Как найти количество элементов в объекте Python? Подсчитываем число элементов в списке, массиве, кортеже
В этой статье мы рассмотрим, как определить количество элементов в объекте Python и при необходимости подсчитать их сумму. Также увидим, как подсчитать количество вхождений конкретного элемента.
Итак, представим, что у нас есть следующий массив:
По условию задачи мы хотим определить, сколько элементов в данном массиве, и какова сумма всех этих элементов.
В первую очередь, вспомним, что в языке программирования Python существует специальная функция, возвращающая длину списка, массива, последовательности и так далее — это len(x), где x — наша последовательность.
Если разобраться, длина последовательности из чисел — это одновременно и количество самих цифр, поэтому мы можем решить поставленную задачу следующим образом:
print(len(array)) 6 Press any key to continue . . .
А для подсчёта суммы можем занести перечисление массива Python в цикл:
array = [6,2,7,4,8,1] sum = 0 for i in range(len(array)): sum = array[i] print(sum)
В принципе, вопрос решён. Но, по правде говоря, перебор целочисленного массива с помощью цикла для получения суммы элементов массива — это, всё же, костыль)). Дело в том, что в Python существует встроенная функция sum(). Она вернёт нам сумму без лишних телодвижений.
Но, по правде говоря, перебор целочисленного массива с помощью цикла для получения суммы элементов массива — это, всё же, костыль)). Дело в том, что в Python существует встроенная функция sum(). Она вернёт нам сумму без лишних телодвижений.
def main():
array = [1,6,3,8,4,9,25,2]
print(sum(array))
if name == 'main':
main()
58
Press any key to continue . . .
Python: количество вхождений конкретного элемента
Бывает, нам надо подсчитать число вхождений определённых элементов в списке и вернуть найденное значение. Для этого в Python есть метод count(). Вот его синтаксис:
Метод принимает аргумент x, значение которого нас интересует. И возвращает число вхождений интересующего элемента в список:
# объявляем список
website_list = ['otus.ru','includehelp.com', 'yandex.by', 'otus.ru']
# подсчитываем вхождения 'otus.ru'
count = website_list.count('otus.ru')
print('otus.ru found',count,'times.')
# подсчитываем вхождения 'yandex. by'
count = website_list.count('yandex.by')
print('yandex.by found',count,'times.')
by'
count = website_list.count('yandex.by')
print('yandex.by found',count,'times.')
 by'
count = website_list.count('yandex.by')
print('yandex.by found',count,'times.')
by'
count = website_list.count('yandex.by')
print('yandex.by found',count,'times.')
Итог будет следующим:
otus.ru found 2 times. yandex.by found 1 times.
Также этот метод успешно работает и с кортежами:
# объявляем кортеж
sample_tuple = ((1,3), (2,4), (4,6))
# условные вхождения (1,2)
count = sample_tuple.count((1,2))
print('(1,2) found',count,'times.')
# условные вхождения (1,3)
count = sample_tuple.count((1,3))
print('(1,3) found',count,'times.')
Результат:
(1,2) found 0 times. (1,3) found 1 times.
Вот и всё, теперь вы знаете, как подсчитывать количество элементов в списке, массиве, кортеже в Python.
Подсчет элементов массива в Python
Как я могу подсчитать количество элементов в массиве, потому что вопреки логике array.count(string) не подсчитывает все элементы в массиве, он просто ищет количество вхождений строки.
Поделиться Источник UnkwnTech 09 октября 2008 в 14:12
5 ответов
- Выберите несколько элементов из массива python
Как я могу выбрать несколько элементов из массива python? Я знаю, что это возможно в массиве numpy, но в данном случае я не могу использовать массив numpy. Я хочу выбрать определенные элементы массива, похожие на использование маскированного массива, но получаю следующую ошибку в python nonzero =…
- подсчет вхождений элементов
Подсчет всех элементов в списке-это однострочный подсчет в Haskell: count xs = toList (fromListWith (+) [(x, 1) | x <- xs]) Вот пример использования: *Main> count haskell scala [(‘ ‘,1),(‘a’,3),(‘c’,1),(‘e’,1),(‘h’,1),(‘k’,1),(‘l’,3),(‘s’,2)] Может ли эта функция быть так изящно выражена и в…
302
Метод len() возвращает количество элементов в списке.
Синтаксис:
len(myArray)
Напр.:
myArray = [1, 2, 3]
len(myArray)
Выход:
3
Поделиться Trent 09 октября 2008 в 14:14
25
len -это встроенная функция, которая вызывает функцию — член __len__ данного контейнерного объекта, чтобы получить количество элементов в объекте.
Функции, заключенные в двойные подчеркивания, обычно являются «special methods», реализующими один из стандартных интерфейсов в Python (контейнер, номер и т. д.). Специальные методы используются с помощью синтаксического сахара (создание объектов, индексация и нарезка контейнеров, доступ к атрибутам, встроенные функции и т. д.).
Использование obj.__len__() не было бы правильным способом использования специального метода, но я не понимаю, почему другие были так сильно модифицированы.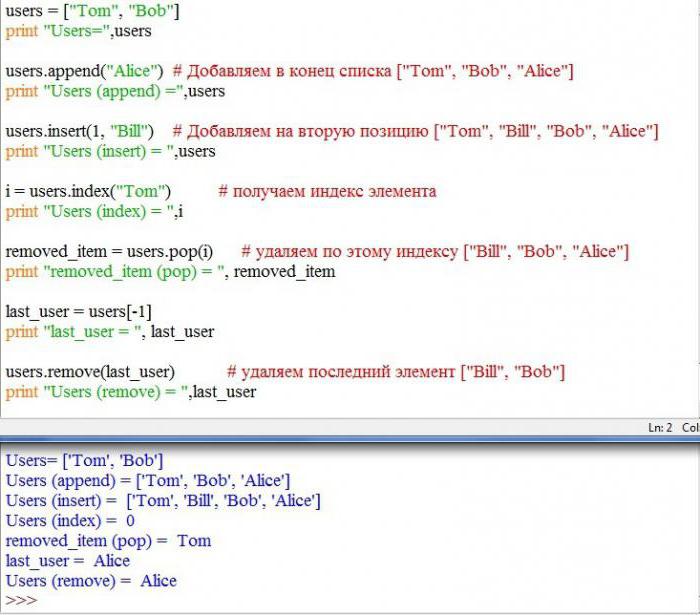
Поделиться Jeremy Brown 09 октября 2008 в 19:40
14
Если у вас есть многомерный массив, len() может не дать вам того значения, которое вы ищете. Например:
import numpy as np
a = np.arange(10).reshape(2, 5)
print len(a) == 2
Этот блок кода вернет true, сообщив вам, что размер массива равен 2. однако на самом деле в этом массиве 2D есть 10 элементов. В случае многомерных массивов len() дает вам длину первого измерения массива, т. е.
import numpy as np
len(a) == np.shape(a)[0]
Получить количество элементов в многомерном массиве произвольной формы:
import numpy as np
size = 1
for dim in np.shape(a): size *= dim
Поделиться
- Как подсчитать количество элементов массива
Я столкнулся с проблемой во время тестирования кода.
Я определяю макрос для получения количества элементов массива следующим образом: #define ARRAY_SIZE(arr) sizeof(arr) / sizeof(arr[0]) Этот макрос отлично работает для подсчета количества элементов массива, инициализаторы которых соответствуют… - PHP подсчет элементов в multidimensional array
Пожалуйста, подумайте о следующем multidimensional array $standings: Array ( [position] => Array ( [0] => 1 [1] => 2 [2] => 3 [3] => 4 ) [name] => Array ( [0] => Tiger Woods [1] => Phil Mickleson [2] => J.B. Holmes [3] => Jim Furyk ) [score] => Array ( [0] => 69…
 Я определяю макрос для получения количества элементов массива следующим образом: #define ARRAY_SIZE(arr) sizeof(arr) / sizeof(arr[0]) Этот макрос отлично работает для подсчета количества элементов массива, инициализаторы которых соответствуют…
Я определяю макрос для получения количества элементов массива следующим образом: #define ARRAY_SIZE(arr) sizeof(arr) / sizeof(arr[0]) Этот макрос отлично работает для подсчета количества элементов массива, инициализаторы которых соответствуют…
3
Или,
myArray.__len__()
если вы хотите быть оопы; «len(myArray)» много проще набрать! 🙂
Поделиться Kevin Little 09 октября 2008 в 14:23
1
Прежде чем я увидел это, я подумал про себя:
for tempVar in arrayName: tempVar+=1
А потом я подумал: «и я был прав.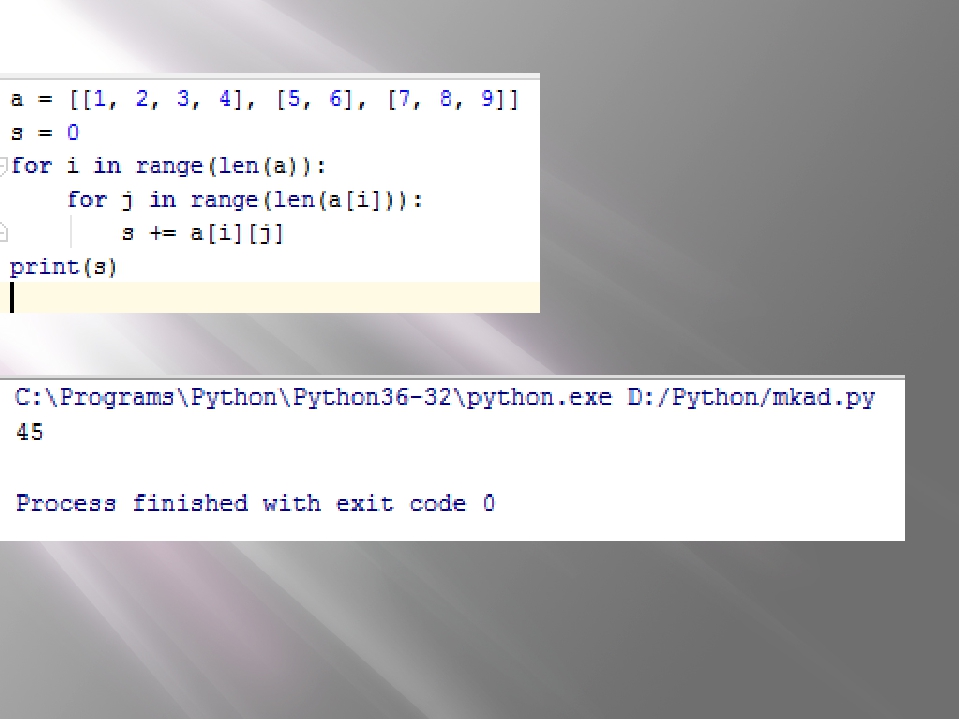
len(arrayName)
Поделиться Evan Young 17 июля 2015 в 03:05
Похожие вопросы:
подсчет элементов в массиве
Итак, я пытаюсь подсчитать элементы массива. Под этим я подразумеваю, что у меня есть большой массив, и каждый элемент будет иметь кратные себе по всему массиву. Я пытаюсь выяснить, сколько раз…
Подсчет количества элементов в matlab
Я новичок в MATLAB. Предположим, у меня есть вектор типа x = [1 1 1 1 1 1 0 0 1 0]. Я хочу вычислить общее количество элементов в векторе и количество ненулевых элементов в векторе. Затем придумайте…
Подсчет последовательностей из k элементов
Если у меня есть два массива целых чисел: a = {2,2,3,3,5,6,7,2,2,2} , b = {6,-5,2,2,2,2,4,5,3,3} и целое число k = 2 , которое определяет количество последовательных последовательностей (SAME в. ..
..
Выберите несколько элементов из массива python
Как я могу выбрать несколько элементов из массива python? Я знаю, что это возможно в массиве numpy, но в данном случае я не могу использовать массив numpy. Я хочу выбрать определенные элементы…
подсчет вхождений элементов
Подсчет всех элементов в списке-это однострочный подсчет в Haskell: count xs = toList (fromListWith (+) [(x, 1) | x <- xs]) Вот пример использования: *Main> count haskell scala [(‘…
Как подсчитать количество элементов массива
Я столкнулся с проблемой во время тестирования кода. Я определяю макрос для получения количества элементов массива следующим образом: #define ARRAY_SIZE(arr) sizeof(arr) / sizeof(arr[0]) Этот макрос…
PHP подсчет элементов в multidimensional array
Пожалуйста, подумайте о следующем multidimensional array $standings: Array ( [position] => Array ( [0] => 1 [1] => 2 [2] => 3 [3] => 4 ) [name] => Array ( [0] => Tiger Woods [1]. ..
..
Подсчет элементов внутри массива в mongodb
Я хочу подсчитать количество элементов в массиве, используя python и pymongo. Вот данные. { _id: 5, type: Student, Applicates: [ { appId: 100, School: dfgdfgd, Name: tony, URL: www.url.com, Time:…
Подсчет элементов списка с помощью `set`
В более старом посте ( Python: подсчет повторяющихся элементов в списке ) я заметил два ответа (Ответ 3 и 5), которые используют set для подсчета повторяющихся элементов списка. В вопросе, который я…
Подсчет вхождений элементов массива JavaScript и ввод нового массива 2d
Привет у меня есть такой массив var a = [5, 5, 5, 2, 2, 2, 2, 2, 9, 4]; моя цель состоит в том, чтобы подсчитать уникальное значение и иметь отчет о любых предметах на нем, так что результат будет…
Посчитать количество одинаковых элементов в списке. Язык Python
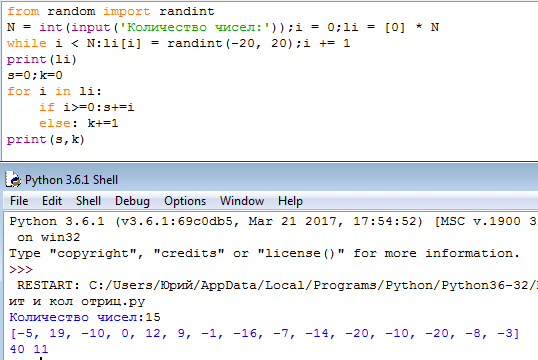
Дан список целых чисел. Посчитать, сколько раз в нем встречается каждое число. Например, если дан список [1, 1, 3, 2, 1, 3, 4], то в нем число 1 встречается три раза, число 3 — два раза, числа 2 и 4 — по одному разу.
Посчитать, сколько раз в нем встречается каждое число. Например, если дан список [1, 1, 3, 2, 1, 3, 4], то в нем число 1 встречается три раза, число 3 — два раза, числа 2 и 4 — по одному разу.
