Подзапрос во фразе FROM
Подзапрос во фразе FROM- Оглавление
- Рекурсивные подзапросы
В первой части по подзапросам мы упоминали, что подзапросы можно использовать во фразе FROM. Но так ни разу этим не воспользовались.
Когда это может быть полезно?
Пример из жизни. Покупать товар по самой дешевой цене всегда приятно. Однако, не всегда удается купить именно по самой дешевой цене. То магазин закрыт, то добираться неудобно…
Допустим, что нас устроит покупка по цене от минимальной до средней на этот товар по всем магазинам.
Мы уже владеем коррелированными подзапросами. Воспользуемся ими для решения задачи:
SELECT *
FROM product_price pp
WHERE pp.price BETWEEN
(SELECT min (ppi.price)
FROM product_price ppi
WHERE ppi.
product_id = pp.product_id)
AND (SELECT avg (ppi.price)
FROM product_price ppi
WHERE ppi.product_id = pp.product_id)
ORDER BY pp.product_id,
pp.price

Не ошиблись ли мы? Не знаю, давай проверим на товаре с product_id = 3:
SELECT pp.product_id,
pp.price
FROM product_price pp
WHERE pp.product_id = 3
ORDER BY pp.price
Вроде бы не ошиблись. А давай в исходном запросе выведем минимальную и среднюю стоимость. Мы же умеем писать коррелированные подзапросы:
SELECT pp.product_id,
pp.store_id,
pp.price,
(SELECT round (min (ppi.price), 2)
FROM product_price ppi
WHERE ppi.product_id = pp.product_id
) AS price_min,
(SELECT round (avg (ppi.price), 2)
FROM product_price ppi
WHERE ppi.product_id = pp.product_id
) AS price_avg
FROM product_price pp
WHERE pp.price BETWEEN
(SELECT min (ppi.price)
FROM product_price ppi
WHERE ppi. product_id = pp.product_id)
AND (SELECT avg (ppi.price)
FROM product_price ppi
WHERE ppi.product_id = pp.product_id)
ORDER BY pp.product_id,
pp.price
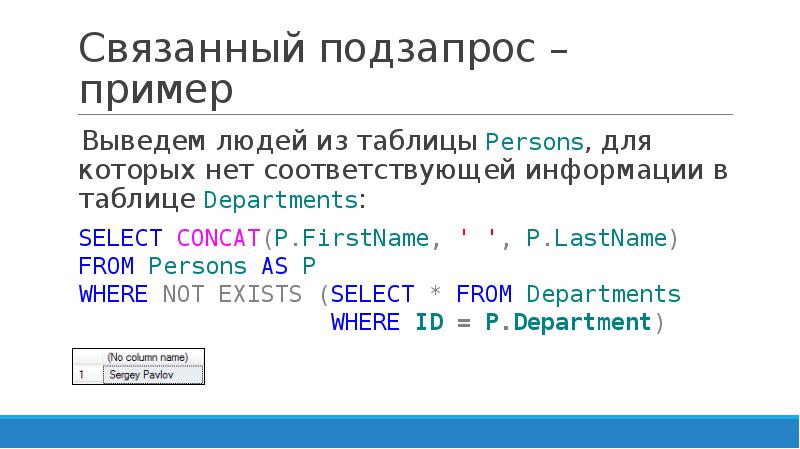
Работает, но читать такое сложновато.
Есть решение лучше. Давай сначала по каждому товару найдем минимальную и среднюю стоимость, а затем найдем товары с ценой в диапазоне от минимальной до средней.
- Определим минимальную и среднюю стоимость по товару:
SELECT pp.product_id,
min (pp.price) AS price_min,
avg (pp.price) AS price_avg
FROM product_price pp
GROUP BY pp.product_id
- Зная минимальную и среднюю стоимость по товару, возьмем товары с нужными ценами.
Можно использовать подзапросы во фразе FROM. В таком случае к результатам подзапроса можно обращаться как к обычной таблице:
SELECT *
FROM (SELECT pp.product_id,
min (pp.price) AS price_min,
avg (pp. price) AS price_avg
FROM product_price pp
GROUP BY pp.product_id
) as ppma

Правда есть одно условие: результату подзапроса нужно назначить псевдоним. Если не задать псевдоним, то возникнет ошибка:
SELECT *
FROM (SELECT pp.product_id,
min (pp.price) AS price_min,
avg (pp.price) AS price_avg
FROM product_price pp
GROUP BY pp.product_id
)
error: subquery in FROM must have an alias
Воспользуемся новыми знаниями для поиска товаров в магазинах с ценой от минимальной до средней:
SELECT pp.product_id,
pp.store_id,
pp.price,
round (ppma.price_min, 2) AS price_min,
round (ppma.price_avg, 2) AS price_avg
FROM (SELECT pp.product_id,
min (pp.price) AS price_min,
avg (pp.price) AS price_avg
FROM product_price pp
GROUP BY pp.product_id
) ppma,
product_price pp
WHERE pp.product_id = ppma. product_id
AND pp.price BETWEEN ppma.price_min AND ppma.price_avg
ORDER BY pp.product_id,
pp.price
 product_id
AND pp.price BETWEEN ppma.price_min AND ppma.price_avg
ORDER BY pp.product_id,
pp.price
product_id
AND pp.price BETWEEN ppma.price_min AND ppma.price_avg
ORDER BY pp.product_id,
pp.price
Практика
Подзапрос во фразе FROM
9.13 EXTRACT — извлечение из даты части (год, месяц, день…)
10.2 Введение в WITH
2.14. Подзапросы — Transact-SQL В подлиннике : Персональный сайт Михаила Флёнова
Наиболее сложной, но в то же время наиболее интересной темой являются подзапросы. Это достаточно мощное средство получения необходимых данных, а с другой стороны, это средство очень сильно бьет по производительности обработки запроса сервером. Сначала мы научимся работать с подзапросами, потому что с их помощью можно быстро решить поставленную задачу, а потом будем учиться избавляться от подзапросов, что идентично оптимизации.
