15 правил написания качественного кода
Есть мириады способов написать плохой код. К счастью, чтобы подняться до уровня качественного кода, достаточно следовать 15 правилам. Их соблюдение не сделает из вас мастера, но позволит убедительно имитировать его.
Правило 1. Следуйте стандартам оформления кода.
У каждого языка программирования есть свой стандарт оформления кода, который говорит, как надо делать отступы, где ставить пробелы и скобки, как называть объекты, как комментировать код и т.д.
Например, в этом куске кода в соответствии со стандартом есть 12 ошибок:
for(i=0 ;i
Изучайте стандарт внимательно, учите основы наизусть, следуйте правилам как заповедям, и ваши программы станут лучше, чем большинство, написанные выпускниками вузов.
Многие организации подстраивают стандарты под свои специфические нужды. Например, Google разработал стандарты для более чем 12 языков программирования. Они хорошо продуманы, так что изучите их, если вам нужна помощь в программировании под Google. Стандарты даже включают в себя настройки редактора, которые помогут вам соблюдать стиль, и специальные инструменты, верифицирующие ваш код на соответствию этому стилю. Используйте их.
Стандарты даже включают в себя настройки редактора, которые помогут вам соблюдать стиль, и специальные инструменты, верифицирующие ваш код на соответствию этому стилю. Используйте их.
Правило 2. Давайте наглядные имена.
Ограниченные медленными, неуклюжими телетайпами, программисты в древности использовали контракты для имён переменных и процедур, чтобы сэкономить время, стуки по клавишам, чернила и бумагу. Эта культура присутствует в некоторых сообществах ради сохранения обратной совместимости. Возьмите, например, ломающую язык функцию C wcscspn (wide character string complement span). Но такой подход неприменим в современном коде.
Используйте длинные наглядные имена наподобие complementSpanLength, чтобы помочь себе и коллегам понять свой код в будущем. Исключения составляют несколько важных переменных, используемых в теле метода, наподобие итераторов циклов, параметров, временных значений или результатов исполнения.
Гораздо важнее, чтобы вы долго и хорошо думали перед тем, как что-то назвать. Является ли имя точным? Имели ли вы в виду highestPrice или bestPrice? Достаточно ли специфично имя, дабы избежать его использования в других контекстах для схожих по смыслу объектов? Не лучше ли назвать метод getBestPrice заместо getBest? Подходит ли оно лучше других схожих имён? Если у вас есть метод ReadEventLog, вам не стоит называть другой NetErrorLogRead. Если вы называете функцию, описывает ли её название возвращаемое значение?
Является ли имя точным? Имели ли вы в виду highestPrice или bestPrice? Достаточно ли специфично имя, дабы избежать его использования в других контекстах для схожих по смыслу объектов? Не лучше ли назвать метод getBestPrice заместо getBest? Подходит ли оно лучше других схожих имён? Если у вас есть метод ReadEventLog, вам не стоит называть другой NetErrorLogRead. Если вы называете функцию, описывает ли её название возвращаемое значение?
В заключение, несколько простых правил именования. Имена классов и типов должны быть существительными. Название метода должно содержать глагол. Если метод определяет, является ли какая-то информация об объекте истинной или ложной, его имя должно начинаться с «is». Методы, которые возвращают свойства объектов, должны начинаться с «get», а устанавливающие значения свойств — «set».
Правило 3. Комментируйте и документируйте.
Начинайте каждый метод и процедуру с описания в комментарии того, что данный метод или процедура делает, параметров, возвращаемого значения и возможных ошибок и исключений. Опишите в комментариях роль каждого файла и класса, содержимое каждого поля класса и основные шаги сложного кода. Пишите комментарии по мере разработки кода. Если вы полагаете, что напишете их потом, то обманываете самого себя.
Опишите в комментариях роль каждого файла и класса, содержимое каждого поля класса и основные шаги сложного кода. Пишите комментарии по мере разработки кода. Если вы полагаете, что напишете их потом, то обманываете самого себя.
Вдобавок, убедитесь, что для вашего приложения или библиотеки есть руководство, объясняющее, что ваш код делает, определяющий его зависимости и предоставляющий инструкции для сборки, тестирования, установки и использования. Документ должен быть коротким и удобным; просто README-файла часто достаточно.
Правило 4. Не повторяйтесь.
Никогда не копируйте и не вставляйте код. Вместо этого выделите общую часть в метод или класс (или макрос, если нужно), и используйте его с соответствующими параметрами. Избегайте использования похожих данных и кусков кода. Также используйте следующие техники:
- Создание справочников API из комментариев, используя Javadoc и Doxygen.
- Автоматическая генерация Unit-тестов на основе аннотаций или соглашений об именовании.

- Генерация PDF и HTML из одного размеченного источника.
- Получение структуры классов из базы данных (или наоборот).

Правило 5. Проверяйте на ошибки и реагируйте на них.
