Строки. Урок 19 курса «Python. Введение в программирование»
Мы уже рассматривали строки как простой тип данных наряду с целыми и вещественными числами и знаем, что строка – это последовательность символов, заключенных в одинарные или двойные кавычки.
В Python нет символьного типа, т. е. типа данных, объектами которого являются одиночные символы. Однако язык позволяет рассматривать строки как объекты, состоящие из подстрок длинной в один и более символов. При этом, в отличие от списков, строки не принято относить к структурам данных. Видимо потому, что структуры данных состоят из более простых типов данных, а для строк в Python нет более простого (символьного) типа.
С другой стороны, строка, как и список, – это упорядоченная последовательность элементов. Следовательно, из нее можно извлекать отдельные символы и срезы.
>>> s = "Hello, World!" >>> s[0] 'H' >>> s[7:] 'World!' >>> s[::2] 'Hlo ol!'
 е. извлекается каждый второй символ. Примечание. Извлекать срезы с шагом также можно из списков.
е. извлекается каждый второй символ. Примечание. Извлекать срезы с шагом также можно из списков.Важным отличием от списков является неизменяемость строк в Python. Нельзя перезаписать какой-то отдельный символ или срез в строке:
>>> s[-1] = '.' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Интерпретатор сообщает, что объект типа str не поддерживает присвоение элементам.
Если требуется изменить строку, то следует создать новую из срезов старой:
>>> s = s[0:-1] + '.' >>> s 'Hello, World.'
В примере берется срез из исходной строки, соединяется с другой строкой. Получается новая строка, которая присваивается переменной s. Ее старое значение при этом теряется.
Методы строк
В Python для строк есть множество методов. Посмотреть их можно по команде dir(str), получить информацию по каждому – help(str. имя_метода). Рассмотрим наиболее интересные из них.
имя_метода). Рассмотрим наиболее интересные из них.
Методы split() и join()
Метод split() позволяет разбить строку по пробелам. В результате получается список слов. Если пользователь вводит в одной строке ряд слов или чисел, каждое из которых должно в программе обрабатываться отдельно, то без split() не обойтись.
>>> s = input() red blue orange white >>> s 'red blue orange white' >>> sl = s.split() >>> sl ['red', 'blue', 'orange', 'white'] >>> s 'red blue orange white'
Список, возвращенный методом split(), мы могли бы присвоить той же переменной s, т. е. s = s.split(). Тогда исходная строка была бы потеряна. Если она не нужна, то лучше не вводить дополнительную переменную.
Метод split() может принимать необязательный аргумент-строку, указывающей по какому символу или подстроке следует выполнить разделение:
>>> s.split('e')
['r', 'd blu', ' orang', ' whit', '']
>>> '40030023'. split('00')
['4', '3', '23']
split('00')
['4', '3', '23'] split('00')
['4', '3', '23']
split('00')
['4', '3', '23']Метод строк join() выполняет обратное действие. Он формирует из списка строку. Поскольку это метод строки, то впереди ставится строка-разделитель, а в скобках — передается список:
>>> '-'.join(sl) 'red-blue-orange-white'
Если разделитель не нужен, то метод применяется к пустой строке:
>>> ''.join(sl) 'redblueorangewhite'
Методы find() и replace()
Данные методы строк работают с подстроками. Методы find() ищет подстроку в строке и возвращает индекс первого элемента найденной подстроки. Если подстрока не найдена, то возвращает -1.
>>> s
'red blue orange white'
>>> s.find('blue')
4
>>> s.find('green')
-1Поиск может производиться не во всей строке, а лишь на каком-то ее отрезке. В этом случае указывается первый и последний индексы отрезка. Если последний не указан, то ищется до конца строки:
>>> letters = 'ABCDACFDA' >>> letters.find('A', 3) 4 >>> letters.find('DA', 0, 6) 3
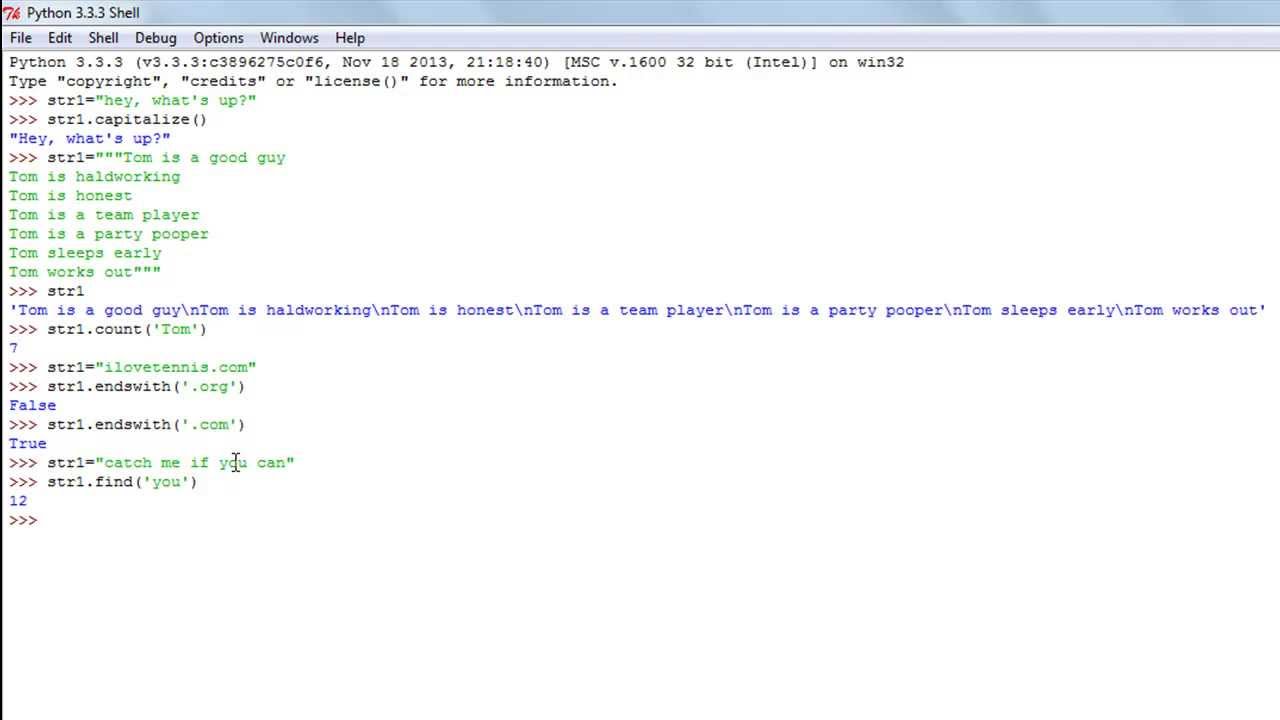
Здесь мы ищем с третьего индекса и до конца, а также с первого и до шестого. Обратите внимания, что метод find() возвращает только первое вхождение. Так выражение letters.find('A', 3) последнюю букву ‘A’ не находит, так как ‘A’ ему уже встретилась под индексом 4.
Метод replace() заменяет одну подстроку на другую:
>>> letters.replace('DA', 'NET')
'ABCNETCFNET'Исходная строка, конечно, не меняется:
>>> letters 'ABCDACFDA'
Так что если результат надо сохранить, то его надо присвоить переменной:
>>> new_letters = letters.replace('DA', 'NET')
>>> new_letters
'ABCNETCFNET'Метод format()
Строковый метод format() уже упоминался при рассмотрении вывода на экран с помощью функции print():
>>> print("This is a {0}. It's {1}."
... .format("ball", "red"))
This is a ball. It's red. It's red.
It's red.Однако к print() он никакого отношения не имеет, а применяется к строкам. Лишь потом заново сформированная строка передается в функцию вывода.
Возможности format() широкие, рассмотрим основные.
>>> size1 = "length - {}, width - {}, height - {}"
>>> size1.format(3, 6, 2.3)
'length - 3, width - 6, height — 2.3'Если фигурные скобки исходной строки пусты, то подстановка аргументов идет согласно порядку их следования. Если в фигурных скобках строки указаны индексы аргументов, порядок подстановки может быть изменен:
>>> size2 = "height - {2}, length - {0}, width - {1}"
>>> size2.format(3, 6, 2.3)
'height - 2.3, length - 3, width - 6'Кроме того, аргументы могут передаваться по слову-ключу:
>>> info = "This is a {subj}. It's {prop}."
>>> info.format(subj="table", prop="small")
"This is a table. It's small."Пример форматирования вещественных чисел:
>>> "{1:. 2f} {0:.3f}".format(3.33333, 10/6)
'1.67 3.333' 2f} {0:.3f}".format(3.33333, 10/6)
'1.67 3.333'
2f} {0:.3f}".format(3.33333, 10/6)
'1.67 3.333'Практическая работа
Вводится строка, включающая строчные и прописные буквы. Требуется вывести ту же строку в одном регистре, который зависит от того, каких букв больше. При равном количестве преобразовать в нижний регистр. Например, вводится строка «HeLLo World», она должна быть преобразована в «hello world», потому что в исходной строке малых букв больше. В коде используйте цикл for, строковые методы upper() (преобразование к верхнему регистру) и lower() (преобразование к нижнему регистру), а также методы isupper() и islower(), проверяющие регистр строки или символа.
