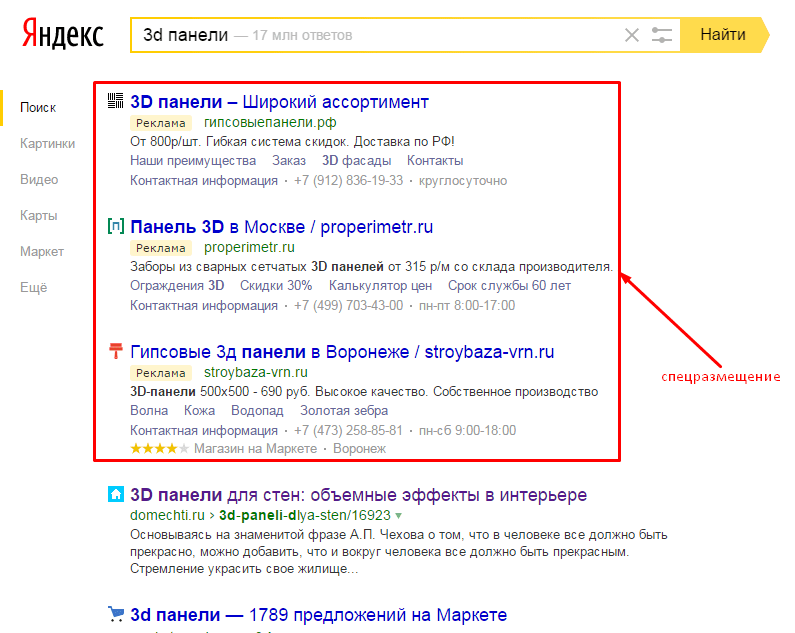 Большое число показов не гарантирует большого числа кликов. Если, несмотря на большое число показов, кликов нет, убедитесь, что сайт хорошо представлен на странице результатов: имеет заголовок и сниппет, соответствующие запросу.
Большое число показов не гарантирует большого числа кликов. Если, несмотря на большое число показов, кликов нет, убедитесь, что сайт хорошо представлен на странице результатов: имеет заголовок и сниппет, соответствующие запросу.
Данные о запросах в недавно созданной группе будут отображаться после обработки информации из поиска за день создания группы.
Я не вижу свой сайт в результатах поиска на указанной позиции. Почему?Позиция в результатах поиска зависит от множества факторов и не является постоянной. Попробуйте найти ваш сайт на соседних позициях. Из обработки исключаются показы и клики на позициях, больших 50.
Виды частотностей поисковых запросов или почему позиция по однословнику не гарантирует получение трафика
У нас иногда спрашивают:
«Почему мой сайт в ТОПе по такому на первый взгляд «жирному» запросу как «металлоконструкции», но трафика на сайт с этого ключевика совсем мало. Какие-то 50-100 человек в месяц! Но ведь частотность у этого запроса огромная, аж 250 тысяч в месяц! Почему такое происходит?»
Какие-то 50-100 человек в месяц! Но ведь частотность у этого запроса огромная, аж 250 тысяч в месяц! Почему такое происходит?»
И правда, если вбить в wordstat.yandex.ru такой запрос, то частотность он нам покажет довольно внушительную:
При такой частотности позиция даже на 10 месте в выдаче должна приносить много трафика, но на деле все происходит совершенно иначе. В чем же причина? Давайте разбираться по порядку. Здесь есть несколько моментов, которые нужно учитывать. Начнем с самых простых и далее – по нарастающей.
Регион
Первое, про что все часто забывают, – это выбор региона при съеме частотности. Ни один коммерческий сайт не может продвигаться сразу по всем регионам, если он, конечно, не имеет офисы в каждом из них. Поэтому частотность снимается именно по тому региону, где находится офис компании. Если регионов несколько – отмечаем их все.
Например, компания, которая специализируется на поставках металлоконструкций и металлопроката, имеет офис в Москве, который добавлен в Яндекс. Справочник. Таким образом, ни по каким другим регионам данный сайт ранжироваться не будет, поэтому и ориентироваться надо в первую очередь на посетителей из Москвы. Значит, в wordstat нужно выставить соответствующий регион: Москва.Ключевой момент – наличие организации в Яндекс.Справочнике, так как именно по нему происходит привязка региона сайту.
Справочник. Таким образом, ни по каким другим регионам данный сайт ранжироваться не будет, поэтому и ориентироваться надо в первую очередь на посетителей из Москвы. Значит, в wordstat нужно выставить соответствующий регион: Москва.Ключевой момент – наличие организации в Яндекс.Справочнике, так как именно по нему происходит привязка региона сайту.
Иногда клиенты нам говорят:
«Я хочу продвигаться по всей России, мой интернет-магазин доставляет товар в любой регион».
И здесь мы вынуждены их разочаровать: к сожалению, даже внутри России интернет-магазин не может ранжироваться, если у него нет филиалов в соответствующих регионах. Под филиалами подразумевается привязанная в Яндекс.Справочнике карточка организации с подтвержденным офисом в регионе.Таким образом, при оценке спроса всегда нужно строго определять региональность.
