Как изучить SQL за 2 месяца с нуля. План обучения / Хабр
То, что данные называют нефтью 21 века известно уже давно: на них учатся нейросети, их мгновенная обработка и передача сильно упростили нашу жизнь, и одной из самых распространенных структур хранения данных является реляционная.
Основным инструментом для взаимодействия с реляционными БД является структурированный язык запросов или же SQL.
Вкратце, на мой взгляд, необходимо знать следующие разделы:
стандартные типы данных;
простые и вложенные запросы;
соединения и изменения данных в таблице;
проектирование схемы БД;
хранимые процедуры;
агрегатные и оконные функции;
древовидные структуры и рекурсивные запросы;
транзакции;
оптимизация запросов;
модули расширения.
Теперь перейдем непосредственно к плану обучения.
Основы
Предлагаю начать с замечательного курса на Stepik интерактивный тренажёр по SQL. В данном курсе очень плавно даётся вся необходимая база сразу же с практическими заданиями. Отсюда вы узнаете о выборке, группировке и корректировке данных, что такое вложенные запросы, какие существуют соединения таблиц и так далее.
В данном курсе очень плавно даётся вся необходимая база сразу же с практическими заданиями. Отсюда вы узнаете о выборке, группировке и корректировке данных, что такое вложенные запросы, какие существуют соединения таблиц и так далее.
Для закрепления пройденного материала желательно ещё пройти задания на PostgreSQL Exercises.
Продвинутые темы
Для выполнения простых задач хватит и предыдущего курса, однако, если вам придётся писать много сложных запросов или же ваша работа будет связана непосредственно с инженерией данных, то этого будет явно недостаточно.
Поэтому переходим к следующему курсу также на Stepik Свободное погружение в СУБД, где уже рассказывается о проектировании схем баз данных, оптимизации запросов, транзакциях, рекурсивных запросах и многом другом. В курсе также уделяется пару слов NoSQL.
После ещё можно пройти небольшой курс на Coursera Advanced Relational Database and SQL.
Литература
Также при прохождении курсов не будет лишним пользоваться литературой для углубления и структурирования информации. Мне понравилась книга «Основы технологий баз данных», Б.А. Новиков, Е.А. Горшкова, Н.Г. Графеева.
Мне понравилась книга «Основы технологий баз данных», Б.А. Новиков, Е.А. Горшкова, Н.Г. Графеева.
Плюс данной книги заключается в том, что она очень хорошо сочетается с вышеуказанными курсами.
Практика
Для практики можно использовать LeetCode и решать задачи по SQL уровня medium и выше, если получится. На данной платформе представлено множество задач с реальных собеседований в компании уровня FAANG и это её главное преимущество.
Если вам известны ещё хорошие ресурсы по SQL, которые не были представлены в статье, то обязательно делитесь ими в комментариях – соберем всю лучшую информацию в одном месте.
Всем успехов!
Дополнительные источники
Начальный уровень:
«SQL: быстрое погружение», Уолтер Шилдс;
«Изучаем SQL» (третье издание), Алан Болье;
«Practical SQL» (second edition), Anthony DeBarros;
«SQL in a Nutshell» (fourth edition), Kevin Kline, Regina O.
 Obe, Leo S. Hsu;
Obe, Leo S. Hsu;Основы SQL – курс Андрея Созыкина;
Знакомство с SQLite – небольшой вводный курс;
Intro to SQL– вводный курс на платформе kaggle;
SQL Tutorial – курс для начинающих от Amigoscode;
Базы данных и SQL – курс от МФТИ по SQL и NoSQL;
SQL Introduction – небольшой курс от Сергея Романенко;
Марафон данных: первое знакомство с SQL и Python – курс Dataskills;
SQL for Data Science – курс начального уровня от университета Калифорнии.
 Obe, Leo S. Hsu;
Obe, Leo S. Hsu;Продвинутый уровень:
«PostgreSQL 15 изнутри», Егор Рогов;
«SQL. Сборник рецептов» (второе издание), Энтони Молинаро, Роберт де Грааф;
«Effective SQL: 61 Specific Ways to Write Better SQL», John L. Viescas, Douglas J. Steele, Ben G. Clothier;
Базы данных – курс от СПбГУ;
Advanced SQL – ещё один курс на платформе kaggle;
Advanced Databases and SQL Querying – курс на платформе udemy;
Advanced SQL (summer 2020) – большой плейлист по продвинутым темам;
Intermediate PostgreSQL – курс среднего уровня от университета Мичигана;
From Data to Insights with Google Cloud – специализация от Google для разных уровней;
Введение в базы данных – совместный курс от НИУ ВШЭ, СПбПУ, Computer Science Center.

Ещё несколько полезных ссылок:
SQL-ex, Codewars, SQLZOO – сайты для практики;
Интерактивные учебники по SQL: один, два, три, четыре;
Полезные каналы: DataLearn, techTFQ, Seattle Data Guy, We Learn SQL;
Документация: PostgreSQL, MySQL, Oracle, Microsoft SQL server, SQLite.
SQL — Формальный непроцедурный язык программирования / Хабр
Формальный непроцедурный язык программирования
Статьи Посты Авторы Компании
Сначала показывать
Порог рейтинга
Уровень сложности
Уровень сложности Простой
Время на прочтение 11 мин
Количество просмотров 2.8KАнализ и проектирование систем *SQL *
Из песочницы
В процессе разработки витрин данных часто возникает задача предоставления клиентам данных в агрегированном виде. Если данных в хранилище немного, то их можно агрегировать “на лету”, но это плохая практика так как, чем больше будет копиться данных, тем дольше будут выполняться запросы, и тем больше Clickhouse будет съедать ресурсов. В этих случаях логично хранить данные в заранее агрегированном виде, вопрос лишь в том, как реализовать расчет данных агрегированных значений.
Если данных в хранилище немного, то их можно агрегировать “на лету”, но это плохая практика так как, чем больше будет копиться данных, тем дольше будут выполняться запросы, и тем больше Clickhouse будет съедать ресурсов. В этих случаях логично хранить данные в заранее агрегированном виде, вопрос лишь в том, как реализовать расчет данных агрегированных значений.
В интернете существуют много однотипных статей иллюстрирующих базовое использование материализованных представлений (далее — матвью) на движке AggregatingMergeTree, но если ваша задача выходит за рамки “1 нода, 1 метрика, 1 параметр агрегации” эти статьи вам мало чем помогут. Я посчитал, что моим коллегам может пригодиться своего рода гайд о том, как пользоваться данными представлениями для более сложных задач.
Гайд выполнен в виде шагов, иллюстрирующих мой путь в понимании данной концепции. Если я совершил какую-либо ошибку в процессе, и вы ее заметили, или у вас есть предложение по улучшению / дополнению данного гайда, прошу написать об этом в комментариях, уверен всем от этого будет только лучше.
В рамках моей задачи хранилище данных (далее — DWH) реализовано в виде реплицированного кластера состоящего из 3 нод, данные на ноды распределяются равномерно в соответствии с ключом сортировки таблиц. Существует исходная таблица source, которая содержит столбцы id, timecode_1, metric_data — данные представляют собой временной ряд утилизации ресурсов с гранулярностью 1 минута. Данные поступают блоками каждые 2 минуты.
Всего голосов 15: ↑15 и ↓0 +15
Комментарии 1
nikolai-averinУровень сложности Средний
Время на прочтение 17 мин
Количество просмотров 3.2KPostgreSQL *SQL *Администрирование баз данных *
В первой части мы рассмотрели базовые операции, такие как добавление новых атрибутов, создание индексов и ограничений и т.д.
Эта статья посвящена двум более сложным миграциям:
— обновление большой таблицы
— разделение таблицы на две
Рассмотрим подходы, которые позволяют провести миграции с минимальным простоем для приложения.
Всего голосов 19: ↑19 и ↓0 +19
Комментарии 2
MrFedkoУровень сложности Средний
Время на прочтение 7 мин
Количество просмотров 5.3KPython *SQL *
Из песочницы
Перевод
Эта статья является переводом статьи Мигеля Гринберга.
Возможно, вы слышали, что основная версия SQLAlchemy 2.0, была выпущена в январе 2023 года. Или, может быть, вы пропустили объявление и это новость для вас. В любом случае, я подумал, что вам будет интересно узнать, что в нем нового, стоит ли его обновлять и насколько сложно это сделать.
