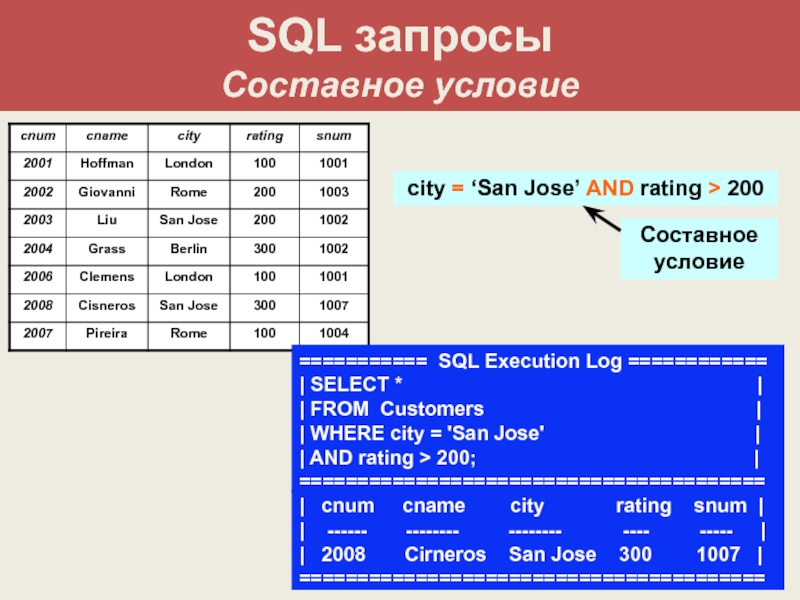
Оператор SELECT. Простой SQL-запрос, синтаксис, примеры
За выборку данных из таблиц базы данных в SQL отвечает оператор SELECT. В этой статье будет рассмотрен его простейший синтаксис и примеры.
Чтобы выполнить простой запрос к базе данных достаточно указать всего 2 условия (предложения):
- Какие столбцы необходимо выгрузить;
- Из какой таблицы необходимо выгрузить столбцы.
На языке SQL это выглядит следующим образом:
SELECT <Перечень столбцов> FROM <Перечень таблиц>
Имена столбцов перечисляются через запятую сразу после ключевого слова SELECT. Затем следует ключевой слово FROM с наименованиями таблиц. Если таблиц несколько, то они так же указываются через запятую.
Запросы к нескольким таблицам не рассматриваются в данном материале, так как это тема относится к соединению таблиц либо требует знания предложения WHERE.
Столбцы и таблицы могут быть перечислены в любом порядке и повторяться несколько раз.
Подключение к базе данных
На сервере часто присутствует более одной базы данных. Поэтому, прежде чем выполнить запрос, потребуется подключиться к конкретной базе. Научимся это делать в SQL Server Management Studio:
Теперь любой запрос будет выполняться именно в ее контексте.
Создание SQL-запроса
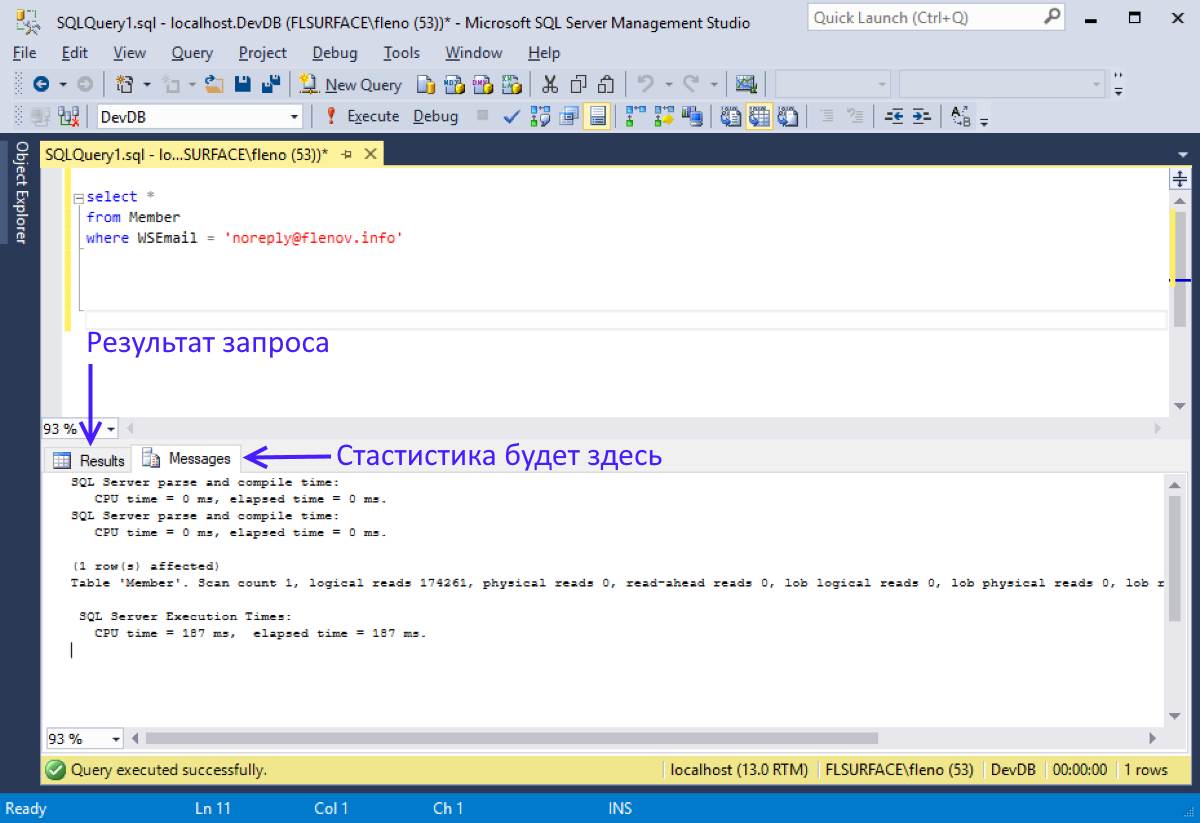
Выполним первую задачу:
Необходимо получить Фамилии, Имена и Отчества всех сотрудников.
В поле запроса введите следующий SQL-код:
SELECT Фамилия, Имя, Отчество FROM Сотрудники
Первая строка запроса содержит выгружаемые столбцы, вторая строка указывает таблицу столбцов. На самом деле, код напоминает обычное предложение: «Выбрать столбцы Фамилия, Имя, Отчество из таблицы Сотрудники».
Нажмите на кнопку «Выполнить» на панели редактора SQL. Внизу окна запроса должен появиться результат его выполнения. Под результатом отображается статус и продолжительность запроса, а также количество выгруженных строк. Если Вы все сделаете правильно, то статус будет сообщать «Запрос успешно выполнен», а количество строк равняться 39.
Пояснения синтаксиса
Не имеет значения в каком регистре будут написаны ключевые слова и наименования. Такой вариант полностью идентичен предыдущему:
select ФаМиЛия, иМЯ, ОтчествО froM сотрудники
Также можно не начинать каждое условие с новой строки.
Рекомендуем писать запросы аккуратно, чтобы их было проще понимать и искать ошибки.
Иные варианты запроса
Перед написанием кода говорилось о необходимости подключения к БД. Но можно обойтись и без подключения в этом конкретном случае (в некоторых программах это обязательное требование). Достаточно в предложении FROM дополнительно указать имя базы данных и имя схемы (по умолчанию dbo):
SELECT Фамилия, Имя, Отчество FROM CallCenter.dbo.Сотрудники
Теперь опишем синтаксис простой инструкции SELECT (необязательные части запроса взяты в квадратные скобки):
SELECT [Имя_таблицы.]Имя_столбца[, [Имя_таблицы.]Имя_столбца2 …] FROM [[Имя_базы_данных.]Имя_Схемы.]Имя_таблицы

Дополнительные имена загромождают код запроса, поэтому можно использовать инструкцию USE. Она переключит контекст на указанную базу данных:
USE CallCenter SELECT Фамилия, Имя, Отчество FROM Сотрудники
Такой подход обеспечит подключение к нужной базе.
Многословные имена столбцов и таблиц могут содержать пробелы между словами. В таких случаях их имена заключаются в квадратные скобки, чтобы запрос сработал корректно. Например, [имя столбца].
- < Назад
- Вперёд >
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
Добавить комментарий
Создание SQL запросов
Создание SQL запросовВ том случае, если встроенного языка запросов ZuluGIS недостаточно, запросы могут выполняться с использованием OGC расширения языка SQL.
В программе используется диалект языка SQL основанный на диалекте Transact-SQL,
разработанном компаниями Microsoft и Sybase (см.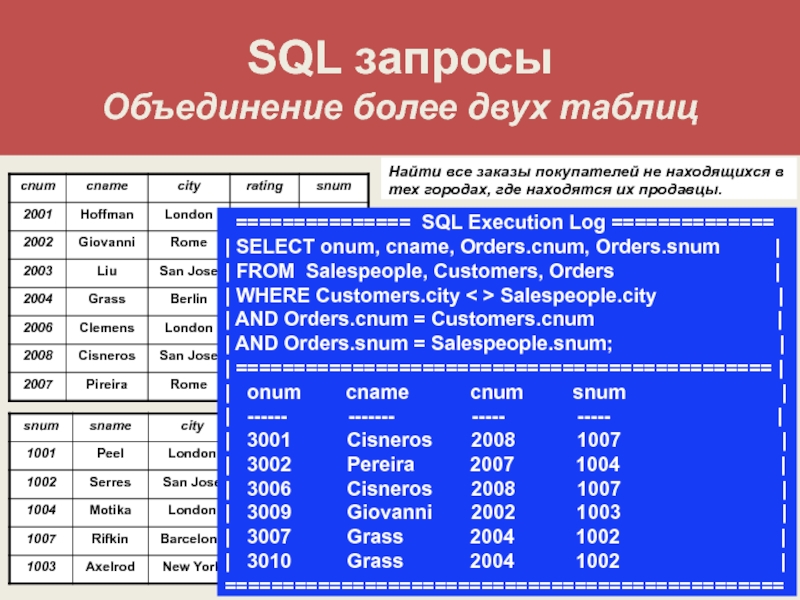 http://msdn.microsoft.com/en-us/library/bb510741(SQL.100).aspx и http://infocenter.sybase.com/help/index.jsp?topic=/com.sybase.help.ase_15.0.sqlug/html/sqlug/title.htm). Используемый диалект дополнен в соответствии с OGC расширением языка SQL, информация о
котором приводится по адресам http://www.opengeospatial.org/standards/sfa (общая
архитектура) и http://www.opengeospatial.org/standards/sfs (SQL
расширение).
http://msdn.microsoft.com/en-us/library/bb510741(SQL.100).aspx и http://infocenter.sybase.com/help/index.jsp?topic=/com.sybase.help.ase_15.0.sqlug/html/sqlug/title.htm). Используемый диалект дополнен в соответствии с OGC расширением языка SQL, информация о
котором приводится по адресам http://www.opengeospatial.org/standards/sfa (общая
архитектура) и http://www.opengeospatial.org/standards/sfs (SQL
расширение).