Виды частотности
После выбора региона сразу видно, что частотность значительно уменьшилась.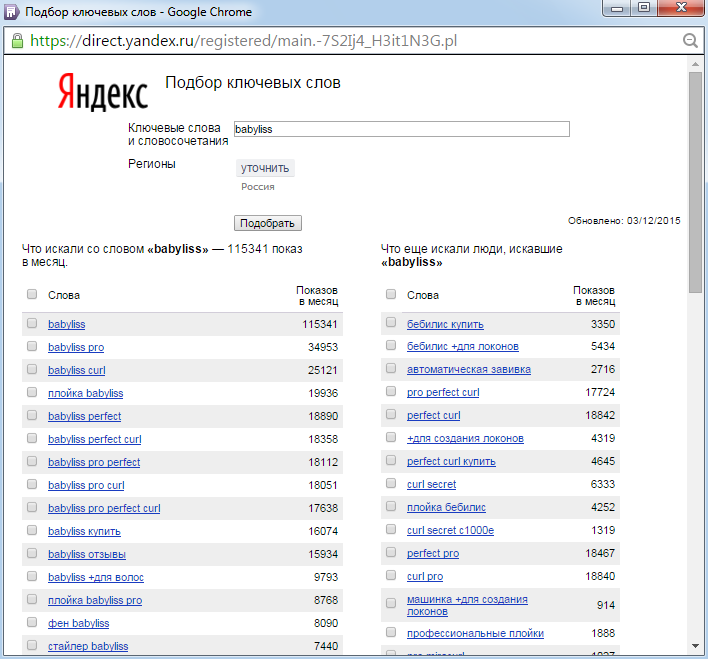
Однако все равно это не реальные цифры конкретных фраз и, чтобы точно определить частотность каждого ключевика, нужно использовать специальный синтаксис.
Базовая частотность
Пока что мы собрали так называемую «Базовую частотность». Такой частотностью называют ту, которую мы получаем при вводе запроса в wordstat без какого-либо синтаксиса, выбрав регион или нет. Такая частотность представляет собой сумму частотностей всех фраз, где встречаются слова из запроса в любых словоформах и в любом порядке. Например, в нашем случае запрос «Металлоконструкции» без указания региона имел частотность около 250 тыс. в месяц по всему миру и 33 тыс по Москве. В эту частотность вошли все фразы, которые содержат слово «металлоконструкции». Причем слово может иметь разные окончания, то есть сюда войдут фразы: «завод металлоконструкций», «сварные металлоконструкции», «купить металлоконструкции недорого» и т.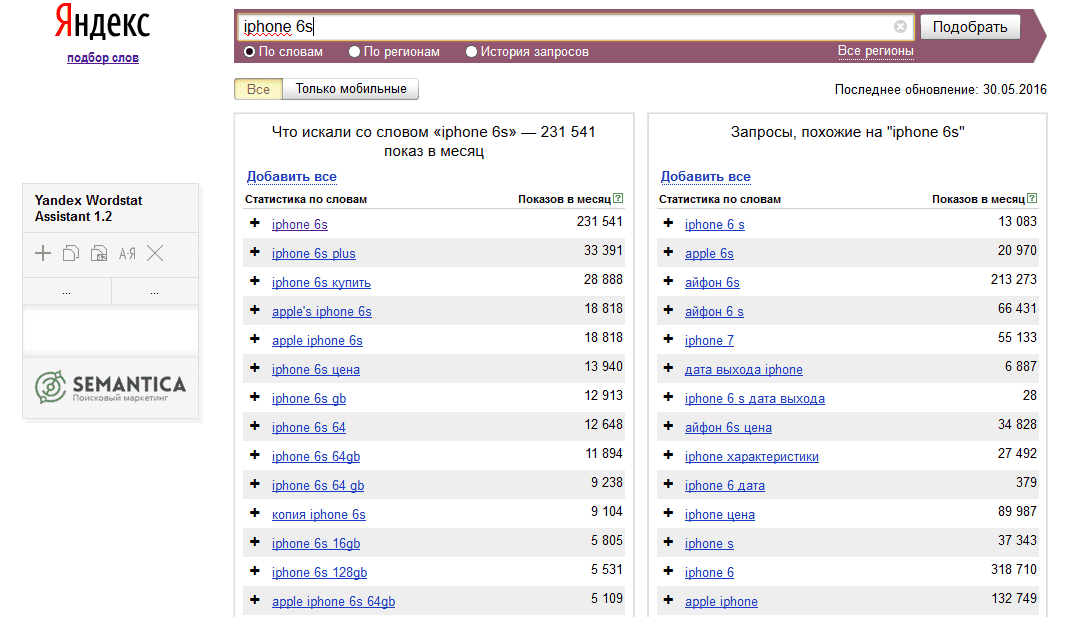 п.
п.
Частотность в кавычках
Если мы хотим узнать частотность поискового запроса более точно, например, отсечь из нее те запросы, где присутствуют другие слова, то нужно брать запрос в кавычки. Иными словами, если вбить в wordstat запрос в таком виде – “металлоконструкции” – то получим следующую цифру:
Теперь мы видим, что отдельно слово «металлоконструкции» по Москве запрашивают в Яндексе только 948 человек. Однако сюда все равно еще подмешиваются словоформы, например, «металлоконструкций» «металлоконструкция». Чтобы их убрать, воспользуемся следующим видом частотности.
Частотность в кавычках и с восклицательным знаком (точная частотность)
Если задать запрос в wordstat в таком виде – “!металлоконструкции” – мы получим самую точную частотность. То есть будет отображаться частотность данного слова именно в таком виде, как мы написали:

Таким образом, видна существенная разница в финальной частотности однословного запроса «металлоконструкции» по сравнению с изначальной базовой.
Точная частотность с учетом порядка слов
Однако, если мы подобным образом будем оценивать запрос, состоящий из двух слов, например, «купить металлоконструкции», то нужно еще учитывать порядок слов.
