Сканируем большие сайты через Screaming Frog SEO Spider — SEO на vc.ru
Привет! Последнее время всё чаще начал сталкиваться со сканирование больших сайтов (от 1 млн страниц), а также встретился со множеством заблуждений от людей, которые этим никогда не занимались. Этот пост не про то, зачем вам парсить сайт, вы наверняка знаете, а про то, как не бояться этого делать и правильно всё настроить.
8765 просмотров
Главные заблуждения:
— Лягушка регулярно падает;
— Сканировать можно до 500 тысяч;
— Это крайне долго;
Более того, полезной и практической информации о сканировании больших сайтов именно этим софтом в интернете просто нет, есть инструкция от разработчиков, где демонстрируется работа с 8 млн страницами и на этом всё.
Своим опытом я делюсь у себя на канале, но поскольку в рамках сообщения в телеге сложно раскрыть отдельные нюансы, не перегружая его, решил оформить в виде поста-мануала здесь, поехали.
Задача — просканировать сайт с Х миллионами страниц и не попасть на передачу
Конфигурация сервера
Чтобы парсинг не мешал основной работе я использую сервер, собранный из китайских запчастей. Моя конфигурация не самая удачная (много жрёт электричества, сильно греется), но с задачей краулинга справляется отлично — два 8 ядерных процессора E5-2689, 1080 (другой не было), 48 GB RAM (REG ECC), ну и Windows Server на борту, поскольку бесплатная на полгода и не перегружена всякой шелухой от майкрософта. Нужен ли такой монстр? Разумеется нет, для объективности, установил в BIOS 2 ядра по 3.5 ггц и запустил те же самые настройки. Скорость парсинга не упала, но загрузка процессоров была 80-90%. Краулить реально без выполнения других задач.
Сканирование в 10 потоков двумя ядрами
Сканирование в 10 потоков 16 ядрами
Настройки программы
Теперь к основному, настройки программы. Первое и самое главное:
Первое и самое главное:
Configuration — Systeam — Storage Mode — Устанавливаем DataBase.
Теперь парсинг идёт не в оперативную память, а на диск. Диск крайне желательно должен быть SSD. Основной плюс в том, что все результаты просто дозаписываются в базу и если произойдет краш, ничего не потеряется (забегая наперёд, после переключения в этот режим падений ни разу не было).
DataBase режим
Вторым шагом зададим размер оперативной памяти (Configuration — Systeam — Memory Allocation). Разработчики рекомендуют от 4 гб для парсинга 2 млн страниц и 8 гб для 5 и более. У меня стоит 24, потому что могу. На самом деле, выставлять 16-32-48 гб памяти здесь нет необходимости, она нужна только для работы каждого из потоков.
Сканирование большого числа страниц = большой размер проекта. Отключаем лишнее. Залетаем в Configuration — Spider
Оставляем только внутренние ссылки
Отключаем лишнее
Т. к. часто на сайтах изображения являются ссылками, софтина их продолжает собирать, несмотря на запрет, лезем в Configuration — Exclude и вставляем следующие исключения, они универсальный для любого парсинга:
к. часто на сайтах изображения являются ссылками, софтина их продолжает собирать, несмотря на запрет, лезем в Configuration — Exclude и вставляем следующие исключения, они универсальный для любого парсинга:
http.*\.jpg
http.*\.JPG
http.*\.jpeg
http.*\.JPEG
http.*\.png
http.*\.PNG
http.*\.gif
http.*\.PDF
Отлично, теперь изображения точно не будут собираться.
Напоследок, Configuration — Speed. Здесь всё крайне индивидуально и зависит от:
— Возможностей сервера с которого идёт парсинг;
— Возможностей сервера который парсим;
— От интернет канал;
Я ставлю от 7 до 10 потоков (10-30 урлов в секунду), этого хватает для комфортной работы всех сторон.
Подводные
Куда без них. Опытным путем выяснил, что от уровня вложенности страниц сайта, при прочих равных, зависит скорость парсинга и размер базы данных, причем зависит серьезно, об этом ниже.
