Инструкция SELECT INTO в T-SQL или как создать таблицу на основе SQL запроса? | Info-Comp.ru
Если у Вас возникала необходимость сохранить результирующий набор данных, который вернул SQL запрос, то данная статья будет Вам интересна, так как в ней мы рассмотрим инструкцию SELECT INTO, с помощью которой в Microsoft SQL Server можно создать новую таблицу и заполнить ее результатом SQL запроса.
Начнем мы, конечно же, с описания самой инструкции SELECT INTO, а затем перейдем к примерам.
Содержание
- Инструкция SELECT INTO в Transact-SQL
- Важные моменты про инструкцию SELECT INTO
- Примеры использования SELECT INTO
- Исходные данные
- Пример 1 – Создание таблицы с помощью инструкции SELECT INTO с объединением данных
- Пример 2 – Создание временной таблицы с помощью инструкции SELECT INTO с группировкой данных
Инструкция SELECT INTO в Transact-SQL
SELECT INTO – инструкция в языке в T-SQL, которая создает новую таблицу и вставляет в нее результирующие строки из SQL запроса. Структура таблицы, т.е. количество и имена столбцов, а также типы данных и свойства допустимости значений NULL, будут на основе столбцов (выражений), указанных в списке выбора из источника в инструкции SELECT. Обычно инструкция SELECT INTO используется для объединения в одной таблице данных из нескольких таблиц, представлений, включая какие-то расчетные данные.
Структура таблицы, т.е. количество и имена столбцов, а также типы данных и свойства допустимости значений NULL, будут на основе столбцов (выражений), указанных в списке выбора из источника в инструкции SELECT. Обычно инструкция SELECT INTO используется для объединения в одной таблице данных из нескольких таблиц, представлений, включая какие-то расчетные данные.
Для того чтобы использовать инструкцию SELECT INTO требуется разрешение CREATE TABLE в базе данных, в которой будет создана новая таблица.
Инструкция SELECT INTO имеет два аргумента:
- new_table — имя новой таблицы;
- filegroup – файловая группа. Если аргумент не указан, то используется файловая группа по умолчанию. Данная возможность доступна начиная с Microsoft SQL Server 2017.
Заметка! Начинающим рекомендую посмотреть мой видеокурс по T-SQL.
Важные моменты про инструкцию SELECT INTO
- Инструкцию можно использовать для создания таблицы на текущем сервере, на удаленном сервере создание таблицы не поддерживается;
- Заполнить данными новую таблицу можно как с текущей базы данных и текущего сервера, так и с другой базы данных или с удаленного сервера.
 Например, указывать полное имя базы данных в виде база_данных.схема.имя_таблицы или в случае с удаленным сервером, связанный_сервер.база_данных.схема.имя_таблицы;
Например, указывать полное имя базы данных в виде база_данных.схема.имя_таблицы или в случае с удаленным сервером, связанный_сервер.база_данных.схема.имя_таблицы; - Столбец идентификаторов в новой таблице не наследует свойство IDENTITY, если: инструкция содержит объединение (JOIN, UNION), предложение GROUP BY, агрегатную функцию, также, если столбец идентификаторов является частью выражения, получен из удаленного источника данных или встречается более чем один раз в списке выбора. Во всех подобных случаях столбец идентификаторов не наследует свойство IDENTITY и создается как NOT NULL;
- С помощью инструкции SELECT INTO нельзя создать секционированную таблицу, даже если исходная таблица является секционированной;
- В качестве новой таблицы можно указать обычную таблицу, а также временную таблицу, однако нельзя указать табличную переменную или возвращающий табличное значение параметр;
- Вычисляемый столбец, если такой есть в списке выбора инструкции SELECT INTO, в новой таблице он становится обычным, т.
- SELECT INTO нельзя использовать вместе с предложением COMPUTE;
- С помощью SELECT INTO в новую таблицу не переносятся индексы, ограничения и триггеры, их нужно создавать дополнительно, после выполнения инструкции, если они нужны;
- Предложение ORDER BY не гарантирует, что строки в новой таблице будут вставлены в указанном порядке.
- В новую таблицу не переносится атрибут FILESTREAM. Объекты BLOB FILESTREAM в новой таблице будут как объекты BLOB типа varbinary(max) и имеют ограничение в 2 ГБ;
- Объем данных, записываемый в журнал транзакций во время выполнения операций SELECT INTO, зависит от модели восстановления. В базах данных, в которых используется модель восстановления с неполным протоколированием, и простая модель, массовые операции, к которым относится SELECT INTO, минимально протоколируются. За счет этого инструкция SELECT INTO может оказаться более эффективней, чем отдельные инструкции по созданию таблицы и инструкции INSERT по заполнение ее данными.
 Например, указывать полное имя базы данных в виде база_данных.схема.имя_таблицы или в случае с удаленным сервером, связанный_сервер.база_данных.схема.имя_таблицы;
Например, указывать полное имя базы данных в виде база_данных.схема.имя_таблицы или в случае с удаленным сервером, связанный_сервер.база_данных.схема.имя_таблицы;

Примеры использования SELECT INTO
Все примеры я буду выполнять в СУБД Microsoft SQL Server 2016 Express.
Исходные данные
Для начала давайте создадим две таблицы и заполним их данными, эти таблицы мы и будем объединять в примерах.
CREATE TABLE TestTable(
[ProductId] [INT] IDENTITY(1,1) NOT NULL,
[CategoryId] [INT] NOT NULL,
[ProductName] [VARCHAR](100) NOT NULL,
[Price] [money] NULL
) ON [PRIMARY]
GO
CREATE TABLE TestTable2(
[CategoryId] [INT] IDENTITY(1,1) NOT NULL,
[CategoryName] [VARCHAR](100) NOT NULL
) ON [PRIMARY]
GO
INSERT INTO TestTable
VALUES (1,'Клавиатура', 100),
(1, 'Мышь', 50),
(2, 'Телефон', 300)
GO
INSERT INTO TestTable2
VALUES ('Комплектующие компьютера'),
('Мобильные устройства')
GO
SELECT * FROM TestTable
SELECT * FROM TestTable2
Пример 1 – Создание таблицы с помощью инструкции SELECT INTO с объединением данных
Давайте представим, что нам необходимо объединить две таблицы и сохранить полученный результат в новую таблицу (например, нам нужно получить товары с названием категории, к которой они относятся).
--Операция SELECT INTO SELECT T1.ProductId, T2.CategoryName, T1.ProductName, T1.Price INTO TestTable3 FROM TestTable T1 LEFT JOIN TestTable2 T2 ON T1.CategoryId = T2.CategoryId --Выборка данных из новой таблицы SELECT * FROM TestTable3
В итоге мы создали таблицу с названием TestTable3 и заполнили ее объединёнными данными.
Пример 2 – Создание временной таблицы с помощью инструкции SELECT INTO с группировкой данных
Сейчас давайте, допустим, что нам нужны сгруппированные данные, например, информация о количестве товаров в определенной категории, при этом эти данные нам нужно сохранить во временную таблицу, например, эту информацию мы будем использовать только в SQL инструкции, поэтому нам нет необходимости создавать полноценную таблицу.
--Создаем временную таблицу (#TestTable) с помощью инструкции SELECT INTO SELECT T2.CategoryName, COUNT(T1.ProductId) AS CntProduct INTO #TestTable FROM TestTable T1 LEFT JOIN TestTable2 T2 ON T1.CategoryId = T2.CategoryId GROUP BY T2.CategoryName --Выборка данных из временной таблицы SELECT * FROM #TestTable

Как видим, у нас получилось создать временную таблицу #TestTable и заполнить ее сгруппированными данными.
Вот мы с Вами и рассмотрели инструкцию SELECT INTO в языке T-SQL, всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
sql — Translation into Russian — examples English
Premium History Favourites
Advertising
Download for Windows It’s free
Download our free app
Advertising
Advertising
No ads with Premium
English
Arabic German English Spanish French Hebrew Italian Japanese Dutch Polish Portuguese Romanian Russian Swedish Turkish Ukrainian Chinese
Russian
Synonyms Arabic German English Spanish French Hebrew Italian Japanese Dutch Polish Portuguese Romanian Russian Swedish Turkish Ukrainian Chinese Ukrainian
Suggestions: sql server sql injection
These examples may contain rude words based on your search.
These examples may contain colloquial words based on your search.
SQL-базы
SQL-
СУБД
язык структурированных запросов
SQL SQL-инъекции SQL-запросы SQL-запросов SQL-сервер SQL-запрос
SQL-запроса
Suggestions
2553
286
sql database 217
ms sql 210
The second line is a
Вторая линия является резервной копии SQL-базы данных вы укажете.
An sql error occurred while fetching this page.
Произошла ошибка SQL при выборке на этой странице.
They could also try to inject sql sentences in order to gain access.
Они также могут попытаться придать SQL предложения для того, чтобы получить доступ.
It is extremely useful when attacking tricky sql vulnerabilities.
ПО является чрезвычайно полезным при атаке сложных уязвимостей SQL-инъекций.
One of the most common methods of hacking websites, working with databases, sql — a SQL-injection.
Один из наиболее распространённых способов взлома веб сайтов, работающих с базами данных SQL — это SQL-инъекция.
No need of installing another sql client.
Не требует установки дополнительного клиентского ПО.
Support of single string comments in sql query texts:
Поддержка однострочных комментариев в текстах sql запросов:
Now you can abort loading of resulting rowsets in sql scripts
Теперь можно прерывать загрузку результирующих множеств в SQL-скриптах
Created queries are saved in files with the sql extension, so that you can later edit them and view the results.
Созданные запросы сохраняются в файлах с расширением «sql«, так что впоследствии можно их редактировать и просматривать результаты.
Accordingly, you affirm that you have the legal right to sql all data, information and files that have been hidden.
Таким образом, Вы подтверждаете, что Вы обладаете законным правом обращаться к данным, информации и файлам.
object INDEX is in use when dropping constraint | IBProvider, Firebird, Interbase sql
тормоза при использовании агрегатных функций | IBProvider, Firebird, Interbase sql
IBPROVIDER classic ASP and Japanese data | IBProvider, Firebird, Interbase sql
Долго убивается коннект | IBProvider, Firebird, Interbase sql
The main difficulty in the case of direct access — «specific» approach to 1C naming tables and fields in a sql database, documentation standards which are not covered by 1C.
Основная сложность в случае прямого доступа — «специфический» подход 1С к именованию таблиц и полей в SQL базе, документация на стандарты которого фирмой 1С не распространяется.
restore sql dump into a new database: «sqlite3» «.read» «.quit»
восстановить SQL дамп в новую базу данных: «sqlite3» «.прочитать» «.уволиться»
In addition, we can not ignore the query language sql, which, although not independently used for programming the site, in conjunction with other languages, for example, the same php, is an essential feature of programming sites, working with databases.
Кроме того, нельзя обойти вниманием язык запросов SQL, который, хотя и самостоятельно не используется для программирования сайтов, в связке с другими языками, например, тем же PHP, является непременным атрибутом программирования сайтов, работающих с базами данных.
IBProvider, Firebird, Interbase sql Error!! when select data from interbase by Linked Server
IBProvider, Firebird, Interbase sql Ошибка подключения к БД
IBProvider, Firebird, Interbase sql IBProvider with Firebird Classic server?
Долго убивается коннект | IBProvider, Firebird, Interbase sql
Need some basic help with reading field data | IBProvider, Firebird, Interbase sql
«Ошибка при выполнении многошаговой операции» | IBProvider, Firebird, Interbase sql
IBProvider 2 — Unknown Order by Column | IBProvider, Firebird, Interbase sql
Ошибка выборки данных результирующего множества | IBProvider, Firebird, Interbase sql
Interact with large databases using SQL.
Работа с большими базами данных с использованием SQL.
Possibly inappropriate content
Examples are used only to help you translate the word or expression searched in various contexts. They are not selected or validated by us and can contain inappropriate terms or ideas. Please report examples to be edited or not to be displayed. Rude or colloquial translations are usually marked in red or orange.
Register to see more examples It’s simple and it’s free
Register Connect
No results found for this meaning.sql server 2553
sql injection 286
sql database 217
ms sql 210
More features with our free app
Voice and photo translation, offline features, synonyms, conjugation, learning games
Results: 3226.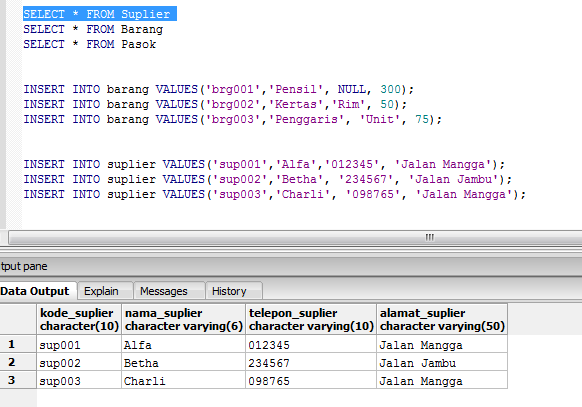 Exact: 3226. Elapsed time: 99 ms.
Exact: 3226. Elapsed time: 99 ms.
Word index: 1-300, 301-600, 601-900
Expression index: 1-400, 401-800, 801-1200
Phrase index: 1-400, 401-800, 801-1200
Селективный индекс от 1С — что выберет MS SQL? / Хабр
В предыдущей статье Партицированная дисциплина программиста в 1С был показан пример запроса на соединение двух таблиц для регистра сведений, и показано как MS SQL выбирает потоки данных для merge join с использованием стандартных индексов 1С . В частности было отмечено, что без дополнительных условий в Index seek, в поток для Megre join попадают все записи индекса и приходится указывать дополнительные фильтры для ограничения. Вопрос: почему так происходит? — остался открытым.
Все что описано ниже, это мои выводы на основании анализа поведения оптимизатора MS SQL 2019 в разных условиях. Официально изложенных алгоритмов, которые использует оптимизатор MS SQL я не нашел, если знаете ссылку пишите в комментариях.
Сначала вспомним понятие селективного индекса.
