Базы данных на Java — первые шаги
одина
Базы данных на Java — введение
Мы приступаем к одному из очень важных разделов программирования на Java — работа с базами данных. Данные являются наверно наиглавнейшей составляющей программирования и вопрос их хранения крайне актуален. Не буду больше говорить о важности этого вопроса — тут можно писать много-много-много разных интересных слов.
Сервер баз данных
Сама идея сервера баз данных и СУБД в виде отдельной программы появилось по совершенно очевидным причинам. Базы данных мгновенно стали МНОГОПОЛЬЗОВАТЕЛЬСКИМИ. Данные нужны всем и возможность одновременного доступа к ним является очевидной. Проблема базы данных в виде обычного файла заключается в том, что к этому файлу будет обращаться сарзу много программ, каждая из которых захочет внести изменения или получить данные. Организовать такой доступ на уровне файловой системы — по сути, невыполнимая задача.
Во-первых — файл должен быть доступен всем пользователям, что требует перекачку данных по сети и хранение этого файла где-то на сетевом диске. Большие объемы данных по сети (пусть даже с высокой скоростью) — кроме слова “отвратительно” у меня ничего не приходит на ум.
В-третьих — организация прав доступа к тем или иным данным тоже становится непосильной задачей.
В-четвертых — надо “разруливать” конфликты при одновременном доступе к одним и тем же данным.
После небольшого анализа, кроме этих вопросов, можно увидеть еще немалое количество проблем, которые надо решить при мультипользовательском доступе к данным.
В итоге было принято (и реализовано) вполне здравое решение — написать специальную программу, которая имеет несколько названий — Система Управления Базами Данных (СУБД), сервер баз данных и т.д. Я буду называть ее СУБД.
- СУБД будет иметь некоторый набор команд, который позволит записывать и получать данные
- СУБД будет сама работать с файловой системой (нередко у нее бывает своя собственная файловая система для скорости)
- СУБД предоставит механизмы разграничения доступа к разным данным
- СУБД будет решать задачи одновременного доступа к данным
В итоге мы получаем достаточно ясную архитектуру — есть СУБД, которая сосредоточена на работе с данными и есть клиенты, которые могут посылать запросы к СУБД.

При работе с СУБД клиенты должны решить достаточно четкие задачи:
- Клиент должен соединиться с СУБД. Как я уже упоминал, чаще всего для общения используется сетевой протокол TCP/IP. В момент подключения клиент также передает свой логин/пароль, чтобы СУБД могла его идентифицировать и в дальнейшем позволить (или не позволить) производить те или иные действия над данными
- Клиент может посылать команды для изменения/получения данных в СУБД
- Данные внутри СУБД хранятся в определенных структурах и к этим структурам можно обратиться через команды
SQL базы данных
Могу предположить,что вышеупомянутые задачи и породили именно SQL-базы данных. В них есть удобные и понятные структуры для хранения данных — таблицы. Эти таблицы можно связывать в виде отношений и тем самым дается возможность хранить достаточно сложно организованные данные. Был придуман специальный язык — SQL (Structured Query Language — структурированный язык запросов). Этот язык хоть и имеет всего 4 команды для манипулирования данными, позволяет создавать очень сложные и заковыристые запросы.
JDBC — Java Database Connectivity — архитектура
Если попробовать определить JDBC простыми словами, то JDBC представляет собой описание интерфейсов и некоторых классов, которые позволяют работать с базами данных из Java. Еще раз: JDBC — это набор интерфейсов (и классов), которые позволяют работать с базами данных.
И вот с этого момента я попробую написать более сложное и в тоже время более четкое описание архитектуры JDBC. Главным принципом архитектуры является унифицированный (универсальный, стандартный) способ общения с разными базами данных. Т.е. с точки зрения приложения на Java общение с Oracle или PostgreSQL не должно отличаться. По возможности совсем не должно отличаться.
