Python Regex Search
Когда я впервые узнал о регулярных выражениях, я не оценил их силу. Но есть причина, по которой регулярные выражения пережили семь десятилетий технологического сбоя: программисты, понимающие регулярные выражения, имеют огромное преимущество при работе с текстовыми данными. Они могут написать в одной строке кода выражение, что занимает десятки других!
Как re.search() работает в Python?
Метод re.search(pattern, string) сопоставляет первое вхождение шаблона в строке и возвращает объект соответствия.
Спецификация :
re.search(pattern, string, flags=0)
Метод re.search() имеет до трех аргументов.
- pattern: шаблон регулярного выражения, который вы хотите сопоставить.
- string: строка, которую вы хотите найти для шаблона.
- flags(необязательный аргумент): более продвинутый модификатор, который позволяет вам настроить поведение функции.


Мы рассмотрим их более подробно позже.
Метод re.search() возвращает объект соответствия. Вы можете спросить (и это правильно):
Что такое объект соответствия?
Если регулярное выражение совпадает с частью вашей строки, с ней приходит много полезной информации: какова точная позиция соответствия? Какие группы регулярных выражений были сопоставлены и где?
Объект соответствия является простой оболочкой для этой информации. Некоторые методы регулярных выражений re-package в Python, такие как search(), автоматически создают объект соответствия при первом сопоставлении с образцом.
На этом этапе вам не нужно детально исследовать объект соответствия. Просто знайте, что мы можем получить доступ к начальной и конечной позициям совпадения в строке, вызвав методы m.end() для объекта соответствия m:
m = re.search('h...o', 'hello world')
m.start()
# 0
m.end()
# 5
'hello world'[m. start():m.end()]
# 'hello'
 start():m.end()]
# 'hello'
start():m.end()]
# 'hello'
В первой строке вы создаете объект m с помощью метода re.search(). Шаблон ‘h… o‘ совпадает в строке ‘hello world’ в начальной позиции 0. Вы используете начальную и конечную позиции для доступа к подстроке, которая соответствует шаблону.
Руководствуясь примером для re.search()
Сначала вы импортируете модуль re и создаете текстовую строку для поиска шаблонов регулярных выражений:
import re
text = '''
Ha! let me see her: out, alas! he's cold:
Her blood is settled, and her joints are stiff;
Life and these lips have long been separated:
Death lies on her like an untimely frost
Upon the sweetest flower of all the field.
'''
Допустим, вы хотите найти в тексте строку «her»:
re.search('her', text)
# Первый аргумент — образец, который нужно найти. В нашем случае это строка «her». Второй аргумент — это текст для анализа. Вы сохранили многострочную строку в переменной — так что вы берете ее в качестве второго аргумента.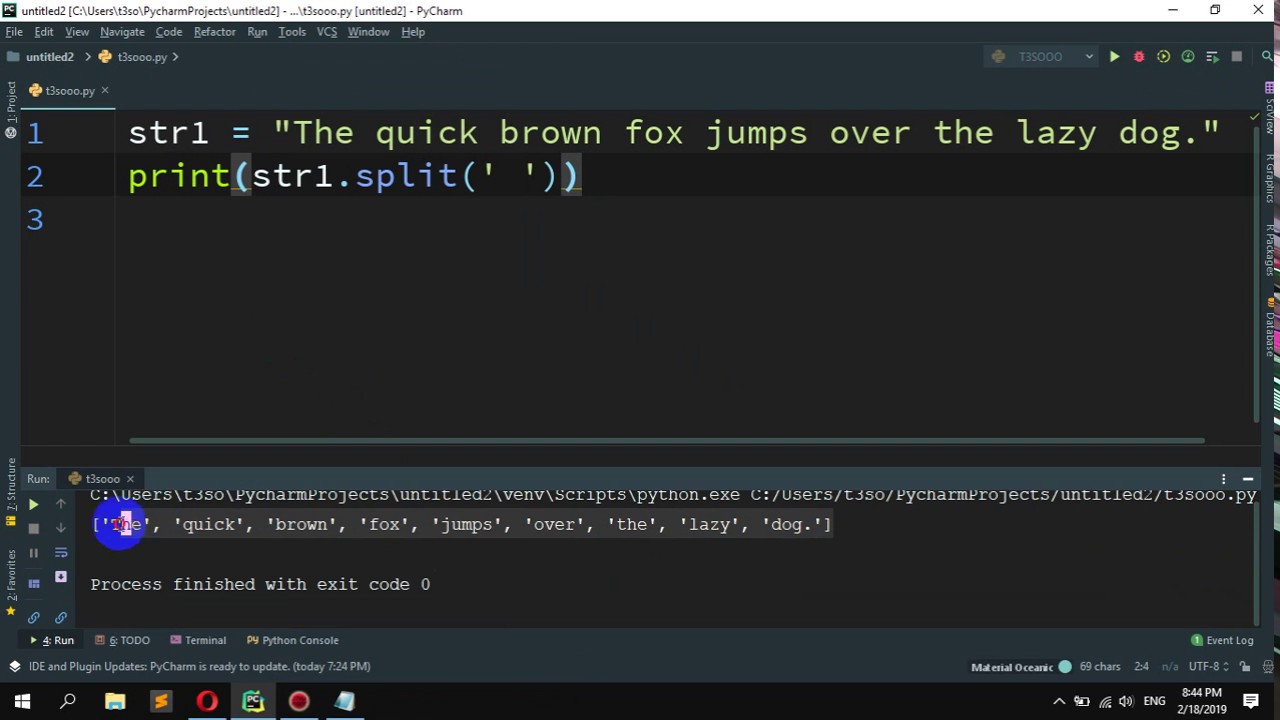
Посмотрите на вывод: это объект соответствия! Объект match дает диапазон совпадения, то есть индексы начала и конца совпадения. Мы также можем напрямую получить доступ к этим границам, используя методы start() и stop() объекта match:
m = re.search('her', text)
m.start()
#20
m.end()
# 23
Проблема в том, что метод search() извлекает только первое вхождение шаблона в строке. Если вы хотите найти все совпадения в строке, вы можете использовать метод findall() библиотеки re.
