Набор Python-скриптов для автоматизации рутинных задач SEO-специалиста — SEO на vc.ru
Статья будет полезна специалистам, которые хотели бы автоматизировать свою работу. Для работы со скриптами потребуются минимальные знания программирования и установленные библиотеки. Для каждого примера в конце есть ссылка на полный код, который нужно открывать в Jupyter Notebook. Больше скриптов в Telegram-канале seo_python.
74 123 просмотров
С каждым годом процесс оптимизации требует всё больше технических навыков. Среди текущих требований к специалисту часто указывают, что необходимо знание какого-либо языка программирования, например, Python.
Python — простой и лаконичный язык, позволяющий автоматизировать значительную часть рутинных задач и анализировать данные, что особенно актуально при работе с крупными проектами.
Одно из преимуществ языка — наличие большого количества написанных библиотек. Так как многие сервисы отдают свои данные по API, у специалистов есть возможность без глубоких знаний программирования писать скрипты для решения рабочих задач.
В западных блогах часто можно встретить подборки специалистов, которые делятся своими наработками. В рунете такой информации пока мало, поэтому в этой статье я бы хотел рассказать о полезных библиотеках и поделиться своим набором скриптов, которые постоянно использую в работе.
1. Генерация RSS-фида для турбо-страниц «Яндекса»
Этот способ подходит для случаев, когда необходимо быстро запустить и протестировать турбо-страницы. Рекомендую использовать скрипт для генерации RSS-канала для статейных сайтов, контент которых изменяется редко. Этот метод подходит для быстрого запуска страниц с целью проверить теорию и посмотреть результаты внедрения технологии «Яндекса».
Что потребуется:
- Netpeak Spider.
- Базовые знания применения XPath.
- Установленные Python-библиотеки.
Плюсы подхода:
- Быстрое внедрение. Не требуется помощь программиста.

- Не нужно подключение к базе, где хранится контент. Весь контент и его разметку берём прямо со страниц (одновременно минус).
- Используем стандартные SEO-инструменты.

Минусы:
- Необновляемый XML-файл. После изменения контента требуется пересобрать контент и формировать новый XML.
- Новые страницы также не будут попадать в файл. Для них будет необходимо заново парсить контент и формировать XML.
- Создаём нагрузку на свой сайт при сборе контента.
Ниже описана последовательность работ.
Подготавливаем данные
С помощью Screaming frog seo spider или Netpeak Spider парсим контент страниц, для которых будем подключать турбо-страницы.
На этом этапе подготавливаем данные для обязательных элементов, необходимых при формировании XML-файла.
Обязательные поля:
- Link — URL страницы.
- h2 — заголовок страницы.
- Turbo:content — содержимое страницы.

Подробнее — на странице.
Используя XPath, парсим контент страниц со всей HTML-разметкой. Копируем через панель разработчика или пишем свой запрос (например, //div[@class=’entry-content entry—item’]).
Экспортируем полученные данные в CSV. В результате в CSV-файле должно быть три столбца:
- Link.
- h2.
- Turbo:content.
Скрипт генерации файла
Подключаем нужные библиотеки.
import csv import pandas as pd import os import math
Считываем файл с подготовленными данными.
data = pd.read_csv(‘internal_all — internal_all.csv’) #дописать «, header=1», если проблема при считывании заголовка
data = data[[‘Address’, ‘h2-1’, ‘текст 1’]]
## Если в таблицу попали лишние страницы, их можно легко отфильтровать. Ниже примеры. # data = data[data[‘Status Code’]==200] # Фильтруем страницы с 200 ответом
# data = data[~data[‘Address’].str.contains(‘page’)] # Фильтруем страницы не содержащие «»
# data = data.drop(index=0)
# data = data[data[‘Status Code’]==200] # Фильтруем страницы с 200 ответом
# data = data[~data[‘Address’].str.contains(‘page’)] # Фильтруем страницы не содержащие «»
# data = data.drop(index=0)
rows_in_rss = 1000 # количество строк в одном rss-канале total_rows = len(data) — 1 total_xml_file = math.ceil((total_rows-1)/rows_in_rss) print(‘Всего в файле строк:’, total_rows) print(‘Будет сгенерировано xml-файлов:’, total_xml_file)
Формируем структуру RSS-канала. Создаём функцию create_xml, отвечающую за создание начала файла.
def create_xml(item_count_next):
rss_file = open(‘rss{:.0f}.xml’.format(item_count_next/rows_in_rss), ‘w’, encoding=»utf-8″)
rss_file.write(
«»»<?xml version=»1.0″ encoding=»UTF-8″?>
<rss xmlns:yandex=»http://news.yandex.ru»
xmlns:media=»http://search.yahoo.com/mrss/»
xmlns:turbo=»http://turbo.
Функция close_xml будет закрывать файл.
def close_xml(item_count_next): rss_file = open(‘rss{:.0f}.xml’.format(item_count_next/rows_in_rss), ‘a’, encoding=»utf-8″) rss_file.write( ‘ </channel>’ + ‘\n’+ ‘</rss>’ ) rss_file.close()
В функцию data_for_rss передаём номер первой и последней строки. Для этого промежутка будем формировать RSS.
Построчно считываем строки в датафрейме и формируем <item>, записывая получившиеся данные в XML-файл. Каждая строка в датафрейме — новая страница.
def data_for_rss(item_count_prev, item_count_next):
data_rss = data[item_count_prev:item_count_next]
if len(data_rss) != 0:
with open(‘rss{:.0f}.xml’.format(item_count_next/rows_in_rss), ‘a’, encoding=»utf-8″) as rss_file:
for index, row in data_rss. iterrows():
url = str(row[0])
h2 = str(row[1])
text = str(row[2])
rss_file.write(«»»<item turbo=»true»>
<link>»»»+ url + «»»</link>
<turbo:content>
<![CDATA[
<header> <h2>»»»+ h2 +»»»</h2>
</header>»»»
+ text+
«»»<div data-block=»share» data-network=»vkontakte,odnoklassniki,facebook,twitter»></div>
]]>
</turbo:content>
</item>»»»)
iterrows():
url = str(row[0])
h2 = str(row[1])
text = str(row[2])
rss_file.write(«»»<item turbo=»true»>
<link>»»»+ url + «»»</link>
<turbo:content>
<![CDATA[
<header> <h2>»»»+ h2 +»»»</h2>
</header>»»»
+ text+
«»»<div data-block=»share» data-network=»vkontakte,odnoklassniki,facebook,twitter»></div>
]]>
</turbo:content>
</item>»»»)
Делаем проверку размера получившихся фидов. Размер XML-файла не должен превышать 15 МБ. Если размер получился больше, изменяем количество строк в одном файле, изменяя значение переменной rows_in_rss.
Если размер получился больше, изменяем количество строк в одном файле, изменяя значение переменной rows_in_rss.
def size_file(item_count_next): size_final_file_MB = os.path.getsize(‘rss{:.0f}.xml’.format(item_count_next/rows_in_rss))/1024/1024 if size_final_file_MB < 15: print(‘Файл создан’) else: print(‘Нужно уменьшить шаг’)
Финальный шаг — генерация фидов.
item_count_prev = 0 item_count_next = 1000 # должен быть равен rows_in_rss count_rss = 0 print(total_xml_file) while count_rss < total_xml_file: create_xml(item_count_next) data_list = data_for_rss(item_count_prev,item_count_next) close_xml(item_count_next) size_file(item_count_next) item_count_prev += rows_in_rss item_count_next += rows_in_rss count_rss += 1
Остаётся добавить RSS в личном кабинете «Яндекс.Вебмастера» и настроить меню, лого, счётчики систем аналитики.
Ссылка на скрипт (открывать в Jupyter Notebook).
2. Техническое задание для копирайтеров
ТЗ для копирайтеров — довольно рутинная работа, которая занимает много времени у специалиста. Ниже рассмотрим три варианта автоматизации этого процесса, используя различные сервисы:
- Семантического ядра нет, статья не написана.
- Семантическое ядро есть, статья не написана.
- Статья написана, требуется рерайт.
Что потребуется:
- Подписка на сервис с доступом к API.
- Подписка на сервис с пополненным балансом.
- Кластеризованное семантическое ядро (я использую KeyAssort) для случая, когда ядро есть, а статья не написана.
Ниже рассмотрим все варианты, для каждого я распишу плюсы и минусы этих подходов. Стоит помнить, что результаты, которые выдают сервисы, стоит перепроверять. Так как везде есть свои технические нюансы.
Так как везде есть свои технические нюансы.
Вариант 1. Семантического ядра нет, статья не написана
Рассмотрим случай, когда нужно написать статью, но у вас нет готового семантического ядра. Для этого подхода нам понадобится только основной маркерный запрос статьи.
Плюсы подхода:
- Не тратим время на сбор ядра (подходит для статей с широкой семантикой и хорошей видимостью URL конкурентов в топе).
- В работу берём максимальное количество ключей, по которым конкуренты имеют видимость.
Минусы:
- Нужна подписка на сервисы.
- Данные, которые выдают сервисы, не всегда точны. Например, Megaindex не определяет длину текста меньше определённого количества знаков (около 200 символов). Поэтому показатели выборочно стоит перепроверить.
- Не можем повлиять на кластеризацию.
Подключаем необходимые библиотеки.
import requests import json import pymorphy2 import re import urllib.request as urlrequest from urllib.parse import urlencode from collections import Counter
Нам понадобятся:
- Token — токен API MegaIndex.
- Ser_id — регион, по которому будут сниматься данные. Полный список можно получить, используя метод get_ser.
- Keywords_list — список ключевых слов, для которых будем получать данные.
token = «xxxxxxxxxxxxxxxxxxx» ser_id = 174 #ID поисковой системы яндекс_спб keywords_list = [‘основной маркерный запрос статьи №1’, ‘основной маркерный запрос статьи №2’, ‘основной маркерный запрос статьи №3’] morph = pymorphy2.MorphAnalyzer() # создаем экземпляр pymorphy2, понадобится нам дальше для морфологического анализа
Для получения ключевых слов по нужным нам маркерным запросам будем использовать метод url_keywords API Serpstat. Этот метод возвращает ключевые фразы в топе поисковой системы по заданному URL. Получать будем видимость конкурентов по URL, которые находятся в топе выбранной поисковой системы.
Получать будем видимость конкурентов по URL, которые находятся в топе выбранной поисковой системы.
Для работы берём пример кода из документации и оборачиваем его в функцию serpstat_keywords. Подставляем свои значения для token и региона se, по которому будем получать данные. Получить полный список регионов можно здесь.
def serpstat_keywords(url): host = ‘http://api.serpstat.com/v3’ method = ‘url_keywords’ params = { ‘query’: ‘{}’.format(url), # string for get info ‘se’: ‘y_213’, # string search engine, y_2 — спб, y_213 — мск ‘token’: ‘xxxxxxxxxxxxxxxxxxx’, # string personal token } api_url = «{host}/{method}?{params}».format( host=host, method=method, params=urlencode(params) ) try: json_data = urlrequest.urlopen(api_url).read() except Exception as e0: print(«API request error: {error}».format(error=e0)) pass data = json.loads(json_data) return data
Используя регулярное выражение, разбиваем исходную фразу на слова. Каждое слово лемматизируем, проверяем на часть речи и добавляем в результирующий список. Возвращаем готовый список.
Каждое слово лемматизируем, проверяем на часть речи и добавляем в результирующий список. Возвращаем готовый список.
def morph_word_lemma(key): meaningfullPoSes=[‘NPRO’, ‘PREP’, ‘CONJ’, ‘PRCL’, ‘INTJ’] # фильтруем граммемы https://pymorphy2.readthedocs.io/en/latest/user/grammemes.html reswords=[] for word in re.findall(«([А-ЯЁа-яё0-9]+(-[А-ЯЁа-яё0-9]+)*)», key): # фразу бьем на слова word = word[0] word_normal_form = morph.parse(word)[0].normal_form form = morph.parse(word)[0].tag if form.POS in meaningfullPoSes: continue else: reswords.append(word_normal_form) return reswords
Не забываем, что pymorphy2 работает только с русским языком. Если в словосочетаниях будут фразы на другом языке, он их пропустит.
Составляем словарь вида «Лемма: [количество упоминаний леммы]».
def counter_dict_list(list_values):
list_values_all=[]
for item in list_values:
list_values_word_lemma = morph_word_lemma(item)
for item in list_values_word_lemma:
list_values_all. append(item)
dict_values_word_lemma = dict(Counter(list_values_all))
sorted_dict_values_word_lemma = list(dict_values_word_lemma.items())
sorted_dict_values_word_lemma.sort(key=lambda i: i[1], reverse=True)
sorted_dict_values_word_lemma = dict(sorted_dict_values_word_lemma)
return (sorted_dict_values_word_lemma)
append(item)
dict_values_word_lemma = dict(Counter(list_values_all))
sorted_dict_values_word_lemma = list(dict_values_word_lemma.items())
sorted_dict_values_word_lemma.sort(key=lambda i: i[1], reverse=True)
sorted_dict_values_word_lemma = dict(sorted_dict_values_word_lemma)
return (sorted_dict_values_word_lemma)
Создаём финальный файл и записываем строку заголовка.
# чистим файл и записываем строку заголовка f = open(‘api.txt’, ‘w’) f.write(«key»+’\t’ + «base_urls»+ ‘\t’ + ‘symbols_median’ + ‘\t’ + ‘\n’) f.close()
Получаем данные по API и парсим полученный текст.
def megaindex_text_score(key):
keyword_list = []
uniq_keyword_list = []
try:
url = ‘http://api.megaindex.com/visrep/text_score?key={}&words={}&ser_id={}’.format(token, key, ser_id)
r = requests.get(url)
json_string = r.text
parsed_string = json.loads(json_string)[‘data’]
list_base_urls = parsed_string[‘serps’][0][‘base_urls’]
symbols_median = parsed_string[‘old_api’][‘fragments’][‘long’][‘symbols_median’]
except Exception as ex_megaindex:
print(«API megaindex request error: {error}». format(error=ex_megaindex))
list_base_urls = []
symbols_median = ‘Данные не получены’
for url in list_base_urls:
url = url.replace(‘http:’, ‘https:’)
data = serpstat_keywords(url)
try:
for keyword in data[‘result’][‘hits’]:
keyword_list.append(keyword[‘keyword’])
except:
pass
for item in set(keyword_list):
uniq_keyword_list.append(item)
count_lemma = counter_dict_list(uniq_keyword_list)
return (list_base_urls, symbols_median, count_lemma)
format(error=ex_megaindex))
list_base_urls = []
symbols_median = ‘Данные не получены’
for url in list_base_urls:
url = url.replace(‘http:’, ‘https:’)
data = serpstat_keywords(url)
try:
for keyword in data[‘result’][‘hits’]:
keyword_list.append(keyword[‘keyword’])
except:
pass
for item in set(keyword_list):
uniq_keyword_list.append(item)
count_lemma = counter_dict_list(uniq_keyword_list)
return (list_base_urls, symbols_median, count_lemma)
Проходимся по списку маркерных запросов и генерируем задание.
print (‘Всего будет сгенерировано ТЗ: ‘, len(keywords_list))
for keywords in keywords_list:
print(keywords)
try:
list_base_urls, symbols_median, count_lemma = megaindex_text_score(keywords)
except Exception as ex:
pass
print(f’Errow: {ex}’)
with open(‘api.txt’, ‘a’) as f:
f. write(‘{}\t{}\t{}\t\n\n’.format(keywords, list_base_urls, symbols_median))
f.write(‘Лемма’ +’\t’ + ‘Количество повторений’ + ‘\n’)
for key, value in count_lemma.items():
f.write(‘{}\t{}\n’.format(key, value))
f.write(‘\n’+’\n’+’\n’)
print (‘end’)
write(‘{}\t{}\t{}\t\n\n’.format(keywords, list_base_urls, symbols_median))
f.write(‘Лемма’ +’\t’ + ‘Количество повторений’ + ‘\n’)
for key, value in count_lemma.items():
f.write(‘{}\t{}\n’.format(key, value))
f.write(‘\n’+’\n’+’\n’)
print (‘end’)
Получившийся результат переносим в «Google Таблицы». Пример ТЗ.
Нужно понимать, что «количество упоминаний леммы» в ТЗ — это сколько раз лемма встречалась в ключевых словах.
Ссылка на скрипт (открывать в Jupyter Notebook).
Вариант 2. Статья написана, требуется рерайт
Подход применим для случаев, когда статья уже написана, но не получает трафика.
Плюсы подхода:
- В автоматическом режиме получаем средний объём текста в топ-10, объём анализируемого текста и разницу этих величин.
- В работу берём максимальное количество ключей, по которым конкуренты имеют видимость.
Минусы (те же, что и у варианта номер один):
- Нужна подписка на сервисы.
- Данные, которые выдают сервисы, не всегда точны. Например, Megaindex не определяет длину текста меньше определённого количества знаков (около 200 символов). Поэтому показатели выборочно стоит перепроверить.
- Не можем повлиять на кластеризацию.

Набор библиотек аналогичен варианту номер один, отличается набор входных параметров. Вместо списка основных маркерных запросов передаём словарь следующего вида:
{‘основной маркерный запрос статьи №1′:’url, соответствующий основному маркерному запросу’}
token = «xxxxxxxxxxxxxxxxxxx» ser_id = 174 #ID поисковой системы яндекс_спб — 174 keywords_url_dict = {‘основной маркерный запрос статьи №1′:’url_основного маркерного запроса статьи №1’, ‘основной маркерный запрос статьи №2′:’url_основного маркерного запроса статьи №2’} morph = pymorphy2.MorphAnalyzer() # создаем экземпляр pymorphy2, понадобится нам дальше для морфологического анализа
Следующие функции копируем из первого варианта:
- serpstat_keywords;
- morph_word_lemma;
- counter_dict_list.

Чистим файл и записываем строку заголовка.
f = open(‘api.txt’, ‘w’) f.write(«key»+’\t’+»compare_urls» + ‘\t’ + «base_urls»+ ‘\t’ + «relevance» + ‘\t’ + ‘symbols median’ + ‘\t’ +’symbols text’+ ‘\t’ + ‘symbols diff’+ ‘\t’+ ‘words median’ + ‘\t’ + ‘words value text’ + ‘\t’ + ‘words diff’ + ‘\n’) f.close()
Получаем данные по API и парсим полученный текст. Получать будем следующие данные для ТЗ:
- list_base_urls — список URL в топ-10 по маркерному запросу;
- relevance — релевантность анализируемой страницы страницам в топе;
- symbols_median — медиана длины текста (знаков без пробелов) по топу;
- symbols_text — количество символов в анализируемом тексте;
- symbols_diff — разница symbols_median и symbols_text;
- words_median — медиана слова в URL по топу;
- words_value_text — медиана слов в анализируемом тексте;
- words_diff — разница слов;
- count_lemma— посчитанные леммы.

def megaindex_text_score(key, key_url):
keyword_list = []
uniq_keyword_list = []
try:
url = ‘http://api.megaindex.com/visrep/text_score?key={}&words={}&ser_id={}&compare_urls={}’.format(token, key, ser_id, key_url)
r = requests.get(url)
json_string = r.text
parsed_string = json.loads(json_string)[‘data’]
list_base_urls = parsed_string[‘serps’][0][‘base_urls’]
relevance = parsed_string[‘serps’][0][‘compare_urls’][0][‘relevance’]*100
symbols_median = parsed_string[‘old_api’][‘fragments’][‘long’][‘symbols_median’]
symbols_text = parsed_string[‘old_api’][‘compare_docs’][key_url][‘fragments’][‘long’][‘symbols’]
symbols_diff = symbols_median — symbols_text
words_median = parsed_string[‘serps’][0][‘compare_urls’][0][‘diffs’][‘word_count’][‘long’][‘median’]
words_value_text = parsed_string[‘serps’][0][‘compare_urls’][0][‘diffs’][‘word_count’][‘long’][‘value’]
words_diff = parsed_string[‘serps’][0][‘compare_urls’][0][‘diffs’][‘word_count’][‘long’][‘diff’]
except Exception as ex_megaindex:
print(«API megaindex request error: {error}». format(error=ex_megaindex))
list_base_urls = []
symbols_median = ‘Данные не получены’
for url in list_base_urls:
url = url.replace(‘http:’, ‘https:’)
data = serpstat_keywords(url)
try:
for keyword in data[‘result’][‘hits’]:
keyword_list.append(keyword[‘keyword’])
except:
pass
for item in set(keyword_list):
uniq_keyword_list.append(item)
count_lemma = counter_dict_list(uniq_keyword_list)
return (list_base_urls, relevance, symbols_median, symbols_text, symbols_diff, words_median, words_value_text, words_diff, count_lemma)
format(error=ex_megaindex))
list_base_urls = []
symbols_median = ‘Данные не получены’
for url in list_base_urls:
url = url.replace(‘http:’, ‘https:’)
data = serpstat_keywords(url)
try:
for keyword in data[‘result’][‘hits’]:
keyword_list.append(keyword[‘keyword’])
except:
pass
for item in set(keyword_list):
uniq_keyword_list.append(item)
count_lemma = counter_dict_list(uniq_keyword_list)
return (list_base_urls, relevance, symbols_median, symbols_text, symbols_diff, words_median, words_value_text, words_diff, count_lemma)
Проходимся по списку маркерных запросов и генерируем задание.
print (‘Всего будет сгенерировано ТЗ: ‘, len(keywords_url_dict))
for keywords in keywords_url_dict.keys():
print(keywords, keywords_url_dict[keywords])
try:
list_base_urls, relevance, symbols_median, symbols_text, symbols_diff, words_median, words_value_text, words_diff, count_lemma = megaindex_text_score(keywords, keywords_url_dict[keywords])
except Exception as ex:
pass
print(f’Errow: {ex}’)
with open(‘api. txt’, ‘a’) as f:
f.write(‘{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t\n\n’.format(keywords, keywords_url_dict[keywords], list_base_urls, relevance, symbols_median, symbols_text, symbols_diff, words_median, words_value_text, words_diff))
f.write(‘Лемма’ +’\t’ + ‘Количество повторений’ + ‘\n’)
for key, value in count_lemma.items():
f.write(‘{}\t{}\n’.format(key, value))
f.write(‘\n’+’\n’+’\n’)
print (‘end’)
txt’, ‘a’) as f:
f.write(‘{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t\n\n’.format(keywords, keywords_url_dict[keywords], list_base_urls, relevance, symbols_median, symbols_text, symbols_diff, words_median, words_value_text, words_diff))
f.write(‘Лемма’ +’\t’ + ‘Количество повторений’ + ‘\n’)
for key, value in count_lemma.items():
f.write(‘{}\t{}\n’.format(key, value))
f.write(‘\n’+’\n’+’\n’)
print (‘end’)
Пример получившегося ТЗ.
Ссылка на скрипт (открывать в Jupyter Notebook).
Вариант 3. Семантическое ядро есть, статья не написана
Рассмотрим ситуацию, когда у специалиста есть собранное и кластеризованное семантическое ядро.
Плюсы подхода:
- Работаем уже с тщательно проработанным и кластеризованным семантическим ядром.
Минусы (почти те же, что и у первого варианта):
- Нужна подписка на сервисы.
- Данные, которые выдают сервисы, не всегда точны. Например, Megaindex не определяет длину текста меньше определённого количества знаков (около 200 символов). Поэтому показатели выборочно стоит перепроверить.
 Например, Megaindex не определяет длину текста меньше определённого количества знаков (около 200 символов). Поэтому показатели выборочно стоит перепроверить.
Например, Megaindex не определяет длину текста меньше определённого количества знаков (около 200 символов). Поэтому показатели выборочно стоит перепроверить.Подключаем необходимые библиотеки, указываем токен для работы с Megaindex и ser_id нужного региона.
import pymorphy2 import requests import json import re morph = pymorphy2.MorphAnalyzer() token = «xxxxxxxxxxxxxxxxxxxxx» ser_id = 174 #174 #ID поисковой системы яндекс_спб
Для работы скрипта нам понадобится txt-файл (‘data_tz.txt’) с кластеризованным ядром.
Формат файла: Ключ → Группа; разделитель табуляция.
item_dict = {}
flag = True
with open(‘data_tz.txt’) as file:
for line in file:
if flag:
flag = False # пропускаем строку заголовка
else:
line = line.strip().split(‘ ‘)
word = line[0]
group = line[1]
if group not in item_dict:
item_dict[group] = []
item_dict[group]. append(word)
else:
item_dict[group].append(word)
append(word)
else:
item_dict[group].append(word)
Работаем со словарём, полученным на предыдущем шаге. Для каждой группы обходим все ключевые фразы, разбиваем их на слова, нормализуем и добавляем в словарь.
group_word_count_dict = {}
for key, value in item_dict.items():
group_word_count_dict.setdefault(key, {})
for item in value:
for word in re.findall(«([А-ЯЁа-яё0-9]+(-[А-ЯЁа-яё0-9]+)*)», item):
word = word[0]
word = morph.parse(word)[0].normal_form
form = morph.parse(word)[0].tag
#не добавляем в словарь местоимение-существительное, предлог, союз, частица, междометие
if (‘NPRO’ in form or ‘PREP’ in form or ‘CONJ’ in form or ‘PRCL’ in form or ‘INTJ’ in form):
continue
else:
group_word_count_dict[key].setdefault(word, 0)
if word in group_word_count_dict[key]:
group_word_count_dict[key][word] += 1
#Сортировка получивщегося словаря
for key, value in group_word_count_dict. items():
sorted_group_word_count_dict = list(value.items())
sorted_group_word_count_dict.sort(key=lambda i: i[1], reverse=True)
sorted_group_word_count_dict = dict(sorted_group_word_count_dict)
group_word_count_dict[key] = sorted_group_word_count_dict
print(group_word_count_dict)
print(‘end’)
items():
sorted_group_word_count_dict = list(value.items())
sorted_group_word_count_dict.sort(key=lambda i: i[1], reverse=True)
sorted_group_word_count_dict = dict(sorted_group_word_count_dict)
group_word_count_dict[key] = sorted_group_word_count_dict
print(group_word_count_dict)
print(‘end’)
Получаем данные по API и парсим полученный текст.
def megaindex_text_score(key): try: url = ‘http://api.megaindex.com/visrep/text_score?key={}&words={}&ser_id={}’.format(token, key, ser_id) r = requests.get(url) json_string = r.text parsed_string = json.loads(json_string)[‘data’] list_base_urls = parsed_string[‘serps’][0][‘base_urls’] symbols_median = parsed_string[‘old_api’][‘fragments’][‘long’][‘symbols_median’] except Exception as ex_megaindex: print(«API megaindex request error: {error}».format(error=ex_megaindex)) list_base_urls = [‘Данные не получены’] symbols_median = 0 return(list_base_urls, symbols_median)
Подготавливаем финальный файл.