Методы могут возвращать признаки ошибки или генерировать исключения. Обрабатывайте их. Не полагайтесь на то, что диск никогда не заполнится, ваш конфигурационный файл всегда будет на месте, ваше приложение будет запущено со всеми нужными правами, запросы на выделение памяти всегда будут успешно исполнены, или что соединение никогда не оборвётся. Да, хорошую обработку ошибок тяжело написать, и она делает код длиннее и труднее для чтения. Но игнорирование ошибок просто заметает проблему под ковёр, где ничего не подозревающий пользователь однажды её обнаружит.
Правило 6. Разделяйте код на короткие, обособленные части.
Каждый метод, функция или блок кода должн умещаться в обычном экранном окне (25-50 строк). Если получилось длиннее, разделите на более короткие куски. Даже внутри метода разделяйте длинный код на блоки, суть которых вы можете описать в комментарии в начале каждого блока.
Более того, каждый класс, модуль, файл или процесс должен выполнять определённый род задач. Если часть кода выполняет совершенно разнородные задачи, то разделите его соответственно.
Правило 7. Используйте API фреймворков и сторонние библиотеки.
Изучите, какие функции доступны с помощью API вашего фреймворка. а также что могут делать развитые сторонние библиотеки. Если библиотеки поддерживаются вашим системным менеджером пакетов, то они скорее всего окажутся хорошим выбором. Используйте код, удерживающий от желания изобретать колесо (при том бесполезной квадратной формы).
Правило 8. Не переусердствуйте с проектированием.
Проектируйте только то, что актуально сейчас. Ваш код можно делать довольно обобщённым, чтобы он поддерживал дальнейшее развитие, но только в том случае, если он не становится от этого слишком сложным. Не создавайте параметризованные классы, фабрики, глубокие иерархии и скрытые интерфейсы для решения проблем, которых даже не существует — вы не можете угадать, что случится завтра. С другой стороны, когда структура кода не подходит под задачу, не стесняйтесь рефакторить его.
С другой стороны, когда структура кода не подходит под задачу, не стесняйтесь рефакторить его.
Правило 9. Будьте последовательны.
Делайте одинаковые вещи одинаковым образом. Если вы разрабатываете метод, функциональность которого похожа на функциональность уже существующего, то используйте похожее имя, похожий порядок параметров и схожую структура тела. То же самое относится и к классам. Создавайте похожие поля и методы, делайте им похожие интерфейсы, и сопоставляйте новые имена уже существующим в похожих классах.
Ваш код должен соответствовать соглашениям вашего фреймворка. Например, хорошей практикой является делать диапазоны полуоткрытыми: закрытыми (включающими) слева (в начале диапазона) и открытыми (исключающими) справа (в конце). Если для конкретного случая нет соглашений, то сделайте выбор и фанатично придерживайтесь его.
Правило 10. Избегайте проблем с безопасностью.
Современный код редко работает изолированно. У него есть неизбежный риск стать мишенью атак. Они необязательно должны приходить из интернета; атака может происходить через входные данные вашего приложения. В зависимости от вашего языка программирования и предметной области, вам возможно стоит побеспокоиться о переполнении буфера, кросс-сайтовых сценариях, SQL-инъекциях и прочих подобных проблемах. Изучите эти проблемы, и избегайте их в коде. Это не сложно.
Они необязательно должны приходить из интернета; атака может происходить через входные данные вашего приложения. В зависимости от вашего языка программирования и предметной области, вам возможно стоит побеспокоиться о переполнении буфера, кросс-сайтовых сценариях, SQL-инъекциях и прочих подобных проблемах. Изучите эти проблемы, и избегайте их в коде. Это не сложно.
Правило 11. Используйте эффективные структуры данных и алгоритмы.
Простой код часто легче сопровождать, чем такой же, но изменённый ради эффективности. К счастью, вы можете совмещать сопровождаемость и эффективность, используя структуры данных и алгоритмы, которые даёт ваш фреймворк. Используйте map, set, vector и алгоритмы, которые работают с ними. Благодаря этому ваш код станет чище, быстрее, более масштабируемым и более экономным с памятью. Например, если вы сохраните тысячу значений в отсортированном множестве, то операция пересечения найдёт общие элементы с другим множеством за такое же число операций, а не за миллион сравнений.
Правило 12. Используйте Unit-тесты.
Сложность современного ПО делает его установку дороже, а тестирование труднее. Продуктивным подходом будет сопровождение каждого куска кода тестами, которые проверяют корректность его работы. Этот подход упрощает отладку, т.к. он позволяет обнаружить ошибки раньше. Unit-тестирование необходимо, когда вы программируете на языках с динамической типизацией, как Python и JavaScript, потому что они отлавливают любые ошибки только на этапе исполнения, в то время как языки со статической типизацией наподобие Java, C# и C++ могут поймать часть из них во время компиляции. Unit-тестирование также позволяет рефакторить код уверенно. Вы можете использовать XUnit для упрощения написания тестов и автоматизации их запуска.
Правило 13. Сохраняйте код портируемым.