В чем разница между re.search() и re.findall()?
Существует два различия между методами re.search(pattern, string) и re.findall(pattern, string):
re.search(pattern, string)re.findall(pattern, string)возвращает список совпадающих строк.re.search(pattern, string)возвращает только первое совпадение в строке, аre.возвращает все совпадения в строке. findall(pattern, string)
 findall(pattern, string)
findall(pattern, string)Оба можно увидеть в следующем примере:
text = 'Python is superior to Python'
re.search('Py...n', text)
#
re.findall('Py...n', text)
# ['Python', 'Python']
Строка «Python is superior to Python» содержит два вхождения «Python». Метод search() возвращает только объект соответствия первого вхождения. Метод
В чем разница между re.search() и re.match()?
Методы re.search(pattern, string) и re.match(pattern, string) оба возвращают объект соответствия первого соответствия. Однако re.match() пытается найти совпадение в начале строки, а re.search() — в любом месте строки.
Вы можете увидеть эту разницу в следующем коде:
text = 'Slim Shady is my name'
re.search('Shady', text)
#
re.match('Shady', text)
# empty
Метод re.search() извлекает совпадение подстроки ‘Shady’ как объект сопоставления.
re.match(), совпадения и возвращаемого значения не будет, потому что подстрока ‘Shady’ не встречается в начале строки ‘Slim Shady is my name’.Как использовать необязательный аргумент flag?
Как вы видели в спецификации, метод search() поставляется с необязательным третьим аргументом ‘flag’:
re.search(pattern, string, flags=0)
Какова цель аргумента flag?
Флаги позволяют вам управлять механизмом регулярных выражений. Поскольку регулярные выражения настолько мощны, они являются полезным способом включения и выключения определенных функций (например, игнорировать ли заглавные буквы при сопоставлении с регулярным выражением).
| re.ASCII | Если вы не используете этот флаг, специальные символы регулярного выражения Python \w, \W, \b, \B, \d, \D, \s и \S будут соответствовать символам Юникода. Если вы используете этот флаг, эти специальные символы будут соответствовать только символам ASCII — как следует из названия. |
| re.A | То же, что и re.ASCII |
| re.DEBUG | |
| re.IGNORECASE | Если вы используете этот флаг, механизм регулярных выражений выполнит сопоставление без учета регистра. Поэтому, если вы ищете [AZ], оно также будет соответствовать [az]. |
| re.I | То же, что и re.IGNORECASE |
| re.LOCALE | Не используйте этот флаг — никогда. Это устарело — идея заключалась в том, чтобы выполнять сопоставление без учета регистра в зависимости от вашей текущей локали. |
| re.L | То же, что и re.LOCALE |
| re.M | То же, что и re.MULTILINE |
| re.DOTALL | Без использования этого флага точка regex ‘.’ соответствует всем символам, кроме символа новой строки ‘\n’. Включите этот флаг, чтобы он действительно соответствовал всем символам, включая символ новой строки. |
| re.S | То же, что и re.DOTALL |
| re.VERBOSE | Чтобы улучшить читаемость сложных регулярных выражений, вы можете разрешить комментарии и (многострочное) форматирование самого регулярного выражения. Это возможно с этим флагом: все пробельные символы и строки, начинающиеся с символа «#», игнорируются в регулярном выражении. |
| re.X | То же, что и re.VERBOSE |
text = 'Python is great!'
re.search('PYTHON', text, flags=re.IGNORECASE)
# Хотя в вашем регулярном выражении ‘PYTHON’ прописные буквы, мы игнорируем заглавные буквы, используя флаг re.IGNORECASE.
объект re.Match, методы re.search, re.finditer, re.findall
Смотреть материал на видео
На предыдущих занятиях мы с вами рассмотрели основы построения регулярных выражений. Теперь пришло время научиться применять их, используя различные методы модуля re.
Существует два различных подхода применения регулярных выражений:
- «здесь и сейчас» для однократного применения правила;
- компиляция и обработка, для многократного использования одного и того же правила.
Ранее, во всех
наших примерах мы использовали режим «здесь и сейчас». Например, для выделения
из строки шаблона цвета в формате:
Например, для выделения
из строки шаблона цвета в формате:
#xxxxxx
где x – шестнадцатиричное число, можно записать такую программу:
import re
text = "<font color=#CC0000>"
match = re.search(r"#[\da-fA-F]{6}\b", text)
print(match)Мы здесь определяем шаблон в виде:
«#[\da-fA-F]{6}\b»
который передаем в виде строки первым параметром метода search, и на выходе получаем объект re.Match со следующими свойствами:
<re.Match object; span=(12, 19), match=’#CC0000′>
Если же вхождение не будет найдено, то метод search возвращает значение None:
match = re.search(r"#[\da-fA-F]{7}\b", text)получаем None. Более детально
это работает так. Метод search сначала компилирует регулярное
выражение в свой внутренний формат, а затем, запускается программный модуль
(написанный на языке Си), который ищет первый подходящий фрагмент в тексте под
этот шаблон. Благодаря тому, что реализации методов модуля re написаны на
языке Си, они довольно быстро выполняют обработку строк.
