Реляционная модель данных — Национальная библиотека им. Н. Э. Баумана
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 20:28, 12 июня 2017.
Реляционная модель — совокупность данных, состоящая из набора двумерных таблиц. В теории множеств таблице соответствует термин отношение (relation), физическим представлением которого является таблица, отсюда и название модели – реляционная. Соответственно теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики, как теория множеств и логика первого порядка. В сравнении с иерархической и сетевой моделью данных, реляционная модель отличается более высоким уровнем абстракции данных. Реляционная модель является удобной и наиболее привычной формой представления данных, так в настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД. На реляционной модели данных строятся реляционные базы данных[1].
Впервые принципы реляционной модели были сформулированы в 1969—1970 годах Э. Ф. Коддом (E. F. Codd). Идеи Кодда были впервые публично изложены в статье «A Relational Model of Data for Large Shared Data Banks». Современную трактовку идей реляционной модели данных можно найти в книге К. Дж. Дейта. «C. J. Date. An Introduction to Database Systems»
Состав частей реляционной модели данных
Наиболее распространенная трактовка реляционной модели данных, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
Структурная часть
Структурная часть (аспект), отвечает за принцип построения структуры реляционной базы данных на нормализированном наборе n-арных отношений, в форме таблиц. Важно что реляционная база данных, структурно может представляться только в виде отношений.
Манипуляционная часть
В манипуляционной части модели утверждаются операторы манипулирования отношениями — реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй — на классическом логическом аппарате исчисления предикатов первого порядка. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Целостная часть
В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Как мы видели в предыдущем разделе, это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений.
Второе требование называется требованием целостности по ссылкам и является несколько более сложным. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений. Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
Структура реляционной модели данных
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствованна соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута –
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формирую дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.
Достоинства и недостатки реляционной модели данных
Достоинства
- Изложение информации в простой и понятной для пользователя форме (таблица).
- Реляционная модель данных основана на строгом математическом аппарате, что позволяет лаконично описывать необходимые операции над данными.
- Независимость данных от изменения в прикладной программе при изменении.
- Позволяет создавать языки манипулирования данными не процедурного типа.
- Для работы с моделью данных нет необходимости полностью знать организацию БД.
Недостатки
- Относительно медленный доступ к данным.
- Трудность в создании БД основанной на реляционной модели.
- Трудность в переводе в таблицу сложных отношений.
- Требуется относительно большой объем памяти.
См. также
Источники
Ссылки
- http://www.bseu.by/it/tohod/lekcii2_3.htm
- http://wiki.mvtom.ru/index.php/%D0%A0%D0%B5%D0%BB%D1%8F%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85
- http://citforum.ru/database/osbd/glava_18.shtml
ru.bmstu.wiki
Реляционные модели базы данных
Введение
Основные идеи современной информационной технологии базируются на концепции баз данных (БД). Согласно данной концепции основой информационной технологии являются данные, организованные в БД, адекватно отражающие реалии действительности в той или иной предметной области и обеспечивающие пользователя актуальной информацией в соответствующей предметной области. В широком смысле слова база данных — это совокупность описаний объектов реального мира и связей между ними, актуальных для конкретной прикладной области.
Как сущности, атрибуты и связи отображаются на структуры данных — определяется моделью данных.
Традиционно все СУБД классифицируются в зависимости от модели данных, которая лежит в их основе. Принято выделять иерархическую, сетевую и реляционную модели данных. Иногда к ним добавляют модель данных на основе инвертированных списков. Соответственно говорят об иерархических, сетевых, реляционных СУБД или о СУБД на базе инвертированных списков.
По распространенности и популярности реляционные СУБД сегодня — вне конкуренции. Они стали фактическим промышленным стандартом, и поэтому отечественному пользователю придется столкнуться в своей практике именно с реляционной СУБД.
Основы реляционной модели данных были впервые изложены в статье Е.Кодда в 1970 г. Эта работа послужила стимулом для большого количества статей и книг, в которых реляционная модель получила дальнейшее развитие. Наиболее распространенная трактовка реляционной модели данных принадлежит К.Дейту[1] . Согласно Дейту, реляционная модель состоит из трех частей:
Структурной части.
Целостной части.
Манипуляционной части.
Структурная часть описывает, какие объекты рассматриваются реляционной моделью. Постулируется, что единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения.
Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей.
Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными — реляционную алгебру и реляционное исчисление.
Цель данной работы рассмотреть структурную и целостную часть реляционной модели базы данных.
1. Структурная часть реляционной модели
1.1 Типы данных
Любые данные, используемые в программировании, имеют свои типы данных.
Реляционная модель требует, чтобы типы используемых данных были простыми.
Для уточнения этого утверждения рассмотрим, какие вообще типы данных обычно рассматриваются в программировании. Как правило, типы данных делятся на три группы:
Простые типы данных.
Структурированные типы данных.
Ссылочные типы данных.
Простые, или атомарные, типы данных не обладают внутренней структурой. Данные такого типа называют скалярами. К простым типам данных относятся следующие типы: Логический, Строковый, Численный[2] .
Различные языки программирования могут расширять и уточнять этот список, добавляя такие типы как:
Целый.
Вещественный.
Дата.
Время.
Денежный.
Перечислимый.
Интервальный.
И т.д.…
Конечно, понятие атомарности довольно относительно. Так, строковый тип данных можно рассматривать как одномерный массив символов, а целый тип данных — как набор битов. Важно лишь то, что при переходе на такой низкий уровень теряется семантика (смысл) данных. Если строку, выражающую, например, фамилию сотрудника, разложить в массив символов, то при этом теряется смысл такой строки как единого целого.
