Классификация таблиц в реляционных базах данных по признакам целостности и избыточности данных
Содержание статьи
Обоснование статьи и некоторые ключевые понятия;
1. Справочники и связки;
1.1. Виды таблиц;
1.2. Виды справочников;
1.3. Виды связок;
2. Обобщение классификации;
2.1. Классификация в табличном виде;
2.2. Классификация в схематичном виде;
3. Некоторые комментарии по применению классификации;
3.1. Применение классификации при нормализации таблиц;
Заключение.
Обоснование статьи и некоторые ключевые понятия
Очень часто присутствовал на обучении дисциплине «Базы данных». Обучался когда-то сам… Как-то даже пришлось проводить целый курс для друзей и знакомых. Во время обучения мною было замечено, что трудности возникают уже на этапе понимания таблиц и того, как ими пользоваться. Многие просто не могли и не могут разработать простейшие базы данных. После более детального рассмотрения такого понятия как таблицы и маленькой классификации, трудности восприятия таблиц в реляционных базах данных почти всегда исчезают. Итак!
В данной статье будет рассмотрена маленькая классификация таблиц по признакам целостности и избыточности. Что это значит? Это значит, что будут приведены примеры с описанием, какую структуру таблиц можно делать, чтобы предотвращать (пытаться предотвращать) избыточность и добиваться целостности в реляционных базах данных.
Для понимания дадим краткие определения целостности и избыточности данных:
Целостность данных – это свойство способности по одним данным восстанавливать другие, при этом не теряя семантическое единство этих данных и отношения между ними (между данными).
Избыточность данных – это состояние базы данных, при котором в таблицах присутствуют лишние данные.
Целостность данных может быть нарушена в результате операций модификации данных. Если в базе данных запрещены операции удаления и обновления, то целостность может быть нарушена только в результате операции добавления, а также неправильно написанных скриптов по отображению данных.
1. Справочники и связки
1.1. Виды таблиц
Немного углубимся в маленькую классификацию таблиц по видам их структуры. Разделим таблицы на два общих вида. Первым видом будут таблицы-справочники, вторым таблицы-связки.
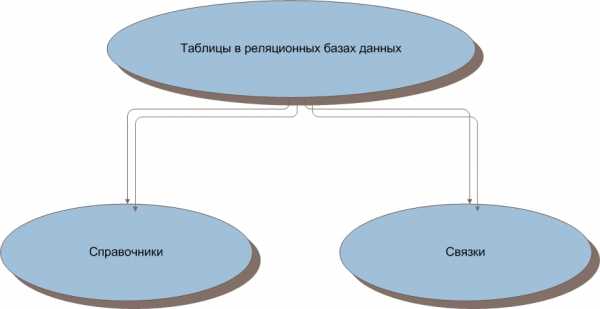
Рисунок 1. Справочники и связки
Информацию в таблицах можно разделить на два вида. На информацию, которая описывает объекты (субъекты), связи и информацию, которая описывает действия, процессы, события, иное.
В связках хранятся данные, взятые из таблиц справочников. Поскольку невыгодно повторять одни и те же данные при описании объектов (субъектов) и при описании их взаимодействия, данные об объектах (субъектах) заносятся в справочники, а в таблицах-связках не хранятся данные объектов (субъектов) в чистом виде, а лишь ссылки на них (внешний ключ). Таким образом, в связках хранятся данные по взаимодействию объектов (субъектов) и ссылки на самих объектов (субъектов) (внешний ключ). Эти «ссылки» являются первичными ключами в таблицах справочниках. Но об этом потом…
Отличие справочника от связки выражается в том, что таблицы-справочники могут быть самостоятельными и независимыми (то есть, при чтении данных некоторых справочников можно в целом понять семантику), а таблицы-связки практически никогда.
1.2. Виды справочников
Справочники могут подразделяться на несколько видов. Это статичные, статично-динамичные и динамичные справочники. Разумеется, вряд ли можно назвать абсолютно статичный справочник, так как в этом мире может измениться всё. Или почти всё.
Статичный справочник – справочник, данные об объектах, субъектах, связях в котором либо никогда не подвергаются модификации после первичной модификации, либо настолько редко подвергаются модификации, что этим можно пренебречь.
Примером таких справочников могут служить список месяцев с названиями и номерами, список дней недели, список времён года, список океанов и так далее…
| Номер | Наименование |
| 1 | Январь |
| 2 | Февраль |
| 3 | Март |
| 4 | Апрель |
| 5 | Май |
| 6 | Июнь |
| 7 | Июль |
| 8 | Август |
| 9 | Сентябрь |
| 10 | Октябрь |
| 11 | Ноябрь |
| 12 | Декабрь |
Таблица 1. Пример статичных справочников
Статично-динамичный справочник – справочник, в котором хранятся данные о связях, если связи носят справочный характер. В таком справочнике могут быть внешние ключи.
Наиболее удачным примером будет таблица с такими медицинскими данными, как вес. Список человек, вес которых измеряется, изменяется не так часто. А вот данные по их весу могут меняться каждый день. Статично-динамичные справочники являются единственными справочниками, где осознанно можно повторять любую информацию. Ещё одним примером может быть справочник окладов по должностям (по коду должности).
| Код должности | Оклад | Дата обновления |
| 1001 | 12 000 | 05.02.2015 |
| 1002 | 17 000 | 01.02.2015 |
| 1003 | 11 500 | 01.02.2015 |
| 1004 | 25 450 | 01.02.2015 |
| 1005 | 10 000 | 01.02.2015 |
| 1006 | 6 000 | 04.02.2015 |
Таблица 2. Пример статично-динамичных справочников
Динамичные справочники – это таблицы, данные об объектах, субъектах, связях в которых меняются часто и используются в других таблицах. От статичных справочников отличаются только частотой модификации в них данных.
