SQL запросы быстро. Часть 1 / Хабр
Введение
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов на основе этих витрин) и администрирования баз данных. И поскольку повседневная работа аналитика неизбежно связана с выгрузками данных и витринами, навык написания SQL запросов может стать фактором, из-за которого кандидат или получит преимущество, или будет отсеян. Печальная новость в том, что не каждый может рассчитывать получить его на студенческой скамье. Хорошая новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен. Особенно это касается тех, кому уже доводилось сталкиваться с более сложными языками.
Обучение SQL запросам я разделил на три части. Эта часть посвящена базовому синтаксису, который используется в 80-90% случаев.
Практика
Введение в синтаксис будет рассмотрено на примере открытой базы данных, предназначенной специально для практики SQL. Чтобы твое обучение прошло максимально эффективно, открой ссылку ниже в новой вкладке и сразу запускай приведенные примеры, это позволит тебе лучше закрепить материал и самостоятельно поработать с синтаксисом.
Кликнуть здесь
После перехода по ссылке можно будет увидеть сам редактор запросов и вывод данных в центральной части экрана, список таблиц базы данных находится в правой части.
Структура sql-запросов
Общая структура запроса выглядит следующим образом:
SELECT ('столбцы или * для выбора всех столбцов; обязательно')
FROM ('таблица; обязательно')
WHERE ('условие/фильтрация, например, city = 'Moscow'; необязательно')
GROUP BY ('столбец, по которому хотим сгруппировать данные; необязательно')
HAVING ('условие/фильтрация на уровне сгруппированных данных; необязательно')
ORDER BY ('столбец, по которому хотим отсортировать вывод; необязательно')
Разберем структуру.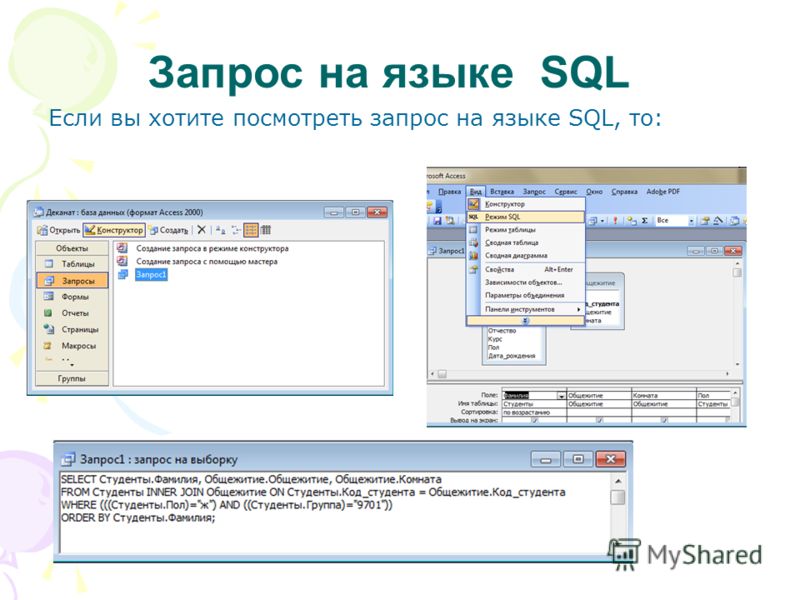
SELECT, FROM
SELECT, FROM — обязательные элементы запроса, которые определяют выбранные столбцы, их порядок и источник данных.
Выбрать все (обозначается как *) из таблицы Customers:
SELECT * FROM Customers
Выбрать столбцы CustomerID, CustomerName из таблицы Customers:
SELECT CustomerID, CustomerName FROM Customers
WHERE
WHERE — необязательный элемент запроса, который используется, когда нужно отфильтровать данные по нужному условию. Очень часто внутри элемента where используются IN / NOT IN для фильтрации столбца по нескольким значениям, AND / OR для фильтрации таблицы по нескольким столбцам.
Фильтрация по одному условию и одному значению:
select * from Customers WHERE City = 'London'
Фильтрация по одному условию и нескольким значениям с применением IN (включение) или NOT IN (исключение):
select * from Customers
where City IN ('London', 'Berlin')select * from Customers
where City NOT IN ('Madrid', 'Berlin','Bern')Фильтрация по нескольким условиям с применением AND (выполняются все условия) или OR (выполняется хотя бы одно условие) и нескольким значениям:
select * from Customers
where Country = 'Germany' AND City not in ('Berlin', 'Aachen') AND CustomerID > 15select * from Customers
where City in ('London', 'Berlin') OR CustomerID > 4GROUP BY
GROUP BY — необязательный элемент запроса, с помощью которого можно задать агрегацию по нужному столбцу (например, если нужно узнать какое количество клиентов живет в каждом из городов).