Наше приложение не должно думать над тем, с какой базе оно работает — все базы должны выглядеть одинаково. Но при всем желании внутреннее устройство передачи данных для разных СУБД разное. Правила передачи байтов для Oracle отличается от правил передачи байтов для MySQL и PostgreSQL. В итоге имеем — с одной стороны все выглядят одинаково, но с другой реализации будут разные. Ничего не приходит в голову ?
Думаю, что вы уже догадались — типичный полиморфизм через интерфейсы. Именно на этом и строится архитектура JDBC. Смотрим рисунок.

Как следует из рисунка, приложение работает с абстракцией JDBC в виде набора интерфейсов. А вот реализация для каждого типа СУБД используется своя. Эта реализация называется “JDBC-драйвер”. Для каждого типа СУБД используется свой JDBC-драйвер — для Oracle свой, для MySQL — свой. Как приложение выбирает, какой надо использовать, мы увидим чуть позже.
Т.е. наше приложение в принципе не различает, обращается оно к Oracle или PostgreSQL — все обращения идут через стандартные интерфейсы, за которыми “прячется” реализация.
Пока я предлагаю отметить несколько важных интерфейсов, которые мы будем рассматривать позже, но мне бы хотелось, чтобы у вас этот список уже был, чтобы вы могли по мере прочтения отмечать — “да, вот он важный интерфейс/класс и я теперь знаю, куда он встраивается”. Вот они:
- java.sql.DriverManager
- java.sql.Driver
- java.sql.Connection
- java.sql.Statement
- java.sql.PreparedStatement
- java.sql.CallableStatement
- java.sql.ResultSet
Теперь давайте рассмотрим несложный пример и поймем, как работает JDBC.
JDBC — пример соединения и простого вызова
Попробуем посмотреть на несложном примере, как используется JDBC-драйвер. В нем же мы познакомимся с некоторыми важными интерфейсами и классами.
Предварительно нам необходимо загрузить JDBC-драйвер для PostgreSQL. На данный момент это можно сделать со страницы PostgreSQL JDBC Download
Если вы не нашли эту страницу, то просто наберите в поисковике “PostgreSQL JDBC download” и в первых же строках найдете нужную страницу.
Т.к. я пишу эти статьи для JDK 1.7 и 1.8, то я выбрал строку “JDBC41 Postgresql Driver, Version 9.4-1208” — может через пару-тройку лет это будет уже не так.
Если вы выполнили SQL-скрипт из раздела Установка PostgreSQL, который создавал таблицу JC_CONTACT и вставил туда пару строк, то эта программа позволит вам “вытащить” эти данные и показать их на экране. Это конечно же очень простая программа, но на ней мы сможем посмотреть очень важные моменты. Итак, вот код:
Java и базы данных | Введение
JDBC
Последнее обновление: 08.08.2018
Для хранения данных мы можем использовать различные базы данных — Oracle, MS SQL Server, MySQL, Postgres и т.д. Все эти системы упраления базами данных имеют свои особенности. Главное, что их объединяет это взаимодействие с хранилищем данных посредством команд SQL. И чтобы определить единый механизм взаимодействия с этими СУБД в Java еще начиная с 1996 был введен специальный прикладной интерфейс API, который называется JDBC.
То есть если мы хотим в приложении на языке Java взаимодействовать с базой данных, то необходимо использовать функциональные возможности JDBC. Данный API входит в состав Java (на текущий момент это версия JDBC 4.3), в частности, для работы с JDBC в программе Java достаточно подключить пакет java.sql. Для работы в Java EE есть аналогичный пакет javax.sql, который расширяет возможности JDBC.
Однако не все базы данных могут поддерживаться через JDBC. Для работы с определенной СУБД также необходим специальный драйвер. Каждый разработчик определенной СУБД обычно предоставляет свой драйвер для работы с JDBC. То есть если мы хотим работать с MySQL, то нам потребуется специальный драйвер для работы именно MySQL. Как правило, большиство драйверов доступны в свободном доступе на сайтах соответствующих СУБД. Обычно они представляют JAR-файлы. И преимущество JDBC как раз и состоит в том, что мы абстрагируемся от строения конкретной базы данных, а используем унифицированный интерфейс, который един для всех.
