Разбираемся с рекурсией на примере связных списков / Хабр
Разбираемся с рекурсией на примере связных списков.Разбираемся с рекурсией на примере связных списков.
Разбираемся с рекурсией на примере связных списков.
Разбираемся с рек-ОШИБКА: ПЕРЕПОЛНЕНИЕ БУФЕРА
Матрёшка в разобранном виде
Примечание: все приведённые ниже реализации будут написаны на Go, если не указано иное. Все строки вывода в консоль опущены для краткости.
На написание этой статьи меня натолкнули размышления о Capstone, а также изучение разнообразных концепций, касающихся структур данных и алгоритмов. Две наиболее интересные из данных тем – это структура данных для представления связных списков и концепция рекурсии как таковая (рекурсия может использоваться в алгоритмах разных типов, но чаще всего применяется в алгоритмах категории «разделяй и властвуй» и в динамическом программировании).
Мне порой было сложно понять отдельные варианты рекурсии с тех самых пор, как я впервые изучал её в старших классах.
Те читатели, которые уже знакомы как со связными списками, так и с рекурсией, могут пропустить введение и сразу переходить к разделу «Постановка задачи». Другие – читайте подряд, сейчас я расскажу об основах связных списков и рекурсии.
Связные списки
Связные списки, как, должно быть, понятно из названия – это совокупности элементов. От обычных коллекций (например, от массивов) они отличаются тем, что не занимают сплошного участка в памяти. Если у вас есть массив чисел, например, [1, 2, 3, 4], то в большинстве языков программирования будет зарезервирован фрагмент памяти, в котором будет храниться весь этот массив.Это явление гораздо понятнее при работе с сильно типизированным языком, например, с Go. Поскольку целые числа занимают определённый объём памяти, компилятору известно, какой максимальный участок памяти нужно зарезервировать под целочисленный массив размером 4, после чего под этот массив отводится соответствующее адресное пространство. Вот пример кода:
Вот пример кода:
func main() {
var nums [4]int
nums[1] = 5
}
Output:
Nums: [0 0 0 0]
nums[0]: 0xc00007e000
nums[3]: 0xc00007e018
Overwriting by index...
Nums: [0 5 0 0]
nums[0]: 0xc00007e000
nums[3]: 0xc00007e018
Допустим, вы хотели бы поменять её на [1, 3, 4]. Можно было бы просто переприсвоить nums[1] следующему значению. Но тогда эту операцию пришлось бы каскадировать на весь остальной массив, перебирая все прочие значения, которые у вас хранятся. В таком случае эта операция приобрела бы сложность O(n), поскольку теоретически длина массива стремится к бесконечности. Для ясности покажу, что вам в таком случае пришлось бы реализовать:
func main() {
var nums [4]int
nums = [4]int{1, 2, 3, 4}
delIdx := 1
for i := delIdx; i < len(nums)-1; i++ {
nums[i] = nums[i+1]
}
}
В результате этих изменений nums принял бы вид [1, 3, 4, 4]. Но теперь у нас возникает иная проблема: размер массива по-прежнему равен 4, причём, последнее значение осталось таким же, что и в самом начале. Поскольку невозможно принудить переменную nums просто «пересчитать» себе размер, приходится импровизировать. Переменная nums может пониматься как окно адресов – значит, нужно скорректировать размер этого окна.
Переменная nums может пониматься как окно адресов – значит, нужно скорректировать размер этого окна.Это довольно легко сделать при помощи применяемой в Go нотации с индексированием срезов: newNums := nums[:3]. Также этот пример демонстрирует, что срез – это просто абстракция реализации массива в Go. Если сравнить указатели &nums[0] и &newNums[0], то видно, что они одинаковы. Но, если попытаться получить доступ к newNums[3], то прилетит ошибка «недействительный индекс». Дело в том, что тип данных для newNums, спрятанный под абстракцией среза – это массив размером 3. Теперь указатель на nums[3] подпадает под сборку мусора и высвобождается, чтобы его можно было использовать под что-нибудь ещё.
