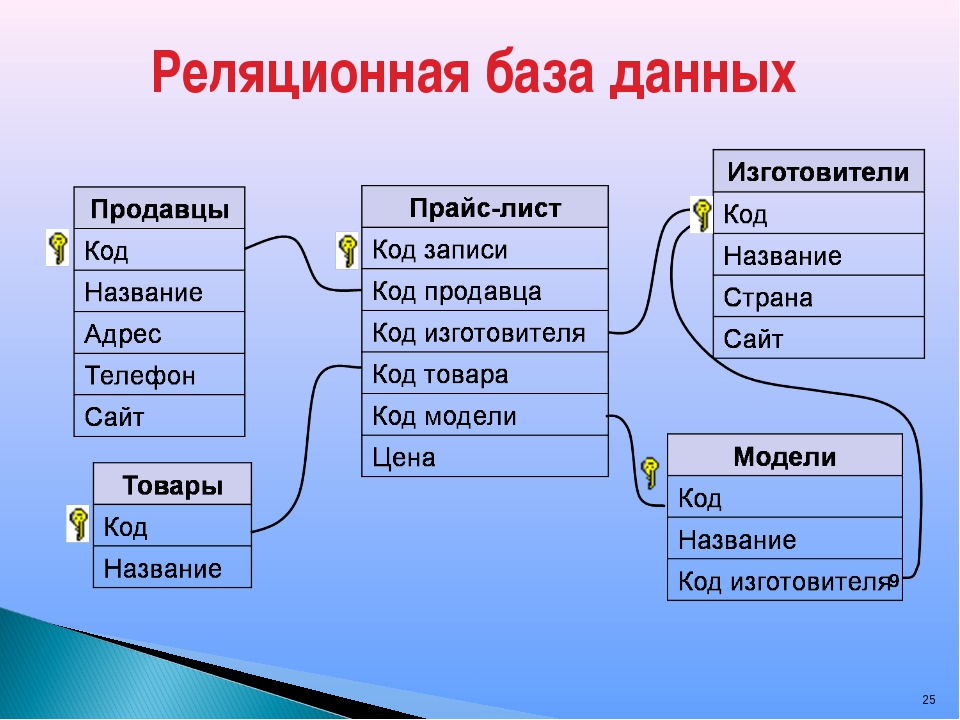
Что такое реляционная база данных
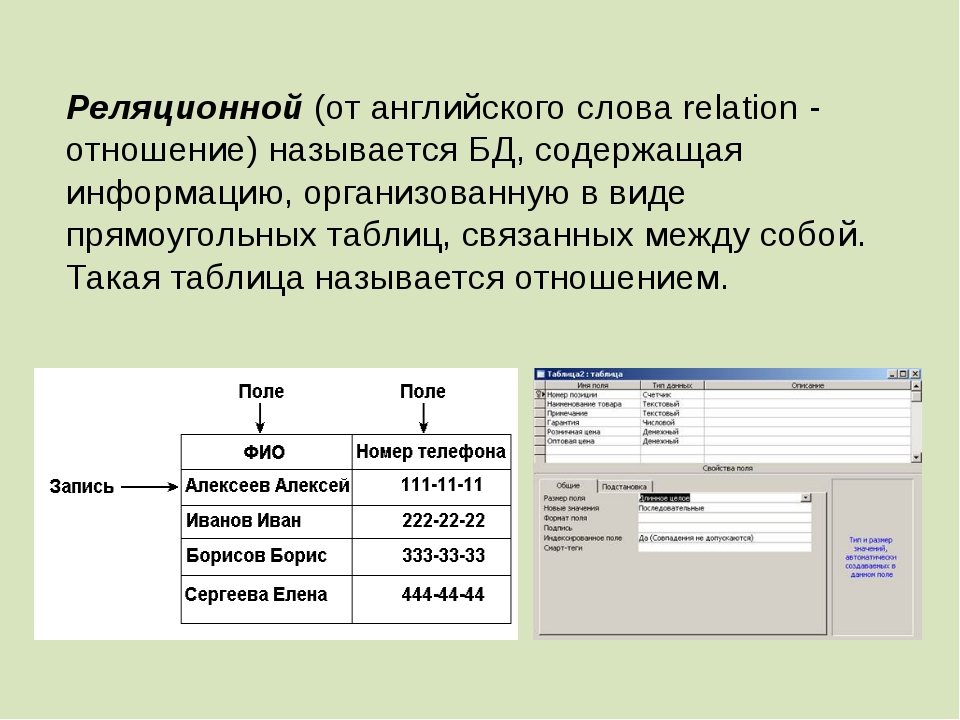
Реляционные базы данных представляют собой базы данных, которые используются для хранения и предоставления доступа к взаимосвязанным элементам информации. Реляционные базы данных основаны на реляционной модели — интуитивно понятном, наглядном табличном способе представления данных. Каждая строка, содержащая в таблице такой базы данных, представляет собой запись с уникальным идентификатором, который называют ключом. Столбцы таблицы имеют атрибуты данных, а каждая запись обычно содержит значение для каждого атрибута, что дает возможность легко устанавливать взаимосвязь между элементами данных.
Структура реляционных баз данных
Реляционная модель подразумевает логическую структуру данных: таблицы, представления и индексы. Логическая структура отличается от физической структуры хранения. Такое разделение дает возможность администраторам управлять физической системой хранения, не меняя данных, содержащихся в логической структуре.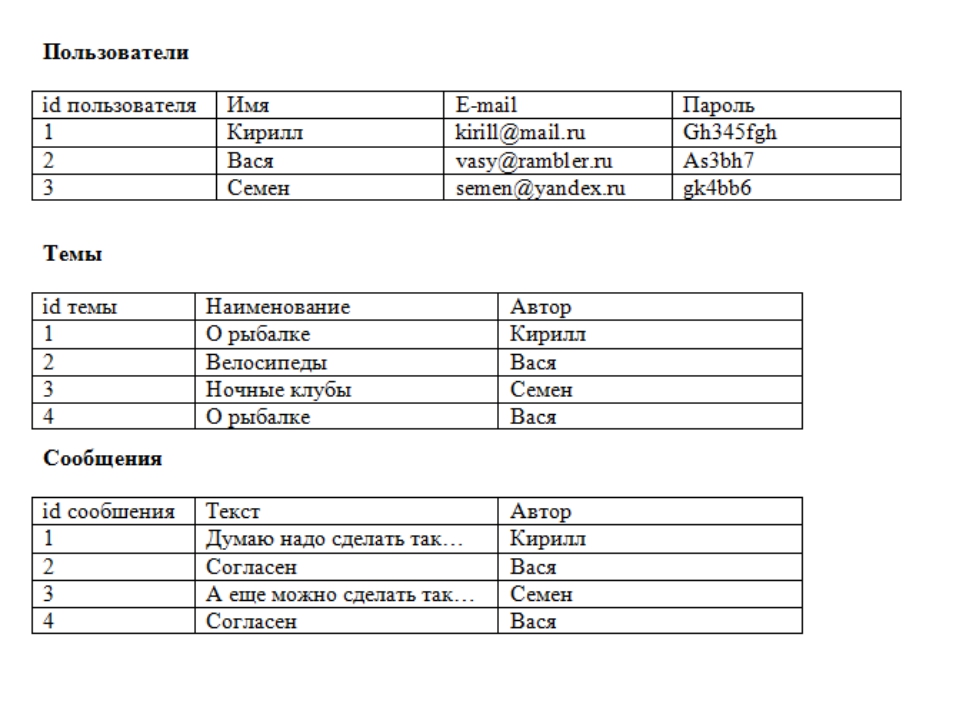
Разделение между физическим и логическим уровнем распространяется в том числе на операции, которые представляют собой четко определенные действия с данными и структурами базы данных. Логические операции дают возможность приложениям определять требования к необходимому содержанию, в то время как физические операции определяют способ доступа к данным и выполнения задачи.
Чтобы обеспечить точность и доступность данных, в реляционных базах должны соблюдаться определенные правила целостности. Например, в правилах целостности можно запретить использование дубликатов строк в таблицах, чтобы устранить вероятность попадания неправильной информации в базу данных.
Реляционная модель
В первых базах данных данные каждого приложения хранились в отдельной уникальной структуре. Если разработчик хотел создать приложение для использования таких данных, он должен был хорошо знать конкретную структуру, чтобы найти необходимые данные. Такой метод организации был неэффективен, сложен в обслуживании и затруднял оптимизацию эффективности приложений. Реляционная модель была разработана, чтобы устранить потребность в использовании разнообразных структур данных.
Такой метод организации был неэффективен, сложен в обслуживании и затруднял оптимизацию эффективности приложений. Реляционная модель была разработана, чтобы устранить потребность в использовании разнообразных структур данных.
Она обеспечила стандартный способ представления данных и отправки запросов, которые могли быть использованы в любых приложениях. Разработчики уяснили, что таблицы являются ключевым преимуществом реляционных баз данных, так как обеспечивают интуитивно понятный, эффективный и гибкий способ хранения структурированной информации и получения к ней доступа.
Со временем, когда разработчики стали использовать язык структурированных запросов (SQL) для записи данных в базу и отправки запросов, стало очевидным и другое преимущество реляционной модели. Вот уже на протяжении многих лет SQL широко используется в качестве языка запросов в базах данных. Он основан на алгоритмах реляционной алгебры и четкой математической структуре, что обеспечивает простоту и эффективность при оптимизации любых запросов к базе данных.
Преимущества реляционных баз данных
Компании всех типов и размеров используют простую, но функциональную реляционную модель для обслуживания разнообразных информационных потребностей. Реляционные базы данных применяются для отслеживания товарных запасов, обработки торговых транзакций через Интернет, управления большими объемами критически важных данных заказчиков и т. д. Реляционные базы данных можно рекомендовать для обслуживания любых информационных потребностей, где элементы данных связаны между собой и необходимо обеспечивать безопасное и надежное управление ими на основе правил целостности.
Реляционные базы данных появились в 1970-х годах. На сегодняшний день преимущества реляционного подхода сделали его самой распространенной моделью для баз данных в мире.
Целостность данных
Реляционная модель наиболее эффективно поддерживает целостность данных во всех приложениях и копиях (экземплярах) базы данных. Например, когда заказчик кладет деньги на счет с помощью банкомата, а затем проверяет баланс на мобильном телефоне, он ожидает, что поступившие средства сразу же отобразятся на счете. Реляционные базы данных отлично подходят для обеспечения целостности данных в различных экземплярах базы в одно и то же время.
Например, когда заказчик кладет деньги на счет с помощью банкомата, а затем проверяет баланс на мобильном телефоне, он ожидает, что поступившие средства сразу же отобразятся на счете. Реляционные базы данных отлично подходят для обеспечения целостности данных в различных экземплярах базы в одно и то же время.
Другие типы баз данных не могут одновременно поддерживать целостность больших объемов данных. Некоторые современные типы баз данных, такие как NoSQL, обеспечивают только так называемую “окончательную целостность.” Это значит, что, когда выполняется масштабирование данных или несколько пользователей одновременно используют одни и те же данные, необходимо некоторое время на “внесение изменений”. В некоторых случаях окончательная целостность вполне приемлема (например, для обновления позиций в товарном каталоге), однако для критически важной операционной деятельности бизнеса (например, транзакций с использованием корзины) реляционные базы представляют собой фундаментальный стандарт.
Фиксация изменений и атомарность
В реляционных базах данных используются очень детальные и строгие бизнес-правила и политики в отношении фиксации изменений в базе данных (то есть сохранения изменений в данных на постоянной основе). Рассмотрим для примера складскую базу данных, в которой отслеживаются три запчасти, всегда использующиеся в комплекте. Когда одну из них извлекают из товарных запасов, две другие также должны извлекаться. Если одна из трех запчастей недоступна, две другие также не могут быть проданы отдельно, то есть, чтобы в базу данных можно было внести изменения, должны быть доступны все три запчасти. Реляционная база данных не разрешит сохранять изменения, если они не касаются всех трех запчастей. Эту особенность реляционных баз данных называют
Хранимые процедуры и реляционные базы данных
Доступ к данным включает в себя множество повторяющихся действий.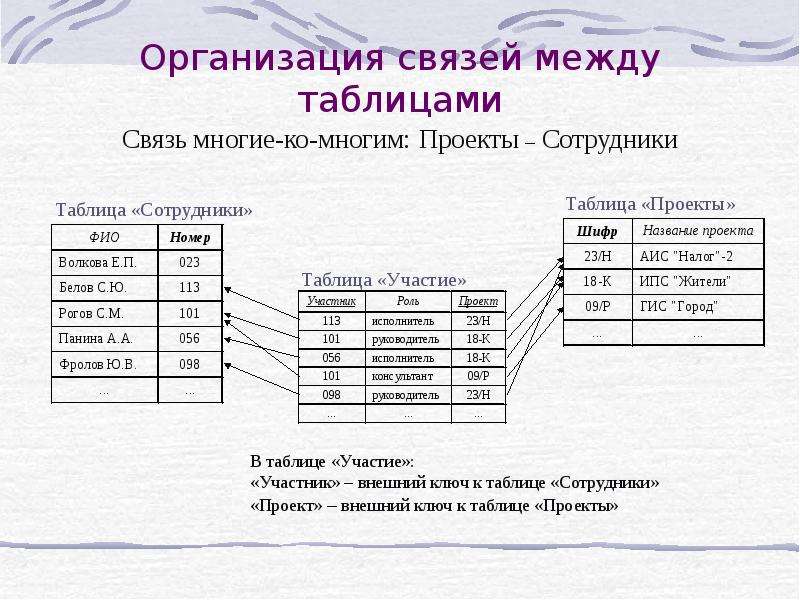 Например, иногда для получения нужного результата простой запрос для получения информации из таблицы необходимо повторить сотню или тысячу раз. Для таких сценариев доступа к базе данных необходимо что-то вроде программного кода. Разработчикам каждый раз писать стандартный код доступа к данным для нового приложения было бы утомительно. К счастью, реляционные базы данных поддерживают хранимые процедуры, представляющие собой блоки кода, к которым можно получить доступ с помощью обычного вызова со стороны кода приложения. Например, одну и ту же хранимую процедуру можно использовать для последовательной маркировки записей в целях удобства пользователей для различных приложений. Хранимые процедуры также помогают разработчикам убедиться в правильной реализации определенных функций данных в приложении.
Например, иногда для получения нужного результата простой запрос для получения информации из таблицы необходимо повторить сотню или тысячу раз. Для таких сценариев доступа к базе данных необходимо что-то вроде программного кода. Разработчикам каждый раз писать стандартный код доступа к данным для нового приложения было бы утомительно. К счастью, реляционные базы данных поддерживают хранимые процедуры, представляющие собой блоки кода, к которым можно получить доступ с помощью обычного вызова со стороны кода приложения. Например, одну и ту же хранимую процедуру можно использовать для последовательной маркировки записей в целях удобства пользователей для различных приложений. Хранимые процедуры также помогают разработчикам убедиться в правильной реализации определенных функций данных в приложении.
Блокировки базы данных и параллельный доступ
Когда несколько пользователей или приложений пытаются одновременно изменить одни и те же данные, это может вести к возникновению конфликта в базе. Блокировки и параллельный доступ снижают вероятность конфликтов и способствуют сохранению целостности данных.
Блокировки и параллельный доступ снижают вероятность конфликтов и способствуют сохранению целостности данных.
Блокировка не разрешает другим пользователям и приложениям получать доступ к данным во время их обновления. В некоторых базах данных блокировка может применяться к целой таблице, что негативно отражается на эффективности приложения. В других типах баз данных, например реляционных базах Oracle, блокировка выполняется на уровне одной записи, оставляя другие записи в таблице доступными. Такой подход помогает сохранить эффективность приложения.
Инструмент параллельного доступа используется, когда несколько пользователей или приложений пытаются одновременно выполнить запросы к одной базе данных. Он обеспечивает доступ пользователей и приложений к базе данных в соответствии с политиками контроля.
Характеристики, на которые следует обратить внимание при выборе реляционной базы данных
Программное обеспечение, которое используется для сохранения, контроля и извлечения данных в базе, а также выполнения к ней запросов, называют системой управления реляционной базой данных (СУРБД).
При выборе типа базы данных и продуктов на основе реляционных баз данных необходимо учитывать несколько факторов. Выбор СУРБД зависит от потребностей Вашей компании. Задайте себе следующие вопросы.
- Каковы наши требования к точности данных? Будем ли мы использовать бизнес-логику для хранения и обеспечения точности данных? Предъявляются ли к нашим данным более строгие требования в отношении точности (например, если Вы работаете с финансовыми данными и отчетностью)?
- Нужна ли нам масштабируемость? Какими объемами данных требуется управлять и каков прогнозируемый рост этих объемов? Должна ли модель базы данных поддерживать зеркальные копии (как отдельные экземпляры) в целях масштабирования? Если да, сможем ли мы обеспечивать целостность данных в этих экземплярах?
- Насколько важно наличие параллельного доступа? Потребуется ли пользователям и приложениям одновременный доступ к данным? Поддерживает ли ПО базы данных параллельный доступ без ущерба для безопасности?
- Каковы наши потребности в эффективности и надежности баз данных? Требуется ли нам высокоэффективная и надежная система? Каковы требования к скорости выполнения запросов? Какие гарантии дает вендор услуг в соответствии с соглашением об обслуживании (SLA) или на случай незапланированного простоя?
Реляционная база данных будущего: автономная база данных
Свойства реляционной таблицы
ОСНОВНЫЕ ПОНЯТИЯ БАЗ ДАННЫХ
База данных (БД) – именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области данных.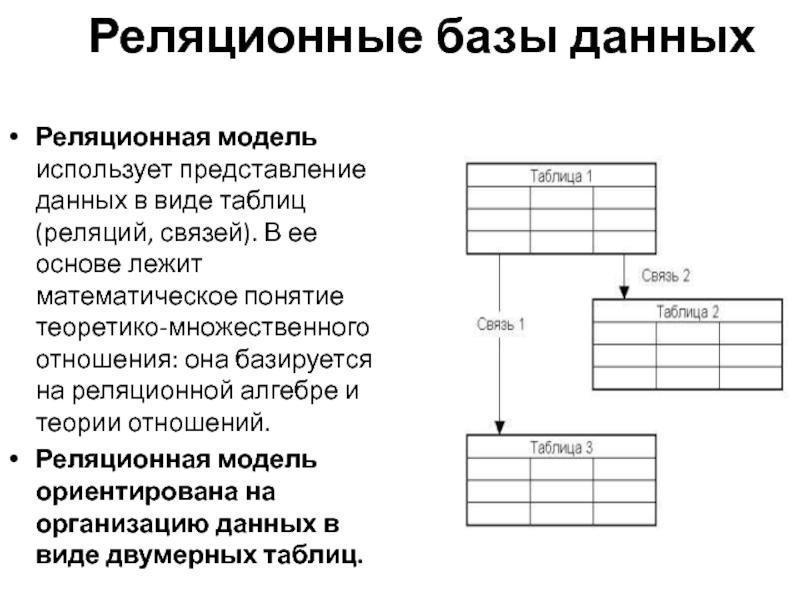
Примеры предметных областей данных: склад, магазин, вуз, больница, учебный процесс и т. д. Именно предметная область определяет совокупность данных, которые должны храниться в базе данных.
Система управления базами данных (СУБД) – совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования базы данных многими пользователями.
Другие определения, имеющие отношение к БД и СУБД.
Банк данных (БнД) – это система специальным образом организованных данных – баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и многоцелевого использования данных.
Информационная система (ИС) – взаимосвязанная совокупность средств, методов и персонала, используемых для хранения, обработки и выдачи информации в интересах достижения поставленной задачи.
Основой практически любой информационной системы является база данных.
Сервер – компьютер или программа, владеющая определенным информационным ресурсом и предназначенная для обработки запросов от программ-клиентов.
Основными моделями данных, определяющие структуру базы данных, являются:
иерархическая модель;
сетевая модель;
реляционная модель.
РЕЛЯЦИОННАЯ МОДЕЛЬ ДАННЫХ
Теоретической основой этой модели является теория отношений и основной структурой данных – отношение. Именно поэтому модель получила название реляционной (от английского слова relation — отношение).
Отношениепредставляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является двумерная таблица. Смысловые значения некоторых элементов реляционной модели приведены в следующей таблице.
Смысловые значения некоторых элементов реляционной модели приведены в следующей таблице.
| Обычное представление | База данных | Реляционная модель |
| Таблица | Таблица | Отношение |
| Строка | Запись | Кортеж |
| Название столбца | Поле | Атрибут |
| Множество значений столбца | Множество значений поля | Домен (множество значений атрибута) |
Подавляющее число создаваемых и используемых баз данных являются реляционными. Их создание и развитие связано с научными работами известного американского математика, специалиста в области систем баз данных Э. Кодда.
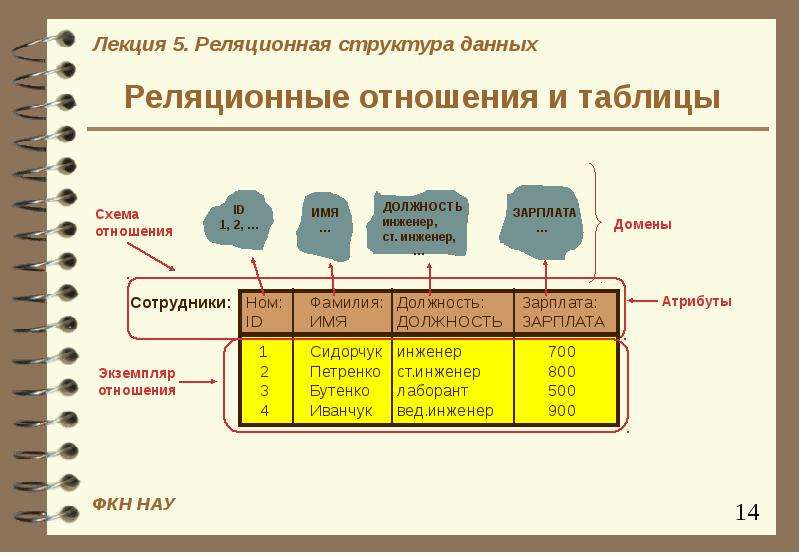
Свойства реляционной таблицы
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
· каждый элемент таблицы — один элемент данных;
· все столбцы (поля, атрибуты) в таблице однородные, т.е. все элементы в одном столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
· каждый столбец имеет уникальное имя;
· одинаковые строки (записи, кортежи) в таблице отсутствуют;
· порядок следования строк и столбцов может быть произвольным.
Каждое поле содержит одну характеристику объекта предметной области. В записи собраны сведения об одном экземпляре этого объекта.
Ключи
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Ключ, состоящий из нескольких полей называется составным ключом. В СУБД Access в качестве ключа может быть использован Счетчик, который автоматически возрастает на единицу при вводе в таблицу новой записи. Такой ключ называют искусственным. Он семантически не связан ни с одним полем таблицы. Из-за этого он допускает повторный ввод одних и тех же записей. Но с помощью него просто устанавливать связь между таблицами. Основное свойство ключа – уникальность, неповторимость.
Такой ключ называют искусственным. Он семантически не связан ни с одним полем таблицы. Из-за этого он допускает повторный ввод одних и тех же записей. Но с помощью него просто устанавливать связь между таблицами. Основное свойство ключа – уникальность, неповторимость.
Типы связей между таблицами
Структура базы данных определяется структурой таблиц и связями между ними.