Если сказать кратко – индекс для данного запроса является селективным , если при его использовании можно выбрать
Больше уникальных строк
С меньшим количеством дублей
Наименьшее количество строк на каждую комбинацию ключевых значений
Про селективность хорошо написано тут (правда для Oracle, но это же общая концепция)
Селективный индекс
Возьмем оптимизированный запрос из предыдущей статьи
ВЫБРАТЬ РАЗЛИЧНЫЕ СУУ_АгрегированныеДенежныеТранзакции.СвязаннаяОпИдИсхСистемы КАК СвязаннаяОпИдИсхСистемы ПОМЕСТИТЬ Врем_ИдОперацийИзТранзакций ИЗ РегистрСведений.СУУ_АгрегированныеДенежныеТранзакции КАК СУУ_АгрегированныеДенежныеТранзакции ГДЕ СУУ_АгрегированныеДенежныеТранзакции.Период >= &ДатаНачала ИНДЕКСИРОВАТЬ ПО СвязаннаяОпИдИсхСистемы ; //////////////////////////////////////////////////////////////////////////////// ВЫБРАТЬ СУУ_АгрегированнаяСделкаКП.
 Период,
СУУ_АгрегированнаяСделкаКП.ИсходнаяСистема,
СУУ_АгрегированнаяСделкаКП.ИдИсхСистемы КАК ИдИсхСистемы,
СУУ_АгрегированнаяСделкаКП.ОсновнойСчет,
СУУ_АгрегированнаяСделкаКП.НогаСделки
ПОМЕСТИТЬ РезультатВыбранныеВерсииСделок
ИЗ
РегистрСведений.СУУ_АгрегированнаяСделкаКП КАК СУУ_АгрегированнаяСделкаКП
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Врем_ИдОперацийИзТранзакций КАК Врем_ИдОперацийИзТранзакций
ПО СУУ_АгрегированнаяСделкаКП.ИдИсхСистемы = Врем_ИдОперацийИзТранзакций.СвязаннаяОпИдИсхСистемы
ГДЕ
СУУ_АгрегированнаяСделкаКП.Период >= ДОБАВИТЬКДАТЕ(&ДатаНачала, МЕСЯЦ, -3)
//И опять его запустим со стандартными индексами 1С. MS SQL нас интересует последний запрос
INSERT INTO #tt3 WITH(TABLOCK) (_Q_001_F_000, _Q_001_F_001RRef, _Q_001_F_002, _Q_001_F_003RRef, _Q_001_F_004RRef) SELECT
T1._Period,
T1._Fld18861RRef,
T1._Fld18865,
T1._Fld18863RRef,
T1._Fld19363RRef
FROM dbo._InfoRg18860 T1 WITH(NOLOCK)
INNER JOIN #tt2 T2 WITH(NOLOCK)
ON (T1._Fld18865 = T2._Q_000_F_000)
WHERE ((T1._Fld628 = @P1)) AND ((T1.
Период,
СУУ_АгрегированнаяСделкаКП.ИсходнаяСистема,
СУУ_АгрегированнаяСделкаКП.ИдИсхСистемы КАК ИдИсхСистемы,
СУУ_АгрегированнаяСделкаКП.ОсновнойСчет,
СУУ_АгрегированнаяСделкаКП.НогаСделки
ПОМЕСТИТЬ РезультатВыбранныеВерсииСделок
ИЗ
РегистрСведений.СУУ_АгрегированнаяСделкаКП КАК СУУ_АгрегированнаяСделкаКП
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Врем_ИдОперацийИзТранзакций КАК Врем_ИдОперацийИзТранзакций
ПО СУУ_АгрегированнаяСделкаКП.ИдИсхСистемы = Врем_ИдОперацийИзТранзакций.СвязаннаяОпИдИсхСистемы
ГДЕ
СУУ_АгрегированнаяСделкаКП.Период >= ДОБАВИТЬКДАТЕ(&ДатаНачала, МЕСЯЦ, -3)
//И опять его запустим со стандартными индексами 1С. MS SQL нас интересует последний запрос
INSERT INTO #tt3 WITH(TABLOCK) (_Q_001_F_000, _Q_001_F_001RRef, _Q_001_F_002, _Q_001_F_003RRef, _Q_001_F_004RRef) SELECT
T1._Period,
T1._Fld18861RRef,
T1._Fld18865,
T1._Fld18863RRef,
T1._Fld19363RRef
FROM dbo._InfoRg18860 T1 WITH(NOLOCK)
INNER JOIN #tt2 T2 WITH(NOLOCK)
ON (T1._Fld18865 = T2._Q_000_F_000)
WHERE ((T1._Fld628 = @P1)) AND ((T1. _Period >= @P2))',N'@P1 numeric(10),@P2 datetime2(3)
_Period >= @P2))',N'@P1 numeric(10),@P2 datetime2(3)
Смотрим общую цену, которую зафиксировал оптимизатор — в попугаях 7767
План получается с Index Seek по типовому индексу _InfoR18860_ByDims18897_STRRRR
Структура индекса
План запроса ниже, видно что основная тяжесть ввода вывода идет на Index Seek и операции Merge
Вроде все хорошо, по правилам и предсказуемо, но давайте добавим ему другой индекс в котором, убрано поле _Fld628 . Это поле содержит 0 поскольку в типовой конфигурации есть, но не используются
Смотрим результат. Неожиданно – SQL сервер выбрал новый индекс сам , даже при том что _Fld628 (разделителя) там вообще нет! Хотя есть индекс _InfoR18860_ByDims18897_STRRRR который формально удовлетворяет всем условиям.
План при этом получился лучше, но не намного
Разница
1) По стандартному индексу идет |—Index Seek(OBJECT:([MIS_PROD2].[dbo].[_InfoRg18860].[_InfoR18860_ByDims18897_STRRRR] AS [T1]), SEEK:([T1]. [_Fld628]=[@P1]), WHERE:([MIS_PROD2].[dbo].[_InfoRg18860].[_Period] as [T1].[_Period]>=[@P2]) ORDERED FORWARD)
[_Fld628]=[@P1]), WHERE:([MIS_PROD2].[dbo].[_InfoRg18860].[_Period] as [T1].[_Period]>=[@P2]) ORDERED FORWARD)
2) По нестандартному индексу идет скан с проверкой всех условий |—Index Scan(OBJECT:([MIS_PROD2].[dbo].[_InfoRg18860].[_InfoR18860_MySuperWithout_Fld628_ByDims18897_STRRRR] AS [T1]), WHERE:([MIS_PROD2].[dbo].[_InfoRg18860].[_Fld628] as [T1].[_Fld628]=[@P1] AND [MIS_PROD2].[dbo].[_InfoRg18860].[_Period] as [T1].[_Period]>=[@P2]) ORDERED FORWARD)
Мы выбираем селективный индекс, а оптимизатор выбирает …
Почему MS SQL так сделал? Скорее всего поле, где _Fld628 = 0 в каждой записи, убивает всю селективность индекса и как только появляется достойная альтернатива MS SQL и сам бежит к ней
Вопрос А в какое место индекса, тогда поставить это поле _Fld628 (ОбластьДанныхОсновныеДанные) , которое 1С по умолчанию ставит в начало (префикс) всех индексов?
Это сложный вопрос. Если ОбластьДанныхОсновныеДанные используется хотябы с несколькими значениями, селективность повысится в стандартном индексе, учитывая условия на равенства которые добавляет 1С T1. _Fld628 = @P1 (равенство всегда в приоритете у оптимизатора нежели >= <=)
_Fld628 = @P1 (равенство всегда в приоритете у оптимизатора нежели >= <=)
Но все очень зависит от СУБД , напр тут описаны мифы о селективных индексах причем с планами для разных СУБД
Use index luke
“The myth is extraordinarily persistent in the SQL Server environment and appears even in the official documentation. The reason is that SQL Server keeps a histogram for the first index column only. But that means that the recommendation should read like “uneven distributed columns first” because histograms are not very useful for evenly distributed columns anyway.”
Т.е. первая колонка в индексе решает все и ее количество уникальных значений. Если там один 0 работа с остальными полями идет уже менее эффективно. Если 0 1 2, то это тоже сильно ситуацию не исправляет, поскольку для Merge без доп условий пойдет поток данных по всему T1._Fld628 = @P1
В целом лучше жить без поля ОбластьДанныхОсновныеДанные , чем с ним, но если без него нельзя то улучшить ситуацию можно только альтернативным построением запроса самой платформы, а это уже другая альтернативная история для следующих статей. Буду рад видеть Вас на нашем канале 😊 t.me/Chat1CUnlimited
Буду рад видеть Вас на нашем канале 😊 t.me/Chat1CUnlimited
Оператор SQL SELECT INTO
В этой статье будет рассмотрен оператор SQL SELECT INTO, включая синтаксис, параметры и использование с несколькими таблицами, файловыми группами и условием WHERE.
Мы регулярно вставляем данные в таблицы SQL Server либо из приложения, либо непосредственно в SSMS. Мы можем вставлять данные с помощью оператора INSERT INTO. Для этого у нас уже должна быть таблица для вставки в нее данных, поскольку мы не можем создать таблицу, используя Insert into the statement.
Нам нужно выполнить следующие задачи, используя оператор INSERT INTO.
- Создайте структуру таблицы с соответствующими типами данных
- Вставьте в него данные
Но хорошая новость заключается в том, что мы можем элегантно выполнить обе задачи вместе, используя оператор SQL SELECT INTO. Он создает структуру таблицы для столбцов, возвращаемых оператором Select.
Предположим, мы хотим обновить много записей в таблице. Мы можем использовать оператор SELECT INTO для создания резервной таблицы с существующей структурой исходной таблицы. Давайте рассмотрим SELECT INTO в этой статье.
Синтаксис оператора SELECT INTO
ВЫБЕРИТЕ столбец 1, столбец 2… Столбец N INTO New_table ИЗ таблиц [Где условия]; |
Параметры в операторе SELECT INTO
- Список столбцов: Нам нужно указать столбец, который мы хотим получить и вставить в новую таблицу
- New_table: Здесь мы можем указать имя новой таблицы. SQL Server создает новую таблицу со столбцами, указанными в списке столбцов. Мы не можем заменить существующую таблицу, используя это. Имя таблицы должно быть уникальным
- Таблицы: Содержит таблицу, из которой мы хотим получить записи. Мы также можем иметь несколько таблиц, определенных здесь, с правильным предложением Join
- Условия WHERE: Мы можем фильтровать записи, используя предложение Where. Это необязательный пункт
Давайте рассмотрим оператор SQL SELECT INTO на примерах.
Окружающая среда:
В этом примере мы используем учебную базу данных AdventureWorks2017. Предположим, мы хотим выбрать записи из таблицы [Employee] и создаем новую таблицу [Employee_Demo] с помощью оператора SELECT INTO. Нам нужны выбранные столбцы только в новой таблице. Давайте запустим оператор select для таблицы Employee со столбцами, которые мы хотим иметь.
1 2 3 4 5 6 7 8 10 3 9 3 | Select Top (10) [nationalDnumber] , [Loginid] , [JobTitle] , [DIRNATE] , [MaritStstatus] , [Пол] , [настаи. ОТ [AdventureWorks2017].[Отдел кадров].[Сотрудник] |
Прежде чем мы выполним оператор SQL SELECT INTO, мы можем убедиться, что таблица Employee_Demo не существует в базе данных AdventureWorks2017 , используя команду sp_help .
sp_help ‘[AdventureWorks2017].[HumanResources].[Employee_Demo]’ |
На следующем снимке экрана мы видим, что таблицы Employee_Demo не существует в моей базе данных.
Выполните следующий запрос, чтобы создать новую таблицу [Employee_Demo], используя оператор SELECT INTO.
1 2 3 4 5 6 7 8 10 3 9 3 | Select Top (10) [NationalIdnumber] , [Loginid] , [JobTitle] , [Dirowdate] , [Maritalstatus] , [Пол] , [нанят] , [каникула ] В [AdventureWorks2017]. FROM [AdventureWorks2017].[HumanResources].[Employee] |
Мы получаем следующее выходное сообщение в Azure Data Studio. Вы можете заметить, что количество затронутых строк равно 10. В запросе мы выбрали 10 лучших записей из 9.0040 Сотрудник табл.
Мы можем получить доступ к данным из вновь созданной таблицы Employee_Demo и убедиться, что она содержит те же записи, что и в нашем предыдущем операторе выбора.
Мы не указывали никаких свойств столбца в операторе SQL SELECT INTO. Давайте сравним столбцы исходной и целевой таблиц и их свойства.
Мы можем запустить команду sp_help ‘tablename’ на обоих Сотрудник и Таблица Employee_Demo . Я скопировал вывод обеих таблиц в Excel (для выбранных столбцов). На следующем снимке экрана видно, что тип данных столбца и их свойства аналогичны.
В предыдущем операторе SQL SELECT INTO мы подготовили целевую таблицу (Employee_Demo) из нескольких столбцов исходной таблицы (Employee).
Давайте создадим еще одну таблицу со всеми столбцами в таблице сотрудников со следующим запросом.
SELECT * INTO [AdventureWorks2017].[HumanResources].[Employee_All] [AdventureWorks2017].[HumanResources].[Employee] |
В выводе мы видим, что он вставил 290 строк в таблицу Employee_All .
Мы убедились, что оператор SELECT INTO создает новую таблицу со столбцами, указанными в списке столбцов. Он также создает аналогичный тип данных в целевой таблице.
Предположим, у нас есть первичный и внешний ключи в исходной таблице. Создает ли он первичный ключ и внешний ключ, аналогичные исходной таблице? Нет, оператор SQL SELECT INTO не создает никаких ключей в целевой таблице. Если мы хотим, мы можем определить ключи в таблице назначения. Проверим это в следующем разделе.
В моем предыдущем примере таблица Employee содержит первичный и внешний ключи, определенные для нее. Мы можем получить список существующих ключей, используя представление INFORMATION_SCHEMA. Выполните следующий код, и он вернет существующие первичный и внешний ключи в таблице сотрудников.
Мы можем получить список существующих ключей, используя представление INFORMATION_SCHEMA. Выполните следующий код, и он вернет существующие первичный и внешний ключи в таблице сотрудников.