Для хранения количества каждого встречающегося в списке значения создадим словарь. В нем ключами будут числа, которые встречаются в списке, а значениями — количества этих чисел в списке. Для примера, приведенного выше, в итоге должен был бы получиться такой словарь: {1:3, 3:2, 2:1, 4:1}.
Пусть в программе будет функция, которая заполняет список случайными числами в диапазоне и количестве, указанными пользователем.
Другая функция будет считать количество каждого значения и заносить данные в словарь. Алгоритм подсчета заключается в следующем. Если очередной элемент списка уже есть в качестве ключа словаря, то следует увеличить значение этого ключа на единицу. Если очередного элемента списка нет в качестве ключа в словаре, то такой ключ следует добавить и присвоить ему значение, равное единице.
Для того, чтобы вывести содержимое словаря в отсортированном по возрастанию ключей виде, используется функция sorted(). Она сортирует ключи словаря и помещает их в список.
def fill_list(m1, m2, amount, l):
from random import randint
for i in range(amount):
l.append(randint(m1, m2))
def analysis(your_list, your_dict):
for i in your_list:
if i in your_dict:
your_dict[i] += 1
else:
your_dict[i] = 1
lst = []
dct = {}
mn = int(input('Минимум: '))
mx = int(input('Максимум: '))
qty = int(input('Количество элементов: '))
fill_list(mn, mx, qty, lst)
analysis(lst, dct)
for item in sorted(dct):
print("'%d':%d" % (item, dct[item]))Пример выполнения:
Минимум: 100 Максимум: 104 Количество элементов: 20 '100':4 '101':7 '102':2 '103':4 '104':3
Как я могу подсчитать вхождения элемента списка в Python? Ru Python
Учитывая элемент, как я могу подсчитать его вхождения в списке в Python?
>>> [1, 2, 3, 4, 1, 4, 1]. count(1) 3  count(1) 3
count(1) 3Если вы используете Python 2.7 или 3 и хотите количество вхождений для каждого элемента:
>>> from collections import Counter >>> z = ['blue', 'red', 'blue', 'yellow', 'blue', 'red'] >>> Counter(z) Counter({'blue': 3, 'red': 2, 'yellow': 1}) Подсчет вхождений одного элемента в список
Для подсчета вхождения только одного элемента списка вы можете использовать count()
>>> l = ["a","b","b"] >>> l.count("a") 1 >>> l.count("b") 2 Подсчет появления всех элементов в списке также известен как «подсчет» списка или создание счетчика счетчиков.
Подсчет всех элементов с count ()
Для подсчета вхождений элементов в l можно просто использовать понимание списка и метод count()
[[x,l.count(x)] for x in set(l)] (или аналогично словарю dict((x,l. ) count(x)) for x in set(l))
count(x)) for x in set(l))
Пример:
>>> l = ["a","b","b"] >>> [[x,l.count(x)] for x in set(l)] [['a', 1], ['b', 2]] >>> dict((x,l.count(x)) for x in set(l)) {'a': 1, 'b': 2} Подсчет всех элементов с помощью счетчика ()
Кроме того, существует более быстрый класс Counter из библиотеки collections
Counter(l) Пример:
>>> l = ["a","b","b"] >>> from collections import Counter >>> Counter(l) Counter({'b': 2, 'a': 1}) Насколько быстрее Counter?
Я проверил, насколько быстрее Counter предназначен для подсчета списков. Я попытался использовать оба метода с несколькими значениями n и кажется, что Counter быстрее с постоянным коэффициентом около 2.
Вот сценарий, который я использовал:
from __future__ import print_function import timeit t1=timeit. Timer('Counter(l)', \ 'import random;import string;from collections import Counter;n=1000;l=[random.choice(string.ascii_letters) for x in range(n)]' ) t2=timeit.Timer('[[x,l.count(x)] for x in set(l)]', 'import random;import string;n=1000;l=[random.choice(string.ascii_letters) for x in range(n)]' ) print("Counter(): ", t1.repeat(repeat=3,number=10000)) print("count(): ", t2.repeat(repeat=3,number=10000)  Timer('Counter(l)', \ 'import random;import string;from collections import Counter;n=1000;l=[random.choice(string.ascii_letters) for x in range(n)]' ) t2=timeit.Timer('[[x,l.count(x)] for x in set(l)]', 'import random;import string;n=1000;l=[random.choice(string.ascii_letters) for x in range(n)]' ) print("Counter(): ", t1.repeat(repeat=3,number=10000)) print("count(): ", t2.repeat(repeat=3,number=10000)
Timer('Counter(l)', \ 'import random;import string;from collections import Counter;n=1000;l=[random.choice(string.ascii_letters) for x in range(n)]' ) t2=timeit.Timer('[[x,l.count(x)] for x in set(l)]', 'import random;import string;n=1000;l=[random.choice(string.ascii_letters) for x in range(n)]' ) print("Counter(): ", t1.repeat(repeat=3,number=10000)) print("count(): ", t2.repeat(repeat=3,number=10000)И выход:
Counter(): [0.46062711701961234, 0.4022796869976446, 0.3974247490405105] count(): [7.779430688009597, 7.962715800967999, 8.420845870045014] Другой способ получить количество вхождений каждого элемента в словаре:
dict((i, a.count(i)) for i in a) Если вы хотите подсчитать все значения сразу, вы можете сделать это очень быстро, используя массивы numpy и bincount следующим образом
import numpy as np a = np.array([1, 2, 3, 4, 1, 4, 1]) np. bincount(a)  bincount(a)
bincount(a)который дает
>>> array([0, 3, 1, 1, 2]) Вот список примеров:
>>> l = list('aaaaabbbbcccdde') >>> l ['a', 'a', 'a', 'a', 'a', 'b', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'e'] list.count Существует метод list.count
>>> l.count('b') 4 Это отлично подходит для любого списка. Этот метод также имеет кортежи:
>>> t = tuple('aabbbffffff') >>> t ('a', 'a', 'b', 'b', 'b', 'f', 'f', 'f', 'f', 'f', 'f') >>> t.count('f') 6 collections.CounterА потом есть коллекции. Каунтер. Вы можете сбрасывать любые итерации в счетчик, а не только список, а счетчик будет сохранять структуру данных для счетчиков элементов.
Применение:
>>> from collections import Counter >>> c = Counter(l) >>> c['b'] 4 Счетчики основаны на словарях Python, их клавишами являются элементы, поэтому ключи должны быть хешируемыми. Они в основном похожи на наборы, которые позволяют содержать в них избыточные элементы.
Они в основном похожи на наборы, которые позволяют содержать в них избыточные элементы.
Дальнейшее использование
collections.CounterВы можете добавить или вычесть с помощью итераторов с вашего счетчика:
>>> c.update(list('bbb')) >>> c['b'] 7 >>> c.subtract(list('bbb')) >>> c['b'] 4 И вы также можете выполнять многопозиционные операции со счетчиком:
>>> c2 = Counter(list('aabbxyz')) >>> c - c2 # set difference Counter({'a': 3, 'c': 3, 'b': 2, 'd': 2, 'e': 1}) >>> c + c2 # addition of all elements Counter({'a': 7, 'b': 6, 'c': 3, 'd': 2, 'e': 1, 'y': 1, 'x': 1, 'z': 1}) >>> c | c2 # set union Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1, 'y': 1, 'x': 1, 'z': 1}) >>> c & c2 # set intersection Counter({'a': 2, 'b': 2}) Почему бы не панды?
Другой ответ:
Почему бы не использовать панды?
Панда – общая библиотека, но она не входит в стандартную библиотеку. Добавление его как зависимости нетривиально.
Добавление его как зависимости нетривиально.
Существуют встроенные решения для этого прецедента в самом объекте списка, а также в стандартной библиотеке.
Если вашему проекту еще не нужны панды, было бы глупо сделать это требование только для этой функции.
У меня была эта проблема сегодня, и я сделал свое собственное решение, прежде чем я решил проверить SO. Эта:
dict((i,a.count(i)) for i in a) действительно, очень медленный для больших списков. Мое решение
def occurDict(items): d = {} for i in items: if i in d: d[i] = d[i]+1 else: d[i] = 1 return d на самом деле немного быстрее, чем решение Counter, по крайней мере для Python 2.7.
Почему бы не использовать Панды?
import pandas as pd l = ['a', 'b', 'c', 'd', 'a', 'd', 'a'] # converting the list to a Series and counting the values my_count = pd.Series(l).value_counts() my_count Вывод:
a 3 d 2 b 1 c 1 dtype: int64 Если вы ищете счетчик определенного элемента, скажем a , попробуйте:
my_count['a'] Вывод:
3 # Python >= 2. 6 (defaultdict) && < 2.7 (Counter, OrderedDict) from collections import defaultdict def count_unsorted_list_items(items): """ :param items: iterable of hashable items to count :type items: iterable :returns: dict of counts like Py2.7 Counter :rtype: dict """ counts = defaultdict(int) for item in items: counts[item] += 1 return dict(counts) # Python >= 2.2 (generators) def count_sorted_list_items(items): """ :param items: sorted iterable of items to count :type items: sorted iterable :returns: generator of (item, count) tuples :rtype: generator """ if not items: return elif len(items) == 1: yield (items[0], 1) return prev_item = items[0] count = 1 for item in items[1:]: if prev_item == item: count += 1 else: yield (prev_item, count) count = 1 prev_item = item yield (item, count) return import unittest class TestListCounters(unittest.TestCase): def test_count_unsorted_list_items(self): D = ( ([], []), ([2], [(2,1)]), ([2,2], [(2,2)]), ([2,2,2,2,3,3,5,5], [(2,4), (3,2), (5,2)]), ) for inp, exp_outp in D: counts = count_unsorted_list_items(inp) print inp, exp_outp, counts self. assertEqual(counts, dict( exp_outp )) inp, exp_outp = UNSORTED_WIN = ([2,2,4,2], [(2,3), (4,1)]) self.assertEqual(dict( exp_outp ), count_unsorted_list_items(inp) ) def test_count_sorted_list_items(self): D = ( ([], []), ([2], [(2,1)]), ([2,2], [(2,2)]), ([2,2,2,2,3,3,5,5], [(2,4), (3,2), (5,2)]), ) for inp, exp_outp in D: counts = list( count_sorted_list_items(inp) ) print inp, exp_outp, counts self.assertEqual(counts, exp_outp) inp, exp_outp = UNSORTED_FAIL = ([2,2,4,2], [(2,3), (4,1)]) self.assertEqual(exp_outp, list( count_sorted_list_items(inp) )) # ... [(2,2), (4,1), (2,1)]  6 (defaultdict) && < 2.7 (Counter, OrderedDict) from collections import defaultdict def count_unsorted_list_items(items): """ :param items: iterable of hashable items to count :type items: iterable :returns: dict of counts like Py2.7 Counter :rtype: dict """ counts = defaultdict(int) for item in items: counts[item] += 1 return dict(counts) # Python >= 2.2 (generators) def count_sorted_list_items(items): """ :param items: sorted iterable of items to count :type items: sorted iterable :returns: generator of (item, count) tuples :rtype: generator """ if not items: return elif len(items) == 1: yield (items[0], 1) return prev_item = items[0] count = 1 for item in items[1:]: if prev_item == item: count += 1 else: yield (prev_item, count) count = 1 prev_item = item yield (item, count) return import unittest class TestListCounters(unittest.TestCase): def test_count_unsorted_list_items(self): D = ( ([], []), ([2], [(2,1)]), ([2,2], [(2,2)]), ([2,2,2,2,3,3,5,5], [(2,4), (3,2), (5,2)]), ) for inp, exp_outp in D: counts = count_unsorted_list_items(inp) print inp, exp_outp, counts self.
6 (defaultdict) && < 2.7 (Counter, OrderedDict) from collections import defaultdict def count_unsorted_list_items(items): """ :param items: iterable of hashable items to count :type items: iterable :returns: dict of counts like Py2.7 Counter :rtype: dict """ counts = defaultdict(int) for item in items: counts[item] += 1 return dict(counts) # Python >= 2.2 (generators) def count_sorted_list_items(items): """ :param items: sorted iterable of items to count :type items: sorted iterable :returns: generator of (item, count) tuples :rtype: generator """ if not items: return elif len(items) == 1: yield (items[0], 1) return prev_item = items[0] count = 1 for item in items[1:]: if prev_item == item: count += 1 else: yield (prev_item, count) count = 1 prev_item = item yield (item, count) return import unittest class TestListCounters(unittest.TestCase): def test_count_unsorted_list_items(self): D = ( ([], []), ([2], [(2,1)]), ([2,2], [(2,2)]), ([2,2,2,2,3,3,5,5], [(2,4), (3,2), (5,2)]), ) for inp, exp_outp in D: counts = count_unsorted_list_items(inp) print inp, exp_outp, counts self.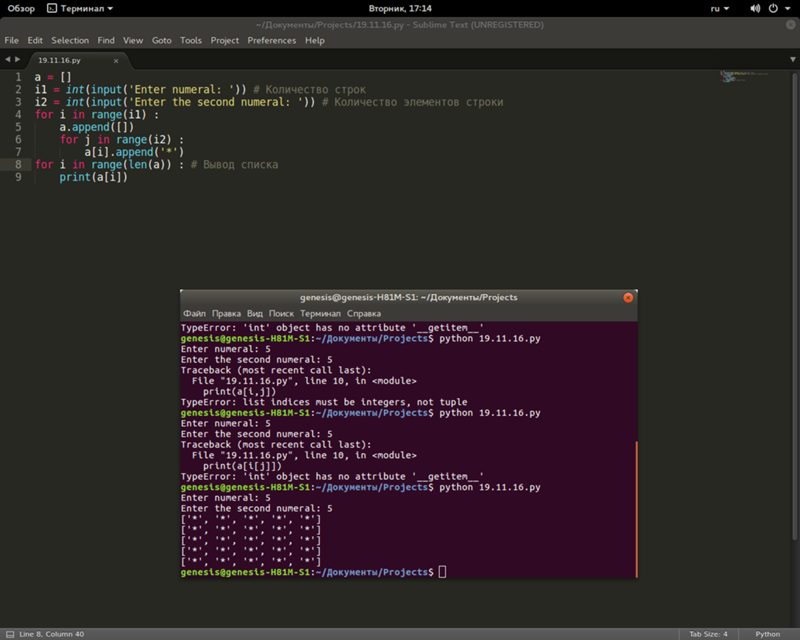 assertEqual(counts, dict( exp_outp )) inp, exp_outp = UNSORTED_WIN = ([2,2,4,2], [(2,3), (4,1)]) self.assertEqual(dict( exp_outp ), count_unsorted_list_items(inp) ) def test_count_sorted_list_items(self): D = ( ([], []), ([2], [(2,1)]), ([2,2], [(2,2)]), ([2,2,2,2,3,3,5,5], [(2,4), (3,2), (5,2)]), ) for inp, exp_outp in D: counts = list( count_sorted_list_items(inp) ) print inp, exp_outp, counts self.assertEqual(counts, exp_outp) inp, exp_outp = UNSORTED_FAIL = ([2,2,4,2], [(2,3), (4,1)]) self.assertEqual(exp_outp, list( count_sorted_list_items(inp) )) # ... [(2,2), (4,1), (2,1)]
assertEqual(counts, dict( exp_outp )) inp, exp_outp = UNSORTED_WIN = ([2,2,4,2], [(2,3), (4,1)]) self.assertEqual(dict( exp_outp ), count_unsorted_list_items(inp) ) def test_count_sorted_list_items(self): D = ( ([], []), ([2], [(2,1)]), ([2,2], [(2,2)]), ([2,2,2,2,3,3,5,5], [(2,4), (3,2), (5,2)]), ) for inp, exp_outp in D: counts = list( count_sorted_list_items(inp) ) print inp, exp_outp, counts self.assertEqual(counts, exp_outp) inp, exp_outp = UNSORTED_FAIL = ([2,2,4,2], [(2,3), (4,1)]) self.assertEqual(exp_outp, list( count_sorted_list_items(inp) )) # ... [(2,2), (4,1), (2,1)]Чтобы подсчитать количество различных элементов, имеющих общий тип:
li = ['A0','c5','A8','A2','A5','c2','A3','A9'] print sum(1 for el in li if el[0]=='A' and el[1] in '01234') дает
3 , а не 6
from collections import Counter country=['Uruguay', 'Mexico', 'Uruguay', 'France', 'Mexico'] count_country = Counter(country) output_list= [] for i in count_country: output_list. append([i,count_country[i]]) print output_list  append([i,count_country[i]]) print output_list
append([i,count_country[i]]) print output_listВыходной список:
[['Mexico', 2], ['France', 1], ['Uruguay', 2]] Вы также можете использовать метод countOf для встроенного модуля.
