Структура оператора SELECT — Проектирование баз данных на SQL (Информатика и программирование)
Лекция 21. Структура оператора SELECT
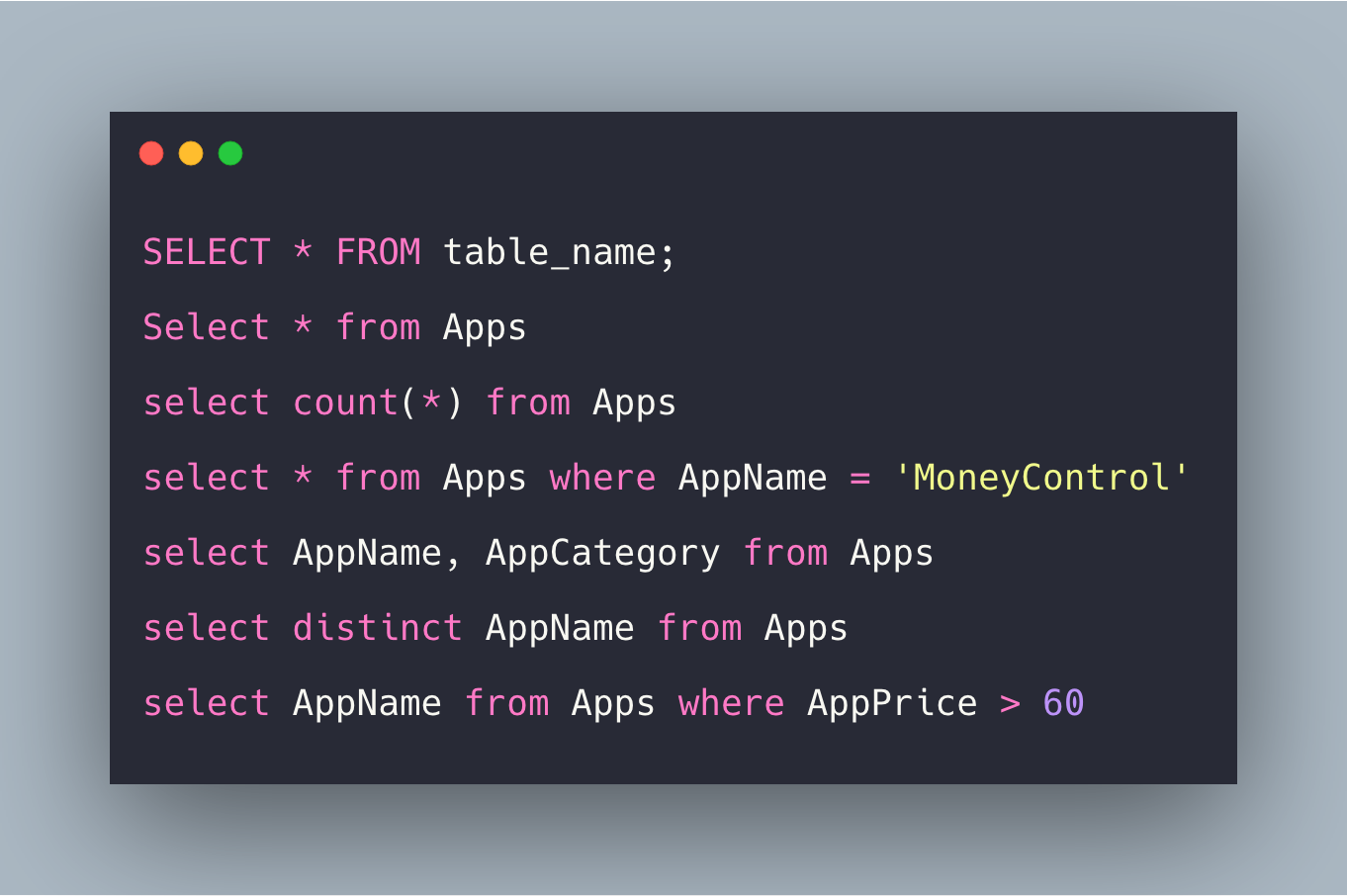
Язык запросов строится на единственном операторе SELECT, используемом чаще всех операторов языка SQL. Он производит выборки данных из таблиц БД и предоставляет их пользователям в необходимом виде. Практически SELECT реализует всю мощь реляционной алгебры.
В наиболее общем виде он имеет следующий формат:
SELECT [DISTINCT или ALL] <имена полей возвращаемых запросом>
FROM <имена таблиц используемых в запросе>
WHERE <условия отбора записей>
GROUP BY <имена группируемых полей>
HAVING <условия отбора>
UNION <оператор select>
PLAN <план выполнения запроса>
ORDER BY <список полей сортировки>
SELECT — ключевое слово, которое сообщает СУБД, что эта команда — запрос. Все запросы начинаются этим служебным словом с последующим пробелом. За ним может следовать способ выборки — с удалением дубликатов записей (DISTINCT) или без удаления (ALL, по умолчанию). Затем через запятую следует список полей включаемых в результат запроса. Может использоваться символ «*» (звездочка) означает, что в результирующий набор включаются все поля из исходных таблиц или из указанной таблицы, например Товары.* (из таблицы товары выбираются все поля). При необходимости поля таблиц можно переименовать, для этого используется оператор AS.
Все запросы начинаются этим служебным словом с последующим пробелом. За ним может следовать способ выборки — с удалением дубликатов записей (DISTINCT) или без удаления (ALL, по умолчанию). Затем через запятую следует список полей включаемых в результат запроса. Может использоваться символ «*» (звездочка) означает, что в результирующий набор включаются все поля из исходных таблиц или из указанной таблицы, например Товары.* (из таблицы товары выбираются все поля). При необходимости поля таблиц можно переименовать, для этого используется оператор AS.
Раздел FROM — используется совместно с SELECT, должен присутствовать в каждом запросе. В нем, через запятую, перечисляются используемые в запросе таблицы. В случае если таблиц несколько, то запрос неявно выполняет декартово произведение. Таблицам можно присвоить имена-псевдонимы, что бывает полезно для осуществления операции соединения таблицы с самой собою или для доступа из вложенного подзапроса к текущей записи внешнего запроса. Все последующие разделы оператора SELECT являются необязательными.
