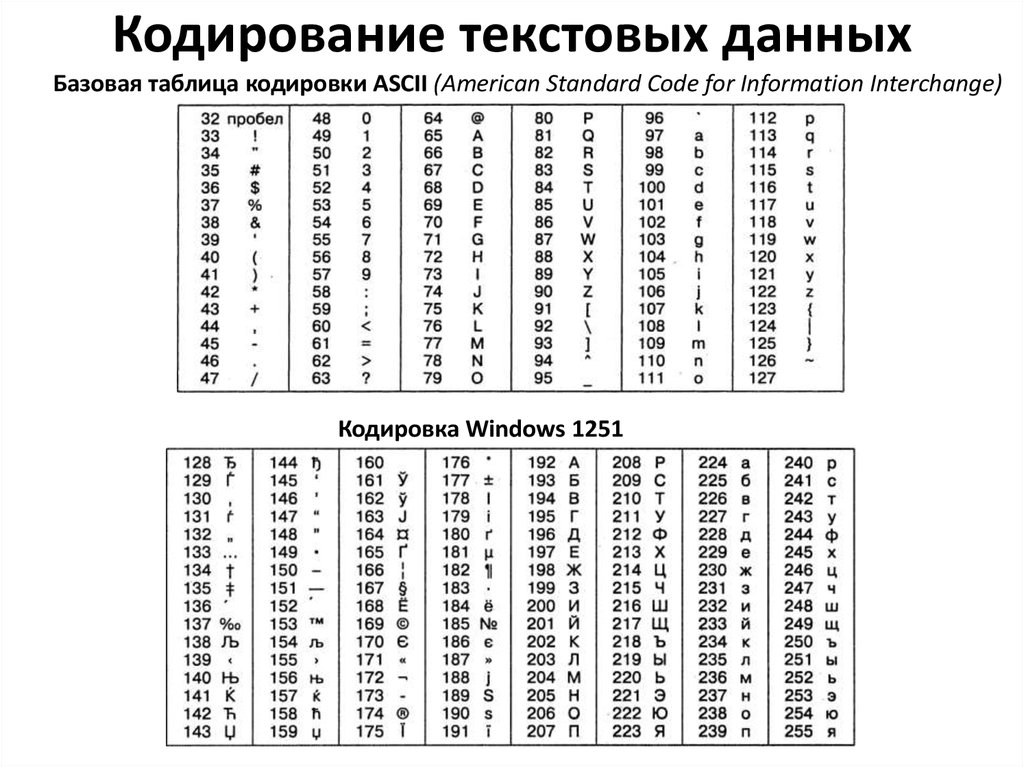
Русская кодировка в LaTeX/PDF: 1251 — 1252? : TeXнические обсуждения
Сообщения без ответов | Активные темы | Избранное
| dvg |
| ||
14/11/16 |
| ||
| |||

| arseniiv |
| |||
27/04/09 |
| |||
| ||||
| dmtrkh |
| ||
14/02/16 |
| ||
| |||

| Lenchik |
| ||
13/07/14 |
| ||
| |||
 Это и cmap для pdflatex (хорошо бы ещё вкупе с переводом на utf8 кодировку исходников), и перевод на utf8, но уже под xetex или lualatex. Есть ещё фокусы с подключением glyphtounicode.
Это и cmap для pdflatex (хорошо бы ещё вкупе с переводом на utf8 кодировку исходников), и перевод на utf8, но уже под xetex или lualatex. Есть ещё фокусы с подключением glyphtounicode.| sergei1961 |
| ||
25/08/11 |
| ||
| |||

| dvg |
| ||
14/11/16 |
| ||
| |||

| sergei1961 |
| ||
25/08/11 |
| ||
| |||

| Lenchik |
| ||
13/07/14 |
| ||
| |||

| sergei1961 |
| ||
25/08/11 |
| ||
| |||
 А что написать в преамбуле, чтобы скопированный текст из исходника теха переносился корректно в текстовый файл или word?
А что написать в преамбуле, чтобы скопированный текст из исходника теха переносился корректно в текстовый файл или word?| arseniiv |
| |||
27/04/09 |
| |||
| ||||
 Скажем, открыть этот файл целиком в ворде, и он, по идее, должен показать диалог с кодировками, где какая-то из них предложена.
Скажем, открыть этот файл целиком в ворде, и он, по идее, должен показать диалог с кодировками, где какая-то из них предложена.| sergei1961 |
| ||
25/08/11 |
| ||
| |||

| arseniiv |
| |||
27/04/09 |
| |||
| ||||
 Перекодировать на лету на основании его содержимого его не станут — такое поведение было бы просто не user-friendly. Так что это наверняка что-то с редактором, если уж в вашем коде представлены кириллические буквы, т. к. тогда кодировка файла просто не может быть Win1252.
Перекодировать на лету на основании его содержимого его не станут — такое поведение было бы просто не user-friendly. Так что это наверняка что-то с редактором, если уж в вашем коде представлены кириллические буквы, т. к. тогда кодировка файла просто не может быть Win1252.| Показать сообщения за: Все сообщения1 день7 дней2 недели1 месяц3 месяца6 месяцев1 год Поле сортировки АвторВремя размещенияЗаголовокпо возрастаниюпо убыванию |
| Страница 1 из 1 | [ Сообщений: 12 ] |
Модераторы: maxal, Karan, Toucan, PAV, Супермодераторы
Кто сейчас на конференции |
Сейчас этот форум просматривают: нет зарегистрированных пользователей |
| Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете добавлять вложения |
| Найти: |
| 13 ��� 12, 14:07����[13157783] �������� | ���������� �������� ���������� | ||||||||
 ru — технологии и ответы на вопросы
ru — технологии и ответы на вопросы cnf (my.ini) для дальнейшей беспроблемной работы с Юникодом.
cnf (my.ini) для дальнейшей беспроблемной работы с Юникодом.

 Для чего нужен этот параметр думаю пояснять не надо.
Для чего нужен этот параметр думаю пояснять не надо.
 Задать кодировку и ее представление можно через команды:
Задать кодировку и ее представление можно через команды: exe пользователем с и без привилегии SUPER:
exe пользователем с и без привилегии SUPER: Изначально люди не придавали этому значения, но в последние несколько лет это стало не так. Возникли разнообразные проблемы переносимости программ, и люди решили создать обобщающие кодировки, содержащие символы всех языков мира (в том числе, разумеется, и русского).
Изначально люди не придавали этому значения, но в последние несколько лет это стало не так. Возникли разнообразные проблемы переносимости программ, и люди решили создать обобщающие кодировки, содержащие символы всех языков мира (в том числе, разумеется, и русского).
 Дело в том, что некоторые символы некоторые языки считают одинаковыми (а иногда считаются одинаковыми символ или последовательность символов). Например, «ü» в немецком языке может быть записан как «ue». С другой стороны, в шведском языке тот же символ может быть записан как «uy».
Дело в том, что некоторые символы некоторые языки считают одинаковыми (а иногда считаются одинаковыми символ или последовательность символов). Например, «ü» в немецком языке может быть записан как «ue». С другой стороны, в шведском языке тот же символ может быть записан как «uy». Например:
Например:




| Re: MS-SQL �� �������� ��������� (���������) � SQL server management studio! [new] | |
| HandKot Member ������: Sergiev Posad | � ���� ��� �������� ? |
| 13 ��� 12, 14:09����[13157802] �������� | ���������� �������� ���������� | |
| Re: MS-SQL �� �������� ��������� (���������) � SQL server management studio! [new] | |
| Aysvel Member � ��� ��������) ��� � ��� �� ����, ��� � ������ ������ ��������� ���������� ���� «N» | |
| 13 ��� 12, 14:10����[13157815] �������� | ���������� �������� ���������� | |
| Re: MS-SQL �� �������� ��������� (���������) � SQL server management studio! [new] | |
| HandKot Member ������: Sergiev Posad | ��� ��� ����� ������ ������ � ��� SSMS ��������� � ������ ����������, � ��� ��� ��������������� � �� ���� |
| 13 ��� 12, 14:17����[13157884] �������� | ���������� �������� ���������� | |
| Re: MS-SQL �� �������� ��������� (���������) � SQL server management studio! [new] | ||||||||
| Aysvel Member ������: ������ |
| |||||||




 Начальный курс | Программирование
Начальный курс | ПрограммированиеОтличие utf-8 и windows 1251
В начале 90-х, когда произошел развал СССР и границы России были открыты, к нам стали поступать программные продукты западного производства. Естественно, все они были англоязычными. В это же время начинает развиваться Интернет. Остро встала проблема русификации ресурсов и программ. Тогда и была придумана русская кодировка Windows 1251. Она позволяет корректно отображать буквы славянских алфавитов:
- русского;
- украинского;
- белорусского;
- сербского;
- болгарского;
- македонского.
Разработка велась русским представительством Microsoft совместно с и «Параграф». За основу были взяты самописные разработки, которые в 1990-91гг имели хождение среди немногочисленных идеологов ИТ в России.
На сегодняшний день разработан более универсальный способ кодировать символы — UTF-8 (Юникод). В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)
В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Оглавление
- Интернет: две
основные кодировки кириллицы для пользователя MS Windows - Микрософтовские
шрифты с кириллицей,
включённые
в поставку MS Windows - Бесплатные не-Микрософтовские
, старые (сделанные для Windows 3. 1) кириллические шрифты
1) кириллические шрифты - Программы-перекодировщики: из одной кодировки в другую
- 235
в кодировке Windows-1251 (используется в странах бывшего СССР для русских, украинских, белорусских и т.п. текстов, а также в Болгарии и странах бывшей Югославии) - 204
в кодировке KOI8-R (используется для русских текстов) - 171
в кодировке DOS-866 (используется в сети Fido7 и на компьютерах с OS/2) - …
- английская ‘r’ — код 114
- цифра 5 — код 53
- двоеточие — 58
- …
- Windows-1251
В меню выбора кодировки в браузерах это выглядит обычно как «Cyrillic(Windows)» или «Cyrillic(Windows-1251)» - KOI8-R
В меню выбора кодировки в браузерах это выглядит обычно как «Cyrillic(KOI8-R)» - OS/2 и DOS (что включает сеть FIDO7) — «CP-866»
- UNIX — «ISO-8859-5» (в России — чаще KOI8-R)
- Apple Macintosh — «Mac Cyrillic»
- некоторые русские Web-страницы
— в кодировке KOI8-R. То есть, браузер должен уметь показывать KOI8-R текст. Кроме того, такие страницы иногда содержат
формы
ввода текста, то есть, там предполагается вводKOI8-R текста в дополнение к выводу KOI8-R на экран. - e-mail
. Часто нужно и отсылать и получать KOI8-R письма по электронной почте - Русскоязычные новостные конференции — Usenet Newsgroups
(Discussion Groups) — часто используют KOI8-R, то есть, KOI8-R используется и при отсылке и при высвечивании сообщений. - Internet Explorer
- Outlook Express
- MS Outlook вер. 2000 и выше
- Netscape вер. 4 и выше и его Почтовый (Mail) и Новостной (News) компоненты
- Мозилла и её Почтовый (Mail) и Новостной (News) компоненты
- чтение
KOI8-R текстов Эти программы сначала конвертируют KOI8-R текст в Windows-1251 текст, а уж потом показывают Вам полученный Windows-1251текст — используя ‘родные’ для Windows шрифты кодировки Windows-1251 типа «Arial» или «Courier New».Это делается, например, в следующих случаях:
когда надо показать KOI8-R
Web-страницу - когда надо показать пришедшее письмо (e-mail
), если оно путешествовало в Интернете в виде текста сетевой, транспортной кодировки KOI8-R - когда надо показать статью в новостной конференции (Newsgroup
, (Discussion Group)) (напомню, что большинство русских Newsgroups используют KOI8-R как ‘общую для всех платформ’ кодировку, то есть это KOI8-R тексты) - Когда нужно писать
в KOI8-R, то есть, создавать KOI8-R текст. Эти программы сначала дают Вам вводить текст, использую ‘родные’ для MS Windows шрифты и клавиатурные средства кодировки Windows-1251 — точно так же, как Вы, скажем, в MS Word вводите текст. Потом, когда ввод окончен, эти программы незаметно для Вас конвертируют введённый текст в KOI8-R текст!Например:
- Вы готовите письмо (e-mail
) или сообщение в новостную конференцию (Newsgroup) и хотите, чтобы
в Интернет Ваш текст ушёл
в кодировке KOI8-R, как большинство делает.Современные программы дают Вам ввести текст, используя обычные (не KOI8-R), шрифты и клавиатурные средства для русского, а потом перекодируют введённый текст в KOI8-Rперед тем
, как послать Ваше сообщение в Интернет — чтобы оно путешествовало в Интернете в виде текста сетевой, транспортной кодировки KOI8-R.
