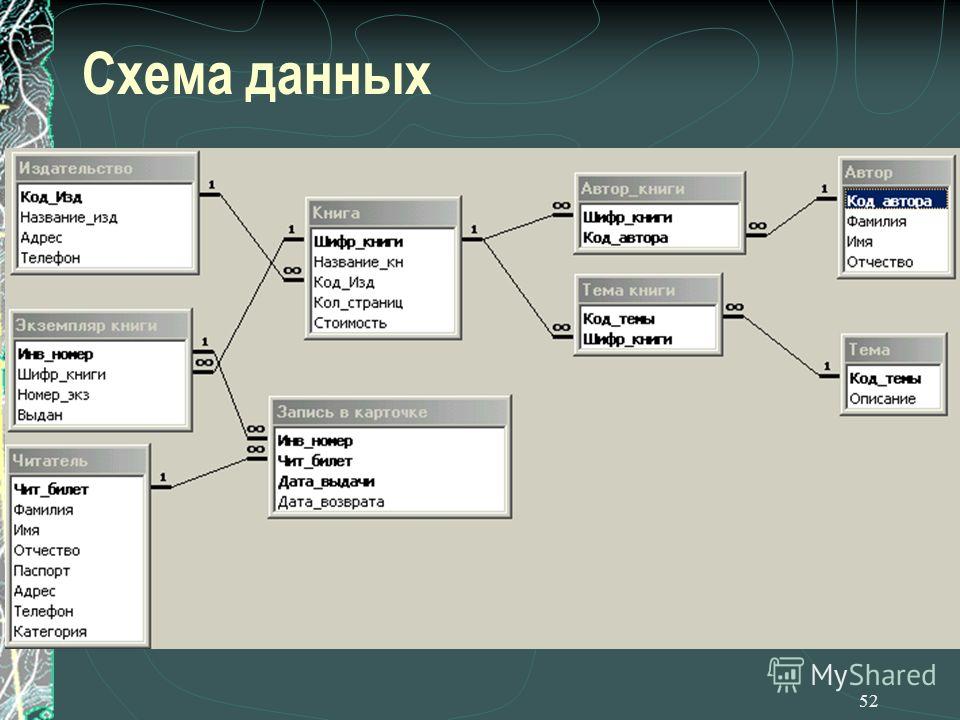
Обратное проектирование реляционных баз данных
ВведениеДалее описываются действия, необходимые для выполнения обратного проектирования базы данных и связывания получившихся таблиц модели данных с проектируемыми классами модели проектирования. Эти действия могут выполняться проектировщиком баз данных в начале внесения изменений в базу данных в рамках цикла эволюционной разработки. Дизайнер баз данных должен управлять обратной проектированием на протяжении всего жизненного цикла проекта. В многих случаях обратное проектирование выполняется на ранних стадиях жизненного цикла проекта, а затем изменения вносятся инкрементально без потребности в по следующем обратном проектировании базы данных. Основные этапы обратного проектирования базы данных и преобразования получившихся элементов модели данных в элементы модели проектирования:
Обратное проектирование базы данных RDBMS или сценария DDL для получения модели данных Результатом обратного проектирования базы данных или сценария на языке определения данных (Data Definition Language —
DDL) обычно является набор элементов модели (таблиц, представлений, хранимых процедур и т. Преобразование модели данных в модель проектированияДалее приводятся инструкции по генерированию классов проектирования на основе элементов модели данных. Репликация структуры базы данных в модели классов выполняется относительно просто. Инструкции, приведенные ниже, содержат алгоритм преобразования элементов модели данных в элементов модели проектирования. В следующей таблице дается сводка общего соответствия элементов моделей данных и проектирования.
Некоторым элементам модели данных нельзя четко противопоставить элемент модели проектирования. Преобразование таблицы в классСоздайте класс для каждой преобразовываемой таблицы. Для каждого столбца таблицы создайте в классе атрибут с соответствующим типом. Попытайтесь найти самое близкое соответствие между типами атрибутов и типами полей таблицы. Пример Рассмотрим таблицу Customer, имеющую следующую структуру:
Структура таблицы Customer Для таблицы создается класс с таким же именем, Customer, имеющий следующую структуру: Первоначальная версия класса В первой версии класса Customer для каждого столбца таблицы Customer в нем присутствует соответствующий
атрибут. Значок в виде знака «+» слева от атрибута означает, что область видимости последнего — ‘public’. По умолчанию все атрибуты, получаемые при преобразовании таблиц RDBMS, должны быть общедоступными, так как в RDBMS разрешено делать запросы ко всем столбцам. Идентификация внутренних и неявных классовКлассы, получающиеся в результате прямого преобразования «таблица — класс», часто содержат атрибуты, которые могут быть выделены в отдельный класс, особенно в случаях, когда эти атрибуты присутствуют в нескольких сгенерированных классах. Такие «общие» атрибуты обычно появляются в результате денормализации таблиц для улучшения производительности, или как следствие слишком упрощенной модели данных. В таких случаях разделите класс таким образом, чтобы он являл собой нормализованное представление таблиц. Пример После определения класса Customer можно определить класс Address, содержащий информацию об адресах
(предположив, что в системе будут другие ссылки на адреса). Класс Customer после выделения из него класса Address Тип связи между этими элементами — агрегирование, т.к. один адрес принадлежит только одному клиенту и следовательно является частью полного определения заказчика. Внешние ключиСоздайте ассоциацию между классами для каждой связи по внешнему ключу в таблице. Удалите атрибут из класса, ссылающегося на столбец внешнего ключа. Если столбец внешнего ключа изначально представлялся в виде атрибута, удалите его из класса. Пример Предположим, что таблица Order имеет следующую структуру:
Структура таблицы Order В таблице Order столбец Customer_ID является внешним ключом. Представление связей через внешние ключи в модели проектирования Внешний ключ представляется в виде ассоциации между классами Order и Item. Отношение «многие-ко-многим»В моделях данных RDBMS отношения «многие-ко-многим» представляются таблицей объединения (join table), или таблицей связей (association table). Таким образом, отношения «многие-ко-многим» представляются с помощью вспомогательных таблиц с первичными ключами двух объединяемых таблиц. Такие вспомогательные таблицы нужны из-за того, что поле внешнего ключа может содержать только один первичный ключ. Если одна запись связана с несколькими записями в другой таблице, и наоборот, то возникает необходимость в таблице связей. Пример Рассмотрим случай продуктов, которые могут поставляться любым из поставщиков.
