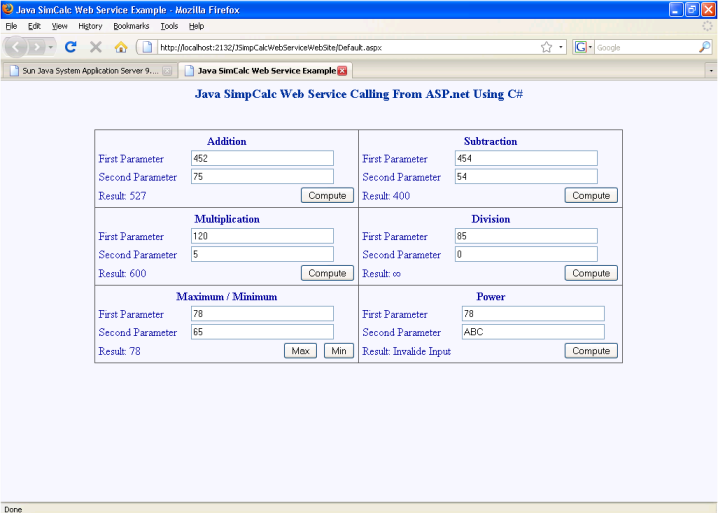
Соединение с базой данных — JavaTutor.net
Было посчитано, что половина всего разрабатываемого программного обеспечения использует клиент/серверные операции. Огромная перспектива Java была в способности строить платформо-независимые клиент/серверные приложения для баз данных. Это осуществляется с помощью Java DataBase Connectivity (JDBC).
Одна из главных проблем баз данных была в особенностях, которые
имеют разные базы данных от разных компаний. Есть «стандартный» язык
баз данных, Структурированный Язык Запросов — Structured Query Language (SQL-92),
но вы должны обычно знать, с базой данных какого производителя вы работаете,
не смотря на стандарт. JDBC разработана так, чтобы быть платформо-независимой,
так что вам нет необходимости беспокоиться во время программирования о базе
данных. Однако все равно есть возможность делать специфичные для производителя
вызовы из JDBC, так что вы не ограничены от выполнения тех задач, которые должны.
Одно место, где программисту может понадобиться использование имен SQL типов — это в SQL выражении TABLE CREATE, когда необходимо создать новую базу данных и определить SQL типы для каждой колонки. К сожалению, есть значительные отличия между SQL типами, поддерживаемыми разными базами данных. Разные базы данных, которые поддерживают SQL типы с одинаковой семантикой и структурой, могут давать этим типам разные имена. Наиболее распространенные базы данных поддерживают SQL типы данных для больших бинарных значений: в Oracle этот тип называется LONG RAW, Sybase называет его IMAGE, а DB2 называет его LONG VARCHAR FOR BIT DATA. Поэтому, если портируемость базы дынных является вашей целью, вы должны попробовать использовать только общие идентификаторы SQL типов.
Портируемость является целью, когда пишите книгу, читатели которой могут
проверять примеры со всеми видами неизвестных хранилищ данных. Я попробовал написать эти
примеры настолько портируемыми, насколько это возможно. Вы должны также иметь в виду, что
специфичный для базы данных код был изолирован, чтобы централизовать любые изменения,
которые вам может понадобиться изменить, чтобы запустить примеры в вашем окружении.
Я попробовал написать эти
примеры настолько портируемыми, насколько это возможно. Вы должны также иметь в виду, что
специфичный для базы данных код был изолирован, чтобы централизовать любые изменения,
которые вам может понадобиться изменить, чтобы запустить примеры в вашем окружении.
JDBC, как и многое другое API, разработано для упрощения. Вызовы методов, которые вы совершаете, соответствуют логическим операциям, о которых вы думаете при получении данных из базы данных: соединение с базой данных, создание выражения (statement) и выполнение запроса, затем просмотр результирующей выборки.
Чтобы обеспечить независимость от платформы, JDBC предоставляет менеджер
драйверов, который динамически поддерживает все объекты-драйверы, необходимые для запроса
к вашей базе данных. Так что, если у вас есть три базы данных различных производителей, с
которыми вы соединяетесь, вам необходимо три различных объекта драйвера.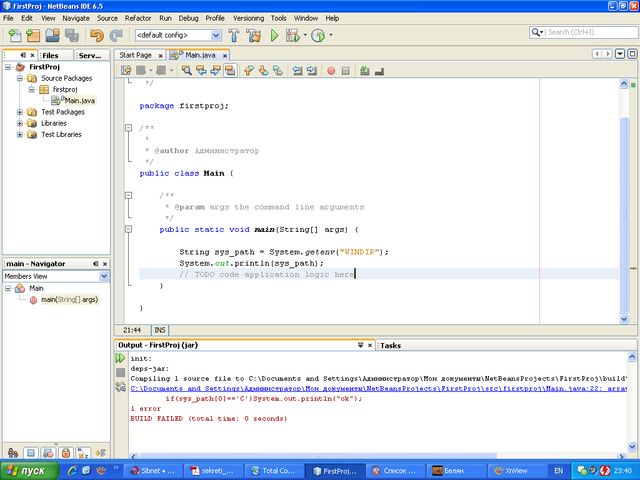
Для открытия базы данных вы должны создать «URL базы данных», в котором указывается:
- Что вы используете JDBC, с помощью «jdbc».
- «Суб протокол»: имя драйвера или имя механизма соединения с базой данных. Так как дизайн JDBC инспирирован ODBC, первый из доступных протоколов — это «jdbc-odbc bridge», который указывается, как «odbc».
- Идентификатор базы данных. Он различен для различных баз данных, но обычно он предоставляет
логическое имя, которое отображается программным обеспечением администрирования базы данных
на физический директорий, в котором расположены таблицы базы данных. Для вашей базы данных
этом может иметь любое значение, вы должны зарегистрировать имя, используя ваше программное
обеспечение администрирования базы данных.
 (Процесс регистрации различается для разных
платформ.)
(Процесс регистрации различается для разных
платформ.)
 (Процесс регистрации различается для разных
платформ.)
(Процесс регистрации различается для разных
платформ.)
Вся эта информация комбинируется в одну строку, «URL базы данных». Например, для соединения через ODBC субпроткол к базе данных с идентификатором «people», URL базы данных должен быть таким:
String dbUrl = "jdbc:odbc:people";
Если вы соединяетесь по сети, URL базы данных будет содержать информацию о соединении, идентифицирующую удаленную машину и поэтому может стать немного пугающей. Вот пример базы данных CloudScape, вызываемой из удаленного клиента, использующего RMI:
jdbc:rmi://192.168.170.27:1099/jdbc:cloudscape:db
Этот URL базы данных реально содержит два JDBC вызова в одном. Первая
часть «jdbc:rmi://192.168.170.27:1099/» использует RMI для создания соединения
с удаленной машиной базы данных, прослушивающей порт 1099 по IP адресу 192.168.170.27. Вторая
часть URL, «jdbc:cloudscape:db» выражает более типичные установки используемого
субпротокола и имени базы данных, но они обычно проявляются только после первой части, которая
устанавливает соединение посредством RMI с удаленной машиной.
Когда вы готовы соединиться с базой данных, вызывайте статический метод DriverManager.getConnection( ) и передавайте ему URL базы данных, имя пользователя и пароль, чтобы получить доступ в базу данных. Назад вы получаете объект Connection, который вы можете затем использовать для запроса и управления базой данных.
Следующий пример открывает контактную информацию базы данных и производит поиск фамилий по заданному в командной строке. В примере выбираются только имена людей, у которых задан EMail адрес, затем происходит печать всех, у кого совпала фамилия:
//: c15:jdbc:Lookup.java
// Поиск email адресов в
// локальной базе данных с использованием JDBC.
// {Broken}
import java.sql.*;public class Lookup {
public static void main(String[] args) throws SQLException,
ClassNotFoundException {
String dbUrl = "jdbc:odbc:people";
String user = "";
String password = "";
// Загружаем драйвер (регистрирует себя)
Class. forName("sun.jdbc.odbc.JdbcOdbcDriver");
Connection c = DriverManager.getConnection(dbUrl, user, password);
Statement s = c.createStatement();
// SQL код:
ResultSet r = s.executeQuery("SELECT FIRST, LAST, EMAIL "
+ "FROM people.csv people " + "WHERE " + "(LAST='" + args[0]
+ "') " + " AND (EMAIL Is Not Null) " + "ORDER BY FIRST");
while (r.next()) {
// Регистр не имеет значения:
System.out.println(r.getString("Last") + ", "
+ r.getString("fIRST") + ": " + r.getString("EMAIL"));
}
s.close(); // Закрываем ResultSet
}
} // /:~ forName("sun.jdbc.odbc.JdbcOdbcDriver");
forName("sun.jdbc.odbc.JdbcOdbcDriver");Вы можете видеть создание URL базы данных, как описано прежде. В этом примере нет пароля защиты для базы данных, так что строки имени пользователя и пароля пустые.
Как только соединение будет установлено с помощью DriverManager.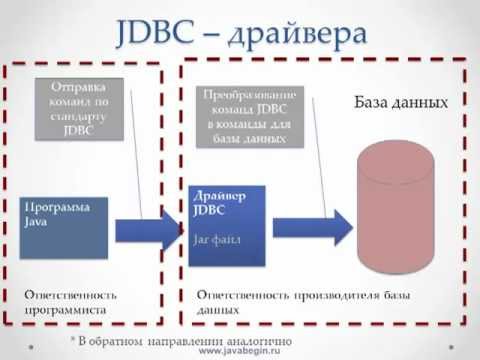 getConnection( ),
вы можете использовать полученный объект Connection для создания объекта Statement с помощью метода
createStatement( ). С помощью полученного объекта Statement вы можете вызвать метод executeQuery( ),
передав в него строку, содержащую SQL выражение в стандарте SQL-92. (Вы увидите, как вы можете
сгенерировать это выражение автоматически, так что вам не нужно знать очень много об SQL.)
getConnection( ),
вы можете использовать полученный объект Connection для создания объекта Statement с помощью метода
createStatement( ). С помощью полученного объекта Statement вы можете вызвать метод executeQuery( ),
передав в него строку, содержащую SQL выражение в стандарте SQL-92. (Вы увидите, как вы можете
сгенерировать это выражение автоматически, так что вам не нужно знать очень много об SQL.)
Метод executeQuery( ) возвращает объект ResultSet, который является итератором:
метод next( ) перемещает итератор на следующую запись в выражении, или возвращает false, если достигнут
конец результирующего множества. Вы всегда будете получать объект ResultSet из метода executeQuery( ),
даже если результатом запроса будет пустое множество (то есть, исключение не выбрасывается). Обратите
внимание, что вы должны вызвать метод next( ) один раз, прежде, чем попробуете прочесть любую запись
с данными. Если результирующее множество пустое, этот первый вызов next( ) вернет false.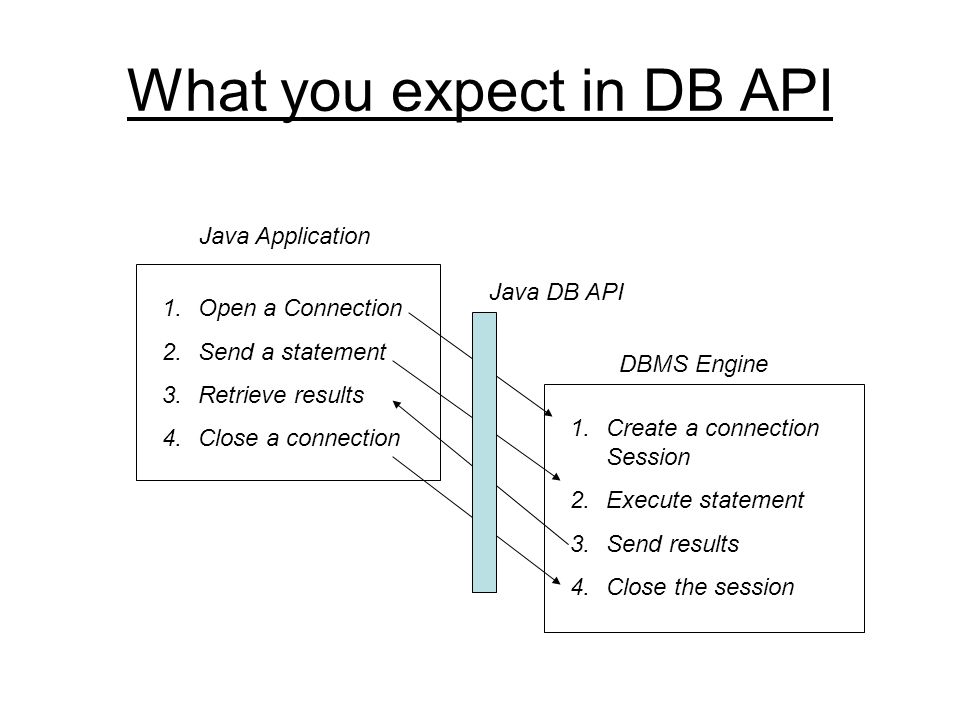
Получение примера для работы
С использованием JDBC, понимание кода относительно упрощается. Сбивающие с толку части заставляют его работать на вашей определенной системе. Причина, по которой эти части сбивают с толку, состоит в том, что вам требуется показать, как получить правильную загрузку вашего JDBC драйвера и как установить базу данных с помощью вашего программного обеспечения для администрирования базы данных.
Конечно же, этот процесс может радикально отличаться на разных машинах, но процесс,
который использовал я, работает на 32-х битной Windows и может дать вам ключ к пониманию, с какой
стороны подойти к вашей собственной ситуации.
Шаг 1: Нахождение JDBC Драйвера
Приведенная ниже программа содержит выражение:
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
Здесь предполагается структура каталогов, которая вводит в заблуждение. В обычной поставке JDK 1.1 не существует файла с названием JdbcOdbcDriver.class, так что если вы заглянете на этот пример и пойдете искать его, вы будите удивлены. Другой опубликованный пример использует псевдо-имя, такое как «myDriver.ClassName», что не намного полезнее. Фактически, вышеприведенная инструкция загрузки для jdbc-odbc драйвера (который реально поставляется с JDK) показана в нескольких местах в онлайн документации (обычно на странице, озаглавленной «JDBC-ODBC Bridge Driver»). Если приведенная выше инструкция загрузки не сработает, то, возможно, изменилось имя, как часть изменений в связи со сменой версии, так что вы должны просмотреть документацию снова.
Если инструкция загрузки ошибочна, вы получите исключение в этом месте. Для проверки того, что ваша инструкция загрузки работает верно, закомментируйте код после этой
инструкции до выражения catch. Если программа не выбросила исключений, это значит, что драйвер
загружен правильно.
Для проверки того, что ваша инструкция загрузки работает верно, закомментируйте код после этой
инструкции до выражения catch. Если программа не выбросила исключений, это значит, что драйвер
загружен правильно.
Шаг 2: Конфигурирование базы данных
Опять таки, это специфично для 32-х битной Windows. Вам может понадобиться некоторое исследование, чтобы получить представление о настройках для вашей собственной платформы.
Во-первых, откройте панель управления. Вы можете найти две иконки, которые
называются «ODBC». Вы должны использовать одну из них, которая называется «32bit
ODBC», так как другая иконка предназначена для обратной совместимости с 16 битным
программным обеспечением ODBC и не даст результатов для JDBC. Когда вы откроете иконку «32bit
ODBC», вы увидите диалог с несколькими закладками, включая «User DNS», «System
DNS», «File DNS» и т. д., в которых «DNS» означает «Data Source
Name». Только одно место важно для JDBC-ODBC моста, это установка базы данных в «System
DNS», но вы захотите протестировать вашу конфигурацию и создать запросы, а для этого вам также
понадобиться установить базу данных в закладке «File DNS». Это позволить инструменту
запросов от Microsoft (который поставляется вместе с Microsof Office) находить базу данных. Обратите
внимание, что существуют другие инструменты запросов от других производителей.
Только одно место важно для JDBC-ODBC моста, это установка базы данных в «System
DNS», но вы захотите протестировать вашу конфигурацию и создать запросы, а для этого вам также
понадобиться установить базу данных в закладке «File DNS». Это позволить инструменту
запросов от Microsoft (который поставляется вместе с Microsof Office) находить базу данных. Обратите
внимание, что существуют другие инструменты запросов от других производителей.
Наиболее интересная база данных — это так, которую вы уже используете.
Стандартный ODBC поддерживает несколько различных форматов файлов, включая такие, как
многоуважаемая рабочая лошадь DBase. Однако, он также включает простые форматы, как
«разделенные запятыми ASCII». В моем случае, я просто взял мою базу данных
«people», которую я поддерживаю многие годы, используя различные инструменты, и
экспортировал ее в разделенный запятыми ASCII файл (они обычно имеют расширения .cvs).
В разделе «System DNS» я выбрал «Add», выбрал текстовый драйвер для
обработки моего разделенного запятыми ASCII файла, а затем убрал пометку с «use
current directory», что позволит мне указать директорий, в котором я поместил
экспортированный файл с данными.
Когда вы сделаете это, вы увидите, что реально вы не указываете файл, а только директорий. Это происходит потому, что база данных обычно представлена набором файлов в одном единственном директории (хотя база данных может быть также представлена в других форматах). Каждый файл обычно содержит единственную таблицу, а SQL выражения могут выдавать результат, который объединяет данные их нескольких таблиц базы данных (это называется join). База данных, которая содержит только одну таблицу (наподобие моей базы данных «people») обычно называется базой данных из плоского файла. Большинство проблем, которые возникают с простыми хранилищами и получением данных, обычно заключается в том, что требуется множество таблиц, которые должны объединятся для получения желаемых результатов, а это называется реляционной базой данных.
Шаг 3: Проверка конфигурации
Для проверки конфигурации вам необходим способ для обнаружения,
является ли база данных видимой из программы, которая опрашивает ее. Конечно, вы можете
просто запустить JDBC программу из приведенного выше примера, и включить в нее
инструкцию:
Конечно, вы можете
просто запустить JDBC программу из приведенного выше примера, и включить в нее
инструкцию:
Connection c = DriverManager.getConnection(dbUrl, user, password);
Если будет выброшено исключение, ваша конфигурация некорректна.
Однако, на этом этапе полезно будет взять инструмент генерации запросов. Я использую Microsoft Query, который поставляется вместе с Microsoft Office, но вы можете выбрать что-то еще. Инструмент запросов должен знать, где располагается база данных, и Microsoft Query требует, чтобы я зашел в ODBC Администратор на закладку «File DNS» и добавить там новую сущность, опять таки указав текстовый драйвер и директорий, в котором живет моя база данных. Вы можете назвать сущность так, как вы хотите, но полезно использовать то же самое имя, которое использовано в «System DNS».
