Компьютеры и Интернет
Сетевая база данных – это модель данных, где несколько записей или файлов могут быть связаны с несколькими владельцами файлов и наоборот. Модель может рассматриваться как перевернутое дерево, где каждый член – это отрасли, связанные с владельцем, который находится в нижней части дерева. По сути, это отношения в чистой форме, где один элемент может указывать на множество элементов данных, и само по себе может быть указано несколько элементов данных.
Модель сетевой базы данных позволяет каждой записи иметь несколько родителей и несколько дочерних записей, которые, когда они визуализируются, принимают форму сетевой структуры сетевых записей. В отличие от иерархической модели данных она может иметь только одну родительскую запись, но может иметь много дочерних записей.
Это свойство иметь несколько ссылок применяется двумя способами: схема и сама база данных может рассматриваться как обобщенный график типов записей, которые связаны типами отношений. Основное достоинство базы данных заключается в том, что она позволяет получить более естественное моделирование связей между записями, в отличие от иерархической модели. Но реляционная модель базы данных начала завоевывать всё большую популярность перед сетевой и иерархической моделями из-за её гибкости и производительности, что стало ещё более очевидным, когда аппаратная технология стала ещё быстрее.
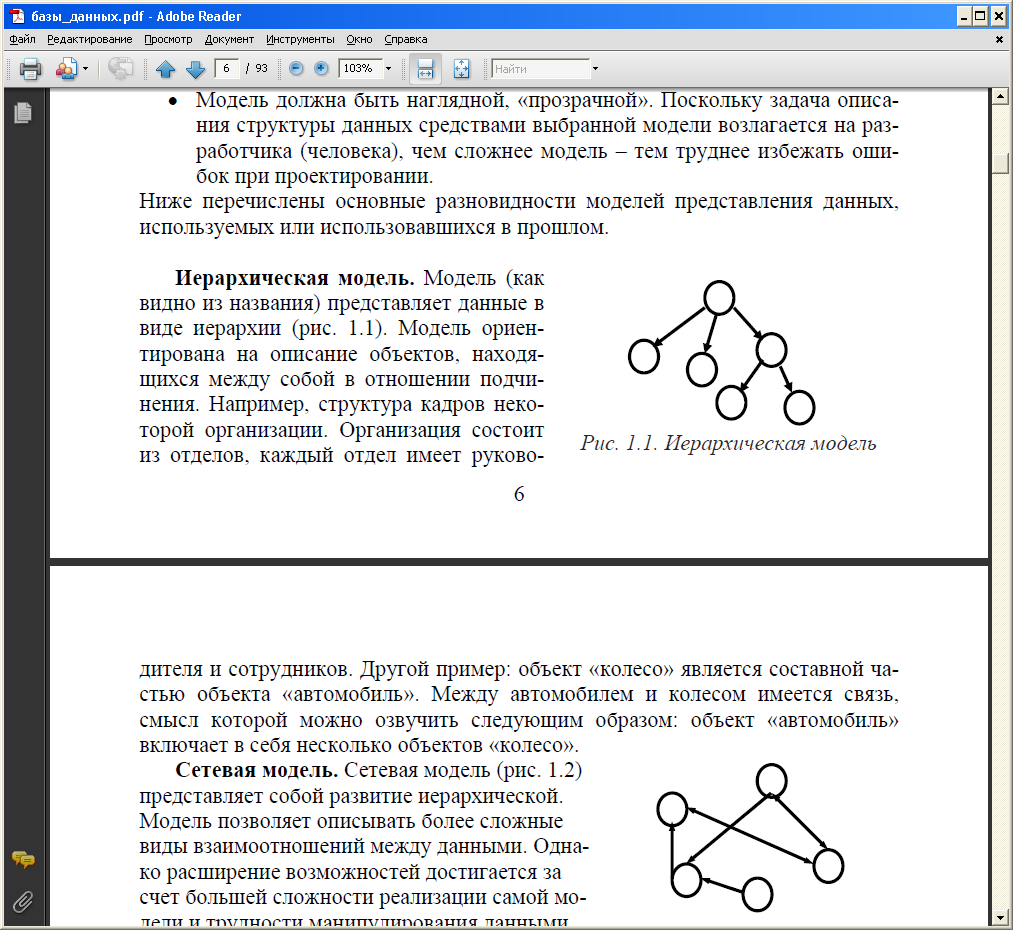
Сетевая модель базы данных
Улучшенная форма иерархической модели данных, сетевая модель представляет данные в виде дерева записей. Связи между таблицами (отчеты) выражаются в виде наборов. В наборе есть одна родительская запись (владелец) и одна или более дочерних записей (члены). Связанные записи в наборе напрямую связаны с указателями, а не путём сопоставления повторяющихся столбцов, как и в случае с реляционной моделью данных.
Записи, связанные с одним владельцем
Модель сетевой базы данных позволяет записям из более чем одной таблицы быть связанными с одним владельцем с записями из другой таблицы. Это обеспечивает определенное преимущество над реляционной базой при запросе результатов из нескольких внешних ключей таблиц, связанных с одним первичным ключом таблицы. В базе данных медиа-коллекции, таких как альбом песен и видео записи, все они могут быть членами собственника в одном комплекте, как показано на рисунке 2. Это означает, что оба альбома и фильмы для данного собственника могут быть получены за одну операцию. При этом отпадает необходимость хранить и потенциально изменять порядок временных результатов в середине операции, что приводит к повышению производительности запросов. Без необходимости хранить и сохранять дубликаты столбцы базы данных также помогают уменьшить дисковое пространство и память.
Исследование эффективности
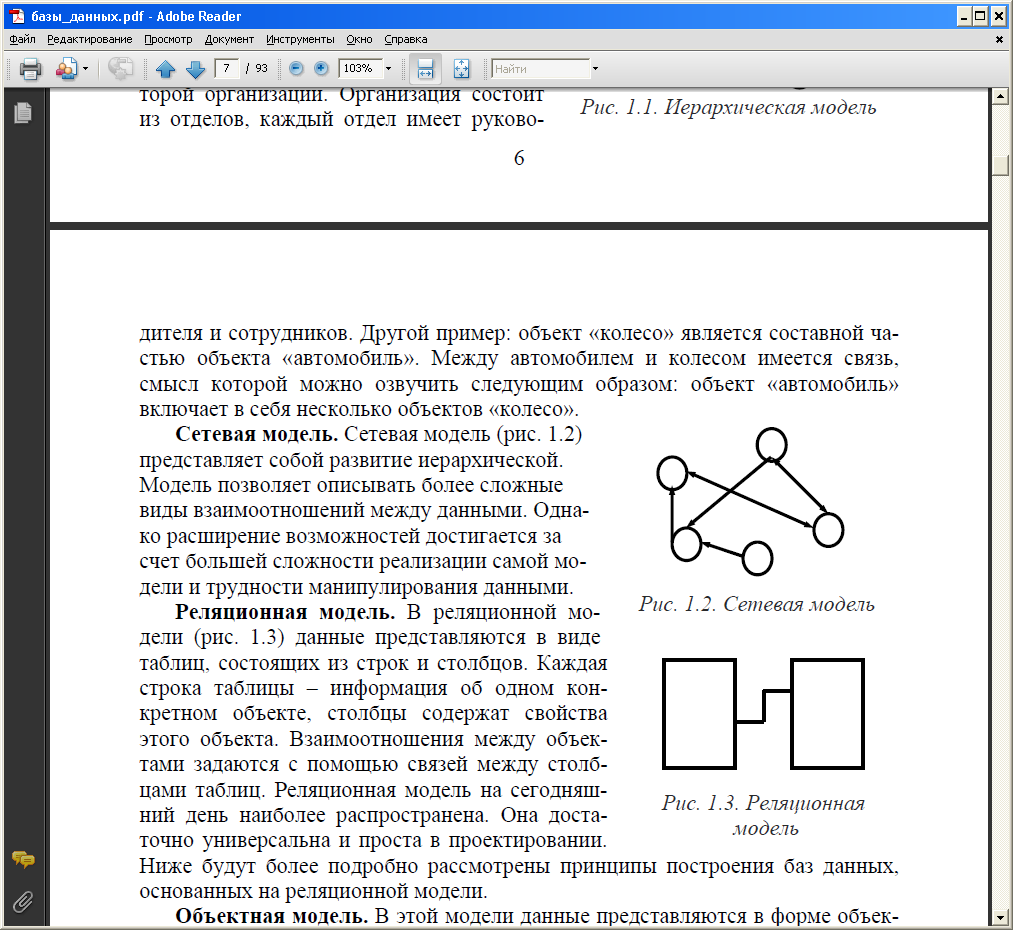
Реальные данные показывают, что прирост производительности и экономия ресурсов с использованием сетевых баз данных может быть довольно значительной. В структуре данных, используются трехсторонние отношения между художником, альбомом и таблицами песни, наши разработчики сравнили изменения данных и выполнение запросов в реляционной модели и сетевой базе данных с помощью настольных систем и небольших, потребительских устройств. Они обнаружили, что сетевая модель использует на 29% меньше дискового пространства для хранения одинакового количества записей и связей, чем реляционная модель данных. Все сбережения при хранении можно отнести к замене ключевых показателей артист-альбом и альбом-песни зарубежные на установленные указатели.
Удаление этих структур данных, оказало огромное влияние на требования к хранению, поскольку типичный индекс B-дерева требует примерно в 1,3 раза больше пространства, чем индексы. Они также обнаружили, что сетевая модель базы данных увеличила до 23 раз лучше производительность вставки и выросла в 123 раза быстрее производительность запросов, как показано в таблице 1.
