Оператор Select (SQL)
Сам перевод аббревиатуры SQL (язык структурно организованных запросов) отражает тот факт, что именно запросы — наиболее часто применяемый элемент в SQL. Выбрать нужные строки, автоматически исключить избыточные данные, пропустить или переупорядочить столбцы поможет Select (SQL) — оператор, содержащий указание СУБД вывести определенную информацию.

Синтаксис оператора
Чтобы правильно использовать любой оператор, необходимо сперва ознакомиться с синтаксисом рассматриваемого языка программирования. Когда говорим конкретно про язык SQL, Select (оператор) имеет следующий синтаксис:
Select | Сообщает базе данных, что мы передаем запрос. Это ключевое слово. |
One, two, three… | Список столбцов для вывода |
From | Указывает на имя таблицы, из которой будут выбираться данные. Также является обязательным ключевым словом. |
Это так называемый «краткий» синтаксис оператора, однако он указывает нам на то, что без ключевых слов Select и from СУБД наш запрос не выполнит.
Полный синтаксис оператора представлен на следующем рисунке:
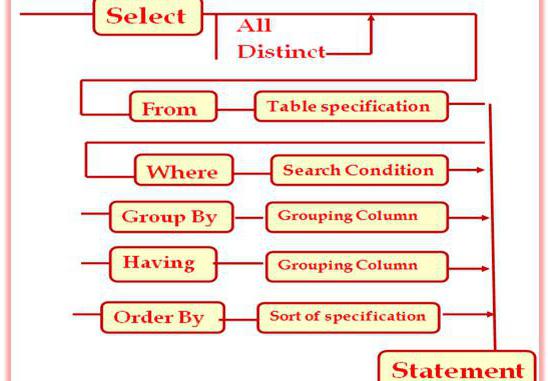
Здесь предложение Where позволяет уточнить поиск, задав условие.
Для группировки значений и применения к ним агрегатной функции используется предложение Group by, а чтобы уточнить результат уже после группировки, используется предложение Having.
Order by позволит отсортировать значения выбранных столбцов по возрастанию либо по убыванию.
Чтобы более наглядно ознакомиться с оператором Select, представим, что в нашей базе данных есть следующая таблица Cats с информацией:
Id | Breed | Name | Birthday | Color |
1 | Бобтейл | Лорд | 01.04.2017 | Grey |
2 | Керл | Финт | 16.03.2017 | White |
3 | Мау | Пантера | 30.03.2017 | Black |
4 | Бобтейл | Тайсон | 23.02.2017 | Grey |
5 | Бурмилла | Афина | 08.01.2017 | Black |
Каждая строка таблицы содержит уникальный номер котенка, его породу, кличку, дату рождения и расцветку. Далее будем рассматривать, как работает оператор Select (SQL), уже опираясь на данные из этой таблицы.
Как происходит выборка данных из таблицы
Как было рассмотрено выше, для выборки нужной информации из таблицы обязательно используются ключевые слова.
После ключевого слова Select указываются столбцы для вывода. Можно сделать перечень нужных столбцов через запятую, тогда вся конструкция будет выглядеть так:
Select color, breed, name From Cats |
Как видим, мы можем упорядочивать столбцы в том порядке, в каком они нам необходимы. Кроме того, можем выводить только необходимые нам столбцы.
Существует также краткая запись для просмотра всех столбцов таблицы. Для этого после Select указывается звездочка (*) через пробел. Вся конструкция будет выглядеть так:
Результат приведенного запроса — вся таблица Cats, представленная в том виде, в каком она содержится в конце прошлого раздела.
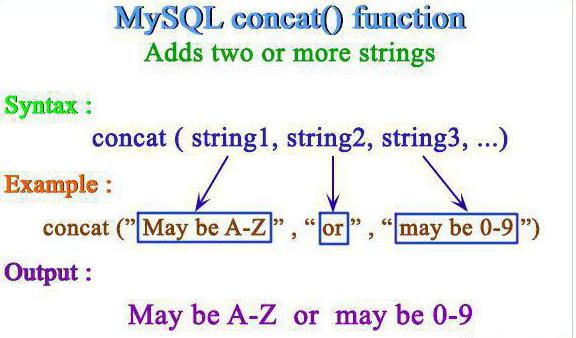
Многие интересуются тем, как разместить результаты выполнения в SQL Select в строку. Чаще всего это требуется, когда необходимо объединить фамилию, имя и отчество человека, размещенные в разобщенных столбцах.
В нашем случае объединим породу и окрас кошек из таблицы Cats. Нюанс заключается в том, что разные СУБД используют для строковой конкатенации разные символы. В одних случаях это просто плюс (+), в других – двойная прямая черта (||) или знак амперсанда (&), порой используется и операнд Concat. Поэтому перед объединением необходимо прочитать аннотацию к конкретной СУБД, с которой вы работаете.
Select breed || ‘, ’ || color From cats |
Результат получим следующий:
Breed, Color |
Бобтейл, Grey |
Керл, White |
Мау, Black |
Бобтейл, Grey |
Бурмилла, Black |
Исключение избыточных данных
Distinct – функция Select (SQL), позволяющая исключить дублирование абсолютно идентичных строк из результата выборки.
Например, мы хотим узнать, кошки каких пород есть в нашей таблице. Если используем простой запрос:
То получим вполне ожидаемый результат:
Breed |
Бобтейл |
Керл |
Мау |
Бобтейл |
Бурмилла |
Как видим, порода бобтейл дублируется два раза. Аргумент Distinct позволит исключить дублирование, достаточно лишь дописать запрос:
Select distinct breed From Cats |
Уточнение запроса
В реальности практически ни один запрос не выводит данные в виде полного набора строк таблицы. Рассмотрим, какое предложение в Select (SQL) позволит задать критерии для отбора только нужных строк.
Таким предложением служит Where. В этом предложении применяется предикат – условное выражение, дающее на выходе значение «истина» или «ложь». Оператор Select извлечет только те данные из таблицы, для которых условное выражение будет иметь значение True, или «истина».
Поможет разобраться с данной конструкцией простая выборка. Допустим, мы хотим знать все о кошках черного окраса.
Select * From cats Where color = ‘Black’ |
Результатом выполнения данного запроса станут следующие строки таблицы:
3 | Мау | Пантера | 30.03.2017 | Black |
5 | Бурмилла | Афина | 08.01.2017 | Black |
Также можно комбинировать условия, используя логические операторы And, Or, Not.
Предложение Group by
Предложение Group by, используемое в Select (SQL), позволяет сгруппировать запросы по значению определенного столбца (или столбцов), а затем применить к ним агрегатную функцию.
К агрегатным функциям относятся:
- Count – вычисляет количество строк, отобранных запросом.
- Sum – арифметическая сумма всех отобранных значений столбца.
- Min – выводит минимальное из отобранных значений столбца.
- Max – соответственно, максимальное из отобранных значений столбца.
- Avg – среднее значение.
Схему работы данного предложения проще всего понять на конкретном примере. Допустим, мы хотим узнать, сколько котят каждой породы у нас есть. Для этого необходимо сформировать следующий простой запрос:
Select breed, count(*) From cats Group by breed |
Результатом выполнения станет следующая таблица:
Breed | Count |
Бобтейл | 2 |
Керл | 1 |
Мау | 1 |
Бурмилла | 1 |
Как видим, котят породы бобтейл у нас двое, остальных же всего по одному. На практике по такому запросу, основываясь на нашей таблице, заводчик может понять, кошки каких пород пользуются спросом у покупателей, а каких – нет.
Вполне вероятно, что из-за огромного количества записей в реальной таблице захочется еще уточнить запрос и вывести только те породы котят, которых осталось не более, к примеру, десяти. Для уточнения или фильтрации групп используется предложение Having. Оно позволяет отбросить определенные группы, аналогично предложению Where, отбрасывающему отдельные строки. Условие задается по агрегатной функции. Допишем запрос:
Select breed, count(*) From cats Group by breed Having count(*) <=10 |
Поскольку условие мы задали «количество котят каждой породы не более 10», то результат получим такой же, как в примере без уточнения. Но тут важно понять саму схему работы предложения Having. А вот если изменим логическое условие на Having count(*) =1, то результат сократится до трех строк и выведет породы котят, которых осталось всего по одному.
Сортировка
Познакомимся с Order by – предложением оператора Select (SQL), позволяющим отсортировать выводимые строки по возрастанию или убыванию значений в одном или нескольких столбцах.

Важно помнить, что Order by – это заключительное предложение всей конструкции оператора Select. Оно размещается после Select, From, Where, Group by, Having.
При проведении сортировки есть три важных момента:
1) Можно указать любое количество столбцов, каждый из которых по отдельности можно отсортировать либо по возрастанию (ASC), либо по убыванию (DESC).
2) Все указанные столбцы в предложении Order by должны обязательно присутствовать среди выбираемых столбцов в Select.
3) Необязательно перечислять конкретные имена столбцов для сортировки, можно просто указать их номера, под которыми они идут в инструкции Select.

Надеемся, что с помощью нашей статьи вы получили базовые знания об использовании SQL запросов и теперь без труда выберете необходимую информацию из вашей СУБД.
fb.ru
Access SQL. Основные понятия, лексика и синтаксис
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Для извлечения данных из базы данных используется язык SQL. SQL — это язык программирования, который очень напоминает английский, но предназначен для программ управления базами данных. SQL используется в каждом запросе в Access.
Это статья из цикла статей о языке SQL для Access. В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.
В этой статье
-
Что такое SQL?
