Разработка надёжных Python-скриптов / Хабр
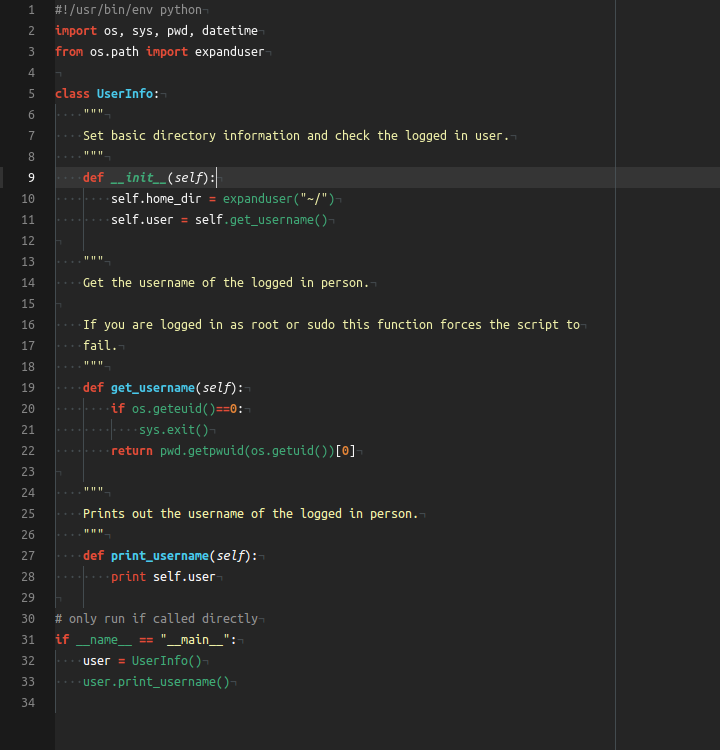
Python — это язык программирования, который отлично подходит для разработки самостоятельных скриптов. Для того чтобы добиться с помощью подобного скрипта желаемого результата, нужно написать несколько десятков или сотен строк кода. А после того, как дело сделано, можно просто забыть о написанном коде и перейти к решению следующей задачи.Если, скажем, через полгода после того, как был написан некий «одноразовый» скрипт, кто-то спросит его автора о том, почему этот скрипт даёт сбои, об этом может не знать и автор скрипта. Происходит подобное из-за того, что к такому скрипту не была написана документация, из-за использования параметров, жёстко заданных в коде, из-за того, что скрипт ничего не логирует в ходе работы, и из-за отсутствия тестов, которые позволили бы быстро понять причину проблемы.
При этом надо отметить, что превратить скрипт, написанный на скорую руку, в нечто гораздо более качественное, не так уж и сложно. А именно, такой скрипт довольно легко превратить в надёжный и понятный код, которым удобно пользоваться, в код, который просто поддерживать как его автору, так и другим программистам.
А именно, такой скрипт довольно легко превратить в надёжный и понятный код, которым удобно пользоваться, в код, который просто поддерживать как его автору, так и другим программистам.
Автор материала, перевод которого мы сегодня публикуем, собирается продемонстрировать подобное «превращение» на примере классической задачи «Fizz Buzz Test». Эта задача заключается в том, чтобы вывести список чисел от 1 до 100, заменив некоторые из них особыми строками. Так, если число кратно 3 — вместо него нужно вывести строку Fizz, если число кратно 5 — строку Buzz, а если соблюдаются оба этих условия — FizzBuzz.
Исходный код
Вот исходный код Python-скрипта, который позволяет решить задачу:import sys
for n in range(int(sys.argv[1]), int(sys.argv[2])):
if n % 3 == 0 and n % 5 == 0:
print("fizzbuzz")
elif n % 3 == 0:
print("fizz")
elif n % 5 == 0:
print("buzz")
else:
print(n)
Поговорим о том, как его улучшить.
Документация
Я считаю, что полезно писать документацию до написания кода. Это упрощает работу и помогает не затягивать создание документации до бесконечности. Документацию к скрипту можно поместить в его верхнюю часть. Например, она может выглядеть так:#!/usr/bin/env python3 """Simple fizzbuzz generator. This script prints out a sequence of numbers from a provided range with the following restrictions: - if the number is divisible by 3, then print out "fizz", - if the number is divisible by 5, then print out "buzz", - if the number is divisible by 3 and 5, then print out "fizzbuzz". """
Аргументы командной строки
Следующей задачей по улучшению скрипта станет замена значений, жёстко заданных в коде, на документированные значения, передаваемые скрипту через аргументы командной строки. Реализовать это можно с использованием модуля argparse. В нашем примере мы предлагаем пользователю указать диапазон чисел и указать значения для «fizz» и «buzz», используемые при проверке чисел из указанного диапазона.
В нашем примере мы предлагаем пользователю указать диапазон чисел и указать значения для «fizz» и «buzz», используемые при проверке чисел из указанного диапазона.import argparse
import sys
class CustomFormatter(argparse.RawDescriptionHelpFormatter,
argparse.ArgumentDefaultsHelpFormatter):
pass
def parse_args(args=sys.argv[1:]):
"""Parse arguments."""
parser = argparse.ArgumentParser(
description=sys.modules[__name__].__doc__,
formatter_class=CustomFormatter)
g = parser.add_argument_group("fizzbuzz settings")
g.add_argument("--fizz", metavar="N",
default=3,
type=int,
help="Modulo value for fizz")
g.add_argument("--buzz", metavar="N",
default=5,
type=int,
help="Modulo value for buzz")
parser.add_argument("start", type=int, help="Start value")
parser.add_argument("end", type=int, help="End value")
return parser.
parse_args(args)
options = parse_args()
for n in range(options.start, options.end + 1):
# ...
Эти изменения приносят скрипту огромную пользу. А именно, параметры теперь надлежащим образом документированы, выяснить их предназначение можно с помощью флага 
--help. Более того, по соответствующей команде выводится и документация, которую мы написали в предыдущем разделе:$ ./fizzbuzz.py --help usage: fizzbuzz.py [-h] [--fizz N] [--buzz N] start end Simple fizzbuzz generator. This script prints out a sequence of numbers from a provided range with the following restrictions: - if the number is divisible by 3, then print out "fizz", - if the number is divisible by 5, then print out "buzz", - if the number is divisible by 3 and 5, then print out "fizzbuzz". positional arguments: start Start value end End value optional arguments: -h, --help show this help message and exit fizzbuzz settings: --fizz N Modulo value for fizz (default: 3) --buzz N Modulo value for buzz (default: 5)
argparse — это весьма мощный инструмент.