Если у вас нет особой причины, не используйте функциональность, доступную только на определённой платформе. Не полагайтесь на то, что определённые типы данных (как integer, указатели и временные метки) будут иметь конкретную длину (например, 32 бита), потому что этот параметр отличается на разных платформах. Храните сообщения программы отдельно от кода и на зашивайте параметры, соответствующие определённой культуре (например, разделители дробной и целой части или формат даты). Соглашения нужны для того, чтобы код мог запускаться в разных странах, так что сделайте локализацию настолько безболезненной, насколько это возможно.
Храните сообщения программы отдельно от кода и на зашивайте параметры, соответствующие определённой культуре (например, разделители дробной и целой части или формат даты). Соглашения нужны для того, чтобы код мог запускаться в разных странах, так что сделайте локализацию настолько безболезненной, насколько это возможно.
Правило 14. Делайте свой код собираемым.
Простая команда должна собирать ваш код в форму, готовую к распространению. Команда должна позволять вам быстро выполнять сборку и запускать необходимые тесты. Для достижения этой цели используйте средства автоматической сборки наподобие Make, Apache Maven, или Ant. В идеале, вы должны установить интеграционную систему, которая будет проверять, собирать и тестировать ваш код при любом изменении.
Правило 15. Размещайте всё в системе контроля версий.
Все ваши элементы — код, документация, исходники инструментов, сборочные скрипты, тестовые данные — должны быть в системе контроля версий. Git и GitHub делают эту задачу дешёвой и беспроблемной. Но вам также доступны и многие другие мощные инструменты и сервисы. Вы должны быть способны собрать и протестировать вашу программу на сконфигурированной системе, просто скачав её с репозитория.
Но вам также доступны и многие другие мощные инструменты и сервисы. Вы должны быть способны собрать и протестировать вашу программу на сконфигурированной системе, просто скачав её с репозитория.
Заключение.
Сделав эти 15 правил частью вашей ежедневной практики, вы в конце концов создадите код, который легче читать, который хорошо протестирован, с большей вероятностью запустится корректно и который будет гораздо проще изменить, когда придёт время. Вы также убережёте себя и ваших пользователей от большого числа головных болей.
Перевод статьи «15 Rules for Writing Quality Code»
Стандарты написания кода в 21-school: The Norm
Среди мануалов и файлов школы затерялся замечательный файл The Nom — Coding Standard — Academy+Plus, в котором описываются стандарты написания кода на с, без соблюдения которых наши программы никогда не смогут пройти проверку больше чем на 0 баллов.
Для проверки
кода надо открыть в терминале в папку с файлами с исходным кодом и запустить в
терминале norminette -R CheckForbiddenSourceHeader ( © @ghildega ).
Сам файл
можно найти здесь:
https://cdn.intra.42.fr/pdf/pdf/960/norme.en.pdf411
Что это за зверь такой — «стандарты написания кода»? https://ru.wikipedia.org/wiki/Стандарт_оформления_кода107
Он полностью на английском, поэтому хочу поделиться с вами своим конспектом-переводом. Я буду рад, если вы поможете мне уточнить перевод в комментариях! Для этого достаточно владеть английским на уровне выше INTERMEDIATE и не пользоваться так же активно гугл-перевордчиком, как я)
И, как говорится, “Ставьте лайки, подписывайтесь”, ставьте uovotes (Стрелочка вверх), комментируйте)
ВНИМАНИЕ! СРЕДИ БУКВ НИЖЕ СМОЖЕТ БЫТЬ МНОЖЕСТВО ОШИБОК И НЕТОЧНОСТЕЙ! СВЕРЯЙТЕСЬ С ОРИГИНАЛОМ: https://cdn.intra.42.fr/pdf/pdf/960/norme.en.pdf411
Глава 1
I.1 Зачем
нужен стандарт?
▪ Для того, чтобы кто угодно (студенты, сотрудники и даже вы) могли легко
прочитать ваш код и разобраться в нем
▪ Чтобы ваш код был простым и коротким
I.2 Стандарт в 21 школе(?)
▪ Все ваши программы на C должны соответствовать стандарту — это будет
проверяться! Если вы сделаете ошибку и ваш код не будет соответствовать
стандарту — вы получите 0 за задание или даже за весь проект!
I. 3 Советы
3 Советы
▪ Скоро вы поймете, что норма не так страшна, как кажется. Наоборот, она
помогает вам: вы заметите, как легко будет читать код ваших одноклассников ваш!
▪ Для проверяющей системы все равно, сколько Nom Error в вашем коде: хоть 1,
хоть 10
▪ Помните о стандарте! В начале это будет замедлять вашу работу, но скоро
перейдет на уровень рефлексов!
I.4 Отказ от
ответственности
▪ Norminette — это программа. И кака всякая программа, она подвержена ошибкам.
Но скорее всего ошибка на вашей стороне)
Глава 2 Нормы:
II.1 Название переменных:
▪ Имя structure должно начинаться с s_.
▪ Имя typedef должно начинаться с t_.