# чистим файл f = open(‘group_word_lemma.txt’, ‘w’) f.write(‘Группа’ +’\t’ + ‘Конкуренты’ +’\t’ + ‘Символов ЗБП’+ ‘\n’) f.close() with open(‘group_word_lemma.txt’ , ‘a’) as f: for key_dict, value_dict in group_word_count_dict.items(): base_urls, symbols_median = megaindex_text_score(key_dict) if symbols_median < 8000: # Ограничение по количеству символов print(key_dict, base_urls, symbols_median) f.write(‘{}\t{}\t{}\n\n’.format(key_dict, base_urls, symbols_median)) f.write(‘Лемма’ +’\t’ + ‘Количество повторений’ + ‘\n’) for key, value in value_dict.items(): print(key, value) f.write(‘{}\t{}\n’.format(key, value)) f.write(‘\n’+’\n’+’\n’) print(‘end’)
Проходимся по списку групп и генерируем задание.
with open(‘group_word_lemma.txt’ , ‘a’) as f:
for key_dict, value_dict in group_word_count_dict. items():
base_urls, symbols_median = megaindex_text_score(key_dict)
if symbols_median < 8000: # Ограничение по количеству символов
print(key_dict, base_urls, symbols_median)
f.write(‘{}\t{}\t{}\n\n’.format(key_dict, base_urls, symbols_median))
f.write(‘Лемма’ +’\t’ + ‘Количество повторений’ + ‘\n’)
for key, value in value_dict.items():
print(key, value)
f.write(‘{}\t{}\n’.format(key, value))
f.write(‘\n’+’\n’+’\n’)
print(‘end’)
items():
base_urls, symbols_median = megaindex_text_score(key_dict)
if symbols_median < 8000: # Ограничение по количеству символов
print(key_dict, base_urls, symbols_median)
f.write(‘{}\t{}\t{}\n\n’.format(key_dict, base_urls, symbols_median))
f.write(‘Лемма’ +’\t’ + ‘Количество повторений’ + ‘\n’)
for key, value in value_dict.items():
print(key, value)
f.write(‘{}\t{}\n’.format(key, value))
f.write(‘\n’+’\n’+’\n’)
print(‘end’)
Так как основной маркерный запрос в этом случае — название категории, нужно следить за полнотой и правильностью её написания.
Аналогично первому варианту, получившийся результат переносим в «Google Таблицы». Получившееся ТЗ в таком же формате.
Ссылка на скрипт (открывать в Jupyter Notebook).
Предложенные скрипты можно дорабатывать, добавляя в них и другие важные на ваш взгляд требования к тексту.
Имея список URL конкурентов, можно парсить:
- Title страниц.
- Заголовки h2 — H6.
- Количество нумерованных, маркированных списков, изображений на странице и так далее.
Аналогичным способом делать морфологический анализ тегов, заголовков и выдавать рекомендации по количеству элементов и упоминаний лемм в этих тегах.
3. Анализ логов
При техническом аудите сайтов полезно анализировать логи сайта. Возможные варианты анализа:
- Использовать возможности, которые предоставляет хостер. Чаще всего это решение в виде надстройки, например, AWStats. Минусы: не гибко, чаще всего предоставляется определённый набор графиков, которые никак не изменить.
- Использовать платные решения. Например, Screaming Frog SEO Log File Analyser — бесплатная версия работает с файлами до 1000 строк. Минусы: цена, не всегда логи вашего сервера будут соответствовать тому виду, который требуется для работы в программе.
- Использовать ELK-стек (elastic + logstash + kibana). Минусы: требуются знания по настройке хранилища и передаче в него данных.
- Решение на Python с использованием библиотек.
Подробнее что про то, что такое логи, их структуру и содержание можно почитать в статье. Перейдём к скрипту.
Что потребуется:
- Лог-файлы сайта.
- Установленные Python-библиотеки.
Плюсы подхода:
- Бесплатное решение.
- Можно быстро проанализировать лог-файл в любом формате.
- Легко обрабатывает большие файлы на несколько миллионов записей.
Минусы:
- Хранение данных на своём устройстве (если работаете не на выделенном сервере).
- Чтобы проанализировать данные за новый период, необходимо заново считать данные, разобрать и записать их в анализируемый CSV-файл.
- В приведённом скрипте только базовые универсальные примеры анализа.

Для работы будем использовать библиотеку apache-log-parser, подробная документация по ссылке на GitHub.
import apache_log_parser import csv
Для начала обработаем наш лог-файл и запишем данные в CSV. Если файлов несколько, склеить их можно следующей командой:
!cat access.log.1 access.log.2 access.log.3 > all_log.log
Создаем файл log.csv и записываем в него строку заголовка с названием столбцов. Столбцы определяются в соответствии с вашим лог-файлом.
csv_file = open(‘log.csv’, ‘w’)
data = [[‘remote_host’, ‘server_name2’, ‘query_string’, ‘time_received_isoformat’, ‘request_method’, ‘request_url’, ‘request_http_ver’, ‘request_url_scheme’, ‘request_url_query’, ‘status’, ‘response_bytes_clf’, ‘request_header_user_agent’, ‘request_header_user_agent__browser__family’, ‘request_header_user_agent__browser__version_string’, ‘request_header_user_agent__os__family’, ‘request_header_user_agent__os__version_string’, ‘request_header_user_agent__is_mobile’]]
with csv_file:
writer = csv. writer(csv_file)
writer.writerows(data)
csv_file.close()
Читаем построчно access.log, парсим строку и записываем разобранные данные в CSV. Используем функцию make_parser, которая принимает строку из файла журнала в указанном нами формате и возвращает проанализированные значения в виде словаря.
Формат строки из журнала указывается в make_parserс помощью поддерживаемых значений, указанных в документации, — supported values.
Пример строки
54.36.148.252 example.ru — [13/Oct/2019:12:00:01 +0300] «GET /lenta/example/example/p1 HTTP/1.1» 301 5 «-» «Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)» 0.137 0.137 .
Пример разбора
with open(‘all_log.log’) as file:
for line in file:
line = line.strip()
line_parser = apache_log_parser.make_parser(«%h %V %q %t \»%r\» %>s %b \»%{Referer}i\» \»%{User-Agent}i\»»)
log_line_data = line_parser(f'{line}’)
#Пишем в файл нужные данные
data = [[log_line_data[‘remote_host’], log_line_data[‘server_name2’], log_line_data[‘query_string’], log_line_data[‘time_received_isoformat’], log_line_data[‘request_method’], log_line_data[‘request_url’], log_line_data[‘request_http_ver’], log_line_data[‘request_url_scheme’], log_line_data[‘request_url_query’], log_line_data[‘status’], log_line_data[‘response_bytes_clf’], log_line_data[‘request_header_user_agent’], log_line_data[‘request_header_user_agent__browser__family’], log_line_data[‘request_header_user_agent__browser__version_string’], log_line_data[‘request_header_user_agent__os__family’], log_line_data[‘request_header_user_agent__os__version_string’], log_line_data[‘request_header_user_agent__is_mobile’]]]
csv_file = open(‘log. csv’, ‘a’)
with csv_file:
writer = csv.writer(csv_file)
writer.writerows(data)
Далее анализируем полученный CSV-файл. Анализ можно провести в Excel или любом другом удобном инструменте. Для примера рассмотрим несколько вариантом получения данных на Python.
Подключаем библиотеку для анализа данных и считываем файл.
import pandas as pd data = pd.read_csv(‘log.csv’)
Посмотрим распределение страниц по статус коду страниц.
status_code_count = data[‘status’].value_counts() print(status_code_count)
Посчитаем количество страниц со статусом 410 для каждого user-agent.
data[data[‘status’]==410][‘request_header_user_agent__browser__family’].value_counts()
В результате работы скрипта мы получили готовый CSV-файл с разобранными по столбцам записями из лог-файла. Далее можно анализировать данные в соответствии с вашими целями.
Ссылка на скрипт (открывать в Jupyter Notebook).
Разработка надёжных Python-скриптов / Хабр
Python — это язык программирования, который отлично подходит для разработки самостоятельных скриптов. Для того чтобы добиться с помощью подобного скрипта желаемого результата, нужно написать несколько десятков или сотен строк кода. А после того, как дело сделано, можно просто забыть о написанном коде и перейти к решению следующей задачи.
Если, скажем, через полгода после того, как был написан некий «одноразовый» скрипт, кто-то спросит его автора о том, почему этот скрипт даёт сбои, об этом может не знать и автор скрипта. Происходит подобное из-за того, что к такому скрипту не была написана документация, из-за использования параметров, жёстко заданных в коде, из-за того, что скрипт ничего не логирует в ходе работы, и из-за отсутствия тестов, которые позволили бы быстро понять причину проблемы.
При этом надо отметить, что превратить скрипт, написанный на скорую руку, в нечто гораздо более качественное, не так уж и сложно. А именно, такой скрипт довольно легко превратить в надёжный и понятный код, которым удобно пользоваться, в код, который просто поддерживать как его автору, так и другим программистам.
Автор материала, перевод которого мы сегодня публикуем, собирается продемонстрировать подобное «превращение» на примере классической задачи «Fizz Buzz Test». Эта задача заключается в том, чтобы вывести список чисел от 1 до 100, заменив некоторые из них особыми строками. Так, если число кратно 3 — вместо него нужно вывести строку Fizz, если число кратно 5 — строку Buzz, а если соблюдаются оба этих условия — FizzBuzz.
Исходный код
Вот исходный код Python-скрипта, который позволяет решить задачу:
import sys
for n in range(int(sys.argv[1]), int(sys.argv[2])):
if n % 3 == 0 and n % 5 == 0:
print("fizzbuzz")
elif n % 3 == 0:
print("fizz")
elif n % 5 == 0:
print("buzz")
else:
print(n)Поговорим о том, как его улучшить.
Документация
Я считаю, что полезно писать документацию до написания кода. Это упрощает работу и помогает не затягивать создание документации до бесконечности. Документацию к скрипту можно поместить в его верхнюю часть. Например, она может выглядеть так:
#!/usr/bin/env python3 """Simple fizzbuzz generator. This script prints out a sequence of numbers from a provided range with the following restrictions: - if the number is divisible by 3, then print out "fizz", - if the number is divisible by 5, then print out "buzz", - if the number is divisible by 3 and 5, then print out "fizzbuzz". """
В первой строке даётся краткое описание цели скрипта. В оставшихся абзацах содержатся дополнительные сведения о том, что именно делает скрипт.
Аргументы командной строки
Следующей задачей по улучшению скрипта станет замена значений, жёстко заданных в коде, на документированные значения, передаваемые скрипту через аргументы командной строки. Реализовать это можно с использованием модуля argparse. В нашем примере мы предлагаем пользователю указать диапазон чисел и указать значения для «fizz» и «buzz», используемые при проверке чисел из указанного диапазона.
import argparse
import sys
class CustomFormatter(argparse.RawDescriptionHelpFormatter,
argparse.ArgumentDefaultsHelpFormatter):
pass
def parse_args(args=sys.argv[1:]):
"""Parse arguments."""
parser = argparse.ArgumentParser(
description=sys.modules[__name__].__doc__,
formatter_class=CustomFormatter)
g = parser.add_argument_group("fizzbuzz settings")
g.add_argument("--fizz", metavar="N",
default=3,
type=int,
help="Modulo value for fizz")
g.add_argument("--buzz", metavar="N",
default=5,
type=int,
help="Modulo value for buzz")
parser.add_argument("start", type=int, help="Start value")
parser.add_argument("end", type=int, help="End value")
return parser. parse_args(args)
options = parse_args()
for n in range(options.start, options.end + 1):
# ... parse_args(args)
options = parse_args()
for n in range(options.start, options.end + 1):
# ...
parse_args(args)
options = parse_args()
for n in range(options.start, options.end + 1):
# ...
Эти изменения приносят скрипту огромную пользу. А именно, параметры теперь надлежащим образом документированы, выяснить их предназначение можно с помощью флага --help. Более того, по соответствующей команде выводится и документация, которую мы написали в предыдущем разделе:
$ ./fizzbuzz.py --help usage: fizzbuzz.py [-h] [--fizz N] [--buzz N] start end Simple fizzbuzz generator. This script prints out a sequence of numbers from a provided range with the following restrictions: - if the number is divisible by 3, then print out "fizz", - if the number is divisible by 5, then print out "buzz", - if the number is divisible by 3 and 5, then print out "fizzbuzz". positional arguments: start Start value end End value optional arguments: -h, --help show this help message and exit fizzbuzz settings: --fizz N Modulo value for fizz (default: 3) --buzz N Modulo value for buzz (default: 5)
Модуль argparse — это весьма мощный инструмент. Если вы с ним не знакомы — вам полезно будет просмотреть документацию по нему. Мне, в частности, нравятся его возможности по определению подкоманд и групп аргументов.
Если вы с ним не знакомы — вам полезно будет просмотреть документацию по нему. Мне, в частности, нравятся его возможности по определению подкоманд и групп аргументов.
Логирование
Если оснастить скрипт возможностями по выводу некоей информации в ходе его выполнения — это окажется приятным дополнением к его функционалу. Для этой цели хорошо подходит модуль logging. Для начала опишем объект, реализующий логирование:
import logging import logging.handlers import os import sys logger = logging.getLogger(os.path.splitext(os.path.basename(sys.argv[0]))[0])
Затем сделаем так, чтобы подробностью сведений, выводимых при логировании, можно было бы управлять. Так, команда logger.debug() должна выводить что-то только в том случае, если скрипт запускают с ключом --debug. Если же скрипт запускают с ключом --silent — скрипт не должен выводить ничего кроме сообщений об исключениях. Для реализации этих возможностей добавим в
Для реализации этих возможностей добавим в parse_args() следующий код:
# В parse_args()
g = parser.add_mutually_exclusive_group()
g.add_argument("--debug", "-d", action="store_true",
default=False,
help="enable debugging")
g.add_argument("--silent", "-s", action="store_true",
default=False,
help="don't log to console")Добавим в код проекта следующую функцию для настройки логирования:
def setup_logging(options):
"""Configure logging."""
root = logging.getLogger("")
root.setLevel(logging.WARNING)
logger.setLevel(options.debug and logging.DEBUG or logging.INFO)
if not options.silent:
ch = logging.StreamHandler()
ch.setFormatter(logging.Formatter(
"%(levelname)s[%(name)s] %(message)s"))
root.addHandler(ch)Основной код скрипта при этом изменится так:
if __name__ == "__main__": options = parse_args() setup_logging(options) try: logger.
 debug("compute fizzbuzz from {} to {}".format(options.start,
options.end))
for n in range(options.start, options.end + 1):
# ..
except Exception as e:
logger.exception("%s", e)
sys.exit(1)
sys.exit(0)
debug("compute fizzbuzz from {} to {}".format(options.start,
options.end))
for n in range(options.start, options.end + 1):
# ..
except Exception as e:
logger.exception("%s", e)
sys.exit(1)
sys.exit(0)
Если скрипт планируется запускать без прямого участия пользователя, например, с помощью crontab, можно сделать так, чтобы его вывод поступал бы в syslog:
def setup_logging(options):
"""Configure logging."""
root = logging.getLogger("")
root.setLevel(logging.WARNING)
logger.setLevel(options.debug and logging.DEBUG or logging.INFO)
if not options.silent:
if not sys.stderr.isatty():
facility = logging.handlers.SysLogHandler.LOG_DAEMON
sh = logging.handlers.SysLogHandler(address='/dev/log',
facility=facility)
sh. setFormatter(logging.Formatter(
"{0}[{1}]: %(message)s".format(
logger.name,
os.getpid())))
root.addHandler(sh)
else:
ch = logging.StreamHandler()
ch.setFormatter(logging.Formatter(
"%(levelname)s[%(name)s] %(message)s"))
root.addHandler(ch) setFormatter(logging.Formatter(
"{0}[{1}]: %(message)s".format(
logger.name,
os.getpid())))
root.addHandler(sh)
else:
ch = logging.StreamHandler()
ch.setFormatter(logging.Formatter(
"%(levelname)s[%(name)s] %(message)s"))
root.addHandler(ch)
setFormatter(logging.Formatter(
"{0}[{1}]: %(message)s".format(
logger.name,
os.getpid())))
root.addHandler(sh)
else:
ch = logging.StreamHandler()
ch.setFormatter(logging.Formatter(
"%(levelname)s[%(name)s] %(message)s"))
root.addHandler(ch)
В нашем небольшом скрипте неоправданно большим кажется подобный объём кода, нужный только для того, чтобы воспользоваться командой logger.debug(). Но в реальных скриптах этот код уже таким не покажется и на первый план выйдет польза от него, заключающаяся в том, что с его помощью пользователи смогут узнавать о ходе решения задачи.
$ ./fizzbuzz.py --debug 1 3 DEBUG[fizzbuzz] compute fizzbuzz from 1 to 3 1 2 fizz
Тесты
Модульные тесты — это полезнейшее средство для проверки того, ведёт ли себя приложения так, как нужно. В скриптах модульные тесты используют нечасто, но их включение в скрипты значительно улучшает надёжность кода. Преобразуем код, находящийся внутри цикла, в функцию, и опишем несколько интерактивных примеров её использования в её документации:
В скриптах модульные тесты используют нечасто, но их включение в скрипты значительно улучшает надёжность кода. Преобразуем код, находящийся внутри цикла, в функцию, и опишем несколько интерактивных примеров её использования в её документации:
def fizzbuzz(n, fizz, buzz): """Compute fizzbuzz nth item given modulo values for fizz and buzz. >>> fizzbuzz(5, fizz=3, buzz=5) 'buzz' >>> fizzbuzz(3, fizz=3, buzz=5) 'fizz' >>> fizzbuzz(15, fizz=3, buzz=5) 'fizzbuzz' >>> fizzbuzz(4, fizz=3, buzz=5) 4 >>> fizzbuzz(4, fizz=4, buzz=6) 'fizz' """ if n % fizz == 0 and n % buzz == 0: return "fizzbuzz" if n % fizz == 0: return "fizz" if n % buzz == 0: return "buzz" return n
Проверить правильность работы функции можно с помощью pytest:
$ python3 -m pytest -v --doctest-modules ./fizzbuzz.py ============================ test session starts ============================= platform linux -- Python 3.
 7.4, pytest-3.10.1, py-1.8.0, pluggy-0.8.0 -- /usr/bin/python3
cachedir: .pytest_cache
rootdir: /home/bernat/code/perso/python-script, inifile:
plugins: xdist-1.26.1, timeout-1.3.3, forked-1.0.2, cov-2.6.0
collected 1 item
fizzbuzz.py::fizzbuzz.fizzbuzz PASSED [100%]
========================== 1 passed in 0.05 seconds ==========================
7.4, pytest-3.10.1, py-1.8.0, pluggy-0.8.0 -- /usr/bin/python3
cachedir: .pytest_cache
rootdir: /home/bernat/code/perso/python-script, inifile:
plugins: xdist-1.26.1, timeout-1.3.3, forked-1.0.2, cov-2.6.0
collected 1 item
fizzbuzz.py::fizzbuzz.fizzbuzz PASSED [100%]
========================== 1 passed in 0.05 seconds ==========================
Для того чтобы всё это заработало, нужно, чтобы после имени скрипта шло бы расширение .py. Мне не нравится добавлять расширения к именам скриптов: язык — это лишь техническая деталь, которую не нужно демонстрировать пользователю. Однако возникает такое ощущение, что оснащение имени скрипта расширением — это самый простой способ позволить системам для запуска тестов, вроде pytest, находить тесты, включённые в код.
В случае возникновения ошибки pytest выведет сообщение, указывающее на расположение соответствующего кода и на суть проблемы:
$ python3 -m pytest -v --doctest-modules .
 /fizzbuzz.py -k fizzbuzz.fizzbuzz
============================ test session starts =============================
platform linux -- Python 3.7.4, pytest-3.10.1, py-1.8.0, pluggy-0.8.0 -- /usr/bin/python3
cachedir: .pytest_cache
rootdir: /home/bernat/code/perso/python-script, inifile:
plugins: xdist-1.26.1, timeout-1.3.3, forked-1.0.2, cov-2.6.0
collected 1 item
fizzbuzz.py::fizzbuzz.fizzbuzz FAILED [100%]
================================== FAILURES ==================================
________________________ [doctest] fizzbuzz.fizzbuzz _________________________
100
101 >>> fizzbuzz(5, fizz=3, buzz=5)
102 'buzz'
103 >>> fizzbuzz(3, fizz=3, buzz=5)
104 'fizz'
105 >>> fizzbuzz(15, fizz=3, buzz=5)
106 'fizzbuzz'
107 >>> fizzbuzz(4, fizz=3, buzz=5)
108 4
109 >>> fizzbuzz(4, fizz=4, buzz=6)
Expected:
fizz
Got:
4
/home/bernat/code/perso/python-script/fizzbuzz.py:109: DocTestFailure
========================== 1 failed in 0.
/fizzbuzz.py -k fizzbuzz.fizzbuzz
============================ test session starts =============================
platform linux -- Python 3.7.4, pytest-3.10.1, py-1.8.0, pluggy-0.8.0 -- /usr/bin/python3
cachedir: .pytest_cache
rootdir: /home/bernat/code/perso/python-script, inifile:
plugins: xdist-1.26.1, timeout-1.3.3, forked-1.0.2, cov-2.6.0
collected 1 item
fizzbuzz.py::fizzbuzz.fizzbuzz FAILED [100%]
================================== FAILURES ==================================
________________________ [doctest] fizzbuzz.fizzbuzz _________________________
100
101 >>> fizzbuzz(5, fizz=3, buzz=5)
102 'buzz'
103 >>> fizzbuzz(3, fizz=3, buzz=5)
104 'fizz'
105 >>> fizzbuzz(15, fizz=3, buzz=5)
106 'fizzbuzz'
107 >>> fizzbuzz(4, fizz=3, buzz=5)
108 4
109 >>> fizzbuzz(4, fizz=4, buzz=6)
Expected:
fizz
Got:
4
/home/bernat/code/perso/python-script/fizzbuzz.py:109: DocTestFailure
========================== 1 failed in 0. 02 seconds ==========================
02 seconds ==========================Модульные тесты можно писать и в виде обычного кода. Представим, что нам нужно протестировать следующую функцию:
def main(options):
"""Compute a fizzbuzz set of strings and return them as an array."""
logger.debug("compute fizzbuzz from {} to {}".format(options.start,
options.end))
return [str(fizzbuzz(i, options.fizz, options.buzz))
for i in range(options.start, options.end+1)]
В конце скрипта добавим следующие модульные тесты, использующие возможности pytest по использованию параметризованных тестовых функций:
# Модульные тесты
import pytest # noqa: E402
import shlex # noqa: E402
@pytest.mark.parametrize("args, expected", [
("0 0", ["fizzbuzz"]),
("3 5", ["fizz", "4", "buzz"]),
("9 12", ["fizz", "buzz", "11", "fizz"]),
("14 17", ["14", "fizzbuzz", "16", "17"]),
("14 17 --fizz=2", ["fizz", "buzz", "fizz", "17"]),
("17 20 --buzz=10", ["17", "fizz", "19", "buzz"]),
])
def test_main(args, expected):
options = parse_args(shlex. split(args))
options.debug = True
options.silent = True
setup_logging(options)
assert main(options) == expected split(args))
options.debug = True
options.silent = True
setup_logging(options)
assert main(options) == expected
split(args))
options.debug = True
options.silent = True
setup_logging(options)
assert main(options) == expected
Обратите внимание на то, что, так как код скрипта завершается вызовом sys.exit(), при его обычном вызове тесты выполняться не будут. Благодаря этому pytest для запуска скрипта не нужен.
Тестовая функция будет вызвана по одному разу для каждой группы параметров. Сущность args используется в качестве входных данных для функции parse_args(). Благодаря этому механизму мы получаем то, что нужно передать функции main(). Сущность expected сравнивается с тем, что выдаёт main(). Вот что сообщит нам pytest в том случае, если всё работает так, как ожидается:
$ python3 -m pytest -v --doctest-modules ./fizzbuzz.py ============================ test session starts ============================= platform linux -- Python 3.
 7.4, pytest-3.10.1, py-1.8.0, pluggy-0.8.0 -- /usr/bin/python3
cachedir: .pytest_cache
rootdir: /home/bernat/code/perso/python-script, inifile:
plugins: xdist-1.26.1, timeout-1.3.3, forked-1.0.2, cov-2.6.0
collected 7 items
fizzbuzz.py::fizzbuzz.fizzbuzz PASSED [ 14%]
fizzbuzz.py::test_main[0 0-expected0] PASSED [ 28%]
fizzbuzz.py::test_main[3 5-expected1] PASSED [ 42%]
fizzbuzz.py::test_main[9 12-expected2] PASSED [ 57%]
fizzbuzz.py::test_main[14 17-expected3] PASSED [ 71%]
fizzbuzz.py::test_main[14 17 --fizz=2-expected4] PASSED [ 85%]
fizzbuzz.py::test_main[17 20 --buzz=10-expected5] PASSED [100%]
========================== 7 passed in 0.03 seconds ==========================
7.4, pytest-3.10.1, py-1.8.0, pluggy-0.8.0 -- /usr/bin/python3
cachedir: .pytest_cache
rootdir: /home/bernat/code/perso/python-script, inifile:
plugins: xdist-1.26.1, timeout-1.3.3, forked-1.0.2, cov-2.6.0
collected 7 items
fizzbuzz.py::fizzbuzz.fizzbuzz PASSED [ 14%]
fizzbuzz.py::test_main[0 0-expected0] PASSED [ 28%]
fizzbuzz.py::test_main[3 5-expected1] PASSED [ 42%]
fizzbuzz.py::test_main[9 12-expected2] PASSED [ 57%]
fizzbuzz.py::test_main[14 17-expected3] PASSED [ 71%]
fizzbuzz.py::test_main[14 17 --fizz=2-expected4] PASSED [ 85%]
fizzbuzz.py::test_main[17 20 --buzz=10-expected5] PASSED [100%]
========================== 7 passed in 0.03 seconds ==========================
Если произойдёт ошибка — pytest даст полезные сведения о том, что случилось:
$ python3 -m pytest -v --doctest-modules .