Структура таблиц Product и Supplier Для связи этих таблиц в целях поиска продуктов, доступных у заданного поставщика используется таблица Product-Supplier.
Структура таблицы Product-Supplier В этой таблице объединения содержатся пары первичных ключей продуктов и поставщиков (с возможностью повторения),
таким образом формируя связь между ними. В модели проектирования эта вспомогательная таблица является избыточной, поскольку объектная модель позволяет представлять отношения «многие-ко-многим» напрямую. На рисунке показаны классы Supplier и Product и их взаимосвязь. Кроме того, на нем показан класс Address, извлеченный из Supplier в соответствии с рекомендациями, оговоренными ранее. Классы Product и Supplier Обобщение Часто среди всех таблиц несколько будут иметь схожую структуру. В модели
данных нет понятия обобщения, поэтому она не позволяет представлять схожесть структуры таблиц. Иногда аналогичная
структура получается в результате денормализации (для повышения производительности), как в случае ‘неявной’ таблицы Address, выделенной из другого класса. Пример Рассмотрим таблицы SoftwareProduct и HardwareProduct:
Таблицы SoftwareProduct и HardwareProduct Общие столбцы выделены синим цветом. Классы SoftwareProduct и HardwareProduct — потомки базового класса Product Соберем все основные классы системы заказов вместе. Сводная диаграмма классов для системы заказов Репликация поведения RDBMS в модель проектированияРепликация поведения — более сложная задача, т.к. обычно реляционные базы данных не являются объектно-ориентированными и провести аналогию между их поведением и операциями с классами в объектной модели сложно. Далее приведены действия, которые могут помочь реконструировать поведение классов, идентифицированных ранее:
Организация элементов в модели проектирования Класс проектирования, создаваемые в результате преобразований «таблица — класс», следует организовывать в модели
проектирования в пакеты проектирования и/или подсистемы проектирования, на основе общей архитектуры
приложения. См. Понятия: Разделение на уровни и Понятия:
Архитектура ПО. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 д.). В зависимости от
сложности базы данных может потребоваться разделить полученные элементы модели на пакеты, содержащие логически
связанные наборы таблиц.
д.). В зависимости от
сложности базы данных может потребоваться разделить полученные элементы модели на пакеты, содержащие логически
связанные наборы таблиц. Примерами таких
элементов являются табличное пространство и собственно база данных, соответствующие физическим параметрам хранения и
представляемые в качестве компонентов. Другим таким элементом являются представления базы данных, фактически являющиеся
«виртуальными» таблицами и не имеющих смысловой нагрузки в модели проектирования. Кроме того, это индексы и
первичные ключи таблиц и триггеров, используемые для оптимизации работы СУБД и имеющие смысловое значение только в
контексте базы данных и модели данных.
Примерами таких
элементов являются табличное пространство и собственно база данных, соответствующие физическим параметрам хранения и
представляемые в качестве компонентов. Другим таким элементом являются представления базы данных, фактически являющиеся
«виртуальными» таблицами и не имеющих смысловой нагрузки в модели проектирования. Кроме того, это индексы и
первичные ключи таблиц и триггеров, используемые для оптимизации работы СУБД и имеющие смысловое значение только в
контексте базы данных и модели данных. Область видимости всех таких атрибутов — public, т.к. возможен запрос к любому столбцу таблицы.
Область видимости всех таких атрибутов — public, т.к. возможен запрос к любому столбцу таблицы.
