C# и .NET | Работа с XML
Последнее обновление: 20.02.2022
На сегодняшний день XML является одним из распространенных стандартов документов, который позволяет в удобной форме сохранять сложные по структуре данные. Поэтому разработчики платформы .NET включили в фреймворк широкие возможности для работы с XML.
Прежде чем перейти непосредственно к работе с XML-файлами, сначала рассмотрим, что представляет собой xml-документ и как он может хранить объекты, используемые в программе на c#.
Например, у нас есть следующий класс:
class Person
{
public string Name { get;}
public int Age { get; set; }
public string Company { get; set; }
public Person(string name, int age, string company)
{
Name = name;
Age = age;
Company = company;
}
}
В программе на C# мы можем создать список объектов класса Person:
var employees = new List<Person>
{
new Person ("Tom", 37, "Microsoft"),
new Person ("Bob", 41, "Google")
};
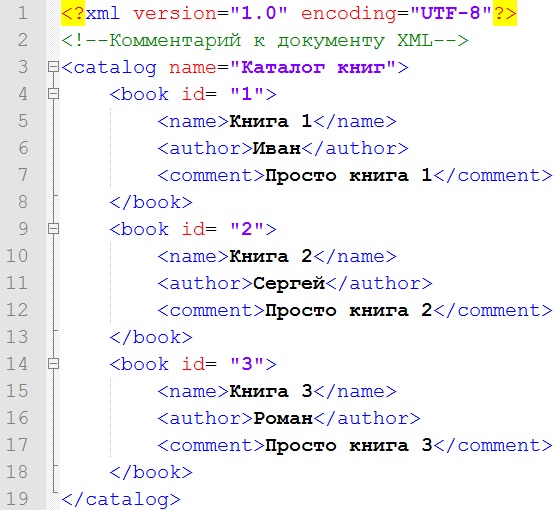
Чтобы сохранить список в формате xml мы могли бы использовать следующий xml-файл:
<?xml version="1.0" encoding="utf-8" ?> <people> <person name="Tom"> <company>Microsoft</company> <age>37</age> </person> <person name="Bob"> <company>Google</company> <age>41</age> </person> </people>
 0" encoding="utf-8" ?>
<people>
<person name="Tom">
<company>Microsoft</company>
<age>37</age>
</person>
<person name="Bob">
<company>Google</company>
<age>41</age>
</person>
</people>
0" encoding="utf-8" ?>
<people>
<person name="Tom">
<company>Microsoft</company>
<age>37</age>
</person>
<person name="Bob">
<company>Google</company>
<age>41</age>
</person>
</people>
XML-документ объявляет строка <?xml version="1.0" encoding="utf-8" ?>. Она задает версию (1.0) и кодировку (utf-8) xml. Далее идет
собственно содержимое документа.
XML-документ должен иметь один единственный корневой элемент, внутрь которого помещаются все остальные элементы. В данном случае таким элементом является
элемент <people>. Внутри корневого элемента <people> задан набор элементов <person>. Вне корневого элемента
мы не можем разместить элементы person.
Каждый элемент определяется с помощью открывающего и закрывающего тегов, например, <person> и </person>, внутри которых
помещается значение или содержимое элементов.
<person /> — в конце элемента помещается слеш.Элемент может иметь вложенные элементы и атрибуты. В данном случае каждый элемент person имеет два вложенных элемента company и
age и атрибут name.
Атрибуты определяются в теле элемента и имеют следующую форму: название="значение". Например, <person name="Bill Gates">,
в данном случае атрибут называется name и имеет значение Bill Gates
Внутри простых элементов помещается их значение. Например, company имеет значение
Google.
Названия элементов являются регистрозависимыми, поэтому <company> и <COMPANY> будут представлять разные элементы.
Таким образом, весь список Users из кода C# сопоставляется с корневым элементом <people>, каждый объект Person — с элементом <person>,
а каждое свойство объекта Person — с атрибутом или вложенным элементом элемента <person>
Что использовать для свойств — вложенные элементы или атрибуты? Это вопрос предпочтений — мы можем использовать как атрибуты, так и вложенные элементы.
<?xml version="1.0" encoding="utf-8" ?>
<people>
<person>
<name>Tom</name>
<company>Microsoft</company>
<age>37</age>
</person>
<person>
<name>Bob</name>
<company>Google</company>
<age>41</age>
</person>
</people>
Теперь рассмотрим основные подходы для работы с XML, которые имеются в C#.
