Работа с файлами в Python: функция open()
Главная / Блог / Работа с файлами в Python
Дата: 15 октября 2020
Автор: Михаил Макарик
Следить за результатами выполнения скрипта в консоли информативно, но не очень весело. Более того, после закрытия терминала весь итог работы кода исчезает. А хочется сохранить всё это куда-то на диск, чтобы потом в любое время рассмотреть повнимательнее. Да и простая задача «работать с файлами» может возникнуть в любое время.
В языке Python для этого предусмотрена встроенная функция open(). Она дает возможность чтения и записи файлов. Об этом ниже.
1. Начало работы
В качестве примера работы с файлами на ПК мы будем использовать war_and_peace.txt (начало романа Л. Н. Толстого «Война и мир»), который разместим в папке скрипта.
В общем виде для открытия файла функцией open() требуется указать либо его расположение относительно текущей директории либо задав абсолютный путь.
Пример – Интерактивный режим
>>> file = open('war_and_peace.txt')
>>> file.read(50)
†Eh bien, mon prince. Gênes et Lucques ne s
>>> file.read()
Тут выведется оставшаяся часть текста...
>>> file.read()
Получим пустую строку
>>> file.close() Рассмотрим подробнее проделанные операции.
1. Мы открыли файл ‘war_and_peace.txt’ и присвоили его переменной file.
2. Далее мы вывели на печать первые 50 символов объекта. Если в метод
Обратите внимание на сам текст: в нем угадываются французские слова и непонятные кракозябры (к слову, у вас могут отобразиться совсем другие символы). Вывод: с кодировкой беда. Так как мы ее не задали явно, определилась та, которая задана системно. В приведенном выше примере функция open() открыла роман в кодировке cp1251
Вывод: с кодировкой беда. Так как мы ее не задали явно, определилась та, которая задана системно. В приведенном выше примере функция open() открыла роман в кодировке cp1251
3. В конце мы закрыли файловый объект, чтобы он не занимал место в памяти.
Нам повезло, что до момента закрытия файла не случилось ошибки, иначе он бы так и остался открытым и занимал некоторый объем памяти.
Читайте также
Кодирование строк — ASCII, Unicode, UTF-8
Чтобы компьютер смог отобразить передаваемые ему символы, они должны быть представлены в конкретной кодировке. Навряд ли найдется человек, который никогда не сталкивался с кракозябрами: открываешь интернет-страницу, а там – набор непонятных знаков; хочешь прочесть книгу в текстовом редакторе, а вместо слов получаешь сплошные знаки вопроса. Причина заключается в неверной процедуре декодирования текста…
Программирование на Python.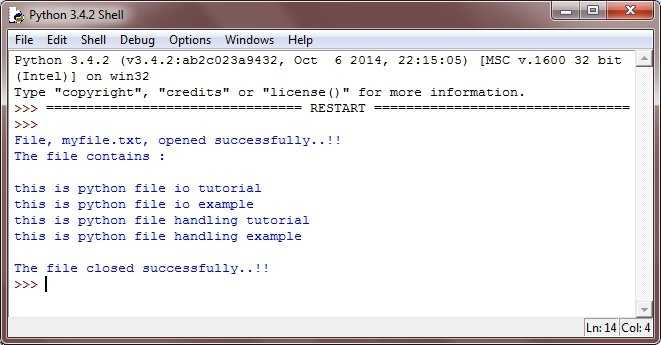 Урок 4. Работа со строками
Урок 4. Работа со строками
Строки в Python. Тип данных: str. Учимся выполнять основные действия над строковым типом данных в Python: создание, экранирование, конкатенация и умножение, срезы, форматирование, строковые методы.
2. Чтение файла целиком
Чтобы случайно не забыть закрыть файл, функция open() может открываться при помощи контекстного менеджера. Лучше пользоваться всегда таким способом как рекомендуемым разработчиками.
Попытаемся еще раз открыть файл, указав кодировку, режим (на чтение обозначается буквой r).
Пример – Интерактивный режим
>>> with open('war_and_peace.txt', 'r', encoding='utf-8') as file:
txt = file.read()
>>> txt[:50]
\ufeff— Eh bien, mon prince. Gênes et Lucques ne sont p
>>> txt[:50]
\ufeff— Eh bien, mon prince. Gênes et Lucques ne sont pВ данном случае код вне контекстного менеджера выполняется после закрытия файлового объекта и очистки памяти (даже если бы возникла ошибка).
Переменная txt имеет тип строка. В ней сохранились не только буквы и знаки препинания, но и все скрытые символы (перевод на новую строку, отступы и т.п.). Так как эта переменная хранит строку, то мы к ней можем обращаться любое количество раз.
Существует второй способ чтения файла целиком: через метод readlines(). Он возвращает список строк. Строки идентифицируются по символу ‘\n’.
Пример – Интерактивный режим
>>> with open('war_and_peace.txt', 'r', encoding='utf-8') as file:
txt = file.readlines()
>>> txt[0]
"\ufeff— Eh bien, mon prince. Gênes et Lucques ne sont plus que des apanages, des поместья, de la famille Buonaparte. Non, je vous préviens que si vous ne me dites pas que nous avons la guerre, si vous vous permettez encore de pallier toutes les infamies, toutes les atrocités de cet Antichrist (ma parole, j'y crois) — je ne vous connais plus, vous n'êtes plus mon ami, vous n'êtes plus мой верный раб, comme vous dites 1.
Ну, здравствуйте, здравствуйте. Je vois que je vous fais peur 2, садитесь и рассказывайте.\n"

Итак, теперь текст отображается правильно. Но, имеется еще один неприятный момент, на который не каждый обратит внимание. Наш файл – достаточно мал по объему. Поэтому мы оправданно присвоили всё его содержимое одной переменной. В случае огромных объектов (например, HD-фильм или база данных на сотню миллионов пользователей) это чревато переполнением памяти и возникновением ошибок.
3. Чтение файла частями
К счастью, файловый объект может читаться построчно при помощи readline(). Следовательно, мы можем посмотреть каждую строку тяжеловесного файла и проделать над ней какие-то операции.
Выведем на печать первые 50 символов двух первых строк.
Пример – Интерактивный режим
>>> with open('war_and_peace. txt', 'r', encoding='utf8') as file:
first_line = file.readline()
second_line = file.readline()
>>> first_line[:50]
\ufeff— Eh bien, mon prince. Gênes et Lucques ne sont p
>>> second_line[:50]
Так говорила в июле 1805 года известная Анна Павло
 txt', 'r', encoding='utf8') as file:
first_line = file.readline()
second_line = file.readline()
>>> first_line[:50]
\ufeff— Eh bien, mon prince. Gênes et Lucques ne sont p
>>> second_line[:50]
Так говорила в июле 1805 года известная Анна Павло
txt', 'r', encoding='utf8') as file:
first_line = file.readline()
second_line = file.readline()
>>> first_line[:50]
\ufeff— Eh bien, mon prince. Gênes et Lucques ne sont p
>>> second_line[:50]
Так говорила в июле 1805 года известная Анна Павло
Такой способ удобен, если нам не нужен весь файл, а лишь его часть. Главный минус – мы можем не знать, сколько строк в файле. А так как
Если методу readline() передать числовой аргумент, то он посчитает окончанием строки это количество символов.
Чтение по строкам можно провести обычной итерацией в цикле по файловому объекту. Это может понадобиться, если нам требуется провести какие-то преобразования в каждой строке, но нужно прекратить их по окончании файла.
Пример – IDE
with open('war_and_peace. txt', 'r', encoding='utf8') as file:
for line in file:
print(line[:15].lower())
Результат выполнения
— eh bien, mon так говорила в «si vous n'avez — dieu, quelle он говорил на т — avant tout di — как можно быт — а праздник ан — я думала, что — ежели бы знал — ne me tourmen — как вам сказа князь василий г быть энтузиастк
В примере выше мы прошлись по всем строкам текста и вывели на печать первые 15 символов каждой строки в нижнем регистре.
4. Запись в файл
Функция open() позволяет не только читать файлы, но и записывать. Для этого требуется сменить режим на
Пример – Интерактивный режим
>>> with open('even. txt', 'w', encoding='utf8') as file:
for num in range(2, 20, 2):
file.write(str(num)) txt', 'w', encoding='utf8') as file:
for num in range(2, 20, 2):
file.write(str(num))
txt', 'w', encoding='utf8') as file:
for num in range(2, 20, 2):
file.write(str(num))В результате появится текстовый файл с четными числами. Но записаны они очень неудобно – в одну строку без пробелов: 24681012141618. Чтобы исправить положение, помимо записи самой строки требуется внести еще и символ окончания строки
Пример – Интерактивный режим
>>> with open('even.txt', 'w', encoding='utf8') as file:
for num in range(2, 20, 2):
file.write(str(num) + '\n')Вот теперь файл выглядит так, как мы запланировали.
Такой способ, конечно, не всегда удобен. Некоторые предпочитают пользоваться другим вариантом записи текста в файл – через привычную функцию print().
Повторим задачу с ее использованием.
Пример – Интерактивный режим
>>> with open('even. txt', 'w', encoding='utf8') as file:
for num in range(2, 20, 2):
print(num, file=file)
По умолчанию функция print() выводит информацию (в большинстве случаев текстовую) в поток STDOUT на устройство отображения (монитор). В нашем случае мы его перенаправляем на файловый объект(поток) file.
Используя методику записи в файл нужно понимать, что если файла нет – то он создается, если же он есть, то все его содержимое удаляется и перезаписывается. А, вдруг, вы забыли переименовать документ и случайно переписали его содержимое? Мало приятного.
Избежать такой беды можно использованием режима x.
Пример – Интерактивный режим
>>> with open('even.txt', 'x', encoding='utf8') as file:
for num in range(2, 20, 2):
print(num, file=file)
При исполнении кода возникнет ошибка FileExistsError, говорящая о том, что такой файл уже имеется на диске. Поэтому либо создавайте документ с другим наименованием, либо удаляйте старый.
Поэтому либо создавайте документ с другим наименованием, либо удаляйте старый.
5. Дозапись в файл
Не всегда требуется записывать в файл единоразово. Во многих ситуациях нужно дополнять имеющийся документ новым контентом (при парсинге, логировании и т.п.). На помощь приходит режим a.
Так как выше мы уже имеем файл с четными числами до 18, дополним его четными числами до 100 включительно.
Пример – Интерактивный режим
>>> with open('even.txt', 'x', encoding='utf8') as file:
for num in range(2, 20, 2):
print(num, file=file)
В документе even.txt теперь имеются все четные числа от 2 до 100.
В статье приведены базовые основы работы с файлами Python на примере функции open(). Она намного сложнее, имеет дополнительные режимы, позволяет взаимодействовать не только с текстовыми документами формата txt, но и любыми другими типами данных (картинками, медиафайлами, excel-таблицами, html-страницами и т. д.).
