Операции с данными для аналитики — извлечение ценной информации
Автоматизация управления данными
Современные среды обработки данных становятся все более распределенными и сложными. Объемы данных растут, а их типы становятся разнообразнее. Мы предлагаем более автоматизированный, основанный на политиках подход к управлению данными, чтобы вы могли получать больше аналитической информации и лучше удовлетворять потребности бизнеса.
Извлечение ценной информации
Легко объединяйте традиционные структурированные бизнес-данные с неструктурированными, чтобы получать совершенно новые результаты.
Маневренность бизнеса
Мы поможем вам обеспечить быстрый и надежный самостоятельный доступ к разнообразным данным, подготовленным для аналитики, в нужное время и в нужном месте.
Ускорение интеграции данных в 15 раз
Получайте новые разнообразные данные в 15 раз быстрее, чем при программировании конвейеров данных вручную.
Запись онлайн-курса Андрея Дорожного по работе с данными для начинающих: конспект, видео и дополнительные материалы
Команда Теплицы социальных технологий подготовила конспект онлайн-курса по работе с данными для НКО. На курсе дата-журналист Андрей Дорожный рассказал об особенностях работы с данными для сотрудников некоммерческих проектов, поделился инструментами и показал на примере, как можно работать с внутренними данными, понятно и красиво их визуализировать.
Мы собрали все видео и материалы курса, чтобы вы научились работать с данными без навыков программирования и начали извлекать из этого пользу в своей работе.
Вебинар № 1: Что такое данные?
Данные – это зарегистрированная информация, которая представлена в любой доступной для человека форме, это необработанные факты и цифры, их можно обрабатывать вручную и автоматическими способами. Данные можно использовать как новый способ рассказывать истории. Они могут помочь по-новому осветить проблему, которой занимается некоммерческий проект.
Данные можно использовать как новый способ рассказывать истории. Они могут помочь по-новому осветить проблему, которой занимается некоммерческий проект.
С помощью данных вы сможете проанализировать свою аудиторию, это даст вам понимание, как привлечь новую и оставить активной уже существующую. С помощью данных в некоммерческой организации можно оптимизировать внутренние процессы, например, лучше работать с финансами и документооборотом.
Дата-грамотность – важный навык современного пользователя, потому что сейчас публикуется огромное количество данных и умение пользоваться ими может дать вам суперсилу. Данные – это новая нефть, но машины не ездят на нефти. Наша задача – научиться обрабатывать данные: собирать, анализировать и визуализировать.
Андрей Дорожный,
дата-журналист и эксперт по визуализации данных
Дополнительные материалы вебинара
Вебинар № 2: Сбор данных. Открытые данные
 youtube.com/embed/p-TfB3RE1dM?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/p-TfB3RE1dM?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Источниками данных может стать государство, коммерческие и некоммерческие компании, также есть альтернативные источники, которые можно сформировать с помощью веб-скрейпинга и краудсорсинга данных.
Веб-скрейпинг – это технология, которая позволяет получать данные из веб-ресурсов.
Краудсорсинг данных – это привлечение большого количества людей для сбора и формирования данных на конкретную тему и для дальнейшей обработки.
Отдельно следует вынести такой вид данных, как «открытые данные» – те, что доступны для машиночитаемого использования и дальнейшей републикации без ограничений авторского права, патентов и других механизмов контроля. Открытые данные позволяют повысить качество предоставления электронных государственных услуг, сделать их более полезными для пользователя и увеличить гражданский контроль, они позволяют делать больше аналитики и создавать на основе этих данных полезные сервисы./database-157334670-5c29939d46e0fb0001edf766.jpg)
Если посмотреть на характеристики основных видов данных, то все они обладают некоторыми свойствами. Государственные и общественные данные самые доступные, а коммерческие доступны, как правило, только по специальным соглашениям. Что касается качества, то общественные и государственные данные имеют чаще всего невысокое качество, а коммерческие данные, напротив, обладают высоким качеством.
Андрей Дорожный,
дата-журналист и эксперт по визуализации данных
Дополнительные материалы вебинара
- Презентация вебинара
- Источники государственных данных: ЕМИСС, Росстат
- Общественные данные: Википедия и Викидата
- Шпаргалка: как запросить открытые данные у государства
- Телеграм-чат открытых данных России
- Международные базы данных: Всемирная Организация Здравоохранения, Организации Объединенных Наций, Population Reference Bureau, Данные UNICEF, Каталог общедоступных данных Google, Хаб данных, Данные DBPedia, Factual, Бесплатные ГИС-данные, Список открытых ресурсов с данными, Репозитории данных по темам, World Research Institute, Quora тема: «Где я могу найти большие массивы данных в открытом доступе?», Директория APIs, Infochimps, Оффшорные Утечки, Investigative Dashboard, Open Corporates, Natural Earth Data, Программа ООН по окружающей среде, Индекс восприятия коррупции, База данных по сделкам с землей, Gapminder, Глобальная Лаборатория Данных
- Dataset Search
- На все случаи данных
- Сборник источников данных в Trello
- Карты данных от Инфокультуры
- Сервисы для веб-скрейпинга: Table capture, Instant data scraper, Data Toolbar (Windows), Web Scraper (All OS)
Вебинар № 3: Очистка данных
 youtube.com/embed/_taIaaJzP94?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/_taIaaJzP94?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Прежде чем начать работать с данными, их необходимо чистить, только после чистки с ними возможно работать: фильтровать и сортировать, обобщать и анализировать, визуализировать и в итоге принимать на их основе решения. В третьем вебинаре вас ждет практика по очистке данных на примере датасета, где вы сможете вместе с ведущим курса подготовить его для дальнейшей обработки.
Есть такое понятие, как tidy data – чистые и структурированные данные. Для чего нам вообще чистить данные? Мы можем анализировать только чистые данные, иначе наши выводы и проекты на их основе не будут отражать реальность и мы не сможем получить корректных результатов.
Андрей Дорожный,
дата-журналист и эксперт по визуализации данных
Чек-лист очистки данных
- Посмотрите датасет, проверьте вкладки, объем датасета.

- Переименуйте файл, вкладку (латинскими буквами).
- Очистите форматирование.
- Очистите шапку, сделайте в одну строку.
- Описания колонок сохраните в отдельную вкладку (латинские буквы).
- Поправьте форматы переменных (числа, текст).
- Заморозьте первую строку.
- Проверьте датасет на дубликаты.
- Если есть, удалите дубликаты.
- Разделите необходимые колонки.
- Проверьте все 10 пунктов.

Дополнительные материалы вебинара
Вебинар № 4: Базовые знания функций табличного редактора
Четвертый вебинар посвящен практике, вы научитесь анализу данных с помощью табличного редактора. Андрей Дорожный использует Google Таблицы, но все действия подходят и для Microsoft Excel, если на вашем личном или рабочем компьютере установлена лицензионная версия. С помощью данного вебинара вы научитесь сортировке и суммированию, расчету среднего значения и процентов, а также узнаете, как объединять датасеты и анализировать изменения показателей в них.
С помощью данного вебинара вы научитесь сортировке и суммированию, расчету среднего значения и процентов, а также узнаете, как объединять датасеты и анализировать изменения показателей в них.
С помощью табличного редактора мы можем фильтровать и сортировать данные, упорядочить по показателям, применять к ним определенные расчеты, использовать макросы. Мы будем делать связку – задавать вопросы к данным и искать с их помощью ответы.
Андрей Дорожный,
дата-журналист и эксперт по визуализации данных
Материал для проработки вебинара
Вебинар № 5: Сводные таблицы. Визуализация данных в google spreadsheet
Пятый вебинар посвящен практике, вы научитесь создавать сводные таблицы с помощью Google Таблицы, задавая правильные вопросы датасету, а также вместе с экспертом создадите визуализацию «в один клик» в табличном редакторе.
Есть такое мнение, что с помощью табличных редакторов невозможно сделать красивую визуализацию. Люди ошибочно полагают, что это очень плохой инструмент, но на самом деле это не так. Табличные редакторы имеют много шаблонов, которые возможно применять для визуализации и которые будут выглядеть отлично.
Андрей Дорожный,
дата-журналист и эксперт по визуализации данных
Материал для проработки вебинара
Вебинар № 6: Визуализация данных
Визуализация позволяет нам сформулировать сообщение, которое мы хотим представить читателю, переводя язык цифр на визуальный язык. Это упрощает коммуникацию и делает проект более понятным и привлекательным.
Процесс работы над визуализацией выглядит так: определить проблему реального мира → выразить проблему в формате данных → выбрать визуальную форму → создание визуализации с помощью инструментов.
Вид графика Bar chart – самый лучший способ визуализировать разницу в показателях, а Pie chart поможет изобразить соотношение между показателями. Если вам нужно представить количественные показатели за определенный период, то для этого лучше всего использовать график Line chart.
Наличие графика не гарантирует, что ваша информация станет релевантной для адресата и натолкнет его на какие-то действия. Для того чтобы успешно донести свое сообщение, нам необходимо правильно его сформулировать – это одна из самых важных и сложных задач в визуализации.
Андрей Дорожный,
дата-журналист и эксперт по визуализации данных
Дополнительные материалы вебинара
Что почитать
Вебинар № 7: Основы картографии
 youtube.com/embed/TGisNBm7VDU?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/TGisNBm7VDU?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Седьмой вебинар посвящен практике: Андрей Дорожный наглядно показал, как сделать карту из простого файла csv без программирования, превратить ее в интерактивную и поставить себе на сайт, а также как преобразовать текстовые адреса в координаты широты и долготы.
С помощью данных с геопривязкой и размещения этих данных на карту можно наилучшим образом показать распространенность того или иного явления. На самом деле есть быстрые и простые способы использования такого рода визуализации.
