9 способов найти удаленный сайт или страницу
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет
К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт».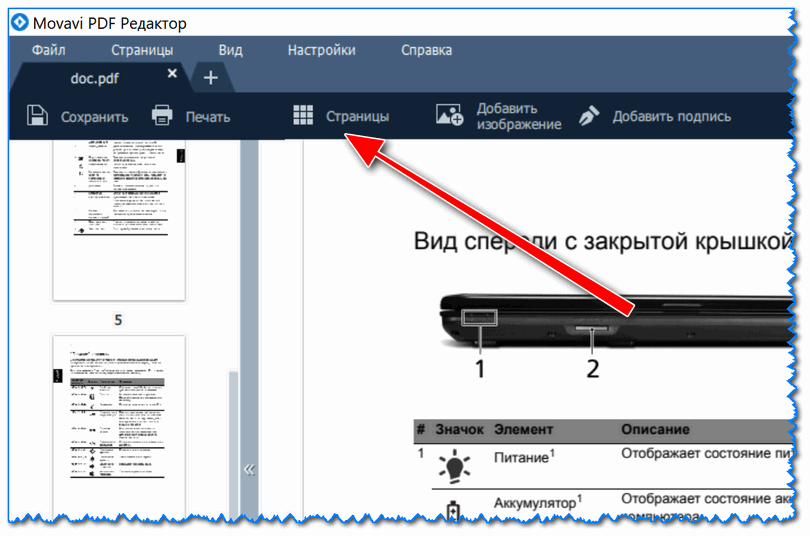 Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.
🤓 Хочешь больше? Подпишись на наш Telegram. … и не забывай читать наш Facebook и Twitter 🍒 В закладки iPhones.ru Сервисы и трюки, с которыми найдётся ВСЁ.
- До ←
СкидOS #270
- После →
Разыграй друзей при помощи браузера
10 инструментов, которые помогут найти удалённую страницу или сайт
Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Сейчас читают 🔥
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы.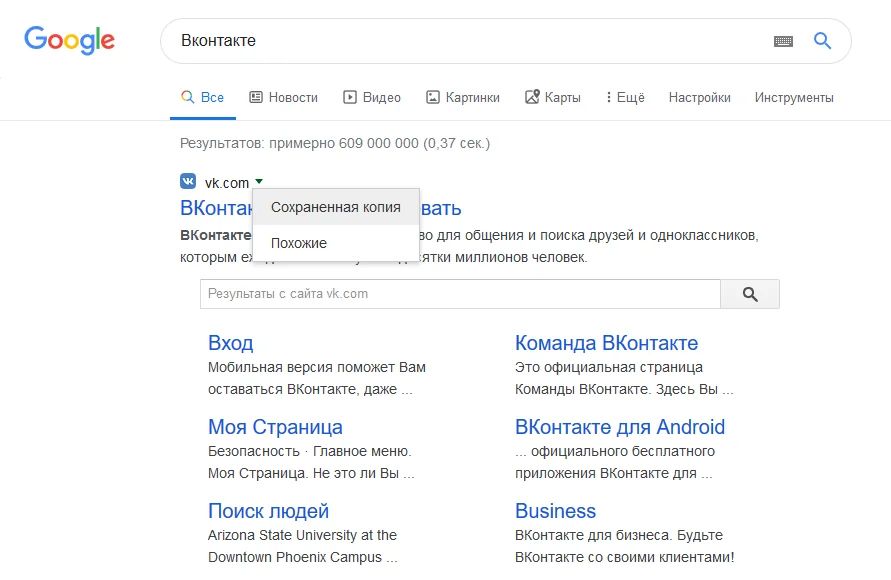 В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive. Today →
Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.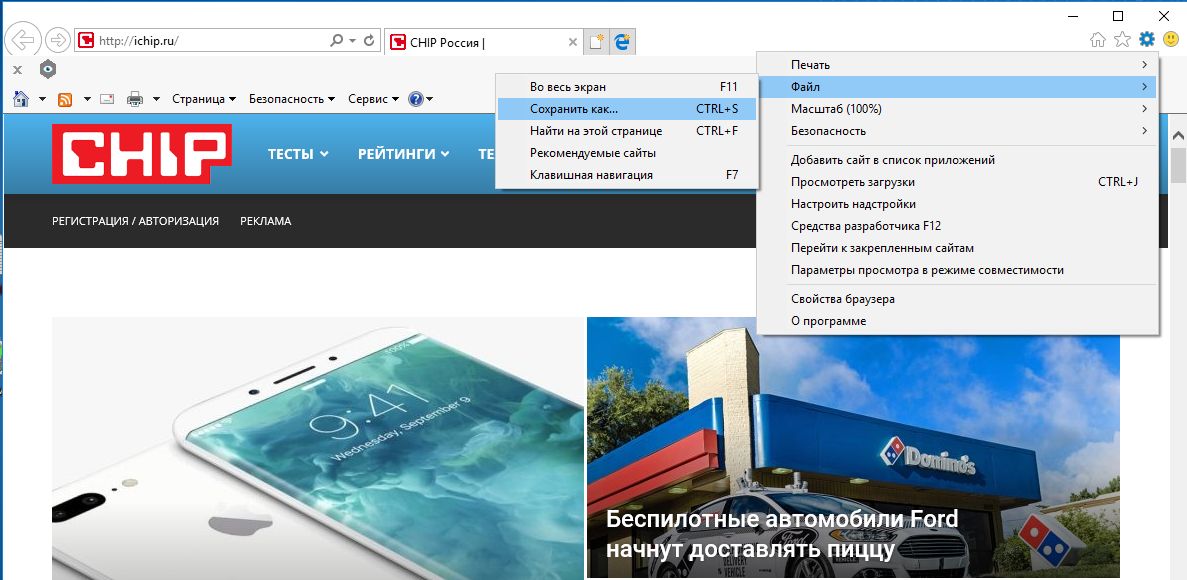
Читайте также 💻🔎🕸
Как открыть сохраненную копию сайта, посмотреть с телефона или ПК (метод 2020 года)
В мире современных технологий мы привыкли, что у нас всегда под рукой Интернет, а вместе с ним и миллионы сайтов с различным контентом. Однако у пользователей нередко возникают ситуации, когда доступ к информации на сайте пропадает. Это происходит по нескольким причинам, при этом такая ситуация вовсе не означает, что данные утрачены безвозвратно. Найти удаленные статьи или страницы сайта помогает кеш Google.
Что такое кеш сайта и зачем он нужен
Поисковая система Google оснащена так называемыми ботами, которые регулярно посещают страницы сайтов и сохраняют их в памяти поисковика. Это и есть кеш, в котором сохраненная копия сайта остается даже в том случае, если сам ресурс был удален. Следует отметить, что боты «гуляют» по Интернету достаточно активно, поэтому информация в кеше, как правило, является актуальной. Однако есть два важных нюанса:
Это и есть кеш, в котором сохраненная копия сайта остается даже в том случае, если сам ресурс был удален. Следует отметить, что боты «гуляют» по Интернету достаточно активно, поэтому информация в кеше, как правило, является актуальной. Однако есть два важных нюанса:
- Чем чаще на сайте появляются новые публикации, тем чаще его посещает бот, а значит, данные будут максимально свежими.
- Нередко случается так, что после удаления статьи с сайта по этой ссылке пользователь видит сообщение об ошибке. Однако бот успел посетить эту пустую страницу и сохранил ее в кеш, удалив прошлую актуальную версию.
Разобравшись с особенностями работы кеша Google, стоит понять, для чего поисковая система хранит в памяти старые версии сайтов. Эксперты приводят несколько серьезных аргументов:
- Страница с материалами была удалена с сайта, а вам срочно нужны именно эти данные.
- Часть информации в нужной публикации была изменена на другие материалы.
- Владелец сайта удалил его или закрыл доступ для пользователей.

- Сайт слишком перегружен, в результате чего страницы загружаются долго.
- На сайт обрушилась ддос-атака, поэтому данные оказались временно заблокированы.
- Программисты проводят технические работы, в результате чего открыть нужную страницу невозможно.
Очевидно, что главная причина поиска сохраненных страниц заключается в утерянной информации и попытке восстановить ее с помощью функционала Google. И если с причинами и особенностями кеширования все понятно, можно переходить к главному вопросу: как посмотреть старую версию сайта и сохранить нужные сведения.
Как посмотреть кеш в Google
Существует несколько способов найти удаленные страницы сайтов. Самый простой – воспользоваться стандартным поиском Google и придерживаться следующего алгоритма действий:
- В поисковой строке вводим адрес сайта, с которого нужно восстановить информацию.
- В выдаче находим нужную ссылку, а под ней – маленькую стрелку зеленого цвета.
- При нажатии на стрелку появляется меню, в котором нужно выбрать графу «Сохраненная копия».
- Система автоматически переходит в архив сайтов и открывает нужные страницы.

Если для работы в Интернете вы используете Google Chrome, вам подойдет еще один простой способ, как посмотреть удаленную страницу в кеше. Для этого достаточно перед адресом сайта ввести слово «cache» и поставить двоеточие. На примере сайта htmlbook.ru это будет выглядеть так: «cache:htmlbook.ru» и далее адрес конкретной страницы, которая вам нужна.
Если по каким-то причинам перечисленные методы не подошли, найти кеш страницы можно и таким способом:
- Открываем новую вкладку в браузере и в адресную строку вставляем текст «webcache.googleusercontent.com/search?q=cache:» (кавычки убираем).
- После двоеточия без пробела вставляем адрес сайта или страницы, которую хотим найти в памяти Google.
- Переходим по ссылке и получаем доступ к последней сохраненной версии.
Обратите внимание! Кеш сайта – это преимущественно текстовая информация. Если на странице были размещены изображения, которые владелец удалил, восстановить их может быть не так просто, как непосредственно статью.
Google Cache Browser
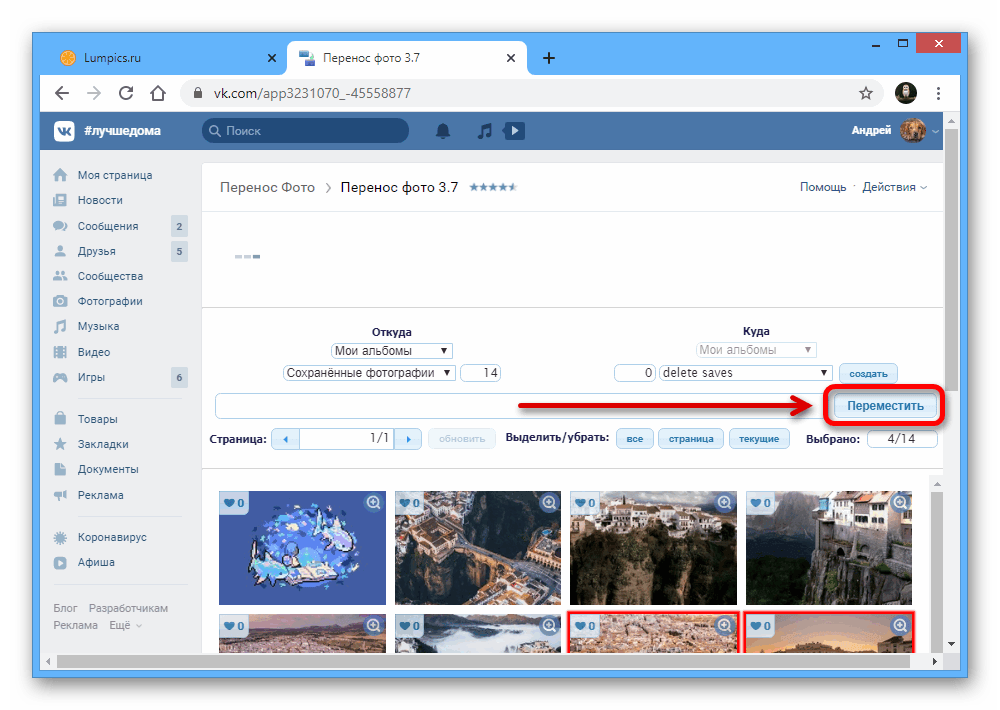
У всех перечисленных способов, как посмотреть кеш в Google, есть один существенный недостаток. С их помощью можно увидеть только одну страницу сайта, после чего придется скопировать ссылку на нужный раздел и проделать всю процедуру заново. Чтобы ускорить этот процесс и получить возможность «бродить» по всему сайту, предлагаем воспользоваться сервисом http://cache.nevkontakte.com/#! и изучить все сохраненные данные в один клик.
