Условие отбора в запросе SQL – SELECT FROM WHERE
Базы данных на реальных предприятиях содержат в своих таблицах огромное количество строк информации, что делает крайне затруднительным работу с ней, используя простые SQL-запросы, которые были рассмотрены в предыдущих статьях. Например, Вам нужно посмотреть продажи за конкретный день или по одному сотруднику, а Ваша компания совершает тысячи продаж в день, то потребуется слишком много времени, чтобы просмотреть миллионы записей за несколько лет ведения торговли.
В этой статье будет рассмотрено предложение WHERE, которое позволяет создать фильтр строк таблицы базы данных.
Предложение с условием отбора начинается с ключевого слова WHERE, которое следует сразу за предложением FROM:
SELECT FROM WHERE
Рассмотрим применение фильтрации строк на примере учебной БД. Задача:
Необходимо выбрать все звонки, которые поступили на линию поддержки автокредитования.
Решение задачи:
Все звонки содержатся в таблице «Звонки», но они содержать только идентификатор линии, без ее описания. Поэтому, чтобы узнать идентификатор нужной линии, сначала необходимо выполнить запрос к таблице «Линии»:
SELECT id FROM Линии WHERE Описание = 'Поддержка автокредитования'
Узнав, что идентификатор линии поддержки автокредитования равен трем, составим запрос к таблице звонков:
SELECT * FROM Звонки WHERE Линия = 3
Количество полученных записей в результате выполнения последнего SQL-запроса должно равняться 14 124.
Множественное условие SQL
Решение задачи, приведенной выше, не очень хорошее, так как выполнено в 2 хода. Решить его можно 1 запросом с несколькими условиями:
SELECT Звонки.* FROM Звонки, Линии WHERE Линии.id = Звонки.Линия AND Линии.Описание = 'Поддержка автокредитования'
Разберем пример более подробно.
В первой строке выгружаются все столбцы из таблицы звонков.
В предложении FROM перечисляются таблицы, к которым будет совершен запрос.
Предложение WHERE включает 2 предиката равенства, объединенных оператором AND. Это означает, что идентификатор линии в таблице звонков должен совпадать с идентификатором линии в таблице линий, у которой описание равно строке «Поддержка автокредитования».
На данном этапе, последний пример может быть не очень понятен, так как подразумевает соединение таблиц. Он приведен с целью показать возможность использования нескольких условии фильтрации.
Объединение таблиц и логические операторы для указания нескольких условий будут рассмотрены в последующих статьях.
Пополним синтаксис оператора SELECT новым предложением:
SELECT [DISTINCT] [Имя_таблицы.]Имя_столбца[, [Имя_таблицы.]Имя_столбца2 …] FROM [[Имя_базы_данных.]Имя_Схемы.]Имя_таблицы [WHERE Условие_отбора]
- < Назад
- Вперёд >
Если материалы office-menu. ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
Добавить комментарий
Как сформировать SQL запросы в Excel? — Разработка на vc.ru
Представьте себе ситуацию, Вы получили целевую выборку из одной базы данных, но для полноты картины, как всегда, нужны дополнительные данные. Проблема может быть в том, что нужная информация хранится в другой базе данных и возможности создать на ней свою таблицу нет, подключиться используя link тоже нельзя, да и количество элементов, по которым нужно получить данные, несколько больше, чем допустимое на данном источнике. Вот и получается, что возможность написать SQL запрос и получить нужные данные есть, но написать придется не один запрос, а потом потратить время на объединение полученных данных.
{«id»:158807,»url»:»https:\/\/vc. ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel»,»title»:»\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel&title=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel&text=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.
ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel»,»title»:»\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel&title=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel&text=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.
3629 просмотров
Выйти из подобной ситуации поможет Excel.
Уверен, что ни для кого не секрет, что MS Excel имеет встроенный модуль VBA и надстройки, позволяющие подключаться к внешним источникам данных, то есть по сути является мощным инструментом для аналитики, а значит идеально подходит для решения подобных задач.
Для того чтобы обойти проблему, нам потребуется таблица с целевой выборкой, в которой содержатся идентификаторы, по которым можно достаточно корректно получить недостающую информацию (это может быть уникальный идентификатор, назовем его ID, или набор из данных, находящихся в разных столбцах), ПК с установленным MS Excel, и доступом к БД с недостающей информацией и, конечно, желание получить ту самую информацию.
 xlsm, после чего приступаем к созданию макроса.
xlsm, после чего приступаем к созданию макроса.Sub job_sql() — Пусть наш макрос называется job_sql.
Пропишем переменные для подключения к БД, записи данных и запроса:
Dim cn As ADODB.Connection Dim rs As ADODB.Recordset Dim sql As String
Опишем параметры подключения:
sql = «Provider=SQLOLEDB. 1;Integrated Security=SSPI;Persist Security Info=True;Data Source=Storoge.company.ru\ Storoge.»
1;Integrated Security=SSPI;Persist Security Info=True;Data Source=Storoge.company.ru\ Storoge.»
Объявим процедуру свойства, для присвоения значения:
Set cn = New ADODB.Connection cn.Provider = » SQLOLEDB.1″ cn.ConnectionString = sql cn.ConnectionTimeout = 0 cn.Open
Вот теперь можно приступать непосредственно к делу.
Организуем цикл:
Как вы уже поняли конечное значение i=1000 здесь только для примера, а в реальности конечное значение соответствует количеству строк в Вашей таблице. В целях унификации можно использовать автоматический способ подсчета количества строк, например, вот такую конструкцию:
Dim LastRow As Long
LastRow = ActiveSheet. UsedRange.Row — 1 + ActiveSheet.UsedRange.Rows.Count
UsedRange.Row — 1 + ActiveSheet.UsedRange.Rows.Count
Тогда открытие цикла будет выглядеть так:
Как я уже говорил выше MS Excel является мощным инструментом для аналитики, и возможности Excel VBA не заканчиваются на простом переборе значений или комбинаций значений. При наличии известных Вам закономерностей можно ограничить объем выгружаемой из БД информации путем добавления в макрос простых условий, например:
If Cells(i, 2) = «Ваше условие» Then
Итак, мы определились с объемом и условиями выборки, организовали подключение к БД и готовы формировать запрос. Предположим, что нам нужно получить информацию о размере ежемесячного платежа [Ежемесячный платеж] из таблицы [payments].[refinans_credit], но только по тем случаям, когда размер ежемесячного платежа больше 0
sql = «select [Ежемесячный платеж] from [PAYMENTS]. [refinans_credit] » & _
«where [Ежемесячный платеж]>0 and [Номер заявки] ='» & Cells(i, 1) & «‘ «
[refinans_credit] » & _
«where [Ежемесячный платеж]>0 and [Номер заявки] ='» & Cells(i, 1) & «‘ «
Если значений для формирования запроса несколько, соответственно прописываем их в запросе:
«where [Ежемесячный платеж]>0 and [Номер заявки] = ‘» & Cells(i, 1) & «‘ » & _ » and [Дата платежа]='» & Cells(i, 2) & «‘»
В целях самоконтроля я обычно записываю сформированный макросом запрос, чтобы иметь возможность проверить его корректность и работоспособность, для этого добавим вот такую строчку:
в третьем столбце записываются запросы.
Выполняем SQL запрос:
А чтобы хоть как-то наблюдать за выполнением макроса выведем изменение i в статус-бар
Application. StatusBar = «Execute script …» & i
Application.ScreenUpdating = False
StatusBar = «Execute script …» & i
Application.ScreenUpdating = False
Теперь нам нужно записать полученные результаты. Для этого будем использовать оператор Do While:
j = 0 Do While Not rs.EOF For ii = 0 To rs.Fields.Count — 1 Cells(i, 4 + j + ii) = rs.Fields(0 + ii) ‘& «;»
Указываем ячейки для вставки полученных данных (4 в примере это номер столбца с которого начинаем запись результатов)
Next ii j = j + rs.Fields.Count s.MoveNext Loop rs.Close End If
— закрываем цикл If, если вводили дополнительные условия
Next i
cn.Close
Application. StatusBar = «Готово»
End Sub
StatusBar = «Готово»
End Sub
— закрываем макрос.
В дополнение хочу отметить, что данный макрос позволяет обращаться как к БД на MS SQL так и к БД Oracle, разница будет только в параметрах подключения и собственно в синтаксисе SQL запроса.
В приведенном примере для авторизации при подключении к БД используется доменная аутентификация.
А как быть если для аутентификации необходимо ввести логин и пароль? Ничего невозможного нет. Изменим часть макроса, которая отвечает за подключение к БД следующим образом:
sql = «Provider= SQLOLEDB. 1;Password=********;User ID=********;Data Source= Storoge.company.ru\ Storoge;APP=SFM»
1;Password=********;User ID=********;Data Source= Storoge.company.ru\ Storoge;APP=SFM»
Но в этом случае при использовании макроса возникает риск компрометации Ваших учетных данных. Поэтому лучше программно удалять учетные данные после выполнения макроса. Разместим поля для ввода пароля и логина на листе и изменим макрос следующим образом:
sql = «Provider= SQLOLEDB.1;Password=» & Sheets(«Лист аутентификации»).TextBox1.Value & «;UserЛист аутентификации «).TextBox2.Value & «;Data Source= Storoge.company.ru\ Storoge;APP=SFM»
Место для расположения текстовых полей не принципиально, можно расположить их на листе с таблицей в первых строках, но мне удобней размещать поля на отдельном листе. Чтобы введенные учетные данные не сохранялись вместе с результатом выполнения макроса в конце исполняемого кода дописываем:
Sheets(«Выгрузка»). TextBox1.Value = «« Sheets(»Выгрузка«).TextBox2.Value = »»
TextBox1.Value = «« Sheets(»Выгрузка«).TextBox2.Value = »»
То есть просто присваиваем текстовым полям пустые значения, таким образом после выполнения макроса поля для ввода пароля и логина окажутся пустыми.
