Python и базы данных | Получение данных из БД PostgreSQL
Последнее обновление: 25.11.2022
Для получения данных применяется SQL-команда SELECT. После выполнения этой команды курсор получает данные, которые можно получить с помощью одного из методов:
fetchall() (возвращает список со всеми строками), fetchmany() (возвращает указанное количество строк) и
fetchone() (возвращает одну в наборе строку). Рассмотрим получение данных на примере следующей таблицы
CREATE TABLE people (id SERIAL PRIMARY KEY, name VARCHAR(50), age INTEGER)
INSERT INTO people (name, age) VALUES ('Tom', 38)
INSERT INTO people (name, age) VALUES ('Bob', 42)
INSERT INTO people (name, age) VALUES ('Sam', 28)
INSERT INTO people (name, age) VALUES ('Alice', 33)
INSERT INTO people (name, age) VALUES ('Kate', 25)
Получение всех строк
Например, получим все ранее добавленные данные из таблицы people:
import psycopg2 conn = psycopg2.connect(dbname="metanit", user="postgres", password="123456", host="127.0.0.1") cursor = conn.cursor() # получаем все данные из таблицы people cursor.execute("SELECT * FROM people") print(cursor.fetchall()) cursor.close() conn.close()

При выполнении этой программы на консоль будет выведен список строк, где каждая строка представляет кортеж:
[(1, 'Tom', 38), (2, 'Bob', 42), (3, 'Sam', 28), (4, 'Alice', 33), (5, 'Kate', 25)]
При необходимости мы можем перебрать список, используя стандартные циклические конструкции:
import psycopg2
conn = psycopg2.connect(dbname="metanit", user="postgres", password="123456", host="127.0.0.1")
cursor = conn.cursor()
cursor.execute("SELECT * FROM people")
for person in cursor.fetchall():
print(f"{person[1]} - {person[2]}")
cursor.close()
conn.close()
Результат работы программы:
Tom - 38 Bob - 42 Sam - 28 Alice - 33 Kate - 25
Стоит отметить, что в примере выше необязательно вызывать метод fetchall, мы можем перебрать курсор в цикле как обычный набор:
for person in cursor:
print(f"{person[1]} - {person[2]}")
Получение части строк
Получение части строк с помощью метода fetchmany(), в который передается количество строк:
import psycopg2 conn = psycopg2.connect(dbname="metanit", user="postgres", password="123456", host="127.0.0.1") cursor = conn.cursor() cursor.execute("SELECT * FROM people") # извлекаем первые 3 строки в полученном наборе print(cursor.fetchmany(3)) cursor.close() conn.close()

Результат работы программы:
[(1, 'Tom', 38), (2, 'Bob', 42), (3, 'Sam', 28)]
Выполнение этого метода извлекает следующие ранее неизвлеченные строки:
# извлекаем первые 3 строки в полученном наборе print(cursor.fetchmany(3)) # [(1, 'Tom', 38), (2, 'Bob', 42), (3, 'Sam', 28)] # извлекаем следующие 3 строки в полученном наборе print(cursor.fetchmany(3)) # [(4, 'Alice', 33), (5, 'Kate', 25)]
Получение одной строки
Метод fetchone() извлекает следующую строку в виде кортежа значений и возвращает его. Если строк больше нет, то возвращает None:
import psycopg2 conn = psycopg2.connect(dbname="metanit", user="postgres", password="123456", host="127.0.0.1") cursor = conn.cursor() cursor.execute("SELECT * FROM people") # извлекаем одну строку print(cursor.fetchone()) # (1, 'Tom', 38) cursor.close() conn.close()
 0.0.1")
cursor = conn.cursor()
cursor.execute("SELECT * FROM people")
# извлекаем одну строку
print(cursor.fetchone()) # (1, 'Tom', 38)
cursor.close()
conn.close()
0.0.1")
cursor = conn.cursor()
cursor.execute("SELECT * FROM people")
# извлекаем одну строку
print(cursor.fetchone()) # (1, 'Tom', 38)
cursor.close()
conn.close()
Данный метод удобно применять, когда нам надо извлечь из базы данных только один объект:
import psycopg2;
conn = psycopg2.connect("metanit.db")
cursor = conn.cursor()
cursor.execute("SELECT name, age FROM people WHERE id=2")
# раскладываем кортеж на две переменных
name, age = cursor.fetchone()
print(f"Name: {name} Age: {age}") # Name: Bob Age: 42
Здесь получаем из бд строку с id=2, и полученный результат раскладываем на две переменных name и age (так как кортеж в Python можно разложить на отдельные значения)
НазадСодержаниеВперед
Python и базы данных | Модуль psycopg. Подключение к серверу PostgreSQL
Последнее обновление: 25.11.2022
Одной из наиболее популярных реляционных систем баз данных является PostgreSQL. Рассмотрим, как работать с базами данных PostgreSQL в приложении на языке Python.
Рассмотрим, как работать с базами данных PostgreSQL в приложении на языке Python.
Перед началом работы естественно должна быть установлена сама PostgreSQL. Про установку PostgreSQL можно прочитать в соответствующей статье Установка сервера PostgreSQL.
Стандартные библиотеки Python не предоставляют встроенного функционала для работы с PostgreSQL, однако есть большое количество сторонних библиотек. Наиболее популярной из них является Psycopg 2 (официальный сайт Psycopg). Данная библиотека реализована на языке C, благодаря чему обладает сравнительно большой производительностью.
