Синтаксис | Документация ClickHouse
- Справка по SQL
В системе есть два вида парсеров: полноценный парсер SQL (recursive descent parser) и парсер форматов данных (быстрый потоковый парсер).
Во всех случаях кроме запроса INSERT, используется только полноценный парсер SQL.
В запросе INSERT используется оба парсера:
INSERT INTO t VALUES (1, 'Hello, world'), (2, 'abc'), (3, 'def')
Фрагмент INSERT INTO t VALUES парсится полноценным парсером, а данные (1, 'Hello, world'), (2, 'abc'), (3, 'def') — быстрым потоковым парсером.
Данные могут иметь любой формат. При получении запроса, сервер заранее считывает в оперативку не более max_query_size байт запроса (по умолчанию, 1МБ), а всё остальное обрабатывается потоково.
Таким образом, в системе нет проблем с большими INSERT запросами, как в MySQL.
При использовании формата Values в INSERT запросе может сложиться иллюзия, что данные парсятся также, как выражения в запросе SELECT, но это не так.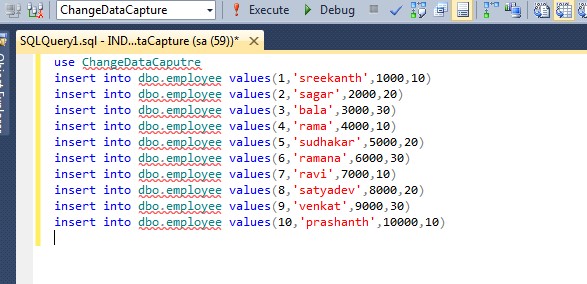
Далее пойдёт речь о полноценном парсере. О парсерах форматов, смотри раздел «Форматы».
Пробелы
Между синтаксическими конструкциями (в том числе, в начале и конце запроса) может быть расположено произвольное количество пробельных символов. К пробельным символам относятся пробел, таб, перевод строки, CR, form feed.
Комментарии
Поддерживаются комментарии в SQL-стиле и C-стиле.
Комментарии в SQL-стиле: от -- до конца строки. Пробел после -- может не ставиться.
Комментарии в C-стиле: от /* до */. Такие комментарии могут быть многострочными. Пробелы тоже не обязательны.
Ключевые слова
Ключевые слова не зависят от регистра, если они соответствуют:
- Стандарту SQL. Например, применение любого из вариантов
SELECT,selectилиSeLeCtне вызовет ошибки. - Реализации в некоторых популярных DBMS (MySQL или Postgres).
 Например,
Например, DateTimeиdatetime.
 Например,
Например, Зависимость от регистра для имён типов данных можно проверить в таблице system.data_type_families.
В отличие от стандарта SQL, все остальные ключевые слова, включая названия функций зависят от регистра.
Ключевые слова не зарезервированы (а всего лишь парсятся как ключевые слова в соответствующем контексте). Если вы используете идентификаторы, совпадающие с ключевыми словами, заключите их в кавычки. Например, запрос SELECT "FROM" FROM table_name валиден, если таблица table_name имеет столбец с именем "FROM".
Идентификаторы
Идентификаторы:
- Имена кластеров, баз данных, таблиц, разделов и столбцов;
- Функции;
- Типы данных;
- Синонимы выражений.
Некоторые идентификаторы нужно указывать в кавычках (например, идентификаторы с пробелами). Прочие идентификаторы можно указывать без кавычек. Рекомендуется использовать идентификаторы, не требующие кавычек. [a-zA-Z_][0-9a-zA-Z_]*$ и не могут совпадать с ключевыми словами. Примеры:
[a-zA-Z_][0-9a-zA-Z_]*$ и не могут совпадать с ключевыми словами. Примеры: x, _1, X_y__Z123_.
Если вы хотите использовать идентификаторы, совпадающие с ключевыми словами, или использовать в идентификаторах символы, не входящие в регулярное выражение, заключите их в двойные или обратные кавычки, например, "id", `id`.
Литералы
Существуют: числовые, строковые, составные литералы и NULL.
Числовые
Числовой литерал пытается распарситься:
- Сначала как знаковое 64-разрядное число, функцией strtoull.
- Если не получилось, то как беззнаковое 64-разрядное число, функцией strtoll.
- Если не получилось, то как число с плавающей запятой, функцией strtod.
- Иначе — ошибка.
Соответствующее значение будет иметь тип минимального размера, который вмещает значение.
Например, 1 парсится как UInt8, а 256 как UInt16. Подробнее о типах данных читайте в разделе Типы данных.
Примеры: 1, 18446744073709551615, 0xDEADBEEF, 01, 0.1, 1e100, -1e-100, inf, nan.
Строковые
Поддерживаются только строковые литералы в одинарных кавычках. Символы внутри могут быть экранированы с помощью обратного слеша. Следующие escape-последовательности имеют соответствующее специальное значение: \b, \f, \r, \n, \t, \0, \a, \v, \xHH. Во всех остальных случаях, последовательности вида \c, где c — любой символ, преобразуется в c . Таким образом, могут быть использованы последовательности \' и \\. Значение будет иметь тип String.
Минимальный набор символов, которых вам необходимо экранировать в строковых литералах: ' и \. Одинарная кавычка может быть экранирована одинарной кавычкой, литералы 'It\'s' и 'It''s' эквивалентны.
Составные
Поддерживаются конструкции для массивов: [1, 2, 3] и кортежей: (1, 'Hello, world!', 2).
На самом деле, это вовсе не литералы, а выражение с оператором создания массива и оператором создания кортежа, соответственно.
Массив должен состоять хотя бы из одного элемента, а кортеж — хотя бы из двух.
Кортежи носят служебное значение для использования в секции IN запроса SELECT. Кортежи могут быть получены как результат запроса, но они не могут быть сохранены в базе данных (за исключением таблицы Memory.)
NULL
Обозначает, что значение отсутствует.
Чтобы в поле таблицы можно было хранить NULL, оно должно быть типа Nullable.
В зависимости от формата данных (входных или выходных) NULL может иметь различное представление. Подробнее смотрите в документации для форматов данных.
При обработке NULL есть множество особенностей. Например, если хотя бы один из аргументов операции сравнения — NULL, то результатом такой операции тоже будет NULL. Этим же свойством обладают операции умножения, сложения и пр. Подробнее читайте в документации на каждую операцию.
Этим же свойством обладают операции умножения, сложения и пр. Подробнее читайте в документации на каждую операцию.
В запросах можно проверить NULL с помощью операторов IS NULL и IS NOT NULL, а также соответствующих функций isNull и isNotNull.
Функции
Функции записываются как идентификатор со списком аргументов (возможно, пустым) в скобках. В отличие от стандартного SQL, даже в случае пустого списка аргументов, скобки обязательны. Пример: now().
Бывают обычные и агрегатные функции (смотрите раздел «Агрегатные функции»). Некоторые агрегатные функции могут содержать два списка аргументов в круглых скобках. Пример: quantile(0.9)(x). Такие агрегатные функции называются «параметрическими», а первый список аргументов называется «параметрами». Синтаксис агрегатных функций без параметров ничем не отличается от обычных функций.
Операторы
Операторы преобразуются в соответствующие им функции во время парсинга запроса, с учётом их приоритета и ассоциативности.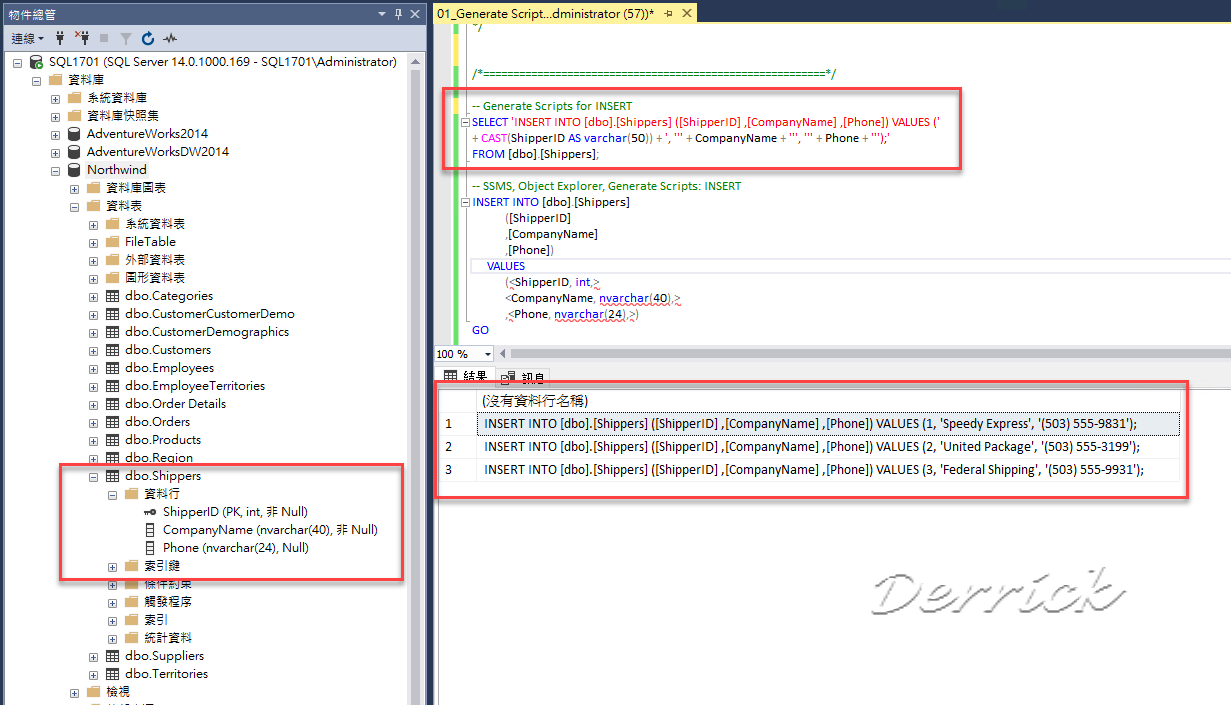
Например, выражение 1 + 2 * 3 + 4 преобразуется в plus(plus(1, multiply(2, 3)), 4).