д.).
15 ОКТЯБРЯ / 2020
Как вам материал?
| ПОКАЗАТЬ КОММЕНТАРИИ |
Читайте также
Работа с файлами в Python
В данном материале мы рассмотрим, как читать и вписывать данные в файлы на вашем жестком диске. В течение всего обучения, вы поймете, что выполнять данные задачи в Python – это очень просто. Начнем же.
Как читать файлы
Python содержит в себе функцию, под названием «open», которую можно использовать для открытия файлов для чтения. Создайте текстовый файл под названием test.txt и впишите:
Python
This is test file line 2 line 3 this line intentionally left lank
This is test file line 2 line 3 this line intentionally left lank |
Вот несколько примеров того, как использовать функцию «открыть» для чтения:
Python
handle = open(«test. txt»)
handle = open(r»C:\Users\mike\py101book\data\test.txt», «r»)
txt»)
handle = open(r»C:\Users\mike\py101book\data\test.txt», «r»)
handle = open(«test.txt») handle = open(r»C:\Users\mike\py101book\data\test.txt», «r») |
В первом примере мы открываем файл под названием test.txt в режиме «только чтение». Это стандартный режим функции открытия файлов. Обратите внимание на то, что мы не пропускаем весь путь к файлу, который мы собираемся открыть в первом примере. Python автоматически просмотрит папку, в которой запущен скрипт для text.txt. Если его не удается найти, вы получите уведомление об ошибке IOError. Во втором примере показан полный путь к файлу, но обратите внимание на то, что он начинается с «r». Это значит, что мы указываем Python, чтобы строка обрабатывалась как исходная. Давайте посмотрим на разницу между исходной строкой и обычной:
Python
>>> print(«C:\Users\mike\py101book\data\test. txt»)
C:\Users\mike\py101book\data est.txt
>>> print(r»C:\Users\mike\py101book\data\test.txt»)
C:\Users\mike\py101book\data\test.txt
txt»)
C:\Users\mike\py101book\data est.txt
>>> print(r»C:\Users\mike\py101book\data\test.txt»)
C:\Users\mike\py101book\data\test.txt
>>> print(«C:\Users\mike\py101book\data\test.txt») C:\Users\mike\py101book\data est.txt
>>> print(r»C:\Users\mike\py101book\data\test.txt») C:\Users\mike\py101book\data\test.txt |
Как видно из примера, когда мы не определяем строку как исходную, мы получаем неправильный путь. Почему это происходит? Существуют определенные специальные символы, которые должны быть отображены, такие как “n” или “t”. В нашем случае присутствует “t” (иными словами, вкладка), так что строка послушно добавляет вкладку в наш путь и портит её для нас. Второй аргумент во втором примере это буква “r”. Данное значение указывает на то, что мы хотим открыть файл в режиме «только чтение». Иными словами, происходит то же самое, что и в первом примере, но более явно. Теперь давайте, наконец, прочтем файл!
Иными словами, происходит то же самое, что и в первом примере, но более явно. Теперь давайте, наконец, прочтем файл!
Введите нижеизложенные строки в скрипт, и сохраните его там же, где и файл test.txt.
Python
handle = open(«test.txt», «r») data = handle.read() print(data) handle.close()
handle = open(«test.txt», «r») data = handle.read() print(data) handle.close() |
После запуска, файл откроется и будет прочитан как строка в переменную data. После этого мы печатаем данные и закрываем дескриптор файла. Следует всегда закрывать дескриптор файла, так как неизвестно когда и какая именно программа захочет получить к нему доступ. Закрытие файла также поможет сохранить память и избежать появления странных багов в программе. Вы можете указать Python читать строку только раз, чтобы прочитать все строки в списке Python, или прочесть файл по частям.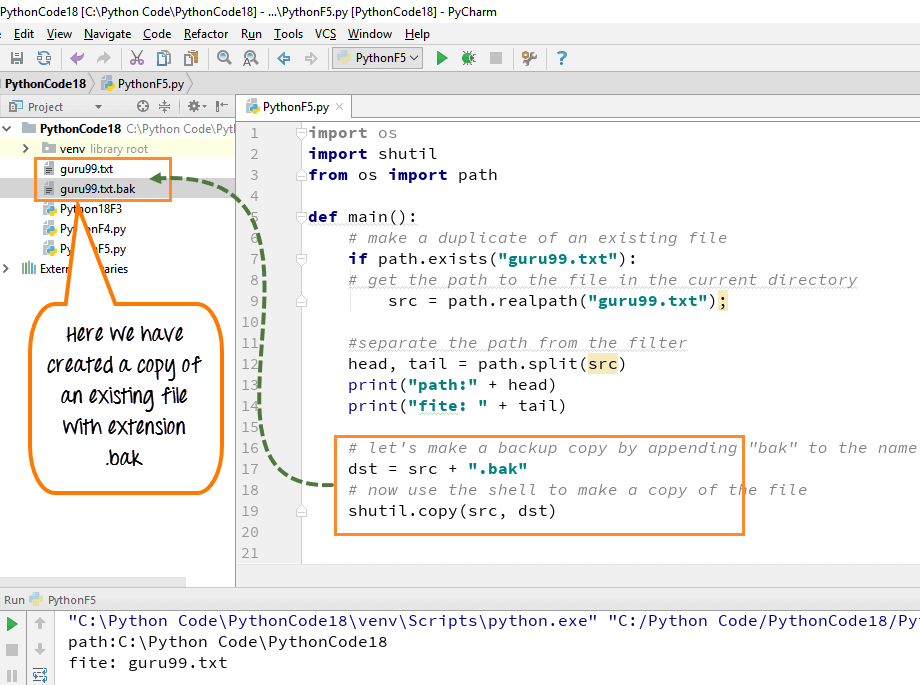 Последняя опция очень полезная, если вы работаете с большими фалами и вам не нужно читать все его содержимое, на что может потребоваться вся память компьютера.
Последняя опция очень полезная, если вы работаете с большими фалами и вам не нужно читать все его содержимое, на что может потребоваться вся память компьютера.
Давайте обратим внимание на различные способы чтения файлов.
Python
handle = open(«test.txt», «r») data = handle.readline() # read just one line print(data) handle.close()
handle = open(«test.txt», «r») data = handle.readline() # read just one line print(data) handle.close() |
Если вы используете данный пример, будет прочтена и распечатана только первая строка текстового файла. Это не очень полезно, так что воспользуемся методом readlines() в дескрипторе:
Python
handle = open(«test.txt», «r») data = handle.readlines() # read ALL the lines! print(data) handle.close()
handle = open(«test. data = handle.readlines() # read ALL the lines! print(data) handle.close() |
 txt», «r»)
txt», «r»)Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Python Форум Помощи
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Подписаться
После запуска данного кода, вы увидите напечатанный на экране список, так как это именно то, что метод readlines() и выполняет. Далее мы научимся читать файлы по мелким частям.
Как читать файл по частям
Самый простой способ для выполнения этой задачи – использовать цикл. Сначала мы научимся читать файл строку за строкой, после этого мы будем читать по килобайту за раз. В нашем первом примере мы применим цикл:
В нашем первом примере мы применим цикл:
Python
handle = open(«test.txt», «r») for line in handle: print(line) handle.close()
1 2 3 4 5 6 | handle = open(«test.txt», «r»)
for line in handle: print(line)
handle.close() |
Таким образом мы открываем файл в дескрипторе в режиме «только чтение», после чего используем цикл для его повторения. Стоит обратить внимание на то, что цикл можно применять к любым объектам Python (строки, списки, запятые, ключи в словаре, и другие). Весьма просто, не так ли? Попробуем прочесть файл по частям:
Python
handle = open(«test.txt», «r») while True: data = handle.read(1024) print(data) if not data: break
1 2 3 4 5 6 7 8 | handle = open(«test.
while True: data = handle.read(1024) print(data)
if not data: break |
 txt», «r»)
txt», «r»)В данном примере мы использовали Python в цикле, пока читали файл по килобайту за раз. Как известно, килобайт содержит в себе 1024 байта или символов. Теперь давайте представим, что мы хотим прочесть двоичный файл, такой как PDF.
Как читать бинарные (двоичные) файлы
Это очень просто. Все что вам нужно, это изменить способ доступа к файлу:
Python
handle = open(«test.pdf», «rb»)
handle = open(«test.pdf», «rb») |
Мы изменили способ доступа к файлу на rb, что значит read-binaryy. Стоит отметить то, что вам может понадобиться читать бинарные файлы, когда вы качаете PDF файлы из интернете, или обмениваетесь ими между компьютерами.
Пишем в файлах в Python
Как вы могли догадаться, следуя логике написанного выше, режимы написания файлов в Python это “w” и “wb” для write-mode и write-binary-mode соответственно. Теперь давайте взглянем на простой пример того, как они применяются.
Теперь давайте взглянем на простой пример того, как они применяются.
ВНИМАНИЕ: использование режимов “w” или “wb” в уже существующем файле изменит его без предупреждения. Вы можете посмотреть, существует ли файл, открыв его при помощи модуля ОС Python.
Python
handle = open(«output.txt», «w») handle.write(«This is a test!») handle.close()
handle = open(«output.txt», «w») handle.write(«This is a test!») handle.close() |
Вот так вот просто. Все, что мы здесь сделали – это изменили режим файла на “w” и указали метод написания в файловом дескрипторе, чтобы написать какой-либо текст в теле файла. Файловый дескриптор также имеет метод writelines (написание строк), который будет принимать список строк, который дескриптор, в свою очередь, будет записывать по порядку на диск.
Выбирайте дешевые лайки на видео в YouTube на сервисе https://doctorsmm.
 com/. Здесь, при заказе, Вам будет предоставлена возможность подобрать не только недорогую цену, но и выгодные персональные условия приобретения. Торопитесь, пока на сайте действуют оптовые скидки!
com/. Здесь, при заказе, Вам будет предоставлена возможность подобрать не только недорогую цену, но и выгодные персональные условия приобретения. Торопитесь, пока на сайте действуют оптовые скидки!Использование оператора «with»
В Python имеется аккуратно встроенный инструмент, применяя который вы можете заметно упростить чтение и редактирование файлов. Оператор with создает диспетчер контекста в Пайтоне, который автоматически закрывает файл для вас, по окончанию работы в нем. Посмотрим, как это работает:
Python
with open(«test.txt») as file_handler: for line in file_handler: print(line)
with open(«test.txt») as file_handler: for line in file_handler: print(line) |
Синтаксис для оператора with, на первый взгляд, кажется слегка необычным, однако это вопрос недолгой практики. Фактически, все, что мы делаем в данном примере, это:
Python
handle = open(«test. txt»)
txt»)
handle = open(«test.txt») |
Меняем на это:
Python
with open(«test.txt») as file_handler:
with open(«test.txt») as file_handler: |
Вы можете выполнять все стандартные операции ввода\вывода, в привычном порядке, пока находитесь в пределах блока кода. После того, как вы покинете блок кода, файловый дескриптор закроет его, и его уже нельзя будет использовать. И да, вы все прочли правильно. Вам не нужно лично закрывать дескриптор файла, так как оператор делает это автоматически. Попробуйте внести изменения в примеры, указанные выше, используя оператор with.