Вот такое вполне жизнеспособное решение, позволяющее сократить трудозатраты при получении и обработке данных, я использую. Надеюсь мой опыт применения SQL запросов в Excel будет полезен и вам в решении текущих задач.
Поиск медленных запросов в SQL Server
Сегодня мы более подробно познакомимся с инструментами, которые позволят вам найти проблемы в запросах, и как искать сами проблемные запросы.
Давайте начнем с первого, как искать запросы. Для этого у меня есть следующий запрос:
declare @dayportion float;
declare @substringlength int;
set @dayportion=-1.0;
set @substringlength=200;
SELECT TOP 15
sum(total_logical_reads) 'Total Logical Reads',
sum(total_logical_writes) 'Total Logical Writes',
sum(total_worker_time) 'Total CPU',
sum(execution_count) 'Count',
sum(total_logical_reads) * 100 / (select sum(total_logical_reads) from sys.dm_exec_query_stats where last_execution_time > dateadd(day, @dayportion, getdate())) 'Pct of Reads',
sum(total_logical_writes) * 100 / (select sum(total_logical_writes) from sys.dm_exec_query_stats where last_execution_time > dateadd(day, @dayportion, getdate())) 'Pct of Writes',
sum(total_worker_time) * 100 / (select sum(total_worker_time) from sys.dm_exec_query_stats where last_execution_time > dateadd(day, @dayportion, getdate())) 'Pct of CPU',
sum(total_logical_reads) / sum(execution_count) 'Avg Reads',
sum(total_logical_writes) / sum(execution_count) 'Avg Writes',
sum(total_worker_time) / sum(execution_count) 'Avg CPU',
statement_text
FROM (
select
total_logical_reads,
total_logical_writes,
total_worker_time,
execution_count,
substring(SUBSTRING(st. text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1), 0, @substringlength) as statement_text
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
WHERE last_execution_time > dateadd(day, @dayportion, getdate())
) x
group by statement_text
ORDER BY 'Pct of CPU' DESC
text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1), 0, @substringlength) as statement_text
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
WHERE last_execution_time > dateadd(day, @dayportion, getdate())
) x
group by statement_text
ORDER BY 'Pct of CPU' DESC
 text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1), 0, @substringlength) as statement_text
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
WHERE last_execution_time > dateadd(day, @dayportion, getdate())
) x
group by statement_text
ORDER BY 'Pct of CPU' DESC
text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1), 0, @substringlength) as statement_text
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
WHERE last_execution_time > dateadd(day, @dayportion, getdate())
) x
group by statement_text
ORDER BY 'Pct of CPU' DESC
Этот запрос мне дали коллега в Клике, когда я только начинал там работать. Впоследствии я его немного доработал и улучшил и теперь делюсь с вами. Дело в том, что на рабочих серверах нельзя устанавливать какие-то утилиты или инструменты, которые бы позволили смотреть визуально подобные вещи, и в те времена не так много доступного было.
У SQL Server Management Studio есть встроенная возможность, но очень это визуальное окно, которое подтормаживает. В те моменты, когда база данных тормозит под нагрузкой у меня не удавалось открыть это окно, а выполнить подобный запрос очень легко.
В те моменты, когда база данных тормозит под нагрузкой у меня не удавалось открыть это окно, а выполнить подобный запрос очень легко.
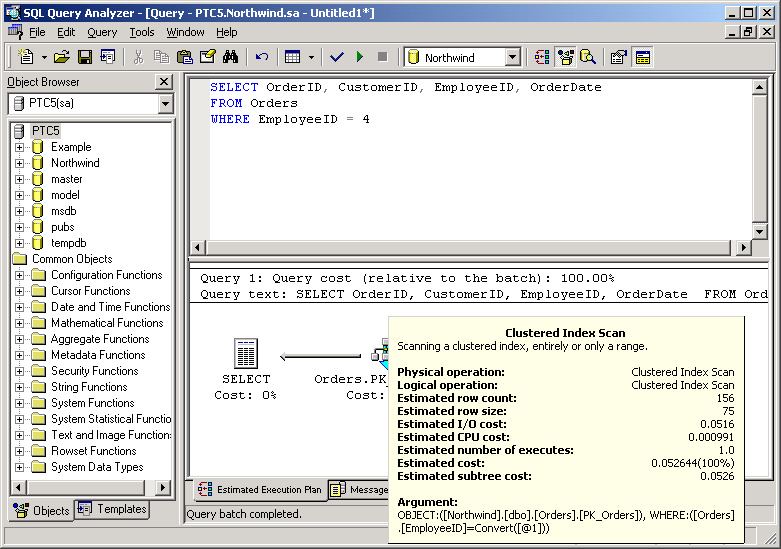
В самом начале есть параметр dayportion – это количество дней, за которые мы хотим получить информацию. Я обычно смотрю за последний день, поэтому параметр равен -1.
Результат отсортирован по колонке Pct of CPU. Это отношение затрат на выполнение запроса к количеству выполнений. Чем медленнее запросы и чаще выполняются, тем выше они будут в результате.
Если сейчас я выполню этот запрос, то в нем ничего не будет, поэтому делаем небольшую паузу и выполню несколько запросов.
Я погонял несколько запросов и у меня получилась вот такая картина:
Самый ужасный запрос – это выборка абсолютно всех людей из таблицы Member. Ну это логично и тут единственный способ оптимизировать – стараться не выполнять такие запросы. Если посмотреть на колонку Count, то видно, что запрос выполнялся только однажды. Это нормально и можно проигнорировать.
У меня был случай, когда этот запрос вернул запрос select без каких-либо фильтров и он выполнялся много раз. В логике программы был баг и в определенный момент запрос мог выполняться без фильтров и это был баг как по логике, так и проблема для сервера.
Второй запрос выполнялся уже два раза:
select * from Member where FacebookProfileID = 7000011
Большое количество чтений, такое же как и у выборке всех данных указывает на то, что индекса нет. Это просто тест, но если в реале такой запрос вылетит вверх, значит он выполняется слишком часто и является явным кандидатом на индексирование.
В общем, вот такой простой запрос я выполнял в течении двух дней после запуска чего-то серьезного и хотя бы раз в месяц (старался каждую неделю по средам) и следил за тем, чтобы среди самых проблемных запросов не появлялось ничего нового. Если что-то появлялось, создавался бак для того, чтобы произвести расследование – что произошло, почему и нужно ли оптимизировать.
А теперь я покажу, как то же самое увидеть визуально, с помощью красивых возможностей SQL Server Management Studio. В Object Explorer кликаем правой кнопкой по самому верхнему элементу дерева (там вы должны видеть имя базы данных) и в контекстном меню выбираем Activity Monitor:
Внизу окна должны есть несколько закладок и наиболее интересными являются – Active Expensive Queries и Recent Expensive Queries:
Теперь по оптимизации и как получить информацию, которая позволит понять, что не так с запросом, и как сделать так, чтобы он выполнялся быстрее.
Я несколько раз уже показывал, как пользоваться статистикой времени и io:
set statistics time on set statistics io on
Первая команда позволяет включить более точное отображение времени выполнения запроса, а вторая позволяет увидеть статистику io, которая является одним из основных способов увидеть проблемы выполнения запросов. Если вы видите большое количество логических чтений – возможно нужно создать индекс. Если вы видите большое количество сканирований, это уже более серьезный указатель на то, что индекс необходим.
Если вы видите большое количество сканирований, это уже более серьезный указатель на то, что индекс необходим.
Но эти две команды не единственные помощники во время поиска проблемных проблем в запросах.
Я уже показывал, как посмотреть предполагаемый и реальные планы выполнения с помощью SQL Server Management Studio, но то же самое можно увидеть и специальными командами в виде результата запроса.
set showplan_text on
Теперь попробуем выполнить простой запрос типа:
select * from Member where MemberID = 7000001
Вместо реального результата мы должны увидеть план выполнения в виде текста, как показано на следующем рисунке:
Отключаем эту функцию, прежде чем перейти к следующей:
set showplan_text off
А следующей опцией будет showplan_all:
set showplan_all on
Теперь в результате мы увидим не просто план выполнения в виде текста, но и подробные вещи, такие как физическая операция, логическая операция, сколько ожидается обработать строк и сколько использовать CPU.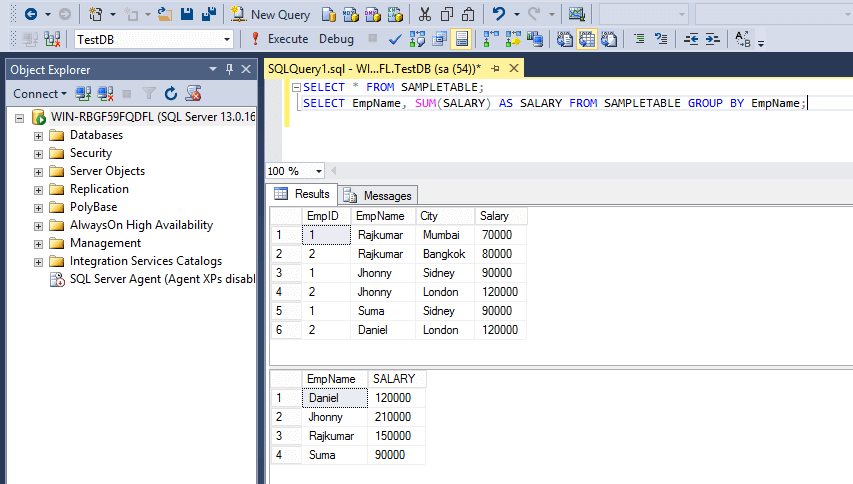 Это все то, что мы видели визуально в плане выполнения раньше, но в этот раз мы это видим в виде результата запроса, колонок и строк. Для очень больших запросов это может быть даже нагляднее, чем визуальная диаграмма.