Как только вы сделаете это, вы увидите, что ваша база данных доступна,
когда вы создадите новый запрос с помощью вашего инструмента запросов.
Шаг 4: Генерация вашего SQL запроса
Запрос, который я создал с помощью Microsoft Query, не только показывает мне, что моя база данных присутствует и в порядке, но этот инструмент также автоматически создал код SQL запроса, который мне нужно вставить в мою Java программу. Мне нужен запрос, который будет искать записи, содержимое поля фамилии которых совпадает с тем, которое введено в командной строке при запуске Java программы. Так что здесь я ищу определенную фамилию «Eckel». Я также хочу отобразить только те имена, для которых есть ассоциированный с ними EMail. Шаги, которые я предпринял для создания этого запроса, следующие:
- Запустил новый запрос и использовал Построитель Запросов. Выбрал базу данных «people». (Это эквивалентно открытию соединения с базой данных с использованием соответствующего URL базы данных.)
- Выбрал таблицу «people» из базы данных. Из этой таблицы выбрал колонки FIRST,
LAST и EMAIL.
- В разделе «File Data» выбрал LAST и выбрал «equals» с аргументом «Eckel». Щелкнул радиокнопку «And».
- Выбрал EMAIL и выбрал «Is not Null».
- В разделе “Sort By” выбрал FIRST.
 Из этой таблицы выбрал колонки FIRST,
LAST и EMAIL.
Из этой таблицы выбрал колонки FIRST,
LAST и EMAIL.
В результате этого запроса будет показано то, что вы хотели.
Теперь вы можете нажать кнопку SQL и без каких-либо исследований с вашей стороны будет показан корректный SQL код, готовый для копи-паста. Этот запрос выглядит примерно так:
SELECT people.FIRST, people.LAST, people.EMAIL FROM people.csv people WHERE (people.LAST=’Eckel’) AND (people.EMAIL Is Not Null) ORDER BY people.FIRST
При создании сложных запросов легко ошибиться, но при использовании
инструмента запросов вы можете интерактивно проверить ваш запрос и автоматически сгенерировать
корректный код. Трудно придумать аргументы, чтобы делать это руками.
Шаг 5: Изменение и вставка в ваш запрос
Вы заметите, что приведенный выше код на вид отличается от того, что используется в программе. Это происходит потому, что инструмент запроса использует полную квалификацию для всех имен, даже когда используется только одна таблица. (Когда привлечена более, чем одна таблица, квалификация предотвращает коллизию между колонками разных таблиц, которые имеют одно и то же имя.) Так как этот запрос вовлекает только одну таблицу, вы можете, по своему усмотрению, удалить квалификатор «people» из большинства имен, например так:
SELECT FIRST, LAST, EMAIL FROM people.csv people WHERE (LAST=’Eckel’) AND (EMAIL Is Not Null) ORDER BY FIRST
Кроме того, вы не хотите, чтобы это программа была жестко запрограммирована на поиск только одного имени. Вместо этого, она должна охотится за именем, заданным как аргумент командной строки. Сделав эти изменения и включив SQL выражение в динамически создаваемую строку, получим:
"SELECT FIRST, LAST, EMAIL " +
"FROM people.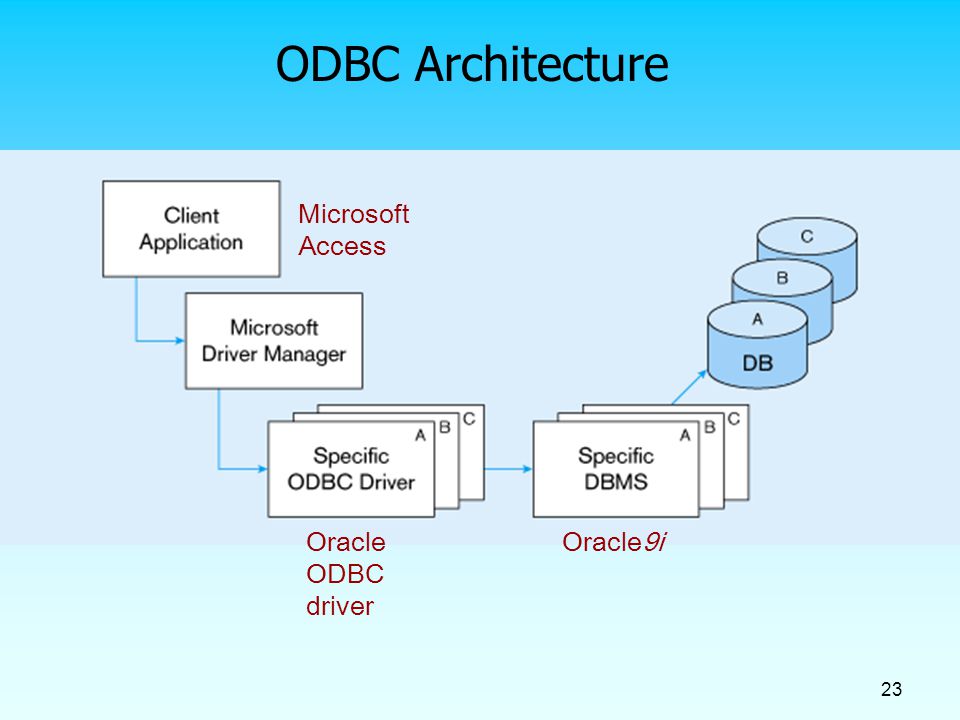 csv people " +
csv people " +
"WHERE " +
"(LAST='" + args[0] + "') " +
" AND (EMAIL Is Not Null) " +
"ORDER BY FIRST");
В SQL существует другой способ вставки имен в запрос, называемый хранимой процедурой, которая используется для увеличения скорости. Но для большинства ваших экспериментов с базами данных и для первой пробы, построение вашей собственной строки запроса в Java — это великолепно.
Вы можете видеть из этого примера, что при использовании инструментов, доступных в настоящее время — для определенных инструментов поддержки базы данных — программирование баз дынных с использованием SQL и JDBC может быть достаточно прямолинейным.
GUI версия программы поиска
Более полезно оставить программу поиска работающей все время, и просто переключаться в нее и печатать имя, которое вы хотите найти. Следующая программа создает программу поиска в виде приложения/апплета, она также добавляет завершение имен, так что данные будут показываться, не заставляя вас печатать полностью фамилию:
//: c15:jdbc:VLookup. java
// GUI version of Lookup.java.
// <applet code=VLookup
// width=500 height=200></applet>
// {Broken}
import javax.swing.*;import java.awt.*;import java.awt.event.*;import javax.swing.event.*;import java.sql.*;import com.bruceeckel.swing.*;public class VLookup extends JApplet {
String dbUrl = "jdbc:odbc:people";
String user = "";
String password = "";
Statement s;
JTextField searchFor = new JTextField(20);
JLabel completion = new JLabel(" ");
JTextArea results = new JTextArea(40, 20);
public void init() {
searchFor.getDocument().addDocumentListener(new SearchL());
JPanel p = new JPanel();
p.add(new Label("Last name to search for:"));
p.add(searchFor);
p.add(completion);
Container cp = getContentPane();
cp. add(p, BorderLayout.NORTH);
cp.add(results, BorderLayout.CENTER);
try {
// Загружаем драйвер (регистрирует себя)
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
Connection c = DriverManager.getConnection(dbUrl, user, password);
s = c.createStatement();
}
catch (Exception e) {
results.setText(e.toString());
}
}
class SearchL implements DocumentListener {
public void changedUpdate(DocumentEvent e) {
}
public void insertUpdate(DocumentEvent e) {
textValueChanged();
}
public void removeUpdate(DocumentEvent e) {
textValueChanged();
}
}
public void textValueChanged() {
ResultSet r;
if (searchFor. getText().length() == 0) {
completion.setText("");
results.setText("");
return;
}
try {
// Автозавершение:
r = s.executeQuery("SELECT LAST FROM people.csv people "
+ "WHERE (LAST Like '" + searchFor.getText()
+ "%') ORDER BY LAST");
if (r.next())
completion.setText(r.getString("last"));
r = s.executeQuery("SELECT FIRST, LAST, EMAIL "
+ "FROM people.csv people " + "WHERE (LAST='"
+ completion.getText() + "') AND (EMAIL Is Not Null) "
+ "ORDER BY FIRST");
}
catch (Exception e) {
results.setText(searchFor.getText() + "n");
results.append(e.toString());
return;
}
results. setText("");
try {
while (r.next()) {
results.append(r.getString("Last") + ", "
+ r.getString("fIRST") + ": " + r.getString("EMAIL")
+ "n");
}
}
catch (Exception e) {
results.setText(e.toString());
}
}
public static void main(String[] args) {
Console.run(new VLookup(), 500, 200);
}
} // /:~ java
java add(p, BorderLayout.NORTH);
add(p, BorderLayout.NORTH); getText().length() == 0) {
getText().length() == 0) { setText("");
setText("");Большая часть логики работы с базой данных та же самая, но вы можете
видеть, что добавлен DocumentListener для отслеживания JTextField (смотрите описание
javax.swing.JTextField в HTML документации по Java на java.sun.com, чтобы получить больше
информации), так что в то время, когда вы напечатаете новый символ, сначала будет
совершена попытка выполнить автозавершение имени путем поиска фамилии в базе данных и
отображения первой найденной.![]() (Она помещается в JLabel завершения и используется как
текст поиска.) Таким образом, как только вы напечатаете достаточное количество символов
для программы для уникального поиска имени, которое вы ищите, вы можете остановиться.
(Она помещается в JLabel завершения и используется как
текст поиска.) Таким образом, как только вы напечатаете достаточное количество символов
для программы для уникального поиска имени, которое вы ищите, вы можете остановиться.
Почему JDBC API выглядит таким сложным
Когда вы просмотрите документацию для JDBC, она может привести в уныние. Обычно в интерфейсте DatabaseMetaData — который просто громоздок, в противовес большинству интерфейсов, которые вы видели в Java — существуют методы, такие как dataDefinitionCausesTransactionCommit( ), getMaxColumnNameLength( ), getMaxStatementLength( ), storesMixedCaseQuotedIdentifiers( ), supportsANSI92IntermediateSQL( ), supportsLimitedOuterJoins( ) и так далее. Что можно сказать об этом?
Как упомянуто раньше, базы данных, по своей сущности, находятся в постоянном
состоянии суматохи, прежде всего потому, что это требуется для приложений, работающих с базами
данных, и поэтому инструменты работы с базами данных так великолепны. Только в последнее время
были достигнуты некоторые договоренности в сторону общего языка SQL (и есть множество
других языков работы с базами данных общего использования). Но даже со «стандартным»
языком есть много вариаций на эту тему, поэтому JDBC должен предоставлять громоздкий интерфейс
DatabaseMetaData, так что ваш код может обнаружить совместимость базы данных, с которой
в настоящее время выполнено соединение, с определенным SQL «стандартом». Короче
говоря, вы можете написать простой, переносимый SQL, но если вы хотите оптимизировать,
скорость вашего кодирования значительно повысится, если вы постигните возможности
базы данных определенного поставщика.
Только в последнее время
были достигнуты некоторые договоренности в сторону общего языка SQL (и есть множество
других языков работы с базами данных общего использования). Но даже со «стандартным»
языком есть много вариаций на эту тему, поэтому JDBC должен предоставлять громоздкий интерфейс
DatabaseMetaData, так что ваш код может обнаружить совместимость базы данных, с которой
в настоящее время выполнено соединение, с определенным SQL «стандартом». Короче
говоря, вы можете написать простой, переносимый SQL, но если вы хотите оптимизировать,
скорость вашего кодирования значительно повысится, если вы постигните возможности
базы данных определенного поставщика.
Конечно же, это не ошибка Java. Различия между продуктами баз данных
является просто тем, что JDBC пробует помочь скомпенсировать. Но имейте в виду, что ваша
жизнь будет облегчена, если вы можете либо писать общие запросы и не беспокоиться о
производительности, либо, если вы должны настраивать производительности, необходимо знать
платформу, для которой вы пишите, так что вам нет необходимости писать весь код для
исследования.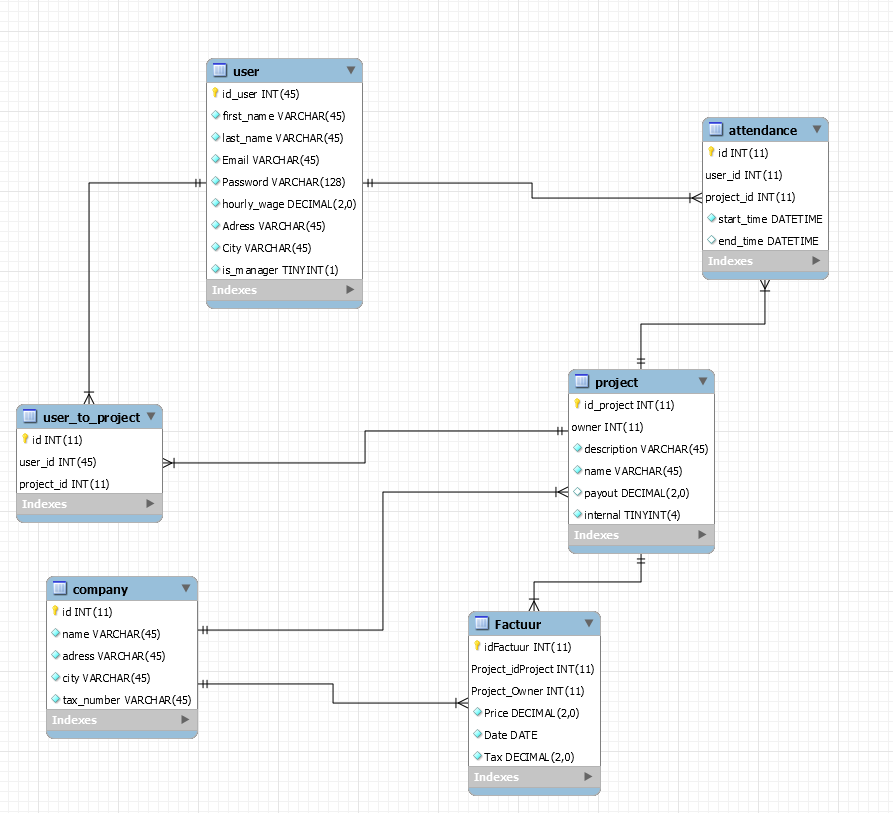
Более сложный пример
Более интересный пример [3] вовлекает многотабличную базу данных, которая расположена на сервере. Здесь база данных подразумевает обеспечение ответственности за общую активность и за то, чтобы позволить людям назначать события, так что она называется Community Interests Database (CID). Этот пример предназначен только для обзора базы данных и ее реализации, и не предназначен для подробной инструкции по разработке базы данных. Есть много книг, семинаров и пакетов программного обеспечения, которые помогут вам в дизайне и разработке базы данных.
Кроме того, этот пример предполагает, что у вас уже есть установленная
SQL база данных на сервере (хотя она может быть также запущена на локальной машине), а также
предполагается, что вами был найден и исследован соответствующий JDBC драйвер для этой базы
данных. Существует несколько бесплатных SQL баз данных, и некоторые из них даже
устанавливаются автоматически с некоторыми разновидностями Linux. Вы ответственны за выбор
базы данных и нахождение JDBC драйвера; приведенных здесь пример основывается на SQL базе
данных, называемой «Cloudscape», которая может быть бесплатно скачена для разработки
(не развертывания) по адресу http://www.Cloudscape.com.
Вам необходимо следовать инструкции, чтобы правильно установить и настроить Cloudscape.
Вы ответственны за выбор
базы данных и нахождение JDBC драйвера; приведенных здесь пример основывается на SQL базе
данных, называемой «Cloudscape», которая может быть бесплатно скачена для разработки
(не развертывания) по адресу http://www.Cloudscape.com.
Вам необходимо следовать инструкции, чтобы правильно установить и настроить Cloudscape.
Чтобы сохранить простоту внесения изменений в информацию для соединения, драйвер базы данных, URL базы данных, имя пользователя и пароль помещаются в отдельном классе:
//: c15:jdbc:CIDConnect.java
// Информация для соединения с базой данных
// community interests database (CID).
public class CIDConnect {
// Вся информация специфична для CloudScape:
public static String dbDriver = "COM.cloudscape.core.JDBCDriver";
public static String dbURL = "jdbc:cloudscape:d:/docs/_work/JSapienDB";
public static String user = "";
public static String password = "";
} // /:~
В этом примере нет пароля защиты для базы данных, так что имя пользователя и
пароль являются пустыми строками. Для Cloudscape dbURL содержит путь к директории, в которой
расположена база данных, но другие JDBC драйверы будут использовать другие способы для
передачи этой информации. Этот пример предполагает, что база данных «JSapienDB»
уже создана, но чтобы заставить базу данных работать, вам необходимо использовать инструмент
cview, который поставляется вместе Cloudscape, чтобы создать новую базу, а затем вы должны изменить
указанный выше dbURL в соответствии с путем, где вы создадите базу данных.
Для Cloudscape dbURL содержит путь к директории, в которой
расположена база данных, но другие JDBC драйверы будут использовать другие способы для
передачи этой информации. Этот пример предполагает, что база данных «JSapienDB»
уже создана, но чтобы заставить базу данных работать, вам необходимо использовать инструмент
cview, который поставляется вместе Cloudscape, чтобы создать новую базу, а затем вы должны изменить
указанный выше dbURL в соответствии с путем, где вы создадите базу данных.