Как же связные списки помогут нам решить эту задачу? Как я уже рассказывал, они не занимают непрерывного участка в памяти. Такая структура данных содержит не только значение конкретного узла, но и значение указателя на следующий узел. Здесь мы имеем дело с односвязным списком.
type LinkedList struct {
Val int
Next *LinkedList
}
А теперь посмотрим, что получится, если расположить наши значения в связном списке.nestedList := &LinkedList{
Val: 1,
Next: &LinkedList{
Val: 2,
Next: &LinkedList{
Val: 3,
Next: &LinkedList{
Val: 4,
},
},
},
}
i.e. 1 -> 2 -> 3 -> 4 -> nil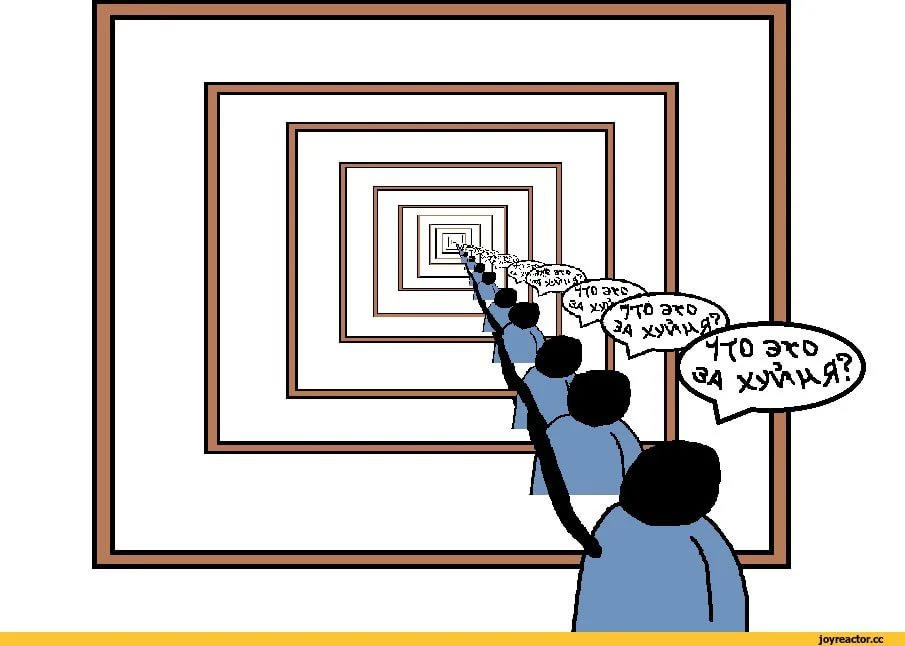
func deleteNthNode(head *LinkedList, n int) *LinkedList {
counter := 1
temp := head
for counter <= n {
temp = temp.Next
counter++
}
*temp = *temp.Next
return head
}
gives us 1 -> 3 -> 4 -> nilРекурсия
В каких-то отношениях рекурсию понять проще, чем связные списки, в каких-то – сложнее. В сущности, рекурсивной называется такая функция, которая вызывает сама себя – элементарно, правда?
В сущности, рекурсивной называется такая функция, которая вызывает сама себя – элементарно, правда?Причина, по которой я решил рассказать о рекурсии и связных списках в рамках одной статьи – при помощи связных списков удобно показать, что рекурсия на определённых уровнях «осведомлена» в том, каковы её аргументы и возвращаемые значения.
Рассмотрим простую рекурсивную функцию – ту самую, при помощи которой я частенько структурирую связный список.
func prettyPrintList(head *LinkedList) {
if head != nil {
fmt.Print(head.Val, " -> ")
prettyPrintList(head.Next)
} else {
fmt.Println("nil")
}
}
Просто показательный пример, демонстрирующий, почему две эти темы так хорошо сочетаются друг с другом. Нельзя просто строчить значения узлов одно за другим, ведь каждому конкретному узлу известно только о следующем. Чтобы подтянуть больше, нужен for-цикл, который постоянно присваивал бы заглушку на месте головного элемента, затем расставлял всё те же ограничивающие операторы nil и так далее.