К цифрам
Всё это было бы бессмысленными теориями, если бы не было обкатано в бою.
Парсинг любого проекта я выполняю в два этапа:
— Первичный, понять очевидно проблемные разделы с мусорными страницами. Собирается 5-10% от будущего объема сайта и на основе данных структуры (Site Structure в сайдбаре) оцениваем что за разделы и для чего они нужны по количеству страниц в них;
— Вторичный, с отключенными проблемными разделами (через Exclude), чтобы найти более мелкие ошибки в рамках всего сайта.
Итак, на последнем проекте изначально было несколько проблемных разделов с 17-ю(!) уровнями вложенности. Размер проекта раздувался в космос, каждый следующий миллион страниц весил дополнительные 100 гб места на диске. Скорость через 1.5 млн страниц упала с 20-30 урлов в секунду до 2-3. Всего урлов в ожидании к тому моменту было 5 млн и это явно не предел.
Вторым этапом, исключив мусорные разделы, запустил парсинг повторно. В итоге, на сайте осталось 2 млн страниц и в 10 потоков (20-30 урлов в секунду, да там хороший сервер) он парсился ровно сутки. Удивился сам, но совпало с теоретическими расчётами: 2 000 000 / 20 (урлов в сек) / 3600 (часов) = 28 часов. При этом размер базы для всего проекта составил порядка 50 гб, что в 4 раза меньше прошлого парсинга для того же количества страниц.
Удивился сам, но совпало с теоретическими расчётами: 2 000 000 / 20 (урлов в сек) / 3600 (часов) = 28 часов. При этом размер базы для всего проекта составил порядка 50 гб, что в 4 раза меньше прошлого парсинга для того же количества страниц.
Выводы
Краулинг значительного объёма страниц реален и не так страшен, как о нём думают. Достаточно 4-х ядерной машины с 8-16 гб оперативной памяти и не сильно большого SSD. Сама лягушка такие объемы тянет и не падает.
При любом сканировании после первых 10-15%, оцените структуру сайта и посмотрите, какие разделы могут генерировать много лишних страниц. Исключите их из парсинга и перезапускайте сканирование уже до финала. Успехов!
Screaming Frog SEO Spider: парсинг сайта, инструкция как пользоваться
4514
7 мин.
Успешный аудит сайта — это фундамент оптимизации SEO. В этой статье разберем инструмент для проведения технического SEO-аудита сайта Screaming Frog. Рассмотрим возможности программы, которыми чаще всего пользуюсь при аудите сайта.
Начнем с загрузки программы.
Скачать Screaming Frog можно на официальном сайте www.screamingfrog.co.uk Программа бесплатная, но за полный функционал придется заплатить. Бесплатная версия включает скриминг 500 Urls и не поддерживает дополнительные расширения.
За годовую подписку на расширенную версию придется потратить около 6 тыс. грн. Если вы SEO-специалист, эта программа must-have на “Рабочем столе”, она существенно облегчит и ускорит сбор и анализ технических недочетов сайта.
Разбор функционала, которым чаще всего пользуюсь.
Скриминг фрог позволяет сканировать сайт несколькими способами:
- Spider:
Сканирование всего сайта, программ ходит по всем URLs ресурса. Это дает полный анализ сайта и позволяет обнаружить все “битые” ссылки. У метода есть недостаток, который заключается в том, что если у сайта поврежденные JS-скрипты или проблемы с пагинацией, сканирование может уйти в бесконечный цикл. Что же делать? Выход есть, с помощью конфигурации Include или Extend можно обозначить парсингуемый раздел или исключить соответственно.

Есть задача спарсить раздел сайта brander.ua/what-we-offer. Для этого я добавляю правило в Configuration — Include.
Затем с помощью регулярного выражения (синтаксис указан в окне) ввожу нужный для сканирования раздел.