Чтобы воспользоваться сервисом, достаточно перейти по ссылке и на главной странице ввести адрес сайта, к которому нужен доступ. Система автоматически находит сохраненную информацию и предоставляет пользователю.
Выходим за рамки Google
Понятно, что сохранением страниц и сайтов в кеше занимается не только поисковая система Google. У пользователей есть еще несколько вариантов, как можно найти удаленную статью или другие данные с сайта:
- Кеш Яндекса. Система работает по такому же принципу, однако сохраненные версии могут отличаться от тех, которые хранит Google. Чтобы открыть кеш Яндекса, необходимо ввести в поиске адрес сайта и перейти к сохраненной копии с помощью зеленой стрелочки (точно так же, как и при работе с Google).
- Специализированный поисковик CachedView.com, который не ограничивается Google, а предлагает пользователям доступ к Всемирному архиву Интернета. Работает по принципу Nevkontakte.com.
- Еще один интересный сервис, на который стоит обратить внимание, находится по адресу archive.is. Его главная функция заключается в том, чтобы пользователь мог самостоятельно сохранять нужные страницы сайта. При этом сервис не требует регистрации и является бесплатным. Дополнительное преимущество архива – возможность искать данные среди страниц, которые сохранили другие пользователи.
 Чтобы открыть кеш Яндекса, необходимо ввести в поиске адрес сайта и перейти к сохраненной копии с помощью зеленой стрелочки (точно так же, как и при работе с Google).
Чтобы открыть кеш Яндекса, необходимо ввести в поиске адрес сайта и перейти к сохраненной копии с помощью зеленой стрелочки (точно так же, как и при работе с Google).Таким образом, даже удаленные из Интернета материалы можно найти и восстановить. Какой способ для этого выбрать? Рекомендуем не останавливаться на одном методе, а попробовать несколько, чтобы наверняка найти нужную страницу или сайт.
как посмотреть кэшированную копию в Яндексе и Гугле
Сохраненная копия сайта (в Яндексе или другой поисковой системе) — это версия страницы, которая уже проиндексирована. Если при вводе поискового запроса посмотреть на сниппет нужного результата, там найдется блок с дополнительными данными. Там-то и лежит «Сохраненная копия».
Если при вводе поискового запроса посмотреть на сниппет нужного результата, там найдется блок с дополнительными данными. Там-то и лежит «Сохраненная копия».
Что это такое, зачем она нужна, как просмотреть и каковы последствия отсутствия копии — вопросы, на которые несложно найти простые ответы.
С помощью сохраненной копии можно просмотреть сайт, если к нему будет внезапно ограничен доступ по той или иной причине.
В Google происходит то же самое — найдя в cash копию и перейдя по ссылке, можно просмотреть, как выглядела страница, когда Гугл в последний раз ее скопировал.
Для чего нужны сохраненные страницы?
Кэш-страницы сайта в поисковых системах позволяют увидеть, какую версию документа уже успели проиндексировать роботы поисковых систем и участвует ли страница в ранжировании. Грубо говоря, если страница начала сохраняться — это главный фактор пройденной индексации.
Бесплатный бэкап
В работе с сайтами, может возникнуть масса непредвиденных ситуаций. Особенно на стадии запуска проекта, на сайте частенько ведутся технические работы, предполагающие корректировку дизайна и текстовых блоков. В такие моменты не исключены ошибки, которые могут «положить» сайт или нарушить его работу, также могут пропасть тексты, изображения и так далее.
Большинству разработчиков знакомы такие ситуации и если не был проведен бэкап, а дешевый хостинг не позволяет сделать «откат», то все печально. Вот тут-то и приходит на помощь кэш сайтов — копия позволяет сохраниться и проверить, какие ошибки нужно исправить.
Важно! Все же не стоит надеяться на Яндекс и Гугл, и хранить сайт только в копиях поисковиков. Если робот попал на нерабочую страницу или ее версию с ошибками, он будет копировать то, что «видел», и старая информация будет недоступна. Так что заранее продумывайте способы «отката» сайта.
SEO-продвижение
Еще один случай, когда кеш придет на помощь, связан с текстами. Например, вы откорректировали текст, чтобы повысить его релевантность. Чтобы проверить, обновилась и проиндексировалась ли нужная страница, достаточно взглянуть на копию.
Чтобы проверить, обновилась и проиндексировалась ли нужная страница, достаточно взглянуть на копию.
Технические проблемы, просрочка оплаты и так далее
Часто интернет-ресурсы бывают недоступны из-за технических проблем на сервере, истечения срока оплаты хостинга и т.п. В этом случае попасть на сайт можно также через копию, которая хранится в кэше.
Как посмотреть кэшированную копию в Яндексе: основные способы
Перед тем как открыть сохраненную копию сайта в Яндексе, выберите удобный способ — с помощью сервисов (Page Promoter в Firefox или RDS bar в Google Chrome) или вручную. Плагины — это удобно, но они могут давать сбой, поэтому стоит освоить и ручной метод просмотра.
Способ № 1 — плагины
Расширения для браузеров, плагины и различные онлайн-сервисы позволяют быстро открывать кэш сайтов. Один из самых популярных на сегодня сервисов — это RDS bar. Плагин отличается интуитивным пользовательским интерфейсом и позволяет посмотреть последние изменения страницы, отсканированной роботами.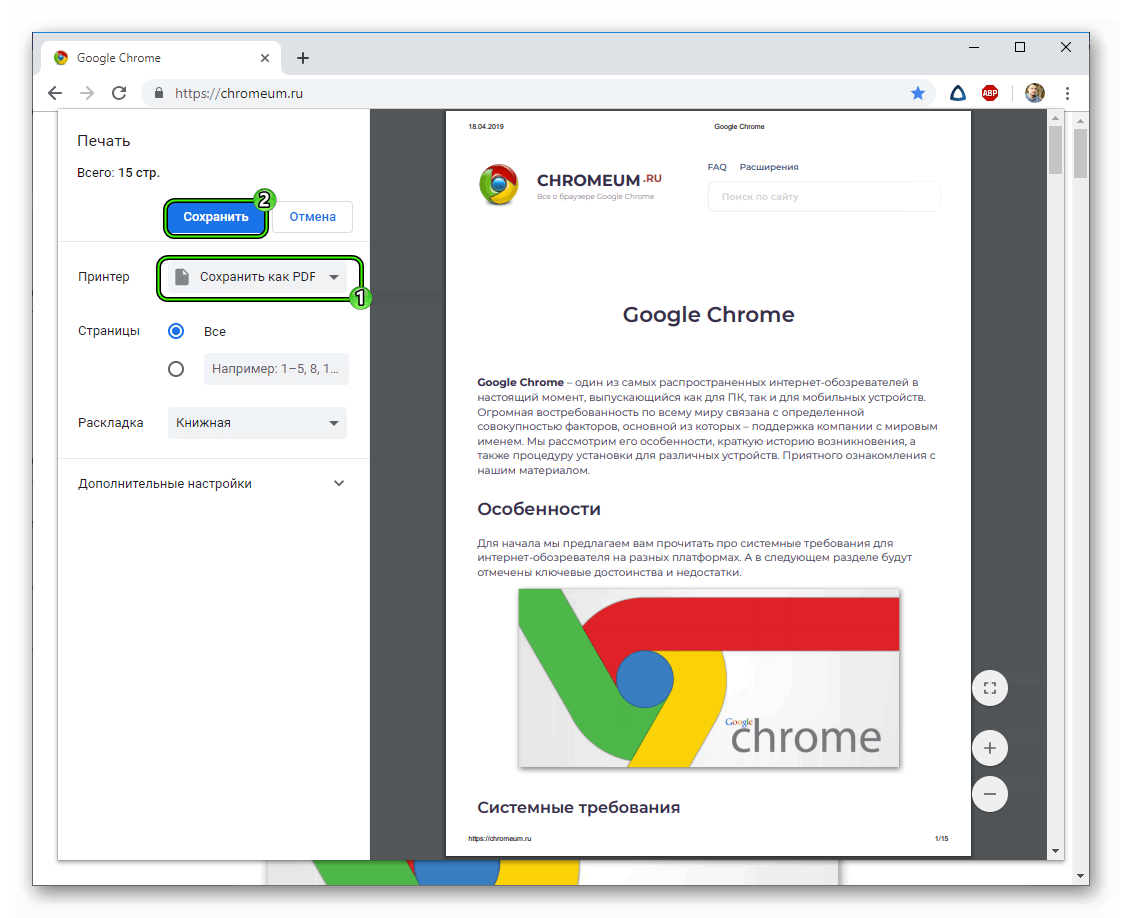 Но если нужная страница еще не проиндексировалась, то и плагин ничего не покажет.
Но если нужная страница еще не проиндексировалась, то и плагин ничего не покажет.
Способ № 2 — вручную
Самый простой и эффективный «механический» способ просмотра. Что нужно сделать:
- Найти в поисковике нужную страницу — по запросу или вбив в поисковую строку адрес сайта.
- В результате поиска в сниппете нажать на маленькую стрелочку.
- В выпавшем окошке нажать «Сохраненная копия».
- Нажать и посетить сайт с данными, сохраненными с последнего визита робота на страницу.
Как посмотреть сохраненную копию страницы в Google
Алгоритм просмотра кэшированных страниц в системе Гугл не отличается от ручного способа для Яндекса. Все просто:
- В браузере вбейте в поисковую строку адрес или название нужного сайта (или поисковый запрос).
- В выдаче справа от URL нажмите на стрелку.
- В выпавшем окошке кликните по разделу «Сохраненная копия».
- Чтобы перейти к текущей версии, просто нажмите на кнопку «Текущая страница».

Почему страницы может не быть?
Иногда во время поиска при нажатии на стрелочку сниппета нужного пункта может и не быть. Это происходит по ряду причин:
- Сбой в работе поисковика. В Яндексе даже не скрывают, что нет никаких гарантий на наличие и показ копий — система может просто не сохранять страницы по какой-либо причине.
- Второй вариант: html-кодировка документа содержит мета-тег «robots» со значением «noarchive», что означает запрет на кэширование. Чтобы не рисковать из-за этого трафиком, стоит внимательно настроить соответствующие блоки и очистить ненужные значения.
Нет копии: чем это грозит?
С точки зрения продвижения — опасность нулевая. А вот сами причины, из-за которых невозможно сохранение, могут быть вредны, нужно разбираться именно в них.
Эксперты уверены, что проблема с копиями может обернуться трудностями при работе с биржами ссылок. Так, на некоторых известных биржах строго контролируют, есть ли в Яндексе копия, проверяя параметр No Index Cache (NIC).
Другие способы
- Наберите в адресной строке http://webcache.googleusercontent.com/search?q=cache:https://www.google.ru/ — где https://www.google.ru поменяйте на адрес нужного вам сайта.
- http://cachedview.com/ — этот сервис ищет копии не только в Google, но и во Всемирном архиве интернета.
- http://www.thesearchenginelist.com/ — а этот ресурс поможет найти копии, если Гугл и Яндекс не сохранили документ. Поочередно перебираем поисковики, рассчитывая на то, что кто-то заглянул на ваш сайт и «заскринил» данные.
Заключение
Всем мы хорошо помним и знаем, что всё нужно бэкапить — от семейных фото с отпуска до страниц сайтов. Но настолько же хорошо мы об этом еще и забываем. В этом случае приходит на помощь сохраненная версия сайта, которую можно найти в Яндексе, Гуле и других поисковых системах и даже вытянуть из Всемирных архивов.
Главное, чтобы поисковые системы успели кэшировать ваши страницы, а от вас дело за малым — просто выбрать удобный способ просмотра копии.