Так, например, если мы проверим точную частотность запросов: “!купить !металлоконструкции” и “!металлоконструкции !купить”, то обнаружим, что странным образом частотность у них будет одинаковая:
Это происходит по той причине, что операторы «кавычки» и «восклицательный знак» не учитывают порядок слов.Чтобы собрать точную частотность фразы «купить металлоконструкции» с учетом порядка слов, нужно использовать оператор «скобки» и вводить фразу следующим образом: “[!купить !металлоконструкции]”:
Таким образом, мы видим, что «купить металлоконструкции» ищут чаще, чем «металлоконструкции купить».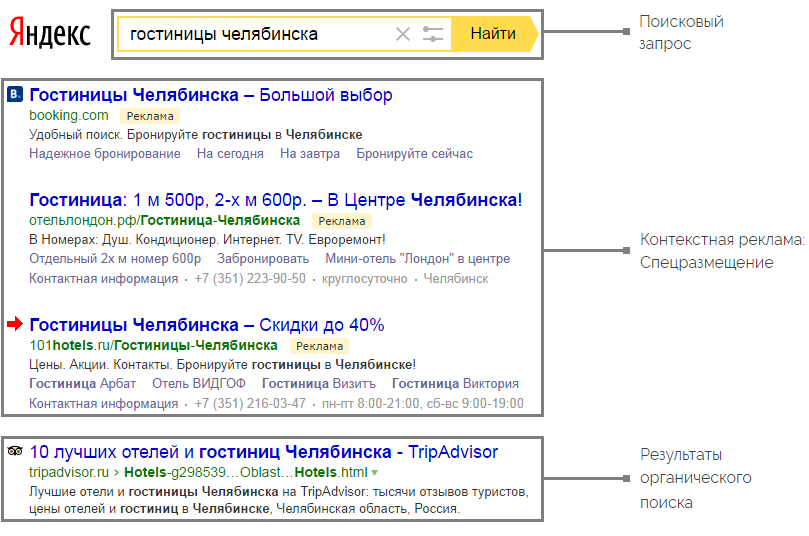
В результате мы разобрались, что основным фактором в оценке спроса по ключевым запросам, который обязательно нужно учитывать, является правильный съем частотности для семантического ядра. В качестве примера мы сравнили базовую и точную частотность для первых трех десятков фраз, которые выдает wordstat по запросу «металлоконструкции». В приведенной таблице в колонке «Показов в месяц» указана базовая частотность, которую выдал Яндекс без учета региона. В колонке «Реальная частотность» указана уже точная частотность по региону Москва и снятая с использованием операторов «кавычки», «восклицательный знак» и «квадратные скобки».

Распределение кликабельности на первой странице выдачи
Но можно справедливо возразить:
Неужели при позиции в ТОП-10 с ключевика частотностью 839 будет всего лишь 50-100 посещений?
В общем-то да!
По разным оценкам распределение CTR в органической выдаче в ТОП-10 примерно такое:
- ТОП-2: 10-25%
- ТОП-3: 7-20%
- ТОП-4: 5-15%
- ТОП-5 – ТОП-10: 3-12%
Подсчеты, конечно, очень обобщенные, но примерно отражают актуальную картину: 3 или даже 4 блока контекстной рекламы забирают больше половины всего CTR. Далее могут идти сервисы Яндекса: маркет, картинки, карты, что делает кликабельность на обычные сайты еще меньше. Учитывая еще то, что позиция в Яндексе редко у какого сайта бывает стабильной в ТОП-10 вследствие работы так называемого алгоритма «бандита», можно смело заключить, что вышеприведенные цифры по количеству трафика являются нормальными.
Оценка CTR через Яндекс.Директ
Наши слова легко проверить – достаточно зайти в Яндекс.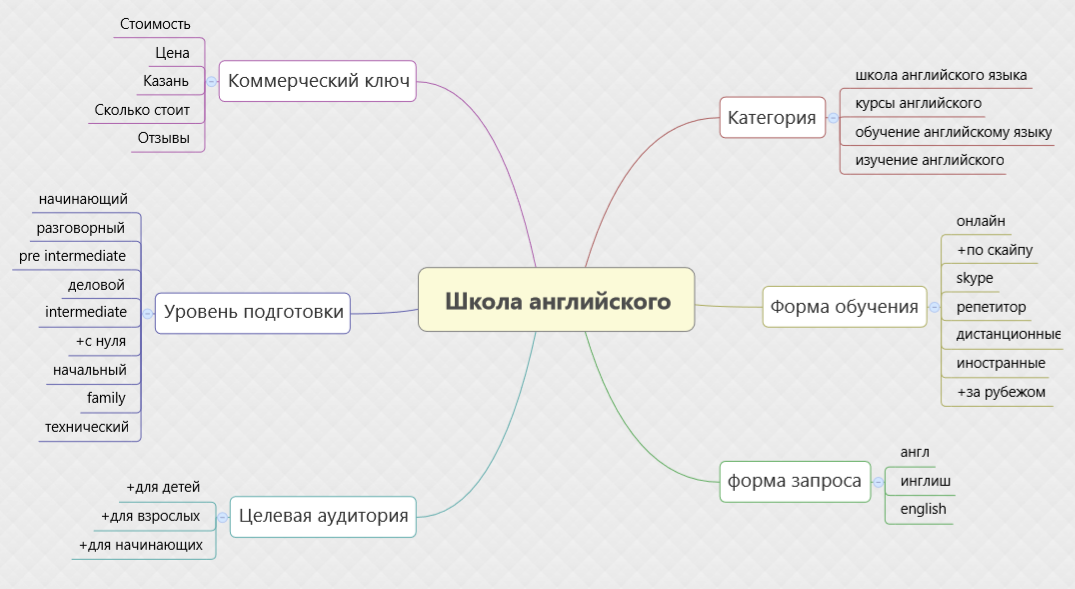
Заключение
В заключении подытожим, что для правильной оценки спроса и составления на ее основе стратегии поискового продвижения сайта важно собирать максимально полное семантическое ядро и правильно снимать частотность у всех фраз, а также задавать регион. Абсолютно неправильно «зацикливаться» на отдельных и предположительно самых «жирных» поисковых фразах и полагать, что, продвинувшись по ним в ТОП-10, сайт станет лидером тематики. Лидерство сайта в поисковом продвижении определяется исключительно совокупной видимостью сайта по определенному семантическому ядру, то есть многочисленному списку поисковых запросов различной частотности и длины.