Андрей Дорожный,
дата-журналист и эксперт по визуализации данных
Дополнительные материалы вебинара
- Презентация вебинара
- Инструменты для создания карт: Геокодер, QGIS, Mapbox, Google Maps, Carto, Datawrapper, Tableau, Flourish
- Что почитать: Блог компании Урбика, Картография в Tableau, Блог компании Mapbox, Блог компании Carto, Картографические сервисы для исследования вашего района
с чего начать.
 Читайте на Cossa.ru
Читайте на Cossa.ruПроведите аудит данных
Для начала вам необходимо составить список всех бизнес-функций и решений, которые вы принимаете. Это может оказаться достаточно долгим и скучным процессом, но хорошая новость заключается в том, что повторять эту работу часто вам не придётся.Классифицируйте данные
Скорее всего, некоторые данные у вас уже имеются или вы знаете, как их можно быстро собрать. С другими же могут возникнуть сложности. Разберите все данные на несколько категорий: есть в наличии, нет в наличии, отсутствуют и неизвестно как их получить, отсутствуют, но есть идеи как их заполучить. Такая классификация поможет вам определиться с дальнейшими шагами и правильно распределить своё время, работая над сбором и аналитикой данных.
Расставьте приоритеты
Как вы прекрасно понимаете, далеко не все данные одинаково полезны. Некоторая информация поможет вам добиться внушительных результатов и позволит вашему бизнесу расти, другая же может оказаться почти бесполезной. Именно поэтому на данном этапе очень важно расставить приоритеты и заняться сбором информации, которой у вас нет, но которую можно найти и которая будет полезна для вашего бизнеса. Ничего страшного, если в процессе работы с данными ваши приоритеты будут меняться.Выстройте способы получения данных
Запомните, работа с данными подразумевает не прекращение вашей основной деятельности. Другими словами, вам не стоит забывать о реальной работе в то время как вы собираете необходимую информацию. Вместо этого выстройте способы получения данных.
Определитесь с местом хранения данных
К сожалению, некоторые аналитики забывают или не уделяют должного внимания вопросы хранения данных. А ведь безопасный обмен данными не менее важен, чем возможность найти информацию. Согласно данным компании Harris Interactive, 92% людей по старинке продолжают отсылать информацию в формате вложения в письмах электронной почты, что значительно повышает вероятность отправить не тот документ, потерять письмо в большом количестве входящей корреспонденции или допустить утечку информации, если случайно забыть телефон в такси. Более надежный вариант — пользоваться безопасными способами обмена данными, например DropBox или Google Drive, или использовать облачное приложение для хранения данных, чтобы у вас был один источник информации.
P.S. Понравилось? Подписывайтесь на рассылку по бизнесу и маркетингу: раз в неделю присылаем полезные советы, ценные идеи из новинок и, конечно, особые скидки на книги — только для своих.
Как это делают крупные компании / Блог компании 1cloud.ru / Хабр
/ фото Jason Tester Guerrilla Futures CC
Компания IDC сообщает, что в 2011 году человечеством было сгенерировано 1,8 зеттабайт информации. В 2012 году эта цифра составила уже 2,8 зеттабайт, а к 2020 она увеличится до 40 зеттабайт.
Существенную часть этих данных генерируют крупные мировые компании, такие как Google, Facebook, Apple. Им нужно не просто хранить данные, но и выполнять резервное копирование, следить за их актуальностью, обрабатывать, причем делать это с минимальными затратами. Поэтому ИТ-отделы крупных организаций разрабатывают собственные системы для решения этих задач.
По словам Шона Галлахера (Sean Gallagher), редактора Ars Technica, компания Google стала одним из первых веб-игроков, кто встретил проблему масштабирования хранилищ грудью.
Если верить исследователю Санджаю Гхемавату (Sanjay Ghemawat) и старшим инженерам Говарду Гобиоффу (Howard Gobioff) и Шунь-Так Лэуну (Shun-Tak Leung) из Google, то GFS разработана с определенной спецификой. Её цель – превратить огромное количество дешевых серверов и жестких дисков в надежное хранилище для сотен терабайт данных, к которым имеют доступ множество приложений одновременно.
GSF является основой практически всех облачных сервисов Google. Google хранит данные приложений в огромных файлах, в которые сотни машин дописывают информацию одновременно. Более того, запись в файл может вестись прямо в тот момент, когда с ним ведется работа.
/ The Google File System
Система содержит мастер-серверы и серверы фрагментов (chunkservers), которые хранят данные. Обычно GFS-кластер состоит из одной главной мастер-машины и множества серверов фрагментов. Файлы в GFS разбиваются на куски с фиксированным, но настраиваемым размером, которые серверы фрагментов хранят как Linux-файлы на локальном жестком диске (однако для повышения надежности каждый фрагмент дополнительно реплицируется на другие серверы).
Файлы в GFS разбиваются на куски с фиксированным, но настраиваемым размером, которые серверы фрагментов хранят как Linux-файлы на локальном жестком диске (однако для повышения надежности каждый фрагмент дополнительно реплицируется на другие серверы).
Что касается мастера, то он отвечает за работу с метаданными и контролирует всю глобальную деятельность системы: управление фрагментами, сборка мусора, перемещение фрагментов между серверами и т. д.
Одной из главных проблем подобной системы значатся частые сбои в работе её компонентов, поскольку она строится на базе большого количества дешевого оборудования. Сбой может быть вызван как недоступностью элемента системы, так и наличием испорченных данных. Но в Google были к этому готовы, поэтому GFS постоянно мониторит компоненты и в случае отказа какого-либо из них принимает необходимые меры для поддержания работоспособности системы.
Поврежденные фрагменты определяются при помощи вычисления контрольных сумм. Каждый кусок разбивается на блоки по 64 КБ с 32-битной контрольной суммой.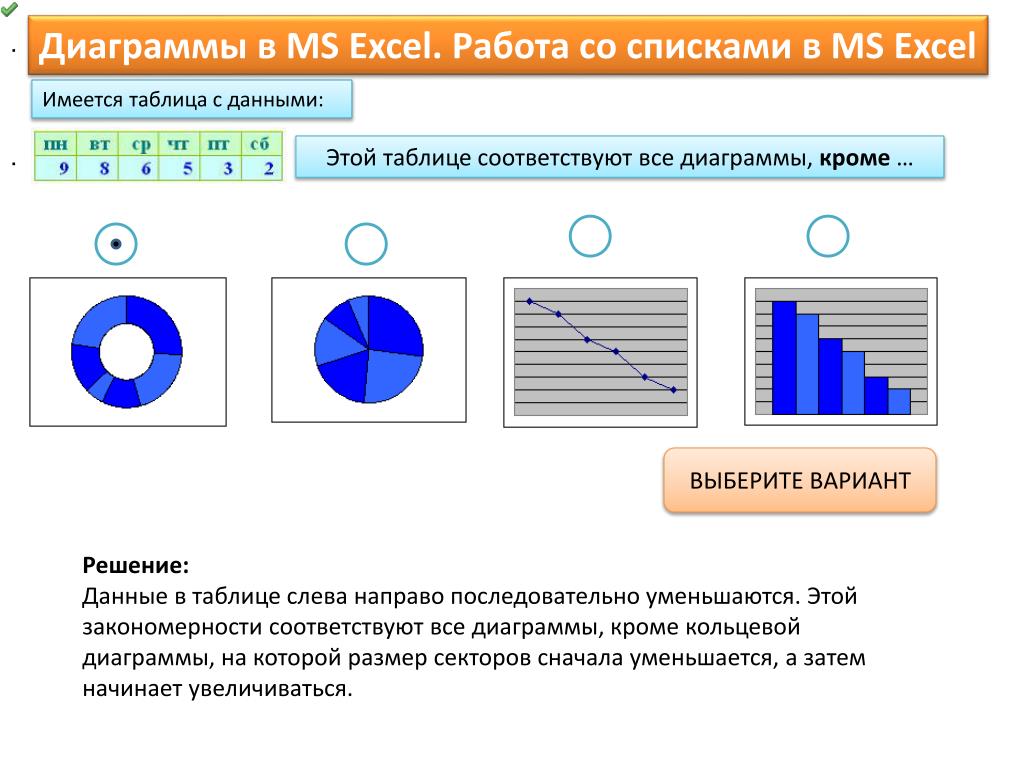
За все время существования GFS платформа Google развивалась и адаптировалась под новые требования, у поисковика появлялись новые сервисы. Получилось так, что размеры кластеров в GFS перестали подходить для эффективного хранения всех типов данных. К 2010 году исследователи компании изучили достоинства и недостатки GFS и применили приобретённые знания для создания новых программных систем.
Так на свет появились распределенная файловая система Colossus (GFS2), Spanner (развитие BigTable) – масштабируемое геораспределенное хранилище с поддержкой версионности данных, масштабируемая система обработки запросов Dremel, Caffeine – инфраструктура поисковых сервисов Google, использующая GFS2, итеративный MapReduce и next-generation BigTable, и др. Сегодня они решают более сложные задачи и обрабатывают большее количество информации, открывая новые возможности.
/ фото Atomic Taco CC
Однако с большими объемами данных «сражается» не только Google. Необычный подход к хранению данных и репликации нашла компания Uber. Вместо того чтобы постоянно синхронизировать базу данных между ЦОДами, специалисты сервиса по предоставлению автомобилей решили организовать внешнюю распределенную систему из телефонов водителей.
Необычный подход к хранению данных и репликации нашла компания Uber. Вместо того чтобы постоянно синхронизировать базу данных между ЦОДами, специалисты сервиса по предоставлению автомобилей решили организовать внешнюю распределенную систему из телефонов водителей.
