Какие бывают структуры данных в Python их виды и особенности.
Содержание
- Что такое структура данных в языке программирования Python
- Базовые структуры данных Python
- Целые числа
- Вещественные типы данных
- Булевы значения
- Встроенные структуры данных Python
- Как и где изучать Python самостоятельно
- Алгоритмы на Python 3. Лекция №1
Что такое структура данных в языке программирования Python
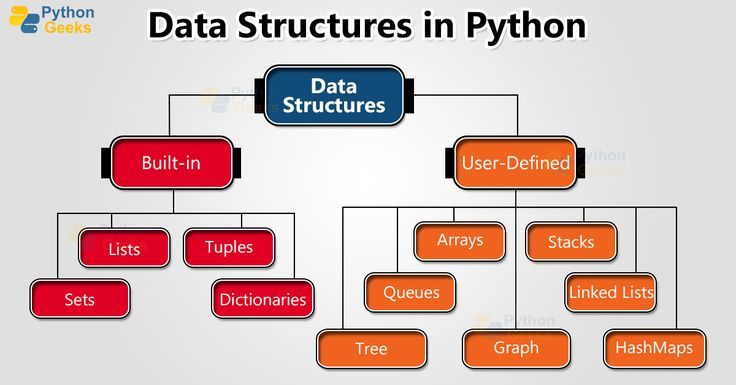
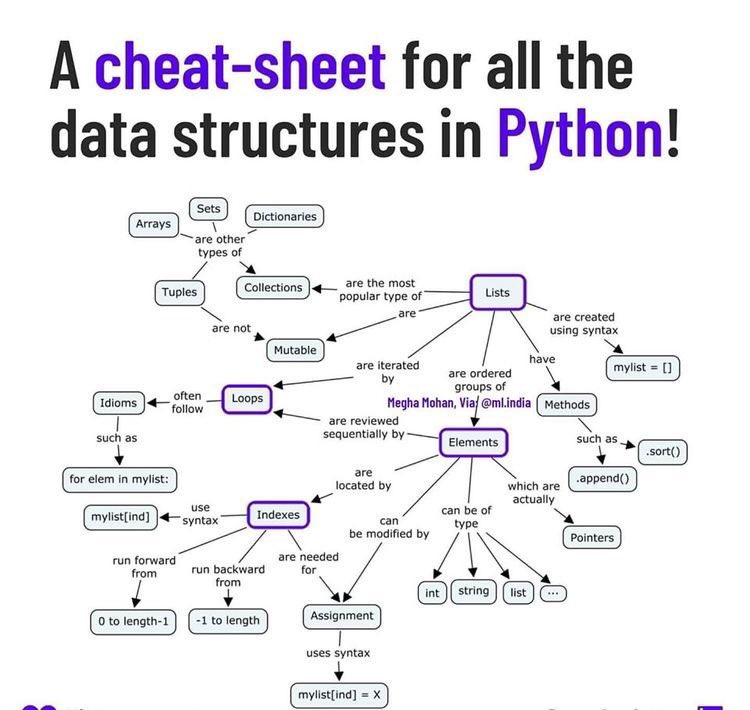
Структуры данных в Python служат для написания программ, которые могут быть как простыми, так и достаточно сложными. Они бывают линейные, нелинейные и специфические.
К линейным структурам данных Python можно отнести массивы, матрицы, стек, очередь, связанный список. К нелинейным график, двоичное дерево, кучу, хэш-таблицу. Специфическими являются кортежи, словари, списки.
Также структуры данных в Питоне классифицируются как базовые, встроенные, динамические, упорядоченные, простейшие, собственные, общие, связанные.
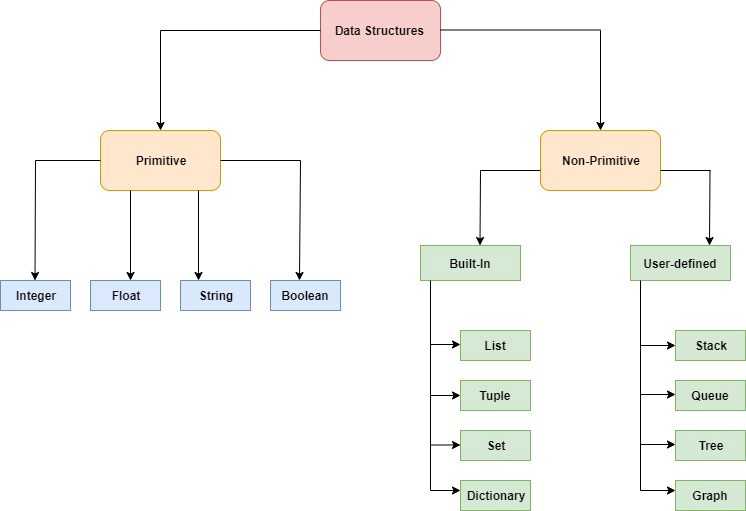
Основные типы данных в Python это числа целые, с плавающей точкой, комплексные, строки, булев тип, тип none, исключения, байты, файлы, множества, функции, кортежи, словари, списки, строки.
Базовые структуры данных Python
К ним относятся:
Целые числа
Над ними можно производить операции сложения (a + b), вычитания (a — b), деления (a / b) – в этом случае результат может стать вещественным если не делится нацело, умножения (a * b). Есть операция остаток от деления (a % b), например, если разделить 5 на 2 (5 % 2 = 1), то остаток от деления будет 1.
Остаток от деления записывается при помощи знака процент %. При помощи двойного слэша ( // ) можно выполнить деление нацело, при этом отбрасывается дробная часть. Например, если разделить нацело 5 на 2, то мы получим 2 (5 // 2 = 2), остаток 1 не будет учитываться.