>>> import operator >>> operator.countOf([1, 2, 3, 4, 1, 4, 1], 1) 3 Я сравнил все предлагаемые решения (и несколько новых) с perfplot ( мой маленький проект).
Подсчет
одного элементаДля достаточно больших массивов оказывается, что
numpy.sum(numpy.array(a) == 1) немного быстрее, чем другие решения.
Подсчет
всех элементовКак было установлено ранее ,
numpy.bincount(a) это то, что вы хотите.
Код для воспроизведения участков:
from collections import Counter from collections import defaultdict import numpy import operator import pandas import perfplot def counter(a): return Counter(a) def count(a): return dict((i, a. count(i)) for i in set(a)) def bincount(a): return numpy.bincount(a) def pandas_value_counts(a): return pandas.Series(a).value_counts() def occur_dict(a): d = {} for i in a: if i in d: d[i] = d[i]+1 else: d[i] = 1 return d def count_unsorted_list_items(items): counts = defaultdict(int) for item in items: counts[item] += 1 return dict(counts) def operator_countof(a): return dict((i, operator.countOf(a, i)) for i in set(a)) perfplot.show( setup=lambda n: list(numpy.random.randint(0, 100, n)), n_range=[2**k for k in range(20)], kernels=[ counter, count, bincount, pandas_value_counts, occur_dict, count_unsorted_list_items, operator_countof ], equality_check=None, logx=True, logy=True, )  count(i)) for i in set(a)) def bincount(a): return numpy.bincount(a) def pandas_value_counts(a): return pandas.Series(a).value_counts() def occur_dict(a): d = {} for i in a: if i in d: d[i] = d[i]+1 else: d[i] = 1 return d def count_unsorted_list_items(items): counts = defaultdict(int) for item in items: counts[item] += 1 return dict(counts) def operator_countof(a): return dict((i, operator.countOf(a, i)) for i in set(a)) perfplot.show( setup=lambda n: list(numpy.random.randint(0, 100, n)), n_range=[2**k for k in range(20)], kernels=[ counter, count, bincount, pandas_value_counts, occur_dict, count_unsorted_list_items, operator_countof ], equality_check=None, logx=True, logy=True, )
count(i)) for i in set(a)) def bincount(a): return numpy.bincount(a) def pandas_value_counts(a): return pandas.Series(a).value_counts() def occur_dict(a): d = {} for i in a: if i in d: d[i] = d[i]+1 else: d[i] = 1 return d def count_unsorted_list_items(items): counts = defaultdict(int) for item in items: counts[item] += 1 return dict(counts) def operator_countof(a): return dict((i, operator.countOf(a, i)) for i in set(a)) perfplot.show( setup=lambda n: list(numpy.random.randint(0, 100, n)), n_range=[2**k for k in range(20)], kernels=[ counter, count, bincount, pandas_value_counts, occur_dict, count_unsorted_list_items, operator_countof ], equality_check=None, logx=True, logy=True, )2.
from collections import Counter from collections import defaultdict import numpy import operator import pandas import perfplot def counter(a): return Counter(a) def count(a): return dict((i, a.count(i)) for i in set(a)) def bincount(a): return numpy.bincount(a) def pandas_value_counts(a): return pandas. Series(a).value_counts() def occur_dict(a): d = {} for i in a: if i in d: d[i] = d[i]+1 else: d[i] = 1 return d def count_unsorted_list_items(items): counts = defaultdict(int) for item in items: counts[item] += 1 return dict(counts) def operator_countof(a): return dict((i, operator.countOf(a, i)) for i in set(a)) perfplot.show( setup=lambda n: list(numpy.random.randint(0, 100, n)), n_range=[2**k for k in range(20)], kernels=[ counter, count, bincount, pandas_value_counts, occur_dict, count_unsorted_list_items, operator_countof ], equality_check=None, logx=True, logy=True, )  Series(a).value_counts() def occur_dict(a): d = {} for i in a: if i in d: d[i] = d[i]+1 else: d[i] = 1 return d def count_unsorted_list_items(items): counts = defaultdict(int) for item in items: counts[item] += 1 return dict(counts) def operator_countof(a): return dict((i, operator.countOf(a, i)) for i in set(a)) perfplot.show( setup=lambda n: list(numpy.random.randint(0, 100, n)), n_range=[2**k for k in range(20)], kernels=[ counter, count, bincount, pandas_value_counts, occur_dict, count_unsorted_list_items, operator_countof ], equality_check=None, logx=True, logy=True, )
Series(a).value_counts() def occur_dict(a): d = {} for i in a: if i in d: d[i] = d[i]+1 else: d[i] = 1 return d def count_unsorted_list_items(items): counts = defaultdict(int) for item in items: counts[item] += 1 return dict(counts) def operator_countof(a): return dict((i, operator.countOf(a, i)) for i in set(a)) perfplot.show( setup=lambda n: list(numpy.random.randint(0, 100, n)), n_range=[2**k for k in range(20)], kernels=[ counter, count, bincount, pandas_value_counts, occur_dict, count_unsorted_list_items, operator_countof ], equality_check=None, logx=True, logy=True, ) sum([1 for elem in <yourlist> if elem==<your_value>]) Это вернет количество вхождения вашего_значения
python — Python: как получить количество элементов в одном списке, которые принадлежат другому
У меня есть список из ~ 3000 предметов. Давайте назовем это listA. И еще один список с 1 000 000 предметов. Давайте назовем это
Давайте назовем это listB.
Я хочу проверить, сколько элементов listA принадлежит listB. Например, чтобы получить ответ типа 436.
Очевидным способом является создание вложенного цикла для поиска каждого элемента, но это происходит медленно, особенно из-за размера списков.
Какой самый быстрый и / или Pythonic способ получить количество элементов одного списка, принадлежащих другому?
-1
Aventinus 25 Сен 2017 в 15:51
3 ответа
Лучший ответ
Сделайте набор из list_b. Это позволит избежать вложенных циклов и выполнить проверку содержимого O(1). Весь процесс будет O(M+N), который должен быть довольно оптимальным:
set_b = set(list_b)
count = sum(1 for a in list_a if a in set_b)
# OR shorter, but maybe less intuitive
count = sum(a in set_b for a in list_a)
# where the bool expression is coerced to int {0; 1} for the summing
Если вы не хотите (или должны) считать повторяющиеся элементы в list_a, вы можете использовать пересечение множеств:
count = len(set(list_a) & set(list_b))
# OR
count = len(set(list_a). intersection(list_b)) # avoids one conversion
 intersection(list_b)) # avoids one conversion
intersection(list_b)) # avoids one conversion
Следует также отметить, что эти операции на основе множеств работают только в том случае, если элементы в ваших списках можно хэшировать (например, не сами списки)!
7
schwobaseggl 26 Сен 2017 в 13:46
Вы можете перебрать содержимое listA и использовать генератор для получения значений для большей эффективности:
def get_number_of_elements(s, a):
for i in s:
if i in a:
yield i
print(len(list(get_number_of_elements(listA, listB))))
0
Ajax1234 25 Сен 2017 в 12:56
Другой вариант — использовать set и найти пересечение:
len(set(listA). intersection(listB))
 intersection(listB))
intersection(listB))
2
Nate Jenson 25 Сен 2017 в 13:05
46405722Подсчет количества элементов в коллекции
Для подсчета вхождений значения в массиве numpy. Это будет работать так:
import numpy as np
a=np.array([0,3,4,3,5,4,7])
print(np.sum(a==3))
>>>Out: 2Логика заключается в том, что Булево выражение создает массив, в котором все вхождения запрошенных значений равны 1, а все остальные равны нулю. Таким образом, суммируя их, мы получим количество случаев вхождения. Это работает для массивов любой формы или типа. Не забудьте убедиться, что вы установили пакет NumPy.
Есть два метода, которые используют для подсчета вхождения всех уникальных значений в numpy: уникальный и бинарный подсчет. Уникальный автоматически выравнивает многомерные массивы, тогда как бинарный подсчет работает только с одномерными массивами, содержащими только положительные целые числа.
unique, counts = np.unique(a, return_counts=True)
print(unique , counts) # counts[i] iравняется вхождениям unique[i] в a
>>>Out:[0 3 4 5 7] [1 2 2 1 1]
>>> bin_count=np.bincount(a)
>>> print(bin_count) # bin_count[i] равняется вхождениям i в a
>>>Out:[1 0 0 2 2 1 0 1]
Если ваши данные представляют собой массивы numpy, как правило, гораздо быстрее использовать методы numpy, чем преобразовывать данные в универсальные методы.
Подсчет всех вхождений всех элементов в итерируемом: collection.Counter
from collections import Counter
c = Counter(["a", "b", "c", "d", "a", "b", "a", "c", "d"])
c
>>>Out: Counter({'a': 3, 'b': 2, 'c': 2, 'd': 2})
c["a"]
>>>Out: 3
c[7] # не в списке (7 входило 0 раз!)
>>>Out: 0
collections.Counter может быть использован для любого итератора и подсчитывает каждое вхождение для каждого элемента.
Примечание: Одно исключение , если dict или другой collections. -как класса дается, то он не будет считать их, а это создает счетчик с этими значениями: Mapping
Mapping
Примечание: Одно исключение , если dict или другой collections.Mapping -как класса дается, то он не будет считать их, а это создает счетчик с этими значениями:
Counter({"e": 2})
>>>Out: Counter({"e": 2})
Counter({"e": "e"}) # предупреждение: Counter не проверяет значения типа int
>>>Out: Counter({"e": "e"}) Подсчет вхождений подстроки в строку: str.count
astring = 'thisisashorttext'
astring.count('t')
>>>Out: 4Это работает даже для подстрок длиннее одного символа:
astring.count('th')
>>>Out: 1
astring.count('is')
>>>Out: 2
astring.count('text')
>>>Out: 1которое не было бы возможно с collections.Counter, который только подсчитывает одиночные символы:
from collections import Counter
Counter(astring)
>>>Out: Counter({'a': 1, 'e': 1, 'h': 2, 'i': 2, 'o': 1, 'r': 1, 's': 3, 't': 4, 'x': 1})Подсчет вхождений одного элемента в последовательности: list.
 count() и tuple.count()
count() и tuple.count()alist = [1, 2, 3, 4, 1, 2, 1, 3, 4]
alist.count(1)
>>>Out: 3
atuple = ('bear', 'weasel', 'bear', 'frog')
atuple.count('bear')
>>>Out: 2
atuple.count('fox')
>>>Out: 0 Получение наиболее распространенного значения: collection.Counter
Подсчет ключи от Mapping не представляется возможным с collections.Counter , но мы можем посчитать значения:
from collections import Counter
adict = {'a': 5, 'b': 3, 'c': 5, 'd': 2, 'e':2, 'q': 5}
Counter(adict.values())
>>>Out: Counter({2: 2, 3: 1, 5: 3})Наиболее распространенные элементы доступны с помощью most_common -метода:
#сортируем их от наиболее распространенного до наименее распространенному значению:
Counter(adict.values()).most_common()
>>>Out: [(5, 3), (2, 2), (3, 1)]
#получаем наиболее распространенные значения
Counter(adict.values()). most_common(1)
>>>Out: [(5, 3)]
# получаем 2 самых распространенных значения
Counter(adict.values()).most_common(2)
>>>Out: [(5, 3), (2, 2)] most_common(1)
>>>Out: [(5, 3)]
# получаем 2 самых распространенных значения
Counter(adict.values()).most_common(2)
>>>Out: [(5, 3), (2, 2)]
most_common(1)
>>>Out: [(5, 3)]
# получаем 2 самых распространенных значения
Counter(adict.values()).most_common(2)
>>>Out: [(5, 3), (2, 2)]Списки в Python — функции методы объекта List ~ PythonRu
Как создать список?
Списки объявляются в квадратных скобках [ ].
z = [3, 7, 4, 2] # Создание спискаВ python списки хранят упорядоченный набор элементов, которые могут быть разных типов. В примере, указанном выше элементы имеют один и тот же тип int. Не обязательно все элементы должны быть одного типа.
# Создание списка с разными типам данных
heterogenousElements = [3, True, 'Витя', 2.0]
Этот список содержит int, bool, string и float.
Доступ к элементам списка
Каждый элемент имеет присвоенный ему индекс. Важно отметить, в python индекс первого элемента в списке — 0.
Важно отметить, в python индекс первого элемента в списке — 0.
z = [3, 7, 4, 2] # создаем список
# обращение к первому элементу списка с индексом 0
print(z[0])
# элемент с индексом 0 -> 3
Также поддерживается отрицательная индексация. Отрицательная индексация начинается с конца. Иногда её удобнее использовать для получения последнего элемента в списке, потому что не нужно знать длину списка, чтобы получить доступ к последнему элементу.