Связи между таблицами бывают трех типов:
«один-к-одному» (1:1) – одной записи в главной таблице соответствует одна запись в подчиненной таблице,
«один-ко-многим» (1:М) – одной записи в главной таблице соответствует несколько записей в подчиненной таблице,
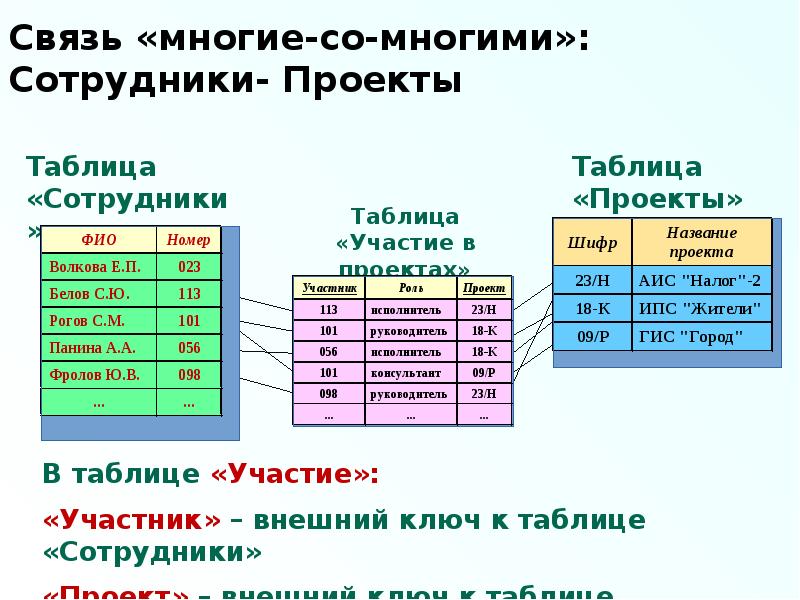
«многие-ко-многим» (М:М) – нескольким записям в главной таблице соответствуют несколько записей в подчиненной таблице. Или одной записи в первой таблице может соответствовать несколько записей во второй таблице. И одной записи во второй таблице могут соответствовать несколько записей в первой таблице.
Создание связей между таблицами
Связь между таблицами устанавливается с помощью ключей. Главной называют таблицу, первичный ключ которой используется для установления связи с другой таблицей, которая в этом случае называется подчиненной.
Чтобы связать две реляционные таблицы, необходимо ключ главной таблицы ввести в состав подчиненной таблицы. Название ключа может быть другим, но обязательно одинаковыми с первичным ключом должны быть тип и размер вторичного ключа в подчиненной таблице. Для удобства лучше обозначение вторичного ключа оставлять таким же, как и первичного. Однако если ключом выбран Счетчик, то вторичный ключ должен иметь тип Числовой — длинное целое (но не Счетчик!). Вторичный ключ – это или обычное поле, или часть первичного ключа в подчиненной таблице.
СУБД Access для реализации связи «многие-ко-многим» требует создать таблицу связи и ввести в нее в качестве вторичных ключей первичные ключи двух таблиц, которые должны иметь такую связь (М:М). После этого устанавливается связь 1:М каждой из двух таблиц с таблицей связи. Между двумя таблицами таким образом реализуется связь М:М. Если в БД «Моя библиотека» создать таблицы Книги и Авторы, то связь между ними будет вида М:М, так как одной записи в таблице Книги (реквизиты одной книги) может соответствовать несколько записей в таблице Авторы. Потому что у одной книги может быть несколько авторов. В свою очередь, одной записи в таблице Авторы могут соответствовать несколько записей в таблице Книги, так как один автор может написать несколько книг. Таблицу связи можно назвать КнигиАвторы, в которую будут включены ключи обеих таблиц – Книги и Авторы. Если требуется, в таблицу связи можно включить и другие поля.
После этого устанавливается связь 1:М каждой из двух таблиц с таблицей связи. Между двумя таблицами таким образом реализуется связь М:М. Если в БД «Моя библиотека» создать таблицы Книги и Авторы, то связь между ними будет вида М:М, так как одной записи в таблице Книги (реквизиты одной книги) может соответствовать несколько записей в таблице Авторы. Потому что у одной книги может быть несколько авторов. В свою очередь, одной записи в таблице Авторы могут соответствовать несколько записей в таблице Книги, так как один автор может написать несколько книг. Таблицу связи можно назвать КнигиАвторы, в которую будут включены ключи обеих таблиц – Книги и Авторы. Если требуется, в таблицу связи можно включить и другие поля.
Среди реляционных баз данных следует различать корпоративные и настольные базы данных.
Из корпоративных реляционных СУБД наиболее распространенными являются: Oracl, IBM DB2, Sybase, Microsoft SQL Server, Informix. Из постреляционных СУБД известна СУБД Cache компании InterSystems.
Наиболее известны в настоящее время следующие настольные БД: Microsoft Access, Paradox (фирмы Borland), FoxPro (Microsoft), dBase IV (IBM), Clarion.
Эти СУБД занимают более 90% всего рынка СУБД.
В следующем разделе дана краткая характеристика СУБД Microsoft Access.
Узнать еще:
Реляционные базы данных обречены? / Хабр
Примечание переводчика: хоть статья довольно старая (опубликована 2 года назад) и носит громкое название, в ней все же дается хорошее представление о различиях реляционных БД и NoSQL БД, их преимуществах и недостатках, а также приводится краткий обзор нереляционных хранилищ.
В последнее время появилось много нереляционных баз данных. Это говорит о том, что если вам нужна практически неограниченная масштабируемость по требованию, вам нужна нереляционная БД.
Если это правда, значит ли это, что могучие реляционные БД стали уязвимы? Значит ли это, что дни реляционных БД проходят и скоро совсем пройдут? В этой статье мы рассмотрим популярное течение нереляционных баз данных применительно к различным ситуациям и посмотрим, повлияет ли это на будущее реляционных БД.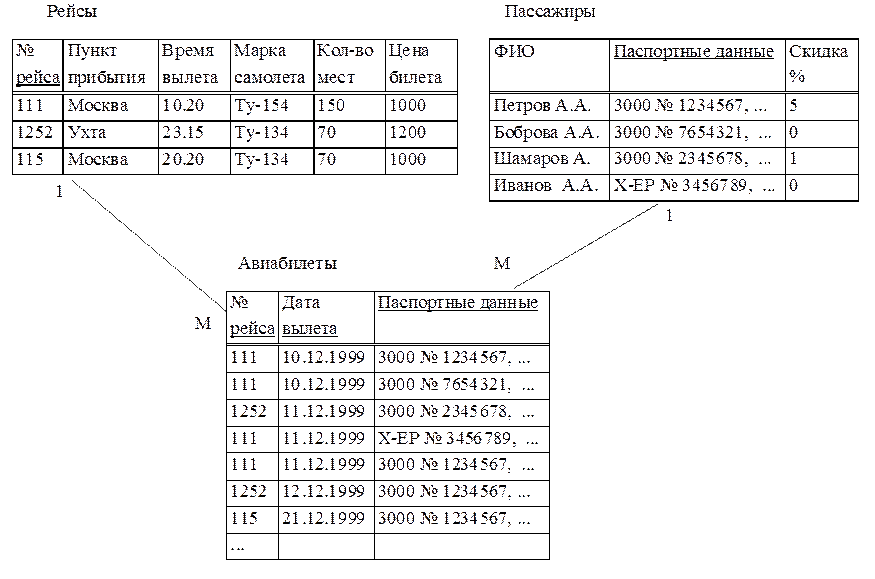
Реляционные базы данных существуют уже около 30 лет. За это время вспыхивало несколько революций, которые должны были положить конец реляционным хранилищам. Конечно, ни одна из этих революций не состоялась, и одна из них ни на йоту не поколебала позиции реляционных БД.
Начнем с основ
Реляционная база данных представляет собой набор таблиц (сущностей). Таблицы состоят из колонок и строк (кортежей). Внутри таблиц могут быть определены ограничения, между таблицами существуют отношения. При помощи SQL можно выполнять запросы, которые возвращают наборы данных, получаемых из одной или нескольких таблиц. В рамках одного запроса данные получаются из нескольких таблиц путем их соединения (JOIN), чаще всего для соединения используются те же колонки, которые определяют отношения между таблицами. Нормализация — это процесс структурирования модели данных, обеспечивающий связность и отсутствие избыточности в данных.
Доступ к реляционным базам данных осуществляется через реляционные системы управления базами данных (РСУБД).
 Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее.
Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее.Причины такого доминирования неочевидны. На протяжении всего существования реляционных БД они постоянно предлагали наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости в сфере управлении данными.
Однако чтобы обеспечить все эти особенности, реляционные хранилища невероятно сложны внутри. Например, простой SELECT запрос может иметь сотни потенциальных путей выполнения, которые оптимизатор оценит непосредственно во время выполнения запроса. Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу.
Проблемы реляционных БД
Хотя реляционные хранилища и обеспечивают наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости, их показатели по каждому из этих пунктов не обязательно выше, чем у аналогичных систем, ориентированных на какую-то одну особенность.
 Это не являлось большой проблемой, поскольку всеобщее доминирование реляционных СУБД перевешивало какие-либо недочеты. Тем не менее, если обычные РБД не отвечали потребностям, всегда существовали альтернативы.
Это не являлось большой проблемой, поскольку всеобщее доминирование реляционных СУБД перевешивало какие-либо недочеты. Тем не менее, если обычные РБД не отвечали потребностям, всегда существовали альтернативы.Сегодня ситуация немного другая. Разнообразие приложений растет, а с ним растет и важность перечисленных особенностей. И с ростом количества баз данных, одна особенность начинает затмевать все другие. Это масштабируемость. Поскольку все больше приложений работают в условиях высокой нагрузки, например, таких как веб-сервисы, их требования к масштабируемости могут очень быстро меняться и сильно расти. Первую проблему может быть очень сложно разрешить, если у вас есть реляционная БД, расположенная на собственном сервере. Предположим, нагрузка на сервер за ночь увеличилась втрое. Как быстро вы сможете проапгрейдить железо? Решение второй проблемы также вызывает трудности в случае использования реляционных БД.
Реляционные БД хорошо масштабируются только в том случае, если располагаются на единственном сервере. Когда ресурсы этого сервера закончатся, вам необходимо будет добавить больше машин и распределить нагрузку между ними. И вот тут сложность реляционных БД начинает играть против масштабируемости. Если вы попробуете увеличить количество серверов не до нескольких штук, а до сотни или тысячи, сложность возрастет на порядок, и характеристики, которые делают реляционные БД такими привлекательными, стремительно снижают к нулю шансы использовать их в качестве платформы для больших распределенных систем.
Когда ресурсы этого сервера закончатся, вам необходимо будет добавить больше машин и распределить нагрузку между ними. И вот тут сложность реляционных БД начинает играть против масштабируемости. Если вы попробуете увеличить количество серверов не до нескольких штук, а до сотни или тысячи, сложность возрастет на порядок, и характеристики, которые делают реляционные БД такими привлекательными, стремительно снижают к нулю шансы использовать их в качестве платформы для больших распределенных систем.
Чтобы оставаться конкурентоспособными, вендорам облачных сервисов приходится как-то бороться с этим ограничением, потому что какая ж это облачная платформа без масштабируемого хранилища данных. Поэтому у вендоров остается только один вариант, если они хотят предоставлять пользователям масштабируемое место для хранения данных. Нужно применять другие типы баз данных, которые обладают более высокой способностью к масштабированию, пусть и ценой других возможностей, доступных в реляционных БД.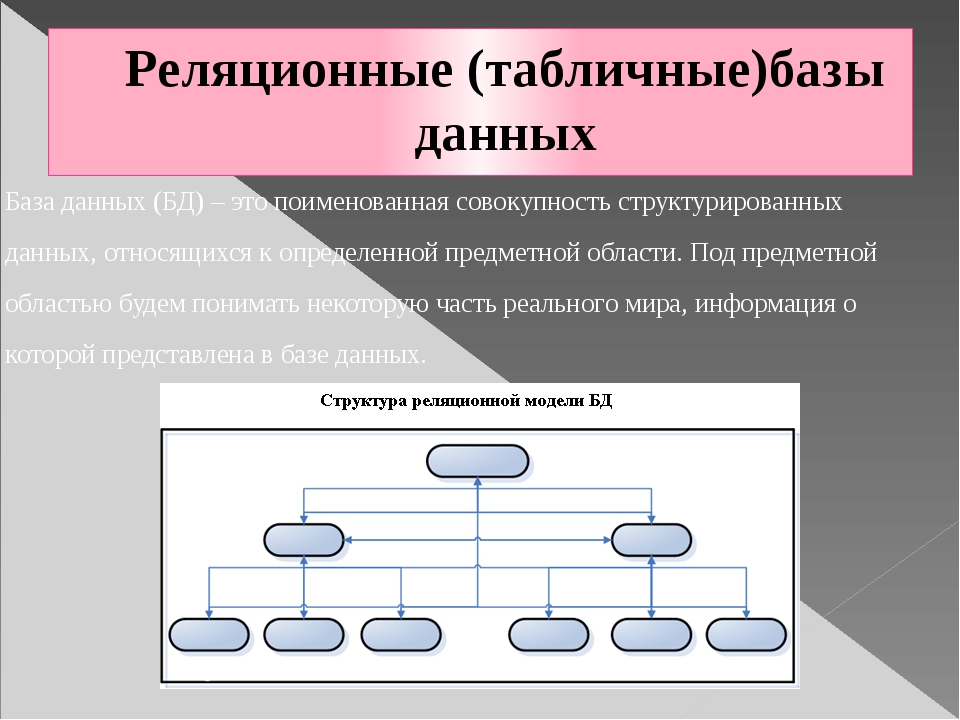
Эти преимущества, а также существующий спрос на них, привел к волне новых систем управления базами данных.
Новая волна
Такой тип баз данных принято называть хранилище типа ключ-значение (key-value store). Фактически, никакого официального названия не существует, поэтому вы можете встретить его в контексте документо-ориентированных, атрибутно-ориентированных, распределенных баз данных (хотя они также могут быть реляционными), шардированных упорядоченных массивов (sharded sorted arrays), распределенных хэш-таблиц и хранилищ типа ключ-значения. И хотя каждое из этих названий указывает на конкретные особенности системы, все они являются вариациями на тему, которую мы будем назвать хранилище типа ключ-значение.
Впрочем, как бы вы его не называли, этот «новый» тип баз данных не такой уж новый и всегда применялся в основном для приложений, для которых использование реляционных БД было бы непригодно. Однако без потребности веба и «облака» в масштабируемости, эти системы оставались не сильно востребованными.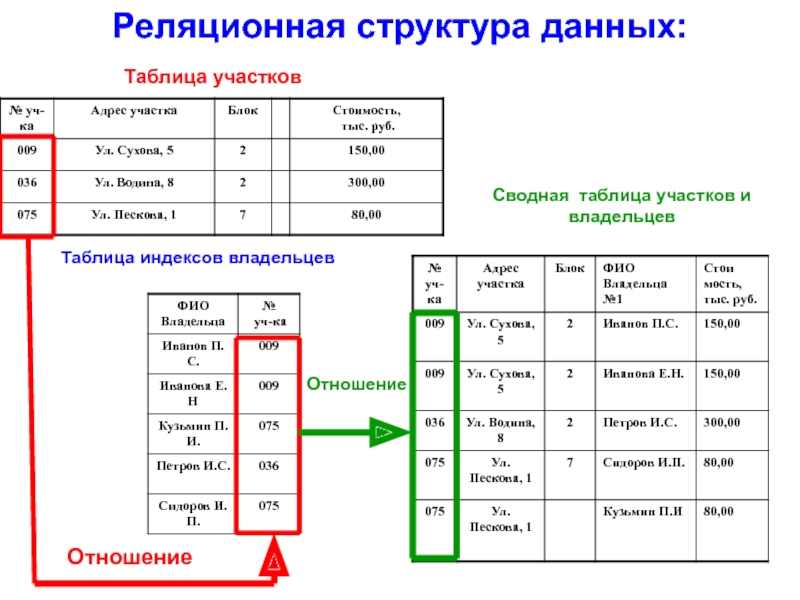 Теперь же задача состоит в том, чтобы определить, какой тип хранилища больше подходит для конкретной системы.
Теперь же задача состоит в том, чтобы определить, какой тип хранилища больше подходит для конкретной системы.
Реляционные БД и хранилища типа ключ-значение отличаются коренным образом и предназначены для решения разных задач. Сравнение характеристик позволит всего лишь понять разницу между ними, однако начнем с этого:
Характеристики хранилищ
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| База данных состоит из таблиц, таблицы содержат колонки и строки, а строки состоят из значений колонок. Все строки одной таблицы имеют единую структуру. |
Для доменов можно провести аналогию с таблицами, однако в отличие от таблиц для доменов не определяется структура данных. Домен – это такая коробка, в которую вы можете складывать все что угодно. Записи внутри одного домена могут иметь разную структуру. |
Модель данных1 определена заранее. Является строго типизированной, содержит ограничения и отношения для обеспечения целостности данных. |
Записи идентифицируются по ключу, при этом каждая запись имеет динамический набор атрибутов, связанных с ней. |
| Модель данных основана на естественном представлении содержащихся данных, а не на функциональности приложения. |
В некоторых реализация атрибуты могут быть только строковыми. В других реализациях атрибуты имеют простые типы данных, которые отражают типы, использующиеся в программировании: целые числа, массива строк и списки. |
| Модель данных подвергается нормализации, чтобы избежать дублирования данных. Нормализация порождает отношения между таблицами. Отношения связывают данные разных таблиц. |
Между доменами, также как и внутри одного домена, отношения явно не определены. |
Никаких join’ов
Хранилища типа ключ-значение ориентированы на работу с записями. Это значит, что вся информация, относящаяся к данной записи, хранится вместе с ней.
 Домен (о котором вы можете думать как о таблице) может содержать бессчетное количество различных записей. Например, домен может содержать информацию о клиентах и о заказах. Это означает, что данные, как правило, дублируются между разными доменами. Это приемлемый подход, поскольку дисковое пространство дешево. Главное, что он позволяет все связанные данные хранить в одном месте, что улучшает масштабируемость, поскольку исчезает необходимость соединять данные из различных таблиц. При использовании реляционной БД, потребовалось бы использовать соединения, чтобы сгруппировать в одном месте нужную информацию.
Домен (о котором вы можете думать как о таблице) может содержать бессчетное количество различных записей. Например, домен может содержать информацию о клиентах и о заказах. Это означает, что данные, как правило, дублируются между разными доменами. Это приемлемый подход, поскольку дисковое пространство дешево. Главное, что он позволяет все связанные данные хранить в одном месте, что улучшает масштабируемость, поскольку исчезает необходимость соединять данные из различных таблиц. При использовании реляционной БД, потребовалось бы использовать соединения, чтобы сгруппировать в одном месте нужную информацию.Хотя для хранения пар ключ-значение потребность в отношения резко падает, отношения все же нужны. Такие отношения обычно существуют между основными сущностями. Например, система заказов имела бы записи, которые содержат данные о покупателях, товарах и заказах. При этом неважно, находятся ли эти данные в одном домене или в нескольких. Суть в том, что когда покупатель размещает заказ, вам скорее всего не захочется хранить информацию о покупателе и о заказе в одной записи.

Вместо этого, запись о заказе должна содержать ключи, которые указывают на соответствующие записи о покупателе и товаре. Поскольку в записях можно хранить любую информацию, а отношения не определены в самой модели данных, система управления базой данных не сможет проконтролировать целостность отношений. Это значит, что вы можете удалять покупателей и товары, которые они заказывали. Обеспечение целостности данных целиком ложится на приложение.
Доступ к данным
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| Данные создаются, обновляются, удаляются и запрашиваются с использованием языка структурированных запросов (SQL). |
Данные создаются, обновляются, удаляются и запрашиваются с использованием вызова API методов. |
| SQL-запросы могут извлекать данные как из одиночной таблица, так и из нескольких таблиц, используя при этом соединения (join’ы). |
Некоторые реализации предоставляют SQL-подобный синтаксис для задания условий фильтрации. |
| SQL-запросы могут включать агрегации и сложные фильтры. |
Зачастую можно использовать только базовые операторы сравнений (=, !=, <, >, <= и =>). |
| Реляционная БД обычно содержит встроенную логику, такую как триггеры, хранимые процедуры и функции. |
Вся бизнес-логика и логика для поддержки целостности данных содержится в коде приложений. |
Взаимодействие с приложениями
| Реляционная БД | Хранилище типа ключ-значение |
|---|---|
| Чаще всего используются собственные API, или обобщенные, такие как OLE DB или ODBC. |
Чаще всего используются SOAP и/или REST API, с помощью которых осуществляется доступ к данным. |
| Данные хранятся в формате, который отображает их натуральную структуру, поэтому необходим маппинг структур приложения и реляционных структур базы. |
Данные могут более эффективно отображаться в структуры приложения, нужен только код для записи данных в объекты. |
Хранилища типа ключ-значение: преимущества
Есть два четких преимущества таких систем перед реляционными хранилищами.
Подходят для облачных сервисов
Первое преимущество хранилищ типа ключ-значение состоит в том, что они проще, а значит обладают большей масштабируемостью, чем реляционные БД. Если вы размещаете вместе собственную систему, и планируете разместить дюжину или сотню серверов, которым потребуется справляться с возрастающей нагрузкой, за вашим хранилищем данных, тогда ваш выбор – хранилища типа ключ-значение.
Благодаря тому, что такие хранилища легко и динамически расширяются, они также пригодятся вендорам, которые предоставляют многопользовательскую веб-платформу хранения данных. Такая база представляет относительно дешевое средство хранения данных с большим потенциалом к масштабируемости. Пользователи обычно платят только за то, что они используют, однако их потребности могут вырасти. Вендор сможет динамически и практически без ограничений увеличить размер платформы, исходя из нагрузки.
Более естественная интеграция с кодом
Реляционная модель данных и объектная модель кода обычно строятся по-разному, что ведет к некоторой несовместимости. Разработчики решают эту проблему при помощи написания кода, который отображает реляционную модель в объектную модель. Этот процесс не имеет четкой и быстро достижимой ценности и может занять довольно значительное время, которое могло быть потрачено на разработку самого приложения. Тем временем многие хранилища типа ключ-значение хранят данные в такой структуре, которая отображается в объекты более естественно. Это может существенно уменьшить время разработки.
Другие аргументы в пользу использования хранилищ типа ключ-значение, наподобие «Реляционные базы могут стать неуклюжими» (кстати, я без понятия, что это значит), являются менее убедительными. Но прежде чем стать сторонником таких хранилищ, ознакомьтесь со следующим разделом.
Хранилища типа ключ-значение: недостатки
Ограничения в реляционных БД гарантируют целостность данных на самом низком уровне.
 Данные, которые не удовлетворяют ограничениям, физически не могут попасть в базу. В хранилищах типа ключ-значение таких ограничений нет, поэтому контроль целостности данных полностью лежит на приложениях. Однако в любом коде есть ошибки. Если ошибки в правильно спроектированной реляционной БД обычно не ведут к проблемам целостности данных, то ошибки в хранилищах типа ключ-значение обычно приводят к таким проблемам.