Числа можно сравнивать. Для этого используются сравнения больше ( > ), меньше ( < ), больше или равно ( >= ), меньше или равно ( <= ), равенства ( == ) – записывается как двойное равенство, не равно ( != ) – записывается как восклицательный знак и равно. Результатом выполнения этих операций является истина или ложь (True) или (False).
Для этого используются сравнения больше ( > ), меньше ( < ), больше или равно ( >= ), меньше или равно ( <= ), равенства ( == ) – записывается как двойное равенство, не равно ( != ) – записывается как восклицательный знак и равно. Результатом выполнения этих операций является истина или ложь (True) или (False).
Также можно делать тройное сравнение, например, (2 < 4 < 6) будет «True» — истина, (5 < 2 < 7) даст результат ложь «False». При помощи тройного сравнения можно проверить попадает ли в нужный диапазон
Вещественные типы данных
Это числа с дробной частью или еще они называются с плавающей точкой. Над ним можно производить все действия применимые к целым. Но операции над вещественными числами происходят с округлением, что может привести к ошибкам. Если сложить (0,3 + 0,3 + 0,3 +0,1), то получим 0.9999999999999999.
Если сложить (0,3 + 0,3 + 0,3 +0,1), то получим 0.9999999999999999.
Для более точных вычислений в языке Python существуют числа с заданной точностью. Все операции между числами с плавающей точкой дают вещественные величины, между вещественным и целым также являются вещественными.
Можно возводить в дробную степень, что фактически является извлечением корня. Вещественное число можно конвертировать в целое ( int(41.3) = 41), а целое можно привести к вещественному ( float(41) = 41.0 ).
Для числовых данных приоритетным является выражение, заключенное в скобки. Далее по приоритетам идет возведение в степень, затем умножение и деление, сложение и вычитание, унарный минус.
Булевы значения
К ним применимы операции булевой алгебры. К ним относятся:
— Логическое сложение – дизъюнкция («или» — на английском языке «or»). В этом случае если есть хотя бы одно «True», то выражение будет истинно
— Логическое умножение – конъюнкция («и» — «and»). Выражение истинно, когда все его элементы одинаковы.
Выражение истинно, когда все его элементы одинаковы.
— Логическое отрицание – инверсия («не» — «not»). Отрицание меняет истину на ложь, а ложь на истину.
Встроенные структуры данных Python
Списки – создаются при помощи квадратных скобок [ ]. В списках находятся значения, которые можно изменять. Это могут быть любые значения: числа, символы, строки и т.д. Также можно создать список при помощи функции list( ).
Словари – формируются при помощи фигурных скобок { } или функцией dict( ). Являются изменяемым объектом и включают себя попарно набор ключей и значений.
Кортежи – инициализируются при помощи обычных скобок ( ), еще можно использовать функцию tuple( ). Их можно назвать неизменяемым списком. После создания кортежа нельзя изменять его значения.
Множество – создание происходит с использованием фигурных скобок, как и в случае со словарем или применив функцию set( ). Множество содержит элементы, которые не повторяются и находятся в случайном порядке. Пустое множество создать нельзя. Множество удобно применять для того, чтобы удалить повторяющиеся элементы.
Множество содержит элементы, которые не повторяются и находятся в случайном порядке. Пустое множество создать нельзя. Множество удобно применять для того, чтобы удалить повторяющиеся элементы.
Как и где изучать Python самостоятельно
Изучать типы и структуры данных в Python лучше постепенно, переходя от простых структур данных и работы с ними к более сложным конструкциям и алгоритмам. Можно найти достаточно много бесплатных курсов в интернете, например, на ресурсе Stepik и многих других.
Есть много книг и самоучителей по программированию на языке Python, где подробно разбираются структуры данных, типы данных с примерами и задачами для самостоятельного выполнения.
Также на платформе ютуб находится множество видеороликов и обучающих материалов по данной теме. Например, МФТИ выкладывает лекции по программированию на Python в свободном доступе на YouTube.
Алгоритмы на Python 3. Лекция №1
 youtube.com/embed/KdZ4HF1SrFs»>
youtube.com/embed/KdZ4HF1SrFs»>16. Структуры данных в Python — Знакомство с Python — codebra
Оглавление урока
- Список
- Кортеж
- Словарь
- Множество
- Заключение
Вступление
В предыдущем уроке мы научились генерировать случайные числа. Теперь стоит более глубоко разобраться с тем, какие структуры есть в Python. Ведь программирование – это в основном работа с данными, а чтобы ими эффективнее манипулировать, необходимо их где-то хранить. Это «где-то» и есть структуры.
Сейчас мы поверхностно рассмотрим четыре структуры, а в следующих уроках разберемся с каждой более подробно. В предыдущих уроках вы поработали с числами и строками. Как вы помните, присвоение переменной значения выглядит так:
Пример
var1 = "Hello"
var1 = 12
print(var1)
Одной из особенностей переменных и типов в Python является возможность динамически присваивать значение переменной. Это сильно упрощает написание и понимание кода. В примере выше мы сначала в переменную
Это сильно упрощает написание и понимание кода. В примере выше мы сначала в переменную var1 добавили строку, а затем число и вывели результат. Например, в типизированном языке С++ так делать нельзя: во-первых, мы сначала должны были объявить эти переменные. Во-вторых, в переменную строкового типа нельзя добавить число. Аналогичный код на С++ выглядел бы так (причем 12 уже является строкой, а не числом):
Пример
string var1 = "Hello";
var1 = "12";
cout << var1;
В Python все является объектами: числа, строки, функции, модули и т.д. Следовательно, любой объект можно присвоить переменной. Теперь самое время обсудить, как хранить эти объекты.