Элемент с индексом -1 (выделен синим)
# выведите последний элемент списка
>>> print(z[-1])
2
Вы также можете получить доступ к одному и тому же элементу с использованием положительных индексов (как показано ниже). Альтернативный способ доступа к последнему элементу в списке z.
Срезы(slice) списка
Срезы хороши для получения подмножества значений с вашего списка. На примере кода, приведенного ниже, он вернет список с элементами из индекса 0 и не включая индекс 2.
На примере кода, приведенного ниже, он вернет список с элементами из индекса 0 и не включая индекс 2.
# Создайте список
z = [3, 7, 4, 2]
# Вывод элементов с индексом от 0 до 2 (не включая 2)
print(z[0:2])
# вывод: [3, 7]
# Все, кроме индекса 3
>>> print(z[:3])
[3, 7, 4]
Код, указанный ниже возвращает список с элементами начиная с индекса 1 до конца.
# начиная с индекса 1 до конца списка
>>> print(z[1:])
[7, 4, 2]
Изменение элементов в списке
Списки в Python изменяемы. Это означает, что после создания списка можно обновить его отдельные элементы.
z = [3, 7, 4, 2] # Создание списка
# Изменяем элемент с индексом 1 на строку 'fish'
z[1] = 'fish'
print(z)
[3, 'fish', 4, 2]Методы и функции списков python
У списков Python есть разные методы, которые помогают в программировании. В этом разделе рассматриваются все методы списков.
В этом разделе рассматриваются все методы списков.
Метод Index
Метод index возвращает положение первого индекса, со значением х. В указанном ниже коде, он возвращает назад 0.
# Создайте список
>>> z = [4, 1, 5, 4, 10, 4]
>>> print(z.index(4))
0
Вы также можете указать, откуда начинаете поиск.
>>> print(z.index(4, 3))
3
Метод Count
Метод count работает так, как звучит. Он считает количество раз, когда значение появляется в списке.
>>> random_list = [4, 1, 5, 4, 10, 4]
>>> print(random_list.count(4))
3
Метод Sort
Сортировка списка — фактическим кодом будем: z.sort()Метод sort сортирует и меняет исходный список.
z = [3, 7, 4, 2]
z.sort()
print(z)
[2, 3, 4, 7]Вышеуказанный код сортирует список чисел от наименьшего к наибольшему. Код, указанный ниже, показывает, как вы можете сортировать список от наибольшего к наименьшему.
# Сортировка и изменение исходного списка от наивысшего к наименьшему
z.sort(reverse = True)
print(z)
[7, 4, 3, 2]Следует отметить, что вы также можете отсортировать список строк от А до Я (или A-Z) и наоборот.
# Сортировка списка строками
names = ["Стив", "Рейчел", "Майкл", "Адам", "Джессика", "Лестер"]
names.sort()
print(names)
['Адам', 'Джессика', 'Лестер', 'Майкл', 'Рейчел', 'Стив']Метод Append
Добавьте значение 3 в конец спискаМетод append добавляет элемент в конец списка. Это происходит на месте.
Это происходит на месте.
z = [7, 4, 3, 2]
z.append(3)
print(z)
[7, 4, 3, 2, 3]Метод Remove
Метод remove удаляет первое вхождение значения в списке.
z = [7, 4, 3, 2, 3]
z.remove(2)
print(z)
Код удаляет первое вхождение значения 2 из списка z.
[7, 4, 3, 3]Метод Pop
z.pop(1) удаляет значение в индексе 1 и возвращает значение 4Метод pop удаляет элемент в указанном индексе. Этот метод также вернет элемент, который был удален из списка. В случае, если вы не указали индекс, он по умолчанию удалит элемент по последнему индексу.
z = [7, 4, 3, 3]
print(z.pop(1))
print(z)
4
[7, 3, 3]Метод Extend
Метод extend расширяет список, добавляя элементы. Преимущество над
Преимущество над append в том, что вы можете добавлять списки.
Добавим [4, 5] в конец z:
z = [7, 3, 3]
z.extend([4,5])
print(z)
[7, 3, 3, 4, 5]То же самое можно было бы сделать, используя +.
>>> print([1,2] + [3,4])
[7, 3, 3, 4, 5]
Метод Insert
Вставляет [1,2] с индексом 4 Метод insert вставляет элемент перед указанным индексом.
z = [7, 3, 3, 4, 5]
z.insert(4, [1, 2])
print(z)
[7, 3, 3, 4, [1, 2], 5]Простые операции над списками
| Метод | Описаниее |
|---|---|
x in s | True если элемент x находится в списке s |
x not in s | True если элемент x не находится в списке s |
s1 + s2 | Объединение списков s1 и s2 |
s * n , n * s | Копирует список s n раз |
len(s) | Длина списка s, т. e. количество элементов в e. количество элементов в s |
min(s) | Наименьший элемент списка s |
max(s) | Наибольший элемент списка s |
sum(s) | Сумма чисел списка s |
for i in list() | Перебирает элементы слева направо в цикле for |
Примеры использование функций со списками:
>>> list1 = [2, 3, 4, 1, 32]
>>> 2 in list1 # 2 в list1?
True
>>> 33 not in list1 # 33 не в list1?
True
>>> len(list1) # количество элементов списка
5
>>> max(list1) # самый большой элемент списка
32
>>> min(list1) # наименьший элемент списка
1
>>> sum(list1) # сумма чисел в списке
42
# генератор списков python (list comprehension)
>>> x = [i for i in range(10)]
>>> print(x)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> print(list1. reverse()) # разворачивает список
[32, 1, 4, 3, 2]
 reverse()) # разворачивает список
[32, 1, 4, 3, 2]
reverse()) # разворачивает список
[32, 1, 4, 3, 2]
Операторы
+ и * для списков+ объединяет два списка.
list1 = [11, 33]
list2 = [1, 9]
list3 = list1 + list2
print(list3)
[11, 33, 1, 9]* копирует элементы в списке.
list4 = [1, 2, 3, 4]
list5 = list4 * 3
print(list5)
[1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]Оператор
in и not inОператор in проверяет находится ли элемент в списке. При успешном результате он возвращает True, в случае неудачи, возвращает False .
>>> list1 = [11, 22, 44, 16, 77, 98]
>>> 22 in list1
True
Аналогично not in возвращает противоположный от оператора in результат.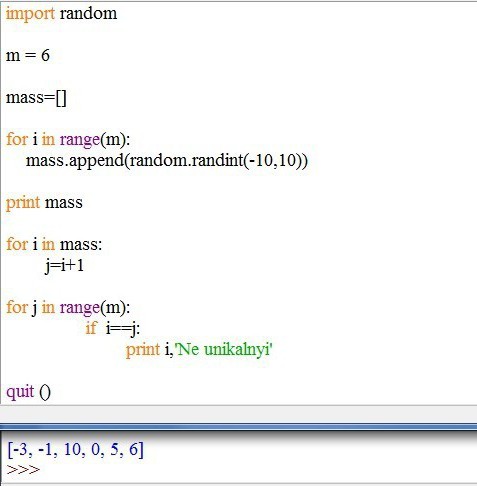
>>> 22 not in list1
False
Итерация по списку с использованием цикла for
Список — последовательность. Ниже способ, которые вы можете использовать для цикла, чтобы перебрать все элементы списка.
list1 = [1,2,3,4,5]
for i in list1:
print(i, end=" ")
1 2 3 4 5Преобразование списка в строку
Как преобразовать список в строку?Для преобразования списка в строку используйте метод join(). В Python это выглядит так: ",".join(["a", "b", "c"]) -> "a,b,c".
Разделитель пишут в кавычках перед join, в список должен состоять из строк.
Вот несколько полезных советов для преобразования списка в строку (или любого другого итерабельного, такого как tuple).
Во-первых, если это список строк, вы можете просто использовать join() следующим образом.
mylist = ['spam', 'ham', 'eggs']
print(', '.join(mylist))
spam, ham, eggsИспользуя тот же метод, вы можете также сделать следующее:
>>> print('\n'.join(mylist))
spam
ham
eggs
Однако этот простой метод не работает, если список содержит не строчные объекты, такие как целые числа. Если вы просто хотите получить строку с разделителями-запятыми, вы можете использовать этот шаблон:
list_of_ints = [80, 443, 8080, 8081]
print(str(list_of_ints).strip('[]'))
80, 443, 8080, 8081Или же этот, если ваши объекты содержат квадратные скобки:
>>> print(str(list_of_ints)[1:-1])
80, 443, 8080, 8081
В конце концов, вы можете использовать map() чтобы преобразовать каждый элемент в список строки и затем присоединиться к ним:
>>> print(', '. join(map(str, list_of_ints)))
80, 443, 8080, 8081
>>> print('\n'.join(map(str, list_of_ints)))
80
443
8080
8081
 join(map(str, list_of_ints)))
80, 443, 8080, 8081
>>> print('\n'.join(map(str, list_of_ints)))
80
443
8080
8081
join(map(str, list_of_ints)))
80, 443, 8080, 8081
>>> print('\n'.join(map(str, list_of_ints)))
80
443
8080
8081
Тест на знание списков в Python
Как создать список?
Продолжить
Что выведет этот код:a = [ 1, 342, 223, 'Африка', 'Очки']
print(a[-3])
Продолжить
Что выведет этот код:sample = [10, 20, 30]
sample.append(60)
sample.insert(3, 40)
print(sample)
Продолжить
Что выведет этот код:lake = ["Python", 51, False, "22"]
lake.
lake.reverse()
print(lake[-2])
Продолжить
Что из перечисленного правда?
Продолжить
Как получить['bar', 'baz'] из спискаa = ['foo', 'bar', 'baz', 'qux', 'quux']?
Продолжить
Как получить'bar' из спискаx = [10, [3.141, 20, [30, 'baz', 2.718]], 'foo']?
Продолжить
Как избавиться от «3» в списке a = [1, 3, 5] и получить [1, 5]?
Продолжить
С помощью какого метода можно добавить сразу два элемента в список?
Продолжить
Что вернет этот код [1, 2] * 3?
Продолжить
Продолжить
{{title}}
{{image}}
{{content}}
{{/global}}Поделиться результатами через
Повторить
Получить количество элементов в списке
Введение
Получение количества элементов в списке в Python — обычная операция. Например, вам нужно будет знать, сколько элементов в списке, когда вы его просматриваете. Помните, что списки могут содержать комбинацию целых чисел, чисел с плавающей запятой, строк, логических значений, других списков и т. Д. В качестве своих элементов:
Например, вам нужно будет знать, сколько элементов в списке, когда вы его просматриваете. Помните, что списки могут содержать комбинацию целых чисел, чисел с плавающей запятой, строк, логических значений, других списков и т. Д. В качестве своих элементов:
# Список только целых чисел
list_a = [12, 5, 91, 18]
# Список целых чисел, чисел с плавающей запятой, строк, логических значений
list_b = [4, 1.2, "привет, мир", True]
Если мы посчитаем элементы в list_a , мы получим всего 5 элементов. Если мы сделаем то же самое для list_b , мы получим 4 элемента.
Есть разные способы узнать количество элементов в списке. Подходы различаются, хотите ли вы подсчитывать вложенные списки как один элемент или все элементы во вложенных списках, или если вас интересуют только уникальные элементы и т. Д.
Встроенная функция
len () Самый простой способ получить количество элементов в списке — использовать встроенную функцию Python len () .
Давайте посмотрим на следующий пример:
list_a = ["Привет", 2, 15, "Мир", 34]
number_of_elements = len (список_a)
print ("Количество элементов в списке:", number_of_elements)
Что распечатывает:
Количество элементов в списке: 5
Как следует из названия функции, len () возвращает длину списка, независимо от типов элементов в нем.
Использование
для контура Другой способ сделать это — создать функцию, которая просматривает список, используя цикл для .Сначала мы инициализируем счетчик элементов равным 0, и каждый раз, когда выполняется итерация цикла, счет увеличивается на 1.
Цикл заканчивается, когда он перебирает все элементы, поэтому счетчик будет представлять общее количество элементов в списке:
list_c = [20, 8.9, «Привет», 0, «слово», «имя»]
def get_number_of_elements (список):
count = 0
для элемента в списке:
count + = 1
счетчик возврата
print ("Количество элементов в списке:", get_number_of_elements (list_c))
Запуск этого кода напечатает:
Количество элементов в списке: 6
Это гораздо более подробное решение по сравнению с функцией len () , но его стоит рассмотреть, поскольку позже в статье мы увидим, что ту же идею можно применить, когда мы имеем дело со списком списков. .Кроме того, вы можете захотеть выполнить некоторые операции либо с самими элементами, либо с операцией в целом, что здесь возможно.
.Кроме того, вы можете захотеть выполнить некоторые операции либо с самими элементами, либо с операцией в целом, что здесь возможно.
Получить количество уникальных элементов в списке
Списки могут состоять из нескольких элементов, включая дубликаты. Если мы хотим получить количество элементов без дубликатов (уникальных элементов), мы можем использовать другую встроенную функцию set () . Эта функция создает объект набора , который отклоняет все повторяющиеся значения.
Затем мы передаем это в функцию len () , чтобы получить количество элементов в наборе :
list_d = [100, 3, 100, «c», 100, 7.9, "в", 15]
number_of_elements = len (список_d)
number_of_unique_elements = len (набор (list_d))
print ("Количество элементов в списке:", number_of_elements)
print ("Количество уникальных элементов в списке:", number_of_unique_elements)
Что печатает:
Количество элементов в списке: 8
Количество уникальных элементов в списке: 5
Мы видим, что list_d имеет всего 8 элементов, 5 из которых уникальны.
Список списков с использованием
len ()Во введении мы увидели, что элементы списков могут иметь разные типы данных.Однако списки, в свою очередь, могут иметь списки в качестве своих элементов. Например:
list_e = [[90, 4, 12, 2], [], [34, 45, 2], [9,4], «char», [7, 3, 19]]
Если мы используем встроенную функцию len () , списки считаются отдельными элементами, поэтому у нас будет:
number_of_elements = len (список_e)
print ("Количество элементов в списке списков:", number_of_elements)
Что печатает:
Количество элементов в списке списков: 6
Обратите внимание, что пустой список считается одним элементом.Если список в списке содержит более одного элемента, они не принимаются во внимание. В этом может пригодиться петля для .