Примером таких таблиц могут быть списки проектов. На самом деле, данные об открытии или закрытии проектов могут находиться в самом справочнике проектов, что в большинстве случаев неправильно и нарушает целостность. С другой стороны, если хранить историю изменений по открытию и закрытию (приостановке) проектов, то можно получить избыточность данных. Целостность и избыточность данных будут бороться с друг другом ещё долго, также как и зима с летом.
| Код проекта | Проект | Нормативный срок выполнения | Дата добавления | Пользователь |
| PT102 | Покраска окон | 15 | 03.01.2014 | 1547 |
| PT103 | Установка дверей | 10 | 04.01.2014 | 9874 |
| PT587 | Проверка пожарных кранов | 2 | 04.01.2014 | 1456 |
| PT588 | Замена люков | 3 | 02.01.2014 | 0147 |
| PT133 | Очистка каналов | 11 | 09.02.2015 | 1547 |
Таблица 3. Пример динамичных справочников
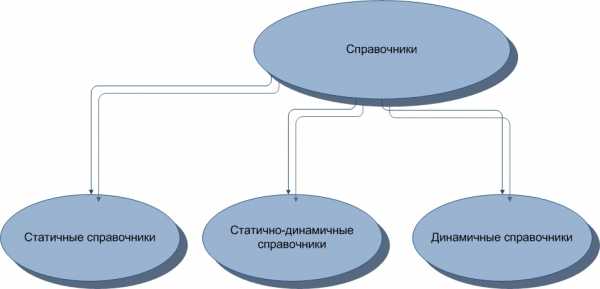
Рисунок 2. Виды справочников
1.3. Виды связок
Таблицы-связки можно разделить на два вида.
Это справочник-связка (сразу же уточним, что справочник-связка справочником не является, назван так, потому что в нём существуют поля, которые образуют справочник, но в справочник выделены быть не могут). Таблица, в которой хранятся внешние ключи, данные, которые не являются справочными и поля, содержащие данные, которые образуют справочник, но не могут быть выделены в отдельную таблицу-справочник.
Примером справочника-связки будет являться таблица платёжных транзакций. Или таблица с данными о футбольном матче.
| Код транзакции | Плательщик | Получатель | Сумма | Дата | Комментарий |
| EEVS-doodi4 | 100045 | 57457 | -10 000 | 25.07.2014 | На сапоги |
| UDFD-ioeed9 | 455780 | 10024 | -900 | 24.06.2014 | NULL |
| PEDD-jdksl4 | 144770 | 56698 | -6980 | 01.01.2015 | NULL |
| FDFE-keiiii0 | 447757 | 1 | 120 | 08.07.2014 |
Таблица 4. Пример справочника-связки
И связка (да, просто связка). Это таблица в которой хранятся только внешние ключи и данные, которые нельзя отнести к справочным, например дата или значения логических полей.
Примером связки будет являться таблица автоматического логирования терминала обработки данных.
Кстати, легко догадаться, что связки почти нигде не используются, поскольку чаще всего находятся данные, которые могут быть записаны в базу, но не содержаться в справочниках, поэтому невозможно сопоставить им внешний ключ.
| Код | Код клиента | Показания счётчика | |
| 2334 | 35643 | 50 | 01.01.2015 |
| 2335 | 235673 | 49 | 01.01.2015 |
| 2335 | 436345 | 56 | 01.01.2015 |
| 2335 | 574733 | 24 | 01.01.2015 |
Таблица 5. Пример связки
Необходимо пояснить, что это за поля, которые образуют справочник, но не могут быть выделены в отдельную таблицу-справочник. Примером таких полей являются поля «комментарий», «жалоба», «описание», «предложение». Словом, если приводить популярный пример, то поле «сообщение» в таблице базы данных любой социальной сети…
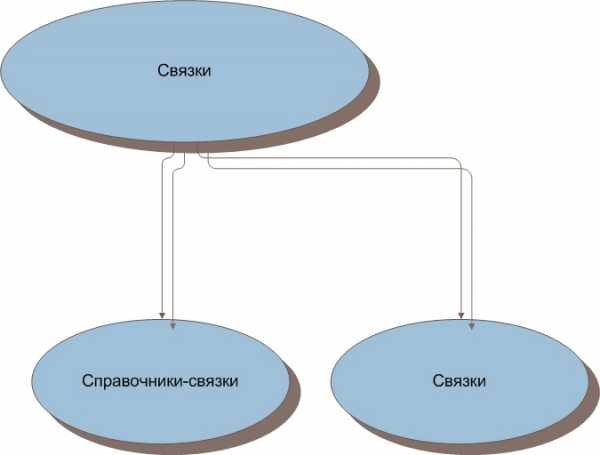
Рисунок 3. Виды связок
2. Обобщение классификации
2.1. Классификация в табличном виде
| Вид таблицы | Описание | Примеры | Плюсы (+) | Минусы(-) |
| Статичный справочник | Таблица. Данные из неё берутся для других таблиц. Из справочника в других таблицах можно использовать только первичный ключ. В статичном справочнике должна содержаться информация, которая либо вообще не изменяется, либо изменяется так редко, что этим можно принебречь. На статичный справочник ссылаются (внешний ключ), когда нужно получить названия, обозначения, нормы, количественные или качественные показатели. Иное. | Справочник (наименований и номеров) месяцев. Справочник складов и цехов предприятия. Справочник правил игры. |
Иногда заменяет системные функции СУБД, позволяет более гибко работать с некоторыми данными. В случае, если меняется редко изменяемая информация, предостерегает от серьёзных последствий. | Использование таблицы с любой структурой может замедлять работу, в случае, если таблица заменяет системное хранилише. Приходится писать дополнительные функции и обработки для данной таблицы, которые не всегда правильно оптимизированны. В некоторых случаях невозможно оптимизировать. |
| Статично-динамичный справочник | Таблица. Данные из неё берутся для других таблиц. Из справочника в других таблицах нельзя использовать внешний ключ этого справочника, однако можно использовать первичный ключ. | Справочник окладов по должностям. Справочник (размеров обуви, веса, роста, размера головы) физиологических параметров. Справочник (менеджеров, компаний) содержащий компании и менеджеров, которые эти компании обслуживают и учитывают. | Позволяет проводить гибкую нормализацию по схеме «Справочник-связка» = «Связка»+«Статично-динамичный справочник». | Справочник, выделенный из справочника-связки, никуда не девается и не имеет никакой реляционной связи, которая позволила бы ему превратиться в статичный или динамичный справочник. А значит, всегда избыточен. |
| Динамичный справочник | Таблица. Данные из неё берутся часто для других таблиц. Из справочника в других таблицах можно использовать только первичный ключ. В динамичном справочнике должна содержаться информация, которая часто изменяется. | Справочник клиентов. Справочник поставщиков. Справочник контрагентов. Справочник менеджеров компании. Справочник работников. Справочник студентов. | Позволяет хранить динамичные данные, при этом давая возможность однозначно ссылаться на них. | Чаще всего накопительного типа и не делим, что создаёт определённую избыточность. |