Старт и вуаля. Мы просканировали только отдельную категорию на сайте. Бывают ситуации, когда необходимые для сканирования страницы не лежат в какой-либо вложенности, а просканировать сайт полностью нет возможности по ряду причин (объем сайта, ломаный js и тд.). Тогда действуем от обратного. Можно внести в исключения Extend все категории, что существенно уменьшит количество урлов, и успешно спарсить остаток.
- List:
Сканирование сайта по списку URLs. Список необходимых для сканирования страниц вы можете вставить как файлом, так и мануально. У сканирования List также есть недостаток. Если есть список урлов, и хочешь спарсить только внешние ссылки, то в отчете лист сделать этого нельзя. Данный метод парсит только конкретные URL и не проходится по ним “пауком”.
Есть возможность просканировать SiteMap. Это позволяет находить ошибки на проиндексированных страницах.

- SERP:
Этот режим не сканирует сайт, а создан для работы с мета-текстами. Можно загрузить меты, редактировать и просматривать, как они отображаются в браузере.
Перед началом сканирования сайта рекомендую подключить аналитику, что позволит не делать отдельных анализов по всем сервисам, а выгрузить все и сразу. Доступна аналитика по Google Analytics, Search Console, Moz, Pagespeed, Ahrefs, Majestiks. Это можно сделать с помощью вкладки Configuration — API Access.
История парсинга находится во вкладке File — Craw Resent.
Широкий функционал утилиты Screaming Frog позволяет исключить из сканирования элементы сайта (картинки, JS, CSS и тд.).
Если сайт мультиязычный, в конфигурации необходимо включить параметры Configuration — Spider — Crawl Linked XML Sitemap.
Отдельно стоит упомянуть парсинг SPA сайтов. При дефолтных настройках результатом будет только парсинг главного урла. Следует в Configuration — Spider во вкладке Rendering выбрать конфигурацию Old AJAX Crawling Scheme и запустить парсинг.
Следует в Configuration — Spider во вкладке Rendering выбрать конфигурацию Old AJAX Crawling Scheme и запустить парсинг.
Есть пару моментов настройки парсинга для сайтов, закрытых от индексации. Необходимо “паука” направить по неиндексированным файлам. Открываем для robots.txt:
Затем в мета роботс:
И проверить отсутствие галки на Respect noindex:
Итак, завершили сканирование сайта. Что мы можем извлечь из результатов сканирования?
- Internal. В этой вкладке содержатся все внутренние ссылки сайта. Тут можем отсортировать URLs по коду ответа и отловить все битые ссылки и редиректы.
Во вкладке доступен фильтр (выбираем элемент сайта).
Ниже доступен подробный отчет.
Самое полезное в нем:
- Куда ссылка ведет и откуда. Выбрав урлы с ошибкой в подробном анализе, выгружаем данные. И получаем файл с местом расположения “некорректного” url.
- Доступна визуализация мета текста в SERP.
- External. Здесь найдете все внешние ссылки сканируемого сайта. По аналогии с внутренними отлавливаем код ответа и в доп. отчете смотрим, на какой странице сайта находятся ссылки с не 200 ответом, и составляем ТЗ на исправление.
 Здесь найдете все внешние ссылки сканируемого сайта. По аналогии с внутренними отлавливаем код ответа и в доп. отчете смотрим, на какой странице сайта находятся ссылки с не 200 ответом, и составляем ТЗ на исправление.
Здесь найдете все внешние ссылки сканируемого сайта. По аналогии с внутренними отлавливаем код ответа и в доп. отчете смотрим, на какой странице сайта находятся ссылки с не 200 ответом, и составляем ТЗ на исправление.- Security. В этой вкладке отображаются данные, связанные с безопасностью внутренних URL-адресов сканируемого сайта (является ли URL индексируемым или неиндексируемым, и почему неиндексирован и тд). Смешанный контент — показывает любые HTML-страницы, загруженные через безопасное соединение HTTPS, которые имеют такие ресурсы как изображения, JavaScript или CSS, загружаемые через небезопасное соединение HTTP. Фильтр Http Urls выявит все http-URLs, выгружаем подробный отчет и избавляемся от всех небезопасных элементов сайта.