 /fizzbuzz.py
[...]
================================== FAILURES ==================================
__________________________ test_main[0 0-expected0] __________________________
args = '0 0', expected = ['0']
@pytest.mark.parametrize("args, expected", [
("0 0", ["0"]),
("3 5", ["fizz", "4", "buzz"]),
("9 12", ["fizz", "buzz", "11", "fizz"]),
("14 17", ["14", "fizzbuzz", "16", "17"]),
("14 17 --fizz=2", ["fizz", "buzz", "fizz", "17"]),
("17 20 --buzz=10", ["17", "fizz", "19", "buzz"]),
])
def test_main(args, expected):
options = parse_args(shlex.split(args))
options.debug = True
options.silent = True
setup_logging(options)
assert main(options) == expected
E AssertionError: assert ['fizzbuzz'] == ['0']
E At index 0 diff: 'fizzbuzz' != '0'
E Full diff:
E - ['fizzbuzz']
E + ['0']
fizzbuzz.py:160: AssertionError
----------------------------- Captured log call ------------------------------
fizzbuzz.
/fizzbuzz.py
[...]
================================== FAILURES ==================================
__________________________ test_main[0 0-expected0] __________________________
args = '0 0', expected = ['0']
@pytest.mark.parametrize("args, expected", [
("0 0", ["0"]),
("3 5", ["fizz", "4", "buzz"]),
("9 12", ["fizz", "buzz", "11", "fizz"]),
("14 17", ["14", "fizzbuzz", "16", "17"]),
("14 17 --fizz=2", ["fizz", "buzz", "fizz", "17"]),
("17 20 --buzz=10", ["17", "fizz", "19", "buzz"]),
])
def test_main(args, expected):
options = parse_args(shlex.split(args))
options.debug = True
options.silent = True
setup_logging(options)
assert main(options) == expected
E AssertionError: assert ['fizzbuzz'] == ['0']
E At index 0 diff: 'fizzbuzz' != '0'
E Full diff:
E - ['fizzbuzz']
E + ['0']
fizzbuzz.py:160: AssertionError
----------------------------- Captured log call ------------------------------
fizzbuzz. py 125 DEBUG compute fizzbuzz from 0 to 0
===================== 1 failed, 6 passed in 0.05 seconds =====================
py 125 DEBUG compute fizzbuzz from 0 to 0
===================== 1 failed, 6 passed in 0.05 seconds =====================
В эти выходные данные включён и вывод команды logger.debug(). Это — ещё одна веская причина для использования в скриптах механизмов логирования. Если вы хотите узнать подробности о замечательных возможностях pytest — взгляните на этот материал.
Итоги
Сделать Python-скрипты надёжнее можно, выполнив следующие четыре шага:
- Оснастить скрипт документацией, размещаемой в верхней части файла.
- Использовать модуль
argparseдля документирования параметров, с которыми можно вызывать скрипт. - Использовать модуль
loggingдля вывода сведений о процессе работы скрипта. - Написать модульные тесты.
Вот полный код рассмотренного здесь примера. Вы можете использовать его в качестве шаблона для собственных скриптов.
Вы можете использовать его в качестве шаблона для собственных скриптов.
Вокруг этого материала развернулись интересные обсуждения — найти их можно здесь и здесь. Аудитория, как кажется, хорошо восприняла рекомендации по документации и по аргументам командной строки, а вот то, что касается логирования и тестов, показалось некоторым читателям «пальбой из пушки по воробьям». Вот материал, который был написан в ответ на данную статью.
Уважаемые читатели! Планируете ли вы применять рекомендации по написанию Python-скриптов, данные в этой публикации?
Пишем простой скрипт на Python
Здарова, щеглы, сегодня мы своими руками будем писать скрипт на Python. Нам понадобятся: интерпретатор Python 3 под «какая-там-у-вас-ОС», текстовый редактор с подсветкой синтаксиса, например, Sublime Text, Google, упаковка прамирацетама, бутылка минеральной воды и 60 минут свободного времени.
Перед тем как писать скрипт, мы должны определиться, что он вообще будет делать. Делать он будет следующее: получив на вход домен и диапазон IP-адресов, многопоточно проходить список этих адресов, совершать HTTP-запрос к каждому, в попытках понять, на каком же из них размещен искомый домен. Зачем это нужно? Бывают ситуации, когда IP-адрес домена закрыт Cloudflare, или Stormwall, или Incapsula, или еще чем-нибудь, WHOIS история не выдает ничего интересного, в DNS-записях такая же канитель, а, внезапно, один из поддоменов ресолвится в адрес из некоторой подсети, которая не принадлежит сервису защиты. И в этот момент нам становится интересно, вдруг и основной домен размещен в той же самой подсети.
Делать он будет следующее: получив на вход домен и диапазон IP-адресов, многопоточно проходить список этих адресов, совершать HTTP-запрос к каждому, в попытках понять, на каком же из них размещен искомый домен. Зачем это нужно? Бывают ситуации, когда IP-адрес домена закрыт Cloudflare, или Stormwall, или Incapsula, или еще чем-нибудь, WHOIS история не выдает ничего интересного, в DNS-записях такая же канитель, а, внезапно, один из поддоменов ресолвится в адрес из некоторой подсети, которая не принадлежит сервису защиты. И в этот момент нам становится интересно, вдруг и основной домен размещен в той же самой подсети.
Погнали, сразу выпиваем половину бутылки воды, и пишем следующий код:
Python
import argparse
import logging
import coloredlogs
import ssl
import concurrent.futures
import urllib.request
from netaddr import IPNetwork
from collections import deque
VERSION = 0.1
def setup_args():
parser = argparse. ArgumentParser(
description = ‘Domain Seeker v’ + str(VERSION) + ‘ (c) Kaimi (kaimi.io)’,
epilog = »,
formatter_class = argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument(
‘-d’,
‘—domains’,
help = ‘Domain list to discover’,
type = str,
required = True
)
parser.add_argument(
‘-i’,
‘—ips’,
help = ‘IP list (ranges) to scan for domains’,
type = str,
required = True
)
parser.add_argument(
‘—https’,
help = ‘Check HTTPS in addition to HTTP’,
action = ‘store_true’
)
parser.add_argument(
‘—codes’,
help = ‘HTTP-codes list that will be considered as good’,
type = str,
default = ‘200,301,302,401,403’
)
parser.add_argument(
‘—separator’,
help = ‘IP/Domain/HTTP-codes list separator’,
type = str,
default = ‘,’
)
parser.add_argument(
‘—include’,
help = ‘Show results containing provided string’,
type = str
)
parser.
ArgumentParser(
description = ‘Domain Seeker v’ + str(VERSION) + ‘ (c) Kaimi (kaimi.io)’,
epilog = »,
formatter_class = argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument(
‘-d’,
‘—domains’,
help = ‘Domain list to discover’,
type = str,
required = True
)
parser.add_argument(
‘-i’,
‘—ips’,
help = ‘IP list (ranges) to scan for domains’,
type = str,
required = True
)
parser.add_argument(
‘—https’,
help = ‘Check HTTPS in addition to HTTP’,
action = ‘store_true’
)
parser.add_argument(
‘—codes’,
help = ‘HTTP-codes list that will be considered as good’,
type = str,
default = ‘200,301,302,401,403’
)
parser.add_argument(
‘—separator’,
help = ‘IP/Domain/HTTP-codes list separator’,
type = str,
default = ‘,’
)
parser.add_argument(
‘—include’,
help = ‘Show results containing provided string’,
type = str
)
parser. add_argument(
‘—exclude’,
help = ‘Hide results containing provided string’,
type = str
)
parser.add_argument(
‘—agent’,
help = ‘User-Agent value for HTTP-requests’,
type = str,
default = ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1’
)
parser.add_argument(
‘—http-port’,
help = ‘HTTP port’,
type = int,
default = 80
)
parser.add_argument(
‘—https-port’,
help = ‘HTTPS port’,
type = int,
default = 443
)
parser.add_argument(
‘—timeout’,
help = ‘HTTP-request timeout’,
type = int,
default = 5
)
parser.add_argument(
‘—threads’,
help = ‘Number of threads’,
type = int,
default = 2
)
args = parser.parse_args()
return args
if __name__ == ‘__main__’:
main()
add_argument(
‘—exclude’,
help = ‘Hide results containing provided string’,
type = str
)
parser.add_argument(
‘—agent’,
help = ‘User-Agent value for HTTP-requests’,
type = str,
default = ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1’
)
parser.add_argument(
‘—http-port’,
help = ‘HTTP port’,
type = int,
default = 80
)
parser.add_argument(
‘—https-port’,
help = ‘HTTPS port’,
type = int,
default = 443
)
parser.add_argument(
‘—timeout’,
help = ‘HTTP-request timeout’,
type = int,
default = 5
)
parser.add_argument(
‘—threads’,
help = ‘Number of threads’,
type = int,
default = 2
)
args = parser.parse_args()
return args
if __name__ == ‘__main__’:
main()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 | import argparse import logging import coloredlogs import ssl
import concurrent. import urllib.request
from netaddr import IPNetwork from collections import deque
VERSION = 0.1
def setup_args(): parser = argparse.ArgumentParser( description = ‘Domain Seeker v’ + str(VERSION) + ‘ (c) Kaimi (kaimi.io)’, epilog = », formatter_class = argparse.ArgumentDefaultsHelpFormatter ) parser.add_argument( ‘-d’, ‘—domains’, help = ‘Domain list to discover’, type = str, required = True ) parser.add_argument( ‘-i’, ‘—ips’, help = ‘IP list (ranges) to scan for domains’, type = str, required = True ) parser.add_argument( ‘—https’, help = ‘Check HTTPS in addition to HTTP’, action = ‘store_true’ ) parser.add_argument( ‘—codes’, help = ‘HTTP-codes list that will be considered as good’, type = str, default = ‘200,301,302,401,403’ ) parser. ‘—separator’, help = ‘IP/Domain/HTTP-codes list separator’, type = str, default = ‘,’ ) parser.add_argument( ‘—include’, help = ‘Show results containing provided string’, type = str ) parser.add_argument( ‘—exclude’, help = ‘Hide results containing provided string’, type = str ) parser.add_argument( ‘—agent’, help = ‘User-Agent value for HTTP-requests’, type = str, default = ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1’ ) parser.add_argument( ‘—http-port’, help = ‘HTTP port’, type = int, default = 80 ) parser.add_argument( ‘—https-port’, help = ‘HTTPS port’, type = int, default = 443 ) parser.add_argument( ‘—timeout’, help = ‘HTTP-request timeout’, type = int, default = 5 ) parser.add_argument( ‘—threads’, help = ‘Number of threads’, type = int, default = 2 )
args = parser.
return args
if __name__ == ‘__main__’: main() |
 futures
futures add_argument(
add_argument( parse_args()
parse_args()Ни одного комментария, какие-то import, непонятные аргументы командной строки и еще эти две последние строчки… Но будьте спокойны, все нормально, это я вам как мастер программирования на Python с 30-минутным стажем говорю. Тем более, как известно, Google не врет, а официальная документация по Python — это вообще неоспоримая истина.
Так что же мы все-таки сделали в вышеописанном фрагменте кода? Мы подключили модули для работы с аргументами коммандной строки, модули для логирования (потокобезопасные между прочим!), модуль для работы с SSL (для одной мелочи, связанной с HTTPS-запросами), модуль для создания пула потоков, и, наконец, модули для совершения HTTP-запросов, работы с IP-адресами и двухсторонней очередью (по поводу различных типов импорта можно почитать здесь).
После этого мы, в соответствии с документацией по модулю argparse, создали вспомогательную функцию, которая будет обрабатывать аргументы, переданные скрипту при запуске из командной строки. Как видите, в скрипте будет предусмотрена работа со списком доменов/IP-диапазонов, а также возможность фильтрации результатов по ключевым словам и по кодам состояния HTTP и еще пара мелочей, как, например, смена User-Agent и опциональная проверка HTTPS-версии искомого ресурса. Последние две строки в основном используются для разделения кода, который будет выполнен при запуске самого скрипта и при импортировании в другой скрипт. В общем тут все сложно, все так пишут. Мы тоже так будем писать. Можно было бы немного модифицировать этот код, например, добавив возврат разных статусов системе в зависимости от того, как отработала функция main, добавить argv в качестве аргумента, и так далее, но мы изучаем Python только 10 минут и ленимся вчитываться в документацию.
Как видите, в скрипте будет предусмотрена работа со списком доменов/IP-диапазонов, а также возможность фильтрации результатов по ключевым словам и по кодам состояния HTTP и еще пара мелочей, как, например, смена User-Agent и опциональная проверка HTTPS-версии искомого ресурса. Последние две строки в основном используются для разделения кода, который будет выполнен при запуске самого скрипта и при импортировании в другой скрипт. В общем тут все сложно, все так пишут. Мы тоже так будем писать. Можно было бы немного модифицировать этот код, например, добавив возврат разных статусов системе в зависимости от того, как отработала функция main, добавить argv в качестве аргумента, и так далее, но мы изучаем Python только 10 минут и ленимся вчитываться в документацию.
Делаем перерыв и выпиваем глоток освежающей минеральной воды.
Поехали дальше.
Python
def main():
# Обрабатываем аргументы и инициализируем логирование
# с блекджеком и цветными записями
args = setup_args()
coloredlogs. install()
# Сообщаем бесполезную информацию, а также запускаем цикл проверки
logging.info(«Starting…»)
try:
check_loop(args)
except Exception as exception:
logging.error(exception)
logging.info(«Finished»)
def check_loop(args):
# Создаем пул потоков, еще немного обрабатываем переданные аргументы
# и формируем очередь заданий
with concurrent.futures.ThreadPoolExecutor(max_workers = args.threads) as pool:
domains = args.domains.split(args.separator)
ips = args.ips.split(args.separator)
codes = args.codes.split(args.separator)
tasks = deque([])
for entry in ips:
ip_list = IPNetwork(entry)
for ip in ip_list:
for domain in domains:
tasks.append(
pool.submit(
check_ip, domain, ip, args, codes
)
)
# Обрабатываем результаты и выводим найденные пары домен-IP
for task in concurrent.
install()
# Сообщаем бесполезную информацию, а также запускаем цикл проверки
logging.info(«Starting…»)
try:
check_loop(args)
except Exception as exception:
logging.error(exception)
logging.info(«Finished»)
def check_loop(args):
# Создаем пул потоков, еще немного обрабатываем переданные аргументы
# и формируем очередь заданий
with concurrent.futures.ThreadPoolExecutor(max_workers = args.threads) as pool:
domains = args.domains.split(args.separator)
ips = args.ips.split(args.separator)
codes = args.codes.split(args.separator)
tasks = deque([])
for entry in ips:
ip_list = IPNetwork(entry)
for ip in ip_list:
for domain in domains:
tasks.append(
pool.submit(
check_ip, domain, ip, args, codes
)
)
# Обрабатываем результаты и выводим найденные пары домен-IP
for task in concurrent. futures.as_completed(tasks):
try:
result = task.result()
except Exception as exception:
logging.error(exception)
else:
if result != None:
data = str(result[0])
if(
( args.exclude == None and args.include == None )
or
( args.exclude and args.exclude not in data )
or
( args.include and args.include in data )
):
logging.critical(«[+] » + args.separator.join(result[1:]))
futures.as_completed(tasks):
try:
result = task.result()
except Exception as exception:
logging.error(exception)
else:
if result != None:
data = str(result[0])
if(
( args.exclude == None and args.include == None )
or
( args.exclude and args.exclude not in data )
or
( args.include and args.include in data )
):
logging.critical(«[+] » + args.separator.join(result[1:]))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | def main(): # Обрабатываем аргументы и инициализируем логирование # с блекджеком и цветными записями args = setup_args() coloredlogs.
# Сообщаем бесполезную информацию, а также запускаем цикл проверки logging.info(«Starting…») try: check_loop(args) except Exception as exception: logging.error(exception) logging.info(«Finished»)
def check_loop(args): # Создаем пул потоков, еще немного обрабатываем переданные аргументы # и формируем очередь заданий with concurrent.futures.ThreadPoolExecutor(max_workers = args.threads) as pool: domains = args.domains.split(args.separator) ips = args.ips.split(args.separator) codes = args.codes.split(args.separator)
tasks = deque([]) for entry in ips: ip_list = IPNetwork(entry) for ip in ip_list: for domain in domains: tasks.append( pool.submit( check_ip, domain, ip, args, codes ) ) # Обрабатываем результаты и выводим найденные пары домен-IP for task in concurrent.futures.as_completed(tasks): try: result = task. except Exception as exception: logging.error(exception) else: if result != None: data = str(result[0]) if( ( args.exclude == None and args.include == None ) or ( args.exclude and args.exclude not in data ) or ( args.include and args.include in data ) ): logging.critical(«[+] » + args.separator.join(result[1:])) |
 install()
install()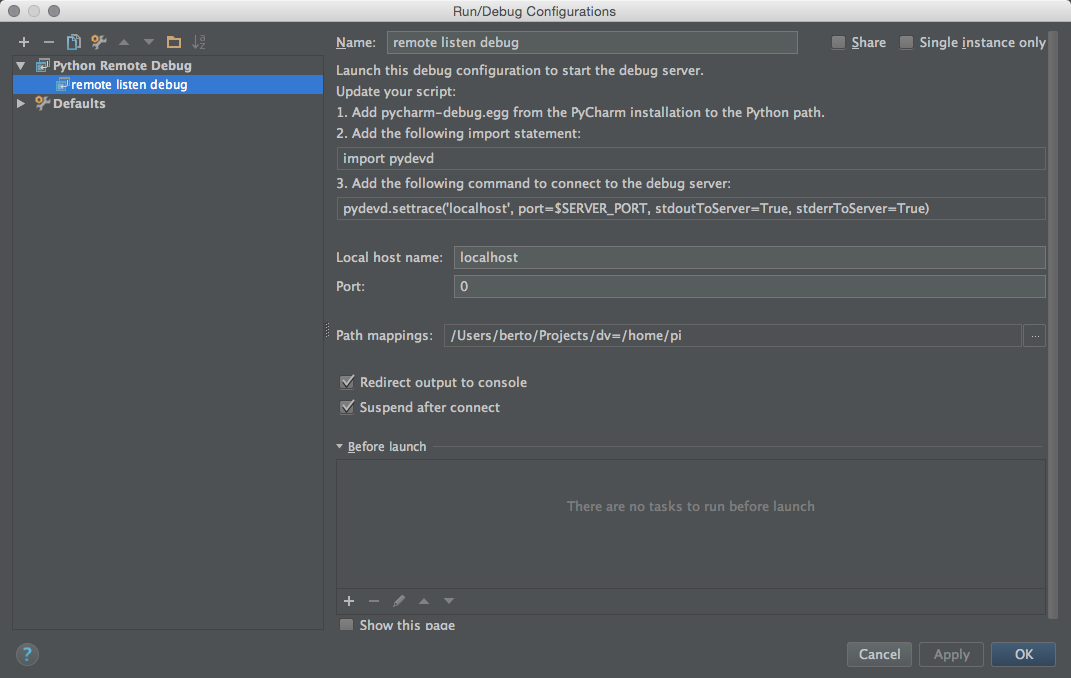 result()
result()В коде появился минимум комментариев. Это прогресс. Надо войти в кураж (не зря мы заготовили прамирацетам) и дописать одну единственную функцию, которая будет осуществлять, непосредственно, проверку. Ее имя уже упомянуто в коде выше: check_ip.
30 минут спустя
Хорошо-то как. Не зря я говорил, что понадобится час времени. Продолжим.
Python
def check_ip(domain, ip, args, codes):
# Преобразуем IP из числа в строку
# Магическая code-flow переменная для совершения двух проверок
# И бесполезное логирование
ip = str(ip)
check_https = False
logging. info(«Checking » + args.separator.join([ip, domain]))
while True:
# Задаем порт и схему для запроса в зависимости от магической переменной
schema = ‘https://’ if check_https else ‘http://’;
port = str(args.https_port) if check_https else str(args.http_port)
request = urllib.request.Request(
schema + ip + ‘:’ + port + ‘/’,
data = None,
headers = {
‘User-Agent’: args.agent,
‘Host’: domain
}
)
# Совершаем запрос, и если получаем удовлетворительный код состояни HTTP,
# то возвращаем содержимое ответа сервера, а также домен и IP
try:
response = urllib.request.urlopen(
request,
data = None,
timeout = args.timeout,
context = ssl._create_unverified_context()
)
data = response.read()
return [data, ip, domain]
except urllib.error.HTTPError as exception:
if str(exception.code) in codes:
data = exception.
info(«Checking » + args.separator.join([ip, domain]))
while True:
# Задаем порт и схему для запроса в зависимости от магической переменной
schema = ‘https://’ if check_https else ‘http://’;
port = str(args.https_port) if check_https else str(args.http_port)
request = urllib.request.Request(
schema + ip + ‘:’ + port + ‘/’,
data = None,
headers = {
‘User-Agent’: args.agent,
‘Host’: domain
}
)
# Совершаем запрос, и если получаем удовлетворительный код состояни HTTP,
# то возвращаем содержимое ответа сервера, а также домен и IP
try:
response = urllib.request.urlopen(
request,
data = None,
timeout = args.timeout,
context = ssl._create_unverified_context()
)
data = response.read()
return [data, ip, domain]
except urllib.error.HTTPError as exception:
if str(exception.code) in codes:
data = exception. fp.read()
return [data, ip, domain]
except Exception:
pass
if args.https and not check_https:
check_https = True
continue
return None
fp.read()
return [data, ip, domain]
except Exception:
pass
if args.https and not check_https:
check_https = True
continue
return None
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | def check_ip(domain, ip, args, codes): # Преобразуем IP из числа в строку # Магическая code-flow переменная для совершения двух проверок # И бесполезное логирование ip = str(ip) check_https = False
logging.info(«Checking » + args.separator.join([ip, domain]))
while True: # Задаем порт и схему для запроса в зависимости от магической переменной schema = ‘https://’ if check_https else ‘http://’; port = str(args.
request = urllib.request.Request( schema + ip + ‘:’ + port + ‘/’, data = None, headers = { ‘User-Agent’: args.agent, ‘Host’: domain } ) # Совершаем запрос, и если получаем удовлетворительный код состояни HTTP, # то возвращаем содержимое ответа сервера, а также домен и IP try: response = urllib.request.urlopen( request, data = None, timeout = args.timeout, context = ssl._create_unverified_context() ) data = response.read() return [data, ip, domain] except urllib.error.HTTPError as exception: if str(exception.code) in codes: data = exception.fp.read() return [data, ip, domain] except Exception: pass
if args.https and not check_https: check_https = True continue
return None |
 https_port) if check_https else str(args.http_port)
https_port) if check_https else str(args.http_port)В общем-то весь наш скрипт готов. Приступаем к тестированию.
Неожиданно узнаем, что у блога есть альтернативный IP-адрес. И действительно:
curl -i ‘http://188.226.181.47/’ —header ‘Host: kaimi.io’
curl -i ‘http://188.226.181.47/’ —header ‘Host: kaimi.io’ |
HTTP/1.1 301 Moved Permanently Server: nginx/1.4.6 (Ubuntu) Date: Sun, 02 Oct 2016 13:52:43 GMT Content-Type: text/html Content-Length: 193 Connection: keep-alive Location: https://kaimi.io/ <html> <head><title>301 Moved Permanently</title></head> <body bgcolor=»white»> <center><h2>301 Moved Permanently</h2></center> <hr><center>nginx/1.4.6 (Ubuntu)</center> </body> </html>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | HTTP/1. Server: nginx/1.4.6 (Ubuntu) Date: Sun, 02 Oct 2016 13:52:43 GMT Content-Type: text/html Content-Length: 193 Connection: keep-alive Location: https://kaimi.io/
<html> <head><title>301 Moved Permanently</title></head> <body bgcolor=»white»> <center><h2>301 Moved Permanently</h2></center> <hr><center>nginx/1.4.6 (Ubuntu)</center> </body> </html> |
 1 301 Moved Permanently
1 301 Moved PermanentlyОднако:
curl -i ‘https://188.226.181.47/’ —header ‘Host: kaimi.io’
curl -i ‘https://188.226.181.47/’ —header ‘Host: kaimi.io’ |
curl: (51) SSL: certificate subject name (*.polygraph.io) does not match target host name ‘188.226.181.47’
curl: (51) SSL: certificate subject name (*. |
 polygraph.io) does not match target host name ‘188.226.181.47’
polygraph.io) does not match target host name ‘188.226.181.47’Какой-то левый хост обрабатывает запросы. Почему? Потому что это прокси, который реагирует на содержимое заголовка Host. В общем скрипт готов, по крайней мере альфа-версия скрипта. Если вам понравилось — подписывайтесь, ставьте лайки, шлите pull-реквесты на github.
Выполнение скрипта Python: ссылка на компонент — Azure Machine Learning
- Статья
- Чтение занимает 7 мин
В этой статье описывается компонент выполнения скрипта Python в конструкторе Машинное обучение Azure.
Используйте этот компонент для выполнения кода Python. Дополнительные сведения об архитектуре и принципах проектирования Python см. в статье выполнение кода Python в конструкторе машинного обучения Azure.
Дополнительные сведения об архитектуре и принципах проектирования Python см. в статье выполнение кода Python в конструкторе машинного обучения Azure.
С помощью Python можно выполнять задачи, которые не поддерживаются существующими компонентами, например:
- Визуализация данных с помощью
matplotlib. - Использование библиотек Python для перечисления наборов данных и моделей в рабочей области.
- Чтение, загрузка и обработка данных из источников, которые не поддерживаются компонентом импорта данных.
- Запустите собственный код глубокого обучения.
Поддерживаемые пакеты Python
Машинное обучение Azure использует дистрибутив Python Anaconda, который включает множество стандартных служебных программ для обработки данных. Мы будем обновлять версию Anaconda автоматически. Текущая версия:
- Дистрибутив Anaconda 4.5+ для Python 3.6
Полный список см. в разделе с предварительно установленными пакетами Python.