Сетевая база данных против реляционной базы данных
Различные требования управления означают разные структуры данных и различные методы хранения и доступа к данным. В результате система может состоять из нескольких таблиц без связей или сотни таблиц, связанных со сложными взаимосвязями. В то время как реляционная модель данных является стандартом де-факто, теперь мы знаем, что она не всегда обеспечивает оптимальные решения для более сложных задач управления данными. Выбор подходящей модели данных, или даже объединение нескольких моделей, может дать гораздо более эффективный результат, чем реляционная модель данных работающая в одиночку. В результате достигается значительная экономия затрат, повышение качества и увеличение пользовательского опыта.
Вывод
В то время как реляционная модель данных является очень популярной из-за её простоты использования, она не требует ключа и индексов таблицы, что существенно замедляет работу приложения. Сетевая модель базы данных обеспечивает более быстрый доступ к данным и является оптимальным методом для быстрого применения. Так что если Вы нажмете на любимого артиста, а также если хотите посмотреть список для поиска лишних альбомов и просмотреть названия фильмов на вашем медиа-плеере, это может быть создано сетевыми моделями СУБД.
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 20:28, 12 июня 2017.
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных[1]. Сетевая модель представляет собой структуру, у которой любой элемент может быть связан с любым другим элементом.Сетевая база данных состоит из наборов записей, которые связаны между собой так, что записи могут содержать явные ссылки на другие наборы записей. Тем самым наборы записей образуют сеть. Связи между записями могут быть произвольными, и эти связи явно присутствуют и хранятся в базе данных.
Наиболее известными сетевыми СУБД являются IDMS, DBMS и db_VISTA III.
История
Сетевая модель была одним из первых подходов, использовавшимся при создании баз данных в конце 50-х — начале 60-х годов. Исторически на разработку этого стандарта большое влияние оказал американский ученый Ч.Бахман. Идеи Бахмана послужили основой для разработки стандартной сетевой модели под эгидой организации CODASYL. После публикации отчетов рабочей группы этой организации в 1969, 1971 и 1973 годах многие компании привели свои сетевые базы данных более-менее в соответствие со стандартами CODASYL. До середины 70-х годов главным конкурентом сетевых баз данных была иерархическая модель данных, представленная ведущим продуктом компании IBM в области баз данных — IBM IMS.
В конце 60-х годов Эдгаром Коддом была предложена реляционная модель данных и после долгих и упорных споров с Бахманом реляционная модель приобрела большую популярность и теперь является доминирующей на рынке СУБД.
Основные понятия используемые в сетевой модели данных
Элемент данных – минимальная информационная единица доступная пользователю.
Агрегат данных – это именованная совокупность данных внутри одной записи. Имя агрегата используется для его идентификации в схеме структуры данного более высокого уровня. Агрегат данных может быть простым, если состоит только из элементов данных, и составным, если включает в свой состав другие агрегаты.
Тип записей – это совокупность логически связанных экземпляров записей. Тип записей представляет некоторый класс реального мира.
Набор — именованная двухуровневая иерархическая структура, которая содержит запись владельца и запись (или записи) членов. Наборы отражают связи «один ко многим» и «один к одному» между двумя типами записей.
Особенности сетевой модели данных
- Сетевая модель данных предпологает наличие в ней произвольного количества записей и наборов в том числе их различных типов.
- Связь между двумя записями может выражаться произвольным количеством наборов.
- В любом наборе может быть только один владелец.
- Тип записи может быть владельцем в одних типах наборов и членом в других типах наборов, а также не входить ни в какой тип наборов.
- Допускается добавление новой записи в качестве экземпляра владельца, если экземпляр-член отсутствует.
- При удалении записи-владельца удаляются соответствующие указатели на экземпляры-члены, но сами записи-члены не уничтожаются (сингулярный набор).
Управление сетевыми данными
Операции с сетевыми данными можно разделить на две группы: навигационные операции с данными и операции модификации данных.
Навигационные операции с данными
Навигационные операции сетевых баз данных осуществляют переход по связям, определенных в схеме баз данных, в результате таких переходов определяется запись, которую называют текущей.
- Найти конкретную запись в наборе однотипных записей и сделать ее текущей;
- Перейти от записи-владельца к записи-члену в некотором наборе;
- Перейти к следующей записи в некоторой связи;
- Перейти от записи-члена к владельцу по некоторой связи.
Операции модификации данных
Операций модификации сетевых баз данных осуществляют добавление новых записей данных, добавление новых наборов данных, удаление записей данных и наборов записей, модификация агрегатов и элементов данных.
- извлечь текущую запись в буфер прикладной программы для обработки;
- заменить в извлеченной записи значения указанных элементов данных на заданные новые их значения;
- запомнить запись из буфера в БД;
- создать новую запись;
- уничтожить запись;
- включить текущую запись в текущий экземпляр набора;
- исключить текущую запись из текущего экземпляра набора.
См. также
Источники
Ссылки
- http://wiki.mvtom.ru/index.php/%D0%A1%D0%B5%D1%82%D0%B5%D0%B2%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85
- http://zametkinapolyah.ru/zametki-o-mysql/setevaya-baza-dannyx-setevaya-model-dannyx.html#i-4
- http://www.bseu.by/it/tohod/lekcii2_2.htm
Базы данных
Базы данных.
Системы управления базами данных (СУБД)
База данных (БД)— это именованная совокупность данных строго определенной структуры, относящихся к определенной предметной области.
Примеры баз данных
справочники,
энциклопедии,
адресная книга,
картотека,
словарь и т.д.
Структурные элементы базы данных:
поле – это минимальный элемент базы данных, содержащий однотипную информацию;
запись — это совокупность логически связанных полей, характеризующих свойства одного объекта, т.е. совокупность характеристик всех значений объекта.
Классификация баз данных
По содержанию хранимой информации:
фактографические БД — содержат данные, представляемые в краткой форме, в строго фиксированных форматах
(бумажные картотеки: библиотечный каталог, каталог видеотеки и др.)
документальные БД – содержат данные в виде документов, которые могут включать различную информацию: текстовую, графическую, мультимедийную, звуковую
(архивы документов: архив судебных дел, архив исторических документов и др. )
По способу хранения данных:
централизованные БД — это БД, полностью хранящиеся на одном компьютере (на автономном компьютере или сервере).
распределенные БД – это БД, разные части которых хранятся на разных компьютерах. Эти БД используются в локальной или глобальной сетях.
По структуре организации данных (модели данных)
Иерархические базы данных — это БД, в которых модель данных представляет собой древовидную (иерархическую) структуру
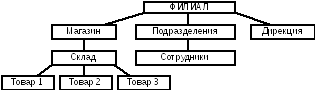
Особенности:
имеется один главный объект и остальные — подчиненные объекты, находящиеся на разных уровнях иерархии;
каждый объект-потомок связан только с одним объектом-предком вышележащего уровня иерархии;
связи между объектами одного уровня не допускаются;
между объектами двух уровней могут поддерживаться только связи «один ко многим» (один филиал – много магазинов, один склад – много товаров) или «один к одному» (один филиал – один директор).
Иерархической базой данных является каталог папок Windows:
Сетевые базы данных — это БД, являющиеся обобщением иерархической за счет допущения объектов, имеющих более одного предка.
На связи между объектами в сетевых моделях данных не накладывается никаких ограничений.
Сетевой базой данных фактически является Всемирная паутина глобальной компьютерной сети Интернет. Гиперссылки связывают между собой сотни миллионов документов в единую распределенную сетевую базу данных.
Реляционные базы данных — это БД, в которых все данные организованы в виде таблиц, между которыми установлены отношения (relation — отношение)
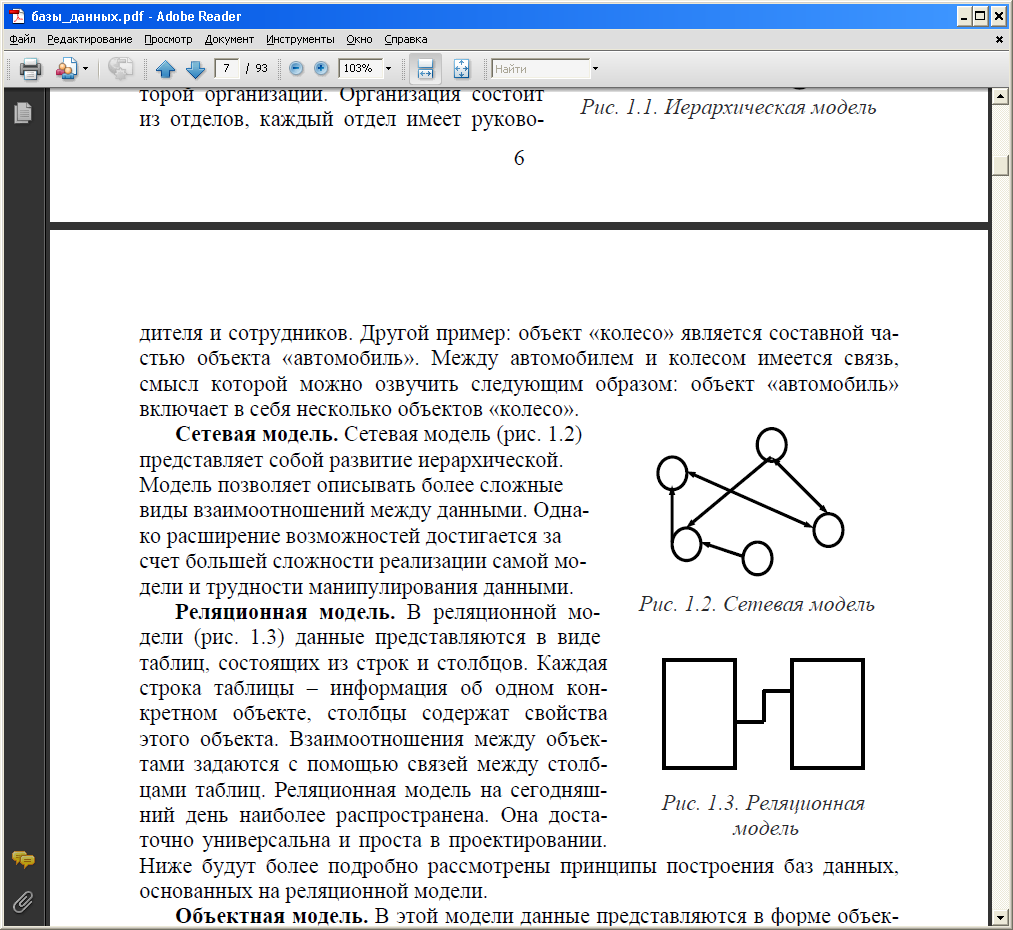
Пример простой реляционной БД:
Таб_№ | ФИО | Дата_рожд | Дата_приема | Должность | Оклад |
001 | Иванов И.И. | 12.05.65 | 1.02.80 | директор | 1000 |
002 | Петров П.П. | 30.10.75 | 2.03.95 | бугалтер | 500 |
003 | Саидов С.С | 4.01.81 | 4.06.00 | исполнитель | 100 |
В реляционных БД:
поле – столбец таблицы, заголовок которого определяет имя поля;
запись — это строка в таблице, содержащая все атрибуты, относящиеся к объекту.
