Screaming Frog Seo Spider — подробное руководство по программе
Attention! Много букв! Много скринов! Много смысла!Доброго времени суток, друзья. Сегодня я хочу рассказать вам о настройке Screaming Frog (он же SF, он же краулер, он же паук, он же парсер — сразу определимся со всеми синонимами, ок?).
SF — очень полезная программа для анализа внутрянки сайтов. С помощью этой утилиты можно быстро выцепить технические косяки сайта, чтобы составить грамотное ТЗ на доработку. Но чтобы увидеть проблему, надо правильно настроить краулера, верно? Об этом мы сегодня с вами и поговорим.
- Примечание автора: сразу скажу — программа имеет много вкладок и настроек, которые по сути не нужны рядовому пользователю, потому я подробно опишу только наиболее важные моменты, а второстепенные пройдем вскользь… хотя кого я обманываю, когда это у меня были статьи меньше 30 к символов? *Зануда mode on*
- Примечание автора 2: при написании статьи я пользовался дополнительными материалами в виде официального мануала от разработчиков. Если что, почитать его можно тут https://www.screamingfrog.co.uk/seo-spider/user-guide/. Не пугайтесь английского, Google-переводчик в помощь — вполне себе сносная адаптация получается.
- Примечание автора 3: я люблю оставлять примечания…
Настройка Screaming Frog по шагам
Рассмотрим основное меню программы, для того чтобы понимать что где лежит и что за что отвечает (тавтология… Вова может в копирайт!).Верхнее меню — управление парсингом, выгрузкой и многое другое
File
Из названия понятно, что это работа с файлами программы (загрузка проектов, конфиги, планирование задач — что-то вроде того).- Open — открыть файл с уже проведенным парсингом.
- Open Recent — открыть последний парсинг (если вы его сохраняли отдельным файлом).
- Save — собственно, сохранить парсинг.

- Configuration — загрузка/сохранение специальных настроек парсинга вроде выведения дополнительных параметров проверки и т.д. (про то, как задавать эти настройки, я далее расскажу подробнее).
- Crawl Recent — повторно парсить один из последних сайтов, который уже проверялся в этой программе.
- Scheduling
- Exit — призвать к ответу Друзя… нет, ну серьезно,тут все очевидно.

Configuration
Один из самых интересных и важных пунктов меню, тут мы задаем настройки парсинга.Ох, сейчас будет сложно — у многих пунктов есть подпункты, у этих подпунктов всплывающие окна с вкладками и кучей настроек…в общем крепитесь, ребята, будет много инфы.
Spider — собственно, настройки парсинга сайта
Вкладка Basic — выбираем что парсить
- Check Images — в отчет включаем анализ картинок.
- Check CSS — в отчет включаем анализ css-файлов (скрипты).
- Check JavaScript — в отчет включаем анализ JS-файлов (скрипты).
- Check SWF — в отчет включаем анализ Flash-анимации.
- Check External Link — в отчет включаем анализ ссылок с сайта на другие ресурсы.
- Check Links Outside of Start Folder — проверка ссылок вне стартовой папки. Т.е. отчет будет только по стартовой папке, но с учетом ссылок всего сайта.
- Follow internal “nofollow” — сканировать внутренние ссылки, закрытые в тег “nofollow”.
- Follow external “nofollow” — сканировать ссылки на другие сайты, закрытые в тег “nofollow”.
- Crawl All Subdomains — парсить все поддомены сайта, если ссылки на них встречаются на сканируемом домене.
- Crawl Outside of Start Folder — позволяет сканировать весь сайт, однако проверка начинается с указанной папки.
- Crawl Canonicals — выведение в отчете атрибута rel=”canonical” при сканировании страниц.
- Crawl Next/Prev — выведение в отчете атрибутов rel=”next”/”prev” при сканировании страниц пагинации.
- Extract hreflang/Crawl hreflang — при сканировании учитываются языковой атрибут hreflang и отображаются коды языка и региона страницы + формирование отчета по таким страницам.
- Extract AMP Links/Crawl AMP Links — извлечение в отчет ссылок с атрибутом AMP (определение версии контента на странице).
- Crawl Linked XML Sitemap — сканирование карты сайта. Тут краулер либо берет sitemap из robots.txt (Auto Discover XML Sitemap via robots.txt), либо берет карту по указанному пользователем пути (Crawl These Sitemaps).
Вкладка Limits — определяем лимиты парсинга
- Limit Crawl Total — задаем лимиты страниц для сканирования. Сколько всего страниц выгружаем для одного проекта.
- Limit Crawl Depth — задаем глубину парсинга. До какого уровня может дойти краулер при сканировании проекта.
- Limit Max Folder Depth — можно контролировать глубину парсинга вплоть до уровня вложенности папки.
- Limit Number of Query Strings — тут, если честно, сам не до конца разобрался, потому объясню так, как понял — мы ограничиваем лимит страниц с параметрами. Другими словами, если на одной статической странице есть несколько фильтров, то их комбинация может породить огромное количество динамических страниц. Вот чтобы такие “полезные” страницы не парсились (увеличивает время анализа в разы, а толковой информации по сути ноль), мы и выводим лимиты по Query Strings. Пример динамики — site.ru/?query1&query2&query3&queryN+1.
- Max Redirects to Follow
- Max URL Length to Crawl — максимальная длина URL для обхода (указываем в символах, я так понимаю).
- Max Links per URL to Crawl — максимальное количество ссылок на URL для обхода (указываем в штуках).
- Max Page Size (KB) to Crawl — максимальный размер страницы для обхода (указываем в килобайтах).

Вкладка Rendering — настраиваем параметры рендеринга (только для JS)
На выбор три опции — “Text Only” (паук анализирует только текст страницы, без учета Аякса и JS), “Old AJAX Crawling Scheme” (проверяет по устаревшей схеме сканирования Аякса) и “JavaScript” (учитывает скрипты при рендеринге). Детальные настройки есть только у последнего, их и рассмотрим.
- Enable Rendered Page Screen Shots — SF делает скриншоты анализируемых страниц и сохраняет их в папке на ПК.
- AJAX Timeout (secs) — лимиты таймаута. Как долго SEO Spider должен разрешать выполнение JavaScript, прежде чем проверять загруженную страницу.
- Window Size — выбор размера окна (много их — смотрим скриншот).
- Sample — пример окна (зависит от выбранного Window Size).
- Чекбокс Rotate — повернуть окно в Sample.
Вкладка Advanced — дополнительные опции парсинга
- Allow Cookies — учитывать Cookies, как это делает поисковый бот.
- Pause on High Memory Used — тормозит сканирование сайта, если процесс забирает слишком много оперативной памяти.
- Always Follows Redirect — разрешаем краулеру идти по редиректам вплоть до финальной страницы с кодом 200, 4хх, 5хх (по факту все ответы сервера, кроме 3хх).
- Always Follows Canonicals — разрешаем краулеру учитывать все атрибуты “canonical” вплоть до финальной страницы. Полезно, если на страницах сайта бардак с настройкой этого атрибута (например, после нескольких переездов).
- Respect Noindex — страницы с “noindex” не отображаются в отчете SF.
- Respect Canonical — учет атрибута “canonical” при формировании итогового отчета. Полезно, если у сайта много динамических страниц с настроенным rel=”canonical” — позволяет убрать из отчета дубли по метаданным (т.к. на страницах настроен нужный атрибут).
- Respect Next/Prev — учет атрибутов rel=”next”/”prev” при формировании итогового отчета. Полезно, если у сайта есть страницы пагинации с настроенными “next”/”prev”- позволяет убрать из отчета дубли по метаданным (т.к. на страницах настроен нужный атрибут).
- Extract Images from img srscet Attribute — изображения извлекаются из атрибута srscet тега <img>. SRSCET — атрибут, который позволяет вам указывать разные типы изображений для разных размеров экрана/ориентации/типов отображения.
- Respect HSTS Policy — если чекбокс активен, SF будет выполнять все будущие запросы через HTTPS, даже если перейдет по ссылке на URL-адрес HTTP (в этом случае код ответа будет 307). Если же чекбокс неактивен, краулер покажет «истинный» код состояния за перенаправлением (например, постоянный редирект 301).
- Respect Self Referencing Meta Refresh — учитывать принудительную переадресацию на себя же (!) по метатегу Refresh.
- Response Timeout — время ожидания ответа страницы, перед тем как парсер перейдет к анализу следующего урла. Можно сделать больше (для медленных сайтов), можно меньше.
- 5хх Response Retries — количество попыток “достучаться” до страниц с 5хх ответом сервера.
- Store HTML — можно сохранить статический HTML-код каждого URL-адреса, просканированного SEO Spider, на диск и просмотреть его до того, как JavaScript “вступит в игру”.
- Store Rendered HTML — позволяет сохранить отображенный HTML-код каждого URL-адреса, просканированного SEO Spider, на диск и просмотреть DOM после обработки JavaScript.
- Extract JSON-LD — извлекаем микроразметку сайта JSON-LD. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema. org, Google Validation, Case-Sensitive).
- Extract Microdata — извлекаем микроразметку сайта Microdata. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
- Extract RDFa — извлекаем микроразметку сайта RDFa. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).

 org, Google Validation, Case-Sensitive).
org, Google Validation, Case-Sensitive).Вкладка Preferences — так называемые “предпочтения”
Здесь задаем желаемые параметры для некоторых сканируемых элементов (title, description, url, h2, h3, alt картинок, размер картинок). Соответственно, если сканируемые элементы сайта не будут соответствовать нашим предпочтениям, программа нам об этом сообщит в научно-популярной форме. Совершенно необязательные настройки — каждый прописывает для себя свой идеал… или вообще их не трогает, от греха подальше (как делаю я).- Page Title Width — оптимальная ширина заголовка страницы. Указываем желаемые размеры от и до в пикселях и в символах.
- Meta Description Width — оптимальная ширина описания страницы. Аналогично, как и с тайтлом, указываем желаемые размеры.
- Other — сюда входит максимальная желаемая длина урл-адреса в символах (Max URL Length Chars), максимальная длина h2 в символах (Max h2 Length Chars), максимальная длина h3 в символах (Max h3 Length Chars), максимальная длина ALT картинок в символах (Max Image Length Chars) и максимальный вес картинок в КБ (Max Image Size Kilobytes).
Robots.txt — определяем каким правилам следовать при парсинге
Вкладка Settings — настраиваем парсинг относительно правил robots.txt
- Respect robots.txt — следуем всем правилам, прописанным в robots.txt. Т.е. учитываем в анализе те папки и файлы, которые открыты для робота.
- Ignore robots.txt — не учитываем robots.txt сайта при парсинге. В отчет попадают все папки и файлы, относящиеся к домену.
- Ignore robots.txt but report status — не учитываем robots.txt сайта при парсинге, однако в дополнительном меню выводится статус страницы (индексируемая или не индексируемая).
- Show internal/external URLs blocked by robots.txt — отмечаем в чекбоксах хотим ли мы видеть в итоговом отчете внутренние и внешние ссылки, закрытые от индексации в robots.txt. Данная опция работает только при условии выбора “Respect robots.txt”.

Вкладка Custom — ручное редактирование robots.txt в пределах текущего парсинга
Удобно, если вам нужно при парсинге сайта учитывать (или исключить) только определенные папки, либо же добавить правила для поддоменов. Кроме того, можно быстро сформировать и проверить свой рабочий robots, чтобы потом залить его на сайт.
Шаг 1. Прописать анализируемый домен в основной строке
Шаг 2. Кликнуть на Add, чтобы добавить robots.txt домена
Тут на самом деле все очень просто, поэтому я по верхам пробегусь по основным опциям (а в конце будет видео, где я бездумно прокликиваю все кнопки).
- Блок Subdomains — сюда, собственно, можно добавлять домены/поддомены, robots.txt которых мы хотим учитывать при парсинге сайта.
- Окно справа — для редактирования выгруженного robots.txt. Итоговый вариант будет считаться каноничным для парсера.
- Окошко снизу — проверка индексации url в зависимости от настроенного robots.txt. Справа выводится статус страницы (Allowed или Disallowed).
URL Rewriting — функция перезаписи URL «на лету»
Тут мы можем настроить перезапись урл-адресов домена прямо в ходе парсинга. Полезно, когда нужно заменить определенные регулярные выражения, которые засоряют итоговый отчет по парсингу.
Вкладка Remove Parameters
Вручную вводим параметры, которые нужно удалять из url при анализе сайта, либо исключить вообще все возможные параметры (чекбокс “Remove all”). Полезно, если у страниц сайта есть идентификаторы сеансов, отслеживание контекста (utm_source, utm_medium, utm_campaign) или другие фишки.
Вкладка Regex Replace
Изменяет все сканируемые урлы с использованием регулярных выражений. Применений данной настройки масса, я приведу только несколько самых распространенных примеров:
- Изменение всех ссылок с http на https (Регулярное выражение: http Заменить: https).
- Изменение всех ссылок на site.by на site.ru (Регулярное выражение: .by Заменить: .ru).
- Удаление всех параметров (Регулярное выражение: \?. * Заменить: ).
- Добавление параметров в URL (Регулярное выражение: $ Заменить: ?ПАРАМЕТР).
Вкладка Options
Вы рассчитывали увидеть здесь еще 100500 дополнительных опций для суперточной настройки URL Rewriting, я прав? Как бы странно это ни звучало, но здесь мы всего лишь определяем перезаписывать все прописные url-адреса в строчные или нет… вот как-то так, не спрашивайте, я сам не знаю почему для этой опции сделали целую отдельную вкладку.
Вкладка Test
Тут мы можем предварительно протестировать видоизменение url перед началом парсинга и, соответственно, подправить регулярные выражения, чтобы на выходе не получилось какой-нибудь ерунды.
CDNs — парсим поддомены, не отходя от кассы
Использование настройки CDNs позволяет включать в парсинг дополнительные домены/поддомены/папки, которые будут обходиться пауком и при этом считаться внутренними ссылками. Полезно, если нужно проанализировать массив сайтов, принадлежащих одному владельцу (например, крупный интернет-магазин с сетью сайтов под регионы). Также можно прописывать регулярные выражения на конкретные пути сканирования — т.е. парсить только определенные папки.
Во вкладке Test можно посмотреть как будут определяться урлы в зависимости от используемых параметров (Internal или External).
Include/Exclude — сканирование/удаление определенных папок
Можно регулярными выражениями задать пути, которые будут сканироваться внутри домена. Также можно запретить парсинг определенных папок. Единственный нюанс в настройках — при использовании Include будут парситься только УКАЗАННЫЕ папки, если же мы добавляем урлы в Exclude, сканироваться будут все папки, КРОМЕ УКАЗАННЫХ.
Выбираем папки для парсинга
Удаляем папки из парсинга
Примеры регулярных выражений для Exclude:
- http://site.by/obidnye-shutki-pro-seo.html (исключение конкретной страницы).
- http://site.by/obidnye-shutki-pro-seo/.* (исключение целой папки).
- http://site.by/.*/obidnye-shutki-pro-seo/.* (исключение всех страниц, после указанной).
- .*\?price.* (исключение страниц с определенным параметром).
- .*jpg$ (исключение файлов с определенным расширением).
- .*seo.* (исключение страниц с вхождением в url указанного слова).
- .*https.* (исключение страниц с https).
- http://site.by/.* (исключение всех страниц домена/поддомена).
Speed — регулируем скорость парсинга сайта
Можно выставить как количество потоков (по умолчанию 5), так и число одновременно сканируемых адресов. Влияет на скорость парсинга и вероятность бана бота, так что тут лучше не усердствовать.
User-Agent — выбираем под кого маскируемся
В списке user-agent можно выбрать от лица какого бота будет происходить парсинг сайта. Удобно, если в настройках сайта есть директивы, блокирующие того или иного бота (например, запрещен google-bot). Также полезно иногда прокраулить сайт гугл-ботом для смартфона, чтобы проверить косяки адаптива или мобильной версии.
Скажу сразу — это опция очень индивидуальна, лично я ее не пользую, потому что чаще всего незачем. В любом случае, настройка реагирования на http-заголовки позволяет определить, как паук будет их обрабатывать (если указаны нюансы в настройках). По крайней мере я так это понял.
В любом случае, настройка реагирования на http-заголовки позволяет определить, как паук будет их обрабатывать (если указаны нюансы в настройках). По крайней мере я так это понял.
Т.е. можно индивидуально настроить, например, какого формата контент обрабатывать, учитывать ли cookie и т.д. Нюансов там довольно много.
Custom — дополнительные настройки поиска по исходному коду
Custom Search
По сути обычный фильтр, с помощью которого можно вытягивать дополнительные данные, например, страницы, в которых вместо тега <strong> используется <bold> или еще лучше — страницы, которые НЕ содержат определенного контента (например, без кода счетчика метрики). Фактически в настройках можно задать все что угодно.
Custom Extraction
Это пользовательское извлечение любых данных из html (например, текстовое содержимое).
User Interface — обнуление настроек для колонок таблицы
Просто сбрасывает сортировку столбцов, ничего особенного, проходим дальше, граждане, не толпимся.
API Access — интеграция с разными сервисами
Для того чтобы получать больше данных по сайту, можно настроить интеграцию с разными сервисами статистики типа Google Analytics или Majestic, при условии того, что у вас есть аккаунт в этом сервисе.При этом для каждого сервиса отдельные настройки выгрузки по типам данных.
На примере GA
Authentification — настройки аутентификации (если есть запрос от сайта)
Есть два вида аутентификации — Standart Based и Form Based. По умолчанию используется Standart Base — если при парсинге от сайта приходит запрос на аутентификацию, в программе появляется соответствующее окно.
Form Based — использование для аутентификации встроенного в SF браузера (полезно, когда для подтверждения аутентификации нужно, например, пройти капчу). В данном случае необходимо вручную вводить урл сайта и в открывшемся окне браузера вводить логин/пароль, кликать recaptcha и т.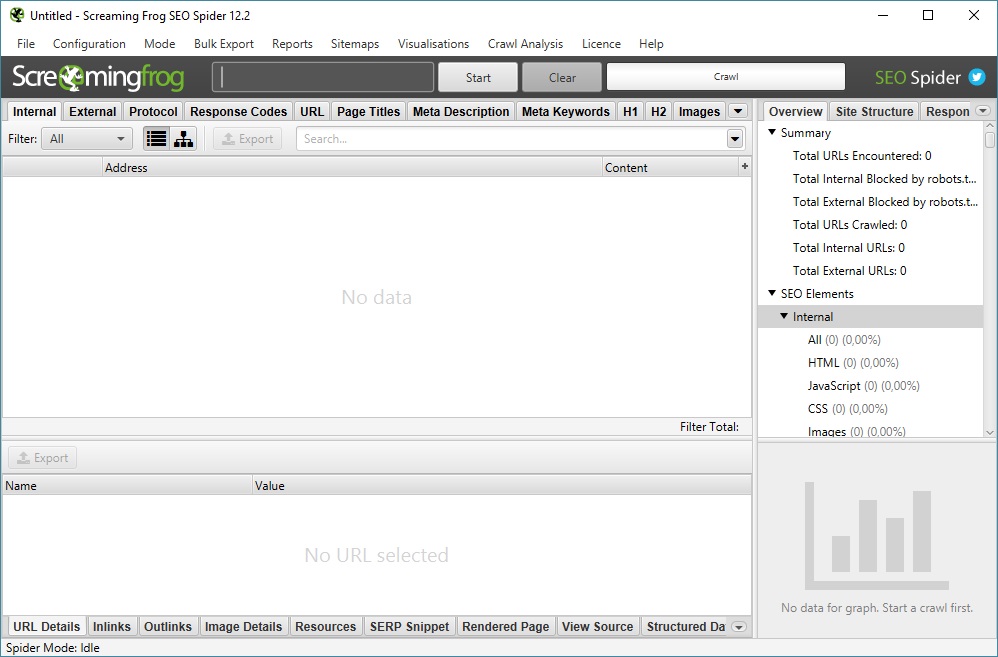 д.