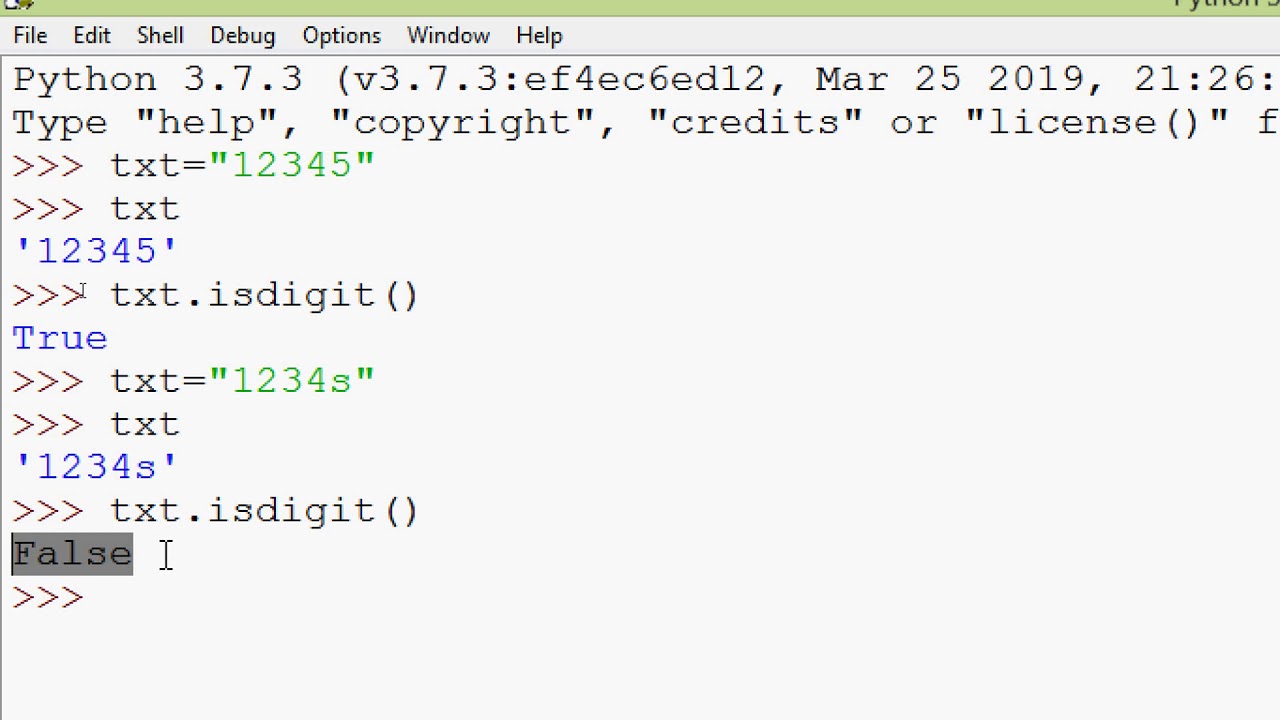
Строковый метод isdigit() проверяет, состоит ли строка только из цифр. Напишите программу, которая запрашивает с ввода два целых числа и выводит их сумму. В случае некорректного ввода программа не должна завершаться с ошибкой, а должна продолжать запрашивать числа. Обработчик исключений try-except использовать нельзя.

Примеры решения и дополнительные уроки в android-приложении и pdf-версии курса
Необыкновенно лёгкий парсинг в Python
Нашёл просто волшебную библиотечку для парсинга в Python (хм, правильно говорить синтаксического анализа),pyparsing. Ниже на простом примере я покажу, как её можно использовать для разбора пользовательских форматов данных.Нашёл так: читая Real World Haskell, узнал про комбинаторную библиотеку для синтаксического анализа Parsec. Примеры в книжке впечатлили. В отличие от традиционного подхода, при этом нет разделения на лексический анализ (выделение «слов»-лексем) и синтаксический анализ (преобразование потока «слов» в упорядоченную структуру данных) — в комбинаторном парсинге эти два этапа объединяются. Берутся небольшие функции, распознающие элементы текста, и затем они комбинируются в соответветствии с синтаксисом текста. Таким образом, сама комбинация функций непосредственно отражает грамматику, и она же, естественно, является и программой для разбора текста.Как у всякой удачной идеи, у Parsec есть множество подражаний. Для Python комбинаторных парсеров нашлось целых двауже триуже четыре — Pysec, Pyparsing, LEPL (для Python 2.6/3.0) и funcparselib. Я буду говорить оpyparsing.В следующей заметке — Ещё одна библиотека для комбинаторного парсинга — смотрите аналогичный пример для библиотечки
funcparserlib.

Итак, перейдём к делу. Предположим нужно читать файлы состоящие из записей следующего вида:
Inspection
# 2 SHOULD Ref. Sys 1
X 28.7493
Y 78.9960
Z -1.0014
Всё необходимое импортируем из модуля
pyparsing. При работе поглядываем в документацию к модулю. Для простоты примера импортируем всё:from pyparsing import *
Теперь начинаем описывать грамматику. Например, определим числа как слова, состоящие из цифр, знака точки и дефиса (минуса)
number = Word(nums + ".
 -")
-")а значения переменных определим как пару заглавной латинской буквы и числа:
var = Regex("[A-Z]") + numberОбратим внимание, что плюс между двумя простыми парсерами (регулярное выражение и слово) создаёт новый парсер, который распознаёт уже последовательность выражений. По-умолчанию
pyparsing игнорирует все лишние пробелы и переводы строк между элементами разбираемого текста (обычно именно это и нужно), поэтому указывать в грамматике наличие пробелов между элементами необязательно.Уже на этом этапе мы можем попробовать наш парсер переменных. Запускаем интерпретатор и выполняем:
>>> var.parseString("X 42.0")
(['X', '42.0'], {})— на выходе получили структуру данных в соответствии с нашей грамматикой (имя переменной и число за ним).
Допишем всё остальное. Для простоты будем считать комментарием всё после знака «#» до конца строки (комбинатор restOfLine):
comment = "#" + restOfLine
Теперь мы можем описать грамматику всей записи в целом.
record = Suppress("Inspection" + comment) + OneOrMore(var)Запись опознаём по слову «Inspection» в начале (здесь строковой литерал Python автоматически конвертируется в
Literal-парсер, проверяющий буквальное соответствие слову). Далее, обнаружив начало записи, состоящие из слова «Inspection» и следующий за ней комментарий, мы можем их просто пропустить (комбинатор Suppress), а вот то, что следует дальше — нам интересно. Мы ожидаем, что дальше могут идти значения для одной или нескольких переменных (применяем комбинатор OneOrMore).Последний штрих. Нужно указать, что в файле таких записей может быть несколько. Для удобства работы с полученной структурой переменные каждой из записей группируем вместе (комбинатор Group):
datafile = OneOrMore(Group(record))
Всё! Синтаксический анализатор для нашего формата данных готов. Использовать можно, например, так:
import sys
print datafile.parseString(sys.
 stdin.read())
stdin.read())Проверяем:
$ python example.py > Inspection
> # 2 SHOULD Ref. Sys 1
> X 28.7493
> Y 78.9960
> Z -1.0014
>
> Inspection
> # 3 SHOULD Ref. Sys 1
> X 54.0394
> Y 64.3977
> Z -0.9950
>
> END
[['X', '28.7493', 'Y', '78.9960', 'Z', '-1.0014'],
['X', '54.0394', 'Y', '64.3977', 'Z', '-0.9950']]
Получили вполне пригодную к использованию в программе структуру данных. Вся грамматика — на пять строк. В общем-то, поняв идею и поглядывая в справку, несложно описать и более сложную грамматику.
Например, чтобы разбирать также и строчку с «#» в моём примере, программку можно изменить так:
from pyparsing import *
number = Word(nums + ".-")
var = Regex("[A-Z]") + number
desc = Suppress("#") + Word(nums) + Word(alphas) \
+ Suppress("Ref.
record = Suppress("Inspection") + desc + Group(OneOrMore(Group(var)))
datafile = OneOrMore(Group(record))
 Sys") + Word(nums)
Sys") + Word(nums)На выходе этот парсер даст:
[['2', 'SHOULD', '1', [['X', '28.7493'], ['Y', '78.9960'], ['Z', '-1.0014']]],
['3', 'SHOULD', '1', [['X', '54.0394'], ['Y', '64.3977'], ['Z', '-0.9950']]]]
P.S. Нормального тьюториала по pyparsing в сети я не нашёл, но автор библиотеки написал и продаёт на O’Reilly учебное электропособие за 10 долларов. Справочная же документация и разные примеры в интернете — вполне толковы.
См. также заметку про funcparserlib.
Разбиение строки, разделенной точкой с запятой, на словарь в Python
У меня есть строка, которая выглядит так:
"Name1=Value1;Name2=Value2;Name3=Value3"
Есть ли встроенный класс/функция в Python, который возьмет эту строку и построит словарь, как если бы я сделал это:
dict = {
"Name1": "Value1",
"Name2": "Value2",
"Name3": "Value3"
}
Я просмотрел доступные модули, но, похоже, не нашел ничего подходящего.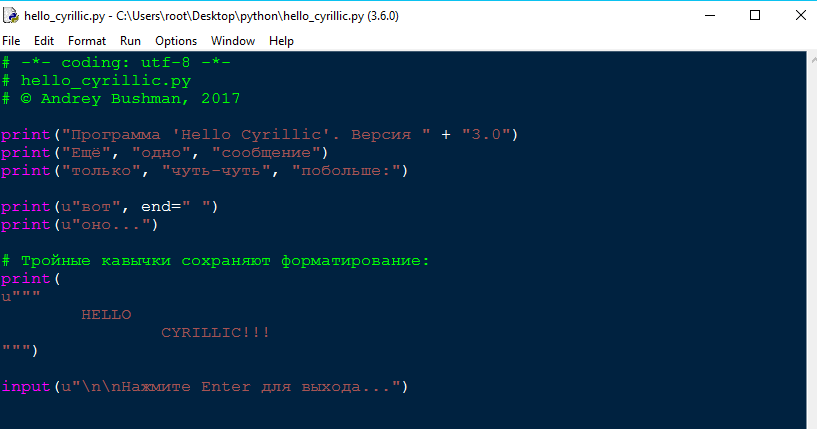
Спасибо, я сам знаю, как сделать соответствующий код, но поскольку такие небольшие решения обычно являются минными полями, ожидающими своего часа (т. е. кто-то пишет: Name1=’Value1=2′;) и т. д., то я обычно предпочитаю какую-то предварительно протестированную функцию.
Тогда я сделаю это сам.
python string dictionary splitПоделиться Источник Lasse V. Karlsen 09 октября 2008 в 11:38
6 ответов
- разделите строку, разделенную запятой, пробелом или точкой с запятой, используя regex
Я использую regex [,; \s]+ для разделения строки, разделенной запятой, пробелом или точкой с запятой. Это прекрасно работает, если строка не имеет запятой в конце: >>> p=re.compile(‘[,;\s]+’) >>> mystring=’a,,b,c’ >>> p.split(mystring) [‘a’, ‘b’, ‘c’] Когда строка имеет…
- Разбиение строки, разделенной «\r\n», на список строк?
Я читаю некоторые данные из метода связи модуля подпроцесса.
Он приходит в виде большой строки, разделенной \r\n. Я хочу разбить это на список строк. Как это делается в python?
