Python | Текстовые файлы
Текстовые файлы
Последнее обновление: 21.06.2017
Запись в текстовый файл
Чтобы открыть текстовый файл на запись, необходимо применить режим w (перезапись) или a (дозапись). Затем для записи применяется метод write(str), в который передается записываемая строка. Стоит отметить, что записывается именно строка, поэтому, если нужно записать числа, данные других типов, то их предварительно нужно конвертировать в строку.
Запишем некоторую информацию в файл «hello.txt»:
with open("hello.txt", "w") as file:
file.write("hello world")
Если мы откроем папку, в которой находится текущий скрипт Python, то увидем там файл hello.txt. Этот файл можно открыть в любом текстовом редакторе и при желании изменить.
Теперь дозапишем в этот файл еще одну строку:
with open("hello.txt", "a") as file:
file.write("\ngood bye, world")
Дозапись выглядит как добавление строку к последнему символу в файле, поэтому, если необходимо сделать запись с новой строки, то можно использовать эскейп-последовательность «\n».
hello world good bye, world
Еще один способ записи в файл представляет стандартный метод print(), который применяется для вывода данных на консоль:
with open("hello.txt", "a") as hello_file:
print("Hello, world", file=hello_file)
Для вывода данных в файл в метод print в качестве второго параметра передается название файла через параметр file. А первый параметр представляет записываемую в файл строку.
Чтение файла
readline(): считывает одну строку из файла
read(): считывает все содержимое файла в одну строку
readlines(): считывает все строки файла в список
Например, считаем выше записанный файл построчно:
with open("hello.txt", "r") as file:
for line in file:
print(line, end="")
Несмотря на то, что мы явно не применяем метод readline() для чтения каждой строки, но в при переборе файла этот метод автоматически вызывается
для получения каждой новой строки.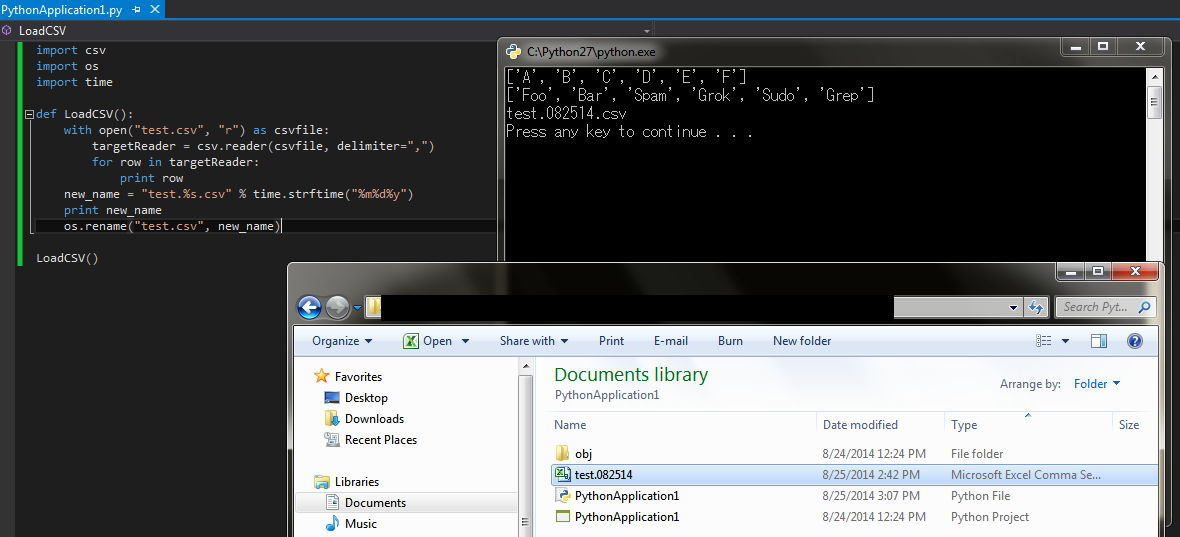
end="".Теперь явным образом вызовем метод readline() для чтения отдельных строк:
with open("hello.txt", "r") as file:
str1 = file.readline()
print(str1, end="")
str2 = file.readline()
print(str2)
Консольный вывод:
hello world good bye, world
Метод readline можно использовать для построчного считывания файла в цикле while:
with open("hello.txt", "r") as file:
line = file.readline()
while line:
print(line, end="")
line = file.readline()
Если файл небольшой, то его можно разом считать с помощью метода read():
with open("hello.txt", "r") as file:
content = file. read()
print(content)
read()
print(content)
 read()
print(content)
read()
print(content)
И также применим метод readlines() для считывания всего файла в список строк:
with open("hello.txt", "r") as file:
contents = file.readlines()
str1 = contents[0]
str2 = contents[1]
print(str1, end="")
print(str2)
При чтении файла мы можем столкнуться с тем, что его кодировка не совпадает с ASCII. В этом случае мы явным образом можем указать кодировку с помощью параметра encoding:
filename = "hello.txt"
with open(filename, encoding="utf8") as file:
text = file.read()
Теперь напишем небольшой скрипт, в котором будет записывать введенный пользователем массив строк и считывать его обратно из файла на консоль:
# имя файла
FILENAME = "messages.txt"
# определяем пустой список
messages = list()
for i in range(4):
message = input("Введите строку " + str(i+1) + ": ")
messages. append(message + "\n")
# запись списка в файл
with open(FILENAME, "a") as file:
for message in messages:
file.write(message)
# считываем сообщения из файла
print("Считанные сообщения")
with open(FILENAME, "r") as file:
for message in file:
print(message, end="")
Пример работы программы:
Введите строку 1: hello Введите строку 2: world peace Введите строку 3: great job Введите строку 4: Python Считанные сообщения hello world peace great job Python
Чтение данных из файла и запись в файл
Создание файла
f2 = open("text2.txt", 'w')Функция open() возвращает файловый объект.
Без ‘b’ создается текстовый файл, представляющий собой поток символов. С ‘b’ — файл, содержащий поток байтов.
В Python также существует режим ‘x’ или ‘xb’. В этом режиме проверяется, есть ли файл. Если файл с определенным именем уже существует, он не будет создан. В режиме ‘w’ файл создается заново, старый при этом теряется.
>>> f1 = open('text1.txt', 'w') >>> f2 = open('text1.txt', 'x') Traceback (most recent call last): File "<stdin>", line 1, in <module> FileExistsError: [Errno 17] File exists: 'text1.txt' >>> f3 = open('text1.txt', 'w')
Чтение данных из файла
Если в функцию open() не передается второй аргумент, файл расценивается как текстовый и открывается на чтение.
Попытка открыть на чтение несуществующий файл вызывает ошибку.
>>> f = open("text10.txt")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IOError: [Errno 2] No such file or directory: 'text10.txt'Перехватить возникшее исключение можно с помощью конструкции try-except.
>>> try:
... f = open("text10.txt")
... except IOError:
... print ("No file")
...
No fileПолучить все данные из файла можно с помощью метода read() файлового объекта, предварительно открыв файл на чтение. При этом файловый объект изменяется и получить из него данные еще раз не получится.
>>> f = open("text.txt") >>> f <_io.TextIOWrapper name='text.txt' mode='r' encoding='UTF-8'> >>> fd = f.read() >>> fd1 = f.read() >>> fd 'Hello\n\tOne\n Two\nThree Four\nШесть!\n' >>> fd1 ''
Методу read() может быть передан один аргумент, обозначающий количество байт для чтения.
>>> f = open("text.txt")
>>> fd = f.read(10)
>>> fd1 = f.read(5)
>>> fd
'Hello\n\tOne'
>>> fd1
'\n T'Метод readline() позволяет получать данные построчно.
>>> f = open("text. txt")
>>> f.readline()
'Hello\n'
>>> f.readline()
'\tOne\n'
>>> f.readline()
' Two\n' txt")
>>> f.readline()
'Hello\n'
>>> f.readline()
'\tOne\n'
>>> f.readline()
' Two\n'
txt")
>>> f.readline()
'Hello\n'
>>> f.readline()
'\tOne\n'
>>> f.readline()
' Two\n'Принимает аргумент — число байт.
>>> f.readline(3) 'Thr' >>> f.readline(3) 'ee ' >>> f.readline(3) 'Fou' >>> f.readline(3) 'r\n' >>> f.readline(5) 'Шесть' >>> f.readline(5) '!\n'
Метод readlines() считывает все строки и помещает их в список.
>>> f = open("text.txt")
>>> fd = f.readlines()
>>> fd
['Hello\n', '\tOne\n', ' Two\n', 'Three Four\n', 'Шесть!\n']Может принимать количество байт, но дочитывает строку до конца.
>>> f = open("text.txt")
>>> fd = f.readlines(3)
>>> fd
['Hello\n']
>>> fd1 = f.readlines(6)
>>> fd1
['\tOne\n', ' Two\n']Запись данных в файл
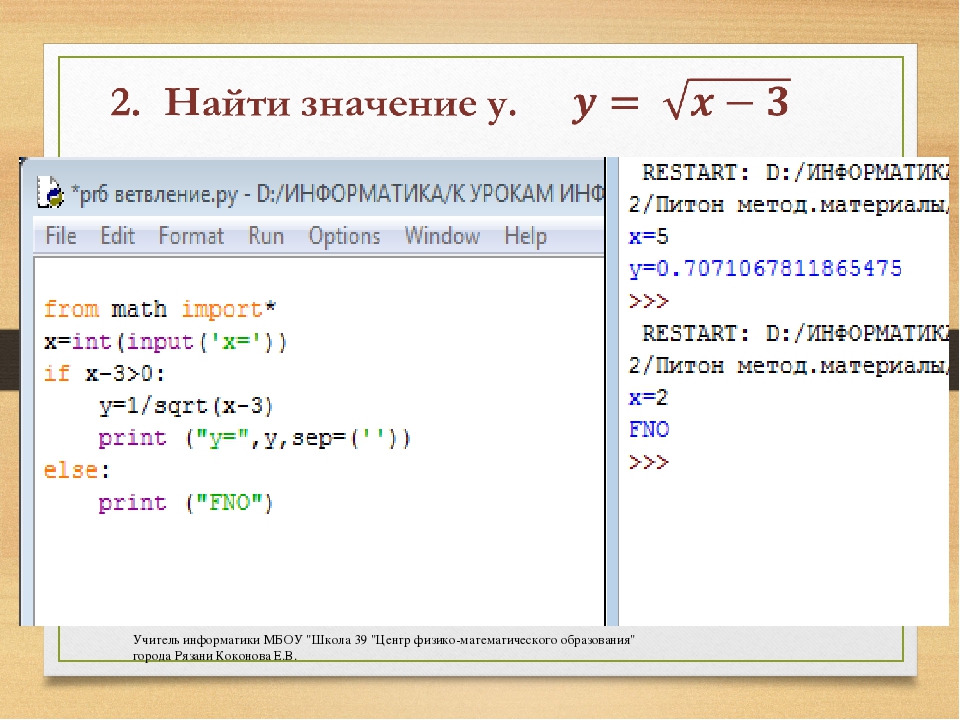
Записать данные в файл можно с помощью метода write(), который возвращает число записанных символов.
>>> f1 = open("text1.txt", 'w')
>>> f1.write("Table, cup.\nBig, small.")
23
>>> a = f1.write("Table, cup.\nBig, small.")
>>> type(a)
<class 'int'>Файл, открытый на запись, нельзя прочитать. Для этого требуется его закрыть, а потом открыть на чтение.
>>> f1.read() Traceback (most recent call last): File "<stdin>", line 1, in <module> io.UnsupportedOperation: not readable >>> f1.close() >>> f1 = open("text1.txt", 'r') >>> f1.read() 'Table, cup.\nBig, small.Table, cup.\nBig, small.'
С помощью метода writelines() можно записать в файл итерируемую последовательность.
>>> a = [1,2,3,4,5,6,7,8,9,0]
>>> f = open("text2.txt",'w')
>>> f.writelines("%s\n" % i for i in a)
>>> f.close()
>>> open("text2.txt").read()
'1\n2\n3\n4\n5\n6\n7\n8\n9\n0\n'
>>> print(open("text2.txt"). read())
1
2
3
4
5
6
7
8
9
0 read())
1
2
3
4
5
6
7
8
9
0
read())
1
2
3
4
5
6
7
8
9
0Смена позиции в файле
>>> f = open('text.txt')
>>> f.read()
'Hello\n\tOne\n Two\nThree Four\nШесть!\n'
>>> f.close()
>>> f = open('text.txt')
>>> f.seek(10)
10
>>> f.read()
'\n Two\nThree Four\nШесть!\n'Двоичные файлы
Пример копирования изображения:
>>> f1 = open('flag.png', 'rb')
>>> f2 = open('flag2.png', 'wb')
>>> f2.write(f1.read())
446
>>> f1.close()
>>> f2.close()Модуль struct позволяет преобразовывать данные к бинарному виду и обратно.