| Справочник-связка | Таблица. Данные из неё не могут содержаться в других таблицах, но на основе них могут быть созданы данные в других таблицах. | Платёжные транзакции. Продажи. Межзаводские перемещения. График перевозок. | Позволяет проводить гибкую нормализацию по схеме «Справочник-связка» = «Связка»+«Статично-динамичный справочник». | Справочник-связка после нормализации превращается в связку и сводит избыточность данных к минимуму, не затрагивая целостность, однако не делим и при архивировании в текущей таблице не подлежит оптимизации. |
| Связка | Таблица. Данные из неё не могут содержаться в других таблицах, но на основе них могут быть созданы данные в других таблицах. Таблица не может содержать кортежей, значения атрибутов в которых являются неделимыми и не уникальными. | Автоматический лог ошибок в программе. Лог запроса сервера. Результаты трассировок. Отчёты о выгрузке и загрузке компонентов. Автоматические отчёты системы безопасности. | Связка сводит избыточность данных к минимуму, не затрагивая целостность. | Накапливаясь, является неделимой таблицей. Сложно оптимизировать. |
Таблица 6. Классификация
2.2. Классификация в схематичном виде
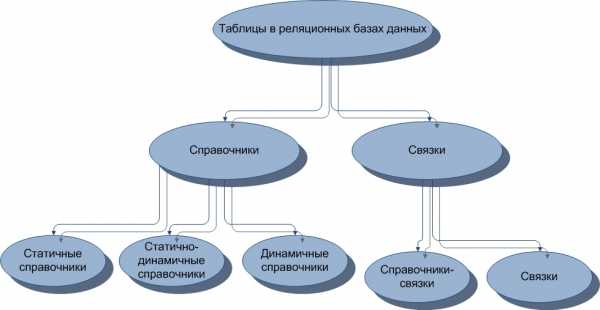
Рисунок 4. Схема классификации таблиц в реляционных базах данных по признакам целостности и избыточности данных
3. Некоторые комментарии по применению классификации
3.1. Применение классификации при нормализации таблиц
Процесс нормализации, если не учитывать некоторые этапы (Но учитывать результаты этих этапов!) — это обычное «дробление» таблиц на более мелкие таблицы с созданием реляционной связи между ними непосредственно или через промежуточные таблицы (связь «Многие ко многим»). Под реляционной связью может не всегда пониматься реляционное отношение!
Преобразование динамичного или статичного справочника в статично-динамичный справочник, а справочника-связки в связку, как и статично-динамичного справочника в справочник-связку — это ни что иное, как дробление таблиц. То есть, преобразование одного вида таблиц в другой через показанную выше классификацию в целях избежания избыточности данных — так можно определить нормализацию (один из вариантов определения).
Для примера. Пусть имеется база данных, в которой единственная операция по модификации данных — это добавление. В таком случае становится неэффективным каждый раз при изменении какого либо отдельного атрибута сущности, «копировать» остальные значения атрибутов уже в другой кортеж. В этом случае используются NULL или же создание статично-динамичного справочника, где описывается ряд атрибутов одной семантики или один атрибут, а дублируется лишь внешний ключ с первичным ключом последовательности. Этот же метод может использоваться в традиционной схеме модификации данных с обновлением и удалением данных.
Заключение
Данная классификация была создана мной на основе наблюдений при проектировании баз данных, а также исходя из прочитанной теории по проектированию в реляционных СУБД. Моим друзьям и знакомым, изучающим дисциплину «базы данных» и занимающимся проектированием баз данных, и мне эта классификация достаточно серьёзно упростила «жизнь» и позволила во многих ситуациях заранее выбрать наиболее подходящий и, как оказывалось потом, правильный вид таблицы для хранения в ней тех или иных данных.
Классификация может быть расширена разделением существующих видов в ней на подвиды (возможно, даже, добавлением новых видов). Также эта классификация показала, что лучше в некоторых ситуациях не использовать тот или иной вид таблиц. Некоторые виды таблиц из данной классификации лучше использовать реже (динамичные справочники). А некоторые пытаться заменить на другие (справочники-связки на связки).
Надеюсь, кому ни будь ещё поможет эта классификация при освоении дисциплины «Базы данных» и при проектировании баз данных в реляционных СУБД.
habr.com
Основы реляционной алгебры / Habr
Реляционная алгебра базируется на теории множеств и является основой логики работы баз данных.Когда я только изучал устройство баз данных и SQL, предварительное ознакомление с реляционной алгеброй очень помогло дальнейшим знаниям правильно уложиться в голове, и я постараюсь что бы эта статья произвела подобный эффект.
Так что если вы собираетесь начать свое обучение в этой области или вам просто стало интересно, прошу под кат.
Реляционная база данных
Для начала введем понятие реляцинной базы данных, в которой будем выполнять все действия.
Реляционной базой данных называется совокупность отношений, содержащих всю информацию, которая должна хранится в базе. В данном определении нам интересен термин отношение, но пока оставим его без строго определения.
Лучше представим себе таблицу продуктов.
таблица PRODUCTS
| ID | NAME | COMPANY | PRICE |
| 123 | Печеньки | ООО ”Темная сторона” | 190 |
| 156 | Чай | ООО ”Темная сторона” | 60 |
| 235 | Ананасы | ОАО ”Фрукты” | 100 |
| 623 | Томаты | ООО ”Овощи” | 130 |
Таблица состоит из 4х строк, строка в таблице является кортежем в реляционной теории. Множество упорядоченных кортежей называется отношением.
Перед тем как дать определение отношения, введем еще один термин — домен. Домены применительно к таблице это столбцы.
Для ясности, теперь введем строгое определение отношения.
Пусть даны N множеств D1,D2, …. Dn (домены), отношением R над этими множествами называется множество упорядоченных N-кортежей вида <d1,d1,…dn>, где d1 принадлежит D1 и тд. Множества D1,D2,..Dn называются доменами отношения R.