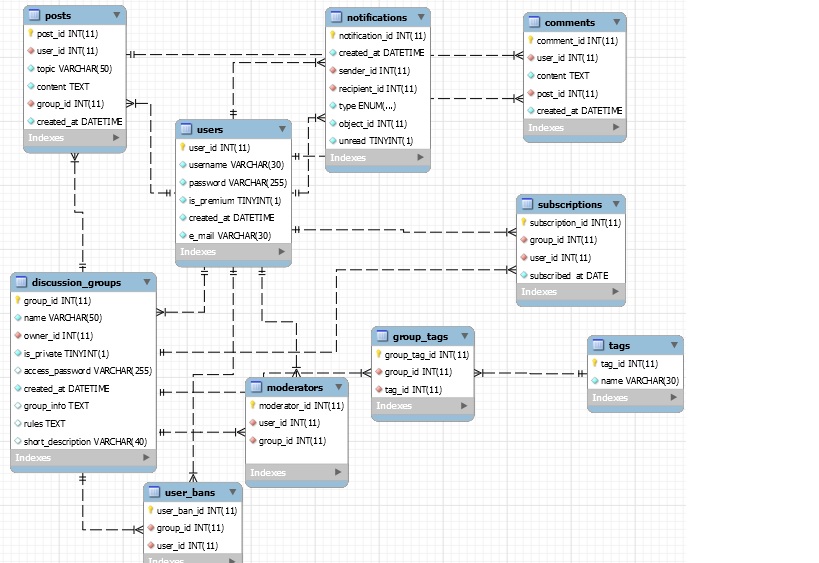
База данных состоит из набора таблиц, которые имеют вот такую структуру:
«Member» содержит общую информацию о членах, «Events» и «Locations» содержат информацию об активности и в каком месте она имела место, а «Evtmems» содержит события и членов, которые хотят следить за этими событиями. Вы можете видеть, что данные о членах в одной таблице являются ключами в другой таблицы.
Следующий класс содержит SQL строки, которые создадут эти таблицы базы данных (обратитесь к руководству по SQL, чтобы понять, что делает этот SQL код):
//: c15:jdbc:CIDSQL. java
java
// SQL строки для создания таблиц для CID.
public class CIDSQL {
public static String[] sql = {
// Создание таблицы MEMBERS:
"drop table MEMBERS",
"create table MEMBERS " + "(MEM_ID INTEGER primary key, "
+ "MEM_UNAME VARCHAR(12) not null unique, "
+ "MEM_LNAME VARCHAR(40), " + "MEM_FNAME VARCHAR(20), "
+ "ADDRESS VARCHAR(40), " + "CITY VARCHAR(20), "
+ "STATE CHAR(4), " + "ZIP CHAR(5), " + "PHONE CHAR(12), "
+ "EMAIL VARCHAR(30))",
"create unique index " + "LNAME_IDX on MEMBERS(MEM_LNAME)",
// Создание таблицы EVENTS
"drop table EVENTS",
"create table EVENTS " + "(EVT_ID INTEGER primary key,"
+ "EVT_TITLE VARCHAR(30) not null,"
+ "EVT_TYPE VARCHAR(20), " + "LOC_ID INTEGER, "
+ "PRICE DECIMAL, " + "DATETIME TIMESTAMP)",
"create unique index " + "TITLE_IDX on EVENTS(EVT_TITLE)",
// Создание таблицы EVTMEMS
"drop table EVTMEMS",
"create table EVTMEMS " + "(MEM_ID INTEGER not null,"
+ "EVT_ID INTEGER not null, " + "MEM_ORD INTEGER)",
"create unique index " + "EVTMEM_IDX on EVTMEMS(MEM_ID, EVT_ID)",
// Создание таблицы LOCATIONS
"drop table LOCATIONS",
"create table LOCATIONS " + "(LOC_ID INTEGER primary key,"
+ "LOC_NAME VARCHAR(30) not null,"
+ "CONTACT VARCHAR(50), " + "ADDRESS VARCHAR(40), "
+ "CITY VARCHAR(20), " + "STATE VARCHAR(4), "
+ "ZIP VARCHAR(5), " + "PHONE CHAR(12), "
+ "DIRECTIONS VARCHAR(4096))",
"create unique index " + "NAME_IDX on LOCATIONS(LOC_NAME)", };
} // /:~
Следующая программа использует информацию CIDConnect и CIDSQL
для загрузки JDBC драйвера, создания соединения с базой данных и для создания
структуры таблиц в соответствии с приведенной выше диаграммой. Для соединения с
базой данных вы вызываете статический метод DriverManager.getConnection( ),
передаете ему URL базы данных, имя пользователя и пароль, чтобы войти в базу данных.
Назад вы получаете объект Connection, который вы можете использовать для запросов и
манипуляции с базой данных. Как только соединение будет установлено, вы можете
просто передать SQL в базу данных, в данном случае путем передачи через массив CIDSQL.
Однако, когда мы запустим эту программу в первый раз, команда «dtop table»
не сработает, а станет причиной исключения, которое будет перехвачено, отрапортовано,
а затем проигнорировано. Причина использования команды «drop table»
состоит в том, что с ней легко экспериментировать: вы можете изменить SQL, затем
определить таблицу, а затем запустить программу, которая заменит старые таблицы новыми.
Для соединения с
базой данных вы вызываете статический метод DriverManager.getConnection( ),
передаете ему URL базы данных, имя пользователя и пароль, чтобы войти в базу данных.
Назад вы получаете объект Connection, который вы можете использовать для запросов и
манипуляции с базой данных. Как только соединение будет установлено, вы можете
просто передать SQL в базу данных, в данном случае путем передачи через массив CIDSQL.
Однако, когда мы запустим эту программу в первый раз, команда «dtop table»
не сработает, а станет причиной исключения, которое будет перехвачено, отрапортовано,
а затем проигнорировано. Причина использования команды «drop table»
состоит в том, что с ней легко экспериментировать: вы можете изменить SQL, затем
определить таблицу, а затем запустить программу, которая заменит старые таблицы новыми.
В этом примере имеет смысл выбрасывать исключения на консоль:
//: c15:jdbc:CIDCreateTables. java
// Создание таблиц базы данных для
// community interests database.
// {Broken}
import java.sql.*;public class CIDCreateTables {
public static void main(String[] args) throws SQLException,
ClassNotFoundException, IllegalAccessException {
// Загружаем драйвер (регистрирует себя)
Class.forName(CIDConnect.dbDriver);
Connection c = DriverManager.getConnection(CIDConnect.dbURL,
CIDConnect.user, CIDConnect.password);
Statement s = c.createStatement();
for (int i = 0; i < CIDSQL.sql.length; i++) {
System.out.println(CIDSQL.sql[i]);
try {
s.executeUpdate(CIDSQL.sql[i]);
}
catch (SQLException sqlEx) {
System.err.println("Probably a 'drop table' failed");
}
}
s. close();
c.close();
}
} // /:~ java
java close();
close();Обратите внимание, что все изменения в базе данных могут быть внесены путем изменения строк в таблице CIDSQL без изменения CIDCreateTables.
executeUpdate( ) обычно будет возвращать количество строк, которые обрабатываются SQL выражением. executeUpdate( ) чаще всего используется для выполнения инструкций INSERT, UPDATE или DELETE, которые изменяют одну или несколько строк. Для таких инструкций, как CREATE TABLE, DROP TABLE и CREATE INDEX метод executeUpdate( ) всегда вернет ноль.
Для тестирования базы данных она загружается некоторыми простыми
данными. Для этого необходимо выполнить серию INSERT’ов, за которыми следуют SELECT’ы,
производящие результирующее множество. Чтобы сделать добавление и изменение тестовых
данных легче, тестовые данные организованы в виде двумерного массива элементов типа Object,
а метод executeInsert( ) может затем использовать информацию из одной строки таблицы
для создания соответствующей SQL команды.
//: c15:jdbc:LoadDB.java
// Загрузка и тестирование базы данных.
// {Broken}
import java.sql.*;class TestSet {
Object[][] data = {
{ "MEMBERS", new Integer(1), "dbartlett", "Bartlett", "David",
"123 Mockingbird Lane", "Gettysburg", "PA", "19312",
"123.456.7890", "[email protected]" },
{ "MEMBERS", new Integer(2), "beckel", "Eckel", "Bruce",
"123 Over Rainbow Lane", "Crested Butte", "CO", "81224",
"123.456.7890", "[email protected]" },
{ "MEMBERS", new Integer(3), "rcastaneda", "Castaneda", "Robert",
"123 Downunder Lane", "Sydney", "NSW", "12345",
"123.456.7890", "[email protected]" },
{ "LOCATIONS", new Integer(1), "Center for Arts", "Betty Wright",
"123 Elk Ave.", "Crested Butte", "CO", "81224",
"123. 456.7890", "Go this way then that." },
{ "LOCATIONS", new Integer(2), "Witts End Conference Center",
"John Wittig", "123 Music Drive", "Zoneville", "PA",
"19123", "123.456.7890", "Go that way then this." },
{ "EVENTS", new Integer(1), "Project Management Myths",
"Software Development", new Integer(1), new Float(2.50),
"2000-07-17 19:30:00" },
{ "EVENTS", new Integer(2), "Life of the Crested Dog",
"Archeology", new Integer(2), new Float(0.00),
"2000-07-19 19:00:00" },
// Match some people with events
{ "EVTMEMS", new Integer(1), // Dave is going to
new Integer(1), // the Software event.
new Integer(0) }, { "EVTMEMS", new Integer(2), // Bruce is
// going to
new Integer(2), // the Archeology event.
new Integer(0) }, { "EVTMEMS", new Integer(3), // Robert is
// going to
new Integer(1), // the Software event.
new Integer(1) }, { "EVTMEMS", new Integer(3), // ... and
new Integer(2), // the Archeology event.
new Integer(1) }, };
// Используем набор данных по умолчанию:
public TestSet() {
}
// Используем другой набор данных:
public TestSet(Object[][] dat) {
data = dat;
}
}public class LoadDB {
Statement statement;
Connection connection;
TestSet tset;
public LoadDB(TestSet t) throws SQLException {
tset = t;
try {
// Загрузка драйвера (регистрирует себя)
Class. forName(CIDConnect.dbDriver);
}
catch (java.lang.ClassNotFoundException e) {
e.printStackTrace(System.err);
}
connection = DriverManager.getConnection(CIDConnect.dbURL,
CIDConnect.user, CIDConnect.password);
statement = connection.createStatement();
}
public void dispose() throws SQLException {
statement.close();
connection.close();
}
public void executeInsert(Object[] data) {
String sql = "insert into " + data[0] + " values(";
for (int i = 1; i < data.length; i++) {
if (data[i] instanceof String)
sql += "'" + data[i] + "'";
else
sql += data[i];
if (i < data.length - 1)
sql += ", ";
}
sql += ')';
System. out.println(sql);
try {
statement.executeUpdate(sql);
}
catch (SQLException sqlEx) {
System.err.println("Insert failed.");
while (sqlEx != null) {
System.err.println(sqlEx.toString());
sqlEx = sqlEx.getNextException();
}
}
}
public void load() {
for (int i = 0; i < tset.data.length; i++)
executeInsert(tset.data[i]);
}
// Выбрасывается исключение на консоль:
public static void main(String[] args) throws SQLException {
LoadDB db = new LoadDB(new TestSet());
db.load();
try {
// Получаем ResultSet из загруженной базы данных:
ResultSet rs = db.statement.executeQuery("select "
+ "e. EVT_TITLE, m.MEM_LNAME, m.MEM_FNAME "
+ "from EVENTS e, MEMBERS m, EVTMEMS em "
+ "where em.EVT_ID = 2 " + "and e.EVT_ID = em.EVT_ID "
+ "and m.MEM_ID = em.MEM_ID");
while (rs.next())
System.out.println(rs.getString(1) + " " + rs.getString(2)
+ ", " + rs.getString(3));
}
finally {
db.dispose();
}
}
} // /:~ 456.7890", "Go this way then that." },
456.7890", "Go this way then that." },
 forName(CIDConnect.dbDriver);
forName(CIDConnect.dbDriver); out.println(sql);
out.println(sql); EVT_TITLE, m.MEM_LNAME, m.MEM_FNAME "
EVT_TITLE, m.MEM_LNAME, m.MEM_FNAME "Класс TestSet содержит набор данных по умолчанию, который
будет воспроизводиться, если вы используете конструктор по умолчанию; однако, вы можете
также создать объект TestSet, используя альтернативный набор данных, с помощью второго
конструктора. Набор данных располагается в двумерном массиве типа Object, поскольку
данные могут быть любого типа, включая String или числовые типы. Метод executeInsert( )
использует RTTI для того, чтобы различать данные типа String (которые должны быть в
кавычках) и не строковые данные, которые встраиваются в SQL команды. После распечатки
этих не строковых данных на консоль, используется executeUpdate( ) для отправки в
базу данных.
После распечатки
этих не строковых данных на консоль, используется executeUpdate( ) для отправки в
базу данных.
Конструктор для LoadDB создает соединение, а load( ) перебирает данные и вызывает метод executeInsert( ) для каждой записи. dispose( ) закрывает выражение и соединение; чтобы гарантировать этот вызов, он помещен внутри выражения finally.
Как только база данных будет загружена, выражения в executeQuery( ) производят простое результирующее множество. Так как запрос комбинирует несколько таблиц, он является примером объединения.
Есть гораздо более обширная информация, доступная в электронной документации, которая поставляется, как часть дистрибутива Java от Sun. Кроме того, вы можете найти больше информации в книге «JDBC Database Access with Java» (Hamilton, Cattel, and Fisher, Addison-Wesley, 1997). Другие книги по JDBC появляются регулярно.
Заключение
Упражнения
- Измените CIDCreateTables. java так, чтобы он читал SQL строки из
текстового файла вместо CIDSQL.
- Сконфигурируйте вашу систему так, чтобы вы могли успешно совершить вызов CIDCreateTables.java и LoadDB.java.
- (Более сложное) Возмите программу VLookup.java и измените ее так, чтобы когда вы кликаете на результирующем имени, она автоматически брала это имя и копировала его в буфер обмена (так чтобы вы могли просто вставить его в ваш email). Вам будет необходимо снова просмотреть Главу 13, чтобы вспомнить, как использовать буфер обмена в JFC.
 java так, чтобы он читал SQL строки из
текстового файла вместо CIDSQL.
java так, чтобы он читал SQL строки из
текстового файла вместо CIDSQL.| ← | Удаленный вызов методов (RMI) | Сервлеты | → |
Базы Данных — Java программирование
База данных — это один или несколько файлов данных, предназначенных для хранения, изменения и обработки больших объемов взаимосвязанной информации. Базы данных используются под управлением систем управления базами данных (СУБД).
Базы данных используются под управлением систем управления базами данных (СУБД).
СУБД представляет собой программное обеспечение, которое используется для создания и работы с базами данных.
SQL — язык структурированных запросов, основной задачей которого является предоставление простого способа считывания и записи информации в базу данных.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
- Каждый элемент таблицы является одним элементом данных.
- Каждый столбец обладает своим уникальным именем.
- Одинаковые строки в таблице отсутствуют.
- Все столбцы в таблице однородные, то есть все элементы в столбце имеют одинаковый тип.
- Порядок следования строк может быть произвольным.
- На пересечении каждого столбца и строки может находиться только атомарное значение (одно значение, не состоящее из группы значений). Таблицы, удовлетворяющие этому условию, называют нормализованными.
 Таблицы, удовлетворяющие этому условию, называют нормализованными.
Таблицы, удовлетворяющие этому условию, называют нормализованными.Предположим, мы захотели создать базу данных для форума. У форума есть зарегистрированные пользователи, которые создают темы и оставляют сообщения в этих темах. Эта информация и должна храниться в базе данных.
Теоретически (на бумаге) мы можем все это расположить в одной таблице, например, так:
| Имя | Пароль | Созданные темы | Созданные сообщения | |
| Кирилл | [email protected] | qwqwq | О рыбалке | Думаю надо сделать так… |
| Вася | [email protected] | dsd | Велосипеды; О рыбалке | Согласен; Согласен |
| Семен | semen@gmail. com com |
dfd | Ночные клубы | А еще можно сделать так… |
Несколько значений в ячейке колонки “Созданные темы” противоречат свойству атомарности (одно значение в одной ячейке). Поэтому разбиваем таблицу на три:
| Имя | Пароль | |
| Кирилл | [email protected] | qwqwq |
| Вася | [email protected] | dsd |
| Семен | [email protected] | dfd |
| Наименование | Автор |
| О рыбалке | Кирилл |
| Велосипеды | Вася |
| О рыбалке | Вася |
| Ночные клубы | Семен |
| Текст | Автор |
| Думаю надо сделать так… | Кирилл |
| Согласен | Вася |
| Согласен | Вася |
| А еще можно сделать так… | Семен |
Таблицы Пользователи, Темы удовлетворяют всем условиям. А вот таблица Сообщения — нет. Ведь в таблице не может быть двух одинаковых строк, а где гарантия, что один пользователь не оставит два одинаковых сообщения. Кроме того, мы знаем, что каждое сообщение обязательно относится к какой-либо теме. А как это можно узнать из наших таблиц? Никак. Для решения этих проблем, в реляционных базах данных существуют ключи.
А вот таблица Сообщения — нет. Ведь в таблице не может быть двух одинаковых строк, а где гарантия, что один пользователь не оставит два одинаковых сообщения. Кроме того, мы знаем, что каждое сообщение обязательно относится к какой-либо теме. А как это можно узнать из наших таблиц? Никак. Для решения этих проблем, в реляционных базах данных существуют ключи.
Первичный ключ (сокращенно РК — primary key) — столбец, значения которого во всех строках различны.
Первичные ключи могут быть:
- логическими (естественными) и
- Суррогатными (искусственными).
Так, для таблицы Пользователи первичным ключом может стать столбец e-mail (ведь теоретически не может быть двух пользователей с одинаковым e-mail). На практике лучше использовать суррогатные ключи, т.к. их применение позволяет абстрагировать ключи от реальных данных. Кроме того, первичные ключи менять нельзя, а что если у пользователя сменится e-mail?
Суррогатный ключ представляет собой дополнительное поле в базе данных. Как правило, это порядковый номер записи (хотя вы можете задавать их на свое усмотрение, контролируя, чтобы они были уникальны).