Все последующие разделы оператора SELECT являются необязательными.
Если необходимо из таблицы А (таблица 6.1) выбрать только записи в необходимых полях (Фамилия, Зарплата), т.е. выполнить проекцию то можно записать следующий код (результат — таблица 7.2):
SELECT A.Фамилия, A.Зарплата FROM А
Полностью вся таблица будет получена в следующем случае:
SELECT * FROM А
В разделе WHERE задаются условия отбора записей в результат запроса, т.е. условие которому должна удовлетворять запись, чтобы попасть в результат запроса, аналог операции селекции в реляционной алгебре.
В выражении условий раздела WHERE могут быть использованы следующие предикаты:
· Предикаты сравнения { =, <>, >, <, >=, <= }, которые имеют традиционный смысл, например, следующий код языка SQL использованный для таблицы 6.1 даст результат, приведенный в таблице 7. 1:
1:
SELECT * FROM А
WHERE Зарплата<3000
· Предикат Between A and В — принимает значения между А и В. Предикат истинен, когда сравниваемое значение попадает в заданный диапазон, включая границы диапазона. Одновременно в стандарте задан и противоположный предикат Not Between A and В, который истинен тогда, когда сравниваемое значение не попадает в заданный интервал, включая его границы. Например:
SELECT * FROM А
WHERE Зарплата Between 2000 and 3000
В результате выполнения этого запроса будут возвращены все записи, у которых значения поля «Зарплата» находятся в интервале от 2000 до 3000, включительно.
· Предикат вхождения во множество — IN (множество) истинен тогда, когда сравниваемое значение входит во множество заданных значений. При этом множество значений может быть задано простым перечислением или встроенным подзапросом.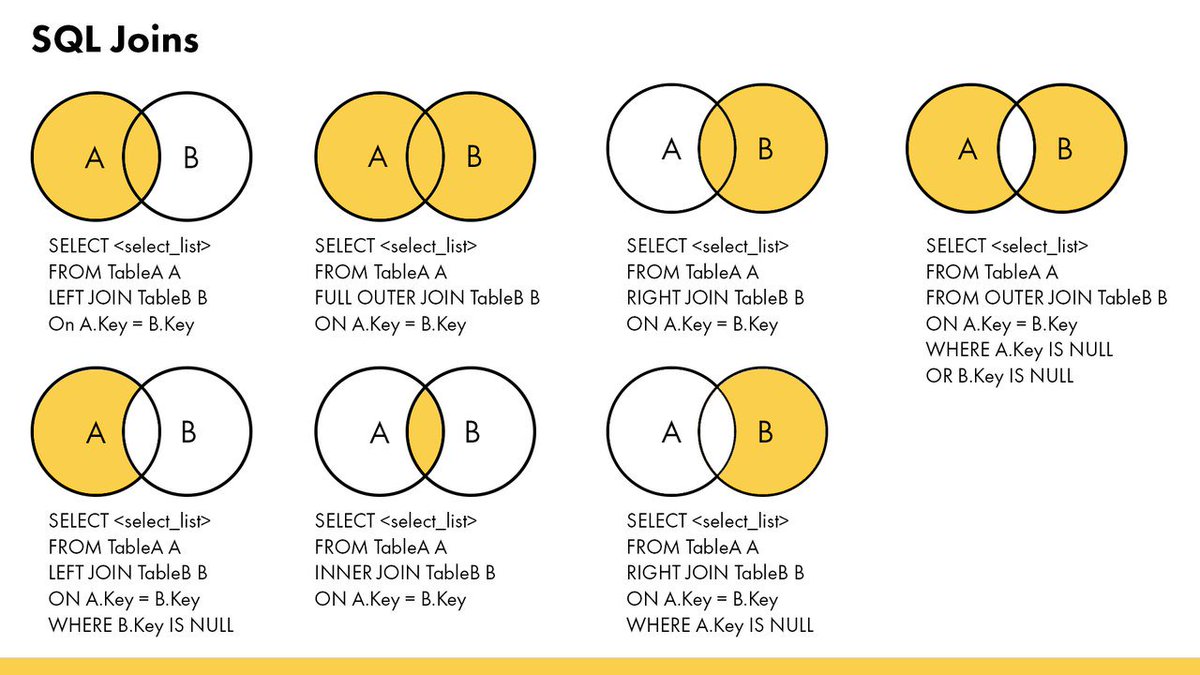 Одновременно существует противоположный предикат NOT IN (множество), который истинен тогда, когда сравниваемое значение не входит в заданное множество.
Одновременно существует противоположный предикат NOT IN (множество), который истинен тогда, когда сравниваемое значение не входит в заданное множество.
SELECT * FROM А
WHERE Фамилия IN(‘Иванов’, ‘Петров’)
В результирующий набор данных будут включены те записи, для которых значения поля «Фамилия» совпадут с элементами множества определенными предикатом сравнения IN, т.е. записи о сотрудниках: Иванов и Петров.
· Предикаты сравнения с образцом LIKE и NOT LIKE. Предикат LIKE требует задания шаблона, с которым сравнивается заданное значение, предикат истинен, если сравниваемое значение соответствует шаблону, и ложен в противном случае. Предикат NOT LIKE имеет противоположный смысл. По стандарту в шаблон могут быть включены специальные символы:
o символ подчеркивания (_) — для обозначения любого одиночного символа;
o символ процента (%) — для обозначения любой произвольной последовательности символов;
o остальные символы, заданные в шаблоне, обозначают самих себя.
SELECT * FROM А
WHERE Фамилия Like ‘П%’
В результате выполнения запроса будут получены все записи, значения поля «Фамилия» для которых совпадет с шаблоном ‘П%’, т.е. Все фамилии сотрудников начинающиеся с символа «П».
· Предикат сравнения с неопределенным значением IS NULL. Понятие неопределенного значения было внесено в концепции БД позднее. Неопределенное значение интерпретируется как значение, неизвестное на данный момент времени. При сравнении неопределенных значений не действуют стандартные правила сравнения: одно неопределенное значение никогда не считается равным другому неопределенному значению. Для вы явления равенства значения некоторого поля неопределенному применяют специальные стандартные предикаты: <имя поля>IS NULL и <имя поля > IS NOT NULL.