Выявление ошибок
Иногда, в ходе работы, ошибки случаются. Файл может быть закрыт, потому что какой-то другой процесс пользуется им в данный момент или из-за наличия той или иной ошибки разрешения. Когда это происходит, может появиться IOError. В данном разделе мы попробуем выявить эти ошибки обычным способом, и с применением оператора with. Подсказка: данная идея применима к обоим способам.
В данном разделе мы попробуем выявить эти ошибки обычным способом, и с применением оператора with. Подсказка: данная идея применима к обоим способам.
Python
try: file_handler = open(«test.txt») for line in file_handler: print(line) except IOError: print(«An IOError has occurred!») finally: file_handler.close()
1 2 3 4 5 6 7 8 | try: file_handler = open(«test.txt») for line in file_handler: print(line) except IOError: print(«An IOError has occurred!») finally: file_handler.close() |
В описанном выше примере, мы помещаем обычный код в конструкции try/except. Если ошибка возникнет, следует открыть сообщение на экране. Обратите внимание на то, что следует удостовериться в том, что файл закрыт при помощи оператора finally. Теперь мы готовы взглянуть на то, как мы можем сделать то же самое, пользуясь следующим методом:
Теперь мы готовы взглянуть на то, как мы можем сделать то же самое, пользуясь следующим методом:
Python
try: with open(«test.txt») as file_handler: for line in file_handler: print(line) except IOError: print(«An IOError has occurred!»)
1 2 3 4 5 6 | try: with open(«test.txt») as file_handler: for line in file_handler: print(line) except IOError: print(«An IOError has occurred!») |
Как вы можете догадаться, мы только что переместили блок with туда же, где и в предыдущем примере. Разница в том, что оператор finally не требуется, так как контекстный диспетчер выполняет его функцию для нас.
Подведем итоги
С данного момента вы уже должны легко работать с файлами в Python. Теперь вы знаете, как читать и вносить записи в файлы двумя способами. Теперь вы сможете с легкостью ориентироваться в данном вопросе.
Теперь вы сможете с легкостью ориентироваться в данном вопросе.
Vasile Buldumac
Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: [email protected]
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
Изучаем Python: работа с файлами
В этой статье мы рассмотрим операции с файлами в Python.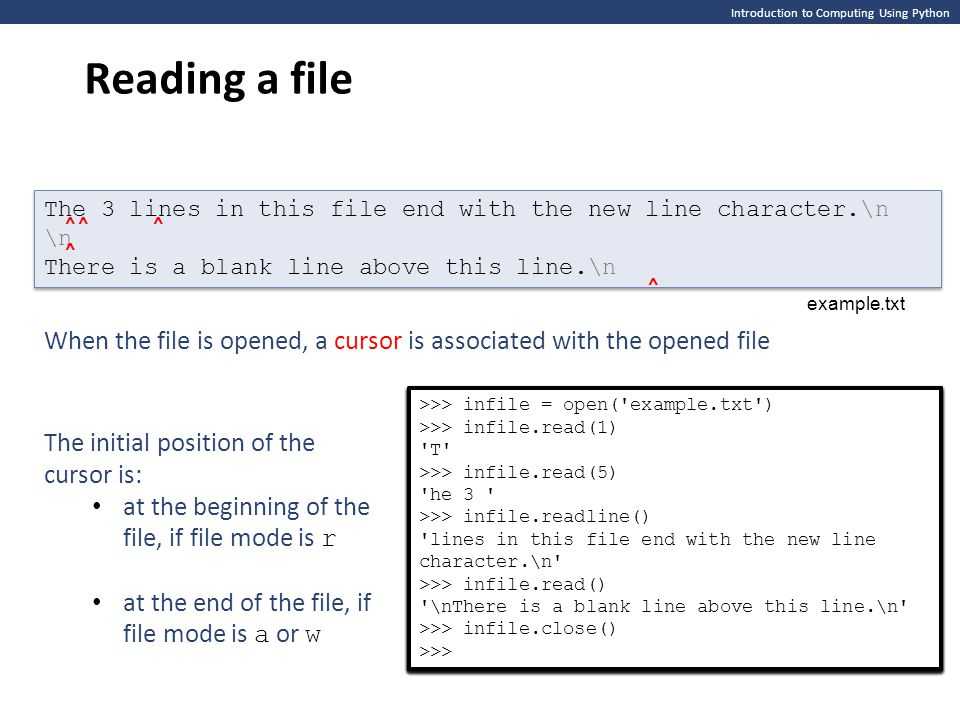 Открытие файла Python. Чтение из файла Python. Запись в файл Python, закрытие файла. А также методы, предназначенные для работы с файлами.
Открытие файла Python. Чтение из файла Python. Запись в файл Python, закрытие файла. А также методы, предназначенные для работы с файлами.
- Работа с файлами питон — что такое файл Python?
- Открытие файла Python
- Как закрыть файл в Python?
- Запись в файл Python
- Чтение из файла Python
- Python работа с файлами — основные методы
Файл – это именованная область диска, предназначенная для длительного хранения данных в постоянной памяти (например, на жёстком диске).
Чтобы прочитать или записать данные в файл, сначала нужно его открыть. После окончания работы файл необходимо закрыть, чтобы освободить связанные с ним ресурсы.
Поэтому в Python операции с файлами выполняются в следующем порядке:
- Открытие файла Python.
- Чтение из файла Python или запись в файл Python (выполнение операции).
- Закрытие файла Python.
Не знаете как открыть файл в питоне? В Python есть встроенная функция open(), предназначенная для открытия файла. Она возвращает объект, который используется для чтения или изменения файла.
Она возвращает объект, который используется для чтения или изменения файла.
>>> f = open("test.txt") # открыть файл в текущей папке
>>> f = open("C:/Python33/README.txt") # указание полного путиПри этом можно указать необходимый режим открытия файла: ‘r’- для чтения,’w’ — для записи,’a’ — для изменения. Мы также можем указать, хотим ли открыть файл в текстовом или в бинарном формате.
По умолчанию файл открывается для чтения в текстовом режиме. При чтении файла в этом режиме мы получаем строки.
В бинарном формате мы получим байты. Этот режим используется для чтения не текстовых файлов, таких как изображения или exe-файлы.
| Открытие файла Python- возможные режимы | |
| Режим | Описание |
| ‘r’ | Открытие файла для чтения. Режим используется по умолчанию. |
| ‘w’ | Открытие файла для записи. Режим создаёт новый файл, если он не существует, или стирает содержимое существующего. |
| ‘x’ | Открытие файла для записи. Если файл существует, операция заканчивается неудачей (исключением). |
| ‘a’ | Открытие файла для добавления данных в конец файла без очистки его содержимого. Этот режим создаёт новый файл, если он не существует. |
| ‘t’ | Открытие файла в текстовом формате. Этот режим используется по умолчанию. |
| ‘b’ | Открытие файла в бинарном формате. |
| ‘+’ | Открытие файла для обновления (чтения и записи). |
f = open("test.txt") # эквивалент 'r' или 'rt'
f = open("test.txt",'w') # запись в текстовом режиме
f = open("img.bmp",'r+b') # чтение и запись в бинарном форматеВ отличие от других языков программирования, в Python символ ‘a’ не подразумевает число 97, если оно не закодировано в ASCII (или другой эквивалентной кодировке).
Кодировка по умолчанию зависит от платформы. В Windows – это ‘cp1252’, а в Linux ‘utf-8’.
Поэтому мы не должны полагаться на кодировку по умолчанию. При работе с файлами в текстовом формате рекомендуется указывать тип кодировки.
f = open("test.txt",mode = 'r',encoding = 'utf-8')Закрытие освободит ресурсы, которые были связаны с файлом. Это делается с помощью метода close(), встроенного в язык программирования Python.
В Python есть сборщик мусора, предназначенный для очистки ненужных объектов, Но нельзя полагаться на него при закрытии файлов.
f = open("test.txt",encoding = 'utf-8')
# выполнение операций с файлом
f.close()Этот метод не полностью безопасен. Если при операции возникает исключение, выполнение будет прервано без закрытия файла.
Более безопасный способ – использование блока try…finally.
try:
f = open("test.txt",encoding = 'utf-8')
# выполнение операций с файлом
finally:
f.close()Это гарантирует правильное закрытие файла даже после возникновения исключения, прерывающего выполнения программы.
Также для закрытия файла можно использовать конструкцию with. Оно гарантирует, что файл будет закрыт при выходе из блока with. При этом не нужно явно вызывать метод close(). Это будет сделано автоматически.
with open("test.txt",encoding = 'utf-8') as f:
# выполнение операций с файломЧтобы записать данные в файл в Python, нужно открыть его в режиме ‘w’, ‘a’ или ‘x’. Но будьте осторожны с режимом ‘w’. Он перезаписывает файл, если то уже существует. Все данные в этом случае стираются.
Запись строки или последовательности байтов (для бинарных файлов) осуществляется методом write(). Он возвращает количество символов, записанных в файл.
with open("test.txt",'w',encoding = 'utf-8') as f:
f.write("my first filen")
f.write("This filenn")
f.write("contains three linesn")Эта программа создаст новый файл ‘test.txt’. Если он существует, данные файла будут перезаписаны. При этом нужно добавлять символы новой строки самостоятельно, чтобы разделять строки.
Чтобы осуществить чтение из файла Python, нужно открыть его в режиме чтения. Для этого можно использовать метод read(size), чтобы прочитать из файла данные в количестве, указанном в параметре size. Если параметр size не указан, метод читает и возвращает данные до конца файла.
>>> f = open("test.txt",'r',encoding = 'utf-8')
>>> f.read(4) # чтение первых 4 символов
'This'
>>> f.read(4) # чтение следующих 4 символов
' is '
>>> f.read() # чтение остальных данных до конца файла
'my first filenThis filencontains three linesn'
>>> f.read() # дальнейшие попытки чтения возвращают пустую строку
''
Метод read() возвращает новые строки как ‘n’. Когда будет достигнут конец файла, при дальнейших попытках чтения мы получим пустые строки.
Чтобы изменить позицию курсора в текущем файле, используется метод seek(). Метод tell() возвращает текущую позицию курсора (в виде количества байтов).
>>> f.tell() # получаем текущую позицию курсора в файле 56 >>> f.
 seek(0) # возвращаем курсор в начальную позицию
0
>>> print(f.read()) # читаем весь файл
This is my first file
This file
contains three lines
seek(0) # возвращаем курсор в начальную позицию
0
>>> print(f.read()) # читаем весь файл
This is my first file
This file
contains three linesМы можем прочитать файл построчно в цикле for.