Естественно, чтобы программа так
работала,
Вы
должны ей указать, что хотите именно в KOI8-R отправить, т.е. в меню надо выбрать эту кодировку. - Ввод текста в форму
на KOI8-R Web-странице. То же самое — Вы вводите текст, используя обычные шрифты и клавиатурные средства для русского MS Windows, и только когда нажмёте кнопку для отсылки введённого, вот тогда браузер, зная, что страница — в кодировке KOI8-R, перекодирует введённый текст в KOI8-R и только потом текст уйдёт из браузера.
 1) кириллические шрифты
1) кириллические шрифтыИнтернет: 2 основные кодировки кириллицы для пользователя MS Windows
Итак, Вы работаете под MS Windows и хотите работать с русскими сайтами в Интернете или же просто читать/писать по-русски в редакторе.
Авторы кириллических сайтов Интернета используют разные
методы представления алфавита, используют разные
кодировки
кириллицы.
Кодировка определяет числовой код
, присваиваемый каждому элементу набора символов. Скажем, букве
‘л’
присвоены разные коды в различных кодировках кириллицы, например:
- 219
в кодировке ISO-8859-5 (используется для русского на некоторых UNIX-машинах, а также, например, в странах бывшей Югославии)
Кодировка тесно связана со шрифтами — шрифт обычно делается под конкретную кодировку, то есть, например в шрифте кодировки KOI8-R позиция 204
отведена под
‘л’
. В шрифте кодировки Windows-1251 буква
В шрифте кодировки Windows-1251 буква
‘л’
находится совсем на другой позиции (
235
), а
204
отведена под букву
‘М’
. Поэтому текст, набранный в кодировке KOI8-R будет нечитабельным, если для его просмотра в редакторе использовать шрифт кодировки Windows-1251 — вместо
‘л’
будет высвечиваться
‘М’
и т.д.
То есть, кодировки кириллицы несовместимы между собой (так исторически сложилось).
А вот у букв английского алфавита — противоположная ситуация: английские буквы, а также цифры, знаки препинания, кавычки и т.п. — так называемый набор ASCII — присутствуют в каждой
из ‘старых’ кодировок мира (новая кодировка Unicode немного по-другому устроена) — кириллических, японских, китайских, … и в каждой из этих кодировок им присвоено одно и то же значение, то есть в
любой
такой кодировке (а, значит, и в любом шрифте):
Поэтому английское слово ‘dog’ будет нормально читаться, какой бы шрифт не был выбран в редакторе — хоть японский, хоть русский.
Это был маленький кусок ‘теории’, а теперь — к практике.
Русскоговорящий пользователь MS Windows
обычно сталкивается в Интернете с
двумя
кодировками кириллицы:
Примечание. В не
-Интернетовских приложениях MS Windows — таких как, например, текстовые редакторы или программы MS Office, используется в настоящее время только
одна
кодировка кириллицы -Windows-1251. Фирма Микрософт выбрала именно эту кодировку для платформы MS Windows, и поэтому когда Вы видите
‘Cyrillic’
в меню выбора скрипта для шрифта или
‘Russian’
в меню выбора клавиатурной раскладки, то на самом деле там подразумевается ‘кодировка Windows-1251’, то есть надо понимать как «Cyrillic, Windows-1251» и «Russian, Windows-1251» соответственно.
Все Микрософтовские шрифты, содержащие кириллицу («Arial», «Times New Roman», …) поддерживают именно кодировку Windows-1251, и клавиатурные раскладки Микрософт обеспечивает только для кодировки Windows-1251.
Современные Интернетовские приложения — браузеры, почтовые и новостные программы, такие, как MS Internet Explorer, Outlook Express, MS Outlook 2000, Netscape вер. 4 и выше, Mozilla, и др.. —не
требуют наличия KOI8-R
шрифтов
, они и без этого умеют обрабатывать KOI8-R тексты (Web-страницы, e-mail, …). Как? Пояснения будут даны ниже, в следующем разделе, посвящённом KOI8-R.
Старые системы (например, Windows 3.1/3.11) и старые программы (например, Netscape 3
) требовали от пользователя установки KOI8-R шрифтов. Некоторые программы и сейчас требуют KOI8-R шрифты для работы с KOI8-R текстом, но таких программ мало, и они не относятся к разряду часто используемых. Это некоторые терминальные программы и т.п.У меня на данной странице предлагается сгрузить KOI8-R шрифты для таких старых систем и/или старых или специфических программ, но я поместил эту информацию в самый конец страницы, так как она редко
кому нужна.
не-Микрософтовские
, старые (от Windows 3.1) кириллические шрифты»
 Это раздел данной страницы, который называется «Бесплатные
Это раздел данной страницы, который называется «БесплатныеЗачем пользователю Windows знать про кодировку KOI8-R? Почему такому пользователю не нужны KOI8-Rшрифты?
Кодировка KOI8-R, так же, как и другие кириллические кодировки, используется для представления русских текстов, например, на Интернетовской странице, но её основное предназначение — быть сетевой, транспортной
кодировкой, каковой она и является де-факто с самых ранних дней Интернета. Ведь разные компьютеры используют разные
локальные
(т.е. только для данной платформы) кодировки для русского:
- MS Windows — «Windows-1251»
К сожалению, все эти кодировки несовместимы
между собой, по-разному кодируют русские буквы. Так исторически сложилось, тут уж ничего не поделаешь. То есть, пользователь Макинтоша
То есть, пользователь Макинтоша
не
сможет вот так просто прочесть русский в файле, если текст там — в кодировке «Windows-1251», нужно использовать спец. средства, конвертеры, и т.п. То же самое — для пользователя Windows, если ему дать текст в кодировке «Mac Cyrillic».
Как же тогда всем этим разным
(в плане кодировок) компьютерам обмениваться русскими сообщениями через Интернет? Используется общая для всех,
транспортная, сетевая
кодировка KOI8-R, которую понимают все компьютеры. То есть, большинство Интернетовских программ с самого начала поддержки русского ‘знали’, что приходящие и уходящие сообщения — в KOI8-R, и скажем, почтовой программе под Макинтошем не надо было уметь обрабатывать все многочисленные русские кодировки, достаточно было своей локальной и KOI8-R в качестве ‘транспортной’.
Если все эти разные компьютеры стали бы слать в Интернет русские сообщения в локальной
кодировке (из-под Windows — в Windows-1251, из-под Mac — в «Mac Cyrillic», и т. д.), то ситуация была бы непростая
д.), то ситуация была бы непростая
Самый простой пример — новостные конференции, Newsgroups. В дискуссии в такой конференции могут участвовать пользователи различных систем — Mac, Windows, Unix. Тогда просто напрашивается правило использования некой общей для всех кодировки сообщений, чтобы на любой платформе читалось. Исторически такой кодировкой стала KOI8-R. А представьте теперь, что так не произошло, и в некой конкретной дискуссии в русской конференции, где тема дискуссии тоже русская, люди бы стали отвечать каждый в кодировке своей платформы: одно сообщение — от пользователя Unix, ответ — от пользователя Макинтоша, ответ ему — от пользователя OS/2 или Windows. Ничего прочесть было бы нельзя…
Поэтому в большинстве русских новостных конференций все посылают сообщения в KOI8-R, на какой бы платформе ни работали. Естественно, если это узко-специальная конференция, где пользователи — только с одной платформы, например, Windows, то тогда они могут договориться и посылать в кодировке «Windows-1251″… Но, кстати, даже в конференциях иерархии microsoft. public.ru.russian.*
public.ru.russian.*
(microsoft.public.ru.russian.windowsxp и др.) всё-таки все пользуются KOI8-R
То же самое для e-mail — большинство писем ‘путешествует’ по сети в виде KOI8-R текстов, и опять же, если группа друзей (все — под Windows) решила для себя, что будут посылать e-mail в кодировке Windows-1251, то это понятно и нормально.
То есть, KOI8-R
это де-факто стандарт для обмена русскими сообщениями в Интернете, это
сетевая, транспортная
кодировка для русского, в то время как на каждом типе компьютеров используется
локальная
кодировка для русского. Одна из таких
локальных
кодировок — «Windows-1251», это то, что используется для русского под
MS Windows
.
Кодировка KOI8-R и Интернетовские программы под MS Windows
Пользователь MS Windows должен иметь возможность работать с текстами в кодировке KOI8-R, а не только с текстами в ‘родной’ для Windows кодировки Windows-1251:
 То есть, браузер должен уметь показывать KOI8-R текст. Кроме того, такие страницы иногда содержат
То есть, браузер должен уметь показывать KOI8-R текст. Кроме того, такие страницы иногда содержатЕсли у Вас старая
программа типа Netscape
3
, то для работы с KOI8-R в указанных выше ситуациях, Вам придётся установить KOI8-R
шрифты
(они предлагаются ниже на данной странице) и, если надо не только читать, но и писать, то придётся установить
клавиатурные
средства для KOI8-R (они предлагаются в разделе Клавиатура моего сайта).
Но в настоящее время при современных
программах, этого
не
требуется! То есть,
не
нужно ни KOI8-R шрифтов, ни KOI8-R клавиатуры. Более того, современные программы просто не могут работать с KOI8-R шрифтами. Подробности — ниже.
Более того, современные программы просто не могут работать с KOI8-R шрифтами. Подробности — ниже.
Современные Интернетовские программы (браузеры, почтовые и новостные), такие как
позволяют Вам работать только с ‘родными’, локальными для MS Windows шрифтами и клавиатурными средствами — кодировки Windows-1251 («Cyrillic(Windows)»), даже если надо читать KOI8-R тексты и/или писать в KOI8-R.
Современные программы позволяют, например, чтобы письмо ушло в Интернет
в сетевой, транспортной кодировке KOI8-R, а вот
создавали
Вы его с помощью Windows-1251 шрифтов и обычной Windows-1251 клавиатуры.
Как эти современные программы это делают? Они, незаметно для пользователя, перекодируют
тексты между KOI8-R и Windows-1251:


Все упомянутые выше программы должны быть настроены на русский
, чтобы так работать. Настройка на русский для Internet Explorer, Outlook Express, MS Outlook вер. 2000 и выше, и для Netscape/Mozilla с их почтовыми (Mail) и новостными (News) компонентами описана в разделе
2000 и выше, и для Netscape/Mozilla с их почтовыми (Mail) и новостными (News) компонентами описана в разделе
«Русский в браузерах, Почтовых, Новостных программах»
моего сайта. Но его следует читать только
после
того, как Вы закончите чтение данной страницы о русских шрифтах и кодировках.
Другие программы, не
упомянутые выше (другие e-mail программы; графические программы, музыкальные, и т.п.) требуют своей собственной, уникальной настройки на русский. Я лично пробовал и знаю только программы, упомянутые в предыдущих параграфах, так что если Вам надо настроить на русский WinAmp, Eudora или что ещё — смотрите
ссылки на сайты других авторов
в разделе
«Ещё о русификации. Вопросы и Ответы, ссылки
«
моего сайта.
Web и два типа шрифтов
В общем, не углубляясь в детали, в Интернете используются 2
метода показа
текста
на экране:
- Гипертекстовые
страницы — обычные страницы, HTML и т. п. Например, страница поискового сервиса Yandex -https://www.yandex.ru/
index.html
. - Простой Текст
— например, экран, показывающий
каталог
на FTP-сайте антивирусной программы McAfee -ftp://ftp.nai.com/pub/datfiles/english/ или экран, показывающий
содержимое
некоего
простого текстового
файла в таком каталоге, например, файла readme.
txt
: ftp://ftp.nai.com/pub/datfiles/english/readme.
txt
 п. Например, страница поискового сервиса Yandex -https://www.yandex.ru/
п. Например, страница поискового сервиса Yandex -https://www.yandex.ru/Каждый из этих 2-х типов экранов использует свой собственный стиль шрифта в браузере:
К Оглавлению
Микрософтовские Windows-1251 шрифты, включённые в Windows
В следующей главке предлагаются для загрузки старые (сделанные для Windows 3.1)не-Микрософтовские кириллические шрифты — и для кодировки KOI8-R, и для кодировки Windows-1251.