НазадСодержаниеВперед
модуль ElementTree для чтения, создания, изменения и удаления
XML или расширяемый язык разметки, который обычно используется для структурирования, хранения и передачи данных между системами. Хотя он и не так распространен, как раньше, он все еще используется в таких службах, как RSS и SOAP, а также для структурирования файлов, таких как документы Microsoft Office.
Поскольку Python является популярным языком для Интернета и анализа данных, вполне вероятно, что в какой-то момент вам понадобится читать или записывать XML-данные, и в этом случае вам повезло.
В этой статье мы в первую очередь рассмотрим модуль ElementTree для чтения, записи и изменения данных XML в Python.
Модули XML
DOM – это упрощенная реализация объектной модели документа. DOM – это интерфейс прикладного программирования, который рассматривает XML как древовидную структуру, где каждый узел в дереве является объектом. Таким образом, использование этого модуля требует, чтобы мы были знакомы с его функциями.
Модуль ElementTree предоставляет более “питонический” интерфейс для работы с XMl и является хорошим вариантом для тех, кто не знаком с DOM. Это также, вероятно, лучший кандидат для использования большим количеством начинающих программистов из-за его простого интерфейса, который вы увидите в этой статье.
В этой статье модуль ElementTree будет использоваться во всех примерах, тогда как minidom также будет продемонстрирован, но только для подсчета и чтения XML-документов.
Пример файла XML
В приведенных ниже примерах мы будем использовать следующий XML-файл, который мы сохраним как «items.xml»:
<data>
<items>
<item name="item1">item1abc</item>
<item name="item2">item2abc</item>
</items>
</data>
Как видите, это довольно простой пример XML, содержащий всего несколько вложенных объектов и один атрибут. Однако этого должно быть достаточно, чтобы продемонстрировать все операции XML в этой статье.
Чтение документов
Чтобы проанализировать XML-документ с помощью minidom, мы должны сначала импортировать его из модуля xml.dom. Этот модуль использует функцию синтаксического анализа для создания объекта DOM из нашего XML-файла. Функция синтаксического анализа имеет следующий синтаксис:
xml.dom.minidom.parse(filename_or_file[, parser[, bufsize]])
Здесь имя файла может быть строкой, содержащей путь к файлу или объект типа файла.
Поскольку каждый узел можно рассматривать как объект, мы можем получить доступ к атрибутам и тексту элемента, используя свойства объекта. В приведенном ниже примере мы получили доступ к атрибутам и тексту определенного узла и всех узлов вместе.
from xml.dom import minidom
# parse an xml file by name
mydoc = minidom.parse('items.xml')
items = mydoc.getElementsByTagName('item')
# one specific item attribute
print('Item #2 attribute:')
print(items[1].attributes['name'].value)
# all item attributes
print('\nAll attributes:')
for elem in items:
print(elem.attributes['name'].value)
# one specific item's data
print('\nItem #2 data:')
print(items[1].firstChild.data)
print(items[1]. childNodes[0].data)
# all items data
print('\nAll item data:')
for elem in items:
print(elem.firstChild.data)

Результат такой:
$ python minidomparser.py Item #2 attribute: item2 All attributes: item1 item2 Item #2 data: item2abc item2abc All item data: item1abc item2abc
Если мы хотим использовать уже открытый файл, мы можем просто передать наш файловый объект для синтаксического анализа следующим образом:
datasource = open('items.xml')
# parse an open file
mydoc = parse(datasource)
Кроме того, если данные XML уже были загружены в виде строки, вместо этого мы могли бы использовать функцию parseString().
Использование ElementTree
ElementTree представляет нам очень простой способ обработки файлов XML. Как всегда, чтобы использовать его, мы должны сначала импортировать модуль.
После импорта мы создаем древовидную структуру с функцией синтаксического анализа и получаем ее корневой элемент. Получив доступ к корневому узлу, мы можем легко перемещаться по Tree.
Используя ElementTree и аналогично предыдущему примеру кода, мы получаем атрибуты узла и текст, используя объекты, связанные с каждым узлом.
