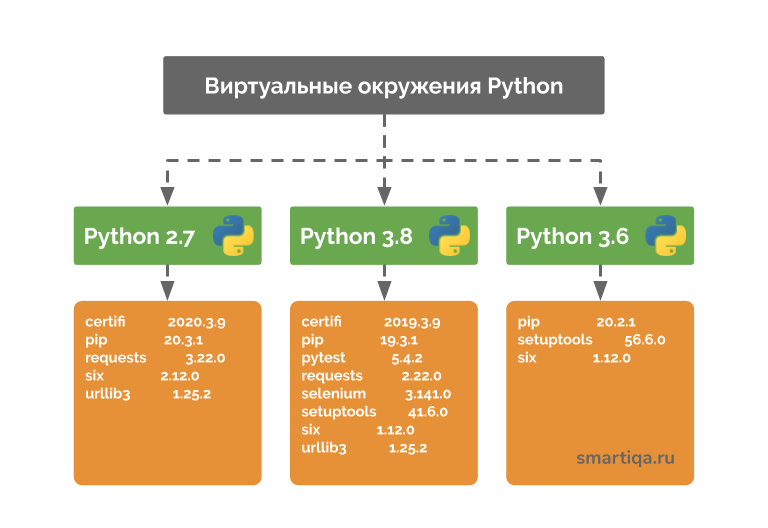
Модуль re в Python, функции регулярных выражений.
Модуль re предоставляет операции сопоставления шаблонов регулярных выражений, аналогичные тем, которые встречаются в языке Perl.
Новое в Python 3.11: Механизм сопоставления регулярных выражений модуля
reбыл частично переработан и теперь использует вычисляемые переходы (или «поточный код«) на поддерживаемых платформах. В результате Python 3.11 выполняет тесты регулярных выраженийpyperformanceна 10% быстрее, чем Python 3.10.
Шаблоны регулярных выражений и строки для поиска могут быть как Unicode strings, так и 8-битными строками . Однако строки Unicode и 8-битные строки не могут быть смешаны. То есть вы не можете сопоставить строку Unicode с байтовым шаблоном регулярного выражения или наоборот. Аналогично, при замене на основе регулярного выражения строка замены должна быть того же типа, что и регулярное выражение и строка поиска.
Регулярные выражения используют символ обратной косой черты '\', чтобы указать специальные формы или разрешить использование специальных символов, используемых в шаблонах поиска без вызова их специального значения. Это противоречит использованию в Python одного и того же символа для той же цели в строковых литералах. Например, чтобы сопоставить обратную косую черту литерала '\', может потребоваться записать '\\\\' как строку шаблона поиска, потому что регулярное выражение должно быть \\, и каждая обратная косая черта должна быть выражена как \\ внутри обычного строкового литерала Python.
Решение заключается в использовании необработанной строковой нотации Python для шаблонов регулярных выражений. Обратная косая черта не обрабатывается особым образом в строковом литерале с префиксом 'r'. Так что r"\n" это двухсимвольная строка, содержащая '\' и 'n', в то время как "\n" односимвольная строка, содержащая новую строку. Обычно шаблоны поиска будут выражаться в коде Python с использованием этой необработанной строковой записи.
Обычно шаблоны поиска будут выражаться в коде Python с использованием этой необработанной строковой записи.
Важно отметить, что большинство операций с регулярными выражениями доступны как функции и методы уровня модуля для скомпилированных регулярных выражений. Функции модуля re не требуют, чтобы вы сначала компилировали объект регулярного выражения, но не допускают некоторые параметры тонкой настройки шаблона для поиска регулярного выражения.
Синтаксис регулярных выражений в Python.
Регулярные выражения могут быть объединены для формирования новых регулярных выражений; если A и B оба являются регулярными выражениями, то AB также является регулярным выражением. Большинство обычных символов, таких как ‘A’, ‘a’или ‘0’, являются простейшими регулярными выражениями; они просто соот
Функция compile() модуля re в Python.
Функция compile() модуля re компилирует шаблон регулярного выражения pattern в объект регулярного выражения, который может быть использован для поиска совпадений
Флаги, используемые в функции re.
 compile() в Python.
compile() в Python.Флаги, используемые для компиляции регулярного выражения.
Функция search() модуля re в Python.
Функция search() модуля re сканирует строку string в поисках первого совпадения с шаблоном pattern регулярного выражения и возвращает соответствующий объект соответствия
Функция match() модуля re в Python.
Функция match() модуля re вернуть соответствующий объект сопоставления, если ноль или более символов в начале строки string соответствуют шаблону регулярного выражения pattern.
Функция fullmatch() модуля re в Python.
Функция fullmatch() модуля re вернет объект сопоставления, если вся строка string соответствует шаблону регулярного выражения pattern.
Функция finditer() модуля re в Python.
Функция finditer() модуля re возвращает итератор объектов сопоставления по всем неперекрывающимся совпадениям для шаблона регулярного выражения в строке.
Функция split() модуля re в Python.
Функция `split()` модуля `re` делит строку по появлению шаблона регулярного выражения `pattern` и возвращает список получившихся подстрок.
Функция findall() модуля re в Python.