Особенности реляционных БД:
каждый столбец таблицы содержит данные одного типа;
каждый столбец имеет уникальное имя;
в таблице нет одинаковых строк.
СУБД — это комплекс программ, предназначенных для создания и обработки баз данных (сортировка, поиск, модификация и др.).
По типу управляемой базы данных СУБД разделяются на:
Основные возможности СУБД:
создание структуры БД и её модификация;
ввод и редактирование данных в БД,
просмотр и сортировка данных;
поиск данных в таблице с последующей их обработкой;
обеспечение наглядного представления данных;
работа в сети.
К реляционным СУБД относятся: Paradox, Clarion, dBASE, FoxBASE, FoxPro, Clipper, Access.
СУБД MS ACCESS
— это реляционная СУБД, которая позволяет создавать автономные и сетевые приложения.
Дополнительные возможности Access:
выполнение различных вычислений,
использование фильтра,
разделение прав доступа к данным,
обеспечение целостности данных,
поддержка стандарта OLE (вставка изображений, формул и т.д.)
добавление элементов собственного интерфейса,
наличие средств визуального программирования.
БД, созданная в Access, может включать объекты:
Таблица – основной объект, содержащий данные;
Форма – объект, предназначенный для просмотра, ввода и вывода данных;
Запрос служит для отбора данных по определенному критерию
Отчет используется для формирования выходного документа, предназначенного для печати
Макрос – представляет описание нескольких действий, сформулированных как одна макрокоманда.
Модули – программы на Visual Basic for Applications (VBA)
Все объекты находятся в контейнере БД:
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой я уже успел рассмотреть установку и настройку MySQL сервера баз данных, а также рассмотрел способы изменения кодировок сервера MySQL при помощи команды SET NAMES и файла конфигураций my.ini. Сегодня будет краткая и если можно так сказать теоретическая статья, посвященная вопросу — что такое базы данных и какие базы данных бывают.

В этой статье я постараюсь изложить кратко какие виды и типы баз данных бывают и остановлюсь на некоторых из них более подробно. Мы поговорим о структуре иерархических баз данных, уделим внимание структуре сетевых баз данных, и более подробно остановимся на структуре реляционных базах данных, рассмотрим особенности реляционных баз данных. И в конце статьи немного затронем тему проектирования баз данных, естественно реляционных, так сервер MySQL это по сути математическая модель реляционных баз данных. Проектирование баз данных и типы данных, с которыми может работать MySQL сервер — это темы для последующих публикаций.
База данных. Математические модели, структура, определение.
Содержание статьи:
Я хоть и не собираюсь на своем блоге подробно рассказывать про математические законы и теории описывающие реляционные базы данных, но принцип того, как они устроены я рассказать должен, если вас заинтересует данная тема, то вы всегда можете посетить специализированный математический ресурс или почитать соответствующую литературу, а можете всегда задать вопрос в комментариях к данной публикации, и я по мере своих возможностей постараюсь вам ответить. Как я уже говорил, тема данной статьи – реляционные базы данных. Я постараюсь ответить на вопрос, что такое реляционные базы данных простым и понятным языком. Затрону основные понятия, относящиеся к реляционным базам данных, терминологию, историю возникновения баз данных вообще и реляционных в частности.
Наверное, самое простое определения баз данных, база данных – это упорядоченное хранение какой-либо информации. То есть, информация хранится в упорядоченном или систематизированном виде. Видов систематизации, упорядочивания и хранения информации может быть множество. Каждый из способов хранения информации отвечает каким-либо специфическим требованиям или предназначен для выполнения каких-либо определенных действий. На страницах своего блога я уже писал, про язык XML, данные в XML структурируются в виде дерева с разветвлениями, узлами и корнем. Но это лишь один из множества способов хранения информации. Более подробно обо всем этом читайте в рубрике Заметки о XML и XLST.
Виды и типы баз данных
Как я уже говорил, видов и типов баз данных очень и очень много и описать их все в данной публикации я просто не смогу, но самые распространенные виды хранения информации или виды баз данных я постараюсь описать. Понятно, что база данных хранит в себе информацию о каких-то объектах, например, информацию о товаре в интернет-магазине. Любой товар в базе данных – это объект с какими-то определенными параметрами и свойствами. Перейдем к конкретным примерам.
Иерархическая база данных, структура иерархических баз данных
Иерархическая база данных – каждый объект при таком хранение информации представляется в виде определенной сущности, то есть, у этой сущности могут быть дочерние элементы, родительские элементы, а у тех дочерних могут быть еще дочерние элементы, но есть один объект, с которого все начинается. Получается своеобразное дерево. Примером иерархической базы данных может быть, документ в формате XML или файловая система компьютера, пример с файловой системой компьютера я приводил, когда рассматривал структуру XML документа, в рубрике Заметки о XML.
Следует сказать, что базы данных подобного вида оптимизированы под чтение информации, то есть, базы данных, имеющие иерархическую структуру умеют очень быстро выбирать, запрашиваемую информацию и отдавать ее пользователям. Но такая структура не позволяет столь же быстро перебирать информацию, тут можно привести пример из жизни, компьютер может легко работать с каким-либо конкретным файлом или папкой (которые, по сути являются объектами иерархической структуры) но проверка компьютера антивирусам осуществляется очень долго. Второй пример – реестр Windows.

На рисунке вы можете увидеть структуру иерархической базы данных, в самом верху находится родитель или корневой элемент, ниже находятся дочерние элементы, элементы, находящиеся на одном уровне называются братьями, ну или соседними элементами. Соответственно чем ниже уровень элемента, тем вложенность этого элемента больше.
Сетевая база данных, структура сетевых баз данных
Сетевые базы данных, являются своеобразной модификацией иерархических баз данных. Если вы внимательно смотрели на рисунок выше, то наверное обратили внимание, что к каждому нижнему элементу идет только одна стрелочка от верхнего элемента. То есть у иерархических баз данных у каждого дочернего элемента может быть только один потомок. Сетевые базы данных отличаются от иерархических тем, что у дочернего элемента может быть несколько предков, то есть, элементов стоящих выше него. Для большей наглядности и понимания структуры сетевых баз данных обратите внимание на рисунок:

Стоит заметить, что сетевые базы данных обладают примерно теми же характеристиками, что и иерархические базы данных. Но, в данной рубрике нас не сильно интересуют иерархические и сетевые базы данных, данная тема больше относится к формату XML, и возможно в рубрике посвященной языку расширяемой разметки, я постараюсь более подробно рассмотреть эту тему. А в рубрике посвященной MySQL нас интересуют реляционные базы данных, на которых мы и остановимся более подробно.
Реляционные базы данных, структура реляционных баз данных
Реляционные базы данных получили очень широкое распространение и многие пытаются писать огромные статьи, посвященные вопросу – почему реляционные базы данных получили такое широкое распространение, делают глубокомысленные выводы и замечания. Но на самом деле все очень просто – реляционные базы данных очень легко описываются в математике, то есть, под них очень хорошо написана математика.
Был когда-то такой математик – Эдгар Франк Кодд, умерший в 2003 году, который в восьмидесятых годах очень подробно описал структуру реляционных баз данных математическим языком. А если есть хорошо написанная математика, то соответственно есть и программная реализация. Останавливаться на биографии Э.Ф. Кодда я не буду, для этого есть различные энциклопедии. Именно благодаря Кодду реляционные базы данных стали активно развиваться. Поэтому-то, когда мы говорим базы данных, чаще всего мы подразумеваем именно реляционные базы данных.