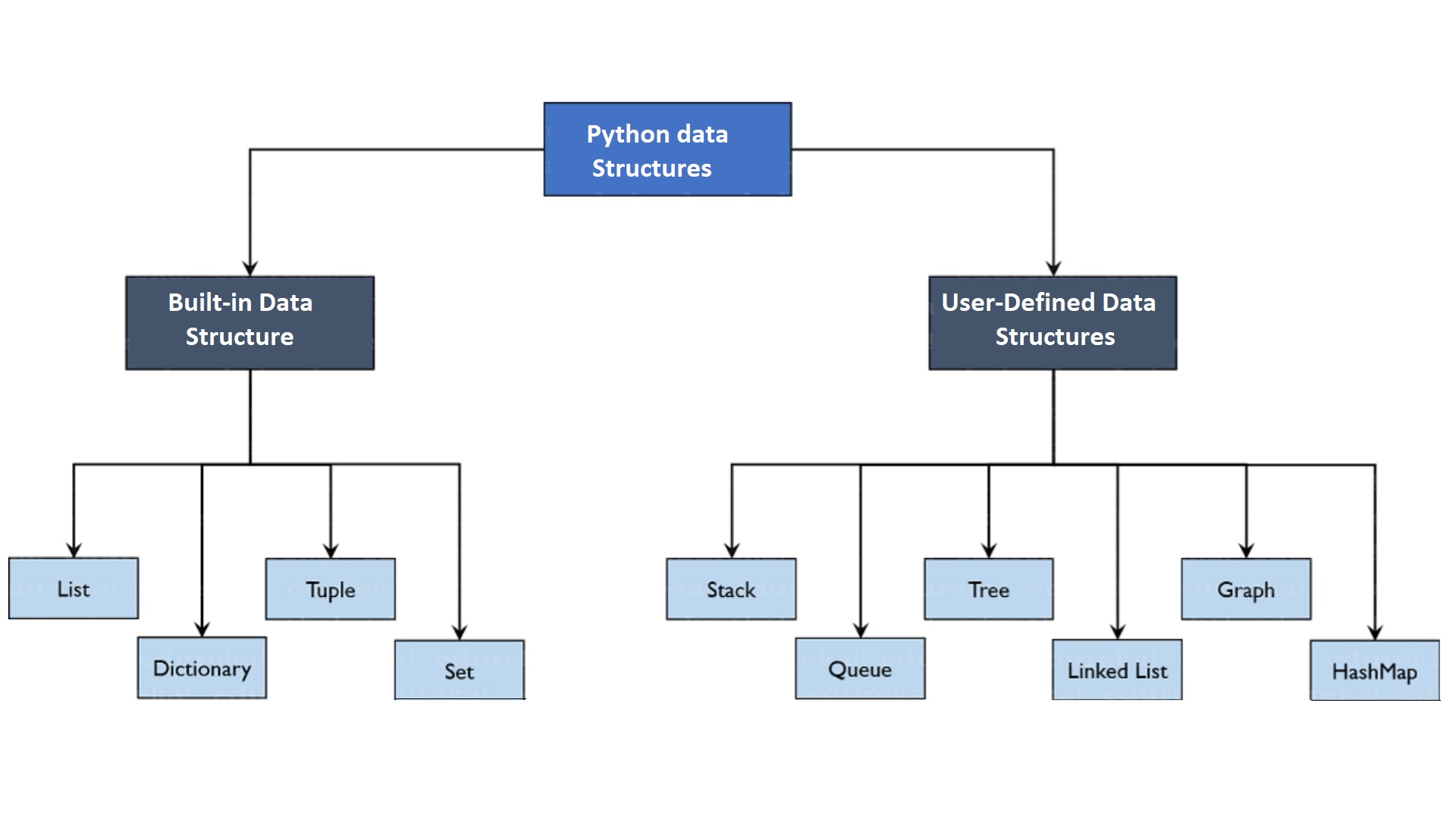
В Python есть четыре встроенных структуры данных, которые вы можете использовать для хранения данных: список, картеж, словарь и множество. Под «встроенными» понимается отсутствие необходимости подключать специальные модули.
Список
В Python списки очень похожи на массивы в других языках программирования. Они так же нумеруются с нуля. Но в отличии от того же С++, количество элементов в списке Python’а может динамически изменяться по необходимости. Те, кто знакомы с С++, могли заметить аналогию с контейнером
Они так же нумеруются с нуля. Но в отличии от того же С++, количество элементов в списке Python’а может динамически изменяться по необходимости. Те, кто знакомы с С++, могли заметить аналогию с контейнером vector из библиотеки STL. Если для вас все вышеназванные понятия в абзаце оказались новыми, не волнуйтесь, сейчас все будет понятно. Массив – это набор элементов, идентифицируемых по индексу. Рассмотрим пример:
Пример
people = ["Иван Иванов", "Петр Петров"]
В данном случае, массив называется people и содержит два элемента. Сейчас мы не будем привязываться к синтаксису Python, пока только знакомимся с базовыми понятиями.
Подробнее поговорим о списках начиная с урока 6.1.
Как мы уяснили, список являются изменяемой структурой, что не скажешь о следующей.
Кортеж
Кортеж – это тоже список, но его нельзя изменить. У многих возникает вопрос: «Зачем нужны неизменяемые списки?». Иногда случаются такие ситуации, когда нам необходимо быть уверенным в том, что список не изменится. Мы еще часто будем встречаться с картежами в дальнейшем.
Мы еще часто будем встречаться с картежами в дальнейшем.
Списки и кортежи отлично подходят для случаев, когда нам необходимо представить данные упорядоченно, т.е. когда порядок элементов важен. Но что, если порядок не важен? Как реализуются ассоциативные (или именованные) массивы в Python?
Подробнее поговорим о кортежах начиная с урока 9.1.