Каждый элемент кортежа представляет собой значение одного из атрибутов, соответствующего одному из доменов.
Ключи в отношениях
В отношении требованием является то, что все кортежи должны различаться. Для однозначной идентификации кортежа существует первичный ключ. Первичный ключ это атрибут или набор из минимального числа атрибутов, который однозначно идентифицирует конкретный кортеж и не содержит дополнительных атрибутов.
Подразумевается, что все атрибуты в первичном ключе должны быть необходимыми и достаточными для идентификации конкретного кортежа, и исключение любого из атрибутов в ключе сделает его недостаточным для идентификации.
Например, в такой таблице ключом будет сочетание атрибутов из первого и второго столбца.
таблица DRIVERS
| COMPANY | DRIVER |
| ООО ”Темная сторона” | Владимир |
| ООО ”Темная сторона” | Михаил |
| ОАО ”Фрукты” | Руслан |
| ООО ”Овощи” | Владимир |
Видно, что в организации может быть несколько водителей, и чтобы однозначно идентифицировать водителя необходимо и значение из столбца “Название организации” и из “Имя водителя”. Такой ключ называется составным.
В реляционной БД таблицы взаимосвязаны и соотносятся друг с другом как главные и подчиненные. Связь главной и подчиненнной таблицы осуществляется через первичный ключ (primary key) главной таблицы и внешний ключ ( foreign key ) подчиненной таблицы.
Внешний ключ это атрибут или набор атрибутов, который в главной таблице является первичным ключем.
Этой подготовительной теории будет достаточно для знакомства с основными операциями реляционной алгебры.
Операции реляционной алгебры
Основные восемь операций реляционной алгебры были предложены Э.Коддом.
- Объединение
- Пересечение
- Вычитание
- Декартово произведение
- Выборка
- Проекция
- Соединение
- Деление
Первая половина операций аналогична таким же операциям над множествами. Часть операций можно выразить через другие операции. Рассмотрим большую часть операций с примерами.
Для понимания важно запомнить, что результатом любой операции алгебры над отношениями является еще одно отношение, которое можно потом так же использовать в других операциях.
Создадим еще одну таблицу, которая нам пригодится в примерах.
таблица SELLERS
| ID | SELLER |
| 123 | OOO “Дарт” |
| 156 | ОАО ”Ведро” |
| 235 | ЗАО “Овоще База” |
| 623 | ОАО ”Фирма” |
Условимся, что в этой таблице ID это внешний ключ, связанный с первичным ключом таблицы PRODUCTS.
Для начала рассмотрим самую простую операцию — имя отношения. Её результатом будет такое же отношение, то есть выполнив операцию PRODUCTS, мы получим копию отношения PRODUCTS.
Проекция
Проекция является операцией, при которой из отношения выделяются атрибуты только из указанных доменов, то есть из таблицы выбираются только нужные столбцы, при этом, если получится несколько одинаковых кортежей, то в результирующем отношении остается только по одному экземпляру подобного кортежа.
Для примера сделаем проекцию на таблице PRODUCTS выбрав из нее ID и PRICE.
Синтаксис операции:
π(ID, PRICE) PRODUCTS
В результате этой операции получим отношение:
| ID | PRICE |
| 123 | 190 |
| 156 | 60 |
| 235 | 100 |
| 623 | 130 |
Выборка
Выборка — это операция, которая выделяет множество строк в таблице, удовлетворяющих заданным условиям. Условием может быть любое логическое выражение.
Для примера сделаем выборку из таблицы с ценой больше 90.
Синтаксис операции:
σ(PRICE>90) PRODUCTS
| ID | NAME | COMPANY | PRICE |
| 123 | Печеньки | ООО ”Темная сторона” | 190 |
| 235 | Ананасы | ОАО ”Фрукты” | 100 |
| 623 | Томаты | ООО ”Овощи” | 130 |
В условии выборки мы можем использовать любое логическое выражение. Сделаем еще одну выборку с ценой больше 90 и ID товара меньше 300:
σ(PRICE>90 ^ ID<300) PRODUCTS
| ID | NAME | COMPANY | PRICE |
| 123 | Печеньки | ООО ”Темная сторона” | 190 |
| 235 | Ананасы | ОАО ”Фрукты” | 100 |
Совместим операторы проекции и выборки. Мы можем это сделать, потому что любой из операторов в результате возвращает отношение и в качестве аргументов использует также отношение.
Из таблицы с продуктами выберем все компании, продающие продуты дешевле 110.
πCOMPANYσ(PRICE<100 ) PRODUCTS
| COMPANY |
| ООО ”Темная сторона” |
| ОАО ”Фрукты” |
Умножение
Умножение или декартово произведение является операцией, производимой над двумя отношениями, в результате которой мы получаем отношение со всеми доменами из двух начальных отношений. Кортежи в этих доменах будут представлять из себя все возможные сочетания кортежей из начальных отношений. На примере будет понятнее.
Получим декартово произведения таблиц PRODUCTS и SELLERS.
Синтаксис операции:
PRODUCTS × SELLERS
Можно заметить, что у двух этих таблиц есть одинаковый домен ID. В подобной ситуации домены с одинаковыми названиями получают префикс в виде названия соответствующего отношения, как показано ниже.
Для краткости перемножим не полные отношения, а выборки с условием ID<235
(цветом выделены одни и те же кортежи)
| PRODUCTS.ID | NAME | COMPANY | PRICE | SELLERS.ID | SELLER |
| 123 | Печеньки | ООО ”Темная сторона” | 190 | 123 | OOO “Дарт” |
| 156 | Чай | ООО ”Темная сторона” | 60 | 156 | ОАО ”Ведро” |
| 123 | Печеньки | ООО ”Темная сторона” | 190 | 156 | ОАО ”Ведро” |
| 156 | Чай | ООО ”Темная сторона” | 60 | 123 | OOO “Дарт” |
Для примера использования этой операции представим себе необходимость выбрать продавцов с ценами меньше 90. Без произведения необходимо было бы сначала получить ID продуктов из первой таблицы, потом по этим ID из второй таблицы получить нужные имена SELLER, а с использованием произведения будет такой запрос:
π(SELLER) σ(RODUCTS.ID=SELLERS.ID ^ PRICE<90) PRODUCTS × SELLERS
В результате этой операции получим отношение:
| SELLER |
| ОАО ”Ведро” |
Соединение и естественное соединение
Операция соединения обратна операции проекции и создает новое отношение из двух уже существующих. Новое отношение получается конкатенацией кортежей первого и второго отношений, при этом конкатенации подвергаются отношения, в которых совпадают значения заданных атрибутов. В частности, если соединить отношения PRODUCTS и SELLERS, этими атрибутами будут атрибуты доменов ID.