Особенности реляционных баз данных
Главной особенностью реляционных баз данных является, то, что объекты внутри таких баз данных хранятся в виде набора двумерных таблиц. То есть, таблица состоит из набора столбцов, в котором может указываться: название, тип данных(дата, число, строка, текст и т.д.). Еще одной важной особенность реляционных БД является, то, что число столбцов фиксировано, то есть, структура базы данных известна заранее, а вот число строк или рядов в реляционных базах данных ничем не ограничено, если говорить грубо, то строки в реляционных базах данных и есть объекты, которые хранятся в базе данных.
На самом деле, базы данных – это абстрактное понятие, таблица – это всего лишь способ хранения информации, набор таблиц может быть связан логически и этот набор называют база данных. Поэтому неправильно говорить, что MySQL это база данных, база данных – это хранящаяся информация. А вот такое понятие, как СУБД – система управления базами данных, это и есть MySQL сервер, именно при помощи него мы управляем хранящимися данными. Или иначе MySQL – это программное воплощение математических идей.
Самой трудной задачей при работе с реляционными базами данных, является проектирование структуры баз данных. Проектирование структуры базы данных, заключается не только в том, чтобы создать таблицу и указать тип данных и наименование столбцов. На самом деле проектирование – это самый сложный этап при работе с базами данных. Потому что мощности ваших компьютеров ограничены. Пока данных мало, мало таблиц и строк в этих таблицах, машина будет их обрабатывать очень и очень быстро. Но, со временем количество информации будет увеличиваться, и мы получим замедление, которое будет увеличиваться, поскольку машине необходимо время на обработку тех или иных запросов(обработка информации). В прошлой статье я уже писал, что реляционные БД прежде всего ориентированы на модификацию(OLTP), то есть, добавить новую запись в таблицу – это очень простая операция для реляционной СУБД, а вот сделать выборку данных, это уже трудоемкая операция. Также есть и изменение данных, это как бы промежуточное звено между чтением и добавлением. Хотя MySQL сервер всегда можно настроить.
Проектирование базы данных
Ну что же, мы немного поговорили о достоинствах и недостатках реляционных баз данных. И теперь, вкратце, я затрону вопрос проектирования баз данных. Под проектированием я понимаю следующее: садится человек за стол, берет бумагу и ручку, и исходя из поставленной задачи, а также, исходя из достоинств и недостатков той или иной системы, в нашем случае СУБД MySQL начинает составлять структуру будущей базы данных. Требование к проектируемой базе данных обычно ставятся следующее:
- База данных должна быть как можно более компактна, то есть, неизыбыточна.
- База данных должна быть простой с точки зрения обработки.
И как вы, наверное, поняли, данные требования противоречат друг другу. Проектирование — это самый важный аспект при работе с базами данных. Обычно, проектировщик – это опытный администратор сервера баз данных, либо архитектор баз данных, с большим опытом работы. В серьезных проектах может быть несколько десятков, а то и сотен таблиц, которые связаны между собой самыми замысловатыми способами связи. Конечно, я не собираюсь углубляться в проектирование баз данных, да и не смогу это сделать, но, кое какие основы проектирования баз данных я попытаюсь осветить на страницах своего блога. Прежде чем приступить к проектированию базы данных, нужно понять, а что мы вообще собираемся проектировать. То есть, должны понять, что у нас должно получиться на выходе.
А на выходе мы должны получить так называемую диаграмму или как ее еще называют схема. Диаграмма – это определение: какая информация будет храниться, в какой таблице она будет храниться, в каком столбце какой тип данных, как называется таблица, сколько столбцов в таблице и их тип, как связаны между собой таблицы. Да, типы данных в столбцах могут быть разными, например, номер телефона или индекс можно записать, как с помощью символов, так и с помощью числового типа данных. Но появляется вопрос: какой тип данных лучше для хранения номера телефона или почтового индекса? Чисто интуитивно на этот вопрос чаще всего отвечают правильно – номер телефона в базе данных должен иметь символьный тип, а вот объяснить, почему именно символьный тип могут немногие. Объяснение очень простое, например, нам потребовались все почтовые индексы, начинающиеся на 637 или номера телефонов начинающиеся на 952, так вот, сделать такую выборку из данных имеющих числовой тип задача довольно проблематичная, а сделать такую же выборку из данных символьного типа довольно легко.
При проектировании баз данных очень часто встречаются такие задачи и поверьте, от того, как вы будете их решать, будет зависеть, то, насколько быстро будет работать ваша система, в следующей статье я продолжу вопрос проектирования баз данных.
На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah.ru
Связи между таблицами базы данных / Хабр
1. Введение
Связи — это довольна важная тема, которую следует понимать при проектировании баз данных. По своему личному опыту скажу, что осознав связи, мне намного легче далось понимание нормализации базы данных.
1.1. Для кого эта статья?
Эта статья будет полезна тем, кто хочет разобраться со связями между таблицами базы данных. В ней я постарался рассказать на понятном языке, что это такое. Для лучшего понимания темы, я чередую теоретический материал с практическими примерами, представленными в виде диаграммы и запроса, создающего нужные нам таблицы. Я использую СУБД Microsoft SQL Server и запросы пишу на T-SQL. Написанный мною код должен работать и на других СУБД, поскольку запросы являются универсальными и не используют специфических конструкций языка T-SQL.
1.2. Как вы можете применить эти знания?
- Процесс создания баз данных станет для вас легче и понятнее.
- Понимание связей между таблицами поможет вам легче освоить нормализацию, что является очень важным при проектировании базы данных.
- Разобраться с чужой базой данных будет значительно проще.
- На собеседовании это будет очень хорошим плюсом.
2. Благодарности
Учтены были советы и критика авторов jobgemws, unfilled, firnind, Hamaruba.
Спасибо!
3.1. Как организовываются связи?
Связи создаются с помощью внешних ключей (foreign key).
Внешний ключ — это атрибут или набор атрибутов, которые ссылаются на primary key или unique другой таблицы. Другими словами, это что-то вроде указателя на строку другой таблицы.
3.2. Виды связей
Связи делятся на:
- Многие ко многим.
- Один ко многим.
- с обязательной связью;
- с необязательной связью;
- Один к одному.
- с обязательной связью;
- с необязательной связью;
Рассмотрим подробно каждый из них.
4. Многие ко многим
Представим, что нам нужно написать БД, которая будет хранить работником IT-компании. При этом существует некий стандартный набор должностей. При этом:
- Работник может иметь одну и более должностей. Например, некий работник может быть и админом, и программистом.
- Должность может «владеть» одним и более работников. Например, админами является определенный набор работников. Другими словами, к админам относятся некие работники.
Работников представляет таблица «Employee» (id, имя, возраст), должности представляет таблица «Position» (id и название должности). Как видно, обе эти таблицы связаны между собой по правилу многие ко многим: каждому работнику соответствует одна и больше должностей (многие должности), каждой должности соответствует один и больше работников (многие работники).
4.1. Как построить такие таблицы?
Мы уже имеем две таблицы, описывающие работника и профессию. Теперь нам нужно установить между ними связь многие ко многим. Для реализации такой связи нам нужен некий посредник между таблицами «Employee» и «Position». В нашем случае это будет некая таблица «EmployeesPositions» (работники и должности). Эта таблица-посредник связывает между собой работника и должность следующим образом:
Слева указаны работники (их id), справа — должности (их id). Работники и должности на этой таблице указываются с помощью id’шников.
На эту таблицу можно посмотреть с двух сторон:
- Таким образом, мы говорим, что работник с id 1 находится на должность с id 1. При этом обратите внимание на то, что в этой таблице работник с id 1 имеет две должности: 1 и 2. Т.е., каждому работнику слева соответствует некая должность справа.
- Мы также можем сказать, что должности с id 3 принадлежат пользователи с id 2 и 3. Т.е., каждой роли справа принадлежит некий работник слева.
4.2. Реализация
Диаграмма
Код на T-SQL
create table dbo.Employee
(
EmployeeId int primary key,
EmployeeName nvarchar(128) not null,
EmployeeAge int not null
)
-- Заполним таблицу Employee данными.
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (1, N'John Smith', 22)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (2, N'Hilary White', 22)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (3, N'Emily Brown', 22)
create table dbo.Position
(
PositionId int primary key,
PositionName nvarchar(64) not null
)
-- Заполним таблицу Position данными.
insert into dbo.Position(PositionId, PositionName) values(1, N'IT-director')
insert into dbo.Position(PositionId, PositionName) values(2, N'Programmer')
insert into dbo.Position(PositionId, PositionName) values(3, N'Engineer')
-- Заполним таблицу EmployeesPositions данными.
create table dbo.EmployeesPositions
(
PositionId int foreign key references dbo.Position(PositionId),
EmployeeId int foreign key references dbo.Employee(EmployeeId),
primary key(PositionId, EmployeeId)
)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (1, 1)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (1, 2)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (2, 3)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (3, 3)ОбъясненияС помощью ограничения foreign key мы можем ссылаться на primary key или unique другой таблицы. В этом примере мы
- ссылаемся атрибутом PositionId таблицы EmployeesPositions на атрибут PositionId таблицы Position;
- атрибутом EmployeeId таблицы EmployeesPositions — на атрибут EmployeeId таблицы Employee;
4.3. Вывод
Для реализации связи многие ко многим нам нужен некий посредник между двумя рассматриваемыми таблицами. Он должен хранить два внешних ключа, первый из которых ссылается на первую таблицу, а второй — на вторую.
5. Один ко многим
Эта самая распространенная связь между базами данных. Мы рассматриваем ее после связи многие ко многим для сравнения.
Предположим, нам нужно реализовать некую БД, которая ведет учет данных о пользователях. У пользователя есть: имя, фамилия, возраст, номера телефонов. При этом у каждого пользователя может быть от одного и больше номеров телефонов (многие номера телефонов).