-
-
Сортировка результатов: предложение ORDER BY
-
Работа со сводными данными: предложения GROUP BY и HAVING
-
Объединение результатов запроса: оператор UNION
Что такое SQL?
SQL — это язык программирования, предназначенный для работы с наборами фактов и отношениями между ними. В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI.
На языке SQL описываются наборы данных, помогающие получать ответы на вопросы. При использовании SQL необходимо применять правильный синтаксис. Синтаксис — это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Например, простая инструкция SQL, извлекающая список фамилий контактов с именем Mary, может выглядеть следующим образом:
SELECT Last_Name
FROM Contacts
WHERE First_Name = 'Mary';
Примечание: Язык SQL используется не только для выполнения операций над данными, но еще и для создания и изменения структуры объектов базы данных, например таблиц. Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных.
Инструкции SELECT
Инструкция SELECT служит для описания набора данных на языке SQL. Она содержит полное описание набора данных, которые необходимо получить из базы данных, включая следующее:
-
таблицы, в которых содержатся данные;
-
связи между данными из разных источников;
-
поля или вычисления, на основе которых отбираются данные;
-
условия отбора, которым должны соответствовать данные, включаемые в результат запроса;
необходимость и способ сортировки.
Предложения SQL
Инструкция SQL состоит из нескольких частей, называемых предложениями. Каждое предложение в инструкции SQL имеет свое назначение. Некоторые предложения являются обязательными. В приведенной ниже таблице указаны предложения SQL, используемые чаще всего.
Предложение SQL | Описание | Обязательное |
|---|---|---|
|
SELECT |
Определяет поля, которые содержат нужные данные. |
Да |
|
FROM |
Определяет таблицы, которые содержат поля, указанные в предложении SELECT. |
Да |
|
WHERE |
Определяет условия отбора полей, которым должны соответствовать все записи, включаемые в результаты. |
Нет |
|
ORDER BY |
Определяет порядок сортировки результатов. |
Нет |
|
|
В инструкции SQL, которая содержит статистические функции, определяет поля, для которых в предложении SELECT не вычисляется сводное значение. |
Только при наличии таких полей |
|
HAVING |
В инструкции SQL, которая содержит статистические функции, определяет условия, применяемые к полям, для которых в предложении SELECT вычисляется сводное значение. |
Нет |
Термины SQL
Каждое предложение SQL состоит из терминов, которые можно сравнить с частями речи. В приведенной ниже таблице указаны типы терминов SQL.
Термин SQL | Сопоставимая часть речи | Определение | Пример |
|---|---|---|---|
|
идентификатор |
существительное |
Имя, используемое для идентификации объекта базы данных, например имя поля. |
Клиенты.[НомерТелефона] |
|
оператор |
глагол или наречие |
|
AS |
|
константа |
существительное |
Значение, которое не изменяется, например число или NULL. |
42 |
|
выражение |
прилагательное |
Сочетание идентификаторов, операторов, констант и функций, предназначенное для вычисления одного значения. |
>= Товары.[Цена] |
К началу страницы
Основные предложения SQL: SELECT, FROM и WHERE
Общий формат инструкций SQL:
SELECT field_1
FROM table_1
WHERE criterion_1
;
Примечания:
-
Access не учитывает разрывы строк в инструкции SQL. Несмотря на это, каждое предложение рекомендуется начинать с новой строки, чтобы инструкцию SQL было удобно читать как тому, кто ее написал, так и всем остальным.
-
Каждая инструкция SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять как в конце последнего предложения, так и на отдельной строке в конце инструкции SQL.
Пример в Access
В приведенном ниже примере показано, как в Access может выглядеть инструкция SQL для простого запроса на выборку.
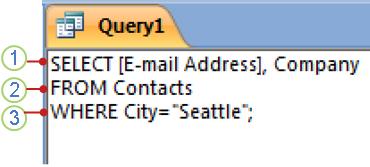
1. Предложение SELECT
2. Предложение FROM
3. Предложение WHERE
Эту инструкцию SQL следует читать так: «Выбрать данные из полей «Адрес электронной почты» и «Компания» таблицы «Контакты», а именно те записи, в которых поле «Город» имеет значение «Ростов».
Разберем пример по предложениям, чтобы понять, как работает синтаксис SQL.
Предложение SELECT
SELECT [E-mail Address], Company
Это предложение SELECT. Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Если идентификатор содержит пробелы или специальные знаки (например, «Адрес электронной почты»), он должен быть заключен в прямоугольные скобки.
В предложении SELECT не нужно указывать таблицы, в которых содержатся поля, и нельзя задать условия отбора, которым должны соответствовать данные, включаемые в результаты.
В инструкции SELECT предложение SELECT всегда стоит перед предложением FROM.
Предложение FROM
FROM Contacts
Это предложение FROM. Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
В предложении FROM не указываются поля для выборки.
Предложение WHERE
WHERE City=»Seattle»
Это предложение WHERE. Оно содержит оператор (WHERE), за которым следует выражение (Город=»Ростов»).
Примечание: В отличие от предложений SELECT и FROM, предложение WHERE является необязательным элементом инструкции SELECT.
С помощью предложений SELECT, FROM и WHERE можно выполнять множество действий. Дополнительные сведения об использовании этих предложений см. в следующих статьях:
К началу страницы
Сортировка результатов: ORDER BY
Как и в Microsoft Excel, в Access можно сортировать результаты запроса в таблице. Используя предложение ORDER BY, вы также можете указать способ сортировки результатов при выполнении запроса. Если используется предложение ORDER BY, оно должно находиться в конце инструкции SQL.
Предложение ORDER BY содержит список полей, для которых нужно выполнить сортировку, в том же порядке, в котором будут применена сортировка.
Предположим, например, что результаты сначала нужно отсортировать по полю «Компания» в порядке убывания, а затем, если присутствуют записи с одинаковым значением поля «Компания», — отсортировать их по полю «Адрес электронной почты» в порядке возрастания. Предложение ORDER BY будет выглядеть следующим образом:
ORDER BY Company DESC, [E-mail Address]
Примечание: По умолчанию Access сортирует значения по возрастанию (от А до Я, от наименьшего к наибольшему). Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Дополнительные сведения о предложении ORDER BY см. в статье Предложение ORDER BY.
К началу страницы
Работа со сводными данными: предложения GROUP BY и HAVING
Иногда возникает необходимость работы со сводными данными, такими как итоговые продажи за месяц или самые дорогие товары на складе. Для этого в предложении SELECT к полю применяется агрегатная функция. Например, если в результате выполнения запроса нужно получить количество адресов электронной почты каждой компании, предложение SELECT может выглядеть следующим образом:
SELECT COUNT([E-mail Address]), Company
Возможность использования той или иной агрегатной функции зависит от типа данных в поле и нужного выражения. Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Задание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо создать предложение GROUP BY. В предложении GROUP BY указываются все поля, к которым не применяется агрегатная функция. Если агрегатные функции применяются ко всем полям в запросе, предложение GROUP BY создавать не нужно.
Предложение GROUP BY должно следовать сразу же за предложением WHERE или FROM, если предложение WHERE отсутствует. В предложении GROUP BY поля указываются в том же порядке, что и в предложении SELECT.
Продолжим предыдущий пример. Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
GROUP BY Company
Дополнительные сведения о предложении GROUP BY см. в статье Предложение GROUP BY.
Ограничение агрегированных значений с помощью условий группировки: предложение HAVING
Если необходимо указать условия для ограничения результатов, но поле, к которому их требуется применить, используется в агрегированной функции, предложение WHERE использовать нельзя. Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Предположим, например, что к первому полю в предложении SELECT применяется функция AVG (которая вычисляет среднее значение):
SELECT COUNT([E-mail Address]), Company
Если вы хотите ограничить результаты запроса на основе значения функции COUNT, к этому полю нельзя применить условие отбора в предложении WHERE. Вместо него условие следует поместить в предложение HAVING. Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
HAVING COUNT([E-mail Address])>1
Примечание: Запрос может включать и предложение WHERE, и предложение HAVING, при этом условия отбора для полей, которые не используются в статистических функциях, указываются в предложении WHERE, а условия для полей, которые используются в статистических функциях, — в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в статье Предложение HAVING.
К началу страницы
Объединение результатов запроса: оператор UNION
Оператор UNION используется для одновременного просмотра всех данных, возвращаемых несколькими сходными запросами на выборку, в виде объединенного набора.
Оператор UNION позволяет объединить две инструкции SELECT в одну. Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Примечание: В запросах на объединение числовой и текстовый типы данных являются совместимыми.
Используя оператор UNION, можно указать, должны ли в результаты запроса включаться повторяющиеся строки, если таковые имеются. Для этого следует использовать ключевое слово ALL.
Запрос на объединение двух инструкций SELECT имеет следующий базовый синтаксис:
SELECT field_1
FROM table_1
UNION [ALL]
SELECT field_a
FROM table_a
;
Предположим, например, что имеется две таблицы, которые называются «Товары» и «Услуги». Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;
Дополнительные сведения об объединении инструкций SELECT с помощью оператора UNION см. в статье Просмотр объединенных результатов нескольких запросов с помощью запроса на объединение.
К началу страницы
support.office.com
SELECT SQL Server — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
В этом учебном пособии вы узнаете, как использовать оператор SELECT в SQL Server (Transact-SQL) с синтаксисом и примерами.
Описание
Оператор SELECT SQL Server (Transact-SQL) используется для извлечения записей из одной или нескольких таблиц в базе данных SQL Server.