При использовании GROUP BY обязательно:
- перечень столбцов, по которым делается разрез, был одинаковым внутри SELECT и внутри GROUP BY,
- агрегатные функции (SUM, AVG, COUNT, MAX, MIN) должны быть также указаны внутри SELECT с указанием столбца, к которому такая функция применяется.
Группировка количества клиентов по городу:
select City, count(CustomerID) from Customers GROUP BY City
Группировка количества клиентов по стране и городу:
select Country, City, count(CustomerID) from Customers GROUP BY Country, City
Группировка продаж по ID товара с разными агрегатными функциями: количество заказов с данным товаром и количество проданных штук товара:
select ProductID, COUNT(OrderID), SUM(Quantity) from OrderDetails GROUP BY ProductID
Группировка продаж с фильтрацией исходной таблицы. В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
select City, count(CustomerID) from Customers WHERE Country = 'Germany' GROUP BY City
Переименование столбца с агрегацией с помощью оператора AS. По умолчанию название столбца с агрегацией равно примененной агрегатной функции, что далее может быть не очень удобно для восприятия.
select City, count(CustomerID) AS Number_of_clients from Customers group by City
HAVING
HAVING — необязательный элемент запроса, который отвечает за фильтрацию на уровне сгруппированных данных (по сути, WHERE, но только на уровень выше).
Фильтрация агрегированной таблицы с количеством клиентов по городам, в данном случае оставляем в выгрузке только те города, в которых не менее 5 клиентов:
select City, count(CustomerID) from Customers group by City HAVING count(CustomerID) >= 5
В случае с переименованным столбцом внутри HAVING можно указать как и саму агрегирующую конструкцию count(CustomerID), так и новое название столбца number_of_clients:
select City, count(CustomerID) as number_of_clients from Customers group by City HAVING number_of_clients >= 5
Пример запроса, содержащего WHERE и HAVING. В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
select City, count(CustomerID) as number_of_clients from Customers
WHERE CustomerName not in ('Around the Horn','Drachenblut Delikatessend')
group by City
HAVING number_of_clients >= 5ORDER BY
ORDER BY — необязательный элемент запроса, который отвечает за сортировку таблицы.
Простой пример сортировки по одному столбцу. В данном запросе осуществляется сортировка по городу, который указал клиент:
select * from Customers ORDER BY City
Осуществлять сортировку можно и по нескольким столбцам, в этом случае сортировка происходит по порядку указанных столбцов:
select * from Customers ORDER BY Country, City
По умолчанию сортировка происходит по возрастанию для чисел и в алфавитном порядке для текстовых значений.
select * from Customers order by CustomerID DESC
Обратная сортировка по одному столбцу и сортировка по умолчанию по второму:
select * from Customers order by Country DESC, City
JOIN
JOIN — необязательный элемент, используется для объединения таблиц по ключу, который присутствует в обеих таблицах. Перед ключом ставится оператор ON.
Запрос, в котором соединяем таблицы Order и Customer по ключу CustomerID, при этом перед названиям столбца ключа добавляется название таблицы через точку:
select * from Orders JOIN Customers ON Orders.CustomerID = Customers.CustomerID
Нередко может возникать ситуация, когда надо промэппить одну таблицу значениями из другой. В зависимости от задачи, могут использоваться разные типы присоединений. INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
select * from Orders join Customers on Orders.CustomerID = Customers.CustomerID where Customers.CustomerID >10
Внутри всего запроса JOIN встраивается после элемента from до элемента where, пример запроса:
Другие типы JOIN’ов можно увидеть на замечательной картинке ниже:
В следующей части подробнее поговорим о типах JOIN’ов и вложенных запросах.
При возникновении вопросов/пожеланий, всегда прошу обращаться!
Сравнение таблиц по срок.полям (лишние внутренние пробелы)
← →
Андрей Пл
(2010-12-22 11:04) [0]
Мне нужно сравнить две таблицы по двум полям и выявить где значения у них не совпадают. И в первой и во второй таблице поле строковое, проблема в том что значения в одной из таблиц могут иметь внутренние лишние пробелы (т. е слова могут разделяться не одним а двумя, тремя…. пробелами). Так вот значения в таблицах считать совпадающими если они полностью идентичны за исключением пробелов:
е слова могут разделяться не одним а двумя, тремя…. пробелами). Так вот значения в таблицах считать совпадающими если они полностью идентичны за исключением пробелов:
«aaa bbb» считать одинаковыми «aaa bbb»
как мне в скюэль запросе удалить лишние внутренние пробелы (заранее не известно сколько) или может есть другой способ сравнить…?