Данные, которые не удовлетворяют ограничениям, физически не могут попасть в базу. В хранилищах типа ключ-значение таких ограничений нет, поэтому контроль целостности данных полностью лежит на приложениях. Однако в любом коде есть ошибки. Если ошибки в правильно спроектированной реляционной БД обычно не ведут к проблемам целостности данных, то ошибки в хранилищах типа ключ-значение обычно приводят к таким проблемам.Другое преимущество реляционных БД заключается в том, что они вынуждают вас пройти через процесс разработки модели данных. Если вы хорошо спроектировали модель, то база данных будет содержать логическую структуру, которая полностью отражает структуру хранимых данных, однако расходится со структурой приложения. Таким образом, данные становятся независимы от приложения. Это значит, что другое приложение сможет использовать те же самые данные и логика приложения может быть изменена без каких-либо изменений в модели базы. Чтобы проделать то же самое с хранилищем типа ключ-значение, попробуйте заменить процесс проектирования реляционной модели проектированием классов, при котором создаются общие классы, основанные на естественной структуре данных.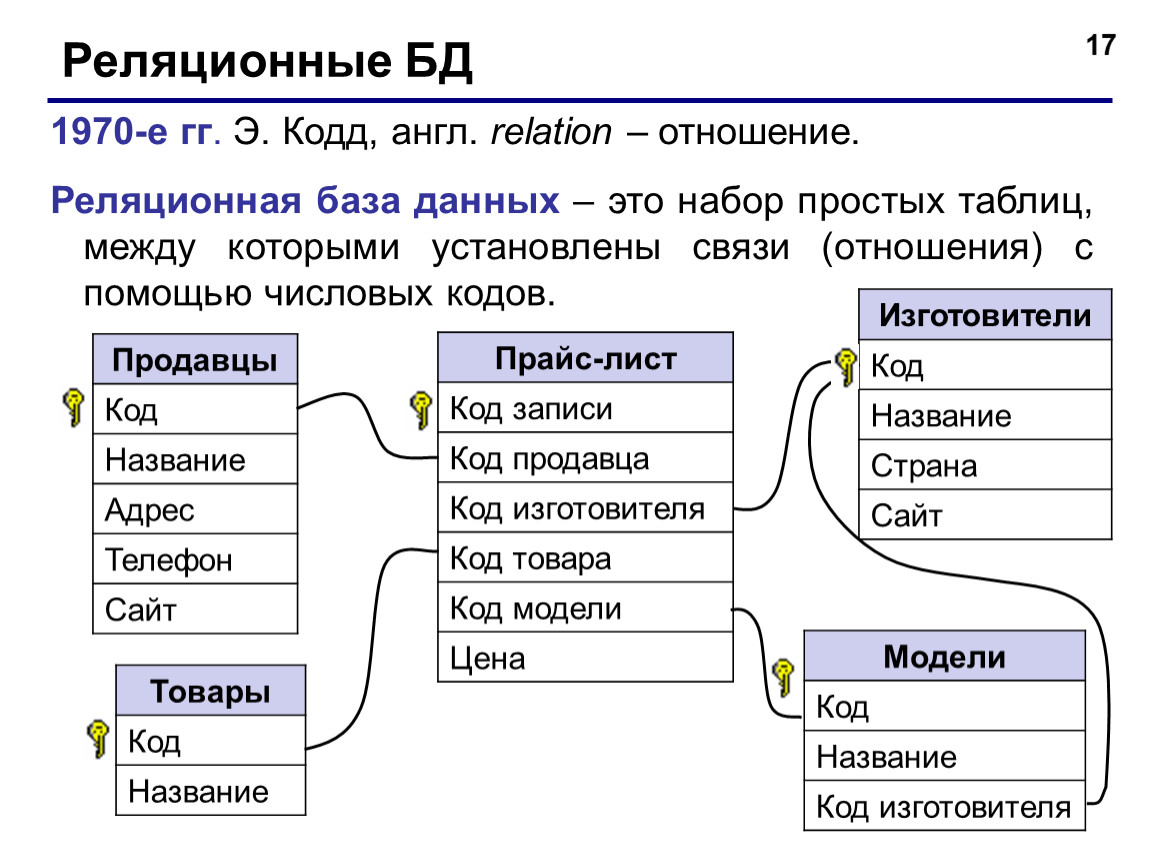
И не забудьте о совместимости. В отличие от реляционных БД, хранилища, ориентированные на использование в «облаке», имеют гораздо меньше общих стандартов. Хоть концептуально они и не отличаются, они все имеют разные API, интерфейсы запросов и свою специфику. Поэтому вам лучше доверять вашему вендору, потому что в случае чего, вы не сможете легко переключиться на другого поставщика услуг. А учитывая тот факт, что почти все современные хранилища типа ключ-значение находятся в стадии бета-версий2, доверять становится еще рискованнее, чем в случае использования реляционных БД.
Ограниченная аналитика данных
Обычно все облачные хранилища строятся по типу множественной аренды, что означает, что одну и ту же систему использует большое количество пользователей и приложений. Чтобы предотвратить «захват» общей системы, вендоры обычно каким-то образом ограничивают выполнение запросов. Например, в SimpleDB запрос не может выполняться дольше 5 секунд. В Google AppEngine Datastore за один запрос нельзя получить больше, чем 1000 записей3.

Эти ограничения не страшны для простой логики (создание, обновление, удаление и извлечение небольшого количества записей). Но что если ваше приложение становится популярным? Вы получили много новых пользователей и много новых данных, и теперь хотите сделать новые возможности для пользователей или каким-то образом извлечь выгоду из данных. Тут вы можете жестко обломаться с выполнением даже простых запросов для анализа данных. Фичи наподобие отслеживания шаблонов использования приложения или системы рекомендаций, основанной на истории пользователя, в лучшем случае могут оказаться сложны в реализации. А в худшем — просто невозможны.
В таком случае для аналитики лучше сделать отдельную базу данных, которая будет заполняться данными из вашего хранилища типа ключ-значение. Продумайте заранее, каким образом это можно будет сделать. Будете ли вы размещать сервер в облаке или у себя? Не будет ли проблем из-за задержек сигнала между вами и вашим провайдером? Поддерживает ли ваше хранилище такой перенос данных? Если у вас 100 миллионов записей, а за один раз вы можете взять 1000 записей, сколько потребуется на перенос всех данных?
Однако не ставьте масштабируемость превыше всего. Она будет бесполезна, если ваши пользователи решат пользоваться услугами другого сервиса, потому что тот предоставляет больше возможностей и настроек.
Она будет бесполезна, если ваши пользователи решат пользоваться услугами другого сервиса, потому что тот предоставляет больше возможностей и настроек.
Облачные хранилища
Множество поставщиков веб-сервисов предлагают многопользовательские хранилища типа ключ-значение. Большинство из них удовлетворяют критериям, перечисленным выше, однако каждое обладает своими отличительными фичами и отличается от стандартов, описанных выше. Давайте взглянем на конкретные пример хранилищ, такие как SimpleDB, Google AppEngine Datastore и SQL Data Services.
Amazon: SimpleDB
SimpleDB — это атрибутно-ориентированное хранилище типа ключ-значение, входящее в состав Amazon WebServices. SimpleDB находится в стадии бета-версии; пользователи могут пользовать ей бесплатно — до тех пор пока их потребности не превысят определенный предел.
У SimpleDB есть несколько ограничений. Первое — время выполнения запроса ограничено 5-ю секундами. Второе — нет никаких типов данных, кроме строк.
 Все хранится, извлекается и сравнивается как строка, поэтому для того, чтобы сравнить даты, вам нужно будет преобразовать их в формат ISO8601. Третье — максимальные размер любой строки составляет 1024 байта, что ограничивает размер текста (например, описание товара), который вы можете хранить в качестве атрибута. Однако поскольку структура данных гибкая, вы можете обойти это ограничения, добавляя атрибуты «ОписаниеТовара1», «Описание товара2» и т.д. Но количество атрибутов также ограничено — максимум 256 атрибутов. Пока SimpleDB находится в стадии бета-версии, размер домена ограничен 10-ю гигабайтами, а вся база не может занимать больше 1-го терабайта.
Все хранится, извлекается и сравнивается как строка, поэтому для того, чтобы сравнить даты, вам нужно будет преобразовать их в формат ISO8601. Третье — максимальные размер любой строки составляет 1024 байта, что ограничивает размер текста (например, описание товара), который вы можете хранить в качестве атрибута. Однако поскольку структура данных гибкая, вы можете обойти это ограничения, добавляя атрибуты «ОписаниеТовара1», «Описание товара2» и т.д. Но количество атрибутов также ограничено — максимум 256 атрибутов. Пока SimpleDB находится в стадии бета-версии, размер домена ограничен 10-ю гигабайтами, а вся база не может занимать больше 1-го терабайта.Одной из ключевых особенностей SimpleDB является использование модели конечной констистенции (eventual consistency model). Эта модель подходит для многопоточной работы, однако следует иметь в виду, что после того, как вы изменили значение атрибута в какой-то записи, при последующих операциях чтения эти изменения могут быть не видны. Вероятность такого развития событий достаточно низкая, тем не менее, о ней нужно помнить. Вы же не хотите продать последний билет пяти покупателям только потому, что ваши данные были неконсистентны в момент продажи.
Вы же не хотите продать последний билет пяти покупателям только потому, что ваши данные были неконсистентны в момент продажи.
Google AppEngine Data Store
Google’s AppEngine Datastore построен на основе BigTable, внутренней системе хранения структурированных данных от Google. AppEngine Datastore не предоставляет прямой доступ к BigTable, но может восприниматься как упрощенный интерфейс взаимодействия с BigTable.
AppEngine Datastore поддерживает большее число типов данных внутри одной записи, нежели SimpleDB. Например, списки, которые могут содержать коллекции внутри записи.
Скорее всего вы будете использовать именно это хранилище данных при разработке с помощью Google AppEngine. Однако в отличии от SimpleDB, вы не сможете использовать AppEngine Datastore (или BigTable) вне веб-сервисов Google.
Microsoft: SQL Data Services
SQL Data Services является частью платформы Microsoft Azure. SQL Data Services является бесплатной, находится в стадии бета-версии и имеет ограничения на размер базы.
 SQL Data Services представляет собой отдельное приложение — надстройку над множеством SQL серверов, которые и хранят данные. Эти хранилища могут быть реляционными, однако для вас SDS является хранилищем типа ключ-значение, как и описанные выше продукты.
SQL Data Services представляет собой отдельное приложение — надстройку над множеством SQL серверов, которые и хранят данные. Эти хранилища могут быть реляционными, однако для вас SDS является хранилищем типа ключ-значение, как и описанные выше продукты.Необлачные хранилища
Существует также ряд хранилищ, которыми вы можете воспользоваться вне облака, установив их у себя. Почти все эти проекты являются молодыми, находятся в стадии альфа- или бета-версии, и имеют открытый код. С открытыми исходниками вы, возможно, будете больше осведомлены о возможных проблемах и ограничениях, нежели в случае использования закрытых продуктов.
CouchDB
CouchDB — это свободно распространяемая документо-ориентированная БД с открытым исходным кодом. В качестве формата хранения данных используется JSON. CouchDB призвана заполнить пробел между документо-ориентированными и реляционными базами данных с помощью «представлений». Такие представления содержат данные из документов в виде, схожим с табличным, и позволяют строить индексы и выполнять запросы.

В настоящее время CouchDB не является по-настоящему распределенной БД. В ней есть функции репликации, позволяющие синхронизировать данные между серверами, однако это не та распределенность, которая нужна для построения высокомасштабируемого окружения. Однако разработчики CouchDB работают над этим.
Проект Voldemort
Проект Voldemort — это распределенная база данных типа ключ-значение, предназначенная для горизонтального масштабирования на большом количестве серверов. Он родилась в процессе разработки LinkedIn и использовалась для нескольких систем, имеющих высокие требования к масштабируемости. В проекте Voldemort также используется модель конечной консистенции.
Mongo
Mongo — это база данных, разрабатываемая в 10gen Гейром Магнуссоном и Дуайтом Меррименом (которого вы можете знать по DoubleClick). Как и CouchDB, Mongo — это документо-ориентированная база данных, хранящая данные в JSON формате. Однако Mongo скорее является объектной базой, нежели чистым хранилищем типа ключ-значение.

Drizzle
Drizzle представляет совсем другой подход к решению проблем, с которыми призваны бороться хранилища типа ключ-значение. Drizzle начинался как одна из веток MySQL 6.0. Позже разработчики удалили ряд функций (включая представления, триггеры, скомпилированные выражения, хранимые процедуры, кэш запросов, ACL, и часть типов данных), с целью создания более простой и быстрой СУБД. Тем не менее, Drizzle все еще можно использовать для хранения реляционных данных. Цель разработчиков — построить полуреляционную платформу, предназначенную для веб-приложений и облачных приложений, работающих на системах с 16-ю и более ядрами.
Решение
В конечном счете, есть четыре причины, по которым вы можете выбрать нереляционное хранилище типа ключ-значение для своего приложения:
- Ваши данные сильно документо-ориентированны, и больше подходят для модели данных ключ-значение, чем для реляционной модели.
- Ваша доменная модель сильно объектно-ориентированна, поэтому использования хранилища типа ключ-значение уменьшит размер дополнительного кода для преобразования данных.

- Хранилище данных дешево и легко интегрируется с веб-сервисами вашего вендора.
- Ваша главная проблема — высокая масштабируемость по запросу.

Однако принимая решение, помните об ограничениях конкретных БД и о рисках, которые вы встретите, пойдя по пути использования нереляционных БД.
Для всех остальных требований лучше выбрать старые добрые реляционные СУБД. Так обречены ли они? Конечно, нет. По крайней мере, пока.
1 — по моему мнению, здесь больше подходит термин «структура данных», однако оставил оригинальное data model.
2 — скорее всего, автор имел в виду, что по своим возможностям нереляционные БД уступают реляционным.
3 — возможно, данные уже устарели, статья датируется февралем 2009 года.
Структура реляционной базы данных — Основы реляционных баз данных
PostgreSQL — СУБД, созданная для работы с реляционными базами данных. Понятие «реляционная» мы рассмотрим в уроке, посвященном реляционной модели, а сейчас сосредоточимся на её прикладных аспектах. В этом уроке обзорно рассказывается о том, как устроены базы данных, а уже начиная со следующего, мы начнём создавать базу собственными руками.
В этом уроке обзорно рассказывается о том, как устроены базы данных, а уже начиная со следующего, мы начнём создавать базу собственными руками.
Данные в реляционных базах данных представлены в табличном виде и хранятся в таблицах. Такая структура очень напоминает Microsoft Excel. Каждая строка в такой таблице — это связанный набор данных, относящийся к одному предмету.
Разные таблицы предназначены для хранения информации о различных предметах: например, пользователи, статьи или заказы в интернет-магазине. В типичных веб-приложениях таблиц десятки и сотни. В больших — тысячи. На Хекслете их несколько сотен.
У таблиц в базе данных есть определённая структура, которая включает в себя фиксированный набор столбцов (говорят: «полей»). Поля расположены в строго определённом порядке, и каждое поле имеет своё уникальное имя в рамках одной таблицы. Кроме того, у таблицы есть имя, которое, как правило, уникально в рамках одной базы данных. Имя таблицы и её структура задаются при создании, но могут быть изменены впоследствии.
Имя таблицы и её структура задаются при создании, но могут быть изменены впоследствии.
Каждому столбцу сопоставлен тип данных. Тип данных ограничивает набор допустимых значений, которые можно присвоить столбцу, и определяет смысловое значение данных для вычислений. Например, в столбец числового типа нельзя записать обычные текстовые строки, но зато его данные можно использовать в математических вычислениях. И наоборот, если столбец имеет тип текстовой строки, для него допустимы практически любые данные, но он непригоден для математических действий (хотя другие операции, например, конкатенация строк, возможны).
Число строк в таблице переменно — оно отражает текущее количество находящихся в ней данных. В отличие от таблиц в Exсel, в таблицах реляционных баз данных нет никаких гарантий относительно порядка строк в таблице. Он может быть любым. При необходимости этот порядок можно задать с помощью языка SQL, который рассматривается далее по курсу.
Количество данных в разных таблицах варьируется очень сильно. Многие справочные таблицы, которые содержат некоторые фиксированные списки (например, список стран) очень небольшие, количество записей в них варьируется от нескольких штук до нескольких сотен. Другие таблицы, напротив, могут иметь значительные размеры. От сотен тысяч до десятков миллионов записей. Ну и совсем большие содержат сотни миллионов и даже миллиарды записей.
Пример описания таблицы с именем users (на псевдоязыке):
Структура
users
first_name string
4.1. Реляционные базы данных. СУБД Microsoft Access
Наиболее распространенными в практике являются реляционные базы данных. Название “реляционная” (в переводе с английского relation — отношение) связано с тем, что каждая запись в таблице содержит информацию, относящуюся только к одному конкретному объекту.
Из таблицы 3 видно, что при внесении в нее данных об альбомах определенной группы каждый раз приходится дублировать информацию первых четырех полей таблицы. Многократное сохранение в БД одних и тех же данных (название группы, страна, дата создания, дата распада) приведет к неэффективному использованию памяти, к тому же существенно возрастет вероятность ошибок при вводе данных. Разбив же данные по таблицам, можно в значительной степени избежать этих трудностей.
Многократное сохранение в БД одних и тех же данных (название группы, страна, дата создания, дата распада) приведет к неэффективному использованию памяти, к тому же существенно возрастет вероятность ошибок при вводе данных. Разбив же данные по таблицам, можно в значительной степени избежать этих трудностей.
Через связь, определенную между этими таблицами, можно узнать
• сколько альбомов выпустила группа;
• выпускались ли альбомы у фирмы EMI;
• в каком году было выпущено максимальное количество альбомов и т.п.
Реляционные базы данных удобны еще и тем, что для получения ответов на различные запросы существует разработанный математический аппарат, который называется исчислением отношений или реляционной алгеброй. Ответы на запросы получаются путем “разрезания” и “склеивания” таблиц по строкам и столбцам. При этом ясно, что ответы также будут иметь форму таблиц.
Надо отметить, что база данных — это, собственно, хранилище информации и не более того.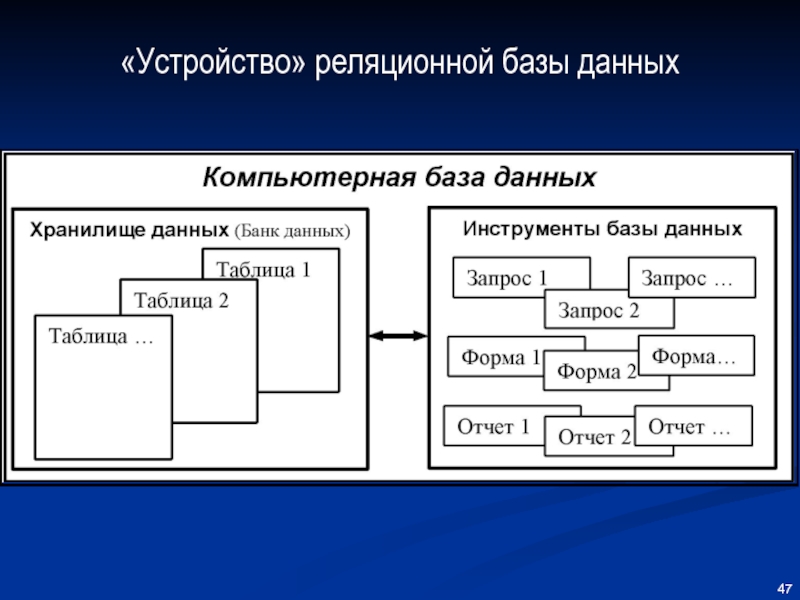 Однако, работа с базами данных трудоемкая и утомительная. Для создания, ведения и осуществления возможности коллективного пользования базами данных используются программные средства, называемые системами управления базами данных (СУБД).
Однако, работа с базами данных трудоемкая и утомительная. Для создания, ведения и осуществления возможности коллективного пользования базами данных используются программные средства, называемые системами управления базами данных (СУБД).
СУБД Microsoft Access
Access — в переводе с английского означает “доступ”. MS Access — это функционально полная реляционная СУБД. Кроме того, MS Access одна из самых мощных, гибких и простых в использовании СУБД. В ней можно создавать большинство приложений, не написав ни единой строки программы, но если нужно создать нечто очень сложное, то на этот случай MS Access предоставляет мощный язык программирования — Visual Basic Application.
Популярность СУБД Microsoft Access обусловлена следующими причинами:
• Access является одной из самых легкодоступных и понятных систем как для профессионалов, так и для начинающих пользователей, позволяющая быстро освоить основные принципы работы с базами данных;
• система имеет полностью русифицированную версию;
• полная интегрированность с пакетами Microsoft Office: Word, Excel, Power Point, Mail;
• идеология Windows позволяет представлять информацию красочно и наглядно;
• возможность использования OLE технологии, что позволяет установить связь с объектами другого приложения или внедрить какие-либо объекты в базу данных Access;
• технология WYSIWIG позволяет пользователю постоянно видеть все результаты своих действий;
• широко и наглядно представлена справочная система;
• существует набор “мастеров” по разработке объектов, облегчающий создание таблиц, форм и отчетов.
Запустить систему Access можно несколькими способами:
• запуск с помощью главного меню в WINDOWS 95;
• запуск с помощью ярлыка на панели инструментов.
После запуска системы появится главное окно Access, рис. 2.24. Здесь можно открывать другие окна, каждое из которых по-своему представляет обрабатываемые данные. Ниже приведены основные элементы главного окна Access, о которых необходимо иметь представление.
Рис.3. Экран СУБД Access
В строке заголовка отображается имя активной в данный момент программы. Строка заголовка главного окна Access всегда отображает имя программыMICROSOFT Access.
Пиктограмма системного меню — условная кнопка в верхнем левом углу главного окна практически любого приложения. После щелчка на этой пиктограмме появляется меню, которое позволяет перемещать, разворачивать, сворачивать или закрывать окно текущего приложения и изменять его размеры. При двойном щелчке на пиктограмме системного меню работа приложения завершается.
При двойном щелчке на пиктограмме системного меню работа приложения завершается.
Полоса меню содержит названия нескольких подменю. Когда активизируется любое из этих названий, на экране появляется соответствующее подменю. Перечень подменю на полосе Access и их содержание изменяются в зависимости от режима работы системы.
Панель инструментов — это группа пиктограмм, расположенных непосредственно под полосой меню. Главное ее назначение — ускоренный вызов команд меню. Кнопки панели инструментов тоже могут изменяться в зависимости от выполняемых операций. Можно изменять размер панели инструментов и передвигать ее по экрану. Также можно отобразить, спрятать, создать новую панель инструментов или настроить любую панель инструментов.
В левой части строки состояния отображается информация о том, что вы делаете в настоящее время.
Окно базы данных появляется при открытой базе данных. В нем сосредоточены все “рычат управления” базой данных. Окно базы данных используется для открытия объектов, содержащихся в базе данных, таких как таблицы, запросы, отчеты, формы, макросы и модули. Кроме того, в строке заголовка окна базы данных всегда отображается имя открытой базы данных.
Окно базы данных используется для открытия объектов, содержащихся в базе данных, таких как таблицы, запросы, отчеты, формы, макросы и модули. Кроме того, в строке заголовка окна базы данных всегда отображается имя открытой базы данных.
