азы для новичков / Хабр
В преддверии старта нового потока по курсу «Backend-разработчик на PHP», а также смежного с ним курса «Framework Laravel», хотим поделиться статьей, которую подготовил наш внештатный автор.Внимание! данная статья не имеет отношения к программе курса и будет полезна только для новичков. Для получения более углубленных знаний приглашаем вас посетить бесплатный двухдневный онлайн интенсив по теме: «Создание Telegram-бота для заказа кофе в заведении и оплаты онлайн». Второй день интенсива будет проходить тут.
Всем привет! Всех с наступившим
[20]{2,}0 годом. Сегодня я хочу затронуть тему, которая иногда является темой для шуток от «Да зачем тебе все это учить, если есть уже есть готовые решения» до «может тебе еще и весь Perl выучить?». Однако время идет, множество программистов начинают осваивать регулярные выражения, а на Хабре нет ни одной свежей (хоть регулярные выражения не слишком изменились за последнее время Пришло время написать ещё одну!
Пришло время написать ещё одну!Регулярные выражения в отрыве от их конкретной реализации
Регулярные выражения (обозначаемые в английском как RegEx или как regex) являются инструментальным средством, которое применяется для различных вариантов изучения и обработки текста: поиска, проверки, поиска и замены того или иного элемента, состоящего из букв или цифр (или любых других символов, в том числе специальных символов и символов пунктуации). Изначально регулярные выражения пришли в мир программирования из среды научных исследований, которые проводились в 50-е годы в области математики.Спустя десятилетия принципы и идеи были перенесены в среду операционной системы UNIX (в частности вошли в утилиту
Если они вроде простые, тогда почему такие страшные на первый взгляд?
На самом деле любое выражение может быть «регулярным» и применяться для проверки или поиска каких-либо символов. Например, слова Pavel или [email protected] тоже могут использоваться как регулярки, только, понятное дело, в довольно узком ключе. Для проверки работы регулярных выражений в среде PHP без запуска своего сервера или хостинга вы можете воспользоваться следующим онлайн сервисом (вот только на нем у меня не работала обработка русских символов). Для начала в качестве регулярного выражения мы используем просто
Например, слова Pavel или [email protected] тоже могут использоваться как регулярки, только, понятное дело, в довольно узком ключе. Для проверки работы регулярных выражений в среде PHP без запуска своего сервера или хостинга вы можете воспользоваться следующим онлайн сервисом (вот только на нем у меня не работала обработка русских символов). Для начала в качестве регулярного выражения мы используем просто Положим у нас есть следующий текст:
Pavel knows too much. Pavel using nginx and he’s not rambler.
Сейчас регулярные выражения нашли оба вхождения слова Pavel. Здорово, но звучит не очень полезно (разве что только вы зачем-то пытаетесь проанализировать что-то вроде количества упоминания слова сударь в Войне и Мире через Vim и Python, но тогда у меня к вам вопросов нет).
Вариативность выражения
Если ваше регулярное выражение вариативно (например, вам известна только некоторая его часть и нужно найти количество вхождений годов, начиная от 2000 и заканчивая 2099), то мы можем использовать следующее регулярное выражение: .
.Текст: Молодые писатели пишут много чего. Например писатель 2002 года рождения очень отличается от 2008 и 2012
Здесь у нас с помощью регулярного выражения найдутся все годы, но пока в этом нет никакого смысла. Скорее всего нам не нужны годы дальше 2012 (хотя молодые писатели младше 8 лет могут обидеться, но не об этом сейчас). Стоит изучить наборы символов, но об этом попозже, потому как сейчас поговорим про другую важную часть регулярных выражений: экранирование метасимволов.
Представим, что нам нужно найти количество вхождений файлов с расширением .doc (допустим, мы экспортируем только определенные файлы загруженные в нашу базу данных). Но ведь точка обозначает просто любой символ? Так как же быть?
Тут к нам на помощь приходит экранирование метасимволов обратным слешем \. Теперь выражение \.doc будет достаточно успешно искать любой текстовое упоминание с расширением .doc:
Регулярное выражение: \.