Типы данных и движки таблиц
Типы данных и движки таблиц в запросе CREATE записываются также, как идентификаторы или также как функции. То есть, могут содержать или не содержать список аргументов в круглых скобках. Подробнее смотрите разделы «Типы данных», «Движки таблиц», «CREATE».
Синонимы выражений
Синоним — это пользовательское имя выражения в запросе.
AS— ключевое слово для определения синонимов. Можно определить синоним для имени таблицы или столбца в секцииSELECTбез использования ключевого словаAS.Например, `SELECT table_name_alias.column_name FROM table_name table_name_alias`. В функции [CAST](../sql_reference/syntax.md#type_conversion_function-cast), ключевое слово `AS` имеет другое значение. Смотрите описание функции.expr— любое выражение, которое поддерживает ClickHouse.Например, `SELECT column_name * 2 AS double FROM some_table`.alias— имя длявыражения. Синонимы должны соответствовать синтаксису идентификаторов.Например, `SELECT "table t".column_name FROM table_name AS "table t"`.

Примечания по использованию
Синонимы являются глобальными для запроса или подзапроса, и вы можете определить синоним в любой части запроса для любого выражения. Например,
Синонимы не передаются в подзапросы и между подзапросами. Например, при выполнении запроса SELECT (SELECT sum(b.a) + num FROM b) - a.a AS num FROM a ClickHouse сгенерирует исключение Unknown identifier: num.
Если синоним определен для результирующих столбцов в секции SELECT вложенного запроса, то эти столбцы отображаются во внешнем запросе. Например, SELECT n + m FROM (SELECT 1 AS n, 2 AS m).
Будьте осторожны с синонимами, совпадающими с именами столбцов или таблиц. Рассмотрим следующий пример:
CREATE TABLE t
(
a Int,
b Int
)
ENGINE = TinyLog()
SELECT
argMax(a, b),
sum(b) AS b
FROM t
Received exception from server (version 18.14.17):
Code: 184. DB::Exception: Received from localhost:9000, 127.0.0.1. DB::Exception: Aggregate function sum(b) is found inside another aggregate function in query.
В этом примере мы объявили таблицу t со столбцом b. Затем, при выборе данных, мы определили синоним sum(b) AS b. Поскольку синонимы глобальные, то ClickHouse заменил литерал b в выражении argMax(a, b) выражением sum(b). Эта замена вызвала исключение. Можно изменить это поведение, включив настройку prefer_column_name_to_alias, для этого нужно установить ее в значение
Звёздочка
В запросе SELECT, вместо выражения может стоять звёздочка. Подробнее смотрите раздел «SELECT».
Подробнее смотрите раздел «SELECT».
Выражения
Выражение представляет собой функцию, идентификатор, литерал, применение оператора, выражение в скобках, подзапрос, звёздочку. А также может содержать синоним.
Список выражений — одно выражение или несколько выражений через запятую.
Функции и операторы, в свою очередь, в качестве аргументов, могут иметь произвольные выражения.
Типы мультитабличных инструкций INSERT | sql-oracle.ru
Существуют разные типы мультитабличных инструкций INSERT:
безусловная инструкция
INSERT;условная инструкция
INSERT ALL;инструкция трансформации
INSERT;условная инструкция
INSERT FIRST.
Для указания типа выполняемой инструкции INSERT используются разные предложения.
Типы мультитабличных инструкций INSERT:
INSERT: для каждой строки, возвращаемой подзапросом, в каждую целевую таблицу вставляется строка.условная инструкция
INSERT ALL: для каждой строки, возвращаемой подзапросом, в каждую целевую таблицу вставляется строка, если выполняется заданное условие.инструкция трансформации
INSERT: это особый вариант безусловной инструкцииINSERT ALL.условная инструкция
INSERT FIRST: для каждой строки, возвращаемой подзапросом, вставляется строка в первую целевую таблицу, в которой выполняется заданное условие.
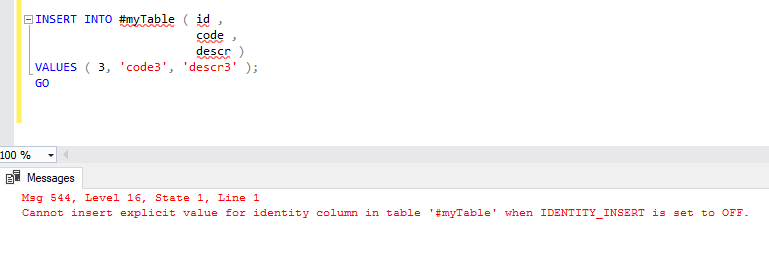
Синтаксис мультитабличных инструкций INSERT
На рисунке отображается общий формат мультитабличной инструкции INSERT.
Безусловная инструкция INSERT: ALL into_clause
Для выполнения безусловной мультитабличной инструкции INSERT задайте параметр ALL, сопровождаемый несколькими предложениями insert_into_clauses. Каждое предложение insert_into_clause выполняется сервером Oracle однократно для каждой строки, возвращаемой подзапросом.
Условная инструкция INSERT: conditional_insert_clause
Для выполнения условной мультитабличной инструкции INSERT задайте conditional_insert_clause. Каждое предложение insert_into_clause фильтруется сервером Oracle через соответствующее условие WHEN, которым определяется, будет ли выполняться это предложение insert_into_clause. Одиночная мультитабличная инструкция INSERT может содержать до 127 предложений WHEN.
Условная инструкция INSERT: ALL
Если задать параметр ALL, сервером Oracle проверяется каждое предложение WHEN независимо от результатов для любого другого предложения WHEN, условие которого по результатам проверки имеет значение True (истина), сервером Oracle выполняется соответствующий список предложений INTO.
Условная инструкция INSERT: FIRST
Если задать параметр FIRST, сервер Oracle проверяет каждое предложение WHEN в том порядке, в котором оно появляется в инструкции. Если первое предложение
Если первое предложение WHEN имеет значение True, сервер Oracle выполняет соответствующее предложение WHEN для заданной строки.
Условное предложение INSERT: ELSE
Если для заданной строки ни одно из предложений WHEN не имеет значение True:
если задано предложение
ELSE, сервер Oracle выполняет список предложенийINTO, связанный с предложениемELSE;если предложение
ELSEне задано, сервер Oracle не выполняет никаких действий для этой строки.
Ограничения, накладываемые на мультитабличные инструкции INSERT
Мультитабличные инструкции
INSERTможно выполнять только над таблицами, а не над представлениями и не над материализованными представлениями.Мультитабличную инструкцию
INSERTневозможно выполнить над удаленной (нелокальной) таблицей.При выполнении мультитабличной инструкции
INSERTневозможно указать выражение для коллекции таблиц.В мультитабличной инструкции
INSERTневозможно объединить предложенияinsert_into_clauses, чтобы задать в сумме более 999 целевых столбцов.

Далее: Поля INTERVAL
sql — База данных в памяти, поддерживающая собственный синтаксис INSERT ALL oracle
Мне нужно написать простой запрос с использованием oracle, java и mybatis:
select * from FOO foo where foo.id IN (ids)
Теперь ids — это большой набор строк, около 7000. К сожалению, oracle имеет ограничение в 1000 элементов для предложения IN.
Чтобы преодолеть это, я могу:
- динамически объедините запрос, чтобы он стал:
select * from FOO foo where foo.id IN (chunk1) or foo.id IN (chunk2) ...Я не уверен, что это вообще работает, и я действительно сомневаюсь, что он работает хорошо - используйте временную таблицу и перепишите запрос на:
select * from FOO foo join SOME_TEMPORARY_ID tempids on foo..

Решил выбрать 2 варианта. Перед выполнением запроса мне нужно как-то выполнить эффективную пакетную вставку в Oracle. К сожалению, Oracle имеет собственный синтаксис для пакетной вставки:
INSERT ALL
INTO some_table VALUES ('foo')
INTO some_table VALUES ('foo1')
INTO some_table VALUES ('foo2')
....
INTO some_table VALUES ('foo12345')
SELECT * FROM DUAL
Я не упомянул, но хочу написать для этого интеграционный тест, в идеале с использованием h3 или любой другой базы данных в памяти. Конечно, h3 не поддерживает этот синтаксис. HSQLDB тоже.