Также для понятности можно представить соеднинение как результат двух операций. Сначала берется произведение исходных таблиц, а потом из полученного отношения мы делаем выборку с условием равенства атрибутов из одинаковых доменов. В данном случае условием явлется равенство PRODUCTS.ID и SELLERS.ID.
Попробуем соединить отношения PRODUCTS и SELLERS и получим отношение.
| PRODUCTS.ID | NAME | COMPANY | PRICE | SELLERS.ID | SELLER |
| 123 | Печеньки | ООО ”Темная сторона” | 190 | 123 | OOO “Дарт” |
| 156 | Чай | ООО ”Темная сторона” | 60 | 156 | ОАО ”Ведро” |
| 235 | Ананасы | ОАО ”Фрукты” | 100 | 235 | ЗАО “Овоще База” |
| 623 | Томаты | ООО ”Овощи” | 130 | 623 | ОАО ”Фирма” |
Натуральное соединение получает схожее отношение, но в случае, если у нас корректно настроена схема в базе ( в данном случае первичный ключ таблицы PRODUCTS ID связан с внешним ключем таблицы SELLERS ID), то в результирующем отношении остается один домен ID.
Синтаксис операции:
PRODUCTS ⋈ SELLERS;
Получится такое отношение:
| PRODUCTS.ID | NAME | COMPANY | PRICE | SELLER |
| 123 | Печеньки | ООО ”Темная сторона” | 190 | OOO “Дарт” |
| 156 | Чай | ООО ”Темная сторона” | 60 | ОАО ”Ведро” |
| 235 | Ананасы | ОАО ”Фрукты” | 100 | ЗАО “Овоще База” |
| 623 | Томаты | ООО ”Овощи” | 130 | ОАО ”Фирма” |
Пересечение и вычитание.
Результатом операции пересечения будет отношение, состоящее из кортежей, полностью входящих в состав обоих отношений.
Результатом вычитания будет отношение, состоящее из кортежей, которые являются кортежами первого отношения и не являются кортежами второго отношения.
Данные операции аналогичны таким же операциям над множествам, так что, я думаю, нет необходимости подробно их расписывать.
Источники информации
- Основы использования и проектирования баз данных — В. М. Илюшечкин
- курс лекций Introduction to Databases — Jennifer Widom, Stanford University
Буду благодарен за аргументированные замечания
habr.com
9. Детерминант; проекция реляционной таблицы; разбиение реляционной таблицы
Функциональная зависимость описывает связь между атрибутами отношения: если в отношении R, содержащем атрибуты А и В, атрибут В функционально зависит от атрибута А, то каждое отдельное значение атрибута А связано только с одним значением атрибута В (причем в качестве А и В могут выступать группы атрибутов). Атрибут или группа атрибутов А называются при этом детерминантом функциональной зависимости.
Таблицы невозможно хранить и обрабатывать, если в базе данных отсутствуют «данные о данных», например, описатели таблиц, столбцов и т.д. Их называют обычно метаданными. Метаданные также представлены в табличной форме и хранятся в словаре данных (data dictionary).
Помимо таблиц, в базе данных могут храниться и другие объекты, такие как экранные формы, отчеты (reports), представления (views) и даже прикладные программы, работающие с базой данных.
Для пользователей информационной системы недостаточно, чтобы база данных просто отражала объекты реального мира. Важно, чтобы такое отражение было однозначным и непротиворечивым. В этом случае говорят, что база данных удовлетворяет условию целостности (integrity).
Для того, чтобы гарантировать корректность и взаимную непротиворечивость данных, на базу данных накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints).
Существует несколько типов ограничений целостности. Требуется, например, чтобы значения в столбце таблицы выбирались только из соответствующего домена. На практике учитывают и более сложные ограничения целостности, например, целостность по ссылкам (referential integrity). Ее суть заключается в том, что внешний ключ не может быть указателем на несуществующую строку в таблице.
Проекция в реляционной алгебре — унарная операция, которая позволяет получить «вертикальное» подмножество данного отношения, или таблицы, то есть такое подмножество, которое получается выбором специфицированных атрибутов с последующим исключением, если это необходимо, избыточных дубликатов кортежей. Пусть дана таблица с именами атрибутов , то есть и некоторое подмножество множества имен атрибутов . Результатом проекции таблицы по выбранным именам атрибутов называется новая таблица , полученная из исходной таблицы вычеркиванием атрибутов, не входящих в выбранное множество, с последующим возможным удалением избыточных дубликатов кортежей.
При осуществление проекции необходимо задать проецируемое отношение и некий набор его атрибутов, который станет заголовком результирующего.
Деление.Пусть даны отношения и , причем атрибуты — общие для двух отношений. Делением отношений на называется отношение с заголовком и телом, содержащим множество кортежей , таких, что для всех кортежей в отношении найдется кортеж .
Отношение выступает в роли делимого , отношение выступает в роли делителя . Деление отношений аналогично делению чисел с остатком.
10. Концептуальный, внешний, внутренний уровни базы данных.
1) Внутренний — это уровень, наиболее близкий к физическому хранению, т.е. связанный со способами сохранения информации на физических устройствах хранения.
2) Внешний — наиболее близок к пользователям, т.е. он связан со способами представления данных для отдельных пользователей.
3) Концептуальный уровень — это промежуточный уровень между двумя первыми; другими словами, это центральное управляющее звено, где БД представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной БД. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась БД. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира.
Внешнее представление — это содержимое БД, каким видит его определенный пользователь (т.е. для этого пользователя внешнее представление и есть БД).