Хотите увеличить продажи с вашего сайта?
За 3 дня составим набор точечных рекомендаций по вашему сайту, как за 1 месяц сделать рост на 30-50%
Адрес вашего сайта
Номер вашего телефона
Нажимая на кнопку, вы даете согласие на обработку ваших персональных данных, согласно политике конфиденциальности
Яндекс — Технологии — Как работает поиск Яндекса
Поисковая система Яндекса отвечает на запросы пользователей релевантными веб-документами, которые она находит в Интернете. Однако размер Интернета в настоящее время исчисляется эксабайтами — квинтиллионами или миллиардами миллиардов байтов информации. Излишне говорить, что Яндекс Поиск не просматривает эту огромную кучу данных каждый раз, когда отвечает на новый поисковый запрос. Система, так сказать, делает свою домашнюю работу.
Для выполнения поиска Яндекс использует поисковый индекс, который представляет собой базу данных всех слов и их местоположений, известных поисковой системе. Расположение слова — это комбинация его положения на веб-странице и адреса веб-страницы в Интернете. Индекс поиска похож на глоссарий или телефонный справочник. В отличие от глоссария, который содержит только избранные термины, индекс поиска регистрирует каждое слово, с которым когда-либо сталкивалась поисковая система. И, в отличие от телефонной книги, в которой перечислены имена и адреса, поисковый индекс содержит более одного «зарегистрированного адреса» для каждого слова.
Расположение слова — это комбинация его положения на веб-странице и адреса веб-страницы в Интернете. Индекс поиска похож на глоссарий или телефонный справочник. В отличие от глоссария, который содержит только избранные термины, индекс поиска регистрирует каждое слово, с которым когда-либо сталкивалась поисковая система. И, в отличие от телефонной книги, в которой перечислены имена и адреса, поисковый индекс содержит более одного «зарегистрированного адреса» для каждого слова.
Механизм веб-поиска работает в два этапа. Во-первых, он сканирует Интернет, сохраняя свою «копию» на своих серверах. Во-вторых, он отвечает на поисковый запрос пользователя, получая ответ со своих серверов.
Прежде чем поисковая система сможет начать поиск, она должна подготовить информацию, которую она находит в Интернете, для поиска. Этот процесс называется индексацией. Специальная компьютерная система — поисковый робот — регулярно просматривает Интернет, загружает новые веб-страницы и обрабатывает их.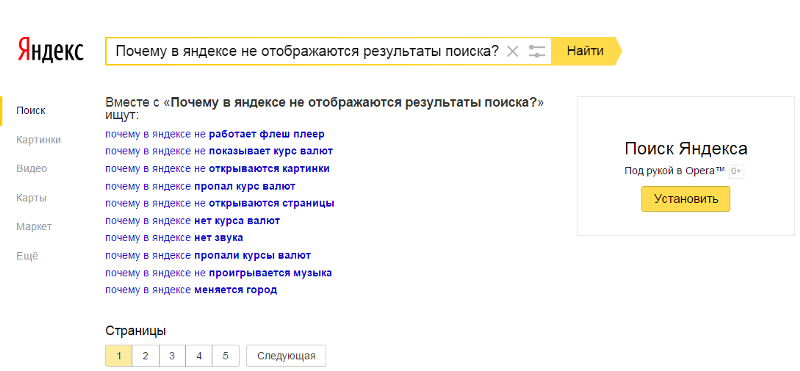 Он создает своего рода «точную копию» Интернета, которая хранится на серверах поисковой системы и обновляется после каждого сканирования.
Он создает своего рода «точную копию» Интернета, которая хранится на серверах поисковой системы и обновляется после каждого сканирования.
У Яндекса есть два краулера: один из них, основной краулер, индексирует все попавшиеся веб-страницы, а другой, известный как Orange, выполняет экспресс-индексацию, чтобы гарантировать, что самые последние документы, включая те, которые появились на веб-минуты или даже секунды до сканирования доступны в индексе поисковой системы. У обоих сканеров есть «списки ожидания» веб-страниц, которые необходимо проиндексировать. В списки постоянно добавляются новые ссылки, которые поисковые роботы находят на страницах, которые они посещают. Новые ссылки также могут появиться в листах ожидания после того, как владельцы сайтов добавят свои страницы в индекс с помощью сервиса Яндекс.Вебмастер. Администраторы веб-сайтов также могут предоставить дополнительную информацию, например, как часто обновляется их веб-сайт и т. д.