Логирование
Если оснастить скрипт возможностями по выводу некоей информации в ходе его выполнения — это окажется приятным дополнением к его функционалу. Для этой цели хорошо подходит модуль logging. Для начала опишем объект, реализующий логирование:import logging import logging.handlers import os import sys logger = logging.getLogger(os.path.splitext(os.path.basename(sys.argv[0]))[0])Затем сделаем так, чтобы подробностью сведений, выводимых при логировании, можно было бы управлять. Так, команда
logger.debug()--debug. Если же скрипт запускают с ключом --silent — скрипт не должен выводить ничего кроме сообщений об исключениях. Для реализации этих возможностей добавим в parse_args() следующий код:# В parse_args() g = parser.
 add_mutually_exclusive_group()
g.add_argument("--debug", "-d", action="store_true",
default=False,
help="enable debugging")
g.add_argument("--silent", "-s", action="store_true",
default=False,
help="don't log to console")
add_mutually_exclusive_group()
g.add_argument("--debug", "-d", action="store_true",
default=False,
help="enable debugging")
g.add_argument("--silent", "-s", action="store_true",
default=False,
help="don't log to console")def setup_logging(options):
"""Configure logging."""
root = logging.getLogger("")
root.setLevel(logging.WARNING)
logger.setLevel(options.debug and logging.DEBUG or logging.INFO)
if not options.silent:
ch = logging.StreamHandler()
ch.setFormatter(logging.Formatter(
"%(levelname)s[%(name)s] %(message)s"))
root.addHandler(ch)
Основной код скрипта при этом изменится так:if __name__ == "__main__":
options = parse_args()
setup_logging(options)
try:
logger.debug("compute fizzbuzz from {} to {}".format(options.start,
options. end))
for n in range(options.start, options.end + 1):
# ..
except Exception as e:
logger.exception("%s", e)
sys.exit(1)
sys.exit(0)
Если скрипт планируется запускать без прямого участия пользователя, например, с помощью 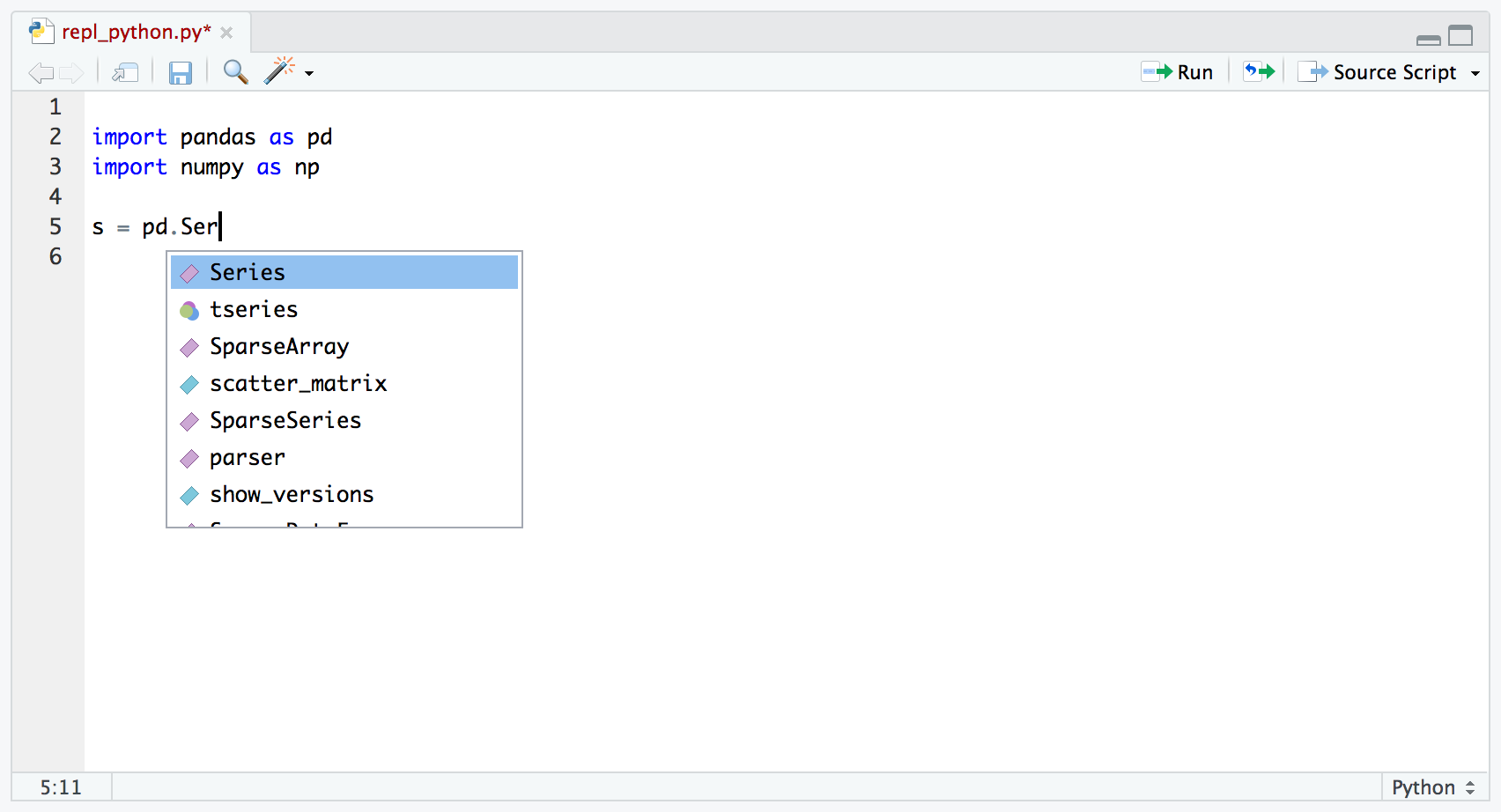
crontab, можно сделать так, чтобы его вывод поступал бы в syslog:def setup_logging(options):
"""Configure logging."""
root = logging.getLogger("")
root.setLevel(logging.WARNING)
logger.setLevel(options.debug and logging.DEBUG or logging.INFO)
if not options.silent:
if not sys.stderr.isatty():
facility = logging.handlers.SysLogHandler.LOG_DAEMON
sh = logging.handlers.SysLogHandler(address='/dev/log',
facility=facility)
sh.setFormatter(logging.Formatter(
"{0}[{1}]: %(message)s".format(
logger.name,
os.getpid())))
root. addHandler(sh)
else:
ch = logging.StreamHandler()
ch.setFormatter(logging.Formatter(
"%(levelname)s[%(name)s] %(message)s"))
root.addHandler(ch)
В нашем небольшом скрипте неоправданно большим кажется подобный объём кода, нужный только для того, чтобы воспользоваться командой 
logger.debug(). Но в реальных скриптах этот код уже таким не покажется и на первый план выйдет польза от него, заключающаяся в том, что с его помощью пользователи смогут узнавать о ходе решения задачи.$ ./fizzbuzz.py --debug 1 3 DEBUG[fizzbuzz] compute fizzbuzz from 1 to 3 1 2 fizz
Тесты
Модульные тесты — это полезнейшее средство для проверки того, ведёт ли себя приложения так, как нужно. В скриптах модульные тесты используют нечасто, но их включение в скрипты значительно улучшает надёжность кода. Преобразуем код, находящийся внутри цикла, в функцию, и опишем несколько интерактивных примеров её использования в её документации:def fizzbuzz(n, fizz, buzz): """Compute fizzbuzz nth item given modulo values for fizz and buzz.