Концептуальное представление — это представление всей информации БД в несколько более абстрактной форме по сравнению с физическим способом хранения данных. Однако концептуальное представление существенно отличается от способа представления данных какому-либо отдельному пользователю. Концептуальное представление — это представление данных такими, какие они есть на самом деле, а не такими, какими вынужден их видеть пользователь. Концептуальная схема — это определение такого представления. В большинстве существующих систем концептуальная схема в действительности представляет собой немного больше, чем простое объединение всех отдельных внешних схем с дополнительными средствами безопасности и правилами обеспечения целостности.
Внутреннее представление — это представление нижнего уровня всей БД. Внутреннее представление так же, как внешнее и концептуальное, не связанно с физическим уровнем. Это представление предполагает бесконечное линейное адресное пространство.
studfiles.net
Реляционная СУБД
2010/04/29 15:35:08
Реляционная СУБД (или РСУБД) — система управления реляционными БД. Понятие реляционный касательно СУБД появилось благодаря работам английского специалиста Эдгара Кодда (Edgar Codd). Такие модели управления можно охарактеризовать простотой, удобным табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Каталог СУБД-решений и проектов доступен на TAdviser.
В реляционных базах данные хранятся в виде таблиц, состоящих из строк и столбцов. Каждая таблица имеет собственный, заранее определенный набор именованных полей. Столбцы таблиц реляционной базы могут содержать скалярные данные фиксированного типа, например числа, строки или даты. Таблицы в реляционной базе данных могут быть связаны отношениями «один-к-одному» или «один-ко-многим». Количество строк записей в таблице неограниченно, и каждая запись соответствует отдельной сущности.
Реляционные базы данных занимают сейчас доминирующее положение. Иерархическая и сетевая структуры баз данных ушли в прошлое, уступив свое место реляционным базам, под которые постороено большинство современных СУБД (MS SQL Server, MS Access, InterBase, FoxPro, PostgreSQL, Paradox и другие).
Подробности
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
- Каждый элемент таблицы является одним элементом данных
- Каждый столбец обладает своим уникальным именем
- Одинаковые строки в таблице отсутствуют
- Все столбцы в таблице однородные, то есть все элементы в столбце имеют одинаковый тип
- Порядок следования строк и столбцов может быть произвольным
Реляционные СУБД, ориентированные на реализацию систем операционной обработки данных, менее эффективны в задачах аналитической обработки, чем многомерные базы данных. Это связано, во-первых, с наличием достаточно жестких ограничений накладываемых существующей реализацией языка SQL. Примером такого реально существующего ограничения является предположение о том, что данные в реляционной базе неупорядочены (или более точно, упорядочены случайным образом). При этом их упорядочивание требует дополнительных затрат времени на сортировку при каждом обращении к базе данных. В аналитических системах ввод и выборка данных осуществляется большими порциями. В свою очередь данные, после того как они попадают в базу данных, остаются неизменными в течение длительного периода времени. И здесь более эффективным оказывается хранение данных в форме частично денормализованных таблиц, в которых для увеличения производительности могут храниться не только детализированные, но и предварительно вычисленные агрегированные значения. А для навигации и выборки могут использоваться специализированные, основанные на предположении о малой изменчивости и малоподвижности данных в базе данных, методы адресации и индексации. Такой способ организации данных, иногда называют предвычисленным, подчеркивая тем самым, его отличие от нормализованного реляционного подхода, предполагающего динамическое вычисление различного вида итогов (агрегация) и установление связей между реквизитами из разных таблиц (операции соединения).
Основные недостатки
Помимо невысокой эффективности, о которой было сказано ранее, к недостаткам традиционных реляционных СУБД можно отнести факт того, что в качестве основного и, часто, единственного механизма, обеспечивающего быстрый поиск и выборку отдельных строк таблице (или в связанных через внешние ключи таблицах), обычно используются различные модификации индексов, основанных на B-деревьях. Такое решение оказывается эффективным только при обработке небольших групп записей и высокой интенсивности модификации данных в базах данных.
Реляционные СУБД, возможно, никогда не уйдут со сцены, но дни их господства определенно сочтены, полагает Пол Крил, опубликовавший в сентябре 2011 года статью об этом в InfoWorld. Он цитирует аналитика Робина Блора, который утверждает, что архитектура реляционных СУБД морально устарела, так как была создана еще в прошлую эпоху и не отвечает современным требованиям.
Реляционные СУБД все еще доминируют в системах обработки финансовых транзакций, но сегодня компании все шире применяют СУБД новой архитектуры NoSQL — горизонтально масштабируемые, распределенные и разрабатываемые в открытых кодах. Примеры таких систем — Hadoop, MapReduce и VoltDB. По оценкам аналитиков Forrester, около 75% данных на предприятиях это либо полуструктурированная информация (XML, электронная почта и EDI), либо неструктурированная (текст, изображения, аудио и видео), и лишь 5% от этих данных хранится в реляционных СУБД, а остальное — в базах других типов или в виде файлов, и неподвластно обработке реляционными системами.
По мнению Блора, реляционные СУБД «могут умереть так, что этого никто не заметит» — например, если Oracle в своей СУБД попросту заменит SQL-механизм на NoSQL. Таким механизмом, считает аналитик, могла бы стать одна из существующих сегодня столбцовых СУБД.
www.tadviser.ru
Реляционная модель данных — Википедия
Материал из Википедии — свободной энциклопедии
Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики, как теория множеств и логика первого порядка.
На реляционной модели данных строятся реляционные базы данных.
Реляционная модель данных включает следующие компоненты:
Кроме того, в состав реляционной модели данных включают теорию нормализации.
Термин «реляционный» означает, что теория основана на математическом понятии отношение (relation). В качестве неформального синонима термину «отношение» часто встречается слово таблица. Необходимо помнить, что «таблица» есть понятие нестрогое и неформальное и часто означает не «отношение» как абстрактное понятие, а визуальное представление отношения на бумаге или экране. Некорректное и нестрогое использование термина «таблица» вместо термина «отношение» нередко приводит к недопониманию. Наиболее частая ошибка состоит в рассуждениях о том, что РМД имеет дело с «плоскими», или «двумерными» таблицами, тогда как таковыми могут быть только визуальные представления таблиц. Отношения же являются абстракциями и не могут быть ни «плоскими», ни «неплоскими».