Словарь
Если порядок не важен, то нам может помочь структура под названием «Словарь». Словари в Python хранят коллекции в виде пар ключ/значение. То есть каждому уникальному ключу соответствует значение (необязательно уникальное). Таких пар может быть произвольное количество. Словари, как и списки, являются динамическими и изменяемыми. Для тех, кто знаком с другими языками программирования, словарь в Python можно сравнить с ассоциативным массивом (в С++ на него похож контейнер map). В уроке, посвященном словарям, мы научимся не только с ними работать, но и сортировать как по ключу, так и по значению.
Подробнее поговорим о словарях начиная с урока 7. 1.
1.
Множество
Последней встроенной структурой является множество. Оно отлично помогает, когда необходимо удалить все повторяющиеся элементы. Множества могут изменяться динамически, как списки и словари. Множества является неупорядоченной структурой, как и словарь. В С++ на него похож контейнер set.
Подробнее поговорим о множествах начиная с урока 8.1.
Заключение
Обозреть все структуры было необходимо, чтобы вы смогли лучше структурировать свои знания в дальнейшем, когда будете более подробно знакомиться с ними.
Подведем краткий итог. Структуры облегчают жизнь программисту. Когда нам нужно создать коллекцию упорядоченных элементов, мы используем списки и кортежи. Если порядок элементов не важен и данные представляются как ключ/значение, то помогут словари. А если вы хотите избавиться от повторов, то выручат множества.
ПРОЧИТАНО
Следующий урок
Предыдущий урок «15. Тест по модулю random Python» Следующий урок «17. Тест по структурам Python»
Тест по структурам Python»
Похожие уроки и записи блога
Типы данных в PythonЗнакомство с Python
Погружение в PythonЗнакомство с Python
Написание модулей в PythonЗнакомство с Python
Обработка исключений (try/except) в PythonЗнакомство с Python
Функциональное программирование: map, filter и reduceЗнакомство с Python
Первое знакомство с PythonЗнакомство с Python
Еще о возможностях модулей в Python Знакомство с Python
Работа с файлами в Python Знакомство с Python
Основы функций в PythonЗнакомство с Python
8 структур данных, которые должен знать каждый программист на Python
Home/Blog/Languages/8 структур данных, которые должен знать каждый программист на Python , работодатели и рекрутеры ищут как время выполнения, так и эффективность использования ресурсов.
Знание того, какая структура данных лучше всего соответствует текущему решению, повысит производительность программы и сократит время, необходимое для ее создания. По этой причине большинство ведущих компаний требуют глубокого понимания структур данных и тщательно проверяют его на собеседовании по программированию.
По этой причине большинство ведущих компаний требуют глубокого понимания структур данных и тщательно проверяют его на собеседовании по программированию.
Вот что мы сегодня рассмотрим:
- Что такое структуры данных?
- Массивы в Python
- Очереди в Python
- стеков в Python
- Связанные списки в Python
- Круговые связанные списки в Python
- Деревья в Python
- Графики в Python
- Хэш-таблицы в Python
- Что узнать дальше
Первое интервью с питоном
Освежите свои навыки программирования на Python, такие как структуры данных, рекурсия и параллелизм, решив более 200 практических задач.
Интервью с первоклассным программистом на Python
Что такое структуры данных?
Структуры данных — это кодовые структуры для хранения и организации данных, упрощающие изменение, навигацию и доступ к информации.
Структуры данных используются почти во всех областях информатики и программирования, от операционных систем до разработки интерфейсов и машинного обучения.
Структуры данных помогают:
- Управление и использование больших наборов данных
- Быстрый поиск определенных данных из базы данных
Создание четких иерархических или реляционных связей между точками данных - Упростить и ускорить обработку данных
Структуры данных — это жизненно важных строительных блоков для эффективного решения реальных задач. Структуры данных — это проверенные и оптимизированные инструменты, которые дают вам простую основу для организации ваших программ. В конце концов, вам не нужно переделывать колесо (или структуру) каждый раз, когда вам это нужно.
У каждой структуры данных есть задача или ситуация, для решения которой она
Большинство структур данных в Python являются их модифицированными формами или используют встроенные структуры в качестве основы.
- List : Массивоподобные структуры, которые позволяют сохранять набор изменяемых объектов одного типа в переменную.
- Кортеж : Кортежи — это неизменяемые списки, то есть элементы не могут быть изменены. Он объявляется в круглых скобках вместо квадратных скобок.
- Set : Наборы являются неупорядоченными коллекциями, что означает, что элементы не индексируются и не имеют последовательности набора. Они объявляются с помощью фигурных скобок.

- Словарь (dict) : Подобно хэш-карте или хеш-таблицам в других языках, словарь представляет собой набор пар ключ/значение. Вы инициализируете пустой словарь пустыми фигурными скобками и заполняете его ключами и значениями, разделенными двоеточиями. Все ключи являются уникальными, неизменяемыми объектами.

Теперь давайте посмотрим, как мы можем использовать эти структуры для создания всех расширенных структур, которые ищут интервьюеры.
Массивы (списки) в Python
Python не имеет встроенного типа массива, но вы можете использовать списки для всех тех же задач. Массив представляет собой набор значений того же типа сохранен под тем же именем .
Каждое значение в массиве называется «элементом», а индексация представляет его позицию. Вы можете получить доступ к определенным элементам, вызвав имя массива с индексом нужного элемента. Вы также можете получить длину массива, используя метод len() .
В отличие от таких языков программирования, как Java, которые имеют статические массивы после объявления, массивы Python
Например, мы могли бы использовать метод append() для добавления дополнительного элемента в конец существующего массива вместо объявления нового массива.