>>> for line in f: ... print(line, end = '') ... This is my first file This file contains three lines
Извлекаемые из файла строки включают в себя символ новой строки ‘n’. Чтобы избежать вывода, используем пустой параметр end метода print(),.
Также можно использовать метод readline(), чтобы извлекать отдельные строки. Он читает файл до символа новой строки.
>>> f.readline() 'This is my first filen' >>> f.readline() 'This filen' >>> f.readline() 'contains three linesn' >>> f.readline() ''
Метод readlines() возвращает список оставшихся строк. Все эти методы чтения возвращают пустую строку, когда достигается конец файла.
>>> f.readlines() ['This is my first filen', 'This filen', 'contains three linesn']
Ниже приводится полный список методов для работы с файлами в текстовом режиме.
| Python работа с файлами — методы | |
| Метод | Описание |
| close() | Закрытие файла. Не делает ничего, если файл закрыт. |
| detach() | Отделяет бинарный буфер от TextIOBase и возвращает его. |
| fileno() | Возвращает целочисленный дескриптор файла. |
| flush() | Вызывает сброс данных (запись на диск) из буфера записи файлового потока. |
| isatty() | Возвращает значение True, если файловый поток интерактивный. |
| read(n) | Читает максимум n символов из файла. Читает до конца файла, если значение отрицательное или None. |
| readable() | Возвращает значение True, если из файлового потока можно осуществить чтение. |
| readline(n=-1) | Читает и возвращает одну строку из файла. Читает максимум n байт, если указано соответствующее значение. |
| readlines(n=-1) | Читает и возвращает список строк из файла. Читает максимум n байт/символов, если указано соответствующее значение. Читает максимум n байт/символов, если указано соответствующее значение. |
| seek(offset,from=SEEK_SET) | Изменяет позицию курсора. |
| seekable() | Возвращает значение True, если файловый поток поддерживает случайный доступ. |
| tell() | Возвращает текущую позицию курсора в файле. |
| truncate(size=None) | Изменяет размер файлового потока до size байт. Если значение size не указано, размер изменяется до текущего положения курсора. |
| writable() | Возвращает значение True, если в файловый поток может производиться запись. |
| write(s) | Записывает строки s в файл и возвращает количество записанных символов. |
| writelines(lines) | Записывает список строк lines в файл. |
Пожалуйста, опубликуйте свои мнения по текущей теме материала. За комментарии, лайки, отклики, дизлайки, подписки огромное вам спасибо!
Сергей Бензенкоавтор-переводчик статьи «Python File IO Read and Write Files in Python»
Глава 8.
 Работа с файлами — Документация по Python 101 1.0
Работа с файлами — Документация по Python 101 1.0В этой главе рассказывается о чтении и записи данных в файлы на жестком диске. Вы обнаружите, что чтение и запись файлов в Python очень просты. Давайте начнем!
Как читать файл
Python имеет встроенную функцию open , которую мы можем использовать, чтобы открыть файл для чтения. Создайте текстовый файл с именем «test.txt» со следующим содержимым:
Это тестовый файл. строка 2 строка 3 эта строка намеренно оставлена пустой
Вот несколько примеров, которые показывают, как использовать open для чтения:
handle = open("test.txt")
handle = open(r"C:\Users\mike\py101book\data\test.txt", "r")
Первый пример открывает файл с именем test.txt в режиме только для чтения. Это режим по умолчанию функции open . Обратите внимание, что мы не передали полный путь к файлу, который хотели открыть в первом примере.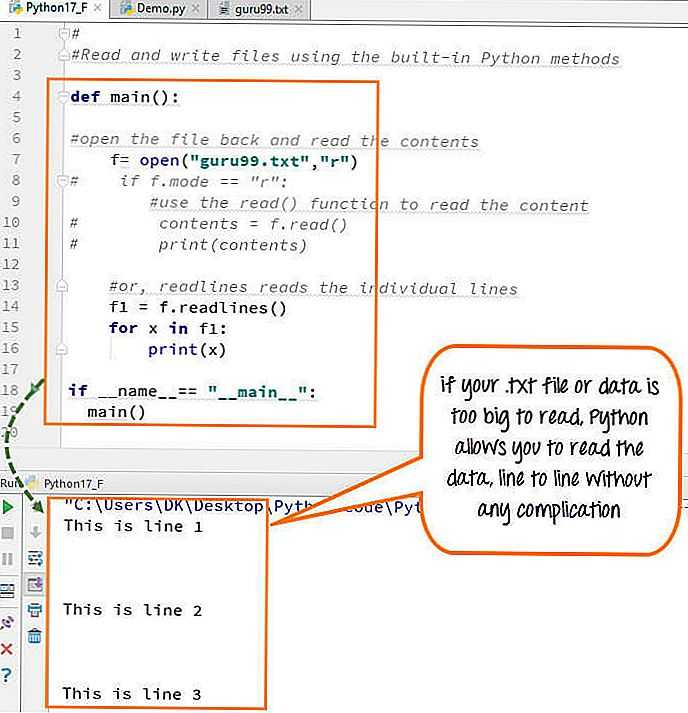 Python будет автоматически искать в папке, в которой запущен скрипт, test.txt . Если он не найдет его, вы получите IOError.
Python будет автоматически искать в папке, в которой запущен скрипт, test.txt . Если он не найдет его, вы получите IOError.
Во втором примере показан полный путь к файлу, но вы заметите, что он начинается с «r». Это означает, что мы хотим, чтобы Python обрабатывал строку как необработанную строку. Давайте рассмотрим разницу между указанием исходной строки и обычной строки:
>>> print("C:\Users\mike\py101book\data\test.txt")
C:\Пользователи\Майк\py101book\данные est.txt
>>> print(r"C:\Users\mike\py101book\data\test.txt")
C:\Пользователи\Майк\py101book\data\test.txt
Как видите, когда мы не указываем его как необработанную строку, мы получаем недопустимый путь. Почему это происходит? Ну, как вы, возможно, помните из главы о строках, существуют определенные специальные символы, которые необходимо экранировать, например «n» или «t». В этом случае мы видим, что есть «t» (то есть табуляция), поэтому строка послушно добавляет табуляцию к нашему пути и портит его для нас.
Второй аргумент во втором примере также является «r». Это сообщает open , что мы хотим открыть файл в режиме только для чтения. Другими словами, он делает то же самое, что и первый пример, но более явно. Теперь давайте на самом деле прочитаем файл!
Поместите следующие строки в сценарий Python и сохраните его в том же месте, что и файл test.txt:
handle = open("test.txt", "r")
данные = дескриптор.чтение()
печать (данные)
ручка.закрыть()
Если вы запустите это, он откроет файл и прочитает весь файл как строку в переменную данных . Затем мы печатаем эти данные и закрываем дескриптор файла. Вы всегда должны закрывать дескриптор файла, поскольку вы никогда не знаете, когда другая программа захочет получить к нему доступ. Закрытие файла также поможет сэкономить память и предотвратить странные ошибки в ваших программах. Вы можете указать Python просто читать строку за раз, читать все строки в список Python или читать файл по частям. Последний вариант очень удобен, когда вы имеете дело с действительно большими файлами и не хотите читать их целиком, что может привести к переполнению памяти ПК.
Последний вариант очень удобен, когда вы имеете дело с действительно большими файлами и не хотите читать их целиком, что может привести к переполнению памяти ПК.
Давайте рассмотрим различные способы чтения файлов.
дескриптор = открыть ("test.txt", "r")
data = handle.readline() # прочитать только одну строку
печать (данные)
ручка.закрыть()
Если вы запустите этот пример, он прочитает только первую строку вашего текстового файла и распечатает ее. Это не слишком полезно, поэтому давайте попробуем метод readlines() дескриптора файла:
handle = open("test.txt", "r")
data = handle.readlines() # прочитать ВСЕ строки!
печать (данные)
ручка.закрыть()
После запуска этого кода вы увидите список Python, напечатанный на экране, потому что это то, что возвращает метод readlines : список! Давайте на минутку научимся читать файл небольшими порциями.
Как читать файлы по частям
Самый простой способ прочитать файл по частям — использовать цикл. Сначала мы научимся читать файл построчно, а затем научимся читать его по килобайтам за раз. Мы будем использовать цикл для для нашего первого примера:
Сначала мы научимся читать файл построчно, а затем научимся читать его по килобайтам за раз. Мы будем использовать цикл для для нашего первого примера:
дескриптор = открыть ("test.txt", "r")
для строки в ручке:
печать (строка)
ручка.закрыть()
Здесь мы открываем дескриптор файла только для чтения, а затем используем цикл for для его итерации. Вы обнаружите, что можете перебирать все виды объектов в Python (строки, списки, кортежи, ключи в словаре и т. д.). Это было довольно просто, верно? Теперь давайте делать это по частям!
дескриптор = открыть ("test.txt", "r")
пока верно:
данные = дескриптор.чтение(1024)
печать (данные)
если не данные:
ломать
В этом примере мы используем цикл Python while для чтения по килобайту файла за раз. Как вы, наверное, знаете, килобайт — это 1024 байта или символа. Теперь давайте представим, что мы хотим прочитать двоичный файл, например PDF.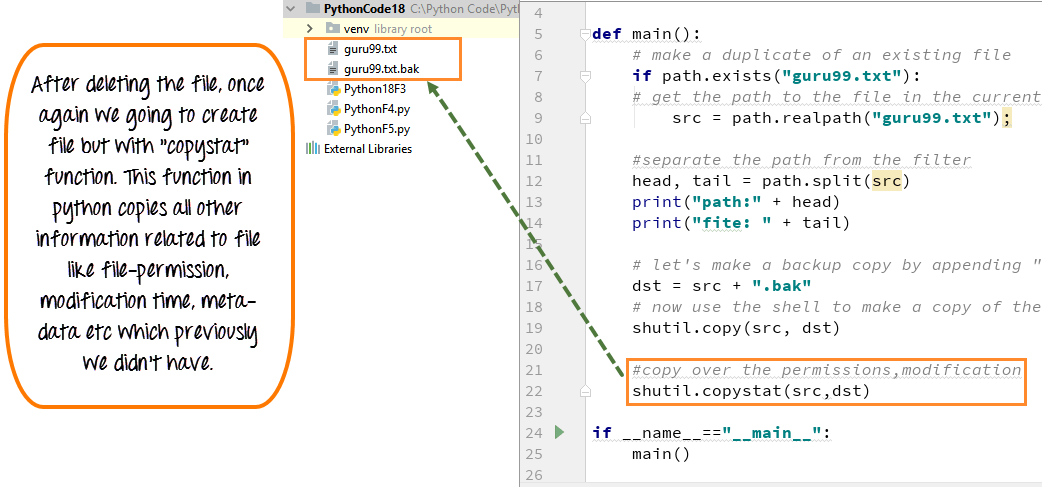
Как читать двоичный файл
Читать двоичный файл очень просто. Все, что вам нужно сделать, это изменить режим файла:
handle = open("test.pdf", "rb")
Итак, на этот раз мы изменили режим файла на rb , что означает чтение-бинарное . Вы обнаружите, что вам может понадобиться читать двоичные файлы, когда вы загружаете PDF-файлы из Интернета или переносите файлы с ПК на ПК.