Это все то, что мы видели визуально в плане выполнения раньше, но в этот раз мы это видим в виде результата запроса, колонок и строк. Для очень больших запросов это может быть даже нагляднее, чем визуальная диаграмма.
Отключаем отображение полной информации о плане:
set showplan_all off
Следующая версия того, что мы уже видели – это showplan_xml:
set showplan_xml on
Эта опция позволяет включить отображение плана выполнения в виде XML. Читать его не так уж и легко, даже если отформатировать с помощью специальных средств:
А вот если кликнуть на плане, то он откроется в виде визуального представления. SQL Server Management Studio умеет рендерить подобные планы в визуальное представление, которое мы видели раньше. Так что XML будет удобен в тех случаях, когда его нужно отправить кому-то на анализ.
Чтобы проще было сохранять XML кликните на него, чтобы открыть визуальное представление. Теперь здесь кликаем правой кнопкой и появляется опция – Save Execution Plan As. ..
..
Теперь мы можем познакомиться с реальным планов выполнения. До сих пор это была информация о предполагаемом плане выполнения. Я показывал вам, что SQL Server Management Studio позволяет визуально посмотреть предполагаемый и реальный план. То же самое и в виде кода.
Итак, реальный план включаем командой:
set statistics profile on
Теперь если выполнить запрос, то мы увидим в панели результата не только реальную найденную строку, но и план выполнения:
То есть перед нами реальный план выполнения, что реально использовалось при выполнении запроса, сколько раз происходили обращения к таблицам и так далее.
Прежде чем переходить к следующей команде, не забываем выключить текущую:
set statistics profile off
А следующая команда – это отображение реального плана выполнения в XML формате:
set statistics xml on
В результате мы увидим не только результирующую строку, но XML, в котором будет реальный план.
Итак, в этой статье мы познакомились с тем, как найти какие запросы работают медленно и получить информацию о том, как эти медленные запросы выполняются. Видео версия этого урока, в которой есть еще чуть больше информации.
Поделитесь с друзьями
Внимание!!! Если ты копируешь эту статью себе на сайт, то оставляй ссылку непосредственно на эту страницу. Спасибо за понимание
SQL запрос where() дата год $year
Я храню даты в своей базе данных в столбце типа данных date .
Допустим, у меня есть столбец date , где я храню такие данные «2011-01-01», «2012-01-01», «2012-02-02» и т. д.
Теперь мне нужно сделать SQL, который выбирает только строки, где date равно 2012
SELECT * FROM table WHERE date=hasSomehowYearEqualTo=2012
Каков будет запрос?
php sqlПоделиться Источник simPod 08 февраля 2012 в 01:43
3 ответа
- Как получить год в формате YY в SQL Server
select Year(Creation_Date) from Asset_Creation where Creation_Date = @Creation_Date Я выполняю этот запрос, где я получаю год как 2013 , когда указана сегодняшняя дата. Я хочу, чтобы запрос вернул только 13 из 2013 года. Как я могу этого достичь?
- Только дата обновления MS SQL
Все, Есть ли способ в SQL обновить поле datetime и изменить только дату? У меня есть данные за год в формате datetime (YYYY-MM-DD XX:XX:XX.XXX), и я хотел бы, чтобы установленная дата для каждого значения была 12/30.. Я попробовал следующее, но безуспешно: UPDATE table SET DATEPART(MONTH,[date]) =…
19
не используйте YEAR(date) — это вычислит YEAR(date) для всех дат, даже для тех, которые вы никогда не используете. Это также сделает использование индекса невозможным-наихудший случай на слое DB.
Воспользуйся
$sql="SELECT * FROM table WHERE `date` BETWEEN '$year-01-01' AND '$year-12-31'"
Как правило: если у вас есть выбор между вычислением по константе и вычислением по полю, используйте первое.
Поделиться Eugen Rieck 08 февраля 2012 в 01:55
11
Проверьте функцию YEAR() docs для MySQL
SELECT * FROM table WHERE YEAR(date)=2012
Поделиться Gabriele Petrioli 08 февраля 2012 в 01:47
-3
выберите * из таблицы, где DATEPART(YEAR, [DATE])=2012
Поделиться user868322 08 февраля 2012 в 03:56
- SQL запрос : найти за каждый год проданных копий > 10000
Я немного практиковался с SQL и наткнулся на это упражнение: Рассмотрим следующую базу данных, касающуюся альбомов, певцов и продаж: Альбом ( Код , Исполнитель, Название) Продажи ( Альбом , Год , CopiesSold) с ограничением ссылочной целостности между атрибутом альбома продаж и ключом отчета…
- Year/Month/Week на сегодняшний день SQL запрос
В настоящее время я разрабатываю платформу, где мне нужно 3 SQL запроса, чтобы вернуть все записи между Year/Month/Week на сегодняшний день. Запросы должны работать динамически без жестко закодированных дат, пожалуйста, потерпите меня, если я разделю их на 3 вопроса, я думаю, что они очень…
Похожие вопросы:
Финансовый год на сегодняшний день в пункте Where (T-SQL)
Финансовый год компании: 1 июля-30 июня У меня есть запрос, в котором я пытаюсь захватить совокупное количество единиц и $ выручку по продукту и центру затрат для финансового year-to-date. Он будет…
Sql запрос за определенный год и данные за предыдущий год
Интересно, как я могу получить данные за любой год и его предыдущий год, когда год указан в пункте where. Пример: если я дам 2012 год как год в предложении where, я должен получить данные как за…
добавьте один год к году в предложении where
У меня есть эта таблица под названием event и столбец year: year ———— 2013.01.01 2014.03.01 2015.02.03 Как я могу запросить что-то подобное в предложении where: SELECT * FROM event WHERE…
Как получить год в формате YY в SQL Server
select Year(Creation_Date) from Asset_Creation where Creation_Date = @Creation_Date Я выполняю этот запрос, где я получаю год как 2013 , когда указана сегодняшняя дата. Я хочу, чтобы запрос вернул…
Только дата обновления MS SQL
Все, Есть ли способ в SQL обновить поле datetime и изменить только дату? У меня есть данные за год в формате datetime (YYYY-MM-DD XX:XX:XX.XXX), и я хотел бы, чтобы установленная дата для каждого…
SQL запрос : найти за каждый год проданных копий > 10000
Я немного практиковался с SQL и наткнулся на это упражнение: Рассмотрим следующую базу данных, касающуюся альбомов, певцов и продаж: Альбом ( Код , Исполнитель, Название) Продажи ( Альбом , Год ,…
Year/Month/Week на сегодняшний день SQL запрос
В настоящее время я разрабатываю платформу, где мне нужно 3 SQL запроса, чтобы вернуть все записи между Year/Month/Week на сегодняшний день. Запросы должны работать динамически без жестко…
Sql YEAR(),MONTH() в Linq
Я искал несколько дней, чтобы решить запрос sql на linq. Это мой запрос sql ([дата] имеет формат datatime2): SELECT [Date], TestingValues FROM [SalesValue].[dbo].[TestTable] WHERE…
SQL Server: выберите * из таблицы, где дата минус один год
Как выбрать год-1? Это мой код: select a.* from (select met_men, kli_kod, pre_kod, galutinis, savik_group, marza, KLR_KOD, KLI_POZ1, KLI_POZ2, KLI_POZ3, KLG_KOD, PRE_RUS, PRE_POZ1, PRE_POZ2,…
Столкновение типов операндов: дата несовместима с ошибкой smallint в sql server
я написал запрос sql, чтобы получить количество нанятых сотрудников в период с 2006 по 2008 год . вот мой код из таблицы adventurework2014.dimemployee SELECT YEAR(cast(‘HireDate’ as int)),…
SQL запрос | Community Creatio
Есть потребность выводить в реестр Контрагентов юридическое наименование и ИНН. Я в запросе для контрагента делаю следующее:
SELECT
[tbl_Account].[ID] AS [ID],
[tbl_Account].[Name] AS [Name],
[tbl_Account].[OfficialAccountName] AS [OfficialAccountName],