Знаете ли вы какую-либо базу данных в памяти, которая полностью поддерживает собственный синтаксис Oracle? Или, по крайней мере, это конкретное предложение INSERT ALL?
0
slnowak 15 Июл 2016 в 17:16
3 ответа
Лучший ответ
Спасибо, что описали свою основную проблему. Проверьте, может это поможет вам
Проверьте, может это поможет вам
where (foo.id, 0) in (('1', 0), ('2', 0),...)
У этого простого обходного пути нет ограничений. Если этот ответ не подходит, дайте мне знать. Я удаляю этот ответ и снова думаю о проблеме вашего ребенка.
2
Evgeniy K. 15 Июл 2016 в 14:47
Предел длины одного оператора INSERT (т.е. количество записей, для которых вы можете указать значения) указывает на то, что эту операцию действительно лучше всего выполнять с несколькими insert заявления.
Можете ли вы перебирать список значений id в программе, вставляя одно (или несколько) за раз в вашу временную таблицу, к которой вы затем можете присоединиться для вашего окончательного запроса?
Конечно, это в конечном итоге напоминает ваш первоначальный вариант №1, но на самом деле это комбинация №1 и №2, я думаю. В любом случае, это сработает! 🙂
В любом случае, это сработает! 🙂
0
SlimsGhost 15 Июл 2016 в 14:52
Хорошо, поэтому я решил, что если я действительно хочу / должен использовать проприетарные функции / синтаксис Oracle, то давайте протестируем его на живом оракуле.
Поэтому, если вас не волнует время выполнения и у вас есть доступ к Docker на вашем CI-сервере, я рекомендую вам эти отличные библиотеки: https://mvnrepository.com/artifact/org.testcontainers (https://github.com/testcontainers/testcontainers-java), включая модуль oracle-xe.
Мне удалось развернуть контейнер oracle-xe во время моих интеграционных тестов и протестировать на живом экземпляре oracle.
1
slnowak 16 Июл 2016 в 20:00
Использование операторов INSERT, UPDATE и DELETE | Windows IT Pro/RE
Иначительная часть работы многих администраторов баз данных и администраторов SQL Server состоит в обеспечении текущей работы базы данных. Сюда относится добавление, изменение и удаление данных из таблиц. Запросы на T-SQL позволяют легко выполнять эти задания. Нужно только использовать предложения INSERT, UPDATE и DELETE. Перед тем как я покажу, как применять эти предложения, вспомним несколько вещей, которые нужно сделать до начала работы.
Сюда относится добавление, изменение и удаление данных из таблиц. Запросы на T-SQL позволяют легко выполнять эти задания. Нужно только использовать предложения INSERT, UPDATE и DELETE. Перед тем как я покажу, как применять эти предложения, вспомним несколько вещей, которые нужно сделать до начала работы.
Предварительные условия
Примеры предложений INSERT, UPDATE и DELETE, которые я использую в этой статье, запускаются на простой базе данных MyDB, содержащей несколько временных таблиц и таблицу MyTable. Таблица MyTable используется для хранения названий разных временных таблиц. Единственная цель временных таблиц — заполнить пространство. Просто присутствуя, они обеспечивают наличие данных в таблице sysobjects, которая используется в качестве источника данных для вставки данных в MyTable.
Предполагая наличие полномочий, необходимых для создания баз данных и таблиц, для запуска предложений, модифицирующих данные, можно создать MyDB, MyTable и временные таблицы при помощи файлов MyDB. sql и MyTable.sql. Эти запросы можно увидеть в листингах 1 и 2.
sql и MyTable.sql. Эти запросы можно увидеть в листингах 1 и 2.
Для запуска запроса откройте окно запроса либо в SQL Server 2005 SQL Server Management Studio (далее SSMS), либо в SQL Server 2000 Query Analyzer и скопируйте код MyDB.sql в окно. В двух записях FILENAME замените C:Program FilesMicrosoft SQL ServerMSSQL.1MSSQLDATAMyDB.mdf на путь на имеющемся сервере. Выполните запрос для создания MyDB. Для разработки MyTable и временных таблиц скопируйте код в MyTable.sql в окно запроса и выполните его.
Перед тем как приступать к работе с данными любой таблицы, нужно ознакомиться с ее структурой. Для этого открываем таблицу MyTable и выполняем следующие действия.
Добавление одной записи
Стандартное предложение INSERT, которое добавляет одиночную запись (или строку) в таблицу, состоит из трех частей и имеет вид
INSERT INTO Part1 (Part2) VALUES (Part3)
В части 1 определена целевая таблица, которая будет содержать новую запись. В части 2 перечисляются названия полей в целевой таблице, для которой имеются данные. Нужно заключить перечень в круглые скобки и использовать запятые для отделения названий полей. В части 3 обеспечивается добавление данных. Когда надо будет установить фактические значения данных, используется параметр VALUES и следующие за ним значения. Требуется заключить перечень значений данных в круглые скобки и отделять значения запятыми. Если это значение символьное, вроде строки или даты, его также нужно заключить в одинарные кавычки (‘‘). Например, выполнение следующего предложения вставляет значения данных TestTable и 2007–09–22 в поля ObjectName и Creation-Date таблицы MyTable, соответственно:
В части 2 перечисляются названия полей в целевой таблице, для которой имеются данные. Нужно заключить перечень в круглые скобки и использовать запятые для отделения названий полей. В части 3 обеспечивается добавление данных. Когда надо будет установить фактические значения данных, используется параметр VALUES и следующие за ним значения. Требуется заключить перечень значений данных в круглые скобки и отделять значения запятыми. Если это значение символьное, вроде строки или даты, его также нужно заключить в одинарные кавычки (‘‘). Например, выполнение следующего предложения вставляет значения данных TestTable и 2007–09–22 в поля ObjectName и Creation-Date таблицы MyTable, соответственно:
INSERT INTO MyTable (ObjectName, CreationDate) VALUES (‘TestTable’, ‘007–09–22’)
Те, кто уже знает мои приемы работы с таблицей MyTable, возможно, заметили, что я просто установил два или три поля в предложение INSERT. Первое поле — это поле идентификатора, которое имеет специальное назначение. Данные этого поля добавляются автоматически, и его значения увеличиваются с каждой новой вставленной записью. Это важное свойство SQL Server, о котором нужно знать. Чтобы узнать больше о типах идентификационных данных, загляните в SQL Server Books Online (BOL) в раздел IDENTITY (Свойство) на msdn2.microsoft.com/en-us/library/ms186775.aspx.
Первое поле — это поле идентификатора, которое имеет специальное назначение. Данные этого поля добавляются автоматически, и его значения увеличиваются с каждой новой вставленной записью. Это важное свойство SQL Server, о котором нужно знать. Чтобы узнать больше о типах идентификационных данных, загляните в SQL Server Books Online (BOL) в раздел IDENTITY (Свойство) на msdn2.microsoft.com/en-us/library/ms186775.aspx.
Чтобы просмотреть вновь вставленную запись, выполните следующее предложение:
SELECT * FROM MyTable
На рисунке 1 показано, как выглядит результат.
Добавление результатов предложением SELECT
Я уже показывал, как получить данные из базы данных, используя предложение SELECT. Можно задействовать оператор INSERT для сохранения данных, извлеченных предложением SELECT, в таблицу. Как и оператор INSERT для отдельной записи, оператор INSERT, который сохраняет результаты предложения SELECT, имеет три части: заданная база данных (часть 1), названия полей (часть 2) и данные (часть 3). Тем не менее вместо параметра VALUES для определения актуальных значений данных в части 3 используется предложение SELECT, которое извлекает данные из другого источника. Например, когда выполняется к базе данных MyDB, запрос
Как и оператор INSERT для отдельной записи, оператор INSERT, который сохраняет результаты предложения SELECT, имеет три части: заданная база данных (часть 1), названия полей (часть 2) и данные (часть 3). Тем не менее вместо параметра VALUES для определения актуальных значений данных в части 3 используется предложение SELECT, которое извлекает данные из другого источника. Например, когда выполняется к базе данных MyDB, запрос
INSERT INTO MyTable (ObjectName, CreationDate) SELECT name, crdate FROM sysobjects WHERE type = ‘U’ ORDER BY name
вставляет в новую таблицу MyTable записи, содержащие название и дату разработки всех пользовательских таблиц в MyDB, упорядоченных в алфавитном порядке в соответствии с названиями. Таким образом, предполагая, что выполнено предложение INSERT с одиночной записью, описанное ранее, результаты этого запроса должны выглядеть так же, как и результаты, показанные на рисунке 2, с двумя исключениями. Значения CreationDate для MyTable и временных таблиц будут содержать дату и время запуска MyTable.sql. Второе поле ObjectName будет шире. Я сократил его из-за недостатка места.
Значения CreationDate для MyTable и временных таблиц будут содержать дату и время запуска MyTable.sql. Второе поле ObjectName будет шире. Я сократил его из-за недостатка места.
На рисунке 2 TestTable — только первая запись. Имя условия ORDER BY только обращается к новым записям, которые вставляет в данный момент оператор SELECT. Таблица TestTable была предварительно дополнена при помощи оператора, состоящего из единичной записи оператора INSERT.