Рассмотрим пример, как можно определить номера телефонов, у которых установлен тип ‘Сотовый рабочий’. Для этого сначала необходимо узнать, какой первичный ключ у нужного типа телефона в таблице tbPhoneType:
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName = ('Сотовый рабочий')
После этого уже находим все записи в таблице tbPhoneNumbers, где поле «idPhoneType» содержит найденное значение типа телефона:
SELECT * FROM tbPhoneNumbers WHERE idPhoneType = идентификатор
Эта задача достаточно просто решается с помощью подзапросов:
SELECT *
FROM tbPhoneNumbers
WHERE idPhoneType =
(
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName = ('Сотовый рабочий')
)
В данном примере мы выбираем все записи из таблицы tbPhoneNumbers.
Попробуем выполнить следующий запрос:
SELECT *
FROM tbPhoneNumbers
WHERE idPhoneType =
(
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName in ('Сотовый рабочий', 'Сотовый домашний')
)
Этот запрос вернет две строки с двумя значениями первичного ключа. В ответ на это, сервер вернет ошибку:
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
(Подзапрос возвращает более чем 1 значение. Это не позволено, когда подзапрос следует после знаков =, !=, <, <= , >, >= или когда подзапрос используется как выражение)
А что же тогда можно использовать? Если немного подумать, то для такого запроса знак равенства нужно заменить на оператор IN:
SELECT *
FROM tbPhoneNumbers
WHERE idPhoneType IN
(
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName in ('Сотовый рабочий', 'Сотовый домашний')
)
Сначала SQL выполнит внутренний запрос, который расположен в скобках и результат подставит во внешний запрос.
Я уже намекнул на то, что результат подзапроса должен состоять только из одной колонки. Это значит, что вы не можете написать во внутреннем запросе SELECT *, а можно только SELECT ИмяОдногоПоля. Помните, что имя должно быть только одно и тип его должен совпадать с типом сравниваемого значения. Подзапросы нужно использовать очень аккуратно, потому что они могут привести к ошибке.
Очень важно, что подзапрос находиться в скобках и справа от знака равенства. Стандарт не позволяет писать подзапросы слева. Это значит, что следующий запрос не верный:
SELECT *
FROM tbPhoneNumbers
WHERE
(
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName = ('Сотовый рабочий')
) = idPhoneType
В этом примере сначала идет подзапрос, потом знак равенства и только после этого указывается поле, с которым необходимо произвести сравнение.
Основной запрос (так же называемый внешним) может обращаться к подзапросу (внутренний запрос). Для этого таблицам необходимо указать псевдонимы. Посмотрим на следующий запрос:
Для этого таблицам необходимо указать псевдонимы. Посмотрим на следующий запрос:
SELECT *
FROM tbPhoneNumbers ot
WHERE idPhoneType IN
(
SELECT idPhoneType
FROM tbPhoneType it
WHERE vcTypeName in ('Сотовый рабочий', 'Сотовый домашний')
AND ot.vcPhoneNumber LIKE '(923)%'
)
Обратите внимание на предпоследнюю строку:
AND ot.vcPhoneNumber LIKE '(923)%'
Здесь происходит сравнение поя «vcPhoneNumber» таблицы ot с шаблоном. Самое интересное здесь в том, что ot – это псевдоним таблицы tbPhoneNumbers, которая описана в секции FROM внешнего запроса. Но, не смотря на это, мы можем из подзапроса обращаться по псевдониму к столбцам внешних запросов. Таким образом, можно наводить достаточно сложные связи между запросами.
Такой запрос будет выполняться по следующему алгоритму:
- Выбрать строку из таблицы tbPhoneNumbers в внешнем запросе. Это будет текущая строка-кандидат.
- Сохранить значения из этой строки-кандидата в псевдониме с именем ot.
- Выполнить подзапрос, при этом, во время поиска участвует и внешний запрос.
- Оценить «idPhoneType» внешнего запроса на основе результатов подзапроса выполняемого в предыдущем шаге. Он определяет — выбирается ли строка-кандидат для вывода на экран.
Подзапросы могут быть не только в секции WHERE, но и в секции SELECT и в секции FROM. Давайте рассмотрим сначала подзапросы из FROM, для этого поставим достаточно сложную, но интересную задачу. Во время группировки мы смогли научиться определять количество пользователей с именем Андрей. А что если создать таблицу, которая будет состоять из трех колонок:
- Имя;
- Количество пользователей с таким именем;
- Количество номеров телефонов для каждого имени.
В виде двух запросов эта задача решается достаточно просто. Следующий запрос определяет количество каждого имени в таблице:
SELECT p.vcName, COUNT (*) as PeopleNumber FROM tbPeoples p GROUP BY p.
 vcName
vcName
Такой запрос мы уже разбирали.
Теперь определим количество телефоном для каждого имени. Именно имени, а не работника. Нас интересует, сколько номеров телефонов у всех Андреев, Иванов и т.д. Эта задача решается с помощью связи из таблиц работников и телефонов, группировкой по имени и подсчетом количества телефонов:
SELECT pl.vcName, COUNT(vcPhoneNumber) AS PhoneNum FROM tbPeoples pl, tbPhoneNumbers pn WHERE pl.idPeoples *= pn.idPeoples GROUP BY vcName
У нас получилось две разных таблицы. А как теперь их объединить в одно целое? Попробуйте самостоятельно решить эту задачу. Мое решение можно увидеть в листинге 2.3.
Листинг 2.3. Получение количества имен и количества телефонов у каждого имени
SELECT * FROM (SELECT p.vcName, COUNT(*) as PeopleNumber FROM tbPeoples p GROUP BY p.vcName) p1, (SELECT pl.vcName, COUNT(vcPhoneNumber) AS PhoneNum FROM tbPeoples pl, tbPhoneNumbers pn WHERE pl.
 idPeoples *= pn.idPeoples
GROUP BY vcName) p2
WHERE p1.vcName=p2.vcName
idPeoples *= pn.idPeoples
GROUP BY vcName) p2
WHERE p1.vcName=p2.vcName
В секции FROM, вместо указания таблиц стоят вышеописанные запросы, заключенные в круглые скобки. Для каждого запроса указывается псевдоним, иначе невозможно работать с полями запросов. Получается, что вместо того, чтобы получить данные непосредственно из таблицы, мы получаем их из запроса.
Для таких запросов, есть только одно ограничение – у каждого поля в подзапросе секции FROM должно быть имя. У нас есть поля, подсчитывающие количество записей и для таких полей имя не устанавливается, поэтому я установил псевдонимы. В первом подзапросе колонка с количеством записей названа как PeopleNumber, а во втором подзапросе — PhoneNum.