Код выглядит следующим образом:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# one specific item attribute
print('Item #2 attribute:')
print(root[0][1].attrib)
# all item attributes
print('\nAll attributes:')
for elem in root:
for subelem in elem:
print(subelem.attrib)
# one specific item's data
print('\nItem #2 data:')
print(root[0][1]. text)
# all items data
print('\nAll item data:')
for elem in root:
for subelem in elem:
print(subelem.text)
 text)
# all items data
print('\nAll item data:')
for elem in root:
for subelem in elem:
print(subelem.text)
text)
# all items data
print('\nAll item data:')
for elem in root:
for subelem in elem:
print(subelem.text)
Результат будет следующим:
$ python treeparser.py Item #2 attribute: item2 All attributes: item1 item2 Item #2 data: item2abc All item data: item1abc item2abc
Как видите, это очень похоже на пример минидома. Одно из основных отличий заключается в том, что объект attrib – это просто объект словаря, что делает его немного более совместимым с другим кодом Python. Нам также не нужно использовать значение для доступа к значению атрибута элемента, как мы это делали раньше.
Возможно, вы заметили, что доступ к объектам и атрибутам с помощью ElementTree немного больше похож на Pythonic, как мы упоминали ранее. Это связано с тем, что данные XML анализируются как простые списки и словари, в отличие от minidom, где элементы анализируются как пользовательские xml. dom.minidom.Attr и «узлы DOM Text».
dom.minidom.Attr и «узлы DOM Text».
Подсчет элементов
Как и в предыдущем случае, минидом нужно импортировать из модуля dom. Этот модуль предоставляет функцию getElementsByTagName, которую мы будем использовать для поиска элемента тега. После получения мы используем встроенный метод len() для получения количества подэлементов, подключенных к узлу. Результат, полученный из приведенного ниже кода, показан на рисунке 3.
from xml.dom import minidom
# parse an xml file by name
mydoc = minidom.parse('items.xml')
items = mydoc.getElementsByTagName('item')
# total amount of items
print(len(items))
$ python counterxmldom.py 2
Имейте в виду, что при этом будет подсчитано только количество дочерних элементов под заметкой, для которой вы выполняете len(), которая в данном случае является корневым узлом. Если вы хотите найти все подэлементы в гораздо большем дереве, вам нужно будет пройти по всем элементам и подсчитать каждого из их дочерних элементов.
Точно так же модуль ElementTree позволяет нам вычислить количество узлов, подключенных к узлу.
Пример кода:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# total amount of items
print(len(root[0]))
Результат такой:
$ python counterxml.py 2
Запись
ElementTree также отлично подходит для записи данных в файлы XML. В приведенном ниже коде показано, как создать XML-файл с той же структурой, что и файл, который мы использовали в предыдущих примерах.
Шаги следующие:
- Создайте элемент, который будет работать как наш корневой элемент. В нашем случае тег для этого элемента – «данные».
- Когда у нас есть корневой элемент, мы можем создавать подэлементы с помощью функции SubElement. Эта функция имеет синтаксис:
Подэлемент (родительский, тег, attrib = {}, ** дополнительный).
Здесь parent – это родительский узел, к которому нужно подключиться, attrib – это словарь, содержащий атрибуты элемента, а extra – дополнительные аргументы ключевого слова. Эта функция возвращает нам элемент, который можно использовать для присоединения других подэлементов, как мы это делаем в следующих строках, передавая элементы в конструктор SubElement.
3. Хотя мы можем добавлять наши атрибуты с помощью функции SubElement, мы также можем использовать функцию set(), как мы это делаем в следующем коде. Текст элемента создается с помощью свойства text объекта Element.
4. В последних трех строках приведенного ниже кода мы создаем строку из XML-дерева и записываем эти данные в файл, который мы открываем.
Пример кода:
import xml.etree.ElementTree as ET
# create the file structure
data = ET.Element('data')
items = ET.SubElement(data, 'items')
item1 = ET.SubElement(items, 'item')
item2 = ET. SubElement(items, 'item')
item1.set('name','item1')
item2.set('name','item2')
item1.text = 'item1abc'
item2.text = 'item2abc'
# create a new XML file with the results
mydata = ET.tostring(data)
myfile = open("items2.xml", "w")
myfile.write(mydata)
 SubElement(items, 'item')
item1.set('name','item1')
item2.set('name','item2')
item1.text = 'item1abc'
item2.text = 'item2abc'
# create a new XML file with the results
mydata = ET.tostring(data)
myfile = open("items2.xml", "w")
myfile.write(mydata)
SubElement(items, 'item')
item1.set('name','item1')
item2.set('name','item2')
item1.text = 'item1abc'
item2.text = 'item2abc'
# create a new XML file with the results
mydata = ET.tostring(data)
myfile = open("items2.xml", "w")
myfile.write(mydata)
Выполнение этого кода приведет к созданию нового файла «items2.xml», который должен быть эквивалентен исходному файлу «items.xml», по крайней мере, с точки зрения структуры данных XML. Вы, вероятно, заметите, что результирующая строка представляет собой только одну строку и не содержит отступов.