Функция findall() модуля re возвращает все неперекрывающиеся совпадения шаблона pattern в строке string в виде списка строк. Строка сканируется слева направо, и совпадения возвращаются в найденном порядке.
Функция sub() модуля re в Python.
Функция sub() модуля re возвращает строку, полученную путем замены крайнего левого неперекрывающегося вхождения шаблона регулярного выражения pattern в строке string на строку замены repl. Если шаблон регулярного выражения не найден, строка возвращается без изменений.
Функция subn() модуля re в Python.
Функция subn() модуля re выполняет ту же операцию, что и функция sub(), но возвращает кортеж (new_string, number_of_subs_made)
Функция escape() модуля re в Python.
Функция `escape()` модуля `re` выполняет экранирование специальных символов в шаблоне. Это полезно, если требуется сопоставить произвольную строку литерала, которая может содержать метасимволы регулярных выражений
Функция purge() модуля re в Python.
Функция `purge()` модуля `re` очищает кэш от регулярных выражений.
Исключение error() модуля re в Python.
Исключение `error()` модуля `re` возникает, когда строка, переданная одной из функций модуля, не является допустимым регулярным выражением, например шаблон может содержать несоответствующие скобки или когда возникает какая-либо другая ошибка во время компиляции шаблона или сопоставления со строкой.
Объект регулярного выражения Pattern модуля re в Python.
Объект регулярного выражения Pattern получается в результате компиляции шаблона регулярного выражения. Скомпилированные объекты регулярных выражений поддерживают рассмотренные ниже методы и атрибуты.
Объект совпадения с шаблоном Match модуля re в Python.
Объект сопоставления регулярного выражения со строкой всегда имеет логическое значение True. Можно проверить, было ли совпадение, с помощью простого утверждения if…else. Объекты сопоставления поддерживают методы и атрибуты.
Документация по модулю Re для Python 3 на русском ~ PythonRu
Регулярные выражения — специальная последовательность символов, которая помогает сопоставлять или находить строки python с использованием специализированного синтаксиса, содержащегося в шаблоне.
Регулярные выражения распространены в мире UNIX.
 Регулярные выражения распространены в мире UNIX.
Регулярные выражения распространены в мире UNIX.Модуль re предоставляет полную поддержку выражениям, подобным Perl в Python. Модуль re поднимает исключение re.error, если возникает ошибка при компиляции или использовании регулярного выражения.
Давайте рассмотрим две функции, которые будут использоваться для обработки регулярных выражений. Важно так же заметить, что существуют символы, которые меняют свое значение, когда используются в регулярном выражении.Чтобы избежать путаницы при работе с регулярными выражениями, записывайте строку как r'expression'.
Функция match
Эта функция ищет pattern в string и поддерживает настройки с помощью дополнительного flags.
Ниже можно увидеть синтаксис данной функции:
re.match(pattern, string, flags=0)
Описание параметров:
| № | Параметр & Описание |
|---|---|
| 1 | pattern — строка регулярного выражения (r'g.) |
| 2 | string — строка, в которой мы будем искать соответствие с шаблоном в начале строки ('google') |
| 3 | flags — модификаторы, перечисленными в таблице ниже. Вы можете указать разные флаги с помощью побитового OR |
 {3}le'
{3}le'Функция re.match возвращает объект match при успешном завершении, или None при ошибке. Мы используем функцию groups() объекта match для получения результатов поиска.
| № | Метод совпадения объектов и описание |
|---|---|
| 1 | group(num=0) — этот метод возвращает полное совпадение (или совпадение конкретной подгруппы) |
| 2 | groups() — этот метод возвращает все найденные подгруппы в tuple |
Пример функции re.match
import re title = "Error 404.
 Page not found"
exemple = re.match( r'(.*)\. (.*?) .*', title, re.M|re.I)
if exemple:
print("exemple.group() : ", exemple.group())
print("exemple.group(1) : ", exemple.group(1))
print("exemple.group(2) : ", exemple.group(2))
print("exemple.groups():", exemple.groups())
else:
print("Нет совпадений!")
Page not found"
exemple = re.match( r'(.*)\. (.*?) .*', title, re.M|re.I)
if exemple:
print("exemple.group() : ", exemple.group())
print("exemple.group(1) : ", exemple.group(1))
print("exemple.group(2) : ", exemple.group(2))
print("exemple.groups():", exemple.groups())
else:
print("Нет совпадений!")
Когда вышеуказанный код выполняется, он производит следующий результат:
exemple.group(): Error 404. Page not found
exemple.group(1): Error 404
exemple.group(2): Page
exemple.groups(): ('Error 404', 'Page')
Функция search
Эта функция выполняет поиск первого вхождения pattern внутри string с дополнительным flags.