1 2 3 4 5 6 7 8 | Выбрать Отличный Constraint_Name AS [Constraint], Table_Schema AS [Schema], Table_Name AS [TableName] от information_schema. |
Мы видим, что таблица Employee содержит первичный и внешний ключи.
Мы скопировали все столбцы в Employee_All из Employee таблицы . Теперь нам нужно проверить первичный и внешний ключ в таблице назначения.
1 2 3 4 5 6 7 8 | SELECT DISTINCT Constraint_Name AS [Ограничение], Table_Schema AS [Схема], Table_Name AS [TableName] FROM INFORMATION_SCHEMA. где Table_Name=’Employee_All’ GO |
 KEY_COLUMN_USAGE
KEY_COLUMN_USAGEМы видим, что он не содержит ключа в таблице назначения. Это дает нам гибкость в определении ключей в целевой таблице.
SQL SELECT INTO — вставка данных из нескольких таблиц
В предыдущих примерах мы создали таблицу, используя команду SELECT INTO 9.0041 выписка из одной таблицы Сотрудник . Мы также можем объединить несколько таблиц и использовать оператор SELECT INTO для создания новой таблицы с данными. В этом разделе мы хотим объединить несколько таблиц вместе. В следующем запросе мы объединили следующие таблицы вместе в AdventureWorks2017.
- [Отдел кадров].[Сотрудник]
- [Человек].[Человек]
- [Персона].[BusinessEntityAddress]
- [Лицо].[Адрес]
- [Человек].[ШтатПровинция]
- [Человек].[СтранаРегион]
- [Человек]. [PersonPhone]
- [Человек].[ТипНомераТелефона]
- [Человек].[Адрес электронной почты]
 [PersonPhone]
[PersonPhone]Выполните следующий запрос. Он дает результаты из нескольких таблиц на основе условия соединения и упомянутых столбцов.
1 2 3 4 5 6 7 8 10 110003 12 13 14 1999000114 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 25 26 27 28 29 30 28 29 30 0002 3132 33 34 35 36 37 | Выберите e. ,e.[JobTitle] ,pp. ,pnt.[Name] AS [PhoneNumberType] ,ea.[EmailAddress] , с. [EmailPromotion] , а. ] ,cr.[Name] AS [CountryRegionName] ,p.[AdditionalContactInfo] FROM [HumanResources].[Employee] e INNER JOIN [Person].[0 3] p 90 p 90 BusinessEntityID] = e.[BusinessEntityID] INNER JOIN [Person].[BusinessEntityAddress] bea ON bea.[BusinessEntityID] = e.[BusinessEntityID] INNER JOIN [Person].[Address] a ON a.[AddressID] = bea.[AddressID] INNER JO [Statevince JO [Person]. ] sp ON sp.[StateProvinceID] = a.[StateProvinceID] INNER JOIN [Person].[CountryRegion] cr ON cr.[CountryRegionCode] = sp.[CountryRegionCode] 3 OUTER 3 .[PersonPhone] pp ON pp.BusinessEntityID = p.[BusinessEntityID] LEFT OUTER JOIN [Person].[PhoneNumberType] pnt ON pp.[PhoneNumberTypeID] = pnt. LEFT OUTER JOIN [Person].[EmailAddress] ea 2 ON. .[BusinessEntityID];ГО |
 [PhoneNumber]
[PhoneNumber] [PhoneNumberTypeID]
[PhoneNumberTypeID]Выполните запрос, и мы получим следующие выходные данные оператора SQL SELECT INTO .
Мы хотим создать таблицу с данными, возвращаемыми с помощью приведенной выше таблицы. Давайте выполним оператор SQL SELECT INTO.
1 2 3 4 5 6 7 8 10 110003 12 13 14 1999000114 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 25 26 27 28 29 30 28 29 30 0002 3132 33 34 35 36 37 38 | Выберите e. ,e.[JobTitle] ,pp.[PhoneNumber] ,pnt.[Name] AS [PhoneNumberType] ,ea.[EmailAddress] , с. Почтовый код] , кр. [Имя] как [CountryRegionName] , с. .[Person] p ON p.[BusinessEntityID] = e.[BusinessEntityID] INNER JOIN [Person].[BusinessEntityAddress] bea ON bea.[BusinessEntityID] = e.[BusinessEntityID] INNER JOIN [Person].[Address] a 90 IDON] a [Address. AddressID]INNER JOIN [Person].[StateProvince] sp ON sp.[StateProvinceID] = a.[StateProvinceID] INNER JOIN [Person].[CountryRegion] cr 90 Region]ON cr. .[CountryRegionCode]LEFT OUTER JOIN [Person].[PersonPhone] стр. на PP.BusinessentityId = p. [BusinessIDID] левый внешний соединение [Person]. ] ea ON p.[BusinessEntityID] = ea.[BusinessEntityID]; ГО |

Он создает таблицу [HumanResources]. [Employee_JoinTables] и вставляет в нее данные. Мы можем проверить записи в этой таблице с помощью оператора select.
[Employee_JoinTables] и вставляет в нее данные. Мы можем проверить записи в этой таблице с помощью оператора select.
Мы видим, что вы можете объединить несколько таблиц вместе и создать выходную таблицу, используя оператор SELECT INTO.
Нам не нужно заботиться об определении типов данных для целевой таблицы. Если мы хотим создать таблицу вручную, нам нужно посмотреть тип данных каждого столбца и соответствующим образом определить тип данных. Если существует несоответствие между типами данных, вы можете получить сообщение об ошибке, подобное следующему.
Ошибка 1: из-за несоответствия типов данных
Сообщение 245, уровень 16, состояние 1, строка 1
Ошибка преобразования при преобразовании значения varchar «GG» в тип данных int.
Ошибка 2: сообщение 8152, уровень 16, состояние 30, строка 2
Строка или двоичные данные будут проигнорированы.
Мы не получаем эти ошибки при вставке данных с помощью инструкции SQL SELECT INTO. Однако мы не можем вставлять данные в существующие таблицы, используя этот метод.
Однако мы не можем вставлять данные в существующие таблицы, используя этот метод.
SELECT INTO — указать файловую группу
В предыдущих разделах мы рассмотрели возможность создания новой таблицы и вставки в нее данных с помощью инструкции SQL SELECT INTO из существующих таблиц. Он создает таблицу только в файловой группе по умолчанию. Мы не можем указать конкретную файловую группу до SQL Server 2016. В SQL Server 2017 мы можем указать конкретную файловую группу, в которой должна быть создана новая таблица. SQL Server создает новую таблицу в этой конкретной таблице Verify Table Filegroup. Если мы не укажем какие-либо файловые группы в SQL Server 2017 и более поздних версиях, будет создана таблица в файловой группе по умолчанию.
Примечание: Мы не можем указать файловые группы в SQL SELECT INTO для SQL Server 2016 и более ранних версий.
Давайте добавим новую файловую группу в базу данных AdventureWorks2017. Щелкните правой кнопкой мыши базу данных и перейдите к Filegroups .
На этой странице Filegroup щелкните Add FileGroup и укажите имя для Filegroup.
Теперь щелкните Files , и в нем будут перечислены существующие файлы базы данных (данные и файл журнала), на этой странице добавьте новый файл данных и укажите FileGroup из раскрывающегося списка. Это должна быть FileGroup, которую мы только что создали.
Мы хотим создать таблицу SQL в файловой группе INSERTFILE . Мы не установили эту файловую группу в качестве файловой группы по умолчанию.
В следующем запросе вы можете видеть, что мы указали имя файловой группы, используя предложение ON. Он работает аналогично обычному оператору SQL SELECT INTO с разницей в файловой группе.
выберите * в person.person_temp ON INSERTFILE —FILEGROUP NAME от чел.лицо |
После создания таблицы выполните команду sp_help для этой вновь созданной таблицы. На следующем снимке экрана мы можем убедиться, что таблица расположена в INSERTFILE FileGroup. Это файловая группа, которую мы создали ранее.
На следующем снимке экрана мы можем убедиться, что таблица расположена в INSERTFILE FileGroup. Это файловая группа, которую мы создали ранее.
Мы также можем проверить это из свойств таблицы. Щелкните правой кнопкой мыши таблицу в SSMS. В разделе Storage видим нужную FileGroup.
SELECT INTO с условием Where
Предположим, мы хотим создать таблицу с оператором SQL SELECT INTO с несколькими записями в ней. Мы можем использовать предложение Where , аналогичное оператору select. В следующем запросе мы хотим создать таблицу person.person_WC для человека с фамилией вроде %Duf%.
выберите * в person.person_WC ON INSERTFILE — Проверить таблицу Filegroup от person.person , где Фамилия типа «%Duf%» |
Заключение
В этой статье мы рассмотрели оператор SQL SELECT INTO и сценарии его использования. Это полезная команда для создания копии таблицы без указания типов данных.
Это полезная команда для создания копии таблицы без указания типов данных.
- Автор
- Последние сообщения
Раджендра Гупта
Привет! Я Раджендра Гупта, специалист по базам данных и архитектор, помогаю организациям быстро и эффективно внедрять решения Microsoft SQL Server, Azure, Couchbase, AWS, устранять связанные проблемы и настраивать производительность с более чем 14-летним опытом.
Я автор книги «DP-300 Administering Relational Database on Microsoft Azure». Я опубликовал более 650 технических статей о MSSQLTips, SQLShack, Quest, CodingSight и MultipleNines.
Я создатель одной из крупнейших бесплатных онлайн-коллекций статей по одной теме, включая его серию из 50 статей о группах доступности SQL Server Always On.
На основании моего вклада в сообщество SQL Server я был признан престижным лучшим автором года непрерывно в 2019, 2020 и 2021 годах (2-й ранг) в SQLShack и награда чемпионов MSSQLTIPS в 2020 году.
Личный блог: https://www.dbblogger.com помогите, свяжитесь со мной по адресу [email protected]
Просмотреть все сообщения Раджендры Гупты
Последние сообщения Раджендры Гупты (посмотреть все)
Оператор SELECT INTO TEMP TABLE в SQL Server
В этой статье мы рассмотрим оператор SELECT INTO TEMP TABLE, его синтаксис и детали использования, а также приведите несколько простых базовых примеров, чтобы закрепить полученные знания.
Введение
Оператор SELECT INTO — это один из простых способов создать новую таблицу, а затем скопировать в нее данные исходной таблицы. только что созданная таблица. Другими словами, оператор SELECT INTO выполняет комбинированную задачу:
- Создает таблицу-клон исходной таблицы с точно такими же именами столбцов и типами данных.
- Читает данные из исходной таблицы
- Вставляет данные во вновь созданную таблицу
Мы можем использовать оператор SELECT INTO TEMP TABLE для выполнения вышеуказанных задач в одном операторе для временного
столы. Таким образом, мы можем быстро скопировать данные исходной таблицы во временные таблицы.
Таким образом, мы можем быстро скопировать данные исходной таблицы во временные таблицы.
Синтаксис оператора SELECT INTO TEMP TABLE
ВЫБРАТЬ * | Column1, Column2… ColumnN INTO #TempDestinationTable FROM Source_Table ГДЕ Условие |
Аргументы SELECT INTO TEMP TABLE
- Список столбцов: Мы можем использовать звездочку (*) для создания полной временной копии исходной таблицы или можем выбрать определенные столбцы исходной таблицы
- Таблица назначения: Эта таблица ссылается на имя временной таблицы, в которую мы будем создавать и вставлять данные. Мы можем указать целевую таблицу как локальную или глобальную временную таблицу. Для локальной временной таблицы мы используем один знак решетки (#), а для глобальной временной таблицы мы используем знак решетки (##).
- Исходная таблица: Источник — это таблица, из которой мы хотим считать данные
- Пункт Where: Мы можем использовать предложение where, чтобы применить фильтр к данным исходной таблицы.

В следующем примере мы вставим данные таблицы Location в таблицу #TempLocation. Другими словами, мы создаст временный клон таблицы Location.
ВЫБЕРИТЕ * INTO #TempLocation FROM Production.Location ПЕРЕЙТИ SELECT * FROM #TempLocation |
Как мы видим, оператор SELECT INTO создает таблицу #TempLocation, а затем вставляет в нее данные таблицы Location.
Когда мы хотим вставить определенные столбцы таблицы Location во временную таблицу, мы можем использовать следующее запрос :
SELECT LocationID, Name, ModifiedDate INTO #TempLocationCol FROM Production.Location GO SELECT * FROM #TempLocationCol |
Здесь следует обратить внимание на то, что имена столбцов временной таблицы и исходной таблицы совпадают. Чтобы изменить
имена столбцов временной таблицы, мы можем дать псевдонимы столбцам исходной таблицы в запросе на выборку.
Чтобы изменить
имена столбцов временной таблицы, мы можем дать псевдонимы столбцам исходной таблицы в запросе на выборку.
SELECT LocationID AS [TempLocationID], Имя AS [TempLocationName] ,ModifiedDate AS [TempModifiedDate] INTO #TempLocationCol FROM Production.Location GO 2 903Location SELECT * FROMC |
В то же время мы можем отфильтровать некоторые строки Location, а затем вставить набор результатов во временную таблицу. следующий запрос фильтрует строки, в которых столбец имени начинается с символа «F», а затем вставляет наборы результатов во временную таблицу.
SELECT LocationID, Name, ModifiedDate INTO #TempLocationCon FROM Production.Location WHERE Name LIKE ‘F%’ GO SELECT * FROM #TempLocationCon |
INSERT INTO SELECT vs SELECT INTO TEMP TABLE
Оператор INSERT INTO SELECT считывает данные из одной таблицы и вставляет их в существующую таблицу. Например, если мы хотим
скопируйте данные таблицы Location во временную таблицу с помощью инструкции INSERT INTO SELECT, мы должны указать
временную таблицу явно, а затем вставить данные.
Например, если мы хотим
скопируйте данные таблицы Location во временную таблицу с помощью инструкции INSERT INTO SELECT, мы должны указать
временную таблицу явно, а затем вставить данные.