 Он приходит в виде большой строки, разделенной \r\n. Я хочу разбить это на список строк. Как это делается в python?
Он приходит в виде большой строки, разделенной \r\n. Я хочу разбить это на список строк. Как это делается в python?
143
Там нет встроенного, но вы можете сделать это довольно просто с помощью понимания генератора:
s= "Name1=Value1;Name2=Value2;Name3=Value3"
dict(item.split("=") for item in s.split(";"))
[Edit] из вашего обновления вы указываете, что вам, возможно, придется обрабатывать цитирование. Это действительно усложняет ситуацию, в зависимости от того, какой именно формат вы ищете (какие символы цитаты принимаются, какие символы побега и т. д.). Возможно, вы захотите взглянуть на модуль csv, чтобы увидеть, может ли он охватить ваш формат. Вот пример: (обратите внимание, что API немного неуклюж для этого примера, так как CSV предназначен для итерации последовательности записей, поэтому вызовы .next() я делаю, чтобы просто посмотреть на первую строку. Отрегулируйте в соответствии с вашими потребностями):
Отрегулируйте в соответствии с вашими потребностями):
>>> s = "Name1='Value=2';Name2=Value2;Name3=Value3"
>>> dict(csv.reader([item], delimiter='=', quotechar="'").next()
for item in csv.reader([s], delimiter=';', quotechar="'").next())
{'Name2': 'Value2', 'Name3': 'Value3', 'Name1': 'Value1=2'}
Однако в зависимости от точной структуры вашего формата вам может потребоваться написать свой собственный простой парсер.
Поделиться Brian 09 октября 2008 в 11:43
6
Это очень близко к тому, чтобы сделать то, что вы хотели:
>>> import urlparse
>>> urlparse.parse_qs("Name1=Value1;Name2=Value2;Name3=Value3")
{'Name2': ['Value2'], 'Name3': ['Value3'], 'Name1': ['Value1']}
Поделиться Kyle Gibson 01 марта 2011 в 02:46
3
s1 = "Name1=Value1;Name2=Value2;Name3=Value3"
dict(map(lambda x: x. split('='), s1.split(';')))
 split('='), s1.split(';')))
split('='), s1.split(';')))
Поделиться D. Om 04 марта 2019 в 13:23
- Разбиение строки на несколько разделителей (запятая, точка с запятой,/)?
У меня есть строка python: names = John, Paul; Sally/Frank Я хочу разделить строку на ,; /. я уже пробовал: names.split(,) но я не уверен, как разделить строку на ALL разделители, которые являются запятой, точкой с запятой и косой чертой. Я также не хочу, чтобы между символами появлялось…
- Разбиение строки, разделенной точкой с запятой, в функции Excel
Можно ли создать Excel-функцию для разделения строки, разделенной точкой с запятой, на n соседних ячеек? Я могу создать функцию, которая делает обратное (объединяет значения n ячеек через точку с запятой и помещает значение в определенную ячейку), противоположное, похоже, не работает. Может ли кто…
1
Это можно просто сделать с помощью соединения строк и понимания списка
","./ /'
p_easytiger_quoting:1.84563302994
{'Name2': 'Value2', 'Name3': 'Value3', 'Name1': 'Value1'}
p_brian:2.30507516861
{'Name2': 'Value2', 'Name3': "'Value3'", 'Name1': 'Value1'}
p_kyle:7.22536420822
{'Name2': ['Value2'], 'Name3': ["'Value3'"], 'Name1': ['Value1']}
import timeit
import urlparse s = "Name1=Value1;Name2=Value2;Name3='Value3'" def p_easytiger_quoting(s):
d = {}
s = s.replace("'", "")
for x in s.split(';'):
k, v = x.split('=')
d[k] = v
return d def p_brian(s):
return dict(item.split("=") for item in s.split(";")) def p_kyle(s):
return urlparse.parse_qs(s) print "p_easytiger_quoting:" + str(timeit.timeit(lambda: p_easytiger_quoting(s)))
print p_easytiger_quoting(s) print "p_brian:" + str(timeit.timeit(lambda: p_brian(s)))
print p_brian(s) print "p_kyle:" + str(timeit.timeit(lambda: p_kyle(s)))
print p_kyle(s)
Поделиться easytiger 26 марта 2013 в 23:59
-2
Если ваши значения Value1, Value2 являются просто заполнителями фактических значений, вы также можете использовать функцию dict() в сочетании с eval() .
>>> s= "Name1=1;Name2=2;Name3='string'"
>>> print eval('dict('+s.replace(';',',')+')')
{'Name2: 2, 'Name3': 'string', 'Name1': 1}
Это происходит потому, что функция dict() понимает синтаксис dict(Name1=1, Name2=2,Name3='string') . Пробелы в строке (например, после каждой точки с запятой) игнорируются. Но обратите внимание, что строковые значения действительно требуют кавычек.
Поделиться Rabarberski 24 апреля 2013 в 10:22
Похожие вопросы:
Разделение строки, разделенной точкой с запятой, в Python
Я хочу split строку, разделенную точкой с запятой, чтобы я мог хранить каждую отдельную строку для использования в качестве текста между тегами XML с использованием Python. Строковое значение…
Указание строки с точкой с запятой в UrlScan.ini
Я хочу заблокировать пользовательские агенты с UrlScan на IIS 6. Однако я не могу указать пользовательский агент с точкой с запятой в строке. Я думаю, что это очень распространенный сценарий, но я…
строки списка, заканчивающиеся точкой или точкой с запятой
как я могу написать команду с помощью grep или egrep для отображения всех строк в файле, которые заканчиваются точкой с запятой“; “ или точкой”.?
разделите строку, разделенную запятой, пробелом или точкой с запятой, используя regex
Я использую regex [,; \s]+ для разделения строки, разделенной запятой, пробелом или точкой с запятой. Это прекрасно работает, если строка не имеет запятой в конце: >>>…
Разбиение строки, разделенной «\r\n», на список строк?
Я читаю некоторые данные из метода связи модуля подпроцесса. Он приходит в виде большой строки, разделенной \r\n. Я хочу разбить это на список строк. Как это делается в python?
Разбиение строки на несколько разделителей (запятая, точка с запятой,/)?
У меня есть строка python: names = John, Paul; Sally/Frank Я хочу разделить строку на ,; /. я уже пробовал: names.split(,) но я не уверен, как разделить строку на ALL разделители, которые являются…
Разбиение строки, разделенной точкой с запятой, в функции Excel
Можно ли создать Excel-функцию для разделения строки, разделенной точкой с запятой, на n соседних ячеек? Я могу создать функцию, которая делает обратное (объединяет значения n ячеек через точку с…
Группа захват строки разделенной точкой с запятой отсутствует последняя группа
Мой входной строки String input= 4313 :F:7222;scott miles:F:7639;Henry Gile:G:3721; Это строки с запятой-разделителем. Он может содержать любое количество значений, разделенных точкой с запятой Я…
Разбор строки, разделенной точкой с запятой, с помощью regex
Я пытаюсь разделить строку чисел с помощью regex. Следующий код C работает, когда числа разделены запятой: #include <stdio.h> int main() { char *multiple = 0.20,0.37,0.75,0.56; char one[4];…
Вывод строки, разделенной точкой с запятой
Допустим, у нас есть этот файл: { persons: [ { friends: 4, phoneNumber: 123456, personID: 11111 }, { friends: 2057, phoneNumber: 432100, personID: 22222 }, { friends: 50, phoneNumber: 147258,…
Работа со строками в Python. Готовимся к собеседованию: вспоминаем азы
Петр Смолович
ведущий разработчик хостинг-провайдера и регистратора доменов REG.RU
В этой статье мы разберем работу со строками в Python с необычного угла — глазами интервьюера на собеседовании. Информация будет полезна как новичку, так и уверенному джуну. В первой части поговорим о базовых операциях. Во второй — разберем примеры задач и вопросов, к которым стоит быть готовым.
Итак, мы на собеседовании, и я хочу узнать, умеете ли вы обращаться со строками.
Как склеить две строки?
>>> s = "abc" + "def"
>>> s += "xyz"Элементарно? Почти. Важно помнить, что строки — это неизменяемые объекты. Каждый раз, когда мы говорим про «изменение» строки, технически мы создаем новый объект и записываем туда вычисленное значение.
А как склеить три строки? Напрашивается ответ «точно так же», и иногда это самый лучший способ. Но интервьюер скорее всего хочет проверить, знаете ли вы про метод .join().
>>> names = ["John", "Paul", "Ringo", "George"]
>>> ", ".join(names)
'John, Paul, Ringo, George'join() — очень удобный метод, позволяющий склеить N строк, причём с произвольным разделителем.
Здесь важно не только получить результат, но и понимать, как работает приведённая конструкция. А именно, что join() — это метод объекта «строка», принимающий в качестве аргумента список и возвращающий на выходе новую строку.
Кстати, хорошая задачка для интервью — написать свою реализацию join().
Разделить строки?
Есть несколько способов получить часть строки. Первый — это split, обратный метод для join. В отличие от join’а, он применяется к целевой строке, а разделитель передаётся аргументом.
>>> s = "Альфа, Браво, Чарли"
>>> s.split(", ")
['Альфа', 'Браво', 'Чарли']Второй — срезы (slices).
Срез s[x:y] позволяет получить подстроку с символа x до символа y. Можно не указывать любое из значений, чтобы двигаться с начала или до конца строки. Отрицательные значения используются для отсчёта с конца (-1 — последний символ, -2 — предпоследний и т.п.).
>>> s = "Hello, world!"
>>> print(s[0:5])
Hello
>>> print(s[-6:])
world!При помощи необязательного третьего параметра s[x:y:N] можно выбрать из подстроки каждый N-ый символ. Например, получить только чётные или только нечётные символы:
>>> s = "0123456789"
>>> print(s[::2])
02468
>>> print(s[1::2])
13579Что насчёт поиска в строке?
Самое быстрое — проверить, начинается ли (заканчивается ли) строка с выбранных символов. Для этого в Python предусмотрены специальные строковые методы./]+)(.*)$», s) >>> print(result.group(1)) https >>> print(result.group(2)) www.reg.ru >>> print(result.group(3)) /hosting/
А замену в строке сделать сможете?
Во-первых, при помощи срезов и склейки строк можно заменить что угодно.
>>> s = "Hello, darling! How are you?"