Достаём потерянные статьи из сетевых хранилищ / Хабр
Решение рассматривается (пока) только для одного сайта — того, на котором мы находимся. Идея появилась в результате того, что один пользователь сделал юзерскрипт, который переадресует страницу на кеш Гугла, если вместо статьи видим «Доступ к публикации закрыт». Понятно, что это решение будет работать лишь частично, но полного решения пока не существует. Можно повысить вероятность нахождения копии выбором результата из нескольких сервисов. Этим стал заниматься скрипт HabrAjax (наряду с 3 десятками других функций). Теперь (с версии 0.859), если пользователь увидел полупустую страницу, с которой можно перейти лишь на главную, в личную страницу автора (если повезёт) и назад, юзерскрипт предоставляет несколько альтернативных ссылок, в которых можно попытаться найти потерю. И тут начинается самое интересное, потому что ни один сервис не заточен на качественное архивирование одного сайта.Кстати, статья и исследования порождены интересным опросом А вас раздражает постоянное «Доступ к публикации закрыт»? и скриптом пользователя dotneter — комментарий habrahabr.
 ru/post/146070/#comment_4914947.
ru/post/146070/#comment_4914947.Требуется, конечно, более качественный сервис, поэтому, кроме описания нынешней скромной функциональности (вероятность найти в Гугл-кеше и на нескольких сайтах-копировщиках), поднимем в статье краудсорсинговые вопросы — чтобы «всем миром» задачу порешать и прийти к качественному решению, тем более, что решение видится близким для тех, кто имеет сервис копирования контента. Но давайте обо всём по порядку, рассмотрим все предложенные на данный момент решения.
Кеш Гугла
В отличие от кеша Яндекса, к нему имеется прямой доступ по ссылке, не надо просить пользователя «затем нажать кнопку „копия“». Однако, все кеширователи, как и известный archive.org, имеют ряд ненужных особенностей.
1) они просто не успевают мгновенно и многократно копировать появившиеся ссылки. Хотя надо отдать должное, что к популярным сайтам обращение у них частое, и за 2 и более часов они кешируют новые страницы. Каждый в своё время.
2) далее, возникает такая смешная особенность, что они могут чуть позже закешировать пустую страницу, говорящую о том, что «доступ закрыт».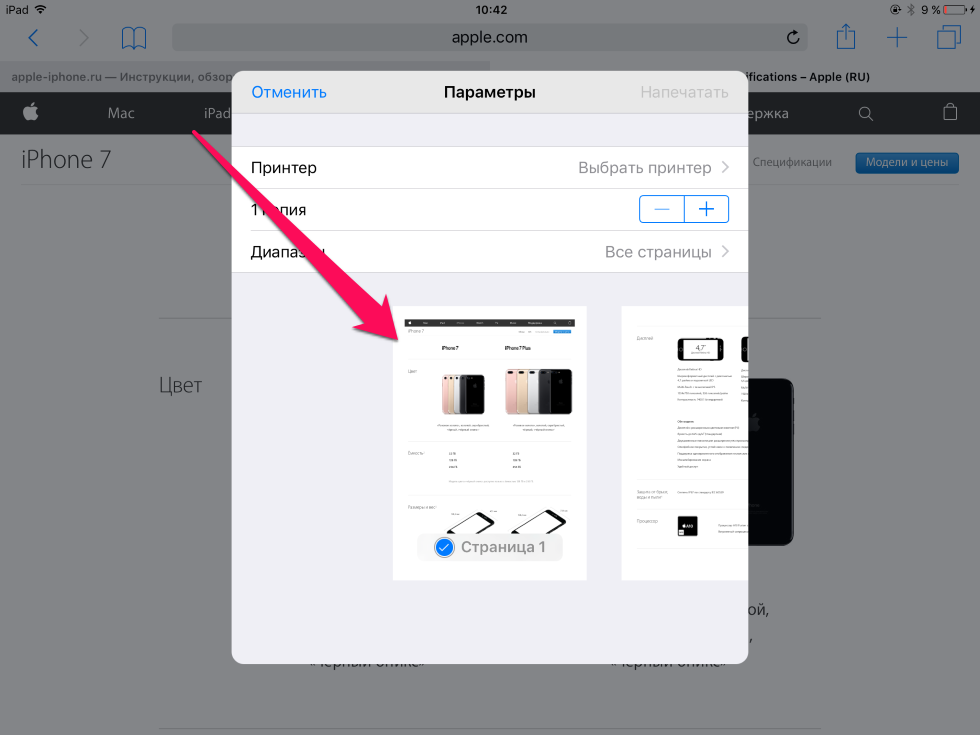
3) поэтому результат кеширования — как повезёт. Можно обойти все такие кеширующие ссылки, если очень надо, но и оттуда информацию стоит скопировать себе, потому что вскоре может пропасть или замениться «более актуальной» бессмысленной копией пустой страницы.
Кеш archive.org
Он работает на весь интернет с мощностями, меньшими, чем у поисковиков, поэтому обходит страницы какого-то далёкого русскоязычного сайта редко. Частоту можно увидеть здесь: wayback.archive.org/web/20120801000000*/http://habrahabr.ru
Да и цель сайта — запечатлеть фрагменты истории веба, а не все события на каждом сайте. Поэтому мы редко будем попадать на полезную информацию.
Кеш Яндекса
Нет прямой ссылки, поэтому нужно просить (самое простое) пользователя нажать на ссылку «копия» на странице поиска, на которой будет одна эта статья (если её Яндекс вообще успел увидеть).
Как показывает опыт, статья, повисевшая пару часов и закрытая автором, довольно успешно сохраняется в кешах поисковиков.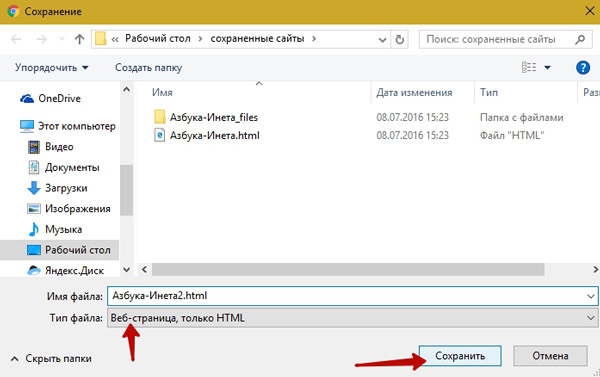 Впоследствии, скорее всего, довольно быстро заменится на пустую. Всё это, конечно, не устроит пользователей веба, который по определению должен хранить попавшую в него информацию.
Впоследствии, скорее всего, довольно быстро заменится на пустую. Всё это, конечно, не устроит пользователей веба, который по определению должен хранить попавшую в него информацию.
Yahoo Pipes
pipes.yahoo.com/pipes/search?q=habrahabr+full&x=0&y=0 и прочие.
Довольно интересное решение. Те, кто умеет их настраивать, возможно, полноценно решат задачу архивирования RSS. Из имеющегося, я не нашёл пайпов с поиском статьи по её номеру, поэтому пока нет прямой ссылки на такие сохранённые полные статьи. (Кто умеет с ним работать — прошу изготовить такую ссылку для скрипта.)
Многочисленные клонировщики
Все из них болеют тем, что не дают ссылки на статью по её номеру, не приводят полный текст статьи, а некоторые вообще ограничиваются «захабренным» или «настолько ленивы», что копируют редко (к примеру, раз в день), что актуально не всегда. Однако, если хотя бы один автор копировщика подкрутит движок на сохранение полноценного и актуального контента, он окажет неоценимую услугу интернету, и его сервис займёт главное место в скрипте HabrAjax.
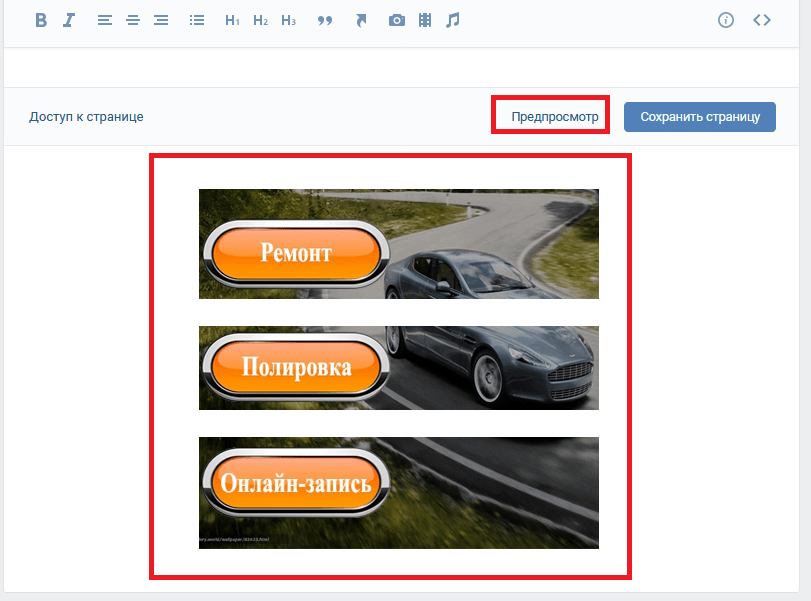
Из живых я нашёл пока что 4, некоторые давно существовавшие (itgator) на данный момент не работали. В общем, пока что они почти бесполезны, потому что заставляют искать статью по названию или ключевым словам, а не по адресу, по которому пользователь пришёл на закрытую страницу (а по словам отлично ищет Яндекс и не только по одному их сайту). Приведены в скрипте для какой-нибудь полезной информации.
Задача
Перед сообществом стоит задача, не утруждая организаторов сайта, довести продукт до качественного, не теряющего информацию ресурса. Для этого, как правильно заметили в комментариях к опросу, нужен архиватор актуальных полноценных статей (и комментариев к ним заодно).
В настоящее время неполное решение её, как описано выше, выглядит так:
Если искать в Яндексе, то подобранный адрес выведет единственную ссылку (или ничего):
Нажав ссылку «копия», увидим (если повезёт) сохранённую копию (страница выбрана исключительно для актуального на данный момент примера):
В Гугле несколько проще — сразу попадаем на копию, если тоже повезёт, и Гугл успел сохранить именно то, что нам надо, а не дубль отсутствующей страницы.
Забавно, что скрипт теперь предлагает «выбор альтернативных сервисов» и в этом случае («профилактические работы»):
Жду предложений по добавлению сервисов и копировщиков (или хотя бы проектов) (для неавторизованных — на почту spmbt0 на известном гуглоресурсе, далее выберем удобный формат).
UPD 23:00: опытным путём для mail.ru было выяснено строение прямой ссылки на кеш:
'http://hl.mailru.su/gcached?q=cache:'+ window.location
Добавил ссылки мейла и ВК в обновление скрипта (habrAjax) (0.861), теперь там — на 2 строчки больше.
Как получить доступ к веб-странице, когда она закрыта
- Подробности
- мая 07, 2017
- Просмотров: 14217
Ничто не исчезает полностью из Интернета. Если веб-страница не работает в течение нескольких минут или нескольких лет, вы можете просмотреть ее содержимое в любом случае.
Если веб-страница не работает в течение нескольких минут или нескольких лет, вы можете просмотреть ее содержимое в любом случае.
Вариант 1. Кэш Google
Google и другие поисковые системы загружают и сохраняют копии проиндексированных веб-страниц. Если веб-страница не работает, вы можете легко просмотреть последнюю копию, сохраненную в кеше Google.
Если вы пытаетесь получить доступ к веб-странице из поиска Google, доступ к кешированной копии получить довольно легко. Просто нажмите кнопку «Назад» в веб-браузере, когда веб-страница не загружается. Нажмите стрелку справа от адреса веб-страницы и нажмите «Сохраненная копия», чтобы просмотреть старую копию.