Синтаксис
В простейшей форме синтаксис оператора SELECT в SQL Server (Transact-SQL):
SELECT expressions
FROM tables
[WHERE conditions];
Полный синтаксис оператора SELECT в SQL Server (Transact-SQL):
SELECT [ ALL | DISTINCT ]
[ TOP (top_value) [ PERCENT ] [ WITH TIES ] ]
expressions
FROM tables
[WHERE conditions]
[GROUP BY expressions]
[HAVING condition]
[ORDER BY expression [ ASC | DESC ]];
Параметры или аргументы
ALL — необязательный. Возвращает все соответствующие строки.
DISTINCT — необязательный. Удаляет дубликаты из набора результатов. Подробнее об операторе DISTINCT …
TOP (top_value) — необязательный. Если указано, то он вернет верхнее число строк в результирующем наборе на основе top_value. Например, TOP (10) вернет первые 10 строк из полного набора результатов.
PERCENT — необязательный. Если указано, то верхние строки основаны на проценте от общего набора результатов (как указано в верхнем значении). Например, TOP (10) PERCENT вернет верхние 10% полного набора результатов.
WITH TIES — необязательный. Если указано, то строки, привязанные на последнем месте в ограниченном результирующем наборе, возвращаются. Это может привести к возврату большего количества строк, чем позволяет параметр TOP.
expressions — столбцы или вычисления, которые вы хотите получить. Используйте *, если вы хотите выбрать все столбцы.
tables — таблицы, из которых вы хотите получить записи. Должна быть хотя бы одна таблица, перечисленная в предложении FROM.
WHERE conditions — необязательный. Условия, которые должны быть выполнены для выбранных записей.
GROUP BY expressions — необязательный. Он собирает данные по нескольким записям и группирует результаты по одному или нескольким столбцам.
HAVING condition — необязательный. Он используется в сочетании с GROUP BY, чтобы ограничить группы возвращаемых строк только теми, чье условие TRUE.
ORDER BY expression — необязательный. Он используется для сортировки записей в вашем результирующем наборе. ASC сортируется в порядке возрастания, а DESC — в порядке убывания.
Пример выборки всех полей из одной таблицы
Рассмотрим пример, как использовать SQL Server SELECT для выбора всех полей из таблицы.
SELECT * FROM inventory WHERE quantity > 5 ORDER BY inventory_id ASC;
SELECT * FROM inventory WHERE quantity > 5 ORDER BY inventory_id ASC; |
В этом примере SQL Server SELECT мы использовали *, чтобы указать, что мы хотим выбрать все поля из таблицы inventory, где quantity больше 5. Набор результатов сортируется по полю inventory_id в порядке возрастания.
Пример выборки отдельных полей из одной таблицы.
Вы также можете использовать оператор SELECT SQL Server для выбора отдельных полей из таблицы.
Например:
SELECT inventory_id, inventory_type, quantity FROM inventory WHERE inventory_id >= 250 AND inventory_type = ‘Программное обеспечение’ ORDER BY quantity DESC, inventory_id ASC;
SELECT inventory_id, inventory_type, quantity FROM inventory WHERE inventory_id >= 250 AND inventory_type = ‘Программное обеспечение’ ORDER BY quantity DESC, inventory_id ASC; |
Этот пример SQL Server SELECT возвращает только данные inventory_id, inventory_type и quantity из таблицы inventory, где inventory_id больше или равно 250, а inventory_type — это ‘Программное обеспечение’. Результаты сортируются по quantity в порядке убывания, а затем inventory_id в порядке возрастания.
Пример выборки полей из нескольких таблиц.
Вы также можете использовать оператор SELECT SQL Server для извлечения полей из нескольких таблиц с помощью объединения (join).
Например:
SELECT inventory.inventory_id, products.product_name, inventory.quantity FROM inventory INNER JOIN products ON inventory.product_id = products.product_id ORDER BY inventory_id;
SELECT inventory.inventory_id, products.product_name, inventory.quantity FROM inventory INNER JOIN products ON inventory.product_id = products.product_id ORDER BY inventory_id; |
Этот пример SQL Server SELECT объединяет вместе две таблицы, чтобы предоставить нам набор результатов, который отображает поля inventory_id, product_name и quantity, где значение product_id совпадает как в таблице inventory, так и в products. Результаты сортируются по inventory_id в порядке возрастания.
Пример использования ключевого слова TOP
Давайте посмотрим на пример SQL Server, где мы используем ключевое слово TOP в операторе SELECT.
Например:
SELECT TOP(3) inventory_id, inventory_type, quantity FROM inventory WHERE inventory_type = ‘Программное обеспечение’ ORDER BY inventory_id ASC;
SELECT TOP(3) inventory_id, inventory_type, quantity FROM inventory WHERE inventory_type = ‘Программное обеспечение’ ORDER BY inventory_id ASC; |
Этот пример SQL Server SELECT выберет первые 3 записи из таблицы inventory, где inventory_type будет ‘Программное обеспечение’. Если в таблице inventory есть другие записи, которые имеют значение inventory_type ‘Программное обеспечение’, они не будут возвращаться оператором SELECT.
Пример использования ключевого слова TOP PERCENT
Рассмотрим пример SQL Server, в котором мы используем ключевое слово TOP PERCENT в операторе SELECT.
Например:
SELECT TOP(10) PERCENT inventory_id, inventory_type, quantity FROM inventory WHERE inventory_type = ‘Программное обеспечение’ ORDER BY inventory_id ASC;
SELECT TOP(10) PERCENT inventory_id, inventory_type, quantity FROM inventory WHERE inventory_type = ‘Программное обеспечение’ ORDER BY inventory_id ASC; |
Этот пример SQL Server SELECT будет выбирать первые 10% записей из полного набора результатов. Таким образом, в этом примере оператор SELECT вернет 10% записей из таблицы inventory, где inventory_type — это ‘Программное обеспечение’. Остальные 90% набора результатов не будут возвращены оператором SELECT.
oracleplsql.ru
Синтаксис оператора SELECT — документация Mysql 4, 5 на русском языке
Используя ключевое слово AS, выражению в SELECT можно присвоить псевдоним. Псевдоним используется в качестве имени столбца в данном выражении и может применяться в ORDER BY или HAVING. Например:
mysql> SELECT CONCAT(last_name,', ',first_name) AS full_name
FROM mytable ORDER BY full_name;
Псевдонимы столбцов нельзя использовать в выражении WHERE, поскольку находящиеся в столбцах величины на момент выполнения WHERE могут быть еще не определены. Проблемы с alias.
Выражение FROM table_references задает таблицы, из которых надлежит извлекать строки. Если указано имя более чем одной таблицы, следует выполнить объединение. Информацию о синтаксисе объединения можно найти в разделе Синтаксис оператора JOIN. Для каждой заданной таблицы по желанию можно указать псевдоним.
table_name [[AS] alias] [[USE INDEX (key_list)] | [IGNORE INDEX (key_list)] | FORCE INDEX (key_list)]]
В версии MySQL 3.23.12 можно указывать, какие именно индексы (ключи) MySQL должен применять для извлечения информации из таблицы. Это полезно, если оператор EXPLAIN (выводящий информацию о структуре и порядке выполнения запроса SELECT), показывает, что MySQL из списка возможных индексов выбрал неправильный. Если нужно. чтобы для поиска записи в таблице применялся только один из возможных индексов, следует задать значение этого индекса в USE INDEX (key_list). Альтернативное выражение IGNORE INDEX (key_list) запрещает использование в MySQL данного конкретного индекса.
В MySQL 4.0.9 можно также указывать FORCE INDEX. Это работает также, как и USE INDEX (key_list) но в дополнение дает понять серверу что полное сканирование таблицы будет ОЧЕНЬ дорогостоящей операцией. Другими словами, в этом случае сканирование таблицы будет использовано только тогда, когда не будет найдено другого способа использовать один из данных индексов для поиска записей в таблице.
Выражения USE/IGNORE KEY являются синонимами для USE/IGNORE INDEX.
Ссылки на таблицы могут даваться как tbl_name (в рамках текущей базы данных), или как dbname.tbl_name с тем, чтобы четко указать базу данных.
Ссылки на столбцы могут задаваться в виде col_name, tbl_name.col_name или db_name.tbl_name.col_name. В выражениях tbl_name или db_name.tbl_name нет необходимости указывать префикс для ссылок на столбцы в команде SELECT, если эти ссылки нельзя истолковать неоднозначно. Имена баз данных, таблиц, столбцов, индексы псевдонимы, где приведены примеры неоднозначных случаев, для которых требуются более четкие определения ссылок на столбцы.
Ссылку на таблицу можно заменить псевдонимом, используя tbl_name [AS] alias_name:
mysql>SELECT t1.name, t2.salary FROM employee AS t1, info AS t2WHERE t1.name = t2.name; mysql>SELECT t1.name, t2.salary FROM employee t1, info t2WHERE t1.name = t2.name;
В выражениях ORDER BY и GROUP BY для ссылок на столбцы, выбранные для вывода информации, можно использовать либо имена столбцов, либо их псевдонимы, либо их позиции (местоположения). Нумерация позиций столбцов начинается с 1:
mysql>SELECT college, region, seed FROM tournamentORDER BY region, seed; mysql>SELECT college, region AS r, seed AS s FROM tournamentORDER BY r, s; mysql>SELECT college, region, seed FROM tournamentORDER BY 2, 3;
Для того чтобы сортировка производилась в обратном порядке, в утверждении ORDER BY к имени заданного столбца, в котором производится сортировка, следует добавить ключевое слово DESC (убывающий). По умолчанию принята сортировка в возрастающем порядке, который можно задать явно при помощи ключевого слова ASC.