Текст: kursach.doc , nepodozritelneyfail.exe, work.doc, shaprgalka.rtf doc
Как видите, мы успешно можем найти количество файлов с расширением .doc в списке. Однако мы не сможем вытащить полные имена файлов с помощью данного регулярного выражения, например, в массив. Пришло время взглянуть на наборы символов.
Совпадение с целым набором символов
В регулярных выражениях совпадения с набором обеспечивается с помощью метасимволов — квадратных скобочек [ ]. Любые два символа ASII могут быть указаны в качестве начала и конца диапазона. Для простой реализации, положим, мы хотим найти все пронумерованные файлы от 0 до 9 с расширением .jpgРегулярное выражение: [0-9]\.jpg
Текст: 1.jpg, 2.jpg, 3.jpg, photo.jpg, anime.jpg, 8.jpg, jkl.jpg
Стоит отметить, что имя файлов из более 1 цифры наше регулярное выражение не охватит.
Таблица пробельных метасимволов
| [\b] | возврат на один символ |
| \f | перевод страницы |
| \n | перевод строки |
| \r | возрат каретки |
| \t | табуляция |
| \v | вертикальная табуляция |
Множественный выбор: делаем простую валидацию
Вооружившись полученными знаниями, попробуем сделать регулярное выражение, которое находит, например, слова короче 3 букв (стандартная задача для антиспама). Если мы попробуем использовать следующее регулярное выражение —
Если мы попробуем использовать следующее регулярное выражение — \w{1,3} (в котором метасимвол \w указывает на любой символ, а фигурные скобки обозначают количество символов от сколько до скольки, то у нас выделятся все символы подряд — нужно как-то обозначить начало и конец слов в тексте. Для этого нам потребуется метасимвол \bРегулярное выражение: \b\w{1,3}\b:
Текст: good word
not
egg
Неплохо! Теперь слова короче трех букв не смогут попадать в нашу базу данных. Посмотрим на валидацию почтового адреса:
Регулярное выражение: \w+@\w+\.\w+
Требования: в электронной почте в начале должен быть любой символ (цифры или буквы, ведь электронная почта, которая состоит только из цифр в начале, встречается довольно часто). Потом идет символ @, затем — сколько угодно символов, после чего экранированная точка (т.е. просто точка) и домен первого уровня.
Подробнее рассмотрим повторение символов
Теперь давайте поподробнее разберем, как можно в регулярных выражениях задать повторение символов.
Регулярное выражение: [2-6]+
Текст: Here are come’s 89 different 234 digits 24 .
Давайте я приведу таблицу всех квантификаторов метасимволов:
| * | символы повторяются 0 и до бесконечности |
| + | повторяются от 1 и до бесконечности |
| {n} | повторяются точно n раз |
| {n,} | от n и до бесконечности |
| {n1, n2} | от n1 и до n2 раз точно |
| ? | 0 или 1 символ, не больше |
В применении квантификаторов нет ничего сложного. Кроме одного нюанса: жадные и ленивые квантификаторы. Приведем таблицу:
| * | *? |
| + | +? |
| {n,} | {n,}? |
Ленивые квантификаторы отличаются от жадных тем, что они выхватывают минимальное, а не максимальное количество символов. Представим, что есть у нас задача найти все теги заголовков h2-h6 и их контент, а весь остальной текст не должен быть затронут (я умышленно ввел несуществующий тэг h7, чтобы не мучаться с экранированием хабровских тэгов):
Представим, что есть у нас задача найти все теги заголовков h2-h6 и их контент, а весь остальной текст не должен быть затронут (я умышленно ввел несуществующий тэг h7, чтобы не мучаться с экранированием хабровских тэгов):
Регулярное выражение: <h[1-7]>.*?<\/h[1-7]>
Текст: <h7> hello </h7> lorem ipsum avada kedavra <h7> buy</h7>
Все сработало успешно, однако только благодаря ленивому квантификатору. В случае применения жадного квантификатора у нас выделился бы весь текст между тегами (полагаю, в иллюстрации это не нуждается).
Границы символьных строк
Границы символьных строк мы уже использовали выше. Приведем здесь более подробную таблицу:| \b | граница слова |
| \B | не граница слова |
| \A | начало строки |
| \Z | конец строки |
| \G | конец действия |
Работа с подвыражениями
Подвыражения в регулярных выражениях делаются с помощью метасимвола группировки().