Внешний объединяющий запрос связывает обе полученные таблицы через поле имени «vcName», а результатом будет общая таблица (см. рис. 2.7), состоящая из четырех колонок – имя и количество из первого запроса, и имя и количество из второго запроса. Одну из колонок имен можно убрать, потому что они идентичны, но я решил оставить, чтобы вы могли увидеть связь.
Результат объединения двух таблиц
Теперь посмотрим, как можно писать подзапросы в секции SELECT. Я не нашел интересного примера, поэтому просто решил вывести всех работников и их телефоны. Но при этом, не наводить связь между таблицами работников и телефонами в секции FROM, а искать номера с помощью подзапросов в секции SELECT:
SELECT pl.*, ( SELECT vcPhoneNumber FROM tbPhoneNumbers pn WHERE pn.idPhoneNumbers=pl.idPeoples ) FROM tbPeoples pl
В секции SELECT сначала запрашиваем все колонки из таблицы tbPeoples (pl.*). После этого, вместо очередного поля в скобках указывается подзапрос, который выбирает данные. При этом в подзапросе в секции WHERE наводиться связь между таблицами. Получается, что и из этого подзапроса мы можем обращаться к полям внешнего запроса.
Единственное ограничение – подзапрос в секции SELECT должен возвращать только одну строку. Если результатом будет несколько строк, то запрос возвращает ошибку.
Все примеры, которые мы рассматривали выше, достаточно просто реализовать, без использования подзапросов. Например, посмотрим на следующий запрос:
SELECT *
FROM tbPhoneNumbers
WHERE idPhoneType =
(
SELECT idPhoneType
FROM tbPhoneType
WHERE vcTypeName = ('Сотовый рабочий')
)
Эта же задача решается следующим образом:
SELECT pn.*
FROM tbPhoneNumbers pn, tbPhoneType pt
WHERE pn.idPhoneType = pt.idPhoneType
AND vcTypeName = ('Сотовый рабочий')
Просто связываем обе таблицы и указываем то же самое условие. Таким образом, мы избавились от подзапроса, и теперь сервер сможет выполнить задачу быстрее. Большинство задач можно решить без подзапросов, если правильно связать таблицы. Именно поэтому, в данной книге я постараюсь минимально пользоваться подзапросами, и все постараемся решать одним оператором SELECT.
А вот следующий запрос, достаточно сложно сделать без подзапросов. Допустим, что вам нужно определить данные последней, добавленной в таблицу строки. Если в качестве первичного ключа используется автоматически увеличиваемое поле, то необходимо узнать наибольшее значение первичного ключа с помощью оператора MAX, а потом найти строку с этим ключом. Вот как определяется последняя строка в таблице tbPeoples:
Допустим, что вам нужно определить данные последней, добавленной в таблицу строки. Если в качестве первичного ключа используется автоматически увеличиваемое поле, то необходимо узнать наибольшее значение первичного ключа с помощью оператора MAX, а потом найти строку с этим ключом. Вот как определяется последняя строка в таблице tbPeoples:
SELECT *
FROM tbPeoples
WHERE idPeoples=
(SELECT MAX(idPeoples) FROM tbPeoples)
Такой запрос нам очень поможет, когда мы будем учиться добавлять записи в таблицу, чтобы быстро можно было увидеть результат работы.
Написание подзапросов в SQL | Расширенный SQL
Начиная здесь? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
- Основы подзапросов
- Использование подзапросов для агрегирования в несколько этапов
- Подзапросы в условной логике
- Объединение подзапросов
- Подзапросы и UNION
На этом уроке вы продолжите работать с теми же данными о преступности в Сан-Франциско, что и на предыдущем уроке.
Основы подзапросов
Подзапросы (также известные как внутренние запросы или вложенные запросы) — это инструмент для выполнения операций в несколько шагов. Например, если вы хотите взять суммы нескольких столбцов, а затем усреднить все эти значения, вам нужно будет выполнить каждую агрегацию на отдельном шаге.
Подзапросы могут использоваться в нескольких местах внутри запроса, но проще всего начать с оператора FROM . Вот пример простого подзапроса:
SELECT sub.*
ОТ (
ВЫБИРАТЬ *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ day_of_week = 'Пятница'
) суб
ГДЕ подразрешение = 'НЕТ'
Давайте разберем, что происходит, когда вы выполняете приведенный выше запрос:
Сначала база данных выполняет «внутренний запрос» — часть в скобках:
SELECT * ИЗ tutorial.sf_crime_incidents_2014_01 ГДЕ day_of_week = 'Пятница'
Если бы вы запустили этот запрос самостоятельно, он выдал бы набор результатов, как и любой другой запрос. Это может показаться пустяком, но это важно: ваш внутренний запрос должен фактически выполняться сам по себе, так как база данных будет рассматривать его как независимый запрос. После запуска внутреннего запроса внешний запрос будет запущен с использованием результатов внутреннего запроса в качестве базовой таблицы :
Это может показаться пустяком, но это важно: ваш внутренний запрос должен фактически выполняться сам по себе, так как база данных будет рассматривать его как независимый запрос. После запуска внутреннего запроса внешний запрос будет запущен с использованием результатов внутреннего запроса в качестве базовой таблицы :
SELECT sub.*
ОТ (
<<результаты внутреннего запроса идут сюда>>
) суб
ГДЕ подразрешение = 'НЕТ'
Подзапросы должны иметь имена, которые добавляются после круглых скобок так же, как вы добавляете псевдоним к обычной таблице. В этом случае мы использовали имя «sub».
Небольшое замечание по форматированию. Важно помнить, что при использовании подзапросов необходимо предоставить читателю возможность легко определить, какие части запроса будут выполняться вместе. Большинство людей делают это, тем или иным образом делая отступ в подзапросе. Примеры в этом руководстве имеют довольно большой отступ — вплоть до круглых скобок. Это нецелесообразно, если вы вкладываете много подзапросов, поэтому довольно часто отступ делается только на два пробела или около того.
Это нецелесообразно, если вы вкладываете много подзапросов, поэтому довольно часто отступ делается только на два пробела или около того.
Практическая задача
Напишите запрос, который выбирает все ордера на арест из набора данных tutorial.sf_crime_incidents_2014_01 , а затем оберните его во внешний запрос, который отображает только неразрешенные инциденты.