Пример синтаксиса для этой функции:
re.search(pattern, string, flags=0)
Описание параметров:
| № | Параметр & Описание |
|---|---|
| 1 | pattern — строка регулярного выражения |
| 2 | string — строка, в которой мы будем искать первое соответствие с шаблоном |
| 3 | flags — модификаторы, перечисленными в таблице ниже. Вы можете указать разные флаги с помощью побитового OR Вы можете указать разные флаги с помощью побитового OR |
Функция re.search возвращает объект match если совпадение найдено, и None, когда нет совпадений. Используйте функцию groups() объекта match для получения результата функции.
| № | Способы совпадения объектов и описание |
|---|---|
| 1 | group(num=0) — метод, который возвращает полное совпадение (или же совпадение конкретной подгруппы) |
| 2 | groups() — метод возвращает все сопоставимые подгруппы в tuple |
Пример функции re.search
import re
title = "Error 404. Page not found"
# добавим пробел в начало паттерна
exemple = re.search( r' (.*)\. (.*?) .*', title, re.M|re.I)
if exemple:
print("exemple.group():", exemple.group())
print("exemple.group(1):", exemple.group(1))
print("exemple. group(2):", exemple.group(2))
print("exemple.groups():", exemple.groups())
else:
print("Нет совпадений!")

Запускаем скрипт и получаем следующий результат:
exemple.group(): 404. Page not found
exemple.group(1): 404
exemple.group(2): Page
exemple.groups(): ('404', 'Page')
Match и Search
Python предлагает две разные примитивные операции, основанные на регулярных выражениях: match выполняет поиск паттерна в начале строки, тогда как search выполняет поиск по всей строке.
Пример разницы re.match и re.search
import re
title = "Error 404. Page not found"
match_exemple = re.match( r'not', title, re.M|re.I)
if match_exemple:
print("match --> match_exemple.group():", match_exemple.group())
else:
print("Нет совпадений!")
search_exemple = re.search( r'not', title, re.M|re.I)
if search_exemple:
print("search --> search_exemple.group():", search_exemple.group())
else:
print("Нет совпадений!")
Когда этот код выполняется, он производит следующий результат:
Нет совпадений! search --> search_exemple.
 group(): not
group(): not
Метод Sub
Одним из наиболее важных методов модуля re, которые используют регулярные выражения, является re.sub.
Пример синтаксиса sub:
re.sub(pattern, repl, string, max=0)
Этот метод заменяет все вхождения pattern в string на repl, если не указано на max. Он возвращает измененную строку.
Пример
import re
born = "05-03-1987 # Дата рождения"
# Удалим комментарий из строки
dob = re.sub(r'#.*$', "", born)
print("Дата рождения:", dob)
# Заменим дефисы на точки
f_dob = re.sub(r'-', ".", born)
print(f_dob)
Запускаем скрипт и получаем вывод:
Дата рождения: 05-03-1987 05.03.1987 # Дата рождения
Модификаторы регулярных выражений: flags
Функции регулярных выражений включают необязательный модификатор для управления изменения условий поиска. Модификаторы задают в необязательном параметре flags. Несколько модификаторов задают с помощью побитового ИЛИ (|), как показано в примерах выше. 4fw] — соответствует любому символу, кроме тех, что в квадратных скобках.
4fw] — соответствует любому символу, кроме тех, что в квадратных скобках.


Примеры регулярных выражений
Поиск по буквам
python – находит “python”. |
Поиск по наборам символов
| № | Паттерн & Результаты |
|---|---|
| 1 | [Pp]ython соответствует “Python” и “python” |
| 2 | rub[ye] соответствует “ruby” и “rube” |
| 3 | [aeiou] Соответствует любой гласной нижнего регистра английского алфавита ([ауоыиэяюёе] для русского) |
| 4 | [0-9] соответствует любой цифре; так же как и [0123456789] |
| 5 | [a-z] соответствует любой строчной букве ASCII (для кириллицы [а-яё]) |
| 6 | [A-Z] соответствует любой прописной букве ASCII (для кириллицы [А-ЯЁ]) |
| 7 | [a-zA-Z0-9] соответствует всем цифрам и буквам |
| 8 | [^aeiou] соответствует всем символам, кроме строчной гласной |
| 9 | [^0-9] Соответствует всем символам, кроме цифр |
Специальные классы символов
| № | Пример & Описание |
|---|---|
| 1 | . A-Za-z0-9_] A-Za-z0-9_] |
Случаи повторения
| № | Примеры |
|---|---|
| 1 | ruby? совпадает с “rub” и “ruby”: “y” необязателен |
| 2 | ruby* совпадает с “rub” и “rubyyyyy”: “y” необязателен и может повторятся несколько раз |
| 3 | ruby+ совпадает с “ruby”: “y” обязателен |
| 4 | \d{3} совпадает с тремя цифрами подряд |
| 5 | \d{3,} совпадает с тремя и более цифрами подряд |
| 6 | \d{3,5} совпадает с 3,4,5 цифрами подряд |
Жадный поиск
| № | Пример & Описание |
|---|---|
| 1 | Жадное повторение: соответствует “perl>” |
| 2 | Ленивый поиск: соответствует “” в “perl>” |
Группирование со скобками
| № | Пример & Описание |
|---|---|
| 1 | \D\d+ Нет группы: + относится только к \d |
| 2 | (\D\d)+ Группа: + относится к паре \D\d |
| 3 | ([Pp]ython(, )?)+ соответствует “Python”, “Python, python, python”. Python соответствует “Python” в начале текста или новой строки текста. Python соответствует “Python” в начале текста или новой строки текста. |
| 2 | Python$ соответствует “Python” в конце текста или строки текста. |
| 3 | \APython соответствует “Python” в начале текста |
| 4 | Python\Z соответствует “Python” в конце текста |
| 5 | \bPython\b соответствует “Python” как отдельному слову |
| 6 | \brub\B соответствует «rub» в начале слова: «rube» и «ruby». |
| 7 | Python(?=!) соответствует “Python”, если за ним следует восклицательный знак. |
| 8 | Python(?!!) соответствует “Python”, если за ним не следует восклицательный знак |
Специальный синтаксис в группах
| № | Пример & Описание |
|---|---|
| 1 | R(?#comment) соответствует «R». Все, что следует дальше — комментарий Все, что следует дальше — комментарий |
| 2 | R(?i)uby нечувствительный к регистру при поиске “uby” |
| 3 | R(?i:uby) аналогично указанному выше |
| 4 | rub(?:y le)) группируется только без создания обратной ссылки (\1) |
Python RegEx
❮ Предыдущий Далее ❯
Регулярное выражение или регулярное выражение представляет собой последовательность символов, образующую шаблон поиска.