С помощью вкладки объектов можно выбрать тип нужного объекта (таблицу, запрос, отчет, форму, макрос, модуль). Необходимо сказать, что при открытии окна базы данных всегда активизируется вкладка-таблица и выводится список доступных таблиц базы данных. Для выбора вкладки других объектов базы данных нужно щелкнуть по ней мышью.
Условные кнопки, расположенные вдоль правого края окна базы данных, используются для работы с текущим объектом базы данных. Они позволяют создавать, открывать или изменять объекты базы данных.
К основным объектам Access относятся таблицы, запросы, формы, отчеты, макросы и модули.
Таблица — это объект, который определяется и используется для хранения данных. Каждая таблица включает информацию об объекте определенного типа. Как уже известно, таблица содержит поля (столбцы) и записи (строки). Работать с таблицей можно в двух основных режимах: в режиме конструктора и в режиме таблицы.
Каждая таблица включает информацию об объекте определенного типа. Как уже известно, таблица содержит поля (столбцы) и записи (строки). Работать с таблицей можно в двух основных режимах: в режиме конструктора и в режиме таблицы.
В режиме конструктора задается структура таблицы, т.е. определяются типы, свойства полей, их число и названия (заголовки столбцов). Он используется, если нужно изменить структуру таблицы, а не хранящиеся в ней данные. В этом режиме каждая строка верхней панели окна соответствует одному из полей определяемой таблицы.
Режим таблицы используется для просмотра, добавления, изменения, простейшей сортировки или удаления данных. Чтобы перейти в режим таблицы, надо дважды щелкнуть мышью по имени нужной таблицы в окне базы данных (или, выделив в окне БД имя нужной таблицы, воспользоваться кнопкой открытого окна БД).
Из режима конструктора перейти в режим таблицы можно, щелкнув по кнопке таблицы на панели инструментов.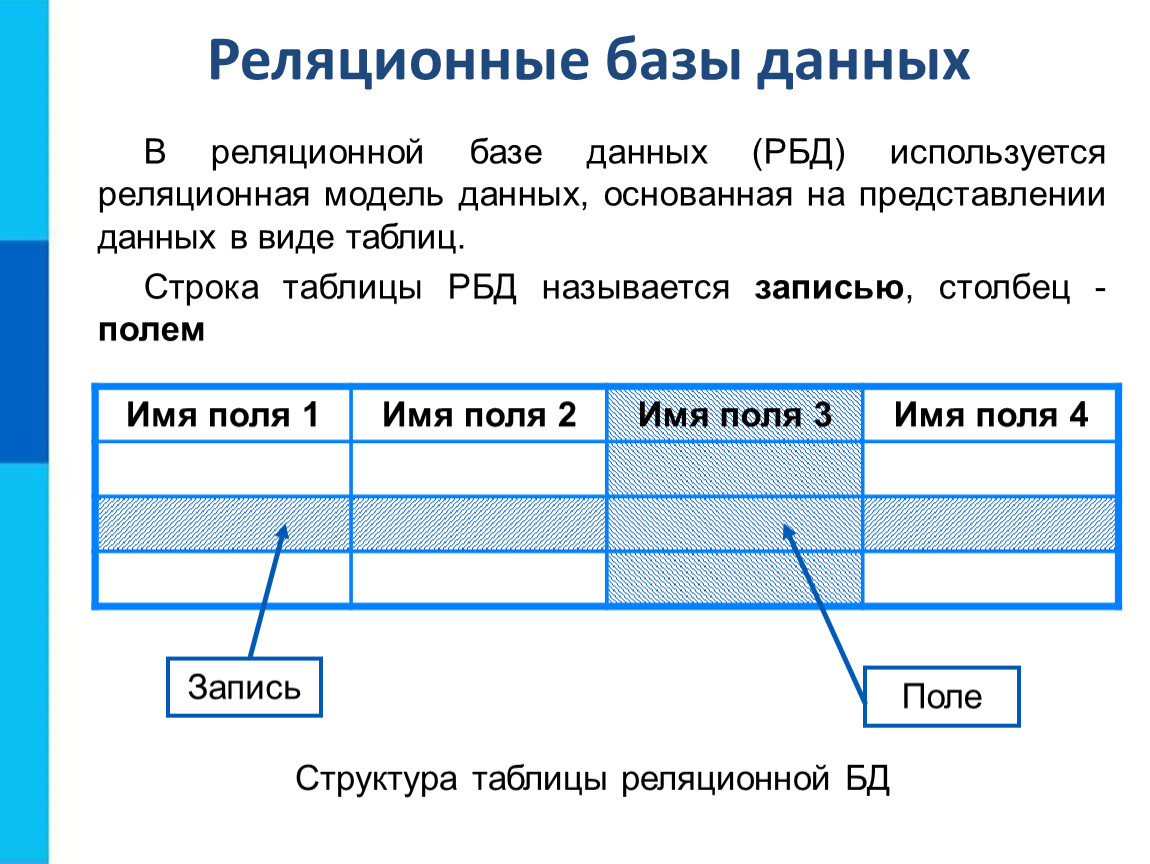
В режиме конструктора и в режиме таблицы перемещение между полями осуществляется с помощью клавиши ТАВ, а также вверх или вниз по записям с помощью клавиш, но в большинстве случаев пользоваться мышью гораздо удобнее.
Вследствие того, что в таблицах, как правило, содержится большое количество записей, размещение всех их на экране невозможно. Поэтом) для перемещения по таблице используют полосы прокрутки, расположенные в нижней и правой части окна. Левее нижней полосы прокрутки выводится номер текущей записи и общее число записей таблицы. Для перехода к записям с нужным номером необходимо активизировать поле Номера записи, щелкнув по нему, или нажать клавишу F5, после чего набрать на клавиатуре новый номер записи и затем нажать клавишу <Enter>.
Запрос — это объект, который позволяет пользователю получить нужные данные из одной или нескольких таблиц. Можно создать запросы на выбор, обновление, удаление или на добавление данных. С помощью запросов можно создавать новые таблицы, используя данные уже существующих одной или нескольких таблиц.
С помощью запросов можно создавать новые таблицы, используя данные уже существующих одной или нескольких таблиц.
По сути дела, запрос — это вопрос, который пользователь задает Access о хранящейся в базе данных информации. Работать с запросами можно в двух основных режимах: в режиме конструктора и в режиме таблицы.
Здесь надо вспомнить о том, что ответы на запросы получаются путем “разрезания” и “склеивания” таблиц по строкам и столбцам, и что ответы будут также иметь форму таблиц. В режиме конструктора формируется вопрос к базе данных.
Форма — это объект, в основном, предназначенный для удобного ввода отображения данных. Надо отметить, что в отличие от таблиц, з формах не содержится информации баз данных (как это может показаться на первый взгляд). Форма — это всего лишь формат (бланк) показа данных на экране компьютера. Формы могут строиться только на основе таблиц или запросов. Построение форм на основе запросов позволяет представлять в них информацию из нескольких таблиц.
В форму могут быть внедрены рисунки, диаграммы, аудио (звук) и видео (изображение).
Режимы работы с формой:
•режим формы используется для просмотра и редактирования данных; предоставляет дружественную среду для работы с данными и удобный дизайн их представления на экране;
•режим конструктора форм необходим, если необходимо изменить определение
формы (структуру или шаблон формы, а не представленные в ней данные), надо открыть форму в режиме конструктора;
•режим таблицы позволяет увидеть таблицу, включающую все поля формы; чтобы переключиться в этот режим при работе с формой, надо нажать кнопку таблицы на панели инструментов.
Отчет — это объект, предназначенный для создания документа, который впоследствии может быть распечатан или включен в документ другого приложения. Отчеты, как и формы, могут создаваться на основе запросов и таблиц, но не позволяют вводить данные.
Режимы работы с отчетом:
Режим предварительного просмотра позволяет увидеть отчет таким, каким он будет воплощен при печати. Для того чтобы открыть отчет в режиме предварительного просмотра, надо
• щелкнуть по вкладке Отчеты,
• кнопкой выбрать необходимый отчет в окне базы данных;
• щелкнуть по кнопке Просмотра.
Режим конструктора предназначен для изменения шаблона (структуры отчета).
Макрос — это объект, представляющий собой структурированное описание одного или нескольких действий, которые должен выполнить Access в ответ на определенное событие. Например, можно определить макрос, который в ответ на выбор некоторого элемента в основной форме открывает другую форму. С помощью другого макроса можно осуществлять проверку значения некоторого поля при изменении его содержания. В макрос можно включить дополнительные условия для выполнения или невыполнения тех или иных включенных в него действии. Возможно также из одного макроса запустить другой макрос или функцию модуля.
Возможно также из одного макроса запустить другой макрос или функцию модуля.
Работа с формами и отчетами существенно облегчается за счет использования макрокоманд. В MS Access имеется свыше 40 макрокоманд, которые можно включать в макросы. Макрокоманды выполняют такие действия, как открытие таблиц и форм, выполнение запросов, запуск других макросов, выбор опций из меню, изменение размеров открытых окон и т.п. Макрокоманды позволяют нажатием одной (или нескольких одновременно) кнопки выполнять комплекс действий, который часто приходится выполнять в течение работы. С их помощью можно даже осуществлять запуск приложений, поддерживающих динамический обмен данных (DDE), например MS Excel, и производить обмен данными между вашей базой данных и этими приложениями. Один макрос может содержать несколько макрокоманд. Можно также задать условия выполнения отдельных макрокоманд или их набора.
Модуль — объект, содержащий программы на MS Access Basic, которые позволяют разбить процесс на более мелкие действия и обнаружить те ошибки, которые невозможно было бы найти с использованием макросов.
Завершив работу с Access (или с ее приложением), надо корректно закончить сеанс. Простое выключение компьютера — плохой метод, который может привести к возникновению проблем. При работе WINDOWS приложения используют множество файлов, о существовании которых пользователь может даже не подозревать. После выключения машины эти файлы останутся открытыми, что в будущем может сказаться на надежности файловой системы жесткого диска.
Безопасно выйти из Access можно несколькими способами:
• двойным щелчком мыши на пиктограмме системного меню в строке заголовка главного окна Access;
• из меню Access выбором пункта Файл Выход,
• нажатием комбинации клавиш Alt + F4.
Что такое реляционная база данных и СУБД. Урок 1
Прежде чем говорить о реляционной базе данных и системе управления базами данных (СУБД), надо определиться с тем, что такое база данных вообще.
Понятие базы данных (БД) абстрактно. Конкретными реализациями являются базы данных чего-либо. Например, база данных библиотеки, сайта или база данных магазина, в которой хранятся сведения о сотрудниках, товарах, поставщиках и покупателях.
Конкретными реализациями являются базы данных чего-либо. Например, база данных библиотеки, сайта или база данных магазина, в которой хранятся сведения о сотрудниках, товарах, поставщиках и покупателях.
Удобнее всего такую информацию хранить в таблицах. Например, база данных может состоять из следующих таблиц: «Сотрудники», «Поставщики», «Покупатели». Каждую таблицу будут формировать свои столбцы и строки.
Так таблица «Сотрудники» может включать столбцы «ФИО», «Должность», «Зарплата». Каждая строка этой таблицы будет содержать сведения об одном человеке. Так создаются таблицы в базах данных. Каждая строка называется записью, каждая ячейка строки – полем. Содержание конкретного поля определяется его столбцом.
Следующий вопрос: где хранить таблицы? Очевидно в файлах или даже одном файле. Например, мы можем открыть Excel или другой табличный процессор и заполнить несколько таблиц. Получится база данных. Нужно ли что-то еще?
Представим, что есть большая база данных, скажем, предприятия. Это очень большой файл, его используют множество человек сразу, одни изменяют данные, другие выполняют поиск информации. Табличный процессор не может следить за всеми операциями и правильно их обрабатывать. Кроме того, загружать в память большую БД целиком – не лучшая идея.
Это очень большой файл, его используют множество человек сразу, одни изменяют данные, другие выполняют поиск информации. Табличный процессор не может следить за всеми операциями и правильно их обрабатывать. Кроме того, загружать в память большую БД целиком – не лучшая идея.
Здесь требуется программное обеспечение с другими возможностями. ПО для работы с базами данных называют системами управления базами данных, то есть СУБД.
Таким образом, у нас должен быть файл определенной структуры, содержащий базу данных, а также ПО, обеспечивающее работу с этим файлом.
Стандартным общепринятым языком для описания баз данных и выполнения к ним запросов является язык SQL.
С другой стороны, существует большое количество различных СУБД. Например: SQLite, MySQL, PostgreSQL и другие. Каждая из них имеет некоторые отличия от других, в результате чего накладывает небольшую специфику на используемый SQL, формируя его диалект.
Таким образом, изучая работу с базами данных, вы, с одной стороны, изучаете универсальный SQL, с другой – приобретаете опыт работы с конкретной СУБД. При этом в последствии перейти с одной СУБД на другую относительно легко.
При этом в последствии перейти с одной СУБД на другую относительно легко.
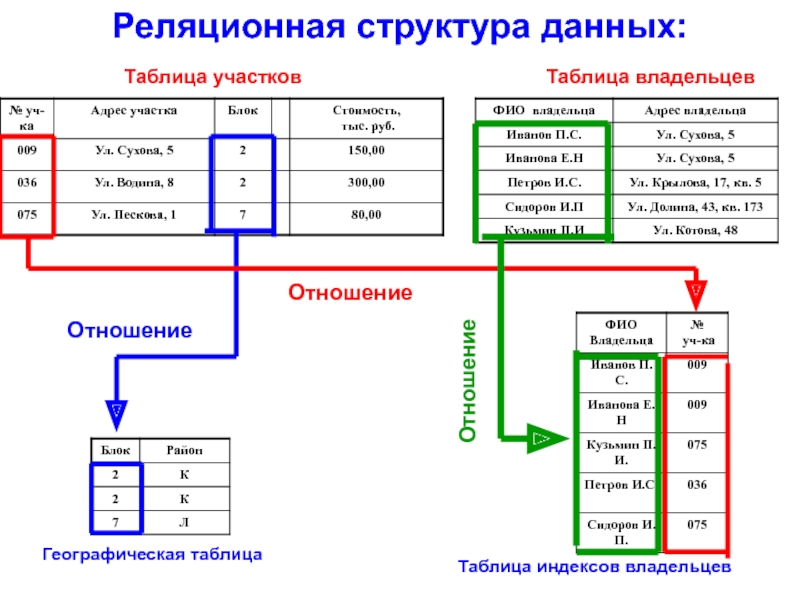
Теперь вернемся к вопросу о том, что такое реляционная базы данных (РБД). Слово «реляция» происходит от «relation», то есть «отношение». Это означает, что в РБД существуют механизмы установления связей между таблицами. Делается это с помощью так называемых первичных и внешних ключей.
Допустим, мы разрабатываем базу данных для сайта. Одна из таблиц будет содержать сведения о страницах сайта. Вторая таблица будет содержать описание разделов сайта. Каждая строка-запись первой таблицы должна в одном из своих полей содержать указание на раздел, к которому принадлежит описываемая этой записью страница.
Таким образом, мы разделяем разные сущности (страницы и разделы) по таблицам, но устанавливаем между ними связь. В последствии используя язык SQL мы сможем, например, создать запрос, который извлечет сведения о конкретном разделе и принадлежащих ему страницах. Хотя такой таблицы исходно нет.
Существуют определенные правила создания реляционных баз данных, их нормализации в основном с целью устранения избыточности. Теория разработки РБД – это целая наука.
Хранение информации в базах данных дает преимущество не только с точки зрения обеспечения к ним быстрого доступа множества процессов. Базы данных, особенно реляционные, позволяют структурировать данные, манипулирования ими и легко наращивать объем.
Можно сказать, что в одной таблице содержатся ассоциированные данные, а в разных таблицах одной БД находятся связанные данные.
§15. Реляционная модель данных | Реляционные базы данных (11_34_pol)
Содержание урока
§13. Таблицы§15. Реляционная модель данныхМатематическое описание базы данных
Реляционные базы данных
Нормализация
Вопросы и задания
Задачи
§16. Работа с таблицей§17. Создание однотабличной базы данных
Работа с таблицей§17. Создание однотабличной базы данных §15. Реляционная модель данных
Реляционные базы данных
Реляционная база данных — это база данных, которая основана на реляционной модели, т. е. представляет собой набор отношений.
Математическая теория Кодда никак не связана с тем, как именно хранятся данные. Однако несложно понять, что отношение удобно представлять в виде прямоугольной таблицы (рис. 3.17).
Рис. 3.17
Эта таблица описывает отношение Группы. Здесь кортежи представлены в виде записей (строк), а атрибуты — это поля (столбцы) в таблице.
Идеи реляционной теории Кодда легко перевести на «табличный язык»:
• каждая таблица описывает один класс объектов;
• порядок расположения полей в таблице не имеет значения;
• все значения одного поля относятся к одному и тому же типу данных;
• в таблице нет двух одинаковых записей;
• порядок записей в таблице не определён.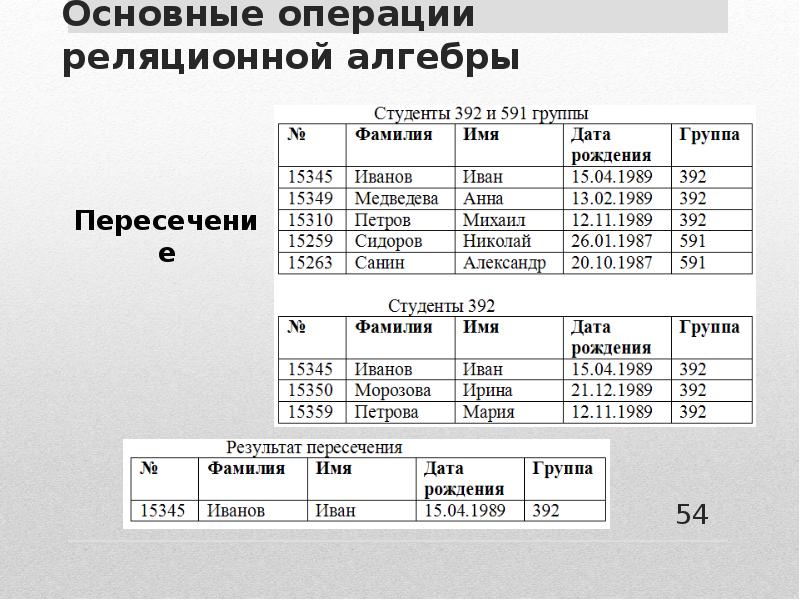
Поэтому на практике часто используют ещё одно, более простое определение:
Реляционная база данных — это база данных, которую можно представить в виде набора таблиц.
Однако не любой набор таблиц можно считать реляционной базой данных. Как мы уже говорили, БД и СУБД неразрывно связаны, и для того чтобы отнести систему базы данных (БД + СУБД) к определённому типу, необходимо выяснить, какие методы управления данными используются в соответствующей СУБД.
Согласно реляционной теории, порядок перечисления свойств в кортеже (порядок столбцов в таблице) не определён, так же как и порядок кортежей в отношении (порядок строк в таблице). Поэтому методы работы с данными в реляционной БД не должны предполагать, что столбцы и строки таблиц расположены в каком-то порядке.
Для управления данными в большинстве современных информационных систем используется язык SQL, в который включены команды для:
• создания новых таблиц;
• добавления новых записей;
• изменения записей;
• удаления записей;
• выборки записей из одной или нескольких таблиц в соответствии с заданным условием и некоторые другие.
Команды языка SQL позволяют управлять данными, не «привязываясь» к формату их хранения, т. е. к порядку расположения столбцов и строк в таблицах. Для выполнения операций (выборки, вставки, удаления, изменения) используются только названия столбцов и таблиц. С помощью команд SQL можно выполнить все основные операции, введённые Коддом, поэтому СУБД (и соответствующие системы баз данных), которые используют язык SQL, традиционно называют реляционными 1.
1 В то же время язык SQL нередко критикуют за то, что он не полностью соответствует реляционной модели данных. Например, в SQL используется понятие «таблица» вместо «отношение»; порядок расположения столбцов таблицы задаётся при её создании; нет запрета на создание одинаковых строк.
Следующая страница Нормализация
Cкачать материалы урока
— обзор
Non-Temporal, Uni-Temporal и Bi-Temporal Data
Рисунок Часть 1.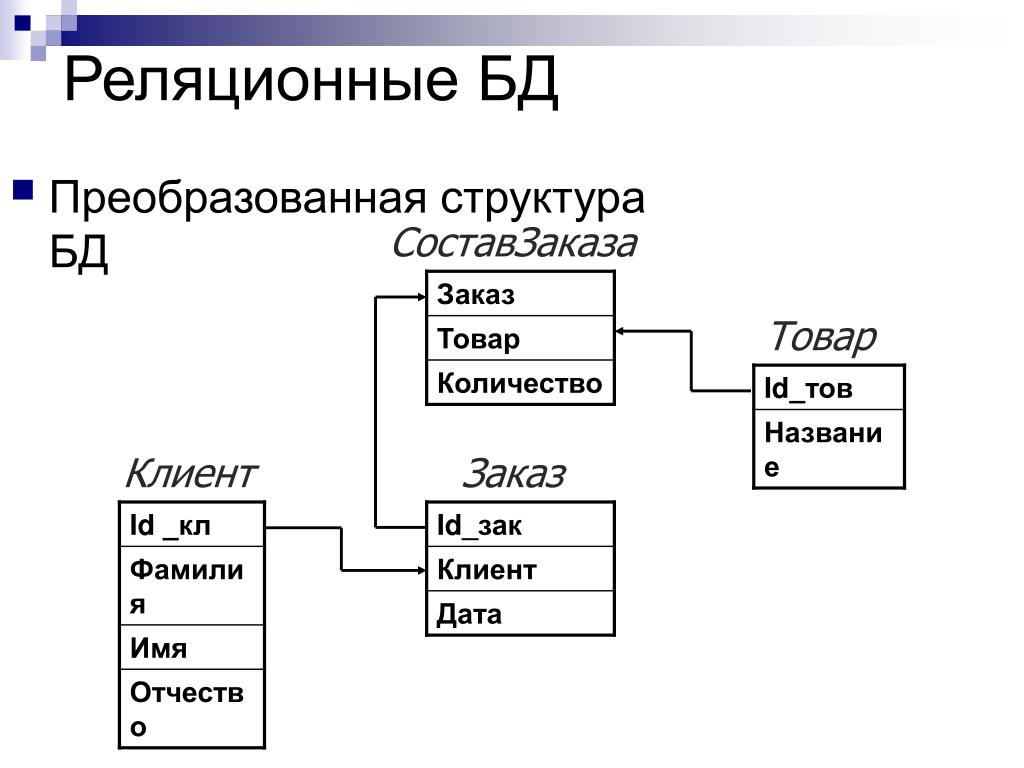 1 представляет собой иллюстрацию строки данных в трех различных типах реляционных таблиц. 1 id — это наше сокращение для «уникального идентификатора», PK для «первичного ключа», bd 1 и ed 1 для одной пары столбцов, один из которых содержит дату начала периода времени. а другой содержит дату окончания этого периода времени, а также bd 2 и ed 2 для столбцов, определяющих второй период времени. 2 Для простоты мы будем использовать таблицы с уникальными идентификаторами, состоящими из одного столбца.
1 представляет собой иллюстрацию строки данных в трех различных типах реляционных таблиц. 1 id — это наше сокращение для «уникального идентификатора», PK для «первичного ключа», bd 1 и ed 1 для одной пары столбцов, один из которых содержит дату начала периода времени. а другой содержит дату окончания этого периода времени, а также bd 2 и ed 2 для столбцов, определяющих второй период времени. 2 Для простоты мы будем использовать таблицы с уникальными идентификаторами, состоящими из одного столбца.
