python — Как правильно передать POST запрос requests
Подскажите, пожалуйста, как можно передать POST запрос из такого набора данных? curl --request POST \ --url https://goo.su/api/links/create \ --header 'content-type: application/json' \ --header 'x-goo-api-token: XXXXXX' \ --data '{ "url":"https://www.api.com", "alias":"cool", "is_public": true, "group_id":2 }'
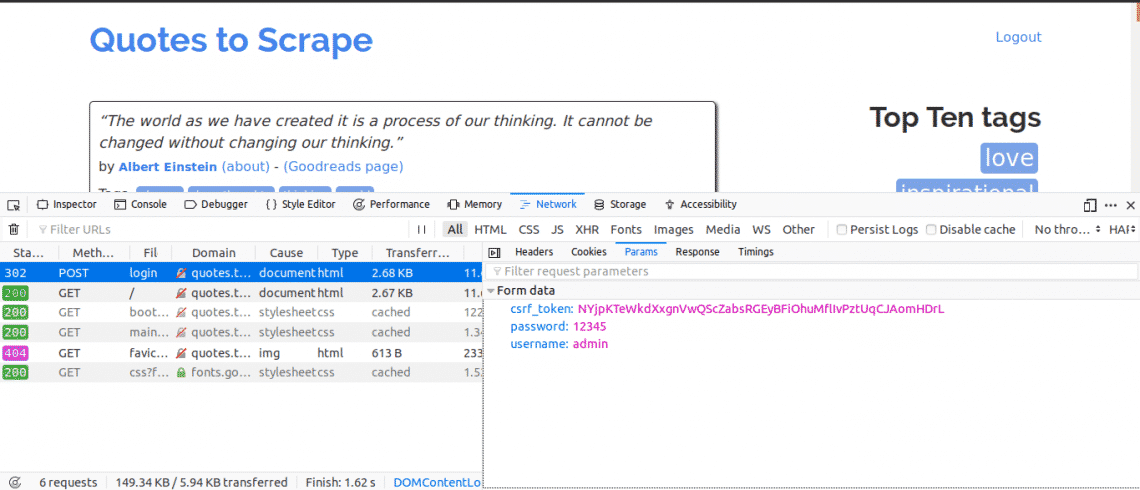
Такое не сработало 404 Not Found. Unknown API Method.
import requests
b = 'https://goo.su/api/links/create/application/json/TOKEN-XXXX'
r = requests.post(b, data={"url":"https://*", "alias":"cool", "is_public": "true", "group_id":2})
Вот такое ввожу
try:
import http.client as http_client
except ImportError:
# Python 2
import httplib as http_client
http_client.HTTPConnection.debuglevel = 1
# You must initialize logging, otherwise you'll not see debug output.
import logging
logging.basicConfig()
logging.getLogger().setLevel(logging.DEBUG)
requests_log = logging.getLogger("requests. packages.urllib3")
requests_log.setLevel(logging.DEBUG)
requests_log.propagate = True
# Test
import requests
API_KEY = 'XXX'
url = 'https://goo.su/api/links/create'
headers = {'content-type': 'application/json','x-goo-api-token': API_KEY}
data = {"url":"https://vk.com/", "alias":"cool", "is_public": "true", "group_id":2}
rs = requests.post(url, headers=headers, data=data)
#rs = requests.get('http://httpbin.org/ip')
print(rs)
print(rs.url)
print(rs.history)
print(rs.cookies)
print(rs.text)
packages.urllib3")
requests_log.setLevel(logging.DEBUG)
requests_log.propagate = True
# Test
import requests
API_KEY = 'XXX'
url = 'https://goo.su/api/links/create'
headers = {'content-type': 'application/json','x-goo-api-token': API_KEY}
data = {"url":"https://vk.com/", "alias":"cool", "is_public": "true", "group_id":2}
rs = requests.post(url, headers=headers, data=data)
#rs = requests.get('http://httpbin.org/ip')
print(rs)
print(rs.url)
print(rs.history)
print(rs.cookies)
print(rs.text)
 packages.urllib3")
requests_log.setLevel(logging.DEBUG)
requests_log.propagate = True
# Test
import requests
API_KEY = 'XXX'
url = 'https://goo.su/api/links/create'
headers = {'content-type': 'application/json','x-goo-api-token': API_KEY}
data = {"url":"https://vk.com/", "alias":"cool", "is_public": "true", "group_id":2}
rs = requests.post(url, headers=headers, data=data)
#rs = requests.get('http://httpbin.org/ip')
print(rs)
print(rs.url)
print(rs.history)
print(rs.cookies)
print(rs.text)
packages.urllib3")
requests_log.setLevel(logging.DEBUG)
requests_log.propagate = True
# Test
import requests
API_KEY = 'XXX'
url = 'https://goo.su/api/links/create'
headers = {'content-type': 'application/json','x-goo-api-token': API_KEY}
data = {"url":"https://vk.com/", "alias":"cool", "is_public": "true", "group_id":2}
rs = requests.post(url, headers=headers, data=data)
#rs = requests.get('http://httpbin.org/ip')
print(rs)
print(rs.url)
print(rs.history)
print(rs.cookies)
print(rs.text)
Вот такое получаю
DEBUG:urllib3.connectionpool:Starting new HTTPS connection (1): goo.su:443 send: b'POST /api/links/create HTTP/1.1\r\nHost: goo.su\r\nUser-Agent: python-requests/2.27.1\r\nAccept-Encoding: gzip, deflate\r\nAccept: */*\r\nConnection: keep-alive\r\ncontent-type: application/json\r\nx-goo-api-token: XXX\r\nContent-Length: 64\r\n\r\n' send: b'POST /api/links/create HTTP/1.1\r\nHost: goo.su\r\nUser-Agent: python-requests/2.27.1\r\nAccept-Encoding: gzip, deflate\r\nAccept: */*\r\nConnection: keep-alive\r\ncontent-type: application/json\r\nx-goo-api-token: XXX\r\nContent-Length: 64\r\n\r\n' send: b'url=https%3A%2F%2Fvk.com%2F&alias=cool&is_public=true&group_id=2' reply: 'HTTP/1.1 400 Bad Request\r\n' header: Date: Mon, 14 Mar 2022 10:53:31 GMT header: Content-Type: application/json header: Transfer-Encoding: chunked header: Connection: keep-alive header: X-Powered-By: PHP/8.0.15 header: Cache-Control: private, must-revalidate header: pragma: no-cache header: expires: -1 header: X-RateLimit-Limit: 85 header: X-RateLimit-Remaining: 84 header: Access-Control-Allow-Origin: * header: CF-Cache-Status: DYNAMIC header: Expect-CT: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct" header: Report-To: {"endpoints":[{"url":"https:\/\/a.nel.cloudflare.com\/report\/v3?s=I6maZNbb%2FOchM%2FkjyEuxex%2FjEi1rL8jg2YqEPDVTpLCyl16ady0dNq1YuFUXmfIetRNtJvairagP4IlWhDUnhpzOtv%2F31z9Y8hx4sNJkiwS19IokHZw%2FAlw%3D"}],"group":"cf-nel","max_age":604800} header: NEL: {"success_fraction":0,"report_to":"cf-nel","max_age":604800} header: Server: cloudflare header: CF-RAY: 6ebc774e1f7d162e-DME header: alt-svc: h4=":443"; ma=86400, h4-29=":443"; ma=86400 DEBUG:urllib3. connectionpool:https://goo.su:443 "POST /api/links/create HTTP/1.1" 400 None <Response [400]> https://goo.su/api/links/create [] <RequestsCookieJar[]> {"message":"Validation error","errors":["The url field is required."]}


Python Requests Post
Введение
Примеры
Простая почта
from requests import post
foo = post('http://httpbin.org/post', data = {'key':'value'})
Будет выполнять простую операцию HTTP POST. Отправленные данные могут быть в большинстве форматов, однако пары ключ-значение являются наиболее распространенными.
Заголовки
Заголовки можно посмотреть:
print(foo.headers)
Пример ответа:
{'Content-Length': '439', 'X-Processed-Time': '0.000802993774414', 'X-Powered-By': 'Flask', 'Server': 'meinheld/0.6.1', 'Connection': 'keep-alive', 'Via': '1.1 vegur', 'Access-Control-Allow-Credentials': 'true', 'Date': 'Sun, 21 May 2017 20:56:05 GMT', 'Access-Control-Allow-Origin': '*', 'Content-Type': 'application/json'}
Заголовки также могут быть подготовлены перед публикацией:
headers = {'Cache-Control':'max-age=0',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5. 0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36',
'Content-Type':'application/x-www-form-urlencoded',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer':'https://www.groupon.com/signup',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'es-ES,es;q=0.8'
}
foo = post('http://httpbin.org/post', headers=headers, data = {'key':'value'})

кодирование
Кодировка может быть установлена и просмотрена примерно так же:
print(foo.encoding) 'utf-8' foo.encoding = 'ISO-8859-1'
Проверка SSL
Запросы по умолчанию проверяют сертификаты SSL доменов. Это может быть отменено:
foo = post('http://httpbin.org/post', data = {'key':'value'}, verify=False)
Перенаправление
Будет выполнено любое перенаправление (например, http на https), это также можно изменить:
foo = post('http://httpbin. org/post', data = {'key':'value'}, allow_redirects=False)
 org/post', data = {'key':'value'}, allow_redirects=False)
org/post', data = {'key':'value'}, allow_redirects=False)
Если после операции была перенаправлена, это значение может быть доступно:
print(foo.url)
Полная история перенаправлений может быть просмотрена:
print(foo.history)
Форма закодированных данных
from requests import post
payload = {'key1' : 'value1',
'key2' : 'value2'
}
foo = post('http://httpbin.org/post', data=payload)
Для передачи закодированных данных формы с помощью операции post данные должны быть структурированы как словарь и предоставлены в качестве параметра данных.