Как и в предыдущих обзорах программного обеспечения, это будет субъективный обзор. Я давно использую SQLAlchemy ORM в веб-проектах, поэтому в этой статье я расскажу о функциях, которые влияют на мою собственную работу, как в положительную, так и в отрицательную сторону.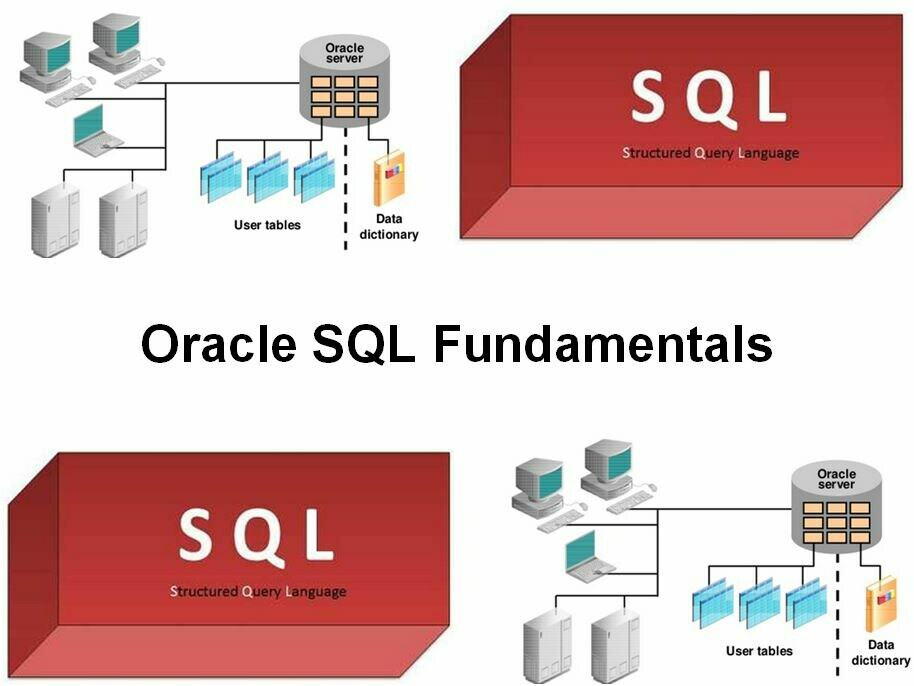 Если вместо этого вам интересно увидеть список всех изменений, внесенных в этот новый релиз, то официальный журнал изменений — это то что вам нужно.
Если вместо этого вам интересно увидеть список всех изменений, внесенных в этот новый релиз, то официальный журнал изменений — это то что вам нужно.
Всего голосов 23: ↑22 и ↓1 +21
Комментарии 2
ph_piterВремя на прочтение 18 мин
Количество просмотров 4KБлог компании Издательский дом «Питер» SQL *Microsoft SQL Server *Администрирование баз данных *Профессиональная литература *
Привет, Хаброжители!Исчерпывающий обзор лучших практик по устранению неисправностей и оптимизации производительности Microsoft SQL Server. Специалисты по базам данных, в том числе разработчики и администраторы, научатся выявлять проблемы с производительностью, системно устранять неполадки и расставлять приоритеты при тонкой настройке, чтобы достичь максимальной эффективности.
Автор книги Дмитрий Короткевич — Microsoft Data Platform MVP и Microsoft Certified Master (MCM) — расскажет о взаимозависимостях между компонентами баз данных SQL Server. Вы узнаете, как быстро провести диагностику системы и найти причину любой проблемы. Методы, описанные в книге, совместимы со всеми версиями SQL Server и подходят как для локальных, так и для облачных конфигураций SQL Server.
Вы узнаете, как быстро провести диагностику системы и найти причину любой проблемы. Методы, описанные в книге, совместимы со всеми версиями SQL Server и подходят как для локальных, так и для облачных конфигураций SQL Server.
Всего голосов 11: ↑11 и ↓0 +11
Комментарии 2
Уровень сложности Простой
Время на прочтение 2 мин
Количество просмотров 2KБлог компании Тензор Ненормальное программирование *PostgreSQL *Программирование *SQL *
Туториал
Решим сегодня простую, казалось бы, задачу: как на PostgreSQL можно в строке провести замены по набору пар строк. То есть в исходной строке 'abcdaaabbbcccdcba' заменить, например, 'а' -> 'x', 'bb' -> 'y', 'ccc' -> 'z' и получить 'xbcdxxxybzdcbx'.
Фактически, мы попробуем создать аналог str_replace или strtr.
Всего голосов 9: ↑9 и ↓0 +9
Комментарии 4
msmerВремя на прочтение 5 мин
Количество просмотров 4.6KPostgreSQL *Программирование *SQL *Хранение данных *
Из песочницы
Перевод
Здравствуйте. Это версия моей первой статьи на русском языке, прошу не судить строго.
Одним из способов хранения древовидных структур в реляционных СУБД является “материализованный путь”. В интернете можно найти множество описаний этого и других способов, следует выбирать исходя из вашей задачи.
В PostgreSQL существует специальное расширение ltree, предоставляющее дополнительные инструменты для работы с метками и путями. О нем и о решении вопросов, связанных с консистентностью (целостностью) данных, и поговорим.
Итак, задача: сделать таблицу item с полем path типа ltree для удобной работы с деревом, а также обеспечить целостность данных на уровне базы.
Терминология:
Читать далееВсего голосов 10: ↑9 и ↓1 +8
Комментарии 6
pluzanovВремя на прочтение 27 мин
Количество просмотров 3.6KБлог компании Postgres Professional PostgreSQL *SQL *
Вместе с окончанием мартовского коммитфеста, закончился прием изменений в 16-ю версию. Пришла пора посмотреть, что в нем было нового и интересного.
Надеюсь, что представленный материал вместе с предыдущими статьями серии (2022-07, 2022-09, 2022-11, 2023-01) поможет сформировать представление о новинках PostgreSQL 16.
Читать дальше →Всего голосов 15: ↑15 и ↓0 +15
Комментарии 0
AndrewShmigУровень сложности Простой
Время на прочтение 4 мин
Количество просмотров 6.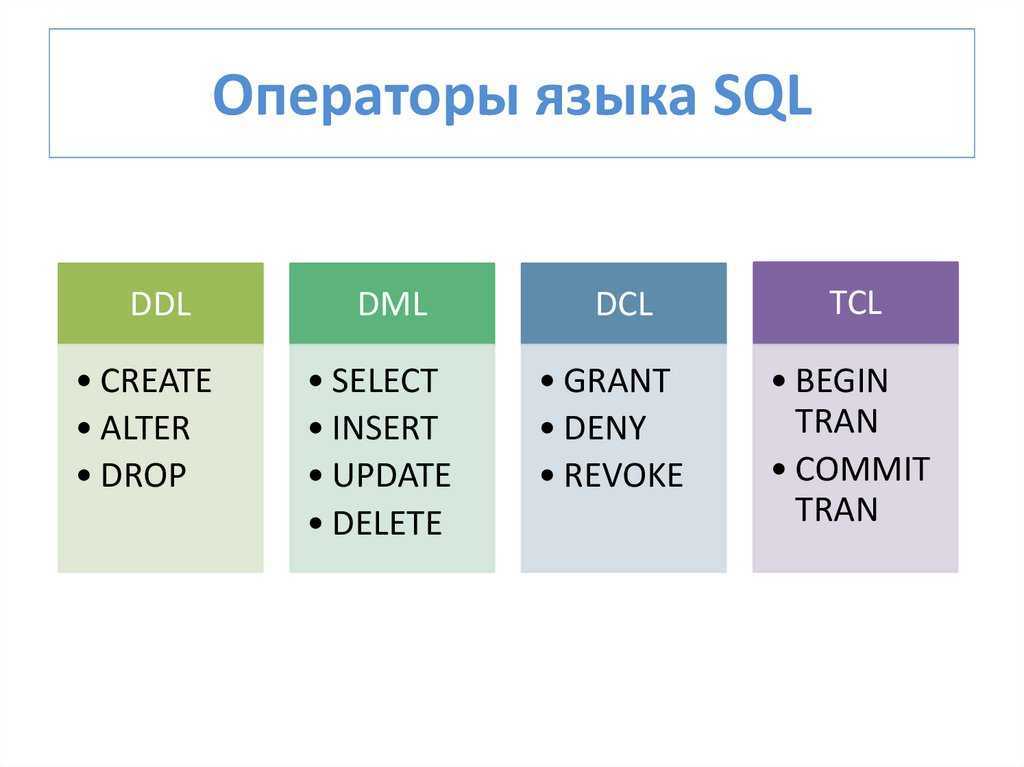 9K
9KSQL *Data Mining *Big Data *Открытые данные *Хранение данных *
Туториал
Привет! Меня зовут Андрей Шмиг, я разработчик платформы DataHub, платформа для совместной работы над данными — своего рода GitHub для данных. В этой статье покажу на что способен веб-редактор MySQL хранилища и почему это отличный инструмент для работы тем, кто изучает SQL.
Читать далееВсего голосов 7: ↑4 и ↓3 +1
Комментарии 9
TatianaLiУровень сложности Простой
Время на прочтение 3 мин
Количество просмотров 7.1KSQL *Учебный процесс в IT
Туториал
Самостоятельное обучение стало проще с Notion AI. Онлайн школы скоро вымрут?Пример SQL курса.
Читать далееВсего голосов 8: ↑6 и ↓2 +4
Комментарии 12
yooteamВремя на прочтение 1 мин
Количество просмотров 605Блог компании ЮMoney SQL *IT-инфраструктура *Конференции IT-компании
Как ЮMoney работает с данными в DWH на Microsoft SQL Server — ежегодный митап High SQL
ИТ-специалисты, вы тут? Начинаем наши митапы, и первый на очереди — High SQL.
Встречаемся 27 апреля в 18:00 по Москве.
Читать далееВсего голосов 2: ↑2 и ↓0 +2
Комментарии 0
badcasedaily1Уровень сложности Простой
Время на прочтение 11 мин
Количество просмотров 17KБлог компании RUVDS.com SQL *NoSQL *Администрирование баз данных *
SQL и NoSQL — две популярные модели баз данных, которые используют для решения различных задач. Чтобы понять, какая из них подойдёт в вашем случае, необходимо разобраться в их различиях, преимуществах и недостатках.В этой статье я рассмотрю основные характеристики SQL- и NoSQL-баз данных и сравню их, чтобы помочь выбрать лучший вариант для вашего проекта.