Как правило, это порядковый номер записи (хотя вы можете задавать их на свое усмотрение, контролируя, чтобы они были уникальны).
| id пользователя | Имя | Пароль | |
| 1 | Кирилл | [email protected] | qwqwq |
| 2 | Вася | [email protected] | dsd |
| 3 | Семен | [email protected] | dfd |
| id темы | Наименование | Автор |
| 1 | О рыбалке | Кирилл |
| 2 | Велосипеды | Вася |
| 3 | О рыбалке | Вася |
| 4 | Ночные клубы | Семен |
| id сообщения | Текст | Автор |
| 1 | Думаю надо сделать так… | Кирилл |
| 2 | Согласен | Вася |
| 3 | Согласен | Вася |
| 4 | А еще можно сделать так… | Семен |
Теперь каждая запись в наших таблицах уникальна.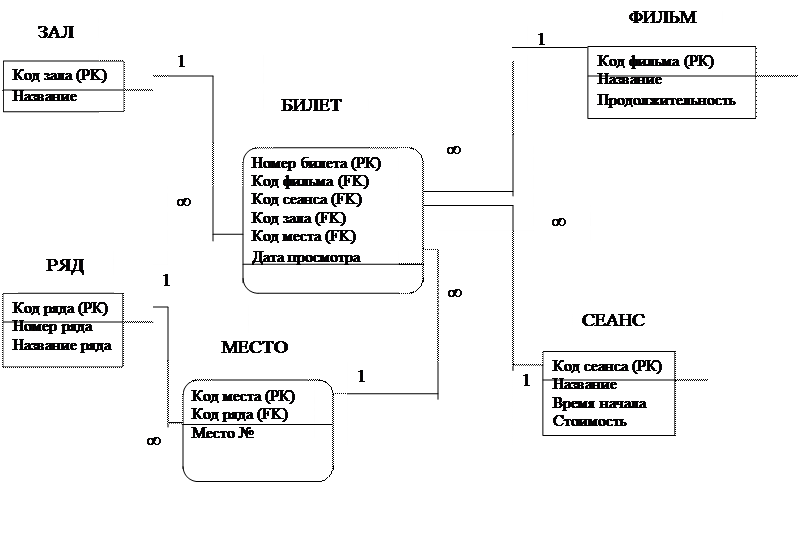 Нам осталось установить соответствие между темами и сообщениями в них. Делается это также при помощи первичных ключей. В таблицу Сообщения мы добавим еще одно поле:
Нам осталось установить соответствие между темами и сообщениями в них. Делается это также при помощи первичных ключей. В таблицу Сообщения мы добавим еще одно поле:
| id сообщения | Текст | Автор | id темы |
| 1 | Думаю надо сделать так… | Кирилл | 1 |
| 2 | Согласен | Вася | 4 |
| 3 | Согласен | Вася | 1 |
| 4 | А еще можно сделать так… | Семен | 1 |
Поле “id темы” называется внешний ключ (сокращенно FK — foreign key). Каждое значение этого поля соответствует какому-либо первичному ключу из таблицы «Темы«. Так устанавливается однозначное соответствие между сообщениями и темами, к которым они относятся.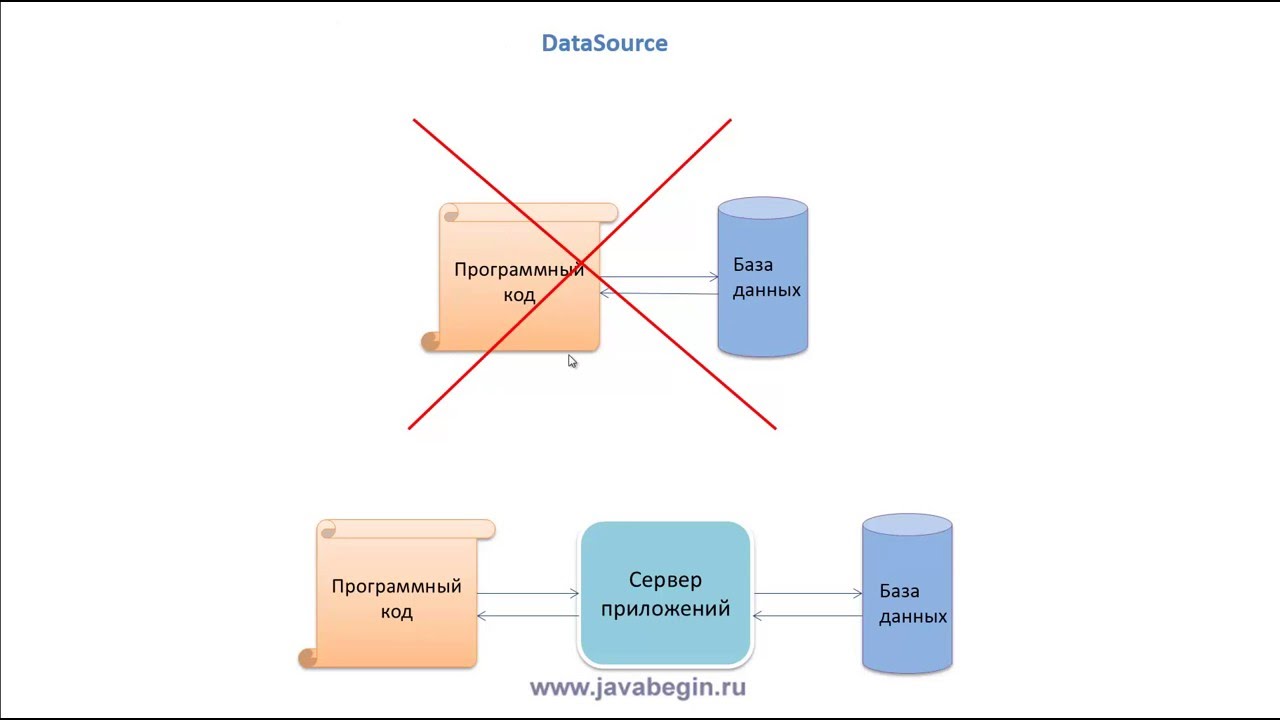
Предположим, у нас добавился новый пользователь, и зовут его тоже Вася. Как мы узнаем, какой именно Вася оставил сообщения? Для этого поля автор в таблицах «Темы» и «Сообщения» мы сделаем также внешними ключами:
| id пользователя | Имя | Пароль | |
| 1 | Кирилл | [email protected] | qwqwq |
| 2 | Вася | [email protected] | dsd |
| 3 | Семен | [email protected] | dfd |
| 4 | Вася | [email protected] | vasya |
| id темы | Наименование | id автора |
| 1 | О рыбалке | 1 |
| 2 | Велосипеды | 2 |
| 3 | О рыбалке | 2 |
| 4 | Ночные клубы | 3 |
| 5 | К кому обратиться | 4 |
| id сообщения | Текст | id автора | id темы |
| 1 | Думаю надо сделать так… | 1 | 1 |
| 2 | Согласен | 2 | 4 |
| 3 | Согласен | 2 | 1 |
| 4 | А еще можно сделать так… | 3 | 1 |
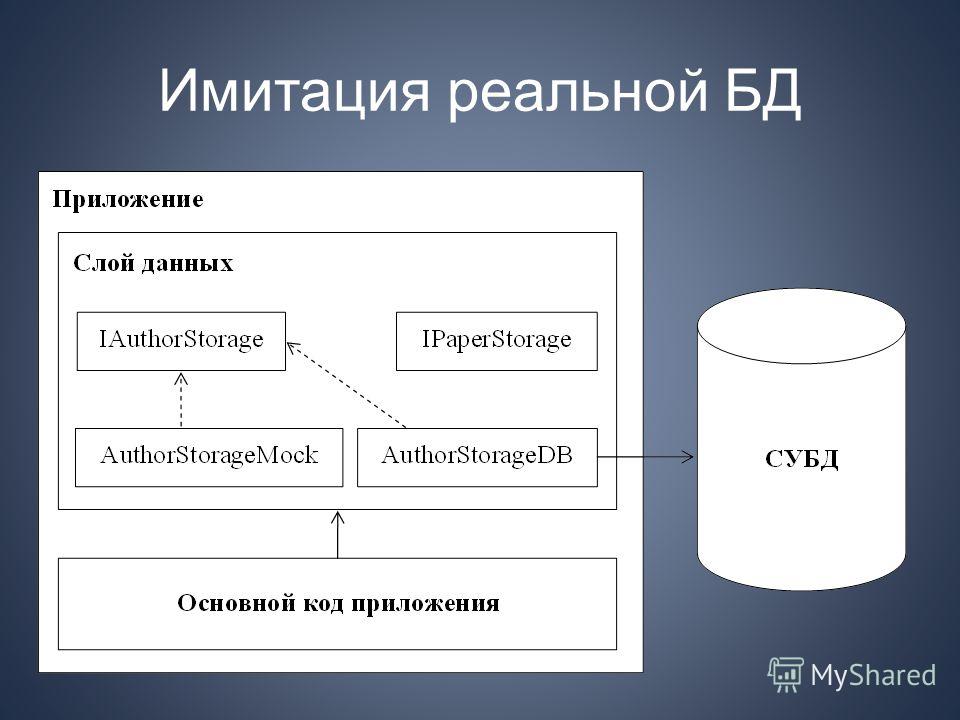
Наша база данных готова. Схематично ее можно представить так:
Схематично ее можно представить так:
Создание новой локальной базы данных с помощью Java
Моя цель-создать локальную базу данных, которую можно читать и записывать с помощью Java. У меня есть некоторый опыт работы с локальной базой данных sqlite с помощью Python и взаимодействия с существующими сетевыми базами данных на Microsoft Azure через VB.Net, но формулировка Java для создания базы данных ускользает от меня.
Большинство источников (например, JDBC Docs), по-видимому, предполагают, что вы обращаетесь к базе данных через сетевой протокол или базу данных, размещенную на localhost. Моя желаемая реализация заключается в создании и хранении базы данных в файле (или коллекции файлов), так что она может быть сохранена и доступна локально, без подключения к сети (предположительно через протокол «file:»).
Учебник JDBC выглядит так, как будто он будет очень полезен, как только я начну работать, но в настоящее время выходит за рамки моей области, так как у меня еще даже нет существующей базы данных.
Многие источники предложили такие решения, как h3, MySQL, Derby или Hypersonic DB. Однако я не хочу устанавливать расширения (если это правильный термин) по ряду причин:
- Этот проект изначально предназначен для того, чтобы помочь мне освоить свой путь вокруг Java-расширение масштабов проекта разбавит мой опыт работы с языком «base» и, вероятно, увеличит соблазн заниматься «cargo cult programming»
- Если этот проект когда-нибудь будет распространен среди других пользователей (правда, маловероятно, но все же!), Я не хочу заставлять их устанавливать больше, чем ядро Java.
- Я просто не знаю, как установить расширения (дополнения? модули?) в Java — один детский шаг за раз!
По аналогичным причинам установка Microsoft SQL Server не будет продуктивной.
Этот ответ выглядит близко к тому, к чему я стремлюсь; однако он дает ошибку:
java.sql.SQLException: No suitable driver found for jdbc:mysql://localhost/?user=root&password=rootpassword
и попытка «jdbc:file://targetFile. sql» дает аналогичную ошибку.
sql» дает аналогичную ошибку.
Я видел термин «embedded» database, который, как мне кажется, является подмножеством «local database» (т. е. локальная база данных хранится в той же системе-встроенная база данных-это локальная база данных, которая используется только одним приложением) — Если я неправильно понял эти определения, пожалуйста, не стесняйтесь меня поправлять!
java sql database local embedded-databaseПоделиться Источник scubbo 03 декабря 2012 в 22:01
4 ответа
- Синхронизация базы данных Azure с локальной базой данных
Можно ли синхронизировать существующую базу данных azure с локальной базой данных? . Нам нужно, чтобы данные локальной базы данных обновлялись данными в базе данных cloud. Запуск синхронизации один раз в день будет работать нормально для нас. Если это возможно, какие решения существуют ( особенно.
.. - Использование локальной базы данных для приложения java
В настоящее время я прохожу проект, который требует базы данных. До сих пор я использовал базу данных sql localhost, мне было интересно, есть ли альтернатива этому. Подобно базе данных micrsoft access, где я мог бы читать из файла локальной базы данных вместо этого?
 ..
..
6
Скорее всего, причина, по которой вы получаете ошибку, связана с тем, что вы не регистрируете драйвер (используя отражение…) до фактического использования его для установления соединения и так далее.
Вероятно, вы захотите сделать что-то вроде Class.forName("driver")
а затем приведите его, если это необходимо, и затем зарегистрируйте его в DriverManager перед вызовом метода getConnection() .
Вот очень полезная ссылка, которая может помочь вам в решении этой проблемы:
http://www. kfu.com/~nsayer/Java/dyn-jdbc.html
kfu.com/~nsayer/Java/dyn-jdbc.html
Тем не менее, если вы действительно хотите использовать локальную базу данных/файл, вы можете взглянуть на SQLite, это может быть одним из способов сделать это, хотя я рекомендую использовать подход MySQL, так как гораздо проще настроить и узнать, как все работает с JDBC.
Если вы все еще рассматриваете SQLite проверить это:
Java и SQLite
Я вижу, что вам нужно некоторое руководство по импорту внешних файлов .jar в ваш код (т. е. сторонних библиотек, таких как те, которые вы будете использовать для драйвера JDBC). Вы используете IDE (например Eclipse, Netbeans, и т. д.) или вы пишете в текстовом редакторе и компилируете вручную?
Поделиться Roveris 03 декабря 2012 в 22:24
3
Недавно появилось несколько встроенных баз данных pure Java, которые имеют очень простой интерфейс, обычно просто java. , не требуют использования JDBC или других артефактов SQL и хранят свои данные в одном файле или каталоге: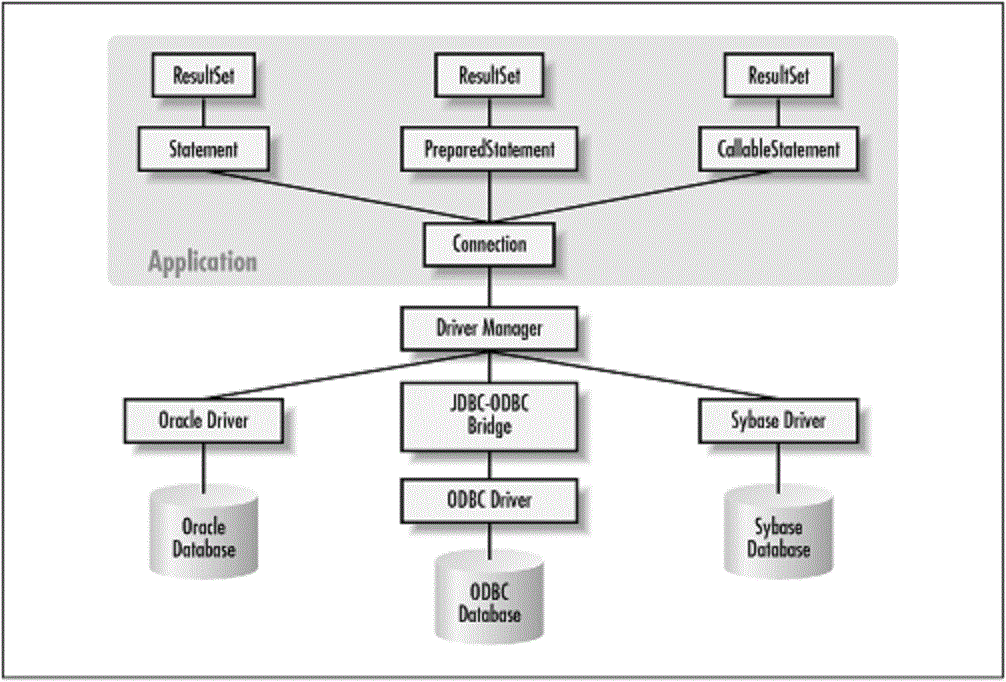 util.Map
util.Map
Главным недостатком является то, что большинство таких баз данных предоставляют только модель simples key-value.
Поделиться leventov 08 июля 2016 в 12:19
0
DBC можно использовать с любой базой данных, имеющей драйвер JDBC, который не обязательно является базой данных в «сетевом режиме», он также может использоваться со встроенными базами данных.
Вот некоторые Java и встраиваемые базы данных:
http://www.h3database.com/html/main.html
http://db.apache.org/derby/
http://hsqldb.org/
Поделиться Bobb Dizzles 03 декабря 2012 в 22:08
- Как сохранить данные из локальной базы данных sdf в текстовый файл?
Есть ли возможность сохранить данные из локальной базы данных sdf в текстовый файл в C# ? Я понятия не имею, как это сделать, и, к сожалению, у меня не так много времени.
. каждая строка базы данных должна быть в новой строке текстового файла - создание локальной базы данных в a C#
Я пишу заявление C# Это автономное тестовое приложение Он импортирует большой файл данных в виде файла .csv Этот файл выбирается пользователем с помощью формы Затем я хочу сохранить информацию, содержащуюся в этом файле .csv, в виде локальной базы данных, чтобы я мог выполнять запросы sql Я…
 . каждая строка базы данных должна быть в новой строке текстового файла
. каждая строка базы данных должна быть в новой строке текстового файла
0
Java-е JDK не включает в себя ни реализацию базы данных, ни драйверы для доступа к ней. Он предоставляет только JDBC в качестве абстракции для подключения к «database». Это зависит от вас, чтобы включить все необходимые библиотеки в свой код.
Если вы хотите иметь автономный код, вы можете просто включить файл .jar встраиваемой базы данных в ваш classpath. Таким образом, вы можете создать экземпляр базы данных в своем коде и минимизировать внешние зависимости.
Вы можете найти здесь список java встраиваемых баз данных
Здесь вы можете найти пример того, как встроить HSQLDB в ваш код.
Поделиться barracel 03 декабря 2012 в 23:16
Похожие вопросы:
SQL Server 2008: Как определить разрешение на создание новой базы данных?
Я хочу определить, имеет ли текущий подключенный пользователь базы данных разрешения на создание новой базы данных. Я хочу добиться этого с помощью SQL. Я попробовал это: WITH perms AS ( SELECT…
Как синхронизировать удаленную базу данных с локальной базой данных в JAVA
Мне нужно создать проект, в котором есть две базы данных-локальная и удаленная. Удаленная база данных должна ежедневно синхронизироваться с локальной базой данных, отражающей изменения, внесенные в…
Oracle: создание новой базы данных удаление существующего пользователя
Я использовал помощник по настройке базы данных для создания новой базы данных, но впоследствии заметил, что все бывшие пользователи базы данных исчезли. Пожалуйста, помогите!
Пожалуйста, помогите!
Синхронизация базы данных Azure с локальной базой данных
Можно ли синхронизировать существующую базу данных azure с локальной базой данных? . Нам нужно, чтобы данные локальной базы данных обновлялись данными в базе данных cloud. Запуск синхронизации один…
Использование локальной базы данных для приложения java
В настоящее время я прохожу проект, который требует базы данных. До сих пор я использовал базу данных sql localhost, мне было интересно, есть ли альтернатива этому. Подобно базе данных micrsoft…
Как сохранить данные из локальной базы данных sdf в текстовый файл?