Если данные не хотят кодироваться формой, просто передайте строку или целое число в параметр данных.
Укажите в словаре параметр json для запросов на автоматическое форматирование данных:
from requests import post
payload = {'key1' : 'value1', 'key2' : 'value2'}
foo = post('http://httpbin.org/post', json=payload) Файл загружен
С помощью модуля запросов, его необходимо предоставить только дескриптор файла , в отличии от содержимого , извлекаемого с . : read()
read()
from requests import post
files = {'file' : open('data.txt', 'rb')}
foo = post('http://http.org/post', files=files)
Имя файла, content_type и заголовки также могут быть установлены:
files = {'file':('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})}
foo = requests.post('http://httpbin.org/post', files=files)
Строки также могут быть отправлены в виде файла, если они поставляются как files параметров.
Несколько файлов
Несколько файлов могут быть предоставлены так же, как один файл:
multiple_files = [
('images',('foo.png', open('foo.png', 'rb'), 'image/png')),
('images',('bar.png', open('bar.png', 'rb'), 'image/png'))]
foo = post('http://httpbin.org/post', files=multiple_files) Ответы
Коды ответов можно посмотреть из почтовой операции:
from requests import post
foo = post('http://httpbin.org/post', data={'data' : 'value'})
print(foo. status_code)
Возвращенные данные
Доступ к данным, которые возвращаются:
foo = post('http://httpbin.org/post', data={'data' : 'value'})
print(foo.text)
Необработанные ответы
В тех случаях, когда вам необходим доступ к базовому объекту urllib3 response.HTTPResponse, это можно сделать следующим образом:
foo = post('http://httpbin.org/post', data={'data' : 'value'})
res = foo.raw
print(res.read()) Аутентификация
Простая HTTP-аутентификация
Простая HTTP-аутентификация может быть достигнута с помощью следующего:
from requests import post
foo = post('http://natas0.natas.labs.overthewire.org', auth=('natas0', 'natas0'))
Технически это короткая рука для следующего:
from requests import post
from requests.auth import HTTPBasicAuth
foo = post('http://natas0.natas.labs.overthewire.org', auth=HTTPBasicAuth('natas0', 'natas0'))
Дайджест-аутентификация HTTP
Проверка подлинности дайджеста HTTP выполняется очень похожим способом, для этого Requests предоставляет другой объект:
from requests import post from requests.
 auth import HTTPDigestAuth
foo = post('http://natas0.natas.labs.overthewire.org', auth=HTTPDigestAuth('natas0', 'natas0'))
auth import HTTPDigestAuth
foo = post('http://natas0.natas.labs.overthewire.org', auth=HTTPDigestAuth('natas0', 'natas0'))
Пользовательская аутентификация
В некоторых случаях встроенных механизмов аутентификации может быть недостаточно, представьте этот пример:
Сервер настроен на прием аутентификации, если отправитель имеет правильную строку агента пользователя, определенное значение заголовка и предоставляет правильные учетные данные через HTTP Basic Authentication. Для достижения этого должен быть подготовлен пользовательский класс аутентификации, подклассифицирующий AuthBase, который является основой для реализаций аутентификации запросов:
from requests.auth import AuthBase
from requests.auth import _basic_auth_str
from requests._internal_utils import to_native_string
class CustomAuth(AuthBase):
def __init__(self, secret_header, user_agent , username, password):
# setup any auth-related data here
self.secret_header = secret_header
self. user_agent = user_agent
self.username = username
self.password = password
def __call__(self, r):
# modify and return the request
r.headers['X-Secret'] = self.secret_header
r.headers['User-Agent'] = self.user_agent
r.headers['Authorization'] = _basic_auth_str(self.username, self.password)
return r
 user_agent = user_agent
self.username = username
self.password = password
def __call__(self, r):
# modify and return the request
r.headers['X-Secret'] = self.secret_header
r.headers['User-Agent'] = self.user_agent
r.headers['Authorization'] = _basic_auth_str(self.username, self.password)
