7. Ввод и вывод | Python 3
- /
- Переводы документации /
- Документация Python 3.8.8 /
- Учебник по Python /
- 7. Ввод и вывод
Ознакомить пользователя с выводом программы можно различными способами — данные могут быть выведены в читаемом виде или записаны в файл для последующего использования. Часть возможностей будет обсуждена в этой главе.
7.1. Удобное форматирование вывода
На данный момент мы выяснили два способа вывода значений: операторы выражения и
функция print(). (Третий способ — использование метода write() объектов
файлов; на файл стандартного вывода можно сослаться как на sys.stdout.
Более подробную информацию по этому пункту смотрите в Справочнике по библиотеке.)
Часто требуется больше контроля над форматированием выходных данных, чем просто печать разделенных пробелом значений. Существует несколько способов форматирования выходных данных.
Для использования форматированных строковых литералов, начните строку с
Fперед открывающей кавычкой или тройной кавычкой. Внутри
этой строки можно записать Python выражение между символами
Внутри
этой строки можно записать Python выражение между символами {и}, которое может ссылаться на переменные или литеральные значения.>>> year = 2016 >>> event = 'Referendum' >>> f'Results of the {year} {event}' 'Results of the 2016 Referendum'Метод
str.format()строки требует больших ручных усилий. Вы по-прежнему будете использовать{и}, чтобы отметить, где переменная будет заменена, и можете предоставить подробные директивы форматирования, но вам также потребуется предоставить информацию для форматирования.>>> yes_votes = 42_572_654 >>> no_votes = 43_132_495 >>> percentage = yes_votes / (yes_votes + no_votes) >>> '{:-9} YES votes {:2.2%}'.format(yes_votes, percentage) ' 42572654 YES votes 49.67%'Наконец, можно выполнить всю обработку строки самостоятельно, используя операции слайсинга и конкатенации строки для создания любого макета, который вы можете себе представить.
Тип строки имеет несколько методов, которые выполняют полезные
операции для заполнения строки заданной ширины столбца.
 Внутри
этой строки можно записать Python выражение между символами
Внутри
этой строки можно записать Python выражение между символами  Тип строки имеет несколько методов, которые выполняют полезные
операции для заполнения строки заданной ширины столбца.
Тип строки имеет несколько методов, которые выполняют полезные
операции для заполнения строки заданной ширины столбца.Если вам не нужны вычурные выходные данные, а просто требуется быстрое
отображение некоторых переменных для отладки, вы можете преобразовать любое
значение в строку функциями repr() или str().
Предназначение функции str() — возвращение значений в читабельной
форме; в отличие от repr(), чьё назначение — генерирование читаемых интерпретатором форм
(или вызвать ошибку SyntaxError, если эквивалентного
синтаксиса не существует). Для тех объектов, у которых нет формы для человеческого
прочтения функция str() возвратит такое же значение, как и repr(). У многих
значений, таких как числа или структуры, вроде списков и словарей, одинаковая форма для
обеих функций. Строки и числа с плавающей точкой, в частности, имеют по
две разных формы.
Некоторые примеры:
>>> s = 'Hello, world.
 '
>>> str(s)
'Hello, world.'
>>> repr(s)
"'Hello, world.'"
>>> str(1/7)
'0.14285714285714285'
>>> x = 10 * 3.25
>>> y = 200 * 200
>>> s = 'The value of x is ' + repr(x) + ', and y is ' + repr(y) + '...'
>>> print(s)
The value of x is 32.5, and y is 40000...
>>> # Функция repr() строки добавляет строковые кавычки и обратную косую черту:
... hello = 'hello, world\n'
>>> hellos = repr(hello)
>>> print(hellos)
'hello, world\n'
>>> # Аргументом для repr() может быть любой объект Python:
... repr((x, y, ('spam', 'eggs')))
"(32.5, 40000, ('spam', 'eggs'))"
'
>>> str(s)
'Hello, world.'
>>> repr(s)
"'Hello, world.'"
>>> str(1/7)
'0.14285714285714285'
>>> x = 10 * 3.25
>>> y = 200 * 200
>>> s = 'The value of x is ' + repr(x) + ', and y is ' + repr(y) + '...'
>>> print(s)
The value of x is 32.5, and y is 40000...
>>> # Функция repr() строки добавляет строковые кавычки и обратную косую черту:
... hello = 'hello, world\n'
>>> hellos = repr(hello)
>>> print(hellos)
'hello, world\n'
>>> # Аргументом для repr() может быть любой объект Python:
... repr((x, y, ('spam', 'eggs')))
"(32.5, 40000, ('spam', 'eggs'))"
Модуль string содержит класс Template, который
предлагает еще один способ замены значения на строки, используя такие
местозаполнители, как $x и заменяя их значения из словаря, но предлагает
гораздо меньше возможностей по управлению форматированием.