д.
System — внутренние настройки самой программы
Настройки работы самой программы — сколько оперативной памяти выделять на процесс, куда сохранять экспорт и т.д.
Давайте как обычно — подробнее о каждом пункте.
- Memory — выделяем лимиты оперативной памяти для парсинга. По дефолту стоит 2GB, но можно выделить больше (если ПК позволяет).
- Storage — выбор базы для хранения данных. Либо сохранение в ОЗУ (для этого у SF есть свой движок), либо в указанной папке на ПК пользователя.
- Proxy — подключение прокси-сервера для парсинга.
- Embedded Browser — использование встроенного в программу браузера (вкл/выкл).
Mode
- Spider (Режим паука) — классический парсинг сайта по внутренним ссылкам. Просто вводим нужный домен в адресную строку программы и запускаем работу.
- List — парсим только предварительно собранный список урл-адресов! Адреса можно выгрузить из файла (From a file), вбить вручную (Enter Manually), подтянуть их из карты сайта (Download Sitemap) и т.д. Если честно, этих трех способов получения списка урлов должно быть более чем достаточно.
- SERP Mode — в этом режиме нет сканирования, зато здесь можно загружать мета-данные сайта, редактировать их и предварительно понимать как они будут отображаться в браузере. Делать все это можно пакетно, что вполне себе удобно.
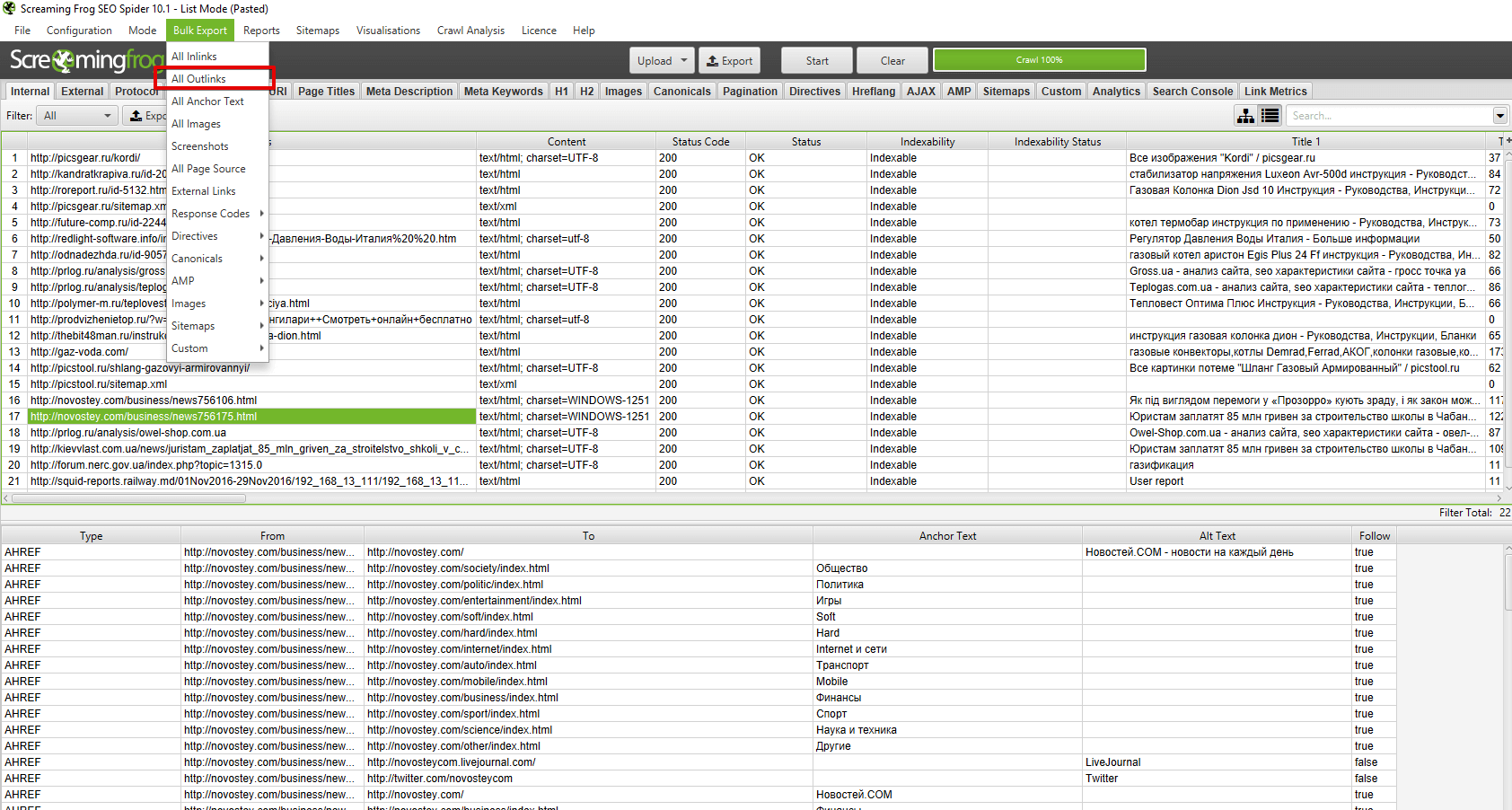
Bulk export
В этом пункте меню висят все опции SF, отвечающие за массовый экспорт данных из основного и дополнительного меню отчета. ..сейчас покажу на скриншоте.
..сейчас покажу на скриншоте.
В общем и целом с помощью bulk export можно вытянуть много разной полезной информации для последующей постановки ТЗ на доработки. Например, выгрузить в excel страницы, на которых найдены ссылки с 3хх ответом сервера + сами 3хх-ссылки, что позволяет сформировать задание для программиста или контент-менеджера (зависит от того, где зашиты 3хх-ссылки) на замену этих 3хх-ссылок на прямые с кодом 200. Теперь подробнее про то, что можно экспортировать при помощи Bulk Export.
- All Inlinks — получаем все входящие ссылки на каждый URI, с которым столкнулся краулер при сканировании сайта.
- All Outlinks — получаем все исходящие ссылки с каждого URI, с которым столкнулся краулер при сканировании сайта.
- All Anchor Text — выгрузка анкоров всех ссылок.
- All Images — выгрузка всех картинок (урл-адресами, естественно).
- Screenshots — экспорт снимков экрана.
- All Page Source — получаем статический HTML-код или обработанный HTML-код просканированных страниц (рендеринг HTML доступен только в режиме рендеринга JavaScript) .
- External Links — все внешние ссылки со всех просканированных страниц.
- Response Codes — все страницы в зависимости от выбранного кода ответа сервера (закрытые от индекса, с кодом 200, с кодом 3хх и т.д.).
- Directives — все страницы с директивами в зависимости от выбранной (Index Inlinks, Noindex Inlinks, Nofollow Inlinks и т.д.).
- Canonicals — страницы, содержащие канонические атрибуты, страницы без указания этих атрибутов, каноникализированные (*перекрестился*) страницы и т.д.
- AMP — страницы с AMP, ссылки с AMP (но код ответа не 200) и т.д.
- Structured Data — выгрузка страниц с микроразметкой.
- Images — выгрузка картинок без альт-текста, тяжелых картинок (в соответствии с указанным в настройках размером).
- Sitemaps — выгрузка всех страниц в карте сайта, неиндексируемых страниц в карте сайта и проч.
- Custom — выгрузка пользовательских фильтров.
Reports
Здесь содержится множество различных отчетов, которые также можно выгрузить.
- Crawl Overview — в этом отчете содержится сводная информация о сканировании, включая такие данные, как количество найденных URL-адресов, заблокированных robots.txt, число сканированных, тип контента, коды ответов и т. д.
- Redirect & Canonical Chains — отчет о перенаправлении и канонических цепочках. Здесь отображаются цепочки перенаправлений и канонических символов, показывается количество переходов по пути и идентифицируется источник, а также цикличность (если есть).
- Non-Indexable Canonicals — здесь можно получить выгрузку, в которой освещаются ошибки и проблемы с canonical. В частности, этот отчет покажет любые канонические файлы, которые не отдают корректного ответа сервера — заблокированы файлом robots.txt, с перенаправлением 3хх, ошибкой 4хх или 5хх (вообще все что угодно, кроме ответа «ОК» 200).
- Pagination — ошибки и проблемы с атрибутами rel=”next” и rel=”prev”, которые используются для обозначения содержимого, разбитого на пагинацию.
- Hreflang — проблемы с атрибутами hreflang (некорректный ответ сервера, страницы, на которые нет гиперссылок, разные коды языка на одной странице и т.д.).
- Insecure Content — показаны любые защищенные (HTTPS) URL-адреса, на которых есть небезопасные элементы, такие как внутренние ссылки HTTP, изображения, JS, CSS, SWF или внешние изображения в CDN, профили социальных сетей и т. д.
- SERP Summary — этот отчет позволяет быстро экспортировать URL-адреса, заголовки страниц и мета-описания с соответствующими длинами символов и шириной в пикселях.
- Orphan Pages — список потерянных страниц, собранных из Google Analytics API, Google Search Console (Search Analytics API) и XML Sitemap, которые не были сопоставлены с URL-адресами, обнаруженными во время парсинга.
- Structured Data — отчет содержит данные об ошибках валидации микроразметки страниц.
.jpg)
Sitemaps
С помощью этого пункта можно сгенерировать XML-карту сайта (страницы и картинки).
Все просто — выбираем что будем генерировать. В появившемся окне при необходимости выбираем нужные параметры и создаем карту сайта, которую потом заливаем в корневой каталог сайта.
Рассмотрим подробнее параметры, которые нам предлагают выбрать при генерации карты сайта.
Вкладка Pages — выбираем какие типы страниц включить в карту сайта.
- Noindex Pages — страницы, закрытые от индексации.
- Canonicalised — каноникализированные (опять это страшное слово!) страницы . Другими словами, динамика, у которой есть rel=”canonical”.
- Paginated URLs — страница пагинации.
- PDFs — PDF-документы.
- No response — страницы с кодом ответа сервера 0 (не отвечает).
- Blocked by robots.txt — страницы закрытые от индекса в robots.txt.
- 2xx — страницы с кодом 2хх (они будут в карте в любом случае).
- 3хх — страницы с кодом ответа 3хх (редиректы).
- 4хх — страницы с кодом ответа 4хх (битые ссылки на несуществующие страницы).
- 5хх — страницы с кодом ответа 5хх (проблема сервера при загрузке).
Вкладка Last Modified — выставляем дату последнего обновления карты.
- nclude <lastmod> tag — использовать в sitemap тег <lastmod> (дата последнего обновления карты).
- Use server report — использовать ответ сервера при создании карты, либо проставить дату вручную.
Вкладка Priority — выставляем приоритет ссылки в зависимости от глубины залегания страницы.
- Include <priority> tag — добавляет в карту сайта тег <priority>, показывающий приоритет страницы.
- Crawl Depth 0-5+ — в зависимости от глубины залегания страницы, можно проставить ее приоритет сканирования для поискового робота.
Вкладка Change Frequency — выставляем вероятную частоту обновления страниц.
- Include <changefreq> tag — использовать тег <changefreq> в карте сайта. Показывает частоту обновления страницы.
- Calculate from Last Modified header — рассчитать тег по последнему измененному заголовку.
- Use crawl depth settings — проставить тег в зависимости от глубины страницы.
Вкладка Images — добавляем картинки в карту сайта.
- Include Images — выводить в общей карте сайта картинки.
- Include Noindex Images — добавить картинки, закрытые от индекса.
- Include only relevant Images with up to … inlinks — добавить только картинки с заданным числом входящих ссылок.
- Regex list of CDNs hosting images to be included — честно, так и не понял что это такое… возможно настройка выгрузки в карту сайта картинок из хостинга (т.е. можно вбить списком несколько хостов и оттуда подтянуть картинки), но это всего лишь мои предположения.
Вкладка Hreflang — использовать в sitemap атрибут <hreflang> (или не использовать).
Visualisations
Это выбор интерактивной визуализации структуры сайта в программе. Можно получить отображение дерева сканирования и дерева каталогов. Основная фишка в том, что открываются эти карты и диаграммы во встроенном браузере программы, что позволяет эффективнее с ними работать (настраивать выведение, масштабировать, перескакивать к нужным урлам через поиск и т.д.).
Crawl Tree Graph — визуализация сканирования. По факту после завершения краулинга показывает текущую структуру сайта на основании анализа.
Directory Tree Graph — показывает ВСЕ каталоги после сканирования. Т.е. отличие от Crawl Tree Graph в том, что в этом отчете показываются, например, папки, закрытые от индекса. Назначение Crawl Tree Graph и Directory Tree Graph в основном заключается в упрощении анализа структуры текущего сайта, можно глазами пробежаться по всем папкам, зацепиться за косяки (т. к. они выделены цветом). При наведении на папку, показывается ее данные (url, title, h2, h3 и т.д.).
к. они выделены цветом). При наведении на папку, показывается ее данные (url, title, h2, h3 и т.д.).
Force Directed Crawl-Diagram — по сути то же самое, что и Crawl Tree Graph, только оформленное по-другому + показывает сканирование сайта относительно главной страницы (ну или стартовой). Кому-то покажется нагляднее, хотя по мне, выглядит гораздо сложнее для восприятия.
Force Directed Tree-Diagram — аналогично, другой тип визуализации дерева каталогов сайта.
Inlink Anchor Text Word Cloud — визуализация анкоров (ссылочного текста) внутренней ссылки. Анализирует каждую страницу по-отдельности. Помогает понять какими анкорами обозначена страница, как их много, насколько разнообразны и т.д.
Р- Разнообразие
Body Text Word Cloud — визуализация плотности отдельных слов на странице. По сути выглядит так же, как и Inlink Anchor Text Word Cloud, так что отдельный скрин делать смысла особого нет — обычное облако слов, по размеру можно определить какое слово встречается чаще, по общему числу посмотреть разнообразие слов на странице и т.д.
Каждая визуализация имеет массу настроек вывода данных, маркировки — про них я писать не буду, если станет интересно, сами поиграетесь, ок? Там ничего сложного.
Crawl Analysis
Большинство параметров сайта вычисляется пауком в ходе сбора статистики, однако некоторые данные (Link Score, некоторые фильтры и прочее) нуждаются в дополнительном анализе, чтобы попасть в финальный отчет. Данные, которые нуждаются в Crawl Analysis, помечены соответствующим образом в правом меню навигации.
Crawl Analysis запускается после основного парсинга. Перед запуском дополнительного анализа, можно настроить его (какие данные выводить в отчет).
- Link Score — присвоение оценок всем внутренним ссылкам сайта.
- Pagination — показывает петлевые пагинации, а также страницы, которые обнаружены только через атрибуты rel=”next”/”prev”.
- Hreflang — урлы hreflang без гиперссылки, битые ссылки.
- AMP — страницы без тегов “html amp”, теги не с 200 кодом ответа.
- Sitemaps — неиндексируемые страницы в карте сайта, урлы в нескольких картах сайта, потерянные страницы (например, есть в Google Analytics, есть в sitemap, не обнаружено при парсинге), страницы, которых нет в карте сайта, страницы в карте сайта.
- Analytics — потерянные страницы (есть в аналитике, нет в парсинге).
- Search Console — потерянные страницы (есть в вебмастере, нет в парсинге).
License
Исходя из названия, логично предположить, что этот пункт меню отвечает за разного рода манипуляции с активацией продукта…иии так оно и есть!
Buy a License — купить лицензию. При клике переход на соответствующую страницу официалов https://www.screamingfrog.co.uk/seo-spider/licence/. Стоимость ключа для одного ПК — 149 фунтов стерлинга. Есть пакеты для нескольких ПК, там, как обычно, идут скидки за опт.
Enter License — ввести логин и ключ лицензии, чтобы активировать полный функционал парсера.
Заметили, да? Лицензия покупается на год, не бессрочная
Help
Помощь юзеру — гайды, FAQ, связь с техподдержкой, в общем все, что связано с работой программы, ее багами и их решением.
- User Guide — мануал по работе с программой. Собственно, его я использовал, как один из источников, для написания этой статьи. При желании, можете ознакомиться, если я что-то непонятно рассказал или не донес. Еще раз оставлю ссылку https://www.screamingfrog.co.uk/seo-spider/user-guide/.
- FAQ — часто задаваемые вопросы по работе с SF и ответы на них https://www.screamingfrog.co.uk/seo-spider/faq/.
- Support — обратная связь с техподдержкой https://www.screamingfrog.co.uk/seo-spider/support/. Если программа ведет себя некрасиво (например, не принимает ключ лицензии), можно пожаловаться куда надо и все починят.
- Feedback — обратная связь. Та же самая страница, что и в Support. Т.е. можно не только жаловаться, но и вносить предложения по работе программы, предлагать партнерку, сказать банальное “спасибо” за такой крутой сервис (думаю ребятам будет приятно).
- Check for Updates и Auto Check for Updates — проверка на наличие обновлений программы. Screaming Frog нерегулярно, но довольно часто дорабатывается, поэтому есть смысл периодически проверять апдейты. Но лучше поставить галочку на Auto Check for Updates и программа сама будет автоматически предлагать обновиться при выходе нового апа.
- Debug — отчет о текущем состоянии программы. Нужно, если вы словили какой-то баг и хотите о нем сообщить разработчику. Там еще дополнительно есть настройки дебага, но я думаю, нет смысла заострять на этом внимание.
- About — собственно, краткая информация о самой программе (копирайт, сервисы, которые использовались при разработке).

Итог
Screaming Frog — очень гибкая в плане настройке утилита, с помощью которой можно вытянуть массу данных для анализа, нужно только (только… ха-ха) правильно настроить парсинг. Я надеюсь, мой мануал поможет вам в этом, хотя и не все я рассмотрел как надо, есть пробелы, но основные функции должны быть понятны.
Теперь от себя — текста много, скринов много, потому, если вы начинающий SEO-специалист, рекомендую осваивать SF поэтапно, не хватайтесь за все сразу, ибо есть шанс упустить важные нюансы.
Ну вот и все, ребята, я отчаливаю за новым материалом для нашего крутого блога. Подписывайтесь, чтобы не пропустить интересные публикации от меня и моих коллег. Всем удачи, всем пока!