В моем случае таких страниц не обнаружено, поэтому кнопка экспорта не активна.
- Response code. Отчет по всем УРЛ, который можно отсортировать по коду ответа и загрузить в отчет для доработки все не 200 ответы.

- Page Titles. Отчет в данной вкладке показывает, на каких страницах проставлен Title мета-текста, и где его нет. Выявляем дубли, слишком короткие/длинные заголовки.
- Meta description. Тот же отчет, что и Page Titles, только для дискрипшена к странице. Находим дубли, длинные/короткие описания, отсутствующее, и оптимизируем.
- h2 и h3. Позволяет найти страницы без заголовка или указывает их количество и длину на странице.
- Images. В этой вкладке анализируем размер изображений на сайте. С помощью фильтра “over 100 Kb” выгружаем в отчет картинки, которые необходимо сжать. Также в этой вкладке доступен анализ Alt-текста, где он пропущен, либо не присвоен атрибут альт.
- Canonical. Отчет отображает канонические и нон-каноникал. В фильтре можно выбрать интересующие ошибки и сделать анализ, где проставить, а где изменить Canonical.

- Pagination. В этом разделе можно отловить все ошибки, связанные с пагинацией. Выявляет первые страницы пагинации с тегом rel = «prev», проверяет наличие этого тега во всех 2+ страницах, показывая, что страница не первая. Указывает URL-адрес разбиения на страницы с кодом ответа не 200. Выявляет несвязные адреса разбиения на страницы.
- Hreflang. Отображены ошибки с атрибутами hreflang (разные коды языка на одной странице и прочее, не 200 ответ сервера, страницы, на которых отсутствуют гиперссылки).
Функционал Screaming Frog позволяет получить визуальную структуру каталога сайта в виде графы или диаграммы.
Описывать все настройки парсинга программы SF можно долго, а и нужно ли? В этой статье рассказала обо всех самых частых и нужных настройках. В нишевых параметрах настройки можно покопаться после освоения базы утилиты. Надеюсь, было полезно. Успешных вам SEO-анализов и ТОПовых позиций в SERP!
04 июня 2021Андреева Надежда
SEO Specialist
Seo — специалист, стартовала в SEO с командой Brander. Образование: системный аналитик. Если вы не хотите рисковать привычными вещами, вам придется смириться с ними.
Образование: системный аналитик. Если вы не хотите рисковать привычными вещами, вам придется смириться с ними.
Микроразметка FAQ важнее, чем вы думали
Sitemap без ошибок для сайта: составляем правильно
Кейсы из digital-маркетинга, дизайна, разработки интернет-магазинов, вебсайтов и мобильных приложений
Учебники SEO Spider — Кричащая лягушка
Руководство по началу работы
Наше руководство для начинающих по началу работы с SEO Spider. Включая первоначальную настройку, сканирование и просмотр отчетов и обнаруженных проблем.
Как найти битые ссылки с помощью SEO Spider
Узнайте, как сканировать свой веб-сайт и находить неработающие ссылки (ошибки 404), просматривать, какие страницы ссылаются на них, текст ссылки и экспортировать в пакетном режиме.
Руководство по архитектуре сайта и визуализации сканирования
Визуализируйте архитектуру сайта и внутренние ссылки, чтобы обмениваться идеями и выявлять базовые закономерности, которые сложнее выявить в данных и электронных таблицах.
Как сравнить сканирование
Сравните обходы, чтобы увидеть, как данные, проблемы и возможности изменились с течением времени, чтобы отслеживать прогресс и отслеживать работоспособность сайта.
Как сканировать веб-сайты JavaScript
Рендеринг веб-страниц с помощью встроенного Chromium WRS для сканирования динамических веб-сайтов и фреймворков с большим количеством JavaScript, таких как Angular, React и Vue. js.
js.
Как сканировать большие веб-сайты
Сканируйте большие веб-сайты, переключаясь в режим хранения базы данных, увеличивая объем памяти и настроив сканирование для извлечения необходимых данных.