Читать дальше →Всего голосов 44: ↑36 и ↓8 +28
Комментарии 30
IzenxВремя на прочтение 6 мин
Количество просмотров 3. 7K
7KРазработка веб-сайтов *PHP *Symfony *Клиентская оптимизация *SQL *
Из песочницы
Всех приветствую! Я планирую создать цикл статей, демонстрирующий распространенные ошибки, влияющие на производительность приложения со стороны бэкенда, а также методы их поиска и устранения. Для этого, я написал приложение, в котором специально допустил различные ошибки, чтобы по порядку найти и исправить их.
В текущей статье, рассмотрим темы — n+1, пагинация и индексы. Приятного чтения!
Описание приложения
Рассматриваемый проект — это веб-журнал посещений различных мест людьми с возможностью выгрузки и загрузки журнала в формате XML. Пользователь может загрузить журнал посещений в формате XML через форму на странице /upload, и на основе информации из файла будет заполнена база данных. Вся информация о посещениях будет отображаться на главной странице /index. Экспорт из системы осуществляется через команду, которая преобразует информацию из системы в формат XML и выгружает ее в файл (data. xml).
xml).
Всего голосов 8: ↑7 и ↓1 +6
Комментарии 3
uhahatbl_tvВремя на прочтение 5 мин
Количество просмотров 7KИнформационная безопасность *SQL *Тестирование веб-сервисов *CTF *
Перевод
И это заключительная часть цикла статей про SQL-инъекции. В ней мы с вами узнаем, как можно собирать информацию о БД путем применения инъекций и затронем тему слепых SQL-инъекций.
Читать далееВсего голосов 12: ↑11 и ↓1 +10
Комментарии 16
igor_suhorukovУровень сложности Простой
Время на прочтение 13 мин
Количество просмотров 2.1KНенормальное программирование *PostgreSQL *Java *SQL *
После выступления на PgConf2023 у меня на выходных появилось время на реализацию идеи, как реализовать логику конечного автомата на SQL в PostgreSQL. Идея применима к любой СУБД, поддерживающей агрегатные функции, определяемые пользователем. И самое грустное, что в одной из самых популярных аналитических баз данных ClickHouse, эту задачу не нашел как вообще можно решить без Python на чистом SQL, хоть автосгенерированном.
Идея применима к любой СУБД, поддерживающей агрегатные функции, определяемые пользователем. И самое грустное, что в одной из самых популярных аналитических баз данных ClickHouse, эту задачу не нашел как вообще можно решить без Python на чистом SQL, хоть автосгенерированном.
Скоро сказка сказывается, да не скоро дело делается… Жил был Вася. Описали летописцы его житие с учебой в виде таблицы. А устои в обществе где он жил, были описаны с помощью конечного автомата. И конечный автомат мудрости — finite-state machine (FSM) был задан в виде таблицы переходов между состояниями, описанными в виде логических выражений на SQL…
Читать далееВсего голосов 5: ↑5 и ↓0 +5
Комментарии 3
uhahatbl_tvУровень сложности Простой
Время на прочтение 5 мин
Количество просмотров 7.7KИнформационная безопасность *SQL *Терминология IT CTF *
Перевод
Это вторая по счету статься из цикла про SQL инъекции. В данном статье мы с вами рассмотрим особенности SQL инъекций при использовании команды UNION.
В данном статье мы с вами рассмотрим особенности SQL инъекций при использовании команды UNION.
Всего голосов 4: ↑1 и ↓3 -2
Комментарии 8
nvvУровень сложности Средний
Время на прочтение 5 мин
Количество просмотров 2.4KPostgreSQL *SQL *Администрирование баз данных *
Использование ограничений на стороне базы данных, таких как внешние ключи, проверки значений, требования уникальности, иногда вызывают споры среди разработчиков. Аргумменты «за» и «против» обеих сторон хорошо известны.Рассмотрим пример, когда ограничения не просто применяются, а реализуют дополнительную логику с помощью дублирования некоторых данных.
Всего голосов 6: ↑5 и ↓1 +4
Комментарии 6
shoenfieldВремя на прочтение 7 мин
Количество просмотров 13KSQL *SQLite *
Из песочницы
Всем доброго дня!
Стал искать задачи по SQL, чтобы освежить свои знания, и к немалому удивлению обнаружил, что, несмотря на очевидную востребованность темы, интересные наборы задач на русскоязычных ресурсах можно пересчитать по пальцам. Хочу поделиться с сообществом своим мнением по поводу этих наборов, тем более что в отличие от самих задач далеко не все их авторские решения мне понравились.
Хочу поделиться с сообществом своим мнением по поводу этих наборов, тем более что в отличие от самих задач далеко не все их авторские решения мне понравились.
Всего голосов 7: ↑6 и ↓1 +5
Комментарии 11
badcasedaily1Уровень сложности Простой
Время на прочтение 9 мин
Количество просмотров 19KSQL *Data Mining *Big Data *Учебный процесс в IT Data Engineering *
Роадмэп
Roadmap, который поможет вам научиться работать с SQL. Чтобы стать настоящим экспертом в SQL, нужно много практиковаться и изучать различные аспекты языка на протяжении многих лет. Мой Roadmap предлагает отличный старт для начала изучения SQL, поэтому я рекомендую вам приступить к обучению согласно плану.
Читать далееВсего голосов 17: ↑14 и ↓3 +11
Комментарии 12
badcasedaily1 000Z» title=»2023-03-28, 10:00″>28 мар в 10:00
000Z» title=»2023-03-28, 10:00″>28 мар в 10:00Уровень сложности Простой
Время на прочтение 5 мин
Количество просмотров 11KАнализ и проектирование систем *SQL *Администрирование баз данных *Big Data *Data Engineering *
Туториал
NULL — это специальное значение, которое используется в SQL для обозначения отсутствия данных. Оно отличается от пустой строки или нулевого значения, так как NULL означает отсутствие какого-либо значения в ячейке таблицы.
История появления NULL в SQL довольно интересна и длинна. В начале 1970-х годов Д. Камерер (D. Chamberlin) и Р. Бойд (R. Boyce) предложили использовать реляционную модель для полной замены иерархических и сетевых моделей данных, которые были актуальны в то время. Полная замена предполагала возможность хранения значений NULL в таблицах структуры базы данных.
Первоначально, NULL был создан как интегральный элемент реляционной модели данных. Это означало, что NULL мог быть использован в качестве значения для любого типа данных (целого числа, строки и т. д.) или даже целой строки (например, таких значений как «неизвестно» или «нет данных»).
д.) или даже целой строки (например, таких значений как «неизвестно» или «нет данных»).
Когда была разработана SQL, NULL был реализован как специальное значение или маркер, который указывает на отсутствие значения в столбце. Таким образом, в SQL NULL означает отсутствие значения или неопределенное значение.
Однако, NULL создал некоторые проблемы при работе с данными в SQL. Например, если вы выполняете операцию на столбце, содержащем NULL значение, результат операции также будет NULL. Это означает, что использование NULL может приводить к нежелательным результатам, таким как непредсказуемое поведение.
Однако, важно понимать, что NULL не обязательно означает отсутствие информации или отсутствие значения в столбце. NULL может быть использован для разных целей, таких как указание на неопределенный результат для вычислений или как маркер для отметки отсутствия значения в таблице.
Читать далееВсего голосов 11: ↑6 и ↓5 +1
Комментарии 5
badcasedaily1 000Z» title=»2023-03-28, 00:18″>28 мар в 00:18
000Z» title=»2023-03-28, 00:18″>28 мар в 00:18Уровень сложности Простой
Время на прочтение 7 мин
Количество просмотров 50KИз песочницы
В 2023 году SQL (Structured Query Language) остается одним из самых популярных языков программирования, используемых в области баз данных и аналитики данных. Изучение SQL может быть полезным как для тех, кто только начинает свой путь в IT, так и для опытных профессионалов, которые хотят расширить свои знания и навыки. В этой статье мы рассмотрим несколько советов и ресурсов, которые помогут вам изучать SQL в 2023 году, и оставаться в курсе последних тенденций и изменений в этой области.
Согласно данным сайта Indeed.com, в 2023 году требования к кандидатам в вакансиях, связанных с базами данных и анализом данных, включают знание SQL в качестве обязательного навыка. Некоторые из таких популярных вакансий включают в себя SQL Developer, Data Analyst, Database Administrator, Business Intelligence Analyst и другие. Согласно данным сайта Glassdoor, зарплата специалистов, владеющих навыками работы с SQL, может составлять от $50 000 до $100 000 в год в зависимости от региона и уровня опыта. В связи с этим, изучение SQL может быть полезным для тех, кто хочет улучшить свои шансы на рынке труда и получать высокую заработную плату в IT-сфере.
Согласно данным сайта Glassdoor, зарплата специалистов, владеющих навыками работы с SQL, может составлять от $50 000 до $100 000 в год в зависимости от региона и уровня опыта. В связи с этим, изучение SQL может быть полезным для тех, кто хочет улучшить свои шансы на рынке труда и получать высокую заработную плату в IT-сфере.