Владимир Еленский
Практикующий SEO-специалист MAXI.BY media. Опыт работы более 5-ти лет. Хороший человек и просто красавчик.Инструменты для интернет-маркетинга, SEO и SMM
Screaming Frog SEO Spider – многофункциональный инструмент аудита и оптимизации сайтов для использования в профессиональной среде. Сканирует по множеству показателей, выявляет ошибки кода, препятствующие эффективному продвижению. Доступна бесплатная ознакомительная версия для проведения экспресс-анализа.
Сканирует по множеству показателей, выявляет ошибки кода, препятствующие эффективному продвижению. Доступна бесплатная ознакомительная версия для проведения экспресс-анализа.
В области SEO-оптимизации сайтов особое место занимают инструменты, способные в короткое время проанализировать внутреннюю структуру ресурса по всем необходимым показателям. Одна из таки программ — Screaming Frog SEO Spider, разработанная британским специалистом на основе популярной Xenu Link Sleuth, но с намного более широким функционалом. Так, Screaming Frog SEO Spider собирает ключевые данные о коде сайта и находит ошибки, препятствующие эффективному продвижению.
Стоит заметить, что программа Screaming Frog SEO Spider – платная, на данный момент покупка лицензии обойдется в 149 фунтов стерлингов в год. Но есть возможность скачать ознакомительную версию. Конечно, возможности демо-версии ограничены: количество проверяемых страниц – не более пятисот, однако ее вполне достаточно для поиска битых ссылок, неуникальных заголовков, дублей, а также генерации XML карты сайта. Для периодического экспресс-аудита бесплатная версия годится лучше всего.
Продвижение и SEO-оптимизация сайта, главная цель которого – продажа товаров, услуг, рекламных площадок, – это долгий и кропотливый процесс. Советуем проводить полное сканирование всего сайта или его разделов, если возникают проблемы с его продвижением. Для этого воспользуйтесь полной версией Screaming Frog SEO Spider.
Итак, что же предлагает нам данный SEO-сканер?
Программа проста в управлении. После инсталляции она открывается в нехитром и понятном интерфейсе. Достаточно лишь ввести в специальную строку адрес главной страницы сайт и нажать «старт». В процессе проверки отображается различная информация о содержании страниц, можно отфильтровать ее по типу (HTML, флэш, адреса картинок и т.д.).
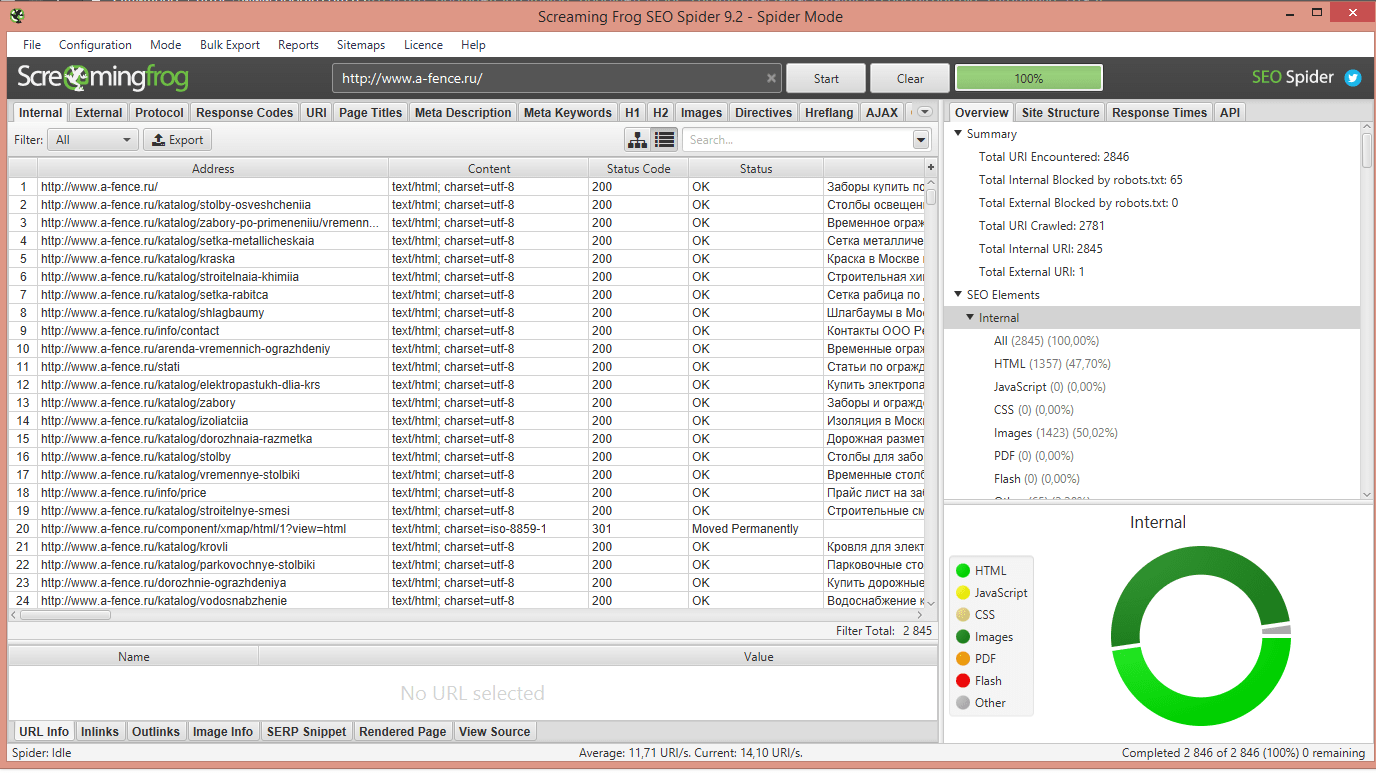
Результаты аудита выводятся в виде таблицы и отсортированы по вкладкам
-
Internal – основные данные (адреса, тип контента и кодировка, статусы и коды ответа веб-сервера, информация о заголовках и других мета-тегах, размер станиц и уровень вложенности, исходящий и входящие внутренние и внешние ссылки, выявление дубликата контента).
-
External – внешние ресурсы, на которые ведут ссылки на проверяемом сайте (адреса, тип, кодировка, данные ответа веб-сервера, вложенность, а также общее количество внешних ссылок).
-
Response Code – информация о перенаправлениях (типы и цель редиректа).
-
URL – список неправильных, битых ссылок, данные других проблемных показателей (дубли, динамические адреса, некорректные символы, количество символов в адресах).
-
Page Titles – информация о тайтлах (заголовках) страниц (здесь ведется поиск страниц с отсутствующими тайтлами, дублями, выводится количество символов по каждому тайтлу, совпадения с h2 заголовками).
-
Meta Description – информация о свойствах данного тега.
-
Meta Keywords – анализ содержания ключевых слов на страницах.
-
вкладки h2 и h3 – результаты по заголовкам на всех анализируемых страницах сайта.
-
Images – количество и вес графических файлов на страницах сайта (необходимая информация для оптимизации и качества загрузки страниц).
-
Meta & Canonical – данные о meta robots и rel=canonical в структуре сайта.

Несмотря на видимую простоту, программа действительно обладает поражающим функционалом, доступным для пользователей лицензии. Информация отображается в реальном времени с быстрой загрузкой данных, есть возможность экспортировать таблицы в файл Excel, а также отфильтровать их вручную по различным показателям.
Для проведения комплексного разбора кода сайтов в сфере SEO-продвижения используются различные сервисы. Screaming Frog SEO Spider – приложение нового поколения, эффективный инструмент оптимизации, который должен быть в арсенале любого профессионального вебмастера и SEO-специалиста.
Назад в раздел
Подробная инструкция по использованию Screaming Frog SEO Spider
Автор Никита Чижиченко На чтение 12 мин. Просмотров 14.4k. Опубликовано
Правильный аудит сайта – это половина успешной оптимизации. Но для его проведения требуется ряд инструментов и их понимание.
Одним из наиболее полезных сервисов является Screaming Frog (SF), который дает возможность с помощью парсинга (сбора информации) получить необходимые данные, например, массово выгрузить пустые страницы или найти все дубликаты по метатегу Title.
В процессе оптимизации мы часто используем данный сервис, поэтому решили составить цикл обзорных статей, чтобы упростить специалистам навигацию по инструментарию и поиску решений нетривиальных задач. В этой статье-переводе расскажем о настройке парсинга и опишем, как без лишних проблем сканировать большие сайты.
Ознакомиться с сервисом более подробно можно в разделе первоисточника User Guide, на этом же сайте можно скачать бесплатную версию (предел парсинга – до 500 страниц, есть ограничение в настройках, поэтому рекомендуем использовать полную версию).
Configuration Options (опции для парсинга)Spider ConfigurationЗдесь задаются основные настройки парсера, которые разбиты по следующим вкладкам:
- Basic;
- Limits;
- Rendering;
- Advanced;
- Preferences.
Если здесь и далее чекбокс отмечен, выполняется указанный вид операции с созданием (при возможности) соответствующего отчета:
- Check Images – анализ картинок.
- Check CSS – анализ CSS-файлов.
- Check JavaScript – анализ JS-файлов.
- Check SWF — анализ Flash-анимаций.
- Check External Link – анализ ссылок с сайта на другие ресурсы.
- Check Links Outside of Start Folder – возможность проанализировать ссылки вне сканирования стартовой папки.
- Follow internal “nofollow” – сканирование внутренних ссылок, закрытые в тег “nofollow”.
- Follow external “nofollow” – сканирование ссылок на другие сайты, закрытые в тег “nofollow”.
- Crawl All Subdomains – парсинг всех поддоменов сайта, если ссылки на них встречаются на сканируемом домене.
- Crawl Outside of Start Folder – сканируется весь сайт, однако проверка начинается с указанной папки.
- Crawl Canonicals – выведение в отчете атрибута rel=”canonical” при сканировании страниц с использованием данного атрибута.
- Crawl Next/Prev – выведение в отчете атрибутов rel=”next”/”prev” при сканировании страниц пагинации.
- Extract hreflang/Crawl hreflang – при сканировании учитывается атрибут hreflang, отображаются коды языка и региона страницы.
- Extract AMP Links/Crawl AMP Links – извлечение в отчет ссылок с атрибутом AMP (определение версии контента на странице).
- Crawl Linked XML Sitemap – сканирование карты сайта.
Если включена данная опция, можно выбрать «Auto Discover XML Sitemaps via robots.txt» (SF сам найдет sitemap.xml с помощью robots.txt) или предоставить список файлов, отметив «Crawl These Sitemap» и вставив их в поле, которое появится.
Limits- Limit Crawl Total – задаем лимиты страниц для сканирования (сколько страниц сканируем для одного проекта).
- Limit Crawl Depth – задаем глубину парсинга: до какого уровня может дойти краулер при сканировании проекта. Если укажете уровень вложенности 1, Screaming Frog выдаст все URL уровня вложенности от введенного документа. Например, если указать главную страницу и в Limit Crawl Depth добавить значение 1, то краулер перейдет по всем ссылкам с главной страницы и остановится. При параметре со значением 0 будет проверен только указанный документ.
- Limit Max Folder Depth – задаем глубину парсинга вплоть до уровня вложенности папки. Указанное значение отвечает за то, как глубоко можно сканировать сайт по адресу URL site.ru/papka-1/papka-2/papka-3/, где значение – параметр в Limit Max Folder Depth.
- Limit Number of Query Strings – задаем глубину парсинга для страниц с параметрами.
- Max Redirects to Follow – задаем максимальное количество редиректов, по которым краулер может переходить с одного адреса.
- Max URL Length to Crawl – максимальная длина URL, допустимого для сканирования.
- Max Links per URL to Crawl – максимальное количество ссылок в сканируемом URL для обхода.
- Max Page Size (KB) to Crawl – максимальный размер страницы для обхода (указываем в килобайтах).
 Например, если указать главную страницу и в Limit Crawl Depth добавить значение 1, то краулер перейдет по всем ссылкам с главной страницы и остановится. При параметре со значением 0 будет проверен только указанный документ.
Например, если указать главную страницу и в Limit Crawl Depth добавить значение 1, то краулер перейдет по всем ссылкам с главной страницы и остановится. При параметре со значением 0 будет проверен только указанный документ.На выбор три опции:
- Text Only – краулер анализирует только текст страницы.
- Old AJAX Crawling Scheme – проверяет по устаревшей схеме сканирования AJAX.
- JavaScript – учитывает скрипты при рендеринге.
Детальные настройки есть только в опции JavaScript.
- Enable Rendered Page Screen Shots – если чекбокс активен, SF делает скриншоты анализируемых страниц и сохраняет их в папке на ПК.
- AJAX Timeout (secs) – лимиты таймаута. Означает, как долго SF должен разрешать выполнение JavaScript, прежде чем проверять загруженную страницу.
- Window Size – выбор размера окна.
- Sample – пример окна.
- Чекбокс Rotate – повернуть окно (было 768х1280, стало 1280х768).

- Allow Cookies – учитывает Cookies, как это делает поисковый бот (можно принимать во внимание при выборе бота для парсинга).
- Pause on High Memory Used – останавливает сканирование сайта, если процесс забирает слишком много оперативной памяти. После остановки можно отключить опцию и продолжить парсинг.
- Always Follows Redirect – разрешает краулеру анализировать все редиректы, вплоть до финальной страницы.
- Always Follows Canonicals – разрешает краулеру анализировать все атрибуты “canonical”, вплоть до финальной страницы.
- Respect Noindex – страницы с “noindex” не отображаются в отчете.
- Respect Canonical – страницы с “canonical” не отображаются в отчете.
- Respect Next/Prev – страницы с rel=”next”/”prev” не отображаются в отчете, кроме первой (основной).
- Extract Images from img srscet Attribute – изображения извлекаются из атрибута srscet тега <img>. SRSCET – атрибут, который позволяет указывать разные типы изображений для разных размеров экрана/ориентации/типов отображения.
- Respect HSTS Policy – если чекбокс активен, SF выполнит все будущие запросы через HTTPS, даже если перейдет по ссылке на URL-адрес HTTP (в этом случае код ответа будет 307). Если же чекбокс неактивен, краулер покажет «истинный» код (например, в случае постоянного редиректа – 301).
- Respect Self Referencing Meta Refresh – учитывает принудительную переадресацию на себя же по метатегу Refresh.
- Response Timeout – время ожидания ответа страницы, перед тем как краулер перейдет к анализу следующего URL. Можно сделать больше (для медленных сайтов) или меньше.
- 5хх Response Retries – количество попыток “достучаться” до страниц с 5хх ответом сервера.
- Store HTML – можно сохранить статический HTML-код каждого просканированного URL-адреса на диск и просмотреть до обработки JavaScript.
- Store Rendered HTML – позволяет сохранить отображенный HTML-код каждого просканированного URL-адреса на диск и просмотреть DOM после обработки JavaScript.
- Extract JSON-LD – извлекает микроразметку сайта JSON-LD.
- Extract Microdata – извлекает микроразметку сайта Microdata.
- Extract RDFa – извлекает микроразметку сайта RDFa.
При выборе последних трех пунктов в каждом случае доступны дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
Здесь задаем желаемые параметры для ряда сканируемых элементов (Title, Description, URL, h2, h3, ALT и размер картинок).
- Page Title Width – оптимальная ширина заголовка страницы. Указываем желаемые размеры от и до в пикселях и в символах.
- Meta Description Width – оптимальная ширина описания страницы. Размеры – как в случае с Title.
- Other – сюда входит максимальная желаемая длина:
- URL-адреса в символах (Max URL Length Chars).
- h2 в символах (Max h2 Length Chars).
- h3 в символах (Max h3 Length Chars).
- ALT картинок в символах (Max Image Length Chars).
- Максимальный вес картинок в КБ (Max Image Size Kilobytes).
Здесь мы указываем парсеру, как именно учитывать файл robots.txt. Блок разделен на две вкладки – Settings и Custom.
SettingsIgnore robots.txtПо умолчанию SF будет подчиняться протоколу robots.txt: например, если сайт запрещен для сканирования в robots.txt, краулер не сможет его спарсить. Однако данная опция позволяет игнорировать этот протокол, таким образом разрешая попадание в отчет всех папок и файлов.
Respect robots.txtПри выборе опции мы можем получить отчет по внутренним и внешним ссылкам, закрытым от индексации в robots. txt. Для этого необходимо выбрать соответствующие чекбоксы: для отчета по внешним ссылкам – Show external URLs blocked by robots.txt, по внутренним – Show internal URLs blocked by robots.txt.
txt. Для этого необходимо выбрать соответствующие чекбоксы: для отчета по внешним ссылкам – Show external URLs blocked by robots.txt, по внутренним – Show internal URLs blocked by robots.txt.
Пользовательский файл robots.txt использует выбранный User Agent в конфигурации, таким образом данная опция позволит просканировать или протестировать robots.txt без необходимости внесения правок для актуальных директив или использования панелей вебмастеров.
Сначала укажите в основной строке название, нажмите кнопку Add, в итоге вы получите robots.txt домена:
В правом нижнем углу есть кнопка Test. Если слева вписать нужный URL домена и нажать на нее, программа покажет доступность URL для индекса с учетом указанных в robots.txt настроек.
URL RewritingДанный блок дает возможность перезаписать сканируемые URL в процессе парсинга. Функция удобна, если во время сканирования надо изменить регулярные выражения, которые не нужны в конечном отчете.
Remove ParametersЗдесь вводят параметры, которые можно удалить из URL при анализе сайта либо исключить все возможные параметры (чекбокс Remove all):
Regex ReplaceИзменяет все сканируемые URL с использованием регулярных выражений. Например, можно изменить все ссылки с HTTP на HTTPS:
OptionsЗдесь определяем перезапись прописных URL в строчные.
TestТут можно тестировать видоизменения URL перед началом парсинга, пример с учетом версии для Regex Replace:
CDNsДанная функция позволяет включать в парсинг дополнительные домены и папки, считая их внутренними ссылками. При этом можно указать для сканирования только конкретные папки:
Во вкладке Test можно посмотреть, как будут определяться URL с учетом параметров Internal и External, где Internal означает, что ссылка считается внутренней, а External – внешней.
Во вкладке Include мы вписываем выражения для парсинга только указанных папок, во вкладке Exclude – исключения, для парсинга всех, кроме указанных.
Разберем логику на примере вкладки Exclude:
Чтобы проверить выражение, можно использовать вкладку Test. Например, нужно запретить парсинг домена.
Если правило указано верно, то в Test при вводе нужного URL будет следующее:
Примеры других выражений:
- Чтобы исключить конкретный URL или страницу: http://www.example.com/do-not-crawl-this-page.html
- Чтобы исключить подкаталог или папку: http://www.example.com/do-not-crawl-this-folder/.*
- Чтобы исключить все после бренда, где иногда могут быть другие папки: http://www.example.com/.*/brand.*
- Если нужно исключить URL с определенным параметром, таким как price, содержащимся во множестве различных каталогов, можно использовать следующее выражение:
.*\?price.*
Важно: “?” является специальным символом в регулярном выражении и должен быть экранирован обратной косой чертой.