Как сканировать промежуточный веб-сайт
Узнайте, как сканировать промежуточный или разрабатываемый веб-сайт с учетом robots.txt, аутентификации и конфигурации SEO Spider.
Как автоматизировать отчеты о сканировании в Looker Studio
Узнайте, как настроить полностью автоматизированные отчеты о сканировании Google Looker Studio, чтобы отслеживать работоспособность сайта, выявлять проблемы и отслеживать производительность.
Как провести аудит Core Web Vitals
Проанализируйте, какие страницы проходят или не проходят оценку Google Core Web Vitals, используя полевые данные из CrUX, чтобы повысить скорость страницы.
Как запустить Screaming Frog SEO Spider в облаке
Узнайте, как запустить Screaming Frog SEO Spider в облаке с помощью Google Compute Engine.
Как проверить дублирующийся контент
Минимизируйте повторяющийся контент, определяя точные дубликаты страниц и почти дублирующийся контент, в котором некоторый текст совпадает между страницами на веб-сайте.
Как работать в команде с помощью SEO Spider
Узнайте о лучших способах совместной работы при использовании SEO Spider.
Страница 1 из 41234»
Вернуться к началу
Что такое SEO? — Screaming Frog
Поисковая оптимизация (SEO) — это практика увеличения количества и качества посетителей веб-сайта за счет улучшения рейтинга в результатах алгоритмической поисковой системы.
Исследования показывают, что веб-сайты на первой странице Google получают почти 95% кликов , а исследования показывают, что результаты, которые появляются выше по странице, получают повышенный рейтинг кликов (CTR) и больше трафика.
Алгоритмические («естественные», «обычные» или «бесплатные») результаты поиска — это те, которые появляются непосредственно под самыми популярными объявлениями с оплатой за клик в Google, как показано ниже.
Кроме того, в результатах поиска Google могут отображаться различные другие списки, такие как списки карт, видео, диаграмма знаний и многое другое. SEO также может включать улучшение видимости в этих наборах результатов.
Как работает SEO?
Google (и Bing, который также обеспечивает результаты поиска Yahoo) оценивают свои результаты поиска в основном на основе релевантность и авторитетность страниц, которые он просканировал и включил в свой веб-индекс, на запрос пользователей, чтобы предоставить лучший ответ.
Google использует более 200 сигналов для оценки своих результатов поиска, а SEO включает в себя технические и творческие действия, чтобы повлиять на некоторые из этих известных сигналов и улучшить их. Часто бывает полезно не слишком зацикливаться на отдельных сигналах ранжирования и смотреть на более широкую цель Google, , чтобы предоставить лучшие ответы для своих пользователей .
Поисковая оптимизация, таким образом, включает в себя обеспечение доступности веб-сайта, его технической исправности, использование слов, которые люди вводят в поисковые системы, и обеспечение превосходного пользовательского опыта с полезным и высококачественным экспертным контентом, который помогает ответить на запрос пользователя.
В Google работает очень большая команда оценщиков качества поиска, которые оценивают качество результатов поиска, которые вводятся в алгоритм машинного обучения. Руководство Google по оценке качества поиска содержит множество деталей и примеров того, что Google классифицирует как высококачественный или низкокачественный контент и веб-сайты, а также их акцент на желании вознаграждать сайты, которые ясно демонстрируют их опыт, авторитет и доверие (EAT).