Структурированные типы данных предназначены для задания сложных структур данных. Структурированные типы данных конструируются из составляющих элементов, называемых компонентами, которые, в свою очередь, могут обладать структурой. В качестве структурированных типов данных можно привести следующие типы данных:
Массивы
Записи (Структуры)
С математической точки зрения массив представляет собой функцию с конечной областью определения. Например, рассмотрим конечное множество натуральных чисел
mirznanii.com
8.4 Реляционная модель базы данных
Появление реляционной модели и вообще теории реляционных СУБД связывают с именем Э.Кодда, опубликовавшего в 1970 году статью с изложением принципов реляционного подхода к созданию и применению СУБД. В основе реляционной модели базы данных лежит математическое понятие отношения, откуда и происходит название этого типа модели БД.
Пусть
–
некоторые множества, необязательно
различные. Выражениеназываетсядекартовым
произведением названных множеств. Оно само является
множеством и состоит из всех упорядоченных
последовательностей или кортежей,
вида
,
где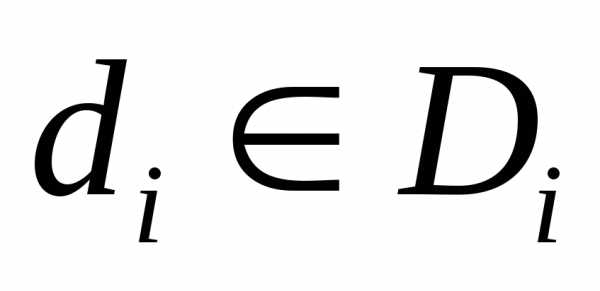 ,i=
1, 2, …, n.
,i=
1, 2, …, n.
В
декартовом произведении D каждое из множеств 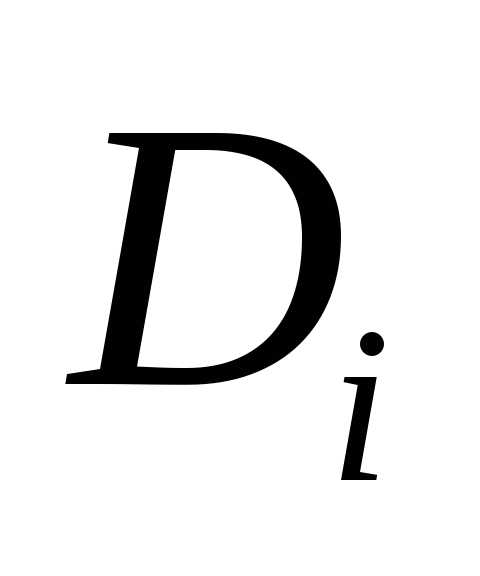 называетсядоменом.
Домены могут быть различны по характеру
и числу входящих в них элементов.
Например, домен
называетсядоменом.
Домены могут быть различны по характеру
и числу входящих в них элементов.
Например, домен  может представлять фамилии (с инициалами)
студентов вуза;
может представлять фамилии (с инициалами)
студентов вуза; —
годы обучения студента в вузе;
—
годы обучения студента в вузе;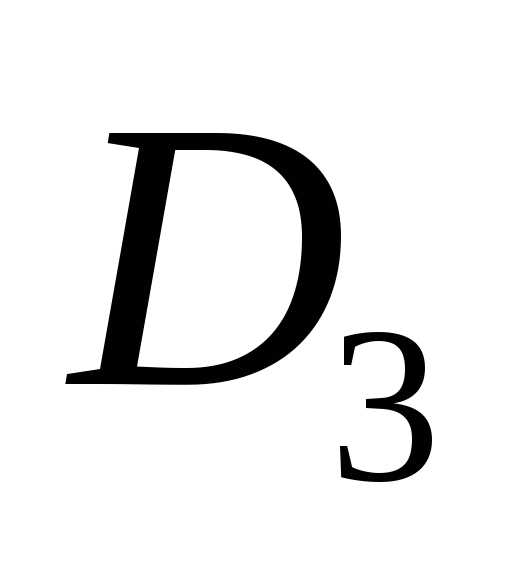 —
названия факультетов и т.д.
—
названия факультетов и т.д.
Подмножество
декартова произведенияD (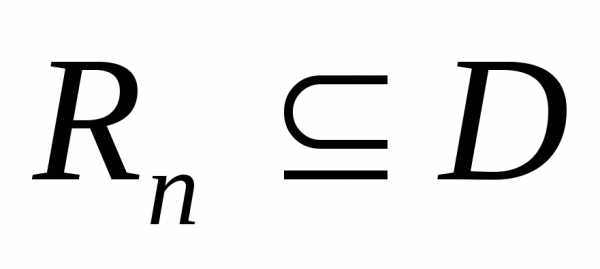 )
называетсяn–местным
отношением. Число n называется степенью или арностью отношения. При n=1
отношение является унарным,
при n=2
– бинарным,
при n=3
– тернарным и т.д. Число всех различных кортежей
,
образующих отношение
)
называетсяn–местным
отношением. Число n называется степенью или арностью отношения. При n=1
отношение является унарным,
при n=2
– бинарным,
при n=3
– тернарным и т.д. Число всех различных кортежей
,
образующих отношение 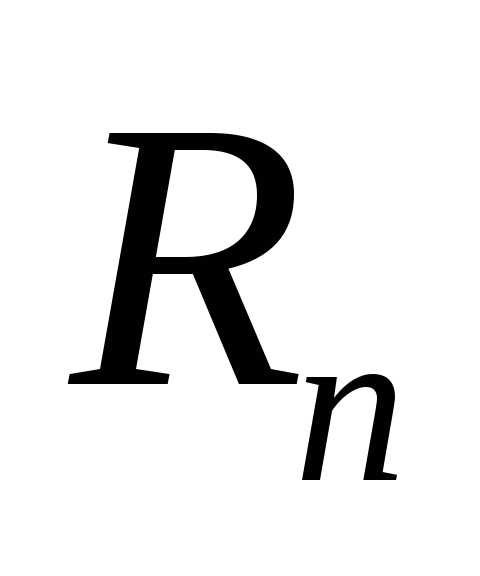 ,
называется кардинальным
числом этого отношения.