Прежде чем начать сканирование, специальная программа – планировщик – создает расписание, порядок посещения веб-страниц.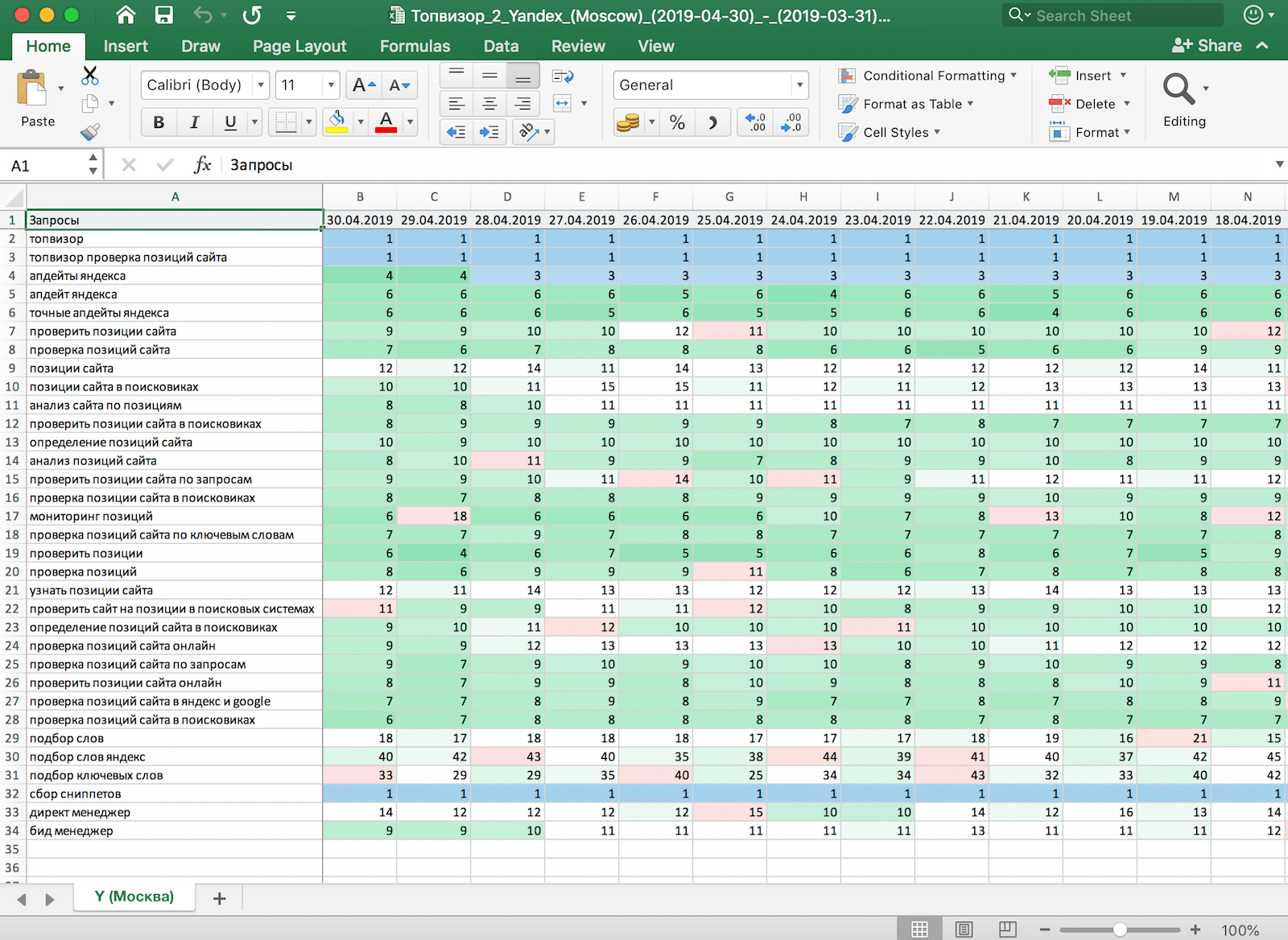 Планирование основано на ряде факторов, необходимых для поиска информации, таких как популярность ссылок или частота обновления страниц. После составления расписания за дело берется другой компонент поисковой системы — паук. Паук регулярно посещает страницы по расписанию. Если веб-сайт доступен для паука и функционирует, программа загружает страницы веб-сайта по расписанию. Он определяет формат (html, pdf, swf и т. д.), код и язык загруженного документа, а затем отправляет эту информацию на серверы для хранения.
Планирование основано на ряде факторов, необходимых для поиска информации, таких как популярность ссылок или частота обновления страниц. После составления расписания за дело берется другой компонент поисковой системы — паук. Паук регулярно посещает страницы по расписанию. Если веб-сайт доступен для паука и функционирует, программа загружает страницы веб-сайта по расписанию. Он определяет формат (html, pdf, swf и т. д.), код и язык загруженного документа, а затем отправляет эту информацию на серверы для хранения.
На сервере хранения другая программа очищает веб-документ от html-разметки, оставляя только текст. Затем он извлекает информацию о расположении каждого слова и добавляет все слова в этом веб-документе в индекс. Исходный документ также хранится на сервере до следующего сканирования. Это позволяет Яндексу предлагать своим пользователям возможность просмотра веб-документов, даже если сайт временно недоступен. Если сайт закрывается, веб-документ удаляется или обновляется, Яндекс удаляет его со своих серверов или заменяет более новой версией.
Индекс поиска вместе с копиями всех проиндексированных документов, включая их тип, код и язык, образует базу данных поиска. Чтобы не отставать от постоянно меняющегося характера интернет-контента и убедиться, что поисковая система может находить самую свежую и наиболее актуальную информацию в ответ на поисковые запросы пользователей, базу данных поиска необходимо регулярно обновлять. Прежде чем поисковая система сможет найти и вернуть результаты конечным пользователям, каждое новое обновление базы данных сначала отправляется на серверы «базового поиска». Базовые поисковые серверы содержат только существенную часть базы данных поиска — без спама, зеркальных сайтов или других нерелевантных документов. Это часть базы данных поиска, непосредственно отвечающая на запросы пользователей.