Чтобы установить пакеты, отсутствующие в предварительно установленном списке (например, scikit-misc), добавьте в сценарий следующий код:
import os os.
 system(f"pip install scikit-misc")
system(f"pip install scikit-misc")
Используйте следующий код, чтобы установить пакеты для повышения производительности, особенно для вывода:
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Примечание
Если конвейер содержит несколько компонентов выполнения скрипта Python, для которых требуются пакеты, отсутствующие в списке предварительно установленных, установите пакеты в каждый компонент.
Предупреждение
Компонент выполнения скрипта Python не поддерживает установку пакетов, зависящих от дополнительных собственных библиотек, с помощью команды вроде «apt-get», например Java, PyODBC и т. д. Это происходит потому, что этот компонент выполняется только в простой среде с предварительно установленным Python и не имеет разрешений администратора.
Доступ к текущей рабочей области и зарегистрированным наборам данных
Чтобы получить доступ к зарегистрированным наборам данных в рабочей области, можно обратиться к следующему примеру кода:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas. DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
 DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Отправка файлов
Компонент выполнения скрипта Python поддерживает отправку файлов с помощью пакета SDK для машинного обучения Azure Python.
В следующем примере показано, как передать файл изображения в компонент выполнения скрипта Python:
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
После завершения выполнения конвейера можно предварительно просмотреть образ в правой панели компонента.
Вы также можете загрузить файл в любое хранилище данных, используя следующий код. Вы можете предварительно просмотреть файл только в своей учетной записи хранения.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml. core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
 core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Настройка выполнения скрипта Python
Компонент выполнения скрипта Python содержит пример кода Python, который можно использовать в качестве отправной точки. Чтобы настроить компонент выполнения скрипта Python, нужно предоставить набор входных данных и выполняемый код Python в текстовом поле скрипт Python.
Добавьте компонент выполнения скрипта Python в конвейер.
Добавьте и подключитесь dataSet1 любые наборы данных из конструктора, которые вы хотите использовать для ввода. Сошлитесь на этот набор данных в скрипте Python как DataFrame1.
Использовать набор данных необязательно. Используйте его, если хотите создать данные с помощью Python, или используйте код Python для импорта данных непосредственно в компонент.
Этот компонент поддерживает добавление второго набора данных в DataSet2.
Сошлитесь на этот набор данных в скрипте Python как DataFrame2.Наборы данных, хранящиеся в модуле Машинного обучения Azure, автоматически преобразуются в кадры с данными из библиотеки Pandas при загрузке с этим компонентом.
Чтобы включить новые пакеты или код Python, подключите сжатый ZIP-файл, содержащий эти дополнительные ресурсы, в порт пакета сценариев. Если размер скрипта превышает 16 КБ, используйте порт пакета сценариев, чтобы избежать ошибок, например Командная строка, превышает ограничение в 16597 символов.
- Упакуйте скрипт и другие дополнительные ресурсы в ZIP-файл.
- Отправьте ZIP-файл в качестве Файла набора данных в студию.
- Перетащите компонент набора данных из списка Наборы данных в левой панели компонента на странице конструктора разработки.
- Подключите компонент набора данных к порту Пакет скрипта компонента выполнения скрипта Python.
Любой файл, содержащийся в загруженном ZIP-архиве, можно использовать во время выполнения конвейера. Если архив содержит структуру каталогов, структура сохраняется.
Важно!
Используйте уникальное и понятное имя для файлов в пакете сценариев, поскольку некоторые распространенные слова (например
test,appи т. д.) зарезервированы для встроенных служб.Ниже приведен пример пакета сценариев, который содержит файл скрипта Python и txt-файл:
Ниже приведено содержимое
my_script.py:def my_func(dataframe1): return dataframe1Ниже приведен пример кода, демонстрирующий использование файлов в пакете скриптов.
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('. /Script Bundle/my_sample.txt', 'r') as text_file:
sample = text_file.read()
return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])
В текстовом поле скрипт Python введите или вставьте допустимый скрипт Python.
Примечание
Будьте внимательны при написании сценария. Убедитесь в отсутствии синтаксических ошибок, таких как использование необъявленных переменных или неимпортированных компонентов или функций. Обратите особое внимание на список предварительно установленных компонентов. Чтобы импортировать компоненты, которых нет в списке, установите соответствующие пакеты в скрипте, например:
import os os.system(f"pip install scikit-misc")
Текстовое поле скрипта Python заполняется с помощью некоторых инструкций в комментариях, а также образцов кода для доступа к данным и вывода данных. Этот код необходимо изменить или заменить. Следуйте соглашениям Python для отступов и регистра:
- Скрипт должен содержать функцию с именем
azureml_mainв качестве точки входа для этого компонента. - Функция точки входа должна иметь два входных аргумента,
Param<dataframe1>иParam<dataframe2>, даже если эти аргументы не используются в скрипте. - ZIP-файлы, подключенные к третьему порту ввода, распаковываются и хранятся в каталоге
.\Script Bundle, который также добавляется в Pythonsys.path.
Если ZIP-файл содержит
mymodule.py, импортируйте его с помощью командыimport mymodule.В конструктор можно вернуть два набора данных, которые должны быть последовательностью типа
pandas.DataFrame. Вы можете создавать другие выходные данные в коде Python и записывать их непосредственно в службу хранилища Azure.Предупреждение
Не рекомендуется подключаться к базе данных или другим внешним хранилищам в компоненте выполнения скрипта Python. Можно использовать компонент импорта данных и компонент экспорта данных
- Скрипт должен содержать функцию с именем
Отправьте конвейер.
Если компонент завершен, проверьте выходные данные, если они ожидались.
Если произошел сбой компонента, необходимо выполнить некоторые действия по устранению неполадок. Выберите компонент и откройте Выходные данные и журналы в правой панели. Откройте 70_driver_log.txt и выполните поиск в azureml_main, так вы сможете найти строку, которая вызвала ошибку. Например, «File «/tmp/tmp01_ID/user_script.py», line 17, in azureml_main» означает, что ошибка произошла в строке 17 вашего скрипта Python.
 Сошлитесь на этот набор данных в скрипте Python как DataFrame2.
Сошлитесь на этот набор данных в скрипте Python как DataFrame2.
 /Script Bundle/my_sample.txt', 'r') as text_file:
sample = text_file.read()
return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])
/Script Bundle/my_sample.txt', 'r') as text_file:
sample = text_file.read()
return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])

Результаты
Результаты любых вычислений с помощью внедренного кода Python должны быть предоставлены как pandas.DataFrame, что автоматически преобразуется в формат набора данных машинное обучение Azure. Затем можно использовать результаты с другими компонентами в конвейере.
Компонент возвращает два набора данных:
Набор данных Results 1, определяемый первым возвращенным кадром данных Pandas в скрипте Python.
Набор данных Results 2, определяемый вторым возвращенным кадром данных Pandas в скрипте Python.

Предварительно установленные пакеты Python
Существуют следующие предустановленные пакеты:
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob 1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1. 0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- cryptography==2.8
- cycler==0.10.0
- dill==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- imbalanced-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1. 1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- MarkupSafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyOpenSSL==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1. 3.0
- requests==2.23.0
- RSA-4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- SecretStorage==3.1.2
- setuptools==46.1.1.post20200323
- six==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- wheel==0.34.2
 0.1b6.post1
0.1b6.post1 1.0
1.0 3.0
3.0Дальнейшие действия
Ознакомьтесь с набором доступных компонентов для Машинного обучения Azure.
Python скрипт как сгенерировать исполняемый файл Windows.exe
Теги: python .exe win .py
Python — это простой и мощный язык программирования, подходящий для написания сценариев и даже разработки приложений. Различные пакеты GUI, доступные в Python, позволяют писать полнофункциональные приложения с использованием Python. Это здорово, но задумывались ли вы когда-нибудь о преобразовании скрипта Python в исполняемый файл? Это кажется отличной идеей по многим причинам! Вы можете повторно развернуть свое приложение без интерпретатора Python. Конечному пользователю не нужно устанавливать Python на своем компьютере. Вы можете закрыть свое приложение (к сожалению) и так далее … Эта статья может показать вам, как создать исполняемый файл win32 из вашего скрипта Python.
Конечному пользователю не нужно устанавливать Python на своем компьютере. Вы можете закрыть свое приложение (к сожалению) и так далее … Эта статья может показать вам, как создать исполняемый файл win32 из вашего скрипта Python.
Python is a simple and powerful language for scripting and even application development. Various GUI packages available for Python makes it suitable for developing full fledged applications in python. Ok that is fine, but ever thought of creating an executable file from the python script you wrote? This seems to be a nice idea, there are many reasons why! You can redistribute your application without python. The end user needn’t to install python on his machine. You can make your application closed source (unfortunate) etc… Read on this article to find how you can create win32 executables from your Python script.
This tutorial will give step by step instruction on how to create Win32 executable from Python script. Make sure that the following are installed on your system.
Этот туториал шаг за шагом расскажет, как создать исполняемый файл Win32 из скрипта Python. Пожалуйста, убедитесь, что в вашей системе установлена следующая программа.
Python. Get Python from http://www.python.org/download/ and install on your machine.
py2exe. Get py2exe from http://www.py2exe.org/Обратите внимание на установленную версию Python при загрузке.
Программа командной строки
В следующем примере кода печатается строка заголовков и цифр от 1 до 10 в командной строке.
test.py
print "Python script to exe test program" count = 0 while count < 10: print "count = " + str(count) +"\n" count = count + 1
- 1
- 2
- 3
- 4
- 5
- 6
Сохраните этот код в файле test.py (или что-то с расширением .py). Используйте интерпретатор Python для первого тестирования и успешного запуска этого кода. Чтобы выполнить этот шаг, просто введите «python test.py» в командной строке. Вы должны увидеть следующий вывод в командной строке.
Наш скрипт на Python готов. Теперь нам также нужно создать скрипт установки. Так называемый скрипт установки на самом деле является еще одним скриптом Python, в котором мы импортируем пакет py2exe и импортируем скрипт установки из пакета distutils. Кроме того, мы указываем, какой скрипт в качестве точки входа исполняемой программы в этом файле. Создайте новый файл с именем setup.py и вставьте в него следующий код.
setup.py
from distutils.core import setup import py2exe setup(console=['test.py'])
- 1
- 2
- 3
Этот код прост и понятен. Импортируйте setup и py2exe в setup.py и вызовите функцию setup () с именем сценария точки входа в качестве параметра. Теперь вы можете запустить этот скрипт и создать исполняемый файл. При создании исполняемого файла запустите «python setup.py py2exe» в командной строке (вам не нужно запускать setup.py). Вы можете увидеть много выходных данных в командной строке. Наконец, вы можете увидеть результат, показанный на рисунке ниже.
На этом процесс сборки исполняемого файла завершен. Теперь вы должны увидеть файл test.exe в подкаталоге \ dist. Переместите подкаталог dist в подходящее место и запустите test.exe, вы увидите следующий вывод командной строки.
Приложение с графическим интерфейсом
Мы успешно преобразовали скрипты Python в исполняемое приложение командной строки. Давайте попробуем создать исполняемую программу с графическим интерфейсом из скрипта Python. При создании GUI с использованием Python мы будем использовать Tkinter (Tk Interface) в качестве инструментария GUI. Создание исполняемого файла из сценария Tkinter-Python GUI очень интуитивно понятно. Просто следуйте нашим шагам при создании программы командной строки для создания исполняемой программы с графическим интерфейсом.
Создайте новый файл, вставьте приведенный ниже код, сохраните его и назовите его «gui.py».
gui.py
from Tkinter import * frmMain = Tk() label = Label(frmMain, text="Welcome to py2exe!") label.
 pack()
frmMain.mainloop()
pack()
frmMain.mainloop()- 1
- 2
- 3
- 4
- 5
- 6
- 7
Этот код также очень интуитивно понятен, мы импортируем инструментарий Tkinter, создаем основную форму, создаем метку, корректируем ее по размеру содержимого и входим в основной цикл программы. Попробуйте ввести «python gui.py» в командной строке, чтобы запустить этот скрипт. Если все идет хорошо, вы должны увидеть окно ниже.
Все идет нормально. Теперь давайте посмотрим, как мы можем построить исполняемую программу для Windows из скрипта. Создайте новый файл с именем setup.py и вставьте в него следующий код.
setup.py
from distutils.core import setup import py2exe setup(console=['gui.py'])
- 1
- 2
- 3
При создании исполняемого файла запустите «python setup.py py2exe» в командной строке. После завершения процесса сборки перейдите в подкаталог \ dist и запустите исполняемый файл, введя «gui.exe» в командной строке. Теперь вы должны увидеть ту же форму, созданную ранее с помощью скрипта Python.
Теперь вы должны увидеть ту же форму, созданную ранее с помощью скрипта Python.
Интеллектуальная рекомендация
Развитие iOS — один случай
Что такое один пример, цель пения? Когда класс — это только один экземпляр, вам необходимо использовать один пример, то есть этот класс имеет только один объект, который не может быть выпущен во время…
Разница между typeof, instanceof и конструктором в js
Оператор typeof возвращает строку. Например: число, логическое значение, строка, объект, неопределенное значение, функция, Но это недостаточно точно. Следующие примеры представляют собой различные рез…
Установка и использование Cocoapods, обработка ошибок
Использование какао-стручков Общие команды CocoaPods: $pod setup Обновите все сторонние индексные файлы Podspec в локальном каталоге ~ / .CocoaPods / repos / и обновите локальное хранилище. $pod repo …
Коллекция инструментов с неограниченной скоростью для облачного диска Baidu
Примечание: Недавно я обнаружил, что скорость загрузки файлов на Baidu Cloud Disk очень низкая. Лао-цзы не может выкупить участников. Невозможно выкупить участников в этой жизни. Если у вас нет денег,…
Лао-цзы не может выкупить участников. Невозможно выкупить участников в этой жизни. Если у вас нет денег,…
Шаблон проектирования — Подробное объяснение шаблона заводского метода
Предисловие В предыдущей статье «Шаблон проектирования — Подробное объяснение простого шаблона Factory», мы можем знать, что у простой фабричной модели есть некоторые недостатки: Класс фабри…
Вам также может понравиться
29 сентября, весенняя облачная суббота
Ложь, правда и ложь, как в шахматы, но кто пешка? «Тень»…
Logstash Delete Field.
Проблема После того, как FileBeat приобретает информацию журнала, Logstash Prints Information. В этом процессе FileBeat передает свою собственную информацию о клиентах в логисту, если лог-журнал отфил…
Глава 2 2.1-2.16 Предварительный просмотр
2.1 Системный каталог Структура Команда: ls = список Используется для перечисления системных каталогов или файлов Корневой каталог является каталогом пользователя, сохраняет файл конфигурации или друг. ..
..
Java фактическое боевое боевое издание 103 страниц Ответ
…
Алгоритм лунного календаря, включая праздники, солнечные термины, сезонные и т. Д.
Эпоха (день 0): пятница, 22 декабря 1899 года, григорианский календарь против китайского Нового года (двадцать пять лет в Гуансу), 20 ноября, зимнее солнцестояние Цзяцзы Диапазон лунного календаря: с …
Запуск python скрипта в windows по расписанию
Содержание
- Автоматизируйте свои скрипты Python с помощью планировщика задач
- Методы
- Создание исполняемого файла Windows для запуска Python
- Настроить задачу в планировщике задач Windows
- Давайте начнем!
- Результат
- В заключение…
- об авторе
- Запуск python скрипта в windows по расписанию
- Ответы (6)
- Запуск Python и python-скрипт на компьютере
- Где запускать Python-скрипты и как?
- Запуск Python-кода интерактивно
- Интерактивный режим в Linux
- Интерактивный режим в macOS
- Интерактивный режим в Windows
- Запуск Python-скриптов в интерактивном режиме
- Как выполняются Python-скрипты?
- Блок-схема выполнения кода интерпретатором
- Как запускать Python-скрипты?
- Как запускать скрипт в командной строке?
- Какой самый простой способ запустить скрипт Python по расписанию с помощью Windows 7?
- 3 ответа
- Выполнение задачи по расписанию
- Видео
Автоматизируйте свои скрипты Python с помощью планировщика задач
Дата публикации Jun 30, 2019
Запускать мои скрипты Python каждый день слишком хлопотно.

Мне нужен способ периодически запускать мои скрипты Python
Представьте, что ваш менеджер просит вас проснуться среди ночи, чтобы запустить сценарий. Это будет ваш самый большой кошмар. Вы просыпаетесь преждевременно, подвергаетесь воздействию ужасного синего света и избегаете приличных снов каждую полночь.
Как любой специалист в области данных, вам может потребоваться запустить несколько сценариев для создания отчетов или развертывания аналитического конвейера. Следовательно, вам нужно узнать опланировщикичтобы не испортить выходные.
Каждый инженер данных и ученый в один момент времени должен выполнять периодические задачи.
К счастью, с помощью Task Scheduler вы теперь можете запускать свой скрипт Python для выполнения периодических задач каждый день / неделю / месяц / год в зависимости от ваших потребностей.
В этом уроке вы узнаете, как запустить планировщик задач длявеб-данные из Lazada(электронная коммерция) и поместите его вСУБД SQLiteБаза данных.
Это быстрый способ запустить ваш скрипт автоматически!
Методы
В этом руководстве мы будем использовать планировщик задач Windows для запуска сценария bat, который будет запускать сценарии Python. Для выполнения этих скриптов у нас есть два простых шага:
Однако, если вы являетесь пользователем Linux и не имеете доступного планировщика задач Windows, вам следует использоватьcron планировщики,
Создание исполняемого файла Windows для запуска Python
Используя bat-файл в качестве нашего исполняемого файла, мы сохраним наш скрипт run в файле, а затем дважды щелкните файл bat, чтобы выполнить команду cmd (командная строка) для запуска скрипта python.
После того, как вы дважды щелкнете по этому файлу bat, Windows откроет вашу командную строку и запустит инструмент веб-поиска. Чтобы запланировать этот двойной щелчок / выполнение, мы подключим наш планировщик задач к файлу bat.
Настроить задачу в планировщике задач Windows
Планировщик задач Windowsявляется приложением Windows по умолчанию для управления задачами в ответ на триггер на основе событий или времени. Например, вы могли бы предложить определенный щелчок и компьютерные действия (такие как перезагрузка) или даже предложить время, каккаждый первый день финансового кварталавыполнить задачу.
Например, вы могли бы предложить определенный щелчок и компьютерные действия (такие как перезагрузка) или даже предложить время, каккаждый первый день финансового кварталавыполнить задачу.
В более широком плане эта задача будет содержать сценарий и метаданные, чтобы определить, что и как будет выполняться действие. Вы можете добавить определенный контекст безопасности в аргумент и контролировать, где планировщик будет запускать программу. Windows будет сериализовать все эти задачи как.JOBфайлы в специальной папке под названиемПапка задач,
В этом руководстве мы собираемся установить событие, основанное на времени, для запуска нашего приложения и вывода данных в SQLite. Всего там
Давайте начнем!
2.Нажмите Create Basic Task в правом окне.,
Вы должны указывать имя задачи (например, веб-очистка) и описание (например, веб-очистка и дамп SQLite автоматически каждый день в 18:00)
3.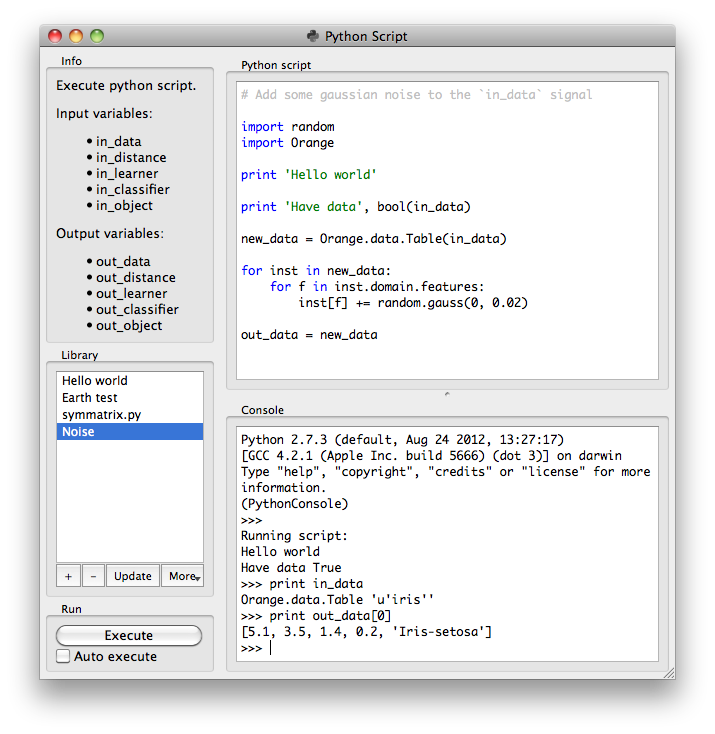 Выберите время срабатывания,
Выберите время срабатывания,
4.Выберите точное время для нашего предыдущего выбора,
Мы выберем месяц январь, апрель, июль и сентябрь, чтобы указать весь ранний финансовый квартал.
5 Запустить программу
Здесь вы сможете запускать скрипты Python, отправлять электронную почту и даже отображать сообщение. Не стесняйтесь выбирать те, которые вам наиболее удобны. Однако вам следует остерегаться устаревших задач, которые будут удалены в последующих исправлениях.
6.Вставьте скрипт вашей программы, где вы сохранили свой bat файл
Это запустит планировщик задач для вашего скрипта Python для автоматизации. Убедитесь, что вы также включили Пуск в папку вашего приложения, чтобы получить доступ ко всем соответствующим элементам (исполняемые файлы Selenium Browser / диск SQLite)
7.Нажмите Готово,
Вы можете проверить созданное расписание задач на первой странице Планировщика задач.
Поздравляем, вы установили свой первый автоматический планировщик в Windows.
Результат
Вот анимация GIF для ваших ссылок. Обратите внимание, как планировщик сам запускает скрипты Python. Как только сценарии завершатся, он извлечет извлеченное значение из базы данных SQLite. В будущем это приложение будет запускаться каждый раз, когда выполняется условие триггера, и добавлять обновленные значения в SQLite.
В заключение…
Я действительно надеюсь, что это было отличное чтение и источник вдохновения для вас, чтобы развиваться и вводить новшества.
пожалуйстаКомментарийниже, чтобы предложить и отзывы.
Если вам действительно это нравится, пожалуйста, проверьте мой профиль. Есть больше о статьях Data Analytics и Python Projects, которые будут соответствовать вашим интересам.
об авторе
Он активно консультирует SMU BI & Analytics Club, руководит начинающими учеными и инженерами в области данных из разных областей и раскрывает свой опыт для бизнеса в разработке своих продуктов.
Источник
Запуск python скрипта в windows по расписанию
32021 просмотра
6 ответа
Windows 10 Python 3.5.2
Ответы (6)
24 плюса
Создание exe должно быть лучшим методом. Но если вы хотите запустить его с помощью планировщика задач, вы можете сделать это следующим образом:
Чтобы гарантировать, что ваш скрипт Python будет работать независимо от учетной записи входа, которую использует задача расписания, и чтобы избежать путаницы в том, какая версия Python используется в смешанных средах (64-битной или 32-битной), рекомендуется запускать исполняемый файл Python с имя вашего файла Python в качестве аргумента для исполняемого файла.
Предположим, что вы хотите запустить скрипт E: \ My script.py. Вместо непосредственного запуска сценария, поручите планировщику задач запустить python.exe со сценарием в качестве аргумента. Например:
C: \ Python27 \ ArcGIS10.2 \ python. exe «E: \ My script.py»
exe «E: \ My script.py»
Расположение python.exe зависит от вашей установки. Если вы не знаете, где это, вы можете обнаружить его местоположение; скопируйте и вставьте следующий код в новый скрипт Python, затем выполните скрипт. Сценарий распечатает расположение python.exe, а также другую информацию о вашей среде Python.
После определения местоположения python.exe, это то, что вводится на панели действий планировщика задач:
Если в вашем скрипте есть дополнительные аргументы (параметры), укажите их после пути к вашему скрипту. Надеюсь это поможет.
7 плюса
Вы должны установить на Action вкладке:
Если это не работает, попробуйте:
Также каждый раз, когда я изменяю задачу, учетная запись пользователя на General вкладке переключается на средний обязательный уровень. Поэтому я должен снова открыть Taks и установить учетную запись пользователя обратно на мое имя пользователя: (см. Этот вопрос )
Если вы все еще не можете запустить свой скрипт, зайдите в журнал событий Applications and Service Log/Microsoft/Windows/TaskScheduler/Operational (щелкните его правой кнопкой мыши, чтобы включить его) и найдите ошибки.
Автор: MagTun Размещён: 02.07.2017 05:46
4 плюса
Я почти потерял свои волосы из-за этого. Я всегда получал 0x1 в результате выполнения описанного выше. Давний опытный администратор Windows сказал мне это:
Создайте командный файл:
Затем укажите пакетный файл в части действия конфигурации задачи. Следует также позаботиться о том, чтобы пользователь, выполняющий сценарий, мог получить доступ ко всем файлам, написанным во время выполнения программы python.
Я попытался использовать скрипт в качестве параметра и python exe в программе / скрипте. Сначала я получаю сообщение об ошибке «Запланированные задачи Windows не выполняются». Затем после некоторой настройки вокруг я получил ошибку 0x1, которая ничего мне не сказала.
1 плюс
Сценарий, который вы выполняете, будет exe, найденным в вашем каталоге python ex) C: \ Python27 \ python.exe
«Аргументом» будет путь к вашему сценарию, например) C: \ Path \ To \ Script. py
py
Так что думайте об этом так: технически вы не выполняете свой сценарий как запланированное задание. Вы выполняете исполняемый файл root для вашего компьютера с вашим сценарием, который подается в качестве параметра.
Автор: Connor Размещён: 23.06.2017 07:06
0 плюса
Это сработало для меня, вы можете попробовать с панели действий: панель действий
Установите флажок «Запускать с наивысшими привилегиями» на вкладке «Общие», и лучше выбрать «Запускать новый экземпляр параллельно» в раскрывающемся меню на вкладке «Настройки».
В конце концов, вы можете установить расписание для задачи на вкладке «Триггеры», чтобы проверить влияние изменений (не забудьте выбрать «Выполнить, вошел ли пользователь в систему или нет» на вкладке «Общие»).