Сделав такую рекурсивную функцию, даём ей связный список. Поскольку эта функция на n-ном уровне имеет доступ только к n-ному узлу, можно и далее вызывать эту функцию до тех пор, пока не будет достигнуто nil, всякий раз передавая ей следующий по цепочке узел.
Однако у рекурсивных функций есть такая причуда: если вы работаете в них с возвращаемым значением, то они не просто идут вниз до того уровня, который нужно достичь. В зависимости от того, как вы используете функцию, она также всплывает с возвращаемым значением. Если вы знакомы с объектной моделью документа (DOM), можете считать, что этот процесс аналогичен просачиванию событий.
Когда функция вызвана, скажем, на 3-м уровне, далее она спускается на уровень ниже, то есть, на 4-й. Если там, на 4-м уровне окажется что-то, соответствующее базовому случаю, либо возникает ситуация, после которой мы не хотим вновь вызывать функцию, то она вернёт нам искомое значение именно с 4-го уровня. Тогда у значения с 3-го уровня будет возвращаемое значение с 4-го уровня. Как только с 3-го уровня происходит возврат, это значение возвращается уже на 2-й уровень. Так происходит до самого всплытия на верхний уровень, когда мы и получаем окончательное значение.
Как только с 3-го уровня происходит возврат, это значение возвращается уже на 2-й уровень. Так происходит до самого всплытия на верхний уровень, когда мы и получаем окончательное значение.
Постановка задачи
Задача, которую мы будем решать, взята с LeetCode. Если хотите, можете сначала попробовать решить её сами, а потом читайте далее.Известно, что нам дан связный список целых чисел, отсортированных в порядке возрастания. Наша задача – удалить те узлы, значения которых фигурируют в списке более одного раза. Нужно не только создать список уникальных значений, но и полностью удалить все прочие узлы с этими значениями.
Также известно, что при рекурсивном обходе узла за узлом у нас будет доступ только к конкретному узлу и к следующему за ним. Это признак общего паттерна, применяемого при работе с рекурсивными функциями – нужно уметь ориентироваться в более широком контексте. Для этого во многих рекурсивных функциях предусмотрены дополнительные аргументы, действующие в качестве флагов в тех ситуациях, когда на предыдущем или последующем уровне выполняются определённые условия.
В контексте поставленной задачи давайте продумаем каждую ситуацию, в которой может оказаться узел, и как она соотносится с фактом потенциального дублирования конкретного значения:
- Недублирующийся узел указывает на дублирующийся узел
- Дублирующийся узел указывает на дублирующийся узел
- Недублирующийся узел указывает на дублирующийся узел
- Дублирующийся узел указывает на недублирующийся узел
Но задумайтесь, что случится, если вы достигнете конечного (nil), имея строку дублей. Допустим, мы работаем с 2 -> 3 -> 3 -> nil, давайте разберём вышеприведённые случаи узел за узлом:
2 -> 32 не равно 3, поэтому здесь мы никаких изменений в узел вносить не будем и вновь вызовем функцию, на этот раз передав ей в качестве аргумента узел ‘3’.

3 -> 3 a bЗдесь значения равны, и нам нужно убрать дубли. К счастью, поскольку в связных списках содержатся указатели, мы можем изменить исходный список, даже не обращаясь напрямую к головному узлу.
В данном случае мы можем перезаписать указатель ‘a’, так, чтобы он стал ‘b’ – в сущности, удалив ‘a’. Теперь снова вызываем функцию, на этот раз передав ей узел ‘b’.
3 -> nil bКак только мы достигнем nil, имея дубль, нам придётся попытаться перезаписать указатель, но мы не сможем — Go выдаст панику, поскольку нельзя присвоить указателю nil. Поэтому нам понадобится реализовать определённую логику, которая позволяла бы перехватывать ситуацию до возникновения паники, и просто возвращать nil, а не перезаписывать с заменой на nil. Но, если мы вернём nil, то всплывём на уровень вверх. Так мы не только потеряем контекст, позволявший судить, является ли данное значение дублем, но и не сможем изменять значение выше по рекурсивной цепочке, поскольку мы не меняли указатель напрямую.