IntelliSense — технология автодополнения, дописывает название функции при вводе начальных букв. Кроме прямого назначения IntelliSense используется для доступа к документации и для устранения неоднозначности в именах переменных, функций и методов. Подсветка синтаксиса — выделение синтаксических конструкций текста с использованием различных цветов, шрифтов и начертаний. Обычно применяется для облегчения чтения исходного текста компьютерных программ, улучшения визуального восприятия.
Рисунок 582. Написание SQL запроса с IntelliSense
| Примечание | |
|---|---|
Видеоуроки с примерами выполнения SQL запросов можно посмотреть в разделе: https://www. |
 politerm.com/videos/geosql/.
politerm.com/videos/geosql/.Для вызова диалога формирования SQL запросов выполните команду меню запрос, либо нажмите кнопку панели инструментов.
Рисунок 583. Диалог SQL запроса
В области ввода задается текст SQL запроса. В правой части диалога расположен навигатор по полям карты (Источник:), позволяющий быстро добавить запрос данных из какого либо поля карты. Для добавления запроса данных поля, выберите в списке требуемый слой, БД и выполните двойной щелчок по названию поля, запрос будет добавлен в область ввода.
| Примечание | |
|---|---|
Для быстрого поиска нужных полей в списке Источник, введите начало названия требуемого
поля в поисковой строке над списком, в списке будут отображаться только поля, начинающиеся с
введенных символов. Для отображения реальных названий полей базы данных в области полей сделайте щелчок правой кнопкой мыши и в контекстном меню выберите . Для возврата к пользовательским названиям надо снять опцию . |

После задания текста запроса нажмите кнопку Выполнить панели инструментов, в области Ответ в нижней части диалога отобразится панель данных с результатами запроса. Панель можно открепить от диалога запроса для дальнейшей работы с результатами, для этого наведите указатель мыши на заголовок панели, нажмите левую кнопку мыши, не отпуская ее, переместите мышь в произвольную часть окна программы ZuluGIS, после чего отпустите кнопку мыши. Подробнее о панели данных см. «Панель данных».
В диалоге SQL запросов предусмотрено сохранение текущего запроса в файл, открытие запроса из файла и создание нового запроса:
Для открытия запроса из файла (в формате .sql) выполните команду меню , или нажмите кнопку панели инструментов – и выберите требуемый файл в стандартном диалоге выбора файлов;
Для сохранения текущего запроса в файле (формата .
 sql) выполните команду меню
, или нажмите кнопку панели инструментов – и задайте требуемое название файла в стандартном диалоге сохранения
файлов.
sql) выполните команду меню
, или нажмите кнопку панели инструментов – и задайте требуемое название файла в стандартном диалоге сохранения
файлов.Для создания нового запроса выполните команду меню , либо нажмите кнопку панели инструментов .
 sql) выполните команду меню
, или нажмите кнопку панели инструментов – и задайте требуемое название файла в стандартном диалоге сохранения
файлов.
sql) выполните команду меню
, или нажмите кнопку панели инструментов – и задайте требуемое название файла в стандартном диалоге сохранения
файлов.SQL Server. Оптимизация запросов SQL. MS SQL Медленно работают запросы SELECT
Введение
В данном руководстве мы изложили некоторые рекомендации по оптимизации запросов SQL.
Оптимизация структуры таблиц SQL Server
Разбивайте сложные таблицы на несколько, помните, чем больше в вашей таблице столбцов и тяжелых типов (nvarchar(max)), тем тяжелее по ней проход. Если некоторые данные не всегда используются в select с ней, выносите их отдельно в таблицу и связывайте через FK
Выберите правильные типы данных. Всегда выбирайте самый маленький тип для данных, которые Вы должны хранить в столбце.
Если текстовые данные в столбце имеют разную длину, используйте тип данных NVARCHAR вместо NCHAR.
Не используйте NVARCHAR или NCHAR типы данных, если Вы не должны сохранить 16-разрядные символьные данные (UNICODE). Они требуют в два раза больше места, чем CHAR и VARCHAR, что повышает расходы времени на ввод-вывод (но если у вас кириллица, то без NVARCHAR не обойтись).
Если Вы должны хранить большие строки данных и их длина меньше чем 8,000 символов, используют тип данных NVARCHAR вместо TEXT. Текстовые поля требуют больше ресурсов для обработки и снижают производительность.
Любое поле, в котором должны быть только отличные от нуля значения, нужно объявлять как NOT NULL
Для любого поля, которое должно содержать уникальные значения, стоит указать модификатор UNIQUE
Хранение изображений в БД нежелательно. Храните в таблице путь к файлу (локальный путь или URL), а сам файл помещайте в файловую систему сервера.
Оптимизация запросов SELECT
Не читайте больше данных, чем надо. Не используйте *
Если ваше приложение позволяет пользователям выполнять запросы, но вы не можете отсечь лишние сотни и тысячи возвращаемых строк, используйте оператор TOP внутри инструкции SELECT.
Не возвращайте клиенту большее количество столбцов или строк, чем действительно необходимо (Не используй * в Select).
Как можно раньше отфильтруйте данные. Не нужно выполнять большой тяжелый подзапрос для всех строк таблицы. Сначала отфильтруйте нужные строки.
Корректно используйте JOIN
Если Вы имеете две или более таблиц, которые часто объединяются вместе, тогда столбцы, используемые для объединений должны иметь соответствующий индекс.
Для лучшей производительности, столбцы, используемые в объединениях должны иметь одинаковые типы данных. И если возможно, это должны быть числовые типы данных, вместо символьных типов.
Избегайте объединять таблицы по столбцам с малым числом уникальных значений.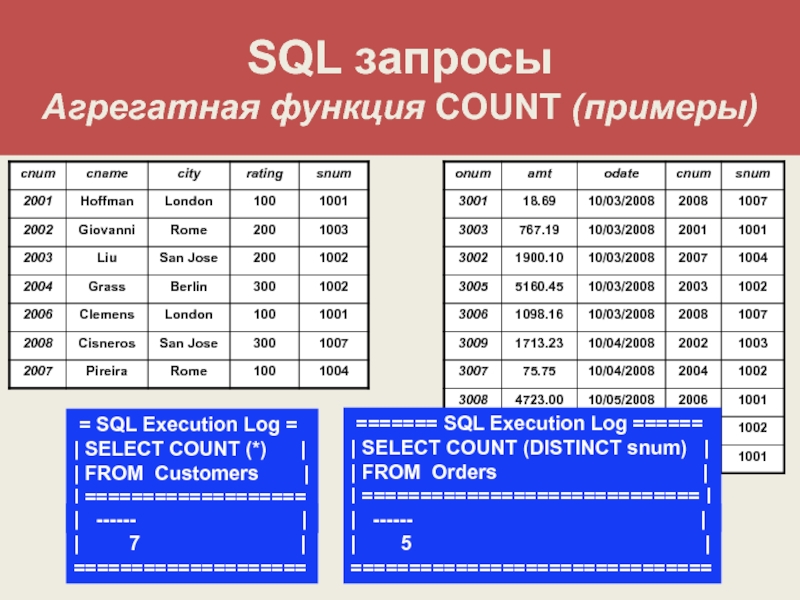 Если столбцы, используемые при объединениях, имеют мало уникальных значений, то SQL сервер будет просматривать всю таблицу, даже если по данному столбцу существует индекс. Для наилучшей производительности объединение таблиц должно производится по столбцам с уникальными индексами.
Если столбцы, используемые при объединениях, имеют мало уникальных значений, то SQL сервер будет просматривать всю таблицу, даже если по данному столбцу существует индекс. Для наилучшей производительности объединение таблиц должно производится по столбцам с уникальными индексами.
Если Вы должны регулярно объединять четыре или более таблиц, для получения recordset’а, попробуйте денормализовать таблицы так, чтобы число таблиц, участвующих в объединении уменьшилось. Часто, при добавлении одного или двух столбцов из одной таблицы в другую, объединения могут быть уменьшены.
Тип JOIN используйте только тот, который вернет вам НЕОБХОДИМЫЕ данные без каких-либо дублей или лишней информации (или совсем отказаться от join). Т.е. не нужно получать всех пользователей таким образом:
select users.username from users
inner join roles on users.roleID=roles.idВ этом случае вы получите много повторов пользователей
Сортировка в SELECT
Самой ресурсоемкой сортировкой является сортировка строк.
При объявлении полей всегда следует использовать размер, который нужен, и не выделять лишние байты про запас.
Группирование в SELECT
Используйте как можно меньше колонок для группировки.
По возможности лучше использовать Where вместо Having, т.к. это уменьшает количество строк для группировки на ранней стадии.
Если требуется группирование, но без использования агрегатных функций (COUNT(), MIN(), MAX и т.д.), разумно использовать DISTINCT.
Ограничить использование DISTINCT
Эта команда исключает повторяющиеся строки в результате. Команда требует повышенного времени обработки. Лучше всего комбинировать с LIMIT.
Ограничить использование SELECT для постоянно изменяющихся таблиц.
Возможно имеет смысл сохранять промежуточные агрегированные данные в какой-то другой таблице, которая обновляется менее часто чем таблица изменений (например, таблица логов).
Оптимизация WHERE в запросе SELECT
Если where состоит из условий, объединенных AND, они должны располагаться в порядке возрастания вероятности истинности данного условия. Чем быстрее мы получим false в одном из условий — тем меньше условий будет обработано и тем быстрее выполняется запрос.
Чем быстрее мы получим false в одном из условий — тем меньше условий будет обработано и тем быстрее выполняется запрос.
Если where состоит из условий, объединенных OR, они должны располагаться в порядке уменьшения вероятности истинности данного условия. Чем быстрее мы получим true в одном из условий — тем меньше условий будет обработано и тем быстрее выполняется запрос.
Исопльзуйте IN вместо OR. Операция IN работает гораздо быстрее, чем серия OR. Запрос «… WHERE column1 = 5 OR column1 = 6» медленнее чем «…WHERE column1 IN (5, 6)».
Используйте Exists вместо Count >0 в подзапросах. Используйте where exists (select id from t1 where id = t.id) вместо where count(select id from t1 where id=t.id) > 0
LIKE. Эту операцию следует использовать только при крайней необходимости, потому что лучше и быстрее использовать поиск, основанный на full-text индексах.
Советы по оптимизации хранимых процедур и SQL пакетов
Инкапсулируйте ваш код в хранимых процедурах
Для обработки данных используйте хранимые SQL процедуры.