- Если нужно исключить все файлы, заканчивающиеся на .jpg, регулярное выражение будет выглядеть так:
.*jpg$
- Если нужно исключить все URL-адреса, заканчивающиеся случайным 6-значным числом после дефиса, например «-402001», регулярное выражение имеет такой вид:
.*-[0-9]{6}$
- Если нужно исключить любой URL, в котором есть produce, регулярное выражение будет:
.*produce.*
- Исключение страниц с HTTPS:
.*HTTPS.*
- Исключение всех страниц на http://www.domain.com: http://www.domain.com/.*
- Если не получается исключить URL-адрес, причиной может служить наличие специальных символов регулярного выражения, например “?”.
Вместо того, чтобы пытаться найти и экранировать их по отдельности (с помощью “\”), можно экранировать всю строку, начиная с \Q и заканчивая \E, например:
\Qhttp://www.example.com/test.php?product=special\E
Можно выставить как количество потоков (по умолчанию 5), так и число одновременно сканируемых адресов. Влияет как на скорость парсинга, так и на вероятность бана бота, поэтому лучше быть осторожными.
User-Agent (с помощью какого “бота” парсим)Опция Preset User-Agents позволяет выбрать, от лица какого бота будет происходить парсинг. Полезно, если в настройках сайта есть директивы, блокирующие конкретного бота. Дополнительно удобно при поиске ошибок, если парсинг производить от “лица” Googlebot Smartphone.
Данная опция позволяет указать конкретный вид контента для сканирования. Настроек много – от Accept-Language, Cookie, Referer или просто указания уникального имени заголовка.
Custom (настройки для парсинга дополнительных данных)Данная вкладка является одной из наиболее ценных, если есть необходимость в поиске конкретной информации по всему сайту.
Custom Search
Функция дает возможность получить отчет с учетом любого регулярного выражения, которое будет указано в соответствующем фильтре. Например, можно получить отчет по страницам, содержащим кодировку utf-8 в HTML-коде:
Используем соответствующий фильтр:
С помощью данной функции можно получить информацию при помощи CSS, XPath или Regex, например:
За счет функции Extract text можно получить данные о количестве статей в разных странах в отчете Custom:
User Interface (сброс сортировки столбцов)Функция для сброса пользовательской сортировки столбцов. Это все 🙂
API Access (интеграция с сервисами)Чтобы получить больше данных по сайту, можно настроить интеграцию с разными сервисами статистики, например, с Google Analytics или Ahrefs, при условии, что у вас есть необходимые данные для интеграции.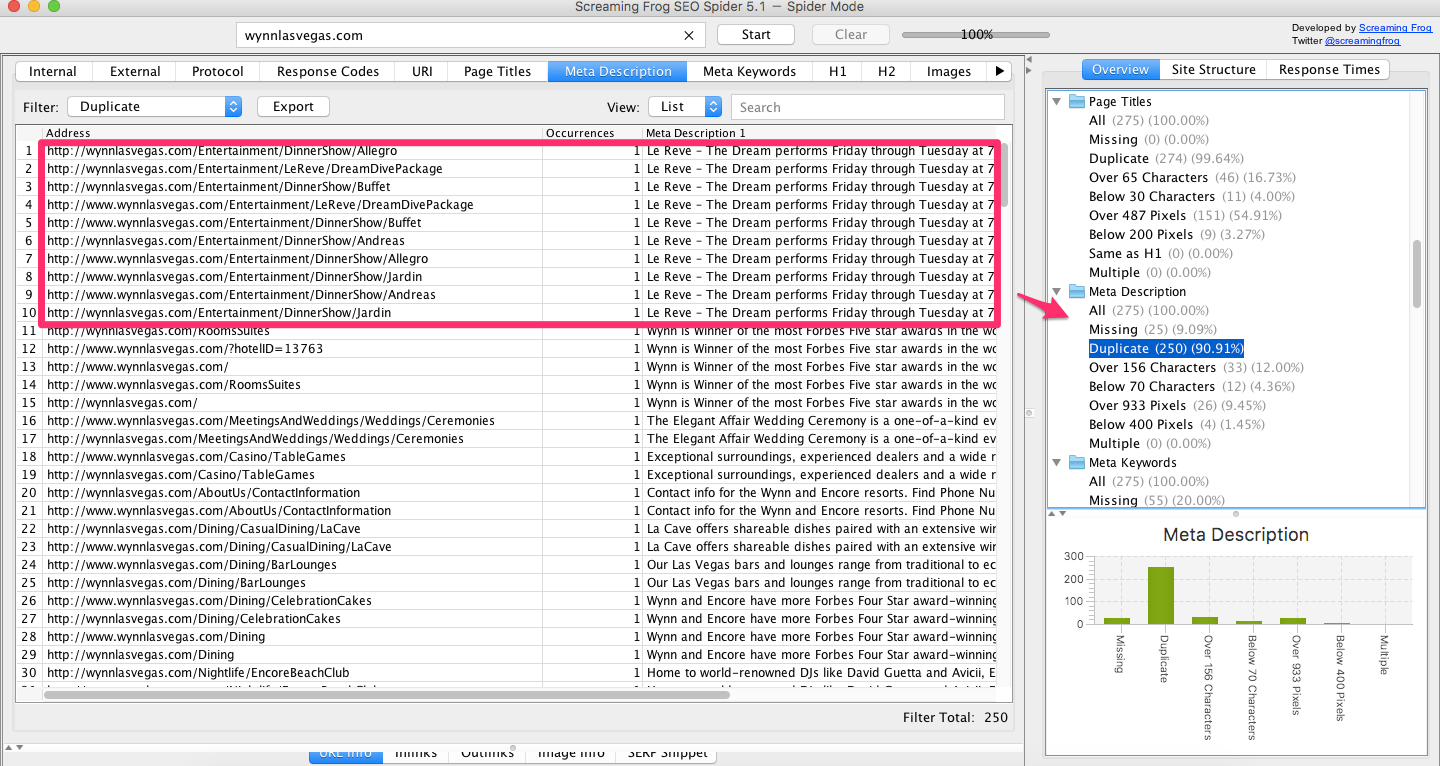
Здесь указываем предел оперативной памяти для парсинга.
Можно указать больше заданного, но делать это нужно осторожно.
StorageЗдесь указывается, куда будут сохраняться отчеты – в папку программы либо по указанному пути.
ProxyУказываете прокси, с помощью которых будет происходить парсинг (используется, если выбран чекбокс).
Embedded BrowserЕсли чекбокс активен, парсер использует встроенный в программу браузер для сканирования.
Mode (режимы сканирования)Выбираем режимы сканирования сайта.
Spider – классический парсинг сайта по внутренним ссылкам, вводим домен в адресную строку.
List – парсим только предварительно собранный список URL-адресов. Указать их можно несколькими способами:
- From a File – выгружаем URL-адреса из файла.
- Paste – выгружаем URL-адреса из буфера обмена.
- Enter Manually – вводим вручную в соответствующее поле.
- Download Sitemap – выгружаем их из карты сайта.
SERP Mode – режим не для сканирования: в нем можно загружать метаданные сайта, редактировать и тестировать для понимания дальнейшего отображения в браузере.
После парсинга информацию можно посмотреть в соответствующих отчетах вверху:
Или сбоку:
С помощью данных настроек можно решить ряд как простых, так и сложных задач в рамках аудита сайта. В других статьях мы будем их рассматривать.
Обновление SEO Spider Screaming Frog
Мы рады запустить Screaming Frog SEO Spider версии 14.0 под внутренним кодовым названием «мания величия».
С момента выпуска версии 13 в июле разработчики были заняты работой над следующим раундом функций для версии 14, основываясь на отзывах пользователей и, как всегда, небольшом внутреннем управлении.
Давайте поговорим о том, что нового в этом выпуске.
1) Темный режим
Возможно, это не самая важная функция в этом выпуске, но она используется на всех скриншотах, поэтому имеет смысл поговорить в первую очередь. Теперь вы можете переключиться в темный режим через «Конфигурация > Пользовательский интерфейс > Тема > Темный».
Это не только поможет снизить нагрузку на глаза для тех, кто работает при слабом освещении (все, кто сейчас живет в условиях пандемии), но и выглядит очень круто – и, как предполагаю (сейчас я), значительно повысит ваши технические навыки SEO.
Те, кто не напрягает глаза, могут заметить, что разработчики также изменили некоторые другие элементы стилей и графики, например, те, что находятся на вкладках обзора справа и структуры сайта.
2) Экспорт в Google Таблицы
Теперь вы можете экспортировать прямо в Google Таблицы.
Вы можете добавить несколько учетных записей Google и быстро подключиться к любой, чтобы сохранить данные сканирования, которые появятся на Google Диске в папке Screaming Frog SEO Spider и будут доступны через Таблицы.
Многие из вас уже знают, что Google Таблицы на самом деле не предназначены для масштабирования и имеют ограничение в 5 м ячеек. Это звучит много, но когда у вас по умолчанию 55 столбцов на вкладке Internal (которые могут легко утроиться в зависимости от вашей конфигурации), это означает, что вы можете экспортировать только около 90 тысяч строк (55 x 90 000 = 4950 000 ячеек).
Если вам нужно экспортировать больше, используйте другой формат экспорта, соответствующий размеру (или уменьшите количество столбцов). Стоит отметить что разработчики начали работу над записью на несколько листов, но на самом деле Таблицы не следует использовать таким образом.
Это также было интегрировано в планирование и командную строку. Это означает, что вы можете запланировать сканирование, которое автоматически экспортирует любые вкладки, фильтры, экспорт или отчеты в таблицу на Google Диске.
Вы можете создать папку с отметкой времени на Google Диске или перезаписать существующий файл.
Это должно быть полезно при обмене данными в командах, с клиентами или для отчетов Google Data Studio.
3) Заголовки HTTP
Теперь вы можете хранить, просматривать и запрашивать полные заголовки HTTP. Это может быть полезно при анализе различных сценариев, которые не охватываются извлеченными заголовками по умолчанию, таких как сведения о состоянии кеширования, set-cookie, content-language, политиках функций, заголовках безопасности и т.
Вы можете извлечь их, выбрав «Конфигурация > Паук > Извлечение» и выбрав «Заголовки HTTP». Заголовки запроса и ответа будут показаны полностью на вкладке «Заголовки HTTP» нижнего окна.
Заголовки HTTP-ответа также добавляются в виде столбцов на вкладке Internal, поэтому их можно просматривать, запрашивать и экспортировать вместе со всеми обычными данными сканирования.
Заголовки также можно экспортировать массово через «Массовый экспорт > Интернет > Все заголовки HTTP».
4) файлы cookie
Теперь вы также можете хранить файлы cookie через сканирование. Вы можете извлечь их, выбрав «Конфигурация > Паук > Извлечение» и выбрав «Файлы cookie». Затем они будут полностью показаны на вкладке Cookies в нижнем окне.
Вам нужно будет использовать режим рендеринга JavaScript, чтобы получить точное представление о файлах cookie, которые загружаются на страницу с помощью JavaScript или тегов изображений пикселей.
SEO Spider будет собирать имя файла cookie, значение, домен (первый или сторонний), срок действия, а также такие атрибуты, как secure и HttpOnly.
Затем эти данные могут быть проанализированы в совокупности, чтобы помочь в проверке файлов cookie, например, для GDPR, через «Отчеты > Файлы cookie > Сводка файлов cookie».
Вы также можете выделить несколько URL-адресов одновременно для массового анализа или экспортировать через «Массовый экспорт > Интернет > Все файлы cookie».
Обратите внимание: при выборе сохранения файлов cookie автоматическое исключение, выполняемое SEO Spider для тегов отслеживания Google Analytics, отключается, чтобы обеспечить точное представление всех выпущенных файлов cookie.
Это означает, что это повлияет на вашу аналитическую отчетность, если вы не решите исключить любые скрипты отслеживания из запуска с помощью конфигурации Exclude («Конфигурация > Исключить») или отфильтровать пользовательский агент «Screaming Frog SEO Spider» аналогично исключению PSI в этом FAQ.
5) Агрегированная структура сайта
SEO Spider теперь отображает количество URL-адресов, обнаруженных в каждом каталоге, в дереве каталогов (к которому вы можете получить доступ через значок дерева рядом с «Экспорт» на верхних вкладках).
Это помогает лучше понять размер и архитектуру веб-сайта, и некоторые пользователи считают его более логичным в использовании, чем традиционное представление списка.
Наряду с этим обновлением команда разработчиков улучшила правую вкладку «Структура сайта», чтобы отобразить агрегированное представление веб-сайта в виде дерева каталогов. Это помогает быстро визуализировать структуру веб-сайта и с первого взгляда определять, где возникают проблемы, например, индексируемость различных путей.
Если вы нашли области сайта с неиндексируемыми URL-адресами, вы можете переключить «вид», чтобы проанализировать «статус индексируемости» этих различных сегментов пути, чтобы увидеть причины, по которым они считаются неиндексируемыми.
Вы также можете переключить представление на глубину сканирования по каталогам, чтобы помочь выявить любые проблемы с внутренними ссылками на разделы сайта и многое другое.
Этот более широкий агрегированный вид веб-сайта должен помочь вам визуализировать архитектуру и принимать более обоснованные решения для различных разделов и сегментов.
6) Новые параметры конфигурации
Предоставлены два новых и важных параметра конфигурации – «Игнорировать неиндексируемые URL-адреса для фильтров на странице» и «Игнорировать URL-адреса с разбивкой на страницы для повторяющихся фильтров».
Оба они включены по умолчанию через «Конфигурация > Паук > Дополнительно» и означают, что неиндексируемые страницы не будут отмечены соответствующими фильтрами на странице для заголовков страниц, мета описаний или заголовков.
Это означает, что URL-адреса не будут считаться «повторяющимися», «более X символов» или «менее X символов», если, например, они являются noindex и, следовательно, не индексируются. Страницы, разбитые на страницы, также не будут помечены на дублирование.
Если вы сканируете промежуточный веб-сайт, у которого нет индекса на всех страницах, не забудьте отключить эти параметры.
Эти параметры немного отличаются от параметров конфигурации «здесь », которые вообще исключают появление неиндексируемых URL-адресов. Неиндексируемые URL-адреса по-прежнему будут отображаться в интерфейсе, они просто не будут помечены для соответствующих проблем.
Прочие обновления
Версия 14.0 также включает ряд небольших обновлений и исправлений ошибок, описанных ниже.
- На вкладке «Изображения» появился новый фильтр «Отсутствующий атрибут Alt». Ранее отсутствующие и пустые атрибуты alt появлялись под единственным фильтром «Отсутствующий замещающий текст». Однако может быть полезно разделить их, так как декоративные изображения должны иметь пустой замещающий текст (alt = “”), а не пропускать атрибут alt, который может вызвать проблемы в программах чтения с экрана. См. Наше руководство «Как найти отсутствующий замещающий текст и атрибуты изображения».
- Headless Chrome, используемый при рендеринге JavaScript, был обновлен, чтобы не отставать от вечнозеленого робота Google.
- «Принимать файлы cookie» было изменено на «Хранилище файлов cookie» с тремя вариантами: «Только сеанс», «Постоянный» и «Не хранить». По умолчанию установлено значение «Только сеанс», что имитирует поведение робота Googlebot без сохранения состояния.
- На вкладке «URL-адрес» доступны новые фильтры для решения распространенных проблем, включая множественные косые черты (//), повторяющийся путь, содержит пробелы и URL-адреса, которые могут быть частью внутреннего поиска.
- На вкладке «Безопасность» теперь есть фильтр «Отсутствует заголовок политики безопасного перехода».
- Теперь на вкладках «Внутренняя» и «Безопасность» есть столбец «Версия HTTP», который показывает, под какой версией было выполнено сканирование. Это подготовка к поддержке встроенного сканирования HTTP / 2 с помощью робота Googlebot.
- Теперь вы можете щелкнуть правой кнопкой мыши и «закрыть» или перетащить и переместить порядок вкладок нижнего окна аналогично верхним вкладкам.
- Неиндексируемые URL-адреса теперь не включаются в фильтр «URL-адреса не в Sitemap», так как мы предполагаем, что они не индексируются правильно и поэтому не должны быть помечены. Дополнительную информацию можно найти в нашем руководстве «Как проводить аудит XML-файлов Sitemap ».
- Проверка функции расширенных результатов Google была обновлена в соответствии с постоянно меняющейся документацией.
- Отчет «Сводка функций расширенных результатов Google», доступный через «Отчеты» в меню верхнего уровня, был обновлен и теперь включает «% подходящих» для расширенных результатов на основе обнаруженных ошибок. Этот отчет также включает общее и уникальное количество ошибок и предупреждений, обнаруженных для каждой функции Rich Result, в качестве обзора.
На данный момент это все, и создатели ПО уже начали работу над функциями для версии 15. Если у вас возникнут проблемы, добро пожаловать в службу поддержки.
А теперь скачайте Screaming Frog SEO Spider версии 14.0 и поделитесь с нами своим мнением!
Источник записи: https://www.screamingfrog.co.uk
Технический анализ сайта с помощью Screaming Frog SEO Spider
Любая работа над сайтом по его SEO-оптимизации начинается с определения текущего состояния его трех составляющих: технической, контентной и внешней (ссылочное присутствие).
В отличие от внешнего анализа, провести технический и
контентный, в теории, возможно и без использования стороннего программного
обеспечения, достаточно лишь знать, куда смотреть в исходном коде страниц
сайта. Тем не менее, как и во многих технических процессах, качественный софт
позволяет ускорить выполнение анализа в десятки, а то и в сотни раз.
Тем не менее, как и во многих технических процессах, качественный софт
позволяет ускорить выполнение анализа в десятки, а то и в сотни раз.
Именно поэтому при проведении технического анализа сайта, оптимизаторы используют так называемые «краулеры». И один из наиболее доступных и удобных, а потому и популярных, краулеров — это Screaming Frog SEO Spider. Именно его использует наша компания при проведении технического анализа сайта.
Суть работы краулера – это запуск на сайт своего робота (по своим свойствам похожего на поисковых роботов Яндекса и Google’а), который сканирует страницу, введенную в запросе, совершает переход по внутренним ссылкам на другие страницы этого сайта, сканирует их, переходит по их ссылкам и так пока не обойдет весь сайт. Данные, собранные своим роботом, программа Screaming Frog SEO Spider собирает в собственные таблицы.
В данном материале мы рассмотрим, какую именно полезную информацию для технического анализа сайта может нам дать Screaming Frog SEO Spider и как ее можно использовать при оптимизации.
Анализ внутренних ссылок
Итак, открываем SF SEO Spider и вводим URL-адрес сайта под анализ. Обход запущен, статус обхода отображается в процентах в правом углу окна программы.