Приведем пример регулярного выражения, которое универсально может находить различные вариации IP — адресов.
Регулярное выражение: (((25[0-5])|(2[0-4]\d)|(1\d{2})|(\d{1,2}))\.){3}(((25[0-5]|(2[0-4]\d)|(1\d{2})|(\d{1,2}))))
Текст: 255.255.255.255 просто адрес
191.198.174.192 wikipedia
87.240.190.67 vk
31.13.72.36 facebook
Здесь используется логический оператор | (или), который позволяет нам составить регулярное выражение, которое соответствует правилу, по которому составляются IP- адреса. В IP адресе должно быть от 1 и до 3 цифр, в котором число из трех чисел может начинаться с 1, с 2 (или тогда вторая цифра должна быть в пределах от 0 и до 4), или начинаться с 25, и тогда 3 цифра оказывается в пределах от 0 и до 5. Также между каждой комбинацией цифр должна стоять точка. Используя приведенные выше таблицы, постарайтесь сами расшифровать регулярное выражение сверху. Регулярные выражения в начале пугают своей длинной, но длинные не значит сложные.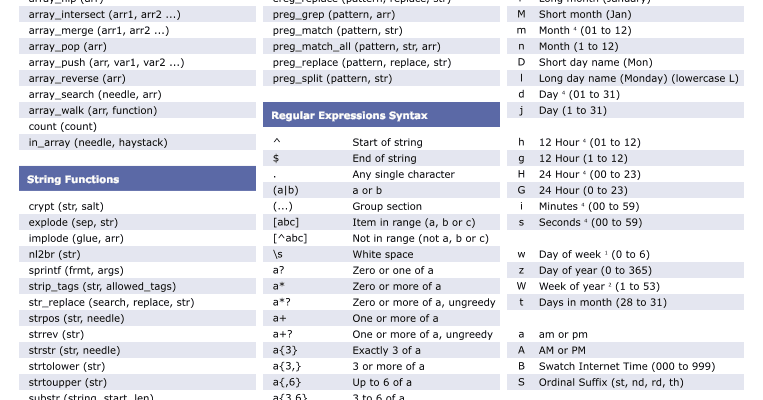 (?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/
(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/
Текст: Qwerty123
Im789098
weakpassword
Особенности работы регулярных выражений именно в PHP
Для изучения работы регулярных выражений в PHP, изучите функции в официальной документации PCRE (Perl Compatible Regular Expressions) которая доступна на официальном сайте. Выражение должно быть заключено в разделители, например, в прямые слеши.Разделителем могут выступать произвольные символы, кроме буквенно-цифровых, обратного слеша ‘\’ и нулевого байта. Если символ разделителя встречается в шаблоне, его необходимо экранировать \. В качестве разделителей доступны комбинации, пришедшие из Perl: (), {}, [].
Какие функции используются в php? В пакете PCRE предоставляются следующие функции для поддержки регулярных выражений:
- preg_grep() — выполняет поиск и возвращает массив совпадений.
- preg_match() — выполняет поиск первого совпадения с помощью регулярных выражений
- preg_match_all() — выполняет глобальный поиск с помощью регулярных выражений
- preg_quote() — принимает шаблон и возвращает его экранированную версию
- preg_replace() — выполняет операцию поиска и замены
- preg_replace_callback() — тоже выполняет операцию поиска и замены, но используют callback – функцию для любой конкретной замены
- preg_split() — разбивает символьную строку на подстроки
Для организации совпадения без учета регистра букв служит модификатор i.
С помощью модификатора m можно активировать режим обработки многострочного текста.
Замещающие строки допускается вычислять в виде кода PHP. Для активизации данного режима служит модификатор e.
Во всех функциях preg_replace(), preg_replace_callback() и preg_split() поддерживается дополнительный аргумент, который вводит ограничения на максимальное количество замен или разбиений.
Обратные ссылки могут обозначаться с помощью знака $ (например $1), а в более ранних версиях вместо знака $ применяются знаки \\.