Но, как писалось выше, Микрософт использует для кириллицы в своих продуктах как раз кодировку Windows-1251 («Cyrillic(Windows)»). В терминологии Операционных Систем это Code Page 1251
— «Кодовая Страница 1251», поэтому часто можно видеть фразы типа «шрифты CP-1251», где CP — от
C
ode
P
age.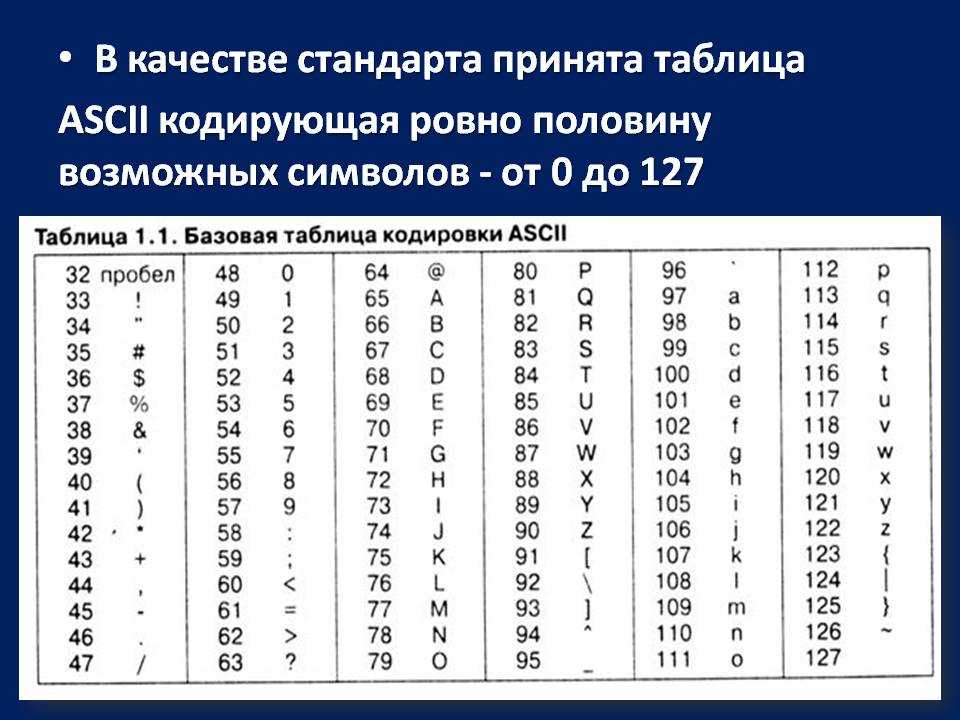
То есть, когда в диалогах Windows Вы видите «Cyrillic», то это на самом деле означает «Cyrillic, CP-1251
«.
Поэтому в 99% случаев нет никакого смысла загружать из Интернета некие не-Микрософтовские русские шрифты кодировки Windows-1251, т.к. в Windows уже включены такие шрифты, а кроме того, качество Микрософтовских шрифтов обычно намного лучше. Более того, большинство современных
приложений просто-напросто не могут работать с такими старыми не-Микрософтовскими шрифтами, а работают с современными юникодовыми шрифтами, включёнными в Windows, такими, как «Arial» и др. (Точно так же в 99% случаев нет смысла загружать из Интернета KOI8-Rшрифты — как было описано выше, современные программы с ними не работают, они обрабатывают KOI8-R тексты без этого.)
Какие же из стандартных шрифтов Windows включают кириллицу? Обычно это многоязычные шрифты «Arial», «Times New Roman», и «Courier New», а часто ещё и «Verdana», «Tahoma», и др.
Кириллица есть в таких стандартных шрифтах Windows даже если сама Windows не русская, а обычная английская (немецкая, …).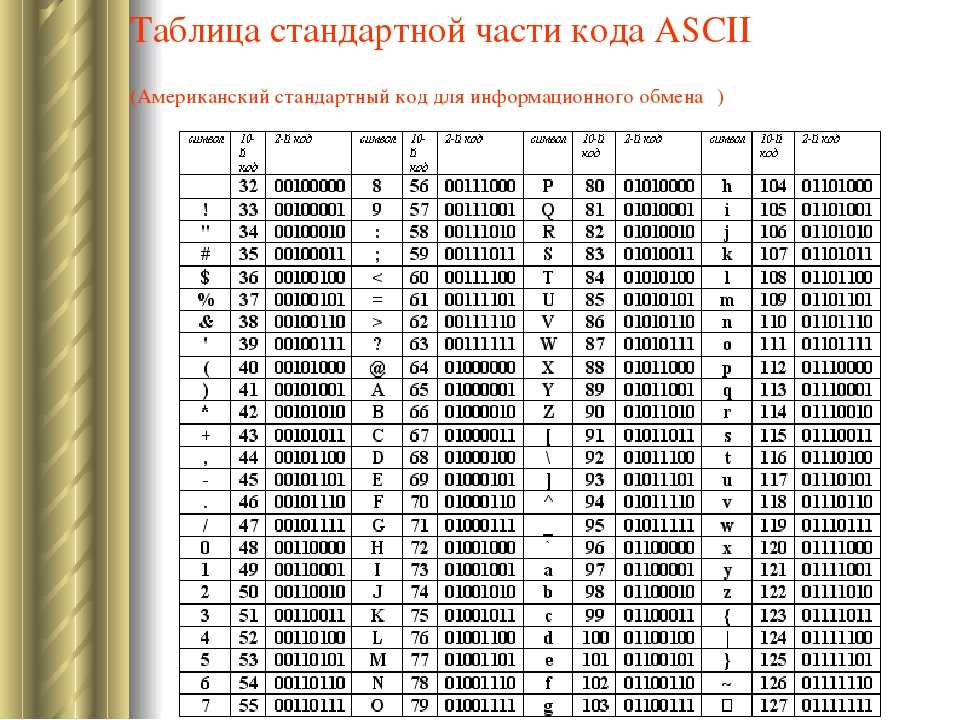 (для совсем старых версий Windows — 3.1/3.11
(для совсем старых версий Windows — 3.1/3.11
— это не так, в то время для английской версии надо было доставать откуда-то русские шрифты типа тех, что предлагаются в следующей главке — они и сделаны были как раз для Windows
3.1
)
Ниже приводится процедура проверки наличия русских Windows-1251 шрифтов в составе Windows 95/98/ME/NT 4.0/2000/XP/2003/Vista и их активации
, если это требуется
1. Русская (локализованная) версия MS Windows
Пользователи такой системы конечно имеют кириллицу в стандартных шрифтах Windows (как и пользователи Пан-Европейской
Windows 95).
Для проверки вызовите редактор Wordpad (Start/Programs/Accessories/Wordpad) и увидите, что стандартные шрифты поддерживают кириллицу
в дополнение к другим скриптам, таким, как «Western», например:
- Пропорциональные шрифты (Proportional fonts) — «Arial (Cyrillic)», «Times New Roman (Cyrillic)»
- Равноширокий шрифт (Fixed font) — «Courier New (Cyrillic)»
2. Windows 95/98/ME
Windows 95/98/ME
Пользователи английской
(и инсталлированной как английская) или другой нерусской версии Windows
95/98/MEизначально
не имеют кириллицы в стандартных шрифтах. Чтобы активировать поддержку кириллицы в стандартных шрифтах,
требуется
запустить Микрософтовский пакет многоязычной поддержки -«
MS Multilanguage Support
» — что делается обычно через Control Panel. (при этом заодно и
клавиатурные
файлы для русского появляются).
Вот моя короткая инструкция по этому пакету: «Поддержка кириллицы в Windows 95/98/ME — MS Multilanguage Support».
3. Windows NT 4.0/2000/XP/2003/Vista
Пользователи английской
(и инсталлированной как английская) или другой нерусской версии Windows
NT 4.0/2000/XP/2003/Vista
уже имеют кириллицу в стандартных шрифтах!
Это легко проверить, вот пара способов:
- Если есть доступ к Интернету, пойти на русский сайт, например, «Поисковая система Яндекс» и убедиться, что русский текст читается, то есть шрифты типа «Arial» или «Times News Roman» — стандартные Микрософтовские, те, что браузер использует для показа, содержат кириллицу, а иначе бы сайт не читался.
- Вызовите редактор Wordpad (Start/Programs/Accessories/Wordpad) и увидите, что стандартные шрифты поддерживают кириллицу
в дополнение к другим скриптам, таким, как «Western», например: Пропорциональные шрифты (Proportional fonts) — «Arial (Cyrillic)», «Times New Roman (Cyrillic)» - Равноширокий шрифт (Fixed font) — «Courier New (Cyrillic)»

Важное замечание — только для Windows 2000:
Хотя шрифты кодировки Windows-1251изначально
активны под Windows 2000, эта версия Windows, в отличие от Windows NT 4.0 и Windows XP/2003/Vista, требует
дополнительного
шага активации кириллицы. Этот шаг обеспечивает
полную
поддержку кириллицы, например, активирует таблицы перекодировки между разными кириллическими кодировками, копирует файлы клавиатурной раскладки для языков, которые кириллицу используют и т.п. Итак, пользователь Windows 2000
обязан
сделать следующее (что не требуется под Windows NT 4.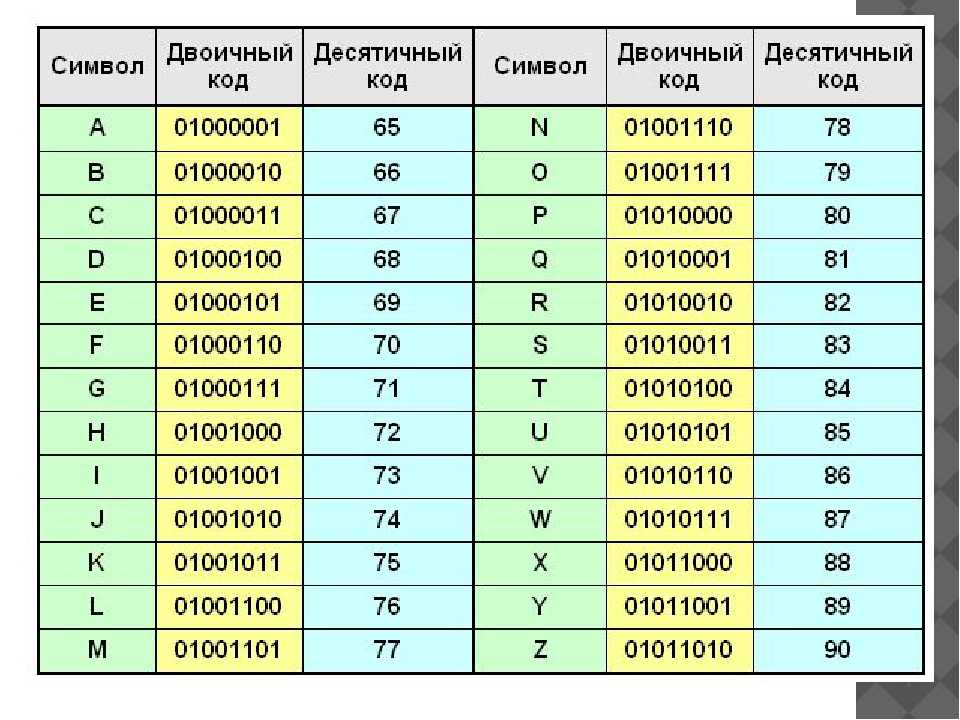 0 и Windows XP/2003/Vista):
0 и Windows XP/2003/Vista):
- Start / Settings / Control Panel
- Щёлкнуть на иконку-глобус Regional Options
- В окне Regional Options, в разделе General
, нижняя часть экрана отведена под пользовательские языковые установки —
Language Settings for the System
. - Найдите там строку «Cyrillic» и если слева не стоит ‘галка’, то поставьте её и нажмите кнопку Apply
. Система попросит вставить инсталялционный CD-ROM Windows 2000 и начнёт установку пакета поддержки кириллицы.
Выше было описано, как активировать поддержку кириллицы (кодировки Windows-1251) в стандартных Микрософтовских шрифтах Windows 95/98/ME/NT 4.0/2000/XP/2003/Vista.
Итак, если в Вашей
версии MS Windows теперь:
- кириллица есть в стандартных шрифтах типа «Arial» и
- Вам не
нужны шрифты кодировку
KOI8-R
(то есть, как было описано выше, Вы работаете с
современными
Интернетовскими программами, которые дают работать с KOI8-R текстами,
не
требуя KOI8-R шрифтов и клавиатуры; или же Вы вообще не работаете с русским в Интернете, только в редакторах типа MS Word)
то Вам не
надо дальше читать данную страницу, т. к. ниже — информация для тех, у кого
к. ниже — информация для тех, у кого
старые
Интернетовские программы, например, Netscape
3
и/или старая Windows — версии 3.1/3.11: там описано, как пользоваться (например, в Netscape 3 и/или под Windows 3.1)
не
-Микрософтовскими шрифтами типа «ER Bukinist»и/или шрифтами KOI8-R. Ни те, ни другие шрифты просто-напросто не работают в современных программх типа Internet Explorer, Outlook Express, Mozilla, и т.д. поэтому пользователям таких программ и не надо дальше эту страницу читать. (Современные программы работают с современными, юникодовыми шрифтами типа «Arial»).
К Оглавлению
Старые не-Микрософтовские кириллические шрифты
Как загрузить эти шрифты с моего сайта
Ниже Вы найдёте ссылку для загрузки старых не-Микрософтовских шрифтов — несколько Windows-1251
шрифтов и несколько
KOI8-R
шрифтов, которые я в своё время нашёл в Интернете и протестировал на пригодность работы, а также их детальное описание. Но такие шрифты нужны в настоящее время
Но такие шрифты нужны в настоящее время
только
в исключительных случаях:
Важно!