Запись файлов в Python
Если вы следили за этим, вы, вероятно, догадались, какой флаг режима файла используется для записи файлов: «w» и «wb» для режима записи и режима записи в двоичном формате. Давайте рассмотрим простой пример, хорошо?
ВНИМАНИЕ : При использовании режимов «w» или «wb», если файл уже существует, он будет перезаписан без предупреждения! Вы можете проверить, существует ли файл, прежде чем открывать его, используя Python 9.Модуль 0007 ОС . См. раздел os.path.exists в , глава 16 .
дескриптор = открыть ("test.txt", "w")
handle.write("Это тест!")
ручка.закрыть()
Это было просто! Все, что мы здесь сделали, это изменили режим файла на «w» и вызвали метод дескриптора файла write , чтобы записать некоторый текст в файл. Дескриптор файла также имеет метод writelines , который принимает список строк, которые дескриптор затем записывает на диск по порядку.
Использование with Operator
В Python есть небольшая встроенная функция with , которую можно использовать для упрощения чтения и записи файлов. Оператор с создает в Python то, что известно как менеджер контекста , который автоматически закроет файл, когда вы закончите его обработку. Давайте посмотрим, как это работает:
с open("test.txt") в качестве file_handler:
для строки в file_handler:
печать (строка)
Синтаксис для с оператором немного странный, но вы довольно быстро разберетесь. По сути, мы заменяем:
По сути, мы заменяем:
handle = open("test.txt")
с этим:
с open("test.txt") как file_handler:
Вы можете выполнять все обычные операции файлового ввода-вывода, которые обычно выполняете, пока находитесь в кодовом блоке с . Как только вы покинете этот блок кода, дескриптор файла закроется, и вы больше не сможете его использовать. Да, вы прочитали это правильно. Вам больше не нужно явно закрывать дескриптор файла, поскольку с оператором делает это автоматически! Посмотрите, сможете ли вы изменить некоторые из предыдущих примеров из этой главы, чтобы они также использовали метод с .
Обнаружение ошибок
Иногда при работе с файлами случаются неприятные вещи. Файл заблокирован, потому что его использует какой-то другой процесс или у вас есть какая-то ошибка разрешения. Когда это произойдет, вероятно, произойдет ошибка IOError . В этом разделе мы рассмотрим, как отлавливать ошибки обычным способом и как их отлавливать с помощью с оператором . Подсказка: идея в основном одинакова в обоих!
Подсказка: идея в основном одинакова в обоих!
попробуйте:
file_handler = открыть ("test.txt")
для строки в file_handler:
печать (строка)
кроме IOError:
print("Произошла ошибка ввода-вывода!")
в конце концов:
file_handler.close()
В приведенном выше примере мы заключаем обычный код в конструкцию try/except . При возникновении ошибки мы выводим сообщение на экран. Обратите внимание, что мы также закрываем файл, используя finally 9Заявление 0008. Теперь мы готовы посмотреть, как бы мы сделали то же самое, используя с :
попробуйте:
с open("test.txt") как file_handler:
для строки в file_handler:
печать (строка)
кроме IOError:
print("Произошла ошибка ввода-вывода!")
Как вы могли догадаться, мы просто завернули блок в блок так же, как и в предыдущем примере. Разница здесь в том, что нам не нужен оператор finally , так как менеджер контекста обрабатывает его за нас.
Подведение итогов
К этому моменту вы должны уже хорошо разбираться в работе с файлами в Python. Теперь вы знаете, как читать и записывать файлы, используя старый стиль и новый стиль со стилем . Вы, скорее всего, увидите оба стиля в дикой природе. В следующей главе мы узнаем, как импортировать другие модули, поставляемые с Python. Это позволит нам создавать программы, используя готовые модули. Давайте начнем!
Работа с файлами Python: полное руководство
Python — это популярный язык программирования с интерпретацией и динамической типизацией для создания веб-сервисов, настольных приложений, сценариев автоматизации и проектов машинного обучения. Программистам часто приходится обращаться к файловой системе операционной системы, когда они работают с программными проектами на основе Python.
Например, мы используем текстовые файлы в качестве входных данных, записываем текстовые файлы в качестве выходных данных и часто обрабатываем двоичные файлы. Как и любой другой популярный язык программирования общего назначения, Python также предлагает функции кросс-платформенной обработки файлов. Python предоставляет функции обработки файлов с помощью нескольких встроенных функций и стандартных модулей.
Как и любой другой популярный язык программирования общего назначения, Python также предлагает функции кросс-платформенной обработки файлов. Python предоставляет функции обработки файлов с помощью нескольких встроенных функций и стандартных модулей.
В этой статье я объясню все, что вам нужно знать об обработке файлов Python, в том числе:
- Чтение файлов
- Запись файлов
- Чтение атрибутов файла
- Создание новых каталогов Python
- Чтение содержимого каталога Python
- Удаление файлов или каталогов
- Выполнение поиска файлов
- Обработка двоичных файлов
- Создание и извлечение данных из архивов Python
- Копирование и перемещение файлов
- Передовой опыт
Предпосылки
Прежде чем приступить к работе с руководством, убедитесь, что у вас установлен интерпретатор Python 3. В противном случае установите последний интерпретатор Python из официальных выпусков. Вы также можете использовать фрагменты кода из этого руководства в своих существующих проектах Python.
Вы также можете использовать фрагменты кода из этого руководства в своих существующих проектах Python.
Чтение файлов в Python
В качестве первого действия давайте напишем код для чтения текстового файла. Сначала нам нужно создать файловый объект для чтения файлов.
Python предлагает встроенную функцию open для создания файлового объекта с несколькими режимами, такими как режим чтения, режим записи и т. д. Создайте текстовый файл с именем myFile.txt и введите следующее содержимое.
языков программирования С С++ Питон JavaScript Идти
Теперь создайте новый файл с именем main.py и добавьте следующий фрагмент кода.
myFile = open("myFile.txt", "r") # или open("myFile.txt")
печать (мой файл. чтение ())
мой файл.close()
Первая строка приведенного выше фрагмента кода создает файловый объект myFile с заданным именем файла. Встроенная функция open создает обработчик файлов, используя режим чтения, потому что мы предоставили флаг r через второй параметр.
Обязательно вызовите метод close , чтобы освободить ресурсы после использования файла. 9Метод 0211 read возвращает содержимое файла, поэтому вы увидите содержимое после выполнения приведенного выше кода, как показано ниже.
Метод read считывает сразу весь файл. Если вы не хотите читать все сразу, вы можете указать размер в байтах с помощью параметра метода read . Например, следующий фрагмент кода считывает только первые 11 байтов.
мой файл = открыть ("мой файл.txt", "r")
print(myFile.read(11)) # Программирование
мой файл.close()
Вы увидите первое слово («Программирование») в качестве вывода — потому что первое слово состоит из 11 букв, а размер буквы равен одному байту в кодировке ASCII. Если вы снова напечатаете результат read(11) , вы увидите следующие 11 байтов («языки\n»), поскольку файловый курсор переместился на 11 позиций при предыдущем вызове метода read(11) . Вы можете сбросить файловый курсор обратно в начало, используя метод
Вы можете сбросить файловый курсор обратно в начало, используя метод seek , как показано в следующем примере.
мой файл = открыть ("мой файл.txt")
print(myFile.read(11)) # Программирование
print(myFile.read(10)) # языков
myFile.seek(0) # Устанавливает курсор файла в начало
print(myFile.read(11)) # Программирование
мой файл.close()
В большинстве сценариев легко обрабатывать содержимое файла построчно. Вам не нужно самостоятельно реализовывать построчный механизм чтения файлов — Python предоставляет встроенные функции для чтения файла построчно. Вы можете прочитать файл построчно с помощью цикла for-in и читает метод , как показано ниже.
мой файл = открыть ("мой файл.txt", "r")
для строки в myFile.readlines():
печать (строка)
мой файл.close()
Можно получить текущий номер строки с помощью цикла for-enumerate , поскольку метод readlines будет возвращать строки, используя тип списка. Следующий фрагмент кода напечатает содержимое строки с соответствующим номером строки.
Следующий фрагмент кода напечатает содержимое строки с соответствующим номером строки.
мой файл = открыть ("мой файл.txt", "r")
для i строка в enumerate(myFile.readlines()):
print(i, line) # номер строки и содержимое
мой файл.close()
Запись файлов на Python
Ранее мы создавали файловые объекты с режимом чтения, используя флаг r . Запись файлов невозможна в режиме чтения, поэтому мы должны использовать режим записи ( w ) для записи файлов.
Более 200 000 разработчиков используют LogRocket для улучшения цифрового взаимодействия
Подробнее →
Также можно одновременно включить режимы чтения и записи с помощью r+ или w+ флаг; мы будем использовать флаг w+ в следующих примерах.
Чтобы начать запись файла, давайте введем следующий текст в текущий файл myFile.txt , написав некоторый код Python.
языков программирования Ржавчина Рубин Машинопись Дартс Сборка
Используйте следующий сценарий, чтобы обновить myFile.txt указанным выше содержимым.
мой файл = открыть ("мой файл.txt", "w")
content = """Языки программирования
Ржавчина
Рубин
Машинопись
Дартс
Сборка"""
myFile.write(содержимое)
мой файл.close()
Здесь мы определили содержимое текстового файла, используя синтаксис многострочных строк Python, и мы записали содержимое в файл, используя метод write . Обязательно используйте режим записи с флагом w — иначе операция записи завершится с ошибкой io.UnsupportedOperation .
Иногда нам часто приходится добавлять новое содержимое к существующему файлу. В этих сценариях чтение и запись всего содержимого не является хорошим подходом из-за более высокого потребления ресурсов. Вместо этого мы можем использовать режим добавления ( и ).
Посмотрите на следующий код. Он добавит новый язык программирования в список в
Он добавит новый язык программирования в список в myFile.txt .
мой файл = открыть ("мой файл.txt", "а")
myFile.write("\nБаш")
мой файл.close()
Приведенный выше фрагмент кода добавляет новый символ строки ( \n ) и новое слово в существующий файл без записи всего содержимого файла. В результате мы увидим новую запись в нашем списке языков программирования. Попробуйте добавить больше записей и посмотрите, что получится!