Когда хранимая процедура выполняется в первый раз (и у нее не определена опция WITH RECOMPILE), она оптимизируется, для нее создается план выполнения запроса, который кешируется SQL сервером. Если та же самая хранимая процедура вызывается снова, она будет использовать кешированный план выполнения запроса, что экономит время и увеличивает производительность.
Всегда включайте в ваши хранимые процедуры инструкцию «SET NOCOUNT ON». Если Вы не включите эту инструкцию, тогда каждый раз при выполнении запроса SQL сервер отправит ответ клиенту, указывающему число строк, на которые воздействует запрос.
Избегайте использования курсоров
По возможности выбирайте быстрый forward-only курсор
При использовании серверного курсора, старайтесь использовать как можно меньший рекордсет. Для этого выбирайте только те столбцы и строки, которые необходимы клиенту для решения его текущей задачи.
Когда Вы закончили использовать курсор, как можно раньше не только ЗАКРОЙТЕ (CLOSE) его, но и ОСВОБОДИТЕ (DEALLOCATE).
Используйте триггеры c осторожностью
Триггеры — это усложнение логики работы приложения, неявное неожиданное выполнение дополнительных действий.
Триггеры усложняют интерфейс хранимых процедур. Поместите все необходимые проверки и действия в рамки хранимых процедур.
Временные таблицы для больших таблиц, табличные переменные — для малых (меньше 1000)
Если вам требуется хранить промежуточные данные в таблицах, то используйте табличные переменные (@t1) для малых таблиц, а временные таблицы (#t1) — для больших.
Подробнее:
http://sqlcom.ru/helpful-and-interesting/compare-temp-table-vs-table-variable-vs-cte/
https://coderoad.ru/27894/%D0%92-%D1%87%D0%B5%D0%BC-%D1%80%D0%B0%D0%B7%D0%BD%D0%B8%D1%86%D0%B0-%D0%BC%D0%B5%D0%B6%D0%B4%D1%83-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B5%D0%B9-%D0%B8-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%87%D0%BD%D0%BE%D0%B9-%D0%BF%D0%B5%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9-%D0%B2-SQL-Server
При определении временной таблицы имеет смысл проверить ее на существование:
IF OBJECT_ID('tempdb. .#eventIDs') IS NOT NULL begin
DROP TABLE #eventIDs
end
CREATE TABLE #eventIDs ( id int primary key,instanceID int )
 .#eventIDs') IS NOT NULL begin
DROP TABLE #eventIDs
end
CREATE TABLE #eventIDs ( id int primary key,instanceID int )
.#eventIDs') IS NOT NULL begin
DROP TABLE #eventIDs
end
CREATE TABLE #eventIDs ( id int primary key,instanceID int )
Также для улучшения быстродействия используйте для временной таблицы первичный ключ и индексы.
Как уменьшить вероятность дедлоков на базе
Дедлок — это взаимная блокировка 2 выполняющихся пакетов sql. Это самым негативным образом сказывается на быстродействии запросов.
Чтобы избежать deadlocks, пытайтесь разрабатывать ваше приложение с учетом следующих рекомендаций:
- Всегда получайте доступ к объектам в одном и том же порядке.
- Старайтесь делать транзакции короткими и заключайте их в один пакет (batch)
- Старайтесь использовать максимально низкий уровень изоляции для пользовательского соединения, которое работает с транзакцией.
Работа с индексами SQL Server
Советы по созданию кластерных индексов
- Первичный ключ не всегда должен быть кластерным индексом. Если Вы создаете первичный ключ, тогда SQL сервер автоматически делает первичный ключ кластерным индексом. Первичный ключ должен быть кластерным индексом, только если он отвечает одной из нижеследующих рекомендаций.
- Кластерные индексы идеальны для запросов, где есть выбор по диапазону или вы нуждаетесь в сортированных результатах. Так происходит потому, что данные в кластерном индексе физически отсортированы по какому-то столбцу. Запросы, получающие выгоду от кластерных индексов, обычно включают в себя операторы BETWEEN, <, >, GROUP BY, ORDER BY, и агрегативные операторы типа MAX, MIN, и COUNT.
- Кластерные индексы хороши для запросов, которые ищут запись с уникальным значением (типа номера служащего) и когда Вы должны вернуть большую часть данных из записи или всю запись. Так происходит потому, что запрос покрывается индексом.
- Кластерные индексы хороши для запросов, которые обращаются к столбцам с ограниченным числом значений, например столбцы, содержащие данные о странах или штатах. Но если данные столбца мало отличаются, например, значения типа «да/нет», «мужчина/женщина», то такие столбцы вообще не должны индексироваться.
- Кластерные индексы хороши для запросов, которые используют операторы GROUP BY или JOIN.
- Кластерные индексы хороши для запросов, которые возвращают много записей, потому что данные находятся в индексе, и нет необходимости искать их где-то еще.
- Избегайте помещать кластерный индекс в столбцы, в которых содержатся постоянно возрастающие величины, например, даты, подверженные частым вставкам в таблицу (INSERT). Так как данные в кластерном индексе должны быть отсортированы, кластерный индекс на инкрементирующемся столбце вынуждает новые данные быть вставленным в ту же самую страницу в таблице, что создает «горячую зону в таблице» и приводит к большому объему дискового ввода-вывода. Постарайтесь найти другой столбец, который мог бы стать кластерным индексом.
 Первичный ключ должен быть кластерным индексом, только если он отвечает одной из нижеследующих рекомендаций.
Первичный ключ должен быть кластерным индексом, только если он отвечает одной из нижеследующих рекомендаций.
Советы по выбору некластерных индексов
- Некластерные индексы лучше подходят для запросов, которые возвращают немного записей (включая только одну запись) и где индекс имеет хорошую селективность (более чем 95 %).
- Если столбец в таблице не содержит по крайней мере 95% уникальных значений, тогда очень вероятно, что Оптимизатор Запроса SQL сервера не будет использовать некластерный индекс, основанный на этом столбце. Поэтому добавляйте некластерные индексы к столбцам, которые имеют хотя бы 95% уникальных записей. Например, столбец с «Да» или «Нет» не имеет 95% уникальных записей.
- Постарайтесь сделать ваши индексы как можно меньшего размера (особенно для многостолбцовых индексов). Это уменьшает размер индекса и уменьшает число чтений, необходимых, чтобы прочитать индекс, что увеличивает производительность.
- Если возможно, создавайте индексы на столбцах, которые имеют целочисленные значения вместо символов. Целочисленные значения имеют меньше потерь производительности, чем символьные значения.
- Если Вы знаете, что ваше приложение будет выполнять один и тот же запрос много раз на той же самой таблице, рассмотрите создание покрывающего индекса на таблице. Покрывающий индекс включает все столбцы, упомянутые в запросе. Из-за этого индекс содержит все данные, которые Вы ищете, и SQL сервер не должен искать фактические данные в таблице, что сокращает логический и/или физический ввод — вывод. С другой стороны, если индекс становится слишком большим (слишком много столбцов), это может увеличить объем ввода — вывода и ухудшить производительность.
- Индекс полезен для запроса только в том случае, если оператор WHERE запроса соответствует столбцу (столбцам), которые являются крайними левыми в индексе. Так, если Вы создаете составной индекс, типа «City, State», тогда запрос » WHERE City = ‘Хьюстон’ » будет использовать индекс, но запрос » WHERE State = ‘TX’ » не будет использовать индекс.
- Любая операция над полем в предикате поиска, которое лежит под индексом, сводит на нет его использование. where isnull(field,’’) = ‘’ здесь индекс не используется, where field = ‘’ and field is not null — здесь используется.

 Из-за этого индекс содержит все данные, которые Вы ищете, и SQL сервер не должен искать фактические данные в таблице, что сокращает логический и/или физический ввод — вывод. С другой стороны, если индекс становится слишком большим (слишком много столбцов), это может увеличить объем ввода — вывода и ухудшить производительность.
Из-за этого индекс содержит все данные, которые Вы ищете, и SQL сервер не должен искать фактические данные в таблице, что сокращает логический и/или физический ввод — вывод. С другой стороны, если индекс становится слишком большим (слишком много столбцов), это может увеличить объем ввода — вывода и ухудшить производительность.Бывает ли слишком много индексов?
Да. Проблема с лишними индексами состоит в том, что SQL сервер должен изменять их при любых изменениях таблицы (INSERT, UPDATE, DELETE).
Лучшим решением ставить сомнительный индекс или нет, будет подождать и собрать статистику по работе индексов.
Лучшие кандидаты на установку индекса
- Это поля, по которым идет Join
- Поля связи, участвующие в подзапросах
- Поля, по которым идет фильтрация в where
- Поля, по которым выполняется сортировка.
Советы по использованию временных таблиц и табличных переменных
Если вы замечаете, что обращаетесь к одной и той же таблице несколько раз, то это явный знак необходимости использовать временную таблицу.
- Временная таблица храниться физически в tempdb, табличная переменная хранится в памяти SQL
- SQL может сам решить сохранить табличную переменную физически, если там будет много данных, это потеря ресурсов, учтите это
- Временная таблица для большого объема данных (полноценная выборка), табличная переменная для малого (справочники или набор ID для чего-то)
- Временная таблица доступна из любой процедуры SQL, табличная переменная только в рамках запроса. Не забывайте очищать временные таблицы после их использования
 Не забывайте очищать временные таблицы после их использования
Не забывайте очищать временные таблицы после их использованияЕсли вы SQL-разработчик или администратор MS SQL Server, и вы хотели бы разрабатывать веб-решения на SQL, то веб-платформа Falcon Space — это то, что вам нужно.
В ней SQL — это основной язык разработки, который позволяет реализовать систему личных кабинетов с формами, таблицами, дашбордами и другими компонентами. Все настраивается на SQL.
Вводная статья по Falcon Space для SQL специалиста
Понятие и назначение SQL запроса: что такое SQL запрос
Содержание статьи:
Вступление
Для работы с различными реляционными базами данных, включая Oracle, MySQL, PostgreSQL, DBase, FoxPro, Clipper, Paradox был создан единый язык запросов к базам данных. Назвали его язык SQL, что означает Structured Query Language — структурированный язык запросов.
В данной статье используем СУБД MySql. Именно для пользователя, СУБД MySql имеет наибольшее практическое применение, как в управлении различными расширениями, так и в их создании. Как-никак, все локальные сервера, CMS, платформы интернет магазинов работают именно с СУБД MySql.
Как-никак, все локальные сервера, CMS, платформы интернет магазинов работают именно с СУБД MySql.
Понятие и назначение SQL запроса для администрирования БД
Реляционная база данных это таблица с информацией, разнесенной по столбцам (поля или атрибуты) и строкам (записи или кортежи) таблицы. Чтобы изменить или удалить данные в столбцах и строках, а также данные в определенных ячейках (пресечение столбца и строки) можно воспользоваться прикладными инструментами (например, phpmyadmin) или сделать SQL запрос к базе данных, по которому выполнится нужное действие.