Есть ли возможность сохранить данные из локальной базы данных sdf в текстовый файл в C# ? Я понятия не имею, как это сделать, и, к сожалению, у меня не так много времени.. каждая строка базы данных…
создание локальной базы данных в a C#
Я пишу заявление C# Это автономное тестовое приложение Он импортирует большой файл данных в виде файла . csv Этот файл выбирается пользователем с помощью формы Затем я хочу сохранить информацию,…
csv Этот файл выбирается пользователем с помощью формы Затем я хочу сохранить информацию,…
Создание локальной базы данных из базы данных сервера в visual studio
У меня есть довольно большая база данных, с которой я работаю, и я готов что-то сломать. Чтобы предотвратить это влияние на текущие данные, как я могу использовать живую базу данных для настройки…
Как перенести данные из локальной базы данных в размещенную базу данных Azure с помощью ADF?
Вопрос выглядит довольно простым, но в моем случае он имеет некоторые сложности, связанные с ним. Так вот в чем дело: Существует одна локальная база данных sql и одна база данных sql Azure. Нам…
Импорт Таблицы Из Другой Базы Данных Создание Новой Таблицы Вместо Добавления Данных В Существующую Таблицу
Я пытаюсь импортировать все данные из таблицы базы данных в существующую таблицу в локальной базе данных. Но это создание новой таблицы, а не копирование данных в таблицу. Я использую следующий…
Я использую следующий…
Урок 34. Работа с базами данных SQLite в Android — Fandroid.info
import android.content.ContentValues;
import android.database.Cursor;
import android.database.sqlite.SQLiteDatabase;
import android.os.Bundle;
import android.support.v7.app.AppCompatActivity;
import android.util.Log;
import android.view.View;
import android.widget.Button;
import android.widget.EditText;
public class MainActivity extends AppCompatActivity implements View.OnClickListener{
Button btnAdd, btnRead, btnClear;
EditText etName, etEmail;
DBHelper dbHelper;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
btnAdd = (Button) findViewById(R.id.btnAdd);
btnAdd.setOnClickListener(this);
btnRead = (Button) findViewById(R. id.btnRead);
id.btnRead);
btnRead.setOnClickListener(this);
btnClear = (Button) findViewById(R.id.btnClear);
btnClear.setOnClickListener(this);
etName = (EditText) findViewById(R.id.etName);
etEmail = (EditText) findViewById(R.id.etEmail);
dbHelper = new DBHelper(this);
}
@Override
public void onClick(View v) {
String name = etName.getText().toString();
String email = etEmail.getText().toString();
SQLiteDatabase database = dbHelper.getWritableDatabase();
ContentValues contentValues = new ContentValues();
switch (v.getId()) {
case R.id.btnAdd:
contentValues.put(DBHelper.KEY_NAME, name);
contentValues.put(DBHelper.KEY_MAIL, email);
database.insert(DBHelper. TABLE_CONTACTS, null, contentValues);
TABLE_CONTACTS, null, contentValues);
break;
case R.id.btnRead:
Cursor cursor = database.query(DBHelper.TABLE_CONTACTS, null, null, null, null, null, null);
if (cursor.moveToFirst()) {
int idIndex = cursor.getColumnIndex(DBHelper.KEY_ID);
int nameIndex = cursor.getColumnIndex(DBHelper.KEY_NAME);
int emailIndex = cursor.getColumnIndex(DBHelper.KEY_MAIL);
do {
Log.d(«mLog», «ID = » + cursor.getInt(idIndex) +
«, name = » + cursor.getString(nameIndex) +
«, email = » + cursor.getString(emailIndex));
} while (cursor.moveToNext());
} else
Log.d(«mLog»,»0 rows»);
cursor. close();
close();
break;
case R.id.btnClear:
database.delete(DBHelper.TABLE_CONTACTS, null, null);
break;
}
dbHelper.close();
}
}
Для работы добавить драйвер sqlite-jdbc в classpath:
Пример вывода:
| РазделыРеклама |
 db»;
db»; prepareStatement(
prepareStatement( executeUpdate(
executeUpdate( next()) {
next()) {работа с SQL базами данных
Spring Framework предоставляет обширную поддержку для работы с SQL базами данных, от прямого доступа JDBC с использованием JdbcTemplate до полных технологий «объектно-реляционного сопоставления» (ORM, “object relational mapping”), таких как Hibernate. Spring Data обеспечивает дополнительный уровень функциональности: создание реализаций репозитория непосредственно из интерфейсов и использование соглашений для генерации запросов из имен ваших методов.
Spring Data обеспечивает дополнительный уровень функциональности: создание реализаций репозитория непосредственно из интерфейсов и использование соглашений для генерации запросов из имен ваших методов.
Настройка DataSource (источника данных)
Java-интерфейс javax.sql.DataSource предоставляет стандартный метод работы с соединениями с базой данных. Традиционно DataSource использует URL-адрес вместе с некоторыми учетными данными для установления соединения с базой данных.
Поддержка встроенных баз данных
Часто удобно разрабатывать приложения, используя встроенную базу данных в памяти. Очевидно, что базы данных в памяти не обеспечивают постоянного хранения. Вам нужно заполнить базу данных, когда ваше приложение запускается, и быть готовым выбросить данные, когда ваше приложение завершается.
Spring Boot может автоматически настраивать встроенные базы данных h3, HSQL и Derby. Вам не нужно указывать URL-адреса подключения. Вам нужно только включить зависимость сборки от встроенной базы данных, которую вы хотите использовать.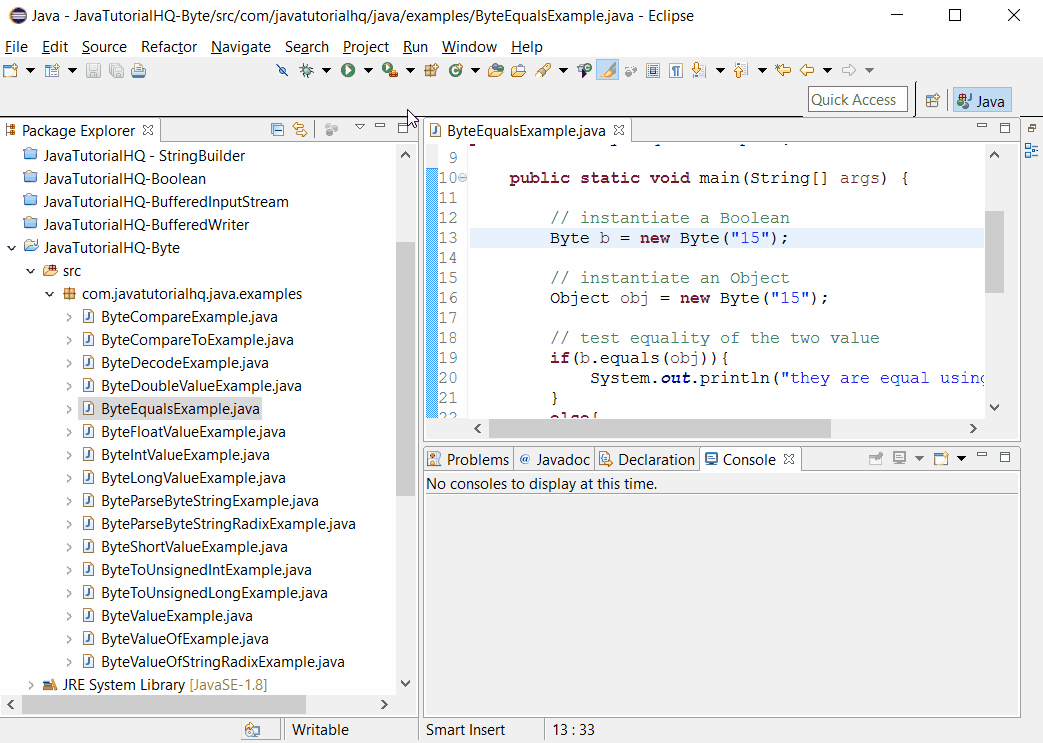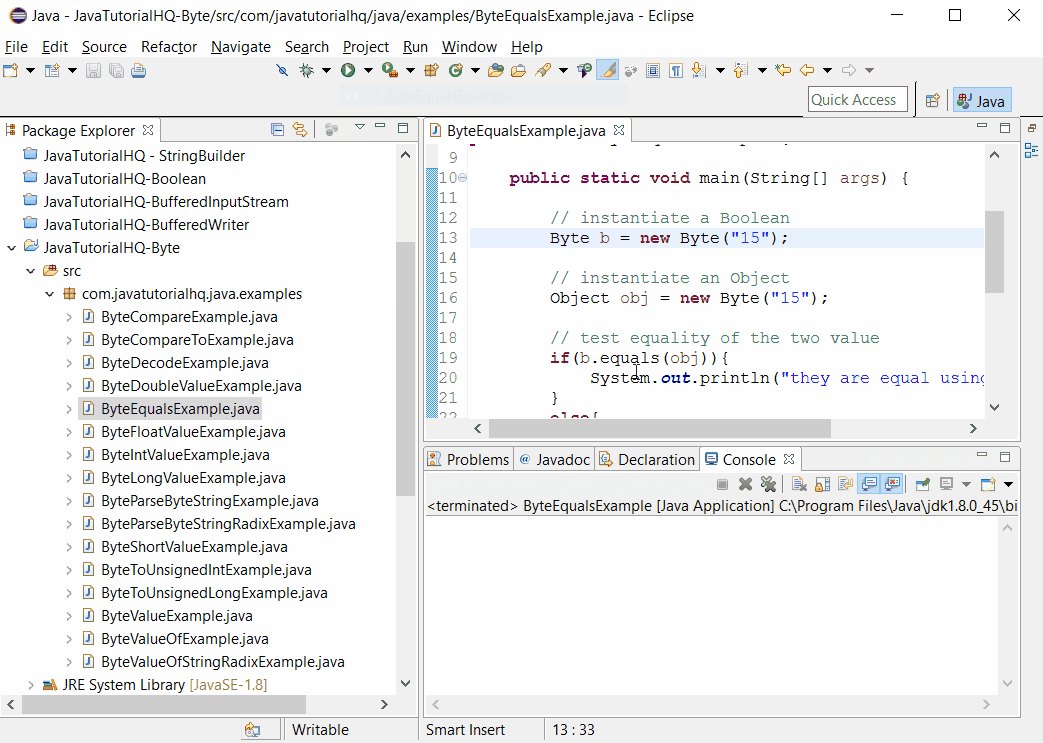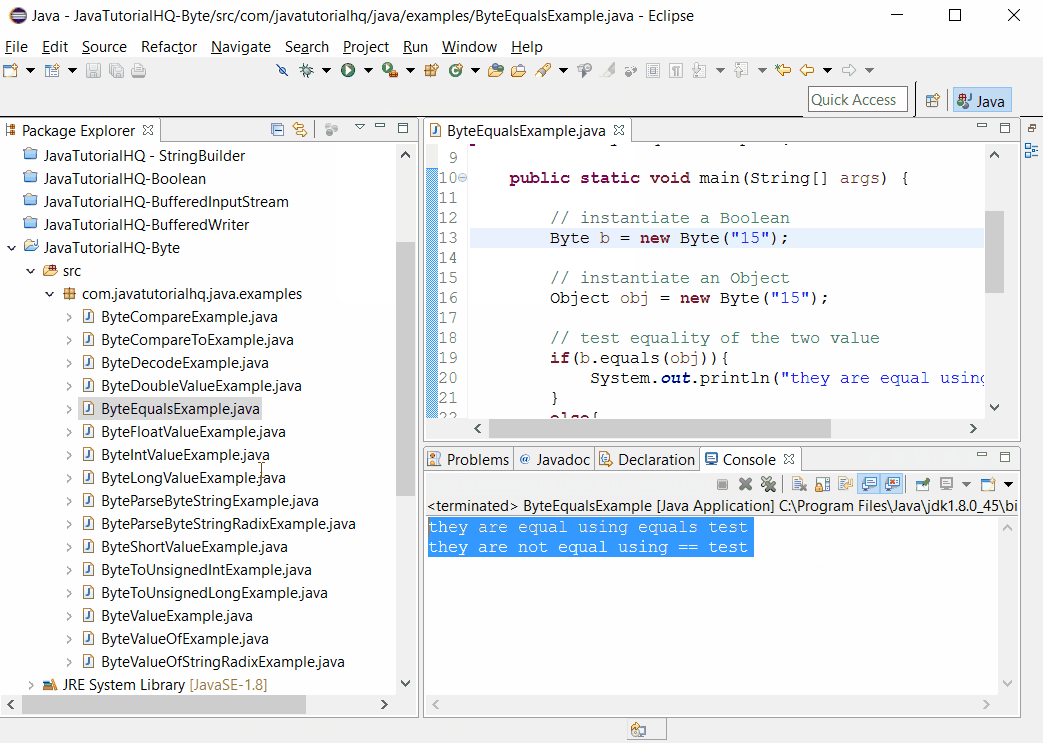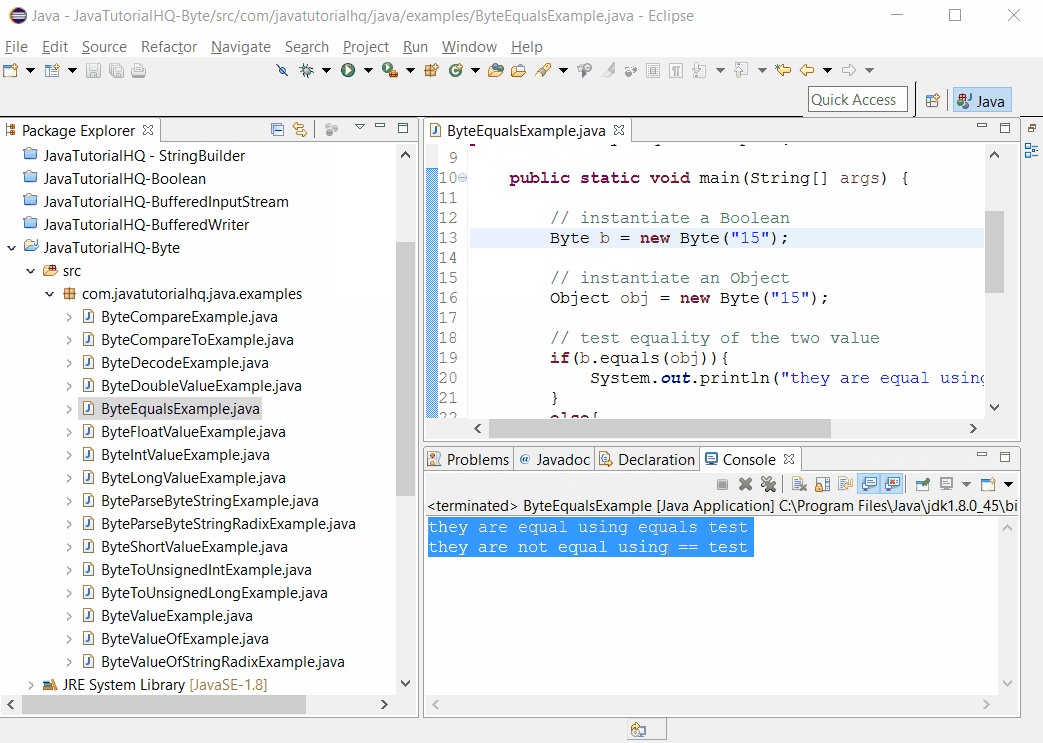
Если вы используете эту функцию в своих тестах, вы можете заметить, что одна и та же база данных повторно используется всем вашим набором тестов, независимо от количества используемых вами контекстов приложения. Если вы хотите убедиться, что у каждого контекста есть отдельная встроенная база данных, вы должны установить для spring.datasource.generate-unique-name значение true.
Например, типичные зависимости POM будут следующими:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
<scope>runtime</scope>
</dependency>
Для автоматической настройки встроенной базы данных вам нужна зависимость от spring-jdbc. В этом примере он транзитивно проходит через spring-boot-starter-data-jpa.
Если по какой-либо причине вы настроили URL-адрес соединения для встроенной базы данных, убедитесь, что автоматическое отключение базы данных отключено. Если вы используете h3, вы должны использовать DB_CLOSE_ON_EXIT=FALSE для этого. Если вы используете HSQLDB, вы должны убедиться, что shutdown=true не используется. Отключение автоматического выключения базы данных позволяет Spring Boot контролировать, когда база данных закрыта, тем самым гарантируя, что это произойдет, когда доступ к базе данных больше не нужен.
Если вы используете h3, вы должны использовать DB_CLOSE_ON_EXIT=FALSE для этого. Если вы используете HSQLDB, вы должны убедиться, что shutdown=true не используется. Отключение автоматического выключения базы данных позволяет Spring Boot контролировать, когда база данных закрыта, тем самым гарантируя, что это произойдет, когда доступ к базе данных больше не нужен.
Читайте также:
Видео урок № 12 Working with databases using JDBC – работа с базой данных.
Видео урок № 12 (автор – Яков Файн) – в этом уроке автор рассказывает, как из Java программы можно работать с данными хранящимся в реляционных базах данных.
Автор Яков Файн (Yakov Fain). Краткое содержание урока:
Краткое содержание урока:
- Relational Database Management System (RDBMS) – Знакомство с реляционными базами данных.
- Structured Query Language (SQL) – знакомство с языком запросов в реляционных базах данных.
- Популярные RDBMS – Oracle, DB2, Microsoft SQL Server, MySQL Server.
- JDBC – API для работы с любой реляционной базой данных. JDBC стандартизирует доступ к базам данных. Для стандартизации работ с различными базами данных, производители баз данных поставляют JDBC драйвера. Переход работы с одной RDBMS на другую RDBMS осуществляется заменой драйвера.
- Альтернатива JDBC – object-relational mapping (ORM) или объектно-реляционное отображение. Сопоставление классов в Java таблицам в реляционной базе данных. Популярные ORM frameworks: Java Persistence API (JPA), Hibernate.
- Типы JDBC драйверов. Тип 1 – драйвер JDBC-ODBC – мост, позволяющий работать программам, написанным на Java через драйвер ODBC от Microsoft. Тип 2 – нативные драйвера, разработанные на языках программирования, привязанных к операционной системе и завернутые в Java код. Тип 3 – драйвера состоящие из двух частей, зависимой и независимой о RDBMS. Тип 4 – драйвера разработанные на Java.
- Derby DB – легковесная реляционная база данных для обучающих целей. Установка и конфигурация. Создание базы данных.
- Использование DriverManager в программах на Java для получения соединения с базой данных. Пример программного кода на Java демонстрирующий получение соединения и выполнение запроса к базе данных.