Установка psycopg
Для установки выполним в терминале следующую команду:
pip install psycopg2
После этого мы можем импортировать библиотеку в программе на Python:
import psycopg2
Подключение к серверу PostgreSQL
Для подключения к серверу PostgreSQL применяется функция connect(). Она принимает настройки подключения:
psycopg2.connect(dbname="db_name", host="db_host", user="db_user", password="db_pass", port="db_port")
Функция принимает следующие параметры:
dbname: имя базы данныхuser: имя пользователяpassword: пароль пользователяhost: хост/адрес сервераport: порт (если не указано, то используется порт по умолчанию — 5432)
При удачном подключении функция connect создает новую сессию базы данных и возвращает объект connection
Класс connection предоставляет ряд методов для работы с подключением к БД:
close(): закрывает подключениеcursor(): возвращает объект cursor для осуществления запросов к бдcommit(): поддверждает транзакциюrollback(): откатывает транзакцию
Например, покдлючимся к стандартной базе данных «postgres» на локальном сервере PostgreSQL:
import psycopg2 conn = psycopg2.connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1", port="5432") print("Подключение установлено") conn.close()

В данном случае подключение идет для встроенного пользователя по умолчанию «postgres».
Курсор и операции с данными
Метод cursor() объекта connection возвращает курсор — объект cursor, через который можно отправлять запросы к базе данных. Для этого класс cursor предоставляет ряд методов:
execute(query, vars=None): выполняет одну SQL-инструкцию. Через второй параметр в код SQL можно передать набор параметров в виде списка или словаряexecutemany(query, vars_list): выполняет параметризованное SQL-инструкцию. Через второй параметр принимает наборы значений, которые передаются в выполняемый код SQL.callproc(procname[, parameters]): выполняет хранимую функцию. Через второй параметр можно передать набор параметров в виде списка или словаряmogrify(operation[, parameters]): возвращает код запроса SQL после привязки параметровfetchone(): возвращает следующую строку из полученного из БД набора строк в виде кортежа.fetchmany([size=cursor.arraysize]): возвращает набор строк в виде списка. количество возвращаемых строк передается через параметр. Если больше строк нет в наборе, то возвращается пустой список.fetchall(): возвращает все (оставшиеся) строки в виде списка. При отсутствии строк возвращается пустой список.scroll(value[, mode='relative']): перемещает курсор в наборе на позицию value в соответствии с режимом mode.

Определение курсора:
import psycopg2 conn = psycopg2.connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1") cursor = conn.cursor() cursor.close() # закрываем курсор conn.close() # закрываем подключение
Закрытие подключения и курсора
Стоит отметить, что оба объекта — connection и cursor могут использоваться как менеджеры контекста. То есть с помощью выражения with
определить контекста. Однако если объект cursor по завершению закрывается, то объект connection НЕ закрывается:
То есть с помощью выражения with
определить контекста. Однако если объект cursor по завершению закрывается, то объект connection НЕ закрывается:
import psycopg2
conn = psycopg2.connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1", port="5432")
with conn:
with conn.cursor() as cursor:
print("Подключение установлено")
print(cursor.closed) # True - курсор закрыт
# cursor.close() # нет смысла - объект cursor уже закрыт
conn.close() # объект conn не закрыт, надо закрывать
Модель выполнения запросов
Перед выполнением первой команды SQL автоматически создается транзакция, в процессе которой можно выполнять различные выражения SQL с помощью методов execute/executemany курсора, но для
подтверждения их выполнения необходимо вызывать метод commit() объекта connection. Условно это может выглядеть так:
import psycopg2 conn = psycopg2.
 connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1")
cursor = conn.cursor()
cursor.execute(sql1)
conn.commit() # реальное выполнение команд sql1
cursor.close()
conn.close()
connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1")
cursor = conn.cursor()
cursor.execute(sql1)
conn.commit() # реальное выполнение команд sql1
cursor.close()
conn.close()
Здесь реальное выполнение условной команды sql1 производится только при выполнении метода conn.commit().
Если же надо, чтобы выражения sql автоматически выполнялись при каждом вызове метода cursor.execute(), то можно установить автокоммит с помощью свойства connection.autocommit:
import psycopg2 conn = psycopg2.connect(dbname="postgres", user="postgres", password="123456", host="127.0.0.1") conn.autocommit = True # устанавливаем актокоммит cursor = conn.cursor() cursor.execute(sql1) # непосредственное выполнение команды sql1 cursor.close() conn.close()
НазадСодержаниеВперед
Программирование баз данных на Python | Основы
Каждая организация, от строительной фирмы до фондовой биржи, зависит от больших баз данных. По сути, это наборы таблиц, связанные друг с другом столбцами. Эти системы баз данных поддерживают SQL, язык структурированных запросов, который используется для создания данных, доступа к ним и управления ими. SQL используется для доступа к данным, а также для создания и использования взаимосвязей между хранимыми данными. Кроме того, эти базы данных поддерживают правила нормализации базы данных, чтобы избежать избыточности данных. Язык программирования Python обладает мощными функциями для программирования баз данных. Python поддерживает различные базы данных, такие как MySQL, Oracle, Sybase, PostgreSQL и т. д. Python также поддерживает язык определения данных (DDL), язык манипулирования данными (DML) и операторы запроса данных. Для программирования баз данных Python DB API является широко используемым модулем, который предоставляет интерфейс программирования приложений для баз данных.