Как объяснялось в конце предыдущей главки, Вам могут потребоваться такие старые (сделанные для Windows 3.1) шрифты
только
в следующих
нестандартных
ситуациях (
большинству
пользователей такие шрифты не нужны):
- Вы работаете с очень старыми версиями Windows -Windows 3.1/3.11
или - Вам нужны шрифты кодировки KOI8-R
. Как было объяснено в начале данной страницы, Вам требуются шрифты KOI8-R
только
если Вы работаете с некой несовременной Интернетовской программой, например, Netscape версии
3
. Редкий случай! Современные программы, как было описано выше,
не
нуждаются в KOI8-R шрифтах при обработке текстов кодировки KOI8-R (и не могут работать с такими шрифтами).
Ниже на данной странице — инструкции только для такой, нестандартной
ситуации, как одна из описанных выше.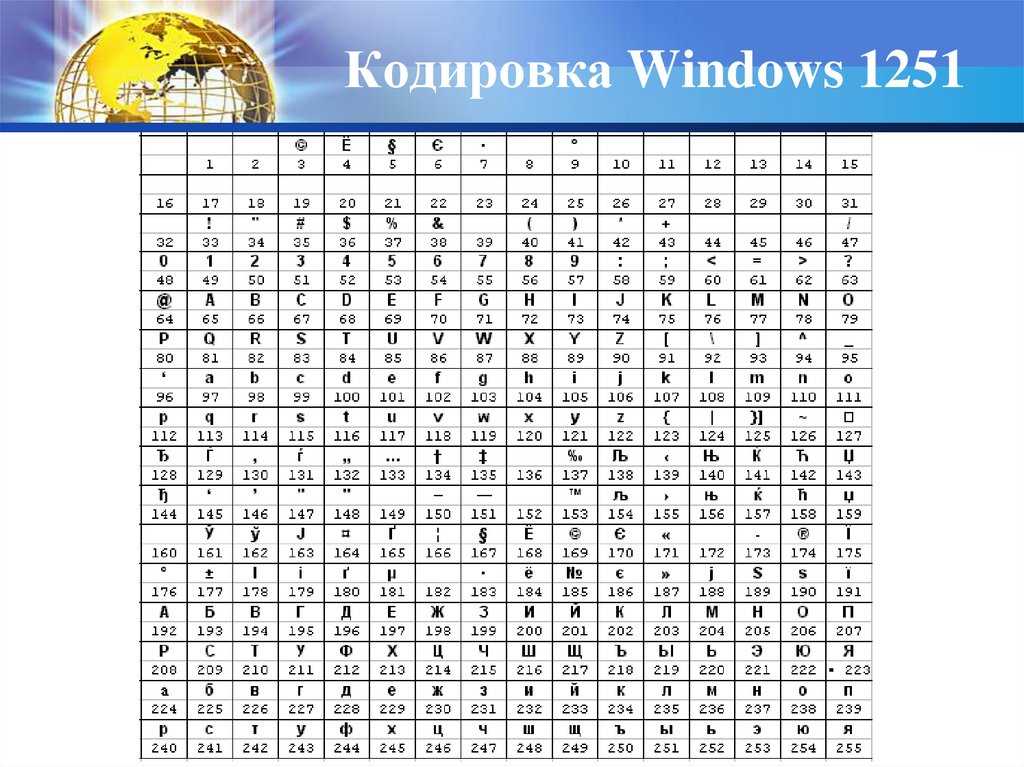 Поэтому если это не Ваш случай, то данная страница закончена, дальше читать не надо.
Поэтому если это не Ваш случай, то данная страница закончена, дальше читать не надо.
Все предлагаемые старые шрифты позволяют Вам читать на Web-странице одновременно и русский, и английский текст.
Вам надо создать каталог(directory,folder
), куда Вы будете загружать из Интернета (
download
) файл со шрифтами, например, каталог
C:\RUSFONTS
.
Я собрал все найденные шрифты в один файл(архив) —ForWWW.
zip. Чтобы загрузить этот файл, просто щёлкните мышкой на подчеркнутом имени файла ниже, и Ваш браузер предложит Вам
Сохранить Файл на диске
(
SAVE FILE
диалог). Там Вы должны будете указать на каталог, созданный Вами для хранения русских шрифтов —
C:\RUSFONTS
.
ПРИМЕЧАНИЕ :
Если вместо предложения «
Сохранить Файл
» Ваш браузер пытается
показать содержимое
этого файла на экране (редко, но бывает), тогда попробуйте загрузить этот файл снова, но при этом нажмите и держите клавишу
SHIFT
в то время, когда Вы щелкаете мышкой на подчеркнутом имени файла.

Вот она, ссылка для загрузки:
файл ForWWW.zip
После записи этого файла-архива на Ваш компьютер, Вам надо раз-архивировать
, извлечь шрифты, хранящиеся в нём —
extract files
.
Для этого Вы можете использовать программу WinZip for Windows, если она у Вас есть, ИЛИ
простую MS DOS программу
pkunzip
. Если у Вас нет программы
pkunzip
, тогда загрузите ее, щёлкнув мышкой на подчеркнутом имени файла -pkunzip.exe, в каталог
C:\WINDOWS
(
C:\WinNT
в NT 4.0/2000) на Вашем компьютере.
Чтобы извлечь файлы из архива с помощью программы pkunzip
, выполните следующие 2 команды MS DOS(первая из них — переход в нужный каталог, вторая — собственно открытие архива):
C:\……..> cd \RUSFONTS C:\RUSFONTS> pkunzip forwww.zip Эти команды можно ввести и будучи в MS Windows — надо открыть окно-приложение MS-DOS Prompt
:
- в Windows 3. 1, 3.11 это иконка «MS-DOS Prompt» в группе Main
- в Windows 95/98/ME — Start / Programs / MS-DOS Prompt
- в Windows NT 4.0 — Start / Programs / Command Prompt
- в Windows 2000/XP/2003/Vista — Start / Programs / Accessories / Command Prompt
 1, 3.11 это иконка «MS-DOS Prompt» в группе Main
1, 3.11 это иконка «MS-DOS Prompt» в группе MainКраткое описание загруженных шрифтов
ПРИМЕЧАНИЕ :
Я собрал в файл ForWWW.zip такие шрифты, которые точно работают в старых версиях Netscape — вер. 2,3 — под всеми вариациями Windows. Если же Вы где-то нашли
другую
версию того же самого шрифта, то он может неверно работать с Netscape 2,3 или с какой-то из версий Windows (например, Windows NT 4.0).
Напоминаю, что при работе со старым
браузером типа Netscape 3 Вам необходимо установить как минимум
4
русских шрифта:
- Proportional и Fixed шрифты для кодировки KOI8-R
- Proportional и Fixed шрифты для кодировки CP-1251(Windows)
(«Windows-1251»)
(как было описано выше на данной странице, современные
браузеры
не
нуждаются в KOI8-R шрифтах, работают
только
с Windows-1251 шрифтами)
а)
Шрифты кодировки
KOI8-R
:
б)
Шрифты кодировки
CP-1251(Windows)
:
- ‘ER Bukinist 1251’
Proportional(Пропорциональный) шрифт — файл
bk1251n. TTF
— датирован 05.03.95 - ‘ER Kurier 1251’
Fixed(Равноширокий) шрифт — файл
co1251n.TTF
— датирован 17.09.95
 TTF
TTFК Оглавлению
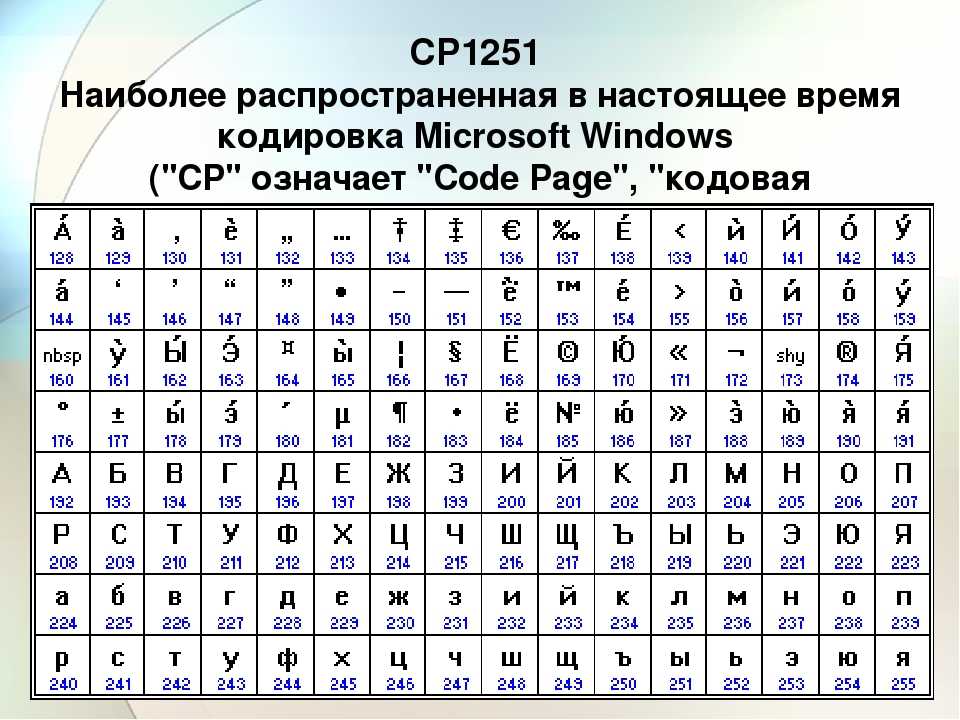
Что такое кодировка windows 1251
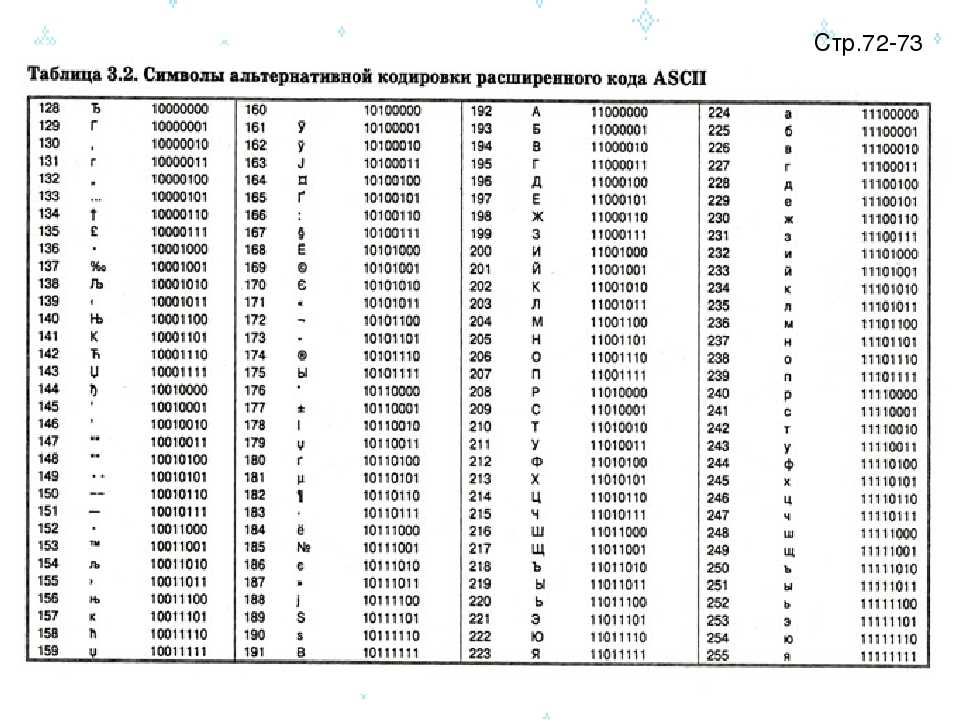
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
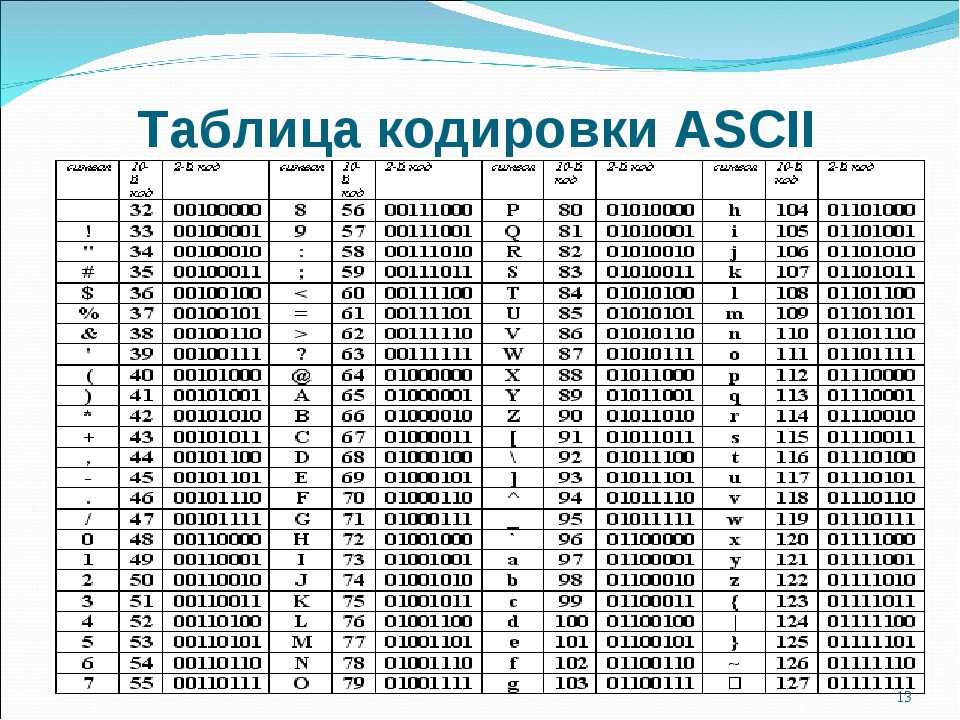
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII.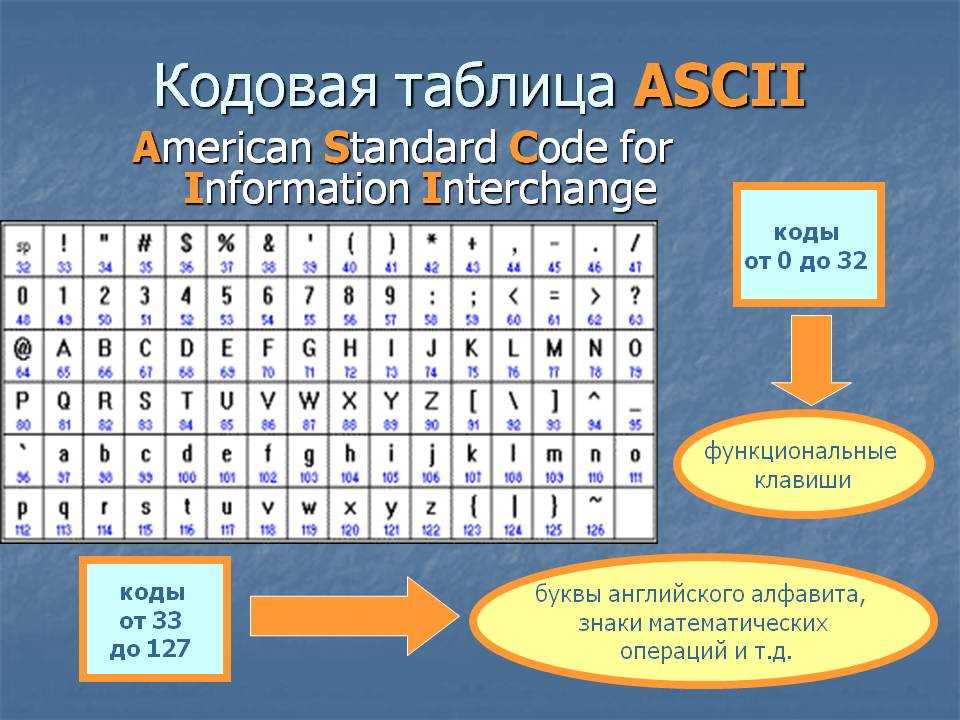 Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Скопировать ссылку
Решения проблемы с кодировкой в CMD. 2 Способ.