Можно использовать любой оператор SELECT, до тех пор пока типы данных в полях, перечисленных в части 2 оператора INSERT, соответствуют полям, определенным в предложении SELECT. Это дает возможность собрать все типы данных. Тем не менее используйте новое знание с осторожностью, чтобы не вставить миллионы записей на занятый сервер или на сервер с ограниченным дисковым пространством.
Модернизация данных
Теперь, когда мы умеем добавлять данные, давайте посмотрим, как работает оператор UPDATE. Простой оператор UPDATE обычно состоит из трех частей:
Простой оператор UPDATE обычно состоит из трех частей:
UPDATE Part1 SET Part2 WHERE Part3
В части 1 определена целевая таблица. В части 2 определены поля, которые должны быть изменены, вместе с новыми данными для каждого поля. Часть 3 не является обязательной, но в большинстве случаев она очень важна. Здесь устанавливается фильтр, использующий оператор WHERE. Если оператор WHERE не установлен, будет изменена каждая единичная запись в таблице. Например, запрос
UPDATE MyTable SET CreationDate = ‘2007–09–23’
изменяет значение CreationDate для каждой записи в таблице MyTable, как показано на рисунке 3. На рисунке видно, что значение CreationDate — это 2007–09–23 00:00:00.000, а не 2007–09–23, как указано в запросе. Так как тип данных поля CreationDate определен как дата и запрос не указывает временную часть, SQL Server допускает, что имеется в виду полночь, и добавляет 00:00:00. 000.
000.
Теперь используем оператор WHERE для изменения полей ObjectName и CreationDate выбранной записи:
UPDATE MyTable SET ObjectName = ‘PartyTime’, CreationDate = ‘1999–12–31 23:00:00’ WHERE TableID = 1
Как показано на рисунке 4, только первая запись (установленная посредством WHERE TableID = 1) изменена с новым названием таблицы PartyTime и новой датой разработки 1999–12–31 23:00:00.
Удаление данных
Каждый администратор баз данных опасается, что предложение DELETE попадет не в те руки. Хотя оно может быть использовано неправильно, оно играет важную роль, когда запросы применяются для изменения данных в таблицах. Типичное предложение DELETE обычно состоит из двух частей:
DELETE Part1
WHERE Part2
В части 1 определяется целевая таблица. В части 2 определяется фильтр, использующий оператор WHERE. Как и оператор WHERE в предложении UPDATE, условие WHERE в выражении DELETE необязательно, но в большинстве случаев необходимо. Если не будет включен оператор WHERE и фильтр, будут удалены все записи в заданной таблице.
В части 2 определяется фильтр, использующий оператор WHERE. Как и оператор WHERE в предложении UPDATE, условие WHERE в выражении DELETE необязательно, но в большинстве случаев необходимо. Если не будет включен оператор WHERE и фильтр, будут удалены все записи в заданной таблице.
Например, нужно удалить из таблицы MyTables все записи с датой разработки ранее 22 сентября 2007 года.
Запрос
DELETE MyTable WHERE CreationDate > ‘2007–09–22’
Приведет к результату, показанному на рисунке 5. Нужно быть внимательным во время изменения данных при помощи предложений DELETE или UPDATE. Оператор WHERE используется всегда, кроме случая, когда надо удалить из таблицы все данные.
Если неизвестно, сколько записей нужно удалить, выполняется предложение SELECT с тем же оператором WHERE. Вместо определения полей в предложении SELECT задается оператор COUNT (*), возвращающий количество строк, которые должны быть удалены. Например, чтобы проверить результат последнего выражения с предложением DELETE, можно выполнить:
Вместо определения полей в предложении SELECT задается оператор COUNT (*), возвращающий количество строк, которые должны быть удалены. Например, чтобы проверить результат последнего выражения с предложением DELETE, можно выполнить:
SELECT COUNT (*) FROM MyTable WHERE CreationDate > ‘2007–09–22’
Если результирующий ряд исчисляется в миллионах, подумайте, надо ли детализировать оператор WHERE. Я расскажу об использовании функции COUNT в следующей статье, поэтому не стоит беспокоиться, если не получится применить это в работе.
Изучите свои данные
Если вы уверены в том, что теперь сможете изменять данные в MyTable, попробуйте выполнить операторы INSERT, UPDATE и DELETE в существующей базе данных на тестовом сервере. Для этого скопируйте код из запроса ExistingDatabaseQuery.sql (см. листинг 3) в окно запроса, поместите MyDB в первой строке к названию существующей базы данных и выполните запрос.
Затем можно переработать примеры из предложений INSERT, UPDATE и DELETE к имеющейся конфигурации и выполнить их. Таким образом вы узнаете, как лучше использовать эти предложения. Возможно, обнаружатся данные, о существовании которых ранее не было известно.
Билл Макэвой ([email protected]) — руководитель и администратор базы данных сайта Cooking with SQL Web
Поделитесь материалом с коллегами и друзьями
НОУ ИНТУИТ | Лекция | Загрузка базы данных
Аннотация: Если предприятие работает достаточно долго, то, наверняка, создалась огромная база данных результатов работы. Возможно даже, что она была создана в отличных от SQL Server системах. Но, решив переходить на SQL Server 2000, вы столкнетесь с проблемой перенесения базы данных из прошлой системы в новую. Понять принципы загрузки базы данных в SQL Server, самостоятельно осуществлять массовое копирование с помощью BCP, обеспечивать целостность данных вы сможете, изучив данный материал.
После создания вашей базы данных и таблиц базы данных вы можете переходить к загрузке ваших данных в эту базу. Имеется несколько методов загрузки данных в базу данных; выбираемый вами метод зависит от типа источника ваших данных, от вида обработки, которая будет выполняться с данными, и от того, куда будут загружаться данные. В этой главе мы рассмотрим следующие методы загрузки в базу данных:
- Использование программы Bulk Copy Program (BCP). BCP – это внешняя программа, поставляемая вместе с Microsoft SQL Server 2000 для загрузки файлов данных в базу данных. BCP можно также использовать для копирования данных из какой-либо таблицы SQL Server в файл данных.
- Использование оператора BULK INSERT. Оператор Transact-SQL (T-SQL) BULK INSERT позволяет вам копировать большие объемы данных из файла данных в таблицу SQL Server в рамках системы SQL Server. Поскольку этот оператор является оператором SQL (выполняется из ISQL, OSQL или анализатора запросов Query Analyzer), то весь процесс выполняется как поток SQL Server. Этот оператор нельзя использовать для копирования данных из SQL Server в файл данных.
- Использование служб преобразования данных Data Transformation Services (DTS). DTS – это набор инструментальных средств, поставляемых вместе с SQL Server, которые намного упрощают задачу копирования данных в SQL Server и из SQL Server. В набор DTS включен мастер для импорта данных и мастер для экспорта данных.
 Поскольку этот оператор является оператором SQL (выполняется из ISQL, OSQL или анализатора запросов Query Analyzer), то весь процесс выполняется как поток SQL Server. Этот оператор нельзя использовать для копирования данных из SQL Server в файл данных.
Поскольку этот оператор является оператором SQL (выполняется из ISQL, OSQL или анализатора запросов Query Analyzer), то весь процесс выполняется как поток SQL Server. Этот оператор нельзя использовать для копирования данных из SQL Server в файл данных.Каждый из этих методов обладает различными возможностями и характеристиками. Вы обязательно найдете хотя бы один метод, отвечающий вашим требованиям.
Примечание. Восстановление базы данных из файла резервной копии можно также рассматривать как форму загрузки в базу данных, но поскольку резервное копирование и восстановление описываются в «Резервное копирование Microsoft SQL Server» и «Восстановление и воспроизведение базы данных» , эти темы здесь не рассматриваются. Определенные параметры конфигурирования базы данных являются общими для программы BCP и для оператора BULK INSERT. Эти параметры базы данных определяют, как выполняется массовое копирование. Эти параметры должны быть заданы до начала операций загрузки данных.
Определенные параметры конфигурирования базы данных являются общими для программы BCP и для оператора BULK INSERT. Эти параметры базы данных определяют, как выполняется массовое копирование. Эти параметры должны быть заданы до начала операций загрузки данных.Для вас могут оказаться полезными следующие дополнительные операции:
- Оператор SELECT…INTO. Этот оператор используется для копирования данных из одной таблицы в другую.
- Переходные таблицы.Переходные таблицы – это временные таблицы, которые обычно используются для преобразования данных внутри базы данных. Вы можете использовать эти таблицы, чтобы облегчить процесс загрузки и модифицировать данные во время загрузки.
Производительность операций загрузки
В этом разделе мы рассмотрим три параметра конфигурирования, которые обычно используются для повышения производительности операций загрузки. Два из этих трех параметров влияют на журнальное протоколирование во время операций массового копирования и третий параметр влияет на блокировку. Массовое копирование – это операция, при которой данные копируются большими порциями; копирование данных большими порциями является наиболее эффективным способом для воспроизведения данных.
Два из этих трех параметров влияют на журнальное протоколирование во время операций массового копирования и третий параметр влияет на блокировку. Массовое копирование – это операция, при которой данные копируются большими порциями; копирование данных большими порциями является наиболее эффективным способом для воспроизведения данных.