По сути, это наборы таблиц, связанные друг с другом столбцами. Эти системы баз данных поддерживают SQL, язык структурированных запросов, который используется для создания данных, доступа к ним и управления ими. SQL используется для доступа к данным, а также для создания и использования взаимосвязей между хранимыми данными. Кроме того, эти базы данных поддерживают правила нормализации базы данных, чтобы избежать избыточности данных. Язык программирования Python обладает мощными функциями для программирования баз данных. Python поддерживает различные базы данных, такие как MySQL, Oracle, Sybase, PostgreSQL и т. д. Python также поддерживает язык определения данных (DDL), язык манипулирования данными (DML) и операторы запроса данных. Для программирования баз данных Python DB API является широко используемым модулем, который предоставляет интерфейс программирования приложений для баз данных.
Преимущества Python для программирования баз данных
Есть много причин использовать Python для программирования приложений баз данных:
- Программирование на Python, возможно, более эффективно и быстро по сравнению с другими языками.
- Python славится своей мобильностью.
- Не зависит от платформы.
- Python поддерживает курсоры SQL.
- Во многих языках программирования разработчику приложения необходимо позаботиться об открытых и закрытых соединениях с базой данных, чтобы избежать дальнейших исключений и ошибок. В Python об этих соединениях заботятся.
- Python поддерживает системы реляционных баз данных.
- API-интерфейсы базы данных Python совместимы с различными базами данных, поэтому очень легко мигрировать и портировать интерфейсы приложений баз данных.

DB-API (SQL-API) для Python
Python DB-API не зависит от какого-либо механизма базы данных, что позволяет писать сценарии Python для доступа к любому механизму базы данных. Реализация Python DB API для MySQL — MySQLdb. Для PostgreSQL он поддерживает модули psycopg, PyGresQL и pyPgSQL. Реализациями DB-API для Oracle являются dc_oracle2 и cx_oracle. Pydb2 — это реализация DB-API для DB2. DB-API Python состоит из объектов подключения, объектов курсора, стандартных исключений и некоторого другого содержимого модулей, которые мы обсудим.
DB-API Python состоит из объектов подключения, объектов курсора, стандартных исключений и некоторого другого содержимого модулей, которые мы обсудим.
Объекты соединения
Объекты соединения создают соединение с базой данных и в дальнейшем используются для различных транзакций. Эти объекты соединения также используются как представители сеанса базы данных.
Соединение создается следующим образом:
>>>conn = MySQLdb.connect('library', user='suhas', password='python') Вы можете использовать объект соединения для вызова таких методов, как commit( ), rollback() и close(), как показано ниже:
>>>cur = conn.cursor() // создает новый объект курсора для выполнения операторов SQL >>>conn.commit() // Фиксирует транзакции >>>conn.rollback() //Откатить транзакции >>>conn.close() //закрывает соединение >>>conn.callproc(proc,param) //вызов хранимой процедуры для выполнения >>>conn.getsource(proc) // извлекает код хранимой процедуры
Объекты курсора
Курсор — одна из мощных функций SQL. Это объекты, которые отвечают за отправку различных операторов SQL на сервер базы данных. В 9 есть несколько классов курсоров0043 MySQLdb.cursors :
Это объекты, которые отвечают за отправку различных операторов SQL на сервер базы данных. В 9 есть несколько классов курсоров0043 MySQLdb.cursors :
-
BaseCursor— это базовый класс для объектов Cursor. -
Курсор— класс курсора по умолчанию.CursorWarningMixIn,CursorStoreResultMixIn,CursorTupleRowsMixInиBaseCursor— это некоторые компоненты классакурсора. -
CursorStoreResultMixInиспользует функциюmysql_store_result()для извлечения наборов результатов из выполненного запроса. Эти наборы результатов хранятся на стороне клиента. -
CursorUseResultMixInиспользует функциюmysql_use_result()для извлечения наборов результатов из выполненного запроса. Эти наборы результатов хранятся на стороне сервера.
В следующем примере показано выполнение команд SQL с использованием объектов курсора. Вы можете использовать execute для выполнения команд SQL, таких как
Вы можете использовать execute для выполнения команд SQL, таких как SELECT . Чтобы зафиксировать все операции SQL, вам нужно закрыть курсор как cursor.close() .
>>>cursor.execute('ВЫБЕРИТЕ * ИЗ книг')
>>>cursor.execute('''SELECT * FROM books WHERE book_name = 'python' AND book_author = 'Mark Lutz' )
>>>cursor.close() Обработка ошибок и исключений в DB-API
Обработка исключений в модуле Python DB-API очень проста. Мы можем размещать предупреждения и сообщения об ошибках в программах. Python DB-API имеет различные варианты для обработки этого, например Warning , InterfaceError , DatabaseError , IntegrityError , InternalError , NotSupportedError , OperationalError и ProgrammingError .