▪ Название union должно начинаться с u_.
▪ Имя enum должно начинаться с e_.
▪ Глобальное имя должно начинаться с g_.
▪ Имена переменных и функций могут содержать только строчные буквы, цифры и символы “_”.
▪ Имена файлов и каталогов могут содержать только строчные буквы, цифры и ‘’_”
▪ Файл должен скомпилироваться.
▪ Символы, которые не являются частью стандартной таблицы ascii, запрещены.
Рекомендации:
▪ Объекты (переменные, функции, макросы, типы, файлы или каталоги) должны иметь понятные имена, благодаря которым среди них можно будет легко ориентироваться и запоминать их.
▪ Только переменные-счетчики могут быть названы по вашему вкусу!
▪ Если вы сокращаете слово в названии переменной — то оно должно оставаться понятным! Если имя содержит более одного слова — слова должны быть разделены символом “_”.
▪ Все идентификаторы (функции, макросы, типы, переменные и т. д.) Должны быть на английском языке.
▪ Любое использование глобальной переменной должно быть оправданным.
II.2 Оформление:
▪ Все ваши файлы должны начинаться со стандартного школьного заголовка (с первой строки файла). Этот заголовок по умолчанию доступен с emacs и vim в дампах.
▪ В качестве откупа используется 4-пробельная табуляция (Внимание! не 4 пробела!)
▪ Каждая функция должна содержать не более 25 строк,
не считая собственных фигурных скобок функции.
▪ Каждая строка должна содержать не более 80 символов, включая комментарии. Предупреждение: один знак табуляции считается за 4 символа!
▪ Одна инструкция на строку.
▪ Пустая строка должна быть пустой: без пробелов и табов
▪ Строка никогда не может заканчиваться пробелами или табами
▪ Вам нужно начинать новую строку после каждой фигурной скобки или конца управляющей структуры.
▪ За каждой запятой или точкой с запятой должен стоять пробел, если это не конец строки
▪ Каждый оператор (двоичный или троичный) или операнд должен быть разделен одним и только одним пробелом.
▪ Каждое ключевое слово C должно сопровождаться пробелом, за исключением ключевых слов для типов (таких как int, char, float и т. Д.), А также sizeof.
▪ ?????Каждое объявление переменной должно иметь отступ в том же столбце.(Each variable declaration must be indented on the same column. )
▪ Звездочки указателей должны быть вплотную к именам переменных.
▪ Одно объявление переменной на строку
▪ Нельзя делать объявление и инициализацию в одной
строке, за исключением глобальных и статических переменных.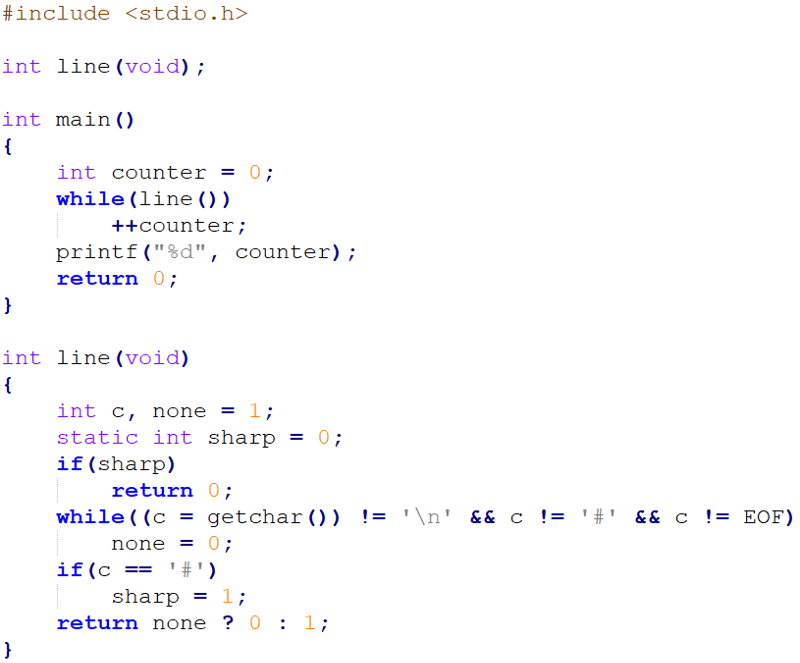
▪ Объявления переменных должны быть в начале функции и должны быть отделены пустой строкой.
▪ Не должно быть пустой строки между объявлениями или реализациями.
▪ Многократные назначения строго запрещены???
▪ Вы можете добавить новую строку после инструкции или управляющей структуры, но вам придется добавить отступ в скобках или оператор присваивания. Операторы должны быть в начале строки. (You may add a new line after an instruction or control structure, but you’ll have to add an indentation with brackets or affectation operator. Operators must be at the beginning of a line. )
II.3 Параметры функции:
▪ Функция должна принимать максимум 4 именованных параметров.
▪ Функция, которая не принимает аргументы, должна быть явно прототипирована с помощью слово «void» в качестве аргумента.