>>> s[:7] + "Василий" + s[14:]
'Hello, Василий! How are you?'Во-вторых, умеешь find(), умей и replace().
>>> s.replace("darling", "Василий")
'Hello, Василий! How are you?'В-третьих, любую проблему можно решить регулярными выражениями. Либо получить две проблемы 🙂 В случае с заменой вам нужен метод re.sub().
>>> s = "https://www.reg.ru/hosting/";
>>> import re
>>> print(re.sub('[a-z]', 'X', s))
XXXXX://XXX.XXX.XX/XXXXXXX/Посимвольная обработка?
Есть бесчисленное множество задачек, которые можно решить, пройдясь в цикле по строке. Например, посчитать количество букв «о».
>>> s = "Hello, world!"
>>> for c in s:
>>> if c == "o":
>>> counter += 1
>>> print(counter)
2Иногда удобнее бежать по индексу.
>>> for i in range(len(s)):
>>> if s[i] == "o":
>>> counter += 1Помним, что строки неизменяемы, поэтому подменить i-ый символ по индексу не получится, нужно создавать новый объект:
>>> s[i] = "X"
Traceback (most recent call last):
File "", line 1, in
TypeError: 'str' object does not support item assignment
>>> s[:i] + "X" + s[i+1:]
'HellX, world!'Либо можно преобразовать строку в список, сделать обработку, а потом склеить список обратно в строку:
>>> arr = list(s)
>>> "".join(arr)
'Hello, world!'А форматирование строк?
Типичная жизненная необходимость — сформировать строку, подставив в неё результат работы программы. Начиная с Python 3.6, это можно делать при помощи f-строк:
>>> f"Строка '{s}' содержит {len(s)} символов."
"Строка 'Hello, world!' содержит 13 символов."В более старом коде можно встретить альтернативные способы
>>> "Строка '%s' содержит %d символов" % (s, len(s))
>>> "Строка '{}' содержит {} символов".format(s, len(s))Технически можно было обойтись склейкой, но это менее элегантно, а еще придётся следить, чтобы все склеиваемые кусочки были строками. Не рекомендую:
>>> "Строка '" + s + "' содержит " + str(len(s)) + " символов."
"Строка 'Hello, world!' содержит 13 символов."***
Цель работодателя на собеседовании — убедиться что вы соображаете и что вы справитесь с реальными задачами. Однако погружение в реальные задачи занимает несколько недель, а время интервью ограничено. Поэтому вас ждут учебные задания, которые можно решить за 10-30 минут, а также вопросы на понимание того, как работает код. О них и поговорим в следующей части.
|
S.capitalize()Метод capitalize() возращает строку, в которой первая буква каждого слова будет прописной, а все остальные буквы становятся маленькими |
|
S.upper()Метод upper() возращает копию строки, в которой все буквы сконвертированы к большому регистру (заглавные буквы). Все остальные символы остаются неизмененными. |
|
S.lower()Метод lower() возращает копию строки, в которой все буквы сконвертированы к маленькому регистру (строчные буквы). Все остальные символы остаются неизмененными. |
|
S.count(sub)Метод count() принимает подстроку sub в качестве одного обязательного параметра. И возращает количество раз непересекающихся вхождений подстроки sub в строку s. |
|
S.count(sub[, start[, end]]В метод count() помимо обязательного параметра sub можно передать 2 необязательных параметра start и end. Тогда подсчет количества вхождения подстроки sub будет выполняться на срезе S[start:end]. |
|
S.find(sub)Метод find() принимает подстроку sub в качестве одного обязательного параметра. И возращает самый маленький индекс первого вхождения подстроки sub в строку s. Если подстоки sub нет, возращает -1. |
|
S.find(sub[, start[, end]])В метод find() помимо обязательного параметра sub можно передать 2 необязательных параметра start и end. Тогда поиск индекса подстроки sub будет выполняться на срезе S[start:end]. Если подстоки sub нет, возращает -1. |
|
S.index(sub)Метод index() принимает подстроку sub в качестве одного обязательного параметра. И возращает самый маленький индекс первого вхождения подстроки sub в строку s. Если подстоки sub нет, вызывается исключение ValueError. |
|
S.index(sub[, start[, end]])В метод index() помимо обязательного параметра sub можно передать 2 необязательных параметра start и end. Тогда поиск индекса подстроки sub будет выполняться на срезе S[start:end]. Если подстоки sub нет, вызывается исключение ValueError. |
|
S.replace(old, new[, count])Метод replace() возвращает копию строки S, где все вхождения строки old заменены на строку new. Метод replace() принимает 2 обязательных параметра: old шаблон замены и строка new, на что будем менять. Также можно передать третий необязательный параметр count, обозначающий какое количество замен необходимо сделать |
|
S.isalpha()Метод isalpha() возращает True, если все символы строки s являются буквами и возвращает False — в противном случае. |
|
S.isdigit()Метод isdigit() возращает True, если все символы строки s являются цифрами и возвращает False — в противном случае. |
|
S.rjust(width[, fillchar])Метод rjust() возращает строку, которая выравнена по правому краю и длина ее дополнена до width. Символ заполнителя по умолчанию равен пробелу, но можно изменить, передав второй необязательный параметр |
|
S.ljust(width[, fillchar])Метод ljust() возращает строку, которая выравнена по левому краю и длина ее дополнена до width. Символ заполнителя по умолчанию равен пробелу, но можно изменить, передав второй необязательный параметр |
Как удалить символ из строки с помощью python? Ru Python
Как я могу удалить средний символ, т. M Из него. Мне не нужен код, что я хочу знать
В Python строки неизменяемы, поэтому вам нужно создать новую строку. У вас есть несколько вариантов создания новой строки. Если вы хотите удалить «M», где бы он ни появлялся:
newstr = oldstr.replace("M", "") Если вы хотите удалить центральный символ:
midlen = len(oldstr)/2 newstr = oldstr[:midlen] + oldstr[midlen+1:] Вы спросили, заканчиваются ли строки специальным символом. Нет, вы думаете, как программист на C. В Python строки сохраняются с их длиной, поэтому любое количество байтов, включая \0 , может отображаться в строке.
Это, наверное, лучший способ:
original = "EXAMPLE" removed = original.replace("M", "") Не беспокойтесь о смещении персонажей и тому подобных. Большинство python происходит на гораздо более высоком уровне абстракции.
Чтобы заменить определенную позицию:
s = s[:pos] + s[(pos+1):] Чтобы заменить конкретный символ:
s = s.replace('M','') Строки неизменяемы. Но вы можете преобразовать их в список, который является изменяемым, а затем преобразовать список обратно в строку после ее изменения.
s = "this is a string" l = list(s) # convert to list l[1] = "" # "delete" letter h (the item actually still exists but is empty) l[1:2] = [] # really delete letter h (the item is actually removed from the list) del(l[1]) # another way to delete it p = l.index("a") # find position of the letter "a" del(l[p]) # delete it s = "".join(l) # convert back to string Вы также можете создать новую строку, как показали другие, взяв все, кроме символа из существующей строки.
Как удалить средний символ
Вы не можете, потому что строки в Python неизменяемы .
Строки в python заканчиваются любым специальным символом?
Нет. Они похожи на списки персонажей; длина списка определяет длину строки, а символ не действует как терминатор.
Это лучший способ – переместить все справа налево, начиная с среднего символа ИЛИ создавая новую строку, а не копируя средний символ?
Вы не можете изменить существующую строку, поэтому вы должны создать новую, содержащую все, кроме среднего символа.
Я не видел, как упоминается упомянутый метод translate() , так вот:
>>> s = 'EXAMPLE' >>> s.translate(None, 'M') 'EXAPLE' UserString.MutableString
изменяемый способ:
import UserString s = UserString.MutableString("EXAMPLE") >>> type(s) <type 'str'> #del 'M' del s[3] #turn it for immutable: s = str(s) card = random.choice(cards) cardsLeft = cards.replace(card, '', 1) Как удалить один символ из строки: Вот пример, где есть стопка карт, представленных в виде символов в строке. Один из них нарисован (импорт случайного модуля для функции random.choice (), который выбирает случайный символ в строке). Новая строка, cardLeft, создана для хранения оставшихся карт, заданных функцией string replace (), где последний параметр указывает, что только одна «карта» должна быть заменена пустой строкой …
def kill_char(string, n): # n = position of which character you want to remove begin = string[:n] # from beginning to n (n not included) end = string[n+1:] # n+1 through end of string return begin + end print kill_char("EXAMPLE", 3) # "M" removed я видел это где-то здесь
Я просто учился кодировать. Вот что я сделал, чтобы нарезать «М»,
s = 'EXAMPLE' s1 = s[:s.index('M')] + s[s.index('M')+1:] Если вы хотите удалить / игнорировать символы внутри строки, так, например, у вас есть эта строка
«[11: L: 0]»
из ответа веб-api или чего-то подобного, например CSV, предположим, что вы используете запросы
import requests udid = 123456 url = 'http://webservices.yourserver.com/action/id-' + udid s = requests.Session() s.verify = False resp = s.get(url, stream=True) content = resp.content цикл и избавиться от нежелательных символов
for line in resp.iter_lines(): line = line.replace("[", "") line = line.replace("]", "") line = line.replace('"', "") дополнительный сплит, и вы сможете считывать значения по отдельности
listofvalues = line.split(':') теперь доступ к каждому значению проще
print listofvalues[0] print listofvalues[1] print listofvalues[2] это напечатает
11
L
0
from random import randint def shuffle_word(word): newWord="" for i in range(0,len(word)): pos=randint(0,len(word)-1) newWord += word[pos] word = word[:pos]+word[pos+1:] return newWord word = "Sarajevo" print(shuffle_word(word)) Строки неизменны в Python, поэтому оба ваши варианта означают одно и то же.
Как разбить строку в Python
Одной из распространенных операций при работе со строками является разбиение строки на массив подстрок с использованием заданного разделителя.В этой статье мы поговорим о том, как разбить строку в Python.
Метод .split ()
В Python строки представлены как неизменяемые strобъекты. Класс str приходит с целым рядом строковых методов , которые позволяют манипулировать строку.
Метод .split() возвращает список подстрок , разделенных разделителем. Он имеет следующий синтаксис:
str.split(delim=None, maxsplit=-1)
Разделитель может быть символом или последовательностью символов, а не регулярным выражением.