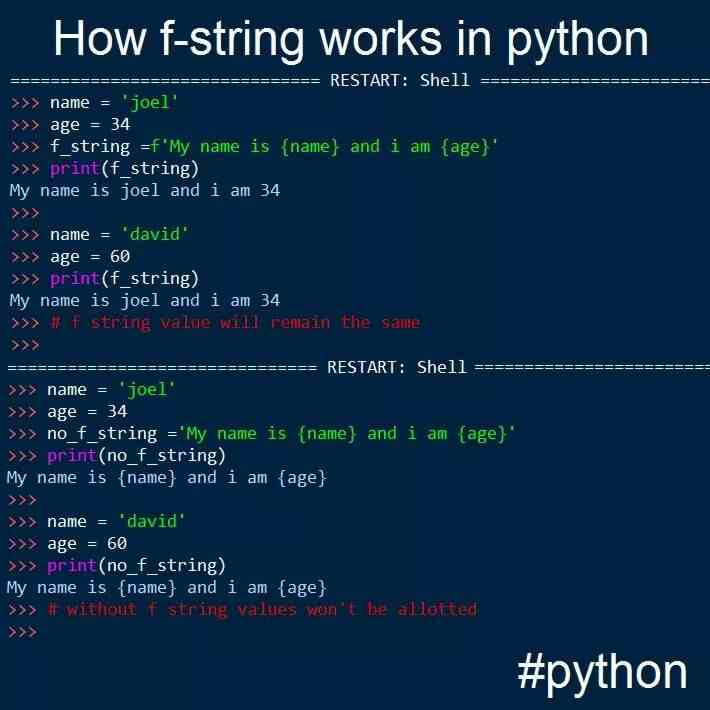
7.1.1. Форматирующие строковые литералы
Форматированные строковые литералы (также называемые f-строками
для краткости) позволяет включить значение
Python выражений в строку префикса строки с F и
запись выражений как {expression}.
За выражением может следовать необязательный спецификатор формата. Это позволяет больше контролировать над форматированием значения. В следующем примере число pi округляется до трёх знаков после запятой:
>>> import math
>>> print(f'The value of pi is approximately {math.pi:.3f}.')
The value of pi is approximately 3.142.
Передача целого числа после ':' приведёт к тому, что это поле будет
минимальным числом символов в ширину. Это полезно для выстраивания столбцов.
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 7678}
>>> for name, phone in table.items():
... print(f'{name:10} ==> {phone:10d}')
...
Sjoerd ==> 4127
Jack ==> 4098
Dcab ==> 7678
Для преобразования значения перед форматированием можно использовать другие
модификаторы. '!a' применяется ascii(), '!s' применяется str() и '!r' применяет repr():
>>> animals = 'eels'
>>> print(f'My hovercraft is full of {animals}. ')
My hovercraft is full of eels.
>>> print(f'My hovercraft is full of {animals!r}.')
My hovercraft is full of 'eels'.
Для получения справки по этим спецификациям формата см. Справочное руководство по Спецификации формата Мини-языка.
7.1.2. Метод format() строки
Основное использование метода str.format() выглядит следующим образом:
>>> print('We are the {} who say "{}!"'.format('knights', 'Ni'))
We are the knights who say "Ni!"
Скобки и символы в них (называемые полями формата) заменяются объектами,
передаваемыми в метод str.format(). Число в скобках можно использовать для
обозначения положения объекта, передаваемого в метод
>>> print('{0} and {1}'.format('spam', 'eggs'))
spam and eggs
>>> print('{1} and {0}'.format('spam', 'eggs'))
eggs and spam
Если ключевые аргументы используются в методе str.format(), на их
значения ссылаются с помощью имени аргумента.
>>> print('This {food} is {adjective}.'.format(
... food='spam', adjective='absolutely horrible'))
This spam is absolutely horrible.
Позиционные и ключевые аргументы могут быть произвольно объединены:
>>> print('The story of {0}, {1}, and {other}.'.format('Bill', 'Manfred',
other='Georg'))
The story of Bill, Manfred, and Georg.
Если у вас действительно длинная форматная строка которую вы не хотите разделять,
было бы неплохо, если бы вы могли ссылаться на форматированные по имени переменные,
а не по положению. Это можно сделать просто
передав словарь и используя квадратные скобки '[]' для доступа к
ключам.
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
>>> print('Jack: {0[Jack]:d}; Sjoerd: {0[Sjoerd]:d}; '
... 'Dcab: {0[Dcab]:d}'.format(table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
Это также можно сделать, передав table в качестве ключевых аргументов с
символом „**“ нотацией.
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
>>> print('Jack: {Jack:d}; Sjoerd: {Sjoerd:d}; Dcab: {Dcab:d}'.format(**table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
Это особенно полезно в сочетании со встроенной функцией vars(), которая
возвращает словарь, содержащая все локальные переменные.
В качестве примера, следующие строки создают точно выровненный набор столбцов с целыми числами и их квадратами и кубами
>>> for x in range(1, 11):
... print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
Полный обзор форматирования строк с помощью str.format() см. в разделе
Синтаксис форматной строки.
7.1.3. Ручное форматирование строки
Вот та же таблица квадратов и кубов, отформатированная вручную:
>>> for x in range(1, 11): ... print(repr(x).
 rjust(2), repr(x*x).rjust(3), end=' ')
... # Обратите внимание на использование 'end' в предыдущей строке
... print(repr(x*x*x).rjust(4))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
rjust(2), repr(x*x).rjust(3), end=' ')
... # Обратите внимание на использование 'end' в предыдущей строке
... print(repr(x*x*x).rjust(4))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
(Обратите внимание, что в первом примере единичные пробелы между колонками
добавлены функцией print(): она всегда вставляет пробелы между своими параметрами.)
Этот пример демонстрирует работу метода строковых объектов str.rjust(), выравнивающего
строку по правому краю в поле переданной ширины, отступая пробелами слева. Имеются
также похожие методы str.ljust() и str.center(). Эти методы не выводят
ничего, они лишь возвращают новую строку. Если строка на входе чересчур длинная, то они не
усекают её, а возвращают без изменения; это испортит вашу столбцовую разбивку, но обычно
это лучше, чем альтернатива, которая бы наврала о значении. (Если вам действительно хочется
сделать обрезку, то всегда можно добавить операцию слайса, например: x..) ljust(n)[:n]
ljust(n)[:n]
Есть другой метод — str.zfill(), который заполняет нулями пространство слева
от числовой строки. Он распознаёт знаки плюс и минус:
>>> '12'.zfill(5) '00012' >>> '-3.14'.zfill(7) '-003.14' >>> '3.14159265359'.zfill(5) '3.14159265359'
7.1.4. Форматирование строк в старом стиле
Оператор % (по модулю) также может использоваться для форматирования строк.