Google использует алгоритм на основе гиперссылок (известный как «PageRank») для расчета популярности и авторитетности страницы, и, хотя сегодня Google гораздо более совершенен, это по-прежнему является фундаментальным сигналом для ранжирования. Следовательно, поисковая оптимизация может также включать действия, помогающие улучшить количество и качество «входящих ссылок» на веб-сайт с других веб-сайтов. Эта деятельность исторически была известна как «построение ссылок», но на самом деле это просто маркетинг бренда с акцентом в Интернете, например, с помощью контента или цифрового PR.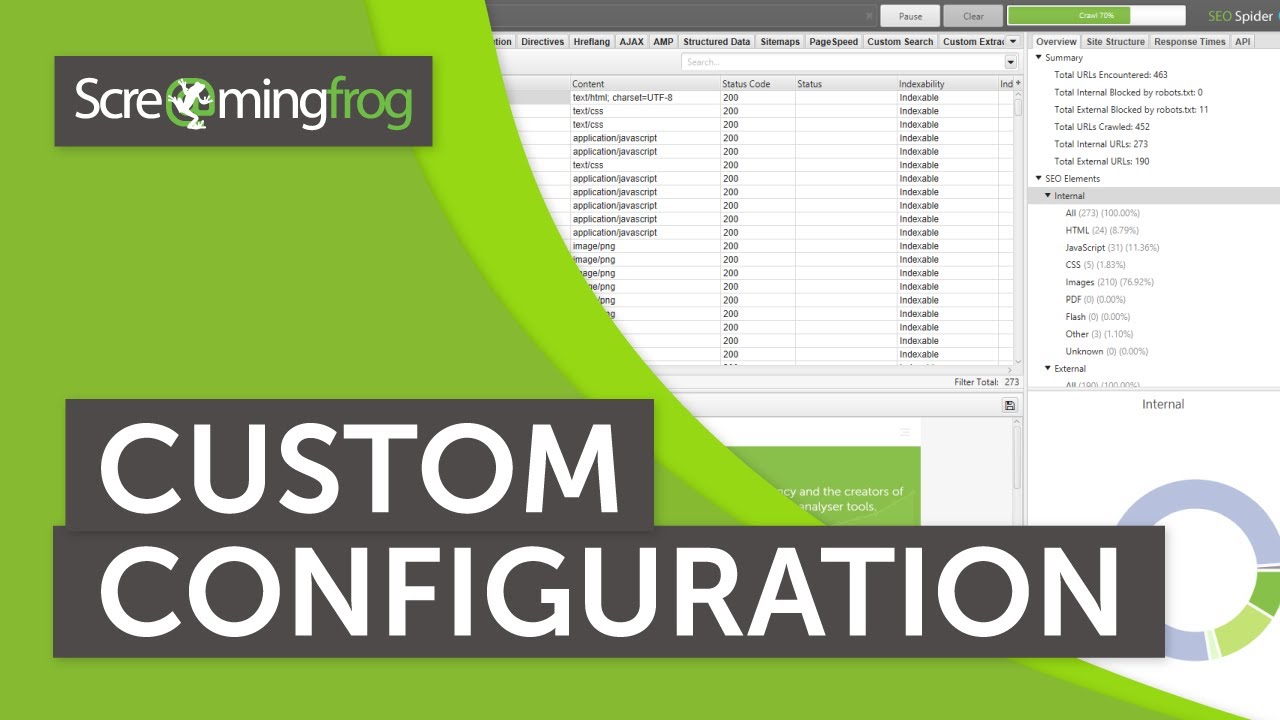
Релевантные и авторитетные веб-сайты, ссылающиеся на какой-либо веб-сайт, являются убедительным сигналом для Google о том, что он может представлять интерес для его пользователей, и ему можно доверять в результатах поиска по релевантным запросам.
Как сделать SEO
Поисковая оптимизация включает технические и творческие действия, которые часто группируются в «Внутреннее SEO» и «Внешнее SEO». Эта терминология довольно устарела, но ее полезно понять, поскольку она разделяет практики, которые можно выполнять на веб-сайте, и вне веб-сайта.
Эти действия требуют опыта, часто от нескольких человек, поскольку наборы навыков, необходимые для их выполнения на высоком уровне, совершенно разные, но им также можно научиться. Другой вариант — нанять профессиональное SEO-агентство или SEO-консультанта для помощи в необходимых областях.
Внутренняя поисковая оптимизация
Внутренняя поисковая оптимизация относится к действиям на веб-сайте, направленным на улучшение органической видимости. В значительной степени это означает оптимизацию веб-сайта и контента для повышения доступности, релевантности и удобства для пользователей. Некоторые из типичных действий включают в себя –
В значительной степени это означает оптимизацию веб-сайта и контента для повышения доступности, релевантности и удобства для пользователей. Некоторые из типичных действий включают в себя –
- Исследование ключевых слов — Анализ типов слов и частотности, используемых потенциальными клиентами для поиска услуг или продуктов брендов. Понимание их намерений и ожиданий пользователей от их поиска.