,
называется кардинальным
числом этого отношения.
Отношение
удобно представлять в виде таблицы.
Строками такой таблицы являются кортежи,
образующие отношение, а каждый из
столбцов соответствует определенному
домену. Для n–арного
отношения i–й
столбец соответствует домену 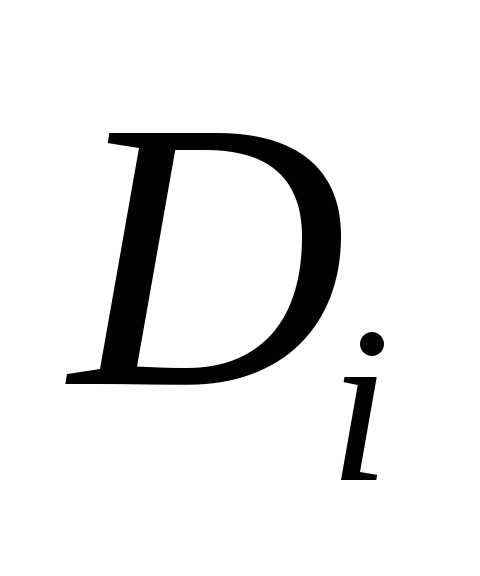 ,
гдеi=1,2,…,n.
Число строк в таблице, представляющей
отношение, равно кардинальному числу
этого отношения. Поскольку по определению
отношение является множеством, порядок
следования кортежей в строках таблицы
безразличен.
,
гдеi=1,2,…,n.
Число строк в таблице, представляющей
отношение, равно кардинальному числу
этого отношения. Поскольку по определению
отношение является множеством, порядок
следования кортежей в строках таблицы
безразличен.
Если каждому из столбцов таблицы присвоить уникальное имя, то можно в произвольном порядке переставлять и столбцы таблицы. Разумеется, при перестановке столбцов необходимо менять местами и соответствующие этим столбцам элементы всех кортежей отношения.
Выраженное в табличной форме отношение совпадает с хорошо известным способом представления набора данных в виде последовательности записей с той же структурой. При этом каждый столбец таблицы-отношения соответствует определенному полю записи, а каждый кортеж – конкретной записи.
Однако не всякая таблица записей является отношением. Для того чтобы таблица была отношением, необходимо выполнение следующих условий:
— все записи в таблице должны иметь одну и ту же структуру;
— каждая запись в таблице должна быть уникальной;
— значения элементов одного и того же столбца таблицы должны принадлежать одному и тому же домену;
— имена столбцов должны быть различны.
В качестве имен столбцов в таблице, представляющей отношение, не всегда можно использовать имена, или обозначения, доменов, так как среди доменов, из которых образуется отношение, могут быть и совпадающие домены.
При рассмотрении реляционной модели БД в табличной форме вместо термина «столбец» обычно используют термин «атрибут«. С использованием понятия атрибута отношение часто выражают в виде символьной строки R(A1,A2,…,AM), где R – название отношения; — A1,A2,…,AM — упорядоченная последовательность имен, или названий, атрибутов.
Как правило, один или несколько атрибутов в каждом отношении используются в качестве ключа. Ключ – такой атрибут (или совокупность нескольких атрибутов), значение которого идентифицирует каждый кортеж, или запись, в таблице, представляющей данное отношение. Ключ, состоящий из нескольких атрибутов, называется комбинированным. Комбинированный ключ должен быть неизбыточным, т.е. таким ключом, из которого нельзя удалить ни один из входящих в него атрибутов без того, чтобы ключ перестал однозначно идентифицировать записи в таблице.
Ключ данного отношения называется первичным ключом. В теории реляционных моделей СУБД используется также понятие «внешний ключ». Внешний ключ – такой атрибут (или комбинация атрибутов) данного отношения, который является первичным ключом для некоторого другого отношения.
В реляционной модели данных каждое отношение должно быть нормализовано. Говорят, что отношение нормализовано, если каждое значение любого атрибута в каждом кортеже отношения является неделимым, или атомарным элементом. Таким элементом может быть данное базового типа (целое или вещественное число, значение логического типа и т.д.) или символьная строка. Определенное таким образом понятие нормализованного отношения соответствует первой нормальной форме и обозначается 1NF. В теории реляционных моделей СУБД изучаются также вторая, третья, четвертая нормальные формы отношений, которые отличаются от формы 1NF различным характером функциональной зависимости атрибутов друг от друга и от первичного ключа.
С точки зрения пользователя реляционная модель базы данных представляется в виде совокупности поименованных нормализованных отношений, различающихся степенями и кардинальными числами. Для более глубокого уяснения сущности реляционной модели БД отношению можно поставить в соответствие традиционный файл с однотипными записями, кортежу отношения – экземпляр записи файла, а атрибуту – поименованное поле в структуре записи файла. Нормализованное отношение нередко называют также плоским файлом вследствие того, что каждое значение атрибута в любом кортеже отношения – неделимый элемент. Такое значение является либо числом, либо строкой символов.
Для манипулирования данными в реляционных СУБД создан целый ряд языков, которые называются также подъязыками данных. В зависимости от характера математического аппарата, лежащего в основе языков, все ЯМД в реляционных СУБД можно разделить на два главных класса: языки реляционной алгебры; языки реляционного исчисления.
Рассмотрим кратко сущности языков обоих классов. Языки реляционной алгебры основаны на реляционной алгебре (ее называют также реляционной алгеброй Кодда), характеризующейся определенным набором операций, которые можно выполнять над отношениями в реляционной СУБД. К таким операциям относятся традиционные операции над множествами (объединение, пересечение, разность, декартово произведение), а также специальные реляционные операции, важнейшими из которых являются операции проекции, соединения и выбора.