Благодаря тому, что реализации методов модуля re написаны на
языке Си, они довольно быстро выполняют обработку строк.
Свойства и методы объекта re.Match
Давайте теперь посмотрим на методы объекта re.Match. И, для его исследования возьмем вот такое регулярное выражение:
match = re.search(r"(\w+)=(#[\da-fA-F]{6})\b", text)Перейдем в консольный режим для удобства работы. Смотрите, у нас здесь две сохраняющие скобки: для атрибута и для значения. В действительности, метод search и другие ему подобные создают следующую иерархию вхождений:
И мы в этом можем легко убедиться, вызвав метод group объекта re.Match:
match.group(0) match.group(1) match.group(2)
Или же, указать все эти индексы через запятую:
match.group(0,1,2)
На выходе получим кортеж из соответствующих вхождений:
(‘color=#CC0000’, ‘color’, ‘#CC0000’)
Также можно вызвать метод
match.
 groups()
groups()который возвращает кортеж из всех групп, начиная с индекса 1. У этого метода есть необязательный параметр default, который определяет возвращаемое значение для групп, не участвующих в совпадении.
Свойство lastindex содержит индекс последней группы:
match.lastindex
Если нам нужно узнать позиции в тексте начала и конца группы, то для этого служат методы start и end:
match.start(1) match.end(1)
Если по каким-то причинам группа не участвовала в совпадении (например, ее вхождение было от 0), то данные методы возвращают -1. Также мы можем получить сразу кортеж с начальной и конечной позициями для каждой группы:
match.span(0) match.span(1)
Для определения первого и последнего индексов, в пределах которых осуществлялась проверка в тексте, служат свойства:
match.endpos match.pos
Следующее свойство re:
pattern = match.
 re
reвозвращает скомпилированное регулярное выражение. А свойство string:
match.string
содержит анализируемую строку.
Давайте теперь реализуем такой шаблон:
match = re.search(r"(?P<key>\w+)=(?P<value>#[\da-fA-F]{6})\b", text)мы здесь определили две именованных группы: key и value. В результате, с помощью метода:
match.groupdict()
можно получить словарь:
{‘key’: ‘color’, ‘value’: ‘#CC0000’}
Свойство
match.lastgroup
возвращает имя последней группы (или значение None, если именованных групп нет). Наконец, с помощью метода
match.expand(r"\g<key>:\g<value>")
можно формировать строку с использованием сохраненных групп:
‘color:#CC0000’
Здесь синтаксис:
- \g<name> — обращение к группе по имени;
-
\1,
\2, … — обращение к группе по номеру.

Вот такие возможности извлечения результатов обработки строк дает объект re.Match.
Методы re.search, re.finditer и re.findall
В заключение этого занятия снова обратимся к методу re.search для поиска первого вхождения в тексте, удовлетворяющего регулярному выражению. Полный синтаксис этого метода следующий:
re.search(pattern, string, flags)
- pattern – регулярное выражение;
- string – анализируемая строка;
- flags – один или несколько флагов.
Ключевой особенностью метода является поиск именно первого вхождения. Например, если взять вот такой текст:
text = "<font color=#CC0000 bg=#ffffff>"
и выполнить его анализ:
match = re.search(r"(?P<key>\w+)=(?P<value>#[\da-fA-F]{6})\b", text)то второй атрибут никак не будет фигурировать в результатах объекта match:
match.
 groups()
groups()выведет всего две группы для первого атрибута:
(‘color’, ‘#CC0000’)
Если нужно найти все совпадения, то можно воспользоваться методом
re.finditer(pattern, string, flags)
который возвращает итерируемый объект для перебора всех вхождений:
for m in re.finditer(r"(?P<key>\w+)=(?P<value>#[\da-fA-F]{6})\b", text):
print(m.groups())На выходе получим две коллекции для первого и второго атрибутов:
(‘color’,
‘#CC0000’)
(‘bg’,
‘#ffffff’)
Однако, часто на практике нам нужно получить лишь список найденных вхождений, групп и это проще реализовать с помощью метода
re.findall(pattern, string, flags)
следующим образом:
match = re.findall(r"(?P<key>\w+)=(?P<value>#[\da-fA-F]{6})\b", text)
print(match)На выходе будет список кортежей:
[(‘color’, ‘#CC0000’), (‘bg’, ‘#ffffff’)]
Недостатком
последнего метода является ограниченность полученных данных: здесь лишь список,
тогда как два предыдущих метода возвращали объект re. Match, обладающий,
как мы только что видели, богатым функционалом. Но, если списка достаточно, то
метод findall может быть
вполне удобным и подходящим.
Match, обладающий,
как мы только что видели, богатым функционалом. Но, если списка достаточно, то
метод findall может быть
вполне удобным и подходящим.
На следующем занятии мы продолжим рассматривать методы модуля re для обработки строк посредством регулярных выражений.
Видео по теме
Регулярные выражения #1: литералы и символьный класс
Регулярные выражения #2: квантификаторы {m,n}
Регулярные выражения #3: сохраняющие скобки и группировка
Регулярные выражения #4: флаги и проверки
Регулярные выражения #5: объект re.Match, методы re.search, re.finditer, re.findall
Регулярные выражения #6: методы re.match, re.split, re.sub, re.subn, re.compile
Регулярные выражения с модулем re в Python
В Python модуль re позволяет работать с регулярными выражениями (регулярными выражениями) для извлечения, замены и разделения строк на основе определенных шаблонов.