II.4 Функции:
▪ Параметры в прототипах функций должны быть названы.
▪ Каждая функция должна быть отделена от следующей пустой строкой.
▪ Вы не можете объявить более 5 переменных в блоке.
▪ Возвращение функции должно быть между скобками.
Рекомендации:
▪ Идентификаторы ваших функций должны быть выровнены в одном и том же файле. То
же самое касается заголовочных файлов.
II.5 Typedef, struct, enum и union Обязательная часть
▪ Добавьте табуляцию при объявлении struct, enum or union.
▪ При объявлении переменной типа struct, enum или union добавьте один пробел в тип.
▪ Добавляйте табуляцию между двумя параметрами typedef.
▪ При объявлении struct, enum or union с помощью typedef применяются все правила. Вы должны выровнять имя typedef с именем struct / union / enum.
▪ Вы не можете объявить struct в файле .c.
II.6 Обязательная часть заголовков
▪ В заголовочных файлах разрешены следующие вещи: включения заголовка (системные или нет), объявления, определения, прототипы и макросы.
▪ Все включения (.c или .h) должны быть в начале файла.
▪ Заголовки защищены от двойных включений. Если файл
ft_foo.h, его bystander macro это
FT_FOO_H.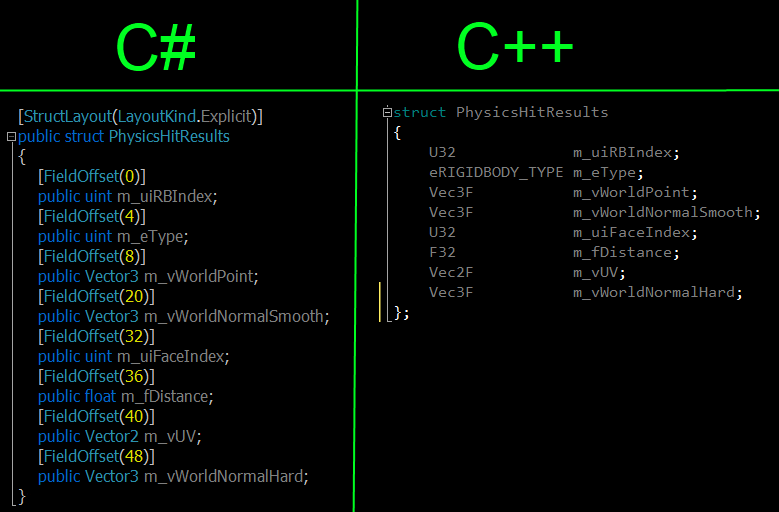
▪ Прототипы функций должны быть исключительно в файлах .h.
▪ Неиспользуемые заголовки (.h) запрещены.
▪ Рекомендации
▪ Все включения заголовка должны быть обоснованы как в файле .c, так и в файле .h.
II.7 Макросы и препроцессоры
▪ Константы препроцессора (или #define), которые вы создаете, должны использоваться только для связывания литеральных и константных значений.
▪ Запрещены все #define, созданные для обхода нормального и / или запутанного кода. Этот момент должен быть проверен человеком.
▪ Вы можете использовать макросы, доступные в стандартных библиотеках, только если они разрешены в рамках данного проекта.
▪ Многострочные макросы запрещены.
▪ Все имена макросов должны быть в верхнем регистре!
▪ Вы должны сделать отступ для символов после #if, #ifdef или #ifndef.
II.8 Запрещено!!
▪ Вам запрещено использовать:
1. for
2. do…while
3. switch
4. case
5. goto
▪ Вложенные троичные операторы, такие как «?».
▪ VLA — массивы переменной длины.
II.9 Комментарии
▪ Вам разрешено комментировать свой код в исходных файлах.
▪ Комментарии не могут быть внутри(inside) тела функции.
▪ Комментарии начинаются и заканчиваются одной строкой. Все промежуточные линии должны совпадать и начинаться с «**».
▪ Нет комментариев с //.
Рекомендации:
▪ Ваши комментарии должны быть на английском языке. И они должны быть
полезными.
▪ Комментарий не может оправдать «ублюдочную» функцию.
II.10 Файлы
▪ Вы не можете включить файл .c.
▪ Вы не можете иметь более 5 определений функций в файле .c.
II.11 Makefile
▪ $ (NAME), clean, fclean, re и все правила являются обязательными.
▪ Если make-файл перелинкует, проект будет считаться нефункциональным.(If the makefile relinks, the project will be considered non-functional )
▪ В случае мультибинарного проекта, в дополнение к
правилам, которые мы видели, у вас должно быть правило, которое компилирует оба
двоичных файла, а также определенное правило для каждого скомпилированного
двоичного файла.
▪ В случае проекта, который вызывает библиотеку функций (например, libft), ваш make-файл должен автоматически скомпилировать эту библиотеку.
▪ Все исходные файлы, которые вам нужны для компиляции вашего проекта, должны быть явно названы в вашем Makefile.