0 плюса
По какой-то причине планировщик задач Windows запускает python.exe в среде, где они терпят неудачу в операторах import-модуля. Мне пришлось использовать обходной путь, используя CMD. exe и передать команду для запуска сценария Python в данной папке.
затем вкладка параметров:
и заполните исходное местоположение во вкладке Start in:
Не уверен, в чем причина этого. Ранее описанные решения у меня не сработали.
Источник
Запуск Python и python-скрипт на компьютере
Код, написанный на языке Python, может храниться в редакторе кода, IDE или файле. И он не будет работать, если не знать, как его правильно запускать.
В этом материале рассмотрим 7 способов запуска кода, написанного на Python. Они будут работать вне зависимости от операционной системы, среды Python или местоположения кода.
Где запускать Python-скрипты и как?
Python-код можно запустить одним из следующих способов:
Запуск Python-кода интерактивно
Для запуска интерактивной сессии нужно просто открыть терминал или командную строку и ввести python (или python3 в зависимости от версии). После нажатия Enter запустится интерактивный режим.
Вот как запустить интерактивный режим в разных ОС.
Интерактивный режим в Linux
Откройте терминал. Он должен выглядеть приблизительно вот так :
После нажатия Enter будет запущен интерактивный режим Python.
Интерактивный режим в macOS
На устройствах с macOS все работает похожим образом. Изображение ниже демонстрирует интерактивный режим в этой ОС.
Интерактивный режим в Windows
Запуск Python-скриптов в интерактивном режиме
В таком режиме можно писать код и исполнять его, чтобы получить желаемый результат или отчет об ошибке. Возьмем в качестве примера следующий цикл.
Для выхода из интерактивного режима нужно написать следующее:
И нажать Enter. Вы вернетесь в терминал, из которого и начинали.
Есть и другие способы остановки работы с интерактивным режимом Python. В Linux нужно нажать Ctrl + D, а в Windows — Ctrl + Z + Enter.
Стоит отметить, что при использовании этого режима Python-скрипты не сохраняются в локальный файл.
Как выполняются Python-скрипты?
Отличный способ представить, что происходит при выполнении Python-скрипта, — использовать диаграмму ниже. Этот блок представляет собой скрипт (или функцию) Python, а каждый внутренний блок — строка кода.
При запуске скрипта интерпретатор Python проходит сверху вниз, выполняя каждую из них. Именно таким образом происходит выполнение кода.
Но и это еще не все.
Блок-схема выполнения кода интерпретатором
Это набор инструкций, которые приводят к финальному результату.
Иногда полезно изучать байткод. Если вы планируете стать опытным Python-программистом, то важно уметь понимать его для написания качественного кода.
Это также пригодится для принятия решений в процессе. Можно обратить внимание на отдельные факторы и понять, почему определенные функции/структуры данных работают быстрее остальных.
Как запускать Python-скрипты?
Для запуска Python-скрипта с помощью командной строки сначала нужно сохранить код в локальный файл.
Возьмем в качестве примера файл, который был сохранен как python_script.py. Сохранить его можно вот так:
Сохранить скрипт в текстовом редакторе достаточно легко. Процесс ничем не отличается от сохранения простого текстового файла.
Но если использовать командную строку, то здесь нужны дополнительные шаги. Во-первых, в самом терминале нужно перейти в директорию, где должен быть сохранен файл. Оказавшись в нужной папке, следует выполнить следующую команду (на linux):
После нажатия Enter откроется интерфейс командной строки, который выглядит приблизительно следующим образом:
Теперь можно писать код и с легкостью сохранять его прямо в командной строке.
Как запускать скрипт в командной строке?
Источник
Какой самый простой способ запустить скрипт Python по расписанию с помощью Windows 7?
Когда я пытаюсь запустить его с помощью планировщика заданий, он никогда не работает. Это дает мне странные ошибки, такие как 0x1, и скрипт никогда не запускается. Я погуглил эту проблему и не могу найти достаточно простого решения. (Кто-то предложил написать пакетный скрипт в Windows, но я не совсем уверен, как это сделать, поэтому сначала я бы попробовал другие пути).
Если есть альтернативный способ запуска скрипта Python по расписанию, я был бы рад услышать об этом. Я бы предпочел не использовать, казалось бы, специальный метод, такой как apscheduler, который может потребовать, чтобы мой скрипт всегда работал (?). Возможно, есть способ демонизировать этот процесс? Я действительно пытался использовать сельдерей, но это не сработало.
тоже не работает, потому что, видимо, это устаревший декоратор. Любая помощь будет оценена. Заявление о печати никогда не печатается.
3 ответа
Следующие два класса демонстрируют, как легко можно запланировать задачу в Python и отделить процесс планировщика от процесса действия. Разделив две задачи, вы предотвратите распространение проблем в планировщике (например, утечки памяти и т. Д.).
Я бы серьезно пересмотрел Task Scheduler.
Я только что настроил быстрый скрипт Python для запуска на моем компьютере в качестве запланированной задачи, и он работает. (Однако я использую Windows 8.1 вместо Windows 7, но я не могу себе представить, что это будет иметь большое значение.)
Если вы не можете заставить скрипт Python работать сам по себе, вы можете написать короткий пакетный скрипт для запуска вашего скрипта Python: что-то вроде следующего должно работать:
Не стесняйтесь использовать полный путь к исполняемому файлу Python и / или различным файлам, упомянутым в этой строке.
Планировщик задач работает хорошо, когда он работает, но когда он не может выполнить задачу, может быть трудно найти, в чем проблема, поскольку планировщик задач обычно показывает только код завершения. Запись вывода / ошибок в файл позволяет увидеть любой вывод или трассировку, которые мог сгенерировать Python, и помочь вам понять, в чем может быть проблема.
Я бы снова обратился к планировщику задач, предполагая, что он всегда работает, когда ПК включен, попробуйте следующее:
1) открыть планировщик задач
2) в строке меню нажмите «Действие», а затем «Создать задачу»
3) на вкладке «Общие» введите имя и описание, а также настройте параметры безопасности
4) под вкладкой триггера нажмите «Новый. «
5) в выпадающем списке «Начать задачу» выберите «При запуске»
6) установите флажок «повторить задачу каждый», а затем установите интервал повторения
7) нажмите «ОК», затем откройте вкладку «Действия»
8) добавить путь к питону в поле «программы / скрипты»
9a) либо добавьте полный путь к вашему сценарию в поле «Добавить аргументы», либо:
9b) добавьте каталог вашего скрипта в поле «start in», а затем просто имя скрипта в поле аргументов
это не должно работать без проблем ОДНАКО, если в любом из ваших путей есть пробелы, вам нужно будет заключить их в кавычки, иначе они будут интерпретироваться как отдельные аргументы, и python не сможет ничего с этим сделать.
Источник
Выполнение задачи по расписанию
Добрый день!
Имеется скрипт который выполняет определенную функцию по расписанию.
В данный момент скрипт выполняет функцию по расписанию, но есть недочет и заключается он в следующем:
если в таблицу mysql добавить данные с одним и тем же временем выполнения то выполнится только та строка которая стоит первой в списке и совпадает с временем выполнения.
Условие проверки времени для выполнения задания находится на 184 строке.
Если переменные hour_l, min_l, sec_l будут равны нулю то будет выполнено заложенное задание в mysql таблице.
Некоторые задания могут выполняться от 5-10 мин и до 1 часа.
Пример таблицы:
| id | message | datetime |
| 1 | Сообщение 1 | 2015-11-16 00:10:00 |
| 2 | Сообщение 2 | 2015-11-16 00:10:00 |
| 3 | Сообщение 3 | 2015-11-16 15:00:00 |
Проблема заключается в том что если добавить 2 задания с одинаковым временем выполнения задания то будет выполнено только одно, нужно чтобы после 1 задания запустилось 2 задание.
Сейчас же после выполнения задания с id №1, будет выполнено задание №3.
Пробовал сделать так: if (hour_l) 0
Выполнение действие по расписанию
Есть некая программа, которая должна выполнятся 24/7. Мне нужно выполнить некое действие(допустим.
Выполнение задачи
помогите написать код к данному алгоритму на Pyton, я уже замучился искать функцию для записи.
Выполнение по расписанию.
Уважаемые, возникла не то, чтобы необходимость, но очень хотелось бы данное действо реализовать. В.
Выполнение кода по расписанию
Подскажите пожалуйста, как реализовать такие задержки, к примеру я хочу чтобы определенный метод.
Решил проблему своими силами.
Пришлось создать еще один arraylist, и там хранить информацию о текущих и следующих задачах.
Теперь все задания выполняются в порядке поступления.
Заказываю контрольные, курсовые, дипломные работы и диссертации здесь.
Выполнение скрипта по расписанию
Добрый день. Помогите решить проблему, необходимо каждый день, вечером, запускать определённый.
Выполнение действий по расписанию
В моей программе пользователь может добавлять различные события и устанавливать время для них.
Выполнение списка заданий по расписанию
Имеется список задач требующих выполнения. Каждая задача выполняется через определенные промежутки.
Выполнение действий по расписанию, в определенное время
как сделать что бы прога отслеживала время и если наступило к примеру 21:00 выполнила какие-то.
Источник
Видео
Как сделать автозапуск программ на Python по расписанию
Планирование и автозапуск Python скриптов по времени
Как запустить python скрипт на windows
Уроки Python / Запуск на сервере по расписанию
Терминал Linux #7.2 — crontab: как запускать Python-скрипт по расписанию
Как сделать запуск программ по расписанию
ИСПОЛЬЗОВАНИЕ CRON ПРИ ЗАПУСКЕ PYTHON-СКРИПТОВ
Как передавать параметры в Python-скрипты | Базовый курс. Программирование на Python.
Как настроить запуск R скриптов по расписанию на Windows
3. Запуск Python программ (скриптов). Основы Python
30 примеров скриптов Python
В настоящее время Python является очень популярным и требовательным языком программирования, потому что он подходит для разработки как очень простых, так и сложных приложений. Если вы новичок в программировании на Python и хотите за короткое время изучить его основы, то эта статья для вас. В этой статье объясняются 30 примеров скриптов Python на очень простых примерах, позволяющих познакомиться с основами Python. Список тем, затронутых в этой статье, приведен ниже:
01. Hello World
02. Объединение двух строк
03. Форматирование строки с плавающей запятой
04. Возведение числа в степень
05. Работа с логическими типами
06. Оператор If else
07. Использование И и ИЛИ операторы
08. Оператор Switch case
09. Цикл While
10. Цикл For
11. Запуск одного скрипта Python из другого
12. Использование аргумента командной строки
13. Использование регулярного выражения
14. Использование getpass
15 , Использование формата даты
16. Добавление и удаление элемента из списка
17. Понимание списка
18. Данные среза
19. Добавление и поиск данных в словаре
20. Добавление и поиск данных в наборе
21. Подсчет элементов в списке
22. Определение и вызов функции
23. Использование исключение throw and catch
24. Чтение и запись файла
25. Список файлов в каталоге
26. Чтение и запись с использованием pickle
27. Определение класса и метода
28. Использование функции диапазона
29. Использование функции карты
30. Использование функции фильтра
Вы можете написать и выполнить простой скрипт Python из терминала, не создавая никакого файла Python. Если скрипт большой, то он требует написания и сохраняет скрипт в любом файле python с помощью любого редактора. Вы можете использовать любой текстовый редактор или любой редактор кода, такой как возвышенный, Visual Studio Code, или любое программное обеспечение IDE, разработанное только для python, такое как PyCharm или Spyder, для написания скрипта. Расширение файла Python — .py . Питон версии 3. 8 и spyder3 IDE Python используются в этой статье для написания скрипта Python. Вы должны установить spyder IDE в своей системе, чтобы использовать его.
Если вы хотите выполнить какой-либо скрипт из терминала, запустите команду « python» или « python3» , чтобы открыть python в режиме взаимодействия. Следующий скрипт Python напечатает текст « Hello World » в качестве вывода.
>>> print(«Hello World»)
Теперь сохраните скрипт в файле с именем c1.py . Вы должны запустить следующую команду из терминала, чтобы выполнить c1.py .
$ python3 c1.py
Если вы хотите запустить файл из spyder3 IDE, вам нужно нажать на кнопку run
редактора. Следующий вывод будет отображаться в редакторе после выполнения кода.
Top
Соединение двух строк:
В Python существует множество способов соединения строковых значений. Самый простой способ объединить два строковых значения в Python — использовать оператор «+». Создайте любой Python со следующим скриптом, чтобы узнать, как соединить две строки. Здесь два строковых значения присваиваются двум переменным, а другая переменная используется для хранения объединенных значений, которые печатаются позже.
c2.py
string1 = «Linux»
string2 = «Подсказка»
join_string = string1 + string2
print(joined_string)
Следующий вывод появится после запуска скрипта из редактора. Здесь соединяются два слова « Linux » и « Hint », и в качестве вывода выводится « LinuxHint ».
Если вы хотите узнать больше о другом варианте объединения в python, вы можете ознакомиться с учебным пособием «Конкатенация строк Python».
Top
Форматирование с плавающей запятой в строке:
Число с плавающей запятой требуется в программировании для генерации дробных чисел, а иногда для целей программирования требуется форматирование числа с плавающей запятой. В python существует множество способов форматирования числа с плавающей запятой. Форматирование строк и интерполяция строк используются в следующем скрипте для форматирования числа с плавающей запятой. format() Метод с шириной формата используется при форматировании строки, а символ «%» с форматом с шириной используется при интерполяции строки. Согласно ширине форматирования, до запятой устанавливаются 5 знаков, а после запятой — 2 знака.
c3.py
# Использование форматирования строк
float1 = 563.78453
print(«{:5.2f}».format(float1))
# Использование интерполяции строк 5.2f» % float2)
Следующий вывод появится после запуска скрипта из редактора.
Если вы хотите узнать больше о форматировании строк в Python, вы можете ознакомиться с учебным пособием «Форматирование строк Python».
Top
Возведение числа в степень:
В Python существует множество способов вычисления x n в Python. В следующем скрипте показаны три способа вычисления xn в Python. Двойной оператор * , метод pow() и метод math.pow() используются для вычисления xn. Значения x и n инициализируются числовыми значениями. Двойные ‘ *’ и методы pow() используются для вычисления степени целочисленных значений. math.pow() может вычислять степень дробных чисел; также, что показано в последней части скрипта.
c4.py
import math
# Присвоение значений x и n
x = 4
n = 3
# Метод 1 is %d» % (x,n,power))
# Метод 2
power = pow(x,n)
print(«%d в степени %d is %d» % (x,n,power) )
# Метод 3
power = math.pow(2,6.5)
print(«%d в степени %d равно %5.2f» % (x,n,power))
После запуска сценария появится следующий вывод. Первые два вывода показывают результат 4 3, , а третий вывод показывает результат 2 6,5 .
Top
Работа с логическими типами:
Различные варианты использования логических типов показаны в следующем сценарии. В первом выводе будет напечатано значение val1, содержащее логическое значение, true. Все положительные числа являются отрицательными, возвращают true в качестве логического значения, и только ноль возвращает false в качестве логического значения. Таким образом, второй и третий выходные данные будут печатать истинных для положительных и отрицательных чисел. Четвертый вывод выведет false для 0, а пятый вывод выведет false , потому что оператор сравнения возвращает false .
c5.py
# Логическое значение
val1 = True
print(val1)
# Число в логическое
number = 10
print(bool(number))
number = -5
print(bool(number))
number = 0
print(bool(number))
# логическое значение из оператора сравнения
val1 = 6
val2 = 3
print(val1 < val2)
После запуска сценария появится следующий вывод.
Top
Использование оператора If else:
В следующем сценарии показано использование условного оператора в Python. Объявление оператора if-else в python немного отличается от других языков. Фигурные скобки не требуются для определения блока if-else в python, как и в других языках, но блок отступа должен использоваться правильно, иначе скрипт покажет ошибку. Здесь очень просто оператор if-else используется в сценарии, который проверяет, является ли значение числовой переменной больше или равным 70 или нет. Двоеточие (:) используется после блоков « if» и « else» для определения начала блока.
c6.py
# Присвоить числовое значение
number = 70
# Проверить больше 70 или нет
if (number >= 70):
print(«Вы прошли»)
else:
print(«Вы не прошли»)
После запуска сценария появится следующий вывод.
Top
Использование операторов И и ИЛИ:
В следующем сценарии показано использование операторов И и ИЛИ в условном выражении. Оператор AND возвращает true , когда два условия возвращают true, и OR , оператор возвращает true , когда любое из двух условий возвращает true . Два числа с плавающей запятой будут приняты в качестве оценок MCQ и теории. И операторы И, и ИЛИ используются в ‘ if’ заявление. В соответствии с условием, если оценки MCQ больше, чем равны 40, а оценки по теории больше или равны 30, то оператор ‘ if’ вернет true или если сумма MCQ и теории больше или равна равно 70, то оператор ‘ if’ также вернет true .
c7.py
# Взять оценки MCQ
mcq_marks = float(input(«Введите отметки MCQ: «))
# Взять оценки теории
theory_marks = float(input(«Введите оценки теории: «))
# Проверить условие прохождения с помощью оператора И и ИЛИ
if (mcq_marks >= 40 и theory_marks >= 30) или (mcq_marks + theory_marks) >=70:
print(«\nВы прошли»)
else:
print («\nВы потерпели неудачу»)
В соответствии со следующим выводом, оператор if возвращает false для входных значений 30 и 35 и возвращает true для входных значений 40 и 45.
Top
оператор case switch:Python не поддерживает оператор switch-case , как другие стандартные языки программирования, но этот тип оператора может быть реализован в python с помощью пользовательской функции. Функция employee_details() создается в следующем скрипте для работы подобно оператору switch-case. Функция содержит один параметр и словарь с именем switcher. Значение параметра функции проверяется с каждым индексом словаря. Если найдено какое-либо совпадение, то из функции будет возвращено соответствующее значение индекса; в противном случае второе значение параметра Метод switcher.get() будет возвращен.
c8.py
# Switcher для реализации вариантов case switch Mita Rahman»,
«1010»: «Имя сотрудника: Сакиб Аль Хасан»,
}
»’Первый аргумент будет возвращен, если совпадение найдено, и
ничего не будет возвращено, если совпадение не найдено»’
return switcher. get(ID, «nothing»)
# Возьмите идентификатор сотрудника
ID = input(«Введите идентификатор сотрудника: «)
# Распечатайте вывод
print(employee_details(ID))
Согласно после вывода сценарий выполняется два раза, и на основе значений идентификаторов печатаются два имени сотрудника.
Top
Использование цикла while:Использование цикла while в python показано в следующем примере. Двоеточие (:) используется для определения начального блока цикла, и все операторы цикла должны быть определены с использованием надлежащего отступа; в противном случае появится ошибка отступа. В следующем сценарии значение счетчика инициализируется значением 1 , которое используется в цикле. Цикл будет повторяться 5 раз и печатать значения счетчика на каждой итерации. Значение счетчика увеличивается на 1 на каждой итерации для достижения условия завершения цикла.
c9. py
# Инициализировать счетчик
counter = 1
# Повторить цикл 5 раз
while counter < 6:
# Вывести значение счетчика
print («Текущее значение счетчика: %d» % counter)
# Увеличение счетчика
counter = counter + 1
После запуска скрипта появится следующий вывод.
Top
Использование цикла for:Цикл for используется для многих целей в python. Начальный блок этого цикла должен быть определен двоеточием (:), а операторы определены с использованием надлежащего отступа. В следующем сценарии определяется список названий дней недели, и цикл for используется для повторения и печати каждого элемента списка. Здесь метод len() используется для подсчета общего количества элементов списка и определения предела функции range().
c10.py
# Инициализировать список
дни недели = [«Воскресенье», «Понедельник», «Вторник»,»Среда», «Четверг»,»Пятница», «Суббота»]
print(«Семь Дни недели:\n»)
# Повторить список, используя цикл for
для дня в диапазоне (len(weekdays)):
print(weekdays[day])
После запуска скрипта появится следующий вывод.
Top
Запуск одного скрипта Python из другого:
Иногда требуется использовать скрипт файла python из другого файла python. Это можно сделать легко, например, импортировать любой модуль с помощью ключевое слово импорта . Здесь файл Vacations.py содержит две переменные, инициализированные строковыми значениями. Этот файл импортируется в файл c11.py с псевдонимом « v» . Здесь определяется список названий месяцев. Переменная флага используется здесь для печати значения переменной Vacation1 один раз для месяцев « июнь», и « июль». Значение переменной Vacation2 будет напечатано для месяца «Декабрь» . Другие имена девяти месяцев будут напечатаны, когда будет выполнена другая часть оператора if-elseif-else .
Vacations.py
# Инициализировать значения список месяцев
месяцев = [«январь», «февраль», «март», «апрель», «май», «июнь»,
«Июль», «Август», «Сентябрь», «Октябрь», «Ноябрь», «Декабрь»]
# Начальная переменная флага для печати летних каникул один раз для месяца в месяцах:
если месяц == «июнь» или месяц == «июль»:
если флаг == 0:
print(«Сейчас»,v. vacation1)
флаг = 1
elif month == «декабрь «:
print(«Сейчас»,v.vacation2)
else:
print(«Текущий месяц»,month)
После запуска сценария появится следующий вывод.
Top
Использование аргумента командной строки:
В следующем сценарии показано использование аргументов командной строки в python. В python существует множество модулей для анализа аргументов командной строки. Модуль «sys» импортирован здесь для анализа аргументов командной строки. Метод len() используется для подсчета всех аргументов, включая имя файла сценария. Затем будут напечатаны значения аргументов.
c12.py
# Import sys module
import sys
# Общее количество аргументов
print(‘Всего аргументов:’, len(sys.argv))
print(«Значения аргументов:»)
# Повторить аргументы командной строки, используя цикл for
for i в sys. argv:
print(i)
Если сценарий выполняется без каких-либо аргументов командной строки, появится следующий вывод, показывающий имя файла сценария.
Значения аргументов командной строки можно установить в редакторе spyder, открыв Запустите диалоговое окно конфигурации для каждого файла , щелкнув меню Запустить . Установите значения с пробелом, щелкнув параметры командной строки в части общих настроек диалогового окна.
Если сценарий выполняется после установки показанных выше значений, появится следующий вывод.
Значения аргументов командной строки можно легко передать в скрипт Python из терминала. Следующий вывод появится, если скрипт выполняется из терминала.
Если вы хотите узнать больше об аргументах командной строки в Python, вы можете ознакомиться с учебным пособием «Как анализировать аргументы в командной строке в Python».
Top
Использование регулярных выражений:
Регулярное выражение или регулярное выражение используется в python для сопоставления или поиска и замены любой конкретной части строки на основе определенного шаблона. Модуль ‘re’ используется в Python для использования регулярного выражения. Следующий скрипт показывает использование регулярного выражения в python. Шаблон, используемый в скрипте, будет соответствовать той строке, где первый символ строки является заглавной буквой. Строковое значение будет взято и сопоставлено с шаблоном, используя 9[A-Z]’
# сопоставить шаблон с входным значением
found = re.match(шаблон, строка)
# Печатать сообщение на основе возвращаемого значения
, если оно найдено:
print(«Входное значение начинается с заглавной буквы буква»)
else:
print(«Вы должны ввести строку, начинающуюся с заглавной буквы»)
Сценарий выполняется два раза в следующем выводе. Функция match() возвращает false при первом выполнении и возвращает true при втором выполнении.
Top
Использование getpass:
getpass — полезный модуль Python, который используется для ввода пароля пользователем. В следующем сценарии показано использование модуля getpass. Здесь используется метод getpass(), чтобы принять ввод в качестве пароля, а оператор « if» используется здесь для сравнения входного значения с определенным паролем. « вы аутентифицированы» сообщение будет напечатано, если пароль совпадает, в противном случае будет напечатано « Вы не аутентифицированы ». Сообщение.
c14.py
# import getpass module
import getpass
# Взять пароль у пользователя
passwd = getpass.getpass(‘Password:’)
# Проверить пароль . режим. Итак, следующий вывод показывает входной пароль в следующем выводе.
Если скрипт выполняется из терминала, введенное значение не будет отображаться, как другие пароли Linux. Сценарий выполняется два раза с терминала с неверным и действительным паролем, что показано в следующем выводе.
Top
Использование формата даты:
Значение даты может быть отформатировано в Python различными способами. Следующий сценарий использует модуль datetim e для установки текущего и пользовательского значения даты. сегодня() 9Здесь используется метод 0037 для чтения текущей системной даты и времени. Затем форматированное значение даты печатается с использованием разных имен свойств объекта даты. Как можно назначить и распечатать пользовательское значение даты, показано в следующей части скрипта.
c15.py
from datetime import date
# Читать текущую дату
current_date = date.today()
# Печатать отформатированную дату » % (текущая_дата.день,текущая_дата.месяц,текущая_дата.год))
# Установить пользовательскую дату
custom_date = date(2020, 12, 16)
print(«Дата:»,custom_date)
После выполнения сценария появится следующий вывод.
Top
Добавить и удалить элемент из списка:
объект списка используется в python для решения различных типов задач. Python имеет множество встроенных функций для работы с объектом списка. В следующем примере показано, как можно вставлять и удалять новый элемент из списка. В сценарии объявлен список из четырех элементов. Метод Insert() используется для вставки нового элемента во вторую позицию списка. метод remove() используется для поиска и удаления определенного элемента из списка. Список печатается после вставки и удаления.
c16.py
# Объявить список фруктов
fruit = [«Манго»,»Апельсин»,»Гуава»,»Банан»]
# Вставить элемент на 2-ю позицию
fruit.insert(1 , «Виноград»)
# Отображение списка после вставки
print(«Список фруктов после вставки:»)
print(fruits)
# Удалить элемент
fruit.remove(«Guava»)
# Распечатать список после удаления
print(«Список фруктов после удаления:»)
print(fruits)
Следующий вывод появится после выполнения скрипта.
Если вы хотите узнать больше о вставке и удалении скрипта Python, вы можете проверить учебник «Как добавлять и удалять элементы из списка в Python».