 Он содержит первичный ключ таблицы
Customer, связывающий ее с Order. Это представляется в модели проектирования следующим образом:
Он содержит первичный ключ таблицы
Customer, связывающий ее с Order. Это представляется в модели проектирования следующим образом: Поставщик может
заниматься несколькими продуктами. Структура таблиц Product и Supplier:
Поставщик может
заниматься несколькими продуктами. Структура таблиц Product и Supplier: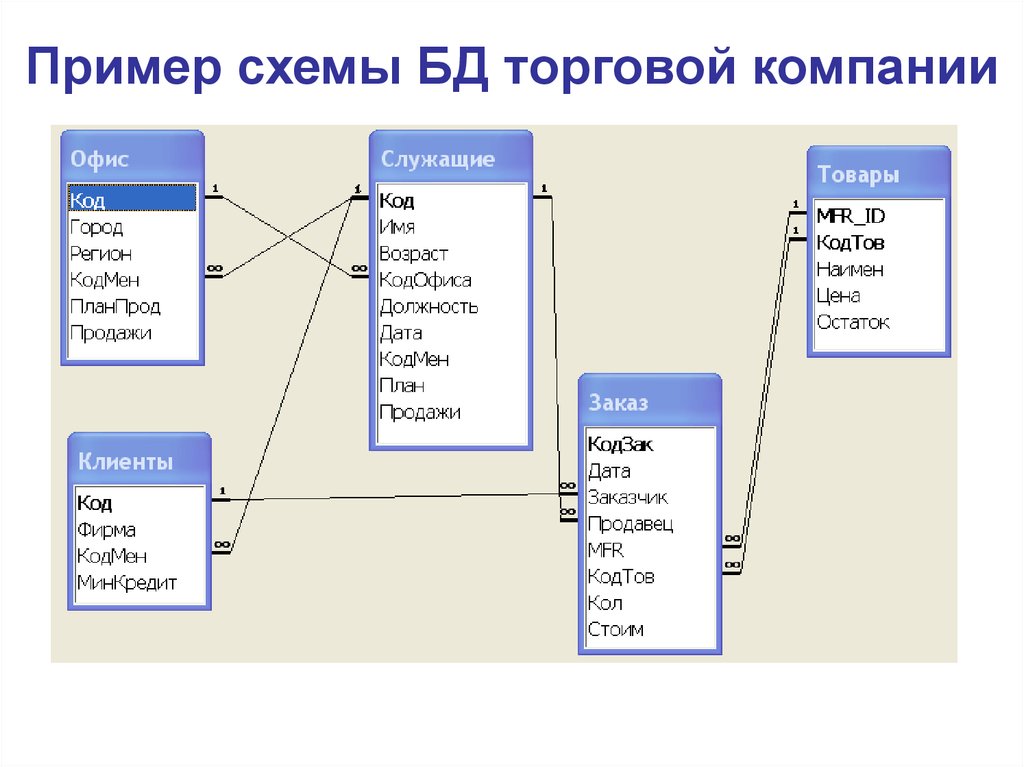
 Одна строка таблицы показывает, что у конкретного поставщика доступен н
конкретный продукт. Если взять все строки, у которых Supplier_ID равен ИД конкретного поставщика, то получим список
продуктов, доступных у него.
Одна строка таблицы показывает, что у конкретного поставщика доступен н
конкретный продукт. Если взять все строки, у которых Supplier_ID равен ИД конкретного поставщика, то получим список
продуктов, доступных у него.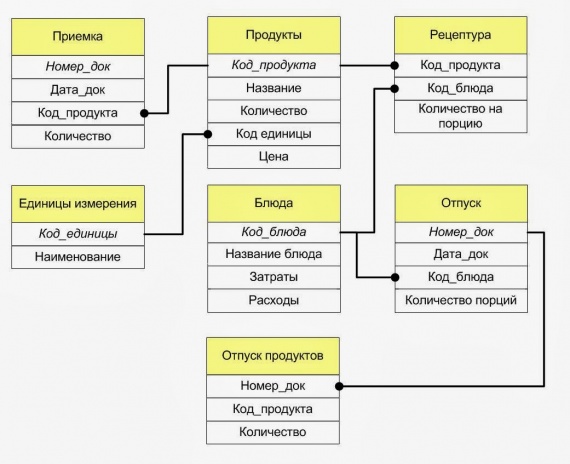 В других случаях более фундаментальные параметры являются общими, которые
можно представить в виде общего базового класса и двух или больше подклассов. Для выявления возможности обобщения ищите
часто повторяющиеся в разных таблицах столбцы, когда таблицы более схожи, чем различны.
В других случаях более фундаментальные параметры являются общими, которые
можно представить в виде общего базового класса и двух или больше подклассов. Для выявления возможности обобщения ищите
часто повторяющиеся в разных таблицах столбцы, когда таблицы более схожи, чем различны.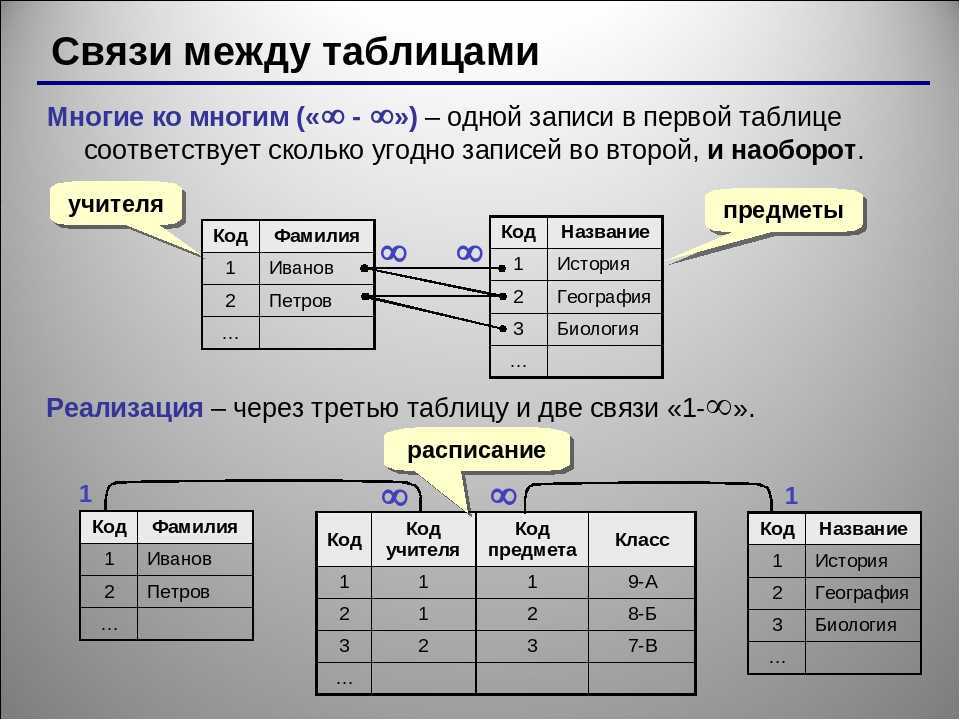 Как видно, общей является большая часть обоих таблиц и они различаются только