Получить количество элементов в списке, содержащем другие списки
Если мы хотим подсчитать все элементы внутри списка, содержащего другие списки, мы можем использовать цикл для . Мы можем инициализировать переменную
Мы можем инициализировать переменную count равной 0 и просмотреть список. На каждой итерации цикла count увеличивается на длину этого списка.
Мы будем использовать встроенную функцию len () , чтобы получить длину:
list_e = [[90, 4, 12, 2], [], [34, 45, 2], [9,4], «char», [7, 3, 19]]
def get_all_elements_in_list_of_lists (список):
count = 0
для элемента в list_e:
count + = len (элемент)
счетчик возврата
print ("Общее количество элементов в списке списков:", get_all_elements_in_list_of_lists (list_e))
Вывод:
Общее количество элементов в списке списков: 16
В этом примере следует отметить несколько важных моментов.Во-первых, на этот раз пустой список не повлиял на общий счет. Это связано с тем, что в каждом цикле мы учитываем длину текущего вложенного списка, а поскольку длина пустого списка равна 0, count увеличивается на 0.
Однако вы можете видеть, что каждый символ строки «char» засчитывается в общее количество элементов. Это связано с тем, что функция len () воздействует на строку, возвращая все ее символы. Мы можем избежать этой ситуации, используя тот же подход, что и в разделе ниже, который также позволит нам иметь элементы, отличные от списков.
Еще один интересный способ сделать то же самое, что и в предыдущем примере, — использовать понимание списка:
number_of_elements = sum ([len (элемент) для элемента в list_e])
По сути, эта строка выполняет две функции. Во-первых, он создает новый список, содержащий длины всех элементов исходного списка. В нашем случае это будет [4, 0, 3, 2, 4, 3] . Во-вторых, он вызывает функцию sum () , используя вновь созданный список в качестве параметра, который возвращает общую сумму всех элементов, давая нам желаемый результат.
Вложенные списки
Вложенные списки — это списки, которые являются элементами других списков. Списки могут быть нескольких уровней внутри друг друга:
Списки могут быть нескольких уровней внутри друг друга:
list_f = [30, 0.9, [8, 56, 22, ["a", "b"]], [200, 3, [5, [89], 10]]]
Мы видим, что ["a", "b"] содержится в списке [8, 56, 22, ["a", "b"]] , который, в свою очередь, содержится в основной список [30, 0.9, [200, 3, [5, [89], 10]]] .
Опять же, мы инициализируем переменную count равной 0.Если мы хотим получить общее количество элементов во вложенном списке, нам сначала нужно проверить, является ли элемент списком или нет. Если это так, мы зацикливаемся внутри списка и рекурсивно вызываем функцию, пока не останутся вложенные списки. Все элементы, кроме списков (целые числа, строки и т. Д.), Увеличивают счетчик на 1.
Обратите внимание, что это также решение проблем, вызванных предыдущим подходом.
Давайте посмотрим на код для подсчета элементов во вложенных списках:
list_f = [30, 0.9, [8, 56, 22, ["а", "привет"]], [200, 3, [5, [89], 10]]]
def get_elements_of_nested_list (элемент):
count = 0
если isinstance (элемент, список):
для каждого_элемента в элементе:
count + = get_elements_of_nested_list (каждый_элемент)
еще:
count + = 1
счетчик возврата
print ("Общее количество элементов во вложенном списке:", get_elements_of_nested_list (list_f))
Выполнение этого кода даст нам:
Общее количество элементов во вложенном списке: 12
Обратите внимание, что мы использовали встроенную функцию isinstance () , которая проверяет, является ли первый аргумент экземпляром класса, заданного вторым аргументом. В приведенной выше функции он проверяет, является ли элемент списком.
В приведенной выше функции он проверяет, является ли элемент списком.
Первый элемент 30 является целым числом, поэтому функция переходит к блоку else и увеличивает счет на 1. Когда мы дойдем до [8, 56, 22, ["a", "hello"]] , функция распознает список и рекурсивно просматривает его, чтобы проверить наличие других списков.
Заключение
Мы увидели, что в зависимости от типа списка, который у нас есть, есть разные способы получить количество элементов. len () — определенно самая быстрая и простая функция, если у нас есть плоские списки.
Для списков списков и вложенных списков len () не будет считать элементы внутри списков. Для этого нам нужно просмотреть весь список.
python — Как узнать количество элементов в списке?
Чтобы узнать размер списка, используйте встроенную функцию, len :
товаров = []
items. append ("яблоко")
Предметы.append ("оранжевый")
items.append ("банан")
 append ("яблоко")
Предметы.append ("оранжевый")
items.append ("банан")
append ("яблоко")
Предметы.append ("оранжевый")
items.append ("банан")
А сейчас:
лен (шт.)
возвращает 3.
Пояснение
Все в Python — это объекты, включая списки. В реализации C все объекты имеют какой-то заголовок.
Списки и другие подобные встроенные объекты с «размером» в Python, в частности, имеют атрибут с именем ob_size , в котором кэшируется количество элементов в объекте. Таким образом, проверка количества объектов в списке выполняется очень быстро.
Но если вы проверяете, равен ли размер списка нулю, не используйте len — вместо этого поместите список в логический контекст — он обрабатывается как False, если он пуст, и как True в противном случае.
Из документации
лён (л)
Возвращает длину (количество элементов) объекта. Аргументом может быть последовательность (например, строка, байты, кортеж, список или диапазон) или коллекция (например, словарь, набор или замороженный набор).

len реализуется с __len__ , из документов модели данных:
объект.__len __ (сам)
Вызывается для реализации встроенной функции
len (). Должен возвращать длину объекта, целое число> = 0. Кроме того, объект, который не определить метод__nonzero __ ()[в Python 2 или__bool __ ()в Python 3], и чей метод__len __ ()возвращает ноль считается ложным в логическом контексте.
И мы также видим, что __len__ — это метод списков:
шт.__len __ ()
возвращает 3.
Встроенные типы, вы можете получить
len (длина)И на самом деле мы видим, что можем получить эту информацию для всех описанных типов:
>>> all (hasattr (cls, '__len__') для cls в (str, bytes, tuple, list,
диапазон, дикт, набор, фрозенсет))
Истинный
Не используйте
len для проверки на пустой или непустой списокДля проверки на определенную длину, конечно, просто проверьте на равенство:
, если len (items) == required_length:
. ..
 ..
..
Но есть особый случай для проверки списка нулевой длины или обратного. В этом случае не проверяйте равенство.
Также нельзя:
если len (items):
...
Вместо этого просто введите:
if items: # Значит, у нас есть какие-то предметы, а не пустые!
...
или
if not items: # Тогда у нас пустой список!
...
Я объясняю, почему здесь, но вкратце, , если элементы или , если не элементы , более читабельны и более производительны.
Как найти длину списка в Python?
Список в Python — это тип данных коллекции, который можно упорядочивать и изменять. Список также может иметь повторяющиеся записи. Метод Python len () используется для определения длины любого объекта. В этой статье мы узнаем, как найти длину списка в Python в следующей последовательности:
Список в Python Список в Python реализован для хранения последовательности различных типов данных. Однако в Python есть шесть типов данных, которые могут хранить последовательности, но наиболее распространенным и надежным типом является список.
Однако в Python есть шесть типов данных, которые могут хранить последовательности, но наиболее распространенным и надежным типом является список.
Список определяется как набор значений или элементов разных типов. Элементы в списке разделяются запятой (,) и заключаются в квадратные скобки [].
Он определяется следующим образом:
list1 = ['edureka', 'python', 2019]; список2 = [1, 2, 3, 4, 5]; list3 = ["а", "б", "в", "г"];Как найти длину списка в Python?
Есть два наиболее часто используемых и основных метода, которые используются для определения длины списка в Python:
Len () MethodСуществует встроенная функция под названием len () для получения итоговой суммы. количество элементов в списке, кортеже, массивах, словаре и т. д.Метод len () принимает аргумент, в котором вы можете указать список, и возвращает длину данного списка.
Метод len () — один из наиболее часто используемых и удобных способов определения длины списка в Python. Это самая обычная техника, принятая сегодня всеми программистами.
Это самая обычная техника, принятая сегодня всеми программистами.
Синтаксис:
len (список)
Параметр List — это список, для которого необходимо подсчитать количество элементов. Возвращает количество элементов в списке.
Пример:
ListName = [«Привет», «Эдурика», 1, 2, 3]
print ("Количество элементов в списке =", len (ListName)) Вывод: 5
Наивный методМетод len () — это наиболее часто используемый метод для определения длины списка в Python.Но есть еще один базовый метод, определяющий длину списка.
В методе Naive можно просто запустить цикл и увеличить счетчик до последнего элемента списка, чтобы узнать его счетчик. Это самая основная стратегия, которую можно использовать при отсутствии других эффективных методов.
Пример:
ListName = ["Hello", "Edureka", 1,2,3]
print ("Список:" + str (ListName))
counter = 0
для i в ListName:
counter = counter + 1
print ("Длина списка с использованием простого метода:" + str (counter)) Вывод:
Список: ["Hello", "Edureka", 1,2,3] Длина списка с использованием наивного метода: 5
Все дело в том, чтобы найти длину списка в Python. Метод len () — самый популярный метод. Принимая во внимание, что вы также можете использовать базовый метод определения длины с помощью Наивного метода.
Метод len () — самый популярный метод. Принимая во внимание, что вы также можете использовать базовый метод определения длины с помощью Наивного метода.
На этом мы подошли к концу нашей статьи. Надеюсь, вы поняли, как найти длину любого списка в Python.
Чтобы получить глубокие знания о Python и его различных приложениях, вы можете записаться на интерактивный курс Python Certification Training с круглосуточной поддержкой и пожизненным доступом.
Есть к нам вопрос? Пожалуйста, укажите это в разделе комментариев этого блога «Длина списка в Python», и мы свяжемся с вами как можно скорее.
Получить количество элементов в списке, списках списков или вложенном списке — thispointer.com
В этой статье мы обсудим различные способы подсчета количества элементов в плоском списке, списках списков или вложенных списках.
Подсчет элементов в плоском списке
Предположим, у нас есть список, т.е.
# Список строк listOfElems = ['Hello', 'Ok', 'is', 'Ok', 'test', 'this', 'is', 'a', 'test']
Чтобы подсчитать элементы в этом списке, у нас есть разные способы.
 Давайте изучим их,
Давайте изучим их,Используйте функцию len (), чтобы получить размер списка
Python предоставляет встроенную функцию для получения размера последовательности, т.е.
len (s)
Аргументы:
- s : последовательность, такая как объект, например, список, строка, байты, кортеж и т. Д.
Возвращает длину объекта, то есть количество элементов в объекте.
Теперь давайте воспользуемся этой функцией len (), чтобы получить размер списка, т.е.
listOfElems = ['Hello', 'Ok', 'is', 'Ok', 'test', 'this', 'is' , 'тест']
# Получить размер списка с помощью len ()
длина = len (listOfElems)
print ('Количество элементов в списке:', длина)
Вывод:
Количество элементов в списке: 9
Как работает функция len ()?
Когда вызывается функция len (s), она внутренне вызывает функцию __len __ () переданного объекта s. Последовательные контейнеры по умолчанию, такие как список, кортеж и строка, имеют реализацию функции __len __ (), которая возвращает количество элементов в этой последовательности.
Последовательные контейнеры по умолчанию, такие как список, кортеж и строка, имеют реализацию функции __len __ (), которая возвращает количество элементов в этой последовательности.
Итак, в нашем случае мы передали объект списка функции len () . Который внутренне вызвал __len __ () объекта списка, чтобы получить количество элементов в списке.
Используйте list .__ len __ () для подсчета элементов в списке
Мы можем напрямую вызвать функцию-член __len __ () списка, чтобы получить размер списка i.е.
listOfElems = ['Hello', 'Ok', 'is', 'Ok', 'test', 'this', 'is', 'a', 'test']
# Получить размер списка с помощью list .__ len __ ()
длина = listOfElems .__ len __ ()
print ('Количество элементов в списке:', длина)
Выход:
Количество элементов в списке: 9
Хотя размер списка мы получили с помощью функции __len __ () .
 Это не рекомендуемый способ, мы всегда должны предпочесть len () для получения размера списка.
Это не рекомендуемый способ, мы всегда должны предпочесть len () для получения размера списка.Подсчитать элементы в списке списков
Предположим, у нас есть список из списка i.е.
# Список списков
listOfElems2D = [[1,2,3,45,6,7],
[22,33,44,55],
[11,13,14,15]] Теперь мы хотим подсчитать все элементы в списке, то есть общее количество в списке.
Но если мы вызовем функцию len () в списках list, то есть
length = len (listOfElems2D)
print ('Количество списков в списке =', длина)
Выход
Количество списков в списке = 3
В случае списка списков len () возвращает количество списков в основном списке i.е. 3. Но мы хотим подсчитать общее количество элементов в списке, включая эти три списка.
 Посмотрим, как это сделать.
Посмотрим, как это сделать.Использование цикла for для подсчета элементов в списке списков
Перебрать список, добавить размер всех внутренних списков с помощью len (), т.е.
# Список списков
listOfElems2D = [[1,2,3,45,6,7],
[22,33,44,55],
[11,13,14,15]]
# Перебираем список и добавляем размер всех внутренних списков
count = 0
для listElem в listOfElems2D:
счетчик + = len (listElem)
print ('Общее количество элементов:', count) Выход:
Общее количество элементов: 14
Использование понимания списка для подсчета элементов в списке списков
Перебирать список списков, используя понимание списка.Создайте новый список размеров внутренних списков. Затем передайте список в sum (), чтобы получить общее количество элементов в списке списков, т.е.
# Список списков
listOfElems2D = [[1,2,3,45,6,7],
[22,33,44,55],
[11,13,14,15]]
# Получить размер списка списка с помощью функции понимания списка и суммы ()
count = sum ([len (listElem) для listElem в listOfElems2D])
print ('Общее количество элементов:', count) Выход:
Общее количество элементов: 14
Подсчитать элементы во вложенном списке
Предположим, у нас есть вложенный список i. е. список, содержащий элементы и другие списки. Также эти внутренние списки могут содержать другие списки, например,
е. список, содержащий элементы и другие списки. Также эти внутренние списки могут содержать другие списки, например,
# Вложенный список nestedList = [2, 3, [44,55,66], 66, [5,6,7, [1,2,3], 6], 10, [11, [12, [13, 24]]]] ]
Как теперь подсчитать количество элементов в таком вложенном списке?