Буду рад Вашим комментариям и уточнениям перевода!
Сейчас можно пользоваться Norminette из дома, а не только из школы программирования 21. Как настроить это в Linux Mint или Ubuntu смотрите в этом видео.
Введение в стандарты кодирования — правила и рекомендации по кодированию
Стандарты кодирования — это набор правил кодирования, руководств и передовых методов. Использование правильного — например, стандартов кодирования C и стандартов кодирования C++ — поможет вам писать более чистый код.
Здесь мы объясняем, почему важны стандарты кодирования, поэтому считайте это руководством по поиску и использованию правил и руководств по кодированию.
Прочтите или перейдите к разделу, который вас больше всего интересует:
- Что такое Правила и рекомендации по написанию кода?
- Почему важны стандарты кодирования?
- Важные стандарты C кодирования
- Важные стандарты кодирования C ++
- Как обеспечить соблюдение стандартов кодирования со статическим анализом кода
- ➡ Начните свой бесплатный анализ статического кода.
Правила и рекомендации по кодированию гарантируют, что программное обеспечение:
- Безопасно: Его можно использовать, не причиняя вреда.
- Безопасность: Невозможно взломать.
- Надежный: Всегда работает как надо.
- Тестируемый: Можно протестировать на уровне кода.
- Поддерживаемый: Его можно поддерживать, даже если ваша кодовая база растет.
- Portable: Работает одинаково в любой среде.
▶️ Веб-семинар по теме: Как применять стандарт кодирования
Почему важны стандарты кодирования?
Причина, по которой стандарты кодирования важны, заключается в том, что они помогают обеспечить безопасность, защищенность и надежность.
Каждая команда разработчиков должна использовать его. Даже самый опытный разработчик может внести дефект кода, не осознавая этого. И этот один дефект может привести к небольшому сбою. Или, что еще хуже, серьезное нарушение безопасности.
Существует четыре основных преимущества использования стандартов кодирования:
1. Соответствие отраслевым стандартам (например, ISO).
2. Стабильное качество кода — независимо от того, кто пишет код.
3. Безопасность программного обеспечения с самого начала.
4. Снижение затрат на разработку и ускорение выхода на рынок.
В отраслях встраиваемых систем эти стандарты необходимы (или настоятельно рекомендуются) для обеспечения соответствия.
Это особенно верно для стандартов функциональной безопасности, включая:- IEC 61508: «Функциональная безопасность электрических/электронных/программируемых электронных систем, связанных с безопасностью»
- ISO 26262: «Дорожные транспортные средства — функциональная безопасность»
- EN 50128: «Железнодорожные приложения. Системы связи, сигнализации и обработки данных. Программное обеспечение для железнодорожных систем управления и защиты»
- IEC 62061: «Безопасность машин: Функциональная безопасность электрических, электронных и программируемых электронных систем управления»
Каждый один написан для определенного языка программирования. Большинство разработчиков встраиваемых систем используют C или C++.
Важные стандарты кодирования C
Язык программирования C является гибким. Он также известен высокой производительностью. Вот почему он популярен среди разработчиков встраиваемых систем.
Но C тоже подвержен риску.
Код C может быть скомпилирован с неопределенным поведением. И это неопределенное поведение открывает ваш код для уязвимостей и дефектов. Или ваш код C может быть непредсказуемым, когда он перенесен на другое оборудование.Использование стандартов кодирования C — это разумный способ найти неопределенное и непредсказуемое поведение.
Существует несколько установленных стандартов. Некоторые из них специально разработаны для обеспечения функциональной безопасности, например MISRA. Другие ориентированы на безопасное кодирование, включая CERT.
Популярные стандарты кодирования для встроенных программ C
Выбор правильного стандарта кодирования C может быть трудным, но это не обязательно.Получить помощь в выборе стандарта кодирования C:
📕 Связанный информационный документ: КАК ВЫБРАТЬ ВСТРОЕННЫЙ СТАНДАРТ кодирования C
Важные стандарты кодирования C++
Язык программирования C++ больше и сложнее, чем C.
Как и C, С++ гибкий. И это признано за высокую производительность.Но чтобы иметь поддерживаемую кодовую базу, важно использовать правила кодирования C++. Это поможет вам исключить неопределенное и непредсказуемое поведение из вашего кода.
Существует несколько установленных стандартов для C++. Некоторые из них относятся к отраслям встраиваемых систем, озабоченным функциональной безопасностью, включая MISRA, AUTOSAR и JSF AV C++. Другие предназначены для безопасного кодирования, например CERT.
Популярные стандарты кодирования для встраиваемых систем C++
Как обеспечить соблюдение стандартов кодирования C и C++ с помощью статического анализа кода
У вас может быть стандарт кодирования, но это не значит, что его соблюдают.
Статические анализаторы, такие как Helix QAC или Klocwork, — лучший способ обеспечить их соблюдение. Используя автоматический статический анализ, вы можете убедиться, что ваш код соответствует требованиям, прежде чем тратить время на экспертную оценку кода.