 >>> fizzbuzz(5, fizz=3, buzz=5)
'buzz'
>>> fizzbuzz(3, fizz=3, buzz=5)
'fizz'
>>> fizzbuzz(15, fizz=3, buzz=5)
'fizzbuzz'
>>> fizzbuzz(4, fizz=3, buzz=5)
4
>>> fizzbuzz(4, fizz=4, buzz=6)
'fizz'
"""
if n % fizz == 0 and n % buzz == 0:
return "fizzbuzz"
if n % fizz == 0:
return "fizz"
if n % buzz == 0:
return "buzz"
return n
>>> fizzbuzz(5, fizz=3, buzz=5)
'buzz'
>>> fizzbuzz(3, fizz=3, buzz=5)
'fizz'
>>> fizzbuzz(15, fizz=3, buzz=5)
'fizzbuzz'
>>> fizzbuzz(4, fizz=3, buzz=5)
4
>>> fizzbuzz(4, fizz=4, buzz=6)
'fizz'
"""
if n % fizz == 0 and n % buzz == 0:
return "fizzbuzz"
if n % fizz == 0:
return "fizz"
if n % buzz == 0:
return "buzz"
return npytest:$ python3 -m pytest -v --doctest-modules ./fizzbuzz.py ============================ test session starts ============================= platform linux -- Python 3.7.4, pytest-3.10.1, py-1.8.0, pluggy-0.8.0 -- /usr/bin/python3 cachedir: .pytest_cache rootdir: /home/bernat/code/perso/python-script, inifile: plugins: xdist-1.26.1, timeout-1.3.3, forked-1.0.2, cov-2.6.0 collected 1 item fizzbuzz.py::fizzbuzz.fizzbuzz PASSED [100%] ========================== 1 passed in 0.Для того чтобы всё это заработало, нужно, чтобы после имени скрипта шло бы расширение05 seconds ==========================
.py. Мне не нравится добавлять расширения к именам скриптов: язык — это лишь техническая деталь, которую не нужно демонстрировать пользователю. Однако возникает такое ощущение, что оснащение имени скрипта расширением — это самый простой способ позволить системам для запуска тестов, вроде pytest, находить тесты, включённые в код.В случае возникновения ошибки pytest выведет сообщение, указывающее на расположение соответствующего кода и на суть проблемы:
$ python3 -m pytest -v --doctest-modules ./fizzbuzz.py -k fizzbuzz.fizzbuzz ============================ test session starts ============================= platform linux -- Python 3.7.4, pytest-3.10.1, py-1.8.0, pluggy-0.8.0 -- /usr/bin/python3 cachedir: .pytest_cache rootdir: /home/bernat/code/perso/python-script, inifile: plugins: xdist-1.26.1, timeout-1.Модульные тесты можно писать и в виде обычного кода. Представим, что нам нужно протестировать следующую функцию:
 3.3, forked-1.0.2, cov-2.6.0
collected 1 item
fizzbuzz.py::fizzbuzz.fizzbuzz FAILED [100%]
================================== FAILURES ==================================
________________________ [doctest] fizzbuzz.fizzbuzz _________________________
100
101 >>> fizzbuzz(5, fizz=3, buzz=5)
102 'buzz'
103 >>> fizzbuzz(3, fizz=3, buzz=5)
104 'fizz'
105 >>> fizzbuzz(15, fizz=3, buzz=5)
106 'fizzbuzz'
107 >>> fizzbuzz(4, fizz=3, buzz=5)
108 4
109 >>> fizzbuzz(4, fizz=4, buzz=6)
Expected:
fizz
Got:
4
/home/bernat/code/perso/python-script/fizzbuzz.py:109: DocTestFailure
========================== 1 failed in 0.02 seconds ==========================
3.3, forked-1.0.2, cov-2.6.0
collected 1 item
fizzbuzz.py::fizzbuzz.fizzbuzz FAILED [100%]
================================== FAILURES ==================================
________________________ [doctest] fizzbuzz.fizzbuzz _________________________
100
101 >>> fizzbuzz(5, fizz=3, buzz=5)
102 'buzz'
103 >>> fizzbuzz(3, fizz=3, buzz=5)
104 'fizz'
105 >>> fizzbuzz(15, fizz=3, buzz=5)
106 'fizzbuzz'
107 >>> fizzbuzz(4, fizz=3, buzz=5)
108 4
109 >>> fizzbuzz(4, fizz=4, buzz=6)
Expected:
fizz
Got:
4
/home/bernat/code/perso/python-script/fizzbuzz.py:109: DocTestFailure
========================== 1 failed in 0.02 seconds ==========================def main(options): """Compute a fizzbuzz set of strings and return them as an array.""" logger.В конце скрипта добавим следующие модульные тесты, использующие возможности
 debug("compute fizzbuzz from {} to {}".format(options.start,
options.end))
return [str(fizzbuzz(i, options.fizz, options.buzz))
for i in range(options.start, options.end+1)]
debug("compute fizzbuzz from {} to {}".format(options.start,
options.end))
return [str(fizzbuzz(i, options.fizz, options.buzz))
for i in range(options.start, options.end+1)]pytest по использованию параметризованных тестовых функций:# Модульные тесты
import pytest # noqa: E402
import shlex # noqa: E402
@pytest.mark.parametrize("args, expected", [
("0 0", ["fizzbuzz"]),
("3 5", ["fizz", "4", "buzz"]),
("9 12", ["fizz", "buzz", "11", "fizz"]),
("14 17", ["14", "fizzbuzz", "16", "17"]),
("14 17 --fizz=2", ["fizz", "buzz", "fizz", "17"]),
("17 20 --buzz=10", ["17", "fizz", "19", "buzz"]),
])
def test_main(args, expected):
options = parse_args(shlex.split(args))
options.debug = True
options.silent = True
setup_logging(options)
assert main(options) == expected
Обратите внимание на то, что, так как код скрипта завершается вызовом sys. exit(), при его обычном вызове тесты выполняться не будут. Благодаря этому  exit()
exit()pytest для запуска скрипта не нужен.Тестовая функция будет вызвана по одному разу для каждой группы параметров. Сущность args используется в качестве входных данных для функции parse_args(). Благодаря этому механизму мы получаем то, что нужно передать функции main(). Сущность expected сравнивается с тем, что выдаёт main(). Вот что сообщит нам pytest в том случае, если всё работает так, как ожидается:
$ python3 -m pytest -v --doctest-modules ./fizzbuzz.py ============================ test session starts ============================= platform linux -- Python 3.7.4, pytest-3.10.1, py-1.8.0, pluggy-0.8.0 -- /usr/bin/python3 cachedir: .pytest_cache rootdir: /home/bernat/code/perso/python-script, inifile: plugins: xdist-1.26.1, timeout-1.3.3, forked-1.0.2, cov-2.6.0 collected 7 items fizzbuzz.py::fizzbuzz.fizzbuzz PASSED [ 14%] fizzbuzz.Если произойдёт ошибка —
 py::test_main[0 0-expected0] PASSED [ 28%]
fizzbuzz.py::test_main[3 5-expected1] PASSED [ 42%]
fizzbuzz.py::test_main[9 12-expected2] PASSED [ 57%]
fizzbuzz.py::test_main[14 17-expected3] PASSED [ 71%]
fizzbuzz.py::test_main[14 17 --fizz=2-expected4] PASSED [ 85%]
fizzbuzz.py::test_main[17 20 --buzz=10-expected5] PASSED [100%]
========================== 7 passed in 0.03 seconds ==========================
py::test_main[0 0-expected0] PASSED [ 28%]
fizzbuzz.py::test_main[3 5-expected1] PASSED [ 42%]
fizzbuzz.py::test_main[9 12-expected2] PASSED [ 57%]
fizzbuzz.py::test_main[14 17-expected3] PASSED [ 71%]
fizzbuzz.py::test_main[14 17 --fizz=2-expected4] PASSED [ 85%]
fizzbuzz.py::test_main[17 20 --buzz=10-expected5] PASSED [100%]
========================== 7 passed in 0.03 seconds ==========================pytest даст полезные сведения о том, что случилось:$ python3 -m pytest -v --doctest-modules ./fizzbuzz.py
[...]