[tbl_Account].[AnnualRevenue] AS [AnnualRevenue],
[tbl_Account].[EmployeesNumber] AS [EmployeesNumber],
[tbl_Account].[Address] AS [Address],
[tbl_Account].[AddressTypeID] AS [AddressTypeID],
[tbl_Account].[Communication1] AS [Communication1],
[tbl_Account].[Communication1TypeID] AS [Communication1TypeID],
[tbl_Account].[Communication2] AS [Communication2],
[tbl_Account].[Communication2TypeID] AS [Communication2TypeID],
[tbl_Account].[Communication3] AS [Communication3],
[tbl_Account].[Communication3TypeID] AS [Communication3TypeID],
[tbl_Account].[Communication4] AS [Communication4],
[tbl_Account].[Communication4TypeID] AS [Communication4TypeID],
[tbl_Account].[Communication5] AS [Communication5],
[tbl_Account].[Communication5TypeID] AS [Communication5TypeID],
[tbl_City].[Name] AS [CityName],
[tbl_Account].[CityID] AS [CityID],
[tbl_Account].[ZIP] AS [ZIP],
[tbl_Campaign].[Name] AS [CampaignName],
[tbl_Account].[CampaignID] AS [CampaignID],
[tbl_Contact].[Name] AS [PrimaryContactName],
[tbl_Account].[PrimaryContactID] AS [PrimaryContactID],
[tbl_Country].[Name] AS [CountryName],
[tbl_Account].[CountryID] AS [CountryID],
[tbl_State].[Name] AS [StateName],
[tbl_Account].[StateID] AS [StateID],
[tbl_Territory].[Name] AS [TerritoryName],
[tbl_Account].[TerritoryID] AS [TerritoryID],
[Owner].[Name] AS [OwnerName],
[tbl_Account].[OwnerID] AS [OwnerID],
[tbl_Account].[ActivityID] AS [ActivityID],
[tbl_Activity].[Name] AS [ActivityName],
[tbl_Account].[FieldID] AS [FieldID],
[tbl_Field].[Name] AS [FieldName],
[tbl_Account].[AccountTypeID] AS [AccountTypeID],
[tbl_AccountType].[Name] AS [AccountTypeName],
[tbl_AddressType].[Name] AS [AddressTypeName],
[CommunicationType1].[Name] AS [Communication1TypeName],
[CommunicationType2].[Name] AS [Communication2TypeName],
[CommunicationType3].[Name] AS [Communication3TypeName],
[CommunicationType4].[Name] AS [Communication4TypeName],
[CommunicationType5].[Name] AS [Communication5TypeName],
[tbl_Account].[Code] AS [Code],
[tbl_Account].[TaxRegistrationCode] AS [TaxRegistrationCode],
[tbl_Account].[CreatedOn] AS [CreatedOn],
[tbl_Account].[CreatedByID] AS [CreatedByID],
[CreatedBy].[Name] AS [CreatedByName],
[tbl_Account].[ModifiedOn] AS [ModifiedOn],
[tbl_Account].[ModifiedByID] AS [ModifiedByID],
[ModifiedBy].[Name] AS [ModifiedByName],
[tbl_Job].[NameOf] AS [JobNameOf],
[tbl_Account].[SettledCredit] AS [SettledCredit],
[tbl_Account].[PostponementPayment] AS [PostponementPayment],
NULL AS [UID1C],
NULL AS [Object1C],
[tbl_Account].[SiteID] AS [SiteID],
[tbl_Account].[IsActive] AS [IsActive],
[tbl_Account].[DoNotCall] AS [DoNotCall],
[vw_AppealInfo].[AppealDate] AS [AppealDate],
[vw_AppealInfo].[AppealStatusID] AS [AppealStatusID],
[AITaskStatus].[Status] AS [AppealStatus],
[vw_AppealInfo].[AppealTypeID] AS [AppealTypeID],
[AITaskType].[Name] AS [AppealTypeName],
[vw_LoyaltyInfo].[LoyContDate] AS [LoyContDate],
[vw_LoyaltyInfo].[LoyContTypeID] AS [LoyContTypeID],
[LITaskType].[Name] AS [LoyContTypeName],
[vw_LoyaltyInfo].[LoyOrderNum] AS [LoyOrderNum],
[vw_LoyaltyInfo].[LoyResultID] AS [LoyResultID],
[LITaskResult].[Result] AS [LoyResultName],
[vw_LoyaltyInfo].[LoyComment] AS [LoyComment],
[vw_LoyaltyRepInfo].[LoyRepCallDate] AS [LoyRepCallDate],
[vw_ReminderInfo].[RemContDate] AS [RemContDate],
[vw_ReminderInfo].[RemContTypeID] AS [RemContTypeID],
[RITaskType].[Name] AS [RemContTypeName],
[vw_ReminderInfo].[RemOrderNum] AS [RemOrderNum],
[vw_ReminderInfo].[RemResultID] AS [RemResultID],
[RITaskResult].[Result] AS [RemResultName],
[vw_ReminderInfo].[RemComment] AS [RemComment],
[vw_ReminderRepInfo].[RemRepCallDate] AS [RemRepCallDate],
[tbl_Account].[SitePaymentRecID] AS [SitePaymentRecID],
[tbl_AccountBillingInfo].[INN] AS [INN],
[tbl_AccountBillingInfo].[Name] AS [NameUr]
FROM
[dbo].[tbl_Account] AS [tbl_Account]
LEFT OUTER JOIN
[dbo].[tbl_Contact] AS [tbl_Contact] ON [tbl_Contact].[ID] = [tbl_Account].[PrimaryContactID]
LEFT OUTER JOIN
[dbo].[tbl_Territory] AS [tbl_Territory] ON [tbl_Territory].[ID] = [tbl_Account].[TerritoryID]
LEFT OUTER JOIN
[dbo].[tbl_Contact] AS [Owner] ON [Owner].[ID] = [tbl_Account].[OwnerID]
LEFT OUTER JOIN
[dbo].[tbl_Campaign] AS [tbl_Campaign] ON [tbl_Campaign].[ID] = [tbl_Account].[CampaignID]
LEFT OUTER JOIN
[dbo].[tbl_City] AS [tbl_City] ON [tbl_City].[ID] = [tbl_Account].[CityID]
LEFT OUTER JOIN
[dbo].[tbl_State] AS [tbl_State] ON [tbl_State].[ID] = [tbl_Account].[StateID]
LEFT OUTER JOIN
[dbo].[tbl_Country] AS [tbl_Country] ON [tbl_Country].[ID] = [tbl_Account].[CountryID]
LEFT OUTER JOIN
[dbo].[tbl_Activity] AS [tbl_Activity] ON [tbl_Activity].[ID] = [tbl_Account].[ActivityID]
LEFT OUTER JOIN
[dbo].[tbl_Field] AS [tbl_Field] ON [tbl_Field].[ID] = [tbl_Account].[FieldID]
LEFT OUTER JOIN
[dbo].[tbl_AccountType] AS [tbl_AccountType] ON [tbl_AccountType].[ID] = [tbl_Account].[AccountTypeID]
LEFT OUTER JOIN
[dbo].[tbl_Contact] AS [CreatedBy] ON [CreatedBy].[ID] = [tbl_Account].[CreatedByID]
LEFT OUTER JOIN
[dbo].[tbl_Contact] AS [ModifiedBy] ON [ModifiedBy].[ID] = [tbl_Account].[ModifiedByID]
LEFT OUTER JOIN
[dbo].[tbl_AddressType] AS [tbl_AddressType] ON [tbl_AddressType].[ID] = [tbl_Account].[AddressTypeID]
LEFT OUTER JOIN
[dbo].[tbl_CommunicationType] AS [CommunicationType1] ON [CommunicationType1].[ID] = [tbl_Account].[Communication1TypeID]
LEFT OUTER JOIN
[dbo].[tbl_CommunicationType] AS [CommunicationType2] ON [CommunicationType2].[ID] = [tbl_Account].[Communication2TypeID]
LEFT OUTER JOIN
[dbo].[tbl_CommunicationType] AS [CommunicationType3] ON [CommunicationType3].[ID] = [tbl_Account].[Communication3TypeID]
LEFT OUTER JOIN
[dbo].[tbl_CommunicationType] AS [CommunicationType4] ON [CommunicationType4].[ID] = [tbl_Account].[Communication4TypeID]
LEFT OUTER JOIN
[dbo].[tbl_CommunicationType] AS [CommunicationType5] ON [CommunicationType5].[ID] = [tbl_Account].[Communication5TypeID]
LEFT OUTER JOIN
[dbo].[tbl_Job] AS [tbl_Job] ON [tbl_Job].[ID] = [tbl_Contact].[JobID]
LEFT OUTER JOIN
[dbo].[vw_AppealInfo] AS [vw_AppealInfo] ON [vw_AppealInfo].[AccountID] = [tbl_Account].[ID]
LEFT OUTER JOIN
[dbo].[vw_LoyaltyInfo] AS [vw_LoyaltyInfo] ON [vw_LoyaltyInfo].[AccountID] = [tbl_Account].[ID]
LEFT OUTER JOIN
[dbo].[vw_LoyaltyRepInfo] AS [vw_LoyaltyRepInfo] ON [vw_LoyaltyRepInfo].[AccountID] = [tbl_Account].[ID]
LEFT OUTER JOIN
[dbo].[vw_ReminderInfo] AS [vw_ReminderInfo] ON [vw_ReminderInfo].[AccountID] = [tbl_Account].[ID]
LEFT OUTER JOIN
[dbo].[vw_ReminderRepInfo] AS [vw_ReminderRepInfo] ON [vw_ReminderRepInfo].[AccountID] = [tbl_Account].[ID]
LEFT OUTER JOIN
[dbo].[tbl_TaskStatus] AS [AITaskStatus] ON [AITaskStatus].[ID] = [vw_AppealInfo].[AppealStatusID]
LEFT OUTER JOIN
[dbo].[tbl_TaskType] AS [AITaskType] ON [AITaskType].[ID] = [vw_AppealInfo].[AppealTypeID]
LEFT OUTER JOIN
[dbo].[tbl_TaskType] AS [LITaskType] ON [LITaskType].[ID] = [vw_LoyaltyInfo].[LoyContTypeID]
LEFT OUTER JOIN
[dbo].[tbl_TaskResult] AS [LITaskResult] ON [LITaskResult].[ID] = [vw_LoyaltyInfo].[LoyResultID]
LEFT OUTER JOIN
[dbo].[tbl_TaskType] AS [RITaskType] ON [RITaskType].[ID] = [vw_ReminderInfo].[RemContTypeID]
LEFT OUTER JOIN
[dbo].[tbl_TaskResult] AS [RITaskResult] ON [RITaskResult].[ID] = [vw_ReminderInfo].[RemResultID]
LEFT OUTER JOIN
[dbo].[tbl_AccountBillingInfo] AS [tbl_AccountBillingInfo] ON [tbl_AccountBillingInfo].[AccountID] = [tbl_Account].[ID]
Использую левое соедиение с таблицей tbl_AccountBillingInfo.