В компании отмечают, что главная цель этого решения – повышение отказоустойчивости. Такой подход надежно защищает данные от сбоев в дата-центрах. При использовании классической стратегии репликации гарантировать сохранение информации о поездке было сложно из-за особенностей систем управления сетями.
Обычное решение при сбоях в ЦОДе – передать данные с активного дата-центра на резервный, однако при наличии более чем двух ЦОДов сложность инфраструктуры резко возрастает, возникает задержка репликации между дата-центрами и требуется высокая скорость соединения.
В случае Uber, если в дата-центре произойдет какая-либо ошибка, информация о поездке всегда сохранится на мобильном устройстве водителя. Поскольку смартфон обладает самыми актуальными данными, то именно с него актуальная информация поступает в ЦОД, а не наоборот.
Мобильные телефоны водителей отправляют данные каждые 4 секунды. «По этой причине перед Uber стояла задача обработки миллионов операций записи в секунду», – отметил Мэтт Рэнни (Matt Ranney), главный разработчик архитектуры системы Uber, в ходе презентации о масштабировании платформы.
Весь процесс выглядит следующим образом. Водитель обновляет свой статус, например, в тот момент, когда забирает пассажира, и отправляет запрос в службу диспетчеризации. Последняя обновляет модель поездки и оповещает об этом службу репликации. Когда репликация выполнена, диспетчер обновляет хранилище данных и сообщает мобильному клиенту об успешном завершении операции.
В это же время служба репликации кодирует информацию и передает её службе обмена сообщениями, поддерживающей двунаправленный канал связи с водителями. Этот канал никак не связан с исходным каналом запросов, поэтому процессы восстановления данных не влияют на бизнес-процессы. Далее служба обмена сообщениями отправляет резервную копию на телефон.
«Цифровая платформа Uber агрегирует поразительное количество данных, – отметил Тайлер Джеймс Джонсон (Tyler James Johnson) в Convergent Technology Advisors. – Карты, маршруты, информация о предпочтениях клиентов, связи – это лишь малая часть содержимого хранилищ Uber. Компания много инвестирует в развитие цифровых технологий. Данные – это основа всего».
Эти данные важно сохранить, поскольку они пригодятся компании в будущем. Не за горами появление автопилотируемых автомобилей. Компания Gartner предсказывает, что одна из пяти машин в мире будет обладать беспроводным подключением уже к 2020 году, а это, на секундочку, 250 миллионов подключенных транспортных средств.
Пока что лидером на этом рынке остается Google, но параллельно с технологическим гигантом над подобными системами работают Tesla, Ford, Apple. Не отстает и Uber. У компании имеется Центр разработки передовых технологий, который работает в партнерстве с Университетом Карнеги – Меллона в Питтсбурге. В нем разрабатывают умные автомобили и другие технологии, способные помочь компании повысить качество предоставляемых сервисов и снизить их стоимость.
В нем разрабатывают умные автомобили и другие технологии, способные помочь компании повысить качество предоставляемых сервисов и снизить их стоимость.
«Увеличение объемов создаваемого и потребляемого цифрового контента приведет к необходимости создания новых более сложных информационных систем, – сказал Джеймс Хайнс (James Hines), руководитель исследований в Gartner. – В то же время применение этих технологий в автосфере приведет к появлению новых бизнес-моделей и подходов к владению автомобилями в городской среде».
P.S. Мы стараемся делиться не только собственным опытом работы над сервисом по предоставлению виртуальной инфраструктуры 1cloud, но и рассказывать о смежных областях знаний в нашем блоге на Хабре. Не забывайте подписываться на обновления, друзья!
Совет по этике работы с данными утвердил первые практики в «Белую книгу»
В Москве прошло первое заседание Совета по этике работы с данным, который будет следить за соблюдением принципов Кодекса этики использования больших данных. Члены совета также утвердили перечень первых добросовестных практик работы с данными для «Белой книги».
Члены совета также утвердили перечень первых добросовестных практик работы с данными для «Белой книги».
В Москве прошло первое заседание Совета по этике работы с данным, который будет следить за соблюдением принципов Кодекса этики использования больших данных. Члены совета также утвердили перечень первых добросовестных практик работы с данными для «Белой книги».
Кодекс этики использования данных был принят ведущими компаниями в декабре 2019 года, документ представляет собой свод правил и положений этичного обращения с данными и является основой саморегулирования рынка больших данных в России.
В состав Совета по этике вошли представители компаний-подписантов Кодекса: Газпром-медиа холдинг, Яндекс, МегаФон, Тинькофф Банк, Сбербанк, Газпромбанк, oneFactor, Группа QIWI, Mail.ru Group, Группа ВТБ, ВымпелКом, Фонд Сколково, Ростелеком, МТС, а также представители Аналитического центра при Правительстве, Ассоциации больших данных и Института развития интернета.
«На мой взгляд, создание Совета по совершенствованию практик работы с данными, — это очень важная инициатива, если мы говорим о серьезном современном подходе к работе с данными», — заявил первый заместитель руководителя Аналитического центра при Правительстве Российской Федерации Владислав Онищенко. Он напомнил, что Аппарат Совета сформирован на базе Аналитического центра, и уже ведёт активную работу над Реестром добросовестных участников рынка данных и «Белой книгой» лучших практик использования данных. «Сегодня данные — это актив, и грамотное управление ими обеспечивает их качество, защиту от утечек, соблюдение этических норм и правил», — уверен Владислав Онищенко. Добровольное присоединение к Кодексу этики использования данных, ведение «Белой книги» лучших практик работы с данными эксперт считает теми инструментами, которые помогают самоорганизации рынка и поддерживают его здоровое развитие. «В ситуации формирования рынка данных именно эти инструменты становятся основой его быстрого становления и успешного развития», — подчеркнул он.
Главные задачи Совета — контроль за соблюдением принципов Кодекса присоединившимися компаниями и наполнение «Белой книги» практиками добросовестного использования данных. Она представляет из себя свод примеров обращения с данными, которые компании лидеры отрасли применяют для улучшения пользовательского опыта, защиты клиентов и предотвращения мошенничества и коррупции. «Белая книга» является значимой для всего рынка данных, так как отражает добросовестность и ответственность участников Кодекса, которые открыто делятся своим опытом. Это живой документ, который будет постоянно дополняться Советом и стимулировать внедрение лучших бизнес-практик в сфере использования данных, а также предупреждать нарушение законодательства Российской Федерации и положений Кодекса этики.
«Институт развития интернета являлся одним из инициаторов разработки Кодекса этики использования данных. В документе закреплены базовые положения добросовестной работы с данными и, как представляется — это только начало пути. Необходимо обеспечить «жизнь» согласованных подписантами принципов через наполнение «Белой книги» реальными практическими кейсами, через профессиональную оценку методов и технологий обработки данных. Хочется надеется, что и предпринимательское сообщество, и потребители смогут «почувствовать» полезность проводимой работы. По итогам заседания был определен перечень добросовестных игроков рынка больших данных и добавлены первые практики-примеры ответственного поведения в отношении обращения с данными в «Белую книгу». Уверен, что Совет способен стать партнером регуляторов при подготовке ими законодательных изменений», — отмечает заместитель генерального директора по правовым вопросам АНО «ИРИ» Борис Едидин.
Необходимо обеспечить «жизнь» согласованных подписантами принципов через наполнение «Белой книги» реальными практическими кейсами, через профессиональную оценку методов и технологий обработки данных. Хочется надеется, что и предпринимательское сообщество, и потребители смогут «почувствовать» полезность проводимой работы. По итогам заседания был определен перечень добросовестных игроков рынка больших данных и добавлены первые практики-примеры ответственного поведения в отношении обращения с данными в «Белую книгу». Уверен, что Совет способен стать партнером регуляторов при подготовке ими законодательных изменений», — отмечает заместитель генерального директора по правовым вопросам АНО «ИРИ» Борис Едидин.
Первыми практиками, закрепленными в «Белой книге», стали примеры работы с данными, направленные на обеспечение удобства и безопасности граждан. Так, добросовестными были признаны практики противодействия мошенничеству со счетами клиентов. Например, рынком одобрен обмен данным между кредитными организациями и операторами сотовой связи (ОСС) для предотвращения мошеннических схем методом социальной инженерии, когда преступники имитируют звонки от банков, и для предотвращения противоправных действий в случаях смены клиентом сим-карты или прекращения договора с оператором связи.
Для обеспечения удобства клиентов при сборе согласий на обработку персональных данных дистанционным способом в «Белую книгу» включена практика по предоставлению клиентам возможности идентификации с помощью цифровых идентификаторов, например, Банк ID или Mobile ID или других надежных альтернативных идентификаторов. Такой пример обращения с данными дает клиентам возможность быстро и удобно подтвердить свою личность без дополнительных согласий и документов.
«Единогласная поддержка Советом практик этичного обращения с данными для включения в «Белую книгу» подчеркивает значимость и пользу от использования единых подходов для взаимодействия бизнеса с гражданами и государством. Крайне важно развивать рынок данных на базе конкретного опыта ведущих игроков, которые убедились в действенности предлагаемых мер, направленных на должное обеспечение безопасности пользователей. Мы призываем компании присоединяться к Кодексу этики для создания доверия между игроками рынка и развития саморегулирования. Так Россия станет лидером в сфере добросовестного обращения с данными», — уверена Президент Ассоциации больших данных Анна Серебряникова.
Так Россия станет лидером в сфере добросовестного обращения с данными», — уверена Президент Ассоциации больших данных Анна Серебряникова.
Источник: Пресс-служба Ассоциации больших данных
Telegram заблокировал каналы с данными участников протестов и силовиков
Telegram заблокировал каналы с личными данными граждан России, как участников протестных акций, так и сотрудников силовых структур, сообщил Интерфакс со ссылкой на основателя мессенджера Павла Дурова.Ранее заблокировать эту информацию требовал Роскомнадзор. Как сообщил Дуров в своем телеграм-канале, за последние недели Telegram заблокировал несколько каналов, «которые выкладывали в публичный доступ телефонные номера и адреса участников протестов в России».