RegEx можно использовать для проверки наличия в строке указанного шаблона поиска.
Модуль регулярных выражений
Python имеет встроенный пакет re , который можно использовать для работы с
Обычные выражения.
Импорт модуля re :
import re
RegEx в Python 9The.*Spain$», txt)
Попробуйте сами »
Функции регулярных выражений
Модуль re предлагает набор функций, который позволяет
нам искать строку для совпадения:
| Функция | Описание |
|---|---|
| находка | Возвращает список, содержащий все совпадения |
| поиск | Возвращает объект Match, если в строке есть совпадение. |
| сплит | Возвращает список, в котором строка была разделена при каждом совпадении |
| суб | Заменяет одно или несколько совпадений строкой |
Метасимволы
Метасимволы — это символы со специальным значением:
| Символ | Описание | Пример | Попробуйте | |
|---|---|---|---|---|
| [] | Набор символов | «[днём]» | Попробуй » 9привет» | Попробуй » |
| $ | Заканчивается на | «планета$» | Попробуй » | |
| * | Ноль или более вхождений | «хе.*о» | Попробуй » | |
| + | Одно или несколько вхождений | «хе.+о» | Попробуй » | |
| ? | Ноль или одно вхождение | «хе.?о» | Попробуй » | |
| {} | Ровно указанное количество вхождений | «он. {2}о» {2}о» | Попробуй » | |
| | | Либо, либо | «падает|остается» | Попробуй » | |
| () | Захват и группировка |
Специальные последовательности
Специальная последовательность представляет собой \ , за которой следует один из символов из списка ниже, и имеет особое значение:
| Символ | Описание | Пример | Попробуйте |
|---|---|---|---|
| \А | Возвращает совпадение, если указанные символы находятся в начале строка | «\А» | Попробуй » |
| \б | Возвращает совпадение, в котором указанные символы находятся в начале или в конце
конец слова («r» в начале означает, что строка обрабатывается как «необработанная строка») | r»\bain» r»ain\b» | Попробуй » Попробуй » |
| \В | Возвращает совпадение, в котором присутствуют указанные символы, но НЕ в начале
(или в
конец) слова («r» в начале означает, что строка обрабатывается как «необработанная строка») | r»\Bain» r»ain\B» | Попробуй » Попробуй » |
| \д | Возвращает совпадение, в котором строка содержит цифры (числа от 0 до 9). ) | «\ д» | Попробуй » |
| \Д | Возвращает совпадение, в котором строка НЕ содержит цифр | «\Д» | Попробуй » |
| \с | Возвращает совпадение, в котором строка содержит символ пробела | «\с» | Попробуй » |
| \С | Возвращает совпадение, в котором строка НЕ содержит символ пробела | «\С» | Попробуй » |
| \ш | Возвращает совпадение, в котором строка содержит любые символы слова (символы из от a до Z, цифры от 0 до 9 и символ подчеркивания _) | «\ш» | Попробуй » |
| \Вт | Возвращает совпадение, в котором строка НЕ содержит символов слова | «\W» | Попробуй » |
| \З | Возвращает совпадение, если указанные символы находятся в конце строки | «Испания\Z» | Попробуй » |
Наборы
Набор — это набор символов, заключенных в пару квадратных скобок [] со специальным значением:
| Набор | Описание | Попробуйте |
|---|---|---|
| [арен] | Возвращает совпадение, в котором один из указанных символов ( a , r или n ) есть
подарок | Попробуй » |
| [а-н] 9арн] | Возвращает совпадение для любого символа, КРОМЕ a , р и н | Попробуй » |
| [0123] | Возвращает совпадение, в котором любая из указанных цифр ( 0 , 1 , 2 или 3 ) являются
подарок | Попробуй » |
| [0-9] | Возвращает совпадение любой цифры между 0 и 9 | Попробуй » |
| [0-5][0-9] | Возвращает совпадение любых двузначных чисел из 00 и . | Попробуй » |
| [a-zA-Z] | Возвращает совпадение любого символа в алфавитном порядке между a и z , нижний регистр ИЛИ верхний регистр | Попробуй » |
| [+] | В наборах, +, *, . , | , () , $ , {} не имеет особого значения, поэтому [+] означает: вернуть совпадение для любого + символов в строке | Попробуй » |
 59
59
Функция findall()
Функция findall() возвращает список, содержащий все совпадения.