Для этого мы создали рекурсивную функцию, которая будет использовать рекурсию для перехода внутрь этого вложенного списка и вычисления общего количества элементов в нем, т.е.
def getSizeOfNestedList (listOfElem):
'' 'Получить количество элементов во вложенном списке' ''
count = 0
# Перебираем список
для элемента в listOfElem:
# Проверяем, является ли тип элемента список
если type (elem) == list:
# Снова вызовите эту функцию, чтобы получить размер этого элемента
count + = getSizeOfNestedList (элемент)
еще:
count + = 1
счетчик возврата Теперь давайте воспользуемся этой функцией для подсчета элементов во вложенном списке i.
 е.
е. # Вложенный список
nestedList = [2, 3, [44,55,66], 66, [5,6,7, [1,2,3], 6], 10, [11, [12, [13, 24]]]] ]
count = getSizeOfNestedList (вложенный список)
print ('Общее количество элементов:', count)
Выход
Общее количество элементов: 18
Он будет перебирать элементы в списке и для каждого элемента будет проверять, является ли его тип списком, затем он снова вызовет эту функцию, чтобы получить размер, иначе возвращает 1.
Полный пример выглядит следующим образом:
def getSizeOfNestedList (listOfElem):
'' 'Получить количество элементов во вложенном списке' ''
count = 0
# Перебираем список
для элемента в listOfElem:
# Проверяем, является ли тип элемента список
если type (elem) == list:
# Снова вызовите эту функцию, чтобы получить размер этого элемента
count + = getSizeOfNestedList (элемент)
еще:
count + = 1
счетчик возврата
def main ():
# Список строк
listOfElems = ['Hello', 'Ok', 'is', 'Ok', 'test', 'this', 'is', 'a', 'test']
print ('**** Подсчитать количество элементов в плоском списке ****')
print ('** Использование len () для получения размера списка **')
# Получить размер списка с помощью len ()
длина = len (listOfElems)
print ('Количество элементов в списке:', длина)
print ('** Используя list. __len __ (), чтобы получить размер списка ** ')
# Получить размер списка с помощью list .__ len __ ()
длина = listOfElems .__ len __ ()
print ('Количество элементов в списке:', длина)
print ('**** Подсчитать количество элементов в списке списков ****')
# Список списков
listOfElems2D = [[1,2,3,45,6,7],
[22,33,44,55],
[11,13,14,15]]
print ('Попробуйте len () в списке списков')
длина = len (listOfElems2D)
print ('Количество списков в списке =', длина)
print ('** Использование итерации для получения количества элементов в списке списков **')
# Перебираем список и добавляем размер всех внутренних списков
count = 0
для listElem в listOfElems2D:
счетчик + = len (listElem)
print ('Общее количество элементов:', count)
print ('** Используйте понимание списка, чтобы получить количество элементов в списке списков **')
# Получить размер списка списка с помощью функции понимания списка и суммы ()
count = sum ([len (listElem) для listElem в listOfElems2D])
print ('Общее количество элементов:', count)
print ('Использование понимания списка')
count = getSizeOfNestedList (listOfElems2D)
print ('Общее количество элементов:', count)
print ('**** Подсчитать элементы во вложенном списке ****')
# Вложенный список
nestedList = [2, 3, [44,55,66], 66, [5,6,7, [1,2,3], 6], 10, [11, [12, [13, 24]]]] ]
count = getSizeOfNestedList (вложенный список)
print ('Общее количество элементов:', count)
count = getSizeOfNestedList (listOfElems)
print ('Общее количество элементов:', count)
если __name__ == '__main__':
main ()  __len __ (), чтобы получить размер списка ** ')
# Получить размер списка с помощью list .__ len __ ()
длина = listOfElems .__ len __ ()
print ('Количество элементов в списке:', длина)
print ('**** Подсчитать количество элементов в списке списков ****')
# Список списков
listOfElems2D = [[1,2,3,45,6,7],
[22,33,44,55],
[11,13,14,15]]
print ('Попробуйте len () в списке списков')
длина = len (listOfElems2D)
print ('Количество списков в списке =', длина)
print ('** Использование итерации для получения количества элементов в списке списков **')
# Перебираем список и добавляем размер всех внутренних списков
count = 0
для listElem в listOfElems2D:
счетчик + = len (listElem)
print ('Общее количество элементов:', count)
print ('** Используйте понимание списка, чтобы получить количество элементов в списке списков **')
# Получить размер списка списка с помощью функции понимания списка и суммы ()
count = sum ([len (listElem) для listElem в listOfElems2D])
print ('Общее количество элементов:', count)
print ('Использование понимания списка')
count = getSizeOfNestedList (listOfElems2D)
print ('Общее количество элементов:', count)
print ('**** Подсчитать элементы во вложенном списке ****')
# Вложенный список
nestedList = [2, 3, [44,55,66], 66, [5,6,7, [1,2,3], 6], 10, [11, [12, [13, 24]]]] ]
count = getSizeOfNestedList (вложенный список)
print ('Общее количество элементов:', count)
count = getSizeOfNestedList (listOfElems)
print ('Общее количество элементов:', count)
если __name__ == '__main__':
main ()
__len __ (), чтобы получить размер списка ** ')
# Получить размер списка с помощью list .__ len __ ()
длина = listOfElems .__ len __ ()
print ('Количество элементов в списке:', длина)
print ('**** Подсчитать количество элементов в списке списков ****')
# Список списков
listOfElems2D = [[1,2,3,45,6,7],
[22,33,44,55],
[11,13,14,15]]
print ('Попробуйте len () в списке списков')
длина = len (listOfElems2D)
print ('Количество списков в списке =', длина)
print ('** Использование итерации для получения количества элементов в списке списков **')
# Перебираем список и добавляем размер всех внутренних списков
count = 0
для listElem в listOfElems2D:
счетчик + = len (listElem)
print ('Общее количество элементов:', count)
print ('** Используйте понимание списка, чтобы получить количество элементов в списке списков **')
# Получить размер списка списка с помощью функции понимания списка и суммы ()
count = sum ([len (listElem) для listElem в listOfElems2D])
print ('Общее количество элементов:', count)
print ('Использование понимания списка')
count = getSizeOfNestedList (listOfElems2D)
print ('Общее количество элементов:', count)
print ('**** Подсчитать элементы во вложенном списке ****')
# Вложенный список
nestedList = [2, 3, [44,55,66], 66, [5,6,7, [1,2,3], 6], 10, [11, [12, [13, 24]]]] ]
count = getSizeOfNestedList (вложенный список)
print ('Общее количество элементов:', count)
count = getSizeOfNestedList (listOfElems)
print ('Общее количество элементов:', count)
если __name__ == '__main__':
main () Вывод:
**** Подсчитать количество элементов в плоском списке **** ** Использование len () для получения размера списка ** Количество элементов в списке: 9 ** Использование списка.
 __len __ (), чтобы получить размер списка **
Количество элементов в списке: 9
**** Подсчитать количество элементов в списке списков ****
Попробуйте len () в списке списков
Количество списков в списке = 3
** Использование итерации для получения количества элементов в списке списков **
Общее количество элементов: 14
** Используйте понимание списка, чтобы получить количество элементов в списке
списков **
Общее количество элементов: 14
Использование понимания списка
Общее количество элементов: 14
**** Подсчет элементов во вложенном списке ****
Общее количество элементов: 18
Общее количество элементов: 9
__len __ (), чтобы получить размер списка **
Количество элементов в списке: 9
**** Подсчитать количество элементов в списке списков ****
Попробуйте len () в списке списков
Количество списков в списке = 3
** Использование итерации для получения количества элементов в списке списков **
Общее количество элементов: 14
** Используйте понимание списка, чтобы получить количество элементов в списке
списков **
Общее количество элементов: 14
Использование понимания списка
Общее количество элементов: 14
**** Подсчет элементов во вложенном списке ****
Общее количество элементов: 18
Общее количество элементов: 9 Найти размер списка в Python
Найти размер списка в Python
В Python список — это тип данных коллекции, который упорядочен и изменяем.Список также может иметь повторяющиеся записи. Здесь задача — найти количество записей в списке. См. Примеры ниже.
Примеры:
Ввод: a = [1, 2, 3, 1, 2, 3] Выход: 6 Подсчитайте количество записей в списке a.
 Ввод: a = []
Выход: 0
Ввод: a = []
Выход: 0
Идея состоит в том, чтобы использовать len () в Python
|
Длина списка: 4
Пример 2:
|
Длина списка: 3
Как работает len ()?
len () работает за время O (1), поскольку список является объектом и имеет член для хранения его размера. Ниже приведено описание len () из документации Python.
Ниже приведено описание len () из документации Python.
Возвращает длину (количество элементов) объекта. Аргументом может быть последовательность (например, строка, байты, кортеж, список или диапазон) или коллекция (например, словарь, набор или замороженный набор).
Как проверить, пуст ли список в Python
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .
Python count элементов списка
Функция Python count List используется для подсчета того, сколько раз элемент повторяется в данном списке. Синтаксис функции подсчета списка:
.имя_списка.count (элемент_списка)
Функция подсчета python подсчитывает общее количество раз, когда элемент повторяется в данном списке. Приведенный ниже код подсчитывает 10 и 20 в целочисленном списке.
Приведенный ниже код подсчитывает 10 и 20 в целочисленном списке.
# Элементы списка подсчета Python
а = [10, 20, 30, 10, 40, 10, 50, 20]
print ("Общее количество повторов 10 =", a.количество (10))
print ("Общее количество повторов 20 =", a.count (20)) Пример списка счетчиков Python
В этом примере мы объявили список строк. Затем мы использовали на нем функцию count.
СОВЕТ: См. Статьи о методах списков и списках в Python.
# Элементы списка подсчета Python
Фрукты = [«Яблоко», «Апельсин», «Банан», «Яблоко», «Виноград», «Банан», «Яблоко»]
print ("Общее количество повторений 'Apple' =", Fruits.count ('Apple'))
print ("Общее количество повторов" банана "=", Fruits.count ('Банан')) Позвольте мне использовать эту функцию подсчета в смешанном списке.
# Элементы списка подсчета Python
MxList = ['Apple', 10, 'Banana', 10, 'Apple', 'Grape', 10, 30, 10, 50, 'Apple']
print ("Общее количество повторений 'Apple' =", MxList. count ('Apple'))
print ("Общее количество повторов: 10 =", MxList.count (10))  count ('Apple'))
print ("Общее количество повторов: 10 =", MxList.count (10))
count ('Apple'))
print ("Общее количество повторов: 10 =", MxList.count (10)) На этот раз мы использовали функцию подсчета списка во вложенном списке (список внутри списка).
# Элементы списка подсчета Python
MxList = [[10, 20], [20, 30], [10, 20], [40, 50], [10, 80]]
print ("Общее количество раз [10,20] повторов =", MxList.count ([10,20])) Список счетчиков Функция Пример 2
Эта программа на Python позволяет пользователю вводить длину списка и цикл For Loop, чтобы добавить эти числа в список. Затем мы использовали функцию подсчета списка для подсчета элемента списка 10.
# Элементы списка подсчета Python
intCountList = []
number = int (input ("Пожалуйста, введите общее количество элементов списка:"))
для i в диапазоне (1, число + 1):
value = int (input ("Введите значение элемента% d:"% i))
intCountList.append (значение)
item = int (input («Пожалуйста, введите предмет, который вы хотите подсчитать:»))
print ("Общее количество повторов =", intCountList. count (элемент))  count (элемент))
count (элемент)) Список счетчиков Функция Пример 3
Эта функция подсчета списка позволяет пользователям вводить свою собственную строку или слова, а затем подсчитывать слово
# Элементы списка подсчета Python
strCountList = []
number = int (input ("Пожалуйста, введите общее количество элементов списка:"))
для i в диапазоне (1, число + 1):
value = input ("Введите значение элемента% d:"% i)
strCountList.append (значение)
item = input ("Пожалуйста, введите предмет, который вы хотите подсчитать:")
print ("Общее количество повторов =", strCountList.count (элемент)) 11. Списки — Как думать как компьютерный ученый: обучение с помощью Python 3
Список — это упорядоченный набор значений. Ценности, составляющие список
называются его элементом или его элементом .
Мы будем использовать термин элемент или элемент , чтобы обозначать одно и то же. Списки
похожи на строки, которые представляют собой упорядоченные наборы символов, за исключением того, что
элементы списка могут быть любого типа. Списки и строки — и другие коллекции
которые поддерживают порядок своих элементов — называются последовательностями .
Списки
похожи на строки, которые представляют собой упорядоченные наборы символов, за исключением того, что
элементы списка могут быть любого типа. Списки и строки — и другие коллекции
которые поддерживают порядок своих элементов — называются последовательностями .
11.1. Значения списка
Есть несколько способов создать новый список; проще всего заключить элементы в квадратных скобках ([и]):
Первый пример — это список из четырех целых чисел. Второй — список из трех струны. Элементы списка не обязательно должны быть одного типа. Следующее список содержит строку, число с плавающей запятой, целое число и (удивительно) другой список:
Список в другом списке называется вложенным .
Наконец, список без элементов называется пустым списком, и обозначается [].
Мы уже видели, что можем назначать значения списков переменным или передавать списки в качестве параметров функциям:
11.2. Доступ к элементам
Синтаксис доступа к элементам списка такой же, как синтаксис для доступ к символам строки — оператор индекса: [] (не для путать с пустым списком). Выражение в скобках указывает индекс. Помните, что индексы начинаются с 0:
.Любое выражение, вычисляющее целое число, может использоваться в качестве индекса:
>>> числа [9-8] 5 >>> числа [1.0] Отслеживание (последний вызов последний): Файл «<интерактивный ввод>», строка 1, в <модуле> TypeError: индексы списка должны быть целыми числами, а не с плавающей запятой
Если вы попытаетесь получить доступ или назначить элемент, который не существует, вы получите среду выполнения ошибка:
>>> числа [2] Отслеживание (последний вызов последний): Файл «<интерактивный ввод>», строка 1, в <модуле> IndexError: список индекса вне допустимого диапазона
Обычно в качестве индекса списка используется переменная цикла.
всадников = [«война», «голод», «мор», «смерть»] для i в [0, 1, 2, 3]: печать (всадники [i])
Каждый раз при прохождении цикла переменная i используется как индекс в list, распечатывая i-й элемент. Этот образец вычислений называется обход списка .