Поиск элементов
Модуль ElementTree предлагает функцию findall(), которая помогает нам находить определенные элементы в дереве. Он возвращает все элементы с указанным условием. Кроме того, в модуле есть функция find(), которая возвращает только первый подэлемент, соответствующий указанным критериям. Синтаксис для обеих этих функций выглядит следующим образом:
findall(match, namespaces=None)
find(match, namespaces=None)
Для обеих этих функций параметром соответствия может быть имя XML-тега или путь. Функция findall() возвращает список элементов, а функция find возвращает один объект типа Element.
Функция findall() возвращает список элементов, а функция find возвращает один объект типа Element.
Кроме того, существует еще одна вспомогательная функция, которая возвращает текст первого узла, соответствующего заданному критерию:
findtext(match, default=None, namespaces=None)
Вот пример кода, который покажет вам, как именно работают эти функции:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# find the first 'item' object
for elem in root:
print(elem.find('item').get('name'))
# find all "item" objects and print their "name" attribute
for elem in root:
for subelem in elem.findall('item'):
# if we don't need to know the name of the attribute(s), get the dict
print(subelem.attrib)
# if we know the name of the attribute, access it directly
print(subelem. get('name'))
 get('name'))
get('name'))
И вот повторное использование этого кода:
$ python findtree.py
item1
{'name': 'item1'}
item1
{'name': 'item2'}
item2
Изменение
В ElementTree модуле представлены несколько инструментов для изменения существующих XML-документов. В приведенном ниже примере показано, как изменить имя узла, изменить имя атрибута и изменить его значение, а также как добавить дополнительный атрибут к элементу.
Текст узла можно изменить, указав новое значение в текстовом поле объекта узла. Имя атрибута можно переопределить с помощью set(name, value) функции. Функция set не просто работать на существующем атрибуту, он также может быть использован для определения нового атрибута.
В приведенном ниже коде показано, как выполнять эти операции:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# changing a field text
for elem in root. iter('item'):
elem.text = 'new text'
# modifying an attribute
for elem in root.iter('item'):
elem.set('name', 'newitem')
# adding an attribute
for elem in root.iter('item'):
elem.set('name2', 'newitem2')
tree.write('newitems.xml')
 iter('item'):
elem.text = 'new text'
# modifying an attribute
for elem in root.iter('item'):
elem.set('name', 'newitem')
# adding an attribute
for elem in root.iter('item'):
elem.set('name2', 'newitem2')
tree.write('newitems.xml')
iter('item'):
elem.text = 'new text'
# modifying an attribute
for elem in root.iter('item'):
elem.set('name', 'newitem')
# adding an attribute
for elem in root.iter('item'):
elem.set('name2', 'newitem2')
tree.write('newitems.xml')
После выполнения кода результирующий XML-файл newitems.xml будет иметь XML-дерево со следующими данными:
<data>
<items>
<item name="newitem" name2="newitem2">new text</item>
<item name="newitem" name2="newitem2">new text</item>
</items>
</data>
Как мы можем видеть при сравнении с исходным XML-файлом, имена элементов item изменились на «newitem», текст на «новый текст», а атрибут «name2» был добавлен к обоим узлам.
Вы также можете заметить, что запись XML-данных таким способом (вызов tree.write с именем файла) добавляет к XML-дереву дополнительное форматирование, поэтому оно содержит символы новой строки и отступы.
Создание подэлементов
У модуля ElementTree есть несколько способов добавить новый элемент. Первый способ, который мы рассмотрим, – это использовать функцию makeelement(), которая имеет имя узла и словарь с его атрибутами в качестве параметров.