Вот что можно сделать для решения этой проблемы: мы можем не только полагаться на флаг, сигнализирующий о дубле и посылаемый вниз по пути с рекурсивным изменением. Вдобавок давайте создадим флаг, сигнализирующий, не всплыли ли мы вверх с того уровня, где было дублирующееся значение, смежное с nil. Таким образом, у нас сохранится уловка, позволяющая добраться до nil, и вместе с тем мы сможем безопасно перезаписывать указатели. А если бы мы достигли уровня, имея этот флаг со значением true, мы переключаем узлы и устанавливаем его в false – так сообщается, что дубля в конце у нас уже нет.
Итак, давайте пошагово распишем этот подход, попутно реализовав его.
Нам потребуется два аргумента: узел и изменившийся флаг, сигнализирующий, изменили ли мы узел, двигаясь вниз по рекурсивной цепочке.
func deDupe(node *LinkedList, changed bool) {}
Также нам понадобится булев флаг, указывающий, дошли мы до nil с дублем или нет.func deDupe(node *LinkedList, changed bool) bool {}
Базовый случай – это когда следующий узел равен nil. Также давайте предусмотрим значение, позволяющее судить, не изменили ли мы узел на данном конкретном уровне рекурсии.
Также давайте предусмотрим значение, позволяющее судить, не изменили ли мы узел на данном конкретном уровне рекурсии....
var didChange bool
if node.Next == nil {
...
} else {
...
}
...
Достигнув nil, мы должны знать, пришли ли мы с дублирующегося узла. Именно здесь нам пригодится параметр changed, который мы просто вернём вверх по цепочке....
if node.Next == nil {
return changed
} else {
...
}
...
Если наш следующий узел – не nil, это означает, что мы можем напрямую изменять указатели. Так что давайте реализуем внутри нашей ветки else всю дополнительную логику, которая нам понадобится. Известно, что нам потребуется сравнивать дубли, так что добавим условие, позволяющее сопоставить значение актуального и последующего узла. Обратите внимание: есть очень важная разница между простым переприсваиванием node и переприсваиванием указателя (*node) на node. Переприсваивая node, мы не меняем исходный список напрямую. Вот почему по пути вниз нам требуется булев элемент changed – если мы придём от дубля, то и встреченное значение нужно перезаписать, так как это дубль. Но в данном случае мы не устанавливаем changed в true, поскольку имеем дело с последним из дублей. Если мы пришли не от дубля, то просто переприсвоим node к node.Next, так как именно node передаётся с функцией.
Но в данном случае мы не устанавливаем changed в true, поскольку имеем дело с последним из дублей. Если мы пришли не от дубля, то просто переприсвоим node к node.Next, так как именно node передаётся с функцией....
} else {
if node.Val != node.Next.Val {
if changed {
*node = *node.Next
} else {
node = node.Next
}
} else {
*node = *node.Next
didChange = true
}
}
...
Итак, с рекурсивной функцией мы почти управились. Теперь нужно её вызвать. Поскольку мы изменяем значения, идя вниз, нас по-настоящему волнует только всплытие булевых значений.... lastIsDupe := deDupe(node, didChange) ...Так удаётся узнать, является ли дублем последнее значение в списке – что послужит нам уведомлением, должны ли мы перенаправить узел nil, найденный на этом уровне. Ведь возможно, что после вызова рекурсивной функции наш узел, переданный с ней, был изменён ещё до того, как мы правильно сбросили флаг lastIsDupe.

...
if lastIsDupe && node.Next != nil {
node.Next = nil
lastIsDupe = false
}
return lastIsDupe
...