Что можно делать с помощью SQL запросов
При помощи запросов SQL можно:
- Создавать таблицы БД;
- Изменять таблицы БД;
- Удалять таблицы БД;
- Вставлять записи (строки) в таблицы БД;
- Редактировать записи в таблицах БД;
- Извлекать выборочную информацию из таблиц БД;
- Удалять выборочную информацию из БД.
Это не полный перечень возможностей SQL запросов, но и он дает представление, что с помощью SQL запросов можно сделать с базой данных всё что необходимо.
Операторы SQL запроса
Язык SQL имеет большой список различных операторов, каждый из которых «задает» определенную команду. Справочник по операторам тут: (http://www.mysql.ru/docs/man/Database_Administration.html/CREATE_TABLE.html). В следующих статьях будем рассматривать, как работают основные операторы SQL и как с их помощью управлять базами данных.
В завершении перечислю, операторы sql запросов, которые будем рассматривать в ближайших статьях раздела:
- CREATE TABLE – оператор sql для создания таблицы базы данных;
- ALTER TABLE – оператор sql для изменения таблицы БД;
- INSERT INTRO – вставка информации (строк) в таблицы БД;
- UPDATE – оператор для редактирования информации в таблицах БД;
- SELECT – извлечение информации из таблиц БД;
- DELET – удаление информации из таблиц БД.
©WebOnTo.ru
Другие статьи раздела: СУБД
Похожие статьи:
Примеры SQL-запросов к данным в Google BigQuery
Если вы уже читали наш блог, то знаете, что в качестве хранилища данных для сквозной аналитики мы рекомендуем Google BigQuery. Эта система позволяет строить отчеты любой структуры на основе полных, несемплированных данных, а также
решать задачи,
с которыми возникают сложности даже в Google Analytics 360.
Эта система позволяет строить отчеты любой структуры на основе полных, несемплированных данных, а также
решать задачи,
с которыми возникают сложности даже в Google Analytics 360.
В этой статье мы поделимся примерами отчетов, которые можно построить с помощью SQL-запросов к данным в Google BigQuery. Сначала расскажем, что можно посчитать благодаря стандартному экспорту из GA 360 в GBQ. Затем покажем, какими уникальными метриками можно дополнить данные Google Analytics благодаря OWOX BI Pipeline. Тексты всех запросов мы собрали в отдельном PDF-файле. Чтобы получить файл, оставьте свой email, и мы пришлем вам ссылку для скачивания.
Отчеты, построенные на данных стандартного экспорта из Google Analytics 360 в Google BigQuery
При создании отчетов в Google Analytics можно столкнуться с
семплированием,
агрегированием данных и другими ограничениями системы. Экспорт данных в Google BigQuery позволяет обойти эти препятствия и строить более сложные отчеты с помощью SQL-запросов.
Экспорт данных в Google BigQuery позволяет обойти эти препятствия и строить более сложные отчеты с помощью SQL-запросов.
1. Действия пользователей в разрезе любых параметров
Допустим, вы внедрили на сайт новые метрики или обновили действующие, чтобы измерять важные для вашего бизнеса KPI. Проверить, правильно ли передаются данные, и вовремя среагировать на сбои в аналитике вам поможет отчет по динамике хитов на сайте. Для него понадобятся такие параметры, как device.deviceCategory, device.browser, hits.type и детализация по действиям пользователей (eventCategory, eventAction, Content Grouping).
Получить всю эту информацию в стандартном отчете Google Analytics не получится, так как в нем можно одновременно выбрать только 2 параметра, в пользовательском отчете немногим больше — 5. В SQL-запросе таких ограничений нет, вы можете указать все параметры и метрики, которые хотите увидеть в отчете.
В SQL-запросе таких ограничений нет, вы можете указать все параметры и метрики, которые хотите увидеть в отчете.
Шаблон запроса, который мы приводим в материалах для скачивания, поможет узнать, как распределено количество сессий, пользователей и хитов по браузерам, устройствам и типам хитов. При необходимости вы можете дополнить запрос любыми другими параметрами. Например, операционная система (device.operatingSystem), информация по устройству (device.mobileDeviceInfo), язык (device.language), регион (geoNetwork.region).
В результате вы получите отчет со всеми необходимыми параметрами:
Кроме того, можно выгрузить в Google BigQuery информацию из ваших внутренних CRM и ERP систем. Это позволит анализировать действия пользователя в разрезе любых нужных вам метрик: продуктовый каталог, маржинальность, категория товаров, свойства пользователя, исполняемость заказов и т. д. Например, вы можете запросить данные по транзакциям, объединить их с выкупленным заказами из CRM и подсчитать долю выполненных online-заказов. Этот параметр покажет, нет ли у вас проблем на пути от оформления заказа до оплаты / доставки.
д. Например, вы можете запросить данные по транзакциям, объединить их с выкупленным заказами из CRM и подсчитать долю выполненных online-заказов. Этот параметр покажет, нет ли у вас проблем на пути от оформления заказа до оплаты / доставки.
2. Статистика по ключевым действиям пользователей
Если вы хотите объединить клиентов в сегменты и настроить персонализированные рассылки, вам понадобится информация про их активность на сайте. И чем детальнее будут данные, тем шире возможности сегментации. В Google Analytics нет отчета, где были бы собраны все действия пользователя и разбиты по типам хитов: pageview, event, social, timing, а также события Enhanced Ecommerce (click, detail, add, remove, checkout, purchase, refund). Также там нельзя посмотреть среднее, максимальное или минимальное значение по типам хитов для определенного пользователя. Всю эту информацию легко получить с помощью SQL-запроса, который вы найдете в материалах для скачивания.
Этот запрос поможет рассчитать для каждого пользователя среднее, максимальное и минимальное:
- Количество просмотров страниц с поисковой выдачей.
- Количество просмотров страниц за посещение.
- Количество добавлений в корзину.
- Количество удалений из корзины.
- Количество товаров, добавленных в корзину.
- Количество товаров, удаленных из корзины.
- Сумму добавленных в корзину товаров.
- Сумму удаленных из корзины товаров.

Также с помощью SQL-запроса можно подсчитать для каждой сессии:
- Количество просмотров страниц с поисковыми запросами.
- Количество просмотренных страниц.
- Количество добавлений/удалений из корзины.
- Количество товаров, добавленных/удаленных из корзины.
- Сумму добавленных/удаленных из корзины товаров.
Эта информация будет полезна для прогнозирования повторных покупок и микроконверсий.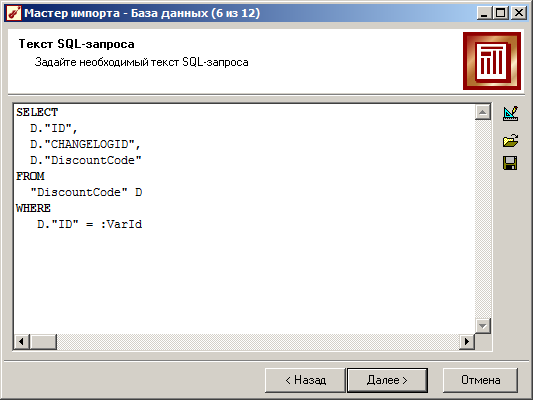
3. Выбор пользователей, которые просмотрели определенные страницы товаров
Если вы хотите оптимизировать воронку продаж, вам нужно проанализировать, что делают посетители вашего сайта перед покупкой. В стандартных отчетах GA нет возможности просмотреть все типы действий пользователя (pageview, event, social, timing). Есть отчет «Статистика по пользователям» (User Explorer), но там нельзя увидеть статистику сразу по всем пользователям, необходимо открывать каждого отдельно и применять расширенные сегменты с фильтрацией на ID товара.
Построив отчет на данных стандартного экспорта, вы сможете просмотреть все действия пользователя, которые отслеживаются через код GA. Например, наш SQL-запрос поможет выбрать пользователей, которые просмотрели определенные страницы товаров. Вы можете использовать эту информацию, чтобы отправлять напоминания тем, кто бросил товар в корзине, показывать товарные рекомендации или составлять портреты пользователей.
4. Действия пользователей, которые купили определенный товар
Все написанное в пункте 3 справедливо и для этого отчета. С помощью SQL-запроса из файла для скачивания можно построить отчет, содержащий все действия пользователей, которые купили определенный товар. Вы можете использовать эту информацию, чтобы предлагать клиентам товары, похожие на те, что они уже приобрели, или аксессуары к ним.
5. Настройка воронки с релевантными для вашего бизнеса шагами
Предположим, вы написали статью в блоге, которая должна мотивировать читателей подписаться на рассылку. Для отслеживания конверсий вам важны оба действия — и чтение статьи и подписка, но в Google Analytics их нельзя объединить, так как это разные типы целей: «Просмотр страницы» и «Событие».
Кроме этого, при настройках целей в GA есть и другие ограничения:
- В одном представлении Google Analytics можно настроить максимум 20 целей. При этом цель нельзя удалить, можно только остановить для нее запись данных.
- В отчет попадают данные, собранные после создания цели. То есть вы не можете применить цель к данным за прошедший период.
Экспорт данных в Google BigQuery и простой SQL-запрос позволяют обойти эти ограничения. Вы можете настроить воронку с любыми необходимыми шагами, чтобы проверить узкие места на сайте и узнать, на каких этапах «отпадает» больше всего пользователей.
Наш шаблон запроса поможет узнать, как часто пользователи открывают раздел «Характеристики товара» и как это влияет на конверсию. В нашем примере воронка выглядит так: 1. Просмотр страницы товара → 2. Просмотр характеристик товара → 3. Добавление товара в корзину. Однако вы можете в качестве шагов воронки выбрать любые действия, которые отслеживаются на сайте. В результате у вас получится примерно такой график:
6. Эффективность работы внутреннего поиска на сайте
Вы можете повысить конверсию за счет улучшения внутреннего поиска на сайте. Например, проанализировать долю нулевых ответов на запрос пользователя и внести правки в контент на сайте, добавить товары-заменители, акции на товары из той же категории и т.д. Или, если какую-нибудь категорию ищут чаще остальных, можно вывести ее в каталоге на более высокую позицию. Для этого вам понадобятся отчеты по поисковым запросам.
Параметры и показатели в отчете GA должны быть одного уровня, то есть иметь одинаковую область доступа: «Хит», «Сессия», «Пользователь» или «Товар». Это значит, что в одном отчете с параметрами, к примеру, уровня «Хит» нельзя посмотреть SKU товаров или рейтинг поискового запроса по количеству сессий.
SQL-запрос из файла для скачивания поможет вам настроить аналитику внутреннего поиска на сайте, чтобы посчитать эффективность сессий с поисковыми запросами и проверить гипотезы о юзабилити.