Чтение атрибутов файла в Python
Помимо исходного содержимого файла, файл на диске будет содержать некоторые метаданные или атрибуты файла, в том числе такие параметры, как размер, время последнего изменения, время последнего доступа и т. д.
Посмотрите на приведенный ниже код файла, в котором отображается размер файла, время последнего доступа и время последнего изменения.
импорт ОС, время
stat = os.stat("myFile.txt")
print("Размер: %s байт" % stat.st_size)
print("Последний доступ: %s" % time. ctime(stat.st_atime))
print("Последнее изменение: %s" % time.ctime(stat.st_mtime))
 ctime(stat.st_atime))
print("Последнее изменение: %s" % time.ctime(stat.st_mtime))
ctime(stat.st_atime))
print("Последнее изменение: %s" % time.ctime(stat.st_mtime))
Функция os.stat возвращает объект результатов статистики с множеством сведений об атрибутах файла. Здесь мы использовали st_size для получения размера файла, at_atime для получения метки времени последнего обращения к файлу и st_mtime для получения метки времени последнего изменения. Объект результатов статистики может отличаться в зависимости от вашей операционной системы. Например, в операционной системе Windows вы можете получить специфичные для Windows атрибуты файла с помощью st_file_attributes 9.ключ 0212.
Если вам нужно получить только размер файла, вы можете использовать метод os.path.getsize без получения всех метаданных, как показано в следующем коде.
импорт ОС, время
размер = os.path.getsize("myFile.txt")
print("Размер: %s байт" % размер)
Создание новых каталогов Python
Python предлагает функцию os. для создания единого каталога. Следующий фрагмент кода создает 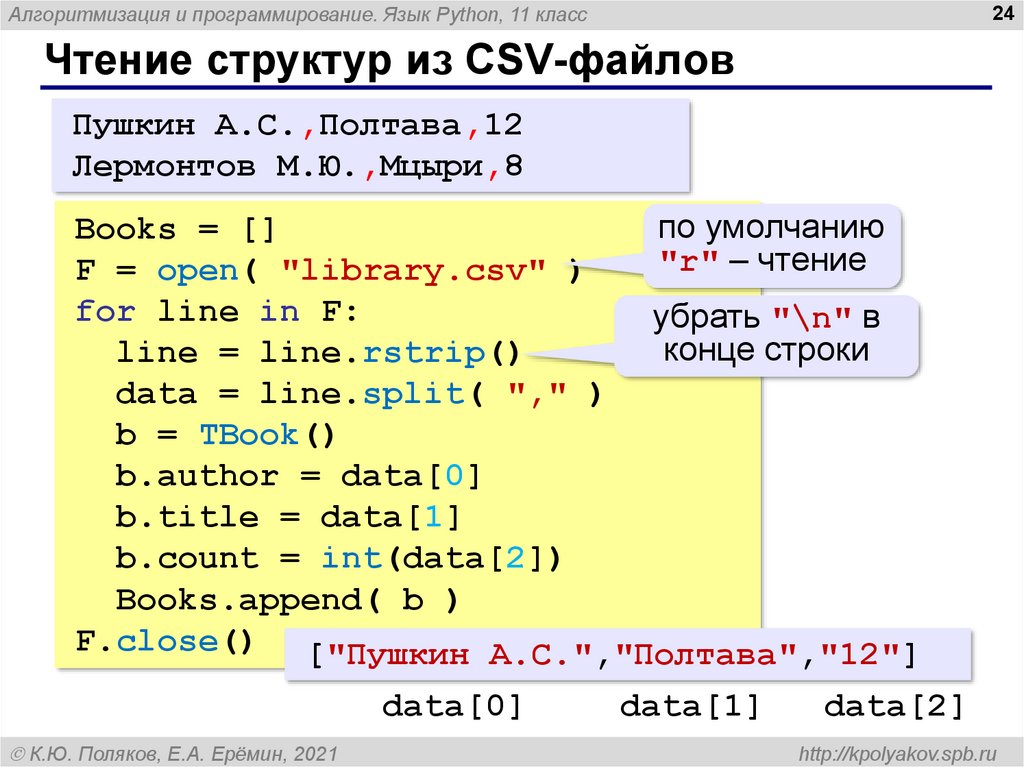 mkdir
mkdir myFolder в текущем рабочем каталоге.
импорт ОС
os.mkdir ("моя папка")
Если вы попытаетесь рекурсивно создать несколько каталогов с помощью приведенного выше кода, произойдет сбой. Например, вы не можете сразу создать myFolder/abc , потому что это требует создания нескольких каталогов. В таких случаях нам поможет функция os.makedirs , как показано ниже.
импорт ОС
os.makedirs("myFolder/abc") # Создает и "myFolder", и "abc"
Чтение содержимого каталога Python
Python также предоставляет простой API для вывода списка содержимого каталога с помощью функции os.listdir . В следующем фрагменте кода перечислены все файлы и каталоги в вашем текущем рабочем каталоге.
импорт ОС
cur_dir = os.getcwd()
записи = os.listdir (cur_dir)
print("Найдено %s записей в %s" % (len(entries), cur_dir))
печать('-' * 10)
для записи в записи:
печать (ввод)
После того, как вы выполните приведенный выше скрипт, он покажет записи вашего текущего каталога, как показано ниже.
Попробуйте запустить сценарий из другого каталога. Затем он отобразит записи этого конкретного каталога, потому что мы используем функцию os.getcwd для получения текущего рабочего каталога.
Иногда нам нужно рекурсивно отображать содержимое каталога. Функция os.walk помогает нам с рекурсивным листингом каталогов. Следующий код рекурсивно выводит список всех записей текущего рабочего каталога.
импорт ОС
cur_dir = os.getcwd()
для root, sub_dirs, файлов в os.walk(cur_dir):
rel_root = os.path.relpath(корень)
print("Показ записей %s" % rel_root)
печать("-" * 10)
для записи в sub_dirs + файлы:
печать (ввод)
Функция os.walk имеет внутреннюю рекурсивную реализацию. Он возвращает три значения для каждой записи:
- Корень
- Подкаталоги
- Файловые записи
Здесь мы использовали переменные root , sub_dirs и files соответственно с циклом for для захвата всех записей.
Удаление файлов или каталогов в Python
Мы можем использовать функцию os.remove для удаления файла. Можно использовать os.path.exists функция перед os.remove для предотвращения исключений. Посмотрите на следующий пример фрагмента кода.
импорт ОС
file_to_remove = "мой файл.txt"
если os.path.exists(file_to_remove):
os.remove (файл_для_удаления)
еще:
print("%s не существует!" % file_to_remove)
Стандартная библиотека Python также предлагает функцию os.rmdir для удаления одного каталога. Он ведет себя аналогично os.mkdir и не удаляет каталог, если в нем есть записи. Сначала попробуйте удалить один каталог с помощью следующего кода.
импорт ОС
dir_to_remove = "моя папка"
если os.path.exists(dir_to_remove):
os.rmdir(dir_to_remove)
еще:
print("%s не существует!" % dir_to_remove)
Приведенный выше код вызовет ошибку, если myFolder содержит вложенные папки или файлы. Используйте следующий фрагмент кода для рекурсивного удаления каталога.
Используйте следующий фрагмент кода для рекурсивного удаления каталога.
импорт ос, шутил
dir_to_remove = "моя папка"
если os.path.exists(dir_to_remove):
Shutil.rmtree(dir_to_remove) # Рекурсивно удалить все записи
еще:
print("%s не существует!" % dir_to_remove)
Выполнение поиска файлов в Python
Когда мы работаем со скриптами автоматизации, иногда нам нужно выполнить поиск файлов на диске. Например, программистам часто нужно найти файлы журналов, файлы изображений и различные текстовые файлы с помощью своих сценариев Python. Существует несколько разных подходов к поиску файлов в Python:
- Поиск всех записей с помощью функции
os.listdirи проверка каждой записи с условиемifвнутридляпетля - Рекурсивный поиск всех записей с помощью функции
os.walktreeи проверка каждой записи с помощью условияifвнутри циклаfor. - Запрос всех записей с помощью функции
glob.и получение только необходимых записей glob
 glob
glob В целом, третий подход лучше всего подходит для большинства сценариев, поскольку он имеет встроенную поддержку фильтрации, очень хорошую производительность и требует минимального кода со стороны разработчика (больше Pythonic). Давайте реализуем поиск файлов с помощью модуля Python glob.
импортировать глобус, ОС
запрос = "**/*.py"
записи = glob.glob (запрос, рекурсивный = Истина)
no_of_entries = len(записи)
если no_of_entries == 0:
print("Нет результатов по запросу: %s" % запрос)
еще:
print("Найдено %s результатов для запроса: %s" % (no_of_entries, запрос))
печать("-" * 10)
для записи в записи:
печать (ввод)
Приведенный выше код рекурсивно отображает все исходные файлы Python в текущем каталоге. Первые две звездочки ( ** ) в переменной запроса указывают Python на поиск во всех подкаталогах, а последняя звездочка относится к любому имени файла.
Запустите приведенный выше сценарий. Вы увидите исходные файлы Python, как показано ниже.
Вы увидите исходные файлы Python, как показано ниже.
Попробуйте выполнить поиск файлов разных типов, изменив переменную запроса .
Обработка бинарных файлов в Python
Ранее мы обрабатывали текстовые файлы. Встроенная функция open создает файловые объекты в текстовом режиме ( t ) по умолчанию. Нетекстовые файлы, такие как файлы изображений, zip-файлы и видеофайлы, нельзя просматривать как обычные текстовые файлы поскольку отсутствуют читаемые двоичные файлы предложений на английском языке. Следовательно, мы должны рассматривать двоичные файлы как нетекстовые файлы посредством обработки на уровне байтов (или на уровне битов).
Чтобы начать работу с двоичными файлами, давайте напишем двоичный файл с несколькими байтами. Мы собираемся сохранить следующие байты в myFile.bin .
01010000 01111001 01110100 01101000 01101111 01101110
Для простоты мы можем представить вышеуказанные байты следующими десятичными значениями соответственно.
80 121 116 104 111 110
Теперь добавьте следующий код в исходный файл Python и выполните его, чтобы создать двоичный файл.
myBinaryFile = open("myFile.bin", "wb") # wb -> записать двоичный файл
байты = массив байтов ([80, 121, 116, 104, 111, 110])
myBinaryFile.write(байты)
мой бинарный файл.close()
Здесь мы передали экземпляр байтового массива в метод записи файлового объекта. Также обратите внимание, что мы использовали двоичный режим ( b ) для создания файлового объекта. После выполнения приведенного выше фрагмента кода откройте только что созданный myFile.bin в своем любимом текстовом редакторе. Вы увидите следующий результат.