return r
user_agent = user_agent
self.username = username
self.password = password
def __call__(self, r):
# modify and return the request
r.headers['X-Secret'] = self.secret_header
r.headers['User-Agent'] = self.user_agent
r.headers['Authorization'] = _basic_auth_str(self.username, self.password)
return r
Это можно затем использовать с помощью следующего кода:
foo = get('http://test.com/admin', auth=CustomAuth('SecretHeader', 'CustomUserAgent', 'user', 'password' )) Доверенные
Каждая операция POST запроса может быть настроена на использование сетевых прокси
HTTP / S Прокси
from requests import post
proxies = {
'http': 'http://192.168.0.128:3128',
'https': 'http://192.168.0.127:1080',
}
foo = requests.post('http://httpbin.org/post', proxies=proxies)
Базовая аутентификация HTTP может быть предоставлена следующим образом:
proxies = {'http': 'http://user:pass@192. 168.0.128:312'}
foo = requests.post('http://httpbin.org/post', proxies=proxies)
 168.0.128:312'}
foo = requests.post('http://httpbin.org/post', proxies=proxies)
168.0.128:312'}
foo = requests.post('http://httpbin.org/post', proxies=proxies)
НОСКИ Прокси
Использование прокси — сервера SOCKS требует 3 — й партии зависимостей requests[socks] после того , как установлены носки прокси используются в очень похожим образом HTTPBasicAuth:
proxies = {
'http': 'socks5://user:pass@host:port',
'https': 'socks5://user:pass@host:port'
}
foo = requests.post('http://httpbin.org/post', proxies=proxies) Синтаксис
Параметры
Примечания
Python Запросы почтового метода
❮ Модуль запросов
Пример
Отправьте запрос POST на веб-страницу и верните текст ответа:
запросы на импорт url = ‘https://www.w3schools.com/python/demopage.php’
myobj = {‘somekey’: ‘somevalue’}
x = request.post(url, json = myobj)
print(x.text)
Определение и использование
Метод post() отправляет запрос POST на указанный URL-адрес.
Метод post() используется, когда вы хотите
отправить некоторые данные на сервер.
Синтаксис
request.post( url , data={ key : value }, json={ key : value } , args )
args означает ноль или более из именованных аргументов в таблице параметров ниже. Пример:
request.post(url, data = myobj, timeout=2.50)
Значения параметров
| Параметр | Описание | |
|---|---|---|
| URL-адрес | Попробуйте | Обязательно. URL-адрес запроса |
| данные | Попробуйте | Дополнительно. Словарь, список кортежей, байтов или файловый объект для отправки на указанный URL |
| json | Попробуйте | Дополнительно. Объект JSON для отправки на указанный URL-адрес |
| файлы | Попробуйте | Дополнительно. Словарь файлов для отправки на указанный URL Словарь файлов для отправки на указанный URL |
| разрешить_перенаправления | Попробуйте | Дополнительно. Логическое значение для включения/отключения перенаправления. По умолчанию True (разрешено перенаправление) |
| автор | Попробуйте | Дополнительно. Кортеж для включения определенной HTTP-аутентификации. По умолчанию Нет |
| сертификат | Попробуйте | Дополнительно. Строка или кортеж, указывающий файл сертификата или ключ. По умолчанию Нет |
| печенье | Попробуйте | Дополнительно. Словарь файлов cookie для отправки на указанный URL. По умолчанию Нет |
| коллекторы | Попробуйте | Дополнительно. Словарь заголовков HTTP для отправки на указанный URL-адрес. По умолчанию Нет |
| прокси | Попробуйте | Дополнительно. Словарь протокола к URL-адресу прокси. По умолчанию Нет |
| поток | Попробуйте | Дополнительно. Логическое указание, должен ли ответ быть немедленно загружен (False) или передан в потоковом режиме (True). По умолчанию Ложь |
| время ожидания | Попробуй | Дополнительно. Число или кортеж, указывающий, сколько секунд ждать, пока клиент установит соединение и/или отправит ответ. По умолчанию Нет означает, что запрос будет продолжен
пока соединение не будет закрыто |
| проверить | Попробуй Попробуй | Дополнительно. Логическое или строковое указание для проверки сертификата TLS серверов или нет. По умолчанию Правда |
Возвращаемое значение
Объект request. Response.
Response.