Наконец, возвращаем флаг lastIsDupe. Если он в процессе всплытия по уровням рекурсии, то мы наткнёмся на предыдущий узел, а следующему узлу присвоим nil, тем самым удалив последний узел – который дублировался. После этого, сбросив флаг в false, мы сообщим на вышестоящие уровни, что дубля в конце уже нет.Итак, давайте соберём всё вместе с кодом исходной функции, в котором предусмотрен вызов на верхнем уровне (обратите внимание, что сигнатура функции изменилось, поскольку на LeetCode соответствующие структуры (связные списки) называются ListNode):
func deleteDuplicates(head *ListNode) *ListNode {
// by default these cases contain no dupes
if head == nil || head.Next == nil {
return head
}
lastIsDupe := deDupe(head, false)
// the reasoning behind this condition
// is the same as in the recursive fn
if lastIsDupe && head. Next != nil {
head.Next = nil
} else if lastIsDupe {
return nil
}
return head
}
func deDupe(node *ListNode, changed bool) bool {
var didChange bool
if node.Next == nil {
return changed
} else {
if node.Val != node.Next.Val {
if changed {
*node = *node.Next
} else {
node = node.Next
}
} else {
*node = *node.Next
didChange = true
}
}
lastIsDupe := deDupe(node, didChange)
if lastIsDupe && node.Next != nil {
node.Next = nil
lastIsDupe = false
}
return lastIsDupe
}
Next != nil {
head.Next = nil
} else if lastIsDupe {
return nil
}
return head
}
func deDupe(node *ListNode, changed bool) bool {
var didChange bool
if node.Next == nil {
return changed
} else {
if node.Val != node.Next.Val {
if changed {
*node = *node.Next
} else {
node = node.Next
}
} else {
*node = *node.Next
didChange = true
}
}
lastIsDupe := deDupe(node, didChange)
if lastIsDupe && node.Next != nil {
node.Next = nil
lastIsDupe = false
}
return lastIsDupe
}
Итак, мы добрались до конца, успешно решив задачу! Не забывайте, что это всего лишь один из вариантов решения – может быть, и не лучший. Его сильная сторона – последовательное изменение значений узлов в одном направлении (учитывая, что сложность по времени — O(n)), но такой подход влечёт серьёзные издержки, сопряжённые со сложностью на уровне операционной системы. Next != nil {
head.Next = nil
} else if lastIsDupe {
return nil
}
return head
}
func deDupe(node *ListNode, changed bool) bool {
var didChange bool
if node.Next == nil {
return changed
} else {
if node.Val != node.Next.Val {
if changed {
*node = *node.Next
} else {
node = node.Next
}
} else {
*node = *node.Next
didChange = true
}
}
lastIsDupe := deDupe(node, didChange)
if lastIsDupe && node.Next != nil {
node.Next = nil
lastIsDupe = false
}
return lastIsDupe
}
Next != nil {
head.Next = nil
} else if lastIsDupe {
return nil
}
return head
}
func deDupe(node *ListNode, changed bool) bool {
var didChange bool
if node.Next == nil {
return changed
} else {
if node.Val != node.Next.Val {
if changed {
*node = *node.Next
} else {
node = node.Next
}
} else {
*node = *node.Next
didChange = true
}
}
lastIsDupe := deDupe(node, didChange)
if lastIsDupe && node.Next != nil {
node.Next = nil
lastIsDupe = false
}
return lastIsDupe
} Ведь все эти рекурсивные вызовы функций будут надстраиваться друг над другом в куче.
Ведь все эти рекурсивные вызовы функций будут надстраиваться друг над другом в куче.Надеюсь, что эта статья помогла вам прояснить некоторые аспекты работы со связными списками или рекурсией/динамическим программированием. Притом, что в ходе чистовой отделки этой реализации я обнаружил некоторые шероховатости, она определённо помогла мне лучше уложить в голове феномен рекурсии в контексте связных списков.
Простыми словами о рекурсии. В программировании рекурсия, или же… | by Артур Хайбуллин | NOP::Nuances of Programming
Published in·
4 min read·
Dec 19, 2020В программировании рекурсия, или же рекурсивная функция — это такая функция, которая вызывает саму себя.
Рекурсию также можно сравнить с матрёшкой. Первая кукла самая большая, за ней идёт точно такая же кукла, но поменьше. Суть матрёшки состоит в том, что вы можете открывать её и доставать из неё точно такую же куклу, только немного меньше. Такой продолжительный процесс длится до тех пор, пока вы не дойдёте до последней куклы, которая и прервёт цикл. Так выглядит визуальная репрезентация рекурсии.