Параметры журнального протоколирования
SQL Server использует достаточно сложный механизм протоколирования, чтобы исключить потери данных в случае отказа системы. Журнальное протоколирование имеет важное значение для целостности данных в системе, но оно может существенно увеличивать нагрузку на систему. Вы можете снижать эту нагрузку за счет уменьшения количества протоколируемых данных во время массовых загрузок.
Примечание.. После отказа системы SQL Server восстановит базу данных. Для всех транзакций, которые не были фиксированы на момент отказа, будет выполнен откат (отмена). Все транзакции, которые были фиксированы на момент отказа, будут повторно выполнены (восстановлены). Откат и повторное выполнение транзакций возвратят систему в состояние, в котором она находилась перед отказом. (О резервном копировании и восстановлении см.
«Резервное копирование Microsoft SQL Server»
и
«Восстановление
и воспроизведение
базы данных»
.)
Откат и повторное выполнение транзакций возвратят систему в состояние, в котором она находилась перед отказом. (О резервном копировании и восстановлении см.
«Резервное копирование Microsoft SQL Server»
и
«Восстановление
и воспроизведение
базы данных»
.)По умолчанию все операции вставки в базу данных полностью протоколируются, что позволяет выполнить восстановление и откат транзакций в случае отказа системы. Отключая полное протоколирование массового копирования (которое выполняется с помощью программы BCP, оператора BULK INSERT или оператора SELECT…INTO ), вы можете снизить количество протоколируемых данных, но при этом будут поддерживаться только операции отката. Это повысит производительность резервного копирования, но потребует повторного запуска всего процесса загрузки в базу данных в случае отказа системы, поскольку не будет выполняться журнальное протоколирование, которое обычно используется для восстановления базы данных. Этот вариант относится к переходным таблицам, только если вы загружаете эти таблицы с помощью описанных выше методов массового копирования.
Этот вариант относится к переходным таблицам, только если вы загружаете эти таблицы с помощью описанных выше методов массового копирования.
Полное протоколирование этих операций массового копирования отключается при выполнении всех следующих условий:
Еще один параметр базы данных – trunc. log on chkpt – отключает сохранение журнальных записей, когда для этого параметра задано значение TRUE. В этом случае происходит усечение журнала транзакций каждый раз, как встречается контрольная точка. Это повышает производительность массового копирования, но означает, что вы не получите ни повторного выполнения, ни отката в случае отказа системы.
Внимание. Если вы активизируете параметр trunc. log on chkpt (задав для него значение TRUE ), то вам следует делать это, только если вы первоначально загрузили данные в базу данных. Полное отключение протоколирования влияет на всю базу данных и может сделать систему невосстанавливаемой. Таким образом, этот параметр никогда не следует использовать в производственной системе при обычных операциях, когда восстановление важно для системы. Если вы все-таки задали значение TRUE для параметра trunc. log on chkpt, не забудьте отключить его, когда закончите операцию массовой загрузки.
Таким образом, этот параметр никогда не следует использовать в производственной системе при обычных операциях, когда восстановление важно для системы. Если вы все-таки задали значение TRUE для параметра trunc. log on chkpt, не забудьте отключить его, когда закончите операцию массовой загрузки.ВСТАВИТЬ
ВСТАВИТЬДоступно на: DSQL, ESQL, PSQL
Описание: Добавляет строки в таблицу базы данных или в одну или несколько таблиц, лежащих в основе представления. Значения полей могут быть указаны в предложении VALUES, они могут полностью отсутствовать (в обоих случаях вставляется ровно одна строка) или они могут поступать из оператора SELECT (от 0 до многих вставленных строк).
Синтаксис:
ВСТАВИТЬ [ОПЕРАЦИЯнаименование] В {имя таблицы|имя просмотра} {ЗНАЧЕНИЯ ПО УМОЛЧАНИЮ | [(<список_колонок>)]<источник_значения>} [ВОЗВРАЩЕНИЕ<список_значений>[INTO<переменные>]]:: =имя столбца[,имя столбца.<источник_значений>:: = ЗНАЧЕНИЯ (<список_значений>) |<список_значений>:: =значение[,значение...]<переменные>:: =:имя переменной[,:имя переменной...]:: = SELECT, набор результатов которого соответствует целевым столбцамОграничения
Директива TRANSACTION доступна только в ESQL.
Предложение RETURNING недоступно в ESQL.
Подпункт «INTO
<переменные>» доступен только в PSQL.При возврате значений в контекстную переменную NEW перед этим именем не должно стоять двоеточие («
:»).Начиная с версии 2.0, ни один столбец не может появляться в списке вставки более одного раза.
 ..]
..]

ВСТАВИТЬ … ЗНАЧЕНИЯ ПО УМОЛЧАНИЮ
Доступно на: DSQL, PSQL
Добавлено в: 2.1
Описание: Предложение DEFAULT VALUES позволяет вставлять запись вообще без предоставления каких-либо значений, ни напрямую, ни из оператора SELECT. Это возможно только в том случае, если каждый столбец NOT NULL или CHECKed в таблице либо имеет действительное значение по умолчанию, либо получает такое значение от триггера BEFORE INSERT. Кроме того, триггеры, предоставляющие обязательные значения полей, не должны зависеть от наличия входных значений.
Это возможно только в том случае, если каждый столбец NOT NULL или CHECKed в таблице либо имеет действительное значение по умолчанию, либо получает такое значение от триггера BEFORE INSERT. Кроме того, триггеры, предоставляющие обязательные значения полей, не должны зависеть от наличия входных значений.
Пример:
вставить в журнал значения по умолчанию возвращение entry_id
Доступно на: DSQL, PSQL
Добавлено в: 2.0
Изменено в: 2.1
Описание: Оператор INSERT, добавляющий не более одной строки , может дополнительно включать предложение RETURNING для возврата значений из вставленной строки. Предложение, если оно присутствует, не обязательно должно содержать все столбцы вставки.
а также может содержать другие столбцы или выражения. Возвращаемые значения отражают любые изменения, которые могли быть внесены в триггеры BEFORE, но не в триггеры AFTER.
Возвращаемые значения отражают любые изменения, которые могли быть внесены в триггеры BEFORE, но не в триггеры AFTER.
Примеры:
вставить в Scholars (имя, фамилия, адрес, телефон, электронная почта) значения ('Генри', 'Хиггинс', 'Уимпол-стрит, 27A', '3231212', null) возвращение фамилии, полного имени, idвставить в гантели (имя, фамилия, iq) выберите fname, lname, iq из списка друзей по порядку iq строк 1 возвращение id, firstname, iq в: id,: fname,: iq;
Примечания:
RETURNING поддерживается только для вставок VALUES и — начиная с версии 2.1 — вставки singleton SELECT.
В DSQL оператор с предложением RETURNING всегда возвращает ровно одну строку. Если на самом деле запись не была вставлена, все поля в этой строке имеют значение
NULL. Это поведение может измениться в более поздних версиях Firebird. В PSQL, если строка не была вставлена, ничего не возвращается, и
принимающие переменные сохраняют свои существующие значения.
 Это поведение может измениться в более поздних версиях Firebird. В PSQL, если строка не была вставлена, ничего не возвращается, и
принимающие переменные сохраняют свои существующие значения.
Это поведение может измениться в более поздних версиях Firebird. В PSQL, если строка не была вставлена, ничего не возвращается, и
принимающие переменные сохраняют свои существующие значения.UNION разрешен в кормлении SELECT
Изменено на: 2.0
Описание: запрос SELECT, используемый в операторе INSERT, теперь может быть UNION.
Пример:
вставить в Участники (номер, наименование)
выберите номер, имя из NewMembers, где Accepted = 1
союз
выберите номер, имя из SuspendedMembers, где Vindicated = 1 Использование команды INSERT в синтаксисе SPSS
Обычно используются одни и те же переменные (пол, дата рождения и т. Д.)) включены в несколько файлов данных, которые собирает или поддерживает ваш офис. Вместо дублирования синтаксиса в файле синтаксиса для каждого файла данных можно сохранить файл синтаксиса меньшего размера, который, например, только помечает переменную и ее значения, а затем запускать его другими файлами синтаксиса с помощью команды INSERT в SPSS.
Д.)) включены в несколько файлов данных, которые собирает или поддерживает ваш офис. Вместо дублирования синтаксиса в файле синтаксиса для каждого файла данных можно сохранить файл синтаксиса меньшего размера, который, например, только помечает переменную и ее значения, а затем запускать его другими файлами синтаксиса с помощью команды INSERT в SPSS.
Команда INSERT полезна для устранения дублированного синтаксиса и поддержания стандартизированных имен, меток и / или обычно производных переменных, когда некоторые из одинаковых переменных (например, дата рождения, раса или основной возраст) включены в несколько файлов данных.Перед использованием команды INSERT необходимо проделать некоторую работу, чтобы убедиться, что имя и формат переменных, используемых во вставленном синтаксисе, стандартизированы для всех файлов данных, с которыми вы планируете использовать.
Часто лучше, если субфайл синтаксиса (имя, которое я использую для файла синтаксиса, который будет запускаться в другом файле) будет использоваться для работы с одной переменной или связанной группой переменных (например, месяц, день, год рождения), которые всегда встречаются вместе. В приведенном ниже примере суб-файла для переменной Gender я также включаю документацию, чтобы объяснить, какие переменные используются из файла данных, номер словаря данных для переменной (ов) (если применимо), какой синтаксис в суб-файле делает (создает метки, выводит переменные и т. д.)), файлы данных, которые будут использовать этот синтаксис, и создатель файла с датой создания или последнего обновления.