В приведенном выше примере индекс i не нужен и не используется ни для чего, кроме получения элементы из списка, поэтому эта более прямая версия — где цикл for получает наименований — могут быть предпочтительны:
всадников = [«война», «голод», «мор», «смерть»] для ч в всадниках: печать (ч)
11.3. Длина списка
Функция len возвращает длину списка, равную числу
его элементов. Если вы собираетесь использовать целочисленный индекс для доступа к списку,
это хорошая идея использовать это значение как верхнюю границу
цикл вместо константы. Таким образом, если размер списка изменится, вы
не придется проходить программу, меняя все петли; они будут работать
правильно для списка любого размера:
Таким образом, если размер списка изменится, вы
не придется проходить программу, меняя все петли; они будут работать
правильно для списка любого размера:
всадников = [«война», «голод», «мор», «смерть»] for i in range (len (всадники)): печать (всадники [i])
Последний раз, когда выполняется тело цикла, лен (всадники) — 1, который является индексом последнего элемента.(Но версия без индекса теперь выглядит даже лучше!)
Хотя список может содержать другой список, вложенный список все равно считается единственный элемент в своем родительском списке. Длина этого списка 4:
.>>> len (["производители автомобилей", 1, ["Ford", "Toyota", "BMW"], [1, 2, 3]]) 4
11,4. Список участников
in и not in — это логические операторы, которые проверяют принадлежность к последовательности. Мы ранее использовали их со строками, но они также работают со списками и другие последовательности:
>>> всадники = ["война", "голод", "мор", "смерть"] >>> "мор" у всадников Истинный >>> "разврат" у всадников Ложь >>> "разврат" не в всадниках Истинный
Использование этого дает более элегантную версию программы вложенного цикла, которую мы использовали ранее. подсчитать количество студентов, изучающих информатику
в разделе Вложенные циклы для вложенных данных :
подсчитать количество студентов, изучающих информатику
в разделе Вложенные циклы для вложенных данных :
студентов = [ («Джон», [«CompSci», «Физика»]), («Вуси», [«Математика», «CompSci», «Статистика»]), («Джесс», [«CompSci», «Бухгалтерский учет», «Экономика», «Менеджмент»]), («Сара», [«InfSys», «Бухгалтерский учет», «Экономика», «CommLaw»]), («Зуки», [«Социология», «Экономика», «Право», «Статистика», «Музыка»])] # Подсчитайте, сколько студентов принимают CompSci counter = 0 для (ФИО, предметы) у студентов: если "CompSci" в предметах: счетчик + = 1 print ("Количество студентов, сдающих CompSci", счетчик)
11.5. Список операций
Оператор + объединяет списки:
>>> a = [1, 2, 3] >>> b = [4, 5, 6] >>> c = a + b >>> c [1, 2, 3, 4, 5, 6]
Аналогично, оператор * повторяет список заданное количество раз:
>>> [0] * 4 [0, 0, 0, 0] >>> [1, 2, 3] * 3 [1, 2, 3, 1, 2, 3, 1, 2, 3]
Первый пример повторяется [0] четыре раза. Второй пример повторяет
list [1, 2, 3] три раза.
Второй пример повторяет
list [1, 2, 3] три раза.
11,6. Список фрагментов
Операции среза, которые мы видели ранее со строками, позволяют нам работать с подсписками:
>>> a_list = ["a", "b", "c", "d", "e", "f"] >>> a_list [1: 3] ['до н.э'] >>> a_list [: 4] ['a', 'b', 'c', 'd'] >>> a_list [3:] ['d', 'e', 'f'] >>> a_list [:] ['a', 'b', 'c', 'd', 'e', 'f']
11,7. Списки изменяемые
В отличие от строк, списки являются изменяемыми , что означает, что мы можем изменять их элементы.Используя оператор индекса в левой части присваивания, мы можем обновить один из элементов:
>>> fruit = ["банан", "яблоко", "айва"] >>> fruit [0] = "груша" >>> fruit [2] = "апельсин" >>> фрукты ['груша', 'яблоко', 'апельсин]
Оператор скобок, применяемый к списку, может появляться в любом месте выражения.
Когда он появляется слева от задания, он меняет один из
элементов в списке, поэтому первый элемент фрукта был изменен с
от «банана» до «груши» и от «айвы» до «апельсина». An
присвоение элементу списка называется присвоением элемента . Элемент
присвоение не работает для строк:
An
присвоение элементу списка называется присвоением элемента . Элемент
присвоение не работает для строк:
>>> my_string = "ТЕСТ" >>> my_string [2] = "X" Отслеживание (последний вызов последний): Файл «<интерактивный ввод>», строка 1, в <модуле> TypeError: объект 'str' не поддерживает назначение элементов
, но для списков:
>>> my_list = ["T", "E", "S", "T"] >>> my_list [2] = "X" >>> мой_лист ['T', 'E', 'X', 'T']
С помощью оператора среза мы можем обновить сразу весь подсписок:
>>> a_list = ["a", "b", "c", "d", "e", "f"] >>> a_list [1: 3] = ["x", "y"] >>> a_list ['a', 'x', 'y', 'd', 'e', 'f']
Мы также можем удалить элементы из списка, назначив им пустой список:
>>> a_list = ["a", "b", "c", "d", "e", "f"] >>> a_list [1: 3] = [] >>> a_list ['a', 'd', 'e', 'f']
И мы можем добавлять элементы в список, сжимая их в пустой фрагмент в желаемое место:
>>> a_list = ["a", "d", "f"] >>> a_list [1: 1] = ["b", "c"] >>> a_list ['a', 'b', 'c', 'd', 'f'] >>> a_list [4: 4] = ["е"] >>> a_list ['a', 'b', 'c', 'd', 'e', 'f']
11.
8. Удаление спискаИспользование фрагментов для удаления элементов списка может быть подвержено ошибкам. Python предоставляет альтернативу, более удобочитаемую. Оператор del удаляет элемент из списка:
>>> a = ["один", "два", "три"] >>> дель а [1] >>> а ['один три']
Как и следовало ожидать, del вызывает выполнение ошибка, если индекс вне допустимого диапазона.
Вы также можете использовать del со срезом для удаления подсписка:
>>> a_list = ["a", "b", "c", "d", "e", "f"] >>> del a_list [1: 5] >>> a_list ['a', 'f']
Как обычно, подсписок, выбранный с помощью среза, содержит все элементы до второго, но не включая его. индекс.
11.9. Объекты и ссылки
После выполнения этих операторов присваивания
мы знаем, что a и b будут относиться к строковому объекту с буквами
«банан». Но мы еще не знаем, указывают ли они на тот же строковый объект .
Но мы еще не знаем, указывают ли они на тот же строковый объект .
Интерпретатор Python может организовать свою память двумя способами:
В одном случае a и b относятся к двум разным объектам, которые имеют одинаковые ценить.Во втором случае они относятся к одному и тому же объекту.
Мы можем проверить, относятся ли два имени к одному и тому же объекту, используя is оператор:
Это говорит нам, что и a, и b относятся к одному и тому же объекту, и что он это второй из двух снимков состояния, который точно описывает взаимосвязь.
Поскольку строки неизменяемы , Python оптимизирует ресурсы, создавая два имени которые относятся к одному и тому же строковому значению, относятся к одному и тому же объекту.
Это не относится к спискам:
>>> a = [1, 2, 3] >>> b = [1, 2, 3] >>> а == б Истинный >>> а это б Ложь
Снимок состояния здесь выглядит так:
a и b имеют одинаковое значение, но не относятся к одному и тому же объекту.
11.10. Псевдоним
Поскольку переменные относятся к объектам, если мы присвоим одну переменную другой, обе переменные относятся к одному и тому же объекту:
>>> a = [1, 2, 3] >>> б = а >>> а это б Истинный
В данном случае снимок состояния выглядит так:
Поскольку один и тот же список имеет два разных имени, a и b, мы говорим, что он — с псевдонимом . Изменения, сделанные с одним псевдонимом, влияют на другой:
>>> b [0] = 5 >>> а [5, 2, 3]
Хотя такое поведение может быть полезным, иногда оно бывает неожиданным или
нежелательно.В общем, при работе безопаснее избегать появления псевдонимов.
с изменяемыми объектами (т.е. списками в этом месте в нашем учебнике,
но мы встретим больше изменяемых объектов
поскольку мы охватываем классы и объекты, словари и множества).
Конечно, для неизменяемых объектов (например, строк, кортежей) проблем нет — это
просто невозможно что-то изменить и получить сюрприз при обращении к псевдониму. Вот почему Python может использовать псевдонимы для строк (и любых других неизменяемых типов данных).
когда видит возможность сэкономить.
11.11. Списки клонирования
Если мы хотим изменить список, а также сохранить копию оригинала, нам нужно возможность сделать копию самого списка, а не только ссылки. Этот процесс иногда называют клонированием , чтобы избежать двусмысленности слова «копия».
Самый простой способ клонировать список — использовать оператор среза:
>>> a = [1, 2, 3] >>> b = a [:] >>> б [1, 2, 3]
При взятии любого фрагмента создается новый список.В этом случае срез состоят из всего списка. Итак, теперь отношения такие:
Теперь мы можем вносить изменения в b, не беспокоясь о том, что мы случайно изменение a:
>>> b [0] = 5 >>> а [1, 2, 3]
11.12. Списки и петли
Как мы уже видели, цикл for также работает со списками. Обобщенный синтаксис для
цикл:
Обобщенный синтаксис для
цикл:
для ПЕРЕМЕННОЙ в СПИСКЕ:
ТЕЛО
Итак, как мы видели
friends = [«Джо», «Зои», «Брэд», «Анджелина», «Зуки», «Танди», «Пэрис»] для друга в друзья: печать (друг)
Это почти читается как по-английски: Для (каждого) друга в (списке) друзей, напечатайте (имя) друга.
В цикле for можно использовать любое выражение списка:
для числа в диапазоне (20): если число% 3 == 0: печать (число) для фруктов в ["банан", "яблоко", "айва"]: print («Я люблю поесть» + фрукты + «ы!»)
В первом примере печатаются все числа, кратные 3, от 0 до 19. Во втором примере пример выражает увлечение различными фруктами.
Поскольку списки изменяемы, мы часто хотим пройти по списку, изменяя
каждый из его элементов. В следующем квадрате все числа в списке xs:
В следующем квадрате все числа в списке xs:
xs = [1, 2, 3, 4, 5] для i в диапазоне (len (xs)): xs [i] = xs [i] ** 2
Подумайте о диапазоне (len (xs)), пока не поймете, как оно работает.
В этом примере нас интересует как значение , так и элемента (мы хотим возводите в квадрат это значение) и его индекс (чтобы мы могли присвоить новое значение этой позиции).Этот шаблон достаточно распространен, поэтому Python предлагает более удобный способ его реализации:
xs = [1, 2, 3, 4, 5] for (i, val) в enumerate (xs): xs [i] = val ** 2
enumerate генерирует пары обоих (индекс, значение) во время обход списка. Попробуйте следующий пример, чтобы более четко увидеть, как перечислить работ:
для (i, v) в перечислении ([«банан», «яблоко», «груша», «лимон»]): печать (я, v)0 бананов 1 яблоко 2 груши 3 лимона
11.
 13. Перечислить параметры
13. Перечислить параметрыПередача списка в качестве аргумента фактически передает ссылку на список, а не скопировать или клонировать список. Таким образом, передача параметров создает для вас псевдоним: вызывающий имеет одну переменную, ссылающуюся на список, а у вызываемой функции есть псевдоним, но там — это только один базовый объект списка. Например, функция ниже принимает список как аргумент и умножает каждый элемент в списке на 2:
def double_stuff (a_list): "" "Заменить каждый элемент в a_list удвоенным значением."" " для (idx, val) в перечислении (a_list): a_list [idx] = 2 * значение
Если мы добавим в наш скрипт следующее:
Когда мы запустим его, мы получим:
В приведенной выше функции параметр
a_list и переменные являются псевдонимами для
тот же объект. Поэтому перед любыми изменениями элементов в списке снимок состояния
выглядит так:
Поэтому перед любыми изменениями элементов в списке снимок состояния
выглядит так:
Поскольку объект списка является общим для двух фреймов, мы нарисовали его между ними.
Если функция изменяет элементы параметра списка, вызывающий абонент видит это изменение.
Используйте визуализатор Python!
Мы уже упоминали визуализатор Python на http://netserv.ict.ru.ac.za/python3_viz. Это очень полезный инструмент для понимания ссылок, псевдонимов, назначений, и передача аргументов функциям. Обратите особое внимание на случаи, когда вы клонируете список или два отдельных списка, а также случаи, когда существует только один базовый список, но несколько переменных имеют псевдонимы для ссылки на список.
11,14. Список методов
Оператор «точка» также может использоваться для доступа к встроенным методам объектов списка. Что ж начните с наиболее полезного метода добавления чего-либо в конец существующего списка:
>>> mylist = [] >>> mylist.
 append (5)
>>> mylist.append (27)
>>> mylist.append (3)
>>> mylist.append (12)
>>> мой список
[5, 27, 3, 12]
append (5)
>>> mylist.append (27)
>>> mylist.append (3)
>>> mylist.append (12)
>>> мой список
[5, 27, 3, 12]
append — это метод списка, который добавляет переданный ему аргумент в конец список.Мы будем активно его использовать при создании новых списков. Продолжая этот пример, мы покажем несколько других методов списков:
>>> mylist.insert (1, 12) # Вставить 12 в позицию 1, сдвинуть остальные элементы вверх >>> мой список [5, 12, 27, 3, 12] >>> mylist.count (12) # Сколько раз в моем списке 12? 2 >>> mylist.extend ([5, 9, 5, 11]) # Помещаем весь список в конец mylist >>> мой список [5, 12, 27, 3, 12, 5, 9, 5, 11]) >>> mylist.index (9) # Найти индекс первых 9 в mylist 6 >>> мой список.обеспечить регресс() >>> мой список [11, 5, 9, 5, 12, 3, 27, 12, 5] >>> mylist.sort () >>> мой список [3, 5, 5, 5, 9, 11, 12, 12, 27] >>> mylist.remove (12) # Удаляем первые 12 из списка >>> мой список [3, 5, 5, 5, 9, 11, 12, 27]
Поэкспериментируйте и поиграйте со списковыми методами, показанными здесь, и читайте их документацию, пока
вы уверены, что понимаете, как они работают.
11.15. Чистые функции и модификаторы
Функции, которые принимают списки в качестве аргументов и изменяют их во время выполнения: называются модификаторами , а вносимые ими изменения называются побочными эффектами .