Когда я вывожу колонки NameUr,INN в реестр контрагентов строка контрагентов начинает повторяться столько раз сколько у контрагента в детали строк, это логично, но мне нужно что бы в реестре строка контрагента выводилась только один раз без дублирований, помогите пожалуйста как это сделать.
Упрощаем вложенные SQL-запросы с помощью представлений
Заметка для читателей онлайн-курса по аналитике, которые прошли хотя бы 5 уроков, уже знают, что такое SQL и умеют писать запросы к базе. Если SQL для вас в новинку, почитайте вводный урок про базы данных.
Результат любого SQL-запроса — это таблица. Значит, к ней можно направлять новые запросы, её можно джоинить с другими таблицами и использовать в фильтрах. Это позволяет реализовывать сложную логику.
Например, в седьмом уроке я рассказываю, как с помощью SQL достать данные для когортного анализа.
Начинаем с безобидного «давайте подсчитаем, сколько людей в каждой когорте»:
SELECT
reg_month AS cohort_id,
count(*) AS cohort_size
FROM
users
GROUP BY 1Потом считаем, сколько денег принесла каждая когорта:
SELECT
users.reg_month AS cohort_id,
orders.month AS month,
sum(orders.sum) AS cohort_revenue
FROM
users INNER JOIN orders
ON users.uid = orders.uid
GROUP BY 1, 2Потом объединяем эти запросы, группируем и получаем вот такого монстра:
SELECT
rev.cohort_id AS cohort_id,
rev.month AS month,
rev.month - rev.cohort_id AS cohort_age,
rev.cohort_revenue / size.cohort_size AS LTV,
rev.cohort_revenue / size.costs * 100 AS ROI
FROM
(
SELECT
reg_month AS cohort_id,
count(*) AS cohort_size
FROM
users
GROUP BY 1
) AS size
INNER JOIN
(
SELECT
users.reg_month AS cohort_id,
orders.month AS month,
sum(orders.sum) AS cohort_revenue
FROM
users INNER JOIN orders
ON users.uid = orders.uid
GROUP BY 1, 2
) AS rev
ON size.cohort_id = rev.cohort_idЗапрос правильный, но слишком громоздкий. Исправлять ошибки и вносить в него изменения — особый тип пытки.
Код можно упростить, если сохранить промежуточные результаты в виде представлений.
Что такое представления и как они работают
Представления (ещё их называют «вью» от английского view) — это сохранённые запросы.
Внешне представление выглядит как ещё одна таблица. Если его использовать в запросе, база найдёт и подставит сохранённый код.
Например, мы сохранили запрос SELECT * FROM some_table в представление my_view. Теперь my_view можно использовать в запросах:
SELECT …
FROM my_view
WHERE …Отправляем запрос — база находит и подставляет сохранённый код:
SELECT …
FROM (SELECT * FROM some_table)
WHERE …Получаем результат, как при использовании вложенного селекта, но но более аккуратным кодом.
Как создать представления
В Бигквери нужно сначала выполнить запрос, затем нажать на кнопку Save View и выбрать название.
В других системах кнопки нет, но зато есть специальный запрос CREATE VIEW.
CREATE VIEW my_view AS
SELECT * FROM some_tableПокажу подробней, как это работает в Бигквери, упрощу огромный запрос из начала статьи.
Сохраню первый запрос в представлении cohort_sizes:
Теперь могу просто запрашивать SELECT * FROM cohort_size, добавлять фильтры, группировки и сортировки.
Повторю процесс для второго запроса: отправлю, получу результат, сохраню представление cohorts.
Теперь заменю вложенные селекты в большом запросе на созданные представления. Смотрите, насколько аккуратней стал запрос:
Было:
SELECT
rev.cohort_id AS cohort_id,
rev.month AS month,
rev.month - rev.cohort_id AS cohort_age,
rev.cohort_revenue / size.cohort_size AS LTV,
rev.cohort_revenue / size.costs * 100 AS ROI
FROM
(
SELECT
reg_month AS cohort_id,
count(*) AS cohort_size
FROM
users
GROUP BY 1
) AS size
INNER JOIN
(
SELECT
users.reg_month AS cohort_id,
orders.month AS month,
sum(orders.sum) AS cohort_revenue
FROM
users INNER JOIN orders
ON users.uid = orders.uid
GROUP BY 1, 2
) AS rev
ON size.cohort_id = rev.cohort_idСтало:
SELECT
rev.cohort_id AS cohort_id,
rev.month AS month,
rev.month - rev.cohort_id AS cohort_age,
rev.cohort_revenue / size.cohort_size AS LTV,
rev.cohort_revenue / size.costs * 100 AS ROI
FROM
cohort_sizes AS size
INNER JOIN
cohorts AS rev
ON size.cohort_id = rev.cohort_idНа этом всё. Успехов.
Новые возможности SQL в MapInfo Pro v2019
Окно SQL запросов существует еще с MapInfo 8, и за последние 10 лет вносились только небольшие улучшения, например, опции ”добавить данные в окно карты“ или ”найти данные в текущем окне» при выполнении запроса. Функциональность окна SQL является важной для всех пользователей, поэтому в новой версии программы она была сильно расширена, а интерфейс был переработан.
Вот некоторые основные изменения новой версии:
Новое, полностью переработанное окно SQL
Новый инструмент запроса «Выбор по расположению»
Новые списки «Избранных» и «Последних» запросов для быстрого доступа
Возможность «Закрыть все открытые запросы»
Новое окно SQL запроса
Новое окно SQL теперь является полным и традиционным инструментом для написания SQL скриптов, предлагающим гораздо больше гибкости и креативности для ваших запросов.
Закрепляемое окно позволяет пользователям выполнять запросы без закрытия окна каждый раз
Цветовое кодирование столбцов, таблиц и выносок значений облегчает визуализацию
Добавлены новые функциональные возможности SQL, такие как «Обновить» и «Удалить», а не только «Выбрать»
«Ограничение» крупномасштабных запросов всего несколькими строками данных
Не беспокойтесь — для всех консервативных пользователей или тех, кому не нужно реализовывать какие-либо новые функции запросов, также осталось и старое окно SQL запроса.
«Выбор по расположению»
Окно «Выбора по расположению» представляет собой простой пользовательский интерфейс для частых выборок на основе местоположения, которые постоянно выполняют пользователи MapInfo. Данный инструмент позволяет вычислять уравнения пространственных отношений на лету, а не писать полный SQL-запрос. После выполнения запроса «Выбор по расположению» его можно изменить в новом окне скрипта SQL, а не создавать его заново с нуля.
Панель быстрого доступа «Избранное» и «Последнее»
При раскрытии меню SQL пользователи теперь смогут увидеть множество последних выполненных несохраненных запросов. Данный функционал экономит много времени и повышает эффективность при тестировании и выполнении разных запросов в одном сеансе. Теперь не нужно сохранять каждый отдельный запрос, но при этом можно все равно иметь быстрый доступ для повторного запуска скрипта в будущем.
Пользователи также могут добавить в избранное часто используемый запрос и быстро получить к нему доступ из раскрывающегося списка SQL — еще одна экономия времени.
Другие улучшения
Новая возможность «Закрыть все открытые запросы» удобна, когда все неназванные и неиспользуемые таблицы запросов начинают накапливаться. Одним щелчком мыши пользователи могут закрыть все из них, чтобы очистить рабочее пространство и предотвратить проблему беспорядка запросов, с которой мы все сталкиваемся.
Кроме того, продолжая создавать запросы, иногда бывает сложно найти тот запрос, который вы ищете. Это особенно актуально, если вы не именовали свои таблицы запросов. В этом случае вы получите множество таблиц запросов с именами Query1, Query2, Query3 и так далее.
Теперь, когда вы наведете указатель мыши на один из этих запросов в Проводнике, вы увидите оператор SQL, с помощью которого была сгенерирована таблица. А если навести указатель мыши на таблицу, то всплывающая подсказка сообщит вам, из какой базовой таблицы были выбраны записи.
Одним из других нововведений является возможностей Копировать SQL. Теперь вы можете щелкнуть правой кнопкой мыши по запросу в Проводнике и скопировать оператор SQL, стоящий за этим запросом.
После того, как вы скопировали текст запроса SQL, вы можете вставить его в любое место, например в новое окно SQL.
Мы надеемся, что вам понравятся новые возможности SQL, а также многие другие улучшения новой MapInfo Pro v2019.
Оставайтесь с нами для получения дополнительной информации!
Предложение
SQL WHERE, SQL SELECT WHERE — с примерами
Как использовать предложение SQL WHERE?
Предложение SQL WHERE фильтрует строки, соответствующие определенным критериям.
Это способ ограничить строки теми, которые вам интересны.
За WHERE следует условие, которое возвращает либо истину, либо ложь.
Предложение WHERE используется с SELECT, UPDATE и DELETE.