Учитывая 'string' % values, экземпляры % в string заменяются нулем
или более элементов values. Операция обычно называется интерполяцией
строк. Например:
>>> import math
>>> print('Значение пи примерно %5.3f.' % math.pi)
Значение пи примерно 3.142.
Дополнительную информацию можно найти в разделе Форматирование строк в стиле printf.
7.2. Чтение и запись файлов
Функция open() возвращает файловый объект и чаще всего используется с двумя аргументами: open(filename, mode).
>>> f = open('workfile', 'w')
Первый аргумент — это строка, содержащая имя файла. Второй — другая строка,
содержащая несколько символов, определяющих способ использования файла. Значение
параметра mode может быть символом 'r' если файл будет открыт только для чтения, 'w' открыт только для записи (существующий файл с таким же именем будет стёрт) и 'a' файл открыт для добавления: любые данные, записанные в файл автоматически
добавляются в конец. Аргумент mode необязателен: если он пропущен — предполагается,
что он равен 'r'.
Обычно файлы открываются в текстовом режиме — это значит что вы читаете из
файла и записываете в файл строки в определённой кодировке. Если кодировка не
указана явно, то используется кодировка по умолчанию, которая зависит от платформы (см. open()). Если добавить к режиму файла символ 'b', файл открывается в двоичном режиме <двоичный режим>:
теперь данные считываются и записываются в виде двоичных объектов. Этот
режим следует использовать для всех файлов, которые не содержат текст.
Этот
режим следует использовать для всех файлов, которые не содержат текст.
При использовании текстового режима, все окончания строк, по умолчанию, специфичные
для платформы (\n в Unix, \r\n в Windows), усекаются до символа \n, при чтении из файла. При записи в текстовом режиме, по умолчанию вхождения \n конвертируются обратно в окончания строк, специфичные для платформы. Эти закулисные
изменения в файловых данных корректно работают в случае текстовых файлов, но испортят
двоичные данные в файлах вроде JPEG или EXE. Внимательно следите за
тем, чтобы использовать двоичный режим при чтении и записи таких файлов.
Рекомендуется использовать with ключевой при работе с файловыми
объектами. Преимущество заключается в том, что файл правильно закрывается после
завершения работы набора, даже если в какой-то момент вызывается исключение.
Использование with также намного короче, чем запись эквивалентных
блоков try—finally:
>>> with open('workfile') as f:
. .. read_data = f.read()
>>> # Мы можем проверить, что файл был автоматически закрыт.
>>> f.closed
True
 .. read_data = f.read()
>>> # Мы можем проверить, что файл был автоматически закрыт.
>>> f.closed
True
.. read_data = f.read()
>>> # Мы можем проверить, что файл был автоматически закрыт.
>>> f.closed
True
Если вы не используете ключевое with, то вам следует вызвать
в f.close(), чтобы закрыть файл и немедленно освободить его любые системные
используемые им ресурсы.
Предупреждение
Вызов f.write() без использования ключевого слова with или вызов f.close() может привести к аргументам f.write() не полностью
записывается на диск, даже если программа успешно завершается.
После закрытия файлового объекта либо оператор with, либо путём
вызова f.close() попытки использования файлового объекта автоматически
завершатся неудачей.
>>> f.close() >>> f.read() Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: I/O operation on closed file.
7.2.1. Методы файловых объектов
В примерах ниже подразумевается, что заранее создан файловый объект с именем f.
Чтобы прочитать содержимое файла, вызовите f.read(size), который считывает
некоторое количество данных и возвращает его как строку (в текстовом
режиме) или байты (в двоичном режиме). size является необязательным числовым
аргументом. Если size пропущен или отрицателен, все содержимое файла будет
прочитано и возвращено; это ваша проблема, если размер файла в два раза
превышает объем памяти компьютера. В противном случае считывается и возвращается
не более size символов (в текстовом режиме) или size байт (в двоичном
режиме). Если достигнут конец файла, f.read() возвращает пустую строку
(''):
>>> f.read() 'This is the entire file.\n' >>> f.read() ''
f.readline() считывает одну строку из файла; символ новой строки (\n)
остается в конце строки и пропускается только в последней строке файла, если файл
не оканчивается на символ новой строки. Это делает возвращаемое значение однозначным; если f. возвращает пустую строку, то достигнут конец файла, в то время
как пустая строка представлена  readline()
readline()'\n', строка, содержащая только один символ новой
строки.
>>> f.readline() 'This is the first line of the file.\n' >>> f.readline() 'Second line of the file\n' >>> f.readline() ''
Для чтения строк из файла можно выполнить цикл над объектом файла. Это эффективно, быстро и обеспечивает простой код:
>>> for line in f: ... print(line, end='') ... This is the first line of the file. Second line of the file
Если требуется прочитать все строки файла в список, можно также использовать list(f) или f.readlines().
f.write(string) записывает содержимое string в файл, возвращая количество
записанных символов.
>>> f.write('This is a test\n')
15
Необходимо преобразовать другие типы объектов — либо в строку (в текстовом режиме) или байтовый объект (в двоичном режиме) — перед их записью:
>>> value = ('the answer', 42)
>>> s = str(value) # преобразовать кортеж в строку
>>> f. write(s)
18
 write(s)
18
write(s)
18
f.tell() — возвращает целое число, дающее текущую позицию файлового объекта в файле
представлен как количество байтов от начала файла в двоичном режиме и
непрозрачный номер в текстовом режиме.
Чтобы изменить положение объекта файла, используйте f.seek(offset, whence).