Так выглядит визуальная репрезентация рекурсии.
Да, такой исход вполне возможен. Однако, как и у функции for или while, рекурсию можно прервать условием break, чтобы функция перестала вызывать саму себя.
Вот пример кода того, как можно реализовать функцию обратного отсчёта с использованием рекурсии:
function countDown(n){
console.log(n)if(n > 1){
countDown(n -1) // вызов рекурсии
} else {
return true // основное действие
}
}
countDown(5)// 5
// 4
// 3
// 2
// 1
countDown(-1)
// - 1 // trueКак прервать рекурсию:
Допустим, у нас имеется функция CountDown, которая принимает аргумент (n). Чтобы реализовать обратный отсчёт, нам следует повторить последовательность действий, понижающих значение параметра. Создадим условие вида:
Если (n) больше 1, то вызвать функцию CountDownи вернуться в начало цикла, затем вычесть единицу и снова проверить, выполняется ли условие (n) > 1.
По умолчанию нам нужно создать базовое условие функции, возвращающее значение true, чтобы предотвратить попадание в бесконечный цикл. Базовым условием функции здесь будет условие о том, что любое значение больше 1 не вызовет прерывание цикла.
Проще говоря, рекурсия делает то же, что и код ниже:
countDown(5)
countDown(4)
countDown(3)
countDown(2)
countDown(1)
return
return
return
return
return
Чтобы правильно описать плюсы и минусы, давайте взглянем на производительность рекурсии.
Плюсы:
- Рекурсивный код снижает время выполнения функции.
Под этим подразумевается, что рекурсии, в сравнении с циклами, тратят меньше времени до завершения функции. Чем меньше строк кода у нас будет, тем быстрее функция будет обрабатывать вызовы внутри себя. Особенно хорошо это проявляется при буферизации данных, что позволяет оптимизировать и ускорить код.
В программировании мемоизация — это метод сохранения результатов выполнения функций для предотвращения повторных вычислений. Это один из способов оптимизации, применяемый для увеличения скорости выполнения программ. — Википедия
Это один из способов оптимизации, применяемый для увеличения скорости выполнения программ. — Википедия
И всё же стоит отметить, что рекурсия не всегда выигрывает по скорости по сравнению с циклами.
- Рекурсию легче отлаживать.
Многие согласятся, что эта причина очень важна. Рекурсия проста в отладке из-за того, что она не содержит сложных и длинных конструкций.
Минусы:
- Рекурсивные функции занимают много места.
Рекурсивные функции занимают значительный объём памяти во время своего выполнения. Это означает, что при каждом вызове функции в стек будет добавляться новый элемент, который будет занимать место до тех пор, пока функция не завершит работу, найдя ответ, либо пока не дойдёт до выполнения базового условия функции.
- Рекурсивные функции замедляют программу.
Несмотря на то, что уже было сказано про мемоизацию, наш код можно ускорить, если применить циклы for или while. Помимо того, что функция может быть попросту плохо написана, мы также рискуем переполнить стек, что в конечном итоге приведёт к снижению скорости и программным ошибкам.
Помимо того, что функция может быть попросту плохо написана, мы также рискуем переполнить стек, что в конечном итоге приведёт к снижению скорости и программным ошибкам.
Стек — это такая структура данных, которая работает по принципу «Last In, First Out» (последним пришёл — первым ушёл). Таким образом, элемент «проталкивается» в стек и добавляется в его конец, а затем «выталкивается» из стека при удалении.
Стеки замечательны тем, что они очень быстрые. Большое «О» этого алгоритма равно O(1). Такая результативность объясняется тем, что при рекурсиях не используются циклы, вместо них используются функции pop(), push() и empty().
Оба этих метода одинаково эффективны для решения задач, однако выбор одного из них зависит от типа проблемы, поставленной перед вами.
Рекурсии эффективны тогда, когда вы работаете с данными, которые слишком сложны, чтобы пройтись по ним с помощью обычных циклов. Стоит также не забывать о ценности памяти и уменьшении времени, идущем вкупе с рекурсивной функцией, в которой накопилось слишком много элементов.