· Предикаты существования EXIST и не существования NOT EXIST. Эти предикаты относятся к встроенным подзапросам.
Раздел ORDER BY определяет список полей сортировки. Последовательность перечисления полей имеет важное значение и определяет порядок сортировки в результирующем отношении. Например, если первым полем списка будет указана Фамилия, а вторым Номер группы, то в результирующем отношении сначала будут собраны в алфавитном порядке студенты, и если найдутся однофамильцы, то они будут расположены в порядке возрастания номеров групп. Приведем простой пример сортировки записей по полю «Фамилия»:
Последовательность перечисления полей имеет важное значение и определяет порядок сортировки в результирующем отношении. Например, если первым полем списка будет указана Фамилия, а вторым Номер группы, то в результирующем отношении сначала будут собраны в алфавитном порядке студенты, и если найдутся однофамильцы, то они будут расположены в порядке возрастания номеров групп. Приведем простой пример сортировки записей по полю «Фамилия»:
SELECT * FROM А
ORDER BY Фамилия
В разделе GROUP BY определяется список полей группировки. При группировке записи таблиц разбиваются на группы. В группы собираются записи, имеющие одинаковые значения полей указанных в разделе GROUP BY. Данный раздел позволяет выполнять операции над группами с применением агрегатных функций указанных в таблице 21.1
Таблица 21.1 – Основные агрегатные (итоговые) функции
В разделе HAVING задаются предикаты-условия, накладываемые на каждую группу, и имеет тот же синтаксис, что и раздел WHERE. Другими словами раздел HAVING используется при группировке вместо раздела WHERE.
Другими словами раздел HAVING используется при группировке вместо раздела WHERE.
Агрегатные функции можно использовать без группировки, если вся таблица будет рассматриваться как одна группа и результатом запроса будет одна строка. Например, требуется определить количество экземпляров книг библиотеки, в этом случае запрос будет иметь вид:
SELECT COUNT(*) AS Количество
FROM Экземпляры;
Если требуется определить количество экземпляров книг имеющихся сейчас в библиотеке, тогда запрос примет вид:
SELECT COUNT(*) AS Количество
FROM Экземпляры
GROUP BY Наличие
HAVING Наличие = Да;
Контрольные вопросы
1. В чем связь реляционной алгебры и оператора SELECT?
2. Назовите формат использования оператора SELECT в общем виде.
3. Как из результатов запроса исключить повторяющиеся записи?
4. Как накладываются условия на отбираемые записи?
5. Что такое предикаты?
Что такое предикаты?
6. Какие предикаты можно использовать в разделе WHERE?
7. Как выполняется сортировка?
8. Что общего между запросами MS Access и SQL?
Задания для самостоятельной работы
14. Организационное обеспечение КИС — лекция, которая пользуется популярностью у тех, кто читал эту лекцию.
Задание 1. Напишите запрос на получение информации о книгах, год издания которых больше 2000.
Задание 2. Получите список инвентарных номеров книг имеющихся в данный момент времени в библиотеке.
Задание 3. Получите список читателей, дата рождения которых находится в каком-либо интервале дат.
Задание 4. Получите список читателей, фамилии которых начинаются с буквы «А»
Задание 5. Напишите запрос на определение количества читателей библиотеки.
Во всех заданиях выполняйте сортировку.
Оператор SQL: SELECT. — it-black.ru
Оператор SQL: SELECT. — it-black.ru
Перейти к содержимому
— it-black.ru
Перейти к содержимомуC помощью оператора SELECT происходит выборка значений, хранящихся в базе данных. В структуру запроса оператора SQL SELECT могут быть включены многие дополнительные операторы: уточняющие условие выборки, производящие группировку, сортировку выходных значений.
Чтобы создать простейший SELECT запрос, необходимо указать имя столбца и название таблицы. Базовый синтаксис:
SELECT column_list FROM table_name [WHERE условие] [GROUP BY условие] [HAVING условие] [ORDER BY условие]
SELECT — ключевое слово, которое сообщает базе данных о том, что оператор является запросом. Все запросы начинаются с этого слова, за ним следует пробел.
Column_list
 Звездочка (*) означает полный список столбцов.
Звездочка (*) означает полный список столбцов.FROM table_name — ключевое слово, которое должно присутствовать в каждом запросе. После него через пробел указывается имя таблицы, являющейся источником данных.
Код в скобках «[]» является не обязательным в операторе SELECT. Он необходим для более точного определения запроса.
Примеры оператора SQL SELECT. Имеется следующая таблица Gruppa:
| ID | Name | FIO | Gruppa | Nomer | Address |
| 1 | Виктор | Иванов | 17-22 | 89742000058 | г.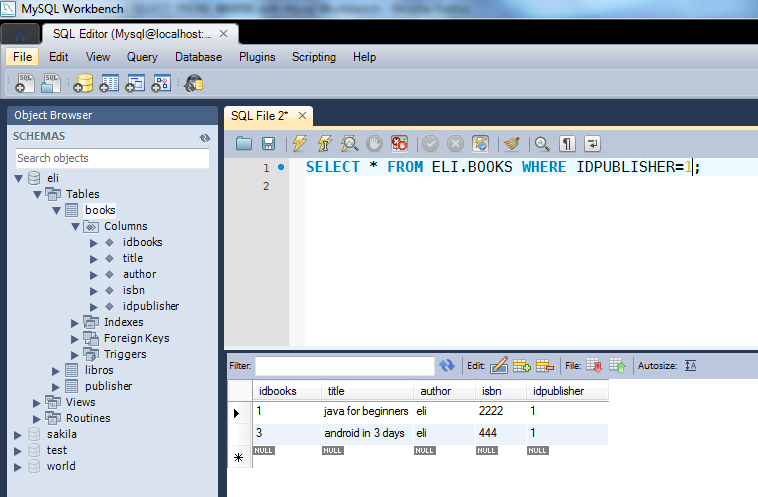 Холмск Холмск |
| 2 | Марк | Петров | 17-22 | 89234006785 | г.Холмск |
| 3 | Валерий | Васильев | 17-22 | 89631224560 | г.Холмск |
Пример 1. С помощью оператора SELECT вывести имена студентов (Name):
SELECT Name FROM Gruppa;
Пример 2. С помощью оператора SELECT вывести информацию о студенте (Иванове):
SELECT * FROM Gruppa WHERE FIO = 'Иванов';
- Виктор Черемных
- 30 мая, 2018
- 4 Comments
Группа в VK
Обнаружили опечатку?