одним полем. Эту общность можно представить выделением общего класса Product и объявление классов SoftwareProduct и HardwareProduct подклассами Product:
Как видно, общей является большая часть обоих таблиц и они различаются только
одним полем. Эту общность можно представить выделением общего класса Product и объявление классов SoftwareProduct и HardwareProduct подклассами Product: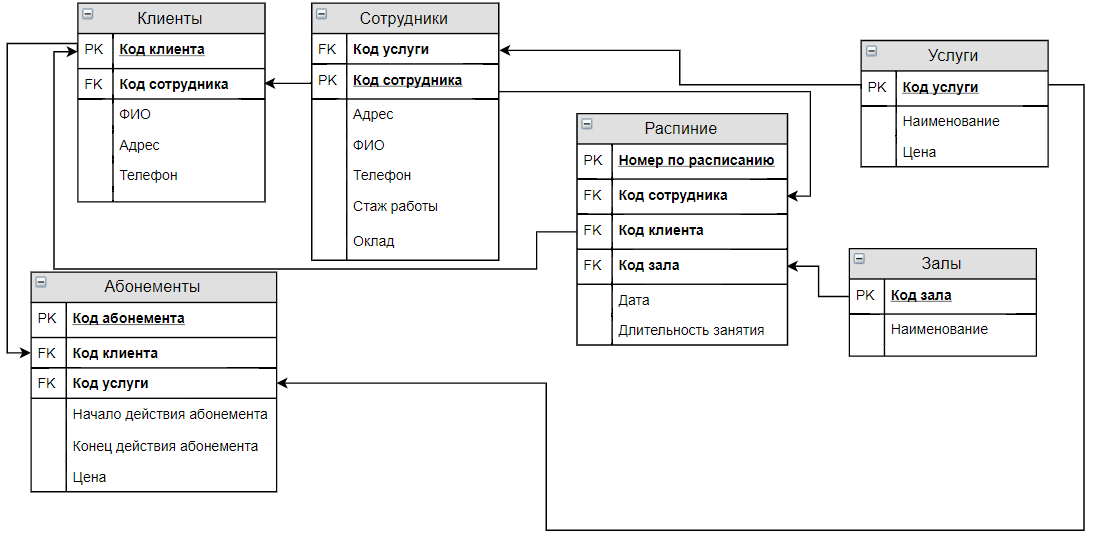 Необходимо иметь возможность задавать, изменять и запрашивать значения
атрибутов объектов. Это необходимо, поскольку к атрибутам объекта можно обращаться только через методы,
предоставляемые его классом. При создании операций, устанавливающих значение атрибута, не забудьте реализовать
проверку на удовлетворение условиям, накладываемым на значение поля в таблице. Если такая проверка не требуется, то
просто зафиксируйте возможность изменения и получения значений атрибутов, указав для них область
видимости «public», как это было сделано в диаграммах выше (значком слева от имени атрибута).
Необходимо иметь возможность задавать, изменять и запрашивать значения
атрибутов объектов. Это необходимо, поскольку к атрибутам объекта можно обращаться только через методы,
предоставляемые его классом. При создании операций, устанавливающих значение атрибута, не забудьте реализовать
проверку на удовлетворение условиям, накладываемым на значение поля в таблице. Если такая проверка не требуется, то
просто зафиксируйте возможность изменения и получения значений атрибутов, указав для них область
видимости «public», как это было сделано в диаграммах выше (значком слева от имени атрибута). Документируйте поведение хранимой процедуры в созданной
операции, указав в описании метода то, что операция реализуется хранимой процедурой.