заранее спасибо.
← →
Ega23 ©
(2010-12-22 11:15) [1]
REPLACE + F1
← →
Jeer ©
(2010-12-22 11:18) [2]
REPLACE ?
← →
Вариант
(2010-12-22 14:09) [3]
> Jeer © (22.12.10 11:18) [2]
Вариант первый короткий — REPLACE-ом удалить вообще все пробелы, коль они не нужны для сравнения типа SELECT REPLACE(строка, » «,»»)
Вариант второй — удалить до одного пробела WHILE + REPLACE, где маской поиска задать два пробела, а заменой дать один пробел — но это не нужно по заданному вопросу, раз можно вариантом 1(разве что для приведения уже имеющихся записей таблицы к «красивому виду»)
← →
Jeer ©
(2010-12-22 14:41) [4]
> Вариант (22. 12.10 14:09) [3]
12.10 14:09) [3]
> > Jeer © (22.12.10 11:18) [2]
Это не ко мне 🙂
← →
Вариант
(2010-12-22 14:58) [5]
> Jeer © (22.12.10 14:41) [4]
Точно, это автору вопроса:-)
← →
ANB
(2010-12-27 18:02) [6]
> Вариант второй — удалить до одного пробела WHILE + REPLACE
while — не даст все сделать в одном запросе — придется писать функцию.
В оракле помог бы RegExp_Replace, но вроде как ms sql тоже научился работать с регулярными выражениями.
← →
Вариант
(2010-12-28 14:29) [7]
A
> NB (27. 12.10 18:02) [6]
12.10 18:02) [6]
> while — не даст все сделать в одном запросе — придется писать
> функцию.
Точно, небольшую функцию
> но вроде как ms sql тоже научился работать с регулярными
> выражениями.
Интересно, не слышал. Поискал для 2005 — там это возможно на уровне подключения сборок .NET или использования COM объектов.
← →
Ega23 ©
(2010-12-28 17:54) [8]
Зачем функция-то?????
что-то типа
WHERE REPLACE(T1.Field, " ", "") = REPLACE(T2.Field, " ", "")
Сам запрос щас в голову уже не лезет, может из дома напишу.
← →
Вариант
(2010-12-29 06:16) [9]
> Ega23 © (28.12.10 17:54) [8]
Для первого варианта не нужна.
> Вариант (22.12.10 14:09) [3]
>
> Вариант первый короткий — REPLACE-ом удалить вообще все
> пробелы, коль они не нужны для сравнения типа SELECT REPLACE(строка,
> » «,»»)
А вот второй, где надо оставить один пробел из неизвестного числа пробелов — мне пришло только с WHILE+REPLACE в голову — скрипт получается несложный, но как его оформить одним запросом?
← →
Ega23 ©
(2010-12-29 08:01) [10]
Нафига вообще второй вариант? Зачем усложнять-то, если автор чётко напейсал:
> проблема в том что значения в одной из таблиц могут иметь
> внутренние лишние пробелы
Убираем ВСЕ пробелы и сравниваем.
← →
Вариант
(2010-12-29 11:12) [11]
> Ega23 © (29. 12.10 08:01) [10]
12.10 08:01) [10]
Для решения заданного автором вопроса в лоб второй вариант не нужен.
Но мне кажется, что наличие фраз в поле содержащие незначимые пробелы нехорошая практика, если тому конечно нет веских оснований. Правильней на мой взгляд сделать «чистку» таблиц(ы) и создать «правило», запрещающее вносить подобные записи В этом случае и сравнения будут быстрее и не будет «мусора» перед глазами пользователя.
← →
Вариант
(2010-12-29 11:16) [12]
И дополнение к
> Вариант (29.12.10 11:12) [11]
В этом случае для чистки таблицы и возможен вариант два. Хотя если это выполнить однократно, то можно просто на уровне скрипта реализовать, выполняемого их студии. И тогда функция не нужна. А вот если включить как правилом для подчистки при вводе строк на уровне базы, то можно и оформить функцией.