Top
Понимание списка:
Понимание списков используется в Python для создания нового списка на основе любой строки, кортежа или другого списка. Ту же задачу можно решить с помощью цикла for и лямбда-функции. В следующем сценарии показаны два разных использования понимания списка. Строковое значение преобразуется в список символов с использованием понимания списка. Далее кортеж таким же образом преобразуется в список.
c17.py
# Создать список символов, используя генератор списка
char_list = [ char вместо char в «linuxhint» ]
print(char_list)
# Определить кортеж веб-сайтов
Websites = («google.com», «yahoo.com», «ask.com», «bing.com»)
# Создать список из кортежа, используя понимание списка
site_list = [сайт для сайта на веб-сайтах]
print(site_list)
Top
Данные среза:
slice() Метод используется в Python для вырезания определенной части строки. Этот метод имеет три параметра. Эти параметры start , стоп, и шаг . Стоп является обязательным параметром, а два других параметра являются необязательными. В следующем сценарии показано использование метода slice() с одним, двумя и тремя параметрами. Когда в методе slice() используется один параметр, тогда он будет использовать обязательный параметр stop . Когда два параметра используются в методе slice() , тогда используются параметры start и stop . Когда используются все три параметра, то 9Используются параметры 0036 start , stop и step .
c18.py
# Присвоение строкового значения
text = «Learn Python Programming»
# Разрез с использованием одного параметра
sliceObj = slice(5)
print(text[sliceObj])
sliceObj = slice(6,12)
print(text[sliceObj])
# Разрез с использованием трех параметров
sliceObj = slice(6,25,5)
print(text[sliceObj])
После запуска скрипта появится следующий вывод. В первом методе slice() в качестве значения аргумента используется 5. Он нарезает пять символов текстовых переменных, которые печатаются в качестве вывода. Во втором методе slice() в качестве аргументов используются 6 и 12. Нарезка начинается с позиции 6 и останавливается после 12 символов. В третьем методе slice() в качестве аргументов используются 6, 25 и 5. Нарезка начинается с позиции 6 и останавливается после 25 символов путем пропуска 5 символов на каждом шаге.
Top
Добавление и поиск данных в словаре:
объект словаря используется в python для хранения нескольких данных, таких как ассоциативный массив других языков программирования. Следующий сценарий показывает, как можно вставить новый элемент и найти любой элемент в словаре. Словарь информации о клиенте объявляется в сценарии, где индекс содержит идентификатор клиента, а значение содержит имя клиента. Затем в конец словаря вставляется информация об одном новом покупателе. Идентификатор клиента используется в качестве входных данных для поиска в словаре. 9Цикл 0036 for и условие if используются для перебора индексов словаря и поиска входного значения в словаре.
c19.py
# Определение словаря
customers = {‘06753′:’Мехзабин Афроуз’,’02457′:’Md. Ali’,
‘02834’:’Mosarof Ahmed’,’05623′:’Mila Hasan’, ‘07895’:’Yaqub Ali’}
# Добавить новые данные
клиентов[‘05634’] = ‘Mehboba Ferdous’
print(«Имена клиентов:»)
# Вывести значения из словаря
для клиента в клиентах:
print(customers[customer])
# Использовать идентификатор клиента для поиска
name = input(«Введите идентификатор клиента:»)
# Поиск идентификатора в словаре
для клиента среди клиентов .
Если вы хотите узнать больше о других полезных методах словаря, вы можете ознакомиться с учебным пособием «10 наиболее полезных методов словаря Python».
Top
Добавление и поиск данных в наборе:
Следующий сценарий показывает способы добавления и поиска данных в наборе Python. В скрипте объявлен набор целочисленных данных. Метод add() используется для вставки новых данных в набор. Затем в качестве входных данных будет взято целочисленное значение для поиска значения в наборе с использованием для цикла и для условия .
c20.py
# Определить набор чисел
номеров = {23, 90, 56, 78, 12, 34, 67}
# Добавить новые данные
numbers.add(50)
# Напечатать заданные значения
print(numbers)
message = «Номер не найден»
# Взять числовое значение для поиска
search_number = int(input («Введите число:»))
# Поиск числа в наборе
для val в цифрах:
if val == search_number:
message = «Число найдено»
break
print(message)
Скрипт выполняется два раза с целочисленным значением 89и 67. 89 не существует в наборе, и печатается « Номер не найден ». 67 существует в наборе, и печатается « Число найдено ».
Если вы хотите узнать об операции union в наборе, вы можете ознакомиться с учебным пособием «Как использовать union в наборе Python».
Верх
Подсчет элементов в списке:
Метод count() используется в python для подсчета того, сколько раз конкретная строка появляется в другой строке. Может принимать три аргумента. Первый аргумент является обязательным, и он ищет конкретную строку во всей части другой строки. Два других аргумента этого метода используются для ограничения поиска путем определения позиций поиска. В следующем сценарии 9Метод 0036 count() используется с одним аргументом, который будет искать и подсчитывать слово « Python » в переменной string .
c21.py
# Определение строки
string = ‘Python Bash Java Python PHP PERL’
# Определение строки поиска
search = ‘Python’
# Сохранение значения счетчика
count = string. count(search )
# Напечатать отформатированный вывод
print(«%s появляется %d раз» % (поиск, количество))
После выполнения скрипта появится следующий вывод.
Если вы хотите узнать больше о методе count(), вы можете ознакомиться с учебным пособием «Как использовать метод count() в python».
Top
Определение и вызов функции:
Как пользовательская функция может быть объявлена и вызвана в python, показано в следующем скрипте. Здесь объявлены две функции. Функция add() содержит два аргумента для вычисления суммы двух чисел и вывода значения. area() Функция содержит один аргумент для вычисления площади круга и возврата результата вызывающей программе с помощью оператор возврата .
c22.py
# Определить функцию сложения
def add(number1, number2):
result = number1 + number2
print(«Результат сложения:»,result)
# Определить функцию области с оператором return
def area(radius):
result = 3. 14 * radius * radius
return result
# Вызов дополнительной функции
add(400, 300)
# Вызов функции области
print(«Площадь круга»,площадь(4))
После выполнения сценария появится следующий вывод.
Если вы хотите узнать подробности о возвращаемых значениях из функции Python, вы можете ознакомиться с учебным пособием «Возврат нескольких значений из функции Python».
Top
Использование исключения throw и catch:
try и catch блок используются для создания и перехвата исключения. Следующий скрипт показывает использование блока try-catch в python. В попробуйте блок , в качестве входных данных будет взято числовое значение, и будет проверено, является ли число четным или нечетным. Если в качестве входных данных указано какое-либо нечисловое значение, будет сгенерировано сообщение об ошибке ValueError , и в блоке catch будет создано исключение для печати сообщения об ошибке.
c23.py
# Try block
try:
# Возьмите число
number = int(input(«Введите число: «))
if number % 2 == 0:
print даже»)
else:
print(«Число нечетное»)
# Блок исключений
кроме (ValueError):
# Распечатать сообщение об ошибке
print(«Введите числовое значение»)
После выполнения сценария появится следующий вывод.
Если вы хотите узнать больше об обработке исключений в Python, вы можете ознакомиться с учебным пособием «Обработка исключений в Python».
Top
Чтение и запись файла:
Следующий сценарий показывает способ чтения и записи в файл в Python. Имя файла определяется в переменной filename. Файл открывается для записи с помощью метод open() в начале скрипта. В файл записываются три строки методом write() . Затем этот же файл открывается для чтения с помощью метода open() , и каждая строка файла считывается и печатается с использованием цикла for .
c24.py
# Присвоить имя файлу
filename = «languages.txt»
# Открыть файл для записи
fileHandler = open(filename, «w»)
# Добавить текст
fileHandler.write(» Баш\n»)
fileHandler.write(«Python\n»)
fileHandler.write(«PHP\n»)
# Закрыть файл
fileHandler.close()
# Открыть файл для чтения
fileHandler = open(filename, «r «)
# Прочитать файл построчно
для строки в fileHandler:
print(line)
# Закрыть файл
fileHandler.close()
После выполнения сценария появится следующий вывод.
Если вы хотите узнать больше о чтении и записи файлов в Python, вы можете ознакомиться с учебным пособием «Как читать и записывать файлы в Python».
Top
Список файлов в каталоге:
Содержимое любого каталога можно прочитать с помощью модуля os Python. Следующий скрипт показывает, как получить список определенного каталога в python с помощью модуля os . Метод listdir() используется в скрипте для получения списка файлов и папок каталога. Цикл для используется для печати содержимого каталога.
c25.py
# Импорт модуля ОС для чтения каталога
import os
# Установить путь к каталогу
path = ‘/home/fahmida/projects/bin’
# Прочитать содержимое файла
files = os.listdir(path)
# Распечатать содержимое каталога
для файла в файлах:
print(file)
Содержимое каталога появится после выполнения сценария, если указанный путь к каталогу существует.
Top
Чтение и запись с помощью pickle:
В следующем сценарии показаны способы записи и чтения данных с помощью модуль pickle Python. В сценарии объект объявляется и инициализируется пятью числовыми значениями. Данные этого объекта записываются в файл с использованием метода dump(). Затем используется метод load() для чтения данных из того же файла и их сохранения в объекте.
c26.py
# Импорт модуля pickle
import pickle
# Объявление объекта для хранения данных
dataObject = []
# Повторение цикла for 5 раз
for num in range(10,15):
dataObject.append(num)
# Открыть файл для записи данных
file_handler = open(‘languages’, ‘wb’)
# Выгрузить данные объекта в file
pickle.dump(dataObject, file_handler)
# закрыть обработчик файла
file_handler.close()
# открыть файл для чтения файла
file_handler = open(‘languages’, ‘rb’)
# загрузить данные из файла после десериализации
dataObject = pickle.load(file_handler)
# Повторить цикл для печати данных
для val в dataObject:
print(‘The data value : ‘, val)
# закрыть обработчик файла
file_handler. close()
После выполнения скрипта появится следующий вывод .
Если вы хотите узнать больше о чтении и записи с помощью pickle, вы можете ознакомиться с учебным пособием «Как рассолить объекты в Python».
Top
Определение класса и метода:
Следующий сценарий показывает, как класс и метод могут быть объявлены и доступны в Python. Здесь класс объявляется с переменной класса и методом. Затем объявляется объект класса для доступа к переменной класса и методу класса.
c27.py
# Определение класса
class Employee:
name = «Mostak Mahmud»
# Определение метода Отдел: Продажи»)
print(«Зарплата: $1000»)
# Создание объекта сотрудника
emp = Employee()
# Вывод переменной класса
print(«Name:»,emp.name)
# Вызов класса method
emp.details()
После выполнения сценария появится следующий вывод.
Top
Использование функции диапазона:
Следующий скрипт показывает различные варианты использования функции диапазона в Python. Эта функция может принимать три аргумента. Это start , stop и step . Аргумент stop является обязательным. Когда используется один аргумент, начальное значение по умолчанию равно 0. Здесь в трех циклах for используется функция range() с одним аргументом, двумя аргументами и тремя аргументами.
c28.py
# range() с одним параметром
для val in range(6):
print(val, end=’ ‘)
print(‘\n’)
# range() с двумя параметр
для значения в диапазоне (5,10):
print(val, end=’ ‘)
print(‘\n’)
# range() с тремя параметрами
для значения в диапазоне (0,8,2 ):
print(val, end=’ ‘)
После выполнения сценария появится следующий вывод.
Верх
Использование функции карты:
Функция map() используется в python для возврата списка с помощью любой определяемой пользователем функции и любого итерируемого объекта. В следующем сценарии функция cal_power() определена для вычисления x n , , и эта функция используется в первом аргументе функции map() . Список с именем чисел используется во втором аргументе функции map() . Значение x будет взято у пользователя, а 9Функция 0036 map() вернет список значений мощности x, на основе значений элементов списка чисел .
c29.py
# Определить функцию для вычисления мощности
def cal_power(n):
return x ** n :»))
# Определить набор чисел
numbers = [2, 3, 4]
# Вычислить x в степени n с помощью map()
result = map(cal_power, numbers)
print(list(result))
После выполнения сценария появится следующий вывод.
Top
Использование функции фильтра:
filter() функция Python использует пользовательскую функцию для фильтрации данных из итерируемого объекта и создания списка с элементами для тех, которые функция возвращает true. В следующем сценарии функция SelectedPerson() используется в сценарии для создания списка отфильтрованных данных на основе элементов выбранный список .
c30.py
# Определить список участников
= [‘Monalisa’, ‘Akbar Hossain’, ‘Jakir Hasan’, ‘Zahadur Rahman’, ‘Zenifer Lopez’]
# Определить функцию для выбранных фильтров Кандидаты
def SelectedPerson(участник):
selected = [‘Акбар Хоссейн’, ‘Зиллур Рахман’, ‘Моналиса’]
if(участник выбран):
return True
selectedList = filter(SelectedPerson, участника)
print(‘ Отобранные кандидаты:’)
для кандидата в selectedList:
print(candidate)
После выполнения сценария появится следующий вывод.
Top
Заключение:
В этой статье основы программирования на Python обсуждаются в 30 различных темах. Я надеюсь, что примеры из этой статьи помогут читателям легко изучить Python с самого начала.
Скачать Python | Python.org
Ищете определенный выпуск?
Выпуски Python по номеру версии:
Версия выпуска Дата выхода Нажмите, чтобы узнать больше
- Питон 3.7.14 6 сентября 2022 г. Скачать Примечания к выпуску
- Питон 3.8.14 6 сентября 2022 г. Скачать Примечания к выпуску
- Питон 3.9.14 6 сентября 2022 г. Скачать Примечания к выпуску
- Питон 3. 10.7
6 сентября 2022 г.
Скачать
Примечания к выпуску
- Питон 3.10.6 2 августа 2022 г. Скачать Примечания к выпуску
- Питон 3.10.5 6 июня 2022 г. Скачать Примечания к выпуску
- Питон 3.9.13 17 мая 2022 г. Скачать Примечания к выпуску
- Питон 3. 10.4
24 марта 2022 г.
Скачать
Примечания к выпуску
- Питон 3.9.12 23 марта 2022 г. Скачать Примечания к выпуску
- Питон 3.10.3 16 марта 2022 г. Скачать Примечания к выпуску
- Питон 3.9.11 16 марта 2022 г. Скачать Примечания к выпуску
- Питон 3. 8.13
16 марта 2022 г.
Скачать
Примечания к выпуску
- Питон 3.7.13 16 марта 2022 г. Скачать Примечания к выпуску
- Питон 3.9.10 14 января 2022 г. Скачать Примечания к выпуску
- Питон 3.10.2 14 января 2022 г. Скачать Примечания к выпуску
- Питон 3. 10.1
6 декабря 2021 г.
Скачать
Примечания к выпуску
- Питон 3.9.9 15 ноября 2021 г. Скачать Примечания к выпуску
- Питон 3.9.8 5 ноября 2021 г. Скачать Примечания к выпуску
- Питон 3.10.0 4 октября 2021 г. Скачать Примечания к выпуску
- Питон 3. 7.12
4 сентября 2021 г.
Скачать
Примечания к выпуску
- Питон 3.6.15 4 сентября 2021 г. Скачать Примечания к выпуску
- Питон 3.9.7 30 августа 2021 г. Скачать Примечания к выпуску
- Питон 3.8.12 30 августа 2021 г. Скачать Примечания к выпуску
- Питон 3. 9.6
28 июня 2021 г.
Скачать
Примечания к выпуску
- Питон 3.8.11 28 июня 2021 г. Скачать Примечания к выпуску
- Питон 3.7.11 28 июня 2021 г. Скачать Примечания к выпуску
- Питон 3.6.14 28 июня 2021 г. Скачать Примечания к выпуску
- Питон 3. 9.5
3 мая 2021 г.
Скачать
Примечания к выпуску
- Питон 3.8.10 3 мая 2021 г. Скачать Примечания к выпуску
- Питон 3.9.4 4 апреля 2021 г. Скачать Примечания к выпуску
- Питон 3.8.9 2 апреля 2021 г. Скачать Примечания к выпуску
- Питон 3. 9.2
19 февраля 2021 г.
Скачать
Примечания к выпуску
- Питон 3.8.8 19 февраля 2021 г. Скачать Примечания к выпуску
- Питон 3.6.13 15 февраля 2021 г. Скачать Примечания к выпуску
- Питон 3.7.10 15 февраля 2021 г. Скачать Примечания к выпуску
- Питон 3. 8.7
21 декабря 2020 г.
Скачать
Примечания к выпуску
- Питон 3.9.1 7 декабря 2020 г. Скачать Примечания к выпуску
- Питон 3.9.0 5 октября 2020 г. Скачать Примечания к выпуску
- Питон 3.8.6 24 сентября 2020 г. Скачать Примечания к выпуску
- Питон 3. 5.10
5 сентября 2020 г.
Скачать
Примечания к выпуску
- Питон 3.7.9 17 августа 2020 г. Скачать Примечания к выпуску
- Питон 3.6.12 17 августа 2020 г. Скачать Примечания к выпуску
- Питон 3.8.5 20 июля 2020 г. Скачать Примечания к выпуску
- Питон 3. 8.4
13 июля 2020 г.
Скачать
Примечания к выпуску
- Питон 3.7.8 27 июня 2020 г. Скачать Примечания к выпуску
- Питон 3.6.11 27 июня 2020 г. Скачать Примечания к выпуску
- Питон 3.8.3 13 мая 2020 г. Скачать Примечания к выпуску
- Питон 2. 7.18
20 апреля 2020 г.
Скачать
Примечания к выпуску
- Питон 3.7.7 10 марта 2020 г. Скачать Примечания к выпуску
- Питон 3.8.2 24 февраля 2020 г. Скачать Примечания к выпуску
- Питон 3.8.1 18 декабря 2019 г. Скачать Примечания к выпуску
- Питон 3. 7.6
18 декабря 2019 г.
Скачать
Примечания к выпуску
- Питон 3.6.10 18 декабря 2019 г. Скачать Примечания к выпуску
- Питон 3.5.9 2 ноября 2019 г. Скачать Примечания к выпуску
- Питон 3.5.8 29 октября 2019 г. Скачать Примечания к выпуску
- Питон 2. 7.17
19 октября 2019 г.
Скачать
Примечания к выпуску
- Питон 3.7.5 15 октября 2019 г. Скачать Примечания к выпуску
- Питон 3.8.0 14 октября 2019 г. Скачать Примечания к выпуску
- Питон 3.7.4 8 июля 2019 г. Скачать Примечания к выпуску
- Питон 3. 6.9
2 июля 2019 г.
Скачать
Примечания к выпуску
- Питон 3.7.3 25 марта 2019 г. Скачать Примечания к выпуску
- Питон 3.4.10 18 марта 2019 г. Скачать Примечания к выпуску
- Питон 3.5.7 18 марта 2019 г. Скачать Примечания к выпуску
- Питон 2. 7.16
4 марта 2019 г.
Скачать
Примечания к выпуску
- Питон 3.7.2 24 декабря 2018 г. Скачать Примечания к выпуску
- Питон 3.6.8 24 декабря 2018 г. Скачать Примечания к выпуску
- Питон 3.7.1 20 октября 2018 г. Скачать Примечания к выпуску
- Питон 3. 6.7
20 октября 2018 г.
Скачать
Примечания к выпуску
- Питон 3.5.6 2 августа 2018 г. Скачать Примечания к выпуску
- Питон 3.4.9 2 августа 2018 г. Скачать Примечания к выпуску
- Питон 3.7.0 27 июня 2018 г. Скачать Примечания к выпуску
- Питон 3. 6.6
27 июня 2018 г.
Скачать
Примечания к выпуску
- Питон 2.7.15 1 мая 2018 г. Скачать Примечания к выпуску
- Питон 3.6.5 28 марта 2018 г. Скачать Примечания к выпуску
- Питон 3.4.8 5 февраля 2018 г. Скачать Примечания к выпуску
- Питон 3. 5.5
5 февраля 2018 г.
Скачать
Примечания к выпуску
- Питон 3.6.4 19 декабря 2017 г. Скачать Примечания к выпуску
- Питон 3.6.3 3 октября 2017 г. Скачать Примечания к выпуску
- Питон 3.3.7 19 сентября 2017 г. Скачать Примечания к выпуску
- Питон 2. 7.14
16 сентября 2017 г.
Скачать
Примечания к выпуску
- Питон 3.4.7 9 августа 2017 г. Скачать Примечания к выпуску
- Питон 3.5.4 8 августа 2017 г. Скачать Примечания к выпуску
- Питон 3.6.2 17 июля 2017 г. Скачать Примечания к выпуску
- Питон 3. 6.1
21 марта 2017 г.
Скачать
Примечания к выпуску
- Питон 3.4.6 17 января 2017 г. Скачать Примечания к выпуску
- Питон 3.5.3 17 января 2017 г. Скачать Примечания к выпуску
- Питон 3.6.0 23 декабря 2016 г. Скачать Примечания к выпуску
- Питон 2. 7.13
17 декабря 2016 г.
Скачать
Примечания к выпуску
- Питон 3.4.5 27 июня 2016 г. Скачать Примечания к выпуску
- Питон 3.5.2 27 июня 2016 г. Скачать Примечания к выпуску
- Питон 2.7.12 25 июня 2016 г. Скачать Примечания к выпуску
- Питон 3. 4.4
21 декабря 2015 г.
Скачать
Примечания к выпуску
- Питон 3.5.1 7 декабря 2015 г. Скачать Примечания к выпуску
- Питон 2.7.11 5 декабря 2015 г. Скачать Примечания к выпуску
- Питон 3.5.0 13 сентября 2015 г. Скачать Примечания к выпуску
- Питон 2. 7.10
23 мая 2015 г.
Скачать
Примечания к выпуску
- Питон 3.4.3 25 февраля 2015 г. Скачать Примечания к выпуску
- Питон 2.7.9 10 декабря 2014 г. Скачать Примечания к выпуску
- Питон 3.4.2 13 октября 2014 г. Скачать Примечания к выпуску
- Питон 3. 3.6
12 октября 2014 г.
Скачать
Примечания к выпуску
- Питон 3.2.6 12 октября 2014 г. Скачать Примечания к выпуску
- Питон 2.7.8 2 июля 2014 г. Скачать Примечания к выпуску
- Питон 2.7.7 1 июня 2014 г. Скачать Примечания к выпуску
- Питон 3. 4.1
19 мая 2014 г.
Скачать
Примечания к выпуску
- Питон 3.4.0 17 марта 2014 г. Скачать Примечания к выпуску
- Питон 3.3.5 9 марта 2014 г. Скачать Примечания к выпуску
- Питон 3.3.4 9 февраля 2014 г. Скачать Примечания к выпуску
- Питон 3. 3.3
17 ноября 2013 г.
Скачать
Примечания к выпуску
- Питон 2.7.6 10 ноября 2013 г. Скачать Примечания к выпуску
- Питон 2.6.9 29 октября 2013 г. Скачать Примечания к выпуску
- Питон 3.3.2 15 мая 2013 г. Скачать Примечания к выпуску
- Питон 3. 2.5
15 мая 2013 г.
Скачать
Примечания к выпуску
- Питон 2.7.5 12 мая 2013 г. Скачать Примечания к выпуску
- Питон 3.2.4 6 апреля 2013 г. Скачать Примечания к выпуску
- Питон 3.3.1 6 апреля 2013 г. Скачать Примечания к выпуску
- Питон 2. 7.4
6 апреля 2013 г.
Скачать
Примечания к выпуску
- Питон 3.3.0 29 сентября 2012 г. Скачать Примечания к выпуску
- Питон 2.6.8 10 апреля 2012 г. Скачать Примечания к выпуску
- Питон 3.2.3 10 апреля 2012 г. Скачать Примечания к выпуску
- Питон 3. 1.5
9 апреля 2012 г.
Скачать
Примечания к выпуску
- Питон 2.7.3 9 апреля 2012 г. Скачать Примечания к выпуску
- Питон 3.2.2 3 сентября 2011 г. Скачать Примечания к выпуску
- Питон 3.2.1 9 июля 2011 г. Скачать Примечания к выпуску
- Питон 2. 7.2
11 июня 2011 г.
Скачать
Примечания к выпуску
- Питон 3.1.4 11 июня 2011 г. Скачать Примечания к выпуску
- Питон 2.6.7 3 июня 2011 г. Скачать Примечания к выпуску
- Питон 2.5.6 26 мая 2011 г. Скачать Примечания к выпуску
- Питон 3. 2.0
20 февраля 2011 г.
Скачать
Примечания к выпуску
- Питон 2.7.1 27 ноября 2010 г. Скачать Примечания к выпуску
- Питон 3.1.3 27 ноября 2010 г. Скачать Примечания к выпуску
- Питон 2.6.6 24 августа 2010 г. Скачать Примечания к выпуску
- Питон 2. 7.0
3 июля 2010 г.
Скачать
Примечания к выпуску
- Питон 3.1.2 20 марта 2010 г. Скачать Примечания к выпуску
- Питон 2.6.5 18 марта 2010 г. Скачать Примечания к выпуску
- Питон 2.5.5 31 января 2010 г. Скачать Примечания к выпуску
- Питон 2. 6.4
26 октября 2009 г.
Скачать
Примечания к выпуску
- Питон 2.6.3 2 октября 2009 г. Скачать Примечания к выпуску
- Питон 3.1.1 17 августа 2009 г. Скачать Примечания к выпуску
- Питон 3.1.0 26 июня 2009 г. Скачать Примечания к выпуску
- Питон 2. 6.2
14 апреля 2009 г.
Скачать
Примечания к выпуску
- Питон 3.0.1 13 февраля 2009 г. Скачать Примечания к выпуску
- Питон 2.5.4 23 декабря 2008 г. Скачать Примечания к выпуску
- Питон 2.5.3 19 декабря 2008 г. Скачать Примечания к выпуску
- Питон 2. 4.6
19 декабря 2008 г.
Скачать
Примечания к выпуску
- Питон 2.6.1 4 декабря 2008 г. Скачать Примечания к выпуску
- Питон 3.0.0 3 декабря 2008 г. Скачать Примечания к выпуску
- Питон 2.6.0 2 октября 2008 г. Скачать Примечания к выпуску
- Питон 2. 3.7
11 марта 2008 г.
Скачать
Примечания к выпуску
- Питон 2.4.5 11 марта 2008 г. Скачать Примечания к выпуску
- Питон 2.5.2 21 февраля 2008 г. Скачать Примечания к выпуску
- Питон 2.5.1 19 апреля 2007 г. Скачать Примечания к выпуску
- Питон 2. 3.6
1 ноября 2006 г.