Давайте рассмотрим их один за другим:
- IntegrityError: Давайте подробно рассмотрим ошибку целостности. В следующем примере мы попытаемся ввести повторяющиеся записи в базу данных. Он покажет ошибку целостности
_mysql_exceptions.IntegrityError, как показано ниже:>>> cursor.execute('вставить значения книг (%s,%s,%s,%s)',('Py9098','Programming With Perl',120,100)) Traceback (последний последний вызов): Файл "", строка 1, в ? Файл "/usr/lib/python2.3/site-packages/MySQLdb/cursors.py", строка 95, в исполнении вернуть self._execute (запрос, аргументы) Файл "/usr/lib/python2.3/site-packages/MySQLdb/cursors.py", строка 114, в _execute self.errorhandler (я, отл, значение) поднять класс ошибки, значение ошибки _mysql_exceptions.IntegrityError: (1062, «Повторяющаяся запись« Py9098 »для ключа 1») - OperationalError: если есть какие-либо ошибки операции, такие как отсутствие выбранных баз данных, Python DB-API обработает эту ошибку как
OperationalError, как показано ниже:>>> cursor.execute('Создать библиотеку базы данных') >>> q='выберите имя из книг, где стоимость>=%s в порядке имени' >>>cursor. execute(q,[50])
Traceback (последний последний вызов):
Файл "", строка 1, в ? Файл "/usr/lib/python2.3/site-packages/MySQLdb/cursors.py", строка 95, в исполнении вернуть self._execute (запрос, аргументы) Файл "/usr/lib/python2.3/site-packages/MySQLdb/cursors.py", строка 114, в _execute self.errorhandler (я, отл, значение) Файл "/usr/lib/python2.3/site-packages/MySQLdb/connections.py", строка 33, в defaulterrorhandler поднять класс ошибки, значение ошибки _mysql_exceptions.OperationalError: (1046, «База данных не выбрана») - ProgrammingError: если есть какие-либо ошибки программирования, такие как дублирование создания базы данных, Python DB-API обработает эту ошибку как
ProgrammingError, как показано ниже:>>> cursor.execute('Создать библиотеку базы данных') Traceback (последний последний вызов):>>> cursor.execute('Создать библиотеку базы данных') Traceback (последний последний вызов): Файл "", строка 1, в ? Файл "/usr/lib/python2. 3/site-packages/MySQLdb/cursors.py", строка 95, выполняется
вернуть self._execute (запрос, аргументы)
Файл "/usr/lib/python2.3/site-packages/MySQLdb/cursors.py", строка 114, в _execute
self.errorhandler (я, отл, значение)
Файл "/usr/lib/python2.3/site-packages/MySQLdb/connections.py", строка 33, в defaulterrorhandler
поднять класс ошибки, значение ошибки
_mysql_exceptions.ProgrammingError: (1007, "Не удается создать базу данных "Библиотека". База данных существует")
 Он покажет ошибку целостности
Он покажет ошибку целостности  execute(q,[50])
Traceback (последний последний вызов):
Файл "
execute(q,[50])
Traceback (последний последний вызов):
Файл " 3/site-packages/MySQLdb/cursors.py", строка 95, выполняется
вернуть self._execute (запрос, аргументы)
Файл "/usr/lib/python2.3/site-packages/MySQLdb/cursors.py", строка 114, в _execute
self.errorhandler (я, отл, значение)
Файл "/usr/lib/python2.3/site-packages/MySQLdb/connections.py", строка 33, в defaulterrorhandler
поднять класс ошибки, значение ошибки
_mysql_exceptions.ProgrammingError: (1007, "Не удается создать базу данных "Библиотека". База данных существует")
3/site-packages/MySQLdb/cursors.py", строка 95, выполняется
вернуть self._execute (запрос, аргументы)
Файл "/usr/lib/python2.3/site-packages/MySQLdb/cursors.py", строка 114, в _execute
self.errorhandler (я, отл, значение)
Файл "/usr/lib/python2.3/site-packages/MySQLdb/connections.py", строка 33, в defaulterrorhandler
поднять класс ошибки, значение ошибки
_mysql_exceptions.ProgrammingError: (1007, "Не удается создать базу данных "Библиотека". База данных существует") Python и MySQL
Python и MySQL — хорошее сочетание для разработки приложений баз данных. После запуска службы MySQL в Linux вам необходимо приобрести MySQLdb, Python DB-API для MySQL, чтобы выполнять операции с базой данных. Вы можете проверить, установлен ли модуль MySQLdb в вашей системе, с помощью следующей команды:
>>>import MySQLdb
Если эта команда выполнена успешно, теперь вы можете начать писать сценарии для своей базы данных.
Чтобы написать приложения базы данных на Python, необходимо выполнить пять шагов:
- Импортируйте интерфейс SQL с помощью следующей команды:
>>> импортировать MySQLdb
- Установите соединение с базой данных с помощью следующей команды:
>>> conn=MySQLdb.
connect(host='localhost',user='root',passwd='') …где
хост— это имя вашего хост-компьютера, за которым следуют имя пользователя и пароль. В случае рута пароль вводить не нужно. - Создайте курсор для подключения с помощью следующей команды:
>>>курсор = соединение.курсор()
- Выполните любой запрос SQL, используя этот курсор, как показано ниже — здесь выходные данные в терминах 1L или 2L показывают количество строк, затронутых этим запросом:
>>> cursor.execute('Создать библиотеку базы данных') 1L // 1L Указывает, сколько строк затронуто >>> cursor.execute('использовать библиотеку') >>>table='создать таблицу books(book_accno char(30) первичный ключ, book_name char(50),no_of_copies int(5),price int(5))' >>> курсор.выполнить(таблица) 0л - Наконец, извлеките набор результатов и выполните итерацию по этому набору результатов. На этом шаге пользователь может получить наборы результатов, как показано ниже:
>>> cursor.