При выполнении операций объединения, пересечения и разности участвующие в них отношения должны удовлетворять свойству совместимости по объединению. Два отношения совместимы по объединению (или просто совместимы), если они имеют одну и ту же степень (т.е. одно и то же число атрибутов) и совпадающие атрибуты, причем значения атрибутов в каждой паре одинаковых атрибутов из обоих отношений должны быть элементами одного и того же домена. Операции объединения, пересечения, разности и декартового произведения в реляционных СУБД обозначают принятыми в математике символами È, Ç, /, ´.
Объединением двух совместимых отношений R1, R2 называется отношение R, состоящее из всех кортежей, принадлежащих хотя бы одному из отношений R1, R2. Пусть, например,
,
где
Тогда
Пересечением двух совместимых отношений R1, R2 называется отношение R, которое состоит из всех кортежей, являющихся общими для отношений R1, R2. Для отношений R1(A,B) и R2(A,B) из предыдущего примера результат пересечения будет
Разностью двух совместимых отношений R1, R2 называется отношение R, состоящее только из тех кортежей отношения R1, которые отсутствуют в отношении R2. Для примера отношений R1(A,B) и R2(A,B) их разность
Декартовым произведением двух отношений R1, R2 (необязательно совместимых) называется отношение R, состоящее из всех таких картежей, каждый из которых есть конкатенация двух кортежей, по одному картежу из отношений R1, R2, причем на первом месте должен быть кортеж из R1. Для отношений R1(A,B), R2(A,B) их декартово произведение
Операции объединения, пересечения и декартового произведения могут быть обобщены на произвольное число участвующих в них отношений.
Обратимся теперь к операциям проекции, соединения и выбора. Операция проекции является унарной и позволяет из заданного отношения R получить другое отношение R‘, в котором множество атрибутов является подмножеством атрибутов отношения R. Из одного и того же исходного отношения с помощью операции проекции можно получить несколько разных отношений. Для выполнения операции проекции необходимо задать исходное отношение, а также подмножество тех его атрибутов, которые должны составлять результирующее отношение. Таким образом, проекция исходного отношения осуществляется на заданные его атрибуты. Сокращенно связь между исходным отношением и отношением, являющимся результатом проекции, можно записать в виде R‘=П R(A) ,где П – обозначение операции проекции; A – подмножество атрибутов исходного отношения R, на которое осуществляется проекция.
Отношение, являющееся результатом операции проекции, состоит из всех кортежей исходного отношения, в которых присутствуют значения атрибутов, входящих в множество А. При этом порядок следования атрибутов в результирующем отношении может отличаться от порядка следования этих же атрибутов в исходном отношении.
Следующая специальная операция реляционной алгебры – операция соединения – позволяет создать новое отношение из двух и более исходных отношений, имеющих хотя бы один общий атрибут. При этом для каждого из исходных отношений можно указать лишь те атрибуты, которые должны войти в результирующее отношение. Для того, чтобы результирующее отношение содержало хотя бы один кортеж, необходимо, чтобы по крайней мере в одном из кортежей каждого исходного отношения общий атрибут имел одно и то же значение.
Последняя из трех основных специальных операций реляционной алгебры – операция выбора – унарная и обеспечивает выбор некоторого подмножества картежей из исходного отношения. В результате операции получается новое отношение, состоящее из таких кортежей исходного отношения, в которых значение одного (или нескольких) атрибута удовлетворяет заданному в операции условию.
Вторая большая группа ЯМД в реляционных СУБД использует реляционное исчисление, основанное на классическом исчислении предикатов и представляющее собой набор правил для записи выражений, которые обеспечивают формирование новых отношений в терминах заданных существующих отношений. При записи таких выражений применяются операторы сравнения =, ¹, <, £, >, ³, логические операторы Ù, Ú,Ø и кванторы $,».
Различие между двумя описанными классами языков реляционных моделей СУБД проявляется главным образом в том, как пользователь может выражать свои запросы к СУБД. Применяя язык реляционной алгебры, пользователь должен записать в соответствующем порядке всю последовательность операций, которые необходимо выполнить для получения желаемого результата. Это, конечно, требует от пользователя больших усилий. В то же время на языке реляционного исчисления пользователь записывает свой запрос лишь в виде декларации желаемого результата, а СУБД автоматически «развернет» эту декларацию в правильную последовательность необходимых действий. Таким образом, различие между языками реляционной алгебры и реляционного исчисления такое же, как и между двумя известными в математике способами определения множества. Один из этих двух способов обеспечивает построение желаемого множества путем выполнения ряда теоретико-множественных операций над некоторыми заданными исходными множествами, а другой способ – путем указания определяющего свойства желаемого множества.
Теория и практика применения СУБД представляет собой в настоящее время стремительно развивающуюся область вычислительной техники, в которой заняты тысячи ученых, инженеров и просто пользователей.
studfiles.net
Модели данных
Центральным понятием в области баз данных является понятие модели данных. Модель данных является ядром любой базы данных.
Модель данных – совокупность структур данных и операций их обработки.
Модель данных – это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, т.е. сведения, содержащие не только данные, но и взаимосвязь между ними.
Среди множества моделей данных выделим иерархические, сетевые, реляционные и комбинированные модели данных.