Документируйте поведение хранимой процедуры в созданной
операции, указав в описании метода то, что операция реализуется хранимой процедурой.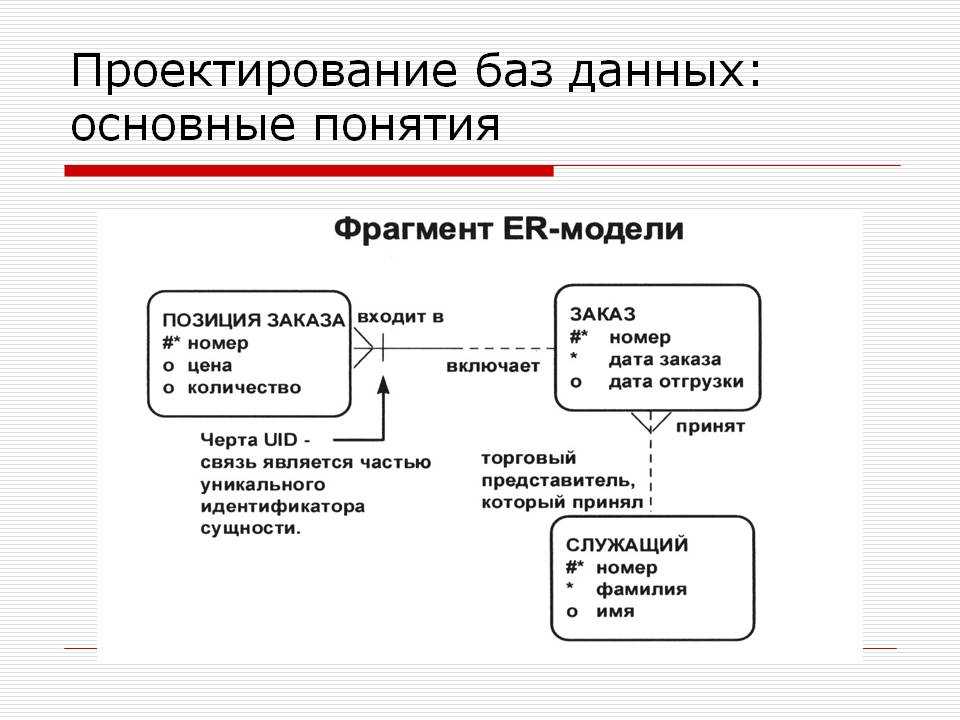 В случае, если в базе данных существуют правила сохранения целостности связей, например, каскадное удаление связанных записей, соответствующее поведение необходимо отразить в задействованных
классах. Например, в базе данных может быть следующее правило: при удалении Order все связанные LineItem также должны удаляться. Если целевой язык поддерживает сбор мусора, создайте механизм удаления
строк из таблиц при освобождении связанного объекта в рамках сбора мусора. Обратите внимание, что корректно
реализовать это достаточно трудно, поскольку вам потребуется реализовать механизм гарантирования того, что среди
подключенных клиентов базы данных нет имеющих ссылки на удаляемый из памяти объект. В данном случае не следует
полагаться на механизм сбора мусора среды выполнения/виртуальной машины, т.к. это всего лишь такой же клиент, как и
любые другие.
В случае, если в базе данных существуют правила сохранения целостности связей, например, каскадное удаление связанных записей, соответствующее поведение необходимо отразить в задействованных
классах. Например, в базе данных может быть следующее правило: при удалении Order все связанные LineItem также должны удаляться. Если целевой язык поддерживает сбор мусора, создайте механизм удаления
строк из таблиц при освобождении связанного объекта в рамках сбора мусора. Обратите внимание, что корректно
реализовать это достаточно трудно, поскольку вам потребуется реализовать механизм гарантирования того, что среди
подключенных клиентов базы данных нет имеющих ссылки на удаляемый из памяти объект. В данном случае не следует
полагаться на механизм сбора мусора среды выполнения/виртуальной машины, т.к. это всего лишь такой же клиент, как и
любые другие. Проанализируйте операторы Select, использующиеся для обращения к базе
данных, для получения картины того, как информация получается и обрабатывается. Для каждого столбца,
непосредственно возвращаемого оператором Select, установите свойство public связанного атрибута равным true; для всех остальных атрибутов укажите private. Для каждого динамически вычисляемого столбца в
операторе Select создайте операцию в связанном классе, рассчитывающую и возвращающую соответствующее значение. В
число рассматриваемых операторов включите встроенные в представления.
Проанализируйте операторы Select, использующиеся для обращения к базе
данных, для получения картины того, как информация получается и обрабатывается. Для каждого столбца,
непосредственно возвращаемого оператором Select, установите свойство public связанного атрибута равным true; для всех остальных атрибутов укажите private. Для каждого динамически вычисляемого столбца в
операторе Select создайте операцию в связанном классе, рассчитывающую и возвращающую соответствующее значение. В
число рассматриваемых операторов включите встроенные в представления.
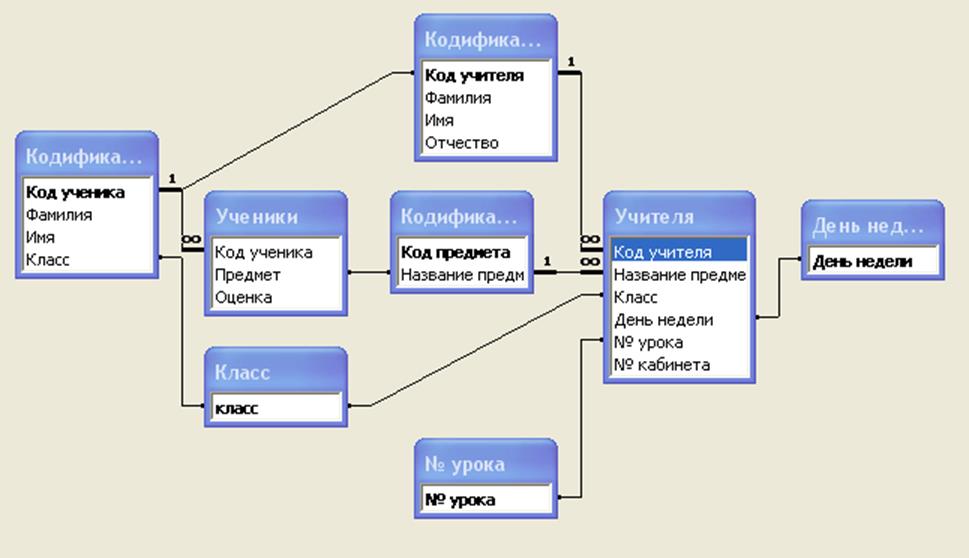
sql — Проектирование базы данных » Расписание преподавателя»
Вопрос задан
Изменён 30 дней назад
Просмотрен 29 раз
Набросал примерную схему базы данных.Прошу подкорректировать если есть минусы с такой схемы. И помочь написать запрос на вывод расписания по имени преподавателя.