Всего голосов 42: ↑37 и ↓5 +32
Комментарии 57
SQL — предметно-ориентированный язык, используемый в программировании и предназначенный для управления данными, хранящимися в системе управления реляционными базами данных, или для потоковой обработки в реляционной системе управления потоками данных. система управления реляционными базами данных или для потоковой обработки в реляционной системе управления потоками данных
Статьи Сообщения Авторы
Показать первым
Лимит рейтинга
Уровень сложности
 000Z» title=»2023-03-10, 16:27″> 10 мар в 16:27
000Z» title=»2023-03-10, 16:27″> 10 мар в 16:27 Время чтения 16 мин
Просмотров 967Корпоративный блог Postgres Professional PostgreSQL *SQL *
Обзор
Перевод
Продолжаем следить за новостями о выпуске PostgreSQL 16, и сегодня результаты четвертого коммита Фестивали проходят стол. Давайте посмотрим.
Если вы пропустили предыдущие CommitFests, ознакомьтесь с нашими обзорами на 2022-07, 2022-09 и 2022-11.
Подробнее →Всего голосов 7: ↑7 и ↓0 +7
Комментарии 0
коцев96Время чтения 9 мин
Просмотров 2.8KPostgreSQL *Java *SQL *NoSQL *Go *
Это цикл статей, посвященных оптимальному выбору между различными системами на реальном проекте или архитектурном интервью.
Эта тема показалась мне актуальной, потому что такие задачи могут встречаться и на работе, и на собеседовании на System Design Interview и вам придется выбирать между этими двумя типами СУБД. Я погрузился в этот вопрос и расскажу что и как. Что лучше в каждом конкретном случае, каковы преимущества и недостатки этих систем и какую выбрать, я покажу на нескольких примерах в конце статьи.
Я погрузился в этот вопрос и расскажу что и как. Что лучше в каждом конкретном случае, каковы преимущества и недостатки этих систем и какую выбрать, я покажу на нескольких примерах в конце статьи.
SQL или NoSQL?
ПодробнееВсего голосов 1: ↑1 и ↓0 +1
Комментарии 0
kaze_no_sagaВремя чтения 10 мин
Просмотров 1KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
Мы продолжаем следить за новостями о предстоящем выпуске PostgreSQL 16. Третий CommitFest завершился в начале декабря. Давайте посмотрим на результаты.
Если вы пропустили предыдущие CommitFests, ознакомьтесь с нашими обзорами: 2022-07, 2022-09.
Вот патчи, о которых я хочу рассказать:
meson: новая система сборки исходного кода
Документация: новая глава по обработке транзакций
psql: \d+ указывает на внешние разделы в многораздельной таблице
psql: расширенная поддержка протокола запросов
Предикатные блокировки материализованных представлений
Отслеживание времени последнего сканирования индексов и таблиц
pg_buffercache: новая функция pg_buffercache_summary
walsender отображает имя базы данных в статусе процесса
Уменьшение нагрузки WAL на замораживание кортежей
Уменьшение энергопотребления при простое
postgres_fdw: пакетный режим для COPY
Модернизация инфраструктуры GUC
Оптимизация построения хэш-индекса
MAINTAIN — новая привилегия для обслуживания таблиц
SET ROLE: улучшенное управление сменой ролей
Поддержка для директив включения файлов в pg_hba. conf и pg_ident.conf
conf и pg_ident.conf
Поддержка регулярных выражений в pg_hba.conf
Всего голосов 1: ↑1 и ↓0 +1
Комментарии 1
kaze_no_sagaВремя чтения 13 мин
Просмотров 1.3KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
Это официально! Вышел PostgreSQL 15, и сообщество активно обсуждает все новые функции свежей версии.
Тем временем прошел октябрьский CommitFest для PostgreSQL 16 со своими заметными дополнениями к коду.
Если вы пропустили июльский CommitFest, наша предыдущая статья поможет вам в кратчайшие сроки.
Вот патчи, о которых я хочу рассказать:
Функция SYSTEM_USER
Информация о замороженных страницах/кортежах в журнале сервера автоочистки
pg_stat_get_backend_idset возвращает фактический идентификатор бэкэнда в секционированные таблицы
Оптимизированный поиск в моментальных снимках
Двунаправленная логическая репликация
pg_auth_members: pg_auth_members: управление предоставлением членства в ролях
pg_auth_members: членство в ролях и наследование привилегий
pg_receivewal и pg_recvlogical теперь могут обрабатывать SIGTERM
Всего голосов 1: ↑1 и ↓0 +1
Комментарии 0
kaze_no_saga 000Z» title=»2022-11-08, 15:14″> 8 ноя 2022 в 15:14
000Z» title=»2022-11-08, 15:14″> 8 ноя 2022 в 15:14 Время чтения 17 мин
Просмотров 1,4KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
До сих пор мы обсуждали этапы выполнения запроса, статистику и два основных метода доступа к данным: последовательное сканирование и индексное сканирование.
Следующий пункт в списке — методы соединения. В этой статье мы напомним вам, какие существуют типы логических соединений, а затем обсудим один из трех физических методов соединения — соединение с вложенным циклом. Кроме того, мы рассмотрим функцию запоминания строки , представленную в PostgreSQL 14.
ПодробнееВсего голосов 4: ↑4 и ↓0 +4
Комментарии 0
kaze_no_sagaВремя чтения 7 мин.
Просмотров 747Корпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
Август был особенным месяцем в цикле выпуска PostgreSQL, так как был проведен первый CommitFest для 16-го выпуска PostgreSQL.
Давайте скомпилируем сервер и оценим крутые новинки!
ПодробнееРейтинг 0
Комментарии 0
kaze_no_sagaВремя чтения 19 мин
Просмотров 1.1KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
В предыдущих статьях мы рассмотрели этапы выполнения запросов, статистику, последовательное сканирование и сканирование индекса, а также два из трех методов соединения : вложенный цикл и хеш-соединение.
Эта последняя статья серии будет посвящена алгоритму слияния и сортировке . Я также покажу, как три метода соединения сравниваются друг с другом.
Подробнее →Всего голосов 3: ↑3 и ↓0 +3
Комментарии 0
kaze_no_sagaВремя чтения 18 мин
Просмотров 2,6KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
Запросы в PostgreSQL.
 Хэширование
ХэшированиеДо сих пор мы рассмотрели этапы выполнения запроса, статистику, последовательное сканирование и сканирование индекса и перешли к соединениям.
Подробнее →Всего голосов 5: ↑5 и ↓0 +5
Комментарии 1
kaze_no_sagaВремя чтения 18 мин
Просмотров 4,3KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Трансляция
В предыдущих статьях мы обсуждали этапы выполнения запросов и статистику. В прошлый раз я начал с методов доступа к данным, а именно с последовательного сканирования. Сегодня мы рассмотрим Index Scan.
Подробнее →Всего голосов 4: ↑4 и ↓0 +4
Комментарии 0
Иван СГлазуновВремя чтения 4 мин
просмотров 2.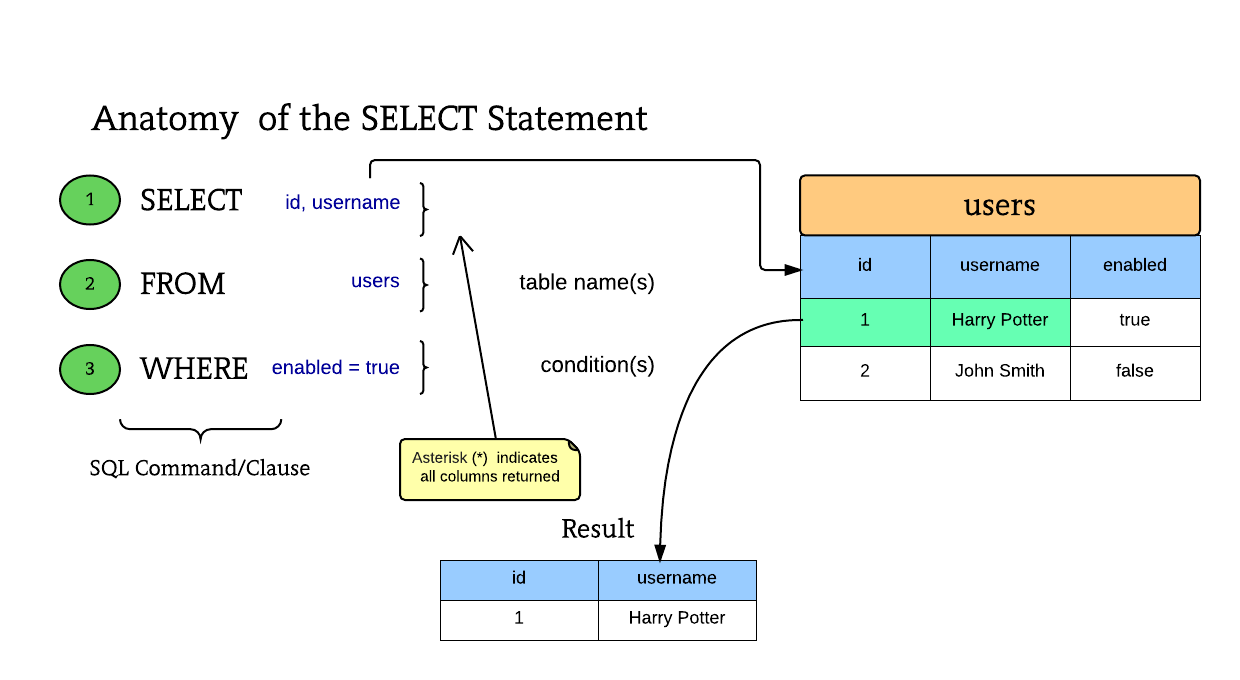 2K
2KSQL *Математика *Инжиниринг данных *
В этой статье мы хотели бы сравнить основные математические основы двух самых популярных теорий и ассоциативной теории.