- re — Операции с регулярными выражениями — Документация по Python 3.11.3
- Регулярные выражения HOWTO — Документация по Python 3.11.3
В этой статье сначала объясняются функции и методы модуля re, затем объясняются метасимволы (специальные символы) и специальные последовательности, доступные в модуле re. Хотя синтаксис в основном стандартный для регулярных выражений, будьте осторожны с флагами, особенно 9.0011 re.ASCII .
Содержание- Компиляция шаблона регулярного выражения: compile()
- Выполнение с функциями уровня модуля
- Выполнить с помощью методов объекта шаблона регулярного выражения
- Спичечный объект
- Начало строки соответствия: match()
- Совпадение в любом месте строки: search()
- Совпадение со всей строкой: fullmatch()
- Получить все совпадения в списке: findall()
- Получить все совпадения как итератор: finditer()
- Заменить совпадающие части: sub(), subn()
- Разделить строку, используя шаблон регулярного выражения: split()
- Метасимволы и специальные последовательности в модуле re
- Флаги
- Совпадение только с символами ASCII: re. ASCII, re.A
- Соответствие без учета регистра: re.IGNORECASE, re.I
- Совпадение в начале и конце каждой строки: re.MULTILINE, re.M
- Укажите несколько флагов
- Совпадение только с символами ASCII: re.
- Жадное и нежадное сопоставление
 ASCII, re.A
ASCII, re.AСкомпилируйте шаблон регулярного выражения:
compile() Существует два способа выполнения обработки регулярных выражений с помощью модуля re.
Выполнение с функциями уровня модуля
В первом методе используются функции уровня модуля. Такие функции, как re.match() и re.sub() , позволяют извлекать и заменять строки на основе шаблонов регулярных выражений.
Эти функции принимают в качестве аргументов строку шаблона регулярного выражения и целевую строку. Подробности будут объяснены позже.
импорт повторно s = '[email protected] [email protected] [email protected]' print(re.match(r'([az]+)@([az]+)\.com', s)) # <объект re.Match; span=(0, 11), match='[email protected]'> print(re.
 sub(r'([az]+)@([az]+)\.com', 'НОВЫЙ_АДРЕС', s))
# НОВЫЙ_АДРЕС
sub(r'([az]+)@([az]+)\.com', 'НОВЫЙ_АДРЕС', s))
# НОВЫЙ_АДРЕС источник: re_compile.py
В этом примере шаблон регулярного выражения [a-z] соответствует любому символу от a до z , а символ + указывает, что предыдущий шаблон должен быть повторен один или несколько раз . Итак, [a-z]+ соответствует строке с одним или несколькими повторяющимися буквенными символами нижнего регистра.
. — это метасимвол, который представляет собой символ со специальным значением, поэтому его необходимо экранировать с помощью \ .
Строки шаблонов регулярных выражений часто используют обратную косую черту \ , поэтому использование необработанных строк, как в этом примере, может быть полезным.
- Необработанные строки в Python
Выполнить с помощью методов объекта шаблона регулярного выражения
Второй метод предполагает использование методов объекта шаблона регулярного выражения.
Вы можете скомпилировать строку шаблона регулярного выражения в объект шаблона регулярного выражения, используя re.compile() .
p = re.compile(r'([az]+)@([az]+)\.com')
печать (р)
# re.compile('([a-z]+)@([a-z]+)\\.com')
печать (тип (р))
# <класс 're.Pattern'>
источник: re_compile.py
Та же обработка, что и функции уровня модуля, такие как re.match() и re.sub() , может быть выполнена с использованием методов объекта регулярного выражения, таких как match() и суб() .
print(p.match(s)) # <объект re.Match; span=(0, 11), match='[email protected]'> печать (p.sub ('НОВЫЙ_АДРЕС', с)) # НОВЫЙ_АДРЕС [email protected] [email protected]
источник: re_compile.py
Все описанные ниже функции, такие как re.xxx() , также предоставляются как методы объектов регулярных выражений.
Более эффективно создавать и повторно использовать объект регулярного выражения при многократном выполнении одной и той же обработки на основе шаблона.
В следующем примере кода функция используется без компиляции, но если один и тот же шаблон используется повторно, рекомендуется предварительно скомпилировать и выполнить его как метод объекта регулярного выражения.
Объект соответствия
Такие функции, как match() и search() , возвращают объект соответствия.
с = '[email protected]' m = re.match(r'[az]+@[az]+\.[az]+', s) печать (м) # <объект re.Match; span=(0, 11), match='[email protected]'> печать (тип (м)) # <класс 're.Match'>
источник: re_match_object.py
Объекты Match имеют различные полезные методы, такие как:
- Получить совпадающие позиции:
start(),end(),диапазон() - Получить совпавшие строки:
group() - Получить строки каждой группы:
groups()
печать (м.старт()) # 0 печать (м.конец()) № 11 печать (м.промежуток ()) # (0, 11) печать (м.
 группа())
# ааа@xxx.com
группа())
# ааа@xxx.com
источник: re_match_object.py
При заключении части шаблона регулярного выражения в круглые скобки () эта часть рассматривается как группа. В этом случае вы можете получить строки частей, которые соответствуют каждой группе, в виде кортежа на групп() .
m = re.match(r'([a-z]+)@([a-z]+)\.([a-z]+)', s) печать (м) # <объект re.Match; span=(0, 11), match='[email protected]'> печать (м.группы()) # ('ааа', 'ххх', 'com')
источник: re_match_object.py
При группировании вы можете указать число в качестве аргумента для group() , чтобы получить строку любой группы. Если он опущен или указан 0 , возвращается все совпадение, а если указан номер из 1 , строки каждой группы возвращаются по порядку.