execute('выбрать * из книг')
2л
>>> курсор.fetchall()
(('Py9098', 'Программирование на Python', 100L, 50L), ('Py9099', 'Программирование на Python', 100L, 50L)) В этом примере функция fetchall() используется для выборки наборов результатов.
 connect(host='localhost',user='root',passwd='')
connect(host='localhost',user='root',passwd='')  execute('выбрать * из книг')
2л
>>> курсор.fetchall()
(('Py9098', 'Программирование на Python', 100L, 50L), ('Py9099', 'Программирование на Python', 100L, 50L))
execute('выбрать * из книг')
2л
>>> курсор.fetchall()
(('Py9098', 'Программирование на Python', 100L, 50L), ('Py9099', 'Программирование на Python', 100L, 50L)) Дополнительные операции SQL
Мы можем выполнять все операции SQL с помощью Python DB-API. Запросы на вставку, удаление, агрегирование и обновление можно проиллюстрировать следующим образом.
- Вставить запрос SQL
>>>cursor.execute('вставить значения книг (%s,%s,%s,%s)',('Py9098','Программирование на Python',100,50)) lL // Затронутые строки. >>> cursor.execute('Вставить значения книг (%s,%s,%s,%s)',('Py9099','Программирование на Python',100,50)) 1L // Затронутые строки.Если пользователь хочет вставить повторяющиеся записи для инвентарного номера книги, Python DB-API покажет ошибку, поскольку это первичный ключ. Следующий пример иллюстрирует это:
>>> cursor.execute('вставить значения книг (%s,%s,%s,%s)',('Py9099','Программирование на Python',100,50)) >>>cursor. execute('Вставить значения книг (%s,%s,%s,%s)',('Py9098','Программирование на Perl',120,100))
Traceback (последний последний вызов):
Файл "", строка 1, в ? Файл "/usr/lib/python2.3/site-packages/MySQLdb/cursors.py", строка 95, выполняется вернуть self._execute (запрос, аргументы) Файл "/usr/lib/python2.3/site-packages/MySQLdb/cursors.py", строка 114, в _execute self.errorhandler (я, отл, значение) Файл "/usr/lib/python2.3/site-packages/MySQLdb/connections.py", строка 33, в defaulterrorhandler поднять класс ошибки, значение ошибки _mysql_exceptions.IntegrityError: (1062, "Повторяющаяся запись" Py9098' для шпонки 1") - SQL-запрос на обновление можно использовать для обновления существующих записей в базе данных, как показано ниже:
>>> cursor.execute('обновить книги по цене=%s, где no_of_copies<=%s',[60,101]) 2л >>> cursor.execute('выбрать * из книг') 2л >>> курсор.fetchall() (('Py9098', 'Программирование на Python', 100L, 60L), ('Py9099', 'Программирование на Python', 100L, 60L)) - SQL-запрос на удаление можно использовать для удаления существующих записей в базе данных, как показано ниже:
>>> cursor.
execute('удалить из книг, где no_of_copies<=%s',[101])
2л
>>> cursor.execute('выбрать * из книг')
0л
>>> курсор.fetchall()
()
>>> cursor.execute('выбрать * из книг')
3л
>>> cursor.fetchall() (('Py9099', 'Python-Cookbook', 200L, 90L), ('Py9098', 'Программирование на Python', 100L, 50L), ('Py9097', 'Python-Nut ракушка, 300л, 80л)) - Агрегированные функции можно использовать с Python DB-API в базе данных, как показано ниже:
>>> cursor.execute('выбрать * из книг') 4л >>> курсор.fetchall() (('Py9099', 'Python-Cookbook', 200L, 90L), ('Py9098', 'Programming With Python', 100L, 50L), ('Py9097', 'Python-Nut shell', 300L, 80L), ("Py9096", "Python-Nut shell", 400 л, 90 л)) >>> cursor.execute("выберите сумму(цену),среднюю(цену) из книг, где book_name='Python-Nut shell'") 1л >>> курсор.fetchall() ((170,0, 85,0),)
 execute('Вставить значения книг (%s,%s,%s,%s)',('Py9098','Программирование на Perl',120,100))
Traceback (последний последний вызов):
Файл "
execute('Вставить значения книг (%s,%s,%s,%s)',('Py9098','Программирование на Perl',120,100))
Traceback (последний последний вызов):
Файл " execute('удалить из книг, где no_of_copies<=%s',[101])
2л
>>> cursor.execute('выбрать * из книг')
0л
>>> курсор.fetchall()
()
>>> cursor.execute('выбрать * из книг')
3л
>>> cursor.fetchall() (('Py9099', 'Python-Cookbook', 200L, 90L), ('Py9098', 'Программирование на Python', 100L, 50L), ('Py9097', 'Python-Nut ракушка, 300л, 80л))
execute('удалить из книг, где no_of_copies<=%s',[101])
2л
>>> cursor.execute('выбрать * из книг')
0л
>>> курсор.fetchall()
()
>>> cursor.execute('выбрать * из книг')
3л
>>> cursor.fetchall() (('Py9099', 'Python-Cookbook', 200L, 90L), ('Py9098', 'Программирование на Python', 100L, 50L), ('Py9097', 'Python-Nut ракушка, 300л, 80л)) Надеюсь, теперь вам понравятся возможности Python для программирования баз данных!