Расчет глубиныВсего голосов 1: ↑1 и ↓0 +1
Комментарии 0
kaze_no_sagaВремя чтения 15 мин
Просмотров 1.9KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
В предыдущих статьях мы обсуждали, как система планирует выполнение запроса и как она собирает статистику для выбора наилучшего плана. Следующие статьи, начиная с этой, будут посвящены тому, что на самом деле представляет собой план, из чего он состоит и как он выполняется.
В этой статье я покажу, как планировщик рассчитывает затраты на выполнение. Я также расскажу о методах доступа и о том, как они влияют на эти затраты, и использую в качестве иллюстрации метод последовательного сканирования. Наконец, я расскажу о параллельном выполнении в PostgreSQL, о том, как оно работает и когда его использовать.
Наконец, я расскажу о параллельном выполнении в PostgreSQL, о том, как оно работает и когда его использовать.
Далее в статье я буду использовать несколько, казалось бы, сложных математических формул. Вам не нужно запоминать ни один из них, чтобы понять, как работает планировщик; они просто там, чтобы показать, откуда я беру свои цифры.
Подробнее →Всего голосов 3: ↑3 и ↓0 +3
Комментарии 0
kaze_no_sagaВремя чтения 18 мин
Просмотров 3.9KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
В прошлой статье мы рассмотрели этапы выполнения запроса. Прежде чем мы перейдем к планированию операций узла (методы доступа к данным и соединения), давайте обсудим хлеб с маслом оптимизатора затрат: статистику.
Узнайте, какие типы статистики собирает PostgreSQL при планировании запросов и как они улучшают оценку стоимости запросов и время выполнения.
Всего голосов 4: ↑3 и ↓1 +2
Комментарии 0
kaze_no_sagaВремя чтения 15 мин
Просмотров 3,7KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
Здравствуйте! Я начинаю очередной цикл статей о внутреннем устройстве PostgreSQL. Этот будет посвящен механике планирования и выполнения запросов.
В первой статье мы разобьем процесс выполнения запроса на этапы и обсудим, что именно происходит на каждом этапе.
ПодробнееВсего голосов 4: ↑4 и ↓0 +4
Комментарии 1
ероговВремя чтения 10 мин
просмотров 13KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
Напомню, что мы уже говорили о блокировках на уровне отношений, блокировках на уровне строк, блокировках на других объектах (включая предикатные блокировки) и взаимосвязях различных виды замков.
Следующее обсуждение блокировок в ОЗУ завершает серию статей. Мы рассмотрим спин-блокировки, легковесные блокировки и буферные пины, а также средства мониторинга событий и выборки.
Рейтинг 0
Комментарии 0
ероговВремя чтения 14 мин.
Просмотров 7.1KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
Мы уже обсуждали некоторые блокировки на уровне объектов (в частности, блокировки на уровне отношений), а также блокировки на уровне строк с их подключение к блокировкам на уровне объекта, а также изучены очереди ожидания, которые не всегда справедливы. На этот раз у нас мешанина. Мы начнем с взаимоблокировок (на самом деле, я планировал обсудить их в прошлый раз, но эта статья была слишком длинной сама по себе), затем кратко рассмотрим блокировок объектного уровня оставшихся и, наконец, обсудим предикатных блокировок .
Для визуализации взаимоблокировки удобно построить граф ожидания. Для этого мы убираем определенные ресурсы, оставляем только транзакции и указываем, какая транзакция ждет какую другую. Если граф содержит цикл (из вершины мы можем попасть в себя обходом по стрелкам), то это тупик.
Всего голосов 6: ↑6 и ↓0 +6
Комментарии 0
ероговВремя чтения 14 мин
Просмотров 11KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
В прошлый раз мы обсуждали блокировки на уровне объектов и, в частности, блокировки на уровне отношений. В этой статье мы увидим, как в PostgreSQL организованы блокировки на уровне строк и как они используются вместе с блокировками на уровне объектов. Мы также поговорим об очередях ожидания и о тех, кто вне очереди.
В этой статье мы увидим, как в PostgreSQL организованы блокировки на уровне строк и как они используются вместе с блокировками на уровне объектов. Мы также поговорим об очередях ожидания и о тех, кто вне очереди. Организация
Напомним несколько весомых выводов предыдущей статьи.- Блокировка должна быть доступна где-то в общей памяти сервера.
- Чем выше степень детализации блокировок, тем ниже конкуренция между параллельными процессами.
- С другой стороны, чем выше степень детализации, тем больше памяти занимают блокировки.
Существуют разные подходы к решению этой проблемы. Некоторые системы управления базами данных применяют эскалацию блокировок: если количество блокировок на уровне строк становится слишком большим, они заменяются одной более общей блокировкой (например, на уровне страницы или на уровне всей таблицы).
Как мы увидим позже, PostgreSQL также применяет эту технику, но только для предикатных блокировок. Ситуация с блокировками на уровне строк иная.
Всего голосов 4: ↑4 и ↓0 +4
Комментарии 2
ероговВремя чтения 13 мин.
Просмотров 13KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
Предыдущие две серии статей посвящены изоляции и многоверсионному управлению параллелизмом и ведению журналов.В этой серии мы обсудим замков .
Эта серия будет состоять из четырех статей:
- Блокировки на уровне отношений (эта статья).
- Замки на уровне строк.
- Блокировки других объектов и предикатные блокировки.
- Блокирует ОЗУ.
 .
.Большое спасибо Елене Индрупской за перевод этих статей на английский язык.
В PostgreSQL есть множество методов, которые служат для блокировки чего-либо (или, по крайней мере, называются так). Поэтому сначала объясню в самых общих чертах, зачем вообще нужны замки, какие они бывают и чем они отличаются друг от друга. Потом разберемся, что из этого многообразия используется в PostgreSQL и только после этого приступим к подробному обсуждению разных видов блокировок.
Подробнее →
Всего голосов 2: ↑2 и ↓0 +2
Комментарии 0
ероговВремя чтения 17 мин
Просмотров 7.6KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
Итак, мы ознакомились со структурой буферного кеша и в связи с этим пришли к выводу, что если все содержимое оперативной памяти потеряно из-за сбоя , для восстановления требовался журнал упреждающей записи (WAL). Размер необходимых файлов WAL и время восстановления ограничены благодаря периодически выполняемой контрольной точке.
Размер необходимых файлов WAL и время восстановления ограничены благодаря периодически выполняемой контрольной точке.В предыдущих статьях мы уже рассмотрели немало важных настроек, которые так или иначе относятся к WAL. В этой статье (последней в этой серии) мы обсудим еще нерешенные проблемы настройки WAL: уровни WAL и их назначение, а также надежность и производительность ведения журнала с опережающей записью.