В приведенном ниже примере строка s будет разделена с использованием запятой ,в качестве разделителя.
s = 'AndreyEx,Alex,Jon's.split(',')Результатом будет список строк:
['AndreyEx', 'Alex', 'Jon']
Строковые литералы обычно заключаются в одинарные кавычки, хотя можно использовать и двойные кавычки.
Последовательность символов также может быть использована в качестве разделителя:
s = 'AndreyEx::Alex::Jon's.split('::')
['AndreyEx', 'Alex', 'Jon']
Когда maxsplitдано, это ограничит количество расколов. Если не указано или -1, количество разделений не ограничено.
s = 'AndreyEx;Alex;Jon's.split(';', 1)
Список результатов будет иметь максимум maxsplit+1 элементов:
['AndreyEx', 'Alex;Jon']
Если значение delimне указано или оно есть Null, строка будет разделена с использованием пробела в качестве разделителя. Все последовательные пробелы рассматриваются как один разделитель. Также, если строка содержит конечные и начальные пробелы, результат не будет содержать пустых строк.
Чтобы лучше проиллюстрировать это, давайте рассмотрим следующий пример:
' AndreyEx Hodor Arya Jaime Bran '.split()
['AndreyEx', 'Hodor', 'Arya', 'Jaime', 'Bran']
' AndreyEx Hodor Arya Jaime Bran '.split(' ')
['', 'AndreyEx', '', 'Hodor', 'Arya', '', '', 'Jaime', 'Bran', '']
Если разделитель не используется, возвращаемый список не содержит пустых строк. Если в качестве разделителя задано пустое пространство ‘ ‘, начальные, конечные и последовательные пробелы приведут к тому, что результат будет содержать пустые строки.
Заключение
Разделение строк является одной из самых основных операций. Прочитав этот урок, вы должны хорошо понимать, как разбивать строки в Python.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Как я могу разбить и проанализировать строку в Python?
Пошаговое руководство по синтаксическому анализу строки Python
Разделить строку на пробел, получить список, показать его тип, распечатать:
el @ apollo: ~ / foo $ python
>>> mystring = "Что говорит лиса?"
>>> mylist = mystring.split ("")
>>> тип печати (мой список)
<тип 'список'>
>>> распечатать мой список
['Что говорит лиса?']
Если у вас есть два разделителя рядом друг с другом, предполагается пустая строка:
el @ apollo: ~ / foo $ python
>>> mystring = "это так пушисто, я УМЕРУ !!!"
>>> напечатайте mystring.расколоть(" ")
['так пушисто что можно умереть!!! ']
Разделить строку на подчеркивание и взять 5-й элемент в списке:
el @ apollo: ~ / foo $ python
>>> mystring = "Time_to_fire_up_Kowalski's_Nuclear_reactor."
>>> mystring.split ("_") [4]
"Ковальского"
Свернуть несколько пробелов в одно
el @ apollo: ~ / foo $ python
>>> mystring = 'свернуть эти пробелы'
>>> mycollapsedstring = ''.присоединиться (mystring.split ())
>>> напечатать mycollapsedstring.split ('')
['свернуть', 'эти', 'пробелы']
Если вы не передаете никаких параметров методу разделения Python, в документации говорится: «последовательные пробелы рассматриваются как один разделитель, и результат не будет содержать пустых строк в начале или в конце, если строка имеет начальные или конечные пробелы».
Держитесь за шляпы, парни, проанализируйте регулярное выражение:
el @ apollo: ~ / foo $ python
>>> mystring = 'zzzzzzabczzzzzzdefzzzzzzzzzghizzzzzzzzzzzz'
>>> импорт ре
>>> mylist = re.split ("[a-m] +", mystring)
>>> распечатать мой список
['zzzzzz', 'zzzzzz', 'zzzzzzzzz', 'zzzzzzzzzzzz']
Регулярное выражение «[a-m] +» означает, что строчные буквы от a до m , встречающиеся один или несколько раз, совпадают в качестве разделителя. re — это библиотека для импорта.
Или, если вы хотите пережевывать предметы по одному:
el @ apollo: ~ / foo $ python
>>> mystring = "В этой туманности есть кофе"
>>> mytuple = mystring.раздел ("")
>>> тип печати (mytuple)
<введите "кортеж">
>>> напечатать mytuple
('theres', '', 'кофе в этой туманности')
>>> вывести mytuple [0]
есть
>>> вывести mytuple [2]
кофе в этой туманности
строка Python | split () — GeeksforGeeks
split () Метод возвращает список строк после разбиения данной строки указанным разделителем.
Синтаксис: str.сплит (разделитель, макссплит)
Параметры:
разделитель: Это разделитель. Строка разделяется по указанному разделителю. Если не указан, то любой пробел является разделителем.maxsplit: Это число, которое говорит нам разделить строку на максимальное заданное количество раз. Если он не предусмотрен, значит, нет предела.
Возвращает: Возвращает список строк после разбиения данной строки указанным разделителем.
КОД 1
|
Выход:
["гики", "для", "вундеркинды"] ["гики", "для", "гики"] ["гики", "для", "гики"] [Cat, Bat, Sat, Fat, Or]
КОД 2
|
Выход:
['выродки, для, выродки, паван'] ["гики", "для", "гики", "паван"] ['geeks', 'for, geeks, pawan']
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .
Обрезка и нарезка строк в Python
СтрокиPython представляют собой последовательности отдельных символов и имеют общие методы доступа с другими последовательностями Python — списками и кортежами. Самый простой способ извлечь отдельные символы из строк (и отдельных членов из любой последовательности) — распаковать их в соответствующие переменные.
>>> s = ‘Don’ >>> s ‘Don’ >>> a, b, c = s # Распаковать в переменные >>> a ‘D’ >>> b ‘o’ >>> c ‘n’ |
К сожалению, не часто мы можем позволить себе заранее знать, сколько переменных нам понадобится для хранения каждого символа в строке.И если количество переменных, которые мы предоставляем, не совпадает с количеством символов в строке, Python выдаст нам ошибку.
s = ‘Don Quijote’ a, b, c = s Отслеживание (последний вызов последним): Файл «», строка 1, в ValueError: слишком много значений для распаковки |
Обычно более полезно получить доступ к отдельным символам строки, используя синтаксис индексирования Python, подобный массиву.Здесь, как и во всех последовательностях, важно помнить, что индексирование начинается с нуля; то есть первый элемент в последовательности — номер 0.
>>> s = ‘Don Quijote’ >>> s [4] # Получить 5-й символ ‘Q’ |
Если вы хотите начать отсчет с конца строки, а не с начала, используйте отрицательный индекс.Например, индекс -1 относится к крайнему правому символу строки.
СтрокиPython неизменяемы, и это просто причудливый способ сказать, что после того, как они были созданы, вы не можете их изменить. Попытка сделать это вызывает ошибку.
>>> s [7] ‘j’ >>> s [7] = ‘x’ Traceback (последний вызов последним): Файл «», строка 1, в TypeError : объект ‘str’ не поддерживает назначение элементов |
Если вы хотите изменить строку, вы должны создать ее как совершенно новую строку.На практике это просто. Мы посмотрим, как это сделать через минуту.
До этого, что, если вы хотите извлечь фрагмент из более чем одного символа с известной позицией и размером? Это довольно просто и интуитивно понятно. Мы немного расширили синтаксис квадратных скобок, чтобы мы могли указывать не только начальную позицию нужного фрагмента, но и то, где он заканчивается.
Давайте посмотрим, что здесь происходит. Как и раньше, мы указываем, что хотим начать с позиции 4 (с нуля) в строке.Но теперь, вместо того чтобы довольствоваться одним символом из строки, мы говорим, что нам нужно больше символов, до , но не включая символа в позиции 8.
Вы могли подумать, что вы также собираетесь получить персонажа на позиции 8. Но это не так. Не волнуйтесь — вы к этому привыкнете. Если это помогает, подумайте о втором индексе ( после , двоеточие) как о указании первого символа, который вам не нужен.Кстати, преимуществом этого механизма является то, что вы можете быстро определить, сколько символов у вас останется, просто вычтя первый индекс из второго.
Используя этот синтаксис, вы можете опустить один или оба индекса. Первый индекс, если он опущен, по умолчанию равен 0, так что ваш фрагмент начинается с начала исходной строки; вторая по умолчанию занимает наивысшую позицию в строке, так что ваш кусок заканчивается в конце исходной строки. Отсутствие обоих индексов вряд ли принесет большую практическую пользу; как вы могли догадаться, он просто возвращает всю исходную строку.
>>> s [4:] ‘Quijote’ # Возврат с позиции 4 до конца строки >>> s [: 4] ‘Don’ # Возврат с начала на позицию 3 >>> s [:] ‘Дон Кихот’ |
Если вы все еще изо всех сил пытаетесь понять тот факт, что, например, s [0: 8] возвращает все до , но не включая , символ в позиции 8, это может помочь, если вы перевернете это немного в голове: для любого значения индекса n , которое вы выберете, значение s [: n] + s [n:] всегда будет таким же, как исходная целевая строка.Если бы механизм индексации был включающим, символ в позиции n появился бы дважды.
>>> s [6] ‘i’ >>> s [: 6] + s [6:] ‘Don Quijote’ |
Как и раньше, вы можете использовать отрицательные числа в качестве индексов, и в этом случае подсчет начинается с конца строки (с индексом -1), а не с начала.
Последним вариантом синтаксиса квадратных скобок является добавление третьего параметра, который определяет «шаг» или количество символов, которые вы хотите переместить вперед после того, как каждый символ будет извлечен из исходной строки. Первый полученный символ всегда соответствует индексу перед двоеточием; но после этого указатель перемещается вперед на столько символов, которое вы указали в качестве шага, и извлекает символ в этой позиции. И так до тех пор, пока конечный индекс не будет достигнут или превышен.Если, как в случаях, которые мы встречали до сих пор, параметр опущен, он по умолчанию равен 1, так что извлекается каждый символ в указанном сегменте. Пример проясняет это.
>>> s [4: 8] ‘Quij’ >>> s [4: 8: 1] # 1 в любом случае является значением по умолчанию, поэтому тот же результат ‘Quij’ >>> s [4: 8: 2] # Вернуть символ, затем переместиться на 2 позиции вперед и т. д. «Ци» # Довольно интересно! |
Вы также можете указать отрицательный шаг. Как и следовало ожидать, это означает, что вы хотите, чтобы Python возвращался назад при извлечении символов.