Вышеприведенные примеры, как и практическая задача, на самом деле не требуют подзапросов — они решают проблемы, которые также можно решить, добавив несколько условий в предложение WHERE . В следующих разделах приводятся примеры, для которых подзапросы являются лучшим или единственным способом решения соответствующих проблем.
Использование подзапросов для агрегирования в несколько этапов
Что делать, если вы хотите выяснить, сколько инцидентов сообщается в каждый день недели? А что, если вы хотите узнать, сколько инцидентов происходит в среднем в пятницу декабря? В январе? Этот процесс состоит из двух шагов: подсчет количества инцидентов каждый день (внутренний запрос), затем определение среднемесячного значения (внешний запрос):
суб. день_недели,
AVG(sub.incidents) КАК среднее_происшествие
ОТ (
ВЫБЕРИТЕ день_недели,
дата,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ НА 1,2
) суб
СГРУППИРОВАТЬ НА 1,2
ЗАКАЗАТЬ ПО 1,2
день_недели,
AVG(sub.incidents) КАК среднее_происшествие
ОТ (
ВЫБЕРИТЕ день_недели,
дата,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ НА 1,2
) суб
СГРУППИРОВАТЬ НА 1,2
ЗАКАЗАТЬ ПО 1,2
Если вы не можете понять, что происходит, попробуйте запустить внутренний запрос отдельно, чтобы понять, как выглядят его результаты. В общем, проще всего сначала написать внутренние запросы и пересматривать их до тех пор, пока результаты не станут для вас понятными, а затем перейти к внешнему запросу.
Практическая задача
Напишите запрос, отображающий среднее количество инцидентов в месяц для каждой категории. Подсказка: используйте tutorial.sf_crime_incidents_cleandate , чтобы немного облегчить себе жизнь.
Подзапросы в условной логике
Вы можете использовать подзапросы в условной логике (в сочетании с WHERE , JOIN / ON или CASE 9 0030). Следующий запрос возвращает все записи с самой ранней даты в наборе данных (теоретически — плохое форматирование столбца даты на самом деле заставляет возвращать значение, отсортированное первым в алфавитном порядке):
Следующий запрос возвращает все записи с самой ранней даты в наборе данных (теоретически — плохое форматирование столбца даты на самом деле заставляет возвращать значение, отсортированное первым в алфавитном порядке):
SELECT *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ Дата = (ВЫБЕРИТЕ МИН (дата)
ИЗ tutorial.sf_crime_incidents_2014_01
)
Приведенный выше запрос работает, поскольку результатом подзапроса является только одна ячейка. Большая часть условной логики будет работать с подзапросами, содержащими результаты с одной ячейкой. Однако IN — это единственный тип условной логики, который будет работать, когда внутренний запрос содержит несколько результатов:
SELECT *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ Дата В (ВЫБЕРИТЕ дату
ИЗ tutorial.sf_crime_incidents_2014_01
ЗАКАЗАТЬ ПО дате
ПРЕДЕЛ 5
)
Обратите внимание, что вы не должны включать псевдоним при написании подзапроса в условном выражении. Это связано с тем, что подзапрос обрабатывается как отдельное значение (или набор значений в случае
Это связано с тем, что подзапрос обрабатывается как отдельное значение (или набор значений в случае IN ), а не как таблица.
Объединение подзапросов
Возможно, вы помните, что вы можете фильтровать запросы в соединениях. Довольно часто присоединяется к подзапросу, который обращается к той же таблице, что и внешний запрос, а не фильтруется в предложении WHERE . Следующий запрос дает те же результаты, что и в предыдущем примере:
ВЫБОР *
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату
ИЗ tutorial.sf_crime_incidents_2014_01
ЗАКАЗАТЬ ПО дате
ПРЕДЕЛ 5
) суб
ON инциденты.дата = суб.дата
Это может быть особенно полезно в сочетании с агрегатами. При присоединении требования к выходным данным вашего подзапроса не такие строгие, как при использовании предложения WHERE . Например, ваш внутренний запрос может выводить несколько результатов. Следующий запрос ранжирует все результаты в зависимости от того, сколько инцидентов было зарегистрировано в данный день. Он делает это путем агрегирования общего количества инцидентов каждый день во внутреннем запросе, а затем использует эти значения для сортировки внешнего запроса:
Следующий запрос ранжирует все результаты в зависимости от того, сколько инцидентов было зарегистрировано в данный день. Он делает это путем агрегирования общего количества инцидентов каждый день во внутреннем запросе, а затем использует эти значения для сортировки внешнего запроса:
ВЫБЕРИТЕ инциденты.*,
sub.incidents AS инциденты_этот_день
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ ПО 1
) суб
ON инциденты.дата = суб.дата
ORDER BY sub.incidents DESC, время
Практическая задача
Напишите запрос, который отображает все строки из трех категорий с наименьшим количеством зарегистрированных инцидентов.
ПопробуйтеСмотреть ответ Подзапросы могут быть очень полезны для повышения производительности ваших запросов. Давайте кратко вернемся к данным Crunchbase. Представьте, что вы хотите собрать все компании, получающие инвестиции, и компании, приобретаемые каждый месяц. Вы можете сделать это без подзапросов, если хотите, но на самом деле не запускайте это, так как для возврата :
Представьте, что вы хотите собрать все компании, получающие инвестиции, и компании, приобретаемые каждый месяц. Вы можете сделать это без подзапросов, если хотите, но на самом деле не запускайте это, так как для возврата :
SELECT COALESCE(acquisitions.acquired_month, Investments.funded_month) AS month,
COUNT(DISTINCT Acquirements.company_permalink) КАК компании_приобретены,
COUNT(DISTINCT Investments.company_permalink) КАК инвестиции
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
СГРУППИРОВАТЬ ПО 1
Обратите внимание, что для того, чтобы сделать это правильно, вы должны соединить поля даты, что вызывает массовый «взрыв данных». По сути, происходит то, что вы соединяете каждую строку в данном месяце из одной таблицы с каждым месяцем в данной строке в другой таблице, поэтому количество возвращаемых строк невероятно велико. Из-за этого мультипликативного эффекта вы должны использовать
Из-за этого мультипликативного эффекта вы должны использовать COUNT(DISTINCT) вместо COUNT , чтобы получить точные подсчеты. Вы можете увидеть это ниже:
Следующий запрос показывает 7414 строк:
ВЫБРАТЬ СЧЕТЧИК(*) ИЗ tutorial.crunchbase_acquisitions
Следующий запрос показывает 83 893 строки:
SELECT COUNT(*) FROM tutorial.crunchbase_investments
Следующий запрос показывает 6 237 396 строк:
SELECT COUNT(*)
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
Если вы хотите понять это немного лучше, вы можете провести дополнительное исследование декартовых произведений. Также стоит отметить, что FULL JOIN и COUNT , приведенные выше, на самом деле работают довольно быстро — это COUNT(DISTINCT) , который занимает вечность. Подробнее об этом в уроке по оптимизации запросов.