Реляционная модель данных
Реляционной считается такая база данных, в которой все данные представлены для пользователя в виде прямоугольных таблиц значений данных, и все операции над базой данных сводятся к манипуляциям с таблицами. Таблица состоит из строк и столбцов и имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта реального мира (сущность), а каждая ее строка — конкретный объект. Значения атрибутов выбираются из множества допустимых значений, которое называется доменом (domain). Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключом (primary key). Если таблица удовлетворяет этому требованию, она называется отношением (relation). Взаимосвязь таблиц является важнейшим элементом реляционной модели данных. Она поддерживается внешними ключами (foreign key). Таблицы невозможно хранить и обрабатывать, если в базе данных отсутствуют «данные о данных», например, описатели таблиц, столбцов и т.д. Их называют обычно метаданными. Метаданные также представлены в табличной форме и хранятся в словаре данных (data dictionary). Помимо таблиц, в базе данных могут храниться и другие объекты, такие как экранные формы, отчеты (reports), представления (views) и даже прикладные программы, работающие с базой данных. Для пользователей информационной системы недостаточно, чтобы база данных просто отражала объекты реального мира. Важно, чтобы такое отражение было однозначным и непротиворечивым. В этом случае говорят, что база данных удовлетворяет условию целостности (integrity). Для того, чтобы гарантировать корректность и взаимную непротиворечивость данных, на базу данных накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints). Существует несколько типов ограничений целостности. Требуется, например, чтобы значения в столбце таблицы выбирались только из соответствующего домена. На практике учитывают и более сложные ограничения целостности, например, целостность по ссылкам (referential integrity). Ее суть заключается в том, что внешний ключ не может быть указателем на несуществующую строку в таблице. Ограничения целостности реализуются с помощью специальных средств, таких как привила (rules), триггеры (triggers) и домены (domains).
Реляционные модели относятся к теоретико-множественным моделям. Появление теоретико-множественных моделей в системах баз данных было предопределено настоятельной потребностью пользователей в переходе от работы с элементами данных, как это делается в графовых моделях, к работе с некоторыми макрообъектами. Основной моделью в этом классе является реляционная модель данных. Простота и наглядность модели для пользователей-непрограммистов, с одной стороны, и серьезное теоретическое обоснование, с другой стороны, определили большую популярность этой модели. Кроме того, развитие формального аппарата представления и манипулирования данными в рамках реляционной модели сделали ее наиболее перспективной для использования в системах представления знаний, что обеспечивает качественно иной подход к обработке данных в больших информационных системах.
Основной структурой данных в модели является отношение, именно поэтому модель получила название реляционной (от английского relation — отношение).
Данная таблица обладает рядом специфических свойств:
1.В таблице нет двух одинаковых строк.
2.Таблица имеет столбцы, соответствующие атрибутам отношения.
3.Каждый атрибут в отношении имеет уникальное имя.
4.Порядок строк в таблице произвольный.
Домен, входящий в отношение принято называть атрибутом. Строки отношения называются кортежами.
Количество атрибутов в отношении называется степенью, или рангом, отношения.
Любое отношение является динамической моделью некоторого реального объекта внешнего мира. Поэтому вводится понятие экземпляра отношения, которое отражает состояние данного объекта в текущий момент времени, и понятие схемы отношения, которая определяет структуру отношения.
Схемой отношения R называется перечень имен атрибутов данного отношения с указанием домена, к которому они относятся:
Sr = (A1, А2, Аn), Ai Di.
Если атрибуты принимают значения из одного и того же домена, то они называются — сравнимыми, где — множество допустимых операций сравнения, заданных для данного домена. Например, если домен содержит числовые данные , то для него допустимы все операции сравнения, тогда = {=, <>,>=, <=,<,>}. Однако и для доменов, содержащих символьные данные, могут быть заданы не только операции сравнения по равенству и неравенству значений. Если для данного домена задано лексикографическое упорядочение, то он имеет также полный спектр операций сравнения.
Схемы двух отношений называются эквивалентными, если они имеют одинаковую степень и возможно такое упорядочение имен атрибутов в схемах, что на одинаковых местах будут находиться сравнимые атрибуты, то есть атрибуты, принимающие значения из одного домена.
Sri = (А1, А2, …, Аn) — схема отношения R1.
Sr2 = (В11, В12,…, В1n) — схема отношения R2 после упорядочения имен атрибутов.
Как уже говорилось ранее, реляционная модель представляет базу данных в виде множества взаимосвязанных отношений. В отличие от теоретико-графовых моделей в реляционной модели связи между отношениями поддерживаются неявным образом.
Первичный ключ – такой атрибут или набор атрибутов, который может быть использован для однозначной идентификации конкретного кортежа. Если первичный ключ состоит из набора атрибутов, то такой ключ называется составным.
В подчиненном отношении для моделирования связи должен присутствовать набор атрибутов, соответствующий первичному ключу основного отношения. Однако здесь этот набор атрибутов уже является вторичным ключом, то есть он определяет множество кортежей подчиненного отношения, которые связаны с единственным кортежем основного отношения. Данный набор атрибутов в подчиненном отношении принято называть внешним ключом (FOREIGN KEY).
Возможно индексирование отношения с использованием атрибутов, отличных от первичного ключа. Данный тип индекса называется вторичным индексом и применяется в целях уменьшения времени доступа при поиске данных в отношении.
Число отношений в БД и конкретные атрибуты, приписываемые каждому отношению, определяются в процессе проектирования БД. Собственно процесс проектирования может быть довольно продолжительным. Однако после завершения этапа проектирования создание БД средствами СУБД можно выполнить достаточно быстро.
studfiles.net
Реляционная база данных — Национальная библиотека им. Н. Э. Баумана
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 12:13, 25 марта 2017.
Реляционная база данных — база данных, построенная на основе реляционной модели[1]. В реляционной базе каждый объект задается записью (строкой) в таблице. Реляционная база создается и затем управляется с помощью реляционной системы управления базами данных.Фактически реляционная база данных это тело связанной информации, сохраняемой в двухмерных таблицах. Связь между таблицами может находить свое отражение в структуре данных, а может только подразумеваться, то есть присутствовать на неформализованном уровне. Каждая таблица БД представляется как совокупность строк и столбцов, где строки соответствуют экземпляру объекта, конкретному событию или явлению, а столбцы — атрибутам (признакам, характеристикам, параметрам) объекта, события, явления. Реляционные базы данных предоставляют более простой доступ к оперативно составляемым отчетам (обычно через SQL) и обеспечивают повышенную надежность и целостность данных благодаря отсутствию избыточной информации.