Пример
Распечатать список всех совпадений:
import re
txt = «Дождь в Испании»
x = re.findall(«ai»,
txt)
печать(x)
Попробуйте сами »
Список содержит совпадения в порядке их обнаружения.
Если совпадений не найдено, возвращается пустой список:
Пример
Возврат пустого списка, если совпадений не найдено:
import re
txt = «Дождь в Испании»
x = re.findall(«Португалия»,
txt)
print(x)
Попробуйте сами »
Функция search()
Функция search() выполняет поиск строки
для совпадения и возвращает объект Match, если есть
соответствовать.
Если имеется более одного совпадения, будет возвращено только первое совпадение:
Пример
Поиск первого символа пробела в строке:
import re
txt = «Дождь в Испании»
x = re.search(«\s»,
txt)
print(«Первый пробел находится в position:», x.start())
Попробуйте сами »
Если совпадений не найдено, возвращается значение Нет :
Пример
Сделать поиск, который не дает совпадений:
import re
txt = «Дождь в Испании»
x = re. search(«Португалия»,
txt)
search(«Португалия»,
txt)
print(x)
Попробуйте сами »
Функция split()
Функция split() возвращает список, в котором
строка была разделена при каждом совпадении:
Пример
Разделена при каждом пробеле:
import re
txt = «Дождь в Испании»
х = re.split(«\s»,
txt)
print(x)
Попробуйте сами »
Вы можете управлять количеством вхождений, указав макссплит параметр:
Пример
Разделить строку только при первом вхождении:
import re
txt = «Дождь в Испании»
x = re.split(«\s»,
текст,
1)
print(x)
Попробуйте сами »
Функция sub()
Функция sub() 9Функция 0014 заменяет совпадения на
текст на ваш выбор:
Пример
Замените каждый пробел цифрой 9:
import re
txt = "Дождь в Испании"
x = re. sub("\s",
"9", txt)
sub("\s",
"9", txt)
print(x)
Попробуйте сами »
Вы можете контролировать количество замен, указав количество параметр:
Пример
Замените первые 2 вхождения:
импорт повторно
txt = "Дождь в Испании"
x = re.sub("\s",
"9", txt, 2)
print(x)
Попробуйте сами »
Match Object
Match Object — это объект, содержащий информацию о поиске и результате.
Примечание: Если совпадений нет, значение None будет
возвращается вместо Match Object.
Пример
Выполните поиск, который вернет объект соответствия:
импорт повторно
txt = "Дождь в Испании"
x = re.search("ai",
txt)
print(x) #this напечатает объект
Попробуйте сами »
Объект Match имеет свойства и методы, используемые для получения информации о поиске и результате:
. возвращает кортеж, содержащий начальную и конечную позиции совпадения.  span()
span()
.string возвращает строку, переданную в функцию
.group() возвращает часть строки, где было совпадение
Пример
Вывести положение (начальное и конечное положение) первого совпадения.
Регулярное выражение ищет любые слова, начинающиеся с прописной буквы "С":
import re
txt = "Дождь в Испании"
x = re.search(r"\bS\w+", txt)
print( x.span() )
Попробуйте сами »
Пример
Вывести строку, переданную в функцию:
import re
txt = "Дождь в Испании"
x = re.search(r"\bS\w+", txt)
print( x.string )
Попробуйте сами »
Пример
Вывести часть строки, в которой было совпадение.
Регулярное выражение ищет любые слова, начинающиеся с прописной буквы "С":
import re
txt = "Дождь в Испании"
x = re.search(r"\bS\w+", txt)
print( x.group() )
Попробуйте сами »
Примечание : Если совпадений нет, значение 9а...с$
абс псевдоним бездна Псевдоним Счеты Python имеет модуль с именем re для работы с RegEx. Вот пример: 9а…с$’
test_string = ‘бездна’
результат = re.match (шаблон, тестовая_строка)
если результат:
print(«Поиск успешен.»)
еще:
print(«Поиск не удался.»)
Здесь мы использовали функцию re. для поиска шаблона в пределах test_string . Метод возвращает объект соответствия, если поиск успешен. Если нет, возвращается  match()
match() None .
В модуле re определены несколько других функций для работы с RegEx. Прежде чем мы исследуем это, давайте узнаем о самих регулярных выражениях. 9 $ * + ? {} () \ |
[] — Квадратные скобки
Квадратные скобки определяют набор символов, которые вы хотите сопоставить.
| Выражение | Строка | Совпало? |
|---|---|---|
[абв] | и | 1 совпадение |
ак | 2 спички | |
Эй, Джуд | Нет соответствия | |
абв де ка | 5 спичек |
Здесь [abc] будет соответствовать, если строка, которую вы пытаетесь сопоставить, содержит любой из a , b или c .
Вы также можете указать диапазон символов, используя - в квадратных скобках. 90-9] означает любой нецифровой символ.