>>> f = open('text3.txt', 'wb')
>>> f.write('3')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' does not support the buffer interface
>>> d = struct.pack('>i',3)
>>> d
b'\x00\x00\x00\x03'
>>> f.write(d)
4
>>> f. close()
>>> f = open('text3.txt')
>>> d = f.read()
>>> d
'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' does not support the buffer interface
>>> f = open('text3.txt', 'rb')
>>> d = f.read()
>>> d
b'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
(3,) close()
>>> f = open('text3.txt')
>>> d = f.read()
>>> d
'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' does not support the buffer interface
>>> f = open('text3.txt', 'rb')
>>> d = f.read()
>>> d
b'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
(3,)
close()
>>> f = open('text3.txt')
>>> d = f.read()
>>> d
'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' does not support the buffer interface
>>> f = open('text3.txt', 'rb')
>>> d = f.read()
>>> d
b'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
(3,)Чтение из файла построчно в Python на примерах readline, readlines и цикла for
Существует много способов чтение из файла построчно в Python. Вы можете считать строки в список или обращаться к каждой из строк в цикле при помощи итератора или вызова функции объекта file.
В этом руководстве мы научимся считывать файл построчно, используя функции readline(), readlines() и объект файла на примерах различных программ.
Пример 1: Чтение файла построчно функцией readline()
В этом примере мы будем использовать функцию readline() для файлового объекта, получая каждую строку в цикле.
Как использовать функцию file.readline()
Следуйте пунктам приведенным ниже для того, чтобы считать файл построчно, используя функцию readline().
- Открываем файл в режиме чтения. При этом возвращается дескриптор файла.
- Создаём бесконечный цикл while.
- В каждой итерации считываем строку файла при помощи
readline(). - Если строка не пустая, то выводим её и переходим к следующей. Вы можете проверить это, используя конструкцию
if not. В противном случае файл больше не имеет строк и мы останавливаем цикл с помощьюbreak.
- В каждой итерации считываем строку файла при помощи
- К моменту выхода из цикла мы считаем все строки файла в итерациях одну за другой.
- После этого мы закрываем файл, используя функцию
close.
# получим объект файла
file1 = open("sample.txt", "r")
while True:
# считываем строку
line = file1.readline()
# прерываем цикл, если строка пустая
if not line:
break
# выводим строку
print(line. strip())
# закрываем файл
file1.close
 strip())
# закрываем файл
file1.close
strip())
# закрываем файл
file1.close
Вывод:
Привет!
Добро пожаловать на PythonRu.
Удачи в обучении!Пример 2: Чтение строк как список функцией readlines()
Функция readlines() возвращает все строки файла в виде списка. Мы можем пройтись по списку и получить доступ к каждой строке.
В следующей программе мы должны открыть текстовый файл и получить список всех его строк, используя функцию readlines(). После этого мы используем цикл for, чтобы обойти данный список.
# получим объект файла
file1 = open("sample.txt", "r")
# считываем все строки
lines = file1.readlines()
# итерация по строкам
for line in lines:
print(line.strip())
# закрываем файл
file1.close
Привет!
Добро пожаловать на PythonRu.
Удачи в обучении!Пример 3: Считываем файл построчно из объекта File
В нашем первом примере, мы считываем каждую строку файла при помощи бесконечного цикла while и функции readline().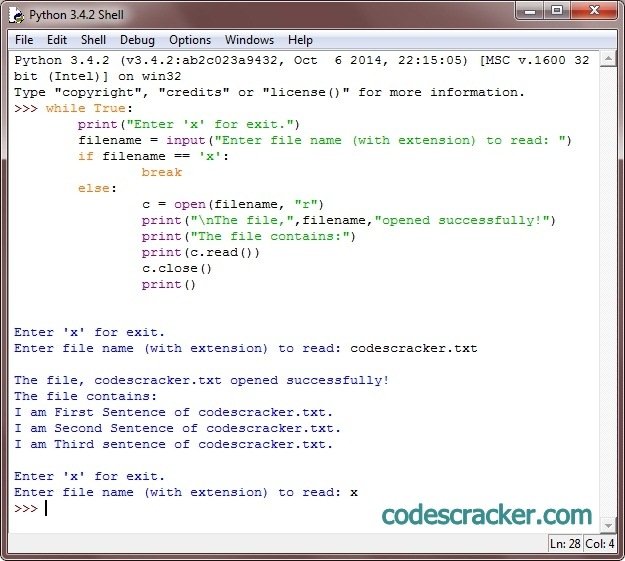 Но Вы можете использовать цикл for для файлового объекта, чтобы в каждой итерации цикла получать строку, пока не будет достигнут конец файла.
Но Вы можете использовать цикл for для файлового объекта, чтобы в каждой итерации цикла получать строку, пока не будет достигнут конец файла.
Ниже приводится программа, демонстрирующая применение оператора for-in, для того, чтобы перебрать строки файла.
Для демонстрации откроем файл с помощью with open. Это применимо и к предыдущим двум примерам.
# получим объект файла
with open("sample.txt", "r") as file1:
# итерация по строкам
for line in file1:
print(line.strip())
Привет!
Добро пожаловать на PythonRu.
Удачи в обучении!Выводы
В этом руководстве мы научились считывать текстовый файл построчно с помощью примеров программ на Python.
Чтение файлов — Документация Python для сетевых инженеров 3.0
В Python есть несколько методов чтения файла:
read— считывает содержимое файла в строкуreadline— считывает файл построчноreadlines— считывает строки файла и создает список из строк
Посмотрим как считывать содержимое файлов, на примере файла r1. txt:
txt:
! service timestamps debug datetime msec localtime show-timezone year service timestamps log datetime msec localtime show-timezone year service password-encryption service sequence-numbers ! no ip domain lookup ! ip ssh version 2 !
readМетод read — считывает весь файл в одну строку.
Пример использования метода read:
In [1]: f = open('r1.txt')
In [2]: f.read()
Out[2]: '!\nservice timestamps debug datetime msec localtime show-timezone year\nservice timestamps log datetime msec localtime show-timezone year\nservice password-encryption\nservice sequence-numbers\n!\nno ip domain lookup\n!\nip ssh version 2\n!\n'
In [3]: f.read()
Out[3]: ''
При повторном чтении файла в 3 строке, отображается пустая строка. Так
происходит из-за того, что при вызове метода read, считывается
весь файл. И после того, как файл был считан, курсор остается в конце
файла. Управлять положением курсора можно с помощью метода seek.
readlineПострочно файл можно считать с помощью метода readline:
In [4]: f = open('r1.txt')
In [5]: f.readline()
Out[5]: '!\n'
In [6]: f.readline()
Out[6]: 'service timestamps debug datetime msec localtime show-timezone year\n'
Но чаще всего проще пройтись по объекту file в цикле, не используя
методы read...:
In [7]: f = open('r1.txt')
In [8]: for line in f:
...: print(line)
...:
!
service timestamps debug datetime msec localtime show-timezone year
service timestamps log datetime msec localtime show-timezone year
service password-encryption
service sequence-numbers
!
no ip domain lookup
!
ip ssh version 2
!
readlinesЕще один полезный метод — readlines. Он считывает строки файла в
список:
In [9]: f = open('r1.txt')
In [10]: f.readlines()
Out[10]:
['!\n',
'service timestamps debug datetime msec localtime show-timezone year\n',
'service timestamps log datetime msec localtime show-timezone year\n',
'service password-encryption\n',
'service sequence-numbers\n',
'!\n',
'no ip domain lookup\n',
'!\n',
'ip ssh version 2\n',
'!\n']
Если нужно получить строки файла, но без перевода строки в конце, можно
воспользоваться методом split и как разделитель, указать символ \n:
In [11]: f = open('r1. txt')
In [12]: f.read().split('\n')
Out[12]:
['!',
'service timestamps debug datetime msec localtime show-timezone year',
'service timestamps log datetime msec localtime show-timezone year',
'service password-encryption',
'service sequence-numbers',
'!',
'no ip domain lookup',
'!',
'ip ssh version 2',
'!',
'']
 txt')
In [12]: f.read().split('\n')
Out[12]:
['!',
'service timestamps debug datetime msec localtime show-timezone year',
'service timestamps log datetime msec localtime show-timezone year',
'service password-encryption',
'service sequence-numbers',
'!',
'no ip domain lookup',
'!',
'ip ssh version 2',
'!',
'']
txt')
In [12]: f.read().split('\n')
Out[12]:
['!',
'service timestamps debug datetime msec localtime show-timezone year',
'service timestamps log datetime msec localtime show-timezone year',
'service password-encryption',
'service sequence-numbers',
'!',
'no ip domain lookup',
'!',
'ip ssh version 2',
'!',
'']
Обратите внимание, что последний элемент списка — пустая строка.
Если перед выполнением split, воспользоваться методом rstrip, список будет без пустой строки в конце:
In [13]: f = open('r1.txt')
In [14]: f.read().rstrip().split('\n')
Out[14]:
['!',
'service timestamps debug datetime msec localtime show-timezone year',
'service timestamps log datetime msec localtime show-timezone year',
'service password-encryption',
'service sequence-numbers',
'!',
'no ip domain lookup',
'!',
'ip ssh version 2',
'!']
seekДо сих пор, файл каждый раз приходилось открывать заново, чтобы снова
его считать. Так происходит из-за того, что после методов чтения, курсор
находится в конце файла. И повторное чтение возвращает пустую строку.
Так происходит из-за того, что после методов чтения, курсор
находится в конце файла. И повторное чтение возвращает пустую строку.
Чтобы ещё раз считать информацию из файла, нужно воспользоваться методом seek, который перемещает курсор в необходимое положение.
Пример открытия файла и считывания содержимого:
In [15]: f = open('r1.txt')
In [16]: print(f.read())
!
service timestamps debug datetime msec localtime show-timezone year
service timestamps log datetime msec localtime show-timezone year
service password-encryption
service sequence-numbers
!
no ip domain lookup
!
ip ssh version 2
!
Если вызывать ещё раз метод read, возвращается пустая строка:
Но с помощью метода seek можно перейти в начало файла (0 означает
начало файла):
После того как с помощью seek курсор был переведен в начало
файла, можно опять считывать содержимое:
In [19]: print(f.read()) ! service timestamps debug datetime msec localtime show-timezone year service timestamps log datetime msec localtime show-timezone year service password-encryption service sequence-numbers ! no ip domain lookup ! ip ssh version 2 !
Изучаем Python: работа с файлами
В этой статье мы рассмотрим операции с файлами в Python. Открытие файла Python. Чтение из файла Python. Запись в файл Python, закрытие файла. А также методы, предназначенные для работы с файлами.
Открытие файла Python. Чтение из файла Python. Запись в файл Python, закрытие файла. А также методы, предназначенные для работы с файлами.
Файл – это именованная область диска, предназначенная для длительного хранения данных в постоянной памяти (например, на жёстком диске).
Чтобы прочитать или записать данные в файл, сначала нужно его открыть. После окончания работы файл необходимо закрыть, чтобы освободить связанные с ним ресурсы.
Поэтому в Python операции с файлами выполняются в следующем порядке:
- Открытие файла Python.
- Чтение из файла Python или запись в файл Python (выполнение операции).
- Закрытие файла Python.
Не знаете как открыть файл в питоне? В Python есть встроенная функция open(), предназначенная для открытия файла. Она возвращает объект, который используется для чтения или изменения файла.
>>> f = open("test.txt") # открыть файл в текущей папке
>>> f = open("C:/Python33/README.txt") # указание полного путиПри этом можно указать необходимый режим открытия файла: ‘r’- для чтения,’w’ — для записи,’a’ — для изменения. Мы также можем указать, хотим ли открыть файл в текстовом или в бинарном формате.
Мы также можем указать, хотим ли открыть файл в текстовом или в бинарном формате.
По умолчанию файл открывается для чтения в текстовом режиме. При чтении файла в этом режиме мы получаем строки.
В бинарном формате мы получим байты. Этот режим используется для чтения не текстовых файлов, таких как изображения или exe-файлы.
| Открытие файла Python- возможные режимы | |
| Режим | Описание |
| ‘r’ | Открытие файла для чтения. Режим используется по умолчанию. |
| ‘w’ | Открытие файла для записи. Режим создаёт новый файл, если он не существует, или стирает содержимое существующего. |
| ‘x’ | Открытие файла для записи. Если файл существует, операция заканчивается неудачей (исключением). |
| ‘a’ | Открытие файла для добавления данных в конец файла без очистки его содержимого. Этот режим создаёт новый файл, если он не существует. |
| ‘t’ | Открытие файла в текстовом формате. Этот режим используется по умолчанию. Этот режим используется по умолчанию. |
| ‘b’ | Открытие файла в бинарном формате. |
| ‘+’ | Открытие файла для обновления (чтения и записи). |
f = open("test.txt") # эквивалент 'r' или 'rt'
f = open("test.txt",'w') # запись в текстовом режиме
f = open("img.bmp",'r+b') # чтение и запись в бинарном форматеВ отличие от других языков программирования, в Python символ ‘a’ не подразумевает число 97, если оно не закодировано в ASCII (или другой эквивалентной кодировке).