Сообщите нам об этом, выделите текст с ошибкой и нажмите Ctrl+Enter, будем очень признательны!
Свежие статьи
Облако меток
Instagram Vk Youtube Telegram OdnoklassnikiПолезно знать
Рубрики
Авторы
SQL Server SELECT Примеры
Автор: Koen Verbeeck |
Обновлено: 12 апреля 2021 г. |
Комментарии | Связанный: Подробнее > TSQL
|
Комментарии | Связанный: Подробнее > TSQL
Проблема
При сохранении данных в разных таблицах базы данных SQL в какой-то момент времени вы захочет получить некоторые из этих данных. Здесь оператор SELECT для Появляется язык SQL. Этот учебник научит вас, как использовать SELECT для чтения, агрегирования и сортировать данные из одной или нескольких таблиц базы данных.
Решение
Примеры инструкции SQL SELECT
В самой простой форме предложение SELECT имеет следующий синтаксис SQL для База данных Microsoft SQL Server:
ВЫБЕРИТЕ * ИЗ <ИмяТаблицы>;
Этот запрос SQL выберет все столбцы и все строки из таблицы.
ВЫБЕРИТЕ * ОТ [Человека].[Человека];
Этот запрос выбирает все данные из таблицы Person в схеме Person.
Если нам нужно только подмножество столбцов, мы можем явно перечислить каждый столбец разделенные запятой, вместо использования символа звездочки, который включает все столбцы.
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, ModifiedDate ОТ [Человека].[Человека];
Синтаксис для сортировки результатов
Иногда требуется отобразить строки в порядке, отличном от порядка SQL. Сервер возвращает результаты. Вы можете сделать это с помощью ПОРЯДОК SQL пункт ПО.
ВЫБЕРИТЕ столбец1, столбец2, столбец3, … ОТ <имя таблицы> ORDER BY columnX ASC | DESC
Вы можете сортировать по одному или нескольким столбцам, и вы можете выбрать сортировку по возрастанию (ASC) или по убыванию (DESC). Вернем строки с восходящей датой изменения:
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, ModifiedDate ОТ [Человека].[Человека] ЗАКАЗАТЬ ПО [Дата изменения] ASC;
 [Человека]
ЗАКАЗАТЬ ПО [Дата изменения] ASC;
[Человека]
ЗАКАЗАТЬ ПО [Дата изменения] ASC;
По возрастанию — значение по умолчанию, поэтому явно указывать ASC не нужно.
Теперь с датой изменения по убыванию:
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, ModifiedDate ОТ [Человека].[Человека] ЗАКАЗАТЬ ПО [Дата изменения] DESC;
Вы можете сортировать по нескольким столбцам, поэтому давайте сортировать по убыванию даты изменения сначала, затем по возрастанию имени.
ВЫБЕРИТЕ BusinessEntityID, Имя, Фамилия, ModifiedDate ОТ [Человека].[Человека] ORDER BY [ModifiedDate] DESC, Имя;
Например, вы можете видеть, как третья и четвертая строки результирующего набора (Carla и Маргарет) поменялись местами.
Фильтрация данных из таблицы
Иногда вам нужно ограничить количество строк, возвращаемых запрос, особенно если у вас есть таблица с большим количеством строк. Если вы просто интересно взглянуть на данные, вы можете использовать ТОР пункт. Например, это вернет первые 10 строк таблицы:
ВЫБЕРИТЕ ВЕРХ(10)
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека]. [Человека];
 [Человека];
[Человека];
Вместо числа можно также использовать процент. Этот запрос возвращает количество строк, равное (или почти равное) 15% от общего количества строк:
ВЫБЕРИТЕ ВЕРХ(15) ПРОЦЕНТОВ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека];
В случае с этой таблицей (всего 19 972 строки) запрос возвращает 2 996 ряды.
Если вы хотите отфильтровать строки по условию, Можно использовать предложение WHERE. Обычно он имеет следующую структуру:
ВЫБЕРИТЕ столбец1, столбец2, … ОТ <имя_таблицы> ГДЕ <логическое выражение>;
Каждая строка, в которой выражение возвращает значение true, возвращается запросом. Следующее запрос возвращает всех лиц с именем «Роб».
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [Имя] = 'Роб';
В следующем примере три запроса возвращают строки, в которых BusinessEntityID равен меньшему размеру
или больше 130.
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [BusinessEntityID] = 130;
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [BusinessEntityID] < 130;
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [BusinessEntityID] > 130;
Вы можете использовать различные функции и операторы, такие как НРАВИТСЯ оператор для более продвинутый поиск строк. В этом примере мы ищем всех людей, у которых имя начинается с «Роб».
ВЫБЕРИТЕ [BusinessEntityID] ,[Имя] ,[Фамилия] ,[Дата изменения] ОТ [Человека].[Человека] ГДЕ [Имя] НРАВИТСЯ 'Rob%';
Дополнительные примеры LIKE см. в совете Синтаксис SQL Server LIKE с подстановочными знаками. Пример с использованием Функция ГОД:
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека]. [Человека]
ГДЕ ГОД([Дата изменения]) = 2011;
 [Человека]
ГДЕ ГОД([Дата изменения]) = 2011;
[Человека]
ГДЕ ГОД([Дата изменения]) = 2011;
Теперь возвращаются только строки, в которых строка была изменена в 2011 году:
Вы можете использовать логические операторы И, ИЛИ и НЕ для объединения различных логических выражения друг с другом. Следующий запрос выбирает все строки, в которых имя равно «Роб», а измененная дата была в 2011 году:
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [Имя] = 'Роб'
И ГОД([Дата изменения]) = 2011;
Мы получим совершенно другой набор результатов, если заменим И на ИЛИ. Теперь все ряды возвращаются, если имя равно Rob или где строка была изменена в 2011.