Метасимволы \E, \l, \L, \u и \U не используются (поэтому они и не были упомянуты в этой статье).
Наша статья была бы неполной без классов символов POSIX, которые также работают в PHP (и в общем вполне могут повысить читабельность ваших регулярок, но не все их спешат учить, потому как часто ломают логику выражения).
| [[:alnum:]] | Любая буква английского алфавита или цифра |
| [[:alpha:]] | Любая буква ([a-zA-Z]) |
| [[:blank:]] | Пробельный символ или символ с кодом 0 и 255 |
| [[:digit:]] | Любая цифра ([0-9]) |
| [[:lower:]] | Любая строчная буква английского алфавита ([a-z]) |
| [[:upper:]] | Любая заглавная буква английского алфавита ([A-Z]) |
| [[:punct:]] | Любой знак пунктуации |
| [[:space:]] | Любой пробельный символ |
| [[:xdigit:]] | Любая шестнадцатеричная цифра ([0-9a-fA-F]) |
Под конец приведу пример конкретной реализации регулярных выражений в PHP, используя упомянутые выше реализации. (?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/’;
if (preg_match($pattern_name, $name) &&
preg_match($pattern_mail, $mail) &&
preg_match($pattern_password, $_POST[‘password’])) {
# тут происходит, к примеру, регистрация нового пользователя, отправка ему письма, и внесение в базу данных
}
(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/’;
if (preg_match($pattern_name, $name) &&
preg_match($pattern_mail, $mail) &&
preg_match($pattern_password, $_POST[‘password’])) {
# тут происходит, к примеру, регистрация нового пользователя, отправка ему письма, и внесение в базу данных
}
Всем спасибо за внимание! Конечно, сегодня мы затронули только часть регулярных выражений и о них можно написать ещё несколько статей. К примеру, мы не поговорили о реализации поиска повторений одинаковых слов в тексте. Но я надеюсь, что полученных знаний хватит, чтобы осмысленно написать свою первую валидацию формы и уже потом перейти к более зубодробительным вещам.
По традиции, несколько полезных ссылок:
Шпаргалка от MIT по регулярным выражениям
Официальная часть документации php по регулярным выражениям.
На этом все. До встречи на интенсиве!
Второй день интенсива пройдет тут
PHP: Функции PCRE — Manual
Change language: EnglishBrazilian PortugueseChinese (Simplified)FrenchGermanJapaneseRussianSpanishTurkishOther
Submit a Pull Request Report a Bug
- preg_filter — Производит поиск и замену по регулярному выражению
- preg_grep — Возвращает массив вхождений, которые соответствуют шаблону
- preg_last_error_msg — Возвращает сообщение об ошибке последней запущенной функции PCRE
- preg_last_error — Возвращает код ошибки выполнения последнего регулярного выражения PCRE
- preg_match_all — Выполняет глобальный поиск шаблона в строке
- preg_match — Выполняет проверку на соответствие регулярному выражению
- preg_quote — Экранирует символы в регулярных выражениях
- preg_replace_callback_array — Выполняет поиск и замену по регулярному выражению с использованием функций обратного вызова
- preg_replace_callback — Выполняет поиск по регулярному выражению и замену с использованием callback-функции
- preg_replace — Выполняет поиск и замену по регулярному выражению
- preg_split — Разбивает строку по регулярному выражению
+add a note
User Contributed Notes 3 notes
up
down
11
steve at stevedix dot de ¶18 years ago
Something to bear in mind is that regex is actually a declarative programming language like prolog : your regex is a set of rules which the regex interpreter tries to match against a string. During this matching, the interpreter will assume certain things, and continue assuming them until it comes up against a failure to match, which then causes it to backtrack. Regex assumes "greedy matching" unless explicitly told not to, which can cause a lot of backtracking. A general rule of thumb is that the more backtracking, the slower the matching process.
During this matching, the interpreter will assume certain things, and continue assuming them until it comes up against a failure to match, which then causes it to backtrack. Regex assumes "greedy matching" unless explicitly told not to, which can cause a lot of backtracking. A general rule of thumb is that the more backtracking, the slower the matching process.It is therefore vital, if you are trying to optimise your program to run quickly (and if you can't do without regex), to optimise your regexes to match quickly.