В этом случае мы наблюдаем следующее: пользователь может иметь многие номера телефонов, но нельзя сказать, что номеру телефона принадлежит определенный пользователь.
Другими словами, телефон принадлежит только одному пользователю. А пользователю могут принадлежать 1 и более телефонов (многие).
Как мы видим, это отношение один ко многим.
5.1. Как построить такие таблицы?
Пользователей будет представлять некая таблица «Person» (id, имя, фамилия, возраст), номера телефонов будет представлять таблица «Phone». Она будет выглядеть так:
Данная таблица представляет три номера телефона. При этом номера телефона с id 1 и 2 принадлежат пользователю с id 5. А вот номер с id 3 принадлежит пользователю с id 17.
Заметка. Если бы у таблицы «Phones» было бы больше атрибутов, то мы смело бы их добавляли в эту таблицу.
5.2. Почему мы не делаем тут таблицу-посредника?
Таблица-посредник нужна только в том случае, если мы имеем связь многие-ко-многим. По той простой причине, что мы можем рассматривать ее с двух сторон. Как, например, таблицу EmployeesPositions ранее:
- Каждому работнику принадлежат несколько должностей (многие).
- Каждой должности принадлежит несколько работников (многие).
Но в нашем случае мы не можем сказать, что каждому телефону принадлежат несколько пользователей — номеру телефона может принадлежать только один пользователь.
Теперь прочтите еще раз заметку в конце пункта 5.1. — она станет для вас более понятной.
5.3. Реализация
Диаграмма
Код на T-SQL
create table dbo.Person
(
PersonId int primary key,
FirstName nvarchar(64) not null,
LastName nvarchar(64) not null,
PersonAge int not null
)
insert into dbo.Person(PersonId, FirstName, LastName, PersonAge) values (5, N'John', N'Doe', 25)
insert into dbo.Person(PersonId, FirstName, LastName, PersonAge) values (17, N'Izabella', N'MacMillan', 19)
create table dbo.Phone
(
PhoneId int primary key,
PersonId int foreign key references dbo.Person(PersonId),
PhoneNumber varchar(64) not null
)
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (1, 5, '11 091-10')
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (2, 5, '19 124-66')
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (3, 17, '21 972-02')
Объяснения
Наша таблица Phone хранит всего один внешний ключ. Он ссылается на некого пользователя (на строку из таблицы Person). Таким образом, мы как бы говорим: «этот пользователь является владельцем данного телефона». Другими словами, телефон знает id своего владельца.
6. Один к одному
Представим, что на работе вам дали задание написать БД для учета всех работников для HR. Начальник уверял, что компании нужно знать только об имени, возрасте и телефоне работника. Вы разработали такую БД и поместили в нее всю 1000 работников компании. И тут начальник говорит, что им зачем-то нужно знать о том, является ли работник инвалидом или нет. Наиболее простое, что приходит в голову — это добавить новый столбец типа bool в вашу таблицу. Но это слишком долго вписывать 1000 значений и ведь true вы будете вписывать намного реже, чем false (2% будут true, например).
Более простым решением будет создать новую таблицу, назовем ее «DisabledEmployee». Она будет выглядеть так:
Выполнив это мы получили связь один к одному.
Заметка. Обратите внимание на то, что мы могли также наложить на атрибут EmloyeeId ограничение primary key. Оно отличается от ограничения unique лишь тем, что не может принимать значения null.
6.1. Вывод
Можно сказать, что отношение один к одному — это разделение одной и той же таблицы на две.
6.2. Реализация
Диаграмма
Код на T-SQL
create table dbo.Employee
(
EmployeeId int primary key,
EmployeeName nvarchar(128) not null,
EmployeeAge int not null
)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (159, N'John Smith', 22)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (722, N'Hilary White', 29)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (937, N'Emily Brown', 19)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (100, N'Frederic Miller', 16)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (99, N'Henry Lorens', 20)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (189, N'Bob Red', 25)
create table dbo.DisabledEmployee
(
DisabledPersonId int primary key,
EmployeeId int unique foreign key references dbo.Employee(EmployeeId)
)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (1, 159)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (2, 722)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (3, 937)Объяснения
Таблица DisabledEmployee имеет атрибут EmployeeId, что является внешним ключом. Он ссылается на атрибут EmployeeId таблицы Employee. Кроме того, этот атрибут имеет ограничение unique, что говорит о том, что в него могут быть записаны только уникальные значения. Соответственно, работник может быть записан в эту таблицу не более одного раза.
7. Обязательные и необязательные связи
Связи можно поделить на обязательные и необязательные.
7.1. Один ко многим
- Один ко многим с обязательной связью:
К одному полку относятся многие бойцы. Один боец относится только к одному полку. Обратите внимание, что любой солдат обязательно принадлежит к одному полку, а полк не может существовать без солдат. - Один ко многим с необязательной связью:
На планете Земля живут все люди. Каждый человек живет только на Земле. При этом планета может существовать и без человечества. Соответственно, нахождение нас на Земле не является обязательным
Одну и ту же связь можно рассматривать как обязательную и как необязательную. Рассмотрим вот такой пример:
У одной биологической матери может быть много детей. У ребенка есть только одна биологическая мать.А) У женщины необязательно есть свои дети. Соответственно, связь необязательна.
Б) У ребенка обязательно есть только одна биологическая мать – в таком случае, связь обязательна.
7.2. Один к одному
- Один к одному с обязательной связью:
У одного гражданина определенной страны обязательно есть только один паспорт этой страны. У одного паспорта есть только один владелец. - Один к одному с необязательной связью:
У одной страны может быть только одна конституция. Одна конституция принадлежит только одной стране. Но конституция не является обязательной. У страны она может быть, а может и не быть, как, например, у Израиля и Великобритании.
Одну и ту же связь можно рассматривать как обязательную и как необязательную:
У одного человека может быть только один загранпаспорт. У одного загранпаспорта есть только один владелец.А) Наличие загранпаспорта необязательно – его может и не быть у гражданина. Это необязательная связь.
Б) У загранпаспорта обязательно есть только один владелец. В этом случае, это уже обязательная связь.
7.3. Многие ко многим
Любая связь многие ко многим является необязательной. Например:
Человек может инвестировать в акции разных компаний (многих). Инвесторами какой-то компании являются определенные люди (многие).А) Человек может вообще не инвестировать свои деньги в акции.
Б) Акции компании мог никто не купить.
8. Как читать диаграммы?
Выше я приводил диаграммы созданных нами таблиц. Но для того, чтобы их понимать, нужно знать, как их «читать». Разберемся в этом на примере диаграммы из пункта 5.3.
Мы видим отношение один ко многим. Одной персоне принадлежит много телефонов.
- Возле таблицы Person находится золотой ключик. Он обозначает слово «один».
- Возле таблицы Phone находится знак бесконечности. Он обозначает слово «многие».
9. Итоги
- Связи бывают:
- Многие ко многим.
- Один ко многим.
1) с обязательной связью;
2) с необязательной связью. - Один к одному.
1) с обязательной связью;
2) с необязательной связью.
- Связи организовываются с помощью внешних ключей.
- Foreign key (внешний ключ) — это атрибут или набор атрибутов, которые ссылаются на primary key или unique другой таблицы. Другими словами, это что-то вроде указателя на строку другой таблицы.
10. Задачи
Для лучшего усвоения материала предлагаю вам решить следующие задачи:
- Описать таблицу фильм: id, название, длительность, режиссер, жанр фильма. Обратите внимание на то, что у фильма может быть более одного жанра, а к одному жанру может относится более, чем один фильм.
- Описать таблицу песня: id, название, длительность, певец. При этом у песни может быть более одного певца, а певец мог записать более одной песни.
- Реализовать таблицу машина: модель, производитель, цвет, цена
- Описать отдельную таблицу производитель: id, название, рейтинг.
- Описать отдельную таблицу цвета: id, название.
У одной машины может быть только один производитель, а у производителя — много машин. У одной машины может быть много цветов, а у одного цвета может быть много машин.
- Добавить в БД из пункта 6.2. таблицу военно-обязанных по типу того, как мы описали отдельную таблицу DisabledEmployee.
Сетевая модель данных — ПИЭ.Wiki
Материал из ПИЭ.Wiki
Сетевая модель данных — это логическая модель данных, представляющая их сетевыми структурами типов записей и связанные отношениями мощности один-к-одному или один-ко-многим.
В отличие от реляционной модели, связи в ней моделируются наборами, которые реализуются с помощью указателей. Сетевые модели данных являются расширенной версией иерархической модели, однако основным отличием является то, что в сетевых моделях данных имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Сетевую модель можно представить как граф узлами, которого является запись, а ребрами — набор. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД.
Историческая справка
В 1971 группа DTBG (Database Task Group) представила в американский национальный институт стандартов отчет, который послужил в дальнейшем основой для разработки сетевых систем управления базами данных. Стандарт сетевой модели был создан в 1975 году организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания.
Типичным представителем систем, основанных на сетевой модели данных, является СУБД IDMS (Integrated Database Management System), разработанная компанией Cullinet Software, Inc. и изначально ориентированная на использования на мейнфреймах компании IBM. Архитектура системы основана на предложениях DBTG организации CODASYL. В настоящее время IDMS принадлежит компании Computer Associates.
Основные элементы сетевой модели данных
- Элемент данных – минимальная информационная единица доступная пользователю.