Если страница загружается долго, вы можете нажать ссылку «Только текст» в верхней части кешированной страницы. Веб-страница загрузится мгновенно, но вы не увидите никаких изображений. Это необходимо, когда сервер веб-сайта отключен, и ваш браузер не может загружать изображения веб-страницы.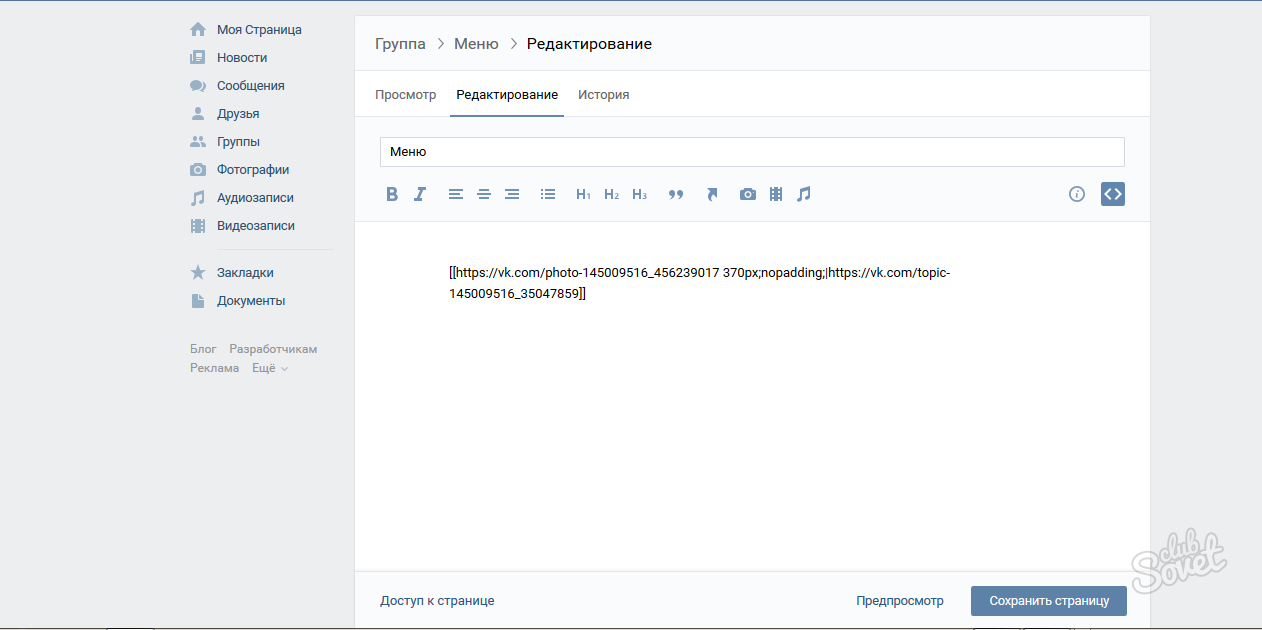
Вы также увидите дату и время, когда Google создала эту кэшированную копию, отображаемую в верхней части страницы.
Также есть быстрый способ просмотра кэшированной копии Google любой веб-страницы без предварительного поиска в Google.
Просто подключите следующий адрес в адресную строку, заменив site.ru/page.htm полным адресом веб-страницы, которую вы хотите.
http://webcache.googleusercontent.com/search?q=cache: site.ru/page.htm
Не забудьте убрать «http: //» или «https: //» из начала адреса веб-страницы. Итак, если вы хотите посмотреть копию данной страницы, просто скопируйте в адресную строку следующий адрес (предварительно убрав пробел и копирайт):
http://webcache.googleusercontent.com/search?q=cache: juice-health.ru/internet/606-dostup-k-veb-stranice
Если вы получаете ошибку 404 значит такой страницы в кэше пока нет.
Хотя тут я рассказал про Google Cache, поисковая система Яндекс также имеет свою подобную функцию. Если вы используете Яндекс, вы также можете щелкнуть стрелку справа от адреса и нажать «Сохраненная копия», чтобы просмотреть копию из кеша Яндекс.
Если вы используете Яндекс, вы также можете щелкнуть стрелку справа от адреса и нажать «Сохраненная копия», чтобы просмотреть копию из кеша Яндекс.
Вариант второй: Wayback Machine или CoralCDN
Интернет-архив Wayback Machine также позволяет просматривать старые копии веб-страницы. В тех случаях, когда Google Cache предлагает вам только одну, самую последнюю сохраненную копию, Wayback Machine предлагает несколько старых версий веб-страницы, возвращающихся гораздо дальше, чтобы вы могли видеть, как выглядела веб-страница несколько лет назад.
Чтобы использовать Wayback Machine, перейдите на страницу https://web.archive.org. Вставьте полный адрес веб-страницы, которую вы хотите просмотреть, в поле и нажмите «Обзор истории». Например, вы можете скопировать и вставить этот адрес из адресной строки вашего браузера, если веб-страница не загружается.
Если вы просто хотите просмотреть последнюю сохраненную в кэше копию веб-страницы, вы можете нажать на дату в верхней части страницы архива.
Если вам нужна более старая копия, вы можете выбрать год и нажать дату в календаре, чтобы просмотреть веб-страницу, как она выглядела в эту дату.
Вы можете щелкнуть ссылки, которые появляются на странице после загрузки, чтобы просмотреть другие веб-страницы по мере их появления в эту дату. Этот инструмент позволяет просматривать целые веб-сайты, которые исчезли или сильно изменились.
Возможно, вы также слышали о CoralCDN (в последнее время не всегда работает). CoralCDN особенно полезен для просмотра кэшированных копий веб-страниц, которые оказались недоступны из-за внезапного высокого трафика. Вышеупомянутые два инструмента должны помочь вам получить копию любой страницы за любое время.
Читайте также
7 способов просмотра кешированных веб-страниц в Chrome и Google »WebNots
Кэш Chrome хранится в папке «C: Users Username AppData Local Google Chrome User Data Default Cache» в Windows 10.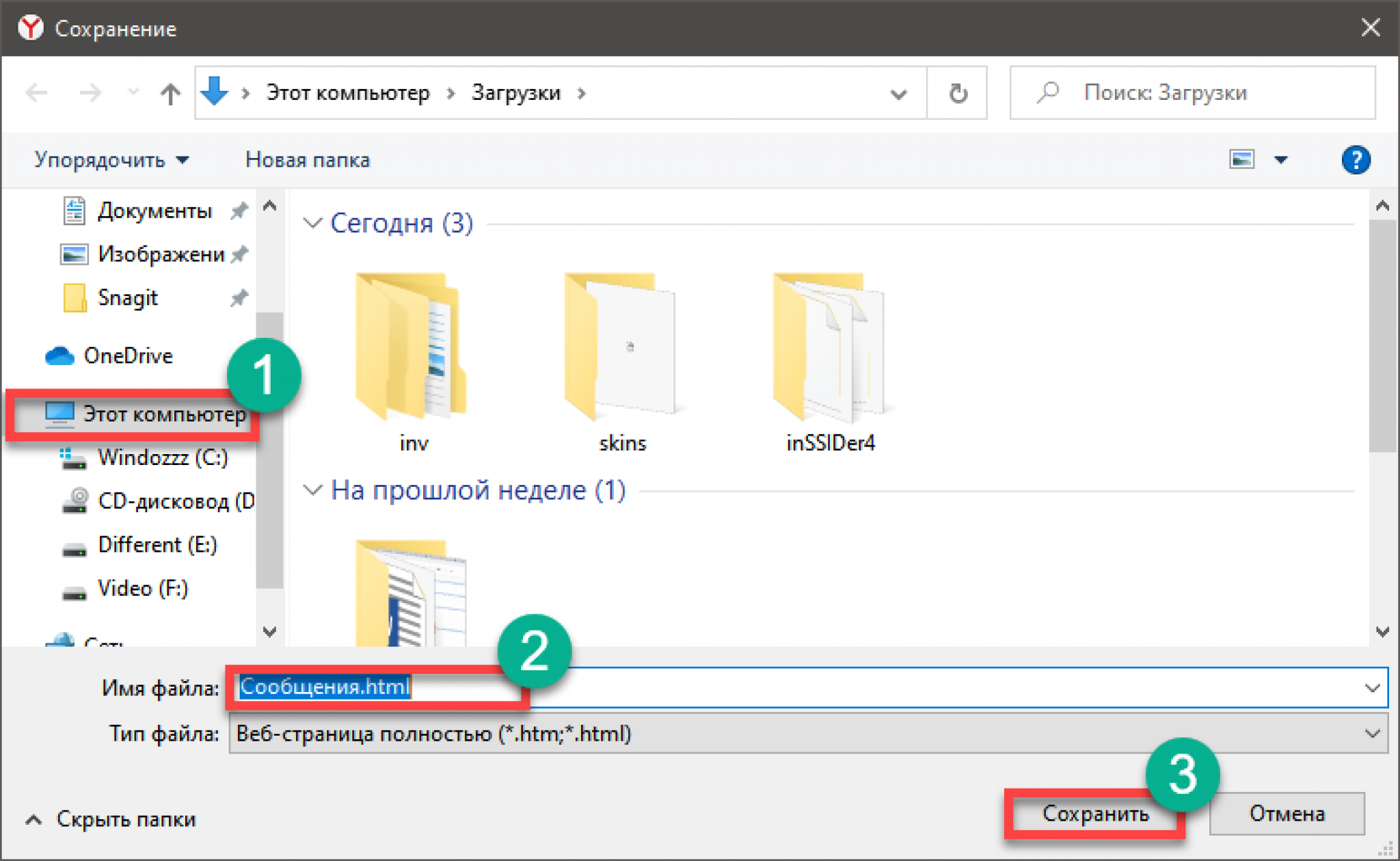 Но эти файлы не будут иметь расширения, и вы не сможете легко просматривать содержимое.
Но эти файлы не будут иметь расширения, и вы не сможете легко просматривать содержимое.
6. Используйте «Показать кнопку» Сохранить копию «в Chrome.
Сначала отключите подключение к Интернету, чтобы не перезаписать кеш Chrome. Теперь перейдите по URL-адресу «chrome: // flags / # show-saved-copy» и выберите опцию «Enable: Primary». Вам следует перезапустить браузер, чтобы изменения вступили в силу.
Включить флажок Chrome для отображения сохраненной копииЭтот флаг позволит просматривать сохраненную копию веб-сайта, когда соединение недоступно, как указано в определении.
Когда страница не загружается, если устаревшая копия страницы существует в кеше браузера, будет представлена кнопка, позволяющая пользователю загрузить эту устаревшую копию. Выбор основного разрешения помещает кнопку в наиболее заметное положение на странице ошибки; вторичный выбор включения делает его вторичным по отношению к кнопке перезагрузки. — Mac, Windows, Linux, Chrome OS, Android.

Как только флаг будет включен, перейдите по URL-адресу веб-страницы, кэш которой вы хотите просмотреть. Chrome покажет ошибку «err_internet_disconnected» вместе с кнопкой «Показать сохраненную копию». Нажмите на кнопку, чтобы просмотреть кешированную копию из Chrome.
Просмотр сохраненной копии веб-страницы в Chrome7. Просмотр кэшированной копии веб-страницы из шестнадцатеричного дампа Chrome.
Поскольку браузер Chrome также хранит кешированные копии сайтов, которые вы посещаете, если действующая страница недоступна, вы можете попробовать получить страницу из кеша браузера Chrome. Перейдите по URL-адресу «chrome: // view-http-cache /» или «chrome: // cache /». На этой странице будут показаны все кешированные страницы вашего браузера Chrome. Найдите URL-адрес, который хотите просмотреть, и щелкните его. Откроется страница, как показано ниже:
Просмотр шестнадцатеричного дампа кэша ChromeЕсли вам не удалось найти URL-адрес, попробуйте открыть его с помощью ярлыка «chrome: // view-http-cache / FULL-URL-HERE».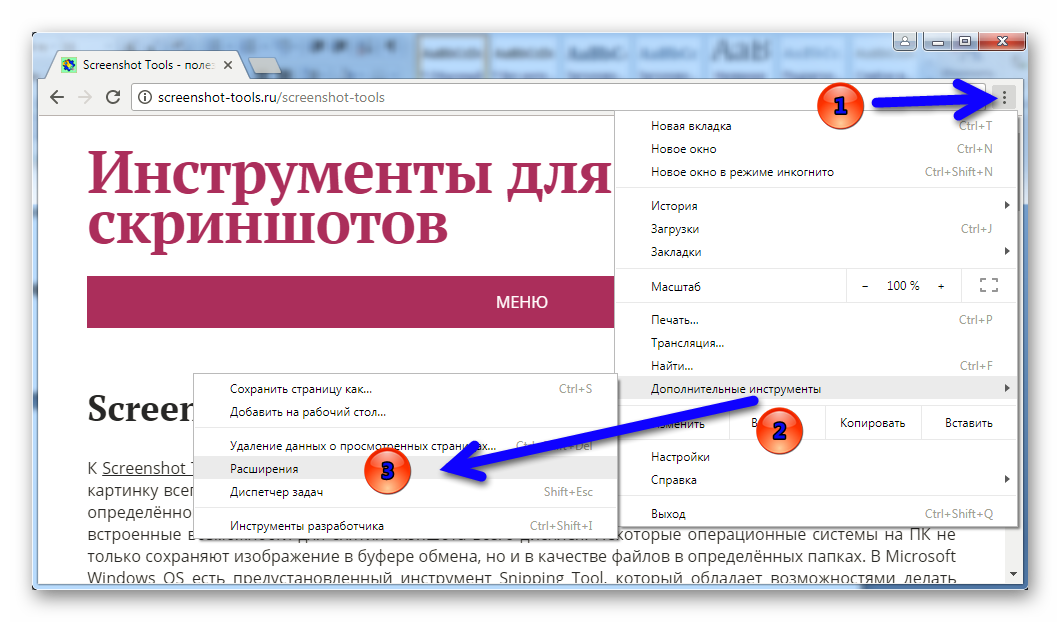 Не забудьте заменить текст «FULL-URL-HERE» на полный URL-адрес, который вы хотите просмотреть (с https / http и www).