В приведенном ниже примере суб-файла для переменной Gender я также включаю документацию, чтобы объяснить, какие переменные используются из файла данных, номер словаря данных для переменной (ов) (если применимо), какой синтаксис в суб-файле делает (создает метки, выводит переменные и т. д.)), файлы данных, которые будут использовать этот синтаксис, и создатель файла с датой создания или последнего обновления.
Этот суб-файл синтаксиса маркирует как переменную Gender, так и ее текущие значения, а затем создает две производные переменные (D_Gender_MF и D_Gender_MFU), чтобы обеспечить другие способы группировки Gender.
В общем, полезно иметь одно место, такое как общая папка, для создания вашей «Синтаксической библиотеки» синтаксических субфайлов. Ниже приведен пример папки и места, где хранится подфайл «Пол» среди многих других.
Команда INSERT имеет синтаксис:
Если вы вставляете несколько субфайлов, которые хранятся в одной папке, вы можете сократить путь к файлу до имени файла, сначала включив команду CD, которая изменяет местоположение рабочего каталога, или, другими словами, указывает SPSS на поиск в конкретной папке, где будут файлы. Пример команды CD показан в первой строке синтаксиса ниже (обратите внимание, как он соответствует пути к файлу в папке, как показано в кружке в окне выше).
Пример команды CD показан в первой строке синтаксиса ниже (обратите внимание, как он соответствует пути к файлу в папке, как показано в кружке в окне выше).
Синтаксис, показанный выше, является небольшой частью основного файла синтаксиса для большого файла стандартизированных данных. Команда CD направляет SPSS в определенную папку, за которой следует список команд ВСТАВИТЬ ФАЙЛ для каждого субфайла синтаксиса, в том числе для Пола. Если вы сначала не направили его в папку с помощью команды CD, каждая команда INSERT FILE потребовала бы каждый раз указывать полный путь к местоположению файла, например: INSERT FILE = ‘P: \ SPSS Syntax Library \ Variables \ Пол.sps ’.
Когда запускается основной файл синтаксиса, он открывает и запускает все подфайлы синтаксиса. Результат выглядит немного иначе, но все равно будут отображаться ошибки и отмечаться любые проблемы, как обычно. Ниже приведен пример выходных данных для подфайла синтаксиса «Пол» после использования команд CD и INSERT.
Вставить в SQL: добавить данные (учебное пособие по MySQL)
После того, как вы создали таблицу, вам нужно добавить в нее данные. Если вы используете phpMyAdmin, вы можете ввести эту информацию вручную.Сначала выберите человек , название вашего стола указано слева. Затем с правой стороны выберите вкладку под названием , вставьте и введите данные, как показано. Вы можете просмотреть свою работу, выбрав человек , а затем вкладку просмотра .
Вставить в SQL — Добавить данные
Анджела Брэдли
Более быстрый способ — добавить данные из окна запроса (выберите значок SQL в phpMyAdmin) или из командной строки, набрав:
ВСТАВИТЬ В людей ЦЕННОСТИ («Джим», 45, 1.75, «02.02.2006, 15:35:00»), («Пегги», 6, 1.12, «2006-03-02 16:21:00»)
Это вставляет данные прямо в таблицу «люди» в указанном порядке. Если вы не уверены, в каком порядке находятся поля в базе данных, вы можете использовать вместо этого эту строку:
Если вы не уверены, в каком порядке находятся поля в базе данных, вы можете использовать вместо этого эту строку:
INSERT INTO люди (имя, дата, рост, возраст) VALUES ("Джим", "2006-02-02 15:35:00", 1.27, 45) Здесь мы сначала сообщаем базе данных порядок отправки значений, а затем фактические значения.
Команда обновления SQL — обновление данных
Анджела Брэдли
Часто бывает необходимо изменить данные, которые есть в вашей базе данных.Предположим, что Пегги (из нашего примера) пришла в гости в свой 7-й день рождения, и мы хотим заменить ее старые данные новыми данными. Если вы используете phpMyAdmin, вы можете сделать это, выбрав свою базу данных слева (в нашем случае человек ), а затем выбрав «Обзор» справа. Рядом с именем Пегги вы увидите значок карандаша; это означает ИЗМЕНИТЬ. Выберите карандаш . Теперь вы можете обновить ее информацию, как показано.
Вы также можете сделать это через окно запроса или командную строку.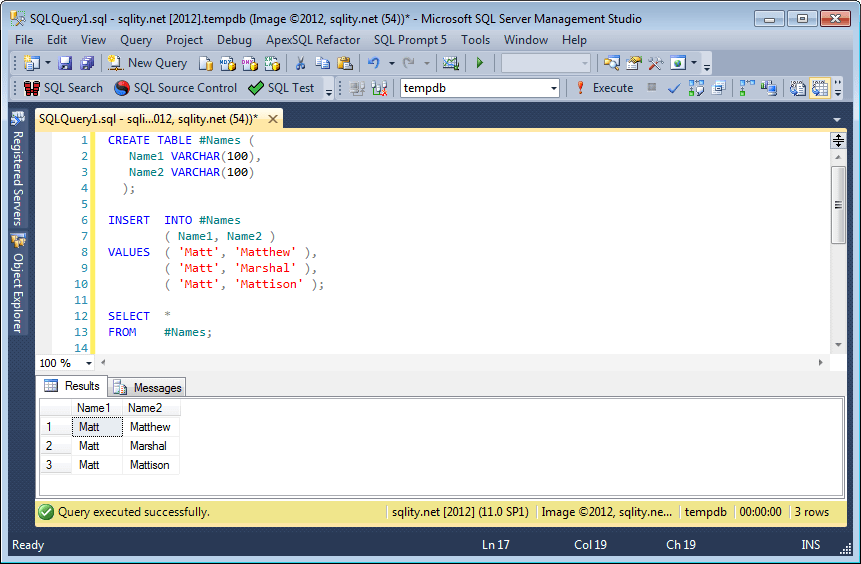 Вы должны быть очень осторожны при обновлении записей таким образом и дважды проверять свой синтаксис, так как очень легко случайно перезаписать несколько записей.
Вы должны быть очень осторожны при обновлении записей таким образом и дважды проверять свой синтаксис, так как очень легко случайно перезаписать несколько записей.
ОБНОВЛЕНИЕ людей УСТАНОВИТЕ age = 7, date = "2006-06-02 16:21:00", height = 1.22 WHERE name = "Peggy"
Это обновляет таблицу «люди», устанавливая новые значения для возраста, даты и роста. Важной частью этой команды является WHERE , которая гарантирует, что информация обновляется только для Пегги, а не для каждого пользователя в базе данных.
Оператор выбора SQL — поиск данных
Анджела Брэдли
Хотя в нашей тестовой базе данных всего две записи, и все легко найти, по мере роста базы данных полезно иметь возможность быстро искать информацию. В phpMyAdmin вы можете сделать это, выбрав свою базу данных, а затем выбрав вкладку search . Показан пример поиска всех пользователей младше 12 лет.
В нашем примере базы данных это вернуло только один результат — Пегги.
Чтобы выполнить тот же поиск из окна запроса или командной строки, мы должны ввести:
ВЫБРАТЬ * ИЗ людей ГДЕ возраст <12
Это означает ВЫБРАТЬ * (все столбцы) из таблицы «люди», ГДЕ поле «возраст» имеет число меньше 12.
Если бы мы хотели видеть только имена людей младше 12 лет, мы могли бы запустить это вместо этого:
ВЫБЕРИТЕ имя ОТ людей ГДЕ возраст <12
Это может быть более полезным, если ваша база данных содержит множество полей, не имеющих отношения к тому, что вы сейчас ищете.
Оператор удаления SQL - удаление данных
Часто вам нужно удалить старую информацию из базы данных. Вы должны быть очень осторожны, , , когда делаете это, потому что как только он исчез, он исчезнет. При этом, когда вы находитесь в phpMyAdmin, вы можете удалить информацию несколькими способами. Сначала выберите базу данных слева. Один из способов удалить записи - выбрать вкладку просмотра справа. Рядом с каждой записью вы увидите красный крестик. При выборе X запись будет удалена. Чтобы удалить несколько записей, вы можете установить флажки в крайнем левом углу, а затем нажать красный крестик внизу страницы.
Еще вы можете выбрать вкладку поиск . Здесь вы можете выполнить поиск. Допустим, у врача в нашей базе данных примера появился новый партнер, который является педиатром. Он больше не будет видеть детей, поэтому всех младше 12 лет нужно удалить из базы данных. Вы можете выполнить поиск людей младше 12 лет на этом экране поиска. Все результаты теперь отображаются в формате просмотра, где вы можете удалить отдельные записи с красным крестиком или проверить несколько записей и выбрать красный X внизу экрана.