В выражении WHERE можно использовать любую из функций, которая поддерживается в MySQL. Функции, используемые в операторах SELECT и WHERE.
Выражение HAVING может ссылаться на любой столбец или псевдоним, упомянутый в выражении select_expression. HAVING отрабатывается последним, непосредственно перед отсылкой данных клиенту, и без какой бы то ни было оптимизации. Не используйте это выражение для определения того, что должно быть определено в WHERE. Например, нельзя задать следующий оператор:
mysql> SELECT col_name FROM tbl_name HAVING col_name > 0;
Вместо этого следует задавать:
mysql> SELECT col_name FROM tbl_name WHERE col_name > 0;
В версии MySQL 3.22.5 или более поздней можно также писать запросы, как показано ниже:
mysql> SELECT user,MAX(salary) FROM users
GROUP BY user HAVING MAX(salary)>10;
В более старых версиях MySQL вместо этого можно указывать:
mysql> SELECT user,MAX(salary) AS sum FROM users
GROUP BY user HAVING sum>10;
Параметры (опции) DISTINCT, DISTINCTROW и ALL указывают, должны ли возвращаться дублирующиеся записи. По умолчанию установлен параметр (ALL), т.е. возвращаются все встречающиеся строки. DISTINCT и DISTINCTROW являются синонимами и указывают, что дублирующиеся строки в результирующем наборе данных должны быть удалены.
Все параметры, начинающиеся с SQL_, STRAIGHT_JOIN и HIGH_PRIORITY, представляют собой расширение MySQL для ANSI SQL.
При указании параметра HIGH_PRIORITY содержащий его оператор SELECT будет иметь более высокий приоритет, чем команда обновления таблицы. Нужно только использовать этот параметр с запросами, которые должны выполняться очень быстро и сразу. Если таблица заблокирована для чтения, то запрос SELECT HIGH_PRIORITY будет выполняться даже при наличии команды обновления, ожидающей, пока таблица освободится.
Параметр SQL_BIG_RESULT можно использовать с GROUP BY или DISTINCT, чтобы сообщить оптимизатору, что результат будет содержать большое количество строк. Если указан этот параметр, MySQL при необходимости будет непосредственно использовать временные таблицы на диске, однако предпочтение будет отдаваться не созданию временной таблицы с ключом по элементам GROUP BY, а сортировке данных.
При указании параметра SQL_BUFFER_RESULT MySQL будет заносить результат во временную таблицу. Таким образом MySQL получает возможность раньше снять блокировку таблицы; это полезно также для случаев, когда для посылки результата клиенту требуется значительное время.
Параметр SQL_SMALL_RESULT является опцией, специфической для MySQL. Данный параметр можно использовать с GROUP BY или DISTINCT, чтобы сообщить оптимизатору, что результирующий набор данных будет небольшим. В этом случае MySQL для хранения результирующей таблицы вместо сортировки будет использовать быстрые временные таблицы. В версии MySQL 3.23 указывать данный параметр обычно нет необходимости.
Параметр SQL_CALC_FOUND_ROWS (MySQL 4.0.0 и более новый) возвращает количество строк, которые вернул бы оператор SELECT, если бы не был указан LIMIT. Искомое количество строк можно получить при помощи SELECT FOUND_ROWS(). Разные функции.
Заметьте, что в версиях MySQL до 4.1.0 это не работает с LIMIT 0, который оптимизирован для того, чтобы немедленно вернуть нулевой результат. Как MySQL оптимизирует LIMIT.
Параметр SQL_CACHE предписывает MySQL сохранять результат запроса в кэше запросов при использовании QUERY_CACHE_TYPE=2 (DEMAND). Кэш запросов в MySQL.
Параметр SQL_NO_CACHE запрещает MySQL хранить результат запроса в кэше запросов. Кэш запросов в MySQL.
При использовании выражения GROUP BY строки вывода будут сортироваться в соответствии с порядком, заданным в GROUP BY, — так, как если бы применялось выражение ORDER BY для всех полей, указанных в GROUP BY. В MySQL выражение GROUP BY расширено таким образом, что для него можно также указывать параметры ASC и DESC:
SELECT a,COUNT(b) FROM test_table GROUP BY a DESC
Расширенный оператор GROUP BY в MySQL обеспечивает, в частности, возможность выбора полей, не упомянутых в выражении GROUP BY. Если ваш запрос не приносит ожидаемых результатов, прочтите, пожалуйста, описание GROUP BY. Функции, используемые в операторах GROUP BY.
При указании параметра STRAIGHT_JOIN оптимизатор будет объединять таблицы в том порядке, в котором они перечислены в выражении FROM. Применение данного параметра позволяет увеличить скорость выполнения запроса, если оптимизатор производит объединение таблиц неоптимальным образом. Синтаксис оператора EXPLAIN (получение информации о SELECT).
Выражение LIMIT может использоваться для ограничения количества строк, возвращенных командой SELECT. LIMIT принимает один или два числовых аргумента. Эти аргументы должны быть целочисленными константами. Если заданы два аргумента, то первый указывает на начало первой возвращаемой строки, а второй задает максимальное количество возвращаемых строк. При этом смещение начальной строки равно 0 (не 1):
Для совместимости с PostgreSQL MySQL также поддерживает синтаксис LIMIT # OFFSET #.
mysql> SELECT * FROM table LIMIT 5,10; # возвращает строки 6-15
Для того, чтобы выбрать все строки с определенного смещения и до конца результата, вы можете использовать значение -1 в качестве второго параметра:
mysql> SELECT * FROM table LIMIT 95,-1; # Retrieve rows 96-last.
Если задан один аргумент, то он показывает максимальное количество возвращаемых строк:
mysql> SELECT * FROM table LIMIT 5; # возвращает первых 5 строк
Другими словами, LIMIT n эквивалентно LIMIT 0,n.
Оператор SELECT может быть представлен в форме SELECT ... INTO OUTFILE 'file_name'. Эта разновидность команды осуществляет запись выбранных строк в файл, указанный в file_name. Данный файл создается на сервере и до этого не должен существовать (таким образом, помимо прочего, предотвращается разрушение таблиц и файлов, таких как /etc/passwd). Для использования этой формы команды SELECT необходимы привилегии FILE. Форма SELECT ... INTO OUTFILE главным образом предназначена для выполнения очень быстрого дампа таблицы на серверном компьютере. Команду SELECT ... INTO OUTFILE нельзя применять, если необходимо создать результирующий файл на ином хосте, отличном от серверного. В таком случае для генерации нужного файла вместо этой команды следует использовать некоторую клиентскую программу наподобие mysqldump --tab или mysql -e "SELECT ..." > outfile. Команда SELECT ... INTO OUTFILE является дополнительной по отношению к LOAD DATA INFILE; синтаксис части export_options этой команды содержит те же выражения FIELDS и LINES, которые используются в команде LOAD DATA INFILE. Синтаксис оператора LOAD DATA INFILE. Следует учитывать, что в результирующем текстовом файле оператор ESCAPED BY экранирует только следующие символы:
-
Символ оператора
ESCAPED BY -
Первый символ оператора
FIELDS TERMINATED BY -
Первый символ оператора
LINES TERMINATED BY
Помимо этого ASCII-символ 0 конвертируется в ESCAPED BY, за которым следует символ 0 (ASCII 48). Это делается потому, что необходимо экранировать любые символы операторов FIELDS TERMINATED BY, ESCAPED BY или LINES TERMINATED BY, чтобы иметь надежную возможность повторить чтение этого файла. ASCII 0 экранируется, чтобы облегчить просмотр файла с помощью программ вывода типа pager. Поскольку результирующий файл не должен удовлетворять синтаксису SQL, нет необходимости экранировать что-либо еще. Ниже приведен пример того, как получить файл в формате, который используется многими старыми программами.
SELECT a,b,a+b INTO OUTFILE "/tmp/result.text" FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY "\n" FROM test_table;
Если вместо INTO OUTFILE использовать INTO DUMPFILE, то MySQL запишет в файл только одну строку без символов завершения столбцов или строк и без какого бы то ни было экранирования. Это полезно для хранения данных типа BLOB в файле.
Следует учитывать, что любой файл, созданный с помощью INTO OUTFILE и INTO DUMPFILE, будет доступен для записи всем пользователям! Причина этого заключается в следующем: сервер MySQL не может создавать файл, принадлежащий только какому-либо текущему пользователю (вы никогда не можете запустить mysqld от пользователя root), соответственно, файл должен быть доступен для записи всем пользователям.
При использовании FOR UPDATE с обработчиком таблиц, поддерживающим блокировку страниц/строк, выбранные строки будут заблокированы для записи.
mysqlru.com
17) Основной синтаксис оператора select
Оператор SELECT – один из наиболее важных и самых распространенных операторов SQL. Он позволяет производить выборки данных из таблиц и преобразовывать к нужному виду полученные результаты.
Будучи очень мощным, он способен выполнять действия, эквивалентные операторам реляционной алгебры, причем в пределах единственной выполняемой команды. При его помощи можно реализовать сложные и громоздкие условия отбора данных из различных таблиц.
Оператор SELECT – средство, которое полностью абстрагировано от вопросов представления данных, что помогает сконцентрировать внимание на проблемах доступа к данным.
Операции над данными производятся в масштабе наборов данных, а не отдельных записей.