1 2 3 4 5 6 7 8 10 11 0003 12 13 | — Объявите временную таблицу — Создание таблицы #Copylocation ( LocationId Smallint Not Null, Имя NVARCHAR (50) Не NULL, Costrate Smallmone 2) НЕ НУЛЕВОЕ, ModifiedDate datetime NOT NULL)
— Копировать данные во временную таблицу — INSERT INTO #CopyLocation SELECT * FROM Production.Location — Выберите данные из временной таблицы — 9000 — ВЫБРАТЬ * ИЗ #CopyLocation |
На самом деле, эти два утверждения выполняют одну и ту же задачу разными способами. Однако они имеют некоторые отличия в
сценарии их использования.
Однако они имеют некоторые отличия в
сценарии их использования.
ВСТАВИТЬ В ВЫБОР | ВЫБЕРИТЕ |
Требуется явно объявить целевую временную таблицу. Таким образом, это позволяет гибко изменять типы данных столбца и возможность создавать индексы. | Автоматически создает целевую временную таблицу. |
Благодаря гибкости определения типов данных столбцов позволяет передавать данные из разных таблиц. | Он может создать резервную копию таблицы с простым синтаксисом. |
SELECT INTO TEMP TABLE производительность
Оператор SELECT INTO TEMP TABLE выполняет две основные задачи в контексте производительности, а именно:
- Чтение данных из исходных данных
- Вставка данных во временную таблицу
Производительность операции чтения данных зависит от производительности запроса select, поэтому нам необходимо оценить производительность
процесс чтения данных в этой области.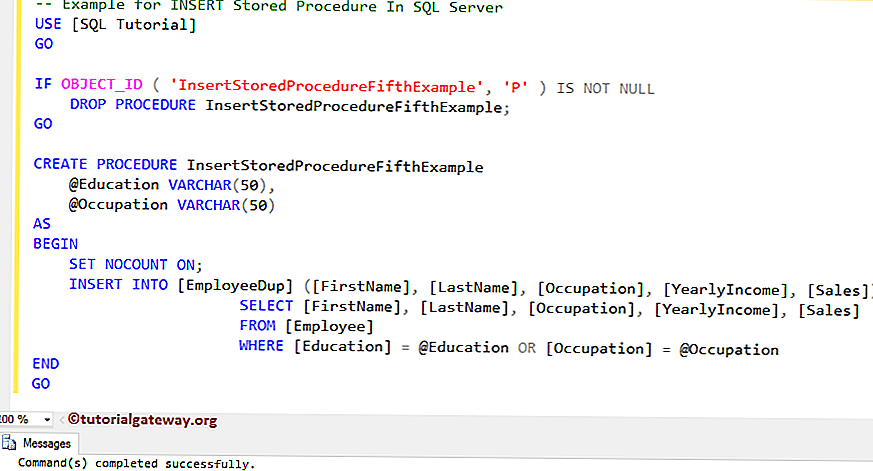 Однако конфигурация базы данных tempdb повлияет на
производительность оператора вставки. В SQL 2014 операторы SELECT … INTO выполняются параллельно, поэтому
они показывают лучшую производительность. Теперь давайте проанализируем следующий план выполнения запроса.
Однако конфигурация базы данных tempdb повлияет на
производительность оператора вставки. В SQL 2014 операторы SELECT … INTO выполняются параллельно, поэтому
они показывают лучшую производительность. Теперь давайте проанализируем следующий план выполнения запроса.
ВЫБЕРИТЕ SalesOrderID, CarrierTrackingNumber, ModifiedDate INTO #TempsSalesDetail FROM Sales.SalesOrderDetail ЗАКАЗ ПО SalesOrderID |
1- Оператор Clustered Index Scan считывает все данные из первичного ключа таблицы SalesOrderDetail и передает все данные в таблицу оператора вставки.
2- Оператор Table Insert добавляет новые данные во временную таблицу и выполняет эту операцию параллельно. способ. Эту ситуацию можно отобразить в атрибуте Фактическое количество строк. Поток 0 не показывает никаких значений потому что это поток координатора.
Оператор Gather Stream объединяет несколько параллельных операций в одну операцию. В этом плане выполнения запроса
мы использовали предложение ORDER BY, но мы не видим никакого оператора в плане выполнения. В то же время
Оператор Clustered Index Scan не возвращает результат в отсортированном виде. Причина этого пункта в том, что нет
гарантия порядка вставки строк в таблицу.
В этом плане выполнения запроса
мы использовали предложение ORDER BY, но мы не видим никакого оператора в плане выполнения. В то же время
Оператор Clustered Index Scan не возвращает результат в отсортированном виде. Причина этого пункта в том, что нет
гарантия порядка вставки строк в таблицу.
Заключение
В этой статье мы изучили синтаксис и детали использования инструкции SELECT INTO TEMP TABLE. Этот Оператор очень удобен для вставки данных таблицы или данных запроса во временные таблицы.
- Автор
- Последние сообщения
Esat Erkec
Esat Erkec — специалист по SQL Server, который начал свою карьеру более 8 лет назад в качестве разработчика программного обеспечения. Он является сертифицированным экспертом по решениям Microsoft для SQL Server.
Большая часть его карьеры была посвящена администрированию и разработке баз данных SQL Server. Его текущие интересы связаны с администрированием баз данных и бизнес-аналитикой.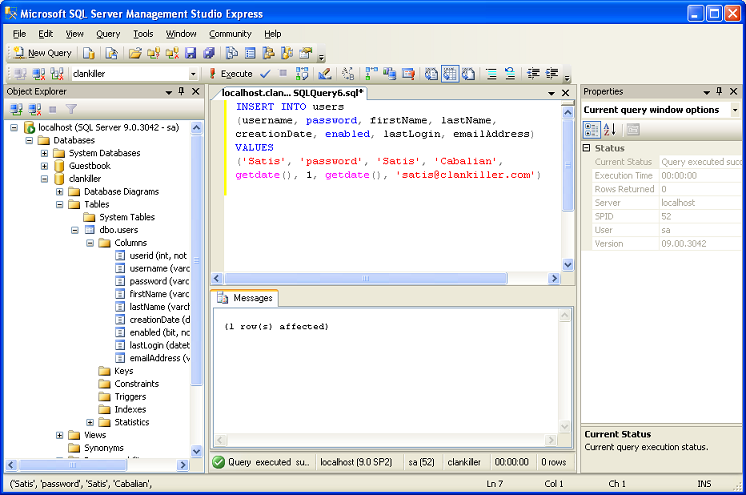 Вы можете найти его в LinkedIn.
Вы можете найти его в LinkedIn.
Просмотреть все сообщения от Esat Erkec
Последние сообщения от Esat Erkec (посмотреть все)
SQL Server SELECT INTO — javatpoint
следующий → ← предыдущая В этой статье будет дан полный обзор инструкции SELECT INTO в SQL Server. Мы будем использовать этот оператор для добавления данных в таблицы. Когда мы используем этот оператор, он сначала создаст новую таблицу в файловой группе по умолчанию, а затем вставит записи, выбранные оператором SELECT, в эту новую таблицу. Следует отметить, что ограничения из исходной таблицы не копируются в целевую таблицу. Синтаксис:Ниже приведен синтаксис, иллюстрирующий оператор SELECT INTO: ВЫБЕРИТЕ список_столбцов INTO новое_имя_таблицы ОТ source_table_name [Где условия]; ПараметрыОбъяснение параметров этого оператора приведено ниже:
ВЫБЕРИТЕ В ПримерДавайте разберемся, как оператор SELECT INTO работает в SQL Server, на нескольких примерах. Предположим, у нас есть таблица «сотрудник» , которая содержит следующие данные: 1. Если мы хотим скопировать все записи таблицы сотрудников в таблицу backup_employee, нам нужно использовать оператор SELECT INTO следующим образом: ВЫБЕРИТЕ * INTO backup_employee FROM сотрудника; Мы можем проверить, успешно ли вставлены данные о сотрудниках в таблицу backup_employee, следующим образом: ВЫБЕРИТЕ * ОТ backup_employee; Вот вывод: 2. ВЫБЕРИТЕ * INTO backup_employee ОТ сотрудника, ГДЕ зарплата> 30000; Мы можем проверить, успешно ли вставлены данные о сотрудниках в таблицу backup_employee, используя оператор SELECT. Вот результат: 3. Если мы хотим скопировать только некоторые столбцы таблицы сотрудников в таблицу backup_employee , нам нужно указать нужные имена столбцов в операторе SELECT INTO следующим образом: ВЫБЕРИТЕ имя, профессию, зарплату INTO backup_employee ИЗ сотрудника; Мы можем проверить, успешно ли вставлены данные о сотрудниках в таблицу backup_employee, используя оператор SELECT. Вот результат: SELECT INTO Вставка данных из нескольких таблиц SQL Server позволяет нам использовать предложение JOIN с оператором SELECT INTO. Рассмотрим следующие таблицы с именем клиент и заказы со следующими данными: Предположим, мы хотим скопировать такие столбцы, как имя, адрес электронной почты, товар, цена и дата покупки из таблицы клиентов и заказов в таблицу customer_order . Мы можем сделать это, указав имена столбцов в операторе SELECT INTO с предложением JOIN следующим образом: ВЫБЕРИТЕ cust.c_name, cust.email, O.item, O.price, O.prchase_date INTO customer_orders ОТ клиента КАК cust Внутренние заказы JOIN AS O ON cust.id = O.order_id; Мы можем проверить, успешно ли вставлены данные таблицы клиентов и заказов в customer_order таблица с помощью оператора SELECT. SELECT INTO и INSERT INTO SELECTОба оператора могут использоваться для перемещения данных из одной таблицы в другую. Поскольку они обеспечивают схожую функциональность, оба утверждения имеют некоторые общие различия, которые могут повлиять на наше решение о том, какой из них выбрать. Различия между ними объясняются следующими пунктами: 1. Мы можем использовать операторы INSERT INTO select только тогда, когда целевая таблица существует в базе данных перед копированием данных из источника в целевую таблицу. С другой стороны, оператор SELECT INTO не требует, чтобы целевая таблица существовала в нашей базе данных перед копированием данных из исходной таблицы. Он автоматически создает целевую таблицу при каждом выполнении. См. заявление ниже: ВСТАВЬТЕ В tempTable ВЫБЕРИТЕ * ОТ сотрудника; Это утверждение вызвано ошибкой, так как tempTable не существует в базе данных. Вот результат: 2. Пример: Созданная выше таблица customer_order содержит столбец цены длиной 8. Оператор SELECT INTO создаст целевую таблицу с точным определением столбца, как в исходной таблице. Когда мы попытаемся вставить данные в столбец цены больше, чем их размер, мы получим ошибку, либо бинарные данные будут обрезаны. Следующая темаАгрегированные функции SQL Server ← предыдущая следующий → |

 Если мы хотим скопировать только некоторые строки таблицы сотрудников в таблицу backup_employee , нам нужно использовать оператор SELECT INTO с предложением WHERE следующим образом:
Если мы хотим скопировать только некоторые строки таблицы сотрудников в таблицу backup_employee , нам нужно использовать оператор SELECT INTO с предложением WHERE следующим образом: Это помогает нам извлекать записи из более чем одной таблицы, а затем вставлять их в новую таблицу. Здесь мы используем INNER JOIN для соединения двух таблиц с использованием столбца идентификатора .
Это помогает нам извлекать записи из более чем одной таблицы, а затем вставлять их в новую таблицу. Здесь мы используем INNER JOIN для соединения двух таблиц с использованием столбца идентификатора .  Вот результат:
Вот результат: Еще одно отличие, которое их отличает, связано со структурой целевых таблиц. Поскольку оператор SELECT INTO автоматически создал структуру таблицы, которая будет такой же, как исходная таблица. Это может привести к проблемам при вставке данных. Приведенный ниже пример иллюстрирует этот момент.
Еще одно отличие, которое их отличает, связано со структурой целевых таблиц. Поскольку оператор SELECT INTO автоматически создал структуру таблицы, которая будет такой же, как исходная таблица. Это может привести к проблемам при вставке данных. Приведенный ниже пример иллюстрирует этот момент.Управление целевой таблицей в операторе SQL SELECT…INTO
Автор: Andy Kim
Введение
Оператор SELECT…INTO — отличный инструмент, который должен быть в вашем арсенале, если вы разработчик SQL. Оператор SELECT…INTO:
Оператор SELECT…INTO:
- Автоматически создает целевую таблицу, избавляя от необходимости создавать таблицу вручную.
- Молниеносно загружает целевую таблицу с использованием минимального ведения журнала (при правильных условиях).
В качестве альтернативы вы можете использовать синтаксис CREATE TABLE, чтобы сначала создать целевую таблицу, а затем использовать оператор вставки, чтобы загрузить ее отдельно. Этот метод может быть намного, намного медленнее, особенно по мере увеличения размера набора данных (от миллионов до миллиардов записей). Однако в некоторых случаях это может быть единственным вариантом.
Хотя и замечательно, что оператор SELECT…INTO автоматически создает для нас целевую таблицу, мы теряем определенный уровень контроля над тем, как создается и определяется целевая таблица. Некоторые задачи требуют, чтобы целевая таблица была в определенном формате для выполнения последующих операций с ней. Некоторые примеры этого могут быть, но не ограничиваются:
- Столбец должен быть ненулевым, чтобы добавить к нему ограничение первичного ключа.
- Оператор ALTER SWITCH требует, чтобы исходная и целевая таблицы/столбцы были почти одинаковыми.

Имеем ли мы какой-либо контроль над тем, как создается целевая таблица при использовании инструкции SELECT…INTO? Оказывается, есть несколько способов манипулировать целевой таблицей. Я хотел бы продемонстрировать некоторые из этих манипуляций в этом сообщении в блоге.
Давайте внимательно посмотрим на исходную таблицу, из которой мы будем извлекать данные. Это будет контрольный стол для наших будущих экспериментов. В частности, обратите внимание на имена столбцов, типы данных и допустимость значений NULL.
Что произойдет, если мы выполним следующую инструкцию? Как создается таблица OrderDetail_Temp?