❮ Модуль запросов
ВЫБОР ЦВЕТА
Лучшие учебники
Учебное пособие по HTMLУчебное пособие по CSS
Учебное пособие по JavaScript
Учебное пособие
Учебное пособие по SQL
Учебное пособие по Python
Учебное пособие по W3.CSS
Учебное пособие по Bootstrap
Учебное пособие по PHP
Учебное пособие по Java
Учебное пособие по C++
Учебное пособие по jQuery
9000 3
Лучшие ссылки
HTML ReferenceCSS Reference
JavaScript Reference
SQL Reference
Python Reference
W3.CSS Reference
Bootstrap Reference
PHP Reference
HTML Colors
Java Reference
Angular Reference
jQuery Reference
902 13 лучших примеров Примеры HTML
Примеры CSS
Примеры JavaScript
Примеры How To
Примеры SQL
Примеры Python
Примеры W3.CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery
FORUM | О
W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания.
Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности.
Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания.
Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности. Copyright 1999-2023 Refsnes Data. Все права защищены.
W3Schools работает на основе W3.CSS.
Быстрый старт — Документация Requests 2.31.0
Хотите начать? Эта страница дает хорошее представление о том, как начать работу с запросами.
Во-первых, убедитесь, что:
Давайте начнем с нескольких простых примеров.
Сделать запрос
Сделать запрос с помощью Requests очень просто.
Начните с импорта модуля «Запросы»:
>>> запросы на импорт
Теперь давайте попробуем получить веб-страницу. Для этого примера давайте получим общедоступный GitHub временная шкала:
>>> r = request.
 get('https://api.github.com/events')
get('https://api.github.com/events')
Теперь у нас есть объект Response с именем r . Мы можем
получить всю необходимую нам информацию от этого объекта.
Requests означает, что все формы HTTP-запросов очевидны. Для например, вот как вы делаете запрос HTTP POST:
>>> r = request.post('https://httpbin.org/post', data={'key': 'value'})
Красиво, правда? А как насчет других типов HTTP-запросов: PUT, DELETE, HEAD и ПАРАМЕТРЫ? Все так же просто:
>>> r = request.put('https://httpbin.org/put', data={'key': 'value'})
>>> r = request.delete('https://httpbin.org/delete')
>>> r = request.head('https://httpbin.org/get')
>>> r = request.options('https://httpbin.org/get')
Это все хорошо, но это только начало того, что могут сделать Запросы. делать.
Передача параметров в URL
Вы часто хотите отправить какие-то данные в строке запроса URL. Если
вы создавали URL-адрес вручную, эти данные будут представлены как ключ/значение
пары в URL-адресе после вопросительного знака, например.
httpbin.org/get?key=val .
Запросы позволяют вам предоставлять эти аргументы в виде словаря строк,
используя аргумент ключевого слова params . Например, если вы хотите пройти key1=value1 и key2=value2 to httpbin.org/get , вы должны использовать
следующий код:
>>> полезная нагрузка = {'key1': 'value1', 'key2': 'value2'}
>>> r = request.get('https://httpbin.org/get', params=payload)
Вы можете убедиться, что URL-адрес был правильно закодирован, распечатав URL-адрес:
>>> print(r.url) https://httpbin.org/get?key2=value2&key1=value1
Обратите внимание, что любой ключ словаря, значение которого равно None , не будет добавлен в
Строка запроса URL.
Вы также можете передать список элементов как значение:
>>> полезная нагрузка = {'ключ1': 'значение1', 'ключ2': ['значение2', 'значение3']}
>>> r = request.get('https://httpbin.org/get', params=payload)
>>> напечатать(r. url)
https://httpbin.org/get?key1=value1&key2=value2&key2=value3
 url)
https://httpbin.org/get?key1=value1&key2=value2&key2=value3
url)
https://httpbin.org/get?key1=value1&key2=value2&key2=value3
Содержание ответа
Мы можем прочитать содержимое ответа сервера. Рассмотрите временную шкалу GitHub еще раз:
>>> запросы на импорт
>>> r = request.get('https://api.github.com/events')
>>> р.текст
'[{"репозиторий":{"open_issues":0,"url":"https://github.com/...
Запросы будут автоматически декодировать контент с сервера. Самый юникод кодировки легко декодируются.
Когда вы делаете запрос, Requests делает обоснованные предположения о кодировке
ответ на основе заголовков HTTP. Кодировка текста, угадываемая Requests
используется при доступе к р.текст . Вы можете узнать, что такое кодировка Requests
using и измените его, используя свойство r.encoding :
>>> р.кодировка 'утф-8' >>> r.encoding = 'ISO-8859-1'
Если вы измените кодировку, запросы будут использовать новое значение r.encoding всякий раз, когда вы звоните r. . Вы можете сделать это в любой ситуации, когда
вы можете применить специальную логику, чтобы выяснить, какая кодировка контента будет
быть. Например, HTML и XML имеют возможность указать свою кодировку в
их тело. В таких ситуациях вы должны использовать  text
text r.content найти
кодировку, а затем установите r.encoding . Это позволит вам использовать r.text с
правильная кодировка.