Основной синтаксис
SELECT [ALL | DISTINCT ]
{* | [имя_столбца [AS новое_имя]]} [,…n] FROM имя_таблицы [[AS] псевдоним] [,…n]
[WHERE <условие_поиска>]
[GROUP BY имя_столбца [,…n]]
[HAVING <критерии выбора групп>]
[ORDER BY имя_столбца [,…n]]
Оператор SELECT определяет поля (столбцы), которые будут входить в результат выполнения запроса.
В списке они разделяются запятыми и приводятся в такой очередности, в какой должны быть представлены в результате запроса.
Если используется имя поля, содержащее пробелы или разделители, его следует заключить в квадратные скобки.
Символом * можно выбрать все поля.
Если обрабатывается ряд таблиц, то (при наличии одноименных полей в разных таблицах) в списке полей используется полная спецификация поля, т.е. Имя_таблицы.Имя_поля.
Обработка элементов оператора SELECT выполняется в следующей последовательности:
FROM – определяются имена используемых таблиц;
WHERE – выполняется фильтрация строк объекта в соответствии с заданными условиями;
GROUP BY – образуются группы строк , имеющих одно и то же значение в указанном столбце;
HAVING – фильтруются группы строк объекта в соответствии с указанным условием;
SELECT – устанавливается, какие столбцы должны присутствовать в выходных данных;
ORDER BY – определяется упорядоченность результатов выполнения операторов.
Предложение FROM задает имена таблиц и представлений, которые содержат поля, перечисленные в операторе SELECT. Необязательный параметр псевдонима – это сокращение, устанавливаемое для имени таблицы.
Параметр WHERE определяет критерий отбора записей из входного набора. Но в таблице могут присутствовать повторяющиеся записи (дубликаты). Предикат ALL задает включение в выходной набор всех дубликатов, отобранных по критерию WHERE (это значение действует по умолчанию).
Предикат DISTINCT следует применять в тех случаях, когда требуется отбросить блоки данных, содержащие дублирующие записи в выбранных полях.
С помощью WHERE-параметра пользователь определяет, какие блоки данных из приведенных в списке FROM таблиц появятся в результате запроса.
За ключевым словом WHERE следует перечень условий поиска, определяющих те строки, которые должны быть выбраны при выполнении запроса.
Существует пять основных типов условий поиска (или предикатов):
1. Сравнение: сравниваются результаты вычисления одного выражения с результатами вычисления другого.
2. Диапазон: проверяется, попадает ли результат вычисления выражения в заданный диапазон значений.
3. Принадлежность множеству: проверяется, принадлежит ли результат вычислений выражения заданному множеству значений.
4. Соответствие шаблону: проверяется, отвечает ли некоторое строковое значение заданному шаблону.
5. Значение NULL: проверяется, содержит ли данный столбец определитель NULL (неизвестное значение).
В языке SQL можно использовать следующие операторы сравнения:
= – равенство;
< – меньше;
>– больше;
<= – меньше или равно;
>= – больше или равно;
<>,!= – не равно.
Более сложные предикаты могут быть построены с помощью логических операторов AND, OR или NOT, а также скобок, используемых для определения порядка вычисления выражения. Вычисление выражения в условиях выполняется по следующим правилам:
Выражение вычисляется слева направо.
Первыми вычисляются подвыражения в скобках.
Операторы NOT выполняются до выполнения операторов AND и OR.
Операторы AND выполняются до выполнения операторов OR.
Для устранения любой возможной неоднозначности рекомендуется использовать скобки.
Оператор BETWEEN используется для поиска значения внутри некоторого интервала, определяемого своими минимальным и максимальным значениями. При этом указанные значения включаются в условие поиска.
При использовании отрицания NOT BETWEEN требуется, чтобы проверяемое значение лежало вне границ заданного диапазона.
Оператор IN используется для сравнения некоторого значения со списком заданных значений, при этом проверяется, соответствует ли результат вычисления выражения одному из значений в предоставленном списке. При помощи оператора IN может быть достигнут тот же результат, что и в случае применения оператора OR, однако оператор IN выполняется быстрее.
NOT IN используется для отбора любых значений, кроме тех, которые указаны в представленном списке.
С помощью оператора LIKE можно выполнять сравнение выражения с заданным шаблоном, в котором допускается использование символов-заменителей:
Символ % – вместо этого символа может быть подставлено любое количество произвольных символов.
Символ _ заменяет один символ строки.
[] – вместо символа строки будет подставлен один из возможных символов, указанный в этих ограничителях.
[^] – вместо соответствующего символа строки будут подставлены все символы, кроме указанных в ограничителях.
Оператор IS NULL используется для сравнения текущего значения со значением NULL – специальным значением, указывающим на отсутствие любого значения.
IS NOT NULL используется для проверки присутствия значения в поле.
Параметр ORDER BY сортирует данные выходного набора в заданной последовательности.
Сортировка может выполняться по нескольким полям, в этом случае они перечисляются за ключевым словом ORDER BY через запятую.
Способ сортировки задается ключевым словом, указываемым в рамках параметра ORDER BY следом за названием поля, по которому выполняется сортировка.
По умолчанию реализуется сортировка по возрастанию. Явно она задается ключевым словом ASC. Для выполнения сортировки в обратной последовательности необходимо после имени поля, по которому она выполняется, указать ключевое слово DESC.
Построение вычисляемых полей
В общем случае для создания вычисляемого (производного) поля в списке SELECT следует указать некоторое выражение языка SQL.
В этих выражениях применяются арифметические операции сложения, вычитания, умножения и деления, а также встроенные функции языка SQL.
Можно указать имя любого столбца (поля) таблицы или запроса, но использовать имя столбца только той таблицы или запроса, которые указаны в списке предложения FROM соответствующей инструкции. При построении сложных выражений могут понадобиться скобки.
Стандарты SQL позволяют явным образом задавать имена столбцов результирующей таблицы, для чего применяется фраза AS.
Использование итоговых функций
С помощью итоговых (агрегатных) функций в рамках SQL-запроса можно получить ряд обобщающих статистических сведений о множестве отобранных значений выходного набора.
Пользователю доступны следующие основные итоговые функции:
Count (Выражение) — определяет количество записей в выходном наборе SQL-запроса;
Min/Max (Выражение) — определяют наименьшее и наибольшее из множества значений в некотором поле запроса;
Avg (Выражение) — эта функция позволяет рассчитать среднее значение множества значений, хранящихся в определенном поле отобранных запросом записей.
Sum (Выражение) — вычисляет сумму множества значений, содержащихся в определенном поле отобранных запросом записей.
Чаще всего в качестве выражения выступают имена столбцов. Выражение может вычисляться и по значениям нескольких таблиц.
studfile.net
Синтаксис SQL | SQL
В этой статье описывается синтаксис SQL запросов. В следующем операторе задана минимальная структура и синтаксис, необходимый для SELECT.
SELECT [DISTINCT | ALL] {* | список_выбора}
FROM {table_name [alias] | имя_представления}Ключевые слова (SELECT, GRANT, DELETE или CREATE) прописаны в синтаксисе SQL и имеют в этом языке предопределенное значение. Можно использовать ключевые слова в верхнем или нижнем регистре. Следующие три запроса равнозначны:
SELECT * FROM EMPLOYEES;
Select * FROM EMPLOYEES;
select * FROM EMPLOYEES;
В некоторых случаях ключевые слова могут быть сокращены. Например, ключевое слово DESCRIBE может быть использовано либо в форме DESC, либо DESCRIBE. Если мы выполним следующие запросы, то в обоих случаях получим структуру таблицы сотрудников.
DESCRIBE EMPLOYEES;
DESC EMPLOYEES;
Идентификаторы – это имена заданные разработчиками для структурных элементов базы данных: таблицы, столбцы, псевдонимы, индексы, представления. В синтаксисе последнего SQL запроса ‘EMPLOYEES’ — это идентификатор, а ‘SELECT‘ — ключевое слово. Правила для создания идентификаторов указываются в спецификации поставщика. Рассмотрим следующую таблицу:
| Правила | Платформа | Описание |
| Идентификатор должен содержать до | SQL2003 | 128 символов. |
| DB2 | 128 символов, в зависимости от платформы. | |
| MySQL | 64 символа. | |
| Oracle | 30 байт; имена базы данных до 8 байт. | |
| PostgreSQL | 31 символ. | |
| Идентификатор может содержать | SQL2003 | Любые цифры, символы и нижнее подчеркивание. |
| DB2 | Любые цифры, символы в верхнем регистре или символ нижнего подчеркивания. | |
| MySQL | Любые цифры или символы. | |
| Oracle | Любые цифры, символы и нижнее подчеркивание (_), знак фунта стерлингов (#) или доллара ($). | |
| PostgreSQL | Любые цифры, символы и нижнее подчеркивание (_). | |
| Первый символ должен быть | SQL2003 | Буквой. |
| DB2 | Буквой. | |
| MySQL | Буквой или цифрой (но не должен содержать только цифры). | |
| Oracle | Буквой. | |
| PostgreSQL | Буквой или нижним подчеркиванием (_). | |
| Идентификатор не может содержать | SQL2003 | Специальные символы или пробелы. |
| DB2 | Специальные символы или пробелы. | |
| MySQL | Точку (.), слэш (/) или ASCII(0) и ASCII(255). Кавычки (‘) и двойные кавычки («) допускаются только в ссылающихся идентификаторах. | |
| Oracle | Пробелы, двойные кавычки («) или специальные символы. | |
| PostgreSQL | Двойные кавычки («). | |
| В синтаксисе SQL запросов символ идентификатора | SQL2003 | Двойные кавычки («). |
| DB2 | Двойные кавычки («). | |
| MySQL | Кавычки ( ‘ ) или двойные кавычки (» ) в режиме совместимости с ANSI. | |
| Oracle | Двойные кавычки («). | |
| PostgreSQL | Двойные кавычки («). | |
| Идентификатор может быть зарезервирован | SQL2003 | Нет, кроме ссылающихся идентификаторов. |
| DB2 | Да. | |
| MySQL | Нет, кроме ссылающихся идентификаторов. | |
| Oracle | Нет, кроме ссылающихся идентификаторов. | |
| PostgreSQL | Нет, кроме ссылающихся идентификаторов. | |
| Адресация к схеме | SQL2003 | Каталог.схема.объект. |
| DB2 | Схема.объект. | |
| MySQL | База_данных.объект. | |
| Oracle | Схема.объект. | |
| PostgreSQL | База_данных.схема.объект. | |
| Идентификатор должен быть уникальным | SQL2003 | Да. |
| DB2 | Да. | |
| MySQL | Да. | |
| Oracle | Да. | |
| PostgreSQL | Да. |
Стандарт SQL не содержит никаких точных указаний по наименованиям, поэтому нужно следовать следующим основным принципам (в том числе и в синтаксисе SQL запросов UPDATE):
- Выбирайте имя, которое содержит смысл и имеет описательный характер. Например, таблица сотрудников не должна называться emp, а столбец имени сотрудника должен называться first_name, а не fname, хотя и «emp», и «fname» это допустимые идентификаторы;
- Используйте для всех объектов в базе данных SQL либо заглавные буквы, либо строчные, поскольку некоторые серверы баз данных чувствительны к регистру.