================================== FAILURES ==================================
__________________________ test_main[0 0-expected0] __________________________
args = '0 0', expected = ['0']
@pytest.mark.parametrize("args, expected", [
("0 0", ["0"]),
("3 5", ["fizz", "4", "buzz"]),
("9 12", ["fizz", "buzz", "11", "fizz"]),
("14 17", ["14", "fizzbuzz", "16", "17"]),
("14 17 --fizz=2", ["fizz", "buzz", "fizz", "17"]),
("17 20 --buzz=10", ["17", "fizz", "19", "buzz"]),
])
def test_main(args, expected):
options = parse_args(shlex. split(args))
options.debug = True
options.silent = True
setup_logging(options)
assert main(options) == expected
E AssertionError: assert ['fizzbuzz'] == ['0']
E At index 0 diff: 'fizzbuzz' != '0'
E Full diff:
E - ['fizzbuzz']
E + ['0']
fizzbuzz.py:160: AssertionError
----------------------------- Captured log call ------------------------------
fizzbuzz.py 125 DEBUG compute fizzbuzz from 0 to 0
===================== 1 failed, 6 passed in 0.05 seconds =====================
В эти выходные данные включён и вывод команды  split(args))
options.debug = True
options.silent = True
setup_logging(options)
assert main(options) == expected
E AssertionError: assert ['fizzbuzz'] == ['0']
E At index 0 diff: 'fizzbuzz' != '0'
E Full diff:
E - ['fizzbuzz']
E + ['0']
fizzbuzz.py:160: AssertionError
----------------------------- Captured log call ------------------------------
fizzbuzz.py 125 DEBUG compute fizzbuzz from 0 to 0
===================== 1 failed, 6 passed in 0.05 seconds =====================
split(args))
options.debug = True
options.silent = True
setup_logging(options)
assert main(options) == expected
E AssertionError: assert ['fizzbuzz'] == ['0']
E At index 0 diff: 'fizzbuzz' != '0'
E Full diff:
E - ['fizzbuzz']
E + ['0']
fizzbuzz.py:160: AssertionError
----------------------------- Captured log call ------------------------------
fizzbuzz.py 125 DEBUG compute fizzbuzz from 0 to 0
===================== 1 failed, 6 passed in 0.05 seconds =====================logger.debug(). Это — ещё одна веская причина для использования в скриптах механизмов логирования. Если вы хотите узнать подробности о замечательных возможностях pytest — взгляните на этот материал.Итоги
Сделать Python-скрипты надёжнее можно, выполнив следующие четыре шага:- Оснастить скрипт документацией, размещаемой в верхней части файла.
- Использовать модуль
argparseдля документирования параметров, с которыми можно вызывать скрипт. - Использовать модуль
loggingдля вывода сведений о процессе работы скрипта. - Написать модульные тесты.

Вокруг этого материала развернулись интересные обсуждения — найти их можно здесь и здесь. Аудитория, как кажется, хорошо восприняла рекомендации по документации и по аргументам командной строки, а вот то, что касается логирования и тестов, показалось некоторым читателям «пальбой из пушки по воробьям». Вот материал, который был написан в ответ на данную статью.
Уважаемые читатели! Планируете ли вы применять рекомендации по написанию Python-скриптов, данные в этой публикации?
Пишем простой скрипт на Python
Здарова, щеглы, сегодня мы своими руками будем писать скрипт на Python.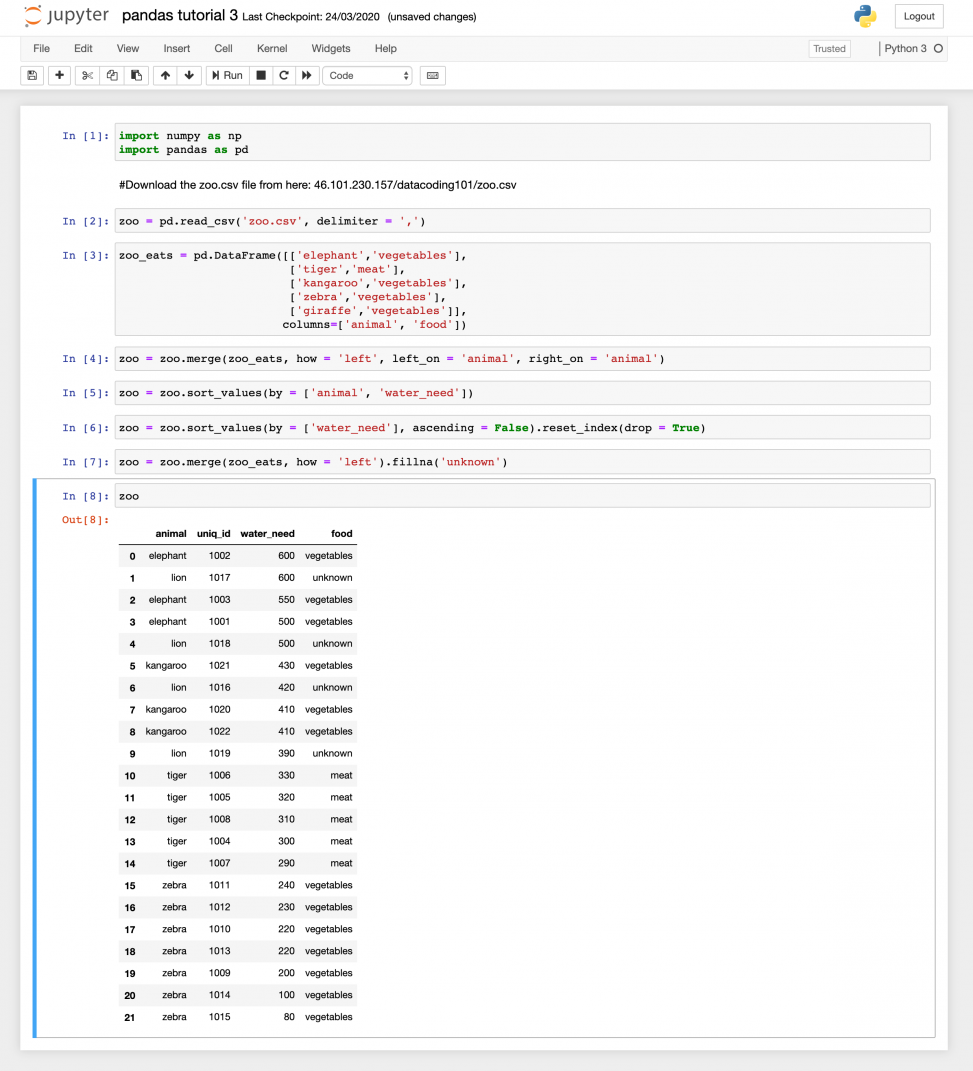 Нам понадобятся: интерпретатор Python 3 под «какая-там-у-вас-ОС», текстовый редактор с подсветкой синтаксиса, например, Sublime Text, Google, упаковка прамирацетама, бутылка минеральной воды и 60 минут свободного времени.
Нам понадобятся: интерпретатор Python 3 под «какая-там-у-вас-ОС», текстовый редактор с подсветкой синтаксиса, например, Sublime Text, Google, упаковка прамирацетама, бутылка минеральной воды и 60 минут свободного времени.
Перед тем как писать скрипт, мы должны определиться, что он вообще будет делать. Делать он будет следующее: получив на вход домен и диапазон IP-адресов, многопоточно проходить список этих адресов, совершать HTTP-запрос к каждому, в попытках понять, на каком же из них размещен искомый домен. Зачем это нужно? Бывают ситуации, когда IP-адрес домена закрыт Cloudflare, или Stormwall, или Incapsula, или еще чем-нибудь, WHOIS история не выдает ничего интересного, в DNS-записях такая же канитель, а, внезапно, один из поддоменов ресолвится в адрес из некоторой подсети, которая не принадлежит сервису защиты. И в этот момент нам становится интересно, вдруг и основной домен размещен в той же самой подсети.