- DataSources – преимущества использования для создания соединений с базой данных. Принцип работы. Пример конфигурационного файла для создания DataSource на сервере приложений WildFly.
- Описание и использование Statement, PreparedStatement. Рекомендации по использованию.
- Транзакции – описание и примеры использования.
 Тип 3 – драйвера состоящие из двух частей, зависимой и независимой о RDBMS. Тип 4 – драйвера разработанные на Java.
Тип 3 – драйвера состоящие из двух частей, зависимой и независимой о RDBMS. Тип 4 – драйвера разработанные на Java.Смотрите также видео уроки по Java 7 на русском языке (автор Яков Файн):
Как работает JDBC?
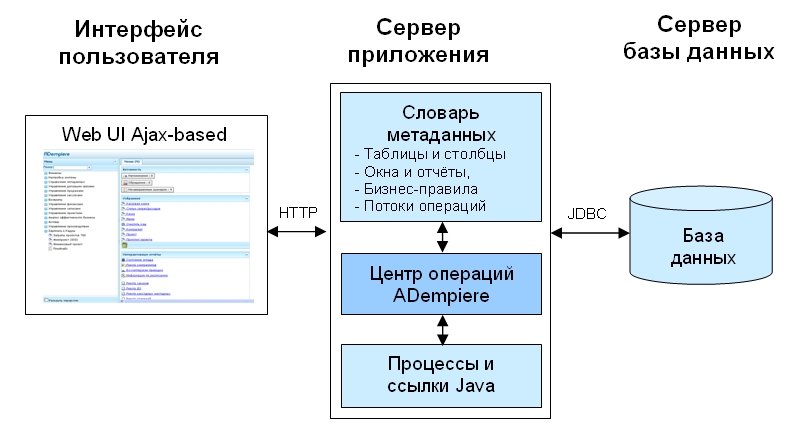
JDBC позволяет устанавливать соединение с источником данных, отправлять запросы и операторы обновления, а также обрабатывать результаты.
Просто JDBC позволяет делать следующие вещи в приложении Java:
- Установить соединение с источником данных
- Отправлять запросы и обновлять операторы источнику данных
- Обработка результатов
На следующем рисунке показаны компоненты модели JDBC.
Приложение Java вызывает классы и интерфейсы JDBC для отправки операторов SQL и получения результатов.
API JDBC реализуется через драйвер JDBC. Драйвер JDBC — это набор классов, реализующих интерфейсы JDBC для обработки вызовов JDBC и возврата наборов результатов в приложение Java. База данных (или хранилище данных) хранит данные, полученные приложением с помощью драйвера JDBC.
Основные объекты JDBC API включают:
- Объект DataSource используется для установления соединений.Хотя диспетчер драйверов также можно использовать для установления соединения, предпочтительным методом является подключение через объект DataSource.
- A Объект подключения управляет подключением к базе данных. Приложение может изменять поведение соединения, вызывая методы, связанные с этим объектом. Приложение использует объект соединения для создания операторов.
- Объекты Statement, PreparedStatement и CallableStatement используются для выполнения операторов SQL.Объект PreparedStatement используется, когда приложение планирует повторно использовать инструкцию несколько раз. Приложение подготавливает SQL, который планирует использовать. После подготовки приложение может указать значения параметров в подготовленном операторе SQL. Оператор может выполняться несколько раз с разными значениями параметров, указанными для каждого выполнения. CallableStatement используется для вызова хранимых процедур, возвращающих значения. CallableStatement имеет методы для получения возвращаемых значений хранимой процедуры.
- Объект ResultSet содержит результаты запроса. ResultSet возвращается приложению, когда SQL-запрос выполняется объектом инструкции. Объект ResultSet предоставляет методы для итерации результатов запроса.

 ResultSet возвращается приложению, когда SQL-запрос выполняется объектом инструкции. Объект ResultSet предоставляет методы для итерации результатов запроса.
ResultSet возвращается приложению, когда SQL-запрос выполняется объектом инструкции. Объект ResultSet предоставляет методы для итерации результатов запроса. Мы разработали серию руководств, которые помогут вам начать работу с нашими драйверами JDBC:
1. Подключение к источнику данных с помощью драйвера JDBC
2. Извлечение метаданных из источника данных с помощью драйвера JDBC
Работа с данными Java в Alteryx
Alteryx предоставляет неспециалистам интерфейс рабочего процесса для извлечения ценности из множества источников данных.Alteryx, как и многие другие аналитические приложения, поддерживает ODBC, общий интерфейс доступа к данным, который позволяет расширить выбор источников данных по умолчанию. Однако Alteryx не включает коннектор, который позволил бы ему получить доступ к источнику данных Java.
Доступ к источникам данных Java осуществляется с помощью соединителя, называемого драйвером JDBC. Драйвер JDBC позволяет приложению Java получать доступ к внешним данным. Например, драйвер JDBC Gemfire XD позволяет приложениям Java получать доступ к данным, хранящимся в Gemfire XD.
Драйвер JDBC позволяет приложению Java получать доступ к внешним данным. Например, драйвер JDBC Gemfire XD позволяет приложениям Java получать доступ к данным, хранящимся в Gemfire XD.
Alteryx не написан на Java. Alteryx использует драйвер ODBC, другое промежуточное ПО для базы данных, для доступа к внешним данным. (Он также включает в себя ряд специальных разъемов, например тот, который позволяет Alteryx получить доступ к Salesforce.com.)
Шлюз ODBC-JDBC соединяет приложение, использующее ODBC, с приложением, которое использует JDBC. Для приложения шлюз ODBC-JDBC является драйвером ODBC. Для драйвера JDBC шлюз ODBC-JDBC — это приложение Java.
Установка и лицензирование шлюза ODBC-JDBC
- Загрузите шлюз Windows ODBC-JDBC. (Требуется регистрация.)
- Установите и лицензируйте шлюз ODBC-JDBC на машине Windows, на которой установлен Alteryx.
Инструкции по установке см. В документации по шлюзу ODBC-JDBC.
- Используйте диалоговое окно ODBC-JDBC Gateway Setup Java Interface для выбора JVM, включенной в дистрибутив JRE / JDK, рекомендованный вашим поставщиком базы данных Java.
Настройка источника данных ODBC
Прежде чем вы сможете использовать ODBC-JDBC Gateway для подключения Alteryx к базе данных Java, вам необходимо настроить источник данных ODBC. Источник данных ODBC хранит сведения о соединении для целевой базы данных.
Источники данных ODBC настраиваются в Администраторе ODBC, который входит в состав Windows. В некоторых версиях Windows администратор ODBC находится в Панели управления > Администрирование .В некоторых версиях Windows можно получить доступ к администратору ODBC, выполнив поиск «ODBC» в поле поиска на панели задач. Если предлагается выбор администраторов ODBC, выберите 64-разрядную, а не 32-разрядную.
Используйте ODBC Administrator для создания источника данных ODBC-JDBC Gateway.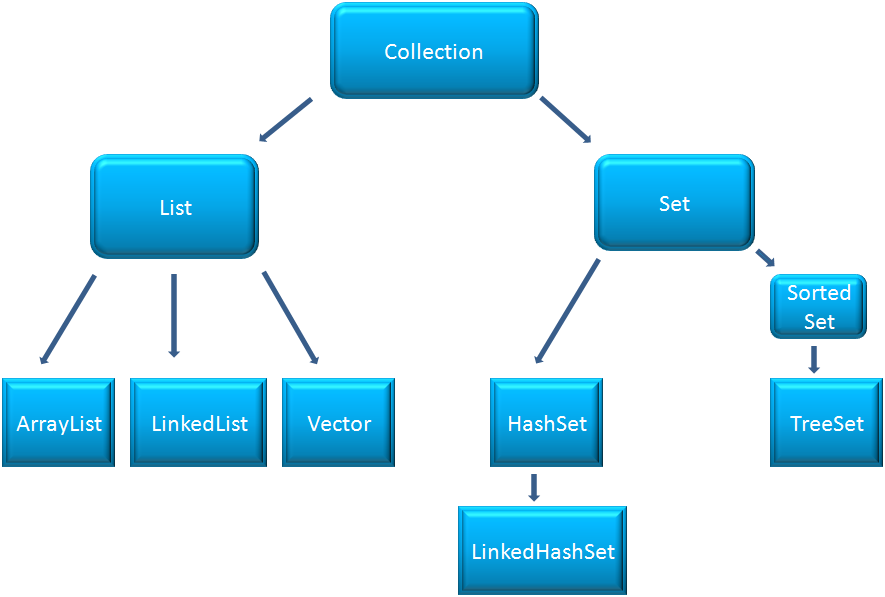
Создание источника данных ODBC шлюза ODBC-JDBC для Gemfire XD
- Выберите вкладку Системный DSN, а затем нажмите Добавить.
- В диалоговом окне «Создать новый источник данных» выберите «ODBC-JDBC Gateway», а затем нажмите «Готово».
- Заполните диалоговое окно настройки DSN шлюза ODBC-JDBC:
Настройка Значение DSN Некий описательный текст для идентификации источника данных в Alteryx. Например, «Gemfire XD». Класс водителя Класс драйвера, который определяет драйвер JDBC для целевой серверной части Java. Например, имя класса драйвера JDBC Gemfire XD — com.pivotal.gemfirexd.jdbc.ClientDriverПуть к классу Путь к JAR-файлу драйвера JDBC. Например, JAR-файл драйвера JDBC Gemfire XD: C: \ Pivotal_GemFireXD_140_b50226_Windows \ lib \ gemfirexd-client.
jar
URL URL-адрес JDBC, содержащий необходимые сведения о подключении для доступа к целевой базе данных Java.Правильный синтаксис URL-адреса JDBC см. В документации по драйверу JDBC. Например, URL-адрес JDBC для Gemfire XD:
jdbc: gemfirexd: // локальный: 1527 /
- Используйте кнопку «Тест», чтобы убедиться, что вы можете успешно подключиться к базе данных Java.
 jar
jar
Теперь вы можете использовать источник данных шлюза ODBC-JDBC для подключения Alteryx к базе данных Java.
Подключение Alteryx к базе данных Java
- В Alteryx добавьте в рабочий процесс элемент управления Входные данные .
- На панели свойств Входные данные в списке Подключение файла или базы данных выберите Подключение к базе данных> Новое подключение ODBC .
Отображается диалоговое окно ODBC Connection .
- В списке Имя источника данных выберите источник данных ODBC-JDBC Gateway. Выберите OK .
Отображается диалоговое окно Выберите таблицу или укажите запрос .
- Выберите вкладку Редактор SQL . Введите запрос, например
SELECT * FROM QUICKTABLE. Выберите OK . - Чтобы получить данные Java в Alteryx, на панели свойств Входные данные выберите Обновить образец .

| CSU Long Beach CECS 323 Основы базы данных Программа Mimi Opkins Home CECS 274 Главная CECS 277 Главная | NetBeans / JavaDB (установка Derby для дома)Веб-сайты Java и NetBeans:
Запуск Derby после установки
Справка по NetBeans / JavaDB:
|
 oracle.com/java/technologies/javase-downloads.html
oracle.com/java/technologies/javase-downloads.html
 apache.org/kb/docs/ide/java-db.html
apache.org/kb/docs/ide/java-db.htmlВведение в объекты данных Java
Введение в объекты данных Java
Джефф Браун, старший инженер-программист OCI
июнь 2002
Введение
Объекты данных Java (JDO) — это спецификация, обеспечивающая прозрачное сохранение объектов Java.
Спецификация JDO существует как запрос спецификации Java 12 (JSR 12) от процесса сообщества Java (JCP). Первая версия спецификации, представленная для всеобщего ознакомления, была опубликована 6 июля 2000 г., а версия 1.0 спецификации была опубликована 30 апреля 2002 г.
Две основные цели спецификации — предоставить API для прозрачного доступа к данным и позволить реализации спецификации быть подключенными к серверам приложений.
JDO и JDBC
Java Database Connectivity (JDBC) и JDO — это API для доступа к данным из Java.В разной степени каждый из них обеспечивает определенный уровень абстракции от деталей хранилища данных.
JDBC позволяет изолировать код приложения от деталей, таких как расположение базы данных и поставщик. В большинстве случаев хранилище данных будет реляционной базой данных.
Хотя драйверы JDBC могут быть реализованы для доступа к нереляционным базам данных, это не является нормой и не подходит для JDBC лучше всего.
С другой стороны, хранилище данных, стоящее за реализацией JDO, может быть реляционной базой данных, объектно-ориентированной базой данных или чем-то совершенно другим.
В случае, когда хранилище данных за реализацией JDO является реляционной базой данных, реализация JDO вполне может использовать JDBC для доступа к базе данных. Но все это скрыто от разработчика приложения / компонента и позаботится о самой реализации JDO.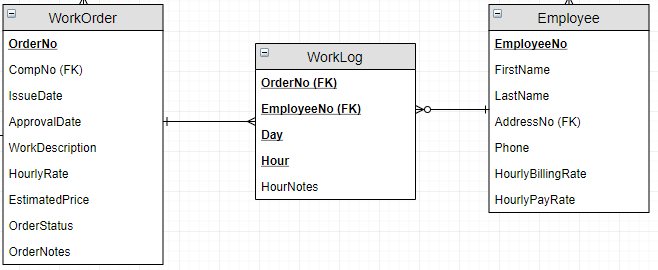
JDBC не обеспечивает объектно-ориентированное представление базы данных. Взгляд JDBC на базу данных в значительной степени сосредоточен на модели реляционной базы данных. Это часто приводит к написанию кода как слоя между приложением и базой данных.В обязанности этого уровня может входить декомпозиция объектов Java.
Декомпозиция Java-объекта — это процесс разбиения объекта на самые мелкие части, поэтому объект может храниться в реляционной базе данных. Точно так же необходимо разработать механизм для преобразования строк данных, полученных из реляционной базы данных, в соответствующие объекты Java.
В отличие от этого, взгляд JDO на базу данных в значительной степени объектно-ориентирован. Этот подход не нов и уже некоторое время существует в объектно-ориентированных базах данных.
Язык запросов, используемый с JDBC, почти всегда — это язык структурированных запросов (SQL).
Язык запросов, используемый JDO, очень похож на код Java. Работа с JDO не требует изучения такого языка, как SQL. Если вы знаете Java, значит, вы знаете язык запросов JDO.
Если вы знаете Java, значит, вы знаете язык запросов JDO.
Реализации
Спецификация JDO определяет интерфейс к реализации JDO и определяет поведение реализации.
Существует эталонная реализация спецификации, доступная от Sun, но по состоянию на май 2002 года она еще не полностью реализует спецификацию.Доступно множество коммерческих реализаций спецификации JDO. Лишь некоторые из них перечислены в следующей таблице.
API
javax.jdo.spi.PersistenceCapable
Любой класс, которым должна управлять реализация JDO, должен реализовывать интерфейс PersistenceCapable .
Экземпляр любого класса, реализующего интерфейс PersistenceCapable , известен как «Экземпляр JDO». Этот интерфейс определяет методы, используемые реализацией JDO для управления экземплярами этого класса.
общедоступный абстрактный javax.jdo.PersistenceManager jdoGetPersistenceManager ();
public abstract void jdoReplaceStateManager (javax.
выдает SecurityException;
public abstract void jdoProvideField (int);
общедоступная аннотация void jdoProvideFields (int []);
общедоступная аннотация void jdoReplaceField (int);
общедоступная аннотация void jdoReplaceFields (int []);
публичный аннотация void jdoReplaceFlags ();
общедоступная аннотация void jdoCopyFields (Object, int []);
public abstract void jdoMakeDirty (String);
публичный абстрактный объект jdoGetObjectId ();
открытый абстрактный объект jdoGetTransactionalObjectId ();
публичный абстрактный логический jdoIsDirty ();
публичный абстрактный логический jdoIsTransactional ();
публичный абстрактный логический jdoIsPersistent ();
публичный абстрактный логический jdoIsNew ();
публичный абстрактный логический jdoIsDeleted ();
общедоступный абстрактный javax.
jdoNewInstance (javax.jdo.spi.StateManager);
общедоступная аннотация javax.jdo.spi.PersistenceCapable
jdoNewInstance (javax.jdo.spi.StateManager, Object);
публичный абстрактный объект jdoNewObjectIdInstance ();
открытый абстрактный объект jdoNewObjectIdInstance (String);
общедоступная аннотация void jdoCopyKeyFieldsToObjectId (Object);
public abstract void jdoCopyKeyFieldsToObjectId (
javax.jdo.spi.PersistenceCapable.ObjectIdFieldSupplier, Object);
public abstract void jdoCopyKeyFieldsFromObjectId (
javax.jdo.spi.PersistenceCapable.ObjectIdFieldConsumer, Object);
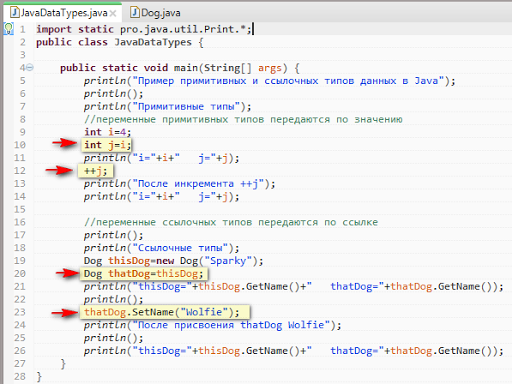 jdo.spi.StateManager)
jdo.spi.StateManager)  jdo.spi.PersistenceCapable
jdo.spi.PersistenceCapable Преобразование обычных классов Java в классы экземпляра JDO обычно выполняется с помощью инструмента, предоставляемого поставщиком реализации JDO. Этот инструмент может использовать один из нескольких различных подходов.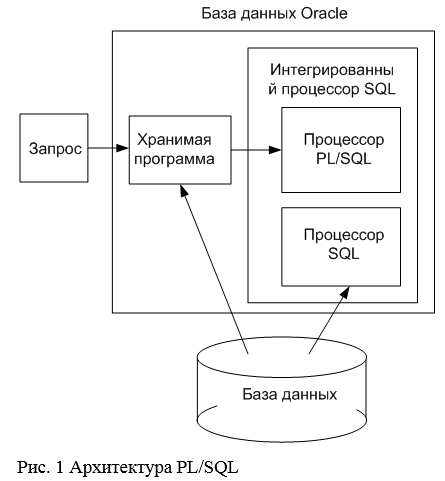
Первый подход заключается в использовании усилителя байт-кода .Усилитель байт-кода JDO преобразует стандартный файл класса Java в класс экземпляра JDO, вставляя весь код, необходимый для реализации интерфейса PersistenceCapable .