Теперь рассмотрим ещё одну ситуацию, когда могут возникнуть проблемы с кодировкой в CMD.
Допустим, ситуация требует сохранить результат выполнения той или иной команды в обычный «TXT» файл. В приделах этого поста возьмём для примера команду «HELP».
Задача
: Сохранить справку CMD в файл «HelpCMD.txt. Для этого создайте Bat файл и запишите в него следующие строки.
После выполнения Bat файла в корне диска «C:» появится файл «HelpCMD. txt» и вместо справки получится вот что:
txt» и вместо справки получится вот что:
Естественно, такой вариант не кому не понравится и что бы сохранить справку в понятном для человека виде, допишите в Bat файл строку.
Теперь содержимое кода будет такое.
После выполнения «Батника» результат будет такой:
draft-winitzki-koi8c-encoding-00
[Поиск] [txt|pdfized|bibtex] [Отслеживание] [Электронная почта] [Nits] Версии: 00
Internet Draft Serge Winitzki
черновик-winitzki-koi8c-encoding-00.txt
Истекает: апрель 2002 г.
Расширенный набор символов кириллицы
КОИ8-С
Статус этого меморандума
Этот меморандум является Интернет-проектом и подлежит всем положениям
Раздела 10 RFC2026.
Интернет-черновики – это рабочие документы Интернета.
Инженерная рабочая группа (IETF), ее области и ее работа
группы. Обратите внимание, что другие группы также могут распространять рабочие
документы в виде Internet-Drafts.
Интернет-черновики — это проекты документов, действительные не более шести
месяцев и могут быть обновлены, заменены или устаревшими другими
документы в любое время. Нецелесообразно использовать
Internet-Drafts в качестве справочного материала или цитировать их, кроме
как «работа в процессе».
Список текущих интернет-драфтов можно найти по адресу
http://www.ietf.org/ietf/1id-abstracts.txt Список
Доступ к теневым каталогам Internet-Draft можно получить по адресу
http://www.ietf.org/shadow.html.
Автор
Серж Виницки
Абстрактный
Этот документ содержит информацию о кодировке символов
KOI8-C (кириллица KOI8) предлагается для использования с русским языком (включая
старая орфография), украинский, белорусский, сербский, македонский
языки со специальными знаками препинания. KOI8-C совместим
с КОИ8-Р [1] и КОИ8-У [2] в области русского, украинского
и белорусские буквы, и дополняет их буквами для старых
Русская орфография, югославская кириллица и
типографские символы в позициях, совместимых с CP1251 для использования
в устаревших приложениях.
Предлагаемое имя набора символов MIME: koi8-c
Введение
Этот документ содержит информацию о предлагаемом новом персонаже
кодирование KOI8-C, расширение стандартов KOI8-R и KOI8-U.
Это расширение обеспечивает поддержку всех русских букв
(в том числе нужных для древнерусской орфографии), а также
Кириллические буквы, используемые в белорусском, македонском, сербском и
украинские языки и некоторые часто используемые типографские
символы, заимствованные из кодировки CP1251. Кодировка KOI8-C
совместим с существующими кодировками KOI8-RU и CP1251 в
соответствующие символы.
Мотивация
Семейство кодировок KOI8 уже давно используется для электронных
обмен кириллическими текстами [1,2]. Следующие соображения
побудили автора предложить расширение KOI8.
1) Большая часть таблицы кодирования KOI8 (большая часть 0x80-0xBF
диапазон) по историческим причинам занят символами
псевдографика, которая не используется в современном программном обеспечении. Эти символы
отсутствуют в большинстве реализаций шрифтов KOI8 без каких-либо последствий
на производительность пользователей. Эти места в таблице кодирования могут быть
используется для представления более часто используемых символов.
2) Недавнее доминирование операционной среды «MS Windows».
привело к широкому распространению текстовых процессоров, использующих «код
page 1251" для отображения кириллицы. Многие интернет-документы
таким образом преобразуются в KOI8 из CP1251 и часто включают
некоторые типографские знаки, такие как апострофы, кавычки или
тире, не представленные в кодировках KOI8, но оставленные без
меняются автоматическими преобразователями. Эти типографские символы падают
в неиспользуемой области псевдографики KOI8.
3) Тексты в древнерусской орфографии (до 1918) содержат четыре
Кириллические буквы не представлены ни одним из широко используемых
Кириллические кодировки. Хотя инструменты на основе Unicode
быть адекватным для рендеринга этих символов, текущая
программное обеспечение в большинстве случаев не имеет необходимой поддержки. Это было бы
удобно иметь 8-битную кодировку, представляющую старую русскую
символов и иметь возможность размещать их непосредственно в шрифте
карта кодирования и раскладка клавиатуры, совместимая с широким диапазоном
текущего программного обеспечения.
Реализация
Автор реализовал кодировку KOI8-C согласно этим
рекомендации: (1) совместимость с символами KOI8-R и KOI8-U
наборы, (2) совместимость с набором символов CP1251 в области
типографские символы и югославская кириллица; (3) нужно быть
умеет конвертировать шрифты в другие кириллические кодировки.
Нижняя часть набора символов KOI8-C является полной копией
ASCII в диапазоне печатных символов (0x20 -- 0x7F).
диапазон (0x00 -- 0x1F) занят псевдографикой и другими
редко используемые специальные символы.
Верхняя часть набора символов KOI8-C содержит все русские,
Белорусские и украинские буквы на позициях, определенных в KOI8-R
и КОИ8-У; часто используемые типографские символы (кавычки,
тире и символы валюты) и югославская кириллица как
определяется кодировкой CP1251; и старыми русскими буквами. Большая коробка
рисование символов из КОИ8-Р, а также некоторые математические
символы, были удалены.
Результирующий набор символов содержит все символы ISO 8859. -5 символов
кроме МЯГКОГО ДЕФИСА и охватывает CP1251 кроме 5 знаков препинания
символов (все также в CP1252).
Веб-страница
содержит разработки автора, связанные с KOI8-C
кодировка и тексты в древнерусской орфографии. Бесплатное растровое изображение
адаптированы шрифты семейства Cronyx для системы X Window
к кодировке KOI8-C, реализуя полную карту KOI8-C (256
символов) во всех шрифтах (проект "xcyr"). Расширение
раскладка клавиатуры, содержащая старые русские буквы, была
предложенный. Словарь проверки орфографии для древнерусского языка
была разработана орфография с использованием кодировки KOI8-C.
Отношение к другим усилиям
Эта кодировка была разработана как модификация [1,2]. Ан
независимый проект разработки шрифтов "CYR-RFX" использует
альтернативная кодировка "КОИ8-О" с аналогичными целями
совместимость с KOI8-R и CP1251, но не содержит
Югославские кириллические символы.
Спецификация кодовой страницы KOI8-C
Описание всех символов верхней половины KOI8-C
кодовая страница указана в соответствии с набором символов Unicode ISO 10646.
(УКС).