«Вместе с ними появились каналы, где публикуются домашние адреса и телефонные номера судей, прокуроров, правоохранителей, а также журналистов и медиаменеджеров. <…> Подобное использование Telegram прямо противоречит нашим правилам, которые запрещают публичные призывы к насилию. Принимая во внимание эмоциональный накал обстановки в России, мы тщательно анализировали ситуацию, не желая нанести вред поспешным решением», — написал он.
Принимая во внимание эмоциональный накал обстановки в России, мы тщательно анализировали ситуацию, не желая нанести вред поспешным решением», — написал он.
Однако, отметил Дуров, «в связи с этими каналами уже более недели не выходит экстренное обновление Telegram для iOS — оно не получает одобрение Apple. В результате сегодня мы приняли решение заблокировать проблемные каналы с личными данными. Прошу авторов публичных Telegram-каналов не распространять призывы к насилию и личные данных других людей. Благодаря этому мы сможем продолжить обновлять Telegram в App Store и Google Play, последовательно применяя наши правила ко всем нарушителям, независимо от их политических взглядов».
Роскомнадзор 1 февраля потребовал от мессенджера Telegram прекратить незаконное распространение персональных данных граждан «на основании полученных обращений граждан», так как публикация персональных данных граждан без их согласия противоречит закону РФ «О персональных данных» и политике самой компании Telegram Group Inc. В ведомстве отметили, что «нарушение конфиденциальности персональных данных угрожает безопасности лиц, чьи данные продолжают оставаться в открытом доступе при попустительстве компании».
В ведомстве отметили, что «нарушение конфиденциальности персональных данных угрожает безопасности лиц, чьи данные продолжают оставаться в открытом доступе при попустительстве компании».
Ранее газета «Коммерсантъ» сообщила, что после несанкционированных митингов оппозиции в поддержку Алексея Навального 23 января в мессенджере Telegram появился канал, который собирает и публикует персональные данные полицейских и росгвардейцев, участвующих в задержаниях.
| Название услуги | Описание услуги | Направление | ПО |
|---|---|---|---|
| Практический обучающий семинар по Avocet | Практический обучающий семинар по Avocet. | Операционная деятельность по добыче | Avocet |
| Сервис по сбору данных в Avocet | Работы по построению загрузчика данных из внешнего источника (сторонней системы) в Avocet. | Операционная деятельность по добыче, Разработка программного обеспечения | Avocet |
| Повышение производительности Avocet | Примеры успешного применения и рекомендации по оптимизации инфраструктуры для Avocet. Проверка на соответствие текущей инфраструктуры требованиям Avocet и настройка для повышения производительности. Включает рекомендации как по аппаратному обеспечению, так и по структуре базы данных. | Операционная деятельность по добыче | Avocet |
| Разработка отчётов в Avocet под требования заказчика | Разработка отчётов под требования заказчика как средствами Avocet, так и сторонними приложениями. | Операционная деятельность по добыче, Разработка программного обеспечения | Avocet |
| Поддержка Avocet на площадке заказчика | Поддержка Avocet на площадке заказчика. Например, еженедельное посещение клиента для оценки процесса сбора данных и подготовка отчёта. | Операционная деятельность по добыче | Avocet |
| Обновление версии Avocet | Обновление до последней версии. | Операционная деятельность по добыче | Avocet |
| Постпроектное сопровождение и аудит Avocet | Ежегодное посещение с целью проверки производительности Avocet, соответствия требованиям клиента и проработка вариантов возможного улучшения. | Операционная деятельность по добыче | Avocet |
| Внедрение Avocet | Установка, настройка, интеграция в инфраструктуру заказчика и оптимизация производительности Avocet. Включает интеграцию с продуктами Шлюмберже и третьесторонними PDMS решениями (FieldView, ADM, TOW, и другое). | Управление и оптимизация добычи, Управление информацией | Avocet |
 Например, MS SQL Server Reporting Services.
Например, MS SQL Server Reporting Services. Включает встречи с техническими специалистами и предоставление отчёта по результатам встреч с указанием вариантов возможного развития.
Включает встречи с техническими специалистами и предоставление отчёта по результатам встреч с указанием вариантов возможного развития.Руководство по визуализации данных для бизнес-профессионалов: Nussbaumer Knaflic, Cole: 978111
53: Amazon. com: Books
com: Books «В серии Storytelling with Data Коул создала , являющееся актуальным дополнением к работе пионеров визуализации данных, таких как Эдвард Тафте . Она работала в некоторых из наиболее ориентированных на данные организациях на планете и работала с ними, а также некоторые из наиболее целеустремленных организаций, не использующих данные. В обоих случаях она помогла отточить их идеи и их мышление.»
— Ласло Бок, старший вице-президент по работе с персоналом, Google, Inc. и автор рабочих правил!
похвалы за рассказывание историй с помощью данных
« Рассказывание историй с помощью данных — это великолепно написанная, мастерская демонстрация редких произведений искусства в мире бизнеса. Коул Нуссбаумер Кнафлик обладает уникальной способностью — даром — рассказывать истории через данные В JPMorgan Chase она помогла улучшить наши возможности объяснять сложный анализ исполнительному руководству и регулирующим органам, с которыми мы работаем. Книга Коул объединяет ее таланты в удобном для чтения руководстве с превосходными примерами, на которых каждый может извлечь уроки, чтобы способствовать более разумному принятию решений. «
Книга Коул объединяет ее таланты в удобном для чтения руководстве с превосходными примерами, на которых каждый может извлечь уроки, чтобы способствовать более разумному принятию решений. «
—Марк Р. Хиллис, Директор по рискам ипотечного банковского обслуживания в JPM Chase
» У нас так много данных, что может быть трудно заставить людей обратить внимание на наши важные выводы. Коул Нуссбаумер Кнафлик преподала нам ценные уроки на своем семинаре, и замечательно видеть, что они были расширены в Storytelling with Data . Моя команда уже использует уроки, которые преподает Коул, чтобы побуждать людей к действию, когда они видят новые жемчужины понимания и меняют жизни других. Теперь могут и другие! «
—Элеанор Белл, Директор по бизнес-аналитике в Фонде Билла и Мелинды Гейтс
« Есть что-то прекрасное в том, чтобы быть последовательными со своими собственными учениями. Коул Нуссбаумер Кнафлик достигает этого в своей первой книге. Она выступает за ясность и лаконичность в визуализации, и ее книга настолько ясна, лаконична и практична, насколько это возможно. Если вы новичок в визуализации или если вам сложно создавать хорошие диаграммы в повседневной работе с помощью таких инструментов, как Excel, Tableau, Qlik и т.п., это отличное место для начала изучения основных принципов ».
— Альберто Каиро, кафедра визуальной журналистики Knight и профессор визуализации в Университете Майами, автор книги The Functional Art
«Слайды данных на самом деле не о данных, они о значении данных.Коул Нуссбаумер Кнафлик понимает это и написал простое и доступное руководство, которое поможет любому, кто общается с помощью данных, более эффективно взаимодействовать со своей аудиторией. «
— Нэнси Дуарте, генеральный директор Duarte, Inc. и автор бестселлеров.
С задней обложки
похвалы за рассказывание историй с данными
« Рассказывание историй с помощью данных — это великолепно написанный, мастерский показ редких произведений искусства в мире бизнеса. Коул Нуссбаумер Кнафлик обладает уникальной способностью — даром — рассказывать истории с помощью данных. В JPMorgan Chase она помогла расширить наши возможности объяснять сложный анализ исполнительному руководству и регулирующим органам, с которыми мы работаем. Книга Коул объединяет ее таланты в удобном для чтения руководстве с превосходными примерами, на которых каждый может извлечь уроки, чтобы способствовать более разумному принятию решений. «
Коул Нуссбаумер Кнафлик обладает уникальной способностью — даром — рассказывать истории с помощью данных. В JPMorgan Chase она помогла расширить наши возможности объяснять сложный анализ исполнительному руководству и регулирующим органам, с которыми мы работаем. Книга Коул объединяет ее таланты в удобном для чтения руководстве с превосходными примерами, на которых каждый может извлечь уроки, чтобы способствовать более разумному принятию решений. «
―Марк Р. Хиллис, Директор по рискам ипотечного банковского обслуживания в JPM Chase
» У нас так много данных, что может быть трудно заставить людей обратить внимание на наши важные выводы.Коул Нуссбаумер Кнафлик преподала нам ценные уроки на своем семинаре, и замечательно видеть, что они были расширены в Storytelling with Data . Моя команда уже использует уроки, которые преподает Коул, чтобы побуждать людей к действию, когда они видят новые жемчужины понимания и меняют жизни других. Теперь могут и другие! «
―Элеанор Белл, Директор по бизнес-аналитике в Фонде Билла и Мелинды Гейтс
» Есть что-то прекрасное в том, чтобы соответствовать своим собственным учениям. Коул Нуссбаумер Кнафлик достигает этого в своей первой книге. Она выступает за ясность и лаконичность в визуализации, и ее книга настолько ясна, лаконична и практична, насколько это возможно. Если вы новичок в визуализации или если вам сложно создавать хорошие диаграммы в повседневной работе с помощью таких инструментов, как Excel, Tableau, Qlik и т.п., это отличное место для начала изучения основных принципов ».
Коул Нуссбаумер Кнафлик достигает этого в своей первой книге. Она выступает за ясность и лаконичность в визуализации, и ее книга настолько ясна, лаконична и практична, насколько это возможно. Если вы новичок в визуализации или если вам сложно создавать хорошие диаграммы в повседневной работе с помощью таких инструментов, как Excel, Tableau, Qlik и т.п., это отличное место для начала изучения основных принципов ».