С помощью SQL вы сможете посчитать для каждого поискового запроса:
- Количество сессий, в которых встречался этот запрос.
- Средний размер поисковой выдачи.
- Суммарный доход по сессиям, в которых был поисковой запрос.
- Рейтинг поискового запроса по количеству сессий.
- Рейтинг поискового запроса по размеру результата выдачи.
- Рейтинг поискового запроса по доходу.
Отчеты, построенные на данных потока OWOX BI Pipeline из Google Analytics в Google BigQuery
Благодаря OWOX BI Pipeline вы сможете обогатить свои данные в Google BigQuery дополнительной информацией, не доступной ни в стандартной, ни в платной версии Google Analytics. Дело в том, что GA позволяет импортировать только агрегированные данные о расходах в привязке к рекламным кампаниям, а в схеме данных стандартного экспорта вообще нет информации о расходах.
С помощью OWOX BI Pipeline можно объединить данные со всех рекламных площадок и передать их в Google BigQuery. При этом сервис привяжет расходы ко всем сессиям. Благодаря этому вы сможете группировать расходы и доходы на уровне каждого пользователя, сегмента или когорты пользователей, а также посадочной страницы.
Ниже мы приведем несколько метрик, которые нельзя рассчитать со стандартным экспортом, но можно с OWOX BI. Все эти отчеты вы можете получить либо при помощи SQL-запросов, либо задавая вопросы обычным языком в OWOX BI Smart Data.
1. Как изменялся атрибутированный расход по источникам и каналам по дням
Этот отчет поможет собрать данные по рекламным расходам за определенный период и проследить динамику показателей во временном отрезке, сравнить с другими периодами, оценить долю рекламы среди источников.
Скриншот отчета из OWOX BI Smart Data:
Например, на графике видно, что 10 июня расходы на facebook / cpc резко снизились. Это может стать сигналом для маркетолога — нужно посмотреть, какие именно кампании, группы объявлений и ключевые слова в этом источнике стали приносить меньше кликов, и разобраться с причинами. Возможно, снизилась доля показов из-за объявлений конкурентов. В таком случае можно попробовать поднять ставки, повысить релевантность объявлений, изменить контент и т.д.
2. Как средняя стоимость привлечения посетителя зависела от города
Как мы уже писали выше, ни Google Analytics, ни стандартный экспорт в Google BigQuery не дают возможности рассчитать ваши расходы на каждую сессию, пользователя, когорту. Зато это легко сделать с OWOX BI.
С помощью этого отчета вы можете узнать, сколько в среднем потратили на привлечения посетителя в разных городах за определенный период. Вот как он выглядит в OWOX BI Smart Data:
Как правило, рекламные кампании настраивают для каждого региона по-разному. Этот отчет подскажет, на какую область обратить внимание. Например, на графике выше мы видим, что средняя стоимость привлечения пользователя (CAC) выше всего в Днепре. Возможно, стоит провести более детальный анализ рекламных кампаний в этом регионе, рассчитать средний чек, стоимость привлечения покупателя в разрезе рекламных кампаний и сравнить ее с пожизненной ценностью клиента (LTV). Если кампании нерентабельны, можно их отключить либо снизить ставки.
3. Как ROAS по валовой прибыли зависел от источника и канала / кампании
Отчет поможет оценить эффективность рекламы и увидеть результаты кампаний с учетом исполняемости заказов и себестоимости товаров из CRM. Чтобы получить такой отчет, нужно предварительно импортировать данные о покупках из вашей внутренней системы в Google BigQuery. В интерфейсе OWOX BI Smart Data он выглядит так:
Этот график показывает лучшие и худшие кампании, а также «середнячков». Маркетологи могут детальнее анализировать лидеров и аутсайдеров, чтобы понять причины успехов или неудач, и выбирать для будущей рекламы наиболее эффективные каналы.
4. Как количество заказов в CRM зависело от способов оплаты и доставки
Этот отчет поможет понять, есть ли проблемы при оформлении заказов, ожидаемо ли работают способы оплаты. Чтобы его построить, нужно выгрузить из CRM в Google BigQuery информацию о выполненных заказах. Затем вы можете использовать наш шаблон SQL-запроса либо же добавить CRM-данные в OWOX BI Smart Data, задать вопрос с нужными метриками и получить такой график:
На графике мы видим, что клиенты платят картой (onlineCard) только в двух случаях доставки из четырех — это самовывоз из магазина и доставка в почтовое отделение. Однако, оплатить картой можно и курьерскую доставку. Если вы предусмотрели такую возможность, но клиенты ею не пользуются, возможно, у вас проблемы с этим функционалом на сайте.
5. Как среднее время доставки зависело от города
Для этого отчета вам также понадобятся данные об исполняемости заказов из CRM. С его помощью можно проверить, нет ли проблем с доставкой в определенных городах, не нарушается ли установленное время.
На скриншоте выше видно, что дольше всего товары доставляют в Москве. Если при этом среднее время доставки больше того, что указано на сайте, необходимо проверить, есть ли в этом регионе склад или offline-магазин. Если нет, возможно, стоит его организовать — это улучшит время доставки. Также не будет лишним измерить удовлетворенность пользователей.
Выводы
С помощью стандартного экспорта данных в Google BigQuery и SQL-запросов можно обойти ограничения Google Analytics и строить отчеты для более глубокого анализа. Например, вы можете:
- Посмотреть действия пользователей в разрезе любого количества параметров.
- Посмотреть статистику по ключевым действиям пользователей, а также среднее, максимальное или минимальное значение по типам хитов для конкретного пользователя.
- Выбрать пользователей, которые посетили определенные страницы товаров, или посмотреть действия людей, которые купили конкретный товар.
- Настроить воронки с любыми необходимыми вам шагами.
- Узнать эффективность работы внутреннего поиска на сайте.
С помощью OWOX BI Pipeline вы можете дополнить свои данные в Google BigQuery и определить, например:
- Как изменялся атрибутированный расход по источникам и каналам.
- Как средняя стоимость привлечения посетителя зависела от города.
- Как ROAS по валовой прибыли зависел от источника и канала / кампании.
- Как количество заказов в CRM зависело от способов оплаты и доставки.
- Как среднее время доставки зависело от города.
Напомним, что шаблоны SQL-запросов для каждого отчета, описанного в этой статье, мы собрали в отдельный PDF-файл. Чтобы получить его, просто заполните форму. Если у вас остались вопросы, с радостью обсудим их в комментариях к статье.
Использованные инструменты
Команда LIKE — поиск по базе данных
Команда LIKE задает поиск по определенному шаблону.
См. также команду NOT, которая делает отрицание (к примеру, так: NOT LIKE).
Синтаксис
SELECT * FROM имя_таблицы WHERE поле LIKE шаблон_поискаПримеры
Все примеры будут по этой таблице workers, если не сказано иное:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 500 |
| 4 | Коля | 30 | 1000 |
| 5 | Иван | 27 | 500 |
| 6 | Кирилл | 28 | 1000 |
Пример
В данном примере команда LIKE найдет все записи, у которых имя заканчивается на ‘я’:
SELECT * FROM workers WHERE name LIKE '%я'SQL запрос выберет следующие строки:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 500 |
| 4 | Коля | 30 | 1000 |
Пример
Давайте выберем те записи, у которых возраст начинается с цифры 2, а затем идет еще один символ:
SELECT * FROM workers WHERE age LIKE '2_'SQL запрос выберет следующие строки:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 500 |
| 5 | Иван | 27 | 500 |
| 6 | Кирилл | 28 | 1000 |
5 Обнаружение с использованием ODBC SQL запросов [Zabbix Documentation 5.4]
Этот тип низкоуровневого обнаружения осуществляется с использованием SQL запросов, полученные результаты которых автоматически преобразуются в объект JSON, пригодный для низкоуровневого обнаружения.
SQL запросы выполняются при помощи элементов данных типа “Монитор баз данных”. Так что, большая часть указаний со страницы ODBC мониторинга применима к получению работающего “Монитора баз данных” правила обнаружения, единственная разница лишь в том, что необходимо использовать ключ
db.odbc.discovery[<описание>,<dsn>]
вместо “db.odbc.select[<описание>,<dsn>]”.
Обнаружение с использованием SQL запросов поддерживается начиная с Zabbix сервера/прокси 3.0.
В качестве практического примера, иллюстрирующего как SQL запрос трансформируется в JSON, рассмотрим низкоуровневое обнаружения Zabbix прокси, выполнив ODBC запрос в Zabbix базу данных. Он может быть полезен для автоматического создания внутренних элементов данных “zabbix[proxy,<имя>,lastaccess]”, чтобы наблюдать какие прокси живы.
Давайте начнем с настройки правила обнаружения:
Все обязательные поля ввода отмечены красной звёздочкой.
Здесь используется следующий прямой запрос в базу данных Zabbix для выборки всех Zabbix прокси вместе с количеством узлов сети, за которыми эти прокси наблюдают. Количество узлов сети можно использовать, например, для фильтрации пустых прокси:
mysql> SELECT h2.host, COUNT(h3.host) AS count FROM hosts h2 LEFT JOIN hosts h3 ON h2.hostid = h3.proxy_hostid WHERE h2.status IN (5, 6) GROUP BY h2.host; +---------+-------+ | host | count | +---------+-------+ | Japan 1 | 5 | | Japan 2 | 12 | | Latvia | 3 | +---------+-------+ 3 rows in set (0.01 sec)
Благодаря внутреннему механизму обработки элемента данных “db.odbc.discovery[]”, результат этого запроса автоматически преобразуется в следующий JSON:
{
"data": [
{
"{#HOST}": "Japan 1",
"{#COUNT}": "5"
},
{
"{#HOST}": "Japan 2",
"{#COUNT}": "12"
},
{
"{#HOST}": "Latvia",
"{#COUNT}": "3"
}
]
}Видно, что имена колонок становятся именами макросов и выбранные строки становятся значениями этих макросов.
Если результат преобразования имени колонки в имя макроса неочевиден, предлагается использовать алиасы к именам колонок, так же как “COUNT(h3.host) AS count” в примере выше.В случае, если имя колонки не удается сконвертировать в допустимое имя макроса, правило обнаружения становится неподдерживаемым с детальным сообщением об ошибке какой номер колонки не удалось преобразовать. Если желательна дополнительная помощь, полученные имена колонки отражаются при DebugLevel=4 в файле журнала Zabbix сервера:
$ grep db.odbc.discovery /tmp/zabbix_server.log
...