Это делает массивы Python особенно простыми в использовании и адаптируемыми на лету.
cars = ["Toyota", "Tesla", "Hyundai"]
print(len(cars))
cars.append("Honda")
cars.pop(1)
for x in автомобили:
print(x)
Преимущества:
- Простота создания и использования последовательностей данных
- Автоматическое масштабирование в соответствии с изменяющимися требованиями к размеру
- Используется для создания более сложных структур данных
Недостатки:
- Не оптимизирован для научных данных (в отличие от массива NumPy)
- Можно управлять только крайним правым концом списка
Приложения:
- Общее хранилище связанных значений или объектов, т. е.
myDogs - Коллекции данных, которые вы будете циклически просматривать
- Наборы структур данных, такие как список кортежей
 е.
е. Общие вопросы интервью с массивами в Python
- Удалить четные целые числа из списка
- Объединить два отсортированных списка
- Найти минимальное значение в списке
- Подсписок максимальной суммы
- Печатная продукция всех элементов
Очереди в Python
Очереди — это линейная структура данных, которая хранит данные в порядке «первым поступил — первым обслужен» (FIFO). В отличие от массивов, вы не можете получить доступ к элементам по индексу и вместо этого можете извлекает только следующий по возрасту элемент
Вы можете думать об очереди как об очереди в продуктовом магазине; кассир не выбирает, кого обслуживать дальше, а обрабатывает человека, который дольше всех простоял в очереди.
Мы могли бы использовать список Python с методами append() и pop() для реализации очереди. Однако это неэффективно, поскольку списки должны сдвигать все элементы на один индекс каждый раз, когда вы добавляете новый элемент в начало.
Вместо этого рекомендуется использовать класс collections . Deques оптимизированы для операций добавления и извлечения. Реализация deque также позволяет создавать двусторонние очереди, которые могут обращаться к обеим сторонам очереди через методы popleft() и popright() .
from collections import deque
# Инициализация очереди
q = deque()
# Добавление элементов в очередь
q.append('a')
q.append('b')
q.append('c')
print("Начальная очередь")
print(q)
# Удаление элементов из очереди
print("\nЭлементы удалены из очереди")
print(q.
popleft()) print(q.popleft())
print(q.popleft())
print( "\nОчередь после удаления элементов")
print(q)
# Раскомментирование q.popleft()
# вызовет IndexError
# поскольку очередь теперь пуста

Преимущества:
- Автоматически упорядочивает данные в хронологическом порядке
- Весы для соответствия требованиям к размерам
- Экономия времени с
dequeclass
Недостатки:
- Доступ к данным возможен только на концах
Приложения:
- Операции с общим ресурсом, таким как принтер или ядро ЦП
- Служит временным хранилищем для систем периодического действия
- Обеспечивает простой порядок по умолчанию для задач равной важности
Общие вопросы интервью очереди в Python
- Обратные первые k элементов очереди
- Реализовать очередь с использованием связанного списка
- Реализовать стек с использованием очереди
Стеки в Python
Стеки — это последовательная структура данных, которая действует как версия очередей по принципу «последним пришел — первым обслужен» (LIFO). Последний элемент, вставленный в стек, считается 9-м.0013 вершина стека и является единственным доступным элементом. Чтобы получить доступ к среднему элементу, вы должны сначала удалить достаточно элементов, чтобы нужный элемент стал вершиной стека.
Последний элемент, вставленный в стек, считается 9-м.0013 вершина стека и является единственным доступным элементом. Чтобы получить доступ к среднему элементу, вы должны сначала удалить достаточно элементов, чтобы нужный элемент стал вершиной стека.
Многие разработчики представляют стопку как стопку обеденных тарелок; вы можете добавлять или удалять тарелки наверху стопки, но должны переместить всю стопку, чтобы поставить одну на дно.
Добавление элементов известно как push, и удаление элементов известно как pop . Вы можете реализовать стеки в Python, используя встроенную структуру списка. При реализации списка операции push используют append() , а операции извлечения используют метод pop() .
stack = []
# функция append() для отправки
# элемент в стеке
stack.append('a')
stack.append('b')
stack.append(' c')
print('Начальный стек')
print(stack)
# функция pop() для извлечения
# элемент из стека в
# порядок LIFO
print('\nЭлементы извлечены из стека: ')
print(stack.
print(stack.pop())
print(stack.pop())
print('\nСтек после извлечения элементов:')
print(stack)
# раскомментирование print(stack.pop( ))
# вызовет IndexError
# так как стек теперь пуст
 pop())
pop()) Преимущества:
- Предлагает управление данными LIFO, которое невозможно с массивами
- Автоматическое масштабирование и очистка объектов
- Простая и надежная система хранения данных
Недостатки:
- Память стека ограничена
- Слишком много объектов в стеке приводит к ошибке переполнения стека
Области применения:
- Используется для создания высокореактивных систем
- Системы управления памятью используют стеки для обработки самых последних запросов в первую очередь
- Полезно для таких вопросов, как соответствие скобок
Общие вопросы интервью по стекам в Python
- Реализовать очередь с использованием стеков
- Вычислить выражение Postfix со стеком
- Следующий наибольший элемент с использованием стека
- Создать функцию
min()с использованием стека
Связанные списки в Python
Связанные списки — это последовательный набор данных, который использует реляционных указателей на каждый узел данных для связи со следующим узлом в списке.
В отличие от массивов, связанные списки не имеют объективных позиций в списке. Вместо этого они имеют реляционные позиции, основанные на окружающих их узлах.
Первый узел в связанном списке называется головным узлом, , а последний называется хвостовым узлом , который имеет нулевой указатель .
Связанные списки могут быть одно- или двусвязными в зависимости от того, имеет ли каждый узел только один указатель на следующий узел или также имеет второй указатель на предыдущий узел.
Связанные списки можно рассматривать как цепочки; отдельные ссылки связаны только со своими непосредственными соседями, но все ссылки вместе образуют более крупную структуру.