Кодировка по умолчанию зависит от платформы. В Windows – это ‘cp1252’, а в Linux ‘utf-8’.
Поэтому мы не должны полагаться на кодировку по умолчанию. При работе с файлами в текстовом формате рекомендуется указывать тип кодировки.
f = open("test.txt",mode = 'r',encoding = 'utf-8')Закрытие освободит ресурсы, которые были связаны с файлом. Это делается с помощью метода close(), встроенного в язык программирования Python.
В Python есть сборщик мусора, предназначенный для очистки ненужных объектов, Но нельзя полагаться на него при закрытии файлов.
f = open("test.txt",encoding = 'utf-8')
# выполнение операций с файлом
f.close()Этот метод не полностью безопасен. Если при операции возникает исключение, выполнение будет прервано без закрытия файла.
Более безопасный способ – использование блока try…finally.
try:
f = open("test.txt",encoding = 'utf-8')
# выполнение операций с файлом
finally:
f.close()Это гарантирует правильное закрытие файла даже после возникновения исключения, прерывающего выполнения программы.
Также для закрытия файла можно использовать конструкцию with. Оно гарантирует, что файл будет закрыт при выходе из блока with. При этом не нужно явно вызывать метод close(). Это будет сделано автоматически.
with open("test.txt",encoding = 'utf-8') as f:
# выполнение операций с файломЧтобы записать данные в файл в Python, нужно открыть его в режиме ‘w’, ‘a’ или ‘x’. Но будьте осторожны с режимом ‘w’. Он перезаписывает файл, если то уже существует. Все данные в этом случае стираются.
Запись строки или последовательности байтов (для бинарных файлов) осуществляется методом write(). Он возвращает количество символов, записанных в файл.
with open("test.txt",'w',encoding = 'utf-8') as f:
f.write("my first filen")
f.write("This filenn")
f.write("contains three linesn")Эта программа создаст новый файл ‘test.txt’. Если он существует, данные файла будут перезаписаны. При этом нужно добавлять символы новой строки самостоятельно, чтобы разделять строки.
Чтобы осуществить чтение из файла Python, нужно открыть его в режиме чтения. Для этого можно использовать метод read(size), чтобы прочитать из файла данные в количестве, указанном в параметре size. Если параметр size не указан, метод читает и возвращает данные до конца файла.
>>> f = open("test.txt",'r',encoding = 'utf-8')
>>> f.read(4) # чтение первых 4 символов
'This'
>>> f.read(4) # чтение следующих 4 символов
' is '
>>> f.read() # чтение остальных данных до конца файла
'my first filenThis filencontains three linesn'
>>> f. read() # дальнейшие попытки чтения возвращают пустую строку
''
 read() # дальнейшие попытки чтения возвращают пустую строку
''
read() # дальнейшие попытки чтения возвращают пустую строку
''
Метод read() возвращает новые строки как ‘n’. Когда будет достигнут конец файла, при дальнейших попытках чтения мы получим пустые строки.
Чтобы изменить позицию курсора в текущем файле, используется метод seek(). Метод tell() возвращает текущую позицию курсора (в виде количества байтов).
>>> f.tell() # получаем текущую позицию курсора в файле 56 >>> f.seek(0) # возвращаем курсор в начальную позицию 0 >>> print(f.read()) # читаем весь файл This is my first file This file contains three lines
Мы можем прочитать файл построчно в цикле for.
>>> for line in f: ... print(line, end = '') ... This is my first file This file contains three lines
Извлекаемые из файла строки включают в себя символ новой строки ‘n’. Чтобы избежать вывода, используем пустой параметр end метода print(),.
Также можно использовать метод readline(), чтобы извлекать отдельные строки. Он читает файл до символа новой строки.
Он читает файл до символа новой строки.
>>> f.readline() 'This is my first filen' >>> f.readline() 'This filen' >>> f.readline() 'contains three linesn' >>> f.readline() ''
Метод readlines() возвращает список оставшихся строк. Все эти методы чтения возвращают пустую строку, когда достигается конец файла.
>>> f.readlines() ['This is my first filen', 'This filen', 'contains three linesn']
Ниже приводится полный список методов для работы с файлами в текстовом режиме.
| Python работа с файлами — методы | |
| Метод | Описание |
| close() | Закрытие файла. Не делает ничего, если файл закрыт. |
| detach() | Отделяет бинарный буфер от TextIOBase и возвращает его. |
| fileno() | Возвращает целочисленный дескриптор файла. |
| flush() | Вызывает сброс данных (запись на диск) из буфера записи файлового потока. |
| isatty() | Возвращает значение True, если файловый поток интерактивный. |
| read(n) | Читает максимум n символов из файла. Читает до конца файла, если значение отрицательное или None. |
| readable() | Возвращает значение True, если из файлового потока можно осуществить чтение. |
| readline(n=-1) | Читает и возвращает одну строку из файла. Читает максимум n байт, если указано соответствующее значение. |
| readlines(n=-1) | Читает и возвращает список строк из файла. Читает максимум n байт/символов, если указано соответствующее значение. |
| seek(offset,from=SEEK_SET) | Изменяет позицию курсора. |
| seekable() | Возвращает значение True, если файловый поток поддерживает случайный доступ. |
| tell() | Возвращает текущую позицию курсора в файле. |
| truncate(size=None) | Изменяет размер файлового потока до size байт. Если значение size не указано, размер изменяется до текущего положения курсора. |
| writable() | Возвращает значение True, если в файловый поток может производиться запись. |
| write(s) | Записывает строки s в файл и возвращает количество записанных символов. |
| writelines(lines) | Записывает список строк lines в файл. |
Данная публикация является переводом статьи «Python File IO Read and Write Files in Python» , подготовленная редакцией проекта.
Работа с файлами в питон
В этом уроке мы разберём, как читать информацию из файлов и записывать ее в файлы в Питоне. В файлы записываются результаты работы программы, которые можно потом использовать в других приложениях. Поэтому необходимо уметь в Питон записывать информацию в файлы Также в файлах может храниться большой объем входной информации, которую должна обработать программа. Поэтому необходимо уметь считывать информацию из файлов в python.
Чтобы начать работу с файлом в Питон, нужно открыть файл. Открыть файл в Питон можно с помощью команды
Открыть файл в Питон можно с помощью команды
with open(“file.ext”, mode) as name: имя перменной файла
with, open и as это ключевые слова. Команда open() открывает файл с именем “file” с разрешением файла “ext”. Параметр mode отвечает за режим открытия файла. Необходимо указать полный путь к файлу, причем используются двойные слеши. например открытие файла на чтение
with open(«C:\Users\user\Desktop\Win\Python\settings\data.txt»,»r») as f:
Существуют различные режимы работы с файлом в python. Файл можно открыть только для считывания информации из файла, можно открыть для добавления в него информации, можно просто создать новый файл с заданным именем. Название и расширение файла пишется в кавычках, расширение файла пишется после названия файла через точку, режим открытия файла пишется в кавычках. Разберем все режимы работы с файлом в Python
Чтение из файла в Python
Разберём режим чтения из файла “r”. Создайте новую программу в Spyder, сохраните её на Рабочем столе. Создайте на рабочем столе текстовый документ text с расширением txt. Внутри файла напишите следующий текст.
Создайте на рабочем столе текстовый документ text с расширением txt. Внутри файла напишите следующий текст.
Привет! Я первая строка.
Вторая строка.
Третья строка.
Чтобы вывести в программе Питон в консоль весь файл, используется команда f.read().
Пример. Программа python,которая читает весь файл и выводит его в консоль.
with open(«text.txt», «r») as f:
text = f.read()
print(text)
Команда f.read(n) может принимать аргумент n, n это количество знаков с начала, которое будет считываться из файла. Например, если будет исполняться команда f.read(50), то программа выведет 50 знаков с начала файла.
Пример. Программа в Python для считывания опредленного количества знаков
with open(«text.txt», «r») as f:
text = f.read(50)
print(text)
Если вы хотите считать текст не с начала файла, а с какого-либо символа, используйте команду f. seek(n), n это символ, с которого начнётся чтение файла. Файл начинается с нулевого символа.
seek(n), n это символ, с которого начнётся чтение файла. Файл начинается с нулевого символа.
Пример. Программа на Python, которая счтитывает информацию из файла с начала второй строки.
with open(«text.txt», «r») as f:
f.seek(27)
text = f.read(50)
print(text)
Python позволяет считать все строки текста файла в отдельный массив с помощью команды f.readlines()
Пример. Программа python выводит в консоль третью строку файла.
with open(«text.txt», «r») as f:
text = f.readlines()
print(text[2])
Для считывания строк файла используется команда f.readline() Команда будет считывать одну строку из файла. Если использовать эту команду несколько раз, то будет считываться строка за строкой Например, если вы написали две команды f.readline(), то первая команда считает первую строку, вторая команда считает вторую строку.
Пример программы python считывание строк из файла с помощью команды f. readline().
readline().
with open(«text.txt», «r») as f:
text = f.readline()
print(text)
print(f.readline())
Часто отдельные части данных разделены каким-либо знаком. Python заменять эти знаки из строк с помощью команды f.replace(start, final), где start это знак, который надо заменить, final это знак, на который надо заменить.
Пример программы, заменяющей все пробелы в строке на знак +.
string = «Всем привет! Я строка.»
print(string.replace(» «, «+»))
Запись данных в файл в python
Разберём режим добавления информации в файл в Питон “w” Для добавления информации в файл в python используется команда f.write(“text”) Эта команда удаляет весь старый текст в файле и вместо него пишет новый. После исполнения программы с этой командой зайдите в тот же файл, там не должно быть старых строк, вместо них будет текст, который вы написали в команде.
Пример программа на Python запись текста в файл с использованием команды f. write().
write().
with open(«text.txt», «w») as f:
f.write(«Текст.»)
Вместо этого текста
Привет! Я первая строка.
Вторая строка.
Третья строка.
Должна появиться эта строка
Текст.
Чтобы написать несколько строк, используется команда f.writelines(line), где line это массив со строками, которые нужно записать в файл
Программа на Python для записи массива строк в файл
with open(«text.txt», «w») as f:
f.writelines([«Первый элемент. «, «Вторая строка.»])
Разберём режим добавления информации “a”. Этот режим отличается от “w” тем, что он не удаляет старую информацию. Все команды в режиме “a” идентичны командам в режиме “w”, но в режиме “a” команды не удаляют старый текст, а записывают текст в конце файла.
Часто в программах на python входная информация считывается из файла, обрабатывается и результат записывается в новый выходной файл. Разберём большой пример работы с файлами в Python. Дан текстовый файл data с двумя столбцами и десятью строками однозначных или двузначных чисел. Числа разделены пробелом. Для каждой строки нужно найти среднее этих чисел и вывести их в новый текстовый файл result.
Дан текстовый файл data с двумя столбцами и десятью строками однозначных или двузначных чисел. Числа разделены пробелом. Для каждой строки нужно найти среднее этих чисел и вывести их в новый текстовый файл result.
Файл data.
11 47
59 15
2 52
64 48
58 88
59 86
37 39
19 92
48 85
16 78
Введём массив для обычных строк line[], массив для строк без пробелов aC[], массив для чисел в каждом столбце a1[] и a2[] и массив res[], в котором будут находиться средние значения.
Откроем файл data.txt и считаем из него числа. Введём цикл for на 10 итераций (повторений) по количеству строк. Считаем строку под номером i с помощью команды f.readline() и запишем её в массив с индексом line[i]
line[i] = f.readline()
Чтобы получить доступ к каждому чилу в строке, необходимо воспользоваться методом split, который удаляет разделитель и записывает все элементы строки в массив уже без разделителя. Подробнее о работе со строками в python
Подробнее о работе со строками в python
Для считывания всех строк файла и перевода их в массивы необходимо написать следующий код
line = {} # строки
with open(«C:\Users\user\Desktop\Win\Python\settings\data.txt»,»r») as f:
for i in range(10):
line[i] = f.readline()
stroka=line[i].split(‘ ‘)
Чтобы получить из строки stroka числовые значения первого элемента и второго, воспользуемся функцией int(). В массив res[i] запишем среднее арифметическое двух элементов строки
a=int(stroka[0])
b=int(stroka[1])
res[i]=(a+b)/2
Чтобы записать все результаты в новый файл, откроем файл result.txt в режиме “a”. С помощью цикла for запишем все результаты в отдельные строки.
with open(«C:\Users\user\Desktop\Win\Python\settings\result.txt», «a») as result:
for i in range(10):
res[i] = str(res[i])
result.write(res[i] + » «)
Полный код программы python считывание числовых столбцов из файла и запись в файл столбца средних значений
line = {} # строки
res={}
with open(«C:\Users\user\Desktop\Win\Python\settings\data. txt»,»r») as f:
txt»,»r») as f:
for i in range(10):
line[i] = f.readline()
stroka=line[i].split(‘ ‘)
a=int(stroka[0])
b=int(stroka[1])
res[i]=(a+b)/2
with open(«C:\Users\user\Desktop\Win\Python\settings\result.txt», «a») as result:
for i in range(10):
res[i] = str(res[i])
result.write(res[i] + » «)
Вернуться к содержанию Следующая тема Библиотека NumPy в Python матрицы в питон
Поделиться:
Файлы. Курс «Python. Введение в программирование»
Большие объемы данных имеет смысл хранить не в списках или словарях, а в файлах. Поэтому в языках программирования предусмотрена возможность работы с файлами. В Python файлы рассматриваются как объекты файловых классов, то есть, например, текстовый файл – это тип данных наряду с типами списка, словаря, целого числа и др.