также будут использовать пользовательские кодировки, если они вам нужны. Если
вы создали свою собственную кодировку и зарегистрировали ее с кодеками модуль, вы можете просто использовать имя кодека в качестве значения r.encoding и
Запросы будут обрабатывать декодирование для вас.
Содержимое двоичного ответа
Вы также можете получить доступ к телу ответа в виде байтов для нетекстовых запросов:
>>> р.содержимое
b'[{"репозиторий":{"open_issues":0,"url":"https://github.com/...
Кодирование передачи gzip и deflate автоматически декодируется для вас.
Кодирование передачи br автоматически декодируется для вас, если библиотека Brotli
например, brotli или brotlicffi.
Например, чтобы создать образ из бинарных данных, возвращаемых запросом, вы можете используйте следующий код:
>>> из изображения импорта PIL >>> из io импортировать BytesIO >>> i = Image.open(BytesIO(r.content))
Содержимое ответа JSON
Также имеется встроенный декодер JSON, если вы имеете дело с данными JSON:
>>> запросы на импорт
>>> r = request.get('https://api.github.com/events')
>>> р.json()
[{'репозиторий': {'open_issues': 0, 'url': 'https://github.com/...
В случае сбоя декодирования JSON r.json() вызывает исключение. Например, если
ответ получает 204 (нет содержимого), или если ответ содержит недопустимый JSON,
попытка r.json() вызывает запросов.исключения.JSONDecodeError . Это исключение оболочки
обеспечивает взаимодействие для нескольких исключений, которые могут быть вызваны разными
версии python и библиотеки сериализации json.
Следует отметить, что успех вызова r.json() делает , а не указать успешность ответа. Некоторые серверы могут возвращать объект JSON в
неудачный ответ (например, сведения об ошибке с HTTP 500). Такой JSON будет декодирован
и вернулся. Чтобы проверить успешность запроса, используйте r.raise_for_status() или проверка r.status_code — это то, что вы ожидаете.
Необработанное содержимое ответа
В редких случаях, когда вы хотите получить необработанный ответ сокета от
сервер, вы можете получить доступ к r.raw . Если вы хотите сделать это, убедитесь, что вы установили stream = True в вашем первоначальном запросе. Как только вы это сделаете, вы можете сделать это:
>>> r = request.get('https://api.github.com/events', stream=True)
>>> r.raw
>>> r.raw.read(10)
б'\x1f\x8b\x08\x00\x00\x00\x00\x00\x00\x03'
В целом, однако, вы должны использовать подобный шаблон, чтобы сохранить то, что передано в файл:
с открытым (имя файла, 'wb') как fd:
для чанка в r. iter_content(chunk_size=128):
fd.write(чанк)
 iter_content(chunk_size=128):
fd.write(чанк)
iter_content(chunk_size=128):
fd.write(чанк)
Использование Response.iter_content будет обрабатывать многое из того, что вы сделали бы в противном случае.
приходится обрабатывать при использовании Response.raw напрямую. При потоковой передаче
загрузки, указанный выше способ является предпочтительным и рекомендуемым способом получения
содержание. Обратите внимание, что chunk_size можно свободно настроить на число, которое
может лучше соответствовать вашим вариантам использования.
Note
Важное примечание об использовании Response.iter_content по сравнению с Response.raw . Response.iter_content автоматически декодирует gzip и deflate трансфер-кодировки. Response.raw — необработанный поток байтов.
преобразовать содержимое ответа. Если вам действительно нужен доступ к байтам, поскольку они
были возвращены, используйте Ответ. . raw
raw
Более сложные запросы POST
Как правило, вы хотите отправить некоторые данные, закодированные в форме — очень похоже на HTML-форму.
Для этого просто передайте словарь в аргумент data . Твой
словарь данных будет автоматически закодирован в форме при запросе:
>>> полезная нагрузка = {'key1': 'value1', 'key2': 'value2'}
>>> r = request.post('https://httpbin.org/post', data=payload)
>>> печать (р.текст)
{
...
"форма": {
"ключ2": "значение2",
"ключ1": "значение1"
},
...