В Python нет встроенной реализации связанных списков, поэтому требуется, чтобы вы реализовали класс Node для хранения значения данных и одного или нескольких указателей.
class Node:
def __init__(self, dataval=None):
self.
self.nextval = None
class SLinkedList:
def __init__(self):
self.headval = Нет
list1 = SLinkedList()
list1.headval = Node("Mon")
e2 = node ("tue")
e3 = node ("wed")
# ссылка Первый узел во второй узел
List1.headval.nextval = e2
# Лика второй узел с третьим узлом
E2 .nextval = e3
 dataval = dataval
dataval = dataval Связанные списки в основном используются для создания расширенных структур данных, таких как графики и деревья, или для задач, требующих частого добавления/удаления элементов в структуре.
Преимущества:
- Эффективная вставка и удаление новых элементов
- Проще реорганизовать, чем массивы
- Полезно в качестве отправной точки для расширенных структур данных, таких как графики или деревья
Недостатки:
- Хранение указателей с каждой точкой данных увеличивает использование памяти
- Необходимо всегда проходить связанный список из узла Head, чтобы найти определенный элемент
Приложения:
- Строительный блок для расширенных структур данных
- Решения, требующие частого добавления и удаления данных
Общие вопросы для собеседования со связанными списками в Python
- Вывести средний элемент заданного связанного списка
- Удалить повторяющиеся элементы из отсортированного связанного списка
- Проверить, является ли односвязный список палиндромом
- Объединить K отсортированных связанных списков
- Найти точку пересечения двух связанных списков
Круговые связанные списки в Python
Основным недостатком стандартного связанного списка является то, что вы всегда должны начинать с узла Head.
Круговой связанный список устраняет эту проблему, заменяя нулевой указатель хвостового узла указателем обратно на головной узел . При обходе программа будет следовать указателям, пока не достигнет узла, с которого она началась.
Преимущество этой настройки в том, что вы можете начать с любого узла и пройти весь список. Это также позволяет вам использовать связанные списки в качестве зацикленной структуры, устанавливая желаемое количество циклов по структуре.
Циклические связанные списки отлично подходят для процессов, которые зацикливаются в течение длительного времени, например распределение ЦП в операционных системах.
Преимущества:
- Можно пройти весь список, начиная с любого узла
- Делает связанные списки более подходящими для циклических структур
Недостатки:
- Сложнее найти узлы Head и Tail в списке без маркера
null
Приложения:
- Регулярно зацикливающие решения, такие как планирование ЦП
- Решения, в которых вы хотите свободно начинать обход в любом узле
Общие вопросы интервью с циклическим связанным списком в Python
- Обнаружение цикла в связанных списках
- Обратный круговой связанный список
- Обратный круговой связанный список в группах заданного размера
Продолжайте совершенствоваться в Python Data Structures
Практическое знание структур данных важно для любого интервьюируемого. Текстовые курсы Educative дают вам сотни практических практических задач, чтобы вы были готовы, когда придет время.
Текстовые курсы Educative дают вам сотни практических практических задач, чтобы вы были готовы, когда придет время.
Ace the Python Coding Interview
Деревья в Python
Деревья — это еще одна структура данных на основе отношений, которая специализируется на представлении иерархических структур. Подобно связному списку, они заполняются объектами Node , которые содержат значение данных и один или несколько указателей для определения его отношения к непосредственным узлам.
Каждое дерево имеет корневой узел, от которого ответвляются все остальные узлы. Корень содержит указатели на все элементы непосредственно под ним, которые известны как его 9 элементов.0013 дочерних узлов . Затем эти дочерние узлы могут иметь собственные дочерние узлы. Двоичные деревья не могут иметь узлов с более чем двумя дочерними узлами.
Любые узлы на одном уровне называются родственными узлами . Узлы без подключенных дочерних узлов известны как листовых узлов .
Узлы без подключенных дочерних узлов известны как листовых узлов .
Наиболее распространенным применением двоичного дерева является двоичное дерево поиска . Двоичные деревья поиска превосходны при поиске в больших наборах данных, поскольку временная сложность зависит от глубины дерева, а не от количества узлов.
Двоичные деревья поиска имеют четыре строгих правила:
- Левое поддерево содержит только узлы, элементы которых меньше корня.
- Правое поддерево содержит только узлы, элементы которых больше корня.
- Левое и правое поддеревья также должны быть бинарным деревом поиска. Они должны следовать приведенным выше правилам с «корнем» своего дерева.
- Не может быть повторяющихся узлов, т. е. никакие два узла не могут иметь одинаковое значение.
class Node:
def __init__(self, data):
self.left = None
self.
self.data = data
def insert(self, data):
# Сравните новое значение с родительским узлом
, если self.data:
, если данные < self.data:
, если self.left равно None:
self.left = Node(data)
else:
self .left.insert(data)
elif data > self.data:
, если self.right равно None:
self.right = Node(data)
else:
self.right.insert(data)
else:
self.data = data
# Печать дерева
def PrintTree(self):
if self.left:
self.left.PrintTree()
print( self.data),
if self.right:
self.right.PrintTree()
# Используйте метод вставки для добавления узлов
root = узел(12)
root.insert(6)
root.insert(14)
root.insert(3)
root.PrintTree()
 right = None
right = None Преимущества:
- Подходит для представления иерархических отношений
- Динамический размер, отличный масштаб
- Операции быстрой вставки и удаления
- В двоичном дереве поиска вставленные узлы упорядочены немедленно.
- Двоичные деревья поиска эффективны при поиске; длина составляет только O (высота) O (высота) O (высота).
Недостатки:
- Затратное время, O(logn)4O(logn)4O(logn)4, для изменения или «балансировки» деревьев или извлечения элементов из известного местоположения
- Дочерние узлы не содержат информации о своем родительском узле, и их может быть трудно пройти назад
- Работает только для отсортированных списков. Несортированные данные превращаются в линейный поиск.