- sql
- база-данных
- postgresql
- запрос
Ну, в принципе, выглядит нормально. Пара вопросов и замечаний только возникает:
- В чём разница между «занятием» и «парой»? Можно ли их в 1 таблицу объединить?
- Почему группа, аудитория, Вид занятия не в таблице занятие?
- Зачем отдельная таблица для дней недели? Можно же хранить тип дня недели (0-6).

- Зачем отдельная таблица для номера недели? Его тоже можно в расписании хранить.
- Лучше изменить названия таблиц на множественные числа Преподаватель -> Преподаватели, Пара -> Пары и т.д.
- Что значит вывод расписания? В консоль? Или вы используете доп. язык для вызова запроса и получения результатов (php, например)?

Вывод расписания будет каким-то таким для ваших таблиц:
SELECT * FROM Расписание JOIN Преподаватель ON Преподаватель.id = Расписание.id_преподавателя JOIN Номер_недели ON Номер_недели.id = Расписание.id_Номера JOIN День_недели ON День_недели.id = Расписание.id_Дня LEFT JOIN Пара ON Пара.id = Расписание.id_пары LEFT JOIN Занятие ON Занятие.id = Расписание.id_Занятия WHERE Имя LIKE '%петя%'
После SELECT я поставил *, чтобы выводить все колонки, вместо неё можете указать нужные вам столбцы. Если учтёте ситуацию в пунктах 3 и 4, то запрос упроститься и не надо будет JOIN-ить ещё 2 таблицы.
Обратите внимание, что при отсутствии данных в таблицах Пара, Занятие столбцы, выбранные из этих таблиц будут со значением null. Это произойдет из-за LEFT JOIN.
5
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Учебное пособие по структуре и дизайну базы данных
Теперь, когда таблицы вашей базы данных преобразованы в таблицы, вы готовы проанализировать отношения между этими таблицами. Кардинальность относится к количеству элементов, которые взаимодействуют между двумя связанными таблицами. Определение кардинальности помогает убедиться, что вы наиболее эффективно разделили данные на таблицы.
Кардинальность относится к количеству элементов, которые взаимодействуют между двумя связанными таблицами. Определение кардинальности помогает убедиться, что вы наиболее эффективно разделили данные на таблицы.
Каждая сущность потенциально может иметь отношения друг с другом, но эти отношения обычно относятся к одному из трех типов:
Отношения «один к одному»
Когда существует только один экземпляр сущности A для каждого экземпляра сущности B, говорят, что они имеют отношение «один к одному» (часто пишется как 1:1). Вы можете указать этот вид связи на диаграмме ER линией с дефисом на каждом конце:
Если у вас нет веских причин не делать этого, связь 1:1 обычно означает, что вам лучше объединить две таблицы. ‘ данные в одну таблицу.
Однако при определенных обстоятельствах может потребоваться создать таблицы с соотношением 1:1. Если у вас есть поле с необязательными данными, такими как «описание», которое пусто для многих записей, вы можете переместить все описания в отдельную таблицу, устранив пустое пространство и улучшив производительность базы данных.
Чтобы гарантировать правильное совпадение данных, вам нужно включить в каждую таблицу хотя бы один идентичный столбец, скорее всего, первичный ключ.
Отношения «один ко многим»
Эти отношения возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или посетитель может взять несколько книг из библиотеки одновременно. Отношения «один ко многим» (1:M) обозначаются так называемой «нотацией гусиной лапки», как в этом примере:
Чтобы реализовать отношение 1:M при настройке базы данных, просто добавьте первичный ключ из «одной» стороны отношения в качестве атрибута в другую таблицу. Когда первичный ключ указан в другой таблице таким образом, он называется внешним ключом. Таблица на стороне «1» отношения считается родительской по отношению к дочерней таблице на другой стороне.
Отношения «многие ко многим»
Когда несколько объектов из таблицы могут быть связаны с несколькими объектами в другой таблице, говорят, что они имеют отношение «многие ко многим» (M:N). Это может произойти в случае студентов и классов, поскольку учащийся может посещать несколько классов, а в классе может быть много студентов.
На диаграмме ER эти отношения изображаются следующими строками:
К сожалению, напрямую реализовать такой вид отношений в базе данных невозможно. Вместо этого вы должны разбить его на два отношения «один ко многим».
Для этого создайте новый объект между этими двумя таблицами. Если между продажами и продуктами существует связь M:N, вы можете назвать эту новую сущность «sold_products», поскольку она будет отображать содержание каждой продажи. И таблицы продаж, и таблицы продуктов будут иметь связь 1:M с проданными_продуктами. Такой промежуточный объект в различных моделях называется таблицей ссылок, ассоциативным объектом или соединительной таблицей.
Каждая запись в таблице ссылок будет соответствовать двум объектам в соседних таблицах (она также может включать дополнительную информацию). Например, таблица связи между учениками и классами может выглядеть так:
Обязательно или нет?
Еще один способ анализа отношений — рассмотреть, какая сторона отношений должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии, где был бы прочерк. Например, страна должна существовать, чтобы иметь представителя в ООН, но обратное неверно:
Две сущности могут быть взаимозависимыми (одна не может существовать без другой).
Рекурсивные связи
Иногда таблица указывает на себя. Например, таблица сотрудников может иметь атрибут «менеджер», который ссылается на другого человека в той же таблице. Это называется рекурсивной связью.