Обновления базы данных поиска отправляются с серверов хранения основного сканера на основные поисковые серверы в «пакетах» раз в несколько дней. Это очень ресурсоемкий процесс. Чтобы снизить нагрузку на серверы, данные передаются ночью — когда поисковый трафик на Яндексе самый низкий.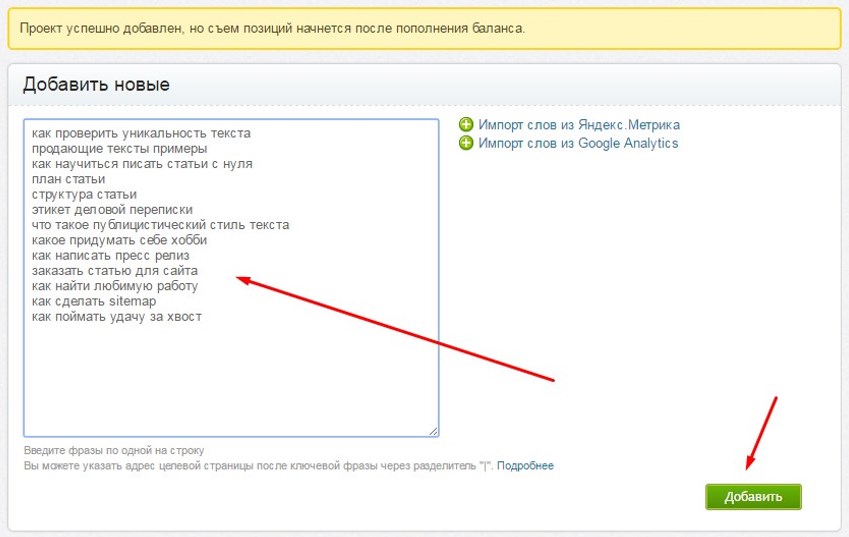 Новые части базы данных сравниваются по ряду параметров с последней версией, доступной при предыдущем обходе, чтобы гарантировать, что обновление не ухудшит качество результатов поиска. После успешной проверки качества старая версия заменяется последней версией.
Новые части базы данных сравниваются по ряду параметров с последней версией, доступной при предыдущем обходе, чтобы гарантировать, что обновление не ухудшит качество результатов поиска. После успешной проверки качества старая версия заменяется последней версией.
Поисковый робот Orange предназначен для поиска в реальном времени. И его планировщик, и паук настроены на поиск последних веб-документов и выбор из огромного количества страниц тех, которые могут представлять интерес. Эти документы мгновенно обрабатываются и отправляются прямо на основные поисковые серверы. Поскольку количество этих документов относительно невелико, обновление может происходить в режиме реального времени даже в течение дня без риска перегрузки серверов.
Веб-поисковик, грубо говоря, работает в два этапа. Первый — сканирование сети, индексация страниц, подготовка их к поиску. Другой — поиск ответа на конкретный запрос пользователя в ранее созданной поисковой базе.
| Яндекс (Еще один индексатор) За 4 года публичного существования Яндекса были и другие толкования. 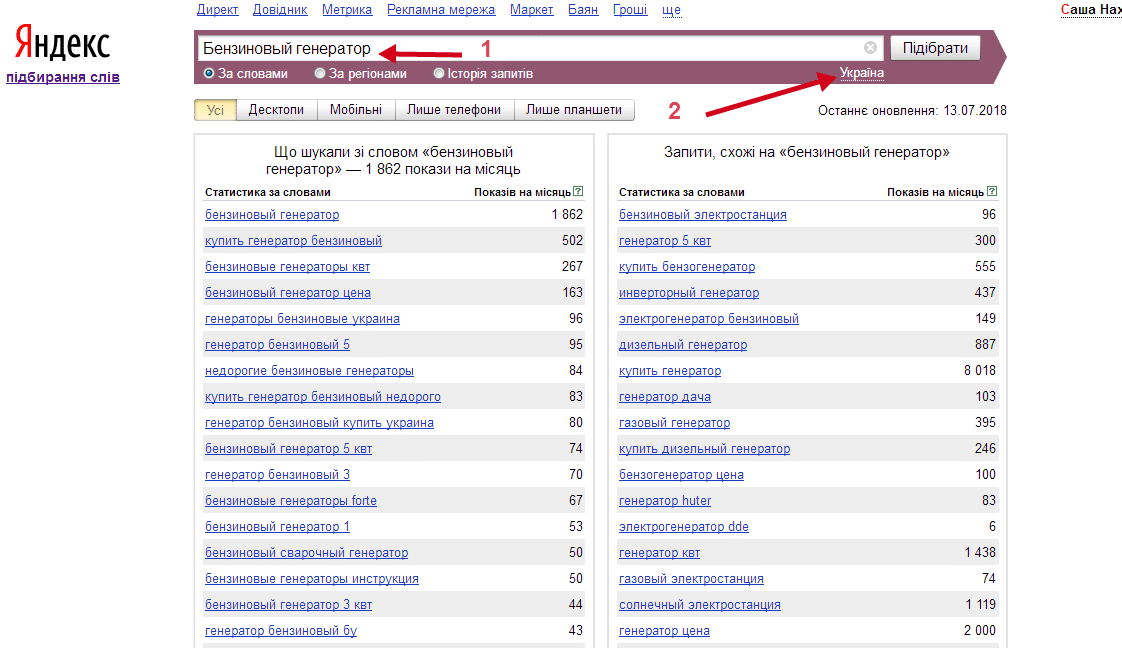 Например, если слово «Индекс» перевести с английского первой буквой («Я» — «Я»), получится «Яндекс». Следует уточнить, что обычно стартовая страница сайта называется ИНДЕКС (index.html, index.php… в зависимости от языка, на котором выполнен сайт). Например, если слово «Индекс» перевести с английского первой буквой («Я» — «Я»), получится «Яндекс». Следует уточнить, что обычно стартовая страница сайта называется ИНДЕКС (index.html, index.php… в зависимости от языка, на котором выполнен сайт).