Приложения:
- Идеально подходит для хранения иерархических данных, таких как местоположение файла
- Используется для реализации лучших алгоритмов поиска и сортировки, таких как двоичные деревья поиска и двоичные кучи
Общие вопросы интервью по дереву в Python
- Проверить, идентичны ли два бинарных дерева
- Реализовать обход порядка уровней двоичного дерева
- Печать периметра двоичного дерева поиска
- Суммировать все узлы на пути
- Соединить всех братьев и сестер бинарного дерева
Графики в Python
Графики — это структура данных, используемая для визуального представления взаимосвязей между данными вершин (Узлы графа). Звенья, которые соединяют вершины вместе, называются ребрами .
Звенья, которые соединяют вершины вместе, называются ребрами .
Ребра определяют, какие вершины соединены, но не указывают направление потока между ними. Каждая вершина имеет соединения с другими вершинами, которые сохраняются в вершине в виде списка, разделенного запятыми.
Ненаправленный
Существуют также специальные графы, называемые ориентированными графами , которые определяют направление отношения, подобно связному списку. Направленные графы полезны при моделировании односторонних отношений или структур, подобных блок-схемам.
Directed
Они в основном используются для передачи визуальных сетей веб-структуры в кодовой форме. Эти структуры могут моделировать множество различных типов отношений, таких как иерархии, ветвящиеся структуры или просто быть неупорядоченной реляционной сетью. Универсальность и интуитивность графиков делают их фаворитом для науки о данных.
При записи в виде обычного текста графы имеют список вершин и ребер:
V = {a, b, c, d, e}
E = {ab, ac, bd, cd, de}
В Python графы лучше всего реализовать с помощью словаря с именем каждой вершины в качестве ключа и списком ребер в качестве значений.
# Создать словарь с элементами графа : ["a", "d"],
"d" : ["e"],
"e" : ["d"]
}
# Распечатать график
print(graph)
Преимущества:
- Быстрая передача визуальной информации с помощью кода
- Может использоваться для моделирования широкого спектра реальных проблем
- Простой для изучения синтаксис
Недостатки:
- Связи вершин трудно понять в больших графах
- Затратно время на анализ данных из графа
Применение:
- Отлично подходит для моделирования сетей или веб-структур
- Используется для моделирования сайтов социальных сетей, таких как Facebook
Общие вопросы интервью по графу в Python
- Обнаружение цикла в ориентированном графе
- Найти «материнскую вершину» в ориентированном графе
- Подсчитать количество ребер в неориентированном графе
- Проверить, существует ли путь между двумя вершинами
- Найти кратчайший путь между двумя вершинами
Хэш-таблицы в Python
Хэш-таблицы представляют собой сложную структуру данных, способную хранить большие объемы информации и эффективно извлекать определенные элементы.
В этой структуре данных используются пары ключ/значение, где ключ — это имя нужного элемента, а значение — это данные, хранящиеся под этим именем.
Каждый входной ключ проходит через хеш-функцию , которая преобразует его из начальной формы в целочисленное значение, называемое хэшем . Хеш-функции должны всегда создавать один и тот же хэш из одних и тех же входных данных, должны быстро выполнять вычисления и создавать значения фиксированной длины. Python включает встроенную функцию hash() , которая ускоряет реализацию.
Затем таблица использует хэш, чтобы найти общее местоположение желаемого значения, называемое сегментом хранения . Затем программа должна искать желаемое значение только в этой подгруппе, а не во всем пуле данных.
Помимо этой общей структуры, хеш-таблицы могут сильно различаться в зависимости от приложения. Некоторые могут разрешать ключи из разных типов данных, в то время как некоторые могут иметь разные настройки сегментов или разные хэш-функции.
Вот пример хеш-таблицы в коде Python:
import pprint
class Hashtable:
def __init__(self, elements):
self.bucket_size = len(elements)
90 002 селф.ведра = [[] для i в диапазоне (self.bucket_size)]self._assign_buckets(elements)
def _assign_buckets(self, elements):
для ключа, значение в элементах: # вычисляет хэш каждого ключа
hashed_value = hash(key)
index = hashed_value % self. Bucket_size # позиционирует элемент в сегменте, используя хэш input_key)
index = hashed_value % self.bucket_size
ведро = self.buckets[index]
для ключа, значение в ведре:
если ключ == input_key:
return(value)
return None
def __str__(self):
900 02 возврат ппринт. pformat(self.buckets) # pformat возвращает печатное представление объекта. «Вашингтон, округ Колумбия»),(«Италия», «Рим»),
(«Канада», «Оттава»)
]
hashtable = Hashtable(capital)
print(hashtable)
print(f"Столица Италии {hashtable.