ВЫБЕРИТЕ
[BusinessEntityID]
,[Имя]
,[Фамилия]
,[Дата изменения]
ОТ [Человека].[Человека]
ГДЕ [Имя] = 'Роб'
ИЛИ ГОД([ModifiedDate]) = 2011;
Группировка данных из таблицы SQL Server
Если вы не хотите возвращать отдельные строки сведений из таблицы, а хотите
сводные результаты, вы можете использовать Предложение GROUP BY. Запрос имеет следующий формат:
Запрос имеет следующий формат:
ВЫБЕРИТЕ столбец 1, столбец 2, <функция агрегации> (столбец 3) ОТ <имя_таблицы> СГРУППИРОВАТЬ ПО столбцу1, столбцу2
В SQL Server существует множество различных функций агрегирования, таких как SUM, AVG, МИН, МАКС и так далее. Вы можете найти список здесь. Если вы используете только агрегации, вам не нужно использовать GROUP BY. пункт. Например, мы можем вернуть количество строк в таблице с помощью Функция СЧЁТ:
ВЫБРАТЬ СЧЕТЧИК(1) КАК RowCnt ОТ [Человека].[Человека];
Новое имя – RowCnt – было присвоено результату с помощью AS ключевое слово. Это также называется «назначением псевдонима». Добавляя ГРУППУ BY по имени и предложению WHERE (см. предыдущий раздел), мы можем посчитать сколько раз имя начинается с «Роб».
ВЫБЕРИТЕ
[Имя]
,COUNT(1) КАК RowCnt
ОТ [Человека].[Человека]
ГДЕ [Имя] НРАВИТСЯ 'Rob%'
СГРУППИРОВАТЬ ПО [Имя];
Каждый столбец, который не используется внутри функции агрегирования и не
константа, должна быть помещена в предложение GROUP BY. Например, если мы добавим Фамилия на SELECT, но не на GROUP BY, мы получаем ошибку:
Например, если мы добавим Фамилия на SELECT, но не на GROUP BY, мы получаем ошибку:
Фильтрация сводных результатов
Используя предложение WHERE, вы можете отфильтровать отдельные строки. Но что, если вы хотите фильтровать результат агрегированной функции? Это невозможно в ГДЕ предложение, так как эти результаты не существуют в исходной таблице. Мы можем сделать это с предложение HAVING. Используя предыдущий пример, мы хотим вернуть только имена — начиная с «Роб» — где количество строк не менее 20. запрос становится:
ВЫБЕРИТЕ
[Имя]
,COUNT(1) КАК RowCnt
ОТ [Человека].[Человека]
ГДЕ [Имя] НРАВИТСЯ 'Rob%'
СГРУППИРОВАТЬ ПО [Имя]
ИМЕЕТ СЧЁТ(1) >= 20;
Выбор данных из нескольких таблиц SQL Server
Часто вам не нужны данные из одной таблицы, но вам нужно
комбинировать разные таблицы, чтобы получить желаемый результат. В SQL вы делаете это, «присоединяясь»
столы. Вы берете одну таблицу и определяете, какие столбцы должны совпадать со столбцами
другого стола. Они разные
типы соединения в SQL:
Они разные
типы соединения в SQL:
- INNER JOIN — возвращаются только строки, совпадающие между обеими таблицами.
- LEFT OUTER JOIN – возвращаются все строки из первой таблицы, а также с любыми соответствующими строками из второй таблицы. Также есть ПРАВОЕ СОЕДИНЕНИЕ, что меняет отношения.
- FULL OUTER JOIN — возвращает все строки из обеих таблиц. Если есть нет соответствия, отсутствующая сторона будет иметь значения NULL вместо фактических значений столбца.
- ПЕРЕКРЕСТНОЕ СОЕДИНЕНИЕ – это декартово произведение всех строк обеих таблиц. Нет соответствия. Если у вас есть 100 строк в первой таблице и 10 в во втором набор результатов будет содержать 100 * 10 = 1000 строк. Этот тип соединения следует использовать с осторожностью, поскольку потенциально он может возвращать много строк. Мы не будем обсуждать это дальше в этом совете.
Сообщение в блоге Наглядное объяснение соединений SQL иллюстрирует каждый тип соединения диаграммой Венна. Давайте проиллюстрируем каждый тип соединения на примере запроса.
Давайте проиллюстрируем каждый тип соединения на примере запроса.
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
Следующий запрос использует INNER JOIN для возврата всех строк и всех столбцов таблицы. таблицы Person и таблицы Employee, но только если они имеют совпадающие идентификаторы BusinessEntityID. Другими словами, запрос возвращает людей, которые являются сотрудниками AdventureWorks.
ВЫБЕРИТЕ * ОТ [Человека].[Человека] INNER JOIN [HumanResources].[Employee] ON [Employee].[BusinessEntityID] = [Person].[BusinessEntityID];
Если вы не хотите вводить имена таблиц каждый раз, когда ссылаетесь на столбец, вы также можете использовать псевдонимы. Здесь таблица Person имеет псевдоним «p». и таблица «Сотрудник» с «e».
ВЫБЕРИТЕ * ОТ [Человек].[Человек] p INNER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
Если между таблицами есть столбцы с одинаковыми именами, необходимо добавить префикс
их с именем таблицы или с соответствующим псевдонимом. В следующем запросе мы
вернуть BusinessEntityID обеих таблиц, поэтому они должны иметь префикс.
В следующем запросе мы
вернуть BusinessEntityID обеих таблиц, поэтому они должны иметь префикс.
ВЫБЕРИТЕ
стр. [Имя]
,стр.[Фамилия]
,стр.[BusinessEntityID]
,e.[BusinessEntityID]
,e.[Дата найма]
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
Рекомендуется добавлять ко всем столбцам в операторе SELECT префикс псевдоним таблицы, так как он покажет, из какой таблицы взят каждый столбец. Этот позволяет избежать путаницы со стороны людей, читающих ваш запрос, особенно если они не знаком со структурой базы данных.
ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Когда мы меняем тип соединения на LEFT OUTER JOIN, все строки из таблицы Person будет возвращен. Неважно, есть ли совпадение с Сотрудником стол. Если есть совпадение, будет возвращено значение столбца HireDate. Если нет, вместо этого будет возвращен NULL.