Синтаксис SQL WHERE
Вот инструкция SELECT с предложением WHERE:
ВЫБЕРИТЕ имена столбцов ОТ имя-таблицы ГДЕ условие
И вот ОБНОВЛЕНИЕ с предложением WHERE:
ОБНОВИТЬ имя-таблицы УСТАНОВИТЬ имя-столбца = значение ГДЕ условие
Наконец, оператор DELETE с предложением WHERE:
УДАЛИТЬ имя-таблицы ГДЕ условие
| КЛИЕНТ |
|---|
| Идентификатор |
| Имя |
| Фамилия |
| Город |
| Страна |
| Телефон |
Примеры предложения SQL WHERE
Задача: Список всех клиентов в Швеции
ВЫБЕРИТЕ Id, FirstName, LastName, City, Country, Phone ОТ Заказчика ГДЕ Страна = 'Швеция'
Результат: 2 записи
| Id | Имя | Фамилия | Город | Страна | Телефон |
|---|---|---|---|---|---|
| 5 | Кристина | Berglund | Лулео | Швеция | 0921-12 34 65 |
| 24 | Мария | Ларссон | Bräcke | Швеция | 0695-34 67 21 |
| ПОСТАВЩИК |
|---|
| Идентификатор |
| Название компании |
| Контактное имя |
| Город |
| Страна |
| Телефон |
| Факс |
Задача: Обновить город Сидней для поставщика Pavlova, Ltd.
ОБНОВЛЕНИЕ Поставщик SET City = "Сидней" ГДЕ Name = 'Павлова, ООО'
Результат: Обновлена 1 запись.
| ПРОДУКТ |
|---|
| Идентификатор |
| Название продукта |
| Идентификатор поставщика |
| Цена за единицу |
| Упаковка |
| Снято с производства |
Проблема: Удалить все товары с ценой выше 50 долларов.
УДАЛИТЬ ИЗ ПРОДУКТА ГДЕ UnitPrice> 50
Результат: 7 записей удалены.
Примечание. Ссылочная целостность может предотвратить это удаление.
Лучшим подходом может быть прекращение выпуска продукта, то есть установка для столбца IsDiscontinued значения true.
SQL Server WHERE
Резюме : в этом руководстве вы узнаете, как использовать предложение SQL Server WHERE для фильтрации строк, возвращаемых запросом.
Введение в SQL Server
WHERE clause Когда вы используете оператор SELECT для запроса данных по таблице, вы получаете все строки этой таблицы, что не является необходимым, поскольку приложение может обрабатывать только набор строк в время.
Чтобы получить строки из таблицы, которые удовлетворяют одному или нескольким условиям, вы используете предложение WHERE следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT select_list ИЗ table_name КУДА search_condition;
В предложении WHERE вы указываете условие поиска для фильтрации строк, возвращаемых предложением FROM .Предложение WHERE возвращает только те строки, которые приводят к тому, что условие поиска оценивается как TRUE .
Условие поиска — это логическое выражение или комбинация нескольких логических выражений. В SQL логическое выражение часто называют предикатом .
Обратите внимание, что SQL Server использует логику трехзначного предиката, где логическое выражение может оцениваться как ИСТИНА , ЛОЖЬ или НЕИЗВЕСТНО . Предложение WHERE не вернет ни одной строки, из-за которой предикат оценивается как FALSE или UNKNOWN .
SQL Server
WHERE examples Мы будем использовать таблицу production.products из образца базы данных для демонстрации
A) Поиск строк с помощью простого равенства
Следующая инструкция извлекает все продукты с идентификатором категории 1:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products КУДА category_id = 1 СОРТИРОВАТЬ ПО list_price DESC;
B) Поиск строк, отвечающих двум условиям
В следующем примере возвращаются продукты, которые соответствуют двум условиям: идентификатор категории — 1 и модель — 2018.Он использует логический оператор И для объединения двух условий.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products КУДА category_id = 1 AND model_year = 2018 СОРТИРОВАТЬ ПО list_price DESC;
C) Поиск строк с помощью оператора сравнения
Следующий оператор находит продукты, прейскурантная цена которых превышает 300, а модель — 2018.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products КУДА list_price> 300 И model_year = 2018 СОРТИРОВАТЬ ПО list_price DESC;
D) Поиск строк, удовлетворяющих любому из двух условий
Следующий запрос находит продукты, цена которых превышает 3000 или модель 2018 г. удовлетворяет одному из этих условий, включается в набор результатов.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products КУДА list_price> 3000 ИЛИ model_year = 2018 СОРТИРОВАТЬ ПО list_price DESC;
Обратите внимание, что для объединения предикатов использовался оператор OR .
E) Поиск строк со значением между двумя значениями
Следующий оператор находит продукты, прейскурантные цены которых находятся в диапазоне от 1899 до 1999.99:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products КУДА list_price МЕЖДУ 1899.00 И 1999.99 СОРТИРОВАТЬ ПО list_price DESC;
F) Поиск строк, имеющих значение в списке значений
В следующем примере оператор IN используется для поиска продуктов, прайс-лист которых 299.99 или 466,99 или 489,99.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ production.products КУДА list_price IN (299,99, 369,99, 489,99) СОРТИРОВАТЬ ПО list_price DESC;
G) Поиск строк, значения которых содержат строку
В следующем примере оператор LIKE используется для поиска продуктов, имя которых содержит строку Cruiser :
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ идантификационный номер продукта, наименование товара, category_id, год выпуска, список цен ИЗ производство.товары КУДА product_name LIKE '% Cruiser%' СОРТИРОВАТЬ ПО список цен;
В этом руководстве вы узнали, как использовать предложение SQL Server WHERE для фильтрации строк на основе одного или нескольких условий.
Учебное пособие и примеры предложения WHERE SQL
Используйте предложение SQL WHERE , чтобы отфильтровать строки, возвращенные вашим оператором SELECT. Предложение where проверяет каждую строку на соответствие одному или нескольким условиям.Когда условия возвращают ИСТИНА, строка включается в результат.
Пункт Где SQL
Вот пример получения всех людей по имени Терри.
ВЫБЕРИТЕ имя, фамилию ОТ Person.Person ГДЕ FirstName = «Терри»
/ * Ответ * / ВЫБЕРИТЕ имя, фамилию ОТ Person.Person ГДЕ FirstName = 'Терри'
Знак равенства (=) вызывается с помощью оператора сравнения.Как упоминалось выше, если сравнение истинно, в результат включается строка.
Мы также можем использовать оператор сравнения «не равно» (<>), чтобы найти всех людей, чье имя не Терри. Сможете ли вы написать запрос, чтобы найти каждого человека без имени Терри?
ВЫБЕРИТЕ имя, фамилию ОТ Person.Person WHERE FirstName = ‘Terry’ — изменить эту строку
/ * Ответ * / ВЫБЕРИТЕ имя, фамилию ОТ Person.Person ГДЕ Имя <> 'Терри'
SQL ГДЕ и В
Вот еще один пример использования оператора IN.Обратите внимание, что результат включает всех людей, чье имя — Терри или Терри.
ВЫБЕРИТЕ имя, фамилию ОТ Person.Person ГДЕ FirstName IN (‘Терри’, ‘Терри’)
/ * Ответ * /
ВЫБЕРИТЕ имя, фамилию
ОТ Person.Person
ГДЕ FirstName IN ('Терри', 'Терри')
Почему бы вам не попробовать сейчас? Попробуйте написать запрос, чтобы выбрать всех людей, имя которых Том, Томас или Томи. Отсортируйте результат по имени и фамилии.
— Запишите свой ответ здесь!
/ * Ответ * / ВЫБЕРИТЕ имя, фамилию ОТ Person.Person ГДЕ FirstName IN («Том», «Томас», «Томми») ЗАКАЗАТЬ ПО Имя, Фамилия
Вы также можете использовать NOT IN в предложении SQL WHERE. Это противоположно IN. Если мы хотим найти каждого человека, которого зовут не Терри или Терри, мы можем написать наш SQL WHERE примерно так:
ВЫБЕРИТЕ имя, фамилию ОТ Person.Person ГДЕ FirstName НЕ ВХОДИТ (‘Терри’, ‘Терри’)
/ * Ответ * /
ВЫБЕРИТЕ имя, фамилию
ОТ человека.Человек
ГДЕ FirstName НЕ ВХОДИТ ('Терри', 'Терри')
В этом случае возвращается TRUE, если FirstName не Terry или Terri. Конечным результатом является запрос, возвращающий все строки, кроме Терри или Терри.
SQL ГДЕ и МЕЖДУ
Вы также можете использовать оператор BETWEEN в предложении SQL WHERE для сравнения значений в пределах диапазона. В этом примере мы ищем людей с идентификаторами от 1000 до 1025:
ВЫБЕРИТЕ BusinessEntityID, FirstName, LastName ОТ человека.Человек ГДЕ BusinessEntityID МЕЖДУ 1000 и 1025
/ * Ответ * / ВЫБЕРИТЕ BusinessEntityID, FirstName, LastName ОТ Person.Person ГДЕ BusinessEntityID МЕЖДУ 1000 и 1025
Дополнительные ресурсы
Если вы хотите узнать больше об использовании предложения WHERE, я бы порекомендовал следующие ресурсы:
SQL Пример предложения Where | SQL Where Query
Предложение SQL WHERE используется для фильтрации записей базы данных.Предложение WHERE используется для извлечения только тех записей, которые соответствуют указанному условию. Предложение SQL WHERE используется для указания условия при выборке данных из одной таблицы или путем объединения нескольких таблиц.
Если данное условие удовлетворяется, то возвращается только конкретное значение из таблицы. Вы должны использовать предложение WHERE для фильтрации записей и получения необходимых записей.
Пример предложения SQL WhereПредложение SQL WHERE используется для указания условия при извлечении данных из одной таблицы или путем объединения с несколькими таблицами.Если данное условие выполнено, то только оно возвращает конкретное значение из таблицы.
Предложение WHERE используется не только в операторе SELECT; он также используется в операторах UPDATE, DELETE.