- Агрегат данных – именованная совокупность элементов данных внутри записи или другого агрегата, которую можно рассматривать как единое целое. Имя агрегата используется для его идентификации в схеме структуры данного более высокого уровня. Агрегат данных может быть простым, если состоит только из элементов данных, и составным, если включает в свой состав другие агрегаты.
- Запись — совокупность агрегатов или элементов данных, отражающих некоторую сущность предметной области. Иными словами, запись — это агрегат, который не входит в состав никакого другого агрегата и может иметь сложную иерархическую структуру, поскольку допускается многократное применение агрегации. Имя записи используется для идентификации типа записи в схемах типов структур более высокого уровня.
- Тип записей – эта совокупность подобных записей. Тип записей представляет некоторый класс реального мира.
- Набор — именованная двухуровневая иерархическая структура, которая содержит запись владельца и запись (или записи) членов. Наборы отражают связи «один ко многим» и «один к одному» между двумя типами записей.
- Наборы бывают нескольких видов:
- С одними и теми же типами записей, но разными типами наборов.
- Наборы из трех записей и более, в том числе с обратной связью.
- Сингулярный набор (только один экземпляр). У такого набора нет естественного владельца и в качестве него выступает система. В дальнейшем такие наборы могут приобрести запись — владельца.
Особенности построения сетевой модели данных
- База данных может состоять из произвольного количества записей и наборов различных типов.
- Связь между двумя записями может выражаться произвольным количеством наборов.
- В любом наборе может быть только один владелец.
- Тип записи может быть владельцем в одних типах наборов и членом в других типах наборов.
- Тип записи может не входить ни в какой тип наборов.
- Допускается добавление новой записи в качестве экземпляра владельца, если экземпляр-член отсутствует.
- При удалении записи-владельца удаляются соответствующие указатели на экземпляры-члены, но сами записи-члены не уничтожаются (сингулярный набор).
Реализация групповых отношений в сетевой модели осуществляется с использованием указателей (адресов связи или ссылок), которые устанавливают связь между владельцем и членом группового отношения. Запись может состоять в отношениях разных типов (1:1, 1:N, M:N). Заметим, что если один из вариантов установления связи 1:1 очевиден (в запись – владелец отношения, поля которой соответствуют атрибутам сущности, включается дополнительное поле – указатель на запись – член отношения), то возможность представления связей 1:N и M:N таким же образом весьма проблематична. Поэтому наиболее распространенным способом организации связей в сетевых СУБД является введение дополнительного типа записей, полями которых являются указатели.
Преимущества
- Стандартизация. Появление стандарта CODASYL, который определил базовые понятия модели и формальный язык описания.
- Быстродействие. Быстродействие сетевых баз данных сравнимо с быстродействием иерархических баз данных.
- Гибкость. Множественные отношения предок/потомок позволяют сетевой базе данных хранить данные, структура которых была сложнее простой иерархии.
- Универсальность. Выразительные возможности сетевой модели данных являются наиболее обширными в сравнении с остальными моделями.
- Возможность доступа к данным через значения нескольких отношений (например, через любые основные отношения).
Недостатки
- Жесткость. Наборы отношений и структуру записей необходимо задавать наперёд. Изменение структуры базы данных ведет за собой перестройку всей базы данных.. Связи закреплены в записях в виде указателей. При появлении новых аспектов использования этих же данных может возникнуть необходимость установления новых связей между ними. Это требует введения в записи новых указателей, т.е. изменения структуры БД, и, соответственно, переформирования всей базы данных.
- Сложность. Сложная структура памяти.
Операции над данными сетевой модели
- Операция ЗАПОМНИТЬ позволяет занести в БД новую запись и автоматически включить эту запись в групповые отношения, где она объявлена подчиненной с соответствующим режимом включения.
- Операция ВКЛЮЧИТЬ В ГРУППОВОЕ ОТНОШЕНИЕ позволяет существующю запись связать с с записью-владельцем.
- Операция ПЕРЕКЛЮЧИТЬ дает возможность подчиненную запись связать с записью-владельцем в том же групповом отношении.
- Операция ОБНОВИТЬ изменять значения элементов записей, существующих в БД. Перед выполнением этого оператора соответствующая запись предварительно должна быть извлечена.
- Операция ИЗВЛЕЧЬ позволяет последовательно (т.е. перебирая) извлечь запись. Запись можно извлечь по значению первичного ключа или используя групповые отношения, в которых они участвуют. Так, от владельца можно перейти к записям – членам, а от записи-члена перейти к владельцу группового отношения.
- Операция УДАЛИТЬ дает возможность убрать из БД ненужную запись. Если удаляемая запись объявлена владельцем в групповом отношении , то анализируется класс членства подчиненных записей. Обязательные члены должны быть предварительно откреплены от этого владельца, т.е. удалены из группового отношения, фиксированные будут удалены вместе с ним, а необязательные останутся в БД.
- Операция ИСКЛЮЧИТЬ ИЗ ГРУППОВОГО ОТНОШЕНИЯ позволяет разорвать связь между записью-владельцем и записью-членом группового отношения, сохранив обе в БД.
Использования сетевой модели
Сетевые модели также создавались для мало ресурсных ЭВМ. Это достаточно сложные структуры, состоящие из «наборов» – поименованных двухуровневых деревьев. «Наборы» соединяются с помощью «записей-связок», образуя цепочки и т.д. При разработке сетевых моделей было выдумано множество «маленьких хитростей», позволяющих увеличить производительность СУБД, но существенно усложнивших последние. Прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п. Один из разработчиков операционной системы UNIX сказал «Сетевая база – это самый верный способ потерять данные».
СУБД, поддерживающие сетевую модель, широко использовались на вычислительных системах серии IBM 360/370 (ЕС ЭВМ). В качестве примеров таких систем можно указать IDMS, UNIBAD (БАНК), аналоги СЕДАН, СЕТОР. На персональных компьютерах сетевые СУБД не получили широкого распространения. Примером сетевой СУБД для персонального компьютера является db_VISTA III. Отметим, что система db_VISTA реализована на языке С и поэтому является переносимой. Система может эксплуатироваться на ПЭВМ типа IBM PC, SUN, Macintosh.
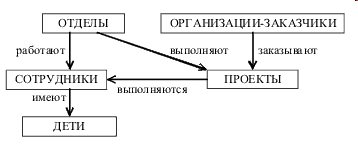
Пример сетевой базы данных
На рисунке показан простой пример схемы сетевой БД.
На этом рисунке показаны три типа записи: Отдел, Служащие и Руководитель и три типа связи: Состоит из служащих, Имеет руководителя и Является служащим.
В типе связи Состоит из служащих типом записи-предком является Отдел, а типом записи-потомком – Служащие (экземпляр этого типа связи связывает экземпляр типа записи Отдел со многими экземплярами типа записи Служащие, соответствующими всем служащим данного отдела).
В типе связи Имеет руководителя типом записи-предком является Отдел, а типом записи-потомком – Руководитель (экземпляр этого типа связи связывает экземпляр типа записи Отдел с одним экземпляром типа записи Руководитель, соответствующим руководителю данного отдела).
Наконец, в типе связи Является служащим типом записи-предком является Руководитель, а типом записи-потомком – Служащие (экземпляр этого типа связи связывает экземпляр типа записи Руководитель с одним экземпляром типа записи Служащие, соответствующим тому служащему, которым является данный руководитель).
Литература
- С. Кузнецов. Базы данных. Вводный курс
- Чертовской В.Д. Базы и банки данных: Учебное пособие СПб: Изд-во МГУП, 2001. 220 с. 300 экз.
Сетевые модели данных — Студопедия
В сетевой структуре любой элемент может быть связан с любым другим элементом (рис. 4.3), и каждый из элементов может являться входом в структуру. Данные в сетевой модели представлены в виде совокупностей записей, а связи – в виде наборов. Сетевая модель является обобщением иерархической модели.
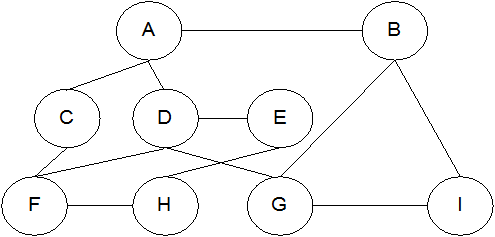
рис. 4.3. Сетевая модель данных.
Сетевую структуру также можно описать с помощью исходных и порожденных элементов: каждый элемент может иметь как несколько порожденных, так и несколько исходных элементов. В ней порожденные элементы располагаются ниже исходных. В простых сетевых структурах между парой элементов поддерживается отношение «один – ко – многим». Направление и характер связи между элементами не является очевидным, и поэтому направление связи должно быть указано.
В сетевых БД все данные считаются потенциально взаимосвязанными. Примером может служить Служба поиска информации, которой пользуются члены парламента, где могут быть вызваны документы, относящиеся к какому-либо делу или имеющие определенную ссылку. Существует функция ключевого слова, позволяющая «помечать» некоторые слова в тексте, как ключевые. Операция вызова выведет названия тех документов, в которых присутствуют эти слова.
Пример схемы простейшей сетевой БД показан на рис. 4. Типы связей обозначены надписями на соединяющих линиях.

рис. 4.4. Пример сетевой БД.
Типичные операции в сетевой модели:
— найти следующую запись данного типа и сделать ее текущей;
— извлечь запись в буфер прикладной программы для обработки;
— заменить в записи значения указанных элементов данных;
— запомнить запись из буфера в БД.