Обычно файлы делят на текстовые и байтовые (бинарные). Первые рассматриваются как содержащие символьные данные, строки. Вторые – как поток байтов. Побайтово считываются, например, файлы изображений.
Первые рассматриваются как содержащие символьные данные, строки. Вторые – как поток байтов. Побайтово считываются, например, файлы изображений.
Работа с бинарными файлами несколько сложнее. Нередко их обрабатывают с помощью специальных модулей Python (pickle, struct). В этом уроке будут рассмотрены базовые приемы чтения текстовых файлов и записи в них.
Функция open() – открытие файла
Открытие файла выполняется с помощью встроенной в Python функции open(). Обычно ей передают один или два аргумента. Первый – имя файла или имя с адресом, если файл находится не в том каталоге, где находится скрипт. Второй аргумент – режим, в котором открывается файл.
Обычно используются режимы чтения ('r') и записи ('w'). Если файл открыт в режиме чтения, то запись в него невозможна. Можно только считывать данные из него. Если файл открыт в режиме записи, то в него можно только записывать данные, считывать нельзя.
Если файл открывается в режиме 'w', то все данные, которые в нем были до этого, стираются. Файл становится пустым. Если не надо удалять существующие в файле данные, тогда следует использовать вместо режима записи, режим дозаписи (
Файл становится пустым. Если не надо удалять существующие в файле данные, тогда следует использовать вместо режима записи, режим дозаписи ('a').
Если файл отсутствует, то открытие его в режиме 'w' создаст новый файл. Бывают ситуации, когда надо гарантировано создать новый файл, избежав случайной перезаписи данных существующего. В этом случае вместо режима 'w' используется режим 'x'. В нем всегда создается новый файл для записи. Если указано имя существующего файла, то будет выброшено исключение. Потери данных в уже имеющемся файле не произойдет.
Если при вызове open() второй аргумент не указан, то файл открывается в режиме чтения как текстовый файл. Чтобы открыть файл как байтовый, дополнительно к букве режима чтения/записи добавляется символ 'b'. Буква 't' обозначает текстовый файл. Поскольку это тип файла по умолчанию, то обычно ее не указывают.
Нельзя указывать только тип файла, то есть open("имя_файла", 'b') есть ошибка, даже если файл открывается на чтение. Правильно –
Правильно – open("имя_файла", 'rb'). Только текстовые файлы мы можем открыть командой open("имя_файла"), потому что и 'r' и 't' подразумеваются по-умолчанию.
Функция open() возвращает объект файлового типа. Его надо либо сразу связать с переменной, чтобы не потерять, либо сразу прочитать.
Чтение файла
С помощью файлового метода read() можно прочитать файл целиком или только определенное количество байт. Пусть у нас имеется файл data.txt с таким содержимым:
one - 1 - I two - 2 - II three - 3 - III four - 4 - IV five - 5 - V
Откроем его и почитаем:
>>> f1 = open('data.txt')
>>> f1.read(10)
'one - 1 - '
>>> f1.read()
'I\ntwo - 2 - II\nthree - 3 - III\n
four - 4 - IV\nfive - 5 - V\n'
>>> f1.read()
''
>>> type(f1.read())
<class 'str'>Сначала считываются первые десять байтов, которые равны десяти символам. Это не бинарный файл, но мы все равно можем читать по байтам. Последующий вызов
Это не бинарный файл, но мы все равно можем читать по байтам. Последующий вызов read() считывает весь оставшийся текст. После этого объект файлового типа f1 становится пустым.
Заметим, что метод read() возвращает строку, и что конец строки считывается как '\n'.
Для того, чтобы читать файл построчно существует метод readline():
>>> f1 = open('data.txt')
>>> f1.readline()
'one - 1 - I\n'
>>> f1.readline()
'two - 2 - II\n'
>>> f1.readline()
'three - 3 — III\n'Метод readlines() считывает сразу все строки и создает список:
>>> f1 = open('data.txt')
>>> f1.readlines()
['one - 1 - I\n', 'two - 2 - II\n',
'three - 3 - III\n',
'four - 4 - IV\n', 'five - 5 - V\n']Объект файлового типа относится к итераторам. Из таких объектов происходит последовательное извлечение элементов. Поэтому считывать данные из них можно сразу в цикле без использования методов чтения:
>>> for i in open('data. txt'):
... print(i)
...
one - 1 - I
two - 2 - II
three - 3 - III
four - 4 - IV
five - 5 - V
>>>  txt'):
... print(i)
...
one - 1 - I
two - 2 - II
three - 3 - III
four - 4 - IV
five - 5 - V
>>>
txt'):
... print(i)
...
one - 1 - I
two - 2 - II
three - 3 - III
four - 4 - IV
five - 5 - V
>>> Здесь при выводе наблюдаются лишние пустые строки. Функция print() преобразует '\n' в переход на новую строку. К этому добавляет свой переход на новую строку. Создадим список строк файла без '\n':
>>> nums = []
>>> for i in open('data.txt'):
... nums.append(i[:-1])
...
>>> nums
['one - 1 - I', 'two - 2 - II',
'three - 3 - III',
'four - 4 - IV', 'five - 5 - V']Переменной i присваивается очередная строка файла. Мы берем ее срез от начала до последнего символа, не включая его. Следует иметь в виду, что '\n' это один символ, а не два.
Запись в файл
Запись в файл выполняется с помощью методов write() и writelines(). Во второй можно передать структуру данных:
>>> l = ['tree', 'four']
>>> f2 = open('newdata. txt', 'w')
>>> f2.write('one')
3
>>> f2.write(' two')
4
>>> f2.writelines(l) txt', 'w')
>>> f2.write('one')
3
>>> f2.write(' two')
4
>>> f2.writelines(l)
txt', 'w')
>>> f2.write('one')
3
>>> f2.write(' two')
4
>>> f2.writelines(l)Метод write() возвращает количество записанных символов.
Закрытие файла
После того как работа с файлом закончена, важно не забывать его закрыть, чтобы освободить место в памяти. Делается это с помощью файлового метода close(). Свойство файлового объекта closed позволяет проверить закрыт ли файл.
>>> f1.close() >>> f1.closed True >>> f2.closed False
Если файл открывается в заголовке цикла (for i in open('fname')), то видимо интерпретатор его закрывает при завершении работы цикла или через какое-то время.
Практическая работа
Создайте файл data.txt по образцу урока. Напишите программу, которая открывает этот файл на чтение, построчно считывает из него данные и записывает строки в другой файл (dataRu.txt), заменяя английские числительные русскими, которые содержатся в списке (
["один", "два", "три", "четыре", "пять"]), определенном до открытия файлов.Создайте файл nums.txt, содержащий несколько чисел, записанных через пробел. Напишите программу, которая подсчитывает и выводит на экран общую сумму чисел, хранящихся в этом файле.
Примеры решения и дополнительные уроки в android-приложении и pdf-версии курса
7. Ввод и вывод — документация Python 3.9.5
Есть несколько способов представить вывод программы; данные можно распечатать в удобочитаемой форме или записаны в файл для использования в будущем. В этой главе будет обсудите некоторые возможности.
7.1. Фантастическое форматирование вывода
До сих пор мы встречали два способа записи значений: операторов выражения и
функция print () . (Третий способ — использовать метод write () файловых объектов; стандартный выходной файл может называться sys.стандартный вывод .
Для получения дополнительной информации см. Справочник по библиотеке.)
Часто требуется больше контроля над форматированием вывода, чем просто печать значений, разделенных пробелами. Форматировать вывод можно несколькими способами.
Чтобы использовать форматированные строковые литералы, начните строку с
fилиFперед открывающей кавычкой или тройной кавычкой. Внутри этой строки вы можете написать выражение Python между{и}символы, которые могут относиться к переменным или буквальным значениям.>>> год = 2016 >>> event = 'Референдум' >>> f'Результаты {года} {события} ' «Итоги референдума 2016 года»Метод строк
str.format ()требует большего количества ручного управления. усилие. Вы по-прежнему будете использовать{и}, чтобы отмечать, где переменная будут заменены и могут предоставить подробные директивы форматирования, но вам также потребуется предоставить информацию для форматирования.>>> yes_votes = 42_572_654 >>> no_votes = 43_132_495 >>> процент = yes_votes / (yes_votes + no_votes) >>> '{: -9} ДА голосов {: 2.2%} '. Формат (yes_votes, процент) '42572654 ДА голоса 49.67%'Наконец, вы можете выполнять всю обработку строк самостоятельно, используя нарезку строк и операции конкатенации для создания любого макета, который вы можете себе представить. В строковый тип имеет несколько методов, которые выполняют полезные операции для заполнения строки с заданной шириной столбца.
Если вам не нужен навороченный вывод, а просто нужно быстро отобразить некоторые
переменные для целей отладки, вы можете преобразовать любое значение в строку с помощью
функции repr () или str () .
Функция str () предназначена для возврата представлений значений, которые
довольно удобочитаемо, в то время как repr () предназначен для генерации представлений
который может быть прочитан интерпретатором (или вызовет SyntaxError , если
нет эквивалентного синтаксиса). Для объектов, не имеющих особого
представление для человеческого потребления, str () вернет то же значение, что и репр () . Многие значения, такие как числа или структуры, такие как списки и
словари имеют одинаковое представление с использованием любой функции.Струны, в
в частности, имеют два различных представления.
Некоторые примеры:
>>> s = 'Привет, мир.'
>>> ул (а)
'Привет мир.'
>>> представитель (ы)
"'Привет мир.'"
>>> str (1/7)
'0,14285714285714285'
>>> х = 10 * 3,25
>>> y = 200 * 200
>>> s = 'Значение x равно' + repr (x) + ', а y равно' + repr (y) + '...'
>>> печать (и)
Значение x равно 32,5, а y равно 40000 ...
>>> # Функция repr () строки добавляет строковые кавычки и обратную косую черту:
... hello = 'привет, мир \ n'
>>> привет = repr (привет)
>>> печать (привет)
'привет, мир \ n'
>>> # Аргументом repr () может быть любой объект Python:
... repr ((x, y, ('спам', 'яйца')))
"(32,5, 40000, ('спам', 'яйца'))"
Модуль string содержит класс Template , который предлагает
еще один способ подставить значения в строки, используя заполнители, такие как $ x и заменяя их значениями из словаря, но предлагает гораздо меньше
контроль форматирования.
7.1.1. Форматированные строковые литералы
Форматированные строковые литералы (также называемые f-строками для
short) позволяют включать значение выражений Python внутри строки с помощью
добавляя к строке префикс f или F и записывая выражения как {выражение} .
За выражением может следовать необязательный спецификатор формата. Это позволяет больше контроль над форматированием значения. В следующем примере число Пи округляется до три знака после запятой:
>>> импорт математики
>>> print (f'Значение числа пи приблизительно равно {math.pi: .3f}. ')
Значение пи составляет приблизительно 3,142.
Передача целого числа после ':' приведет к тому, что это поле будет минимальным
количество символов в ширину. Это полезно для выравнивания столбцов.
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 7678}
>>> для имени, телефона в table.items ():
... print (f '{name: 10} ==> {phone: 10d}')
...
Шёрд ==> 4127
Джек ==> 4098
Dcab ==> 7678
Для преобразования значения перед форматированием можно использовать другие модификаторы. '! A' применяет ascii () , '! S' применяет str () и '! R' применяется repr () :
>>> животные = 'угри'
>>> print (f'Мое судно на воздушной подушке полно {животных}. ')
Мое судно на воздушной подушке полно угрей.
>>> print (f'Мое судно на воздушной подушке полно {животных! r}. ')
Мое судно на воздушной подушке полно угрей'.
Для получения информации об этих спецификациях формата см. справочное руководство по мини-языку спецификации формата.
7.1.2. Метод String format ()
Базовое использование метода str.format () выглядит так:
>>> print ('Мы те {}, которые говорят "{}!". Format (' рыцари ',' Ни '))
Мы рыцари, которые говорят «Ни!»