Рисунок Часть 1.1. Нетемпоральные, унивременные и би-темпоральные данные.
Первая иллюстрация на Рисунке Часть 1.1 представляет собой невременную таблицу. Это обычный садовый стол, с которым мы обычно имеем дело. Мы также будем называть его обычным столом . В этой невременной таблице id является первичным ключом. Для наших иллюстративных целей все остальные данные в таблице, независимо от того, из скольких столбцов она состоит, представлены одним блоком, помеченным как «данные».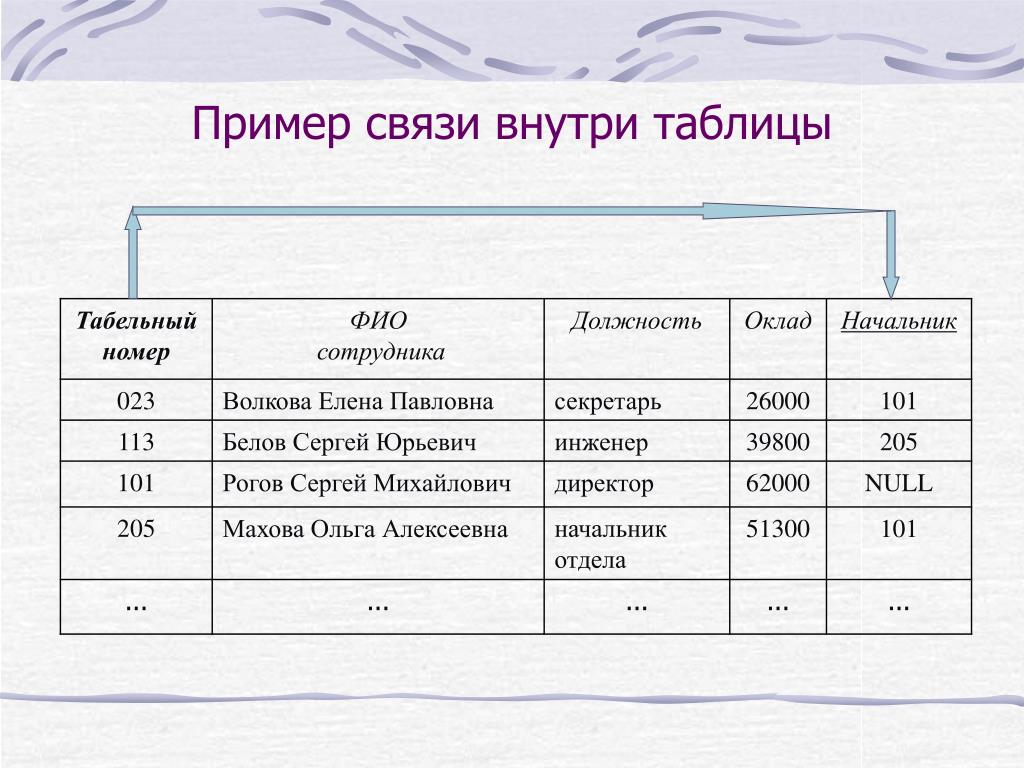
В невременной таблице каждая строка обозначает конкретный экземпляр того, о чем таблица. Так, например, в таблице «Клиенты» каждая строка обозначает конкретного покупателя, и каждый покупатель имеет уникальное значение для идентификатора покупателя. Пока бизнес имеет дисциплину использовать уникальное значение идентификатора для каждого клиента, СУБД будет честно гарантировать, что таблица Customer никогда не будет одновременно содержать две или более строк для одного и того же клиента.
Вторая иллюстрация на рисунке Часть 1.1 — это одновременная таблица Customer. В такой таблице у нас может быть несколько строк для одного и того же клиента. Каждая такая строка содержит данные, описывающие этого клиента в течение определенного периода времени, периода времени, ограниченного bd 1 и ed 1 .
Чтобы сделать этот пример как можно более простым, давайте воздержимся от обсуждения того, должны ли мы добавлять только дату начала периода или только дату окончания периода к первичному ключу, или мы должны добавить обе даты.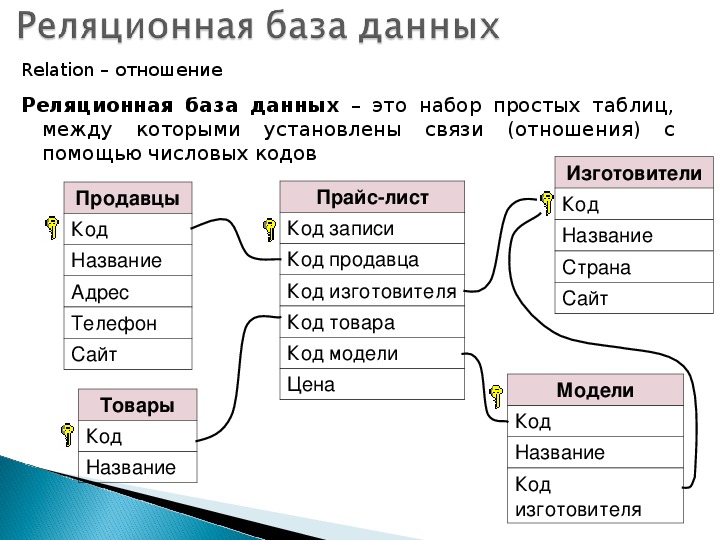 Итак, на второй иллюстрации на рисунке Часть 1.1 мы показываем как bd 1 , так и ed 1 , добавленные к первичному ключу, а на рисунке Часть 1.2 мы показываем образец одновременной таблицы.
Итак, на второй иллюстрации на рисунке Часть 1.1 мы показываем как bd 1 , так и ed 1 , добавленные к первичному ключу, а на рисунке Часть 1.2 мы показываем образец одновременной таблицы.
Рисунок Часть 1.2. Одновременная таблица.
Следуя стандартному соглашению, которое мы использовали в статьях, предшествующих этой книге, заголовки столбцов первичного ключа подчеркнуты. Для удобства даты представлены в виде месяца и года. Две строки для идентификатора клиента 1 показывают историю этого клиента за период с мая 2012 года по январь 2013 года.С мая по август данные клиента были 123; с августа по январь это было 456.
Теперь у нас может быть несколько строк для одного и того же клиента в нашей таблице Customer, и мы (и СУБД) можем сохранять их разными. Каждая из этих строк представляет собой версию клиента, а таблица теперь является версионной таблицей Customer. Мы используем эту терминологию в этой книге, но обычно предпочитаем добавлять термин «одновременный», потому что термин «одновременный» предполагает идею единственного временного измерения данных, единственного вида времени, связанного с данными, и это понятие одного (или двух) временных измерений полезно иметь в виду. Фактически, может быть полезно думать об этих двух временных измерениях как об осях X и Y декартового графа, а также о каждой строке в двухвременной таблице, представленной прямоугольником на этом графике.
Фактически, может быть полезно думать об этих двух временных измерениях как об осях X и Y декартового графа, а также о каждой строке в двухвременной таблице, представленной прямоугольником на этом графике.
Теперь мы подошли к последней из трех иллюстраций на Рисунке Часть 1.1. Совершенно очевидно, что мы можем преобразовать вторую таблицу в эту третью таблицу точно так же, как мы преобразовали первую во вторую: мы можем добавить еще одну пару дат к первичному ключу. И точно так же мы достигаем того же эффекта.Так же, как первые два столбца даты позволяют нам сохранить несколько строк с одним и тем же идентификатором, bd 2 и ed 2 позволяют нам сохранить несколько строк с одним и тем же идентификатором и . те же первые два свидания.
По крайней мере, такова идея. На самом деле, как мы все знаем, первичный ключ из пяти столбцов позволяет нам хранить любое количество строк в таблице до тех пор, пока значение только в одном столбце отличает этот первичный ключ от всех остальных.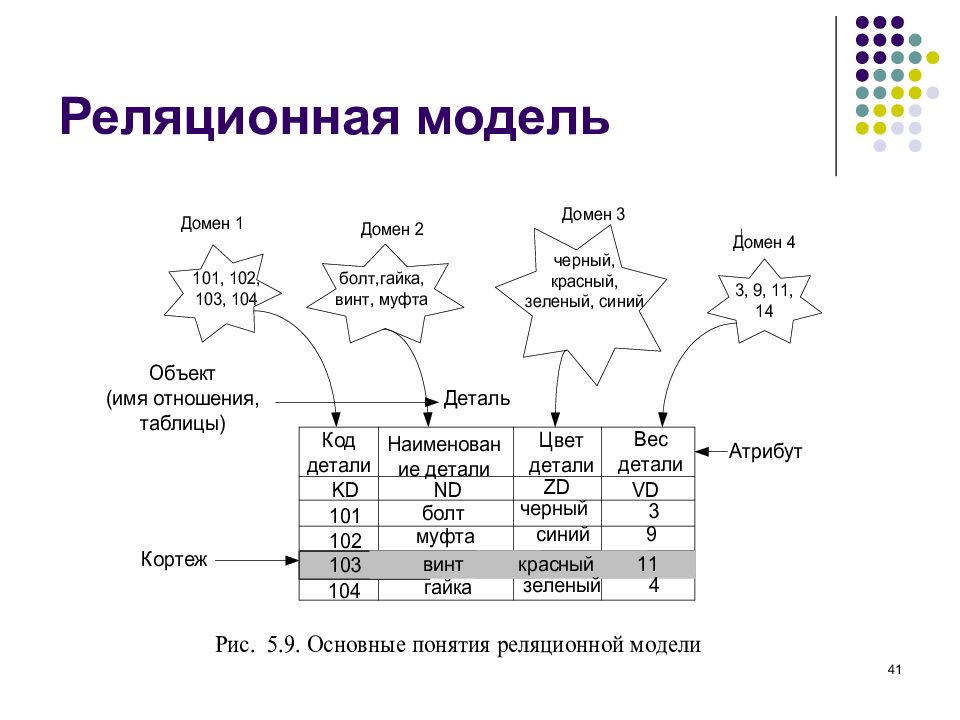 Так, например, СУБД позволит нам иметь несколько строк с одним и тем же идентификатором и со всеми четырьмя датами, за исключением, скажем, первой даты начала.
Так, например, СУБД позволит нам иметь несколько строк с одним и тем же идентификатором и со всеми четырьмя датами, за исключением, скажем, первой даты начала.
Этот первый пример двухвременных данных показывает нам несколько важных вещей. Однако он также может ввести нас в заблуждение, если мы не будем осторожны. Итак, давайте попробуем сделать из этого обоснованные выводы и напомним себе, какие выводы делать не следует.
Прежде всего, третья иллюстрация на Рисунке Часть 1.1 действительно показывает действительную двухвременную схему. Это таблица, первичный ключ которой содержит три логических компонента. Первый — это уникальный идентификатор объекта, который представляет строка. В данном случае это конкретный заказчик. Второй — уникальный идентификатор периода времени. Это период времени, в течение которого объект существовал с характеристиками, которые ему приписывает строка, например период времени, в течение которого этот конкретный клиент имел это конкретное имя и адрес, этот конкретный статус клиента и так далее.
Третий логический компонент первичного ключа — это пара дат, определяющая второй период времени. Это период времени, в течение которого мы считаем, что строка верна, что то, что она говорит, что ее объект похож в течение этого первого периода времени, действительно верно. Основная причина введения этого второго периода времени состоит в том, чтобы справиться со случаями, когда данные на самом деле неверны. Ведь если это неверно, теперь у нас есть способ сохранить ошибку (например, для аудита или других нормативных целей), а также заменить ее исправлением.
Теперь у нас может быть две строки с одинаковым идентификатором и точно таким же первым периодом времени. И наше соглашение будет заключаться в том, что из этих двух строк та, второй период которой начинается позже, будет строкой, обеспечивающей исправление, а строка с более ранним вторым периодом времени будет исправляемой строкой. На рисунке Часть 1.3 показан образец двухвременной таблицы, содержащей версии и исправление одной из этих версий.
Рисунок Часть 1.3. Би-темпоральный стол.
В столбце ed 2 значение 9999 представляет собой самую высокую дату, которую может представлять СУБД. Например, для SQL Server эта дата — 31.12.1999. Как мы объясним позже, при использовании в столбцах даты окончания это значение представляет собой неизвестную дату окончания, а период времени, который оно ограничивает, интерпретируется как все еще текущий.
Последняя строка на Рисунке Часть 1.3 — это исправление ко второй строке. Из-за используемых значений даты в примере предполагается, что в настоящее время это немного позже марта 2013 года.До марта 2013 года в этой таблице говорилось, что у клиента id-1 были данные 456 с августа 2013 года по январь следующего года. Но начиная с марта 2013 года в таблице указано, что у клиента с идентификатором 1 были данные 457 точно за тот же период времени.
Теперь мы можем воссоздать отчет (или запустить запрос) о клиентах в течение этого периода времени, который представляет собой либо отчет как было , либо отчет как было . В отчете указывается дата между bd 2 и ed 2 .Если указанная дата — любая дата с августа 2012 г. по март 2013 г., будет создан отчет «как было». Он покажет только первые три строки, потому что указанная дата не попадает во второй период времени для четвертой строки в таблице. Но если указанная дата наступит с марта 2013 г., будет создан отчет «как есть». В этом отчете будут показаны все строки, кроме второй, поскольку он попадает во второй период времени для этих строк, но не попадает во второй период времени для второй строки.
В отчете указывается дата между bd 2 и ed 2 .Если указанная дата — любая дата с августа 2012 г. по март 2013 г., будет создан отчет «как было». Он покажет только первые три строки, потому что указанная дата не попадает во второй период времени для четвертой строки в таблице. Но если указанная дата наступит с марта 2013 г., будет создан отчет «как есть». В этом отчете будут показаны все строки, кроме второй, поскольку он попадает во второй период времени для этих строк, но не попадает во второй период времени для второй строки.
Оба отчета будут отображать непрерывную историю идентификатора клиента-1 с мая 2012 года по январь 2013 года. Первый будет сообщать, что идентификатор клиента-1 имел данные 123 и 456 за этот период времени. Второй сообщит, что у клиента id-1 были данные 123 и 457 за тот же период времени. Таким образом, bd 1 и ed 1 определяют период времени в мире, в течение которого все было так, как их описывают данные, тогда как bd 2 и ed 2 ограничивают период времени в таблице, период времени, в течение которого мы утверждали, что все было так, как утверждает каждая строка данных.
Очевидно, что с обеими строками в таблице любой запрос, ищущий версию этого клиента, то есть строку, представляющую этого клиента, каким он был в определенный момент или период времени, должен будет различать две строки. В любом запросе нужно будет указать, какой из них правильный (или неправильный, если такова цель). И, чтобы не предвидеть слишком многого, мы можем заметить, что если дата окончания второго периода времени в неправильной строке установлена на то же значение, что и дата начала второго периода времени в его корректирующей строке, то просто путем запроса строки, второй период которых содержит текущую дату, мы всегда будем уверены, что получим правильную строку для нашей конкретной версии нашего конкретного клиента.
Это много информации, которую можно почерпнуть из рисунков Часть 1.1, Часть 1.2 и Часть 1.3. Но многие опытные разработчики моделей данных и их менеджеры построили и управляли структурами, подобными третьей строке, показанной на Рисунке Часть 1. 1. Кроме того, большинство компьютерных ученых, которые работали над проблемами, связанными с двухвременными данными, распознают эту строку как пример двухвременной структуры данных.
1. Кроме того, большинство компьютерных ученых, которые работали над проблемами, связанными с двухвременными данными, распознают эту строку как пример двухвременной структуры данных.
Это иллюстрирует, как мы думаем, тот простой факт, что, когда хорошие умы думают о схожих проблемах, они часто придумывают аналогичные решения.Подобные решения, да; но не одинаковые. И здесь нам нужно быть осторожными, чтобы не быть введенными в заблуждение.
Концепции реляционных баз данных
Концепции реляционных баз данныхГлава 2 Термины и концепции базы данных
Система управления реляционными базами данных (СУБД) хранит и извлекает данные, представленные в таблицах. Реляционная база данных состоит из набора таблиц, в которых хранятся взаимосвязанные данные.
В этом разделе представлены некоторые термины и концепции, которые важны при разговоре о реляционных базах данных.
Таблицы базы данных
В реляционной базе данных все данные хранятся в таблицах ,
которые состоят из строк и столбцов .
Каждая таблица имеет один или несколько столбцов, и каждому столбцу назначается конкретный тип данных , например целое число, последовательность символов (для текста) или дата. Каждая строка в таблица имеет значение для каждого столбца.
Типичный фрагмент таблицы, содержащей информацию о сотрудниках может выглядеть так:
emp_ID | emp_lname | emp_fname | emp_phone |
|---|---|---|---|
10057 | Хуонг | Чжан | 1096 |
10693 | Дональдсон | Энн | 7821 |
Таблицы реляционной базы данных имеют некоторые важные характеристики:
- Нет значения
порядок столбцов или строк.
- Каждая строка содержит одно и только одно значение для каждого столбец.
- Каждое значение для данного столбца имеет один и тот же тип.

The В следующей таблице перечислены некоторые формальные и неформальные отношения термины базы данных, описывающие таблицы и их содержимое, вместе с их аналог в других нереляционных базах данных. В этом руководстве используются неформальные условия.
Формальный термин отношений | Неформальный термин отношений | Эквивалентный термин, не связанный с отношениями |
|---|---|---|
Отношение | Стол | Файл |
Атрибут | Колонна | Поле |
Кортеж | Ряд | Запись |
При разработке базы данных убедитесь, что каждый
таблица в базе данных содержит информацию о конкретной вещи,
например, сотрудники, продукты или клиенты.
Создавая базу данных таким образом, вы можете создать структуру что устраняет избыточность и несогласованность. Например, оба отделы продаж и кредиторской задолженности могут искать информацию о клиентах. В реляционной базе данных информация о клиенты вводятся только один раз в таблицу, в которой оба отдела может получить доступ.
Реляционная база данных — это набор связанных таблиц. Ты используешь первичный и внешний ключи для описания отношений между информацией в разных таблицах.
Первичный и внешний ключи
Первичный и внешний ключи определяют реляционную структуру база данных. Эти ключи позволяют каждой строке в таблицах базы данных быть идентифицированным, и определить отношения между таблицами.
Таблицы имеют первичный ключ
Все таблицы в реляционной базе данных должны иметь первичный номер .
ключ . Первичный ключ — это столбец или набор столбцов,
это позволяет однозначно идентифицировать каждую строку в таблице. Нет
две строки в таблице с первичным ключом могут иметь один и тот же первичный ключ
ключевое значение.
Нет
две строки в таблице с первичным ключом могут иметь один и тот же первичный ключ
ключевое значение.
Если первичный ключ не назначен, все столбцы вместе становятся первичный ключ. Рекомендуется хранить первичный ключ для каждый стол максимально компактный.
Примеры
В таблице, содержащей информацию о сотрудниках, основной ключом может быть идентификационный номер, присвоенный каждому сотруднику.
В примере базы данных таблица позиций заказа на продажу имеет следующие столбцы:
- Номер заказа, идентифицирующий заказ, частью которого является товар
- Номер строки, идентифицирующий каждую позицию в любом заказе.
- Идентификатор продукта, идентифицирующий заказываемый продукт.
- Количество, показывающее, сколько единиц было заказано.
- Дата отгрузки, показывающая, когда заказ был отправлен.
Чтобы идентифицировать конкретный товар, укажите как номер заказа, так и
номер строки обязателен. Первичный ключ состоит из обоих
столбцы.
Первичный ключ состоит из обоих
столбцы.
Таблицы связаны внешними ключами
Информация в одной таблице связана с информацией в других таблицах. по внешних ключей .
Пример
В образце базы данных есть одна таблица, содержащая информацию о сотрудниках. и одна таблица, содержащая информацию об отделе. Стол отдела имеет следующие столбцы:
- dept_id Идентификационный номер отдела. Это первичный ключ для стола.
- dept_name Столбец, содержащий название отдела.
- dept_head_id Идентификатор сотрудника для руководителя отдела.
Чтобы узнать название отдела конкретного сотрудника,
нет необходимости указывать название отдела сотрудника
в таблицу сотрудников. Вместо этого таблица сотрудников содержит
столбец, содержащий идентификатор отдела отдела сотрудника.
Это называется внешним ключом для отдела.
Таблица.Внешний ключ ссылается на конкретную строку в таблице, содержащую
соответствующий первичный ключ.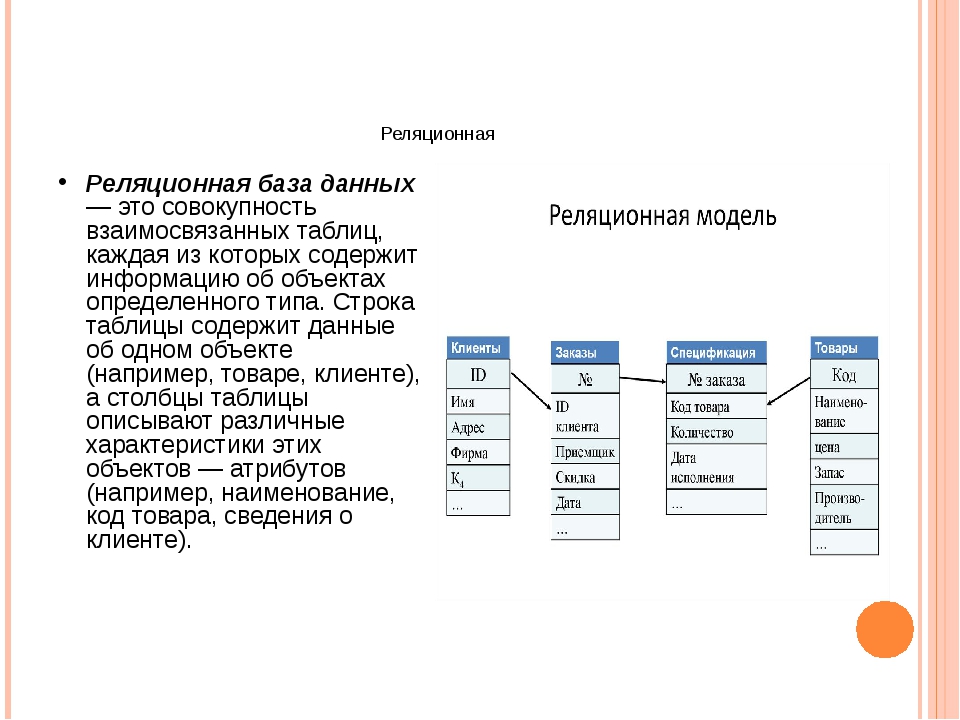
В этом примере таблица сотрудников (которая содержит внешнюю ключ в связи) называется внешней таблицей или , ссылающейся Таблица . Таблица отделов (которая содержит указанные первичный ключ) называется первичной таблицей или таблица , на которую ссылается .
Другие объекты базы данных
Реляционная база данных содержит больше, чем набор связанных таблиц.Среди других объектов, составляющих реляционную базу данных:
- Индексы Индексы позволяют быстро искать информацию. Концептуально,
указатель в базе данных похож на указатель в книге. В книге
index связывает каждый проиндексированный термин со страницей или страницами, на которых этот
слово появляется. В базе данных индекс связывает каждый индексированный столбец
значение в физическое местоположение, в котором строка данных, содержащая
индексированное значение сохраняется.