―Альберто Каиро, кафедра визуальной журналистики Knight и профессор визуализации в Университете Майами, автор книги The Functional Art
«Слайды с данными на самом деле не о данных, они о значении данных.Коул Нуссбаумер Кнафлик понимает это и написал простое и доступное руководство, которое поможет любому, кто общается с помощью данных, более эффективно взаимодействовать со своей аудиторией. «
―Нэнси Дуарте, генеральный директор Duarte, Inc. и автор бестселлеров
Об авторе
Коул Нуссбаумер Кнафлик рассказывает истории с помощью данных. Она является основателем и генеральным директором компании storytelling with data (SWD) и автором бестселлера storytelling with data: руководство по визуализации данных для бизнес-профессионалов , переведенное на дюжину языков, используется в качестве справочника. учебник более 100 университетов и учебник для десятков тысяч участников семинаров по SWD.
Она является основателем и генеральным директором компании storytelling with data (SWD) и автором бестселлера storytelling with data: руководство по визуализации данных для бизнес-профессионалов , переведенное на дюжину языков, используется в качестве справочника. учебник более 100 университетов и учебник для десятков тысяч участников семинаров по SWD.
В течение почти десяти лет Коул и его команда проводили интерактивные обучающие сессии, пользующиеся большим спросом у людей, компаний и благотворительных организаций по всему миру, ориентированных на данные. Они также помогают людям создавать понятные графики и вплетать их в увлекательную историю с помощью популярного блога SWD, подкастов, ежемесячных заданий, событий в прямом эфире и других ресурсов. Узнайте больше на сайте storytellingwithdata.com.
Давайте попрактикуемся в повествовании с данными | Шарль Солнье | Nightingale
Другой случай, когда смешанная аудитория затруднена, — это когда у них разные требования к уровню детализации: один член аудитории хочет вникнуть в историю, а другой хочет просмотреть ее построчно. Нельзя делать все сразу, в любом случае вы кого-то не устраиваете! Возможно, вам удастся определить тех членов аудитории, которым нужен такой уровень детализации, посидеть с ними заранее, чтобы, когда вы доберетесь до большого собрания, вы могли сосредоточиться на общей картине. Или запланируйте с ними какое-то время после.
Нельзя делать все сразу, в любом случае вы кого-то не устраиваете! Возможно, вам удастся определить тех членов аудитории, которым нужен такой уровень детализации, посидеть с ними заранее, чтобы, когда вы доберетесь до большого собрания, вы могли сосредоточиться на общей картине. Или запланируйте с ними какое-то время после.
Любое количество времени и мыслей, которые люди уделяют: «как мне сделать этот сценарий успешным для меня?» будут потрачены не зря. Кто наша аудитория? Как мы им представляем? Что мы представляем в первую очередь? Все это играет на этом роль.Возможно, вы ищете волшебный рецепт успеха, но его нет! Ограничения каждый раз разные, и это одна из причин, почему эта работа так интересна. И есть много подходов, которые могут сработать. Обдумывая, как мы подходим к этому, как мы проектируем наши данные, как мы их представляем, мы увеличиваем наши шансы на успех.
CS: Это напрямую связано с одним из инструментов в вашей книге, листом «Большая идея», куда вы переходите из всех возможных аудиторий и сужаете их до одной цели, не так ли?
CNK: Верно! Часто у нас есть большая аудитория, но в ней есть кто-то или небольшая группа людей, которые будут нашей основной целью: лица, принимающие решения, влиятельные лица, поэтому мы можем в первую очередь помнить о них, чтобы они были немного стратегическими.
CS: Ваша первая книга вышла в 2015 году; Как изменилось ваше мастерство и, возможно, ваша точка зрения между двумя вашими книгами?
CNK: Для меня одно из самых больших изменений, когда я думаю о том, где все было в 2015 году и как обстоят дела сейчас, ну, основные принципы не изменились. Между книгами существует поток, поскольку процесс остается прежним. История, однако, сильно изменилась со времени выхода первой книги, а вместе с ней и компоненты, которые есть в Let’s Practice! : сюжетная линия, напряжение… Вспоминая историю с первой книгой, я все еще пытался придумать, как говорить об этом и учить этому в деловой обстановке.И это один из элементов, который с тех пор прошел долгий путь. И в моем собственном понимании истории, и в том, как быть стратегическим и тактическим в отношении того, как использовать ее в рабочей обстановке или когда вы преподаете данные.
Я думаю, что очень интересно, как люди думают об истории: они представляют маркетинг, какие-то пушистые вещи, что совсем не так или не должно быть вообще. Вы можете стратегически подходить к тому, как использовать историю, чтобы действительно заставить людей обратить внимание на ваши данные и сосредоточиться на правильных вещах или, надеюсь, на правильных действиях, к которым вы ведете.
Вы можете стратегически подходить к тому, как использовать историю, чтобы действительно заставить людей обратить внимание на ваши данные и сосредоточиться на правильных вещах или, надеюсь, на правильных действиях, к которым вы ведете.
CS: Говоря об истории, вы недавно взяли интервью у Нэнси Дуарте о повествовании с данными p. для ее книги Data Story . Она выдвинула концепцию «объяснителей данных». Как вы относитесь к этой роли (которая, как мне кажется, растет) и как мы можем улучшить этот аспект нашей практики?
CNK: Я думаю, что это интересная эволюция.Не так давно технические навыки были востребованы в отношении отчетности и визуализации данных. Но есть предостережение: если вы можете разобраться в данных самостоятельно, но не можете помочь другим разобраться в своих выводах, значительная часть вашей работы будет потеряна.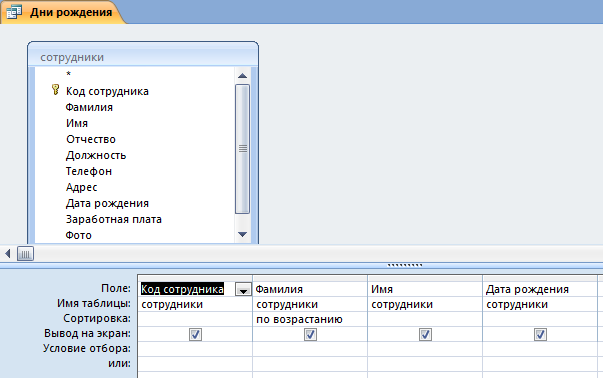 Однако этот набор навыков сложно развить, потому что часто люди, обученные технической стороне дела, не тратили так много времени на общение. У вас есть такой опыт, но вы не можете сделать шаг назад, чтобы занять место вашей аудитории.
Однако этот набор навыков сложно развить, потому что часто люди, обученные технической стороне дела, не тратили так много времени на общение. У вас есть такой опыт, но вы не можете сделать шаг назад, чтобы занять место вашей аудитории.
Люди, которые осознают ценность этой части процесса и вкладывают время в оттачивание этих навыков, получат огромную пользу. Есть невероятная ценность, которую можно извлечь из работы, которая уже выполняется, но не сообщается должным образом. Высокотехнологичные люди, статистики, которые потратят время на то, чтобы инвестировать в эти так называемые «мягкие навыки», как вы говорите о своих данных, как вы помещаете их в бизнес-контекст, чтобы они могли процветать от вашей работы, будут действительно вознаграждены.
Невероятная ценность, которую можно извлечь из работы, которая уже выполняется, но не сообщается должным образом.
CS: Можно ли сказать, что это недостающее звено, позволяющее доказать, что анализ данных может принести пользу предприятиям и заинтересованным сторонам? Потому что они часто думают о работе с точки зрения рентабельности инвестиций?
CNK: ROI всегда сложно измерить. Визуализация данных редко приводит к немедленным и измеримым действиям: например, продажи выросли на X процентов.Для меня проверка эффективности больше похожа на «если вам нужно, чтобы что-то произошло в результате вашего анализа, произошло ли это?» Обсуждение, которое необходимо было провести, решение, которое необходимо было принять — разве бы оно развернулось по-другому, если бы вы его не сообщили?
Визуализация данных редко приводит к немедленным и измеримым действиям: например, продажи выросли на X процентов.Для меня проверка эффективности больше похожа на «если вам нужно, чтобы что-то произошло в результате вашего анализа, произошло ли это?» Обсуждение, которое необходимо было провести, решение, которое необходимо было принять — разве бы оно развернулось по-другому, если бы вы его не сообщили?
Трудно измерить, потому что ответ чаще всего содержит нюансы, но это то, как вы делаете все данные, насколько они полезны и используются?
CS: Ранее на этой неделе у меня было обсуждение с другим членом DVS, Фрэнсисом Ганьоном , который больше занимается дизайном, а не технической стороной, и который сказал что часто его клиенты обращаются к ним, когда сталкиваются с ситуациями, когда им приходится решать, что делать или умереть.«Если я не изложу свою точку зрения, наш проект может потерпеть неудачу или мы можем даже потерять клиента», например. Быть услышанным как дизайнер обычно становится легче в таких ситуациях, потому что они тратят деньги на ваш опыт для определенного проекта или количества времени.
К сожалению, мы не всегда попадаем в такую ситуацию. Как бы вы убедили заинтересованные стороны в том, что стоит вкладывать время и ресурсы в создание историй, которые приведут к эффективным результатам?
CNK: Вы имеете в виду, как вы обосновываете, что стоит тратить время на рассказывание историй? Во-первых, вы должны осознавать, что это не обязательно означает, что вам нужно вернуться и, например, полностью изменить дизайн отчета.Один из способов перейти на следующий уровень — начать с отчета, как он есть, вы его просматриваете. Какой бы тип отчета у вас ни был (информационная панель, система показателей, электронная таблица), это инструмент для отображения ваших данных и определения того, где все работает так, как должно, а где они меньше соответствуют нашим ожиданиям . .. вы не пытаетесь создать историю из каждого из них. Иногда будет только одна история: все, как ожидалось.