Первая сетевая структура появилась в середине 60-х годов прошлого века. Это была система IDS (Integrated Data Store) фирмы General Electric. Сетевая СУБД создавалась для представления более сложных взаимосвязей между данными, чем те, которые можно было моделировать с помощью иерархических структур.
Наибольшее распространение среди сетевых моделей получила модель КОДАСИЛ (CODASYL Conference on Data System Language – Ассоциация по языкам систем обработки данных), предложенная Рабочей группой по БД (DBTG – Data Base Task Group). Эта модель считается наиболее развитой сетевой моделью данных, постоянно развивается, поддерживается и сопровождается, являясь стандартом. Основная цель КОДАСИЛ – создание сетевой модели, позволяющей описывать отношения М:М, т.е. уменьшить недостатки иерархической модели.
Недостатки сетевой модели данных:
1. Обладает ограниченной гибкостью по отношению к изменению требований к данным и методам доступа.
2. Доступ к данным осуществляется путем перемещения (навигации) по структуре.
3. При работе с сетевыми БД прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру БД для осуществления навигации среди различных экземпляров, наборов, записей и т.п. «Сетевая БД – это самый верный способ потерять данные».
Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: DSM (корпорация UNIVAC), IDMS (Cullinane), DBMS (DEC), IDS (Honeywell), db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
Иерархическая и сетевая модели считаются моделями БД первого поколения. Помимо перечисленных выше их недостатков этим двум моделям присущи общие недостатки:
1. Даже для выполнения простых запросов с использованием переходов и доступом к определенным записям необходимо создавать достаточно сложные программы.
2. Независимость от данных существует лишь в минимальной степени.
3. Отсутствие общепризнанных теоретических основ.
Недостатки иерархической и сетевой модели являются следствием того, что они тесно связаны с концепциями традиционной обработки файлов.
Модель сети
Модель сети заменяет иерархическое дерево графиком, что позволяет более общие соединения между узлами. Основным отличием сетевой модели от иерархической модели является ее способность обрабатывать отношения многие ко многим (N: N). Другими словами, это позволяет записи иметь более одного родителя. Предположим, что сотрудник работает в двух отделах. Строгое иерархическое расположение здесь невозможно, и дерево становится более обобщенным графом — сетью.Сетевая модель была разработана специально для обработки неиерархических отношений. Как показано ниже, данные могут принадлежать нескольким родителям. Обратите внимание, что существуют как боковые, так и нисходящие соединения. Таким образом, сетевая структура допускает отношения 1: 1 (один: один), l: M (один: много), M: M (много: много) между объектами.
В терминологии сетевой базы данных связь — это набор. Каждый набор состоит как минимум из двух типов записей: запись владельца (эквивалентная родителю в иерархической модели) и запись члена (аналогично дочерней записи в иерархической модели).
База данных Customer-Loan, которую мы обсуждали ранее для иерархической модели, теперь представлена для сетевой модели, как показано.
В можно легко изобразить, что теперь информация о совместном кредите L1 появляется один раз, а в случае иерархической модели она появляется два раза. Таким образом, это уменьшает избыточность и лучше по сравнению с иерархической моделью.

Сетевое представление образца базы данных
Снова рассматривая пример базы данных о поставщиках, отображается ее сетевое представление.В дополнение к типам записей деталей и поставщиков вводится третий тип записей, который мы будем называть соединителем. Вхождение соединителя определяет связь (отгрузку) между одним поставщиком и одной деталью. Он содержит данные (количество поставляемых деталей), описывающие связь между поставщиком и записями деталей.

Все экземпляры соединителей для данного поставщика помещаются в цепочку. Цепочка начинается с поставщика и, наконец, возвращается к поставщику.Точно так же все вхождения соединителя для данной детали помещаются в цепочку, начиная с детали и, наконец, возвращаясь к той же самой детали.
Операции в сети Модель
Подробное описание всех основных операций в сетевой модели приведено ниже:
Операция вставки : Чтобы вставить новую запись, содержащую сведения о новом поставщике, мы просто создаем новую запись.Изначально не будет разъема. Цепочка нового поставщика будет состоять из одного указателя, начиная с самого поставщика.
Например, поставщик S4 может быть вставлен в модель сети, которая не предоставляет какую-либо часть в качестве новой записи вхождения с одним указателем от S4 на себя. Это невозможно в случае иерархической модели. Аналогичным образом может быть вставлена новая деталь, которую не поставляет ни один поставщик.
Рассмотрим еще один случай, если поставщик S 1 теперь начинает снабжать деталь P3 количеством 100, затем в модель добавляется новый соединитель, содержащий 100 в качестве поставляемого количества, и указатель S1 и P3 изменяется, как показано ниже.
Мы можем резюмировать, что в сетевой модели нет аномалий вставки, как в иерархической модели.
Операция обновления: В отличие от иерархической модели, где обновление выполнялось поиском и имело много проблем с несогласованностью, в сетевой модели обновление записи намного проще. Мы можем изменить город S I с Qadian на Jalandhar без проблем с поиском или несогласованностью, потому что город для S1 появляется только в одном месте в сетевой модели.Аналогичным образом выполняется та же операция для изменения любого атрибута детали.
Операция удаления: Если мы хотим удалить информацию какой-либо части, например, PI, то вхождение этой записи можно удалить, удалив соответствующие указатели и соединители, не затрагивая поставщика, который поставляет эту часть, т.е. P1, модель модифицируется. как показано. Аналогичным образом выполняется та же операция по удалению информации о поставщике.
Чтобы удалить информацию об отправке, соединитель для этой отправки и соответствующие ему указатели удаляются, не затрагивая информацию о поставщике и детали.
Например, если поставщик SI прекращает поставку детали PI с количеством 250, модель изменяется, как показано ниже, не затрагивая информацию P1 и S1.
Операция поиска: Методы поиска записи для сетевой модели симметричны, но сложны.Чтобы понять это, рассмотрим следующие примеры запросов:
Запрос 1. Найти номер поставщика для поставщиков, поставляющих деталь P2.
Решение: Чтобы получить требуемую информацию, сначала мы ищем требуемую часть, то есть P2, мы получим только одно вхождение P2 из всей базы данных, затем создается цикл для посещения каждого соединителя в этой части i.е. P2. Затем для каждого соединителя мы проверяем поставщика по этому соединителю, и номер поставщика для соответствующей записи поставщика печатается, как показано в алгоритме ниже.
Алгоритмполучить [следующую] часть, где PNO = P2;
делать до, пока больше нет разъемов под эту часть;
получить следующий разъем под этой частью;
получить поставщика через этот разъем;
печать СНО;
Запрос 2. Найти номер детали для деталей, поставляемых поставщиком S2.
Решение: Для получения необходимой информации используется та же процедура. Сначала мы ищем требуемого поставщика, то есть S2, и мы получим только одно вхождение S2 из всей базы данных. Затем конструируется петля для посещения каждого соединителя под этим поставщиком, то есть S2. Затем для каждого соединителя мы проверяем деталь над этим соединителем, и номер детали для соответствующего экземпляра записи детали печатается, как показано в алгоритме ниже.
Алгоритм:
получить [следующий] поставщик, где SNO = S2;
делать до, пока не останется больше разъемов у этого поставщика;
получить следующий разъем под этим поставщиком;
получить часть через этот разъем;
распечатать PNO;
конец;
Из обоих вышеприведенных алгоритмов можно сделать вывод, что алгоритмы поиска симметричны, но они сложны, поскольку в них задействовано много указателей.
Заключение: Как объяснялось ранее, мы можем заключить, что сетевая модель не страдает от аномалий вставки, аномалий обновления и аномалий удаления, также операция извлечения является симметричной по сравнению с иерархической моделью, но основным недостатком является сложность. модели. Поскольку каждая вышеуказанная операция включает в себя модификацию указателей, что делает всю модель сложной и сложной.
Преимущества и недостатки сетевой модели
Модель сети сохраняет почти все преимущества иерархической модели, устраняя при этом некоторые ее недостатки.
Основными преимуществами сетевой модели являются:
Концептуальная простота: Как и иерархическая модель, сетевая модель также концептуально проста и легка в разработке.
Возможность обработки большего количества типов отношений : Сетевая модель может обрабатывать отношения один ко многим (l: N) и многие ко многим (N: N), что является реальной помощью при моделировании реальных ситуаций.
Удобство доступа к данным : доступ к данным проще и гибче, чем иерархическая модель.
Целостность данных : сетевая модель не позволяет члену существовать без владельца. Таким образом, пользователь должен сначала определить запись владельца, а затем запись участника. Это обеспечивает целостности данных.
Независимость данных: Сетевая модель лучше, чем иерархическая модель, в изоляции программ от сложных деталей физической памяти.
Стандарты баз данных: Одним из основных недостатков иерархической модели была недоступность универсальных стандартов для проектирования и моделирования баз данных.Модель сети основана на стандартах, сформулированных DBTG и дополненных ANSI / SP ARC (Американский национальный институт стандартов / Комитет по планированию стандартов и требований) в 1970-х годах. Все системы управления сетевыми базами данных соответствовали этим стандартам. Эти стандарты включали язык определения данных (DDL) и язык манипулирования данными (DML), что значительно улучшило администрирование и переносимость базы данных.
Недостатки сетевой модели
Хотя модель сетевой базы данных была значительно лучше, чем модель иерархической базы данных, она также имела много недостатков.Некоторые из них:
Сложность системы: Все записи ведутся с использованием указателей и, следовательно, вся структура базы данных становится очень сложной.