Как видите, поскольку мы идем в обратном направлении, имеет смысл, чтобы начальный индекс был выше конечного индекса (иначе ничего не было бы возвращено).
По этой причине, если вы указываете отрицательный шаг, но опускаете первый или второй индекс, Python по умолчанию устанавливает для отсутствующего значения все, что имеет смысл в данных обстоятельствах: начальный индекс до конца строки и конечный индекс до конца строки. начало строки.Я знаю, от мысли об этом может заболеть голова, но Python знает, что делает.
>>> s [4 :: — 1] # Конечный индекс по умолчанию равен началу строки ‘Q noD’ >>> s [: 4: -1] # Начальный индекс по умолчанию до конца строка ‘etojiu’ |
Итак, это синтаксис квадратных скобок, который позволяет вам извлекать фрагменты символов, если вы знаете точное положение требуемого фрагмента в строке.
Но что, если вы хотите получить фрагмент на основе содержимого строки, о котором мы можем не знать заранее?
Осмотр содержимого
Python предоставляет строковые методы, которые позволяют нам разрезать строку в соответствии с указанными разделителями. Другими словами, мы можем сказать Python искать определенную подстроку в нашей целевой строке и разбивать целевую строку вокруг этой подстроки. Он делает это, возвращая список результирующих подстрок (без разделителей).Кстати, мы можем выбрать не указывать разделитель явно, и в этом случае по умолчанию используется символ пробела (пробел, ‘\ t’, ‘\ n’, ‘\ r’, ‘\ f’) или последовательность таких персонажей.
Помните, что эти методы не влияют на строку, для которой вы их вызываете; они просто возвращают новую строку.
>>> s.split () [‘Don’, ‘Quijote’] >>> s # s.split () не изменен |
Более полезно, мы можем собрать возвращенный список непосредственно в соответствующие переменные.
>>> title, handle = s.split () >>> title ‘Don’ >>> handle ‘Quijote’ |
Оставив на мгновение нашего испанского героя на его ветряных мельницах, давайте представим, что у нас есть строка, содержащая время в часах, минутах и секундах, разделенное двоеточиями. В этом случае мы могли бы разумно собрать отдельные части в переменные для дальнейших манипуляций.
>>> tim = ’16: 30: 10 ‘ >>> часы, минуты, секунды = tim.split (‘: ‘) >>> часы ‘ 16 ‘ >>> минут ’30’ >>> сек ’10’ |
Мы можем захотеть разделить целевую строку только один раз, независимо от того, сколько раз встречается разделитель. Метод split () принимает второй параметр, указывающий максимальное количество выполняемых разделений.
>>> tim.split (‘:’, 1) # split () только один раз [’16’, ’30: 10 ‘] |
Здесь строка разбивается на первое двоеточие, а остальная часть остается нетронутой. А если мы хотим, чтобы Python начал искать разделители с другого конца строки? Что ж, есть вариантный метод под названием rsplit () , который делает именно это.
>>> тим.rsplit (‘:’, 1) [’16: 30 ‘,’ 10 ‘] |
Строительство перегородки
Аналогичный строковый метод — partition () . Это также разбивает строку на основе содержимого, разница в том, что результатом является кортеж , и он сохраняет разделитель вместе с двумя частями целевой строки по обе стороны от него. В отличие от split () , partition () всегда выполняет только одну операцию разделения, независимо от того, сколько раз разделитель появляется в целевой строке.
>>> tim = ’16: 30: 10 ‘ >>> tim.partition (‘: ‘) (‘ 16 ‘,’: ‘, ’30: 10’) |
Как и метод split () , существует вариант partition () , rpartition () , который начинает поиск разделителей с другого конца целевой строки.
>>> тим.rpartition (‘:’) (’16: 30 ‘,’: ‘,’ 10 ‘) |
А теперь вернемся к нашему Дон Кихоту. Ранее, когда мы пытались преобразовать его имя в английский язык, заменив ‘j’ на ‘x’, присвоив ‘x’ непосредственно s [7] , мы обнаружили, что не можем этого сделать, потому что вы можете ‘ t изменить существующие строки Python. Но мы можем обойти это, создав новую строку, которая нам больше нравится, на основе старой строки. Это можно сделать с помощью строкового метода replace () .
>>> s.replace (‘j’, ‘x’) ‘Дон Кихот’ >>> s # Дон Кихот не изменен |
Опять же, наша строка вообще не изменилась. Произошло то, что Python просто вернул новую строку в соответствии с инструкциями, которые мы дали, а затем немедленно отбросил ее, оставив исходную строку без изменений.Чтобы сохранить нашу новую строку, нам нужно присвоить ее переменной.
>>> new_s = s.replace (‘j’, ‘x’) >>> s ‘Don Quijote’ >>> new_s ‘Don Quixote’ |
Но, конечно, вместо того, чтобы вводить новую переменную, мы можем просто повторно использовать существующую.
>>> с = с.replace (‘j’, ‘x’) >>> s ‘Дон Кихот’ |
И здесь, хотя может показаться, что мы изменили исходную строку, на самом деле мы просто отбросили ее и сохранили на ее месте новую строку.
Обратите внимание, что по умолчанию replace () заменяет каждое вхождение подстроки поиска новой подстрокой.
>>> s = ‘Don Quijote’ >>> s.replace (‘o’, ‘a’) ‘Dan Quijate’ |
Мы можем контролировать эту расточительность, добавив дополнительный параметр, определяющий максимальное количество раз, которое должна быть заменена подстрока поиска.
>>> s.replace (‘o’, ‘a’, 1) ‘Dan Quijote’ |
Наконец, метод replace () не ограничивается действиями с отдельными символами.Мы можем заменить целую часть целевой строки некоторым указанным значением.
>>> s.replace (‘Qui’, ‘key’) ‘Donkey jote’ |
Ссылки на используемые строковые методы см .:
Анализ текста с помощью Python · vipinajayakumar
Я ненавижу парсинг файлов, но это то, что мне приходилось делать в начале почти каждого проекта.Разбор — дело непростое, и он может стать камнем преткновения для новичков. Однако, как только вы освоитесь с синтаксическим анализом файлов, вам больше не придется беспокоиться об этой части проблемы. Вот почему я рекомендую новичкам освоиться с анализом файлов на ранних этапах обучения программированию. Эта статья предназначена для начинающих Python, которым интересно научиться анализировать текстовые файлы.
В этой статье я познакомлю вас со своей системой парсинга файлов. Я кратко коснусь синтаксического анализа файлов в стандартных форматах, но я хочу сосредоточиться на синтаксическом анализе сложных текстовых файлов.Что я имею в виду под сложным? Что ж, мы до этого доберемся, молодой падаван.
Для справки, здесь можно найти набор слайдов, который я использую для презентации по этой теме. Весь код и образец текста, которые я использую, доступны в моем репозитории Github здесь.
Во-первых, давайте разберемся, в чем проблема. Зачем нам вообще нужно разбирать файлы? В воображаемом мире, где все данные существовали в одном формате, можно было ожидать, что все программы будут вводить и выводить эти данные. Не было бы необходимости разбирать файлы.Однако мы живем в мире, где существует большое разнообразие форматов данных. Некоторые форматы данных лучше подходят для разных приложений. Можно ожидать, что отдельная программа будет обслуживать только некоторые из этих форматов данных. Таким образом, неизбежно возникает необходимость конвертировать данные из одного формата в другой для использования различными программами. Иногда данные даже не в стандартном формате, что немного усложняет задачу.
Итак, что такое парсинг?
- Разбор
- Анализируйте (строку или текст) на логические синтаксические компоненты.
Мне не нравится приведенное выше определение из Оксфордского словаря. Итак, вот мое альтернативное определение.
- Разбор
- Преобразование данных определенного формата в более удобный формат.
Имея в виду это определение, мы можем представить, что наш ввод может быть в любом формате. Итак, первый шаг, когда вы сталкиваетесь с любой проблемой синтаксического анализа, — это понять формат входных данных. Если повезет, будет документация, описывающая формат данных. Если нет, возможно, вам придется расшифровать формат данных самостоятельно.Это всегда весело.
После того, как вы разберетесь с входными данными, следующим шагом будет определение более удобного формата. Что ж, это полностью зависит от того, как вы планируете использовать данные. Если программа, в которую вы хотите ввести данные, ожидает формат CSV, то это ваш конечный продукт. Для дальнейшего анализа данных я настоятельно рекомендую прочитать данные в pandas DataFrame .
Если вы аналитик данных Python, то, скорее всего, вы знакомы с pandas. Это пакет Python, который предоставляет класс DataFrame и другие функции для безумно мощного анализа данных с минимальными усилиями.Это абстракция поверх Numpy, которая предоставляет многомерные массивы, похожие на Matlab. DataFrame — это 2D-массив, но он может иметь несколько индексов строк и столбцов, которые pandas называет MultiIndex , что по сути позволяет хранить многомерные данные. Операции в стиле SQL или базы данных можно легко выполнять с помощью pandas (сравнение с SQL). Pandas также поставляется с набором инструментов ввода-вывода, который включает функции для работы с CSV, MS Excel, JSON, HDF5 и другими форматами данных.
Хотя мы хотели бы считывать данные в многофункциональную структуру данных, такую как pandas DataFrame , было бы очень неэффективно создавать пустой DataFrame и напрямую записывать в него данные. DataFrame — это сложная структура данных, и запись чего-либо в DataFrame элемент за элементом требует больших вычислительных ресурсов. Намного быстрее читать данные в примитивном типе данных, таком как список или dict . После того, как список или dict создан, pandas позволяет нам легко преобразовать его в DataFrame , как вы увидите позже.На изображении ниже показан стандартный процесс анализа любого файла.
Если ваши данные имеют стандартный или достаточно близкий формат, то, вероятно, существует уже существующий пакет, который вы можете использовать для чтения ваших данных с минимальными усилиями.
Например, у нас есть файл CSV, data.txt:
а, б, в
1,2,3
4,5,6
7,8,9
Вы можете легко справиться с этим с помощью pandas.
| |
а б в
0 1 2 3
1 4 5 6
2 7 8 9
Python невероятен, когда дело касается строк. Стоит усвоить все стандартные строковые операции. Мы можем использовать эти методы для извлечения данных из строки, как вы можете видеть в простом примере ниже.
| |
Шаг 0: [«Имена», «Ромео, Джульетта»]
Шаг 1: Ромео, Джульетта
Шаг 2: [«Ромео», «Джульетта»]
Шаг 3: [«Ромео», «Джульетта»]
Конечный результат за раз: [«Ромео», «Джульетта»]
Как вы видели в предыдущих двух разделах, если проблема синтаксического анализа проста, мы можем обойтись простым использованием существующего синтаксического анализатора или некоторых строковых методов.Однако жизнь не всегда так проста. Как мы подходим к синтаксическому анализу сложного текстового файла?