Погнали, сразу выпиваем половину бутылки воды, и пишем следующий код:
Python import argparse
import logging
import coloredlogs
import ssl
import concurrent. futures
import urllib.request
from netaddr import IPNetwork
from collections import deque
VERSION = 0.1
def setup_args():
parser = argparse.ArgumentParser(
description = ‘Domain Seeker v’ + str(VERSION) + ‘ (c) Kaimi (kaimi.io)’,
epilog = »,
formatter_class = argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument(
‘-d’,
‘—domains’,
help = ‘Domain list to discover’,
type = str,
required = True
)
parser.add_argument(
‘-i’,
‘—ips’,
help = ‘IP list (ranges) to scan for domains’,
type = str,
required = True
)
parser.add_argument(
‘—https’,
help = ‘Check HTTPS in addition to HTTP’,
action = ‘store_true’
)
parser.add_argument(
‘—codes’,
help = ‘HTTP-codes list that will be considered as good’,
type = str,
default = ‘200,301,302,401,403’
)
parser.
futures
import urllib.request
from netaddr import IPNetwork
from collections import deque
VERSION = 0.1
def setup_args():
parser = argparse.ArgumentParser(
description = ‘Domain Seeker v’ + str(VERSION) + ‘ (c) Kaimi (kaimi.io)’,
epilog = »,
formatter_class = argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument(
‘-d’,
‘—domains’,
help = ‘Domain list to discover’,
type = str,
required = True
)
parser.add_argument(
‘-i’,
‘—ips’,
help = ‘IP list (ranges) to scan for domains’,
type = str,
required = True
)
parser.add_argument(
‘—https’,
help = ‘Check HTTPS in addition to HTTP’,
action = ‘store_true’
)
parser.add_argument(
‘—codes’,
help = ‘HTTP-codes list that will be considered as good’,
type = str,
default = ‘200,301,302,401,403’
)
parser. add_argument(
‘—separator’,
help = ‘IP/Domain/HTTP-codes list separator’,
type = str,
default = ‘,’
)
parser.add_argument(
‘—include’,
help = ‘Show results containing provided string’,
type = str
)
parser.add_argument(
‘—exclude’,
help = ‘Hide results containing provided string’,
type = str
)
parser.add_argument(
‘—agent’,
help = ‘User-Agent value for HTTP-requests’,
type = str,
default = ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1’
)
parser.add_argument(
‘—http-port’,
help = ‘HTTP port’,
type = int,
default = 80
)
parser.add_argument(
‘—https-port’,
help = ‘HTTPS port’,
type = int,
default = 443
)
parser.add_argument(
‘—timeout’,
help = ‘HTTP-request timeout’,
type = int,
default = 5
)
parser.
add_argument(
‘—separator’,
help = ‘IP/Domain/HTTP-codes list separator’,
type = str,
default = ‘,’
)
parser.add_argument(
‘—include’,
help = ‘Show results containing provided string’,
type = str
)
parser.add_argument(
‘—exclude’,
help = ‘Hide results containing provided string’,
type = str
)
parser.add_argument(
‘—agent’,
help = ‘User-Agent value for HTTP-requests’,
type = str,
default = ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1’
)
parser.add_argument(
‘—http-port’,
help = ‘HTTP port’,
type = int,
default = 80
)
parser.add_argument(
‘—https-port’,
help = ‘HTTPS port’,
type = int,
default = 443
)
parser.add_argument(
‘—timeout’,
help = ‘HTTP-request timeout’,
type = int,
default = 5
)
parser. add_argument(
‘—threads’,
help = ‘Number of threads’,
type = int,
default = 2
)
args = parser.parse_args()
return args
if __name__ == ‘__main__’:
main()
add_argument(
‘—threads’,
help = ‘Number of threads’,
type = int,
default = 2
)
args = parser.parse_args()
return args
if __name__ == ‘__main__’:
main()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 | import argparse import logging import coloredlogs import ssl
import concurrent. import urllib.request
from netaddr import IPNetwork from collections import deque
VERSION = 0.1
def setup_args(): parser = argparse.ArgumentParser( description = ‘Domain Seeker v’ + str(VERSION) + ‘ (c) Kaimi (kaimi.io)’, epilog = », formatter_class = argparse.ArgumentDefaultsHelpFormatter ) parser.add_argument( ‘-d’, ‘—domains’, help = ‘Domain list to discover’, type = str, required = True ) parser.add_argument( ‘-i’, ‘—ips’, help = ‘IP list (ranges) to scan for domains’, type = str, required = True ) parser.add_argument( ‘—https’, help = ‘Check HTTPS in addition to HTTP’, action = ‘store_true’ ) parser.add_argument( ‘—codes’, help = ‘HTTP-codes list that will be considered as good’, type = str, default = ‘200,301,302,401,403’ ) parser. ‘—separator’, help = ‘IP/Domain/HTTP-codes list separator’, type = str, default = ‘,’ ) parser.add_argument( ‘—include’, help = ‘Show results containing provided string’, type = str ) parser.add_argument( ‘—exclude’, help = ‘Hide results containing provided string’, type = str ) parser.add_argument( ‘—agent’, help = ‘User-Agent value for HTTP-requests’, type = str, default = ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1’ ) parser.add_argument( ‘—http-port’, help = ‘HTTP port’, type = int, default = 80 ) parser.add_argument( ‘—https-port’, help = ‘HTTPS port’, type = int, default = 443 ) parser.add_argument( ‘—timeout’, help = ‘HTTP-request timeout’, type = int, default = 5 ) parser.add_argument( ‘—threads’, help = ‘Number of threads’, type = int, default = 2 )
args = parser.
return args
if __name__ == ‘__main__’: main() |
 futures
futures add_argument(
add_argument( parse_args()
parse_args()Ни одного комментария, какие-то import, непонятные аргументы командной строки и еще эти две последние строчки… Но будьте спокойны, все нормально, это я вам как мастер программирования на Python с 30-минутным стажем говорю. Тем более, как известно, Google не врет, а официальная документация по Python — это вообще неоспоримая истина.
Так что же мы все-таки сделали в вышеописанном фрагменте кода? Мы подключили модули для работы с аргументами коммандной строки, модули для логирования (потокобезопасные между прочим!), модуль для работы с SSL (для одной мелочи, связанной с HTTPS-запросами), модуль для создания пула потоков, и, наконец, модули для совершения HTTP-запросов, работы с IP-адресами и двухсторонней очередью (по поводу различных типов импорта можно почитать здесь).
После этого мы, в соответствии с документацией по модулю argparse, создали вспомогательную функцию, которая будет обрабатывать аргументы, переданные скрипту при запуске из командной строки. Как видите, в скрипте будет предусмотрена работа со списком доменов/IP-диапазонов, а также возможность фильтрации результатов по ключевым словам и по кодам состояния HTTP и еще пара мелочей, как, например, смена User-Agent и опциональная проверка HTTPS-версии искомого ресурса. Последние две строки в основном используются для разделения кода, который будет выполнен при запуске самого скрипта и при импортировании в другой скрипт. В общем тут все сложно, все так пишут. Мы тоже так будем писать. Можно было бы немного модифицировать этот код, например, добавив возврат разных статусов системе в зависимости от того, как отработала функция main, добавить argv в качестве аргумента, и так далее, но мы изучаем Python только 10 минут и ленимся вчитываться в документацию.