История
Реляционные системы берут свое начало в математической теории множеств. Эдгар Кодд, сотрудник исследовательской лаборатории корпорации IBM в Сан-Хосе, по существу, создал и описал концепцию реляционных баз данных в своей основополагающей работе «Реляционная модель для крупных, совместно используемых банков данных» (A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, июнь 1970).
Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин «запись», который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин «кортеж длины n» или просто «кортеж», которому дал точное определение.
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных. Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним.
Правила Кодда
Правило 0: Основное правило (Foundation Rule):
- Система, которая рекламируется или позиционируется как реляционная система управления базами данных, должна быть способна управлять базами данных, используя исключительно свои реляционные возможности.
Правило 1: Информационное правило (The Information Rule):
- Вся информация в реляционной базе данных на логическом уровне должна быть явно представлена единственным способом: значениями в таблицах.
Правило 2: Гарантированный доступ к данным (Guaranteed Access Rule):
- В реляционной базе данных каждое отдельное (атомарное) значение данных должно быть логически доступно с помощью комбинации имени таблицы, значения первичного ключа и имени столбца.
Правило 3: Систематическая поддержка отсутствующих значений (Systematic Treatment of Null Values):
- Неизвестные, или отсутствующие значения NULL, отличные от любого известного значения, должны поддерживаться для всех типов данных при выполнении любых операций. Например, для числовых данных неизвестные значения не должны рассматриваться как нули, а для символьных данных — как пустые строки.
Правило 4: Доступ к словарю данных в терминах реляционной модели (Active On-Line Catalog Based on the Relational Model):
- Словарь данных должен сохраняться в форме реляционных таблиц, и СУБД должна поддерживать доступ к нему при помощи стандартных языковых средств, тех же самых, которые используются для работы с реляционными таблицами, содержащими пользовательские данные.
Правило 5: Полнота подмножества языка (Comprehensive Data Sublanguage Rule):
- Система управления реляционными базами данных должна поддерживать хотя бы один реляционный язык, который
- (а) имеет линейный синтаксис,
- (б) может использоваться как интерактивно, так и в прикладных программах,
- (в) поддерживает операции определения данных, определения представлений, манипулирования данными (интерактивные и программные), ограничители целостности, управления доступом и операции управления транзакциями (begin, commit и rollback).
Правило 6: Возможность изменения представлений (View Updating Rule):
- Каждое представление должно поддерживать все операции манипулирования данными, которые поддерживают реляционные таблицы: операции выборки, вставки, изменения и удаления данных.
Правило 7: Наличие высокоуровневых операций управления данными (High-Level Insert, Update, and Delete):
- Операции вставки, изменения и удаления данных должны поддерживаться не только по отношению к одной строке реляционной таблицы, но и по отношению к любому множеству строк.
Правило 8: Физическая независимость данных (Physical Data Independence):
- Приложения не должны зависеть от используемых способов хранения данных на носителях, от аппаратного обеспечения компьютеров, на которых находится реляционная база данных.
Правило 9: Логическая независимость данных (Logical Data Independence):
- Представление данных в приложении не должно зависеть от структуры реляционных таблиц. Если в процессе нормализации одна реляционная таблица разделяется на две, представление должно обеспечить объединение этих данных, чтобы изменение структуры реляционных таблиц не сказывалось на работе приложений.
Правило 10: Независимость контроля целостности (Integrity Independence):
- Вся информация, необходимая для поддержания целостности, должна находиться в словаре данных. Язык для работы с данными должен выполнять проверку входных данных и автоматически поддерживать целостность данных.
Правило 11: Независимость от расположения (Distribution Independence):
- База данных может быть распределённой, может находиться на нескольких компьютерах, и это не должно оказывать влияния на приложения. Перенос базы данных на другой компьютер не должен оказывать влияния на приложения.
Правило 12: Согласование языковых уровней (The Nonsubversion Rule):
- Если используется низкоуровневый язык доступа к данным, он не должен игнорировать правила безопасности и правила целостности, которые поддерживаются языком более высокого уровня.
Сущность реляционной базы данных
Реляционная база данных представляет собой набор таблиц (сущностей). Таблицы состоят из колонок и строк (кортежей). Внутри таблиц могут быть определены ограничения, между таблицами существуют отношения. При помощи SQL можно выполнять запросы, которые возвращают наборы данных, получаемых из одной или нескольких таблиц. В рамках одного запроса данные получаются из нескольких таблиц путем их соединения (JOIN), чаще всего для соединения используются те же колонки, которые определяют отношения между таблицами.
Нормализация — это процесс структурирования модели данных, обеспечивающий связность и отсутствие избыточности в данных. Целью нормализации реляционной базы данных является устранение недостатков структуры базы данных, приводящих к избыточности, которая, в свою очередь, потенциально приводит к различным аномалиям и нарушениям целостности данных.Теоретики реляционных баз данных в процессе развития теории выявили и описали типичные примеры избыточности и способы их устранения. Реляционные хранилища обеспечивают наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости. Касаемо масштабируемости, реляционные БД хорошо масштабируются только в том случае, если располагаются на единственном сервере.
Особенностью реляционной базы данных является использование в ней реляционной модели данных и вытекающие из этого последствия:
- Модель данных в реляционных БД определена заранее. Является строго типизированной, содержит ограничения и отношения для обеспечения целостности данных.
- Модель данных основана на естественном представлении содержащихся данных, а не на функциональности приложения.
- Модель данных подвергается нормализации, чтобы избежать дублирования данных. Нормализация порождает отношения между таблицами. Отношения связывают данные разных таблиц.