Ссылки
- Веб-сайт Python
- Programming Python Марк Лутц, O’Reilly Publications
- Доступ к базам данных с использованием Python DBAPI-2. 0 Федерико Ди Грегорио
 0 Федерико Ди Грегорио
0 Федерико Ди ГрегориоЭта статья была впервые опубликована 1 мая 2009 г. и недавно обновлена 10 апреля 2019 г.
Базы данных — Full Stack Python
файловая система операционной системы, которая делает разработчикам проще создавать приложения, которые создают, читают, обновляют и удалить постоянные данные.
Зачем нужны базы данных?
На высоком уровне веб-приложения хранят данные и представляют их пользователям в полезный способ. Например, Google хранит данные о дорогах и предоставляет направления, чтобы добраться из одного места в другое, проезжая через Приложение Карты. Направления движения возможно, потому что данные хранятся в структурированном формате.
Базы данных делают структурированное хранилище надежным и быстрым. Они также дают вам
ментальную основу для того, как данные должны быть сохранены и извлечены вместо
необходимость выяснять, что делать с данными каждый раз, когда вы создаете новый
приложение.
Базы данных — это концепция, имеющая множество реализаций, включая PostgreSQL, MySQL и SQLite. Также существуют нереляционные базы данных, называемые хранилищами данных NoSQL. Узнайте больше в главе о данных или просмотрите оглавление по всем темам.
Реляционные базы данных
Абстракция хранения базы данных, наиболее часто используемая в веб-разработке Python это наборы реляционных таблиц. Объясняются альтернативные абстракции хранения на странице NoSQL.
Реляционные базы данных хранят данные в виде набора таблиц. Соединения между таблицами указаны как внешние ключи . Внешний ключ — это уникальная ссылка из одной строки в реляционной таблице на другую строку в таблица, которая может быть одной и той же таблицей, но чаще всего другой таблицей.
Реализации хранения баз данных различаются по сложности. SQLite, база данных
включенный в Python, создает один файл для всех данных для каждой базы данных.
Другие базы данных, такие как PostgreSQL,
MySQL, Oracle и Microsoft SQL Server имеют больше
сложные схемы сохранения, предлагая дополнительные расширенные функции
которые полезны для хранения данных веб-приложений. Эти передовые
функции включают, но не ограничиваются:
Эти передовые
функции включают, но не ограничиваются:
- репликация данных между главной базой данных и одним или несколькими ведомыми только для чтения экземпляры
- расширенных типов столбцов, которые могут эффективно хранить полуструктурированные данные например, нотация объектов JavaScript (JSON)
- , что позволяет горизонтально масштабировать несколько баз данных, каждый служит экземпляром для чтения и записи за счет задержки в данных консистенция
- мониторинг, статистика и другая полезная информация о времени выполнения для схемы базы данных и таблицы
Обычно веб-приложения начинаются с одного экземпляра базы данных, например
как PostgreSQL с простой схемой. Со временем база данных
схема превращается в более сложную структуру с использованием миграции схемы и
расширенные функции, такие как репликация, сегментирование и мониторинг, становятся
более полезным, поскольку использование базы данных увеличивается в зависимости от приложения
потребности пользователей.
Наиболее распространенные базы данных для веб-приложений Python
PostgreSQL и MySQL являются двумя наиболее распространенными системами с открытым исходным кодом. базы данных для хранения данных веб-приложений Python.
SQLite — это база данных, которая хранится в одном файл на диске. SQLite встроен в Python, но создан только для доступа по одному соединению за раз. Поэтому настоятельно рекомендуется не запустить производственное веб-приложение с SQLite.
База данных PostgreSQL
PostgreSQL — рекомендуемая реляционная база данных для работы с Python веб-приложения. Набор функций PostgreSQL, активное развитие и стабильность способствовать его использованию в качестве серверной части для миллионов приложений в реальном времени в Сети сегодня.
Узнайте больше об использовании PostgreSQL с Python на Страница PostgreSQL.
База данных MySQL
MySQL — еще одна жизнеспособная реализация базы данных с открытым исходным кодом для Python. Приложения. MySQL имеет немного более легкую начальную кривую обучения, чем
PostgreSQL, но не такой многофункциональный.
Приложения. MySQL имеет немного более легкую начальную кривую обучения, чем
PostgreSQL, но не такой многофункциональный.
Узнайте о приложениях Python с поддержкой MySQL на выделенном Страница MySQL.
Подключение к базе данных с помощью Python
Для работы с реляционной базой данных с помощью Python необходимо использовать код библиотека. Наиболее распространенные библиотеки для реляционных баз данных:
психокопг (исходный код) для PostgreSQL.
MySQLdb (исходный код) для MySQL. Обратите внимание, что разработка этого драйвера в основном заморожена, поэтому оценка альтернативных драйверов имеет смысл, если вы используете MySQL в качестве бэкенда.
cx_Oracle для База данных Oracle (исходный код).