Подробнее об этом в уроке по оптимизации запросов.
Конечно, вы могли бы решить эту проблему намного эффективнее, объединив две таблицы по отдельности, а затем соединив их вместе, чтобы подсчеты выполнялись для гораздо меньших наборов данных: приобретения.companies_acquired, Investments.companies_rec_investment ОТ ( ВЫБЕРИТЕ приобретаете_месяц КАК месяц, COUNT(DISTINCT company_permalink) AS company_acquired ИЗ tutorial.crunchbase_acquisitions СГРУППИРОВАТЬ ПО 1 ) приобретения ПОЛНОЕ СОЕДИНЕНИЕ ( ВЫБЕРИТЕ funded_month AS месяц, COUNT(DISTINCT company_permalink) КАК company_rec_investment ИЗ tutorial.crunchbase_investments СГРУППИРОВАТЬ ПО 1 )вложения ON приобретения.месяц = инвестиции.месяц ЗАКАЗАТЬ ПО 1 ДЕСК
Примечание. Мы использовали FULL JOIN выше на тот случай, если в одной таблице были наблюдения за месяц, которых не было в другой таблице. Мы также использовали
Мы также использовали COALESCE для отображения месяцев, когда в подзапросе поступлений не было записей о месяцах (предположительно, в эти месяцы не было поступлений). Мы настоятельно рекомендуем вам повторно выполнить запрос без некоторых из этих элементов, чтобы лучше понять, как они работают. Вы также можете запускать каждый из подзапросов независимо, чтобы лучше понять их.
Практическая задача
Напишите запрос, который подсчитывает количество основанных и приобретенных компаний по кварталам, начиная с первого квартала 2012 года. Создайте агрегации в двух отдельных запросах, а затем соедините их.
Попробуйте См. ответПодзапросы и ОБЪЕДИНЕНИЯ
В следующем разделе мы возьмем урок, посвященный ОБЪЕДИНЕНИЯМ, снова используя данные Crunchbase:
SELECT * ИЗ tutorial.crunchbase_investments_part1 СОЮЗ ВСЕХ ВЫБИРАТЬ * ИЗ tutorial.crunchbase_investments_part2
Набор данных нередко бывает разделен на несколько частей, особенно если данные проходят через Excel в какой-либо момент (Excel может обрабатывать только около 1 млн строк на электронную таблицу). Две приведенные выше таблицы можно рассматривать как разные части одного и того же набора данных — почти наверняка вы захотите выполнять операции со всем объединенным набором данных, а не с отдельными его частями. Вы можете сделать это с помощью подзапроса:
Две приведенные выше таблицы можно рассматривать как разные части одного и того же набора данных — почти наверняка вы захотите выполнять операции со всем объединенным набором данных, а не с отдельными его частями. Вы можете сделать это с помощью подзапроса:
SELECT COUNT(*) AS total_rows
ОТ (
ВЫБИРАТЬ *
ИЗ tutorial.crunchbase_investments_part1
СОЮЗ ВСЕХ
ВЫБИРАТЬ *
ИЗ tutorial.crunchbase_investments_part2
) суб
Это довольно просто. Попробуйте сами:
Практическая задача
Напишите запрос, который ранжирует инвесторов из приведенного выше комбинированного набора данных по общему количеству сделанных ими инвестиций.
ПопробуйтеСмотреть ответПрактическая задача
Напишите запрос, который делает то же самое, что и в предыдущей задаче, но только для компаний, которые все еще работают. Подсказка: рабочий статус указан в tutorial.crunchbase_companies 9.0030 .
Руководство для начинающих (с примерами кода)
Каждый специалист по данным должен разбираться в базе данных SQL, включая подзапросы. Вот введение.
В этой статье мы рассмотрим основы подзапросов SQL, их синтаксис, их полезность, а также когда и как их использовать при выполнении запросов к базе данных.
В этой статье предполагается, что у вас есть базовые знания о выборе данных с помощью SQL, таких как группировка данных, агрегатные функции, фильтрация и базовые соединения.
Что такое подзапрос
Подзапрос — это не что иное, как запрос внутри другого запроса. В основном мы используем их для добавления нового столбца к основному результату запроса, для создания фильтра или для создания консолидированного источника, из которого можно выбирать данные.
Подзапрос всегда будет заключен в круглые скобки и может появляться в разных местах в основном запросе, в зависимости от цели — обычно в оговорках SELECT , FROM или WHERE . Кроме того, количество подзапросов не ограничено, что означает, что вы можете иметь столько вложенных запросов, сколько вам нужно.
Кроме того, количество подзапросов не ограничено, что означает, что вы можете иметь столько вложенных запросов, сколько вам нужно.
База данных
Чтобы написать реальный код SQL, мы будем использовать базу данных Chinook в качестве примера. Это образец базы данных, доступный для нескольких типов баз данных.
База данных содержит информацию о вымышленном цифровом музыкальном магазине, такую как данные об исполнителях, песнях, плейлистах, музыкальных жанрах и альбомах из музыкального магазина, а также информацию о сотрудниках магазина, покупателях и покупках.
Это схема базы данных, чтобы вы могли лучше понять, как работают запросы, которые мы напишем:
Подзапрос для создания нового столбца
Первый вариант использования подзапроса заключается в его использовании для добавления нового столбца к выходным данным основного запроса. Вот как будет выглядеть синтаксис:
ВЫБЕРИТЕ столбец_1,
столбцы_2,
(ВЫБИРАТЬ
. ..
ИЗ таблицы_2
СГРУППИРОВАТЬ ПО 1)
ИЗ таблицы_1
GROUP BY 1  ..
ИЗ таблицы_2
СГРУППИРОВАТЬ ПО 1)
ИЗ таблицы_1
GROUP BY 1
..