Скобки и символы в них (называемые полями формата) заменяются на
объекты переданы в метод str.format () . Число в
скобки могут использоваться для обозначения позиции объекта, переданного в ул.format () метод.
>>> print ('{0} и {1}'. Формат ('спам', 'яйца'))
спам и яйца
>>> print ('{1} и {0}'. format ('спам', 'яйца'))
яйца и спам
Если аргументы ключевого слова используются в методе str.format () , их значения
упоминаются с использованием имени аргумента.
>>> print ('Эта {еда} есть {прилагательное}.'. Format (
... food = 'spam', прилагательное = 'абсолютно ужасно'))
Этот спам просто ужасен.
Позиционные аргументы и аргументы ключевого слова можно произвольно комбинировать:
>>> print ('История о {0}, {1} и {other}.'.format (' Билл ',' Манфред ',
other = 'Георг'))
История Билла, Манфреда и Георга.
Если у вас действительно длинная строка формата, которую вы не хотите разделять, она
было бы неплохо, если бы вы могли ссылаться на переменные для форматирования по имени
вместо должности. Это можно сделать, просто передав dict и используя
квадратные скобки '[]' для доступа к клавишам.
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
>>> print ('Джек: {0 [Джек]: d}; Шорд: {0 [Шорд]: d};'
... 'Dcab: {0 [Dcab]: d}'. Формат (таблица))
Джек: 4098; Шорд: 4127; Dcab: 8637678
Это также можно сделать, передав таблицу в качестве аргументов ключевого слова с «**» обозначение.
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
>>> print ('Jack: {Jack: d}; Sjoerd: {Sjoerd: d}; Dcab: {Dcab: d}'. format (** таблица))
Джек: 4098; Шорд: 4127; Dcab: 8637678
Это особенно полезно в сочетании со встроенной функцией. vars () , который возвращает словарь, содержащий все локальные переменные.
В качестве примера следующие строки создают аккуратно выровненный набор столбцов с целыми числами и их квадратами и кубами:
>>> для x в диапазоне (1, 11):
... print ('{0: 2d} {1: 3d} {2: 4d}'. format (x, x * x, x * x * x))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
Полный обзор форматирования строк с помощью str.format () см.
Синтаксис строки формата.
7.1.3. Ручное форматирование строки
Вот та же таблица квадратов и кубов, отформатированная вручную:
>>> для x в диапазоне (1, 11): ... print (repr (x) .rjust (2), repr (x * x) .rjust (3), end = '') ... # Обратите внимание на использование 'end' в предыдущей строке ... печать (repr (x * x * x) .rjust (4)) ... 1 1 1 2 4 8 3 9 27 4 16 64 5 25 125 6 36 216 7 49 343 8 64 512 9 81 729 10 100 1000
(обратите внимание, что один пробел между каждым столбцом был добавлен
способ print () работает: он всегда добавляет пробелы между своими аргументами.)
Метод str.rjust () строковых объектов выравнивает строку по правому краю в
поле заданной ширины, заполняя его пробелами слева. Есть
аналогичные методы str.ljust () и str.center () . Эти методы делают
ничего не пишут, они просто возвращают новую строку. Если входная строка слишком
long, они не усекают его, а возвращают без изменений; это испортит ваш
расположение столбцов, но обычно это лучше, чем альтернатива, которая была бы
ложь о стоимости.(Если вам действительно нужно усечение, вы всегда можете добавить
операция среза, как в x.ljust (n) [: n] .)
Существует еще один метод, str.zfill () , который заполняет числовую строку на
осталось с нулями. Он разбирается в плюсах и минусах:
>>> '12'.zfill (5) "00012" >>> '-3.14'.zfill (7) '-003,14' >>> '3.141559'.zfill (5) "3.141559"
7.1.4. Старое форматирование строки
Оператор% (по модулю) также может использоваться для форматирования строк.Учитывая 'строку'
% значений , экземпляры % в строке заменяются нулем или более
элементы значений . Эта операция широко известна как строка
интерполяция. Например:
>>> импорт математики
>>> print ('Значение пи примерно% 5.3f.'% math.pi)
Значение пи составляет приблизительно 3,142.
Дополнительную информацию можно найти в разделе «Форматирование строк в стиле printf».
7.2. Чтение и запись файлов
open () возвращает файловый объект и чаще всего используется с
два аргумента: открыть (имя файла, режим) .
>>> f = open ('рабочий файл', 'w')
Первый аргумент — это строка, содержащая имя файла. Второй аргумент
другая строка, содержащая несколько символов, описывающих способ, которым файл
будет использовано. режим может быть 'r' , когда файл будет только читаться, 'w' только для записи (существующий файл с таким же именем будет удален), и 'a' открывает файл для добавления; любые данные, записанные в файл,
автоматически добавляется в конец. 'r +' открывает файл как для чтения, так и для
письмо. Аргумент mode является необязательным; 'r' будет принято, если это
опущено.
Обычно файлы открываются в текстовом режиме , то есть вы читаете и пишете
строки из файла и в файл, которые закодированы в определенной кодировке. Если
кодировка не указана, значение по умолчанию зависит от платформы (см. открытый () ). 'b' , добавленное к режиму, открывает файл в двоичный режим : теперь данные читаются и записываются в виде байтов
объекты.Этот режим следует использовать для всех файлов, не содержащих текста.
В текстовом режиме при чтении по умолчанию выполняется преобразование строки, зависящей от платформы.
окончания ( \ n в Unix, \ r \ n в Windows) до \ n . При записи в
текстовый режим, по умолчанию вхождения \ n обратно в
окончание строк, зависящее от платформы. Эта закулисная модификация
в файл данных подходит для текстовых файлов, но приведет к повреждению двоичных данных, подобных этому в файлов JPEG или EXE .Будьте очень осторожны при использовании двоичного режима, когда
чтение и запись таких файлов.
Рекомендуется использовать с ключевым словом при работе с
с файловыми объектами. Преимущество в том, что файл правильно закрыт
после завершения его набора, даже если на каком-то
точка. Использование с также намного короче, чем написание
эквивалент попробуйте — наконец блоков:
>>> с open ('рабочий файл') как f:
... read_data = f.read ()
>>> # Мы можем проверить, что файл был автоматически закрыт.>>> f.closed
Правда
Если вы не используете с ключевым словом , вам следует позвонить f.close () , чтобы закрыть файл и немедленно освободить любую систему.
ресурсы, используемые им.
Предупреждение
Вызов f.write () без использования с ключевым словом или вызова f.close () может привести к аргументам
of f.write () не полностью записывается на диск, даже если
программа успешно завершается.
После закрытия файлового объекта либо с оператором или вызывая f.close () , попытки использовать файловый объект будут
автоматически терпит неудачу.
>>> f.close () >>> f.read () Отслеживание (последний вызов последний): Файл "", строка 1, в ValueError: операция ввода-вывода для закрытого файла.
7.2.1. Методы файловых объектов
В остальных примерах этого раздела предполагается, что файловый объект с именем f уже создан.
Чтобы прочитать содержимое файла, позвоните по номеру f.read (size) , который читает некоторое количество
data и возвращает их в виде строки (в текстовом режиме) или байтового объекта (в двоичном режиме). размер — необязательный числовой аргумент. Если размер опущен или отрицателен,
будет прочитано и возвращено все содержимое файла; это ваша проблема, если
размер файла вдвое превышает объем памяти вашего компьютера. В противном случае не более размер символов (в текстовом режиме) или размером байт (в двоичном режиме) считываются и возвращаются.Если достигнут конец файла, f.read () вернет пустой
строка ( '' ).
>>> f.read () "Это весь файл. \ N" >>> f.read () ''
f.readline () читает одну строку из файла; символ новой строки ( \ n )
остается в конце строки и опускается только в последней строке
file, если файл не заканчивается новой строкой. Это делает возвращаемое значение
однозначный; если f.readline () возвращает пустую строку, конец файла
был достигнут, а пустая строка представлена как '\ n' , строка
содержащий только одну новую строку.
>>> f.readline () "Это первая строка файла. \ N" >>> f.readline () 'Вторая строка файла \ n' >>> f.readline () ''
Для чтения строк из файла вы можете перебрать объект файла. Это память эффективный, быстрый и простой код:
>>> для строки в f: ... печать (строка, конец = '') ... Это первая строка файла. Вторая строка файла
Если вы хотите прочитать все строки файла в списке, вы также можете использовать список (е) или ф.Чтение линий () .
f.write (строка) записывает содержимое строки в файл, возвращая
количество написанных символов.
>>> f.write ('Это тест \ n')
15
Остальные типы объектов необходимо преобразовать — либо в строку (в текстовом режиме) или байтовый объект (в двоичном режиме) — перед их записью:
>>> value = ('ответ', 42)
>>> s = str (value) # преобразовать кортеж в строку
>>> е.написать (а)
18
f.tell () возвращает целое число, указывающее текущую позицию файлового объекта в файле.
представлен как количество байтов от начала файла в двоичном режиме и
непрозрачный номер в текстовом режиме.
Чтобы изменить положение файлового объекта, используйте f.seek (смещение, откуда) . Позиция вычисляется
от добавления смещения к опорной точке; точка отсчета выбирается , откуда аргумент. , откуда значение 0 отсчитывает от начала
файла, 1 использует текущую позицию файла, а 2 использует конец файла как
ориентир., откуда можно опустить и по умолчанию 0, используя
начало файла в качестве ориентира.
>>> f = open ('рабочий файл', 'rb +')
>>> f.write (b'0123456789abcdef ')
16
>>> f.seek (5) # Перейти к 6-му байту в файле
5
>>> f.read (1)
b'5 '
>>> f.seek (-3, 2) # Перейти к 3-му байту до конца
13
>>> f.read (1)
b'd '
В текстовых файлах (открытых без b в строке режима) выполняется поиск только
относительно начала файла разрешены (исключение — поиск
до самого конца файла с seek (0, 2) ), и единственными допустимыми значениями смещения являются
те, что вернулись из ф.tell () или ноль. Любое другое значение смещения дает
неопределенное поведение.
Файловые объекты имеют некоторые дополнительные методы, такие как isatty () и truncate () , которые используются реже; обратиться в библиотеку
Справочник для полного руководства по файловым объектам.
7.2.2. Сохранение структурированных данных с помощью
json Строки можно легко записывать и читать из файла. Числа занимают немного больше
усилия, поскольку метод read () возвращает только строки, которые должны
передается в функцию типа int () , которая принимает строку типа '123' и возвращает его числовое значение 123.Если вы хотите сохранить более сложные данные
типы, такие как вложенные списки и словари, парсинг и сериализация вручную
усложняется.
Вместо того, чтобы заставлять пользователей постоянно писать и отлаживать код для экономии
сложные типы данных в файлы, Python позволяет использовать популярные данные
формат обмена называется JSON (JavaScript Object Notation). Стандартный модуль под названием json может принимать Python
иерархии данных и преобразовать их в строковые представления; этот процесс
позвонил , сериализуя .Реконструкция данных из строкового представления
называется десериализацией . Между сериализацией и десериализацией
строка, представляющая объект, могла быть сохранена в файле или данных, или
отправлено через сетевое соединение на какую-то удаленную машину.
Примечание
Формат JSON обычно используется современными приложениями для обработки данных. обмен. Многие программисты уже знакомы с ним, что делает это хороший выбор для взаимодействия.
Если у вас есть объект размером x , вы можете просмотреть его строковое представление JSON с
простая строка кода:
>>> импортировать json >>> x = [1, 'простой', 'список'] >>> json.свалки (x) '[1, «простой», «список»] »
Другой вариант функции dumps () , называемый dump () ,
просто сериализует объект в текстовый файл. Итак, если f — это
объект текстового файла, открытый для записи, мы можем сделать это:
Для повторного декодирования объекта, если f — это объект текстового файла, имеющий
открыт для чтения:
Этот простой метод сериализации может обрабатывать списки и словари, но
сериализация произвольных экземпляров класса в JSON требует немного дополнительных усилий.Ссылка на модуль json содержит объяснение этого.
См. Также
pickle — модуль pickle
В отличие от JSON, pickle — это протокол, который позволяет сериализация произвольно сложных объектов Python. Таким образом, это специфичен для Python и не может использоваться для связи с приложениями написано на других языках. По умолчанию это тоже небезопасно: десериализация данных рассола, поступающих из ненадежного источника, может выполнить произвольный код, если данные были созданы опытным злоумышленником.
Чтение и запись в текстовые файлы в Python
Python предоставляет встроенные функции для создания, записи и чтения файлов. Существует два типа файлов, которые могут обрабатываться в Python: обычные текстовые файлы и двоичные файлы (написанные на двоичном языке, нули и единицы).
- Текстовые файлы: В файлах этого типа каждая строка текста заканчивается специальным символом EOL (конец строки), который по умолчанию является символом новой строки (‘\ n’) в Python.
- Двоичные файлы: В файлах этого типа отсутствует терминатор для строки, и данные сохраняются после их преобразования в понятный для машины двоичный язык.