- Технический аудит — Обеспечение возможности сканирования и индексации веб-сайта, правильности геотаргетинга, отсутствия ошибок или барьеров взаимодействия с пользователем.
- Внутренняя оптимизация — Улучшение структуры веб-сайта, внутренней навигации, выравнивания на странице и релевантности контента, чтобы помочь расставить приоритеты в ключевых областях и настроить таргетинг на релевантные поисковые фразы.
- Взаимодействие с пользователем . Обеспечение того, чтобы содержимое демонстрировало компетентность, авторитет и доверие, было простым в использовании, быстрым и, в конечном итоге, предоставляло пользователям наилучшие возможности по сравнению с конкурентами.

Приведенный выше список касается лишь небольшого числа действий, связанных с SEO на месте, в качестве обзора.
Внешняя поисковая оптимизация
Внешняя поисковая оптимизация относится к действиям, проводимым за пределами веб-сайта для улучшения органической видимости. Это часто называют «линкбилдингом», целью которого является увеличение количества авторитетных ссылок с других веб-сайтов, поскольку поисковые системы используют их в качестве оценки в качестве вотума доверия.
Ссылки с веб-сайтов и страниц с большим доверием, популярностью и релевантностью принесут больше пользы другому веб-сайту, чем неизвестный, плохой веб-сайт, которому не доверяют поисковые системы. Таким образом, качество ссылки является наиболее важным сигналом.
Некоторые из типичных действий включают –
- Контент («Маркетинг») – Сайты с хорошей репутацией ссылаются на исключительный контент. Таким образом, создание потрясающего контента поможет привлечь ссылки. Это может быть руководство, история, визуализация, новости или исследования с убедительными данными.
- Цифровой PR — PR дает повод другим веб-сайтам общаться и ссылаться на веб-сайт. Это может быть внутренний поток новостей, статьи для внешних изданий, оригинальные исследования или исследования, экспертные интервью, цитаты, продакт-плейсмент и многое другое.
- Информационно-пропагандистская деятельность и продвижение . Это включает в себя общение с ключевыми журналистами, блогерами, влиятельными лицами или веб-мастерами о бренде, ресурсе, контенте или PR, чтобы получить освещение и, в конечном итоге, получить ссылки на веб-сайт.
 Это может быть руководство, история, визуализация, новости или исследования с убедительными данными.
Это может быть руководство, история, визуализация, новости или исследования с убедительными данными. Очевидно, существует огромное количество причин, по которым один веб-сайт может ссылаться на другой, и не все из них подходят для описанных выше действий. Это может включать в себя выступление на мероприятии, которое освещают местные блоггеры, спонсирование местной футбольной команды или включение в список поставщиков, например.
Хорошее эмпирическое правило в отношении того, является ли ссылка ценной, заключается в рассмотрении качества реферального трафика (посетителей, которые могут щелкнуть ссылку, чтобы посетить ваш веб-сайт). Если сайт не будет присылать посетителей или аудитория совершенно не связана с ним и не имеет отношения к делу, возможно, это не та ссылка, которую стоит использовать.
Важно помнить, что такие схемы ссылок, как покупка ссылок, чрезмерный обмен ссылками или низкокачественные каталоги и статьи, направленные на манипулирование рейтингом, противоречат рекомендациям Google, и они могут принять меры, наказав веб-сайт.
Лучший и наиболее устойчивый подход к улучшению входящих ссылок на веб-сайт — это зарабатывать их, предоставляя веб-сайтам подлинные и убедительные причины цитировать и ссылаться на бренд и контент для того, кто они есть, услуги или продукт, которые они предоставляют, или контент, который они создают.
Ресурсы для изучения SEO
В Интернете есть множество полезных ресурсов, которые помогут узнать больше о SEO.