Transact-SQL
ВЫБРАТЬ * В dbo.OrderDetail_Temp ОТ dbo.OrderDetail_Source
ВЫБЕРИТЕ * В dbo.OrderDetail_Temp ИЗ dbo.OrderDetail_Source |
Если мы посмотрим в проводнике объектов, мы увидим, что он был создан на основе исходной таблицы и фактически соответствует исходному на этом уровне детализации.
Изменение имен столбцов в целевой таблице
Первый простой способ управления целевой таблицей — задать имя столбца. Этого можно добиться, назначив столбцу в запросе псевдоним, как показано ниже.
После выполнения этого оператора:
Transact-SQL
ВЫБЕРИТЕ [ID записи] ,[CustomerID] as CustomerKey — псевдоним для другого имени ,[OrderID] as OrderKey — псевдоним для другого имени ,[OrderDetailID] as OrderDetailKey — псевдоним для другого имени ,[ДатаВремя Создания] ,[Дата и время изменения] В dbo.OrderDetail_Temp ИЗ dbo.OrderDetail_Source s
1 2 3 4 5 6 7 8 | Выберите [RecordID] , [CustomerId] в качестве CustomerKey- псевдоним для другого имени , [OrderId] в качестве OrderKey- псевдоним для другого имени , [OrderDetailId] как OrderDetailKey- псевдоним для другого имени ,[CreatedDateTime] ,[ModifiedDateTime] INTO dbo. ОТ dbo.OrderDetail_Source s |
 OrderDetail_Temp
OrderDetail_Temp Мы видим, что целевая таблица создана с именами столбцов с псевдонимами:
Создание новых типов данных в целевой таблице
Еще один простой способ манипулирования целевой таблицей — преобразование или преобразование в другие данные. тип. Вы можете добиться этого, приведя/преобразовав столбец в запросе, как показано ниже.
После выполнения этого оператора:
Transact-SQL
ВЫБЕРИТЕ [ID записи] ,cast([CustomerID] как varchar(255)) как CustomerKey ,cast([OrderID] как bigint) как OrderKey ,[OrderDetailID] как OrderDetailKey ,cast([CreatedDateTime] как datetime2(0)) как CreatedDateTime ,[Дата и время изменения] В dbo.OrderDetail_Temp ОТ dbo.OrderDetail_Source s
1 2 3 4 5 6 7 8 | SELECT [RecordID] ,cast([CustomerID] as varchar(255)) as CustomerKey ,cast([OrderID] as bigint) as OrderKey ,[OrderCetailID] as OrderDetailKeyDrecastate[ 900 ] as datetime2(0)) as CreatedDateTime,[ModifiedDateTime] INTO dbo. FROM dbo.OrderDetail_Source s |
 OrderDetail_Temp
OrderDetail_TempМы видим, что целевая таблица создана с указанными типами данных:
При литье или преобразовании нам нужно помнить, что наши данные могут ограничивать наши возможности. Кроме того, нам нужно будет понять последствия, такие как потеря точности в некоторых случаях.
Управление свойством столбцов, допускающих значение NULL
Оператор NULLIF можно использовать для создания столбца, допускающего значение NULL, а оператор ISNULL — для создания столбца, не допускающего значения NULL, как показано ниже.
После выполнения этого оператора:
Transact-SQL
ВЫБЕРИТЕ [ID записи]
,NULLIF(приведение([CustomerID] как varchar(255)),-1) как CustomerKey
,cast([OrderID] как bigint) как OrderKey
,[OrderDetailID] как OrderDetailKey
,cast([CreatedDateTime] как datetime2(0)) как CreatedDateTime
,ISNULL([ModifiedDateTime],’1/1/1900′) as ModifiedDateTime
В dbo.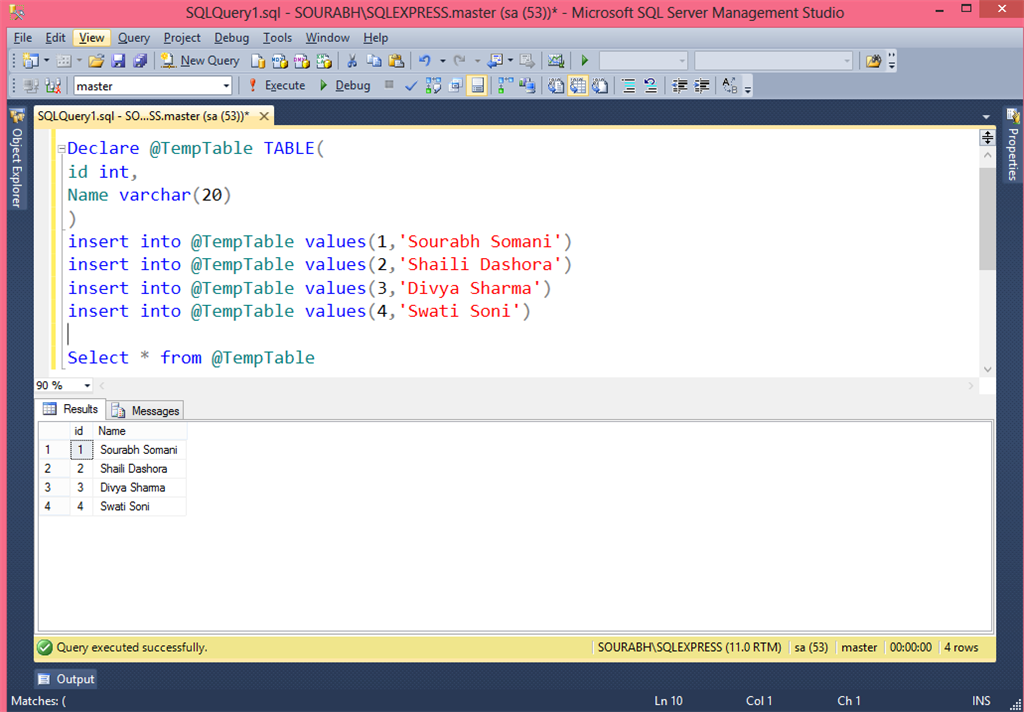 OrderDetail_Temp
ОТ dbo.OrderDetail_Source s
OrderDetail_Temp
ОТ dbo.OrderDetail_Source s
1 2 3 4 5 6 7 8 | SELECT [RecordID] ,NULLIF(cast([CustomerID] as varchar(255)),-1) as CustomerKey ,cast([OrderID] as bigint) as OrderKey ,[OrderDetailID] as OrderDetailKey ,cast([CreatedDateTime] as datetime2(0)) as CreatedDateTime ,ISNULL([ModifiedDateTime],’1/1/1900′) as ModifiedDateTime INTO dbo.OrderDetail_Temp FROM dbo.OrderDetail_9Source0003 |
Мы видим, что целевая таблица создана с указанной нулевой способностью:
Избегайте внесения свойства Identity в результирующую таблицу
Хотя это не видно на снимках экрана, в исходной таблице есть идентификатор в столбце RecordID. Идентификатор переносится в новую таблицу.
Распространенным приемом, позволяющим избежать переноса свойства удостоверения в целевую таблицу, является выполнение фиктивного соединения или объединения. : В результате фиктивного объединения или объединения свойство identity не переносится.
: В результате фиктивного объединения или объединения свойство identity не переносится.
Этот оператор создаст идентификатор в столбце RecordID в целевой таблице:
Transact-SQL
ВЫБЕРИТЕ [ID записи] ,NULLIF(приведение([CustomerID] как varchar(255)),-1) как CustomerKey ,cast([OrderID] как bigint) как OrderKey ,[OrderDetailID] как OrderDetailKey ,cast([CreatedDateTime] как datetime2(0)) как CreatedDateTime ,ISNULL([ModifiedDateTime],’1/1/1900′) как ModifiedDateTime В dbo.OrderDetail_Temp ОТ dbo.OrderDetail_Source s
1 2 3 4 5 6 7 8 | SELECT [RecordID] ,NULLIF(cast([CustomerID] as varchar(255)),-1) as CustomerKey ,cast([OrderID] as bigint) as OrderKey ,[OrderDetailID] as OrderDetailKey , преобразование ([CreatedDateTime] как datetime2 (0)) как CreatedDateTime ,ISNULL([ModifiedDateTime],’1/1/1900′) as ModifiedDateTime В dbo. ИЗ dbo.OrderDetail_Source s |
 OrderDetail_Temp
OrderDetail_TempХотя этот оператор НЕ создаст удостоверение , потому что есть соединение:
Transact-SQL
ВЫБЕРИТЕ [ID записи] ,NULLIF(приведение([CustomerID] как varchar(255)),-1) как CustomerKey ,cast([OrderID] как bigint) как OrderKey ,[OrderDetailID] как OrderDetailKey ,cast([CreatedDateTime] как datetime2(0)) как CreatedDateTime ,ISNULL([ModifiedDateTime],’1/1/1900′) как ModifiedDateTime В dbo.OrderDetail_Temp ИЗ dbo.OrderDetail_Source s ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.DummyTable dt on 1 = 0 — условие никогда не выполняется
1 2 3 4 5 6 7 8 10 3 9 3 | SELECT [RecordID] ,NULLIF(cast([CustomerID] as varchar(255)),-1) as CustomerKey ,cast([OrderID] as bigint) as OrderKey ,[OrderDetailID] as OrderDetailKey ,cast([CreatedDateTime] as datetime2(0)) as CreatedDateTime ,ISNULL([ModifiedDateTime],’1/1/1900′) as ModifiedDateTime INTO dbo.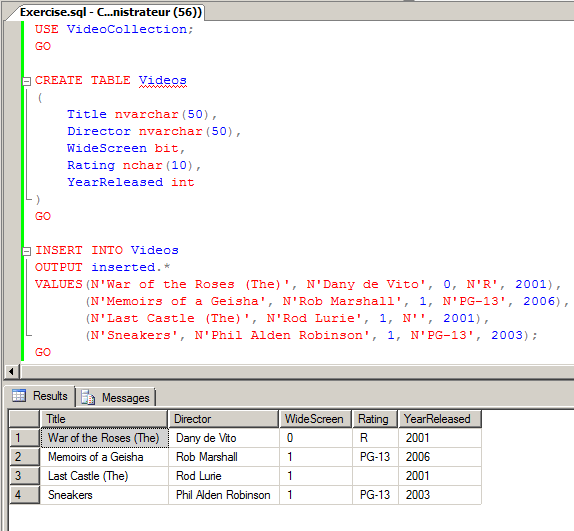 OrmpderDetail OrmpderDetailFROM dbo.OrderDetail_Source s ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.DummyTable dt on 1 = 0 — условие никогда не выполняется |
Добавление столбца идентификаторов в результирующую таблицу
Допустим, мы хотим добавить новый столбец идентификаторов в целевую таблицу. Мы можем сделать это так:
Transact-SQL
ВЫБЕРИТЕ ИДЕНТИФИКАЦИЮ (INT, 1, 1) AS NewIdentityColumn ,[ID записи] ,NULLIF(приведение([CustomerID] как varchar(255)),-1) как CustomerKey ,cast([OrderID] как bigint) как OrderKey ,[OrderDetailID] как OrderDetailKey ,cast([CreatedDateTime] как datetime2(0)) как CreatedDateTime ,ISNULL([ModifiedDateTime],’1/1/1900′) as ModifiedDateTime В dbo.OrderDetail_Temp ИЗ dbo.OrderDetail_Source s ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.DummyTable dt on 1 = 0 — условие никогда не выполняется
1 2 3 4 5 6 7 8 10 11 | SELECT IDENTITY (INT, 1, 1) AS NewIdentityColumn ,[RecordID] ,NULLIF(cast([CustomerID] as varchar(255)),-1) as CustomerKey ,cast([OrderID] as bigint) как OrderKey , [OrderDetailID] как OrderDetailKey , приведение ([CreatedDateTime] как datetime2(0)) как CreatedDateTime ,ISNULL([ModifiedDateTime],’1/1/1900′) as ModifiedDateTime INTO dbo. FROM dbo.OrderDetail_Source s ВНУТРЕННЕЕ СОЕДИНЕНИЕ условие = никогда 1-0 dbo.DummyTable 0 90 dt 3 правда |
 OrderDetail_Temp
OrderDetail_TempМы видим, что целевая таблица имеет новый столбец идентификации.
Направление вашей таблицы в определенную файловую группу
В SQL Server 2017 теперь вы также можете использовать предложение ON, чтобы указать, что целевая таблица должна быть создана в определенной файловой группе, отличной от используемой по умолчанию.
Transact-SQL
ВЫБЕРИТЕ ИДЕНТИФИКАЦИЮ (INT, 1, 1) AS NewIdentityColumn
,[ID записи]
,NULLIF(приведение([CustomerID] как varchar(255)),-1) как CustomerKey
,cast([OrderID] как bigint) как OrderKey
,[OrderDetailID] как OrderDetailKey
,cast([CreatedDateTime] как datetime2(0)) как CreatedDateTime
,ISNULL([ModifiedDateTime],’1/1/1900′) as ModifiedDateTime
INTO dbo.OrderDetail_Temp ON [Другая группа файлов]
ИЗ dbo. OrderDetail_Source s
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.DummyTable dt
on 1 = 0 — условие никогда не выполняется
OrderDetail_Source s
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.DummyTable dt
on 1 = 0 — условие никогда не выполняется
1 2 3 4 5 6 7 8 10 11 | SELECT IDENTITY (INT, 1, 1) AS NewIdentityColumn ,[RecordID] ,NULLIF(cast([CustomerID] as varchar(255)),-1) as CustomerKey ,cast([OrderID] as bigint) как OrderKey , [OrderDetailID] как OrderDetailKey , приведение ([CreatedDateTime] как datetime2(0)) как CreatedDateTime , isnull ([ModifiedDateTime], ‘1/1/1900’) в качестве ModifiedDateTime в dbo.orderdetail_temp на [notherfilegroup] от dbo.orderdetail_source S Inner innectab — условие никогда не истинно |
Заключение
Теперь, когда мы рассмотрели несколько различных способов манипулирования целевой таблицей при использовании оператора SELECT…INTO, я рекомендую вам попробовать их в следующий раз, когда представится возможность. Я также хотел бы услышать о других манипуляциях с оператором SELECT… INTO, которые вы использовали. Пожалуйста, оставьте комментарий!