.. вы не пытаетесь создать историю из каждого из них. Иногда будет только одна история: все, как ожидалось.
Когда это , а не , вы можете аргументировать это и использовать многое из того, что мы делаем на семинарах, чтобы достучаться до вашей аудитории, направить ее внимание, сказать им: «Мы можем продолжать делать то же, что и в прошлое, и вот что, вероятно, произойдет.Или мы могли бы использовать уже проведенный нами анализ, и вот самые важные элементы, на которые вам нужно обратить внимание, чтобы мы вышли на следующий уровень ». Здесь в игру вступят ваши техники повествования. И когда вы начнете это делать, вы укрепите уверенность в своих навыках, а также доверие к клиентам и заинтересованным сторонам. Они будут знать, что вы сосредотачиваетесь на правильных вещах, и вы сможете увести их от всех деталей, чтобы теперь начать обсуждение истории.
Для меня это одна из самых интересных вещей, которые происходят при эффективном обмене данными: разговор меняется. Это больше не о графике или о том, что он означает, или о запросах дополнительных данных, больше данных, больше данных! Он становится следующим: что на самом деле означают эти данные и как мы можем использовать их с точки зрения нашего бизнеса? Это волшебное превращение. Это никогда не бывает легко, это требует времени и легко может стать ошеломляющим. Начните с малого, с низко висящих плодов, вещей, о которых никто не будет кричать, если они изменятся и будут набирать обороты.Вы сможете завоевать доверие и привести к более серьезным изменениям.
Это никогда не бывает легко, это требует времени и легко может стать ошеломляющим. Начните с малого, с низко висящих плодов, вещей, о которых никто не будет кричать, если они изменятся и будут набирать обороты.Вы сможете завоевать доверие и привести к более серьезным изменениям.
Для меня это одна из самых интересных вещей, которые происходят при эффективном обмене данными: разговор меняется.
CS: Слушая в последнее время подкасты и интервью, и учитывая то, что вы только что упомянули, приятно осознавать, что это всегда требует времени. Что даже люди, на которых я равняюсь в этой области, все еще могут спросить себя: правильно ли я делаю это?
CNK: Да, и вам нужно привыкнуть к методам проб и ошибок, но каждый раз учиться чему-то: изучать, что прошло хорошо, что подражать в будущем, а что не сработало для меня и должно быть исключено пути.Здесь нет экспертов, каждый может стать порядочным, более тонким в своем подходе к данным, и это одна из причин, почему это пространство так весело!
CS: Теперь, когда книга вышла, я предполагаю, что у вас НАМНОГО больше времени в ваших руках 🙂 Это может быть своего рода вопрос левого поля, но он освободил вас, чтобы проверить некоторые элементы на вашем список для чтения?
CNK: На моей тумбочке лежит книга Elefant швейцарского автора Мартина Сутера. Я начал читать его, когда путешествовал с семьей в Цюрих летом. Он на немецком, который я понимаю, но мне нужно действительно сосредоточиться, чтобы все уследить. Я тут и там читал короткую главу, но планирую закончить ее в декабре, когда у меня будет свободное время. Все остальное время я уделяю семье!
CS: Есть ли шанс дать мне возможность взглянуть на следующее соревнование SWD? (который сейчас доступен здесь .)
CNK: Скажем так: это подразумевает возврат к основам, но с изюминкой … Оставайтесь с нами!
CS: У меня есть последний вопрос (на который Коул был достаточно любезен, чтобы ответить в Twitter DM, так как я забыл его вживую, потому что, да, я болтал с Коулом Нуссбаумером Кнафликом !!) Есть намного больше на этот раз нарисованные вручную иллюстрации, выполненные Кэтрин Мэдден. (Ваше сообщение в блоге о создании книги объясняет, почему вы использовали этот подход).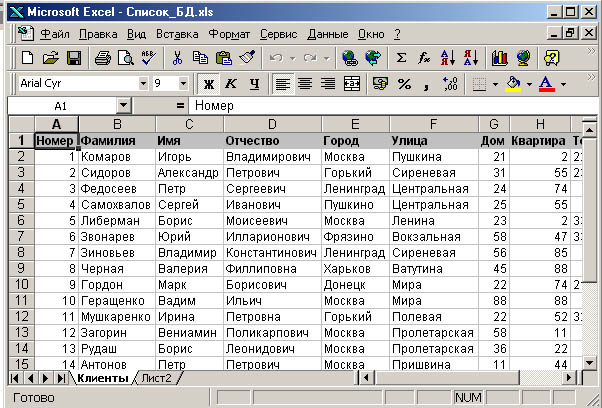
Я, например, не всегда уделяю время наброскам в своей повседневной работе; Я подозреваю, что многие люди с техническим опытом могут сразу перейти к своим ноутбукам для создания прототипов. Как бы вы убедили профессионалов (и заинтересованных лиц) посвятить некоторое время наброскам и созданию прототипов, не требующих высоких технологий, в процессе их проектирования? Другими словами, какую добавленную стоимость может дать нам набросок?
CNK: Хотя кажется более эффективным сразу перейти к нашим инструментам, есть важные преимущества в сопротивлении этому побуждению и началу проектирования нашей передачи данных в низкотехнологичной манере.Лучше всего это сделать после того, как вы потратите некоторое время на ознакомление со своими данными, но до того, как потратите время на создание красивых версий графиков или другого контента.
Возьмите чистый лист бумаги и начните рисовать. У рисования есть несколько замечательных преимуществ. Это освобождает нас от ограничений наших инструментов (или того, что мы умеем делать в наших инструментах). Кроме того, у нас меньше шансов сформировать привязанность — я могу набросать сумасшедшую идею, которая у меня есть, для графика и увидеть, что она может не сработать. Если бы я потратил время на создание того же сумасшедшего графика в своем инструменте, я был бы менее готов отпустить его, даже если бы он в конечном итоге не послужил моей цели.Наконец, это не займет много времени (большие преимущества, если вы потратите всего пять-десять минут, а рисунки могут быть грубыми и некрасивыми, и это совершенно нормально), И это оптимизирует остальную часть вашего процесса.
Это освобождает нас от ограничений наших инструментов (или того, что мы умеем делать в наших инструментах). Кроме того, у нас меньше шансов сформировать привязанность — я могу набросать сумасшедшую идею, которая у меня есть, для графика и увидеть, что она может не сработать. Если бы я потратил время на создание того же сумасшедшего графика в своем инструменте, я был бы менее готов отпустить его, даже если бы он в конечном итоге не послужил моей цели.Наконец, это не займет много времени (большие преимущества, если вы потратите всего пять-десять минут, а рисунки могут быть грубыми и некрасивыми, и это совершенно нормально), И это оптимизирует остальную часть вашего процесса.
Когда у вас будет набросок вашего графика или набросок вашей истории, получите обратную связь с заинтересованными сторонами, чтобы увидеть, на правильном ли вы пути или вам нужно изменить направление. Возможно, вы получите обратную связь от кого-то другого (или снова от вашей заинтересованной стороны) после того, как вы внесли изменения. Предварительное согласование означает, что в остальной части процесса будет меньше итераций (все еще всегда, что неизбежно, но такого рода низкотехнологичное планирование сделает остальную часть процесса более эффективной).В Let’s Practice! Есть ряд упражнений! , который поможет читателю осуществить низкотехнологичное планирование: формирование Большой идеи, создание раскадровки, рисование графиков и т. Д., Что, с моей точки зрения, является одной из наиболее важных частей процесса эффективного обмена данными.
Предварительное согласование означает, что в остальной части процесса будет меньше итераций (все еще всегда, что неизбежно, но такого рода низкотехнологичное планирование сделает остальную часть процесса более эффективной).В Let’s Practice! Есть ряд упражнений! , который поможет читателю осуществить низкотехнологичное планирование: формирование Большой идеи, создание раскадровки, рисование графиков и т. Д., Что, с моей точки зрения, является одной из наиболее важных частей процесса эффективного обмена данными.
(Спойлер: это была тема презентации Коула на конференции Tableau, см. Видео ниже!)
Презентация Коула на конференции Tableau 2019Еще раз спасибо Коулу за то, что он нашел время поговорить со мной.Еще раз поздравляем с новой книгой и желаем всего наилучшего в отношении всех других мероприятий, связанных с рассказыванием историй с использованием данных!
Чтобы узнать больше о деятельности Cole и с использованием данных , воспользуйтесь следующими ссылками:
Веб-сайт | Twitter | LinkedIn | Страница Facebook
Особая благодарность Алиссе Белл за ее щедрое сотрудничество над этой статьей!
Обзор «рассказывания историй с использованием данных» | Шарль Солнье | Nightingale
Книга Коула Нуссбаумера Кнафлика — доступный ресурс для практиков в области визуализации данных, клиентов и всех, кто находится между ними.

Три года назад я был на перекрестке карьеры. Как консультант по бизнес-аналитике, я какое-то время разрабатывал отчеты для разных клиентов. Я всегда получал восторженные отзывы как инструктор, когда обучал персонал работе с такими инструментами, как Excel, SSRS и Power BI, но начал замечать, что люди все равно возвращались к своим старым привычкам после окончания обучения. Как разработчик (тогда я не осмеливался называть себя дизайнером!) Меня расстраивало то, что мои работы чаще всего не находили широкого распространения. Люди часто использовали эти отчеты только для извлечения данных, а не в качестве инструментов информации и принятия решений.