Указатели — важный элемент дизайна для высокой производительности, однако их использование прозрачно для пользователя. - Представления Представления — это вычисляемые таблицы или виртуальные таблицы. Они
выглядят как таблицы для клиентских приложений, но не содержат данных.
Вместо этого, всякий раз, когда к ним обращаются, информация в них
вычисляется из базовых таблиц.
Таблицы, которые фактически содержат информацию, иногда называется базовыми таблицами , чтобы отличить их от взгляды. - Хранимые процедуры и триггеры Это процедуры, хранящиеся в самой базе данных, которые
действовать в соответствии с информацией в базе данных.
Вы можете создавать собственные хранимые процедуры и давать им имена для выполнения конкретные запросы к базе данных и для выполнения других задач базы данных. Хранится процедуры могут принимать параметры. Например, вы можете создать хранимая процедура, которая возвращает имена всех клиентов, у которых есть потрачено больше суммы, указанной вами в качестве параметра в вызов на процедуру.Триггер — это специальная хранимая процедура, которая автоматически срабатывает всякий раз, когда пользователь обновляет, удаляет или вставляет данные, в зависимости от от того, как вы определяете триггер.
Вы связываете триггер с таблицей
или столбцы в таблице. Триггеры полезны для автоматического
ведение бизнес-правил в базе данных. - Пользователи и группы У каждого пользователя базы данных есть идентификатор пользователя и пароль. Вы можете установить разрешения для каждого пользователя, чтобы конфиденциальная информация хранится в секрете, и пользователи не могут делать несанкционированные изменения. Пользователи могут быть распределены по группам, чтобы администрирование разрешений проще.
- Объекты Java Вы можете установить классы Java в базу данных.Классы Java предоставляют мощный способ встраивать логику в ваш база данных и специальный класс определяемых пользователем типов данных для хранения Информация.
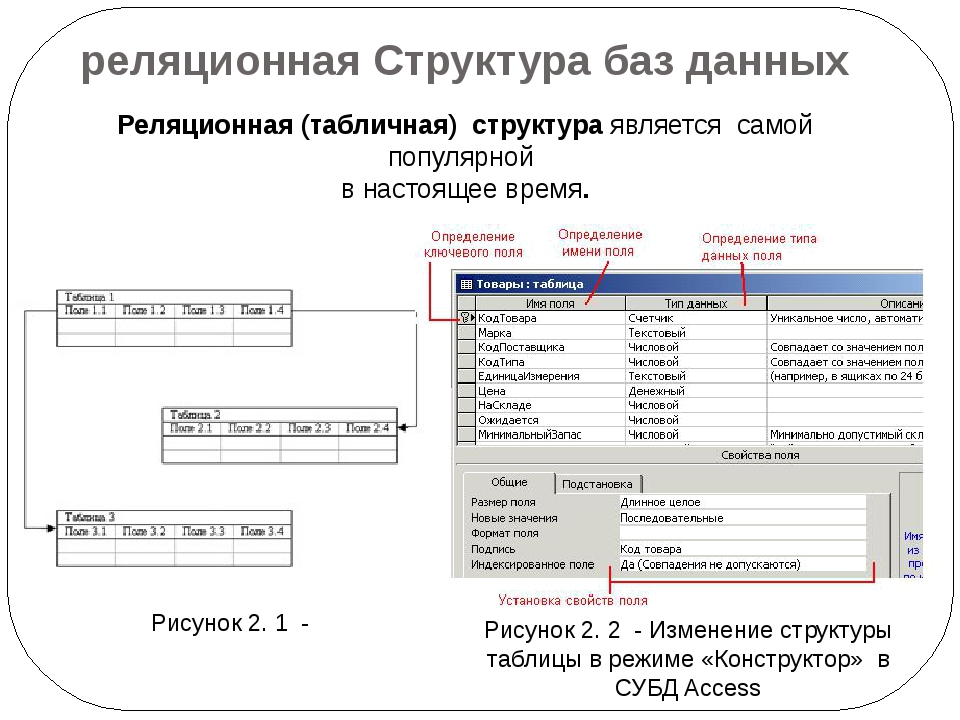
 Вы связываете триггер с таблицей
или столбцы в таблице. Триггеры полезны для автоматического
ведение бизнес-правил в базе данных.
Вы связываете триггер с таблицей
или столбцы в таблице. Триггеры полезны для автоматического
ведение бизнес-правил в базе данных. Запросы
Получить данные из базы данных с помощью оператора SELECT.
Основные операции запроса в реляционной системе — это проекция,
ограничение, и присоединяйтесь. Оператор SELECT реализует
все эти операции.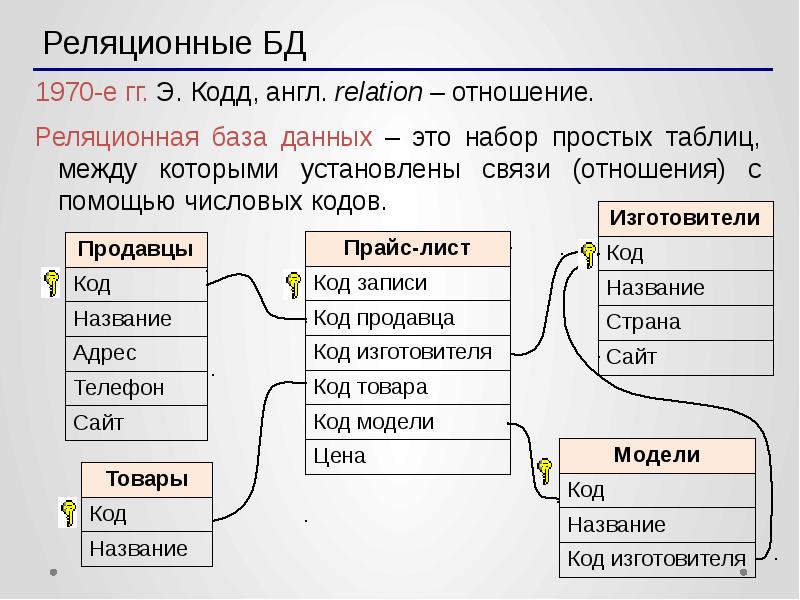
Проекция — это подмножество столбцов в таблице. Ограничение (также называемое выбором ) — это подмножество строк в таблице, основанное на некоторых условиях.
Например, следующий оператор SELECT извлекает названия и цены всех продуктов, которые стоят более 15 долларов:
ВЫБЕРИТЕ имя, unit_price
FROM product
WHERE unit_price> 15
В этом запросе используются оба ограничения (WHERE unit_price> 15) и проекция (ВЫБЕРИТЕ имя, unit_price)
A JOIN связывает строки в двух или более таблицах, сравнивая значения в ключевых столбцах и возвращающие строки с совпадающими значениями. Например, вы можете выбрать идентификационные номера товаров. и названия продуктов для всех товаров, для которых более десятка отгружено:
ВЫБЕРИТЕ sales_order_items.id, product.name
FROM product KEY JOIN sales_order_items
WHERE sales_order_items.quantity> 12
Таблица товаров и sales_order_items
таблицы объединяются на основе отношений внешнего ключа
между ними.
Другие операторы SQL
С помощью SQL можно сделать больше, чем просто запрос. SQL включает инструкции которые создают таблицы, представления и другие объекты базы данных. Он также включает операторы, которые изменяют таблицы и команды, которые выполняют многие другие задачи базы данных, обсуждаемые в этом руководстве.
Системные таблицы
Каждая база данных содержит набор из системных таблиц , которые — это специальные таблицы, которые система использует для управления данными и системой. Эти таблицы иногда называют словарем данных , или системный каталог .
Системные таблицы содержат информацию о базе данных. Ты
никогда не изменяйте системные таблицы напрямую так, как вы можете изменить
другие таблицы. Системные таблицы содержат информацию о таблицах
в базе данных пользователи базы данных, столбцы в каждой таблице,
и так далее.Эта информация представляет собой данные о данных или метаданные .
| © Sybase, Inc., 2000. Все права защищены. | ||
Реляционные таблицы — Справочный центр Acoustic
Реляционная таблица — это таблица столбцов или полей, которые описывают список (или строки) данных, аналогично базе данных Acoustic Campaign. Например, реляционная таблица может содержать такие поля, как идентификатор клиента, номер транзакции, приобретенный продукт, цена продукта, дата продажи и место покупки.
В Acoustic Campaign есть два способа создать реляционную таблицу:
- Путем импорта файла CSV, TSV или PSV; или
- Через API
Примечание: Ограничение по умолчанию для реляционных таблиц на организацию — 10. Если вашей организации требуется больше реляционных таблиц, обратитесь в службу поддержки.
Элемент
Эта функция позволяет вам экспоненциально расширять данные, доступные в ваших контактных записях, путем сопоставления вашей базы данных с реляционными таблицами. Вы можете хранить несколько строк данных о покупках, посещаемости мероприятий, действиях и сопоставлять их с одной записью, предлагая целостное представление о клиенте.
Вы можете хранить несколько строк данных о покупках, посещаемости мероприятий, действиях и сопоставлять их с одной записью, предлагая целостное представление о клиенте.
Когда вы используете эту функцию, ваши данные могут использоваться в запросах и сегментации, динамическом содержании и персонализации в электронных письмах.
Полезно связать базу данных с реляционной таблицей, чтобы вы могли использовать данные из баз данных в своих электронных письмах.
Отношение «один ко многим» в реляционной таблице
В реляционных базах данных отношение «один ко многим» возникает, когда родительская запись в одной таблице потенциально может ссылаться на несколько дочерних записей в другой таблице.
В отношении «один ко многим» родительский элемент не обязан иметь дочерние записи; следовательно, отношение «один ко многим» допускает нулевые дочерние записи, одну дочернюю запись или несколько дочерних записей. Важно то, что у дочернего элемента не может быть более одной родительской записи.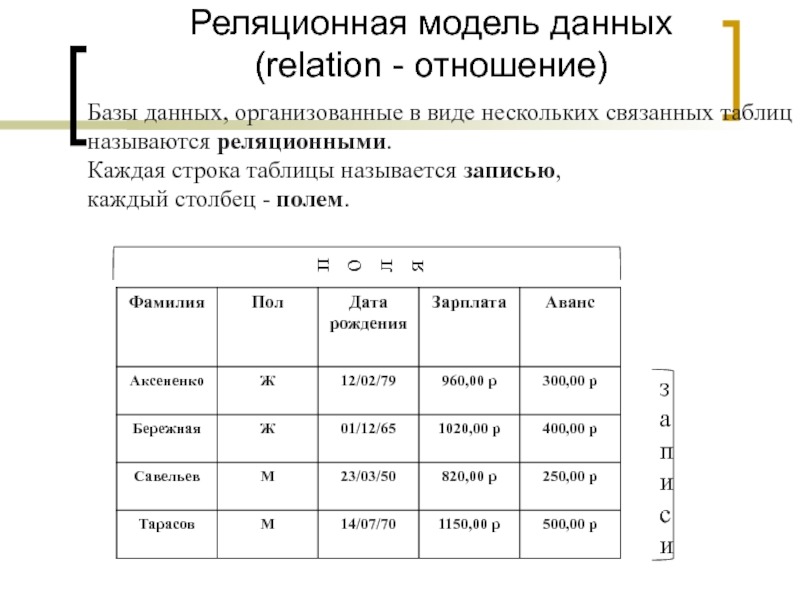
Каждая таблица содержит уникальный идентификатор, поле с отдельным значением для каждой строки. Один и тот же идентификатор клиента отображается или «повторяется» в нескольких строках. В правильной модели данных это поле будет однозначно содержаться в базе данных, что позволит вам хранить несколько покупок для одного контакта.
Противоположностью отношения «один ко многим» является отношение «многие ко многим», в котором дочерняя запись может ссылаться на несколько родительских записей.
Отношение «многие к одному» в реляционной таблице
Отношение «многие к одному» — это когда один объект (обычно столбец или набор столбцов) содержит значения, которые относятся к другому объекту (столбцу или набору столбцов), который имеет уникальные значения.
В реляционных базах данных эти отношения «многие к одному» часто устанавливаются отношениями внешний ключ / первичный ключ, а отношения обычно устанавливаются между таблицами фактов и измерений, а также между уровнями иерархии. Отношения часто используются для описания классификаций или группировок. Например, в географической схеме, содержащей таблицы «Регион», «Штат» и «Город», есть много штатов, которые находятся в данном регионе, но нет штатов в двух регионах. Аналогично для городов, город находится только в одном штате (города с одинаковым названием, но находятся в нескольких штатах, должны обрабатываться немного по-другому). Ключевым моментом является то, что каждый город существует ровно в одном штате, но в штате может быть много городов, отсюда и термин «многие к одному».«
Отношения часто используются для описания классификаций или группировок. Например, в географической схеме, содержащей таблицы «Регион», «Штат» и «Город», есть много штатов, которые находятся в данном регионе, но нет штатов в двух регионах. Аналогично для городов, город находится только в одном штате (города с одинаковым названием, но находятся в нескольких штатах, должны обрабатываться немного по-другому). Ключевым моментом является то, что каждый город существует ровно в одном штате, но в штате может быть много городов, отсюда и термин «многие к одному».«
Различные элементы или уровни иерархии должны иметь взаимно-однозначные отношения между дочерними и родительскими уровнями, независимо от того, представлена ли иерархия физически в схеме звезды или снежинки; то есть данные должны соответствовать этим отношениям. Чистые данные, необходимые для обеспечения взаимосвязей «многие к одному», являются важной характеристикой размерной схемы.
Если уникальное поле в реляционной таблице не повторяется в другом месте таблицы, вы можете многократно использовать его данные в базе данных.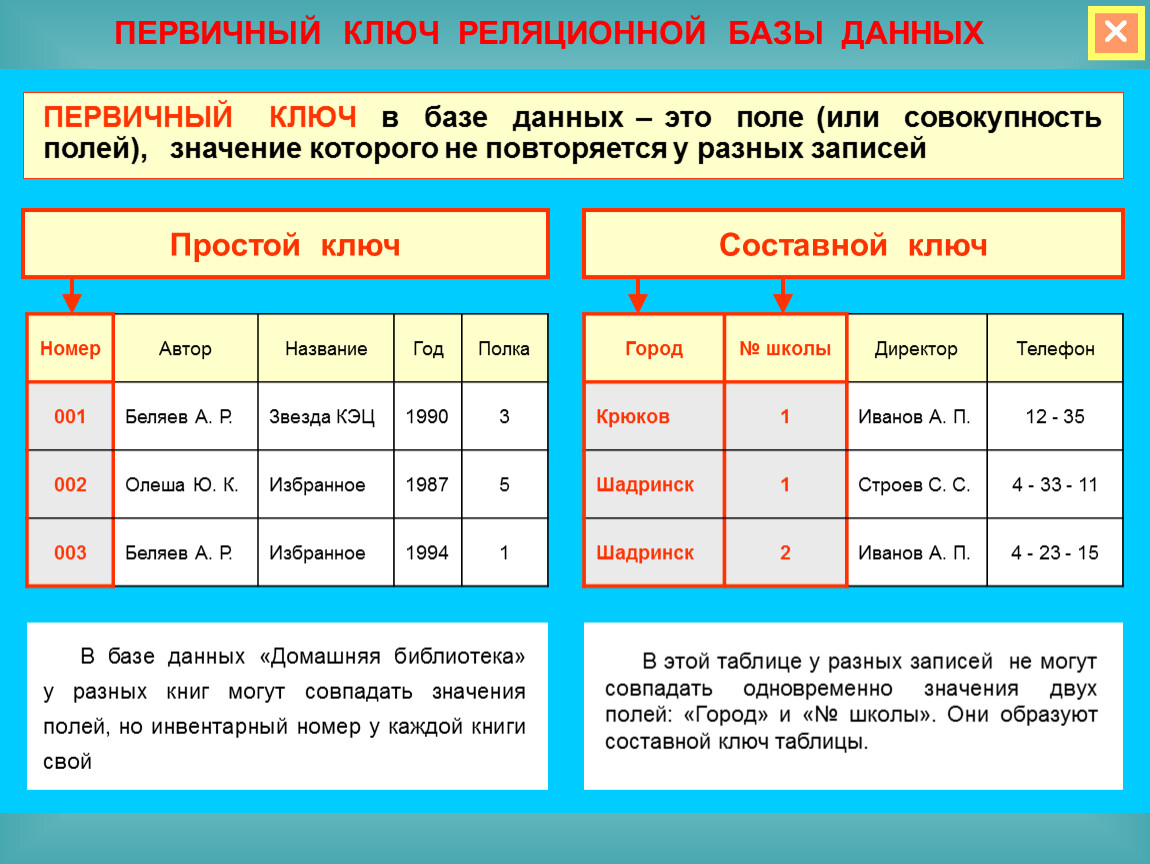 Эти данные могут быть связаны со многими контактами в базе данных и являются примером связи «многие к одному».
Эти данные могут быть связаны со многими контактами в базе данных и являются примером связи «многие к одному».
Реляционная модель данных в СУБД: концепции, ограничения, пример
Что такое реляционная модель?
Реляционная модель (RM) представляет базу данных как набор отношений. Отношение — это не что иное, как таблица значений. Каждая строка в таблице представляет собой набор связанных значений данных. Эти строки в таблице обозначают сущность или отношение реального мира.
Имя таблицы и имена столбцов помогают интерпретировать значение значений в каждой строке. Данные представлены в виде набора отношений. В реляционной модели данные хранятся в виде таблиц. Однако физическое хранение данных не зависит от логической организации данных.
Вот некоторые популярные системы управления реляционными базами данных:
- DB2 и Informix Dynamic Server — IBM
- Oracle и RDB — Oracle
- SQL Server and Access — Microsoft
В этом руководстве вы изучите
Relational Концепции модели
- Атрибут: Каждый столбец в таблице.Атрибуты — это свойства, определяющие отношение. например, Student_Rollno, NAME и т. д.
- Таблицы — В реляционной модели отношения сохраняются в формате таблицы. Он хранится вместе со своими сущностями. Таблица имеет две строки свойств и столбцы. Строки представляют записи, а столбцы представляют атрибуты.
- Кортеж — это не что иное, как одна строка таблицы, которая содержит одну запись.
- Схема отношения: Схема отношения представляет имя отношения с его атрибутами.
- Степень: Общее количество атрибутов, которые в отношении называются степенью отношения.
- Количество элементов: Общее количество строк в таблице.
- Столбец: Столбец представляет набор значений для определенного атрибута.
- Экземпляр отношения — Экземпляр отношения — это конечный набор кортежей в системе СУБД. У экземпляров отношения никогда не бывает повторяющихся кортежей.
- Ключ отношения — Каждая строка имеет один, два или несколько атрибутов, что называется ключом отношения.
- Домен атрибутов — Каждый атрибут имеет некоторое предопределенное значение и область, известную как домен атрибута
Ограничения реляционной целостности
Ограничения реляционной целостности в СУБД относятся к условиям, которые должны присутствовать для действительного отношения. Эти реляционные ограничения в СУБД вытекают из правил мини-мира, который представляет база данных.
В СУБД существует множество типов ограничений целостности. Ограничения в системе управления реляционной базой данных в основном делятся на три основные категории:
- Ограничения домена
- Ключевые ограничения
- Ограничения ссылочной целостности
Ограничения домена
Ограничения домена могут быть нарушены, если значение атрибута не отображается в соответствующий домен или он не относится к соответствующему типу данных.
Ограничения домена указывают, что внутри каждого кортежа, и значение каждого атрибута должно быть уникальным. Это указывается как типы данных, которые включают стандартные типы данных целые числа, действительные числа, символы, логические значения, строки переменной длины и т. Д.
Пример:
Создать DOMAIN CustomerName CHECK (значение не NULL)
Показанный пример демонстрирует создание ограничения домена таким образом, что CustomerName не равно NULL
Ключевые ограничения
Атрибут, который может однозначно идентифицировать кортеж в отношении, называется ключом таблицы.Значение атрибута для разных кортежей в отношении должно быть уникальным.
Пример:
В данной таблице CustomerID является ключевым атрибутом таблицы клиентов. Скорее всего, у него будет один ключ для одного клиента, CustomerID = 1 предназначен только для CustomerName = «Google».
| CustomerID | CustomerName | Статус |
| 1 | Активный | |
| 2 | Amazon | Активный |
| 3 Apple 9016 902 9016 |
Ограничения ссылочной целостности
Ограничения ссылочной целостности в СУБД основаны на концепции внешних ключей.Внешний ключ — важный атрибут отношения, на который следует ссылаться в других отношениях. Состояние ограничения ссылочной целостности возникает, когда отношение относится к ключевому атрибуту другого или того же отношения. Однако этот ключевой элемент должен существовать в таблице.
Пример:
В приведенном выше примере у нас есть 2 отношения: Клиент и Биллинг.
Кортеж для CustomerID = 1 упоминается дважды в отношении Billing. Итак, мы знаем, что CustomerName = Google выставил счет на сумму 300 долларов США
Операции в реляционной модели
Четыре основных операции обновления, выполняемые в модели реляционной базы данных:
Вставка, обновление, удаление и выбор.
- Insert используется для вставки данных в отношение
- Delete используется для удаления кортежей из таблицы.
- Modify позволяет изменять значения некоторых атрибутов в существующих кортежах.
- Select позволяет выбрать определенный диапазон данных.
При применении одной из этих операций ограничения целостности, указанные в схеме реляционной базы данных, никогда не должны нарушаться.
Операция вставки
Операция вставки дает значения атрибута для нового кортежа, который должен быть вставлен в отношение.
Операция обновления
Вы можете видеть, что в приведенной ниже таблице отношений CustomerName = ‘Apple’ изменено с «Неактивно» на «Активно».
Операция удаления
Чтобы указать удаление, условие для атрибутов отношения выбирает кортеж для удаления.
В приведенном выше примере CustomerName = «Apple» удален из таблицы.
Операция удаления может нарушить ссылочную целостность, если на удаляемый кортеж ссылаются внешние ключи из других кортежей в той же базе данных.
Выбрать операцию
В приведенном выше примере выбрано CustomerName = «Amazon»
Рекомендации по созданию реляционной модели
- Данные должны быть представлены в виде набора отношений
- Каждое отношение должно быть четко изображено в таблице
- Строки должны содержать данные об экземплярах сущности
- Столбцы должны содержать данные об атрибутах сущности
- Ячейки таблицы должны содержать одно значение
- Каждому столбцу должно быть присвоено уникальное имя
- Нет два строки могут быть идентичными
- Значения атрибута должны быть из одного домена
Преимущества использования реляционной модели
- Простота : Реляционная модель данных в СУБД проще, чем иерархическая и сетевая модель.
- Структурная независимость : Реляционная база данных связана только с данными, а не со структурой. Это может улучшить характеристики модели.
- Простота использования : Реляционная модель в СУБД проста, поскольку таблицы, состоящие из строк и столбцов, вполне естественны и просты для понимания
- Возможность запросов : Это позволяет языку запросов высокого уровня, таким как SQL, избежать сложная навигация по базе данных.
- Независимость данных : Структура реляционной базы данных может быть изменена без изменения какого-либо приложения.
- Масштабируемость : Что касается количества записей или строк, а также количества полей, база данных должна быть увеличена для повышения удобства использования.
Недостатки использования реляционной модели
- Некоторые реляционные базы данных имеют ограничения на длину полей, которые нельзя превышать.