ВЫБЕРИТЕ
стр. [Имя]
,стр.[Фамилия]
,стр. [BusinessEntityID]
,e.[BusinessEntityID]
,e.[Дата найма]
ОТ [Человек].[Человек] p
LEFT OUTER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
 [BusinessEntityID]
,e.[BusinessEntityID]
,e.[Дата найма]
ОТ [Человек].[Человек] p
LEFT OUTER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
[BusinessEntityID]
,e.[BusinessEntityID]
,e.[Дата найма]
ОТ [Человек].[Человек] p
LEFT OUTER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID];
В результирующем наборе видно, что HireDate не возвращается для лица, не являющиеся работниками:
RIGHT OUTER JOIN использует точно такой же принцип, но возвращает все строки из вторая таблица и только совпадающие результаты из первой таблицы. Обычно это не часто используется, так как LEFT OUTER JOIN легче читать.
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Чтобы проиллюстрировать концепцию FULL OUTER JOIN, мы используем JobCandidate также стол. Эта таблица содержит 13 строк. Только 2 из этих 13 кандидатов на самом деле были приняты на работу, и у них BusinessEntityID не равен NULL.
В следующем запросе мы сначала объединяем Person и Employee вместе, чтобы
найти всех сотрудников. Затем мы используем FULL OUTER JOIN, чтобы получить всех кандидатов на работу. также в наборе результатов запроса.
также в наборе результатов запроса.
ВЫБЕРИТЕ
стр. [Имя]
,стр.[Фамилия]
,стр.[BusinessEntityID]
,e.[BusinessEntityID]
,j.[BusinessEntityID]
,e.[Дата найма]
,j.[JobCandidateID]
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources].[Employee] e ON p.[BusinessEntityID] = e.[BusinessEntityID]
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ [HumanResources].[JobCandidate] j ON e.[BusinessEntityID] = j.[BusinessEntityID];
290 сотрудников и 13 кандидатов на работу. Принято на работу двух кандидатов, так они тоже наемные работники. Это означает, что общая сумма возвращенных строк должно быть 301 (290 + 13 – 2).
Первые строки — это сотрудники, которых невозможно найти в таблице JobCandidate. Столбец JobCandidateID имеет значение NULL.
В конце набора результатов добавляются кандидаты на работу:
На красной площади у нас 11 кандидатов на работу, которые не были приняты на работу. Все
столбцы равны NULL, за исключением столбца JobCandidateID. В зеленом квадрате имеем
пример кандидата на работу, который был принят на работу. Все столбцы имеют значения в этом
случай.
В зеленом квадрате имеем
пример кандидата на работу, который был принят на работу. Все столбцы имеют значения в этом
случай.
Наконечник Пример присоединения к SQL Server немного подробнее рассказывает о различных присоединениях. типы.
Заключение
Давайте объединим все предыдущие разделы в один запрос. Этот запрос возвращает количество всех сотрудников, имя которых начинается с «Роб», отсортированы по этому счету по возрастанию.
ВЫБЕРИТЕ
стр. [Имя]
,COUNT(1) КАК RowCnt
ОТ [Человек].[Человек] p
INNER JOIN [HumanResources].[Employee] e ON e.[BusinessEntityID] = p.[BusinessEntityID]
ГДЕ p.[FirstName] LIKE 'Rob%'
СГРУППИРОВАТЬ ПО [p].[Имя]
ЗАКАЗАТЬ ПО [RowCnt] ASC;
Как видно из запроса, вы также можете сортировать по псевдонимам (в данном примере RowCnt) и не только на реальных физических столбцах из таблицы.
Следующие шаги
- В этом совете мы только слегка коснулись того, что делает оператор SELECT. сможет сделать. Вот еще несколько сложных конструкций:
- Объединение наборов результатов с UNION (ALL): UNION против UNION ALL в SQL Server
- Использование подзапросов - Пример подзапроса SQL Server — и связанные подзапросы: Некоррелированный и коррелированный подзапрос SQL Server.
- Создание коррелированных запросов или использование табличных функций с APPLY: SQL Server ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ и ВНЕШНЕЕ ПРИМЕНЕНИЕ
- Более продвинутая группировка с использованием НАБОРЫ КУБ, РОЛЛАП и ГРУППИРОВКА.
- Дополнительные статьи для обзора:
- Различия между удалением и усечением в SQL Server
- Производительность SQL Server SELECT INTO по сравнению с SQL INSERT INTO
- Примеры таблицы перетаскивания SQL с T-SQL и SQL Server Management Studio
 сможет сделать. Вот еще несколько сложных конструкций:
сможет сделать. Вот еще несколько сложных конструкций:Об авторе
Коэн Вербек — опытный консультант по бизнес-аналитике в AE. Он имеет более чем десятилетний опыт работы с платформой данных Microsoft в различных отраслях. Он имеет несколько сертификатов и активно пишет материалы о службах SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake и Azure. Он выступал на PASS, SQLBits, dataMinds Connect и проводит вебинары на MSSQLTips.com. Коэн на протяжении многих лет удостаивался награды Microsoft MVP Data Platform.
Он имеет несколько сертификатов и активно пишет материалы о службах SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake и Azure. Он выступал на PASS, SQLBits, dataMinds Connect и проводит вебинары на MSSQLTips.com. Коэн на протяжении многих лет удостаивался награды Microsoft MVP Data Platform.Посмотреть все мои советы
Последнее обновление статьи: 12 апреля 2021 г.
Базовая инструкция T-SQL SELECT
Язык SQL используется на многих платформах реляционных баз данных. Грег Ларсен объясняет основы инструкции SELECT для SQL Server.
Оператор SELECT является наиболее часто используемым оператором языка T-SQL. Он выполняется для извлечения столбцов данных из одной или нескольких таблиц. Оператор SELECT может ограничивать возвращаемые данные с помощью WHERE или HAVING , и отсортируйте или сгруппируйте результаты, используя предложения ORDER BY и GROUP BY соответственно. Оператор
Оператор SELECT также может состоять из множества различных операторов SELECT , обычно называемых подзапросами.