Термин литералы относится к фиксированным значениям данных. SQL распознает четыре типа литералов: числовые значения, строки символов, дата или время, логическое значение. Например, 100, -120, 544, 03, -458, 25, 3e2, 5E-2 являются действительными числовыми литералами. ‘США‘, ‘2000‘, ‘SQL Синтаксис‘, ‘1 января 1981‘ являются действительными строками символов (должны быть заключены в одинарные кавычки (‘ ‘)). Логические литералы и литералы даты/времени выглядят следующим образом: TRUE и ‘JAN-28-1976 21:12:40:00‘.
Операторы работают с отдельными элементами данных и возвращают результат. Операторы используются в различных операциях SQL, таких как SELECT, INSERT, UPDATE или DELETE. А также при создании различных объектов базы данных, таких как функции, представления, триггеры и хранимые процедуры. MS SQL синтаксис запросов поддерживает различные типы операторов, хотя не все СУБД поддерживают все операторы.
Смотрите таблицу ниже:
| Операторы | Работают во |
| Арифметические операторы | Всех базах данных. |
| Операторы присвоения | Всех базах данных. |
| Побитовые операторы | Microsoft SQL Server. |
| Операторы сравнения | Всех базах данных. |
| Логические операторы | DB2, Oracle, SQL Server и PostgreSQL. |
| Унарные операторы | DB2, Oracle и SQL Server. |
Приоритетность — это порядок, в котором база данных оценивает различные операторы в одном выражении. В синтаксисе SQL запросов при выполнении выражения, содержащего несколько операторов (например, +, -, /), сначала выполняются операторы с высшей приоритетностью, а затем с более низкой. При оценке операторов с одинаковой приоритетностью операторы выполняются в порядке их расстановки в выражении слева направо.
Если в выражении есть круглые скобки, то операторы в них вычисляется в первую очередь, а остальные части выражения, которые находятся вне скобок, вычисляются после этого. В следующей таблице перечислены уровни приоритетности операторов SQL от высокого к низкому.
| Приоритетность операторов |
| ( ) (выполняются в первую очередь). |
| +, -, ~ (унарные операторы). |
| *, /, % (математические операторы). |
| +, — (арифметические операторы). |
| =, >, <, >=, <=, <>, !=, !>, !< (операторы сравнения). |
| I^ (Побитовый OR), & (Побитовый AND), | (Побитовый OR). |
| NOT. |
| AND. |
| ALL, ANY, BETWEEN, IN, LIKE, OR, SOME. |
| = (присвоение переменных). |
Следующие выражения в запросе MySQL возвращают разные результаты:
SELECT 12 * 2 + 24;
12 * 2 + 24
48

SELECT 12 * (2 + 24)
12 * (2 + 24)
312
Комментарии в синтаксисе SQL запросов — это необязательный текст, который описывает, что делает программа и почему код был изменен. Компилятор всегда игнорирует комментарии. Комментарий вводится через двойное тире и пробел:
— Это комментарий SQL
В качестве альтернативы, можно использовать блок комментариев C-стиля:
/ * Это первая строка комментария Это вторая строка комментария * /.
Пробелы, как правило, игнорируются в операторах SQL, что позволяет проще форматировать код для удобства чтения.
На следующей диаграмме приведены элементы синтаксиса SQL запросов, которые составляют одиночный оператор:
Список ключевых слов SQL:
| ABSOLUTE | ACTION | ADD | ADMIN |
| AFTER | AGGREGATE | ALIAS | ALL |
| ALLOCATE | ALTER | AND | ANY |
| ARE | ARRAY | AS | ASC |
| ASSERTION | ASSERTION | AT | ATOMIC |
| AUTHORIZATION | BEFORE | BEGIN | BIGINT |
| BINARY | BIT | BLOB | BOOLEAN |
| BOTH | BREADTH | BY | CALL |
| CASCADE | CASCADED | CASE | CAST |
| CATALOG | CHAR | CHARACTER | CHECK |
| CLASS | CLOB | CLOSE | COLLATE |
| COLLATION | COLLECT | COLUMN | COMMIT |
| COMPLETION | CONDITION | CONNECT | CONNECTION |
| CONSTRAINT | CONSTRAINTS | CONSTRUCTOR | CONTAINS |
| CONTINUE | CORRESPONDING | CREATE | CROSS |
| CUBE | CURRENT | CURRENT_DATE | CURRENT_PATH |
| CURRENT_ROLE | CURRENT_TIME | CURRENT_TIMESTAMP | CURRENT_USER |
| CURSOR | CYCLE | DATA | DATALINK |
| DATE | DAY | DEALLOCATE | DEC |
| DECIMAL | DECLARE | DEFAULT | DEFERRABLE |
| DELETE | DEPTH | DEREF | DESC |
| DESCRIPTOR | DESTRUCTOR | DIAGNOSTICS | DICTIONARY |
| DISCONNECT | DO | DOMAIN | DOUBLE |
| DROP | ELEMENT | END-EXEC | EQUALS |
| ESCAPE | EXCEPT | EXCEPTION | EXECUTE |
| EXIT | EXPAND | EXPANDING | FALSE |
| FIRST | FLOAT | FOR | FOREIGN |
| FREE | FROM | FUNCTION | FUSION |
| GENERAL | GET | GLOBAL | GOTO |
| GROUP | GROUPING | HANDLER | HASH |
| HOUR | IDENTITY | IF | IGNORE |
| IMMEDIATE | IN | INDICATOR | INITIALIZE |
| INITIALLY | INNER | INOUT | INPUT |
| INSERT | INT | INTEGER | INTERSECT |
| INTERSECTION | INTERVAL | INTO | IS |
| ISOLATION | ITERATE | JOIN | KEY |
| LANGUAGE | LARGE | LAST | LATERAL |
| LEADING | LEAVE | LEFT | LESS |
| LEVEL | LIKE | LIMIT | LOCAL |
| LOCALTIME | LOCALTIMESTAMP | LOCATOR | LOOP |
| MATCH | MEMBER | MEETS | MERGE |
| MINUTE | MODIFIES | MODIFY | MODULE |
| MONTH | MULTISET | NAMES | NATIONAL |
| NATURAL | NCHAR | NCLOB | NEW |
| NEXT | NO | NONE | NORMALIZE |
| NOT | NULL | NUMERIC | OBJECT |
| OF | OFF | OLD | ON |
| ONLY | OPEN | OPERATION | OPTION |
| OR | ORDER | ORDINALITY | OUT |
| OUTER | OUTPUT | PAD | PARAMETER |
| PARAMETERS | PARTIAL | PATH | PERIOD |
| POSTFIX | PRECEDES | PRECISION | PREFIX |
| PREORDER | PREPARE | PRESERVE | PRIMARY |
| PRIOR | PRIVILEGES | PROCEDURE | PUBLIC |
| READ | READS | REAL | RECURSIVE |
| REDO | REF | REFERENCES | REFERENCING |
| RELATIVE | REPEAT | RESIGNAL | RESTRICT |
| RESULT | RETURN | RETURNS | REVOKE |
| RIGHT | ROLE | ROLLBACK | ROLLUP |
| ROUTINE | ROW | ROWS | SAVEPOINT |
| SCHEMA | SCROLL | SEARCH | SECOND |
| SECTION | SELECT | SEQUENCE | SESSION |
| SESSION_USER | SET | SETS | SIGNAL |
| SIZE | SMALLINT | SPECIFIC | SPECIFICTYPE |
| SQL | SQLEXCEPTION | SQLSTATE | SQLWARNING |
| START | STATE | STATIC | STRUCTURE |
| SUBMULTISET | SUCCEEDS | SUM | SYSTEM_USER |
| TABLE | TABLESAMPLE | TEMPORARY | TERMINATE |
| THAN | THEN | TIME | TIMESTAMP |
| TIMEZONE_HOUR | TIMEZONE_MINUTE | TO | TRAILING |
| TRANSACTION | TRANSLATION | TREAT | TRIGGER |
| TRUE | UESCAPE | UNDER | UNDO |
| UNION | UNIQUE | UNKNOWN | UNTIL |
| UPDATE | USAGE | USER | USING |
| VALUE | VALUES | VARCHAR | VARIABLE |
| VARYING | VIEW | WHEN | WHENEVER |
| WHERE | WHILE | WITH | WRITE |
| YEAR | ZONE |
Данная публикация представляет собой перевод статьи «SQL Syntax» , подготовленной дружной командой проекта Интернет-технологии.ру
www.internet-technologies.ru
Выполнение простой команды SELECT
Практические возможности команды SELECT реализованы в исполнении команды. Ключевым моментом при выполнении любых запросов является понимание синтаксиса и правил его использования. Мы рассмотрим базовый синтаксис, затем процесс выполнения и наконец выражения и операторы, постепенно увеличивая использования данных из реляционных таблиц. Рассмотрим концпецию значения NULL и подводные камни его использования. Эти вопросы рассматриваются в следующих подпунктах
Синтаксис простой команды SELECT
Правила которые следует соблюдать
Выражения и операторы
NULL – это ничего
Синтаксис простой команды SELECT
В самой примитивной форме команда SELECT поддерживает проекцию столбцов и использование арифметических, строковых выражений, а также работу с датами. Также доступна возможность исключения дубликатов из результирующего набора. Базовый синтаксис команды SELECT
SELECT * | {[DISTINCT] column|expression [alias],…}
FROM table;
Ключевое слово (или зарезервированное) команды SELECT написано в верхнем регистре. Когда пишете команду, регистр ключевых слов не важен, но ключенвые слова нельзя использовать как название столбцов или имени другого объекта базы данных. SELECT, DISTINCT и FROM это ключевые слова. Команда SELECT обычно содержит два или более параметров. Два обязательных параметра это сама команда SELECT и слово FROM. Символ | используется как лоическое ИЛИ. То есть вы можете прочитать предыдущую команду как
SELECT * FROM table
В таком формате символ * используется для обозначения всех столбцов. SELECT * это простой способ попросить Oracle вернуть все доступные столбцы. Такой формат используется как быстрый способ вместо набора SELECT column1, column2, … columnN для выбора всех столбцов. Параметр FROM указывает какие таблицы использовать для выбора столбцов требуемых в команде SELECT. Вы можете выполнить следующий запрос для получения всех столбцов всех строк из таблицы REGIONS в схеме HR
select * from regions;
Когда выполнится это команда, результатом будет набор всех строк со всеми столбцами принадлежащие этой таблице. Использование звёздочки в команде SELECT иногда называют «слепым» запросом так как столбцы которые будут возвращены не указаны.