Положение вычисляется на основе добавления offset к точке отсчета;
точка отсчета выбирается аргументом whence. Значение 0 параметра whence отмеряет
смещение от начала файла, 1 использует текущее положение файла, а 2 использует конец
файла в качестве точки отсчета. whence может быть пропущен и по умолчанию равен
0, используя начало файла в качестве опорной точки.
>>> f = open('workfile', 'rb+')
>>> f.write(b'0123456789abcdef')
16
>>> f.seek(5) # Перейти к 6-му байту в файле
5
>>> f.read(1)
b'5'
>>> f.seek(-3, 2) # Перейти к 3-му байту до конца
13
>>> f.read(1)
b'd'
В текстовых файлах (открытые без b в строке режима), выполнять позиционирование
позволяется только от начала файла (за исключением прокрутки в конец файла с
использованием seek(0, 2)), и только те значения offset допустимы,
что возвращаются от f. или 0. Любые другие значения offset производят неопределенное поведение. tell()
tell()
Файловые объекты имеют некоторые дополнительные методы, такие как isatty() и truncate(), которые реже используются; обратитесь к Справочнику по библиотеке
для более полного обзора по файловым объектам.
7.2.2. Сохранение структурированных данных с помощью
jsonСтроки могут быть легко записаны и прочитаны из файла. Числа требуют немного большего
усилия, потому что метод read() возвращает только строки, которые придется
передать функции типа int(), принимающая строку типа '123' и возвращающая
ее числовое значение 123. Если вы хотите сохранить более сложные типы данных типа
списков и словарей, парсинг и сериализация вручную усложняется.
Вместо принуждения пользователей постоянно писать и отлаживать код
для сохранения сложных типов данных в файлы, Python позволяет вам использовать популярный
формат обмена данными, называемый JSON (Объектная нотация JavaScript). Стандартный модуль под названием
Стандартный модуль под названием json, может брать на входе иерархии данных Python-а, и
преобразовывать их в строковые представления; этот процесс называется сериализация.
Восстановление данных из строкового представления называется десериализация.
Между сериализацией и десериализацией строки, представляющей объект, может быть
сохранена в файле или в данных, или быть послана по сетевому соединению на некоторую
удаленную машину.
Примечание
Формат JSON часто используется современными приложениями для обмена данными. Многие программисты уже знакомы с ним, что делает его хорошим выбором ради совместимости.
Если у вас есть объект x, вы можете посмотреть его строковое представление с помощью
простой строчки кода:
>>> import json >>> json.dumps([1, 'simple', 'list']) '[1, "simple", "list"]'
Другой вариант функции: dumps(), называемый: dump(),
просто сериализует объект в текстовый файл. Таким образом, если
Таким образом, если f является
текстовым файлом объект открыт для записи, мы можем сделать следующее:
json.dump(x, f)
Для повторного декодирования объекта, если f является открытым текстовым файлом,
открытым для чтения:
x = json.load(f)
Это простая техника сериализации может обрабатывать списки и словари, но сериализация
произвольных экземпляров классов в JSON требует немного дополнительных усилий. Справка
по модулю json содержит объяснение этого.
« предыдущий | следующий »
Форматирование строк. Оператор % | Python 3 для начинающих и чайников
Иногда (а точнее, довольно часто) возникают ситуации, когда нужно сделать строку, подставив в неё некоторые данные, полученные в процессе выполнения программы (пользовательский ввод, данные из файлов и т. д.). Подстановку данных можно сделать с помощью форматирования строк. Форматирование можно сделать с помощью оператора %, и метода format.
Метод format является наиболее правильным, но часто можно встретить программный код с форматированием строк в форме оператора %.
Если для подстановки требуется только один аргумент, то значение — сам аргумент:
>>> 'Hello, %s!' % 'Vasya' 'Hello, Vasya!'
А если несколько, то значением будет являться кортеж со строками подстановки:
>>> '%d %s, %d %s' % (6, 'bananas', 10, 'lemons') '6 bananas, 10 lemons'
Теперь, а почему я пишу то %d, то %s? А всё зависит от того, что мы используем в качестве подстановки и что мы хотим получить в итоге.
| Формат | Что получится |
| ‘%d’, ‘%i’, ‘%u’ | Десятичное число. |
| ‘%o’ | Число в восьмеричной системе счисления. |
| ‘%x’ | Число в шестнадцатеричной системе счисления (буквы в нижнем регистре). |
| ‘%X’ | Число в шестнадцатеричной системе счисления (буквы в верхнем регистре). |
| ‘%e’ | Число с плавающей точкой с экспонентой (экспонента в нижнем регистре). |
| ‘%E’ | Число с плавающей точкой с экспонентой (экспонента в верхнем регистре). |
| ‘%f’, ‘%F’ | Число с плавающей точкой (обычный формат). |
| ‘%g’ | Число с плавающей точкой. с экспонентой (экспонента в нижнем регистре), если она меньше, чем -4 или точности, иначе обычный формат. |
| ‘%G’ | Число с плавающей точкой. с экспонентой (экспонента в верхнем регистре), если она меньше, чем -4 или точности, иначе обычный формат. |
| ‘%c’ | Символ (строка из одного символа или число — код символа). |
| ‘%r’ | Строка (литерал python). |
| ‘%s’ | Строка (как обычно воспринимается пользователем). |
| ‘%%’ | Знак ‘%’. |
Спецификаторы преобразования записываются в следующем порядке:
- %.
- Ключ (опционально), определяет, какой аргумент из значения будет подставляться.
- Флаги преобразования.
- Минимальная ширина поля. Если *, значение берётся из кортежа.
- Точность, начинается с ‘.’, затем — желаемая точность.
- Модификатор длины (опционально).
- Тип (см. таблицу выше).