}
Аргумент данных также может иметь несколько значений для каждого ключа. Это может быть
делается путем создания данных либо списка кортежей, либо словаря со списками
как ценности. Это особенно полезно, когда форма содержит несколько элементов,
используйте тот же ключ:
>>> payload_tuples = [('ключ1', 'значение1'), ('ключ1', 'значение2')]
>>> r1 = request.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = request. post('https://httpbin.org/post', data=payload_dict)
>>> печать(r1.текст)
{
...
"форма": {
"ключ1": [
"значение1",
"значение2"
]
},
...
}
>>> r1.текст == r2.текст
Истинный
 post('https://httpbin.org/post', data=payload_dict)
>>> печать(r1.текст)
{
...
"форма": {
"ключ1": [
"значение1",
"значение2"
]
},
...
}
>>> r1.текст == r2.текст
Истинный
post('https://httpbin.org/post', data=payload_dict)
>>> печать(r1.текст)
{
...
"форма": {
"ключ1": [
"значение1",
"значение2"
]
},
...
}
>>> r1.текст == r2.текст
Истинный
В некоторых случаях вам может потребоваться отправить данные, не закодированные в форме. Если
вы передаете строку вместо dict , эти данные будут отправлены напрямую.
Например, GitHub API v3 принимает данные POST/PATCH в формате JSON:
>>> импорт json
>>> url = 'https://api.github.com/some/endpoint'
>>> полезная нагрузка = {'некоторые': 'данные'}
>>> r = request.post(url, data=json.dumps(полезная нагрузка))
Обратите внимание, что приведенный выше код НЕ добавит Заголовок Content-Type (поэтому, в частности, он НЕ будет устанавливать его на application/json ).
Если вам нужен этот набор заголовков и вы не хотите самостоятельно кодировать dict ,
вы также можете передать его напрямую, используя параметр json (добавлен в версии 2. 4.2)
и он будет закодирован автоматически:
4.2)
и он будет закодирован автоматически:
>>> url = 'https://api.github.com/some/endpoint'
>>> полезная нагрузка = {'некоторые': 'данные'}
>>> r = request.post(url, json=payload)
Обратите внимание, что параметр json игнорируется, если передается данных или файлов .
POST файл, закодированный из нескольких частей
Запросы упрощают загрузку файлов с кодировкой Multipart:
>>> URL = 'https://httpbin.org/post'
>>> files = {'файл': open('report.xls', 'rb')}
>>> r = request.post(url, files=файлы)
>>> р.текст
{
...
"файлы": {
"file": "<цензурированные...бинарные...данные>"
},
...
}
Вы можете указать имя файла, тип содержимого и заголовки явно:
>>> URL = 'https://httpbin.org/post'
>>> files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})}
>>> r = request.post(url, files=файлы)
>>> р.текст
{
.. .
"файлы": {
"file": "<цензурированные...бинарные...данные>"
},
...
}
 .
"файлы": {
"file": "<цензурированные...бинарные...данные>"
},
...
}
.
"файлы": {
"file": "<цензурированные...бинарные...данные>"
},
...
}
При желании вы можете отправить строки для получения в виде файлов:
>>> URL = 'https://httpbin.org/post'
>>> files = {'file': ('report.csv', 'some,data,to,send\nanother,row,to,send\n')}
>>> r = request.post(url, files=файлы)
>>> р.текст
{
...
"файлы": {
"file": "некоторые,данные,кому,отправить\\nanother,строка,кому,отправить\\n"
},
...
}
Если вы публикуете очень большой файл как multipart/form-data запрос, вы можете захотеть передать запрос. По умолчанию запрашивает не
поддерживают это, но есть отдельный пакет, который делает — запросов-toolbelt . Вы должны прочитать документацию по поясу инструментов для получения более подробной информации о том, как его использовать.
Для отправки нескольких файлов в одном запросе обратитесь к расширенным раздел.
Предупреждение
Настоятельно рекомендуется открывать файлы в двоичном формате
режим. Это связано с тем, что запросы могут пытаться предоставить
Это связано с тем, что запросы могут пытаться предоставить Content-Length заголовок для вас, и если он делает это значение
будет установлено число байт в файле. Могут возникать ошибки
если открыть файл в текстовом режиме .
Коды состояния ответа
Мы можем проверить код состояния ответа:
>>> r = request.get('https://httpbin.org/get')
>>> r.status_code
200
Requests также поставляется со встроенным объектом поиска кода состояния для легкого ссылка:
>>> r.status_code == request.codes.ok Истинный
Если мы сделали неверный запрос (ошибка клиента 4XX или ответ об ошибке сервера 5XX), мы
может поднять его с Ответ.raise_for_status() :
>>> bad_r = request.get('https://httpbin.org/status/404')
>>> bad_r.status_code
404
>>> bad_r.raise_for_status()
Traceback (последний последний вызов):
Файл "requests/models.py", строка 832, в raise_for_status
поднять http_error
запросы. исключения.HTTPError: 404 Ошибка клиента
 исключения.HTTPError: 404 Ошибка клиента
исключения.HTTPError: 404 Ошибка клиента
Но, так как наши status_code для r было 200 , когда мы звоним raise_for_status() получаем:
>>> r.raise_for_status() Никто
Все хорошо.