Кроме того, это делает этапы проверки кода и тестирования более эффективными.Стандарты кодирования и передовой опыт
Содержание
Что такое стандарты кодирования?Думайте о стандартах кодирования как о наборе правил, методов и передовых методов для создания более чистого, более читаемого и более эффективного кода с минимальным количеством ошибок. Они предлагают единый формат, который инженеры-программисты могут использовать для создания сложного и высокофункционального кода.
Преимущества внедрения стандартов кодирования- Обеспечивает единообразие кода, созданного разными инженерами.
- Позволяет создавать повторно используемый код.
- Облегчает обнаружение ошибок.
- Сделать код проще, читабельнее и легче в обслуживании.
- Повышение эффективности программиста и ускорение получения результатов.
- Выберите отраслевые стандарты кодирования
Передовой опыт и стандарты кодирования различаются в зависимости от отрасли, для которой создается конкретный продукт.
Стандарты, необходимые для программного обеспечения для роскошных автомобилей, будут отличаться от стандартов для программного обеспечения для игр.Например, MISRA C и C++ были написаны для автомобильной промышленности и считаются стандартами де-факто для создания приложений, уделяющих особое внимание безопасности. В настоящее время они считаются лучшими практиками написания кода в отрасли.
Соблюдение отраслевых стандартов упрощает написание точного кода, соответствующего ожиданиям продукта. Становится легче писать код, который удовлетворит конечных пользователей и будет соответствовать бизнес-требованиям.
- Сосредоточьтесь на удобочитаемости кода
Читаемый код легко читается, оптимизирует пространство и время. Вот несколько способов добиться этого:
- Пишите как можно меньше строк.
- Используйте соответствующие соглашения об именах.
- Разделить блоки кода в одном разделе на абзацы.
- Используйте отступ для обозначения начала и конца структур управления. Четко укажите код между ними.
- Не используйте длинные функции. В идеале одна функция должна выполнять одну задачу.
- Используйте принцип DRY (не повторяйтесь). Автоматизируйте повторяющиеся задачи, когда это необходимо. Один и тот же фрагмент кода не должен повторяться в сценарии.
- Избегайте глубокой вложенности. Слишком большое количество уровней вложенности затрудняет чтение и выполнение кода.
- Используйте специальные слова и имена функций SQL с заглавной буквы, чтобы отличать их от имен таблиц и столбцов.
- Избегайте длинных очередей. Людям легче читать блоки строк, которые являются короткими по горизонтали и длинными по вертикали.
- Стандартизируйте заголовки для разных модулей
Код легче понимать и поддерживать, когда заголовки разных модулей соответствуют единому формату. Например, каждый заголовок должен содержать:
- Имя модуля
- Дата создания
- Имя создателя модуля
- История изменений
- Краткое описание того, что делает модуль
- Функции в этом модуле
- Доступ к переменным модуль
- Не используйте один идентификатор для нескольких целей
Присвойте каждой переменной имя, четко описывающее ее назначение.
Естественно, одной переменной нельзя присвоить несколько значений или использовать для множества функций. Это запутало бы всех, кто читает код, и затруднило бы реализацию будущих улучшений. Всегда назначайте уникальные имена переменных.- Превратите ежедневное резервное копирование в инстинкт
Несколько событий могут вызвать потерю данных — сбой системы, разряженный аккумулятор, программный сбой, повреждение оборудования и т. д. Чтобы предотвратить это, сохраняйте код ежедневно и после каждой модификации, какой бы незначительной она ни была. Создайте резервную копию рабочего процесса в TFS, SVN или любом другом механизме контроля версий.
- Оставляйте комментарии и расставляйте приоритеты в документации
Не думайте, что только потому, что все остальные, просматривающие код, являются разработчиками, они инстинктивно поймут его без пояснений. Разработчики тоже люди, и им гораздо проще читать комментарии, описывающие функции кода, чем сканировать код и делать предположения.
Потратьте лишнюю минуту, чтобы написать комментарий, описывающий функцию кода в различных точках скрипта. Убедитесь, что комментарии помогут читателям разобраться с реализованным алгоритмом и логикой. Конечно, это требуется только тогда, когда цель кода не очевидна. Не трудитесь оставлять комментарии к понятному коду.
- Попытаться формализовать обработку исключений
«Исключение» относится к проблемам, проблемам или необычным событиям, возникающим при запуске кода и нарушающим нормальный ход выполнения. Это либо приостанавливает, либо завершает выполнение программы, чего следует избегать.
Однако, когда они все же возникают, используйте следующие приемы, чтобы свести к минимуму ущерб общему выполнению с точки зрения времени и усилий разработчиков:
- Сохраняйте код в блоке try-catch.
- Убедитесь, что автоматическое восстановление активировано и его можно использовать.
- Учтите, что это может быть связано с программным обеспечением/медленностью сети. Подождите несколько секунд, пока не появятся необходимые элементы.
- Использовать анализ журнала в реальном времени.