23876:20150114:153410.856 In db_odbc_discovery() query:'SELECT h2.host, COUNT(h3.host) FROM hosts h2 LEFT JOIN hosts h3 ON h2.hostid = h3.proxy_hostid WHERE h2.status IN (5, 6) GROUP BY h2.host;'
23876:20150114:153410.860 db_odbc_discovery() column[1]:'host'
23876:20150114:153410.860 db_odbc_discovery() column[2]:'COUNT(h3.host)'
23876:20150114:153410.860 End of db_odbc_discovery():NOTSUPPORTED
23876:20150114:153410.860 Item [Zabbix server:db.odbc.discovery[proxies,{$DSN}]] error: Cannot convert column #2 name to macro.Теперь, когда мы понимаем как SQL запрос трансформируется в JSON объект, мы можем использовать макрос {#HOST} в прототипах элементов данных:
Как только обнаружение будет выполнено, элемент данных будет создан по каждому прокси:
Запись операторов SQL для запроса базы данных
Написание операторов SQL для запроса базы данных
Вы можете использовать операторы языка структурированных запросов (SQL) для управления тем, что вы импортируете из базы данных. Когда вы открываете файл базы данных в JMP, вы фактически отправляете в базу данных инструкцию SQL. По умолчанию этот оператор получает все столбцы и записи в таблице базы данных. В некоторых случаях это слишком много данных. Если вас интересует только подмножество данных таблицы, вы можете настроить запрос SQL, чтобы запрашивать только те данные, которые вам нужны.После выполнения запроса SQL его код сохраняется в таблице данных в переменной таблицы SQL.
В этом разделе описывается, как писать операторы SQL для извлечения данных. Для интерактивного запроса данных без написания операторов SQL используйте Query Builder. Вы также можете начать создание запроса в Query Builder, а затем добавить свой собственный SQL. См. Раздел «Написание операторов SQL в построителе запросов».
1. Выберите «Файл»> «База данных»> «Открыть таблицу».
Появится окно открытой таблицы базы данных (рисунок 3.67).
2. Подключитесь к базе данных, если необходимо, или выберите существующее соединение с базой данных. Следуйте инструкциям в разделе «Подключение к базе данных».
В поле «Подключения» перечислены источники данных, к которым подключен JMP. В поле «Схемы — таблицы» перечислены схемы для тех баз данных, которые их поддерживают.
Примечание. SQL-запрос, который вы запускаете в этом окне, работает только с таблицами и процедурами, отображаемыми в левой части окна. Выполнение несвязанного SQL здесь не дает результатов.
3. В окне «Открыть таблицу базы данных» нажмите кнопку «Дополнительно», чтобы открыть определенные подмножества таблицы.
4. Введите допустимый оператор SQL или измените оператор по умолчанию. На рис. 3.68 показан оператор SQL Select по умолчанию, подходящий для выбранного файла. См. В разделе «Язык структурированных запросов (SQL): справочник» описание операторов SQL, которые вы можете использовать.
Вместо этого вы можете добавить выражения, нажав кнопку Where и используя редактор WHERE Clause для создания выражений.См. Использование редактора предложений WHERE.
Рисунок 3.68 Чтение всех переменных из таблицы растворимости, хранящейся в файле Excel
5. Нажмите «Выполнить SQL». Появится таблица данных JMP с выбранными столбцами. См. Использование переменных таблицы данных.
6. Чтобы просмотреть состояние всех запущенных запросов, выберите «Просмотр»> «Выполняющиеся запросы».
Обратите внимание, что вы можете ввести любой допустимый оператор SQL и щелкнуть «Выполнить SQL», чтобы выполнить команду. Допустимый SQL зависит от источника данных и драйвера ODBC.
SQLBolt — Изучение SQL — Урок SQL 1: SELECT запросы 101
Чтобы получить данные из базы данных SQL, нам нужно написать операторов SELECT , которые часто
обозначается как запросов . Запрос сам по себе — это просто заявление, в котором объявляется, какими данными мы являемся.
ищет, где его найти в базе данных и, при желании, как его преобразовать перед возвратом.
Однако у него есть особый синтаксис, который мы изучим в следующих упражнениях.
Как мы упоминали во введении, вы можете думать о таблице в SQL как о типе объекта (например, Dogs), и каждая строка в этой таблице как конкретный экземпляр этого типа (т. е. мопс, бигль, другой цветной мопс и т. д.). Это означает, что столбцы тогда будут представлять общие свойства, общие по всем экземплярам этой сущности (т.е. по цвету меха, длине хвоста и т. д.).
И учитывая таблицу данных, самый простой запрос, который мы могли бы написать, — это запрос, который выбирает для пары столбцы (свойства) таблицы со всеми строками (экземплярами).
Выбрать запрос для определенных столбцов
ВЫБРАТЬ столбец, другой_столбец,…
ИЗ mytable; Результатом этого запроса будет двумерный набор строк и столбцов, фактически копия table, но только с теми столбцами, которые мы запросили.
Если мы хотим получить абсолютно все столбцы данных из таблицы, мы можем использовать звездочку ( * )
сокращение вместо перечисления всех имен столбцов по отдельности.
Выбрать запрос для всех столбцов
ВЫБРАТЬ *
ИЗ mytable; Этот запрос, в частности, действительно полезен, потому что это простой способ проверить таблицу путем сброса все данные сразу.
Мы будем использовать базу данных с данными о некоторых классических фильмах Pixar для большинства наших упражнений. В этом первом упражнении будет задействована только таблица Movies и запрос по умолчанию, приведенный ниже. показывает все свойства каждого фильма. Чтобы перейти к следующему уроку, измените запрос, чтобы найти точная информация, которая нам нужна для каждой задачи.
SQL Server SELECT — запрос данных из одной таблицы
Резюме : это руководство знакомит вас с основами оператора SQL Server SELECT , уделяя особое внимание тому, как выполнять запросы к одной таблице.
Базовый SQL Server
Оператор SELECT Таблицы базы данных — это объекты, в которых хранятся все данные в базе данных. В таблице данные логически организованы в формате строк и столбцов, который похож на электронную таблицу.
В таблице каждая строка представляет уникальную запись, а каждый столбец представляет поле в записи. Например, таблица клиентов содержит данные клиента, такие как идентификационный номер клиента, имя, фамилию, телефон, электронную почту и адрес, как показано ниже:
SQL Server использует схемы для логической группировки таблиц и других объектов базы данных.В нашей тестовой базе данных у нас есть две схемы: продаж и производственных . Схема sales группирует все таблицы, связанные с продажами, а схема production группирует все таблицы, связанные с производством.
Для запроса данных из таблицы используйте оператор SELECT . Ниже приведена самая простая форма оператора SELECT :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT select_list ИЗ schema_name.table_name;
В этом синтаксисе:
- Сначала укажите список разделенных запятыми столбцов, из которых вы хотите запросить данные, в предложении
SELECT. - Во-вторых, укажите исходную таблицу и ее имя схемы в предложении
FROM.
При обработке оператора SELECT SQL Server сначала обрабатывает предложение FROM , а затем предложение SELECT , даже если предложение SELECT появляется в запросе первым.
SQL Server
Примеры операторов SELECT Давайте воспользуемся таблицей клиентов в образце базы данных для демонстрации.
A) SQL Server
SELECT — получить некоторые столбцы примера таблицыСледующий запрос находит имя и фамилию всех клиентов:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT имя, Фамилия ИЗ sales.customers;
Вот результат:
Результат запроса называется набором результатов.
Следующий оператор возвращает имена, фамилии и адреса электронной почты всех клиентов:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT имя, Фамилия, электронное письмо ИЗ продажи.клиенты;
B) SQL Server
SELECT — получить все столбцы из примера таблицы Чтобы получить данные из всех столбцов таблицы, вы можете указать все столбцы в списке выбора. Вы также можете использовать SELECT * как сокращение, чтобы сэкономить время при вводе:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT * ИЗ sales.customers;
SELECT * полезен для изучения столбцов и данных таблицы, с которой вы не знакомы.Это также полезно для специальных запросов.
Однако вам не следует использовать SELECT * для реального производственного кода по следующим основным причинам:
- Во-первых,
SELECT *часто извлекает больше данных, чем требуется вашему приложению для работы. Это приводит к передаче ненужных данных из SQL Server в клиентское приложение, что требует больше времени для передачи данных по сети и замедляет работу приложения. - Во-вторых, если в таблицу добавляется один или несколько новых столбцов,
SELECT *просто извлекает все столбцы, которые включают в себя недавно добавленные столбцы, которые не были предназначены для использования в приложении.Это могло привести к сбою приложения.
C) SQL Server
SELECT — сортировка набора результатов Для фильтрации строк на основе одного или нескольких условий используйте предложение WHERE , как показано в следующем примере:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT * ИЗ sales.customers ГДЕ состояние = 'CA';
В этом примере запрос возвращает клиентов, которые находятся в Калифорнии.
Когда доступно предложение WHERE , SQL Server обрабатывает предложения запроса в следующей последовательности: FROM , WHERE и SELECT .
Чтобы отсортировать набор результатов по одному или нескольким столбцам, используйте предложение ORDER BY , как показано в следующем примере:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT * ИЗ sales.customers ГДЕ состояние = 'CA' СОРТИРОВАТЬ ПО имя;
В этом примере предложение ORDER BY сортирует клиентов по их именам в возрастающем порядке.
В этом случае SQL Server обрабатывает предложения запроса в следующей последовательности: FROM , WHERE , SELECT и ORDER BY .
D) SQL Server
SELECT — пример группировки строк в группы Чтобы сгруппировать строки в группы, вы используете предложение GROUP BY . Например, следующая инструкция возвращает все города клиентов, расположенных в Калифорнии, и количество клиентов в каждом городе.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ Город, СЧИТАТЬ (*) ИЗ продажи.клиенты ГДЕ состояние = 'CA' ГРУППА ПО город СОРТИРОВАТЬ ПО город;
В этом случае SQL Server обрабатывает предложения в следующей последовательности: FROM , WHERE , GROUP BY , SELECT и ЗАКАЗАТЬ ПО .
E) SQL Server
SELECT — пример групп фильтров Для фильтрации групп на основе одного или нескольких условий используется предложение HAVING .В следующем примере возвращается город в Калифорнии, в котором более 10 клиентов:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT Город, СЧИТАТЬ (*) ИЗ sales.customers ГДЕ состояние = 'CA' ГРУППА ПО город ИМЕЮЩИЕ COUNT (*)> 10 СОРТИРОВАТЬ ПО город;
Обратите внимание, что предложение WHERE фильтрует строки, а предложение HAVING фильтрует группы.
В этом руководстве вы узнали, как использовать оператор SQL Server SELECT для запроса данных из одной таблицы.
Как создать таблицу из запроса SQL
База данных:
Операторы:
СОЗДАТЬ ТАБЛИЦУ КАК ВЫБРАТЬ, ВЫБРАТЬ ВПроблема:
Вы хотите создать новую таблицу в базе данных с данными, определенными SQL-запросом.