#
0x01 U25C6 # ЧЕРНЫЙ АЛМАЗ
0x02 U2592 # СРЕДНИЙ ОТТЕНОК
0x03 U00D7 # ЗНАК УМНОЖЕНИЯ
0x04 U00F7 # ЗНАК РАЗДЕЛЕНИЯ
0x05 U2030 # ПРОМЫШЛЕННЫЙ ЗНАК
0x06 U2248 # ПОЧТИ РАВНО
0x07 U00B5 # ЗНАК МИКРО
0x08 U00B1 # ЗНАК ПЛЮС-МИНУС
0x09 U00B6 # ЗНАК НАШИВКИ
0x0A U2021 # ДВОЙНОЙ КИНЖАЛ
0x0B U2518 # ЧЕРТЕЖИ В КОРОБКЕ ЗАЖИГАЮТСЯ ВВЕРХ И ВЛЕВО
0x0C U2510 # ЧЕРТЕЖИ КОРОБКИ ПОДСВЕТКА ВНИЗ И ВЛЕВО
0x0D U250C # ЧЕРТЕЖИ В КОРОБКЕ ПОДСВЕТКА ВНИЗ И ВПРАВО
0x0E U2514 # ЧЕРТЕЖИ ЗАЖИГАЮТСЯ ВВЕРХ И СПРАВА
0x0F U253C # ЧЕРТЕЖИ КОРОБКИ ОСВЕЩЕНИЕ ВЕРТИКАЛЬНО И ГОРИЗОНТАЛЬНО
0x10 UFFFD # ЗАМЕНЯЮЩИЙ СИМВОЛ
0x11 UFFFD # ЗАМЕНЯЮЩИЙ СИМВОЛ
0x12 U2500 # ЧЕРТЕЖИ СВЕТ ГОРИЗОНТАЛЬНЫЙ
0x13 UFFFD # ЗАМЕНЯЮЩИЙ СИМВОЛ
0x14 UFFFD # СИМВОЛ ЗАМЕНЫ
0x15 U251C # ЧЕРТЕЖИ КОРОБКИ ПОДСВЕТКА ВЕРТИКАЛЬНАЯ И ПРАВАЯ
0x16 U2524 # ЧЕРТЕЖИ КОРОБКИ ПОДСВЕТКА ВЕРТИКАЛЬНАЯ И СЛЕВА
0x17 U2534 # ЧЕРТЕЖИ КОРОБКИ ЗАСВЕТЯТСЯ И ГОРИЗОНТАЛЬНО
0x18 U252C # ЧЕРТЕЖИ В КОРОБКЕ СВЕТ ВНИЗ И ГОРИЗОНТАЛЬНО
0x19U2502 # ЧЕРТЕЖИ В КОРОБКЕ СВЕТ ВЕРТИКАЛЬНЫЙ
0x1A U2264 # МЕНЬШЕ ИЛИ РАВНО
0x1B U2265 # БОЛЬШЕ ИЛИ РАВНО
0x1C U03C0 # СТРОЧНАЯ ГРЕЧЕСКАЯ БУКВА ПИ
0x1D U2260 # НЕ РАВНО
0x1E U00A4 # ЗНАК ВАЛЮТЫ
0x1F U00B2 # НАДПИСЬ ДВА
0x20 U0020 # ПРОБЕЛ
0x21 U0021 # ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК
0x22 U0022 # КАвычки
0x23 U0023 # ЗНАК НОМЕРА
0x24 U0024 # ЗНАК ДОЛЛАРА
0x25 U0025 # ЗНАК ПРОЦЕНТА
0x26 U0026 # АМПЕРСАНД
0x27 U0027 # АПОСТРОФ
0x28 U0028 # ЛЕВАЯ СКОБКА
0x29U0029 # ПРАВАЯ СКОБКА
0x2A U002A # ЗВЕЗДОЧКА
0x2B U002B # ЗНАК ПЛЮС
0x2C U002C # ЗАПЯТАЯ
0x2D U002D # ДЕФИС-МИНУС
0x2E U002E # ПОЛНАЯ СТОП
0x2F U002F # СОЛИДУС
0x30 U0030 # ЦИФРА НОЛЬ
0x31 U0031 # ЦИФРА ОДИНА
0x32 U0032 # ВТОРАЯ ЦИФРА
0x33 U0033 # ЦИФРА ТРИ
0x34 U0034 # ЦИФРА ЧЕТЫРЕ
0x35 U0035 # ПЯТАЯ ЦИФРА
0x36 U0036 # ЦИФРА ШЕСТЬ
0x37 U0037 # СЕДЬМАЯ ЦИФРА
0x38 U0038 # ВОСЕМЬ ЦИФРА
0x39U0039 # ЦИФРА ДЕВЯТЬ
0x3A U003A # ТОЛСТАЯ
0x3B U003B # ТОЧКА С ЗАПЯТОЙ
0x3C U003C # ЗНАК МЕНЬШЕ
0x3D U003D # ЗНАК РАВНО
0x3E U003E # ЗНАК БОЛЬШЕ
0x3F U003F # ВОПРОСИТЕЛЬНЫЙ ЗНАК
0x40 U0040 # КОММЕРЧЕСКОЕ В
0x41 U0041 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A
0x42 U0042 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА B
0x43 U0043 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА C
0x44 U0044 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА D
0x45 U0045 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E
0x46 U0046 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА F
0x47 U0047 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА G
0x48 U0048 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА H
0x49U0049 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I
0x4A U004A # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА J
0x4B U004B # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА K
0x4C U004C # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА L
0x4D U004D # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА M
0x4E U004E # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА N
0x4F U004F # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O
0x50 U0050 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА P
0x51 U0051 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Q
0x52 U0052 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА R
0x53 U0053 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА S
0x54 U0054 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА T
0x55 U0055 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U
0x56 U0056 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА V
0x57 U0057 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА W
0x58 U0058 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА X
0x59U0059 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Y
0x5A U005A # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Z
0x5B U005B # ЛЕВАЯ КВАДРАТНАЯ СКОБКА
0x5C U005C # ОБРАТНЫЙ СОЛИДУС
0x5D U005D # ПРАВАЯ КВАДРАТНАЯ СКОБКА
0x5E U005E # ЦИРКУМФЛЕКС АКЦЕНТ
0x5F U005F # НИЗКАЯ ЛИНИЯ
0x60 U0060 # МОГИЛЬНЫЙ АКЦЕНТ
0x61 U0061 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A
0x62 U0062 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B
0x63 U0063 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C
0x64 U0064 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D
0x65 U0065 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E
0x66 U0066 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА F
0x67 U0067 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G
0x68 U0068 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H
0x69U0069 # ЛАТИНСКАЯ СТРОЧНАЯ БУКВА I
0x6A U006A # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА J
0x6B U006B # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА K
0x6C U006C # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L
0x6D U006D # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА M
0x6E U006E # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N
0x6F U006F # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O
0x70 U0070 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА P
0x71 U0071 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Q
0x72 U0072 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R
0x73 U0073 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S
0x74 U0074 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T
0x75 U0075 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U
0x76 U0076 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА V
0x77 U0077 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА W
0x78 U0078 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА X
0x79U0079 # ЛАТИНСКАЯ СТРОЧНАЯ БУКВА Y
0x7A U007A # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z
0x7B U007B # ЛЕВАЯ ФИГУРНАЯ СКОБКА
0x7C U007C # ВЕРТИКАЛЬНАЯ ЛИНИЯ
0x7D U007D # ПРАВАЯ ФИГУРНАЯ СКОБКА
0x7E U007E # ТИЛЬДА
0x7F U00AC # НЕ ЗНАК
0x80 U0402 # ЗАГЛАВНАЯ БУКВА DJE
0x81 U0403 # ЗАГЛАВНАЯ БУКВА GJE
0x82 U00B8 # СЕДИЛЬЯ
0x83 U0453 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА GJE
0x84 U201E # ДВОЙНАЯ МЛАДШАЯ-9 КАВАТЫ
0x85 U2026 # ГОРИЗОНТАЛЬНЫЙ ЭЛЛИПСИС
0x86 U2020 # КИНЖАЛ
0x87 U00A7 # ЗНАК СЕКЦИИ
0x88 U20AC # ЗНАК ЕВРО
0x89U00A8 # ДИЭРЕЗИС
0x8A U0409 # ЗАГЛАВНАЯ БУКВА LJE
0x8B U2039 # ОДИНОЧНЫЙ УГОЛ, УКАЗЫВАЮЩИЙ ВЛЕВО, КАВАТЫ
0x8C U040A # ЗАГЛАВНАЯ БУКВА NJE
0x8D U040C # ЗАГЛАВНАЯ БУКВА KJE
0x8E U040B # ЗАГЛАВНАЯ БУКВА ТШЕ
0x8F U040F # ЗАГЛАВНАЯ БУКВА ДЖЕ
0x90 U0452 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА DJE
0x91 U2018 # ЛЕВАЯ ОДИНАРНАЯ КАВАТЫ
0x92 U2019 # ПРАВАЯ ОДИНАРНАЯ КАВАТЫ
0x93 U201C # ЛЕВАЯ ДВОЙНАЯ КАВАТЫ
0x94 U201D # ПРАВАЯ ДВОЙНАЯ КАПОТА
0x95 U2022 # ПУЛЯ
0x96 U2013 # В ТИРЕ
0x97 U2014 # ЭМ ТИРЕ
0x98 U00A3 # ЗНАК ФУНТА
0x99 U00B7 # СРЕДНЯЯ ТОЧКА
0x9A U0459 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА LJE
0x9B U203A # ОДИНОЧНЫЙ УГОЛ НАПРАВЛЕНИЯ ВПРАВО КАВАТЫ
0x9C U045A # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА NJE
0x9D U045C # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА KJE
0x9E U045B # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЦШЕ
0x9F U045F # СТРОЧНАЯ БУКВА ДЖЕ
0xA0 U00A0 # НЕРАЗРЫВНЫЙ ПРОБЕЛ
0xA1 U0475 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ИЖИЦА
0xA2 U0463 # СТРОЧНАЯ БУКВА ЯТЬ
0xA3 U0451 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА IO
0xA4 U0454 # СТРОЧНАЯ КИРИЛЛИЧНАЯ УКРАИНСКАЯ БУКВА IE
0xA5 U0455 # СТРОЧНАЯ БУКВА ДЗЕ
0xA6 U0456 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БЕЛОРУССКАЯ-УКРАИНСКАЯ БУКВА I
0xA7 U0457 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЙИ
0xA8 U0458 # СТРОЧНАЯ БУКВА JE
0xA9U00AE # ЗАРЕГИСТРИРОВАННЫЙ ЗНАК
0xAA U2122 # ЗНАК ТОРГОВОЙ МАРКИ
0xAB U00AB # НАПРАВЛЯЮЩАЯ ВЛЕВО ДВОЙНАЯ УГЛОВАЯ КАВАТЫ
0xAC U0473 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ФИТА
0xAD U0491 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА GHE С ВВЕРХОМ
0xAE U045E # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КОРОТКАЯ U
0xAF U00B4 # ОСТРЫЙ АКЦЕНТ
0xB0 U00B0 # ЗНАК СТЕПЕНИ
0xB1 U0474 # ЗАГЛАВНАЯ БУКВА ИЖИЦА
0xB2 U0462 # ЗАГЛАВНАЯ БУКВА ЯТЬ
0xB3 U0401 # ЗАГЛАВНАЯ БУКВА IO
0xB4 U0404 # ЗАГЛАВНАЯ БУКВА УКРАИНСКИЙ IE
0xB5 U0405 # ЗАГЛАВНАЯ БУКВА ДЗЕ
0xB6 U0406 # ЗАГЛАВНАЯ БУКВА БЕЛОРУССКИЙ-УКРАИНСКИЙ I
0xB7 U0407 # ЗАГЛАВНАЯ БУКВА YI
0xB8 U0408 # ЗАГЛАВНАЯ БУКВА JE
0xB9U2116 # ЗНАК ЦИФРЫ
0xBA U00A2 # ЗНАК ЦЕНТА
0xBB U00BB # ДВУХУГОЛЬНАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВПРАВО
0xBC U0472 # ЗАГЛАВНАЯ БУКВА ФИТА
0xBD U0490 # ЗАГЛАВНАЯ БУКВА GHE С ВВЕРХОМ
0xBE U040E # ЗАГЛАВНАЯ БУКВА КОРОТКАЯ U
0xBF U00A9 # ЗНАК АВТОРСКОГО ПРАВА
0xC0 U044E # СТРОЧНАЯ БУКВА Ю
0xC1 U0430 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА A
0xC2 U0431 # СТРОЧНАЯ БУКВА BE
0xC3 U0446 # СТРОЧНАЯ БУКВА ТСЕ
0xC4 U0434 # СТРОЧНАЯ БУКВА DE
0xC5 U0435 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА IE
0xC6 U0444 # СТРОЧНАЯ БУКВА EF
0xC7 U0433 # СТРОЧНАЯ БУКВА GHE
0xC8 U0445 # СТРОЧНАЯ БУКВА HA
0xC9U0438 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА I
0xCA U0439 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КОРОТКАЯ I
0xCB U043A # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КА
0xCC U043B # СТРОЧНАЯ БУКВА EL
0xCD U043C # СТРОЧНАЯ БУКВА EM
0xCE U043D # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА EN
0xCF U043E # СТРОЧНАЯ БУКВА O в кириллице
0xD0 U043F # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА PE
0xD1 U044F # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА Я
0xD2 U0440 # СТРОЧНАЯ БУКВА ER
0xD3 U0441 # СТРОЧНАЯ БУКВА ES
0xD4 U0442 # СТРОЧНАЯ БУКВА TE
0xD5 U0443 # СТРОЧНАЯ БУКВА U
0xD6 U0436 # СТРОЧНАЯ БУКВА ЖЕ
0xD7 U0432 # СТРОЧНАЯ БУКВА ВЕ
0xD8 U044C # МЯГКИЙ ЗНАК СТРОЧНОЙ БУКВЫ КИРИЛЛИЦЫ
0xD9U044B # СТРОЧНАЯ БУКВА ЕРУ
0xDA U0437 # СТРОЧНАЯ БУКВА ZE
0xDB U0448 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ША
0xDC U044D # СТРОЧНАЯ БУКВА Е
0xDD U0449 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЩА
0xDE U0447 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЧЕ
0xDF U044A # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЖЕСТКИЙ ЗНАК
0xE0 U042E # ЗАГЛАВНАЯ БУКВА Ю
0xE1 U0410 # ЗАГЛАВНАЯ БУКВА A
0xE2 U0411 # ЗАГЛАВНАЯ БУКВА BE
0xE3 U0426 # ЗАГЛАВНАЯ БУКВА TSE
0xE4 U0414 # ЗАГЛАВНАЯ БУКВА DE
0xE5 U0415 # ЗАГЛАВНАЯ БУКВА IE
0xE6 U0424 # ЗАГЛАВНАЯ БУКВА EF
0xE7 U0413 # ЗАГЛАВНАЯ БУКВА GHE
0xE8 U0425 # ЗАГЛАВНАЯ БУКВА HA
0xE9U0418 # ЗАГЛАВНАЯ БУКВА I
0xEA U0419 # ЗАГЛАВНАЯ БУКВА КОРОТКАЯ I
0xEB U041A # ЗАГЛАВНАЯ БУКВА КА
0xEC U041B # ЗАГЛАВНАЯ БУКВА EL
0xED U041C # ЗАГЛАВНАЯ БУКВА EM
0xEE U041D # ЗАГЛАВНАЯ БУКВА EN
0xEF U041E # ЗАГЛАВНАЯ БУКВА О
0xF0 U041F # ЗАГЛАВНАЯ БУКВА PE
0xF1 U042F # ЗАГЛАВНАЯ БУКВА Я
0xF2 U0420 # ЗАГЛАВНАЯ БУКВА ER
0xF3 U0421 # ЗАГЛАВНАЯ БУКВА ES
0xF4 U0422 # ЗАГЛАВНАЯ БУКВА TE
0xF5 U0423 # ЗАГЛАВНАЯ БУКВА U
0xF6 U0416 # ЗАГЛАВНАЯ БУКВА ЖЕ
0xF7 U0412 # ЗАГЛАВНАЯ БУКВА VE
0xF8 U042C # МЯГКИЙ ЗНАК ЗАГЛАВНОЙ КИРИЛЛИЧЕСКОЙ БУКВЫ
0xF9U042B # ЗАГЛАВНАЯ БУКВА ЕРУ
0xFA U0417 # ЗАГЛАВНАЯ БУКВА ZE
0xFB U0428 # ЗАГЛАВНАЯ БУКВА SHA
0xFC U042D # ЗАГЛАВНАЯ БУКВА E
0xFD U0429 # ЗАГЛАВНАЯ БУКВА ЩА
0xFE U0427 # ЗАГЛАВНАЯ БУКВА ЧЕ
0xFF U042A # ТВЕРДЫЙ ЗНАК ЗАГЛАВНОЙ БУКВЫ КИРИЛЛИЦЫ
Вопросы безопасности
Этот меморандум не вызывает никаких известных проблем с безопасностью.