Как видите, в скрипте будет предусмотрена работа со списком доменов/IP-диапазонов, а также возможность фильтрации результатов по ключевым словам и по кодам состояния HTTP и еще пара мелочей, как, например, смена User-Agent и опциональная проверка HTTPS-версии искомого ресурса. Последние две строки в основном используются для разделения кода, который будет выполнен при запуске самого скрипта и при импортировании в другой скрипт. В общем тут все сложно, все так пишут. Мы тоже так будем писать. Можно было бы немного модифицировать этот код, например, добавив возврат разных статусов системе в зависимости от того, как отработала функция main, добавить argv в качестве аргумента, и так далее, но мы изучаем Python только 10 минут и ленимся вчитываться в документацию.
Делаем перерыв и выпиваем глоток освежающей минеральной воды.
Поехали дальше.
Python def main():
# Обрабатываем аргументы и инициализируем логирование
# с блекджеком и цветными записями
args = setup_args()
coloredlogs. install()
# Сообщаем бесполезную информацию, а также запускаем цикл проверки
logging.info(«Starting…»)
try:
check_loop(args)
except Exception as exception:
logging.error(exception)
logging.info(«Finished»)
def check_loop(args):
# Создаем пул потоков, еще немного обрабатываем переданные аргументы
# и формируем очередь заданий
with concurrent.futures.ThreadPoolExecutor(max_workers = args.threads) as pool:
domains = args.domains.split(args.separator)
ips = args.ips.split(args.separator)
codes = args.codes.split(args.separator)
tasks = deque([])
for entry in ips:
ip_list = IPNetwork(entry)
for ip in ip_list:
for domain in domains:
tasks.append(
pool.submit(
check_ip, domain, ip, args, codes
)
)
# Обрабатываем результаты и выводим найденные пары домен-IP
for task in concurrent.
install()
# Сообщаем бесполезную информацию, а также запускаем цикл проверки
logging.info(«Starting…»)
try:
check_loop(args)
except Exception as exception:
logging.error(exception)
logging.info(«Finished»)
def check_loop(args):
# Создаем пул потоков, еще немного обрабатываем переданные аргументы
# и формируем очередь заданий
with concurrent.futures.ThreadPoolExecutor(max_workers = args.threads) as pool:
domains = args.domains.split(args.separator)
ips = args.ips.split(args.separator)
codes = args.codes.split(args.separator)
tasks = deque([])
for entry in ips:
ip_list = IPNetwork(entry)
for ip in ip_list:
for domain in domains:
tasks.append(
pool.submit(
check_ip, domain, ip, args, codes
)
)
# Обрабатываем результаты и выводим найденные пары домен-IP
for task in concurrent. futures.as_completed(tasks):
try:
result = task.result()
except Exception as exception:
logging.error(exception)
else:
if result != None:
data = str(result[0])
if(
( args.exclude == None and args.include == None )
or
( args.exclude and args.exclude not in data )
or
( args.include and args.include in data )
):
logging.critical(«[+] » + args.separator.join(result[1:]))
futures.as_completed(tasks):
try:
result = task.result()
except Exception as exception:
logging.error(exception)
else:
if result != None:
data = str(result[0])
if(
( args.exclude == None and args.include == None )
or
( args.exclude and args.exclude not in data )
or
( args.include and args.include in data )
):
logging.critical(«[+] » + args.separator.join(result[1:]))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | def main(): # Обрабатываем аргументы и инициализируем логирование # с блекджеком и цветными записями args = setup_args() coloredlogs.
# Сообщаем бесполезную информацию, а также запускаем цикл проверки logging.info(«Starting…») try: check_loop(args) except Exception as exception: logging.error(exception) logging.info(«Finished»)
def check_loop(args): # Создаем пул потоков, еще немного обрабатываем переданные аргументы # и формируем очередь заданий with concurrent.futures.ThreadPoolExecutor(max_workers = args.threads) as pool: domains = args.domains.split(args.separator) ips = args.ips.split(args.separator) codes = args.codes.split(args.separator)
tasks = deque([]) for entry in ips: ip_list = IPNetwork(entry) for ip in ip_list: for domain in domains: tasks.append( pool.submit( check_ip, domain, ip, args, codes ) ) # Обрабатываем результаты и выводим найденные пары домен-IP for task in concurrent.futures.as_completed(tasks): try: result = task. except Exception as exception: logging.error(exception) else: if result != None: data = str(result[0]) if( ( args.exclude == None and args.include == None ) or ( args.exclude and args.exclude not in data ) or ( args.include and args.include in data ) ): logging.critical(«[+] » + args.separator.join(result[1:])) |
 install()
install() result()
result()В коде появился минимум комментариев. Это прогресс. Надо войти в кураж (не зря мы заготовили прамирацетам) и дописать одну единственную функцию, которая будет осуществлять, непосредственно, проверку. Ее имя уже упомянуто в коде выше: check_ip.
30 минут спустя
Хорошо-то как. Не зря я говорил, что понадобится час времени. Продолжим.
Python def check_ip(domain, ip, args, codes):
# Преобразуем IP из числа в строку
# Магическая code-flow переменная для совершения двух проверок
# И бесполезное логирование
ip = str(ip)
check_https = False
logging. info(«Checking » + args.separator.join([ip, domain]))
while True:
# Задаем порт и схему для запроса в зависимости от магической переменной
schema = ‘https://’ if check_https else ‘http://’;
port = str(args.https_port) if check_https else str(args.http_port)
request = urllib.request.Request(
schema + ip + ‘:’ + port + ‘/’,
data = None,
headers = {
‘User-Agent’: args.agent,
‘Host’: domain
}
)
# Совершаем запрос, и если получаем удовлетворительный код состояни HTTP,
# то возвращаем содержимое ответа сервера, а также домен и IP
try:
response = urllib.request.urlopen(
request,
data = None,
timeout = args.timeout,
context = ssl._create_unverified_context()
)
data = response.read()
return [data, ip, domain]
except urllib.error.HTTPError as exception:
if str(exception.code) in codes:
data = exception.
info(«Checking » + args.separator.join([ip, domain]))
while True:
# Задаем порт и схему для запроса в зависимости от магической переменной
schema = ‘https://’ if check_https else ‘http://’;
port = str(args.https_port) if check_https else str(args.http_port)
request = urllib.request.Request(
schema + ip + ‘:’ + port + ‘/’,
data = None,
headers = {
‘User-Agent’: args.agent,
‘Host’: domain
}
)
# Совершаем запрос, и если получаем удовлетворительный код состояни HTTP,
# то возвращаем содержимое ответа сервера, а также домен и IP
try:
response = urllib.request.urlopen(
request,
data = None,
timeout = args.timeout,
context = ssl._create_unverified_context()
)
data = response.read()
return [data, ip, domain]
except urllib.error.HTTPError as exception:
if str(exception.code) in codes:
data = exception. fp.read()
return [data, ip, domain]
except Exception:
pass
if args.https and not check_https:
check_https = True
continue
return None
fp.read()
return [data, ip, domain]
except Exception:
pass
if args.https and not check_https:
check_https = True
continue
return None
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | def check_ip(domain, ip, args, codes): # Преобразуем IP из числа в строку # Магическая code-flow переменная для совершения двух проверок # И бесполезное логирование ip = str(ip) check_https = False
logging.info(«Checking » + args.separator.join([ip, domain]))
while True: # Задаем порт и схему для запроса в зависимости от магической переменной schema = ‘https://’ if check_https else ‘http://’; port = str(args.
request = urllib.request.Request( schema + ip + ‘:’ + port + ‘/’, data = None, headers = { ‘User-Agent’: args.agent, ‘Host’: domain } ) # Совершаем запрос, и если получаем удовлетворительный код состояни HTTP, # то возвращаем содержимое ответа сервера, а также домен и IP try: response = urllib.request.urlopen( request, data = None, timeout = args.timeout, context = ssl._create_unverified_context() ) data = response.read() return [data, ip, domain] except urllib.error.HTTPError as exception: if str(exception.code) in codes: data = exception.fp.read() return [data, ip, domain] except Exception: pass
if args.https and not check_https: check_https = True continue
return None |
 https_port) if check_https else str(args.http_port)
https_port) if check_https else str(args.http_port)В общем-то весь наш скрипт готов. Приступаем к тестированию.