← →
Ega23 ©
(2010-12-29 11:17) [13]
> Правильней на мой взгляд сделать «чистку» таблиц(ы) и создать
> «правило», запрещающее вносить подобные записи
http://delphimaster. net/view/15-1293519707/
net/view/15-1293519707/
Буквально вчера писал:
Ega23 © (28.12.10 18:27) [53]
> А какой смысл решать техническими средствами организационные
> вопросы?
А это есть частое заблуждение, которым многие (да и я сам, чё скрывать-то) грешат. Всегда хочется, хотя бы ради искусства, чтобы «программа приняла вид лома с кучей настраиваемых шарниров». А лучше фреймворк написать.
А заказчику не нужна «автоматическая обрывалка ушей оператору», ему проще человека специального нанять. Или лучше оператора штрафовать за косяк.
И потом начинаются изгаления по распознаванию введённого текста.
Как сделать, чтобы программа поняла, что «Рога и Копыта Российской Федерации», «Рога и Копыта РФ» и «Poгa и Koпытa PФ» — одна и та же организация с одним ID.
А не надо делать, надо оператора покарать за такой ввод.
← →
Вариант
(2010-12-29 11:28) [14]
> Ega23 © (29. 12.10 11:17) [13]
12.10 11:17) [13]
Насчет оператора -согласен, покарать. Но где можно — надо помочь.
Есть просто информационные поля, типа памятки, мемо -их нафиг и не нужно проверять, они не поисковые. И есть «важные» поля, поля в справочниках, где разарабатывается шаблон ввода, как например для ввода сотовых телефонов или еще какие другие. И если есть возможность задать этот шаблон, то почему бы и нет? Если к вам со стороны пришел такой справочник и вы будете информацию из него добавлять в свой, то почему бы его не привести в порядок там, где это возможно? Хотя думаю это тема уже скорее в «потрепаться».
← →
Ega23 ©
(2010-12-29 11:35) [15]
Практика показывает, что полной защиты от дурака — нет. Всё равно лазейку найдут.
Отсюда следует, что разрабатывать офигенно-навороченную защиту от дурака можно, если это по ТЗ требуется. В остальных случаях проще ограничиться чем-то совсем ненапряжным.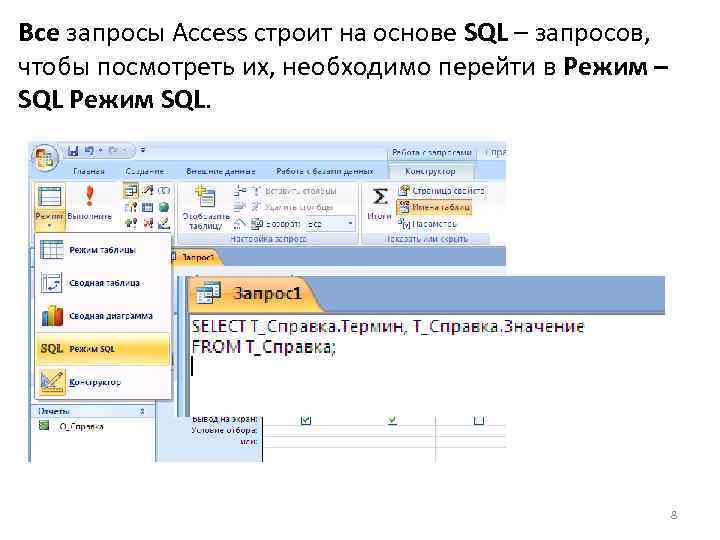
← →
Вариант
(2010-12-29 11:45) [16]
> Ega23 © (29.12.10 11:35) [15]
> Практика показывает, что полной защиты от дурака — нет.
> Всё равно лазейку найдут.
Согласен.
> Отсюда следует, что разрабатывать офигенно-навороченную
> защиту от дурака можно, если это по ТЗ требуется. В остальных
> случаях проще ограничиться чем-то совсем ненапряжным
Я и не предлагал напряженного варианта. Кстати кроме ТЗ стимулом к действию еще может быть собственная эксплуатация своего же продукта, особенно в экстримальных условиях, при нехватке времени … очень может простимулировать. Или опять таки каждодневная рутина, которую опять таки надо делать самому и в какой-то момент понимаешь, что можно сократить время работы, количество действий ну и т.д.
Впрочем, не нравится тебе вариант два — не делай, я же не против:-). Не нужен он автору вопроса, то же его усмотрение…
Не нужен он автору вопроса, то же его усмотрение…
← →
evvcom ©
(2010-12-31 13:41) [17]
Извините, но я понимаю «лишние пробелы» — это когда вместо одного их 2 и более (в том числе и символы табуляции), но удалятьсовершенновсепробелывофразеэтонеправильно! Это аналогично удалению 0 в числах. Если 0 лидирующий, то его можно безболезненно удалить, если уже где-то после первой значимой цифры, то и сам он становится значимым.