Для взаимодействия с базой данных через JDBC используются запросы SQL. В то же время возможности SQL для работы с каждой конкретной СУБД могут отличаться. Например, в MS SQL Server это T-SQL, в Oracle — это PL/SQL. Но в целом эти разновидности языка SQL не сильно отличаются.
Особенности запуска программы
На процесс компиляции необходимость работы с БД никак не сказывается, но влияет на процесс запуска программы. При запуске программы в командной строке необходимо указать путь к JAR-файлу драйвера после параметра -classpath.
java -classpath путь_к_файлу_драйвера:путь_к_классу_программы главный_класс_программы
Например, в папке C:\Java располагаются файл программы — Program.java, скомпилированный класс Program и файл драйвер, допустим, MySQL — mysql-connector-java-8.0.11.jar. Для выполнения класса Program мы можем использовать следующую команду:
java -classpath c:\Java\mysql-connector-java-8.0.11.jar;c:\Java Program
Если C:\Java является текущим каталогом, то мы можем сократить команду:
java -classpath mysql-connector-java-8.0.11.jar;. Program
В принципе мы можем и не использовать параметр -classpath, и запустить програму на выполнение обычным способом с помощью команды «java Program». Но в этом случае путь к драйверу должен быть добавлен в переменную Path.
metanit.com
Работа с базой данных Java DB (Derby)
Вь этом документе описывается настройка соединения с базой данных Java DB в IDE NetBeans. По завершении установки подключения можно начинать работу с базой данных в среде IDE, позволяющей создавать таблицы, заполнять их данными, выполнять операторы и запросы SQL и т.д.
База данных Java DB является поддерживаемым корпорацией Sun дистрибутивом Apache Derby. Java DB — полностью транзакционный безопасный сервер базы данных на основе стандартов, написанный целиком на языке Java, полностью поддерживающий технологии SQL, интерфейс API JDBC и Java EE. База данных Java DB поставляется с сервером приложений GlassFish , а также включена в пакет JDK 6. Дополнительные сведения о базе данных Java DB приведены в официальной документации.
Содержание

Для работы с этим учебным курсом требуется следующее программное обеспечение и ресурсы.
Примечание.
- Java DB был установлен при установке JDK 7 или JDK 8 (за исключением Mac OS X). При использовании Mac OS X можно загрузить и установить базу данных Java вручную или использовать базу данных Java, установленную с помощью версии Java EE средства установки IDE NetBeans.
Настройка базы данных
При регистрации сервера GlassFish Server в установленной среде IDE NetBeans база данных Java DB также будет зарегистрирована. Для получения дополнительных сведений обратитесь к разделу Запуск сервера и создание базы данных.
Если сервер GlassFish загружен отдельно, и требуется помощь в регистрации его в среде IDE NetBeans, ознакомьтесь со справкой по среде IDE (F1), раздел Регистрация экземпляра сервера GlassFish.
Если вы только что самостоятельно загрузили Java DB, выполните следующие действия.
- Выполните самораспаковывающийся файл. В месте хранения файла будет создана папка javadb. Если требуется, чтобы сервер базы данных находился не в той папке, в которую он был извлечен, его необходимо переместить сразу по завершении загрузки Java DB.
- Создайте в системе новый каталог для использования в качестве домашнего каталога для отдельных экземпляров сервера базы данных. Например, можно создать эту папку в корневом каталоге базы данных Java DB (javadb) или в другой папке.
Перед продолжением работы необходимо изучить компоненты, расположенные в корневом каталоге Java DB.
- Подкаталог demo содержит демонстрационные версии программ.
- Подкаталог bin содержит сценарии для выполнения служебных программ и настройки среды.