печать (м.группа()) # ааа@xxx.com печать (м.группа (0)) # ааа@xxx.com печать (м.группа (1)) # ааа печать (м.группа (2)) # ххх печать (м.группа (3)) # ком
источник: re_match_object. py
py
Дополнительную информацию об объектах сопоставления см. в следующей статье.
- Как использовать объекты сопоставления регулярных выражений в Python
Начало строки соответствия:
match() match() возвращает объект соответствия, если начало строки соответствует шаблону. Как упоминалось выше, вы можете использовать объект match для извлечения совпадающей подстроки или проверки совпадения.
match() проверяет только начало строки и возвращает None , если совпадений нет.
s = '[email protected] [email protected] [email protected]' print(re.match(r'[az]+@[az]+\.com', s)) # <объект re.Match; span=(0, 11), match='[email protected]'> print(re.match(r'[az]+@[az]+\.net', s)) # Никто
источник: re_match_search_fullmatch.py
Совпадение в любом месте строки:
search() search() ищет всю строку и возвращает объект соответствия, если совпадение найдено. Если найдено несколько совпадений, возвращается только первое.
Если найдено несколько совпадений, возвращается только первое.
s = '[email protected] [email protected] [email protected]' print(re.search(r'[az]+@[az]+\.net', s)) # <объект re.Match; span=(12, 23), match='[email protected]'> print(re.search(r'[az]+@[az]+\.[az]+', s)) # <объект re.Match; span=(0, 11), match='[email protected]'>
источник: re_match_search_fullmatch.py
Если вы хотите получить все совпадающие части, используйте findall() или finditer() , описанные ниже.
Совпадение со всей строкой:
fullmatch() Используйте fullmatch() , чтобы проверить, соответствует ли вся строка шаблону регулярного выражения. Он возвращает объект соответствия, если совпадает вся строка, и None в противном случае.
с = '[email protected]' print(re.fullmatch(r'[az]+@[az]+\.com', s)) # <объект re.Match; span=(0, 11), match='[email protected]'> s = '[email protected]!!!' print(re.fullmatch(r'[az]+@[az]+\.com', s)) # Никто
источник: re_match_search_fullmatch. py
py
Получить все совпадения в списке:
findall() findall() возвращает все совпадающие подстроки в виде списка. Обратите внимание, что элементы списка являются строками, а не объектами соответствия.
s = '[email protected] [email protected] [email protected]' результат = re.findall(r'[az]+@[az]+\.[az]+', s) печать (результат) # ['[email protected]', '[email protected]', '[email protected]']
источник: re_findall_finditer.py
Чтобы проверить количество совпавших частей, используйте встроенную функцию len() .
печать (длина (результат)) № 3
источник: re_findall_finditer.py
Если вы используете скобки () для группировки в шаблоне регулярного выражения, возвращается список кортежей, содержащих строки каждой группы.
print(re.findall(r'([az]+)@([az]+)\.([az]+)', s))
# [('aaa', 'xxx', 'com'), ('bbb', 'yyy', 'net'), ('ccc', 'zzz', 'org')]
источник: re_findall_finditer.py
Поскольку скобки группировки () могут быть вложенными, если вы хотите получить полное совпадение, вы можете заключить весь шаблон в круглые скобки () .
print(re.findall(r'(([az]+)@([az]+)\.([az]+))', s))
# [('[email protected]', 'aaa', 'xxx', 'com'), ('[email protected]', 'bbb', 'yyy', 'net'), ('ccc@ zzz.org», «ccc», «zzz», «org»)]
источник: re_findall_finditer.py
Если совпадений нет, возвращается пустой кортеж.
print(re.findall('[0-9]+', s))
# []
источник: re_findall_finditer.py
Получить все совпадения как итератор:
finditer() finditer() возвращает все совпадающие части в виде итератора с совпадающими объектами в качестве элементов.
Итератор не отображает свои элементы при печати с помощью print() . Чтобы извлечь элементы один за другим, используйте встроенную функцию next() или цикл for .
s = '[email protected] [email protected] [email protected]' результат = re.finditer(r'[az]+@[az]+\.[az]+', s) печать (результат) # <объект callable_iterator по адресу 0x107863070> печать (тип (результат)) # <класс 'вызываемый_итератор'> для m в результате: печать (м) # <объект re.
 Match; span=(0, 11), match='
Match; span=(0, 11), match='источник: re_findall_finditer.py
Вы также можете преобразовать итератор в список, используя list() .
l = list(re.finditer(r'[az]+@[az]+\.[az]+', s)) печать (л) # [<объект re.Match; span=(0, 11), match='[email protected]'>,, ] печать (л [0]) # <объект re.Match; span=(0, 11), match='[email protected]'> печать (тип (l [0])) # <класс 're.Match'> печать (l[0].span()) # (0, 11)
источник: re_findall_finditer.py
Если вы хотите получить позиции всех совпадающих частей, использование включения списка более удобно, чем использование list() .
- Списковые включения в Python
print([m.span() for m in re.finditer(r'[az]+@[az]+\.[az]+', s)]) # [(0, 11), (12, 23), (24, 35)]
источник: re_findall_finditer. py
py
Итераторы обращаются к элементам по порядку. Будьте осторожны, чтобы не пытаться получить доступ к элементам после достижения конца, так как ничего не останется.