- Реляционные базы данных могут иногда становиться сложными по мере увеличения объема данных и усложнения отношений между частями данных.
- Сложные системы реляционных баз данных могут привести к изолированным базам данных, информация в которых не может быть передана из одной системы в другую.
Сводка
- Моделирование реляционной базы данных представляет базу данных как набор отношений (таблиц)
- Атрибут, таблицы, кортеж, схема отношения, степень, мощность, столбец, экземпляр отношения — некоторые важные компоненты реляционной модели
- Ограничения реляционной целостности относятся к условиям, которые должны присутствовать для правильного подхода к отношениям в СУБД.
- Ограничения домена могут быть нарушены, если значение атрибута не отображается в соответствующем домене или не относится к соответствующему типу данных
- Insert, Выбор, изменение и удаление — это операции, выполняемые в ограничениях реляционной модели.
- Реляционная база данных связана только с данными, а не со структурой, которая может улучшить производительность модели.
- Преимущества реляционной модели в СУБД — это простота, структурная независимость, простота использования, возможность запросов, независимость данных, масштабируемость и т. д.
- Некоторые реляционные базы данных имеют ограничения на длину полей, которые нельзя превышать.
Что такое реляционная база данных?
Реляционная база данных — это набор информации, который упорядочивает точки данных с определенными отношениями для облегчения доступа. В модели реляционной базы данных структуры данных, включая таблицы данных, индексы и представления, остаются отдельными от физического хранилища, что позволяет администраторам редактировать физическое хранилище данных, не влияя на логическую структуру данных.
Таблицы данных, используемые в реляционной базе данных, хранят информацию о связанных объектах. Каждая строка содержит запись с уникальным идентификатором, известным как ключ, и каждый столбец содержит атрибуты данных. Каждая запись присваивает значение каждой функции, что упрощает выявление взаимосвязей между точками данных.
Стандартным пользовательским и прикладным программным интерфейсом (API) реляционной базы данных является язык структурированных запросов (SQL). Операторы SQL используются как для интерактивных запросов информации из реляционной базы данных, так и для сбора данных для отчетов.Необходимо соблюдать определенные правила целостности данных, чтобы реляционная база данных была точной и доступной.
Реляционные базы данных полезны для организаций всех типов и размеров, где необходимо согласованно управлять и защищать связанные точки данных. Например, предприятия электронной коммерции могут использовать реляционную модель для обработки покупок и отслеживания запасов. Реляционная база данных — это наиболее широко используемая модель базы данных.
Что входит в модель реляционной базы данных?Реляционная база данных была изобретена в 1970 году Э.Ф. Кодд, тогда молодой программист в IBM. В своей статье «Реляционная модель данных для больших общих банков данных» Кодд предложил перейти от хранения данных в иерархических или навигационных структурах к организации данных в таблицах, содержащих строки и столбцы.
Каждая таблица — иногда называемая отношением — в реляционной базе данных содержит одну или несколько категорий данных в столбцах или атрибутов . Каждая строка — также называемая записью или кортежем — содержит уникальный экземпляр данных — или ключ — для категорий, определенных столбцами.Каждая таблица имеет уникальный первичный ключ, который идентифицирует информацию в таблице. Затем связь между таблицами может быть установлена с помощью внешних ключей — поля в таблице, которое ссылается на первичный ключ другой таблицы.
Например, типичная база данных для ввода бизнес-заказов будет включать таблицу, описывающую клиента, со столбцами для имени, адреса, номера телефона и т. Д. Другая таблица будет описывать заказ, включая такую информацию, как продукт, клиент, дата и цена продажи.
Затем пользователь реляционной базы данных может получить представление базы данных в соответствии со своими потребностями. Например, менеджеру филиала может быть интересен просмотр или отчет обо всех клиентах, купивших продукты после определенной даты. Менеджер по финансовым услугам в той же компании может из тех же таблиц получить отчет о счетах, которые необходимо оплатить.
Реляционная база данных включает таблицы, содержащие строки и столбцы.При создании реляционной базы данных вы можете определить область возможных значений в столбце данных и дополнительные ограничения, которые могут применяться к этому значению данных.Например, домен возможных клиентов может допускать до 10 возможных имен клиентов, но ограничен в одной таблице, позволяя указать только три из этих имен клиентов.
Два ограничения относятся к целостности данных, а также к первичному и внешнему ключам:
- Целостность объекта гарантирует, что первичный ключ в таблице уникален и что значение не установлено равным нулю.
- Ссылочная целостность требует, чтобы каждое значение в столбце внешнего ключа находилось в первичном ключе таблицы, из которой оно возникло.
Кроме того, реляционные базы данных обладают физической независимостью от данных. Это относится к способности системы вносить изменения во внутреннюю схему без изменения внешних схем или прикладных программ. Изменения внутренней схемы могут включать:
- использование новых запоминающих устройств;
- модифицирующие индексы;
- переход с одного метода доступа на другой;
- с использованием различных структур данных; и
- с использованием различных структур хранения или файловых организаций.
Логическая независимость данных — это способность системы управлять концептуальной схемой без изменения внешней схемы или прикладных программ. Изменения концептуальной схемы могут включать в себя добавление или удаление новых отношений, сущностей или атрибутов без изменения существующих внешних схем или переписывания прикладных программ.
Примеры реляционных баз данных
Стандартные реляционные базы данных позволяют пользователям управлять предопределенными отношениями данных в нескольких базах данных.Популярные примеры стандартных реляционных баз данных включают Microsoft SQL Server, Oracle Database, MySQL и IBM DB2.
Облачные реляционные базы данных или база данных как услуга (DBaaS) также широко используются, потому что они позволяют компаниям отдавать на аутсорсинг обслуживание баз данных, установку исправлений и поддержку инфраструктуры. Облачные реляционные базы данных включают Amazon Relational Database Service (RDS), Google Cloud SQL, IBM DB2 on Cloud, SQL Azure и Oracle Cloud.
Типы баз данныхСуществует ряд категорий баз данных: от базовых плоских файлов, которые не являются реляционными, до NoSQL и более новых графовых баз данных, которые считаются даже более реляционными, чем стандартные реляционные базы данных.
База данных плоских файлов состоит из одной таблицы данных, которые не имеют взаимосвязи — обычно текстовых файлов. Этот тип файла позволяет пользователям указывать атрибуты данных, такие как столбцы и типы данных.
Плоский файл против реляционной базы данныхБаза данных NoSQL — это альтернатива реляционным базам данных, которая особенно полезна для работы с большими наборами распределенных данных. Эти базы данных могут поддерживать различные модели данных, включая форматы «ключ-значение», «документ», «столбец» и «график».
База данных графов выходит за рамки традиционных реляционных моделей данных на основе столбцов и строк; эта база данных NoSQL использует узлы и ребра, которые представляют связи между отношениями данных и могут обнаруживать новые отношения между данными. Графические базы данных более сложны, чем реляционные базы данных, и поэтому их использование включает в себя механизмы обнаружения мошенничества или веб-рекомендаций.
Объектно-реляционная база данных (ORD) состоит из системы управления реляционными базами данных (RDBMS) и объектно-ориентированной системы управления базами данных (OODBMS).ORD содержит характеристики моделей RDBMS и OODBMS. В ORD для хранения данных используется традиционная база данных. Затем к нему обращаются и манипулируют с помощью запросов, написанных на языке запросов, таком как SQL. Следовательно, основной подход ORD основан на реляционной базе данных.
Однако ORD также можно рассматривать как объектное хранилище, особенно для программного обеспечения, написанного на объектно-ориентированном языке программирования (ООП), тем самым опираясь на объектно-ориентированные характеристики.В этой ситуации API-интерфейсы используются для хранения и извлечения данных.
Преимущества реляционных баз данныхОсновным преимуществом реляционных баз данных является то, что они позволяют пользователям легко классифицировать и хранить данные, которые впоследствии могут быть запрошены и отфильтрованы для извлечения конкретной информации для отчетов. Реляционные базы данных также легко расширяются и не зависят от физической организации. После создания исходной базы данных можно добавить новую категорию данных без изменения всех существующих приложений.
Другие преимущества реляционной базы данных:
- Точность: Данные сохраняются только один раз, что исключает дедупликацию данных.
- Гибкость: Пользователи могут легко выполнять сложные запросы.
- Сотрудничество: Несколько пользователей могут получить доступ к одной базе данных.
- Доверие: Модели реляционных баз данных являются зрелыми и хорошо изученными.
- Безопасность: Данные в таблицах в СУБД могут быть ограничены, чтобы разрешить доступ только определенным пользователям.
Большинство программных продуктов на сегодняшнем рынке включают в себя как реляционные базы данных, так и стандартные базы данных. Следовательно, они могут управлять базами данных как в реляционной табличной форме, так и в файловой форме, или и то, и другое. По сути, на сегодняшнем рынке реляционная база данных — это база данных, и наоборот; тем не менее, между двумя системами по-прежнему существуют существенные различия в хранении данных.
Наиболее важное отличие состоит в том, что в реляционной базе данных данные хранятся в табличной форме или в виде таблицы со строками и столбцами, а в базе данных данные хранятся в виде файлов.Другие отличия включают:
- Нормализация базы данных присутствует в реляционной базе данных, но отсутствует в базе данных.
- Реляционная база данных поддерживает распределенную базу данных, а база данных не поддерживает распределенную базу данных.
- В реляционной базе данных значения данных хранятся в форме таблиц, и каждая таблица имеет первичный ключ. В базе данных данные обычно хранятся в иерархической или навигационной форме.
- Поскольку данные хранятся в форме таблиц в реляционной базе данных, то также сохраняется связь между этими значениями данных.Поскольку база данных хранит данные в виде файлов, между значениями или таблицами нет никакой связи.
- В реляционной базе данных ограничения целостности определены для ACID. С другой стороны, база данных не использует никаких средств защиты от манипуляций с данными.
- В то время как реляционная база данных предназначена для поддержки больших объемов данных и нескольких пользователей, база данных предназначена для работы с небольшими объемами данных и одним пользователем.
Последнее, важное отличие заключается в том, что хранилище данных в реляционной базе данных доступно, то есть значение может обновляться системой.Кроме того, данные в СУБД физически и логически независимы.
13 Реляционные данные | R для науки о данных
Введение
Редко, когда анализ данных включает только одну таблицу данных. Обычно у вас есть много таблиц данных, и вы должны объединить их, чтобы ответить на интересующие вас вопросы. В совокупности несколько таблиц данных называются реляционными данными , потому что это отношения, а не только отдельные наборы данных. важный.
Отношения всегда определяются между парой таблиц. Все остальные отношения построены на этой простой идее: отношения трех или более таблиц всегда являются свойством отношений между каждой парой. Иногда оба элемента пары могут быть одной и той же таблицей! Это необходимо, если, например, у вас есть таблица людей, и у каждого человека есть ссылка на своих родителей.
Для работы с реляционными данными вам нужны команды, которые работают с парами таблиц. Есть три семейства глаголов, предназначенных для работы с реляционными данными:
Мутирующие соединения , которые добавляют новые переменные в один фрейм данных из сопоставления наблюдения в другом.
Объединяет фильтрацию , которая фильтрует наблюдения из одного кадра данных на основе соответствуют ли они наблюдению в другой таблице.
Операции набора , которые обрабатывают наблюдения, как если бы они были элементами набора.
Чаще всего реляционные данные можно найти в системе управления реляционными базами данных (или СУБД) (или РСУБД), термин, охватывающий почти все современные базы данных. Если вы раньше использовали базу данных, вы почти наверняка использовали SQL.Если это так, вам должны быть знакомы концепции в этой главе, хотя их выражение в dplyr немного отличается. Как правило, dplyr немного проще в использовании, чем SQL, потому что dplyr специализируется на анализе данных: он упрощает общие операции анализа данных за счет того, что затрудняет выполнение других вещей, которые обычно не требуются для анализа данных.
Предпосылки
Мы будем исследовать реляционные данные из nycflights13 , используя глаголы с двумя таблицами из dplyr.
nycflights13
Мы будем использовать пакет nycflights13, чтобы узнать о реляционных данных. nycflights13 содержит четыре таблицы, которые связаны с таблицей Flight , которую вы использовали при преобразовании данных:
Airlinesпозволяет найти полное название перевозчика по его сокращенному код:авиакомпании #> # Стол: 16 x 2 #> название оператора #>#> 1 9E Endeavour Air Inc.#> 2 AA American Airlines Inc. #> 3 AS Alaska Airlines Inc. №> 4 B6 JetBlue Airways #> 5 DL Delta Air Lines Inc. №> 6 EV ExpressJet Airlines Inc. #> #… С еще 10 строками аэропортыдает информацию о каждом аэропорту, идентифицированномfaaкод аэропорта:аэропортов #> # Стол: 1,458 x 8 #> faa name lat lon alt tz dst tzone #>#> 1 04G Аэропорт Лансдаун 41.1 -80,6 1044-5 A Америка / Новый_Г… #> 2 06A Moton Field Municipal Airp… 32,5 -85,7 264-6 A Америка / Чика… #> 3 06C Шаумбург Региональный 42,0 -88,1 801-6 A Америка / Чика… #> 4 06N Randall Airport 41,4 -74,4 523-5 A America / New_Y… #> 5 09J Аэропорт Джекил Айленд 31,1 -81,4 11-5 A America / New_Y… #> 6 0A9 Elizabethton Municipal Air… 36,4 -82,2 1593-5 A America / New_Y… #> #… С еще 1,452 строками самолетовдает информацию о каждом самолете, идентифицируемом его хвостовым номеромсамолетов #> # Стол: 3,322 x 9 #> tailnum год тип производитель модель двигатели сиденья скорость двигатель #>#> 1 N10156 2004 Неподвижное крыло mu… EMBRAER EMB-1… 2 55 NA Turbo-… #> 2 N102UW 1998 Неподвижное крыло mu… AIRBUS INDUST… A320-… 2 182 NA Turbo-… №> 3 N103US 1999 Неподвижное крыло mu… AIRBUS INDUST… A320-… 2 182 NA Turbo-… №> 4 N104UW 1999 Неподвижное крыло mu… AIRBUS INDUST… A320-… 2 182 NA Turbo-… #> 5 N10575 2002 Неподвижное крыло mu… EMBRAER EMB-1… 2 55 NA Turbo-… №> 6 N105UW 1999 Неподвижное крыло mu… AIRBUS INDUST… A320-… 2 182 NA Turbo-… #> #… С еще 3,316 строками погодапоказывает погоду в каждом аэропорту Нью-Йорка на каждый час:погода #> # Таблица: 26,115 x 15 #> происхождение год месяц день час температура роса влажный wind_dir wind_speed wind_gust #>#> 1 EWR 2013 1 1 1 39.0 26,1 59,4 270 10,4 нет данных #> 2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06 NA #> 3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5 NA #> 4 EWR 2013 1 1 4 39,9 28,0 62,2 250 12,7 нет данных #> 5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7 NA #> 6 EWR 2013 1 1 6 37,9 28,0 67,2 240 11,5 нет данных #> #… С еще 26 109 строками и еще 4 переменными: ускорение , давление , #> # visib , time_hour
Один из способов показать взаимосвязи между различными таблицами — с помощью чертежа:
Эта диаграмма немного ошеломляет, но она проста по сравнению с теми, которые вы увидите в дикой природе! Ключ к пониманию подобных диаграмм — помнить, что каждое отношение всегда относится к паре таблиц.Вам не нужно все понимать; вам просто нужно разобраться в цепочке отношений между интересующими вас таблицами.
Для nycflights13:
рейсподключается ксамолетамчерез единственную переменнуюtailnum.рейсысоединяется савиакомпаниямичерез переменнуюперевозчика.Рейсы
аэропортамидвумя способами: через исходную точкуdestпеременных.рейсысоединяется спогодойчерезпроисхождение(местоположение), игод,месяц,деньичас(время).
Упражнения
Представьте, что вы хотите нарисовать (приблизительно) маршрут, по которому летит каждый самолет. его происхождение к месту назначения. Какие переменные вам понадобятся? Какие столы вам нужно объединить?
Я забыл нарисовать связь между
погодойиаэропортами.Каковы отношения и как они должны отображаться на диаграмме?погодасодержит информацию только для аэропортов отправления (Нью-Йорк). Если в нем были записи погоды для всех аэропортов США, какие еще связь будет ли это определять срейсами?Мы знаем, что некоторые дни в году «особенные», и народу меньше, чем на них летают обычные. Как вы могли бы представить эти данные в виде фрейма данных? Какими будут первичные ключи этой таблицы? Как бы он подключился к существующие таблицы?
Ключи
Переменные, используемые для соединения каждой пары таблиц, называются ключами .Ключ — это переменная (или набор переменных), которая однозначно идентифицирует наблюдение. В простых случаях для идентификации наблюдения достаточно одной переменной. Например, каждый самолет однозначно идентифицируется своим хвостовым номером . В других случаях может потребоваться несколько переменных. Например, чтобы идентифицировать наблюдение в погоде , вам нужно пять переменных: год , месяц , день , час и происхождение .
Есть два типа ключей:
Первичный ключ однозначно идентифицирует наблюдение в его собственной таблице.Например,
самолетов $ tailnumявляется первичным ключом, потому что он однозначно определяет каждый самолет всамолетахтабл.Внешний ключ однозначно идентифицирует наблюдение в другой таблице. Например,
flight $ tailnum— это внешний ключ, потому что он появляется врейсовтаблица, в которой каждый рейс соответствует уникальному самолету.
Переменная может быть как первичным ключом , так и внешним ключом.Например, origin является частью первичного ключа weather , а также является внешним ключом для таблицы airport .
После того, как вы определили первичные ключи в своих таблицах, рекомендуется убедиться, что они действительно однозначно идентифицируют каждое наблюдение. Один из способов сделать это - использовать count () первичных ключей и искать записи, где n больше единицы:
самолетов%>%
count (tailnum)%>%
фильтр (n> 1)
#> # Стол: 0 x 2
#> #… С двумя переменными: tailnum , n
погода%>%
количество (год, месяц, день, час, происхождение)%>%
фильтр (n> 1)
#> # Стол: 3 x 6
#> год месяц день час происхождение n
#>
#> 1 2013 11 3 1 EWR 2
#> 2 2013 11 3 1 JFK 2
#> 3 2013 11 3 1 LGA 2 Иногда таблица не имеет явного первичного ключа: каждая строка является наблюдением, но никакая комбинация переменных не позволяет ее надежно идентифицировать.Например, каков первичный ключ в таблице полетов ? Вы можете подумать, что это будет дата плюс номер рейса или бортовой номер, но ни один из них не уникален:
полетов%>%
количество (год, месяц, день, полет)%>%
фильтр (n> 1)
#> # Таблица: 29 768 x 5
#> год месяц день рейс n
#>
#> 1 2013 1 1 1 2
#> 2 2013 1 1 3 2
#> 3 2013 1 1 4 2
#> 4 2013 1 1 11 3
#> 5 2013 1 1 15 2
#> 6 2013 1 1 21 2
#> #… С еще 29 762 строками
рейсы%>%
количество (год, месяц, день, хвост)%>%
фильтр (n> 1)
#> # Таблица: 64 928 x 5
#> год месяц день tailnum n
#>
#> 1 2013 1 1 N0EGMQ 2
#> 2 2013 1 1 N11189 2
#> 3 2013 1 1 N11536 2
#> 4 2013 1 1 N11544 3
#> 5 2013 1 1 N11551 2
#> 6 2013 1 1 N12540 2
#> #… С еще 64 922 строками Приступая к работе с этими данными, я наивно предполагал, что каждый номер рейса будет использоваться только один раз в день: это значительно упростило бы сообщение о проблемах с конкретным рейсом.К сожалению, это не так! Если в таблице отсутствует первичный ключ, иногда полезно добавить его с mutate () и row_number () . Это упрощает сопоставление наблюдений, если вы выполнили некоторую фильтрацию и хотите вернуться к исходным данным. Это называется суррогатным ключом .
Первичный ключ и соответствующий внешний ключ в другой таблице образуют отношение . Отношения обычно бывают один-ко-многим. Например, у каждого рейса есть один самолет, но у каждого самолета много рейсов.В других данных вы иногда будете видеть отношения один-к-одному. Вы можете думать об этом как об особом случае «1 ко многим». Вы можете смоделировать отношения «многие ко многим» с помощью отношения «многие к 1» и отношения «1 ко многим». Например, в этих данных существует связь "многие ко многим" между авиакомпаниями и аэропортами: каждая авиакомпания выполняет рейсы во многие аэропорты; каждый аэропорт обслуживает множество авиакомпаний.
Упражнения
Добавьте суррогатный ключ к
рейсам.Определите ключи в следующих наборах данных
-
Лахман :: Ватин, -
babynames :: babynames -
nasaweather :: атмос -
fueleconomy :: автомобили -
ggplot2 :: алмазы
(Возможно, вам потребуется установить некоторые пакеты и прочитать документацию.)
-
Нарисуйте схему, иллюстрирующую соединения между
Batting,ЛюдииЗарплатытаблиц в пакете Lahman. Нарисуйте еще одну диаграмму который показывает отношения междулюдьми,менеджерами,менеджерами наград.Как бы вы охарактеризовали отношения между
Ватин,PitchingиFieldingстолы?
Мутация присоединяется
Первый инструмент, который мы рассмотрим для объединения пары таблиц, - это мутирующее соединение .Мутирующее соединение позволяет комбинировать переменные из двух таблиц. Сначала он сопоставляет наблюдения по их ключам, а затем копирует переменные из одной таблицы в другую.
Как и mutate () , функции соединения добавляют переменные справа, поэтому, если у вас уже есть много переменных, новые переменные не будут распечатаны. В этих примерах мы упростим понимание того, что происходит в примерах, создав более узкий набор данных:
полетов2 <- полетов%>%
выберите (год: день, час, происхождение, место назначения, хвост, перевозчик)
полеты2
#> # Таблица: 336,776 x 8
#> год месяц день час происхождение dest tailnum carrier
#>
#> 1 2013 1 1 5 EWR IAH N14228 UA
#> 2 2013 1 1 5 LGA IAH N24211 UA
№> 3 2013 1 1 5 JFK MIA N619AA AA
№> 4 2013 1 1 5 JFK BQN N804JB B6
#> 5 2013 1 1 6 LGA ATL N668DN DL
№> 6 2013 1 1 5 EWR ORD N39463 UA
#> #… С еще 336 770 строками (Помните, что когда вы работаете в RStudio, вы также можете использовать View () , чтобы избежать этой проблемы.)
Представьте, что вы хотите добавить полное название авиакомпании к данным flight2 . Вы можете объединить кадры данных Airlines и Flight2 с left_join () :
рейса 2%>%
выберите (-origin, -dest)%>%
left_join (авиакомпании, by = "carrier")
#> # Таблица: 336,776 x 7
#> год месяц день час tailnum имя оператора связи
#>
№> 1 2013 1 1 5 N14228 UA United Air Lines Inc.№> 2 2013 1 1 5 N24211 UA United Air Lines Inc.
№> 3 2013 1 1 5 N619AA AA American Airlines Inc.
№> 4 2013 1 1 5 N804JB B6 JetBlue Airways
№> 5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
№> 6 2013 1 1 5 N39463 UA United Air Lines Inc.