ИЗ таблицы_2
СГРУППИРОВАТЬ ПО 1)
ИЗ таблицы_1
GROUP BY 1 Давайте рассмотрим практический пример.
Здесь мы хотим увидеть количество плейлистов в приложении, в которые пользователи добавили каждую песню.
Основной запрос возвращает два столбца: название песни и количество плейлистов, в которые ее добавили пользователи. Это второй столбец, который требует подзапроса. Подзапрос здесь необходим, потому что мы должны сопоставить track_id , назначенный списку воспроизведения, с track_id в таблице дорожек, а затем подсчитать их для каждой дорожки.
ВЫБЕРИТЕ т.имя,
(ВЫБИРАТЬ
количество (playlist_id)
ИЗ playlist_track pt
ГДЕ pt.track_id = t.track_id
) как количество_плейлистов
С дорожки т
СГРУППИРОВАТЬ ПО 1
ORDER BY number_of_playlists DESC
ПРЕДЕЛ 50 Затем мы получаем этот вывод:
| имя | количество_плейлистов |
|---|---|
Сон в летнюю ночь, Op. 61 Музыкальное сопровождение: No.7 Notturno 61 Музыкальное сопровождение: No.7 Notturno | 5 |
| Aria Mit 30 Veränderungen, BWV 988 "Вариации Гольдберга": Ария | 5 |
| Аве Мария | 5 |
| Кармен: Увертюра | 5 |
| Кармина Бурана: О Фортуна | 5 |
| Cavalleria Rusticana \ Act \ Intermezzo Sinfonico | 5 |
| Концерт для фортепиано № 2 фа минор, соч. 21: II. Ларгетто | 5 |
| Концерт для скрипки, струнных и континуо соль мажор, соч. 3, № 9: И. Аллегро | 5 |
| Das Lied Von Der Erde, Von Der Jugend | 5 |
| Валькирия: Полет валькирий | 5 |
| Die Zauberflöte, K.620: "Der Hölle Rache Kocht in Meinem Herze" | 5 |
| Фантазия на зеленых рукавах | 5 |
| Интоитус: обожаю Деум | 5 |
| Юпитер, несущий веселье | 5 |
Карелия Сюита, Op. 11: 2. Баллада (Tempo Di Menuetto) 11: 2. Баллада (Tempo Di Menuetto) | 5 |
| Кояанискаци | 5 |
| Плач Иеремии, первый набор \ Incipit Lamentatio | 5 |
| Метопы, соч. 29: Калипсо | 5 |
| Мизерере Мей, Деус | 5 |
Выполнение математических операций
При создании нового столбца подзапрос также может быть полезен для выполнения некоторых вычислений. Конечно, в этом случае выводом подзапроса должно быть одно число.
В следующем запросе мы хотим узнать процент треков каждого жанра в нашей базе данных. Синтаксис в основном такой же, как и в последнем примере, только подзапрос будет частью создания нового столбца, а не всего нового столбца.
Для этой задачи нам нужно разделить количество песен в каждом жанре на общее количество песен в этой таблице дорожек. Мы можем легко получить доступ к общему количеству треков с помощью этого запроса:
ВЫБИРАТЬ
count(*) как total_tracks
С трека
| общее количество треков |
|---------------|
| 3503 | Мы можем найти общее количество треков в каждом жанре с помощью следующего запроса:
ВЫБИРАТЬ
g. name как жанр,
count(t.track_id) как number_of_tracks
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ЗАКАЗАТЬ ПО 2 DESC  name как жанр,
count(t.track_id) как number_of_tracks
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ЗАКАЗАТЬ ПО 2 DESC
name как жанр,
count(t.track_id) как number_of_tracks
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ЗАКАЗАТЬ ПО 2 DESC | жанр | количество_треков |
|---|---|
| Камень | 1297 |
| Латинский | 579 |
| Металл | 374 |
| Альтернатива и панк | 332 |
| Джаз | 130 |
| Телешоу | 93 |
| Блюз | 81 |
| Классический | 74 |
| Драма | 64 |
| R&B/соул | 61 |
| Регги | 58 |
| Поп | 48 |
| Саундтрек | 43 |
| Альтернатива | 40 |
| Хип-хоп/рэп | 35 |
| Электроника/Танец | 30 |
| Тяжелый металл | 28 |
| Мир | 28 |
| Научная фантастика и фэнтези | 26 |
| Легкая музыка | 24 |
| Комедия | 17 |
| Босса-Нова | 15 |
| Научная фантастика | 13 |
| Рок-н-ролл | 12 |
| Опера | 1 |
Если мы объединим эти два запроса так, что первый будет подзапросом, результатом будет процентное соотношение песен в каждом жанре:
ВЫБИРАТЬ
g. name как жанр,
round(cast(count(t.track_id) as float) / (SELECT count(*) FROM track), 2) as perc
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ORDER BY 2 DESC  name как жанр,
round(cast(count(t.track_id) as float) / (SELECT count(*) FROM track), 2) as perc
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ORDER BY 2 DESC
name как жанр,
round(cast(count(t.track_id) as float) / (SELECT count(*) FROM track), 2) as perc
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ORDER BY 2 DESC | Жанр | проц |
|---|---|
| Камень | 0,37 |
| Латинский | 0,17 |
| Металл | 0,11 |
| Альтернатива и панк | 0,09 |
| Джаз | 0,04 |
| Телешоу | 0,03 |
| Блюз | 0,02 |
| Классический | 0,02 |
| Драма | 0,02 |
| R&B/соул | 0,02 |
| Регги | 0,02 |
| Альтернатива | 0,01 |
| Легкая музыка | 0,01 |
| Электроника/Танец | 0,01 |
| Тяжелый металл | 0,01 |
| Хип-хоп/рэп | 0,01 |
| Поп | 0,01 |
| Научная фантастика и фэнтези | 0,01 |
| Саундтрек | 0,01 |
| Мир | 0,01 |
| Босса-Нова | 0 |
| Комедия | 0 |
| Опера | 0 |
| Рок-н-ролл | 0 |
| Научная фантастика | 0 |
Подзапрос как фильтр
Использование подзапроса SQL в качестве фильтра основного запроса — один из моих любимых вариантов использования. В этом сценарии подзапрос будет находиться в предложении
В этом сценарии подзапрос будет находиться в предложении WHERE , и мы можем использовать такие операторы, как IN , = , <> , > и < для фильтрации в зависимости от вывода подзапроса.