Существует множество различных аспектов оператора SELECT , что делает его очень сложным оператором T-SQL. Эта статья является первой в серии статей, в которых будут рассмотрены различные нюансы Оператор SELECT . В этой статье я расскажу только об основах оператора SELECT .
Оператор SELECT
Оператор SELECT состоит из множества различных частей, что делает его многогранным. Основные предложения, поддерживаемые оператором SELECT , которые можно найти в документации Microsoft, показаны на рис. 1.
Для обсуждения каждого из этих различных вариантов потребовалась бы очень длинная статья. Для целей этой статьи я сосредоточусь только на нескольких пунктах, которые я представляю в качестве основных 9.0232 SELECT синтаксис показан на рисунке 2.
ГДЕ пункт .
Список SELECT
Компонент select_list определяет данные, которые будут возвращены при выполнении инструкции SELECT . Это единственная часть, которая требуется в каждом Оператор SELECT . Все остальные атрибуты оператора SELECT являются опциями.
Список select_list определяет один или несколько элементов данных, которые будут возвращены при выполнении оператора SELECT . Если в списке указано несколько элементов, каждый элемент отделяется запятой. Аргументы списка выбора могут принимать различные формы, такие как имя столбца, вычисление, вызов функции или литеральная константа, и это лишь некоторые из них.
Формат select_list , найденный в документации по предложению SELECT, показан на рисунке 3.
Рисунок 3: Select_list спецификации Оператор SELECT , содержащий только список выбора. В списке есть два разных столбца данных, которые будут возвращены.
В списке есть два разных столбца данных, которые будут возвращены.
Листинг 1. Возврат вычисляемого поля и литерального значения
ИСПОЛЬЗОВАТЬ базу данных tempdb; GO SELECT 1024*1024, 'Основной оператор выбора'; |
В отчете 1 показаны значения двух столбцов, возвращенные при выполнении листинга 1.
Отчет 1: столбцы, возвращенные при выполнении листинга 1
Первый возвращенный столбец является результатом вычисления, умножающего 1024 на 1024. Второй отображаемый столбец - это просто буквальная строка Базовый оператор выбора . Возвращенным столбцам не были присвоены имена столбцов, поэтому имена столбцов говорят (нет имени столбца).
Отсутствие имени столбца для некоторых столбцов в результирующем наборе на самом деле не является проблемой, если только вам не нужно ссылаться на возвращаемые данные по имени. Чтобы присвоить имена этим двум столбцам, можно использовать псевдоним столбца.
Чтобы присвоить имена этим двум столбцам, можно использовать псевдоним столбца.
Назначение псевдонимов столбцов
Псевдоним столбца полезен, когда вы хотите присвоить определенное имя столбцу данных, возвращаемых из Оператор SELECT . Если вы обратитесь к спецификациям select_list , приведенным на рис. 3, есть два способа определить псевдоним столбца. Один из способов — использовать ключевое слово AS , за которым следует имя псевдонима столбца. Ключевое слово AS является необязательным. Другой способ — использовать оператор равенства ( = ), где псевдоним определяется слева от знака = . Оператор SELECT в листинге 2 возвращает те же данные, что и в листинге 1, но каждому элементу, идентифицированному в списке выбора, теперь присвоен псевдоним столбца.
Листинг 2: Определение псевдонимов столбцов
ИСПОЛЬЗОВАТЬ базу данных tempdb; GO SELECT 1024*1024 AS NumOfBytesInMB, 'Основной оператор выбора' BasicSelectStatement; |
При выполнении листинга 2 каждому возвращаемому столбцу будет назначен псевдоним столбца, как показано в отчете 2.
Отчет 2: результаты выполнения листинга 2
В листинге 2 псевдонимы обоих столбцов не содержат пробелов. Если вы хотите включить пробелы в псевдоним, то имя должно быть заключено в кавычки. Кавычки могут быть как набором квадратных скобок, так и одинарными или двойными кавычками. В листинге 3 показано, как использовать различные варианты цитирования.
Листинг 3. Создание псевдонимов с пробелами
1 2 3 4 5 6 | ИСПОЛЬЗОВАТЬ базу данных tempdb; GO SET QUOTED_IDENTIFIER ON SELECT 1024*1024 AS [Число байтов в МБ], "Использование двойных кавычек" = 'Основной оператор выбора', 9000 2 'ABC' AS 'Строка ABC'; |
Вывод в отчете 3 создается при выполнении листинга 3.
Отчет 3: Псевдонимы с пробелами в имени
Предложение FROM
The 9Предложение 0232 FROM в SQL Server используется для идентификации таблицы или таблиц, в которых необходимо получить данные. В этой базовой статье
В этой базовой статье SELECT я буду обсуждать только получение данных из одной таблицы SQL Server. В следующих статьях речь пойдет об извлечении данных из нескольких таблиц.
Таблица в SQL Server хранится в базе данных. У данного экземпляра SQL Server может быть много баз данных, и в базе данных может быть много таблиц. Таблицы в базе данных сгруппированы и организованы по схеме. Иерархия баз данных, схем и таблиц означает, что в экземпляре SQL Server может быть несколько таблиц с одинаковыми именами. Поскольку заданное имя таблицы может находиться в различных схемах, базах данных или даже экземплярах, используемое имя таблицы должно быть однозначно идентифицировано в ИЗ ст. Чтобы уникально идентифицировать таблицу в предложении FROM , ее можно назвать, используя одно-, двух-, трех- или четырехчастное имя, где каждая часть отделяется точкой ( . ).
Имя таблицы, состоящее из одной части, — это имя таблицы, которое не содержит точки, например Заказы или Клиенты. Если в предложении
Если в предложении FROM используется однокомпонентное имя, ядро базы данных должно определить, какой схеме принадлежит таблица. Чтобы определить схему, которой принадлежит однокомпонентное имя таблицы, SQL Server использует двухэтапный процесс. Первый шаг — посмотреть, находится ли таблица в схеме по умолчанию, связанной с пользователем, отправившим Оператор SELECT . Если таблица находится в схеме по умолчанию для пользователя, то используется эта таблица, и механизму базы данных не нужно выполнять второй шаг. Если таблица не найдена в схеме пользователя по умолчанию, то выполняется второй шаг идентификации таблицы. Второй шаг просматривает схему dbo , чтобы попытаться найти таблицу. Когда база данных содержит только одну схему с именем dbo, имеет смысл использовать имена, состоящие из одной части. Однако при наличии нескольких схем в базе данных лучше всего использовать несколько имен таблиц частей, чтобы уточнить, какая таблица используется. Это упрощает объем работы, которую SQL Server должен выполнить для идентификации таблицы.