Не забудьте заменить текст «FULL-URL-HERE» на полный URL-адрес, который вы хотите просмотреть (с https / http и www).
Chrome хранит кеш в виде дампа шестнадцатеричного кода, поэтому просмотреть страницу в том виде, в котором она отображается, с живого сервера невозможно. Вы можете прочитать статью в переполнение стека и проверьте, можно ли использовать любой из упомянутых сценариев для ваших целей.
Что делать, если вы не можете просмотреть кешированную версию?
В некоторых ситуациях вы не можете найти кешированную версию сайта. Это происходит, когда администратор изменяет файл robots.txt, чтобы предотвратить процесс кеширования. Люди могут это сделать, если не хотят, чтобы контент оставался где-то еще. На самом деле существует огромная темная территория Интернета, к которой поисковые роботы не могут получить доступ, например информация, хранящаяся за системой на основе входа в систему, частные дискуссионные форумы, платные онлайн-газеты и другие.
Вы можете подтвердить это, выполнив поиск content = «noarchive» запись в исходном коде веб-страницы. Если файл robots.txt не позволяет сканерам проиндексировать веб-сайт, не следует ожидать, что вы увидите кешированный контент в результатах поиска Google или Wayback Machine. Также вы можете использовать инструмент проверки кеша Google, чтобы проверить, есть ли у Google кешированная копия страницы и дата кеширования.
Если файл robots.txt не позволяет сканерам проиндексировать веб-сайт, не следует ожидать, что вы увидите кешированный контент в результатах поиска Google или Wayback Machine. Также вы можете использовать инструмент проверки кеша Google, чтобы проверить, есть ли у Google кешированная копия страницы и дата кеширования.
Но вы должны иметь возможность получить кеш из кеша локального браузера Chrome.
Вывод
Если вы активно ищете информацию в Интернете, вам пригодится Google Cache. В большинстве случаев вы можете получить копию веб-сайта, проиндексированного поисковым роботом. Даже если вы редко используете его ежедневно, должно быть время, когда вы получите от него пользу. Это особенно актуально, если веб-страница становится недоступной по разным причинам. В других ситуациях веб-страница по-прежнему доступна, но администратор удалил часть важной информации.
Если онлайн-кеш недоступен по каким-либо причинам, например, если владелец сайта ограничил доступ сканеров, вам следует попытаться получить кешированную копию веб-страницы из локального кеша браузера Chrome.
Просмотры: 529
Сохранить страницу WE — Интернет-магазин Chrome
Сохранение полной веб-страницы (в том виде, в котором она отображается в данный момент) в виде одного HTML-файла, который можно открыть в любом браузере.
ИЗМЕНЕНИЯ Версия 25.9 • Устраняет проблему, препятствовавшую сохранению некоторых страниц. • Прочие мелкие исправления ошибок. ОБЗОР Сохранить страницу WE предоставляет простое средство для сохранения веб-страницы (в том виде, в котором она отображается в данный момент) в виде одного файла HTML, который можно открыть в любом браузере. Сохраненная страница - это очень точное представление исходной страницы. Несколько страниц можно сохранить, выбрав несколько вкладок или загрузив список URL-адресов страниц.При использовании с Print Edit WE, Save Page WE теперь требует Print Edit WE 26.1 или более поздней версии для полной совместимости. КНОПКА ПАНЕЛИ ИНСТРУМЕНТОВ После установки Save Page WE на главной панели инструментов появится новая синяя кнопка «дискета».
 Чтобы сохранить веб-страницы во всех выбранных в данный момент файлах вкладок, просто нажмите кнопку «Сохранить страницу WE» на панели инструментов.
Есть варианты, чтобы установить действие кнопки как:
• Сохранить выбранные вкладки (основные, стандартные или настраиваемые)
• Сохранять указанные в списке URL-адреса (базовые, стандартные или настраиваемые).
Существует возможность использовать новый метод сохранения, позволяющий сохранить больше страниц (см. Раздел «Способы сохранения» ниже).По умолчанию сохраненный HTML-файл будет иметь расширение .html.
КОНТЕКСТНОЕ МЕНЮ И КНОПНОЕ МЕНЮ
Чтобы сохранить веб-страницу в виде файла HTML или выполнить операции с ранее сохраненной страницей, щелкните правой кнопкой мыши содержимое страницы, чтобы открыть контекстное меню, выберите подменю «Сохранить страницу WE», а затем выберите одно из Пункты меню:
• Сохранить выбранные вкладки (основные, стандартные или настраиваемые)
• Сохранять указанные в списке URL-адреса (базовые, стандартные или настраиваемые).
• Отменить Сохранить
• Просмотр сохраненной информации о странице (при просмотре сохраненной страницы)
• Удалить загрузчик ресурсов (при просмотре сохраненной страницы - до 15.2)
• Извлечь изображение / аудио / видео (при просмотре сохраненной страницы)
ГОРЯЧИЕ КЛАВИШИ
Чтобы сохранить веб-страницу в виде HTML-файла, нажмите Alt + A.
Чтобы отменить сохранение одной или нескольких страниц, нажмите Alt + C.
СОХРАНЕНИЕ НЕСКОЛЬКИХ СТРАНИЦ
Есть два способа сохранить несколько страниц:
• Выделите несколько вкладок, а затем выберите пункт меню «Сохранить выбранные вкладки».
• Загрузите файл, содержащий список URL-адресов, в диалоговом окне «Параметры масштабирования страницы WE», а затем выберите пункт меню «Сохранить указанные URL-адреса».
При сохранении нескольких страниц вкладки переводятся на передний план, если включена опция загрузки отложенного содержимого.СОХРАНЕННЫЕ ПРЕДМЕТЫ
Есть варианты выбора сохраненных элементов:
• Сохранить основные элементы - сохраняет основные элементы.
• Сохранить стандартные элементы - сохраняет основные элементы и некоторые дополнительные элементы.
• Сохранить настраиваемые элементы - сохраняет основные элементы и элементы, выбранные из списка.
СОХРАНЕННОЕ ИМЯ ФАЙЛА
Есть возможность указать формат имени сохраняемого файла.
Этот формат используется при сохранении всей страницы и при извлечении ресурса (Изображение / Аудио / Видео).
Имя сохраненного файла может содержать следующие предопределенные поля:
•% TITLE% - (сохранение страницы) заголовок документа или, если он пуст, то же, что и% FILE%
•% TITLE% - (извлечение ресурса) то же, что и% FILE%
•% DATE (x)% - текущая дата в формате ГГГГxMMxDD, где «x» - любой символ или может быть опущено.•% TIME (x)% - текущее время в формате HHxMMxSS, где «x» - любой символ или может быть опущено.
•% DATEP (x)% - дата публикации в формате ГГГГxMMxDD, где «x» - любой символ или может быть опущено.
•% TIMEP (x)% - опубликованное время в формате HHxMMxSS, где «x» - любой символ или может быть опущено.
•% HOST% - имя хоста в URL страницы или ресурса
•% HOSTW% - то же, что и% HOST%, но без www. приставка.
•% PATH% - путь в URL страницы или ресурса.
•% PATHW% - то же, что и% PATH%, но без символа '.расширение 'суффикс.
•% FILE% - имя файла в последнем сегменте пути в URL страницы или ресурса.
•% FILEW% - то же, что и% FILE%, но без суффикса ".extension".
•% QUERY (p)% - строка запроса в URL страницы, если «p» опущено, или значение параметра «p».
•% FRAGMENT% - строка фрагмента в URL страницы.
Существуют варианты замены пробелов в имени сохраненного файла на определяемый пользователем символ и установка максимальной длины имени сохраненного файла.
СПОСОБЫ СОХРАНИТЬ
Есть два альтернативных метода сохранения: старый и новый.По умолчанию используется старый метод сохранения.
Старый метод сохранения запоминает последнее место сохранения, но не может сохранить некоторые страницы (например, Yahoo) в Chrome 84 или новее.
Новый метод сохранения не запоминает последнее место сохранения, но может сохранять все страницы.
НАСТРОЙКА ХРОМА
Нажмите кнопку меню Chrome> Настройки> Дополнительно.
В разделе «Загрузки» укажите расположение папки загрузок и включите или отключите параметр «Спрашивать, где сохранить каждый файл перед загрузкой».
После сохранения страницы элемент загрузки появится на панели загрузки в нижней части окна браузера.Щелкните стрелку в элементе загрузки и включите или отключите параметр «Всегда открывать файлы этого типа».
ИСПОЛЬЗОВАНИЕ АВТОМАТИЗАЦИИ
Существует возможность использовать режим автоматизации, позволяющий сохранять страницу из командной строки.
Если эта опция включена:
• При запуске Firefox автоматически запускается страница сохранения WE с использованием текущего действия кнопки.
• Когда операция сохранения будет завершена, Firefox будет автоматически закрыт.
Чтобы выйти из режима автоматизации, сразу после запуска Firefox используйте команду меню «Отменить сохранение» или сочетание клавиш, чтобы отменить операцию сохранения, а затем отключите возможность использования автоматизации.СЛУЖБА ПОДДЕРЖКИ
Пожалуйста, по электронной почте:
Чтобы сохранить веб-страницы во всех выбранных в данный момент файлах вкладок, просто нажмите кнопку «Сохранить страницу WE» на панели инструментов.
Есть варианты, чтобы установить действие кнопки как:
• Сохранить выбранные вкладки (основные, стандартные или настраиваемые)
• Сохранять указанные в списке URL-адреса (базовые, стандартные или настраиваемые).
Существует возможность использовать новый метод сохранения, позволяющий сохранить больше страниц (см. Раздел «Способы сохранения» ниже).По умолчанию сохраненный HTML-файл будет иметь расширение .html.
КОНТЕКСТНОЕ МЕНЮ И КНОПНОЕ МЕНЮ
Чтобы сохранить веб-страницу в виде файла HTML или выполнить операции с ранее сохраненной страницей, щелкните правой кнопкой мыши содержимое страницы, чтобы открыть контекстное меню, выберите подменю «Сохранить страницу WE», а затем выберите одно из Пункты меню:
• Сохранить выбранные вкладки (основные, стандартные или настраиваемые)
• Сохранять указанные в списке URL-адреса (базовые, стандартные или настраиваемые).
• Отменить Сохранить
• Просмотр сохраненной информации о странице (при просмотре сохраненной страницы)
• Удалить загрузчик ресурсов (при просмотре сохраненной страницы - до 15.2)
• Извлечь изображение / аудио / видео (при просмотре сохраненной страницы)
ГОРЯЧИЕ КЛАВИШИ
Чтобы сохранить веб-страницу в виде HTML-файла, нажмите Alt + A.
Чтобы отменить сохранение одной или нескольких страниц, нажмите Alt + C.
СОХРАНЕНИЕ НЕСКОЛЬКИХ СТРАНИЦ
Есть два способа сохранить несколько страниц:
• Выделите несколько вкладок, а затем выберите пункт меню «Сохранить выбранные вкладки».