Вторая форма запроса SELECT использует такую же часть FROM но другой формат SELECT
SELECT {[DISTINCT] column|expression [alias],…} FROM table;
Такой запрос может быть разбит на два формата
SELECT column1 (possibly other columns or expressions) [alias optional]
или
SELECT DISTINCT column1 (possibly other columns or expressions) [alias optional]
Алиас это альтернативное имя столбца или выражения. Алиасы обычно используются для отображения результата в понятном пользователю виде. Они также используются для сокращения количество символов для набора когда ссылаешься на столбец или выражение. Перечисляя столбцы в команде SELECT вы фактически проецируете конкретную выборку результата которую вы хотите получить. Следующий запрос вернёт только столбец REGION_NAME таблицы REGIONS
select region_name from regions;
Вас могут попросить предоставить все должности сотрудников организации за всё время. Для этого вы можете выполнить команду SELECT * FROM JOB_HISTORY. Но такой запрос вернёт вам также EMPLOYEE_ID, START_DATE и END_DATE столбцы. Запрос который возвращает только нужные столбцы JOB_ID и DEPARTMENT_ID можно написать так
select job_id, department_id from job_history;
Использование ключевого слова DISTINCT позволит убрать дубликаты из результата. В некоторых случаях уникальность строк необходима. Важно понимать что критерий определения уникальности для Oracle находится после слова DISTINCT. Выборка уникальных значений job_ib из таблицы job_history с помощью следующего запроса вернёт восемь уникальных должностей
select distinct job_id from job_history
Важно понимать что уникальность определяется комбинацией столбцов после слова DISTINCT.
select distinct department_id from job_history;
select distinct job_id,department_id from job_history;
Правила которые следует соблюдать
SQL достаточно строгий язык с точки зрения синтаксиса, но он остаётся достаточно простым и гибким для поддержки разных стилей программирования. В этом разделе рассмотрим несколько базовых правил управляющих SQL запросами.
Верхний или нижний регистр
Регист в запросах это дело вкуса разработчика. Многие предпочитают писать запросы в нижнем регистре. Также некоторые считают что ключевые слова нужно писать в верхнем регистре, но это не так. Однако стоит придерживаться одного и того же последовательного и стандартизированного формата в группе разработчиков.
Есть только один нюанс в использовании разного регистра. Когда вы работаете со значениями литералов – регистр имеет значение. Раасмотрим столбец JOB_ID таблицы JOB_HISTORY. Этот столбец хранит строки данных в верхнем регистре: SA_REP, ST_CLERK и т.д. Когда вы пишете запрос который будет ограничиваться значениями литералов – регистр важен. Oracle рассматривает запрос к таблице JOB_HISTORY с условием St_Clerk по другому чем запрос с условием ST_CLERK.
Метаданные об объектах БД хранятся по умолчанию в верхнем регистре в словаре данных. Если вы посмотрите данные о таблицах в схеме HR – все имена будут в верхнем регистре. Это не значит что таблица не может быть создана с именем в нижнем регистре – это можно делать. Это всего лишь общее поведение по умолчанию.
Exam tip
SQL запросы могут быть написаны с использованием любого регистра. Нужно следить за регистром когда вы работаете со значениями-литералами и алиасами. Использование в запросе JOB_ID или job_id в названии столбца вернёт одинаковый результат, но запрос на поиск значения PRESIDENT или President вернёт разный результат.
Символ конца запроса
Обычно используется “;” как символ конца запроса. SQL *Plus всегда требует символа конца запроса и обычно это “;”. Запросы или группы запросов часто сохраняются как файлы скрипты для будущего использования. Запросы в скриптах обычно пишутся в нескольких строках разделяемых символом перевода строки и после завершения одной команды используется “/” или “;”. Вы можете написать команду SELECT разбить её на строки символом переноса строки, а затем после последней строки добавить новую строку в которой будет “/” и сохранить это как файл. Затем файл можно вызвать из SQL *Plus. SQL Developer не требует символа конца строки если создаётся только один запрос. Считается хорошим тоном всегда завершать ваши запросы символом конца строки. Рассмотрим два запроса в SQL *Plus:
select country_name, country_id, location_id from countries;
select
city,
location_id,
state_province,
country_id
from
locations
;
Первый пример показывает два важных правила. Первое – запрос заканчивается “;”. Второе – весь запрос написан в одну строку. Допустимо использовать и первый и второй варинты запроса, главное чтобы все слова запроса были до символа конца запроса.
Отступы, читаемость и good practices
Рассмотрим запрос
select
city,
location_id,
state_province,
country_id
from
locations
/
Этот запрос показывает преимущества разделения запроса на строки для улучшения читаемости кода. Oracle всё равно как написан запрос, в одну строку или в несколько, какие отступы использованы и так далее. Хорошим тоном считается разделение блоков запроса на разные строки. Когда выражения в блоке SELECT или WHERE достаточно сложные, то разбиение этих блоков на разные строки существенно улучшает читаемость запроса. Когда вы пишете запрос – обычно этот процесс итеративный. Интерпретатор SQL гораздо более полезен если вы разрабатываете сложные выражения разбивая их на строки, так как ошибки интерпретатора выглядят как “Error at line X:”. Процесс отладки станет гораздо проще.
Выражения и операторы
В синтаксисе простого запроса SELECT мы видели что можно использовать столбцы или выражения. Выражения – это обычно результат какой-либо операции над значениями одного (или нескольких) столбцов или выражений. Операторы которые могут использоваться в выражениях зависят от типа данных операндов. Для численных значений доступны сложение, вычитание, умножение и деление. Для строк доступно сложения (конкатенация). Сложение и вычитание доступно для типов данных даты и времени. Как и в обычной арифметике существует предопределённый порядок выполнения операторов (operator precedence) если в выражении используется больше чем один оператор. Круглые кавычки имеют самый высокий приоритет. Деление и умножение следующие в иерархии и рассчитываются до выполнения операторов сложения и вычитания, которые имеют наименьший приоритет.
Операторы с одинаковым приоритетом вычисляются слева направо. Круглые кавычки можно использовать для изменения поведения по умолчанию. Использование кавычек нельзя недооценить при создании сложных выражений. Использование выражений открывает много возможностей в работе с данными.
Арифметические операторы
Рассмотрим таблицу JOB_HISTORY где хранится дата начала и конца назначения должности сотруднику. Для расчёта налогов или пенсии может возникнуть потребность расчёта как долго сотрудник занимал определённую должность. Эту информацию можно получить используя арифметический оператор. Рассмотрим некоторые элементы запроса и результата выполнения этого запроса показанные на рисунке 9-5.
Рисунок 9-5 – Запрос с использованием арфметического оператора
В блоке SELECT перечислены пять элементов. Четыре из них это обычные столбцы таблицы JOB_HISTORY, когда пятый используя значения исходных столбцов рассчитывает сколько дней провел сотрудник в конкретной должности. Рассмотрим сотрудника с номером 176, 9 строку результата. Этот сотрудник работал как менеджер по продажам с 1 Января 2007 года по 31 Декабря 2007 года. То есть сотрудник работал в этой должности ровно один год, 2007, который состоял из 365 дней.