Второй способ – через SubElement() класс, который принимает в качестве входных данных родительский элемент и словарь атрибутов.
В нашем примере ниже мы показываем оба метода. В первом случае у узла нет атрибутов, поэтому мы создали пустой словарь (attrib = {}). Во втором случае мы используем заполненный словарь для создания атрибутов.
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# adding an element to the root node
attrib = {}
element = root.makeelement('seconditems', attrib)
root.append(element)
# adding an element to the seconditem node
attrib = {'name2': 'secondname2'}
subelement = root[0][1]. makeelement('seconditem', attrib)
ET.SubElement(root[1], 'seconditem', attrib)
root[1][0].text = 'seconditemabc'
# create a new XML file with the new element
tree.write('newitems2.xml')
 makeelement('seconditem', attrib)
ET.SubElement(root[1], 'seconditem', attrib)
root[1][0].text = 'seconditemabc'
# create a new XML file with the new element
tree.write('newitems2.xml')
makeelement('seconditem', attrib)
ET.SubElement(root[1], 'seconditem', attrib)
root[1][0].text = 'seconditemabc'
# create a new XML file with the new element
tree.write('newitems2.xml')
После запуска этого кода результирующий XML-файл будет выглядеть так:
<data>
<items>
<item name="item1">item1abc</item>
<item name="item2">item2abc</item>
</items>
<seconditems>
<seconditem name2="secondname2">seconditemabc</seconditem>
</seconditems>
</data>
Как мы видим при сравнении с исходным файлом, были добавлены элемент «seconditems» и его подэлемент «seconditem». Кроме того, узел «seconditem» имеет атрибут «name2», а его текст – «seconditemabc», как и ожидалось.
Удаление
Как и следовало ожидать, модуль ElementTree имеет необходимые функции для удаления атрибутов и подэлементов узла.
Удаление атрибута
В приведенном ниже коде показано, как удалить атрибут узла с помощью функции pop(). Функция применяется к параметру объекта attrib. Он определяет имя атрибута и устанавливает для него значение «Нет».
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# removing an attribute
root[0][0].attrib.pop('name', None)
# create a new XML file with the results
tree.write('newitems3.xml')
Результатом будет следующий XML-файл:
<data>
<items>
<item>item1abc</item>
<item name="item2">item2abc</item>
</items>
</data>
Как видно из XML-кода выше, первый элемент не имеет атрибута «name».
Удаление одного подэлемента
Один конкретный подэлемент можно удалить с помощью remove функции. Эта функция должна указать узел, который мы хотим удалить.
Эта функция должна указать узел, который мы хотим удалить.
В следующем примере показано, как его использовать:
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# removing one sub-element
root[0].remove(root[0][0])
# create a new XML file with the results
tree.write('newitems4.xml')
Результатом будет следующий XML-файл:
<data>
<items>
<item name="item2">item2abc</item>
</items>
</data>
Как видно из приведенного выше XML-кода, теперь есть только один узел «элемент». Второй был удален из исходного дерева.
Удаление всех подэлементов
В ElementTree модуле представляет нам с clear() функцией, которая может быть использована для удаления всех вложенных элементов данного элемента.
В приведенном ниже примере показано, как использовать clear():
import xml.
 etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# removing all sub-elements of an element
root[0].clear()
# create a new XML file with the results
tree.write('newitems5.xml')
etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# removing all sub-elements of an element
root[0].clear()
# create a new XML file with the results
tree.write('newitems5.xml')
Результатом будет следующий XML-файл:
<data>
<items />
</data>
Как видно из приведенного выше XML-кода, все подэлементы элемента «items» были удалены из дерева.
Заключение
Python предлагает несколько вариантов обработки файлов XML. В этой статье мы рассмотрели ElementTree модуль и использовали его для анализа, создания, изменения и удаления файлов XML. Мы также использовали minidom модель для анализа файлов XML. Лично я бы рекомендовал использовать этот ElementTree модуль, так как с ним намного проще работать и он является более современным модулем из двух.
XML Tutorial
❮ Главная Далее ❯
Пример XML 1
 0″ encoding=»UTF-8″?>
0″ encoding=»UTF-8″?>
Не забывайте меня в эти выходные!