Важно понимать, что робот начинает обход сайта именно с той страницы, которая введена в запросе. Если введена главная, робот начнет с нее и перейдет на дочерние (при наличии ссылок на них), а если введена дочерняя, робот начнет с нее и перейдет на ее дочерние, родительские и так далее (при наличии ссылок на них). При этом очевидно, что если продвигаемой страницы нет в результатах обхода, то и ссылок на других страницах сайта на нее нет. Такое явление называется «страница-сирота» и является грубой ошибкой в SEO.
Скриншоты в данном материале взяты с технического анализа сайта нашего клиента, но для сохранения конфиденциальности мы скрыли его домен.
После окончания обхода рассмотрим данные в первой таблице — Internal. Исходя из названия, здесь собраны внутренние ссылки сайта. (Все скриншоты в
материале увеличиваются при клике по ним).
Исходя из названия, здесь собраны внутренние ссылки сайта. (Все скриншоты в
материале увеличиваются при клике по ним).
В селекторе Filter мы можем отсортировать ссылки по типу, где html – это страницы сайта, а CSS, JavaScript, Images и остальное – соответствующие вложения и скачиваемые файлы.
В таблице Internal нас в первую очередь интересуют столбцы Status Code, Status, Indexability и Indexability Status.
Вот небольшая справка от наших SEO-специалистов по кодам ответа (Status Code):
- 200 – ссылка ведет на существующую страницу, все нормально
- 300, 301, 302 и т. д. – ссылка ведет на страницу, с которой происходит принудительное перенаправление на другой URL
- 400, 404 и т.д. – ссылка ведет на несуществующую страницу
- 500, 501, 505 и т. д. — переход по ссылке блокируется сервером сайта
- 0 – ссылка заблокирована в файле robots.txt (ее реальный код не важен роботу, так как переход заблокирован в любом случае).
Что с этим делать? Здесь все проще, чем может показаться. По 200 и 0 все очевидно – первые индексируются, вторые нет.
В ходе исследований и тестов, наши оптимизаторы определили, что ссылок 400 и 500 на сайте быть не должно, это ошибки в любом случае. Поэтому рекомендуется ручная чистка на страницах, где они заданы, вырезание из файлов шаблона, либо создание правила запрета на индекс в robots (менее желательное решение, лучше вычистить). 300 – приемлемый ответ, если конечная страница после перенаправления отдает 200, но все же если таких ссылок не много, лучше сразу им задать конечный URL.
Чтобы определить, на каких именно страницах на сайте находится та или иная ссылка (например, чтобы вычистить ссылку, отдающую код 400 или 500), необходимо кликнуть ЛКМ на ссылку в основной таблице, и внизу окна программы выбрать вкладку Inlinks. Все страницы, содержащие данную ссылку, выведены в столбце From.
Касательно столбцов Indexability и Indexability Status, они
отражают, доступен ли URL для индексации. Несложно заметить, что индексируются
только URL, отдающие код 200, однако и те не все. Некоторые из них помечены
статусом Canonicalised, но об этом чуть позже.
Несложно заметить, что индексируются
только URL, отдающие код 200, однако и те не все. Некоторые из них помечены
статусом Canonicalised, но об этом чуть позже.
Идем далее, переходим на страницу External. Здесь собраны уже ссылки с нашего сайта на страницы других сайтов, либо же файлы JS, CSS, изображений или других вложений, которые интегрированы на сайт с другого ресурса. Также смотрим на коды ответов, ссылаться или принимать файл с другого сайта с ошибками 400 или 500 крайне нежелательно для SEO. В случае с 300 так же проверяем доступность конечного URL.
Таблицы Response Codes и URL также выдают нам информацию о кодах ответа и статусе индексации ссылок, но в отличие от предыдущих таблиц, здесь нет разделения на внутренние и внешние URL.
Зато, здесь есть удобные фильтры в селекторе Filters – в таблице Response Codes можно четко отфильтровать URL по коду ответа, а в URL – вывести только URL, содержащие кириллицу (Non ASCII Characters), содержащие заглавные буквы (Uppercases), содержащие параметры (Parametrs), содержащие символ нижнего подчеркивания (Underscores), и содержащие более 115 символов. Все эти URL (кроме параметров и нижних подчеркиваний для не HTML-файлов) являются ошибками оптимизации, потому отлавливать их здесь весьма полезно.
И последнее из анализа ссылок, что нас интересует в SF SEO Spider – это таблица Canonicals.
Здесь собраны данные о работе механизма канонических ссылок на сайте. Основная их функция – это определять URL с параметрами (в самой ссылке параметры указаны после символа «?» и позволяют работать динамическим механизмам сайта, таким как фильтрация и сортировка товаров и т.д.) как ту же самую страницу, что и с URL без параметра, а не ее дубль. Таким образом, правильно настроенные канонические ссылки защищают страницы от образования дублей.
Таблица Canonicals отображает канонические ссылки
HTML-страницы сайта. Каждая страница без параметров должна иметь каноническую
ссылку сама в себя, страницы с параметрами – в себя без них. Страницы пагинации
– тоже сами в себя. Несоответствие этим стандартам свидетельствует об ошибке
оптимизации канонических ссылок, которые здесь легко определить.
Страницы пагинации
– тоже сами в себя. Несоответствие этим стандартам свидетельствует об ошибке
оптимизации канонических ссылок, которые здесь легко определить.
Также, селектор Filters здесь может вывести каждый случай канонизации отдельно.
Анализ мета-тегов и контента
Теперь посмотрим, чем нам может помочь Screaming Frog SEO Spider при анализе мета-тегов и контента сайта. Для этого нас интересуют таблицы Page Titles, Meta Descriptions, Meta Keywords, h2 и h3. Все эти таблицы имеют одинаковую структуру – отображают кол-во выбранного тега на странице, содержимое, длину в символах и в пикселях. Удобно видеть сразу превышение кол-ва и длины тегов, а также проблемы в оптимизации их контента.
Также, внизу окна программы есть вкладка SERP Snippet. Кликнув в основной таблице на любой URL и перейдя в нее, вам отобразится — как выглядит сниппет этой страницы в поисковой выдаче Google. Полезно сразу увидеть, какая часть тегов title и description отобразится, а какая будет скрыта за многоточием.
В селекторе Filters данных таблиц также можно отобразить проблемные страницы – с дублирующимися тегами (Duplicate), с отсутствующими (Missing), более одного (Multiple), а также превышающие рекомендуемые пределы (Over *** charecters).
Несколько рекомендаций по данным мета-тегам от SEO-отдела нашей компании:
- Title – строго не больше и не меньше одного, до 80 символов, содержит ключевой запрос, захватные слова (купить, цена, отзывы и т.д.), региональную принадлежность (в Москве, в Воронеже и т.д.).
- Meta Descriptions – строго не больше и не меньше одного, длина — 160-180 символов, содержит ключевой запрос, имеет призыв и привлекателен для клика на выдаче.
- Meta Keywords — на сегодняшний день является устаревшим и его наличие на сайте не несет ничего хорошего, поэтому в этой таблице смотрим, чтобы их просто не было.
- h2 – строго не больше и не меньше одного, содержит ключ.
- h3 — может быть несколько, содержат побочные ключи.
Таблица Images содержит список всех изображений на сайте. В основной таблице отображен тип и размер каждого, но нас больше интересует содержимое параметров alt. Его можно найти в уже знакомой нам вкладке Inlinks, так как одно изображение на каждой странице может иметь различный alt. Alt’ы рекомендовано содержат ключевой или побочный ключ.
Также, в последней версии программы Screaming Frog SEO Spider (13.0 на момент написания материала) добавили таблицу Content. Здесь в столбце Word Count указано количество слов на странице, что полезно при поиске малоинформативных (менее 30-50 слов в зависимости от наполнения шапки и подвала). Здесь же можно проверять грамматические ошибки и описки в текстах страниц, если включить эту функцию в настройках Configuration – Content – Spelling and Grammar и выбрать русский язык.
Безусловно, это лишь часть функционала программы Screaming Frog SEO Spider. Анализ страниц пагинации, ссылок hreflang, микроразметок, файлов Sitemap, скорости загрузки и других параметров используется при расширенном и более тщательном техническом анализе сайта. Однако, выявление и устранение ошибок, описанных в данном материале, уже поможет поднять позиции сайта топ в 80% случаев.
Конечно, для рядового владельца сайта или бизнеса подобная аналитика может показаться техническими дебрями. В таком случае у компании Business Boom Studio есть комплексное решение – SEO-аудит и SEO-продвижение сайта любой сложности с гарантией результата. Доверьте всю технику и работу с текстами профессионалам, и увеличьте поисковый трафик на ваш веб-ресурс от 50% до 500%.
Screaming Frog Seo Spider. Как аккаунт-менеджер ПО настраивал
Статья пригодиться тем, чья работа не только стоит на потоке в плане сканирования проектов, но и при этом требует установить такие настройки, которые одинаково подойдут, как на средние проекты с количеством URL до 500 тыс. , так и для небольших сайтов.
, так и для небольших сайтов.
Начну с того, что в нашей компании, как и в любом более-менее крупном рекламном digital-агентстве, остро стоит вопрос оптимизации и автоматизации рутинных процессов, освобождая время для решения более важных стратегических задач.
Так вот: пройдя испытательный срок и проработав в агентстве примерно 2 месяца, взялся я за задачи ежемесячного сканирования по нескольким проектам. В seo я, в принципе, не новичок, но моя основная специализация — это аккаунт-менеджмент и маркетинг.
Время от времени, я как аккаунт-менеджер для собственных нужд по проекту и обсуждения деталей продвижения с клиентами провожу анализ выдачи их сайтов в выдаче в целом, в ТОП 10 поисковиков, но иной раз есть потребность в том, чтобы провести подробное сканирование сайта.
Сканирование проектов осуществляю, как и все на ПО Screaming Frog SEO Spider . Установил прогу, получил от руководства на нее лицензию и не трогал в ней ничего из настроек параметров сканирования (ибо все работало, а как известно не надо чинить то, что не сломалось).
Ну и шло все своим чередом, пока не попался мне в ведение проект довольно масштабный, особенно в рамках своей профессиональной деятельности.
Запускал я сканирование несколько раз, где выяснилось, что величина проекта примерно 430 тыс. URL , при том, что прошлые процессы сканирования ограничивались проектами величиной max 1200-1700 URL . И проблема не в том, что сканирование проекта занимало около суток (как я понял из прочитанных мной материалов — это норма), а в том, что, оставляя на ночь работающий процесс, возвращался я к неизменно зависшей программе на прогрессе в 88-94%!
Инструкция к screaming frog seo spider , естественно, более чем подробно дает понимание того, что и для чего настраивается, но конкретных рекомендаций по настройке не дает.
Далее я обратился к поиску на тему того как правильно использовать seo spider tool . Перечитав несколько статей, посвященных настройке программы, сделал вывод, что в них описано то же самое, что и в инструкции, но более кратко и попроще.
В итоге по своему вопросу решил я воспользоваться помощью наших опытных специалистов, которые (за что им действительно огромное спасибо) буквально на пальцах объясняли мне по каким принципам данное ПО работает и дали несколько очень дельных рекомендаций по настройке.
В итоге, после 3 дней путем проб, ошибок и консультаций с коллегами я пришел к следующему
Характеристики устройства:
Процессор — Intel ( R ) Core ( TM )
i 3-7020 U
CPU 2.30 GHz
Оперативная память — 8,00 ГБ
Тип системы — 64-разрядная операционная система, процессор x64
Как видите показатели устройства весьма средние, но мне по роду обязанностей очень мощное железо то и не нужно, т. к. на выполнения своих задач, такой машины более чем хватает.
Настройки программы Screaming Seo spider (версия 14.1, последнее обновление):
1. Все данные по проекту записываются на SSD диск, размером 107 Гб. За заполняемостью диска конечно же надо следить и ненужные устаревшие данные стирать вручную. Компенсировать можно сделав экспорт проекта.
2. Включен рендер с использованием javascript
3. Отключены ограничения количества потоков сканирования
4. Максимальное количество URL в секунду — 2
5. Если вы параллельно выполняете еще трудоемкие процессы на рабочей машине (например работаете с парсингом в KeyCollector ), то обязательно ставьте краулинг на паузу.
Ниже привожу скрины с настройками Spider Configuration :
ВНИМАНИЕ!
В обязательном порядке, в настройках программы необходимо в методах записи информации по проекту выставить запись на жесткий диск, который обязательно SSD !
При описанных характеристиках устройства и настройках Screaming Frog, сканирование проекта величиной в 420-450 тыс. URL занимает порядка 30 часов, при условии того, что как минимум 12 часов сканирование выполняется параллельно с другими задачами на рабочем устройстве.
P. S. Решение о написании и публикации данного материала было принято после безуспешных попыток найти в пространстве рунета статьи о том, какие настройки рекомендуется выставлять в программе Screaming Frog . Находилась лишь общая информация о том, какие пункты в программе и ее конфигурации что обозначают, что человеку сведущему в SEO «как мертвому припарка». Поэтому, коллеги, читайте, пользуйтесь, делитесь с другими, и да пребудет с Вами Сила!)
Находилась лишь общая информация о том, какие пункты в программе и ее конфигурации что обозначают, что человеку сведущему в SEO «как мертвому припарка». Поэтому, коллеги, читайте, пользуйтесь, делитесь с другими, и да пребудет с Вами Сила!)
Анализ сайта с помощью Screaming Frog SEO Spider
Анализ сайта является монотонной задачей, если выполнять ее вручную. Но с помощью таких инструментов, как Screaming Frog SEO Spider, можно значительно облегчить эту работу.
Screaming Frog сканирует URL-адреса, ссылки, изображения и выявляет недостатки, которые не позволяют сайту продвигаться вперед. Этот инструмент может быть установлен на компьютере, и он полностью бесплатный. Но чтобы воспользоваться дополнительными функциями, придется приобрести лицензию.
Рассмотрим наиболее важные функции Screaming Frog, которые помогают провести полный анализ сайта.
При редизайне сайта разработчики часто удаляют связанные страницы или забывают обновить URL-адрес при его изменении. Это приводит к возникновению битых ссылок. Они отображаются как «ошибка 404» и приводят к уменьшению объема трафика, поступающего на сайт.
SEO Frog Spider помогает мгновенно находить битые ссылки, что упрощает работу и позволяет уменьшить количество «ошибок 404», возникающих на сайте.
Уникальные метаданные важны для SEO. Ключевые слова должны быть правильно употреблены в теге title и мета-описании. Хороший заголовок должен иметь длину не более 60 символов, а ключевое слово должно использоваться в его начале. Для мета-описания рекомендуется длина 160 символов.
SEO Frog Spider работает так же, как профессионалы поисковой оптимизации. Инструмент исправляет тайтлы и описания, которые слишком длинны и неприемлемы для поисковой системы. Он отдельно отображает результаты по заголовкам: URL-адрес, вхождения, длина и содержимое. Затем вы сможете устранить выявленные ошибки и внести необходимые исправления.
Поисковые системы не индексируют изображения, которые имеют слишком большой размер, высокое разрешение или долго грузятся. Размер изображения не должен превышать 100 КБ. Не забудьте добавить ключевое слово в альтернативный текст. Он должен подробно описывать изображение, чтобы, если оно не может быть загружено, посетитель сайта мог воспользоваться этим текстом.
Размер изображения не должен превышать 100 КБ. Не забудьте добавить ключевое слово в альтернативный текст. Он должен подробно описывать изображение, чтобы, если оно не может быть загружено, посетитель сайта мог воспользоваться этим текстом.
SEO Frog Spider находит на сайте изображения, которые не подходят, и их нужно сжимать. Также можно изучить исчерпывающий отчет об изображениях, размещенных на сайте. Если вы используете на ресурсе «неоригинальные изображения», инструмент предложит создать свои собственные картинки, чтобы повысить качество контента.
Важно, чтобы на каждом сайте была XML карта, и поисковая система могла быстро получать доступ к веб-страницам. Sitemap помогает поисковику просканировать весь контент, размещенный на ресурсе.
Используя SEO Frog Spider, можно быстро и просто создавать файлы XML-Sitemap. Добавление изображений в карту сайта необязательно. После того, как вы создали XML-файл, можно будет вручную изменить частоту обхода некоторых страниц.
Правильно прописанный URL-адрес поможет улучшить индексацию сайта. Но существуют сайты, которые используют некачественные URL-адреса. В результате поисковая система не индексирует их.
На вкладке «URL-адреса» вы сможете проанализировать все URL сайта. Screaming Frog SEO Spider проверяет длину всех URL-адресов, находит слишком длинные и повторяющиеся.
Screaming Frog SEO Spider является полезным инструментом для аудита редиректов при переносе сайта на новый домен или изменении структуры URL-адресов. В этих случаях рекомендуется проверять URL, чтобы определить, правильно ли они перенаправлены. С этим могут быть связаны многие проблемы поисковой оптимизации.
SEO Frog Spider решает проблему неправильных редиректов.
С помощью SEO Frog Spider вы сможете получить информацию, связанную с тегом Meta robots, rel = next / prev и каноническими ссылками. А также файлом robots.txt, который используется на сайте.
Кроме этого вы сможете просмотреть URL-адреса, заблокированные вrobots.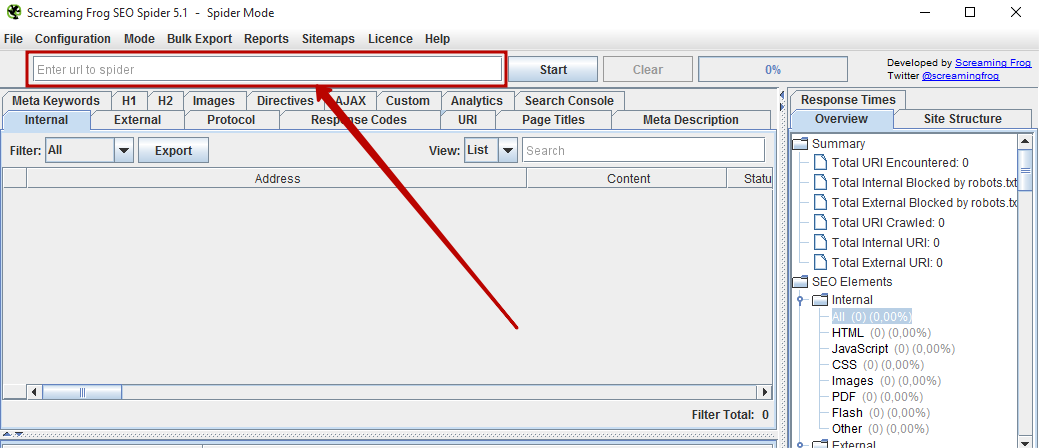 txt. Эта функция также полезна для поиска страниц, которые не должны индексироваться.
txt. Эта функция также полезна для поиска страниц, которые не должны индексироваться.
Особенность SEO Frog заключается в том, что он может использовать API Google Analytics. То есть, напрямую извлекать из аналитического сервиса показатели по посещениям и сессиям, отказов и конверсии.
Сначала нужно выбрать учетную запись Google Search Console, из которой хотите извлечь данные и определить диапазон дат. После этого вы сможете увидеть страницы сайта с низким трафиком или те, на которых трафик вообще отсутствует.Если вы проводите рекламную кампанию в Google AdWords, вы также сможете получать данные по количеству показов, а также кликами затратам.