Основная задача WAL — обеспечить восстановление после сбоя. Но раз нам все равно приходится вести журнал, мы также можем адаптировать его для других задач, добавив в него дополнительную информацию. Существует несколько уровней ведения журнала. Параметр wal_level задает уровень, и каждый следующий уровень включает в себя все, что попадает в WAL предыдущего уровня плюс что-то новое.Подробнее →
Всего голосов 2: ↑2 и ↓0 +2
Комментарии 0
ероговВремя чтения 11 мин
Просмотров 5.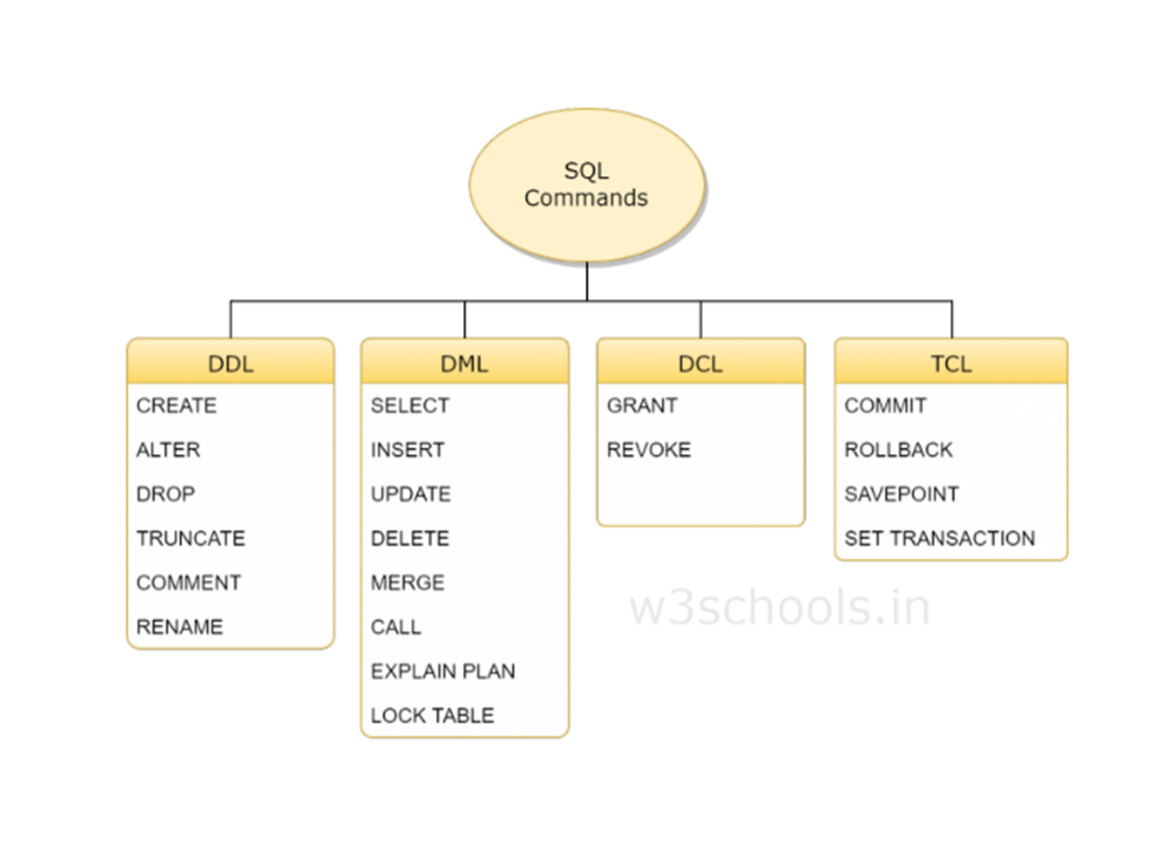 8K
8KКорпоративный блог Postgres Professional PostgreSQL *SQL *
Перевод
Мы уже ознакомились со структурой буферного кеша — одного из основных объектов разделяемой памяти — и пришли к выводу, что восстанавливать после сбой, когда все содержимое ОЗУ теряется, необходимо вести журнал упреждающей записи (WAL).Нерешенная проблема, на которой мы остановились в прошлый раз, заключается в том, что мы не знаем, с чего начать воспроизведение записей WAL во время восстановления. Начинать с начала, как советовал Король из Алисы Льюиса Кэролла, не вариант: невозможно хранить все записи WAL с момента старта сервера — это потенциально и огромный объем памяти, и не менее огромная продолжительность восстановление. Нам нужна такая точка, которая постепенно движется вперед и с которой мы можем начать восстановление (и соответственно безопасно удалить все предыдущие записи WAL). А это контрольно-пропускной пункт , который будет рассмотрен ниже.
Какими функциями должна обладать КПП? Мы должны быть уверены, что все записи WAL, начинающиеся с контрольной точки, будут применены к сброшенным на диск страницам.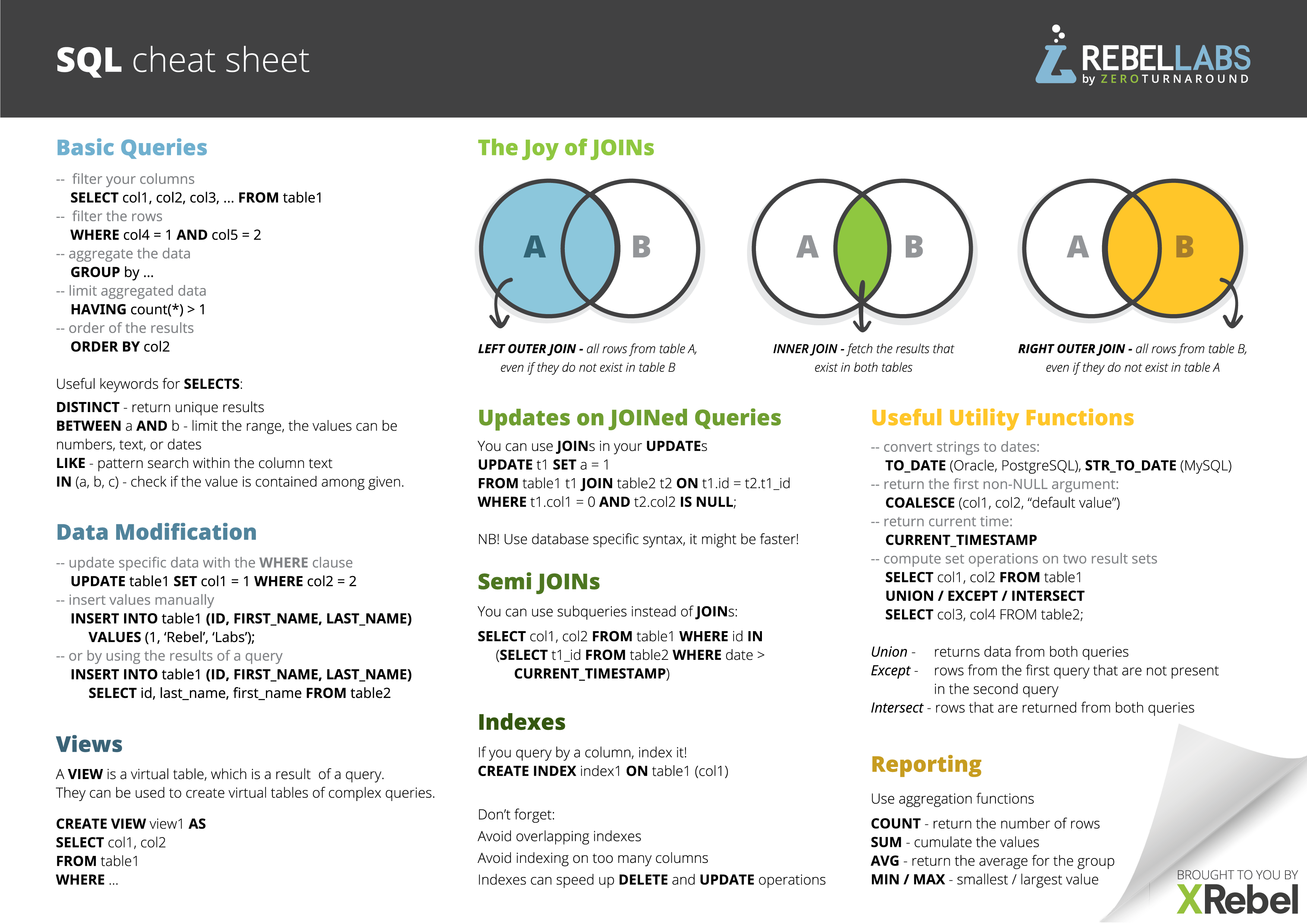 Если бы это было не так, то во время восстановления мы могли бы прочитать с диска слишком старую версию страницы, применить к ней WAL-запись и тем самым необратимо повредить данные.
Если бы это было не так, то во время восстановления мы могли бы прочитать с диска слишком старую версию страницы, применить к ней WAL-запись и тем самым необратимо повредить данные. Подробнее →
Всего голосов 4: ↑3 и ↓1 +2
Комментарии 0
хатривиджайВремя чтения 5 мин
просмотров 2,6 тыс.учебник
Что такое транзакция?Стандартное определение транзакции гласит, что «Каждый пакет запросов, который выполняется на сервере SQL, является транзакцией». Это означает, что любой запрос, который вы запускаете на сервере SQL, будет рассматриваться как транзакция, это может быть либо простой запрос SELECT. или любой запрос UPDATE или ALTER.
Если вы запускаете запрос без упоминания ключевого слова BEGIN TRAN, то он будет рассматриваться как Неявный переход .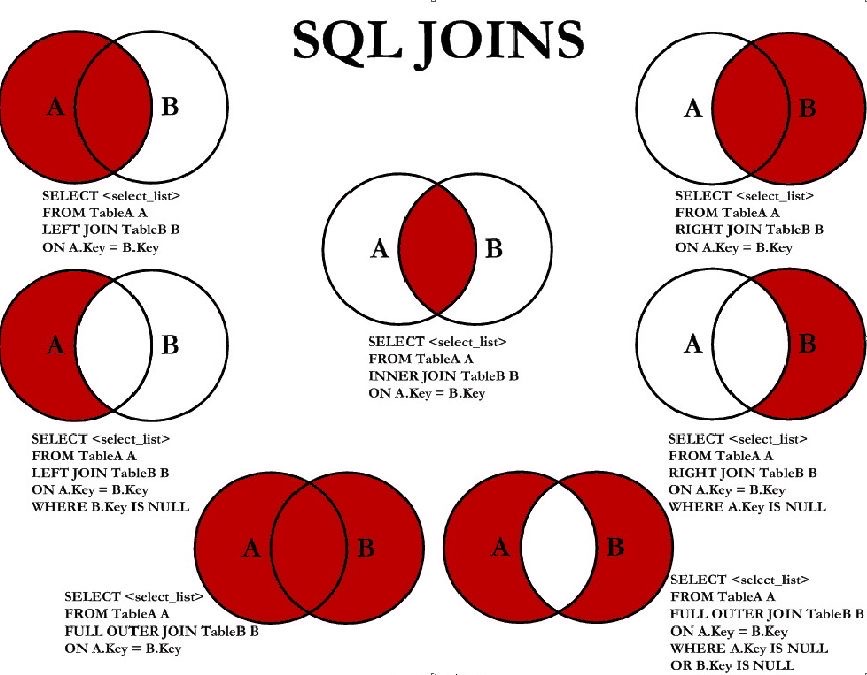
Если вы запускаете запрос, который начинается с BEGIN TRAN и заканчивается COMMIT или ROLLBACK, то он будет рассматриваться как Explicit Transaction.