ПредысторияИстория компании «Яндекс» началась в 1990 году с разработки поискового программного обеспечения в компании «Аркадия». За два года работы были созданы две информационно-поисковые системы – Международная классификация изобретений 4-й и 5-й редакции, а также Классификатор товаров и услуг. Обе системы работали под DOS и позволяли искать, выбирая слова из заданного словаря, используя стандартные логические операторы. В 1993 году Arcadia стала подразделением CompTek. В 1993-1994 годах программные технологии были существенно усовершенствованы благодаря сотрудничеству с лабораторией Ю.А. Д. Апресян (Институт проблем передачи информации РАН). В частности, словарь, обеспечивающий поиск с учетом морфологии русского языка, весил всего 300 Кб, то есть загружался в оперативную память и работал очень быстро. С этого момента пользователь может задавать любые формы слов в запросе. На основе новой технологии в 1994 году был создан «Библейский компьютерный справочник» (информационно-поисковая система, обеспечивающая работу с синодальным переводом Ветхого и Нового Заветов). В 1995 году стартовал проект «Академическое издание классики на компакт-дисках», разработанный совместно с НТЦ «Информрегистр» и ИМЛИ им. За два года работы были созданы две информационно-поисковые системы – Международная классификация изобретений 4-й и 5-й редакции, а также Классификатор товаров и услуг. Обе системы работали под DOS и позволяли искать, выбирая слова из заданного словаря, используя стандартные логические операторы. В 1993 году Arcadia стала подразделением CompTek. В 1993-1994 годах программные технологии были существенно усовершенствованы благодаря сотрудничеству с лабораторией Ю.А. Д. Апресян (Институт проблем передачи информации РАН). В частности, словарь, обеспечивающий поиск с учетом морфологии русского языка, весил всего 300 Кб, то есть загружался в оперативную память и работал очень быстро. С этого момента пользователь может задавать любые формы слов в запросе. На основе новой технологии в 1994 году был создан «Библейский компьютерный справочник» (информационно-поисковая система, обеспечивающая работу с синодальным переводом Ветхого и Нового Заветов). В 1995 году стартовал проект «Академическое издание классики на компакт-дисках», разработанный совместно с НТЦ «Информрегистр» и ИМЛИ им. М. Горького РАН при поддержке Роскоминформа. Для этого проекта была создана универсальная технология «Аргонавт», включающая в себя как средства разметки и отображения, так и средства навигации, а также различные поиски — как текстовые, так и атрибутивные. На основе этой технологии появилось 3 издания — справочник стандартов «Информ — Норматив», электронное научное издание «А. С. Грибоедов» и «Пушкин. Электронный фонд русской классической литературы». Также был создан словарь языка Грибоедова. В начале 1996 года был разработан алгоритм построения гипотез. Отныне морфологический анализ перестал быть привязанным к словарю — если слова в словаре нет, то находятся словарные слова, наиболее похожие на него, и по ним строится модель словоизменения. В это время интернет в России только начинался… М. Горького РАН при поддержке Роскоминформа. Для этого проекта была создана универсальная технология «Аргонавт», включающая в себя как средства разметки и отображения, так и средства навигации, а также различные поиски — как текстовые, так и атрибутивные. На основе этой технологии появилось 3 издания — справочник стандартов «Информ — Норматив», электронное научное издание «А. С. Грибоедов» и «Пушкин. Электронный фонд русской классической литературы». Также был создан словарь языка Грибоедова. В начале 1996 года был разработан алгоритм построения гипотез. Отныне морфологический анализ перестал быть привязанным к словарю — если слова в словаре нет, то находятся словарные слова, наиболее похожие на него, и по ним строится модель словоизменения. В это время интернет в России только начинался…НачалоЛетом 1996 года руководство CompTek и разработчики поисковика пришли к выводу, что разработка самой технологии важнее и интереснее, чем создание прикладных продуктов на основе поиска. Исследование рынка показало актуальность и большие перспективы поисковых технологий. Потом в Интернете и появился «Яндекс». Слово «Яндекс» было придумано несколькими годами ранее одним из главных и старейших разработчиков поисковой системы. «Яндекс» означает «Языковой индекс», или, если по-английски, «Яндекс» — «Еще один индексатор». За 4 года публичного существования Яндекса были и другие интерпретации. Например, если в слове «Index» перевести с английского первую букву («I» — «я»), получится «Яндекс». На выставке Netcom’96 18 октября 1996 года CompTek анонсировала первые продукты серии Яндекс (Яндекс.