• Загрузите файл, содержащий список URL-адресов, в диалоговом окне «Параметры масштабирования страницы WE», а затем выберите пункт меню «Сохранить указанные URL-адреса».
При сохранении нескольких страниц вкладки переводятся на передний план, если включена опция загрузки отложенного содержимого.СОХРАНЕННЫЕ ПРЕДМЕТЫ
Есть варианты выбора сохраненных элементов:
• Сохранить основные элементы - сохраняет основные элементы.
• Сохранить стандартные элементы - сохраняет основные элементы и некоторые дополнительные элементы.
• Сохранить настраиваемые элементы - сохраняет основные элементы и элементы, выбранные из списка.
СОХРАНЕННОЕ ИМЯ ФАЙЛА
Есть возможность указать формат имени сохраняемого файла.
Этот формат используется при сохранении всей страницы и при извлечении ресурса (Изображение / Аудио / Видео).
Имя сохраненного файла может содержать следующие предопределенные поля:
•% TITLE% - (сохранение страницы) заголовок документа или, если он пуст, то же, что и% FILE%
•% TITLE% - (извлечение ресурса) то же, что и% FILE%
•% DATE (x)% - текущая дата в формате ГГГГxMMxDD, где «x» - любой символ или может быть опущено.•% TIME (x)% - текущее время в формате HHxMMxSS, где «x» - любой символ или может быть опущено.
•% DATEP (x)% - дата публикации в формате ГГГГxMMxDD, где «x» - любой символ или может быть опущено.
•% TIMEP (x)% - опубликованное время в формате HHxMMxSS, где «x» - любой символ или может быть опущено.
•% HOST% - имя хоста в URL страницы или ресурса
•% HOSTW% - то же, что и% HOST%, но без www. приставка.
•% PATH% - путь в URL страницы или ресурса.
•% PATHW% - то же, что и% PATH%, но без символа '.расширение 'суффикс.
•% FILE% - имя файла в последнем сегменте пути в URL страницы или ресурса.
•% FILEW% - то же, что и% FILE%, но без суффикса ".extension".
•% QUERY (p)% - строка запроса в URL страницы, если «p» опущено, или значение параметра «p».
•% FRAGMENT% - строка фрагмента в URL страницы.
Существуют варианты замены пробелов в имени сохраненного файла на определяемый пользователем символ и установка максимальной длины имени сохраненного файла.
СПОСОБЫ СОХРАНИТЬ
Есть два альтернативных метода сохранения: старый и новый.По умолчанию используется старый метод сохранения.
Старый метод сохранения запоминает последнее место сохранения, но не может сохранить некоторые страницы (например, Yahoo) в Chrome 84 или новее.
Новый метод сохранения не запоминает последнее место сохранения, но может сохранять все страницы.
НАСТРОЙКА ХРОМА
Нажмите кнопку меню Chrome> Настройки> Дополнительно.
В разделе «Загрузки» укажите расположение папки загрузок и включите или отключите параметр «Спрашивать, где сохранить каждый файл перед загрузкой».
После сохранения страницы элемент загрузки появится на панели загрузки в нижней части окна браузера.Щелкните стрелку в элементе загрузки и включите или отключите параметр «Всегда открывать файлы этого типа».
ИСПОЛЬЗОВАНИЕ АВТОМАТИЗАЦИИ
Существует возможность использовать режим автоматизации, позволяющий сохранять страницу из командной строки.
Если эта опция включена:
• При запуске Firefox автоматически запускается страница сохранения WE с использованием текущего действия кнопки.
• Когда операция сохранения будет завершена, Firefox будет автоматически закрыт.
Чтобы выйти из режима автоматизации, сразу после запуска Firefox используйте команду меню «Отменить сохранение» или сочетание клавиш, чтобы отменить операцию сохранения, а затем отключите возможность использования автоматизации.СЛУЖБА ПОДДЕРЖКИ
Пожалуйста, по электронной почте: Страница сохранения WE — Получите это расширение для 🦊 Firefox (en-US)
ИЗМЕНЕНИЯВерсия 25.10
• Незначительное исправление ошибки.
ОБЗОР
Сохранить страницу WE предоставляет простую возможность для сохранения веб-страницы (в том виде, в каком она отображается в данный момент) в виде одного файла HTML, который можно открыть в любом браузере. Сохраненная страница — это очень точное представление исходной страницы.Несколько страниц можно сохранить, выбрав несколько вкладок или загрузив список URL-адресов страниц.
Страница сохранения WE реализована с использованием API WebExtensions и доступна как для Firefox, так и для Chrome с идентичными функциями и пользовательскими интерфейсами.
Если используется с Print Edit WE, Save Page WE теперь требует Print Edit WE 26.1 или более поздней версии для полной совместимости.
СТРАНИЦА ОПЦИЙ
Доступ к странице «Сохранить страницу параметров WE» можно получить следующим образом:
• Firefox — щелкните правой кнопкой мыши кнопку панели инструментов, выберите «Управление расширением», нажмите кнопку ••• и выберите «Параметры».
• Chrome — щелкните правой кнопкой мыши кнопку на панели инструментов и выберите «Параметры».
КНОПКА ПАНЕЛИ ИНСТРУМЕНТОВ
После установки страницы сохранения WE на главной панели инструментов появится новая синяя кнопка «дискета».
Чтобы сохранить веб-страницы во всех выбранных в данный момент файлах вкладок, просто нажмите кнопку «Сохранить страницу WE» на панели инструментов.
Существуют параметры для установки действия кнопки как:
• Сохранить выбранные вкладки (основные, стандартные или настраиваемые элементы)
• Сохранить указанные URL-адреса (основные, стандартные или настраиваемые элементы)
Существует возможность предложить пользователю вводите комментарии при сохранении файла.
Существует возможность использовать новый метод сохранения, который позволяет сохранить больше страниц (см. Раздел «Способы сохранения» ниже).
Существует возможность всегда отображать диалоговое окно «Сохранить как» при сохранении страницы с использованием нового метода сохранения. Если этот параметр не включен, диалоговое окно «Сохранить как» будет отображаться только в том случае, если для параметра «Загрузки» Firefox установлено значение «Всегда спрашивать, куда сохранять файлы».
Есть возможность закрыть вкладку после сохранения страницы.
Есть опции для указания формата имени сохраняемого файла.См. Раздел «Сохраненное имя файла» ниже.
По умолчанию сохраненный файл HTML будет иметь расширение .html.
КОНТЕКСТНОЕ МЕНЮ И КНОПНОЕ МЕНЮ
Чтобы сохранить веб-страницу в виде файла HTML или выполнить операции на ранее сохраненной странице, щелкните правой кнопкой мыши содержимое страницы, чтобы открыть контекстное меню, выберите подпункт «Сохранить страницу WE». -menu, а затем выберите один из пунктов меню:
• Сохранить выбранные вкладки
— Основные, Стандартные или Пользовательские элементы
— Базовые, Стандартные или Пользовательские элементы с или без прокрутки / сжатия
• Сохранить указанные URL-адреса
— Базовый, Стандартный или настраиваемые элементы
— базовые, стандартные или настраиваемые элементы с или без прокрутки / сжатия
• Отменить сохранение
• Просмотр информации о сохраненной странице
• Удалить загрузчик ресурсов
• Извлечь изображение / аудио / видео
Или щелкните правой кнопкой мыши на Сохранить Страница WE кнопка панели инструментов, чтобы открыть меню кнопок, а затем выберите один из пунктов меню.
Есть возможность показать / скрыть пункт подменю «Сохранить страницу WE» в контекстном меню.
Обратите внимание, что пункт меню «Удалить загрузчик ресурсов» отображается только при просмотре страницы, сохраненной с помощью «Сохранить страницу» WE 15.1 или более ранней версии.
Обратите внимание, что пункт меню «Извлечь изображение / аудио / видео» отображается в контекстном меню только при щелчке правой кнопкой мыши по изображениям на сохраненных страницах.
ЯРЛЫКИ КЛАВИАТУРЫ
Чтобы сохранить веб-страницу в виде файла HTML, нажмите Alt + A.
Чтобы отменить сохранение одной или нескольких страниц, нажмите Alt + C.
Эти ярлыки можно перенастроить на вкладке «Ярлыки» страницы «Параметры WE сохранения страницы».
СОХРАНЕНИЕ НЕСКОЛЬКИХ СТРАНИЦ
Есть два способа сохранить несколько страниц:
• Выделите несколько вкладок и затем выберите пункт меню «Сохранить выбранные вкладки».
• Загрузите файл, содержащий список URL-адресов, в диалоге параметров Zoom Page WE, а затем выберите пункт меню «Сохранить перечисленные URL-адреса».
При сохранении нескольких страниц вкладки переключаются на передний план, если включена опция загрузки отложенного содержимого.
СОХРАНЕННЫЕ ЭЛЕМЕНТЫ
Сохранить основные элементы — сохраняет следующие элементы:
• HTML-элементы
• HTML-файлы изображений (отображаются в данный момент)
• HTML-графика на холсте
• Таблицы стилей CSS
• CSS-файлы изображений (отображаются в данный момент)
• CSS файлы шрифтов (используемые этим браузером)
Сохранить стандартные элементы — сохраняет основные элементы и следующие элементы:
• Файлы изображений HTML (все)
• Аудио и видео файлы HTML
• Файлы объектов HTML и встраиваемые файлы
• Файлы шрифтов CSS (woff для любого браузера)
Сохранить настраиваемые элементы — сохраняет основные элементы и элементы, выбранные из этого списка:
• Файлы изображений HTML (все)
• Аудио и видео файлы HTML
• Объект HTML и файлы встраивания
• CSS файлы изображений (все)
• Файлы шрифтов CSS (woff для любого браузера)
• Файлы шрифтов CSS (все)
• Сценарии (во фреймах одного происхождения)
Обратите внимание, скрипты во фреймах с перекрестным источником никогда не сохраняются.
Существует возможность загружать ленивое содержимое двумя альтернативными методами: прокрутка страницы или сжатие страницы.
Есть возможность загружать ленивые изображения в существующий контент.
Есть возможность сохранить фреймы с перекрестным началом при сохранении страницы. Обратите внимание, что окна iframe с разными источниками часто содержат рекламу или комментарии посетителей.
Есть возможность объединить повторяющиеся изображения CSS (для уменьшения размера сохраняемого файла).
Существует возможность разрешить выполнение сохраненных сценариев (по умолчанию выполнение сценариев запрещено).
Существуют варианты удаления или повторного скрытия элементов, скрытых самой страницей или другими расширениями, такими как редакторы страниц (например, Print Edit WE) или блокировщики контента (например, uBlock Origin).
Есть возможность включить информационную панель вверху сохраненной страницы.
Есть возможность включить метрики и сводку ресурсов в сохраненный файл.
Есть возможность установить максимальную глубину сохраняемых вложенных фреймов / iframe.
ИМЯ СОХРАНЕННОГО ФАЙЛА
Существует возможность указать формат имени сохраненного файла.
Этот формат используется при сохранении всей страницы и при извлечении ресурса (Изображение / Аудио / Видео).
Имя сохраненного файла может содержать следующие предопределенные поля:
•% TITLE% — (сохранение страницы) заголовок документа или, если он пуст, то же самое, что и% FILE%.
•% TITLE% — (извлечение ресурса) то же, что и% FILE%.
•% DATE (x)% — текущая дата в формате ГГГГxMMxDD, где «x» — любой символ или может быть опущено.
•% TIME (x)% — текущее время в формате HHxMMxSS, где «x» — любой символ или может быть опущено.
•% DATEP (x)% — дата публикации в формате ГГГГxMMxDD, где «x» — любой символ или может быть опущено.
•% TIMEP (x)% — опубликованное время в формате HHxMMxSS, где «x» — любой символ или может быть опущено.
•% HOST% — имя хоста в URL страницы или ресурса.
•% HOSTW% — то же, что и% HOST%, но без www. приставка.
•% PATH% — путь в URL страницы или ресурса.
•% PATHW% — то же, что и% PATH%, но без суффикса «.extension».
•% FILE% — имя файла в последнем сегменте пути в URL страницы или ресурса.
•% FILEW% — то же, что и% FILE%, но без суффикса «.extension».