Показать XML-файл » Отобразить XML-файл как примечание »
Пример XML 2
Два наших знаменитых
Бельгийские вафли с большим количеством настоящего кленового сиропа
<калорий>650
<еда>
Светлый бельгийский
вафли с клубникой и взбитыми сливками
<калорий>900
<еда>
Бельгийский
вафли, покрытые ассорти из свежих ягод и взбитые
сливки
Толстые ломтики
из нашего домашнего хлеба на закваске
Два яйца, бекон или колбаса, тост и наша всегда популярная окрошка
коричневые
Показать XML-файл » Отображение с помощью XSLT »
×Заголовок
Зачем изучать XML?
XML играет важную роль во многих различных ИТ-системах.
XML часто используется для распространения данных через Интернет.
Важно (для всех типов разработчиков программного обеспечения!) хорошо разбираться в XML.
Чему вы научитесь
Этот учебник даст вам четкое представление о:
- Что такое XML?
- Как работает XML?
- Как я могу использовать XML?
- Для чего можно использовать XML?
Важные стандарты XML
В этом руководстве также подробно рассматриваются следующие важные стандарты XML:
- XML AJAX
- XML DOM
- XML XPath
- XML XSLT
- XML XQuery
- XML DTD
- XML-схема
- Службы XML
Мы рекомендуем читать это руководство в порядке, указанном в левом меню.
Учитесь на примерах
Примеры лучше, чем 1000 слов. Примеры часто легче понять чем текстовые пояснения.
Этот учебник дополняет все пояснения поясняющими примерами «Попробуйте сами».
- Примеры XML
- Примеры AJAX
- Примеры DOM
- Примеры XPath
- Примеры XSLT
XML Quiz Test
Проверьте свои навыки работы с XML в W3Schools!
Начните XML-викторину!
Мое обучение
Отслеживайте свои успехи с помощью бесплатной программы «Мое обучение» здесь, в W3Schools.
Войдите в свою учетную запись и начните зарабатывать баллы!
Это дополнительная функция. Вы можете учиться в W3Schools без использования My Learning.
Начните свою карьеру
Получите сертификат, пройдя курс
Получите сертификат
w3schoolsCERTIFIED.2023❮ Главная Следующий ❯
НАБОР ЦВЕТА
Лучшие учебники
Учебник HTMLУчебник CSS
Учебник JavaScript
How To Tutorial
Учебник SQL
Учебник Python
Учебник W3.
 CSS
CSS Учебник Bootstrap
Учебник PHP
Учебник Java
Учебник C++
Учебник jQuery
Основные ссылки
Справочник по HTMLСправочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3.CSS
Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
4 Top5 Examples
Примеры HTML
Примеры CSS
Примеры JavaScript
Примеры How To
Примеры SQL
Примеры Python
Примеры W3.CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery
FORUM | О
W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания. Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности.
Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности.
Авторское право 1999-2023 по данным Refsnes. Все права защищены.
W3Schools работает на основе W3.CSS.
XML Введение
❮ Предыдущий Далее ❯
XML — это независимый от программного и аппаратного обеспечения инструмент для хранения и передачи данных.
Что такое XML?
- XML означает расширяемый язык разметки
- XML — это язык разметки, очень похожий на HTML .
- XML был разработан для хранения и передачи данных
- XML был разработан, чтобы быть самоописательным
- XML — это рекомендация W3C .
XML ничего не делает
Возможно, это немного сложно понять, но XML ничего не делает.
Это записка для Туве от Яни, сохраненная в формате XML:
<заметка>
Приведенный выше XML-код говорит сам за себя:
- Имеется информация об отправителе
- Имеет информацию о приемнике
- Он имеет заголовок .
- Имеет тело сообщения

Тем не менее, приведенный выше XML ничего не делает. XML — это просто информация, заключенная в теги.
Кто-то должен написать программу для отправки, получения, хранения или отображения:
Примечание
Кому: Туве
От: Яни
Напоминание
Не забудь меня в эти выходные!
Разница между XML и HTML
XML и HTML были разработаны с разными целями:
- XML был разработан для переноса данных с упором на то, что такое данные
- HTML был разработан для отображения данных с упором на то, как данные выглядят
- Теги XML не предопределены, как теги HTML
XML не использует предварительно определенные теги
Язык XML не имеет предварительно определенных тегов.
Теги в приведенном выше примере (например,
HTML работает с предопределенными тегами, такими как
,
 д.
д. 09.2015 08:30
09.2015 08:30