I recommend the use of a tool such as "The Regex Coach" to debug your regex strings.
http://weitz.de/files/regex-coach.exe (Windows installer) http://weitz.de/files/regex-coach.tgz (Linux tar archive)
 During this matching, the interpreter will assume certain things, and continue assuming them until it comes up against a failure to match, which then causes it to backtrack. Regex assumes "greedy matching" unless explicitly told not to, which can cause a lot of backtracking. A general rule of thumb is that the more backtracking, the slower the matching process.
During this matching, the interpreter will assume certain things, and continue assuming them until it comes up against a failure to match, which then causes it to backtrack. Regex assumes "greedy matching" unless explicitly told not to, which can cause a lot of backtracking. A general rule of thumb is that the more backtracking, the slower the matching process.up
down
4
stronk7 at moodle dot org ¶15 years ago
One comment about 5.2.x and the pcre.backtrack_limit:Note that this setting wasn't present under previous PHP releases and the behaviour (or limit) under those releases was, in practise, higher so all these PCRE functions were able to "capture" longer strings.
With the arrival of the setting, defaulting to 100000 (less than 100K), you won't be able to match/capture strings over that size using, for example "ungreedy" modifiers.
So, in a lot of situations, you'll need to raise that (very small IMO) limit.
The worst part is that PHP simply won't match/capture those strings over pcre.backtrack_limit and will it be 100% silent about that (I think that throwing some NOTICE/WARNING if raised could help a lot to developers).
There is a lot of people suffering this changed behaviour from I've read on forums, bugs and so on).
Hope this note helps, ciao :-)
up
down
-11
Svoop ¶14 years ago
I have written a short introduction and a colorful cheat sheet for Perl Compatible Regular Expressions (PCRE):http://www.bitcetera.com/en/techblog/2008/04/01/regex-in-a-nutshell/
+add a note
PHP: Подшаблоны — Руководство
Изменение языка: английскийбразильский португальскийкитайский (упрощенный)французскийнемецкийяпонскийрусскийиспанскийтурецкийДругое
Отправить запрос на вытягивание Сообщить об ошибке
Подшаблоны заключаются в скобки (круглые скобки),
которые могут быть вложены. Пометка части шаблона как подшаблона
делает две вещи:
Пометка части шаблона как подшаблона
делает две вещи:
Он локализует набор альтернатив. Например, узор
cat(aract|erpillar|)соответствует одному из слов «кошка», «катаракта» или «гусеница». Без круглых скобок это будет соответствовать «катаракта», «эрпилляр» или пустая строка.Он устанавливает подшаблон как захватывающий подшаблон (как определено выше). Когда весь шаблон совпадает, эта часть строки темы который соответствует подшаблону, передается обратно вызывающей стороне через ovector аргумент pcre_exec() . Открывающие скобки считаются слева направо (начиная с 1) до получить номера захватываемых подшаблонов.
Например, если строка «красный король» сопоставляется с
шаблон ((красное|белое) (король|королева)) захваченные подстроки: «красный король», «красный» и «король»,
и имеют номера 1, 2 и 3.
Тот факт, что простые круглые скобки выполняют две функции, не
всегда полезно. Часто бывают случаи, когда группирующий подшаблон
требуется без требования захвата. Если
за открывающей скобкой следует «?:», подшаблон делает
не выполнять никакого захвата и не учитывается при вычислении
количество любых последующих подшаблонов захвата. Например,
если строка «белая королева» сопоставляется с
шаблон ((?:красное|белое) (король|королева)) захваченные подстроки — «белая королева» и «королева», и
пронумерованы 1 и 2. Максимальное количество захваченных подстрок
составляет 65535. Возможно, не удастся скомпилировать такие большие шаблоны,
однако, в зависимости от параметров конфигурации libpcre.
В качестве удобного сокращения, если какие-либо настройки параметров требуется в начале незахватывающего подшаблона, буквы опций могут появляться между «?» и «:». Таким образом два узора
соответствуют точно такому же набору строк. Потому что альтернатива
ветки пробуются слева направо, а опции не
сбрасывать до тех пор, пока не будет достигнут конец подшаблона, опция
установка в одной ветке влияет на последующие ветки, поэтому
приведенные выше шаблоны соответствуют «ВОСКРЕСЕНЬЮ», а также «Субботе».