Синтаксис оператора SELECT с предложением WHERE следующий.
ВЫБРАТЬ столбец1, столбец2, столбецN FROM table_name WHERE [условие]
«SELECT column1, column2, column3 FROM tableName» — это стандартный оператор SELECT.
«ГДЕ» — это ключевое слово, ограничивающее набор результатов запроса выбора, а «условие» — это фильтр, применяемый к результатам.Фильтр может быть диапазоном, одним значением или подзапросом.
Теперь мы перейдем к примеру, но перед этим вы можете проверить мои Создание таблицы в SQL и Как вставлять данные в сообщения базы данных.
Если вы следовали этому руководству, то в этом руководстве я создал таблицу и вставил несколько записей.
Теперь мы получаем записи на основе предложения WHERE.
Хорошо, теперь давайте сначала получим все записи.
Для этого мне нужно написать следующий запрос.
ВЫБРАТЬ * ИЗ ПРИЛОЖЕНИЙ
См. Следующий вывод.
SQL WHERE QuerySQL требует заключения текстовых значений в одинарные кавычки. Однако числовые поля не следует заключать в кавычки.
Хорошо, теперь давайте воспользуемся запросом WHERE для фильтрации записи. Получим запись по столбцу CreatorName .
Напишите следующий запрос.
Выбрать * из приложений Где CreatorName = 'Krunal'
См. Вывод.
Получим строку, отфильтровав AppCategory.
Выбрать * из приложений Где AppCategory = 'Investment'
См. Вывод.
Вы можете указать условие, используя сравнение или логические операторы, такие как>, <, =, LIKE, NOT и т. Д.
Оператор SQL Where с логическим операторомМы можем использовать логический оператор с Предложение Where для фильтрации данных путем сравнения.
Допустим, мы получаем данные, для которых AppPrice больше 70 $. См. Следующий запрос.
Выбрать * из приложений Где AppPrice> 70
См. Вывод.
Операторы в разделе WHEREСледующие операторы могут использоваться в разделе WHERE.
| Оператор | Описание |
|---|---|
| = | Равно |
| > | Больше |
| < | Меньше |
| > = | Больше или равно |
| <= | Меньше или равно |
| <> | Не равно. Примечание: В некоторых версиях SQL этот оператор может быть записан как! = |
| МЕЖДУ | Между определенным диапазоном |
| КАК | Поиск шаблона |
| IN | Чтобы указать несколько возможных значения для столбца |
Предложение WHERE при использовании с оператором AND выполняется только в том случае, если соблюдаются все указанные критерии фильтрации.См. Следующий запрос.
Выберите CreatorName из приложений Где AppPrice> 70 AND AppName = 'Moneycontrol'
Итак, мы получаем единственное CreatorName, в котором AppPrice> 70 и AppName = MoneyControl. См. Вывод ниже.
Предложение WHERE в сочетании с IN Ключевое словоПредложение WHERE при использовании вместе с ключевым словом IN влияет только на строки, значения которых соответствуют списку значений, предоставленному в ключевом слове IN.IN помогает сократить количество предложений OR, которые вам, возможно, придется использовать. См. Следующий запрос.
Выбрать * из приложений Где AppPrice IN (50, 60, 110)
В приведенном выше запросе мы выбираем те записи, AppPrice которых равен 50, 60 или 110. Если AppPrice совпадает в базе данных, тогда он даст нам эту строку в выходных данных. .
В нашем случае только 50 и 60 совпадений, 110 нет в базе. Итак, будут возвращены две строки.
Предложение WHERE в сочетании с ЛОГИЧЕСКИМ оператором ORПредложение WHERE при использовании с оператором OR выполняется только в том случае, если выполняется любой или все указанные критерии фильтрации.См. Следующий запрос.
Выбрать * из приложений Где AppPrice = 50 OR AppCategory = 'Fashion'
В приведенном выше запросе удерживается либо AppPrice = 50, либо AppCategory = Fashion.
Если оба верны, то тоже дает результат. Смотрите вывод.
Предложение WHERE в сочетании с NOT IN Ключевое словоПредложение WHERE, используемое с ключевым словом NOT IN, не влияет на строки, значения которых совпадают со списком значений, указанным в ключевом слове NOT IN.См. Следующий запрос.
Выбрать * из приложений Где AppPrice NOT IN (40, 50, 60)
Итак, он вернет те строки, в которых нет AppPrice 40, 50, 60. Он даст нам оставшиеся строки.
Оператор SQL WHERE используется для ограничения количества строк, затронутых запросом SELECT, UPDATE или DELETE. Термин WHERE может использоваться в сочетании с логическими операторами, такими как И и ИЛИ, операторами сравнения, такими как равенство (=) и т. Д.
При использовании с логическим оператором И должны выполняться все критерии.При использовании с логическим оператором ИЛИ должен быть соблюден любой из критериев. Ключевое слово IN используется для выбора строк, соответствующих списку значений.
Наконец, пример предложения SQL Where | SQL Where Query Tutorial окончен.
Разница между WHERE и ON в данных SQL для JOIN
Последнее изменение: 7 февраля 2021 г.
Есть ли разница между предложением WHERE и ON?
Да. ON следует использовать для определения условия соединения, а WHERE следует использовать для фильтрации данных.Я использовал слово «должен», потому что это не жесткое правило. Разделение этих целей с соответствующими предложениями делает запрос наиболее читаемым, а также предотвращает получение неверных данных при использовании типов JOIN, отличных от INNER JOIN.
Чтобы углубиться в подробности, мы рассмотрим два варианта использования, которые могут поддерживаться WHERE или ON:
- Объединение данных
- Данные фильтрации
Объединение данных
Оба этих предложения могут использоваться для объединения данных путем определения условия, при котором две таблицы объединяются.Чтобы продемонстрировать это, давайте воспользуемся примером набора данных друзей facebook и подключений linkedin.
Мы хотим видеть людей, которые являются и нашими друзьями, и нашей связью. Так что в данном случае это будет только Мэтт. Теперь давайте сделаем запрос, используя различные определения условия JOIN.
Все три запроса дают одинаковый правильный результат:
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
ГДЕ facebook.name = linkedin.name
ВЫБРАТЬ *
ИЗ facebook, linkedin
ГДЕ facebook.name = linkedin.name
Первые два — это типы явного соединения, а последний — неявное соединение. Явное JOIN явно сообщает вам, как присоединиться к данным, указав тип JOIN и условие соединения в предложении ON. Неявное JOIN не указывает тип JOIN и не использует предложение WHERE для определения условия соединения.
Читаемость
Основное различие между этими запросами заключается в том, насколько легко понять, что происходит.В первом запросе мы можем легко увидеть, как таблицы соединяются в предложениях FROM и JOIN. Мы также можем ясно видеть условие соединения в предложении ON. Во втором запросе это кажется столь же ясным, однако мы можем дважды взглянуть на предложение WHERE, поскольку оно обычно используется для фильтрации данных, а не для присоединения к ним. В последнем запросе мы должны внимательно посмотреть, как установить, к какой таблице присоединяются, и как они присоединяются.
Последний запрос использует так называемое неявное СОЕДИНЕНИЕ (СОЕДИНЕНИЕ, которое явно не указано в запросе.В большинстве случаев неявные СОЕДИНЕНИЯ будут действовать как ВНУТРЕННИЕ СОЕДИНЕНИЯ. Если вы хотите использовать JOIN, отличное от INNER JOIN, заявив, что это явно проясняет, что происходит.
ПРИСОЕДИНЕНИЕ к предложению WHERE может вызвать путаницу, поскольку это не типичная цель. Чаще всего используется для фильтрации данных. Поэтому, когда к предложению WHERE добавляются дополнительные условия фильтрации в дополнение к его использованию для определения того, как ПРИСОЕДИНЯТЬСЯ к данным, становится труднее понять.
ВЫБРАТЬ *
ИЗ facebook, linkedin
ГДЕ facebook.name = linkedin.name И (facebook.name = Matt OR linkedin.city = "SF")
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name
ГДЕ facebook.name = Мэтт ИЛИ linkedin.city = "SF"
Несмотря на то, что в первом запросе меньше символов, чем во втором, его не так легко понять.
Оптимизация
Иногда написание запроса другим способом может улучшить скорость. Однако в этом случае не должно быть преимуществ в скорости из-за того, что называется планом запроса.План запроса — это код, который SQL предлагает для выполнения запроса. Он принимает запрос, а затем создает оптимизированный способ поиска данных. Использование WHERE или ON для JOIN данных должно привести к тому же плану запроса.
Однако способ создания планов запросов может различаться в зависимости от языка и версии SQL, опять же, в этом случае все должно быть одинаковым, но вы можете протестировать его в своей базе данных, чтобы увидеть, повысится ли производительность. Будьте осторожны, чтобы кеширование не повлияло на результаты ваших запросов.
Фильтрация данных
И предложение ON, и предложение WHERE можно использовать для фильтрации данных в запросе. Есть проблемы с удобочитаемостью и точностью, которые нужно решить с помощью фильтрации в предложении ON. Давайте воспользуемся немного большим набором данных, чтобы продемонстрировать это.
На этот раз мы ищем людей, которые являются нашими друзьями и связями, но мы хотим видеть только тех, кто также живет в Сан-Франциско.
Читаемость
Давайте оценим, насколько удобочитаема каждая опция, эти два запроса дадут одинаковый результат:
ВЫБРАТЬ *
ПРИСОЕДИНЯЙТЕСЬ linkedin
На Фейсбуке.name = linkedin.name
ГДЕ facebook.city = 'SF'
ВЫБРАТЬ *
С Фейсбука
ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name И facebook.city = 'SF'
Первый запрос ясен, каждое предложение имеет свое назначение. Второй запрос труднее понять, потому что предложение ON используется как для СОЕДИНЕНИЯ данных, так и для их фильтрации.