Узнайте больше об обработке исключений в Selenium WebDriver.
- При выборе стандартов подумайте о закрытых и открытых
Рассмотрите CERT и MISRA. CERT уделяет особое внимание сотрудничеству и участию сообщества. Он предлагает стандарт кодирования, который находится в свободном доступе в виде веб-вики. С помощью CERT пользователи могут комментировать определенные рекомендации — комментарии учитываются при пересмотре и обновлении стандартов.
С другой стороны, MISRA представляет собой набор стандартов кодирования C и C++, разработанный и поддерживаемый Ассоциацией надежности программного обеспечения автомобильной промышленности (MISRA). В первую очередь он считается стандартом кодирования де-факто для встраиваемых отраслей.
MISRA была создана и обновляется рабочими группами в соответствии с заранее определенными планами.
Несмотря на то, что он безопасен и надежен, он не доступен бесплатно, хотя допускает некоторые отзывы сообщества при внедрении обновлений.Естественно, с CERT работать проще. Но открытые стандарты быстро меняются, что затрудняет их отслеживание. Однако закрытые стандарты, такие как MISRA, лучше подходят для критически важных с точки зрения безопасности отраслей, поскольку они обеспечивают единообразие между командами, организациями и поставщиками. Другими словами, они предлагают надежную ссылку, которая требует соблюдения ряда обязательных требований. Для продуктов, подобных тем, которые создаются автомобильной промышленностью, стандарты должны быть закреплены в камне, потому что на карту поставлены реальные жизни.
Несмотря на то, что вы придерживаетесь рекомендаций по кодированию, описанных выше, имейте в виду, что весь код необходимо тщательно протестировать в реальных браузерах и на реальных устройствах. Вместо того, чтобы иметь дело со многими недостатками эмуляторов и симуляторов, тестировщикам лучше использовать реальное облако устройств, которое предлагает реальные устройства, браузеры и операционные системы по запросу для мгновенного тестирования.
Запуская тесты в реальном облаке устройств, можно проводить тесты производительности, чтобы каждый раз получать точные результаты. Всестороннее и безошибочное тестирование гарантирует, что ни одна крупная ошибка не останется незамеченной в рабочей среде, что позволяет программному обеспечению предлагать максимально возможный уровень взаимодействия с пользователем.
Будь то ручное тестирование или автоматизированное тестирование Selenium, реальные устройства не подлежат обсуждению в уравнении тестирования. При отсутствии собственной лаборатории устройств (регулярно пополняемой новыми устройствами и поддерживающей каждое из них на самом высоком уровне функциональности) выбирайте облачную инфраструктуру тестирования. Начните проводить тесты на более чем 2000 реальных браузерах и устройствах в облаке реальных устройств BrowserStack. Запускайте параллельные тесты в Cloud Selenium Grid, чтобы получать более быстрые результаты без ущерба для точности. Выявляйте ошибки до того, как это сделают пользователи, тестируя программное обеспечение в реальных условиях.

 Это особенно верно для стандартов функциональной безопасности, включая:
Это особенно верно для стандартов функциональной безопасности, включая: Код C может быть скомпилирован с неопределенным поведением. И это неопределенное поведение открывает ваш код для уязвимостей и дефектов. Или ваш код C может быть непредсказуемым, когда он перенесен на другое оборудование.
Код C может быть скомпилирован с неопределенным поведением. И это неопределенное поведение открывает ваш код для уязвимостей и дефектов. Или ваш код C может быть непредсказуемым, когда он перенесен на другое оборудование. Как и C, С++ гибкий. И это признано за высокую производительность.
Как и C, С++ гибкий. И это признано за высокую производительность. Кроме того, это делает этапы проверки кода и тестирования более эффективными.
Кроме того, это делает этапы проверки кода и тестирования более эффективными. Стандарты, необходимые для программного обеспечения для роскошных автомобилей, будут отличаться от стандартов для программного обеспечения для игр.
Стандарты, необходимые для программного обеспечения для роскошных автомобилей, будут отличаться от стандартов для программного обеспечения для игр. Четко укажите код между ними.
Четко укажите код между ними. Естественно, одной переменной нельзя присвоить несколько значений или использовать для множества функций. Это запутало бы всех, кто читает код, и затруднило бы реализацию будущих улучшений. Всегда назначайте уникальные имена переменных.
Естественно, одной переменной нельзя присвоить несколько значений или использовать для множества функций. Это запутало бы всех, кто читает код, и затруднило бы реализацию будущих улучшений. Всегда назначайте уникальные имена переменных.
 Подождите несколько секунд, пока не появятся необходимые элементы.
Подождите несколько секунд, пока не появятся необходимые элементы. Несмотря на то, что он безопасен и надежен, он не доступен бесплатно, хотя допускает некоторые отзывы сообщества при внедрении обновлений.
Несмотря на то, что он безопасен и надежен, он не доступен бесплатно, хотя допускает некоторые отзывы сообщества при внедрении обновлений.