Пример:
Мы хотим создать таблицу gamer на основе SQL-запроса. В этом запросе мы выбираем данные из другой таблицы с именем Championship , представленной ниже.
| id | gamer | счет | Championship_date |
|---|---|---|---|
| 1 | Алиса | 14 | 2020-08-10 |
| 2 | руководитель | 10 | 2020-09-28 |
| 3 | happyman | 0 | 2020-08-10 |
| 4 | Лукас | 6 | 2020-08-10 |
| 5 | oli | 12 | 2020-08-10 |
| 6 | biggamer | 7 | 2020-09-12 |
В базе данных давайте создадим новую таблицу с именем gamer , которая будет хранить данные во всех столбцах, определенных в таблице Championship ( id , gamer , score , и Championship_date ).
Решение 1:
СОЗДАТЬ ТАБЛИЦУ gamer В ВИДЕ ВЫБРАТЬ * ОТ чемпионата;
Обсуждение:
Если вы хотите создать новую таблицу, первым делом нужно использовать предложение CREATE TABLE и имя новой таблицы (в нашем примере: gamer ). Затем используйте ключевое слово AS и предоставьте оператор SELECT , который выбирает данные для новой таблицы. В нашем примере мы выбрали все столбцы из таблицы чемпионат с помощью звездочки (*).Набор результатов отображает все записи в таблице чемпионат .
Однако, если вы хотите создать таблицу только с подмножеством записей, вы можете указать выбранный запрос, как в примере ниже.
Решение 2:
СОЗДАТЬ ТАБЛИЦУ gamer В ВИДЕ ВЫБРАТЬ игрок, счет, чемпионат_дата ОТ чемпионата ГДЕ Championship_dateВот результат:
| игрок | счет | Championship_date |
|---|---|---|
| Алиса | 14 | 2020-08-10 |
| happyman | 0 | 2020-08-10 |
| Лукас | 6 | 2020-08-10 |
| Оли | 12 | 2020-08-10 |
Запрос SELECT извлекает только записи с датой Championship_date , равной или старше 10 августа 2020 г. ( WHERE Championship_date).В новой таблице хранится меньше столбцов, чем в предыдущем примере ( SELECT gamer, score, championship_date ) без столбца id .
Аналогичное решение этой проблемы — использовать предложение SELECT INTO для создания новой таблицы и копирования данных из другой таблицы. Взгляните на код:
Решение 3:
ВЫБРАТЬ игрок, счет, чемпионат_дата INTO gamer ОТ чемпионата ГДЕ Championship_dateИтоговая таблица такая же.Обратите внимание, что эта конструкция отсутствует в стандарте SQL. В этой команде SQL мы сначала записываем
SELECT, затем список столбцов, затем ключевое словоINTOи, наконец, имя новой таблицы, которую мы хотим создать. Затем вы можете добавитьWHEREи другие предложения SQL, такие какGROUP BYилиHAVING, для фильтрации записей для новой таблицы.
Что скрывается за простым запросом SQL? | Николай Димоларов
Краткое изучение того, что происходит, когда приложение / разработчик запускает SQL-запрос для получения данных из базы данных PostgresDB.
Откуда мясо? Фото Влада Чецана из PexelsТак же, как и большинство детей в наши дни, кажется, не знают, откуда берутся их мясо (подсказка: не растет на деревьях, а может быть из лаборатории) или почему небо голубое (подсказка: синий свет короче , меньшие волны), тревожное количество разработчиков (на самом деле) не знают, откуда берутся их данные и как они обрабатываются и хранятся. Эта статья должна стать отправной точкой на пути инженера к пониманию того, как это работает. Это очень хорошо, независимо от того, какую платформу или платформу без кода пытаются научить вас.Особенно, если данные действительно являются новой нефтью (очевидно, так было уже несколько лет), возможно, стоит посмотреть, как работают базы данных.
Отказ от ответственности: это не учебник по SQL.
Без лишних слов простой оператор SQL для выборки всех пользователей из БД с именем users:
Отказ от ответственности 2: суть не в том, чтобы писать причудливые операторы SQL, а в том, чтобы продемонстрировать, что происходит, когда вы делаете
SELECT * FROM users;
Итак, многие ли из вас на самом деле знают, что происходит между нажатием Enter в терминале psql и получением результата?
Основы
Чтобы понять это, нужно начать с начала — архитектуры PostgresDB.
В конце концов, это клиент-серверное приложение, написанное на C ++. Клиент — это любой, кто обращается к БД, например. ваш терминал psql, ваша функция Lambda, драйвер JDBC и т. д., а сервер — это бэкэнд PGDB, который принимает ваши запросы, хранит данные и т. д.
Вот базовый обзор архитектуры PostgresDB, который будет увеличиваться на протяжении всей статьи:
Это своего рода старая школа, но она все еще работает 🙂 Источник: SlideShareПуть запроса
В глубине официальной документации PostgresDB есть довольно хороший обзор «пути запроса».Вот что вам следует знать:
1. Установить соединение, передать запрос и дождаться результатов
PGDB может обрабатывать несколько соединений одновременно (через «постмастера», см. Архитектуру), и для каждого соединения он создает новый процесс ( «Postgres», см. Архитектуру) для обработки запросов (например, операторов SQL) этого соединения. Другими словами, это простая модель клиент / сервер «процесс на пользователя». Постмастер обрабатывает начальное соединение и аутентификацию, а затем передает это соединение новому процессу postgres.Эти процессы взаимодействуют друг с другом с помощью общей памяти и семафоров для обеспечения общей целостности данных даже при одновременных подключениях (помните ACID?)
2. Анализ запроса
Он состоит из 2 этапов:
- Анализ: Парсер PGDB использует инструменты UNIX bison и flex в качестве парсера и лексера, чтобы проверить, является ли входящая строка запроса (текст ASCII) допустимым запросом SQL. Это делается только с фиксированными правилами синтаксиса SQL без какого-либо понимания базовой семантики строки запроса.Результатом является дерево синтаксического анализа:
- Transform: использует дерево синтаксического анализатора для построения дерева запроса, которое содержит семантическую интерпретацию запроса, например. на какие таблицы, типы данных, операторы и функции ссылаются. Корнем деревьев запросов является определенная здесь структура данных запроса. Результат:
Мини-подробный анализ запроса:
- targetList: содержит вывод запроса и его тип данных, в данном случае идентификатор столбца и данные, которые являются целыми числами
- rtable: содержит ссылку на таблица
- Jointree: содержит операторы FROM и WHERE
- sortClause: содержит способ сортировки данных
Важное примечание прямо из официальных документов:
Причина отделения необработанного синтаксического анализа от семантического анализа заключается в том, что поиск в системном каталоге может быть выполнено только внутри транзакции, и мы не хотим начинать транзакцию сразу после получения строки запроса.Стадии необработанного синтаксического анализа достаточно для идентификации команд управления транзакцией (BEGIN, ROLLBACK и т. Д.), И затем они могут быть правильно выполнены без какого-либо дальнейшего анализа. Как только мы узнаем, что имеем дело с фактическим запросом (таким как SELECT или UPDATE), можно начать транзакцию, если мы еще не в ней. Только после этого может быть запущен процесс преобразования.
3. Система перезаписи Rewrite
PGDB использует дерево запросов в качестве входных данных и выполняет преобразования на основе правил, хранящихся в его системных каталогах, которые могут применяться к дереву запросов.Результатом снова будет дерево запросов. Хорошим примером является реализация представлений (виртуальных таблиц), в которых система перезаписи перезаписывает пользовательский запрос для доступа к исходным таблицам в определении представления вместо псевдонима представления.
Здесь можно найти исчерпывающий пример того, как работает система правил для представлений.
4. План запроса
Планировщик / оптимизатор использует переписанное дерево запросов с последнего шага для создания оптимального / дешевого (= самого быстрого / наиболее эффективного) плана выполнения для запроса — плана запроса.Оптимизатор просматривает все возможные пути для выполнения запроса. Если в инструкции нет большого количества объединений, превышающих geqo_treshold, когда рассмотрение всех возможностей невозможно с вычислительной точки зрения. В этом случае вместо него используется универсальный оптимизатор запросов.
Тот же пример с планом запроса / деревом плана. Источник: interdb.jpПример на диаграмме выше показывает простой пример, когда исполнитель должен выполнить последовательное сканирование таблицы tbl_a с последующей сортировкой.
Вы можете проверить свой план запроса, набрав EXPLAIN перед запросом:
EXPLAIN SELECT (...)
5. Исполнитель
Официальная документация объясняет это так ясно, как только можно:
Исполнитель рекурсивно проходит через дерево плана и извлекает строки способом, представленным планом. Исполнитель использует систему хранения при сканировании отношений, выполняет сортировку и объединение, оценивает квалификации и, наконец, возвращает полученные строки.
Исполнитель используется для оценки всех 4 основных типов SQL-запросов: SELECT, INSERT, DELETE и UPDATE.Здесь вы можете найти более подробную информацию о действиях исполнителя для каждого типа запроса.
Бонус: ускорение графического процессора
На самом деле существуют инструменты, такие как PG Strom для ускорения графического процессора, особенно для оптимизатора запросов и исполнителя, как показано на этой диаграмме:
Снова что-то вроде старой школы, но что не нравится? 🙂 Источник: SlideShareЭто не то, что тестировалось для статьи, но это может вдохновить вас проверить, что там есть, так как это кажется довольно крутой технологией.
Память
ОК. Теперь вы знаете, (1) что происходит, когда вы подключаетесь к экземпляру PGDB, и (2) как SQL-запросы анализируются, оптимизируются и выполняются. Единственное, чего не хватает, так это того, как хранятся данные, чтобы охватить (самые) основы работы современных * баз данных.
* Вы можете принять слово «современный» с долей скептицизма, учитывая возраст PostgresDB, но он все еще очень широко используется и является одной из основных реляционных баз данных, используемых сегодня.
Здесь есть отличное объяснение этой темы, поэтому ниже приводится лишь краткое изложение.
(Очень) Общий обзор архитектуры памяти PostgresDB. Источник: multiplenines.comСуществует 2 типа памяти:
1. Локальная память
Используется каждым серверным процессом postgres. Эта память выделяется каждым процессом для обработки запросов и состоит из:
- temp_buffers: хранение временных таблиц исполнителем
- work_mem: используется исполнителем для объединений и т. Д.
- maintenance_work_mem: обслуживание операций, таких как REINDEX
2.Общая память
Она выделяется при запуске сервера PGDB и используется всеми внутренними процессами для обеспечения целостности данных (помните начало статьи?) Это также память, с которой взаимодействует внутренний процесс — обычно она не взаимодействует. напрямую с постоянным хранилищем. Эта общая память состоит из:
- Общий буферный пул: где страницы в таблицах и индексах загружаются в
- буфер WAL: Postgres имеет журнал упреждающей записи i.е. журнал транзакций, гарантирующий, что данные не потеряны из-за сбоя сервера. Данные WAL сохраняются в буфере WAL перед передачей в постоянное хранилище.
- Журнал фиксации: содержит все состояния транзакций как часть механизма управления параллелизмом.