>>> print ('%(language)s has %(number)03d quote types.' % {"language": "Python", "number": 2})
Python has 002 quote types.Флаги преобразования:
| Флаг | Значение |
| «#» | Значение будет использовать альтернативную форму. |
| «0» | Свободное место будет заполнено нулями. |
| «-« | Свободное место будет заполнено пробелами справа. |
| » « | Свободное место будет заполнено пробелами справа. |
| «+» | Свободное место будет заполнено пробелами слева. |
>>> '%.2s' % 'Hello!' 'He' >>> '%.*s' % (2, 'Hello!') 'He' >>> '%-10d' % 25 '25 ' >>> '%+10f' % 25 '+25.000000' >>> '%+10s' % 'Hello' ' Hello'
Для вставки кода на Python в комментарий заключайте его в теги <pre><code>Ваш код</code></pre>
Свежее
- Модуль csv — чтение и запись CSV файлов
- Создаём сайт на Django, используя хорошие практики. Часть 1: создаём проект
- Онлайн-обучение Python: сравнение популярных программ
 Часть 1: создаём проект
Часть 1: создаём проектКатегории
- Книги о Python
- GUI (графический интерфейс пользователя)
- Курсы Python
- Модули
- Новости мира Python
- NumPy
- Обработка данных
- Основы программирования
- Примеры программ
- Типы данных в Python
- Видео
- Python для Web
- Работа для Python-программистов
Полезные материалы
- Сделай свой вклад в развитие сайта!
- Самоучитель Python
- Карта сайта
- Отзывы на книги по Python
- Реклама на сайте
Мы в соцсетях
python — форматирование строк: % против .format против литерала f-строки
Задавать вопрос
спросил
Изменено 9 месяцев назад
Просмотрено 1,0 м раз
Существуют различные методы форматирования строк:
- Python <2. 6:
«Привет %s» % имя - Python 2.6+:
"Привет {}".format(name)(используетсяstr.format) - Python 3.6+:
f"{name}"(использует f-строки)
 6:
6: Что лучше и для каких ситуаций?
Следующие методы дают одинаковый результат, так в чем же разница?
имя = "Алиса" "Здравствуйте, %s" % имя "Здравствуйте, {0}".format(имя) f"Привет, {имя}" # Использование именованных аргументов: "Привет, %(kwarg)s" % {'kwarg': имя} "Привет {kwarg}".format(kwarg=имя) f"Привет, {имя}"Когда запускается форматирование строк и как избежать снижения производительности во время выполнения?
Если вы пытаетесь закрыть повторяющийся вопрос, который просто ищет способ форматирования строки, используйте Как поместить значение переменной в строку?.
- python
- производительность
- форматирование строк
- f-строка
Чтобы ответить на ваш первый вопрос. ..
.. .format во многих отношениях кажется более сложным. Раздражает то, что % также может принимать либо переменную, либо кортеж. Вы могли бы подумать, что всегда будет работать следующее:
"Привет %s" % name
однако, если name окажется (1, 2, 3) , он выдаст TypeError . Чтобы гарантировать, что он всегда печатается, вам нужно сделать
"Hello %s" % (name,) # предоставить единственный аргумент как кортеж из одного элемента
просто уродство. .format не имеет этих проблем. Также во втором примере, который вы привели, пример .format выглядит намного чище.
Используйте его только для обратной совместимости с Python 2.5.
Чтобы ответить на ваш второй вопрос, форматирование строки происходит одновременно с любой другой операцией — когда вычисляется выражение форматирования строки. А Python, не будучи ленивым языком, вычисляет выражения перед вызовом функций, поэтому выражение log. сначала оценит строку, например.  debug("некоторая отладочная информация: %s" % some_info)
debug("некоторая отладочная информация: %s" % some_info) "некоторая отладочная информация: roflcopters активны" , затем эта строка будет передана в log.debug() .
То, что не может сделать оператор по модулю ( % ), afaik:
tu = (12,45,22222,103,6)
print '{0} {2} {1} {2} {3} {2} {4} {2}'.format(*tu)
результат
12 22222 45 22222 103 22222 6 22222
Очень полезно.
Другая точка: format() , будучи функцией, может использоваться в качестве аргумента в других функциях:
li = [12,45,78,784,2,69,1254,4785,984]
напечатать карту('число равно {}'.format,li)
Распечатать
из datetime импортировать дату и время, timedelta
Once_upon_a_time = дата и время (2010, 7, 1, 12, 0, 0)
дельта = дельта времени (дни = 13, часы = 8, минуты = 20)
gen =(once_upon_a_time +x*дельта для x в xrange(20))
print '\n'.join(map('{:%Y-%m-%d %H:%M:%S}'. format, gen))
 format, gen))
format, gen))
Результат:
['число 12', 'число 45', 'число 78', 'число 784', 'число 2', 'число 69', ' число 1254", "число 4785", "число 984"] 2010-07-01 12:00:00 2010-07-14 20:20:00 2010-07-28 04:40:00 2010-08-10 13:00:00 2010-08-23 21:20:00 2010-09-06 05:40:00 2010-09-19 14:00:00 2010-10-02 22:20:00 2010-10-16 06:40:00 2010-10-29 15:00:00 2010-11-11 23:20:00 2010-11-25 07:40:00 2010-12-08 16:00:00 2010-12-22 00:20:00 2011-01-04 08:40:00 2011-01-17 17:00:00 2011-01-31 01:20:00 2011-02-13 09:40:00 2011-02-26 18:00:00 2011-03-12 02:20:0010
Предполагая, что вы используете модуль Python logging , вы можете передать аргументы форматирования строки в качестве аргументов методу .debug() , а не выполнять форматирование самостоятельно:
log.debug("некоторая отладочная информация: % с", некоторая_информация)
, что позволяет избежать форматирования, если только регистратор действительно что-то не регистрирует.