Я также хотел бы услышать о других манипуляциях с оператором SELECT… INTO, которые вы использовали. Пожалуйста, оставьте комментарий!
Ссылки
Выбрать в заявление Общая информация
https://docs.microsoft.com/en-us/sql/t-sql/queries/select-into-clause-transact-sql?view=sql-server- 2017
Выбрать в определенную файловую группу
https://www.mssqltips.com/sqlservertip/5018/selectinto-enhancements-in-sql-server-2017/
Есть вопросы?
Спасибо за внимание! Мы надеемся, что вы нашли этот пост в блоге полезным. Дайте нам знать, если у вас есть какие-либо вопросы или идеи по теме, связанные с BI, аналитикой, облаком, машинным обучением, SQL Server (Звездные войны) или чем-либо еще, о чем вы хотели бы, чтобы мы написали. Просто оставьте нам комментарий ниже, и мы посмотрим, что мы можем сделать!
Держите аналитику данных в тонусе, подписавшись на нашу рассылку
Получайте свежий контент Key2, посвященный бизнес-аналитике, хранению данных, аналитике и т.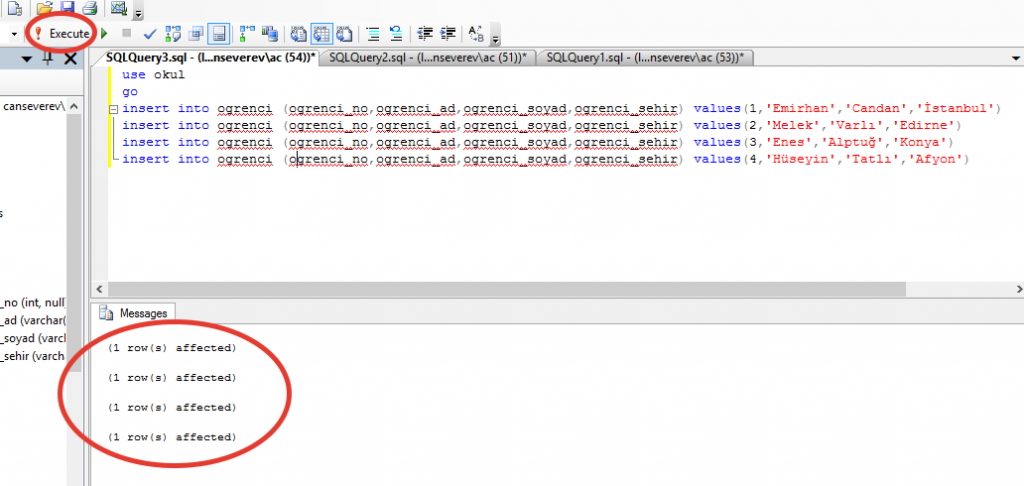 д., прямо на ваш почтовый ящик!
д., прямо на ваш почтовый ящик!
Key2 Consulting — компания по хранению данных и бизнес-аналитике, расположенная в Атланте, штат Джорджия. Мы создаем и поставляем настраиваемые решения для хранилищ данных, решения для бизнес-аналитики и настраиваемые приложения.
Учебное пособие по вставке SQL — вставка записей в базу данных
12 августа 2019 г.
Научитесь вставлять данные в базы данных SQL, как профессионал!
Одна из ключевых ролей специалиста по обработке и анализу данных — извлекать закономерности и идеи из необработанных данных. Поскольку большая часть государственных и корпоративных данных в мире организована в реляционных базах данных, имеет смысл, что специалисты по данным должны знать, как работать с этими структурами баз данных. Написание SQL-запросов для вставки, извлечения и фильтрации данных в базах данных является ключевым навыком для всех, кто интересуется анализом данных или наукой о данных.
SQL (язык структурированных запросов) основан на реляционной модели Э. Ф. Кодда и алгебре для управления реляционными базами данных. Это язык запросов к базе данных, используемый для создания, вставки, запроса и управления реляционной базой данных и используемый большим количеством приложений.
Несмотря на то, что это существует уже несколько десятилетий, изучение SQL по-прежнему является важным навыком для современных специалистов по данным и вообще для всех, кто работает с данными, поскольку SQL используется во всех видах программного обеспечения реляционных баз данных, включая MySQL, SQL Server, Oracle. и PostgreSQL.
В этом руководстве мы подробно узнаем об операциях вставки SQL. Вот список тем, которые мы изучим в этом уроке:
- Вставка SQL
- Вставка записей в базу данных
- Вставка Pandas DataFrames в базу данных с помощью команды вставки
- Вставка фреймов данных Pandas в базу данных с помощью команды to_sql()
- Чтение записей из базы данных
- Обновление записей в базе данных
Хотите достичь более высокого уровня владения SQL? Зарегистрируйтесь бесплатно и ознакомьтесь с курсами Dataquest по SQL, чтобы получить исчерпывающие интерактивные уроки по всем навыкам SQL, которые вам понадобятся для работы с данными.
Вставка SQL
Вставка SQL — важная операция, которую должны понимать работники, работающие с данными. Вставка отсутствующих данных или добавление новых данных является основной частью процесса очистки данных в большинстве проектов по науке о данных.
Вставка — это также то, как большинство данных попадают в базы данных в первую очередь, поэтому это также важно в любое время, когда вы собираете данные. Например, когда ваша компания получает новые данные о клиенте, велика вероятность, что вставка SQL будет тем, как эти данные попадут в вашу существующую базу данных клиентов.
На самом деле, знаете ли вы об этом или нет, данные постоянно поступают в базы данных с помощью SQL-вставок! Когда вы заполняете маркетинговый опрос, совершаете транзакцию, заполняете онлайн-форму для правительства или выполняете тысячи других действий, ваши данные, скорее всего, вставляются в базу данных где-то с помощью SQL.
Давайте углубимся в то, как мы можем использовать SQL для вставки данных в базу данных. Мы можем вставлять данные строку за строкой или добавлять несколько строк одновременно.
Мы можем вставлять данные строку за строкой или добавлять несколько строк одновременно.
Вставка записей в базу данных
г. В SQL мы используем команду INSERT для добавления записей/строк в данные таблицы. Эта команда не изменит фактическую структуру таблицы, в которую мы вставляем, она просто добавит данные.
Давайте представим, что у нас есть таблица данных, подобная приведенной ниже, которая используется для хранения некоторой информации о сотрудниках компании.
Теперь давайте представим, что у нас есть новые сотрудники, которых нужно ввести в систему.
Эта таблица сотрудников может быть создана с использованием CREATE TABLE , поэтому мы могли использовать эту команду для создания совершенно новой таблицы. Но было бы очень неэффективно создавать совершенно новую таблицу каждый раз, когда мы хотим добавить данные! Вместо этого давайте воспользуемся командой INSERT , чтобы добавить новые данные в нашу существующую таблицу.
Вот основной синтаксис для использования INSERT в SQL:
Мы начинаем с команды INSERT INTO , за которой следует имя таблицы, в которую мы хотим вставить данные. После имени таблицы мы перечисляем столбцы новых данных, которые мы вставляем, столбец за столбцом, в круглых скобках. Затем в следующей строке мы использовали команду ЗНАЧЕНИЯ вместе со значениями, которые мы хотим вставить (по порядку внутри круглых скобок.
Итак, для нашей таблицы employee , если бы мы добавляли нового сотрудника по имени Кабир, наша команда INSERT могла бы выглядеть так:
Вставка записей в базу данных из Python
Поскольку мы часто работаем с нашими данными в Python, занимаясь наукой о данных, давайте вставим данные из Python в базу данных MySQL. Это обычная задача, которая имеет множество приложений в науке о данных.
Мы можем отправлять и получать данные в базу данных MySQL, установив соединение между Python и MySQL. Существуют различные способы установить эту связь; здесь мы будем использовать
Существуют различные способы установить эту связь; здесь мы будем использовать pymysql для подключения к базе данных.
Вот общие шаги, которые нам нужно выполнить, чтобы подключить pymysql , вставить наши данные, а затем извлечь данные из MySQL:
Давайте рассмотрим этот процесс шаг за шагом.
Шаг 1: Импортируйте модуль pymysql. г.# Импорт модуля pymysql импортировать pymysqlШаг 2: Создание подключения к базе данных MySQL
Создайте соединение, используя функцию pymysql s connect() с параметрами хост, пользователь, имя базы данных и пароль.
(Приведенные ниже параметры предназначены только для демонстрационных целей; вам нужно будет указать конкретные данные доступа, необходимые для базы данных MySQL, к которой вы обращаетесь.)
# Подключиться к базе данных
соединение = pymysql.connect (хост = 'localhost',
пользователь = 'корень',
пароль='12345',
БД='сотрудник') г.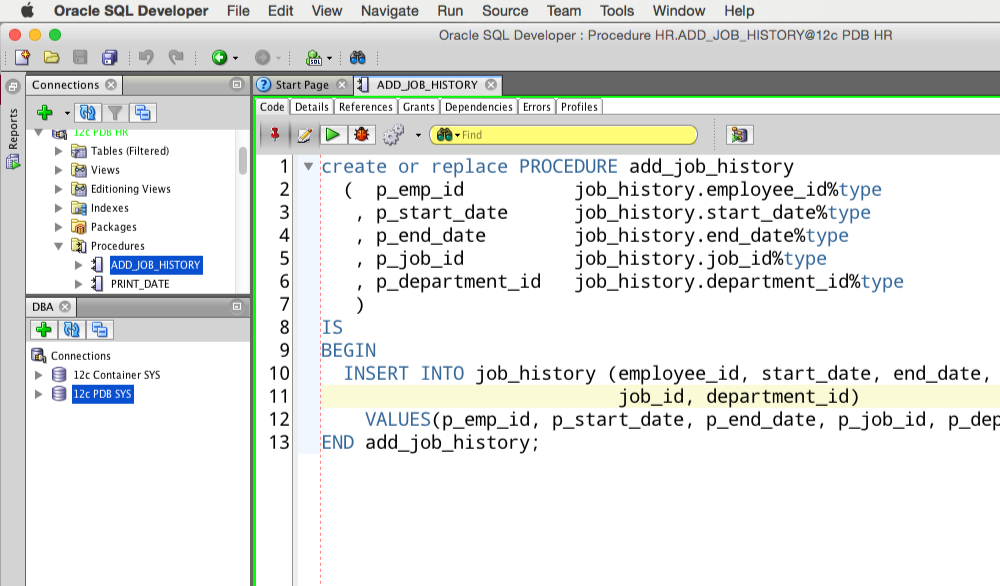 Шаг 3: Создайте курсор с помощью функции cursor().
Шаг 3: Создайте курсор с помощью функции cursor().Это позволит нам выполнить SQL-запрос после его написания.
курсор = соединение.курсор ()Шаг 4: Выполнение требуемого SQL-запроса
Зафиксируйте изменения с помощью функции commit() и проверьте вставленные записи. Обратите внимание, что мы можем создать переменную с именем sql , присвоить ей синтаксис нашего запроса, а затем передать sql и конкретные данные, которые мы хотим вставить в качестве аргументов, в курсор.выполнить() .
Затем мы зафиксируем эти изменения с помощью commit() .
# Создать новую запись sql = "ВСТАВИТЬ В `employee` (`EmployeeID`, `Ename`, `DeptID`, `Salary`, `Dname`, `Dlocation`) ЗНАЧЕНИЯ (%s, %s, %s, %s, %s, %s)" # Выполнить запрос курсор.execute(sql, (1008, 'Кабир', 2,5000, 'IT', 'Нью-Дели')) # по умолчанию соединение не фиксируется автоматически.
 Поэтому мы должны зафиксировать сохранение наших изменений.
соединение.коммит()
Поэтому мы должны зафиксировать сохранение наших изменений.
соединение.коммит() Давайте быстро проверим, действительно ли запись, которую мы хотели вставить, была вставлена.
Мы можем сделать это, запросив в базе данных все содержимое сотрудника , а затем выбрав и распечатав эти результаты.
# Создайте новый запрос, который выбирает все содержимое `employee`
sql = "ВЫБЕРИТЕ * ИЗ `сотрудника`"
курсор.execute(sql)
# Получить все записи и использовать цикл for для вывода их по одной строке за раз
результат = курсор.fetchall()
для я в результате:
распечатать (я) г.(1001, «Джон», 2, 4000, «IT», «Нью-Дели») (1002, «Анна», 1, 3500, «HR», «Мумбаи») (1003, «Джеймс», 1, 2500, «HR», «Мумбаи») (1004, «Дэвид», 2, 5000, «ИТ», «Нью-Дели») (1005, «Марк», 2, 3000, «ИТ», «Нью-Дели») (1006, «Стив», 3, 4500, «Финансы», «Мумбаи») (1007, «Алиса», 3, 3500, «Финансы», «Мумбаи») (1008, Кабир, 2, 5000, IT, Нью-Дели)
Сработало! Выше мы видим, что новая запись была вставлена и теперь является последней строкой в нашей базе данных MySQL.
Теперь, когда мы закончили, мы должны закрыть соединение с базой данных, используя метод close() .
# Закрыть соединение соединение.закрыть()
Конечно, было бы лучше написать этот код так, чтобы он лучше обрабатывал исключения и ошибки. Мы можем сделать это, используя try , чтобы содержать тело нашего кода и за исключением вывода ошибок, если таковые возникнут. Затем мы можем использовать finally , чтобы закрыть соединение, как только мы закончим, независимо от того, была ли попытка успешной или неудачной.