В реляционной базе данных данные создаются, обновляются, удаляются и запрашиваются с использованием языка структурированных запросов (SQL). SQL-запросы могут извлекать данные как из одиночной таблица, так и из нескольких таблиц.Такие запросы могут включать агрегации и сложные фильтры. Реляционная БД обычно содержит встроенную логику, такую как триггеры, хранимые процедуры и функции.
Реляционная система управления базой данных (РСУБД)
Реляционная система управления базой данных (РСУБД) — СУБД, управляющая реляционными базами данных.
Доступ к реляционным базам данных осуществляется через реляционные системы управления базами данных (РСУБД). Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее. Причины такого доминирования неочевидны. На протяжении всего существования реляционных БД они постоянно предлагали наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости в сфере управлении данными.
Например, простой SELECT запрос может иметь сотни потенциальных путей выполнения, которые оптимизатор оценит непосредственно во время выполнения запроса. Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу. Однако чтобы обеспечить все эти особенности, реляционные хранилища невероятно сложны внутри.
Реляционная система управления базой данных содержит:
- командный язык;
- язык программирования с ориентацией на обработку таблиц;
- интерпретирующую и/или компилирующую систему; и
- пользовательскую оболочку.
Источники
Ссылки
- https://habrahabr.ru/company/mailru/blog/266811/
- http://informatic.ugatu.ac.ru/lib/office/Proekt.html
- http://de.ifmo.ru/—books/sql/1-1.html
- http://www.osp.ru/cw/2001/05/9215/
- https://habrahabr.ru/post/103021/
ru.bmstu.wiki
3.3. Реляционная модель данных
Модель данных определяет некоторый набор родовых понятий и признаков, которыми должны обладать все конкретные СУБД и управляемые ими базы данных, если они основываются на этой модели.
Общая характеристика
Наиболее распространенная трактовка реляционной модели данных, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту
Реляционная модель данных – набор правил и определений, которым подчиняются все объекты, находящиеся внутри базы данных, включающий три компонента: структурный, манипуляционный и целостный:
(1) В структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных БД, является нормализованное n-арное отношение:
тип данных, домен, атрибут, отношение, схема отношения, кортеж, схема БД.
(2) В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными БД — реляционная алгебра и реляционное исчисление:
первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями),
второй механизм — на классическом логическом аппарате исчисления предикатов первого порядка.
Целостность сущности и ссылок
(3) В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД.
Первое требование называется требованием целостности сущностей.
Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений (строки/записи таблиц).
Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Как мы видели в предыдущем разделе, это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений.
Второе требование называется требованием целостности по ссылкам и является несколько более сложным.
Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений.
Например, нам требуется представить в реляционной базе данных:
При правильном проектировании соответствующей БД в ней появятся два отношения:
ОТДЕЛЫ (ОТДЕЛ_НОМЕР, ОТДЕЛ_КОЛ, …) (первичный ключ — ОТДЕЛ_НОМЕР)
СОТРУДНИКИ (СОТРУДНИК_НОМЕР, СОТРУДНИК_ИМЯ, СОТРУДНИК_ОКЛАД, СОТРУДНИК_ОТДЕЛ_НОМЕР) (первичный ключ — СОТРУДНИК_НОМЕР).
Атрибут СОТРУДНИК_ОТДЕЛ_НОМЕР появляется в отношении СОТРУДНИКИ не потому, что номер отдела является собственным свойством сотрудника, а лишь для того, чтобы иметь возможность восстановить при необходимости полную сущность ОТДЕЛ. Значение атрибута СОТРУДНИК_ОТДЕЛ_НОМЕР в любом кортеже отношения СОТРУДНИКИ должно соответствовать значению атрибута ОТДЕЛ_НОМЕР в некотором кортеже отношения ОТДЕЛЫ.
Атрибут такого рода называется внешним ключом, поскольку его значения однозначно характеризуют сущности, представленные кортежами некоторого другого отношения (т.е. задают значения их первичного ключа). Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором такой же атрибут является первичным ключом.
Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что:
для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать – NULL).
Для нашего примера это означает, что если в записи сотрудника указан номер отдела, то этот отдел должен существовать в таблице «Отделы».
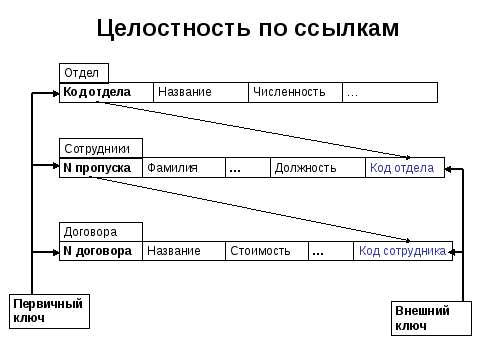
Поддержка целостности на уровне СУБД
Ограничения целостности сущности и по ссылкам должны поддерживаться СУБД.
1) Для соблюдения целостности сущности достаточно гарантировать отсутствие в любом отношении кортежей с одним и тем же значением первичного ключа.
2) С целостностью по ссылкам дела обстоят несколько более сложно.
Понятно, что при обновлении ссылающегося отношения (вставке новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. Но как быть при удалении кортежа из отношения, на которое ведет ссылка?
Здесь существуют три подхода, каждый из которых поддерживает целостность по ссылкам.
Первый подход заключается в том, что запрещается производить удаление кортежа, на который существуют ссылки (т.е. сначала нужно либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа).
При втором подходе при удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа автоматически становится неопределенным (NULL).
Наконец, третий подход (каскадное удаление) состоит в том, что при удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения автоматически удаляются все ссылающиеся кортежи.