Поддержка SQLite встроена в Python 2.7+ и поэтому является отдельной библиотекой.
не обязательно. Просто «импортируйте sqlite3», чтобы начать взаимодействие с
единая файловая база данных.
Объектно-реляционное сопоставление
Объектно-реляционное сопоставление (ORM) позволяет разработчикам получать доступ к данным из backend, написав код Python вместо SQL-запросов. Каждая сеть Платформа приложения обрабатывает интеграцию ORM по-разному. есть целая страница по объектно-реляционному отображению (ORM), которые вы должны прочитать, чтобы разобраться в этом вопросе.
Сторонние службы баз данных
Многочисленные компании используют масштабируемые серверы баз данных в качестве размещенной службы. Размещенные базы данных часто могут обеспечивать автоматическое резервное копирование и восстановление, ужесточенные настройки безопасности и легкое вертикальное масштабирование в зависимости от провайдер.
Служба реляционных баз данных Amazon (RDS) предоставляет предварительно настроенные экземпляры MySQL и PostgreSQL. Экземпляры могут масштабироваться до больших или меньших конфигураций в зависимости от хранилища и производительности потребности.
Google Cloud SQL — это служба с управляемыми, резервными, реплицированными и автоматически исправляемыми экземплярами MySQL. Облако SQL интегрируется с Google App Engine, но может использоваться и независимо.
BitCan обеспечивает размещение как MySQL, так и MongoDB. базы данных с обширными службами резервного копирования.
ElephantSQL — компания, предлагающая программное обеспечение как услугу. который размещает базы данных PostgreSQL и обрабатывает конфигурацию сервера, резервное копирование и подключения к данным поверх экземпляров Amazon Web Services.
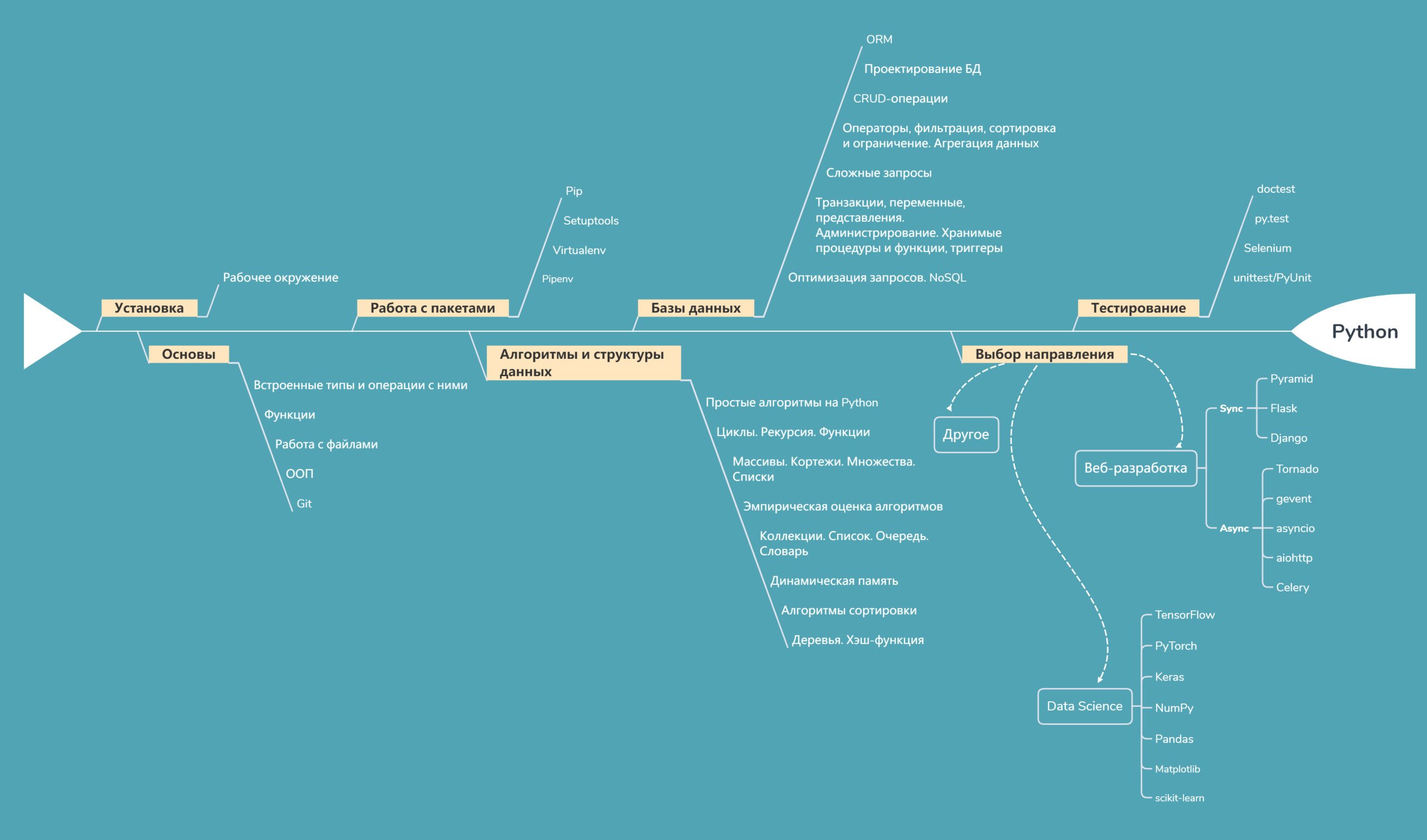
Ресурсы SQL
Возможно, вы планируете использовать
объектно-реляционный преобразователь (ORM)
как ваш основной способ взаимодействия с базой данных, но вы все равно должны
изучите основы SQL для создания схем и понимания кода SQL
генерируется ORM. Следующие ресурсы могут помочь вам подняться до
скорость на SQL, если вы никогда ранее не использовали его.