Вот как это выглядит вместе:
импорт pymysql
пытаться:
# Подключиться к базе данных
соединение = pymysql.connect (хост = 'localhost',
пользователь = 'корень',
пароль='12345',
БД='сотрудник')
курсор=соединение. курсор()
# Создать новую запись
sql = "ВСТАВИТЬ В `employee` (`EmployeeID`, `Ename`, `DeptID`, `Salary`, `Dname`, `Dlocation`) ЗНАЧЕНИЯ (%s, %s, %s, %s, %s, %s)"
курсор.выполнить(sql, (1009,'Морган',1,4000,'HR','Мумбаи'))
# соединение не является автоматическим по умолчанию. Поэтому мы должны зафиксировать сохранение наших изменений.
соединение.коммит()
# Выполнить запрос
sql = "ВЫБЕРИТЕ * ИЗ `сотрудника`"
курсор.execute(sql)
# Получить все записи
результат = курсор.fetchall()
для я в результате:
печать (я)
кроме ошибки как e:
печать (е)
в конце концов:
# закрыть соединение с базой данных с помощью метода close().
соединение.закрыть() г. курсор()
# Создать новую запись
sql = "ВСТАВИТЬ В `employee` (`EmployeeID`, `Ename`, `DeptID`, `Salary`, `Dname`, `Dlocation`) ЗНАЧЕНИЯ (%s, %s, %s, %s, %s, %s)"
курсор.выполнить(sql, (1009,'Морган',1,4000,'HR','Мумбаи'))
# соединение не является автоматическим по умолчанию. Поэтому мы должны зафиксировать сохранение наших изменений.
соединение.коммит()
# Выполнить запрос
sql = "ВЫБЕРИТЕ * ИЗ `сотрудника`"
курсор.execute(sql)
# Получить все записи
результат = курсор.fetchall()
для я в результате:
печать (я)
кроме ошибки как e:
печать (е)
в конце концов:
# закрыть соединение с базой данных с помощью метода close().
соединение.закрыть()
курсор()
# Создать новую запись
sql = "ВСТАВИТЬ В `employee` (`EmployeeID`, `Ename`, `DeptID`, `Salary`, `Dname`, `Dlocation`) ЗНАЧЕНИЯ (%s, %s, %s, %s, %s, %s)"
курсор.выполнить(sql, (1009,'Морган',1,4000,'HR','Мумбаи'))
# соединение не является автоматическим по умолчанию. Поэтому мы должны зафиксировать сохранение наших изменений.
соединение.коммит()
# Выполнить запрос
sql = "ВЫБЕРИТЕ * ИЗ `сотрудника`"
курсор.execute(sql)
# Получить все записи
результат = курсор.fetchall()
для я в результате:
печать (я)
кроме ошибки как e:
печать (е)
в конце концов:
# закрыть соединение с базой данных с помощью метода close().
соединение.закрыть() ((1001, 'Джон', 2, 4000, 'IT', 'Нью-Дели'), (1002, 'Анна', 1, 3500, 'HR', 'Мумбаи'), (1003, 'Джеймс', 1, 2500, 'HR', 'Мумбаи'), (1004, 'Дэвид', 2, 5000, 'IT', 'Нью-Дели'), (1005, 'Марк', 2, 3000, 'IT', ' Нью-Дели»), (1006, «Стив», 3, 4500, «Финансы», «Мумбаи»), (1007, «Алиса», 3, 3500, «Финансы», «Мумбаи»), (1008, «Кабир ', 2, 5000, 'IT', 'Нью-Дели'), (1009, 'Морган', 1, 4000, 'HR', 'Мумбаи'), (1009, 'Морган', 1, 4000, 'HR' , 'Мумбаи'))
Вставка фреймов данных Pandas в базы данных с помощью INSERT
При работе с данными в Python мы часто используем pandas , и наши данные часто хранятся в виде pandas DataFrame. К счастью, нам не нужно делать никаких преобразований, если мы хотим использовать SQL с нашими кадрами данных; мы можем напрямую вставить кадр данных pandas в базу данных MySQL, используя
К счастью, нам не нужно делать никаких преобразований, если мы хотим использовать SQL с нашими кадрами данных; мы можем напрямую вставить кадр данных pandas в базу данных MySQL, используя INSERT .
Еще раз, мы будем делать это шаг за шагом.
Шаг 1: Создание кадра данных с использованием словаряМы также можем импортировать данные из CSV или создать DataFrame любым другим способом, но для целей этого примера мы просто создадим небольшой DataFrame, в котором будут храниться названия и цены некоторых учебников по науке о данных.
# Импорт панд
импортировать панд как pd
# Создать фрейм данных
данные = pd.DataFrame({
'книга_id': [12345, 12346, 12347],
'title':['Программирование на Python', 'Изучаем MySQL', 'Поваренная книга по науке о данных'],
'цена': [29, 23, 27]
})
данные | book_id | заголовок | цена | |
|---|---|---|---|
| 0 | 12345 | Программирование на Python | 29 |
| 1 | 12346 | Изучите MySQL | 23 |
| 2 | 12347 | Поваренная книга по науке о данных | 27 |
Прежде чем вставлять данные в MySQL, мы собираемся создать таблицу book в MySQL для хранения наших данных. Если бы такая таблица уже существовала, мы могли бы пропустить этот шаг.
Если бы такая таблица уже существовала, мы могли бы пропустить этот шаг.
Мы будем использовать оператор CREATE TABLE, чтобы создать нашу таблицу, за которым следует имя нашей таблицы (в данном случае book_details ), а затем перечислите каждый столбец и соответствующий ему тип данных.
Создав эту таблицу, мы можем снова создать соединение с базой данных из Python, используя pymysql .
импорт pymysql
# Подключиться к базе данных
соединение = pymysql.connect (хост = 'localhost',
пользователь = 'корень',
пароль='12345',
БД='книга')
# создать курсор
курсор=соединение.курсор() г. Шаг 4: Создайте список столбцов и вставьте строки Затем мы создадим список столбцов и вставим строки нашего фрейма данных одну за другой в базу данных, перебирая каждую строку и используя INSERT INTO для вставки значений этой строки в базу данных.
(Также можно вставить весь DataFrame сразу, и мы рассмотрим способ сделать это в следующем разделе, но сначала давайте посмотрим, как это сделать построчно).
# создание списка столбцов для вставки
cols = "`,`".join([str(i) для i в data.columns.tolist()])
# Вставляем записи DataFrame одну за другой.
для i, строка в data.iterrows():
sql = "ВСТАВИТЬ В `book_details` (`" +cols + "`) VALUES (" + "%s,"*(len(row)-1) + "%s)"
курсор.execute (sql, кортеж (строка))
# соединение не фиксируется автоматически по умолчанию, поэтому мы должны зафиксировать, чтобы сохранить наши изменения
соединение.коммит() г. Шаг 5: Запросите базу данных, чтобы проверить нашу работуОпять же, давайте запросим базу данных, чтобы убедиться, что наши вставленные данные были сохранены правильно.
# Выполнить запрос
sql = "ВЫБЕРИТЕ * ИЗ `book_details`"
курсор.execute(sql)
# Получить все записи
результат = курсор.fetchall()
для я в результате:
печать (я) (12345, «Программирование на Python», 29) (12346, «Изучение MySQL», 23) (12347, «Поваренная книга по науке о данных», стр.г.
 27)
27) Когда мы убедимся, что все выглядит правильно, мы можем закрыть соединение.
соединение.close()
Вставка фреймов данных Pandas в базу данных с помощью функции to_sql()
Теперь давайте попробуем сделать то же самое — вставить кадр данных pandas в базу данных MySQL — используя другую технику. На этот раз мы будем использовать модуль sqlalchemy для создания нашего соединения и функцию to_sql() для вставки наших данных.
Этот подход обеспечивает тот же конечный результат более прямым способом и позволяет нам сразу добавить весь фрейм данных в базу данных MySQL.
# Импорт модулей
импортировать панд как pd
# Создать фрейм данных
данные = pd. DataFrame ({
'книга_id': [12345,12346,12347],
'title':['Программирование на Python','Изучаем MySQL','Поваренная книга по науке о данных'],
'цена': [29,23,27]
})
данные | book_id | заголовок | цена | |
|---|---|---|---|
| 0 | 12345 | Программирование на Python | 29 |
| 1 | 12346 | Изучите MySQL | 23 |
| 2 | 12347 | Поваренная книга по науке о данных | 27 |
Импортируйте модуль sqlalchemy и создайте движок с параметрами пользователя, пароля и имени базы данных. Вот как мы подключаемся и входим в базу данных MySQL.
Вот как мы подключаемся и входим в базу данных MySQL.
# импортируем модуль
из импорта sqlalchemy create_engine
# создаем движок sqlalchemy
engine = create_engine("mysql+pymysql://{пользователь}:{pw}@localhost/{db}"
.format (пользователь = «корень»,
пв = "12345",
дб="сотрудник")) г. После подключения мы можем экспортировать весь DataFrame в MySQL, используя функцию to_sql() с именем таблицы параметров, именем движка, if_exists и chunksize.
Мы подробнее рассмотрим, к чему относится каждый из этих параметров, но сначала посмотрим, насколько проще вставить кадр данных pandas в базу данных MySQL с помощью этого метода. Мы можем сделать это всего одной строкой кода:
. # Вставить весь DataFrame в MySQL
data.to_sql('book_details', con = engine, if_exists = 'append', chunksize = 1000) г. Теперь давайте подробнее рассмотрим, что делает каждый из этих параметров в нашем коде.
-
book_details— это имя таблицы, в которую мы хотим вставить наш DataFrame. -
con = engineпредоставляет информацию о соединении (напомним, что мы создали engine, используя наши данные аутентификации на предыдущем шаге). -
if_exists = 'append'проверяет, существует ли уже указанная нами таблица, а затем добавляет новые данные (если они существуют) или создает новую таблицу (если нет). -
размер фрагментазаписывает записи партиями заданного размера за раз. По умолчанию все строки будут записаны одновременно.
Чтение записей из базы данных
После того, как мы использовали SQL-вставки для передачи данных в базу данных, нам нужно иметь возможность прочитать их обратно! До сих пор в этом руководстве мы проверяли наши вставки SQL, просто печатая всю базу данных, но очевидно, что это не лучший вариант для больших баз данных, где вы должны печатать тысячи строк (или больше).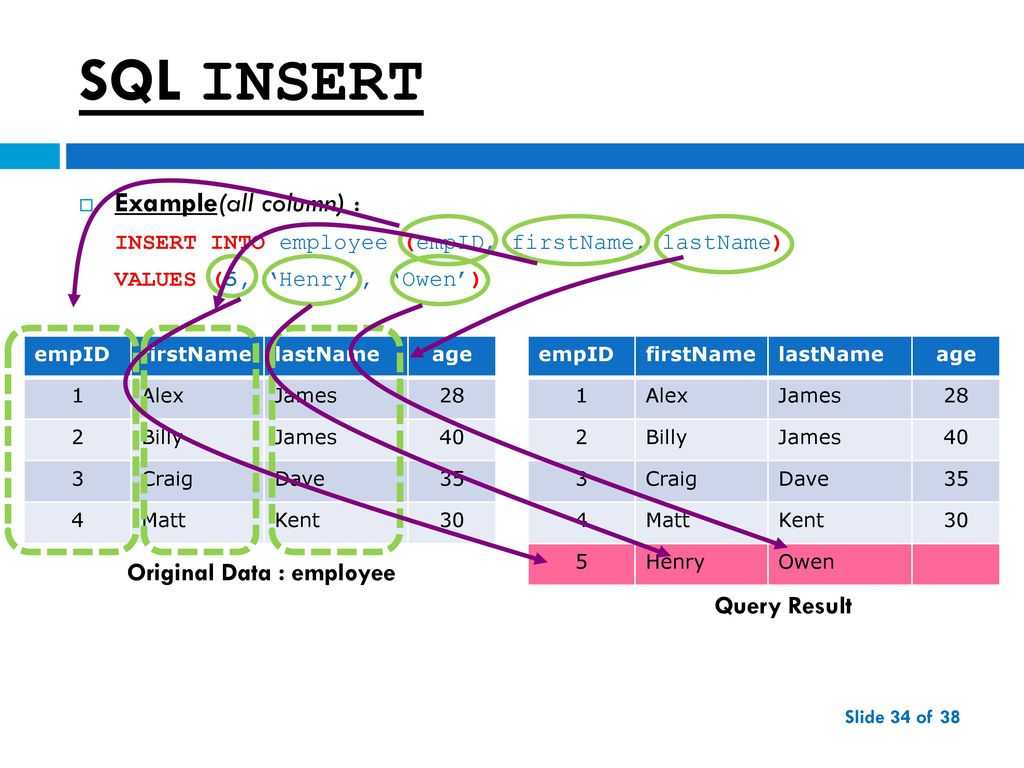 Итак, давайте более подробно рассмотрим, как мы можем считывать записи, которые мы создали или вставили в нашу базу данных SQL.
Итак, давайте более подробно рассмотрим, как мы можем считывать записи, которые мы создали или вставили в нашу базу данных SQL.
Мы можем читать записи из базы данных SQL с помощью команды SELECT . Мы можем выбрать определенные столбцы или использовать * , чтобы выбрать все из данной таблицы. Мы также можем выбрать возврат только тех записей, которые соответствуют определенному условию, используя команду WHERE .
Вот как выглядит синтаксис этих команд:
Мы начинаем с предложения SELECT , за которым следует список столбцов, или * , если мы хотим выбрать все столбцы. Затем мы будем использовать FROM , чтобы назвать таблицу, которую мы хотели бы просмотреть. WHERE можно использовать для фильтрации записей, за которым следует условие фильтрации, а также можно использовать ORDER BY для сортировки записей. (Предложения WHERE и ORDER BY являются необязательными).
Для больших баз данных WHERE полезно для возврата только тех данных, которые мы хотим видеть. Так что, если, например, мы только что вставили новые данные об определенном отделе, мы могли бы использовать ГДЕ указать отдел ID в нашем запросе, и он вернет только записи с идентификатором отдела, который соответствует указанному нами.
Сравните, например, результаты этих двух запросов, используя нашу предыдущую таблицу employee . В первом мы возвращаем все строки. Во втором случае мы возвращаем только те строки, которые запросили. Это может не иметь большого значения, когда наша таблица состоит из семи строк, но когда вы работаете с семью строками тысяч строк или даже семь миллионов , использование WHERE для возврата только нужных результатов очень важно!
Если мы хотим сделать это из Python, мы можем использовать тот же сценарий, который мы использовали ранее в этом руководстве, для запроса этих записей. Единственное отличие состоит в том, что мы скажем
Единственное отличие состоит в том, что мы скажем pymysql выполнить команду SELECT , а не команду INSERT , которую мы использовали ранее.