Это синтаксис:
ВЫБИРАТЬ
столбец_1,
столбцы_2
ИЗ таблицы_1
ГДЕ столбец_1 в
(ВЫБИРАТЬ
...
FROM table_2) Допустим, в нашем примере мы хотим узнать, сколько клиентов, потративших не менее 100 долларов США в магазине, назначено каждому сотруднику. Давайте сделаем это в два этапа.
Во-первых, давайте просто получим количество клиентов для каждого сотрудника. Это простой запрос.
ВЫБЕРИТЕ идентификатор_сотрудника,
е.фамилия,
count(различный customer_id) как number_of_customers
ОТ работника е
ВНУТРЕННЕЕ ПРИСОЕДИНЕНИЕ клиент c on e.employee_id = c.support_rep_id
СГРУППИРОВАТЬ НА 1,2
ORDER BY 3 DESC Это вывод:
| employee_id | фамилия | количество_клиентов |
|---|---|---|
| 3 | Павлин | 21 |
| 4 | Парк | 20 |
| 5 | Джонсон | 18 |
Теперь давайте посмотрим, какие клиенты потратили в магазине не менее 100 долларов США. Это запрос:
Это запрос:
ВЫБИРАТЬ
c.customer_id,
раунд (сумма (i.total), 2) как итог
ОТ клиента c
Счет INNER JOIN i на c.customer_id = i.customer_id
СГРУППИРОВАТЬ ПО c.customer_id
ИМЕЮЩАЯ сумма (i.total)> 100
ORDER BY 2 DESC Это вывод:
| customer_id | всего |
|---|---|
| 5 | 144,54 |
| 6 | 128,7 |
| 46 | 114,84 |
| 58 | 111,87 |
| 1 | 108,9 |
| 13 | 106,92 |
| 34 | 102,96 |
Теперь, чтобы объединить эти два запроса, первый будет основным запросом, а второй будет в Предложение WHERE для фильтрации основного запроса.
Как это работает:
ВЫБЕРИТЕ идентификатор_сотрудника,
е.фамилия,
count(различный customer_id) как number_of_customers
ОТ работника е
ВНУТРЕННЕЕ ПРИСОЕДИНЕНИЕ клиент c on e. employee_id = c.support_rep_id
ГДЕ customer_id в (
ВЫБИРАТЬ
c.customer_id
ОТ клиента c
Счет INNER JOIN i на c.customer_id = i.customer_id
СГРУППИРОВАТЬ ПО c.customer_id
ИМЕЮЩАЯ сумма (i.total)> 100)
СГРУППИРОВАТЬ ПО 1, 2
ЗАКАЗАТЬ ПО 3 DESC  employee_id = c.support_rep_id
ГДЕ customer_id в (
ВЫБИРАТЬ
c.customer_id
ОТ клиента c
Счет INNER JOIN i на c.customer_id = i.customer_id
СГРУППИРОВАТЬ ПО c.customer_id
ИМЕЮЩАЯ сумма (i.total)> 100)
СГРУППИРОВАТЬ ПО 1, 2
ЗАКАЗАТЬ ПО 3 DESC
employee_id = c.support_rep_id
ГДЕ customer_id в (
ВЫБИРАТЬ
c.customer_id
ОТ клиента c
Счет INNER JOIN i на c.customer_id = i.customer_id
СГРУППИРОВАТЬ ПО c.customer_id
ИМЕЮЩАЯ сумма (i.total)> 100)
СГРУППИРОВАТЬ ПО 1, 2
ЗАКАЗАТЬ ПО 3 DESC Это окончательный вывод:
| employee_id | фамилия | количество_клиентов |
|---|---|---|
| 3 | Павлин | 3 |
| 4 | Парк | 3 |
| 5 | Джонсон | 1 |
Обратите внимание на два важных момента:
- Мы удалили столбец
total_purchasedпри размещении запроса 2 вWHEREпункт основного запроса. Это потому, что мы хотим, чтобы этот запрос возвращал только один столбец, который основной запрос использует в качестве фильтра. Если бы мы этого не сделали, то увидели бы такое сообщение об ошибке (в зависимости от версии SQL):
sub-select возвращает 2 столбца - ожидается 1
- Мы использовали оператор
IN. Как следует из названия, мы хотели проверить, какие клиенты были В списке столбцов с покупками на сумму более 100 долларов США.
 Как следует из названия, мы хотели проверить, какие клиенты были В списке столбцов с покупками на сумму более 100 долларов США.
Как следует из названия, мы хотели проверить, какие клиенты были В списке столбцов с покупками на сумму более 100 долларов США. Чтобы использовать математический оператор, такой как = или <> , подзапрос должен возвращать число, а не столбец. В этом примере это не так, но мы можем легко адаптировать код для такой работы, когда это необходимо.
Подзапрос как новая таблица
Последний подход к использованию подзапроса SQL, который мы рассмотрим в этой статье, заключается в его использовании для создания нового консолидированного источника, из которого можно извлекать данные.
Мы используем этот подход, когда основной запрос становится слишком сложным и мы хотим, чтобы наш код был читабельным и организованным, а также когда мы будем использовать этот новый источник данных повторно для разных целей, и мы не хотим переписывать его снова и снова. над.
Обычно это выглядит так:
ВЫБИРАТЬ
столбец_1,
столбец_2
ОТ
(ВЫБИРАТЬ
. ..
ИЗ таблицы_1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ таблица_2)
ГДЕ column_1 > 100  ..
ИЗ таблицы_1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ таблица_2)
ГДЕ column_1 > 100
..