для m в результате:
печать (м)
# <объект re.Match; span=(0, 11), match='[email protected]'>
# <объект re.Match; span=(12, 23), match='[email protected]'>
# <объект re.Match; span=(24, 35), match='[email protected]'>
распечатать (список (результат))
# []
источник: re_findall_finditer.py
Замена совпадающих частей:
sub() , subn() sub() позволяет заменить совпадающие части другой строкой. Укажите шаблон регулярного выражения в качестве первого аргумента, строку замены в качестве второго и целевую строку в качестве третьего.
s = '[email protected] [email protected] [email protected]' print(re.sub('[az]+@', 'ABC@', s)) # [email protected] [email protected] [email protected]
источник: re_sub_subn.py
Вы можете указать максимальное количество замен в качестве четвертого аргумента, count .
print(re.sub('[az]+@', 'ABC@', s, 2))
# [email protected] [email protected] [email protected]
источник: re_sub_subn.py
Если вы группируете с помощью круглых скобок () , вы можете использовать совпадающую строку в строке замены.
По умолчанию \1 , \2 и \3 соответствуют частям, сопоставленным первой () , второй () и третьей () . При использовании обычных строк вместо необработанных строк вам необходимо экранировать обратную косую черту, например '\\1' .
print(re.sub('([az]+)@([az]+)', '\\2@\\1', s))
# [email protected] [email protected] [email protected]
print(re.sub('([az]+)@([az]+)', r'\2@\1', s))
# [email protected] [email protected] [email protected]
источник: re_sub_subn.py
Написав ?P в начале () в шаблоне reg, чтобы дать группе имя, вместо этого вы можете указать имя с \g числа вроде \1 .
print(re.sub('(?P[az]+)@(?P[az]+)', r'\g@\g', s ))
# [email protected] [email protected] [email protected]
источник: re_sub_subn.py
Вы также можете указать функцию, которая принимает объект сопоставления в качестве аргумента для второго аргумента, что позволяет выполнять более сложную обработку.
функция защиты (matchobj):
вернуть matchobj.group(2).upper() + '@' + matchobj.group(1)
print(re.sub('([az]+)@([az]+)', func, s))
# [email protected] [email protected] [email protected]
источник: re_sub_subn.py
Также можно использовать лямбда-выражения.
- Лямбда-выражения в Python
print(re.sub('([az]+)@([az]+)', lambda m: m.group(2).upper() + '@' + m.group(1), s ))
# [email protected] [email protected] [email protected]
источник: re_sub_subn.py
subn() возвращает кортеж, содержащий замененную строку и количество замененных частей (количество совпадений с шаблоном).
t = re.subn('[az]*@', 'ABC@', s)
печать (т)
# ('ABC@xxx. com [email protected] [email protected]', 3)
печать (тип (т))
# <класс 'кортеж'>
печать (т [0])
# [email protected] [email protected] [email protected]
печать (т [1])
№ 3
 com
com источник: re_sub_subn.py
Способ указания аргументов такой же, как и для sub() . Вы можете использовать сгруппированные части с () и указать аргумент count .
print(re.subn('([az]+)@([az]+)', r'\2@\1', s, 2))
# ('[email protected] [email protected] [email protected]', 2)
источник: re_sub_subn.py
Дополнительные сведения о замене строк см. в следующей статье.
- Замена строк в Python (replace, translate, re.sub, re.subn)
Разбить строку, используя шаблон регулярного выражения:
split() split() разбивает строку на части, соответствующие шаблону, и возвращает результат в виде списка.
При сопоставлении в начале или конце строки имейте в виду, что пустая строка '' будет включена в начало и конец результирующего списка.
с = '111aaa222bbb333'
print(re.split('[az]+', s))
# ['111', '222', '333']
print(re.split('[0-9]+', с))
# ['', 'ааа', 'ббб', '']
источник: re_split.py
Вы можете указать максимальное количество разбиений в качестве третьего аргумента, maxsplit .
print(re.split('[az]+', s, 1))
# ['111', '222bbb333']
источник: re_split.py
Дополнительные сведения о разделении строк см. в следующей статье.
- Разделить строки в Python (разделитель, разрыв строки, регулярное выражение и т. д.)
Метасимволы и специальные последовательности в модуле re
Ниже перечислены основные метасимволы регулярных выражений и специальные последовательности, которые можно использовать в модуле re.
| Метасимвол | Описание |
|---|---|
| Совпадает с началом строки | |
$ | Соответствует концу строки |
* | Соответствует 0 или более повторениям предыдущего шаблона |
+ | Соответствует 1 или более повторениям предыдущего шаблона |
? | Соответствует 0 или 1 повторению предыдущего шаблона |
{м} | Соответствует м повторений предыдущего шаблона |
{м, п} | Совпадения между м и n повторений предыдущего шаблона |
[] | Соответствует набору символов (любому одному символу в пределах [] ) |
| | ИЛИ ( A|B соответствует либо A , либо B , где A и B — шаблоны) |
| Специальная последовательность | Описание |
|---|---|
\д | Десятичная цифра Юникода |
\Д | Напротив \d |
\с | Символ пробела Unicode |
\С | Напротив \с |
\ш | символ слова Unicode и _ |
\ Вт | Напротив \w |
Полный список см. в официальной документации:
в официальной документации:
- re — Синтаксис регулярных выражений — Операции с регулярными выражениями — Документация по Python 3.11.3
Обратите внимание, что некоторые символы имеют другое значение в Python 2.
- 7.2. re — Синтаксис регулярных выражений — Операции с регулярными выражениями — Документация по Python 2.7.18
Основные примеры этих символов см. в следующей статье:
- Извлечение подстроки из строки в Python (позиция, регулярное выражение)
Флаги
Флаги влияют на поведение метасимволов и специальных последовательностей в шаблонах регулярных выражений.
Здесь представлены только основные флаги. Для других обратитесь к официальной документации.