. — Точка
Точка соответствует любому одиночному символу (кроме новой строки '\n' ).
| Выражение | Строка | Совпало? |
|---|---|---|
.. | и | Нет соответствия |
ак | 1 совпадение | абв | 1 совпадение |
акб | Нет совпадений (начинается с a , но не сопровождается b ) |
$ — Доллар
Символ доллара $ используется для проверки того, заканчивается ли строка на определенным символом.
| Выражение | Строка | Совпало? |
|---|---|---|
$ | и | 1 совпадение |
формула | 1 совпадение | |
кабина | Нет соответствия |
* — Звезда
Символ звезды * соответствует нулю или более вхождений оставшегося шаблона.
| Выражение | Строка | Совпало? |
|---|---|---|
основной | мин | 1 совпадение |
мужчина | 1 совпадение | |
маан | 1 совпадение | |
основной | Нет соответствия (за и не следует n ) | |
женщина | 1 совпадение |
+ — Плюс
Символ плюс + соответствует одному или нескольким вхождениям оставшегося шаблона.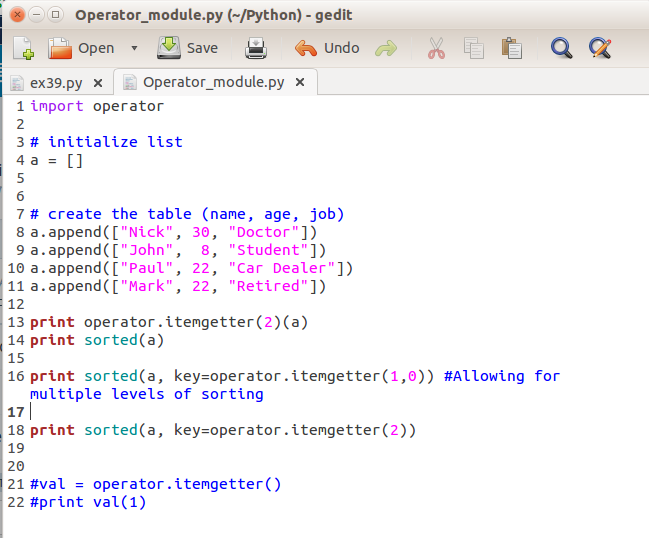
| Выражение | Строка | Совпало? |
|---|---|---|
м+н | мин | Нет соответствия (без символ ) |
мужчина | 1 совпадение | |
маан | 1 совпадение | |
основной | Нет совпадений (за a не следует n) | |
женщина | 1 совпадение |
? — Знак вопроса
Знак вопроса ? соответствует нулю или одному вхождению оставшегося шаблона.
| Выражение | Строка | Совпало? |
|---|---|---|
основной | мин | 1 совпадение |
мужчина | 1 совпадение | |
маан | Нет совпадения (более одного символа и ) | |
основной | Нет совпадения (за a не следует n) | |
женщина | 1 совпадение |
{} — Скобы
Рассмотрим этот код: {n,m} . Это означает, что ему осталось не менее 90 726 n 90 727 и не более 90 726 m 90 727 повторений паттерна.
Это означает, что ему осталось не менее 90 726 n 90 727 и не более 90 726 m 90 727 повторений паттерна.
| Выражение | Строка | Совпало? |
|---|---|---|
а{2,3} | абв дат | Нет соответствия |
абв даат | 1 спичка ( d aa t ) | |
аабв дааат | 2 спички (at aa bc и d aaa t ) | |
аабв даааат | 2 спички (at aa bc и d aaa at ) |
Давайте попробуем еще один пример. Это регулярное выражение [0-9]{2, 4} соответствует как минимум 2 цифрам, но не более 4 цифрам
| Выражение | Строка | Совпало? |
|---|---|---|
[0-9]{2,4} | ab123csde | 1 совпадение (совпадение по адресу ab 123 csde ) |
12 и 345673 | 3 совпадения ( 12 , 3456 , 73 ) | |
1 и 2 | Нет соответствия |
| — Чередование
Вертикальная перекладина | Для чередования используется (оператор или ).
| Выражение | Строка | Совпало? |
|---|---|---|
а|б | Код | Нет соответствия |
аде | 1 совпадение (совпадение по и по ) | |
акдбеа | 3 спички ( a cd b e a ) |
Здесь a|b соответствует любой строке, содержащей либо a , либо b
() — Group
30014 используется для группировки подшаблонов. Например,
(a|b|c)xz соответствует любой строке, которая соответствует либо a , либо b , либо c , за которыми следует xz | Выражение | Строка | Совпало? |
|---|---|---|
(a|b|c)xz | аб хз | Нет соответствия |
абхз | 1 совпадение (совпадение на а бхз ) | |
аксз кабксз | 2 совпадения (at axz bc ca bxz ) |
\ — Обратная косая черта
Обратная косая черта \ используется для экранирования различных символов, включая все метасимволы. Например,
Например,
\$a соответствует, если строка содержит $ , за которыми следует a . Здесь $ не интерпретируется движком RegEx особым образом.
Если вы не уверены, имеет ли символ особое значение или нет, вы можете поставить перед ним \. Это гарантирует, что с персонажем не обращаются особым образом.