Шаг 1. Ознакомьтесь с форматом ввода
| |
Пример текста
В викторине приняли участие некоторые студенты из Ривердейл Хай и Хогвартс.
Ниже приведены их результаты.
Школа = Средняя школа Ривердейла
Оценка = 1
Номер студента, Имя
0, Фиби
1, Рэйчел
Номер ученика, Оценка
0, 3
1, 7
Оценка = 2
Номер студента, Имя
0, Анжела
1, Тристан
2, Аврора
Номер ученика, Оценка
0, 6
1, 3
2, 9
Школа = Хогвартс
Оценка = 1
Номер студента, Имя
0, Джинни
1, Луна
Номер ученика, Оценка
0, 8
1, 7
Оценка = 2
Номер студента, Имя
0, Гарри
1, Гермиона
Номер ученика, Оценка
0, 5
1, 10
Оценка = 3
Номер студента, Имя
0, Фред
1, Георгий
Номер ученика, Оценка
0, 0
1, 0
Это довольно сложный входной файл! Уф! Данные, которые он содержит, довольно просты, как вы можете видеть ниже:
Имя Оценка
Номер школьного класса
Хогвартс 1 0 Джинни 8
1 Луна 7
2 0 Гарри 5
1 Гермиона 10
3 0 Фред 0
1 Георгий 0
Ривердейл Хай 1 0 Фиби 3
1 Рэйчел 7
2 0 Анджела 6
1 Тристан 3
2 Аврора 9
Образец текста похож на CSV в том, что в нем используются запятые для разделения некоторой информации.Вверху файла есть заголовок и некоторые метаданные. Есть пять переменных: школа, оценка, номер ученика, имя и оценка. Ключевыми являются школа, класс и номер ученика. Имя и Оценка — это поля. Для данной школы, класса и номера ученика есть имя и оценка. Другими словами, школа, класс и номер учащегося вместе образуют составной ключ.
Данные представлены в иерархическом формате. Сначала объявляется школа, затем оценка. Далее следуют две таблицы, в которых указаны имя и оценка для каждого номера учащегося.Затем оценка увеличивается. Далее следует еще один набор таблиц. Затем образец повторяется для другой Школы. Обратите внимание, что количество учеников в классе или количество классов в школе непостоянны, что добавляет немного сложности к файлу. Это всего лишь небольшой набор данных. Вы можете легко представить, что это огромный файл с множеством школ, оценок и студентов.
Само собой разумеется, что формат данных исключительно плохой. Я сделал это специально. Если вы поймете, как с этим справиться, вам будет намного проще освоить более простые форматы.Такие файлы не редкость, если приходится иметь дело с большим количеством устаревших систем. В прошлом, когда эти системы разрабатывались, возможно, не требовалось, чтобы выходные данные были машиночитаемыми. Однако в настоящее время все должно быть машиночитаемым!
Шаг 2: Импортируйте необходимые пакеты
Нам понадобится модуль регулярных выражений и пакет pandas. Итак, давайте продолжим и импортируем их.
| |
Шаг 3. Определите регулярные выражения
На последнем этапе мы импортировали re, модуль регулярных выражений.Но что это?
Итак, ранее мы видели, как использовать строковые методы для извлечения данных из текста. Однако при синтаксическом анализе сложных файлов мы можем столкнуться с большим количеством операций по удалению, разбиению, нарезке и тому подобному, и код может выглядеть довольно нечитабельным. Именно здесь на помощь приходят регулярные выражения. По сути, это крошечный язык, встроенный в Python, который позволяет вам сказать, какой строковый шаблон вы ищете. Между прочим, он не уникален для Python (домик на дереве).
Вам не нужно быть мастером регулярных выражений.Однако некоторые базовые знания регулярных выражений могут быть очень полезны в вашей карьере программиста. В этой статье я научу вас только самым основам, но я призываю вас продолжить изучение. Я также рекомендую regexper для визуализации регулярных выражений. regex101 — еще один отличный ресурс для тестирования вашего регулярного выражения.
Нам понадобятся три регулярных выражения. Первый из них, как показано ниже, поможет нам идентифицировать школу. Его регулярное выражение — School = (. *) \ N .Что означают символы?
-
.: любой символ -
*: 0 или более из предыдущего выражения -
(. *): Помещение части регулярного выражения в круглые скобки позволяет сгруппировать эту часть выражения. Итак, в данном случае сгруппированная часть — это название школы. -
\ n: символ новой строки в конце строки
Затем нам понадобится регулярное выражение для оценки. Его регулярное выражение — Grade = (\ d +) \ n .Это очень похоже на предыдущее выражение. Новые символы:
-
\ d: сокращение от [0-9] -
+: 1 или более из предыдущего выражения
Наконец, нам нужно регулярное выражение, чтобы определить, является ли таблица, следующая за выражением в текстовом файле, таблицей имен или оценок. Его регулярное выражение — (Имя | Оценка) . Новый символ:
-
|: логика или утверждение, поэтому в данном случае оно означает «Имя» или «Оценка».’
Нам также необходимо понимать несколько функций регулярных выражений:
-
re.compile (шаблон): скомпилировать шаблон регулярного выражения вRegexObject.
A RegexObject имеет следующие методы:
-
match (строка): если начало строки совпадает с регулярным выражением, вернуть соответствующий экземплярMatchObject. В противном случае вернитеНет. -
search (строка): сканировать строку в поисках места, где это регулярное выражение дало совпадение, и возвращать соответствующий экземплярMatchObject.ВернутьНет, если совпадений нет.
MatchObject всегда имеет логическое значение True . Таким образом, мы можем просто использовать оператор if для определения положительных совпадений. Имеет следующий метод:
-
group (): возвращает одну или несколько подгрупп соответствия. На группы можно ссылаться по их индексу.group (0)возвращает все совпадение.group (1)возвращает первую подгруппу в скобках и так далее.Используемые нами регулярные выражения имеют только одну группу. Легко! Однако что, если было несколько групп? Было бы сложно вспомнить, к какому номеру принадлежит группа. Специфичное для Python расширение позволяет нам называть группы и вместо этого ссылаться на них по имени. Мы можем указать имя в заключенной в скобки группе(...), например:(? P....)
Давайте сначала определим все регулярные выражения. Обязательно используйте необработанные строки для регулярного выражения, т.е. используйте индекс r перед каждым шаблоном.
| |
Шаг 4. Напишите синтаксический анализатор строки
Затем мы можем определить функцию, которая проверяет совпадения регулярных выражений.
| |
Шаг 5: Напишите анализатор файла
Наконец, для главного события у нас есть функция парсера файлов.Он довольно большой, но, надеюсь, комментарии в коде помогут вам понять логику.
| |
Шаг 6. Протестируйте синтаксический анализатор
.Мы можем использовать наш синтаксический анализатор для нашего образца текста следующим образом:
| |
Имя Оценка
Номер школьного класса
Хогвартс 1 0 Джинни 8
1 Луна 7
2 0 Гарри 5
1 Гермиона 10
3 0 Фред 0
1 Георгий 0
Ривердейл Хай 1 0 Фиби 3
1 Рэйчел 7
2 0 Анджела 6
1 Тристан 3
2 Аврора 9
Это все хорошо, и вы можете увидеть, сравнив ввод и вывод на глаз, что синтаксический анализатор работает правильно.Однако лучше всего всегда писать модульные тесты, чтобы убедиться, что ваш код выполняет то, что вы хотели. Каждый раз, когда вы пишете синтаксический анализатор, убедитесь, что он хорошо протестирован. У меня возникли проблемы с моими коллегами из-за того, что я использовал парсеры без тестирования ранее. Угу! Также стоит отметить, что это не обязательно должен быть последний шаг. Действительно, многие программисты проповедуют разработку через тестирование. Я не включил сюда набор тестов, так как хотел, чтобы это руководство было кратким.
Я разбирал текстовые файлы в течение года и со временем усовершенствовал свой метод. Тем не менее, я провел дополнительное исследование, чтобы узнать, есть ли лучшее решение. В самом деле, я должен поблагодарить различных членов сообщества, которые посоветовали мне оптимизировать мой код. Сообщество также предложило несколько различных способов синтаксического анализа текстового файла. Некоторые из них были умными и интересными. Моим личным фаворитом был этот. Я представил свой пример проблемы и решения на форумах ниже:
- Сообщение Reddit
- Сообщение Stackoverflow
- Сообщение с обзором кода
Если ваша проблема еще более сложная и регулярные выражения ее не решают, то следующим шагом будет анализ библиотек.Вот несколько мест для начала:
- Разбор ужасных вещей с помощью Python: Лекция Эрика Роуза по PyCon, в которой рассматриваются плюсы и минусы различных библиотек синтаксического анализа.
- Разбор в Python: инструменты и библиотеки: Инструменты и библиотеки, позволяющие создавать парсеры, когда регулярных выражений недостаточно.
Теперь, когда вы понимаете, насколько сложным и раздражающим может быть анализ текстовых файлов, если вы когда-нибудь окажетесь в привилегированном положении при выборе формата файла, выбирайте его с осторожностью.Вот лучшие практики Стэнфорда для форматов файлов.
Я бы солгал, если бы сказал, что мне понравился мой метод синтаксического анализа, но я не знаю другого способа, быстрого синтаксического анализа текстового файла, который так же удобен для новичков, как то, что я представил выше. Если вы знаете лучшее решение, я всем внимателен! Надеюсь, я дал вам хорошую отправную точку для анализа файла на Python! Я потратил пару месяцев на то, чтобы пробовать множество различных методов и писать какой-то безумно нечитаемый код, прежде чем я наконец понял это, и теперь я не думаю дважды о разборе файла.Итак, я надеюсь, что мне удалось сэкономить вам время. Получайте удовольствие от синтаксического анализа текста с помощью Python!
