PostgreSQL функция count — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
В этом учебном пособии вы узнаете, как использовать PostgreSQL функцию count с синтаксисом и примерами.
Описание
Функция count PostgreSQL возвращает количество выражений.
Синтаксис
Синтаксис функции count в PostgreSQL:
SELECT count(aggregate_expression)
FROM tables
[WHERE conditions];
Или синтаксис функции count при группировке результатов по одному или нескольким столбцам:
SELECT expression1, expression2,… expression_n,
count(aggregate_expression)
FROM tables
[WHERE conditions]
GROUP BY expression1, expression2,… expression_n;
Параметры или аргументы
- expression1, expression2,… expression_n
- Выражения, которые не заключены в функцию count и должны быть включены в оператор GROUP BY в конце SQL-запроса.
- aggregate_expression
- Это столбец или выражение, чьи ненулевые значения будут учитываться.

- tables
- Таблицы, из которых вы хотите получить записи. В операторе FROM должна быть указана хотя бы одна таблица.
- WHERE conditions
- Необязательный. Это условия, которые должны быть соблюдены для выбора записей.

Включает только значения NOT NULL
Не все это понимают, но функция count будет включать в счет только записи, в которых значение expression в count(expression) равно NOT NULL. Когда expression содержит значение NULL, оно не включается в вычисления count.
Рассмотрим пример функции count, который демонстрирует, как значения NULL оцениваются функцией count.
Например, если у вас есть следующая таблица с именем suppliers:
| supplier_id | supplier_name | state |
|---|---|---|
| 1 | IBM | CA |
| 2 | Microsoft | |
| 3 | NVIDIA |
И если вы запустили следующий оператор SELECT, которая использует функцию count:
SELECT count(supplier_id) FROM suppliers; —Результат: 3
SELECT count(supplier_id) FROM suppliers;
—Результат: 3 |
Этот пример count вернет 3, так как все значения supplier_id в результирующем наборе запроса не равны NULL
Однако, если вы запустили следующий оператор SELECT, которая использует функцию count:
SELECT count(state) FROM suppliers; —Результат: 1
SELECT count(state) FROM suppliers;
—Результат: 1 |
В этом примере count будет возвращать только 1, поскольку только одно значение state в результирующем наборе запроса NOT NULL. Это будет первая строка, где state = ‘CA’. Это единственная строка, которая включена в расчет функции count.
Это будет первая строка, где state = ‘CA’. Это единственная строка, которая включена в расчет функции count.
Применение
Функция count может использоваться в следующих версиях PostgreSQL:
- PostgreSQL 11, PostgreSQL 10, PostgreSQL 9.6, PostgreSQL 9.5, PostgreSQL 9.4, PostgreSQL 9.3, PostgreSQL 9.2, PostgreSQL 9.1, PostgreSQL 9.0, PostgreSQL 8.4
Пример — с одним выражением
Рассмотрим некоторые примеры функций count, чтобы понять, как использовать функцию count в PostgreSQL.
Например, вам может потребоваться узнать количество записей из таблицы products, которые имеют product_type ‘Hardware’
SELECT count(*) AS «Number of products» FROM products WHERE product_type = ‘Hardware’;
SELECT count(*) AS «Number of products» FROM products WHERE product_type = ‘Hardware’; |
В этом примере функции count мы назвали выражение count(*) как «Number of products». В результате, «Number of products» будет отображаться как имя поля при возвращении набора результатов.
В результате, «Number of products» будет отображаться как имя поля при возвращении набора результатов.
Пример — использование DISTINCT
Вы можете использовать оператор DISTINCT в функции count. Например, приведенный ниже оператор SQL возвращает количество уникальных department (отделов), в которых хотя бы один сотрудник зарабатывает более 35000 $ в год.
SELECT count(DISTINCT department) AS «Unique departments» FROM employees WHERE salary > 35000;
SELECT count(DISTINCT department) AS «Unique departments» FROM employees WHERE salary > 35000; |
Опять же, поле count(DISTINCT department) имеет псевдоним «Unique departments». Это имя поля, которое будет отображаться в результирующем наборе.
Пример — использование GROUP BY
В некоторых случаях вам потребуется использовать оператор GROUP BY с функцией count.
Например, вы также можете использовать функцию count, чтобы вернуть записи с department (название отдела) и «Number of employees» (количество сотрудников в соответствующем отделе), зарплата которых, составляют более 40000 $ США в год.