Это упрощает объем работы, которую SQL Server должен выполнить для идентификации таблицы.
Имя, состоящее из двух частей, состоит из имени таблицы и схемы, содержащей таблицу с точкой ( . ) между ними, например Sales.Orders, или Sales.Customer. При написании операторов SELECT , которые запрашивают данные только из таблиц в одной базе данных с несколькими схемами, рекомендуется использовать имена таблиц, состоящие из двух частей.
В большинстве случаев, когда оператор SELECT использует таблицы в одной базе данных, используются одно- и двухкомпонентные имена таблиц. Имена таблиц, состоящие из трех частей, необходимы, когда код запускается в контексте одной базы данных и ему необходимо получить данные из другой базы данных или вы объединяете данные из нескольких таблиц, находящихся в разных базах данных. Третья часть имени предшествует имени таблицы, состоящему из двух частей, и идентифицирует базу данных, в которой находится таблица, например 9. 0112 AdventureWorks2019.Продажи.Заказы.
0112 AdventureWorks2019.Продажи.Заказы.
Последний способ однозначно идентифицировать таблицу в предложении FROM — включить имя экземпляра в качестве четвертой части. Имя экземпляра помещается перед полным именем таблицы, состоящим из трех частей. Имена из четырех частей используются для запросов между экземплярами с использованием связанного сервера. Обсуждение связанных серверов — это совершенно отдельная тема, которую я оставлю для будущей статьи.
Пример оператора SELECT в листинге 4 выполняется в контексте 9База данных 0112 AdventureWorks2019 , использующая имя таблицы, состоящее из двух частей, для возврата всех данных в таблице Territory , принадлежащей схеме Sales .
Листинг 4. Использование имени таблицы из двух частей
ИСПОЛЬЗОВАТЬ AdventureWorks2019; GO SELECT * FROM Sales.SalesTerritory; |
Оператор в листинге 5 использует имя таблицы, состоящее из трех частей, для возврата всех данных из Territory в схеме Sales в базе данных AdventureWorks2019 , но выполняется в контексте базы данных tempdb .
Листинг 5. Использование имени таблицы из трех частей
USE tempdb GO SELECT * FROM AdventureWorks2019.Sales.SalesTerritory; |
Строки, отображаемые в отчете 4, создаются при выполнении кода из листинга 4 или листинга 5.
Отчет 4: вывод при выполнении листинга 4 или 5
В листинге 4 и листинге 5 для опции select_list использовался подстановочный знак * . * сообщает SQL Server, что все столбцы из таблицы AdventureWorks2019.Sales.SalesTerritory должны быть возвращены на основе их порядковых позиций в таблице. Использование подстановочного знака * в списке выбора — это простой способ указать и выбрать все столбцы в таблице. Я бы не рекомендовал использовать подстановочные знаки для производственного кода, потому что, если столбцы добавляются или удаляются из запрашиваемой таблицы, количество возвращаемых столбцов будет основано на определении таблицы во время запроса. Лучше всего не использовать подстановочные знаки, а вместо этого специально указывать имена столбцов для данных, которые необходимо вернуть. Обратите внимание, что в некоторых ситуациях подстановочные знаки имеют смысл, и я расскажу о них в следующих статьях.
Лучше всего не использовать подстановочные знаки, а вместо этого специально указывать имена столбцов для данных, которые необходимо вернуть. Обратите внимание, что в некоторых ситуациях подстановочные знаки имеют смысл, и я расскажу о них в следующих статьях. Оператор SELECT в листинге 6 возвращает те же результаты, что и в листингах 4 и 5, но указывает фактические имена столбцов в кавычках вместо подстановочного знака * .
Листинг 6. Указание имен столбцов
1 2 3 4 5 6 7 8 9 9 0003 10 11 12 13 | ЕГЭ AdventureWorks2019; GO SELECT [TerritoryID], [Name], [CountryRegionCode], [Group], [SalesYTD], [SalesLastYear], [CostYTD], [CostLastYear ], [rowguid], [ModifiedDate] FROM Sales. |
 SalesTerritory;
SalesTerritory;Предложение WHERE
Показанные мной примеры операторов SELECT возвращают все строки в AdventurewWorks2019.Sales.SalesTerritory таблица. Могут быть случаи, когда вы не хотите возвращать все строки в таблице, а хотите вернуть только подмножество строк. В этом случае можно использовать предложение WHERE для ограничения возвращаемых строк.
При использовании предложения WHERE необходимо указать критерии поиска. Критерии поиска определяют одно или несколько выражений, известных как предикаты, которым должна соответствовать каждая строка, чтобы быть выбранной. Логические операторы И , ИЛИ и НЕ можно использовать для объединения нескольких выражений для точной настройки возвращаемых строк.
В листинге 7 есть инструкция SELECT , содержащая одно выражение в предложении WHERE . В этом случае будут возвращены только те записи Sales. SalesTerritory , значение SalesLastYear которых превышает 3 000 000.
SalesTerritory , значение SalesLastYear которых превышает 3 000 000.
Листинг 7. Простое условие поиска в операторе WHERE
ИСПОЛЬЗОВАТЬ AdventureWorks2019; GO SELECT * FROM Sales.SalesTerritory ГДЕ SalesLastYear > 3000000; |
При выполнении кода в листинге 6 возвращаются строки в отчете 5.
Отчет 5: строки, возвращенные при выполнении листинга 7
Иногда для получения определенного подмножества строк требуются более сложные условия поиска. Оператор SELECT в листинге 8 использует два разных условия в предложении WHERE , чтобы сузить возвращаемые строки. Два разных условия используют логический оператор AND для создания сложного составного условия поиска.
Листинг 8. Использование двух выражений с оператором И
ИСПОЛЬЗОВАТЬ AdventureWorks2019; GO SELECT * FROM Sales. |