На этой странице: .split (), .join () и list ().Разделение предложения на слова: .split ()Ниже Мэри представляет собой одну струну. Несмотря на то, что это предложение, слова не представлены в виде скрытых единиц. Для этого вам понадобится другой тип данных: список строк, где каждая строка соответствует слову..split () — это метод, который нужно использовать:
Разделение на определенную подстрокуПредоставляя необязательный параметр, .split (‘x’) можно использовать для разделения строки на определенную подстроку ‘x’. Без указания ‘x’ .split () просто разбивается на все пробелы, как показано выше.
Строка в список символов: list ()Но что, если вы хотите разбить строку на список символов? В Python символы — это просто строки длиной 1.Функция list () превращает строку в список отдельных букв:
Присоединение к списку строк: .join ()Если у вас есть список слов, как собрать их в одну строку? .join () — это метод, который нужно использовать. Вызывается в строке-разделителе ‘x’, ‘x’.join (y) объединяет каждый элемент в списке y, разделенный’ x ‘. Ниже слова в mwords объединяются обратно в строку предложения с пробелом между ними:
|
Как разделить строку в Python
При работе со строками одной из повседневных операций является разделение строки на массив подстрок с использованием заданного разделителя.
В этой статье мы поговорим о том, как разбить строку в Python.
.split () Метод №
В Python строки представлены как неизменяемые объекты str . Класс str имеет ряд строковых методов, которые позволяют управлять строкой.
Метод .split () возвращает список подстрок, разделенных разделителем. Требуется следующий синтаксис:
str.split (delim = None, maxsplit = -1)
Разделителем может быть символ или последовательность символов, а не регулярное выражение.
В примере ниже мы разделяем строку s , используя запятую (, ) в качестве разделителя:
s = 'Sansa, Tyrion, Jon's.split (',')
Результатом является список строк:
['Sansa', 'Tyrion', 'Jon']
Строковые литералы обычно заключаются в одинарные кавычки, хотя вы также можете использовать двойные кавычки.
Последовательность символов также может использоваться в качестве разделителя:
s = 'Sansa :: Tyrion :: Jon's.split ('::')
['Санса', 'Тирион', 'Джон']
Когда задано maxsplit , оно ограничивает количество разделений. Если не указано или -1 , количество разделений не ограничено.
s = 'Sansa; Tyrion; Jon's.split (';', 1)
В списке результатов будет максимум maxsplit + 1 элементов:
['Sansa', 'Tyrion ; Джон ']
Если разделитель не указан или равен Null , строка будет разделена с использованием пробела в качестве разделителя.Все последовательные пробелы считаются одним разделителем. Кроме того, если строка содержит завершающие и ведущие пробелы, в результате не будет пустых строк.
Чтобы лучше проиллюстрировать это, давайте рассмотрим следующий пример:
'Дейенерис Ходор Арья Хайме Бран' .split () ['Дейенерис', 'Ходор', 'Арья', 'Хайме' , 'Бран']
'Дейенерис Ходор Арья Хайме Бран' .split ('') ['', 'Дейенерис', '', 'Ходор', 'Арья', '', '', 'Хайме', 'Отруби', '']
Если разделитель не используется, возвращаемый список не содержит пустых строк.Если в качестве разделителя установлено пустое пространство '' , начальные, конечные и последовательные пробелы приведут к тому, что результат будет содержать пустые строки.
Заключение #
Разделение строк — одна из самых основных операций. После прочтения этого руководства вы должны хорошо понимать, как разбивать строки в Python.
Если у вас есть вопросы или отзывы, не стесняйтесь оставлять комментарии.
Как преобразовать строку Python в int — Real Python
Смотреть сейчас В этом руководстве есть связанный видеокурс, созданный командой Real Python.Посмотрите его вместе с письменным руководством, чтобы углубить свое понимание: Преобразование строки Python в int
Целые числа — это целые числа. Другими словами, в них нет дробной составляющей. Для хранения целого числа в Python можно использовать два типа данных: int и str . Эти типы предлагают гибкость для работы с целыми числами в различных обстоятельствах. В этом руководстве вы узнаете, как преобразовать строку Python в int . Вы также узнаете, как преобразовать int в строку.
К концу этого руководства вы поймете:
- Как хранить целые числа с помощью
strиint - Как преобразовать строку Python в
int - Как преобразовать Python
intв строку
Приступим!
Python Pit Stop: Это руководство представляет собой quick и практический способ найти нужную информацию, так что вы вернетесь к своему проекту в кратчайшие сроки!
Представление целых чисел в Python
Целое число может храниться с использованием различных типов.Два возможных типа данных Python для представления целого числа:
-
ул -
внутренний
Например, вы можете представить целое число с помощью строкового литерала:
Здесь Python понимает, что вы хотите сохранить целое число 110 в виде строки. Вы можете сделать то же самое с целочисленным типом данных:
Важно понимать, что конкретно вы подразумеваете под "110" и 110 в приведенных выше примерах.Как человек, который всю свою жизнь использовал десятичную систему счисления, может быть очевидно, что вы имеете в виду число сто десять . Однако существует несколько других систем счисления, таких как двоичная и шестнадцатеричная , которые используют разные основания для представления целых чисел.
Например, вы можете представить число сто десять в двоичном и шестнадцатеричном формате как 1101110 и 6e соответственно.
Вы также можете представить свои целые числа в других системах счисления в Python, используя типы данных str и int :
>>> двоичный = 0b1010
>>> шестнадцатеричный = "0xa"
Обратите внимание, что двоичный и шестнадцатеричный используют префиксы для обозначения системы счисления.Все целочисленные префиксы имеют вид 0? , в котором вы заменяете ? с символом, относящимся к системе счисления:
- b: двоичный (с основанием 2)
- o: восьмеричное (основание 8)
- d: десятичное (основание 10)
- x: шестнадцатеричное (основание 16)
Технические детали: Префикс не требуется ни в целочисленном, ни в строковом представлении, если его можно вывести.
int предполагает, что буквальное целое число — десятичное :
>>> десятичное = 303
>>> шестнадцатеричный_с_префиксом = 0x12F
>>> шестнадцатеричный_no_prefix = 12F
Файл "", строка 1
шестнадцатеричный_но_префикс = 12F
^
SyntaxError: недопустимый синтаксис
Строковое представление целого числа более гибкое, поскольку строка содержит произвольные текстовые данные:
>>> >>> decimal = "303"
>>> шестнадцатеричный_with_prefix = "0x12F"
>>> шестнадцатеричный_no_prefix = "12F"
Каждая из этих строк представляет собой одно и то же целое число.
Теперь, когда у вас есть базовые знания о том, как представлять целые числа с помощью str и int , вы узнаете, как преобразовать строку Python в int .
Преобразование строки Python в
int Если у вас есть десятичное целое число, представленное в виде строки, и вы хотите преобразовать строку Python в int , вы просто передаете строку в int () , которая возвращает десятичное целое число:
>>> int ("10")
10
>>> type (int ("10"))
<класс 'int'>
По умолчанию int () предполагает, что строковый аргумент представляет собой десятичное целое число.Если, однако, вы передадите шестнадцатеричную строку в int () , вы увидите ValueError :
>>> int ("0x12F")
Отслеживание (последний вызов последний):
Файл "", строка 1, в
ValueError: недопустимый литерал для int () с базой 10: '0x12F'
В сообщении об ошибке говорится, что строка не является допустимым десятичным целым числом.
Примечание:
Важно понимать разницу между двумя типами неудачных результатов передачи строки в int () :
- Синтаксическая ошибка: Ошибка
ValueErrorвозникает, когдаint ()не знает, как проанализировать строку, используя предоставленную базу (по умолчанию 10). - Логическая ошибка:
int ()знает, как анализировать строку, но не так, как вы ожидали.
Вот пример логической ошибки:
>>> >>> двоичный = "11010010"
>>> int (binary) # Используем базу по умолчанию 10 вместо 2
11010010
В этом примере вы имели в виду, что результатом будет 210 , что является десятичным представлением двоичной строки. К сожалению, поскольку вы не указали такое поведение, int () предполагает, что строка является десятичным целым числом.
Хорошей защитой от такого поведения является постоянное определение строковых представлений с использованием явных оснований:
>>> >>> int ("0b11010010")
Отслеживание (последний вызов последний):
Файл "", строка 1, в
ValueError: недопустимый литерал для int () с базой 10: '0b11010010'
Здесь вы получаете ValueError , потому что int () не знает, как проанализировать двоичную строку как десятичное целое число.
Когда вы передаете строку в int () , вы можете указать систему счисления, которую вы используете для представления целого числа.Чтобы указать систему счисления, используйте основание :
>>> int ("0x12F", base = 16)
303
Теперь int () понимает, что вы передаете шестнадцатеричную строку и ожидаете десятичное целое число.
Технические детали: Аргумент, который вы передаете в base , не ограничивается 2, 8, 10 и 16:
>>> int ("10", base = 3)
3
Отлично! Теперь, когда вы знакомы с тонкостями преобразования строки Python в int , вы научитесь выполнять обратную операцию.
Преобразование Python
int в строку В Python вы можете преобразовать Python int в строку, используя str () :
>>> str (10)
'10'
>>> тип (str (10))
<класс 'str'>
По умолчанию str () ведет себя как int () в том смысле, что приводит к десятичному представлению:
>>> str (0b11010010)
'210'
В этом примере str () достаточно умен, чтобы интерпретировать двоичный литерал и преобразовать его в десятичную строку.
Если вы хотите, чтобы строка представляла целое число в другой системе счисления, используйте форматированную строку, например f-строку (в Python 3.6+), и параметр, определяющий основание:
>>> >>> восьмеричное число = 0o1073
>>> f "{octal}" # Десятичный
'571'
>>> f "{octal: x}" # Шестнадцатеричный
'23b'
>>> f "{octal: b}" # Двоичный
"1000111011"
str — это гибкий способ представления целого числа в различных системах счисления.
Заключение
Поздравляем! Вы так много узнали о целых числах и о том, как представлять и преобразовывать их между типами данных Python string и int .
Из этого урока вы узнали:
- Как использовать
strиintдля хранения целых чисел - Как указать явную систему счисления для целочисленного представления
- Как преобразовать строку Python в
int - Как преобразовать Python
intв строку
Теперь, когда вы так много знаете о str и int , вы можете узнать больше о представлении числовых типов с помощью float () , hex () , oct () и bin () !
Смотреть сейчас В этом руководстве есть связанный видеокурс, созданный командой Real Python.