- Подкаталог javadoc содержит документацию по интерфейсу API, созданную из комментариев исходного кода.
- Подкаталог docs содержит документацию по Java DB.
- Подкаталог lib содержит архивы JAR базы данных Java DB.
Регистрация базы данных в IDE NetBeans
Теперь, после настройки базы данных, выполните следующие шаги для регистрации Java DB в среде IDE.
- В окне ‘Службы’ щелкните правой кнопкой мыши узел базы данных DB Database и выберите ‘Свойства’, чтобы открыть диалоговое окно ‘Настройки DB Java’.
- В текстовое поле «Установка Java DB» введите путь к корневому каталогу Java DB (javadb), указанный в предыдущем шаге.
- В ка
netbeans.org
Простой пример JDBC для начинающих / Habr
Здравствуйте! В этой статье я напишу простой пример соединения с базами данных на Java.Эта статья предназначена новичкам.Здесь я опишу каждую строчку объясню что зачем.Но для начала немного теории.
JDBC (Java DataBase Connectivity — соединение с базами данных на Java) предназначен для взаимодействия Java-приложения с различными системами управления базами данных (СУБД). Всё движение в JDBC основано на драйверах которые указываются специально описанным URL.
А теперь практика.
Для начала создаём maven проект и в pom.xml помещаем зависимость для соединения с СУБД (В моём случае СУБД будет выступать MySQL):
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
</dependencies>
Должно получится так:
Дальше подключаемся к базе данных нужной вам(я пользуюсь IDEA Ultimate по этому я подключаюсь именно так).
Дальше заполняем Database, User и Password.Обязательно проверяем соединение.
Дальше мы создаём сам класс.
А теперь разберём его построчно:
В начале мы создаём три переменные url,username и password. Образец указания url:
Username по умолчанию root.Password вы должны знать сами.
После с помощью строчки Class.forName(«com.mysql.jdbc.Driver») регестрируем драйвера. Дальше устанавливаем соединение с помощью DriverManager.getConnection (ваш url, username, password).
После с помощью connection (соединения) создаём простой запрос Statement методом createStatement().
Дальше создаём экземпляр класса ResultSet и формируем запрос через statement методом executeQuery (запрос).
Дальше мы заставляем пробежаться resultSet по всей базе данных и вывести то что нам нужно. Так с помощью объекта resultSet и его методов (getString,getInt и т.д. в зависимости от типа переменных в колонке) мы выводим.Так как мой запрос был для того что бы вывести всё, мы можем вывести любую колонку.
После закрываем resultSet,statement и connection (именно в такой последовательности). В процессе он будет показывать ошибки так как будет запрашивать обработку исключений в catch.Так что пишите catch заранее.
Теперь когда практика есть на неё можно наложить более глубокую теорию.Тема правда очень большая, желаю удачи в её изучении.
Этот проект на github тут.
habr.com
Базы данных Java | Блог только про Java
 Запрос может вернуть множественные результаты. Это может произойти при выполнении хранимой процедуры или в базах данных, которые позволяют также выполнение множества операторов SELECT в одном запросе. Ниже показано, как можно получить все множественные наборы: Читать →
Запрос может вернуть множественные результаты. Это может произойти при выполнении хранимой процедуры или в базах данных, которые позволяют также выполнение множества операторов SELECT в одном запросе. Ниже показано, как можно получить все множественные наборы: Читать →
 Некоторые JAR-файлы JDBC(например, драйвер Derby, входящий в состав Java SE 6) автоматически регистрируют класс драйвера. JAR-файл может автоматически зарегистрировать класс драйвера, если он содержит файл: Читать →
Некоторые JAR-файлы JDBC(например, драйвер Derby, входящий в состав Java SE 6) автоматически регистрируют класс драйвера. JAR-файл может автоматически зарегистрировать класс драйвера, если он содержит файл: Читать →
 Прокручиваемые результирующие наборы предлагают богатые возможности, однако они не свободны от недостатков. В течении всего времени взаимодействия с пользователем соединения с базой данных должно быть открыто. Однако пользователь может отлучиться на длительное время, а открытое соединение будет потреблять ресурсы.