Замечание. В большинстве реляционных СУБД (включая, MS Access) обычно можно выбрать способ поддержания целостности по ссылкам для каждой отдельной ситуации определения внешнего ключа. Конечно, для принятия такого решения необходимо анализировать требования конкретной прикладной области.
studfiles.net
Реляционная модель данных — ПИЭ.Wiki
Материал из ПИЭ.Wiki
Реляционная модель данных – логическая модель данных. Впервые была предложена британским учёным сотрудником компании IBM Эдгаром Франком Коддом (E. F. Codd) в 1970 году в статье «A Relational Model of Data for Large Shared Data Banks» (русский перевод статьи, в которой она впервые описана, опубликован в журнале «СУБД» N 1 за 1995 г.). В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД.
В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. В упомянутой статье Е.Ф. Кодда утверждается, что «реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т.е. без потребности введения какой-либо дополнительной структуры для целей машинного представления». Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от английского relation – «отношение»).
В состав реляционной модели данных обычно включают теорию нормализации.
Состав реляционной модели данных
Кристофер Дейт определил три составные части реляционной модели данных:
- структурная
- манипуляционная
- целостная
Структурная часть модели определяет, что единственной структурой данных является нормализованное n-арное отношение. Отношения удобно представлять в форме таблиц, где каждая строка есть кортеж, а каждый столбец – атрибут, определенный на некотором домене. Данный неформальный подход к понятию отношения дает более привычную для разработчиков и пользователей форму представления, где реляционная база данных представляет собой конечный набор таблиц.
Манипуляционная часть модели определяет два фундаментальных механизма манипулирования данными – реляционная алгебра и реляционное исчисление. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Целостная часть модели определяет требования целостности сущностей и целостности ссылок. Первое требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
Структура реляционной модели данных
Можно провести аналогию между элементами реляционной модели данных и элементами модели «сущность-связь». Реляционные отношения соответствуют наборам сущностей, а кортежи – сущностям. Поэтому, также как и в модели «сущность-связь» столбцы в таблице, представляющей реляционное отношение, называют атрибутами.
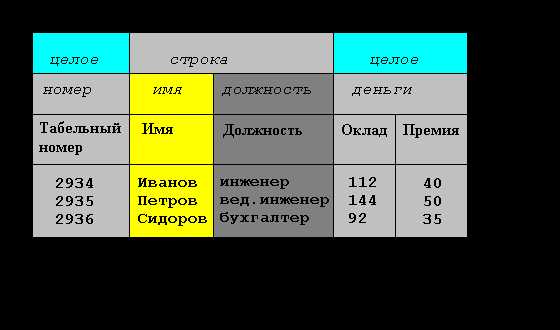
Основные компоненты реляционного отношения
Каждый атрибут определен на домене, поэтому домен можно рассматривать как множество допустимых значений данного атрибута. Несколько атрибутов одного отношения и даже атрибуты разных отношений могут быть определены на одном и том же домене.
В примере, показанном на рисунке, атрибуты «Оклад» и «Премия» определены на домене «Деньги». Поэтому, понятие домена имеет семантическую нагрузку: данные можно считать сравнимыми только тогда, когда они относятся к одному домену. Таким образом, в рассматриваемом нами примере сравнение атрибутов «Табельный номер» и «Оклад» является семантически некорректным, хотя они и содержат данные одного типа.
Именованное множество пар «имя атрибута – имя домена» называется схемой отношения. Мощность этого множества — называют степенью или «арностью» отношения. Набор именованных схем отношений представляет из себя схему базы данных.
Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). В нашем случае ключом является атрибут «Табельный номер», поскольку его значение уникально для каждого работника предприятия. Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ. Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными ключами.
В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей.
Применение реляционной модели данных
Пример базы данных, содержащей сведения о подразделениях предприятия и работающих в них сотрудниках, применительно к реляционной модели будет иметь вид:
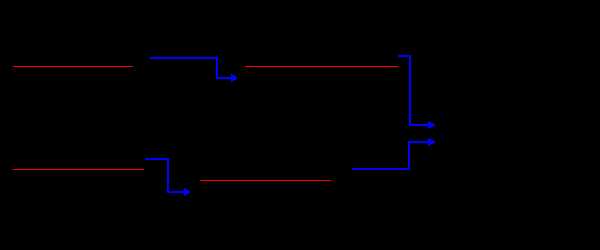
База данных о подразделениях и сотрудниках предприятия
Например, связь между отношениями ОТДЕЛ и СОТРУДНИК создается путем копирования первичного ключа «Номер_отдела» из первого отношения во второе. Таким образом:
- для того, чтобы получить список работников данного подразделения, необходимо:
- из таблицы ОТДЕЛ установить значение атрибута «Номер_отдела», соответствующее данному «Наименованию_отдела»
- выбрать из таблицы СОТРУДНИК все записи, значение атрибута «Номер_отдела» которых равно полученному на предыдущем шаге
- для того, чтобы узнать в каком отделе работает сотрудник, нужно выполнить обратную операцию:
- определяем «Номер_отдела» из таблицы СОТРУДНИК
- по полученному значению находим запись в таблице ОТДЕЛ
Атрибуты, представляющие собой копии ключей других отношений, называются внешними ключами.
Достоинства и недостатки реляционной модели данных
Достоинства реляционной модели:
- простота и доступность для понимания пользователем. Единственной используемой информационной конструкцией является «таблица»;
- строгие правила проектирования, базирующиеся на математическом аппарате;
- полная независимость данных. Изменения в прикладной программе при изменении реляционной БД минимальны;
- для организации запросов и написания прикладного ПО нет необходимости знать конкретную организацию БД во внешней памяти.
Недостатки реляционной модели:
- далеко не всегда предметная область может быть представлена в виде «таблиц»;
- в результате логического проектирования появляется множество «таблиц». Это приводит к трудности понимания структуры данных;
- БД занимает относительно много внешней памяти;
- относительно низкая скорость доступа к данным.
Ссылки
wiki.mvtom.ru