Скачать
Примечания к выпуску
- Питон 2.4.4 18 октября 2006 г. Скачать Примечания к выпуску
- Питон 2.5.0 19 сентября 2006 г. Скачать Примечания к выпуску
- Питон 2.4.3 15 апреля 2006 г. Скачать Примечания к выпуску
- Питон 2. 4.2
27 сентября 2005 г.
Скачать
Примечания к выпуску
- Питон 2.4.1 30 марта 2005 г. Скачать Примечания к выпуску
- Питон 2.3.5 8 февраля 2005 г. Скачать Примечания к выпуску
- Питон 2.4.0 30 ноября 2004 г. Скачать Примечания к выпуску
- Питон 2. 3.4
27 мая 2004 г.
Скачать
Примечания к выпуску
- Питон 2.3.3 19 декабря 2003 г. Скачать Примечания к выпуску
- Питон 2.3.2 3 октября 2003 г. Скачать Примечания к выпуску
- Питон 2.3.1 23 сентября 2003 г. Скачать Примечания к выпуску
- Питон 2. 3.0
29 июля 2003 г.
Скачать
Примечания к выпуску
- Питон 2.2.3 30 мая 2003 г. Скачать Примечания к выпуску
- Питон 2.2.2 14 октября 2002 г. Скачать Примечания к выпуску
- Питон 2.2.1 10 апреля 2002 г. Скачать Примечания к выпуску
- Питон 2. 1.3
9 апреля 2002 г.
Скачать
Примечания к выпуску
- Питон 2.2.0 21 декабря 2001 г. Скачать Примечания к выпуску
- Питон 2.0.1 22 июня 2001 г. Скачать Примечания к выпуску
Посмотреть старые выпуски
Лицензии
Все выпуски Python имеют открытый исходный код. Исторически сложилось так, что большинство, но не все выпуски Python также были совместимы с GPL. На странице «Лицензии» подробно описаны GPL-совместимость и условия.
Подробнее
Исходники
Для большинства систем Unix необходимо загрузить и скомпилировать исходный код. Тот же архив исходного кода также можно использовать для сборки версий для Windows и Mac, и он является отправной точкой для переноса на все другие платформы.
Загрузите последний исходный код Python 3 и Python 2.
Подробнее
Альтернативные реализации
На этом сайте размещена «традиционная» реализация Python (по прозвищу CPython). Также доступен ряд альтернативных реализаций.
Подробнее
История
Python был создан в начале 1990-х годов Гвидо ван Россумом из Stichting Mathematisch Centrum в Нидерландах как преемник языка под названием ABC. Гвидо остается основным автором Python, хотя он включает в себя множество вкладов других.
Подробнее
Информация о конкретных портах и информация о разработчике
- Windows
- Макинтош
- Другие платформы
- Источник
- Руководство разработчика Python
- Средство отслеживания проблем Python
Открытые ключи OpenPGP
Исходные и бинарные исполняемые файлы подписываются менеджером релиза или сборщиком бинарных файлов, используя их
Ключ OpenPGP. Файлы выпусков для поддерживаемых в настоящее время выпусков подписаны следующим образом:
- Пабло Галиндо Сальгадо (исходные файлы и теги 3.10.x и 3.11.x) (идентификатор ключа: 64E628F8D684696D)
- Стив Дауэр (двоичные файлы Windows) (идентификатор ключа: FC62 4643 4870 34E5)
- Лукаш Ланга (исходные файлы и теги 3.8.x и 3.9.x) (идентификатор ключа: B269 95E3 1025 0568)
- Нед Дейли (двоичные файлы macOS, исходные файлы и теги 3.7.x/3.6.x) (идентификаторы ключей: 2D34 7EA6 AA65 421D, FB99 2128 6F5E 1540 и Apple Developer ID DJ3H93M7VJ )
- Ларри Хастингс (исходные файлы и теги 3.5.x) (идентификатор ключа: 3A5C A953 Ф73С 700Д)
- Benjamin Peterson (исходные файлы и теги 2.7.z) (идентификатор ключа: 04C3 67C2 18AD D4FF и A4135B38)
Файлы выпуска для более старых выпусков, срок службы которых уже подошёл к концу, могли быть подписаны одним из следующих лиц:
- Энтони Бакстер (идентификатор ключа: 0EDD C5F2 6A45 C816)
- Георг Брандл (идентификатор ключа: 0A5B 1018 3658 0288)
- Мартин против Лёвиса (идентификатор ключа: 6AF0 53F0 7D9D C8D2)
- Рональд Уссорен (id ключа: C9БЭ 28DE E6DF 025C)
- Барри Варшава (идентификаторы ключей: 126E B563 A74B 06BF, D986 6941 EA5B BD71 и ED9D77D5)
Вы можете импортировать открытые ключи человека с сетевого сервера открытых ключей вы доверяете, выполнив команду вроде:
gpg --recv-keys [идентификатор ключа]
или, во многих случаях, открытые ключи также могут быть найдены
на keybase. io.
На страницах загрузки для конкретной версии вы должны увидеть ссылку на
загружаемый файл и отдельный файл подписи. Для проверки подлинности
загрузки, возьмите оба файла, а затем выполните эту команду:
gpg --verify Python-3.6.2.tgz.asc
Обратите внимание, что вы должны использовать имя файла подписи, и вы должны использовать тот, который подходит для загрузки, которую вы проверяете.
- (Эти инструкции предназначены для Пользователи командной строки GnuPG и Unix.)
Другие полезные элементы
- Ищете сторонние модули Python ? В Package Index их много.
- Вы можете просмотреть стандартную документацию онлайн, или вы можете скачать его в HTML, PostScript, PDF и других форматах. См. главное Страница документации.
- Информация об инструментах для распаковки архивных файлов предоставленный на python.org доступен.
- Совет : даже если вы скачаете готовый бинарник для своего
платформу, имеет смысл также загрузить исходный код. Это позволяет просматривать стандартную библиотеку (подкаталог Lib )
и стандартные наборы демо ( Demo ) и инструменты
( Инструменты ), которые идут в комплекте. Вы можете многому научиться у
источник!
- Существует также коллекция пакетов Emacs которые Emacsing Pythoneer может найти полезными. Это включает основные режимы редактирования Python, C, C++, Java и т. д., отладчик Python интерфейсы и многое другое. Большинство пакетов совместимы с Emacs и XEmacs.
Хотите внести свой вклад?
Хотите внести свой вклад? См. Руководство разработчика Python чтобы узнать, как управляется разработка Python.
Узнайте, как запустить ваш скрипт Python — скрипт Python
Историческое размытие между языками сценариев и языками программирования общего назначения привело к тому, что Python стал рассматриваться широкой аудиторией как язык сценариев. Сценарий Python — это файл, содержащий команды, структурированные для выполнения в виде программы. Но как вы его запускаете? Что мы имеем в виду под запуском скрипта Python? Давайте узнаем ответы на все эти вопросы с помощью этого блога о Python Script.
- Что такое Python Script
- Как можно выполнить программу Python?
- Необходимость написания сценариев
- Преимущества написания сценариев
- Python и Java
- Как писать сценарии Python?
- Необходимость документирования кода
- Как перезагрузить модули
- Преобразование скрипта Python в файл .exe
- В чем разница между кодом, сценарием и модулями?
Сценарий Python, файл, содержащий команды, структурирован для выполнения как программа. Эти файлы предназначены для содержания различных функций и импорта различных модулей. Интерактивная оболочка Python или соответствующая командная строка используются для выполнения сценария, для выполнения определенной задачи. Сценарий структурируется путем определения набора определений функций, а затем указывается основная программа, используемая для вызова функций.
Программа состоит из множества задач; эти задачи могут быть выполнены с помощью скриптов. В отличие от библиотек, сценарии можно использовать без импорта, и они требуют меньше кода.
Как можно выполнить программу Python?Различные способы успешного выполнения программы Python:
- Терминалом Python. Интерактивный режим программирования используется для разработки новых решений с нуля и их реализации самыми современными способами.
- Путем реализации сценариев.
Разработка сложных программ с использованием терминала Python очень сложна, сложна и требует много времени. Скрипты используются для разработки таких сложных и больших программ.
Сначала выполняются шаги для методов, затем запись программы на Python в блокноте, сохранение программы, сохраненной с использованием расширения .py, и, наконец, выполнение соответствующей программы путем ввода имени программы в командная строка «python filename.py».
Примечание: Правильно установите переменную пути перед выполнением скрипта.
Пользователи Mac:Дважды щелкните сценарий в Finder, чтобы запустить приложение сценария. События и результаты нельзя просмотреть, если приложение-скрипт запущено вне редактора Script .
Преимущества сценариевСоздание сценариев, разработка набора команд, предназначенных для совместной работы для выполнения необходимой задачи или набора задач.
Спрос на языки сценариев растет, поскольку на рынке существует потребность в простых решениях для разработки сложных программ. По мере роста популярности и популярности этих языков сценариев разработчики пытаются раздвинуть границы, чтобы получить более быстрые и лучшие результаты. Они просты в разработке и могут быть выполнены в короткие сроки.
Примечание: Python по-прежнему имеет преимущество, и скрипты в основном можно использовать для задач, связанных с интеграцией. Разработчики должны знать границы и уважать их.
Python и JavaСкрипты Python — это не что иное, как коды, написанные в программах Python.
Как и в Java, в Python есть PVM (виртуальная машина Python). PVM может преобразовать сценарий в байтовый код. Файлы .pyc в python, также известные как скомпилированные файлы python, используют аналогичную архитектуру для выполнения. В python процесс выполняется для модулей для повышения производительности во время выполнения.
Состояние Python: Язык Python интерпретируется по своей природе. Из-за наличия компилятора байт-кода различие между интерпретируемым и скомпилированным почти размыто. Нет необходимости создавать исполняемый файл для запуска, так как исходные файлы можно запускать напрямую.
Архитектура программы отличается от сплошного скрипта. Он сложен и разнообразен.
Как писать сценарии Python?Скрипт на питоне и шелл-скрипт почти одно и то же. Обе они представляют собой строки кода Python, написанные в текстовом файле; эти коды Python разработаны как решения, которые выполняются систематически.
Необходим текстовый редактор с подсветкой синтаксиса. Разработчики могут легко создавать и редактировать скрипт Python с помощью хорошего текстового редактора.
Наиболее универсальным текстовым редактором, доступным в настоящее время на рынке, является VSCode, предоставляемый Microsoft.
Пользователи Windows:Можно установить и запустить напрямую или через Anaconda
Пользователи Mac:Можно установить и запустить через Anaconda.
Необходимость документирования кода Очень важно документировать написанный код Python. Это помогает легко использовать код для других, а также для себя. При наличии надлежащей документации структуру и использование соответствующего кода можно легко запомнить для будущих целей. Для документирования исходного кода мы используем комментарии. Комментарии обозначаются #. Python игнорирует текст, написанный в виде комментариев.
Примечание:
- Файлы с обычным текстом можно использовать для создания и хранения команд Python
- Используйте python <имя сценария> для запуска соответствующего файла
- Расширение .py обычно используется для сценариев python.
- Всегда выбирайте текстовый редактор с подсветкой синтаксиса для редактирования сценариев Python.
- Используйте комментарии, так как они улучшают читабельность вашего кода и могут использоваться для понимания структуры и использования скрипта в будущих целях.
Модуль Python представляет собой набор параметров и функций в одном файле . py. Это файлы, реализованные при необходимости предопределенных функций.
При импорте модуля Python защищает команды для импорта соответствующего модуля. Если другой оператор делает команду для импорта того же модуля, Python автоматически игнорирует эту команду. Папка сис. modules содержит список уже загруженных модулей. Загрузка одного и того же модуля может занять много времени.
Для принудительной перезагрузки модуля при отладке скрипта с использованием файла .exe или запуске программы из оболочки IPython необходимо использовать команду reload. В противном случае внесенные в скрипт изменения не будут обновлены после повторного выполнения скрипта.
Преобразование сценария Python в файл .exeС помощью файла .exe разработанная программа может быть запущена в системе без использования оболочки IDE.
Шаг 1: Используйте команду: pip install pyinstaller, введите ее в командной строке
Шаг 2: Откройте каталог, в котором находится соответствующий файл . py.
Шаг 3: Откройте окно оболочки Power, нажав правую кнопку и одновременно нажав кнопку Shift.
Шаг 4: Используйте команду: pyinstaller –onefile -w ‘имя_файла.py’, введите ее в командной строке
Шаг 5: После выполнения команды перейдите в новый каталог, откройте папка dist для файла exe.file
В чем разница между кодом, сценарием и модулями?| Код | Сценарий | Модули |
|---|---|---|
| Сценарий представляет собой набор инструкций, которые компьютер понимает без помощи компилятора или интерпретатора для выполнения определенных поставленных задач. | Модули представляют собой наиболее независимо работающий набор компьютерных инструкций, которые в основном используются для интеграции одного устройства с другим, с модулями, содержащими определенный код, который является переносимым, совместимым и эффективным. После разработки может быть интегрирован с небольшими изменениями или без изменений. | |
| Пример: Обычный исходный код этапа 1, который напишет любой программист | Пример: JavaScript, Perl и т. д. | Пример: ERP с множеством модулей, таких как посещаемость, отпуск и т. д. Их можно внедрить в любую компанию с минимальными изменениями или без них. |
Интерпретатор Python:
Python — это построчный интерпретатор, то есть он выполняет код построчно. Как мы все знаем, компьютеры не могут понять наш язык и могут понимать только машинный язык, широко известный как двоичный. В результате интерпретатор Python преобразует написанный пользователем код Python в язык, понятный компьютерному оборудованию или системам. Это происходит каждый раз, когда вы запускаете свой скрипт Python.
Код Python можно создать в любом текстовом редакторе и сохранить в нашей системе с расширением «.py». Так что же не так с этим кодом? Некоторые программы или программное обеспечение, такие как «python» или «python3», должны быть установлены на вашем компьютере, и они должны запускать код Python. Этот тип программного обеспечения известен как интерпретатор.
Python включает ряд полезных функций.
Поскольку интерпретатор Python сначала получает команду, затем оценивает ее, выводит результаты, а затем возвращается к чтению команды, только Python называется REPL (чтение, оценка, печать, цикл).
Перейдите по этой ссылке, чтобы загрузить последнюю версию Python
Запуск интерпретатора Python
Чтобы начать интерпретацию Python, вам необходимо загрузить и установить новейшее бесплатное программное обеспечение Python с открытым исходным кодом. Мы можем использовать интерпретатор Python после завершения установки. С чего начать? Это вопрос, который возникает. Итак, в ответ на этот запрос у нас есть несколько вариантов для начала работы с интерпретацией Python на досуге. Для успешного кодирования вы можете выбрать один из вариантов ниже.
Метод 1: Используйте обычный блокнот для написания кода, сохраните его с расширением a.py, затем запустите его, перетащив файл во встроенную командную строку Python, которую мы называем Python Shell /RELP.
Метод 2: Используйте Python IDE, часть программного обеспечения, помогающую создавать и выполнять файлы кода.
Метод 3: Используйте онлайн-интерпретаторы Python или рабочие среды, такие как Google Colab или другие IDE Python.
Метод 4: Другие бесплатные варианты IDE с открытым исходным кодом для интерпретации кода Python включают Anaconda, Jupyter Notebook, Spyder и другие.
Интерактивный запуск кода Python
Для итеративного запуска кода у нас есть возможность использовать Python SHELL/RELP. Это помогает нам запускать код в интерактивном режиме в том смысле, что он будет принимать код построчно и давать немедленный вывод на следующей строке.
Шаги для начала работы с Python SHELL
Чтобы использовать оболочку Python, введите python в командной строке или оболочке Power в Windows или в окне терминала на Mac >> >>> появится приглашение Python с тремя символами «больше» >> > Теперь вы можете получить результат всего одним предложением. Введите базовую фразу, например 7 – 2, и нажмите Enter; результат появится на следующей строке, как показано ниже.
Как запустить скрипт Python с помощью интерпретатора?
Для этого необходимо выполнить следующие шаги:
- Интерпретатор сначала обрабатывает операторы или выражения сценария в последовательном порядке.
- Затем код преобразуется в байт-код, который является типом набора инструкций.
- Код преобразуется в байт-код, который является языком низкого уровня. Это машинно-независимый промежуточный код, оптимизирующий процесс выполнения кода. В результате, когда интерпретатор снова запускает код, он пропускает стадию компиляции.
Наконец, интерпретатор отправляет код процессору для выполнения. Виртуальная машина Python (PVM) — это заключительный этап в интерпретаторе Python. Это компонент среды Python, установленный на вашем компьютере. В среде выполнения Python PVM загружает байт-код, считывает каждую операцию и выполняет ее.
Как запустить скрипт Python с помощью командной строки?Самый популярный метод — использование обычного текстового редактора для написания программы Python. Код, написанный в интерактивном сеансе Python, теряется после его закрытия, хотя это позволяет пользователю написать много строк кода. Файлы имеют расширение a.py в Windows.
Если вы только начинаете работать с Python, вы можете использовать простые текстовые редакторы, такие как Sublime или Notepad++, или любой другой текстовый редактор.
Затем просто нажмите клавишу ENTER на клавиатуре. На экране вы можете увидеть фразу Hello World! Поздравляю! Вы только что закончили выполнять свой первый скрипт Python.
Если вы не получили вывод, вам следует проверить системный PATH и место, где вы сохранили файл. Если это все еще не работает, попробуйте переустановить Python на свой компьютер.
Как запускать сценарии Python из IDE или текстового редактора
Помимо основных инструментов, интегрированная среда разработки (IDE) — это приложение, которое позволяет разработчику создавать программное обеспечение в интегрированной среде.
Для написания, отладки, изменения и запуска ваших модулей и скриптов вы можете использовать Python IDLE, базовую IDE, включенную в стандартный дистрибутив Python. Другие IDE, которые позволяют вам запускать сценарии в своей среде, включают Spyder, PyCharm, Eclipse и Jupyter Notebook.
Скрипты Python также можно запускать в популярных текстовых редакторах, таких как Sublime и Atom.
Прежде чем запускать сценарий Python из IDE или текстового редактора, необходимо создать проект. Вы можете либо добавить к нему свой файл .py после его создания, либо просто создать его.
В диспетчере файлов необходимо дважды щелкнуть значок файла, чтобы запустить сценарий Python. Этот вариант в основном используется на этапе производства после выпуска исходного кода.
Однако для этого необходимо следовать различным критериям:
Вы должны сохранить файл сценария с расширением .py для python.exe и .pyw для pythonw.exe в Windows, чтобы запустить его двойным щелчком в теме.
Если вы запускаете свой скрипт из командной строки, вы почти наверняка столкнетесь с ситуацией, когда на экране будет мигать черное окно. Включите оператор input(‘Enter’) в конец скрипта, чтобы избежать этого. Когда вы нажмете клавишу ENTER, программа закроется. Стоит отметить, что функция input() будет работать только в том случае, если ваш код не содержит ошибок.
- Ваш сценарий Python должен включать строку hashbang и разрешения на выполнение в GNU/Linux и других Unix-подобных системах. В файловом менеджере метод двойного щелчка иначе работать не будет.
Хотя запустить скрипт, дважды щелкнув его, просто, этот метод не считается жизнеспособным из-за его ограничений и зависимостей, таких как операционная система, файловый менеджер, права на выполнение и файловые ассоциации.
В результате этот параметр следует использовать только после того, как код отлажен и пригоден для производства.
Это подводит нас к концу блога о том, как запустить скрипт Python. Мы надеемся, что вы поняли концепцию всесторонне. Чтобы узнать больше о таких концепциях, присоединяйтесь к курсу Great Learning PGP по искусственному интеллекту и машинному обучению и повышайте квалификацию уже сегодня. Курс PGP-AIML предлагает онлайн-наставничество и поддержку карьеры, чтобы помочь вам продвинуться вперед в своей карьере.
Сочетание обучения со всемирно известными преподавателями Массачусетского технологического института, практических проектов, индивидуального наставничества и от отраслевых экспертов год может стать вашим шлюзом к освоению новейших инструментов и методов в области науки о данных. В программе «Прикладная наука о данных» MIT Professional Education и «Наука о данных и машинное обучение: принятие решений на основе данных» MIT IDSS есть учебные программы, разработанные преподавателями MIT, которые могут помочь вам в этом. Заинтересованы? Загрузите брошюры по программе «Прикладная наука о данных» и «Наука о данных и машинное обучение: принятие решений на основе данных».
Что такое скрипт Python?
Сценарий Python — это набор команд, включенных в файл, предназначенный для запуска аналогично программе. Идея заключается в том, что файл будет запускаться или выполняться из командной строки или из интерактивной оболочки Python для выполнения определенного действия. Конечно, файл включает в себя методы и импортирует разные модули.
Является ли .PY скриптом?
Python — это интерпретируемый объектно-ориентированный язык программирования, а файлы PY — это программные файлы или сценарии, созданные в Python. Для его создания и изменения можно использовать текстовые редакторы, но для его выполнения требуется интерпретатор Python. Веб-серверы, а также другие административные компьютерные системы часто программируются с помощью файлов PY.
Где мы используем сценарии Python?
Python часто используется для создания веб-сайтов и приложений, автоматизации повторяющихся задач, а также для анализа и отображения данных. Python использовался многими непрограммистами, в том числе бухгалтерами и учеными, для различных рутинных действий, включая управление финансами, потому что он чрезвычайно прост в освоении.
Легко ли научиться написанию сценариев на Python?
Python обычно считается одним из самых простых языков программирования для новичков. Python — прекрасная отправная точка, если вы хотите изучить язык программирования. Кроме того, это один из самых популярных языков.
Коллекция из 20 полезных скриптов Python
Python — один из самых простых языков программирования для изучения. Кроме того, он пользуется большим спросом в сфере разработки программного обеспечения. Он позволяет автоматизировать процессы, делая утомительные задачи прогулкой по парку. В этой статье мы рассмотрим 20 лучших скриптов Python, которые вы можете использовать сегодня.
Давайте погрузимся в это!
1.
Преобразование часов в секундыПри работе над проектами, требующими преобразования часов в секунды, вы можете использовать следующий скрипт Python.
преобразование по умолчанию (секунды):
секунды = секунды % (24 * 3600)
час = секунды // 3600
секунд %= 3600
минуты = секунды // 60
секунд %= 60
вернуть "%d:%02d:%02d" % (час, минуты, секунды)
# Драйверная программа
п = 12345
print(convert(n)) 2.
Возведение числа в степень Другой популярный скрипт Python вычисляет степень числа. Например, 2 в степени 4. Здесь есть как минимум три метода на выбор. Вы можете использовать math.pow(), pow(), или **. Вот сценарий.
импорт математики
# Присвоить значения x и n
х = 4
п = 3
# Способ 1
мощность = х ** н
print("%d в степени %d равно %d" % (x,n,степень))
# Способ 2
мощность = мощность (x, n)
print("%d в степени %d равно %d" % (x,n,степень))
# Способ 3
мощность = math.pow(2,6.5)
print("%d в степени %d равно %5.2f" % (x,n,power)) 3.
Оператор If/elseЭто, пожалуй, один из наиболее часто используемых операторов в Python. Это позволяет вашему коду выполнять функцию, если выполняется определенное условие. В отличие от других языков, вам не нужно использовать фигурные скобки. Вот простой сценарий if/else.
# Присвоить значение
число = 50
# Проверяем больше 50 или нет
если (число >= 50):
print("Вы прошли")
еще:
print("Вы не прошли") 4.
Преобразование изображений в JPEG Большинство обычных систем редко принимают такие форматы изображений, как PNG. Таким образом, вам потребуется преобразовать их в файлы JPEG. К счастью, есть скрипт Python, который позволяет автоматизировать этот процесс.
импорт ОС
импорт системы
из изображения импорта PIL
если len(sys.argv) > 1:
если os.path.exists(sys.argv[1]):
im = Image.open(sys.argv[1])
target_name = sys.argv[1] + ".jpg"
rgb_im = im.convert('RGB')
rgb_im.save (имя_цели)
print("Сохранено как " + target_name)
еще:
печать (sys.argv[1] + "не найдено")
еще:
print("Использование: convert2jpg.py <файл>") 5.
Загрузить изображения GoogleЕсли вы работаете над проектом, требующим большого количества изображений, есть скрипт Python, который позволит вам это сделать. С его помощью вы можете загружать сотни изображений одновременно. Однако вам следует избегать нарушения условий авторского права. Для получения дополнительной информации нажмите здесь.
6.
Чтение уровня заряда батареи Bluetooth-устройства Этот сценарий позволяет вам считать уровень заряда батареи вашей Bluetooth-гарнитуры. Это особенно важно, если уровень не отображается на вашем ПК. Однако он поддерживает не все гарнитуры Bluetooth. Для его запуска в вашей системе должен быть установлен Docker. Для получения дополнительной информации нажмите здесь.
7.
Удалить сообщения TelegramПосмотрим правде в глаза, приложения для обмена сообщениями занимают большую часть памяти вашего устройства. И Telegram ничем не отличается. К счастью, этот скрипт позволяет вам удалять все сообщения супергрупп. Вам необходимо ввести информацию о супергруппе для запуска скрипта. Для получения дополнительной информации нажмите здесь.
8.
Получить тексты песен Это еще один популярный скрипт Python, который позволяет вам собирать тексты песен с сайта Genius. В основном он работает со Spotify, однако другие медиаплееры с DBus MediaPlayer2 также могут использовать этот скрипт. С ним вы можете подпевать любимой песне. Для получения дополнительной информации нажмите здесь.
9.
Хостинг HerokuHeroku — один из самых популярных хостингов. Используемый тысячами разработчиков, он позволяет создавать приложения бесплатно. Точно так же вы можете размещать свои приложения и скрипты Python на Heroku с помощью этого скрипта. Для получения дополнительной информации нажмите здесь.
10.
Действия на GithubЕсли вы участвуете в проектах с открытым исходным кодом, рекомендуется вести учет ваших вкладов. Вы не только отслеживаете свой вклад, но и выглядите профессионально, демонстрируя свою работу другим людям. С помощью этого скрипта вы можете создать надежный график активности. Щелкните здесь для получения информации.
11.
Удаление повторяющихся кодов При создании больших приложений или работе над проектами наличие дубликатов в вашем списке является нормальным явлением. Это не только усложняет кодирование, но и делает ваш код непрофессиональным. С помощью этого скрипта вы можете легко удалить дубликаты.
12.