•% QUERY (p)% — строка запроса в URL-адресе страницы, если «p» опущено, или значение параметра «p».
•% FRAGMENT% — строка фрагмента в URL страницы.
Есть опции для замены пробелов в сохраненном имени файла на определяемый пользователем символ и для установки максимальной длины сохраняемого имени файла.
НАСТРОЙКА FIREFOX
Перейдите в Главное меню Firefox> Инструменты> Параметры> Общие.
В разделе «Приложения» установите действие для типа содержимого «HTML-документ Firefox»:
• Всегда спрашивайте — «Что Firefox должен делать с этим файлом?» будет показано диалоговое окно.
• Использовать Firefox — сохраненный файл будет открыт в Firefox.
• Сохранить файл — действие зависит от настроек в разделе «Загрузки».
В разделе «Загрузки» укажите расположение папки «Сохранить файлы в» и включите или отключите параметр «Всегда спрашивать, куда сохранять файлы».
ЗАГРУЗКА РЕСУРСОВ
Существует возможность установить максимальное время, разрешенное для загрузки указанного URL.
Существует возможность установить максимальный размер, разрешенный для больших или многократно используемых ресурсов.
Существует возможность установить максимальное время, разрешенное для загрузки отдельных ресурсов.
Есть возможность разрешить загрузку пассивного смешанного контента (изображения, аудио, видео).
Есть возможность отправить заголовок referer при запросе ресурса. Возможные варианты: не отправлять заголовок ссылки, отправлять заголовок ссылки только с источником или отправлять заголовок ссылки с источником и путем (источник только в приватном просмотре).
НЕ СОХРАНЕННЫЕ РЕСУРСЫ
Есть возможность показать предупреждение, если какие-либо ресурсы не могут быть сохранены.
Есть возможность показать список всех ресурсов, которые нельзя сохранить.
Существует возможность удалить URL-адреса несохраненных ресурсов, что позволяет избежать загрузки несохраненных ресурсов из Интернета при открытии сохраненной страницы.
ИСПОЛЬЗОВАНИЕ АВТОМАТИЗАЦИИ
Существует возможность использовать режим автоматизации, позволяющий сохранять страницу из командной строки.
Если эта опция включена:
• При запуске Firefox автоматически запускается сохранение страницы WE с использованием текущего действия кнопки.
• Когда операция сохранения будет завершена, Firefox будет автоматически закрыт.
Чтобы выйти из режима автоматизации, сразу после запуска Firefox используйте команду меню «Отменить сохранение» или сочетание клавиш, чтобы отменить операцию сохранения, а затем отключите возможность использования автоматизации.
Если для параметра «Действие кнопки» задано значение «Сохранить выбранные вкладки», то все вкладки сохраняются при включенной опции автоматизации использования.
Новый сохраненный метод всегда используется, когда включена опция автоматизации использования.
СПОСОБЫ СОХРАНЕНИЯ
Ниже приведены некоторые важные сведения о новых и старых методах сохранения.
Старый метод сохранения:
• По умолчанию в версии 18.0 или более ранней.
• Запоминает последнее место сохранения как в Firefox, так и в Chrome.
• Невозможно сохранить несколько страниц (например, Yahoo) в Chrome 84 или новее.
• В этом случае сохранение не будет выполнено без сообщений об ошибках.
• Используйте новый метод сохранения для этих страниц.
Новый метод сохранения:
• По умолчанию в версии 19.0. Необязательно в версии 20.0 или новее.
• Запоминает последнее место сохранения в Firefox 78 или новее, но не в Chrome.
• Можно сохранить все страницы.
• Другие расширения загрузки могут изменить имя сохраненного файла на UUID.
• Например, «9bd65c08-5f1c-491c-bf61-63dbf9e.html».
• В этом случае попробуйте удалить и переустановить Save Page WE.
• Или воспользуйтесь старым методом сохранения.
ФОРМАТ СОХРАНЕННОГО ФАЙЛА
Элементы HTML (в том виде, в каком они отображаются в данный момент) и все ресурсы, на которые есть ссылки, сохраняются в одном файле (.html).
Внешние таблицы стилей CSS преобразуются во внутренние таблицы стилей CSS. Содержимое фрейма и внешние скрипты хранятся как URI данных UTF-8 в атрибуте src. Содержимое iframe хранится как текст UTF-8 в атрибуте srcdoc.
Все двоичные ресурсы (изображения, шрифты, аудио, видео и т. Д.) Хранятся как URI данных Base64. Изображения CSS, на которые в кадре ссылаются несколько раз, будут сохранены в нем только один раз. Шрифты CSS и изображения / аудио / видео HTML будут сохраняться один раз для каждой ссылки.
Обратите внимание, что не все фреймы с перекрестными исходными точками могут быть сохранены. Фрейм с перекрестным источником будет сохранен только в том случае, если все его кадры-предки с перекрестным источником могут запускать сценарии содержимого. Скрипты во фреймах с перекрестным началом не сохраняются.
Есть возможность отформатировать исходный HTML-код в сохраненном файле.
ПРЕОБРАЗОВАНИЕ ФАЙЛОВ MAF И UnMHT (.maff & .mht)
Для Save Page WE невозможно выполнить автоматическое преобразование файла формата архива Mozilla (.maff или .mht) или файла UnMHT (.mht) в файл страницы сохранения WE (.html). Надстройки Firefox WebExtensions, такие как Save Page WE, не могут читать локальные файлы.
Рекомендуется конвертировать файлы .maff / .mht следующим образом:
• Откройте сохраненный файл .maff / .mht в Firefox.
• Повторно сохраните как файл .htm (+ папку ресурсов), используя Firefox «Сохранить страницу как …» (веб-страницу, завершено).
• Обслуживайте сохраненный файл .htm (+ папка ресурсов) через локальный веб-сервер и откройте его в Firefox.
• Выполните повторное сохранение с помощью страницы сохранения WE.
Что касается локального веб-сервера, рекомендуется использовать приложение Google Chrome под названием «Веб-сервер для Chrome», доступное в Интернет-магазине Chrome: https://chrome.google.com/webstore/detail/web-server- for-chrome / ofhbbkphhbklhfoeikjpcbhemlocgigb
Обратите внимание, что с помощью Firefox 56 и Mozilla Archive Format 5.2.0 можно выполнить массовое преобразование файлов .maff / .mht в файлы .htm (+ папки ресурсов), как описано здесь: http://maf.mozdev.org/index.html.
ПОДДЕРЖКА
Электронная почта: dw-dev @ gmx.com
ЛИЦЕНЗИЯ
Распространяется по Стандартной общественной лицензии GNU версии 2.
См. файл LICENCE.txt и http://www.gnu.org/licenses/
Где я могу найти сохраненные страницы в моем браузере Android
Как правило, для доступа в Интернет используется очень много веб-браузеров. В настоящее время все смартфоны или планшеты поставляются с одним или двумя браузерами, установленными по умолчанию или предустановленными. Используя эти браузеры, пользователи могут легко получить доступ к Интернету. Теперь в некоторых браузерах есть функция чтения в автономном режиме, которая позволяет читать документы, даже когда вы не в сети.Эта функция известна как «Сохранить для чтения в автономном режиме». Это означает, что с помощью этой функции вы можете сохранять свои любимые страницы для чтения в автономном режиме. Затем вы можете получить к нему доступ с помощью опции сохраненных страниц .
Эта функция присутствует почти во всех последних мобильных телефонах Android. Сохранение для чтения в автономном режиме. Функция позволяет читать сохраненные страницы в автономном режиме. Но некоторые пользователи понятия не имеют, как сохранять страницы для чтения в автономном режиме. Итак, здесь мы обсудим процесс сохранения страниц для чтения, даже если вы не в сети.Используя which, вы можете легко привыкнуть к этой функции.
Как сохранять страницы для чтения в автономном режиме
Здесь мы обсудим весь процесс по шагам. Итак, теперь взгляните на него и наслаждайтесь чтением страниц в автономном режиме.
- Прежде всего, откройте браузер по умолчанию с нашего устройства под управлением Android, который предустановлен на вашем устройстве.
- Теперь, откройте любой веб-сайт , страницы которого вы хотите сохранить.Например, выполните поиск в кибербезопасности в браузере по умолчанию.
- Теперь в правом верхнем углу дисплея вы можете увидеть три точки . Нажмите на эти точки.
- Это откроет для вас варианты. В котором также есть одна опция « Сохранить для чтения в автономном режиме ».
- Теперь нажмите на эту опцию, и вы сделали работу.
Этот метод сохранения страниц для чтения в автономном режиме прост в использовании. Но у пользователей также появляется запрос после сохранения страниц, например, где они могут найти сохраненные страницы на устройстве.Итак, здесь у нас тоже есть решение этой проблемы.
Как получить доступ к сохраненным страницам на устройстве Android
Найти сохраненные страницы в браузере Android очень просто. Просто следуйте инструкциям, указанным ниже.
- Откройте на устройстве браузер по умолчанию.
- Теперь проведите по экрану влево три раза.
- После этого вы попадете на экран сохраненных страниц. При этом вы можете увидеть все страницы, которые были сохранены вами.
Используя опцию трех точек, вы также можете получить доступ к сохраненным страницам. Просто нажмите на эти точки, а затем нажмите на опцию « Saved Pages ». Преимущество этой функции заключается в том, что вы можете читать содержимое определенных страниц, даже если вы не в сети. Это также означает, что вам не требуется подключение для передачи данных или Wi-Fi для чтения страниц сохранения.
См. Также: Игра с сохраненным паролем Опция
Мы должны надеяться, что это обсуждение может быть очень полезным для вас, когда вы захотите сохранить свои любимые страницы прямо с сайтов.Если вы думаете, что это очень полезная информация, поделитесь ею с друзьями и коллегами. Вы также можете отправить нам отзыв об этом.
Save Page WE — это расширение Firefox и Chrome, которое может сохранять веб-страницу в файле HTML.
Наличие ресурса, доступного в автономном режиме, часто является хорошей идеей, поскольку вы можете получить к нему доступ в любое время, не беспокоясь о подключении к Интернету или доступности ресурс в Интернете. Все современные веб-браузеры поддерживают базовую функциональность для сохранения веб-страниц в локальной системе.
Обычно, когда вы выбираете опцию «Сохранить страницу как», браузер загружает содержимое на страницу и сохраняет его как файл HTML и папку, содержащую мультимедиа, значки, код CSS и другие веб-элементы, которые были присутствует на странице. Количество файлов в папке варьируется от веб-сайта к веб-сайту и от страницы к странице.
Использование таких расширений, как «Один файл» (Chrome, Firefox) или «Сохранить страницу». Мы можем помочь вам сохранять веб-страницы в виде файлов HTML без папок. Этот единственный файл содержит все содержимое, которое было на веб-странице.
Прежде чем мы перейдем к параметрам расширения, позвольте мне показать вам пример. Я сохранил эту страницу Википедии с помощью встроенной в Firefox опции «сохранить страницу». Я отключил Интернет и открыл страницу со своего жесткого диска.
Теперь сравните его с сохраненным расширением Save Page WE. Вы видите различия?
Разрешите выделить их. Значок веб-страницы на панели вкладок, логотип Википедии в верхнем левом углу, значок языка слева и значок пользователя в правом верхнем углу отсутствуют в значке, сохраненном инструментом браузера.Расширение, с другой стороны, прекрасно сохранило их все в виде копии 1: 1 и, что более важно, всего в одном файле. Для сравнения, в Firefox в опции «Сохранить» было всего 17 файлов (HTML + папка, содержащая 16 файлов).
Это может не иметь большого значения для данной конкретной страницы, но если вы сохранили что-то еще для использования в будущем и позже обнаружили, что в нем отсутствует какое-то важное содержимое, это может раздражать.
Сохранить страницу WE
Расширение помещает значок дискеты на панель инструментов, щелкните по нему, чтобы сохранить текущую веб-страницу.Сочетание клавиш для этого — Alt + A. В зависимости от содержимого на странице может потребоваться несколько секунд, чтобы упаковать все это в один файл HTML. Появится диалоговое окно загрузки, которое вы можете использовать для сохранения HTML-документа. Вы можете открыть его в любом браузере по вашему выбору, даже в мобильном браузере, поскольку все они поддерживают открытие файлов HTML.