И это еще не все, вот функции, которые делают SEO Frog Spider незаменимым инструментом:
1) Экспорт данных: SEO Frog Spider предлагает функцию экспорта для преобразования всех данных в формат Excel. Если вы хотите экспортировать данные в соответствии с фильтром, инструмент может перенести только их.
Также доступна опция «Групповые отчеты». Например, если нужно экспортировать все «Входящие ссылки» и «Исходящие ссылки», вы сможете сделать это, выбрав указанный столбец.
2) Визуализация данных: Это дополнительная функция Screaming Frog SEO Spider, которая предоставляется в платной версии. С ее помощью можно получить все необходимые данные в понятной форме. Это поможет сделать отчет визуально привлекательным.
3) Сканирование крупных сайтов: когда дело доходит до больших сайтов, увеличивается объем памяти, необходимой для сохранения и обработки данных. Screaming Frog SEO Spider использует гибридный движок, который позволяет осуществлять широкомасштабное сканирование. Чтобы сохранять данные сканирования на диск, необходимо настроить SEO Spider.Это позволит ему сканировать сайт беспрецедентно быстро.
Также Screaming Frog SEO Spider предлагает два типа хранилища:
- Хранилище памяти. Если на вашем компьютере объем оперативной памяти меньше, чем объем жесткого диска, лучше оставить режим «Хранилище памяти».
- Хранилище базы данных. Рекомендуется пользователям, на компьютере которых установлен SSD-накопитель, поскольку это позволяет сканироваться URL-адресов.

Screaming Frog SEO Spider — отличный инструмент для оптимизации сайта, повышения его производительности и выявления недостатков. Очень важно оптимизировать интернет-ресурс под поисковые системы.А вручную выявлять и исправлять возникающие проблемы неудобно.
Screaming Frog SEO Spider позволяет бесплатно сканировать до 500 URL- адресов (в версии «lite»). Но бесплатная версия не предоставляет доступ к выборочному извлечению источников, аналитике Google, визуализации данных иинтеграции с Google Search Console. Для использования расширенных функций требуется платная лицензия, которая стоит 149 фунтов стерлингов в год.
Данная публикация является переводом статьи «Analyzing Your Website With the Screaming Frog SEO Spider (2018 Guide)» , подготовленная редакцией проекта.
SEO Spider General | Кричащая лягушка
Существует множество отчетов, к которым можно получить доступ через навигацию верхнего уровня «отчеты». К ним относятся следующие ниже.
Отчет об обзоре сканирования
В этом отчете представлена сводная информация о сканировании, включая такие данные, как количество обнаруженных URL, заблокированных файлом robots.txt, количество просканированных страниц, тип контента, коды ответов и т. Д. Он предоставляет сводную информацию верхнего уровня о числах в каждая вкладка и соответствующие фильтры.
«Общее описание URI» предоставляет информацию о том, каков номер столбца «Общий URI» для каждой отдельной строки, чтобы (попытаться) избежать путаницы.
Отчеты обо всех перенаправлениях, цепочках перенаправления и перенаправлениях и канонических цепочках
В этих отчетах подробно описаны редиректы, обнаруженные на веб-сайте, и исходные URL-адреса, на которых они обнаружены.
Отчет «Все переадресации» показывает все обнаруженные единичные переадресации и цепочки, «Цепочки переадресации» сообщает о переадресации с 2+ переадресациями в цепочке, а «Переадресация и канонические цепочки» показывает любые 2+ переадресации или канонические переадресации в цепочке.
Отчеты «Цепочки перенаправления» и «Цепочки перенаправления и канонические цепочки» отображают цепочки перенаправлений и канонических ссылок, количество переходов на пути и идентифицируют источник, а также наличие петли. В режиме «Паук» («Режим»> «Паук») в этих отчетах будут отображаться все перенаправления, начиная с одного прыжка вверх. Он будет сообщать «количество перенаправлений» в столбце и идентифицированный «тип цепочки», будь то перенаправление HTTP, перенаправление JavaScript, каноническое и т. Д. Он также отмечает петли перенаправления.Если отчеты пустые, это означает, что у вас нет циклов или цепочек перенаправления, которые можно сократить.
Отчеты «Перенаправления», «Цепочки перенаправления» и «Цепочки перенаправления и канонические цепочки» также могут использоваться в режиме списка (Режим> Список). Они будут отображать строку для каждого URL-адреса, указанного в списке. Установив флажки «Всегда следовать перенаправлениям» и «Всегда следовать каноническим», SEO Spider продолжит сканирование перенаправлений и канонических ссылок в режиме списка и игнорирует глубину сканирования, что означает, что он будет сообщать обо всех переходах до конечного пункта назначения.См. Наше руководство по аудиту перенаправлений при миграции сайта.
Обратите внимание: если вы выполняете только частичное сканирование или некоторые URL-адреса заблокированы через robots.txt, вы можете не получить все коды ответов для URL-адресов в этом отчете.
Canonicals Reports
В отчетах «Канонические цепочки» и «Неиндексируемые канонические» указываются ошибки и проблемы с каноническими элементами ссылок или реализацией канонических HTTP-ссылок в ходе сканирования. Пожалуйста, прочтите «Как проводить аудит Canonicals» для получения нашего пошагового руководства.
В отчете «Канонические цепочки» выделяются все URL-адреса, в цепочке которых есть более двух канонических значений. Здесь URL-адрес имеет канонический URL-адрес для другого местоположения (и является «каноническим»), который затем снова имеет канонический URL-адрес для другого URL-адреса (цепочка канонических URL-адресов).
В отчете «Неиндексируемые канонические файлы» указаны ошибки и проблемы с каноническими файлами. В частности, в этом отчете будут показаны все канонические материалы, на которые нет ответа, заблокированные из-за robots.txt, 3XX редиректа, 4XX или 5XX ошибок (что угодно, кроме ответа 200 «ОК»).
В этом отчете также представлены данные о любых URL-адресах, которые обнаруживаются только через канонические ссылки и не связаны с сайтом (в столбце «Несвязанные» при значении «true»).
Отчеты о разбиении на страницы
В отчетах «Не-200 URL разбиения на страницы» и «Несвязанные URL разбиения на страницы» выявляются ошибки и проблемы с атрибутами rel = «next» и rel = «prev», которые, конечно же, используются для обозначения содержимого с разбивкой на страницы. Пожалуйста, прочтите «Как проводить аудит атрибутов rel =» next «и rel =» prev «разбиения на страницы для нашего пошагового руководства.
В отчете «Не-200 URL-адресов пагинации» будут показаны все URL-адреса rel = «next» и rel = «prev», на которые нет ответа, заблокированные файлом robots.txt, перенаправлением 3XX, ошибкой 4XX или 5XX (кроме 200 ответ «ОК»).
Отчет «Несвязанные URL-адреса разбиения на страницы» предоставляет данные по любым URL-адресам, которые обнаруживаются только с помощью атрибута rel = «next» и rel = «prev» и не связаны с сайтом (в столбце «несвязанные», когда «true» ‘).
Отчеты Hreflang
Отчеты Hreflang относятся к реализации hreflang, обнаруженной на веб-сайте.Пожалуйста, прочтите How to Audit Hreflang для нашего пошагового руководства.
Существует 7 отчетов hreflang, которые позволяют экспортировать данные в большом количестве, включая следующие —
- Все URL-адреса Hreflang — это отчет 1: 1 обо всех URL-адресах и URL-адресах hreflang, включая значения региона и языка, обнаруженных при сканировании.
- URL-адреса Hreflang, отличные от 200 — В этом отчете показаны все URL-адреса в аннотациях hreflang, которые не являются ответом 200 (нет ответа, заблокировано robots.txt, ответы 3XX, 4XX или 5XX).
- Несвязанные URL-адреса Hreflang — в этом отчете показаны все URL-адреса hreflang, на которые не ссылаются гиперссылки на сайте.
- Отсутствуют ссылки для подтверждения — в этом отчете отображается страница, на которой отсутствует ссылка для подтверждения, и какая страница не является подтверждающей.
- Несоответствующие языковые ссылки для подтверждения — В этом отчете показаны страницы подтверждения, которые используют разные языковые коды для одной и той же страницы.
- Неканонические подтверждающие ссылки — в этом отчете показаны подтверждающие ссылки, ведущие к неканоническим URL-адресам.
- Ссылки подтверждения Noindex — В этом отчете показаны ссылки подтверждения, которые относятся к URL-адресам noindex.
Отчет о небезопасном содержимом
В отчете о небезопасном содержимом будут показаны все защищенные (HTTPS) URL-адреса, содержащие небезопасные элементы, такие как внутренние HTTP-ссылки, изображения, JS, CSS, SWF или внешние изображения в CDN, социальных профилях и т. Д. веб-сайт для защиты (HTTPS) от незащищенного (HTTP), может быть сложно получить все небезопасные элементы, и это может привести к предупреждениям в браузере —
Вот краткий пример того, как может выглядеть отчет (в данном случае с небезопасными изображениями) —
Сводный отчет по поисковой выдаче
Этот отчет позволяет быстро экспортировать URL-адреса, заголовки страниц и метаописания с их соответствующей длиной символа и шириной в пикселях.
Этот отчет также можно использовать в качестве шаблона для повторной загрузки обратно в SEO Spider в режиме «поисковой выдачи».
Отчет о потерянных страницах
Отчет о потерянных страницах содержит список URL-адресов, собранных с помощью Google Analytics API, Google Search Console (Search Analytics API) и XML Sitemap, которые не были сопоставлены с URL-адресами, обнаруженными в ходе сканирования.
Этот отчет будет пустым, если вы не подключились к Google Analytics, Search Console или не настроили сканирование XML Sitemap и получение данных во время сканирования.
Вы также можете видеть URL-адреса страниц-сирот непосредственно в SEO Spider, но для этого требуется правильная конфигурация. Мы рекомендуем прочитать наше руководство о том, как найти страницы-сироты.
Столбец «Источник» отчета о бесхозных страницах показывает, какой именно источник URL был обнаружен, но не сопоставлен с URL при сканировании. К ним относятся —
- GA — URL-адрес был обнаружен через Google Analytics API.
- GSC — URL-адрес был обнаружен в консоли поиска Google с помощью Search Analytics API.
- Карта сайта — URL-адрес был обнаружен с помощью XML-файла Sitemap.
- GA, GSC и карта сайта — URL-адрес был обнаружен в Google Analytics, Google Search Console и XML Sitemap.
Этот отчет может включать любые URL-адреса, возвращаемые Google Analytics для запроса, выбранного в конфигурации Google Analytics. Следовательно, это может включать области входа в систему или URL-адреса корзины покупок, поэтому часто наиболее полезные данные для SEO-специалистов возвращаются путем запроса параметра пути целевой страницы и сегмента «органического трафика».Это может затем помочь идентифицировать —
- Страницы-сироты — это страницы, на которые нет внутренних ссылок на веб-сайте, но которые существуют. Это могут быть просто старые страницы, пропущенные при миграции старого сайта или страницы, найденные только извне (через внешние ссылки или ссылающиеся сайты). Этот отчет позволяет просматривать список и видеть, какие из них актуальны и могут быть загружены в режиме списка.
- Ошибки — Отчет может включать 404 ошибки, которые иногда включают в себя ссылающийся веб-сайт в URL (для них вам понадобится сегмент «весь трафик»).Это может быть полезно для поиска веб-сайтов с целью исправления внешних ссылок или для 301 перенаправления ошибочного URL-адреса на правильную страницу! Этот отчет также может включать URL-адреса, которые могут быть канонизированы или заблокированы файлом robots.txt, но на самом деле все еще индексируются и доставляют некоторый трафик.
- Проблемы сопоставления URL-адресов GA или GSC — Если данные не совпадают с URL-адресами при сканировании, вы можете проверить, какие URL-адреса возвращаются через GA или GSC API. Это может выявить любые проблемы с конкретным представлением Google Analytics, такие как фильтры URL-адресов, такие как взлом расширенного URL и т. Д.Чтобы SEO Spider возвращал данные по URL-адресам при сканировании, URL-адреса должны совпадать. Так что переход на «исходное» представление Google Analytics, которое в любом случае не затрагивалось, может помочь.
Отчеты со структурированными данными
Отчет «Сводка ошибок и предупреждений проверки» объединяет структурированные данные с обнаруженными уникальными ошибками проверки и предупреждениями (а не сообщает о каждом экземпляре) и показывает количество URL-адресов, затронутых каждой проблемой, с образцом URL-адреса с конкретной проблемой.Пример отчета можно увидеть ниже.
В отчете «Ошибки проверки и предупреждения» отображаются все ошибки и предупреждения проверки структурированных данных на уровне URL-адреса, включая URL-адрес, имя свойства (организация и т. Д.), Формат (JSON-LD и т. Д.), Серьезность проблемы (ошибка или предупреждение), валидацию. тип (продукт Google и т. д.) и сообщение о проблеме (требуется свойство / review и т. д.).
Отчет «Сводка функций расширенных результатов Google» объединяет функции расширенных результатов Google, обнаруженных при сканировании, и показывает количество URL-адресов, имеющих каждую функцию.
Отчет «Функции расширенных результатов Google» сопоставляет каждый URL-адрес со всеми доступными функциями и показывает, какие из них были обнаружены для каждого URL-адреса.
Отчеты о скорости страницы
Отчеты PageSpeed относятся к фильтрам, указанным на вкладке PageSpeed, которые раскрывают значение каждого из них. Эти отчеты позволяют экспортировать страницы и их конкретные ресурсы с возможностью ускорения или диагностики.
Они требуют настройки и подключения к PageSpeed Insights.
Отчет «Сводка возможностей PageSpeed» содержит сводные данные обо всех уникальных возможностях, обнаруженных на сайте, количестве URL-адресов, на которые они влияют, а также о средней и общей потенциальной экономии в размере и миллисекундах, чтобы помочь расставить приоритеты в масштабе.
В отчете «Сводка покрытия CSS» указывается, какая часть каждого файла CSS не используется при сканировании, а также потенциальную экономию, которую можно получить, удалив неиспользуемый код, загружаемый по всему сайту.
Отчет «Сводка охвата JavaScript» показывает, какая часть каждого файла JS не используется при сканировании, а также потенциальную экономию, которую можно получить, удалив неиспользуемый код, загружаемый по всему сайту.
Сводный отчет по заголовку HTTP
Здесь показано агрегированное представление всех заголовков ответов HTTP, обнаруженных во время сканирования. Он показывает каждый уникальный заголовок HTTP-ответа и количество уникальных URL-адресов, которые ответили этим заголовком.
«Заголовки HTTP» должны быть включены для извлечения через «Конфигурация> Паук> Извлечение» для заполнения.
Более подробную информацию об URL-адресах и заголовках можно увидеть на вкладке «Заголовки HTTP» в нижнем окне и с помощью экспорта «Массовый экспорт> Интернет> Все заголовки HTTP».
Кроме того, заголовки HTTP можно запросить на вкладке Internal, где они добавляются в отдельные уникальные столбцы.
Сводный отчет о файлах cookie
Здесь показано агрегированное представление об уникальных файлах cookie, обнаруженных во время сканирования, с учетом их имени, домена, срока действия, безопасности и значений HttpOnly. Также будет отображаться количество URL-адресов, по которым был выпущен каждый уникальный файл cookie. Само значение cookie дисконтируется в этом агрегировании (поскольку они уникальны!).
«Cookies» должны быть включены для извлечения через «Config> Spider> Extraction» для заполнения.Также необходимо настроить режим рендеринга JavaScript, чтобы получить точное представление о файлах cookie, которые загружаются на страницу с помощью JavaScript или тегов изображений пикселей.
Этот сводный отчет чрезвычайно полезен для GDPR. Более подробную информацию об URL-адресах и файлах cookie, содержащихся в них, можно увидеть на вкладке «Файлы cookie» нижнего окна, а также в разделе «Массовый экспорт»> «Интернет»> «Все файлы cookie».
Отчет о пути сканирования
Этого отчета нет в раскрывающемся списке «отчеты» в меню верхнего уровня, он доступен после щелчка правой кнопкой мыши URL-адреса в верхней панели окна и выбора опции «экспорт».Например —
В этом отчете показан кратчайший путь, который просканировал SEO Spider для обнаружения URL-адреса, который может быть действительно полезен для глубоких страниц, вместо просмотра «входящих ссылок» множества URL-адресов для обнаружения исходного URL-адреса (например, для бесконечных URL-адресов, вызванных календарь).
Отчет о пути сканирования следует читать снизу вверх. Первый URL внизу столбца «источник» — это самый первый просканированный URL (с уровнем «0»). «Пункт назначения» показывает, какие URL-адреса были просканированы следующим образом, и они составляют следующие «исходные» URL-адреса для следующего уровня (1) и так далее, выше.
Конечный «целевой» URL в самом верху отчета будет URL отчета о пути сканирования.
Анализатор файлов журнала SEO | Кричащая лягушка
Об инструменте
Анализатор файлов журнала Screaming Frog позволяет быстро загрузить файл журнала и проанализировать его с точки зрения SEO. Данные файла журнала чрезвычайно ценны, поскольку они точно показывают, что произошло, когда бот поисковой системы посещает ваш сайт. Однако файлы журналов могут быть очень большими по размеру и их трудно анализировать без опыта программирования или подходящего инструмента.Анализатор файлов журнала специально разработан для оптимизаторов поисковых систем, чтобы сделать этот процесс менее болезненным.
Анализатор файлов журнала поддерживает расширенный формат файлов журнала Apache и W3C, который охватывает серверы Apache, IIS и NGINX. Это также относится к настраиваемому формату файла журнала Amazon Elastic Load Balancing.
Просто перетащите файл журнала или файлы журнала прямо в пользовательский интерфейс, и инструмент автоматически обработает данные, чтобы вы могли анализировать и фильтровать общие проблемы SEO в пользовательском интерфейсе программы или экспортировать в CSV и Excel.
Анализируйте 1 тыс. Событий журнала бесплатно
Бесплатная версия инструмента Log File Analyzer можно загрузить и использовать бесплатно. Однако эта версия ограничена анализом 1k событий журнала и не позволяет сохранять более одного проекта за раз.
Всего за 99 фунтов стерлингов в год вы можете приобрести лицензию, которая снимает ограничение в 1 КБ событий журнала и позволяет сохранять несколько проектов.
Или нажмите кнопку «купить лицензию» в анализаторе файлов журнала, чтобы купить лицензию после загрузки и тестирования программного обеспечения.
Часто задаваемые вопросы и руководство пользователя
Руководство и советы по использованию Screaming Frog SEO Log File Analyzer —
- Анализатор файлов журнала поддерживает форматы файлов журнала Apache, W3C Extended и Amazon Elastic Load Balancing.
- Вы можете проверить, поддерживается ли ваш формат журнала, попробовав бесплатную версию инструмента. Если у вас есть какие-либо проблемы, отправьте их через журналы анализатора файлов журналов («Справка»> «Отладка»> «Сохранить журналы») в нашу службу поддержки, и мы сможем помочь.