Точность
Фильтрация в предложении ON может привести к неожиданным результатам при использовании LEFT, RIGHT или OUTER JOIN.Эти два запроса не дадут одинаковый результат:
ВЫБРАТЬ *
С Фейсбука
ЛЕВЫЙ ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name
ГДЕ facebook.city = 'SF'
В LEFT JOIN он вводит каждую строку из первой таблицы «facebook» и присоединяется везде, где истинно условие соединения (facebook.name = linkedin.name), это будет верно как для Мэтта, так и для Дэйва. Так и была бы промежуточная таблица.
Затем предложение WHERE фильтрует эти результаты в строки, где facebook.city = ‘SF’, оставив одну строку.
ВЫБРАТЬ *
С Фейсбука
ЛЕВЫЙ ПРИСОЕДИНЯЙТЕСЬ linkedin
НА facebook.name = linkedin.name И facebook.city = 'SF'
В этом запросе другое условие соединения. LEFT JOIN вводит каждую строку, а данные, которые присоединяются из linkedin, происходят только тогда, когда facebook.name = linkedin.name AND facebook.city = ‘SF’. Он не отфильтровывает все строки, в которых не было facebook.city = ‘SF’
.Оптимизация
Здесь есть потенциальные вариации в том, как строится план запроса, поэтому может быть полезно попробовать фильтрацию в ON.Некоторые языки SQL могут фильтровать при присоединении, а другие могут ждать, пока будет построена полная таблица, перед фильтрацией. Первый план будет быстрее.
Сводка
Сохраняйте контекст отдельно между , соединяющим таблицы и фильтрующим объединенной таблицей. Он наиболее читаемый, с наименьшей вероятностью может быть неточным и не должен быть менее производительным.
- JOIN данные в ON
- Данные фильтра в ГДЕ
- Напишите явные JOIN, чтобы сделать ваш запрос более читаемым
- Отфильтруйте данные в предложении WHERE вместо JOIN, чтобы убедиться, что они правильные и читаемые
- Различные языки SQL могут иметь разные планы запросов на основе фильтрации в предложении ON и в предложении WHERE, поэтому проверьте производительность в своей базе данных
Написано:
Мэтт Дэвид
Проверено:
Предложение WHERE в операторах SQL
Предложение WHERE используется для указания / применения любого условия при извлечении, обновлении или удалении данных из таблицы.Это предложение в основном используется с запросами SELECT , UPDATE и DELETE .
Когда мы указываем условие с помощью предложения WHERE , тогда запрос выполняется только для тех записей, для которых условие, указанное в предложении WHERE , истинно.
Синтаксис для
WHERE пункт Вот как вы можете использовать предложение WHERE с оператором DELETE или любым другим оператором,
УДАЛИТЬ ИЗ имя_таблицы ГДЕ [условие]; Предложение WHERE используется в конце любого SQL-запроса, чтобы указать условие для выполнения.
Время для примера
Рассмотрим стол ученик ,
| s_id | имя | возраст | адрес |
|---|---|---|---|
| 101 | Адам | 15 | Ченнаи |
| 102 | Алекс | 18 | Дели |
| 103 | Abhi | 17 | Banglore |
| 104 | Ankit | 22 | Мумбаи |
Теперь мы будем использовать оператор SELECT для отображения данных таблицы на основе условия, которое мы добавим в наш запрос SELECT с помощью предложения WHERE .
Давайте напишем простой SQL-запрос для отображения записи для студента с s_id как 101.
ВЫБРАТЬ s_id,
имя,
возраст,
адрес
ОТ студента ГДЕ s_id = 101; Ниже будет результат вышеуказанного запроса.
| s_id | имя | возраст | адрес |
|---|---|---|---|
| 101 | Adam | 15 | Noida |
Применение условия к текстовым полям
В приведенном выше примере мы применили условие к полю целочисленного значения, но что, если мы хотим применить условие к полю name .В этом случае мы должны заключить значение в одинарную кавычку '' . Некоторые базы данных даже принимают двойные кавычки, но одинарные кавычки принимаются всеми.
ВЫБРАТЬ s_id,
имя,
возраст,
адрес
ОТ ученика ГДЕ name = 'Адам'; Ниже будет результат вышеуказанного запроса.
| s_id | имя | возраст | адрес |
|---|---|---|---|
| 101 | Adam | 15 | Noida |
Операторы для
WHERE условие Ниже приводится список операторов, которые можно использовать при указании условия предложения WHERE .
| Оператор | Описание |
|---|---|
= | Равно |
! = | Не равно |
< | Менее |
> 900 | Больше |
<= | Меньше или равно |
> = | Больше или равно |
МЕЖДУ | Между указанным диапазоном значений |
LIKE | Используется для поиска шаблона в значении. |
IN | В заданном наборе значений |
SQL объединяется с использованием WHERE или ON | Средний уровень SQL
Начиная с этого места? Этот урок является частью полного руководства по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
Фильтрация в предложении ON
Обычно фильтрация обрабатывается в предложении WHERE после того, как две таблицы уже были объединены.Однако возможно, что вы захотите отфильтровать одну или обе таблицы , прежде чем присоединится к ним. Например, вы хотите создавать совпадения между таблицами только при определенных обстоятельствах.
Используя данные Crunchbase, давайте еще раз посмотрим на пример LEFT JOIN из предыдущего урока (на этот раз мы добавим предложение ORDER BY ):
SELECT companies.permalink AS companies_permalink,
company.name AS имя_компании,
приобретения.company_permalink AS acquisitions_permalink,
acquisitions.acquired_at AS Дата_ приобретения
ОТ tutorial.crunchbase_companies компании
LEFT JOIN tutorial.crunchbase_acquisitions acquisitions
ON companies.permalink = acquisitions.company_permalink
ЗАКАЗАТЬ ПО 1
Сравните следующий запрос с предыдущим, и вы увидите, что все в таблице tutorial.crunchbase_acquisitions было объединено с , за исключением для строки, для которой company_permalink составляет '/ company / 1000memories' :
ВЫБРАТЬ компании.постоянная ссылка AS companies_permalink,
company.name AS имя_компании,
acquisitions.company_permalink AS acquisitions_permalink,
acquisitions.acquired_at AS Дата_ приобретения
ОТ tutorial.crunchbase_companies компании
LEFT JOIN tutorial.crunchbase_acquisitions acquisitions
ON companies.permalink = acquisitions.company_permalink
И acquisitions.company_permalink! = '/ Company / 1000memories'
ЗАКАЗАТЬ ПО 1
Что происходит выше, так это то, что условный оператор AND... оценивается до того, как произойдет соединение. Вы можете думать об этом как о предложении WHERE , которое применяется только к одной из таблиц. Вы можете сказать, что это происходит только в одной из таблиц, потому что постоянная ссылка 1000memories все еще отображается в столбце, извлеченном из другой таблицы:
Фильтрация в предложении WHERE
Если вы переместите тот же фильтр в предложение WHERE , вы заметите, что фильтр применяется после объединения таблиц. В результате строка 1000memories присоединяется к исходной таблице, но затем она полностью отфильтровывается (в обеих таблицах) в предложении WHERE перед отображением результатов.
SELECT companies.permalink AS companies_permalink,
company.name AS имя_компании,
acquisitions.company_permalink AS acquisitions_permalink,
acquisitions.acquired_at AS Дата_ приобретения
ОТ tutorial.crunchbase_companies компании
LEFT JOIN tutorial.crunchbase_acquisitions acquisitions
ON companies.permalink = acquisitions.company_permalink
ГДЕ acquisitions.company_permalink! = '/ Company / 1000memories'
ИЛИ acquisitions.company_permalink ЕСТЬ NULL
ЗАКАЗАТЬ ПО 1
Вы можете видеть, что строка 1000memories не возвращается (она была бы между двумя выделенными строками ниже).Также обратите внимание, что фильтрация в предложении WHERE также может фильтровать нулевые значения, поэтому мы добавили дополнительную строку, чтобы обязательно включить нули.
Отточите свои навыки работы с SQL
Для этого набора практических задач мы собираемся представить новый набор данных: tutorial.crunchbase_investments . Эта таблица также получена из Crunchbase и содержит большую часть той же информации, что и данные tutorial.crunchbase_companies . Однако он имеет другую структуру: он содержит одну строку на инвестиций .В каждой компании может быть несколько инвестиций - даже возможно, что один инвестор может инвестировать в одну и ту же компанию несколько раз. Имена столбцов говорят сами за себя. Важно то, что company_permalink в таблице tutorial.crunchbase_investments соответствует permalink в таблице tutorial.crunchbase_companies . Имейте в виду, что некоторые случайные данные были удалены из этой таблицы для этого урока.
Очень вероятно, что вам нужно будет провести некоторый исследовательский анализ этой таблицы, чтобы понять, как вы можете решить следующие проблемы.
Практическая задача
Напишите запрос, который показывает название компании, «статус» (находится в таблице «Компании») и количество уникальных инвесторов в этой компании. Порядок по количеству инвесторов от наибольшего к наименьшему. Ограничение только для компаний в штате Нью-Йорк.
Попробуй это Посмотреть ответПрактическая задача
Напишите запрос, в котором будут перечислены инвесторы по количеству компаний, в которые они вложили средства.Включите строку для компаний без инвестора и закажите от большинства компаний до наименьшего.
Попробуй это Посмотреть ответ .