Прокручиваемые результирующие наборы предлагают богатые возможности, однако они не свободны от недостатков. В течении всего времени взаимодействия с пользователем соединения с базой данных должно быть открыто. Однако пользователь может отлучиться на длительное время, а открытое соединение будет потреблять ресурсы.
В подобной ситуации целесообразно использовать набор строк(row set). Интерфейс RowSet расширяет интерфейс ResultSet, но набор строк не привязан к соединению с базой данных.
Наборы строк также применяемы в случае, если требуется переместить результаты выполнения запроса на другой уровень сложного приложения или на другое устройство, например, на мобильный телефон. Переместить результирующий набор нельзя, так как он связан с соединением, кроме того, размеры структуры данных могут быть очень велики. Читать →
Опубликовано в Базы данных Java | Метки rowset java, rowset java пример, наборы строк java | | Каждый JDBC-драйвер принадлежит одному из перечисленных ниже типов.
Каждый JDBC-драйвер принадлежит одному из перечисленных ниже типов.
- Драйвер типа 1. Транслирует JDBC в ODBC и для взаимодействия с базой данных использует драйвер ODBC. Компания Sun включила в состав JDK один такой драйвер — мост JDBC/ODBC. Однако для его использования требуется соответствующим образом установить и конфигурировать ODBC-драйвер. В первом выпуске JDBC этот мост предполагалось использовать только для тестирования, а не для рабочего применения. В настоящее время уже имеется большое количество более удачных драйверов.
- Драйвер типа 2. Создается преимущественно на языке Java и частично на собственном языке программирования, который используется для взаимодействия с клиентским API базы данных. Для использования такого драйвера нужно помимо библиотеки Java установить специфический для данной платформы код. Читать →
 Синтаксис «перехода»(escape syntax) поддерживает средства, которые обычно поддерживаются базами данных, но в разных вариантах, в зависимости от конкретного синтаксиса базы данных. Драйвер JDBC отвечает ща преобразование синтаксиса перехода в синтаксис конкретной базы данных.
Синтаксис «перехода»(escape syntax) поддерживает средства, которые обычно поддерживаются базами данных, но в разных вариантах, в зависимости от конкретного синтаксиса базы данных. Драйвер JDBC отвечает ща преобразование синтаксиса перехода в синтаксис конкретной базы данных.
Переходы предусмотрены для следующих средств:
- литералы времени и даты;
- вызов скалярных функций;
- вызов хранимых процедур;
- внешние соединения;
- символ перехода в операциях LIKE. Читать →
Работа с базой данных Java Читать →
Опубликовано в Базы данных Java | | Большинство баз данных поддерживают механизм автоматической нумерации строк в базе данных. К сожалению, у разных поставщиков эти механизмы существенно отличаются. Эти автоматические номера часто используются в качестве первичных ключей.
Большинство баз данных поддерживают механизм автоматической нумерации строк в базе данных. К сожалению, у разных поставщиков эти механизмы существенно отличаются. Эти автоматические номера часто используются в качестве первичных ключей.