Потому что альтернатива
ветки пробуются слева направо, а опции не
сбрасывать до тех пор, пока не будет достигнут конец подшаблона, опция
установка в одной ветке влияет на последующие ветки, поэтому
приведенные выше шаблоны соответствуют «ВОСКРЕСЕНЬЮ», а также «Субботе».
Можно назвать подшаблон, используя синтаксис (?P<имя>шаблон) . Затем этот подшаблон
быть проиндексирован в массиве совпадений по его обычному числовому положению и
также по имени. Есть два альтернативных синтаксиса (?<имя>шаблон) и (?'имя'шаблон) .
Иногда необходимо иметь множественные соответствия, но чередующиеся
подгруппы в регулярном выражении. Обычно каждому из них дается
их собственный номер обратной ссылки, даже если только один из них когда-либо
возможно совпадают. Чтобы преодолеть это, синтаксис (?| позволяет
наличие повторяющихся номеров. Рассмотрим следующее регулярное выражение, сопоставленное с
строка Воскресенье :
Здесь Sun хранится в обратной ссылке 2, а
обратная ссылка 1 пуста. Соответствие дает
Соответствие дает сб в
обратная ссылка 1, а обратная ссылка 2 не существует. Изменение шаблона
использовать (?| устраняет эту проблему:
Используя этот шаблон, как Sun , так и Sat будет храниться в обратной ссылке 1.
+ добавить примечание
Пользовательские примечания 1 примечание
вверх
вниз
1
Майк в eastghost точка com ¶8 лет назад
(?:(?!string).) ?: создает подшаблон
?! является негативным взглядом вперед.
Помещение отрицательного прогноза перед точкой приводит к тому, что обработчик регулярных выражений сначала находит любое вхождение отрицательной строки прогноза, и только затем, если негативная строка прогноза отсутствует, должен быть произвольный символ (из-за точки ) соответствовать.
+ добавить примечание
Regex Tester — Javascript, PCRE, PHP
Регулярные выражения
- JavascriptPCRE
- флаги
Тестовая строка
Замена
Сохранить это регулярное выражение
Имя:
Описание:
Верхние регулярные выражения
Проверка URL с http:// или https:// или без них
Только буквы и цифры
Регулярное выражение проверки URL | Регулярное выражение — формат даты Taha
(гггг-мм-дд)
тест nginx
Извлечение строки между двумя STRINGS
совпадение всего слова
проверка специальных символов
соответствие всему, что заключено в квадратные скобки.
Найти подстроку в строке, которая начинается и заканчивается скобками
Простая дата дд/мм/гггг
Блокировка сайта с разблокированными играми
Соответствует, если не начинается со строки
RegEx для Json
Соответствует чему-либо после указанного
все, кроме слова
Переменная Java
10-значный номер телефона с дефисами
Найти любое слово в списке слов
Регулярное выражение для десятичной проверки | Taha
Памятка
| Классы персонажей | ||
|---|---|---|
| . | любой символ кроме новой строки | |
| \ш\д\с | слово, цифра, пробел | 9абв$начало/конец строки |
| \б | граница слова | |
| Экранированные символы | ||
\. \*\ \*\ | экранированные специальные символы | |
| \т \н \р | вкладка, перевод строки, возврат каретки | |
| \u00A9 | Юникод экранирован © | |
| Группы и поиск | ||
| (абв) | группа захвата | |
| \1 | обратная ссылка на группу #1 | |
| (?:abc) | группа без захвата | |
| (?=abc) | положительный прогноз | |
| (?!abc) | отрицательный просмотр вперед | |
| Квантификаторы и чередование | ||
| а* а+ а? | 0 или более, 1 или более, 0 или 1 | |
| а{5} а{2,} | ровно пять, два или больше | |
| а{1,3} | между одним и тремя | |
| а+? а{2,}? | соответствует как можно меньшему числу | |
| аб|кд | соответствует ab или cd | |
RegexPal еще не оптимизирован для мобильных устройств.