Избыточные отношения
Избыточные отношения — это отношения, которые выражены более одного раза. Как правило, вы можете удалить одно из отношений без потери важной информации. Например, если сущность «студенты» имеет прямую связь с другой сущностью, называемой «учителя», но также косвенно связана с учителями через «классы», вы хотите удалить связь между «учениками» и «учителями». Лучше удалить эту связь, потому что единственный способ, которым учащиеся назначаются учителям, — это классы.
Руководство по проектированию схемы базы данных: примеры и рекомендации
Эксперты прогнозируют, что глобальный рынок управления корпоративными данными будет расти со среднегодовым темпом роста 12,1% в период с 2023 по 2030 год. В базах данных вашей организации хранятся все корпоративные данные, необходимые для программного обеспечения. приложений, систем и ИТ-сред, помогая вам принимать более взвешенные бизнес-решения на основе данных.
Вот основные сведения о проектировании схемы базы данных:
- Проектирование схемы базы данных относится к стратегиям и методам построения схемы базы данных.
- Схема базы данных — это описание того, как данные структурированы или организованы в базе данных.
- Существует шесть типов схем базы данных: плоская модель, иерархическая модель, сетевая модель, реляционная модель, схема «звезда» и схема «снежинка».
- Правильный дизайн схемы базы данных поможет вам лучше использовать корпоративные данные.
Не все базы данных одинаковы. Дизайн схемы базы данных влияет на эффективность работы вашей базы данных и скорость извлечения информации. Однако о проектировании схемы базы данных легче сказать, чем сделать. В этой статье представлен обзор того, как работает проектирование схемы базы данных, а также примеры и рекомендации, которые помогут вам оптимизировать проектирование схемы базы данных.
Содержание
- Что такое схема базы данных?
- 6 типов схем баз данных
- Что такое схема базы данных?
- Почему важно разработать схему базы данных?
- Как разработать схему базы данных
- Передовой опыт проектирования схемы базы данных
Единый стек для современных групп данных
Получите персонализированную демонстрацию платформы и 30-минутную сессию вопросов и ответов с инженером по решениям
Что такое схема базы данных?
Проще говоря, схема базы данных — это формальное описание структуры или организации конкретной базы данных (БД). Термин схема базы данных чаще всего используется для реляционных баз данных, которые организуют информацию в таблицах и используют язык запросов SQL. Нереляционные (или «NoSQL») базы данных бывают нескольких разных форматов и не имеют «схемы» в отличие от реляционных баз данных (хотя у них есть базовая структура).
Дополнительная литература: SQL и NoSQL: 5 важных различий
Любая схема базы данных состоит из двух основных компонентов:
- Схема физической базы данных: Схема физической базы данных описывает, как вы физически храните данные в системе хранения, и форму используемого хранилища (файлы, пары ключ-значение, индексы и т. д.).
- Логическая схема базы данных: Логическая схема базы данных описывает логические ограничения, применяемые к данным, и определяет поля, таблицы, отношения, представления, ограничения целостности и т. д. Эти требования предоставляют программистам полезную информацию, которую они могут применить к физической структуре базы данных. Правила или ограничения, определенные в этой логической модели, определяют, как данные в разных таблицах соотносятся друг с другом.
Определение физических таблиц в схеме исходит из логической модели данных. Сущности становятся таблицами, атрибуты сущностей становятся полями таблиц и т. д.
6 типов схем баз данных
Узнайте больше о шести наиболее распространенных типах схем баз данных ниже:
- Плоская модель: Схема базы данных плоской модели упорядочивает данные в одном двумерном отображении — представьте себе электронную таблицу Microsoft Excel или файл CSV. Эта схема лучше всего подходит для простых таблиц и баз данных без сложных отношений между различными сущностями.
- Иерархическая модель: Схемы базы данных в иерархической модели имеют «древовидную» структуру с дочерними узлами, отходящими от корневого узла данных. Эта схема идеальна для хранения вложенных данных, например, генеалогических деревьев или биологических таксономий.
- Сетевая модель: Сетевая модель, как и иерархическая модель, рассматривает данные как узлы, связанные друг с другом; однако он допускает более сложные соединения, такие как отношения «многие ко многим» и циклы. Эта схема может моделировать перемещение товаров и материалов между местоположениями или рабочие процессы, необходимые для выполнения конкретной задачи.
- Реляционная модель: Как обсуждалось выше, эта модель упорядочивает данные в виде ряда таблиц, строк и столбцов, создавая отношения между различными объектами. Следующий раздел и остальная часть этого руководства будут посвящены реляционной модели.
- Звездообразная схема: Звездообразная схема представляет собой эволюцию реляционной модели, которая упорядочивает данные по фактам и измерениям. Фактические данные являются числовыми (например, количество продаж продукта), а размерные данные — описательными (например, цена продукта, цвет, вес и т. д.).
- Схема снежинки: Схема снежинки — это дополнительная абстракция поверх схемы звезды. Он содержит таблицу фактов, которая соединяется с многомерной таблицей, расширяя описательность, возможную в базе данных. Как вы могли догадаться, схема снежинки получила свое название от замысловатых узоров снежинки, где более мелкие структуры расходятся от центральных ветвей снежинки.
Дополнительная литература: 6 Схемы баз данных и способы их использования
Что такое проектирование схемы базы данных?
Проектирование схемы базы данных, иногда называемое проектированием схемы SQL, относится к методам и стратегиям построения схемы базы данных. Вы можете думать о схеме базы данных как о плане хранения огромных объемов информации в базе данных. Схема — это абстрактная структура или структура, представляющая логическое представление базы данных в целом. Определяя категории данных и отношения между этими категориями, дизайн схемы базы данных значительно упрощает извлечение, потребление, обработку и интерпретацию данных.