Вы можете настроить эти значения и количество выделенной им памяти, чтобы повысить производительность вашей базы данных. Еще больше информации об утилитах для каждой части памяти можно найти здесь.
Объединяем / А как насчет постоянного хранилища?
Что в итоге происходит? Как данные сохраняются? Исполнитель может читать / записывать из / в таблицы и индексы в базе данных через диспетчер буферов, который может получать доступ к данным из постоянного хранилища, добавляя их в общий пул буферов.
Резюме
К настоящему моменту вы должны иметь базовое представление о внутренней работе одной из самых популярных баз данных! В конце концов, вы просто взаимодействуете с очень умным приложением на C ++ — насколько это круто? Надеюсь, это снимет некоторую стигму с «сложными базами данных». Возможно, это даже вдохновит вас копнуть глубже и понять, как вы можете оптимизировать свои приложения, лучше понимая, как хранятся ваши данные — безусловно, одно из самых больших узких мест в современной разработке программного обеспечения.
Источники:
Порядок выполнения SQL-запроса
Блог
SQL — один из самых мощных инструментов аналитика. В SQL Superstar мы даем вам практические советы, которые помогут вам максимально эффективно использовать этот универсальный язык и создавать красивые и эффективные запросы.
Создание заказа
Шаги, которые вы предпринимаете для достижения цели, имеют значение! Когда вы печете торт, вы должны предварительно разогреть его, смазать сковороду и смешать ингредиенты в правильном порядке, иначе вместо вкусного угощения у вас получится беспорядок.Выбор правильного порядка операций SQL также важен, если вы хотите выполнять эффективные и действенные запросы. В этой статье вы познакомитесь с некоторыми передовыми практиками, которые помогут вам начать оптимизацию порядка запросов SQL.
Получите советы и рекомендации по SQL от наших экспертов:
Читать далееОпределение порядка выполнения SQL
Порядок выполнения SQL определяет порядок, в котором оцениваются условия запроса. Некоторые из наиболее распространенных проблем с запросами, с которыми сталкиваются люди, можно легко избежать, если лучше понять порядок выполнения SQL, который иногда называют порядком операций SQL.Понимание порядка запросов SQL может помочь вам диагностировать, почему запрос не выполняется, и даже чаще поможет вам оптимизировать запросы, чтобы они выполнялись быстрее.
В современном мире планировщики SQL-запросов могут делать всевозможные трюки, чтобы запросы выполнялись более эффективно, но они всегда должны получать тот же окончательный ответ, что и запрос, который выполняется в стандартном порядке выполнения SQL. Это заказ:
ИЗ пункта Предложение fromSQL выбирает и объединяет ваши таблицы и является первой выполненной частью запроса.Это означает, что в запросах с объединениями в первую очередь выполняется объединение.
Рекомендуется ограничивать или предварительно агрегировать таблицы перед потенциально большими объединениями, которые в противном случае могут потребовать очень много памяти. Многие современные планировщики SQL используют логику и различные типы объединений для оптимизации под разные запросы, которые могут быть полезны, но на них нельзя полагаться.
В примере ниже планировщик SQL может знать, что нужно предварительно фильтровать эхо-запросы. Это технически нарушает правильный порядок запросов SQL, но вернет правильный результат.
выбрать
считать(*)
из
пинги
присоединиться
подписки
на
pings.cookie = signups.cookie
где
pings.url ilike '% / blog%' Однако, если вы собираетесь использовать столбцы таким образом, чтобы предотвратить предварительную фильтрацию, базе данных придется отсортировать и объединить обе полные таблицы. Например, следующий запрос требует столбца из каждой таблицы и будет принудительно объединен перед любой фильтрацией.
- || используется для конкатенации
Выбрать
считать(*)
из
first_names
присоединиться к last_names
на first_names.id = last_names.id
где
first_names.name || last_names.name ilike '% a%' Чтобы ускорить запрос, вы можете предварительно отфильтровать имена с буквой «a» в них:
с limited_first_names как (
Выбрать
*
из
first_names
где
назовите ilike '% a%'
)
, limited_last_names как (
Выбрать
*
из
фамилии
где
назовите ilike '% a%'
)
Выбрать
считать(*)
из
limited_first_names
присоединиться
limited_last_names
на
limited_last_names.id = limited_first_names.id Чтобы узнать больше, вы также можете прочитать о том, как мы ускорили наши собственные запросы в 50 раз с помощью предварительной агрегации.
ГДЕ ПунктПредложение where используется для ограничения теперь объединяемых данных значениями в столбцах вашей таблицы. Это можно использовать с любым типом данных, включая числа, строки или даты.
, где nmbr> 5;
где strng = 'Скайуокер';
где dte = '2017-01-01'; Одна из частых ошибок в SQL — это попытка использовать оператор where для фильтрации агрегатов, что нарушает порядок выполнения правил SQL. Это связано с тем, что при оценке оператора where оператор «группировать по» еще не был выполнен и агрегированные значения неизвестны.Таким образом, следующий запрос не будет выполнен:
выбрать
страна
, сумма (площадь)
из
страны
где
сумма (площадь)> 1000
группа по
1 Но это может быть решено с помощью оговорки о наличии, описанной ниже.
GROUP BY Пункт
Group by сворачивает поля набора результатов в их отдельные значения. Это предложение используется с агрегациями, такими как sum () или count (), для отображения одного значения на сгруппированное поле или комбинацию полей.
При использовании группировки по: Группировать по X означает поместить всех с одинаковым значением X в одну строку.Сгруппируйте по X, Y поместите все те, у которых одинаковые значения для X и Y, в одну строку.
Предложение group by заслуживает отдельной публикации по многим причинам, и вы можете найти гораздо больше информации о «group by» в других сообщениях нашего блога или в нашем техническом документе о советах по порядку запросов SQL и множестве других уловок. и передовой опыт.
Получите советы и рекомендации по SQL от наших экспертов:
Читать далееКрис Мейер — менеджер по аналитическим разработкам в Sisense. Он имеет 8-летний опыт работы в области данных и аналитики в Ernst & Young и Soldsie.Он увлечен созданием современных стеков данных, которые открывают трансформационные идеи для бизнеса.
QUERY BY SQL
С помощью команды QUERY BY SQL можно воспользоваться преимуществами ядра SQL, интегрированного в 4D. Он может выполнить простой запрос SELECT, который можно записать следующим образом:
SELECT *
FROM table
WHERE
aTable — это имя таблицы, переданной в первом параметре, а sqlFormula — это строка запроса, переданная в второй параметр.
Например, следующий оператор:
([Сотрудники]; "name = 'smith'")
эквивалентен следующему запросу SQL:
SELECT * FROM Employees WHERE "name = 'smith'" Команда QUERY BY SQL аналогична команде QUERY BY FORMULA. Ищет записи в указанной таблице. Он изменяет текущий выбор aTable для текущего процесса и делает первую запись нового выбора текущей записью.
Примечание: Команда QUERY BY SQL не может использоваться в контексте внешнего SQL-соединения; он подключается непосредственно к интегрированному SQL-механизму 4D.
QUERY BY SQL применяет sqlFormula к каждой записи в выбранной таблице. sqlFormula — это логическое выражение, которое должно возвращать True или False . Как вы, возможно, знаете, в стандарте SQL условие поиска может давать результат True, , False, или NULL. Все записи (строки), в которых условие поиска возвращает True , включены в новый текущий выбор.
Выражение sqlFormula может быть простым, например, сравнивать поле (столбец) со значением; или он может быть сложным, например выполнение вычислений.Как и QUERY BY FORMULA, QUERY BY SQL может оценивать информацию в связанных таблицах (см. Пример 4). sqlFormula должен быть допустимым оператором SQL, совместимым со стандартом SQL-2 и с учетом ограничений текущей реализации SQL 4D. Дополнительные сведения о поддержке SQL в 4D см. В Справочном руководстве по 4D SQL.
Параметр sqlFormula может использовать ссылки на четырехмерные выражения. Используемый синтаксис такой же, как для встроенных команд SQL или кода, включенного между тегами Begin SQL / End SQL, i.е .: <
Примечание: Эта команда совместима с командами SET QUERY LIMIT и SET QUERY DESTINATION.
Напоминание: У вас не может быть ссылок на локальные переменные в скомпилированном режиме. Для получения дополнительной информации о программировании SQL в 4D обратитесь к разделу Обзор команд SQL.
QUERY BY SQL не использует отношения между таблицами, определенные в редакторе структуры 4D. Если вы хотите использовать связанные данные, вам нужно будет добавить в запрос JOIN.Например, предположим, что у нас есть следующая структура с отношением «Многие к одному» от [Люди] Город к [Города] Имя:
[Люди]
Имя
Город
[Города]
Имя
Население
Использование в команде QUERY BY FORMULA вы можете написать:
Используя QUERY BY SQL, вы должны написать следующий оператор, независимо от того, существует ли связь:
QUERY BY SQL ([People]; "people.city = cities.name AND города.население> 1000 ") Примечание. QUERY BY SQL обрабатывает отношения» один ко многим «и» многие ко многим «иначе, чем QUERY BY FORMULA.
В этом примере показаны офисы, в которых объем продаж превышает 100. Запрос SQL:
SELECT *
FROM Office
WHERE Sales> 100
При использовании команды QUERY BY SQL :
C_TEXT ($ queryFormula)
$ queryFormula: = "Продажи> 100"
ЗАПРОС ПО SQL ([Офисы]; $ queryFormula) В этом примере показаны заказы, которые попадают в диапазон от 3000 до 4000.Запрос SQL:
SELECT *
FROM Orders
WHERE Amount BETWEEN 3000 AND 4000
При использовании команды QUERY BY SQL:
C_TEXT ($ queryFormula)
$ queryFormula: = "Всего МЕЖДУ 3000 И 4000"
QUERY BY SQL ([Orders]; $ queryFormula) В этом примере показано, как получить результат запроса, упорядоченный по определенному критерию. Запрос SQL:
SELECT *
FROM People
WHERE City = ’Paris’
ORDER BY Name
При использовании команды QUERY BY SQL :
C_TEXT ($ queryFormula)
$ queryFormula: = "City =‘ Paris ’ЗАКАЗАТЬ ПО ИМЯ"
ЗАПРОС ПО SQL ([People]; $ queryFormula) В этом примере показан запрос с использованием связанных таблиц в 4D.В SQL вы должны использовать JOIN для моделирования этого отношения. Предположим, у нас есть две следующие таблицы:
[Счета-фактуры] со следующими столбцами (полями):
ID_Inv: Longint
Date_Inv: Date
Amount: Real
[Lines_Invoices] со следующими столбцами (полями):
ID_Line: Longint
ID_Inv: Longint
Код: Alpha (10)
Между [Lines_Invoices] ID_Inv и [Invoices] ID_Inv существует отношение «многие к одному».