Мы получили «Python» в качестве вывода, потому что байты массива байтов представляют известные символы ASCII. Например, 80 ( 01010000 ) представляет букву P в кодировке ASCII. Несмотря на то, что мы сохранили читаемый текст внутри бинарного файла, почти все бинарные файлы содержат нечитаемые потоки байтов. Попробуйте открыть файл изображения через текстовый редактор.
Попробуйте открыть файл изображения через текстовый редактор.
Теперь мы можем увидеть операцию чтения двоичного файла в следующем примере кода.
myBinaryFile = открыть ("myFile.bin", "rb")
байты = myBinaryFile.read()
print(bytes) # bytearray(b'Python')
print("Bytes: ", list(bytes)) # Bytes: [80, 121, 116, 104, 111, 110]
мой бинарный файл.close()
Python возвращает байты с помощью метода чтения для двоичного режима. Здесь мы преобразовали байты в экземпляр bytearray , используя конструктор bytearray .
Программисты часто используют архивные файлы с веб-приложениями, веб-службами, настольными приложениями и служебными программами на основе Python для одновременного вывода или ввода нескольких файлов. Например, если вы создаете веб-файловый менеджер, вы можете предложить пользователям возможность одновременной загрузки нескольких файлов с помощью программно созданного zip-файла.
Стандартная библиотека Python предлагает API-интерфейсы для обработки архивных файлов через модуль Shutil . Для начала создадим архив с содержимым
Для начала создадим архив с содержимым myFolder . Посмотрите на следующий код. Обязательно создайте myFolder и добавьте в него несколько файлов перед запуском фрагмента кода.
импортный шутил output_file = "мой архив" input_dir = "моя папка" Shutil.make_archive(выходной_файл, "zip", входной_каталог)
Вы можете извлечь архивный файл в myNewFolder со следующим кодом.
импортный шутил input_file = "мойАрхив.zip" output_dir = "МояНоваяПапка" Shutil.unpack_archive (входной_файл, выходной_каталог)
Копирование и перемещение файлов
Модуль Shutil также предлагает кросс-платформенные функции API для копирования и перемещения файлов. Посмотрите на следующие примеры.
импортный шутил
# скопировать main.py -> main_copy.py
Shutil.copy("main.py", "main_copy.py")
# переместить (переименовать) main_copy.py -> main_backup.py
Shutil.move("main_copy.py", "main_backup.py")
# рекурсивная копия myFolder -> myFolder_copy
Shutil. copytree ("моя папка", "myFolder_copy")
# переместить (переименовать) myFolder_copy -> myFolder_backup
# если myFolder_backup существует, исходник перемещается внутрь папки
Shutil.move("myFolder_copy", "myFolder_backup")
распечатать("Готово")
 copytree ("моя папка", "myFolder_copy")
# переместить (переименовать) myFolder_copy -> myFolder_backup
# если myFolder_backup существует, исходник перемещается внутрь папки
Shutil.move("myFolder_copy", "myFolder_backup")
распечатать("Готово")
copytree ("моя папка", "myFolder_copy")
# переместить (переименовать) myFolder_copy -> myFolder_backup
# если myFolder_backup существует, исходник перемещается внутрь папки
Shutil.move("myFolder_copy", "myFolder_backup")
распечатать("Готово")
Лучшие методы обработки файлов Python
Программисты следуют различным практикам кодирования. Точно так же программисты Python также следуют различным методам кодирования при работе с файлами.
Например, некоторые программисты используют обработчики блокировки и закрытия файлов try-finally вручную. Некоторые программисты позволяют сборщику мусора закрыть обработчик файла, опуская вызов метода close , что не является хорошей практикой. Между тем, другие программисты используют синтаксис с для работы с обработчиками файлов.
В этом разделе я подытожу некоторые рекомендации по работе с файлами в Python. Во-первых, взгляните на следующий код, который следует рекомендациям по обработке файлов.
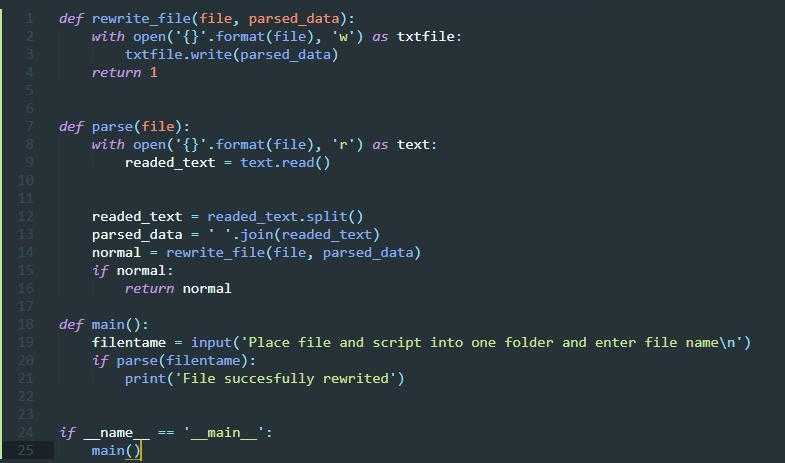
по определению print_file_content (имя файла):
с открытым (имя файла) как myFile:
содержимое = мой файл.read()
распечатать (содержание)
file_to_read = "мой файл.txt"
пытаться:
print_file_content (файл_для_чтения)
кроме:
print("Невозможно открыть файл %s " % file_to_read)
еще:
print("Успешно распечатать содержимое %s" % file_to_read)
Здесь мы использовали ключевое слово с , чтобы неявно закрыть обработчик файла. Кроме того, мы обрабатываем возможные исключения с помощью блока try-except. Пока вы работаете с обработкой файлов Python, можете убедиться, что ваш код имеет следующие моменты.
- Никогда не игнорируйте исключения — особенно с длительно работающими процессами Python. Тем не менее можно игнорировать исключения для простых служебных сценариев, поскольку необработанные исключения мешают дальнейшему выполнению служебных сценариев .
- Если вы не используете синтаксис
с, обязательно правильно закройте обработчики открытых файлов. Сборщик мусора Python очистит незакрытые обработчики файлов, но всегда полезно закрыть обработчик файлов с помощью нашего кода, чтобы избежать нежелательного использования ресурсов . - Обязательно унифицируйте синтаксис обработки файлов в кодовой базе. Например, если вы используете
с ключевым словомдля обработки файлов, обязательно используйте один и тот же синтаксис для всех мест, где вы обрабатываете файл . - Избегайте повторного открытия одного и того же файла при чтении или записи с помощью нескольких обработчиков. Вместо этого используйте методы
flushиseek, как показано ниже:
 Сборщик мусора Python очистит незакрытые обработчики файлов, но всегда полезно закрыть обработчик файлов с помощью нашего кода, чтобы избежать нежелательного использования ресурсов
Сборщик мусора Python очистит незакрытые обработчики файлов, но всегда полезно закрыть обработчик файлов с помощью нашего кода, чтобы избежать нежелательного использования ресурсов def process_file (имя файла):
с open(имя файла, "w+") как myFile:
# w+: чтение/запись и создание, если не существует, в отличие от r+
# Написать контент
myFile.write("Привет, Питон!")
print("Положение курсора: ", myFile.tell()) # 13
# Сбросить внутренний буфер
мой файл.flush()
# Установить курсор в начало
myFile. seek(0)
print("Позиция курсора: ", myFile.tell()) # 0
# Распечатать новый контент
содержимое = мой файл.read()
распечатать (содержание)
print("Положение курсора: ", myFile.tell()) # 13
file_to_read = "мой файл.txt"
пытаться:
process_file (file_to_read)
кроме:
print("Невозможно обработать файл %s " % file_to_read)
еще:
print("Успешно обработано %s" % file_to_read)  seek(0)
print("Позиция курсора: ", myFile.tell()) # 0
# Распечатать новый контент
содержимое = мой файл.read()
распечатать (содержание)
print("Положение курсора: ", myFile.tell()) # 13
file_to_read = "мой файл.txt"
пытаться:
process_file (file_to_read)
кроме:
print("Невозможно обработать файл %s " % file_to_read)
еще:
print("Успешно обработано %s" % file_to_read)
seek(0)
print("Позиция курсора: ", myFile.tell()) # 0
# Распечатать новый контент
содержимое = мой файл.read()
распечатать (содержание)
print("Положение курсора: ", myFile.tell()) # 13
file_to_read = "мой файл.txt"
пытаться:
process_file (file_to_read)
кроме:
print("Невозможно обработать файл %s " % file_to_read)
еще:
print("Успешно обработано %s" % file_to_read) Приведенное выше содержимое сначала сохраняет строку в файл. После этого он снова считывает только что добавленный контент, сбрасывая внутренний буфер. Метод flush очищает временно сохраненные данные в памяти, поэтому при следующем чтении будет возвращен только что добавленный контент. Кроме того, нам нужно использовать вызов метода seek(0) для сброса курсора в начало, потому что метод write устанавливает его в конец.
Заключение
Python предлагает простой синтаксис для программистов. Поэтому почти все операции с файлами легко реализовать. Но у Python есть некоторые проблемы с дизайном стандартной библиотеки, поэтому для одной и той же вещи используется несколько функций API. Поэтому вам необходимо выбрать наиболее подходящий стандартный модуль в соответствии с вашими требованиями.
Но у Python есть некоторые проблемы с дизайном стандартной библиотеки, поэтому для одной и той же вещи используется несколько функций API. Поэтому вам необходимо выбрать наиболее подходящий стандартный модуль в соответствии с вашими требованиями.
Кроме того, Python — медленный язык по сравнению с другими популярными языками программирования. Имея это в виду, обязательно оптимизируйте свой скрипт Python, не используя слишком много ресурсов. Например, вы можете оптимизировать производительность, обрабатывая большие текстовые файлы построчно, не обрабатывая все содержимое сразу.
В этом руководстве мы обсудили общую обработку текстовых файлов и обработку двоичных файлов. Если вам нужно обрабатывать определенные форматы файлов, возможно, стоит выбрать лучшую библиотеку или стандартный модуль. Например, вы можете использовать стандартный модуль csv для обработки файлов CSV и библиотеку PyPDF2 для обработки файлов PDF. Кроме того, стандартный модуль pickle помогает хранить (и загружать) объекты данных Python с помощью файлов.
Как создать (записать) текстовый файл в Python
Автор: Стив Кэмпбелл
ЧасовОбновлено
Обработка файлов Python
В Python нет необходимости импортировать внешнюю библиотеку для чтения и записи файлов. Python предоставляет встроенную функцию для создания, записи и чтения файлов.
Как открыть текстовый файл в Python
Чтобы открыть файл, вам нужно использовать встроенную функцию open . Функция открытия файла Python возвращает файловый объект, содержащий методы и атрибуты для выполнения различных операций по открытию файлов в Python.
Синтаксис функции открытия файла Python
file_object = open("имя файла", "режим") Здесь
- имя файла: дает имя файла, который открыл файловый объект.