Я понял, что, хотя я хорошо умею создавать отчеты, мне нужны ресурсы для разработки чего-то, что отвечало бы выраженным и неосознанным потребностям моей аудитории и приводило к НАСТОЯЩЕМУ принятию. Я начал копать в поисках ресурсов и даже вернулся в школу! Там я получил настоящее откровение во время урока по дашбордингу: хорошие отчеты — это не только технические продукты, но и тонкий баланс данных, дизайна, человеческого познания и информатики. Я не мог справиться со всем этим за одну ночь, но я знал, что мне нужно научиться лучше общаться с данными, если я хочу видеть ценность своей работы.
Я не мог справиться со всем этим за одну ночь, но я знал, что мне нужно научиться лучше общаться с данными, если я хочу видеть ценность своей работы.
В комплекте S повествование с данными : «Руководство по визуализации данных для бизнес-профессионалов», , книга, доступная для начинающих, охватывает многое основ визуализации данных, и можно поделиться с коллегами и заинтересованными сторонами, которые не имеют представления о данных, а именно. За те два года, которые у меня есть, это все еще первая книга, которую я рекомендую коллегам, которые хотят узнать больше о визуализации, независимо от того, являются они дизайнерами или нет.
Почему эта книга? Его структура ориентирована на практические данные, а именно, что очень хорошо подходит для деловой среды. Главы относительно короткие и посвящены теме, они ориентированы на общение и важность контекста. Это книга, которую можно легко продать как обучающую.
Это книга, которую можно легко продать как обучающую.
Одна концепция, в частности, Большая идея, поразила меня: объясните вашего визуала и что с того? в одном предложении, которое (1) формулирует вашу уникальную точку зрения, (2) передает то, что поставлено на карту, и (3) состоит из полного предложения.Теперь я помню об этом, когда придумываю что-нибудь, чтобы судить о том, понятна ли моя цель аудитории. Например, теперь я добавляю свою Большую идею к комментариям к первому слайду моих презентаций Powerpoint и возвращаюсь к ней по мере создания слайдов, чтобы убедиться, что я остаюсь в курсе, и что все, что я добавляю, поддерживает ее. Что касается визуальных элементов или информационных панелей, я стараюсь резюмировать это в основном с помощью заголовков, например, на этом простом графике информационной панели по продажам мороженого:
Не самое удивительное понимание продаж мороженого, но вывод очевиден! Еще один главный аргумент для меня — это то, как Коул позволяет нам понять свой мыслительный процесс при построении графиков. Книги часто показывают вам до и после; Я нахожу гораздо более поучительным, когда вы видите итерации и почему они не были сохранены в качестве окончательного решения. Целая глава посвящена тематическим исследованиям, которые часто отсутствуют в академических работах.
Его сильная сторона также может быть его основной слабостью: охватывая все основные темы визуализации на языке, подходящем для бизнес-аудитории, он никогда не вникает так глубоко в любой из них.Я бы сказал, что если у вас есть опыт работы с принципами гештальт, атрибутами предварительного внимания и высокой грамотностью в визуализации данных, вы больше не являетесь целевой аудиторией этой книги. Если вы ищете ресурс, в частности, о дашбордах, есть и другие книги, к которым можно обратиться. Его можно использовать как ступеньку к книгам, посвященным более академическим предметам, таким как человеческое восприятие, ориентированный на пользователя дизайн и т. Д., Если вы почувствуете, что освоили их основы.
Д., Если вы почувствуете, что освоили их основы.
Таким образом, я определенно рекомендую S torytelling с Data как часть любой начинающей (и опытной) библиотеки данных, а именно библиотеки практикующего специалиста.Если вы хотите, чтобы клиенты и коллеги понимали ценность хорошо разработанных графиков, диаграмм и отчетов, это будет отличный ресурс. Он отлично подходит для объяснения относительно сложных концепций на языке, понятном как дизайнерам, так и бизнес-профессионалам.
Вы можете обратиться к другим книгам и авторам, когда вы наберетесь опыта и захотите развить определенные области ваших данных, а именно набор навыков. Но вы не найдете много книг, которые были бы столь же доступны, как эта, и позволили бы вам говорить о визуализации на языке, понятном вашим близким.Это была моя первая профессиональная покупка, о которой я ни разу не пожалел!
Для заинтересованных: веб-сайт , рассказывающий истории с данными , наполнен дополнительным контентом, а ежемесячный #SWDchallenge подталкивает всех участников оттачивать свои навыки, оспаривать предположения и пробовать новые инструменты и методы. Следующая книга, рассказывание историй с использованием данных: давайте попрактикуемся! , также будет опубликован этой осенью.
Следующая книга, рассказывание историй с использованием данных: давайте попрактикуемся! , также будет опубликован этой осенью.
Ссылка: NUSSBAUMER KNAFLIC, Cole. Истории с данными: Руководство по визуализации данных для профессионалов бизнеса.John Wiley and Sons, Нью-Джерси, 2015. ISBN 10: 11157
Огромное спасибо Джейсону Форресту за то, что помог мне набраться сил для моей первой публикации. Дополнительная благодарность Элайдже Миксу и Исааку Леви-Рубинетту за их помощь в создании более удобного для чтения материала!
Начните работу с Data Quality Unit
Вы — администратор Salesforce в Gelato, супергигантской компании, занимающейся новыми медиа-технологиями. Gelato разработала передовую платформу для потоковой передачи рекламного контента 4K Ultra HD.Пока что он используется во множестве теле- и кино-приложений и веб-сайтов. Вы работаете в сфере B2B, а вашими клиентами являются компании, в том числе рекламодатели, медиа-агентства и другие участники рекламной индустрии.
Для развития бизнеса Gelato новый директор по продажам хочет лучше определять клиентов и их потребности. Поскольку вы являетесь гуру Salesforce, она просит вас предоставить полный обзор аккаунтов Gelato. Вы подходите к ноутбуку, открываете освежающий напиток, создаете несколько отчетов Salesforce и наслаждаетесь ливнем похвалы.
Звучит просто, правда?
Неправильно!
Вы просматриваете отчеты, и вот что вы видите только для аккаунтов в западном регионе США.
Несколько вещей действительно выделяются. Отсутствуют записи. Только в Калифорнии у вашей компании более 500 клиентов, но в отчетах представлены данные только по 200 учетным записям во всем западном регионе. Дублирующиеся записи. Быстрый взгляд на список учетных записей показывает, что данные для клиентов с несколькими местоположениями фиксируются в нескольких записях учетных записей.На самом деле, в стольких записях фигурирует так много клиентов, что вы даже не понимаете, что определяет клиента. Это адрес? Название компании? Нет стандартов данных. В региональной разбивке представлены клиенты в 87 штатах. Урок географии был давным-давно, но вы, кажется, помните только 50 штатов. Например, Калифорния указана как: CA, Calif, Cali, и, ваш любимый, «Surfin’, USA «. Неполные записи Почти во всех учетных записях в западном регионе отсутствуют ключевые данные. В учетных записях потребителей отсутствуют такие данные, как телефон и электронная почта.В бизнес-аккаунтах не указаны отрасль, выручка и количество сотрудников. Устаревшие данные По крайней мере половина всех аккаунтов в западном регионе не обновлялась за последние 6 месяцев, поэтому вы не знаете, насколько точны данные. И в эти данные даже не входят аккаунты, не зарегистрированные в Salesforce.
Это адрес? Название компании? Нет стандартов данных. В региональной разбивке представлены клиенты в 87 штатах. Урок географии был давным-давно, но вы, кажется, помните только 50 штатов. Например, Калифорния указана как: CA, Calif, Cali, и, ваш любимый, «Surfin’, USA «. Неполные записи Почти во всех учетных записях в западном регионе отсутствуют ключевые данные. В учетных записях потребителей отсутствуют такие данные, как телефон и электронная почта.В бизнес-аккаунтах не указаны отрасль, выручка и количество сотрудников. Устаревшие данные По крайней мере половина всех аккаунтов в западном регионе не обновлялась за последние 6 месяцев, поэтому вы не знаете, насколько точны данные. И в эти данные даже не входят аккаунты, не зарегистрированные в Salesforce.
При таких проблемах с данными отчет в лучшем случае является неполным, а в худшем — неточным. Естественно, вы обеспокоены. Вы запускаете ветку Chatter, запрашивая мнение всех ваших менеджеров по продажам.
Региональный менеджер в Нью-Йорке откровенно говорит вам: «В Salesforce слишком сложно найти нужную информацию, поэтому мои команды просто не используют ее так часто».
Другой менеджер по продажам из Лондона объясняет вам: «Мы пытались удалить все дубликаты в нашем регионе, но они принадлежали какой-то другой команде».
Менеджер по маркетингу из Гонконга в чате: «У потенциальных клиентов недостаточно подробностей, чтобы определить, какие действия нужно предпринять. И кажется, что данные, которые у нас есть, устарели на следующий день после их получения.Оказывается, он прав: данные постоянно меняются.
Вы понимаете, что рост вашей компании и ее бизнес-решения связаны с качеством данных Salesforce. Вы делитесь своими наблюдениями с директором по продажам. Она ценит вашу проницательность, но у нее есть один вопрос: «Насколько важно качество данных ?»
Аудиокнига недоступна | Audible.com
Evvie Drake: более чем
- Роман
- К: Линда Холмс
- Рассказал: Джулия Уилан, Линда Холмс
- Продолжительность: 9 часов 6 минут
- Несокращенный
В сонном приморском городке в штате Мэн недавно овдовевшая Эвелет «Эвви» Дрейк редко покидает свой большой, мучительно пустой дом почти через год после гибели ее мужа в автокатастрофе. Все в городе, даже ее лучший друг Энди, думают, что горе держит ее внутри, а Эвви не поправляет их. Тем временем в Нью-Йорке Дин Тенни, бывший питчер Высшей лиги и лучший друг детства Энди, борется с тем, что несчастные спортсмены, живущие в своих худших кошмарах, называют «ура»: он больше не может бросать прямо, и, что еще хуже, он не может понять почему.