# Модуль импорта
импортировать pymysql
# создать соединение
соединение = pymysql.connect (хост = 'localhost',
пользователь = 'корень',
пароль='12345',
БД='сотрудник')
# Создать курсор
мой_курсор = соединение.курсор()
# Выполнить запрос
my_cursor.execute("ВЫБРАТЬ * от сотрудника")
# Получить записи
результат = my_cursor.fetchall()
для я в результате:
печать (я)
# Закрыть соединение
соединение.закрыть() г.(1001, «Джон», 2, 4000, «IT», «Нью-Дели») (1002, «Анна», 1, 3500, «HR», «Мумбаи») (1003, «Джеймс», 1, 2500, «HR», «Мумбаи») (1004, «Дэвид», 2, 5000, «ИТ», «Нью-Дели») (1005, «Марк», 2, 3000, «ИТ», «Нью-Дели») (1006, «Стив», 3, 4500, «Финансы», «Мумбаи») (1007, «Алиса», 3, 3500, «Финансы», «Мумбаи») (1008, «Кабир», 2, 5000, «ИТ», «Нью-Дели») (1009, «Морган», 1, 4000, «HR», «Мумбаи») (1009, «Морган», 1, 4000, «HR», «Мумбаи»)
Выше мы выбрали и распечатали всю базу данных, но если мы хотим использовать ГДЕ для более тщательной, ограниченной выборки, подход тот же:
my_cursor.
 execute("ВЫБЕРИТЕ * ОТ сотрудника, ГДЕ DeptID=2")
execute("ВЫБЕРИТЕ * ОТ сотрудника, ГДЕ DeptID=2") Обновление записей в базе данных
Часто нам нужно изменить записи в таблице после их создания.
Например, представьте, что сотрудник в нашей таблице сотрудников получил повышение. Мы хотели бы обновить данные об их зарплате. 9Команда 1808 INSERT INTO нам здесь не поможет, потому что мы не хотим добавлять совершенно новую строку.
Чтобы изменить существующие записи в таблице, нам нужно использовать команду UPDATE . ОБНОВЛЕНИЕ используется для изменения содержимого существующих записей. Мы можем указать определенные столбцы и значения для изменения с помощью SET , а также внести условные изменения с помощью WHERE , чтобы применить эти изменения только к строкам, которые соответствуют этому условию.
Теперь давайте обновим записи из нашей таблицы сотрудников и отобразим результаты. В этом случае, допустим, Дэвид получил повышение — мы напишем запрос с использованием UPDATE , который устанавливает Зарплата в 6000 только в столбцах, где идентификатор сотрудника равен 1004 (идентификатор Дэвида).
Будьте осторожны — без предложения WHERE этот запрос обновил бы все записи в таблице, так что не забывайте об этом!
После выполнения вышеуказанного запроса обновленная таблица будет выглядеть так:
Заключение
В этом руководстве мы рассмотрели вставки SQL и способы вставки данных в базы данных MySQL из Python. Мы также научились вставлять Pandas DataFrames в базы данных SQL, используя два разных метода, включая высокоэффективный метод to_sql() .
Конечно, это только вершина айсберга, когда дело доходит до SQL-запросов. Если вы действительно хотите стать мастером SQL, зарегистрируйтесь бесплатно и погрузитесь в один из интерактивных курсов Dataquest по SQL, чтобы получить интерактивные инструкции и практический опыт написания всех запросов, которые вам понадобятся для продуктивной профессиональной работы с данными.
Также ознакомьтесь с другими нашими бесплатными ресурсами, связанными с SQL:
- Нужна ли вам сертификация SQL?
- Вопросы SQL для собеседования для подготовки к собеседованию
- Наша шпаргалка по SQL
beginnerSQLsql inserttutorialTutorials
Об авторе
Авинаш Навлани
Вставка данных в таблицу
[00:00]
В этом уроке мы рассмотрим, как вставлять данные в таблицу в базе данных. Я начну с создания нового именованного запроса и назову его «Вставить данные», а затем продолжу и нажму кнопку «Создать именованный запрос». Здесь, в моем именованном запросе, я хочу начать с установки подключения к базе данных для внутренней БД, и поскольку мы собираемся вставлять новые данные в базу данных и обновлять эту таблицу, мы хотим изменить тип запроса для обновления запроса. В моем запросе не будет никаких параметров, поэтому при желании я могу избавиться от обоих этих параметров. Затем я могу вставить свой запрос ниже. Вы можете видеть, что с запросом на вставку мы начинаем с команды вставки в, а затем перечисляем таблицу, в которую мы хотим вставить данные. В данном случае инвентаризация.
Я начну с создания нового именованного запроса и назову его «Вставить данные», а затем продолжу и нажму кнопку «Создать именованный запрос». Здесь, в моем именованном запросе, я хочу начать с установки подключения к базе данных для внутренней БД, и поскольку мы собираемся вставлять новые данные в базу данных и обновлять эту таблицу, мы хотим изменить тип запроса для обновления запроса. В моем запросе не будет никаких параметров, поэтому при желании я могу избавиться от обоих этих параметров. Затем я могу вставить свой запрос ниже. Вы можете видеть, что с запросом на вставку мы начинаем с команды вставки в, а затем перечисляем таблицу, в которую мы хотим вставить данные. В данном случае инвентаризация.
[01:03]
Далее в скобках я перечисляю имена столбцов. Это столбцы, для которых я предоставляю данные, которые будут вставлены как новая строка. Наконец, мы используем значения ключевого слова, а затем снова в круглых скобках перечисляем значения, которые мы хотим вставить в указанные столбцы. Значения должны быть перечислены в порядке столбцов, которые мы установили ранее, поэтому в этом случае у меня есть имя рабочих станций, местонахождение магазина и количество 15. Я могу перейти на вкладку «Тестирование» и попробуйте выполнить этот запрос. Поскольку я вставляю данные, я не ожидаю, что они вернут мне данные, но они возвращают количество строк, затронутых моим запросом. В этом случае мы видим набор результатов, равный единице, что означает, что я вставил одну новую строку в свою таблицу. Я хочу вернуться, взглянуть на запрос и отметить две вещи.
Наконец, мы используем значения ключевого слова, а затем снова в круглых скобках перечисляем значения, которые мы хотим вставить в указанные столбцы. Значения должны быть перечислены в порядке столбцов, которые мы установили ранее, поэтому в этом случае у меня есть имя рабочих станций, местонахождение магазина и количество 15. Я могу перейти на вкладку «Тестирование» и попробуйте выполнить этот запрос. Поскольку я вставляю данные, я не ожидаю, что они вернут мне данные, но они возвращают количество строк, затронутых моим запросом. В этом случае мы видим набор результатов, равный единице, что означает, что я вставил одну новую строку в свою таблицу. Я хочу вернуться, взглянуть на запрос и отметить две вещи.
[02:04]
Во-первых, можно вставлять динамические значения, создавая параметры для каждого значения, которое вы хотите сделать динамическим. Так что в этом случае я мог бы сделать параметр для имени, параметр для местоположения и параметр для количества. Затем я могу заменить жестко запрограммированные значения этими параметрами. Это позволит мне вставлять новые значения при запуске запроса. Второе, что я хотел отметить, это то, что можно вставить несколько строк данных с помощью одного запроса на вставку. Я собираюсь вставить сюда некоторые дополнительные значения, и вы можете видеть, что все, что нам нужно сделать, это просто перечислить дополнительные наборы значений, разделенные запятыми. Если я перейду на вкладку «Тестирование» и попытаюсь выполнить этот запрос, вы увидите, что мой набор результатов теперь равен семи, что указывает на то, что я вставил в свою таблицу семь новых строк.
Так что в этом случае я мог бы сделать параметр для имени, параметр для местоположения и параметр для количества. Затем я могу заменить жестко запрограммированные значения этими параметрами. Это позволит мне вставлять новые значения при запуске запроса. Второе, что я хотел отметить, это то, что можно вставить несколько строк данных с помощью одного запроса на вставку. Я собираюсь вставить сюда некоторые дополнительные значения, и вы можете видеть, что все, что нам нужно сделать, это просто перечислить дополнительные наборы значений, разделенные запятыми. Если я перейду на вкладку «Тестирование» и попытаюсь выполнить этот запрос, вы увидите, что мой набор результатов теперь равен семи, что указывает на то, что я вставил в свою таблицу семь новых строк.
В этом уроке мы рассмотрим, как вставлять данные в таблицу в базе данных. Я начну с создания нового именованного запроса и назову его «Вставить данные», а затем продолжу и нажму кнопку «Создать именованный запрос». Здесь, в моем именованном запросе, я хочу начать с установки подключения к базе данных для внутренней БД, и поскольку мы собираемся вставлять новые данные в базу данных и обновлять эту таблицу, мы хотим изменить тип запроса для обновления запроса. В моем запросе не будет никаких параметров, поэтому при желании я могу избавиться от обоих этих параметров. Затем я могу вставить свой запрос ниже. Вы можете видеть, что с запросом на вставку мы начинаем с команды вставки в, а затем перечисляем таблицу, в которую мы хотим вставить данные. В данном случае инвентаризация.
[01:03] Далее в скобках я перечисляю имена столбцов. Это столбцы, для которых я предоставляю данные, которые будут вставлены как новая строка. Наконец, мы используем значения ключевого слова, а затем снова в круглых скобках перечисляем значения, которые мы хотим вставить в указанные столбцы. Значения должны быть перечислены в порядке столбцов, которые мы установили ранее, поэтому в этом случае у меня есть имя рабочих станций, местонахождение магазина и количество 15.
Здесь, в моем именованном запросе, я хочу начать с установки подключения к базе данных для внутренней БД, и поскольку мы собираемся вставлять новые данные в базу данных и обновлять эту таблицу, мы хотим изменить тип запроса для обновления запроса. В моем запросе не будет никаких параметров, поэтому при желании я могу избавиться от обоих этих параметров. Затем я могу вставить свой запрос ниже. Вы можете видеть, что с запросом на вставку мы начинаем с команды вставки в, а затем перечисляем таблицу, в которую мы хотим вставить данные. В данном случае инвентаризация.
[01:03] Далее в скобках я перечисляю имена столбцов. Это столбцы, для которых я предоставляю данные, которые будут вставлены как новая строка. Наконец, мы используем значения ключевого слова, а затем снова в круглых скобках перечисляем значения, которые мы хотим вставить в указанные столбцы. Значения должны быть перечислены в порядке столбцов, которые мы установили ранее, поэтому в этом случае у меня есть имя рабочих станций, местонахождение магазина и количество 15.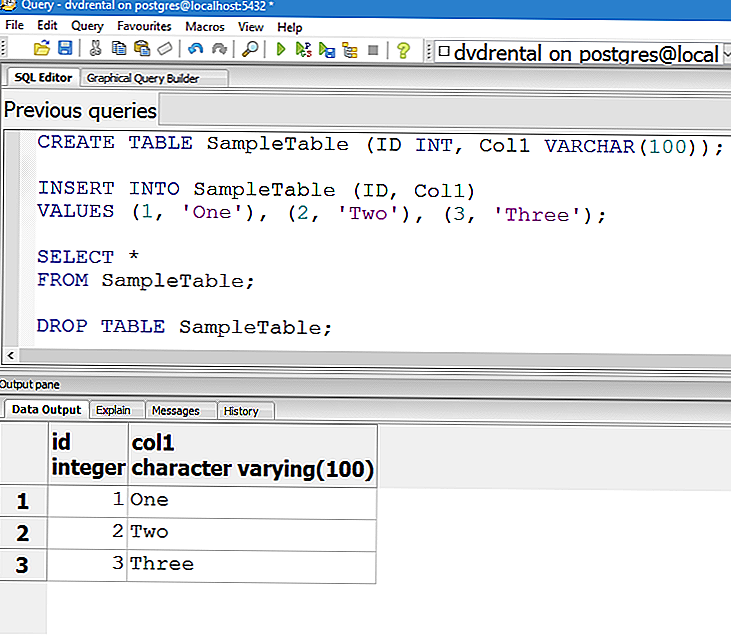 Я могу перейти на вкладку «Тестирование» и попробуйте выполнить этот запрос. Поскольку я вставляю данные, я не ожидаю, что они вернут мне данные, но они возвращают количество строк, затронутых моим запросом. В этом случае мы видим набор результатов, равный единице, что означает, что я вставил одну новую строку в свою таблицу. Я хочу вернуться, взглянуть на запрос и отметить две вещи.
[02:04] Во-первых, можно вставлять динамические значения, создавая параметры для каждого значения, которое вы хотите сделать динамическим. Так что в этом случае я мог бы сделать параметр для имени, параметр для местоположения и параметр для количества. Затем я могу заменить жестко запрограммированные значения этими параметрами. Это позволит мне вставлять новые значения при запуске запроса. Второе, что я хотел отметить, это то, что можно вставить несколько строк данных с помощью одного запроса на вставку. Я собираюсь вставить сюда некоторые дополнительные значения, и вы можете видеть, что все, что нам нужно сделать, это просто перечислить дополнительные наборы значений, разделенные запятыми.
Я могу перейти на вкладку «Тестирование» и попробуйте выполнить этот запрос. Поскольку я вставляю данные, я не ожидаю, что они вернут мне данные, но они возвращают количество строк, затронутых моим запросом. В этом случае мы видим набор результатов, равный единице, что означает, что я вставил одну новую строку в свою таблицу. Я хочу вернуться, взглянуть на запрос и отметить две вещи.
[02:04] Во-первых, можно вставлять динамические значения, создавая параметры для каждого значения, которое вы хотите сделать динамическим. Так что в этом случае я мог бы сделать параметр для имени, параметр для местоположения и параметр для количества. Затем я могу заменить жестко запрограммированные значения этими параметрами. Это позволит мне вставлять новые значения при запуске запроса. Второе, что я хотел отметить, это то, что можно вставить несколько строк данных с помощью одного запроса на вставку. Я собираюсь вставить сюда некоторые дополнительные значения, и вы можете видеть, что все, что нам нужно сделать, это просто перечислить дополнительные наборы значений, разделенные запятыми.