Для лучшего понимания РМД следует отметить три важных обстоятельства:
- модель является логической, то есть отношения являются логическими (абстрактными), а не физическими (хранимыми) структурами;
- для реляционных баз данных верен информационный принцип: всё информационное наполнение базы данных представлено одним и только одним способом, а именно — явным заданием значений атрибутов в кортежах отношений; в частности, нет никаких указателей (адресов), связывающих одно значение с другим;
- наличие реляционной алгебры позволяет реализовать декларативное программирование и декларативное описание ограничений целостности, в дополнение к навигационному (процедурному) программированию и процедурной проверке условий.
Принципы реляционной модели были сформулированы в 1969—1970 годах Э. Ф. Коддом (E. F. Codd). Идеи Кодда были впервые публично изложены в статье «A Relational Model of Data for Large Shared Data Banks»[1][2], ставшей классической.
Строгое изложение теории реляционных баз данных (реляционной модели данных) в современном понимании можно найти в книге К. Дж. Дейта. «C. J. Date. An Introduction to Database Systems» («Дейт, К. Дж. Введение в системы баз данных»).
Наиболее известными альтернативами реляционной модели являются иерархическая модель, и сетевая модель. Некоторые системы, использующие эти старые архитектуры, используются до сих пор. Кроме того, можно упомянуть об объектно-ориентированной модели, на которой строятся так называемые объектно-ориентированные СУБД, хотя однозначного и общепринятого определения такой модели нет.
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — 1328 с. — ISBN 0-321-19784-4.
- Томас Коннолли, Каролин Бегг. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management Third Edition. — 3-е изд. — М.: «Вильямс», 2003. — С. 1436. — ISBN 0-201-70857-4.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. — ISBN 978-5-94774-736-2.
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — С. 800. — ISBN 5-279-02276-4.
ru.wikipedia.org
Реляционная база данных — Национальная библиотека им. Н. Э. Баумана
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 12:13, 25 марта 2017.
Реляционная база данных — база данных, построенная на основе реляционной модели[1]. В реляционной базе каждый объект задается записью (строкой) в таблице. Реляционная база создается и затем управляется с помощью реляционной системы управления базами данных.Фактически реляционная база данных это тело связанной информации, сохраняемой в двухмерных таблицах. Связь между таблицами может находить свое отражение в структуре данных, а может только подразумеваться, то есть присутствовать на неформализованном уровне. Каждая таблица БД представляется как совокупность строк и столбцов, где строки соответствуют экземпляру объекта, конкретному событию или явлению, а столбцы — атрибутам (признакам, характеристикам, параметрам) объекта, события, явления. Реляционные базы данных предоставляют более простой доступ к оперативно составляемым отчетам (обычно через SQL) и обеспечивают повышенную надежность и целостность данных благодаря отсутствию избыточной информации.
История
Реляционные системы берут свое начало в математической теории множеств. Эдгар Кодд, сотрудник исследовательской лаборатории корпорации IBM в Сан-Хосе, по существу, создал и описал концепцию реляционных баз данных в своей основополагающей работе «Реляционная модель для крупных, совместно используемых банков данных» (A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, июнь 1970).
Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин «запись», который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин «кортеж длины n» или просто «кортеж», которому дал точное определение.
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных. Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним.
Правила Кодда
Правило 0: Основное правило (Foundation Rule):
- Система, которая рекламируется или позиционируется как реляционная система управления базами данных, должна быть способна управлять базами данных, используя исключительно свои реляционные возможности.
Правило 1: Информационное правило (The Information Rule):
- Вся информация в реляционной базе данных на логическом уровне должна быть явно представлена единственным способом: значениями в таблицах.
Правило 2: Гарантированный доступ к данным (Guaranteed Access Rule):
- В реляционной базе данных каждое отдельное (атомарное) значение данных должно быть логически доступно с помощью комбинации имени таблицы, значения первичного ключа и имени столбца.
Правило 3: Систематическая поддержка отсутствующих значений (Systematic Treatment of Null Values):
- Неизвестные, или отсутствующие значения NULL, отличные от любого известного значения, должны поддерживаться для всех типов данных при выполнении любых операций. Например, для числовых данных неизвестные значения не должны рассматриваться как нули, а для символьных данных — как пустые строки.
Правило 4: Доступ к словарю данных в терминах реляционной модели (Active On-Line Catalog Based on the Relational Model):
- Словарь данных должен сохраняться в форме реляционных таблиц, и СУБД должна поддерживать доступ к нему при помощи стандартных языковых средств, тех же самых, которые используются для работы с реляционными таблицами, содержащими пользовательские данные.
Правило 5: Полнота подмножества языка (Comprehensive Data Sublanguage Rule):
- Система управления реляционными базами данных должна поддерживать хотя бы один реляционный язык, который
- (а) имеет линейный синтаксис,
- (б) может использоваться как интерактивно, так и в прикладных программах,
- (в) поддерживает операции определения данных, определения представлений, манипулирования данными (интерактивные и программные), ограничители целостности, управления доступом и операции управления транзакциями (begin, commit и rollback).
Правило 6: Возможность изменения представлений (View Updating Rule):
- Каждое представление должно поддерживать все операции манипулирования данными, которые поддерживают реляционные таблицы: операции выборки, вставки, изменения и удаления данных.
Правило 7: Наличие высокоуровневых операций управления данными (High-Level Insert, Update, and Delete):
- Операции вставки, изменения и удаления данных должны поддерживаться не только по отношению к одной строке реляционной таблицы, но и по отношению к любому множеству строк.
Правило 8: Физическая независимость данных (Physical Data Independence):
- Приложения не должны зависеть от используемых способов хранения данных на носителях, от аппаратного обеспечения компьютеров, на которых находится реляционная база данных.
Правило 9: Логическая независимость данных (Logical Data Independence):
- Представление данных в приложении не должно зависеть от структуры реляционных таблиц. Если в процессе нормализации одна реляционная таблица разделяется на две, представление должно обеспечить объединение этих данных, чтобы изменение структуры реляционных таблиц не сказывалось на работе приложений.
Правило 10: Независимость контроля целостности (Integrity Independence):
- Вся информация, необходимая для поддержания целостности, должна находиться в словаре данных. Язык для работы с данными должен выполнять проверку входных данных и автоматически поддерживать целостность данных.