Благодарности
Автор выражает благодарность Маркусу Куну (Computer Science
лаборатории Кембриджского университета, Великобритания) за помощь в создании
Таблица кодирования KOI8-C.
использованная литература
[1] Чернов А., "Регистрация кириллического набора символов", RFC
1489, июль 1993 г.
[2] Украинский набор символов KOI8-U, RFC 2319. 1998.
Адрес автора
Серж Виницки
4 Аризона тер. #2
Арлингтон, Массачусетс, 02474
США
 Нецелесообразно использовать
Internet-Drafts в качестве справочного материала или цитировать их, кроме
как «работа в процессе».
Список текущих интернет-драфтов можно найти по адресу
http://www.ietf.org/ietf/1id-abstracts.txt Список
Доступ к теневым каталогам Internet-Draft можно получить по адресу
http://www.ietf.org/shadow.html.
Автор
Серж Виницки
Нецелесообразно использовать
Internet-Drafts в качестве справочного материала или цитировать их, кроме
как «работа в процессе».
Список текущих интернет-драфтов можно найти по адресу
http://www.ietf.org/ietf/1id-abstracts.txt Список
Доступ к теневым каталогам Internet-Draft можно получить по адресу
http://www.ietf.org/shadow.html.
Автор
Серж Виницки  Это расширение обеспечивает поддержку всех русских букв
(в том числе нужных для древнерусской орфографии), а также
Кириллические буквы, используемые в белорусском, македонском, сербском и
украинские языки и некоторые часто используемые типографские
символы, заимствованные из кодировки CP1251. Кодировка KOI8-C
совместим с существующими кодировками KOI8-RU и CP1251 в
соответствующие символы.
Мотивация
Семейство кодировок KOI8 уже давно используется для электронных
обмен кириллическими текстами [1,2]. Следующие соображения
побудили автора предложить расширение KOI8.
1) Большая часть таблицы кодирования KOI8 (большая часть 0x80-0xBF
диапазон) по историческим причинам занят символами
псевдографика, которая не используется в современном программном обеспечении. Эти символы
отсутствуют в большинстве реализаций шрифтов KOI8 без каких-либо последствий
на производительность пользователей. Эти места в таблице кодирования могут быть
используется для представления более часто используемых символов.
Это расширение обеспечивает поддержку всех русских букв
(в том числе нужных для древнерусской орфографии), а также
Кириллические буквы, используемые в белорусском, македонском, сербском и
украинские языки и некоторые часто используемые типографские
символы, заимствованные из кодировки CP1251. Кодировка KOI8-C
совместим с существующими кодировками KOI8-RU и CP1251 в
соответствующие символы.
Мотивация
Семейство кодировок KOI8 уже давно используется для электронных
обмен кириллическими текстами [1,2]. Следующие соображения
побудили автора предложить расширение KOI8.
1) Большая часть таблицы кодирования KOI8 (большая часть 0x80-0xBF
диапазон) по историческим причинам занят символами
псевдографика, которая не используется в современном программном обеспечении. Эти символы
отсутствуют в большинстве реализаций шрифтов KOI8 без каких-либо последствий
на производительность пользователей. Эти места в таблице кодирования могут быть
используется для представления более часто используемых символов. 2) Недавнее доминирование операционной среды «MS Windows».
привело к широкому распространению текстовых процессоров, использующих «код
page 1251" для отображения кириллицы. Многие интернет-документы
таким образом преобразуются в KOI8 из CP1251 и часто включают
некоторые типографские знаки, такие как апострофы, кавычки или
тире, не представленные в кодировках KOI8, но оставленные без
меняются автоматическими преобразователями. Эти типографские символы падают
в неиспользуемой области псевдографики KOI8.
3) Тексты в древнерусской орфографии (до 1918) содержат четыре
Кириллические буквы не представлены ни одним из широко используемых
Кириллические кодировки. Хотя инструменты на основе Unicode
быть адекватным для рендеринга этих символов, текущая
программное обеспечение в большинстве случаев не имеет необходимой поддержки. Это было бы
удобно иметь 8-битную кодировку, представляющую старую русскую
символов и иметь возможность размещать их непосредственно в шрифте
карта кодирования и раскладка клавиатуры, совместимая с широким диапазоном
текущего программного обеспечения.
2) Недавнее доминирование операционной среды «MS Windows».
привело к широкому распространению текстовых процессоров, использующих «код
page 1251" для отображения кириллицы. Многие интернет-документы
таким образом преобразуются в KOI8 из CP1251 и часто включают
некоторые типографские знаки, такие как апострофы, кавычки или
тире, не представленные в кодировках KOI8, но оставленные без
меняются автоматическими преобразователями. Эти типографские символы падают
в неиспользуемой области псевдографики KOI8.
3) Тексты в древнерусской орфографии (до 1918) содержат четыре
Кириллические буквы не представлены ни одним из широко используемых
Кириллические кодировки. Хотя инструменты на основе Unicode
быть адекватным для рендеринга этих символов, текущая
программное обеспечение в большинстве случаев не имеет необходимой поддержки. Это было бы
удобно иметь 8-битную кодировку, представляющую старую русскую
символов и иметь возможность размещать их непосредственно в шрифте
карта кодирования и раскладка клавиатуры, совместимая с широким диапазоном
текущего программного обеспечения. Реализация
Автор реализовал кодировку KOI8-C согласно этим
рекомендации: (1) совместимость с символами KOI8-R и KOI8-U
наборы, (2) совместимость с набором символов CP1251 в области
типографские символы и югославская кириллица; (3) нужно быть
умеет конвертировать шрифты в другие кириллические кодировки.
Нижняя часть набора символов KOI8-C является полной копией
ASCII в диапазоне печатных символов (0x20 -- 0x7F).
диапазон (0x00 -- 0x1F) занят псевдографикой и другими
редко используемые специальные символы.
Верхняя часть набора символов KOI8-C содержит все русские,
Белорусские и украинские буквы на позициях, определенных в KOI8-R
и КОИ8-У; часто используемые типографские символы (кавычки,
тире и символы валюты) и югославская кириллица как
определяется кодировкой CP1251; и старыми русскими буквами. Большая коробка
рисование символов из КОИ8-Р, а также некоторые математические
символы, были удалены.
Результирующий набор символов содержит все символы ISO 8859.
Реализация
Автор реализовал кодировку KOI8-C согласно этим
рекомендации: (1) совместимость с символами KOI8-R и KOI8-U
наборы, (2) совместимость с набором символов CP1251 в области
типографские символы и югославская кириллица; (3) нужно быть
умеет конвертировать шрифты в другие кириллические кодировки.
Нижняя часть набора символов KOI8-C является полной копией
ASCII в диапазоне печатных символов (0x20 -- 0x7F).
диапазон (0x00 -- 0x1F) занят псевдографикой и другими
редко используемые специальные символы.
Верхняя часть набора символов KOI8-C содержит все русские,
Белорусские и украинские буквы на позициях, определенных в KOI8-R
и КОИ8-У; часто используемые типографские символы (кавычки,
тире и символы валюты) и югославская кириллица как
определяется кодировкой CP1251; и старыми русскими буквами. Большая коробка
рисование символов из КОИ8-Р, а также некоторые математические
символы, были удалены.
Результирующий набор символов содержит все символы ISO 8859. -5 символов
кроме МЯГКОГО ДЕФИСА и охватывает CP1251 кроме 5 знаков препинания
символов (все также в CP1252).
Веб-страница
-5 символов
кроме МЯГКОГО ДЕФИСА и охватывает CP1251 кроме 5 знаков препинания
символов (все также в CP1252).
Веб-страница
 (УКС).
(УКС).
 Благодарности
Автор выражает благодарность Маркусу Куну (Computer Science
лаборатории Кембриджского университета, Великобритания) за помощь в создании
Таблица кодирования KOI8-C.
использованная литература
[1] Чернов А., "Регистрация кириллического набора символов", RFC
1489, июль 1993 г.
[2] Украинский набор символов KOI8-U, RFC 2319. 1998.
Адрес автора
Серж Виницки
4 Аризона тер. #2
Арлингтон, Массачусетс, 02474
США
Благодарности
Автор выражает благодарность Маркусу Куну (Computer Science
лаборатории Кембриджского университета, Великобритания) за помощь в создании
Таблица кодирования KOI8-C.
использованная литература
[1] Чернов А., "Регистрация кириллического набора символов", RFC
1489, июль 1993 г.
[2] Украинский набор символов KOI8-U, RFC 2319. 1998.
Адрес автора
Серж Виницки
4 Аризона тер. #2
Арлингтон, Массачусетс, 02474
США
Кириллица (русская) в Gmail
Кириллица (русская) в Gmail1. Как на
отправить кириллическое (русское) письмо из Gmail Gmail предоставляет два варианта для отправки незападноевропейских текстов.
По умолчанию Gmail пытается «угадать», в какой кодировке находится набранный вами текст.
(это первый вариант), а затем отправляет ваше сообщение, используя эту кодировку.
Если я набираю русский текст, Gmail разбирается и готовит исходящие
сообщение в русской кодировке «Кириллица(KOI8-R)».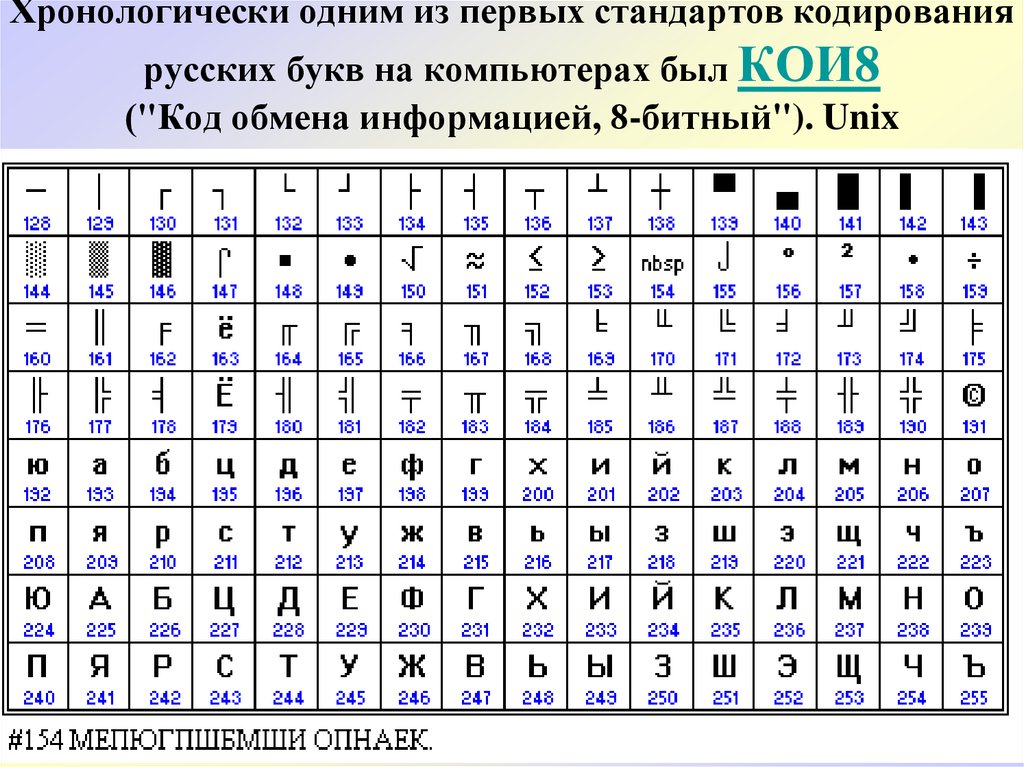
Если я наберу какой-нибудь русский и какой-нибудь немецкий , Gmail тоже правильно решает, что кодировка должна быть Unicode (UTF-8).