ИЗ таблицы_1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ таблица_2)
ГДЕ column_1 > 100 Например, это будет наш подзапрос:
ВЫБЕРИТЕ c.customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ЗАКАЗАТЬ ПО 6 DESC Результатом является новая таблица:
| customer_id | фамилия | страна | состояние | количество_покупок | всего куплено | кол_треков |
|---|---|---|---|---|---|---|
| 5 | Вихтерлова | Чехия | Нет | 18 | 144,54 | 146 |
| 6 | Холи | Чехия | Нет | 12 | 128,7 | 130 |
| 46 | О'Рейли | Ирландия | Дублин | 13 | 114,84 | 116 |
| 58 | Парик | Индия | Нет | 13 | 111,87 | 113 |
| 1 | Гонсалвеш | Бразилия | СП | 13 | 108,9 | 110 |
| 13 | Рамос | Бразилия | ДФ | 15 | 106,92 | 108 |
| 34 | Фернандес | Португалия | Нет | 13 | 102,96 | 104 |
| 3 | Трембле | Канада | КК | 9 | 99,99 | 101 |
| 42 | Жирар | Франция | Нет | 11 | 99,99 | 101 |
| 17 | Смит | США | Вашингтон | 12 | 98. 01 01 | 99 |
| 50 | Муньос | Испания | Нет | 11 | 98.01 | 99 |
| 53 | Хьюз | Соединенное Королевство | Нет | 11 | 98.01 | 99 |
| 57 | Рохас | Чили | Нет | 13 | 97.02 | 98 |
| 20 | Миллер | США | СА | 12 | 95.04 | 96 |
| 37 | Циммерманн | Германия | Нет | 10 | 94.05 | 95 |
| 22 | Ликок | США | Флорида | 12 | 92.07 | 93 |
| 21 | Чейз | США | НВ | 11 | 91.08 | 92 |
| 30 | Фрэнсис | Канада | НА | 13 | 91. 08 08 | 92 |
| 26 | Каннингем | США | ТХ | 12 | 86.13 | 87 |
| 36 | Шнайдер | Германия | Нет | 11 | 85,14 | 86 |
| 27 | Серый | США | АЗ | 9 | 84,15 | 85 |
| 2 | Келер | Германия | Нет | 11 | 82,17 | 83 |
| 12 | Алмейда | Бразилия | РДЖ | 11 | 82,17 | 83 |
| 35 | Сампайо | Португалия | Нет | 16 | 82,17 | 83 |
| 55 | Тейлор | Австралия | Новый Южный Уэльс | 10 | 81,18 | 82 |
В этой новой таблице мы объединили идентификатор, фамилию, страну, штат, количество покупок, общую сумму потраченных долларов и количество треков, приобретенных для каждого клиента в базе данных.
Теперь мы можем увидеть, какие пользователи в США приобрели не менее 50 песен:
ВЫБИРАТЬ
новая_таблица.*
ОТ
(ВЫБЕРИТЕ c.customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ГДЕ
new_table.count_tracks >= 50
И new_table.country = 'США' Обратите внимание, что нам просто нужно выбрать столбцы и применить нужные фильтры в подзапросе SQL.
Это вывод:
| customer_id | фамилия | страна | состояние | количество_покупок | всего куплено | кол_треков |
|---|---|---|---|---|---|---|
| 17 | Смит | США | Вашингтон | 12 | 98. 01 01 | 99 |
| 20 | Миллер | США | СА | 12 | 95.04 | 96 |
| 22 | Ликок | США | Флорида | 12 | 92.07 | 93 |
| 21 | Чейз | США | НВ | 11 | 91.08 | 92 |
| 26 | Каннингем | США | ТХ | 12 | 86.13 | 87 |
| 27 | Серый | США | АЗ | 9 | 84,15 | 85 |
| 18 | Брукс | США | Нью-Йорк | 8 | 79,2 | 80 |
| 25 | Стивенс | США | Висконсин | 10 | 76,23 | 77 |
| 16 | Харрис | США | СА | 8 | 74,25 | 75 |
| 28 | Барнетт | США | UT | 10 | 72,27 | 73 |
| 24 | Ральстон | США | Ил | 8 | 71,28 | 72 |
| 23 | Гордон | США | МА | 10 | 66,33 | 67 |
| 19 | Гойер | США | СА | 9 | 54,45 | 55 |
Мы также можем увидеть количество пользователей, купивших не менее 50 песен в каждом штате:
ВЫБИРАТЬ
состояние,
считать(*)
ОТ
(ВЫБЕРИТЕ c. customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ГДЕ
new_table.count_tracks >= 50
И new_table.country = 'США'
СГРУППИРОВАТЬ ПО new_table.state
ЗАКАЗАТЬ ПО 2 дес  customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ГДЕ
new_table.count_tracks >= 50
И new_table.country = 'США'
СГРУППИРОВАТЬ ПО new_table.state
ЗАКАЗАТЬ ПО 2 дес
customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ГДЕ
new_table.count_tracks >= 50
И new_table.country = 'США'
СГРУППИРОВАТЬ ПО new_table.state
ЗАКАЗАТЬ ПО 2 дес Теперь нам нужно только добавить функцию агрегации count и предложение GROUP BY . Мы продолжаем работать с подзапросом, как если бы это был новый источник данных.
Выход:
| состояние | количество(*) |
|---|---|
| СА | 3 |
| АЗ | 1 |
| Флорида | 1 |
| Ил | 1 |
| МА | 1 |
| НВ | 1 |
| Нью-Йорк | 1 |
| ТХ | 1 |
| UT | 1 |
| Вашингтон | 1 |
| Висконсин | 1 |
Также можно использовать эту новую таблицу SQL для выполнения некоторых математических действий и выбора 10 лучших пользователей с наибольшей средней суммой денег, потраченных на заказ:
ВЫБИРАТЬ
Пользовательский ИД,
фамилия,
round(total_purchased / number_of_purchases, 2) как avg_purchase
ОТ
(ВЫБЕРИТЕ c. customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ЗАКАЗАТЬ ПО 3 DESC
ПРЕДЕЛ 10  customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ЗАКАЗАТЬ ПО 3 DESC
ПРЕДЕЛ 10
customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ЗАКАЗАТЬ ПО 3 DESC
ПРЕДЕЛ 10 Мы используем два столбца в подзапросе для выполнения вычисления и получаем этот результат:
| customer_id | фамилия | avg_purchase |
|---|---|---|
| 3 | Трембле | 11.11 |
| 6 | Холи | 10,72 |
| 29 | Коричневый | 10,15 |
| 18 | Брукс | 9,9 |
| 37 | Циммерманн | 9,4 |
| 27 | Серый | 9,35 |
| 16 | Харрис | 9,28 |
| 42 | Жирар | 9,09 |
| 50 | Муньос | 8,91 |
| 53 | Хьюз | 8,91 |
Существует множество других способов использования данных в этом подзапросе, в зависимости от потребностей пользователя, или даже для создания более крупного подзапроса, если это необходимо.