Файлы cookie
Если ответ содержит несколько файлов cookie, вы можете быстро получить к ним доступ:
>>> url = 'http://example.com/some/cookie/setting/url' >>> r = запросы.get(url) >>> r.cookies['example_cookie_name'] 'example_cookie_value'
Чтобы отправить собственные файлы cookie на сервер, вы можете использовать печенье параметр:
>>> URL = 'https://httpbin.org/cookies'
>>> cookies = dict(cookies_are='working')
>>> r = request.get(url, cookies=cookies)
>>> р.текст
'{"cookies": {"cookies_are": "рабочие"}}'
куки возвращаются в RequestsCookieJar ,
который действует как dict , но также предлагает более полный интерфейс,
подходит для использования в нескольких доменах или путях. Баночки для печенья могут
также передаваться в запросы:
Баночки для печенья могут
также передаваться в запросы:
>>> jar = запросы.cookies.RequestsCookieJar()
>>> jar.set('tasty_cookie', 'ням', domain='httpbin.org', path='/cookies')
>>> jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/в другом месте')
>>> URL = 'https://httpbin.org/cookies'
>>> r = request.get(url, cookies=jar)
>>> р.текст
'{"cookies": {"tasty_cookie": "ням"}}'
Перенаправление и история
По умолчанию запросы будут выполнять перенаправление местоположения для всех команд, кроме ГОЛОВА.
Мы можем использовать свойство history объекта Response для отслеживания перенаправления.
Список Response.history содержит Ответ объектов, созданных для
завершить запрос. Список отсортирован от самого старого к самому последнему
ответ.
Например, GitHub перенаправляет все HTTP-запросы на HTTPS:
>>> r = request.get('http://github.com/')
>>> р.url
'https://github. com/'
>>> r.status_code
200
>>> р.история
[<Ответ [301]>]
 com/'
>>> r.status_code
200
>>> р.история
[<Ответ [301]>]
com/'
>>> r.status_code
200
>>> р.история
[<Ответ [301]>]
Если вы используете GET, OPTIONS, POST, PUT, PATCH или DELETE, вы можете отключить
обработка перенаправления с параметром allow_redirects :
>>> r = request.get('http://github.com/', allow_redirects=False)
>>> r.status_code
301
>>> р.история
[]
Если вы используете HEAD, вы также можете включить перенаправление:
>>> r = request.head('http://github.com/', allow_redirects=True)
>>> р.url
'https://github.com/'
>>> р.история
[<Ответ [301]>]
Тайм-ауты
Вы можете указать Requests прекратить ожидание ответа после заданного количества
секунд с параметром timeout . Почти весь производственный код должен использовать
этот параметр почти во всех запросах. Невыполнение этого требования может привести к тому, что ваша программа
висеть на неопределенный срок:
>>> request.get('https://github.com/', timeout=0.001)
Traceback (последний последний вызов):
Файл "", строка 1, в
request. exceptions.Timeout: HTTPConnectionPool (host = 'github.com', port = 80): время ожидания запроса истекло. (время ожидания = 0,001)
 exceptions.Timeout: HTTPConnectionPool (host = 'github.com', port = 80): время ожидания запроса истекло. (время ожидания = 0,001)
exceptions.Timeout: HTTPConnectionPool (host = 'github.com', port = 80): время ожидания запроса истекло. (время ожидания = 0,001)
Примечание
тайм-аут не является ограничением по времени на загрузку всего ответа;
скорее, исключение возникает, если сервер не выдал
ответ на тайм-аут секунд (точнее, если ни один байт не был
получено на базовом сокете в течение тайм-аутов секунд). Если тайм-аут не указан явно, запросы
не тайм-аут.
Ошибки и исключения
В случае проблемы с сетью (например, сбой DNS, отказ в подключении и т. д.)
Запросы поднимут Исключение ConnectionError .
Response.raise_for_status() будет
поднять HTTPError , если HTTP-запрос
вернул неудачный код состояния.
Если время ожидания запроса истекает, возникает исключение Timeout .
поднятый.
Если запрос превышает настроенное максимальное количество перенаправлений, Возникает исключение TooManyRedirects .