Начиная с Python 3.6 (2016) вы можете использовать f-строки для замены переменных:
>>> origin = "London"
>>> пункт назначения = "Париж"
>>> f"от {отправителя} до {назначения}"
'из Лондона в Париж'
Обратите внимание на префикс f" . Если вы попробуете это в Python 3.5 или более ранней версии, вы получите SyntaxError .
См. https://docs.python.org/3.6/reference/lexical_analysis.html# f-строки
3 PEP 3101 предлагает заменить оператор % новым расширенным форматированием строк в Python 3, где он будет использоваться по умолчанию.
Но, пожалуйста, будьте осторожны, только что я обнаружил одну проблему при попытке заменить все % на .format в существующем коде: '{}'.format(unicode_string) попытается закодировать unicode_string и вероятно, потерпит неудачу.
Просто взгляните на этот интерактивный журнал сеансов Python:
Python 2.7.2 (по умолчанию, 27 августа 2012 г., 19:52:55) [GCC 4.1.2 20080704 (Red Hat 4.1.2-48)] на linux2 ; с='й' ; у=у'й' ; с '\xd0\xb9' ; ты у'\u0439'
s — это просто строка (называемая «массивом байтов» в Python3), а u — это строка Unicode (называемая «строкой» в Python3):
; '%SS '\xd0\xb9' ; '%s' % и у'\u0439'
Когда вы передаете объект Unicode в качестве параметра оператору % , он создаст строку Unicode, даже если исходная строка не была Unicode:
; '{}'.формат(ы)
'\xd0\xb9'
; '{}'.format(u)
Traceback (последний последний вызов):
Файл "", строка 1, в
UnicodeEncodeError: кодек 'latin-1' не может кодировать символ u'\u0439' в позиции 0: порядковый номер не в диапазоне (256)
, но функция .format вызовет «UnicodeEncodeError»:
; u'{}'.формат(ы)
и'\xd0\xb9'
; u'{}'. format(u)
у'\u0439'
 format(u)
у'\u0439'
format(u)
у'\u0439'
, и он будет работать с аргументом Unicode, только если исходная строка была Unicode.
; '{}'.format(u'i')
'я'
или если строка аргумента может быть преобразована в строку (так называемый «массив байтов»)
8 % дает лучшую производительность, чем формат из моего теста.
Тестовый код:
Python 2.7.2:
время импорта
напечатать 'формат:', timeit.timeit("'{}{}{}'.format(1, 1.23, 'привет')")
напечатать '%:', timeit.timeit("'%s%s%s' % (1, 1.23, 'привет')")
Результат:
> формат: 0.4703249 > %: 0,357107877731
Python 3.5.2
время импорта
print('format:', timeit.timeit("'{}{}{}'.format(1, 1.23, 'привет')"))
print('%:', timeit.timeit("'%s%s%s' % (1, 1.23, 'привет')"))
Результат
> формат: 0,5864730989560485 > %: 0,013593495357781649
Это выглядит в Python2, разница небольшая, тогда как в Python3 % намного быстрее, чем формат .
Спасибо @Chris Cogdon за пример кода.
Изменить 1:
Повторно протестировано в Python 3.7.2 в июле 2019 года.
Результат:
> формат: 0.86600608 > %: 0,630180146
Большой разницы нет. Я предполагаю, что Python постепенно улучшается.
Изменить 2:
После того, как кто-то упомянул f-строку python 3 в комментарии, я провел тест для следующего кода в python 3.7.2:
import timeit
print('format:', timeit.timeit("'{}{}{}'.format(1, 1.23, 'привет')"))
print('%:', timeit.timeit("'%s%s%s' % (1, 1.23, 'привет')"))
print('f-string:', timeit.timeit("f'{1}{1.23}{\"привет\"}'"))
Результат:
формат: 0.8331376779999999 %: 0,6314778750000001 f-строка: 0,766649943
Кажется, f-строка все еще медленнее, чем % , но лучше, чем формат .
Еще одно преимущество .format (которого я не вижу в ответах): он может принимать свойства объекта.
В [12]: класс А (объект):
....: def __init__(я, х, у):
....: сам.х = х
....: сам.у = у
....:
В [13]: а = А(2,3)
В [14]: 'x равно {0.x}, y равно {0.y}'.format(a)
Out[14]: 'x равно 2, y равно 3'
Или, как аргумент ключевого слова:
В [15]: 'x есть {a.x}, y есть {a.y}'.format(a=a)
Out[15]: 'x равно 2, y равно 3'
Насколько я могу судить, это невозможно с % .
Как я обнаружил сегодня, старый способ форматирования строк через % не поддерживает Decimal , модуль Python для десятичной арифметики с фиксированной и плавающей запятой, из коробки.
Пример (с использованием Python 3.3.5):
#!/usr/bin/env python3
из десятичного импорта *
получитьконтекст().prec = 50
d = Decimal('3.12375239e-24') # никакого магического числа, я скорее произвел его, ударившись головой о клавиатуру
печать('%.50f' % д)
печать('{0:.50f}'.формат(г))
Вывод:
0.
00009907464850 0.0000000000000000000000031237523
00000000000000
 00000000000000000000000031237523
00000000000000000000000031237523 Конечно, могут быть обходные пути, но вы все же можете рассмотреть возможность использования метода format() прямо сейчас.
Если ваш python >= 3.6, литерал в формате F-строки — ваш новый друг.
Это проще, чище и производительнее.
В [1]: params=['Привет', 'адам', 42]
В [2]: %timeit "%s %s, ответ на все %d."%(params[0],params[1],params[2])
448 нс ± 1,48 нс на петлю (среднее значение ± стандартное отклонение для 7 запусков, 1000000 циклов в каждом)
В [3]: %timeit "{} {}, ответ на все: {}.".format(*params)
449нс ± 1,42 нс на петлю (среднее значение ± стандартное отклонение для 7 прогонов, 1 000 000 циклов в каждом)
В [4]: %timeit f"{params[0]} {params[1]}, ответ на все: {params[2]}."