Если вы не хотите полагаться на такое «угадывание» или иметь с ним проблемы, то есть второй вариант — нажмите на «Настройки» вверху слева строка опций и на этой странице перейдите к опции «Кодировка исходящего сообщения» и выбрать их 2-ю — попросите Gmail использовать кодировку -always- UTF-8 для всех без исключения сообщение, которое вы отправляете.
Сможет ли получатель прочитать такое русскоязычное электронное письмо
(где русский текст представлен как текст в кодировке UTF-8, а не как текст какой-либо русской
кодирование) или нет, зависит от программного обеспечения, которое он использует.
Gmail формирует правильный системный заголовок со спецификацией кодировки:
кодировка = utf-8
Современные программы электронной почты, такие как Outlook Express, Mozilla (Thunderbird), MS Outlook, прекрасно отображают такое входящее письмо UTF-8.
Если получатель не использует программу mail , а использует современную веб-службу электронной почты, такую как как и Mail2web.com, то тоже должно быть нормально -. ему просто нужно выбрать кодировку UTF-8 в меню браузера, чтобы прочитать такое входящее письмо:
- Internet Explorer — Вид/Кодировка/Юникод(UTF-8)
- Mozilla/Firefox — Вид/Кодировка символов/Юникод (UTF-8)
2. Как
читать входящее кириллическое (Россия) письмо в GmailGMail работает с входящим русским (польским, греческим и т.д.) письмом следующим образом:
он всегда использует кодировку UTF-8, то есть преобразует все входящие электронные письма в UTF-8.
Следовательно:
- бесполезно пытаться изменить кодировку в меню вашего браузера — либо русский читается сразу либо вообще не читается.
- Если сообщение электронной почты было отправлено в GMail из современной программы Mail с правильным системным заголовком — заголовок MIME с указанной кодировкой, например
as charset=windows-1251 для почты России в кодировке «Кириллица, Windows-1251»,
то GMail будет отображать читаемый русский текст сразу:во-первых, зная кодировку этого входящего электронного письма, Gmail преобразует текст в кодировку UTF-8 , то есть, используя приведенный выше пример, Gmail выполнит преобразование
«Кириллица (Windows)» —> UTF-8а затем покажет текст на своей странице UTF-8.
- Во всех остальных случаях (см. ниже) письмо будет НЕчитаемо, просто какая-то тарабарщина. Случаи могут быть:
- электронное письмо было отправлено из Outlook Express, где отправитель НЕ менял настройки по умолчанию.
Настройки по умолчанию (в Tools/Options/Send): «нет MIME-заголовка, используйте Uuencode»,
то есть электронные письма отправляются без MIME-заголовка и, следовательно, НЕТ спецификации кодировки!
(чтобы правильно настроить Outlook Express, Mozilla Mail или Thunderbitd, пожалуйста, см. раздел этого сайта «Кириллица (русская) в браузерах/почте/новостях»Таким образом, Gmail получает электронное письмо, кодировка которого неизвестна. Таким образом, Gmail предполагает, что кодировка «западноевропейская» и выполняет — на русском тексте! — преобразование в UTF-8 по схеме
Очевидно, что искажает все буквы кириллицы!
«западноевропейский» —> UTF-8Более того, поскольку теперь это текст UTF-8 на странице UTF-8, а не русская или, скажем, немецкая страница, тогда нет смысла пытаться изменить кодировку в меню браузера — текст UTF-8 изменится на , а не на , почтовое сообщение останется нечитаемым.
- электронная почта была отправлена не из настоящей почтовой программы, а с использованием веб-интерфейса.
почтовый сервис, такой как Mail2Web.com.
Такие услуги:
- электронное письмо было отправлено из Outlook Express, где отправитель НЕ менял настройки по умолчанию.
Настройки по умолчанию (в Tools/Options/Send): «нет MIME-заголовка, используйте Uuencode»,
то есть электронные письма отправляются без MIME-заголовка и, следовательно, НЕТ спецификации кодировки!

Обходной путь для нечитаемых сообщений электронной почты:
- Открыть письмо на странице Gmail
- Найдите «дополнительные параметры» стрелку в правом верхнем углу рамки письма (рядом со словом «Ответить»)
- нажмите на него и выберите там «Текст сообщения искажен?»
- Затем на этой специальной странице просмотра вы можете выбрать кодировку в меню вашего браузера, чтобы сделать текст читабельным, например, в Internet Explorer попробуй Вид/Кодировка/»Кириллица(Windows)» и это не поможет тогда попробуй Кодировка KOI8-R. То есть пробуйте разные, пока не увидите читаемый текст.
Кодировка Base64 слова «Россия» — Base64 Encode and Decode
Встречайте Base64 Decode and Encode, простой онлайн-инструмент, который делает именно то, что говорит: декодирует из кодировки Base64, а также быстро и легко кодирует в нее.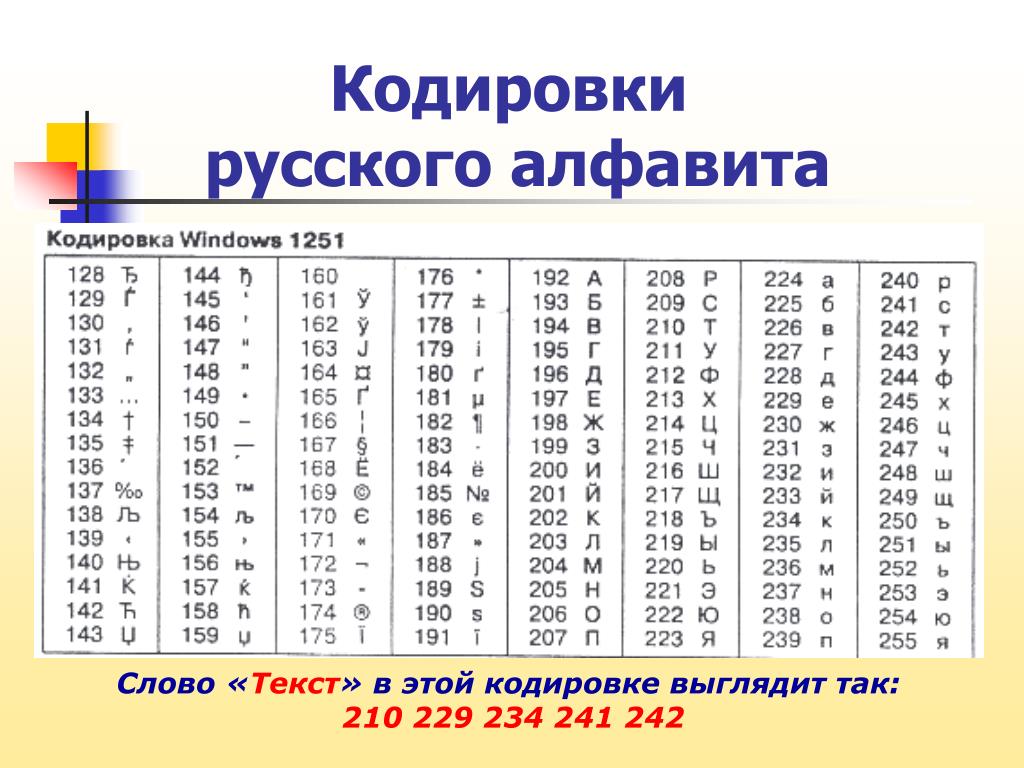 Base64 кодирует ваши данные без проблем или декодирует их в удобочитаемый формат.
Base64 кодирует ваши данные без проблем или декодирует их в удобочитаемый формат.
Схемы кодирования Base64 обычно используются, когда необходимо кодировать двоичные данные, особенно когда эти данные необходимо хранить и передавать через носители, предназначенные для работы с текстом. Это кодирование помогает гарантировать, что данные останутся нетронутыми без изменений во время транспортировки. Base64 обычно используется в ряде приложений, включая электронную почту через MIME, а также для хранения сложных данных в XML или JSON.
Дополнительные параметры
- Набор символов: Наш веб-сайт использует набор символов UTF-8, поэтому ваши входные данные передаются в этом формате. Измените этот параметр, если вы хотите преобразовать данные в другой набор символов перед кодированием. Обратите внимание, что в случае текстовых данных схема кодирования не содержит набора символов, поэтому вам может потребоваться указать соответствующий набор в процессе декодирования. Что касается файлов, то по умолчанию используется двоичный вариант, который исключает любое преобразование; эта опция необходима для всего, кроме обычных текстовых документов.
- Разделитель новой строки: В системах Unix и Windows используются разные символы разрыва строки, поэтому перед кодированием любой вариант будет заменен в ваших данных выбранным параметром. Для раздела файлов это частично не имеет значения, так как файлы уже содержат соответствующие разделители, но вы можете определить, какой из них использовать для функций «кодировать каждую строку отдельно» и «разбить строки на куски».
- Кодируйте каждую строку отдельно: Даже символы новой строки преобразуются в их закодированные формы Base64. Используйте эту опцию, если вы хотите закодировать несколько независимых записей данных, разделенных разрывами строк. (*)
- Разделить строки на части: Закодированные данные станут непрерывным текстом без пробелов, поэтому отметьте этот параметр, если хотите разбить его на несколько строк. Применяемое ограничение на количество символов определено в спецификации MIME (RFC 2045), в которой указано, что длина закодированных строк не должна превышать 76 символов. (*)
- Выполнить безопасное кодирование URL-адресов: Использование стандартного Base64 в URL-адресах требует кодирования символов «+», «/» и «=» в их процентно-кодированную форму, что делает строку излишне длинной. Включите этот параметр для кодирования в вариант Base64, совместимый с URL и именами файлов (RFC 4648 / Base64URL), где символы «+» и «/» соответственно заменены на «-» и «_», а также отступы «=». знаки опущены.
- Режим реального времени: Когда вы включаете эту опцию, введенные данные немедленно кодируются встроенными функциями JavaScript вашего браузера, без отправки какой-либо информации на наши серверы. В настоящее время этот режим поддерживает только набор символов UTF-8.
 Что касается файлов, то по умолчанию используется двоичный вариант, который исключает любое преобразование; эта опция необходима для всего, кроме обычных текстовых документов.
Что касается файлов, то по умолчанию используется двоичный вариант, который исключает любое преобразование; эта опция необходима для всего, кроме обычных текстовых документов. Применяемое ограничение на количество символов определено в спецификации MIME (RFC 2045), в которой указано, что длина закодированных строк не должна превышать 76 символов. (*)
Применяемое ограничение на количество символов определено в спецификации MIME (RFC 2045), в которой указано, что длина закодированных строк не должна превышать 76 символов. (*) 
Надежно и безопасно
Вся связь с нашими серверами осуществляется через безопасные зашифрованные соединения SSL (https). Мы удаляем загруженные файлы с наших серверов сразу после обработки, а полученный загружаемый файл удаляется сразу после первой попытки загрузки или 15 минут бездействия (в зависимости от того, что короче). Мы никоим образом не храним и не проверяем содержимое отправленных данных или загруженных файлов. Ознакомьтесь с нашей политикой конфиденциальности ниже для получения более подробной информации.
Совершенно бесплатно
Наш инструмент можно использовать бесплатно. Отныне вам не нужно скачивать какое-либо программное обеспечение для таких простых задач.
Детали кодирования Base64
Base64 — это общий термин для ряда подобных схем кодирования, которые кодируют двоичные данные, обрабатывая их численно и переводя в представление base-64. Термин Base64 происходит от конкретной кодировки передачи контента MIME.
Дизайн
Конкретный выбор символов, составляющих 64 символа, необходимых для Base64, зависит от реализации. Общее правило состоит в том, чтобы выбрать набор из 64 символов, который является одновременно 1) частью подмножества, общего для большинства кодировок, и 2) также пригодным для печати. Эта комбинация оставляет маловероятной возможность изменения данных при передаче через такие системы, как электронная почта, которые традиционно не были 8-битными. Например, реализация MIME Base64 использует A-Z, a-z и 0-9 для первых 62 значений, а также «+» и «/» для последних двух. Другие варианты, обычно производные от Base64, разделяют это свойство, но отличаются символами, выбранными для последних двух значений; примером является безопасный вариант URL и имени файла «RFC 4648 / Base64URL», в котором используются «-» и «_».
Пример
Вот фрагмент цитаты из «Левиафана» Томаса Гоббса:
» Человек отличается не только своим разумом, но..