- Пожалуйста, прочтите наше руководство пользователя, регулярно обновляемые FAQ и руководство по способам выполнения анализа файлов журнала для вдохновения.
- Пожалуйста, также посмотрите демонстрационное видео, приведенное выше. Мы планируем со временем расширять наши видеоуроки.
Обновления
Будьте в курсе будущих выпусков, подписавшись на нашу RSS-ленту или подписавшись на нас в Twitter @screamingfrog.
Поддержка и отзывы
Если у вас есть какие-либо технические проблемы, отзывы или пожелания по использованию анализатора файлов журнала, просто свяжитесь с нами через нашу службу поддержки.Мы планируем регулярно обновлять анализатор файлов журналов, и в настоящее время у нас в разработке много новых функций!
ОбзорSEO Spider | TechRadar
SEO Spider — это инструмент для поисковой оптимизации (SEO), разработанный британским поисковым агентством по веб-сайтам под названием Screaming Frog. С помощью SEO Spider вы можете оценивать различные страницы веб-сайтов и извлекать ключевые фрагменты информации для анализа их качества SEO.
Как вы узнаете из этого обзора SEO Spider, это программное обеспечение выделяется тем, что позволяет представлять сложные данные SEO в удобном для понимания формате.Однако есть несколько проблем, о которых стоит упомянуть, например, отсутствие доступа через облако и серьезные ограничения функций, наложенные на бесплатную версию пакета.
(Изображение предоставлено: Screaming Frog)Планы и цены
Хотя вам не нужно обновляться, чтобы обнаруживать неработающие ссылки или анализировать метаданные сайта, когда дело доходит до более продвинутых функций, есть несколько более серьезных недостатков. неоплачиваемая версия этой платформы. Ключевые инструменты, такие как интеграция с Google Analytics и PageSpeed Insights, доступны, например, только в премиум-версии.Кроме того, платная лицензия необходима для сохранения поисковых сканирований и установки дополнительных параметров конфигурации.
Существует две версии инструмента SEO Spider от Screaming Frog. Один бесплатный, а другой стоит 149 фунтов стерлингов (примерно 195 долларов США) в год. Если вы управляете большой организацией и вам необходимо приобрести несколько лицензий, чтобы каждый в вашей команде мог использовать программное обеспечение, Screaming Frog предоставит вам скидку, если вы купите сразу более пяти лицензий.
Основное различие между бесплатной и платной версиями SEO Spider заключается в том, что бесплатная версия может использоваться только для сканирования 500 URL-адресов одновременно, в то время как платная версия работает для неограниченного количества.Если вам не нужно часто исследовать SEO-свойства большого веб-сайта с сотнями различных поддоменов, само по себе это ограничение не должно помешать вам использовать бесплатную версию SEO Spider.
(Изображение предоставлено: Screaming Frog)Характеристики
Во время нашего обзора SEO Spider выделялся эффективностью поиска и широким набором функций. Если вам нужно запланировать регулярные поисковые обходы для определенных URL-адресов, оценить неопубликованные веб-сайты, к которым можно получить доступ только через логин, или извлечь базы данных для использования в другой программе, это вполне может быть подходящим инструментом для вас.
Обнаружение повторяющегося содержания
Google и другие основные поисковые системы не одобряют дублированный контент, поэтому наличие копий одних и тех же страниц на вашем сайте может быстро привести к снижению рейтинга страницы. Но, конечно, если у вас большой сайт, практически невозможно вручную проверить наличие клонированных страниц. SEO Spider может решить эту проблему с помощью расширенного алгоритмического поиска, который находит на вашем сайте любые страницы с одинаковыми заголовками, названиями или описаниями.
Визуализация файлов Sitemap
Используя SEO Spider, вы можете создавать диаграммы сканирования и древовидные диаграммы, которые действительно полезны для понимания архитектуры вашего сайта.В любом случае вы можете отображать до 10 000 URL-адресов одновременно. В то время как древовидные диаграммы разделены на «уровни глубины», в диаграммах сканирования используются узлы с цветовой кодировкой, чтобы дать вам целостный обзор системы индексирования страниц вашего сайта.
(Изображение предоставлено: Screaming Frog)Просмотр отчетов о пути сканирования
Одна из распространенных проблем с другими службами сканирования веб-сайтов SEO заключается в том, что невозможно определить, как программа нашла конкретный URL. Если конкретный URL-адрес должен быть скрыт от общедоступного поиска, это, очевидно, может стать большой головной болью.С помощью SEO Spider вы можете просто щелкнуть правой кнопкой мыши URL-адрес и нажать «Отчет о пути сканирования», чтобы увидеть, как именно он был обнаружен.
Интерфейс и использование
SEO Spider работает на любом компьютере под управлением Windows, Mac или Ubuntu. Независимо от того, с какой версией вы работаете, установка будет относительно быстрой и безболезненной.
В целом интерфейс SEO Spider может показаться немного сложным для пользователей, которые никогда раньше не работали с инструментами SEO-анализа. Однако, несмотря на объем представленной информации, все хорошо продумано, и даже новички должны чувствовать себя комфортно с этим программным обеспечением через пару часов.
Как только установка будет завершена, вы должны быть готовы к выполнению своего первого обходного поиска.
Под верхней строкой меню вы увидите область URL-адреса. После того, как вы подключили сюда свой веб-сайт, просто нажмите «Пуск». Затем инструмент будет искать каждую ссылку, которую он может найти на вашей домашней странице, и открывать их для анализа. Пока ваш сайт настроен правильно, SEO Spider должен найти все ваши общедоступные страницы.
(Изображение предоставлено: SEO Spider)Главный экран SEO Spider настроен так, чтобы вы могли легко видеть ключевые результаты, полученные при сканировании вашего веб-сайта.Например, на вкладке «h2» вы сможете увидеть список основных заголовков, используемых на каждой из страниц вашего веб-сайта. С первого взгляда это может показать, отсутствуют ли у вас теги h2 или есть повторяющиеся заголовки, что может повредить SEO-производительности вашего сайта.
Поддержка
Техническая поддержка доступна только для оплаченных пользователей программы SEO Spider. Однако Руководство пользователя Screaming Frog должно решить большинство, если не все, проблемы, с которыми вы сталкиваетесь при работе с программным обеспечением. Также доступна дополнительная помощь по электронной почте и через систему заявок в службу поддержки.
The Competition
При цене 149 фунтов стерлингов SEO Spider заметно дешевле некоторых альтернативных программ анализа SEO, таких как SerpStat, который стоит 69 долларов в месяц. Однако стоит отметить, что SEO Spider имеет более технический интерфейс, чем некоторые инструменты SEO, такие как Yoast SEO, и его сложнее настроить, если вы хотите получать автоматические оповещения о снижении рейтинга страниц.
Окончательный вердикт
Возможно, у него не самый удобный интерфейс, но SEO Spider — отличный вариант для получения подробных данных о дизайне SEO и производительности вашего веб-сайта.Благодаря расширенным функциям, таким как аутентификация на основе форм, вы обязательно окупите свои деньги с помощью этой аккуратной маленькой программы от Screaming Frog.
SEO Spider Tool: самое мощное программное обеспечение для сканирования
Быстрый и комплексный SEO-аудит.
Инструмент WebSite Auditor SEO Spider просматривает ваш сайт так же, как это делают роботы поисковых систем, не оставляя тегов. неотвернутый, и помогает выявлять проблемы во всех типах ресурсов вашего сайта. Он очищает не только HTML, но и также CSS, JavaScript, Flash, изображения, видео, PDF-файлы и другие ресурсы, внутренние и внешние.
1
Сканируйте веб-сайты со всеми их поддоменами.
Если ваш сайт включает поддомены и каталоги, WebSite Auditor позволит вам легко сканировать их. вместе с вашим основным доменом, чтобы вы могли проводить аудит и анализировать все свои страницы и ресурсы — и ваш сайт структура в целом — в едином проекте.
Где найти: , если вы создаете новый проект, проверьте Показать экспертные параметры на шаге 1, перейдите к Дополнительные параметры и отметьте Сканирование поддомены ящик.Для существующий проект, перейдите в Preferences> Crawler Settings , чтобы сделать то же самое, и нажмите Rebuild Проект .
2
Сканируйте сайты, защищенные паролем.
Инструмент позволяет сканировать и проверять веб-сайты, требующие аутентификации, и оптимизировать защищенные паролем страниц.
Где найти: при создании нового проекта проверьте Показать параметры эксперта. Установите флажок на шаге 1 и выберите бота. Для существующего проекта перейдите в Preferences> Crawler Settings , чтобы сделать то же самое, и нажмите Rebuild Project .
3
Сканируйте веб-сайты JavaScript и динамически генерируемый контент.
WebSite Auditor SEO Spider может выполнять JavaScript и сканировать динамически созданный контент для отображения сети. страницы полностью, включая копии и ссылки.
Где найти: если вы создаете проект, проверьте Показать экспертные параметры на шаге 1, перейдите к Дополнительные параметры и включите Выполнить JavaScript .Для существующий проект, перейдите в Preferences> Crawler Settings , чтобы сделать то же самое, и нажмите Rebuild Проект .
4
Определите цепочки переадресации.
Сканируйте URL-адреса, чтобы проанализировать, есть ли на сайте цепочки переадресации. Вы увидите список страниц, на которые выполняется переадресация. исходить из, вместе с полным путем перенаправления, чтобы вы могли быстро увидеть, что и где нужно исправить.
Где найти: В разделе Структура сайта> Аудит сайта , в раздел Redirects .
5
Проверяйте технические факторы SEO, чтобы определить медленные страницы.
WebSite Auditor SEO Spider определяет, подходят ли страницы для мобильных устройств или, вероятно, слишком велики и могут негативно влияют на рейтинг SEO и пользовательский опыт.Размер страницы рассчитывается всесторонне путем добавления размера HTML-кода каждого ресурса, используемого на странице, включая изображения, видео и JavaScript. В инструмент проверяет, может ли какая-либо из ваших страниц использоваться некоторая оптимизация скорости. Вы найдете список таких URL прямо в панель мониторинга сайта вместе с размером каждой страницы в мегабайтах.
Где найти: В разделе Структура сайта> Аудит сайта , в Кодировка и технические факторы раздел.
6
Проверьте неработающие ссылки и ошибки сервера.
Используйте инструмент SEO Spider, чтобы быстро найти неработающие ссылки (стр. 404) и ошибки сервера. Также позаботьтесь о страницы с чрезмерным количеством внешних ссылок, чтобы избежать санкций поисковых систем.
Где найти: В разделе Структура сайта> Аудит сайта , в Индексирование и возможность сканирования и Ссылки раздел.
7
Быстрый аудит всех изображений сайта.
WebSite Auditor SEO Spider увидит, не работают ли какие-либо из них или имеют ли они пустые текстовые теги, и покажет вам список страниц, на которых находятся проблемные изображения.
Где найти: В разделе Структура сайта> Аудит сайта , в раздел изображений .
Найдите слишком длинные заголовки страниц, повторяющиеся URL-адреса, пустые или повторяющиеся теги и метаописания. Исправить дублированный контент в заголовках страниц.
Где найти: В разделе Структура сайта> Аудит сайта , в На странице раздел.
9
Найдите страницы, слишком глубоко погребенные на вашем сайте.
Показатель «Глубина кликов» позволяет идентифицировать страницы вашего сайта, которые трудно найти пользователям и выполнить поиск. двигатели. Глубина кликов показывает количество кликов, необходимых для перехода на заданную страницу с домашней страницы. Идеально, все страницы должны быть доступны при максимальном количестве щелчков 4, чтобы улучшить сканирование и избежать потери слишком большого PageRank.
Где найти: Для новых проектов — Click Depth column будет автоматически добавлен в рабочую область Все страницы (на панели мониторинга Pages ).Для существующие проекты, вам нужно будет добавить его вручную, щелкнув правой кнопкой мыши заголовок любого столбца.
10
Посмотрите, как ваши страницы и ресурсы связаны между собой.
Ссылки имеют решающее значение для оценки SEO сайта. Хотите знать, насколько хорошо связаны ссылки на страницу? Изучите все внутренние и внешние ссылки на страницу и со страницы в один клик.
Где это найти: В разделе Структура сайта> Все ресурсы и Структура сайта> Страницы .
11
Визуализируйте архитектуру сайта.
Инструмент интерактивной визуализации позволяет построить структуру вашего сайта и взаимосвязь страниц. Информативные диаграммы покажут самые сильные страницы, а также те, которым нужно больше связей.
12
Просмотрите микроданные и разметку Open Graph.
Посмотрите, какие из ваших страниц не структурированы данные на месте, разметка, используемая Google для списков Сети знаний, расширенных фрагментов и местные чины. Вы также можете проверить заголовки, описания и изображения Open Graph каждой страницы — этот тип метаданные используются в сниппетах, когда вашими страницами делятся в социальных сетях.Где найти: В Структура сайта> Страницы , под Разметка структурированных данных, заголовок OG, изображение OG, описание OG столбцов.
13
Провести аудит локализации.
Инструмент Website Auditor SEO Spider проанализирует ваши локализованные страницы и сообщит о проблемах с Hreflang. элементы. Чтобы избежать проблем с дублированным контентом, используйте элементы Hreflang или файл Sitemap, в котором вы сообщаете Google и другие поисковые системы о том, какую языковую версию лучше загружать пользователям, говорящим на других языках.
14
Создавайте XML-карты сайта и инструкции для роботов.
Создавайте XML-файлы Sitemap, чтобы сделать вашу структуру URL-адресов более доступной для ботов. Создавайте файлы robots.txt с мета-директивы роботов (например, noindex, dofollow, nofollow), чтобы указать ботам, как сканировать URL-адреса на вашем сайт. Инструмент позволяет сохранять XML-файлы Sitemap и мета-роботов на ваш компьютер или загружать прямо на сайт. через FTP.
15
Используйте Систему пользовательского поиска, чтобы получить любой фрагмент контента на своем сайте.
Параметр пользовательского поиска WebSite Auditor позволяет находить все экземпляры любого фрагмента контента на веб-сайте. — будь то HTML-тег, скрипт, плагин или ключевые слова в заголовках и текстах. А если вы дизайнер или веб разработчик, вам обязательно понравится опция CSS Selector для поиска определенных элементов с синтаксисом CSS.
Где это найти: В разделе Структура сайта> Страницы> Пользовательские Кнопка поиска в верхней строке меню. Ознакомьтесь с нашими 10 вариантами использования пользовательского поиска.16
Выявите скрытые проблемы с подмодулем
All Resources .WebSite Auditor SEO Spider анализирует каждый HTML-тег и поле заголовка ваших страниц, чтобы выявить проблемы. другие краулеры не найдут.К ним относятся все, от распространенных проблем HTML, таких как пустой «href» атрибуты для ссылок или атрибуты «src» для изображений к многочисленным тегам (часто создаются автоматически с помощью CMS), iframe, скриптов Google Analytics и плагинов для совместного использования в социальных сетях.
Чтобы убедиться, что у вас есть все нужные скрипты и элементы на нужных страницах, нужно всего лишь мгновение. Заметили слишком тяжелую или медленную страницу? Просмотрите все использованные ресурсы, чтобы найти виновника.
Где это найти: В Структура сайта> Все ресурсы , автор нажав на ресурс и проверив Найдено в столбце.
Готовы к тестированию? Если у вас еще не установлен Аудитор веб-сайта, загрузите его для бесплатно и создайте новый проект для своего сайта — это займет всего несколько кликов.Как использовать «Кричащую лягушку» SEO-паук
- Дом
- | Блог
- | Максимальное использование возможностей Screaming Frog в 2020 году
Многие факторы играют ключевую роль в рейтинге веб-сайта в поисковых системах, включая ключевые слова и обратные ссылки.Но структура сайта, которая упрощает сканирование для роботов поисковых систем, также важна.
Индексирование позволяет веб-сайту отображаться в результатах поиска, и для этого боты должны иметь возможность эффективно сканировать ваш сайт. Поиск неиндексированного сайта практически невозможен (если только не произошел недавний сбой индексации), и это сделало бы сайт практически несуществующим, поскольку его нельзя найти нигде в Интернете.
И именно поэтому структура сайта, обеспечивающая эффективное сканирование, является жизненно важной частью успешной стратегии SEO на странице.
ЭкспертыSEO используют различные инструменты, чтобы роботы поисковых систем могли сканировать и индексировать веб-сайты. Screaming Frog — один из таких инструментов — это поисковый робот, который помогает вам проверять ваш сайт и дает представление о его производительности.
Программное обеспечение может быть непростым в использовании, если вы только начинаете, но не волнуйтесь. Наше подробное руководство по Screaming Frog поможет вам изучить этот инструмент и использовать его в своих интересах.
Что такое кричащая лягушка?
Скриншот с сайта Screaming Frog на YouTube
Screaming Frog работает как сканеры Google: с его помощью можно сканировать любой веб-сайт, включая сайты электронной коммерции.Но этот инструмент SEO-паук поднимается на ступеньку выше, предоставляя вам релевантные данные на сайте и создавая удобоваримые статистические данные и отчеты. Используя более простые данные сайта из Screaming Frog, вы можете легко увидеть, над какими областями ваш сайт должен работать.
Программное обеспечение Screaming Frog может помочь вам выполнить следующие задачи для ваших усилий по поисковой оптимизации:
- Поиск битых ссылок
- Поиск с временным и постоянным перенаправлением
- Анализ метаданных
- Поиск дублированного контента
- Обзор роботов.txt и другие директивы
- Создание карты сайта XML
- Анализ архитектуры сайта
И, конечно же, с Screaming Frog вы можете сделать гораздо больше. Мы рассмотрим эти дополнительные функции в другом разделе.
Начало работы с Screaming Frog
Установка программного обеспечения
Прежде чем выполнять сканирование сайтов с помощью инструмента Screaming Frog SEO spider, вам необходимо установить программное обеспечение на свой компьютер. Вы можете скачать инструмент с веб-сайта Screaming Frog.
Программа работает в Windows, Mac и Linux. Вот как установить Screaming Frog на любую из этих систем:
Окна
- Найдите программу установки Screaming Frog в папке «Загрузки».
- Дважды щелкните программу установки.
- Нажмите «Да» на экране «Контроль учетных записей», чтобы продолжить установку программного обеспечения.
- Выберите тип установки, затем нажмите кнопку «Установить».
- После завершения установки программного обеспечения нажмите «Закрыть».
macOS
- Перейдите в папку «Загрузки» в Finder.
- Дважды щелкните программу установки.
- На вашем экране появится новое окно со значком программного обеспечения и папкой «Приложения». Щелкните значок «Кричащая лягушка» и перетащите его в папку «Приложения».
- Закройте окно.
- Перейдите в Finder и найдите имя «ScreamingFrogSEOSpider» в списке устройств.
- Щелкните значок извлечения рядом с именем установщика, чтобы завершить установку.
Linux
Вы можете использовать пользовательский интерфейс Ubuntu или функцию командной строки для установки Screaming Frog на свой компьютер.
Пользовательский интерфейс Ubuntu
- Дважды щелкните файл .deb программного обеспечения.