Специальные последовательности
Специальные последовательности упрощают запись часто используемых шаблонов. Вот список специальных последовательностей:
\A — Соответствует, если указанные символы находятся в начале строки.
| Выражение | Строка | Совпало? |
|---|---|---|
\Athe | солнце | Матч |
На солнце | Нет соответствия |
\b — Соответствует, если указанные символы находятся в начале или в конце слова.
| Выражение | Строка | Совпало? |
|---|---|---|
\bfoo | футбольный мяч | Матч |
футбольный мяч | Матч | |
футбол | Нет соответствия | |
foo\b | фу | Матч |
тест афу | Матч | |
самый нижний | Нет соответствия |
\B — Напротив \b . Соответствует, если указанные символы равны , а не в начале или конце слова.
| Выражение | Строка | Совпало? |
|---|---|---|
\Bfoo | футбольный мяч | Нет соответствия |
футбольный мяч | Нет совпадения | |
футбол | Матч | |
foo\B | фу | Нет соответствия |
тест афу | Нет соответствия | |
самый нижний | Матч |
\d — соответствует любой десятичной цифре.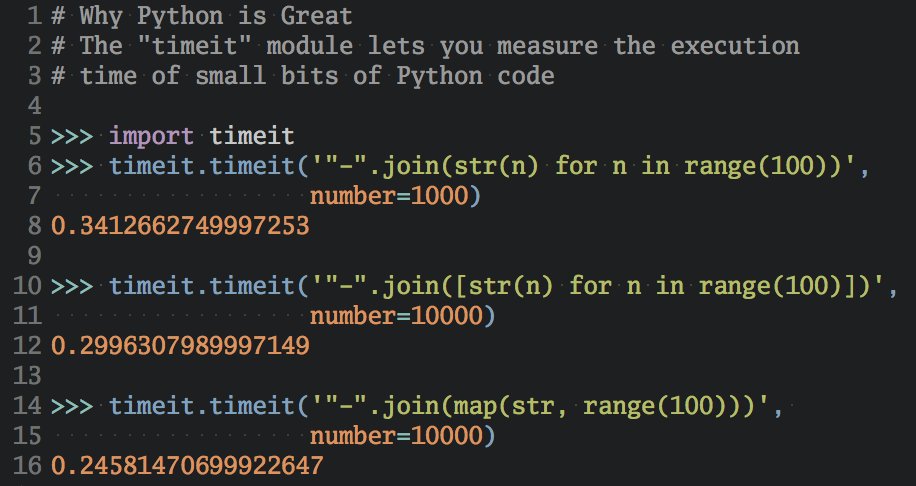 Эквивалент
Эквивалент [0-9]
| Выражение | Строка | Совпало? |
|---|---|---|
\Д | 1ab34"50 | 3 совпадения (в 1 аб 34 " 50 ) |
1345 | Нет соответствия |
\s — Соответствует строкам, содержащим любой пробельный символ. Эквивалент 9\t\n\r\f\v] .
| Выражение | Строка | Совпало? |
|---|---|---|
\С | а б | 2 спички (по a b ) |
| Нет соответствия |
\w — Соответствует любому буквенно-цифровому символу (цифры и буквы). Эквивалент
Эквивалент [a-zA-Z0-9_] . Кстати, подчеркивание _ тоже считается буквенно-цифровым символом.
| Выражение | Строка | Совпало? |
|---|---|---|
\ш | 12"": ;c | 3 совпадения (в 12 &": ; c ) |
%"> ! | Нет соответствия |
| Выражение | Строка | Совпало? |
|---|---|---|
\Вт | 1а2%с | 1 совпадение (в 1 a 2 % c ) |
Питон | Нет соответствия |
\Z — Соответствует, если указанные символы находятся в конце строки.
| Выражение | Строка | Совпало? |
|---|---|---|
Python\Z | Мне нравится Python | 1 совпадение |
Мне нравится программировать на Python | Нет соответствия | |
Python — это весело. | Нет соответствия |
Совет: Для создания и тестирования регулярных выражений можно использовать инструменты проверки регулярных выражений, такие как regex101. Этот инструмент не только поможет вам в создании регулярных выражений, но и поможет вам изучить их.
Теперь вы понимаете основы RegEx, давайте обсудим, как использовать RegEx в вашем коде Python.
Python RegEx
Python имеет модуль с именем re для работы с регулярными выражениями. Чтобы использовать его, нам нужно импортировать модуль.
Чтобы использовать его, нам нужно импортировать модуль.
import re
Модуль определяет несколько функций и констант для работы с RegEx.
re.findall()
Метод re.findall() возвращает список строк, содержащих все совпадения.
Пример 1: re.findall()
# Программа для извлечения чисел из строки импортировать повторно строка = 'привет 12 привет 89. Привет 34' шаблон = '\d+' результат = re.findall (шаблон, строка) печать (результат) # Вывод: ['12', '89', '34']
Если шаблон не найден, re.findall() возвращает пустой список.
re.split()
Метод re.split разбивает строку, в которой есть совпадение, и возвращает список строк, в которых произошло разбиение.
Пример 2: re.split()
импортировать повторно строка = 'Двенадцать:12 восемьдесят девять:89.' шаблон = '\d+' результат = re.split (шаблон, строка) печать (результат) # Вывод: ['Двенадцать:', ' Восемьдесят девять:', '.