Удалить данные с помощью поиска из окна запроса или командной строки очень просто, но, пожалуйста, будьте осторожны :
УДАЛИТЬ ОТ людей ГДЕ возрастом <12
Если таблица больше не нужна, вы можете удалить всю таблицу, выбрав вкладку Drop в phpMyAdmin или запустив эту строку:
DROP TABLE человек
Примеры запросов приложений Microsoft Access и синтаксис запросов SQL INSERT
Запрос INSERT добавляет записи в конец таблицы.
Запрос на добавление нескольких записей
INSERT INTO target [(field1 [, field2 [,]])] [IN externalDB] ВЫБЕРИТЕ [источник.] Поле1 [, поле2 [,]] ИЗ источника [присоединиться] ГДЕ критерии
Оператор UPDATE состоит из следующих частей:
| цель | Имя таблицы для вставки (добавления) новых записей |
| полей | Имена полей для получения новых значений (порядок должен соответствовать полям в разделе источника SELECT) |
| внешний DB | Предложение IN используется, если данные попадают в таблицу. в другой базе данных.Необходимо указать полный путь к базе данных в кавычках. |
| исходные поля | Подобно стандартному оператору SELECT, список полей здесь должен соответствовать порядку полей в целевой список полей (также можно заменить запросом) |
| присоединиться | Предложение JOIN при связывании с другой таблицей (ами), чтобы указать, какие записи извлекаются |
| критерии | Выражение, определяющее, какие записи обновляются.Обновляются только записи, удовлетворяющие выражению. |
Запрос на добавление отдельной записи
Вы также можете использовать запрос INSERT для добавления одной записи в таблицу без данных, поступающих из таблицы. Указать имя и значение для каждого поля добавляемой записи. Если вы не укажете поле, в него будет вставлено значение по умолчанию или Null.
INSERT INTO target [(field1 [, field2 [,]])] ЗНАЧЕНИЯ (значение1 [, значение2 [,]])
Примечания (от Microsoft)
Вы также можете использовать INSERT INTO для добавления набора записей из другой таблицы или запроса с помощью SELECT... FROM, как показано выше в синтаксис запроса на добавление нескольких записей. В этом случае предложение SELECT указывает поля, которые нужно добавить в указанную целевую таблицу. Исходная или целевая таблица может указывать на таблицу или запрос.
Если запрос указан, ядро базы данных Microsoft Access добавляет записи во все таблицы. указанный запросом. INSERT INTO не является обязательным, но если он включен, он предшествует оператору SELECT.
Если ваша целевая таблица содержит первичный ключ, убедитесь, что вы добавили уникальные, ненулевые значения в поле или поля первичного ключа; если вы этого не сделаете, ядро базы данных Microsoft Access не добавит записи.Если вы добавляете записи в таблицу с полем AutoNumber и хотите изменить нумерацию добавленных записи, не включайте поле AutoNumber в свой запрос. Включите поле AutoNumber в запрос, если вы хотите сохранить исходные значения из поля.
Используйте предложение IN для добавления записей в таблицу в другой базе данных. Чтобы создать новую таблицу, используйте SELECT ... INTO вместо этого для создания запрос make-table. Чтобы узнать, какие записи будут добавлены, прежде чем вы запустите запрос на добавление, сначала выполните и просмотрите результаты запроса на выборку, в котором используются те же критерии выбора.Запрос на добавление копирует записи из одной или нескольких таблиц в другую. Таблицы, содержащие добавляемые вами записи, не подвержены влиянию добавить запрос. Вместо добавления существующих записей из другой таблицы вы можете указать значение для каждого поля. в одной новой записи с помощью предложения VALUES. Если вы опустите список полей, предложение VALUES должно включать значение для каждого поля в таблице; в противном случае операция INSERT завершится ошибкой. Используйте дополнительный INSERT INTO с предложением VALUES для каждой дополнительной записи, которую вы хотите создать.
Важно
- Чтобы избежать ситуаций, когда имя поля конфликтует с зарезервированным словом или если в именах полей есть пробелы, используйте квадратные скобки вокруг них.
- Вы можете просмотреть запрос перед его запуском, переключившись на таблицу данных. Для INSERT запросы, поля и добавляемые данные отображаются.
Использование оператора массовой вставки в MySQL
Использование инструкции массовой вставки
Оператор INSERT в MySQL также поддерживает использование синтаксиса VALUES для вставки нескольких строк в качестве оператора массовой вставки.Для этого включите несколько списков значений столбцов, каждый из которых заключен в круглые скобки и разделен запятыми.
Красота этого заключается в его способности вставлять несколько записей в MySQL в одном операторе вставки, который по умолчанию используется в одной транзакции, и как таковые, вставка этих записей либо успешна, либо неудачна. Это избавляет нас от кодирования нескольких операторов вставки и создания нескольких туда и обратно на сервер MySQL для вставок.
Для eaxmple ниже представлен оператор массовой вставки для таблицы shippers в нашей популярной базе данных Northwind.
вставить в значения `shippers` (` ShipperID`, `CompanyName`,` Phone`)
(1, 'Speedy Express', '(503) 555-9831'),
(2, 'United Package', '( 503) 555-3199 '),
(3, «Федеральное пароходство», «(503) 555-9931»);
По сравнению со следующими 3 сценариями SQL, оператор массовой вставки более эффективен.
вставить в `shippers` (` ShipperID`, `CompanyName`,` Phone`)
значений (1, 'Speedy Express', '(503) 555-9831'); вставить в `shippers` (` ShipperID`, ` CompanyName`, `Phone`)
значений (2, 'United Package', '(503) 555-3199'); вставить в` shippers` (`ShipperID`,` CompanyName`, `Phone`)
значений (3, «Федеральное пароходство», «(503) 555-9931»);
Настроить max_allowed_packet
Один из практических примеров использования оператора массовой вставки показан в этой статье Как загрузить IP-адреса стран в вашу базу данных MySQL.Таблица IPCountry экспортируется как оператор массовой вставки SQL и автоматически разбивается на несколько строк операторов массовой вставки по уважительной причине - ограничить размер каждого оператора вставки в max_allowed_packet.
Когда клиент MySQL или сервер mysqld получает пакет, размер которого превышает max_allowed_packet байтов, он выдает ошибку «Пакет слишком большой» и закрывает соединение. (Пакет связи - это один оператор SQL, отправляемый на сервер MySQL, одна строка, отправляемая клиенту, или событие двоичного журнала, отправляемое с главного сервера репликации на подчиненное устройство.)
Если вам нужно вставить пару сотен тысяч строк, не кодируйте их в один оператор массовой вставки. В противном случае скорее всего вы получите ошибку превышения максимально допустимого размера пакета в MySQL - пакеты больше чем max_allowed_packet не допускаются.
Чтобы просмотреть значение по умолчанию для переменной max_allowed_packet, выполните следующую команду в MySQL:
показывает такие переменные, как 'max_allowed_packet';
Стандартная установка MySQL имеет значение по умолчанию 1048576 байт (1 МБ).Его можно увеличить, установив более высокое значение для сеанс или соединение.
Это устанавливает значение 500 МБ для всех (это то, что означает GLOBAL):
УСТАНОВИТЬ ГЛОБАЛЬНЫЙ max_allowed_packet = 524288000;
Затем вы можете запустить команду show GLOBAL variables, чтобы проверить, изменилось ли значение.
показывает ГЛОБАЛЬНЫЕ переменные, такие как 'max_allowed_packet';
Или запустите эту команду show variables в новом соединении (например, повторно откройте свой клиентский инструмент).
показывает такие переменные, как 'max_allowed_packet';
Проблема с использованием приведенной выше команды заключается в том, что при перезапуске сервера MySQL max_allowed_packet сбрасывается до значения по умолчанию. К навсегда измените max_allowed_packet, отредактируйте файл конфигурации my.ini под [mysqld] в СЕКЦИИ СЕРВЕРА. Либо добавьте одну строку в [mysqld] или отредактируйте его значение, если в вашем my.ini уже есть эта строка. Затем перезапустите службу MySQL, чтобы это значение вступило в силу.
По словам MySQL, можно безопасно увеличивать значение этой переменной, потому что дополнительная память выделяется только при необходимости.Например, mysqld выделяет больше памяти только тогда, когда вы выдаете длинный запрос или когда mysqld должен вернуть большую строку результата. Небольшое значение переменной по умолчанию является мерой предосторожности для перехвата неправильных пакетов между клиентом и сервером, а также для предотвращения нехватки памяти из-за случайного использования больших пакетов.
Удачного кодирования!
Другие руководства в этой категории
1. Оператор обновления в MySQL
2. Как обновлять данные в определенном порядке в MySQL
3.Как обновить верхние N строк данных в MySQL
4. Использовать внешнее объединение в обновлении
5. Как выполнить обновление кросс-таблицы в MySQL - Часть 1
6. Как выполнить обновление кросс-таблицы в MySQL - Часть 2
7. Базовый оператор вставки
8. Как создать и использовать столбец AUTO_INCREMENT и использовать функцию LAST_INSERT_ID
9. Объединить обновление и вставить в один оператор
10. Использование MySQL REPLACE (INTO) для имитации DELETE + INSERT
Вернуться к странице указателя учебного пособия
Element.insertAdjacentElement () - Веб-API | MDN
Метод insertAdjacentElement () Элемент интерфейса вставляет заданный узел элемента в заданную позицию
относительно элемента, к которому он применяется.
targetElement.insertAdjacentElement (позиция, элемент); Параметры
-
позиция - A
DOMString, представляющая положение относительноtargetElement; должен соответствовать (без учета регистра) одному из следующих струны:-
«до начала»: доtargetElementсам. -
'afterbegin': прямо внутриtargetElementдо своего первого дочернего элемента. -
'beforeend': прямо внутриtargetElement, после его последнего дочернего элемента. -
'afterend': ПослеtargetElementсам.