← →
Вариант
(2010-12-31 18:30) [18]
> evvcom © (31.12.10 13:41) [17]
н
> о удалятьсовершенновсепробелывофразеэтонеправильно!
А удалять все в самом поле никто не предлагает.
← →
sniknik ©
(2011-01-02 00:07) [19]
> А удалять все в самом поле никто не предлагает.
а не про удаление в поле речь… а о значимости «пустых» символов при сравнении, в зависимости от того где они.
т.е. варианты с «мама», «ма ма» и » мама» в одном случае не равнозначны, в другом равны.
← →
Вариант
(2011-01-05 07:23) [20]
> sniknik © (02.01.11 00:07) [19]
Согласен, если вопрос стоит именно так. Но в
> Андрей Пл (22.12.10 11:04)
об этом сказано явно —
> значения в таблицах считать совпадающими если они полностью
> идентичны за исключением пробелов
>
← →
Вариант
(2011-01-05 07:31) [21]
> sniknik © (02.01.11 00:07) [19]
Хотя возможна ситуация ложного сравнения, согласен (мне и кажется такая вероятность мала, но тем не менее зачем иметь проблемы, если их можно избежать). Например «12» и «1 2» будут равнозначны. Тогда вариант №2
Например «12» и «1 2» будут равнозначны. Тогда вариант №2
> Вариант (22.12.10 14:09) [3]
— удалить лишние пробелы до одного.
Преимущества безмасляных винтовых компрессоров — MAN Diesel & Turbo — Каталоги в формате PDF | Техническая документация
Добавить в избранное
{{requestButtons}}
Выдержки из каталога
Преимущества безмасляной винтовой техники Будущее — с 1758 года.
MAN Diesel & Turbo имеет около 60 лет опыта В таблице ниже приведены средние значения доступности в конструкции , изготовление и эксплуатация винтовой способности, надежности и т.д. для различных типов компрессоров. Компрессорные агрегаты. Более 3000 машин имеют таблицу, основанную на статистике, представленной в мага- зе за это время. То ли в отношении хай-зина «Углеводородная обработка» несколько лет назад. наилучшее давление нагнетания, наибольший или наименьший объемный расход Показывает, что температура центробежного и безмасляного винтового сжатия на всасывании – MAN Diesel & Turbo имеет самую высокую температуру. ..
..
Объем всасывания [ACFM] 100 Винтовой компрессор Тип CP Тип SKUEL Винтовой компрессор Тип SKUEL Газы с различной молекулярной массой У MAN Diesel & Turbo есть много ссылок для этого, поскольку молекулярная масса оказывает лишь незначительное влияние на работу, например, для кокса печной газ, кальцинированная сода, достижимая степень сжатия – отличается от центробежного комбутадиена, мономера стирола и т. д. Для снижения давления – винтовой компрессор идеален для использования при температуре нагнетания, в процессах с колеблющейся молекулярной массой может вводиться вода. Такой винтовой компрессор для предотвращения полимеризации. Большой…
Все данные, представленные в этом документе, не являются обязательными. Эти данные служат только для информационных целей и не гарантируются никоим образом. В зависимости от последующих конкретных отдельных проектов соответствующие данные могут быть изменены и будут оцениваться и определяться индивидуально для каждого проекта. Это будет зависеть от конкретных характеристик каждого отдельного проекта, особенно от конкретной площадки и условий эксплуатации. Copyright © MAN Diesel & Turbo. D02082008EN Отпечатано в Германии GMC-OBH09121.0 MAN Diesel & Turbo Steinbrinkstr. 1 46145 Оберхаузен, Германия Телефон 49 208…
Copyright © MAN Diesel & Turbo. D02082008EN Отпечатано в Германии GMC-OBH09121.0 MAN Diesel & Turbo Steinbrinkstr. 1 46145 Оберхаузен, Германия Телефон 49 208…
Все каталоги и технические брошюры MAN Diesel & Turbo
MOPICO — система сжатия газопровода
6 страниц
MAN 35/44 газовые варианты
13 страниц
MAN 51/60 Газ Варианты
11 страниц
Программа электростанций 2015
154 страницы
MARC_Steam_Turbines
16 страниц
Product_Range
8 страниц
Газовая турбина FT8
2 страницы
Компрессоры и турбины для нефтяной и газовой промышленности
28 страниц
Разработка центробежного компрессора — процесс тестирования технологии
8 страниц
Ассортимент продукции
6 страниц
Архивные каталоги
MOPICO — Компрессор трубопровода двигателя
4 страницы
Турбомашины для установок по производству аммиака
20 страниц
Энергетические решения для комбинированного производства тепла и электроэнергии
12 страниц
Промышленные паровые турбины
20 страниц
Обзор продуктов семейства газовых турбин THM
2 страницы
Сравнить
Удалить все
Сравнить 10 продуктов
Riviera — Центр новостей
16 августа 2013 г. by Riviera Newsletters
by Riviera Newsletters
Компания MAN Diesel & Turbo получила заказ на двухступенчатые компрессорные установки для шести морских нефтедобывающих установок из Бразилии Энергетическая компания Петробрас. Контрагент &O…
Компания MAN Diesel & Turbo получила заказ от бразильской энергетической компании Petrobras на двухступенчатые компрессорные установки для шести морских нефтедобывающих установок. Контрактный партнер Óleo e Gás также имеет опцион на еще две установки, и MAN Diesel & Turbo Brazil впервые будет выступать в качестве подрядчика в Бразилии.