 ']
']
Если шаблон не найден, re.split() возвращает список, содержащий исходную строку.
Вы можете передать аргумент maxsplit методу re.split() . Это максимальное количество расщеплений, которое может произойти.
импортировать повторно строка = 'Двенадцать:12 восемьдесят девять:89Девять: 9». шаблон = '\d+' # макссплит = 1 # разбить только при первом вхождении результат = re.split (шаблон, строка, 1) печать (результат) # Вывод: ['Двенадцать:', ' Восемьдесят девять:89 Девять:9.']
Кстати, значение по умолчанию maxsplit равно 0; что означает все возможные расщепления.
re.sub()
Синтаксис re.sub() :
re.sub(шаблон, замена, строка)
Метод возвращает строку, в которой совпадающие вхождения заменяются содержимым заменяет переменную .
Пример 3: re.sub()
# Программа для удаления всех пробелов импортировать повторно # многострочная строка строка = 'абв 12\ де 23 \н ф45 6' # соответствует всем пробельным символам шаблон = '\s+' # пустая строка заменить = '' new_string = re.
 sub (шаблон, замена, строка)
печать (новая_строка)
# Вывод: abc12de23f456
sub (шаблон, замена, строка)
печать (новая_строка)
# Вывод: abc12de23f456
Если шаблон не найден, re.sub() возвращает исходную строку.
Вы можете передать count в качестве четвертого параметра в метод re.sub() . Если его опустить, результатом будет 0. Это заменит все вхождения.
импортировать повторно # многострочная строка строка = 'абв 12\ де 23 \н ф45 6' # соответствует всем пробельным символам шаблон = '\s+' заменить = '' new_string = re.sub(r'\s+', заменить, строка, 1) печать (новая_строка) # Выход: # abc12de 23 # ф45 6
re.subn()
Функция re.subn() аналогична re.sub() , за исключением того, что она возвращает кортеж из двух элементов, содержащих новую строку и количество произведенных замен.
Пример 4: re.subn()
# Программа для удаления всех пробелов импортировать повторно # многострочная строка строка = 'абв 12\ де 23 \н ф45 6' # соответствует всем пробельным символам шаблон = '\s+' # пустая строка заменить = '' new_string = re.
 subn (шаблон, замена, строка)
печать (новая_строка)
# Вывод: ('abc12de23f456', 4)
subn (шаблон, замена, строка)
печать (новая_строка)
# Вывод: ('abc12de23f456', 4)
re.search()
Метод re.search() принимает два аргумента: шаблон и строку. Метод ищет первое место, где шаблон RegEx создает совпадение со строкой.
Если поиск успешен, re.search() возвращает объект соответствия; если нет, возвращается None .
match = re.search(pattern, str)
Пример 5: re.search()
импортировать повторно
string = "Питон - это весело"
# проверить, стоит ли 'Python' в начале
match = re.search('\APython', строка)
если совпадают:
print("Шаблон найден внутри строки")
еще:
print("шаблон не найден")
# Вывод: шаблон найден внутри строки
Здесь совпадение содержит объект соответствия.
Объект соответствия
Вы можете получить методы и атрибуты объекта совпадения, используя функцию dir().
Некоторые из часто используемых методов и атрибутов объектов соответствия:
match.
 group()
group() Метод group() возвращает часть строки, в которой есть совпадение.
Пример 6: Подбор объекта
импортировать повторно
строка = '39801 356, 2102 1111'
# Трехзначное число, за которым следует пробел, за которым следует двузначное число
шаблон = '(\d{3}) (\d{2})'
# переменная match содержит объект Match.
match = re.search(шаблон, строка)
если совпадают:
печать (совпадение.группа())
еще:
print("шаблон не найден")
# Вывод: 801 35
Здесь match переменная содержит объект match.
Наш шаблон (\d{3}) (\d{2}) имеет две подгруппы (\d{3}) и (\d{2}) . Вы можете получить часть строки этих подгрупп в скобках. Вот как:
>>> match.group(1) «801» >>> match.group(2) '35' >>> match.group(1, 2) («801», «35») >>> match.groups() («801», «35»)
match.start(), match.end() и match.span()
Функция start() возвращает индекс начала совпадающей подстроки. Аналогично,
Аналогично, end() возвращает конечный индекс совпадающей подстроки.
>>> match.start() 2 >>> match.end() 8
Функция span() возвращает кортеж, содержащий начальный и конечный индексы совпадающей части.
>>> match.span() (2, 8)
match.re и match.string
Атрибут re совпадающего объекта возвращает объект регулярного выражения. Точно так же string атрибут возвращает переданную строку.
>>> match.re
re.compile('(\\d{3}) (\\d{2})')
>>> match.string
'39801 356, 2102 1111'
Мы рассмотрели все часто используемые методы, определенные в модуле re . Если вы хотите узнать больше, посетите модуль Python 3 re.
Использование префикса r перед регулярным выражением
Когда префикс r или R используется перед регулярным выражением, это означает необработанную строку. Например, '\n' — это новая строка, тогда как r'\n' означает два символа: обратную косую черту \ , за которой следует n .