Операционные аномалии: Как обсуждалось ранее, операции вставки, удаления и обновления сетевой модели любой записи требуют большого количества корректировок указателя, что делает ее реализацию очень сложной и сложной.
Отсутствие структурной независимости: Поскольку метод доступа к данным в модели сетевой базы данных является навигационной системой, внесение структурных изменений в базу данных в большинстве случаев очень сложно, а в некоторых случаях невозможно.Если вносятся изменения в структуру базы данных, то все прикладные программы необходимо изменить, прежде чем они смогут получить доступ к данным. Таким образом, даже несмотря на то, что модель сетевой базы данных преуспевает в достижении независимости данных, она все же не может достичь структурной независимости.
Из-за упомянутых недостатков и сложности внедрения и администрирования модель реляционной базы данных заменила как иерархическую, так и сетевую модели базы данных в 1980-х годах. Эволюция модели реляционной базы данных считается одним из величайших событий — серьезным прорывом в истории управления базами данных.
Статьи по теме (Вам также может понравиться)
{loadposition DBMS_And_RDBMS}
Что такое база данных? Что такое SQL?
- Home
Тестирование
- 9000 9000
- J0005 000
- Ручное тестирование
- Мобильное тестирование S000S0005 Управление тестированием
- S0005
SAP
- Назад
- ABAP
- APO 9000 5
- Новичок
- Базис
- БПК
- 9000 9000
- Назад
- PI / PO
- PP
- SD
- Solution Manager
- SAPUI5
- Безопасность
- Successfactors
- SAP Обучение
веб
- Назад
- Apache
- Android
- AngularJS
- ASP.Чистая
- C
- C #
- C ++
- CodeIgniter
- СУБД
- Назад
- Java
- JavaScript
- JSP
- Kotlin
M000
- Back
- Perl
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL5000
- SQL000
- UML
- VB.Net
- VBScript
- Веб-сервисы
- WPF
Необходимо учиться!
- Назад
- Учет
- Алгоритмы
- Blockchain
- Бизнес-аналитик
- Сложение Сайт
- CCNA
- Cloud Computing
- COBOL
- Compiler Design
- Embedded Systems
- Назад
- Ethical Hacking
- Excel Учебники
- Go Программирование
- IoT
- ITIL
- Дженкинс
- MIS
- Networking
- Операционная система
- Prep
- Назад
- PMP
- Photoshop Управление
- Проект
- Отзывы
- Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Складирование данных 000000000 HBB
- Назад
- Главная
Испытание
- Назад
- Agile тестирование
- BugZilla
- Огурцы
- База данных Тестирование
- ETL Тестирование
- Jmeter
- JIRA
- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- 000000P000 000000P000
000000P000
000000- 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
- Управление тестированием
- TestLink
SAP
- Назад
- ABAP
- APO
- Новичок
- Основа
- Bods
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- КУКИШ
- HANA
- HR
- MM
- QM
- Заработная плата
- Назад
- Java
- JavaScript
- JSP
- Kotlin M000 M000 js
- Back
- Perl
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL5000
- SQL000
- UML
- VB.Net
- VBScript
- Веб-сервисы
- WPF
Необходимо учиться!
- Назад
- Учет
- Алгоритмы
- Blockchain
- Бизнес-аналитик
- Сложение Сайт
- CCNA
- Cloud Computing
- COBOL
- Compiler Design
- Embedded Systems
- Назад
- Ethical Hacking
- Excel Учебники
- Go Программирование
- IoT
- ITIL
- Дженкинс
- MIS
- Networking
- Операционная система
- Prep
- Назад
- PMP
- Photoshop Управление
- Проект
- Отзывы
- Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Складирование данных 000000000 HBB
- Назад
Настройка сетевого шифрования данных
< Не удаляйте этот текст, потому что он является заполнителем для сгенерированного списка «основных» тем при запуске в браузере>
Это руководство демонстрирует простоту и эффективность сетевого шифрования. Чтобы зашифровать сетевой трафик между сервером базы данных Oracle и, возможно, сотнями или тысячами клиентов Oracle, вам нужно только включить шифрование на сервере.
Цель защищенной криптосистемы — преобразовать данные открытого текста в неразборчивый зашифрованный текст на основе ключа таким образом, чтобы было очень трудно (вычислительно неосуществимо) преобразовать зашифрованный текст обратно в соответствующий ему открытый текст без знания правильного ключа.
Примерно 30 минут.
В этом руководстве вы выполняете следующие задачи:
- Установить соединение между клиентом Oracle и удаленной базой данных Oracle
- ‘»Sniff» сетевой трафик, чтобы увидеть открытый текст
- Включить шифрование сети только на сервере базы данных Oracle
- «Наблюдай» за сетевым трафиком, чтобы увидеть шифротекст
Ниже приведен список требований к программному обеспечению:
- Oracle Database 11g
- Oracle Advanced Security Database опция
Прежде чем начать этот урок, вы должны:
. | Установите базу данных Oracle 11g |
|---|---|
, | Установите опцию Oracle Advanced Security Database, опция |
Чтобы настроить клиент ПК для подключения к удаленной базе данных, выполните следующие действия:
. | На вашем ПК-клиенте нажмите Пуск, а затем Все программы.Раскройте свой Oracle Home. Разверните Инструменты настройки и миграции. Вызвать Net Manager. |
|---|---|
. | Развернуть Local. Выберите Service Naming и нажмите зеленый знак плюс (+), чтобы создать новое имя сервиса. |
. | В поле Имя сетевого сервиса введите имя для сетевого имени сервиса, которое вы хотите создать.В этом примере используется имя «remote_db». Нажмите кнопку «Далее. |
. | Выберите «TCP / IP (Интернет-протокол)» и нажмите «Далее». |
. | Введите имя хоста или IP-адрес сервера для вашей базы данных.Примите номер порта по умолчанию 1521 или введите номер порта, соответствующий вашему прослушивателю базы данных. Нажмите кнопку «Далее. |
. | Выберите «Имя службы (Oracle8i или новее)» и укажите имя службы своей базы данных. Нажмите кнопку «Далее. |
, | Нажмите Тест, чтобы проверить конфигурацию подключения. Примечание. По умолчанию соединение проверяется с использованием имени пользователя SCOTT с паролем TIGER. |
, | Вы можете изменить пользователя для проверки соединения, нажав Изменить логин. |
, | Введите имя пользователя и пароль. Нажмите ОК. |
, | Нажмите Test еще раз. |
, | После успешной проверки соединения нажмите «Закрыть». |
, | Выберите новое имя службы и убедитесь, что информация верна. |
, | Выберите Сохранить конфигурацию сети в меню Файл, чтобы сохранить конфигурацию. |
, | Выберите «Выход» в меню «Файл», чтобы выйти из Oracle Net Manager. |
Для мониторинга сетевого трафика выполните следующие действия:
. | На вашем ПК-клиенте вызовите SQL * Plus. Подключитесь как пользователь HR с соответствующим паролем. Выполните следующую инструкцию SQL, чтобы извлечь строку из таблицы HR.EMPLOYEES: ВЫБРАТЬ фамилию, зарплату ОТ сотрудников, ГДЕ employee_id = 100; |
|---|---|
. | На своем сервере базы данных используйте инструмент, например Wireshark, для просмотра сетевого трафика, включая оператор SQL, выполненный на шаге 1.Как показано в этом примере, вы должны увидеть значение «Король» и значение зарплаты в строке, выбранной из таблицы EMPLOYEES. |
Чтобы настроить шифрование сетевых данных на сервере базы данных Oracle, выполните следующие действия:
. | Введите netmgr в командной строке операционной системы. |
|---|---|
. | Откроется страница приветствия Oracle Net Manager. Развернуть Local. |
, | Выберите профиль. Выберите Oracle Advanced Security в меню именования. |
, | Откройте вкладку Шифрование. |
, | Убедитесь, что в поле Шифрование установлено значение СЕРВЕР. Выберите необходимый в меню Тип шифрования. Введите менее 70 случайных символов в поле «Шифрование». Выберите метод шифрования, выделив его в списке «Доступные методы» и нажав>, чтобы переместить его в список «Выбранные методы». |
, | Выберите Файл -> Сохранить конфигурацию сети, чтобы сохранить изменения. |
, | Выберите Выход для выхода из Oracle Net Manager. |
Чтобы отслеживать сетевой трафик и проверять шифрование сетевых данных, выполните следующие действия:
. | На вашем ПК-клиенте снова вызовите SQL * Plus. Подключитесь как пользователь HR с соответствующим паролем. Выполните следующую инструкцию SQL, чтобы извлечь строку из таблицы HR.EMPLOYEES: ВЫБРАТЬ фамилию, зарплату ОТ сотрудников, ГДЕ employee_id = 100; |
|---|---|
. | На своем сервере базы данных снова используйте инструмент, такой как Wireshark, для просмотра сетевого трафика, включая оператор SQL, выполненный на шаге 1. Как показано в этом примере, теперь, когда данные зашифрованы, вы больше не можете видеть значение » Король «или значение заработной платы в строке, выбранной из таблицы EMPLOYEES. |
В этом руководстве вы узнали, что шифрование необходимо включать только на сервере, что значительно упрощает развертывание встроенного сетевого шифрования для любого количества клиентов Oracle.
Из этого урока вы узнали, как:
- Настройка клиента для подключения к удаленной базе данных
- Настройка сетевого шифрования данных на сервере базы данных Oracle
- Руководство администратора Oracle Database Advanced Security 11g, выпуск 2 (11.2)
Кредиты
- Ведущий учебный план Разработчик: Донна Кислинг
- Автор: Peter Wahl