-
-
элемент - Элемент, который нужно вставить в дерево.
Возвращаемое значение
Элемент, который был вставлен, или null , если вставка не удалась.
Исключения
| Исключение | Пояснение |
|---|---|
SyntaxError | Указанная позиция не является распознанным значением. |
Тип Ошибка | Указанный элемент не является допустимым элементом. |
Визуализация названий позиций
перед началом->
после начала-> фуперед->после->
Примечание: до начала и afterend позиций работают, только если узел находится в дереве и имеет элемент
родитель.
beforeBtn.addEventListener ('click', function () {
var tempDiv = document.createElement ('div');
tempDiv.style.backgroundColor = randomColor ();
if (activeElem) {
activeElem.insertAdjacentElement ('до начала', tempDiv);
}
setListener (tempDiv);
});
afterBtn.addEventListener ('щелчок', function () {
var tempDiv = document.createElement ('div');
tempDiv.style.backgroundColor = randomColor ();
if (activeElem) {
activeElem.insertAdjacentElement ('afterend', tempDiv);
}
setListener (tempDiv);
}); Взгляните на наш insertAdjacentElement.html
демо на GitHub (см. источник
код тоже.) Здесь у нас есть последовательность элементов Таблицы BCD загружаются только в браузере Этот пост представляет собой руководство по запросам BigQuery INSERT и UPDATE. Google BigQuery - это полностью управляемая служба хранилища данных. Он имеет комплексный уровень запросов с самыми современными возможностями обработки и временем отклика. BigQuery помогает клиентам испытать мощное хранилище данных, не тратя деньги на его разработку и обслуживание. BigQuery предлагается на основе модели с оплатой по факту. Помимо стандартных функций хранилища данных, BigQuery также предлагает множество вспомогательных функций. BigQuery ML помогает пользователям запускать модели для данных BigQuery с помощью запросов SQL.Связанные листы помогают пользователям анализировать данные в BigQuery с помощью Google Таблиц. Помимо данных, находящихся в собственном хранилище, BigQuery также может получать доступ к данным из различных других мест, включая Google Диск, Cloud SQL и т. Д. Вот общее описание того, что мы рассмотрим в этом блоге: Hevo предлагает более быстрый способ перемещения данных из баз данных или приложений SaaS в ваше хранилище данных для визуализации в инструменте бизнес-аналитики. Hevo полностью автоматизирован и, следовательно, не требует программирования. Ознакомьтесь с некоторыми интересными функциями Hevo: Вы можете попробовать Hevo бесплатно, подписавшись на 14-дневную бесплатную пробную версию. Поскольку BigQuery - это служба хранилища данных, уровень запросов играет большую роль в ее приемлемости для вариантов использования. Операторы обработки данных в BigQuery - это неявные транзакции, то есть они фиксируются автоматически. В BigQuery нет поддержки транзакций с несколькими операторами. Еще одно интересное поведение - это возможность одновременно выполнять запросы манипулирования данными.Это означает, что одновременное выполнение инструкций, которые конфликтуют друг с другом, может вызвать ошибки и привести к сбою. Теперь, когда вы узнали об основах BigQuery DML, давайте определим схему в BigQuery, которую можно будет использовать в оставшейся части руководства. Рассмотрим следующие три таблицы для нашего руководства по BigQuery Выходной стол Биржевой стол Таблица StockDetails Теперь вы изучите основные конструкции оператора INSERT для взаимодействия с приведенными выше определениями таблиц. Запрос INSERT следует стандартному синтаксису SQL. Вставляемые значения следует использовать в том же порядке, что и столбцы. Вы можете выполнить базовый запрос INSERT со столбцами, указанными ниже. Запрос INSERT без указания столбцов может быть выполнен, как показано ниже. Запрос INSERT с использованием подзапроса может быть выполнен следующим образом. BigQuery также поддерживает ключевое слово WITH в синтаксисе QUERY. Здесь следует отметить неявное отображение типов данных, которое выполняется BigQuery в случае операторов INSERT. Это может привести к повреждению баз данных, если пользователь не будет осторожен. BigQuery выдаст ошибку из-за несоответствия типа данных только в тех случаях, когда входящий столбец не может быть преобразован в тип данных целевого столбца. В случае BigQuery каждый оператор UPDATE должен включать предложение WHERE. Это обеспечивает защиту от массовых ошибочных обновлений, если разработчик случайно забыл предложение WHERE. Чтобы обновить полную таблицу, вы должны отдельно указать WHERE TRUE. Самый простой пример ОБНОВЛЕНИЯ будет выглядеть, как показано ниже. Чтобы обновить записи с помощью операции сопоставления строк, запрос будет следующим. Приведенный выше оператор обновит цвет всех записей, в названии которых содержится «Примечание». Оператор Update, использующий предложение JOIN, может выполняться, как показано ниже. Приведенный выше запрос обновляет цвет всех записей, принадлежащих определенному магазину. Должно использоваться явное ключевое слово JOIN в случае, если JOIN находится между таблицами, которые не обновляются. Пример будет следующим. Приведенная выше команда установит количество как 10 для всех товаров во всех торговых точках, принадлежащих локации «Нью-Йорк». Это охватывает основы операторов INSERT и UPDATE в BigQuery. При реализации конвейера ETL для синхронизации данных между транзакционными базами данных и хранилищем данных можно использовать автоматизированный запланированный сценарий, использующий вышеуказанные конструкции. Реализация такого сценария сопряжена с гораздо большей сложностью из-за наличия многих факторов, таких как повторяющиеся строки, перевод типов данных и т. Д. Но есть альтернатива. Это использование полностью управляемого инструмента ETL, такого как Hevo, который может легко выполнять передачу данных между различными источниками и местами назначения. Hevo абстрагирует все болевые точки и ограничения, упомянутые выше. Кроме того, отказоустойчивые алгоритмы Hevo автоматически обрабатывают любые ошибки в потоке данных, тем самым гарантируя, что на вашем складе всегда будут актуальные данные. Hevo избавляет вас от дополнительных сложностей, связанных с написанием и обслуживанием пользовательских сценариев для перемещения данных из множества источников данных. Hevo изначально интегрируется с приложениями для продаж и маркетинга, приложениями для аналитики, базами данных и т. Д., Что позволяет вашей организации эффективно создавать корпоративное хранилище данных бизнес-аналитики. Используя инструмент интеграции данных вместо того, чтобы писать код самостоятельно, вы можете сэкономить время и деньги ваших инженеров, поскольку вы позволите им сосредоточиться на других дополнительных действиях. Подпишитесь на 14-дневную бесплатную пробную версию Hevo и испытайте беспрепятственный перенос данных из Google BigQuery. Вот краткий обзор Hevo: Поделитесь своими мыслями о запросах BigQuery INSERT и UPDATE. insertAdjacentElement () . Операторы вставки и обновления BigQuery: подробное руководство - изучение
Введение
Предварительные требования
Общие сведения о BigQuery SQL
[
{"name": "название_вывода", "type": "строка"},
{"имя": "местоположение", "тип": "строка"}
]
[
{"name": "product", "type": "string"},
{"имя": "количество", "тип": "целое число"},
{"имя": "розетка", "тип": "строка"}
]
[
{"name": "product", "type": "string"},
{"имя": "цвет", "тип": "строка"},
{"имя": "цена", "тип": "строка"},
{"name": "expiry_months", "type": "integer"},
] Заявления и примеры использования BigQuery INSERT
ВСТАВИТЬ В набор данных. StockDetails (название, цена) ЗНАЧЕНИЯ («Samsung Galaxy Note 10,’ 999 ’’)
ВСТАВИТЬ В набор данных. StockDetails ЗНАЧЕНИЯ (‘SG Note 10’, ’Mystic Black’, ’999’, ’24’)
ВСТАВИТЬ В dataset.stockDetails (продукт, цвет) ЗНАЧЕНИЯ («SG Note 10», ВЫБРАТЬ цвет из набора данных. StockDetails ГДЕ продукт = «Samsung Galaxy Note 20») Заявления и примеры использования BigQuery UPDATE
ОБНОВЛЕНИЕ набора данных. StockDetails SET color = «Mystic Green» ГДЕ продукт = ’SG Note 20 Ultra’
ОБНОВИТЬ набор данных. StockDetails SET color = «Mystic Green» ГДЕ продукт КАК «% Note%»
ОБНОВИТЬ набор данных. StockDetails a SET color = ‘black’ FROM dataset.Stock b WHERE a.product = b.product AND b.outlet = ‘central_park’
ОБНОВИТЬ набор данных. StockDetails SET количество = ’10 ’ИЗ набора данных. Stock INNER JOIN datasetset. Store on Stock.outlet = Outlet. Outlet_name ГДЕ StockDetails.product = Stock.product и Outlet.location = «Нью-Йорк» Использование Hevo