Щелкните правой кнопкой мыши значок панели инструментов Save Page WE, чтобы просмотреть его контекстное меню. У него есть три варианта: «Сохранить основные элементы», «Сохранить стандартные элементы» и «Пользовательские элементы».Что они делают? Основные элементы сохраняют содержимое текущей веб-страницы, такое как элементы HTML и CSS, изображения и стили шрифтов. Стандартные элементы включают в себя все основные элементы + HTML-аудио, видео, объекты и встроенные файлы. Пользовательские элементы позволяют вам выбрать, что вы хотите сохранить из упомянутого выше контента. Используйте страницу управления надстройкой Firefox (или щелкните правой кнопкой мыши значок в Chrome), чтобы получить доступ к параметрам расширения.
Вкладка «Общие» позволяет вам установить действие кнопки по умолчанию (метод сохранения) вместе с опцией сохранения заголовка страницы.Некоторые веб-страницы могут содержать элементы, которые нельзя сохранить; вы можете выбрать, должно ли надстройка предупреждать вас, когда страница содержит такие элементы, а также должна ли она перечислять все несохраняемые элементы. Вторая вкладка, Сохраненные элементы, позволяет вам определить, какие пользовательские элементы должны быть сохранены при использовании Опция «Сохранить пользовательские элементы». Хотя он также содержит список основных и стандартных элементов, ни один из этих параметров не может быть изменен.
Сохранить страницу Мы сохраняем контент в соответствии со сценарием на веб-сайте, и если вы хотите избежать элементов, которые были заблокированы блокировщиками контента (блокировщиками рекламы, такими как uBlock Origin), редакторами страниц и т. Д., Вы можете включить «Очистить Элементы «на вкладке» Дополнительно «.Это также может помочь уменьшить размер файла. Другие параметры на этой вкладке включают блокирующий заголовок реферера, разрешающий смешанный мультимедийный контент, и настройки для управления вложенными фреймами, размером ресурсов и загрузкой. Вы можете установить собственный ярлык для действия надстройки с сохранением страницы на вкладке Ярлыки.
Преимущества сохранения веб-страниц в формате HTML
Сохранение веб-страниц в виде одного файла упрощает их совместное использование, особенно если вы хотите отправить несколько страниц. Вы можете прикрепить их к письму или через сообщение обмена мгновенными сообщениями, загрузить их на облачный диск или даже перенести на свой телефон для чтения на ходу, не беспокоясь о дополнительных папках.
Если на вашем компьютере сохранены десятки или сотни веб-страниц, каждая из них будет иметь свою собственную папку, и когда вы поместите их все вместе в каталог, это может стать немного беспорядочным. Это не тот случай, если вы сохраняете страницу как отдельный файл HTML, поэтому с точки зрения организации у нее есть преимущество. Это также помогает переименовывать сохраненные страницы без нарушения каких-либо содержащихся в них элементов.
Сохранить страницу Мы не только упаковываем содержимое в HTML, но и немного сжимаем его. Размер файла веб-страницы иногда может быть проблемой, в большинстве случаев расширение сохраняло его в меньшем размере, но иногда встроенный инструмент браузера был лучше.Вот 2 примера скриншотов. На первом изображении мы видим, что надстройка немного превосходит встроенный инструмент.
На втором рисунке показано, что Save Page МЫ сохранили страницу в файле размером 13 МБ, в то время как Firefox удалось сохранить его меньше 3 МБ.
Опять же, это зависит от веб-страницы, и когда вы накапливаете тонны веб-страниц, это может иметь значение в зависимости от того, сколько памяти вы можете сэкономить. Вы можете загрузить Save Page WE из интернет-магазина Chrome или из репозитория надстроек Firefox.
Предупреждение : Мне не удалось найти исходный код или даже веб-страницу для страницы сохранения WE. Два других дополнения от того же разработчика — «Рекомендовано Mozilla», что является хорошим знаком. Я тоже давно им пользуюсь.
Рейтинг автора
Название программного обеспечения
Страница сохранения WE
Операционная система
Firefox, Chrome
Категория программного обеспечения
Интернет
Цена
Бесплатно
Целевая страница
РекламаПоиск архива — Справка: Мой архив Сохраненные товары
Закрыть окно | Содержание справки Пропустите следующую подсказку и перейдите к основному содержаниюВы просматриваете содержимое во всплывающем окне.Поиск архива останется открытым в исходном окне. Если вы являетесь пользователем JAWS, перемещайтесь между окнами браузера с помощью Alt + Tab. Вернитесь на одну страницу назад, используя Alt + стрелка влево. Перейдите на одну страницу вперед, используя Alt + стрелку вправо. Обновите страницу с помощью Вставить + Escape. Закройте это всплывающее окно, используя Alt + F4.
Что такое страница «Сохраненные элементы»?
На странице Сохраненные элементы перечислены все библиографические записи. вы сохранили в Мой архив .Это позволяет хранить записи за пределами одного сеанс, просмотр Полная запись , электронная почта, печать и загрузка выбранных записей, аннотирование их или удалите из своего списка. Вы можете сохранять записи в Мой архив из Полная запись репозитория страница, коллекция Полная запись page или Отмеченный список . На странице есть отдельные разделы для записей коллекций и записей репозитория; ссылки перехода вверху страницы позволяют перемещаться между двумя разделами.
Выбор записей
Обратите внимание, что вы должны выбрать интересующие вас элементы, прежде чем отправлять их по электронной почте, распечатывать, загружать или удалять. Выбранные элементы отмечены флажком и выделены фоном. По умолчанию все элементы отображаются как выбранные, но вы можете отменить выбор элементов, нажав флажок рядом с записью, чтобы убрать галочку / выделение. Чтобы выбрать невыделенный элемент, просто щелкните флажок еще раз, чтобы поле было отмечено флажком, а элемент выделен.
Отправка и печать отчетов по электронной почте
Вы можете выбрать записи на странице Сохраненные элементы и отправить их себе по электронной почте или другие или распечатайте их.
- Установите соответствующий флажок для записей, которые вы хотите отправить по электронной почте,
или
Установите флажок Выбрать / Очистить все элементы на этой странице над списком, если вы хотите отправить все записи в списке по электронной почте.
- Щелкните ссылку Электронная почта , чтобы открыть Электронная почта страница.
Скачивание записей
Вы можете выбрать записи на странице Сохраненные элементы и загрузить их.
- Установите соответствующий флажок для записей, которые вы хотите загрузить,
или
Установите флажок Выбрать / очистить все элементы на этой странице над списком, если вы хотите загрузить все записи в списке.
- Щелкните ссылку Download Citations , чтобы открыть ссылку Download Citations страница, на которой отображаются выбранные вами записи, готовые для экспорта в менеджер цитирования или загрузки в файл или на компьютер.
Добавление примечания к сохраненной записи
Вы можете добавить пояснительную записку к сохраненной записи. Один раз вы создали заметку, которую вы можете просмотреть, отредактировать или удалить в любое время. Вы также можете отправить его по электронной почте как часть сохраненной записи записи себе или другим лицам.
Выход из системы
Сохраненные элементы являются одной из функций с контролируемым доступом Archive Finder , так что в список добавляются только те элементы, которые вы сохраняете.
Чтобы никто другой не использовал ваши сохраненные предметы, пока вас нет с вашего компьютера, мы рекомендуем вам выйти из сохраненных элементов страница, когда вы закончите ее использовать:
- Щелкните ссылку Выйти из моего архива вверху страницы.
Импорт / экспорт пользовательских сохраненных параметров страницы Fusion — ThemeFusion
Новое в Avada 5.3 — это возможность импортировать / экспортировать индивидуальные параметры страницы Avada.Вы увидите вкладку «Импорт / экспорт» внизу каждой страницы, которую вы редактируете. Все это позволяет вам сохранять / экспортировать настроенные параметры Avada для любой страницы, а затем загружать / импортировать на любую новую или существующую страницу / публикацию, экономя ваше время и улучшая рабочий процесс.
ВАЖНОЕ ПРИМЕЧАНИЕ: Экспортированные параметры страницы Avada для страниц, сообщений или сообщений портфолио являются взаимозаменяемыми. Вы можете, например, импортировать параметры страницы Avada со страницы в сообщение «Портфолио» и наоборот; Будут импортированы только идентичные типы опций, неидентичные типы опций будут просто игнорироваться в процессе импорта.
-
Сохранить параметры страницы — Сохраните текущие параметры страницы Avada в качестве настраиваемого набора для повторного использования на любой странице или публикации, использующей параметры страницы Avada.
-
Управление параметрами страницы — выберите набор сохраненных параметров страницы Avada, затем выберите их импорт или удаление.
-
Параметры страницы экспорта — Нажмите кнопку экспорта, чтобы экспортировать текущий набор параметров страницы Avada в виде файла json.
-
Параметры страницы импорта — щелкните «Импорт», чтобы выбрать набор параметров страницы Avada (файл json), который будет использоваться.
ВАЖНОЕ ПРИМЕЧАНИЕ: Не забудьте сохранить страницу / сообщение перед экспортом или сохранением параметров страницы Avada.
Как сохранить параметры страницы Avada
После внесения изменений в параметры страницы Avada сначала сохраните страницу / сообщение. Затем на вкладке «Импорт / экспорт» введите имя в текстовое поле для «Сохранить параметры страницы» и нажмите кнопку «Сохранить параметры страницы».
Важное примечание: Обязательно используйте уникальное имя для каждого сохраненного набора, это позволит вам различать его при загрузке сохраненных параметров страницы через раскрывающееся меню «Параметры управления».
Как управлять параметрами страницы Avada
Щелкните раскрывающееся меню с надписью «Выберите набор параметров страницы», и вы найдете набор сохраненных параметров страницы (если они уже есть). После того, как вы выбрали опцию сохраненной страницы, появятся кнопки «Импорт» и «Удалить». Щелкните Импорт, чтобы загрузить параметр сохраненной страницы, и щелкните Удалить, чтобы удалить его.
Важное примечание: Не забудьте сохранить страницу / сообщение перед экспортом и после импорта.
Как экспортировать параметры страницы Avada
Чтобы экспортировать текущий набор параметров страницы Avada в виде файла .json, нажмите кнопку «Экспорт параметров страницы». Вы можете использовать этот файл на других своих веб-сайтах Avada (если они есть) с версией не ниже 5.3.
Важное примечание: Сохраните страницу / сообщение перед экспортом.
Как импортировать параметры страницы Avada
Чтобы импортировать набор параметров страницы Avada, нажмите кнопку «Импортировать параметры страницы» и выберите файл.json для импорта, и новые настройки будут применены автоматически.
Важное примечание: Не забудьте сохранить страницу / сообщение после импорта.
Как использовать библиотеку шаблонов Elementor
Elementor Библиотека шаблонов дает вам доступ к сотням дизайнерских макетов Page и блоков , все с высококачественными стоковыми изображениями, которые вы можете свободно использовать на своем сайте.
Как вставлять шаблоны
- Щелкните значок Добавить шаблон из библиотеки , чтобы добавить шаблон страницы, блок или собственный сохраненный шаблон из экрана редактирования.
- При первой вставке шаблона вам будет предложено подключить бесплатную учетную запись Elementor для доступа к библиотеке шаблонов. Если у вас еще нет учетной записи, вы можете зарегистрировать ее бесплатно во время этого процесса.
- Щелкните значок увеличительного стекла, чтобы просмотреть шаблон.
- Нажмите ВСТАВИТЬ , чтобы выбрать требуемый шаблон.
- Подарите своим любимым шаблонам сердечко и сохраните их в МОИ ИЗБРАННЫЕ .
- Щелкните стрелку в правом верхнем углу, чтобы загрузить файл .json или .zip файл.
Как сохранять страницы как шаблоны
- Нажмите зеленую кнопку, расположенную в нижней части панели
- Выберите Сохранить шаблон
- Дайте имя вашему шаблону и сохраните
Сохранение разделов как шаблонов
- Выберите раздел, который вы хотите сохранить, и щелкните правой кнопкой мыши Параметры раздела
- Дайте ему имя и нажмите Сохранить
Как экспортировать шаблоны
Вы можете экспортировать сохраненные шаблоны.
- Установите соответствующий флажок для записей, которые вы хотите загрузить,