В этой статье мы сосредоточимся на открытии, закрытии, чтении и записи данных в текстовый файл.
Режимы доступа к файлам
Режимы доступа определяют тип операций, возможных в открытом файле. Это относится к тому, как файл будет использоваться после его открытия. Эти режимы также определяют расположение дескриптора файла в файле. Дескриптор файла подобен курсору, который определяет, откуда данные должны быть прочитаны или записаны в файле. В python есть 6 режимов доступа.
- Только чтение («r»): Открыть текстовый файл для чтения. Ручка находится в начале файла. Если файл не существует, возникает ошибка ввода-вывода. Это также режим по умолчанию, в котором открывается файл.
- Чтение и запись («r +»): Откройте файл для чтения и записи. Ручка находится в начале файла. Вызывает ошибку ввода-вывода, если файл не существует.
- Только запись («w»): Откройте файл для записи.Для существующего файла данные усекаются и перезаписываются. Ручка находится в начале файла. Создает файл, если файл не существует.
- Запись и чтение («w +») : Откройте файл для чтения и записи. Для существующего файла данные усекаются и перезаписываются. Ручка находится в начале файла.
- Только приложение (‘a’) : Откройте файл для записи. Если файл не существует, он создается. Ручка находится в конце файла.Записываемые данные будут вставлены в конце после существующих данных.
- Добавить и прочитать («a +»): Откройте файл для чтения и записи. Если файл не существует, он создается. Ручка находится в конце файла. Записываемые данные будут вставлены в конце после существующих данных.
Открытие файла
Это делается с помощью функции open (). Для этой функции импорт модуля не требуется.
File_object = open (r "File_Name", "Access_Mode")
Файл должен существовать в том же каталоге, что и программный файл python, иначе полный адрес файла должен быть записан вместо имени файла.
Примечание: r помещается перед именем файла, чтобы символы в строке имени файла не рассматривались как специальные символы. Например, если в адресе файла есть \ temp, то \ t рассматривается как символ табуляции и возникает ошибка недопустимого адреса. R делает строку необработанной, то есть сообщает, что в строке нет специальных символов. Букву r можно игнорировать, если файл находится в том же каталоге, а адрес не помещается.
|
Здесь file1 создается как объект для MyFile1 и file2 как объект для MyFile2
Закрытие файла
Функция close () закрывает файл и освобождает пространство памяти, полученное этот файл.Он используется тогда, когда файл больше не нужен или если его нужно открыть в другом файловом режиме.
File_object.close ()
|
Запись в файл
Есть два способа записи в файл.
- write (): Вставляет строку str1 в одну строку в текстовый файл.
File_object.write (str1)
- writelines (): Для списка строковых элементов каждая строка вставляется в текстовый файл. Используется для одновременной вставки нескольких строк.
File_object.writelines (L) для L = [str1, str2, str3]
Чтение из файла
Есть три способа чтения данных из текстового файла.
- read (): Возвращает прочитанные байты в виде строки. Читает n байтов, если n не указано, читает весь файл.
File_object.read ([n])
- readline (): Считывает строку файла и возвращает в виде строки. Для указанного n считывает не более n байтов. Однако не читает более одной строки, даже если n превышает длину строки.
File_object.readline ([n])
- readlines (): Считывает все строки и возвращает их как каждую строку как строковый элемент в списке.
File_object.readlines ()
Примечание. ‘\ n’ рассматривается как специальный символ из двух байтов
print file1.read ( 9 ) print |
Вывод:
Вывод функции чтения Привет Это Дели Это париж Это лондон Вывод функции Readline: Привет Вывод функции Read (9): Привет Чт Вывод функции Readline (9): Привет Вывод функции Readlines: ['Привет \ n', 'Это Дели \ n', 'Это Париж \ n', 'Это Лондон \ n']
Добавление к файлу
file |
Выход:
Вывод Readlines после добавления ['Это Дели \ n', 'Это Париж \ n', 'Это Лондон \ n', 'Сегодня \ n'] Вывод строк чтения после записи ['Завтра \ n']
Статья по теме:
Объекты файлов в Python
Автором этой статьи является Harshit Agrawal . Если вам нравится GeeksforGeeks, и вы хотите внести свой вклад, вы также можете написать статью, используя свой вклад.geeksforgeeks.org или отправьте свою статью по адресу [email protected]. Посмотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или если вы хотите поделиться дополнительной информацией по теме, обсуждаемой выше.
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .И чтобы начать свое путешествие по машинному обучению, присоединитесь к курсу Машинное обучение - базовый уровень
Чтение файла построчно в Python
Предварительные требования:
Python предоставляет встроенные функции для создания, записи и чтения файлов. Существует два типа файлов, которые могут обрабатываться в Python: обычные текстовые файлы и двоичные файлы (написанные на двоичном языке, нули и единицы). В этой статье мы изучим построчное чтение из файла.
Чтение построчно
Использование readlines ()
readlines () используется для чтения всех строк за один раз, а затем возвращает их как строковый элемент в каждой строке списка.Эту функцию можно использовать для небольших файлов, поскольку она считывает все содержимое файла в память, а затем разбивает его на отдельные строки. Мы можем перебирать список и удалять символ новой строки «\ n» с помощью функции strip ().
Пример:
Python3
|
Вывод:
Line1: Компьютерщики Line2: для Line3: Компьютерщики
Использование readline ()
Функция readline () считывает строку файла и возвращает ее в виде строки. Он принимает параметр n, который указывает максимальное количество байтов, которые будут прочитаны. Однако не читает более одной строки, даже если n превышает длину строки.Это будет эффективно при чтении большого файла, потому что вместо получения всех данных за один раз он выбирает строку за строкой. readline () возвращает следующую строку файла, которая в конце содержит символ новой строки. Кроме того, если достигнут конец файла, он вернет пустую строку.
Пример:
Python3
|
Вывод:
Line1 Geeks Line2 для Line3 Компьютерщики
Использование цикла for
Итерируемый объект возвращается функцией open () при открытии файла.Этот последний способ построчного чтения файла включает итерацию файлового объекта в цикле for. При этом мы используем встроенную функцию Python, которая позволяет нам перебирать файловый объект неявно, используя цикл for в сочетании с использованием итерируемого объекта. Этот подход требует меньшего количества строк кода, что всегда является наилучшей практикой, которой следует придерживаться.
Пример:
Python3
|
Вывод:
Использование цикла for Строка 1: Гики Line2: для Строка 3: Компьютерщики
С оператором
В приведенных выше подходах каждый раз, когда файл открывается, его необходимо закрывать явно. Если забыть закрыть файл, это может привести к появлению нескольких ошибок в коде, т.е. многие изменения в файлах не вступят в силу, пока файл не будет должным образом закрыт.Чтобы предотвратить это, можно использовать оператор with. Оператор With в Python используется при обработке исключений, чтобы сделать код более понятным и понятным. Это упрощает управление общими ресурсами, такими как файловые потоки. Обратите внимание на следующий пример кода, показывающий, как использование оператора with делает код более чистым. При использовании с оператором нет необходимости вызывать file.close (). Сам оператор with обеспечивает правильное получение и высвобождение ресурсов.
Пример:
Python3
|
Вывод:
Использование readlines () Строка 1: Гики Line2: для Line3: Компьютерщики Использование readline () Строка 1: Гики Line2: для Line3: Компьютерщики Использование цикла for Строка 1: Гики Line2: для Line3: Компьютерщики
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .И чтобы начать свое путешествие по машинному обучению, присоединяйтесь к Машинное обучение - курс базового уровня
Как создавать, открывать, добавлять, читать, писать
В Python нет необходимости импортировать внешнюю библиотеку для чтения и записи файлов. . Python предоставляет встроенную функцию для создания, записи и чтения файлов.
В этом руководстве по обработке файлов в Python мы узнаем:
Как открыть текстовый файл в Python
Чтобы открыть файл, вам необходимо использовать встроенную функцию open .Функция открытия файла Python возвращает объект файла, который содержит методы и атрибуты для выполнения различных операций по открытию файлов в Python.
Синтаксис функции открытого файла Python
file_object = open ("имя файла", "режим")
Здесь
- filename: дает имя файла, который открыл файловый объект.
- mode: атрибут файлового объекта сообщает вам, в каком режиме был открыт файл.
Более подробная информация об этих режимах объясняется ниже
Как создать текстовый файл в Python
с Python для записи в файл, вы можете создать файл.текстовые файлы (guru99.txt) с помощью кода, который мы продемонстрировали здесь:
Шаг 1)
f = open ("guru99.txt", "w +") - Мы объявили переменную f для открытия файла с именем guru99.txt. Open принимает 2 аргумента: файл, который мы хотим открыть, и строку, представляющую типы разрешений или операций, которые мы хотим выполнить с файлом.
- Здесь мы использовали букву «w» в нашем аргументе, которая указывает Python на запись в файл. и он создаст файл, если он не существует в библиотеке
- Знак плюс указывает как чтение, так и запись для операции создания файла Python.
Шаг 2)
для i в диапазоне (10):
f.write ("Это строка% d \ r \ n"% (i + 1)) - У нас есть цикл for, который работает с диапазоном из 10 чисел.
- Использование функции записи для ввода данных в файл.
- Результат, который мы хотим повторить в файле, - это «это номер строки», который мы объявляем с помощью функции записи Python в текстовый файл, а затем процента d (отображает целое число)
- Итак, в основном мы вводим номер строки, который мы пишут, затем помещают его в символ возврата каретки и символа новой строки
Шаг 3)
f.close ()
- Это закроет экземпляр сохраненного файла guru99.txt
Вот результат после выполнения кода для Python create file
Когда вы щелкаете текстовый файл в нашем случае "guru99.txt", он будет выглядеть примерно так
Как добавить к файлу в Python
Вы также можете добавить / добавить новый текст к уже существующему файлу или новому файлу.
Шаг 1)
f = open ("guru99.txt", "a +") Еще раз, если вы можете увидеть знак плюса в коде, это означает, что он создаст новый файл, если это произойдет. не существует.Но в нашем случае у нас уже есть файл, поэтому нам не нужно создавать новый файл для Python, добавляемого к операции с файлом.
Шаг 2)
для i в диапазоне (2):
f.write ("Добавленная строка% d \ r \ n"% (i + 1)) Это запишет данные в файл в режиме добавления.
Результат можно увидеть в файле "guru99.txt". Результатом кода является то, что более ранний файл добавляется с новыми данными Python к операции добавления к файлу.
Как читать файлы в Python
Вы можете прочитать файл в Python, позвонив.txt в "режиме чтения" (r).
Шаг 1) Открыть файл в режиме чтения
f = open ("guru99.txt", "r") Шаг 2) Мы используем функцию режима в коде, чтобы проверить, находится ли файл в открытом режиме. Если да, продолжаем
if f.mode == 'r':
Шаг 3) Используйте f.read для чтения данных файла и сохраните его в переменном содержимом для чтения файлов в Python
content = f.read ()
Шаг 4) Распечатать содержимое для текстового файла чтения Python
Вот результат примера файла чтения Python:
Как читать файл построчно в Python
Вы можете также прочтите ваш.txt построчно, если ваши данные слишком велики для чтения. Код readlines () разделит ваши данные в удобном для чтения режиме.
Когда вы запускаете код ( f1 = f.readlines ()) для чтения файла построчно в Python, он разделяет каждую строку и представляет файл в читаемом формате. В нашем случае строка короткая и читабельная, вывод будет похож на режим чтения. Но если есть сложный файл данных, который не читается, этот фрагмент кода может быть полезен.
Файловые режимы в Python
Ниже приведены различные файловые режимы в Python :
| Режим | Описание |
|---|---|
| 'r' | Это режим по умолчанию.Открывает файл для чтения. |
| 'w' | Этот режим Открывает файл для записи. Если файл не существует, создается новый файл. Если файл существует, он обрезает файл. |
| 'x' | Создает новый файл. Если файл уже существует, операция не выполняется. |
| 'a' | Открыть файл в режиме добавления. Если файл не существует, создается новый файл. |
| 't' | Это режим по умолчанию.Открывается в текстовом режиме. |
| 'b' | Открывается в двоичном режиме. |
| '+' | Это откроет файл для чтения и записи (обновления) |
Вот полный код для Python print () в Пример файла
Python 2 Пример
def main ():
f = open ("guru99.txt", "w +")
# f = open ("guru99.txt", "a +")
для i в диапазоне (10):
f.write ("Это строка% d \ r \ n"% (i + 1))
f.Закрыть()
# Откройте файл и прочтите его содержимое
# f = open ("guru99.txt", "r")
# если f.mode == 'r':
# contents = f.read ()
# распечатать содержимое
# или readlines считывает отдельную строку в список
#fl = f.readlines ()
# для x in fl:
#print x
если __name __ == "__main__":
main () Пример Python 3
Ниже показан другой пример Python print () в файл:
def main ():
f = open ("guru99.txt "," w + ")
# f = open ("guru99.txt", "a +")
для i в диапазоне (10):
f.write ("Это строка% d \ r \ n"% (i + 1))
f.close ()
# Откройте файл и прочтите его содержимое
# f = open ("guru99.txt", "r")
#if f.mode == 'r':
# contents = f.read ()
# print (содержимое)
# или readlines считывает отдельную строку в список
#fl = f.readlines ()
# для x in fl:
#print (x)
если __name __ == "__main__":
main () Сводка
- Python позволяет читать, записывать и удалять файлы
- Используйте функцию open ("filename", "w +") для создания текстового файла Python.Знак + сообщает интерпретатору Python для открытого текстового файла Python с разрешениями на чтение и запись.