Правило 11: Независимость от расположения (Distribution Independence):
- База данных может быть распределённой, может находиться на нескольких компьютерах, и это не должно оказывать влияния на приложения. Перенос базы данных на другой компьютер не должен оказывать влияния на приложения.
Правило 12: Согласование языковых уровней (The Nonsubversion Rule):
- Если используется низкоуровневый язык доступа к данным, он не должен игнорировать правила безопасности и правила целостности, которые поддерживаются языком более высокого уровня.
Сущность реляционной базы данных
Реляционная база данных представляет собой набор таблиц (сущностей). Таблицы состоят из колонок и строк (кортежей). Внутри таблиц могут быть определены ограничения, между таблицами существуют отношения. При помощи SQL можно выполнять запросы, которые возвращают наборы данных, получаемых из одной или нескольких таблиц. В рамках одного запроса данные получаются из нескольких таблиц путем их соединения (JOIN), чаще всего для соединения используются те же колонки, которые определяют отношения между таблицами.
Нормализация — это процесс структурирования модели данных, обеспечивающий связность и отсутствие избыточности в данных. Целью нормализации реляционной базы данных является устранение недостатков структуры базы данных, приводящих к избыточности, которая, в свою очередь, потенциально приводит к различным аномалиям и нарушениям целостности данных.Теоретики реляционных баз данных в процессе развития теории выявили и описали типичные примеры избыточности и способы их устранения. Реляционные хранилища обеспечивают наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости. Касаемо масштабируемости, реляционные БД хорошо масштабируются только в том случае, если располагаются на единственном сервере.
Особенностью реляционной базы данных является использование в ней реляционной модели данных и вытекающие из этого последствия:
- Модель данных в реляционных БД определена заранее. Является строго типизированной, содержит ограничения и отношения для обеспечения целостности данных.
- Модель данных основана на естественном представлении содержащихся данных, а не на функциональности приложения.
- Модель данных подвергается нормализации, чтобы избежать дублирования данных. Нормализация порождает отношения между таблицами. Отношения связывают данные разных таблиц.
В реляционной базе данных данные создаются, обновляются, удаляются и запрашиваются с использованием языка структурированных запросов (SQL). SQL-запросы могут извлекать данные как из одиночной таблица, так и из нескольких таблиц.Такие запросы могут включать агрегации и сложные фильтры. Реляционная БД обычно содержит встроенную логику, такую как триггеры, хранимые процедуры и функции.
Реляционная система управления базой данных (РСУБД)
Реляционная система управления базой данных (РСУБД) — СУБД, управляющая реляционными базами данных.
Доступ к реляционным базам данных осуществляется через реляционные системы управления базами данных (РСУБД). Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее. Причины такого доминирования неочевидны. На протяжении всего существования реляционных БД они постоянно предлагали наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости в сфере управлении данными.
Например, простой SELECT запрос может иметь сотни потенциальных путей выполнения, которые оптимизатор оценит непосредственно во время выполнения запроса. Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу. Однако чтобы обеспечить все эти особенности, реляционные хранилища невероятно сложны внутри.
Реляционная система управления базой данных содержит:
- командный язык;
- язык программирования с ориентацией на обработку таблиц;
- интерпретирующую и/или компилирующую систему; и
- пользовательскую оболочку.
Источники
Ссылки
- https://habrahabr.ru/company/mailru/blog/266811/
- http://informatic.ugatu.ac.ru/lib/office/Proekt.html
- http://de.ifmo.ru/—books/sql/1-1.html
- http://www.osp.ru/cw/2001/05/9215/
- https://habrahabr.ru/post/103021/
ru.bmstu.wiki
Реляционная модель данных — Национальная библиотека им. Н. Э. Баумана
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 20:28, 12 июня 2017.
Реляционная модель — совокупность данных, состоящая из набора двумерных таблиц. В теории множеств таблице соответствует термин отношение (relation), физическим представлением которого является таблица, отсюда и название модели – реляционная. Соответственно теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики, как теория множеств и логика первого порядка. В сравнении с иерархической и сетевой моделью данных, реляционная модель отличается более высоким уровнем абстракции данных. Реляционная модель является удобной и наиболее привычной формой представления данных, так в настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД. На реляционной модели данных строятся реляционные базы данных[1].
Впервые принципы реляционной модели были сформулированы в 1969—1970 годах Э. Ф. Коддом (E. F. Codd). Идеи Кодда были впервые публично изложены в статье «A Relational Model of Data for Large Shared Data Banks». Современную трактовку идей реляционной модели данных можно найти в книге К. Дж. Дейта. «C. J. Date. An Introduction to Database Systems»
Состав частей реляционной модели данных
Наиболее распространенная трактовка реляционной модели данных, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
Структурная часть
Структурная часть (аспект), отвечает за принцип построения структуры реляционной базы данных на нормализированном наборе n-арных отношений, в форме таблиц. Важно что реляционная база данных, структурно может представляться только в виде отношений.
Манипуляционная часть
В манипуляционной части модели утверждаются операторы манипулирования отношениями — реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй — на классическом логическом аппарате исчисления предикатов первого порядка. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Целостная часть
В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Как мы видели в предыдущем разделе, это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений.
Второе требование называется требованием целостности по ссылкам и является несколько более сложным. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений. Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
Структура реляционной модели данных
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствованна соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формирую дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.
Достоинства и недостатки реляционной модели данных
Достоинства
- Изложение информации в простой и понятной для пользователя форме (таблица).
- Реляционная модель данных основана на строгом математическом аппарате, что позволяет лаконично описывать необходимые операции над данными.
- Независимость данных от изменения в прикладной программе при изменении.
- Позволяет создавать языки манипулирования данными не процедурного типа.
- Для работы с моделью данных нет необходимости полностью знать организацию БД.
Недостатки
- Относительно медленный доступ к данным.
- Трудность в создании БД основанной на реляционной модели.
- Трудность в переводе в таблицу сложных отношений.
- Требуется относительно большой объем памяти.
См. также
Источники
Ссылки
- http://www.bseu.by/it/tohod/lekcii2_3.htm
- http://wiki.mvtom.ru/index.php/%D0%A0%D0%B5%D0%BB%D1%8F%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85
- http://citforum.ru/database/osbd/glava_18.shtml
ru.bmstu.wiki