- re — Флаги — Операции с регулярными выражениями — Документация по Python 3.11.3
Совпадение только с символами ASCII:
re.ASCII , re.A По умолчанию, в отличие от стандартных регулярных выражений, \w не эквивалентно [a-zA-Z0-9_] . Например,
Например, \w соответствует буквенно-цифровым символам полной ширины, японскому языку и т. д.
print(re.match(r'\w+', 'あいう漢字ABC123'))
# <объект re.Match; span=(0, 11), match='あいう漢字ABC123'>
print(re.match('[a-zA-Z0-9_]+', 'あいう漢字ABC123'))
# Никто
источник: re_flag.py
Чтобы соответствовать только символам ASCII, используйте re.ASCII в качестве аргумента flags в каждой функции или добавьте встроенный флаг (?a) в начало строки шаблона регулярного выражения. В этом случае \w эквивалентно [a-zA-Z0-9_]
print(re.match(r'\w+', 'あいう漢字ABC123', flags=re.ASCII)) # Никто print(re.match(r'(?a)\w+', 'あいう漢字ABC123')) # Никто
источник: re_flag.py
То же самое относится к использованию re.compile() для компиляции шаблона. Используйте аргумент flags или встроенный флаг.
p = re.compile(r'\w+', flags=re.ASCII) печать (р) # re.
 compile('\\w+', re.ASCII)
print(p.match('あいう漢字ABC123'))
# Никто
p = перекомпилировать (r'(?a)\w+')
печать (р)
# re.compile('(?a)\\w+', re.ASCII)
print(p.match('あいう漢字ABC123'))
# Никто
compile('\\w+', re.ASCII)
print(p.match('あいう漢字ABC123'))
# Никто
p = перекомпилировать (r'(?a)\w+')
печать (р)
# re.compile('(?a)\\w+', re.ASCII)
print(p.match('あいう漢字ABC123'))
# Никто
источник: re_flag.py
re.ASCII также доступен как re.A .
печать (re.ASCII - это re.A) # Истинный
источник: re_flag.py
\W , который представляет собой противоположность \w , также подвержен влиянию re.ASCII или (?a) .
print(re.match(r'\W+', 'あいう漢字ABC123')) # Никто print(re.match(r'\W+', 'あいう漢字ABC123', flags=re.ASCII)) # <объект re.Match; span=(0, 11), match='あいう漢字ABC123'>
источник: re_flag.py
\d и \s по умолчанию соответствуют как полуширинным, так и полноширинным символам. re.ASCII или (?a) ограничивает их символами половинной ширины.
print(re.match(r'\d+', '123')) # <объект re.
 Match; диапазон = (0, 3), совпадение = '123'>
print(re.match(r'\d+', '123'))
# <объект re.Match; span=(0, 3), match='123'>
print(re.match(r'\d+', '123', flags=re.ASCII))
# <объект re.Match; диапазон = (0, 3), совпадение = '123'>
print(re.match(r'\d+', '123', flags=re.ASCII))
# Никто
print(re.match(r'\s+', ' ')) # 全角スペース
# <объект re.Match; диапазон = (0, 1), совпадение = '\ u3000'>
print(re.match(r'\s+', ' ', flags=re.ASCII))
# Никто
Match; диапазон = (0, 3), совпадение = '123'>
print(re.match(r'\d+', '123'))
# <объект re.Match; span=(0, 3), match='123'>
print(re.match(r'\d+', '123', flags=re.ASCII))
# <объект re.Match; диапазон = (0, 3), совпадение = '123'>
print(re.match(r'\d+', '123', flags=re.ASCII))
# Никто
print(re.match(r'\s+', ' ')) # 全角スペース
# <объект re.Match; диапазон = (0, 1), совпадение = '\ u3000'>
print(re.match(r'\s+', ' ', flags=re.ASCII))
# Никто
источник: re_flag.py
Их противоположности, \D и \S , также подвержены влиянию re.ASCII или (?a) .
Соответствие без учета регистра:
re.IGNORECASE , re.I По умолчанию при сопоставлении учитывается регистр.
Используйте re.IGNORECASE для сопоставления без учета регистра, что эквивалентно флагу i в стандартном регулярном выражении.
print(re.match('[a-zA-Z]+', 'abcABC'))
# <объект re.Match; span=(0, 6), match='abcABC'>
print(re. match('[az]+', 'abcABC', flags=re.IGNORECASE))
# <объект re.Match; span=(0, 6), match='abcABC'>
print(re.match('[AZ]+', 'abcABC', flags=re.IGNORECASE))
# <объект re.Match; span=(0, 6), match='abcABC'>
9[a-z]+', s, flags=re.MULTILINE))
# ['ааа', 'ббб', 'ссс']
 match('[az]+', 'abcABC', flags=re.IGNORECASE))
# <объект re.Match; span=(0, 6), match='abcABC'>
print(re.match('[AZ]+', 'abcABC', flags=re.IGNORECASE))
# <объект re.Match; span=(0, 6), match='abcABC'>
9[a-z]+', s, flags=re.MULTILINE))
# ['ааа', 'ббб', 'ссс']
match('[az]+', 'abcABC', flags=re.IGNORECASE))
# <объект re.Match; span=(0, 6), match='abcABC'>
print(re.match('[AZ]+', 'abcABC', flags=re.IGNORECASE))
# <объект re.Match; span=(0, 6), match='abcABC'>
9[a-z]+', s, flags=re.MULTILINE))
# ['ааа', 'ббб', 'ссс']
источник: re_flag.py
Аналогично, $ соответствует концу строки. По умолчанию он соответствует концу всей строки. Используйте вместо MULTILINE, чтобы соответствовать концу каждой строки.
print(re.findall('[az]+$', s))
# ['ззз']
print(re.findall('[az]+$', s, flags=re.MULTILINE))
# ['xxx', 'yyy', 'zzz']
источник: re_flag.py
Вы также можете использовать встроенный флаг (?m) или аббревиатуру 9\ш+’, с))
# [‘ааа’, ‘ббб’]
источник: re_flag.py
Жадное и нежадное сопоставление
Это общая проблема регулярных выражений, не специфичная для Python, но стоит упомянуть, так как это может быть распространенной ошибкой.