Подробнее →Всего голосов 2: ↑1 и ↓1 0
Комментарии 0
SQL или NoSQL? / Хабр
Это цикл статей, посвященных оптимальному выбору между разными системами на реальном проекте или архитектурном интервью.
В этой серии статей я не буду рассказывать о глубоких истоках этих технологий, не буду разбирать каждую деталь, а сосредоточусь на том, как правильно подать эти технологии на собеседование и выбрать правильный и кратчайший путь, который бы убедил собеседнику, что вы приняли наилучшее решение в вашей конкретной ситуации.
Эта тема показалась мне актуальной, потому что такие задачи могут встречаться и на работе, и на собеседовании на System Design Interview и вам придется выбирать между этими двумя типами СУБД. Я погрузился в этот вопрос и расскажу что и как. Что лучше в каждом конкретном случае, каковы преимущества и недостатки этих систем и какую выбрать, я покажу на нескольких примерах в конце статьи.
Что лучше в каждом конкретном случае, каковы преимущества и недостатки этих систем и какую выбрать, я покажу на нескольких примерах в конце статьи.
Чтобы разобраться в теме, нужно немного погрузиться в структуру этих баз.
Высокоуровневые различия между SQL и NoSQL
Хранение:
SQL хранит данные в таблицах, где каждая строка представляет объект, а каждый столбец представляет информацию об этом объекте.
Самыми популярными базами данных SQL являются PostgreSQL (скорее всего, вы выберете ее на собеседовании в 80% случаев, потому что она одна из самых распространенных и простых в освоении), Microsoft SQL, Oracle Database (обе идеально подходят для больших корпоративные системы, такие как банки) и MySQL.
NoSQL имеет разные модели хранения данных, такие как ключ-значение, граф, документ, колонка и т. д.
Самый популярный NoSQL по типу хранилища, который вы, скорее всего, выберете на собеседовании и о котором вам стоит хотя бы прочитать пару статей:
Ключ-значение: Redis и Amazon DynamoDB.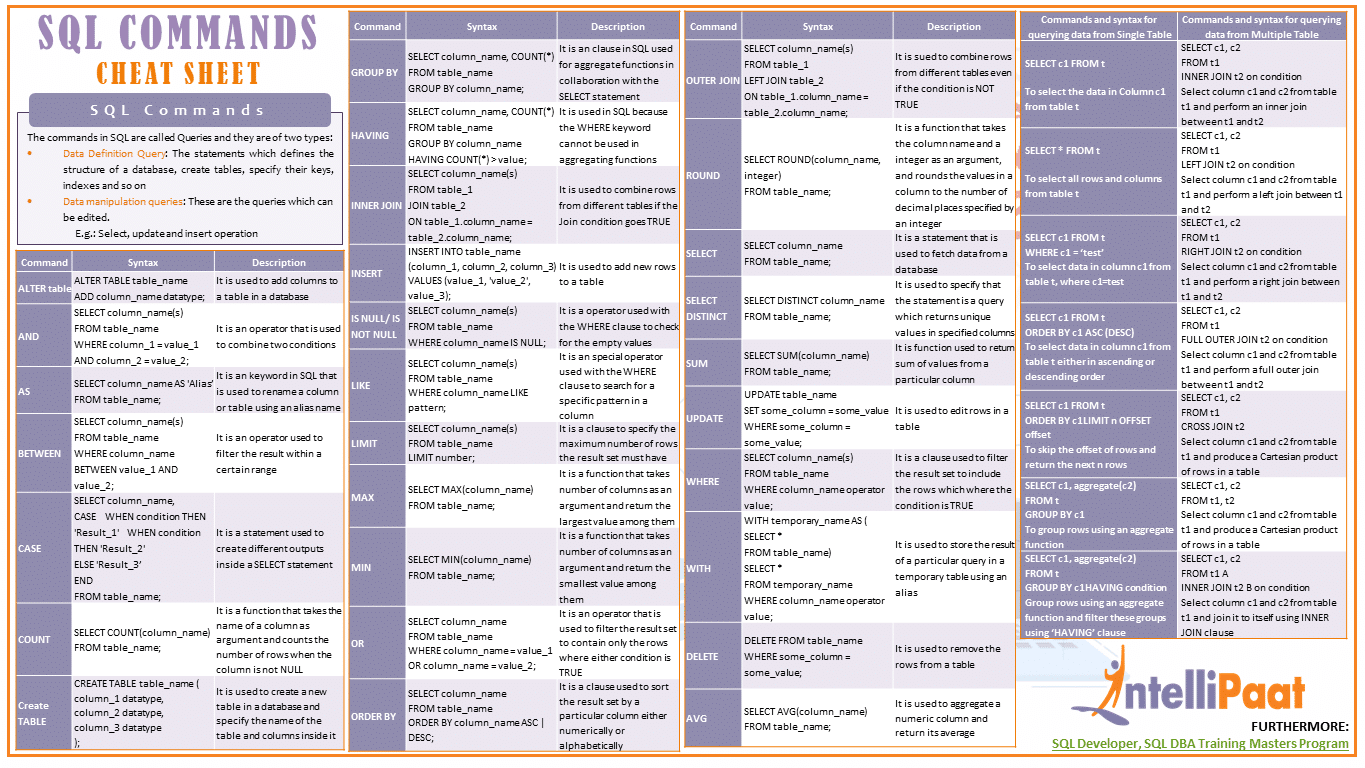
Документоориентированный: MongoDB.
Graph: Neo4j, GraphDB
Columnar: Apache HBase, Apache Cassandra
Скорее всего на собеседовании будет такая задача, где нужно будет выбрать первые 2 типа (если конечно предпочтение не NoSQL), так что стоит изучить их подробнее и написать какой-нибудь небольшой проект с использованием, например, Redis и MongoDB.
Различные показатели для разных нереляционных баз данных
Схема:
Схема в базе данных SQL относится к организации или структуре данных в базе данных. Он определяет таблицы, поля, отношения и ограничения, из которых состоит база данных, и служит образцом организации и хранения данных. Схемы можно использовать для обеспечения целостности и согласованности данных, а также они могут помочь в управлении доступом к данным, определяя, какие пользователи или роли имеют разрешение на выполнение определенных действий.
В базе данных NoSQL концепция схемы часто менее жесткая и структурированная по сравнению с базой данных SQL. Базы данных NoSQL могут быть бессхемными, а это означает, что структура хранимых данных может динамически изменяться и ее не нужно определять заранее.
Базы данных NoSQL могут быть бессхемными, а это означает, что структура хранимых данных может динамически изменяться и ее не нужно определять заранее.
Однако некоторые базы данных NoSQL имеют форму схемы, но она может быть более гибкой и динамичной, чем в базах данных SQL. Например, в ориентированной на документы базе данных NoSQL, такой как MongoDB, каждый документ может иметь свой собственный уникальный набор полей, а структура данных может меняться от документа к документу. В хранилище «ключ-значение», таком как Redis, каждая пара «ключ-значение» может иметь разные типы данных, поэтому структура данных является неявной и не требует явного определения.
Конкретная схема базы данных NoSQL зависит от типа базы данных и выбора дизайна, сделанного разработчиком или архитектором.
Запросы:
Для запросов к базам данных SQL соответственно используется язык SQL с различными модификациями от разработчиков баз данных, для удобной привязки языков программирования с базами данных SQL используется ORM, в случае Java, это Hibernate, Spring Data
Определенного языка для запросов в NoSQL БД нет, все зависит от типа БД, который был описан ранее, с использованием специализированных API, декларативно структурированных и Query-by-Example запросов
Примеры запросов в базе данных SQL и NoSQL MongoDB:
В этом запросе мы ищем контакты, которые либо имеют хотя бы один рабочий номер телефона, либо были приняты на работу после определенной даты. Опять же, мы видим, что эквивалент MongoDB довольно прост.
Опять же, мы видим, что эквивалент MongoDB довольно прост.
Обратите внимание на использование знаков доллара в именах операторов (`$or`, `$gt`) в качестве синтаксического сахара. Также обратите внимание, что в обоих примерах важно использовать в нашем сравнении фактическую дату, а не строку.
Масштабируемость:
В большинстве случаев базы данных SQL являются вертикальными, и это может быть дорого с точки зрения бюджета. Вы можете масштабировать такие базы данных по горизонтали, но это требует определенного навыка, знаний и специфики базы данных, с которой вы работаете, иначе есть риск потерять данные. По этому поводу вы можете подробно прочитать о шардинге, партиционировании и репликации.
Но с базами данных NoSQL горизонтальное масштабирование работает лучше. Базы данных NoSQL масштабируются горизонтально, что означает, что мы можем легко добавлять дополнительные серверы в нашу инфраструктуру баз данных NoSQL для обработки большого трафика.
Многие технологии NoSQL также автоматически распределяют данные между серверами. Почему NoSQL легче масштабировать? Потому что нет операции JOIN. Поэтому операции JOIN плохо масштабируются, и это основная проблема реляционного подхода. Однако этому (в большинстве случаев) также не хватает свойств ACID, что может привести к потере данных, несоответствиям и другим недостаткам не-ACID-систем.