Отправка электронной почтыЭлектронная почта имеет решающее значение для коммуникаций любого бизнеса. С помощью Python вы можете разрешить сайтам и веб-приложениям отправлять их без сбоев. Однако предприятия не хотят отправлять каждое электронное письмо вручную, вместо этого они предпочитают автоматизировать процесс. Этот скрипт позволяет вам выбирать, на какие электронные письма отвечать.
13.
Поиск определенных файлов в вашей системеЧасто вы забываете имена или расположение файлов в вашей системе. Это не только раздражает, но и отнимает время при навигации по разным папкам. Хотя существуют программы, которые помогают вам искать файлы, вам нужна программа, которая может автоматизировать этот процесс.
К счастью, этот сценарий позволяет вам выбирать, какие файлы и типы файлов искать. Например, если вы хотите найти файлы MP3, вы можете использовать этот скрипт .
импорт fnmatch импорт ОС корневой путь = '/' шаблон = '*.
14.
Генерация случайных паролейПароли обеспечивают конфиденциальность пользователей приложений и веб-сайтов. Кроме того, они предотвращают мошенническое использование учетных записей киберпреступниками. Таким образом, вам необходимо создать приложение или веб-сайт, которые могут генерировать случайные надежные пароли. С помощью этого скрипта вы можете легко их генерировать.
строка импорта из случайного импорта * символы = строка.ascii_letters + строка.пунктуация + строка.цифры пароль = "".join(выбор(символы) для x в диапазоне(randint(8, 16))) print (пароль)
15.
Печать нечетных чисел В некоторых проектах может потребоваться печать нечетных чисел в пределах определенного диапазона. Хотя вы можете сделать это вручную, это отнимает много времени и подвержено ошибкам. Это означает, что вам нужна программа, которая может автоматизировать процесс. Благодаря этому скрипту вы можете этого добиться.
16.
Получить значение датыPython позволяет форматировать значение даты различными способами. С модулем DateTime этот скрипт позволяет вам считывать текущую дату и устанавливать пользовательское значение.
17.
Удаление элементов из спискаВам часто придется изменять списки в своих проектах. Python позволяет сделать это с помощью методов Insert() и remove(). Вот сценарий, который вы можете использовать для достижения этой цели.
# Объявить список фруктов
фрукты = ["манго","апельсин","гуава","банан"]
# Вставить элемент во 2-ю позицию
fruit.insert(1, "Виноград")
# Отображение списка после вставки
print("Список фруктов после вставки:")
печать (фрукты)
# Удалить элемент
фрукты.удалить("Гуава")
# Распечатать список после удаления
print("Список фруктов после удаления:")
принт(фрукты) 18.
Подсчет элементов списка Используя метод count(), вы можете вывести, сколько раз одна строка появляется в другой строке. Вам нужно указать строку, которую Python будет искать. Вот сценарий, который поможет вам в этом.
# Определяем строку
строка = 'Python Bash Java PHP PHP PERL'
# Определяем строку поиска
поиск = 'П'
# Сохраняем значение счетчика
количество = строка. количество (поиск)
# Печатаем отформатированный вывод
print("%s появляется %d раз" % (поиск, количество)) 19.
Захват текстаС помощью этого скрипта Python вы можете сделать снимок экрана и скопировать в него текст. Для получения дополнительной информации нажмите здесь.
20.
Поиск твитовВы когда-нибудь искали твиты безрезультатно? Раздражает, право! Что ж, почему бы не использовать этот скрипт и позволить ему сделать всю работу за вас.
Окончательный вердикт Видите ли, Python позволяет нам автоматизировать некоторые из самых рутинных процессов. И с помощью этих лучших скриптов Python вы можете сделать процесс разработки своего приложения без стресса. Итак, какие скрипты Python вы используете? Дайте нам знать в разделе комментариев.
12 полезных скриптов Python для разработчиков
Ни для кого не секрет, что повседневная работа разработчика часто связана с созданием и поддержкой небольших служебных скриптов. Эти сценарии являются связующим звеном, соединяющим различные аспекты вашей системы или среды сборки. Хотя эти сценарии Python могут быть несложными, их поддержка может стать утомительной рутинной работой, которая может стоить вам времени и денег.
Один из способов облегчить обслуживание — использовать автоматизацию сценариев. Вместо того, чтобы тратить время на выполнение сценариев (часто вручную) автоматизация сценариев позволяет запланировать выполнение этих задач по определенному расписанию или запускать их в ответ на определенные события.
В этой статье рассматриваются двенадцать сценариев Python, которые были выбраны за их общую полезность, простоту использования и положительное влияние на вашу рабочую нагрузку. Они варьируются по сложности от простого до среднего и сосредоточены на обработке текста и управлении файлами. В частности, мы рассмотрим следующие варианты использования:
- Создание надежных случайных паролей
- Текст извлечения из PDF
- Текстовая обработка с Pandoc
- Манипулирование аудио с Pydub
- Text
- Поиск
- . images
- Получение контента из Википедии
- Создание приложений Heroku и управление ими
Эти сценарии можно добавить практически в любой рабочий процесс или запустить как часть автоматизированного сценария с помощью такого инструмента, как Runbook для самолетов.
Использование Airplane для управления и выполнения сценариев Python
Airplane — это платформа для разработчиков, позволяющая за считанные минуты преобразовывать API, SQL-запросы и сценарии во внутренние приложения. Платформа предоставляет центральное место для хранения ваших скриптов Python, а также для их безопасного запуска, управления и совместного использования.
Вы также можете использовать расписания Airplane вместо cron и других планировщиков заданий, а Airplane предоставляет разрешения, журналы аудита, потоки утверждений и многое другое из коробки.
Прежде чем мы перейдем к некоторым полезным сценариям Python, давайте быстро рассмотрим, как вы можете использовать Airplane для управления ими и их выполнения.
Вы можете начать работу, зарегистрировав бесплатную учетную запись Airplane и перейдя по ссылке: Библиотека > Новая задача . Задача представляет собой один шаг или операцию, например «достичь конечной точки X» или «запустить сценарий X».
Существует несколько различных вариантов создания задачи. Выбираем Python. Обратите внимание, что вы можете создать свою задачу из пользовательского интерфейса, как описано ниже, но вы также можете создать и полностью определить свою задачу в коде из CLI.
Добавьте имя и описание задачи и нажмите Продолжить .
Сначала мы создадим нашу задачу, а затем развернем наш код. Нажмите Создать задачу , чтобы завершить добавление задачи в Airplane.
Далее мы воспользуемся инструментом командной строки Airplane, чтобы написать сценарий для этой задачи. Этот инструмент позволит вам создавать сценарии и управлять ими локально на вашем компьютере.
Обязательно поместите свой код в функцию с именем main . Зависимости могут быть включены в файл requirements.txt 9.0037, сохраненный в родительском каталоге вашего скрипта.
Перед развертыванием нашего скрипта Python в Airplane мы создадим файл yaml , содержащий имя скрипта, чтобы его было легко идентифицировать.
Например, если вы фильтруете текст с помощью регулярных выражений, вы можете назвать этот файл regex_filter.task.yaml . Объяснение определения задачи можно найти в документации по определению задачи «Самолет».
Ваш завершенный файл yaml должен выглядеть так, как показано в примере ниже:
python
После создания сценария Python и файла определения задачи yaml вы можете развернуть его в Airplane с помощью интерфейса командной строки:
Дополнительные сведения о начале работы можно найти в документации разработчика Airplane для Python, кратком руководстве и руководстве по началу работы с модулями Runbook.
Теперь, когда мы знаем, как использовать Airplane для управления и выполнения скриптов Python, давайте пройдемся по некоторым самим скриптам.
Скрипты Python для разработчиков
Давайте рассмотрим двенадцать служебных скриптов Python, которые мы можем использовать для облегчения нашей жизни. Образцы кода из этой статьи можно найти в этом репозитории GitHub.
1. Создание надежных случайных паролей
Существует множество причин для создания надежных случайных паролей: от регистрации новых пользователей до обеспечения рабочего процесса сброса пароля и создания нового пароля при смене учетных данных. Вы можете легко использовать скрипт Python без зависимостей, чтобы автоматизировать этот процесс:
python
2. Извлечение текста из PDF-файлов
Python также можно использовать для простого извлечения текста из PDF-файлов с помощью пакета PyPDF2 . Получение текста из файла PDF оказывается полезным для интеллектуального анализа данных, сверки счетов или создания отчетов, а процесс извлечения можно автоматизировать всего несколькими строками кода. Вы можете запустить pip install PyPDF2 в своем терминале, чтобы установить пакет. Ниже приведены несколько примеров того, чего можно добиться с помощью Py2PDF2:
Допустим, вы получили многостраничный PDF-файл, но вам нужна только первая страница. Приведенный ниже скрипт позволяет извлечь текст с первой страницы PDF-файла всего несколькими строками кода Python:
python
Возможно, вы захотите скопировать текст из двух PDF-файлов и объединить текст в новый PDF-файл. Вы можете сделать это, используя приведенный ниже код:
python
Эти примеры, наряду с несколькими другими, можно найти здесь.
3. Обработка текста с помощью Pandoc
Pandoc — это полнофункциональный инструмент командной строки, который позволяет преобразовывать разметку между различными форматами. Это означает, что вы можете использовать Pandoc для преобразования текста Markdown непосредственно в docx или разметки MediaWiki в DocBook. Преобразование форматов разметки позволяет обрабатывать внешний контент или предоставленную пользователем информацию, не ограничивая данные одним форматом. Вы можете установить 9Пакет 1663 pandoc с пунктом . Ниже приведены несколько примеров того, что вы можете сделать с pandoc .
Во-первых, предположим, что вы получили отформатированный документ markdown , но вам нужно преобразовать его в PDF. pandoc упрощает эту задачу:
python
Или, может быть, вы хотите преобразовать файл уценки в объект json . Для этого вы можете использовать следующий скрипт:
python
Вы можете найти много других примеров функций здесь или проверить 9Документация по пакету 1663 pandoc для получения дополнительной информации.
4. Работа со звуком с помощью Pydub
Pydub — это пакет Python, который позволяет вам управлять звуком, включая преобразование звука в различные форматы файлов, такие как wav или mp3 . Кроме того, Pydub может сегментировать аудиофайл на миллисекундные сэмплы, что может быть особенно полезно для задач машинного обучения. Pydub можно установить, введя pip install pydub в терминале.
Допустим, вы работаете со звуком и вам необходимо обеспечить правильную громкость каждого файла. Вы можете использовать этот скрипт для автоматизации задачи:
python
Pydub имеет множество дополнительных функций, не описанных в этом примере. Вы можете найти больше из них в репозитории Pydub GitHub.
5. Фильтрация текста
Сопоставление и фильтрация текста с помощью регулярных выражений в Python — это просто, а преимущества могут быть огромными. Допустим, у вас есть система для пакетной обработки сообщений с подтверждением продажи, и вам нужно извлечь кредитную карту из текста сообщения электронной почты. Приведенный ниже скрипт может быстро найти любой номер кредитной карты, соответствующий шаблону, что позволяет легко отфильтровать эту информацию из любого текстового контента:
python
6. Найдите адреса
Поиск адреса может быть полезен, если вы имеете дело с доставкой или логистикой доставки или для простых задач по профилированию пользователей. Для начала установите geocoder , запустив pip install geocoder в своем терминале. Приведенный ниже скрипт позволяет легко найти координаты широты и долготы для любого адреса или найти адрес по любому набору координат:
python
7. Преобразование CSV в Excel
Вы можете часто управлять выходными файлами CSV из аналитической платформы или набора данных. Открыть CSV-файл в Excel относительно просто, но Python позволяет пропустить этот шаг вручную, автоматизировав преобразование. Это также позволяет вам манипулировать данными CSV перед преобразованием в Excel, экономя дополнительное время и усилия.
Начните с загрузки пакета openpyxl с помощью pip install openpyxl . После установки openpyxl вы можете использовать приведенный ниже сценарий для преобразования файла CSV в электронную таблицу Excel:
python
Приведенный выше скрипт является частью репозитория Awesome Python Scripts GitHub.
8. Сопоставление шаблонов с регулярными выражениями
Сбор данных из неструктурированных источников может быть очень утомительным процессом. Как и в приведенном выше примере с фильтрацией, Python позволяет выполнять более детальное сопоставление с образцом с помощью регулярных выражений. Это полезно для категоризации текстовой информации как части рабочего процесса обработки данных или поиска определенных ключевых слов в пользовательском контенте. Встроенная библиотека регулярных выражений называется re , и как только вы освоите синтаксис регулярных выражений, вы сможете автоматизировать практически любой скрипт сопоставления с образцом.
Например, вы хотите сопоставить любые адреса электронной почты, найденные в тексте, который вы обрабатываете. Для этого вы можете использовать этот скрипт:
python
Вы можете использовать этот скрипт, если вам нужно сопоставить телефонные номера в вашем тексте:
python
Automate the Boring Stuff есть отличная глава о настройке и использовании регулярных выражений в Питоне.
9. Преобразование изображений в JPG
Формат .jpg , пожалуй, самый популярный из используемых в настоящее время форматов изображений. Вам может понадобиться преобразовать изображения из других форматов для создания активов проекта или распознавания изображений. Пакет подушки от Python упрощает преобразование изображений в формат jpg :
python
10. Сжатие изображений
временную целевую страницу и, возможно, не захочет делать это вручную, или вам придется отправить задачу во внешнюю службу обработки изображений. Использование подушка , вы можете легко сжимать изображения JPG, чтобы уменьшить размер файла при сохранении качества изображения. Установите подушку с помощью подушки для установки пипа .
Пример ниже уменьшит размер изображения размером 2,5 МБ до 293 КБ:
python
11. Получить содержимое из Википедии
В Википедии представлен фантастический общий обзор многих тем. Эту информацию можно использовать для добавления дополнительной информации в транзакционные электронные письма, отслеживания изменений в определенном наборе статей или для создания учебной документации или отчетов. К счастью, также очень легко собирать информацию с помощью пакета Wikipedia для Python.
Вы можете установить пакет Wikipedia, используя pip install wikipedia . Когда установка завершена, вы готовы начать.
Если вы уже знаете конкретное содержимое страницы, которое хотите получить, вы можете сделать это прямо с этой страницы:
python
Этот пакет также позволяет вам искать страницы, соответствующие указанному тексту:
python
12. Создание и управление приложениями Heroku
Heroku — популярная платформа для развертывания и размещения веб-приложений. В качестве управляемой службы он позволяет разработчикам легко устанавливать, настраивать, поддерживать и даже удалять приложения через API Heroku. Вы также можете легко создавать приложения Heroku или управлять ими с помощью модулей Runbook Airplane, поскольку Airplane позволяет чрезвычайно легко обращаться к API и запускать события.
В приведенном ниже примере используется пакет heroku3 , который можно установить с помощью команды pip install heroku3 . Обратите внимание, что для доступа к платформе вам понадобится ключ API Heroku.
Подключитесь к Heroku с помощью Python:
python
После подключения к Heroku вы можете просмотреть список доступных приложений и выбрать приложение для прямого управления:
python
Затем следующий скрипт позволит вам создать приложение как часть runbook Airplane:
python
После создания приложения вы можете управлять им напрямую с помощью пакета heroku3 . Перейдите в репозиторий Heroku3.py GitHub для получения полного списка параметров.
Начало работы
В этой статье мы описали двенадцать простых сценариев Python, которые можно использовать для автоматизации различных ручных задач. Мы выбрали эти сценарии не только из-за их простоты и полезности, но и из-за их влияния по сравнению с их относительным размером.
Лучше всего то, что вы можете использовать Airplane для беспрепятственного и безопасного управления и запуска этих сценариев. Модули Runbook для самолетов позволяют легко управлять сценариями Python и развертывать их, а также создавать многоэтапные рабочие процессы. Airplane также позволяет управлять сценариями на локальном компьютере, что позволяет использовать среду разработки для написания и тестирования сценариев перед развертыванием.
Хотя в этой статье мы рассмотрели Python, вы также можете создавать рабочие процессы в Airplane, используя Node.js или Docker для запуска сценариев оболочки. Airplane также позволяет работать с SQL и REST и автоматизирует оповещения через Slack и электронную почту. Вы можете зарегистрировать бесплатную учетную запись, чтобы попробовать ее.
Автор: Элвин Чарити
Элвин Чарити — писатель, музыкант, звукорежиссер, редактор аудио/видео и программист-самоучка на Javascript из Вашингтона, округ Колумбия.
13 расширенных сценариев Python для повседневного программирования | by Haider Imtiaz
Удобные скрипты для ваших проектов на Python
Фото Разработано wayhomestudio on FreepikКаждый день мы сталкиваемся со множеством задач программирования, которые требуют продвинутого кодирования. Вы не можете решить эти проблемы с помощью простого синтаксиса Python Basic. В этом блоге я поделюсь 13 расширенных сценариев Python , которые могут быть удобным инструментом для вас в ваших проектах. Сделайте закладку на эту статью для будущего использования и приступайте к работе.
Этот продвинутый скрипт позволит вам проверить скорость интернета с помощью Python. Просто вам нужно установить модули проверки скорости и запустить следующий код.
# pip install pyspeedtest
# pip install speedtest
# pip install speedtest-cli#method 1
import speedtestspeedTest = speedtest.
print(speedTest.get_best_server())#Проверить скорость загрузки
print(speedTest.download())#Проверить скорость загрузки
print(speedTest.upload())# Метод 2import pyspeedtest
st = pyspeedtest.SpeedTest()
st.ping()
st.download()
st.upload ()
Вы можете извлечь URL-адреса перенаправления из поисковой системы Google. Установите следующий модуль упоминаний и следуйте Кодексу.
# pip install googlefrom googlesearch import searchquery = "Medium.com"для URL в поиске(query):
print(url)
10 самых полезных библиотек в Python, которые вы, вероятно, никогда не использовали
Эти пакеты повысят уровень вашего программирования на Python.
python.plainenglish.io
Этот скрипт поможет вам автоматизировать веб-сайты с помощью Python. Вы можете создать веб-бота, который может управлять любым веб-сайтом. Проверьте приведенный ниже код. Этот скрипт удобен для веб-скрейпинга и веб-автоматизации.
# pip install seleniumimport time
from selenium import webdriver
from selenium.webdriver.common.keys import Keysbot = webdriver.Chrome("chromedriver.exe")
bot.get('http://www.google.com')search = bot.find_element_by_name('q')
search.send_keys("@codedev101")
search.send_keys(Keys.RETURN)
time.sleep (5)
bot.quit()
Этот расширенный скрипт покажет вам, как получить текст из любой песни. Сначала вам нужно было получить бесплатный ключ API с веб-сайта Lyricsgenius, а затем вам нужно было следовать приведенному ниже коду.
# pip install Lyricgeniusimport Lyricgeniusapi_key = "xxxxxxxxxxxxxxxxxxxxx"genius = Lyricgenius.Genius(api_key)
artist = Genius.search_artist("Pop Smoke", max_songs=5,sort="title")
song = artist.song("100k On a Coupe")print(song.lyrics)
Получить данные Exif любой фотографии с модулем Python Pillow. Проверьте приведенный ниже код упоминания. Я дал два метода извлечения данных Exif из фотографий. Метод 1 i]: j
для i, j в img._getexif().items()
if i in PIL.ExifTags.TAGS
}
print(exif_data)
# Метод 2
# pip install ExifRead
import exifreadfilename = open(path_name, 'rb')tags = exifread.process_file(filename)
print(tags)
OCR — это метод распознавания текста из цифровых и отсканированных документов. Многие разработчики используют его для чтения рукописных данных. Ниже приведен код Python, который поможет вам преобразовать отсканированные изображения в текстовый формат OCR.
Примечание: Вам нужно было скачать tesseract.exe с Github
# pip install pytesseractimport pytesseract
from PIL import Imagepytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
t=Image.open("img.png")
text = pytesseract.image_to_string(t, config='')print(text)
Этот простой расширенный скрипт преобразует вашу фотографию в формат Cartonize. Ознакомьтесь с приведенным ниже примером кода и попробуйте его.
# pip install opencv-pythonimport cv2img = cv2.imread('img.jpg')
greyimg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
greyimg = cv2.medianBlur(grayimg, 5)ребер = cv2.Laplacian(grayimg , cv2.CV_8U, ksize=5)
r,mask =cv2.threshold (края, 100 255, cv2.THRESH_BINARY_INV) img2 = cv2.bitwise_and (img, img, маска = маска)
img2 = cv2.medianBlur (img2, 5)cv2.imwrite («cartooned.jpg», маска)
Этот простой скрипт позволит вам очистить корзину с помощью Python. Ознакомьтесь с приведенным ниже кодом, чтобы узнать, как это сделать.
# pip install winshellimport winshell
try:
winshell.recycle_bin().empty(confirm=False, /show_progress=False, sound=True)
print("Корзина теперь пуста")
кроме:
print("Корзина уже пуста")
Улучшите свою фотографию, чтобы она выглядела лучше, с помощью библиотеки Python Pillow. В приведенном ниже коде я реализовал четыре метода для улучшения любой фотографии.
# pip install Pillowfrom PIL import Image,ImageFilter
from PIL import ImageEnhanceim = Image.open('img.jpg')
# Выберите свой фильтр
# добавьте Hastag в начале, если вы не хотите использовать фильтр нижеen = ImageEnhance.Color(im)
en = ImageEnhance.Contrast(im)
en = ImageEnhance.Brightness(im)
en = ImageEnhance.Sharpness(im) # result
en.enhance(1.5).show("enhanced")
Этот простой сценарий позволит вам получить полную версию окна, которую вы сейчас используете.
# Версия окнаimport wmi
data = wmi.WMI()
для os_name в data.Win32_OperatingSystem():
print(os_name.Caption) # Microsoft Windows 11 Домашняя
Преобразование всех страниц PDF в изображения с помощью следующего фрагмента кода.
# PDF to Imagesimport fitzpdf = 'sample_pdf.pdf'
doc = fitz.open(pdf)для страницы в документе:
pix = page.getPixmap(alpha=False)
pix.writePNG('page-%i. png' % page.
Этот скрипт просто преобразует Hex в RGB. Посмотрите приведенный ниже пример кода.
# Hex to RGBdef Hex_to_Rgb(hex):
h = hex.lstrip('#')
return tuple(int(h[i:i+2], 16) for i in (0, 2, 4)) print(Hex_to_Rgb('#c96d9d')) # (201, 109, 157)
print(Hex_to_Rgb('#fa0515')) # (250, 5, 21)
Вы можете проверить, работает ли сайт или нет, с помощью Python. Проверьте следующий код: статус 200 означает, что веб-сайт работает, а если вы получили статус 404, это означает, что веб-сайт не работает.
# запросы на установку pip#метод 1import urllib.requestfrom urllib.request import Request, urlopenreq = Request('https://medium.com/@codedev101', headers={'User-Agent': 'Mozilla/5.0'} )
webpage = urlopen(req).getcode()
print(webpage) # 200# метод 2импорт запросов
r = request.get("https://medium.com/@codedev101")
print(r.status_code) # 200 Это 13 расширенных скриптов, которые вы можете использовать в своем проекте Python. Я надеюсь, что вы найдете эту статью полезной и интересной для чтения. Не стесняйтесь отвечать, а также делиться ❤️ этой статьей с друзьями Pythonier. Удачного программирования на Python!
Вы можете поддержать меня, став участником Medium и проверив все мои знания ниже. 👇
Присоединяйтесь к Medium по моей реферальной ссылке - Хайдер Имтиаз
Как член Medium часть вашего членского взноса идет авторам, которых вы читаете, и вы получаете полный доступ к каждой истории…
codedev101.medium.com
Никогда не переставайте учиться! Ознакомьтесь с другими моими статьями, надеюсь, вы найдете их интересными 😃
7 скрытых приемов Python, которые вы, вероятно, никогда не использовали Никогда не использовал
Список невероятных функций, о которых не знает большинство программистов.
python.plainenglish.io
9 Идеи крутых проектов Python для программистов
Список крутых и забавных проектов Python, которые вы можете закончить на этих выходных.
python.plainenglish.io
Скрытые функции Python, о которых вы, вероятно, никогда не слышали
Малоизвестные функции Python, советы и рекомендации
python.plainenglish.io
12 профессиональных советов и рекомендаций для разработчиков Python
Список советов и рекомендаций для более быстрого и эффективного написания кода на Python.
python.plainenglish.io
13 расширенных фрагментов кода Python для повседневных задач
Статья об использовании расширенных кодов для облегчения повседневных задач Python.
python.plainenglish.io
13 функций Python, которые большинство программистов никогда не использовали
Список невероятных функций, о которых большинство программистов не знает.
python.plainenglish.io
20 фрагментов кода Python для повседневных задач программирования
Повысьте свои навыки программирования с помощью этих полезных фрагментов кода Python
python. plainenglish.io
Вот несколько бесплатных конструкторов резюме, которые вы можете использовать для создания своего резюме в кратчайшие сроки.
python.plainenglish.io
17 потрясающих веб-сайтов, которые должен посетить каждый программист
98% программистов и разработчиков не знают об этих сайтах.
python.plainenglish.io
Создайте современный графический интерфейс на Python с использованием PyQt5 Framework
Научитесь разрабатывать программу современного дизайна с графическим интерфейсом на Python с использованием PyQt5 Framework
python.plainLineenglish.io Вы должны знать
Полезные однострочные фрагменты Python для решения любой проблемы кодирования всего одной строкой
python.plainenglish.io
9 простых способов заработать деньги, изучая Python
Не оставайтесь в постели, если вы не можете зарабатывать деньги в постели
python.plainenglish. io
22 полезных фрагмента кода Pro in Python
Получение гласных, поиск анаграмм, сортировка словаря, n-кратная строка, определение размера байта, фильтрация и т. д. Вы узнаете гораздо больше…
Наиболее часто используемые приемы, которые улучшат ваши навыки программирования на Python.
python.plainenglish.io
Скрытые функции Python, о которых вы, вероятно, никогда не слышали
Малоизвестные функции Python, советы и рекомендации
Потрясающие советы и рекомендации для лучшего и профессионального кодирования на Python, которые вы должны знать как программист.
python.plainenglish.io
17 советов и приемов Python, которые помогут улучшить ваши навыки программирования
Сделайте вашу жизнь проще с помощью этих лучших советов и приемов Python
python.plainenglish.io
От нуля до героя в Python всего за 10 минут
90 Все вам нужно научиться идти от нуля до героя в Python.