Все в городе, даже ее лучший друг Энди, думают, что горе держит ее внутри, а Эвви не поправляет их. Тем временем в Нью-Йорке Дин Тенни, бывший питчер Высшей лиги и лучший друг детства Энди, борется с тем, что несчастные спортсмены, живущие в своих худших кошмарах, называют «ура»: он больше не может бросать прямо, и, что еще хуже, он не может понять почему.
- 3 из 5 звезд
Что-то заставляло меня слушать….
- К Каролина Девушка на 10-12-19
Отвечая на вопросы с данными
Цитата : Crump, M. J. C., Navarro, D., & Suzuki, J. (2019, 5 июня). Отвечая на вопросы с данными (Учебник): Вводная статистика для студентов-психологов.https://doi.org/10.17605/OSF.IO/JZE52
J. C., Navarro, D., & Suzuki, J. (2019, 5 июня). Отвечая на вопросы с данными (Учебник): Вводная статистика для студентов-психологов.https://doi.org/10.17605/OSF.IO/JZE52
Важные примечания
Это бесплатный учебник вводной статистики для студентов факультетов психологии. Этот учебник является частью более крупного пакета курсов ООР по обучению студентов статистике психологии, включая этот учебник, лабораторное руководство и веб-сайт курса. Все материалы являются бесплатными и копируемыми, а исходный код хранится в репозиториях Github. Ссылки ниже относятся к различным компонентам проекта. Основная ссылка на проект OSF: https: // osf.io / 3s68c /.
Веб-сайт курса
Все ресурсы выпущены под лицензией Creative Commons CC BY-SA 4.0. Щелкните ссылку, чтобы узнать больше о лицензии, или прочитайте больше ниже в разделе лицензий.
Авторы
Члены команды, вносящие новый контент, включают Мэтью Крампа, Аллу Чаваргу, Анджали Кришнан, Джеффри Сузуки и Стивена Волца. Этот учебник был написан Мэтью Дж. К. Крампом. Джефф предоставил видеоролики на YouTube, которые были добавлены в учебник.Все статистические видео Джеффа доступны на его канале Youtube: Плейлист «Статистическое видео».
Этот учебник был написан Мэтью Дж. К. Крампом. Джефф предоставил видеоролики на YouTube, которые были добавлены в учебник.Все статистические видео Джеффа доступны на его канале Youtube: Плейлист «Статистическое видео».
Алла, Анджали и Стивен написали лабораторные упражнения для SPSS, JAMOVI и Excel. Мэтт Крамп написал лабораторные упражнения для R
.Мэтт Крамп написал бесплатный и копируемый веб-сайт курса на R Markdown. На сайте курса также есть слайды для лекций.
Атрибуции
Две главы были адаптированы из замечательного (и более крупного) бесплатного учебника Даниэль Наварро, который также находится под той же лицензией Creative Commons.Цитата для этого учебника: Navarro, D. (2018). Статистика обучения с R: учебник для студентов-психологов и других начинающих (версия 0.6). Веб-сайт: https://compcogscisydney.org/learning-statistics-with-r/
. Примечания к главам в книге предназначены для обозначения разделов, в которые был включен материал из Наварро. Краткое резюме здесь
Краткое резюме здесь
Глава 1: Почему статистика , адаптирована почти дословно с некоторыми редакционными изменениями из глав 1 и 2, Navarro, D.
Глава 4: Вероятность, выборка и оценка , адаптировано и расширено из глав 9 и 10, Navarro D.
Лицензия CC BY-SA 4.0
Эта лицензия означает, что вы можете:
- Поделиться: копировать и распространять материал на любом носителе или любом формате
- Адаптировать: ремикшировать, преобразовывать и дополнять материал для любых целей, даже в коммерческих целях.
Лицензиар не может отозвать эти свободы, пока вы соблюдаете условия лицензии.
На следующих условиях:
- Атрибуция: Вы должны указать соответствующую ссылку, предоставить ссылку на лицензию и указать, были ли внесены изменения. Вы можете сделать это любым разумным способом, но не любым способом, который предполагает, что лицензиар одобряет вас или ваше использование.
- ShareAlike: если вы ремикшируете, трансформируете или дополняете материал, вы должны распространять свои материалы по той же лицензии, что и оригинал.
- Без дополнительных ограничений: вы не можете применять юридические условия или технические меры, которые юридически ограничивают других делать все, что разрешено лицензией.

Копирование учебника
Этот учебник был написан в R-Studio с использованием R Markdown и скомпилирован в формат веб-книги с использованием пакета bookdown. В целом, я благодарю более широкое сообщество R за все замечательные инструменты, которые они создали, и за то, что они сделали эти инструменты открытыми, чтобы я мог использовать их для создания этой штуки.
Весь исходный код для компиляции книги доступен в репозитории GitHub для этой книги:
https://github.com/CrumpLab/statistics
В принципе, любой может разветвить или иным образом загрузить этот репозиторий.Загрузите файл Rproj в R-studio, а затем скомпилируйте всю книгу. Затем отдельные файлы .rmd для каждой главы можно было бы отредактировать по содержанию и стилю, чтобы они лучше соответствовали вашим потребностям.
Затем отдельные файлы .rmd для каждой главы можно было бы отредактировать по содержанию и стилю, чтобы они лучше соответствовали вашим потребностям.
Если вы хотите внести свой вклад в эту версию учебника, вы можете делать запросы на вытягивание на GitHub или обсуждать проблемы и запросы на вкладке «Проблемы».
Благодарности
Спасибо библиотекарям Бруклинского колледжа CUNY, особенно Мириам Дойч и Эмили Фейри, за их поддержку на протяжении всего процесса.Спасибо CUNY за поддержку разработки ООР и за грант, который мы получили на развитие этой работы. Спасибо Дженн Ричлер за то, что разрешила мне все лето говорить о статистике.
Почему мы это сделали
Зачем писать еще один учебник по статистике, если их уже не так много? Да это так. У нас было несколько причин. Во-первых, мы хотели бы сделать R более доступным для студентов, и мы написали этот учебник, посвященный возможностям R. Учебник был полностью написан на R-Studio, и большинство примеров связано с R-кодом. В учебнике R не уделяется особого внимания, но в лабораторном руководстве есть введение в использование R для решения задач анализа данных. Многие инструкторы по-прежнему используют SPSS, Excel или новые бесплатные графические интерфейсы, такие как JAMOVI, поэтому мы также сделали лабораторные упражнения для каждого из них.
Это слегка самоуверенное, нетрадиционное введение в статистику. В нем признаются некоторые основные идеи традиционных частотных подходов и некоторые байесовские подходы. Большая часть концептуальной основы уходит корнями в моделирование, которое может быть проведено в R.Мы используем некоторые формулы, но в основном объясняем вещи без формул. Учебник был написан с учетом математической фобии и попытки уменьшить фобию, связанную с арифметическими вычислениями. Многого не хватает, но, вероятно, следует добавить. По мере обновления учебника мы будем стараться добавлять необходимые вещи.
Hypothes.is
Hypothesis — это надстройка для веб-браузера, которая позволяет комментировать веб-сайты, выделяя текст, а затем оставляя комментарии. Не стесняйтесь использовать гипотезы в этом учебнике.Будем читать ваши комментарии.
Не стесняйтесь использовать гипотезы в этом учебнике.Будем читать ваши комментарии.
- Используйте Hypothes.is, замечательный инструмент для аннотирования в Интернете.
Зайдите на Hypothes.is и начните работу
Установите надстройку для Chrome или другого браузера
Вот и все, включите Hypothes.is, когда будете читать этот учебник, и вы увидите все общедоступные аннотации, сделанные кем-либо еще.
Computing with Data — Введение в индустрию данных | Гай Ливан
Эта книга знакомит с базовыми компьютерными навыками, предназначенными для профессионалов отрасли, не имеющих большого опыта в области компьютерных наук.Написанный в легкодоступной форме и сопровождаемый удобным веб-сайтом, он служит руководством для самостоятельного изучения науки о данных и инженерии данных для тех, кто стремится начать карьеру в области вычислительной техники или расширить свою текущую роль в различных областях. такие как прикладная статистика, большие данные, машинное обучение, интеллектуальный анализ данных и информатика.
такие как прикладная статистика, большие данные, машинное обучение, интеллектуальный анализ данных и информатика.
Авторы опираются на свой совместный опыт работы в компаниях-разработчиках программного обеспечения и социальных сетях, над продуктами с большими данными в нескольких крупных интернет-магазинах, а также на своем опыте создания систем больших данных для стартапа AI.Эта книга, охватывающая от базовой внутренней работы компьютера до передовых методов обработки данных, открывает читателям двери для быстрого изучения и расширения своих компьютерных знаний.
Вычисления с использованием данных включает широкий спектр вычислительных тем, важных для специалистов по обработке данных, аналитиков и инженеров, предоставляя им необходимые инструменты для достижения успеха в любой должности, связанной с вычислениями с данными. Введение является самодостаточным, и главы развиваются от базовых концепций оборудования до операционных систем, языков программирования, построения графиков и обработки данных, инструментов тестирования и программирования, фреймворков больших данных и облачных вычислений.
Книга рассчитана на несколько аудиторий. Читатели без сильного образования в области CS или те, кто нуждается в переподготовке, найдут главы об аппаратном обеспечении, операционных системах и языках программирования особенно полезными. Читатели с сильным образованием в области CS, но без значительного отраслевого опыта, найдут следующие главы особенно полезными: изучение R, тестирование, программирование, визуализация и обработка данных на Python и R, проектирование систем для больших данных, хранилища данных и программное обеспечение. мастерство.
.