Данные из пятого элемента нашего запроса показывают сколько сотрудник проработал в той или иной должности и могут быть использованы для расчёта сколько и в какой должности сотрудник работал в компании. Пятый элемент запроса и есть выражение. Это выражение показывает арифметическую операцию произведённую над информацией типа данных дата, которая возвращает численное значение представляющее собой количество дней.
Для улучшения читаемости, подвыражение (операция вычитания над датами) end_date-start_date выделено кавычками. Добавление единицы заставляет результат учитывать последний день.
Tip
Во время работы с SQL вы можете часто встречать две распространённые ошибки «ORA-00923: FROM keyword not found where expected» и «ORA-00942: table or view does not exist». Обычно они указаывают на ошибку в синтаксисе или пунктуации, такие как пропущенная круглая кавычка или забытый символ конца литерала при работе со строками.
Выражения и псевдонимы столбцов
На рисунке 9-5 показан новый принцип называющийся псевдонимом столбца. Обратите внимание что столбец с результатом выражения в результате выполнения запроса озаглавлен понятным названием “Days Employed”. Этот заголовок – это и есть псевдоним. Псевдоним это альтернативное имя для столбца или выражения. Если в этом выражении не использовать псевдоним, заголовок столбца будет (END_DATE-START_DATE)+1, что не очень понятно. Псевдонимы особенно полезны при работе с выражениями или суммированием и могут реализовываться несколькими способами. Есть несколько правил при работе с псевдонимами в команде SELECT. Псевдоним “Days Employed” на рисунке 9-5 был указан путём добавления пробела после выражения и заключен в двойные кавычки. Эти кавычки обязательны по двум причинам. Во-первых, псевдоним сотоит из нескольких слов. Во-вторых, сохранение регистра псевдонима возможно только при его заключении в двойные кавычки. Если вы укажете псевдоним из двух слов разделённых пробелом без кавычек – вы получите ошибку «ORA-00923: FROM keyword not found where expected». SQL предлагает более формальный метод указания псевдонимов путём добавления ключевого слова AS между столбцом или выражением и его псевдонимом.
SELECT
EMPLOYEE_ID AS «Employee ID»,
JOB_ID AS «Occupation»,
START_DATE, END_DATE,
(END_DATE-START_DATE)+1 «Days Employed»
FROM JOB_HISTORY;
Оператор для работы со строками
Символ || представляет оператор конкатенации строк. Этот оператор используется для объединения строк или выражений вместе для создания более длинного выражения. Столбцы таблицы можно объединять между собой или с значением строкового-литерала для создания одного результирующего выражения.
Оператор конкатенации достаточно гибкий для использования несколько раз и в любом месте выражения. Рассмотрим пример
SELECT ‘THE ‘||REGION_NAME||’ region is on Planet Earth’ «Planetary Location» FROM REGIONS;
В этом запросе строковый-литерал “The” конкатенируется со значением столбца REGION_NAME. Затем полученная строка также конкатенируется со строковым литералом “region is on Planet Earth” и всему выражению назначается псевдоним “Planetary location”.
Литералы и таблица DUAL
Литералы часто используются в выражениях и ссылаются на данные которые не принадлежат объектам базы данных. Конечно конкатенация существующих столбцов тоже используется, но что делать с обработкой литералов которые не зависят от данных в столбцах таблицы. Чтобы обеспечивать согласованность, Oracle придумал решение проблемы использования базы данных для вычисления выражений которым не нужны данные объектов БД. Для того чтобы база данных рассчитала выражение, должна быть выполнена синтаксически корректная команда SELECT. Что делать если вы хотите узнать сумму двух чисел? Вы можете использовать специальную таблицу с одной строкой и одним столбцом с названием DUAL.
Вызов таблицы DUAL показан на рисунке 9-1. В таблице доступен один столбец с названием DUMMY и типом данных строка. Вы можете выполнить запрос SELECT * FROM DUAL и вам вернётся строка с одним столбцом со значением “X”. Тестирование сложных выражений в процессе разработки выполняя запросы к таблице DUAL – это эффективный метод проверки того что вычисление выражений работает как задумано. Выражения с литералами можно проверять на любой таблице, но помните что выражения будут обрабатываться для всех строк в таблице, а в таблице DUAL всего одна строка.
select ‘literal ‘||’processing using the REGIONS table’ from regions;
select ‘literal ‘||’processing using the DUAL table’ from dual;
Первый запрос вернёт вам четыре строки, так как в таблице REGIONS четыре строки, а второй запрос вернёт одну строку.
Кавычки
Строковые литералы в нашим примерах были простыми выражениями иногда добавляемыми к столбцам. Такие строковые литералы заключаются в одинарные кавычки. Например
select ‘I am a character literal string’ from dual;
А что если литерал уже содержит символ кавычки? Рассмотрим пример
select ‘Plural’s have one quote too many’ from dual;
Этот запрос вернёт ошибку ORA-00923. Так как обрабатывать такие строки? Для этого доступно два способа. Первый и самый популярный это добавление дополнительной одинарной кавычки для каждого встречаемого значения кавычки в выражении. Предыдущий пример с использованием этого способа будет выглядеть так
select ‘Plural»s have one quote too many’ from dual;
Использование двух одинарных кавычек для обработки каждой кавычки в тексте может быть неудобным и приводить к ошибкам по мере увеличения количества таких кавычек. Oracle предоставляет способ переопределить символ начала и конца литерала с помощью оператора q. Oracle выбрала одинарную кавычку как символ начала и конца строки, но этим символом можно назначить другой символ.
Рассмотрим оператор q. Он позволяет установить символом начала и конца строкового литерала либо одинарный символ или один из четырёх видо скобок (), {}, [], <>. Рассмотрим примеры использования оператора q
SELECT q'<Plural’s can also be specified with alternate quote operators>’ «q<>» FROM DUAL;
SELECT q'[Even square brackets’ [] can be used for Plural’s]’ «q[]» FROM DUAL;
SELECT q’XWhat about UPPER CASE X for Plural’sX’ «qX» FROM DUAL;
Синтаксис оператора q
q‘delimiter character literal which may include single quotes delimiter’
где delimiter может быть символ или соотвествующая скобка. В примерах выше показано использование скобок (в первом и втором запросе), и использование символа “X” как символа начала и конца строкового литерала. Обратите внимание что символ X тоже может использоваться в значении литерала – конец строки обозначается символом “X” и одинарной кавычкой.
NULL – это ничего
NULL обозначает отсутствие данных. Строка в которой содержится NULL в столбце – рассматривается как строка у которой нет данного для этого столбца. Формально NULL обозначает значение, которое неизвестно или непреминимо. Если не обрабатывать специальным образом значения NULL то ваши запросы скорее всего не выполнятся или что ещё хуже, вернёт неправильный результат. В этом разделе мы рассматриваем как обрабатывать значение NULL в столбце и как значение NULL влияет на вычисление выражений.
Обязательные и необязательные столбцы
Таблица хранят строки данные которые разбиты на один или несколько столбцов. У этих столбцов есть названия и тип данных. Некоторые из столбцов имею ограничения на обязательность указания значения. Таким образом любая строка дожна хранить какое либо значение отличное от NULL в этих столбцах. Когда столбец таблицы не указан как обязательный то вы рискуете встретить значение NULL для этого столбца.
Tip
Любая арифметическая операция со значением NULL всегда возвращает NULL
Oracle позволяет работать со значением NULL используя специальные функции. Подробнее об этом мы поговорим в главе 10. Деление на NULL вернёт NULL, а деление на 0 приведёт к ошибке. Когда строка объединяется со значением NULL – то значение NULL игнорируется.
SELECT 1+NULL FROM DUAL;
SELECT ‘1’||NULL FROM DUAL;
Внешние ключи и необязательные столбцы
Модель данных иногда ведёт к проблемным ситуациям когда таблицы связаны через первичный и внешний ключ, но столбец внешнего ключа необязателен.
Первичный ключ таблицы DEPARTAMENTS – это столбец DEPARTMENT_ID. В таблице EMPLOYEES столбец DEPARTMENT_ID хранит ограничение внешнего ключа для связи с таблицей DEPARTAMENTS. Это значит что в таблице EMPLOYEES не может находиться запись с таким значением столбца DEPARTMENT_ID которого нет в таблице DEPARTMENTS. Такое ограничение обусловлено выполнением третьей нормальной формы и критически важно для ограничения целостности базы данных.
А что насчёт значений NULL? Может быть значение NULL в столбце DEPARTAMENT_ID таблицы DEPARTAMENTS? Ответ – нет. Значение первичного ключа всегда должно быть указано. А значение в таблице EMPLOYEES? Это спорный вопрос, так как для обеспечения гибкости и покрытия всех возможных сценаривев, Oracle не может настаивать на том чтобы столбцы используемые для обеспечения ссылочной целостности были обязательными.
Поэтому поле DEPARTMENT_ID в таблице EMPLOYEES необязательное и существует вероятность что в таблице будут существовать записи со значением NULL в столбце DEPARTMENT_ID. И такие записи существуют. Модель данных позвоняет сотруднику работать в каком-то отделе или не работать ни в одном отделе. Когда происходит операция объединения то абсолютно возможно что какие-то записи которые содержат NULL в значении ключа будут отсутствовать в результате. В главе 12 мы рассмотрим как работать с объединениями.
oracledb.ru