Несмотря на то что JDBC не предлагает решения, независимого от поставщиков, для генерирования этих ключей, она предлагает эффективный способ их получения. Когда вы вставляете новую строку в таблицу, и когда происходит автоматическая генерация ключа, вы можете получить их с помощью следующего кода: Читать →
Опубликовано в Базы данных Java | Метки генерируемых ключей, ключей SQL, Получение автоматически генерируемых ключей | |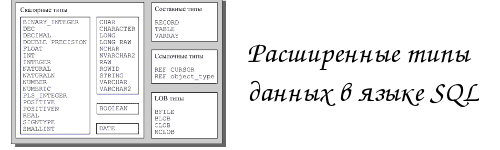 Тип ARRAY языка SQL представляет собой последовательность значений. Например, таблица Student может иметь столбец с оценками Scores типа ARRAY OF INTEGER, то есть с массивом целочисленных значений. Для возвращения данных типа java.sql.Array используется метод getArray(). В интерфейсе java.sql.Array также предусмотрены методы извлечения значений массива. Читать →
Тип ARRAY языка SQL представляет собой последовательность значений. Например, таблица Student может иметь столбец с оценками Scores типа ARRAY OF INTEGER, то есть с массивом целочисленных значений. Для возвращения данных типа java.sql.Array используется метод getArray(). В интерфейсе java.sql.Array также предусмотрены методы извлечения значений массива. Читать →
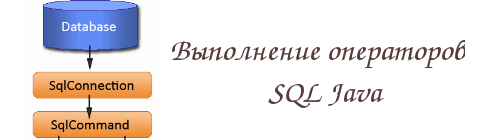 Для выполнения оператора SQL нужно создать объект Statement. Для этой цели используется объект Connection, который можно получить, вызвав метод DriverManager.getConnection():
Для выполнения оператора SQL нужно создать объект Statement. Для этой цели используется объект Connection, который можно получить, вызвав метод DriverManager.getConnection():
Statement stat = conn.createStatement(); |
Затем потребуется создать строку с требуемой SQL-командой:
String command = "UPDATE Books" | |
+ " SET Price = Price - 5.00" | |
+ " WHERE Title NOT LIKE ;%Introduction%'"; |
Далее необходимо вызвать метод executeUpdate() класса Statement: Читать →
Опубликовано в Базы данных Java | Метки SQL, Выполнение операторов SQL, операторов SQL | | Каждое SQL-исключение имеет цепочку объектов SQLException, которые извлекаются посредством метода getNextException. Эта цепочка исключений является дополнением цепочки «cause» объектов Throwable, имеющихся в каждом исключении. Чтобы полностью перечислить все исключения, может потребоваться два вложенных цикла.К счастью, в Java SE 6 был усовершенствован класс SQLException для реализации интерфейса Iterable<Throwable>.
Каждое SQL-исключение имеет цепочку объектов SQLException, которые извлекаются посредством метода getNextException. Эта цепочка исключений является дополнением цепочки «cause» объектов Throwable, имеющихся в каждом исключении. Чтобы полностью перечислить все исключения, может потребоваться два вложенных цикла.К счастью, в Java SE 6 был усовершенствован класс SQLException для реализации интерфейса Iterable<Throwable>.
Метод iterator() дает Iterator<Throwable>, который осуществляет перебор в обеих цепочках, сначала проходя по цепочке «cause» первого SQLException, а затем переходя к следующему SQLException и т.д. Вы можете просто использовать улучшенный цикл for: Читать →
Опубликовано в Базы данных Java | Метки SQL, SQL исключения, SQL исключения Java | |pro-java.ru
Как с интерфейса (JAVA)добавлять в базу данных информацию
Stack Overflow на русскомLoading…
- 0
- +0
- Тур Начните с этой страницы, чтобы быстро ознакомиться с сайтом
- Справка Подробные ответы на любые возможные вопросы
- Мета Обсудить принципы работы и политику сайта
- О нас Узнать больше о компании Stack Overflow
- Бизнес Узнать больше о поиске разработчиков или рекламе на сайте
ru.stackoverflow.com
Как вывести всех студентов из базы данных MYSQL в JAVA
Stack Overflow на русскомLoading…
- 0
- +0
- Тур Начните с этой страницы, чтобы быстро ознакомиться с сайтом
- Справка Подробные ответы на любые возможные вопросы
- Мета Обсудить принципы работы и политику сайта
- О нас Узнать больше о компании Stack Overflow
- Бизнес Узнать больше о поиске разработчиков или рекламе на сайте
- Войти Регистрация
-
текущее сообщество
- Stack Overflow на русском справка чат
ru.stackoverflow.com