Чистая функция не вызывает побочных эффектов. Он общается с вызывающая программа только через параметры, которые она не изменяет, и возврат ценить. Вот double_stuff, записанный как чистая функция:
def double_stuff (a_list): "" "Вернуть новый список, содержащий дублирует элементы в a_list. "" " new_list = [] для значения в a_list: new_elem = 2 * значение новый_лист.добавить (новый_элемент) вернуть новый_лист
Эта версия double_stuff не меняет своих аргументов:
>>> things = [2, 5, 9] >>> xs = double_stuff (вещи) >>> вещи [2, 5, 9] >>> хз [4, 10, 18]
Раннее правило, которое мы видели для присваивания, гласило: «сначала оцените правую часть, затем
присвоить полученное значение переменной ». Так что вполне безопасно назначить функцию
результат в ту же переменную, которая была передана в функцию:
Так что вполне безопасно назначить функцию
результат в ту же переменную, которая была передана в функцию:
>>> things = [2, 5, 9] >>> вещи = double_stuff (вещи) >>> вещи [4, 10, 18]
Какой стиль лучше?
Все, что можно сделать с помощью модификаторов, можно сделать и с чистыми функциями.Фактически, некоторые языки программирования допускают только чистые функции. Существует некоторое свидетельство того, что программы, использующие чистые функции, быстрее разрабатывать и меньше подвержены ошибкам, чем программы, использующие модификаторы. Тем не менее, модификаторы временами удобны, а в некоторых случаях функциональные программы менее эффективны.
В общем, мы рекомендуем вам писать чистые функции всякий раз, когда это необходимо. разумно сделать это и прибегать к модификаторам только при наличии убедительных преимущество. Этот подход можно назвать стилем функционального программирования .
11,16.
 Функции, формирующие списки
Функции, формирующие спискиЧистая версия double_stuff, приведенная выше, использовала важный шаблон для вашего инструментария. Всякий раз, когда вам нужно напишите функцию, которая создает и возвращает список, шаблон обычно:
Покажем еще одно использование этого паттерна.Предположим, у вас уже есть функция is_prime (x), который может проверить, является ли x простым. Напишите функцию чтобы вернуть список всех простых чисел меньше n:
def primes_lessthan (n): "" "Вернуть список всех простых чисел меньше n." "" результат = [] для i в диапазоне (2, n): если is_prime (i): result.append (я) вернуть результат
11,17.
 Строки и списки
Строки и спискиДва наиболее полезных метода для строк включают преобразование в и из списков подстрок.Метод разделения (который мы уже видели) разбивает строку на список слов. К по умолчанию любое количество пробелов считается границей слова:
>>> song = "Дождь в Испании ..." >>> wds = song.split () >>> wds ['The', 'rain', 'in', 'Spain ...']
Необязательный аргумент, называемый разделителем , может использоваться, чтобы указать, какой строка для использования в качестве граничного маркера между подстроками. В следующем примере в качестве разделителя используется строка ai:
>>> песня.сплит ("ай")
['The r', 'n in Sp', 'n ...']
Обратите внимание, что разделитель не отображается в результате.
Метод, обратный методу разделения, — соединение. Вы выбираете желаемый разделитель строка (часто называемый клеем ) и соединяем список клеем между каждым из элементов:
>>> клей = ";" >>> s = glue.
 join (wds)
>>> с
"Дождь; в Испании ..."
join (wds)
>>> с
"Дождь; в Испании ..."
Список, который вы склеиваете (в данном примере wds), не изменяется.Кроме того, поскольку эти В следующих примерах показано, что в качестве клея можно использовать пустой клей или многосимвольные строки:
>>> "---" .join (wds) "Дождь --- в --- Испании ..." >>> "" .join (wds) 'TheraininSpain ...'
11.18. список и диапазон
Python имеет встроенную функцию преобразования типов, которая называется список, который пытается превратить все, что вы ему даете в список.
>>> xs = list («Хрустящая лягушка») >>> хз [«C», «r», «u», «n», «c», «h», «y», «», «F», «r», «o», «g»] >>> "".присоединиться (хз) 'Хрустящая лягушка'
Особенностью диапазона является то, что он
не вычисляет сразу все свои значения: он «откладывает» вычисление,
и делает это по запросу или «лениво». Мы скажем, что он дает обещание для получения значений, когда они необходимы. Это очень удобно, если ваш
вычисление прерывает поиск и возвращает раньше, как в этом случае:
Это очень удобно, если ваш
вычисление прерывает поиск и возвращает раньше, как в этом случае:
def f (n): "" "Найдите первое положительное целое число от 101 до менее чем n, которое делится на 21 "" " для i в диапазоне (101, n): если (i% 21 == 0): вернуть я тест (f (110) == 105) тест (f (1000000000) == 105)
Во втором тесте, если диапазон будет стремиться создать список со всеми этими элементами вы скоро исчерпаете доступный память и вылет программы.Но это еще умнее! Это вычисление работает просто отлично, потому что объект диапазона — это просто обещание создать элементы если и когда они понадобятся. Как только условие в if становится истинным, нет генерируются дополнительные элементы, и функция возвращается. (Примечание: до Python 3 ассортимент не поленился. Если вы используете более ранние версии Python, YMMV!)
YMMV: ваш пробег может отличаться
Аббревиатура YMMV означает , ваш пробег может отличаться от .
 Американская реклама автомобилей
часто приводятся цифры расхода топлива для автомобилей, например.грамм. что они получат 28 миль за
галлон. Но это всегда должно было сопровождаться легальным мелким шрифтом.
предупреждая читателя, что они могут не получить то же самое. Термин YMMV теперь используется
идиоматически означать «ваши результаты могут отличаться»,
например Время автономной работы в этом телефоне 3 дня, но YMMV.
Американская реклама автомобилей
часто приводятся цифры расхода топлива для автомобилей, например.грамм. что они получат 28 миль за
галлон. Но это всегда должно было сопровождаться легальным мелким шрифтом.
предупреждая читателя, что они могут не получить то же самое. Термин YMMV теперь используется
идиоматически означать «ваши результаты могут отличаться»,
например Время автономной работы в этом телефоне 3 дня, но YMMV. Иногда можно встретить ленивый диапазон, заключенный в вызов списка. Это заставляет Python, чтобы превратить ленивое обещание в реальный список:
>>> range (10) # Создаем ленивое обещание диапазон (0, 10) >>> list (range (10)) # Вызов обещания для создания списка.[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
19.11. Вложенные списки
Вложенный список — это список, который появляется как элемент другого списка. В этом list элемент с индексом 3 является вложенным списком:
>>> nested = ["привет", 2.
 0, 5, [10, 20]]
0, 5, [10, 20]]
Если мы выведем элемент с индексом 3, мы получим:
>>> печать (вложенный [3]) [10, 20]
Чтобы извлечь элемент из вложенного списка, мы можем выполнить два шага:
>>> elem = nested [3] >>> элем [0] 10
Или мы можем объединить их:
Операторы скобок вычисляются слева направо, поэтому это выражение получает 3-й элемент вложенного и извлекает из него 1-й элемент.
11.20. Матрицы
Вложенные списки часто используются для представления матриц. Например, матрица:
можно представить как:
>>> mx = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
mx — это список из трех элементов, где каждый элемент является строкой матрица. Обычным способом мы можем выделить целую строку из матрицы:
Или мы можем извлечь один элемент из матрицы, используя форму с двойным индексом:
Первый индекс выбирает строку, а второй индекс выбирает столбец.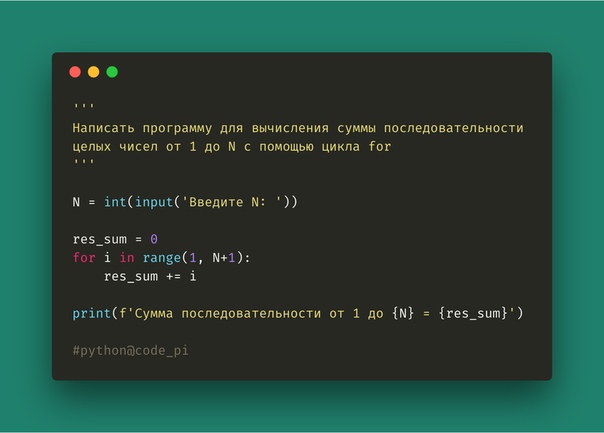 Хотя такой способ представления матриц распространен, это не единственный
возможность. Небольшой вариант — использовать список столбцов вместо списка
ряды. Позже мы увидим более радикальную альтернативу с использованием словаря.
Хотя такой способ представления матриц распространен, это не единственный
возможность. Небольшой вариант — использовать список столбцов вместо списка
ряды. Позже мы увидим более радикальную альтернативу с использованием словаря.
11.21. Глоссарий
- псевдонимов
- Несколько переменных, содержащих ссылки на один и тот же объект.
- клон
- Для создания нового объекта, имеющего то же значение, что и существующий объект. Копирование ссылки на объект создает псевдоним, но не клонирует объект.
- разделитель
- Символ или строка, используемые для указания места разделения строки.
- элемент
- Одно из значений в списке (или другой последовательности). Оператор скобок выбирает элементы списка. Также называется товар .
- неизменное значение данных
- Значение данных, которое нельзя изменить. Присвоения элементам или
срезы (части) неизменяемых значений вызывают ошибку времени выполнения.
- индекс
- Целочисленное значение, указывающее позицию элемента в списке.Индексы начинаются с 0.
- товар
- См. Элемент .
- список
- Набор значений, каждое из которых находится в фиксированной позиции в списке. Как и другие типы str, int, float и т. Д., Существует также функция преобразователя типов списка, которая пытается преобразовать любой аргумент вы вносите это в список.
- обход списка
- Последовательный доступ к каждому элементу списка.
- модификатор
- Функция, которая изменяет свои аргументы внутри тела функции.Только изменяемые типы могут быть изменены модификаторами.
- значение изменяемых данных
- Значение данных, которое можно изменить. Типы всех изменяемых значений являются составными типами. Списки и словари изменяемы; струны а кортежи — нет.
- вложенный список
- Список, который является элементом другого списка.
- объект
- Вещь, на которую может ссылаться переменная.
- узор
- Последовательность утверждений или стиль кодирования чего-то, что имеет общая применимость в ряде различных ситуаций.Часть стать зрелым компьютерным ученым — значит изучить и установить шаблоны и алгоритмы, составляющие ваш инструментарий. Выкройки часто соответствуют вашим «мысленным фрагментам».
- обещание
- Объект, который обещает выполнить некоторую работу или предоставить некоторые ценности, если в конечном итоге они нужны, но это сразу же откладывает выполнение работы. Диапазон звонков дает обещание.
- чистая функция
- Функция, не имеющая побочных эффектов. Только чистые функции вносят изменения вызывающей программе через их возвращаемые значения.
- последовательность
- Любой из типов данных, которые состоят из упорядоченного набора элементов с каждый элемент идентифицируется индексом.
- побочный эффект
- Изменение состояния программы, вызванное вызовом функции. Сторона
эффекты могут быть произведены только модификаторами.
- размер шага
- Интервал между последовательными элементами линейной последовательности. В третий (и необязательный аргумент) функции диапазона называется размер шага. Если не указано, по умолчанию используется 1.

11.22. Упражнения
Как интерпретатор Python отвечает на следующее?
>>> список (диапазон (10, 0, -2))
Три аргумента функции range : start , stop и step , соответственно. В этом примере начало больше, чем остановка. Что происходит, если start
Рассмотрим этот фрагмент кода:
импортная черепаха tess = черепаха.Черепаха () Алекс = Тесс alex.color ("горячий розовый")Создает ли этот фрагмент одну или две черепахи? Имеет ли установка цвет алекса тоже меняет цвет тесс? Объясните подробно.
Нарисуйте снимок состояния для a и b до и после третьей строки выполняется следующий код Python:
a = [1, 2, 3] б = а [:] б [0] = 5
Что будет на выходе следующей программы?
this = [«я», «я», «не», «а», «мошенник»] that = ["я", "я", "не", "а", "мошенник"] print ("Тест 1: {0}".формат (это то)) это = это print ("Тест 2: {0}". формат (это тот))Предоставьте подробное описание результатов.
Списки могут использоваться для представления математических векторов . В этом упражнении и несколько, которые последуют за вами, напишут функции для выполнения стандартных операции над векторами. Создайте скрипт с именем vectors.py и напишите код Python для прохождения тестов в каждом случае.
Напишите функцию add_vectors (u, v), которая принимает два списка номеров той же длины и возвращает новый список, содержащий суммы соответствующие элементы каждого:
тест (add_vectors ([1, 1], [1, 1]) == [2, 2]) test (add_vectors ([1, 2], [1, 4]) == [2, 6]) test (add_vectors ([1, 2, 1], [1, 4, 3]) == [2, 6, 4])
Напишите функцию scalar_mult (s, v), которая принимает число, s и list, v и возвращает скалярное кратное v на s.
:тест (scalar_mult (5, [1, 2]) == [5, 10]) тест (scalar_mult (3, [1, 0, -1]) == [3, 0, -3]) test (scalar_mult (7, [3, 0, 5, 11, 2]) == [21, 0, 35, 77, 14])
Напишите функцию dot_product (u, v), которая принимает два списка номеров одинаковой длины и возвращает сумму произведений соответствующих элементы каждого (dot_product).
тест (dot_product ([1, 1], [1, 1]) == 2) тест (dot_product ([1, 2], [1, 4]) == 9) test (dot_product ([1, 2, 1], [1, 4, 3]) == 12)
Дополнительная задача для математически склонного : написать функцию cross_product (u, v), который принимает два списка чисел длиной 3 и возвращает их перекрестное произведение.Вам следует напишите свои собственные тесты.
Опишите связь между «» .join (song.split ()) и песня во фрагменте кода ниже.
Они одинаковы для всех струн, назначенных песне?
Когда они будут другими?song = "Дождь в Испании ..."
Напишите функцию replace (s, old, new), которая заменяет все вхождения старый с новым в строке s:
test (заменить ("Mississippi", "i", "I") == "MIssIssIppI") s = "Я люблю спом! Спом - моя любимая еда.Spom, spom, yum! " test (replace (s, "om", "am") == «Я люблю спам! Спам - моя любимая еда. Спам, спам, конфетка!») test (replace (s, "o", "a") == «Я люблю спам! Спам - мой любимый фаворит. Спам, спам, конфетка!»)Совет : используйте методы разделения и соединения.
Предположим, вы хотите поменять местами значения двух переменных. Вам решать чтобы учесть это в функции многократного использования, и напишите этот код:
def swap (x, y): # Неверная версия print ("перед оператором обмена: x:", x, "y:", y) (х, у) = (у, х) print ("после оператора обмена: x:", x, "y:", y) a = ["Это", "это", "весело"] b = [2,3,4] print ("перед вызовом функции подкачки: a:", a, "b:", b) своп (а, б) print ("после вызова функции подкачки: a:", a, "b:", b)Запустите эту программу и опишите результаты.
 :
: Они одинаковы для всех струн, назначенных песне?
Когда они будут другими?
Они одинаковы для всех струн, назначенных песне?
Когда они будут другими?