#> #… С еще 336 770 строками Результатом присоединения авиакомпаний к рейсам2 является дополнительная переменная: name . Вот почему я называю этот тип соединения мутирующим соединением.В этом случае вы могли попасть в то же место, используя mutate () и базовое подмножество R:
рейса 2%>%
выберите (-origin, -dest)%>%
mutate (имя = авиакомпания $ имя [соответствие (перевозчик, авиакомпания $ перевозчик)])
#> # Таблица: 336,776 x 7
#> год месяц день час tailnum имя оператора связи
#>
№> 1 2013 1 1 5 N14228 UA United Air Lines Inc.№> 2 2013 1 1 5 N24211 UA United Air Lines Inc.
№> 3 2013 1 1 5 N619AA AA American Airlines Inc.
№> 4 2013 1 1 5 N804JB B6 JetBlue Airways
№> 5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
№> 6 2013 1 1 5 N39463 UA United Air Lines Inc.
#> #… С еще 336 770 строками Но это трудно обобщить, когда вам нужно сопоставить несколько переменных и нужно внимательно читать, чтобы выяснить общее намерение.
В следующих разделах подробно объясняется, как работают мутирующие соединения. Вы начнете с изучения полезного визуального представления объединений. Затем мы воспользуемся этим, чтобы объяснить четыре функции мутирующего соединения: внутреннее соединение и три внешних соединения. При работе с реальными данными ключи не всегда однозначно идентифицируют наблюдения, поэтому теперь мы поговорим о том, что происходит, когда нет уникального совпадения. Наконец, вы узнаете, как указать dplyr, какие переменные являются ключами для данного соединения.
Понимание объединений
Чтобы помочь вам узнать, как работают объединения, я воспользуюсь визуальным представлением:
x <- триббл (
~ ключ, ~ val_x,
1, "x1",
2, "х2",
3, "х3"
)
у <- трибл (
~ ключ, ~ val_y,
1, "y1",
2, "y2",
4, "у3"
) Цветной столбец представляет «ключевую» переменную: они используются для сопоставления строк между таблицами.Серый столбец представляет собой столбец «стоимость», который используется во время поездки. В этих примерах я покажу одну ключевую переменную, но идея простым образом обобщается на несколько ключей и несколько значений.
Соединение - это способ соединения каждой строки в x с нулем, одной или несколькими строками в y . На следующей диаграмме каждое потенциальное совпадение показано как пересечение пары линий.
(Если приглядеться, можно заметить, что мы поменяли порядок столбцов ключей и значений на x .Это сделано для того, чтобы подчеркнуть, что соединения совпадают на основе ключа; ценность просто уносится с собой для поездки.)
В реальном соединении совпадения будут отмечены точками. Количество точек = количество совпадений = количество строк в выводе.
Внутреннее соединение
Самым простым типом соединения является внутреннее соединение . Внутреннее соединение соответствует парам наблюдений, если их ключи равны:
(Чтобы быть точным, это внутреннее эквисоединение , потому что ключи сопоставляются с помощью оператора равенства.Поскольку большинство соединений являются равными, мы обычно отказываемся от этой спецификации.)
Результатом внутреннего соединения является новый фрейм данных, содержащий ключ, значения x и значения y. Мы используем на , чтобы указать dplyr, какая переменная является ключевой:
х%>%
inner_join (y, by = "ключ")
#> # Стол: 2 x 3
#> ключ val_x val_y
#>
#> 1 1 x1 y1
#> 2 2 x2 y2 Самым важным свойством внутреннего соединения является то, что несовпадающие строки не включаются в результат.Это означает, что внутренние объединения обычно не подходят для использования в анализе, потому что слишком легко потерять наблюдения.
Наружные стыки
Внутреннее соединение хранит наблюдения, которые появляются в обеих таблицах. Внешнее соединение хранит наблюдения, которые появляются по крайней мере в одной из таблиц. Существует три типа внешних соединений:
- Левое соединение сохраняет все наблюдения в формате
x. - Правое соединение сохраняет все наблюдения в диапазоне
и. - Полное соединение сохраняет все наблюдения в
xиy.
Эти объединения работают путем добавления дополнительного «виртуального» наблюдения к каждой таблице. Это наблюдение имеет ключ, который всегда совпадает (если не совпадают другие ключи), и значение, заполненное NA .
Графически это выглядит так:
Наиболее часто используемым соединением является левое соединение: вы используете его всякий раз, когда ищете дополнительные данные из другой таблицы, потому что оно сохраняет исходные наблюдения, даже если совпадений нет.Левое соединение должно быть вашим объединением по умолчанию: используйте его, если у вас нет веских причин предпочитать одно из других.
Другой способ изобразить различные типы соединений - это диаграмма Венна:
Однако это не очень хорошее представление. Это может пробудить вашу память о том, какое соединение сохраняет наблюдения, в какой таблице, но оно страдает серьезным ограничением: диаграмма Венна не может показать, что происходит, когда ключи не однозначно идентифицируют наблюдение.
Дубликаты ключей
До сих пор все диаграммы предполагали, что ключи уникальны.Но так бывает не всегда. В этом разделе объясняется, что происходит, когда ключи не уникальны. Есть две возможности:
Одна таблица имеет повторяющиеся ключи. Это полезно, когда вы хотите добавьте дополнительную информацию, так как обычно отношение.
Обратите внимание, что я поместил ключевой столбец в немного другое положение. на выходе. Это отражает то, что ключ является первичным ключом в
и. и внешний ключ размеромx.x <- триббл ( ~ ключ, ~ val_x, 1, "x1", 2, "х2", 2, "х3", 1, "х4" ) у <- трибл ( ~ ключ, ~ val_y, 1, "y1", 2, "y2" ) left_join (x, y, by = "ключ") #> # Стол: 4 x 3 #> ключ val_x val_y #>#> 1 1 x1 y1 #> 2 2 x2 y2 #> 3 2 x3 y2 #> 4 1 x4 y1 Обе таблицы имеют повторяющиеся ключи.Обычно это ошибка, потому что в ни в одной таблице ключи не идентифицируют однозначно наблюдение. Когда ты присоединяешься дублированные ключи, вы получаете все возможные комбинации, декартово произведение:
x <- триббл ( ~ ключ, ~ val_x, 1, "x1", 2, "х2", 2, "х3", 3, "х4" ) у <- трибл ( ~ ключ, ~ val_y, 1, "y1", 2, "y2", 2, "у3", 3, "у4" ) left_join (x, y, by = "ключ") #> # Стол: 6 x 3 #> ключ val_x val_y #>#> 1 1 x1 y1 #> 2 2 x2 y2 #> 3 2 x2 y3 #> 4 2 x3 y2 #> 5 2 x3 y3 #> 6 3 x4 y4
Определение ключевых столбцов
До сих пор пары таблиц всегда объединялись одной переменной, и эта переменная имела одно и то же имя в обеих таблицах.Это ограничение было закодировано с помощью = "key" . Вы можете использовать другие значения для на , чтобы соединить таблицы другими способами:
По умолчанию,
by = NULL, используются все переменные, которые появляются в обеих таблицах, так называемое естественное соединение . Например, таблицы полетов и погоды. совпадают по их общим переменным:год,месяц,день,часипроисхождение.рейса 2%>% left_join (погода) #> Присоединение, by = c ("год", "месяц", "день", "час", "происхождение") #> # Таблица: 336,776 x 18 #> год месяц день час происхождение dest tailnum carrier temp dewp влажный #>№> 1 2013 1 1 5 EWR IAH N14228 UA 39.0 28,0 64,4 #> 2 2013 1 1 5 LGA IAH N24211 UA 39,9 25,0 54,8 №> 3 2013 1 1 5 JFK MIA N619AA AA 39,0 27,0 61,6 #> 4 2013 1 1 5 JFK BQN N804JB B6 39,0 27,0 61,6 #> 5 2013 1 1 6 LGA ATL N668DN DL 39,9 25,0 54,8 №> 6 2013 1 1 5 EWR ORD N39463 UA 39,0 28,0 64,4 #> #… С еще 336 770 строками и еще 7 переменными: wind_dir , #> # wind_speed , wind_gust , осадков , давление , #> # visib , time_hour Вектор символов,
by = "x".Это похоже на естественное соединение, но использует только некоторые из общих переменных. Например,рейсовисамолетовимеютгодпеременных, но они означают разные вещи, поэтому мы хотим присоединиться толькоtailnum.рейса 2%>% left_join (самолеты, by = "tailnum") #> # Таблица: 336,776 x 16 #> year.x месяц день час origin dest tailnum carrier year.y тип #>#> 1 2013 1 1 5 EWR IAH N14228 UA 1999 Fixe… #> 2 2013 1 1 5 LGA IAH N24211 UA 1998 Исправление… #> 3 2013 1 1 5 JFK MIA N619AA AA 1990 Fixe… #> 4 2013 1 1 5 JFK BQN N804JB B6 2012 Fixe… #> 5 2013 1 1 6 LGA ATL N668DN DL 1991 Исправление… #> 6 2013 1 1 5 EWR ORD N39463 UA 2012 Fixe… #> #… С еще 336 770 строками и еще 6 переменными: производитель , #> # модель , двигатели , сиденья , скорость , двигатель Обратите внимание, что переменные
года(которые появляются в обоих фреймах входных данных, но не обязаны быть равными) устраняются в выводе с помощью суффикс.Именованный вектор символов:
by = c ("a" = "b"). Это будет сопоставьте переменнуюaв таблицеxпеременнойbв таблицеy. В переменные изxбудут использоваться в выводе.Например, если мы хотим нарисовать карту, нам нужно объединить данные о рейсах с данными аэропортов, которые содержат местоположение (
широтаидолгота) каждый аэропорт. Каждый рейс имеет пункт отправления и назначения, аэропорт, поэтому мы необходимо указать, к какому из них мы хотим присоединиться:рейса 2%>% left_join (аэропорты, c ("dest" = "faa")) #> # Таблица: 336,776 x 15 #> год месяц день час происхождение dest tailnum имя носителя lat lon alt #>№> 1 2013 1 1 5 EWR IAH N14228 UA Geor… 30.0 -95,3 97 #> 2 2013 1 1 5 LGA IAH N24211 UA Geor… 30,0 -95,3 97 №> 3 2013 1 1 5 JFK MIA N619AA AA Майам… 25,8 -80,3 8 #> 4 2013 1 1 5 JFK BQN N804JB B6 NA NA NA #> 5 2013 1 1 6 LGA ATL N668DN DL Hart… 33,6 -84,4 1026 #> 6 2013 1 1 5 EWR ORD N39463 UA Chic… 42,0 -87,9 668 #> #… С еще 336 770 строками и еще 3 переменными: tz , dst , #> # tzone рейсы2%>% left_join (аэропорты, c ("origin" = "faa")) #> # Таблица: 336,776 x 15 #> год месяц день час происхождение dest tailnum имя носителя lat lon alt #> №> 1 2013 1 1 5 EWR IAH N14228 UA Newa… 40.7 -74,2 18 №> 2 2013 1 1 5 LGA IAH N24211 UA La G… 40,8 -73,9 22 #> 3 2013 1 1 5 JFK MIA N619AA AA Джон… 40,6 -73,8 13 #> 4 2013 1 1 5 JFK BQN N804JB B6 Джон… 40,6 -73,8 13 #> 5 2013 1 1 6 LGA ATL N668DN DL La G… 40,8 -73,9 22 №> 6 2013 1 1 5 EWR ORD N39463 UA Newa… 40,7 -74,2 18 #> #… С еще 336 770 строками и еще 3 переменными: tz , dst , #> # tzone
Упражнения
Вычислите среднюю задержку по пунктам назначения, затем подключитесь к аэропортам
(Не волнуйтесь, если вы не понимаете, что делает
semi_join ()- вы узнайте об этом дальше.)Вы можете использовать
размерилицветточек для отображения средняя задержка для каждого аэропорта.Добавьте местоположение исходной и конечной точки (т.е.
latиlon) нарейсы.Есть ли связь между возрастом самолета и его задержками?
Какие погодные условия увеличивают вероятность задержки?
Что произошло 13 июня 2013 г.? Отобразите пространственный образец задержек, а затем используйте Google для перекрестной ссылки с погодой.
Другие реализации
base :: merge () может выполнять все четыре типа мутирующего соединения:
внутреннее_соединение (x, y) | объединить (x, y) |
left_join (x, y) | объединить (x, y, all.x = ИСТИНА) |
правое_соединение (x, y) | слияние (x, y, all.y = ИСТИНА) , |
full_join (x, y) | объединить (x, y, все.x = ИСТИНА, all.y = ИСТИНА) |
Преимущества конкретных глаголов dplyr в том, что они более четко передают цель вашего кода: разница между объединениями действительно важна, но скрыта в аргументах merge () . Соединения dplyr выполняются значительно быстрее и не изменяют порядок строк.
SQL является источником условных обозначений dplyr, поэтому перевод прост:
inner_join (x, y, by = "z") | ВЫБРАТЬ * ИЗ x ВНУТРЕННЕЕ СОЕДИНЕНИЕ y ИСПОЛЬЗОВАНИЕ (z) |
left_join (x, y, by = "z") | ВЫБРАТЬ * ИЗ x ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ y ИСПОЛЬЗОВАНИЕ (z) |
right_join (x, y, by = "z") | ВЫБРАТЬ * ИЗ x ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ y ИСПОЛЬЗОВАНИЕ (z) |
full_join (x, y, by = "z") | ВЫБРАТЬ * ИЗ x ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ y ИСПОЛЬЗОВАНИЕ (z) |
Обратите внимание, что «INNER» и «OUTER» являются необязательными и часто опускаются.
Объединение различных переменных между таблицами, например inner_join (x, y, by = c ("a" = "b")) использует немного другой синтаксис в SQL: SELECT * FROM x INNER JOIN y ON x.a = y.b . Как предполагает этот синтаксис, SQL поддерживает более широкий диапазон типов соединений, чем dplyr, потому что вы можете соединять таблицы, используя ограничения, отличные от равенства (иногда называемые неэквивалентными соединениями).
Фильтрация объединяет
Фильтрация объединяет наблюдения сопоставления так же, как мутирующие объединения, но влияет на наблюдения, а не на переменные.Есть два типа:
-
semi_join (x, y)сохраняет всех наблюдений вx, которые совпадают вy. -
anti_join (x, y)удаляет все наблюдения вx, которые совпадают вy.
Полусоединения полезны для сопоставления отфильтрованных сводных таблиц с исходными строками. Например, представьте, что вы нашли десятку самых популярных направлений:
top_dest <- рейсы%>%
count (dest, sort = TRUE)%>%
голова (10)
top_dest
#> # Стол: 10 x 2
#> dest n
#>
#> 1 ORD 17283
#> 2 ATL 17215
#> 3 LAX 16174
#> 4 BOS 15508
#> 5 MCO 14082
#> 6 CLT 14064
#> #… С еще 4 строками Теперь вы хотите найти каждый рейс, выполнявший одно из этих направлений.Вы можете построить фильтр самостоятельно:
полетов%>%
фильтр (цель% в% top_dest $ dest)
#> # Таблица: 141145 x 19
#> год месяц день dep_time sched_dep_time dep_delay arr_time sched_arr_time
#>
#> 1 2013 1 1 542 540 2 923 850
#> 2 2013 1 1 554 600-6 812 837
#> 3 2013 1 1 554 558-4 740 728
#> 4 2013 1 1 555 600-5 913 854
#> 5 2013 1 1 557 600-3 838 846
#> 6 2013 1 1 558 600-2 753 745
#> #… С дополнительными 141 139 строками и еще 11 переменными: arr_delay ,
#> # перевозчик , рейс , tailnum , origin , dest ,
#> # air_time , расстояние , час , минута , time_hour Но этот подход сложно распространить на несколько переменных.Например, представьте, что вы нашли 10 дней с самыми высокими средними задержками. Как бы вы построили оператор фильтра, который использовал год , месяц и день , чтобы сопоставить его с рейсами ?
Вместо этого вы можете использовать полусоединение, которое соединяет две таблицы как мутирующее соединение, но вместо добавления новых столбцов сохраняет только те строки размером x , которые совпадают в y :
полетов%>%
semi_join (самое верхнее)
#> Присоединение, by = "dest"
#> # Таблица: 141145 x 19
#> год месяц день dep_time sched_dep_time dep_delay arr_time sched_arr_time
#>
#> 1 2013 1 1 542 540 2 923 850
#> 2 2013 1 1 554 600-6 812 837
#> 3 2013 1 1 554 558-4 740 728
#> 4 2013 1 1 555 600-5 913 854
#> 5 2013 1 1 557 600-3 838 846
#> 6 2013 1 1 558 600-2 753 745
#> #… С дополнительными 141 139 строками и еще 11 переменными: arr_delay ,
#> # перевозчик , рейс , tailnum , origin , dest ,
#> # air_time , расстояние , час , минута , time_hour Графически полусоединение выглядит так:
Важно только наличие совпадения; не имеет значения, какое наблюдение согласовано.Это означает, что при фильтрации объединений никогда не дублируются строки, как в случае изменяющихся объединений:
Обратное к полусоединению является антисоединением. Анти-соединение сохраняет строки, которым не соответствует :
Антисоединения полезны для диагностики несовпадений соединений. Например, при стыковке рейсов и самолетов вам может быть интересно узнать, что есть много рейсов , которые не совпадают в самолетах :
полетов%>%
anti_join (самолеты, by = "tailnum")%>%
count (tailnum, sort = ИСТИНА)
#> # Стол: 722 x 2
#> tailnum n
#>
#> 1 2512
#> 2 N725MQ 575
#> 3 N722MQ 513
#> 4 N723MQ 507
#> 5 N713MQ 483
#> 6 N735MQ 396
#> #… С дополнительными 716 строками Упражнения
Что значит для рейса отсутствие
tailnum? Что делают бортовые номера, у которых нет совпадающих записей всамолетах, имеют общие? (Подсказка: одна переменная объясняет ~ 90% проблем.)Отфильтровать полеты, чтобы показывать только полеты с самолетами, на которых совершено не менее 100 полеты.
Объедините
fueleconomy :: автомобилииfueleconomy :: общий, чтобы найти только записи для самых распространенных моделей.Найдите 48 часов (в течение всего года) с наихудшими задержки. Сравните его с данными погоды
Что вам сообщает
anti_join (рейсы, аэропорты, by = c ("dest" = "faa"))? Что вам сообщаетanti_join (аэропорты, рейсы, by = c ("faa" = "dest"))?Можно предположить, что существует неявная связь между плоскостями и авиакомпания, потому что каждый самолет обслуживает одна авиакомпания.Подтверждать или отвергните эту гипотезу, используя инструменты, которые вы узнали выше.
Установить операции
Последний тип глагола с двумя таблицами - операции над множеством. Обычно я использую их реже всего, но иногда они полезны, когда вы хотите разбить один сложный фильтр на более простые части. Все эти операции работают с полной строкой, сравнивая значения каждой переменной. Они ожидают, что входные данные x и y будут иметь одинаковые переменные, и рассматривают наблюдения как наборы:
Учитывая эти простые данные:
df1 <- tribble (
~ х, ~ у,
1, 1,
2, 1
)
df2 <- триббл (
~ х, ~ у,
1, 1,
1, 2
) Четыре возможности:
пересечь (df1, df2)
#> # Стол: 1 x 2
#> x y
#>
#> 1 1 1
# Обратите внимание, что мы получаем 3 строки, а не 4
союз (df1, df2)
#> # Стол: 3 x 2
#> x y
#>
#> 1 1 1
#> 2 2 1
#> 3 1 2
setdiff (df1, df2)
#> # Стол: 1 x 2
#> x y
#>
#> 1 2 1
setdiff (df2, df1)
#> # Стол: 1 x 2
#> x y
#>
#> 1 1 2 Таблица, запись, поля и т. Д. В концепции СУБД
A Relational Database Management System (RDBMS) - это система управления базами данных, основанная на реляционной модели, представленной Э.F Codd. В реляционной модели данные хранятся в отношениях (таблицы) и представлены в виде кортежей (строк).
RDBMS используется для управления реляционной базой данных. Реляционная база данных - это набор организованных таблиц, связанных друг с другом, из которых можно легко получить доступ к данным. Реляционная база данных в наши дни является наиболее часто используемой базой данных.
СУБД: что такое таблица?
В модели реляционной базы данных таблица представляет собой набор элементов данных, организованных в виде строк и столбцов.Таблица также рассматривается как удобное представление отношений . Но таблица может иметь повторяющиеся строки данных, в то время как истинное отношение не может иметь повторяющихся данных. Таблица - самая простая форма хранения данных. Ниже приведен пример таблицы сотрудников.
| ID | Имя | Возраст | Заработная плата |
|---|---|---|---|
| 1 | Адам | 34 | 13000 |
| 2 | Alex | 20 | 18000 |
| 4 | Росс | 42 | 19020 |
РСУБД: что такое кортеж?
Отдельная запись в таблице называется кортежем или записью или строкой .Кортеж в таблице представляет набор связанных данных. Например, приведенная выше таблица Employee имеет 4 кортежа / записи / строки.
Ниже приведен пример отдельной записи или кортежа.
РСУБД: что такое атрибут?
Таблица состоит из нескольких записей (строки), каждая запись может быть разбита на несколько более мелких частей данных, известных как Атрибуты . Приведенная выше таблица Employee состоит из четырех атрибутов: ID , Name , Age и Salary .
Домен атрибутов
Когда атрибут определен в отношении (таблице), он определяется для хранения только определенного типа значений, который известен как область атрибутов .
Следовательно, атрибут Имя будет содержать имя сотрудника для каждого кортежа. Если мы сохраним адрес сотрудника там, это будет нарушением модели реляционной базы данных.
| Имя |
|---|
| Адам |
| Алекс |
| Стюарт - 9/401, OC Street, Амстердам |
| Росс |
Что такое схема отношений?
Схема отношения описывает структуру отношения с именем отношения (имя таблицы), его атрибутами, их именами и типом.
Что такое ключ отношения?
Ключ отношения - это атрибут, который может однозначно идентифицировать конкретный кортеж (строку) в отношении (таблице).
Ограничения реляционной целостности
Каждое отношение в модели реляционной базы данных должно подчиняться или следовать нескольким ограничениям, чтобы быть допустимым отношением, эти ограничения называются Relational Integrity Constraints .
Три основных ограничения целостности:
- Ключевые ограничения
- Ограничения домена
- Ограничения ссылочной целостности
Ключевые ограничения
Мы храним данные в таблицах, чтобы в дальнейшем обращаться к ним при необходимости.В каждой таблице один или несколько атрибутов вместе используются для выборки данных из таблиц. Ключевое ограничение указывает, что в отношении (таблице) должен быть такой атрибут (столбец), который можно использовать для выборки данных для любого кортежа (строки).
Атрибут Key никогда не должен быть NULL или одинаковым для двух разных строк данных.
Например, в таблице Employee мы можем использовать атрибут ID для получения данных для каждого сотрудника.Никакое значение ID не является нулевым и уникально для каждой строки, следовательно, это может быть наш ключевой атрибут .
Ограничение домена
Ограничения домена относятся к правилам, определенным для значений, которые могут быть сохранены для определенного атрибута.
Как мы объясняли выше, мы не можем сохранить Адрес сотрудника в столбце для Имя .
Аналогичным образом, номер мобильного телефона не может превышать 10 цифр.
Ограничение ссылочной целостности
Подробнее об этом мы поговорим позже.А пока запомните этот пример: если я скажу, что Supriya - моя девушка, то девушка по имени Supriya также должна существовать для этих отношений.