Select Star SQL — интерактивная книга для изучение SQL. Настоятельно рекомендуется, даже если вы чувствуете, что будете только работать с объектно-реляционным картографом на ваших проектах, потому что вы никогда не знаете, когда вам нужно будет заглянуть в SQL для улучшения низкой производительности сгенерированного запроса.
Руководство для начинающих по SQL хорошо объясняет основные ключевые слова, используемые в операторах SQL например,
ВЫБЕРИТЕ,ГДЕ,ИЗ,ОБНОВЛЕНИЕиУДАЛИТЬ.Учебное пособие по SQL обучает основам SQL, которые можно используется во всех основных реализациях реляционных баз данных.
Жизнь SQL-запроса объясняет, что происходит как концептуально, так и технически в базе данных при выполнении SQL-запроса. Автор использует PostgreSQL в качестве примера базы данных и синтаксиса SQL на протяжении всего поста.
Вероятно, неполное исчерпывающее руководство по многим различным способам соединения таблиц в SQL подробно описывает одну из самых сложных частей написания операторов SQL соединяющие одну или несколько таблиц:
ПРИСОЕДИНЯЙТЕСЬ.Написание более разборчивого SQL представляет собой краткое руководство по стилю кода, облегчающее чтение ваших запросов.
SQL Intermediate — это учебник, выходящий за рамки основ, который использует открытые данные из Бюро финансовой защиты потребителей США в качестве примеров для подсчета, запроса и использования представлений в PostgreSQL.

Общие ресурсы базы данных
Как работает реляционная база данных? подробный подробный пост о сортировке, поиске, слиянии и других операции, которые мы часто принимаем как должное при использовании установленного реляционного базы данных, такие как PostgreSQL.
Базы данных 101 дает отличный обзор основных концепций реляционной базы данных, который актуален даже не разработчикам в качестве введения.
Пять ошибок, которые допускают новички при работе с базами данных объясняет, почему вы не должны хранить изображения в базах данных, а также почему будьте осторожны с тем, как вы нормализуете свою схему.
DB-Engines — самые популярные системы управления базами данных.
DB Weekly — это еженедельный обзор общей базы данных. статьи и ресурсы.
Проектирование высокомасштабируемых архитектур баз данных охватывает горизонтальное и вертикальное масштабирование, репликацию и кэширование в реляционные архитектуры баз данных.
онлайн-миграции в масштабе отличное чтение о том, как разобраться в сложности схемы базы данных миграция для рабочей базы данных. Подход авторской команды использовался четырехэтапный шаблон двойного письма для тщательной разработки способа данные о подписках сохранялись, чтобы их можно было перенести на новый, более Эффективная модель хранения.
Универсальная база данных не подходит никому объясняет конкретное обоснование Amazon Web Services для того, чтобы иметь так много типов реляционных и нереляционных баз данных на своей платформе, но статья также является хорошим обзором различных моделей баз данных и вариантов их использования.
SQL исполнилось 43 года — вот 8 причин, по которым мы все еще используем его сегодня перечисляет, почему SQL обычно используется почти всеми разработчиками, даже если язык приближается к своему пятидесятилетию.
ключей SQL в глубину дает отличное объяснение того, что такое первичные ключи и как вы следует использовать их.
Изучение набора данных в SQL хороший пример того, как можно использовать только SQL для анализ данных. В этом руководстве используются данные Spotify чтобы показать, как извлечь то, что вы хотите узнать, из набора данных.
Стратегии тестирования интеграции баз данных охватывает сложную тему, которая возникает в каждом реальном проекте.
GitLab предоставили свои вскрытие сбоя базы данных 31 января как способ быть прозрачным для клиентов и помогать другим разработкам команды узнают, как они облажались со своими системами баз данных, а затем нашли способ выздороветь.
Асинхронный Python и базы данных — подробная статья, объясняющая, почему многие драйверы баз данных Python не могут использоваться без изменений из-за различий в блокировке и асинхронные событийные модели. Определенно стоит прочитать, если вы используете WebSockets через Tornado или gevent.
PostgreSQL против MS SQL Server — один из точки зрения на различия между двумя серверами баз данных с аналитик данных.



Контрольный список для изучения баз данных
Установите PostgreSQL на свой сервер. Предполагая, что вы пошли с запуском Ubuntu
sudo apt-get установить postgresql.Убедитесь, что библиотека psycopg находится в вашем зависимости приложения.
Настройте веб-приложение для подключения к экземпляру PostgreSQL.
Создавайте модели в ORM либо с помощью Django встроенный ORM или SQLAlchemy с Flask.
Создайте таблицы базы данных или синхронизируйте модели ORM с PostgreSQL.