 get_value('Италия')}")
get_value('Италия')}") Преимущества: 90 014
- Можно преобразовать ключи в любой форме в целые индексы
- Чрезвычайно эффективен для больших наборов данных
- Очень эффективная функция поиска
- Постоянное количество шагов для каждого поиска и постоянная эффективность добавления или удаления элементов
- Оптимизировано в Python 3
Недостатки:
- Хэши должны быть уникальными, преобразование двух ключей в один и тот же хэш вызывает ошибку коллизии
- Ошибки столкновения требуют полного пересмотра хеш-функции
- Сложная сборка для начинающих
Приложения:
- Используется для больших и часто используемых баз данных
- Поисковые системы, использующие клавиши ввода
Общие вопросы интервью по хеш-таблицам в Python
- Построить хеш-таблицу с нуля (без встроенных функций)
- Формирование слов с помощью хеш-таблицы
- Найдите два числа, которые в сумме дают «k»
- Реализовать открытую адресацию для обработки коллизий
- Определить цикличность списка с помощью хэш-таблицы
Что узнать дальше
Для каждой из этих 8 структур данных существуют десятки вопросов и форматов интервью.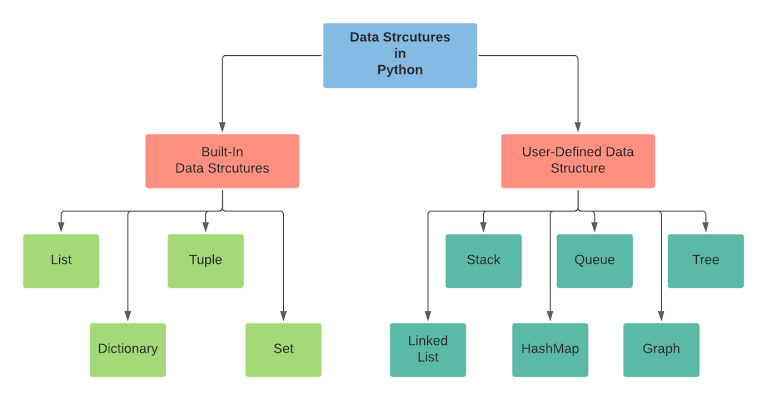 Лучший способ подготовиться к собеседованию — продолжать решать практические задачи.
Лучший способ подготовиться к собеседованию — продолжать решать практические задачи.
Чтобы помочь вам стать экспертом по структурам данных, Educative создала программу Ace the Python Coding Interview Path . Этот тщательно подобранный план обучения включает практические материалы по всем наиболее обсуждаемым понятиям, таким как структуры данных, рекурсия и параллелизм.
К концу вы решите более 250 практических задач и получите практический опыт, позволяющий решить любой вопрос на собеседовании.
Приятного обучения!
Продолжить чтение об интервью Python
- 50 вопросов и ответов на собеседовании по Python
- Топ-5 вопросов для интервью по параллелизму для инженеров-программистов
- Мастер-алгоритмы с Python для кодирования интервью
НАПИСАН BYRyan Thelin
Введение в структуры данных и алгоритмы | Бесплатные курсы
Перейти к содержимомуБесплатный курс
Уверенно примите участие в собеседовании.
В сотрудничестве с
Об этом курсе
Технические собеседования проходят по определенной схеме. Если вы знаете шаблон, вы будете на шаг впереди конкурентов. Этот курс познакомит вас с общими структурами данных и алгоритмами в Python. Вы ознакомитесь с часто задаваемыми техническими вопросами интервью и узнаете, как структурировать свои ответы.
Вы будете решать практические задачи и тесты, чтобы проверить свои способности. Затем вы потренируетесь на пробных собеседованиях, чтобы получить конкретные рекомендации по улучшению. Будьте готовы ко всему, что бросит вам технический интервьюер.
Тщательно подобранный контент
Преподается экспертами отрасли
Самостоятельный прогресс
Чему вы научитесь
Введение и эффективность
- Введение в темы, затронутые в этом конечно.
- Приведите определение эффективности, а также объяснение обозначений, обычно используемых для описания эффективности.
- Практика описания эффективности с помощью фрагментов кода.
Коллекции на основе списков
- Изучите формальное определение списка, см. определения и примеры структур данных на основе списков, массивов, связанных списков, стеков и очередей.
- Изучите эффективность общих методов списка и попрактикуйтесь в использовании этих структур данных и управлении ими.
Поиск и сортировка
- Узнайте, как выполнять поиск и сортировку со структурами данных на основе списков, включая двоичный поиск и всплывающее окно, слияние и быструю сортировку.
- Изучите эффективность каждого из них и узнайте, как использовать рекурсию при поиске и сортировке.
- Посмотрите и напишите примеры этих методов, а также другие алгоритмы сортировки, такие как сортировка вставками.
Карты и хеширование
- Понимание концепций множеств, карт (словарей) и хеширования.
- Изучите распространенные проблемы и подходы к хешированию и попрактикуйтесь на примерах хеш-таблиц и хэш-карт.
Деревья
- Изучите концепции и терминологию, связанные с древовидными структурами данных.
- Изучение распространенных типов деревьев, таких как бинарные деревья поиска, кучи и самобалансирующиеся деревья.
- Ознакомьтесь с примерами распространенных методов обхода дерева, изучите эффективность обходов и общих функций дерева, а также попрактикуйтесь в управлении деревьями.
Графы
- Изучить теоретическую концепцию графа и понять общие графовые термины, кодированные представления, свойства, обходы и пути.
- Практика работы с графиками и определение эффективности, связанной с графиками.
Примеры алгоритмов
- Изучите известные задачи информатики, в частности, задачу о кратчайшем пути, задачу о рюкзаке и задачу коммивояжера.
- Узнайте о решениях таких проблем методом грубой силы, жадным и динамическим программированием.
Методы технического собеседования
- Узнайте об «алгоритме» ответов на распространенные технические вопросы интервью.
- Узнайте, как прояснить и объяснить практические вопросы для интервью, используя понятия, изучаемые в этом курсе, и получите советы, как дать интервьюерам именно то, что они ищут на собеседовании.
- Узнайте об «алгоритме» ответов на распространенные технические вопросы интервью.
Практическое собеседование
- Используйте Pramp, чтобы встретиться с другим студентом Udacity и пройти техническое собеседование в режиме реального времени.


Предпосылки и требования
- Владение устным и письменным английским языком
- Питон (средний уровень)
- Алгебра (средний уровень)
См. Технологические требования для использования Udacity.
Зачем проходить этот курс?
Ключом к успешному техническому собеседованию является практика. В этом курсе вы ознакомитесь с распространенными структурами данных и алгоритмами Python. Вы научитесь объяснять свои решения технических проблем. Этот курс идеально подходит для вас, если вы никогда не изучали структуры данных или алгоритмы.