Второй подход — это генератор кода , который анализирует простой исходный код Java и выводит версию этого исходного кода, которая реализует интерфейс PersistenceCapable . Реализовать этот интерфейс «вручную» нецелесообразно.
javax.jdo.PersistenceManagerFactory
Интерфейс PersistenceManagerFactory — это механизм, используемый для получения экземпляра PersistenceManager .В интерфейсе существует два заводских метода.
must
public PersistenceManager getPersistenceManager ()
public PersistenceManager getPersistenceManager (String userid,
String password)
Поскольку реализует интерфейс класса vendor, который является интерфейсом PersistenceManagerFa. использоваться как механизм начальной загрузки. Это должен быть единственный код конкретного производителя, который использует приложение JDO.По этой причине спецификация JDO предлагает реализовать фабричный класс уровня приложения, который возвращает соответствующий экземпляр
использоваться как механизм начальной загрузки. Это должен быть единственный код конкретного производителя, который использует приложение JDO.По этой причине спецификация JDO предлагает реализовать фабричный класс уровня приложения, который возвращает соответствующий экземпляр PersistenceManagerFactory , чтобы реализации могли быть заменены с минимальным влиянием на код приложения. В этом случае потребуется изменить только фабрику приложения.
// Создание экземпляра реализации SolarMetric интерфейса
// PersistenceManagerFactory ...
PersistenceManagerFactory managerFactory =
новый com.solarmetric.kodo.impl.jdbc.JDBCPersistenceManagerFactory ();
// получить менеджера ...
PersistenceManager manager = managerFactory.getPersistenceManager ();
javax.jdo.PersistenceManager
Интерфейс PersistenceManager — это основная точка контакта между приложением Java и реализацией JDO.
использует PersistenceManager для извлечения объектов Java из хранилища данных и добавления объектов Java в хранилище данных. Интерфейс PersistenceManager также служит фабрикой для нескольких других компонентов JDO, обсуждаемых ниже.
В интерфейсе PersistenceManager существует несколько методов, которые добавляют объекты JDO Instance в хранилище данных.
public abstract void makePersistent (Object);
общедоступная аннотация void makePersistentAll (Object []);
public abstract void makePersistentAll (java.util.Collection);
Передача объектов экземпляра JDO любому из этих методов добавляет эти объекты в хранилище данных.
// получить менеджера ...
PersistenceManager manager = managerFactory.getPersistenceManager ();
// класс Employee должен реализовывать PersistenceCapable .
Employee newEmployee = new Employee (...);
менеджер.makePersistent (newEmployee);
 ..
.. javax.jdo.Extent
Объекты Extent представляют все экземпляры определенного класса, которые в настоящее время находятся в хранилище данных. В интерфейсе PersistenceManager существует фабричный метод для получения объектов Extent .
public Extent getExtent (Класс persistenceCapableClass, логические подклассы)
Аргумент Class указывает тип извлекаемых объектов.Логический аргумент указывает, должны ли быть включены подклассы указанного класса.
Интерфейс Extent определяет метод iterator () , который возвращает java.util.Iterator для итерации по всем экземплярам, представленным Extent .
// получить менеджера ...
PersistenceManager manager = managerFactory.
// класс Employee должен реализовывать PersistenceCapable...
Объем сотрудниковExtent = manager.getExtent (Employee.class, false);
java.util.Iterator iterator = employeeExtent.iterator ();
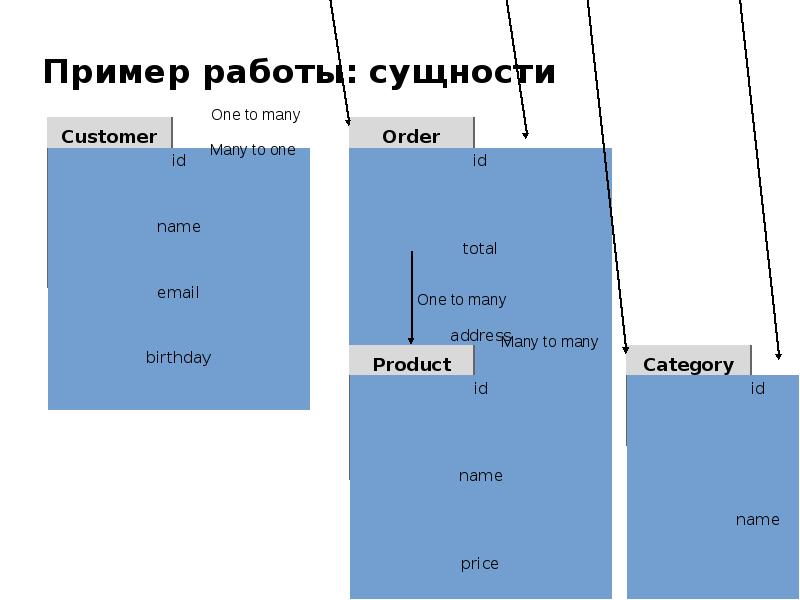 getPersistenceManager ();
getPersistenceManager (); javax.jdo.Query
Интерфейс Query позволяет извлекать экземпляры из хранилища данных на основе некоторых предоставленных критериев. Query Экземпляры должны быть получены с помощью одного из перегруженных методов newQuery () в интерфейсе PersistenceManager .
Интерфейс Query определяет несколько перегруженных версий метода execute () , которые выполняют запрос Query и возвращают результаты сопоставления.
// получить менеджера ...
PersistenceManager manager = managerFactory.getPersistenceManager ();
// класс Employee должен реализовывать PersistenceCapable .
Extent employeeExtent = manager.getExtent (Employee.class, ложь);
// запрос для получения всех сотрудников, которые были
// в компании более 5 лет ...
Query query = manager.newQuery (Employee .class, employeeExtent,
"yearsOfEmployement> 5");
// выполнить запрос ...
Сотрудники коллекции = (Коллекция) запрос.выполнить ();
// обрабатываем результаты ...
Iterator iterator = employee.iterator ();
while (iterator.hasNext ()) {
Employee employee = (Employee) iterator.next ();
(...)
}
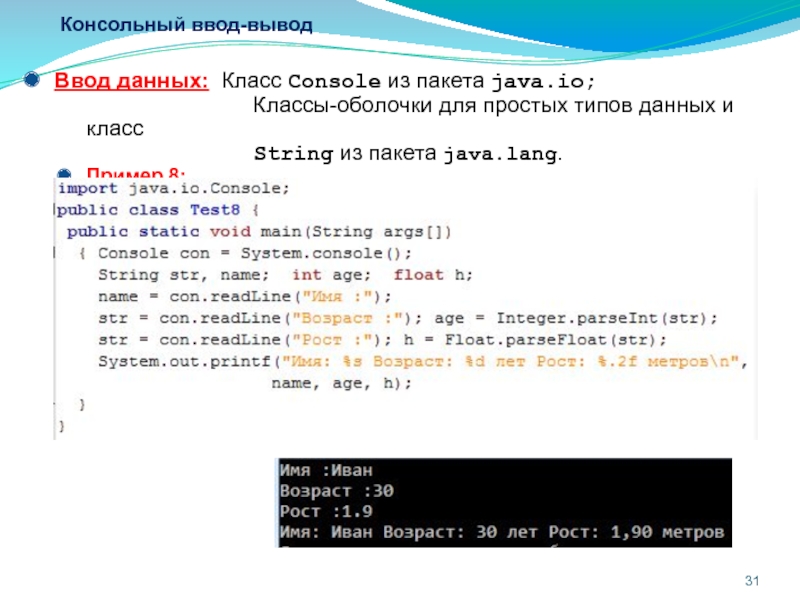 ..
.. Обратите внимание на третий аргумент метода newQuery () , «yearsOfEmployement> 5». Это выражение ограничивает, какие объекты будут возвращены из магазина.
Чтобы это работало, в классе Employee должно быть поле под названием yearsOfEmployment . В это логическое выражение может быть включен любой из стандартных операторов отношения языка Java.
В это логическое выражение может быть включен любой из стандартных операторов отношения языка Java.
Пример кода
Обзор
Следующие примеры демонстрируют некоторые основные способы использования JDO.
Код демонстрирует, как заполнять и извлекать данные из хранилища данных.
Примечание. Здесь используется реализация SolarMetric Kodo JDO.Механизмы для создания схемы базы данных, улучшения байт-кода, чтобы объекты домена реализовалиPersistenceCapableи специфичную для поставщика реализациюPersistenceManagerFactory, являются единственными используемыми здесь особенностями Kodo JDO. Все остальное должно работать с любой реализацией JDO.
Объекты домена
Примеры будут работать с небольшим набором классов, которые представляют объекты Fleet of Vehicle .Определены два конкретных типа Vehicle s: Bicycle и MotorVehicle .
Объекты MotorVehicle имеют атрибут Engine .
Исходный код объекта домена
/ **
* Fleet.java
* /
package com.ociweb.jdodemo;
импорт java.util.Iterator;
импорт java.util.List;
import java.util.Vector;
Общественный флот {
частный список транспортных средств = новый вектор ();
public void addVehicle (Транспортное средство) {
Vehicles.add (транспортное средство);
}
public Iterator getVehicles () {
возврат транспортных средств.итератор ();
}
public String toString () {
StringBuffer buffer = new StringBuffer ("Fleet: \ n");
Итератор iter = getVehicles ();
while (iter.
buffer.append ("\ t" + iter.next () + "\ n");
}
буфер возврата.нанизывать();
}
}
/ **
* Vehicle.java
* /
package com.ociweb.jdodemo;
Транспортное средство общественного класса {
частное int numberOfWheels;
Общественный транспорт (int numberOfWheels) {
this.numberOfWheels = numberOfWheels;
}
public int getNumberOfWheels () {
return numberOfWheels;
}
}
/ **
* Bicycle.java
* /
- do
; пакет
Public class Bicycle extends Vehicle {
частная модель String;
общественный велосипед (модель String) {
super (2);
это.
}
public String toString () {
return "Bike: Model" + model;
}
}
/ **
* MotorVehicle.java
* /
b.do пакет
Общественный класс MotorVehicle расширяет транспортное средство {
частный двигатель двигателя;
Public MotorVehicle (int numberOfWheels, Engine engine) {
super (numberOfWheels);
это.двигатель = двигатель;
}
public String toString () {
return «MotorVehicle With» + getNumberOfWheels ()
+ «Wheels.
}
}
/ **
* Engine.java
* /
пакетociweb.
Двигатель общего класса {
private int numberOfCylinders;
Public Engine (int numberOfCylinders) {
this.numberOfCylinders = numberOfCylinders;
}
public int getNumberOfCylinders () {
return numberOfCylinders;
}
public String toString () {
return numberOfCylinders + "Cylinder Engine.";
}
}
 hasNext ()) {
hasNext ()) { модель = модель;
модель = модель; 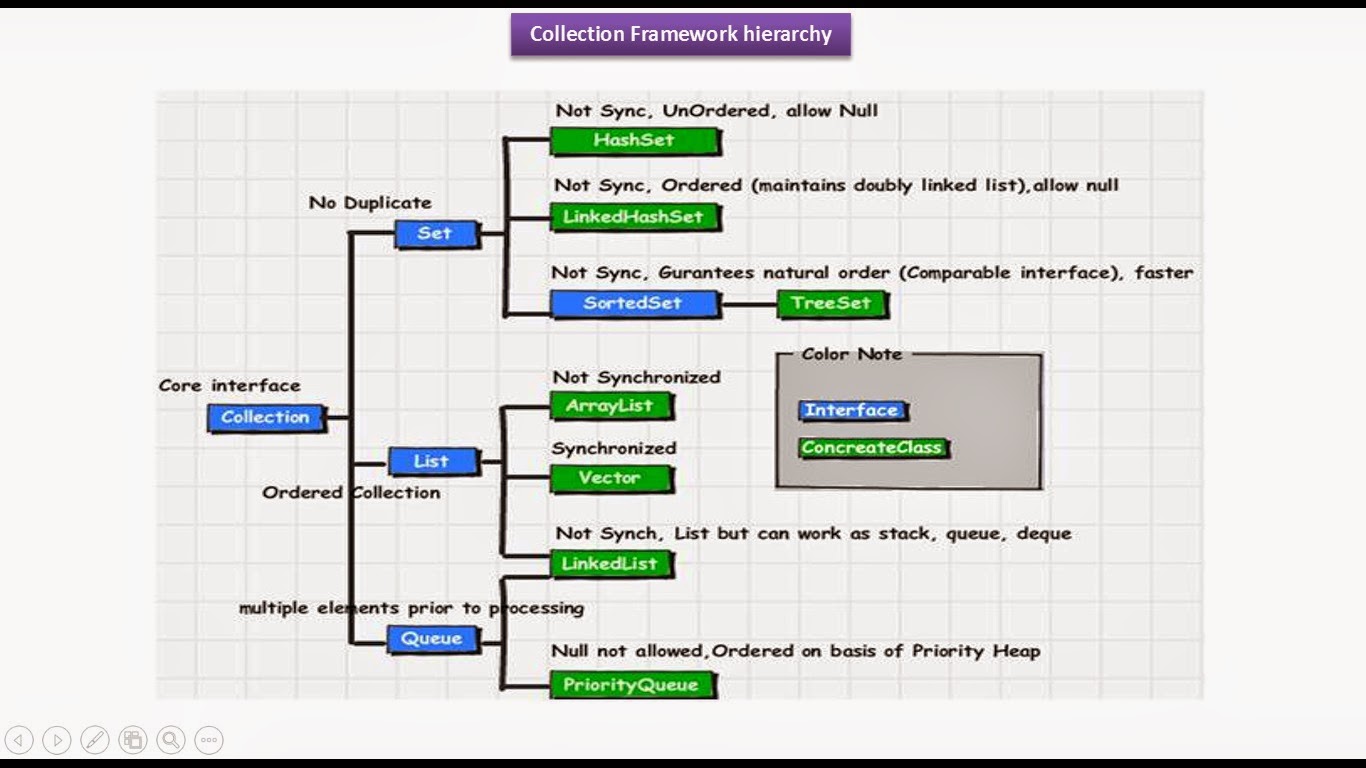 jdodemo;
jdodemo; Особенности Kodo JDO
Kodo JDO включает собственные служебные классы для создания схемы базы данных и улучшения байт-кода.
Инструмент создания схемы используется для создания схемы базы данных, которая будет использоваться для сохранения экземпляров JDO. В официально поддерживаемый список баз данных входят:
- DB2
- InstantDB
- SQLServer
- MySQL
- Оракул
- PostgreSQL
Другие базы данных с драйверами JDBC могут быть подключены с некоторым дополнительным кодом.Подробности см. В документации Kodo JDO.
Их инструмент генерации схем полагается на файл package.jdo , который должен быть написан для определения некоторых деталей о классах экземпляра JDO.
Ниже приведен файл, используемый для этих образцов. См. Документацию Kodo JDO для получения подробной информации о формате и содержимом этого файла.
Схема .bat предоставляется для запуска генератора схемы. Файл .jdo необходимо передать в качестве аргумента в командной строке.
schematool.bat package.jdo
После того, как схема была сгенерирована, файлы классов для объектов домена должны быть улучшены для реализации интерфейса PersistenceCapable .
Файл jdoc.bat предназначен для помощи в запуске средства улучшения байт-кода. Пакетный файл jdoc.bat также требует, чтобы файл .jdo передавался в качестве аргумента в командной строке.
Шаги, показанные выше для создания схемы и улучшения байт-кода, относятся к реализации Kodo JDO и не определены как часть спецификации JDO. У других поставщиков могут быть свои собственные шаги для выполнения этих шагов. См. Документацию поставщика.
Заполнение хранилища данных
После настройки базы данных, проектирования и кодирования наших доменных объектов и расширения байт-кода до PersistenceCapable , экземпляры этих классов теперь могут быть созданы и добавлены в хранилище данных.
Следующий класс создаст экземпляр Fleet , заполнит его несколькими транспортными средствами, а затем сохранит эти транспортные средства.
/ **
* SeedDatabase.java
* /
пакет com.ociweb.jdodemo;
// реализация поставщиками PersistenceManagerFactory
import com.solarmetric.kodo.impl.jdbc.JDBCPersistenceManagerFactory;
импорт javax.jdo.PersistenceManager;
import javax.jdo.Transaction;
public class SeedDatabase {
public static void main (String [] args) {
- 9000 флот = новый флот ();
// создать парк транспортных средств ...
флот.addVehicle (новый велосипед ("Швинн"));
fleet.addVehicle (новый Велосипед («Гигант»));
fleet.addVehicle (новый MotorVehicle (4, новый двигатель (8)));
fleet.addVehicle (новый MotorVehicle (2, новый двигатель (4)));
fleet.addVehicle (новый MotorVehicle (4, новый двигатель (4)));
// получить PersistenceManager ...
PersistenceManager pm =
новый JDBCPersistenceManagerFactory ().getPersistenceManager ();
// начинаем транзакцию ...
Transaction transaction = pm.currentTransaction ();
transaction.begin ();
// сохранить флот ...
pm.makePersistent (флот);
// фиксируем транзакцию ...
транзакция.совершить ();
// закройте менеджера ...
pm.close ();
}
}
Получение данных из хранилища данных
Следующий код извлекает все экземпляры класса Vehicle (включая подклассы) из хранилища данных и распечатывает их в стандартном виде.
/ **
* ListAll.java
* /
пакет com.ociweb.jdodemo;
// реализация поставщиками PersistenceManagerFactory
import com.solarmetric.kodo.impl.jdbc.JDBCPersistenceManagerFactory;
import javax.jdo.Extent;
импорт javax.jdo.PersistenceManager;
импорт javax.jdo.PersistenceManagerFactory;
импорт javax.jdo.Query;
импорт java.util.Collection;
импорт java.util.Iterator;
общедоступный класс ListAll {
общедоступный статический void main (String [] args) {
...
, специфичная для производителя реализацияPersistenceManagerFactory managerFactory =
новый JDBCPersistenceManagerFactory ();
// получить менеджера...