По умолчанию * , + и ? выполнить жадное сопоставление, сопоставив максимально длинную строку.
s = '[email protected] [email protected]' m = re.match(r'.+com', s) печать (м) # <объект re.Match; span=(0, 23), match='[email protected] [email protected]'> печать (м.группа()) # [email protected] [email protected]
источник: re_greedy.py
Добавляя ? (т. е. *?, +?, ??), выполняется нежадное (минимальное) сопоставление, сопоставляющее кратчайшую возможную строку.
m = re.match(r'.+?com', s) печать (м) # <объект re.Match; span=(0, 11), match='[email protected]'> печать (м.группа()) # ааа@xxx.com
источник: re_greedy.py
re.search() против re.findall() в регулярном выражении Python
следующий → ← предыдущая Регулярное выражение , , также известное как рациональное выражение , — это последовательность символов, используемая для определения шаблона поиска. В основном он используется для сопоставления шаблонов со строками или сопоставления строк, таких как операции поиска и замены. (RE) используются для указания набора строк, соответствующих шаблону. Для понимания аналогии RE, 9: используется для сопоставления начала $ : используется для сопоставления конца . : используется для сопоставления любого символа, кроме символа новой строки. ? : используется для сопоставления нуля или одного вхождения. | : Это означает ИЛИ. Это используется для сопоставления с любым из символов, разделенных им. * : Используется для любого количества вхождений (включая 0 вхождений) + : используется для одного или нескольких вхождений {} : используется для указания количества вхождений предыдущего RE для сопоставления. () : используется для включения группы RE. Метод re.search() Метод re.search() используется для возврата None (в случае несовпадения шаблона) или re.MatchObject , который содержит всю информацию о совпадающих частях строки. Пример: импортировать повторно # Мы будем использовать регулярное выражение для сопоставления строки данных # в виде названия дня недели, за которым следует номер дня регулярное выражение = r»([A-Za-z]+) (\d+)» match = re.search(regex, «Сегодня день и дата — вторник 12») если совпадение != Нет: print («Совпадение строки по индексу % s, % s» % (match.start(), match.end()))) print («Полное совпадение с шаблоном: % s» % (match.group(0))) print («Сегодняшний день недели: % s» % (match.group(1))) print («Сегодняшняя дата: % s» % (match.group(2))) еще: print («Шаблон регулярного выражения Python не соответствует строке импортированных данных».) Вывод: Совпадение строки по индексу 25, 35 Полное совпадение Узора: вторник 12 День недели сегодня: вторник Сегодняшняя дата: 12 Объяснение: В приведенном выше коде мы импортировали модуль re и использовали регулярное выражение для сопоставления строки данных с шаблоном, то есть День недели и Дата сегодняшнего дня. Выражение «([A-Za-z]+) (\d+)» должен соответствовать строке импортированных данных. Затем он напечатает [25, 35] , поскольку он соответствует строке с 25-м индексом и заканчивается 35-м номером индекса. Мы использовали функцию group() для получения всех совпадений и захваченных групп для получения требуемого вывода в шаблоне. Эти группы содержат совпадающие значения. Например: match.group(0) всегда будет возвращать полностью совпадающую строку данных, match.group(1) и match.group(2) вернет группы захвата в порядке слева направо во входной строке. (match.group() также означает match.group(0)). Если строка данных соответствует шаблону, она будет напечатана в правильной последовательности; в противном случае он будет использовать оператор else. Метод re.findall() Метод re. Пример: импортировать повторно # Строка текста, в которой будет выполняться поиск по регулярному выражению. string_1 = «»»Вот идентификатор студента, студент А: 676 студент Б: 564 студент С: 567 студент Д: 112 студент Э: 234″»» # Установка регулярного выражения для поиска цифр в строке. регулярное выражение_1 = «(\d+)» match_1 = re.findall (регулярное выражение_1, строка_1) печать (match_1) Вывод: ['676', '564', '567', '112', '234'] Объяснение: В приведенном выше коде мы сначала импортируем строку текста, содержащую несколько цифр. Затем мы устанавливаем регулярное выражение «(\d+)» для сопоставления строки с шаблоном. |
 Регулярные выражения — это обобщенный способ сопоставления шаблонов с последовательностями символов.
Регулярные выражения — это обобщенный способ сопоставления шаблонов с последовательностями символов. Этот метод перестает работать после первого совпадения, поэтому он идеально подходит для проверки регулярного выражения, а не для извлечения данных.
Этот метод перестает работать после первого совпадения, поэтому он идеально подходит для проверки регулярного выражения, а не для извлечения данных.
 findall() используется для получения в качестве возврата всех непересекающихся совпадений шаблона в строке данных в виде списка строк. Строка данных будет просканирована слева направо, и ее совпадения будут возвращены в том же порядке, в котором они были найдены.
findall() используется для получения в качестве возврата всех непересекающихся совпадений шаблона в строке данных в виде списка строк. Строка данных будет просканирована слева направо, и ее совпадения будут возвращены в том же порядке, в котором они были найдены.