Структура схемы БД организует данные в отдельные объекты, определяет, как создавать отношения между организованными объектами, и влияет на применение ограничений к данным. Дизайнеры создают схемы базы данных, чтобы дать другим пользователям базы данных, таким как программисты и аналитики, логическое понимание данных.
Почему важно разработать схему базы данных?
Неэффективно организованные базы данных потребляют тонны энергии и ресурсов, их сложно поддерживать и администрировать. Вот где в игру вступает дизайн схемы базы данных. Вам будет сложно извлечь выгоду из корпоративных данных без чистой, эффективной и согласованной схемы базы данных. Правильный дизайн схемы удаляет дублирующиеся и несогласованные данные в разных местах.
Системы реляционных баз данных зависят от надежной схемы базы данных. Цели хорошего дизайна схемы включают в себя:
- Сокращение или устранение избыточности данных
- Предотвращение несоответствий и неточностей данных
- Обеспечение правильности и целостности данных
- Содействие быстрому поиску, извлечению и анализу данных
- Обеспечение безопасности и доступности важных и конфиденциальных данных для тех, кто в них нуждается.
Как разработать схему базы данных
Схемы базы данных описывают архитектуру базы данных и обеспечивают следующие основные принципы базы данных:
- Данные имеют согласованное форматирование
- Все записи записей имеют уникальный первичный ключ
- Вы не пропускаете важные данные
Схема схемы БД может существовать как в виде визуального представления, так и в виде набора формул или использования ограничений, управляющих базой данных. Затем разработчики выражают эти формулы на разных языках определения данных, в зависимости от используемой вами системы баз данных. Ведущие системы баз данных определяют схемы несколько иначе. Однако MySQL, Oracle Database и Microsoft SQL Server поддерживают оператор CREATE SCHEMA.
Предположим, вы хотите создать базу данных для хранения информации для вашего бухгалтерского отдела. Конкретная схема для этой базы данных может описывать структуру двух простых таблиц:
| Таблица 1: Пользователи | Таблица 2: Оплата сверхурочных |
| ID | ID |
| Полное имя | Полное имя |
| Электронная почта | Период времени |
| Дата рождения | Оплачено часов |
| Отдел |
Эта отдельная схема содержит ценную информацию, такую как:
- Название каждой таблицы
- Поля, которые содержит каждая таблица
- Отношения между таблицами (например, привязка сверхурочной оплаты сотрудника к его личности через его идентификационный номер)
- Любая дополнительная соответствующая информация
Разработчики и администраторы баз данных могут преобразовать эти таблицы схемы в код SQL.
Рекомендации по проектированию схемы базы данных
Чтобы максимально использовать возможности проектирования схемы базы данных, важно следовать рекомендациям. Это гарантирует, что у разработчиков будет четкая точка отсчета для таблиц и полей в проекте. Вот некоторые из этих передовых методов:
Соглашения об именах
- Определите и используйте соответствующие соглашения об именах, чтобы сделать схему вашей базы данных более эффективной. Несмотря на то, что вы можете выбрать определенный стиль или придерживаться стандарта ISO, самое главное — быть последовательным в полях имени.
- Старайтесь не использовать зарезервированные слова в именах таблиц, именах столбцов, полях и т. д., что может вызвать синтаксическую ошибку.
- Не используйте дефисы, кавычки, пробелы и специальные символы. Они либо потребуют дополнительной работы, либо не будут действительными.
- В именах таблиц используйте существительные в единственном числе, а не во множественном числе (например, используйте StudentName вместо StudentNames). Таблица представляет коллекцию, поэтому нет необходимости ставить название во множественном числе.
- Не используйте ненужные формулировки для имен таблиц (например, используйте Department вместо DepartmentList или TableDepartments)
Безопасность
- Безопасность данных начинается с хорошей схемы базы данных. Используйте шифрование для конфиденциальных данных, таких как личная информация (PII) и пароли. Не давайте роли администратора каждому пользователю; вместо этого запросите аутентификацию пользователя для доступа к базе данных.
Документация
- Схемы базы данных полезны еще долго после того, как вы их создали, и их будут просматривать многие другие люди. Таким образом, хорошая документация имеет важное значение. Задокументируйте схему своей базы данных с подробными инструкциями и напишите строки комментариев для сценариев, триггеров и других команд.
Нормализация
- Нормализация гарантирует, что независимые объекты и отношения не группируются в одной таблице, что уменьшает избыточность и повышает целостность. При необходимости используйте нормализацию для оптимизации производительности базы данных. Как чрезмерная, так и недостаточная нормализация могут привести к проблемам.
Опыт
- Понимание ваших данных и атрибутов каждого элемента поможет вам создать наиболее эффективную схему. Хорошо спроектированная схема может обеспечить экспоненциальный рост ваших данных. Продолжая расширять свои данные, анализируйте каждое поле по отношению к другим полям, которые вы собираете в своей схеме.
Как Integrate.io помогает при разработке схемы базы данных
Разработка схемы базы данных — это только первый шаг к эффективному управлению данными. Хорошо разработанные схемы гарантируют, что вы сможете эффективно извлекать и анализировать данные. Однако вам нужен такой инструмент, как Integrate.io, чтобы фактически выполнять этот поиск и анализ.
Integrate.io — это мощная, многофункциональная платформа конвейера данных без кода, которая создает конвейеры данных из баз данных и других источников в централизованный целевой репозиторий в облаке.