12,7 нс ± 0,0129 нс на петлю (среднее значение ± стандартное отклонение для 7 запусков, 100000000 циклов каждый)
1 В качестве примечания: вам не нужно снижать производительность, чтобы использовать форматирование в новом стиле с ведением журнала. Вы можете передать любой объект в
Вы можете передать любой объект в logging.debug , logging.info и т. д., который реализует __str__ магический метод. Когда модуль протоколирования решил, что он должен выдать ваш объект сообщения (что бы это ни было), он перед этим вызывает str(message_object) . Таким образом, вы можете сделать что-то вроде этого:
журнал импорта
класс NewStyleLogMessage (объект):
def __init__(я, сообщение, *args, **kwargs):
self.message = сообщение
self.args = аргументы
self.kwargs = кварги
защита __str__(я):
args = (i() if callable(i) else i для i в self.args)
kwargs = dict((k, v() if callable(v) else v) for k, v в self.kwargs.items())
вернуть self.message.format(*args, **kwargs)
N = НьюСтилелогмессаже
# Ни одно из этих сообщений не форматируется (или вычисляется), пока не будет
# нужный
# Выдает в лог "лениво отформатированную запись: 123 foo"
logging.debug(N('Запись журнала с ленивым форматированием: {0} {keyword}', 123, keyword='foo'))
защита дорогая_функция():
# Сделать что-то, что занимает много времени. ..
вернуть "фу"
# Выдает в лог "Дорогая запись в логе: foo"
logging.debug(N('Дорогая запись в журнале: {ключевое слово}', ключевое слово=expensive_func))
 ..
вернуть "фу"
# Выдает в лог "Дорогая запись в логе: foo"
logging.debug(N('Дорогая запись в журнале: {ключевое слово}', ключевое слово=expensive_func))
..
вернуть "фу"
# Выдает в лог "Дорогая запись в логе: foo"
logging.debug(N('Дорогая запись в журнале: {ключевое слово}', ключевое слово=expensive_func))
Все это описано в документации Python 3 (https://docs.python.org/3/howto/logging-cookbook.html#formatting-styles). Однако он будет работать и с Python 2.6 (https://docs.python.org/2.6/library/logging.html#using-arbitrary-objects-as-messages).
Одним из преимуществ использования этого метода, помимо того факта, что он не зависит от стиля форматирования, является то, что он допускает ленивые значения, например. функция из списка дорогих_функций выше. Это более элегантная альтернатива советам, данным в документации по Python здесь: https://docs.python.org/2.6/library/logging.html#optimization.
Одна из ситуаций, когда % может помочь, — это форматирование выражений регулярных выражений. Например,
'{type_names} [a-z]{2}'.format(type_names='треугольник|квадрат')
вызывает IndexError . В этой ситуации вы можете использовать:
В этой ситуации вы можете использовать:
'%(type_names)s [a-z]{2}' % {'type_names': 'треугольник|квадрат'}
Это позволяет избежать записи регулярного выражения как '{type_names} [a-z]{{2}}' . Это может быть полезно, когда у вас есть два регулярных выражения, одно из которых используется без форматирования, а конкатенация обоих форматируется.
Я бы добавил, что начиная с версии 3.6 мы можем использовать fstrings, как показано ниже:
foo = "john"
бар = "кузнец"
print(f"Меня зовут {foo} {bar}")
Которые дают
Меня зовут Джон Смит
Все конвертируется в строки
mylist = ["foo", "bar"]
печать (f"мой список = {мой список}")
Результат:
мой список = [‘фу’, ‘бар’]
вы можете передать функцию, как и в методе других форматов
print(f'Привет, вот дата: {time. strftime("%d/%m/%Y")}')
 strftime("%d/%m/%Y")}')
strftime("%d/%m/%Y")}')
Подача например
0Здравствуйте, вот дата: 16.04.2018
Сравнение Python 3.6.7:
#!/usr/bin/env python
импортировать время
определение time_it (fn):
"""
Измерение времени выполнения функции
"""
обертка def (*args, **kwargs):
t0 = timeit.default_timer()
fn(*args, **kwargs)
t1 = timeit.default_timer()
печать ("{0:.10f} секунд". формат (t1 - t0))
возвратная упаковка
@time_it
определение новый_новый_формат(ы):
print("new_new_format:", f"{s[0]} {s[1]} {s[2]} {s[3]} {s[4]}")
@time_it
определение новый_формат(ы):
print("new_format:", "{0} {1} {2} {3} {4}".format(*s))
@time_it
def old_format(s):
print("old_format:", "%s %s %s %s %s" % s)
деф основной():
образцы = (("uno", "dos", "tres", "cuatro", "cinco"), (1,2,3,4,5), (1.1, 2.1, 3.1, 4.1, 5.1), ( "уно", 2, 3.14, "куатро", 5.5))
для s в выборках:
новый_новый_формат(ы)
новый_формат(ы)
старый_формат(ы)
Распечатать("-----")
если __name__ == '__main__':
основной()
Вывод:
new_new_format: uno dos tres cuatro cinco 0,0000170280 секунд new_format: uno dos tres cuatro cinco 0,0000046750 секунд old_format: uno dos tres cuatro cinco 0,0000034820 секунд ----- новый_новый_формат: 1 2 3 4 5 0,0000043980 секунд новый_формат: 1 2 3 4 5 0,0000062590 секунд старый_формат: 1 2 3 4 5 0,0000041730 секунд ----- новый_новый_формат: 1.1
 1 2.1 3.1 4.1 5.1
0,0000092650 секунд
новый_формат: 1.1 2.1 3.1 4.1 5.1
0,0000055340 секунд
старый_формат: 1.1 2.1 3.1 4.1 5.1
0,0000052130 секунд
-----
новый_новый_формат: uno 2 3.14 куатро 5.5
0,0000053380 секунд
новый_формат: uno 2 3.14 куатро 5.5
0,0000047570 секунд
old_format: uno 2 3.14 куатро 5.5
0,0000045320 секунд
-----
1 2.1 3.1 4.1 5.1
0,0000092650 секунд
новый_формат: 1.1 2.1 3.1 4.1 5.1
0,0000055340 секунд
старый_формат: 1.1 2.1 3.1 4.1 5.1
0,0000052130 секунд
-----
новый_новый_формат: uno 2 3.14 куатро 5.5
0,0000053380 секунд
новый_формат: uno 2 3.14 куатро 5.5
0,0000047570 секунд
old_format: uno 2 3.14 куатро 5.5
0,0000045320 секунд
-----
Для версии Python >= 3.6 (см. PEP 498)
s1='albha'
s2='бета'
ф'{s1}{s2:>10}'
#выход
'альбха бета'
Но одна вещь заключается в том, что даже если у вас есть вложенные фигурные скобки, формат не будет работать, но % будет работать.