Неожиданно узнаем, что у блога есть альтернативный IP-адрес. И действительно:
curl -i ‘http://188.226.181.47/’ —header ‘Host: kaimi.io’
curl -i ‘http://188.226.181.47/’ —header ‘Host: kaimi.io’ |
HTTP/1.1 301 Moved Permanently Server: nginx/1.4.6 (Ubuntu) Date: Sun, 02 Oct 2016 13:52:43 GMT Content-Type: text/html Content-Length: 193 Connection: keep-alive Location: https://kaimi.io/ <html> <head><title>301 Moved Permanently</title></head> <body bgcolor=»white»> <center><h2>301 Moved Permanently</h2></center> <hr><center>nginx/1.4.6 (Ubuntu)</center> </body> </html>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | HTTP/1. Server: nginx/1.4.6 (Ubuntu) Date: Sun, 02 Oct 2016 13:52:43 GMT Content-Type: text/html Content-Length: 193 Connection: keep-alive Location: https://kaimi.io/
<html> <head><title>301 Moved Permanently</title></head> <body bgcolor=»white»> <center><h2>301 Moved Permanently</h2></center> <hr><center>nginx/1.4.6 (Ubuntu)</center> </body> </html> |
 1 301 Moved Permanently
1 301 Moved PermanentlyОднако:
curl -i ‘https://188.226.181.47/’ —header ‘Host: kaimi.io’
curl -i ‘https://188.226.181.47/’ —header ‘Host: kaimi.io’ |
curl: (51) SSL: certificate subject name (*.polygraph.io) does not match target host name ‘188.226.181.47’
curl: (51) SSL: certificate subject name (*.polygraph.io) does not match target host name ‘188. |
 226.181.47′
226.181.47′Какой-то левый хост обрабатывает запросы. Почему? Потому что это прокси, который реагирует на содержимое заголовка Host. В общем скрипт готов, по крайней мере альфа-версия скрипта. Если вам понравилось — подписывайтесь, ставьте лайки, шлите pull-реквесты на github.
python-скриптов · Темы GitHub · GitHub
Вот 229 публичных репозиториев соответствует этой теме…
ваууи / Вуи
Звезда 2кTheLastGimbus / GooglePhotosTakeoutПомощник
Спонсор Звезда 2кАвинашкранжан / Удивительные Python-скрипты
Спонсор Звезда 1,4кХаршКаспер / Гнилые сценарии
Звезда 1,3ктдамдуни / Питониста
Звезда 937Py-участники / удивительные скрипты
Звезда 487технический лагерь / Python для DevOps
Звезда 312пратимакод-концентратор / Awesome_Python_Scripts
Звезда 284АдаршАдди / Хактоберфест2022_для_новичков
Спонсор Звезда 231Молния-ИИ / учебники
Звезда 219мощностьэксплуатация / Awesome-Python-Scripts
Звезда 205gil9red / SimplePyScripts
Звезда 133яссы / обучающий питон
Звезда 110Лаки1376 / ОРИОН-Бомбардировщик
Звезда 108OSSpk / Awesome-Python-игры
Звезда 73гадилашанк / Научный центр
Звезда 67Эсри / коллекционные инструменты
Звезда 67РахулШагри / MultiPy
Звезда 59arup-группа / социальные данные
Звезда 51владунько / ноутбук-окружение
Звезда 47Улучшить эту страницу
Добавьте описание, изображение и ссылки на
python-скрипты
страницу темы, чтобы разработчикам было легче узнать о ней.
Курировать эту тему
Добавьте эту тему в свой репозиторий
Чтобы связать ваш репозиторий с python-скрипты тему, перейдите на целевую страницу репозитория и выберите «управление темами».
Узнать больше
30 скриптов Python для начинающих
01. Hello World: # Следующий скрипт Python напечатает текст «Hello World!» как вывод.
print("Привет, мир!")
02. Соедините две строки:
# Два слова "Programming" и "Languages" объединяются, и "ProgrammingLanguages" печатается в качестве вывода. х = "Программирование" у = "Языки" г = х + у печать (г)
03.
 Формат с плавающей запятой в строке:
Формат с плавающей запятой в строке: # Использование форматирования строки
х = 462,75897
печать ("{: 5.2f}". формат (х))
# Использование интерполяции строк
у = 462,75897
печать("%5.2f" % у)
04. Возведение числа в степень:
импорт математики
# Присвоить значения a и n
а = 4
п = 3
# Способ 1
б = а**н
print("%d в степени %d равно %d" % (a,n,b))
# Способ 2
б = мощность (а, п)
print("%d в степени %d равно %d" % (a,n,b))
# Способ 3
b = math.pow(a,n)
print("%d в степени %d равно %5.2f" % (a,n,b))
05. Работа с логическими типами:
# Булево значение х = Истина печать (х) # число в логическое значение х = 10 печать (логический (х)) х = -5 печать (логический (х)) х = 0 печать (логический (х)) # логическое значение из оператора сравнения х = 6 у = 3 печать (х < у)
06.
 Оператор If else:
Оператор If else: # Присвоить числовое значение
х = 35
# Проверяем больше 35 или нет
если (х >= 35):
print("Вы прошли")
еще:
print("Вы не прошли")
07. Использование операторов И и ИЛИ:
# Ставить практические оценки
x = float(input("Введите практические оценки: "))
# Берем оценки по теории
y = float(input("Введите отметки теории: "))
# Проверяем условие прохождения с помощью операторов И и ИЛИ
если (x >= 25 и y >= 45) или (x + y) >= 70:
print("\nВы прошли")
еще:
print("\nВы потерпели неудачу")
08. Описание корпуса переключателя:
# Переключатель для реализации вариантов корпуса переключателя
def employee_details (ID):
переключатель = {
"5006": "Имя сотрудника: Джон",
"5008": "Имя сотрудника: Рам",
"5010": "Имя сотрудника: Мохаменд",
}
'''Первый аргумент будет возвращен, если совпадение найдено и
идентификатор сотрудника не существует, будет возвращен, если совпадение не найдено '''
return switcher. get(ID, "ID сотрудника не существует")
# Берём ID сотрудника
ID = input("Введите ID сотрудника: ")
# Распечатать вывод
печать (детали_сотрудника (ID))
 get(ID, "ID сотрудника не существует")
# Берём ID сотрудника
ID = input("Введите ID сотрудника: ")
# Распечатать вывод
печать (детали_сотрудника (ID))
get(ID, "ID сотрудника не существует")
# Берём ID сотрудника
ID = input("Введите ID сотрудника: ")
# Распечатать вывод
печать (детали_сотрудника (ID))
09. Цикл while:
# Инициализировать счетчик
счетчик = 1
# Повторить цикл 9 раз
пока счетчик < 10:
# Распечатать значение счетчика
печать ("%d" % счетчик)
# Увеличиваем счетчик
счетчик = счетчик + 1
11. Использование аргумента командной строки:
# Импорт системного модуля
импорт системы
# Общее количество аргументов
print('Всего аргументов:', len(sys.argv))
print("Значения аргументов:")
# Перебираем аргументы командной строки, используя цикл for
для я в sys.argv:
печать (я)
9[А-Я]'
# сопоставить шаблон с входным значением
найдено = re.match(шаблон, строка)
# Вывести сообщение на основе возвращаемого значения
если найдено:
print("Входное значение начинается с заглавной буквы")
еще:
print("Вы должны ввести строку, начинающуюся с заглавной буквы")
14.