- Чтобы добавить данные в существующий файл или выполнить операцию печати Python в файл, используйте команду open («Имя файла», « a »).
- Используйте функцию чтения файла Python для чтения ВСЕГО содержимого файла.
- Используйте функция readlines для чтения содержимого файла по очереди.
Чтение и запись файлов на Python
Файлы
Файлы - это места на диске, в которых хранится соответствующая информация.Они используются для постоянного хранения данных в энергонезависимой памяти (например, на жестком диске).
Поскольку оперативная память (RAM) является энергозависимой (которая теряет свои данные при выключении компьютера), мы используем файлы для будущего использования данных, постоянно сохраняя их.
Когда мы хотим читать или записывать в файл, нам нужно сначала открыть его. Когда мы закончим, его нужно закрыть, чтобы освободить ресурсы, связанные с файлом.
Следовательно, в Python файловая операция выполняется в следующем порядке:
- Открыть файл
- Чтение или запись (выполнение операции)
- Закройте файл
Открытие файлов в Python
Python имеет встроенную функцию open () для открытия файла.Эта функция возвращает файловый объект, также называемый дескриптором, поскольку он используется для чтения или изменения файла соответственно.
>>> f = open ("test.txt") # открыть файл в текущем каталоге
>>> f = open ("C: /Python38/README.txt") # указание полного пути Мы можем указать режим при открытии файла. В режиме мы указываем, хотим ли мы прочитать r , записать w или добавить в файл a . Мы также можем указать, хотим ли мы открыть файл в текстовом или двоичном режиме.
По умолчанию чтение в текстовом режиме. В этом режиме мы получаем строки при чтении из файла.
С другой стороны, двоичный режим возвращает байты, и это режим, который следует использовать при работе с нетекстовыми файлами, такими как изображения или исполняемые файлы.
| Режим | Описание |
|---|---|
р | Открывает файл для чтения. (по умолчанию) |
w | Открывает файл для записи.Создает новый файл, если он не существует, или обрезает файл, если он существует. |
x | Открывает файл для монопольного создания. Если файл уже существует, операция не выполняется. |
| Открывает файл для добавления в конец файла без его усечения. Создает новый файл, если он не существует. |
т | Открывается в текстовом режиме. (по умолчанию) |
б | Открывается в двоичном режиме. |
+ | Открывает файл для обновления (чтения и записи) |
f = open ("test.txt") # эквивалентно 'r' или 'rt'
f = open ("test.txt", 'w') # писать в текстовом режиме
f = open ("img.bmp", 'r + b') # чтение и запись в двоичном режиме В отличие от других языков, символ a не подразумевает число 97, пока он не будет закодирован с использованием ASCII (или других эквивалентных кодировок).
Более того, кодировка по умолчанию зависит от платформы. В Windows это cp1252 , но utf-8 в Linux.
Итак, мы не должны также полагаться на кодировку по умолчанию, иначе наш код будет вести себя по-разному на разных платформах.
Следовательно, при работе с файлами в текстовом режиме настоятельно рекомендуется указывать тип кодировки.
f = open ("test.txt", mode = 'r', encoding = 'utf-8') Закрытие файлов в Python
Когда мы закончили выполнение операций с файлом, нам нужно правильно закрыть файл.
Закрытие файла освободит ресурсы, которые были связаны с файлом. Это делается с помощью метода close () , доступного в Python.
Python имеет сборщик мусора для очистки объектов, на которые нет ссылок, но мы не должны полагаться на него при закрытии файла.
f = open ("test.txt", encoding = 'utf-8')
# выполнять файловые операции
f.close () Этот метод не совсем безопасен. Если при выполнении какой-либо операции с файлом возникает исключение, код завершается без закрытия файла.
Более безопасный способ - использовать блок try ... finally.
попробуйте:
f = open ("test.txt", encoding = 'utf-8')
# выполнять файловые операции
наконец-то:
f.close () Таким образом, мы гарантируем, что файл будет правильно закрыт, даже если возникает исключение, вызывающее остановку выполнения программы.
Лучший способ закрыть файл - использовать с оператором . Это гарантирует, что файл будет закрыт при выходе из блока внутри с оператором .
Нам не нужно явно вызывать метод close () . Это делается изнутри.
с open ("test.txt", encoding = 'utf-8') как f:
# выполнять файловые операции Запись в файлы на Python
Чтобы записать в файл на Python, нам нужно открыть его в режиме записи w , добавить в или в режиме монопольного создания x .
Мы должны быть осторожны с режимом w , так как он будет перезаписан в файл, если он уже существует.Благодаря этому стираются все предыдущие данные.
Запись строки или последовательности байтов (для двоичных файлов) выполняется с помощью метода write () . Этот метод возвращает количество символов, записанных в файл.
с open ("test.txt", 'w', encoding = 'utf-8') как f:
f.write ("мой первый файл \ n")
f.write ("Этот файл \ n \ n")
f.write ("содержит три строки \ n") Эта программа создаст новый файл с именем test.txt в текущем каталоге, если он не существует.Если он существует, он перезаписывается.
Мы должны сами включить символы новой строки, чтобы различать разные строки.
Чтение файлов в Python
Чтобы прочитать файл на Python, мы должны открыть файл в режиме чтения r .
Для этого доступны различные методы. Мы можем использовать метод read (size) для чтения размера данных. Если параметр size не указан, он читает и возвращает до конца файла.
Мы можем прочитать файл text.txt , который мы написали в предыдущем разделе, следующим образом:
>>> f = open ("test.txt", 'r', encoding = 'utf-8')
>>> f.read (4) # читать первые 4 данных
'Этот'
>>> f.read (4) # читать следующие 4 данных
' является '
>>> f.read () # читать остаток до конца файла
'мой первый файл \ nЭтот файл \ nсодержит три строки \ n'
>>> f.read () # дальнейшее чтение возвращает пустое жало
' Мы видим, что метод read () возвращает новую строку как '\ n' .По достижении конца файла при дальнейшем чтении мы получаем пустую строку.
Мы можем изменить текущий файловый курсор (позицию), используя метод seek () . Точно так же метод tell () возвращает нашу текущую позицию (в байтах).
>>> f.tell () # получаем текущую позицию в файле
56
>>> f.seek (0) # переводим файловый курсор в исходную позицию
0
>>> print (f.read ()) # читать весь файл
Это мой первый файл
Этот файл
содержит три строки Мы можем читать файл построчно, используя цикл for.Это одновременно эффективно и быстро.
>>> для строки в f:
... печать (строка, конец = '')
...
Это мой первый файл
Этот файл
содержит три строки В этой программе строки в самом файле содержат символ новой строки \ n . Итак, мы используем конечный параметр функции print () , чтобы избежать появления двух символов новой строки при печати.
В качестве альтернативы мы можем использовать метод readline () для чтения отдельных строк файла.Этот метод читает файл до новой строки, включая символ новой строки.
>>> f.readline ()
'Это мой первый файл \ n'
>>> f.readline ()
'Этот файл \ n'
>>> f.readline ()
'содержит три строки \ n'
>>> f.readline ()
' Наконец, метод readlines () возвращает список оставшихся строк всего файла. Все эти методы чтения возвращают пустые значения, когда достигается конец файла (EOF).
>>> ф.readlines ()
['Это мой первый файл \ n', 'Этот файл \ n', 'содержит три строки \ n'] Методы файла Python
С файловым объектом доступны различные методы. Некоторые из них были использованы в приведенных выше примерах.
Вот полный список методов в текстовом режиме с кратким описанием:
| Метод | Описание |
|---|---|
| закрыть () | Закрывает открытый файл. Не действует, если файл уже закрыт. |
| отсоединить () | Отделяет базовый двоичный буфер от TextIOBase и возвращает его. |
| fileno () | Возвращает целое число (дескриптор файла) файла. |
| заподлицо () | Очищает буфер записи файлового потока. |
| isatty () | Возвращает True , если файловый поток является интерактивным. |
| читать ( n ) | Считывает из файла не более n символов.Читает до конца файла, если оно отрицательное или Нет . |
| читаемый () | Возвращает True , если файловый поток может быть прочитан. |
| строка чтения ( n = -1) | Читает и возвращает одну строку из файла. Считывает не более n байт, если указано. |
| строк чтения ( n = -1) | Читает и возвращает список строк из файла. Считывает не более n байт / символов, если указано. |
поиск ( смещение , от = SEEK_SET ) | Изменяет позицию файла на , смещение байтов, по отношению к с (начало, текущее, конец). |
| для поиска () | Возвращает True , если файловый поток поддерживает произвольный доступ. |
| сказать () | Возвращает текущее расположение файла. |
усечь ( размер = Нет ) | Изменяет размер файлового потока до , размер байт.Если размер не указан, изменяется в соответствии с текущим местоположением. |
| с возможностью записи () | Возвращает True , если возможна запись в файловый поток. |
| запись ( с ) | Записывает строку s в файл и возвращает количество записанных символов. |
| линий записи ( строк ) | Записывает в файл список из строк . |
Построчное чтение файла на Python
Введение
На протяжении моей трудовой жизни у меня была возможность использовать множество концепций программирования и технологий для бесчисленного множества вещей.Некоторые из этих вещей связаны с относительно низкими результатами моего труда, такими как автоматизация подверженных ошибкам или рутинных задач, таких как создание отчетов, автоматизация задач и общее переформатирование данных. Другие были гораздо более ценными, например разработка продуктов данных, веб-приложений, конвейеров анализа и обработки данных. Одна вещь, которая примечательна почти во всех этих проектах, - это необходимость просто открыть файл, проанализировать его содержимое и что-то с ним сделать.
Однако что делать, если файл, который вы пытаетесь использовать, довольно велик? Что делать, если файл содержит несколько ГБ данных или больше? Опять же, это был еще один частый аспект моей карьеры программиста, который в основном был проведен в секторе биотехнологий, где часто встречаются файлы размером более 1 ТБ.
Ответ на эту проблему состоит в том, чтобы читать файл по частям, обрабатывать его, а затем освобождать его из памяти, чтобы вы могли извлечь и обработать другой фрагмент, пока не будет обработан весь массивный файл. Хотя определение подходящего размера блока зависит от программиста, для многих приложений целесообразно обрабатывать файл по одной строке за раз.
В этой статье мы рассмотрим несколько примеров кода, чтобы показать, как читать файлы построчно. Если вы хотите самостоятельно опробовать некоторые из этих примеров, код, использованный в этой статье, можно найти в следующем репозитории GitHub.
Базовый файловый ввод-вывод в Python
Будучи отличным языком программирования общего назначения, Python имеет ряд очень полезных функций файлового ввода-вывода в своей стандартной библиотеке встроенных функций и модулей. Встроенная функция open () - это то, что вы используете для открытия файлового объекта для чтения или записи.
fp = open ('путь / к / file.txt', 'r')
Функция open () принимает несколько аргументов. Мы сосредоточимся на первых двух, первый из которых является позиционным строковым параметром, представляющим путь к файлу, который должен быть открыт.Второй необязательный параметр также является строкой, которая определяет режим взаимодействия, который вы предполагаете для файлового объекта, возвращаемого вызовом функции. Наиболее распространенные режимы перечислены в таблице ниже, по умолчанию для чтения используется буква r.
| Режим | Описание |
|---|---|
r | Открыт для чтения обычного текста |
w | Открыт для ввода обычного текста |
| Открыть существующий файл для добавления простого текста |
руб | Открыт для чтения двоичных данных |
ВБ | Открыть для записи двоичных данных |
После того, как вы написали или прочитали все требуемые данные для файлового объекта, вам необходимо закрыть файл, чтобы можно было перераспределить ресурсы в операционной системе, в которой выполняется код.
фп. Закрыть ()
Вы часто увидите множество фрагментов кода в Интернете или в обычных программах, которые не закрывают явным образом файловые объекты, созданные в соответствии с приведенным выше примером. Всегда полезно закрывать ресурс файлового объекта, но многие из нас либо слишком ленивы, либо забывают это делать, либо думают, что мы умны, потому что документация предполагает, что открытый файловый объект сам закроется после завершения процесса. Это не всегда так.