Пример:
>>> '{{0}, {1}}'.format(1,2)
Traceback (последний последний вызов):
Файл "", строка 1, в
'{{0}, {1}}'.format(1,2)
ValueError: одиночное '}' встречается в строке формата
>>> '{%s, %s}'%(1,2)
'{1, 2}'
>>>
1python — Как печатать как printf в Python3?
В Python 2 я использовал:
print "a=%d,b=%d" % (f(x,n),g(x,n))
Я пробовал:
print("a=%d,b=%d") % (f(x,n),g(x,n))
- Python
- строка
- Python-3. x
 x
x В Python2 print было ключевым словом, которое вводило утверждение:
печатать "Привет"
В Python3 print — это функция, которую можно вызвать:
print ("Привет")
В обеих версиях % — это оператор, который требует строку слева и значение или кортеж значений или объект отображения (например, dict ) справа.
Итак, ваша строка должна выглядеть так:
print("a=%d,b=%d" % (f(x,n),g(x,n)))
Кроме того, для Python3 и новее рекомендуется использовать {} Форматирование в стиле вместо % Форматирование в стиле :
print('a={:d}, b={:d}'.format(f(x,n),g(x,n) )))
Python 3.6 представляет еще одну парадигму форматирования строк: f-строки.
print(f'a={f(x,n):d}, b={g(x,n):d}')
2 Наиболее рекомендуемый способ — использовать метод формата . Подробнее об этом читайте здесь
Подробнее об этом читайте здесь
a, b = 1, 2
печать («а = {0}, б = {1}». формат (а, б))
Простая функция printf() из Поваренной книги Python O’Reilly.
система импорта
def printf(формат, *аргументы):
sys.stdout.write (формат% аргументов)
Пример вывода:
i = 7
пи = 3,14159265359
printf("привет, i=%d, pi=%.2f\n", i, pi)
# привет, i=7, pi=3.14
1Python 3.6 представил f-строки для встроенной интерполяции. Что еще лучше, он расширил синтаксис, чтобы также разрешить спецификаторы формата с интерполяцией. Над чем я работал, пока гуглил (и наткнулся на этот старый вопрос!):
print(f'{account:40s} ({ratio:3.2f}) -> AUD {splitAmount}')
PEP 498 содержит подробную информацию. И… он разобрался с моей любимой мозолью со спецификаторами формата на других языках — позволяет использовать спецификаторы, которые сами могут быть выражениями! Ура! См.: Спецификаторы формата.
2Простой пример:
print("foo %d, bar %d" % (1,2))
Более простой.
def printf(формат, *значения):
печать (формат% значений)
Затем:
printf("Здравствуйте, меня зовут %s и мой возраст %d", "Мартин", 20)
print("Имя={}, баланс={}".format(имя-переменной, баланс-переменной))
Поскольку ваши % находятся за пределами скобок print(...) , вы пытаетесь вставить свои переменные в результат вашего вызова print . print(...) возвращает None , так что это не сработает, и есть также небольшая проблема в том, что вы уже напечатали свой шаблон к этому времени, и путешествие во времени запрещено законами вселенной, в которой мы живем.
Все, что вы хотите напечатать, включая % и его операнд, должно быть внутри вашего вызова print(...) , чтобы строка могла быть построена до того, как она будет напечатана.
print( "a=%d,b=%d" % (f(x,n), g(x,n))
Я добавил несколько дополнительных пробелов, чтобы было понятнее (хотя они не обязательны и обычно не считаются хорошим стилем).
Вы можете буквально использовать printf в Python через ctypes (или даже ваш собственный модуль расширения C).
В Linux вы должны иметь возможность
импортировать ctypes
libc = ctypes.cdll.LoadLibrary("libc.so.6")
printf = libc.printf
printf(b"Целое число: %d\n"
b"Строка: %s\n"
b"Двойной: %f (стиль %%f)\n"
b"Двойной: %g (стиль %%g)\n",
42, b"некоторая строка", ctypes.c_double(3.20), ctypes.c_double(3.20))
В Windows эквивалент будет иметь
libc = ctypes.cdll.msvcrt printf = libc.printf
Как указано в документации:
Нет, целые числа, байтовые объекты и строки (юникод) — единственные нативные объекты Python, которые можно напрямую использовать в качестве параметров в этих вызовах функций. None передается как указатель C NULL, объекты bytes и строки передаются как указатель на блок памяти, содержащий их данные (char* или wchar_t*).