 Использование getpass:
Использование getpass: # import getpass module
импортировать getpass
# Взять пароль у пользователя
passwd = getpass.getpass('Пароль:')
# Проверить пароль
если пароль == "питон":
print("Вы проверены")
еще:
print("Вы не прошли верификацию")
15. Использование формата даты:
с даты импорта даты и времени
# Читаем текущую дату
текущая_дата = дата.сегодня()
# Печатаем отформатированную дату
print("Сегодня :%d-%d-%d" % (current_date.day,current_date.month,current_date.year))
# Установить пользовательскую дату
custom_date = дата (2026, 12, 26)
print("Дата:",custom_date)
16. Добавить и удалить элемент из списка:
# Объявить список фруктов
фрукты = ["манго","апельсин","гуава","банан"]
# Вставить элемент во 2-ю позицию
fruit.insert(1, "Яблоко")
# Отображение списка после вставки
print("Список фруктов после вставки:")
печать (фрукты)
# Удалить элемент
фрукты. удалить("Банан")
# Распечатать список после удаления
print("Список фруктов после удаления:")
печать (фрукты)
 удалить("Банан")
# Распечатать список после удаления
print("Список фруктов после удаления:")
печать (фрукты)
удалить("Банан")
# Распечатать список после удаления
print("Список фруктов после удаления:")
печать (фрукты)
17. Понимание списка:
# Создайте список символов, используя понимание списка
char_list = [символ для символа в "Python"]
печать (char_list)
# Определить кортеж веб-сайтов
веб-сайты = ("google.com", "yahoo.com", "history.com", "quora.com")
# Создать список из кортежа, используя понимание списка
site_list = [сайт для сайта на веб-сайтах]
печать (сайт_список)
18. Данные среза:
# Присвоить строковое значение text = "Язык программирования Python" # Разрезать по одному параметру sliceObj = срез (5) печать (текст [sliceObj]) # Разрезать по двум параметрам sliceObj = срез (6,12) печать (текст [sliceObj]) # Разрезать по трем параметрам sliceObj = срез (6,25,5) печать (текст [sliceObj])
19.
 Добавление и поиск данных в словаре:
Добавление и поиск данных в словаре: # Определение словаря
клиенты = {'05453':'Рам','04457':'Кришна',
«02834»: «Вишну», «01655»: «Шива», «07559».':'Дэйвид'}
# Добавляем новые данные
клиенты['06934'] = 'Саломон'
print("Имена клиентов:")
# Распечатать значения словаря
для клиента в клиентах:
print(клиенты[клиент])
# Использовать идентификатор клиента в качестве входных данных для поиска
name = input("Введите идентификатор клиента:")
# Ищем ID в словаре
для клиента в клиентах:
если клиент == имя:
print(клиенты[клиент])
перерыв
20. Добавление и поиск данных в наборе:
# Определить числовой набор
числа = {13, 10, 56, 18, 12, 44, 87}
# Добавляем новые данные
числа.добавить(63)
# Распечатать установленные значения
печать (числа)
сообщение = "Номер не найден"
# Берем числовое значение для поиска
search_number = int(input("Введите число:"))
# Поиск номера в наборе
для val в цифрах:
если val == search_number:
message = "Найден номер"
перерыв
распечатать (сообщение)
21.
 Количество элементов в списке:
Количество элементов в списке: # Определение строки
string = 'Python Go JavaScript HTML CSS MYSQL Python'
# Определяем строку поиска
поиск = 'Питон'
# Сохраняем значение счетчика
количество = строка. количество (поиск)
# Печатаем отформатированный вывод
print("%s появляется %d раз" % (поиск, количество))
22. Определить и вызвать функцию:
# Определить дополнительную функцию
определение сложения (число1, число2):
результат = число1 + число2
print("Результат добавления:",результат)
# Определяем функцию области с оператором return
площадь защиты (радиус):
результат = 3,14 * радиус * радиус
вернуть результат
# Функция добавления вызова
дополнение(5, 3)
# Функция зоны вызова
print("Площадь круга",площадь(2))
23. Исключение использования броска и ловли:
# Пробная блокировка
пытаться:
# Берем число
число = int(input("Введите число:"))
если число % 2 == 0:
print("Число четное")
еще:
print("Число нечетное")
# Блок исключений
кроме (ValueError):
# Распечатать сообщение об ошибке
print("Введите числовое значение")
24.
 Чтение и запись файла:
Чтение и запись файла: #Назначить имя файла
имя файла = "имена.txt"
# Открыть файл для записи
fileHandler = открыть (имя файла, "w")
# Добавляем текст
fileHandler.write("Оперативная память\n")
fileHandler.write("Джон\n")
fileHandler.write("Дэвид\n")
# Закрыть файл
файлHandler.close()
# Открыть файл для чтения
fileHandler = открыть (имя файла, "r")
# прочитать файл построчно
для строки в fileHandler:
печать (строка)
# Закрыть файл
файлHandler.close()
25. Список файлов в каталоге:
# Импорт модуля ОС для чтения каталога
импорт ОС
# Установить путь к каталогу
путь = '/Пользователи/Мандзю/'
# прочитать содержимое файла
файлы = os.listdir(путь)
# Распечатать содержимое каталога
для файла в файлах:
распечатать файл)
26. Чтение и запись с помощью pickle:
# Импорт модуля pickle импортный рассол # Объявить объект для хранения данных объект данных = [] # Повторить цикл for 5 раз для числа в диапазоне (10,15): dataObject.
 append(число)
# Открыть файл для записи данных
file_handler = открыть («числа», «вес»)
# Скидываем данные объекта в файл
pickle.dump(dataObject, file_handler)
# закрыть обработчик файла
file_handler.close()
# Открыть файл для чтения файла
file_handler = открыть ('числа', 'рб')
# Загружаем данные из файла после десериализации
dataObject = pickle.load (обработчик_файла)
# Повторяем цикл для печати данных
для val в dataObject:
печать (значение)
# закрыть обработчик файла
file_handler.close()
append(число)
# Открыть файл для записи данных
file_handler = открыть («числа», «вес»)
# Скидываем данные объекта в файл
pickle.dump(dataObject, file_handler)
# закрыть обработчик файла
file_handler.close()
# Открыть файл для чтения файла
file_handler = открыть ('числа', 'рб')
# Загружаем данные из файла после десериализации
dataObject = pickle.load (обработчик_файла)
# Повторяем цикл для печати данных
для val в dataObject:
печать (значение)
# закрыть обработчик файла
file_handler.close()
27. Определить класс и метод:
# Определить класс
класс Сотрудник:
имя = "Джонсон"
# Определяем метод
Детали защиты (я):
print("Сообщение: Партнер")
print("Отдел: КК")
print("Зарплата: $6000")
# Создаем объект сотрудника
эмп = Сотрудник ()
# Распечатать переменную класса
печать ("Имя:", emp.name)
# Вызов метода класса
emp.details()
28.