Вместо того, чтобы твердить о том, насколько важно всегда вызывать close () для файлового объекта, я хотел бы предоставить альтернативный и более элегантный способ открытия файлового объекта и гарантировать, что интерпретатор Python очистится после нас 🙂
с open ('path / to / file.txt') как fp:
Просто используя с ключевым словом (введенное в Python 2.5) для обертывания нашего кода для открытия файлового объекта, внутренние компоненты Python будут делать что-то похожее на следующий код, чтобы гарантировать, что независимо от того, какой файловый объект закрывается после использования .
попробовать:
fp = open ('путь / к / file.txt')
наконец-то:
fp.close ()
Подходит любой из этих двух методов, причем первый пример является более «питоническим» способом.
Строка чтения за строкой
Теперь перейдем к чтению файла. Файловый объект, возвращаемый из open () , имеет три общих явных метода ( чтения , строки чтения и строк чтения ) для чтения данных и еще один неявный способ.
Метод read считывает все данные в одну текстовую строку. Это полезно для файлов меньшего размера, когда вы хотите выполнять манипуляции с текстом всего файла или что-то еще, что вам подходит. Затем есть строка чтения , которая является одним из полезных способов чтения только отдельных строк с приращениями за раз и возврата их в виде строк. Последний явный метод, readlines , будет читать все строки файла и возвращать их в виде списка строк.
Как упоминалось ранее, вы можете использовать эти методы только для загрузки небольших фрагментов файла за раз.Чтобы сделать это с помощью этих методов, вы можете передать им параметр, указывающий, сколько байтов загружать за раз. Это единственный аргумент, который принимают эти методы.
Одна реализация для чтения текстового файла по одной строке за раз показана ниже, которая выполняется с помощью метода readline () .
Примечание : В оставшейся части этой статьи я буду демонстрировать, как читать в тексте книги «Илиада Гомера», которую можно найти на gutenberg.org, а также в репозитории GitHub, где код для этой статьи.
В readline.py вы найдете следующий код. В терминале, если вы запустите $ python readline.py , вы увидите результат чтения всех строк Илиады, а также их номера строк.
filepath = 'Iliad.txt'
с открытым (путь к файлу) как fp:
линия = fp.readline ()
cnt = 1
а строка:
print ("Строка {}: {}". формат (cnt, line.strip ()))
линия = fp.readline ()
cnt + = 1
Приведенный выше фрагмент кода открывает файловый объект, хранящийся как переменная с именем fp , затем читает по очереди, вызывая readline для этого файлового объекта итеративно в цикле while и выводит его на консоль.
Запустив этот код, вы должны увидеть что-то вроде следующего:
$ python forlinein.py
Строка 0: КНИГА I
Линия 1:
Строка 2: Ссора между Агамемноном и Ахиллом - Ахилл уходит
Строка 3: с войны и посылает свою мать Фетиду просить Юпитера о помощи.
Строка 4: Троянцы - Сцена между Юпитером и Юноной на Олимпе.
Строка 5:
Строка 6: Пой, о богиня, гнев Ахилла, сына Пелея, который принес
Строка 7: бесчисленные беды ахейцам. Многие храбрые души послали
Строка 8: спешить в Аид, и многие герои стали жертвой собак и
Строка 9: стервятники, ибо так исполнились советы Юпитера с того дня.
...
Хотя это прекрасно, есть еще один способ, о котором я мельком упомянул ранее, он менее явный, но немного более элегантный, который я очень предпочитаю. Этот последний способ построчного чтения файла включает в себя итерацию файлового объекта в цикле для , присвоение каждой строке специальной переменной, называемой строка . Приведенный выше фрагмент кода можно воспроизвести в следующем коде, который можно найти в скрипте Python forlinein.py:
filepath = 'Илиада.текст'
с открытым (путь к файлу) как fp:
для cnt строка в enumerate (fp):
print ("Строка {}: {}". формат (cnt, строка))
В этой реализации мы используем встроенную функциональность Python, которая позволяет нам выполнять итерацию по объекту файла неявно, используя цикл для в сочетании с использованием итеративного объекта fp . Это не только проще для чтения, но и требует написания меньшего количества строк кода, что всегда является передовой практикой, которой стоит следовать.
Пример приложения
- 30-дневная гарантия возврата денег без вопросов
- От начального до продвинутого
- Регулярно обновляется (последнее обновление июнь 2021 г.)
- Обновляется бонусными ресурсами и руководствами
Было бы упущением написать приложение о том, как потреблять информацию в текстовом файле без демонстрации хотя бы тривиального использования такого достойного навыка. При этом я продемонстрирую небольшое приложение, которое можно найти в wordcount.py, который вычисляет частоту каждого слова, присутствующего в «Илиаде Гомера», использованной в предыдущих примерах. Это создает простой набор слов, который обычно используется в приложениях НЛП.
импортная система
импорт ОС
def main ():
filepath = sys.argv [1]
если не os.path.isfile (путь к файлу):
print ("Путь к файлу {} не существует. Выходит ...". формат (путь к файлу))
sys.exit ()
bag_of_words = {}
с открытым (путь к файлу) как fp:
cnt = 0
для строки в fp:
print ("строка {} содержимое {}".формат (cnt, строка))
record_word_cnt (line.strip (). split (''), bag_of_words)
cnt + = 1
sorted_words = order_bag_of_words (bag_of_words, desc = True)
print ("10 наиболее часто встречающихся слов {}". формат (sorted_words [: 10]))
def order_bag_of_words (bag_of_words, desc = False):
words = [(word, cnt) вместо слова, cnt в bag_of_words.items ()]
вернуть отсортированный (слова, ключ = лямбда x: x [1], обратный = по убыванию)
def record_word_cnt (слова, bag_of_words):
словом в словах:
если слово! = '':
если слово.lower () в bag_of_words:
bag_of_words [word.lower ()] + = 1
еще:
bag_of_words [word.lower ()] = 1
если __name__ == '__main__':
основной()
Приведенный выше код представляет сценарий python командной строки, который ожидает путь к файлу, переданный в качестве аргумента. Сценарий использует модуль os , чтобы убедиться, что переданный путь к файлу - это файл, который существует на диске. Если путь существует, каждая строка файла считывается и передается в функцию с именем record_word_cnt в виде списка строк с разделителями пробелов между словами, а также в словарь с именем bag_of_words .Функция record_word_cnt подсчитывает каждый экземпляр каждого слова и записывает его в словарь bag_of_words .
После того, как все строки файла прочитаны и записаны в словарь bag_of_words , вызывается последний вызов функции order_bag_of_words , который возвращает список кортежей в формате (слово, количество слов) , отсортированных по количество слов. Возвращенный список кортежей используется для печати 10 наиболее часто встречающихся слов.
Заключение
Итак, в этой статье мы исследовали способы построчного чтения текстового файла двумя способами, включая способ, который, как мне кажется, немного более Pythonic (это второй способ, продемонстрированный в forlinein.py). Подводя итоги, я представил тривиальное приложение, которое потенциально полезно для чтения и предварительной обработки данных, которые можно использовать для текстовой аналитики или анализа тональности.
Как всегда, я с нетерпением жду ваших комментариев и надеюсь, что вы сможете использовать то, что обсуждалось, для разработки интересных и полезных приложений.
python - как прочитать файл построчно в список?
Чтобы прочитать файл в списке, вам нужно сделать три вещи:
- Открыть файл
- Прочитать файл
- Сохранить содержимое как список
К счастью, Python позволяет очень легко делать эти вещи, поэтому самый короткий способ чтения файла в список:
lst = список (открыть (имя файла))
Однако я добавлю еще несколько пояснений.
Открытие файла
Я предполагаю, что вы хотите открыть определенный файл и не имеете дело непосредственно с дескриптором файла (или дескриптором, подобным файлу).Наиболее часто используемая функция для открытия файла в Python - это open , она принимает один обязательный аргумент и два необязательных аргумента в Python 2.7:
- Имя файла
- Режим
- Буферизация (я проигнорирую этот аргумент в этом ответе)
Имя файла должно быть строкой, представляющей путь к файлу . Например:
open ('afile') # открывает файл с именем afile в текущем рабочем каталоге
open ('adir / afile') # относительный путь (относительно текущего рабочего каталога)
open ('C: / users / aname / afile') # абсолютный путь (окна)
open ('/ usr / local / afile') # абсолютный путь (linux)
Обратите внимание, что необходимо указать расширение файла.Это особенно важно для пользователей Windows, поскольку расширения файлов, такие как .txt или .doc и т. Д., Скрыты по умолчанию при просмотре в проводнике.
Второй аргумент - это режим , по умолчанию это r , что означает «только для чтения». Это именно то, что вам нужно в вашем случае.
Но если вы действительно хотите создать файл и / или записать в файл, вам понадобится другой аргумент. Если вам нужен обзор, есть отличный ответ.
Для чтения файла вы можете опустить режим или передать его явно:
открыто (имя файла)
open (имя файла, 'r')
Оба откроют файл в режиме только для чтения. Если вы хотите читать двоичный файл в Windows, вам необходимо использовать режим rb :
открыто (имя файла, 'rb')
На других платформах 'b' (двоичный режим) просто игнорируется.
Теперь, когда я показал, как открыть файл , давайте поговорим о том факте, что вам всегда нужно закрыть файл снова.В противном случае он будет сохранять открытый дескриптор файла до тех пор, пока процесс не завершится (или Python не испортит дескриптор файла).
Пока можно было использовать:
f = open (имя файла)
# ... делать что-нибудь с f
f.close ()
При этом не удается закрыть файл, когда что-то между open и close вызывает исключение. Вы можете избежать этого, используя , попробуйте и , наконец, :
f = open (имя файла)
# ничего промежуточного!
пытаться:
# делать что-нибудь с f
наконец-то:
f.Закрыть()
Однако Python предоставляет диспетчеры контекста с более красивым синтаксисом (но для open он почти идентичен , попробуйте и , наконец, выше):
с открытым (имя файла) как f:
# делать что-нибудь с f
# Файл всегда закрывается после окончания области видимости.
Последний подход - это рекомендуемый подход для открытия файла в Python!
Чтение файла
Хорошо, вы открыли файл, теперь как его читать?
Функция open возвращает объект file и поддерживает итерационный протокол Pythons.Каждая итерация даст вам строку:
с открытым (имя файла) как f:
для строки в f:
печать (строка)
Будет напечатана каждая строка файла. Однако обратите внимание, что каждая строка будет содержать символ новой строки \ n в конце (вы можете проверить, построен ли ваш Python с универсальной поддержкой новой строки - в противном случае у вас также может быть \ r \ n в Windows или \ r на Mac как символы новой строки). Если вы этого не хотите, вы можете просто удалить последний символ (или последние два символа в Windows):
с открытым (имя файла) как f:
для строки в f:
печать (строка [: - 1])
Но последняя строка не обязательно имеет завершающую новую строку, поэтому не следует ее использовать.Можно проверить, заканчивается ли он завершающим символом новой строки, и если да, то удалить его:
с открытым (имя файла) как f:
для строки в f:
если line.endswith ('\ n'):
строка = строка [: - 1]
печать (строка)
Но вы можете просто удалить все пробелы (включая символ \ n ) с конца строки , это также удалит все остальные конечных пробелов , поэтому вы должны быть осторожны, если они важны:
с открытым (имя файла) как f:
для строки в f:
печать (f.rstrip ())
Однако, если строки заканчиваются на \ r \ n ("новые строки" Windows), то .rstrip () также позаботится о \ r !
Сохранить содержимое как список
Теперь, когда вы знаете, как открыть файл и прочитать его, пора сохранить содержимое в списке. Самый простой вариант - использовать функцию list :
с открытым (имя файла) как f:
lst = список (f)
В случае, если вы хотите удалить завершающие символы новой строки, вы можете вместо этого использовать понимание списка:
с открытым (имя файла) как f:
lst = [строка.rstrip () для строки в f]
Или даже проще: метод .readlines () объекта файла по умолчанию возвращает список строк:
с открытым (имя файла) как f:
lst = f.readlines ()
Это также будет включать завершающие символы новой строки, если они вам не нужны, я бы рекомендовал подход [line.rstrip () for line in f] , потому что он позволяет избежать хранения двух списков, содержащих все строки в памяти.
Есть дополнительная опция для получения желаемого результата, но она скорее «неоптимальная»: читает весь файл в строке, а затем разбивает его на новые строки:
с открытым (имя файла) как f:
lst = f.read (). split ('\ n')
или:
с открытым (имя файла) как f:
lst = f.read (). splitlines ()
Они автоматически обрабатывают завершающие символы новой строки, потому что разделенный символ не включен.Однако они не идеальны, потому что вы храните файл как строку и как список строк в памяти!
Сводка
- Используйте
с open (...) как fпри открытии файлов, потому что вам не нужно заботиться о закрытии файла самостоятельно, и он закрывает файл, даже если происходит какое-то исключение. -
файл Объектыподдерживают протокол итераций, поэтому построчное чтение файла так же просто, какдля строки в the_file_object:.