- режим: атрибут файлового объекта сообщает вам, в каком режиме был открыт файл.
Более подробная информация об этих режимах описана ниже.
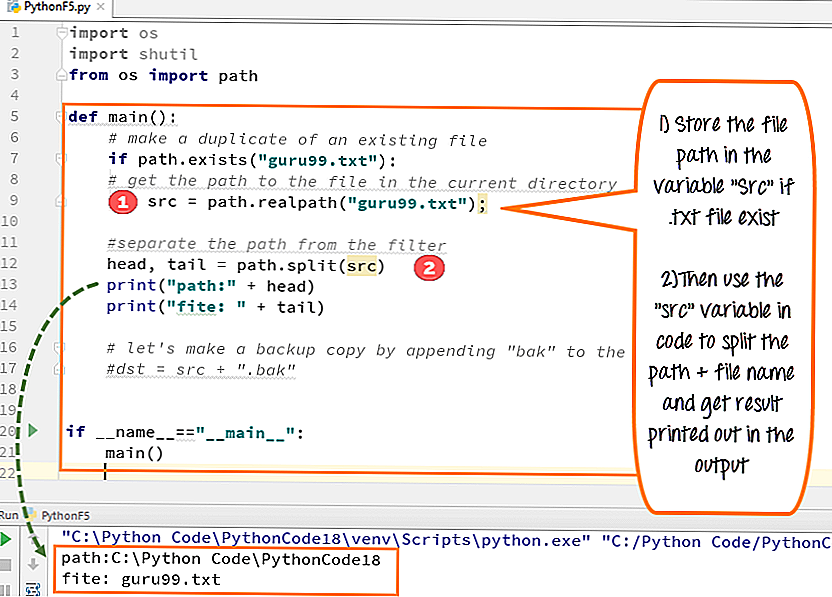
Как создать текстовый файл в Python9.txt) с помощью кода, который мы продемонстрировали здесь:
Шаг 1) Откройте файл .txt
f= open("guru99.txt","w+") - Мы объявили переменную “ f», чтобы открыть файл с именем guru99.txt. Open принимает 2 аргумента: файл, который мы хотим открыть, и строку, представляющую виды разрешений или операций, которые мы хотим выполнить с файлом .
- Здесь мы использовали букву «w» в нашем аргументе, которая указывает Python на запись в файл, и он создаст файл в Python, если он не существует в библиотеке 9.0180
- Знак плюс указывает на чтение и запись для операции создания файла Python.
Шаг 2) Введите данные в файл
для i в диапазоне (10):
f.write("Это строка %d\r\n" % (i+1)) - У нас есть цикл for, который работает с диапазоном из 10 чисел.
- Использование функции записи для ввода данных в файл.
- Вывод, который мы хотим повторить в файле, это «это номер строки», который мы объявляем с помощью функции записи файла Python, а затем процент d (отображает целое число)
- Итак, в основном мы вводим номер строки, которую мы пишем, затем помещаем его в возврат каретки и символ новой строки .

Шаг 3) Закройте экземпляр файла
f.close()
- Это закроет экземпляр файла guru99.txt, сохраненный
Вот результат после выполнения кода для создания текстового файла в примере Python:
Как создать текстовый файл в Python
При нажатии на текстовый файл в нашем случае «guru99.txt» он будет выглядеть примерно так
Пример создания текстового файла в Python
Как добавить текстовый файл в Python
Вы также можете добавлять/добавлять новый текст в уже существующий файл или в новый файл.
Шаг 1)
f=open("guru99. txt", "a+")  txt", "a+")
txt", "a+") Еще раз, если вы видите знак плюс в коде, это означает, что он создаст новый файл, если это произойдет не существует. Но в нашем случае у нас уже есть файл, поэтому нам не требуется создавать новый файл для операции добавления в файл в Python.
Шаг 2)
для i в диапазоне (2):
f.write("Добавленная строка %d\r\n" % (i+1)) Это запишет данные в файл в режиме добавления.
Как добавить текстовый файл в Python
Результат можно увидеть в файле «guru99.txt». Вывод кода заключается в том, что к предыдущему файлу добавляются новые данные с помощью операции добавления Python в файл.
Пример добавления текстового файла в Python
Как читать файлы в Python
Вы можете прочитать файл в Python, вызвав файл .txt в «режиме чтения» (r).
Шаг 1) Открыть файл в режиме чтения
f=open("guru99.txt", "r") Шаг 2) Мы используем функцию режима в коде, чтобы проверить, что файл в открытом режиме. Если да, продолжаем
Если да, продолжаем
if f.mode == 'r':
Шаг 3) Используйте f.read для чтения данных файла и сохранения их в переменном содержимом для чтения файлов в Python
contents =f. читать()
Шаг 4) Распечатать содержимое прочитанного текстового файла Python
Вот вывод прочитанного файла Пример Python:
Как читать файлы в Python
Как читать файл построчно в Python
Вы также можете читать файл .txt построчно, если ваши данные слишком велики для чтения. Код readlines() разделит ваши данные в удобном для чтения режиме.
Как прочитать файл построчно в Python
При запуске кода ( f1=f.readlines()) для чтения файла построчно в Python, он будет разделять каждую строку и представлять файл в читаемом формате. В нашем случае строка короткая и читабельная, вывод будет похож на режим чтения. Но если есть сложный файл данных, который не читается, этот фрагмент кода может быть полезен.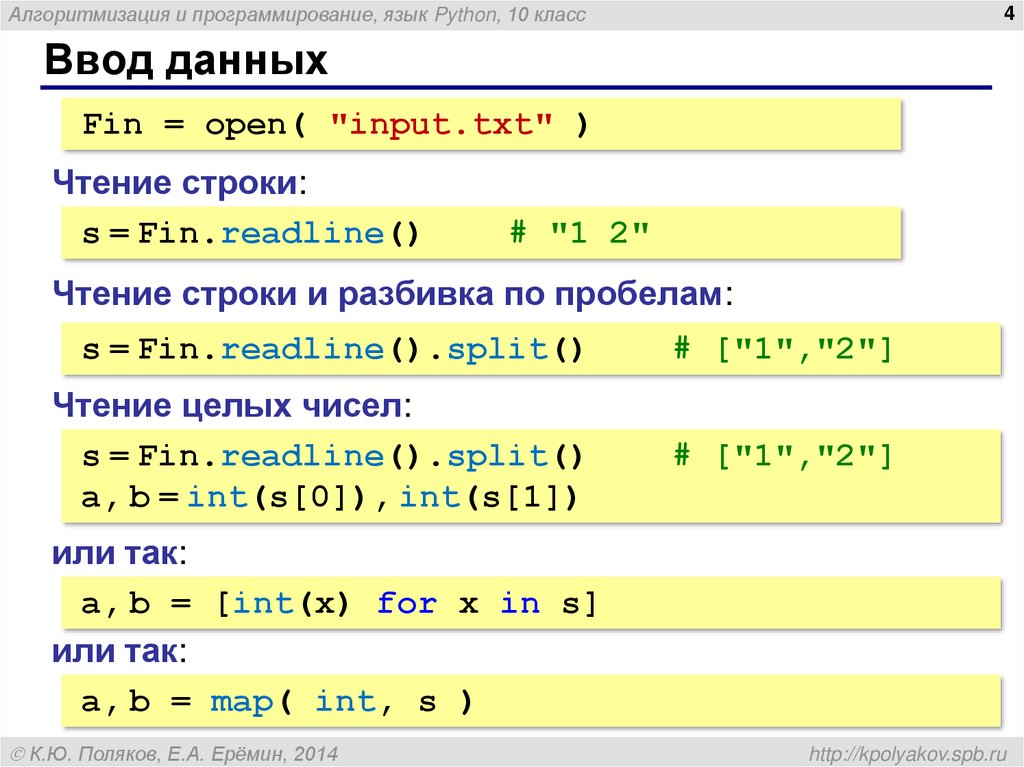
Режимы файлов в Python
Ниже приведены различные режимы файлов в Python :
| Режим | Описание |
|---|---|
| «р» | Это режим по умолчанию. Открывает файл для чтения. |
| ‘ш’ | Этот режим открывает файл для записи. Если файл не существует, создается новый файл. Если файл существует, он усекается. |
| ‘х’ | Создает новый файл. Если файл уже существует, операция завершается ошибкой. |
| «а» | Открыть файл в режиме добавления. Если файл не существует, создается новый файл. |
| ‘т’ | Это режим по умолчанию. Он открывается в текстовом режиме. |
| ‘б’ | Это открывается в двоичном режиме. |
| «+» | Это откроет файл для чтения и записи (обновления) |
Вот полный код для Python print() to File Example
Python 2 Пример
def main():
f= открыть("guru99. txt","w+")
#f=открыть("guru99.txt","а+")
для я в диапазоне (10):
f.write("Это строка %d\r\n" % (i+1))
е.закрыть()
#Открываем файл обратно и читаем содержимое
#f=открыть("гуру99.txt", "р")
# если f.mode == 'r':
# содержимое =f.read()
# распечатать содержимое
#или, readlines считывает отдельную строку в список
#fl =f.readlines()
#для x в fl:
#распечатать х
если __name__== "__main__":
main()  txt","w+")
#f=открыть("guru99.txt","а+")
для я в диапазоне (10):
f.write("Это строка %d\r\n" % (i+1))
е.закрыть()
#Открываем файл обратно и читаем содержимое
#f=открыть("гуру99.txt", "р")
# если f.mode == 'r':
# содержимое =f.read()
# распечатать содержимое
#или, readlines считывает отдельную строку в список
#fl =f.readlines()
#для x в fl:
#распечатать х
если __name__== "__main__":
main()
txt","w+")
#f=открыть("guru99.txt","а+")
для я в диапазоне (10):
f.write("Это строка %d\r\n" % (i+1))
е.закрыть()
#Открываем файл обратно и читаем содержимое
#f=открыть("гуру99.txt", "р")
# если f.mode == 'r':
# содержимое =f.read()
# распечатать содержимое
#или, readlines считывает отдельную строку в список
#fl =f.readlines()
#для x в fl:
#распечатать х
если __name__== "__main__":
main() Пример Python 3
Ниже приведен еще один пример Python print() в файл:
def main():
f= открыть("guru99.txt","w+")
#f=открыть("guru99.txt","а+")
для я в диапазоне (10):
f.write("Это строка %d\r\n" % (i+1))
е.закрыть()
#Открываем файл обратно и читаем содержимое
#f=открыть("гуру99.txt", "р")
#if f.mode == 'r':
# содержимое =f.read()
# распечатать (содержимое)
#или, readlines считывает отдельную строку в список
#fl =f.readlines()
#для x в fl:
# печать (х)
если __name__== "__main__":
main() Сводка
- Python позволяет читать, записывать и удалять файлы
- Используйте функцию open(«filename», «w+») для создания текстового файла Python.