- Выберите «Установить», затем введите свой пароль.
- Примите лицензию ttf-mscorefonts-install перед установкой Screaming Frog.
- Подождите, пока компьютер завершит установку программного обеспечения.
Командная строка
1.Введите следующую команду в открытом окне терминала:
Скриншот от Screaming Frog
2. Введите свой пароль.
3. Введите Y, чтобы продолжить установку программного обеспечения, и примите лицензионное соглашение с конечным пользователем (EULA) ttf-mscorefonts-install.
Помните, что вы устанавливаете бесплатную версию Screaming Frog. Бесплатная версия позволяет сканировать не более 500 URL-адресов, и вам потребуется лицензия для сканирования большего количества веб-сайтов.Вы можете купить лицензию на программное обеспечение на сайте Screaming Frog.
Чтобы начать использовать премиум-версию Screaming Frog, перейдите в меню «Лицензия». Нажмите на опцию «Ввести лицензию» и введите свой лицензионный ключ. Вы должны увидеть диалоговое окно, в котором отображается срок действия лицензии и срок ее действия.
Изучение пользовательского интерфейса
Скриншот с сайта Screaming Frog на YouTube
После установки инструмента Screaming Frog лучше всего изучить меню, параметры и настройки программного обеспечения.Давайте подробнее рассмотрим различные меню и настройки, которые вы можете использовать.
Файл
Это меню позволяет сохранить сканирование в виде файла и просмотреть шесть (6) последних выполненных сканирований, если вы еще не сохранили их. Кроме того, меню «Файл» позволит вам установить настройки по умолчанию для программного обеспечения.
Конфигурация
Если вам нужны пользовательские настройки сканирования, меню конфигурации Screaming Frog позволяет вам установить и настроить эти параметры. Вы можете использовать приведенные ниже параметры, чтобы настроить параметры сканирования.
- Spider — с помощью параметра Spider вы можете выбрать контент для сканирования и данные для отчетов.
- Включить и исключить — этот параметр позволяет включать и исключать определенные URL-адреса из сканирования.
- Доступ к API — выберите этот вариант, чтобы интегрировать Google Analytics или Google Search Console в сканирование сайта.
Массовый экспорт
Как следует из названия, меню «Массовый экспорт» позволяет экспортировать несколько URL-адресов.Screaming Frog будет принимать ссылки с различными элементами сайта, в том числе:
- Коды ответов
- Директивы
- Inlinks
- Якорный текст
- Изображения
Отчеты
Меню «Отчеты» создает загружаемые обзоры сканирования и отчеты с данными на сайте. Вы можете использовать эти отчеты в своих SEO-аудитах.
Карты сайта
С помощью этого меню вы можете создать карту сайта своего веб-сайта. Вы узнаете больше о создании файлов Sitemap в последней части этого руководства по поисковой оптимизации Screaming Frog.
Настройка памяти и хранилища вашего устройства
Скриншот с сайта Screaming Frog на YouTube
Сканирование сайтов применяется к большим и маленьким сайтам. Но сканирование более крупных веб-сайтов требует больше памяти и вычислительной мощности. С помощью Screaming Frog вы можете выделить определенный объем памяти вашего устройства для сканирования веб-сайтов. Для этого в программе предусмотрены режимы хранения базы данных и оперативной памяти.
Режим хранения базы данныхScreaming Frog идеально подходит для пользователей с твердотельными накопителями (SSD).Чтобы использовать режим, выполните следующие действия:
- Щелкните меню Конфигурация.
- Выберите «Система», затем нажмите «Хранилище».
- Выберите опцию Database Storage Mode.
Между тем, пользователи без твердотельных накопителей могут согласиться на режим хранения ОЗУ с настройкой по умолчанию 1 ГБ ОЗУ для 32-разрядных компьютеров и 2 ГБ ОЗУ для 64-разрядных устройств. Более низкий объем оперативной памяти предотвращает зависание и сбои при сканировании с помощью Screaming Frog.
Но если вы хотите выделить больше ОЗУ для обходов, вы можете изменить значение ОЗУ по умолчанию на большее число.Изменения вступят в силу после перезапуска Screaming Frog.
Настройка параметров
Скриншот с сайта Screaming Frog на YouTube
Screaming Frog уже использует настройки по умолчанию для обхода сайтов. Но вы можете настроить эти параметры и собрать конкретные данные с помощью многочисленных инструментов программного обеспечения. Используя эти инструменты, ваши обходы будут занимать меньше времени и вычислительной мощности. Вы можете настроить свои параметры в меню «Конфигурация».
Настройка окон и столбцов
Скриншот с сайта Screaming Frog на YouTube
Помимо настройки параметров, Screaming Frog позволяет настраивать окна и столбцы для облегчения доступа. Когда вы запустите программу, вы увидите три (3) окна, а в правом столбце вы сможете получить доступ к элементам и фильтрам SEO. С другой стороны, прямо под основным вы найдете окно, в котором отображаются данные определенной веб-страницы.
Регулировка размеров окна — отличный способ настроить вид в Screaming Frog.Вы можете изменить размер окон, перетащив их до желаемого размера. Кроме того, программное обеспечение позволит вам настраивать столбцы так, как вы хотите.
Щелчок и перетаскивание столбца переместит его в желаемое положение, а щелчок по столбцу сортирует данные. Например, если вы хотите отсортировать столбцы по номерам, вы можете просто щелкнуть столбец, и программа упорядочит числа от самого высокого до самого низкого.
Использование Screaming Frog для основных задач SEO
Screaming Frog отличается от других инструментов SEO тем, что позволяет искать, фильтровать и настраивать сканирование.Он также предлагает множество преимуществ, от анализа улучшений сайта и ошибок до фильтрации способа отображения ваших веб-страниц.
От сканирования веб-сайта до создания карты сайта — вот как выполнять некоторые задачи SEO в Screaming Frog.
Сканирование веб-сайта
- Щелкните меню «Конфигурация», затем выберите параметр «Паук».
- Установите флажок «Сканировать все поддомены» в меню конфигурации. Вы также можете выбрать любые другие параметры, если сканируете мультимедиа или скрипты.
- Запустите сканирование и дождитесь его завершения.
- Когда программа завершит сканирование, перейдите на вкладку «Внутренний».
- Отфильтруйте результаты по HTML, затем экспортируйте данные.
Проведение аудита ссылок
- Установите флажок «Сканировать все субдомены» в меню конфигурации Spider. Вы можете не отмечать CSS, изображения, Javascript, Flash и другие несущественные параметры.
- Если вы сканируете ссылки nofollow, установите соответствующие флажки.
- Начните сканирование и дождитесь его завершения.
- Экспортируйте результаты в файл CSV, щелкнув меню «Расширенный отчет», затем «Все ссылки».
Проведение контентного аудита
- Выполните полное сканирование сайта, затем перейдите на вкладку Внутренний.
- Используйте фильтр HTML, затем отсортируйте столбец количества слов от меньшего к большему.
- Перейдите на вкладку «Изображения». На вкладке вы можете искать изображения без замещающего текста при использовании фильтра «отсутствующий замещающий текст».
- Перейдите на вкладку Заголовки страниц, затем отфильтруйте мета-заголовки, содержащие более 70 символов. Вы также можете найти на этой вкладке повторяющиеся мета-заголовки.
- Выявите проблемы с дублированием с помощью фильтра дубликатов на вкладке URL. Этот фильтр также применяется к повторяющимся метаописаниям и повторяющимся страницам с разными заголовками на вкладке метаописаний.
- Вкладка URL-адреса также позволит вам выбрать страницы с нестандартными или нечитаемыми URL-адресами. Затем вы можете исправить эти страницы.
- И последнее, но не менее важное: вы можете обнаружить страницы или ссылки с директивами на вкладке «Директивы».
Создание карты сайта XML
- Проведите полное сканирование вашего веб-сайта и субдоменов.
- Выберите меню «Расширенный экспорт», затем нажмите «XML Sitemap». Эта опция превращает вашу карту сайта в редактируемую таблицу Excel.
- Открыв файл, нажмите кнопку «Читать в Интернете».
- Затем нажмите кнопку «Открыть как таблицу SML». Теперь вы можете редактировать карту сайта в Интернете, сохранять ее в формате XML и загружать в Google.
Другие полезные функции Screaming Frog
В большинстве случаев вы можете просто сканировать веб-сайты с помощью основных инструментов Screaming Frog.Но по мере изучения программного обеспечения вы обнаружите и другие полезные функции для сканирования сайтов. Вот некоторые из его других функций, которые вы могли пропустить:
- Поддержка сканирования промежуточных сайтов — Наряду с живыми веб-сайтами Screaming Frog позволяет сканировать промежуточные сайты. Но вам нужно будет ввести свои учетные данные, прежде чем вы сможете начать.
- Сравнить и запустить несколько обходов. — Вы можете запускать Screaming Frog в нескольких окнах и сканировать несколько веб-сайтов (и сравнивать эти обходы одновременно).
- Поддержка сканирования веб-форм — Screaming Frog предназначен не только для сканирования веб-сайтов — он также может сканировать веб-формы. Чтобы получить доступ к этой функции, перейдите в раздел «Конфигурация»> «Аутентификация»> «На основе форм», чтобы начать сканирование формы.
- Параметр «Весь текст привязки» — эта функция в меню «Массовый экспорт» включает весь текст привязки вашего веб-сайта в файл CSV. Он также показывает расположение текста и ссылки.
- Анализ сканирования — функция анализа сканирования помогает вычислять оценки ссылок.Другие фильтры также могут потребовать расчета после того, как вы просканируете свой веб-сайт.
Повысьте поисковый рейтинг с помощью углубленного SEO-аудита
SEO-аудита помогут вам выявить возможные изменения в различных элементах вашего сайта. Таким образом, вы сможете подняться на вершину поисковой лестницы и превзойти своих конкурентов. Кроме того, вы можете использовать выводы ваших аудитов для улучшения UX и других технических элементов вашего сайта.
Имея на своей стороне надежного партнера, вы можете ближе познакомиться с производительностью вашего сайта и узнать, как вы можете ее улучшить.Свяжитесь с Growth Rocket сегодня, и мы поможем вам постепенно подняться на вершину поискового рейтинга.
Screaming Frog SEO Spider — Урок цифрового маркетинга
Цифровой маркетинг — Примечания к исследованию:
Поиск и диагностика технических проблем
Screaming Frog SEO Spider — действительно хороший инструмент. Любой технический специалист по поисковой оптимизации или опытный специалист по поисковой оптимизации будет использовать этот инструмент, и у него есть модель freemium.
Вы можете сканировать до 500 URL-адресов, и вы можете получить ограниченные функции бесплатно, или вы можете заплатить за премиальный пакет, который предоставит вам все ваши URL-адреса и более продвинутые функции.
Очень хорошо диагностирует технические проблемы:
- Находит ошибки URL в реальном времени: В консоли поиска Google обычно наблюдается небольшая задержка. Если вы выпустили новый веб-сайт, на то, чтобы сообщить о некоторых из этих ошибок, может потребоваться день, два или даже три дня.А с Screaming Frog SEO Spider вы, надеюсь, сможете поймать их намного быстрее.
- Получает полный список URL-адресов для сканирования: Это может быть весьма полезно.
- Проверяет ключевые элементы SEO на странице: Это очень хорошо для проверки элементов SEO на странице.
Когда и почему следует использовать этот инструмент?
Когда вы новичок на веб-сайте, это очень хорошо для первоначальной оценки. Это также помогает вам оценить, с каким объемом контента вы имеете дело и с каким количеством страниц имеете дело.И может быть неплохо просто посмотреть, насколько хорошо оптимизированы теги заголовков, метаописания на самом деле на сайте.
Была ли проделана предыдущая работа по SEO? Или, может быть, не было проделанной работы. А если вы не воспользуетесь этим инструментом, вы можете обнаружить, что немного теряете доверие поисковых систем, потому что на вашем сайте может появиться больше ошибок. Кроме того, это может означать, что вы просто упустите возможность найти неоптимизированные теги заголовков, описания и тому подобное.
Вернуться к началуРесурсы цифрового маркетинга:
Джо Уильямс
Управляющий директор и SEO-тренер в Zen Optimize
- Основатель и SEO-тренер Zen Optimize с 10-летним опытом поисковой оптимизации
- Zen Optimize — это лондонская обучающая компания по цифровому маркетингу.
- Консультант и инструктор по SEO для сотен малых, средних и крупных компаний, включая Qantas Airlines, Sky, Eurostar, EasyCruise и Anti-Slavery
Правила защиты данных влияют практически на все аспекты цифрового маркетинга.Поэтому DMI подготовила краткий курс по GDPR для всех наших студентов. Если вы хотите узнать больше о GDPR, вы можете сделать это здесь:
Краткий курс DMI: GDPR
Следующие фрагменты контента из Библиотеки членства Института цифрового маркетинга были выбраны, чтобы предложить дополнительные материалы, которые могут быть вам интересны или полезны.
Вы можете найти больше информации и контента в Библиотеке членства Института цифрового маркетинга
Вы будете оценивать это содержание на выпускном экзамене , а не .
Как использовать Screaming Frog: Руководство по SEO Spider
Одним из первых и наиболее важных шагов при подписании клиента на услуги SEO является сканирование его веб-сайта в его текущем состоянии. Это влечет за собой сканирование каждого URL-адреса на сайте, чтобы идентифицировать каждую HTML-страницу, изображение, код Javascript, лист CSS и т. Д., Чтобы создать карту того, как структурирован веб-сайт, выявить технические ошибки и определить, что необходимо корректироваться так, чтобы влиять на производительность и рейтинг.
Конечно, достаточно просто ввести веб-сайт в службу сканирования, заставить ее выдать электронную таблицу URL-адресов, а затем начать ее сканирование, чтобы выявить проблемные области. Но время дорого.
Вот где огромную помощь может оказать более глубокий инструмент сканирования сайтов. Хороший поисковый робот расчистит информацию и упростит выбор именно тех вещей, которые вы ищете, вместо того, чтобы бесконечно проверять их взад и вперед на самом сайте или собирать вместе различные инструменты для выполнения то же самое.
Существует множество поисковых роботов, и любой из них выполнит свою работу. Но в SEOM есть один, который мы предпочитаем из-за его скорости, гибкости и простоты использования: The Screaming Frog SEO Spider.
Разработанный британской фирмой по поисковому маркетингу Screaming Frog, SEO Spider стал основным инструментом в отрасли, и не без оснований. Хотя в SEO Spider есть бесчисленное множество полезных функций, я сократил их до списка функций и атрибутов, которые я использую чаще всего — и тех, которые отличают этот инструмент от других подобных сервисов сканирования сайтов.
Скорость
Прежде чем мы углубимся в особенности, которые предлагает SEO Spider, я должен указать, насколько быстро он выполняет сканирование. Посмотрите, как сканирование сайта SEO Spider в действии:
На сканирование каждого из 579 URL-адресов на указанном мной сайте ушло около 20 секунд. Неплохо, правда? Это особенно удобно, если вам нужно часто сканировать более крупный сайт и использовать для этого инструмент планирования SEO Spider.
Заголовки, мета и заголовки
Теперь, когда мы прошли сканирование сайта, давайте рассмотрим теги заголовков и метаописания сайта.SEO Spider имеет удобную и удобную навигацию для просмотра всей этой информации отдельно по URL — вплоть до более подробной информации, такой как контент с тегами h2 или h3 на странице.
Программа автоматически проверяет общие проблемы, вызывающие беспокойство, такие как длина тегов и их сходство с другим контентом на сайте. Вы также можете фильтровать сканирование, что значительно сэкономит время, когда вы хотите улучшить теги.
Поиск неработающих ссылок
При сканировании сайта одна из самых важных вещей, на которые следует обратить внимание, — это ссылки, которые приводят к ошибкам 404.Вы же не хотите направлять пользователей на тупиковые страницы. Кроме того, ошибка 404 может негативно повлиять на рейтинг сайта в обычном поиске.
SEO Spider позволяет невероятно легко идентифицировать ошибки 404, где бы они ни находились на сайте. Как? Запустите сканирование, отфильтруйте его по кодам ответа 4xx, щелкните ссылку, вызывающую нарушение, а затем перейдите к «inlinks» на нижней панели. Вы увидите страницу, на которой находится неработающая ссылка, и ее якорный текст.
Инструмент структурированных данных
Структурированные данные или схема могут быть очень полезны для органического ранжирования страницы.Он предоставляет сканерам поисковых систем лучшее представление о содержании этой страницы, тем самым облегчая сопоставление ее с релевантными поисковыми запросами. Тем не менее, обычное разочарование при настройке структурированных данных заключается в том, чтобы убедиться, что в коде нет ошибок, и убедиться, что данные будут правильно прочитаны поисковыми системами, поскольку для индексации может потребоваться время.
Это еще одно место, где SEO Spider может вас спасти. В нем есть встроенное окно предварительного просмотра, которое можно использовать для определения схемы и, при необходимости, устранения неполадок на любой странице сайта, который вы просканировали.
Фрагмент SERP
SEO Spider также имеет встроенное окно предварительного просмотра, которое позволяет вам увидеть, как та или иная страница будет отображаться в обычных результатах поиска. Еще более полезным является тот факт, что этот предварительный просмотр фрагмента SERP дает вам возможность редактировать заголовок и мета-описание, как они отображаются в предварительном просмотре. Это позволяет вам экспериментировать с новыми тегами заголовков и метаописаниями, чтобы увидеть, насколько хорошо они подходят и передают ли сообщение прямо в инструменте.Расширенные фрагменты кода, включая схему, также появятся в этом предварительном просмотре, предлагая еще один способ устранения неполадок. Выберите HTML-страницу, для которой вы хотите просмотреть предварительный просмотр, и выберите «Фрагмент поисковой выдачи» внизу, чтобы получить доступ к этому инструменту.
Заинтересованы?
Если вы хотите протестировать любую из этих функций на себе, Screaming Frog предлагает бесплатный пакет для SEO Spider, который предлагает основные функции аудита и позволяет сканировать до 500 URL-адресов одновременно. Обновление до платного пакета дает вам множество дополнительных функций, таких как анализ структурированных данных, сканирование по расписанию, интеграция с Google Analytics и многое другое.
Более того, платный пакет также снимает ограничение на количество URL-адресов, которые вы можете сканировать на одном сайте, что имеет решающее значение для крупных клиентов и сайтов электронной коммерции. Платный пакет начинается от 192 долларов в год за лицензию (или 149 фунтов стерлингов, поскольку Screaming Frog базируется в Соединенном Королевстве), с постепенным снижением цены за одновременное получение большего количества лицензий.
Здесь, в SEOM, мы ежедневно используем множество различных инструментов для решения различных задач. Когда нам приходится часто перебирать так много разных пользовательских интерфейсов и программ, каждая из которых имеет свои особенности, приятно иметь возможность полагаться на что-то столь же функциональное и простое в использовании, как Screaming Frog SEO Spider.Особенно для трудоемкой (и, честно говоря, иногда монотонной) задачи, такой как сканирование сайта.