PersistenceManager manager =
managerFactory.getPersistenceManager ();
Экстент ext = manager.getExtent (Vehicle.class, true);
Query query = manager.newQuery (Vehicle.class, ext, "");
Сборные автомобили = (Сбор) query.execute ();
Итератор итератор = автомобили.итератор ();
while (iterator.hasNext ()) {
Автомобиль автомобиль = (Автомобиль) iterator.next ();
System.out.println ("транспортное средство =" + транспортное средство);
}
manager.close ();
}
}
Вывод программы ListAll :
транспортное средство = Мотоцикл: Модель Schwinn Vehicle = Мотоцикл: Модель Giant Автомобиль = Моторный автомобиль с 4 колесами.8-цилиндровый двигатель. транспортное средство = двухколесный двухколесный автомобиль. 4-цилиндровый двигатель. Автомобиль = Моторный автомобиль с 4 колесами. 4-цилиндровый двигатель.
Чтобы ограничить результаты объекта Query до Автомобиль с 4 цилиндрами, критерии должны быть переданы методу newQuery () . Обратите внимание, что в этом примере Extent и Query используют класс MotorVehicle вместо Vehicle , поскольку только объекты MotorVehicle имеют Engines .
/ **
* ListFourCylinderVehicles
* /
package com.ociweb.jdodemo;
// реализация поставщиками PersistenceManagerFactory
import com.solarmetric.kodo.impl.jdbc.JDBCPersistenceManagerFactory;
import javax.jdo.Extent;
импорт javax.jdo.PersistenceManager;
импорт javax.jdo.PersistenceManagerFactory;
импорт javax.jdo.Query;
импорт java.util.Collection;
импорт java.util.Iterator;
общедоступный класс ListFourCylinderVehicles {
public static void main (String [] args) {
- 9000or7..
// Заводская реализация
PersistenceManagerFactory managerFactory =
новый JDBCPersistenceManagerFactory ();
// получить менеджера ...
PersistenceManager manager =
managerFactory.getPersistenceManager ();
Extent ext = manager.getExtent (MotorVehicle.класс, правда);
// извлечение автомобилей только с 4 цилиндрами ...
Query query = manager.newQuery (MotorVehicle.class, ext,
"engine.numberOfCylinders == 4");
Сборные автомобили = (Сбор) query.execute ();
Итератор iterator = Vehicles.iterator ();
в то время как (итератор.hasNext ()) {
Автомобиль Автомобиль = (Автомобиль) iterator.next ();
System.out.println ("транспортное средство =" + транспортное средство);
}
manager.close ();
}
}
Вывод программы ListFourCylinderVehicles :
транспортное средство = двухколесный двухколесный автомобиль. 4-цилиндровый двигатель.Автомобиль = Моторный автомобиль с 4 колесами. 4-цилиндровый двигатель.
Сводка
JDO обеспечивает представление хранилища данных, которое намного более объектно-ориентировано по сравнению с использованием JDBC. Подробная информация о сопоставлении объектов и поставщике хранилища данных скрыта от разработчика приложения / компонента. Действия по заполнению, извлечению и управлению содержимым хранилища данных просты и понятны. Количество кода, связанного с персистентностью, которое должны написать разработчики, относительно невелико.Это некоторые из причин, по которым JDO является такой убедительной технологией для сохранения Java.
Список литературы
Software Engineering Tech Trends (SETT) — это регулярное издание, посвященное новым тенденциям в разработке программного обеспечения.
5 лучших бесплатных и лучших курсов для изучения JDBC и подключения к базам данных в 2021 году | автор: javinpaul | Javarevisited
Здравствуйте, ребята! Если вы программист на Java и ищете бесплатных курсов JDBC , чтобы начать изучение доступа к базам данных на Java, то вы попали в нужное место.
В этой статье я собираюсь поделиться некоторыми из бесплатных и лучших онлайн-курсов JDBC (Java Database Connectivity) с популярных сайтов, таких как Udemy и Pluralsight, чтобы дать вам фору в вашем долгом путешествии по написанию реального Java-приложения. который взаимодействует с базой данных.
Поскольку данные являются важнейшей частью любого Java-приложения, крайне важно хорошо знать, как взаимодействовать с базой данных из Java-приложения, и JDBC является первым шагом в этом направлении.
JDBC расшифровывается как Java Database Connectivity и предоставляет базовый API для подключения к базе данных и чтения / записи данных. Вы можете выполнять SQL-запросы, вызывать хранимые процедуры и анализировать ResultSet для создания объектов Java.
JDBC API предоставляет несколько классов, таких как Connection, DataSource, Statement, PreparedStatement , CallableStatement , ResultSet , RowSet и т. Д., Чтобы справиться с любыми вашими потребностями в отношении написания кода доступа к данным.
Хотя написать код JDBC непросто. Вам не только нужно знать основы, которым вас научат эти курсы JDBC, но также необходимо знать, как правильно использовать API.
Чтобы получить максимальную отдачу от JDBC API и написать надежный уровень доступа к данным, который может обрабатывать большой объем данных, необходимо следовать некоторым проверенным передовым методам JDBC.
В этом блоге я поделился множеством советов и руководств по JDBC, к которым вы можете получить доступ после прохождения этих курсов JDBC, чтобы изучить основы.
Вы можете дополнительно улучшить свои навыки JDBC и доступа к данным, изучив Spring и Hibernate, в то время как первый упрощает работу с простым JDBC, устраняя все хлопоты, связанные с созданием соединений и работой с SQLException, позже — ORM или объектно-реляционная структура который позволяет вам работать с единственным объектом, в то время как он заботится о взаимодействии с базой данных.
Вот мой список некоторых бесплатных курсов для изучения JDBC на Udemy и Pluralsight. Я включил изучение простого JDBC, а также Spring JDBC, который необходим для эффективного использования JDBC API в реальном приложении, сняв всю боль, связанную с подключениями и шаблонным кодом, связанным с ошибками, который лучше оставить для фреймворка. как весна.
В общем, без лишних слов, вот список бесплатных курсов JDBC для программистов Java от Udemy и Pluralsight.
Это бесплатный курс по Udemy для изучения JDBC с MySQL, одной из популярных и моих любимых баз данных. Это также помогает, потому что MySQL бесплатен, и вы можете загрузить и установить на свой компьютер, чтобы практиковаться во время курса.
В этом курсе Chat Darby научит вас, как подключиться к базе данных MySQL, как выполнять SQL-запросы, как простые, так и связанные запросы с использованием PreparedStatement, читать и записывать файлы BLOB-объектов и клубных данных, а также выполнять все основные операции, такие как вставка, выбрать, обновить и удалить.
Курс также затрагивает некоторые сложные концепции, такие как вызов хранимой процедуры и обработка параметров IN, OUT и INOUT. В целом, хороший короткий курс для бесплатного изучения JDBC.
Вот ссылка для присоединения к курсу — Подключение к базе данных Java: JDBC и MySQL
Это еще один хороший курс от Udemy, где вы изучите основы JDBC, но с точки зрения веб-приложения. Поскольку JDBC в основном используется в веб-приложениях Java с сервлетами и JSP, этот курс отлично подходит для веб-разработчиков Java, которые не знают JDBC.
В отличие от предыдущего курса, он платный, но этот обучает вас основам JDBC, таким как подключение к базе данных, выполнение SQL-запросов, анализ наборов результатов и обработка ошибок.
Самое лучшее в этом курсе — это то, что это прямая запись в классе, которая немного отличается от показа экрана с помощью слайдов. В общем, аудиторные лекции более интерактивны и увлекательны, чем скринкастинг.
Вот ссылка для присоединения к курсу — Java Database Connectivity (JDBC)
Это другой тип курса, который полезен только в том случае, если вы знаете основы JDBC.В этом курсе вы найдете обучение в классе на этом курсе. Этот курс научит вас многим важным концепциям JDBC, которые аналогичны тем, что я поделился в моем списке основных и расширенных вопросов JDBC.
Я многому научился, следуя этому курсу, и обнаружил, что его метод побуждает вас исследовать и учиться, читая сообщения в блоге и подписываясь на статьи, но он работает только в том случае, если вы кое-что знаете.
Вот почему я предлагаю вам сначала пройти два предыдущих курса, чтобы изучить основы JDBC, прежде чем проходить этот курс.
Вот ссылка для присоединения к курсу — Complete JDBC Programming Part-1 and 2
Это правильный курс JDBC от Pluralsight, который научит вас работать с базой данных. Автор Сехар Сринивасан — корпоративный тренер и старший архитектор в LSSolutions Pvt. Ltd.
Это комплексный курс по работе с базой данных, и вы узнаете много вещей, таких как
- , как читать и управлять данными из реляционных баз данных,
- вызов хранимых процедур,
- работа с подготовленными операторами,
- управление транзакциями,
- чтение и хранение данных CLOB,
- пул соединений,
- работа с метаданными и т. д.
Короче говоря, хороший курс для всех разработчиков Java, которые хотят работать с JDBC API.
Вот ссылка для присоединения к курсу — Java Platform: Работа с базами данных с использованием JDBC
Если вы использовали JDBC, то вы знаете, что при всей его мощности, гибкости и управляемости он также связан с бременем стандартного кода. для управления ресурсами и работы с SQLException.
Хотя такие фреймворки, как Hibernate и iBatis, упрощают работу с базой данных в приложениях Java, их нельзя использовать повсюду.
Поскольку вы не можете использовать Hibernate или любую структуру ORM везде, где вам нужен доступ к базе данных из программы Java, я предпочитаю использовать Spring JDBC, который не только решает проблему, связанную с созданием и управлением соединениями, но также и с ошибками.
В этом курсе Брайан Хассен, автор курсов Spring Fundamentals и Spring Security Fundamentals по Pluralsight объясняет, как эффективно использовать Spring JDBC для взаимодействия с Java-приложением из базы данных.
Вы узнаете о настройке и настройке, PreparedStatements , RowMapper , NamedParameter и их различных подходах, использующих интерфейс JdbcTemplate и JdbcOperation для работы с базой данных из Java-приложения на основе Spring.
Вот ссылка для присоединения к курсу — Создание приложений с использованием Spring JDBC
Кстати, оба курса Pluralsight, о которых я рассказал в этой статье, не являются полностью бесплатными. Для доступа к этим курсам вам потребуется членство Pluralsight , которые стоят около 29 долларов в месяц, но это стоит каждого пенни. По мере того, как вы получаете полный доступ к их 5000+ высококачественным курсам, чтобы улучшить свои знания и навыки.
У меня есть годовая подписка, которую я получил за 199 долларов на их промо-акцию со скидкой 33% , и большая часть моего обучения зависит от этого.Вы также можете воспользоваться этим предложением.
Если вы пропустите это предложение, вы все равно можете получить эти курсы бесплатно, подписавшись на 10-дневную бесплатную пробную версию , которой достаточно, чтобы посетить этот курс, а также получить обзор того, что вы можете получить, присоединившись Pluralsight.
Это все о бесплатных курсах JDBC для программистов на Java . Это отличные ресурсы для начала работы с JDBC, который является ключевым при написании реальных Java-приложений. Поскольку данные — самая важная часть любого приложения, а JDBC — самый простой способ работы с данными в приложении Java, хорошее знание JDBC имеет большое значение для того, чтобы стать хорошим разработчиком Java.
Прочие Бесплатные онлайн-курсы Вы можете изучить
- Мои любимые бесплатные учебные пособия по JavaScript для начинающих
- 15 курсов Docker, Kubernetes и AWS для веб-разработчиков
- 10 платформ JavaScript, которые могут изучить веб-разработчики
- 7 бесплатных курсов для изучения SQL и баз данных для начинающих
- Полная дорожная карта разработчика React.js
- 10 книг и курсов для изучения Angular в 2021 г.
- 5 лучших курсов для изучения веб-разработки
- Мои любимые бесплатные курсы для изучения HTML и CSS
- 5 Бесплатные курсы Docker для Frontend-разработчиков
- Полная дорожная карта для веб-разработчиков
Спасибо, что прочитали эту статью.Если вам нравятся эти бесплатные курсы JDBC, поделитесь ими с друзьями и коллегами. Если у вас есть какие-либо вопросы или отзывы, напишите нам.
Другие статьи среднего уровня, которые могут вам понравиться
mysql — Как написать правильный класс для подключения к базе данных в Java
Существуют различные способы подключения к реляционной базе данных для хранения и получения информации. В зависимости от ваших потребностей вы можете выбрать низкоуровневую реализацию или более высокую.
Вы можете напрямую использовать JDBC.Вам нужен драйвер, который знает, как общаться с вашей конкретной базой данных, вы открываете соединение, вы готовите оператор с некоторым SQL-запросом, устанавливаете необходимые параметры для оператора (если есть), выполняете оператор, получаете обратно набор результатов, выполнить итерацию набора результатов для создания объектов из результатов, а затем закрыть использованные ресурсы (набор результатов, оператор, соединение).
Это самый низкоуровневый способ сделать это. Но есть и недостатки:
- У вас много шаблонного кода: получить соединение, создать оператор, выполнить оператор, просмотреть результаты, построить объекты, освободить используемые ресурсы.Вы должны делать это каждый раз, когда хотите запустить некоторый SQL. Только SQL каждый раз различается, остальное вам придется делать снова и снова.
- вы открываете соединение с базой данных каждый раз, когда запускаете запрос. Это связано с некоторыми накладными расходами, и в зависимости от того, сколько запросов вы выполняете одновременно, вы можете открыть слишком много соединений. Некоторые базы данных могут иметь ограничения для каждого клиента, поэтому вы не можете зайти слишком высоко.
Для ограничения открываемых вами соединений вы можете использовать пул соединений, например Apache DBCP, C3P0, HikariCP и т. Д.У вас по-прежнему тот же код шаблона, но теперь вместо создания и закрытия соединения вы заимствуете его и возвращаете в пул. Более эффективным.
Теперь, поскольку шаблонная пластина каждый раз одна и та же, почему бы не переместить ее в какую-нибудь структуру или библиотеку, которая сделает это за вас, и вы просто сконцентрируетесь на написании SQL. Вот что делает, например, картограф данных вроде MyBatis. Вы настраиваете его один раз, пишете необходимые SQL-запросы и сопоставляете их с методами, сообщаете MyBatis, как сопоставить результат из строк с объектами, и MyBatis обрабатывает все шаблоны за вас.Запустите метод и верните нужные объекты.
С MyBatis вам нужно только написать SQL. Но некоторые люди даже не хотят этим заниматься. У вас есть шаблонный код и соединения, обрабатываемые какой-то библиотекой / фреймворком, но почему бы также не избавиться от SQL?
Это то, что делают ORM, такие как Hibernate. Вы сопоставляете классы с таблицами, а затем Hibernate обрабатывает все за вас. Он генерирует необходимый SQL, когда вы хотите сохранить или получить данные из базы данных. После настройки Hibernate вы можете сделать вид, что база данных не существует (по крайней мере, какое-то время).
У каждого из этих методов есть свои преимущества и недостатки.
- с JDBC, вам нужно написать много шаблонного кода, самостоятельно управлять транзакциями, следить за тем, чтобы у вас не было утечки ресурсов и т. Д. Это низкий уровень;
- с преобразователями данных, необходимыми для написания SQL. Средство отображения данных не делает вид, что базы данных нет, вы должны с этим иметь дело.
- с ORM, вы можете притвориться, что реляционная база данных не задействована. Вы имеете дело только с объектами. ORM отлично подходят для приложений CRUD, но для других ORM может доставить вам некоторые проблемы.Есть такая вещь, которая называется объектно-реляционным несоответствием импеданса, которое показывает, что это уродливо. И когда это происходит, производительность обычно становится первым, что падает насмарку.
Это ваши варианты. Посмотрите на свое приложение и посмотрите, какое решение может быть более подходящим. Учитывая ваш вопрос, вы можете захотеть использовать что-то легкое (не такое низкое, как прямой JDBC, и не такое высокое, как Hibernate).
Но не изобретайте велосипед . Что-то вроде Commons DbUtils, например, может быть хорошей отправной точкой.Он забирает у вас стандартный код JDBC без каких-либо изменений / дополнений в способах взаимодействия с базой данных.
(PDF) Подключение к базе данных Java с использованием MySQL: Учебное пособие
International Journal of Advanced Engineering and Science, Vol. 7, No 1, 2018
ISSN 2304-7712
International Journal of Advanced Engineering and Science
Издатель: Elite Hall Publishing House
Главный редактор:
Dr.Мохаммад Мохсин (Индия)
E-mail: [email protected]
Редакционная коллегия:
Г-н К. Ленин,
Доцент, Джавахарлал Неру
технологический университет Кукатпалли, Индия
E-mail: gkatpally @ gmail.com
Доктор Джейк М. Лагуадор
Профессор инженерного факультета
Лицей Филиппинского университета, Батангас
Город, Филиппины
Эл. почта: [email protected]
Др.Т. Субраманьям
ФАКУЛЬТЕТ, MS Quantitative Finance, Департамент
статистики
Центральный университет Пондичерри, Индия
Электронная почта: [email protected]
Доктор Г. Раджараджан,
Профессор физики, Центр исследований и
Девелопмент
Инженерный колледж Махендры, Индия
Электронная почта: [email protected]
Мисс Гаятри Д. Найк.
Профессор, факультет компьютерной инженерии, YTIET
Энгский колледж, Университет Мумбаи, Индия
Электронная почта: gayatri8984 @ gmail.com
Г-н Рудраруп Гупта
Академический исследователь, Калькутта, Индия
Эл. почта: [email protected]
Г-н Белай Зерга
Магистр управления земельными ресурсами, Аддис
Университет Абеба,
Эфиопия
-mail: [email protected]Г-жа Суканья Рой
Помощник профессора (BADM), Сет GDSB Patwari
Колледж, Раджастан, Индия
Электронная почта: [email protected]
Mr. Начимани Чарде
Кафедра механики, материалов и
Технологии производства, Университет
Ноттингем, Малайзия Кампус
Эл. Почта: keyx9nac @ nottingham.edu.my
Д-р Судхансу Сехар Панда
Доцент кафедры механики
Инженерное дело
ИИТ Патна, Индия
Электронная почта: [email protected]
Д-р Дж. Дилли Бабу
Доцент, Кафедра механики
Engineering,
VR Siddhartha Engineering College, Андхра
Прадеш, Индия
Электронная почта: [email protected]
Г-н Джимит Р. Патель
Научный сотрудник, Департамент математики,
Университет Сардара , Индия
Электронная почта: [email protected]
Д-р Джума Э., Алалвани
Доцент, Департамент промышленности
Инженерное дело,
Инженерный колледж в Янбу, Янбу, Саудовская Аравия
Аравия
Электронная почта: [email protected].
Доктор Цзя Чи Цоу
Доцент, Китайский технологический университет
, Тайвань
Электронная почта: jtsou.