Сайт, Yndex.Dict). Яндекс.Сайт — поиск по вашему сайту — теперь установлен на сотнях серверов Рунета. Yndex.Dict, морфологическое расширение запроса, до сих пор используется, например, для отправки запроса в Yahoo, хотя на сегодняшний день это уже не так актуально — Yahoo индексирует рунет гораздо хуже российских поисковых систем. Через полгода появился Yndex.CD — поиск документов на CD-ROM, а затем Yndex. Исследование рынка показало актуальность и большие перспективы поисковых технологий. Потом в Интернете и появился «Яндекс». Слово «Яндекс» было придумано несколькими годами ранее одним из главных и старейших разработчиков поисковой системы. «Яндекс» означает «Языковой индекс», или, если по-английски, «Яндекс» — «Еще один индексатор». За 4 года публичного существования Яндекса были и другие интерпретации. Например, если в слове «Index» перевести с английского первую букву («I» — «я»), получится «Яндекс». На выставке Netcom’96 18 октября 1996 года CompTek анонсировала первые продукты серии Яндекс (Яндекс.Сайт, Yndex.Dict). Яндекс.Сайт — поиск по вашему сайту — теперь установлен на сотнях серверов Рунета. Yndex.Dict, морфологическое расширение запроса, до сих пор используется, например, для отправки запроса в Yahoo, хотя на сегодняшний день это уже не так актуально — Yahoo индексирует рунет гораздо хуже российских поисковых систем. Через полгода появился Yndex.CD — поиск документов на CD-ROM, а затем Yndex. Lib — полнофункциональная библиотека Яндекса для встраивания в различные приложения и базы данных. Через полгода стало очевидно, что CompTek ничто не отделяет от создания собственной глобальной поисковой системы. Объем Рунета тогда составлял всего несколько гигабайт. Осенью 1997 года был открыт «Яндекс.Ру». Необходимость поддержки работы Яндекс.Ру в условиях больших объемов и больших нагрузок (несколько запросов в секунду) приводит к оптимизации алгоритмов, которые затем используются в других продуктах Яндекса. Lib — полнофункциональная библиотека Яндекса для встраивания в различные приложения и базы данных. Через полгода стало очевидно, что CompTek ничто не отделяет от создания собственной глобальной поисковой системы. Объем Рунета тогда составлял всего несколько гигабайт. Осенью 1997 года был открыт «Яндекс.Ру». Необходимость поддержки работы Яндекс.Ру в условиях больших объемов и больших нагрузок (несколько запросов в секунду) приводит к оптимизации алгоритмов, которые затем используются в других продуктах Яндекса.Поисковая системаЯндекс появился на рынке, когда там царили поисковики, которые искали по английскому принципу. Известно, что в английском языке слова почти не склоняются. Сегалович взял Библейскую симфонию, изучил принцип, потому что она была сделана с учетом морфологии. Сначала велась электронная Библия (точнее справочник), позже этот принцип был принят за основу. Поисковая система Яндекс.ру была официально анонсирована 23 сентября 19 года.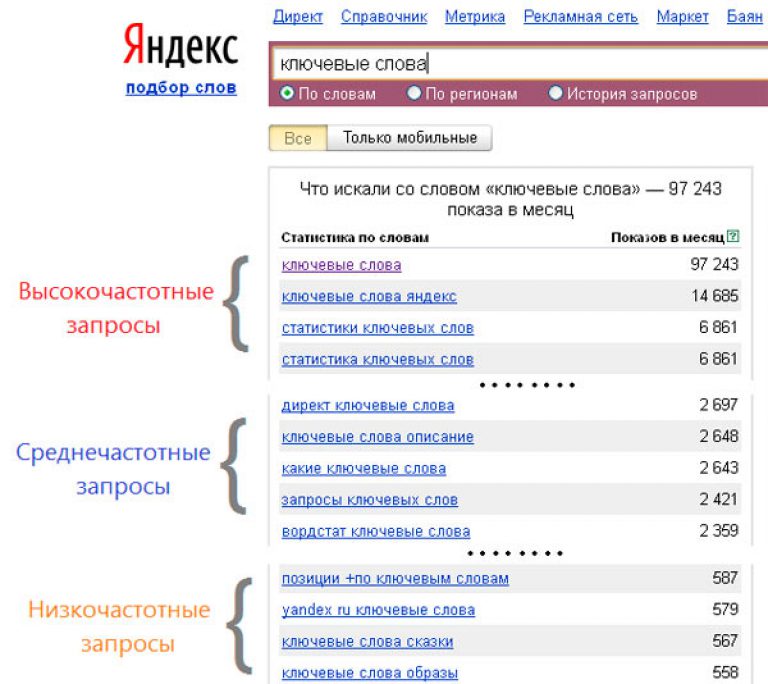 97, и впервые он был разработан в рамках CompTek International. Как отдельная компания «Яндекс» образован в 2000 году. Компания вышла на самоокупаемость в 2002 году, оборот за 2009 год составил 278 миллионов долларов. Кстати, поисковик Яндекс мог купить Рамблер (на тот момент лидера поиска в Рунете), причем очень недорого, но не смог оценить перспективы. 97, и впервые он был разработан в рамках CompTek International. Как отдельная компания «Яндекс» образован в 2000 году. Компания вышла на самоокупаемость в 2002 году, оборот за 2009 год составил 278 миллионов долларов. Кстати, поисковик Яндекс мог купить Рамблер (на тот момент лидера поиска в Рунете), причем очень недорого, но не смог оценить перспективы.ОфисыВсе офисы Яндекса на карте мира Главный офис компании находится в Москве. Компания имеет офисы в Санкт-Петербурге, Екатеринбурге, Новосибирске, Одессе, Симферополе, Киеве и Казани.В середине июня 2008 года компания объявила об открытии Яндекс Лаборатории, офиса в США, штат Калифорния. Возможности поиска Яндекса
|
 Родился 11 февраля 1964 г. н.э. в городе Гурьеве Казахской ССР (ныне Атырау).
Родился 11 февраля 1964 г. н.э. в городе Гурьеве Казахской ССР (ныне Атырау). 