SELECT department, count(*) AS «Number of employees» FROM employees WHERE salary > 40000 GROUP BY department;
SELECT department, count(*) AS «Number of employees» FROM employees WHERE salary > 40000 GROUP BY department; |
Поскольку в вашем операторе SELECT указан один столбец, который не инкапсулирован в функции count, необходимо использовать оператор GROUP BY. Поэтому поле department должно быть указано в операторе GROUP BY.
sql — Выбор COUNT (*) с DISTINCT
спросил
Изменено сегодня
Просмотрено 1,4 млн раз
В SQL Server 2005 у меня есть таблица cm_production , в которой перечислены все коды, запущенные в производство.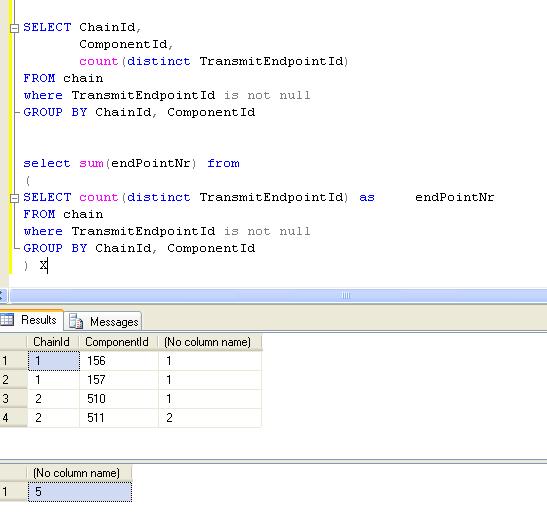 Таблица имеет номер
Таблица имеет номер ticket_number , program_type
program_name и push_number вместе с некоторыми другими столбцами.ЦЕЛЬ: Подсчитать все названия программ DISTINCT по типу программы и номеру push-уведомления.
На данный момент у меня есть:
DECLARE @push_number INT; SET @push_number = [HERE_ADD_NUMBER]; SELECT DISTINCT COUNT(*) AS Count, program_type AS [Тип] ОТ cm_production ГДЕ push_number=@push_number СГРУППИРОВАТЬ ПО типу_программы
Это подводит меня к цели, но она считает все имена программ, а не отдельные (чего я не ожидаю в этом запросе). Я думаю, я просто не могу понять, как сказать ему подсчитывать только отдельные имена программ, не выбирая их. Или что-то.
- sql
- sql-сервер
- sql-сервер-2005
- tsql
Подсчитайте все имена программ DISTINCT по типу программы и нажмите номер
SELECT COUNT(DISTINCT имя_программы) AS Count, program_type AS [Тип] ОТ cm_production ГДЕ push_number=@push_number СГРУППИРОВАТЬ ПО типу_программы
DISTINCT COUNT(*) вернет строку для каждого уникального счетчика. Вам нужно
Вам нужно COUNT(DISTINCT : оценивает выражение для каждой строки в группе и возвращает количество уникальных ненулевых значений.
Мне нужно было получить количество вхождений каждого отдельного значения. Столбец содержал информацию о регионе. В итоге я получил простой SQL-запрос:
SELECT Region, count(*) ИЗ товара ГДЕ Регион не является нулевым ГРУППА ПО РЕГИОНАМ
Что даст мне список, например:
Регион, количество Дания, 4 Швеция, 1 США, 101
Вы должны создать производную таблицу для отдельных столбцов, а затем запросить количество из этой таблицы:
SELECT COUNT(*)
ОТ (ВЫБЕРИТЕ РАЗЛИЧНЫЕ столбец 1, столбец 2
ОТ имя_таблицы
ГДЕ условие ) как dt
Здесь dt — производная таблица.
SELECT COUNT(DISTINCT имя_программы) AS Count, тип_программы AS [Тип] ОТ cm_production ГДЕ push_number=@push_number СГРУППИРОВАТЬ ПО типу_программы1
попробуйте это:
ВЫБЕРИТЕ
COUNT(имя_программы) AS [Количество],тип_программы AS [Тип]
ОТ (ВЫБЕРИТЕ РАЗЛИЧНЫЕ имя_программы,тип_программы
ОТ cm_production
ГДЕ push_number=@push_number
) дт
СГРУППИРОВАТЬ ПО типу_программы
Вы можете попробовать следующий запрос.
ВЫБЕРИТЕ столбец 1, СЧЕТЧИК (*) КАК Счетчик ОТ имя_таблицы, где дата создания >= '2022-07-01'::группа дат по столбцу1
Чтобы подсчитать различные имена программ по типу программы и номеру отправки в SQL Server 2005, вы можете использовать подзапрос, чтобы сначала выбрать различные имена программ, а затем выполнить подсчет во внешнем запросе. Вот пример запроса, который должен дать желаемый результат:
DECLARE @push_number INT;
SET @push_number = [HERE_ADD_NUMBER];
SELECT COUNT(DISTINCT имя_программы) AS Count, тип_программы AS [Тип]
ОТ (
SELECT DISTINCT имя_программы, тип_программы
ОТ cm_production
ГДЕ push_number = @push_number
) AS подзапрос
СГРУППИРОВАТЬ ПО типу_программы;
В этом запросе подзапрос выбирает отдельные имена программ и типы программ из таблицы cm_production на основе указанного push_number. Затем во внешнем запросе вы выполняете подсчет различных имен программ и группируете результаты по типу программы.