В комплект входит комбинация безмасляных винтовых компрессоров MAN Diesel & Turbo SKUEL и CP, каждый из которых обеспечивает одну ступень сжатия. Комбинация двух типов компрессоров объединяет их соответствующие преимущества: ступень SKUEL предварительно сжимает технологический газ, увеличивая его плотность и уменьшая его объемный расход. Затем стадия CP может дополнительно увеличить давление.
Винтовые компрессоры SKUEL имеют корпус с горизонтальным разъемом и могут работать с большими объемными расходами при сравнительно низком давлении нагнетания. Имея три различных соотношения длины к диаметру, серия SKUEL обеспечивает скорость всасывания от 4 000 м 90 147 ³ 90 148 /ч до 100 000 м 90 147 ³ 90 148 /ч с давлением нагнетания до 16 бар.
Имея три различных соотношения длины к диаметру, серия SKUEL обеспечивает скорость всасывания от 4 000 м 90 147 ³ 90 148 /ч до 100 000 м 90 147 ³ 90 148 /ч с давлением нагнетания до 16 бар.
Компрессоры типа СР, напротив, могут генерировать примерно в три раза более высокое давление нагнетания, но обрабатывать меньшие объемные потоки. Серия CP имеет три различных соотношения длины и диаметра, обеспечивающие скорость всасывания от 200 м ³ /ч до 20 000 м ³ /ч, а корпус с вертикальным разъемом обеспечивает давление нагнетания свыше 50 бар.
Корпуса этих винтовых компрессоров для технологического газа отлиты и могут быть изготовлены из чугуна с шаровидным графитом, литого углеродистого сплава, литой стали или литой нержавеющей стали, при этом корпуса подшипников являются составной частью корпуса.
Роторы изготавливаются из различных сталей, от углеродистой до нержавеющей, для снижения риска коррозии или эрозии компонентов в различных газовых смесях. Роторы всегда цельнокованые с асимметричным профилем ротора. Синхронизированные шестерни размещены на свободном конце пары роторов, и, хотя зазоры малы, установка обеспечивает бесконтактную работу. Подшипники — гидродинамические скольжения, а упорные подшипники — конические подшипники. Смазка подается принудительно, и MAN Diesel & Turbo прогнозирует неограниченный срок службы подшипников.
Роторы всегда цельнокованые с асимметричным профилем ротора. Синхронизированные шестерни размещены на свободном конце пары роторов, и, хотя зазоры малы, установка обеспечивает бесконтактную работу. Подшипники — гидродинамические скольжения, а упорные подшипники — конические подшипники. Смазка подается принудительно, и MAN Diesel & Turbo прогнозирует неограниченный срок службы подшипников.
Эта бизнес-модель обеспечивает высокую степень местного производства, что было жизненно важно для проекта из-за существующего соглашения между Petrobras и бразильским правительством, которое уделяло больше внимания компонентам отечественного производства в новых установках. В качестве подрядчика MAN Diesel & Turbo Brazil координирует и контролирует упаковку, которую выполняет бразильский партнер.
Использование местных компонентов гарантирует, что значительная часть завода может быть произведена в Бразилии, что является важным элементом проекта. Тем не менее, основные компоненты и все инженерные решения по-прежнему поступают из Оберхаузена, Германия.