Надежность:
Большинство реляционных баз данных используют свойства ACID. Это означает, что когда речь идет о целостности данных и надежности транзакций, базы данных являются лучшим выбором.
С другой стороны, нереляционные базы данных жертвуют ACID ради быстрого масштабирования и высокой производительности, поэтому такие базы данных следует использовать там, где безопасность данных и транзакционность не должны быть на уровне 99,9%.
Подытожим, что и когда использовать.
SQL если нужно:
— Структурированные данные со строгой схемой
— Реляционные данные
— Необходимость сложных соединений (использование подзапросов, соединение)
— Транзакции
— Поиск по индексу
NoSQL если нужно:
— Динамическая или гибкая схема
— Нереляционные данные
— Не требуются сложные подключения к данным
— Высокоинтенсивная работа с данными 900 03
— Высокая пропускная способность для IOPS (стандартный IOPS)
Пример 1: Система управления библиотекой
Представьте, что вы строите систему управления библиотекой, в которой вам необходимо отслеживать книги, авторов и членов библиотеки, а также проверки и возвраты. , и штрафы. В этом случае было бы целесообразнее использовать базу данных SQL, потому что:
, и штрафы. В этом случае было бы целесообразнее использовать базу данных SQL, потому что:
Структура данных:
Данные могут быть легко структурированы в таблицы для книг, авторов, членов библиотеки, касс, возвратов и штрафов, с взаимосвязями между ними.
Книги, авторы и члены библиотеки могут быть представлены в таблицах со столбцами для соответствующей информации. Например, в таблице books могут быть столбцы для названия книги, ISBN, автора и даты публикации.
Отношения между таблицами могут быть установлены через внешние ключи. Например, таблица books может иметь внешний ключ к таблице author, который будет связывать каждую книгу с ее автором.
Проверки, возвраты и штрафы также могут быть представлены в таблицах со столбцами для соответствующей информации. Например, в таблице проверок могут быть столбцы для члена библиотеки, книги и даты проверки.
Непротиворечивость и точность данных:
Непротиворечивость и точность данных важны, поскольку библиотеке необходимо отслеживать точную информацию о своих книгах, авторах и членах, а также о проверках, возвратах и штрафы.
Базы данных SQL предоставляют ACID-транзакции, чтобы гарантировать, что все обновления базы данных либо успешно завершены, либо отменены.Транзакции ACID гарантируют, что все обновления в базе данных будут успешно завершены или отменены в случае сбоя. Это означает, что система управления библиотекой может обрабатывать несколько запросов на получение одной и той же книги одновременно без потери или повреждения данных.
 Базы данных SQL предоставляют ACID-транзакции, чтобы гарантировать, что все обновления базы данных либо успешно завершены, либо отменены.
Базы данных SQL предоставляют ACID-транзакции, чтобы гарантировать, что все обновления базы данных либо успешно завершены, либо отменены.Сложные запросы:
Базы данных SQL предоставляют богатый язык запросов, позволяющий системе управления библиотекой создавать отчеты и анализировать данные. Например, система управления библиотекой может сгенерировать отчет обо всех покупках определенного автора за последний год, используя такой запрос:
ВЫБЕРИТЕ books.title, checkouts.checkout_date ИЗ книг ПРИСОЕДИНЯЙТЕСЬ к кассам ON books.book_id = checkouts.book_id ГДЕ books.author = "Джейн Остин" AND checkouts.checkout_date >= DATE_SUB(NOW(), INTERVAL 1 YEAR)
Целостность данных:
Целостность данных имеет решающее значение, и система должна применять правила, гарантирующие, что каждая проверка записывается в правильную книгу, и каждый штраф регистрируется в отношении правильного члена библиотеки.
Базы данных SQL имеют ограничения и триггеры, которые могут применять эти правила.Ограничения и триггеры могут использоваться для обеспечения соблюдения правил и обеспечения правильного ввода данных. Например, можно использовать ограничение, чтобы гарантировать, что участник библиотеки не может получить более 5 книг одновременно. Триггер можно использовать для автоматического обновления таблицы штрафов всякий раз, когда проверка возвращается с опозданием.
 Базы данных SQL имеют ограничения и триггеры, которые могут применять эти правила.
Базы данных SQL имеют ограничения и триггеры, которые могут применять эти правила.Умеренный объем операций записи и чтения:
Система управления библиотекой должна обрабатывать умеренный объем операций записи и чтения, а базы данных SQL хорошо подходят для обработки такого типа рабочей нагрузки.
Базы данных SQL хорошо подходят для обработки небольшого объема операций записи и чтения. Система управления библиотекой может обрабатывать несколько запросов на получение и возврат книг, а также создавать отчеты без каких-либо проблем с производительностью.

В заключение, в этом сценарии база данных SQL, такая как MySQL или PostgreSQL, обеспечит надежное, масштабируемое и гибкое решение для системы управления библиотекой.
Пример 2: Приложение для социальных сетей
Представьте, что вы создаете приложение для социальных сетей, в котором пользователи могут размещать обновления, комментировать сообщения и лайкать сообщения. В этом случае было бы более целесообразно использовать NoSQL, давайте расширим пример, чтобы увидеть, как будет работать база данных NoSQL:
Структура данных:
Данные для каждого пользователя, сообщения, комментария и подобные могут храниться как отдельные документы. Например, документ публикации может содержать текст публикации, пользователя, опубликовавшего ее, а также дату и время публикации. Документ комментария может содержать текст комментария, пользователя, оставившего комментарий, а также дату и время его создания.
Подобный документ может содержать пользователя, которому понравился пост, а также дату и время, когда он ему понравился.Взаимосвязь между сообщениями, комментариями и отметками «Нравится» может быть сохранена в виде ссылок или встроена в документы. Например, документ публикации может содержать массив ссылок на комментарии и лайки, связанные с этой публикацией.
 Подобный документ может содержать пользователя, которому понравился пост, а также дату и время, когда он ему понравился.
Подобный документ может содержать пользователя, которому понравился пост, а также дату и время, когда он ему понравился.Согласованность и точность данных:
База данных NoSQL может обеспечивать согласованность в конечном итоге, что означает, что для обновления данных на всех узлах кластера может потребоваться некоторое время. Это приемлемо в приложении для социальных сетей, где непротиворечивость данных в реальном времени не имеет решающего значения.
Сложные запросы:
Базы данных NoSQL могут не иметь такого богатого языка запросов, как базы данных SQL, но они предназначены для быстрого поиска данных. Например, приложение социальной сети может получить все сообщения для определенного пользователя с помощью запроса вида:
db.
 posts.find({user: "Jane Doe"})
posts.find({user: "Jane Doe"}) Целостность данных:
Базы данных NoSQL могут не обеспечивать такой же уровень обеспечения целостности данных, как базы данных SQL, но они все же могут обеспечивать соблюдение ограничений данных с помощью кода и логики приложения. Например, приложение для социальных сетей может применять правило, согласно которому пользователь не может лайкнуть свою собственную публикацию, проверяя идентификатор пользователя в подобном документе, прежде чем разрешать его сохранение.
Большой объем операций записи и чтения:
Базы данных NoSQL оптимизированы для обработки большого объема операций записи и чтения, что делает их хорошим выбором для приложений социальных сетей. Приложение для социальных сетей может обрабатывать несколько обновлений, комментариев и лайков в режиме реального времени без каких-либо проблем с производительностью.
Масштабируемость:
В заключение, в этом сценарии база данных NoSQL, такая как MongoDB, Cassandra, Redis или Aerospike, обеспечит масштабируемое, быстрое и гибкое решение для приложения для социальных сетей.
Пример 3: Система управления журналами
Представьте, что вы создаете систему управления журналами, в которой вам необходимо собирать и обрабатывать большие объемы данных журналов из различных источников. В этом случае было бы более целесообразно использовать базу данных NoSQL, потому что:
Данные неструктурированы и могут часто изменяться по мере добавления новых источников журналов или изменения форматов данных журналов. Базы данных NoSQL имеют гибкую схему, которая легко приспосабливается к этим изменениям.
Системе необходимо обрабатывать большой объем операций записи, поскольку данные журнала генерируются непрерывно. Базы данных NoSQL предназначены для обработки больших нагрузок записи.
Система должна быть масштабируемой для размещения растущих объемов данных журналов, а базы данных NoSQL можно легко масштабировать горизонтально, добавляя дополнительные узлы в кластер.

Система управления журналами может использовать базу данных NoSQL, такую как Apache Cassandra или Apache HBase, которые предназначены для обработки больших нагрузок записи и имеют гибкую схему для адаптации к меняющимся форматам данных журнала.
Пример 4: Банковская система
Представьте, что вы строите банковскую систему, в которой вам необходимо отслеживать счета клиентов, транзакции и кредиты. В этом случае было бы более целесообразно использовать базу данных SQL, потому что:
Данные легко структурируются в таблицы для клиентов, счетов, транзакций и кредитов с отношениями между ними.
Согласованность и точность данных очень важны, так как финансовые операции должны регистрироваться правильно. Базы данных SQL предоставляют ACID-транзакции, чтобы гарантировать, что все обновления базы данных либо успешно завершены, либо отменены.
Система должна поддерживать сложные запросы для создания отчетов или анализа данных.