Кстати, с помощью dbForge Studio для SQL Server вы можете легко писать, выполнять и анализировать ваши SQL-запросы.
Это хороший пример, когда вы хотите получить количество PIN-кодов, хранящихся в последнем поле адреса 9.0005
ВЫБЕРИТЕ ОТЛИЧНЫЙ
НАПРАВО (адрес, 6),
count(*) КАК считать
ОТ
файл данных
ГДЕ
адрес НЕ НУЛЬ
ГРУППА ПО
НАПРАВО (адрес, 6)
SQL для поиска количества различных значений в столбце
спросил
Изменено 2 месяца назад
Просмотрено 733 тыс. раз
Я могу выбрать все различные значения в столбце следующими способами:
-
SELECT DISTINCT имя_столбца ИЗ имя_таблицы; -
ВЫБРАТЬ имя_столбца ИЗ имя_таблицы ГРУППИРОВАТЬ ПО имени_столбца;
Но как мне получить количество строк из этого запроса? Требуется ли подзапрос?
- sql
- отдельный
Вы можете использовать DISTINCT ключевое слово в агрегатной функции COUNT :
SELECT COUNT(DISTINCT column_name) AS some_alias FROM table_name
При этом будут учитываться только уникальные значения для этого столбца.
Это даст вам ОБА отдельные значения столбца и количество каждого значения. Обычно я обнаруживаю, что хочу знать обе части информации.
ВЫБЕРИТЕ [имя_столбца], count([имя_столбца]) КАК CountOf ОТ [имя_таблицы] СГРУППИРОВАТЬ ПО [название столбца]0
Сумма sql уникальных значений имени_столбца, отсортированных по частоте:
ВЫБЕРИТЕ имя_столбца, СЧЕТ(*) ИЗ имя_таблицы ГРУППИРОВАТЬ ПО имени_столбца ORDER BY 2 DESC;0
Имейте в виду, что Count() игнорирует значения null, поэтому, если вам нужно разрешить null как отдельное значение, вы можете сделать что-то хитрое, например:
select count(distinct my_col)
+ count (отличный случай, когда my_col равен нулю, а затем 1, иначе конец равен нулю)
из my_table
/
4SELECT COUNT(DISTINCT имя_столбца) ИЗ таблицы как количество_столбцов;
вы должны посчитать этот отдельный столбец, а затем дать ему псевдоним.
выберите количество (*) из ( ВЫБЕРИТЕ отдельный столбец 1, столбец 2, столбец 3, столбец 4 ИЗ abcd ) Т
Это даст количество отдельных групп столбцов.
выберите Count (отличное имя столбца) как columnNameCount из tableName0
Используя следующий SQL, мы можем получить число различных значений столбца в Oracle 11g.
выберите количество (различное (имя_столбца)) из имени таблицы
После MS SQL Server 2012 вы также можете использовать функцию окна.
SELECT имя_столбца, COUNT(имя_столбца) OVER (РАЗДЕЛЕНИЕ ПО имени_столбца) ОТ имя_таблицы СГРУППИРОВАТЬ ПО имя_столбца
Чтобы сделать это в Presto, используйте OVER :
SELECT DISTINCT my_col,
count(*) OVER (PARTITION BY my_col
ORDER BY my_col) AS num_rows
ОТ my_tbl
Использование этого подхода на основе OVER , конечно, необязательно. В приведенном выше SQL я обнаружил, что необходимо указать
В приведенном выше SQL я обнаружил, что необходимо указать DISTINCT и ORDER BY .
Предостережение. Согласно документации, использование GROUP BY может быть более эффективным.
выберите количество (различное (имя_столбца)) AS columndatacount из имени_таблицы, где некоторое условие = истина
Вы можете использовать этот запрос для подсчета различных данных.
Без использования DISTINCT вот как мы могли бы это сделать-
ВЫБЕРИТЕ СЧЕТ(С) ОТ (ВЫБЕРИТЕ СЧЕТ(имя_столбца) как C ОТ имя_таблицы СГРУППИРОВАТЬ ПО имя_столбца)
Вы можете это сделать.
Выберите отдельный PRODUCT_NAME_X ,количество (название_продукта) products_# из таблицы X Группа по PRODUCT_NAME
Он вернет
продуктов PRODUCT_NAME ХХХХХХХХХ 4760
Count(distinct({fieldname})) является избыточным
Просто Count({fieldname}) дает вам все уникальные значения в этой таблице. Он не будет (как многие предполагают) просто дать вам количество таблицы [т. е. НЕ то же самое, что Count(*) из таблицы]
е. НЕ то же самое, что Count(*) из таблицы]
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но никогда не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.